
Schlüsselwörter:KI-Sicherheit, Ethik der künstlichen Intelligenz, KI-Agenten, 3D-Generierung, Code-Modelle, KI-Risikobewertung, Gemini 2.5 Pro Videoanalyse, AssetGen 2.0 3D-Generierung, Seed-Coder Code-Modell, AgentOps Agentenbetrieb
🔥 Fokus
Sicherheitsrisiken von KI erregen Aufmerksamkeit, Experten fordern Risikobewertung nach Vorbild der Nuklearsicherheit: Die internationale Gemeinschaft ist zunehmend besorgt über die potenziellen Risiken der künstlichen Intelligenz. Experten (wie Max Tegmark) fordern KI-Unternehmen auf, vor der Veröffentlichung gefährlicher KI-Systeme eine strenge Bewertung der Wahrscheinlichkeit eines Kontrollverlusts von KI (Compton-Konstante) durchzuführen, ähnlich den Sicherheitsberechnungen von Robert Oppenheimer beim ersten Atomtest. Ziel ist es, einen Branchenkonsens zu schaffen, den Aufbau globaler KI-Sicherheitsmechanismen voranzutreiben und katastrophale Folgen durch Superintelligenz zu verhindern. (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)

Der neue Papst Franziskus (Pseudonym Leo XIV.) schenkt den durch KI verursachten gesellschaftlichen Veränderungen hohe Aufmerksamkeit: Der neu gewählte Papst Franziskus (angeblich Leo XIV.) hat künstliche Intelligenz als eine der größten Herausforderungen für die Menschheit identifiziert. Er wählte den Namen „Leo“ zum Teil aufgrund der durch KI verursachten neuen sozialen Probleme und der industriellen Revolution, was an die Reaktion von Papst Leo XIII. auf die erste industrielle Revolution erinnert. Der Papst betont, dass KI eine Herausforderung für die Wahrung von „Menschenwürde, Gerechtigkeit und Arbeit“ darstellt und plant, in Zukunft wichtige Dokumente zur KI-Ethik zu veröffentlichen, was die tiefe Besorgnis religiöser Führer über die ethischen und sozialen Auswirkungen der KI-Technologie zeigt. (Quelle: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

Google veröffentlicht 76-seitiges Whitepaper zu KI-Agenten, erläutert AgentOps und zukünftige Anwendungen: Google hat ein 76-seitiges Whitepaper zu KI-Agenten veröffentlicht, das den Aufbau, die Bewertung und die Anwendung von Agenten detailliert erläutert. Das Whitepaper betont die Bedeutung von Agent Operations (AgentOps) als Zweig des Betriebs generativer KI. AgentOps konzentriert sich auf das Tool-Management, die Einrichtung von Kern-Prompts, Speicherfunktionen und die Aufgabenzerlegung, die für den effizienten Betrieb von Agenten erforderlich sind. Das Whitepaper untersucht auch Architekturen für die Zusammenarbeit mehrerer Agenten, bei denen verschiedene Agenten Rollen wie Planung, Abruf, Ausführung und Bewertung übernehmen, um gemeinsam komplexe Aufgaben zu erledigen. Es werden zudem Zukunftsperspektiven für den Einsatz von Agenten in Unternehmen zur Unterstützung von Mitarbeitern und zur Automatisierung von Backend-Aufgaben aufgezeigt, wie z.B. NotebookLM Enterprise Edition und Agentspace. (Quelle: WeChat)

Meta stellt AssetGen 2.0 vor: Text/Bild-generierte hochwertige 3D-Assets: Meta hat sein neuestes 3D-Basis-KI-Modell AssetGen 2.0 veröffentlicht, das hochwertige 3D-Assets basierend auf Text- und Bild-Prompts erstellen kann. AssetGen 2.0 besteht aus zwei Submodellen: eines zur Generierung von 3D-Meshes, das ein einstufiges 3D-Diffusionsmodell verwendet, um Details und Genauigkeit zu verbessern; ein weiteres TextureGen-Modell zur Generierung von Texturen, das Methoden zur Verbesserung der Ansichtskonsistenz, Texturreparatur und höheren Texturauflösung einführt. Die Technologie wird derzeit intern bei Meta zur Erstellung von 3D-Welten eingesetzt und soll später in diesem Jahr für Horizon-Ersteller eingeführt werden. (Quelle: Reddit r/artificial)

🎯 Trends
ByteDance Seed veröffentlicht 8B Code-Modell Seed-Coder als Open Source und führt neues Paradigma für modellgesteuertes Datenmanagement ein: Das Seed-Team von ByteDance hat erstmals sein 8B Code-Modell Seed-Coder als Open Source veröffentlicht, das die Versionen Base, Instruct und Reasoning umfasst. Das Modell zeigt in mehreren Benchmarks zur Codegenerierung hervorragende Leistungen und übertrifft insbesondere Modelle wie Qwen3 bei HumanEval und MBPP. Die Kerninnovation von Seed-Coder liegt in der Einführung einer „modellzentrierten“ Datenverarbeitungsmethode, bei der LLMs selbst hochwertige Code-Trainingsdaten generieren und filtern, darunter Code auf Dateiebene, Repository-Ebene, Commit-Daten und codebezogene Netzwerkdaten, mit einem Gesamtvolumen von 6T Tokens an Trainingsdaten. Ziel ist es, den manuellen Aufwand zu reduzieren und die Leistungsfähigkeit von Code-Modellen zu steigern. (Quelle: WeChat)
Gemini 2.5 Pro erzielt Durchbrüche im Videoverständnis und realisiert native Integration von Audio, Video und Code: Die neuesten Modelle Gemini 2.5 Pro und Flash von Google haben signifikante Fortschritte im Bereich des Videoverständnisses erzielt. Gemini 2.5 Pro erreicht in mehreren wichtigen Benchmarks für Videoverständnis State-of-the-Art-Niveau und übertrifft sogar GPT 4.1. Die Gemini 2.5-Modellreihe realisiert erstmals eine native und nahtlose Integration von Audio- und Videoinformationen mit anderen Datenformaten wie Code. Sie kann Videos direkt in interaktive Anwendungen (z. B. Lern-Apps) umwandeln, p5.js-Animationen basierend auf Videos generieren sowie Videoclips präzise abrufen und beschreiben, was eine starke Fähigkeit zum zeitlichen Reasoning demonstriert. Diese Funktionen sind bereits in Google AI Studio, der Gemini API und Vertex AI verfügbar. (Quelle: WeChat)

ModelScope veröffentlicht einheitliches Bildmodell Nexus-Gen als Open Source, zielt auf Bildfähigkeiten von GPT-4o ab: Das ModelScope-Team hat Nexus-Gen vorgestellt, ein einheitliches multimodales Modell, das gleichzeitig Bildverständnis, -generierung und -bearbeitung verarbeiten kann und darauf abzielt, mit den Bildverarbeitungsfähigkeiten von GPT-4o zu konkurrieren. Das Modell verwendet den technischen Ansatz Token → Transformer → Diffusion → Pixel und kombiniert die Textmodellierungsfähigkeiten von MLLMs mit den Bildrenderfähigkeiten von Diffusionsmodellen. Um das Problem der Fehlerakkumulation bei der autoregressiven Vorhersage kontinuierlicher Bild-Embeddings zu lösen, schlug das Team eine Pre-Filling-Autoregressive-Strategie vor. Nexus-Gen wurde auf etwa 25 Millionen Bild-Text-Daten trainiert, einschließlich des kürzlich von der ModelScope-Community als Open Source veröffentlichten ImagePulse-Bearbeitungsdatensatzes. (Quelle: WeChat)

Cursor Version 0.50 veröffentlicht, vereinfacht Preisgestaltung und verbessert mehrere Code-Bearbeitungsfunktionen: Der KI-Code-Editor Cursor hat Version 0.50 veröffentlicht, die wichtige Updates mit sich bringt. Das Preismodell wurde zu einem anfragebasierten Modell vereinfacht, wobei der Max-Modus alle Top-KI-Modelle unterstützt und eine Token-basierte Preisgestaltung verwendet. Zu den Funktionsverbesserungen gehören: ein neues Tab-Modell unterstützt dateiübergreifende Vorschläge und Code-Refactoring; ein Hintergrund-Agent (Preview-Version) unterstützt die parallele Ausführung mehrerer Agenten und die Ausführung von Aufgaben in Remote-Umgebungen; der Codebasis-Kontext ermöglicht das Hinzufügen ganzer Codebasen über @folders; die Inline-Bearbeitungs-UI wurde optimiert und um Funktionen zur Bearbeitung ganzer Dateien und zum Senden an Agenten erweitert; die Bearbeitung langer Dateien führt ein Such- und Ersetzungstool ein; Unterstützung für Multi-Root-Workspaces zur Verarbeitung mehrerer Codebasen; verbesserte Chat-Funktionen mit Unterstützung für den Export als Markdown und zum Kopieren. (Quelle: op7418)
llama.cpp fügt Unterstützung für Visual Language Models (VLM) hinzu, ermöglicht Aufbau eines vollständigen Vision RAG-Prozesses: Das Open-Source-Projekt llama.cpp hat die Unterstützung für Visual Language Models (VLM) angekündigt. Benutzer können nun über den llama.cpp-Server und die Web-UI visuelle Funktionen nutzen. Dieses Update bedeutet, dass auf llama.cpp dasselbe Basismodell mit Unterstützung für mehrere LoRAs sowie Embedding-Modelle geladen werden können, was den Aufbau eines vollständigen Vision Retrieval Augmented Generation (Vision RAG)-Prozesses ermöglicht. Dies erweitert die Fähigkeit von llama.cpp, große Sprachmodelle lokal auszuführen, und ermöglicht die Verarbeitung multimodaler Aufgaben. (Quelle: mervenoyann, mervenoyann)
Tencent veröffentlicht HunyuanCustom: Eine auf HunyuanVideo basierende, anpassbare Architektur zur Videogenerierung: Tencent hat HunyuanCustom auf Hugging Face veröffentlicht, eine multimodale, treibergestützte Architektur, die speziell für die anpassbare Videogenerierung entwickelt wurde. Diese Arbeit baut auf HunyuanVideo auf und legt besonderen Wert auf die Beibehaltung der Konsistenz des Subjekts bei der Generierung von Videos. Gleichzeitig unterstützt sie die Eingabe verschiedener Bedingungen wie Bilder, Audio, Video und Text und bietet Benutzern flexiblere und personalisierte Möglichkeiten zur Videoerstellung. (Quelle: _akhaliq)
Qwen Chat fügt „Webentwicklung“-Modus hinzu, generiert React-Webanwendungen mit einem Satz: Alibaba Qwen Chat führt den „Web Dev“-Modus (Webentwicklung) ein, mit dem Benutzer mit nur einem Satz Anweisungen Webanwendungen erstellen können, die HTML, CSS und JavaScript enthalten, wobei im Hintergrund das React-Framework und Tailwind CSS verwendet werden. Diese Funktion kann schnell persönliche Websites erstellen, bestehende Web-Oberflächen (wie Twitter, GitHub) nachbilden oder spezifische Formulare und Animationen basierend auf Beschreibungen erstellen. Benutzer können verschiedene Qwen-Modelle auswählen und den „Deep Thinking“-Modus kombinieren, um die Webseitenqualität zu verbessern. Diese Funktion zielt darauf ab, den Frontend-Entwicklungsprozess zu vereinfachen und schnell Anwendungsprototypen zu erstellen. (Quelle: WeChat)
Unitree Robotics reagiert auf Sicherheitslücke beim Go1-Roboterhund und betont, dass Nachfolgeprodukte aktualisiert wurden: Unitree Robotics hat auf Gerüchte über eine „Backdoor-Schwachstelle“ in seiner seit etwa zwei Jahren eingestellten Go1-Roboterhundserie reagiert und das Problem als Sicherheitslücke eingeräumt. Angreifer könnten den Verwaltungsschlüssel eines Cloud-Tunnel-Dienstes eines Drittanbieters verwenden, um Benutzergerätedaten zu ändern, Kamerabilder abzurufen und Systemberechtigungen zu erlangen. Unitree Robotics gab an, dass nachfolgende Roboterserien sicherere, aktualisierte Versionen verwenden und von dieser Schwachstelle nicht betroffen sind. Der Vorfall hat Bedenken hinsichtlich der Sicherheit der Lieferkette intelligenter Roboter und des Datenschutzes ausgelöst, insbesondere vor dem Hintergrund des ersten Jahres der Kommerzialisierung humanoider Roboter, in dem die Branche mit vielfältigen Herausforderungen wie technologischen Durchbrüchen, Kostenkontrolle und der Erforschung von Kommerzialisierungspfaden konfrontiert ist. (Quelle: 36氪)

Claude Code unterstützt jetzt das Referenzieren anderer .MD-Dateien und optimiert die Organisation von Anweisungen: Claude Code von Anthropic hat seine Funktionalität aktualisiert. Version 0.2.107 ermöglicht es CLAUDE.md-Dateien, andere Markdown-Dateien zu importieren. Benutzer können durch Hinzufügen von [u/path/to/file].md in der Hauptdatei CLAUDE.md zusätzliche Dateiinhalte beim Start laden. Diese Verbesserung ermöglicht es Benutzern, die Anweisungen für Claude besser zu organisieren und zu verwalten, erhöht die Zuverlässigkeit und Modularität der Anweisungskonfiguration in großen Projekten und löst das bisherige Problem der Unübersichtlichkeit durch verstreute Dateien. (Quelle: Reddit r/ClaudeAI)

US Copyright Office nimmt härtere Haltung gegenüber KI-Vortraining ein und schwächt „Fair Use“-Verteidigung: Ein neu veröffentlichter Bericht des US Copyright Office nimmt eine härtere Haltung zur Verwendung urheberrechtlich geschützten Materials in der Vortrainingsphase von KI-Modellen ein. Der Bericht stellt fest, dass KI-Labore nun behaupten, ihre Modelle könnten mit Rechteinhabern konkurrieren (z. B. durch die Erstellung von Inhalten, die Originalwerken ähneln), was ihre Verteidigung mit „Fair Use“ in Urheberrechtsklagen schwächt. Diese Änderung könnte erhebliche Auswirkungen auf die Datenquellen und die Compliance von KI-Modellen haben. (Quelle: Dorialexander)

Nvidia veröffentlicht professionelle Grafikkarte RTX Pro 5000 mit 48 GB GDDR7-Speicher: Nvidia hat die neue professionelle Desktop-GPU RTX Pro 5000 vorgestellt, die auf der Blackwell-Architektur basiert. Die Grafikkarte ist mit 48 GB GDDR7-Speicher ausgestattet, bietet eine Speicherbandbreite von bis zu 1344 GB/s und hat eine Leistungsaufnahme von 300 W. Obwohl sie offiziell als „preisgünstige“ 48-GB-Blackwell-Grafikkarte bezeichnet wird, wird ein hoher Preis erwartet (Kommentare erwähnen die 4000-Dollar-Klasse). Sie richtet sich hauptsächlich an professionelle Workstation-Benutzer und bietet leistungsstarke Rechenleistung für Aufgaben wie das Training von KI-Modellen und umfangreiche 3D-Renderings. (Quelle: Reddit r/LocalLLaMA)

🧰 Tools
RunwayML führt References-Funktion ein, mit der verschiedene Referenzmaterialien zur Inhaltserstellung gemischt werden können: Die neue Funktion “References” von RunwayML ermöglicht es Benutzern, verschiedene Referenzmaterialien (wie Bilder, Stile) als „Rohstoffe“ zu mischen und basierend auf beliebigen Kombinationen dieser „Rohstoffe“ neue visuelle Inhalte zu generieren. Die Funktion wird als eine nahezu echtzeitfähige Kreativmaschine angesehen, die Benutzern helfen kann, verschiedene kreative Ideen schnell umzusetzen und die Flexibilität und Möglichkeiten von KI bei der Erstellung visueller Inhalte erheblich zu erweitern. (Quelle: c_valenzuelab)
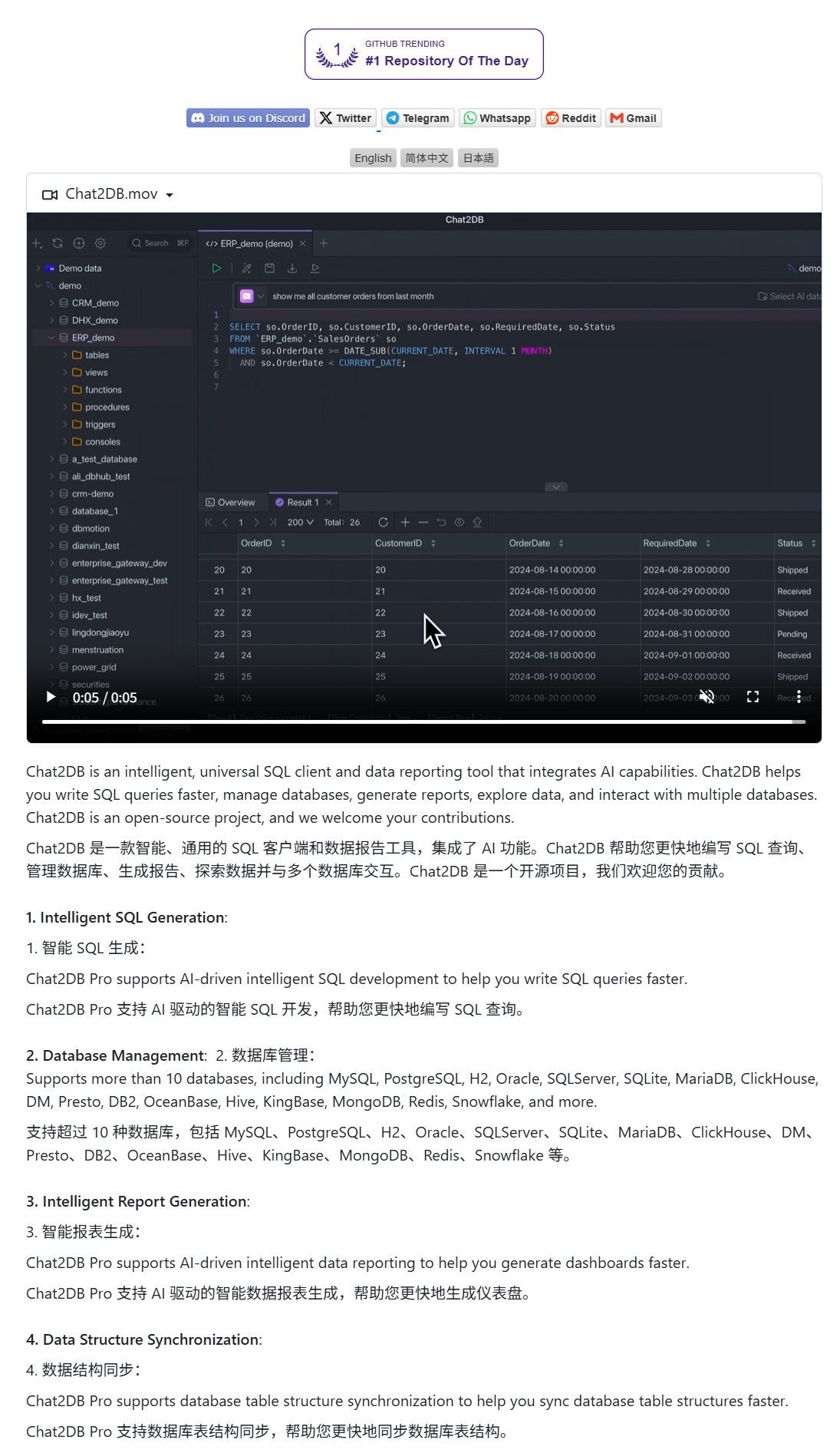
Chat2DB: KI-Client für Datenbankbedienung mittels natürlicher Sprache: Chat2DB ist ein KI-gestütztes Datenbank-Client-Tool, das Benutzern die Interaktion mit Datenbanken über natürliche Sprache ermöglicht. Beispielsweise kann ein Benutzer fragen: „Welcher Kunde hat diesen Monat am meisten ausgegeben?“. Chat2DB kann die Frage mithilfe von KI verstehen und basierend auf der Tabellenstruktur der Datenbank automatisch entsprechende SQL-Abfrageanweisungen generieren, die Abfrage ausführen und die Ergebnisse zurückgeben. Dies senkt die technische Hürde für die Datenbankbedienung erheblich und ermöglicht auch nicht-technischen Mitarbeitern eine bequeme Datenabfrage und -analyse. Das Projekt ist auf GitHub als Open Source verfügbar. (Quelle: karminski3)
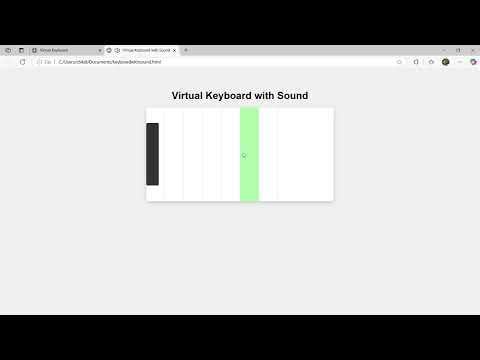
Qwen 3 8B-Modell zeigt ausgezeichnete Code-Fähigkeiten, kann HTML-Tastatur generieren: Das Qwen 3 8B-Modell (Q6_K quantisierte Version) zeigt trotz seiner geringen Parameteranzahl hervorragende Leistungen bei der Codegenerierung. Ein Benutzer ließ das Modell mit zwei kurzen Prompts erfolgreich einen spielbaren HTML-Tastaturcode generieren. Dies zeigt das Potenzial kleinerer Modelle, auch bei spezifischen Aufgaben eine hohe Praktikabilität zu erreichen, was besonders für ressourcenbeschränkte lokale Bereitstellungsszenarien attraktiv ist. (Quelle: Reddit r/LocalLLaMA)
Ollama Chat: Lokales LLM-Chat-Tool mit Claude-ähnlicher Oberfläche: Ollama Chat ist eine Web-Chat-Oberfläche, die für lokale große Sprachmodelle entwickelt wurde und deren UI-Stil und Benutzererfahrung sich an Claude von Anthropic orientieren. Das Tool unterstützt das Hochladen von Textdateien, die Aufzeichnung des Gesprächsverlaufs und die Einstellung von System-Prompts und zielt darauf ab, eine einfach zu bedienende und ästhetisch ansprechende Lösung für die lokale LLM-Interaktion bereitzustellen. Das Projekt ist auf GitHub als Open Source verfügbar, sodass Benutzer es selbst bereitstellen und verwenden können. (Quelle: Reddit r/LocalLLaMA)
Prompt-Techniken für KI-generierte personalisierte Karten (Geburtstag/Muttertag): Ein Benutzer teilte Prompt-Techniken für die Verwendung von KI zur Erstellung personalisierter Karten (z. B. Geburtstagskarten, Muttertagskarten). Entscheidend ist die klare Angabe des Kartenthemas (z. B. Muttertag, Geburtstag), des Stils (z. B. femininer Stil, kindlicher Stil), des Empfängers (z. B. Mama, Sandy, Jimmy), des Alters (z. B. 30 Jahre, 6 Jahre) sowie des spezifischen Inhalts des Grußtextes oder eines warmen, süßen Tons. Durch die Kombination dieser Elemente kann die KI angeleitet werden, Kartendesigns zu generieren, die den Anforderungen entsprechen. (Quelle: dotey)

📚 Lernen
Google veröffentlicht Whitepaper zu Prompt Engineering, leitet Benutzer an, wie sie effektiv Fragen stellen können: Google hat ein Whitepaper zu Prompt Engineering veröffentlicht (zugänglich über Kaggle), das Benutzern beibringen soll, wie sie KI-Modellen effektiver Fragen stellen können. Das Tutorial ist klar strukturiert und beschreibt detailliert, wie Ausgabeanforderungen präzisiert, der Ausgabebereich eingeschränkt und Variablen verwendet werden können. Dies hilft Benutzern, die Effizienz und Effektivität der Interaktion mit großen Sprachmodellen zu verbessern und so präzisere und nützlichere Antworten zu erhalten. (Quelle: karminski3)

Team der HKUST (Guangzhou) stellt MultiGO vor: Hierarchische Gaußsche Modellierung zur Generierung texturierter 3D-Menschen aus Einzelbildern: Ein Team der Hong Kong University of Science and Technology (Guangzhou) hat ein innovatives Framework namens MultiGO vorgestellt, das durch hierarchische Gaußsche Modellierung texturierte 3D-Menschenmodelle aus einem einzigen Bild rekonstruiert. Die Methode zerlegt den menschlichen Körper in verschiedene Genauigkeitsebenen wie Skelett, Gelenke und Falten und verfeinert diese schrittweise. Die Kerntechnologie verwendet Gaußsche Splatting-Punkte als 3D-Primitive und umfasst Module zur Skelett-, Gelenk- und Faltenoptimierung. Diese Forschungsarbeit wurde für die CVPR 2025 ausgewählt und bietet neue Ansätze für die 3D-Rekonstruktion von Menschen aus Einzelbildern. Der Code wird in Kürze als Open Source veröffentlicht. (Quelle: WeChat)

Tsinghua, Fudan und HKUST veröffentlichen gemeinsam RM-BENCH: Erster Benchmark zur Bewertung von Reward-Modellen: Angesichts der aktuellen Probleme bei der Bewertung von Reward-Modellen für große Sprachmodelle, wie „Form vor Inhalt“ und Stil-Bias, haben Forschungsteams der Tsinghua University, Fudan University und der Hong Kong University of Science and Technology gemeinsam den ersten systematischen Benchmark zur Bewertung von Reward-Modellen, RM-BENCH, veröffentlicht. Dieser Benchmark deckt vier Hauptbereiche ab: Chat, Code, Mathematik und Sicherheit. Durch die Bewertung der Sensibilität des Modells für feine Inhaltsunterschiede und seiner Robustheit gegenüber Stilabweichungen zielt er darauf ab, einen zuverlässigeren neuen Standard für „Inhaltsrichter“ zu etablieren. Die Studie ergab, dass bestehende Reward-Modelle in den Bereichen Mathematik und Code schlecht abschneiden und allgemein Stil-Bias aufweisen. Diese Arbeit wurde für ICLR 2025 Oral angenommen. (Quelle: WeChat)

Tianjin University und Tencent veröffentlichen COME-Lösung als Open Source: Verbessert TTA-Robustheit mit 5 Codezeilen, löst Modellzusammenbrüche: Die Tianjin University und Tencent haben gemeinsam die COME (Conservatively Minimizing Entropy)-Methode vorgestellt, die darauf abzielt, das Problem der übermäßigen Konfidenz und des Zusammenbruchs von Modellen während der Test-Time Adaptation (TTA) zu lösen, das durch Entropieminimierung (EM) verursacht wird. COME modelliert explizit die Vorhersageunsicherheit durch Einführung subjektiver Logik und kontrolliert die Unsicherheit indirekt durch eine adaptive Logit-Beschränkung (Einfrieren der Logit-Norm), um eine konservative Entropieminimierung zu erreichen. Die Methode erfordert keine Änderung der Modellarchitektur und kann mit nur wenigen Codezeilen in bestehende TTA-Methoden eingebettet werden. Sie verbessert die Robustheit und Genauigkeit von Modellen auf Datensätzen wie ImageNet-C signifikant bei minimalem Rechenaufwand. Das Paper wurde für ICLR 2025 angenommen und der Code ist Open Source. (Quelle: WeChat)
Huawei und IIE CAS schlagen DEER vor: Mechanismus „Dynamic Early Exit“ in Chain-of-Thought verbessert Effizienz und Präzision von LLM-Inferenz: Huawei hat gemeinsam mit dem Institute of Information Engineering, Chinese Academy of Sciences (IIE CAS) den DEER (Dynamic Early Exit in Reasoning)-Mechanismus vorgeschlagen. Dieser zielt darauf ab, das Problem des übermäßigen Nachdenkens bei großen Sprachmodellen während der Inferenz mit langen Chain-of-Thought (Long CoT) zu lösen. DEER überwacht Inferenz-Übergangspunkte, induziert experimentelle Antworten und bewertet deren Konfidenz, um dynamisch zu entscheiden, ob das Denken vorzeitig beendet und eine Schlussfolgerung generiert werden soll. Experimente zeigen, dass DEER bei Inferenz-LLMs wie der DeepSeek-Serie die Länge der generierten Chain-of-Thought ohne zusätzliches Training im Durchschnitt um 31 % bis 43 % reduziert und gleichzeitig die Genauigkeit um 1,7 % bis 5,7 % erhöht. (Quelle: WeChat)

CAS et al. schlagen R1-Reward vor: Training multimodaler Reward-Modelle durch stabiles Reinforcement Learning: Forschungsteams der Chinesischen Akademie der Wissenschaften (CAS), der Tsinghua University, Kuaishou und der Nanjing University haben R1-Reward vorgeschlagen, eine Methode zum Training multimodaler Reward-Modelle (MRM) mithilfe des stabilen Reinforcement-Learning-Algorithmus StableReinforce, um deren Fähigkeit zum Langzeit-Reasoning zu verbessern. StableReinforce behebt Instabilitätsprobleme, die bei bestehenden RL-Algorithmen wie PPO beim Training von MRMs auftreten können, durch eine Pre-Clip-Strategie, einen Advantage-Filter und einen neuartigen Konsistenz-Reward-Mechanismus (Einführung eines Schiedsrichtermodells zur Überprüfung der Konsistenz von Analyse und Antwort), um den Trainingsprozess zu stabilisieren. Experimente zeigen, dass R1-Reward auf mehreren MRM-Benchmarks besser abschneidet als SOTA-Modelle und die Leistung durch mehrfaches Sampling und Abstimmung während der Inferenz weiter verbessert werden kann. (Quelle: WeChat)
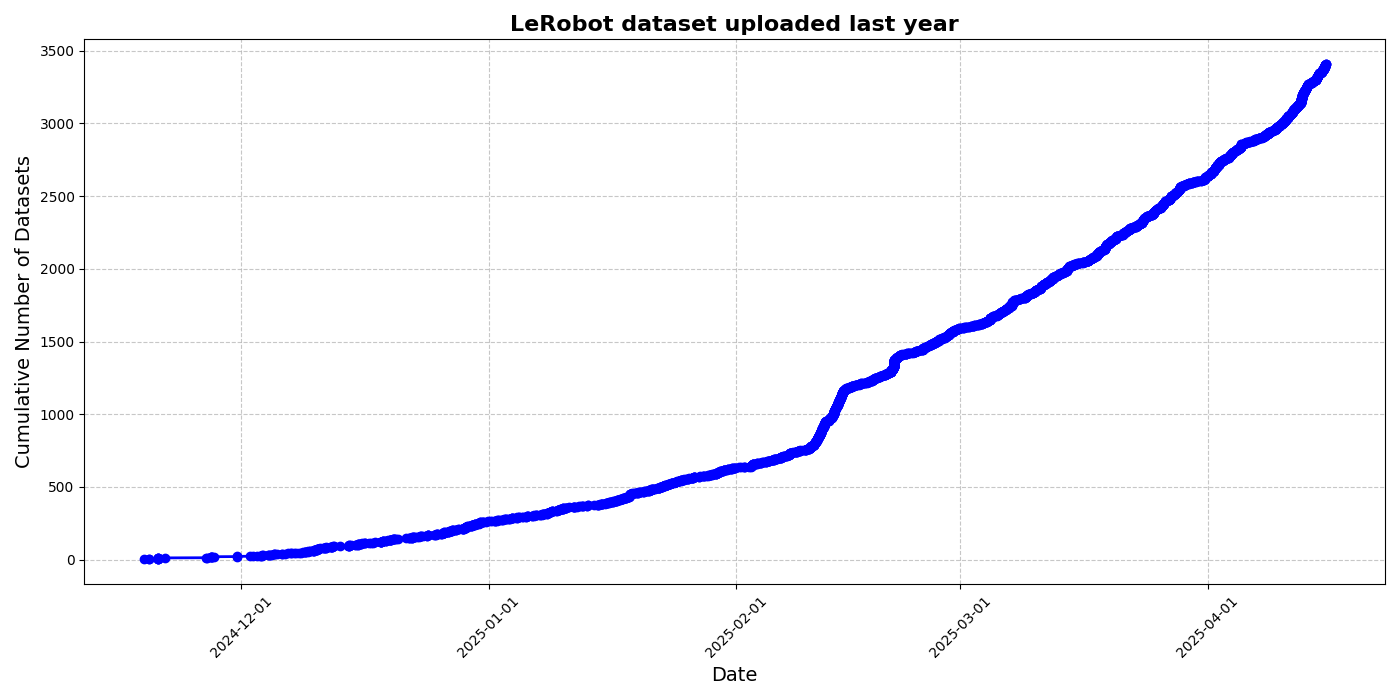
HuggingFace startet LeRobot Community-Datensatz-Initiative, um den „ImageNet-Moment“ für Roboter zu fördern: HuggingFace hat das LeRobot Community-Datensatz-Projekt initiiert, das darauf abzielt, ein „ImageNet“ für den Bereich Robotik zu schaffen und durch Community-Beiträge die Entwicklung allgemeiner Robotertechnologie voranzutreiben. Der Artikel betont die Bedeutung der Datenvielfalt für die Generalisierungsfähigkeit von Robotern und weist darauf hin, dass bestehende Roboterdatensätze oft aus eingeschränkten akademischen Umgebungen stammen. LeRobot vereinfacht die Datenerfassung, den Upload-Prozess und senkt die Hardwarekosten, um Benutzer zu ermutigen, Daten von verschiedenen Robotern (wie So100, Koch-Roboterarm) bei vielfältigen Aufgaben (wie Schachspielen, Bedienung von Schubladen) zu teilen. Gleichzeitig schlägt der Artikel Qualitätsstandards für Daten und eine Liste von Best Practices vor, um Herausforderungen wie inkonsistente Datenannotationen und unklare Merkmalszuordnungen zu bewältigen und den Aufbau hochwertiger, vielfältiger Roboterdatensätze zu fördern. (Quelle: HuggingFace Blog, LoubnaBenAllal1)
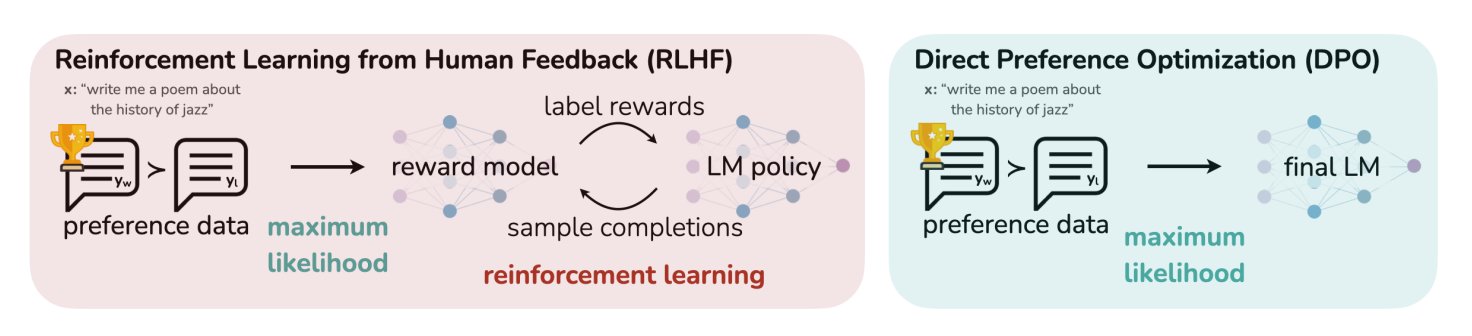
HuggingFace-Blogbeitrag fasst 11 Alignment- und Optimierungsalgorithmen für LLMs zusammen: TheTuringPost teilte einen Artikel auf HuggingFace, der 11 Alignment- und Optimierungsalgorithmen für Large Language Models (LLMs) zusammenfasst. Zu diesen Algorithmen gehören PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization), SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback) sowie SPIN (Self-Play Fine-Tuning). Der Artikel bietet Links und weitere Informationen zu diesen Algorithmen und gibt Forschern und Entwicklern einen Überblick über LLM-Optimierungsmethoden. (Quelle: TheTuringPost)
UC Berkeley teilt Kursmaterialien für den Graduiertenkurs CS280 in Computer Vision: Die Professoren Angjoo Kanazawa und Jitendra Malik von der University of California, Berkeley, haben alle Vorlesungsmaterialien ihres in diesem Semester unterrichteten Graduiertenkurses CS280 in Computer Vision geteilt. Sie sind der Meinung, dass dieses Material, das klassische und moderne Inhalte der Computer Vision kombiniert, gut funktioniert hat, und stellen es Lernenden zur Verfügung. (Quelle: NandoDF)
GVM-RAFT: Dynamisches Sampling-Framework zur Optimierung von Chain-of-Thought-Inferenzen: Ein neues Paper stellt das GVM-RAFT-Framework vor, das Chain-of-Thought-Inferenzen optimiert, indem es die Sampling-Strategie für jeden Prompt dynamisch anpasst, um die Gradientenvarianz zu minimieren. Diese Methode soll bei mathematischen Reasoning-Aufgaben eine 2-4-fache Beschleunigung erreichen und die Genauigkeit verbessern. (Quelle: _akhaliq)
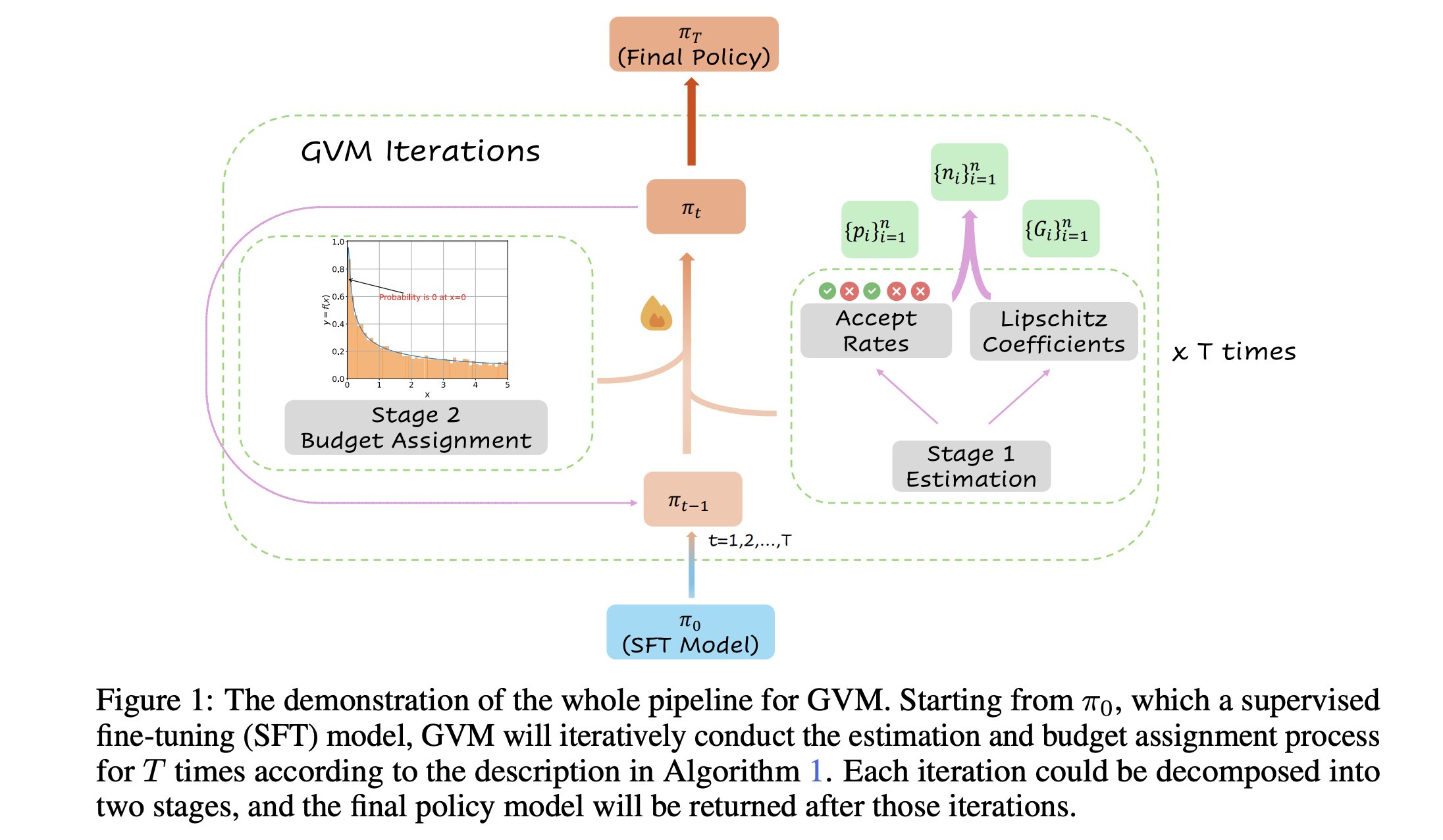
Neues Framework R&B verbessert die Leistung von Sprachmodellen durch dynamisches Ausbalancieren von Trainingsdaten: Eine neue Studie namens R&B schlägt ein neues Framework vor, das die Leistung von Sprachmodellen durch dynamisches Ausbalancieren der Trainingsdaten verbessert, wobei nur 0,01 % zusätzlicher Rechenaufwand anfällt. Diese Methode zielt darauf ab, die Effizienz der Datennutzung zu optimieren, um mit geringen Kosten eine Verbesserung der Modellleistung zu erzielen. (Quelle: _akhaliq)
Paper diskutiert neue Perspektive auf KI-Sicherheit: Gesellschaftlicher und technologischer Fortschritt als Nähen einer Flickendecke: Ein neues auf arXiv veröffentlichtes Paper mit dem Titel „Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt“ schlägt eine neue Sichtweise auf KI-Sicherheit vor und argumentiert, dass der Kern der KI-Sicherheit darin liegen sollte, zu verhindern, dass Meinungsverschiedenheiten zu Konflikten eskalieren. Das Paper vergleicht den gesellschaftlichen und technologischen Fortschritt mit dem Nähen einer ständig wachsenden, sich verändernden, fleckigen und vielfarbigen Decke und betont die Bedeutung der Aufrechterhaltung von Stabilität und Zusammenarbeit in komplexen Systemen. (Quelle: jachiam0)
Paper diskutiert adaptives Computing in autoregressiven Sprachmodellen: Eine Diskussion erwähnt die Interessantheit des adaptiven Computings im Deep Learning und listet relevante technologische Entwicklungen auf: PonderNet (DeepMind, 2021) als frühes Werkzeug zur Integration von neuronalen Netzen und Schleifen; Diffusionsmodelle, die Berechnungen durch mehrfache Forward-Propagation durchführen; und neuere Inferenz-Sprachmodelle, die durch die Generierung einer beliebigen Anzahl von Tokens ähnliche Effekte erzielen. Dies spiegelt den Trend zu Flexibilität und Dynamik bei der Zuweisung und Nutzung von Rechenressourcen durch Modelle wider. (Quelle: jxmnop)
Paper diskutiert, wie „schlechte Daten“ zu „guten Modellen“ führen können: Ein Paper der Harvard University aus dem Jahr 2025 mit dem Titel „When Bad Data Leads to Good Models“ (arXiv:2505.04741) untersucht, wie in bestimmten Fällen scheinbar minderwertige Daten (z. B. Vortrainingsdaten, die Inhalte von 4chan enthalten) paradoxerweise dazu beitragen können, Modelle besser auszurichten und ihr „Power Level“ zu verbergen, wodurch sie sich besser verhalten. Dies löst eine Diskussion über Datenqualität, Modellausrichtung und die Authentizität des Modellverhaltens aus. (Quelle: teortaxesTex)

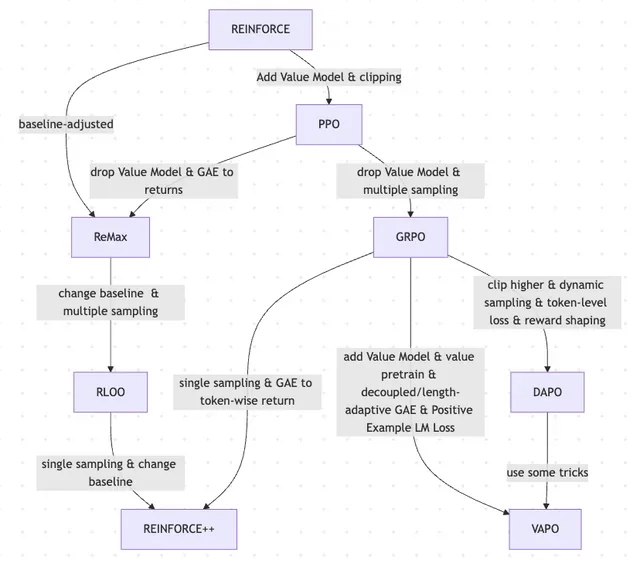
Paper diskutiert die Entwicklung von RLHF und seinen Varianten, von REINFORCE bis VAPO: Ein Forschungsartikel fasst die Entwicklung von Reinforcement Learning (RL)-Methoden zusammen, die zum Finetuning von Large Language Models (LLMs) verwendet werden. Der Artikel zeichnet die Entwicklung von klassischen Algorithmen wie PPO und REINFORCE bis hin zu neueren Methoden wie GRPO, ReMax, RLOO, DAPO und VAPO nach und analysiert dabei den Verzicht auf Wertemodelle, Änderungen der Sampling-Strategien, Anpassungen der Baseline sowie die Anwendung von Techniken wie Reward Shaping und Token-Level Loss. Die Studie zielt darauf ab, die Forschungslandschaft von RLHF und seinen Varianten im Bereich des LLM-Alignments klar darzustellen. (Quelle: Reddit r/MachineLearning)
Paper „Absolute Zero“: KI führt Reinforcement Self-Play Reasoning ohne menschliche Daten durch: Ein Whitepaper mit dem Titel „Absolute Zero: Reinforced Self-Play Reasoning with Zero Data“ (arXiv:2505.03335) untersucht neue Methoden zum Training von Logik-KI. Forscher trainierten Logik-KI-Modelle ohne Verwendung von menschlich annotierten Datensätzen. Die Modelle konnten selbstständig Reasoning-Aufgaben generieren, Probleme lösen und Lösungen durch Codeausführung validieren. Dies löste eine Diskussion darüber aus, ob KI in einer völlig ursprünglichen Umgebung ohne Vorwissen (wie Mathematik, Physik, Sprache) von Grund auf symbolische Repräsentationen erfinden, logische Strukturen definieren, Zahlensysteme entwickeln und kausale Modelle erstellen kann, sowie über das Potenzial und die Risiken einer solchen „fremdartigen Intelligenz“. (Quelle: Reddit r/ArtificialInteligence, Reddit r/artificial)
Intelligent Human-Computer Interaction Lab der Fudan University rekrutiert Master- und Doktoranden für den Jahrgang 2026: Das Intelligent Human-Computer Interaction Lab der School of Computer Science and Technology der Fudan University rekrutiert Master- und Doktoranden für das Sommercamp/die Empfehlungszulassung des Jahrgangs 2026. Das Labor wird von Professor Shang Li geleitet und seine Forschungsrichtungen umfassen tragbare AGI (Kombination von MemX Smart Glasses und LLM), Open-Source Embodied Intelligence, Modellkomprimierung (von groß zu klein) sowie Machine-Learning-Systeme (wie ML-Kompilierungsoptimierung, KI-Prozessoren). Das Labor widmet sich der Erforschung menschenzentrierter Intelligenz und der Integration neuer Paradigmen der Mensch-Maschine-Interaktion mit großen Modellen und intelligenten tragbaren, verkörperten intelligenten Systemen. (Quelle: WeChat)

💼 Wirtschaft
Überblick über 10 KI-Startups mit einer Bewertung von über 1 Milliarde US-Dollar und weniger als 50 Mitarbeitern: Business Insider hat 10 KI-Startups aufgelistet, die eine Bewertung von über 1 Milliarde US-Dollar haben, aber weniger als 50 Mitarbeiter beschäftigen. Dazu gehören Safe Superintelligence (Bewertung 320 Milliarden US-Dollar, 20 Mitarbeiter), OG Labs (Bewertung 20 Milliarden US-Dollar, 40 Mitarbeiter), Magic (Bewertung 1,58 Milliarden US-Dollar, 20 Mitarbeiter), Sakana AI (Bewertung 1,5 Milliarden US-Dollar, 28 Mitarbeiter) und andere. Diese Unternehmen zeigen das Potenzial im KI-Bereich, mit kleinen Teams hohe Bewertungen zu erzielen, und spiegeln den hohen Wert von Technologie und Innovation auf dem Kapitalmarkt wider. (Quelle: hardmaru)
Fourier Intelligence vertieft Anwendung im Pflege- und Rehabilitationsbereich, kooperiert mit Shanghai International Medical Center zur Schaffung einer Basis für Embodied Intelligence in der Rehabilitation: Das Embodied Intelligence Einhorn Fourier Intelligence kündigte auf seinem ersten Embodied Intelligence Ecosystem Summit an, mit dem Shanghai International Medical Center zusammenzuarbeiten, um gemeinsam die Anwendung von Embodied Intelligence Robotern in der medizinischen Rehabilitation voranzutreiben. Dies umfasst den Aufbau von Standards, die gemeinsame Entwicklung von Lösungen und wissenschaftliche Forschung sowie die Schaffung der ersten Demonstrationsbasis für Embodied Intelligence in der Rehabilitation in China. Fourier-Gründer Gu Jie formulierte die Kernstrategie für die nächsten zehn Jahre als „Fokus auf Pflege und Rehabilitation, Konzentration auf Interaktion, Dienst am Menschen“ und betonte, dass die medizinische Rehabilitation die Grundlage des Unternehmens sei. Seit seiner Gründung im Jahr 2015 hat das Unternehmen sein Angebot von Rehabilitationsrobotern schrittweise auf allgemeine humanoide Roboter der GR-1- und GRx-Serie erweitert und bereits Hunderte von Einheiten ausgeliefert. (Quelle: 36氪)
Meta soll ehemalige Pentagon-Beamte rekrutieren, möglicherweise zur Stärkung der Präsenz im Militärbereich: Laut Forbes rekrutiert Meta ehemalige Pentagon-Beamte. Dieser Schritt könnte darauf hindeuten, dass das Unternehmen plant, seine Aktivitäten im Bereich Militärtechnologie oder verteidigungsbezogene Bereiche zu verstärken. Diese Entwicklung hat Diskussionen und Aufmerksamkeit hinsichtlich der Beteiligung großer Technologieunternehmen an militärischen Anwendungen ausgelöst. (Quelle: Reddit r/artificial)

🌟 Community
Andrej Karpathys These, dass dem LLM-Lernen ein wichtiges Paradigma des „System Prompt Learning“ fehlt, löst heiße Diskussionen aus: Andrej Karpathy ist der Ansicht, dass dem aktuellen LLM-Lernen ein wichtiges Paradigma fehlt, das er „System Prompt Learning“ nennt. Er weist darauf hin, dass Vortraining dem Wissenserwerb dient und Finetuning (Supervised/Reinforcement Learning) dem habituellen Verhalten, wobei beides Parameteränderungen beinhaltet. Jedoch scheinen die umfangreichen menschlichen Interaktionen und Rückmeldungen nicht ausreichend genutzt zu werden. Er vergleicht dies damit, dem Protagonisten von „Memento“ ein Notizbuch zu geben, um globales Problemlösungswissen und Strategien zu speichern. Diese Ansicht löste eine breite Diskussion aus. Einige meinen, dies ähnele der Philosophie von DSPy oder betreffe Probleme des Gedächtnisses/der Optimierung und des kontinuierlichen Lernens, und diskutierten, wie ähnliche Mechanismen in Langgraph implementiert werden könnten. (Quelle: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
Forderung von KI-Unternehmen an Bewerber, keine KI für Bewerbungsschreiben zu nutzen, löst heiße Diskussionen aus: Die Forderung von KI-Unternehmen wie Anthropic, dass Bewerber bei der Erstellung von Bewerbungsunterlagen (z. B. Lebensläufen) keine KI-Tools verwenden sollen, hat in der Community Diskussionen ausgelöst. Einige Personalverantwortliche gaben an, dass die von KI generierten Lebensläufe oft „Textmüll“ seien und selbst erfahrene Fachkräfte dadurch den Fokus verlieren könnten. Andere Bewerber argumentieren jedoch, dass KI ihnen helfen könne, ihre Lebensläufe besser auf die Stellenanforderungen abzustimmen, Fähigkeiten hervorzuheben und die Lesbarkeit zu verbessern. Die Diskussion erstreckte sich auch auf das Phänomen, dass Plattformen wie LinkedIn mit KI-generierten Inhalten überflutet werden, und ob andere Methoden wie Videos zur Bewertung von Bewerbern eingesetzt werden sollten. (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)

Die „Erkennbarkeit“ von KI-generierten Inhalten löst Diskussionen aus, Nutzer halten sie für leicht wahrnehmbar: In Community-Diskussionen wird darauf hingewiesen, dass von KI (insbesondere ChatGPT) generierte Inhalte leicht zu erkennen sind, nicht nur aufgrund bestimmter Satzzeichen (wie Gedankenstriche) oder Satzmuster (wie „Das ist nicht x; das ist y.“), sondern vielmehr aufgrund ihres charakteristischen „Rhythmus“ und ihrer „Flachheit“. Sobald KI-Spuren erkannt werden, wirken die Inhalte unecht und unpersönlich. Einige Nutzer berichten, dass sie in E-Mails, Social-Media-Posts und sogar Videospielen auf solche Fälle gestoßen sind und meinen, dass die direkte Verwendung von KI zur Erstellung ganzer Inhalte zu langweiligen und unaufrichtigen Ergebnissen führt. Sie empfehlen Nutzern, KI als Werkzeug zur Modifikation und Personalisierung einzusetzen. (Quelle: Reddit r/ChatGPT)
KI-Entwicklung zeigt „Flitterwochen-Rückschlag“-Zyklus, spiegelt menschliche Präferenz für Authentizität wider: Es gibt die Ansicht, dass das Aufkommen neuer generativer KI-Modelle (Text, Bild, Musik usw.) oft von einer „Flitterwochenphase“ begleitet wird, in der die Menschen von ihren Fähigkeiten begeistert sind. Doch bald, wenn die Menschen beginnen, die „Muster“ oder „Spuren“ der KI-Generierung zu erkennen, kommt es zu einem Rückschlag, bei dem Lob in Skepsis umschlägt und die Werke sogar als „seelenlos“ empfunden werden. Dieses schnelle Erlernen der Erkennung von KI-Werken und die Tendenz zu fehlerhaften menschlichen Schöpfungen könnte bedeuten, dass KI eher als Hilfsmittel dient und menschliche Schöpfer nicht vollständig ersetzt, da die Menschen die Geschichten hinter den Werken, die Absicht des Autors und die Authentizität schätzen. (Quelle: Reddit r/ArtificialInteligence)
Interne KI-Code-Generierungsrate bei Anthropic über 70 %, löst Assoziationen mit KI-Selbstiteration aus: Mike Krieger von Anthropic gab bekannt, dass intern über 70 % der Pull Requests nun von KI generiert werden. Diese Zahl löste eine Community-Diskussion aus, wobei einige an Szenarien der Selbstbearbeitung und -verbesserung von Maschinen dachten, ähnlich wie in Science-Fiction-Werken. Gleichzeitig äußerten andere Zweifel an der Echtheit dieser Daten und ihrer genauen Bedeutung (z. B. der Komplexität dieser PRs). (Quelle: Reddit r/ClaudeAI)

Nvidia CEO Jensen Huang betont, dass alle Mitarbeiter KI-Agenten nutzen sollen, KI wird die Rolle von Entwicklern neu definieren: Nvidia CEO Jensen Huang erklärte, dass das Unternehmen alle Mitarbeiter mit KI-Assistenten ausstatten wird. KI-Agenten werden in den täglichen Entwicklungsprozess integriert, um Code zu optimieren, Schwachstellen zu finden und das Prototyping zu beschleunigen. Er ist der Ansicht, dass in Zukunft jeder mehrere KI-Assistenten befehligen wird und die Produktivität exponentiell steigen wird. Meta CEO Zuckerberg, Microsoft CEO Nadella und andere teilen ähnliche Ansichten und glauben, dass KI den Großteil der Programmierarbeit übernehmen wird und sich die Rolle der Entwickler hin zu „KI befehligen“ und „Anforderungen definieren“ wandeln wird. Dieser Trend deutet auf eine tiefgreifende Veränderung im Softwareentwicklungszyklus hin, bei der KI-Programmierwerkzeuge wie GitHub Copilot, Cursor usw. alltäglich werden. (Quelle: WeChat)

Diskussion: Ist es für ML-Forscher machbar, jährlich 1000-2000 Paper zu lesen?: In der Community wird diskutiert, dass Spitzenforscher im Bereich Machine Learning jährlich möglicherweise fast 2000 wissenschaftliche Arbeiten lesen. Einige Kommentatoren sind der Meinung, dass die Anzahl der gelesenen Paper an sich nur ein Proxy-Indikator ist. Wirklich wichtig sei die Fähigkeit, aus einer großen Menge an Informationen Signale herauszufiltern, effektive Informationen zu extrahieren und diese korrekt anzuwenden. Mit den Highlights und Trends des Fachgebiets Schritt zu halten und bei Bedarf tief in spezifische Inhalte einzutauchen – diese Informationsfilterfähigkeit sei eine Schlüsselkompetenz dieses Jahrhunderts. (Quelle: torchcompiled)
Diskussion: GPU kaufen vs. mieten für Modelltraining/Finetuning: Praktiker des maschinellen Lernens stehen bei der Wahl der GPU-Ressourcen vor der Entscheidung zwischen Kauf und Miete. Erfahrene Nutzer empfehlen eine hybride Strategie: eine lokal konfigurierte Consumer-GPU mit akzeptabler Leistung für kleine Experimente und die Anmietung von Cloud-GPUs für umfangreiche Trainingsaufgaben. Die Wahl hängt von der Modellkomplexität, der Datenmenge und dem Budget ab. Cloud-GPUs haben Vorteile bei der Organisation von ML Ops, aber gängige Cloud-GPUs wie die T4 bieten bei gleichem Preis möglicherweise nicht die Leistung von High-End-Consumer-Karten (wie 3090/4090), obwohl die Cloud Top-GPUs wie A100/H100 mit größerem Grafikspeicher anbieten kann. (Quelle: Reddit r/MachineLearning)
💡 Sonstiges
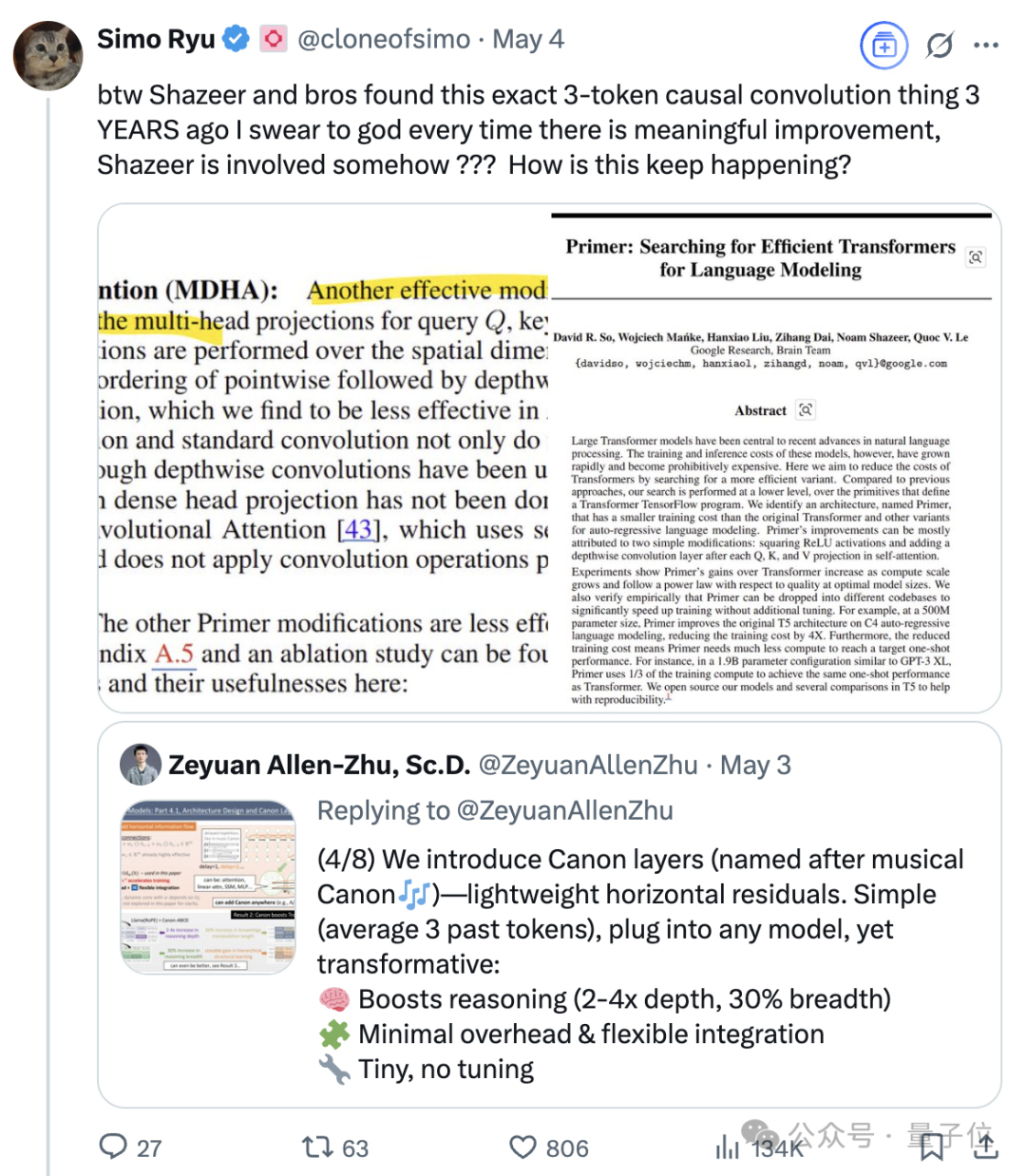
Der anhaltende Einfluss von Noam Shazeer, einem der acht Transformer-Autoren: Noam Shazeer, einer der acht Autoren des Transformer-Architektur-Papiers „Attention Is All You Need“, wird weithin als einer der Hauptbeitragenden angesehen. Sein Einfluss reicht weit darüber hinaus und umfasst frühe Forschungen zur Einführung von Sparse Gating Mixture-of-Experts (MoE) in Sprachmodelle, den Adafactor-Optimierer, Multi-Query Attention (MQA) sowie Gated Linear Units (GLU) in Transformern. Diese Arbeiten legten den Grundstein für die Architekturen der heutigen Mainstream-Großsprachmodelle und machen Shazeer zu einer Schlüsselfigur, die kontinuierlich technische Paradigmen im KI-Bereich definiert. Er verließ Google, um Character.AI zu gründen, kehrte später mit der Übernahme des Unternehmens zu Google zurück und leitete gemeinsam das Gemini-Projekt. (Quelle: WeChat)
Tech-Giganten stehen vor einer durch KI ausgelösten „Midlife-Crisis“: Ein Artikel analysiert, dass die „Glorreichen Sieben“ der Technologiebranche, darunter Google, Apple, Meta und Tesla, vor disruptiven Herausforderungen durch künstliche Intelligenz stehen und sich in einer „Midlife-Crisis“ befinden. Googles Suchgeschäft wird durch KI-gestützte Direktantwortmodelle bedroht, Apple macht langsame Fortschritte bei KI-Innovationen, Meta versucht, KI in soziale Netzwerke zu integrieren, aber Llama 4 hat die Erwartungen nicht erfüllt, und Tesla kämpft mit sinkenden Verkaufszahlen und Aktienkursen. Diese einstigen Branchenführer müssen, ähnlich den Fallbeispielen in „The Innovator’s Dilemma“, auf die durch KI verursachten neuen Märkte und Geschäftsmodelle reagieren, andernfalls könnten sie im KI-Zeitalter zu „Nokias“ werden. (Quelle: WeChat)

Google KI übertrifft menschliche Ärzte in simulierten medizinischen Gesprächen: Studien zeigen, dass ein KI-System, das für medizinische Interviews trainiert wurde, in Gesprächen mit simulierten Patienten und bei der Auflistung möglicher Diagnosen basierend auf der Krankengeschichte die Leistung menschlicher Ärzte erreicht oder sogar übertrifft. Forscher glauben, dass solche KI-Systeme das Potenzial haben, zur Universalisierung und Demokratisierung von Gesundheitsdiensten beizutragen. (Quelle: Reddit r/ArtificialInteligence)
