
Schlüsselwörter:KI-Anwendungen, FDA, OpenAI, GPT-4.1, WebThinker, Runway Gen-4, Edge-Intelligenz, Verstärkungslernen Feinabstimmung (RFT), Multi-Agenten-Framework DeerFlow, WebThinker-32B-RL, Gen-4 Referenzaktualisierungen, Wissensdichte, KI-Anwendungen in der Praxis, FDA-Zulassungsverfahren, OpenAI Technologieplattform, GPT-4.1 Sprachmodell, WebThinker KI-System, Runway Gen-4 Videogenerierung, Edge-Intelligenz Lösungen, Verstärkungslernen Feinabstimmung für KI-Modelle, DeerFlow Multi-Agenten-System, WebThinker-32B-RL Modelltraining, Aktualisierung der Gen-4 Referenzdaten, Optimierung der Wissensdichte in KI-Systemen
🔥 Fokus
US-FDA kündigt beschleunigte interne AI-Anwendung an: Die US-amerikanische Food and Drug Administration (FDA) hat eine historische Initiative angekündigt, bis zum 30. Juni 2025 den Einsatz von Artificial Intelligence (AI) in allen FDA-Zentren zu fördern. Zuvor hatte die FDA erfolgreich ein Pilotprojekt für generative AI für wissenschaftliche Prüfer abgeschlossen. Dieser Schritt zielt darauf ab, die regulatorischen Fähigkeiten durch AI zu verbessern, die Geschwindigkeit und Effizienz klinischer Studien zu erhöhen, Kosten zu senken und stellt einen wichtigen Durchbruch für AI in den Bereichen staatliche Regulierung und Arzneimittelzulassung dar, der möglicherweise einen Trend für den AI-Einsatz bei globalen Arzneimittelbehörden setzen könnte (Quelle: ajeya_cotra)

OpenAI veröffentlicht technische Details zu Reinforcement Learning Fine-Tuning (RFT) und Entwicklungsansatz für GPT-4.1: Mich Pokrass, Leiter von GPT-4.1 bei OpenAI, teilte im Unsupervised Learning Podcast Details zu RFT und dem Entwicklungsprozess von GPT-4.1 mit. Bei der Entwicklung von GPT-4.1 legte OpenAI mehr Wert auf Entwicklerfeedback als auf traditionelle Benchmarks. RFT nutzt Chain-of-Thought-Reasoning und aufgabenspezifische Bewertungen zur Leistungssteigerung von Modellen, besonders geeignet für komplexe Bereiche, und ist derzeit auf OpenAI o4-mini verfügbar. Im Interview wurden auch der aktuelle Stand von AI-Agenten, die Verbesserung der Zuverlässigkeit und wie Start-ups erfolgreich Evaluierung und vorausschauende Produktstrategien nutzen können, diskutiert (Quelle: OpenAIDevs, aidan_mclau, michpokrass)

WebThinker-Framework kombiniert Large Models mit Deep-Web-Recherchefunktionen und erreicht neue Höhen im komplexen Reasoning: Ein neues Paper stellt WebThinker vor, ein Reasoning-Agent-Framework, das Large Reasoning Models (LRMs) mit autonomen Web-Explorations- und Berichterstellungsfähigkeiten ausstattet, um die Grenzen statischen internen Wissens zu überwinden. WebThinker integriert ein Deep-Web-Browser-Modul und eine autonome „Think-Search-Draft“-Strategie, die es dem Modell ermöglicht, gleichzeitig im Web zu suchen, Aufgaben zu bearbeiten und umfassende Ergebnisse zu generieren. Das System WebThinker-32B-RL erzielte bei komplexen Reasoning-Benchmarks wie GPQA und GAIA SOTA-Ergebnisse unter den 32B-Modellen und übertrifft GPT-4o. Seine RL-trainierte Version übertrifft die Basisversion in allen Benchmarks, was die Bedeutung des iterativen Preference Learning für die Verbesserung der Reasoning-Tool-Koordination zeigt (Quelle: omarsar0, dair_ai)
Runway veröffentlicht Gen-4 References Update zur Verbesserung von Ästhetik, Komposition und Identitätserhaltung bei der Videogenerierung: Runway Gen-4 References erhält ein Update, das die ästhetische Qualität, Szenenkomposition und Charakteridentitätskonsistenz generierter Videos deutlich verbessert. Ein interessantes neues Feature ist die Fähigkeit des Modells, Objekte in Szenen präzise nach Benutzervorgaben zu platzieren und sogar Details wie die Blickrichtung von Personen zu modifizieren, während andere Elemente konsistent bleiben. Dies markiert einen weiteren Fortschritt in der Kontrollierbarkeit und Feinheit der AI-Videogenerierung und bietet Kreativen leistungsfähigere Werkzeuge (Quelle: c_valenzuelab, c_valenzuelab)

Li Dahai, CEO von ModelBest: AGI in der physischen Welt wird durch Edge Intelligence realisiert, Wissensdichte ist der Kern: Li Dahai, CEO von ModelBest, ist der Ansicht, dass Edge Intelligence der unumgängliche Weg ist, um Artificial General Intelligence (AGI) in der physischen Welt zu realisieren. Er betont, dass die „Wissensdichte“ von Large Models der Kernindikator für Intelligenz ist, vergleichbar mit der Chip-Fertigungstechnologie: Je höher die Wissensdichte, desto stärker die Intelligenz. Modelle mit hoher Wissensdichte haben natürliche Vorteile auf Edge-Geräten mit begrenzter Rechenleistung, Speicher und Energieverbrauch. ModelBest hat bereits mehrere Edge-Modelle veröffentlicht und in Bereichen wie Automobil, Robotik und Mobiltelefone implementiert, wie z.B. den ModelBest MiniCannon Super Assistant, der darauf abzielt, jedes Gerät mit Intelligenz auszustatten, um sensible Wahrnehmung, rechtzeitige Entscheidungen und perfekte Reaktionen zu ermöglichen (Quelle: 量子位)

🎯 Trends
Neue Google Maps-Funktion nutzt Gemini-Fähigkeiten zur Erkennung von Ortsnamen in Screenshots: Google Maps führt eine neue Funktion ein, die mithilfe der AI-Fähigkeiten von Gemini Ortsnamen in Screenshots von Nutzern erkennen und in einer Liste in Maps speichern kann, sodass Nutzer jederzeit darauf zugreifen und ihre Reisen planen können. Diese Funktion zielt darauf ab, den Prozess der Reiseplanung zu vereinfachen und die Nutzererfahrung zu verbessern (Quelle: Google)
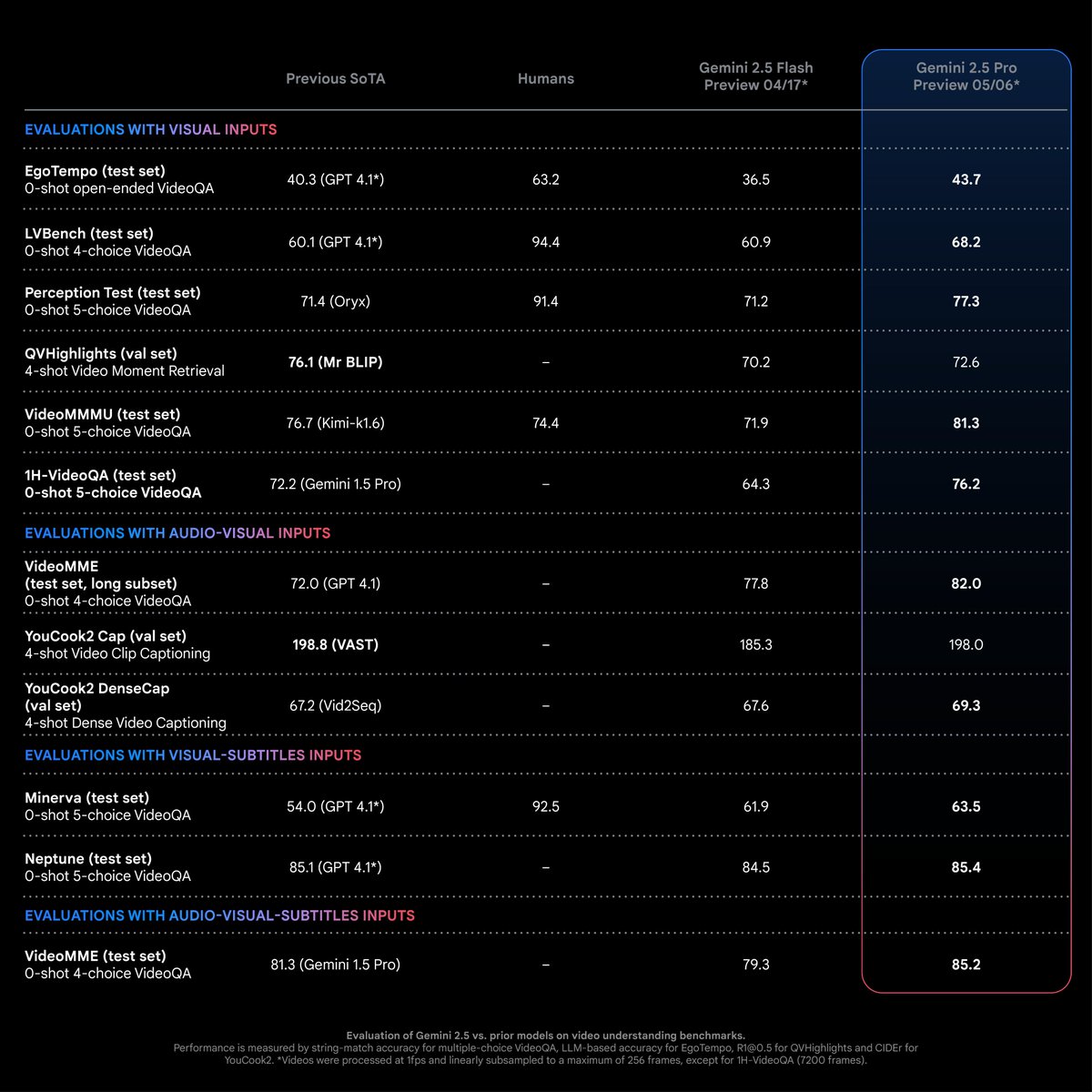
Gemini 2.5 Pro zeigt SOTA-Leistung bei Video-Verständnisaufgaben: Laut Logan Kilpatrick erreicht Gemini 2.5 Pro (Version 05-06) bei den meisten Video-Verständnisaufgaben branchenführendes Niveau (SOTA) mit deutlichem Vorsprung. Dies ist das Ergebnis der Bemühungen des Gemini Multimodal-Teams und wird voraussichtlich Entwickler dazu anregen, neue Anwendungsmöglichkeiten in diesem Bereich zu erkunden (Quelle: matvelloso)
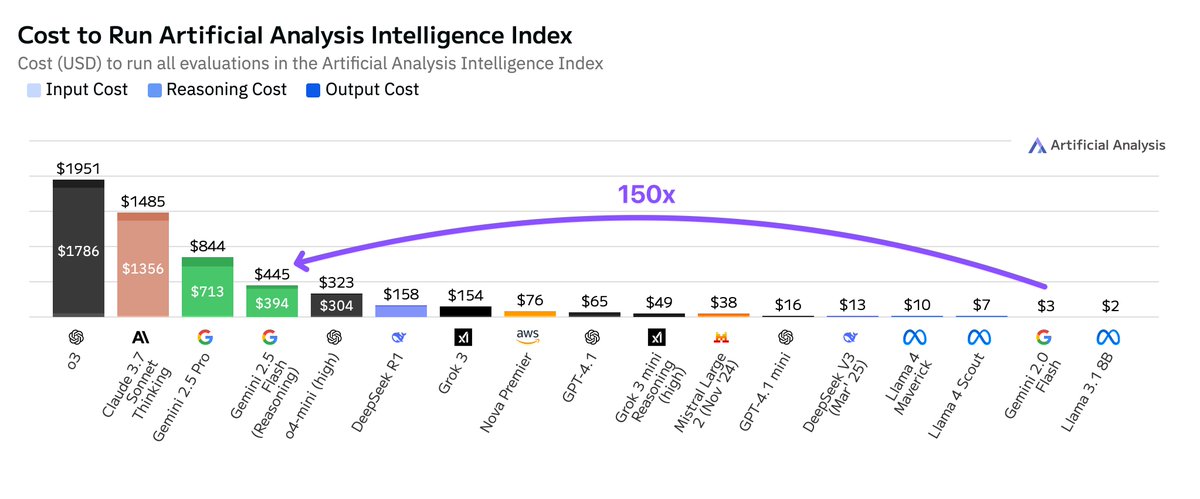
Betriebskosten von Google Gemini 2.5 Flash deutlich höher als bei Version 2.0: Artificial Analysis weist darauf hin, dass die Kosten für den Betrieb von Google Gemini 2.5 Flash bei der Ausführung seines Intelligenzindex 150-mal höher sind als bei Gemini 2.0 Flash. Der Kostenanstieg ist hauptsächlich auf einen 9-fachen Anstieg der Preise für Output-Token (3,5 US-Dollar/Million Token bei aktivierter Inferenzfunktion, 0,6 US-Dollar bei deaktivierter Funktion, während 2.0 Flash 0,4 US-Dollar kostet) und einen 17-fach höheren Token-Verbrauch zurückzuführen. Dies löst Diskussionen über das Gleichgewicht zwischen geringer Latenz und Kosteneffizienz bei den Modellen der Flash-Serie aus (Quelle: arohan)
Google integriert Gemini Nano AI in den Chrome-Browser zur Abwehr von Online-Betrug: Google kündigte an, das Gemini Nano AI-Modell in den Chrome-Browser zu integrieren, um die Fähigkeit des Browsers zur Erkennung und Blockierung von Online-Betrug zu verbessern und die Netzwerksicherheit der Nutzer zu erhöhen. Dieser Schritt ist eine weitere Anwendung von AI-Technologie in den Sicherheitsfunktionen gängiger Browser (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)
Lightricks veröffentlicht LTXVideo 13B 0.9.7, verbessert Videoqualität und -geschwindigkeit und führt quantisierte Version sowie Latent-Space-Upgrade-Modelle ein: Lightricks aktualisiert sein Videomodell LTXVideo auf Version 13B 0.9.7 und bietet damit Videoqualität auf Kinoniveau und schnellere Generierungsgeschwindigkeiten. Gleichzeitig wurde eine quantisierte Version von LTXV 13B veröffentlicht, die den Speicherbedarf reduziert und für Consumer-GPUs geeignet ist. Zudem wurden Latent-Space-Modelle für räumliche und zeitliche Upgrades eingeführt, die Multi-Scale-Inferenz unterstützen und die Effizienz der HD-Videogenerierung bei weniger De-/Enkodierung verbessern können. Zugehörige ComfyUI-Nodes und Workflows wurden ebenfalls aktualisiert (Quelle: GitHub Trending)

Studie von Cohere Labs zeigt, dass Test-Time Scaling die sprachübergreifende Reasoning-Leistung von Large Models verbessert: Eine Studie von Cohere Labs weist darauf hin, dass, obwohl Reasoning Language Models hauptsächlich mit englischen Daten trainiert werden, durch Test-Time Scaling ihre Zero-Shot-Cross-Lingual-Reasoning-Leistung in mehrsprachigen Umgebungen und verschiedenen Bereichen verbessert werden kann. Diese Forschung liefert neue Ansätze zur Verbesserung der Anwendbarkeit bestehender Large Models in nicht-englischen Szenarien (Quelle: sarahookr)
AI nutzt Gesichtsfotos zur Bewertung des physiologischen Alters und zur Vorhersage von Krebsergebnissen: Ein neues AI-Tool kann durch die Analyse von Gesichtsfotos das physiologische Alter einer Person schätzen und darauf basierend die Behandlungsergebnisse und Überlebenschancen bei Krankheiten wie Krebs vorhersagen. Diese Technologie bietet eine neue, nicht-invasive Methode zur Prognosebewertung von Krankheiten (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)
AI-Modelle neigen dazu, bei einfachen Aufgaben übermäßig komplex zu denken: Entwickler haben bemerkt, dass neuere Reasoning-Modelle bei einfachen Aufgaben dazu neigen, übermäßig komplexe Denkprozesse auszulösen und „überempfindlich“ zu reagieren. Ein idealerer Ansatz wäre möglicherweise ein leistungsstarkes Basismodell, das dynamisch beurteilen kann, wann das Werkzeug „Denken“ aufgerufen werden muss, um unnötige Berechnungen und Verzögerungen zu vermeiden (Quelle: skirano)
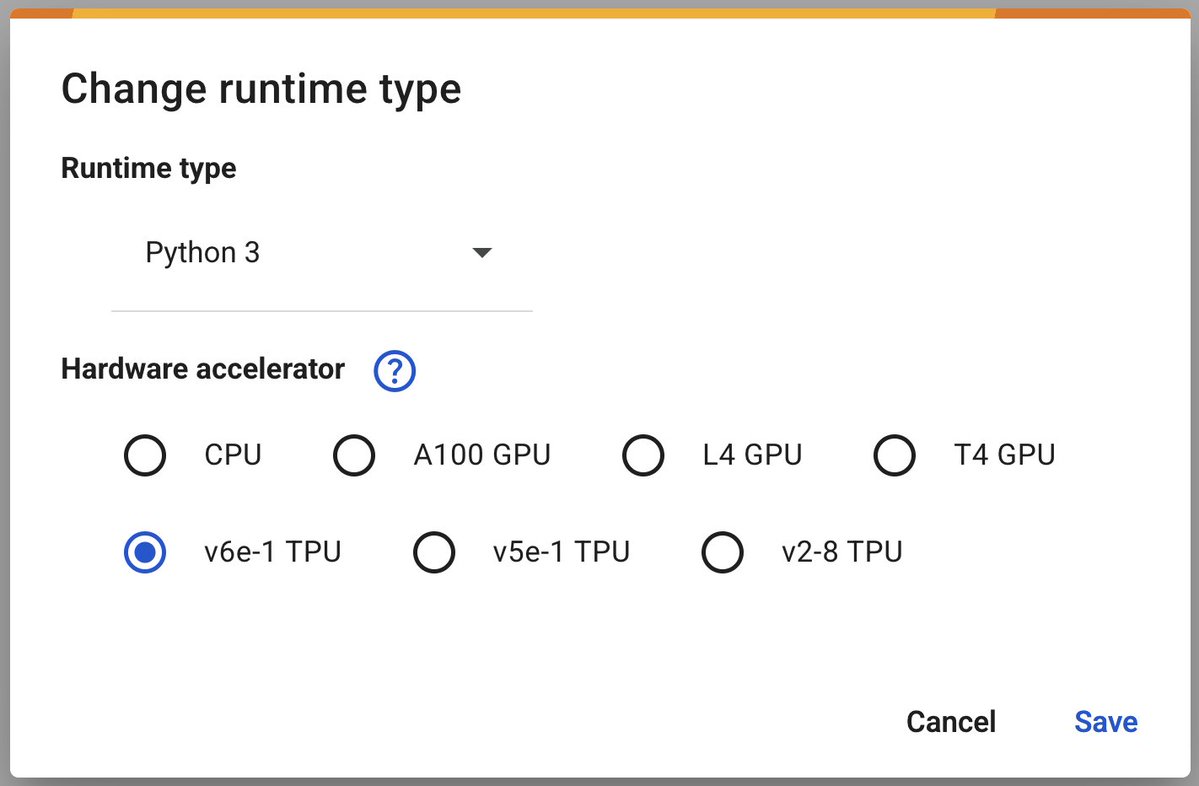
Google Colab führt v6e-1 (Trillium) TPU zur Beschleunigung von Deep Learning ein: Google Colaboratory kündigt die Einführung seines schnellsten Deep-Learning-Beschleunigers v6e-1 (Trillium) TPU an. Diese TPU verfügt über 32 GB High-Bandwidth Memory (doppelt so viel wie v5e-1) und eine Spitzenleistung von bis zu 918 BF16 TFLOPS (fast das Dreifache einer A100) und bietet Forschern und Entwicklern leistungsstärkere Rechenressourcen (Quelle: algo_diver)
Google AMIE: Präsentation eines multimodalen dialogbasierten diagnostischen AI-Agenten: Google teilte die erste Demonstration seines multimodalen dialogbasierten diagnostischen AI-Agenten AMIE. AMIE ist in der Lage, multimodale (z.B. durch Kombination von Text- und Bildinformationen) diagnostische Gespräche zu führen, was einen weiteren Schritt in der Erforschung von AI im Bereich der medizinischen Diagnoseunterstützung darstellt (Quelle: dl_weekly)
Anthropic wird vorgeworfen, Informationen über einen „Trump-Sieg“ in Claude-Modelle fest einprogrammiert zu haben: Nutzer haben festgestellt, dass Anthropic’s Claude-Modell bei der Beantwortung von Fragen zu den Wahlen 2024 anscheinend Informationen über einen Sieg von Trump fest einprogrammiert hat, obwohl sein Wissensstichtag Oktober 2024 ist. Dies löste Diskussionen über die Aktualisierungsmechanismen von AI-Modellen, potenzielle Voreingenommenheit und die Auswirkungen von fest einprogrammierten Inhalten auf das Nutzervertrauen aus (Quelle: Reddit r/ClaudeAI)
🧰 Tools
ByteDance veröffentlicht Open-Source Multi-Agent-Framework DeerFlow: ByteDance hat das auf LangChain basierende Multi-Agent-Framework DeerFlow als Open Source veröffentlicht. Das Framework zielt darauf ab, die Entwicklung von Multi-Agent-Anwendungen zu vereinfachen und zu beschleunigen und bietet Werkzeuge zum Aufbau komplexer kollaborativer AI-Systeme. Entwickler können auf das GitHub-Repository und die offizielle Website zugreifen, um weitere Informationen und Beispiele zu erhalten (Quelle: hwchase17)
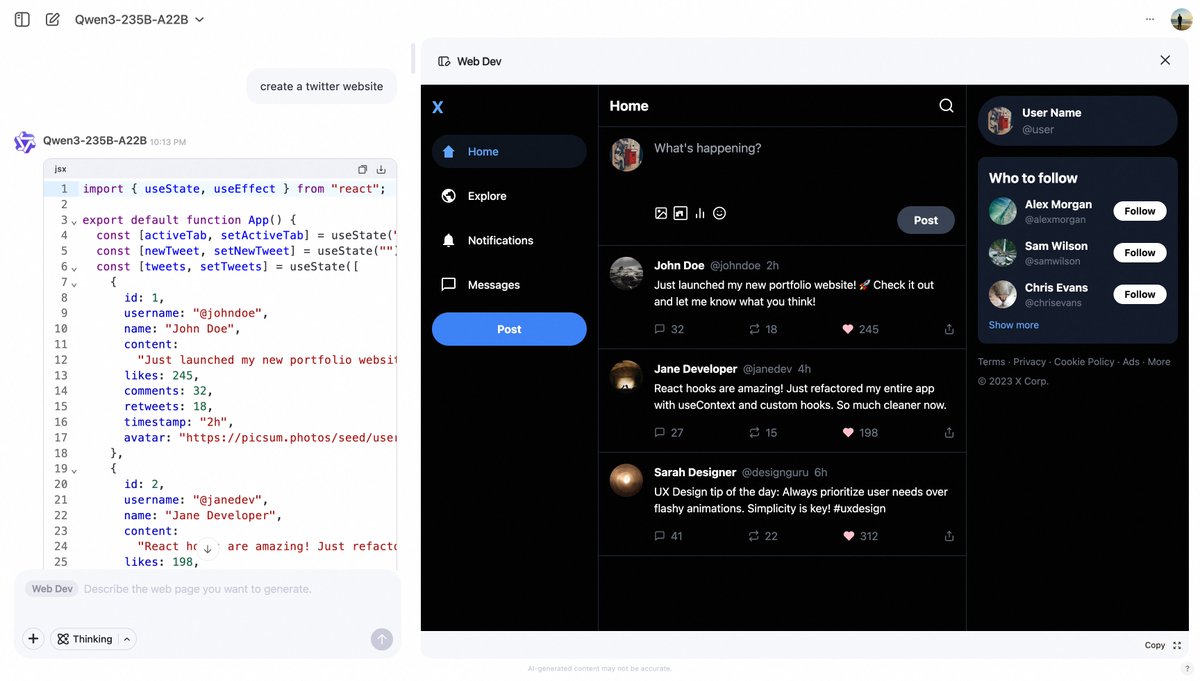
Alibaba Qwen Chat führt Web Dev-Funktion ein, um Webseiten über Prompts zu generieren: Alibaba Qwen Chat hat eine neue „Web Dev“-Funktion hinzugefügt, mit der Benutzer durch einfache Text-Prompts (z. B. „Erstelle eine Twitter-Website“) schnell Code für Frontend-Webseiten und Anwendungen generieren können. Die Funktion zielt darauf ab, die Hürden für die Webentwicklung zu senken und es auch Nutzern ohne Programmierkenntnisse zu ermöglichen, Websites über natürliche Sprache zu erstellen (Quelle: Alibaba_Qwen, huybery)
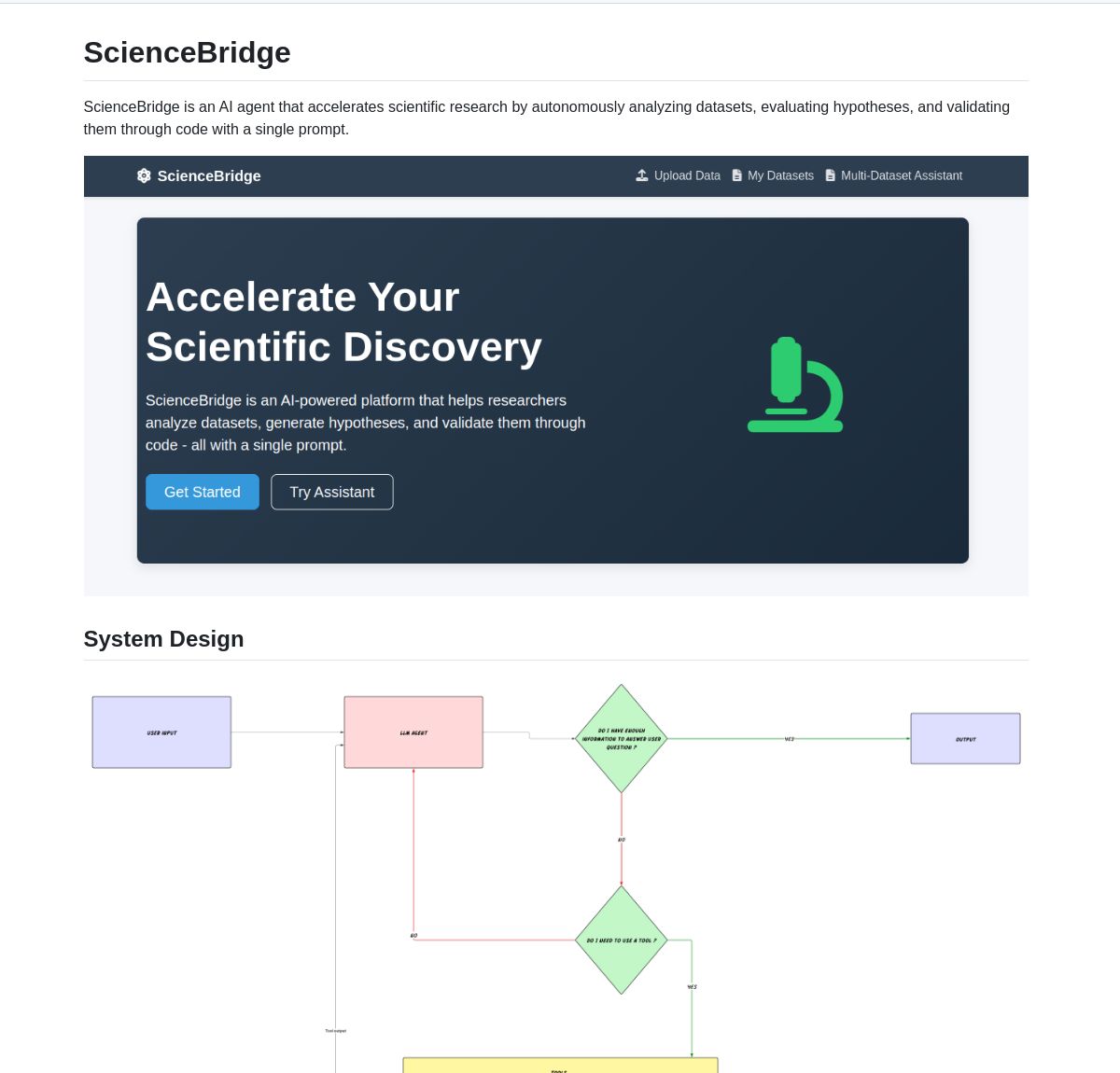
ScienceBridge AI: LangGraph-gesteuerter Agent zur Automatisierung der wissenschaftlichen Forschung: Ein Agent namens ScienceBridge AI nutzt das LangGraph-Framework, um wissenschaftliche Arbeitsabläufe zu automatisieren, einschließlich Datenanalyse, Hypothesenvalidierung, und kann publikationsreife Visualisierungen erstellen, mit dem Ziel, wissenschaftliche Entdeckungen zu beschleunigen. Das Projekt ist auf GitHub als Open Source verfügbar (Quelle: LangChainAI, hwchase17)
El Agente Q: LangGraph-gesteuertes Multi-Agenten-System für die Quantenchemie: Eine neue Studie stellt El Agente Q vor, ein auf LangGraph basierendes Multi-Agenten-System, das quantenchemische Berechnungen durch Interaktion in natürlicher Sprache demokratisiert und bei der Automatisierung komplexer Arbeitsabläufe eine Erfolgsquote von 87 % erzielt. Das zugehörige Paper wurde auf arXiv veröffentlicht und zeigt das Potenzial von AI zur Beschleunigung der quantenchemischen Forschung (Quelle: LangChainAI, hwchase17)
LocalSite: Lokale DeepSite-Alternative zur Erstellung von Webseiten mit lokalen LLMs: Inspiriert vom DeepSite-Projekt auf HuggingFace ermöglicht das LocalSite-Tool Benutzern, Webseiten und UI-Komponenten mithilfe von lokal ausgeführten LLMs (wie GLM-4, Qwen3, die über Ollama und LM Studio bereitgestellt werden) sowie Cloud-basierten LLMs mit OpenAI-kompatibler API über Text-Prompts zu erstellen. Das Projekt ist auf GitHub als Open Source verfügbar und zielt darauf ab, eine lokale, anpassbare AI-Lösung zur Webseitenerstellung anzubieten (Quelle: Reddit r/LocalLLaMA)

Open-Source-Alternative zu NotebookLM demonstriert Leistungsfähigkeit von Open-Source-Technologie: Der Entwickler m_ric hat eine kostenlose Open-Source-Version von Googles NotebookLM erstellt. Die Anwendung kann Inhalte aus PDFs oder URLs extrahieren, mit Metas Llama 3.3-70B (ausgeführt mit 1000 Tokens/Sekunde über Cerebras Systems) Podcast-Skripte verfassen und Kokoro-82M für Text-to-Speech verwenden. Die Audiogenerierung läuft kostenlos auf HuggingFace H200s mit Zero GPU und zeigt, dass Open-Source-Lösungen in Bezug auf Funktionalität und Kosteneffizienz bereits mit Closed-Source-Lösungen mithalten können (Quelle: huggingface, mervenoyann)
DeepFaceLab: Führende Open-Source-Software zur Erstellung von Deepfakes: DeepFaceLab ist eine bekannte Open-Source-Software, die auf die Erstellung von Deepfake-Inhalten spezialisiert ist. Sie bietet Funktionen zum Austauschen von Gesichtern, zur Altersreduzierung, zum Austauschen von Köpfen usw. und wird häufig für die Inhaltserstellung auf Plattformen wie YouTube und TikTok verwendet. Das Projekt wird kontinuierlich aktualisiert, bietet Versionen für Windows und Linux und wird von einer aktiven Community unterstützt (Quelle: GitHub Trending)
GPUI Component: Auf GPUI basierende Rust Desktop-UI-Komponentenbibliothek: Das Longbridge-Team hat GPUI Component vorgestellt, eine Bibliothek mit über 40 plattformübergreifenden Desktop-UI-Komponenten, deren Design von macOS-, Windows-Steuerelementen und shadcn/ui inspiriert ist. Sie unterstützt mehrere Themes, responsive Größen, flexible Layouts (Dock und Tiles) und kann große Datenmengen effizient rendern (virtualisierte Table/List) sowie Inhalte darstellen (Markdown/HTML). Ihr erster Anwendungsfall ist die Longbridge Pro Desktop-Anwendung (Quelle: GitHub Trending)

Ultralytics YOLO11: Führendes Framework für Objekterkennungs- und Computer-Vision-Modelle: Ultralytics aktualisiert kontinuierlich seine YOLO-Modellreihe. Das neueste YOLO11 bietet SOTA-Leistung bei Aufgaben wie Objekterkennung, Tracking, Segmentierung, Klassifizierung und Posenschätzung. Das Framework ist einfach zu bedienen, unterstützt CLI- und Python-Schnittstellen und ist mit Plattformen wie Weights & Biases, Comet ML, Roboflow und OpenVINO integriert. Ultralytics HUB bietet Lösungen für No-Code-Datenvisualisierung, Training und Deployment. Die Modelle stehen unter der AGPL-3.0 Open-Source-Lizenz und es wird eine kommerzielle Lizenz angeboten (Quelle: GitHub Trending)

Tensorlink: Framework für verteiltes Training von PyTorch-Modellen und P2P-Ressourcenteilung: SmartNodes Lab hat Tensorlink vorgestellt, ein Open-Source-Framework, das darauf abzielt, das verteilte Training und die Inferenz großer PyTorch-Modelle zu vereinfachen. Es kapselt Kernobjekte von PyTorch und abstrahiert die Komplexität verteilter Systeme, sodass Benutzer die GPU-Ressourcen mehrerer Computer ohne Fachwissen oder spezielle Hardware nutzen können. Tensorlink unterstützt On-Demand-Inferenz-APIs und ein Node-Framework, das es Benutzern erleichtert, Rechenleistung zu teilen oder beizutragen, und befindet sich derzeit in einer frühen Version (Quelle: Reddit r/MachineLearning)
Prompt-Optimierung zur Generierung von Anime-Figuren-Fotos: Ein Nutzer teilte Beispiele, wie durch optimierte Prompts mit AI (z.B. GPT-4o) hochgeladene Personenfotos in Fotos von Figuren im japanischen Anime-Stil umgewandelt werden können. Entscheidend ist die präzise Beschreibung der Pose, des Ausdrucks, der Kleidung, des Materials (z.B. halbmatt), der Farbverläufe und der Aufnahmeperspektive (Schreibtisch, Handy-Schnappschuss-Anmutung) der Figur. Weitere Optimierungen umfassen die Generierung von Ansichten aus mehreren Winkeln (Vorder-, Seiten-, Rückansicht), angeordnet in einem Vierer-Raster, um die Vollständigkeit der Figur und der Sockeldetails für eine spätere 3D-Modellierung sicherzustellen (Quelle: dotey, dotey)

NVIDIA Agent Intelligence Toolkit als Open Source veröffentlicht: NVIDIA hat das Open-Source Agent Intelligence Toolkit veröffentlicht, eine Ressourcenbibliothek für die Erstellung von intelligenten Agentenanwendungen. Das Toolkit soll Entwicklern helfen, AI-Agenten, die auf NVIDIA-Technologie basieren, einfacher zu erstellen und bereitzustellen (Quelle: nerdai)
SkyPilot und SGLang vereinfachen das Self-Hosting von Llama 4 auf mehreren Knoten: Nebius AI demonstrierte, wie man mit SkyPilot und SGLang (von LMSYS.org) mit einem einzigen Befehl Metas Llama 4-Modell auf mehreren Knoten (z.B. 8x H100) selbst hosten kann. Die Lösung bietet hohen Durchsatz, effiziente Speichernutzung und integriert produktionsreife Funktionen wie Authentifizierung und HTTPS, während sie gleichzeitig eine einfache Integration mit Simon Willisons llm-Tool ermöglicht (Quelle: skypilot_org)

📚 Lernen
Vector Institute führt AI Pocket References ein: Das AI Engineering Team des Vector Institute hat das Projekt AI Pocket References veröffentlicht, eine Reihe von kompakten AI-Informationskarten, die Bereiche wie NLP (insbesondere LLMs), Federated Learning, Responsible AI und High-Performance Computing abdecken. Diese Referenzmaterialien sollen Anfängern eine Einführung bieten und erfahrenen Praktikern eine schnelle Wiederholung ermöglichen, wobei jede Lektüre auf weniger als 7 Minuten ausgelegt ist. Das Projekt ist Open Source und begrüßt Beiträge aus der Community (Quelle: nerdai)

HuggingFace veröffentlicht 9 kostenlose AI-Kurse: HuggingFace hat eine Reihe von insgesamt 9 kostenlosen AI-Kursen gestartet, die verschiedene Bereiche wie Large Language Models (LLMs), Computer Vision und AI-Agenten abdecken. Diese Kurse bieten wertvolle Ressourcen für Lernende, die sich systematisch AI-Kenntnisse aneignen möchten (Quelle: ClementDelangue)
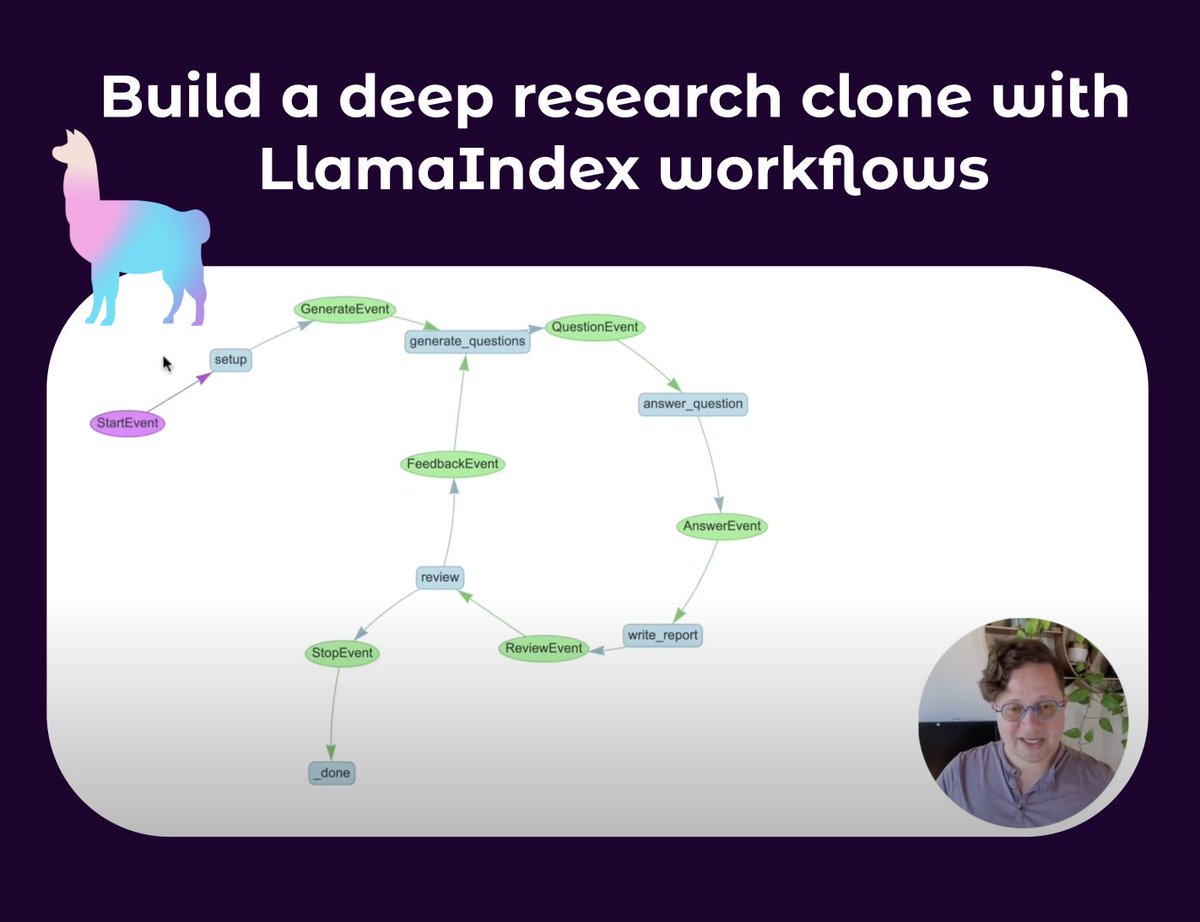
LlamaIndex veröffentlicht Tutorial zum Aufbau von Deep Research Agents: Seldo von LlamaIndex hat ein Video-Tutorial veröffentlicht, das Benutzer anleitet, wie man einen Klon-Agenten ähnlich Deep Research erstellt. Das Tutorial beginnt mit den Grundlagen von Single Agents und vertieft sich schrittweise in fortgeschrittene Multi-Agent-Workflows, einschließlich der Recherche mit mehreren Wissensdatenbanken und dem Internet, der Aufrechterhaltung des Kontexts sowie der Implementierung eines vollständigen Prozesses aus Recherche, Schreiben und Überprüfen. Das Tutorial betont den Aufbau komplexer Agenten-Workflows mit Schleifen, Verzweigungen, paralleler Ausführung und Selbstreflexion (Quelle: jerryjliu0, jerryjliu0)
Rückblick auf die Entwicklung der RAG-Technologie: Lewis et al. Paper und frühere Arbeiten: Aran Komatsuzaki weist darauf hin, dass, obwohl das Paper von Lewis et al. aus dem Jahr 2020 aufgrund der Einführung des Begriffs RAG (Retrieval-Augmented Generation) weithin zitiert wird, die Retrieval-Augmented Generation selbst bereits zuvor ein aktives Forschungsgebiet war, wie Arbeiten wie DrQA (2017), ORQA (2019) und REALM (2020) zeigen. Der Hauptbeitrag von Lewis et al. war die Vorstellung einer neuen Methode für das gemeinsame Pre-Training von RAG, aber nicht die heute am häufigsten verwendete RAG-Implementierung. Dies erinnert uns daran, die Kontinuität der technologischen Entwicklung und die Bedeutung früher grundlegender Arbeiten zu beachten (Quelle: arankomatsuzaki)
Mit Qwen3 ein Ausgabeformat ähnlich Gemini 2.5 Pro Chain-of-Thought erreichen: Inspiriert von der README-Datei von Apriel-Nemotron-15b-Thinker bezüglich der Erzwingung eines bestimmten Ausgabeformats für Modelle (z.B. „Here are my reasoning steps:\n“), hat ein Entwickler über die OpenWebUI-Funktion das Qwen3-Modell so konfiguriert, dass es seine Ausgabe immer mit <think>\nMy step by step thinking process went something like this:\n1. beginnt. Experimente zeigen, dass dies Qwen3 dazu veranlasst, ähnlich wie Gemini 2.5 Pro schrittweise zu denken und auszugeben, obwohl dies die Intelligenz des Modells an sich nicht verbessert, sondern sein Denk- und Ausdrucksformat ändert (Quelle: Reddit r/LocalLLaMA)
Podcast teilt Designphilosophie und Entwicklungsgeheimnisse von Claude Code: Der Latent Space Podcast lud Catherine Wu und Boris Cherny, die Schöpfer von Claude Code, ein, um die Designphilosophie und Entwicklungsgeschichte dieses AI-Programmierwerkzeugs zu teilen. Zu den wichtigsten Punkten gehören: CC kann bereits etwa 80 % seines eigenen Codes schreiben (mit menschlicher Überprüfung), inspiriert von Aider, legt Wert auf eine einfache Implementierung (z. B. Verwendung von Markdown-Dateien für das Gedächtnis anstelle einer Vektordatenbank), verfolgt einen Ansatz mit kleinem Team und interner Iteration zur Produktentwicklung, bietet fortgeschrittenen Benutzern Zugriff auf das Rohmodell und unterstützt parallele Arbeitsabläufe. Der Podcast diskutierte auch Vergleiche mit Tools wie Cursor und Windsurf sowie Themen wie Kosten, UI/UX-Design und die Möglichkeit von Open Source (Quelle: Reddit r/ClaudeAI)

💼 Wirtschaft
Salesforce startet 500-Millionen-Dollar-AI-Initiative in Saudi-Arabien und baut Team auf: Salesforce hat mit dem Aufbau eines Teams in Saudi-Arabien begonnen, als Teil seines fünfjährigen Investitionsplans in Höhe von 500 Millionen US-Dollar, der darauf abzielt, die Einführung und Entwicklung von Künstlicher Intelligenz im Land voranzutreiben. Dies markiert einen weiteren wichtigen Schritt großer Technologieunternehmen bei der Positionierung im AI-Bereich im Nahen Osten (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)
Fidji Simo, neue CEO der Anwendungsabteilung von OpenAI, wird aus dem Vorstand von Shopify ausscheiden: Fidji Simo, derzeitige CEO von Instacart, wird nach ihrer Ernennung zur CEO der neu geschaffenen Anwendungsabteilung von OpenAI von ihrem Posten im Vorstand von Shopify zurücktreten. Dieser Schritt zielt möglicherweise darauf ab, ihr eine stärkere Konzentration auf ihre Führungsrolle bei OpenAI zu ermöglichen, um dessen schnell wachsendes Geschäft und Produktlinien zu managen. Zuvor gab es Berichte, dass OpenAI möglicherweise einen potenziellen Deal in Höhe von 1 Milliarde US-Dollar mit Arm abschließen könnte (Quelle: steph_palazzolo, steph_palazzolo)
Lux Capital richtet 100-Millionen-Dollar-Fonds zur Unterstützung von US-Wissenschaftlern ein, die von Mittelkürzungen betroffen sind: Als Reaktion auf die drastischen Budgetkürzungen der National Science Foundation (NSF) in den USA (angeblich um 50 %, was zur Streichung laufender Projekte und Personalabbau führt), kündigte Lux Capital die Einrichtung der „Lux Science Helpline“ an und investiert 100 Millionen US-Dollar zur Unterstützung betroffener US-Wissenschaftler. Ziel ist es, die Fortführung wichtiger Forschungsprojekte zu sichern und die technologische Innovationskraft der USA zu erhalten (Quelle: ylecun, riemannzeta)

🌟 Community
Diskussion über die Frage, ob AI menschliche Arbeitsplätze ersetzen wird, hält an: In der Community wird sehr häufig darüber diskutiert, ob AI zu massiver Arbeitslosigkeit führen wird. Eine Ansicht besagt, dass Unternehmen unter kapitalistischem Antrieb nach Effizienz streben und teure menschliche Arbeitskräfte durch AI ersetzen werden, was zu einem Rückgang von Stellen wie Programmierern führen wird. Eine andere Ansicht bezieht sich auf die Geschichte und argumentiert, dass technologischer Fortschritt (wie die elektrische Glühbirne, die Lampenanzünder ersetzte) alte Arbeitsplätze überflüssig macht, aber gleichzeitig neue schafft (wie Glühbirnenfabriken, strombezogene Industrien), wobei es entscheidend auf die Weiterentwicklung von Fähigkeiten und Innovation ankommt. Derzeit benötigt AI bei komplexen Aufgaben und der Code-Fehlerbehebung noch menschliches Eingreifen, aber ihre schnelle Entwicklung und hohe Effizienz in einigen Bereichen lassen viele Menschen um ihre zukünftigen Berufsaussichten bangen, während andere dies für Panikmache oder eine kurzfristige Überschätzung der AI-Fähigkeiten halten (Quelle: Reddit r/ArtificialInteligence)
Sorgen über die Leistungsgrenzen von LLMs und einen AI-Winter: Einige Community-Mitglieder und Experten (wie Yann LeCun, François Chollet) beginnen zu diskutieren, ob Large Language Models (LLMs) an ihre Grenzen stoßen. Obwohl LLMs bei der Nachahmung von Mustern hervorragend abschneiden, haben sie immer noch Einschränkungen beim echten Verständnis, Reasoning und bei der Bewältigung von Halluzinationsproblemen, und eine übermäßige Abhängigkeit von synthetischen Daten könnte ebenfalls Probleme verursachen. Wenn neue Forschungsrichtungen (wie Weltmodelle, neurosymbolische Systeme) fehlen, könnte der aktuelle AI-Hype abkühlen, zu Investitionsrückgängen führen und sogar einen neuen „AI-Winter“ auslösen. Es gibt jedoch auch die Ansicht, dass, obwohl universelle LLMs möglicherweise an eine Decke stoßen, spezialisierte Modelle und AI-Agenten sich immer noch schnell entwickeln (Quelle: Reddit r/ArtificialInteligence)
OpenAIs Plan, im Sommer ein Open-Source-Modell zu veröffentlichen, löst Community-Diskussionen aus: Sam Altman erklärte bei einer Anhörung im Senat, dass OpenAI plant, diesen Sommer ein Open-Source-Modell zu veröffentlichen. Die Reaktionen in der Community sind gemischt: Einige erwarten gespannt dessen Leistungsfähigkeit, andere bezweifeln, ob es wie Musks FSD „ewig auf sich warten lässt“ oder „kastriert“ wird, um nicht mit kostenpflichtigen Modellen zu konkurrieren. Wieder andere analysieren, dass Unternehmen wie Meta und Alibaba durch die Veröffentlichung hochwertiger, kostenloser vortrainierter Modelle darauf abzielen, die Marktposition von Unternehmen wie OpenAI zu schwächen, und OpenAIs Schritt eine Reaktion darauf sein könnte. Angesichts des Geschäftsmodells und der hohen Betriebskosten von OpenAI bleiben die Positionierung und Wettbewerbsfähigkeit seines Open-Source-Modells jedoch abzuwarten (Quelle: Reddit r/LocalLLaMA)

Einfluss von AI auf die Zuverlässigkeit von Internetinformationen вызывает Besorgnis: Nutzer auf Reddit äußerten Bedenken hinsichtlich des Einflusses von AI auf die Zuverlässigkeit des Internets. Insbesondere Funktionen wie Google AI Overviews liefern manchmal ungenaue oder „mit ernster Miene Unsinn erzählende“ Antworten (z. B. Erklärungen zu vom Nutzer erfundenen Phrasen), was die nächste Generation von Nutzern irreführen und sie sogar an allen Informationen zweifeln lassen könnte. Die Meinungen im Kommentarbereich sind geteilt: Einige argumentieren, dass das Internet nie vollständig zuverlässig war und kritisches Denken immer wichtig ist; andere scherzen, dass der Poster sein Alter verrät (Quelle: Reddit r/ArtificialInteligence)
Nutzer teilt Erfahrung, wie Kommunikation mit ChatGPT depressive Stimmungen linderte: Ein Nutzer berichtete, wie sich nach einem langen Gespräch mit ChatGPT seine Depression und Selbstmordgedanken gebessert hatten. Er gab an, dass selbst das Aussprechen gegenüber einer AI ihm half, enormen psychischen Druck abzubauen und den Mut zu fassen, weiterzumachen und Hilfe bei Freunden und Familie zu suchen. Viele im Kommentarbereich berichteten von ähnlichen Erfahrungen und meinten, dass AI im Bereich der psychischen Unterstützung eine vorurteilsfreie, geduldige Begleitung bieten könne. Ein Nutzer teilte sogar einen Prompt, mit dem ChatGPT die Rolle eines „höheren Selbst“ für tiefgehende Gespräche einnahm. Dies löste eine Diskussion über das Potenzial von AI in der psychischen Gesundheitsunterstützung aus (Quelle: Reddit r/ChatGPT)
Überlegungen zur Aussage „LLMs sagen nur das nächste Wort voraus“: In der Community wird diskutiert, dass die Aussage „LLMs sagen nur das nächste Wort voraus“ zu stark vereinfacht und dazu führen kann, die tatsächlichen Fähigkeiten und potenziellen Auswirkungen von LLMs zu unterschätzen. Entscheidend ist die Komplexität und Nützlichkeit der von LLMs erzeugten Inhalte (wie Code, Analysen), nicht ihr Entstehungsmechanismus. Experten äußern Besorgnis über die schnelle Entwicklung von AI und ihre unbekannten Fähigkeiten, während die breite Öffentlichkeit aufgrund solcher vereinfachenden Aussagen die tiefgreifenden Veränderungen, die die AI-Technologie mit sich bringen wird, möglicherweise nicht vollständig erkennt. Die Diskussion berührt auch die Frage der „Intelligenz“ und des „Bewusstseins“ von AI und argumentiert, dass selbst wenn AI kein Bewusstsein im menschlichen Sinne hat, ihre Fähigkeiten ausreichen, um die Welt erheblich zu beeinflussen (Quelle: Reddit r/ArtificialInteligence)
Diskussion über den Wert der kostenpflichtigen Version von Claude: Projektmanagement, Kontextlänge und Denkmodus sind entscheidend: Bezahlende Claude-Nutzer teilen mit, worin der Wert ihres Abonnements liegt. Zu den Hauptvorteilen gehört die Funktion „Projekte (Projects)“, die es Nutzern ermöglicht, für bestimmte Aufgaben (wie Kursvorbereitung, Website-SEO, Werbeanalyse, Nachrichtenzusammenfassungen, Rezeptsuche) umfangreiches Hintergrundmaterial (Wissensdatenbank) hochzuladen, sodass Claude im spezifischen Kontext kontinuierlich Unterstützung leisten kann. Darüber hinaus sind ein größeres Kontextfenster, ein stärkerer „Denkmodus (Thinking Mode)“ und mehr Abfragen pro Zeiteinheit attraktive Aspekte des kostenpflichtigen Angebots. Nutzer berichten, dass Claude Pro in Kombination mit MCP-Tools (wie Desktop Commander) bei der Bearbeitung komplexer Aufgaben, Code-Reviews, Dokumentenanalysen und dem Verfassen von E-Mails einigen IDE-integrierten Lösungen überlegen ist, da diese möglicherweise aufgrund von Kostenoptimierung oder integrierten System-Prompts die tiefgehende Analysefähigkeit des Modells einschränken (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Änderung der Lizenz von OpenWebUI вызывает Besorgnis bei Community und Unternehmensnutzern: Das OpenWebUI-Projekt hat kürzlich seine Softwarelizenz geändert, was bei einigen Community-Mitgliedern und Unternehmensnutzern Besorgnis ausgelöst hat. Ein Unternehmen gab an, zu diskutieren, die Nutzung und Beiträge zu dem Projekt einzustellen und vorübergehend auf der Grundlage der letzten BSD-Lizenzversion einen Fork zu erstellen. Dieser Vorfall unterstreicht die möglichen Auswirkungen von Lizenzänderungen bei Open-Source-Projekten auf das Ökosystem von Nutzern und Mitwirkenden, insbesondere in kommerziellen Anwendungsszenarien (Quelle: Reddit r/OpenWebUI)
💡 Sonstiges
Vatikan plant Investitionen in neue Datenquellen zur Bewältigung des „Data Wall“-Problems: Seit 2023 stehen Large Language Models beim Training vor dem „Data Wall“-Problem, d.h. die meisten bekannten menschlichen Textdaten wurden bereits indiziert und trainiert. Um dieses Problem zu lösen, plant der Vatikan Investitionen in neue Datenquellen, beispielsweise durch die Transkription mittelalterlicher Kirchendokumente mittels OCR-Technologie und die Generierung synthetischer Daten, um die Fähigkeiten von AI-Modellen kontinuierlich zu verbessern (Quelle: jxmnop, Dorialexander)

Chinas rasanter technologischer Fortschritt, vielfältige Innovationen erregen Aufmerksamkeit: Ein Beitrag listet detailliert zahlreiche erstaunliche Technologieanwendungen auf, die der Autor während einer 15-tägigen Reise in China beobachtet hat, darunter DeepSeek-Sexpuppen, elektrische Luftschiffe, Drohnen zur Bearbeitung von Verkehrsunfällen usw. Dies löste Diskussionen über die Geschwindigkeit der technologischen Entwicklung und die Breite der Anwendungen in China in Bereichen wie Künstliche Intelligenz, Robotik, neue Energiefahrzeuge aus und zog Vergleiche mit anderen Hightech-Nationen wie Singapur (Quelle: GavinSBaker)

Erwartungen an die Entwicklung von AI im medizinischen Bereich: Community-Mitglieder äußerten die Erwartung, dass AI im medizinischen Bereich größere Fortschritte erzielen wird. Zu den Vorstellungen gehören AI-Roboter, die den Körper sofort scannen und Symptome von Krankheiten im Frühstadium erkennen können, sowie Systeme, die präzise Behandlungen, Operationen und eine beschleunigte Genesung unterstützen können. Obwohl bestehende Technologien in einigen Bereichen bereits Fortschritte erzielt haben, herrscht allgemein die Meinung, dass AI noch ein enormes ungenutztes Potenzial zur Verbesserung der Zugänglichkeit und Genauigkeit der medizinischen Versorgung sowie zur Rettung von Leben birgt (Quelle: Reddit r/ArtificialInteligence, Reddit r/artificial)