
Schlüsselwörter:Gemini-Modell, Mistral AI, NVIDIA NeMo, LTX-Video, Safari-Browser, RTX 5060, KI-Agent, Feinabstimmung durch bestärkendes Lernen, Native Bildgenerierung mit Gemini, Programmierleistung von Mistral Medium 3, Modulares NeMo-Framework 2.0, Echtzeit-Videogenerierung mit DiT, KI-gestützte Suchfunktionsoptimierung
🔥 Fokus
Google Gemini native Bildgenerierungsfunktion verbessert visuelle Qualität und Genauigkeit der Textwiedergabe: Google kündigte ein wichtiges Update für die native Bildgenerierungsfunktion seines Gemini-Modells an. Die neue Version „gemini-2.0-flash-preview-image-generation“ ist in Google AI Studio und Vertex AI verfügbar. Dieses Upgrade verbessert die visuelle Qualität von Bildern und die Genauigkeit der Textwiedergabe erheblich und reduziert die Latenz. Die neuen Funktionen unterstützen die Verschmelzung von Bildelementen, Echtzeitbearbeitung (wie das Hinzufügen von Objekten, Ändern lokaler Inhalte) sowie die Kombination mit Gemini 2.0 Flash, um KI-gestützte Konzeption und Bildgenerierung zu ermöglichen. Nutzer können es kostenlos in Google AI Studio ausprobieren, und API-Aufrufe kosten 0,039 US-Dollar pro Bild. Obwohl die Fortschritte bemerkenswert sind, sind einige Nutzer der Meinung, dass die Gesamtleistung immer noch etwas hinter der von GPT-4o zurückbleibt. (Quelle: 量子位)

Mistral AI veröffentlicht Mistral Medium 3, fokussiert auf Programmierung und Multimodalität, Kosten drastisch gesenkt: Das französische KI-Startup Mistral AI hat sein neuestes multimodales Modell Mistral Medium 3 vorgestellt. Das Modell zeichnet sich durch herausragende Leistungen bei Programmier- und STEM-Aufgaben aus und soll in verschiedenen Benchmarks die Leistung von Claude Sonnet 3.7 zu 90 % erreichen oder übertreffen, während die Kosten nur 1/8 betragen (0,4 US-Dollar/Million Tokens für Input, 2 US-Dollar/Million Tokens für Output). Mistral Medium 3 verfügt über unternehmensreife Funktionen wie hybride Bereitstellung, benutzerdefiniertes Post-Training und Integration mit Unternehmenswerkzeugen und ist bereits auf Mistral La Plateforme und Amazon Sagemaker verfügbar, weitere Cloud-Plattformen sollen folgen. Gleichzeitig hat Mistral AI auch einen Chatbot-Dienst für Unternehmen namens Le Chat Enterprise eingeführt. (Quelle: 量子位)

NVIDIA NeMo Framework 2.0 veröffentlicht, verbessert Modularität und Benutzerfreundlichkeit, unterstützt Hugging Face Modelle und Blackwell GPU: Das NVIDIA NeMo Framework wurde auf Version 2.0 aktualisiert. Zu den Kernverbesserungen gehören die Verwendung von Python-Konfigurationen anstelle von YAML zur Erhöhung der Flexibilität, die Vereinfachung von Experimenten und Anpassungen durch modulare Abstraktionen von PyTorch Lightning sowie die nahtlose Skalierung von Großexperimenten mit dem NeMo-Run-Tool. Die neue Version bietet Unterstützung für das Pre-Training und Fine-Tuning von Hugging Face AutoModelForCausalLM-Modellen und unterstützt bereits vorläufig die NVIDIA Blackwell B200 GPU. Darüber hinaus integriert das NeMo Framework Unterstützung für die NVIDIA Cosmos World Foundation Model Plattform, um die Entwicklung von Weltmodellen für physikalische KI-Systeme zu beschleunigen, einschließlich der Videoverarbeitungsbibliothek NeMo Curator und des Cosmos Tokenizers. (Quelle: GitHub Trending)

Lightricks veröffentlicht LTX-Video: Echtzeit-DiT-Videogenerierungsmodell: Lightricks hat LTX-Video als Open Source veröffentlicht, das als erstes Echtzeit-Videogenerierungsmodell auf Basis von Diffusion Transformer (DiT) gilt. Das Modell kann hochwertige Videos mit einer Auflösung von 1216×704 bei 30 FPS generieren und unterstützt verschiedene Funktionen wie Text-zu-Bild, Bild-zu-Video, Keyframe-Animation, Videoerweiterung und Video-zu-Video-Konvertierung. Die neueste Version 13B v0.9.7 verbessert die Befolgung von Prompts und das physikalische Verständnis und führt eine Multi-Skalen-Videopipeline für schnelle und qualitativ hochwertige Renderings ein. Das Modell ist auf Hugging Face verfügbar und verfügt über Integrationen für ComfyUI und Diffusers. (Quelle: GitHub Trending)

Apple erwägt grundlegende Überarbeitung des Safari-Browsers, möglicherweise Hinwendung zu KI-gestützter Suche, Beziehung zu Google im Fokus: Apples Senior Vice President Eddy Cue sagte im Kartellverfahren des US-Justizministeriums gegen Google aus, dass Apple aktiv eine Überarbeitung des Safari-Browsers erwägt, mit einem Schwerpunkt auf KI-gestützten Suchmaschinen. Er wies darauf hin, dass das Suchvolumen von Safari erstmals zurückgegangen sei, teilweise weil Nutzer zu KI-Tools wie OpenAI und Perplexity AI wechseln. Apple hat bereits Gespräche mit Perplexity AI geführt und könnte weitere KI-Suchoptionen in Safari integrieren. Dieser Schritt könnte Apples jährlichen Vertrag mit Google über rund 20 Milliarden US-Dollar für die Standardsuchmaschine beeinflussen und sich auf die Aktienkurse beider Unternehmen auswirken. Apple hat ChatGPT bereits in Siri integriert und plant, Google Gemini hinzuzufügen. (Quelle: 36氪)

🎯 Trends
NVIDIA RTX 5060 Desktop-Grafikkarte kommt am 20. Mai in den Handel, Preis in China 2499 Yuan: NVIDIA kündigte an, dass die RTX 5060 Desktop-Grafikkarte am 20. Mai Pekinger Zeit in den Handel kommen wird, zum Preis von 2499 Yuan in China. Die Karte basiert auf der Blackwell RTX-Architektur, verfügt über 3840 CUDA-Kerne, 8 GB GDDR7-Speicher und eine Gesamtleistungsaufnahme von 145 W. Offiziell soll sie in Spielen, die DLSS 4 Multi-Frame Generation unterstützen, die doppelte Leistung der RTX 4060 bieten, mit dem Ziel, dass Nutzer Spiele mit über 100 FPS spielen können. Testberichte und Verkaufsstart erfolgen am selben Tag. (Quelle: 量子位)

Google Gemini API führt implizite Cache-Funktion ein, spart 75 % Kosten: Google hat eine implizite Cache-Funktion für seine Gemini API angekündigt. Wenn Anfragen von Nutzern den Cache treffen, können die Kosten für die Nutzung des Gemini 2.5-Modells automatisch um 75 % gesenkt werden. Gleichzeitig wurde die Mindestanzahl an Tokens, die zum Auslösen des Caching erforderlich sind, gesenkt: für Gemini 2.5 Flash auf 1K Tokens und für Gemini 2.5 Pro auf 2K Tokens. Diese Funktion zielt darauf ab, die Kosten für Entwickler bei der Nutzung der Gemini API zu senken, ohne dass explizit ein Cache erstellt werden muss. (Quelle: matvelloso, demishassabis, algo_diver, jeremyphoward)
Meta FAIR ernennt Rob Fergus zum neuen Leiter, Fokus auf Advanced Machine Intelligence (AGI): Meta gab bekannt, dass Rob Fergus die Leitung des Fundamental AI Research (FAIR) Teams übernehmen wird. Yann LeCun erklärte, dass FAIR sich wieder auf Advanced Machine Intelligence konzentrieren wird, allgemein bekannt als menschenähnliche KI oder AGI. Diese Nachricht wurde von der KI-Forschungsgemeinschaft mit großer Aufmerksamkeit und Glückwünschen aufgenommen. (Quelle: ylecun, Ar_Douillard, soumithchintala, aaron_defazio, sainingxie)
OpenAI führt Reinforcement Learning Fine-Tuning (RFT) für o4-mini Modell ein: OpenAI gab bekannt, dass sein o4-mini Modell nun Reinforcement Learning Fine-Tuning (RFT) unterstützt. Diese seit letztem Dezember entwickelte Technologie nutzt Chain-of-Thought-Reasoning und aufgabenspezifische Bewertungen, um die Modellleistung insbesondere in komplexen Bereichen zu verbessern. Ein von Ambience mit RFT optimiertes Modell übertraf Experten-Kliniker bei der ICD-10-Kodierungsgenauigkeit um 27 %. Harvey trainierte ebenfalls Modelle mit RFT, um die Genauigkeit von Zitaten in juristischen Aufgaben zu verbessern. Gleichzeitig ist auch OpenAIs schnellstes und kleinstes Modell, 4.1-nano, für Fine-Tuning verfügbar. (Quelle: stevenheidel, aidan_mclau, andrwpng, teortaxesTex, OpenAIDevs, OpenAIDevs)
Tsinghua Universität stellt Absolute Zero Reasoner vor: KI generiert eigene Trainingsdaten für überragendes Reasoning: Ein Team der Tsinghua Universität hat ein KI-Modell namens Absolute Zero Reasoner entwickelt, das Trainingsaufgaben vollständig durch Self-Play generieren und daraus lernen kann, ohne externe Daten. In Bereichen wie Mathematik und Programmierung übertrifft seine Leistung bereits Modelle, die auf von Experten kuratierten Daten trainiert wurden. Dieses Ergebnis könnte bedeuten, dass der Datenengpass in der KI-Entwicklung gemildert wird und neue Wege zur AGI eröffnet werden. (Quelle: corbtt)

Meta und NVIDIA kooperieren zur Verbesserung der Faiss GPU-Vektorsuchleistung durch cuVS: Meta und NVIDIA kündigten eine Zusammenarbeit an, um NVIDIAs cuVS (CUDA Vector Search) in Metas Open-Source-Ähnlichkeitssuchbibliothek Faiss v1.10 zu integrieren und so die Leistung der Vektorsuche auf GPUs erheblich zu verbessern. Diese Integration führt zu einer bis zu 4,7-fachen Verbesserung der Erstellungszeit von IVF-Indizes und einer bis zu 8,1-fachen Reduzierung der Suchlatenz; bei Graph-Indizes ist die Erstellungszeit von CUDA ANN Graph (CAGRA) 12,3-mal schneller als bei CPU HNSW, und die Suchlatenz wird um das 4,7-fache reduziert. (Quelle: AIatMeta)
Google AI Studio und Firebase Studio integrieren Gemini 2.5 Pro: Google gab bekannt, dass das Gemini 2.5 Pro Modell in Gemini Code Assist (Personal Edition) und Firebase Studio integriert wurde. Dies wird Entwicklern mehr Komfort und leistungsstarke Funktionen bei der Nutzung von Top-Coding-Modellen auf diesen Plattformen bieten, mit dem Ziel, die Codiereffizienz und -erfahrung zu verbessern. (Quelle: algo_diver)
Microsoft Copilot führt Pages-Funktion ein, unterstützt Inline-Bearbeitung und Texthervorhebung: Microsoft Copilot hat eine neue „Pages“-Funktion hinzugefügt, die es Benutzern ermöglicht, KI-generierte Antworten direkt in der Copilot-Oberfläche inline zu bearbeiten. Sie können Text hervorheben und spezifische Änderungsanforderungen stellen. Diese Funktion soll Benutzern helfen, Fragen und Forschungsergebnisse schneller und intelligenter in nutzbare Dokumente umzuwandeln und die Arbeitseffizienz zu steigern. (Quelle: yusuf_i_mehdi)
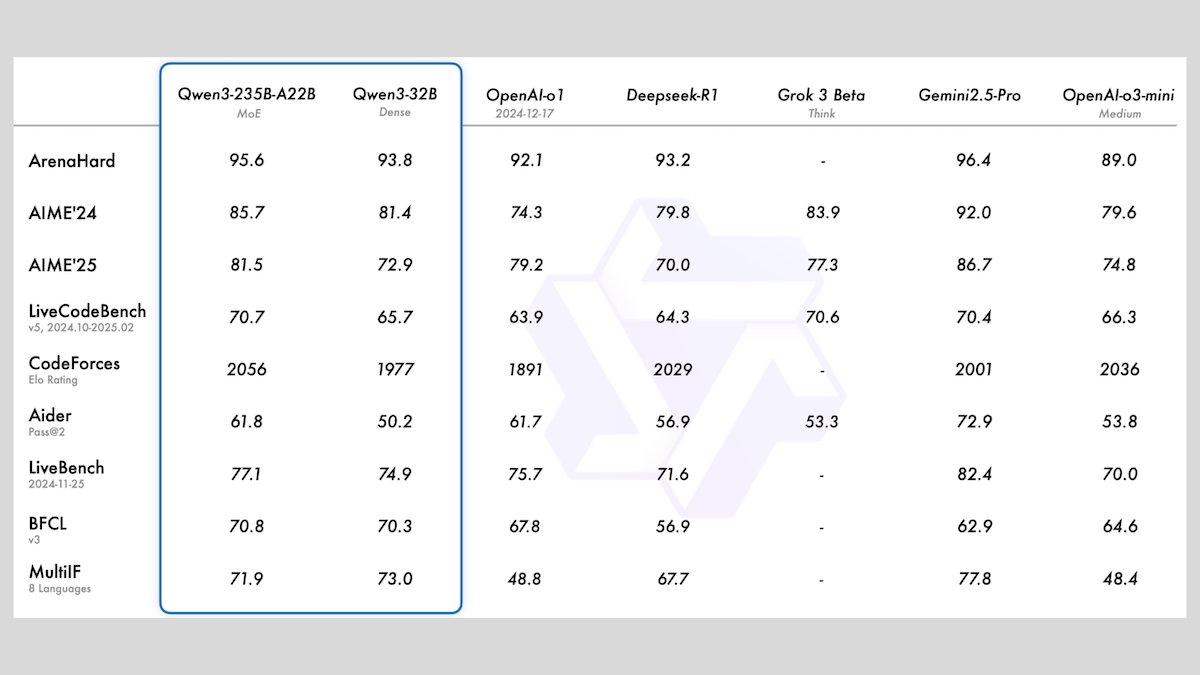
Alibaba stellt Qwen3-Modellreihe vor, mit 8 Open-Source-Large-Language-Modellen: Alibaba hat die Qwen3-Reihe veröffentlicht, die 8 Open-Source-Large-Language-Modelle umfasst, darunter 2 Mixture-of-Experts (MoE)-Modelle und 6 Dense-Modelle mit Parametergrößen von 0,6B bis 32B. Alle Modelle unterstützen optionale Inferenzmodi und Mehrsprachigkeit für 119 Sprachen. Qwen3-235B-A22B und Qwen3-30B-A3B zeigen hervorragende Leistungen bei Inferenz-, Codierungs- und Funktionsaufrufaufgaben und können mit Spitzenmodellen wie denen von OpenAI konkurrieren, wobei insbesondere Qwen3-30B-A3B aufgrund seiner starken Leistung und lokalen Ausführbarkeit Beachtung findet. (Quelle: DeepLearningAI)
Meta stellt Meta Locate 3D-Modell für präzise Objektlokalisierung in 3D-Umgebungen vor: Meta AI hat Meta Locate 3D veröffentlicht, ein Modell, das speziell für die präzise Lokalisierung von Objekten in 3D-Umgebungen entwickelt wurde. Das Modell soll Robotern helfen, ihre Umgebung genauer zu verstehen und natürlicher mit Menschen zu interagieren. Meta hat das Modell, Datensätze, Forschungspapiere sowie eine Demo zur öffentlichen Nutzung und zum Ausprobieren bereitgestellt. (Quelle: AIatMeta)
Google veröffentlicht neuen Bericht zur Nutzung von KI im Kampf gegen Online-Betrug: Google hat einen neuen Bericht darüber veröffentlicht, wie das Unternehmen Künstliche Intelligenz zur Bekämpfung von Online-Betrug in seiner Suchmaschine, dem Chrome-Browser und dem Android-System einsetzt. Der Bericht beschreibt detailliert Googles über zehnjährige Bemühungen und die neuesten Fortschritte beim Einsatz von KI zum Schutz der Nutzer vor Online-Betrug und betont die Schlüsselrolle der KI bei der Identifizierung und Blockierung von Betrugsversuchen. (Quelle: Google)
Cohere stellt Embed 4 Embedding-Modell vor, stärkt KI-Suche und Retrieval-Fähigkeiten: Cohere hat sein neuestes Embedding-Modell Embed 4 veröffentlicht, das darauf abzielt, den Zugriff auf und die Nutzung von Unternehmensdaten zu revolutionieren. Embed 4, als Coheres bisher leistungsstärkstes Embedding-Modell, konzentriert sich auf die Verbesserung der Genauigkeit und Effizienz von KI-Suche und Retrieval und hilft Organisationen, verborgene Werte in ihren Daten zu erschließen. (Quelle: cohere)

Google kündigt Google I/O Konferenz für den 20. Mai an: Google hat offiziell bekannt gegeben, dass seine jährliche Entwicklerkonferenz Google I/O am 20. Mai stattfinden wird und die Registrierung geöffnet ist. Es wird Keynotes, Produktneuheiten und technologische Ankündigungen geben, wobei KI voraussichtlich eines der Kernthemen sein wird. (Quelle: Google)
NVIDIA Parakeet-Modell stellt neuen Rekord bei Audiotranskription auf: 60 Minuten Audio in 1 Sekunde transkribiert: NVIDIAs Parakeet-Modell hat einen Durchbruch bei der Audiotranskription erzielt und kann bis zu 60 Minuten Audio in nur 1 Sekunde transkribieren. Es rangiert damit an der Spitze der entsprechenden Hugging Face-Ranglisten. Dieser Erfolg demonstriert NVIDIAs führende Position in der Spracherkennungstechnologie und stellt Entwicklern hocheffiziente Werkzeuge zur Audioverarbeitung zur Verfügung. (Quelle: huggingface)

🧰 Tools
LlamaParse fügt Unterstützung für GPT 4.1 und Gemini 2.5 Pro hinzu, stärkt Dokumentenanalysefähigkeiten: LlamaParse hat kürzlich eine Reihe von Funktionsupdates erhalten, darunter die Einführung neuer Analysemodelle GPT 4.1 und Gemini 2.5 Pro zur Verbesserung der Genauigkeit. Darüber hinaus bietet die neue Version automatische Ausrichtungs- und Schräglagenerkennung für eine perfekt ausgerichtete Analyse, Konfidenzwerte zur Bewertung der Analysequalität und ermöglicht es Benutzern, die Fehlertoleranz und den Umgang mit fehlerhaften Seiten anzupassen. LlamaParse bietet ein kostenloses Kontingent von 10.000 Seiten pro Monat. (Quelle: jerryjliu0)

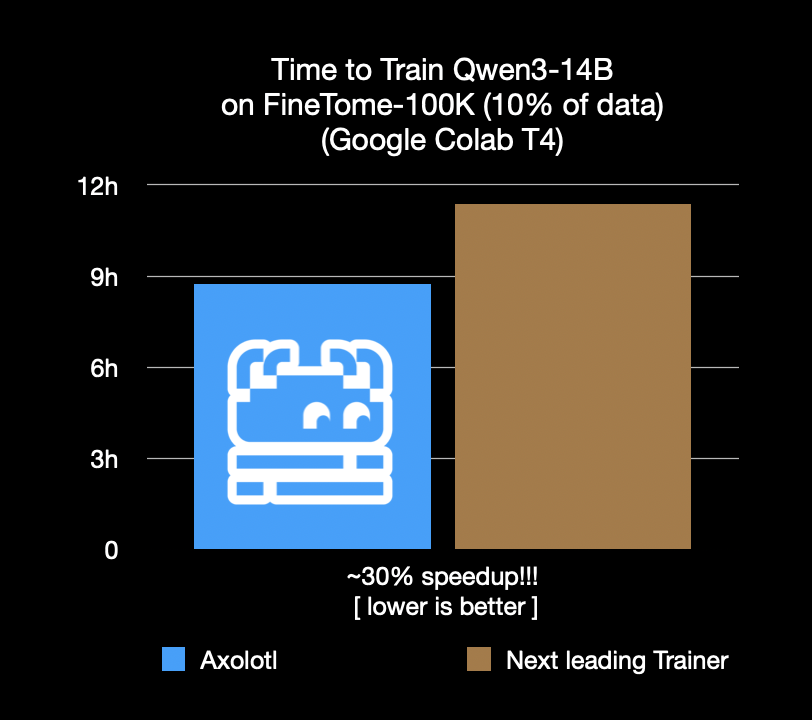
Axolotl Fine-Tuning Framework um 30 % beschleunigt, spart Kosten und Zeit: Das Axolotl Fine-Tuning Framework gab bekannt, dass es bei realen Workloads wie FineTome-100k um 30 % schneller ist als suboptimale Frameworks. Für mittelgroße bis große Machine-Learning-Teams bedeutet dies eine monatliche Kostenersparnis von mehreren Tausend Dollar. Die Optimierung des Frameworks zielt darauf ab, Benutzern ein effizienteres und kostengünstigeres Modell-Fine-Tuning zu ermöglichen. (Quelle: Teknium1, winglian, maximelabonne)
Runway veröffentlicht Animations-Pilotfolge „Mars & Siv: No Vacancy“ und demonstriert Fähigkeiten des Gen-4 Modells: Das KI-Studio von Runway hat die Animations-Pilotfolge „Mars & Siv: No Vacancy“ veröffentlicht, kreiert von Jeremy Higgins und Britton Korbel. Das Werk demonstriert die Anwendung von Runways Gen-4 Modell in verschiedenen Phasen des Animationsprozesses, vom Konzept bis zum Endprodukt, und unterstreicht das Potenzial von KI bei der Generierung kreativer Inhalte. (Quelle: c_valenzuelab, c_valenzuelab)
Replit fügt Notion-Integration hinzu, unterstützt Notion-Inhalte als Anwendungsbackend: Replit kündigte eine neue Integrationspartnerschaft mit Notion an, die es Entwicklern ermöglicht, Notion als Backend für ihre Anwendungen zu nutzen. Benutzer können Notion-Datenbanken mit Replit-Projekten verbinden, um FAQs anzuzeigen, dokumentenbasierte benutzerdefinierte KI-Chatbots zu betreiben und Support-Ticket-Aufzeichnungen zurück in Notion zu speichern. Dieser Schritt zielt darauf ab, die Backend-Organisationsfähigkeiten von Notion mit den flexiblen Frontend-Erstellungsmöglichkeiten von Replit zu kombinieren. (Quelle: amasad, amasad, pirroh)
Langchain-huggingface v0.2 veröffentlicht, unterstützt HF Inference Providers: Langchain-huggingface hat Version v0.2 veröffentlicht, die Unterstützung für Hugging Face Inference Providers hinzufügt. Dieses Update wird die Nutzung der von Hugging Face bereitgestellten Inferenzdienste innerhalb des LangChain-Ökosystems vereinfachen. (Quelle: LangChainAI, huggingface, ClementDelangue, hwchase17, Hacubu)
smolagents 1.15 veröffentlicht, fügt Streaming-Output-Funktion hinzu: Das KI-Agenten-Framework smolagents hat Version 1.15 veröffentlicht und führt die Funktion für Streaming-Outputs ein. Benutzer können diese aktivieren, indem sie stream_outputs=True bei der Initialisierung von CodeAgent setzen, was alle Interaktionsprozesse flüssiger erscheinen lässt. (Quelle: huggingface, AymericRoucher, ClementDelangue)
Better-Qwen3 Projekt: Lässt Qwen3-Modell automatisch den Denkmodus wechseln: Ein GitHub-Projekt namens Better-Qwen3 hat Aufmerksamkeit erregt. Es zielt darauf ab, dass das Qwen3-Modell basierend auf der Komplexität der Benutzeranfrage automatisch steuert, ob der „Denkmodus“ aktiviert wird. Bei einfachen Fragen antwortet das Modell direkt; bei komplexen Fragen wechselt es automatisch in den Denkmodus, um eine tiefere Antwort zu geben. Projektadresse: http://github.com/AaronFeng753/Better-Qwen3 (Quelle: karminski3, Reddit r/LocalLLaMA)
MLX-Audio: TTS/STT/STS-Bibliothek basierend auf Apples MLX-Framework: MLX-Audio ist eine speziell für Apple Silicon entwickelte Text-to-Speech (TTS), Speech-to-Text (STT) und Speech-to-Speech (STS) Bibliothek, die auf Apples MLX-Framework basiert und darauf abzielt, effiziente Sprachverarbeitungsfähigkeiten bereitzustellen. Die Bibliothek unterstützt mehrere Sprachen, Stimmanpassung, Geschwindigkeitskontrolle und bietet eine interaktive Weboberfläche sowie eine REST-API. (Quelle: GitHub Trending)
Runway References Modell unterstützt Bild-Outpainting-Funktion: Das References Modell von Runway unterstützt jetzt die Bild-Outpainting-Funktion. Benutzer müssen lediglich ein Bild in References platzieren, das gewünschte Ausgabeformat auswählen, den Prompt leer lassen und dann auf Generieren klicken, um das Originalbild zu erweitern. Diese Funktion erweitert die Fähigkeiten von Runway im Bereich Bildbearbeitung und -erstellung weiter. (Quelle: c_valenzuelab)

Docker2exe: Konvertiert Docker-Images in ausführbare Dateien: Docker2exe ist ein Werkzeug, das Docker-Images in eigenständige ausführbare Dateien konvertieren kann, um das Teilen und Ausführen zu erleichtern. Es unterstützt einen Einbettungsmodus, bei dem das Tarball des Docker-Images direkt in die ausführbare Datei gepackt wird. Wenn es auf dem Zielgerät ausgeführt wird und das entsprechende Docker-Image lokal nicht vorhanden ist, lädt es automatisch das eingebettete Image oder zieht es aus dem Netzwerk. (Quelle: GitHub Trending)
Smoothie Qwen: Glättet Token-Wahrscheinlichkeiten des Qwen-Modells zur Balancierung mehrsprachiger Generierung: Smoothie Qwen ist ein leichtgewichtiges Anpassungswerkzeug, das durch Glättung der Token-Wahrscheinlichkeiten im Qwen-Modell darauf abzielt, die Balance des Modells bei der mehrsprachigen Generierung zu verbessern, unbeabsichtigte Präferenzen für bestimmte Sprachen (wie Chinesisch) zu reduzieren und gleichzeitig die Kernleistung beizubehalten. Das Werkzeug verwendet Unicode-Bereiche zur Identifizierung von Tokens, führt eine N-Gramm-Analyse durch und passt die Token-Gewichte im lm_head an. Vorab angepasste Modelle sind auf Hugging Face verfügbar. (Quelle: Reddit r/LocalLLaMA)

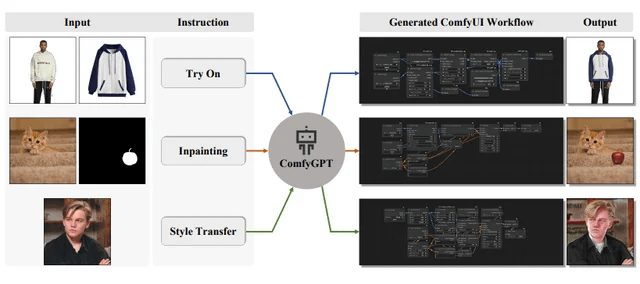
ComfyGPT: Selbstoptimierendes Multi-Agenten-System zur Generierung von ComfyUI-Workflows: Ein Paper mit dem Titel „ComfyGPT: A Self-Optimizing Multi-Agent System for Comprehensive ComfyUI Workflow Generation“ wurde bei arXiv eingereicht und stellt ein System namens ComfyGPT vor. Dieses System nutzt einen selbstoptimierenden Multi-Agenten-Ansatz, um umfassend ComfyUI-Workflows zu generieren und so die Erstellung komplexer Bildgenerierungsprozesse zu vereinfachen. (Quelle: Reddit r/LocalLLaMA)
Anthropic Claude-Modell erhält neues Websuche-Tool: Anthropic hat ein neues Websuche-Tool für sein Claude-Modell veröffentlicht. Dieses Tool ermöglicht es Claude, bei der Generierung von Antworten Websuchen durchzuführen und die Suchergebnisse als Grundlage für Antworten mit Zitaten zu verwenden. Diese Funktion wurde in die langchain-anthropic-Bibliothek integriert und verbessert Claudes Fähigkeit, Echtzeitinformationen abzurufen und zu nutzen. (Quelle: LangChainAI, hwchase17)
Glass Health führt Workspace-Funktion ein, nutzt KI zur Unterstützung klinischer Diagnosen und Behandlungsplanung: Glass Health hat die neue Workspace-Funktion veröffentlicht, die es Klinikern ermöglicht, KI effektiver für komplexe diagnostische Überlegungen, Behandlungsplanung und Dokumentationsworkflows einzusetzen. Ziel ist es, die Effizienz und Qualität der medizinischen Arbeit durch KI-Technologie zu verbessern. (Quelle: GlassHealthHQ)
OpenWebUI fügt KI-gestützte Notizen und Meeting-Aufzeichnungsfunktionen hinzu: Die neueste Version von OpenWebUI enthält KI-gestützte Notizfunktionen. Benutzer können Notizen erstellen, Meeting- oder Sprachaufnahmen anhängen und die KI die Audio-Transkription nutzen lassen, um Notizen sofort zu verbessern, zusammenzufassen oder zu optimieren. Darüber hinaus werden Funktionen zur Aufzeichnung und zum Import von Meeting-Audio unterstützt, um Benutzern die Überprüfung und Extraktion wichtiger Diskussionsinformationen zu erleichtern. (Quelle: Reddit r/OpenWebUI)
📚 Lernen
UN veröffentlicht 200-seitigen Bericht über KI und globale menschliche Entwicklung: Das Entwicklungsprogramm der Vereinten Nationen (UNDP) hat einen 200-seitigen Bericht veröffentlicht, der Künstliche Intelligenz aus der Perspektive der globalen menschlichen Entwicklung untersucht. Der Bericht erörtert die Auswirkungen von KI auf nachhaltige Entwicklungsziele, Ungleichheit, Governance und die Zukunft der Arbeit und gibt politische Empfehlungen. Der Bericht hat aufgrund seiner klaren Standpunkte Aufmerksamkeit erregt. (Quelle: random_walker)
The Turing Post veröffentlicht ausführliche Analyse des Agent2Agent (A2A)-Protokolls: Angesichts des großen Interesses der Community an Kommunikationsprotokollen zwischen KI-Agenten hat The Turing Post seine ausführliche Analyse des Google A2A-Protokolls kostenlos auf Hugging Face veröffentlicht. Der Artikel untersucht die Bedeutung des A2A-Protokolls (das darauf abzielt, KI-Agenten-Silos aufzubrechen und Zusammenarbeit zu ermöglichen), potenzielle Anwendungen (wie die Zusammenarbeit spezialisierter Agententeams, unternehmensübergreifende Workflows, die Standardisierung der Mensch-Maschine-Kollaboration, durchsuchbare Agentenverzeichnisse) sowie dessen Funktionsweise und Einstiegsmethoden. (Quelle: TheTuringPost, TheTuringPost, TheTuringPost, dl_weekly)

Prompt-Ingenieur teilt mit: Wie man einfach nützliche Prompt-Vorlagen schreibt: Prompt-Ingenieur dotey teilte eine Drei-Schritte-Methode zur Erstellung effizienter Prompt-Vorlagen: 1. Sammeln von Prompts im gleichen Stil, aber zu unterschiedlichen Themen; 2. Gemeinsamkeiten und Unterschiede herausfinden (ggf. mit KI-Unterstützung); 3. Wiederholtes Testen und Optimieren. Er betonte, dass gute Vorlagen wie Funktionen in Programmen sind, bei denen durch geringfügige Änderungen von Variablen unterschiedliche Ergebnisse erzielt werden können. Er teilte auch eine Befehlsvorlage zur schnellen Generierung neuer Prompts mit KI und wies darauf hin, dass nicht alle Stile für Vorlagen geeignet sind und Themen mit komplexen Details weiterhin eine individuelle Optimierung erfordern. (Quelle: dotey)

DeepMind-Forscher John Jumper Team stellt ein, erweitert wissenschaftliche Entdeckungen basierend auf LLMs: Google DeepMind-Forscher John Jumper gab bekannt, dass sein Team mehrere Stellen ausschreibt, um die Arbeit an wissenschaftlichen Entdeckungen basierend auf Large Language Models (LLMs) zu erweitern. Die ausgeschriebenen Stellen umfassen Research Scientists (RS) und Research Engineers (RE) und zielen darauf ab, die Zukunft der KI in den Naturwissenschaften voranzutreiben. (Quelle: demishassabis, NandoDF)
Ragas Blog teilt zweijährige Erfahrungen mit der Verbesserung von KI-Anwendungen: Shahules786 veröffentlichte einen Artikel im Ragas Blog, der die Lehren aus zwei Jahren enger Zusammenarbeit mit KI-Teams, der Durchführung von Bewertungszyklen und der Verbesserung von LLM-Systemen zusammenfasst. Der Artikel zielt darauf ab, Praktikern, die KI-Anwendungen erstellen und optimieren, praktische Anleitungen und Einblicke zu geben. (Quelle: Shahules786)

Kyunghyun Cho diskutiert Lehrmethoden für Machine-Learning-Graduiertenkurse im LLM-Zeitalter: Professor Kyunghyun Cho von der New York University teilte seine Überlegungen und Experimente zu den Lehrinhalten für Machine-Learning-Graduiertenkurse im ersten Jahr im aktuellen Zeitalter von LLMs und großskaligem Computing. Er schlägt vor, alle Inhalte zu lehren, die SGD (Stochastic Gradient Descent) akzeptieren und keine LLMs sind, und die Studenten anzuleiten, klassische Paper zu lesen. (Quelle: ylecun, sainingxie)

Intelligent Document Processing (IDP) Rangliste veröffentlicht, vereinheitlicht Bewertung der Dokumentenverständnisfähigkeiten von VLMs: Eine neue Rangliste für Intelligent Document Processing (IDP) wurde veröffentlicht, die darauf abzielt, ein einheitliches Benchmarking für verschiedene Aufgaben des Dokumentenverständnisses wie OCR, KIE, VQA und Tabellenextraktion bereitzustellen. Die Rangliste umfasst 6 Kern-IDP-Aufgaben, 16 Datensätze und 9229 Dokumente. Erste Ergebnisse zeigen, dass Gemini 2.5 Flash insgesamt führend ist, aber alle Modelle beim Verständnis langer Dokumente schlecht abschneiden und die Tabellenextraktion weiterhin ein Engpass darstellt. Die Leistung der neuesten Version von GPT-4o ist sogar gesunken. (Quelle: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
LangGraph führt Cron Jobs-Funktion ein, unterstützt zeitgesteuertes Auslösen von KI-Agenten: Die LangGraph-Plattform von LangChain hat eine neue Cron Jobs-Funktion hinzugefügt, die es Benutzern ermöglicht, zeitgesteuerte Aufgaben einzurichten, um KI-Agenten automatisch auszulösen. Diese Funktion ermöglicht es KI-Agenten, Aufgaben nach einem voreingestellten Zeitplan auszuführen, was für Szenarien geeignet ist, die eine periodische Verarbeitung oder Überwachung erfordern. (Quelle: hwchase17)
💼 Business
KI-Software-Debugging-Tool Lightrun erhält 70 Millionen US-Dollar in Serie-B-Finanzierung, angeführt von Accel und Insight Partners: Der Entwickler von KI-Software-Observability- und Debugging-Tools Lightrun gab den Abschluss einer Serie-B-Finanzierungsrunde in Höhe von 70 Millionen US-Dollar bekannt, angeführt von Accel und Insight Partners, mit Beteiligung von Citigroup und anderen. Die Gesamtfinanzierung beläuft sich auf 110 Millionen US-Dollar. Das Kernprodukt Runtime Autonomous AI Debugger kann problematischen Code in der IDE präzise lokalisieren und Reparaturvorschläge unterbreiten, mit dem Ziel, die Debugging-Zeit von Stunden auf Minuten zu verkürzen. Das Unternehmen steigerte seinen Umsatz im Jahr 2024 um das 4,5-fache und zählt Fortune-500-Unternehmen wie Citigroup und Microsoft zu seinen Kunden. (Quelle: 36氪)

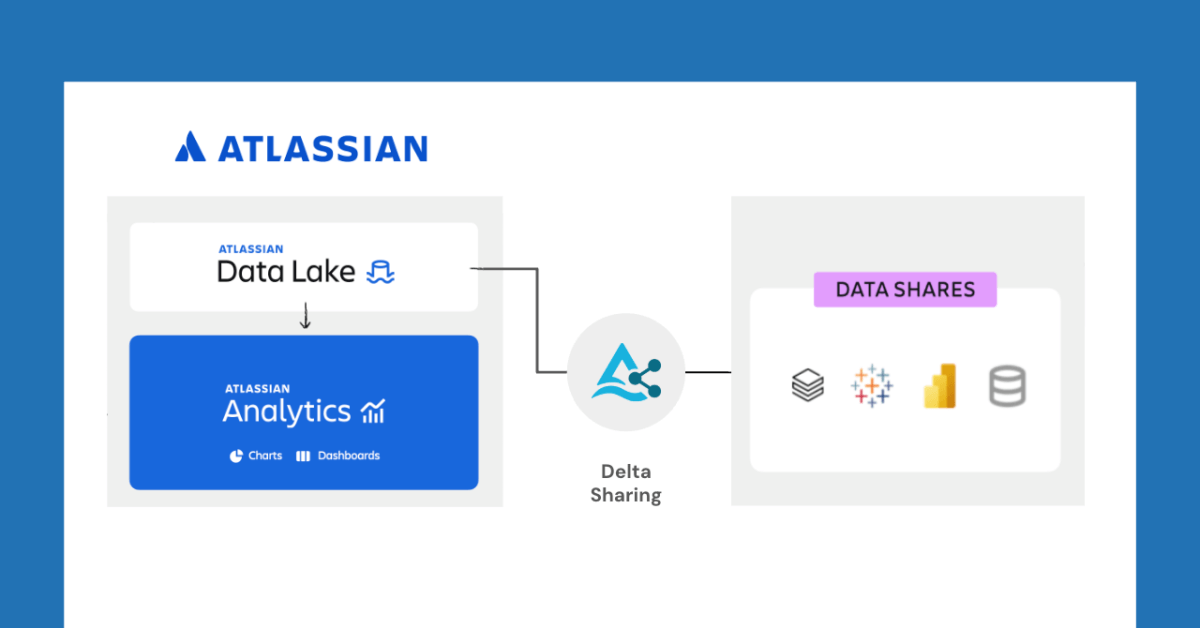
Databricks und Atlassian kooperieren, um neue Datenfreigabefunktionen durch Delta Sharing zu ermöglichen: Databricks kündigte eine Zusammenarbeit mit Atlassian an, um Atlassian Analytics neue Datenfreigabefähigkeiten zu verleihen. Durch das offene Protokoll von Delta Sharing können Atlassian-Kunden mit Werkzeugen ihrer Wahl sicher auf ihre Daten im Atlassian Data Lake zugreifen und diese analysieren. Diese Funktion unterstützt Anwendungsfälle wie BI-Integration, benutzerdefinierte Datenworkflows und teamübergreifende Zusammenarbeit. (Quelle: matei_zaharia)
Fastino erhält 17,5 Millionen US-Dollar Finanzierung, konzentriert sich auf aufgabenspezifische Sprachmodelle (TLM): Das Startup-Unternehmen Fastino gab eine Finanzierung in Höhe von 17,5 Millionen US-Dollar (insgesamt 25 Millionen US-Dollar Pre-Seed-Runde) unter Führung von Khosla Ventures bekannt, um seine innovativen aufgabenspezifischen Sprachmodelle (TLM) zu entwickeln. Fastino gibt an, dass seine TLM-Architektur klein und aufgabenspezifisch ist und auf Low-End-Gaming-GPUs trainiert werden kann, was kosteneffizient ist. TLM eliminieren Parameterredundanz und Architekturschwächen durch Aufgabenspezialisierung auf Architektur-, Pre-Training- und Post-Training-Ebene, mit dem Ziel, die Genauigkeit für spezifische Aufgaben zu verbessern und in latenz- und kostensensible Anwendungen eingebettet werden zu können. (Quelle: Reddit r/MachineLearning)

🌟 Community
KI-gestützte Bewerbungshilfen lösen Betrugsbedenken aus, Unternehmen verstärken Gegenmaßnahmen: In letzter Zeit nimmt die Nutzung von KI-Tools zur Unterstützung bei Online-Interviews und schriftlichen Tests zu. Diese „KI-Interview-Artefakte“ können Antworten basierend auf dem Lebenslauf des Nutzers anpassen und Bewerbern helfen, sich im Bewerbungsprozess einen Vorteil zu verschaffen. Der Zugang zu solcher Software ist einfach, es werden sogar verschiedene kostenpflichtige Pakete und Fernanleitungen angeboten. Dieser Trend lässt sich bis zum Aufkommen früherer KI-Betrugstools wie „Interview Coder“ zurückverfolgen. Unternehmen haben begonnen, Gegenmaßnahmen zu ergreifen, wie z. B. die Beobachtung von auffälligem Verhalten von Bewerbern während Interviews, die Erwägung der Einführung von Bildschirmüberwachung oder die Rückkehr zu persönlichen Interviews. Anwälte weisen darauf hin, dass die Verwendung von KI zum Betrügen einen Verstoß gegen das Integritätsprinzip darstellt, zur Kündigung des Arbeitsvertrags führen kann und Risiken für den Datenschutz birgt. (Quelle: 36氪)

LangChain CEO Harrison Chase stellt Konzepte „Ambient Agents“ und „Agent Inbox“ vor: LangChain CEO Harrison Chase teilte auf dem Sequoia AI Ascent Event seine Ansichten zur zukünftigen Entwicklung von KI-Agenten und stellte die Konzepte „Ambient Agents“ und „Agent Inbox“ vor. Ambient Agents sind KI-Systeme, die kontinuierlich im Hintergrund laufen und auf Ereignisse anstatt auf direkte menschliche Anweisungen reagieren, während die Agent Inbox eine neue Mensch-Maschine-Schnittstelle zur Verwaltung und Überwachung der Aktivitäten dieser Agenten darstellt. (Quelle: hwchase17, hwchase17, hwchase17)

Jim Fan schlägt „Physical Turing Test“ als neuen Nordstern für KI vor: NVIDIA-Wissenschaftler Jim Fan schlug auf dem Sequoia AI Ascent Event den „Physical Turing Test“ als nächsten „Nordstern“ im Bereich der KI vor. Der Test stellt sich ein Szenario vor: Nach einem Sonntags-Hackathon ist das Haus ein Chaos, am Montagabend kommt man nach Hause und findet das Wohnzimmer makellos sauber und ein Candle-Light-Dinner vorbereitet vor, und man kann nicht unterscheiden, ob dies von einem Menschen oder einer Maschine getan wurde. Er betrachtet dies als das Ziel der allgemeinen Robotik und teilte die wichtigsten Prinzipien zur Lösung dieses Problems, einschließlich Datenstrategien und Skalierungsgesetzen. (Quelle: DrJimFan, killerstorm)
KI-Modellbewertung in der Krise, EvalEval-Allianz fordert Verbesserungen: Angesichts der aktuellen Mängel bei den Bewertungsmethoden für KI-Modelle, wie z. B. Benchmark-Sättigung und mangelnde wissenschaftliche Strenge, wurde die EvalEval-Allianz erwähnt. Sie zielt darauf ab, Personen, denen der Zustand der Bewertung am Herzen liegt, zusammenzubringen, um gemeinsam an der Verbesserung der Bewertungsberichte, der Lösung von Sättigungsproblemen, der Steigerung der wissenschaftlichen Qualität der Bewertung und der Infrastruktur zu arbeiten. In entsprechenden Diskussionen wird argumentiert, dass der Schwerpunkt stärker auf der Validität der Bewertung liegen sollte. (Quelle: ClementDelangue)

Reddit-Diskussion: Beobachtungen und Erfahrungen beim Aufbau von LLM-Workflows: Ein Entwickler teilte auf Reddit seine Erfahrungen aus dem vergangenen Jahr beim Aufbau komplexer LLM-Workflows zusammen. Wichtige Punkte sind: Aufgabenzerlegung in kleinste Schritte und verkettete Prompt-Aufrufe sind besser als einzelne komplexe Prompts; die Verwendung von XML-Tags zur Strukturierung von Prompts funktioniert besser; LLMs muss klar mitgeteilt werden, dass ihre Rolle nur die semantische Analyse und Transformation ist und sie kein eigenes Wissen einbringen sollten; traditionelle NLP-Bibliotheken wie NLTK sollten zur Validierung von LLM-Ausgaben verwendet werden; für kleine Aufgaben sind feinabgestimmte BERT-ähnliche Klassifikatoren oft besser als LLMs; LLMs als Schiedsrichter oder zur Konfidenzbewertung sind unzuverlässig, insbesondere wenn klare Bewertungskriterien fehlen; in agentischen Schleifen ist die Festlegung der Bedingungen, unter denen LLMs die Schleife verlassen, schwierig; die Leistung nimmt typischerweise ab, wenn das Eingabekontextfenster 4K Tokens überschreitet; 32B-Modelle sind für strukturierte Aufgaben ausreichend; strukturierte CoT ist besser als unstrukturierte; selbst geschriebene CoT ist besser als sich auf Inferenzmodelle zu verlassen; langfristiges Ziel ist das Fine-Tuning aller Komponenten und der Aufbau ausgewogener Fine-Tuning-Datensätze. (Quelle: Reddit r/LocalLLaMA)
Reddit-Nutzer diskutieren Claude Sonnet 3.7 Systemeinstellungen für Prompts: Nutzer der Reddit-Community r/ClaudeAI berichten von Instabilitäten des Claude Sonnet 3.7 Modells bei der Befolgung von Anweisungen, Code-Reparaturen und Kontextgedächtnis und bitten um effektive System-Prompts. Einige Nutzer teilten Prompts, die das Verhalten von Sonnet 3.5 nachahmen, sowie detaillierte Anweisungen, die effiziente, praktische Lösungen und die Einhaltung grundlegender Informatikprinzipien (wie DRY, KISS, SRP) betonen. Andere Nutzer schlugen vor, die Wirkung zu verbessern, indem Claude die System-Prompts selbst umschreibt und optimiert oder indem prägnante einzeilige Anweisungen verwendet werden. (Quelle: Reddit r/ClaudeAI)
Diskussion über die Anzahl der für das LLM-Fine-Tuning erforderlichen Epochen: Auf Reddit r/MachineLearning stellte ein Benutzer Fragen zum Deepseek R1-Paper, in dem das Deepseek-V3-Base-Modell (ca. 800.000 Samples) mit nur 2 Epochen feinabgestimmt wurde, und diskutierte Metriken jenseits der Verlustfunktion, die die Anzahl der Fine-Tuning-Epochen bestimmen, wie z. B. die Leistung der Evaluierungsdaten und die Datenqualität. (Quelle: Reddit r/MachineLearning)
💡 Sonstiges
François Chollet: Der Aufbau solider Denkmodelle ist Voraussetzung für die Lösung schwieriger Probleme: Der KI-Vordenker François Chollet betont, dass der Aufbau klarer, in sich stimmiger Denkmodelle die Voraussetzung für die kreative Lösung schwieriger Probleme (anstatt sich auf Glück zu verlassen) ist, was sich von der Fähigkeit unterscheidet, einfache Probleme schnell zu lösen. Er betrachtet Eleganz als eine Kombination aus Ausdruckskraft und Einfachheit, die eng mit Kompression verbunden ist. (Quelle: fchollet, teortaxesTex, fchollet, pmddomingos)

Replit CEO Amjad Masad: KI-Agenten werden die neue Welle der Programmierung sein: Amjad Masad, CEO und Mitbegründer von Replit, erklärte in einem Interview mit The Turing Post, dass er immer davon überzeugt war, dass KI-Agenten die nächste Welle der Programmierung anführen werden. Er teilte seine Gedanken zum Wandel vom Unterrichten von Programmierung hin zum Aufbau von Agenten, die automatisch programmieren können. Er erwähnte, dass Software-Agenten bereits in der Praxis Wirkung zeigen, beispielsweise indem sie Immobilienunternehmen helfen, Algorithmen zur Lead-Verteilung zu optimieren und die Konversionsrate um 10 % zu steigern. Er glaubt, dass zukünftige Milliarden-Dollar-Startups von KI-gestärkten Einzelgründern aufgebaut werden könnten und diskutierte die dafür notwendigen Bedingungen, den aktuellen Stand und die Zukunft der Programmierung, die Entwicklung der Vision von Replit sowie die Bedeutung von AGI und Open Source. (Quelle: TheTuringPost, TheTuringPost)
LazyVim: Neovim-Konfiguration für „Faule“: LazyVim ist eine Neovim-Konfigurationslösung, die auf lazy.nvim basiert und darauf abzielt, Benutzern die einfache Anpassung und Erweiterung ihrer Neovim-Umgebung zu ermöglichen. Es bietet eine vorkonfigurierte, funktionsreiche IDE-ähnliche Erfahrung, während gleichzeitig eine hohe Flexibilität erhalten bleibt, sodass Benutzer Anpassungen nach Bedarf vornehmen können. (Quelle: GitHub Trending)
