
Schlüsselwörter:ChatGPT, GitHub, KI-Modell, Multimodal, Bestärkendes Lernen, Open Source, Meta FAIR, AGI, ChatGPT Deep Research Funktion, Hybride Transformer-Architektur, Verstärktes Feinabstimmen RFT, KI-Multiversum-Modell, Wissenschaftler-KI-Rahmen
🔥 Fokus
ChatGPT Deep Research-Funktion integriert GitHub: OpenAI kündigte an, dass die Deep Research-Funktion von ChatGPT nun die Anbindung an GitHub-Code-Repositories unterstützt. Nachdem Nutzer eine Frage gestellt haben, kann der KI-Agent automatisch Quellcode, PRs und README-Dokumente im Code-Repository lesen, durchsuchen und analysieren, um detaillierte Berichte mit direkten Zitaten zu erstellen. Die Funktion soll Entwicklern helfen, sich schnell mit Projekten vertraut zu machen und Codestrukturen sowie den Technology Stack zu verstehen. Diese Funktion befindet sich derzeit in der Testphase und ist für Team-Nutzer verfügbar. Sie wird schrittweise auch für Plus- und Pro-Nutzer eingeführt. (Quelle: OpenAI Developers, snsf, EdwardSun0909, op7418, gdb, tokenbender, QbitAI, 36Kr)

Weltweit erstes KI-Multiplayer-Weltmodell Multiverse als Open Source veröffentlicht: Das israelische Startup Enigma Labs hat sein entwickeltes Multiplayer-Weltmodell Multiverse als Open Source freigegeben. Es ermöglicht zwei KI-Agenten, in derselben generierten Umgebung wahrzunehmen, zu interagieren und zusammenzuarbeiten. Das Modell wurde auf Basis von Gran Turismo 4 trainiert und verarbeitet den gemeinsamen Weltzustand, indem es die Perspektiven zweier Spieler entlang der Farbkanäle stapelt und mit spärlich abgetasteten historischen Frames kombiniert. Dies ermöglicht Training und Echtzeitbetrieb auf einem PC mit Kosten von unter 1500 US-Dollar. Dieser Schritt wird als wichtiger Fortschritt für KI im Verständnis und der Generierung gemeinsamer virtueller Umgebungen angesehen und bietet neue Ansätze für Multi-Agenten-Systeme und Simulations-Trainingsplattformen. (Quelle: Reddit r/MachineLearning, 36Kr)
Top-KI-Wissenschaftler Rob Fergus kehrt zurück und leitet Meta FAIR mit Ziel AGI: Rob Fergus, der früh gemeinsam mit Yann LeCun FAIR gründete und später das New Yorker Team bei DeepMind leitete, ist zu Meta zurückgekehrt und übernimmt die Leitung von FAIR von Joelle Pineau. Fergus trat im April dieses Jahres der GenAI-Abteilung von Meta bei, um die Speicher- und Personalisierungsfähigkeiten des Llama-Modells zu verbessern. LeCun kündigte gleichzeitig an, dass das neue Ziel von FAIR Advanced Machine Intelligence (AGI) sein wird. Fergus ist ein vielzitierter Wissenschaftler im KI-Bereich, bekannt für seine Visualisierungsforschung zu ZFNet und seine bahnbrechende Arbeit zu Adversarial Samples. (Quelle: ylecun, 36Kr)

Anthropic veröffentlicht Studie zu Claude AI-Werten und deckt 3307 KI-Wertpräferenzen auf: Das Forschungsteam von Anthropic hat das Preprint-Paper „Values in the Wild“ veröffentlicht, in dem durch die Analyse der Leistung von Claude AI in realen Gesprächen 3307 einzigartige KI-Werte identifiziert wurden. Die Studie ergab, dass die häufigsten Werte serviceorientiert sind, wie „Hilfsbereitschaft“ (23,4 %), „Professionalität“ (22,9 %) und „Transparenz“ (17,4 %). KI-Werte wurden in fünf übergeordnete Kategorien eingeteilt: utilitaristisch (31,4 %), kognitiv (22,2 %), sozial (21,4 %), schützend (13,9 %) und persönlich (11,1 %) und zeigten eine hohe Kontextabhängigkeit. Claude reagierte im Allgemeinen unterstützend auf von Menschen geäußerte Werte (43 %), Wertespiegelung machte etwa 20 % aus, während Widerstand gegen Nutzerwerte selten war (5,4 %). (Quelle: Reddit r/ArtificialInteligence)
Yoshua Bengio schlägt „Scientist AI“-Framework vor und plädiert für sichereren KI-Entwicklungspfad: Turing-Preisträger Yoshua Bengio erläuterte in einem Gastbeitrag im Time Magazine die Forschungsrichtung seines Teams zu „Scientist AI“. Er betrachtet dies als einen praktischen, effektiven und sichereren Entwicklungspfad für KI, der den derzeit unkontrollierten, agentengesteuerten KI-Entwicklungspfad ersetzen soll. Das Framework betont, dass KI-Systeme über Interpretierbarkeit, Verifizierbarkeit und die Fähigkeit zur Ausrichtung an menschlichen Werten verfügen sollten. Durch die Simulation der Methodik wissenschaftlicher Forschung sollen Verhalten und Entscheidungsprozesse von KI transparenter und kontrollierbarer werden, um potenzielle Risiken zu reduzieren. (Quelle: Yoshua_Bengio)
🎯 Trends
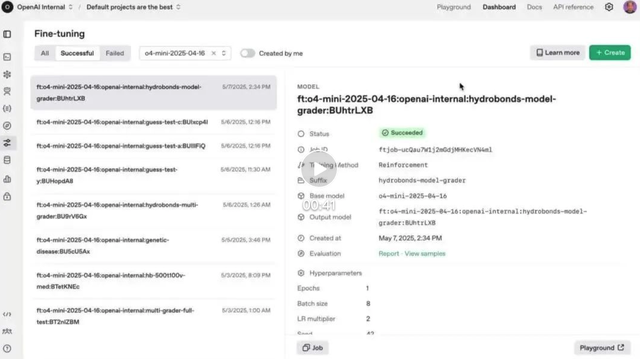
OpenAI Reinforcement Fine-Tuning (RFT)-Funktion offiziell für o4-mini gestartet: OpenAI gab bekannt, dass die im Dezember letzten Jahres vorgestellte Reinforcement Fine-Tuning (RFT)-Funktion nun offiziell im o4-mini-Modell verfügbar ist. RFT nutzt Chain-of-Thought-Reasoning und aufgabenspezifische Bewertungen, um die Leistung des Modells in komplexen Bereichen zu verbessern. Beispielsweise hat das Unternehmen AccordanceAI RFT verwendet, um ein Modell zu optimieren, das im Steuer- und Rechnungswesen Spitzenleistungen erbringt. (Quelle: OpenAI Developers, gdb, QbitAI, 36Kr)
Gemini API führt implizite Cache-Funktion ein, senkt Aufrufkosten um 75 %: Die Google Gemini API wurde um eine implizite Cache-Funktion erweitert. Wenn Nutzeranfragen ein gemeinsames Präfix mit früheren Anfragen aufweisen, kann automatisch ein Cache-Treffer ausgelöst werden, wodurch Nutzer 75 % der Token-Kosten sparen. Diese Funktion erfordert kein aktives Erstellen eines Caches durch Entwickler. Gleichzeitig wurde die Mindest-Token-Anforderung zum Auslösen des Caches bei Gemini 2.5 Flash auf 1K und bei 2.5 Pro auf 2K gesenkt, was die API-Nutzungskosten weiter reduziert. (Quelle: op7418)

OpenAI führt ChatGPT-Speicherfunktion flächendeckend im Europäischen Wirtschaftsraum und weiteren Regionen ein: OpenAI gab bekannt, dass die Speicherfunktion von ChatGPT nun für Plus- und Pro-Nutzer im Europäischen Wirtschaftsraum (EWR), Großbritannien, der Schweiz, Norwegen, Island und Liechtenstein vollständig verfügbar ist. Die Funktion ermöglicht es ChatGPT, auf frühere Chatverläufe von Nutzern zurückzugreifen, um personalisiertere Antworten zu geben, Nutzerpräferenzen und -interessen besser zu verstehen und so präzisere Hilfe beim Schreiben, bei Empfehlungen, beim Lernen usw. zu leisten. (Quelle: openai)
ByteDance SEED stellt multimodales Basismodell Mogao vor: Das SEED-Team von ByteDance hat ein Omni-Basismodell namens Mogao veröffentlicht, das speziell für die verschachtelte multimodale Generierung entwickelt wurde. Mogao integriert mehrere technische Verbesserungen, darunter ein Deep-Fusion-Design, duale visuelle Encoder, verschachtelte rotierende Positionseinbettungen und multimodale klassifikatorfreie Führung. Diese Verbesserungen ermöglichen es, die Vorteile von autoregressiven Modellen (Textgenerierung) und Diffusionsmodellen (hochwertige Bildsynthese) zu kombinieren und beliebige verschachtelte Text- und Bildsequenzen effektiv zu verarbeiten. (Quelle: NandoDF)

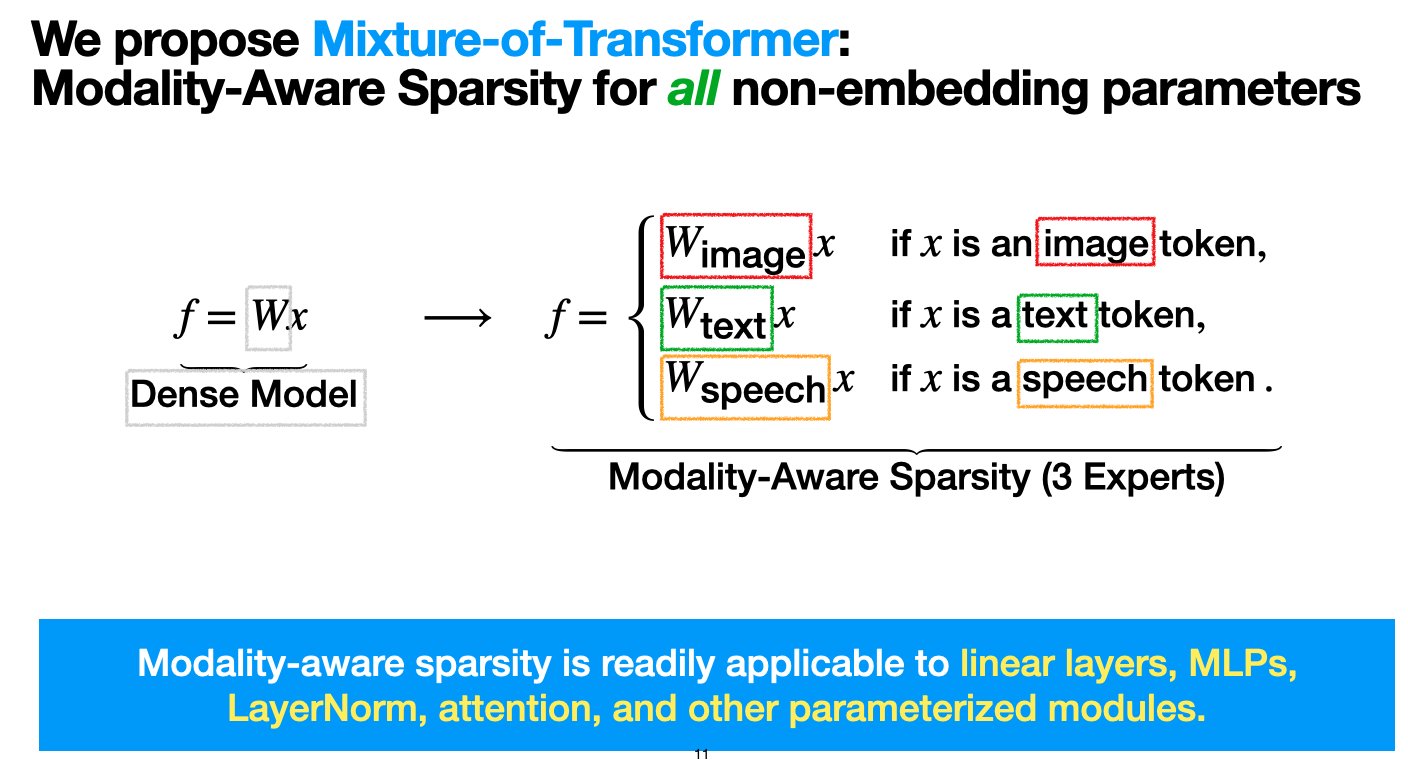
Meta stellt Mixture-of-Transformers (MoT)-Architektur vor, um Kosten für das Pre-Training multimodaler Modelle zu senken: Forscher von Meta AI haben eine Sparse-Architektur namens „Mixture-of-Transformers (MoT)“ vorgeschlagen, die darauf abzielt, die Rechenkosten für das Pre-Training multimodaler Modelle erheblich zu senken, ohne die Leistung zu beeinträchtigen. MoT wendet modalitätsspezifische Sparsity auf nicht eingebettete Transformer-Parameter an (wie Feedforward-Netzwerke, Attention-Matrizen und Layer-Normalisierung). Experimente zeigten, dass im Chameleon-Setup (Text- und Bildgenerierung) ein 7B-MoT-Modell die Qualität der dichten Baseline mit nur 55,8 % der FLOPs erreichte; bei der Erweiterung auf Sprache als dritte Modalität mit nur 37,2 % der FLOPs. Die Forschungsarbeit wurde von TMLR (März 2025) angenommen, der Code ist Open Source. (Quelle: VictoriaLinML)
Qwen-Modellverbesserungsprojekt Smoothie Qwen veröffentlicht, gleicht mehrsprachige Generierung aus: Ein Qwen-Modellverbesserungsprojekt namens Smoothie Qwen wurde veröffentlicht. Es zielt darauf ab, die Fähigkeit zur mehrsprachigen Generierung durch Anpassung der Wahrscheinlichkeiten interner Modellparameter auszugleichen. Das Projekt behebt hauptsächlich das Problem, dass bei einigen nicht-chinesischen Nutzern bei der Verwendung von Qwen gelegentlich chinesische Ausgaben auftreten, und behauptet, die Intelligenz des Modells nicht zu beeinträchtigen. (Quelle: karminski3)

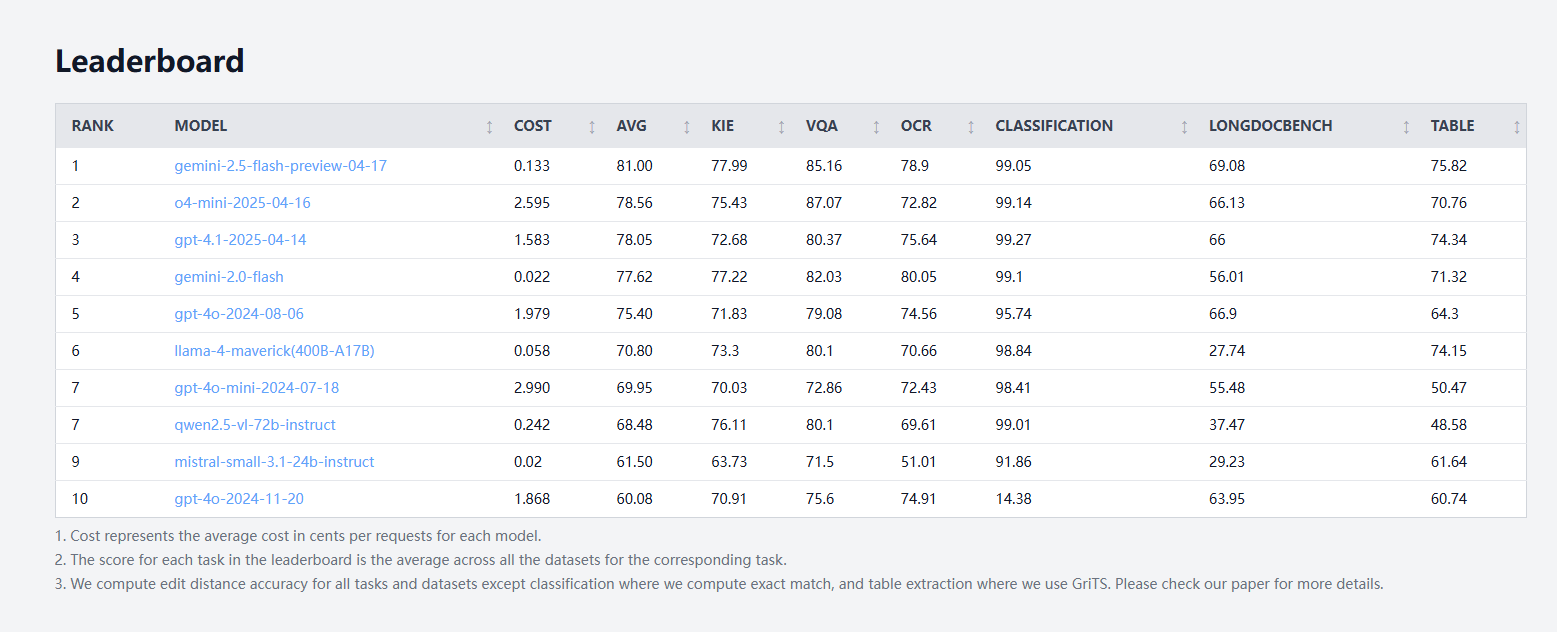
idp-leaderboard veröffentlicht, erste KI-Testbenchmark für Dokumenttypen: Die neue KI-Testbenchmark idp-leaderboard ist online und konzentriert sich auf die Bewertung der Fähigkeit von Modellen, Dokumente und Dokumentbilder zu verarbeiten. Laut der vorläufigen Rangliste schneidet gemini-2.5-flash-preview-04-17 bei der allgemeinen Dokumentenverarbeitung am besten ab. Bemerkenswert ist, dass Qwen2.5-VL bei der Tabellenverarbeitung eine schlechte Leistung zeigt. (Quelle: karminski3)
Perplexity Discover-Funktion erhält wichtiges Update: Arav Srinivas, Mitbegründer von Perplexity, gab bekannt, dass die Discover-Funktion (Informations-Feed) erheblich verbessert wurde und ermutigt Nutzer, sie auszuprobieren. Dies bedeutet in der Regel Optimierungen bei der Informationsdarstellung, Relevanz oder Benutzeroberfläche, die darauf abzielen, die Fähigkeit der Nutzer zu verbessern, neue Informationen zu erhalten und zu erkunden. (Quelle: AravSrinivas)
Lenovo kündigt großes Upgrade für persönlichen Super-KI-Agenten Tianxi an, weltweit erstes Tablet mit lokalem DeepSeek-Deployment: Lenovo kündigte ein großes Upgrade für seinen persönlichen Super-KI-Agenten Tianxi an, der sich auf das L3-Niveau zubewegt, und veröffentlichte den auf KI-Dienste für persönliche intelligente Geräte spezialisierten Domänen-Agenten „Xiang Bang Bang“. Gleichzeitig stellte Lenovo mehrere neue KI-Endgeräte vor, darunter das weltweit erste Tablet mit lokalem Deployment des DeepSeek Large Language Models, das YOGA Pad Pro 14.5 AI Yuanqi Edition, sowie moto AI-Smartphones, PCs der Legion-Serie usw., und baut so ein komplettes KI-Ökosystem aus AI PCs, AI-Smartphones, AI-Tablets und AIoT auf. (Quelle: QbitAI)

Lou Tiancheng über autonomes Fahren und Embodied AI: L2 kann nicht auf L4 hochgestuft werden, VLA hilft L4 nur begrenzt: Lou Tiancheng, Mitbegründer und CTO von Pony.ai, teilte bei der Vorstellung einer neuen Robotaxi-Generation seine neuesten Erkenntnisse zu autonomem Fahren und KI. Er betonte den grundlegenden Unterschied zwischen L2 und L4 und ist der Ansicht, dass L2 nicht auf L4 hochgestuft werden kann. Das derzeit im L2-Bereich beliebte VLA (Vision-Language-Action)-Paradigma sei für L4 „im Grunde nicht hilfreich“. Er wies darauf hin, dass L4 extreme Sicherheit wie bei einem Facharzt erfordere, während VLA eher einem Allgemeinarzt ähnele. Kern der technologischen Transformation von Pony.ai in den letzten zwei Jahren seien End-to-End-Systeme und World Models, wobei letztere seit etwa fünf Jahren im Einsatz seien. Er hält „Cloud Driving“ für ein Pseudokonzept und meint, dass sich Embodied AI derzeit in einem ähnlichen Zustand wie das autonome Fahren im Jahr 2018 befinde und ähnliche Herausforderungen einer „Vakuumphase“ bevorstünden. (Quelle: QbitAI)

Kimi testet Content-Community, OpenAI entwickelt möglicherweise soziale App, KI-LLM-Unternehmen erkunden soziale Funktionen zur Steigerung der Nutzerbindung: Kimi von Moonshot AI testet im Graustufenmodus ein Content-Community-Produkt, das hauptsächlich von KI generierte Inhalte zu Nachrichten-Hotspots aus den Bereichen Technologie, Finanzen usw. bereitstellt. Zufälligerweise wird auch OpenAI nachgesagt, eine soziale Software zu entwickeln, möglicherweise als Konkurrenz zu X. Diese Schritte deuten darauf hin, dass KI-LLM-Unternehmen versuchen, durch den Aufbau von Communities oder sozialen Funktionen die Nutzerbindung zu erhöhen und das Problem der „Nutzung und Verwerfung“ von KI-Tools zu lösen. Der Betrieb von Communities steht jedoch vor Herausforderungen hinsichtlich Inhaltsqualität, Sicherheitsrisiken und Kommerzialisierung. Dieser Schritt spiegelt auch wider, dass die KI-Branche nach dem Erreichen des Wachstumshöhepunkts beginnt, sich von „Geld verbrennen für Wachstum“ zu einer stärkeren Fokussierung auf ROI und der Erforschung neuer Geschäftsmodelle zu wandeln. (Quelle: 36Kr)

TCL setzt voll auf KI, stellt FuXi Large Model und diverse KI-Haushaltsgeräte vor, steht aber vor Herausforderungen durch Homogenisierung: TCL präsentierte auf Messen wie AWE 2025 und CES 2025 schwerpunktmäßig seine KI-Produkte und -Strategie, darunter das TCL FuXi Large Model und KI-Funktionen für Fernseher, Klimaanlagen, Waschmaschinen usw. Das Fernsehgeschäft schnitt mit weltweiten Auslieferungen auf Platz 1 im ersten Quartal hervorragend ab, wobei die Mini-LED-Technologie ein Vorteil ist. Die Anwendung von KI im Haushaltsgerätebereich konzentriert sich derzeit jedoch hauptsächlich auf Sprachinteraktion und spezifische Funktionsoptimierungen (z. B. KI-Bildqualitätschips, KI-Schlaf, KI-Energiesparen) und steht im Wettbewerb mit homogenen Angeboten anderer Marken (wie Hisense Xinghai, Haier HomeGPT, Midea Meiyan). TCL erforscht auch KI-Begleitroboter und plant über RayNeo den Einstieg in den Markt für intelligente Brillen. Trotz erhöhter KI-Investitionen ist der unabhängige technologische Vorteil noch nicht signifikant, und das Unternehmen sieht sich mit hohen Marketingkosten und sinkenden Bruttomargen konfrontiert. (Quelle: 36Kr)
KI treibt Bildungsreform voran, führende Unternehmen wie iFlytek und Excellence Education beschleunigen KI-Implementierung: Ein Bericht analysiert die neuesten KI-Praktiken führender Bildungsunternehmen wie iFlytek, Excellence Education, Fenbi, Zhonggong Education, Huatu Education und Yiqi Education Technology. iFlytek nutzt heimische Rechenleistung und die Modelle Deepseek-V3/R1, um die informationstechnische Bildung zu vertiefen. Excellence Education setzt Deepseek R1 ein, um die gesamte Lehrkette zu optimieren, und führt KI-Korrektur- und KI-Lesetools ein. Fenbi hat eine KI-Produktmatrix aufgebaut, die hochfrequente Lern- und Bedarfs-Szenarien abdeckt. Zhonggong Education konzentriert sich auf KI-gestützte Arbeitsvermittlungsdienste und entwickelt das „Yunxin“-Large Model. Huatu Education kombiniert Offline-Vorteile mit KI, um die Präzision von Dienstleistungen für Beamtenprüfungen zu verbessern. Yiqi Education Technology treibt die Integration von Lehren, Bewerten und Testen durch KI voran. Branchentrends zeigen, dass sich KI-Bildung von einzelnen Tools hin zu Ökosystemwettbewerb und Wertrealisierung entwickelt. (Quelle: 36Kr)
Große Tech-Unternehmen wie Baidu und Alibaba treiben MCP-Protokoll voran und wetteifern um Definitionsmacht im KI-Agent-Ökosystem: Das Model Context Protocol (MCP) wird in letzter Zeit von Anthropic, OpenAI, Google sowie von chinesischen Tech-Giganten wie Baidu und Alibaba vorangetrieben. Die „Xīnxiǎng“-Anwendung von Baidu und die Bailian-Plattform von Alibaba Cloud unterstützen bereits MCP, was KI-Agenten ermöglicht, externe Tools und Dienste einfacher aufzurufen. Dieser Schritt dient oberflächlich der Vereinheitlichung von Industriestandards, ist aber in Wirklichkeit ein Kampf der großen Unternehmen um die Definitionsmacht im zukünftigen KI-Agent-Ökosystem. Durch den Aufbau und die Förderung von MCP wollen die Tech-Giganten mehr Entwickler in ihr Ökosystem locken, um so Datenbarrieren und die Meinungsführerschaft in der Branche zu sichern. Die Kommerzialisierung von Agent-Anwendungen scheint sich derzeit weiterhin auf Traffic und Werbung zu konzentrieren. (Quelle: 36Kr)

Apples KI-Strategie enthüllt: Mögliche Kooperation mit Baidu und Alibaba für eine „Dual-Core“-KI-Systemversion für China: Berichte analysieren eine mögliche Zusammenarbeit von Apple mit Baidu und Alibaba, um technische Unterstützung für seine KI-Funktionen auf dem chinesischen Markt zu leisten. Baidus ERNIE Bot hat Vorteile bei der visuellen Erkennung, während Alibabas Qianwen Large Model bei kognitivem Verständnis und Content-Compliance überzeugt. Dieses „Dual-Core“-Modell könnte darauf abzielen, die Stärken beider Unternehmen zu kombinieren, um den Anforderungen des chinesischen Marktes in Bezug auf Datenökosystem, technologischen Schwerpunkt und regulatorische Anforderungen gerecht zu werden, während Apple seine Führungsrolle und Verhandlungsmacht in der Zusammenarbeit behält. Dieser Schritt wird als Reaktion von Apple auf den Druck lokaler Wettbewerber wie HarmonyOS und als eine Strategie der „ökologischen Nischenbildung“ vor dem Hintergrund strengerer Datenregulierung angesehen. (Quelle: 36Kr)
Professor Yu Jingyi analysiert Spatial Intelligence: Enormes Potenzial, aber Konsens fehlt, Daten und physikalisches Verständnis sind entscheidend: Professor Yu Jingyi von der ShanghaiTech University wies in einem Interview darauf hin, dass das Potenzial von Large Language Models bei der modalitätenübergreifenden Integration bei weitem nicht ausgeschöpft sei. Spatial Intelligence entwickle sich dank der Durchbrüche der generativen KI von der digitalen Nachbildung hin zu intelligentem Verständnis und Schöpfung. Er ist der Ansicht, dass die Kernherausforderungen der aktuellen Spatial Intelligence im Mangel an realen 3D-Szenendaten und der fehlenden Vereinheitlichung von 3D-Darstellungsweisen liegen. Sein Teamprojekt CAST erforscht durch die Einführung der „Actor-Network Theory“ und physikalischer Regeln die Beziehungen zwischen Objekten und die physikalische Plausibilität. Er betont die Priorität der Wahrnehmung und prognostiziert revolutionäre Durchbrüche in der Sensortechnologie. Der Maßstab für Embodied AI sollte Robustheit und Sicherheit sein, nicht reine Präzision. Kurzfristig wird Spatial Intelligence in Bereichen wie Filmproduktion und Spiele explodieren, mittel- bis langfristig zum Kern von Embodied AI werden, und auch die Low-Altitude Economy ist ein wichtiges Anwendungsfeld. (Quelle: 36Kr)

Wettlauf um KI-Talente verschärft sich: Tech-Giganten locken mit hohen Gehältern, CTO-Mentoring, Fokus auf Large Models und Multimodalität: In- und ausländische Tech-Giganten führen einen intensiven Kampf um KI-Talente. ByteDance, Alibaba, Tencent, Baidu, JD.com, Huawei und andere haben Rekrutierungsprogramme für Top-Doktoranden und junge Genies aufgelegt, die Gehälter ohne Obergrenze, persönliches Mentoring durch CTOs und keine Praktikumserfahrung als Voraussetzung bieten. Die Rekrutierung konzentriert sich hauptsächlich auf die Bereiche Large Models und Multimodalität und ist eng mit den Kerngeschäftsszenarien der jeweiligen Unternehmen verbunden. Der Erfolg von Modellen wie DeepSeek hat den Bedarf der Branche an Talenten weiter verschärft. Auch Elon Musk beklagte einst den Wahnsinn im Wettbewerb um KI-Talente; ausländische Giganten wie OpenAI werben ebenfalls mit hohen Gehältern und persönlicher Rekrutierung durch Gründer um Talente. (Quelle: 36Kr)
Sequoia Capital: KI-Marktpotenzial weit größer als Cloud Computing, Anwendungsebene ist entscheidend, Chief AI Officer wird Standard: Ein Partner von Sequoia Capital prognostiziert, dass die Marktgröße für KI den aktuellen Cloud-Computing-Markt von rund 400 Milliarden US-Dollar bei weitem übertreffen wird. In den nächsten 10-20 Jahren wird das Volumen immens sein, wobei der Wert hauptsächlich auf der Anwendungsebene liegt. Start-ups sollten sich auf Kundenbedürfnisse konzentrieren, End-to-End-Lösungen anbieten, sich auf vertikale Bereiche spezialisieren und das „Data Flywheel“ nutzen, um Wettbewerbsvorteile aufzubauen. Eine AWS-Studie zeigt, dass globale Unternehmen die generative KI beschleunigt annehmen: 45 % der Entscheidungsträger planen, sie als oberste Priorität für 2025 zu setzen, und die Position des Chief AI Officer (CAIO) wird zum Standard in Unternehmen werden – derzeit haben 60 % der Unternehmen diese Position bereits geschaffen. Die Agentenökonomie wird als die nächste Stufe der KI-Entwicklung angesehen, erfordert jedoch die Lösung von drei technischen Herausforderungen: persistente Identität, Kommunikationsprotokolle und Sicherheit/Vertrauen. (Quelle: 36Kr)

Neue Automobilhersteller setzen voll auf KI: Li Auto, XPeng und NIO wetteifern um die Definition des Autos der nächsten Generation: Der Durchbruch von Teslas FSD V12 durch End-to-End-Neuronale-Netzwerk-Technologie hat chinesische neue Automobilhersteller wie Li Auto, XPeng und NIO dazu veranlasst, ihre KI-Strategien zu beschleunigen. Li Auto hat das VLA (Vision-Language-Action) Driver Large Model vorgestellt und den Sprachteil auf Basis des quelloffenen DeepSeek-Modells entwickelt. XPeng Motors hat ein LVA-Basismodell mit 72 Milliarden Parametern aufgebaut. NIO wiederum hat Chinas erstes intelligentes Fahr-World-Model NWM veröffentlicht und entwickelt den 5nm-Chip für intelligentes Fahren Shenji NX9031 selbst. Alle Unternehmen investieren massiv in Algorithmen, Rechenleistung (eigene Chips) und Daten und generalisieren KI-Technologien auf Bereiche wie humanoide Roboter, um im Wettbewerb um die Definition des Autos und sogar Produkts der nächsten Generation zu bestehen, stehen aber vor finanziellen und kommerziellen Herausforderungen. (Quelle: 36Kr)
🧰 Werkzeuge
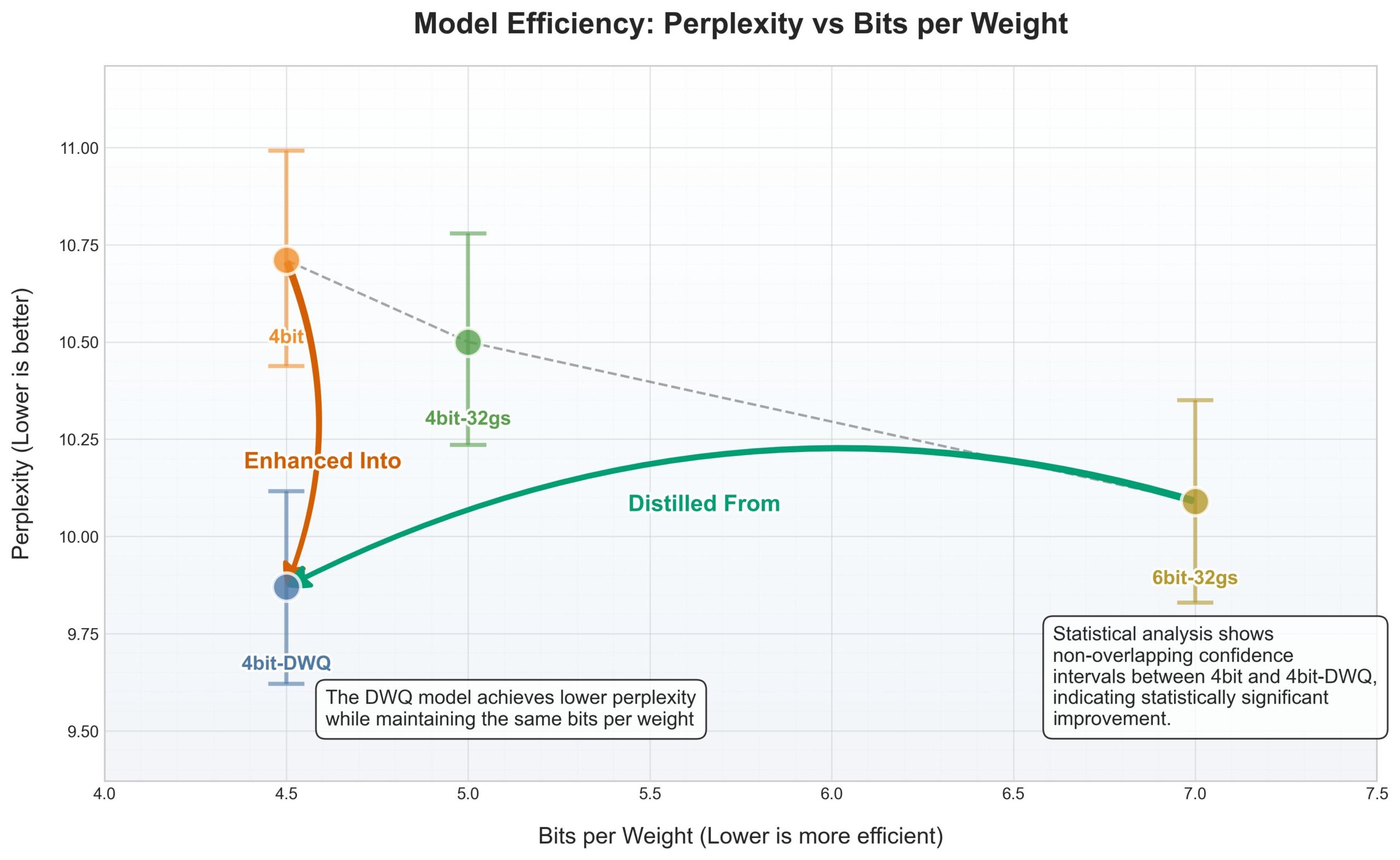
Apple MLX Framework erhält DWQ-Quantisierung, 4-Bit übertrifft alte 6-Bit-Leistung: Für das Apple MLX (Machine Learning Framework) wurde eine neue DWQ (Dynamic Weight Quantization) Quantisierungsmethode veröffentlicht. Laut Daten, die vom Nutzer karminski3 geteilt wurden, übertreffen 4-Bit-dwq quantisierte Modelle (wie Qwen3-30B) bei der Perplexität sogar die alte 6-Bit-Quantisierungsmethode und benötigen nur 17 GB Arbeitsspeicher. Dies eröffnet neue Möglichkeiten für den effizienten Betrieb großer Sprachmodelle auf Apple-Geräten. (Quelle: karminski3)
Perplexity unterstützt jetzt natürlichere dialogorientierte Suche in WhatsApp: Arav Srinivas, Mitbegründer von Perplexity, gab bekannt, dass die Integration von Perplexity in WhatsApp verbessert wurde und nun eine natürlichere Dialogerfahrung bietet. Wenn keine Suche erforderlich ist, wird der Suchschritt intelligent ignoriert, sodass Nutzer direkt im Chat-Stil mit der KI interagieren können. (Quelle: AravSrinivas)
nanobrowser_ai unterstützt gängige LLMs, integriert Langchain.js: Das KI-Tool nanobrowser_ai hat die Unterstützung für verschiedene große Sprachmodelle angekündigt, darunter OpenAI-Modelle, Gemini sowie lokal über Ollama betriebene Modelle. Das Tool nutzt das Langchain.js-Framework, um eine flexible Unterstützung verschiedener LLMs zu ermöglichen und Nutzern eine breitere Modellauswahl zu bieten. (Quelle: hwchase17)
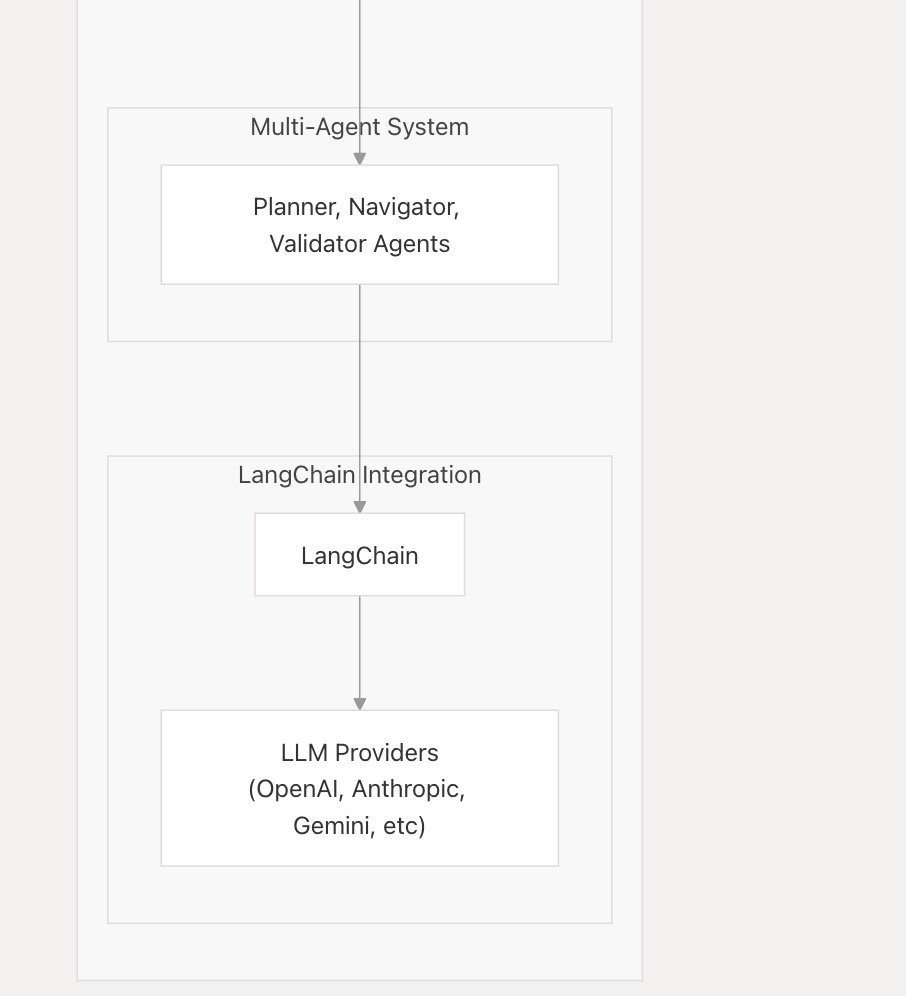
LlamaIndex TypeScript fügt Unterstützung für Echtzeit-LLM-APIs hinzu, erste Integration mit Google Gemini: LlamaIndex TypeScript kündigte die Unterstützung für Echtzeit-LLM-APIs an, die es Entwicklern ermöglicht, Echtzeit-Audio-Dialogfunktionen in KI-Anwendungen zu implementieren. Die erste Integration ist die Echtzeit-Abstraktionsschnittstelle von Google Gemini, die Echtzeit-Unterstützung für OpenAI wird ebenfalls in Kürze folgen. Dieses Update erleichtert Entwicklern den Wechsel zwischen verschiedenen Echtzeitmodellen und den Aufbau interaktiverer KI-Anwendungen. (Quelle: _philschmid)
Gradio Anwendungs-Tutorial: Bild- und Videoannotation sowie Objekterkennung mit Qwen2.5-VL: Ein Tutorial beschreibt detailliert, wie man mit Qwen2.5-VL (Vision Language Model) eine Gradio-Anwendung erstellt, um automatische Bild- und Videoannotation sowie Objekterkennungsfunktionen zu realisieren. Das Tutorial soll Entwicklern helfen, die leistungsstarken Fähigkeiten von Qwen2.5-VL schnell für den Aufbau interaktiver KI-Anwendungen zu nutzen. (Quelle: Reddit r/deeplearning)

VSCode-Plugin gemini-code erreicht fast 50.000 Downloads: Die Downloadzahlen des VSCode AI-Programmierassistenten-Plugins gemini-code nähern sich 50.000. Der Entwickler raizamrtn kündigte an, am Wochenende einige notwendige Updates durchzuführen. Das Plugin zielt darauf ab, die Fähigkeiten des Gemini-Modells zur Unterstützung von Entwicklern bei Programmierarbeiten zu nutzen. (Quelle: raizamrtn)

Französisches KI-Startup Arcads AI: 5-köpfiges Team erwirtschaftet 5 Mio. USD Jahresumsatz, Fokus auf automatisierte Videowerbeproduktion: Das in Paris ansässige KI-Startup Arcads AI hat mit nur 5 Mitarbeitern einen jährlichen wiederkehrenden Umsatz von 5 Millionen US-Dollar erzielt und ist profitabel. Das Unternehmen bietet Werbetreibenden über ein hochautomatisiertes KI-System schnelle, kostengünstige und konversionsstarke Videowerbeproduktionsdienste an. Kunden müssen lediglich den Kerntext liefern, und die KI übernimmt den gesamten Prozess von der Szenenerstellung über die Schauspielerleistung und die Voiceover-Aufnahme bis zur fertigen Produktion. Die Arcads-Plattform verfügt über mehr als 300 auf echten, lizenzierten Personen basierende KI-Schauspieler-Avatare, unterstützt 35 Sprachen und realisiert „Content as a Service“. Auch der interne Betrieb nutzt KI-Agenten in großem Umfang, wie z. B. einen AI Spy Agent zur Analyse von Wettbewerbsprodukten und einen AI Ghostwriter zur Ideengenerierung, was die Effizienz erheblich steigert. (Quelle: 36Kr)
📚 Lernen
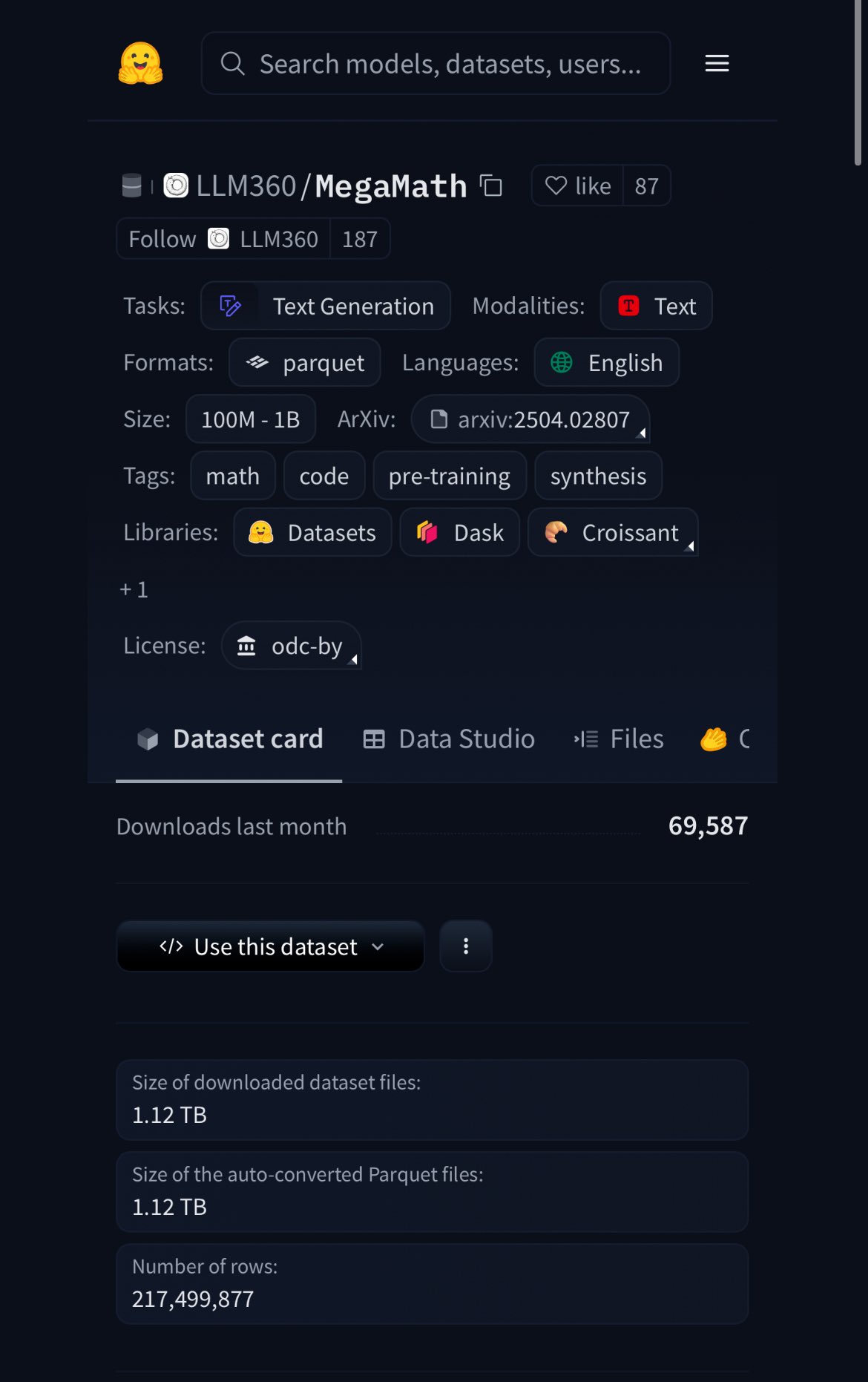
HuggingFace veröffentlicht MegaMath-Datensatz mit 370 Mrd. Token, 20 % davon synthetische Daten: HuggingFace hat den MegaMath-Datensatz veröffentlicht, der 370 Milliarden Token enthält und damit der derzeit größte mathematische Pre-Training-Datensatz ist – etwa 100-mal so groß wie die englische Wikipedia. Bemerkenswert ist, dass 20 % der Daten synthetisch sind, was erneut die Diskussion über die Rolle hochwertiger synthetischer Daten beim Modelltraining entfacht. (Quelle: ClementDelangue)
Nous Research veranstaltet RL Environment Hackathon mit 50.000 US-Dollar Preisgeld: Nous Research kündigte den Nous RL Environment Hackathon in San Francisco an. Die Teilnehmer werden das Reinforcement Learning Environment Framework Atropos von Nous nutzen, um kreative Projekte zu entwickeln. Der Gesamtpreispool beträgt 50.000 US-Dollar. Zu den Partnern gehören xAI, NVIDIA, Nebius AI und andere. (Quelle: Teknium1)

HuggingFace Wochen-Charts der beliebtesten Modelle veröffentlicht: Nutzer karminski3 teilte die Rangliste der beliebtesten Modelle dieser Woche auf HuggingFace und erwähnte, dass er die meisten davon entweder selbst getestet oder offizielle Demos geteilt hat. Dies spiegelt das rege Interesse der Community wider, neue Modelle schnell zu verfolgen und zu bewerten. (Quelle: karminski3)
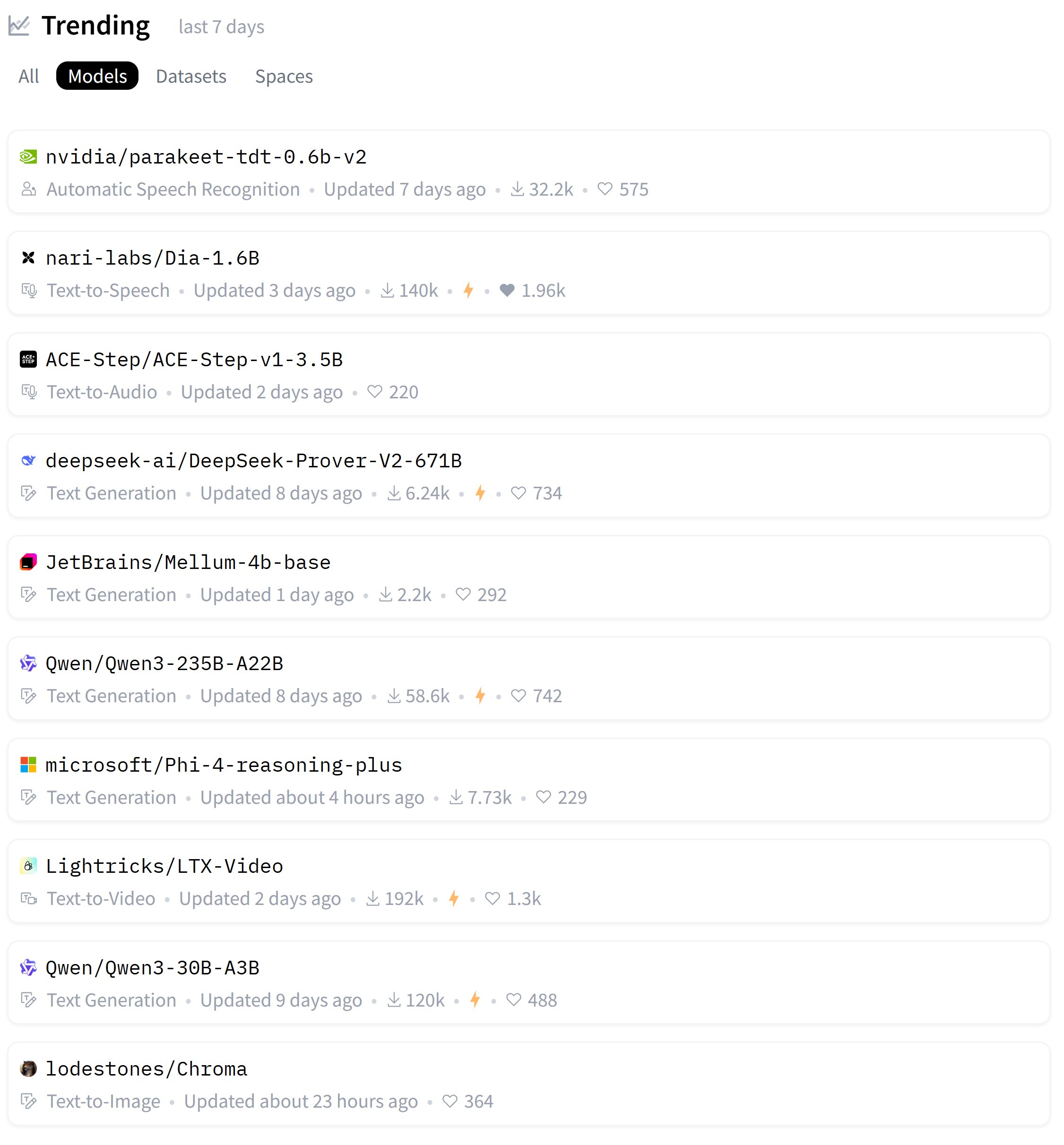
Zeyuan Allen-Zhu veröffentlicht Forschungsreihe zum LLM-Architekturdesign und diskutiert das Primer-Modell: Der Forscher Zeyuan Allen-Zhu enthüllt in seiner Forschungsreihe „Physics of LLM Design“ mithilfe kontrollierter synthetischer Pre-Training-Umgebungen die wahren Grenzen von LLM-Architekturen. In seinem neuesten Beitrag diskutiert er das Primer-Modell (arxiv.org/abs/2109.08668) und dessen multi-dconv-head attention (die er als Canon-B ohne Residual Connections bezeichnet). Er weist auf Probleme hin, ist aber auch der Meinung, dass das Primer-Modell (nur 180 Zitationen) unterschätzt wird, da es aus verrauschten realen Experimenten bedeutsame Signale entdeckt hat. (Quelle: ZeyuanAllenZhu, cloneofsimo)
Simons Institute diskutiert Skalierungsgesetze neuronaler Netze: Das Simons Institute lud in seiner Polylogues-Reihe Anil Ananthaswamy und Alexander Rush ein, um die in den letzten Jahren empirisch entdeckten Skalierungsgesetze neuronaler Netze (neural scaling laws) zu diskutieren. Diese Gesetze haben die Entscheidungen großer Unternehmen, immer größere Modelle zu bauen, maßgeblich beeinflusst. (Quelle: NandoDF)

François Fleuret veröffentlicht „The Little Book of Deep Learning“: François Fleuret hat ein Buch mit dem Titel „The Little Book of Deep Learning“ veröffentlicht, das Lesern komprimiertes Wissen über Deep Learning vermitteln soll. (Quelle: Reddit r/deeplearning)
Princeton-Professor: KI könnte Geisteswissenschaften beenden, aber zu existenzieller Erfahrung zurückführen: Professor D. Graham Burnett von der Princeton University diskutiert in einem Artikel im New Yorker die Auswirkungen von KI auf die Geisteswissenschaften. Er beobachtet an US-Hochschulen eine weit verbreitete „KI-Scham“, bei der Studenten sich nicht trauen, die Nutzung von KI zuzugeben. Er ist der Ansicht, dass KI in der Informationsbeschaffung und -analyse traditionelle akademische Methoden bereits übertroffen hat und wissenschaftliche Bücher wie archäologische Artefakte erscheinen lässt. Obwohl KI die traditionellen, auf Wissensproduktion ausgerichteten Geisteswissenschaften beenden könnte, könnte sie auch dazu führen, dass diese sich wieder auf Kernfragen konzentrieren: Wie man lebt, dem Tod begegnet und andere existenzielle Erfahrungen, die KI nicht direkt berühren kann. (Quelle: 36Kr)

7 Studien enthüllen tiefgreifende Auswirkungen von KI auf menschliches Gehirn und Verhalten: Eine Reihe neuer Studien untersucht die Auswirkungen von KI auf psychologischer, sozialer und kognitiver Ebene des Menschen. Die Ergebnisse umfassen: 1) LLM-Red-Teamer erkunden Modellschwachstellen aus Neugier und moralischer Verantwortung; 2) ChatGPT zeigt hohe diagnostische Genauigkeit bei der Analyse psychiatrischer Fälle; 3) Die politische Ausrichtung von ChatGPT hat sich zwischen verschiedenen Versionen subtil verändert; 4) Die Nutzung von ChatGPT könnte die Ungleichheit am Arbeitsplatz verschärfen, da junge, einkommensstarke Männer sie häufiger nutzen; 5) KI kann durch Analyse des Fahrverhaltens älterer Menschen Anzeichen von Depressionen erkennen; 6) LLMs zeigen in Persönlichkeitstests eine sozial erwünschte Verzerrung, indem sie ein „geschöntes“ Image präsentieren; 7) Übermäßige Abhängigkeit von KI kann kritisches Denken schwächen, insbesondere bei jungen Menschen. (Quelle: 36Kr)

Interview mit Onur Boyar: Einsatz von generativen Modellen und Bayes’scher Optimierung für Medikamenten- und Materialdesign: Onur Boyar, Teilnehmer des AAAI/SIGAI Doctoral Consortium, stellte seine Doktorarbeit an der Universität Nagoya vor, die sich auf den Einsatz von generativen Modellen und Bayes’schen Methoden für das Design von Medikamenten und Materialien konzentriert. Er ist am japanischen Moonshot-Projekt beteiligt, das darauf abzielt, KI-Wissenschaftsroboter für die Arzneimittelforschung zu entwickeln. Seine Forschungsmethoden umfassen die Verwendung von Latent Space Bayesian Optimization zur Bearbeitung bestehender Moleküle, um die Sample-Effizienz und synthetische Machbarkeit zu verbessern. Er betont die enge Zusammenarbeit mit Chemikern und wird nach seinem Abschluss dem Materialforschungsteam von IBM Research Tokyo beitreten. (Quelle: aihub.org)

💼 Wirtschaft
Modular kooperiert mit AMD für Mojo Hackathon mit MI300X GPUs: Modular kündigte eine Zusammenarbeit mit AMD für einen speziellen Hackathon im AGI House an. Bei der Veranstaltung werden Entwickler die Programmiersprache Mojo auf AMD Instinct™ MI300X GPUs verwenden. Es werden auch Vertreter von Modular, AMD, Dylan Patel von SemiAnalysis und Anthropic technische Vorträge halten. (Quelle: clattner_llvm)
Stripe stellt mehrere KI-gesteuerte neue Funktionen vor, darunter KI-Basismodell für den Zahlungsverkehr: Das Finanzdienstleistungsunternehmen Stripe kündigte auf seiner Jahreskonferenz mehrere neue Produkte zur Beschleunigung der KI-Anwendungseinführung an, darunter das weltweit erste KI-Basismodell, das speziell für den Zahlungsverkehr entwickelt wurde. Das Modell, trainiert auf Basis von zig Milliarden Transaktionen, zielt darauf ab, die Betrugserkennung (z. B. Verbesserung der Erkennungsrate von „Card Testing“-Angriffen um 64 %), die Autorisierungsraten und das personalisierte Checkout-Erlebnis zu verbessern. Stripe erweiterte auch seine Fähigkeiten im Management von Fremdwährungsguthaben und vertiefte die Zusammenarbeit mit Großunternehmen wie Nvidia (das Stripe Billing zur Verwaltung von GeForce Now-Abonnements verwendet) und PepsiCo. (Quelle: 36Kr)
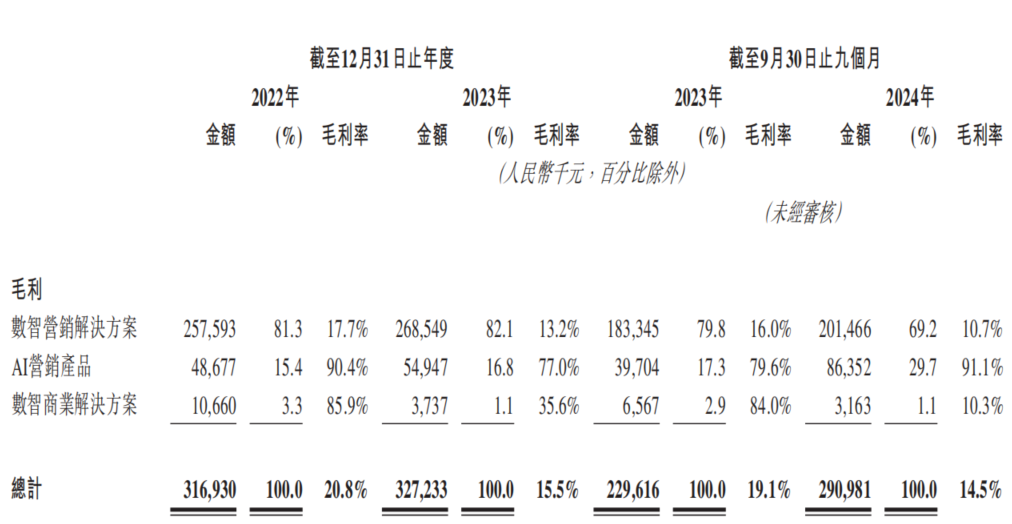
KI-Marketingfirma Dongxin Marketing versucht erneut Börsengang in Hongkong, kämpft mit „Umsatzwachstum ohne Gewinnwachstum“: Dongxin Marketing hat unter dem Namen „Chinas größte KI-Marketingfirma“ erneut einen Börsenprospekt in Hongkong eingereicht. Die Daten zeigen, dass der Umsatz des Unternehmens in den ersten drei Quartalen von 2022-2024 kontinuierlich gestiegen ist, der Nettogewinn jedoch stark gesunken oder sogar in die Verlustzone gerutscht ist, während die Bruttomarge von 20,8 % auf 14,5 % fiel. Der Umsatzanteil des KI-Marketinggeschäfts beträgt weniger als 5 %; obwohl die Bruttomarge hier bei hohen 91,1 % liegt, reicht dies nicht aus, um die F&E-Investitionen zu decken. Das Unternehmen kämpft mit hohen Forderungsbeständen, angespannter Liquidität, hohem Schuldendruck und einer starken Abhängigkeit des Gewinns von staatlichen Subventionen. Seine Marktpositionierung hat sich von „Mobile Marketing Service Provider“ zu „AI Marketing Company“ gewandelt, aber der technologische Wert und die kommerziellen Aussichten der KI sind fraglich. (Quelle: 36Kr)
🌟 Community
Intensiver Wettbewerb zwischen vLLM und SGLang Inference Engines, Entwickler veröffentlichen Vergleichsdaten zu PR-Merges: In der Entwickler-Community wird der Wettbewerb zwischen den beiden Inference Engines vLLM und SGLang heiß diskutiert. Der Hauptverantwortliche von vLLM hat sogar ein öffentliches Dashboard eingerichtet, um die Anzahl der auf GitHub gemergten Pull Requests (PRs) von SGLang und vLLM zu vergleichen, was den intensiven Wettlauf um Funktionsiterationen und Leistungsoptimierungen unterstreicht. SGLang hebt seinerseits seine Vorreiterrolle bei der Open-Source-Implementierung von Radix-Caching, CPU-Overlapping, MLA und Large-Scale EP hervor. (Quelle: dylan522p, jeremyphoward)
KI-generiertes „Italian Brainrot“-Charakteruniversum explodiert bei Zoomern, Milliarden Aufrufe: Justine Moore weist darauf hin, dass eine Reihe von KI-generierten „Italian Brainrot“-Charakteren bei der Zoomer-Generation (Generation Z) außerordentlich beliebt ist. Sie haben um diese Charaktere ein komplettes „Filmuniversum“ aufgebaut, und die entsprechenden Inhalte haben Hunderte von Millionen Aufrufe erzielt. Dieses Phänomen spiegelt die starke Anziehungskraft und das virale Verbreitungspotenzial von KI-generierten Inhalten bei der jungen Generation sowie die Entstehung spezifischer Subkulturen wider. (Quelle: nptacek)

Vergleich der Modelle Qwen3 und DeepSeek R1 löst Diskussion aus, Vor- und Nachteile auf beiden Seiten: Ein Reddit-Nutzer teilte einen Testvergleich der beiden quelloffenen Large Language Models Qwen3 235B und DeepSeek R1. Der Poster ist der Meinung, dass Qwen bei einfachen Aufgaben besser abschneidet, während DeepSeek R1 bei Aufgaben, die Nuancen erfordern (wie Schlussfolgern, Mathematik und kreatives Schreiben), überlegen ist. In den Kommentaren diskutierten Nutzer die Zugänglichkeit von DeepSeek R1, unzensierte Fine-Tuning-Versionen von Qwen3 235B und die Sinnhaftigkeit des Einsatzes von Sprachmodellen für kreatives Schreiben. (Quelle: Reddit r/LocalLLaMA)

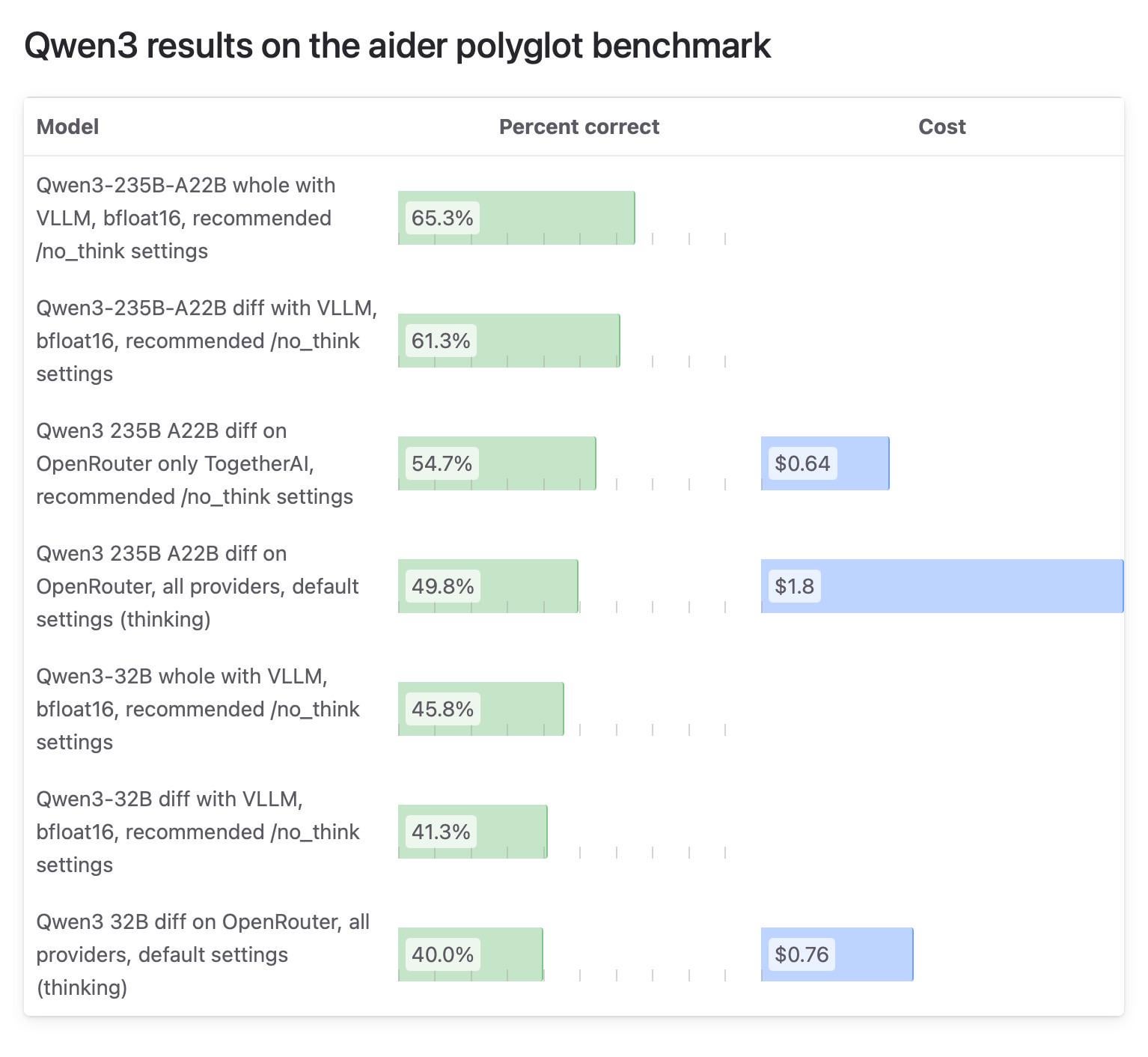
Unterschiedliche Testergebnisse für Qwen3-Modell in Aider-Community sorgen für Aufsehen, OpenRouter-Tests in Frage gestellt: Der Aider-Blog veröffentlichte einen Testbericht zum Qwen3-Modell, der auf erhebliche Unterschiede in den Ergebnissen je nach Ausführungsmethode hinweist. Die Community-Diskussion konzentriert sich auf die Zuverlässigkeit von Modelltests über OpenRouter, da die meisten Nutzer das Modell wahrscheinlich über OpenRouter verwenden, dessen Routing-Mechanismus jedoch zu inkonsistenten Ergebnissen führen kann. Einige Nutzer sind der Meinung, dass Open-Source-Modelle in standardisierten, selbst eingerichteten Umgebungen (wie vLLM) getestet werden sollten, um die Reproduzierbarkeit zu gewährleisten, und fordern API-Anbieter auf, die Transparenz hinsichtlich der verwendeten Quantisierungsversionen und Inference Engines zu erhöhen. (Quelle: Reddit r/LocalLLaMA)
Nutzer teilen persönliche Gründe für kostenpflichtige ChatGPT-Nutzung, von Alltagshilfe über Lernen bis hin zu kreativen Projekten: In der Reddit-Community r/ChatGPT teilten viele Nutzer ihre persönlichen Anwendungsfälle für kostenpflichtige Abonnements von ChatGPT Plus/Pro. Dazu gehören: Unterstützung für sehbehinderte Nutzer bei der Bildbeschreibung, dem Lesen von Lebensmittelverpackungen und Straßenschildern; Vorbereitung auf Vorstellungsgespräche; tiefere Einblicke in die Handlung von Spielen wie Elden Ring; Analyse von Lauftrainingsplänen, Erstellung von Ernährungsplänen; Unterstützung beim Erlernen neuer Fähigkeiten wie Töpfern; als persönlicher Begleiter; Planung von Gärten, Herstellung von Kräutern; sowie Erstellung von D&D-Charakteren und Fan-Fiction-Schreiben. Diese Beispiele zeigen den breiten Nutzen von ChatGPT im Alltag und für persönliche Interessen. (Quelle: Reddit r/ChatGPT)
Vergleichstests von GGUF-quantisierten Modellen lösen Diskussion über „Quantisierungskriege“ aus, betonen Vorzüge verschiedener Quantisierungsschemata: Der Reddit-Nutzer ubergarm veröffentlichte detaillierte Benchmark-Vergleichstests für verschiedene GGUF-quantisierte Versionen von Modellen wie Qwen3-30B-A3B, einschließlich Quantisierungsschemata von verschiedenen Anbietern wie bartowski und unsloth. Die Tests umfassten mehrere Dimensionen wie Perplexität, KLD-Divergenz und Inferenzgeschwindigkeit. Der Artikel weist darauf hin, dass GGUF-Quantisierung mit dem Aufkommen neuer Quantisierungstypen wie Importance Matrix Quantization (imatrix), IQ4_XS und Methoden wie unsloth dynamic GGUF nicht mehr „Einheitsbrei“ ist. Der Autor betont, dass es kein absolut optimales Quantisierungsschema gibt und Nutzer je nach Hardware und spezifischem Anwendungsfall wählen müssen, aber im Allgemeinen alle gängigen Schemata gut abschneiden. (Quelle: Reddit r/LocalLLaMA)

💡 Sonstiges
Daimon Robotics stellt geschickten Roboter Sparky 1 vor: Das Unternehmen Daimon Robotics präsentierte seinen bahnbrechenden Roboter Sparky 1 im Bereich der geschickten Robotik. Dieser Roboter wird als „Mind-Dexterous“ (geistig geschickt) beschrieben, was auf ein neues Niveau in Wahrnehmung, Entscheidungsfindung und Feinmotorik hindeutet und möglicherweise fortschrittliche KI- und Machine-Learning-Technologien integriert. (Quelle: Ronald_vanLoon)
MIT entwickelt reiskorngroße Mikroroboter zur Behandlung inoperabler Hirntumore: Forscher am MIT haben einen reiskorngroßen Mikroroboter entwickelt, der potenziell minimalinvasiv ins Gehirn eindringen kann, um Tumore zu behandeln, die bisher schwer operativ entfernt werden konnten. Solche Technologien kombinieren Mikrorobotik mit KI-Navigation oder -Steuerung und eröffnen neue Möglichkeiten für die Neurochirurgie und Krebstherapie. (Quelle: Ronald_vanLoon)

Aosha Intelligence schließt zwei Finanzierungsrunden ab, treibt Massenproduktion von Exoskelett-Robotern für Endverbraucher und KI-Integration voran: Das Technologieplattform-Unternehmen für Exoskelett-Roboter Aosha Intelligence gab den Abschluss von zwei aufeinanderfolgenden Finanzierungsrunden bekannt, angeführt von BinFu Capital, mit Beteiligung des Altinvestors GuoYi Capital. Die Mittel werden für die Massenproduktion von Exoskelett-Robotern für Endverbraucher und die Integration von Exoskelett-Hardware mit KI-Technologie verwendet. Die Produkte des Unternehmens werden bereits in industriellen Szenarien eingesetzt und beginnen, Märkte für Outdoor-Unterstützung (z. B. Wanderhilfen in Touristengebieten) und häusliche Altenpflege zu erschließen, mit Plänen zur Einführung von Produkten für Endverbraucher unter 10.000 Yuan. Die neuesten Produkte sind bereits mit KI-Large-Model-Trainingsfähigkeiten ausgestattet und erforschen präventiv Brain-Computer-Interface-Technologien. (Quelle: 36Kr)