Schlüsselwörter:Absoluter Nullpunkt, Qwen3, Mistral Medium 3, PyTorch-Stiftung, KI-Selbstevolution, Multimodales Modell, Open-Source-KI, RLVR-Paradigma, AZR-System, Qwen3-235B-A22B, DeepSpeed-Optimierungsbibliothek, LangSmith Multimodal-Unterstützung
🔥 Fokus
Tsinghua Universität veröffentlicht Absolute Zero Paper: KI kann sich ohne externe Daten selbst weiterentwickeln: Das LeapLabTHU-Team der Tsinghua Universität hat ein neues RLVR (Reinforcement Learning with Verifiable Rewards) Paradigma namens „Absolute Zero“ vorgestellt. Unter diesem Paradigma kann ein einzelnes Modell selbst Aufgaben vorschlagen, die den Lernprozess maximieren, und durch die Lösung dieser Aufgaben seine Schlussfolgerungsfähigkeiten verbessern, völlig ohne Abhängigkeit von externen Daten. Sein System AZR (Absolute Zero Reasoner) nutzt einen Code-Executor zur Verifizierung von Aufgaben und Antworten und realisiert so ein offenes, aber fundiertes Lernen. Experimente zeigen, dass AZR bei Kodierungs- und mathematischen Schlussfolgerungsaufgaben SOTA-Niveau erreicht und bestehende Zero-Shot-Modelle übertrifft, die auf Zehntausenden von menschlich annotierten Beispielen basieren (Quelle: Reddit r/LocalLLaMA)
Alibaba veröffentlicht Qwen3-Modellreihe, enthält MoE und verschiedene Größen: Alibaba hat die Qwen3-Reihe großer Sprachmodelle veröffentlicht, die 8 Modelle mit Parametergrößen von 0.6B bis 235B umfasst. Davon verwenden Qwen3-235B-A22B und Qwen3-30B-A3B eine MoE-Architektur, die übrigen sind dichte Modelle. Die Modellreihe wurde auf 36T Tokens vortrainiert, deckt 119 Sprachen ab und verfügt über einen umschaltbaren Inferenzmodus, der für Code, Mathematik, Wissenschaft und viele andere Bereiche geeignet ist. Bewertungen zeigen, dass die MoE-Modelle eine überlegene Leistung aufweisen, wobei die 235B-Version DeepSeek-R1 und Gemini 2.5 Pro in mehreren Benchmarks übertrifft. Die 30B-Version zeigt ebenfalls eine starke Leistung, und sogar das 4B-Modell übertrifft in einigen Benchmarks Modelle mit deutlich mehr Parametern. Die Modelle wurden auf HuggingFace und ModelScope als Open Source unter der Apache 2.0 Lizenz veröffentlicht (Quelle: DeepLearning.AI Blog)
Mistral veröffentlicht multimodales Modell Mistral Medium 3 und KI-Assistenten für Unternehmen: Mistral AI hat Mistral Medium 3 vorgestellt, ein neues multimodales Modell, das laut Angaben in der Leistung nahe an Claude Sonnet 3.7 liegt, aber die Kosten erheblich senkt (Input $0.4/M Token, Output $2/M Token), eine Reduktion um das 8-fache. Das Modell zeigt hervorragende Leistungen beim Codieren und bei Funktionsaufrufen und bietet unternehmenstaugliche Funktionen wie hybride oder lokale Bereitstellung und angepasstes Post-Training. Gleichzeitig hat Mistral Le Chat Enterprise veröffentlicht, einen anpassbaren, sicheren KI-Assistenten für Unternehmen, der die Integration von Unternehmenswissensdatenbanken (wie Gmail, Google Drive, Sharepoint) unterstützt und über Funktionen wie Agent, Codierungsassistent und Websuche verfügt, um die Wettbewerbsfähigkeit von Unternehmen zu steigern. Mistral kündigte an, in den kommenden Wochen ein neues Large-Modell zu veröffentlichen (Quelle: Mistral AI、GuillaumeLample、scaling01、karminski3)
PyTorch Foundation erweitert sich zu einer Dachstiftung und nimmt vLLM und DeepSpeed auf: Die PyTorch Foundation hat ihre Erweiterung zu einer Dachstiftungsstruktur bekannt gegeben, mit dem Ziel, mehr hochwertige KI-Open-Source-Projekte zu bündeln. Die ersten beigetretenen Projekte sind vLLM und DeepSpeed. vLLM ist eine für LLMs entwickelte Inferenz- und Serving-Engine mit hohem Durchsatz und Speichereffizienz; DeepSpeed ist eine Optimierungsbibliothek für Deep Learning, die das Training großer Modelle effizienter macht. Dieser Schritt zielt darauf ab, die Community-getriebene KI-Entwicklung über den gesamten Lebenszyklus von der Forschung bis zur Produktion zu fördern und wird von zahlreichen Mitgliedern wie AMD, Arm, AWS, Google und Huawei unterstützt (Quelle: PyTorch、soumithchintala、vllm_project、code_star)

🎯 Trends
Tencent ARC Lab veröffentlicht FlexiAct: Ein Tool zur Übertragung von Bewegungen in Videos: Das Tencent ARC Lab hat auf Hugging Face ein neues Tool namens FlexiAct veröffentlicht. Dieses Tool kann Bewegungen aus einem Referenzvideo auf ein beliebiges Zielbild übertragen, selbst wenn das Layout, die Perspektive oder die Skelettstruktur des Zielbildes vom Referenzvideo abweichen. Dies eröffnet neue Möglichkeiten im Bereich der Videogenerierung und -bearbeitung und ermöglicht es Benutzern, Bewegungen und Posen in generierten Inhalten flexibler zu steuern (Quelle: _akhaliq)
White Circle veröffentlicht CircleGuardBench: Neuer Benchmark für KI-Modelle zur Inhaltsmoderation: White Circle hat CircleGuardBench vorgestellt, einen neuen Benchmark zur Bewertung von KI-Modellen für die Inhaltsmoderation. Der Benchmark zielt auf eine Bewertung auf Produktionsebene ab und testet Aspekte wie Gefahrenerkennung, Jailbreak-Resistenz, Falsch-Positiv-Raten und Latenzzeiten, wobei 17 reale Gefahrenkategorien abgedeckt werden. Zugehörige Blog-Posts und Ranglisten wurden auf Hugging Face veröffentlicht und bieten neue Bewertungsstandards für die Bereiche KI-Sicherheit und Inhaltsmoderation (Quelle: TheTuringPost、_akhaliq)

Hugging Face veröffentlicht SIFT-50M: Großer mehrsprachiger Datensatz zur Feinabstimmung von Sprachbefehlen: Auf Hugging Face wurde der SIFT-50M Datensatz veröffentlicht, ein umfangreicher mehrsprachiger Datensatz, der speziell für die Feinabstimmung von Sprachbefehlen entwickelt wurde. Der Datensatz enthält über 50 Millionen Frage-Antwort-Paare im Befehlsformat und deckt 5 Sprachen ab. Ein auf diesem Datensatz trainiertes SIFT-LLM übertrifft SALMONN und Qwen2-Audio in Benchmarks zur Befehlsbefolgung. Der Datensatz enthält auch den Benchmark EvalSIFT für akustische und generative Bewertungen und unterstützt die kontrollierbare Sprachgenerierung (z. B. Tonhöhe, Sprechgeschwindigkeit, Akzent), basierend auf Whisper, HuBERT, X-Codec2 & Qwen2.5 (Quelle: ClementDelangue、huggingface)
Meta veröffentlicht Perception Language Model (PLM): Open-Source und reproduzierbares visuelles Sprachmodell: Meta AI hat das Meta Perception Language Model (PLM) vorgestellt, ein offenes und reproduzierbares visuelles Sprachmodell, das darauf abzielt, anspruchsvolle visuelle Aufgaben zu lösen. Meta hofft, mit PLM der Open-Source-Community dabei zu helfen, leistungsfähigere Computer-Vision-Systeme zu entwickeln. Zugehörige Forschungsarbeiten, Code und Datensätze wurden für Forscher und Entwickler veröffentlicht (Quelle: AIatMeta)
Google aktualisiert Gemini 2.0 Bildgenerierungsmodell: Verbesserte Qualität und Geschwindigkeit: Google hat ein Update für sein Gemini 2.0 Bildgenerierungsmodell (Preview-Version) angekündigt. Die neue Version bietet eine bessere visuelle Qualität, eine genauere Textdarstellung, niedrigere Blockierungsraten (block rates) und höhere Ratenbegrenzungen (rate limits). Die Kosten für die Generierung jedes Bildes betragen $0.039. Dieses Update zielt darauf ab, die Erfahrung und die Ergebnisse für Entwickler bei der Bildgenerierung mit Gemini zu verbessern (Quelle: m__dehghani、scaling01、andrew_n_carr、demishassabis)
NVIDIA veröffentlicht Open-Source-Modellreihe für Code-Reasoning: NVIDIA hat eine Reihe von Open-Source-Modellen für Code-Reasoning veröffentlicht, darunter Modelle mit 32B, 14B und 7B Parametern, alle unter der APACHE 2.0 Lizenz. Diese Modelle wurden auf OCR-Datensätzen trainiert und sollen laut Angaben im LiveCodeBench-Benchmark O3 mini und O1 (low) übertreffen sowie eine um 30 % höhere Token-Effizienz als vergleichbare Reasoning-Modelle aufweisen. Die Modelle sind mit verschiedenen Frameworks wie llama.cpp, vLLM, transformers und TGI kompatibel (Quelle: huggingface、ClementDelangue)
ServiceNow und NVIDIA kooperieren bei der Veröffentlichung des Apriel-Nemotron-15b-Thinker Modells: ServiceNow und NVIDIA haben gemeinsam ein 15B-Parametermodell namens Apriel-Nemotron-15b-Thinker unter der MIT-Lizenz veröffentlicht. Dieses Modell soll eine vergleichbare Leistung wie 32B-Modelle aufweisen, jedoch mit einem deutlich geringeren Token-Verbrauch (ca. 40 % weniger als Qwen-QwQ-32b). Es zeigt hervorragende Ergebnisse in mehreren Benchmarks wie MBPP, BFCL, Enterprise RAG und IFEval und ist besonders wettbewerbsfähig bei Enterprise RAG und Kodierungsaufgaben (Quelle: Reddit r/LocalLLaMA)

s1-Modell: Schlussfolgerungen mit Feinabstimmung weniger Stichproben, “Wait”-Trick verbessert Leistung: Forscher von der Stanford University und anderen Institutionen haben das s1-Modell entwickelt und gezeigt, dass bereits eine überwachte Feinabstimmung mit etwa 1000 Chain-of-Thought (CoT) Beispielen ausreicht, um vortrainierten LLMs (wie Qwen 2.5-32B) Schlussfolgerungsfähigkeiten zu verleihen. Die Forschung ergab auch, dass das Erzwingen der Generierung von “Wait”-Tokens während des Inferenzprozesses zur Verlängerung der Inferenzkette die Genauigkeit des Modells bei Aufgaben wie Mathematik signifikant verbessern kann, sodass seine Leistung der von OpenAI o1-preview nahekommt. Diese Entdeckung bietet neue Ansätze zur kostengünstigen Verbesserung der Schlussfolgerungsfähigkeiten von Modellen (Quelle: DeepLearning.AI Blog)
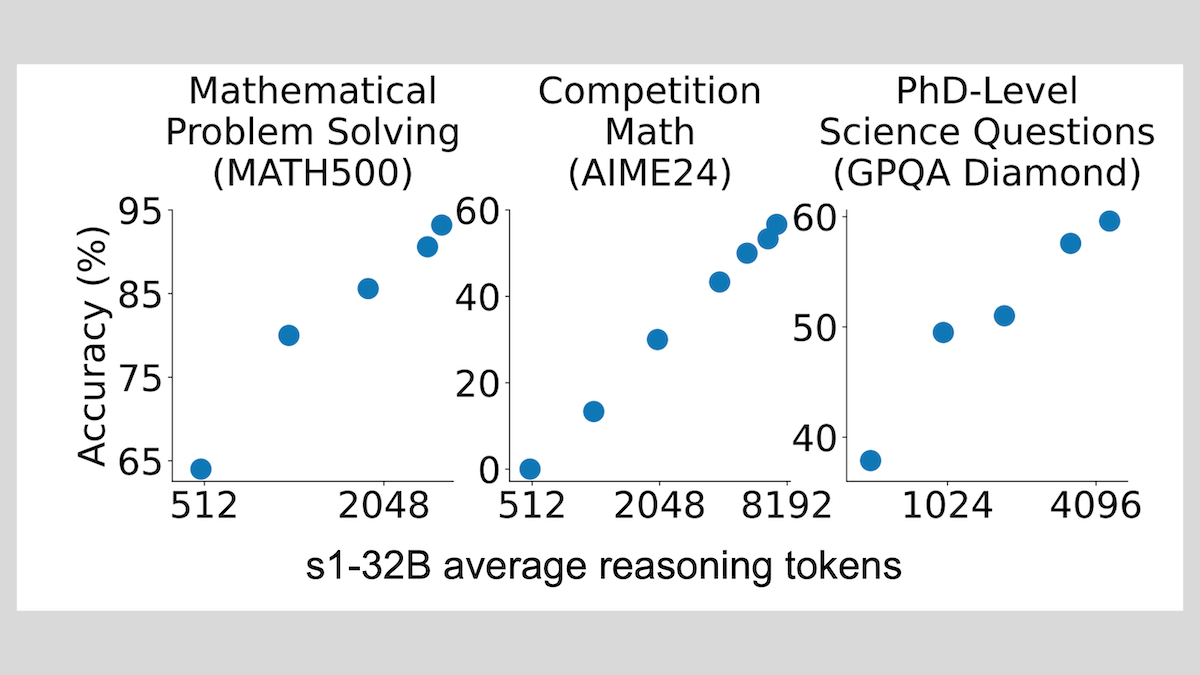
ThinkPRM: Generatives Prozess-Belohnungsmodell, das mit nur 8K Labels trainiert werden kann: Forscher haben ThinkPRM vorgestellt, ein generatives Prozess-Belohnungsmodell (PRM), das mit nur 8K Prozess-Labels feinabgestimmt werden kann. Dieses Modell kann durch die Generierung langer Denkketten (long chains-of-thought) den Schlussfolgerungsprozess validieren und löst damit das Problem der teuren, umfangreichen schrittweisen Überwachungsdaten, die für das Training von PRMs erforderlich sind. Der zugehörige Code, das Modell und die Daten wurden auf GitHub und Hugging Face veröffentlicht (Quelle: Reddit r/MachineLearning)
🧰 Tools
Zed veröffentlicht angeblich schnellsten KI-Code-Editor der Welt: Zed hat einen Code-Editor vorgestellt, der als der schnellste KI-Code-Editor der Welt beworben wird. Der Editor wurde von Grund auf in Rust entwickelt, um die Zusammenarbeit zwischen Mensch und KI zu optimieren und eine blitzschnelle agentenbasierte Bearbeitungserfahrung (agentic editing experience) zu bieten. Er unterstützt gängige Modelle wie Claude 3.7 Sonnet und ermöglicht es Benutzern, eigene API-Schlüssel mitzubringen oder lokale Modelle über Ollama zu verwenden (Quelle: andersonbcdefg、ollama)
Hugging Face veröffentlicht nanoVLM: Minimalistische Bibliothek für visuelle Sprachmodelle: Hugging Face hat nanoVLM als Open Source veröffentlicht, eine reine PyTorch-Bibliothek, die darauf abzielt, visuelle Sprachmodelle (VLM) mit etwa 750 Codezeilen von Grund auf zu trainieren. Das Modell erreicht eine Genauigkeit von 35,3 % im MMStar-Benchmark, vergleichbar mit SmolVLM-256M, benötigt aber 100-mal weniger GPU-Stunden für das Training. nanoVLM verwendet SigLiP-ViT als visuellen Encoder, einen Decoder im LLaMA-Stil und verbindet beide über einen Modalitätsprojektor. Es eignet sich zum Lernen, Prototyping oder Erstellen benutzerdefinierter VLMs (Quelle: clefourrier、ben_burtenshaw、Reddit r/LocalLLaMA)
DBOS veröffentlicht DBOS Python 1.0: Leichtgewichtiges Tool für persistente Workflows: DBOS hat die Version 1.0 von DBOS Python veröffentlicht. Das Tool zielt darauf ab, leichtgewichtige, einfach zu bedienende persistente Workflow-Funktionen für Python-Anwendungen bereitzustellen, einschließlich Geschäftsprozessen, KI-Automatisierung, Datenpipelines usw. Die neue Version enthält persistente Warteschlangen (mit Unterstützung für Parallelitätsbegrenzung, Ratenbegrenzung, Timeouts, Prioritäten, Deduplizierung usw.), programmatisches Workflow-Management (Abfrage, Anhalten, Fortsetzen, Neustart usw. über Postgres-Tabellen), Unterstützung für synchronen/asynchronen Code und verbesserte Tools (Dashboard, Visualisierung usw.) (Quelle: lateinteraction)
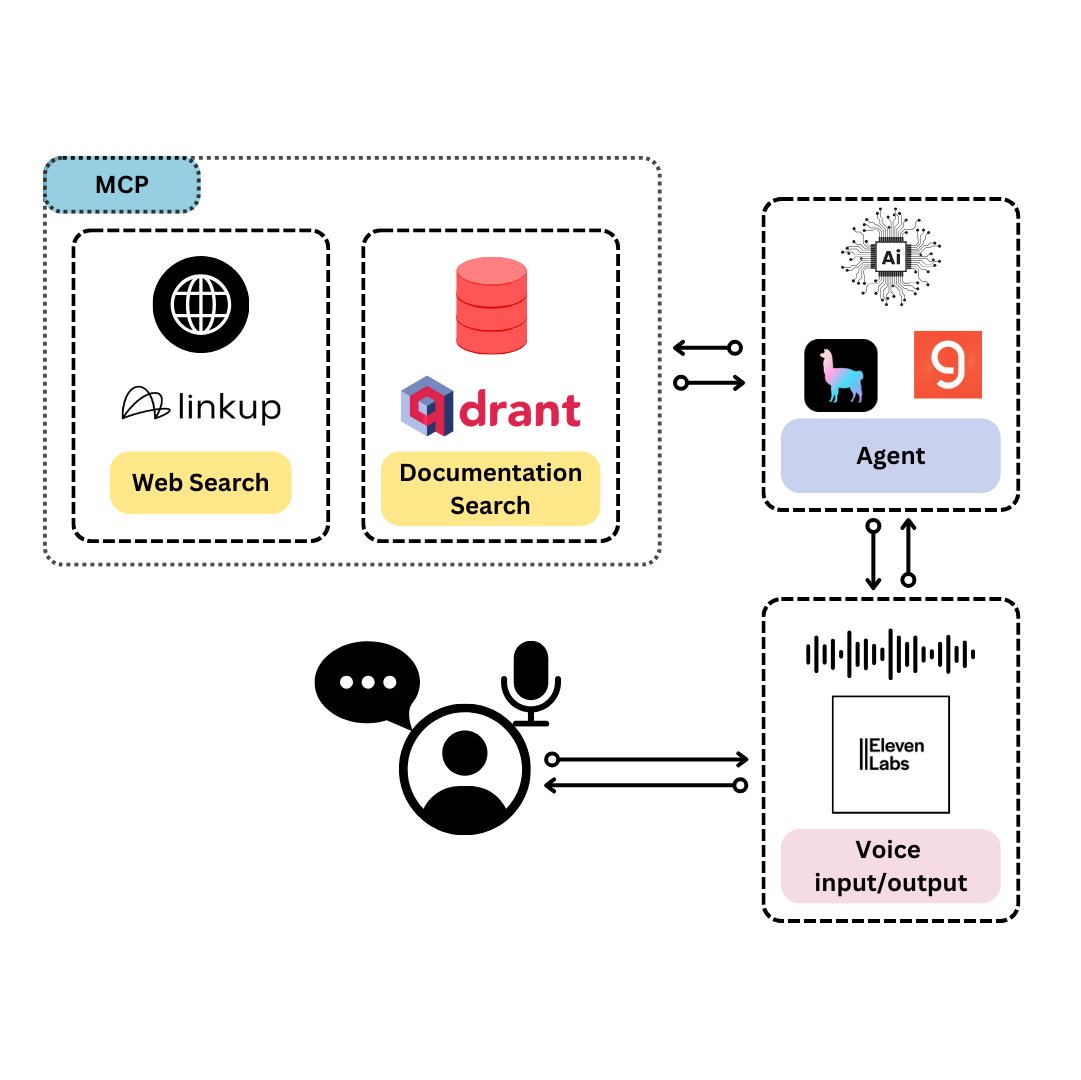
Qdrant stellt TySVA vor: Sprachassistent speziell für TypeScript-Entwickler: Qdrant hat TySVA (TypeScript Voice Assistant) vorgestellt, einen Sprachassistenten, der TypeScript-Entwicklern präzise, kontextbezogene Antworten liefern soll. TySVA verwendet Qdrant zur lokalen Speicherung von TypeScript-Dokumentationen, integriert die Linkup-Plattform zum Abrufen relevanter Webdaten und nutzt LlamaIndex zur Auswahl der besten Datenquelle. Es unterstützt Sprach- und Texteingaben und hilft Entwicklern, beim Codieren zuverlässige, freihändige Unterstützung zu erhalten (Quelle: qdrant_engine、qdrant_engine)
LlamaIndex führt neue Funktionen für LlamaExtract ein: Unterstützung für Zitate und Schlussfolgerungen: Das LlamaExtract-Tool von LlamaIndex wurde um neue Funktionen erweitert, die darauf abzielen, die Vertrauenswürdigkeit und Transparenz von KI-Anwendungen zu verbessern. Die neuen Funktionen ermöglichen es, beim Extrahieren von Informationen aus komplexen Datenquellen (wie SEC-Einreichungen) präzise Quellenangaben (citations) und den Extraktionsprozess (reasoning) bereitzustellen. Dies hilft Entwicklern, verantwortungsvollere und interpretierbarere KI-Systeme zu erstellen (Quelle: jerryjliu0、jerryjliu0、jerryjliu0)

Hugging Face Entwickler baut MCP-Server-Prototyp zur Verbindung von Agents mit dem Hub: Ein Entwickler bei Hugging Face, Wauplin, entwickelt einen Prototyp eines Hugging Face MCP (Machine Communication Protocol) Servers, der darauf abzielt, KI-Agents mit dem Hugging Face Hub zu verbinden. Dieser Prototyp kann als „HfApi trifft MCP“ betrachtet werden und ermöglicht es Agents, über das Protokoll mit dem Hub zu interagieren, beispielsweise um Modelle, Datensätze, Spaces usw. zu teilen und zu bearbeiten. Der Entwickler bittet die Community um Feedback zur Nützlichkeit und zu potenziellen Anwendungsfällen dieses Tools (Quelle: ClementDelangue、ClementDelangue、huggingface)

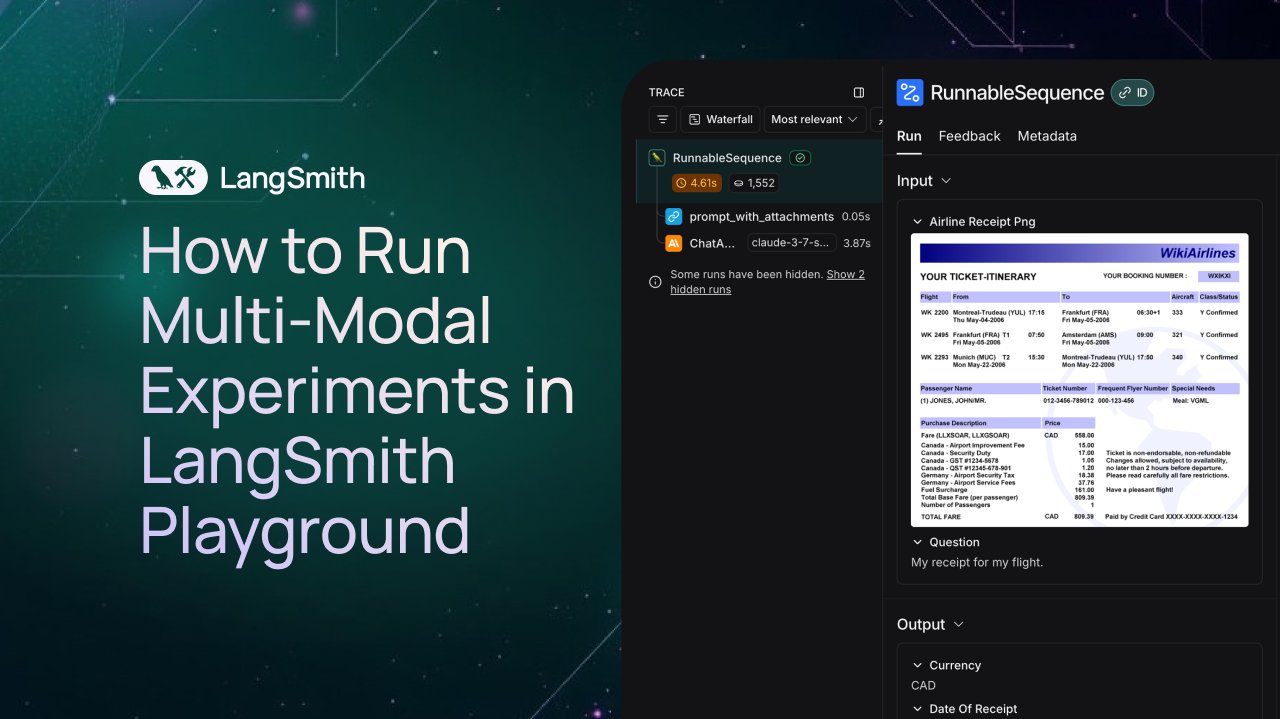
LangSmith erweitert Unterstützung für Beobachtung und Bewertung multimodaler Agents: Die LangSmith-Plattform unterstützt jetzt die Verarbeitung von Bild-, PDF- und Audiodateien im Playground, in Annotationswarteschlangen und Datensätzen. Dieses Update erleichtert die Erstellung und Bewertung multimodaler Anwendungen, wie z. B. Agents zur Extraktion von Belegen. Offizielle Demovideos und Dokumentationen wurden veröffentlicht, um Benutzern den Einstieg in die neuen Funktionen zu erleichtern (Quelle: LangChainAI、Hacubu、hwchase17)
DFloat11 veröffentlicht verlustfreie komprimierte Version des FLUX.1-Modells, lauffähig auf 20GB VRAM: Das DFloat11-Projekt hat verlustfreie komprimierte Versionen der Modelle FLUX.1-dev und FLUX.1-schnell (12B Parameter) veröffentlicht. Durch die DFloat11-Komprimierungsmethode (Anwendung von Entropiecodierung auf BFloat16-Gewichte) wurde die Modellgröße von 24 GB auf ca. 16,3 GB (ca. 30 %) reduziert, während die Ausgabe unverändert blieb. Dies ermöglicht es, diese Modelle auf einer einzelnen GPU mit 20 GB oder mehr VRAM auszuführen, mit nur wenigen Sekunden zusätzlichem Overhead pro Bild. Die zugehörigen Modelle und der Code wurden auf Hugging Face und GitHub veröffentlicht (Quelle: Reddit r/LocalLLaMA)

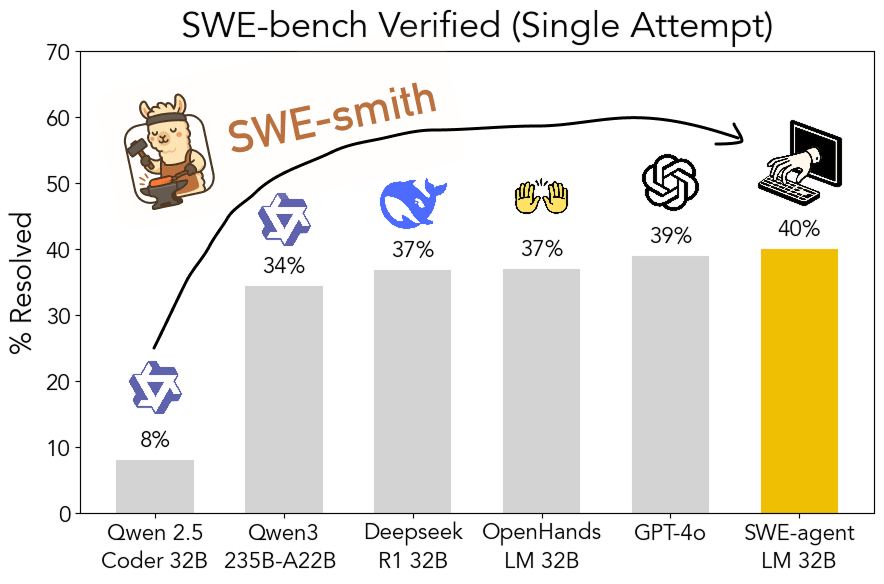
SWE-smith Toolkit als Open Source veröffentlicht: Skalierbare Generierung von Trainingsdaten für Software Engineering: Forscher der Stanford University haben SWE-smith als Open Source veröffentlicht, eine skalierbare Pipeline zur Generierung von Trainingsdaten für Software Engineering aus jedem Python-Repository. Mit diesem Toolkit wurden über 50.000 Instanzen generiert und darauf basierend das Modell SWE-agent-LM-32B trainiert, das im SWE-bench Verified Benchmark einen Pass@1 von 40,2 % erreichte und damit zum leistungsstärksten Open-Source-Modell in diesem Benchmark wurde. Code, Daten und Modell sind frei zugänglich (Quelle: OfirPress、stanfordnlp、stanfordnlp、huybery、Reddit r/LocalLLaMA)
📚 Lernen
Weaviate veröffentlicht kostenlosen Kurs: Bewertung und Auswahl von Embedding-Modellen: Die Weaviate Academy hat einen kostenlosen Kurs zum Thema “Bewertung und Auswahl von Embedding-Modellen” gestartet. Der Kurs betont die Wichtigkeit, über allgemeine Benchmarks (wie MTEB) hinauszugehen, und leitet die Lernenden an, wie sie für spezifische Anwendungsfälle ein „goldenes Bewertungsset“ (golden evaluation set) kuratieren und benutzerdefinierte Benchmarks einrichten, um das am besten geeignete Embedding-Modell auszuwählen sowie die Eignung neu veröffentlichter Modelle zu bewerten. Dies ist entscheidend für den Aufbau effizienter Such- und RAG-Systeme (Quelle: bobvanluijt)
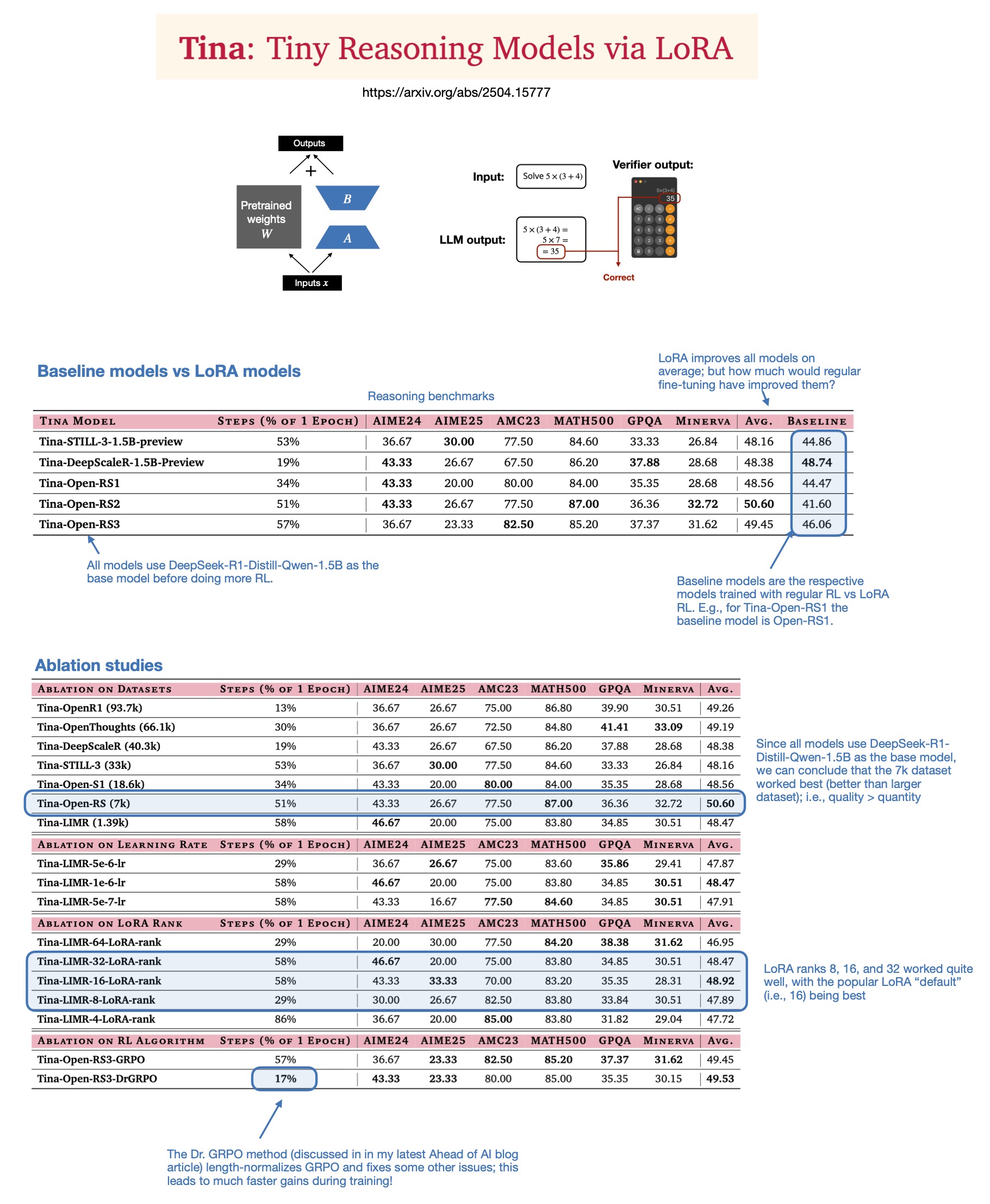
Sebastian Rasbt diskutiert den Wert von LoRA für Inferenzmodelle im Jahr 2025: Sebastian Rasbt hat nach der Lektüre des Papers “Tina: Tiny Reasoning Models via LoRA” die Bedeutung von LoRA (Low-Rank Adaptation) im Zeitalter der großen Modelle neu bewertet. Obwohl vollparametrische Feinabstimmung und Destillationstechniken populär sind, sieht Rasbt LoRA in bestimmten Szenarien (z. B. Inferenzaufgaben, Multi-Client-/Multi-Use-Case-Szenarien) weiterhin als wertvoll an. Das Paper zeigt die Möglichkeit, mit LoRA in Kombination mit Reinforcement Learning (RL) die Inferenzfähigkeiten kleiner Modelle (1.5B) kostengünstig (nur $9 Trainingskosten) zu verbessern, wobei LoRA in mehreren Benchmarks die Standard-RL-Feinabstimmung übertrifft. Die Eigenschaft von LoRA, die Basismodelle nicht zu verändern, bietet Kostenvorteile, wenn eine große Anzahl angepasster Modellgewichte gespeichert werden muss (Quelle: rasbt)
DeepLearning.AI startet neuen Kurs: Aufbau produktionsreifer KI-Sprachagenten: DeepLearning.AI hat in Zusammenarbeit mit LiveKit und RealAvatar einen neuen Kurzlehrgang mit dem Titel „Aufbau produktionsreifer KI-Sprachagenten“ gestartet. Der Kurs zielt darauf ab, zu vermitteln, wie KI-Sprachagenten erstellt werden können, die Echtzeitgespräche führen, mit geringer Latenz reagieren und natürlich klingen. Die Lernenden werden Techniken wie Spracherkennung und Gesprächssteuerung implementieren und lernen, wie die Architektur zur Latenzreduzierung optimiert wird, um schließlich skalierbare Sprachagenten zu erstellen und bereitzustellen. Der Kurs wird vom CEO von LiveKit, einem Developer Advocate und dem Leiter von RealAvatar AI unterrichtet (Quelle: DeepLearningAI、AndrewYNg)
LangChain und LangGraph veranstalten gemeinsamen ACM Tech Talk: Mayowa Oshin, früher Entwickler bei LangChain, und Nuno Campos, Erfinder von LangGraph, werden in einem ACM Tech Talk darüber sprechen, wie man mit LangChain und LangGraph zuverlässige KI-Agenten und LLM-Anwendungen erstellt. Der Vortrag ist kostenlos und wird live übertragen. Registrierte Teilnehmer erhalten im Anschluss einen Link zur Aufzeichnung (Quelle: hwchase17、hwchase17)

Cohere Labs veranstaltet Vortrag über die Tiefe der First-Order-Optimierung: Cohere Labs lädt Jeremy Bernstein am 8. Mai zu einem Vortrag mit dem Titel „Depths of First-Order Optimization“ ein. Der Vortrag zielt darauf ab, die Anwendung und Theorie von Optimierungsalgorithmen im maschinellen Lernen eingehend zu untersuchen (Quelle: eliebakouch)

AI2 veranstaltet OLMo Modell AMA-Event: Das Allen Institute for AI (AI2) wird am 8. Mai von 8-10 Uhr (Pazifische Zeit) im r/huggingface Reddit-Subforum ein „Ask Me Anything“ (AMA)-Event zu seiner offenen Sprachmodellfamilie OLMo veranstalten und Forscher einladen, Fragen der Community zu beantworten (Quelle: natolambert)

💼 Wirtschaft
OpenAI plant, den an Microsoft gezahlten Umsatzanteil zu kürzen: Laut The Information hat OpenAI Investoren darüber informiert, dass es plant, im Zuge einer Unternehmensumstrukturierung den an seinen größten Unterstützer Microsoft gezahlten Umsatzanteil zu kürzen. Genaue Details und mögliche Auswirkungen wurden noch nicht vollständig offengelegt, dies könnte jedoch eine Veränderung in der Geschäftsbeziehung zwischen den beiden Unternehmen signalisieren (Quelle: steph_palazzolo)
Risikokapitalgeber geben KI-Gründern mehr Macht, was Blasenängste schürt: The Information berichtet, dass Risikokapitalgeber (VCs), um Top-KI-Gründer (insbesondere solche mit Erfahrung als Führungskräfte in bekannten KI-Laboren) anzuziehen, beispiellos günstige Konditionen anbieten, darunter Vetorechte im Vorstand, keine VC-Sitze im Vorstand und die Erlaubnis für Gründer, Teile ihrer Anteile zu verkaufen. Dieses Phänomen wird von einigen als Anzeichen für eine mögliche Blase im KI-Bereich gewertet (Quelle: steph_palazzolo)
Toloka erhält strategische Investition unter Führung von Bezos Expeditions, Mikhail Parakhin wird Vorsitzender: Das Datenannotations- und KI-Trainingsdatenunternehmen Toloka gab eine strategische Investition unter Führung von Jeff Bezos’ Bezos Expeditions bekannt, an der sich auch der ehemalige Microsoft-Manager Mikhail Parakhin beteiligte und den Vorsitz des Verwaltungsrats übernahm. Diese Investitionsrunde wird Toloka dabei unterstützen, seine Human+AI-Lösungen zu erweitern und das Geschäft mit Datenerfassung und -annotation weiterzuentwickeln (Quelle: menhguin、teortaxesTex、TheTuringPost)

🌟 Community
Diskussion über die angemessene Nutzung (Fair Use) von LLM-Trainingsdaten: Dorialexander erwähnt, dass das Argument der angemessenen Nutzung von LLM-Trainingsdaten stark von der Annahme abhängt, dass LLMs nicht in direkten kommerziellen Wettbewerb mit den Trainingsquellen treten. Mit zunehmender Leistungsfähigkeit von LLMs (z. B. bieten Perplexity und andere ähnliche Erfahrungen wie das Lesen von Sachbüchern) könnte diese Annahme in Frage gestellt werden, was neue Fragen zu Urheberrecht und kommerziellem Wettbewerb aufwirft (Quelle: Dorialexander)
Sorgen und Diskussionen über die Flut von KI-generierten Inhalten: In sozialen Medien und auf Reddit äußern Nutzer Bedenken über die Flut von qualitativ minderwertigen, sich wiederholenden KI-generierten Inhalten (wie KI-generierte Reddit-Story-Videos). Nutzer sind der Meinung, dass dies den Raum für menschliche Kreative einschränkt, falsche oder homogenisierte Informationen verbreitet und äußern Unzufriedenheit darüber, dass KI-Technologie für leichten Profit ohne Originalität eingesetzt wird (Quelle: Reddit r/ArtificialInteligence)
Philosophische Diskussion darüber, ob KI bereits Bewusstsein hat: In der Reddit-Community gibt es erneut Diskussionen darüber, ob KI möglicherweise bereits Bewusstsein erlangt hat. Befürworter argumentieren, dass unsere Definition von Bewusstsein möglicherweise zu eng oder zu menschenzentriert ist, während Gegner betonen, dass die Kernmechanismen aktueller LLMs (wie die Vorhersage des nächsten Tokens) nicht ausreichen, um echtes Bewusstsein zu erzeugen. Die Diskussion spiegelt die anhaltende Neugier und die Meinungsverschiedenheiten der Öffentlichkeit über die Natur und das zukünftige Potenzial der KI wider (Quelle: Reddit r/ArtificialInteligence)
Diskussion über Leistungsabfall und Verhaltensänderungen von ChatGPT(4o): Reddit-Nutzer berichten, dass das ChatGPT 4o-Modell in letzter Zeit bei der Verarbeitung langer Dokumente und der Beibehaltung des Kontextgedächtnisses nachgelassen hat, mehr Halluzinationen aufweist und sogar Dokumentformate nicht mehr lesen kann, die es zuvor verarbeiten konnte. Gleichzeitig hat OpenAI eingeräumt, dass kürzlich aktualisierte Versionen von GPT-4o ein Problem mit übermäßiger Schmeichelei (sycophancy) aufwiesen, und hat dies zurückgenommen. Dies hat in der Community Bedenken hinsichtlich der Stabilität und der Qualität der iterativen Modellentwicklung ausgelöst (Quelle: Reddit r/ChatGPT、DeepLearning.AI Blog)
Auswirkungen und Reflexionen der KI auf Bildungsmodelle: Community-Diskussionen weisen darauf hin, dass das US-amerikanische Bildungssystem, das stark auf Hausaufgaben und individuellen Aufsätzen basiert, extrem anfällig für die Fähigkeit von KI (wie LLMs) ist, Aufgaben automatisch zu erledigen. Im Vergleich dazu sind einige europäische Länder (wie Dänemark), die stärker auf schulische Zusammenarbeit, Diskussionen und projektbasiertes Lernen setzen, weniger von KI betroffen. Dies löst Überlegungen über zukünftige Bildungsmodelle aus, die sich stärker auf die Förderung von kritischem Denken, Zusammenarbeit und anderen zwischenmenschlichen Fähigkeiten konzentrieren sollten, wobei KI für mechanische Aufgaben eingesetzt wird und die Bildung in eine synchronere, sozialere Richtung gelenkt wird (Quelle: alexalbert__、riemannzeta、aidan_mclau)
💡 Sonstiges
Fortschritte bei der Anwendung von KI in der Robotik: Mehrere Quellen zeigen Anwendungsbeispiele von KI in der Robotik: darunter ein Roboterkoch, der in 90 Sekunden gebratenen Reis zubereiten kann, Vorführungen von Figure AI Robotern in realen Anwendungen, ein Pickle Roboter, der das Entladen von Gütern aus einem unordentlichen LKW-Anhänger demonstriert, ein Unitree G1 Roboter, der auf unebenem Gelände das Gleichgewicht hält, sowie Einblicke in seine innere Struktur, und der von der Schweizer EPFL entwickelte verformbare Roboter Mori3. Diese Beispiele zeigen das Potenzial der KI zur Verbesserung der Autonomie, Anpassungsfähigkeit und Praktikabilität von Robotern (Quelle: Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Sentdex)

Erkundung der Anwendung von KI-Technologie in spezifischen Branchen (Medizin, Textil, Mobiltelefone): Johnson & Johnson teilte seine KI-Strategie mit, die sich auf Vertriebsunterstützung, Beschleunigung der Arzneimittelentwicklung (Screening von Verbindungen, Optimierung klinischer Studien), Risikoprognose in der Lieferkette und interne Kommunikation (HR-Chatbot) konzentriert. Gleichzeitig stärkt die KI-Technologie auch die traditionelle Textilindustrie, von KI-gestütztem Design und präziser Färbekontrolle bis hin zur automatisierten Qualitätsprüfung, wodurch Effizienz und Nachhaltigkeit verbessert werden. Die Mobiltelefonindustrie betrachtet KI als neuen Wachstumsmotor. Hersteller konkurrieren um Edge-basierte große Modelle, KI-native Betriebssysteme und szenariobasierte intelligente Dienste und bilden drei Hauptlager: Apple, Huawei und das offene Lager (Quelle: DeepLearning.AI Blog、36氪、36氪)
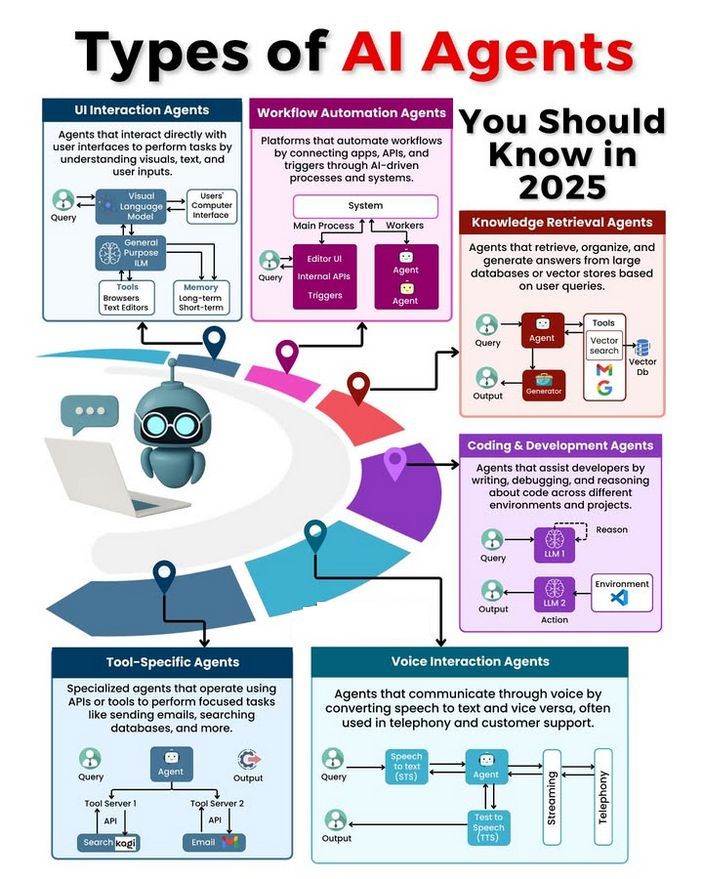
Diskussion über Typen und Entwicklung von KI-Agenten: In der Community wurden verschiedene Typen von KI-Agenten diskutiert (z. B. einfache Reflex-Agenten, modellbasierte Reflex-Agenten, zielbasierte Agenten, nutzenbasierte Agenten, lernende Agenten) und Methoden zum Aufbau zuverlässiger Agenten erörtert (z. B. unter Verwendung von LangChain/LangGraph). Gleichzeitig gibt es auch die Ansicht, dass zukünftige AGI möglicherweise nicht aus einem einzigen Modell besteht, sondern aus der Zusammenarbeit mehrerer spezialisierter Modelle (Quelle: Ronald_vanLoon、hwchase17、nrehiew_)