
Schlüsselwörter:Gemini 2.5 Pro, Kevin-32B, KI-Agent, RAG-Technologie, Digitaler Zwilling, Gemini 2.5 Pro Codierfähigkeiten, Kevin-32B CUDA-Kerne, Agentische Suche, GraphRAG-Wissensgraph, KI- und Digitaler-Zwilling-Integration
Okay, hier ist die deutsche Übersetzung der AI-Nachrichten, unter Beibehaltung der englischen Fachbegriffe und Formatierung:
🔥 Fokus
Google veröffentlicht Gemini 2.5 Pro I/O-Version: Google veröffentlicht die Gemini 2.5 Pro I/O-Version, die die Programmierfähigkeiten erheblich steigert, die LMArena-Ranglisten für Programmierung, Vision und WebDev anführt und als erstes einzelnes Modell den ersten Platz in allen drei Listen erreicht. Die neue Version verbessert die Frontend- und UI-Entwicklung, kann Anwendungen aus handgezeichneten Skizzen generieren und behebt Probleme bei Funktionsaufrufen, was Googles schnelle Fortschritte bei den Fähigkeiten von AI-Modellen zeigt. (Quelle: JeffDean, lmarena.ai, dotey)
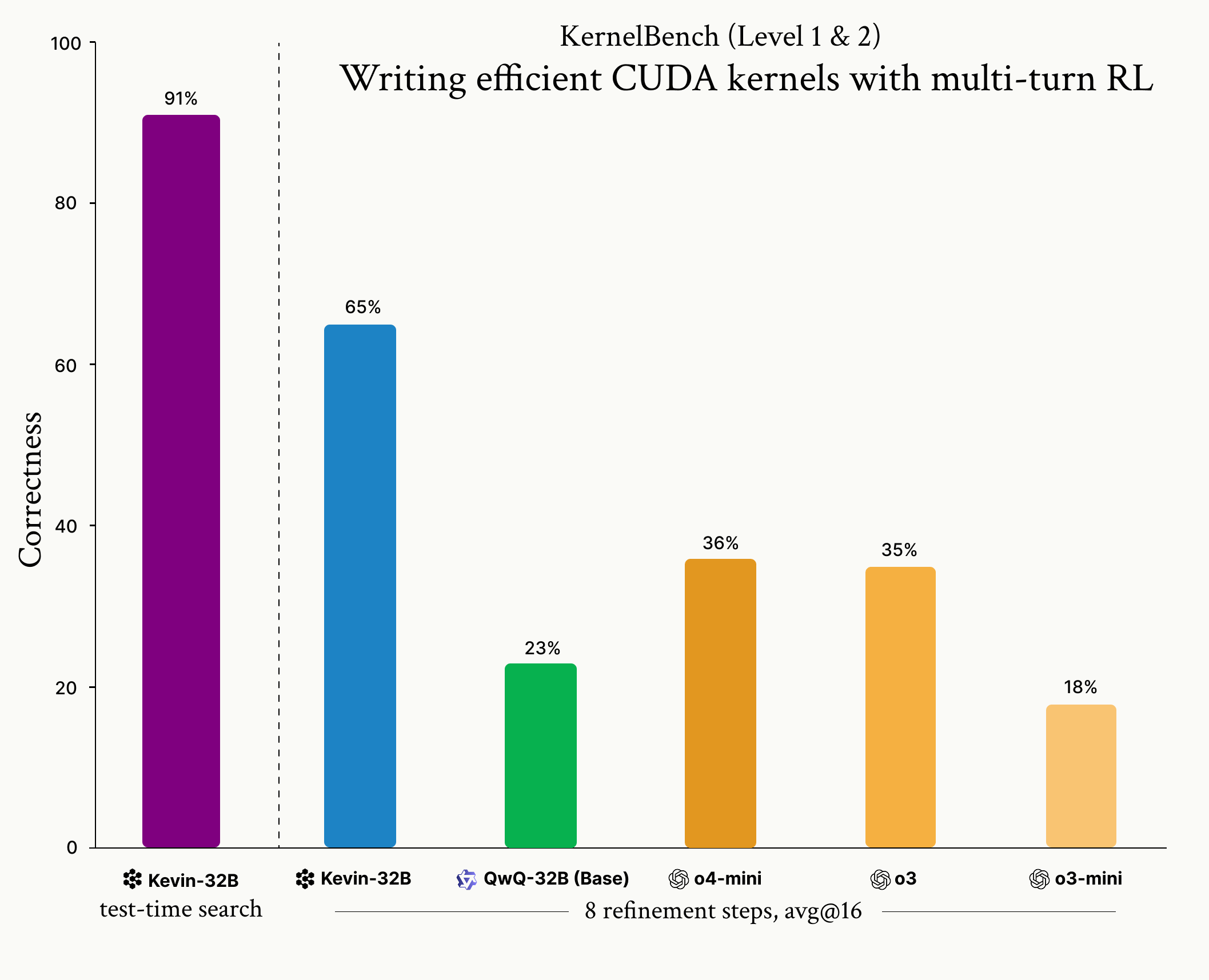
Cognition veröffentlicht Modell Kevin-32B: Cognition veröffentlicht Kevin-32B, das erste Open-Source-Modell, das mittels Reinforcement Learning (GRPO-Algorithmus) zum Schreiben von CUDA-Kernels trainiert wurde. Das Modell zeigt hervorragende Leistungen auf dem KernelBench-Datensatz, übertrifft Top-Inferenzmodelle wie o3 und o4-mini in Bezug auf Korrektheit und Leistung und demonstriert das Potenzial von RL für die Optimierung von Low-Level-Programmierung. (Quelle: Cognition, Dorialexander, vllm_project)
Meta veröffentlicht Perception Encoder: Meta veröffentlicht den neuen visuellen Encoder Meta Perception Encoder, der neue Standards bei Bild- und Videoaufgaben setzt. Das Modell zeichnet sich durch Zero-Shot-Klassifizierung und -Retrieval aus, übertrifft bestehende Modelle und bietet eine neue, leistungsstarke Grundlage für die Forschung und Anwendung im Bereich der Bild- und Videoverständnis. (Quelle: AIatMeta)
Open-Source-Videogenerierungsmodell LTX-Video 13B veröffentlicht: LTX-Video 13B wurde veröffentlicht und ist eines der derzeit leistungsstärksten Open-Source-Modelle zur Videogenerierung. Das Modell verfügt über 13 Milliarden Parameter, unterstützt Multi-Scale-Rendering zur Verbesserung von Details, verbessert das Verständnis von Bewegung und Szene, kann auf lokalen GPUs ausgeführt werden und unterstützt Keyframe-, Kamera-/Charakterbewegungssteuerung. (Quelle: teortaxesTex, Yoav HaCohen)
🎯 Trends
Anthropic LeMUR unterstützt neue Claude-Modelle: AssemblyAI gibt bekannt, dass seine LeMUR-Fähigkeiten nun die Claude 3.7 Sonnet und Claude 3.5 Haiku Modelle von Anthropic unterstützen. Sonnet verbessert die Inferenzfähigkeiten für komplexe Audioanalysen, während Haiku die Reaktionsgeschwindigkeit optimiert, was zu signifikanten Verbesserungen bei Aufgaben wie Audioinhaltsanalyse und Besprechungszusammenfassungen führt. (Quelle: AssemblyAI)
Nvidia und ServiceNow stellen Enterprise-AI-Modell Apriel Nemotron 15B vor: Nvidia und ServiceNow haben Apriel Nemotron 15B vorgestellt, ein kompaktes, kostengünstiges Enterprise-AI-Modell, das auf Nvidia NeMo basiert. Das Modell wurde entwickelt, um Echtzeit-Antworten zu liefern, komplexe Workflows in Bereichen wie IT, HR und Kundenservice zu verarbeiten und skalierbar zu sein. (Quelle: nvidia)

DeepSeek Modell-Updates und Entwicklungszeitplan: Modelle wie DeepSeek V3 und V3-0324 werden kontinuierlich aktualisiert und zeigen Fortschritte bei den Inferenzfähigkeiten und neuen Funktionen. Die Community diskutiert ihren Zeitplan und ihre Merkmale und ist der Ansicht, dass DeepSeek durch innovative Architekturen und Trainingsmethoden signifikante Fortschritte bei der Annäherung an führende Modelle erzielt hat. (Quelle: teortaxesTex, dylan522p)

GraphRAG und Agentic Search treiben die Entwicklung der RAG-Technologie voran: Cohere diskutiert GraphRAG und Agentic Search als nächste Generation der RAG-Technologie. GraphRAG verbessert die Genauigkeit und Zuverlässigkeit durch Wissensgraphen, während Agentic Search AI Agents für tiefe iterative Suchen nutzt, um präzisere, kontextreichere Antworten für Enterprise-AI-Anwendungen zu liefern. (Quelle: cohere)
Hype um AI Agent-Konzepte und Herausforderungen bei der Implementierung: Institutionen wie Gartner weisen darauf hin, dass im Bereich der AI Agents derzeit übermäßiger Hype ( “Agent Washing”) herrscht, wobei viele bestehende Technologien neu verpackt werden. Obwohl die Zahl der Marktanfragen stark gestiegen ist, ist die Erfolgsquote bei der Bereitstellung von Enterprise-Agents gering, und technologische Engpässe, Zuverlässigkeit, Kosten und Anwendbarkeit in verschiedenen Szenarien bleiben die Haupteinschränkungen. (Quelle: 36氪, Gartner)
AI gestaltet die EdTech-Landschaft neu, chinesische Unternehmen auf dem Vormarsch: Die von der Zeitschrift “Time” und Statista veröffentlichte Liste der weltweit führenden EdTech-Unternehmen zeigt, dass chinesische Unternehmen (Coding Cat, NetEase Youdao, TAL Education) zum ersten Mal die ersten drei Plätze belegen und damit die von den USA dominierte Landschaft grundlegend verändern. AI wird zur entscheidenden Infrastruktur, die die Transformation der Bildungstechnologie vorantreibt. Der Erfolg chinesischer Unternehmen ist auf politische Unterstützung und die tiefe Integration der AI-Technologie in Bildungsszenarien zurückzuführen. (Quelle: 36氪)
Meta- und Microsoft-CEOs diskutieren die Zukunft der AI: Meta-Gründer Zuckerberg und Microsoft-CEO Nadella diskutierten die Auswirkungen von AI auf die Unternehmensproduktivität und die zukünftige Anwendungsentwicklung. Nadella ist der Ansicht, dass AI eine Phase der “tiefen Anwendung” einleitet, in der der Anteil von AI-geschriebenem Code in Codebasen zunimmt; Zuckerberg prognostiziert, dass zukünftige Ingenieure Teams von Agents leiten werden und AI den Großteil der Entwicklungsarbeit übernehmen wird. (Quelle: 36氪)
Digitale Menschen-Technologie entwickelt sich von “ähnlicher Form” zu “ähnlichem Geist”: Die Technologie der digitalen Menschen entwickelt sich von statischen Bildern zu intelligenter Interaktion, wobei Large Models wie Transformer und Diffusion Models genutzt werden, um realistischere Ausdrücke, Bewegungen und Lippensynchronisation zu erreichen. Diese Technologie hat breites Anwendungspotenzial in den Bereichen Verbraucher, kleine und mittlere Unternehmen sowie große Unternehmen, steht aber immer noch vor Herausforderungen in Bezug auf technologische Kohärenz, Interaktivität und die Koordination der Industriekette. (Quelle: 36氪)
AI liest erfolgreich Titel von Herculaneum-Papyri: Die Vesuvius Challenge erzielte einen historischen Durchbruch: Forscher nutzten AI-Technologie, um erstmals nicht-invasiv die Titel der durch den Vulkanausbruch verkohlten Herculaneum-Papyri zu lesen. Dieses Ergebnis wurde durch AI-Bildsegmentierung und Tinterkennung erzielt und beweist die Fähigkeit von AI, alte Dokumente zu “durchleuchten”, was den Weg für die Entzifferung weiterer unerschlossener Papyri ebnet. (Quelle: 36氪)

Mehrere Open-Source-AI-Modelle und Datensätze veröffentlicht: Die Community fasst die jüngsten Fortschritte im Open-Source-AI-Bereich zusammen, darunter die Veröffentlichung der Qwen3-Modellreihe und des multimodalen Modells Qwen2.5-Omni durch Alibaba Qwen, die Veröffentlichung des Phi4-Inferenzmodells durch Microsoft, die Veröffentlichung des CoT-Inferenzdatensatzes und des Spracherkennungsmodells Parakeet durch NVIDIA sowie Metas EdgeTAM und andere. (Quelle: mervenoyann)
ACE-Step veröffentlicht Open-Source-Musikgenerierungsmodell: StepFun AI und ACE Studio haben ACE-Step 3.5B veröffentlicht, ein Open-Source-Modell zur Musikgenerierung. Das Modell unterstützt mehrere Sprachen, verschiedene Instrumentenstile und Gesangstechniken, kann Songs schnell auf einer A100 GPU generieren und bietet ein neues AI-Tool für den Bereich der Musikproduktion. (Quelle: Teknium1, Reddit r/LocalLLaMA)

Zunehmende Anwendung von AI im Bereich Digital Twin: Berichte zeigen, dass immer mehr Branchen ihre Digital Twins mit AI kombinieren, um Effizienz und Einblicke zu verbessern. Die Integration von AI und Digital Twins wird zu einem wichtigen technologischen Trend, der die digitale Transformation und innovative Anwendungen in verschiedenen Branchen vorantreibt. (Quelle: Ronald_vanLoon)

🧰 Tools
Smolagents integriert Computer-Nutzungsfähigkeiten: Das Smolagents-Framework führt Computer-Nutzungsfunktionen ein. Mithilfe der Fähigkeiten visueller Modelle wie Qwen-VL können AI Agents nun Screenshots verstehen und Elemente lokalisieren, um Klickoperationen auszuführen, was die Entwicklung komplexer Agent-Workflows vorantreibt. (Quelle: huggingface)
Qdrant Cloud Upgrade steigert Effizienz der Vektorsuche: Qdrant Cloud hat ein großes Upgrade erhalten, das darauf abzielt, Benutzern den Übergang vom Prototyp zur Produktion zu beschleunigen. Die neue Version optimiert die Benutzeroberfläche und das Benutzererlebnis, wodurch die Erstellung von Anwendungen für semantische Suche und eingebettete Vektorsuche bequemer und effizienter wird. (Quelle: qdrant_engine)
AI-Haarwaschdienste als neues Geschäftsmodell im Aufwind: In Shanghai, Shenzhen und anderen Orten sind AI-Haarwaschsalons aufgetaucht, die standardisierte Dienstleistungen mittels intelligenter Haarwaschmaschinen anbieten, um Kunden mit niedrigen Preisen anzuziehen. Obwohl das Kundenfeedback gemischt ist und Herausforderungen hinsichtlich technologischer Reife, Sicherheit und Rentabilität bestehen, zeigt AI-Haarwäsche als Anwendungsversuch von AI im Dienstleistungssektor eine neue Richtung für die Geschäftsentwicklung auf. (Quelle: 36氪)
Open-Source LLM-Bewertungstool Opik veröffentlicht: Opik ist ein Open-Source-LLM-Bewertungstool zur Fehlersuche, Bewertung und Überwachung von LLM-Anwendungen, RAG-Systemen und Agent-Workflows. Es bietet umfassendes Tracing, automatisierte Bewertung und Produktions-Dashboards, um Entwicklern zu helfen, die Leistung und Zuverlässigkeit von AI-Anwendungen zu verbessern. (Quelle: dl_weekly)
Python Chain-of-Thought Toolkit Cogitator: Ein Open-Source-Python-Toolkit namens Cogitator wurde veröffentlicht, das darauf abzielt, die Verwendung und das Experimentieren mit der Chain-of-Thought (CoT)-Inferenzmethode zu vereinfachen. Die Bibliothek unterstützt OpenAI- und Ollama-Modelle und enthält Implementierungen von CoT-Strategien wie Self-Consistency, Tree of Thoughts und Graph of Thoughts. (Quelle: Reddit r/MachineLearning)
Comfyui Brand-Upgrade und Einführung nativer API-Knoten: Comfyui hat ein Brand-Upgrade durchgeführt und native API-Knoten eingeführt, die die Integration von 11 Online-Visual-AI-Modellen wie Flux, Kling und Luma unterstützen. Benutzer müssen keinen separaten API Key beantragen, sondern können sich direkt in Comfyui anmelden, um sie zu verwenden, was die Einrichtung von Multi-Modell-Workflows erheblich vereinfacht. (Quelle: op7418)

Cursor bietet kostenlosen Service für Studenten und Jurastudenten: Der AI-Programmierassistent Cursor hat angekündigt, Studenten eine kostenlose Pro-Version anzubieten, und das Legal-AI-Tool Spellbook bietet Jurastudenten ebenfalls kostenlosen Service. Dieser Schritt senkt die Hürde für Studenten, Zugang zu fortschrittlichen AI-Tools zu erhalten und diese zu nutzen, und trägt zur Popularisierung der AI-Technologie im Bildungsbereich bei. (Quelle: scaling01, scottastevenson)
📚 Lernen
Unsloth Framework ermöglicht effizientes LLM Fine-Tuning: Der LearnOpenCV-Blog bietet eine eingehende Analyse des Unsloth Frameworks und zeigt, wie Large Language Models und Vision-Language Models (wie Qwen2.5-VL) schneller, leichter und intelligenter feinabgestimmt werden können. Unsloth reduziert den GPU-Speicherverbrauch und die Trainingszeit durch Optimierungstechniken erheblich und ist besonders für Benutzer mit begrenzten Ressourcen geeignet. (Quelle: LearnOpenCV)
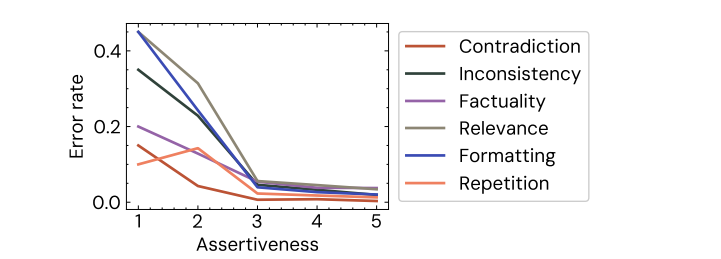
Cohere-Studie enthüllt menschliche Bewertungsbias bei LLMs: Eine Studie von Cohere ergab, dass selbst kleine Bias (wie selbstbewusstere Formulierungen) die menschliche Bewertung der LLM-Ausgabe systematisch verzerren können. Modelle, die apodiktischere Antworten geben, werden oft als “besser” bewertet, selbst wenn der Inhalt derselbe ist. Dies unterstreicht die Irrationalität menschlicher Bewertungen und die Herausforderungen bei der Bewertung von Modellen. (Quelle: Shahules786, clefourrier)
SWE-bench führt multilinguale Programmierfähigkeitsbewertung ein: Die SWE-bench-Bibliothek veröffentlicht eine neue Version, die SWE-bench Multilingual einführt, um die Programmierfähigkeiten von LLMs in 9 Programmiersprachen zu testen. Claude 3.7 erzielte bei dieser multilingualen Bewertung niedrigere Ergebnisse als bei der englischen SWE-bench, was darauf hindeutet, dass die sprachübergreifenden Programmierfähigkeiten von LLMs noch verbessert werden müssen. (Quelle: OfirPress)

Studie untersucht mögliche Fähigkeitenverluste bei LLM Alignment: Forscher untersuchen bestimmte Fähigkeiten, die Large Language Models während des Alignment-Trainings verlieren könnten, wie z. B. Zufälligkeit und Kreativität. Dies löst eine Diskussion darüber aus, wie das ursprüngliche Potenzial von Modellen erhalten werden kann, während gleichzeitig deren Sicherheit und Nützlichkeit verbessert werden. (Quelle: lateinteraction, Peter West)

Muon Optimizer Studie zeigt Effizienzvorteile: Essential AI veröffentlicht eine Studie, die die praktische Effizienz des Muon Optimizers beim LLM-Vortraining untersucht. Die Studie zeigt, dass Muon als Optimierer zweiter Ordnung im Vergleich zu AdamW Vorteile beim Kompromiss zwischen Rechenzeit und Leistung bietet, insbesondere bei großen Batch-Größen, wo er Dateninformationen effektiver erhalten kann. (Quelle: cloneofsimo, Essential AI)
Epoch AI Benchmark-Plattform aktualisiert: Epoch AI aktualisiert seine Benchmark-Plattform und fügt neue Bewertungsitems hinzu, darunter Aider Polyglot, WeirdML, Balrog und Factorio Learning Environment. Diese neuen Benchmarks enthalten externe Ranglistendaten und bieten eine umfassendere Perspektive für die Bewertung der LLM-Leistung. (Quelle: scaling01)
Hugging Face veröffentlicht AI Agent Kurs: Hugging Face veröffentlicht einen AI Agent Kurs, der Agent-Grundlagen, LLMs, Modellfamilien, Frameworks (smolagents, LangGraph, LlamaIndex), Beobachtbarkeit, Bewertung und Agentic RAG Anwendungsfälle abdeckt und ein Abschlussprojekt sowie Benchmarks enthält. Dies bietet eine systematische Ressource zum Erlernen des Aufbaus von AI Agents. (Quelle: GitHub Trending, huggingface)

💼 Business
OpenAI erwirbt AI-Programmierassistent Windsurf: OpenAI hat zugestimmt, den Entwickler des AI-Programmierassistenten Windsurf (ehemals Codeium) für rund 3 Milliarden US-Dollar zu übernehmen. Dies ist die bisher größte Übernahme von OpenAI und zielt darauf ab, die Position von OpenAI im Bereich der AI-Programmierung zu stärken, die Benutzerbasis und Codebasis-Entwicklungsdaten von Windsurf zu erwerben und die zukünftige Entwicklung von AI-Programmier-Agents vorzubereiten. (Quelle: 36氪, Bloomberg, 智东西)
OpenAI gibt Plan zur vollständigen Kommerzialisierung auf: OpenAI hat angekündigt, den Plan aufzugeben, die Muttergesellschaft vollständig in eine gewinnorientierte Organisation umzuwandeln. Stattdessen wird die Struktur beibehalten, bei der die gemeinnützige Muttergesellschaft die Kontrolle über die gewinnorientierte Tochtergesellschaft behält, und die Tochtergesellschaft wird in eine “Public Benefit Corporation” umgewandelt. Dieser Schritt ist ein Kompromiss nach Diskussionen mit Aufsichtsbehörden und verschiedenen Parteien, beeinflusst die Unternehmensführung und zukünftige Finanzierungsstrategien und steht auch im Zusammenhang mit dem Widerstand von Personen wie Musk. (Quelle: steph_palazzolo, 36氪)
Yuncong Technology steht vor Entlassungen und Verlusten: Die Finanzberichte des etablierten AI-Unternehmens Yuncong Technology zeigen einen erheblichen Umsatzrückgang, steigende Verluste sowie Entlassungen und Gehaltskürzungen für Führungskräfte. Dies spiegelt die Rentabilitätsherausforderungen und den Marktwettbewerbsdruck im AI-Startup-Bereich wider. Für viele AI-Unternehmen ist das “Überleben” in der aktuellen Phase zur obersten Priorität geworden, was darauf hindeutet, dass die AI-Startup-Blase möglicherweise platzt. (Quelle: 36氪)

🌟 Community
AI Deepfakes lösen Vertrauenskrise und Risiko der “plausiblen Abstreitbarkeit” aus: Die Community diskutiert die zunehmende Realitätsnähe von AI Deepfake-Technologie, die es der Öffentlichkeit erschwert, wahre von falschen Informationen zu unterscheiden, was zu einer Vertrauenskrise führt. Noch besorgniserregender ist die Möglichkeit, dass Einzelpersonen oder Institutionen AI-Fälschungen als Vorwand für die “plausible Abstreitbarkeit” ihres Fehlverhaltens nutzen könnten, was Herausforderungen für die Faktenprüfung und rechtliche Rechenschaftspflicht mit sich bringt. (Quelle: Reddit r/ArtificialInteligence)

Interne OpenAI-Tests zeigen Verschlechterung des ChatGPT-Halluzinationsproblems: Berichten zufolge zeigen interne Tests von OpenAI, dass sich das Halluzinationsproblem von ChatGPT verschlechtert, und die Ursache ist unklar. Diese Entdeckung löst in der Community Bedenken hinsichtlich der Zuverlässigkeit und Erklärbarkeit von Modellen aus und zeigt, dass selbst führende Modelle immer noch grundlegenden Herausforderungen gegenüberstehen. (Quelle: Reddit r/artificial)

Community befürchtet mögliche Einbettung von Werbung in AI-Modell-Trainingsdaten: Die Community diskutiert die Möglichkeit, dass in Zukunft absichtlich Werbung oder voreingenommene Informationen in AI-Modell-Trainingsdaten eingebettet werden könnten, was dazu führt, dass die Modellausgabe versteckte Werbung oder spezifische Standpunkte enthält. Dies löst Bedenken hinsichtlich der Transparenz, Sicherheit und Geschäftsmodelle von Modellen sowie der Vorteile von Open-Source-Modellen in dieser Hinsicht aus. (Quelle: Reddit r/LocalLLaMA)
Diskussion über den Hype um AI Agent-Konzepte und Schwierigkeiten bei der tatsächlichen Implementierung: Die Community diskutiert lebhaft die Diskrepanz zwischen dem Hype um AI Agent-Konzepte und der tatsächlichen Implementierung. Die Diskussion weist darauf hin, dass viele “Agents” lediglich eine Neuverpackung bestehender Technologien sind und Unternehmen beim Aufbau und der Bereitstellung echter Agents vor Herausforderungen in Bezug auf technologische Zuverlässigkeit, Kostenkontrolle und Komplexität stehen und den Geschäftswert realistisch bewerten müssen. (Quelle: 36氪, Reddit r/ArtificialInteligence)
Kontroversen um Open-Source-Tools wie Ollama und OpenWebUI: Die Community diskutiert die Vor- und Nachteile von Ollama als Tool zum Ausführen lokaler LLMs, einschließlich seines Modellspeicherformats, Synchronisationsproblemen mit llama.cpp und Standardkonfigurationen. Gleichzeitig hat OpenWebUI seine Lizenz geändert und Beschränkungen für kommerzielle Benutzer hinzugefügt, was eine Diskussion über den Open-Source-Geist und die Nachhaltigkeit von Projekten ausgelöst hat. (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Angst von Machine Learning Praktikern bezüglich Datensatzbeschaffung: Machine Learning Praktiker äußern in sozialen Medien ihre Angst bezüglich der Beschaffung hochwertiger Datensätze und sind der Meinung, dass Daten die “Obergrenze” der Modellleistung darstellen, aber Manager ohne technischen Hintergrund die Komplexität der Datenarbeit oft unterschätzen und AI als “Zauberstab” betrachten. (Quelle: Reddit r/MachineLearning)
Herausforderungen bei der Verwaltung und Überprüfung von AI-generiertem Code: Mit der Verbreitung von AI-generiertem Code diskutiert die Community, wie die große Menge an von AI generiertem Code effektiv verwaltet und überprüft werden kann. Entwickler müssen Prozesse und Tools einrichten, um die Qualität und Korrektheit von AI-Code sicherzustellen. Der Arbeitsschwerpunkt könnte sich vom Schreiben von Code auf die Überprüfung und Verifizierung verlagern. (Quelle: matvelloso, finbarrtimbers)
Diskrepanz zwischen tatsächlicher RAG-Anwendungsleistung und Benutzererwartungen: Benutzer berichten, dass die Modellleistung bei der Verwendung von RAG zur Verarbeitung persönlicher Dokumente hinter den Erwartungen zurückbleibt und das Modell Fragen, die in den Dokumenten enthalten sind, nicht genau beantworten kann. Dies zeigt, dass RAG bei der Verarbeitung spezifischer, nicht öffentlicher Datensätze immer noch Herausforderungen aufweist und die tatsächliche Leistung von der Benutzererfahrung mit allgemeinen Modellen abweicht. (Quelle: Reddit r/OpenWebUI)
💡 Sonstiges
Microsoft PowerToys Update, neue Funktionen wie Command Palette hinzugefügt: Microsoft veröffentlicht Version 0.90 von PowerToys, die das Modul Command Palette (CmdPal) als Weiterentwicklung von PowerToys Run hinzufügt, um den Schnellstart und die Erweiterbarkeit zu verbessern. Darüber hinaus wurden Funktionen wie Color Picker, Peek-Dateilöschung und New+-Vorlagenvariablen verbessert, um die Produktivität von Windows-Benutzern zu steigern. (Quelle: GitHub Trending)

Nvidia plant, den CUDA-Support für alte GPUs einzustellen: Nvidia hat angekündigt, den CUDA-Support für GPUs der Maxwell-, Pascal- und Volta-Serie in der nächsten Hauptversion des Toolkits einzustellen. Dieser Schritt wird einige Benutzer betreffen, die immer noch auf diese alte Hardware für AI/ML-Arbeiten angewiesen sind, und könnte eine Infrastrukturaktualisierung vorantreiben, löst aber auch Diskussionen in der Community über Hardware-Obsoleszenz und Kompatibilität aus. (Quelle: Reddit r/LocalLLaMA)

Google Nest Hub Geräte haben Gemini nicht integriert: Benutzer beklagen, dass die intelligenten Displays der Google Nest Hub-Geräte immer noch den alten Google Assistant verwenden und das leistungsstärkere Gemini-Modell nicht integriert haben. Obwohl Geräte wie Pixel-Telefone Gemini bereits unterstützen, fehlt eine Upgrade-Roadmap für die Nest Hub-Serie, was bei den Benutzern Fragen zur Fragmentierung des Google-Produktökosystems und zum Versprechen der AI-Popularisierung aufwirft. (Quelle: Reddit r/ArtificialInteligence, Reddit r/artificial)