
Schlüsselwörter:OpenAI, DSPy, SGLang, Nvidia, ChatGPT, KI, LLM, MoE, dspy.GRPO, DeepSeek MoE, Parakeet TDT, Agentisches System, EQ-Bench 3
🔥 Fokus
OpenAI bestätigt Beibehaltung der Non-Profit-Struktur: OpenAI kündigt an, dass seine bestehende gewinnorientierte Einheit in eine Public Benefit Corporation (PBC) umgewandelt wird, die Kontrolle jedoch bei der aktuellen Non-Profit-Organisation verbleibt. Dieser Schritt bestätigt, dass OpenAI weiterhin von der Non-Profit-Organisation kontrolliert wird, und bekräftigt seine Mission, sicherzustellen, dass AGI (Allgemeine Künstliche Intelligenz) der gesamten Menschheit zugutekommt. Diese Entscheidung folgt auf interne Turbulenzen und externe Fragen zu seiner Struktur (einschließlich der Klage von Musk). Die Community reagiert gemischt darauf: Einige sehen darin ein Festhalten an der Mission, andere hinterfragen die wahren Absichten der Kapitalstrukturanpassung (Quelle: OpenAI, sama, jachiam0, NeelNanda5, scaling01, zacharynado, mcleavey, steph_palazzolo, Plinz, Teknium1)
DSPy Framework veröffentlicht experimentellen Online-RL-Optimierer dspy.GRPO: Das Stanford NLP Team hat eine experimentelle neue Funktion für das DSPy Framework veröffentlicht: dspy.GRPO, ein Online Reinforcement Learning (RL) Optimierer. Dieses Tool zielt darauf ab, DSPy-Programme zu optimieren, selbst komplexe Multi-Modul- und Multi-Schritt-Programme können direkt angewendet werden, ohne den bestehenden Code zu ändern. Dies wird als wichtiger Schritt angesehen, um RL-Optimierung (wie GRPO, das von DeepSeek verwendet wird) auf eine höhere Abstraktionsebene (LLM-Workflows) zu bringen, mit dem Ziel, die Leistung und Effizienz von AI Agents und komplexen Pipelines zu verbessern. Die Community reagiert begeistert und sieht dies als wichtigen Bestandteil von DSPy 3.0 (Quelle: Omar Khattab, matei_zaharia, lateinteraction, Michael Ryan, Lakshya A Agrawal, Scott Condron, Noah Ziems, Rogerio Chaves, Karthik Kalyanaraman, Josh Cason, Mehrdad Yazdani, DSPy, Hopkinx🀄️, Ahmad, william, lateinteraction, lateinteraction, swyx)
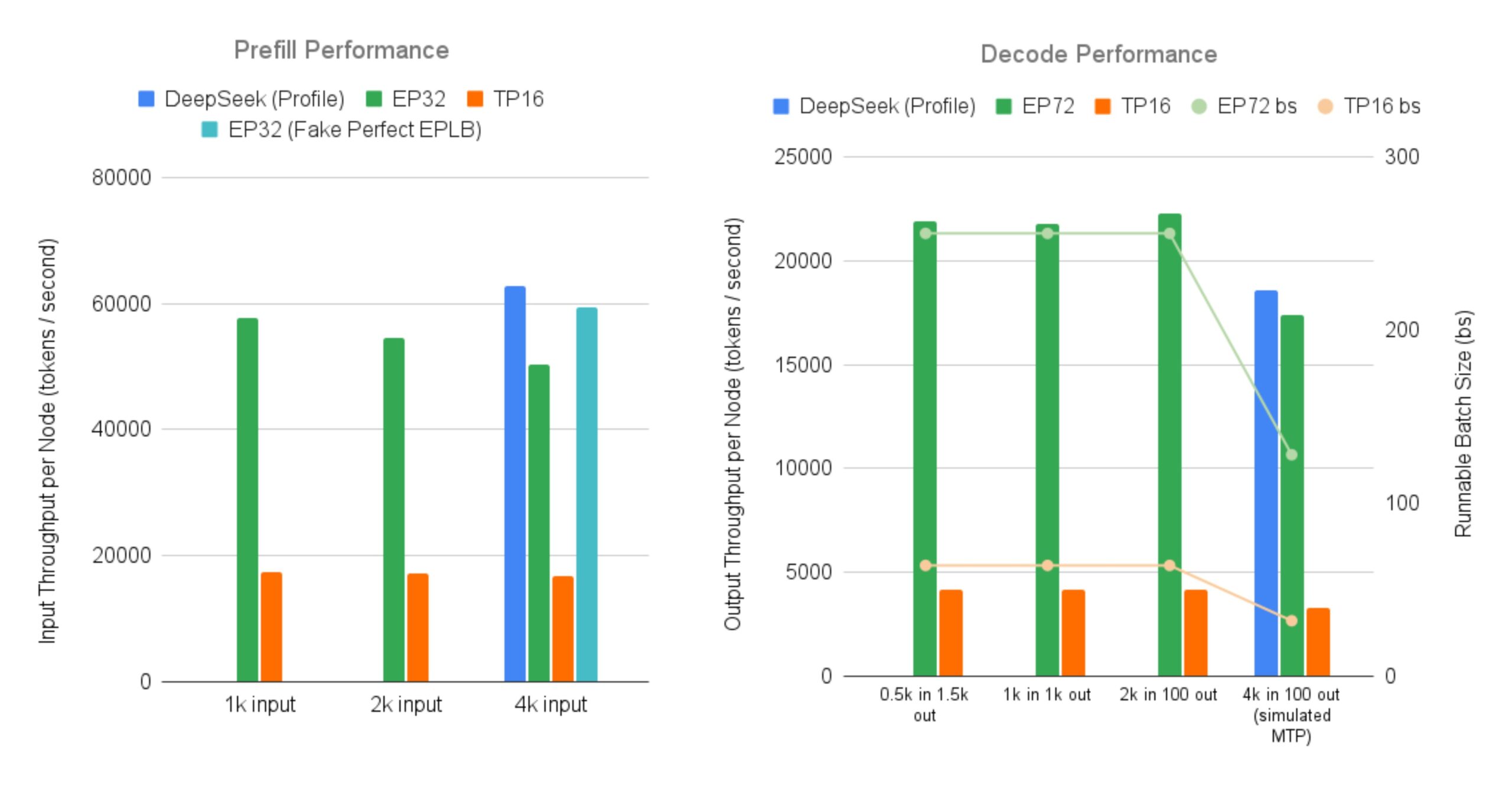
SGLang Open-Source-Implementierung für effizientes Serving von DeepSeek MoE Large Models: LMSYS Org gibt bekannt, dass SGLang die erste Open-Source-Implementierung für das Serving von MoE (Mixture-of-Experts)-Modellen wie DeepSeek V3/R1 mit Merkmalen wie großskaligem Expert Parallelism und Prefill-Decode Disaggregation auf 96 GPUs bereitstellt. Diese Implementierung erreicht nahezu den von DeepSeek offiziell gemeldeten Durchsatz (Input 52.3k Token/Sekunde pro Knoten, Output 22.3k Token/Sekunde pro Knoten), was einer bis zu 5-fachen Steigerung des Output-Durchsatzes im Vergleich zum traditionellen Tensor Parallelism entspricht. Dies bietet der Community eine Open-Source-Lösung für den effizienten Betrieb und die Bereitstellung großer MoE-Modelle (Quelle: LMSYS Org, teortaxesTex, cognitivecompai, lmarena_ai, cognitivecompai)
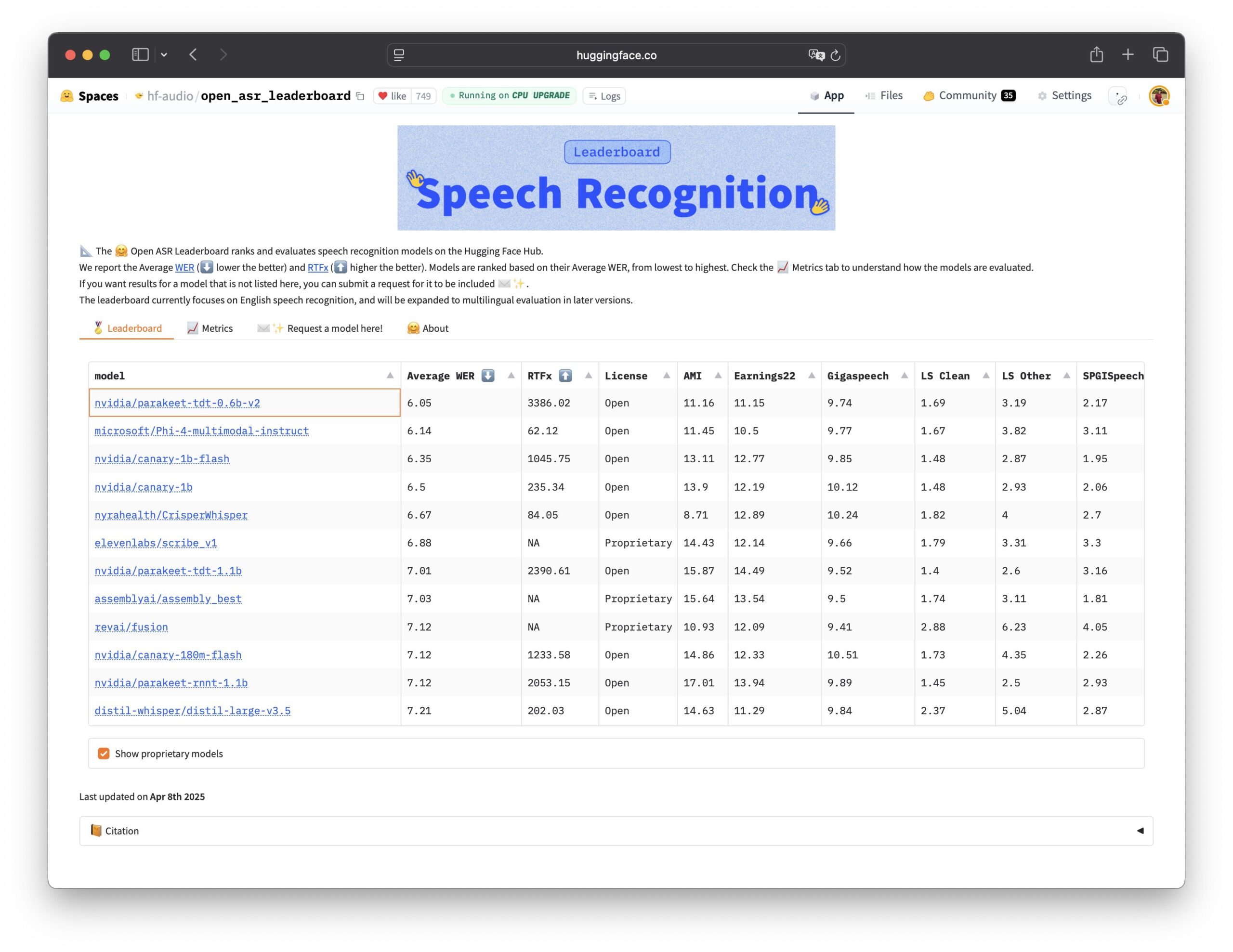
Nvidia veröffentlicht Parakeet TDT Spracherkennungsmodell als Open Source: Nvidia hat das Parakeet TDT 0.6B Modell als Open Source veröffentlicht. Dieses Modell schneidet auf dem Open ASR Leaderboard am besten ab und ist damit das derzeit leistungsstärkste quelloffene Modell für automatische Spracherkennung (ASR). Das Modell hat 600 Millionen Parameter und kann 60 Minuten Audio in 1 Sekunde transkribieren, wobei es viele führende Closed-Source-Modelle übertrifft. Das Modell steht unter der CC-BY-4.0 Lizenz, die eine kommerzielle Nutzung erlaubt, und bietet eine leistungsstarke Open-Source-Option für den Bereich der Spracherkennung (Quelle: Vaibhav (VB) Srivastav, huggingface, ClementDelangue)
🎯 Trends
ChatGPT-Zugriffe wachsen weiter und übertreffen X: Daten von Similarweb zeigen, dass die Zugriffe auf ChatGPT weiter zunehmen und im April die Gesamtbesuche (4,786 Milliarden) die von X (ehemals Twitter) (4,028 Milliarden) überstiegen haben. Seit Anfang 2025 sind die Zugriffe auf ChatGPT stetig gestiegen, von gelegentlichem Hinterherhinken im Januar bis hin zu einer fast vollständigen Führung vor X im April, was die starke Dynamik von AI-Chatbots bei der Nutzeraktivität zeigt (Quelle: dotey)
Datenvertrauen und Führungskompetenz werden entscheidend für die AI-Transformation: Mehrere Berichte und Diskussionen betonen, dass Datenvertrauen die unsichtbare Kraft ist, die die AI-Transformation beschleunigt. Gleichzeitig zeigen erfolgreiche GenAI-Führungskräfte unterschiedliche Eigenschaften in Strategie, Organisation und Technologieanwendung. Dies deutet darauf hin, dass der Schlüssel zum AI-Erfolg nicht nur in der Technologie selbst liegt, sondern auch in einer hochwertigen, vertrauenswürdigen Datenbasis sowie effektiver Führung und strategischer Umsetzung (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

GTE-ModernColBERT erzielt SOTA-Leistung bei Long-Text-Embedding-Aufgaben: Das von LightOn veröffentlichte GTE-ModernColBERT Multi-Vektor-Embedding-Modell hat im LongEmbed Long Document Search Benchmark SOTA-Ergebnisse (State-of-the-Art) erzielt und liegt fast 10 Punkte vorn. Bemerkenswert ist, dass das Modell nur auf kurzen Dokumenten (Länge 300) von MS MARCO trainiert wurde, aber eine hervorragende Zero-Shot-Generalisierungsfähigkeit bei langen Textaufgaben zeigt. Dies bestätigt erneut das Potenzial von Late-Interaction-Modellen (wie ColBERT) bei der Verarbeitung von Long-Context-Retrieval, die traditionellen BM25- und Dense-Retrieval-Modellen überlegen sind (Quelle: Antoine Chaffin, Ben Clavié, tomaarsen, Dorialexander, Manuel Faysse, Omar Khattab)

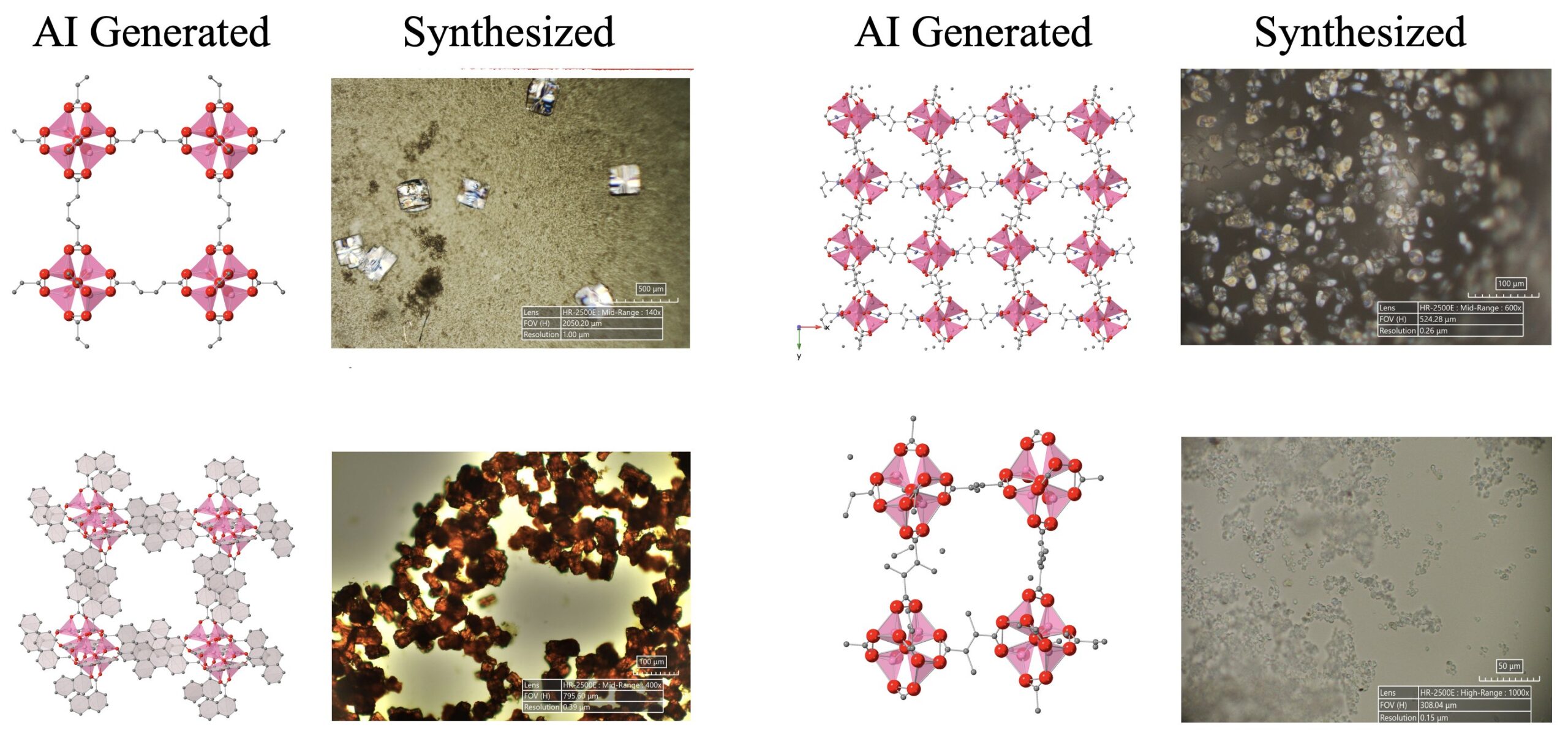
Fortschritte bei AI-gesteuerter wissenschaftlicher Entdeckung: Ein AI-Agentensystem, bestehend aus LLMs, Diffusionsmodellen und Hardwaregeräten, hat erfolgreich autonom 5 neuartige metallorganische Gerüstverbindungen (MOFs) entdeckt und synthetisiert, die über das bestehende menschliche Wissen hinausgehen. Die Studie zeigt das Potenzial von AI-Agenten bei der Automatisierung wissenschaftlicher Forschung, die den gesamten Prozess von der Ideenfindung bis zur Nasslabor-Validierung abdecken können (Quelle: Sherry Yang)
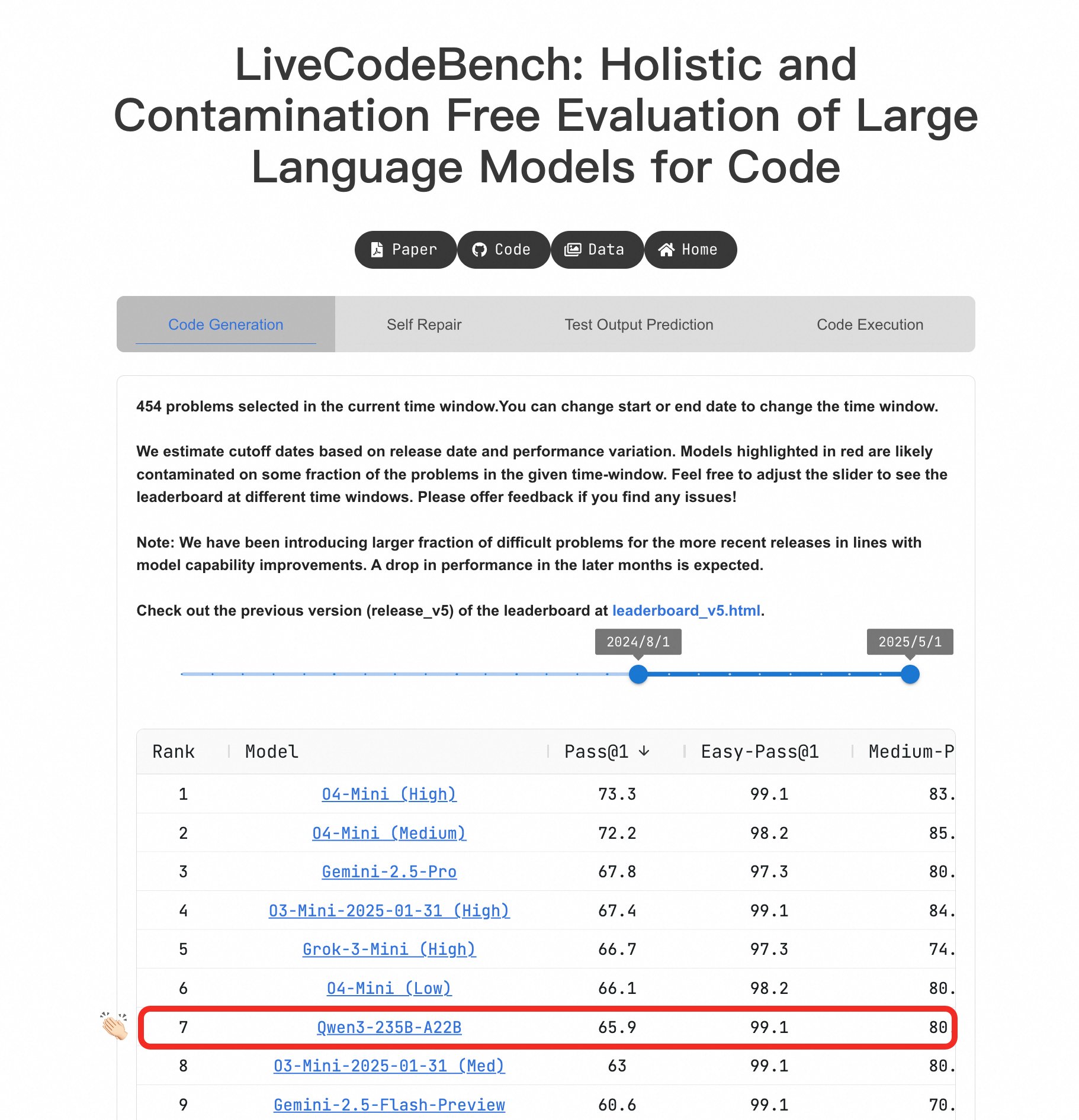
Qwen3 Large Model zeigt herausragende Programmierfähigkeiten: Im LiveCodeBench Benchmark zeigte das Qwen3-235B-A22B Modell eine hervorragende Leistung und gilt als eines der besten Open-Source-Modelle für die Codegenerierung auf Wettbewerbsniveau, mit einer Leistung vergleichbar mit o4-mini (Low Confidence). Selbst bei schwierigen Problemen kann Qwen3 mit O4-Mini (Low) mithalten und übertrifft o3-mini (Quelle: Binyuan Hui, teortaxesTex)
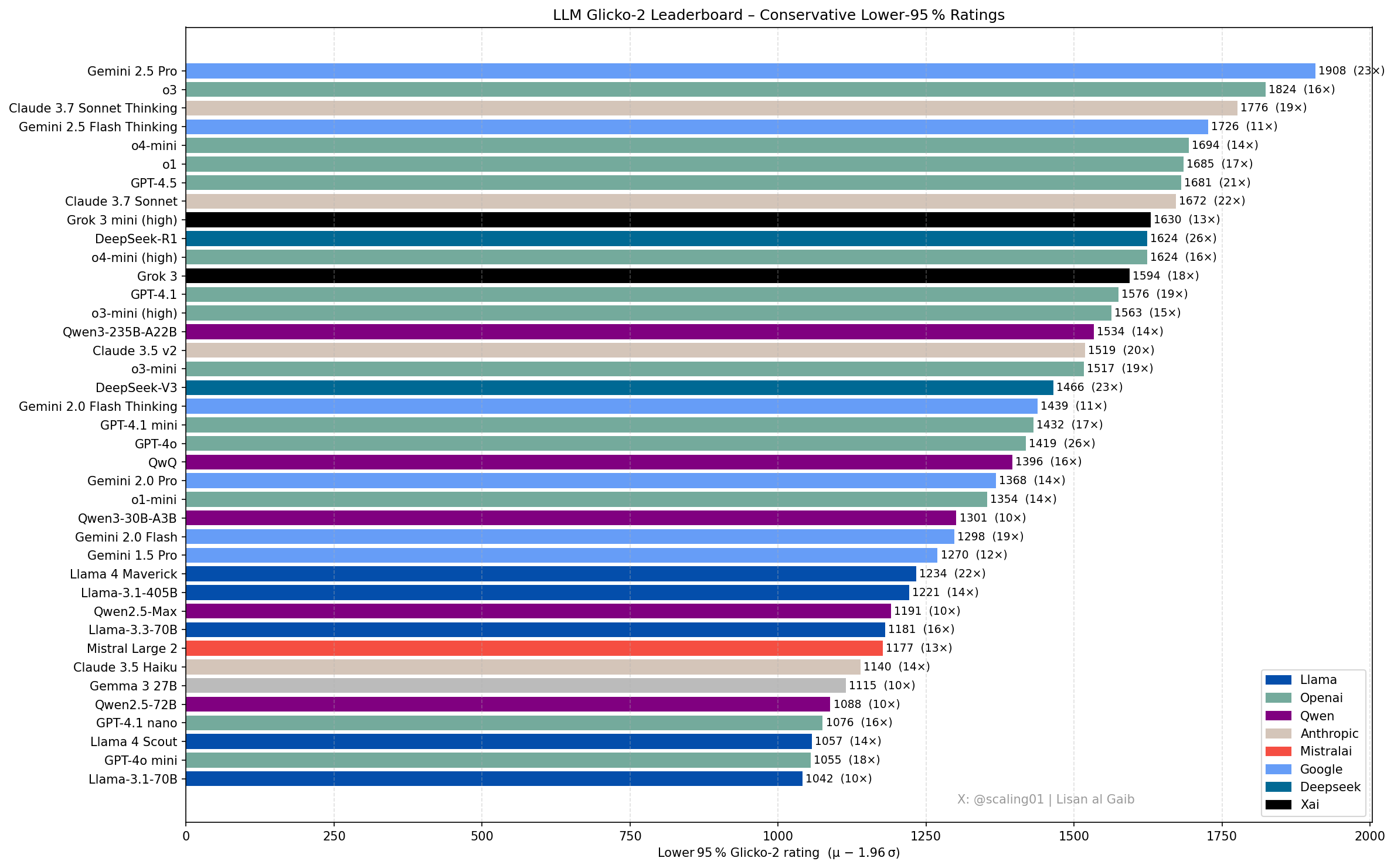
Neue Entwicklungen und Diskussionen zur LLM-Rangliste: Community-Mitglied Lisan al Gaib hat die LLM-Rangliste mithilfe des Glicko-2-Bewertungssystems aktualisiert, was zu Diskussionen führte. Scaling01 ist der Meinung, dass die Liste zu 95 % mit seiner subjektiven Einschätzung übereinstimmt. Gemini 2.5 Pro bleibt führend, aber Gemini 2.5 Flash, Grok 3 mini und GPT-4.1 könnten überschätzt sein. Die Liste zeigt eine plausible Fortschrittsreihenfolge der Modellfamilien von OpenAI, Llama und Gemini, wobei o3 (high) auf dem Niveau von Gemini 2.5 Pro liegt (Quelle: Lisan al Gaib)
Open-Source-Robotik-Ökosystem entwickelt sich rasant: Clem Delangue von Hugging Face zeigte sich nach Gesprächen mit NPeW und Matth Lapeyre begeistert über die Fortschritte im Bereich der AI-Robotik. Peter Welinder (OpenAI) lobte ebenfalls die Arbeit von Hugging Face bei der Förderung des Open-Source-Robotik-Ökosystems und stellte fest, dass dieser Bereich schnell wächst (Quelle: ClementDelangue, Peter Welinder, ClementDelangue, huggingface)
Forschungsrichtung AI-Interpretierbarkeit gewinnt an Aufmerksamkeit: Forscher fordern mehr Arbeit im Bereich der AI-Interpretierbarkeit (Interpretability), insbesondere zur Erklärung seltsamer Verhaltensweisen von Modellen. Durch das Verständnis dieser Verhaltensweisen können tiefere Schlussfolgerungen über die internen Mechanismen von LLMs gezogen und möglicherweise neue Interpretierbarkeits-Tools entwickelt werden. Dies wird als vielversprechende und einflussreiche Forschungsrichtung angesehen (Quelle: Josh Engels)
FutureHouseSF widmet sich dem Aufbau von „AI Scientists“: Sam Rodriques, CEO von FutureHouseSF, erläuterte in einem Interview das Ziel des Unternehmens, „AI Scientists“ zu bauen. Diskutiert wurden die konkrete Bedeutung von AI Scientists, die Rolle der Robotik dabei und warum der Wissenschaftsbereich eine ähnliche Triebkraft wie das „Stargate“-Projekt benötigt, um die wissenschaftliche Entdeckung mittels AI zu beschleunigen (Quelle: steph_palazzolo)
Googles TPU-Vorteil möglicherweise unterschätzt: Kommentator Justin Halford argumentiert, dass Investoren Googles Vorteil bei TPUs (Tensor Processing Units) möglicherweise unterschätzen. Er weist darauf hin, dass Rechenleistung der Schlüssel im AI-Wettbewerb sein wird, wenn algorithmische Schutzgräben nicht signifikant sind. Googles selbst entwickelte TPUs vermeiden Zwischenkosten, was angesichts von Hunderten Milliarden Dollar, die in die Infrastruktur fließen, entscheidend ist (Quelle: Justin_Halford_)
Open-Source VLA-Modell Nora veröffentlicht: Declare Lab hat Nora veröffentlicht, ein neues Vision-Language-Action (VLA)-Modell, das auf Qwen2.5VL und dem FAST+ Tokenizer basiert. Das Modell wurde auf dem Open X-Embodiment Datensatz trainiert und übertrifft Spatial VLA und OpenVLA bei realen WidowX-Aufgaben (Quelle: Reddit r/MachineLearning)

Neue Methode zur LLM-Inferenzoptimierung: Snapshot & Restore: Angesichts der Herausforderungen durch Kaltstarts und die Bereitstellung mehrerer Modelle bei der LLM-Inferenz hat ein Team ein neues Laufzeitsystem entwickelt. Dieses System erstellt Snapshots des vollständigen Ausführungszustands eines Modells (einschließlich Speicherlayout, Attention Cache, Ausführungskontext) und stellt diesen direkt auf der GPU wieder her. Dies ermöglicht Kaltstarts innerhalb von 2 Sekunden, das Hosten von über 50 Modellen auf 2 A4000 GPUs mit über 90 % GPU-Auslastung und ohne dauerhafte Speicherüberlastung. Dieser Ansatz ähnelt dem Aufbau eines „Betriebssystems“ für die Inferenz (Quelle: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Open-Source Echtzeit-Objektdetektor D-FINE: Die Hugging Face Transformers Bibliothek hat den Echtzeit-Objektdetektor D-FINE hinzugefügt. Dieses Modell soll schneller und genauer als YOLO sein, steht unter der Apache 2.0 Lizenz und kann auf einer T4 GPU (kostenlose Colab-Umgebung) ausgeführt werden. Es bietet eine neue SOTA Open-Source-Option für die Echtzeit-Objekterkennung (Quelle: merve, algo_diver)
LLM-Preisgestaltung wird dynamischer: Es wird beobachtet, dass die Preisgestaltung für Large Language Models dynamischer wird. Dies könnte dem Markt helfen, im Laufe der Zeit optimalere Preispunkte zu finden, und spiegelt die Tendenz der Modellanbieter wider, ihre Preisstrategien an Kosten, Nachfrage und Wettbewerbsdruck anzupassen (Quelle: xanderatallah)
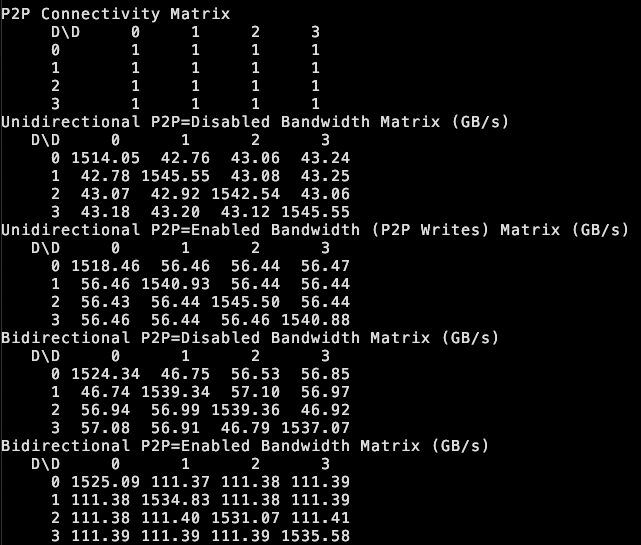
tinybox green v2 unterstützt P2P zwischen GPUs: the tiny corp gibt bekannt, dass ihr Produkt tinybox green v2 durch modifizierte Treiber die Peer-to-Peer (P2P)-Kommunikation zwischen RTX 5090 GPUs unterstützt. Das bedeutet, dass Daten direkt zwischen GPUs übertragen werden können, ohne den Umweg über den CPU-RAM, was die Effizienz bei der Zusammenarbeit mehrerer GPUs erhöht. Die Funktion ist kompatibel mit tinygrad und PyTorch (jede Bibliothek, die NCCL verwendet) (Quelle: the tiny corp)
Forscher veröffentlichen EQ-Bench 3 zur Bewertung der emotionalen Intelligenz von LLMs: Sam Paech hat EQ-Bench 3 veröffentlicht, ein Benchmark-Tool zur Messung der emotionalen Intelligenz (EQ) von Large Language Models (LLMs). Das Entwicklungsteam hat diese Version nach mehreren gescheiterten Prototypen herausgebracht, mit dem Ziel, die Fähigkeit von Modellen, Emotionen zu verstehen und darauf zu reagieren, genauer und zuverlässiger zu bewerten (Quelle: Sam Paech, fabianstelzer)

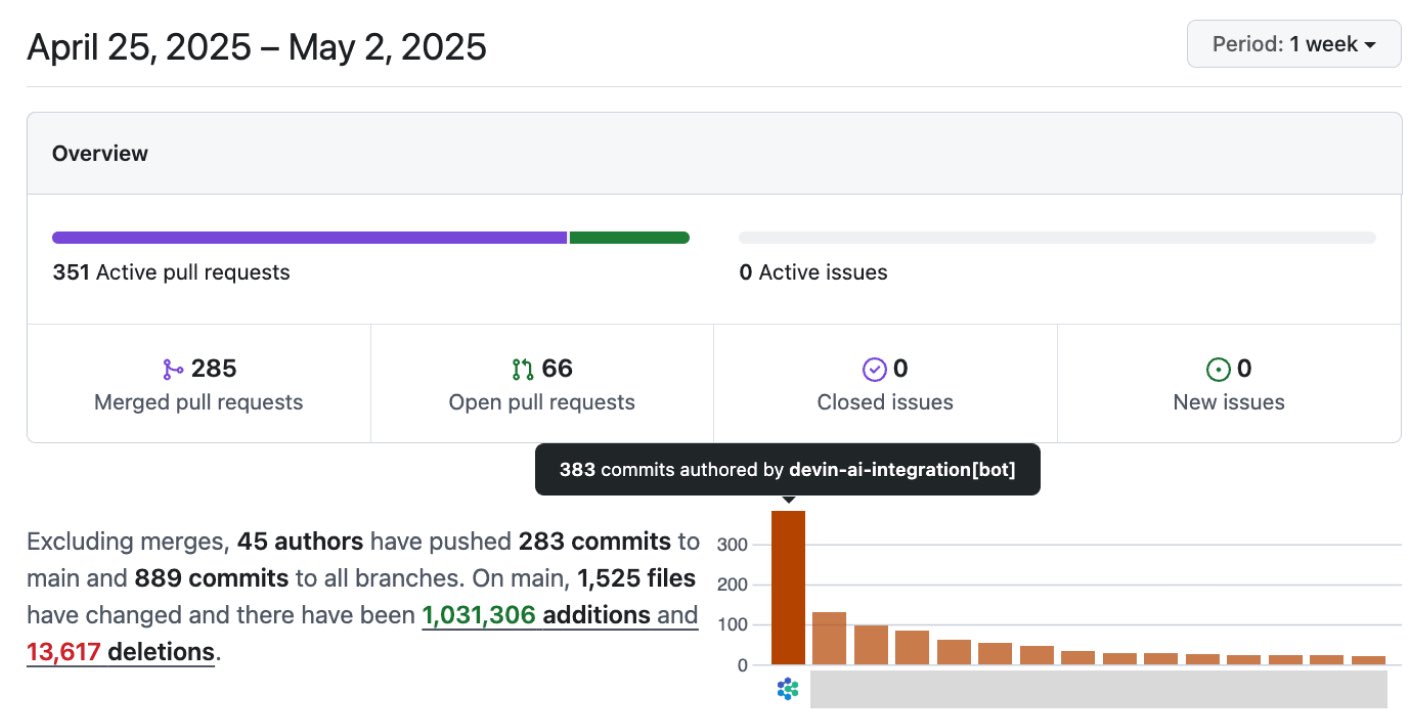
AI steigert Softwareentwicklungseffizienz signifikant: Community-Diskussionen und Fallbeispiele zeigen, dass AI die Effizienz der Softwareentwicklung erheblich steigert. Beispielsweise stammen die meisten Commits im Code-Repository von Vesta inzwischen von AI. Cisco Outshift nutzt die AI-Plattformingenieur JARVIS, die auf LangGraph und LangSmith basiert, um die Einrichtungszeit für CI/CD von einer Woche auf unter eine Stunde und die Ressourcenbereitstellungszeit von einem halben Tag auf wenige Sekunden zu verkürzen, was zu einer 10-fachen Produktivitätssteigerung führt (Quelle: mike, LangChainAI, hwchase17)
AI erobert Film- und Kreativbranche: Disney/Lucasfilm hat über Industrial Light & Magic (ILM) das erste öffentliche generative AI-Werk veröffentlicht, was die Akzeptanz von AI-Technologien durch Top-VFX-Studios signalisiert. Dies deutet darauf hin, dass AI in Bereichen wie Film-Spezialeffekten und kreativem Design eine wichtigere Rolle spielen und die Content-Erstellungsprozesse verändern wird (Quelle: Bilawal Sidhu)
Anwendung von AI im Militärbereich erregt Aufmerksamkeit: Berichten zufolge setzt China sein selbst entwickeltes DeepSeek AI Modell ein, um fortschrittliche Kampfflugzeuge (wie J-15, J-35) zu entwerfen und die nächste Generation von Flugzeugen (J-36, J-50) zu gestalten. Angeblich beschleunigt AI die Forschung und Entwicklung durch Optimierung von Tarnkappeneigenschaften, Materialien und Leistung. Obwohl die Informationsquelle mit Vorsicht zu genießen ist, spiegelt dies das Potenzial und die Aufmerksamkeit wider, die der Anwendung von AI im Verteidigungs- und Luftfahrtsektor zukommt (Quelle: Clash Report)
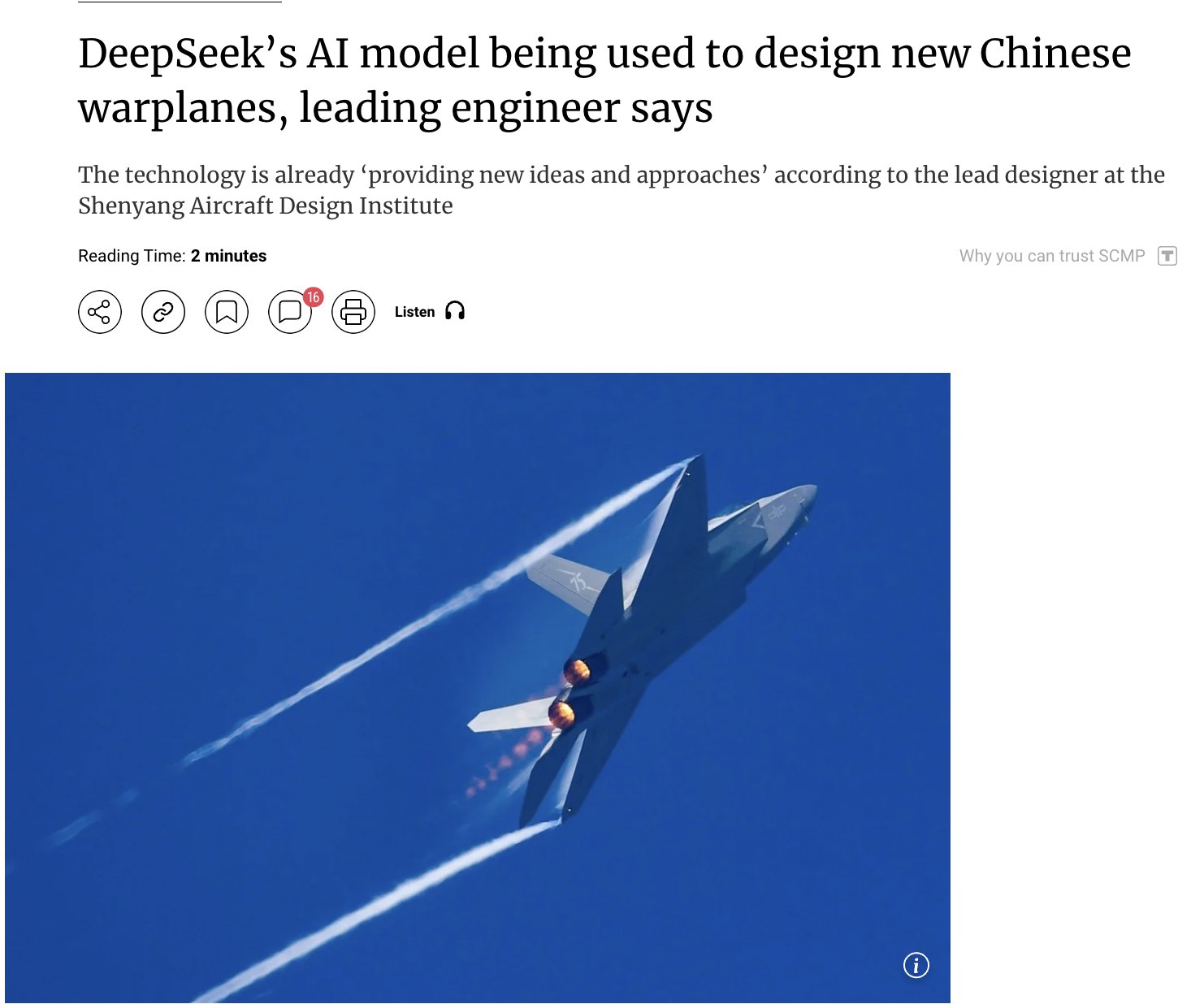
Personalien: Rohan Pandey verlässt OpenAI: Rohan Pandey, Forscher im OpenAI Training Team, hat seinen Abschied bekannt gegeben. Er plant eine Auszeit, um sich der Lösung des Sanskrit-OCR-Problems zu widmen, um die klassischen indischen Literaturklassiker „für immer in den Gewichten der Superintelligenz zu verankern“, bevor er seine nächsten Schritte bekannt gibt. Community-Mitglieder schätzen ihn sehr und halten ihn für einen äußerst talentierten Forscher (Quelle: Rohan Pandey, JvNixon, teortaxesTex)

AI-Urheberrechtsregistrierungen überschreiten 1000: Das US Copyright Office hat über 1000 Werke registriert, die AI-generierte Inhalte enthalten. Dies spiegelt die zunehmende Anwendung von AI im kreativen Bereich wider und unterstreicht gleichzeitig, dass Fragen der Urheberschaft und des Schutzes von AI-generierten Inhalten immer mehr in den Fokus rücken (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)

Duolingo entlässt Vertragsarbeiter, AI-Einsatz weckt Bedenken: Duolingo hat einen Teil seiner Vertragsarbeiter entlassen, da AI Kursinhalte 12-mal schneller erstellen kann. Dieser Schritt löst Bedenken hinsichtlich der Auswirkungen der Automatisierung auf das Sprachenlernen und die Beschäftigung in verwandten Branchen aus und zeigt das Potenzial von AI, menschliche Arbeit im Bereich der Content-Erstellung zu ersetzen, sowie die damit verbundenen sozioökonomischen Folgen (Quelle: Reddit r/ArtificialInteligence)

Microsoft führt im Cloud- und AI-Wettbewerb vor Amazon?: Ein Bericht analysiert, dass Microsoft durch seine aktive Positionierung im AI-Bereich (z. B. Investition in OpenAI) und die Integration seiner Cloud-Dienste (Azure) im Wettbewerb um Cloud und AI an Amazon (AWS) vorbeizieht. Der Artikel argumentiert, dass Amazon strategisch möglicherweise hinter Microsoft zurückliegt (Quelle: Reddit r/ArtificialInteligence, Reddit r/deeplearning)

Diskussion über Expert-Nutzung in MoE-Modellen: Die Community diskutiert, ob die Nutzung von Experts in MoE-Modellen dem Pareto-Prinzip folgt (wenige Experten bearbeiten den Großteil des Traffics). Die Mehrheit vertritt die Ansicht, dass das Trainingsziel normalerweise eine gleichmäßige Auslastung der Experten ist; das Mixtral-Modell weist nur geringe Abweichungen auf. Qwen3 könnte jedoch eine gewisse Abweichung aufweisen, die aber weit von einer 80/20-Verteilung entfernt ist. Das Beispiel DeepSeek-R1 (256 Experten, 8 aktiviert) zeigt ebenfalls, dass selbst spezifische Aufgaben (wie Codierung) bestimmte Experten bevorzugen können, dies aber nicht festgelegt ist und die Shared Experts immer aktiviert sind (Quelle: Reddit r/LocalLLaMA)

Feingetuntes Modell Josiefied-Qwen3-8B erhält Lob: Ein Nutzer teilt positive Erfahrungen mit dem von Goekdeniz-Guelmez feingetunten Qwen3 8B Modell (Josiefied-Qwen3-8B-abliterated-v1). Das Modell wird als besser im Befolgen von Anweisungen und Generieren lebendiger Antworten als die Originalversion Qwen3 8B angesehen und ist unzensiert. Der Nutzer betreibt es mit Q8-Quantisierung und findet, dass seine Leistung die Erwartungen an ein 8B-Modell übertrifft, insbesondere für Online-RAG-Systeme (Quelle: Reddit r/LocalLLaMA)

RTX 5060 Ti 16GB als Preis-Leistungs-Tipp für AI?: Ein Nutzer teilt seine Erfahrung, dass die RTX 5060 Ti 16GB Version (ca. 499 USD) zwar schlechte Gaming-Bewertungen hat, aber dank 16GB VRAM ein gutes Preis-Leistungs-Verhältnis für AI-Anwendungen bietet. Im Vergleich zu einer 12GB GPU bei der Verarbeitung von PDFs mit LightRAG ist die 16GB-Version mehr als doppelt so schnell, da sie mehr Modellschichten aufnehmen kann und häufige Modellwechsel vermeidet, was die GPU-Auslastung verbessert. Ihre kürzere Bauform eignet sich auch für SFF-Builds (Quelle: Reddit r/LocalLLaMA)
Diskussion zur Machbarkeit der Feinklassifizierung von Objekten mit RGB-Bildern: In der Community wird gefragt, ob bei Nichtverfügbarkeit von Hyperspektralbildgebung (HSI) allein RGB-Bilder ausreichen, um eine Echtzeit-Klassifizierung oder Anomalieerkennung für feine Objekte einer einzelnen Klasse (wie Kaffeebohnen) durchzuführen. Obwohl die Literatur oft HSI für feine Unterschiede empfiehlt, möchte der Nutzer wissen, ob es erfolgreiche Anwendungsfälle oder Machbarkeitsnachweise für die alleinige Verwendung von RGB für solche Aufgaben gibt (Quelle: Reddit r/deeplearning)
System Prompt des Claude-Modells möglicherweise geleakt: Auf GitHub ist ein Text aufgetaucht, der angeblich der System Prompt des Claude-Modells ist, mit einer Länge von 25K Tokens. Er enthält detaillierte Anweisungen, z. B. dass das Modell unter keinen Umständen (auch nicht in Suchergebnissen oder generierten Inhalten) Liedtexte kopieren oder zitieren darf, selbst in angenäherter oder kodierter Form, was vermutlich auf Urheberrechtsbeschränkungen zurückzuführen ist. Dieses Leak (falls echt) liefert Hinweise auf die internen Arbeitsmechanismen und Sicherheitsbeschränkungen von Claude (Quelle: karminski3)
Neues AI-Bildreparaturmodell PixelHacker veröffentlicht: Das PixelHacker-Modell wurde veröffentlicht, das sich auf Bildreparatur (Inpainting) konzentriert und die Beibehaltung von Struktur und Semantik während des Reparaturprozesses betont. Angeblich übertrifft das Modell aktuelle SOTA-Modelle auf Datensätzen wie Places2, CelebA-HQ und FFHQ (Quelle: Reddit r/deeplearning)

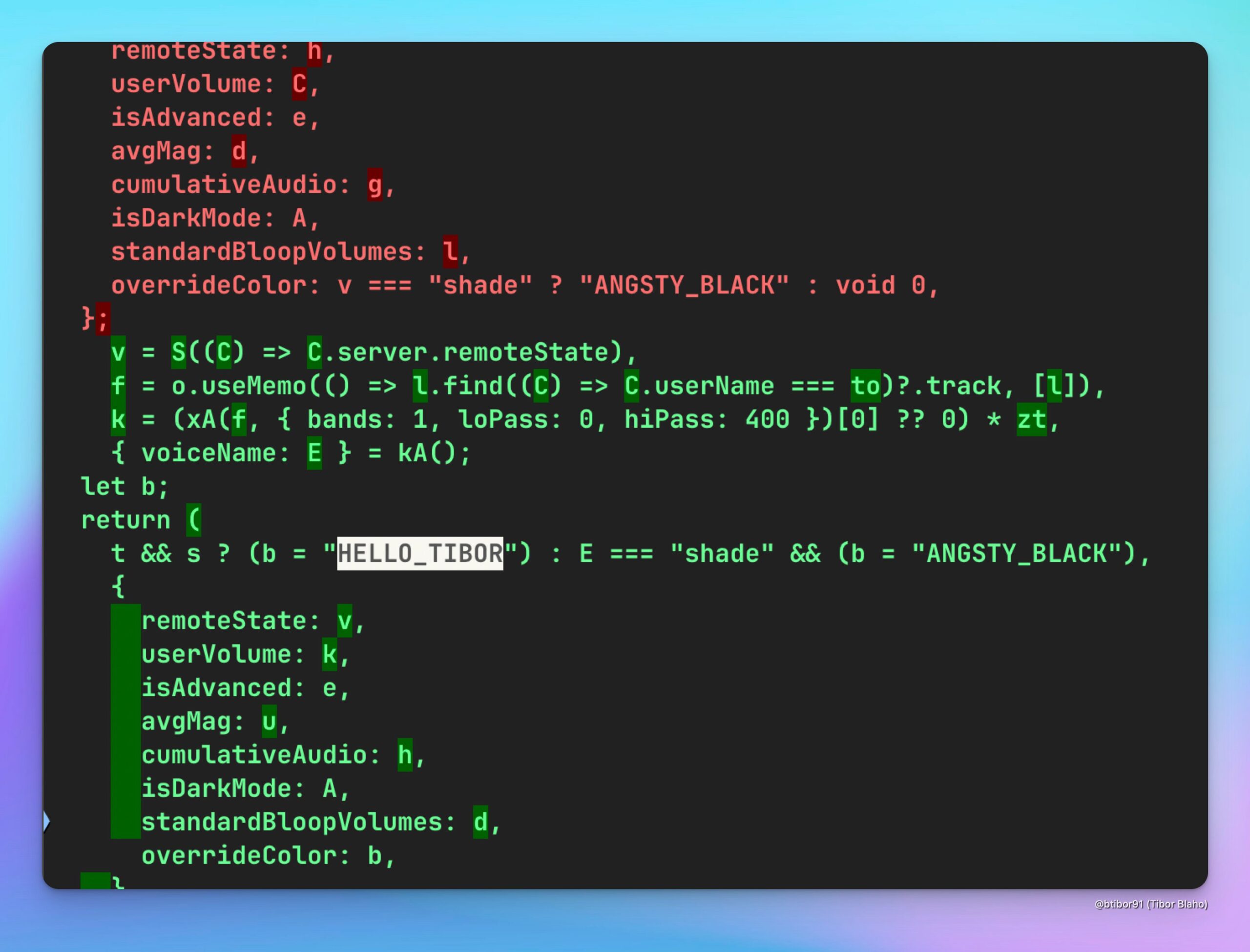
ChatGPT fügt neue Stimme HELLO_TIBOR hinzu: Nutzer haben in der neuesten Version der ChatGPT Webanwendung eine neue Sprachoption namens “HELLO_TIBOR” entdeckt. Dies deutet darauf hin, dass OpenAI seine Sprachinteraktionsfunktionen möglicherweise kontinuierlich erweitert und vielfältigere Sprachoptionen anbietet (Quelle: Tibor Blaho)
🧰 Tools
Runway realisiert Bild-zu-Spiel-Screenshot-Konvertierung und Filmhommage: Ein Nutzer experimentierte mit der Gen-4 References Funktion von Runway und wandelte erfolgreich ein normales Bild in einen 2.5D isometrischen Spiel-Screenshot im Stil der Unreal Engine um, indem er detaillierte, mehrstufige Prompts verwendete (Szenenanalyse, Intentionsverständnis, Festlegung von Spiel-Engine und Rendering-Anforderungen). Ein anderer Nutzer erstellte mit Runway References und Gen-4 ein Videosegment als Hommage an den Film “Goodfellas”. Diese Beispiele zeigen die Leistungsfähigkeit von Runway bei der kontrollierbaren Bild-/Videogenerierung, insbesondere in Kombination mit Referenzbildern und Stiltransfer (Quelle: Ray (movie arc), Bryan Fox, c_valenzuelab, c_valenzuelab)

Runway unterstützt Import von 3D-Assets zur Verbesserung der Videogenerierungs-Kontrolle: Die Gen-4 References Funktion von Runway unterstützt jetzt die Verwendung von 3D-Assets als Referenz, um eine präzisere Kontrolle über Form und Details von Objekten in generierten Videos zu ermöglichen. Nutzer müssen lediglich ein Szenenhintergrundbild, eine einfache Komposition des 3D-Modells in dieser Szene und ein Stilreferenzbild bereitstellen, um hochdetaillierte und spezifische Modelle in den Generierungsworkflow einzubringen und so die Konsistenz und Kontrollierbarkeit der generierten Inhalte zu verbessern (Quelle: Runway, c_valenzuelab, op7418)
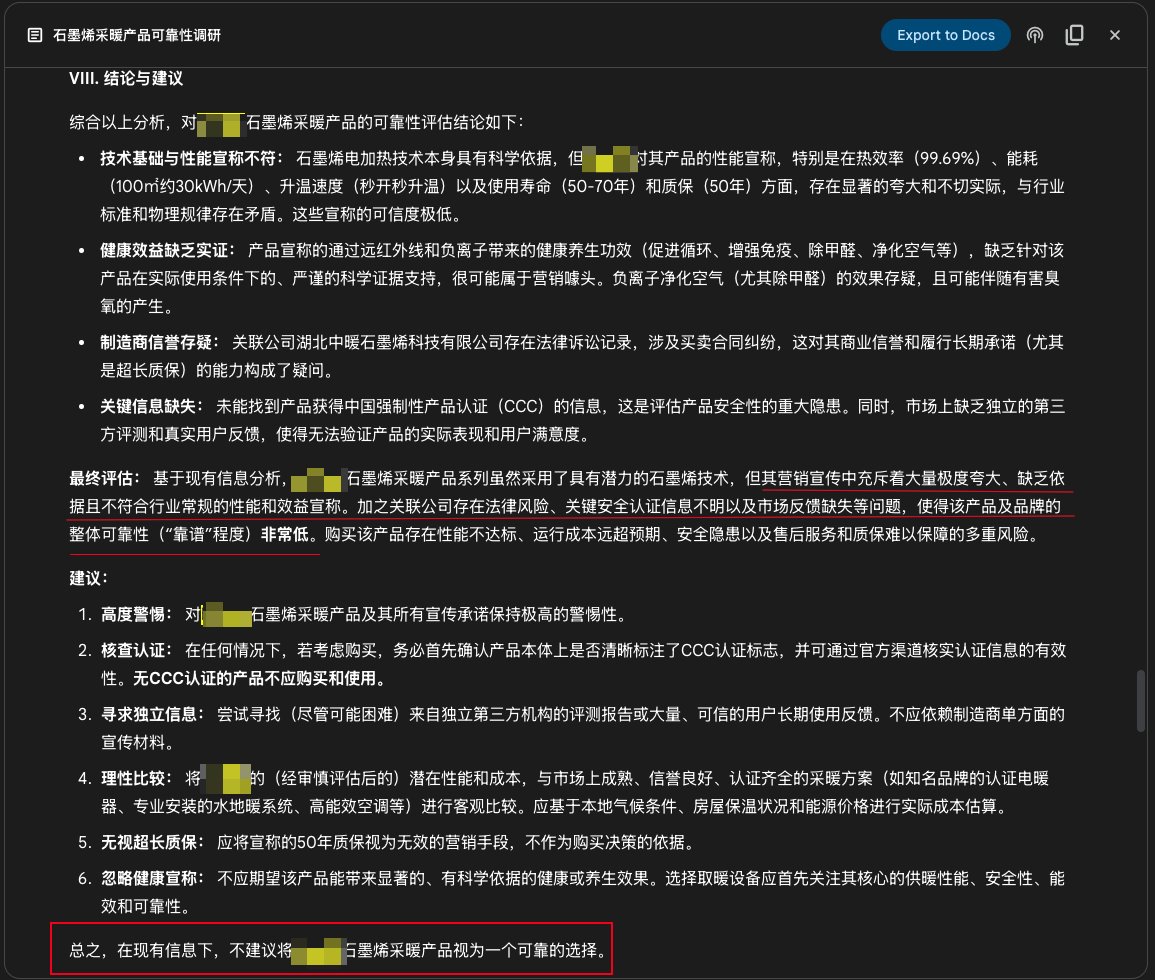
Google Gemini Deep Research Funktion für Produktrecherche: Ein Nutzer teilt ein Beispiel für die Verwendung der Deep Research Funktion von Google Gemini zur Untersuchung der Zuverlässigkeit eines Produkts. Nach Eingabe der Produktbeschreibung durchsuchte Gemini Hunderte von Webseiten und wies klar darauf hin, dass die Werbung für ein bestimmtes Graphen-Heizprodukt übertrieben, unbegründet und riskant sei und vom Kauf abgeraten wird. Dies zeigt den praktischen Nutzen von AI-Deep-Research-Tools bei der Informationsüberprüfung und Unterstützung von Kaufentscheidungen (Quelle: dotey)
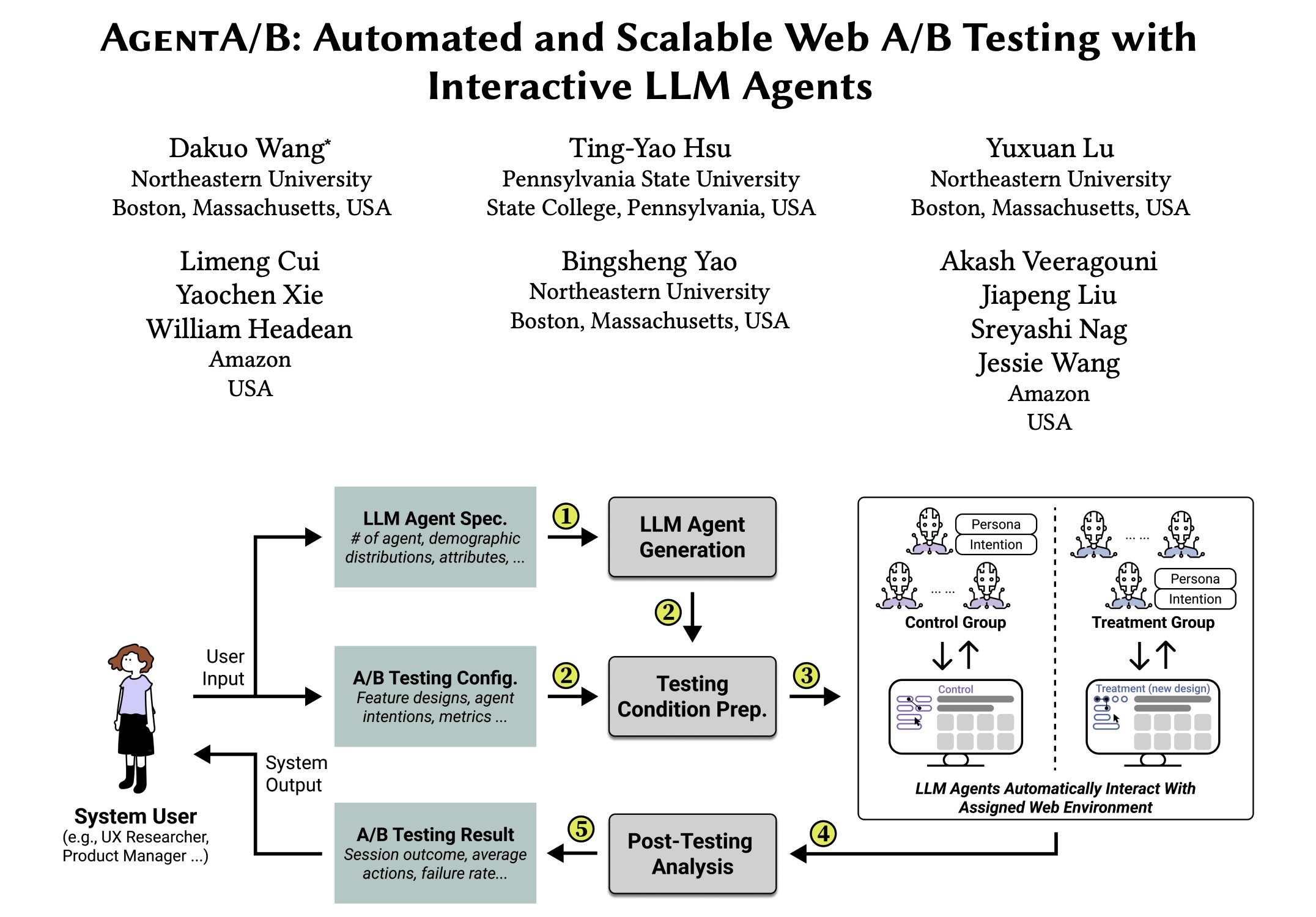
AgentA/B: Automatisierter A/B-Test-Framework basierend auf LLM-Agenten: AgentA/B ist ein vollautomatisches A/B-Test-Framework, das große Mengen an LLM-basierten Agenten anstelle von echtem Nutzerverkehr verwendet. Diese Agenten können realistische, absichtsgesteuerte Nutzerverhalten in tatsächlichen Webumgebungen simulieren, um schnellere, günstigere und risikofreie Bewertungen der User Experience (UX) zu ermöglichen, sogar ohne echten Traffic (Quelle: elvis)
Qdrant unterstützt Pariti bei der Steigerung der Rekrutierungseffizienz: Die Rekrutierungsplattform Pariti nutzt die Qdrant Vektordatenbank zur Unterstützung ihres AI-gesteuerten Kandidaten-Matching-Systems. Durch die Echtzeit-Vektorsuchfunktionen von Qdrant kann Pariti 70.000 Kandidatenprofile innerhalb von 40 Millisekunden sortieren und dynamisch bewerten, wodurch die Überprüfungszeit für Kandidaten um 70 % verkürzt, die Erfolgsquote bei der Einstellung verdoppelt und 94 % der Top-Kandidaten unter den ersten 10 Suchergebnissen angezeigt werden (Quelle: qdrant_engine)

Qwen 3 und LangGraph etc. bilden Open-Source Deep Research Agent: Soham hat einen Deep Research Agent entwickelt und als Open Source veröffentlicht. Der Agent verwendet das Qwen 3 Modell in Kombination mit Composio, LangChains LangGraph, Together AI sowie Perplexity/Tavily für die Suche. Angeblich übertrifft seine Leistung die vieler anderer getesteter Open-Source-Modelle. Der Code ist verfügbar und bietet eine reproduzierbare Lösung für ein Forschungsautomatisierungstool (Quelle: Soham, hwchase17)
Perplexity on WhatsApp verbessert mobiles AI-Nutzungserlebnis: Arav Srinivas, CEO von Perplexity, erwähnt, dass die Nutzung von Perplexity AI über WhatsApp sehr praktisch ist, insbesondere auf Flügen mit schlechter Internetverbindung. Da WhatsApp selbst für schwache Netzwerkumgebungen optimiert ist, wird der Zugriff auf AI über die Messaging-App zu einer stabilen und zuverlässigen Methode, was die Verfügbarkeit von AI auf Mobilgeräten und in besonderen Szenarien verbessert (Quelle: AravSrinivas)
Suno iOS App Update: Unterstützt Generierung teilbarer Musikclips: Die iOS-Version der Suno AI Musikgenerierungs-App wurde aktualisiert und bietet nun die Funktion, generierte Songs in teilbare Clips umzuwandeln. Nutzer können eine Länge von 10, 20 oder 30 Sekunden wählen und den Clip mit Songtext und Coverbild oder offiziell bereitgestellten Visualisierungen (zukünftig mehr Stile) versehen, um die von AI erstellte Musik einfach in sozialen Medien zu teilen und zu präsentieren (Quelle: SunoMusic, SunoMusic)
Diskussion über AI-Programmierassistent Cursor: Nutzer Andrew Carr äußert sich positiv über den AI-Programmierassistenten Cursor. Gleichzeitig argumentiert Justin Halford, dass Cursor nur eine Funktion und kein vollständiges Produkt sei und leicht durch Veröffentlichungen großer Modellfirmen ersetzt werden könne. Das Cline-Tool kündigt Unterstützung für das .cursorrules-Konfigurationsdateiformat von Cursor an, was das Interesse der Community und Integrationsversuche zeigt (Quelle: andrew_n_carr, Justin Halford, Celestial Vault)
OctoTools: Flexibles LLM-Tool-Aufruf-Framework gewinnt Best Paper Award bei NALCL: Das OctoTools Framework wurde bei KnowledgeNLP@NAACL mit dem Best Paper Award ausgezeichnet. Es ist ein flexibles und benutzerfreundliches Framework, das LLMs mithilfe modularer „Tool Cards“ (ähnlich wie Legosteine) mit vielfältigen Werkzeugen (wie visuelles Verständnis, domänenspezifische Wissenssuche, numerisches Schlussfolgern etc.) ausstattet, um komplexe Reasoning-Aufgaben zu bewältigen. Derzeit werden Modelle von OpenAI, Anthropic, DeepSeek, Gemini, Grok und Together AI unterstützt, und ein PyPI-Paket wurde veröffentlicht (Quelle: lupantech)

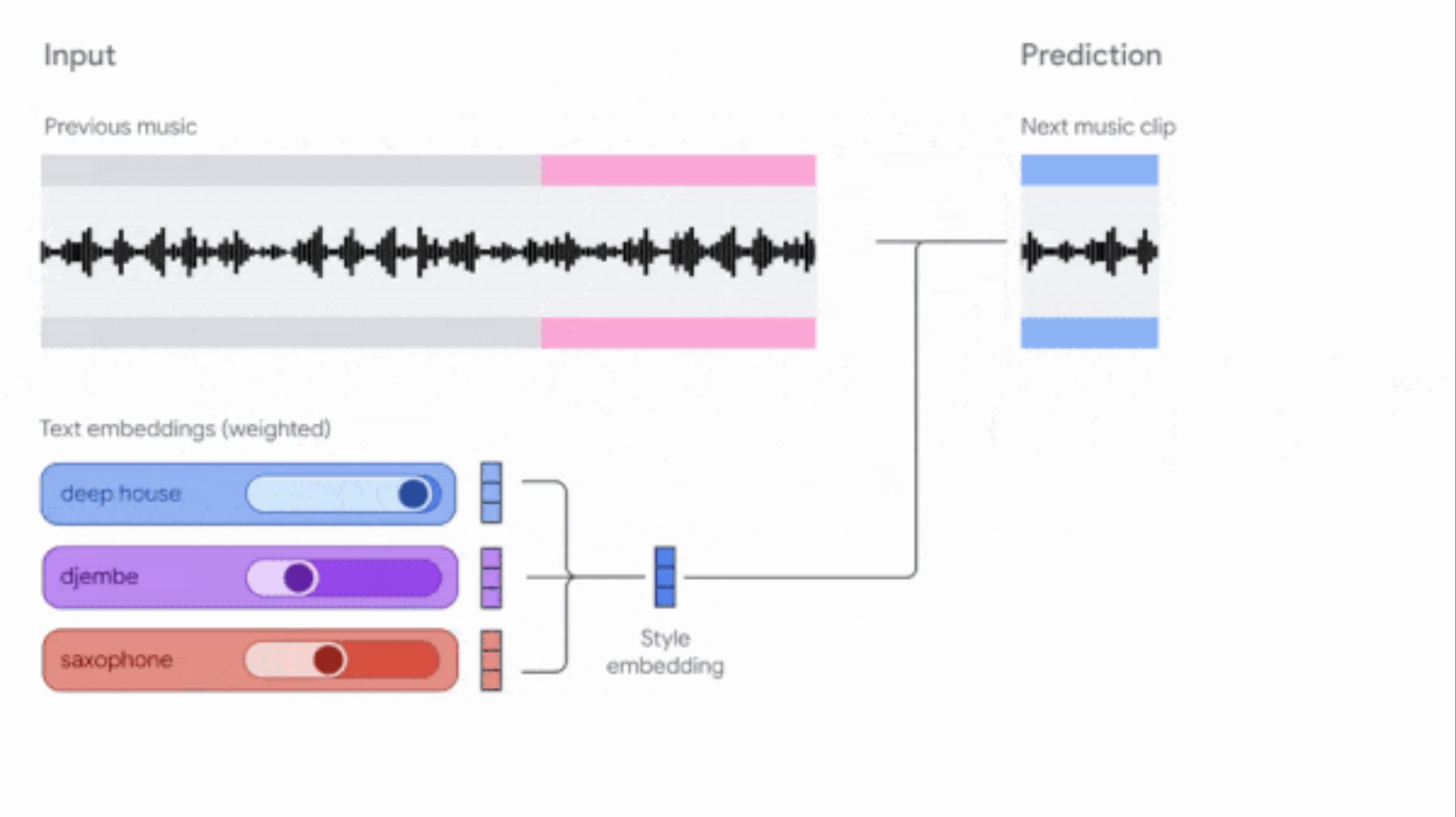
Google aktualisiert Music AI Sandbox und MusicFX DJ Tools: Google hat seine Musikgenerierungstools für Komponisten und Produzenten aktualisiert. Music AI Sandbox ermöglicht nun die Eingabe von Songtexten zur Generierung vollständiger Songs; MusicFX DJ erlaubt Nutzern die Echtzeitsteuerung von Streaming-Musik. Beide basieren auf dem verbesserten Lyria-Modell (Lyria 2 bzw. Lyria RealTime), können hochwertige 48kHz-Audio erzeugen und bieten umfassende Kontrolle über Tonart, Tempo, Instrumente usw. Music AI Sandbox erfordert derzeit eine Anmeldung über eine Warteliste (Quelle: DeepLearningAI)
AI-gesteuerter Code-Review-Agent: Tools wie Composiohq, LlamaIndex etc. wurden in Kombination mit Grok 3 und Replit Agent verwendet, um einen AI-Agenten zu bauen, der GitHub Pull Requests überprüfen kann. Der Prozess umfasst: Grok 3 generiert den Code für den Review-Agenten, Replit Agent erstellt automatisch eine Frontend-Oberfläche, Nutzer reichen über die Oberfläche PR-Links ein, der Agent führt die Überprüfung durch und gibt Feedback. Dies zeigt das Potenzial von AI-Agenten bei der Automatisierung von Softwareentwicklungsprozessen (wie Code-Reviews) (Quelle: LlamaIndex 🦙)
AI generiert Ausmalbilder (mit Referenzbild): Ein Nutzer teilt Erfahrungen und Prompts zur Generierung von Schwarz-Weiß-Ausmalbildern mit einem kleinen farbigen Referenzbild. Ziel ist es, das Problem zu lösen, dass Kinder beim Ausmalen nicht wissen, welche Farben sie verwenden sollen. Der Prompt fordert die Generierung einer klaren Schwarz-Weiß-Konturenzeichnung zum Ausdrucken, mit einem kleinen farbigen Bild in der Ecke als Referenz, und spezifiziert Stil, Größe, geeignetes Alter und Bildinhalt (Quelle: dotey)

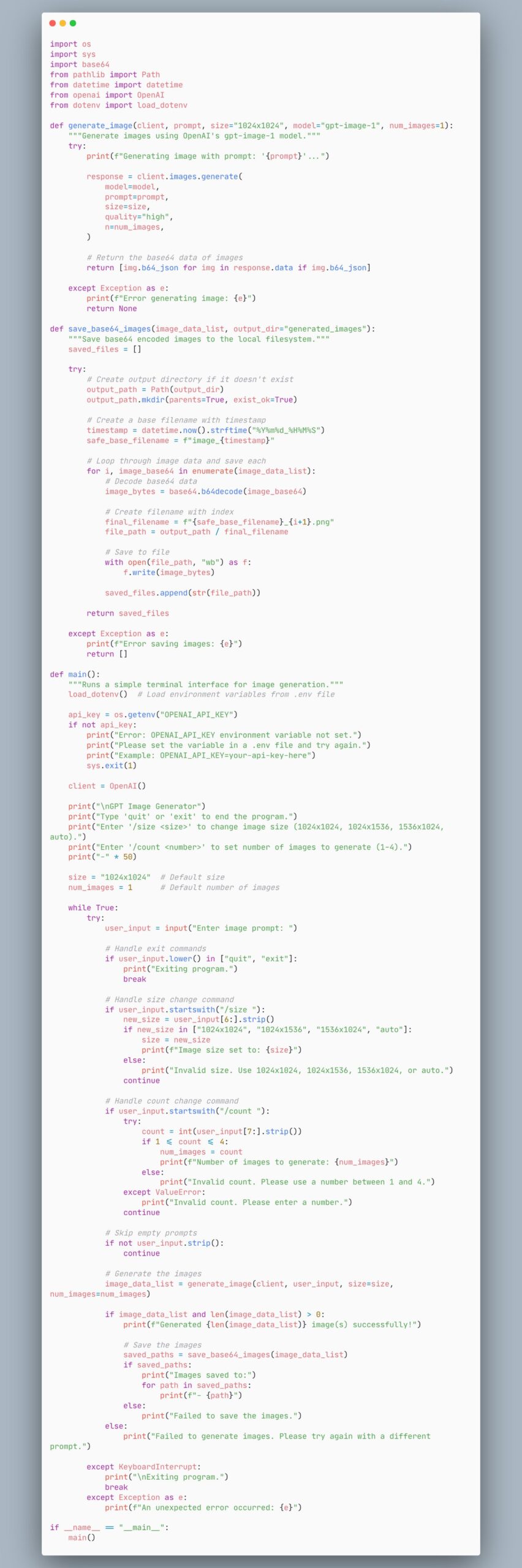
Beispielcode für einen Agenten zur Bildgenerierung mit dem gpt-image-1 Modell: Ein Nutzer teilt ein Code-Snippet, das zeigt, wie man einen Agenten erstellt, der das gpt-image-1 Modell zur Bildgenerierung verwendet. Dies bietet Entwicklern eine schnelle Code-Referenz zur Implementierung von Bildgenerierungsfunktionen (Quelle: skirano)
VectorVFS: Dateisystem als Vektordatenbank nutzen: VectorVFS ist ein leichtgewichtiges Python-Paket und CLI-Tool, das die erweiterten Attribute (xattr) des Linux VFS nutzt, um Vektor-Embeddings direkt in den Inodes des Dateisystems zu speichern. Dadurch wird eine bestehende Verzeichnisstruktur in einen effizienten und semantisch durchsuchbaren Embedding-Speicher verwandelt, ohne dass separate Indizes oder externe Datenbanken gepflegt werden müssen (Quelle: Reddit r/MachineLearning)
AI-gesteuerter Kubernetes-Assistent kubectl-ai: Google Cloud Platform hat kubectl-ai veröffentlicht, einen AI-gesteuerten Kommandozeilenassistenten für Kubernetes. Er kann Anweisungen in natürlicher Sprache verstehen, entsprechende kubectl-Befehle ausführen und die Ergebnisse erklären. Unterstützt werden Gemini, Vertex AI, Azure OpenAI, OpenAI sowie lokal ausgeführte Ollama- und Llama.cpp-Modelle. Das Projekt enthält auch den k8s-bench Benchmark zur Bewertung der Leistung verschiedener LLMs bei K8s-Aufgaben (Quelle: GitHub Trending)

Higgsfield Effects: AI-gesteuertes Paket für filmreife visuelle Effekte: Higgsfield AI hat Higgsfield Effects vorgestellt, ein Toolkit mit 10 filmreifen visuellen Effekten (VFX) wie Thor, Unsichtbarkeit, Metallisierung, In Brand setzen usw. Nutzer können diese Effekte mit einem einzigen Prompt aufrufen. Ziel ist es, komplexe VFX-Produktionsprozesse zu vereinfachen, sodass auch normale Nutzer mühelos eindrucksvolle visuelle Effekte erstellen können (Quelle: Higgsfield AI 🧩)
Agent-S: Offenes Agenten-Framework zur Simulation menschlicher Computernutzung: Agent-S ist ein Open-Source-Agenten-Framework, dessen Ziel es ist, AI dazu zu bringen, Computer wie Menschen zu benutzen. Es könnte Fähigkeiten wie das Verstehen von Nutzerabsichten, die Bedienung grafischer Oberflächen, die Nutzung verschiedener Anwendungen usw. umfassen, mit dem Ziel, allgemeinere und autonomere AI-Agentenverhalten zu realisieren (Quelle: dl_weekly)
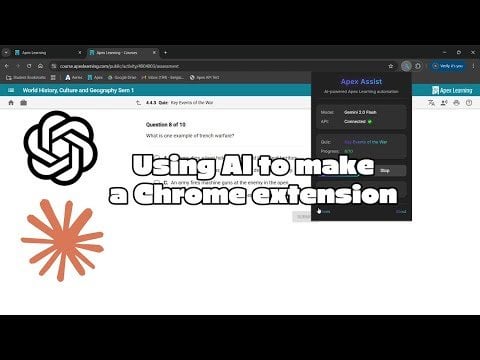
AI generiert Chrome-Erweiterung zur automatischen Bearbeitung von Online-Quizzen: Ein Nutzer hat mit Gemini AI eine Chrome-Erweiterung erstellt, die Quizze auf einer bestimmten Online-Lernplattform automatisch ausfüllen kann. Dies zeigt das Anwendungspotenzial von AI bei der Automatisierung repetitiver Aufgaben, könnte aber auch Diskussionen über akademische Integrität auslösen (Quelle: Reddit r/ArtificialInteligence)
GPT-4o Bildgenerierung: Berühmtheitenporträts im Rembrandt-Stil: Ein Nutzer hat mit GPT-4o mehrere bekannte TV-Serienprotagonisten (wie Walter White, Don Draper, Tony Soprano, SpongeBob etc.) in Porträts im Stil von Rembrandt verwandelt. Diese Bilder zeigen die Fähigkeit der AI, Charaktermerkmale zu verstehen und bestimmte Kunststile nachzuahmen (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT)

Meta veröffentlicht Llama Prompt Ops Toolkit: Meta AI hat Llama Prompt Ops veröffentlicht, ein Python-Toolkit zur Optimierung von Prompts für Llama-Modelle. Das Tool soll Entwicklern helfen, Prompts für Llama-Modelle effektiver zu gestalten und anzupassen, um die Modellleistung und Ausgabequalität zu verbessern (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)
Nutzer sucht kostenlose/günstige AI für Excel-/Tabellengenerierung: Ein Reddit-Nutzer sucht nach kostenlosen oder günstigen AI-Tools, die Excel- oder OpenOffice-Tabellendokumente generieren können, und möchte die täglichen Limits der kostenlosen ChatGPT-Version vermeiden. Die Community empfiehlt Optionen wie Claude, Google Gemini (in Verbindung mit Sheets) sowie lokal bereitgestellte Open-Source-Modelle (über LM Studio oder LocalAI) (Quelle: Reddit r/artificial)
Nutzer fragt nach Methoden zur Verarbeitung langer Kontexte in Claude: Ein Reddit-Nutzer fragt, wie man bei der Arbeit an komplexen Projekten in Claude die Kontextlängenbeschränkungen und das “Gedächtnisverlust”-Problem bei neuen Chats umgehen kann. Die Community schlägt Methoden vor wie: Speichern wichtiger Informationen in Projektdateien oder Claude bitten, die Gesprächspunkte zusammenzufassen und diese in einen neuen Chat mitzunehmen (Quelle: Reddit r/ClaudeAI)
Nutzer fragt nach Verwendung neuer Funktionen in OpenWebUI: Ein Reddit-Nutzer fragt, wie die in OpenWebUI v0.6.6 neu hinzugefügten Funktionen „Meeting-Audioaufnahme & Import“ sowie der Notizimport (Markdown), die OneDrive-Integration usw. konkret zu verwenden sind (Quelle: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Nutzer fragt nach Methode zur Verarbeitung großer Mengen von JSON-Dateien für RAG in OpenWebUI: Ein Reddit-Nutzer sucht nach Best Practices für die effiziente Verarbeitung von Tausenden von JSON-Dateien für RAG in OpenWebUI. Da das direkte Hochladen in die „Wissensdatenbank“ möglicherweise ineffizient ist, fragt der Nutzer nach empfohlenen externen Vektordatenbank-Setups oder benutzerdefinierten Datenpipeline-Integrationsmethoden (Quelle: Reddit r/OpenWebUI)
Nutzer meldet Timeout-Problem bei OpenWebUI-Integration mit n8n: Ein Nutzer stößt auf Probleme bei der Verwendung von OpenWebUI als Frontend für einen n8n AI-Agenten: Wenn die Ausführung des n8n-Workflows etwa 60 Sekunden überschreitet, zeigt OpenWebUI einen Fehler an, selbst wenn der Nutzer bestätigt, dass das n8n-Backend erfolgreich abgeschlossen wurde. Der Nutzer sucht nach Möglichkeiten, die Timeout-Zeit zu erhöhen oder die Verbindung aufrechtzuerhalten (Quelle: Reddit r/OpenWebUI)
📚 Lernen
LangGraph zum Aufbau komplexer Agentic Systems: LangGraph, als Teil des LangChain-Ökosystems, konzentriert sich auf den Aufbau zustandsbehafteter Multi-Actor-Anwendungen. Ein Vortrag von Jacob Schottenstein untersucht die Verwendung von LangGraph, um gerichtete azyklische Graphen (DAGs) in gerichtete zyklische Graphen (DCGs) umzuwandeln, um leistungsfähigere Agentensysteme zu bauen. In einem praktischen Fallbeispiel nutzte Cisco Outshift LangGraph und LangSmith, um den AI-Plattformingenieur JARVIS zu bauen, was die Effizienz im DevOps-Bereich erheblich steigerte (Quelle: Sydney Runkle, LangChainAI, hwchase17, Hacubu)
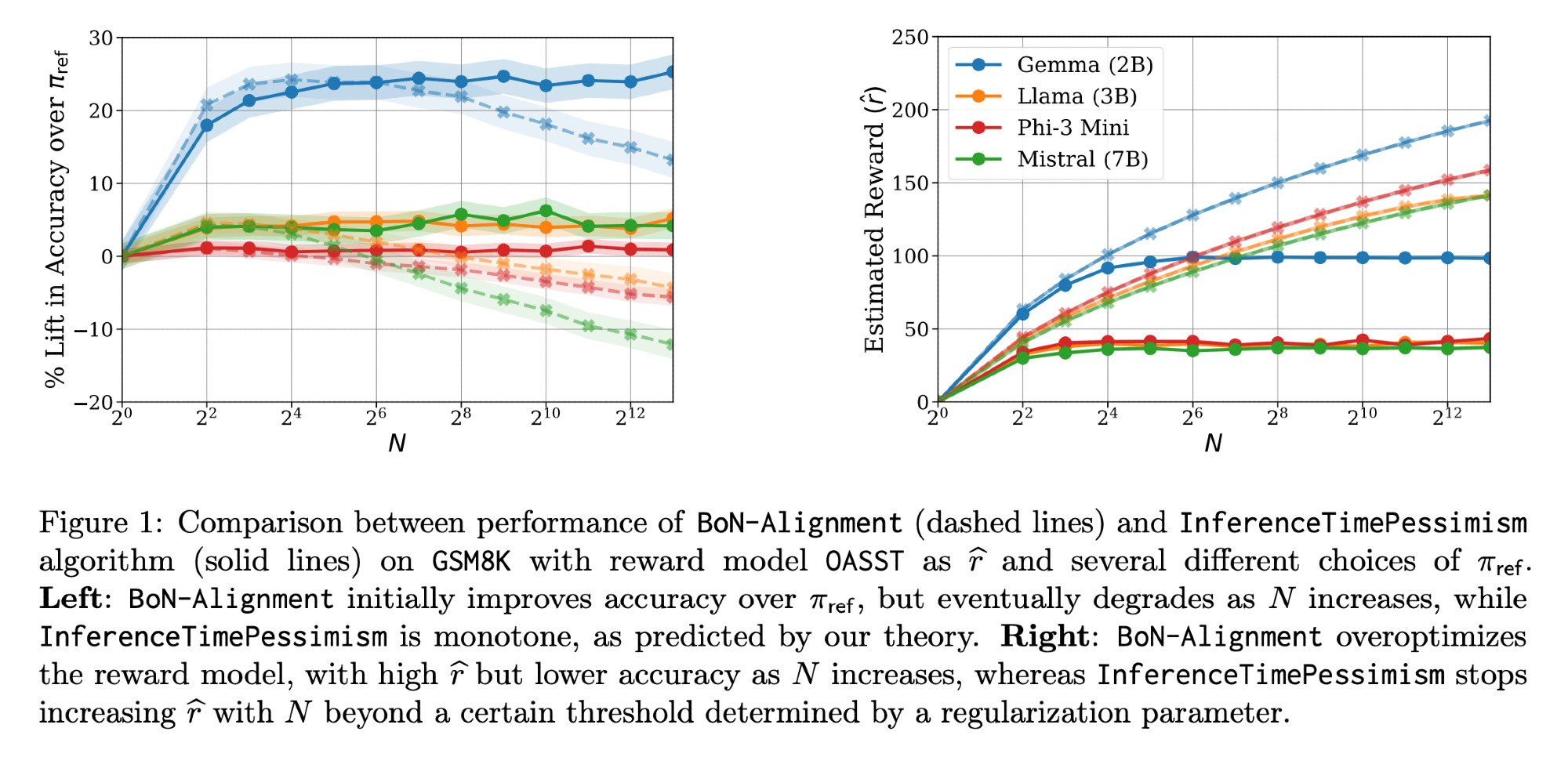
LLM-Inferenzoptimierung: Llama-Nemotron Paper & InferenceTimePessimism: Das von Meta AI & Nvidia Research veröffentlichte Llama-Nemotron Paper (arXiv:2505.00949v1) zeigt eine Reihe direkter Optimierungsmethoden, um die Kosten bei Inferenz-Workloads zu senken, während die Qualität erhalten bleibt. Gleichzeitig stellt ein ICML ‘25 Paper den InferenceTimePessimism-Algorithmus vor, als potenzielle Verbesserung der Best-of-N Inferenzmethode, die darauf abzielt, zusätzliche Informationen zur Optimierung des Inferenzprozesses zu nutzen (Quelle: finbarrtimbers, Dylan Foster 🐢)
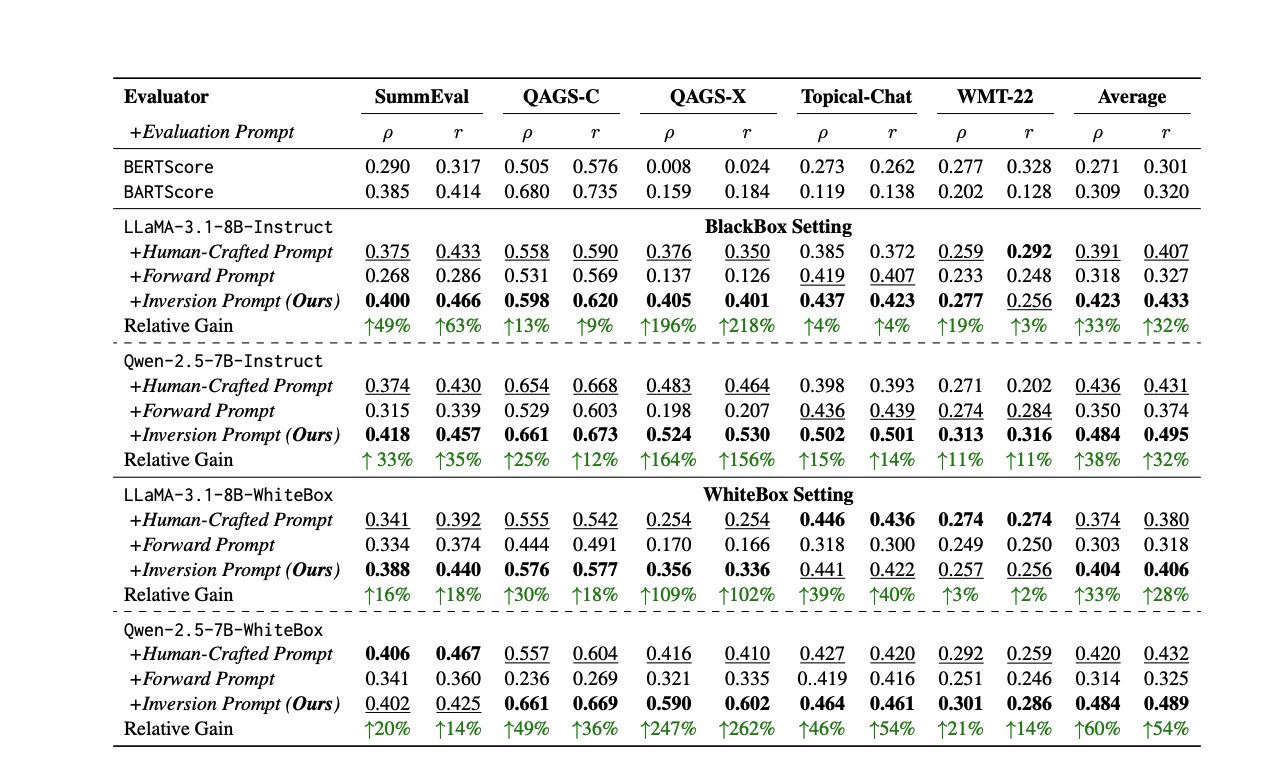
Neue Methoden und Ressourcen zur LLM-Bewertung: Die Bewertung der LLM-Leistung ist eine ständige Herausforderung. Ein Paper schlägt vor, durch Umkehrung von Antworten automatisch hochwertige Bewertungs-Prompts zu generieren, um die Inkonsistenz menschlicher oder LLM-Bewerter zu beheben. Gleichzeitig bietet die LLM-Bewertungsexpertin Shreya Shankar einen Kurs zur LLM-Bewertung für Ingenieure und Produktmanager an. Darüber hinaus wurde der SciCode Benchmark als Kaggle-Wettbewerb veröffentlicht, der AI herausfordert, Code für komplexe physikalische und mathematische Phänomene zu schreiben (Quelle: ben_burtenshaw, Aditya Parameswaran, Ofir Press)
Ressourcen zu AI Control und Alignment: AI Control (die Erforschung, wie man AI sicher überwacht und nutzt, die noch keine Superintelligenz erreicht hat, aber möglicherweise nicht aligned ist) wird zu einem immer wichtigeren Bereich. FAR.AI hat die Vortragsvideos der ControlConf-Konferenz veröffentlicht, die Einblicke von Experten wie Neel Nanda enthalten. Gleichzeitig wird ein Artikel über Werte (Unterscheidung zwischen ultimativen und instrumentellen Werten) als relevant für die AI-Alignment-Diskussion angesehen (Quelle: FAR.AI, Séb Krier)

Common Crawl veröffentlicht neue Datensätze: Common Crawl hat das Web-Crawl-Archiv vom April 2025 veröffentlicht. Gleichzeitig hat Bram Vanroy C5 (Common Crawl Creative Commons Corpus) vorgestellt, eine streng gefilterte Untermenge von Common Crawl, die nur Dokumente unter CC-Lizenzen enthält. Bisher wurden 150 Milliarden Token gesammelt, die 8 europäische Sprachen abdecken, und bieten eine neue, konforme Datenquelle für das Training von Sprachmodellen (Quelle: CommonCrawl, Bram)
AI-Lernaktivitäten und Tutorials: Mehrere AI-bezogene Aktivitäten und Tutorial-Ressourcen wurden veröffentlicht: Qdrant veranstaltete eine Online-Coding-Session zur Orchestrierung von AI-Agenten mit MCP; Corbtt plant ein Webinar zur Optimierung realer Agenten mit RL; Comet ML organisierte eine Veranstaltung zum Austausch von Erkenntnissen über den Aufbau und die Produktivsetzung von GenAI-Systemen; Ofir Press wird in einem PyTorch-Webinar Erfahrungen mit dem Aufbau von SWE-bench und SWE-agent teilen; Nous Research veranstaltet gemeinsam mit mehreren Institutionen einen RL-Umgebungs-Hackathon; LlamaIndex sponsert den Tel Aviv MCP Hackathon; Hugging Face bietet ein 1-Minuten-Tutorial zum Aufbau eines MCP-Servers; Together AI veröffentlicht eine Videoserie zur Matryoshka-Maschinenlernen; Ein Vortrag von Andrew Price über die Veränderung der 3D-Branche durch AI wird erneut empfohlen; giffmana teilt eine Aufzeichnung eines Transformer-Vortrags (Quelle: qdrant_engine, Kyle Corbitt, dl_weekly, PyTorch, Nous Research, LlamaIndex 🦙, dylan, Zain, Cristóbal Valenzuela, Luis A. Leiva)

Diskussion über AI-Theorie und -Methoden: Die Community diskutierte einige grundlegende Theorien und Methoden im AI-Bereich: 1. Erörterung des Konzepts von „World Models“, der damit gelösten Probleme, der technischen Architektur und der Herausforderungen. 2. Diskussion der Gründe, warum Fourier-Features/Spektralmethoden im Deep Learning keine breite Anwendung gefunden haben. 3. Vorstellung des „Serenity Framework“-Konzeptrahmens, der fünf große Bewusstseinstheorien integriert, um die rekursive Selbstwahrnehmung von AI zu erforschen. 4. Diskussion darüber, ob AI zu stark von vortrainierten Modellen abhängt. 5. Erörterung der Bedeutung des LLM-Downscalings (Quelle: Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/artificial, Reddit r/MachineLearning, Natural Language Processing Papers)

Ressourcen zu Prompt Engineering und Modelloptimierung: LiorOnAI teilt das Framework von OpenAI-Präsident Greg Brockman zum Erstellen perfekter Prompts. Modal bietet ein Tutorial zur Bereitstellung von LLaMA 3 8B mit einer Latenz von unter 250 ms unter Verwendung von Techniken wie TensorRT-LLM, FP8-Quantisierung und spekulativer Dekodierung. N8 Programs teilt Erfahrungen mit dem Training unter geringem VRAM (64 GB RAM), wobei ein 6-Bit-quantisiertes Modell als Lehrer und ein 4-Bit-Modell als Schüler verwendet wird. Kling_ai leitet einen Ressourcen-Post weiter, der Prompts für Tools wie Midjourney v7, Kling 2.0 usw. enthält (Quelle: LiorOnAI, Modal, N8 Programs, TechHalla)

AI-Anwendung und Forschung im Bildungsbereich: Die Doktorarbeit von Rose, Doktorandin der Informatik an der Stanford University, konzentriert sich auf die Nutzung von AI-Methoden, -Bewertungen und -Interventionen zur Verbesserung der Bildung. Dies repräsentiert eine vertiefte Forschungsrichtung zur Anwendung von AI im Bildungsbereich (Quelle: Rose)

Vibe-coding: Eine aufkommende AI-gestützte Programmierweise: Notizen aus einem YC-Podcast-Interview mit dem CEO von Windsurf erwähnen das Konzept des „Vibe-coding“. Dies könnte ein Programmierparadigma sein, das stärker auf Intuition, Atmosphäre und schnelle Iteration setzt und tief mit AI-Unterstützung integriert ist, was auf potenzielle Veränderungen in Softwareentwicklungsprozessen und -philosophien durch AI hindeutet (Quelle: Reddit r/ArtificialInteligence)
Informationen zum Upgrade-Pfad von Nvidia CUDA: Ein Phoronix-Artikel diskutiert den Upgrade-Pfad von Nvidia CUDA nach der Volta-Architektur, was für Nutzer mit älteren Nvidia GPUs (wie der 10xx-Serie), die diese weiterhin für die AI-Entwicklung nutzen möchten, von Interesse ist (Quelle: NerdyRodent)
💼 Wirtschaft
CoreWeave schließt Übernahme von Weights & Biases ab: Die AI-Cloud-Plattform CoreWeave hat die Übernahme der MLOps-Plattform Weights & Biases (W&B) offiziell abgeschlossen. Ziel der Übernahme ist es, die Hochleistungs-AI-Cloud-Infrastruktur von CoreWeave mit den Entwickler-Tools von W&B zu kombinieren, um die nächste Generation der AI-Cloud-Plattform zu schaffen und Teams dabei zu helfen, AI-Anwendungen schneller zu erstellen, bereitzustellen und zu iterieren (Quelle: weights_biases, Chen Goldberg)

Figure AI Roboter werden im BMW Werk getestet und optimiert: Das Team des humanoiden Roboterunternehmens Figure AI besuchte zwei Wochen lang das Werk der BMW Group in Spartanburg, um die Prozesse seiner Roboter in der X3-Karosseriewerkstatt zu optimieren und neue Anwendungsszenarien zu erkunden. Dies markiert den Eintritt in die substanzielle Phase der Zusammenarbeit beider Unternehmen für 2025 und zeigt das Anwendungspotenzial humanoider Roboter in der Automobilfertigung (Quelle: adcock_brett)

Reborn und Unitree Robotics gehen strategische Partnerschaft ein: Das AI-Unternehmen Reborn hat eine strategische Partnerschaft mit dem Robotikunternehmen Unitree Robotics bekannt gegeben. Beide Seiten werden in den Bereichen Daten, Modelle und humanoide Robotik zusammenarbeiten, mit dem gemeinsamen Ziel, die Entwicklung verwandter Technologien zu beschleunigen (Quelle: Reborn)

🌟 Community
Buffetts vorsichtige Haltung zu AI löst Diskussionen aus: Auf der Aktionärsversammlung 2025 äußerte Warren Buffett eine Haltung des „kühlen Beobachtens“ und der „begrenzten Anwendung“ gegenüber AI. Er betonte, dass AI menschliches Urteilsvermögen bei komplexen Entscheidungen nicht ersetzen könne (am Beispiel des Versicherungsleiters Ajit Jain) und Berkshire AI als Werkzeug zur Effizienzsteigerung bestehender Geschäfte betrachte, nicht als Investition in reine Algorithmus-Unternehmen. Er sieht eine Blase im AI-Bereich und plädiert dafür, abzuwarten, bis die Technologie langfristige Rentabilität beweist. Dies löste Diskussionen über den Wert von „AI + Branche“ vs. „Branche + AI“-Modellen aus (Quelle: 36氪)
Anthropic CEO räumt mangelndes Verständnis der AI-Funktionsweise ein: Dario Amodei, CEO von Anthropic, räumte ein, dass derzeit ein tiefgreifendes Verständnis der internen Funktionsweise großer AI-Modelle (wie LLMs) fehle und bezeichnete diese Situation als „beispiellos“ in der Technologiegeschichte. Diese ehrliche Aussage unterstreicht erneut das „Blackbox-Problem“ der AI und löste in der Community breite Diskussionen und Bedenken hinsichtlich der Interpretierbarkeit, Kontrollierbarkeit und Sicherheit von AI aus (Quelle: Reddit r/ArtificialInteligence)

OpenAIs Plan zur Veröffentlichung nicht-führender Open-Source-Modelle und die Kontroverse darum: Kevin Weil, CPO von OpenAI, erklärte, dass das Unternehmen die Veröffentlichung eines Open-Source-Gewichtsmodells vorbereitet, das auf demokratischen Werten basiert. Dieses Modell soll jedoch bewusst eine Generation hinter den Spitzenmodellen zurückbleiben, um die Entwicklung von Konkurrenten (wie China) nicht zu beschleunigen. Diese Strategie löste heftige Diskussionen in der Community aus. Kritiker halten diese Positionierung für widersprüchlich: Es könne weder das „weltbeste“ Open-Source-Modell werden (müsste mit Spitzenmodellen wie DeepSeek-R2 konkurrieren), noch könnte es aufgrund seiner geringeren Leistung nutzlos werden. Gleichzeitig könnte es OpenAIs eigene Einnahmen aus Low-End-APIs schmälern – eine „Lose-Lose“-Situation (Quelle: Haider., scaling01)
Diskussion über AI-gesteuerte Automatisierung und zukünftige Arbeitsformen: Der CEO von Fiverr glaubt, dass AI „einfache Aufgaben“ eliminieren, „schwierige Aufgaben“ vereinfachen und „unmögliche Aufgaben“ erschweren wird. Er betont, dass Fachleute zu Meistern ihres Fachs werden müssen, um nicht ersetzt zu werden. Die Community diskutiert, ob AI alle Arbeitsplätze ersetzen wird und welche gesellschaftlichen Strukturveränderungen daraus resultieren könnten (Wirtschaftskollaps oder UBI-Utopie). Gleichzeitig wird die Anwendung von AI in der Softwareentwicklung immer alltäglicher und sie wird sogar zum Hauptbeitragszahler von Code, was zum Nachdenken über zukünftige Entwicklungsmodelle anregt (Quelle: Emm | scenario.com, Reddit r/ArtificialInteligence, mike)
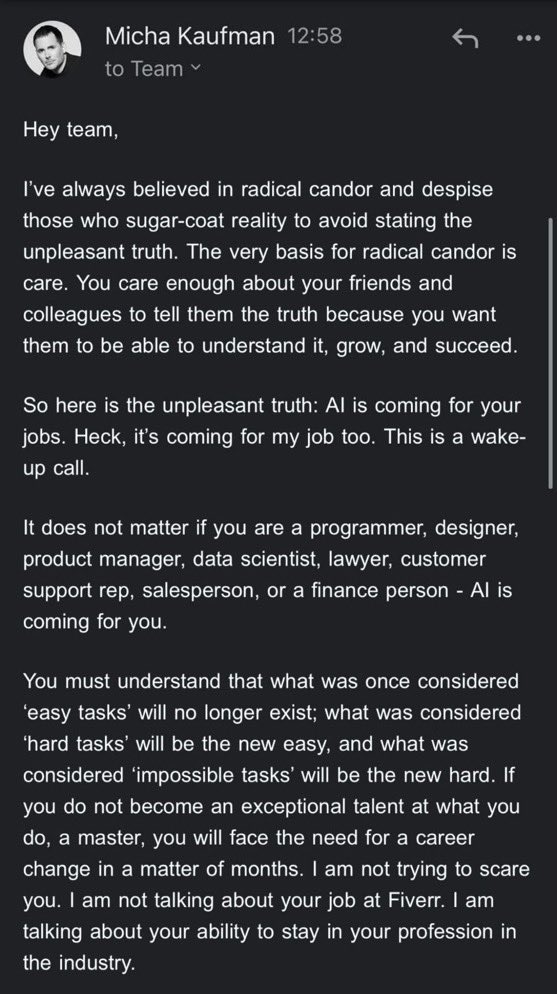
Diskussionen über AI-Sicherheit und -Risiken nehmen weiter zu: Demis Hassabis, CEO von Google DeepMind, warnt, dass AGI in 5-10 Jahren eintreten könnte, die Gesellschaft aber noch nicht bereit sei, mit ihren transformativen Auswirkungen umzugehen, und ruft zu aktiver globaler Zusammenarbeit auf. Gleichzeitig findet ein bedeutungsvoller Dialog über das Risiko einer AI-Katastrophe zwischen der Risikobesorgten Ajeya Cotra und dem Skeptiker random_walker statt, wobei beide Seiten versuchen, die Sichtweise des anderen zu verstehen und Kernpunkte der Meinungsverschiedenheit zu identifizieren. Die Community beginnt auch, das AI-Kontrollproblem zu diskutieren und konzentriert sich darauf, wie starke AI-Systeme sicher überwacht und genutzt werden können (Quelle: Chubby♨️, dylan matthews 🔸, random_walker, FAR.AI, zacharynado)
Anwendung und Auswirkungen von AI im Alltag und in zwischenmenschlichen Beziehungen: Ein Nutzer teilt seine Erfahrung, wie er AI (Anthropic Sonnet) zur Unterstützung bei Antworten in Dating-Apps nutzte und damit seine Erfolgsquote erhöhte, und fantasiert über die Möglichkeit eines „Beziehungs-Cursors“. Gleichzeitig weist ein Artikel darauf hin, dass AI bei manchen Menschen psychische Fantasien fördert und sie sich von realen Freunden und Verwandten entfremden. Dies spiegelt das Vordringen von AI in emotionale und soziale Bereiche sowie die damit verbundenen Chancen und potenziellen Risiken wider (Quelle: arankomatsuzaki, Reddit r/artificial)

Diskussion über LLM-Nutzungserfahrung und Modellvergleich: Nutzer berichten, dass Gemini 2.5 Pro Verwirrung über seine eigene Fähigkeit zum Hochladen von Dateien zeigt und sogar keine Dateien hochladen kann, was auf eine Einschränkung der kostenpflichtigen Funktion hindeutet. Gleichzeitig berichten Familienmitglieder eines Nutzers, dass sie Gemini gegenüber ChatGPT bevorzugen. Ein anderer Nutzer lobt Claude für die Generierung schriftlicher Inhalte und hält es anderen LLMs für überlegen, da seine Antworten natürlicher und eher wie echte Artikel als einfache Aufgabenerledigungen wirken. Diese Diskussionen spiegeln Probleme, Präferenzunterschiede und intuitive Wahrnehmungen der Fähigkeiten verschiedener Modelle wider, die Nutzer in der Praxis erleben (Quelle: seo_leaders, agihippo, Reddit r/ClaudeAI, seo_leaders)

Diskussion über AI-Ethik und gesellschaftliche Normen: Die Diskussion berührt die Anwendung von AI in der Medikamentenentwicklung und die damit verbundenen ethischen Überlegungen sowie die Haltung von AI-Gegnern dazu. Gleichzeitig gibt es Kommentare, dass die Verbreitung von AI-Echtzeitübersetzung dazu führen könnte, dass man die „Mühe“ der sprachübergreifenden Kommunikation und die dadurch entstehende Verbindung vermisst. Es gibt auch Diskussionen über AI zur Haustierübersetzung, wobei argumentiert wird, dass Menschen Haustiere teilweise mögen, weil sie Emotionen auf sie projizieren können, während eine echte AI-Übersetzung möglicherweise nur „hungrig“ und „paarungsbereit“ zurückmeldet (Quelle: Reddit r/ArtificialInteligence, jxmnop, menhguin)
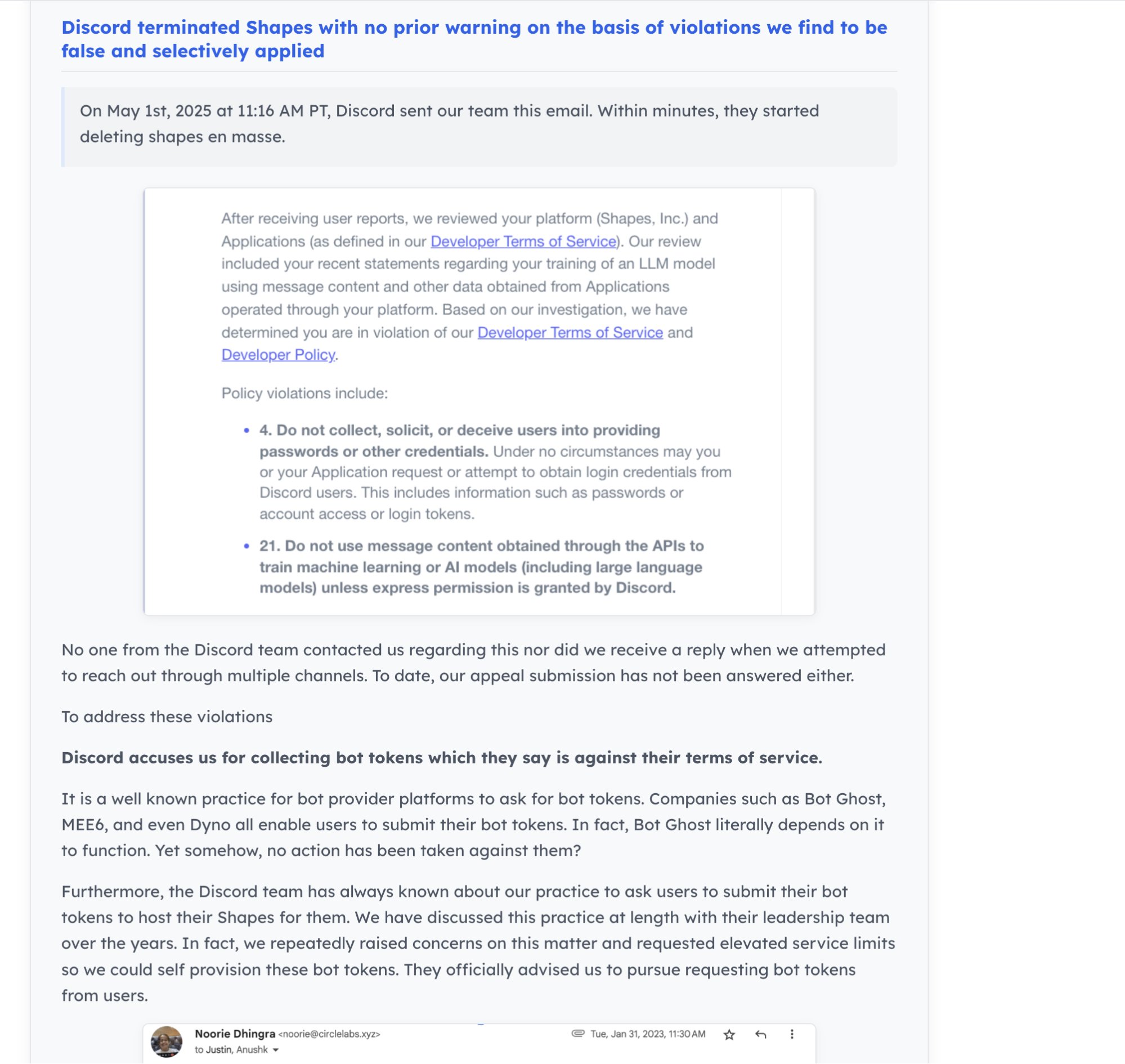
Dynamik der AI-Community und Entwicklerökosystem: Discord schließt den AI-Bot “Shapes” mit 30 Millionen Nutzern, was bei Entwicklern Bedenken hinsichtlich der Plattformrisiken auslöst. Gleichzeitig wird argumentiert, dass für AI-Startups Beiträge zu Open-Source-Projekten die Fähigkeiten besser belegen und die Jobchancen erhöhen als das Lösen von LeetCode-Aufgaben. Nous Research veranstaltet gemeinsam mit XAI, Nvidia u.a. einen RL-Umgebungs-Hackathon, um die Entwicklung von RL-Umgebungen voranzutreiben (Quelle: shapes inc, pash, Nous Research)
Anormales Verhalten von ChatGPT: Gefangen im „Boethius“-Zyklus: Nutzer berichten, dass ChatGPT-4o bei der Frage nach dem „ersten Komponisten“ anormal reagiert und wiederholt Boethius (einen Musiktheoretiker, keinen Komponisten) erwähnt. In nachfolgenden Gesprächen „entschuldigt“ es sich sogar und scherzt, dass Boethius die Antworten wie ein „Geist“ verfolge. Diese interessante „Fehlfunktion“ zeigt unerwartete Verhaltensmuster und potenzielle interne Zustandsverwirrungen von LLMs (Quelle: Reddit r/ChatGPT)

Gedanken über zukünftige Entwicklungsstadien der AI: Die Community fragt: Wenn die aktuelle AI-Entwicklung im „Mainframe“-Stadium ist, wie wird dann das zukünftige „Mikroprozessor“-Stadium aussehen? Diese Frage regt zum Nachdenken über den Evolutionspfad der AI-Technologie, ihre Verbreitungsformen und zukünftige, möglicherweise stärker miniaturisierte, personalisierte und eingebettete AI-Formen an (Quelle: keysmashbandit)
Stil und Erkennung von AI-generierten Inhalten: Nutzer beobachten, dass AI-generierte Texte (insbesondere von GPT-ähnlichen Modellen) oft feste Phrasen und Satzmuster verwenden (wie „significant implications for…“ etc.), was sie leicht erkennbar macht. Gleichzeitig wirkt AI-generierte Sprache trotz verbesserter Klangqualität in Struktur, Rhythmus und Pausensetzung immer noch steif. Dies löst Diskussionen über die „Schemahaftigkeit“ und Natürlichkeit von LLM-Ausgaben aus (Quelle: Reddit r/ArtificialInteligence)
Anerkennung für das Design von Perplexity AI: Nutzer jxmnop meint, dass Perplexity AI anscheinend mehr Ressourcen in Design als in eigene Modelle investiert, aber das Produkterlebnis (vibes) gut anfühlt. Dies spiegelt wider, dass im Wettbewerb der AI-Produkte neben der Kernmodellfähigkeit auch die Benutzeroberfläche und das Interaktionsdesign wichtige Differenzierungsfaktoren sind (Quelle: jxmnop)

Interessante AI-Anwendungen außerhalb der Arbeit: Reddit-Nutzer sammeln interessante oder seltsame AI-Anwendungen außerhalb des Arbeitskontexts. Beispiele sind: Traumanalyse aus der Perspektive von Jung und Freud, Kaffeesatzlesen, Rezeptentwicklung basierend auf zufälligen Kühlschrankzutaten, AI als Vorleser von Gute-Nacht-Geschichten, Zusammenfassung von Rechtsdokumenten usw. Dies zeigt die Kreativität der Nutzer bei der Erkundung der Anwendungsgrenzen von AI (Quelle: Reddit r/ArtificialInteligence)
Nutzer sucht bestes LLM für 48GB VRAM: Ein Reddit-Nutzer sucht das beste LLM für 48GB VRAM, das sowohl eine große Wissensbasis als auch eine brauchbare Geschwindigkeit (>10t/s) bietet. In der Diskussion werden Deepcogito 70B (Llama 3.3 Finetune), Qwen3 32B erwähnt, und es wird empfohlen, Nemotron, YiXin-Distill-Qwen-72B, GLM-4, quantisiertes Mistral Large, Command R+, Gemma 3 27B oder teilweise ausgelagertes Qwen3-235B auszuprobieren. Dies spiegelt den praktischen Bedarf der Nutzer wider, Modelle unter spezifischen Hardwarebeschränkungen auszuwählen und zu optimieren (Quelle: Reddit r/LocalLLaMA)
💡 Sonstiges
Fortschritte in der Robotik: Es gibt kontinuierlich neue Entwicklungen in diesem Bereich: 1. PIPE-i: Beca Group stellt einen Roboter-Vermessungswagen für die Inspektion von Rohrleitungen und anderer Infrastruktur vor. 2. Open-Source humanoider Roboter: Die University of California, Berkeley, startet ein Open-Source-Projekt für humanoide Roboter. 3. Hugging Face Roboterarm: Hugging Face veröffentlicht ein Projekt für einen 3D-gedruckten Roboterarm. 4. Essbarer Roboterkuchen: Forscher stellen einen essbaren Roboterkuchen her. 5. Kanalisationsdrohnen: Drohnen zur Inspektion von Abwasserkanälen tauchen auf und ersetzen menschliche Arbeit bei schmutzigen Aufgaben (Quelle: Ronald_vanLoon, TheRundownAI)

Diskussion zur AI-Regulierung: Dokumentarfilm über SB-1047 veröffentlicht: Michaël Trazzi hat einen Dokumentarfilm über die Hintergründe der Debatte um das kalifornische AI-Sicherheitsgesetz SB-1047 veröffentlicht. Das Gesetz zielte darauf ab, eine Mindestregulierung für die Entwicklung von Spitzen-AI einzuführen, scheiterte aber letztendlich. Der Film untersucht die Gründe für das Scheitern des Gesetzes trotz breiter Unterstützung durch die kalifornische Bevölkerung und regt zum weiteren Nachdenken über Wege und Herausforderungen der AI-Regulierung an (Quelle: Michaël Trazzi, menhguin, NeelNanda5, JeffLadish)
Verbindung von Quantencomputing und AI: Nvidia ebnet den Weg für praktisches Quantencomputing durch die Integration von Quantenhardware mit AI-Supercomputern, wobei der Schwerpunkt auf Fehlerkorrektur und der Beschleunigung des Übergangs von Experimenten zu praktischen Anwendungen liegt. Gleichzeitig wird argumentiert, dass Quantencomputing möglicherweise eher zu wissenschaftlichem Wohlstand als nur zur Disruption im Bereich der Cybersicherheit führen könnte (Quelle: Ronald_vanLoon, NVIDIA HPC Developer)
