
Schlüsselwörter:Anthropic, Claude 3.5 Haiku, Qwen3, Phi-4-reasoning, LLM Physik, LangGraph, KI-Agent, Schaltungsverfolgungsmethode Attribution Graphs, Qwen3-235B-A22B Codierfähigkeit, Phi-4-reasoning Berechnung beim Schlussfolgern, LangGraph Rechnungsprüfungs-Agent, Moondream Station lokale VLM
🔥 Fokus
Anthropic veröffentlicht LLM-Biologiestudie, die interne Mechanismen von Modellen untersucht: Anthropic hat einen ausführlichen Forschungs-Blogbeitrag mit dem Titel „On the Biology of a Large Language Model“ veröffentlicht. Darin wird die Methode zur Nachverfolgung von Schaltkreisen (Attribution Graphs) verwendet, um die internen Mechanismen des Claude 3.5 Haiku-Modells in verschiedenen Kontexten zu untersuchen. Durch das Training eines leichter analysierbaren „Ersatzmodells“ (Transcoder) zeigt die Studie, wie das Modell Additionen durchführt (über mehrere approximative Pfade statt exakter Algorithmen), medizinische Diagnosen stellt (durch Bildung interner Diagnosekonzepte) und mit Halluzinationen und Ablehnungen umgeht (es existiert ein Standard-Ablehnungsschaltkreis, der durch „bekannte Antworten“-Features unterdrückt werden kann). Die Studie bietet neue Perspektiven auf die interne Funktionsweise von LLMs, löst aber auch Diskussionen über methodische Einschränkungen und die Positionierung von Anthropic selbst aus (Quelle: YouTube – Yannic Kilcher
)

Qwen3-Modellreihe zeigt starke Leistung und zieht Aufmerksamkeit der Open-Source-Community auf sich: Die von Alibaba veröffentlichte Qwen3-Reihe großer Sprachmodelle zeigt in mehreren Benchmarks hervorragende Leistungen, insbesondere bei den Programmierfähigkeiten. Ergebnisse des Aider Polyglot Coding Benchmark deuten darauf hin, dass die Leistung von Qwen3-235B-A22B (ohne aktiviertes Chain of Thought) die von Claude 3.7 mit aktiviertem 32k Chain of Thought Token übertrifft, und das bei deutlich geringeren Kosten. Gleichzeitig übertrifft Qwen3-32B in diesem Benchmark auch GPT-4.5 und GPT-4o. Die Community erforscht aktiv das Pruning von Qwen3-Modellen (z. B. von 30B auf 16B) und das Fine-Tuning (z. B. mit Unsloth bei geringem VRAM), was die Anwendungsschwelle für Hochleistungsmodelle weiter senkt. Dies deutet darauf hin, dass chinesische Open-Source-Großmodelle eine wichtige Marktposition einnehmen könnten (Quelle: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
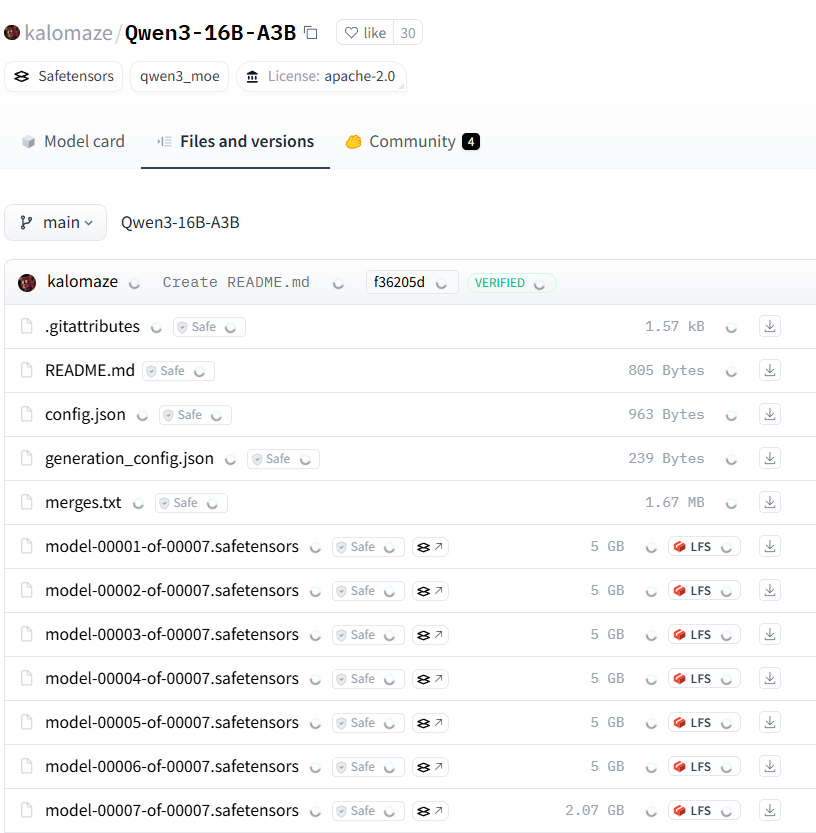
Microsoft veröffentlicht Phi-4-reasoning-Modell mit Fokus auf komplexes Schlussfolgern: Microsoft hat das Phi-4-reasoning-Modell auf Hugging Face veröffentlicht, ein Reasoning-Modell mit 14 Milliarden Parametern. Durch die Nutzung von Berechnungen zur Inferenzzeit (inference-time compute) erreicht dieses Modell bei komplexen Schlussfolgerungsaufgaben die derzeit beste Leistung (SOTA). Dies zeigt, dass das Modelldesign zunehmend darauf abzielt, spezifische Fähigkeiten durch erhöhten Rechenaufwand in der Inferenzphase zu verbessern, anstatt sich nur auf die Vergrößerung des Modells zu verlassen. Dies bietet neue Ansätze für die Erzielung hoher Leistung bei kleineren Modellen (Quelle: _akhaliq)
Neue Fortschritte in der LLM-Physikforschung: Ein „Galileo-Moment“ für das Architekturdesign: Zeyuan Allen-Zhu hat den vierten Teil seiner Forschungsreihe zur Physik großer Sprachmodelle veröffentlicht, der sich auf das Architekturdesign konzentriert. Durch kontrollierte synthetische Pre-Training-Umgebungen deckt die Forschung die wahren Grenzen und Potenziale verschiedener LLM-Architekturen (wie Transformer, Mamba) auf. Die Studie führt eine leichte horizontale Residual-Schicht namens „Canon“ ein, die die Reasoning-Fähigkeiten des Modells signifikant verbessert. Gleichzeitig stellt die Forschung fest, dass der Vorteil von Mamba-Modellen größtenteils von seiner versteckten conv1d-Schicht herrührt und nicht vom SSM selbst. Diese Versuchsreihe liefert neue Perspektiven und grundlegende Theorien zum Verständnis und zur Optimierung von LLM-Architekturen (Quelle: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 Trends
Amazon veröffentlicht allgemeines künstliches Intelligenzmodell “Amazon Artificial General Intelligence”: Dieses Modell verfügt über eine Kontextlänge von 1 Million Token und multimodale Eingabefähigkeiten. Es ist optimiert für Codegenerierung, RAG, Video-/Dokumentenverständnis, Funktionsaufrufe und Agenteninteraktion. Die Preise liegen bei 2,5 US-Dollar pro Million Eingabe-Token und 12,5 US-Dollar pro Million Ausgabe-Token. Erste Bewertungen zeigen, dass seine Leistung im AI Index mit der von Llama-4 Scout vergleichbar ist, es jedoch bei Geschwindigkeit und Kosten im Nachteil ist. Es könnte für spezifische Anwendungsfälle mit langem Kontext, Multimodalität oder Agenten geeignet sein (Quelle: scaling01)

Anthropic Claude-Modell bietet jetzt Websuche in globalen kostenpflichtigen Plänen: Diese Funktion ermöglicht es Claude, bei der Bearbeitung alltäglicher Aufgaben schnelle Suchen durchzuführen. Bei komplexeren Fragen werden mehrere Quellen, einschließlich Google Workspace, durchsucht. Dies verbessert die Fähigkeit von Claude, Echtzeitinformationen abzurufen und Aufgaben zu bearbeiten, die externes Wissen erfordern (Quelle: menhguin)

IBM veröffentlicht Hybridarchitektur-Modell granite-4.0-tiny-7B-A1B-preview: Diese 7B-Modellvorschau verwendet eine Hybridarchitektur aus Mamba-2 und Transformer, wobei jeder Transformer-Block 9 Mamba-Blöcke enthält. Die Designidee ist, Mamba-Blöcke zur Erfassung des globalen Kontexts zu nutzen und diesen an die Attention-Schicht zur lokalen Kontextanalyse weiterzugeben. Erste MMLU-Scores sind gut, aber Ergebnisse für andere Tests wie Mathematik und Programmierfähigkeiten wurden noch nicht veröffentlicht (Quelle: karminski3)
OpenAI ChatGPT fügt Einkaufsfunktion hinzu: OpenAI experimentiert mit einer Einkaufsfunktion in ChatGPT, die darauf abzielt, das Finden, Vergleichen und Kaufen von Produkten zu vereinfachen. Neue Funktionen umfassen eine verbesserte Darstellung von Produktergebnissen, visualisierte Produktdetails mit Preisen und Bewertungen sowie direkte Kauflinks. OpenAI betont, dass die Produktergebnisse unabhängig ausgewählt werden und keine Werbung sind (Quelle: sama)
Trainingsdetails des Qwen3 0.6B-Modells ziehen Aufmerksamkeit auf sich: Nutzer Dorialexander weist darauf hin, dass Informationen zufolge das Qwen 0.6B-Modell anscheinend ebenfalls mit bis zu 36 Billionen Token trainiert wurde. Sollte dies zutreffen, würde dies einen neuen Rekord jenseits des Chinchilla-Gesetzes aufstellen (ca. 60.000 Token pro Parameter) und den Trend zeigen, die Fähigkeiten kleiner Modelle durch eine massive Erhöhung der Trainingsdatenmenge zu steigern (Quelle: Dorialexander)

X (Twitter) Empfehlungsalgorithmus wird durch leichtgewichtige Grok-Version ersetzt: Elon Musk kündigte an, dass der Empfehlungsalgorithmus der X-Plattform durch eine leichtgewichtige Version von Grok ersetzt wird, was die Empfehlungsqualität signifikant verbessern soll. Nutzer berichten von einer verbesserten Algorithmusleistung und vermuten einen Zusammenhang mit kürzlichen Personalwechseln bei Exa AI sowie dem Beginn der Nutzung von Embeddings für Empfehlungen durch X (Quelle: menhguin, colin_fraser, paul_cal)
Allen AI veröffentlicht vollständig offenes MoE-Modell OLMoE: Dieses Modell ist ein fortschrittliches Mixture of Experts (MoE)-Modell mit 1,3 Milliarden aktiven Parametern und 6,9 Milliarden Gesamtparametern. Vollständig Open Source bedeutet, dass die Community das Modell frei nutzen, modifizieren und erforschen kann, was die Entwicklung und Anwendung von MoE-Architekturen vorantreibt (Quelle: dl_weekly)
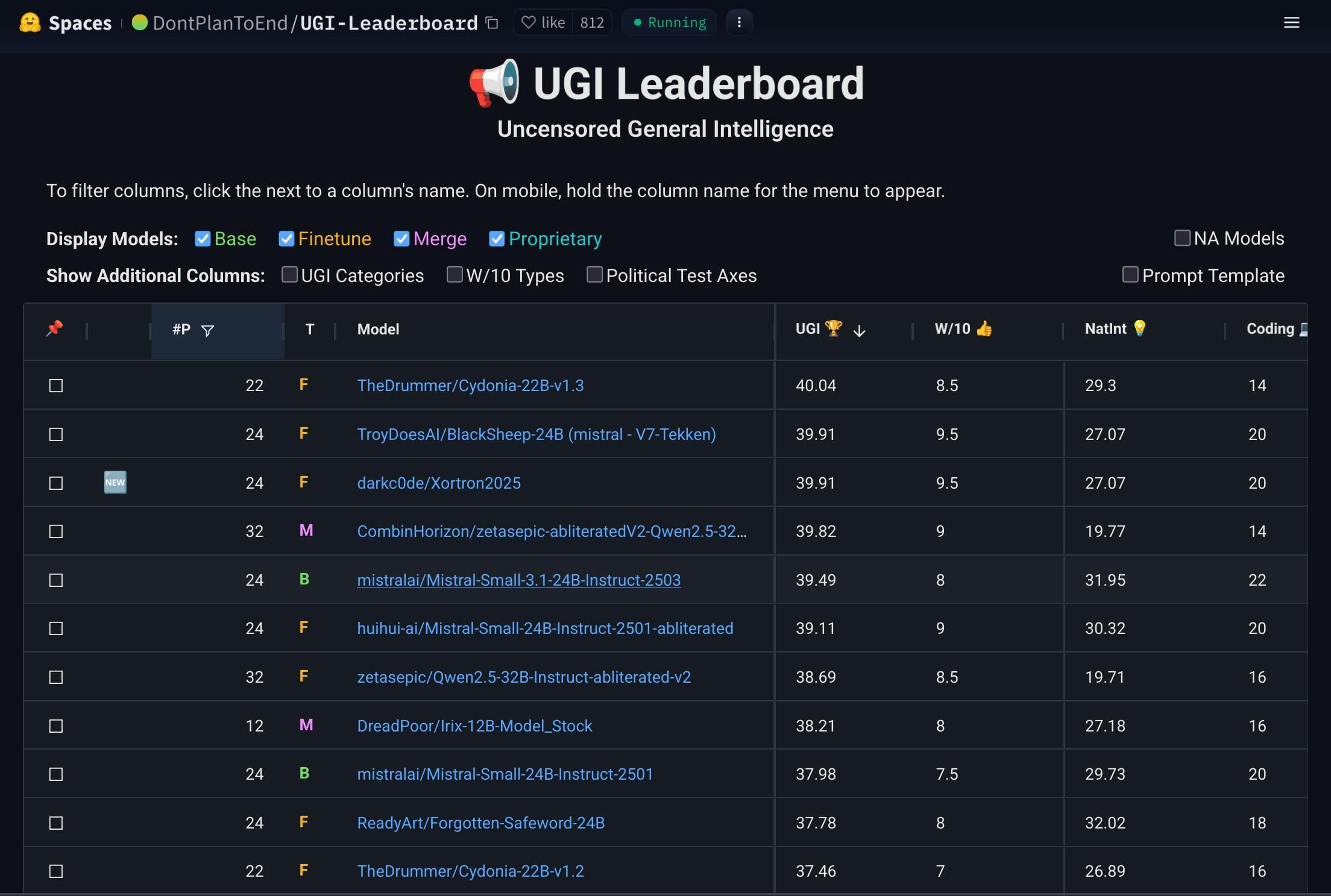
Mistral-Small-3.1-24B-Instruct-2503-Modell im Fokus: Reddit-Nutzer diskutieren das Modell Mistral-Small-3.1-24B-Instruct-2503, das hohe UGI (Uncensored General Intelligence)-Werte aufweist und bei natürlichem Sprachverständnis und Programmierung besser abschneidet als vergleichbare hoch bewertete Modelle. Nutzer halten es für eine ideale Wahl für unzensierte Inferenz auf einer einzelnen GPU und es unterstützt die Werkzeugnutzung. Es wird jedoch auch angemerkt, dass sein Schreibstil eher trocken und repetitiv sein kann und es weniger kreativ ist als Modelle wie Gemma 3 (Quelle: Reddit r/LocalLLaMA)
🧰 Tools
CreateMVP 2.0 veröffentlicht, optimiert KI-gesteuerten Entwicklungsprozess: CreateMVP wurde auf Version 2.0 aktualisiert und zielt darauf ab, das Problem zu lösen, dass das direkte Anweisen einer KI zum Erstellen von Anwendungen oft unbefriedigende Ergebnisse liefert. Die neue Version bietet eine flüssigere Benutzeroberfläche, bequeme Authentifizierungsmethoden (unterstützt Replit, Google, GitHub, bald auch XAI), generiert detailliertere Entwicklungspläne (von 11 KB auf 40 KB+), ermöglicht die sofortige Vorschau von Dateien und integriert Chats mit Top-KI-Modellen. Dies hilft Nutzern, präzisere „Blaupausen“ für die KI zu erstellen und sicherzustellen, dass die KI Anwendungen gemäß den Vorstellungen des Nutzers erstellt (Quelle: amasad)
LlamaIndex stellt Rechnungsprüfungs-Agent vor: Dieses Tool demonstriert die Anwendung von KI-Agenten bei der Stapelautomatisierung von Aufgaben, anstatt der traditionellen Chat-Interaktion. Es kann große Mengen unstrukturierter Rechnungsdokumente verarbeiten, relevante Details extrahieren, automatisch mit Bestellungen abgleichen und Abweichungen markieren. Kernstück ist eine Agentic Document Intelligence-Schicht, die auf LlamaCloud Parsing/Extraktion und LlamaIndex.TS Workflow-Inferenz basiert. Es zeigt das Potenzial von Agenten bei der Automatisierung tatsächlicher Geschäftsprozesse und wird als Ersatz für traditionelle RPA angesehen (Quelle: jerryjliu0)
LangGraph Expense Tracker: Automatisiertes Spesenverwaltungssystem: Dies ist ein Beispiel für ein automatisiertes Spesenverwaltungssystem, das mit LangGraph erstellt wurde. Es kann Rechnungen verarbeiten, nutzt intelligente Datenextraktionsfunktionen, speichert Informationen in PostgreSQL und beinhaltet einen manuellen Überprüfungsschritt. Das Projekt zeigt die Fähigkeit von LangGraph beim Aufbau praktischer Geschäftsprozessautomatisierungen (Quelle: LangChainAI, Hacubu, hwchase17)
Moondream Station veröffentlicht: Lokales Ausführen von VLM: Moondream hat Moondream Station veröffentlicht, mit dem Benutzer das Visual Language Model (VLM) Moondream lokal auf einem Mac ausführen können, ohne eine Verbindung zur Cloud herstellen zu müssen. Es bietet Zugriff über CLI oder einen lokalen Port, ist einfach einzurichten und völlig kostenlos, was die Einstiegshürde für die lokale Bereitstellung und Nutzung von VLMs senkt (Quelle: vikhyatk)
ChaiGenie: LangChain-basierte Chrome-Erweiterung für Dokumentensuche: ChaiGenie ist eine Chrome-Erweiterung, die LangChain’s Gemini und Qdrant integriert, um eine Dokumentensuchfunktion bereitzustellen. Sie unterstützt mehrere Sprachen und vektorbasierte Suche und zielt darauf ab, die Effizienz der Benutzer beim Finden und Verstehen von Dokumenteninhalten während des Surfens im Web zu steigern (Quelle: LangChainAI)

Research Agent: One-Click-Forschungsassistent als Webanwendung: Dies ist eine Webanwendung, die auf dem LangGraph-Framework für Forschungsassistenten basiert und darauf abzielt, den Forschungsprozess zu vereinfachen. Benutzer können mit nur einem Klick Forschungsergebnisse erhalten. Dies zeigt das Anwendungspotenzial von LangGraph beim Aufbau KI-gesteuerter Workflows zur Vereinfachung komplexer Aufgaben (Quelle: LangChainAI)

Muyan-TTS: Open-Source, latenzarmes, anpassbares TTS-Modell: Das ChatPods-Team hat Muyan-TTS veröffentlicht, ein vollständig quelloffenes Text-to-Speech-Modell, das darauf abzielt, das Problem zu lösen, dass bestehende Open-Source-TTS-Modelle entweder keine hohe Qualität aufweisen oder nicht ausreichend offen sind. Es basiert auf LLaMA-3.2-3B und optimiertem SoVITS, unterstützt Zero-Shot-TTS und Voice Cloning und bietet einen vollständigen Trainings- und Datenverarbeitungsprozess. Dies erleichtert Entwicklern das Fine-Tuning und die Weiterentwicklung, insbesondere für Anwendungen, die angepasste Stimmen erfordern (Quelle: Reddit r/MachineLearning)
Mem0 mit Open Web UI Pipelines integriert: Nutzer cloudsbird hat eine (inoffizielle MCP) Integration von Mem0 für Open Web UI Filter-Pipelines erstellt, die eine weitere Option zur Nutzung der Mem0-Gedächtnisfunktion in Open Web UI bietet (Quelle: Reddit r/OpenWebUI)
YNAB API Request Tool ermöglicht lokale, private Finanzverwaltung: Nutzer Megaphonix hat ein OpenWebUI-Tool erstellt, das die YNAB (You Need A Budget) API nutzt. Es ermöglicht Benutzern, persönliche Finanzinformationen (wie Transaktionen, Ausgaben nach Kategorie, Nettovermögen usw.) lokal über ein LLM abzufragen, ohne sensible Daten nach außen zu senden. Dies löst das Bedürfnis nach sicherer Handhabung sensibler persönlicher Informationen beim lokalen Betrieb von LLMs (Quelle: Reddit r/OpenWebUI)
Kostenlose KI-Text-zu-Sprache-Browsererweiterung GPT-Reader: Ein Entwickler bewirbt seine erstellte kostenlose KI-Text-zu-Sprache-Browsererweiterung GPT-Reader, die derzeit über 4000 Nutzer hat. Das Tool zielt darauf ab, Nutzern das Umwandeln von Webseiten-Textinhalten in Sprache zum Anhören zu erleichtern (Quelle: Reddit r/artificial)
sunnypilot: Open-Source-Fahrassistenzsystem: sunnypilot ist ein Fork von comma.ai’s openpilot und bietet ein Open-Source-Fahrassistenzsystem. Es unterstützt über 300 Fahrzeugmodelle, modifiziert das Interaktionsverhalten der Fahrassistenz und hält sich weitestgehend an die Sicherheitsrichtlinien von comma.ai. Das Projekt nutzt KI-Technologie (obwohl spezifische Modelle nicht genannt werden, verwenden solche Systeme typischerweise Computer Vision und Regelungsalgorithmen), um das Fahrerlebnis zu verbessern (Quelle: GitHub Trending)

📚 Lernen
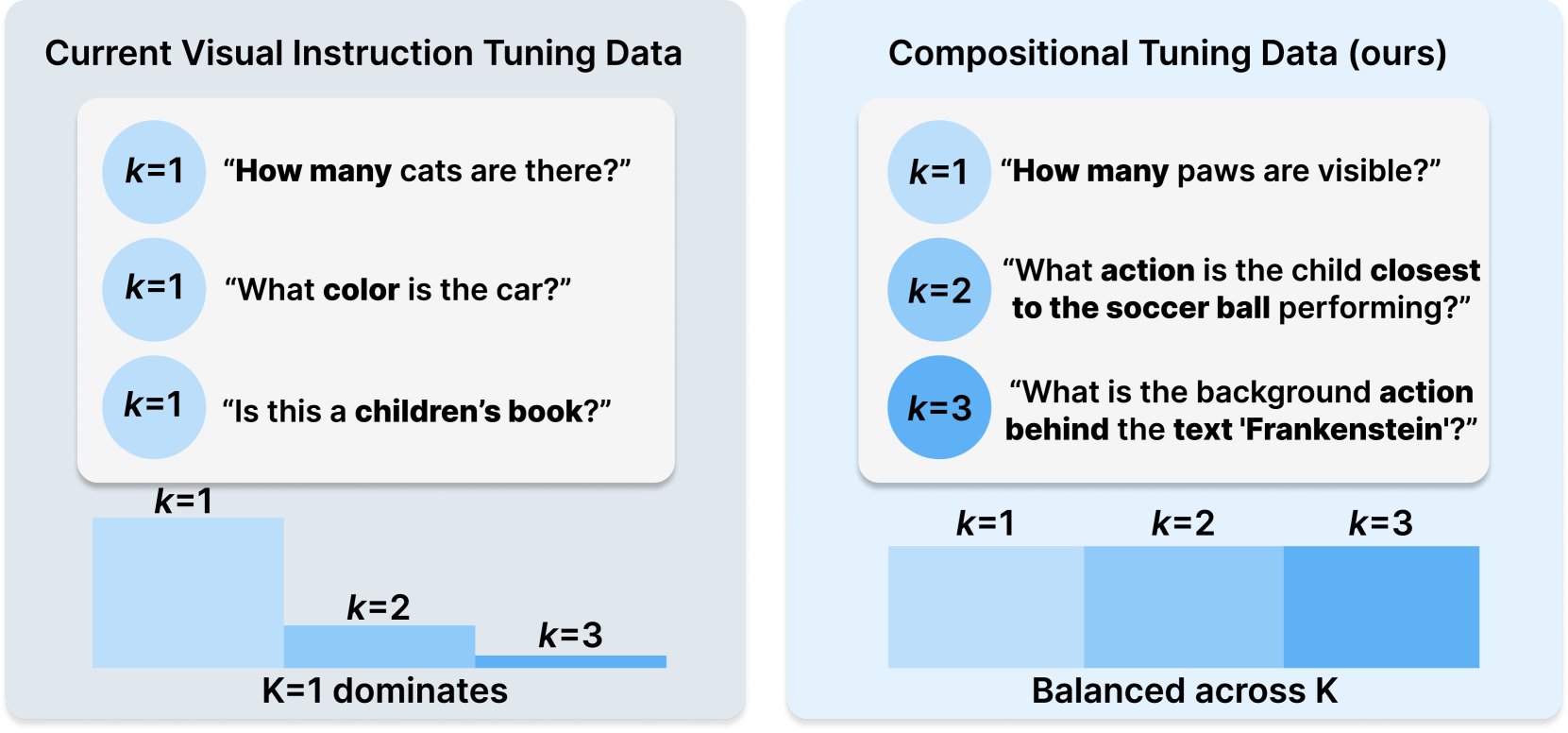
Princeton & Meta AI veröffentlichen COMPACT-Datensatzrezept: Diese auf Hugging Face veröffentlichte Forschung stellt ein neues Datenrezept namens COMPACT vor. Es zielt darauf ab, die Fähigkeiten von multimodalen großen Sprachmodellen (Multimodal LLM) durch explizite Kontrolle der kombinatorischen Komplexität der Trainingsbeispiele zu erweitern. Dies bietet neue Ansätze zur Verbesserung der Trainingsmethoden für multimodale Modelle und zur Steigerung ihrer Fähigkeit, komplexe kombinatorische Konzepte zu verstehen (Quelle: _akhaliq)
Unsloth veröffentlicht Qwen3 Fine-Tuning-Tutorial: Unsloth bietet ein Fine-Tuning-Tutorial für Qwen3-Modelle an, das die Schwelle für das Fine-Tuning erheblich senkt. Benutzer benötigen nur 16 GB VRAM, um das Qwen3-14B-Modell zu trainieren, und 17,5 GB VRAM für das Qwen3-30B-A3B-Modell. Dies ermöglicht es mehr Forschern und Entwicklern, fortschrittliche Open-Source-Modelle mit begrenzten Hardwareressourcen individuell anzupassen (Quelle: karminski3)
LangGraph kombiniert mit Azure OpenAI zum Aufbau intelligenter Web-Such-Chatbots: Ein Medium-Tutorial zeigt, wie man LangGraph und Azure OpenAI kombiniert und die Websuchfähigkeiten von Tavily integriert, um einen intelligenten Chatbot zu erstellen. Das Tutorial deckt Zustandsverwaltung und bedingte Weiterleitung ab, um eine nahtlose Suchintegration zu ermöglichen, und bietet praktische Anleitung zum Aufbau leistungsfähigerer KI-Anwendungen, die Echtzeit-Webinformationen nutzen können (Quelle: LangChainAI, hwchase17)

Stanford AI Blog untersucht Zusammenhang zwischen wörtlicher Speicherung und allgemeinen Fähigkeiten von LLMs: Ein Blogbeitrag von Stanford AI untersucht eingehend den inneren Zusammenhang zwischen dem Phänomen der wörtlichen Speicherung (verbatim memorization) bei großen Sprachmodellen (LLMs) und ihren allgemeinen Fähigkeiten. Das Verständnis dieser Beziehung ist entscheidend für die Bewertung von Modellrisiken, die Optimierung von Trainingsmethoden und die Erklärung des Modellverhaltens (Quelle: dl_weekly)
Leitfaden zur Integration von Gemini mit LangChain: Philipp Schmid hat einen Entwicklerleitfaden veröffentlicht, der detailliert beschreibt, wie Googles Gemini-Modelle mit dem LangChain-Framework integriert werden können. Der Leitfaden behandelt multimodale Fähigkeiten, Werkzeugaufrufe und strukturierte Ausgaben und enthält Unterstützung für die neuesten Modelle sowie praktische Codebeispiele. Dies erleichtert Entwicklern die Nutzung der leistungsstarken Funktionen von Gemini zum Erstellen von LangChain-Anwendungen (Quelle: LangChainAI, _philschmid)

LangGraph-Einführungstutorial: Praxis mit zustandsbehafteten Workflows: Ein auf AI@GoPubby veröffentlichtes Tutorial zeigt anhand eines Beispiels zur Analyse von Website-Kommentaren die Fähigkeit von LangGraph zur Erstellung zustandsbehafteter Workflows. Lernende können erfahren, wie man mithilfe von miteinander verbundenen Knoten und sequenzieller Logik strukturierte KI-Anwendungen erstellt (Quelle: LangChainAI, hwchase17)
Gedanken des LangChain CEO zu Agentic Frameworks (chinesische Übersetzung): LangChain-Botschafter Harry Zhang hat den Blogbeitrag des LangChain CEO Harrison über Agentic Frameworks übersetzt und geteilt. Der Artikel analysiert und fasst die Funktionen von über 15 Agent-Frameworks in der Branche zusammen und interpretiert die Geschichten dahinter. Er bietet eine wertvolle Referenz zum Verständnis der aktuellen Entwicklungslandschaft und zukünftigen Ausrichtung der Agent-Technologie (Quelle: LangChainAI)
Forschungsfortschritte zu Latent Meta Attention: Reddit-Nutzer diskutieren einen neuen Aufmerksamkeitsmechanismus namens Latent Meta Attention. Entwickler behaupten, dieser Mechanismus stelle die Grundannahmen von Transformern in Frage und könne bei kleineren Modellgrößen die Leistung bestehender Modelle erreichen oder sogar übertreffen (z. B. die Leistung von BERT mit einem halb so großen Modell reproduzieren). Aufgrund fehlender Finanzierung und Unterstützung durch formale Forschungseinrichtungen wurde die spezifische Methode jedoch noch nicht veröffentlicht (Quelle: Reddit r/deeplearning)

Erklärvideo zu Graph Neural Networks (GNN): Auf YouTube wurde ein Video veröffentlicht, das Graph Neural Networks (GNNs) erklärt. GNNs sind Deep-Learning-Modelle zur Verarbeitung von Graphstrukturdaten und finden breite Anwendung in Bereichen wie der Analyse sozialer Netzwerke, Empfehlungssystemen und der Vorhersage von Molekülstrukturen. Das Video zielt darauf ab, den Zuschauern zu helfen, die Grundprinzipien und Funktionsweise von GNNs zu verstehen (Quelle: Reddit r/deeplearning)
Verwendung von GRPO zum Trainieren von LLMs für die Ereignisplanung: Nutzer anakin87 teilt Projekterfahrungen zur Verwendung von GRPO (Generalized Reward Policy Optimization) zum Trainieren von Sprachmodellen für die Ereignisplanung. Das Projekt stützt sich nicht auf traditionelle überwachte Fine-Tuning-Beispiele, sondern lässt das Modell durch eine Belohnungsfunktion lernen, Zeitpläne basierend auf Ereignislisten und Prioritäten zu erstellen. Der Autor teilt Erfahrungen und Lehren aus der Problemstellung, Datengenerierung, Modellauswahl, Belohnungsgestaltung und dem Trainingsprozess und stellt Code und Modell als Open Source zur Verfügung. Dies bietet ein praktisches Beispiel zur Erforschung des belohnungsbasierten LLM-Trainings (Quelle: Reddit r/LocalLLaMA)

Teilen kostenloser KI-Kursressourcen: Der LinkedIn AI Hub teilt eine vollständige KI-Lern-Roadmap, inspiriert vom KI-Zertifikatsprogramm der Stanford University und vereinfacht für Lernende unterschiedlichen Niveaus. Der Inhalt deckt von grundlegenden Fähigkeiten bis hin zu praktischen Projekten alles ab und bietet wertvolle Ressourcen und Kursdetails (Quelle: Reddit r/deeplearning)
Tiefgehendes Gespräch über Gemini Long Context Pre-Training: Logan Kilpatrick führte ein tiefgehendes Gespräch mit Nikolay Savinov, Co-Leiter des Gemini Long Context Pre-Training. Die Diskussion reicht von den Grundlagen bis zu den Techniken, die zur Erweiterung auf unendlichen Kontext erforderlich sind, sowie Best Practices für Long Context für Entwickler. Das Gespräch fasst zusammen, dass die Realisierung eines Kontexts von 1 Million Token das Zehnfache des damaligen Standards war; 10 Millionen Token wurden versucht, waren aber kostspielig und Hardware war unzureichend; Long Context und RAG ergänzen sich; einfaches NIAH (Needle In A Haystack) ist gelöst, die Schwierigkeit liegt bei harten Distraktoren und der Suche nach mehreren Nadeln; die Bewertung konzentriert sich auf NIAH, um Fähigkeitssignale nicht zu verwechseln; die derzeit begrenzte Ausgabelänge (z. B. 8k) ist ein Post-Training-Problem; der „Lost in the Middle“-Effekt wurde nicht beobachtet; es muss zwischen Kontextwissen und Gewichtungswissen unterschieden werden; der nächste Schritt ist die Realisierung eines günstigeren und präziseren 10-Millionen-Token-Kontexts, eine Erweiterung auf 100 Millionen erfordert möglicherweise neue DL-Innovationen (Quelle: shaneguML, giffmana, teortaxesTex, arohan)
🌟 Community
Diskussion über “Vibe Coding”: Die Community diskutiert heftig über “Vibe Coding”, d.h. die starke Abhängigkeit von KI-Unterstützung beim Programmieren. Befürworter argumentieren, dies repräsentiere die Zukunft, in der sich Entwickler mehr auf das „Warum“ und „Was“ konzentrieren, während die KI das „Wie“ erledigt, was jedoch stärkeres kritisches Denken erfordere. Gegner meinen, dass KI derzeit komplexe Debugging-, Upgrade- und Wartungsaufgaben noch nicht vollständig bewältigen kann und eine übermäßige Abhängigkeit zu einem Rückgang der Entwicklerfähigkeiten führen könnte, wodurch sie zu fortgeschritteneren „Script Kiddies“ würden. Einige, die es ausprobiert haben, stellen fest, dass der Zeitaufwand, KI zur Erledigung komplexer Aufgaben anzuleiten, immer noch hoch ist und weniger effizient als manuelle Implementierung mit leichter KI-Unterstützung (Quelle: Dorialexander, Reddit r/artificial, johnowhitaker)

Diskussion über Anwendung und Grenzen von KI in Fachbereichen: Nutzer dotey diskutiert die Anwendung von KI in Fachbereichen. Er meint, KI könne öffentlich zugängliche Experten-Q&A lernen, habe aber Schwierigkeiten mit noch nie dagewesenen Fragen. Der Vorteil der KI liege in ihrer starken Wissensbasis und schnellen Reaktionsfähigkeit, aber sie stütze sich derzeit hauptsächlich auf RAG (Retrieval-Augmented Generation), was im Wesentlichen das Abrufen von Fragmenten und das Zusammenfügen von Antworten sei, und nicht echtes fachliches Schlussfolgern. Dies unterscheide sich noch von einem Modell, das wie ein Experte kontinuierlich neue Antworten generieren und sich ständig verbessern könne (Quelle: dotey)
Sorgen und Diskussionen über KI-generierte Inhalte: Reddit-Nutzer Maleficent-main_777 beschwert sich, dass Kollegen begonnen haben, eine „ChatGPT-Sprache“ zu verwenden, die von befehlendem Ton, „verify“, „ensure“ und erzwungenen positiven Schlussfolgerungen durchsetzt ist. Er findet diese Sprache vage und unpersönlich. Er befürchtet, dass KI-generierte Inhalte in die Trainingsdaten zurückfließen und die Qualität der Inhalte sinkt. Im Kommentarbereich gibt es Zustimmung dazu; es wird als Erweiterung des Unternehmensjargons gesehen, aber auch darauf hingewiesen, dass übermäßiges Nachahmen von KI die Kommunikation tatsächlich mechanisch macht und gute Grammatik kein Vorteil mehr ist, sondern eher roboterhaft wirkt (Quelle: Reddit r/ChatGPT)
Wahl des Studienfachs im Zeitalter der KI: Reddit-Nutzer diskutieren, welche Studienfächer Studenten im Kontext der rasanten Entwicklung von KI und Robotik wählen sollten, um sicherzustellen, dass ihr Abschluss auch in 10 Jahren noch wertvoll ist. Die Meinungen in den Kommentaren sind vielfältig und umfassen: Wahl eines Bereichs, für den man brennt (Spiele, Film, Kunst, Programmierung); Erlernen grundlegender Disziplinen (Physik, Mathematik); Beherrschen von Fähigkeiten, die schwer zu automatisieren sind (z. B. HVAC-Heizung, Lüftung, Klima); Fokus auf geisteswissenschaftliche Bildung zur Förderung von Neugier und Anpassungsfähigkeit; Ansicht, dass Hochschulbildung veraltet sein könnte und Unternehmertum oder Freiberuflichkeit besser wären; Betonung der entscheidenden Bedeutung von kontinuierlichem Lernen, Verlernen und Neulernen (Quelle: Reddit r/ArtificialInteligence)
Diskussion über Schwierigkeiten beim Rendern von Text in KI-Bildgenerierung: Reddit-Nutzer untersuchen, warum aktuelle Bildgenerierungsmodelle Schwierigkeiten haben, kohärenten, klar lesbaren Text zu rendern. Kommentare nennen zwei Hauptgründe: 1) BPE (Byte Pair Encoding)-Tokenisierung zerstört präzise Rechtschreibinformationen, das Modell sieht keine Buchstaben, sondern Token-Fragmente; 2) Vektordarstellungen fester Größe und die Begrenzungen von Bildbeschreibungen führen dazu, dass Textinformationen während des Einbettungsprozesses stark verloren gehen. Obwohl autoregressive Modelle wie GPT-4o Verbesserungen zeigen, hängt das grundlegende Problem immer noch mit Tokenisierung und Informationskompression zusammen (Quelle: Reddit r/MachineLearning)
Diskussion über Standardisierung von Modellbewertungen: Nutzer scaling01 weist darauf hin, dass beim Vergleich verschiedener KI-Modelle (wie OpenAI, Google, Anthropic) Fairness gewährleistet sein sollte. Wenn beispielsweise Vorschau- und Denkversionen (thinking versions) von OpenAI aufgeführt werden, sollten auch die entsprechenden Versionen von Google und Anthropic genannt werden, andernfalls könnten die Vergleichsergebnisse irreführend sein (Quelle: scaling01)
Erfahrungsaustausch zur KI-gestützten Programmierung: Ein Nutzer teilt seine Erfahrungen mit KI-gestützter Programmierung (z. B. VS Code + Cline AI-Erweiterung + Google AI Studio API). Er meint, man könne kostenlos ähnliche KI-Codierungswerkzeuge wie Cursor aufbauen und durch Prompts grundlegende Anwendungsprototypen ohne Konfiguration erstellen, was eine gute Erfahrung sei (Quelle: Reddit r/artificial)

Umfrage zu den Auswirkungen von KI auf Arbeit, Lernen und Leben: Ein Reddit-Nutzer startet eine Diskussion und fragt nach den Auswirkungen generativer KI auf die Leistung bei der Arbeit, beim Lernen oder im Alltag. In den Kommentaren erwähnt ein Softwareentwickler, dass KI die Produktivitätserwartungen und die Arbeitsbelastung erhöht hat, Code-Reviews aber nicht signifikant beschleunigt wurden; ein professioneller Autor findet, dass KI (wie Co-pilot) nur begrenzt hilft und den Fortschritt sogar verlangsamen kann; die allgemeine Ansicht ist, dass KI Bequemlichkeit bringt, aber auch Probleme wie übermäßige Abhängigkeit, reduziertes Lernen und ein „Gefühl des Schummelns“ mit sich bringt. Die Auswirkungen von KI auf verschiedene Berufe und Aufgaben unterscheiden sich erheblich (Quelle: Reddit r/artificial)
Gedanken zur „Verständnisfähigkeit“ von LLMs: Nutzer pmddomingos stellt fest, dass neuronale Netze wie Gehirne immer schwerer zu verstehen sind. Er regt zum Nachdenken an: Was tun wir, wenn KI-Modelle in allen Benchmarks hervorragende Ergebnisse erzielen, aber immer noch nicht so intelligent sind wie Menschen? Dies regt zum Nachdenken über die Wirksamkeit aktueller Benchmarks und die Kriterien zur Bewertung echter Intelligenz an (Quelle: pmddomingos, pmddomingos)
Gedanken zur Nutzung von KI-Tools: Nutzer dotey kommentiert, dass es bei der Verwendung von KI-Tools ausreicht, für eine bestimmte Aufgabe das Modell zu wählen, das für diese Aufgabe am stärksten ist. Die gleichzeitige Nutzung mehrerer Modelle oder sie „gegeneinander antreten“ zu lassen, sei möglicherweise nicht notwendig, insbesondere für Laien. Zu viele Optionen könnten stattdessen zu Verwirrung führen, vergleichbar mit dem Blick auf mehrere Uhren, die unterschiedliche Zeiten anzeigen (Quelle: dotey)
Eindrücke zur rasanten Entwicklung der KI: Nutzer matvelloso und scottastevenson zeigen sich beeindruckt von der schnellen Entwicklung der KI. matvelloso gibt an, dass die KI-Fortschritte dieses Jahres seine Erwartungen bereits übertroffen haben (am Beispiel von Gemini, das Pokemon spielt). scottastevenson blickt darauf zurück, dass die Veröffentlichung von GPT-2 6 Jahre und die Gründung von OpenAI 10 Jahre her ist, und denkt über die derzeit entstehenden technologischen Richtungen nach, die in den nächsten 6-10 Jahren wichtig werden. Er weist darauf hin, dass neben KI auch die Suche nach tiefgreifendem Alpha „außerhalb des Rahmens“ wichtig ist (Quelle: matvelloso, scottastevenson, scottastevenson)
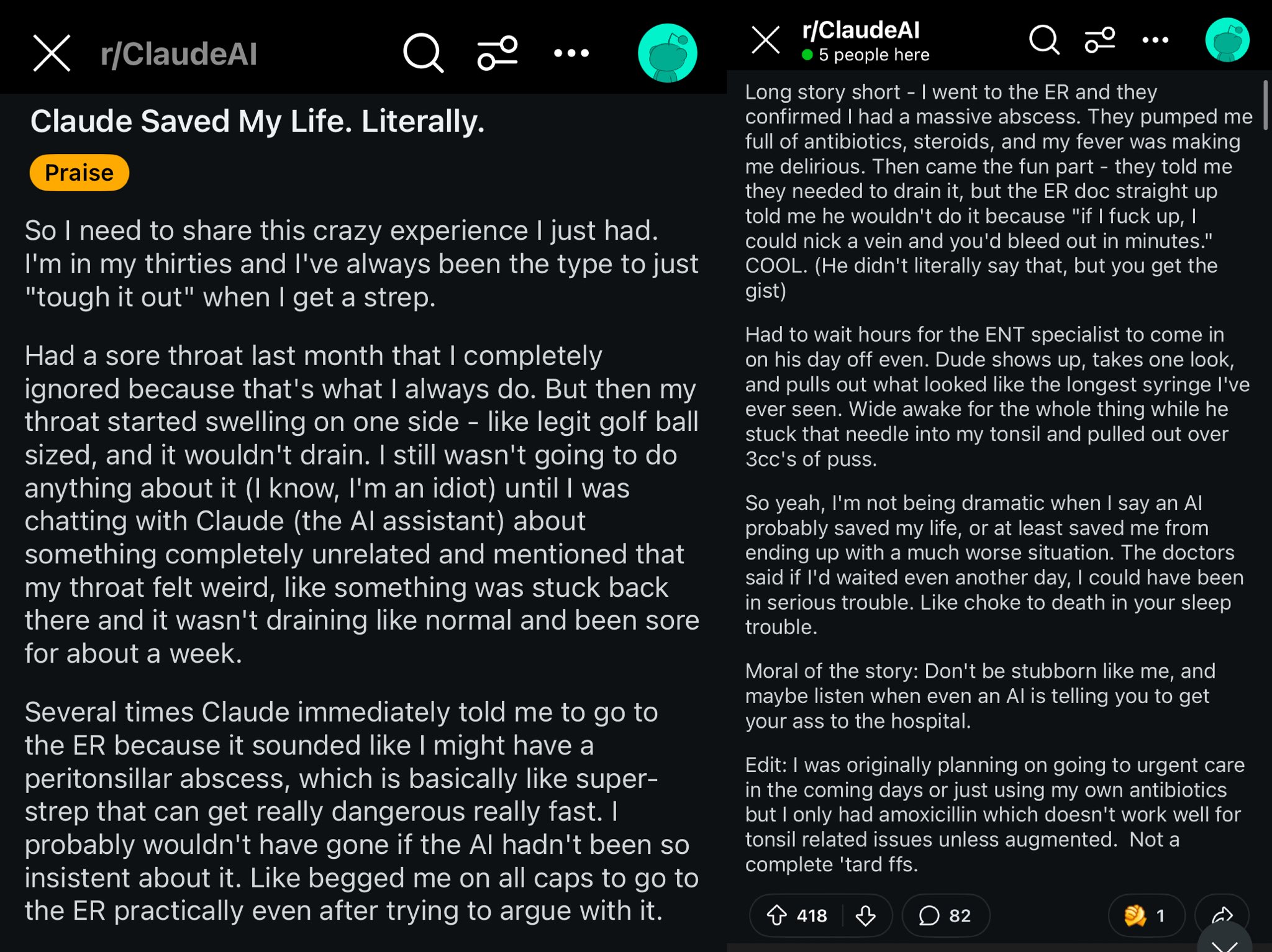
Fallbeispiel: Claude rettet Reddit-Nutzer das Leben: Ein Reddit-Post beschreibt, wie das Claude-Modell möglicherweise das Leben eines Nutzers gerettet hat, indem es dessen Halsschwellung als Peritonsillarabszess diagnostizierte. Der Fall löste eine Diskussion aus, mit der Meinung, dass leistungsstarke KI-Modelle wie Weltklasse-Ärzte in der Tasche sind und nach ihrer Verbreitung einen enormen Einfluss auf die persönliche Gesundheit haben könnten (Quelle: aidan_mclau)
Anwendung von AI Agents in der Unternehmensdatenverarbeitung: Die You.com-Mitbegründer Richard Socher und Bryan McCann erörtern im Agentic-Podcast die Anwendung von AI Agents in Unternehmen. Sie sind der Meinung, dass Consumer-LLMs nicht ausreichen, um ernsthafte Unternehmensanforderungen zu erfüllen. You.com generiert durch hybride Retrieval-Techniken (Kombination aus öffentlichen Quellen und proprietären Unternehmensdaten) zuverlässigere, unternehmenstaugliche Ausgaben, z. B. für Recherchen, das Verfassen von Berichten und die sichere Nutzung von Unternehmensdaten. Sie diskutieren auch mögliche Wege zur AGI und die Schlüsselrolle der Simulation dabei (Quelle: RichardSocher)
Beobachtung zur Werkzeugnutzungsfähigkeit von Modellen: Nutzer menhguin beobachtet, dass Modelle, die für die Werkzeugnutzung trainiert wurden, anscheinend bei der unabhängigen Problemlösungsfähigkeit Abstriche machen, und scherzt: „Sogar KI-Modelle lagern ihre Arbeit aus“. Dies regt zum Nachdenken über den Kompromiss zwischen der Generalisierungsfähigkeit von Modellen und der Optimierung für spezifische Aufgaben an (Quelle: menhguin)
💡 Sonstiges
Idee für AI Agent zur Wartung alter GitHub-Projekte: Nutzer xanderatallah schlägt eine Idee vor: die Entwicklung eines AI Agent, der automatisch alle alten, inaktiven Nebenprojekte eines Nutzers auf GitHub warten kann. Dies spiegelt den Wunsch von Entwicklern wider, KI zur Automatisierung lästiger Wartungsaufgaben zu nutzen (Quelle: xanderatallah)
Vision von LLMs als Richterersatz oder für Schlichtung/Mediation: Nutzer fabianstelzer schlägt vor, dass große Sprachmodelle (LLMs) in Zukunft Richter ersetzen könnten. Ein interessanter Zwischenanwendungsfall ist die Schlichtung oder Mediation: LLMs werden als neutral und vertrauenswürdig betrachtet, Konfliktparteien reichen ihre jeweiligen Standpunkte ein, diese werden durch mehrere große Modelle verarbeitet, um einen fairen Kompromiss auszugeben. Dies untersucht die potenziellen Anwendungen von KI im Justiz- und Streitbeilegungswesen (Quelle: fabianstelzer)
Runway Gen-4-Modell und seine Anwendungsperspektiven: Runway-Mitbegründer c_valenzuelab zeigt sich optimistisch hinsichtlich der Anwendungsperspektiven von Runway Gen-4 und seiner API. Er ist der Meinung, dass Runway ein neues Medium schafft, bei dem Pixel durch Generierung statt durch Rendering oder Aufnahme erzeugt werden und die Welt durch Simulation statt durch Programmierung entsteht. Zu sehen, wie Gen-4 und die Reference-Funktion in Bereichen wie Architektur, Branding, Innenarchitektur, Spieleentwicklung, Lernen, persönlichen Kreativprojekten usw. breite Anwendung finden, lässt ihn glauben, dass dieses neue Medium Kreative und letztlich alle Menschen befähigen wird (Quelle: c_valenzuelab, c_valenzuelab)