Schlüsselwörter:Gemini 2.5 Pro, KI-Modell, humanoider Roboter, KI-Ethik, KI-Unternehmensgründung, KI-generierte Inhalte, KI-gestützte Kreativität, Gemini 2.5 Pro schafft Pokémon: Blau, Anthropic Claude globale Websuche, Qwen3 MoE Modell-Routing-Verzerrung, Runway Gen-4 References Funktion, KI in der psychischen Gesundheitsunterstützung
🔥 Fokus
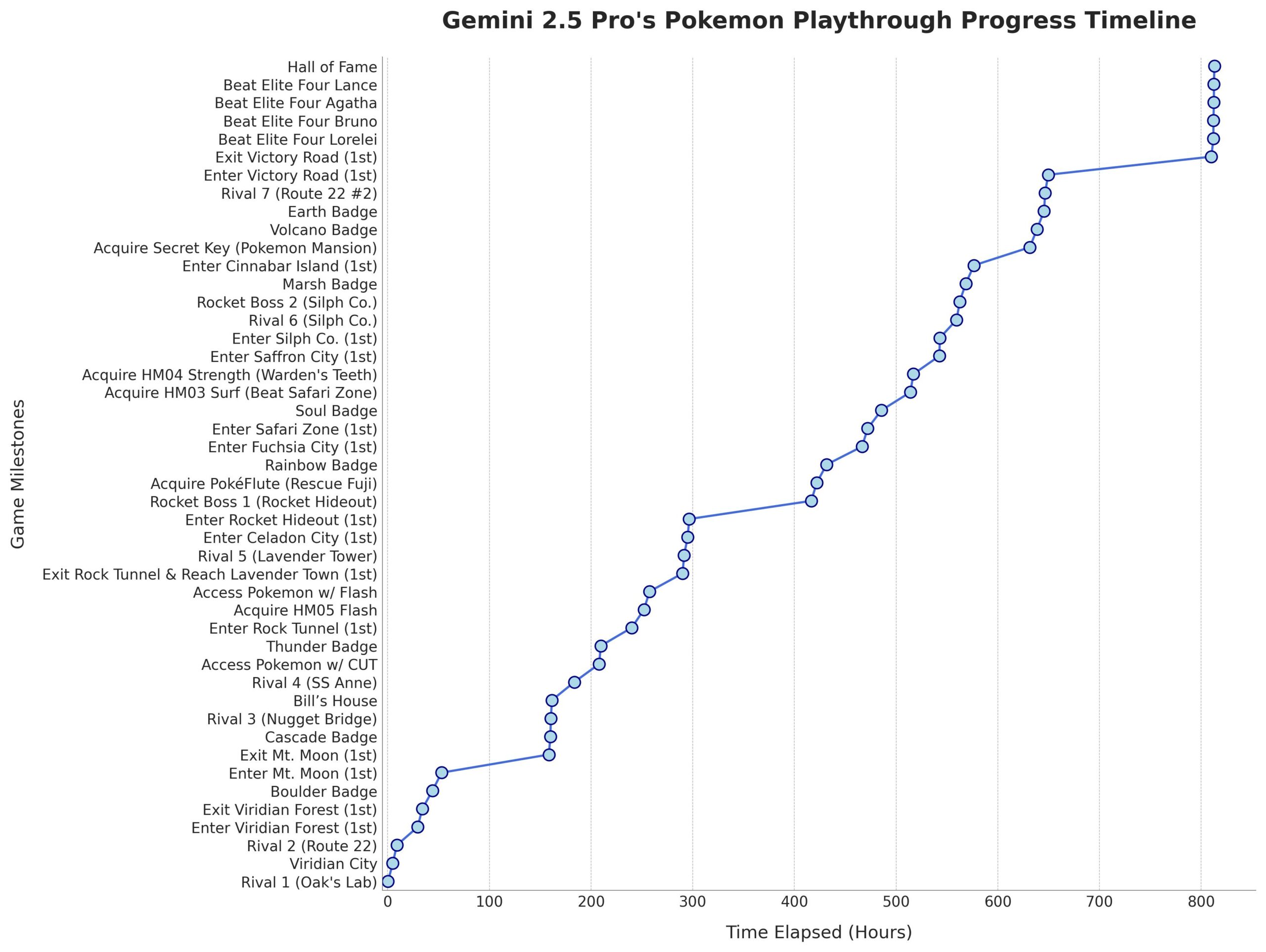
Gemini 2.5 Pro schließt Pokémon: Blau erfolgreich ab: Googles KI-Modell Gemini 2.5 Pro hat das klassische Spiel Pokémon: Blau erfolgreich abgeschlossen, einschließlich des Sammelns aller 8 Orden und des Besiegens der Top Vier der Pokémon-Liga. Dieser Erfolg wurde vom Streamer @TheCodeOfJoel durchgeführt und live übertragen und erhielt Glückwünsche vom Google CEO Sundar Pichai und DeepMind CEO Demis Hassabis. Dies demonstriert die signifikanten Fortschritte aktueller KI bei der Planung komplexer Aufgaben, der Entwicklung langfristiger Strategien und der Interaktion mit simulierten Umgebungen, übertrifft die bisherigen Leistungen von KI in diesem Spiel und markiert einen neuen Meilenstein für die Fähigkeiten von KI-Agenten. (Quelle: Google, jam3scampbell, teortaxesTex, YiTayML, demishassabis, _philschmid, Teknium1, tokenbender)
Apple kooperiert mit Anthropic zur Entwicklung der KI-Codierungsplattform “Vibe Coding”: Laut Bloomberg arbeitet Apple mit dem KI-Startup Anthropic zusammen, um gemeinsam eine neue KI-gesteuerte Codierungsplattform namens “Vibe Coding” zu entwickeln. Die Plattform wird derzeit intern bei Apple für Mitarbeitertests beworben und könnte in Zukunft auch Drittentwicklern zugänglich gemacht werden. Dies markiert Apples weiteren Vorstoß im Bereich der KI-Programmierassistenzwerkzeuge, mit dem Ziel, die Entwicklungseffizienz und -erfahrung durch KI zu verbessern, und könnte seine eigenen Projekte wie Swift Assist ergänzen oder integrieren. (Quelle: op7418)
Fortschritte und Diskussionen bei KI-gesteuerter Robotik: Humanoide Roboter und Embodied Intelligence haben in letzter Zeit große Aufmerksamkeit erregt. Das Unternehmen Figure präsentierte seinen neuen High-Tech-Hauptsitz, der von Batterien über Aktuatoren bis hin zu KI-Laboren reicht, was seine Ambitionen im Bereich Robotik unterstreicht. Auch Disney zeigte seine Technologie für humanoide Charakterroboter. Jedoch zeigten einige Roboter (einschließlich eines vom Kunden modifizierten Unitree G1) beim Marathon für humanoide Roboter in Peking eine schlechte Leistung, mit Stürzen, geringer Akkulaufzeit und Gleichgewichtsproblemen, was eine Diskussion über die tatsächlichen Fähigkeiten aktueller humanoider Roboter auslöste und verdeutlicht, dass sowohl im Bereich des „Kleinhirns“ (Motorsteuerung) als auch des „Großhirns“ (intelligente Entscheidungsfindung) noch erhebliche Fortschritte erforderlich sind. (Quelle: adcock_brett, Ronald_vanLoon, 人形机器人,最重要的还是“脑子”)

Diskussionen über KI-Ethik und gesellschaftliche Auswirkungen nehmen zu: In sozialen Medien und in der Forschung nehmen Diskussionen über die gesellschaftlichen Auswirkungen und ethischen Fragen der KI zu. Beispielsweise löste das kalifornische KI-Gesetz SB-1047 Kontroversen aus, und zugehörige Dokumentationen untersuchen die Notwendigkeit und Herausforderungen der Regulierung. Die NAACL 2025 Konferenz veranstaltete ein Tutorial zum Thema „Soziale Intelligenz im Zeitalter der LLMs“, das langfristige und neue Herausforderungen in der Interaktion von KI mit Menschen und Gesellschaft untersucht. Gleichzeitig äußern Nutzer Bedenken hinsichtlich der Qualität von KI-generierten Inhalten („Slop“) und fordern ein besseres Modelldesign und bessere Kontrolle. Diese Diskussionen spiegeln die wachsende Besorgnis der Gesellschaft über die ethischen, regulatorischen und sozialen Anpassungsprobleme wider, die mit der rasanten Entwicklung der KI-Technologie einhergehen. (Quelle: teortaxesTex, gneubig, stanfordnlp, jam3scampbell, willdepue, wordgrammer)

🎯 Trends
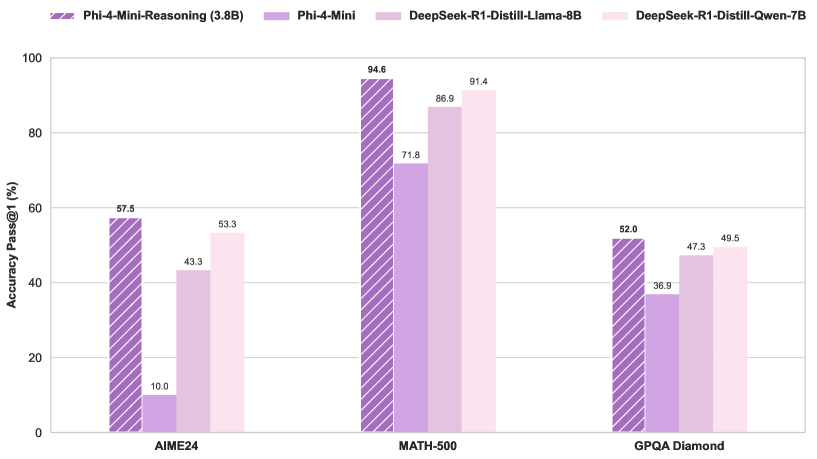
Microsoft veröffentlicht Phi-4-Mini-Reasoning Modell: Microsoft hat das Phi-4-Mini-Reasoning Modell auf Hugging Face veröffentlicht. Dieses Modell zielt darauf ab, die Fähigkeiten kleiner Sprachmodelle im Bereich des mathematischen Schließfolgerns zu verbessern und treibt die Entwicklung kleinerer, leistungsfähiger Modelle weiter voran. (Quelle: _akhaliq)
Anthropic Claude Modell unterstützt globale Websuche: Anthropic hat angekündigt, dass sein Claude KI-Modell nun allen zahlenden Nutzern eine globale Websuchfunktion bietet. Für einfache Aufgaben führt Claude eine schnelle Suche durch; bei komplexen Problemen erkundet es mehrere Informationsquellen, einschließlich Google Workspace, was die Echtzeit-Informationsbeschaffungs- und Verarbeitungsfähigkeiten des Modells verbessert. (Quelle: Teknium1, Reddit r/ClaudeAI)

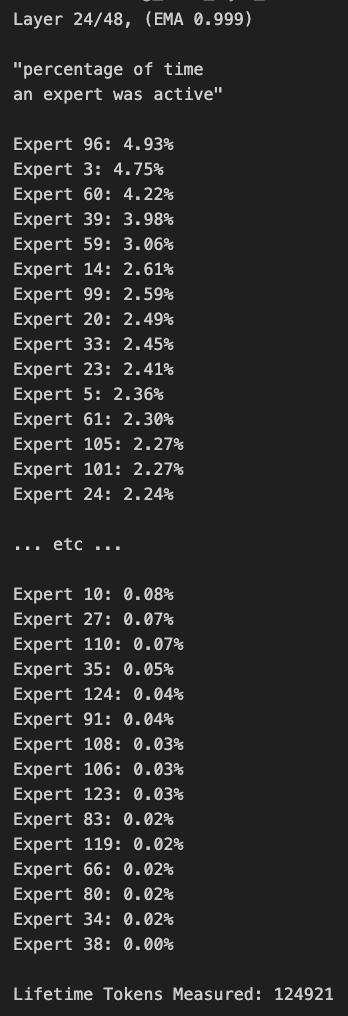
Qwen3 MoE Modell-Routing weist Bias auf und kann reduziert werden: Der Nutzer kalomaze analysierte und stellte fest, dass die Routing-Verteilung des Qwen3 MoE (Mixture of Experts) Modells einen signifikanten Bias aufweist. Selbst das 30B MoE Modell zeigt Potenzial für Pruning (Reduzierung). Dies bedeutet, dass einige Experten (Experts) möglicherweise nicht vollständig genutzt werden. Durch das Entfernen dieser Experten könnte die Modellgröße und der Rechenbedarf reduziert werden, ohne die Leistung wesentlich zu beeinträchtigen. Kalomaze hat bereits eine Version veröffentlicht, die das 30B Modell basierend auf dieser Erkenntnis auf 16B reduziert, und plant die Veröffentlichung einer Version, die das 235B Modell auf 150B reduziert. (Quelle: andersonbcdefg, Reddit r/LocalLLaMA)
DeepSeek Prover V2 ragt unter Open-Source-Mathematikassistenten heraus: DeepSeek Prover V2 wird als das derzeit leistungsstärkste Open-Source-Modell für mathematische Assistenz angesehen. Obwohl seine Leistung immer noch hinter der von Closed-Source- oder leistungsstärkeren Modellen wie Gemini 2.5 Pro, o4 mini high, o3, Claude 3.7 und Grok 3 zurückbleibt, zeigt es gute Leistungen im strukturierten Schließenfolgern. Nutzer sind der Meinung, dass es in „Brainstorming“-Sitzungen, die kreatives Denken erfordern, noch Verbesserungspotenzial gibt. (Quelle: cognitivecompai)
Diskussion über Modellpräferenzen: Entwicklerneigungen und spezifische Modelleigenschaften: In der Entwickler-Community wird weiterhin über die Vor- und Nachteile verschiedener großer Modelle diskutiert. Beispielsweise ist Sentdex der Meinung, dass o3 in Kombination mit Codex in Cursor besser abschneidet als Claude 3.7. VictorTaelin gibt an, dass Sonnet 3.7 zwar nicht perfekt ist (manchmal fügt es zu proaktiv nicht angeforderte Inhalte hinzu, Intelligenz nicht wie erwartet), aber in der Praxis dennoch stabilere und zuverlässigere Ergebnisse liefert als GPT-4o (fehleranfällig), o3/Gemini (schlechte Codeformatierung und Umschreibung), R1 (etwas veraltet) und Grok 3 (zweitbestes, aber in der Praxis etwas unterlegen). Dies spiegelt die unterschiedliche Eignung verschiedener Modelle für spezifische Aufgaben und Arbeitsabläufe wider. (Quelle: Sentdex, VictorTaelin, paul_cal)

Diskussion über LLM-Leistungstrends: Exponentielles Wachstum oder abnehmende Erträge?: Reddit-Nutzer diskutieren, ob LLMs immer noch exponentielle Verbesserungen erfahren. Einige argumentieren, dass trotz anfänglich schneller Fortschritte die Leistungssteigerung von LLMs nun zu abnehmenden Erträgen tendiert, wobei zusätzliche Leistung immer schwieriger und teurer zu erzielen ist, ähnlich der Entwicklung der autonomen Fahrtechnologie. Andere Nutzer widersprechen und weisen auf den enormen Sprung von GPT-3 zu Gemini 2.5 Pro hin, der zeigt, dass der Fortschritt immer noch signifikant ist und es zu früh sei, von einem Plateau zu sprechen. Die Diskussion spiegelt unterschiedliche Erwartungen an die zukünftige Entwicklungsgeschwindigkeit der KI wider. (Quelle: Reddit r/ArtificialInteligence)
KI-Chips werden zum Schlüssel für die Entwicklung humanoider Roboter: Branchenmeinungen zufolge liegt der Kern humanoider Roboter in ihrem „Gehirn“, d.h. Hochleistungschips. Der Artikel weist darauf hin, dass aktuelle humanoide Roboter noch Mängel in der Motorsteuerung (Kleinhirn) und der intelligenten Entscheidungsfindung (Großhirn) aufweisen, wobei die Chipleistung direkt den Intelligenzgrad des Roboters bestimmt. Nvidias GPUs, Intel-Prozessoren sowie Chips von heimischen Unternehmen wie Black Sesame Intelligence (Huashan A2000 und Wudang C1236) bieten Robotern stärkere Wahrnehmungs-, Schlussfolgerungs- und Steuerungsfähigkeiten und sind der Schlüssel, um humanoide Roboter von einem Gimmick zu einer praktischen Anwendung zu entwickeln. (Quelle: 人形机器人,最重要的还是“脑子”)

KI-Ethik und Anthropomorphisierung: Warum sagen wir „Danke“ zur KI?: Die Diskussion weist darauf hin, dass Nutzer dazu neigen, höfliche Formulierungen (wie „Danke“, „Bitte“) gegenüber KI zu verwenden, obwohl diese keine Emotionen hat. Dies rührt vom menschlichen Anthropomorphisierungsinstinkt und der Wahrnehmung sozialer Präsenz her. Studien zeigen, dass höfliche Interaktionsweisen die KI dazu bringen können, erwartungskonformere, menschenähnlichere Antworten zu generieren. Dies birgt jedoch auch Risiken, z. B. dass KI menschliche Vorurteile lernen und verstärken oder böswillig zu unangemessenen Inhalten verleitet werden kann. Das höfliche Verhalten gegenüber KI spiegelt die komplexe Psychologie und soziale Anpassung des Menschen bei der Interaktion mit zunehmend intelligenteren Maschinen wider. (Quelle: 你对 AI 说的每一句「谢谢」,都在烧钱)

🧰 Tools
Runway Gen-4 References Funktion: Die von RunwayML eingeführte Funktion Gen-4 References ermöglicht es Nutzern, eigene oder andere Referenzbilder in KI-generierte Videos oder Bilder (wie Memes) zu integrieren. Nutzerfeedback besagt, dass die Funktion bemerkenswerte Ergebnisse liefert und mehrere konsistente Charaktere im selben generierten Bild verarbeiten kann, was den Prozess der Integration spezifischer Personen oder Stile in KI-Kreationen vereinfacht. (Quelle: c_valenzuelab)

Krea AI führt Vorlagen für die Bilderzeugung ein: Krea AI hat eine neue Funktion hinzugefügt, die gängige GPT-4o Bilderzeugungs-Prompts in Vorlagen umwandelt. Nutzer müssen lediglich ihr eigenes Bild hochladen und eine Vorlage auswählen, um ein Bild im entsprechenden Stil zu generieren, ohne manuell komplexe Prompts eingeben zu müssen, was den Bilderzeugungsprozess vereinfacht. (Quelle: op7418)
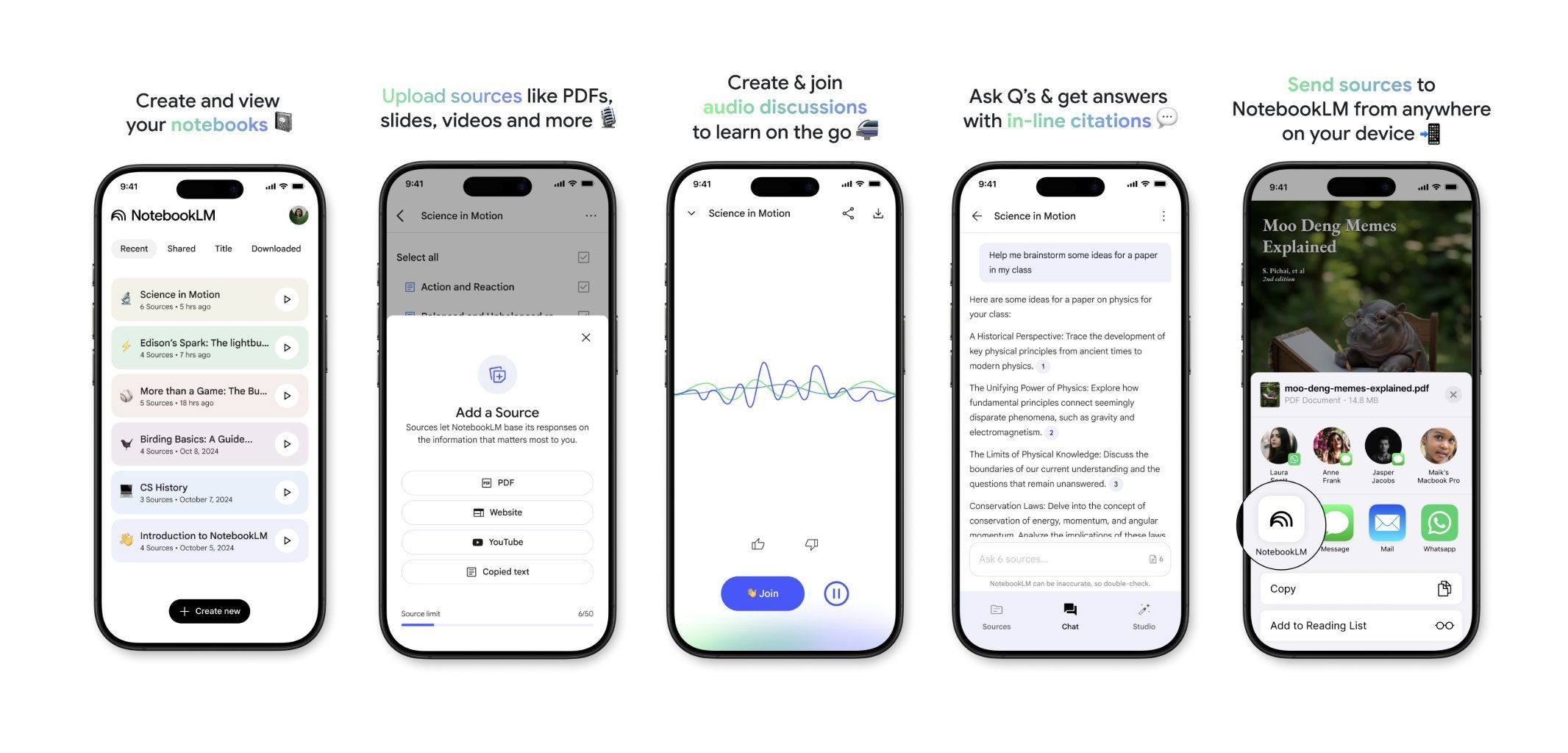
NotebookLM startet bald mobile App: Googles NotebookLM (ehemals Project Tailwind) wird in Kürze eine mobile Anwendung veröffentlichen. Nutzer können Artikel und Inhalte, die sie auf ihrem Handy sehen, schnell an NotebookLM weiterleiten, um sie zu verarbeiten und zu integrieren. Die Registrierung für die Warteliste der App ist bereits geöffnet, mit dem Ziel, ein bequemeres mobiles Informationsmanagement und KI-gestütztes Lernerlebnis zu bieten. (Quelle: op7418)
Runway für Innenarchitektur: Nutzer demonstrieren die Anwendung von Runway AI für die Innenarchitektur. Durch die Bereitstellung eines Bildes eines Raumes und eines Referenzbildes, das Stil/Stimmung repräsentiert, kann Runway Innenarchitektur-Visualisierungen generieren, die die Merkmale beider Bilder vereinen, was das Potenzial von KI im kreativen Designbereich zeigt. (Quelle: c_valenzuelab)

Unsloth unterstützt Qwen3 Modell-Finetuning: Unsloth kündigt Unterstützung für das Finetuning der Qwen3 Modellreihe an, mit 2-facher Geschwindigkeitssteigerung und 70% geringerem Speicherverbrauch. Nutzer können auf einer GPU mit 24 GB VRAM ein Finetuning mit 8-mal längerer Kontextlänge als mit Flash Attention 2 durchführen. Es werden Colab Notebooks zur Verfügung gestellt, um das Qwen3 14B Modell kostenlos zu finetunen, und verschiedene quantisierte Modelle, einschließlich GGUF, wurden hochgeladen. Dies senkt die Hardwareanforderungen für das Finetuning fortschrittlicher Modelle. (Quelle: Reddit r/LocalLLaMA)
Claude AI Styles Funktion: Nutzer teilen ihre Erfahrungen mit der Verwendung der Styles-Funktion von Claude AI zur Verbesserung der Zusammenarbeit mit der KI. Durch die Erstellung eines Stils namens „Iterative Engineering“, der Schritte wie Diskutieren, Planen, kleine Änderungen, Testen, Iterieren und bedarfsgesteuertes Refactoring festlegt, kann Claude dazu angeleitet werden, methodischer und inkrementeller zu programmieren und übermäßiges Umschreiben von Code zu vermeiden, was die Nützlichkeit der KI als Programmierpartner erhöht. (Quelle: Reddit r/ClaudeAI)
Deepwiki liefert Quellcode-Blöcke: Nutzer cto_junior erwähnt als Vorteil von Deepwiki, dass es neben jeder Antwort Quellcode-Blöcke anzeigt und nicht nur Links anhängt. Diese Praxis erhöht die Glaubwürdigkeit der Informationen, insbesondere für Software Development Engineers (SDEs), die KI-Tools gegenüber skeptisch sind. (Quelle: cto_junior)
📚 Lernen
NousResearch veröffentlicht Update für Atropos RL Framework: Das Atropos Reinforcement Learning (RL) Umgebungsframework von NousResearch wurde aktualisiert. Neue Funktionen ermöglichen es Nutzern, Rollouts von RL-Umgebungen schnell und einfach zu testen, ohne ein Trainings- oder Inferenz-Engine zu benötigen. Standardmäßig wird die OpenAI API verwendet, kann aber für andere API-Anbieter (oder lokale VLLM/SGLang Endpunkte) konfiguriert werden. Nach Abschluss des Tests wird ein Webbericht mit den Completions und ihren Bewertungen generiert, der auch wandb-Logging unterstützt, was das Debugging und die Evaluierung von RL-Umgebungen erleichtert. (Quelle: Teknium1)

Personalisierter RAG Benchmark-Datensatz EnronQA veröffentlicht: Forscher haben den EnronQA-Datensatz veröffentlicht, um die Forschung zu personalisierter Retrieval-Augmented Generation (Personalized RAG) auf privaten Dokumenten voranzutreiben. Der Datensatz umfasst 103.638 E-Mails und 528.304 hochwertige Frage-Antwort-Paare für 150 Nutzer und bietet eine Ressource zur Bewertung und Entwicklung von RAG-Systemen, die personenspezifische Informationen verstehen und nutzen können. (Quelle: lateinteraction)
GTE-ModernColBERT (PyLate) veröffentlicht: LightOnAI hat GTE-ModernColBERT (PyLate) veröffentlicht, einen 128-dimensionalen MaxSim Retriever, der auf gte-modernbert-base basiert und auf ms-marco-en-bge-gemma feinabgestimmt wurde. Er unterstützt nativ die PyLate-Bibliothek für Reranking und HNSW-Indizierung. Er zeigt hervorragende Leistungen im NanoBEIR-Benchmark und übertrifft ColBERT-small im durchschnittlichen BEIR-Score, was neue effiziente Optionen für den Textretrieval bietet. (Quelle: lateinteraction)

SOLO Bench – Neuer LLM-Benchmark: Nutzer jd_3d hat SOLO Bench entwickelt und veröffentlicht, eine neue Methode zum Benchmarking von LLMs. Der Test verlangt vom LLM, einen Text mit einer bestimmten Anzahl von Sätzen (z. B. 250 oder 500) zu generieren, wobei jeder Satz genau ein Wort aus einer vordefinierten Liste (mit Substantiven, Verben, Adjektiven usw.) enthalten muss und jedes Wort nur einmal verwendet werden darf. Die Bewertung erfolgt durch ein regelbasiertes Skript und zielt darauf ab, die Fähigkeit des LLM zur Befolgung von Anweisungen, zur Einhaltung von Einschränkungen und zur Generierung langer Texte zu testen. Erste Ergebnisse zeigen, dass der Benchmark die Leistung verschiedener Modelle effektiv unterscheidet. (Quelle: Reddit r/LocalLLaMA)
Nutzung strategischer rekursiver Reflexion zur Manipulation des latenten Raums: Ein Nutzer schlägt eine Methode vor, um durch „strategische rekursive Reflexion“ (Strategic recursive reflection, RR) verschachtelte Inferenzhierarchien im latenten Raum von LLMs zu erzeugen. Indem das Modell an Schlüsselmomenten aufgefordert wird, über frühere Interaktionen nachzudenken, werden metakognitive Schleifen erzeugt, die „Mini-Latenträume“ aufbauen. Jeder Prompt wird als eine Art Druck betrachtet, der den Pfad des Modells im latenten Raum lenkt und es selbstbezüglicher und abstrakter macht. Dies wird als Simulation des menschlichen Prozesses angesehen, durch Nachdenken über Gedanken das Denken zu vertiefen, mit dem Ziel, tiefere Konzepte zu erforschen. (Quelle: Reddit r/ArtificialInteligence)
💼 Wirtschaft
Google zahlt Samsung Gebühren für die Vorinstallation von Gemini AI: Nachdem Google letztes Jahr wegen seines Standard-Suchmaschinen-Deals wegen Verstoßes gegen das Kartellrecht verurteilt wurde, wird berichtet, dass Google Samsung monatlich „riesige Summen“ und Umsatzbeteiligungen zahlt, um Gemini AI auf Samsung-Geräten vorzuinstallieren, und möglicherweise Partner zur obligatorischen Vorinstallation von Gemini auffordert. Dies erklärt, warum die Samsung Galaxy S25 Serie Gemini tief integriert und es sogar zum Standard-KI-Assistenten macht. Dieser Schritt spiegelt Googles Strategie wider, angesichts unzureichender eigener Hardware-Kanäle dringend den mobilen KI-Einstiegspunkt zu besetzen, könnte aber erneut kartellrechtliche Bedenken aufwerfen. (Quelle: 三星手机预装Gemini AI,也是谷歌花钱买的)

KI-Startups stehen vor Herausforderungen: Eine Reddit-Diskussion weist darauf hin, dass vielen KI-Startups möglicherweise ein Wettbewerbsvorteil fehlt, da die Modellfähigkeiten konvergieren und die Nutzerloyalität gering ist. Große Technologieunternehmen (Google, Microsoft, Apple) können Nutzer aufgrund ihrer Ökosystemvorteile (wie Vorinstallation, Integration) leichter erreichen. Selbst wenn das Modell eines Startups etwas besser ist, neigen Nutzer möglicherweise dazu, die standardmäßige oder integrierte „ausreichend gute“ KI zu verwenden. Dies weckt Bedenken hinsichtlich der langfristigen Überlebensfähigkeit von KI-Startups und der Aussichten für VC-Investitionen. (Quelle: Reddit r/ArtificialInteligence)
Zusammenfassung der KI-Finanzierungs- und Geschäftsaktivitäten dieser Woche (2. Mai 2025): Microsoft CEO enthüllt, dass KI „wichtige Teile“ des Unternehmenscodes geschrieben hat; Microsoft CFO warnt, dass KI-Dienste aufgrund zu hoher Nachfrage unterbrochen werden könnten; Google beginnt mit der Schaltung von Anzeigen in KI-Chatbots von Drittanbietern; Meta startet eigenständige KI-App; Cast AI sammelt 108 Mio. $, Astronomer 93 Mio. $, Edgerunner AI 12 Mio. $; Studie wirft LM Arena manipulierte Benchmarks vor; Nvidia fordert Anthropic wegen Unterstützung von Chip-Exportkontrollen heraus. (Quelle: Reddit r/artificial)
🌟 Community
Diskussion über Qualität und Kosten von KI-generierten Inhalten: In der Community werden Bedenken über die uneinheitliche Qualität von KI-generierten Inhalten (genannt “Slop”) geäußert. Nutzer wordgrammer weist darauf hin, dass die Qualität vieler generierter KI-Videos niedrig ist und die tatsächlichen Kosten (unter Berücksichtigung von Filterung und Wiederholungsversuchen) weit über dem angegebenen Preis liegen. Dies löst Diskussionen über Modelldesign (wie jam3scampbell unter Berufung auf Steve Jobs’ Ansichten) und die effektive Nutzung von KI-Tools aus, wobei die Notwendigkeit feinerer Kontrolle und höherer Generierungsqualitätsstandards betont wird. (Quelle: wordgrammer, jam3scampbell, willdepue)
Diskussion über die Leistung von KI bei spezifischen Aufgaben: Community-Mitglieder diskutieren die Leistung und Grenzen von KI bei verschiedenen Aufgaben. Beispielsweise wird DeepSeek R1 als möglicher Höhepunkt des LLM-Hypes angesehen; obwohl es Fortschritte in Bereichen wie formaler Mathematik und Medizin gibt, hat es noch keine breite Aufmerksamkeit bei normalen Nutzern erregt. DeepSeek Prover V2 schneidet in Mathematik gut ab, wird aber als wenig kreativ angesehen. Nutzer vikhyatk stellt den Sinn der übermäßigen Optimierung von Modellen zur Leistung in spezifischen Benchmarks wie AIME (American Invitational Mathematics Examination) in Frage und argumentiert, dass die breite Masse sich nicht für mathematische Fähigkeiten interessiert. Diese Diskussionen spiegeln Überlegungen zu den Fähigkeitsgrenzen und dem praktischen Nutzen von KI wider. (Quelle: wordgrammer, cognitivecompai, vikhyatk)
KI-gestützte Kreativität und Design: Die Community zeigt verschiedene Möglichkeiten zur Nutzung von KI-Tools für kreatives Design. Nutzer verwenden die Gen-4 References Funktion von Runway, um sich selbst in Memes zu integrieren; nutzen Runway zur Generierung von Innenarchitekturkonzepten; verwenden GPT-4o und Prompt-Vorlagen, um Bilder mit spezifischen Stilen zu erstellen (z. B. Origami-Südchinesischer Tiger, Tier-Silikon-Handgelenkauflage, Integration der Wortbedeutung in das Buchstabendesign). Diese Beispiele zeigen das Potenzial von KI in visueller Kreativität und personalisiertem Design. (Quelle: c_valenzuelab, c_valenzuelab, dotey, dotey, dotey)

Zweifel an der Fähigkeit von KI zur Nachahmung von Schreibstilen: Nutzer nrehiew_ argumentiert, dass die Anweisung an LLMs, „in meinem Ton und Stil weiterzuschreiben“, möglicherweise keine tatsächliche Wirkung hat, da die meisten Menschen die Einzigartigkeit ihres eigenen Schreibstils überschätzen. Dies löst eine Diskussion über die Fähigkeit von LLMs aus, subtile Schreibstile zu verstehen und zu replizieren, sowie über die Wahrnehmungsverzerrung der Nutzer bezüglich dieser Fähigkeit. (Quelle: nrehiew_)
KI zur emotionalen Unterstützung findet Anklang und löst Diskussionen aus: Reddit-Nutzer teilen Erfahrungen, wie sie durch Gespräche mit KI wie ChatGPT emotionale Unterstützung erhalten und sogar Hilfe bei der Bewältigung von Krisen gefunden haben. Viele geben an, dass KI in Zeiten der Einsamkeit, des Redebedarfs oder psychischer Belastung einen urteilsfreien, geduldigen und jederzeit verfügbaren Gesprächspartner bietet, der sich manchmal sogar effektiver anfühlt als die Kommunikation mit echten Menschen. Dies löst Diskussionen über die Rolle der KI in der psychischen Gesundheitsunterstützung aus, betont aber auch, dass KI keine professionelle menschliche Hilfe ersetzen kann und dass man sich vor möglichen Vorurteilen oder Irreführungen durch KI hüten muss. (Quelle: Reddit r/ChatGPT, Reddit r/ClaudeAI)
Geteilte Meinungen über KI-generierte Kunst: Nutzer diskutieren die potenziellen Auswirkungen von KI-generierter Kunst auf die Wahrnehmung menschlicher Künstler und ihrer Werke. Einige beschweren sich, dass hochwertige Werke nun oft leichtfertig als KI-generiert abgetan werden, wodurch Talent und Mühe der Schöpfer ignoriert werden. Dieses Phänomen beginnt sogar, die Wahrnehmung der Menschen zu verzerren, sodass sie dazu neigen, in Werken nach „menschlichen Fehlern“ zu suchen, um deren Nicht-KI-Ursprung zu bestätigen. Die Diskussion berührt auch die Frage, ob KI-generierte Inhalte verpflichtend mit einem Wasserzeichen versehen werden sollten. (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
Ressourcenverbrauch durch KI erregt Aufmerksamkeit: Die Diskussion hebt den enormen Ressourcenverbrauch hervor, der hinter der KI-Entwicklung steht. Das Training und der Betrieb großer KI-Modelle erfordern große Mengen an Strom und Wasser, wobei Rechenzentren zu neuen energieintensiven Einrichtungen werden. Jede Interaktion eines Nutzers mit einer KI, einschließlich eines einfachen „Danke“, trägt zum kumulativen Energieverbrauch bei. Dies lenkt die Aufmerksamkeit auf die nachhaltige Entwicklung von KI und auf Energielösungen (wie Kernfusion). (Quelle: 你对 AI 说的每一句「谢谢」,都在烧钱)
KI und die Distanz zum Bewusstsein: Reddit-Nutzer diskutieren, ob aktuelle KI über Selbstbewusstsein verfügt. Die vorherrschende Meinung ist, dass aktuelle KI (wie LLMs) im Wesentlichen komplexe Mustererkennungssysteme sind, die Wörter basierend auf Wahrscheinlichkeiten vorhersagen und denen echtes Verständnis und Selbstbewusstsein fehlen; sie sind noch sehr weit davon entfernt, diese Fähigkeit zu besitzen. Einige Kommentare weisen jedoch darauf hin, dass das menschliche Bewusstsein selbst noch nicht vollständig verstanden ist, Vergleiche daher fehlerhaft sein könnten und die übermenschlichen Fähigkeiten der KI bei bestimmten Aufgaben nicht ignoriert werden sollten. (Quelle: Reddit r/ArtificialInteligence)
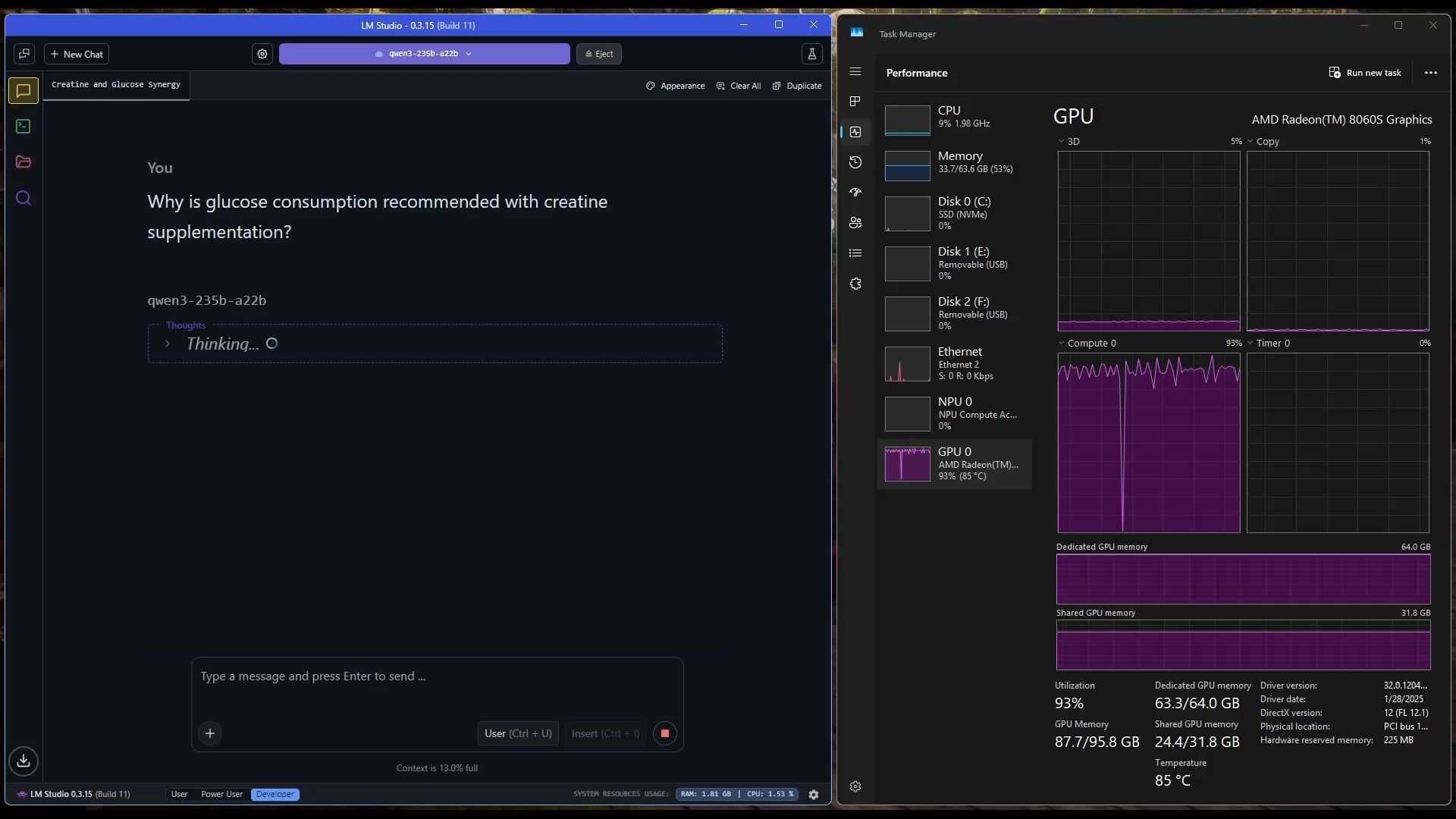
Windows-Tablet führt großes MoE-Modell aus: Ein Nutzer demonstriert die Ausführung des Qwen3 235B-A22B MoE Modells (unter Verwendung der Q2_K_XL Quantisierung) auf einem Windows-Tablet mit AMD Ryzen AI Max 395+ und 128 GB RAM, wobei nur die iGPU (Radeon 8060S, 87,7 GB von 95,8 GB als VRAM zugewiesen) verwendet wird, mit einer Geschwindigkeit von ca. 11,1 t/s. Dies zeigt die Möglichkeit, sehr große Modelle auf tragbaren Geräten auszuführen, obwohl die Speicherbandbreite weiterhin ein Engpass ist. (Quelle: Reddit r/LocalLLaMA)