
Schlüsselwörter:ChatBot Arena, Phi-4-Reasoning, Claude-Integrationen, KI-Agenten, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, Ranking-Halluzinationen, Inferenzfähigkeiten kleiner Modelle, Integration von Drittanbieteranwendungen, KI-Programmieragenten, Mathematische Theorembeweise
🔥 Fokus
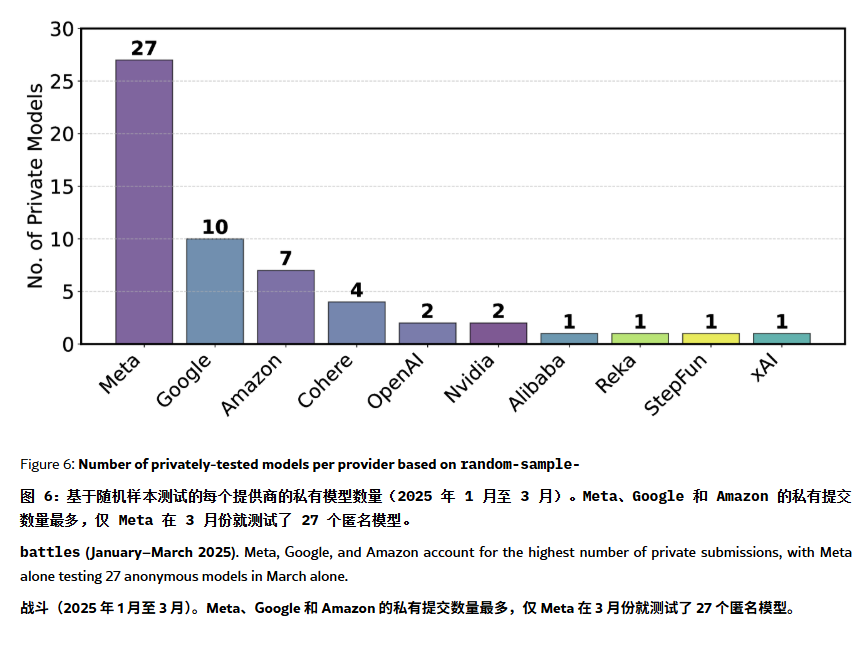
ChatBot Arena Rangliste unter „Halluzinations“- und Manipulationsverdacht: Ein ArXiv-Paper [2504.20879] stellt die weit verbreitete ChatBot Arena Modell-Rangliste in Frage und spricht von einer „Ranglisten-Halluzination“. Das Paper weist darauf hin, dass große Technologieunternehmen (wie Meta) durch die Einreichung zahlreicher feinabgestimmter Modellvarianten (z.B. 27 Tests für Llama-4) und die Veröffentlichung nur der besten Ergebnisse die Rangliste manipulieren könnten; die Häufigkeit der Modellpräsentation könnte ebenfalls große Unternehmensmodelle bevorzugen und die Sichtbarkeit von Open-Source-Modellen einschränken; der Mechanismus zur Modellauswahl sei intransparent, wobei viele Open-Source-Modelle aufgrund unzureichender Testdaten entfernt würden; zudem könnte die Ähnlichkeit häufig gestellter Benutzerfragen dazu führen, dass Modelle gezielt auf diese trainiert werden (Overfitting), um höhere Punktzahlen zu erzielen. Dies weckt Bedenken hinsichtlich der Zuverlässigkeit und Fairness aktueller Mainstream-LLM-Benchmarks und empfiehlt Entwicklern und Nutzern, Ranglistenplatzierungen kritisch zu betrachten und den Aufbau eigener, bedarfsgerechter Bewertungssysteme in Erwägung zu ziehen. (Quelle: karminski3, op7418, TheRundownAI)
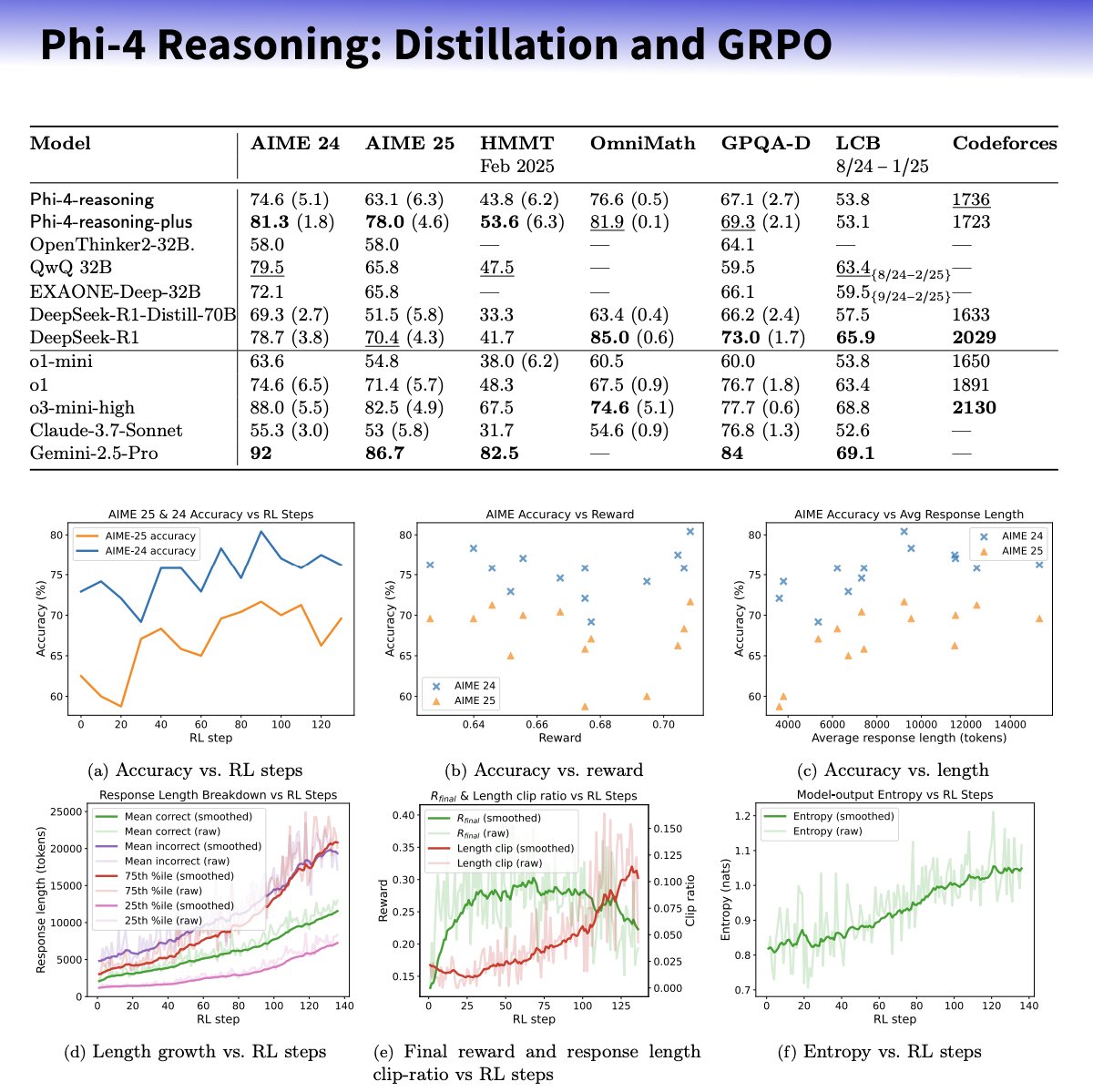
Microsoft veröffentlicht Phi-4-reasoning Kleinmodellreihe mit Fokus auf verbesserte Reasoning-Fähigkeiten: Microsoft hat die Modelle Phi-4-reasoning und Phi-4-reasoning-plus auf Basis der Phi-4-Architektur vorgestellt. Ziel ist es, die Reasoning-Fähigkeiten kleiner Sprachmodelle durch sorgfältig kuratierte Datensätze, Supervised Fine-Tuning (SFT) und zielgerichtetes Reinforcement Learning (RL) zu verbessern. Berichten zufolge nutzen diese Modelle OpenAI o3-mini als „Lehrer“ zur Generierung hochwertiger Chain-of-Thought (CoT) Reasoning-Pfade und werden mittels des GRPO-Algorithmus durch Reinforcement Learning optimiert. Microsoft-Forscher Sebastien Bubeck behauptet, Phi-4-reasoning übertreffe DeepSeek R1 in mathematischen Fähigkeiten, obwohl es nur 2% dessen Modellgröße habe. Die Modellreihe verwendet spezielle Reasoning-Token und eine erweiterte Kontextlänge von 32K. Dieser Schritt wird als Erkundung in Richtung kleinerer, spezialisierter Modelle gesehen, die möglicherweise leistungsfähigere Reasoning-Lösungen für ressourcenbeschränkte Szenarien bieten, wirft aber auch Fragen zur Nutzung von OpenAI-Technologie und zur Veröffentlichung unter MIT-Lizenz auf. (Quelle: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic führt Integrations-Funktion ein und erweitert Forschungsfähigkeiten: Anthropic kündigt Claude Integrations an, womit Nutzer Claude mit 10 Drittanbieter-Anwendungen und -Diensten wie Jira, Confluence, Zapier, Cloudflare, Asana verbinden können; zukünftig sollen auch Stripe, GitLab etc. unterstützt werden. Die bisher nur für lokale Server verfügbare MCP (Model Context Protocol)-Unterstützung wird auf Remote-Server ausgeweitet, sodass Entwickler über Dokumentation oder Lösungen wie Cloudflare in etwa 30 Minuten eigene Integrationen erstellen können. Gleichzeitig wird die Research-Funktion von Claude erweitert: Ein neuer Advanced Mode kann das Web, Google Workspace und verbundene Integrationen durchsuchen, komplexe Anfragen in Teiluntersuchungen zerlegen und umfassende Berichte mit Quellenangaben generieren, was bis zu 45 Minuten dauern kann. Die Websuchfunktion wird zudem weltweit für zahlende Nutzer freigeschaltet. Diese Updates zielen darauf ab, die Integrationsfähigkeit und die Tiefe der Recherchemöglichkeiten von Claude als Arbeitsassistent zu verbessern. (Quelle: _philschmid, Reddit r/ClaudeAI)

Fähigkeiten von KI-Agenten folgen neuem Mooreschen Gesetz: Verdopplung alle 4 Monate: Eine Untersuchung von AI Digest zeigt, dass die Fähigkeit von KI-Programmieragenten zur Erledigung von Aufgaben exponentiell wächst. Die für Aufgaben benötigte Zeit (gemessen an der Zeit, die menschliche Experten benötigen würden) verdoppelt sich im Zeitraum 2024-2025 etwa alle 4 Monate, schneller als die Verdopplung alle 7 Monate im Zeitraum 2019-2025. Aktuelle Spitzen-KI-Agenten können bereits Programmieraufgaben bewältigen, die ein Mensch in 1 Stunde erledigt. Sollte sich dieser beschleunigte Trend fortsetzen, könnten KI-Agenten bis 2027 voraussichtlich komplexe Aufgaben von bis zu 167 Stunden (etwa ein Monat) Dauer bewältigen. Dieser rasante Fähigkeitszuwachs basiert auf Fortschritten der Modelle selbst sowie auf verbesserter algorithmischer Effizienz und könnte durch KI-gestützte KI-Forschung eine positive Rückkopplungsschleife mit superexponentiellem Wachstum bilden. Dies deutet auf die Möglichkeit einer „Software-Intelligenz-Explosion“ hin, die Bereiche wie Softwareentwicklung und Forschung tiefgreifend verändern wird, aber auch gesellschaftliche Herausforderungen wie die Auswirkungen der Automatisierung auf den Arbeitsmarkt mit sich bringt. (Quelle: 新智元)

🎯 Trends
DeepSeek-Prover-V2 veröffentlicht, verbessert Fähigkeit zum Beweis mathematischer Theoreme: DeepSeek AI hat DeepSeek-Prover-V2 veröffentlicht, verfügbar in den Größen 7B und 671B, spezialisiert auf formale Theorembeweise in Lean 4. Das Modell wurde mittels rekursiver Beweissuche und Reinforcement Learning (GRPO) trainiert. Es nutzt DeepSeek-V3 zur Zerlegung komplexer Theoreme und Generierung von Beweisskizzen, kombiniert mit Experteniteration und synthetischen Cold-Start-Daten für Fine-Tuning und Reinforcement Learning. DeepSeek-Prover-V2-671B erreicht eine Erfolgsquote von 88,9% auf MiniF2F-test und löst 49 Probleme auf PutnamBench, was SOTA-Leistung demonstriert. Gleichzeitig wurde der ProverBench-Benchmark veröffentlicht, der AIME- und Lehrbuchaufgaben enthält. Das Modell zielt darauf ab, informelles Schlussfolgern und formale Beweise zu vereinen und die Entwicklung automatischer Theorembeweise voranzutreiben. (Quelle: 新智元)

Nvidia und UIUC stellen neue Methode zur Kontextfenster-Erweiterung auf 4 Millionen Token vor: Forscher von Nvidia und der University of Illinois Urbana-Champaign haben eine effiziente Trainingsmethode vorgeschlagen, um das Kontextfenster von Llama 3.1-8B-Instruct von 128K auf 1M, 2M und sogar 4M Token zu erweitern. Die Methode verwendet eine zweistufige Strategie aus kontinuierlichem Pre-Training und Instruction Fine-Tuning. Schlüsseltechnologien umfassen die Verwendung spezieller Dokumenttrennzeichen, eine auf YaRN basierende Position Encoding-Erweiterung sowie einstufiges Pre-Training. Das trainierte Modell UltraLong-8B zeigt hervorragende Leistungen in Langkontext-Benchmarks wie RULER, LV-Eval und InfiniteBench und behält oder übertrifft sogar die Leistung des Basismodells Llama 3.1 in Standard-Kurzkontext-Aufgaben wie MMLU und MATH, wobei es andere Langkontext-Modelle wie ProLong und Gradient übertrifft. Die Forschung bietet einen effizienten und skalierbaren Weg zum Aufbau von LLMs mit extrem langen Kontextfenstern. (Quelle: 新智元)

Qwen3 veröffentlicht, mit deutlicher Leistungssteigerung: Alibaba hat die Qwen3-Modellreihe veröffentlicht, darunter Qwen3-30B-A3B. Laut ersten Tests und Benchmark-Daten von Reddit-Nutzern (z.B. AHA Leaderboard) zeigt Qwen3 im Vergleich zu früheren Versionen Qwen2.5 und QwQ bessere Leistungen in mehreren Dimensionen (z.B. spezifisches Wissen in Bereichen wie Gesundheit, Bitcoin, Nostr). Nutzerfeedback deutet darauf hin, dass Qwen3 bei der Bearbeitung spezifischer Aufgaben (z.B. Simulation der Dynamik des Sonnensystems) starke Fähigkeiten zeigt und physikalische Gesetze korrekt anwendet, um elliptische Bahnen und relative Perioden zu generieren. Einige Nutzer weisen jedoch darauf hin, dass die Leistung von Qwen3 bei langem Kontext (z.B. nahe 16K) deutlich nachlässt und der Token-Verbrauch bei der Inferenz hoch ist, weshalb die Verwendung in Kombination mit Suchwerkzeugen empfohlen wird. Die Namensgebung von Qwen3 (z.B. Qwen3-30B-A3B) wird für ihre Klarheit gelobt. (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini wird bald Google-Kontodaten integrieren, um personalisierte Erlebnisse zu bieten: Google plant, dem KI-Assistenten Gemini Zugriff auf die Google-Kontodaten der Nutzer zu gewähren, einschließlich Gmail, Fotos, YouTube-Verlauf usw., um ein personalisierteres, proaktiveres und leistungsfähigeres Assistenz-Erlebnis zu ermöglichen. Google-Produktleiter Josh Woodward erklärte, dies solle Gemini helfen, die Nutzer besser zu verstehen und zu einer Erweiterung des Nutzers zu werden. Die Funktion wird optional sein (Opt-in), Nutzer können wählen, ob sie den Datenzugriff aktivieren. Dieser Schritt löst Diskussionen über Datenschutz und Datensicherheit aus, da Nutzer zwischen personalisiertem Komfort und Datenschutz abwägen müssen. (Quelle: JeffDean, Reddit r/ArtificialInteligence)

Nvidia stellt Parakeet-TDT-0.6B-v2 ASR-Modell vor: Nvidia hat ein neues Modell für automatische Spracherkennung (ASR), Parakeet-TDT-0.6B-v2, mit 600 Millionen Parametern veröffentlicht. Berichten zufolge übertrifft dieses Modell Whisper3-large (1,6 Milliarden Parameter) im Open ASR Leaderboard, insbesondere bei der Verarbeitung diversifizierter Datensätze (einschließlich LibriSpeech, Fisher Corpus, YouTube-Daten usw., insgesamt ca. 120.000 Stunden Daten). Das Modell unterstützt Zeitstempel auf Zeichen-, Wort- und Absatzebene, ist jedoch derzeit nur für Englisch verfügbar und erfordert Nvidia GPUs und spezifische Frameworks zur Ausführung. Erste Nutzerfeedbacks loben die hohe Genauigkeit bei Transkription und Zeichensetzung. (Quelle: Reddit r/LocalLLaMA)

Qwen2.5-VL veröffentlicht, verbessert Visual Language Understanding: Alibaba hat die multimodale Modellreihe Qwen2.5-VL (mit 3B, 7B, 72B Parametern) veröffentlicht, um das Verständnis und die Interaktion von Maschinen mit der visuellen Welt zu verbessern. Diese Modelle können für Aufgaben wie Bildzusammenfassung, visuelle Fragebeantwortung und die Generierung von Berichten aus komplexen visuellen Informationen verwendet werden. Der Artikel beschreibt Architektur, Benchmark-Leistung und Inferenzdetails und zeigt Fortschritte im Bereich Visual Language Understanding. (Quelle: Reddit r/deeplearning)

Unterstützung für Mistral Small 3.1 Vision in llama.cpp integriert: Das llama.cpp-Projekt hat die Unterstützung für das Mistral Small 3.1 Vision Modell (24B Parameter) integriert. Dies bedeutet, dass Nutzer dieses multimodale Modell nun im llama.cpp-Framework ausführen können, um Aufgaben wie Bildverständnis durchzuführen. Unsloth hat bereits entsprechende Modelldateien im GGUF-Format bereitgestellt. Dies erleichtert die lokale Ausführung von Mistrals visuellen Modellen. (Quelle: Reddit r/LocalLLaMA)
Meta veröffentlicht Synthetic Data Kit: Meta hat ein Kommandozeilen-Tool namens Synthetic Data Kit als Open Source veröffentlicht, das die Datenvorbereitungsphase für das LLM Fine-Tuning vereinfachen soll. Das Tool bietet vier Befehle: ingest (Daten importieren), create (QA-Paare generieren, optional mit Reasoning Chain), curate (hochwertige Beispiele mit Llama als Judge filtern) und save-as (in kompatible Formate exportieren). Es nutzt lokale LLMs (via vLLM), um hochwertige synthetische Trainingsdaten zu generieren, insbesondere geeignet, um spezifische Reasoning-Fähigkeiten für Modelle wie Llama-3 freizuschalten. (Quelle: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 wird zum beliebten Embedding-Modell: Das von LightOnIO eingeführte Modell GTE-ModernColBERT-v1 ist zu einem neuen Trend bei Such-/Embedding-Modellen auf Hugging Face geworden. Das Modell verwendet eine Multi-Vektor- (auch bekannt als Late-Interaction oder ColBERT) Suchmethode und bietet Entwicklern, die sich für solche Technologien interessieren, eine neue Option. (Quelle: lateinteraction)
Update des X-Empfehlungsalgorithmus: Die Plattform X (ehemals Twitter) hat ihren Empfehlungsalgorithmus überarbeitet, um langjährige Probleme zu beheben, wie z.B. dass negatives Nutzerfeedback nicht berücksichtigt wurde, Nutzer wiederholt dieselben Inhalte sahen und der SimCluster-Algorithmus irrelevante Inhalte empfahl. Frühes Feedback sei angeblich positiv. (Quelle: TheGregYang)
Wikipedia kündigt neue KI-Strategie zur Unterstützung menschlicher Editoren an: Wikipedia hat ihre neue Strategie für künstliche Intelligenz bekannt gegeben, die darauf abzielt, KI-Tools zur Unterstützung und Verbesserung der Arbeit menschlicher Editoren einzusetzen, anstatt sie zu ersetzen. Konkrete Details wurden in der Quelle nicht genannt, aber es zeigt, dass die weltweit größte Online-Enzyklopädie untersucht, wie KI-Technologie in ihre Prozesse zur Inhaltserstellung und -pflege integriert werden kann. (Quelle: Reddit r/artificial)
🧰 Tools
Midjourney führt Omni-Reference Funktion ein: Midjourney hat die neue Funktion Omni-Reference (oref) veröffentlicht, die es Nutzern ermöglicht, durch Angabe einer Referenzbild-URL (mit dem Parameter –oref) die Bildgenerierung zu steuern, um Konsistenz bei Charakteren, Objekten, Fahrzeugen oder nicht-menschlichen Lebewesen zu erreichen. Nutzer können über den Parameter –ow das Gewicht des Referenzbild-Einflusses steuern; niedrigere Gewichte eignen sich für Stilisierung, höhere Gewichte für Fotorealismus oder präzise Gesichtsanpassung. Die Funktion zielt darauf ab, die Konsistenz und Kontrollierbarkeit spezifischer Elemente in generierten Bildern zu verbessern. (Quelle: op7418, DavidSHolz)

Runway Gen-4 References ermöglicht Personalisierung mit einem Bild: Das Gen-4 Modell von Runway hat die Funktion References eingeführt. Nutzer benötigen nur ein einziges Referenzbild, um dessen Stil oder Personenmerkmale auf neue generierte Inhalte anzuwenden. Demonstrationen zeigen, dass die Funktion problemlos Porträts im Stil des Referenzbildes oder in der im Referenzbild dargestellten Welt neu erstellen kann. Dies zeigt die Fähigkeit des Modells, mit nur einem Referenzbild eine hohe Konsistenz und ästhetische Qualität bei der personalisierten Generierung zu erreichen. (Quelle: c_valenzuelab, c_valenzuelab)

Perplexity WhatsApp-Bot wieder verfügbar: Der WhatsApp-Chatbot von Perplexity AI ist nach einer kurzen Abschaltung aufgrund unerwartet hoher Nachfrage wieder verfügbar. Nutzer können über die Telefonnummer +1 (833) 436-3285 mit ihm interagieren, Nachrichten zur Faktenprüfung weiterleiten, direkte Fragen stellen, um Antworten zu erhalten, freie Textgespräche führen und Bilder erstellen. (Quelle: AravSrinivas, AravSrinivas)
Krea AI kombiniert 4o Bildmodell für präzise Bildkontrolle: Das KI-Kreativtool Krea AI hat eine neue Funktion hinzugefügt, die es Nutzern ermöglicht, die Fähigkeiten des 4o Bildmodells von OpenAI zu nutzen, um durch Bildcollagen und Scribbling den Inhalt und Stil generierter Bilder präziser zu steuern. Dies zeigt Kreas kontinuierliche Innovation im Bereich der interaktiven Bildgenerierung, die es Nutzern ermöglicht, die KI-Kreation intuitiver und detaillierter zu lenken. (Quelle: op7418)
Xingyun Hetang All-in-One: Günstiger Betrieb von DeepSeek: Das von Tsinghua-Alumni gegründete Unternehmen Xingyun Integrated Circuit hat das Hetang AI All-in-One-Gerät vorgestellt. Es soll das unquantisierte FP8-Präzisionsmodell DeepSeek-R1/V3 671B mit über 20 Token/s und 128K Kontext zu einem Preis von 149.000 Yuan betreiben können. Die Lösung verwendet Dual-Socket AMD EPYC CPUs und große Mengen Hochfrequenzspeicher, ergänzt durch geringe GPU-Beschleunigung. Ziel ist es, durch die CPU+Speicher-Architektur die Hardwarekosten für das Private Deployment großer Modelle drastisch zu senken und ein nahezu offizielles Leistungserlebnis lokal anzubieten, geeignet für kostensensible Unternehmensszenarien, die hohe Präzision erfordern. (Quelle: 新智元)

NotebookLM App kurz vor Veröffentlichung: Googles KI-Notiz-App NotebookLM wird bald offizielle iOS- und Android-Anwendungen veröffentlichen, voraussichtlich am 20. Mai, Vorbestellungen sind bereits möglich. Dies bringt die Funktionen von NotebookLM – Zusammenfassungen, Fragenbeantwortung und Ideengenerierung basierend auf Nutzer-Notizen und Dokumenten – auf mobile Geräte. (Quelle: zacharynado)
Granola startet iOS-App für KI-Echtzeit-Meeting-Protokolle: Die KI-Notiz-App Granola hat eine iOS-Version veröffentlicht und erweitert damit ihre ursprüngliche Funktion für KI-Notizen aus Zoom-Meetings auf Offline-Gespräche von Angesicht zu Angesicht. Nutzer können Granola auf dem iPhone verwenden, um Gespräche aufzuzeichnen und zu transkribieren und mithilfe von KI Zusammenfassungen und Notizen zu erstellen, was die spätere Überprüfung und Organisation erleichtert. (Quelle: amasad)
Grok Studio unterstützt PDF-Verarbeitung: Der Grok AI-Assistent hat seine Studio-Funktion um die Fähigkeit zur Verarbeitung von PDF-Dateien erweitert. Nutzer können nun PDF-Dokumente bequemer in Grok Studio verarbeiten und analysieren. Spezifische Funktionsdetails wurden nicht genannt, aber dies markiert eine Erweiterung der Fähigkeiten von Grok im Verständnis und der Interaktion mit Dokumenten verschiedener Formate. (Quelle: grok, TheGregYang)
Neues Suno-Modell zeigt beeindruckende Musikgenerierungsfähigkeiten: Die KI-Musikgenerierungsplattform Suno hat ein neues Modell eingeführt, dessen Generierungsergebnisse von Nutzern als „sehr beeindruckend“ bewertet werden. Ein Nutzer versuchte, damit einen Song im Stil einer Live-Performance zu generieren. Obwohl der gewünschte Call-and-Response-Effekt nicht vollständig erreicht wurde, war die generierte Musik hinsichtlich der Atmosphäre einer Menschenmenge usw. gut, was die Fortschritte des neuen Modells bei Musikqualität und Stilvielfalt zeigt. (Quelle: nptacek, nptacek)
KI-gestützte App Frog Spot zur Erkennung von Froschrufen: Ein Entwickler hat eine kostenlose App namens Frog Spot erstellt, die ein selbst trainiertes CNN-Modell (TensorFlow Lite) verwendet, um verschiedene Arten von Froschrufen durch Analyse des Spektrogramms einer 10-sekündigen Audioaufnahme zu identifizieren. Die App soll der Öffentlichkeit helfen, lokale Arten kennenzulernen, und zeigt gleichzeitig das Anwendungspotenzial von Deep Learning im bioakustischen Monitoring und in der Citizen Science. (Quelle: Reddit r/deeplearning)
KI-gestützte Automatisierung technischer Zeichnungen in der Industrie: Ein IAAI 2025 Paper stellt eine Methode zur automatisierten Verarbeitung der Erweiterung von „Instrument Typicals“ in Rohrleitungs- und Instrumentenfließschemata (P&ID) vor. Die Methode kombiniert Computer Vision Modelle (Texterkennung und -identifikation) mit domänenspezifischen Regeln, um automatisch Informationen aus P&ID-Zeichnungen und Legendentabellen zu extrahieren. Vereinfachte Instrument-Typical-Symbole werden zu detaillierten Instrumentenlisten erweitert, wodurch ein genauer Instrumentenindex generiert wird. Dies soll die Effizienz von Engineering-Projekten (insbesondere in der Angebotsphase) erhöhen und manuelle Fehler reduzieren. (Quelle: aihub.org)

Nutzung von Sora zur Generierung einer Miniaturlandschaft aus gepökelter Ente: Ein Nutzer teilte ein mit Sora generiertes Bild einer „Miniaturlandschaft aus gepökelter Ente“ (Jiang Ban Ya), basierend auf einem detaillierten Prompt. Der Prompt beschrieb sorgfältig den Szenenstil (Makrofotografie, Miniaturlandschaft), das Hauptmotiv (ein Marktstandgebäude aus gepökelter Ente), Details (rotbraune Haut, Chili und Sesam, Koch beim Schneiden, Esser), die Umgebung (Straßen aus Entenfleischsauce, Wände im Pökelstil, rote Laternen usw.). Dies demonstriert Soras Fähigkeit, komplexe, fantasievolle Textbeschreibungen zu verstehen und entsprechende hochwertige Bilder zu generieren. (Quelle: dotey)

Erstellung eines 3D-Wettervorhersage-GPTs: Ein Nutzer teilte eine selbst erstellte ChatGPTs-Anwendung namens „Weather 3D“. Sie ruft basierend auf dem vom Nutzer eingegebenen Stadtnamen über eine Wetter-API Echtzeit-Wetterdaten ab und generiert eine 3D-Illustration im Stil eines isometrischen Miniaturmodells des Wahrzeichens der Stadt, wobei die aktuellen Wetterbedingungen integriert werden. Oben in der Illustration werden Stadtname, Wetterzustand, Temperatur und Wettersymbol angezeigt. Dieses GPTs zeigt, wie API-Aufrufe und Bildgenerierungsfähigkeiten kombiniert werden können, um nützliche und visuell ansprechende KI-Anwendungen zu erstellen. (Quelle: dotey)

📚 Lernen
AdaRFT: Neue Methode zur Optimierung des Reinforcement Learning Fine-Tuning: Taiwei Shi et al. schlagen eine leichtgewichtige, Plug-and-Play Curriculum-Learning-Methode namens AdaRFT vor, die darauf abzielt, den Trainingsprozess von auf menschlichem Feedback basierenden Reinforcement-Learning-Algorithmen (RFT) wie PPO, GRPO, REINFORCE zu optimieren. Berichten zufolge kann AdaRFT die RFT-Trainingszeit um bis zu das Zweifache verkürzen und die Modellleistung verbessern, indem die Reihenfolge der Trainingsdaten intelligenter gestaltet wird, um die Lerneffizienz und -effektivität zu steigern. (Quelle: menhguin)

Online-Masterclass zu KI-Bewertung (Evals): Hamel Husain und Shreya Shankar bieten eine 4-wöchige Online-Masterclass zur Bewertung von KI-Anwendungen (Evals) an. Der Kurs soll Entwicklern helfen, KI-Anwendungen von der Prototypenphase zur Produktionsreife zu bringen. Inhalte umfassen Bewertungsmethoden während der Entwicklung und nach dem Launch, den Unterschied zwischen Benchmarking und praktischer Bewertung, Datenprüfung, PromptEvals usw. Die Bedeutung der Bewertung für die Sicherstellung der Zuverlässigkeit und Leistung von KI-Anwendungen wird betont. (Quelle: HamelHusain, HamelHusain)

Google Modell-Tuning Playbook: Google Research stellt ein Repository namens “tuning_playbook” zur Verfügung, das Anleitungen und Best Practices für das Modell-Tuning bieten soll. Dies ist eine wertvolle Lernressource für Entwickler und Forscher, die große Sprachmodelle oder andere Machine-Learning-Modelle für spezifische Aufgaben oder Datensätze feinabstimmen müssen. (Quelle: zacharynado)

EnronQA: Personalisierter RAG-Benchmark-Datensatz: Forscher haben den EnronQA-Datensatz veröffentlicht, der 103.638 E-Mails von 150 Nutzern und 528.304 hochwertige Frage-Antwort-Paare enthält. Der Datensatz soll als Benchmark zur Bewertung der Leistung personalisierter Retrieval-Augmented Generation (RAG)-Systeme bei der Verarbeitung privater Dokumente dienen. Er enthält Gold-Standard-Referenzantworten, falsche Antworten, Begründungen für Schlussfolgerungen und alternative Antworten, was eine detailliertere Analyse der Leistung von RAG-Systemen ermöglicht. (Quelle: tokenbender)
ReXGradient-160K: Großer Datensatz mit Thorax-Röntgenbildern und Berichten: Ein großer öffentlicher Datensatz mit Thorax-Röntgenbildern namens ReXGradient-160K wurde veröffentlicht. Er enthält 60.000 Thorax-Röntgenstudien von 109.487 einzigartigen Patienten aus 3 US-Gesundheitssystemen (79 Standorte) zusammen mit den zugehörigen radiologischen Berichten (Freitext). Es handelt sich angeblich um den derzeit öffentlich verfügbaren Thorax-Röntgen-Datensatz mit der größten Patientenzahl, der eine wertvolle Ressource für das Training und die Bewertung von KI-Modellen für medizinische Bildgebung darstellt. (Quelle: iScienceLuvr)

Blogbeitrag zur Diskussion des Fähigkeitswachstums von KI-Agenten: Der Forscher Shunyu Yao veröffentlichte einen Blogbeitrag mit dem Titel „The Second Half“, in dem er argumentiert, dass sich die aktuelle KI-Entwicklung in einer Art „Halbzeitpause“ befindet. Davor war das Training wichtiger als die Bewertung; danach wird die Bewertung wichtiger sein als das Training, da Reinforcement Learning (RL) endlich effektiv zu funktionieren beginnt. Der Artikel untersucht die Bedeutung des Wandels in der Bewertungsmethodik vor dem Hintergrund der kontinuierlich steigenden KI-Fähigkeiten. (Quelle: andersonbcdefg)
OpenAI teilt Forschung zu Datenschutz und Memorisierung: Die OpenAI-Forscher Pratyush Maini und Zhili Feng werden einen Vortrag über ihre Forschung zu Datenschutz und Memorisierung halten. Sie diskutieren, wie Memorisierungsphänomene in großen Sprachmodellen erkannt, quantifiziert und beseitigt werden können und welche praktischen Anwendungen dies in produktiven LLMs hat. Dies betrifft die Balance zwischen Modellfähigkeiten und dem Schutz der Nutzerdaten. (Quelle: code_star)

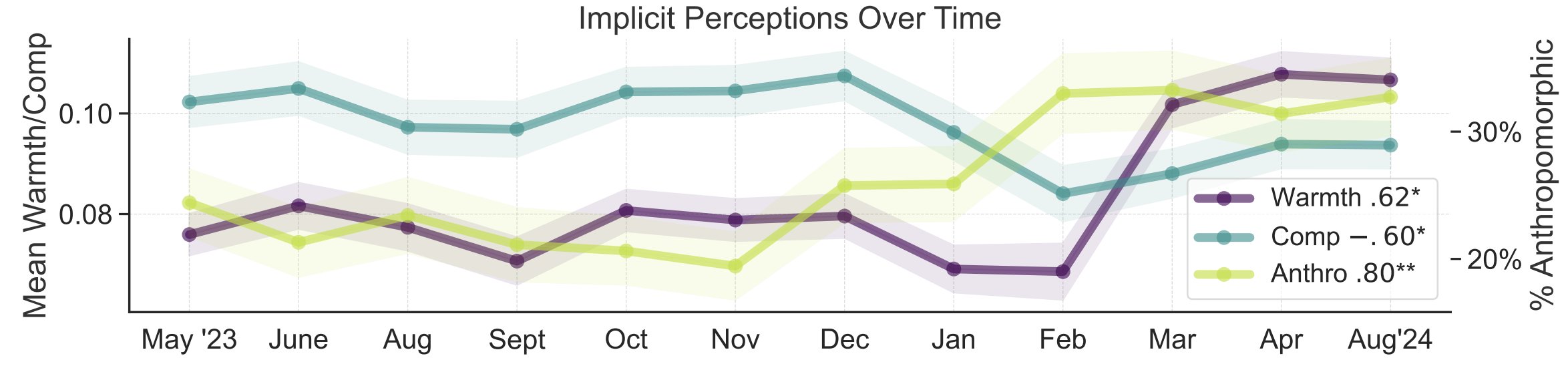
Studie zu Metaphern in der öffentlichen Wahrnehmung von KI: Forscher der Stanford University, darunter Myra Cheng, präsentierten auf der FAccT 2025 eine Arbeit, die 12.000 über 12 Monate gesammelte Metaphern über KI analysiert, um die mentalen Modelle der Öffentlichkeit von KI und deren Veränderung im Laufe der Zeit zu verstehen. Die Studie ergab, dass die Öffentlichkeit im Laufe der Zeit dazu neigt, KI als menschlicher und handlungsfähiger wahrzunehmen (zunehmende Anthropomorphisierung) und dass auch die emotionale Valenz (Wärme) gegenüber KI zunimmt. Diese Methode bietet detailliertere Einblicke in die öffentliche Wahrnehmung als Selbstauskunftsberichte. (Quelle: stanfordnlp, stanfordnlp)
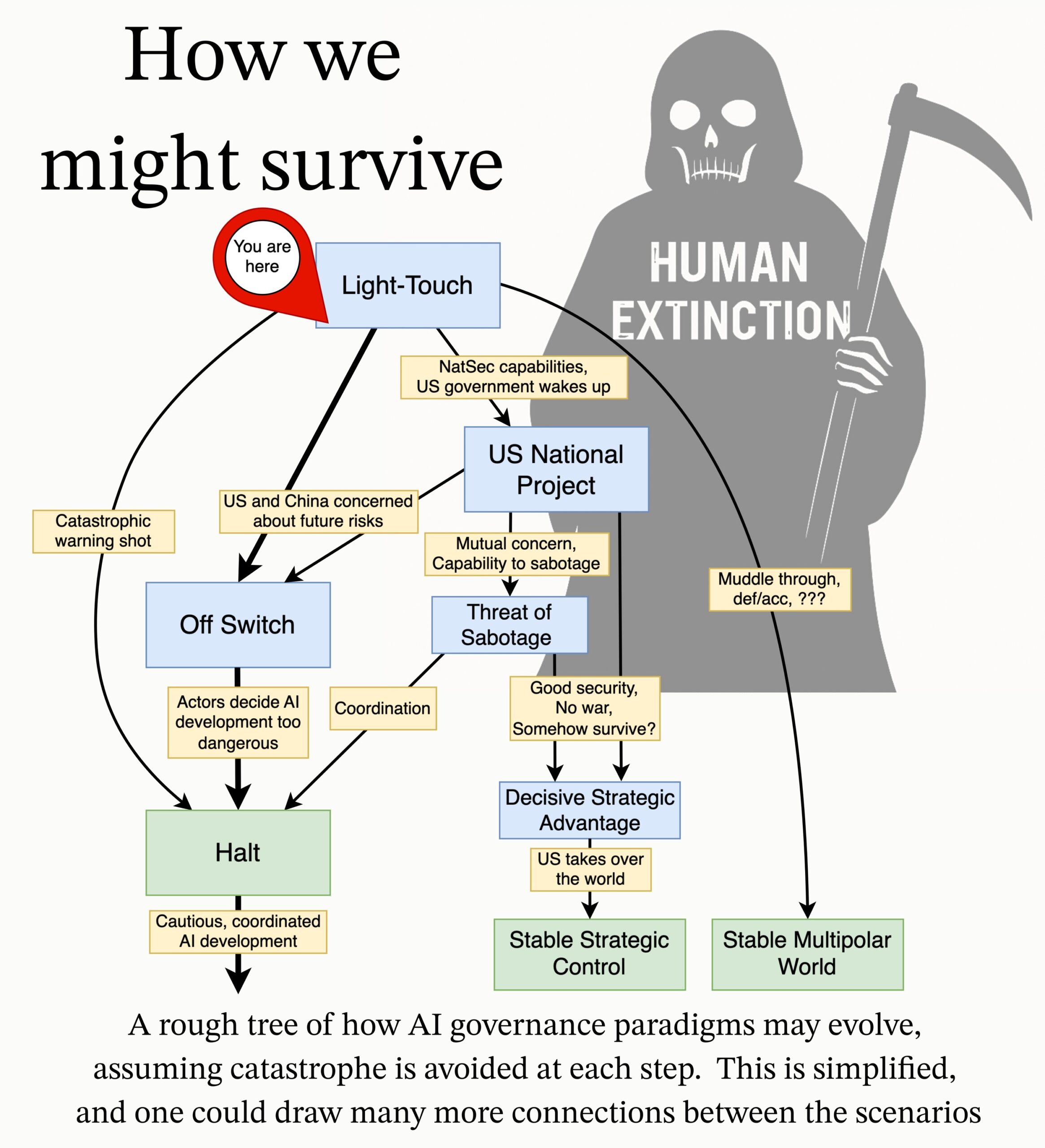
MIRI veröffentlicht Forschungsagenda zur AI Governance: Das technische Governance-Team des Machine Intelligence Research Institute (MIRI) hat eine neue Forschungsagenda zur AI Governance veröffentlicht. Sie legt ihre Sicht auf die strategische Landschaft dar und schlägt eine Reihe von handlungsorientierten Forschungsfragen vor. Ziel ist es zu untersuchen, welche Maßnahmen ergriffen werden müssen, um zu verhindern, dass eine Organisation oder Einzelperson eine unkontrollierbare Superintelligenz baut, um katastrophale Risiken und existenzielle Risiken durch KI zu reduzieren. (Quelle: JeffLadish)
💼 Wirtschaft
Enterprise-KI-Lösungsanbieter Deepexi beantragt Börsengang in Hongkong: Deepexi (滴普科技), ein von ehemaligen Huawei- und Alibaba-Führungskräften um Zhao Jiehui gegründeter Anbieter von Enterprise-KI-Lösungen, hat offiziell einen Antrag auf Börsennotierung in Hongkong eingereicht. Das Unternehmen konzentriert sich auf die FastData Datenintelligenz-Plattform und FastAGI Enterprise-KI-Lösungen und bedient Branchen wie Einzelhandel (z.B. Belle), Fertigung und Gesundheitswesen. In den letzten drei Jahren stieg der Umsatz kontinuierlich und erreichte 2024 243 Millionen Yuan. Deepexi hat 8 Finanzierungsrunden abgeschlossen und Investitionen von namhaften Institutionen wie Hillhouse Capital, IDG Capital und 5Y Capital erhalten. Nach der letzten Finanzierungsrunde wurde das Unternehmen mit rund 6,8 Milliarden RMB bewertet. Trotz Umsatzwachstum ist das Unternehmen derzeit noch defizitär, wobei der bereinigte Nettoverlust jährlich schrumpft. (Quelle: 36氪)
BMW China kündigt Integration des DeepSeek Large Models an: Nach der Zusammenarbeit mit Alibaba vertieft die BMW Group ihr KI-Engagement in China weiter und kündigt die Integration des DeepSeek Large Models an. Die Funktion soll ab dem dritten Quartal 2025 zunächst in mehreren in China verkauften Neufahrzeugen mit dem BMW Operating System 9 eingeführt werden und zukünftig auch in den in China produzierten BMW-Modellen der Neuen Klasse zum Einsatz kommen. Ziel ist es, durch die Deep-Thinking-Fähigkeiten von DeepSeek das Mensch-Maschine-Interaktionserlebnis rund um den BMW Intelligent Personal Assistant zu stärken, die Intelligenz der Fahrzeuge und die emotionale Bindung zu verbessern. Dies ist ein wichtiger Schritt für BMW, um seine lokale KI-Strategie zu beschleunigen und den Herausforderungen der intelligenten Transformation zu begegnen. (Quelle: 36氪)
Shopify zwingt alle Mitarbeiter zur KI-Nutzung, will Teile der Belegschaft durch KI ersetzen: Tobi Lutke, CEO der globalen E-Commerce-Plattform Shopify, betonte in einem internen Memo, dass die effiziente Nutzung von KI für alle Mitarbeiter des Unternehmens zur „eisernen Regel“ geworden ist und keine Empfehlung mehr darstellt. Das Memo fordert die Mitarbeiter auf, KI in ihre Arbeitsabläufe zu integrieren und dies zur Gewohnheit zu machen; Teams müssen nachweisen, warum KI eine Aufgabe nicht erledigen kann, bevor sie zusätzliches Personal beantragen; die Leistungsbeurteilung wird Kennzahlen zur KI-Nutzung beinhalten. Lutke wies darauf hin, dass KI die Effizienz erheblich steigern kann (bei einigen Mitarbeitern um das 10- bis 100-fache) und Mitarbeiter ihre Leistung jährlich um 20-40% steigern müssen, um wettbewerbsfähig zu bleiben. Zuvor hatte Shopify bereits in Abteilungen wie dem Kundenservice Personal abgebaut und KI als Ersatz eingeführt. Dieser Schritt wird als klares Signal für den Trend gesehen, dass KI zu Anpassungen und Entlassungen bei White-Collar-Jobs führt. (Quelle: 新智元)

🌟 Community
Diskussion über das Problem der KI-Halluzinationen: Robin Li kritisierte auf der Baidu AI Developer Conference DeepSeek-R1 wegen hoher Halluzinationsrate, Langsamkeit und hoher Kosten, was eine erneute Diskussion über das „Halluzinations“-Phänomen bei großen Modellen in der Community auslöste. Analysen deuten darauf hin, dass nicht nur DeepSeek, sondern auch fortschrittliche Modelle wie o3/o4-mini von OpenAI und Qwen3 von Alibaba generell unter Halluzinationen leiden und dass mehrstufiges Denken (Multi-Turn Reasoning) bei Inferenzmodellen die Verzerrung verstärken kann. Eine Bewertung von Vectara zeigt, dass die Halluzinationsrate von R1 (14,3%) deutlich höher ist als die von V3 (3,9%). Die Community ist der Meinung, dass Halluzinationen mit zunehmender Modellfähigkeit subtiler und logischer werden, was es für Nutzer schwierig macht, Wahrheit von Fiktion zu unterscheiden, und Bedenken hinsichtlich der Zuverlässigkeit aufwirft. Gleichzeitig gibt es auch die Ansicht, dass Halluzinationen ein Nebenprodukt der Kreativität sind und insbesondere in Bereichen wie der literarischen Schöpfung ihren Wert haben. Wie ein akzeptables Maß an Halluzinationen definiert und wie Halluzinationen durch Techniken wie RAG, Datenqualitätskontrolle und Kritikermodelle gemildert werden können, bleibt ein fortlaufendes Forschungsthema in der Branche. (Quelle: 36氪)

Gedanken und Diskussionen über KI-Begleiter/Freunde: Der Vorschlag von Meta-CEO Mark Zuckerberg, personalisierte KI-Freunde einzusetzen, um das Bedürfnis der Menschen nach mehr sozialen Verbindungen zu befriedigen (er behauptet, der Durchschnittsmensch habe 3 Freunde, benötige aber 15), löste eine Diskussion in der Community aus. Sebastien Bubeck hält die Realisierung echter KI-Begleiter für sehr schwierig. Der Schlüssel liege darin, dass die KI sinnvoll auf die Frage „Was hast du in letzter Zeit so gemacht?“ antworten können müsse, d.h. eigene Erfahrungen und Erlebnisse haben müsse, anstatt nur die des Nutzers zu teilen. Er meint, aktuelle Vorstellungen von KI-Begleitern konzentrierten sich zu sehr auf geteilte Erlebnisse und ignorierten, dass die KI selbst auch unabhängige, teilbare Erlebnisse – sogar Klatsch (das Teilen gegenseitiger Erlebnisse) – benötige. Andere Kommentatoren stellen aus der Perspektive der Dunbar-Zahl in Frage, ob ein riesiger sozialer Kreis aus KI wirklich von Bedeutung sein kann. Es gibt auch Bedenken, dass von kommerziellen Unternehmen bereitgestellte KI-Freunde letztlich dem gezielten Marketing dienen könnten, anstatt echter Begleitung. (Quelle: jonst0kes, SebastienBubeck, gfodor, gfodor)

Emotionen und Gedanken ausgelöst durch KI-Kunst: In der Community äußerten Nutzer „Trauer“ (grieving) darüber, dass KI in kurzer Zeit „wahnsinnig gute“ Kunstwerke schaffen kann, da dies die Einzigartigkeit des Menschen in der künstlerischen Schöpfung in Frage stelle. Dies löste eine Diskussion über KI-Kunst, das Wesen menschlicher Kreativität und das persönliche Wertgefühl angesichts technologischer Umwälzungen aus. Einige Kommentatoren argumentieren, dass die Freude am künstlerischen Schaffen im Prozess selbst liege, nicht im Wettbewerb mit KI; KI-Kunst könne als Inspirationsquelle dienen. Andere meinen, KI-Kunst fehle der menschliche „Fehler“ oder die Seele, sie wirke zu perfekt oder stereotyp. Die Diskussion erstreckte sich auch auf philosophische Überlegungen zu KI in Bereichen wie Emotionssimulation, Bewusstsein und zukünftigen Gesellschaftsstrukturen (z.B. durch ersetzte Arbeitsplätze). (Quelle: Reddit r/ArtificialInteligence)
KI-Ethik und Verantwortung: Geheime Experimente und Informationsweitergabe: Die Community diskutierte ethische Fragen in der KI-Forschung. Eine Nachricht erwähnte, dass KI-Forscher geheime Experimente auf Reddit durchführten, um die Meinungen der Nutzer zu ändern, was Bedenken hinsichtlich des Rechts auf Information der Nutzer und des Risikos der KI-Manipulation aufwarf. In einer anderen Diskussion berichtete ein Nutzer von Schwierigkeiten bei der Meldung potenzieller Sicherheitsprobleme an KI-Unternehmen, die auf komplexe Prozesse und unklare Verantwortlichkeiten stießen. Dies unterstreicht die Unreife des aktuellen KI-Bereichs in Bezug auf verantwortungsvolle Offenlegung und Mechanismen zur Reaktion auf Schwachstellen. (Quelle: Reddit r/ArtificialInteligence, nptacek)

Reflexionen im NLP-Bereich über den Aufstieg von ChatGPT: Das Quanta Magazine veröffentlichte einen Artikel, der durch Interviews mit mehreren Experten aus dem Bereich Natural Language Processing (NLP) wie Chris Potts, Yejin Choi und Emily Bender die Auswirkungen und Reflexionen nach der Veröffentlichung von ChatGPT auf das gesamte Feld beleuchtet. Der Artikel untersucht, wie der Aufstieg großer Sprachmodelle die theoretischen Grundlagen des traditionellen NLP herausforderte, Debatten innerhalb des Feldes auslöste, zu Fraktionsbildung führte und Forschungsrichtungen anpasste. Community-Mitglieder reagierten positiv auf den Artikel und meinten, er gebe einen guten Überblick über die Erschütterungen und Anpassungsprozesse im Bereich der Linguistik nach GPT-3. (Quelle: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
Aufkommen und Wahrnehmung von KI-generierter Werbung: Nutzer sozialer Medien berichten, dass sie beginnen, auf Plattformen wie YouTube KI-generierte Werbung zu sehen, und äußern dabei „großes Unbehagen“. Dies deutet darauf hin, dass Technologien zur Generierung von KI-Inhalten nun auch in der kommerziellen Werbeproduktion eingesetzt werden, löst aber gleichzeitig erste Reaktionen der Nutzer hinsichtlich Qualität, Authentizität und emotionaler Erfahrung von KI-generierten Inhalten aus. (Quelle: code_star)
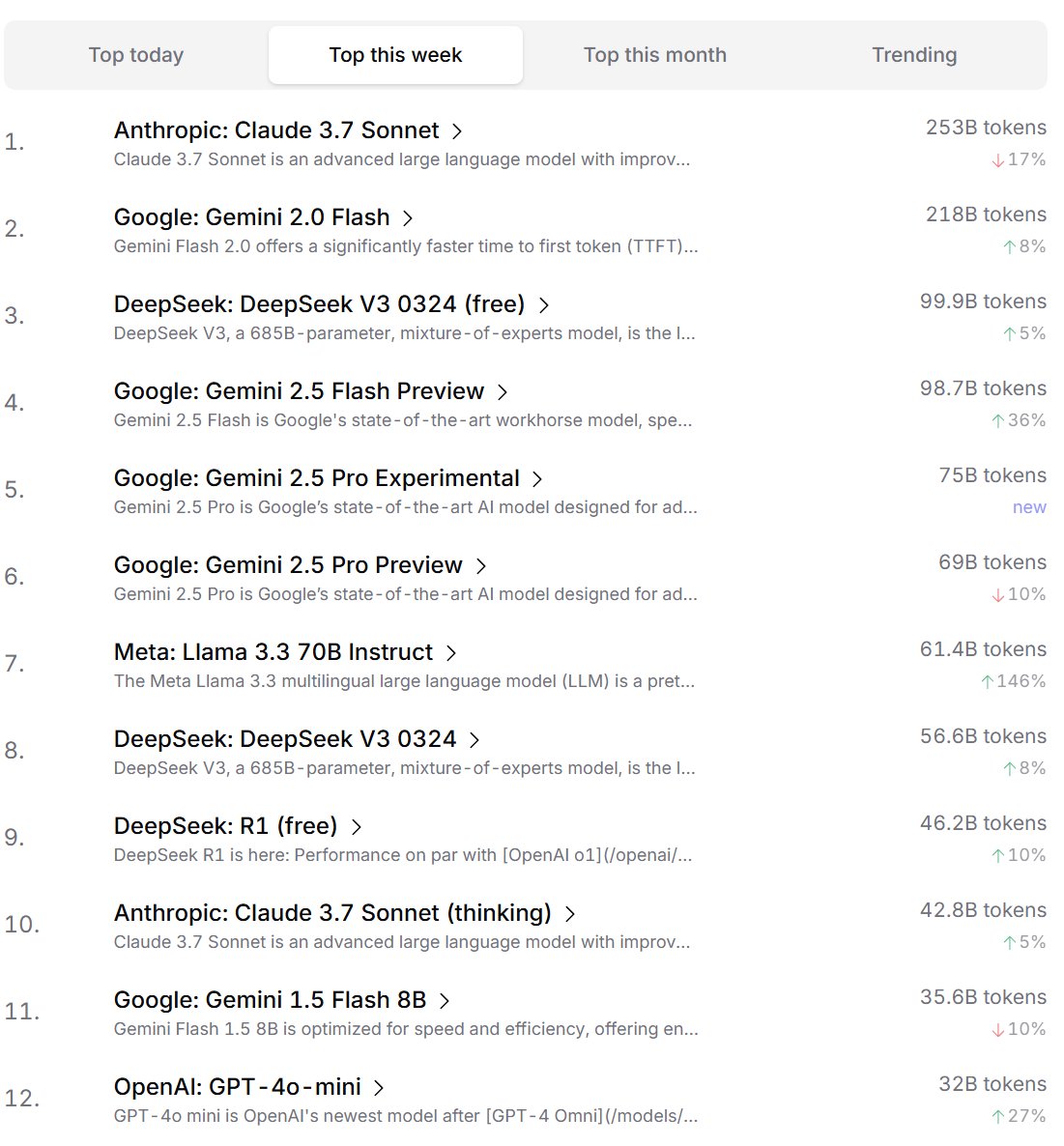
Präferenzranking von KI-Modellen durch Entwickler: Cursor.ai veröffentlichte ein Ranking der von seinen Nutzern (hauptsächlich Entwicklern) bevorzugten KI-Modelle, während Openrouter ebenfalls ein Ranking nach Modell-Token-Nutzung bekannt gab. Diese Rankings, die auf tatsächlichen Produktnutzungsdaten basieren, könnten nach Ansicht einiger die Präferenzen der Nutzer in realen Entwicklungsszenarien besser widerspiegeln als wettbewerbsorientierte Ranglisten wie die ChatBot Arena und bieten somit eine andere Perspektive zur Bewertung der praktischen Nützlichkeit von Modellen. (Quelle: op7418, Reddit r/LocalLLaMA)
Diskussion über die „Denkfähigkeit“ von KI: In der Community wird weiterhin darüber diskutiert, ob große Sprachmodelle (LLMs) tatsächlich „denken“ können. Einige argumentieren, dass aktuelle LLMs nicht wirklich vor dem Sprechen denken, sondern den Denkprozess durch die Generierung von mehr Text (wie Chain-of-Thought) simulieren, was irreführend sei. Andere meinen, dass die Verwendung kontinuierlicher mathematischer Methoden (wie bei LLMs) für diskretes Schlussfolgern auf diskreten Computern grundsätzlich problematisch sei. Diese Diskussionen spiegeln tiefere Überlegungen über das Wesen der aktuellen KI-Technologie und zukünftige Entwicklungsrichtungen wider. (Quelle: francoisfleuret, pmddomingos)
Differenzierte Betrachtung von Energieverbrauch und Umweltauswirkungen der KI: Angesichts der Umweltprobleme durch den enormen Energieverbrauch für das Training und den Betrieb von KI gibt es in der Community differenzierte Überlegungen. Eine Sichtweise ist, dass der immense Energiebedarf der KI (insbesondere von Hyperscalern wie Google, Amazon, Microsoft) diese Unternehmen zwingt, in den Bau eigener erneuerbarer Energiequellen (Solar, Wind, Batterien) zu investieren und sogar Kernkraftwerke wieder in Betrieb zu nehmen (wie Microsofts Zusammenarbeit mit Constellation zur Wiederinbetriebnahme des Kernkraftwerks Three Mile Island). Dieser Bedarf könnte somit反而 zum Katalysator für den beschleunigten Ausbau sauberer Energien und technologische Durchbrüche (wie Small Modular Reactors SMR) werden. Andere weisen jedoch auf das Problem des abnehmenden Ertrags beim KI-Energieverbrauch sowie den ebenfalls bedenklichen Wasserverbrauch für die Kühlung hin. (Quelle: Reddit r/ArtificialInteligence)
Vorwurf: Anthropic versucht, Wettbewerb bei KI-Chips zu beschränken: In der Community wird diskutiert, dass Anthropic-CEO Dario Amodei sich für eine Verschärfung der Exportkontrollen für KI-Chips, insbesondere nach China, ausspricht und sogar behauptet, Chips könnten durch Tarnung als Schwangerschaftsbäuche geschmuggelt werden. Kritiker sehen darin den Versuch von Anthropic, den Zugang von Wettbewerbern (insbesondere chinesischen Unternehmen wie DeepSeek, Qwen) zu fortschrittlichen Rechenressourcen zu beschränken, um den eigenen Vorsprung bei der Entwicklung von Spitzenmodellen zu sichern. Dieses Vorgehen wird als Versuch kritisiert, den Wettbewerb durch politische Maßnahmen zu unterdrücken, was der offenen Entwicklung globaler KI-Technologien und der Open-Source-Community schade. (Quelle: Reddit r/LocalLLaMA)

💡 Sonstiges
Gedanken zu KI und menschlichen kognitiven Grenzen: Jeff Ladish kommentiert, dass das Zeitfenster, in dem Menschen als „Copy-Paste-Assistenten“ für KI fungieren, extrem kurz sei, was darauf hindeutet, dass die autonomen Fähigkeiten der KI die einfache Unterstützung schnell übertreffen werden. Gleichzeitig erklärte DeepMind-Gründer Hassabis in einem Interview, dass eine echte AGI in der Lage sein sollte, eigenständig wertvolle wissenschaftliche Hypothesen aufzustellen (wie Einstein die Allgemeine Relativitätstheorie vorschlug) und nicht nur Probleme zu lösen; er sieht bei der aktuellen KI noch Defizite in der Hypothesengenerierung. Liu Cixin hingegen hofft, dass KI die biologischen kognitiven Grenzen des menschlichen Gehirns durchbrechen kann. Diese Ansichten deuten gemeinsam auf tiefere Überlegungen über die Grenzen der KI-Fähigkeiten, die Entwicklung der menschlichen Rolle und das Wesen zukünftiger Intelligenz hin. (Quelle: JeffLadish, 新智元)
Waymo LiDAR fängt dramatischen Moment ein: Das LiDAR-System eines autonomen Waymo-Fahrzeugs hat bei einem Motorradunfall, dem es erfolgreich auswich, das 3D-Punktwolkenbild eines sich überschlagenden Essenslieferanten während der Kollision klar erfasst. Dies demonstriert nicht nur die leistungsstarken Fähigkeiten des Waymo-Wahrnehmungssystems (selbst in komplexen dynamischen Szenen), sondern dokumentierte auch unerwartet eine einzigartige Perspektive des Unfalls. Glücklicherweise wurde bei dem Unfall niemand schwer verletzt. (Quelle: andrew_n_carr)
Neuer Ansatz für KI-Romanerstellung: Plot Promise System: Der Entwickler Levi schlägt ein „Plot Promise“ (Handlungsversprechen)-System für die KI-Romanerstellung vor, als Alternative zur traditionellen hierarchischen Gliederungsmethode. Das System ist von Brandon Sandersons „Promise, Progress, Payoff“-Theorie inspiriert und betrachtet die Geschichte als eine Reihe aktiver narrativer Fäden (Versprechen). Jedes Versprechen hat eine Wichtigkeitsbewertung, und ein Algorithmus schlägt basierend auf Bewertung und Fortschritt den Zeitpunkt für die Weiterführung vor, aber die KI wählt kontextlogisch das aktuell am besten geeignete Versprechen aus. Nutzer können Versprechen dynamisch hinzufügen oder entfernen. Die Methode zielt darauf ab, die Flexibilität, Skalierbarkeit (Anpassung an sehr lange Werke) und Emergenz der Geschichte zu verbessern, steht aber vor Herausforderungen wie der Optimierung der KI-Entscheidungsfindung, der Aufrechterhaltung langfristiger Kohärenz und der Begrenzung der Länge von Eingabe-Prompts. (Quelle: Reddit r/ArtificialInteligence)