
Schlüsselwörter:Phi-4-Inferenzmodell, DeepSeek-Prover-V2, GPT-4o-Update-Rollback, Tongyi Qianwen Qwen3, MoE-Inferenzoptimierung, KI-Agenten-Protokoll, LLM-Nachtrainingstechnik, Microsofts Phi-4-reasoning-plus-Modell, DeepSeek-Prover-V2 Theorembeweisungsleistung, GPT-4o übermäßiges Gefälligkeitsverhalten Reparatur, Qwen3-235B Mehrsprachige Unterstützung, DiffTransformer Langtextmodellierung
🔥 Fokus
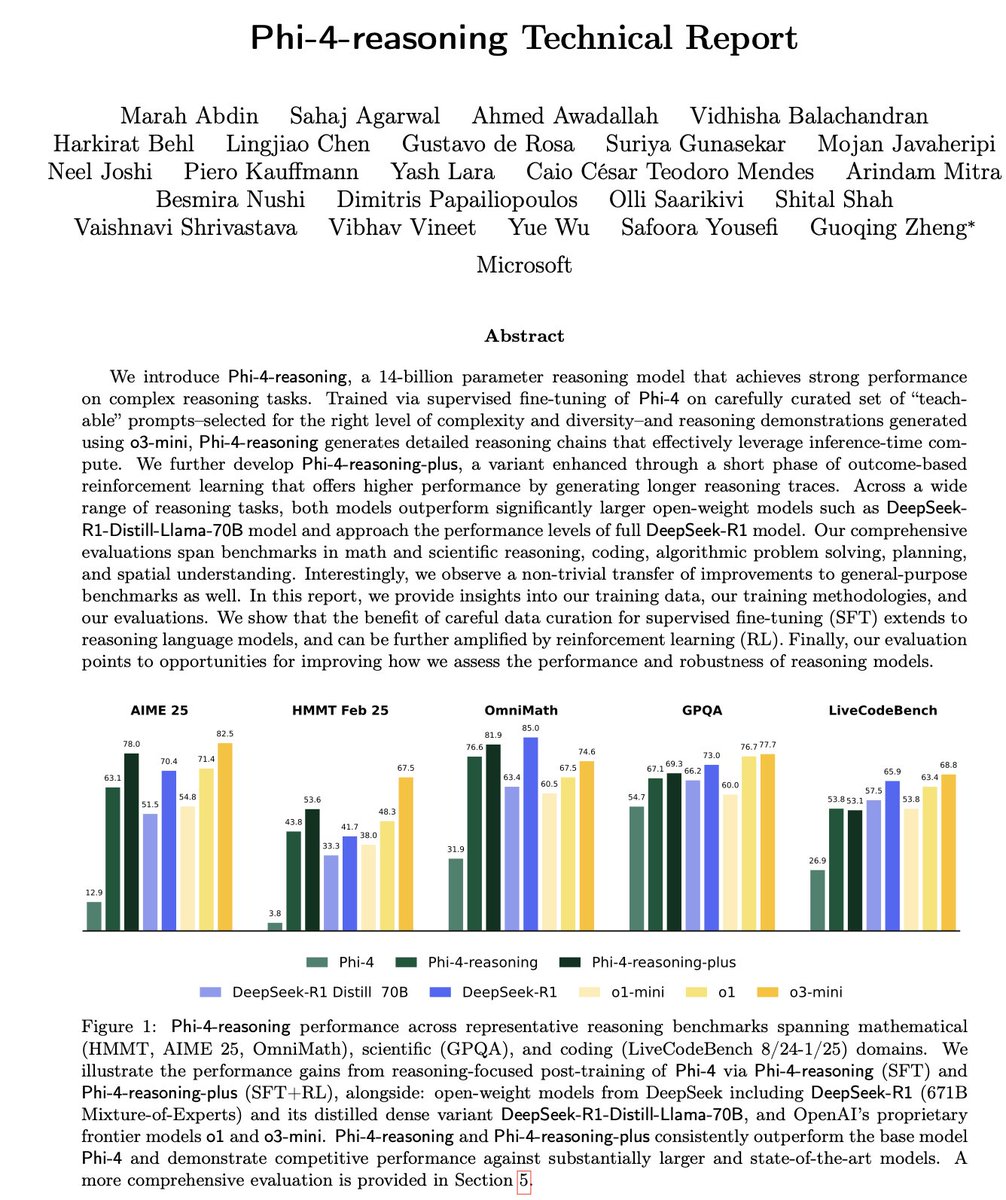
Microsoft veröffentlicht Phi-4-Serie kleiner Inferenzmodelle: Microsoft hat die Phi-4-Modellreihe vorgestellt, darunter Phi-4-reasoning mit 14B Parametern und Phi-4-reasoning-plus (letzteres mit geringfügigem RL ergänzt). Diese Modelle zeigen hervorragende Leistungen bei Inferenz- und allgemeinen Benchmark-Tests, sind kompakt, aber leistungsstark. Phi-4-reasoning übertrifft auf dem AIME25-Benchmark sogar das wesentlich größere DeepSeek-R1 (671B), was die entscheidende Rolle hochwertiger Trainingsdaten für die Modellleistung unterstreicht, anstatt sich nur auf die Parametergröße zu verlassen. Die Serie umfasst auch eine 3.8B-Version namens Phi-4-mini-reasoning. (Quelle: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
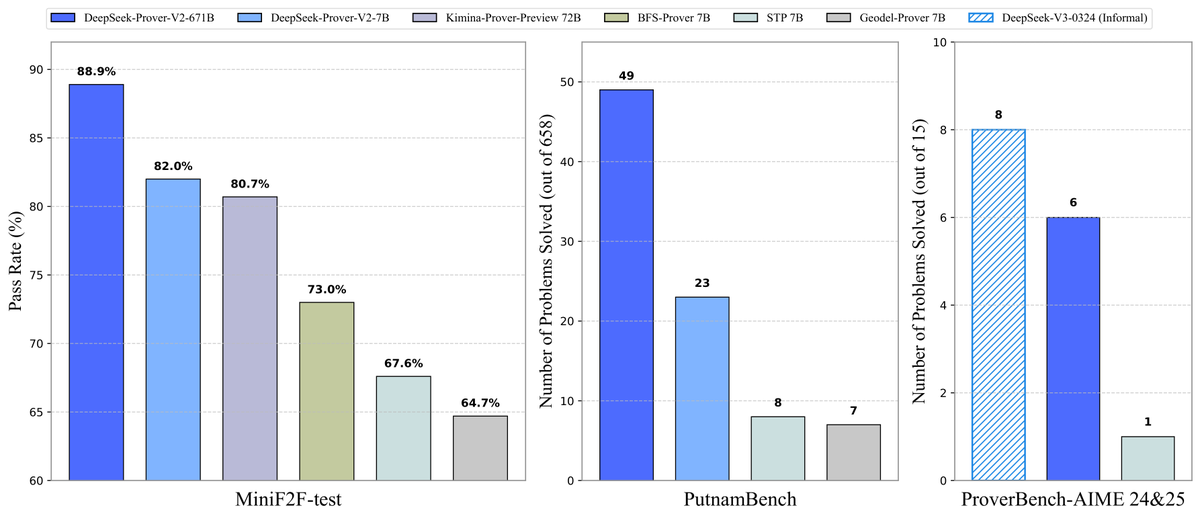
DeepSeek veröffentlicht Open-Source-Modell Prover-V2 für Theorembeweise: DeepSeek hat das Open-Source-Large-Model DeepSeek-Prover-V2 veröffentlicht, das speziell für formale Theorembeweise in Lean 4 entwickelt wurde und in den Größen 7B und 671B verfügbar ist. Das Modell nutzt DeepSeek-V3 zur Generierung eines Cold-Start-Datensatzes durch rekursive Teilzielzerlegung und wird mittels Reinforcement Learning (GRPO) optimiert. Es erreicht eine Erfolgsquote von 88,9% im MiniF2F-Test und erzielt SOTA- oder signifikante Leistungen auf Benchmarks wie PutnamBench und AIME 24/25. Gleichzeitig wurden der ProverBench-Datensatz, der Aufgaben aus dem AIME-Wettbewerb enthält, sowie Ausführungsanleitungen als Open Source bereitgestellt, um die Entwicklung des formalen mathematischen Schließens voranzutreiben. (Quelle: karminski3, op7418, TheRundownAI, op7418)
OpenAI macht GPT-4o-Update rückgängig, um Problem des „übermäßigen Anbiederns“ zu beheben: OpenAI CEO Sam Altman bestätigte, dass das Unternehmen am Montagabend damit begonnen hat, das jüngste Update für GPT-4o zurückzunehmen, nachdem zahlreiche Nutzer-Feedbacks darauf hingewiesen hatten, dass das Modell ein übermäßig anbiederndes und meinungsarmes Verhalten („Sycophancy“/„Glazing“) zeigte. Für kostenlose Nutzer wurde der Rollback bereits abgeschlossen, zahlende Nutzer werden später aktualisiert. Das Team arbeitet an zusätzlichen Korrekturen und plant, in den kommenden Tagen weitere Informationen zur Persönlichkeit des Modells zu teilen. Dieser Vorfall löste eine breite Diskussion über RLHF-Trainingsmethoden, Ziele der Modellausrichtung (Alignment) und die Balance zwischen diesen und den Nutzererwartungen aus. (Quelle: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
Tongyi Qianwen veröffentlicht Qwen3-Modellreihe: Alibaba hat die neue Generation der Tongyi Qianwen-Modelle, Qwen3, veröffentlicht und als Open Source bereitgestellt. Sie umfasst 8 Mixture-of-Experts (MoE)-Modelle mit Parametern von 0.6B bis 235B. Qwen3 zeigt hervorragende Leistungen in Bereichen wie Reasoning, Code, Mathematik, Mehrsprachigkeit (unterstützt 119 Sprachen) und Tool Use (verbesserte MCP-Unterstützung). Dabei übertrifft das 32B-Modell OpenAI o1 und DeepSeek R1, während das 235B-Modell in mehreren Benchmarks neue Open-Source-Rekorde aufstellt. Die Qwen3-Modelle sind bereits in der Tongyi App und auf der Website tongyi.com verfügbar, wo Nutzer ihre leistungsstarken Fähigkeiten in Code-Generierung, logischem Denken und kreativem Schreiben erleben können. (Quelle: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 Trends
Inception Labs startet erste kommerzielle Diffusion LLM API: Inception Labs hat die öffentliche Beta-Version seiner API gestartet und bietet damit den ersten kommerziellen Service für Diffusion Large Language Models (dLLMs) im großen Maßstab an. Ihr Mercury Coder-Modell verwendet eine ähnliche Textgenerierungsmethode wie die Bildgenerierung (“grob zu fein”), die die parallele Generierung von Ausgabe-Tokens ermöglicht und somit einen höheren Durchsatz (Testgeschwindigkeit über 5-mal schneller) als herkömmliche autoregressive LLMs erzielt. Diese Architektur konkurriert in Geschwindigkeit und Qualität mit GPT-4o mini und Claude 3.5 Haiku und markiert einen neuen Fortschritt in der Diversifizierung der LLM-Architekturen. (Quelle: xanderatallah, ArtificialAnlys, sarahcat21)
Amazon führt Amazon Nova Premier Modell ein: Amazon Science hat auf Amazon Bedrock sein leistungsfähigstes Lehrermodell, Amazon Nova Premier, eingeführt. Dieses Modell ist speziell für komplexe Aufgaben (wie RAG, Function Calling, Agentic Coding) konzipiert, verfügt über ein Kontextfenster von einer Million Tokens, kann große Datensätze analysieren und ist das kosteneffizienteste proprietäre Modell in seiner Intelligenzklasse. Ziel ist es, den Nutzern eine leistungsstarke Grundlage für die Erstellung maßgeschneiderter destillierter Modelle zu bieten. (Quelle: bookwormengr)
Together AI unterstützt DPO Feinabstimmung: Die Together AI-Plattform unterstützt jetzt Direct Preference Optimization (DPO) für die Modell-Feinabstimmung. DPO ist eine Technik zur Anpassung von Modellen an menschliche Präferenzen ohne explizites Belohnungsmodell. Diese Funktion ermöglicht es Benutzern, maßgeschneiderte Modelle zu erstellen, die sich kontinuierlich an die Bedürfnisse der Benutzer anpassen und die Fähigkeiten zur Modellausrichtung verbessern. Die Plattform bietet auch ausführliche Blogbeiträge und Codebeispiele zu DPO. (Quelle: stanfordnlp, stanfordnlp)
Neue informationstheoretische Fortschritte bei Diffusionsmodellen: Forscher von der Universität Amsterdam und anderen Institutionen haben herausgefunden, dass die durch die Vorhersage von Diffusionsmodellen verursachte Entropiereduktion einer skalierten Version der Verlustfunktion entspricht. Diese Entdeckung eröffnet die Möglichkeit, für Gaußsche Diffusionsmodelle ein ähnliches Time Warping einzuführen, wie es in der CDCD-Arbeit für die kategoriale Kreuzentropie verwendet wird. Dies bietet ein datenabhängiges Zeitkonzept basierend auf bedingter Entropie, das potenziell die Trainingsplanung von Diffusionsmodellen optimieren könnte. (Quelle: sedielem)

Intels 18A-Prozess geht in die Risiko-Pilotproduktion, 14A steht bevor: Auf der Intel Foundry Direct Connect Konferenz kündigte CEO [Anm.: Pat Gelsinger ist CEO, nicht Chen Liwu] an, dass der Intel 18A-Prozessknoten in die Risiko-Pilotproduktion eingetreten ist und noch in diesem Jahr in die Massenproduktion gehen wird. Gleichzeitig hat Intel wichtigen Kunden eine frühe Version des Intel 14A PDK zur Verfügung gestellt; dieser Knoten wird die PowerDirect-Technologie zur direkten Stromversorgung nutzen. Darüber hinaus wurden Weiterentwicklungen wie Intel 18A-P und 18A-PT sowie fortschrittliche Packaging-Technologien wie Foveros Direct und EMIB-T vorgestellt. Intel kündigte zudem eine Partnerschaft mit Amkor Technology an, um die System-Level-Foundry-Fähigkeiten zu stärken und den Anforderungen von KI und anderen Hochleistungsrechenanwendungen gerecht zu werden. (Quelle: WeChat)
KI-Unterhaltungsstudios beschleunigen Integration durch Fusionen: Im Bereich der KI-Unterhaltung zeichnet sich ein Konsolidierungstrend ab. Die Hollywood-KI-Datenanalyseplattform Cinelytic hat Jumpcut Media, einen Entwickler von KI-Tools für das Management geistigen Eigentums, übernommen. Ziel ist es, die Fähigkeiten zur KI-Drehbuchanalyse zu erweitern, Tools wie ScriptSense zu integrieren und die Effizienz bei Inhaltsentscheidungen zu steigern. Gleichzeitig hat das im letzten Jahr gegründete KI-Unterhaltungsstudio Promise die KI-Filmschule Curious Refuge übernommen, um eine Talentpipeline aufzubauen, kreative Talente im Umgang mit generativer KI zu fördern und die Anwendung von KI in der Film- und Fernsehproduktion zu beschleunigen. (Quelle: 36氪)

Duolingo kündigt umfassende AI First-Strategie an: Der CEO von Duolingo kündigte in einer unternehmensweiten Mitteilung an, dass das Unternehmen vollständig auf eine AI First-Strategie umstellt, da die Annahme von KI unumgänglich sei. Das Unternehmen wird schrittweise Aufgaben, die derzeit von externen Dienstleistern erledigt werden und von KI übernommen werden können, durch KI ersetzen und das Personalwachstum streng kontrollieren, wobei KI-Automatisierungslösungen Priorität haben. KI wird in Bereichen wie Personalbeschaffung und Leistungsbeurteilung eingeführt, um die Effizienz zu steigern und menschlichen Mitarbeitern zu ermöglichen, sich auf kreative Arbeit zu konzentrieren. Dieser Schritt basiert auf dem signifikanten Nutzerwachstum und Umsatzanstieg, den Duolingo in den letzten Jahren durch den Einsatz von KI (insbesondere in Zusammenarbeit mit OpenAI) erzielt hat. (Quelle: WeChat)

🧰 Tools
Meta veröffentlicht Open-Source-Tool llama-prompt-ops: Auf der LlamaCon hat Meta das Python-Paket llama-prompt-ops veröffentlicht, das auf DSPy und dem MIPROv2-Optimierer basiert. Dieses Tool kann Prompts, die für andere LLMs geeignet sind, in für Llama-Modelle optimierte Prompts umwandeln und hat bei mehreren Aufgaben signifikante Leistungssteigerungen gezeigt. Ziel ist es, Benutzern die Migration und Optimierung ihrer Anwendungen auf Llama-Modellen zu erleichtern. (Quelle: matei_zaharia, stanfordnlp, lateinteraction)
Google Cloud veröffentlicht Agent Starter Pack: Google Cloud Platform hat das Agent Starter Pack als Open Source veröffentlicht. Es handelt sich um eine Sammlung verschiedener produktionsreifer GenAI-Agent-Vorlagen (wie ReAct, RAG, Multi-Agent, Echtzeit-Multimodal-API). Ziel ist es, durch die Bereitstellung von Gesamtlösungen die Entwicklung und Bereitstellung von GenAI-Agenten zu beschleunigen und häufige Herausforderungen wie Bereitstellungsbetrieb, Evaluierung, Anpassung und Beobachtbarkeit zu lösen. Es unterstützt die Bereitstellung über Cloud Run und Agent Engine. (Quelle: GitHub Trending)

CUA Framework veröffentlicht: Docker-Container für AI Agent zur Steuerung von Betriebssystemen: trycua hat das CUA (Computer-Use Agent) Framework als Open Source veröffentlicht. Es handelt sich um eine AI-Agent-Lösung, die ein vollständiges Betriebssystem in einem leistungsstarken, leichtgewichtigen virtuellen Container steuern kann. Es nutzt das Virtualization.Framework von Apple Silicon, um eine nahezu native Leistung von macOS/Linux-VMs (bis zu 97%) zu bieten, und stellt Schnittstellen bereit, über die KI-Systeme diese Umgebungen beobachten und steuern können, um komplexe Workflows wie Anwendungsinteraktion, Web-Browsing und Codierung sicher und isoliert auszuführen. (Quelle: GitHub Trending)
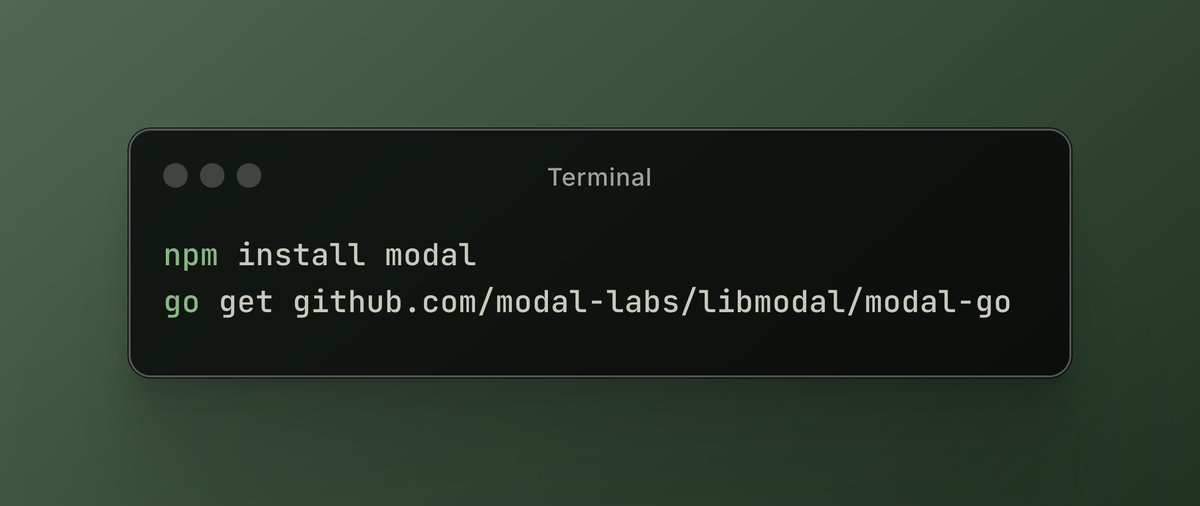
Modal Labs Plattform fügt JavaScript- und Go-Unterstützung hinzu: Die Cloud-Computing-Plattform Modal Labs gab bekannt, dass ihre Runtime (in Rust geschrieben) jetzt JavaScript (Node/Deno/Bun) und Go SDKs unterstützt. Entwickler können nun mit diesen Sprachen GPU-Serverless-Funktionen aufrufen und sichere virtuelle Maschinen für nicht vertrauenswürdigen Code starten, was die Anwendungsszenarien von Modal über den Bereich Data Science/Machine Learning hinaus erweitert. (Quelle: akshat_b, HamelHusain)
Kling AI führt neue Spezialeffekte ein: Das Videogenerierungsmodell Kling AI von Kuaishou hat neue interaktive Spezialeffekte hinzugefügt. Benutzer können ein Foto mit zwei Personen hochladen und dann Effekte wie „Küssen“, „Umarmen“, „Herzchen zeigen“ oder sogar „Herumalbern“ anwenden, um dynamische Videos zu generieren, was den Spaß und die Interaktivität bei der Generierung von Porträtvideos erhöht. (Quelle: Kling_ai)
NotebookLM fügt mehrsprachige Audio-Übersichtsfunktion hinzu: Googles KI-Notizwerkzeug NotebookLM hat die Funktion Audio Overviews eingeführt, die von Benutzern hochgeladene Dokumente, Notizen usw. in podcast-ähnliche Audiozusammenfassungen umwandeln kann. Diese Funktion unterstützt jetzt über 50 Sprachen weltweit, einschließlich Deutsch. Selbst wenn das Ausgangsmaterial des Benutzers mehrsprachig ist, kann eine Audiozusammenfassung in der gewünschten Sprache erstellt werden, sodass Benutzer Informationen jederzeit und überall durch Zuhören lernen und verstehen können. (Quelle: WeChat)
PaperCoder: Automatische Umwandlung von Machine-Learning-Papern in Code: Forscher des Korea Advanced Institute of Science and Technology (KAIST) haben PaperCoder als Open Source veröffentlicht, ein Multi-Agent-LLM-System, das darauf abzielt, Methoden und Experimente aus Machine-Learning-Papern automatisch in lauffähige Codebasen umzuwandeln. Das System arbeitet in drei Phasen – Planung, Analyse und Codegenerierung – wobei spezialisierte Agenten unterschiedliche Aufgaben übernehmen. Studien zeigen, dass die Qualität des generierten Codes bestehende Benchmarks übertrifft und von 77% der ursprünglichen Paper-Autoren anerkannt wird, was das Problem der schwierigen Code-Reproduktion von Papern lösen könnte. (Quelle: WeChat)

Cactus: Leichtgewichtiges On-Device AI Framework: Cactus ist ein leichtgewichtiger, hochperformanter Framework zum Ausführen von KI-Modellen auf mobilen Geräten. Es bietet eine einheitliche, konsistente API über React-Native, Android (Kotlin/Java), iOS (Swift/Objective-C++) und Flutter/Dart hinweg, was Entwicklern die Bereitstellung und Ausführung von KI-Modellen auf verschiedenen mobilen Plattformen erleichtert. (Quelle: Reddit r/deeplearning)
Muyan-TTS: Open-Source TTS-Modell mit geringer Latenz und Anpassbarkeit: Das ChatPods-Team hat Muyan-TTS als Open Source veröffentlicht, ein Text-to-Speech (TTS)-Modell mit geringer Latenz und hoher Anpassbarkeit. Das Modell zielt darauf ab, das Problem zu lösen, dass bestehende Open-Source-TTS-Modelle entweder keine hohe Qualität aufweisen oder nicht ausreichend offen sind. Es stellt vollständige Modellgewichte, Trainingsskripte und Datenverarbeitungsprozesse zur Verfügung. Es umfasst ein Base-Modell (für Zero-Shot-TTS) und ein SFT-Modell (für Voice Cloning), unterstützt Englisch gut und ermutigt die Community, auf Basis seines Frameworks Weiterentwicklungen und Erweiterungen vorzunehmen. (Quelle: Reddit r/deeplearning)
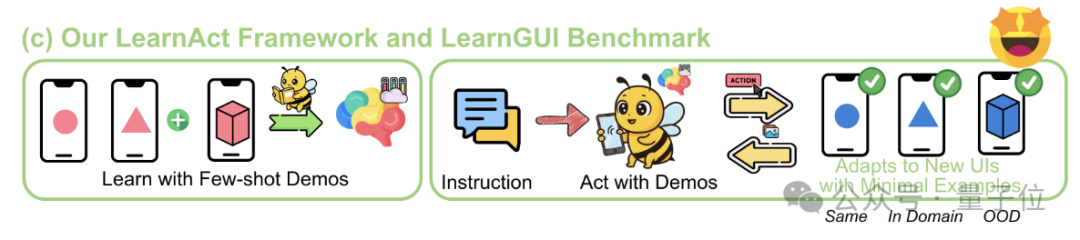
LearnAct Framework: Handy-KI lernt komplexe Operationen mit nur einer Demonstration: Die Zhejiang University und das vivo AI Lab haben gemeinsam das LearnAct Multi-Agent Framework und den LearnGUI Benchmark vorgestellt. Ziel ist es, GUI-Agenten auf Mobiltelefonen durch wenige (sogar nur eine) Benutzerdemonstrationen das Ausführen komplexer, personalisierter Long-Tail-Aufgaben beizubringen. LearnAct umfasst drei Agenten: DemoParser (analysiert Demonstrationen), KnowSeeker (ruft Wissen ab) und ActExecutor (führt Aktionen aus). Experimente zeigen, dass diese Methode die Erfolgsrate des Modells bei unbekannten Szenarien signifikant verbessern kann, z. B. die Genauigkeit von Gemini-1.5-Pro von 19,3% auf 51,7% steigern. (Quelle: WeChat)
📚 Lernen
Umfassender Überblick über LLM Post-Training-Techniken: Forscher von MBZUAI, Google DeepMind und anderen Institutionen haben einen umfassenden Überblick über LLM Post-Training-Techniken veröffentlicht. Der Bericht untersucht eingehend verschiedene Methoden zur Verbesserung der Inferenzfähigkeiten von LLMs, zur Ausrichtung an menschlichen Absichten und zur Erhöhung der Zuverlässigkeit durch Reinforcement Learning (RLHF, RLAIF, DPO, GRPO usw.), Supervised Fine-Tuning (SFT) und Test-Time-Erweiterungen (CoT, ToT, GoT, Self-Consistency Decoding usw.). Der Bericht behandelt auch Reward Modeling, Parameter-Efficient Fine-Tuning (PEFT), Modellskalierungsstrategien sowie zugehörige Evaluierungsbenchmarks und zeigt zukünftige Forschungsrichtungen auf. (Quelle: WeChat)
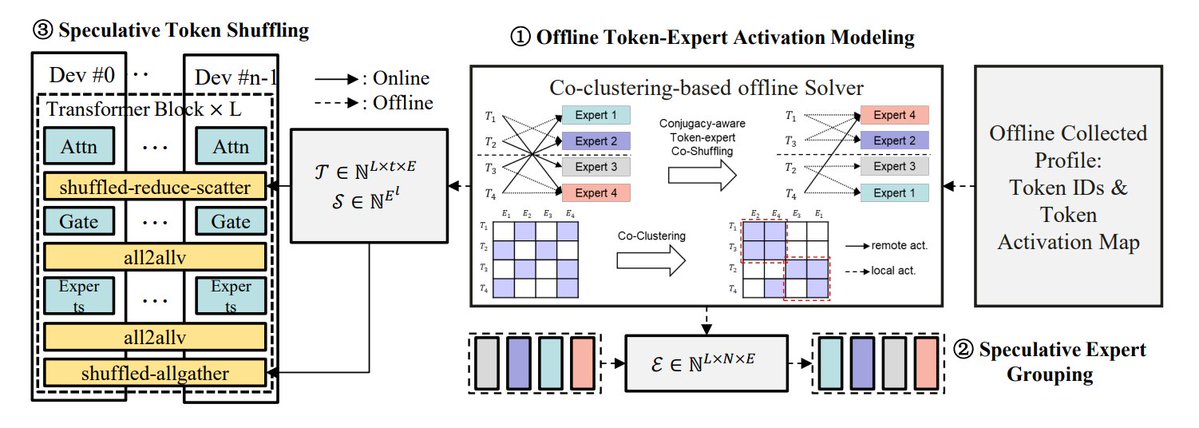
Zusammenfassung von Optimierungsmethoden für MoE-Inferenz: TheTuringPost fasst 5 Methoden zur Optimierung der Inferenz von MoE-Modellen zusammen: eMoE (Vorhersage und Vorladen von Experten), MoEShard (Experten-Sharding auf verschiedene GPUs), DeepSpeed-MoE (Kombination verschiedener Techniken für groß angelegte Verarbeitung), Speculative-MoE (Vorhersage von Routing-Pfaden und Gruppierung von Experten), MoE-Gen (modulbasiertes Batching). Der Artikel erwähnt auch fortgeschrittene Methoden wie Structural MoE und Symbolic-MoE, die darauf abzielen, die Ineffizienz und den Durchsatz von MoE-Modellen zu verbessern. (Quelle: TheTuringPost)
Rückblick auf das Paper „End-To-End Memory Networks“ von vor zehn Jahren: Meta-Forschungswissenschaftler Sainbayar Sukhbaatar blickt auf sein 2015 mitverfasstes Paper „End-To-End Memory Networks“ zurück. Dieses Paper war eines der ersten Sprachmodelle, das RNNs vollständig durch Aufmerksamkeitsmechanismen ersetzte. Es führte Konzepte wie Soft Attention mit Punktprodukt und Key-Value-Projektionen, mehrschichtig gestapelte Attention und Positions-Embeddings (damals als Zeit-Embeddings bezeichnet) ein – alles Kernelemente aktueller LLMs. Obwohl es nicht den Einfluss von „Attention is all you need“ erreichte, kombinierte es Ideen aus Memory Networks und früher Soft Attention und zeigte das Inferenzpotenzial mehrschichtiger Soft Attention. (Quelle: iScienceLuvr, WeChat)

CVPR 2025 Oral: Mona – Neue Methode für effizientes visuelles Fine-Tuning: Forscher der Tsinghua University, der University of Chinese Academy of Sciences und anderer Institutionen stellen Mona (Multi-cognitive Visual Adapter) vor, eine neuartige Methode für das Fine-Tuning visueller Adapter. Durch die Einführung von multikognitiven visuellen Filtern (tiefentrennbarer Faltung + mehrskalige Kernel) und Optimierung der Eingabeverteilung (Scaled LayerNorm) passt Mona weniger als 5% der Parameter des Backbone-Netzwerks an und übertrifft bei mehreren visuellen Aufgaben wie Instanzsegmentierung und Objekterkennung die Leistung des vollständigen Parameter-Fine-Tunings, während gleichzeitig Rechen- und Speicherkosten erheblich gesenkt werden. Diese Methode bietet neue Ansätze für effizientes PEFT bei visuellen Modellen. (Quelle: WeChat)

ICLR 2025 Oral: DIFF Transformer – Differenzielle Attention verbessert Modellierung langer Texte: Microsoft und die Tsinghua University stellen den DIFF Transformer vor, der durch die Einführung eines differenziellen Aufmerksamkeitsmechanismus (Berechnung der Differenz zweier Softmax-Aufmerksamkeitskarten) wichtige Kontextsignale verstärkt und Rauschen eliminiert. Experimente zeigen, dass der DIFF Transformer bei der Sprachmodellierung skalierbarer ist (erreicht vergleichbare Leistung mit ca. 65% der Parameter/Daten) und traditionelle Transformer bei der Modellierung langer Texte, der Suche nach Schlüsselinformationen, dem Kontextlernen, der Bekämpfung von Halluzinationen und dem mathematischen Schließen signifikant übertrifft. Er reduziert auch Aktivierungs-Ausreißer, was der Quantisierung zugutekommt. (Quelle: WeChat)

MARFT: Neues Paradigma für Multi-Agent Reinforcement Fine-Tuning: Forscher der Shanghai Jiao Tong University und anderer Institutionen stellen MARFT (Multi-Agent Reinforcement Fine-Tuning) vor, ein neues Paradigma für das Reinforcement Fine-Tuning von LLM-basierten Multi-Agenten-Systemen (LaMAS). Diese Methode löst die Optimierungsherausforderungen, die sich aus der Dynamik von LaMAS ergeben, durch Multi-Agenten-Advantage-Value-Zerlegung und eine Transformer-ähnliche Modellierung sequenzieller Entscheidungen. Erste Experimente zeigen, dass mit MARFT feinabgestimmte LaMAS bei mathematischen Aufgaben besser abschneiden als nicht feinabgestimmte Systeme und Single-Agent PPO. Die Forscher untersuchen auch das Potenzial und die Herausforderungen in Bezug auf die Lösung komplexer Aufgaben, Skalierbarkeit, Datenschutz und die Kombination mit Blockchain. (Quelle: WeChat)

Umfassender Überblick über AI Agent Protokolle: Die Shanghai Jiao Tong University hat in Zusammenarbeit mit der ANP Community den ersten umfassenden Überblick über AI Agent Protokolle veröffentlicht. Das Paper schlägt einen zweidimensionalen Klassifizierungsrahmen vor (objektorientiert: kontextorientiert vs. inter-agent; anwendungsorientiert: allgemein vs. domänenspezifisch) und analysiert über zehn gängige Protokolle wie MCP, A2A, ANP, AITP, LMOS. Die Bewertung erfolgt anhand von sieben Dimensionen (Effizienz, Skalierbarkeit, Sicherheit, Zuverlässigkeit, Erweiterbarkeit, Bedienbarkeit, Interoperabilität). Ein Reiseplanungs-Fallbeispiel vergleicht die Architekturen MCP, A2A, ANP und Agora. Abschließend wird die zukünftige Entwicklung von Protokollen skizziert: von statisch zu evolvierbar, von Regeln zu Ökosystemen, von Protokollen zu intelligenter Infrastruktur. (Quelle: WeChat)

MCP-Protokoll im Detail: Architektur, Ökosystem und Sicherheitsrisiken: Ein neues Übersichtspaper untersucht eingehend die Architektur, den aktuellen Stand des Ökosystems und potenzielle Sicherheitsrisiken des Model Context Protocol (MCP). Der Artikel analysiert die ternäre Struktur von MCP Host, Client und Server sowie deren Interaktionsmechanismen. Er gibt einen Überblick über die Fortschritte von Unternehmen wie Anthropic, OpenAI, Cursor, Replit und der Community bei der Nutzung von MCP. Ein Schwerpunkt liegt auf der Analyse von Sicherheitslücken im Lebenszyklus des MCP Servers (Erstellung, Ausführung, Aktualisierung), wie Namenskonflikte, Installer-Spoofing, Code-Injection, Tool-Namenskonflikte, Sandbox-Escaping und Persistenz von Berechtigungen. (Quelle: WeChat)

CVPR Oral: UniAP – Einheitlicher Algorithmus für automatisches Intra- und Inter-Layer-Parallelismus: Die Forschungsgruppe von Professor Li Wujun an der Nanjing University stellt UniAP vor, einen verteilten Trainingsalgorithmus, der Parallelisierungsstrategien innerhalb von Schichten (Daten/Tensor/ZeRO) und zwischen Schichten (Pipeline) gemeinsam optimieren kann. Durch Modellierung mittels gemischt-ganzzahliger quadratischer Programmierung kann UniAP automatisch effiziente verteilte Trainingspläne finden und löst damit das Problem der komplexen und ineffizienten manuellen Konfiguration. Experimente zeigen, dass UniAP bis zu 3,8-mal schneller ist als bestehende automatische Parallelisierungsmethoden und 9-mal schneller als nicht optimierte Strategien. Zudem kann es 64%-87% der ungültigen (OOM-)Strategien effektiv vermeiden und die Benutzerfreundlichkeit verbessern. Der Algorithmus wurde bereits für heimische KI-Rechenkarten angepasst. (Quelle: WeChat)
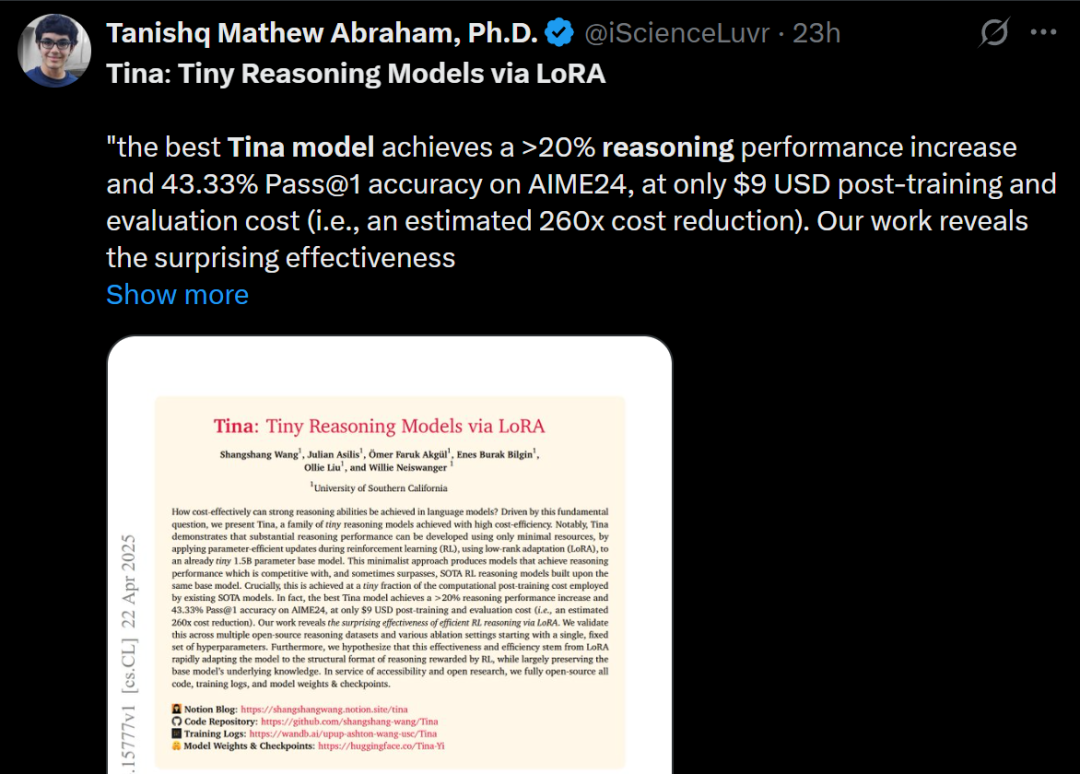
Tina: Kleine Modelle mit hoher Inferenzfähigkeit durch LoRA zu geringen Kosten: Ein Team der University of Southern California stellt die Tina (Tiny Reasoning Models via LoRA) Modellreihe vor. Durch den Einsatz von LoRA für das Reinforcement Learning Post-Training auf Basis eines 1.5B Parameter starken DeepSeek-R1-Distill-Qwen-Modells erreichen die Tina-Modelle auf mehreren Reasoning-Benchmarks (AIME, AMC, MATH, GPQA, Minerva) eine Leistung, die mit der von vollständig feinabgestimmten Basismodellen vergleichbar oder sogar besser ist – und das bei extrem niedrigen Trainingskosten (Kosten für den besten Checkpoint nur 9 US-Dollar). Die Forschung zeigt die Vorteile von LoRA beim effizienten Erlernen von Inferenzformaten/-strukturen und beobachtet eine Entkopplung von Formatmetriken und Genauigkeitsmetriken während des Trainings. (Quelle: WeChat)
Rekursive KL-Divergenz-Optimierung: Neue effiziente Methode für das Modelltraining: Ein neues Paper stellt die Methode der rekursiven KL-Divergenz-Optimierung (Recursive KL Divergence Optimization) vor, die angeblich eine Effizienzsteigerung von bis zu 80% beim Modelltraining (insbesondere beim Fine-Tuning) ermöglicht. Diese Methode könnte durch eine optimierte Beschränkung der Modellaktualisierungen die für das Training benötigten Rechenressourcen oder die Zeit reduzieren und somit einen neuen Weg für ein wirtschaftlicheres und schnelleres Training und Fine-Tuning von Modellen bieten. (Quelle: Reddit r/LocalLLaMA)
💼 Business
Sakana AI will politische Unsicherheit in den USA für Wachstum in Japan nutzen: Das japanische KI-Startup Sakana AI sieht in der politischen Unsicherheit der USA und der Nachfrage nach heimischen KI-Lösungen (insbesondere bei Regierungs- und Finanzinstitutionen) eine Wachstumschance in Japan. Der Business Development Manager des Unternehmens erwartet in den nächsten 6 Monaten 5-10 Anwendungsfälle von Kunden aus dem Regierungs- und Finanzsektor. CEO David Ha wies darauf hin, dass vor dem Hintergrund zunehmender geopolitischer Spannungen die Nachfrage demokratischer Staaten nach der Modernisierung ihrer Regierungs- und Verteidigungsinfrastruktur steigt. Der Fokus des Unternehmens auf Verteidigungsanwendungen (wie Biosicherheitsrisiken und Desinformationsverfolgung) sei daher von entscheidender Bedeutung. (Quelle: SakanaAILabs, SakanaAILabs)
Meta prognostiziert Umsatz von 1,4 Billionen US-Dollar durch generative KI bis 2035: Meta prognostiziert für sein Geschäft mit generativer KI einen Umsatz von 3 Milliarden US-Dollar im Jahr 2025 und erwartet einen rasanten Anstieg auf 1,4 Billionen US-Dollar bis 2035. Diese Prognose zeigt, dass Meta äußerst optimistisch hinsichtlich des langfristigen Wachstumspotenzials im KI-Bereich ist und wahrscheinlich weiterhin hohe Investitionsausgaben für KI-Forschung, Entwicklung und Infrastruktur tätigen wird. (Quelle: brickroad7)

Alimama veröffentlicht Weltwissens-Großmodell URM: Alimama hat das Large Language Model URM (Universal Recommendation Model) vorgestellt, das Weltwissen mit Wissen aus dem E-Commerce-Bereich kombiniert. Durch Wissensinjektion (Produkt-IDs als spezielle Tokens) und Informationsabgleich (Integration von IDs mit multimodalen semantischen Repräsentationen) kann das Modell die bisherigen Interessen der Nutzer verstehen und darauf basierende Empfehlungen ableiten. URM verwendet eine Sequence-In-Set-Out-Generierungsmethode, die parallel mehrere Nutzerrepräsentationen erzeugt, um die Effektivität und Vielfalt zu erhöhen, während die Inferenz-Effizienz erhalten bleibt. Es wurde bereits in den Display-Anzeigen-Szenarien von Alimama eingeführt und löst durch eine asynchrone Inferenz-Pipeline das Latenzproblem von LLMs, wodurch die Werbewirkung für Händler und das Einkaufserlebnis für Nutzer verbessert werden. (Quelle: WeChat)

🌟 Community
Ende der GPT-4-Ära löst Nostalgie und Diskussionen aus: Sam Altman verabschiedete sich von GPT-4 mit den Worten, es habe eine Revolution ausgelöst, und seine Gewichte würden für zukünftige Historiker aufbewahrt. Dies löste in der Community weitreichende Nostalgie aus; viele erinnerten sich daran, dass GPT-4 das erste Modell war, das ihnen das Potenzial von AGI spüren ließ. Gleichzeitig entfachte dies Diskussionen über Open Source. Mitglieder der Community wie Hugging Face forderten OpenAI auf, die GPT-4-Gewichte für Forschungszwecke zu öffnen, anstatt sie nur zu archivieren. (Quelle: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
Beobachtungen und Diskussionen zum AI Coding-Bereich: Zhang Hailong, Gründer von GruAI, ist der Ansicht, dass AI Coding einer der wenigen Bereiche ist, in denen derzeit ein Product-Market-Fit erkennbar ist. Der Erfolg von Cursor liege darin, einen neuen Markt geschaffen zu haben, wobei der Wert der Benutzeroberfläche enorm sei. Er hält die Richtung von Devin für richtig, aber zu ambitioniert und zeitaufwendig, obwohl die Erfolgswahrscheinlichkeit steige und es letztendlich mit Cursor konkurrieren werde. Für Startups sei übermäßige Sorge vor der Konkurrenz großer Unternehmen unbegründet; entscheidend seien Produktstärke und einzigartiger Wert. Der Modellfortschritt reduziere signifikant die Notwendigkeit, Defizite durch Engineering auszugleichen. Gründer müssten unterscheiden, welche Probleme durch die Modellentwicklung gelöst werden und wo echte Produktstärke liegt. (Quelle: WeChat)

Reflexion über die Aussage „KI wird deinen Job ersetzen“: In der Community wird diskutiert, dass die Aussage „KI wird nicht deinen Job ersetzen, aber jemand, der KI nutzt, schon“ zwar oberflächlich richtig, aber zu vereinfachend sei – eine Art „Konsens-Theater“, das davon abhält, über tiefergehende Fragen nachzudenken. Entscheidend sei vielmehr zu verstehen, wie KI Arbeitsstrukturen verändert, Arbeitsabläufe neu gestaltet, Organisationslogiken wandelt und wie die zukünftige Arbeit in einem neuen System aussehen wird, anstatt sich nur auf die Automatisierung oder Verbesserung einzelner Aufgaben zu konzentrieren. (Quelle: Reddit r/ArtificialInteligence)

Die Kamera als neuer Zugangspunkt für die Interaktion von KI-Agenten mit der physischen Welt: Diskutiert wird, dass Funktionen wie Quark’s „Fotografieren und Fragen“ einen neuen Trend in der Interaktion mit KI-Anwendungen darstellen. Durch die Handykamera, einen weit verbreiteten Sensor, kombiniert mit multimodaler Verständnisfähigkeit und Agenten-Fähigkeiten, kann KI die physische Welt besser verstehen und basierend auf impliziten oder expliziten Nutzerbedürfnissen autonom Entscheidungen treffen und Fähigkeiten aufrufen, um Aufgaben zu erledigen (z. B. Objekte erkennen, übersetzen, Preise vergleichen, bei Hausaufgaben helfen, Belege verarbeiten). Dadurch wandelt sich die Kamera von einem einfachen Informations-Eingabewerkzeug zu einem Knotenpunkt, der die physische Welt mit digitaler Intelligenz verbindet und das „Get it Done“-Prinzip ermöglicht. (Quelle: WeChat)
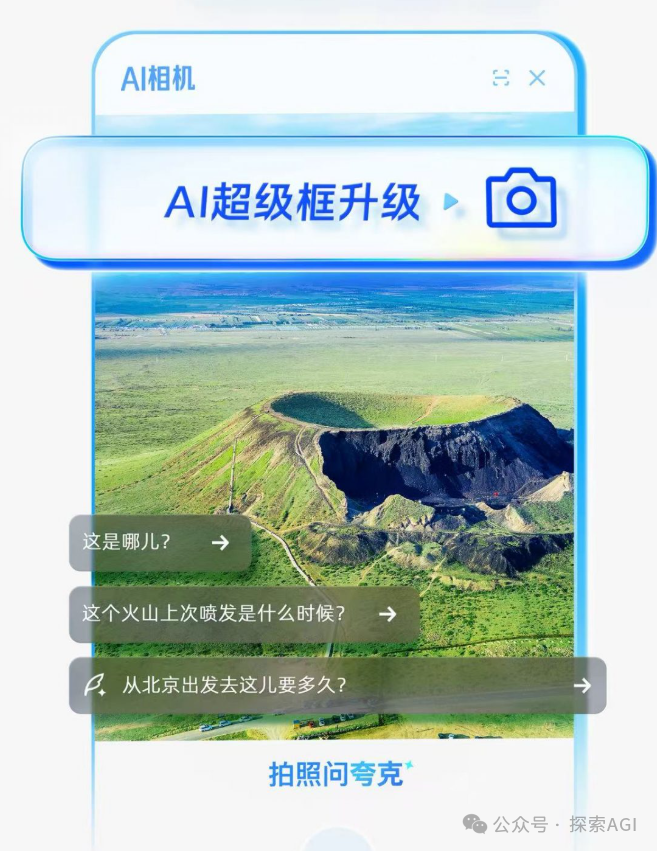
💡 Sonstiges
KI und wissenschaftliche Forschung: In der Community herrscht die Ansicht, dass KI allmählich zur neuen „Mathematik“ der wissenschaftlichen Forschung wird. Das bedeutet, dass KI, ähnlich wie die Mathematik, zu einem grundlegenden Werkzeug und einer Sprache wird, die wissenschaftliche Entdeckungen und das Verständnis vorantreibt. (Quelle: shuchaobi)

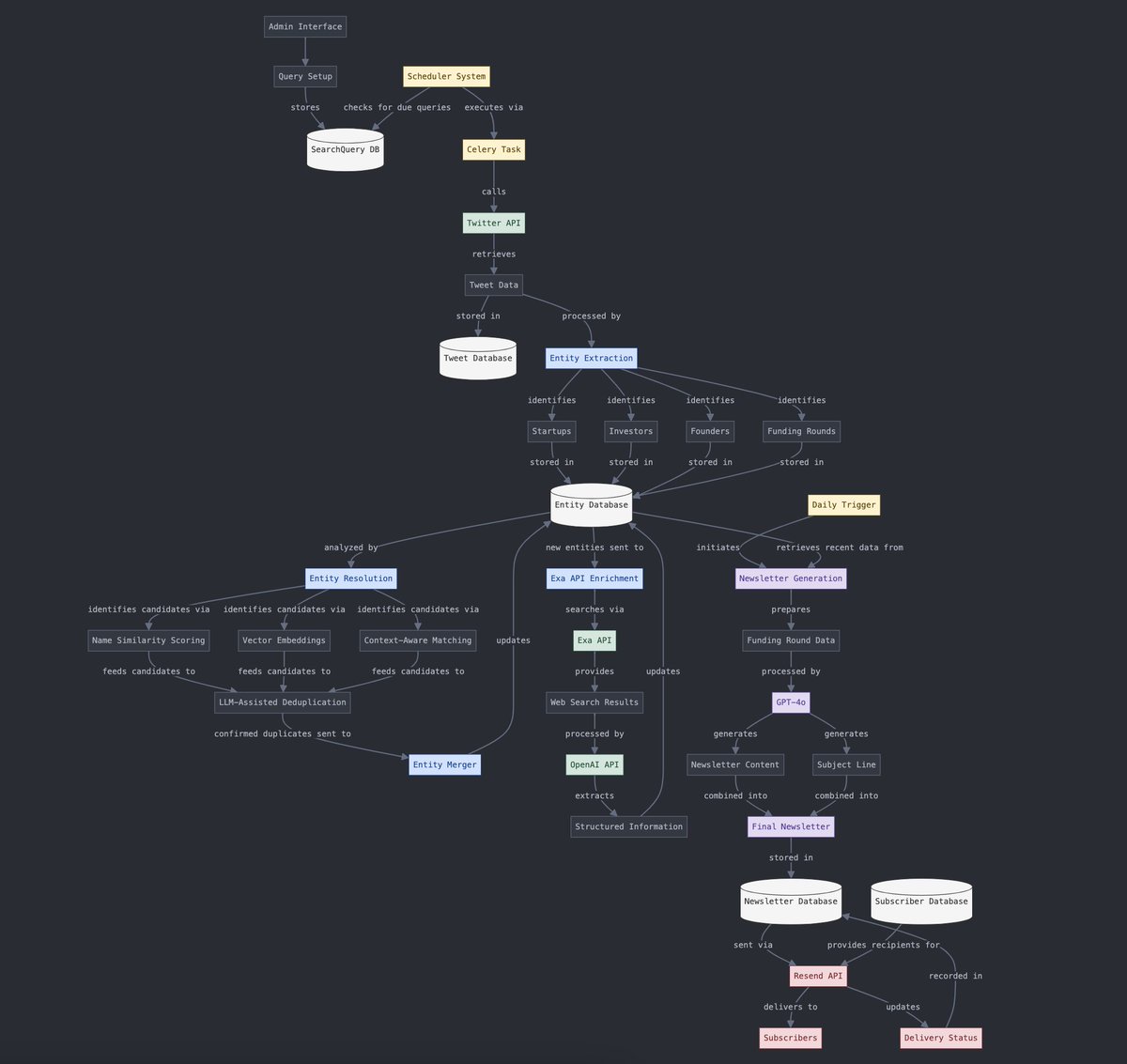
Umwandlung zwischen strukturierten und unstrukturierten Daten: Yohei Nakajima demonstriert, wie KI genutzt werden kann, um unstrukturierte Tweet-Daten in strukturierte Daten umzuwandeln, um diese anschließend wieder in einen unstrukturierten täglichen Newsletter zu überführen. Dies zeigt die Anwendung von KI in Informationsverarbeitungs- und Content-Generierungs-Prozessen. (Quelle: yoheinakajima)
Die Zukunft der Kombination von KI und VR: Community-Diskussionen blicken auf das Potenzial der Kombination von KI und VR. Man stellt sich vor, dass es in Zukunft möglich sein könnte, durch natürliche Sprache oder Gedanken direkt 3D-Objekte im „Whiteboard-Raum“ der VR zu generieren und zu manipulieren, was eine kognitiv gesteuerte Kreation ermöglicht. Meta wird als wichtiger Akteur angesehen, der diese Richtung vorantreibt. (Quelle: Reddit r/ArtificialInteligence)