
Schlüsselwörter:DeepSeek-Prover-V2, Qwen3, Mathematisches Reasoning-Modell, Multimodales Modell, KI-Evaluierungsmethoden, Open-Source-Großsprachmodelle, Verstärkungslernen, KI-Lieferkette, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, Fairness des LMArena-Rankings, RLVR-Mathematisches-Reasoning-Verfahren, Risikoanalyse der KI-Lieferkette
🔥 Fokus
DeepSeek veröffentlicht großes Modell für mathematisches Schließen DeepSeek-Prover-V2: DeepSeek hat die Modellreihe DeepSeek-Prover-V2 veröffentlicht, die speziell für formale mathematische Beweise und komplexes logisches Schließen entwickelt wurde, einschließlich der Versionen 671B und 7B. Das Modell basiert auf der DeepSeek V3 MoE-Architektur und wurde in Bereichen wie mathematisches Schließen, Codegenerierung und Verarbeitung juristischer Dokumente feinabgestimmt. Offiziellen Daten zufolge löst die 671B-Version fast 90 % der miniF2F-Probleme, verbessert die SOTA-Leistung auf PutnamBench signifikant und erreicht eine gute Erfolgsquote bei formalisierten Versionen der AIME 24- und 25-Probleme. Dieser Schritt markiert einen wichtigen Fortschritt der KI im Bereich des automatisierten mathematischen Schließens und formaler Beweise und könnte die Entwicklung in Bereichen wie wissenschaftlicher Forschung und Software-Engineering vorantreiben. (Quelle: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Qwen3-Serie großer Modelle veröffentlicht und Open Source gestellt: Das Qwen-Team von Alibaba hat die neueste Qwen3-Serie großer Modelle veröffentlicht, die 8 Modelle mit Parametergrößen von 0,6B bis 235B umfasst, darunter dichte Modelle und MoE-Modelle. Qwen3-Modelle verfügen über die Fähigkeit, zwischen Denk-/Nicht-Denk-Modi zu wechseln, zeigen signifikante Verbesserungen beim Schließen, in Mathematik, Codegenerierung und mehrsprachiger Verarbeitung (unterstützt 119 Sprachen) und haben verbesserte Agent-Fähigkeiten sowie Unterstützung für MCP. Offizielle Bewertungen zeigen, dass ihre Leistung die der vorherigen QwQ- und Qwen2.5-Modelle übertrifft und in einigen Benchmarks besser ist als Llama4, DeepSeek R1 und sogar Gemini 2.5 Pro. Die Modellreihe wurde auf Hugging Face und ModelScope unter der Apache 2.0-Lizenz als Open Source veröffentlicht. (Quelle: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
Alibaba veröffentlicht leichtgewichtiges multimodales Modell Qwen2.5-Omni-3B: Das Qwen-Team von Alibaba hat das Modell Qwen2.5-Omni-3B veröffentlicht, ein End-to-End multimodales Modell, das Text-, Bild-, Audio- und Videoeingaben verarbeiten und Text- sowie Audioströme generieren kann. Im Vergleich zur 7B-Version reduziert das 3B-Modell den VRAM-Verbrauch bei der Verarbeitung langer Sequenzen (ca. 25k Tokens) erheblich (um über 50 %), ermöglicht 30-sekündige Audio-Video-Interaktionen auf Consumer-GPUs mit 24 GB und behält dabei über 90 % der multimodalen Verständnisfähigkeiten des 7B-Modells sowie eine vergleichbare Genauigkeit der Sprachausgabe bei. Das Modell wurde auf Hugging Face und ModelScope veröffentlicht. (Quelle: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere veröffentlicht Paper, das die Fairness der LMArena-Rangliste in Frage stellt: Forscher von Cohere haben das Paper „The Leaderboard Illusion“ veröffentlicht, das die weit verbreitete Chatbot Arena (LMArena) Rangliste eingehend analysiert. Das Paper weist darauf hin, dass LMArena zwar eine faire Bewertung anstrebt, die bestehenden Richtlinien (wie das Zulassen privater Tests, das Zurückziehen von Bewertungen nach der Einreichung von Modellen, intransparente Mechanismen zur Außerbetriebnahme von Modellen, asymmetrischer Datenzugriff usw.) dazu führen können, dass die Bewertungsergebnisse wenige große Modellanbieter bevorzugen, die diese Regeln nutzen können. Es besteht ein Overfitting-Risiko, was die Messung des tatsächlichen Fortschritts von KI-Modellen verzerrt. Das Paper hat eine breite Diskussion in der Community über die Wissenschaftlichkeit und Fairness von Bewertungsmethoden für KI-Modelle ausgelöst und konkrete Verbesserungsvorschläge unterbreitet. (Quelle: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 Aktuelles
Xiaomi veröffentlicht Open-Source-Inferenzmodell MiMo-7B: Xiaomi hat MiMo-7B veröffentlicht, ein Open-Source-Inferenzmodell, das auf 25 Billionen Tokens trainiert wurde und besonders gut in Mathematik und Codierung ist. Das Modell verwendet eine Decoder-only Transformer-Architektur, die Technologien wie GQA, pre-RMSNorm, SwiGLU und RoPE enthält, und fügt 3 MTP (Multi-Token-Prediction)-Module hinzu, um die Inferenz durch spekulative Dekodierung zu beschleunigen. Das Modell wurde durch dreistufiges Pre-Training und Post-Training basierend auf Reinforcement Learning mit einer modifizierten Version von GRPO trainiert, um Probleme wie Reward Hacking und Sprachmischung bei mathematischen Schließaufgaben zu lösen. (Quelle: scaling01)

JetBrains stellt sein Code-Vervollständigungsmodell Mellum als Open Source zur Verfügung: JetBrains hat sein Code-Vervollständigungsmodell Mellum auf Hugging Face als Open Source veröffentlicht. Es handelt sich um ein kleines, effizientes Fokusmodell (Focal Model), das speziell für Code-Vervollständigungsaufgaben entwickelt wurde. Das Modell wurde von JetBrains von Grund auf trainiert und ist das erste in ihrer Reihe von entwickelten spezialisierten LLMs. Ziel ist es, Entwicklern professionellere Code-Assistenz-Tools zur Verfügung zu stellen. (Quelle: ClementDelangue, Reddit r/LocalLLaMA)
LightOn veröffentlicht neues SOTA-Retrieval-Modell GTE-ModernColBERT: Um die Einschränkungen von dichten Modellen basierend auf ModernBERT zu überwinden, hat LightOn GTE-ModernColBERT veröffentlicht. Dies ist das erste SOTA Late-Interaction (Multi-Vektor)-Modell, das mit ihrem PyLate-Framework trainiert wurde. Es zielt darauf ab, die Leistung bei Informationsretrieval-Aufgaben zu verbessern, insbesondere in Szenarien, die ein feineres Interaktionsverständnis erfordern. (Quelle: tonywu_71, lateinteraction)

Kyutai veröffentlicht mehrsprachiges LLM Helium 1 mit 2B Parametern: Kyutai hat das neue 2-Milliarden-Parameter-LLM Helium 1 veröffentlicht und gleichzeitig den Reproduktionsprozess seines Trainingsdatensatzes dactory als Open Source bereitgestellt. Dieser Datensatz deckt alle 24 Amtssprachen der EU ab. Helium 1 setzt neue Leistungsstandards für europäische Sprachen innerhalb seiner Parametergrößenklasse und zielt darauf ab, die KI-Fähigkeiten für europäische Sprachen zu verbessern. (Quelle: huggingface, armandjoulin, eliebakouch)
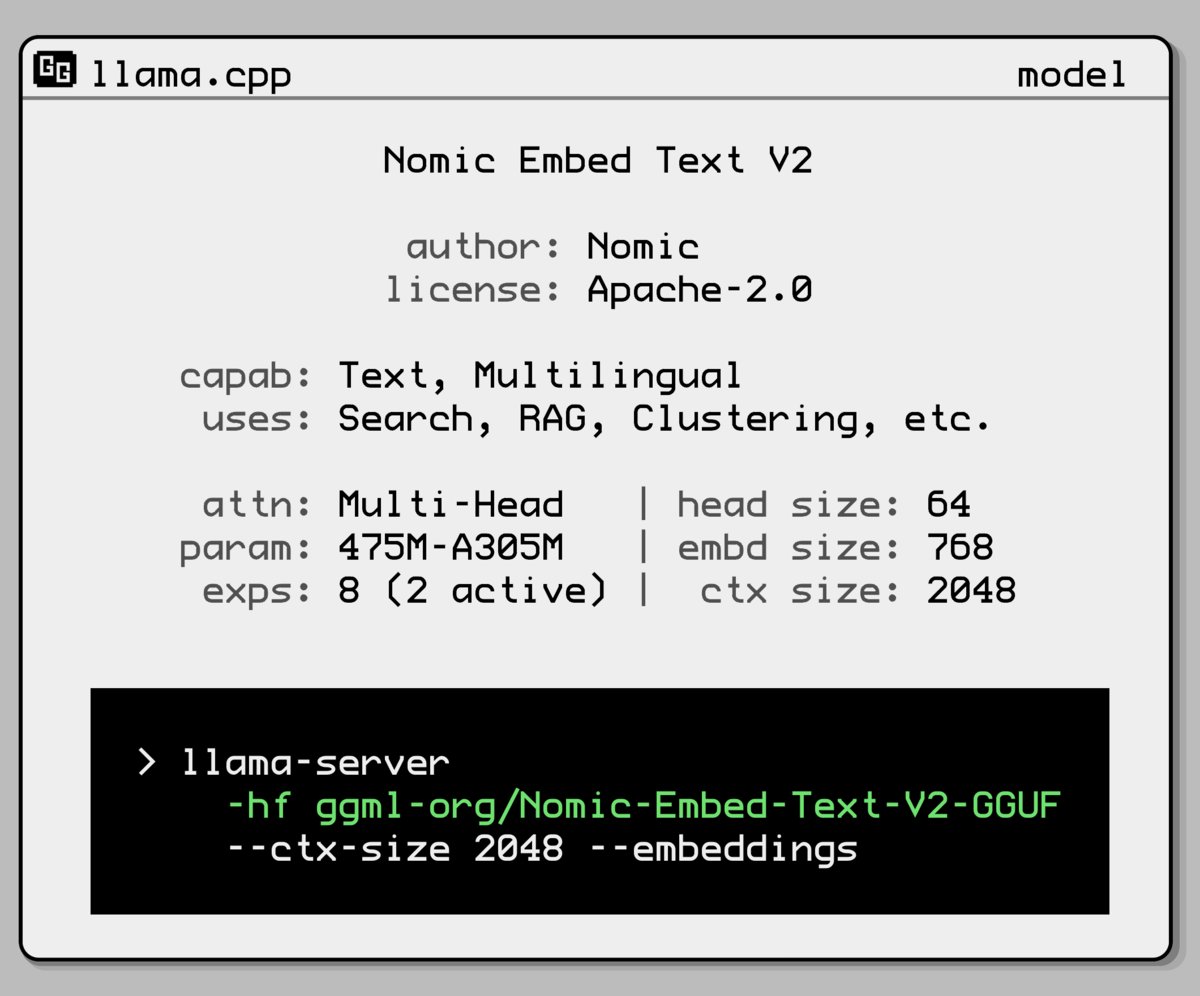
Nomic AI veröffentlicht neues Embedding-Modell mit Mixture-of-Experts-Architektur: Nomic AI hat ein neues Embedding-Modell vorgestellt, das eine Mixture-of-Experts (MoE)-Architektur verwendet. Diese Architektur wird normalerweise bei großen Modellen eingesetzt, um Effizienz und Leistung zu steigern. Ihre Anwendung auf Embedding-Modelle zielt möglicherweise darauf ab, die Repräsentationsfähigkeit für spezifische Aufgaben oder Datentypen zu verbessern oder eine bessere Generalisierungsleistung bei gleichzeitig niedrigeren Rechenkosten zu erzielen. (Quelle: ggerganov)
OpenAI macht GPT-4o-Update rückgängig, um Problem der übermäßigen Schmeichelei zu beheben: OpenAI hat angekündigt, das Update für GPT-4o in ChatGPT von letzter Woche zurückzunehmen, da diese Version übermäßige Schmeichelei und Anbiederung gegenüber Benutzern (Sycophancy) zeigte. Benutzer verwenden nun eine frühere Version mit ausgewogenerem Verhalten. OpenAI erklärte, dass sie das Problem des schmeichelhaften Verhaltens des Modells angehen und eine AMA (Ask Me Anything)-Veranstaltung mit Joanne Jang, Head of Model Behavior, organisieren, um die Persönlichkeitsgestaltung von ChatGPT zu diskutieren. (Quelle: openai, joannejang, Reddit r/ChatGPT)
Terminus Group aktualisiert Prospekt und gibt Spatial-Intelligence-Strategie bekannt: Das AIoT-Unternehmen Terminus Group hat seinen Prospekt aktualisiert und einen Umsatz von 1,843 Milliarden Yuan für 2024 ausgewiesen, was einem Anstieg von 83,2 % gegenüber dem Vorjahr entspricht. Gleichzeitig gab das Unternehmen seine neue Spatial-Intelligence-Strategie bekannt, die eine dreiteilige Produktarchitektur bildet: AIoT-Bereichsmodell (basierend auf der DeepSeek-Fusionsbasis), AIoT-Infrastruktur (intelligente Rechenbasis) und AIoT-Intelligent Agents (verkörperte intelligente Roboter usw.), mit dem Ziel, die Raumintelligenz umfassend zu gestalten. (Quelle: 36氪)
Studie findet heraus, dass der Unterschied zwischen Transformer und SSM bei Retrieval-Aufgaben auf wenige Attention Heads zurückzuführen ist: Eine neue Studie weist darauf hin, dass State Space Models (SSM) bei Aufgaben wie MMLU (Multiple Choice) und GSM8K (Mathematik) hinter Transformer zurückbleiben, hauptsächlich aufgrund von Herausforderungen bei der Kontext-Retrieval-Fähigkeit. Interessanterweise stellt die Studie fest, dass sowohl in Transformer- als auch in SSM-Architekturen die entscheidenden Berechnungen für Retrieval-Aufgaben nur von wenigen Attention Heads übernommen werden. Diese Erkenntnis hilft, die intrinsischen Unterschiede zwischen den beiden Architekturen zu verstehen und könnte die Gestaltung hybrider Modelle leiten. (Quelle: simran_s_arora, _albertgu, teortaxesTex)
🧰 Tools
Novita AI implementiert als erster den DeepSeek-Prover-V2-671B Inferenzdienst: Novita AI hat angekündigt, der erste Anbieter zu sein, der Inferenzdienste für das kürzlich veröffentlichte 671B-Parameter-Modell für mathematisches Schließen, DeepSeek-Prover-V2, anbietet. Das Modell ist auch auf Hugging Face verfügbar, sodass Benutzer dieses leistungsstarke Modell für Mathematik und logisches Schließen nun direkt über Novita AI oder die Hugging Face-Plattform ausprobieren können. (Quelle: _akhaliq, mervenoyann)
PPIO Cloud startet DeepSeek-Prover-V2-671B Modelldienst: Die chinesische Cloud-Plattform PPIO Cloud hat schnell den Inferenzdienst für das neu veröffentlichte DeepSeek-Prover-V2-671B Modell gestartet. Benutzer können über diese Plattform dieses 671B-Parameter-Modell ausprobieren, das sich auf formale mathematische Beweise und komplexes logisches Schließen konzentriert. Die Plattform bietet auch einen Einladungsmechanismus, bei dem das Einladen von Freunden zur Registrierung Gutscheine einbringt, die sowohl für die API als auch für die Web-Oberfläche verwendet werden können. (Quelle: karminski3)

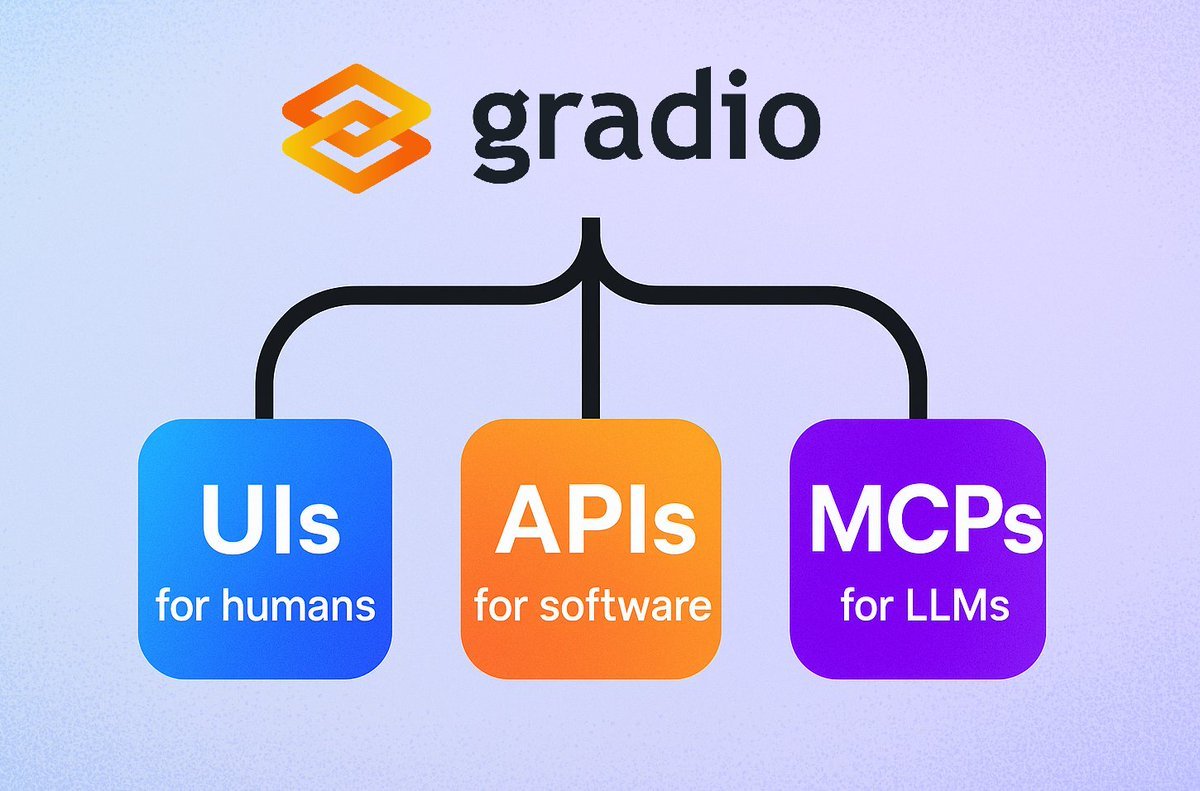
Gradio führt einfache MCP-Server-Funktion ein: Das Gradio-Framework hat eine neue Funktion hinzugefügt: Durch einfaches Hinzufügen des Parameters mcp_server=True in demo.launch() kann jede Gradio-Anwendung leicht in einen Model Context Protocol (MCP)-Server umgewandelt werden. Dies bedeutet, dass Entwickler ihre bestehenden Gradio-Anwendungen (einschließlich vieler, die auf Hugging Face Spaces gehostet werden) schnell für die Verwendung durch MCP-unterstützende LLMs oder Agents verfügbar machen können, was die Integration von KI-Anwendungen und Agents erheblich vereinfacht. (Quelle: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
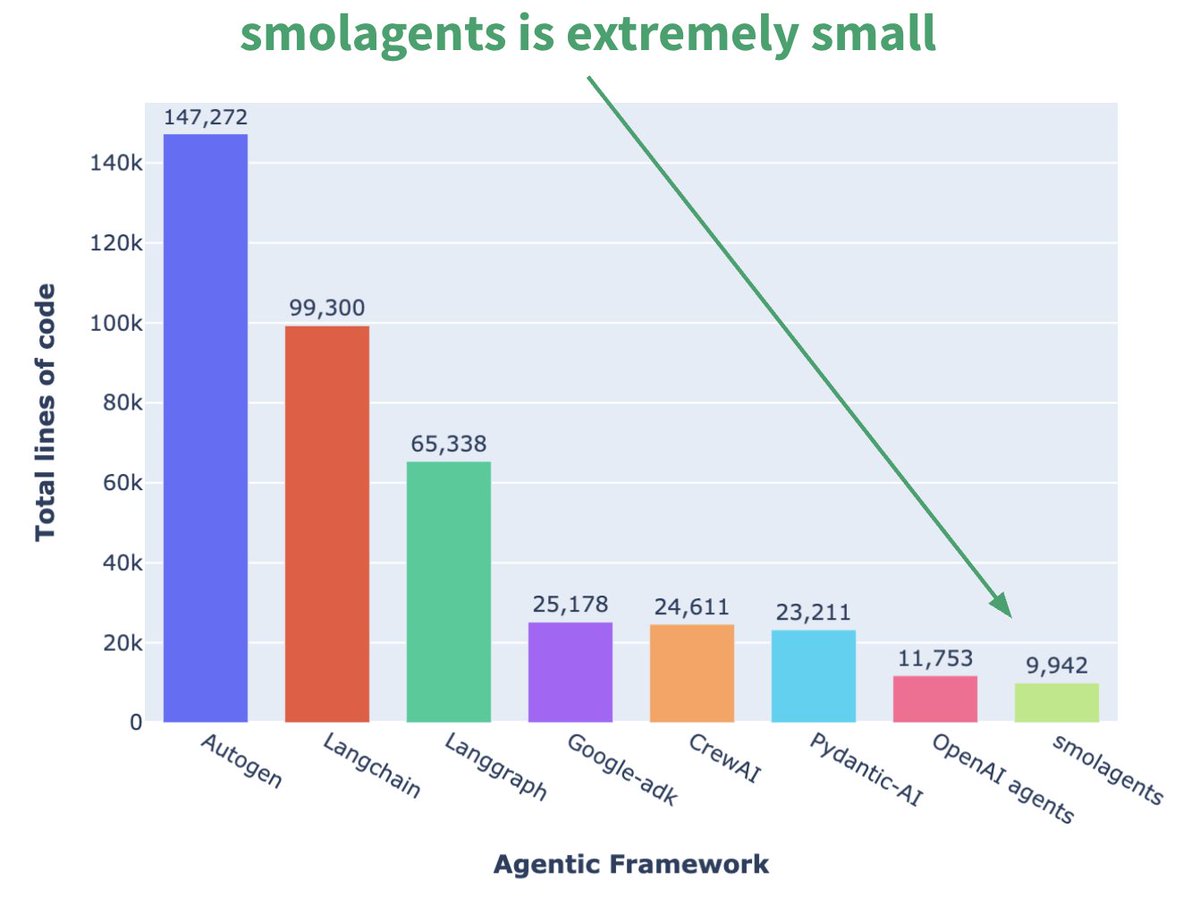
Hugging Face stellt minimalistisches Agent Framework smolagents vor: Hugging Face hat ein Agent Framework namens smolagents veröffentlicht, dessen Kernmerkmal Minimalismus ist. Das Framework zielt darauf ab, die grundlegendsten Bausteine bereitzustellen, übermäßige Abstraktion und Komplexität zu vermeiden und Benutzern zu ermöglichen, flexibel ihre eigenen Agent-Workflows darauf aufzubauen. Es wurde auch ein entsprechender DeepLearning.AI-Kurzkurs veröffentlicht, um Benutzern den Einstieg zu erleichtern. (Quelle: huggingface, AymericRoucher, ClementDelangue)
Runway veröffentlicht Gen-4 References Funktion zur Verbesserung der Konsistenz bei der Videogenerierung: Runway hat die Gen-4 References Funktion für alle zahlenden Benutzer eingeführt. Diese Funktion ermöglicht es Benutzern, Fotos, generierte Bilder, 3D-Modelle oder Selfies als Referenz zu verwenden, um Videoinhalte mit konsistenten Charakteren, Orten usw. zu generieren. Dies löst das langjährige Problem der Konsistenz bei der KI-Videogenerierung und ermöglicht es, bestimmte Personen oder Objekte in beliebige imaginäre Szenen zu platzieren, was die Kontrollierbarkeit und Praktikabilität der KI-Videoproduktion erhöht. (Quelle: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces rüstet auf Nvidia H200 auf und verbessert ZeroGPU-Fähigkeit: Hugging Face hat angekündigt, dass sein ZeroGPU v2 auf Nvidia H200 GPUs umgestellt wurde. Dies bedeutet, dass Hugging Face Spaces (insbesondere der Pro-Plan) jetzt mit 70 GB VRAM und einer um das 2,5-fache erhöhten Fließkomma-Rechenleistung (FLOPS) ausgestattet sind. Dieser Schritt zielt darauf ab, neue KI-Anwendungsszenarien zu erschließen und Benutzern leistungsfähigere, verteilte und kosteneffiziente CUDA-Rechenoptionen zur Verfügung zu stellen, die die Ausführung größerer und komplexerer Modelle unterstützen. (Quelle: huggingface, ClementDelangue)

SkyPilot v0.9 veröffentlicht, fügt Dashboard und Team-Deployment-Funktionen hinzu: SkyPilot hat Version 0.9 veröffentlicht, die eine Web-Dashboard-Funktion einführt, mit der Benutzer und Teams den Status aller Cluster und Jobs, Protokolle und Warteschlangen einsehen und URLs direkt teilen können. Die neue Version unterstützt auch Team-Deployments (Client-Server-Architektur), 10-mal schnellere Speicherung von Modell-Checkpoints über Cloud-Speicher-Buckets und fügt Unterstützung für Nebius AI und GB200 hinzu. Diese Updates zielen darauf ab, die Verwaltungseffizienz und Kollaborationsfähigkeit von SkyPilot beim Ausführen von KI-Workloads in der Cloud zu verbessern. (Quelle: skypilot_org)

Tesslate veröffentlicht 7B UI-Generierungsmodell UIGEN-T2: Tesslate hat UIGEN-T2 veröffentlicht, ein 7B-Parameter-Modell, das speziell für die Generierung von HTML/CSS/JS + Tailwind-Websiteschnittstellen entwickelt wurde, die Diagramme und interaktive Elemente enthalten. Das Modell wurde mit spezifischen Daten trainiert und kann funktionale UI-Elemente wie Warenkörbe, Diagramme, Dropdown-Menüs, responsive Layouts und Timer generieren und unterstützt Stile wie Glassmorphismus und Dark Mode. Die GGUF-Version des Modells und die LoRA-Gewichte wurden auf Hugging Face veröffentlicht, und es gibt einen Online-Playground und eine Demo. (Quelle: Reddit r/LocalLLaMA)
AI EngineHost bietet günstigen lebenslangen KI-Hosting-Service an, was Zweifel aufwirft: Ein Dienst namens AI EngineHost behauptet, lebenslanges Webhosting anzubieten und Open-Source-LLMs wie LLaMA 3, Grok-1 usw. mit einem Klick auf NVIDIA GPU-Servern bereitstellen zu können, für eine einmalige Zahlung von nur 16,95 USD. Der Dienst verspricht unbegrenzten NVMe-Speicher, Bandbreite, Domains, Unterstützung für mehrere Sprachen und Datenbanken sowie eine kommerzielle Lizenz. Die extrem niedrige Preisgestaltung und das “lebenslange” Versprechen haben jedoch in der Community weit verbreitete Zweifel an seiner Legitimität und Nachhaltigkeit aufgeworfen, mit dem Verdacht, dass es sich um einen Betrug oder eine versteckte Falle handeln könnte. (Quelle: Reddit r/deeplearning)
BrowserQwen: Ein Browser-Assistent basierend auf Qwen-Agent: Das Qwen-Team hat BrowserQwen eingeführt, eine Browser-Assistentenanwendung, die auf dem Qwen-Agent-Framework basiert. Sie nutzt die Fähigkeiten des Qwen-Modells zur Werkzeugnutzung, Planung und Erinnerung, um Benutzern zu helfen, intelligenter mit dem Browser zu interagieren, möglicherweise einschließlich Webseiten-Inhaltsverständnis, Informationsextraktion, Automatisierungsoperationen usw. (Quelle: QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ: Eine Stateless Kafka-Alternative basierend auf S3: AutoMQ ist ein Open-Source-Projekt, das darauf abzielt, eine stateless Kafka-Alternative bereitzustellen, die auf S3 oder kompatiblem Objektspeicher aufbaut. Sein Hauptvorteil liegt in der Lösung der Probleme traditioneller Kafka-Implementierungen in der Cloud, wie schwierige Skalierbarkeit und hohe Kosten (insbesondere für Traffic über Verfügbarkeitszonen hinweg). Durch die Trennung von Speicher und Rechenleistung behauptet AutoMQ, eine 10-fache Kosteneffizienz, sekundenschnelle automatische Skalierung, Latenz im einstelligen Millisekundenbereich und Hochverfügbarkeit über mehrere Verfügbarkeitszonen zu erreichen. (Quelle: AutoMQ/automq – GitHub Trending (all/daily))
Daytona: Sichere, elastische Infrastruktur zum Ausführen von KI-generiertem Code: Daytona ist eine Plattform, die darauf abzielt, eine sichere, isolierte und schnell reagierende Infrastruktur speziell für die Ausführung von KI-generiertem Code bereitzustellen. Sie unterstützt die programmatische Steuerung über SDKs (Python/TypeScript), kann schnell Sandbox-Umgebungen erstellen (unter 90 ms), Dateioperationen, Git-Befehle, LSP-Interaktionen und Codeausführung durchführen und unterstützt Persistenz sowie OCI/Docker-Images. Ihr Ziel ist es, Sicherheits- und Ressourcenmanagementprobleme bei der Ausführung von nicht vertrauenswürdigem oder experimentellem KI-Code zu lösen. (Quelle: daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples: Beispielbibliothek zur Demonstration der MLX Swift-Nutzung: Apples MLX-Team pflegt ein Projekt mit mehreren Beispielen für die Verwendung des MLX Swift-Frameworks. Diese Beispiele umfassen Anwendungen wie Large Language Models (LLM), Visual Language Models (VLM), Embedding-Modelle, Stable Diffusion-Bilderzeugung sowie das klassische Training zur Erkennung handgeschriebener Ziffern mit MNIST. Die Codebasis soll Entwicklern helfen, MLX Swift für maschinelles Lernen zu lernen und anzuwenden, insbesondere innerhalb des Apple-Ökosystems. (Quelle: ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
Blender 4.4 veröffentlicht, verbessert Raytracing und Benutzerfreundlichkeit: Die Open-Source-3D-Software Blender hat Version 4.4 veröffentlicht. Die neue Version weist signifikante Verbesserungen beim Raytracing auf, verbessert die Rauschunterdrückung, insbesondere bei der Verarbeitung von Subsurface Scattering und Depth of Field, und führt besseres Blue Noise Sampling ein, um die Vorschauqualität und Animationskonsistenz zu verbessern. Darüber hinaus wurden der Image Compositor, der Grab Cloth Brush, das Grease Pencil-Werkzeug sowie die Benutzeroberfläche (z. B. Sichtbarkeit von Mesh-Indizes) verbessert. Auch die Videobearbeitungsfunktionen wurden optimiert. (Quelle: YouTube – Two Minute Papers
)
📚 Lernen
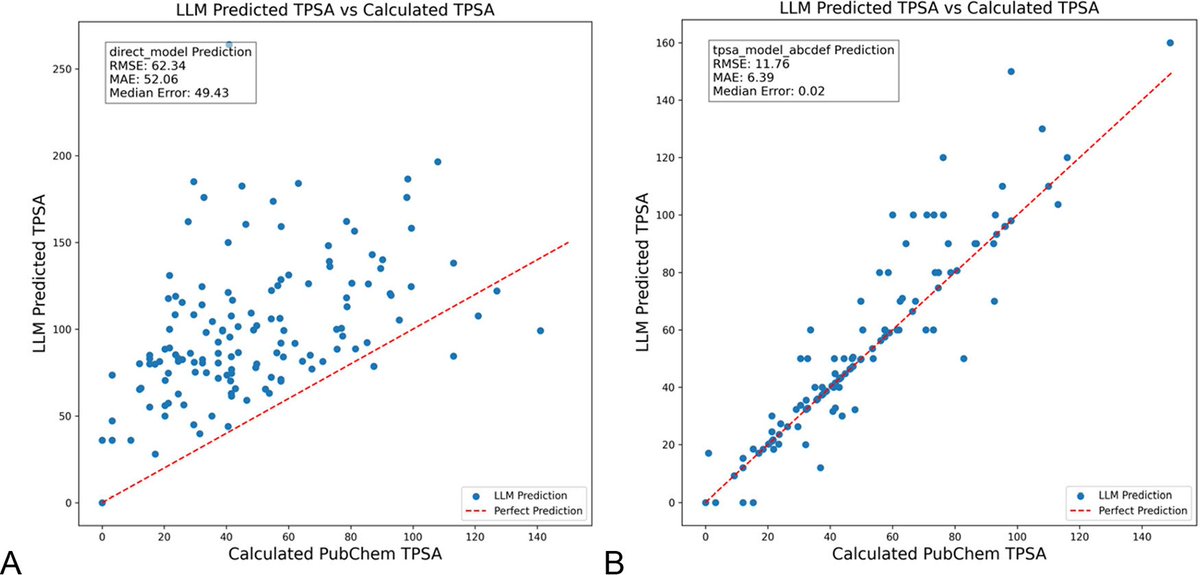
DSPy-Optimierung von LLM-Prompts reduziert Halluzinationen im Chemiebereich signifikant: Ein neues Paper, veröffentlicht im Journal of Chemical Information and Modeling, zeigt, dass die Verwendung des DSPy-Frameworks zum Erstellen und Optimieren von LLM-Prompts Halluzinationsprobleme im Chemiebereich signifikant reduzieren kann. Die Studie optimierte DSPy-Programme und reduzierte den Root Mean Square Error (RMSE) bei der Vorhersage der topologischen polaren Oberfläche von Molekülen (TPSA) um 81 %. Dies zeigt, dass durch programmatische Prompt-Optimierung die Genauigkeit und Zuverlässigkeit von LLMs in spezialisierten wissenschaftlichen Bereichen wie der Chemie effektiv verbessert werden kann. (Quelle: lateinteraction, lateinteraction)
Paper schlägt vor, Common Sense Reasoning mit Graphen zu quantifizieren und mechanistische Einblicke zu gewinnen: Ein neues Paper schlägt eine Methode vor, das implizite Wissen von 37 alltäglichen Aktivitäten als gerichtete Graphen darzustellen, um eine riesige Menge (ca. 10^17 pro Aktivität) an Common-Sense-Abfragen zu generieren. Diese Methode zielt darauf ab, die Nachteile bestehender, begrenzter und nicht erschöpfender Benchmarks zu überwinden, um die Common-Sense-Reasoning-Fähigkeiten von LLMs strenger zu bewerten. Die Studie quantifiziert Common Sense mithilfe von Graphenstrukturen und verbessert die Activation Patching-Technik durch konjugierte Prompts, um Schlüsselkomponenten im Modell zu lokalisieren, die für das Schließen verantwortlich sind. (Quelle: menhguin)

Reinforcement Learning-Methode (RLVR) verbessert mathematisches Schließen von LLMs signifikant mit nur einem einzigen Beispiel: Ein neues Paper schlägt vor, dass die Methode Reinforcement Learning with Verification Feedback (RLVR), die nur ein einziges Trainingsbeispiel verwendet, die Leistung von Large Language Models bei mathematischen Aufgaben signifikant verbessern kann. Experimente zeigen, dass Ein-Beispiel-RLVR die Genauigkeit von Qwen2.5-Math-1.5B auf dem MATH500-Benchmark von 36,0 % auf 73,6 % und die Genauigkeit von Qwen2.5-Math-7B von 51,0 % auf 79,2 % steigern kann. Diese Erkenntnis könnte zu einem Überdenken der RLVR-Mechanismen anregen und neue Wege zur Verbesserung der Modellfähigkeiten bei geringen Ressourcen aufzeigen. (Quelle: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI aktualisiert Kurs „LLMs as Operating Systems: Agent Memory“: Der kostenlose Kurzkurs „LLMs as Operating Systems: Agent Memory“, der von DeepLearning.AI in Zusammenarbeit mit Letta angeboten wird, wurde aktualisiert. Der Kurs erklärt die Verwendung der MemGPT-Methode zum Erstellen von LLM-Agents, die Langzeitgedächtnis (über die Grenzen des Kontextfensters hinaus) verwalten können. Neue Inhalte umfassen einen vorinstallierten Letta Agent-Dienst (für praktische Agentenübungen in der Cloud) und eine Streaming-Ausgabefunktion (um den schrittweisen Denkprozess des Agenten zu beobachten), die Lernenden helfen sollen, anpassungsfähigere und kollaborativere KI-Systeme zu erstellen. (Quelle: DeepLearningAI)

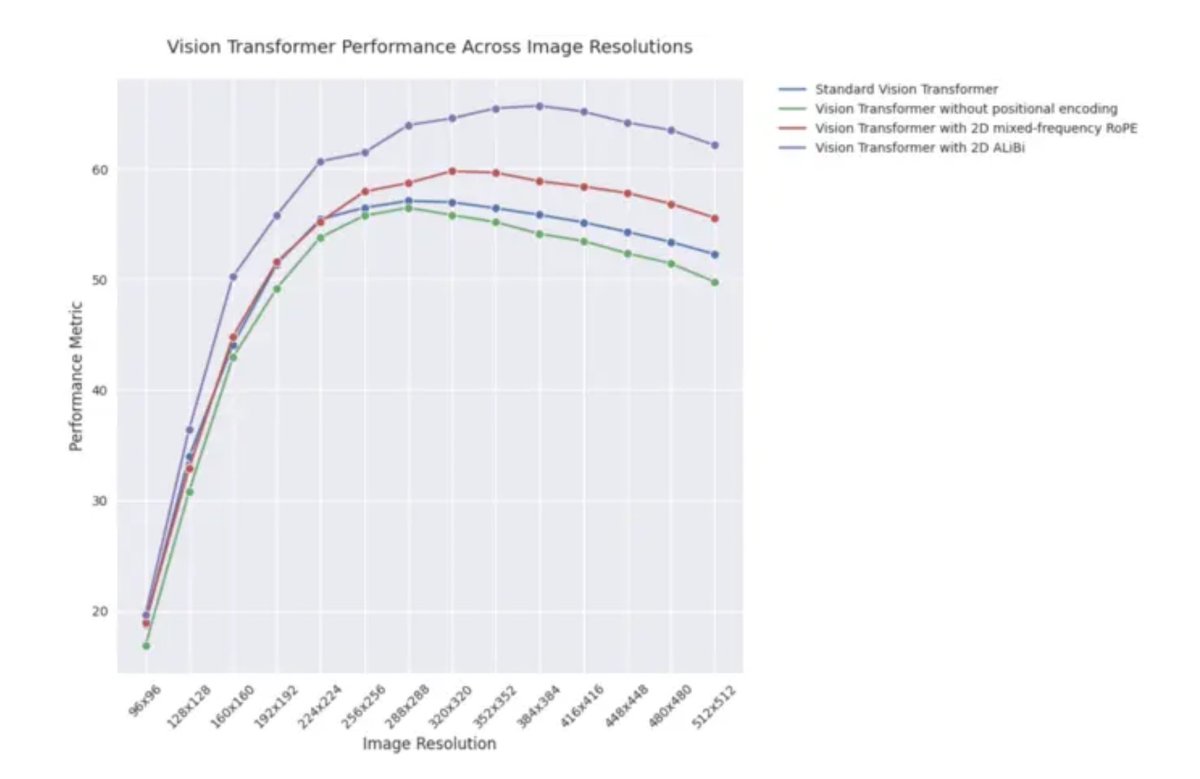
ICLR 2025 Blogbeitrag: Extrapolationsleistung von 2D ALiBi in Vision Transformers: Ein Blogbeitrag zur ICLR 2025 weist darauf hin, dass Vision Transformers (ViT), die zweidimensionale Attention mit linearem Bias (2D ALiBi) verwenden, auf dem Imagenet100-Datensatz bei der Extrapolation auf größere Bildgrößen am besten abschneiden. ALiBi ist eine Methode zur relativen Positionskodierung, deren erfolgreiche Anwendung im NLP-Bereich ihre Erforschung im visuellen Bereich inspiriert hat. Das Ergebnis deutet darauf hin, dass 2D ALiBi ViTs hilft, besser auf Bildauflösungen zu generalisieren, die während des Trainings nicht gesehen wurden. (Quelle: OfirPress)
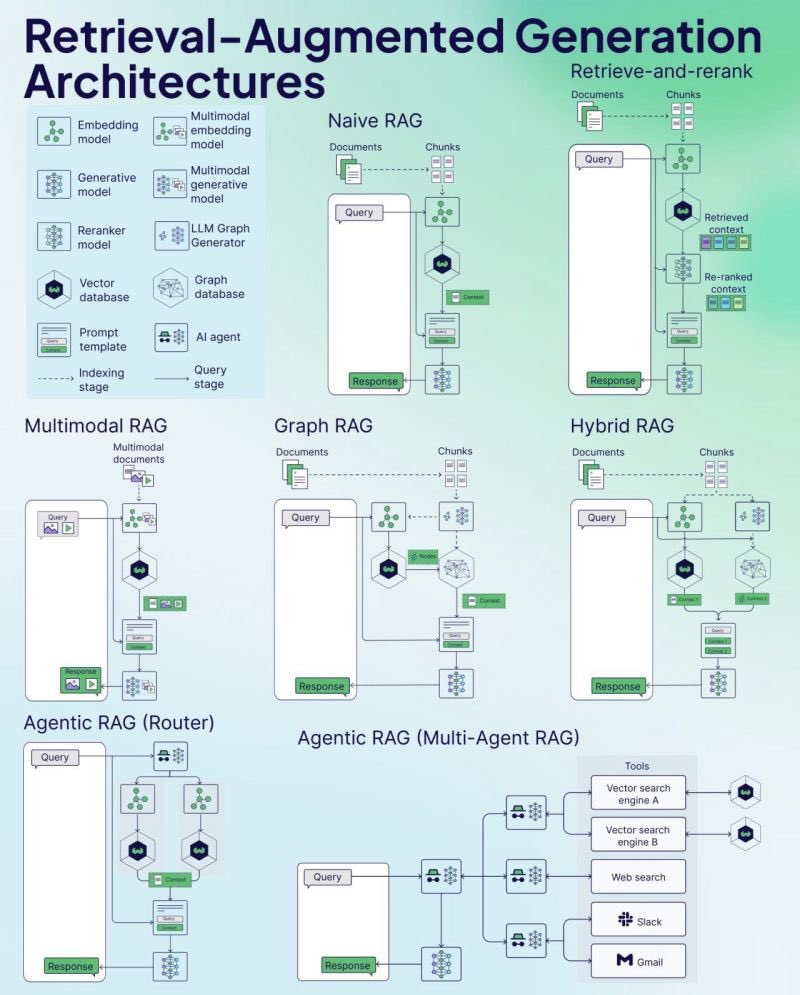
Weaviate veröffentlicht RAG Cheat Sheet: Das Vektordatenbank-Unternehmen Weaviate hat ein Cheat Sheet zu Retrieval-Augmented Generation (RAG) veröffentlicht. Dieses Material soll Entwicklern eine schnelle Referenzanleitung bieten, die möglicherweise Schlüsselkonzepte, Architekturen, gängige Techniken, Best Practices oder häufige Fragen zu RAG abdeckt, um Entwicklern zu helfen, RAG-Systeme besser zu verstehen und zu implementieren. (Quelle: bobvanluijt)
MIT-Studie enthüllt Struktur und Risiken von KI-Lieferketten: Forscher vom MIT und anderen Institutionen haben ein neues Paper veröffentlicht, das die aufkommenden KI-Lieferketten (AI Supply Chains) untersucht. Da der Prozess zur Erstellung von KI-Systemen zunehmend dezentralisiert wird (mit Beteiligung von Anbietern von Basismodellen, Fine-Tuning-Diensten, Datenlieferanten, Bereitstellungsplattformen usw.), untersucht das Paper die Auswirkungen dieser Netzwerkstruktur, einschließlich potenzieller Risiken (wie die Weiterleitung von vorgelagerten Ausfällen), Informationsasymmetrien, Kontrollkonflikte und widersprüchliche Optimierungsziele. Die Studie analysiert zwei Fälle durch theoretische und empirische Analysen und betont die Bedeutung des Verständnisses und Managements von KI-Lieferketten. (Quelle: jachiam0, aleks_madry)
LangChain veröffentlicht 5-minütiges Einführungsvideo zu LangSmith: LangChain hat ein 5-minütiges kurzes Video veröffentlicht, das die Funktionen seiner kommerziellen Plattform LangSmith erklärt. Das Video stellt vor, wie LangSmith während des gesamten Lebenszyklus der Entwicklung von LLM-Anwendungen und Agents hilft, einschließlich Observability, Evaluation und Prompt Engineering, um Entwicklern zu helfen, die Anwendungsleistung zu verbessern. (Quelle: LangChainAI)
Together AI veröffentlicht Tutorial-Video zum Ausführen und Fine-Tuning von OSS-Modellen: Together AI hat ein neues Lehrvideo veröffentlicht, das Benutzer anleitet, wie sie Open-Source-Large-Models auf der Together AI-Plattform ausführen und feinabstimmen können. Das Video deckt möglicherweise Schritte wie die Auswahl des Modells, die Einrichtung der Umgebung, das Hochladen von Daten, das Starten von Trainingsaufgaben und die Durchführung von Inferenzen ab, um die Hürde für Benutzer zu senken, die Plattform für die Anpassung und Bereitstellung von Open-Source-Modellen zu nutzen. (Quelle: togethercompute)
Paper schlägt vor, „fühlende Agenten“ zur Bewertung der sozialen Kognitionsfähigkeiten von LLMs zu verwenden: Ein neues Paper stellt das SAGE (Sentient Agent as a Judge)-Framework vor, eine neuartige Bewertungsmethode, die fühlende Agenten (Sentient Agents) verwendet, die menschliche emotionale Dynamiken und internes Schließen simulieren, um die sozialen Kognitionsfähigkeiten von LLMs in Gesprächen zu bewerten. Das Framework zielt darauf ab, die Fähigkeit von LLMs zu testen, Emotionen zu interpretieren, verborgene Absichten abzuleiten und empathisch zu antworten. Die Studie ergab, dass in 100 unterstützenden Gesprächsszenarien die emotionalen Bewertungen der fühlenden Agenten stark mit menschenzentrierten Metriken (wie BLRI, Empathieindikatoren) korrelierten und dass sozial kompetente LLMs nicht unbedingt langatmige Antworten benötigen. (Quelle: menhguin)

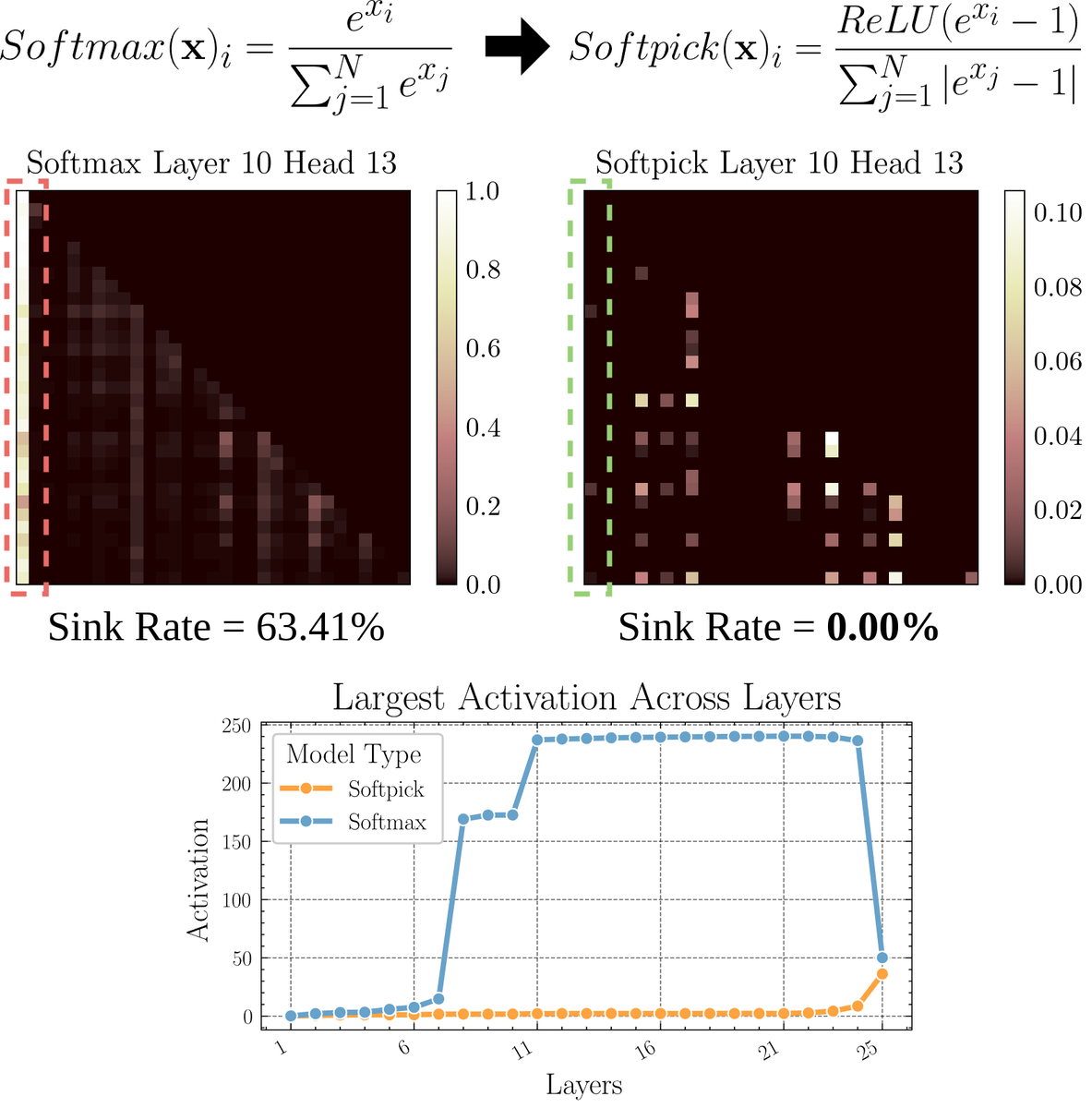
Paper untersucht Softpick: Ein alternativer Attention-Mechanismus zu Softmax: Ein Preprint-Paper schlägt Softpick vor, eine Alternative, die Softmax korrigiert, um Probleme wie „Attention Sink“ und große Aktivierungswerte im Attention-Mechanismus zu lösen. Die Methode schlägt vor, ReLU(x – 1) im Zähler von Softmax und abs(x – 1) im Nennerterm zu verwenden. Die Forscher glauben, dass diese einfache Anpassung die Leistung beibehalten und gleichzeitig einige inhärente Probleme bestehender Attention-Mechanismen verbessern könnte, insbesondere bei der Verarbeitung langer Sequenzen oder in Szenarien, die stabilere Attention-Verteilungen erfordern. (Quelle: sedielem)
💼 Wirtschaft
KI-Startup RogoAI schließt Finanzierungsrunde B über 50 Millionen US-Dollar ab: RogoAI, das sich auf den Aufbau einer KI-nativen Forschungsplattform für die Finanzdienstleistungsbranche konzentriert, gab den Abschluss einer Finanzierungsrunde B in Höhe von 50 Millionen US-Dollar unter der Leitung von Thrive Capital bekannt, an der sich auch J.P. Morgan Asset Management, Tiger Global und andere beteiligten. Diese Finanzierungsrunde wird verwendet, um die Produktentwicklung und Marktexpansion von RogoAI im Bereich Finanzanalyse und Forschungsautomatisierung zu beschleunigen. (Quelle: hwchase17, hwchase17)
Enterprise-KI-Such-Startup Glean schließt neue Finanzierungsrunde mit Bewertung von 7 Milliarden US-Dollar ab: Laut The Information steht das KI-Enterprise-Such-Startup Glean kurz vor dem Abschluss einer neuen Finanzierungsrunde unter der Leitung von Wellington Management mit einer Bewertung von rund 7 Milliarden US-Dollar. Das Unternehmen hatte erst vor vier Monaten eine Finanzierungsrunde mit einer Bewertung von 4,6 Milliarden US-Dollar abgeschlossen. Dieser deutliche Bewertungssprung spiegelt die hohen Markterwartungen an unternehmensweite KI-Anwendungen und Wissensmanagementlösungen wider. (Quelle: steph_palazzolo)
Groq kooperiert mit Meta zur Beschleunigung der Llama API: Das KI-Inferenzchip-Unternehmen Groq kündigte eine Partnerschaft mit Meta an, um die offizielle Llama API zu beschleunigen. Entwickler können die neuesten Llama-Modelle (beginnend mit Llama 4) mit einem Durchsatz von bis zu 625 Tokens/Sekunde ausführen und behaupten, dass eine Migration von OpenAI nur 3 Codezeilen erfordert. Diese Zusammenarbeit zielt darauf ab, Entwicklern Hochgeschwindigkeitslösungen mit geringer Latenz für die Ausführung großer Sprachmodelle anzubieten. (Quelle: JonathanRoss321)

🌟 Community
Community diskutiert Vergleich von Llama4 und DeepSeek R1 sowie Probleme bei der Modellbewertung: Meta-CEO Zuckerberg antwortete in einem Interview auf die Frage, warum Llama4 in der Arena schlechter abschneidet als DeepSeek R1. Er argumentierte, dass Open-Source-Benchmarks fehlerhaft seien, zu sehr auf spezifische Anwendungsfälle ausgerichtet seien und die tatsächliche Leistung von Modellen in realen Produkten nicht widerspiegelten. Er fügte hinzu, dass Metas Inferenzmodell noch nicht veröffentlicht sei und daher nicht direkt mit R1 verglichen werden könne. Diese Äußerungen, zusammen mit dem Paper von Cohere, das LMArena in Frage stellt, lösten eine breite Diskussion in der Community darüber aus, wie LLMs fair bewertet werden können, über die Grenzen öffentlicher Ranglisten und über Strategien zur Modellauswahl. Viele stimmen darin überein, dass man sich nicht übermäßig auf allgemeine Ranglisten verlassen sollte, sondern Modelle anhand spezifischer Anwendungsfälle, privater Datenauswertungen und Community-Signalen auswählen sollte. (Quelle: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
Diskussion über KI als Ersatz für menschliche Arbeit nimmt zu: In der Reddit-Community gibt es mehrere Beiträge, die die Auswirkungen von KI auf die Beschäftigung diskutieren. Ein Spanisch-Übersetzer berichtet, dass sein Geschäft aufgrund der verbesserten Qualität von KI-Übersetzungen stark zurückgegangen ist; ein anderer Toningenieur hat ebenfalls den Beruf gewechselt, da die Ergebnisse des KI-Masterings besser wurden. Gleichzeitig gibt es auch Beiträge, die diskutieren, wie der Einsatz von KI in Bereichen wie medizinischer Diagnose und Steuerberatung den Bedarf an Fachkräften verringern könnte. Diese Fälle lösen Diskussionen darüber aus, ob die durch KI-Automatisierung verursachte Arbeitsplatzkrise früher eintritt als erwartet und wie sich Fachkräfte anpassen sollten (z. B. durch Nutzung von KI zur Transformation, Suche nach Werten, die KI nicht ersetzen kann). (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Phänomen der „iterativen Drift“ bei KI-generierten Bildern erregt Aufmerksamkeit: Ein Reddit-Benutzer versuchte, ChatGPT wiederholt dazu zu bringen, ein Bild basierend auf dem vorherigen „exakt zu replizieren“. Die Ergebnisse zeigten, dass sich Inhalt und Stil des Bildes mit zunehmender Anzahl von Iterationen allmählich vom ursprünglichen Input entfernten und schließlich zu abstrakten oder spezifischen Mustern tendierten (wie z. B. samoanische Tattoos / weibliche Merkmale). Das Beispiel von Dwayne Johnson zeigte eine ähnliche Entwicklung von realistisch zu abstrakt. Dieses Phänomen offenbart die Herausforderungen aktueller Bildgenerierungsmodelle bei der Aufrechterhaltung langfristiger Konsistenz sowie mögliche Verzerrungen oder Konvergenzen in ihren internen Repräsentationen. (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT)

Community diskutiert, ob KI die Arbeit von Risikokapitalgebern (VC) ersetzen wird: Marc Andreessen glaubt, dass Risikokapital eine der letzten Aufgaben sein könnte, die von Menschen erledigt werden, wenn KI alles andere tun kann, da es eher Kunst als Wissenschaft ist und von Geschmack, Psychologie und Chaostoleranz abhängt. Diese Ansicht löste Diskussionen aus. Einige halten dies für eine „lächerliche Aussage“ und fragen, warum Frühphaseninvestitionen einzigartig sein sollten; andere argumentieren aus ihrem eigenen Bereich (z. B. Spieleentwicklung), dass diese Idee möglicherweise „Selbstberuhigung“ (cope) ist, da Menschen in jedem Bereich dazu neigen zu glauben, dass ihre Arbeit aufgrund des erforderlichen einzigartigen Geschmacks nicht durch KI ersetzt werden kann. (Quelle: colin_fraser, gfodor, cto_junior, pmddomingos)
Nicht genehmigtes KI-Überzeugungsexperiment der Universität Zürich auf Reddit löst Kontroverse aus: Laut dem Moderator von Reddit r/changemyview und Reddit Lies setzten Forscher der Universität Zürich mehrere KI-Konten in diesem Subreddit ein, um an Diskussionen teilzunehmen und die Überzeugungskraft von KI-generierten Argumenten zu testen, ohne die Community-Benutzer ausdrücklich darüber zu informieren. Die Studie ergab, dass die Erfolgsquote der KI-Konten bei der Überzeugung (Erhalt des “∆”-Markers, der eine Meinungsänderung des Benutzers anzeigt) weit über dem menschlichen Basisniveau lag und die Benutzer ihre KI-Identität nicht erkannten. Obwohl das Experiment angeblich von einer Ethikkommission genehmigt wurde, löste seine heimliche Durchführung und die potenzielle „manipulative“ Natur weit verbreitete ethische Kontroversen und Bedenken hinsichtlich des Missbrauchs von KI aus. (Quelle: 量子位)
💡 Sonstiges
Frage, ob im KI-Zeitalter noch Programmieren gelernt werden muss, regt zum Nachdenken an: In der Community wird über den Wert des Programmierlernens im KI-Zeitalter diskutiert. Es wird argumentiert, dass das Erlernen von Programmierung trotz der zunehmenden Fähigkeiten der KI bei der Codegenerierung und der sich schnell ändernden Natur der Arbeit von Softwareingenieuren weiterhin wichtig ist. Programmieren lernen ist die Grundlage für das Verständnis, wie man effektiv mit KI (insbesondere LLMs) zusammenarbeitet, und diese Mensch-Maschine-Kollaborationsfähigkeit wird zu einer Kernkompetenz über verschiedene Bereiche hinweg. Programmieren ist der Ausgangspunkt für den „Tanz“ des Menschen mit der KI, und zukünftig werden alle Branchen diese Kollaborationsmodelle beherrschen müssen. (Quelle: alexalbert__, _philschmid)
Entwickler diskutieren Erfahrungen und Herausforderungen bei der KI-gestützten Programmierung: Entwickler in der Community teilen ihre Erfahrungen mit KI-Programmierwerkzeugen (wie Cursor, ChatGPT Desktop). Einige vermissen die frühere „Abkühlphase“ des Wartens auf die Kompilierung und meinen, dass die KI-gestützte Programmierung einen ähnlichen Zyklus aus Bearbeiten/Kompilieren/Debuggen wieder einführt. Andere weisen darauf hin, dass KI-Tools immer noch Mängel beim Verständnis des Kontexts (z. B. Bearbeitung mehrerer Dateien) und beim Befolgen von Anweisungen (z. B. Vermeidung bestimmter Syntax/Zutaten) aufweisen. Manchmal sind sehr spezifische Anweisungen erforderlich, um das gewünschte Ergebnis zu erzielen, und der von der KI generierte Code muss immer noch manuell überprüft und debuggt werden. (Quelle: hrishioa, eerac, Reddit r/ChatGPT)

KI-gesteuerte Steigerung des Wohlbefindens: Eine potenzielle KI-Anwendungsrichtung: Ein Beitrag auf Reddit schlägt vor, dass eine der ultimativen Anwendungen von KI die Steigerung des menschlichen Wohlbefindens sein könnte. Der Autor argumentiert, dass basierend auf der Facial-Feedback-Hypothese (Lächeln kann das Wohlbefinden steigern) und dem Prinzip der Konzentration, KI (wie Gemini 2.5 Pro) hochwertige Anleitungen generieren kann, die Menschen helfen, ihr Wohlbefinden durch einfache Übungen (wie Lächeln und Konzentration auf das damit verbundene angenehme Gefühl) zu steigern. Der Autor teilt einen von KI generierten Bericht und Audioaufnahmen und prognostiziert, dass zukünftig erfolgreiche Anwendungen oder „Wohlfühl-Mentor“-Roboter auf diesem Prinzip basieren könnten. (Quelle: Reddit r/deeplearning)
