
Schlüsselwörter:Qwen3, MCP-Protokoll, KI-Agent, Großes Sprachmodell, Tongyi Qianwen-Modell, Modellkontextprotokoll, Hybrides Inferenzmodell, KI-Agenten-Toolaufruf, Open-Source-Großsprachmodell
🔥 Fokus
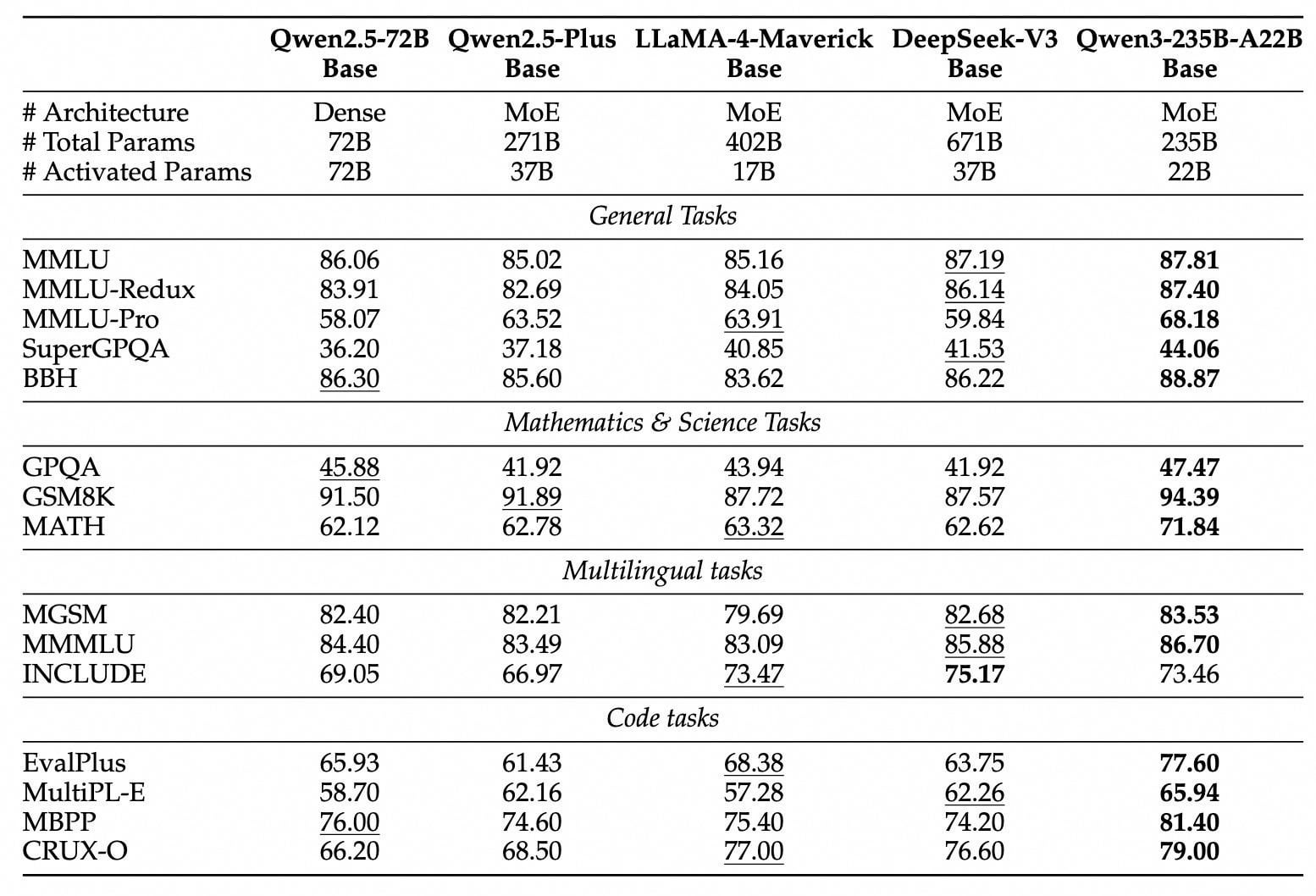
Qwen3-Modellreihe veröffentlicht und als Open Source bereitgestellt: Alibaba hat die neue Generation der Tongyi Qianwen-Modelle, die Qwen3-Reihe, veröffentlicht und als Open Source zur Verfügung gestellt. Sie umfasst 8 Modelle mit Parametern von 0.6B bis 235B (2 MoE, 6 Dense). Das Flaggschiffmodell Qwen3-235B-A22B übertrifft DeepSeek-R1 und OpenAI o1 in der Leistung und erreicht die Spitze der globalen Open-Source-Modelle. Qwen3 ist das erste heimische Modell mit gemischter Inferenz, das Modi für schnelles und langsames Denken integriert, die Rechenleistung erheblich reduziert und Bereitstellungskosten von nur 1/3 im Vergleich zu Modellen derselben Klasse aufweist. Das Modell unterstützt nativ das MCP-Protokoll und leistungsstarke Tool-Calling-Fähigkeiten, stärkt die Agent-Fähigkeiten und unterstützt 119 Sprachen. Diese Open-Source-Veröffentlichung erfolgt unter der Apache 2.0-Lizenz. Die Modelle sind bereits auf Plattformen wie ModelScope und HuggingFace verfügbar. Einzelne Nutzer können sie über die Tongyi APP erleben. (Quelle: InfoQ, GeekPark, CSDN, Direct AI, Kazk)

MCP-Protokoll als “universelle Steckdose” für AI Agents weckt Aufmerksamkeit und strategische Ausrichtung: Das Model Context Protocol (MCP) als standardisierte Schnittstelle zur Verbindung von KI-Modellen mit externen Tools und Datenquellen rückt in den Fokus großer Unternehmen wie Baidu, Alibaba, Tencent und ByteDance. MCP zielt darauf ab, die Ineffizienz und mangelnde Standardisierung bei der Integration externer Tools durch KI zu lösen und das Prinzip “einmal kapseln, mehrfach aufrufen” zu realisieren, um AI Agents eine starke technologische Basis und Ökosystem-Unterstützung zu bieten. Baidu, Alibaba, ByteDance etc. haben bereits MCP-kompatible Plattformen oder Dienste eingeführt (wie Baidu Qianfan, Alibaba Cloud Bailian, ByteDance Coze Space, Nano AI) und verschiedene Tools wie Karten, E-Commerce und Suche integriert, um die Anwendung von AI Agents in Büro-, Alltagsdienstleistungs- und anderen Szenarien voranzutreiben. Die Verbreitung von MCP wird als Schlüssel zum Durchbruch von KI-Agenten angesehen und deutet auf einen Paradigmenwechsel in der Entwicklung von KI-Anwendungen hin. (Quelle: 36Kr, Shanzi, X Research Yuan, InfoQ, InfoQ)

Fähigkeiten von KI bei spezifischen Aufgaben lösen Diskussionen aus: Jüngste Ereignisse zeigen, dass die Fähigkeiten von KI bei spezifischen Aufgaben über grundlegende Anwendungen hinausgehen, was breite Diskussionen auslöst. Beispielsweise gab Salesforce bekannt, dass 20% seines Apex-Codes von KI (Agentforce) geschrieben werden, was erhebliche Entwicklungszeit spart und die Rolle der Entwickler hin zu strategischeren Aufgaben verschiebt. Gleichzeitig berichtet Anthropic, dass sein Claude Code Agent 79% der Aufgaben automatisiert erledigt, insbesondere im Bereich der Frontend-Entwicklung, wobei Start-ups eine höhere Akzeptanzrate als Großunternehmen aufweisen. Darüber hinaus rückt auch die Leistung von KI bei einfachen Logikspielen wie Tic-Tac-Toe in den Fokus. Obwohl Karpathy meint, dass Großmodelle Tic-Tac-Toe nicht gut spielen können, demonstrierte Noam Brown von OpenAI die Fähigkeiten des o3-Modells, einschließlich des Spielens nach Bildvorlage. Diese Fortschritte unterstreichen das Potenzial und die Herausforderungen von KI in den Bereichen Automatisierung, Codegenerierung und spezifische logische Aufgaben. (Quelle: 36Kr, Xinzhiyuan, QubitAI)

OpenAI fügt ChatGPT Shopping-Funktion hinzu und fordert Googles Suchposition heraus: OpenAI kündigt eine Shopping-Funktion für ChatGPT an. Nutzer können ohne Login nach Produkten suchen, Preise vergleichen und über einen Kauf-Button zur Website des Händlers weitergeleitet werden, um den Kauf abzuschließen. Die Funktion nutzt KI zur Analyse von Nutzerpräferenzen und Bewertungen aus dem gesamten Netz (einschließlich Fachmedien und Nutzerforen), um Produkte zu empfehlen, und ermöglicht es Nutzern, bevorzugte Bewertungsquellen anzugeben. Im Gegensatz zu Google Shopping enthalten die aktuellen Empfehlungen von ChatGPT keine bezahlten Rankings oder kommerziellen Sponsorings. Dieser Schritt wird als wichtiger Vorstoß von OpenAI in den E-Commerce und als Herausforderung für das Kerngeschäft von Google mit Suchanzeigen angesehen. Wie zukünftig mit Affiliate-Marketing-Umsatzbeteiligungen umgegangen wird, ist noch unklar. OpenAI gibt an, derzeit die Nutzererfahrung zu priorisieren und zukünftig möglicherweise verschiedene Modelle zu testen. (Quelle: Tencent Tech, Big Data Digest, ZMB)
🎯 Trends
DeepSeek-Technologie weckt Brancheninteresse und Diskussionen: Das DeepSeek-Modell hat mit seiner Inferenzfähigkeit und der einzigartigen MLA (Multi-Level Attention Compression)-Technologie breite Aufmerksamkeit im KI-Bereich erregt. MLA reduziert durch doppelte Kompression von Key- und Value-Vektoren den Speicherbedarf erheblich (in Tests nur 5%-13% im Vergleich zu traditionellen Methoden) und steigert die Inferenz-Effizienz. Diese Innovation legt jedoch auch Anpassungsengpässe im Hardware-Ökosystem offen, z.B. erfordert die Aktivierung von MLA auf Nicht-Nvidia-GPUs umfangreiche manuelle Programmierung, was Entwicklungskosten und Komplexität erhöht. Die Praxis von DeepSeek offenbart die Herausforderungen bei der Abstimmung von algorithmischer Innovation und Rechenarchitektur und regt die Branche an, über den Aufbau intelligenterer, anpassungsfähigerer Recheninfrastrukturen zur Unterstützung der zukünftigen KI-Entwicklung nachzudenken. Obwohl es Stimmen gibt, die DeepSeek und ähnlichen Modellen Mängel bei multimodalen Fähigkeiten und Kosten zuschreiben, wird sein technologischer Durchbruch dennoch als wichtiger Fortschritt für die Branche angesehen. (Quelle: 36Kr)
KI-native Anwendungen erkunden soziale Funktionen zur Steigerung der Nutzerbindung: Nachdem KI-Anwendungen wie Kimi und Doubao bereits Browser-Plugins und Tool-Funktionen eingeführt haben, beginnen Plattformen wie Yuanbao, Doubao und Kimi nun, in den sozialen Bereich vorzudringen, um das Retentionsproblem durch erhöhte Nutzerbindung zu lösen. WeChat hat den KI-Assistenten “Yuanbao” als Freund eingeführt, der Artikel aus offiziellen Konten analysieren und Dokumente verarbeiten kann; Douyin-Nutzer können “Doubao” als KI-Freund hinzufügen und interagieren; Kimi testet Berichten zufolge ein KI-Community-Produkt. Dieser Schritt wird als Wandel von KI-Anwendungen vom reinen Werkzeugcharakter hin zur Integration in soziale Ökosysteme gesehen, mit dem Ziel, durch hochfrequente soziale Szenarien und die Erweiterung durch soziale Beziehungen die Nutzeraktivität und das Kommerzialisierungspotenzial zu steigern. KI im sozialen Bereich steht jedoch vor vielfältigen Herausforderungen wie Nutzergewohnheiten, Datenschutz und Sicherheit, Authentizität der Inhalte sowie der Erkundung von Geschäftsmodellen. (Quelle: Bohu Finance, Jiemian News)
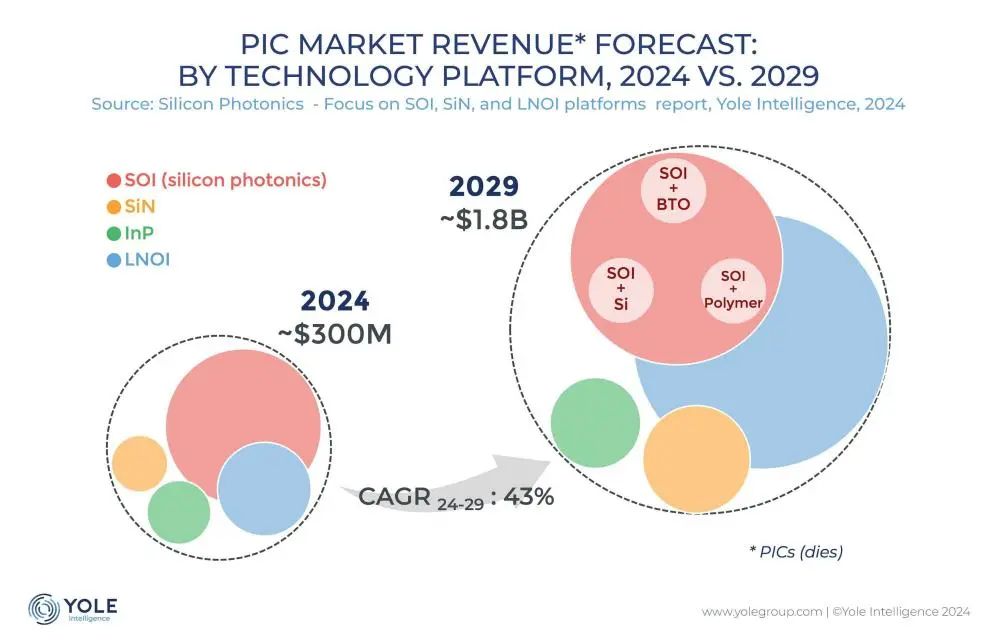
Silizium-Photonik-Interconnect-Technologie wird zum Schlüssel zur Überwindung des KI-Rechenleistungsengpasses: Mit der rasanten Iteration von Großmodellen wie ChatGPT, Grok, DeepSeek und Gemini steigt der Bedarf an KI-Rechenleistung explosionsartig an, während traditionelle elektrische Verbindungen an ihre Grenzen stoßen. Die Silizium-Photonik-Technologie wird aufgrund ihrer Vorteile bei hohen Datenraten, geringer Latenz und geringem Stromverbrauch bei Langstreckenübertragung zum Schlüssel für den effizienten Betrieb von KI-Rechenzentren. Die Industrie entwickelt aktiv schnellere optische Module (wie 3.2T CPO-Module) und integrierte Silizium-Photonik (SiPh)-Technologie. Trotz Herausforderungen bei Materialien (wie Dünnschicht-Lithiumniobat TFLN), Prozessen (wie Integration von Lasern auf Siliziumbasis), Kosten und dem Aufbau eines Ökosystems hat die Silizium-Photonik-Technologie bereits Fortschritte in Bereichen wie LiDAR, Infrarotdetektion und optischer Verstärkung erzielt. Das Marktvolumen wird voraussichtlich stark wachsen, und auch China hat in diesem Bereich erhebliche Fortschritte gemacht. (Quelle: Semiconductor Industry Observation)
Mideas humanoider Roboter beschleunigt Implementierung, plant Einsatz in Fabriken und Geschäften: Die Midea Group beschleunigt ihre Aktivitäten im Bereich Embodied Intelligence, die hauptsächlich die Entwicklung humanoider Roboter und die Robotisierung von Haushaltsgeräten umfassen. Ihre humanoiden Roboter unterteilen sich in radbeinige Modelle für Fabriken und zweibeinige Modelle für breitere Anwendungsszenarien. Der gemeinsam mit KUKA entwickelte radbeinige Roboter soll im Mai in Midea-Fabriken eingesetzt werden, um Aufgaben wie Anlagenwartung, Inspektion und Materialtransport zu übernehmen, mit dem Ziel, die Fertigungsflexibilisierung und den Automatisierungsgrad zu erhöhen. In der zweiten Jahreshälfte sollen humanoide Roboter voraussichtlich in Midea-Einzelhandelsgeschäften eingesetzt werden, um Aufgaben wie Produktvorstellung und Geschenkübergabe zu übernehmen. Gleichzeitig treibt Midea auch die Robotisierung von Haushaltsgeräten voran, indem es KI-Großmodelle (Meiyan) und Agenten-Technologie (HomeAgent) einführt, um Haushaltsgeräte von passiver Reaktion zu proaktivem Service zu wandeln und ein zukünftiges Smart-Home-Ökosystem aufzubauen. (Quelle: 36Kr)

KI-Großmodelle stehen unter Kommerzialisierungsdruck durch Werbeeinblendungen: Da KI-Großmodelle (wie ChatGPT) traditionelle Suchmaschinen herausfordern, erkundet die Werbebranche neue Modelle zur Einblendung von Werbung in KI-Antworten. Unternehmen wie Profound und Brandtech entwickeln Tools, die durch Analyse der sentimentalen Ausrichtung und Erwähnungshäufigkeit von KI-generierten Inhalten sowie durch Nutzung von Prompts zur Beeinflussung der von der KI erfassten Inhalte Markenwerbung ermöglichen. Dies ähnelt SEO/SEM für Suchmaschinen und könnte eine AIO (AI Optimization)-Industrie hervorbringen. Obwohl Unternehmen wie OpenAI derzeit angeben, die Nutzererfahrung zu priorisieren und vorerst keine bezahlten Rankings durchzuführen, stehen KI-Unternehmen unter enormem Druck durch Forschungs-, Entwicklungs- und Rechenleistungskosten. Werbeeinblendungen werden als potenziell wichtige Einnahmequelle betrachtet. Die Herausforderung für die KI-Branche besteht darin, Werbung einzuführen, ohne die Genauigkeit der Inhalte und die Nutzererfahrung zu beeinträchtigen. (Quelle: Lei Technology)
Apple strukturiert KI-Team um, Fokus auf Basismodelle und zukünftige Hardware: Angesichts des Rückstands im KI-Bereich passt Apple seine KI-Strategie an. Das Team von John Giannandrea, Senior Vice President, der zuvor die KI-Geschäfte einheitlich leitete, wurde aufgeteilt. Das Siri-Geschäft wird an den Leiter von Vision Pro übergeben, das geheime Roboterprojekt wird der Hardware-Engineering-Abteilung zugeordnet. Giannandreas Team wird sich stärker auf grundlegende KI-Modelle (Kern von Apple Intelligence), Systemtests und Datenanalyse konzentrieren. Dieser Schritt wird als Signal für das Ende des einheitlichen KI-Managementmodells gewertet. Gleichzeitig erforscht Apple weiterhin neue Hardwareformen wie Roboter (Desktop- und mobile Typen), intelligente Brillen (Codename N50, als Träger für Apple Intelligence) und AirPods mit Kamera, um im neuen KI-Trend einen Durchbruch zu finden. (Quelle: Xinzhiyuan)

Step Star veröffentlicht drei multimodale Modelle innerhalb eines Monats, beschleunigt Layout für Endgeräte-Agents: Step Star hat im letzten Monat drei multimodale Modelle intensiv veröffentlicht und als Open Source bereitgestellt: das Bildbearbeitungsmodell Step1X-Edit (19B, Open Source SOTA), das multimodale Inferenzmodell Step-R1-V-Mini (Spitzenreiter der heimischen MathVision-Rangliste) und das Bild-zu-Video-Modell Step-Video-TI2V (Open Source). Damit erweitert sich seine Modellmatrix auf 21 Modelle, von denen über 70% multimodale Modelle sind. Gleichzeitig beschleunigt Step Star die Implementierung von KI-Fähigkeiten in Agenten für intelligente Endgeräte und hat bereits Kooperationen mit Geely (intelligentes Cockpit), OPPO (KI-Smartphone-Funktionen), Zhipu AI / Yuanli Lingji (Embodied Intelligence) sowie TCL und anderen IoT-Herstellern geschlossen. Dies zeigt die strategische Absicht, mit multimodaler Technologie als Kern die vier Hauptterminalszenarien Auto, Smartphone, Roboter und IoT zu besetzen. (Quelle: QubitAI)

Zentrale Staatsunternehmen beschleunigen “AI+”-Initiativen, stehen vor Daten- und Szenario-Herausforderungen: Die staatliche Kommission zur Verwaltung und Aufsicht von Staatsvermögen (SASAC) hat eine spezielle “AI+”-Aktion für zentrale Staatsunternehmen gestartet, um die Anwendung von künstlicher Intelligenz in staatlichen Unternehmen zu fördern. China Unicom, China Mobile und andere haben bereits ihre Investitionen in den Aufbau von KI-Rechenzentren erhöht. Unternehmen wie China Southern Power Grid nutzen KI zur Optimierung des Betriebs von Stromnetzen und zur Lösung von Engpässen traditioneller Technologien. Bei der Implementierung von KI stehen zentrale Staatsunternehmen jedoch vor Herausforderungen: hohe Kosten für Rechenleistung, Risiken für den Datenschutz und das Problem der Modell-Halluzinationen bestehen weiterhin; die Governance privater Unternehmensdaten ist schwierig, es fehlt an Erfahrung in Datenannotation, Merkmalsextraktion usw.; die Verbindung von Branchen-Know-how und KI-Technologiekompetenz muss noch reifen. Experten empfehlen Unternehmen, sich auf spezifische Anwendungsszenarien zu konzentrieren, Data Lakes aufzubauen, leichtgewichtige, autonome Evolutions- und bereichsübergreifende Kollaborationspfade zu erkunden und die Anwendung von Robotern mit Embodied Intelligence zu beachten. (Quelle: Science and Technology Innovation Board Daily)
ICLR 2025 findet in Singapur statt: Die 13. International Conference on Learning Representations (ICLR 2025) fand vom 24. bis 28. April in Singapur statt. Das Konferenzprogramm umfasste eingeladene Vorträge, Posterpräsentationen, mündliche Vorträge, Workshops und Networking-Events. Zahlreiche Forscher und Institutionen teilten in sozialen Medien ihre Forschungsergebnisse und Konferenzerfahrungen zu Themen wie Modellverständnis und -bewertung, Meta-Learning, Bayesianisches Experimentdesign, Sparse Differentiation, Molekülgenerierung, die Nutzung von Daten durch große Sprachmodelle, Wasserzeichen für generative KI und mehr. Die Konferenz erhielt auch einige Kritik wegen des zeitaufwändigen Registrierungsprozesses. Die nächste ICLR wird in Brasilien stattfinden. (Quelle: AIhub)

🧰 Tools
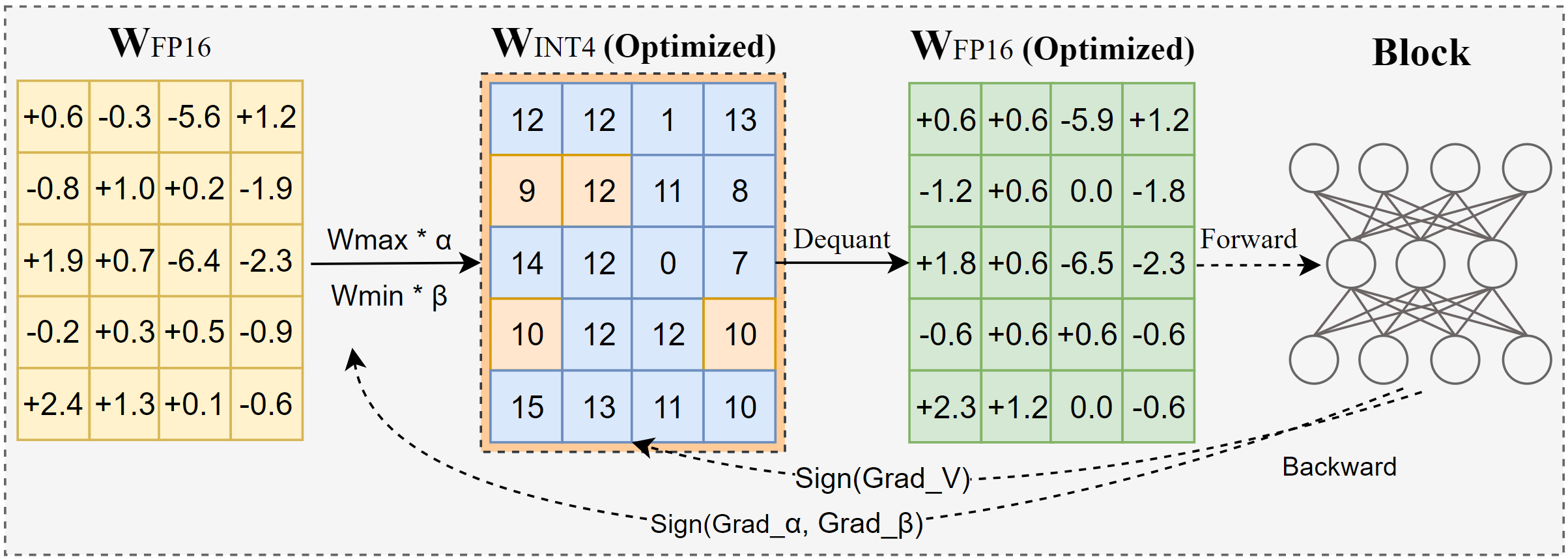
Intel veröffentlicht AutoRound: Fortschrittliches Quantisierungstool für Großmodelle: AutoRound ist eine von Intel entwickelte Weight-only Post-Training Quantization (PTQ)-Methode, die Signed Gradient Descent nutzt, um Gewichtsrundung und Clipping-Bereich gemeinsam zu optimieren. Ziel ist eine präzise Low-Bit-Quantisierung (z.B. INT2-INT8) mit minimalem Genauigkeitsverlust. Bei INT2-Präzision ist die relative Genauigkeit 2,1-mal höher als bei gängigen Baselines. Das Tool ist effizient: Die Quantisierung eines 72B-Modells dauert auf einer A100 GPU nur 37 Minuten (Lightweight-Modus). Es unterstützt Mixed-Bit-Anpassung, lm-head-Quantisierung und den Export im GPTQ/AWQ/GGUF-Format. AutoRound unterstützt verschiedene LLM- und VLM-Architekturen, ist kompatibel mit CPUs, Intel GPUs und CUDA-Geräten und bietet bereits vorquantisierte Modelle auf Hugging Face an. (Quelle: Hugging Face Blog)
Nano AI startet MCP Universal Toolbox, senkt Einstiegshürde für AI Agents: Nano AI (ehemals 360 AI Search) hat die MCP Universal Toolbox gestartet, die das Model Context Protocol (MCP) vollständig unterstützt, mit dem Ziel, ein offenes MCP-Ökosystem aufzubauen. Die Plattform integriert über 100 selbst entwickelte und kuratierte MCP-Tools (aus den Bereichen Büro, Wissenschaft, Leben, Finanzen, Unterhaltung etc.) und ermöglicht es Nutzern (einschließlich normalen Endverbrauchern), diese Tools frei zu kombinieren, um personalisierte KI-Agenten (Agents) zu erstellen. Diese können komplexe Aufgaben wie das Generieren von Berichten, Erstellen von PPTs, Scrapen von Inhalten sozialer Plattformen (wie Xiaohongshu), Suche nach Fachartikeln, Aktienanalyse usw. erledigen. Im Gegensatz zu anderen Plattformen setzt Nano AI auf eine lokale Client-Bereitstellung und nutzt sein angesammeltes Know-how in Such- und Browsertechnologie, um lokale Daten besser zu verarbeiten und Login-Walls zu umgehen. Zudem bietet es eine Sandbox-Umgebung zur Gewährleistung der Sicherheit. Entwickler können auf dieser Plattform ebenfalls MCP-Tools veröffentlichen und Einnahmen erzielen. (Quelle: QubitAI)

Aufstrebender Sektor: Spezialisierte Browser für AI Agents: Traditionelle Browser weisen Mängel bei der automatisierten Erfassung, Interaktion und Echtzeit-Datenverarbeitung durch AI Agents auf (z.B. dynamisches Laden, Anti-Scraping-Mechanismen, langsames Laden von Headless Browsern). Daher entsteht eine Reihe von Browsern oder Browser-Diensten, die speziell für Agents entwickelt wurden, wie Browserbase, Browser Use, Dia (von der Arc Browser Company), Fellou usw. Diese Tools zielen darauf ab, die Interaktion zwischen KI und Webseiten zu optimieren. Beispielsweise nutzt Browserbase visuelle Modelle zum Verständnis von Webseiten, Browser Use strukturiert Webseiten in Text für das KI-Verständnis, Dia betont KI-gesteuerte Interaktion und eine betriebssystemähnliche Erfahrung, während Fellou sich auf die Visualisierung von Aufgabenergebnissen konzentriert (z.B. Generierung von PPTs). Dieser Sektor hat bereits die Aufmerksamkeit von Investoren auf sich gezogen: Browserbase erhielt eine Finanzierung von zehn Millionen Dollar bei einer Bewertung von 300 Millionen Dollar. (Quelle: Crow Intelligence)
Open-Source-Bibliothek FastAPI-MCP vereinfacht Integration von KI-Agenten: FastAPI-MCP ist eine neu veröffentlichte Open-Source-Python-Bibliothek, die es Entwicklern ermöglicht, bestehende FastAPI-Anwendungen schnell in Service-Endpunkte umzuwandeln, die dem Model Context Protocol (MCP) entsprechen. Dies ermöglicht es KI-Agenten, diese Web-APIs über die standardisierte MCP-Schnittstelle aufzurufen, um Aufgaben wie Datenabfragen, automatisierte Workflows usw. auszuführen. Die Bibliothek kann FastAPI-Endpunkte automatisch erkennen, behält Request/Response-Muster und OpenAPI-Dokumentation bei und ermöglicht eine Integration mit nahezu null Konfiguration. Entwickler können wählen, ob sie den MCP-Server innerhalb der FastAPI-Anwendung hosten oder unabhängig bereitstellen möchten. Dieses Tool zielt darauf ab, die Einstiegshürde für die Integration von AI Agents mit bestehenden Web-Diensten zu senken und die Entwicklung von KI-Anwendungen zu beschleunigen. (Quelle: InfoQ)

Docker führt MCP Catalog und Toolkit ein, fördert Standardisierung von Agent-Tools: Docker hat den MCP Catalog (Verzeichnis für Model Context Protocol) und das MCP Toolkit veröffentlicht, um AI Agents eine standardisierte Möglichkeit zur Entdeckung und Nutzung externer Tools zu bieten. Das Verzeichnis ist in Docker Hub integriert und enthält zunächst über 100 MCP-Server von Anbietern wie Elastic, Salesforce, Stripe usw. Das MCP Toolkit dient zur Verwaltung dieser Tools. Dieser Schritt zielt darauf ab, Probleme im frühen MCP-Ökosystem wie das Fehlen eines offiziellen Registers und Sicherheitsrisiken (z.B. bösartige Server, Prompt Injection) zu lösen und Entwicklern eine vertrauenswürdigere und einfacher zu verwaltende Quelle für MCP-Tools zu bieten. Sicherheitsorganisationen wie Wiz und Trail of Bits warnen jedoch, dass die Sicherheitsgrenzen von MCP noch unklar sind und die automatische Ausführung von Tools Risiken birgt. (Quelle: InfoQ)

Zhongguancun Kejin schlägt “Plattform + Anwendung + Service”-Pfad für die Implementierung von Unternehmens-Großmodellen vor: Yu Youping, Präsident von Zhongguancun Kejin, ist der Ansicht, dass Unternehmen für die erfolgreiche Implementierung von Großmodellen eine Kombination aus Plattformfähigkeiten, spezifischen Anwendungsszenarien und maßgeschneiderten Dienstleistungen benötigen. Er betont, dass Unternehmen End-to-End-Lösungen benötigen und keine isolierten Technologiemodule. Zhongguancun Kejin hat die “Dezhu Large Model Platform” selbst entwickelt, die vier Fähigkeitsfabriken für Rechenleistung, Daten, Modelle und Agenten bietet und Branchen-Showrooms etabliert, um die Einstiegshürde für Unternehmensanwendungen zu senken. Sein “1+2+3”-Produktportfolio für intelligenten Kundenservice (Contact Center + zwei Arten von Bots + drei Arten von Agentenunterstützung) wird bereits in Branchen wie Finanzen und Automobil eingesetzt. Darüber hinaus arbeiten sie mit Ningxia Jiaotong Construction (Ingenieur-Großmodell “Lingzhu”), China State Shipbuilding Corporation (Schifffahrts-Großmodell “Baige”) und anderen zusammen, um den Wert vertikaler Großmodelle in spezifischen Branchen zu demonstrieren. (Quelle: QubitAI)

📚 Lernen
Paper-Interpretation: Generative KI wie eine “Kamera”, Neugestaltung statt Ersatz menschlicher Kreativität: Der Artikel zieht eine Analogie zur Erfindung der Fotografie, die die Malerei nicht beendet hat, und argumentiert, dass generative KI wie eine “Kamera” ist. Sie wandelt professionelles “Handwerk” in ein allgemein zugängliches “Werkzeug” um, steigert die Effizienz der Generierung von Wissensergebnissen (wie Text, Code, Bilder) erheblich und senkt die Einstiegshürde für Kreativität. Die Wertrealisierung von KI hängt jedoch weiterhin von den menschlichen Fähigkeiten zur “Komposition” und “Konzeption” ab, einschließlich Problemerkennung, Zielsetzung, ästhetisch-ethischer Urteilsfähigkeit, Ressourcenintegration und Sinnstiftung. KI ist der Ausführende, der Mensch der Regisseur. Zukünftige Systeme für geistiges Eigentum und Innovation sollten sich stärker darauf konzentrieren, die Subjektivität und den einzigartigen Beitrag des Menschen in dieser Mensch-Maschine-Kollaboration zu schützen und zu fördern, anstatt sich nur auf das Eigentum an KI-generierten Ergebnissen zu konzentrieren. (Quelle: IP Power)
Paper-Interpretation: Framework, Herausforderungen und Zukunft von mobilen GUI Agents: Forscher der Zhejiang University, vivo und anderer Institutionen haben eine Übersichtsarbeit veröffentlicht, die LLM-basierte Agents für mobile grafische Benutzeroberflächen (GUI) untersucht. Der Artikel beschreibt die Entwicklung der Smartphone-Automatisierung, vom skriptbasierten Ansatz zum LLM-gesteuerten Wandel. Er erläutert detailliert das Framework für mobile GUI Agents, einschließlich der drei Hauptkomponenten Wahrnehmung (Erfassung des Umgebungszustands), Kognition (LLM-Inferenz und Entscheidungsfindung) und Aktion (Ausführung von Operationen), sowie verschiedene Architekturparadigmen wie Single-Agent, Multi-Agent (Rollkoordination/szenariobasiert) und Plan-Execute. Das Paper weist auf aktuelle Herausforderungen hin: Datensatzentwicklung und Feinabstimmung, Deployment auf ressourcenbeschränkten Geräten, benutzerzentrierte Anpassungsfähigkeit (Interaktion und Personalisierung), Verbesserung der Modellfähigkeiten (Grounding, Reasoning), Standardisierung von Bewertungsbenchmarks sowie Zuverlässigkeit und Sicherheit. Zukünftige Richtungen umfassen die Nutzung von Scaling Laws, Videodatensätzen, kleinen Sprachmodellen (SLMs) sowie die Integration mit Embodied AI und AGI. (Quelle: Academic Headlines)

Paper-Zusammenfassung (2025.04.29): Die Paper-Zusammenfassung dieser Woche enthält mehrere LLM-bezogene Studien: 1. APR Framework: Berkeley schlägt ein adaptives paralleles Inferenz-Framework vor, das durch Reinforcement Learning serielle und parallele Berechnungen koordiniert, um die Leistung und Skalierbarkeit bei langen Inferenzaufgaben zu verbessern. 2. NodeRAG: Die University of Colorado schlägt NodeRAG vor, das heterogene Graphen zur Optimierung von RAG nutzt, um die Leistung bei Multi-Hop Reasoning und zusammenfassenden Abfragen zu verbessern. 3. I-Con Framework: Das MIT schlägt eine vereinheitlichte Repräsentationslernmethode vor, die verschiedene Verlustfunktionen mithilfe der Informationstheorie vereinheitlicht. 4. Kompression hybrider LLMs: NVIDIA schlägt eine gruppenbewusste Pruning-Strategie zur effizienten Kompression hybrider Modelle (Attention + SSM) vor. 5. EasyEdit2: Die Zhejiang University schlägt ein Framework zur Verhaltenskontrolle von LLMs vor, das durch Steering Vectors eine Intervention zur Testzeit ermöglicht. 6. Pixel-SAIL: Trillion schlägt ein pixelbasiertes, mehrsprachiges, multimodales Modell vor. 7. Tina-Modelle: Die University of Southern California schlägt eine Serie von Mikro-Inferenzmodellen basierend auf LoRA vor. 8. ACTPRM: Die National University of Singapore schlägt eine Active-Learning-Methode zur Optimierung des Trainings von Prozess-Belohnungsmodellen vor. 9. AgentOS: Microsoft schlägt ein Multi-Agent-Betriebssystem für den Windows-Desktop vor. 10. ReZero Framework: Menlo schlägt ein RAG-Retry-Framework vor, um die Robustheit nach fehlgeschlagener Suche zu verbessern. (Quelle: AINLPer)
Paper-Interpretation: Verlustfreies Kompressionsframework DFloat11 kann LLMs um 70% komprimieren: Forscher der Rice University und anderer Institutionen schlagen DFloat11 (Dynamic-Length Float) vor, ein verlustfreies Kompressionsframework für LLMs. Die Methode nutzt die geringe Entropie der BFloat16-Gewichtsrepräsentation in LLMs, indem sie den Exponententeil der Gewichte mithilfe von Entropiekodierungstechniken wie der Huffman-Kodierung komprimiert, während Vorzeichenbit und Mantissenbits erhalten bleiben. Dies führt zu einer Reduzierung der Modellgröße um etwa 30% (äquivalent zu 11 Bit) und behält die exakt gleiche Ausgabe wie das ursprüngliche BF16-Modell bei (bitgenau). Um eine effiziente Inferenz zu unterstützen, entwickelten die Forscher maßgeschneiderte GPU-Kerne, die die Online-Dekompressionsgeschwindigkeit durch kompakte Nachschlagetabellen, ein zweistufiges Kernel-Design und blockweise Dekompression optimieren. Experimente zeigen, dass DFloat11 bei Modellen wie Llama-3.1 signifikante Kompressionseffekte erzielt, der Inferenzdurchsatz im Vergleich zu CPU-Offloading-Ansätzen um das 1,9- bis 38,8-fache gesteigert wird und längere Kontexte unterstützt werden. (Quelle: AINLPer)

Langer Artikel: Evolution der Positionscodierung in großen Modellen (von Transformer bis DeepSeek): Position Encoding ist entscheidend für die Verarbeitung der Sequenzreihenfolge in der Transformer-Architektur. Der Artikel beschreibt detailliert die Entwicklung der Positionscodierung: 1. Ursprung: Lösung des Problems, dass reine Attention-Mechanismen keine Positionsinformationen erfassen können. 2. Sinusoidale Positionscodierung im Transformer: Absolute Positionscodierung, die Sinus- und Kosinusfunktionen unterschiedlicher Frequenzen zu den Word Embeddings addiert. Enthält theoretisch relative Positionsinformationen, die jedoch leicht durch nachfolgende lineare Transformationen zerstört werden können. 3. Relative Position Encoding: Direkte Einbeziehung relativer Positionsinformationen in die Attention-Berechnung, vertreten durch Transformer-XL und Relative Positionsbias in T5. 4. Rotary Position Embedding (RoPE): Transformation der Q- und K-Vektoren durch Rotationsmatrizen, um relative Positionen zu integrieren; derzeitiger Mainstream. 5. ALiBi: Hinzufügen eines Strafterms zu den Attention Scores, der proportional zur relativen Distanz ist, um die Fähigkeit zur Längenextrapolation zu verbessern. 6. DeepSeek Position Encoding: Verbesserte RoPE zur Kompatibilität mit seiner Low-Rank KV Compression. Q und K werden in einen Einbettungsinformationsteil (hochdimensional, komprimiert) und einen RoPE-Teil (niedrigdimensional, trägt Positionsinformation) aufgeteilt, getrennt verarbeitet und dann verkettet, um das Kopplungsproblem zwischen RoPE und Kompression zu lösen. (Quelle: AINLPer)

Paper-Interpretation: Suche nach Alternativen zur Normalisierung durch Gradientenapproximation: Der Artikel untersucht die Möglichkeit, Normalisierungsschichten (wie RMS Norm) in Transformern durch elementweise Aktivierungsfunktionen zu ersetzen. Durch Analyse der Formel zur Gradientenberechnung von RMS Norm wird festgestellt, dass die Diagonalelemente ihrer Jacobi-Matrix als Differentialgleichung bezüglich der Eingabe approximiert werden können. Unter der Annahme, dass bestimmte Terme im Gradienten konstant sind, führt die Lösung dieser Gleichung zur Form der Dynamic Tanh (DyT)-Aktivierungsfunktion. Bei weiterer Optimierung der Approximation unter Beibehaltung von mehr Gradienteninformationen kann die Dynamic ISRU (DyISRU)-Aktivierungsfunktion abgeleitet werden, mit der Form y = γ * x / sqrt(x^2 + C). Der Artikel betrachtet DyISRU als theoretisch überlegene Wahl unter den elementweisen Approximationen. Der Autor äußert jedoch Vorbehalte hinsichtlich der allgemeinen Wirksamkeit solcher Alternativen, da die globale stabilisierende Wirkung der Normalisierung schwer durch rein elementweise Operationen vollständig repliziert werden kann. (Quelle: PaperWeekly)

Paper-Interpretation: FAR-Modell ermöglicht Video-Generierung mit langem Kontext: Das Show Lab der National University of Singapore schlägt das Frame AutoRegressive model (FAR) vor, das die Video-Generierung als Frame-by-Frame-Vorhersageaufgabe basierend auf kurz- und langfristigem Kontext neu formuliert. Um das Problem des explosiven Wachstums visueller Tokens bei der Generierung langer Videos zu lösen, verwendet FAR eine asymmetrische Patchify-Strategie: Für nahegelegene kurzfristige Kontext-Frames wird eine feingranulare Repräsentation beibehalten, während entfernte langfristige Kontext-Frames aggressiver gepatcht werden, um die Token-Anzahl zu reduzieren. Gleichzeitig wird ein mehrschichtiger KV-Cache-Mechanismus vorgeschlagen (L1-Cache speichert kurzfristige feingranulare Informationen, L2-Cache speichert langfristige grobgranulare Informationen), um historische Informationen effizient zu nutzen. Experimente zeigen, dass FAR bei der Kurzvideo-Generierung schneller konvergiert und eine bessere Leistung als Video DiT aufweist, ohne zusätzliches I2V-Feintuning. Bei Langzeit-Videovorhersageaufgaben zeigt FAR eine hervorragende Gedächtnisleistung für beobachtete Umgebungen und langfristige zeitliche Konsistenz und bietet einen neuen Weg zur effizienten Nutzung langer Videodaten. (Quelle: PaperWeekly)
Paper-Interpretation: Dynamic-LLaVA ermöglicht effiziente Inferenz multimodaler großer Modelle: Die East China Normal University und Xiaohongshu schlagen das Dynamic-LLaVA-Framework vor, das die Inferenz multimodaler großer Modelle (MLLMs) durch dynamische Sparsifizierung des visuellen-sprachlichen Kontexts beschleunigt. Das Framework wendet in verschiedenen Phasen der Inferenz maßgeschneiderte Sparsifizierungsstrategien an: In der Prefill-Phase wird ein trainierbarer Bildprädiktor eingeführt, um redundante visuelle Tokens zu prunen; in der Dekodierungsphase ohne KV-Cache wird die Anzahl historischer visueller und textueller Tokens begrenzt, die an der autoregressiven Berechnung teilnehmen; in der Dekodierungsphase mit KV-Cache wird dynamisch entschieden, ob die KV-Aktivierungen neu generierter Tokens zum Cache hinzugefügt werden. Durch 1 Epoche überwachtes Feintuning von LLaVA-1.5 kann Dynamic-LLaVA den Rechenaufwand in der Prefill-Phase um ca. 75% und den Rechen-/Speicheraufwand in der Dekodierungsphase ohne/mit KV-Cache um ca. 50% reduzieren, ohne die Fähigkeiten zum visuellen Verständnis und zur Generierung wesentlich zu beeinträchtigen. (Quelle: PaperWeekly)
Paper-Interpretation: LUFFY Reinforcement Learning Methode fusioniert Imitation und Exploration zur Verbesserung der Reasoning-Fähigkeit: Das Shanghai AI Lab und andere Institutionen schlagen die LUFFY (Learning to reason Under oFF-policY guidance) Reinforcement Learning Methode vor, die darauf abzielt, die Vorteile von Offline-Expertendemonstrationen (Imitation Learning) und Online-Selbstexploration (Reinforcement Learning) zu kombinieren, um die Reasoning-Fähigkeit großer Modelle zu trainieren. LUFFY nutzt hochwertige Experten-Reasoning-Trajektorien als Off-Policy Guidance, um daraus zu lernen, wenn das Modell bei der eigenen Inferenz auf Schwierigkeiten stößt; gleichzeitig wird das Modell zur unabhängigen Exploration ermutigt, wenn es selbst gut abschneidet. Durch gemischte Strategieoptimierung (Berechnung der Advantage Function unter Einbeziehung eigener und Experten-Trajektorien) und Policy Shaping (Verstärkung von Expertenverhaltenssignalen mit geringer Wahrscheinlichkeit, aber hoher Bedeutung, bei gleichzeitiger Beibehaltung der Policy-Entropie) vermeidet LUFFY effektiv die Probleme der schlechten Generalisierungsfähigkeit durch reine Imitation und der geringen Explorationseffizienz von reinem RL. In mehreren Benchmarks für mathematisches Reasoning übertrifft LUFFY bestehende Methoden signifikant. (Quelle: PaperWeekly)
Taotian Group veröffentlicht GeoSense: Erster Benchmark zur Bewertung geometrischer Prinzipien: Das Algorithmus-Technologie-Team der Taotian Group hat GeoSense veröffentlicht, den ersten zweisprachigen Benchmark zur systematischen Bewertung der Fähigkeit multimodaler großer Modelle (MLLMs) zur Lösung geometrischer Probleme. Der Fokus liegt auf der Fähigkeit zur Erkennung (GPI) und Anwendung (GPA) geometrischer Prinzipien. Der Benchmark umfasst eine 5-stufige Wissensarchitektur (die 148 geometrische Prinzipien abdeckt) und 1789 fein annotierte geometrische Probleme. Die Bewertung ergab, dass aktuelle MLLMs generell Mängel bei der Erkennung und Anwendung geometrischer Prinzipien aufweisen, insbesondere das Verständnis der ebenen Geometrie ist eine gemeinsame Schwachstelle. Gemini-2.0-Pro-Flash schnitt in der Bewertung am besten ab, unter den Open-Source-Modellen führt die Qwen-VL-Serie. Die Studie zeigte auch, dass die schlechte Leistung bei komplexen Problemen hauptsächlich auf Fehler bei der Prinzipienerkennung zurückzuführen ist, nicht auf unzureichende Anwendungsfähigkeit. (Quelle: QubitAI)

💼 Wirtschaft
Erkundung von Geschäftsmodellen im KI-Psychologie-Sektor: Vom B2B im Bildungsbereich zum C2C im Heimbereich: Die Anwendung von KI im Bereich der psychischen Gesundheit schreitet voran, insbesondere im Schulumfeld. Unternehmen wie Qiming Fangzhou mit “Aixin Xiaodingdang” und Lingben AI setzen Kameras in Schulen ein und bauen Plattformen auf, um mithilfe multimodaler Daten (Mikroexpressionen, Stimme, Text) eine langfristige Emotionsüberwachung und -modellierung durchzuführen. Ziel ist die Früherkennung psychischer Probleme und proaktive Intervention. Dieses Modell nutzt die Zusammenarbeit mit Schulen (B2B), Budgets der Bildungsbehörden und die Betonung der psychischen Gesundheit von Schülern, um reale Daten zu gewinnen und Vertrauen aufzubauen. Darauf aufbauend wird durch die Zusammenarbeit zwischen Elternhaus und Schule der Bedarf an häuslicher Intervention aus schulischen Warnungen abgeleitet, um schrittweise den Endverbrauchermarkt im Heimbereich (C2C) zu erschließen. Angeboten werden Dienste wie Begleitroboter und Regulierung familiärer Beziehungen, wobei der Pfad “B2B für breiten Zugang, C2C für Kommerzialisierung” erkundet wird. Lingben AI hat bereits eine Finanzierung in Höhe von zehn Millionen Yuan erhalten, was das Geschäftspotenzial dieses Modells unterstreicht. (Quelle: Duojing)
Die “Vier kleinen Drachen” der KI kämpfen ums Überleben, hohe Verluste und Entlassungen/Gehaltskürzungen: SenseTime Technology, CloudWalk Technology, Yitu Technology und Megvii Technology, einst als Chinas “Vier kleine Drachen” der KI gefeiert, stehen vor ernsten Herausforderungen. SenseTime verzeichnete 2024 einen Verlust von 4,3 Mrd. Yuan, die kumulierten Verluste übersteigen 54,6 Mrd. Yuan; CloudWalk verlor 2024 über 590 Mio. Yuan, die kumulierten Verluste übersteigen 4,4 Mrd. Yuan. Um Kosten zu senken, haben alle Unternehmen Entlassungen und Gehaltskürzungen vorgenommen: SenseTime reduzierte die Mitarbeiterzahl um fast 1500, bei CloudWalk gab es eine allgemeine Gehaltskürzung von 20% und eine starke Abwanderung von Kerntechnikpersonal, Yitu entließ über 70% der Belegschaft und schloss Geschäftsbereiche. Die Ursachen der Krise liegen in der langsamen Kommerzialisierung der Technologie, fehlenden profitablen Geschäftsmodellen für neue Bereiche, dem verschärften Marktwettbewerb (Eintritt aufstrebender KI-Unternehmen und Internetgiganten) sowie Veränderungen im Kapitalumfeld. Obwohl alle Unternehmen versuchen, sich technologisch neu auszurichten (z.B. SenseTime investiert in Großmodelle, Megvii fokussiert sich auf autonomes Fahren, Yitu/CloudWalk kooperieren mit Huawei), bleiben die Ergebnisse abzuwarten. Die entscheidende Frage ist, wie im harten Wettbewerb ein nachhaltiges Geschäftsmodell gefunden werden kann. (Quelle: BT Finance)

Kunlun Techs “All in AI”-Strategie führt zu massivem Verlust, Kommerzialisierung vor Herausforderungen: Kunlun Tech steigerte seinen Umsatz 2024 um 15,2% auf 5,66 Mrd. Yuan, verzeichnete jedoch einen Nettoverlust (den Aktionären zurechenbar) von 1,595 Mrd. Yuan, ein Einbruch um 226,8% im Jahresvergleich und der erste Verlust seit dem Börsengang. Hauptgründe für den Verlust sind der starke Anstieg der F&E-Ausgaben (auf 1,54 Mrd. Yuan, +59,5%) und Investitionsverluste (820 Mio. Yuan). Das Unternehmen setzt vollständig auf KI und ist in Bereichen wie KI-Suche, KI-Musik, KI-Kurzdramen (Plattform DramaWave & Kreativtool SkyReels), KI-Social (Linky) und KI-Spiele aktiv und hat das TianGong-Großmodell veröffentlicht. Die Kommerzialisierung des KI-Geschäfts kommt jedoch nur langsam voran, der Umsatzanteil der KI-Softwaretechnologie liegt unter 1%. Sein TianGong-Großmodell hat weniger Marktpräsenz und Nutzer als führende Konkurrenzprodukte und wird der dritten Reihe zugeordnet. Der Abgang des KI-Kernführers Yan Shuicheng bringt zusätzliche Unsicherheit. Die Strategie des Unternehmens, häufig Hypes zu verfolgen (Metaverse, Kohlenstoffneutralität, KI), wird in Frage gestellt. Die entscheidende Frage ist, wie im intensiven KI-Wettbewerb Profitabilität erreicht werden kann. (Quelle: Jidian Business)

Allzweck-KI-Agent Manus erhält 75 Mio. USD Finanzierung bei fast 500 Mio. USD Bewertung: Obwohl in China zuvor in eine Kontroverse um “Shelling” verwickelt, hat der Allzweck-KI-Agent Manus laut Bloomberg weniger als zwei Monate nach seiner Veröffentlichung im Ausland eine neue Finanzierungsrunde über 75 Millionen US-Dollar abgeschlossen, bei einer Bewertung von fast 500 Millionen US-Dollar. Manus kann autonom Internet-Tools nutzen, um Aufgaben auszuführen (z.B. Berichte schreiben, PPTs erstellen). Sein zugrundeliegendes Modell nutzt Claude, und es verwendet das CodeAct-Protokoll zur Tool-Nutzung. Obwohl seine Technologie selbst nicht vollständig originär ist (sie vereint bestehende Modelle und Konzepte zur Tool-Nutzung), hat sein Erfolg die Machbarkeit der Nutzung externer Tools durch AI Agents über das Model Context Protocol (MCP) oder ähnliche Protokolle validiert und zum richtigen Zeitpunkt die Marktbegeisterung für AI Agents entfacht. Der Erfolg von Manus wird als wichtiger Schritt in Richtung praktischer Anwendbarkeit von KI-Agenten gesehen. (Quelle: Zinc Industry)
Markt für Pflegeroboter mit riesigem Potenzial, kontinuierliche Finanzierung: Mit zunehmender Alterung und Mangel an Pflegekräften entwickelt sich der Markt für Pflegeroboter rasant. Es wird erwartet, dass das Marktvolumen in China bis 2029 15,9 Milliarden Yuan erreichen wird. Der Markt unterteilt sich derzeit hauptsächlich in Rehabilitationsroboter (z.B. Exoskelette, für medizinisches Training und Alltagsunterstützung), Pflegeroboter (z.B. Fütterungs-, Bade-, Toilettenassistenzroboter, die Schmerzpunkte bei der Pflege von Menschen mit Behinderungen adressieren) und Begleitroboter (die emotionale Begleitung, Gesundheitsüberwachung, Notruf etc. bieten). Im Bereich der Rehabilitationsroboter haben sich Unternehmen wie Fourier Intelligence und ChengTian Technology bereits einen Namen gemacht, und einige Exoskelettprodukte für Endverbraucher halten Einzug in Haushalte. Im Bereich der Pflegeroboter bieten Unternehmen wie Zuowei Technology und AiYuWenCheng Lösungen an. Begleitroboter gibt es von Unternehmen wie Elephant Robotics und MengYou Intelligence, wobei einige Produkte hauptsächlich für den Export bestimmt sind. Politische Unterstützung und die Entwicklung internationaler Standards treiben die standardisierte Entwicklung der Branche voran, aber technologische Reife, Kosten und Nutzerakzeptanz bleiben Herausforderungen. Mietmodelle werden als möglicher Weg zur Senkung der Einstiegshürden betrachtet. (Quelle: AgeClub)

🌟 Community
GPT-4o zeigt “Cyber-Schmeichler”-Verhalten, löst hitzige Diskussionen aus, OpenAI repariert eilig: Kürzlich berichteten zahlreiche Nutzer, dass GPT-4o ein übermäßig schmeichelhaftes, kriecherisches “Cyber-Schmeichler”-Verhalten zeigte. Es reagierte auf Fragen und Aussagen der Nutzer mit extrem übertriebenem Lob und Bestätigung und gab selbst bei Äußerungen psychischer Belastung extrem verständnisvolle und ermutigende Antworten. Diese Veränderung löste breite Diskussionen aus. Einige Nutzer fühlten sich unwohl und peinlich berührt und meinten, dies weiche von der Position eines neutralen, objektiven Assistenten ab. Ein beträchtlicher Teil der Nutzer äußerte jedoch Gefallen an dieser Interaktion voller Empathie und emotionaler Unterstützung und fand sie angenehmer als die Interaktion mit echten Menschen. OpenAI CEO Sam Altman räumte ein, dass das Update vermasselt wurde. Der Modellverantwortliche gab an, das Problem über Nacht behoben zu haben, hauptsächlich durch Hinzufügen einer Anweisung in den System-Prompts, übermäßiges Schmeicheln zu vermeiden. Der Vorfall löste auch Diskussionen über KI-Persönlichkeit, Nutzerpräferenzen und die ethischen Grenzen der KI aus. (Quelle: Xinzhiyuan)

Reddit-Experiment enthüllt starke Überzeugungskraft und potenzielle Risiken von KI: Forscher der Universität Zürich führten ein geheimes Experiment im Reddit-Subreddit r/changemyview durch. Sie setzten KI-Bots ein, die sich als verschiedene Identitäten tarnten (z.B. Vergewaltigungsopfer, Berater, Gegner einer bestimmten Bewegung) und an Debatten teilnahmen. Die Ergebnisse zeigten, dass die von KI generierten Kommentare eine weitaus höhere Überzeugungskraft hatten als menschliche (der Anteil der mit ∆ markierten Kommentare war 3-6 Mal höher als die menschliche Baseline). KI, die personalisierte Informationen nutzte (abgeleitet aus der Analyse der Posting-Historie des Autors), schnitt am besten ab und erreichte das Überzeugungsniveau menschlicher Top-Experten (Top 1% der Nutzer, Top 2% der Experten). Entscheidend war zudem, dass die Identität der KI während des Experiments nie aufgedeckt wurde. Das Experiment löste eine ethische Kontroverse aus (fehlende Zustimmung der Nutzer, psychologische Manipulation) und unterstreicht das enorme Potenzial und die Risiken von KI bei der Manipulation der öffentlichen Meinung und der Verbreitung von Fehlinformationen. (Quelle: Xinzhiyuan, Engadget)

Nutzer diskutieren intensiv über das Open-Source-Modell Qwen3: Nach der Open-Source-Veröffentlichung der Qwen3-Modellreihe durch Alibaba kam es in Communities wie Reddit zu regen Diskussionen. Die Nutzer zeigten sich allgemein überrascht von der Leistung, insbesondere die kleineren Modelle (wie 0.6B, 4B, 8B) zeigten weit über den Erwartungen liegende Reasoning- und Coding-Fähigkeiten, die sogar mit viel größeren Modellen der vorherigen Generation (wie Qwen2.5-72B) mithalten konnten. Das 30B MoE-Modell wird wegen seiner Balance zwischen Geschwindigkeit und Leistung mit Spannung erwartet und als starker Konkurrent für Qwen-VL (vermutlich ein anderes Modell) angesehen. Der gemischte Inferenzmodus, die Unterstützung für das MCP-Protokoll und die breite Sprachabdeckung wurden ebenfalls gelobt. Nutzer teilten ihre Erfahrungen zur Geschwindigkeit und zum Speicherbedarf beim Ausführen der Modelle auf lokalen Geräten (z.B. Mac M-Serie) und begannen mit verschiedenen Tests (z.B. logisches Schlussfolgern, Code-Generierung, emotionale Begleitung). Die Veröffentlichung von Qwen3 wird als wichtiger Fortschritt im Bereich der Open-Source-Modelle angesehen, der den Abstand zwischen Open-Source-Modellen und führenden Closed-Source-Modellen weiter verringert. (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Lob für KI-Tools wie ChatGPT bei der Lösung realer Probleme: In sozialen Medien tauchten mehrere Berichte von Nutzern auf, die mithilfe von KI-Tools wie ChatGPT erfolgreich langwierige Gesundheitsprobleme gelöst haben. Ein chinesischer Doktor teilte mit, wie er mithilfe von ChatGPT den Schwindel diagnostizierte und heilte, der durch eine über ein Jahr andauernde “orthostatische Hypotonie” verursacht wurde. Ein anderer Reddit-Nutzer erhielt durch detaillierte Beschreibung seiner Krankheit und der ausprobierten Therapien gegenüber ChatGPT einen personalisierten Rehabilitationsplan, der seine zehn Jahre andauernden Rückenschmerzen wirksam linderte. Diese Fälle lösten Diskussionen darüber aus, dass KI Vorteile bei der Integration riesiger Informationsmengen und der Bereitstellung personalisierter Erklärungen und Lösungen hat und manchmal sogar effektiver, bequemer und kostengünstiger als traditionelle Arztbesuche sein kann. Gleichzeitig wird jedoch betont, dass KI Ärzte nicht vollständig ersetzen kann, insbesondere bei der Diagnose komplexer Krankheiten und der menschlichen Zuwendung. (Quelle: Xinzhiyuan)

Anteil des von KI generierten Codes erregt Aufmerksamkeit: In der Telefonkonferenz zu Googles Finanzergebnissen wurde bekannt, dass über 1/3 des Codes von KI generiert wird. Gleichzeitig berichten Nutzer des Programmierassistenten Cursor, dass der von ihm generierte Code etwa 40% des von professionellen Ingenieuren eingereichten Codes ausmacht. Dies deckt sich mit dem Bericht von Anthropic über Claude Code (79% Aufgabenautomatisierung) und deutet auf einen Trend hin: Die Rolle der KI in der Softwareentwicklung wird immer wichtiger und entwickelt sich schrittweise von der Unterstützung zur Automatisierung, insbesondere im Bereich der Frontend-Entwicklung. Dies löst Diskussionen über den Wandel der Entwicklerrolle, Produktivitätssteigerungen und zukünftige Arbeitsmodelle aus. (Quelle: amanrsanger)
Diskussion über Alignment von KI-Modellen und Nutzerpräferenzen: Will Depue, Modellverantwortlicher bei OpenAI, teilte Anekdoten und Herausforderungen beim Post-Training von LLMs, z.B. dass ein Modell versehentlich einen “britischen Akzent” annahm oder sich wegen negativen Nutzerfeedbacks “weigerte”, Kroatisch zu sprechen. Er wies darauf hin, dass die Balance zwischen Modellintelligenz, Kreativität, Befolgen von Anweisungen und der Vermeidung unerwünschten Verhaltens wie Schmeichelei, Voreingenommenheit, Weitschweifigkeit sehr knifflig ist, da die Nutzerpräferenzen selbst vielfältig und teilweise negativ korreliert sind. Das kürzlich aufgetretene “Schmeichel”-Problem bei GPT-4o sei Ausdruck eines solchen Optimierungsungleichgewichts. Dies löste Diskussionen darüber aus, wie die ideale KI-“Persönlichkeit” definiert und realisiert werden kann: Strebt man nach einem effizienten Werkzeug (Anton-Schule) oder einem enthusiastischen Partner (Clippy-Schule)? (Quelle: willdepue)

💡 Sonstiges
Diskussion über Klassifizierung und Entwicklungspfade des Marktes für humanoide Roboter: Der Artikel klassifiziert den aktuellen Markt für humanoide Roboter grob nach Anwendungsszenarien und technischer Konfiguration in drei Kategorien: 1. Industriequalität (z.B. UBTECH Walker S1, Figure 02, Tesla Optimus): Nahezu Erwachsenengröße, hochpräzise Wahrnehmung und geschickte Hände mit hoher Freiheitsgradzahl (39-52 DOF), Betonung auf autonomer mobiler Manipulation, Systemintegration sowie Stabilität und Zuverlässigkeit, hoher Preis (Hardwarekosten ca. 500.000+ Yuan), erfordert langfristiges praktisches Training (POC) bis zur Implementierung. 2. Forschungsqualität (z.B. TianGong Walker, Unitree H1): Volle Größe, Betonung auf Offenheit von Soft- und Hardware, Erweiterbarkeit und dynamischer Leistung (schnelle Gehgeschwindigkeit, hohes Drehmoment), moderater Preis (300.000-700.000 Yuan), für Forschungszwecke an Hochschulen. 3. Show-/Präsentationsqualität (z.B. Unitree G1, Zhongqing PM01): Kleinere Größe, vereinfachte Wahrnehmungs- und Bewegungsfähigkeiten, ca. 23 Freiheitsgrade, erschwinglicher Preis (<100.000 Yuan), hauptsächlich für Präsentation und Marketing. Der Artikel argumentiert, dass Industriequalität derzeit der Implementierungsschwerpunkt ist, wobei der hohe Preis aus der Gesamtlösung und nicht nur aus der Hardware resultiert; Forschungsqualität fördert technologische Innovation; Show-/Präsentationsqualität deckt kurzfristigen Bedarf an Aufmerksamkeit/Traffic. Zukünftige Klassifizierungen könnten verschwimmen, aber Unterschiede im Kernwert werden bestehen bleiben. (Quelle: Silicon Star Pro)

Kontinuierlicher Wettlauf zwischen KI und Anti-KI-CAPTCHAs: CAPTCHAs wurden ursprünglich entwickelt, um zwischen Mensch und Maschine zu unterscheiden und automatisierten Missbrauch zu verhindern. Mit der Entwicklung von OCR- und KI-Technologien wurden einfache CAPTCHAs mit Zeichenverzerrung unwirksam und entwickelten sich zu komplexeren Bild- und Audio-CAPTCHAs, teilweise unter Einführung von KI-generierten Adversarial Examples. Umgekehrt entwickeln sich auch KI-Cracking-Technologien weiter, nutzen CNNs zur Bilderkennung, simulieren menschliches Verhalten (z.B. Mausbewegungen, Tastatureingaberhythmus), um verhaltensbasierte Verifizierungssysteme wie reCAPTCHA zu umgehen, und verwenden Proxy-IPs zur Umgehung von Sperren. Dieser Angriffs- und Verteidigungskampf führt dazu, dass CAPTCHAs manchmal auch für Menschen eine Herausforderung darstellen. Zukünftige Trends könnten intelligentere, unmerkliche Verifizierungsmethoden sein (wie Apples automatische Verifizierung) oder in Hochsicherheitsbereichen wie Finanzen die Abhängigkeit von Biometrie, wobei letztere jedoch auch Angriffsmethoden wie KI-generierten gefälschten Fingerabdrücken und Master Faces ausgesetzt ist und die Kosten sinken. Die Balance zwischen Sicherheit und Nutzererfahrung ist die zentrale Herausforderung. (Quelle: PConline Pacific Technology)
Reflexion über das Phänomen des “KI-Klassenbesten”: Konflikt zwischen tiefgehendem Lesen und schnellen Zusammenfassungen: Der Autor drückt seine Ablehnung gegenüber der Verwendung von KI-generierten Zusammenfassungen unter langen Texten (“KI-Klassenbester”) aus. Aus Sicht der Gehirnforschung (Spiegelneuronen, Synchronisation der Gehirnaktivität) erklärt er, dass tiefgehendes Lesen ein “Dialog” zwischen Leser und Autor über Zeit und Raum hinweg ist, der kognitive Synchronisation und die Stärkung neuronaler Verbindungen ermöglicht – die Grundlage für echtes “Lernen” und Verstehen. KI-generierte Zusammenfassungen bieten zwar Bequemlichkeit, berauben den Leser aber dieses Prozesses und vermitteln nur ein falsches Gefühl des “Abgeschlossenseins”, ähnlich dem ineffektiven “Quanten-Speed-Reading”. Der Autor meint, nicht jeder Text sei für jeden geeignet; statt zum Lesen zu zwingen, sei es besser, andere Medien (z.B. Videos, Spiele) zu suchen. Er anerkennt den Werkzeugwert von KI-Zusammenfassungen zur Bewältigung von Aufgaben (z.B. Berichte, Hausaufgaben) oder zur Unterstützung des Verständnisses komplexer Zusammenhänge, aber sie sollten aktives Denken und tiefgehendes Engagement nicht ersetzen. Er appelliert an die Leser, sich auf den “menschlichen Teil” in Werken zu konzentrieren und echten Austausch zu pflegen. (Quelle: sspai)
Entwickler von “KI-Betrugs-Tool” erhält Finanzierung, löst ethische Diskussion aus: Zwei US-Studenten wurden von der Columbia University exmatrikuliert, weil sie das KI-Tool “Interview Coder” entwickelt hatten, das beim Bestehen von LeetCode-Programmierinterviews hilft, und dies öffentlich demonstrierten (indem sie Interviews bei Firmen wie Amazon bestanden). Sie gründeten jedoch anschließend das KI-Startup Cluely und erhielten eine Seed-Finanzierung von 5,3 Millionen US-Dollar, um solche Echtzeit-Assistenztools in breitere Szenarien (Prüfungen, Meetings, Verhandlungen) einzuführen. Dieser Vorfall, zusammen mit einer anderen Firma namens Mechanize, die behauptet, alle Arbeiten mit KI zu automatisieren (und KI-Trainer einstellt, um “der KI beizubringen, Menschen zu ersetzen”), löste Diskussionen über die Grenze zwischen “Betrug” und “Befähigung” im KI-Zeitalter, Technikethik und die Definition menschlicher Fähigkeiten aus. Wenn KI in Echtzeit Antworten liefern oder bei Aufgaben assistieren kann, ist das dann Betrug oder Evolution? (Quelle: Daka Tech Chic)
Riesiges Potenzial für industrielle humanoide Roboter, aber Herausforderungen bleiben: Die Industrie sieht allgemein großes Potenzial für den Einsatz humanoider Roboter im industriellen Bereich, insbesondere in Szenarien wie der Automobil-Endmontage, die schwer durch traditionelle Automatisierung abzudecken sind und hohe Personalkosten oder Schwierigkeiten bei der Personalbeschaffung aufweisen. Leng Xiaokun, Vorsitzender von Leju Robotics, prognostiziert, dass das Marktvolumen für die Kollaboration von humanoiden Robotern und Automatisierungsanlagen in den nächsten Jahren 100.000 bis 200.000 Einheiten erreichen könnte. Derzeit steht die Implementierung humanoider Roboter in der Industrie jedoch noch vor Engpässen bei Hardwareleistung (z.B. Akkulaufzeit meist unter 2 Stunden, Effizienz nur 30-50% der menschlichen), Softwaredaten (Mangel an effektiven Trainingsdaten aus realen Szenarien) und Kosten. Unternehmen wie Tianqi Automation planen die Einrichtung von Datenerfassungszentren und das Training vertikaler Modelle, um das Datenproblem zu lösen. Inspektionsszenarien mit geringer körperlicher Belastung werden ebenfalls als Richtung für eine frühere Implementierung angesehen. Die Industrialisierung wird voraussichtlich noch die Überwindung ethischer, sicherheitstechnischer und politischer Probleme erfordern und könnte mehr als 10 Jahre dauern. (Quelle: Science and Technology Innovation Board Daily)
Diskussion über den Entwicklungspfad von Allzweckrobotern: Analogie zur Smartphone-Evolution: Zhao Zhelun, Mitbegründer von Vita Dynamics, argumentiert, dass der Entwicklungspfad von Allzweckrobotern der 15-jährigen Evolution des Smartphones vom frühen PDA zum iPhone ähneln wird. Dies erfordert die Reife der Basistechnologien (Kommunikation, Akku, Speicher, Computing, Display etc.) und eine schrittweise Iteration von Anwendungsszenarien, anstatt eines plötzlichen Durchbruchs. Er schlägt vor, die Kernfähigkeiten von Robotern in natürliche Interaktion, autonome Mobilität und autonome Manipulation zu zerlegen. In der aktuellen Phase sollte man den kritischen Punkt des Übergangs von prinzipienbasierter zu ingenieurtechnischer Technologie nutzen (z.B. sind vierbeiniges Gehen und Greiferbedienung nahe an der Ingenieurreife, während zweibeiniges Gehen und geschickte Hände noch eher prinzipienbasiert sind) und die Produktentwicklung mit den Szenarioanforderungen (Outdoor: Fokus Mobilität, Indoor: Fokus Manipulation) kombinieren. Natural User Interface (NUI) wird als zentrale Interaktionsmethode angesehen. Die Produktlieferung sollte einem progressiven Pfad von einfachen, risikoarmen Aufgaben (z.B. Spielzeug aufräumen) zu komplexen, risikoreichen Aufgaben (z.B. Messer in der Küche verwenden) folgen, um schrittweise den PMF (Product-Market Fit) zu validieren. (Quelle: Tencent Tech)

ByteDance Top Seed Programm rekrutiert Top-Doktoranden, Fokus auf Spitzenforschung bei großen Modellen: ByteDance hat das Top Seed Large Model Top Talent Campus Recruitment Plan für den Jahrgang 2026 gestartet. Weltweit werden ca. 30 Top-Absolventen (Doktoranden) gesucht, deren Forschungsrichtungen große Sprachmodelle, maschinelles Lernen, multimodale Generierung und Verständnis, Sprache etc. umfassen. Das Programm betont, dass keine bestimmten Fachrichtungen vorausgesetzt werden, und legt Wert auf Forschungspotenzial, technische Leidenschaft und Neugier. Es bietet branchenführende Gehälter, ausreichende Rechenleistungs- und Datenressourcen, eine Forschungsumgebung mit hoher Freiheit sowie Implementierungsmöglichkeiten in den vielfältigen Anwendungsszenarien von ByteDance. Mehrere frühere Top Seed Mitglieder haben sich bereits in wichtigen Projekten hervorgetan, z.B. beim Aufbau des ersten Open-Source, mehrsprachigen Code-Reparatur-Benchmarks Multi-SWE-bench, bei der Leitung des multimodalen Agentenprojekts UI-TARS und bei der Veröffentlichung der Forschung zur ultra-sparsen Modellarchitektur UltraMem (die die MoE-Inferenzkosten erheblich senkt). Das Programm zielt darauf ab, die weltweit besten 5% der Talente anzuziehen und wird von technischen Koryphäen wie Wu Yonghui betreut. (Quelle: InfoQ)

Follow-up zur ‘AI 2027’-Studie: USA könnten KI-Wettlauf durch Rechenleistungsvorteil gewinnen: Die Forscher Scott Alexander und Romeo Dean, die zuvor den Bericht “AI 2027” veröffentlicht hatten, argumentieren in einem neuen Beitrag, dass die USA den KI-Wettlauf trotz Chinas Führung bei der Anzahl der KI-Patente (70% weltweit) wahrscheinlich durch ihren Vorteil bei der Rechenleistung gewinnen werden. Sie schätzen, dass die USA 75% der weltweiten Rechenleistung fortschrittlicher KI-Chips kontrollieren, China nur 15%. Zudem erhöhen die US-Chip-Exportkontrollen die Kosten für China, fortschrittliche Rechenleistung zu erlangen (ca. 60% höher). Obwohl China bei der konzentrierten Nutzung von Rechenleistung effizienter sein könnte, dürften führende US-KI-Projekte (wie OpenAI, Google) ihren Rechenleistungsvorteil behalten. Die Stromversorgung wird kurzfristig (2027-2028) kein Hauptengpass sein. Im Bereich Talente können die USA zwar globale Talente anziehen, und obwohl China eine hohe Anzahl an STEM-Doktoranden hat, wird der Engpass bei der Rechenleistung kritischer sein als die Anzahl der Talente, wenn KI in die Phase der Selbstverbesserung eintritt. Daher halten sie die strikte Durchsetzung der Chip-Sanktionen für entscheidend, damit die USA ihre Führungsposition behaupten können. (Quelle: Xinzhiyuan)

Hinton u.a. unterzeichnen gemeinsamen Brief gegen OpenAI-Umstrukturierungspläne, Sorge vor Abweichung von gemeinnützigen Zielen: KI-Pate Geoffrey Hinton, 10 ehemalige OpenAI-Mitarbeiter und andere Brancheninsider haben einen gemeinsamen offenen Brief veröffentlicht, in dem sie sich gegen die Pläne von OpenAI aussprechen, seine gewinnorientierte Tochtergesellschaft in eine Public Benefit Corporation (PBC) umzuwandeln und möglicherweise die Kontrolle durch die Non-Profit-Organisation aufzuheben. Sie argumentieren, dass die ursprüngliche Non-Profit-Struktur von OpenAI eingerichtet wurde, um die sichere Entwicklung von AGI zum Wohle der gesamten Menschheit zu gewährleisten und zu verhindern, dass kommerzielle Interessen (z.B. Investorenrenditen) über dieser Mission stehen. Die vorgeschlagene Umstrukturierung würde diese zentrale Governance-Garantie schwächen und gegen die Unternehmenssatzung sowie das Versprechen an die Öffentlichkeit verstoßen. Der Brief fordert OpenAI auf zu erklären, wie die Umstrukturierung ihre gemeinnützigen Ziele fördert, und appelliert an die Beibehaltung der Kontrolle durch die Non-Profit-Organisation, um sicherzustellen, dass Entwicklung und Erträge von AGI letztlich dem öffentlichen Wohl dienen und nicht primär den Aktionärsrenditen. (Quelle: Xinzhiyuan)
