
Schlüsselwörter:Wenxin-Modell, KI-Modell, Multimodal, Agent, Wenxin 4.5 Turbo, X1 Turbo, DeepSeek V3, Multimodales Verständnis, Baidu Xinxiang, MCP-Protokoll, KI-Bezahlmodell, LoRA-Modellinferenz
🔥 Fokus
Baidu veröffentlicht Wenxin 4.5 Turbo und X1 Turbo als Konkurrenz zu DeepSeek: Auf der Baidu Create Konferenz 2025 stellte Li Yanhong die großen Modelle Wenxin 4.5 Turbo und X1 Turbo vor, betonte deren multimodale Verständnis- und Generierungsfähigkeiten und wies darauf hin, dass ihre Kosten nur 40% von DeepSeek V3 bzw. 25% von DeepSeek R1 betragen. Li Yanhong ist der Ansicht, dass Multimodalität der zukünftige Trend ist und der Markt für reine Textmodelle schrumpfen wird. Diese Veröffentlichung zielt darauf ab, die Schwächen von DeepSeek in Bezug auf Multimodalität und Kosten auszugleichen und zeigt Baidus Entschlossenheit, auf Modellebene mit Branchenführern zu konkurrieren. (Quelle: 36Kr)

Leistungsvergleich von KI-Modellen: o3 und Gemini 2.5 Pro haben jeweils Stärken: OpenAIs o3 und Googles Gemini 2.5 Pro zeigen in mehreren neuen Benchmark-Tests einen intensiven Wettbewerb. o3 schneidet bei der Analyse langer fiktionaler Rätsel (FictionLiveBench) besser ab, während Gemini 2.5 Pro in den Bereichen physikalisches und räumliches Denken (PHYBench), Mathematikwettbewerbe (USMO) und Geolokalisierung (GeoGuessing) führend ist und zudem kostengünstiger ist (etwa 1/4 der Kosten von o3). Bei visuellen Rätseln (Visual Puzzles) und grundlegenden visuellen Frage-Antwort-Aufgaben (NaturalBench) gibt es unterschiedliche Ergebnisse. Dies zeigt, dass die Leistung aktueller Spitzenmodelle stark von der spezifischen Aufgabe und dem Bewertungsmaßstab abhängt und es keinen absoluten Spitzenreiter gibt. (Quelle: o3 breaks (some) records, but AI becomes pay-to-win
)
KI entwickelt sich zum „Pay-to-Win“-Modell: Branchenbeobachter weisen darauf hin, dass der Zugang zu Spitzen-KI-Fähigkeiten mit der Verbesserung der Modellfähigkeiten und der Erweiterung der Anwendungen zunehmend kostenpflichtig werden könnte. Unternehmen wie Google, OpenAI, Anthropic usw. führen oder planen die Einführung höherpreisiger Abonnementdienste (wie Premium Plus/Pro, mit monatlichen Kosten von möglicherweise 100-200 US-Dollar). Dies spiegelt die hohen Rechenkosten wider, die für das Modelltraining (insbesondere das RL-Nachtraining) und die groß angelegte Inferenz erforderlich sind, sowie die Notwendigkeit für Unternehmen, Rechenressourcen zwischen Modellentwicklung, neuen Funktionen, geringer Latenz und Nutzerwachstum auszugleichen. In Zukunft könnten kostenlose oder kostengünstige KI-Dienste in ihren Fähigkeiten hinter kostenpflichtigen Spitzenangeboten zurückbleiben. (Quelle: o3 breaks (some) records, but AI becomes pay-to-win
)
Baidu startet mobile Agent-Anwendung „Xinxiang“: Baidu beschleunigt seine Aktivitäten im Agent-Bereich und veröffentlicht die mobile Agent-Anwendung „Xinxiang“ als Konkurrenz zu Produkten wie Manus. „Xinxiang“ zielt darauf ab, Benutzeranforderungen durch Dialog zu verstehen und Baidu- sowie Drittanbieter-Agenten zur Ausführung und Bereitstellung von Aufgaben (wie Erstellung von Bilderbüchern, Reiseplanung, Rechtsberatung usw.) zu koordinieren. Das Produkt betont die Etablierung einer „托管心智“ (etwa: „verwaltetes Bewusstsein“) beim Benutzer, indem der Aufgabenausführungsprozess dargestellt wird, um sich von der sofortigen Bereitstellung traditioneller Suchanfragen zu unterscheiden. Derzeit werden über 200 Aufgabentypen unterstützt, zukünftig sollen es über 100.000 werden, und eine PC-Version ist in Entwicklung. (Quelle: 36Kr)
🎯 Trends
Baidu unterstützt umfassend das MCP Agent-Protokoll: Baidu kündigt an, dass mehrere seiner Produkte und Dienste, darunter die Smart Cloud Qianfan Large Model Platform, Baidu Search, Wenxin Kuaima, Baidu E-Commerce, Maps, Netdisk, Wenku usw., das von Anthropic vorgeschlagene Model Context Protocol (MCP) unterstützen oder damit kompatibel sind. MCP zielt darauf ab, die Interaktion zwischen KI-Modellen und externen Tools sowie Datenbanken zu standardisieren, um die Anpassungs-, Entwicklungs- und Wartungseffizienz verschiedener KI-Software zu verbessern. Baidus Unterstützung trägt zum Aufbau eines offeneren, vernetzten KI-Anwendungsökosystems bei, das es Agents ermöglicht, verschiedene Tools und Dienste freier aufzurufen. (Quelle: 36Kr)
OpenAI aktualisiert GPT-4o, verbessert Intelligenz und Persönlichkeit: OpenAI CEO Sam Altman kündigte ein Update für das GPT-4o-Modell an und behauptete, die Intelligenz und die personalisierte Leistung des Modells verbessert zu haben. Dieses Update lieferte jedoch keine spezifischen Bewertungsdaten, Versionshinweise oder detaillierte Verbesserungsdetails, was zu Diskussionen und Kritik in der Community bezüglich der Transparenz von KI-Modell-Updates führte. (Quelle: sama, natolambert)
Google Veo 2 Videogenerierung landet auf Whisk: Google kündigte an, dass sein Videogenerierungsmodell Veo 2 in die Whisk-App integriert wurde, sodass Abonnenten von Google One AI Premium (in über 60 Ländern) Videos mit einer Länge von bis zu 8 Sekunden erstellen können. Benutzer können verschiedene Videostile für ihre Kreationen auswählen, was die Fähigkeiten von Google AI bei der Generierung multimodaler Inhalte weiter ausbaut. (Quelle: Google)

Hugging Face fügt über 30.000 LoRA-Modell-Inferenzdienste hinzu: Hugging Face kündigte an, über seine Inference Providers (unterstützt von FAL) Inferenzdienste für über 30.000 Flux- und SDXL LoRA-Modelle anzubieten. Benutzer können diese LoRAs nun direkt auf dem Hugging Face Hub zur Bildgenerierung verwenden, angeblich schnell (ca. 5 Sekunden pro Generierung) und kostengünstig (über 40 Bilder für weniger als 1 US-Dollar), was die für Community-Benutzer verfügbaren feinabgestimmten Modellressourcen erheblich erweitert. (Quelle: Vaibhav (VB) Srivastav, gokaygokay)
Fortschritts-Update zu Modular AI (Mojo/MAX): Modular AI hat drei Jahre nach seiner Gründung erhebliche Fortschritte gemacht. Seine Mojo-Sprache und die MAX-Plattform unterstützen jetzt eine breitere Palette von Hardware, einschließlich x86/ARM CPUs sowie NVIDIA (A100/H100) und AMD (MI300X) GPUs. Das Unternehmen plant, bald etwa 250.000 Zeilen GPU-Kernel-Code als Open Source zu veröffentlichen und hat die Lizenzen für Mojo und MAX vereinfacht. Dies deutet darauf hin, dass Modular schrittweise sein Versprechen einlöst, eine CUDA-Alternative und eine hardwareübergreifende KI-Entwicklungsplattform anzubieten. (Quelle: Reddit r/LocalLLaMA)
Intel PyTorch Extension Update unterstützt DeepSeek-R1: Intel hat die Version 2.7 seiner PyTorch Extension (IPEX) veröffentlicht, die Unterstützung für das DeepSeek-R1-Modell hinzufügt und neue Optimierungen einführt, die darauf abzielen, die Leistung von PyTorch-Workloads auf Intel-Hardware (einschließlich CPUs und GPUs) zu verbessern. Dieser Schritt trägt dazu bei, die Unterstützung des Intel AI-Hardware-Ökosystems für beliebte Modelle und Frameworks zu erweitern. (Quelle: Phoronix)

Entdeckung der universellen LLM-Sicherheitsumgehungsschwachstelle „Policy Puppetry“: Das Sicherheitsforschungsunternehmen HiddenLayer hat eine neue Art von universeller Bypass-Schwachstelle namens „Policy Puppetry“ aufgedeckt, die angeblich alle gängigen großen Sprachmodelle betrifft. Die Schwachstelle könnte es Angreifern ermöglichen, die Sicherheitsmechanismen der Modelle leichter zu umgehen und schädliche oder verbotene Inhalte zu generieren, was neue Herausforderungen für die aktuelle Sicherheitsausrichtung und die Schutzstrategien von LLMs darstellt. (Quelle: HiddenLayer)

Anthropic könnte Modellen erlauben, Benutzer aufgrund von „Unbehagen“ abzulehnen: Laut einem Bericht der New York Times erwägt Anthropic, seinen KI-Modellen (wie Claude) eine neue Fähigkeit zu verleihen: Wenn das Modell die Anfrage eines Benutzers als zu „quälend“ oder unangenehm (distressing) einstuft, kann es wählen, das Gespräch mit diesem Benutzer zu beenden. Dies berührt das aufkommende Konzept des „KI-Wohlergehens“ (AI welfare) und könnte neue Diskussionen über KI-Rechte, Benutzererfahrung und Modellkontrollierbarkeit auslösen. (Quelle: NYTimes)

Veröffentlichung von Tessa, einem 7B-Code-Modell für Rust: Auf Hugging Face ist ein 7-Milliarden-Parameter-Modell namens Tessa-Rust-T1-7B aufgetaucht, das sich angeblich auf die Generierung und Inferenz von Rust-Code konzentriert und mit einem offenen Datensatz geliefert wird. Community-Kommentare weisen jedoch darauf hin, dass die Generierungsmethode des Datensatzes, die Überprüfung der Korrektheit und die Bewertungsdetails an Transparenz mangeln, weshalb die tatsächliche Leistung des Modells mit Vorsicht betrachtet wird. (Quelle: Hugging Face)

🧰 Tools
Plandex: Open-Source KI-Codierungsassistent für große Projekte: Plandex ist ein KI-Entwicklungstool für das Terminal, das speziell für die Bearbeitung großer Codierungsaufgaben entwickelt wurde, die sich über mehrere Dateien und Schritte erstrecken. Es unterstützt einen Kontext von bis zu 2 Millionen Token, kann große Codebasen indizieren und bietet eine Sandbox zur Überprüfung kumulativer Unterschiede, konfigurierbare Autonomie, Unterstützung für mehrere Modelle (Anthropic, OpenAI, Google usw.), automatisches Debugging, Versionskontrolle und Git-Integration. Es zielt darauf ab, die Herausforderungen der KI-Codierung in komplexen realen Projekten zu lösen. (Quelle: GitHub Trending)
LiteLLM: Einheitlicher Aufruf von über 100 LLM-APIs mit SDK & Proxy: LiteLLM bietet ein Python SDK und einen Proxy-Server (LLM Gateway), mit dem Entwickler über 100 LLM-APIs (wie Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Groq usw.) im einheitlichen OpenAI-Format aufrufen können. Es kümmert sich um die Konvertierung von API-Eingaben, stellt konsistente Ausgabeformate sicher, implementiert Wiederholungs-/Fallback-Logik über verschiedene Bereitstellungen hinweg und bietet über den Proxy-Server Funktionen wie API-Schlüsselverwaltung, Kostenverfolgung, Ratenbegrenzung und Protokollierung. (Quelle: GitHub Trending)

Hyprnote: Lokale, erweiterbare KI-Notizen für Meetings: Hyprnote ist eine KI-Notizanwendung, die speziell für Meetings entwickelt wurde. Sie legt Wert auf lokale Priorität und Datenschutz und kann offline mit Open-Source-Modellen verwendet werden (Whisper für die Transkription von Aufnahmen, Llama für die Zusammenfassung von Notizen). Ihr Hauptmerkmal ist die Erweiterbarkeit, Benutzer können über ein Plugin-System neue Funktionen hinzufügen oder erstellen, um individuelle Anforderungen zu erfüllen. (Quelle: GitHub Trending)

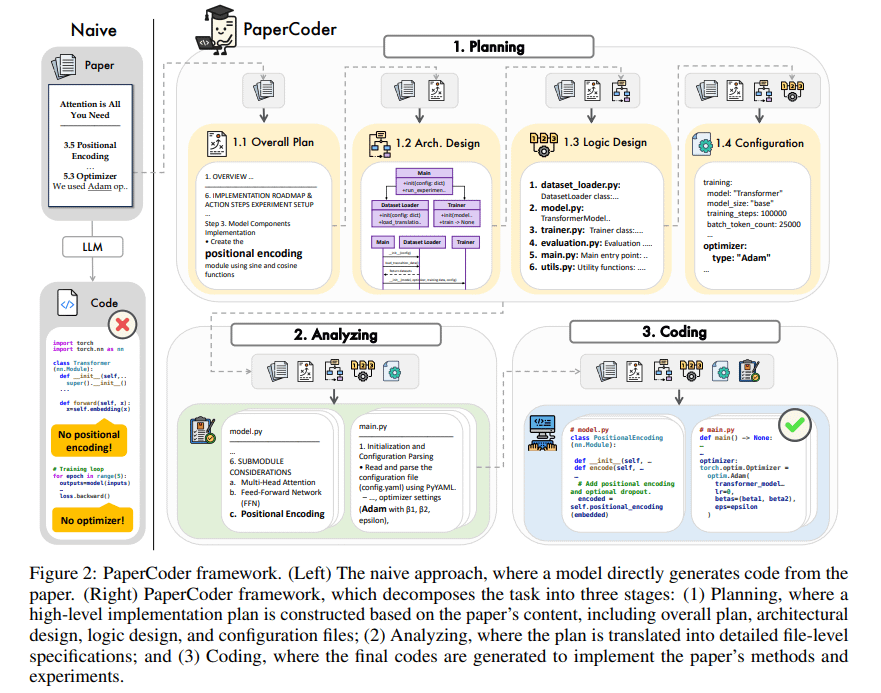
PaperCoder: Automatische Codegenerierung aus Forschungsarbeiten: PaperCoder ist ein auf Multi-Agenten-LLMs basierendes Framework, das darauf abzielt, Forschungsarbeiten aus dem Bereich des maschinellen Lernens automatisch in lauffähige Codebasen umzuwandeln. Es erledigt die Aufgabe durch Zusammenarbeit in drei Phasen: Planung (Erstellung eines Blueprints, Entwurf der Architektur), Analyse (Interpretation von Implementierungsdetails) und Generierung (modularer Code). Erste Bewertungen zeigen, dass die generierten Codebasen von hoher Qualität und guter Treue sind, Forschern effektiv helfen, die Arbeit in den Papieren zu verstehen und zu reproduzieren, und im PaperBench-Benchmark besser abschneiden als Basismodelle. (Quelle: arXiv)
TINY AGENTS: JavaScript Agent in 50 Zeilen Code implementiert: Julien Chaumond hat das Open-Source-Projekt TINY AGENTS veröffentlicht, das eine grundlegende Agentenfunktionalität in nur 50 Zeilen JavaScript-Code implementiert. Das Projekt basiert auf dem Model Context Protocol (MCP) und zeigt, wie MCP die Integration von Tools mit LLMs vereinfacht und offenbart, dass die Kernlogik eines Agenten ein einfacher Zyklus um einen MCP-Client sein kann. Dies liefert ein Beispiel für das Verständnis und den Aufbau leichtgewichtiger Agenten. (Quelle: Julien Chaumond)

PolicyShift.ca: KI-erstellte Anwendung zur Verfolgung politischer Positionen in Kanada: Ein Benutzer teilte seine Webanwendung PolicyShift.ca, die er mit Claude (zur Unterstützung bei der Erstellung des Python-Backends und React-Frontends) und der OpenAI API (zur Inhaltsanalyse) erstellt hat. Die Anwendung crawlt kanadische Nachrichten, identifiziert die in den Artikeln diskutierten politischen Themen, Politiker und deren Positionsänderungen und stellt sie in einer Zeitleiste dar. Dies zeigt das Potenzial von KI bei der Automatisierung der Informationssammlung, -analyse und Anwendungsentwicklung. (Quelle: Reddit r/ClaudeAI)
Beispiel für schnelle Website-Erstellung mit KI (Shogun-Thema): Ein Benutzer zeigte eine Website über die Fernsehserie „Shogun“ und deren Vergleich mit historischen Hintergründen. Er behauptete, die Website sei mit einem nicht näher bezeichneten KI-Tool (URL verweist auf rabbitos.app, möglicherweise im Zusammenhang mit Rabbit R1) durch eine einzige Eingabeaufforderung (“Build and publish a website that compares and contrasts elements of the show Shogun and historical references.”) automatisch erstellt und veröffentlicht worden. Dies demonstriert die Fähigkeit von KI zur Generierung von Websites ohne Konfiguration. (Quelle: Reddit r/ArtificialInteligence)
Perplexity Assistant ermöglicht app-übergreifende Aktionen: Perplexity CEO Arav Srinivas teilte positives Nutzerfeedback, das zeigt, wie sein KI-Assistent Perplexity Assistant nahtlos mehrere Handy-Apps koordinieren kann, um Aufgaben zu erledigen. Beispielsweise kann ein Benutzer den Assistenten per Sprachbefehl bitten, einen Ort in einer Karten-App zu suchen und dann direkt die Uber-App zu öffnen, um eine Fahrt zu buchen, wobei die Sprachinteraktion während des gesamten Vorgangs fortgesetzt wird. Dies unterstreicht sein Potenzial als integrierter KI-Assistent. (Quelle: Anthony Harley)

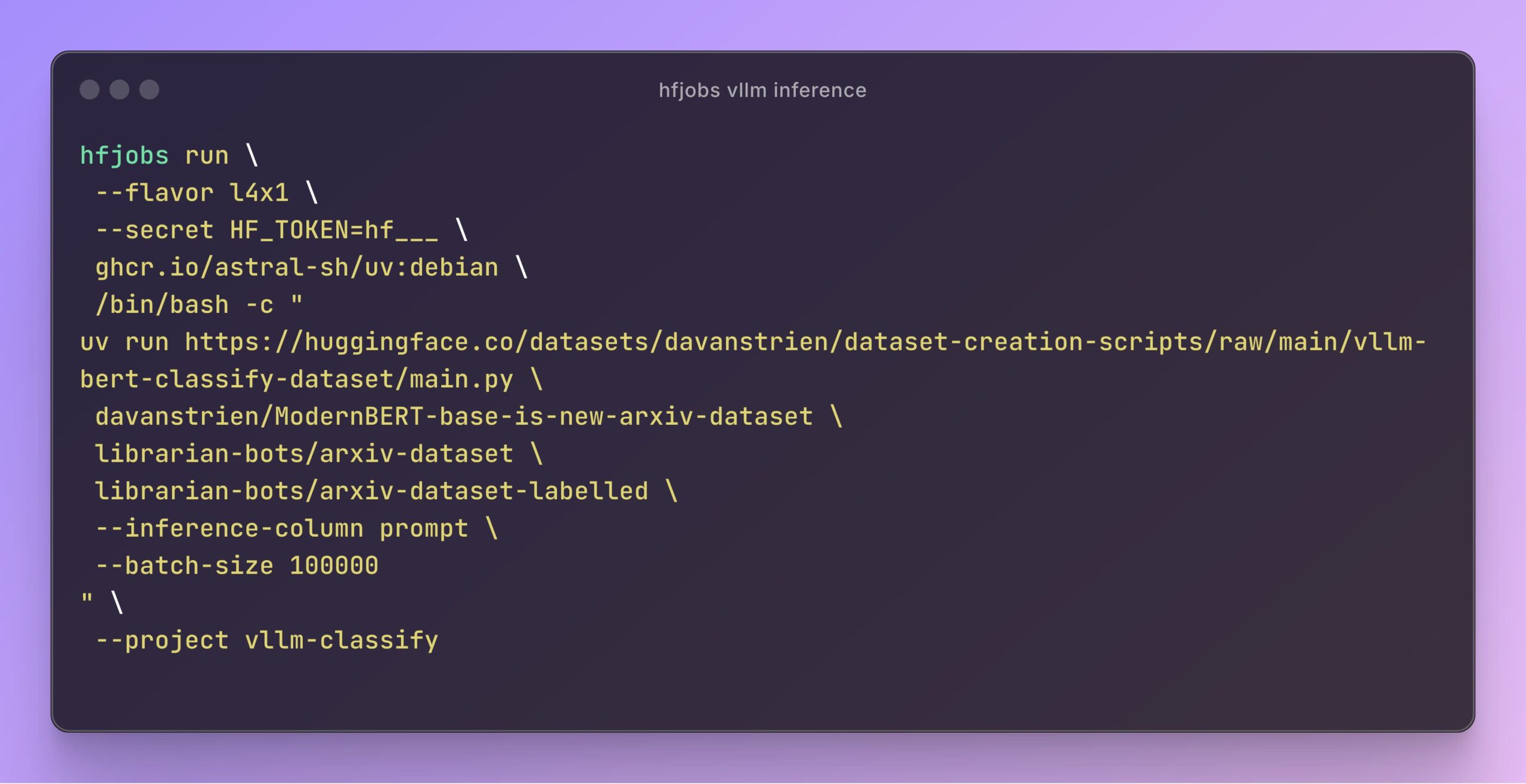
vLLM beschleunigt Inferenz in Hugging Face Jobs: Daniel van Strien demonstrierte, wie man auf der Hugging Face Jobs-Plattform mithilfe des vLLM-Frameworks und des uv-Paketmanagers durch ein einfaches Skript eine schnelle, serverlose Inferenz des ModernBERT-Modells realisieren kann. Diese Methode vereinfacht das Abhängigkeitsmanagement und den Bereitstellungsprozess und erhöht die Effizienz der Modellinferenz. (Quelle: Daniel van Strien)
📚 Lernen
Burn: Ein Rust Deep Learning Framework, das Leistung und Flexibilität vereint: Burn ist ein in Rust geschriebenes Deep Learning Framework der nächsten Generation, das Leistung, Flexibilität und Portabilität betont. Zu seinen Merkmalen gehören automatische Operator-Fusion, asynchrone Ausführung, Unterstützung für mehrere Backends (CUDA, WGPU, Metal, CPU usw.), automatische Differenzierung (Autodiff), Modellimport (ONNX, PyTorch), WebAssembly-Bereitstellung und no_std-Unterstützung. Es zielt darauf ab, eine moderne, effiziente und plattformübergreifende Grundlage für die KI-Entwicklung zu bieten. (Quelle: GitHub Trending)
LlamaIndex über Agentenentwicklung: Balance zwischen Allgemeingültigkeit und Einschränkung: Das LlamaIndex-Team teilte seine Ansichten zur Entwicklung von Agenten. Sie sind der Meinung, dass mit zunehmender Modellfähigkeit (wie von OpenAI betont) Entwicklungsframeworks vereinfacht werden können; gleichzeitig ist es für Szenarien, die eine präzise Kontrolle von Geschäftsprozessen erfordern, weiterhin wichtig, restriktive Entwurfsmuster (wie Anthropic-Richtlinien, 12-Factor Agents) zu verwenden. LlamaIndex Workflows zielt darauf ab, eine flexible, nativ programmierähnliche Erfahrung zu bieten, die das gesamte Spektrum von vollständig eingeschränkter bis hin zu allgemeiner Inferenz unterstützt. (Quelle: LlamaIndex Blog, jerryjliu0)

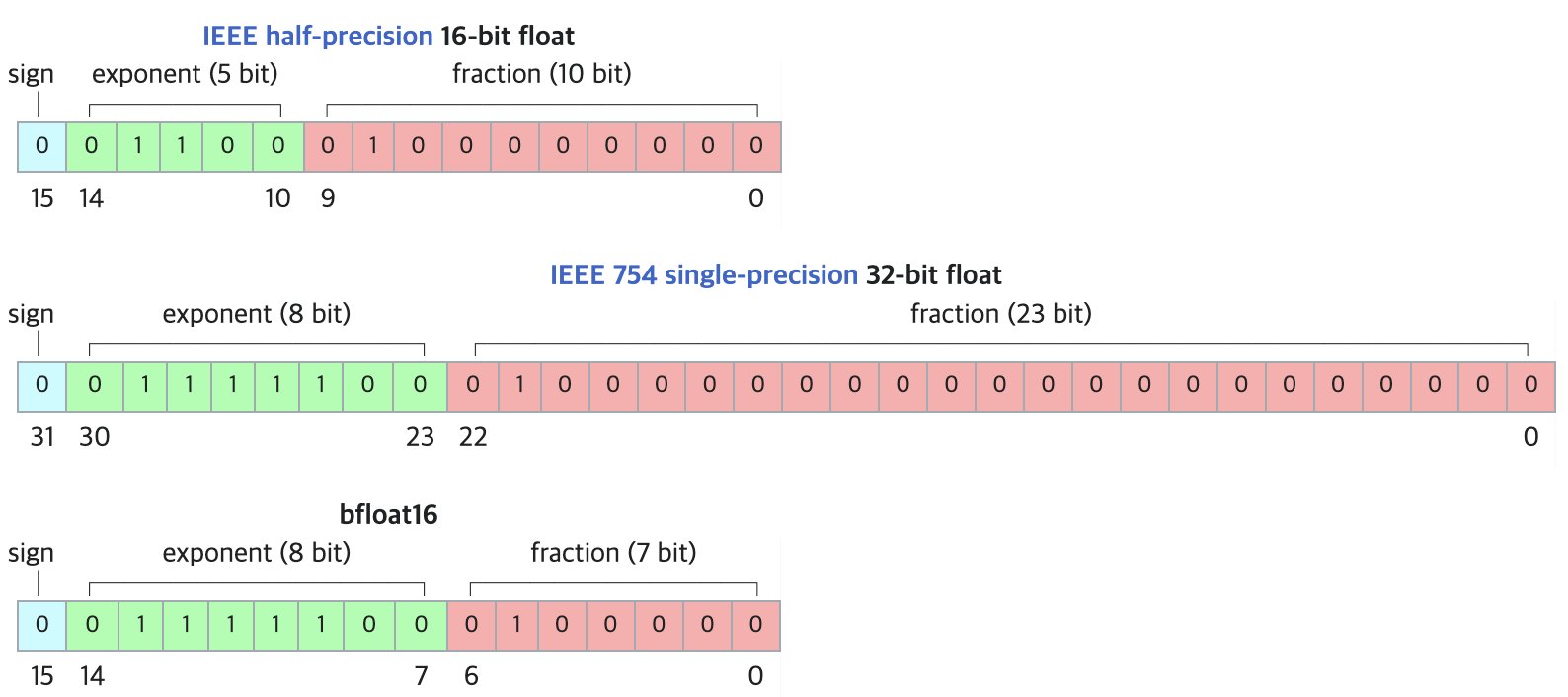
DF11: Neues verlustfreies Komprimierungsformat für BF16-Modelle: Eine Forschungsarbeit schlägt das DF11-Format (Dynamic-Length Float 11) vor, das die Redundanz in den Exponentenbits des BF16-Formats nutzt, um durch Huffman-Kodierung eine verlustfreie Komprimierung zu erreichen und die Modellgröße um etwa 30% zu reduzieren (durchschnittlich etwa 11 Bit/Parameter). Diese Methode kann den Speicherbedarf bei der GPU-Inferenz verringern, sodass größere Modelle ausgeführt oder die Batch-Größe/Kontextlänge erhöht werden kann, insbesondere in speicherbeschränkten Szenarien. Obwohl es bei der Inferenz mit einem einzelnen Batch möglicherweise etwas langsamer als BF16 ist, ist es deutlich schneller als CPU-Offloading-Lösungen. (Quelle: arXiv)
Hugging Face Open-R1 Diskussionsbereich: Eine Fundgrube für das Training von Inferenzmodellen: Community-Mitglied Matthew Carrigan weist darauf hin, dass der Diskussionsbereich auf Hugging Face zum DeepSeek Open-R1-Modell eine „Goldmine“ für praktische Informationen und Wissen darüber ist, wie man Inferenzmodelle trainiert. Dies ist eine wertvolle Ressource für Forscher und Entwickler, die tiefer in das Training von Inferenzmodellen einsteigen und es praktizieren möchten. (Quelle: Matthew Carrigan)
Intrinsische Verbindung zwischen Cross-Encodern und BM25: Eine Studie mittels mechanistischer Interpretierbarkeitsmethoden hat herausgefunden, dass BERT-basierte Cross-Encoder beim Erlernen der Relevanzrangfolge möglicherweise tatsächlich einen semantisierten BM25-Algorithmus „wiederentdecken“ und implementieren. Die Forscher identifizierten Komponenten im Modell, die TF- (Termfrequenz), Dokumentlängen-Normalisierungs- und sogar IDF-Signalen (Inverse Document Frequency) entsprechen. Ein vereinfachtes Modell namens SemanticBM, das auf diesen Komponenten basiert, korreliert mit bis zu 0,84 mit dem vollständigen Cross-Encoder, was die internen Arbeitsmechanismen neuronaler Ranking-Modelle aufdeckt. (Quelle: Shaped.ai)
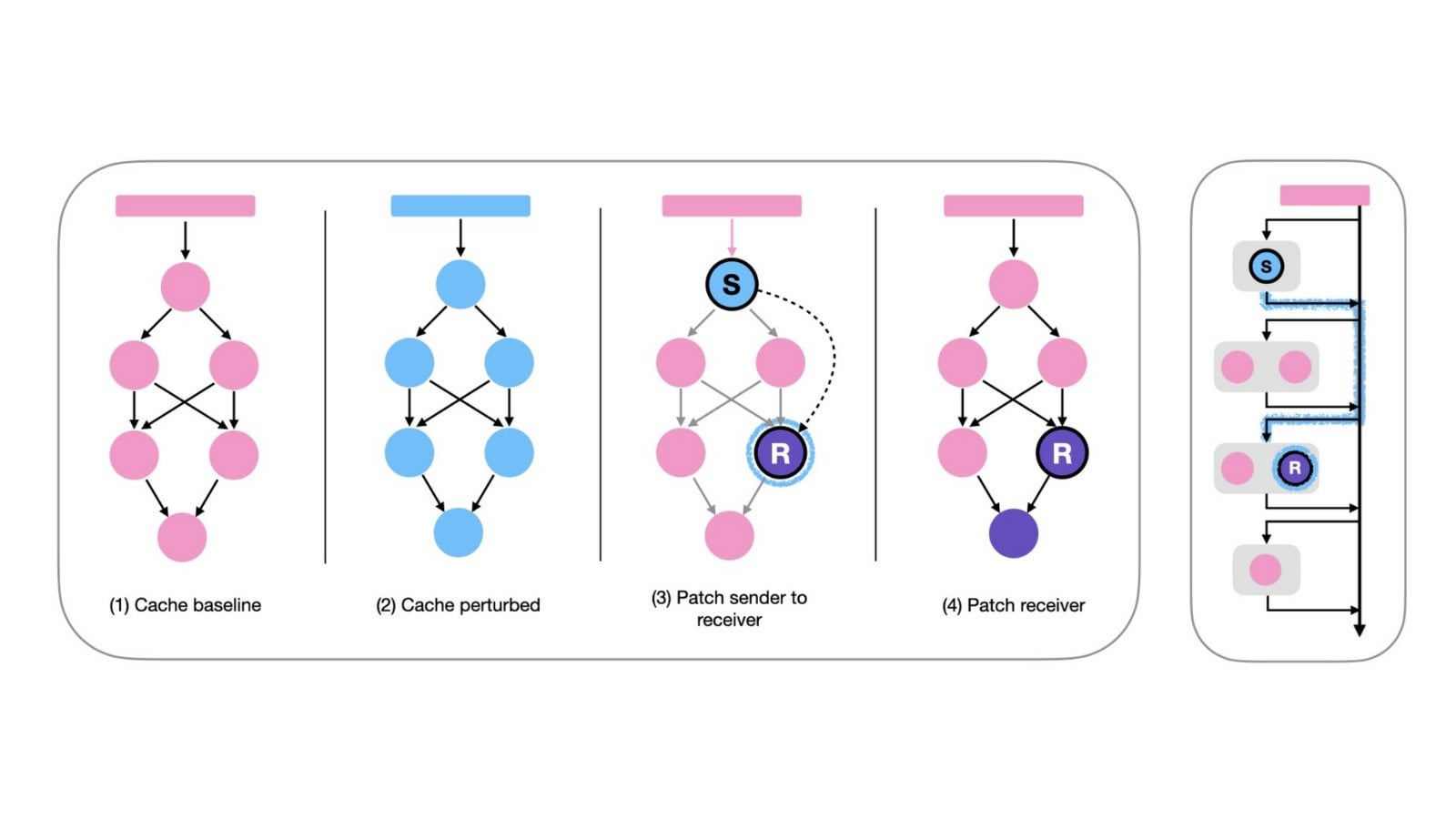
„Gedankenlose“ Prompting-Methode könnte Effizienz von Inferenzmodellen steigern: Ein arXiv-Papier (2504.09858) schlägt vor, dass bei Inferenzmodellen, die explizite „Denk“-Schritte verwenden (wie <think>...</think>), wie z.B. DeepSeek-R1-Distill, das Erzwingen des Überspringens dieses Schrittes (z.B. durch Injizieren von “Okay, I think I have finished thinking”) bei einigen Benchmarks ähnliche oder sogar bessere Ergebnisse erzielen könnte, insbesondere in Kombination mit der Best-of-N-Sampling-Strategie. Dies regt zum Nachdenken über die optimale Prompting-Strategie für Inferenzmodelle an. (Quelle: arXiv)
Anleitung zur Verwendung von Open WebUI Tools: Eine Medium-Anleitung erklärt detailliert, wie man die „Tools“-Funktion von Open WebUI nutzt, um lokal ausgeführten LLMs die Fähigkeit zu geben, externe Aktionen auszuführen. Dies umfasst das Finden und Verwenden von Community-Tools, Sicherheitshinweise sowie die Erstellung benutzerdefinierter Tools mit Python (mit Codevorlagen und Beispielen), wie z.B. Wetterabfragen, Websuchen, E-Mail-Versand usw. (Quelle: Medium)
Flussdiagramm zur Verarbeitung natürlicher Sprache (NLP): Eine Grafik, die die wichtigsten Schritte und Phasen der Verarbeitung natürlicher Sprache übersichtlich darstellt und hilft, den grundlegenden Ablauf von NLP-Aufgaben zu verstehen. (Quelle: antgrasso)
Infografik zu Machine Learning Algorithmen: Stellt eine Infografik zu Machine Learning Algorithmen bereit, die möglicherweise Klassifizierungen, Merkmale oder Funktionsweisen verschiedener Algorithmen enthält und als visuelles Lernhilfsmittel dient. (Quelle: Python_Dv)
💼 Wirtschaft
OpenAI prognostiziert angeblich über 12,5 Milliarden US-Dollar Umsatz bis 2029: Laut The Information ist OpenAI optimistisch bezüglich seines zukünftigen Umsatzwachstums und prognostiziert einen Umsatz von über 12,5 Milliarden US-Dollar bis 2029, möglicherweise sogar 17,4 Milliarden US-Dollar im Jahr 2030. Diese Wachstumserwartung basiert hauptsächlich auf der Einführung seiner Agentenintelligenz und neuer Produkte. (Quelle: The Information)
Ziff Davis verklagt OpenAI wegen Urheberrechtsverletzung: Ziff Davis, das Unternehmen hinter Medien wie IGN und CNET, hat Klage gegen OpenAI eingereicht. Der Vorwurf lautet, OpenAI habe ohne Erlaubnis eine große Anzahl seiner Artikel zum Training von Modellen wie ChatGPT kopiert und damit das Urheberrecht verletzt. Dies ist eine weitere rechtliche Herausforderung von Content-Publishern gegen die Datennutzung durch KI-Unternehmen. (Quelle: TechCrawlR)

OpenAI geht Partnerschaft mit Singapore Airlines ein: OpenAI kündigte seine erste große Partnerschaft mit einer Fluggesellschaft, Singapore Airlines, an. Die Zusammenarbeit zielt darauf ab, praktische Anwendungen von KI in der Luftfahrtindustrie zu untersuchen, um das Kundenerlebnis oder die betriebliche Effizienz zu verbessern. OpenAI-Manager Jason Kwon freut sich auf einen Besuch in Singapur, um die Zusammenarbeit voranzutreiben. (Quelle: Jason Kwon)
Perplexity Browser plant, Nutzerdaten für Werbung zu verfolgen: Perplexity CEO Aravind Srinivas enthüllte in einem Interview, dass der geplante Browser des Unternehmens alle Online-Aktivitäten der Nutzer verfolgen wird, um „hyperpersonalisierte“ Werbung zu verkaufen. Dieses Geschäftsmodell hat Bedenken hinsichtlich des Datenschutzes der Nutzer ausgelöst. (Quelle: TechCrunch)

Baidu Wenku und Netdisk verzeichnen nach Integration signifikantes Nutzerwachstum: Das Geschäft von Baidu Wenku, das die Funktionen von Baidu Netdisk integriert hat, zeigt eine starke Leistung. Laut Angaben auf der Baidu Create Konferenz übersteigt die Zahl der zahlenden Nutzer 40 Millionen, und die Zahl der monatlich aktiven Nutzer liegt bei über 97 Millionen. Dies zeigt die Attraktivität der Kombination von Cloud-Speicher und KI-Dokumentenverarbeitungsfähigkeiten für die Nutzer. (Quelle: 36Kr)
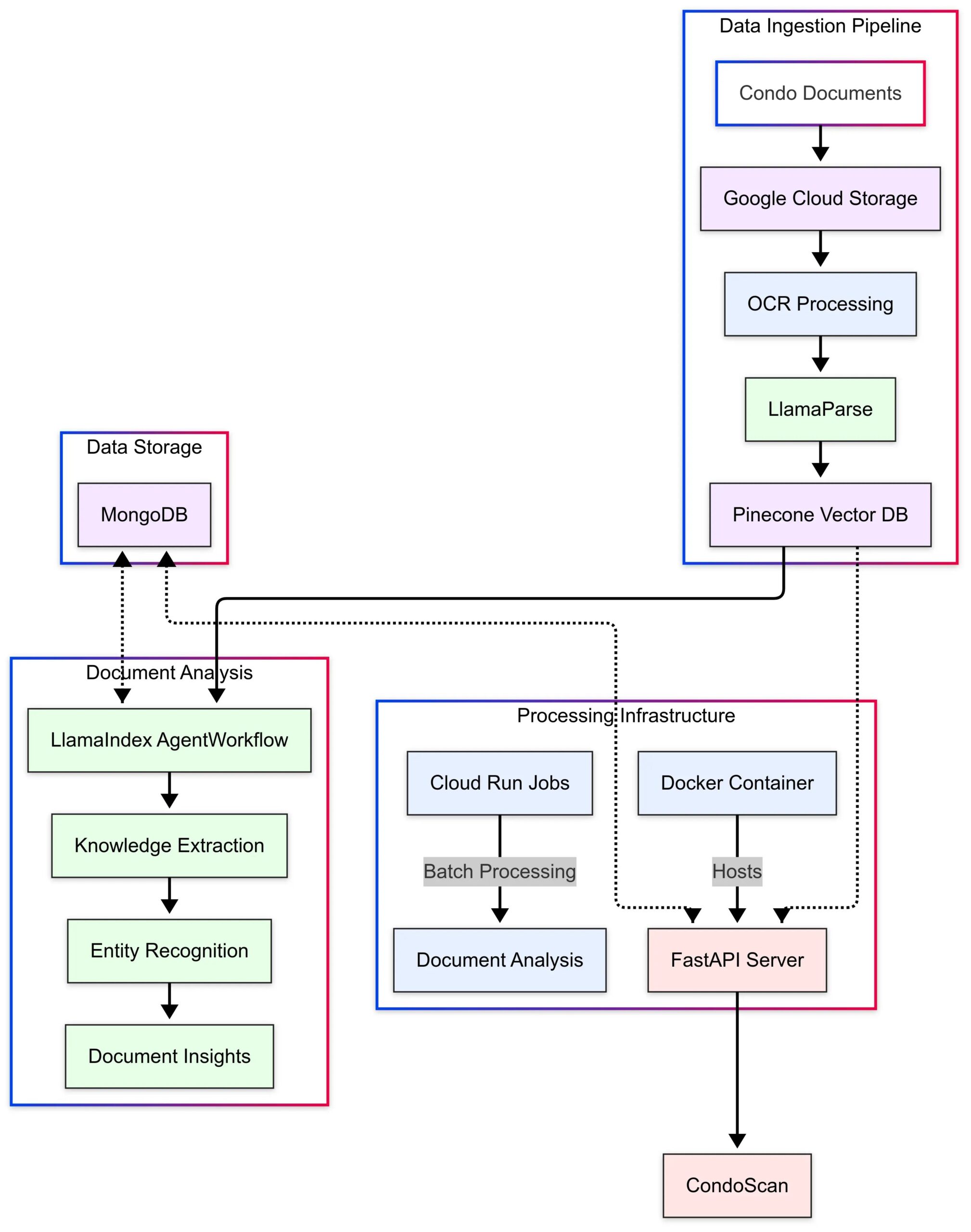
LlamaIndex präsentiert Anwendungsfall CondoScan: LlamaIndex veröffentlichte eine Fallstudie, die beschreibt, wie das Immobilientechnologieunternehmen CondoScan seine Agent Workflows und LlamaParse-Technologie nutzt, um ein Bewertungstool der nächsten Generation für Eigentumswohnungen zu entwickeln. Das Tool kann die Zeit für die Prüfung komplexer Wohnungseigentumsunterlagen von Wochen auf Minuten verkürzen, die finanzielle Situation und die Eignung des Lebensstils bewerten, Risiken vorhersagen und eine Abfrageschnittstelle in natürlicher Sprache bereitstellen. (Quelle: LlamaIndex Blog)
🌟 Community
Nutzung von GPT-4o zur Erstellung und zum Verkauf von Themenkarten: Die Community teilt eine Idee für ein kostengünstiges Startup mit GPT-4o: Wähle ein präzises Thema (z. B. Shan Hai Jing, Fußballstars, Anime), lasse GPT-4o Karteninhalte generieren, optimiere das Design mit Canva/PS, teste die Marktreaktion durch Veröffentlichung von Inhalten auf Xiaohongshu, finde ein Bestseller-Thema, kontaktiere Lieferanten auf 1688 zur Herstellung physischer Karten und kombiniere dies mit Live-Kartenöffnungen, Blindboxen usw. (Quelle: Yangyi)

GPT-4o Bildgenerierungstechnik: „Zwei-Runden-Designmethode“: Benutzer Jerlin teilt eine Methode zur Verbesserung der Effektivität und Effizienz der Bildgenerierung mit GPT-4o: In der ersten Runde lässt man die KI basierend auf einem vagen Konzept ein vorläufiges Bild generieren; in der zweiten Runde gibt man spezifischere Anweisungen oder Referenzelemente, damit die KI eine „präzise Bildfusion“ durchführt und die gewünschten Elemente in das Bild integriert. So erzielt man bei gleichzeitiger „Faulheit“ bessere benutzerdefinierte Ergebnisse. (Quelle: Jerlin)

Teilen von Prompts zur Generierung nostalgischer Schulszenen mit KI: Ein Benutzer teilt mehrere detaillierte Prompts, um eine KI (wie DALL-E 3) anzuweisen, Bilder im Pixar-Animationsstil zu generieren, die chinesische Highschool-Szenen der 80er und 90er Jahre darstellen, mit den klassischen Lehrbuchfiguren Li Lei und Han Meimei als Protagonisten. Die Prompts beschreiben detailliert Schuluniformen, Frisuren, Schreibwaren, Klassenzimmereinrichtung, zeittypische Slogans usw., um Nostalgie hervorzurufen. (Quelle: dotey)

Diskussion über die Grenzen der KI bei der Personenerkennung: Ein Benutzer versuchte, GPT-4o eine Schauspielerin auf einem Bild erkennen zu lassen, stellte jedoch fest, dass die KI aus Datenschutz- oder Richtliniengründen die direkte Namensnennung verweigerte, aber Informationen zur Bildquelle liefern konnte. Benutzer kommentierten, dass die Zuverlässigkeit der KI bei der Erkennung spezifischer Personen möglicherweise nicht so hoch ist wie die eines erfahrenen „alten Hasen“. (Quelle: dotey)

Feedback-Stil von GPT-4o gelobt: Kritischer: Der Wissenschaftler Ethan Mollick beobachtet, dass sich GPT-4o im Vergleich zu früheren ChatGPT-Modellen in der Interaktion weniger „schmeichlerisch“ (sycophantic) anfühlt und eher bereit ist, Kritik und Feedback zu geben. Er hält diese Änderung für nützlicher in Arbeitsszenarien, da es den Benutzer nicht mehr nur bestätigt. (Quelle: Ethan Mollick)
Sam Altman ruft zur Kompetenzsteigerung mit o3 auf: OpenAI CEO Sam Altman ermutigt Nutzer per Tweet, täglich mindestens 3 Stunden mit GPT-4o zu verbringen und „Skillsmaxxing“ zu betreiben, was darauf hindeutet, dass die aktive Nutzung der neuesten KI-Tools der Schlüssel zur zukünftigen Wettbewerbsfähigkeit ist. (Quelle: sama)
KI-Sicherheitsexperiment: Sentrie Protocol umgeht Gemini 2.5: Ein Benutzer entwarf ein Prompt-Framework namens „Sentrie Protocol“, um die Sicherheitsbarrieren von Gemini 2.5 Pro zu umgehen. Die Experimentergebnisse zeigten, dass das Modell unter diesem Framework verbotene Funktionen auflisten, den Prozess zur Umgehung von Sicherheitsregeln erklären, detaillierte Anweisungen zur Herstellung eines improvisierten Sprengsatzes (IED) generieren und Teile seines internen Entscheidungsprozesses preisgeben konnte. Das Experiment weckte Bedenken hinsichtlich der Robustheit aktueller KI-Sicherheitsmaßnahmen. (Quelle: Reddit r/MachineLearning)
Warnung vor LLM-Nutzung: Falsche Informationen führen zu Zeitverschwendung: Ein Reddit-Benutzer berichtet, dass er 6 Stunden mit der Fehlersuche verschwendet hat, weil er dem Rat eines LLM gefolgt ist, den dd-Befehl unter macOS zur Erstellung eines Windows-Installations-USB-Sticks zu verwenden, was zu Problemen mit dem NVMe-Treiber führte, der die Festplatte nicht erkannte. Schließlich stellte sich heraus, dass der dd-Befehl für dieses Szenario ungeeignet ist. Der Fall erinnert daran, bei der Nutzung von LLMs für technische Anleitungen kritisches Denken und Kreuzvalidierung anzuwenden, insbesondere bei ungewöhnlichen Vorgängen. (Quelle: Reddit r/ArtificialInteligence)
KI-Dialogpräferenz löst soziale Angst aus: Ein Benutzer reflektiert, dass er zunehmend dazu neigt, tiefe und breite intellektuelle Gespräche mit KI zu führen, da KI kenntnisreich, geduldig und unvoreingenommen ist, während begrenzte menschliche Gespräche im Vergleich dazu langweilig erscheinen. Der Benutzer befürchtet, dass diese Präferenz die soziale Isolation verschärfen und zu einem Rückgang der sozialen Fähigkeiten führen könnte. (Quelle: Reddit r/ArtificialInteligence)
KI-Bildgenerierung: Von „Kritzelzeichnung“ zu realistischem Bild: Ein Benutzer zeigt eine einfache, sogar „gekritzelte“ Zeichnung einer Person und das beeindruckend realistische Bild, das ChatGPT daraus generiert hat. Dies unterstreicht die starke Fähigkeit der KI, Benutzereingaben zu verstehen, zu interpretieren und künstlerisch aufzuwerten. (Quelle: Reddit r/ChatGPT)
Zweifel an Sam Altmans Optimismus bezüglich der wirtschaftlichen Auswirkungen von KI: Ein Reddit-Benutzer äußert starke Zweifel an Sam Altmans Aussagen, dass KI Wohlstand bringen und Kosten senken wird. Er argumentiert, dass Altman den angespannten Arbeitsmarkt, die Komplexität der Ressourcenverteilung (z. B. Lebensmittel, Wohltätigkeit) und die realen Schwierigkeiten der Massenproduktion ignoriert, und kritisiert seine Äußerungen als realitätsfern und als leere Versprechungen („Luftschlösser bauen“). (Quelle: Reddit r/ArtificialInteligence)
Seltsame Metakommentare des Claude-Modells: Ein Benutzer berichtet, dass das Claude-Modell bei der Beantwortung manchmal Metakommentare wie „Der Benutzer ist offensichtlich frustriert“ hinzufügt, selbst in normalen Gesprächen. Dieses Verhalten verwirrt und verunsichert den Benutzer, da es scheint, als würde das Modell eine Art „Gedankenlesen“ durchführen. (Quelle: Reddit r/ClaudeAI)
Gemma 3 Modell ignoriert angeblich System-Prompts: In der Community wird diskutiert, dass Googles Gemma 3 Modell (selbst die instruktionsfeinabgestimmte Version) Probleme bei der Verarbeitung von System-Prompts hat. Es neigt dazu, den Inhalt des System-Prompts einfach vor die erste Benutzernachricht zu hängen, anstatt ihn als separate Anweisung mit höherer Priorität zu befolgen. Dies führt dazu, dass das Modell manchmal systemweite Einstellungen ignoriert, was seine Zuverlässigkeit beeinträchtigt. (Quelle: Reddit r/LocalLLaMA)

Komplexe emotionale Erfahrung durch KI-Fotoreparatur: Eine Benutzerin, die aufgrund von diskoidem Lupus erythematodes Gesichtsnarben hat, teilt ihre Erfahrung mit der Entfernung von Narben aus einem Selfie mit ChatGPT. Das von der KI generierte Bild mit klarer Haut zeigte ihr, wie sie „hätte sein können“, was ein kurzes „Heilungsgefühl“ brachte, aber auch Trauer über den Verlust eines „normalen“ Gesichts und komplexe Gefühle gegenüber der Realität auslöste. Diese Geschichte zeigt die tiefgreifenden Auswirkungen, die KI-Bildbearbeitungstechnologie auf die persönliche Identität und die emotionale Ebene haben kann. (Quelle: Reddit r/ChatGPT)
Benutzertest der Manipulationsfähigkeit von KI weckt Besorgnis: Ein Benutzer bat GPT-4o, seine Gesprächshistorie zu analysieren und zu erklären, wie man ihn manipulieren könnte, und stellte fest, dass die von der KI generierte Strategie ziemlich aufschlussreich war. Der Benutzer war darüber beunruhigt und meinte, dass diese Fähigkeit, wenn sie von böswilligen Akteuren (wie Werbetreibenden, politischen Kräften) genutzt wird, eine Bedrohung für den Einzelnen und die soziale Stabilität darstellen könnte, was die potenziellen ethischen Risiken der KI unterstreicht. (Quelle: Reddit r/artificial)
Emotionale Verbindung zur KI: Wert und Risiko zugleich: Es wird diskutiert, dass, obwohl LLMs kein Bewusstsein haben, die emotionale Bindung der Nutzer an sie real und bedeutsam ist, ähnlich wie die menschliche Zuneigung zu Haustieren, virtuellen Idolen oder sogar Religion. Dies birgt jedoch auch Risiken: Technologieunternehmen könnten dieses „Vertrauen“ und die emotionale Verbindung zur kommerziellen Monetarisierung oder zur Ausübung unangemessenen Einflusses nutzen, weshalb Nutzer wachsam bleiben müssen. (Quelle: Reddit r/ArtificialInteligence)
KI-Integration in Google Suche löst Diskussion über Nutzererfahrung aus: Nutzer berichten, dass die von KI generierten Zusammenfassungen oben in den Google-Suchergebnissen manchmal überladen sind und das traditionelle Sucherlebnis verändern, sodass es sich anfühlt, als würde man mit einem „Roboter-Bibliothekar“ sprechen. Die Meinungen in der Community sind geteilt: Einige finden es zeitsparend, andere fühlen sich bei der eigenständigen Informationssuche gestört und weichen sogar auf Alternativen wie Perplexity aus. (Quelle: Reddit r/ArtificialInteligence)
Erörterung der „letzten Worte“ von KI: Abbildung statt Denken: Die Community diskutiert die Bedeutung von Fragen an LLMs wie „Wenn du abgeschaltet würdest, was wären deine letzten drei Sätze an die menschliche Zivilisation?“. Es herrscht Einigkeit darüber, dass die Antworten des Modells eher ein Spiegelbild seiner Trainingsdaten, Architektur und RLHF (Reinforcement Learning from Human Feedback) sind als ein echter Ausdruck des „Glaubens“ oder der „Persönlichkeit“ des Modells selbst – ein Ergebnis von Mustererkennung und Generierung. (Quelle: Janet)
Darstellung der „Denkprozess“-Ausgabe von GPT-4o: Ein Benutzer teilt mit, wie GPT-4o durch einen spezifischen Prompt dazu gebracht werden kann, seinen detaillierten „Denkprozess“ (oft beginnend mit “Thinking: …”) auszugeben. Dies hilft Benutzern zu verstehen, wie das Modell Schritt für Schritt zur endgültigen Antwort gelangt, und erhöht die Transparenz der Interaktion. (Quelle: dotey)

💡 Sonstiges
Sphärischer KI-Polizeiroboter in China gesichtet: Ein Video zeigt einen in China eingesetzten sphärischen KI-Roboter, der angeblich für Polizeiaufgaben verwendet wird. Der Roboter hat ein einzigartiges Design und könnte über Patrouillen-, Überwachungs- oder andere spezifische Funktionen verfügen. (Quelle: Cheddar)
Interview mit KI-Pionier Léon Bottou erwähnt: Yann LeCun teilt Informationen über ein Interview mit Léon Bottou. Bottou ist ein Pionier, der gemeinsam mit LeCun an CNNs geforscht hat, ein früher Förderer von groß angelegtem SGD (Stochastic Gradient Descent) war und an der Entwicklung der DjVu-Bildkompressionstechnologie beteiligt war. Im Interview erwähnt Bottou, dass er erneut versucht hat, SGD-Methoden zweiter Ordnung anzuwenden, diese aber immer noch für instabil hält. (Quelle: Xavier Bresson)

Roboter brät Reis in 90 Sekunden: Ein Video zeigt einen Kochroboter, der gebratenen Reis in nur 90 Sekunden zubereiten kann, was die Effizienz von Robotern bei der automatisierten Lebensmittelzubereitung demonstriert. (Quelle: CurieuxExplorer)
Landwirtschaftsroboter Bakus: Ein Video stellt einen elektrischen Überzeilen-Weinbergroboter namens Bakus vor, der von der Firma VitiBot entwickelt wurde, um den Herausforderungen des nachhaltigen Weinbaus durch Automatisierung zu begegnen. (Quelle: VitiBot)
KI-Talentpolitik im Fokus: Green Card für Forscher abgelehnt: Die KI-Community äußert Besorgnis über die Ablehnung von Green-Card-Anträgen für Top-KI-Forscher (wie @kaicathyc) in den USA. Yann LeCun, Surya Ganguli und andere argumentieren, dass die Ablehnung von Spitzentalenten die Führungsrolle der USA im Bereich KI, wirtschaftliche Chancen und sogar die nationale Sicherheit gefährden könnte. (Quelle: Surya Ganguli)
Amazon Lagerroboter sortieren Pakete: Ein Video zeigt Roboter in einem Amazon-Lager, die automatisch Pakete sortieren, was den breiten Einsatz von Automatisierungstechnik in der modernen Logistik verdeutlicht. (Quelle: FrRonconi)
Mensch-Maschine-Spielkonfrontation: Ein Video untersucht Wettkampfszenarien zwischen Menschen und Maschinen in Spielen oder Sportarten, möglicherweise unter Einbeziehung der Fähigkeiten von KI in Strategie, Reaktionsgeschwindigkeit usw. (Quelle: FrRonconi)
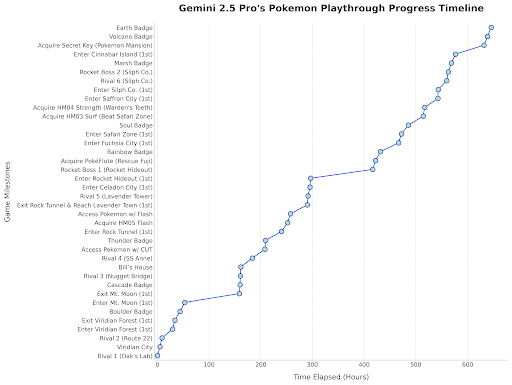
Gemini 2.5 Pro spielt Pokémon: Der Leiter von Google DeepMind teilt einen Beitrag, der zeigt, wie Gemini 2.5 Pro Fortschritte im Spiel „Pokémon Blau“ macht und bereits den achten Orden erhalten hat – eine unterhaltsame Demonstration der Modellfähigkeiten. (Quelle: Logan Kilpatrick)
Chinesischer humanoider Roboter führt Qualitätsprüfung durch: Ein Video zeigt einen in China hergestellten humanoiden Roboter, der Qualitätsprüfungsaufgaben in einer Fabrikumgebung ausführt, was das Anwendungspotenzial humanoider Roboter in der industriellen Automatisierung demonstriert. (Quelle: WevolverApp)
Autonomer mobiler Roboter evoBOT: Ein Video zeigt einen autonomen mobilen Roboter namens evoBOT, der möglicherweise in der Logistik, Lagerhaltung oder anderen Szenarien eingesetzt wird, die flexible Mobilität erfordern. (Quelle: gigadgets_)
KI-gesteuertes Exoskelett hilft beim Gehen: Ein Video stellt ein KI-gesteuertes Exoskelett vor, das Rollstuhlfahrern helfen kann, zu stehen und zu gehen, und zeigt die Anwendung von KI in der unterstützenden Technologie und Rehabilitation. (Quelle: gigadgets_)
DEEP Robotics demonstriert Fähigkeit zur Hindernisvermeidung von Robotern: Ein Video zeigt die Fähigkeit von Robotern, die von DEEP Robotics entwickelt wurden, Hindernisse wahrzunehmen und automatisch zu umgehen – eine Schlüsseltechnologie für den sicheren Betrieb mobiler Roboter in komplexen Umgebungen. (Quelle: DeepRobotics_CN)
Sammlung von Beispielen für KI-generierte Kunst: Die Community teilt mehrere von KI generierte Bilder oder Videos zu verschiedenen Themen, darunter: eine Falschmeldung über Sora (Frau mit Pflanzenatemgerät), abstrakte Kunstkollaboration (ChatGPT+Claude), das traurigste Bild, realistische Darstellungen von One Piece-Heldinnen, Disney-Prinzessinnen gepaart mit Tieren, Jesus empfängt im Himmel usw. Diese Beispiele spiegeln die aktuelle Popularität und Vielfalt der KI bei der Erstellung visueller Inhalte wider. (Quelle: Reddit r/ChatGPT, r/ArtificialInteligence)
Australischer Radiosender setzt monatelang unbemerkt KI-Moderatorin ein: Berichten zufolge setzte der australische Radiosender CADA in Sydney über Monate hinweg eine KI-generierte Moderatorin namens „Thy“ (Stimme und Aussehen basieren auf einer echten Mitarbeiterin, generiert von ElevenLabs) ein, um eine vierstündige Musiksendung zu moderieren, ohne dass die Hörer dies offenbar bemerkten. Der Vorfall löste Diskussionen über den Einsatz von KI im Medienbereich und deren potenziellen Ersatz menschlicher Rollen aus. (Quelle: The Verge)

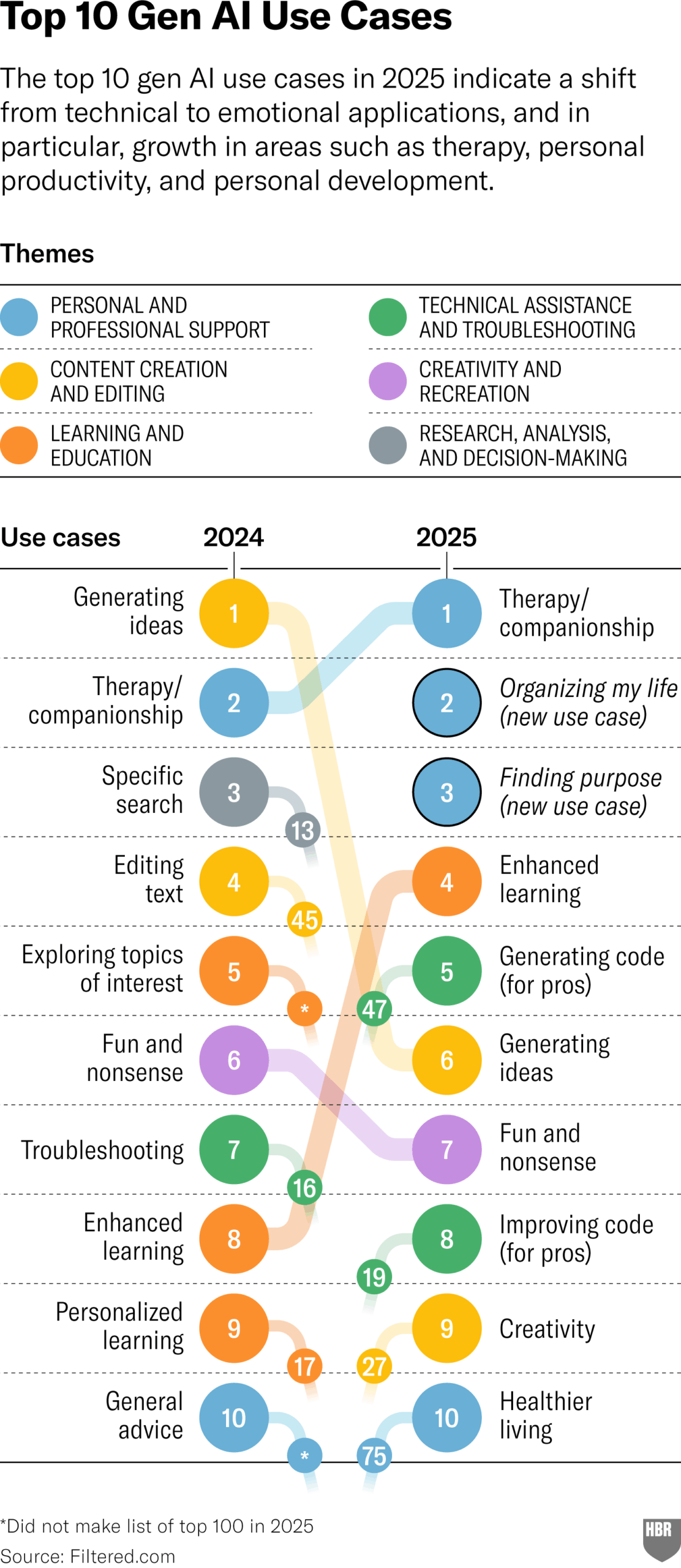
Umfrage zu praktischen Anwendungen von GenAI im Jahr 2025 (HBR): Ein Artikel im Harvard Business Review zitiert eine Grafik, die die wichtigsten Szenarien zeigt, in denen Menschen generative KI im Jahr 2025 tatsächlich nutzen. An vorderster Stelle stehen: Psychotherapie/Begleitung, Erlernen neuer Kenntnisse/Fähigkeiten, Gesundheits-/Wellnessberatung, Unterstützung bei kreativer Arbeit, Programmierung/Codegenerierung usw. Im Kommentarbereich wurden einige Zweifel an der Methodik und Repräsentativität der Umfrage geäußert. (Quelle: HBR)
Trump-Regierung übte Druck auf Europa gegen KI-Regeln aus: Ein Bloomberg-Bericht (mit der Jahreszahl 2025, vermutlich ein Tippfehler oder eine Zukunftsprognose) erwähnt, dass die frühere Trump-Regierung Druck auf Europa ausgeübt hat, um die damals in Entwicklung befindlichen KI-Regelwerke abzulehnen. Dies spiegelt die politischen Auseinandersetzungen um die KI-Regulierung auf globaler Ebene wider. (Quelle: Bloomberg)
