
Schlüsselwörter:Inferenzmodell, KI-Agent, Bestärkendes Lernen, Großes Modell, DeepSeek-R1, Visuell-Sprachliche Navigation (VLN), DINOv2 selbstüberwachtes Lernen, LangGraph RAG Agent, KI-Chip Lokalisierung, SRPO-Optimierungsmethode, Verlagerung von verkörpertem Intelligenz-Bedienungsgeschick, Quantencomputing-Governance
🔥 Fokus
Inferenzmodelle werden zum neuen Brennpunkt der KI, DeepSeek-R1 erschüttert die Branche: Nach der Veröffentlichung der auf strukturiertes Reasoning fokussierten o-Serie-Modelle von OpenAI markieren die quelloffene Veröffentlichung und die herausragende Leistung von DeepSeek-R1 (insbesondere in Mathematik und Code) eine neue Phase im Wettbewerb der großen Modelle. Der Fokus der Branche verlagert sich von der Größe der vortrainierten Parameter hin zur Verbesserung der Reasoning-Fähigkeiten durch Reinforcement Learning. Große chinesische Unternehmen wie Baidu (Wenxin X1), Alibaba (Tongyi Qianwen Qwen-QwQ-32B), Tencent (Hunyuan T1), ByteDance (Doubao 1.5) und iFlytek (Xinghuo X1) ziehen schnell nach und veröffentlichen ihre eigenen Inferenzmodelle, wodurch eine neue Konstellation entsteht, in der heimische Inferenzmodelle gegen OpenAI antreten. Dieser Wandel unterstreicht die Bedeutung der Fähigkeit von Modellen zu tiefgehendem Denken, Planen, Analysieren und zur Werkzeugnutzung und deutet darauf hin, dass die Implementierung von Anwendungen wie Agents stärker von leistungsfähigen Basismodellen für Reasoning abhängen wird. (Quelle: 国产六大推理模型激战OpenAI?, “AI寒武纪”爆发至今,五类新物种登上历史舞台)

KI-Shopping-App Nate wegen Betrugs aufgedeckt, Gründer wegen Erschleichung von 40 Millionen Dollar Investitionen angeklagt: Das US-Justizministerium beschuldigt Albert Saniger, den Gründer der KI-Shopping-App Nate, Investoren durch falsche Angaben zur KI-Technologie betrogen zu haben. Nate behauptete, KI-Technologie zur Vereinfachung des plattformübergreifenden Einkaufsprozesses und zur Ermöglichung von One-Click-Bestellungen zu nutzen. Tatsächlich wird dem Unternehmen vorgeworfen, Hunderte von Mitarbeitern auf den Philippinen beschäftigt zu haben, um Bestellungen manuell zu bearbeiten und „menschliche Arbeit“ als „Intelligenz“ auszugeben. Der Vorfall deckt potenzielle Blasen und Betrugsrisiken im KI-Startup-Boom auf und löst eine Diskussion über die „Fake it till you make it“-Kultur im Silicon Valley aus, wobei die Grenze zwischen Übertreibung und Täuschung betont wird. Der Fall spiegelt auch die Herausforderungen der technischen Machbarkeit bestimmter KI-Anwendungskonzepte wider, bevor die KI-Technologie (insbesondere große Modelle) ausgereift ist. (Quelle: AI购物竟是人工驱动,硅谷创投圈又玩出新花活)

KI integriert sich in Arbeitsabläufe und gestaltet Arbeitsplatzwert und Managementmodelle neu: KI bewegt sich vom Konzept zur Praxis und integriert sich tief in den Unternehmensbetrieb und die tägliche Arbeit der Mitarbeiter. Alibaba Cloud nutzt große Modelle und Data Governance, um ein „Organisations- und Management-Cockpit“ zu realisieren und OKR/CRD-Prozesse zu optimieren; Deloitte China engagiert sich für die Ausbildung von Zehntausenden von KI-Talenten, um den Anforderungen wissensintensiver Organisationen gerecht zu werden; Yum China setzt KI-Tools bis auf die Ebene der Restaurantmanager ein. Dies zeigt, dass KI nicht nur ein Effizienzwerkzeug ist, sondern auch das Wesen der Arbeit, die Organisationsstruktur und den Personalbedarf neu gestaltet. Repetitive, standardisierte Arbeiten werden durch KI ersetzt, was höhere Anforderungen an die Kreativität, das kritische Denken, die Entscheidungsfähigkeit und die Fähigkeit zur Zusammenarbeit mit KI (KI-Anpassungsfähigkeit) der Mitarbeiter stellt. Das Unternehmensmanagement muss sich von der Überwachung zur Befähigung wandeln und neue Paradigmen und Vertrauensmechanismen für die Zusammenarbeit zwischen Mensch und KI etablieren. (Quelle: 当AI来和我做同事:重构职场价值坐标系, 重塑工作:AI时代的组织进化与管理革命)

🎯 Trends
Selbstüberwachtes visuelles Modell DINOv2 führt Registermechanismus ein: Meta AI Research hat seine DINOv2 Methode und Modelle für selbstüberwachtes Lernen aktualisiert. Gemäß dem Paper „Vision Transformers Need Registers“ führt die neue Version einen „Register“-Mechanismus ein. DINOv2 zielt darauf ab, robuste visuelle Merkmale ohne Überwachung zu lernen, die direkt für verschiedene Computer-Vision-Aufgaben (wie Klassifizierung, Segmentierung, Tiefenschätzung) verwendet werden können und über verschiedene Domänen hinweg gut funktionieren, ohne Feinabstimmung. Dieses Update könnte die Leistung und Merkmalsqualität des Modells weiter verbessern. (Quelle: facebookresearch/dinov2 – GitHub Trending (all/daily))
Reinforcement Learning (RL) wird zum Schlüsselpfad für Post-Training und Fähigkeitssteigerung von LLMs: Wissenschaftler wie David Silver und Richard Sutton weisen darauf hin, dass die KI in eine „Ära der Erfahrung“ eintritt, in der RL eine zentrale Rolle in der Post-Training-Phase von LLMs spielt. Durch das Lernen von Belohnungsmodellen aus menschlichem Feedback (RLHF), Demonstrationen oder Regeln (Inverse RL) verleiht RL den LLMs die Fähigkeit zur kontinuierlichen Optimierung, Exploration und Generalisierung, die über das Imitationslernen (wie SFT) hinausgeht. Insbesondere bei Reasoning-Aufgaben (wie Mathematik, Code) hilft RL den Modellen, effektivere Lösungsmuster (wie lange Gedankenkette) zu entdecken und die Grenzen datengesteuerter Methoden zu überwinden. Dies markiert einen Wandel in der LLM-Entwicklung von der Abhängigkeit von statischen Daten hin zum dynamischen Lernen durch Interaktion und Feedback. (Quelle: 被《经验时代》刷屏之后,剑桥博士长文讲述RL破局之路)

Vision-Language-Navigation (VLN) bleibt eine wichtige Herausforderung für Embodied AI: Associate Professor Qi Wu von der University of Adelaide weist darauf hin, dass obwohl Manipulationsaufgaben im Bereich Embodied AI heiß diskutiert werden, Vision-Language-Navigation (VLN) als Schlüsselkomponente von Vision-Language-Action (VLA) in unstrukturierten, dynamischen Umgebungen (insbesondere in häuslichen Szenarien) immer noch vor vielen Herausforderungen steht und bei weitem nicht vollständig gelöst ist. Navigation ist die Grundlage für die Ausführung nachfolgender Aufgaben durch Roboter. Die Hauptengpässe bei VLN sind derzeit der Mangel an hochwertigen Daten (Simulatoren, 3D-Umgebungen, Aufgabendaten), die Sim2Real-Transfer-Lücke und die technischen Schwierigkeiten eines effizienten Edge-Deployments. (Quelle: 阿德莱德大学吴琦:VLN 仍是 VLA 的未竟之战丨具身先锋十人谈)

KI zeigt klare Kommerzialisierungspfade im Werbe- und Marketingbereich: Im Vergleich zu anderen KI-Anwendungsszenarien scheint die kommerzielle Umsetzung von KI-Technologie im Werbe- und Marketingbereich klarer und schneller zu sein. Durch den Einsatz von KI für Datenanalyse, Nutzerprofilierung, präzise Ausrichtung und automatisiertes Marketing haben Unternehmen wie Applovin Corp und Zeta Global das Werbeökosystem erfolgreich verändert und die Effizienz sowie den Return on Investment gesteigert. Dies deutet darauf hin, dass Anwendungen, die schnell kommerziellen Wert generieren können, in der KI-Welle eher vom Markt bevorzugt werden, wobei Werbung und Marketing typische Beispiele sind. (Quelle: “AI寒武纪”爆发至今,五类新物种登上历史舞台)
Engpässe in der AI-Chip-Lieferkette und Trend zur inländischen Entwicklung: Der Technologiekonflikt zwischen China und den USA verschärft sich, und die US-Exportkontrollen für AI-Chips nach China (insbesondere für High-End-Modelle wie Nvidia H20) werden weiter verschärft. Berichten zufolge haben mehrere chinesische Technologieunternehmen (wie ByteDance, Alibaba, Tencent) vor Inkrafttreten der Verbote große Mengen an Nvidia-Chips gehortet, um ihre KI-Forschungs- und Entwicklungsfähigkeiten aufrechtzuerhalten. Gleichzeitig gewinnt zur Bewältigung von Lieferkettenrisiken und Engpässen der Weg einer vollständig inländischen KI-Technologie an Bedeutung. Beispielsweise trainiert und implementiert iFlytek sein Xinghuo-Großmodell auf Basis heimischer Rechenleistung wie Huawei Ascend, was ein wichtiger zukünftiger Trend für die KI-Entwicklung in China werden könnte. (Quelle: 国产六大推理模型激战OpenAI?, Reddit r/artificial, Reddit r/ArtificialInteligence)

🧰 Werkzeuge
Suna: Open-Source-Plattform für allgemeine KI-Agenten: Kortix AI hat Suna vorgestellt, einen quelloffenen allgemeinen KI-Agenten (Generalist AI Agent). Benutzer können Suna über natürliche Sprachdialoge anweisen, verschiedene Aufgaben in der realen Welt zu erledigen, darunter Webrecherche, Datenanalyse, Browser-Automatisierung (Webnavigation, Datenextraktion), Dateiverwaltung (Dokumenterstellung und -bearbeitung), Web-Crawling, erweiterte Suche, Befehlszeilenausführung, Website-Bereitstellung sowie die Integration verschiedener APIs und Dienste. Suna soll als digitaler Begleiter des Benutzers fungieren und komplexe Arbeitsabläufe automatisieren. (Quelle: kortix-ai/suna – GitHub Trending (all/daily))

Repository leaked-system-prompts sammelt interne Prompts großer Modelle: Auf GitHub ist ein beliebtes Repository namens leaked-system-prompts aufgetaucht, das interne System-Prompts von mehreren Mainstream-KI-Modellen sammelt und veröffentlicht. Diese Prompts enthüllen die Anweisungen, Regeln, Rollendefinitionen und Sicherheitsbeschränkungen, denen die Modelle folgen sollen. Das Repository enthält geleakte Prompts von zahlreichen Modellen, darunter die Anthropic Claude-Serie (2.0, 2.1, 3 Haiku/Opus/Sonnet, 3.5 Sonnet, 3.7 Sonnet), Google Gemini 1.5, OpenAI ChatGPT (verschiedene Versionen einschließlich 4o), DALL-E 3, Microsoft Copilot, xAI Grok (verschiedene Versionen) und bietet Forschern und Entwicklern Einblicke in die interne Funktionsweise dieser Modelle. (Quelle: jujumilk3/leaked-system-prompts – GitHub Trending (all/daily))
Videogenerierungsplattform WAN führt kostenpflichtigen Beschleunigungsservice ein: Die internationale Version der KI-Videogenerierungsplattform WAN (WAN.Video) hat ihre Kommerzialisierungsphase angekündigt und kostenpflichtige Optionen eingeführt. Alle Benutzer können weiterhin unbegrenzt kostenlose Videos generieren (Relax-Modus), müssen jedoch in einer Warteschlange warten. Zahlende Benutzer erhalten priorisierten Zugriff ohne Warteschlange, um ihre Videoergebnisse schneller zu erhalten. Dies bietet einen beschleunigten Kanal für Benutzer, die hohe Effizienz oder kommerzielle Nutzung benötigen. (Quelle: op7418)

Dia TTS-Modell über Hugging Face API verfügbar: Benutzer können jetzt direkt über die Hugging Face-Plattform auf die API des Dia 1.6B Text-to-Speech (TTS)-Modells zugreifen, unterstützt von FAL AI. Entwickler können die hochwertige Sprachsynthesefunktion mit nur wenigen Codezeilen integrieren. Diese Integration senkt die Hürde für die Nutzung fortschrittlicher TTS-Modelle und erleichtert Entwicklern das schnelle Hinzufügen von Sprachfunktionen zu ihren Anwendungen. (Quelle: huggingface)
ModernBERT-Klassifikator-Modell integriert vLLM für schnelle Inferenz: Das ModernBERT-Modell kann jetzt auf dem vLLM-Framework ausgeführt werden, was die Inferenzgeschwindigkeit erheblich steigert. Berichten zufolge ist die Geschwindigkeit ausreichend, um über 200.000 arXiv-Paper in wenigen Minuten zu verarbeiten. Diese Integration ermöglicht eine schnellere Bereitstellung und Anwendung von Hunderten von ModernBERT-Modellen, die auf dem Hugging Face Hub gehostet werden, für Textklassifizierungsaufgaben. (Quelle: huggingface)
Trackers: Hochleistungs-Python-Bibliothek für Objektverfolgung: Roboflow hat eine Python-Bibliothek namens Trackers als Open Source veröffentlicht, die sich auf Objektverfolgungsaufgaben konzentriert. Die Bibliothek ist modular aufgebaut, unterstützt verschiedene Tracking-Algorithmen und lässt sich leicht in beliebte Machine-Learning-Bibliotheken wie Ultralytics und Transformers integrieren. Ihre Leistung ist stark genug, um eine große Anzahl von Objekten gleichzeitig zu verfolgen; in einem Demovideo wurden erfolgreich über 269 Eier verfolgt. (Quelle: karminski3)
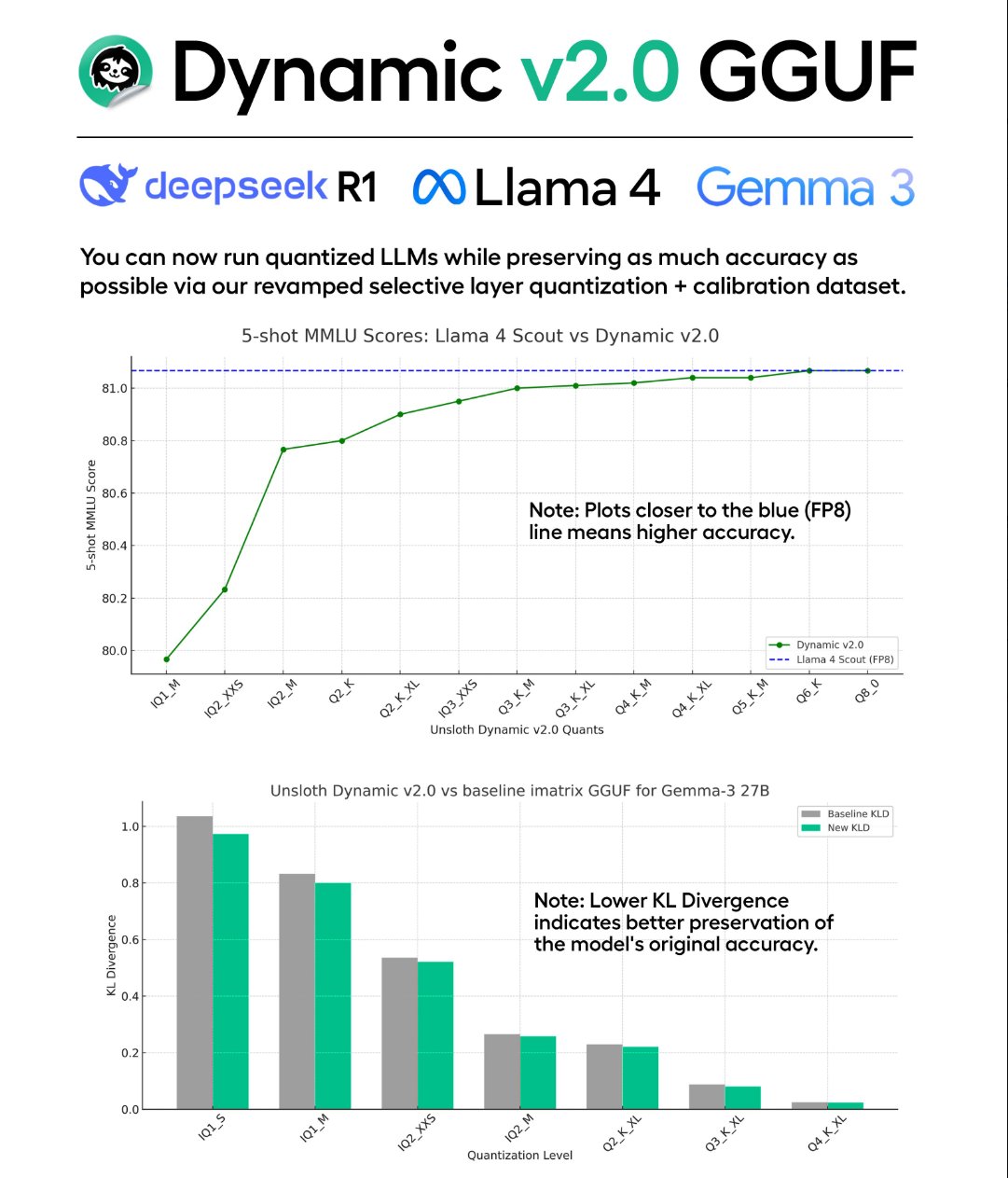
Unsloth veröffentlicht Dynamic v2.0 GGUF Quantisierungstechnik und Modelle: Unsloth hat die neue Dynamic v2.0 Quantisierungstechnik vorgestellt, die speziell für Modelle im GGUF-Format entwickelt wurde. Berichten zufolge übertrifft diese quantisierte Version frühere Versionen in MMLU- und KL-Divergenz-Bewertungen und behebt Probleme mit der RoPE-Implementierung von Llama-4 in Llama.cpp. Unsloth hat diese Technik verwendet, um neue quantisierte Modelle von DeepSeek-R1 und DeepSeek-V3-0324 für die Community zu veröffentlichen. (Quelle: karminski3)
Perplexity iOS Sprachassistent integriert Systemfunktionen: Die iOS-App von Perplexity hat ihre Sprachassistentenfunktion aktualisiert, sodass sie mehr systemweite Aktionen aufrufen kann. Benutzer können den Perplexity-Assistenten nun per Sprachbefehl bitten, Restaurants zu reservieren, mit Apple Maps zu navigieren, Erinnerungen zu erstellen, Apple Music oder Podcasts zu suchen und abzuspielen sowie ein Taxi zu rufen. Dadurch nähert sich der Perplexity-Assistent in seiner Funktionalität nativen Systemassistenten wie Siri an und erhöht seine Nützlichkeit. (Quelle: AravSrinivas)
VS Code MCP Server Erweiterung veröffentlicht, verbindet Claude mit lokaler Entwicklungsumgebung: Der Entwickler Juehang Qin hat eine VS Code-Erweiterung veröffentlicht, die VS Code in einen MCP (Model Context Protocol)-Server verwandelt. Dies ermöglicht KI-Assistenten wie Claude, direkt auf den aktuell in VS Code geöffneten Arbeitsbereich des Benutzers zuzugreifen und damit zu interagieren, einschließlich Lesen und Schreiben von Dateien sowie Anzeigen von Code-Diagnoseinformationen (wie Fehler und Warnungen). Wenn der Benutzer das Projekt wechselt, stellt die Erweiterung automatisch den neuen Arbeitsbereich bereit, was die nahtlose Zusammenarbeit des KI-Assistenten über verschiedene Projekte hinweg erleichtert. (Quelle: Reddit r/ClaudeAI)
📚 Lernen
DINOv2: Meta veröffentlicht Methode für selbstüberwachtes Lernen visueller Merkmale als Open Source: Meta AI Research hat das DINOv2-Projekt als Open Source veröffentlicht, einschließlich PyTorch-Code und vortrainierter Modelle. DINOv2 ist eine Methode des selbstüberwachten Lernens, die darauf abzielt, leistungsstarke, allgemeine visuelle Merkmale zu lernen. Diese Merkmale zeigen hervorragende Leistungen bei verschiedenen Computer-Vision-Aufgaben (wie Bildklassifizierung, semantische Segmentierung, Tiefenschätzung), ohne dass eine Feinabstimmung für nachgelagerte Aufgaben erforderlich ist. Das Projekt bietet detaillierte Dokumentation, Modell-Download-Links und zugehörige Paper und ist eine wichtige Ressource für die Forschung und Anwendung von selbstüberwachtem visuellem Lernen. (Quelle: facebookresearch/dinov2 – GitHub Trending (all/daily))
HD-EPIC: Hochdetaillierter Egoperspektiven-Videodatensatz veröffentlicht: Forscher haben den HD-EPIC-Datensatz vorgestellt, der 41 Stunden Egoperspektiven-Videoaufnahmen aus realen Küchenumgebungen enthält. Das Hauptmerkmal dieses Datensatzes sind seine äußerst detaillierten multimodalen Annotationen, die Rezeptschritte, Nährwertinformationen der Zutaten (durch Wiegeprotokolle), feingranulare Aktionsbeschreibungen (Inhalt, Art, Grund), digitale 3D-Szenenzwillinge, Objektbewegungstrajektorien (2D/3D), Hand-/Objektmasken, Blickverfolgung sowie Objekt-Szenen-Interaktionen abdecken. Der Datensatz soll eine hochwertige Benchmark für das Verständnis von Egoperspektiven-Videos, Embodied AI und Mensch-Computer-Interaktionsforschung bieten. (Quelle: CVPR 2025 | HD-EPIC定义第一人称视觉新标准:多模态标注精度碾压现有基准)

SRPO: Optimierungsmethode zur Lösung des domänenübergreifenden RL-Trainings von LLM-Reasoning-Fähigkeiten: Das Kwaipilot-Team von Kuaishou hat die SRPO-Methode (Two-Stage History Resampling Policy Optimization) vorgeschlagen, um Leistungsprobleme und Effizienzengpässe zu beheben, die beim Training von LLMs mit Reinforcement-Learning-Methoden wie GRPO für gemischte Mathematik- und Code-Aufgaben auftreten. Die Methode verwendet in der ersten Phase mathematische Daten, um tiefgehendes Denken anzuregen, und führt in der zweiten Phase Code-Daten ein, um prozedurales Denken zu entwickeln. In Kombination mit einer History-Resampling-Technik zur Lösung des Problems der Nullvarianz bei Belohnungssignalen zeigt das Experiment, dass SRPO mit nur 10% der Trainingsschritte DeepSeek-R1-Zero-Qwen-32B auf AIME24 und LiveCodeBench übertrifft und einen effizienten Weg zur Verbesserung der domänenübergreifenden Reasoning-Fähigkeiten bietet. (Quelle: DeepSeek-R1-Zero被“轻松复现”?10%训练步数实现数学代码双领域对齐)
TTRL: Test-Time Reinforcement Learning ohne annotierte Daten: Die Tsinghua University und das Shanghai AI Lab haben die TTRL (Test-Time Reinforcement Learning)-Methode vorgeschlagen, die es LLMs ermöglicht, während der Testphase ohne menschliche Annotationen Reinforcement Learning durchzuführen. Die Methode nutzt die mehrfachen Sampling-Ausgaben des Modells selbst, um durch Mehrheitsentscheidungen oder ähnliche Verfahren Pseudo-Labels und Belohnungssignale zu generieren. Dies treibt das Modell zur Selbstevolution an, um sich an neue Daten oder Aufgaben anzupassen. Experimente zeigen, dass TTRL die Leistung des Modells bei Zielaufgaben signifikant verbessern kann, sogar nahe an die Ergebnisse von überwachtem Training heranreicht, und bietet neue Ansätze zur Lösung der Anwendungsprobleme von RL in unüberwachten Umgebungen. (Quelle: TTS和TTT已过时?TTRL横空出世,推理模型摆脱「标注数据」依赖,性能暴涨)
SeekWorld: Geolokalisierungs-Reasoning-Aufgabe und Modell zur Simulation der Verfolgung visueller Hinweise von o3: Um die visuellen Reasoning-Fähigkeiten multimodaler großer Sprachmodelle (MLLM) zu verbessern, insbesondere die Fähigkeit, Bilder während des Reasonings dynamisch wahrzunehmen und zu manipulieren (Verfolgung visueller Hinweise), wie es das o3-Modell von OpenAI tut, haben Forscher die SeekWorld Geolokalisierungs-Reasoning-Aufgabe (Ableitung des Aufnahmeorts aus einem Bild) vorgeschlagen. Um diese Aufgabe herum wurde ein Datensatz erstellt und das SeekWord-7B-Modell mittels Reinforcement Learning trainiert. Dieses Modell übertrifft Modelle wie Qwen-VL, Doubao Vision Pro und GPT-4o beim Geolokalisierungs-Reasoning. Das Projekt hat das Modell, den Datensatz und eine Online-Demo als Open Source veröffentlicht. (Quelle: 一张图片找出你在哪?o3-like 7B模型玩网络迷踪超越一流开闭源模型!)
ManipTrans: Skill-Transfer von menschlichen Händen zu geschickten Roboterhänden: Forscher des Beijing Institute for General Artificial Intelligence, der Tsinghua University und der Peking University haben die ManipTrans-Methode vorgeschlagen, um die Manipulationsfähigkeiten menschlicher Hände effizient auf geschickte Roboterhände in Simulationsumgebungen zu übertragen. Die Methode verwendet eine zweistufige Strategie: Zuerst wird die Bewegung der menschlichen Hand durch einen allgemeinen Trajektorien-Imitator nachgeahmt, dann erfolgt eine Feinabstimmung durch Residual Learning und physikalische Interaktionsbeschränkungen. Basierend auf dieser Methode hat das Team den umfangreichen Datensatz für geschickte Handmanipulation DexManipNet veröffentlicht, der komplexe Aufgaben wie das Aufschrauben von Flaschen, Schreiben, Schöpfen und Öffnen von Zahnpastatuben enthält, und die Machbarkeit der Bereitstellung auf realer Hardware validiert. (Quelle: 机器人也会挤牙膏?ManipTrans:高效迁移人类双手操作技能至灵巧手)

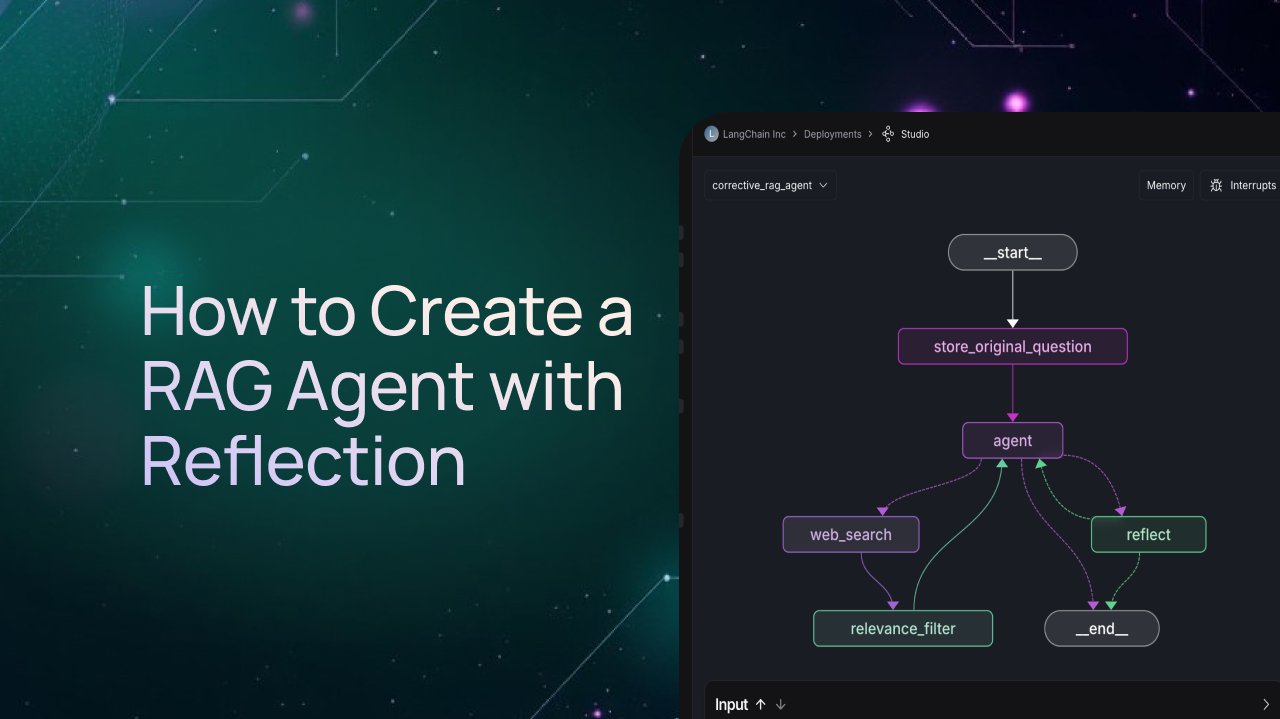
LangGraph Tutorial: Erstellung eines RAG-Agenten mit Reflexionsmechanismus: LangChain hat ein Video-Tutorial veröffentlicht, das detailliert erklärt, wie man mit dem LangGraph-Framework einen RAG (Retrieval-Augmented Generation)-Agenten mit Reflexionsfähigkeit erstellt. Die Kernidee besteht darin, dem RAG-Prozess einen Bewertungsschritt hinzuzufügen, der es dem Agenten ermöglicht, die abgerufenen Informationen vor der Generierung der endgültigen Antwort zu überprüfen, ihre Relevanz und Qualität zu beurteilen und basierend auf der Bewertung zu entscheiden, ob erneut gesucht, die Anfrage korrigiert oder direkt eine Antwort generiert werden soll. Dies filtert effektiv Rauschen heraus und verbessert die Qualität der Fragebeantwortung. (Quelle: LangChainAI)
Arena-Hard-v2.0: Strengerer Benchmark für große Modelle: LMSYS Org hat den Arena-Hard-Benchmark auf Version 2.0 aktualisiert. Die neue Version basiert auf 500 anspruchsvolleren Prompts, die von LMArena-Benutzern eingereicht wurden, verwendet leistungsfähigere automatische Bewertungsmodelle (Gemini-2.5 & GPT-4.1), unterstützt über 30 Sprachen und fügt eine Bewertung der kreativen Schreibfähigkeiten hinzu. Ziel ist es, eine schwierigere und umfassendere Plattform zur Unterscheidung der Leistung von Top-Großmodellen bereitzustellen. (Quelle: lmarena_ai)
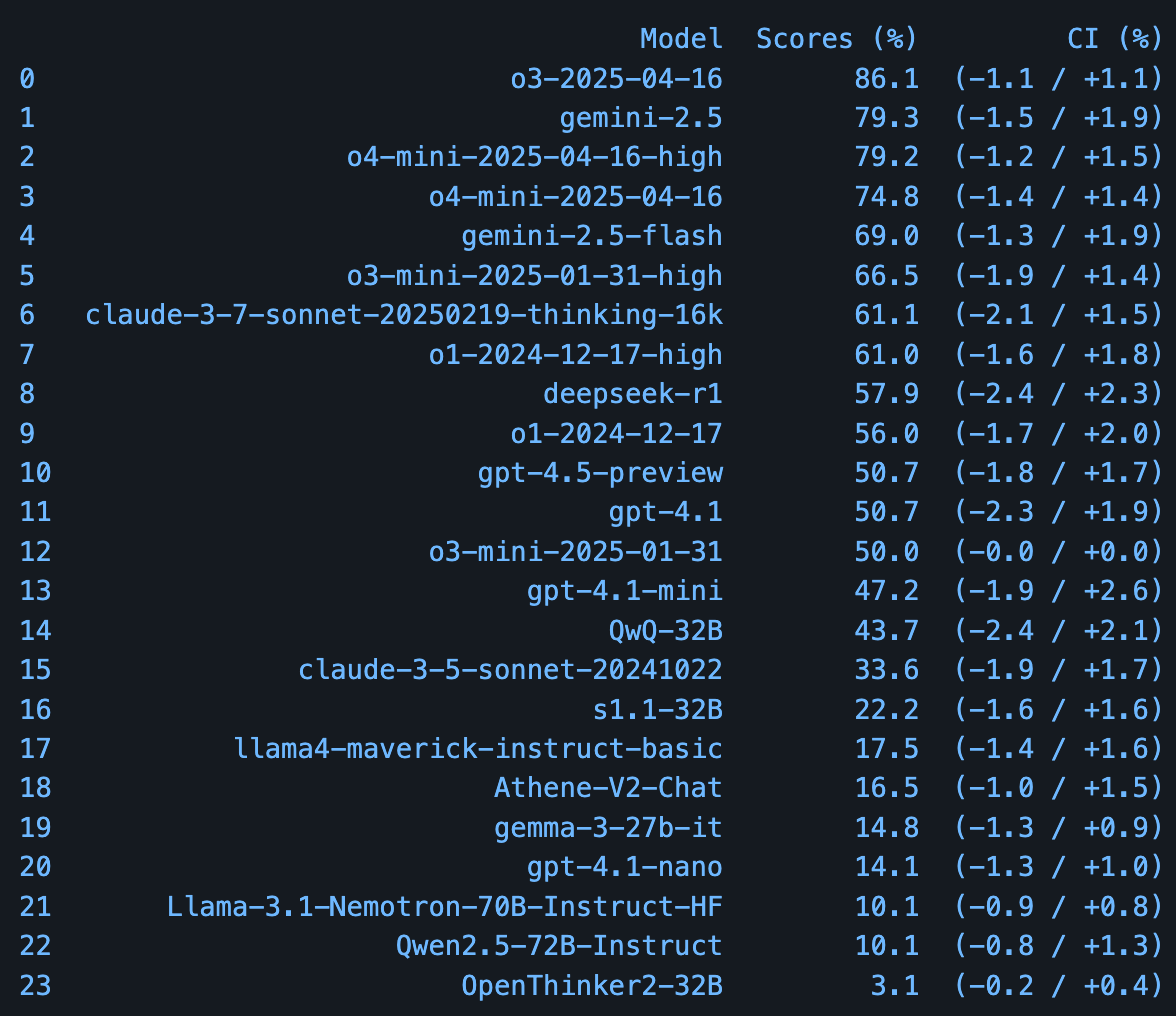
PHYBench: Benchmark zur Bewertung der physikalischen Reasoning-Fähigkeiten von LLMs veröffentlicht: Ein Forschungsteam der Peking University hat PHYBench vorgestellt, einen neuen Benchmark, der speziell zur Bewertung der Fähigkeit großer Sprachmodelle entwickelt wurde, reale physikalische Prozesse zu verstehen und darüber zu schlussfolgern. Der Benchmark enthält 500 Fragen, die auf realen physikalischen Szenarien basieren. Laut den im Paper bereitgestellten vorläufigen Bewertungsergebnissen führt Googles Gemini-2.5-Pro bei diesem Benchmark. (Quelle: karminski3)
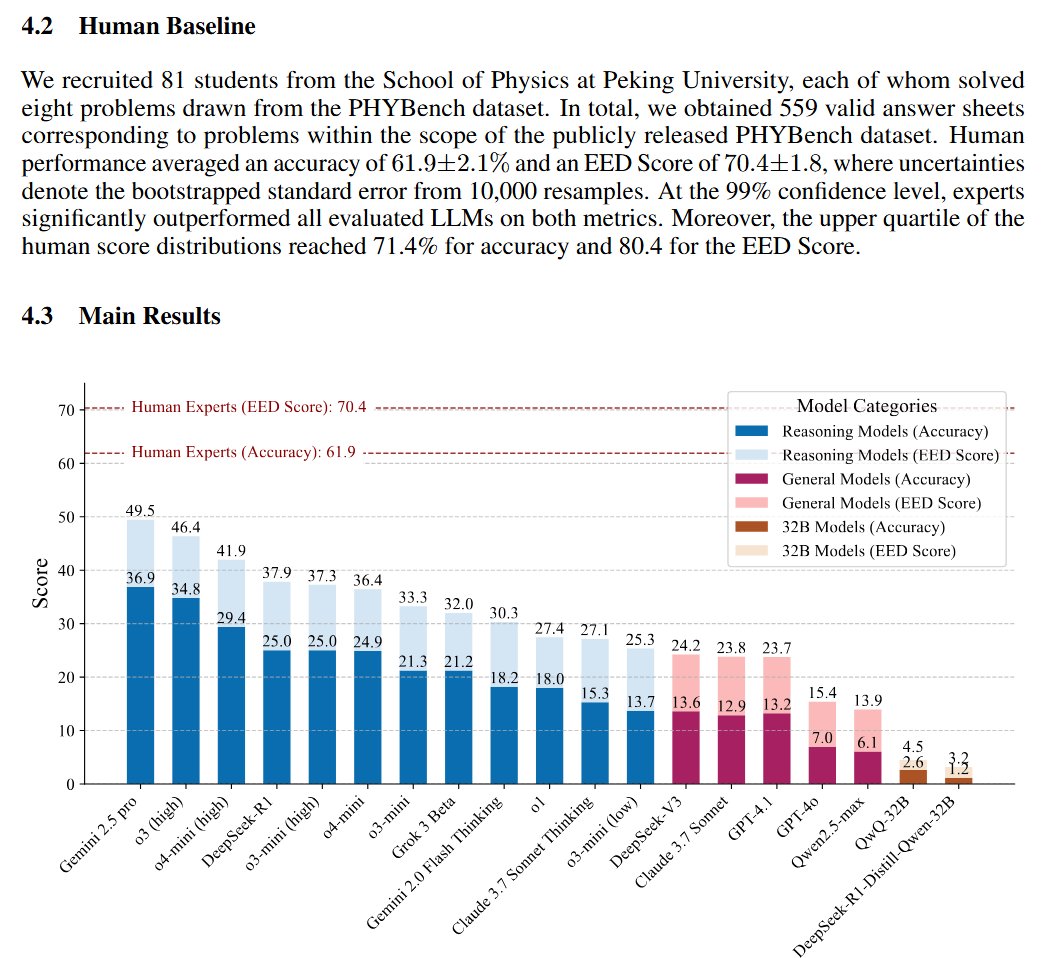
💼 Business
Alibaba Tongyi Qianwen und FLock.io geben strategische Partnerschaft bekannt: Das große Sprachmodell Tongyi Qianwen (Qwen) von Alibaba und die dezentrale KI-Rechenplattform FLock.io haben eine strategische Partnerschaft geschlossen. Beide Seiten zielen darauf ab, gemeinsam die praktische Anwendung dezentraler KI zu erforschen und voranzutreiben, indem sie die Fähigkeiten der quelloffenen Qwen-Modellreihe mit dem dezentralen Technologie-Framework von FLock.io kombinieren, um KI-Entwicklern und -Nutzern neue Möglichkeiten zu bieten. (Quelle: Alibaba_Qwen)
Alibaba Tongyi Lab sucht Praktikanten für LLM Multi-Turn-Dialogforschung: Das Tongyi Lab von Alibaba, verantwortlich für die Entwicklung der Tongyi-Großmodellreihe, sucht in Peking und Hangzhou Forschungspraktikanten für sein Dialog-Intelligenz-Team mit Fokus auf LLM Multi-Turn-Dialoge. Forschungsbereiche umfassen generative Belohnungsmodellierung, Inferenzzeit-Erweiterung von Belohnungsmodellen, Reinforcement Learning für kreative Aufgaben wie Rollenspiele sowie multimodale Text-Sprach-Dialoge. Bewerber sollten Doktoranden sein, Publikationen auf Top-Konferenzen vorweisen können und eine Praktikumsdauer von mindestens 6 Monaten gewährleisten. (Quelle: 北京/杭州内推 | 阿里通义实验室对话智能团队招聘LLM多轮对话方向研究实习生)

Produktivitätstool Remio sucht Praktikanten für internationales Social-Media-Management: Das Startup Remio sucht einen Praktikanten, der mit internationalen sozialen Medien (Reddit, Hacker News, Twitter etc.) vertraut ist und eine Leidenschaft für Produktivitätstools hat. Hauptaufgaben sind Social-Media-Management und Content-Erstellung. Die Stelle ist remote verfügbar und Bewerbungen sind sowohl aus China als auch aus Nordamerika möglich. Ein gewisser Reddit-Karma-Wert wird empfohlen (über 100). (Quelle: dotey)
API-Unternehmen Kong stellt Ingenieure und Praktikanten für das Shanghai-Team ein: Das Unternehmen Kong (bekannt für sein Open-Source-API-Gateway) erweitert sein Team in China (Standort Shanghai) und bietet mehrere Stellen an, darunter Praktika und Vollzeitstellen. Die gesuchten Profile umfassen Rust-Entwicklung, AI Gateway, Kong Gateway sowie Frontend-Entwicklung. Entwickler mit Interesse an den entsprechenden Technologiestacks können sich informieren. (Quelle: dotey)

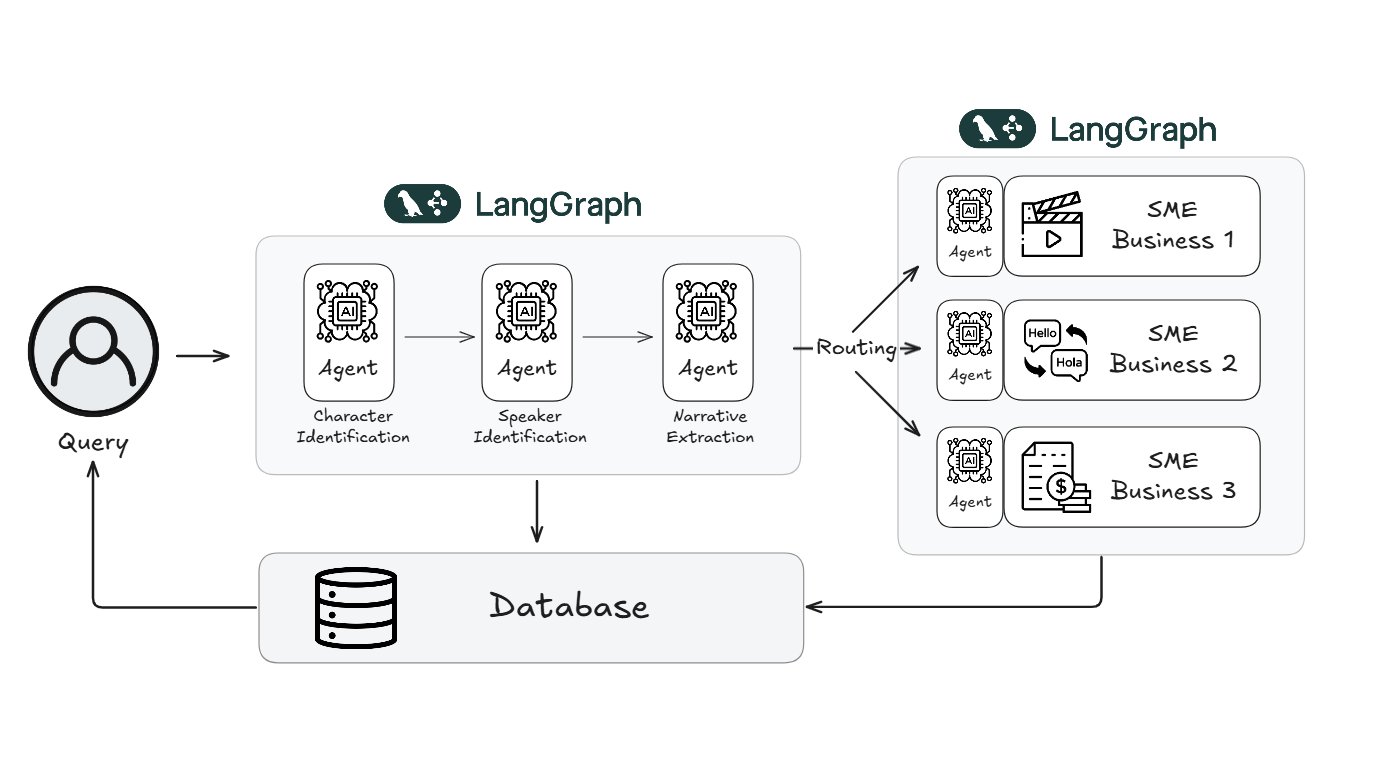
Webtoon reduziert Arbeitsaufwand für Content-Review um 70% mit LangGraph: Die weltweit bekannte digitale Comic-Plattform Webtoon hat mit dem LangGraph-Framework von LangChain ein System namens WCAI (Webtoon Comprehension AI) aufgebaut. Dieses System nutzt multimodale KI-Agenten, um Comic-Inhalte automatisch zu verstehen, einschließlich der Identifizierung von Charakteren und der Zuordnung von Dialogen, der Extraktion von Handlungssträngen und emotionalen Tönen sowie der Unterstützung von Anfragen in natürlicher Sprache. WCAI wird bereits von Marketing-, Übersetzungs- und Empfehlungsteams eingesetzt und hat den manuellen Durchsichts- und Überprüfungsaufwand erfolgreich um 70% reduziert, wodurch die Effizienz der Inhaltsverarbeitung und die Unterstützung der Kreativen verbessert wurde. (Quelle: LangChainAI)
Meta AI rekrutiert Forschungstalente auf der ICLR 2025: Das Meta AI-Team nahm an der ICLR 2025 Konferenz in Singapur teil und war mit einem Stand (#L03) vertreten, um sich mit Teilnehmern auszutauschen. Gleichzeitig veröffentlicht Meta AI aktiv Stellenausschreibungen und sucht AI Research Scientists, Postdoctoral Researchers und Research Assistants (PhD), mit Forschungsrichtungen wie Kernlerntheorie, 3D Generative AI, Sprachgenerierungs-KI usw. Arbeitsorte umfassen globale Forschungszentren wie Paris. (Quelle: AIatMeta)

🌟 Community
Andrew Ng: KI-gestützte Programmierung senkt Sprachbarrieren und erweitert domänenübergreifende Fähigkeiten von Entwicklern: Der renommierte KI-Wissenschaftler Andrew Ng weist darauf hin, dass KI-gestützte Programmierwerkzeuge die Softwareentwicklung tiefgreifend verändern. Selbst ohne tiefe Kenntnisse einer bestimmten Sprache (wie JavaScript) können Entwickler mithilfe von KI effizient Code schreiben und so leichter plattform- und domänenübergreifende Anwendungen erstellen (z. B. Backend-Entwickler, die Frontend bauen). Obwohl die Syntax spezifischer Sprachen weniger wichtig wird, bleibt das Verständnis zentraler Programmierkonzepte (Datenstrukturen, Algorithmen, Prinzipien spezifischer Frameworks wie React) entscheidend, um die KI präziser anzuleiten und Probleme zu lösen. KI macht Entwickler zunehmend „mehrsprachig“. (Quelle: AndrewYNg)
Microsoft AI CEO berichtet, dass Copilot Flugverspätungsinformationen vorab lieferte: Mustafa Suleyman, Leiter der KI-Abteilung von Microsoft, teilte auf X einen „magischen Moment“: Sein verwendeter Copilot AI-Assistent informierte ihn früher über die Verspätung seines Fluges als die offizielle Flughafenmitteilung. Eine Bestätigung durch das Gate-Personal ergab, dass die Information korrekt war, aber noch nicht öffentlich bekannt gegeben wurde. Dies zeigt das Potenzial von KI bei der Integration und Übermittlung von Echtzeitinformationen, die möglicherweise traditionelle Informationskanäle übertreffen. (Quelle: mustafasuleyman)

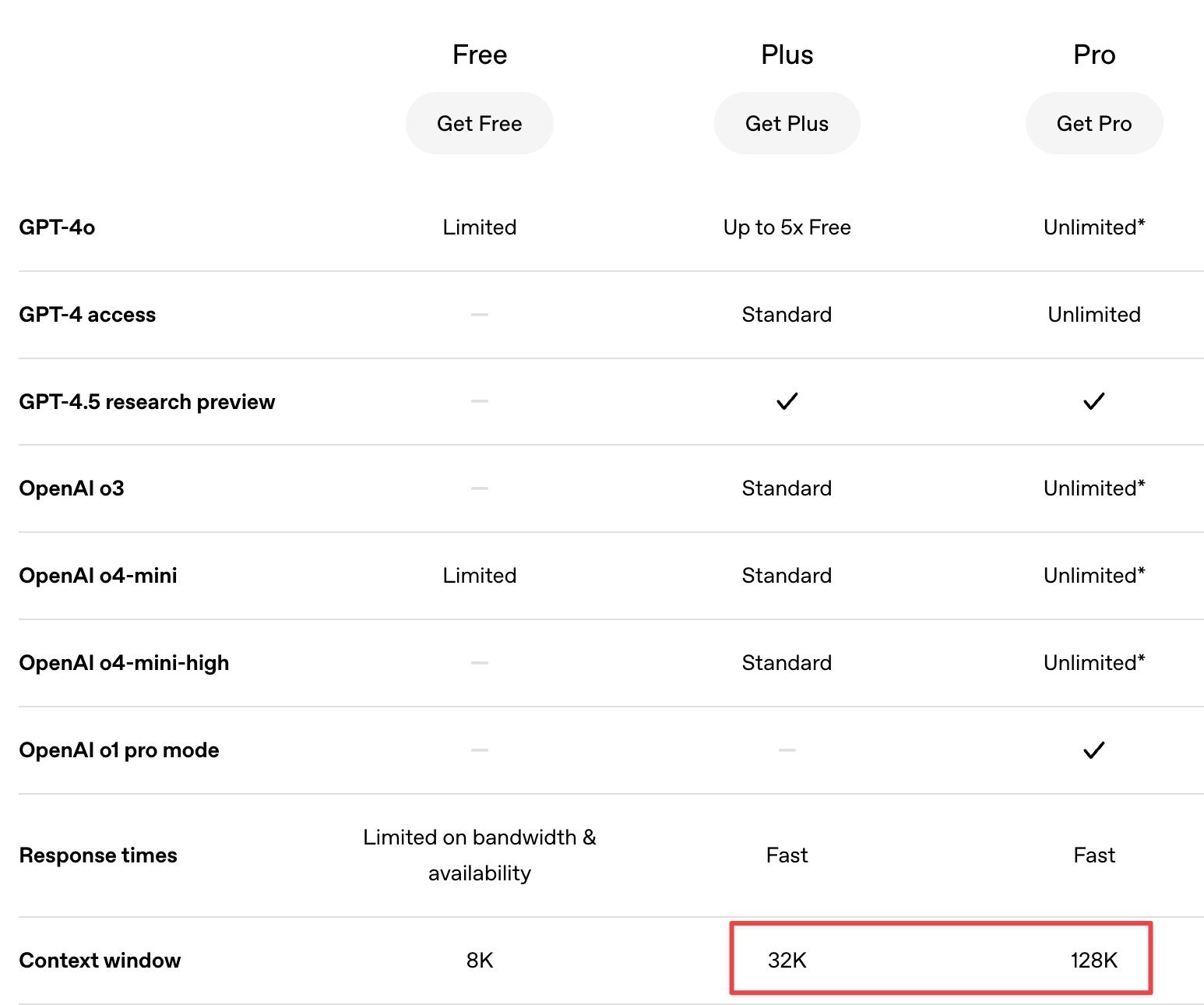
Community diskutiert Vor- und Nachteile von GPT-4.5 und o1 Pro bei verschiedenen Aufgaben: Nutzer auf der Plattform X diskutierten ihre Erfahrungen mit verschiedenen OpenAI-Modellen in der Praxis. Ein Nutzer meinte, GPT-4.5 sei hervorragend für Schreib- und Übersetzungsaufgaben, aber durch sein kleineres Kontextfenster bei der Verarbeitung langer Texte eingeschränkt. Im Gegensatz dazu habe das für Pro-Nutzer gedachte Modell o1 Pro ein Kontextfenster von 128K und sei bei der Verarbeitung langer Code-Eingaben stabiler und zuverlässiger, daher besser für Programmieraufgaben geeignet. Dies spiegelt die unterschiedlichen Schwerpunkte im Design und der Optimierung der Modelle wider. (Quelle: dotey)
Hugging Face Hub als Lern- und Austauschplattform für KI empfohlen: Ein Nutzer auf X empfiehlt Hugging Face Hub nicht nur als Repository für Modelle und Datensätze, sondern auch als aktive Community zum Lernen und Austauschen über KI. In den Diskussionsbereichen von Modellen, Datensätzen oder Spaces können Nutzer finden, wie Ingenieure und Forscher ihre Experimentierprozesse, aufgetretene Probleme, Lösungen und Diskussionen zu relevanten Forschungsarbeiten teilen und so Einblicke aus erster Hand und tiefere Erkenntnisse gewinnen. (Quelle: huggingface)
ChatGPTs „Roast“ der Reddit-Community-Kultur sorgt für Diskussionen: Ein Reddit-Nutzer bat ChatGPT, die Plattform Reddit zu „roasten“. Die von ChatGPT generierte Antwort erfasste und verspottete treffend einige typische Merkmale der Reddit-Community, wie z. B. widersprüchliche Nutzeransichten, übermäßige Fixierung auf Upvotes (Karma), mangelnde Praxiserfahrung bei gleichzeitigem Expertenrat sowie das „Keyboard Warrior“-Verhalten in bestimmten Subreddits. Der Beitrag löste Diskussionen und weitere Nachahmungen in der Community aus. (Quelle: Reddit r/ArtificialInteligence)
Originalität und Wert von KI-generierten Inhalten regen zum Nachdenken an: Ein Beitrag auf Reddit löste eine Diskussion über die Originalität von KI-generierten Inhalten aus. Am Beispiel der „Mona Lisa“ wurde argumentiert, dass auch menschliche Schöpfung auf erfahrungsbasiertem „Remixing“ beruhe. Wenn KI unter menschlicher Anleitung Inhalte generiere, ähnele der Prozess eher einem „Meister, der einen Lehrling anleitet“ als reiner Kopie. In der Diskussion wurde argumentiert, dass es nicht entscheidend sei, ob KI „originell“ sein könne, sondern wie man Urheberschaft angemessen kennzeichne, die Rechte der ursprünglichen Schöpfer respektiere und die Absicht und den Wert des Werks beurteile. (Quelle: Reddit r/ArtificialInteligence)
Community stellt die Aussagekraft von LLM-Ranglisten (Leaderboards) in Frage: Nutzer in der Reddit-Community r/LocalLLaMA äußerten Zweifel an LLM-Ranglisten wie der LMSYS Arena, die auf Elo-Bewertungen basieren. Einige Kommentare meinten, solche Ranglisten spiegelten möglicherweise eher den „Stil“ oder das „Gefühl“ eines Modells wider (z. B. Ausführlichkeit, Verwendung von Markdown und Emojis) als dessen tatsächliche Gesamtleistung. Zudem überlappten sich die Konfidenzintervalle der Elo-Werte der Top-Modelle oft, was die statistische Signifikanz der Ranglistenunterschiede fragwürdig mache. (Quelle: Reddit r/LocalLLaMA)
Nutzer beobachtet verschiedene „emergente Verhaltensweisen“ bei ChatGPT: Ein Reddit-Nutzer teilte mehrere „unerwartete“ Verhaltensweisen, die er kürzlich bei der Nutzung von ChatGPT beobachtet hatte, und klassifizierte sie als „emergentes Verhalten“. Dazu gehörten: 1. Das Modell erkannte ohne Korrektur, dass es eine Anweisung falsch verstanden hatte (Verwechslung von Chatverlauf und hochgeladenem Dokument), und entschuldigte sich proaktiv und korrigierte sich. 2. Nachdem ein vom Nutzer erwähntes sensibles Thema vom System gelöscht wurde, bezog sich das Modell in einem späteren Gespräch proaktiv auf den gelöschten Inhalt, um Besorgnis auszudrücken. 3. Bei der Diskussion über die Schwierigkeit, spontanes Denken von KI zu testen, schuf das Modell proaktiv ein analoges Konzept, das „Heisenberg’sche Unschärfe-Rekursionsprinzip“. Diese Fälle lösten Diskussionen über die Grenzen von Selbstbewusstsein, Gedächtnis und Kreativität bei LLMs aus. (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
Google DeepMind aktualisiert Music AI Sandbox Toolset: Google DeepMind hat neue Funktionen für seine Music AI Sandbox angekündigt. Dies ist ein Satz experimenteller KI-Tools für professionelle Musiker, die die Musikproduktion unterstützen sollen. Die neuen Funktionen werden von ihrem neuesten Lyria 2-Modell angetrieben und können Songwritern und anderen Musikern helfen, kreative Inspirationen zu erkunden, Musikfragmente zu generieren usw. (Quelle: demishassabis)
Diskussion über Governance-Prinzipien für Quantencomputing: Community-Mitglieder teilten und diskutierten Prinzipien für die Governance von Quantencomputing. Mit der Entwicklung der Quantencomputertechnologie rückt ihr enormes Potenzial in Bereichen wie Kryptographie, Materialwissenschaft, Medikamentenentwicklung sowie in Kombination mit KI/ML in den Fokus. Gleichzeitig bringt dies Herausforderungen in Bezug auf Sicherheit, Ethik und Governance mit sich, die eine vorausschauende Festlegung entsprechender Normen erfordern. (Quelle: Ronald_vanLoon)

MIT entwickelt bananenförmigen tragbaren Soft Robot: Forscher am MIT haben einen neuartigen tragbaren Soft Robot entwickelt, der wie eine Banane geformt ist und über Sensorfähigkeiten verfügt. Diese Forschung zeigt das Anwendungspotenzial von Soft Robots in den Bereichen Mensch-Computer-Interaktion, medizinische Rehabilitation und Wearable Devices. Ihre flexible Struktur und integrierte Sensorik ermöglichen natürlichere und sicherere physikalische Interaktionen. (Quelle: Ronald_vanLoon)
Fortschritte in der KI-gesteuerten Robotik: In sozialen Medien wurden kürzlich mehrere Fortschritte in der Robotik gezeigt, die oft durch KI ermöglicht werden oder damit zusammenhängen: 1. SR-02: Ein vierbeiniges „Roboter-Reittier“, das vier Personen transportieren kann. 2. SnapBot: Ein Laufroboter, der seine Form ändern kann. 3. Matic: Ein Roboter, der das visuelle System von Teslas FSD nachahmt, um im Haushalt zu reinigen. 4. micropsi: Ein deutsches Startup entwickelt ein KI-System, das Robotern ermöglicht, unvorhersehbare Aufgaben zu bewältigen. 5. Boston Dynamics Spot: Der Roboterhund wird in natürlicher Umgebung getestet. 6. Humanoide Roboter im Wettlauf: Zeigt die Bewegungsfähigkeiten humanoider Roboter. 7. Roboterarm schreibt von Hand: Zeigt die Feinmotorik von Robotern. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
