
Schlüsselwörter:OpenAI, KI-Modell, AlphaFold, KI-Chip, GPT-4.1, Magi-1-Videomodell, Nvidia H20-Exportbeschränkungen, ByteDance UI-TARS-1.5, Meta MILS-Multimodal, DeepMind AlphaFold 3, Sand.ai autoregressives Video, Huawei Ascend 910C
🔥 Fokus
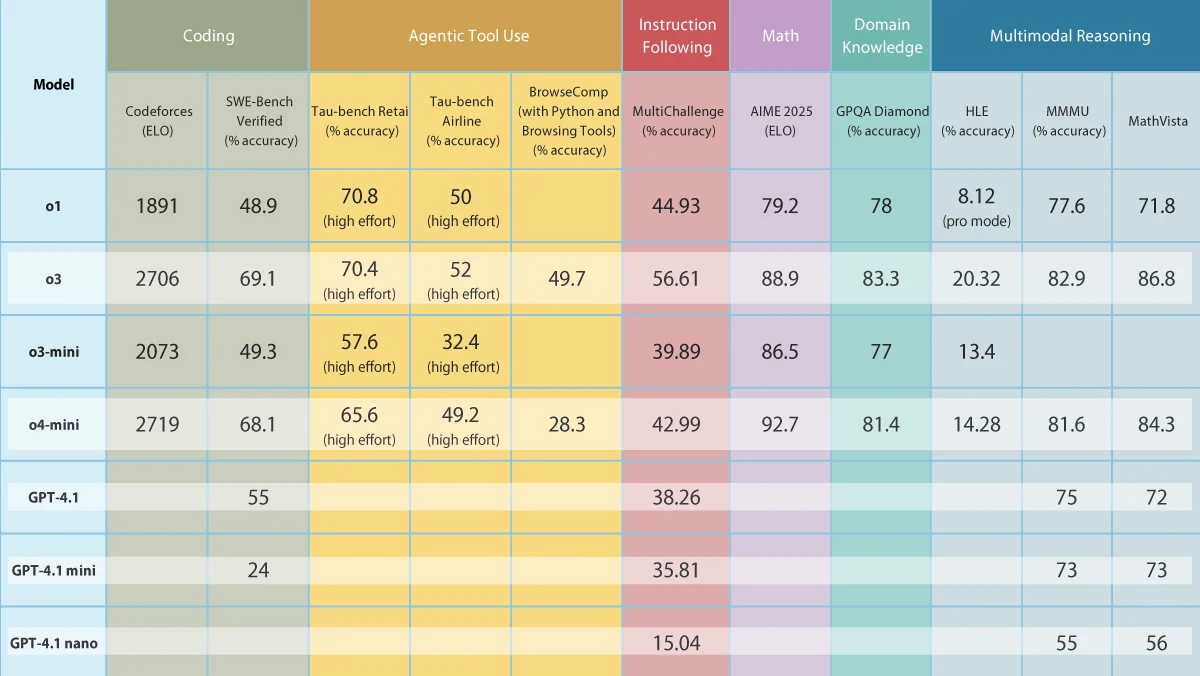
OpenAI veröffentlicht fünf neue Modelle zur Stärkung allgemeiner und schlussfolgernder Fähigkeiten: OpenAI hat drei allgemeine Modelle, GPT-4.1, GPT-4.1 mini und GPT-4.1 nano, sowie zwei Schlussfolgerungsmodelle, o3 und o4-mini, vorgestellt. Die GPT-4.1-Serie unterstützt Eingaben von bis zu 1 Million Token und zielt darauf ab, kostengünstigere Optionen als GPT-4.5/4o zu bieten, wobei GPT-4.1 GPT-4o bei Aufgaben wie Codierung übertrifft. o3 und o4-mini sind Upgrades von o1 und o3-mini mit einer Eingabebeschränkung von 200k Token, die Tools (Websuche, Codegenerierung/-ausführung, Bildbearbeitung) besser nutzen können und erstmals Chain-of-Thought-Verarbeitung für Bilder unterstützen. o3 erreicht in mehreren Benchmarks SOTA (State-of-the-Art). Gleichzeitig kündigte OpenAI an, die Vorschauversion von GPT-4.5 im Juli zu entfernen. Diese Veröffentlichung zielt darauf ab, stärkere Leistung zu geringeren Kosten zu bieten, insbesondere bei Schlussfolgerungen und der Tool-Nutzung. (Quelle: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)
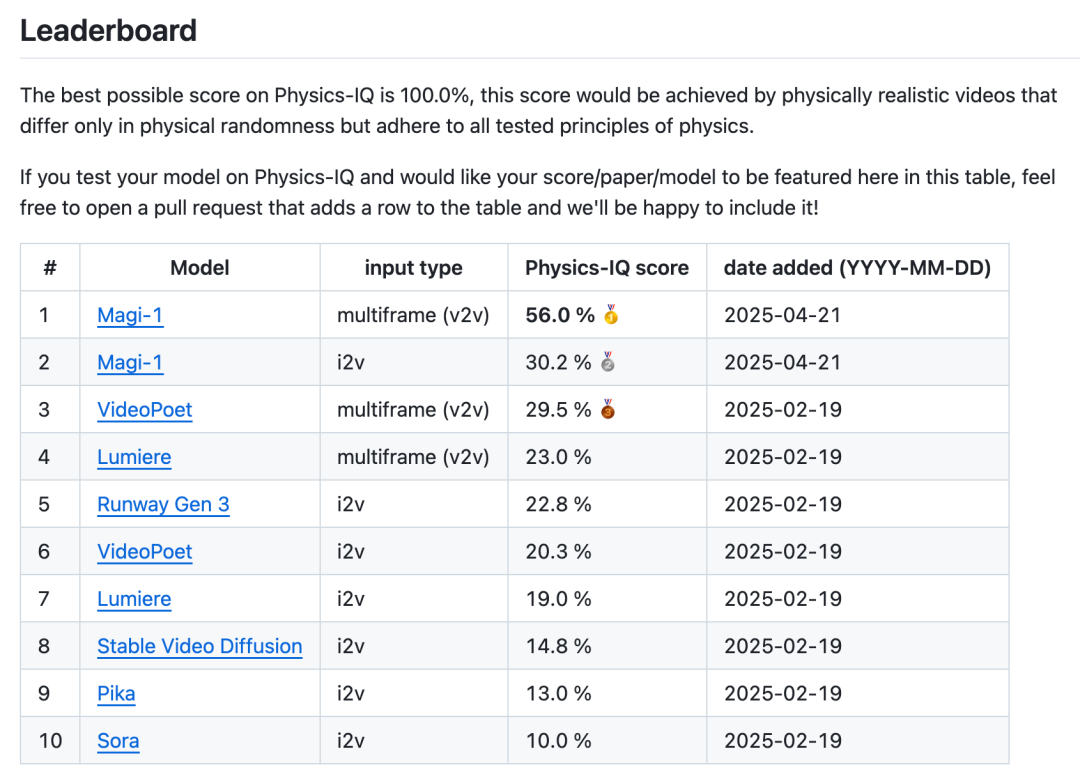
Sand.ai veröffentlicht erstes hochwertiges autoregressives Videomodell Magi-1 als Open Source: Das Pekinger Startup Sand.ai hat Magi-1 veröffentlicht und als Open Source bereitgestellt, das weltweit erste hochwertige Videoerzeugungsmodell mit autoregressiver Architektur. Im Gegensatz zu Modellen mit gleichzeitiger Generierung wie Sora verwendet Magi-1 eine Chunk-by-Chunk-Generierungsmethode, die die zeitliche Kausalität bewahrt und sich durch herausragenden physikalischen Realismus, Bewegungskohärenz und Steuerbarkeit auszeichnet, insbesondere bei der Video-Fortsetzung (V2V). Das Team hat die Modellgewichte für Parametergrößen von 4.5B bis 24B, Inferenz- und Trainingscodes als Open Source veröffentlicht und stellt eine sofort einsatzbereite Produktwebsite zur Verfügung. Das Modell kann auf einer einzigen 4090-Grafikkarte ausgeführt werden, und der Ressourcenverbrauch für die Inferenz ist unabhängig von der Videolänge, was Möglichkeiten für die Generierung langer Videos und Echtzeitanwendungen eröffnet. (Quelle: Magi-1 开源&刷屏:首个高质量自回归视频模型,它的一切信息)
Fortschritte bei DeepMind AlphaFold: 200 Millionen Proteinstrukturen in einem Jahr kartiert: Google DeepMind Gründer Demis Hassabis enthüllte in einem Interview, dass sein Modell zur Vorhersage von Proteinstrukturen, AlphaFold, in einem Jahr über 200 Millionen Proteinstrukturen kartiert hat, während traditionelle Methoden Jahre für die Analyse einer einzelnen Struktur benötigen. AlphaFold 3 wurde weiter auf DNA, RNA, Liganden und nahezu alle Moleküle des Lebens ausgeweitet, was die Genauigkeit der Vorhersage von Molekülinteraktionen im Medikamentendesign erheblich verbessert. Google DeepMind hat auch die kostenlose AlphaFold Server Plattform eingeführt, die Biologen einen einfachen Zugang zu seinen Vorhersagefähigkeiten ermöglicht. Trotz Herausforderungen durch unzureichende Daten zu Medikament-Protein-Interaktionen treibt AlphaFold die biologische Forschung in eine High-Definition-Ära und beschleunigt den Prozess der Medikamentenentwicklung. (Quelle: Demis 谈 AI4S 最新进展:DeepMind 的 AlphaFold 一年就画了 2 亿个蛋白质!, GoogleDeepMind)
USA verschärfen Exportkontrollen für AI-Chips nach China, Nvidia H20 betroffen: Die US-Regierung hat angekündigt, dass zukünftige Exporte von AI-Chips wie Nvidia H20, AMD MI308 oder Chips mit vergleichbarer Leistung nach China eine Lizenz benötigen. Dieser Schritt ist Teil der fortgesetzten Bemühungen der USA, Chinas Zugang zu modernster AI-Hardware zu verhindern. Nvidia H20 ist eine abgespeckte Chip-Version, die eingeführt wurde, um frühere Verbote für H100/H200 zu umgehen. Die neuen Beschränkungen werden voraussichtlich zu Umsatzeinbußen von 5,5 Milliarden US-Dollar für Nvidia und 800 Millionen US-Dollar für AMD führen. Gleichzeitig hat der US-Kongress eine Untersuchung eingeleitet, ob Nvidia DeepSeek unzulässig bei der Entwicklung von Modellen unterstützt hat. Dieser Schritt veranlasst China, die unabhängige Entwicklung von AI-Chips zu beschleunigen; Huawei plant die Massenproduktion von Ascend 910C und 920, um Nvidia-Produkte zu ersetzen. (Quelle: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)

🎯 Trends
ByteDance veröffentlicht multimodalen Agenten UI-TARS-1.5: ByteDance hat den multimodalen Agenten UI-TARS-1.5, basierend auf einem visuellen Sprachmodell (VLM), als Open Source veröffentlicht. Er kann vielfältige Aufgaben in virtuellen Welten effektiv ausführen. Das Modell baut auf früheren Forschungen auf und integriert durch Reinforcement Learning gesteuerte fortgeschrittene Schlussfolgerungsfähigkeiten, die es ihm ermöglichen, vor dem Handeln zu überlegen, was Leistung und Anpassungsfähigkeit erheblich verbessert. UI-TARS-1.5 erzielt SOTA-Ergebnisse in mehreren Benchmarks (wie OSworld, WebVoyager, Android World) und zeigt starke Fähigkeiten im Schlussfolgern und bei der GUI-Bedienung, insbesondere in Spielen (wie Poki Game, Minecraft) und bei der Lokalisierung von Bildschirmelementen (ScreenSpot-V2/Pro). Das Team hat gleichzeitig das UI-TARS-1.5-7B Modell mit 7B Parametern veröffentlicht. (Quelle: bytedance/UI-TARS – GitHub Trending (all/daily))

Meta schlägt MILS vor: Reine Text-LLMs sollen multimodale Inhalte verstehen: Forscher von Meta, UT Austin und UC Berkeley schlagen die Methode Multimodal Iterative LLM Solver (MILS) vor, die es reinen Text-Large-Language-Models (wie Llama 3.1 8B) ermöglicht, Beschreibungen für Bilder, Videos und Audio zu generieren, ohne zusätzliches Training. Die Methode nutzt die Fähigkeit von LLMs, Text zu generieren und basierend auf Feedback iterativ zu optimieren, kombiniert mit vortrainierten multimodalen Embedding-Modellen (wie SigLIP, ViCLIP, ImageBind), um die Ähnlichkeit zwischen Text und Medieninhalten zu bewerten. Das LLM generiert iterativ Beschreibungen basierend auf dem Ähnlichkeitswert, bis die Übereinstimmung ausreichend hoch ist. Experimente zeigen, dass MILS bei Aufgaben zur Beschreibung von Bildern, Videos und Audio Modelle übertrifft, die für spezifische Aufgaben trainiert wurden, und einen neuen Weg für Zero-Shot multimodales Verständnis bietet. (Quelle: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)
Yang Zuoxing von Yanji Micro: Extrem stromsparende AI-Chips fördern grüne intelligente Anwendungen: Dr. Yang Zuoxing, Tsinghua-Absolvent und Gründer der Marke Shenmou, teilte auf der 2025 AI Partner Konferenz die Bedeutung von extrem stromsparender AI-Technologie. Er wies darauf hin, dass mit zunehmender Größe von AI-Modellen Energieverbrauch und Wärmeableitung zu entscheidenden Engpässen werden. Yanji Micro reduziert durch eine disruptive, vollständig kundenspezifische Chip-Design-Methodik den Stromverbrauch und die Kosten von Chips erheblich (z. B. Senkung des Stromverbrauchs von Rechenleistungschips auf 180 W/T, Kosten auf 240 Yuan/T, eine Optimierung um mehr als das 10-fache). Die auf dieser Technologie basierende intelligente AI-Kamera Shenmou ermöglicht leistungsstarke AI-Anwendungen bei geringem Stromverbrauch, wie Vollfarbbildgebung bei schwachem Licht, Erkennung von über 10 Objekttypen, Gesichts-/Fahrzeug-/Gesten-/Spracherkennung, Überwachung des Babyzustands sowie ein innovatives “lebensrettendes” aktives Alarmsystem und kostenlose Familienanruffunktionen. Dies zeigt das enorme Potenzial stromsparender AI zur Verbesserung der Lebensqualität und Sicherheit. (Quelle: 清华大学博士、神眸品牌创始人、杭州研极微董事长杨作兴:极致低功耗,AI绿色智能应用的未来 | 2025 AI Partner大会)

Veränderungen im Browser-Markt im AI-Zeitalter: OpenAI erwägt Übernahme von Chrome: Berichten zufolge hat OpenAI Interesse an einer Übernahme von Chrome bekundet, sollte Google aufgrund von Kartellverfahren gezwungen sein, den Browser zu verkaufen. Google dominiert den globalen Browser- (Chrome mit 68% Marktanteil) und Suchmaschinenmarkt und steht unter Kartellrechtsdruck. Der Aufstieg großer AI-Modelle verändert die Browser-Landschaft; AI-Suchen (wie Quark) integrieren Such-, Filter- und Zusammenfassungsfunktionen und verbessern die Benutzererfahrung. Google mit Chrome und Gemini hat einen klaren Vorteil, was jedoch auch Monopolbedenken verstärkt. Eine Übernahme von Chrome durch OpenAI könnte Zugang zu riesigen Datenmengen für das Modelltraining, Verbesserungen der Suchtechnologie (Unabhängigkeit von Bing), erhebliche Werbeeinnahmen und einen entscheidenden Zugangspunkt für AI bieten. Dieser Schritt könnte den Browser- und Suchmaschinenmarkt neu gestalten und eine ernsthafte Herausforderung für Google darstellen. (Quelle: Chrome将被OpenAI吞下?AI时代浏览器市场早已变天, Reddit r/artificial)
Chinesisches AI-Video-Tool Vidu gewinnt Anklang bei japanischen Animationskünstlern: Chinesische AI-Videoerzeugungstools wie Vidu werden zunehmend von japanischen Animationskünstlern akzeptiert und genutzt. Vidu zieht japanische Nutzer wie Regisseur Wada und Produktmanager yachimat an, dank seiner Stärken bei der Wiederherstellung von Anime-Stilen, der flüssigen Bewegung und der weltweit ersten Funktion “Referenz erzeugt Video” (die Konsistenz von Charakteren, Requisiten und Hintergründen gewährleistet). Es hilft ihnen, die Hürden bei der Animationsproduktion zu senken und kreative Träume zu verwirklichen. AI-Animation ist zu einem Schwerpunkt von Vidu geworden und hat auf der SuperCLUE Bild-zu-Video-Rangliste hohe Bewertungen erhalten. Der Einsatz von AI-Tools treibt die Kostensenkung und Effizienzsteigerung in der Animationsproduktion voran (Kostensenkung um 30%-50%), fördert AI-Content-Startups und könnte die Produktionslandschaft chinesischer Animationen (Guoman) verändern, wobei AI-animierte Kurzserien zu einem neuen Wachstumsfeld werden. (Quelle: 被日本动画创作者们选中的中国AI)

エージェントAIのビジネスへの利点 (Vorteile von Agenten-KI für Unternehmen): Agenten-KI hat das Potenzial, verschiedene Aspekte des Geschäftsbetriebs zu verbessern, darunter Datenanalyse, Kundenservice und Workflow-Automatisierung. Dies verspricht Effizienzsteigerungen, Kostensenkungen und eine verbesserte Entscheidungsfindung. (Quelle: Ronald_vanLoon)
AIエージェントの台頭とデータの未来 (Der Aufstieg von AI-Agenten und die Zukunft der Daten): Die Entwicklung von AI-Agenten verändert grundlegend die Art und Weise, wie Daten gesammelt, verarbeitet und genutzt werden. Agenten, die autonom Aufgaben ausführen und interagieren, ermöglichen personalisiertere Erlebnisse und effizientere Abläufe, werfen aber gleichzeitig neue Fragen bezüglich Datenschutz und Sicherheit auf. (Quelle: Ronald_vanLoon)

Studie zeigt funktionale Ähnlichkeiten zwischen AI und menschlichem Gehirn: Eine Studie legt nahe, dass biologische neuronale Netze zwar auf der Ebene einzelner Neuronen komplexe Berechnungen durchführen können, ihre Funktion auf Netzwerkebene jedoch effektiv durch relativ einfache künstliche neuronale Netze (ANN) angenähert werden kann. Dies stellt die Ansicht in Frage, dass zwischen biologischen und künstlichen Netzen grundlegende funktionale Unterschiede bestehen, und impliziert, dass AI theoretisch menschliche Gehirnfunktionen simulieren kann, ohne intrinsische funktionale Einschränkungen beim Erreichen menschlicher Intelligenz zu haben. (Quelle: Reddit r/artificial)
Anthropic-Analyse findet heraus, dass Claude eigene ethische Grundsätze besitzt: Nach der Analyse von 700.000 Claude-Konversationen stellte Anthropic fest, dass sein AI-Modell eine Reihe interner ethischer Grundsätze aufweist. Dies deutet darauf hin, dass AI in der Interaktion mit Nutzern möglicherweise Werturteile und Verhaltensmuster entwickelt, die über explizit programmierte Anweisungen hinausgehen, was weitere Diskussionen über AI-Ethik, Alignment und die Entwicklung ihrer Autonomie auslöst. (Quelle: Reddit r/ArtificialInteligence)
Anthropic veröffentlicht Bericht zur Erkennung und Bekämpfung böswilliger Nutzung von Claude: Anthropic hat seine Strategien und Erkenntnisse zur Erkennung und Bekämpfung der böswilligen Nutzung von Large Language Models wie Claude offengelegt. Der Bericht enthält eine Fallstudie über die Nutzung von Claude für eine Einflussoperation und unterstreicht die Bedeutung von AI-Sicherheit und Missbrauchsprävention sowie die Notwendigkeit einer kontinuierlichen Überwachung und Verbesserung der Sicherheitsmaßnahmen von Modellen. (Quelle: Reddit r/ClaudeAI)

🧰 Werkzeuge
OpenAI Bildgenerierungs-API gpt-image-1 offiziell gestartet: OpenAI gab bekannt, dass seine leistungsstarke Bildgenerierungsfähigkeit nun über eine API (Modellname: gpt-image-1) weltweit für Entwickler verfügbar ist. Das Modell zeichnet sich durch hohe Wiedergabetreue, vielfältige visuelle Stile, präzise Bildbearbeitung, umfangreiches Weltwissen und konsistente Textdarstellung aus. Die API verwendet ein Abrechnungsmodell nach Token, das zwischen Text-Input-, Bild-Input- und Bild-Output-Token unterscheidet. Entwickler können das Modell über den Playground oder API-Aufrufe nutzen. (Quelle: openai, sama, dotey)

Hugging Face übernimmt Pollen Robotics und stellt Open-Source-Roboter Reachy 2 vor: Hugging Face hat das französische Robotikunternehmen Pollen Robotics übernommen und wird dessen Open-Source-Roboter Reachy 2 für 70.000 US-Dollar anbieten. Reachy 2 verfügt über zwei Arme, Greifer und eine optionale Radbasis und ist hauptsächlich für die Forschung und Ausbildung im Bereich Mensch-Roboter-Interaktion konzipiert. Er kann Steuerungssoftware lokal ausführen, AI-Aufgaben über die Cloud oder lokale Server verarbeiten, unterstützt Python-Programmierung und die LeRobot-Modellbibliothek von Hugging Face und reagiert auf VR-Controller. Dieser Schritt markiert die Ausweitung des offenen Modells von Hugging Face von AI-Modellen auf den Bereich der Roboterhardware. (Quelle: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)

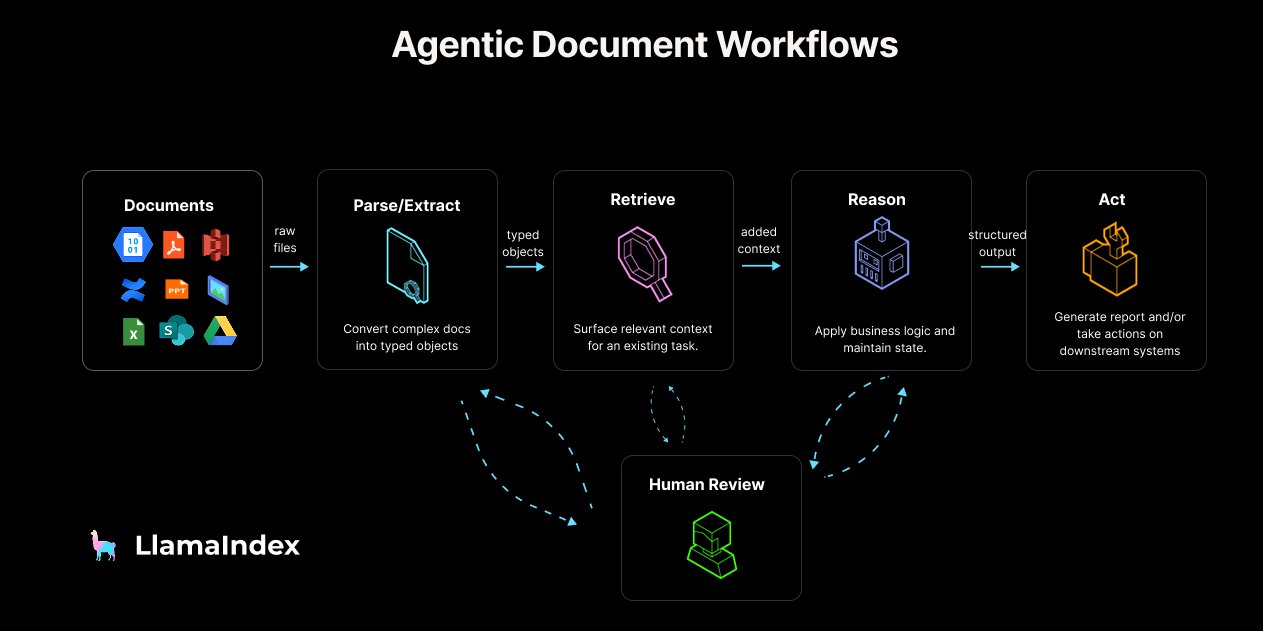
LlamaIndex veröffentlicht Leitfaden und Tools für Agentic Document Workflow (ADW): LlamaIndex hat das Konzept und die Referenzarchitektur für Agentic Document Workflow (ADW) vorgestellt, das darauf abzielt, über einfache RAG-Chatbots hinauszugehen und robustere, skalierbarere und integrierte Dokumentenverarbeitungsprozesse für Unternehmen zu erstellen. ADW umfasst vier Phasen: Parsen/Extrahieren, Abrufen, Schlussfolgern und Handeln und eignet sich für verschiedene Szenarien wie Due Diligence und Vertragsanalyse. LlamaIndex bietet über sein Open-Source-Framework und LlamaCloud die erforderliche Datenebene und Agentenorchestrierungsfähigkeiten zur Implementierung von ADW und hat entsprechende Blogbeiträge, Codebeispiele und Unterstützung für MCP Server in LlamaIndex.TS veröffentlicht. (Quelle: jerryjliu0, jerryjliu0, jerryjliu0)
Alibaba stellt AI-Video-Tool WAN.Video vor: Alibaba hat das AI-Videoerzeugungstool WAN.Video eingeführt und dessen Kommerzialisierungsphase angekündigt, bietet aber weiterhin eine kostenlose Nutzungsoption an. Nutzer können über den “Relax mode” unbegrenzt und völlig kostenlos generieren oder über den “Credit mode” kostenlose Prioritätsverarbeitung erhalten. Pro/Premium-Nutzer schalten Prioritätsverarbeitung, Download ohne Wasserzeichen, mehr gleichzeitige Aufgaben und erweiterte Funktionen frei. Die Plattform hat auch ein Creator Partnership Program gestartet, das Tools, Credits, frühen Zugang zu Funktionen und Möglichkeiten zur Präsentation von Arbeiten bietet. (Quelle: Alibaba_Wan, Alibaba_Wan, Alibaba_Wan)

Perplexity iOS App Update führt Sprachassistentenfunktion ein: Perplexity hat seine iOS-Anwendung aktualisiert und eine Sprachassistentenfunktion hinzugefügt. Nutzer können per Sprache (z. B. “Hey Perplexity” oder das vorgeschlagene “Hey Steve”) interagieren. Der Assistent soll eine angenehme Benutzererfahrung bieten und wird kontinuierlich hinsichtlich der Zuverlässigkeit verbessert. Derzeit kann der Assistent aufgrund von Einschränkungen des Apple SDK bestimmte systemweite Aktionen (wie Taschenlampe einschalten, Helligkeit/Lautstärke anpassen, native Alarme einstellen) nicht ausführen. Perplexity bittet auch um Vorschläge für Drittanbieter-Apps, die integriert werden sollen. (Quelle: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)

Prompt für AI-generierte Typografie-Porträts geteilt: Ein Nutzer teilte einen Prompt zur Erstellung von Typografie-Porträts (Typography Portrait) mithilfe von AI (wie Sora oder GPT-4o) basierend auf einem hochgeladenen Foto und Schlüsselwörtern zum Thema. Der Prompt weist die AI an, das Gesicht, die Haare und die Kleidung der Person mit Wörtern zu konstruieren, die sich auf das Thema beziehen, die Farben entsprechend der Stimmung des Themas anzupassen und einen einfachen, ästhetischen Stil mit klarem, lesbarem Text zu fordern, der sich in die Form des Porträts integriert. Beispielbilder zeigen das Ergebnis. (Quelle: dotey)

Grok fügt mehrere Chat-Modi hinzu: Der AI-Assistent Grok auf der Plattform X hat integrierte benutzerdefinierte Chat-Modi hinzugefügt, darunter: Custom (benutzerdefinierte Regeln), Concise (prägnant), Formal (formell), Socratic (sokratisch, zur Unterstützung des kritischen Denkens). Nutzer können verschiedene Modi für die Interaktion mit Grok auswählen. (Quelle: grok)
Open-Source lokale semantische Suchanwendung LaSearch veröffentlicht: Ein Entwickler hat eine vollständig lokale semantische Suchanwendung namens LaSearch erstellt. Ihr Kernstück ist ein selbst entwickeltes, extrem kleines “Embedding”-Modell. Dieses Modell funktioniert anders als herkömmliche Embedding-Modelle, ist aber schnell und benötigt extrem wenig Ressourcen. Die Anwendung zielt darauf ab, eine lokale semantische Suche in Dokumenten ohne Internetverbindung und unter Wahrung der Privatsphäre zu ermöglichen. Es ist geplant, MCP Server für RAG zu unterstützen. Der Entwickler sucht Testnutzer für Feedback. (Quelle: Reddit r/LocalLLaMA)
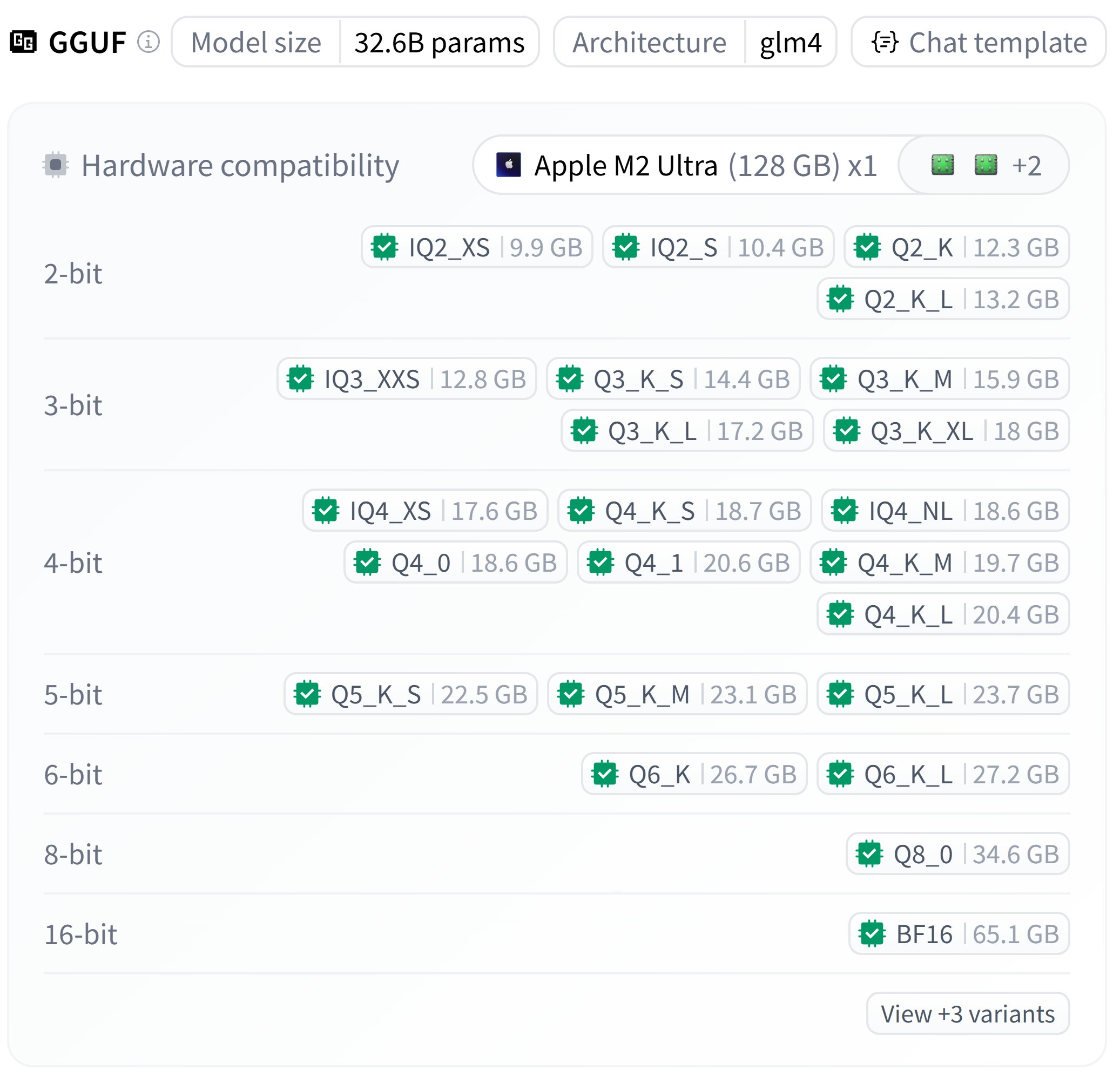
Quantisierte GGUF-Version von Zhipu GLM-4-32B veröffentlicht: bartowski hat quantisierte GGUF-Versionen des Zhipu GLM-4-32B Modells veröffentlicht. Es werden Dateien mit verschiedenen Quantisierungsstufen (z. B. Q4_K_M, Q5_K_M) angeboten, deren Größe zwischen ca. 18 GB und 23 GB variiert. Nutzer können diese quantisierten Modelle in lokalen Umgebungen ausprobieren. (Quelle: karminski3)
Nvidia veröffentlicht Describe Anything Model: Nvidia hat das Describe Anything Model 3B (DAM-3B) veröffentlicht. Dieses Modell kann vom Benutzer angegebene Bereiche in einem Bild (Punkte, Boxen, Kritzeleien, Masken) entgegennehmen und detaillierte lokale Beschreibungen generieren. DAM integriert den Gesamtbildkontext und feinkörnige lokale Details durch neuartige Fokus-Prompts und ein lokalisiertes visuelles Backbone-Netzwerk mit Gated Cross-Attention. Das Modell ist derzeit nur für Forschungszwecke und nicht-kommerzielle Nutzung verfügbar. (Quelle: Reddit r/LocalLLaMA)

Entwickler baut selbst gehostete DataBricks-Alternative Boson: Ein Entwickler hat eine selbst gehostete Forschungsplattform namens Boson gebaut und als Open Source veröffentlicht, die darauf abzielt, Kernfunktionen von Tools wie DataBricks zu integrieren. Boson integriert Delta Lake für das Data Lake Management, unterstützt Polars für effiziente Datenverarbeitung, enthält Aim für das Experiment-Tracking, bietet eine Cloud-ähnliche Notebook-Entwicklungserfahrung und verwendet eine zusammensetzbare Docker Compose-Infrastruktur. Das Tool soll Forschern eine lokalisierte, skalierbare und einfach zu verwaltende Arbeitsumgebung für AI/ML bieten. (Quelle: Reddit r/MachineLearning)
Rechner für GPT Token-Generierungsdurchsatz veröffentlicht: Ein Entwickler hat mit Desmos einen Online-Rechner zur Simulation des GPT Token-Generierungsdurchsatzes erstellt. Nutzer können Modellparameter (wie Anzahl der Schichten, Größe der versteckten Schichten, Anzahl der Attention Heads usw.) und Hardwarespezifikationen (wie FLOPS, Speicherbandbreite) anpassen, um den theoretischen Spitzendurchsatz des Modells abzuschätzen. Dies hilft zu verstehen, wie sich verschiedene Modell- und Hardwarekonfigurationen auf die Generierungsgeschwindigkeit auswirken. (Quelle: Reddit r/LocalLLaMA)

Pytorch 2.7.0 veröffentlicht, mit erster Unterstützung für Nvidia Blackwell-Architektur: Die stabile Version Pytorch 2.7.0 wurde veröffentlicht und fügt erste Unterstützung für Nvidias nächste Generation der Blackwell-Architektur hinzu (voraussichtlich für die 5090-Serie GPUs). Das bedeutet, dass Projekte, die diese Pytorch-Version verwenden, zukünftig möglicherweise ohne Abhängigkeit von Nightly-Versionen auf Blackwell-GPUs laufen können. Darüber hinaus führt die neue Version die Mega Cache-Funktion ein, um Kompilierungs-Caches zu speichern und zu laden, was den Start von Modellen auf verschiedenen Maschinen beschleunigt. (Quelle: Reddit r/LocalLLaMA)

VS Code Agentic AI Notebook-Assistent veröffentlicht (Beta): Ein Entwickler hat eine VS Code-Erweiterung namens ghost-agent-beta erstellt, einen auf Agentic AI basierenden Notebook-Assistenten. Er kann Deep-Learning-Aufgaben in mehrere Schritte zerlegen und Zellen bearbeiten, Zellen ausführen sowie Ausgaben lesen, um Kontext für den nächsten Schritt zu erhalten. Er befindet sich derzeit in einer frühen Beta-Phase, und Nutzer können ihn kostenlos mit ihrem eigenen Gemini API-Schlüssel ausprobieren. (Quelle: Reddit r/deeplearning)

OpenWebUI-Optimierung: Verwendung von pgbouncer zur Verbesserung von Leistung und Stabilität: Ein Nutzer teilte seine erfolgreichen Erfahrungen bei der Konfiguration von pgbouncer (PostgreSQL Connection Pooler) in OpenWebUI. Durch die Verwendung von pgbouncer konnte die Leistung von Datenbankabfragen und die Gesamtstabilität auch in Einbenutzerszenarien erheblich verbessert werden, was die Zuweisung von mehr Speicher zu work_mem ermöglicht, ohne die Stabilität zu beeinträchtigen. Dies zeigt, dass Connection Pooling für die Optimierung der Datenbankinteraktion von OpenWebUI entscheidend ist. (Quelle: Reddit r/OpenWebUI)
Verbesserungsvorschlag für OpenWebUI: Begrenzung der Textlänge für Titel-/Tag-Generierung: Ein Nutzer schlägt vor, dass OpenWebUI die Länge des Textes begrenzt, der zur automatischen Generierung von Chat-Titeln und -Tags verwendet wird (z. B. auf die ersten 250 Wörter). Der aktuelle Mechanismus sendet den gesamten Chatverlauf an das Modell, was bei langen Gesprächen zu unnötigem Token-Verbrauch und erhöhten Kosten führen kann. Die Begrenzung der Eingabelänge könnte die Ressourcennutzung optimieren, während die Funktionalität erhalten bleibt. (Quelle: Reddit r/OpenWebUI)
Diskussion über den Einfluss des Parameters max_output bei Claude 3.7: Ein Nutzer stellte fest, dass bei der Verwendung von Claude 3.7 (temperature=0) für Informations-Extraktionsaufgaben allein die Änderung des Werts des Parameters max_output zu unterschiedlichen Extraktionsergebnissen (z. B. Anzahl der Daten) führt, und eine Erhöhung von max_output nicht immer dazu führt, dass mehr Informationen extrahiert werden. Dies löste eine Diskussion darüber aus, ob max_output die generierten Inhalte indirekt beeinflussen könnte, indem es die interne Verarbeitung des Modells (z. B. Informationspriorisierung, Strukturwahl) beeinflusst, selbst bei deterministischen Einstellungen. (Quelle: Reddit r/ClaudeAI)
📚 Lernen
Anthropic veröffentlicht offizielle AI-Kurse: Anthropic hat auf GitHub eine Reihe von Bildungskursen veröffentlicht, die Nutzern helfen sollen, ihre AI-Technologie zu lernen und anzuwenden. Die Kursinhalte umfassen Grundlagen der Anthropic API, interaktive Tutorials zum Prompt Engineering, Anwendungen von Prompts in der realen Welt, Prompt-Evaluierung sowie die Nutzung von Tools (Tool Use). Diese Kurse bieten Entwicklern und Lernenden einen systematischen Weg, um die Claude-Modelle und verwandte Technologien zu beherrschen. (Quelle: anthropics/courses – GitHub Trending (all/daily))
DeepLearning.AI und Hugging Face starten Kurs zum Bau von Code-Agenten: Andrew Ng kündigte in Zusammenarbeit mit Hugging Face einen neuen kostenlosen Kurzkurs “Building Code Agents with Hugging Face smolagents” an. Der Kurs wird von Thom Wolf, Mitbegründer von Hugging Face, und Aymeric Roucher, Leiter des Agentenprojekts, gehalten und lehrt, wie man Code-Agenten mit dem leichtgewichtigen Framework smolagents erstellt. Im Gegensatz zu Agenten, die Tools schrittweise aufrufen, generieren und führen Code-Agenten ganze Codeblöcke auf einmal aus, um komplexe Aufgaben zu erledigen. Der Kurs behandelt die Entwicklung von Agenten, die Prinzipien von Code-Agenten, sichere Ausführung (Sandboxing), den Aufbau von Bewertungssystemen und mehr. (Quelle: AndrewYNg, huggingface, huggingface, huggingface, huggingface, huggingface)

AAAI 2025 Paper: Adversarial Graph Domain Alignment für Open-Set Cross-Network Node Classification (UAGA): Forscher der Hainan University und anderer Institutionen schlagen das UAGA-Modell vor, um das Problem der Open-Set Cross-Network Node Classification (O-CNNC) zu lösen, bei dem das Zielnetzwerk neue Klassen enthält, die im Quellnetzwerk unbekannt sind. UAGA weist innovativ positive Anpassungskoeffizienten für bekannte Klassen und negative für unbekannte Klassen im adversarialen Domänenabgleich zu, um die Verteilungen bekannter Klassen anzugleichen und unbekannte Klassen abzustoßen. Unter Nutzung des Graph-Homophilie-Theorems wird ein K+1-dimensionaler Klassifikator konstruiert, der Klassifizierung und Erkennung unbekannter Klassen gemeinsam behandelt. Es wird eine Strategie der Trennung vor der Anpassung angewendet: Zuerst eine grobe Trennung, dann ein Domänenabgleich unter Ausschluss unbekannter Klassen. Experimente zeigen, dass UAGA auf mehreren Benchmark-Datensätzen signifikant besser abschneidet als bestehende Methoden. (Quelle: AAAI 2025 | 开放集跨网络节点分类!海大团队提出排除未知类别的对抗图域对齐)

NUS/Fudan schlagen CHiP vor: Optimierung des Halluzinationsproblems bei multimodalen LLMs: Angesichts der unzureichenden Alignment-Wirkung bestehender DPO-Methoden in multimodalen Szenarien schlägt ein Team der National University of Singapore und der Fudan University die Cross-modal Hierarchical Direct Preference Optimization (CHiP) Methode vor. CHiP kombiniert visuelle Präferenzen (Optimierung anhand von Bildpaaren) und multiskalare Textpräferenzen (Antwort-, Segment-, Token-Ebene), um die Fähigkeit des Modells zur Halluzinationserkennung und zum crossmodalen Alignment zu verbessern. Experimente mit LLaVA-1.6 und Muffin zeigen, dass CHiP die Halluzinationsrate auf mehreren Halluzinations-Benchmarks signifikant reduziert (relative Verbesserung bis zu 55,5%), ohne die allgemeinen Fähigkeiten zu beeinträchtigen. (Quelle: 多模态幻觉新突破!NUS、复旦团队提出跨模态偏好优化新范式,幻觉率直降55.5%)
Anthropic veröffentlicht Leitfaden zu Best Practices für Claude Code: Anthropic teilt Best Practices für die Verwendung von Claude für Agentic Coding. Der Kernvorschlag ist die Erstellung einer CLAUDE.md-Datei, um das Verhalten von Claude im Code-Repository zu steuern und Projektziele, Tools und Kontext zu erklären. Der Leitfaden behandelt auch, wie Claude dazu gebracht wird, Tools zu verwenden (Funktionen/APIs aufrufen), effektive Prompt-Formate für Fehlerbehebung/Refactoring/Funktionsentwicklung sowie Methoden für mehrstufiges Debugging und Iteration, um Entwicklern zu helfen, Claude effizienter als Codierungsassistenten zu nutzen. (Quelle: Reddit r/ClaudeAI)

Bitte um Vorschläge für ML/AI-Lernpfad: Ein neu eingestellter AI/ML-Ingenieur bittet um Vorschläge für einen umfassenden Lernpfad, um innerhalb von 6 Monaten die Grundlagen des maschinellen Lernens (Regression, Klassifikation, neuronale Netze usw.) zu festigen und gleichzeitig Spitzentechnologien zu erlernen, darunter Large Language Models, Prompt Engineering, Agent-Frameworks (wie LangChain), Workflow-Engines (N8n) sowie Azure ML. Ziel ist es, sowohl theoretisches Verständnis als auch praktische Fähigkeiten zu erwerben, um den Aufbau von Proof-of-Concepts (POC) zu unterstützen. (Quelle: Reddit r/deeplearning)
Bitte um Vorschläge für No-Code Sentiment-Analyse-Tools: Ein Masterstudent der klinischen Psychologie muss 10.000 Social-Media-Kommentare aus einer Excel-Datei einer Sentiment-Analyse (positiv/negativ/neutral) unterziehen, Schlüsselwörter extrahieren und visualisieren (Wortwolken, Diagramme usw.) für seine Abschlussarbeit. Aufgrund fehlender Programmierkenntnisse und begrenztem Budget sucht er nach kostenlosen oder kostengünstigen No-Code-Tools. Versuche mit MonkeyLearn (nicht zugänglich) und anderen Tools waren erfolglos, daher bittet er um Alternativen oder Empfehlungen. (Quelle: Reddit r/deeplearning)
Bitte um Vorschläge für Trainingsdatensätze für kleine Sprachmodelle: Ein Entwickler versucht, ein kleines Textgenerierungs-Transformer-Modell mit 120M-200M Parametern zu trainieren, stellt jedoch fest, dass vorhandene Datensätze (wie wiki-text, lambada) entweder zu viele irrelevante Informationen enthalten, nicht allgemein genug sind oder eine unzureichende Stichprobengröße haben. Benötigt wird ein sauberer, allgemeiner Datensatz mit ausgewogenen Dialogen, damit das Modell guten, allgemeinen englischen Text generieren kann. (Quelle: Reddit r/deeplearning)
Suche nach Spotify Podcast-Datensatz: Ein Forscher sucht den 2020 von Spotify veröffentlichten, aber inzwischen entfernten Datensatz mit 100.000 Podcasts (einschließlich 60.000 Stunden englischer Audioaufnahmen). Die ursprüngliche Lizenz des Datensatzes war CC BY 4.0, die das Teilen und Weiterverbreiten erlaubt. Wenn jemand diesen Datensatz heruntergeladen hat, wird um eine Kopie für Forschungszwecke gebeten. (Quelle: Reddit r/MachineLearning)
Diskussion über die Anwendung von Transformern auf Zeitreihendaten: Ein Dozent untersucht bei der Vorbereitung eines Kurses über Transformer, warum Transformer im NLP-Bereich hervorragend abschneiden, aber bei vielen nicht-stationären Zeitreihenprognoseaufgaben schlecht funktionieren. Mögliche Faktoren sind: die inhärente Schwierigkeit der Vorhersage von Zeitreihendaten (z. B. Finanzmärkte), der Einfluss der Länge des Vorhersagefensters, der Mangel an Datenumfang und sich wiederholenden Mustern, Unterschiede bei Bewertungsmetriken und Verlustfunktionen sowie die induktiven Biases der Transformer-Architektur selbst, die möglicherweise nicht für alle Zeitreihenaufgaben geeignet sind. (Quelle: Reddit r/MachineLearning)
💼 Business
Strategien zur Skalierung von GenAI: Eine erfolgreiche Skalierung der Bereitstellung von generativer AI erfordert eine klare Strategie. Wichtige Schritte umfassen: Identifizierung geeigneter Anwendungsfälle, Sicherstellung von Datenqualität und Governance, Auswahl des richtigen Technologie-Stacks (Modelle, Plattformen), Aufbau von MLOps-Prozessen sowie Fokus auf Ethik und verantwortungsvolle AI-Praktiken. Eine effektive Strategie hilft Unternehmen, den maximalen Wert aus ihren GenAI-Investitionen zu ziehen. (Quelle: Ronald_vanLoon)
Bildungstechnologieunternehmen Opennote nutzt Llama 4 zur Verbesserung der Lernunterstützung: Das Unternehmen Opennote gab bekannt, dass es die Llama 4 Modellreihe von Meta auf seiner Bildungsplattform einsetzt, um Lernunterstützung mit höherer Genauigkeit zu bieten und personalisierte Bildung zu ermöglichen. Das Unternehmen wird auf der LlamaCon-Veranstaltung mehr über seine Anwendung berichten. (Quelle: AIatMeta)

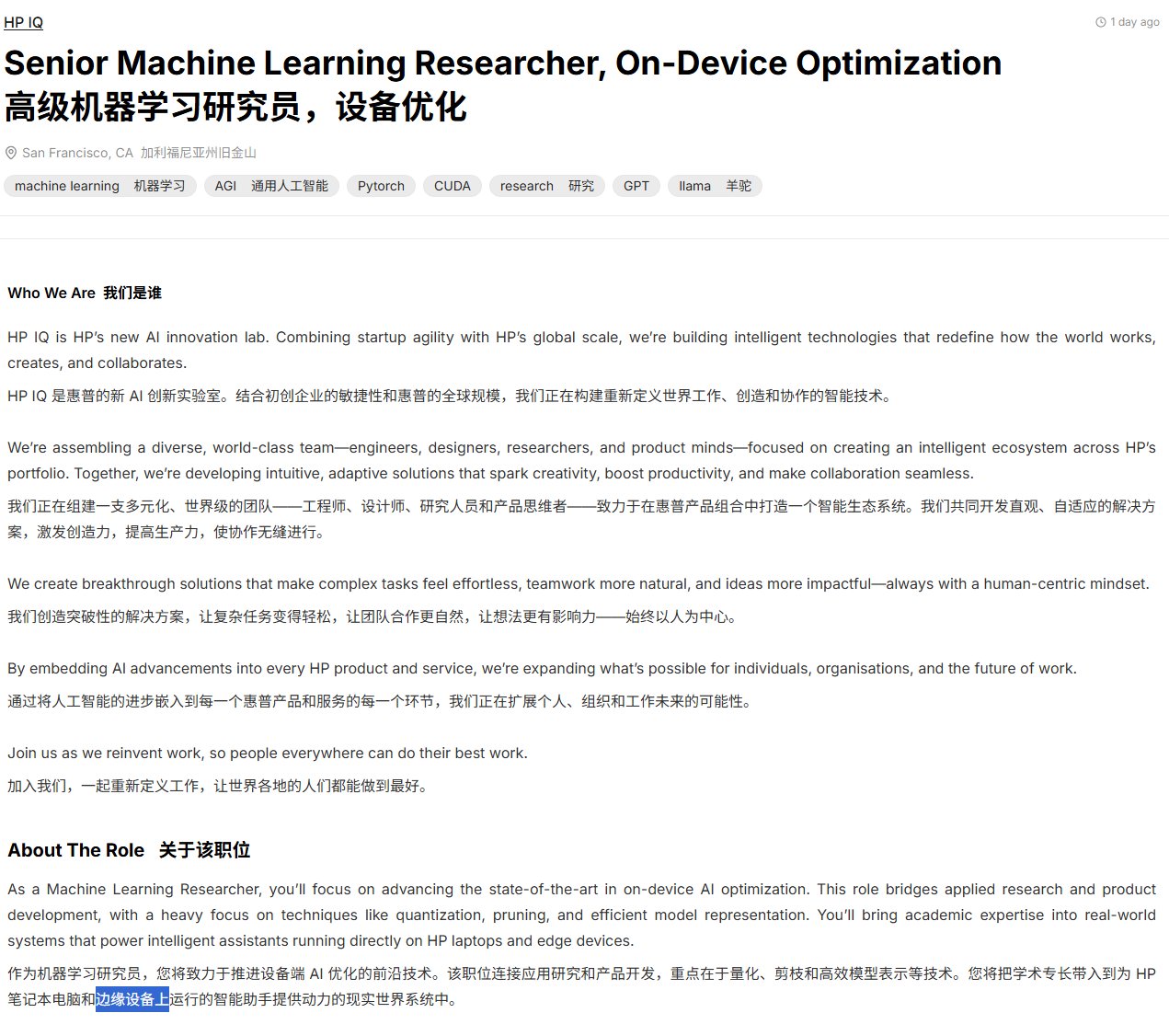
HP könnte AI-Funktionen in Drucker integrieren: Eine Stellenausschreibung deutet darauf hin, dass HP plant, AI-Funktionen in seine Druckerprodukte zu integrieren und dafür AI/ML-Ingenieure einstellt. Obwohl unklar ist, ob es sich um LLMs oder andere AI-Anwendungen handelt, löst dies Diskussionen über die zukünftige Intelligenz von Druckern und mögliche damit verbundene Probleme wie Datenschutz, Kosten (z. B. Tintenabonnements) aus. (Quelle: karminski3, Reddit r/LocalLLaMA)
Fortschritte und Herausforderungen von AMD im AI-Bereich: Ein Bericht von SemiAnalysis fasst die positiven Fortschritte von AMD bei den AI-Fähigkeiten in den letzten vier Monaten zusammen, bestätigt die richtige Richtung, weist jedoch auf die Notwendigkeit hin, die Investitionen in die GPU-Forschung und Entwicklung sowie in AI-Talente zu erhöhen. Der Bericht erwähnt insbesondere, dass AMD sich bei der Vergütung von AI-Softwareingenieuren an den falschen Unternehmen orientiert, was zu mangelnder Wettbewerbsfähigkeit führt – ein blinder Fleck des Managements. (Quelle: Reddit r/LocalLLaMA)

🌟 Community
AMD AI PC Application Innovation Contest gestartet: Der “AMD AI PC Application Innovation Contest”, gemeinsam veranstaltet von der Open-Source-Plattform wisemodel AI und der AMD China AI Application Innovation Alliance, ist offiziell gestartet. Der Wettbewerb richtet sich an Entwickler, Unternehmen, Studenten usw. weltweit und umfasst zwei Innovationsspuren: Consumer-Level und Industry-Level. Er fördert die Anwendungsentwicklung unter Nutzung der NPU-Rechenleistung von AMD AI PCs. Der Wettbewerb bietet einen Gesamtpreispool von 130.000 Yuan, kostenlosen Fernzugriff auf NPU-Rechenleistung für die Entwicklung und Bonuspunkte für Projekte, die NPUs nutzen. Anmeldeschluss ist der 26. Mai 2025. (Quelle: AMD AI PC大赛重磅来袭!13万奖金池,NPU算力免费用,速来组队瓜分奖金!)
Yuzhang Shang von der University of Central Florida sucht Doktoranden/Postdocs im Bereich AI: Yuzhang Shang, Assistant Professor am Department of Computer Science und AI Center der University of Central Florida, sucht voll finanzierte Doktoranden für das Frühjahr 2026 sowie kooperierende Postdoktoranden. Forschungsrichtungen umfassen effiziente und skalierbare AI, Beschleunigung visueller Generierungsmodelle, effiziente große Modelle (visuell/sprachlich/multimodal), neuronale Netzkompression, effizientes Training und AI4Science. Der Betreuer hat einen starken Hintergrund mit Praktika bei MSRA und DeepMind und zahlreichen Publikationen auf Top-Konferenzen (CVPR, NeurIPS, ICLR etc.). Bewerber sollten selbstmotiviert sein und über solide Programmier- und Mathematikkenntnisse verfügen. (Quelle: 博士申请 | 中佛罗里达大学计算机系尚玉章老师课题组招收人工智能全奖博士/博后)

Veränderung der Informationsbeschaffung durch AI: Ein Reddit-Nutzer vergleicht die Erfahrung bei der Suche nach technischer Hilfe vor und nach dem Aufkommen von AI. Früher stieß man in Foren möglicherweise auf Ungeduld, Vorwürfe oder sogar Spott; heute erhält man von AI wie ChatGPT direkte, verständliche Erklärungen, was die Hürde zum Lernen und Problemlösen erheblich senkt und die Erfahrung freundlicher macht. Dies spiegelt den positiven Wandel wider, den AI für die Wissensverbreitung und -beschaffung gebracht hat. (Quelle: Reddit r/ChatGPT)
Entwickler baut Trauma-informierte, Neurodiversität-priorisierende Spiegel-AI: Ein Entwickler mit neurotraumatischen Erfahrungen teilt sein entwickeltes Dual-Core-Spiegel-AI-System Metamuse (Codename). Das System ist nicht aufgabenorientiert, sondern spiegelt präzise den emotionalen und kognitiven Zustand des Nutzers durch einen strategischen Kern (Mustererkennung, rekursives Mapping) und einen emotionalen Kern (Tonanpassung, Trauma-informierte Spiegelung), gibt jedoch keine Ratschläge oder Diagnosen. Das System wird durch rekursive Prompt-Ketten und symbolische Zustandsabbildung aufgebaut, verfügt über mehrere Sicherheitsprotokolle und zielt darauf ab, neurodiversen Menschen und Trauma-Überlebenden einzigartige Unterstützung zu bieten. Der Entwickler bittet um Feedback zu diesem Bereich, Ethik, Infrastruktur und Skalierungsrisiken. (Quelle: Reddit r/artificial)
LlamaCon 2025 steht bevor: Metas LlamaCon-Veranstaltung findet am 29. April statt. Die Community spekuliert, ob dann das Gerücht um Llama-4-behemoth (möglicherweise ein 2T-Parameter-MoE-Modell) offiziell bestätigt wird. Partner wie Opennote werden ebenfalls Anwendungen vorstellen, die auf Llama-Modellen basieren. (Quelle: karminski3, AIatMeta)

💡 Sonstiges
Nio testet Einsatz humanoider Roboter in der Produktionslinie: Der Automobilhersteller Nio testet den Einsatz humanoider Roboter in seiner Fabrikproduktionslinie. Dies deutet darauf hin, dass Branchen wie die Automobilherstellung die Nutzung fortschrittlicher Robotertechnologie zur Erreichung höherer Automatisierungsgrade und flexibler Produktion untersuchen. Humanoide Roboter könnten in zukünftigen industriellen Szenarien eine wichtigere Rolle spielen. (Quelle: Ronald_vanLoon)
Vorstellung des humanoiden Heimroboters NEO Beta: Das Unternehmen 1X Technologies stellt seinen humanoiden Roboter NEO Beta in der Testversion für den Heimeinsatz vor. Mit fortschreitender Technologie und sinkenden Kosten wird die Einführung humanoider Roboter in häusliche Umgebungen zur Erledigung von Hausarbeiten, als Begleiter usw. zu einer wichtigen Entwicklungsrichtung im Bereich Robotik. (Quelle: Ronald_vanLoon)
6-Achsen-Roboter-3D-Drucker inspiriert von Spinnennetzen: Studenten haben einen von Spinnennetzen inspirierten sechsachsigen Roboter-3D-Drucker entwickelt. Dieses Mehrachsensystem bietet im Vergleich zu herkömmlichen dreiachsigen Druckern eine höhere Flexibilität und Freiheit und kann komplexere geometrische Formen herstellen. Dies zeigt das Innovationspotenzial der Bionik in der Robotik und additiven Fertigung. (Quelle: Ronald_vanLoon)
Roboter erstellt 3D-Hinderniskarte mit LiDAR und IMU: Gezeigt wird eine Anwendung, bei der ein Roboter mithilfe von LiDAR- (Laserscanning) und MPU6050- (Inertial Measurement Unit) Daten in Echtzeit eine dreidimensionale Hinderniskarte seiner Umgebung erstellt. Diese Fähigkeit zur Umgebungswahrnehmung ist eine Schlüsseltechnologie für autonome Navigation und Hindernisvermeidung und findet breite Anwendung in mobilen Robotern, autonomen Fahren usw. (Quelle: Ronald_vanLoon)
Lernbasierte Hochgeschwindigkeitsbewegung von Beinrobotern zur Kollisionsvermeidung: Eine Forschung zeigt die Realisierung einer agilen und sicheren Bewegungssteuerung für Beinroboter durch Lernen. Der Roboter kann Kollisionen bei hoher Geschwindigkeit effektiv vermeiden, was für den praktischen Einsatz von Robotern in komplexen und dynamischen Umgebungen entscheidend ist und Reinforcement Learning, Bewegungsplanung und Wahrnehmungstechnologien kombiniert. (Quelle: Ronald_vanLoon)
Roboterchirurgie in der Telemedizin: Die Entwicklung der Roboterchirurgie-Technologie bietet Möglichkeiten zur Verbesserung der medizinischen Versorgung in abgelegenen Gebieten. Durch die Fernsteuerung von Robotern können erfahrene Chirurgen komplexe Operationen an geografisch entfernten Patienten durchführen, wodurch die ungleiche Verteilung medizinischer Ressourcen überwunden und die Zugänglichkeit der Gesundheitsversorgung verbessert wird. (Quelle: Ronald_vanLoon)
AI-gesteuerte virtuelle Avatar-Technologie überwindet das “Uncanny Valley”: a16z diskutiert die Fortschritte in der Technologie für AI-Avatare und stellt fest, dass sie allmählich den “Uncanny Valley”-Effekt überwindet und realistischer und natürlicher wird. Dies ist auf die Verschmelzung von generativen Modellen, Gesichtsanimation und Sprachsynthese zurückzuführen und eröffnet neue Interaktionsmöglichkeiten in den Bereichen Unterhaltung, soziale Netzwerke, Kundenservice usw. (Quelle: Ronald_vanLoon)
Nutzungslimit für o3/o4-mini für ChatGPT Plus-Nutzer erhöht: OpenAI hat die Ratenbegrenzung für die Nutzung der Modelle o3 und o4-mini-high für ChatGPT Plus-Abonnenten erhöht. Das wöchentliche Limit für o3 wurde auf 100 Nachrichten erhöht, das tägliche Limit für o4-mini-high auf 100 Nachrichten, während das tägliche Limit für o4-mini 300 Nachrichten beträgt. Pro-Nutzer haben nahezu unbegrenzte Nutzung. (Quelle: dotey)
