Schlüsselwörter:Humanoider Roboter, KI-Anwendungen, AGI, Autonomes Fahren, Humanoid-Roboter-Marathon, Agent+MCP, DeepMind AGI-Prognose, Tesla reine visuelle FSD, GPT-SoVITS Sprachklonierung, ChemAgent chemische Schlussfolgerung, Geschäftsmodell von Zhiyuan Robotern, Herausforderung der NVIDIA GPU-Monopolstellung
🔥 Fokus
Humanoide Roboter feiern „Debüt“ beim Pekinger Halbmarathon, Chancen und Herausforderungen zugleich: Beim Beijing Yizhuang Halbmarathon 2025 traten erstmals 21 Teams humanoider Roboter gegen menschliche Läufer an. Tiangong Ultra, Songyan Dynamics N2 und Zhuoyide Walker II belegten die ersten drei Plätze. Der Wettbewerb verdeutlichte das Potenzial humanoider Roboter, offenbarte aber auch zahlreiche Herausforderungen wie Stürze, Akkulaufzeit und Steuerung (meist ferngesteuert). Unitree Technology kommentierte den Sturz seines G1-Roboters und wies darauf hin, dass die Eigenentwicklung und Bedienung durch den Nutzer die Leistung des Roboters stark beeinflusst. Die Veranstaltung zeigte nicht nur den anfänglichen Umfang der chinesischen Industrie für humanoide Roboter, sondern löste auch breite Diskussionen über technologische Reife, Kosten (Songyan N2 Vorverkaufspreis ab 39.900 Yuan), Kommerzialisierungspfade (Vermietung, industrielle Anwendungen) und zukünftige Entwicklung (AI Large Models, autonomes Lernen) aus. Obwohl die Branche Kapital anzieht, ist kurzfristige Rentabilität schwierig und die Markteinführung benötigt noch Zeit (Quelle: 摔倒的宇树和人形机器人的“求生”博弈, 从进厂到马拉松:人形机器人离“实用”还有多远?)
Neues Paradigma für AI-Anwendungen: Agent+MCP wird zur Erfolgsformel für 2025: Die Kombination der autonomen Planungs- und Handlungsfähigkeiten von Agents mit der Fähigkeit des MCP-Protokolls, externe Tools und Daten aufzurufen, entwickelt sich zu einem neuen Trend bei AI-Anwendungen. Produkte wie „扣子空间“, Fellou, Dia, GenSpark und Zhipu AutoGLM tauchen auf und ziehen Aufmerksamkeit auf sich. Viele dieser Produkte entwickelten sich aus der AI-Suche und versuchen, durch unterschiedliche Produktdesigns (Benutzerfreundlichkeit, Recherchefähigkeiten, Umsetzung) Barrieren im Nutzererlebnis aufzubauen. Trotz des enormen Potenzials bestehen derzeit noch Herausforderungen wie Obergrenzen der Modellfähigkeiten, plattformübergreifende Informationsbeschaffung und Kommerzialisierungsmodelle. Microsoft hat ebenfalls das Multi-Agent-System UFO² für Desktops vorgestellt, was darauf hindeutet, dass AM (Agent+MCP) eine wichtige Richtung für AI-Produkte werden wird (Quelle: 2025年,AI应用的爆款公式只有一个)
Heftige Debatte über die Zukunft der AI: Hassabis prophezeit Heilung aller Krankheiten in zehn Jahren, Harvard-Historiker warnt vor Auslöschung der Menschheit durch AGI: Google DeepMind CEO Demis Hassabis prognostizierte in einem Interview, dass AI in 5-10 Jahren AGI erreichen und potenziell innerhalb eines Jahrzehnts alle Krankheiten heilen könnte, wobei er AI-Fortschritte wie Project Astra vorstellte. Er betrachtet AI als das ultimative Werkzeug zur Beschleunigung wissenschaftlicher Entdeckungen. Der Harvard-Historiker Niall Ferguson warnt jedoch, dass die Ankunft von AGI dazu führen könnte, dass die Menschheit wie Pferdekutschen überflüssig wird oder sogar ausgelöscht wird – zu „Aliens“, die von uns selbst geschaffen wurden. Er weist darauf hin, dass Trends wie institutionelle Verkrustung und sinkende globale Geburtenraten dazu führen könnten, dass die Menschheit angesichts von AGI beschließt, „von der Bühne der Geschichte abzutreten“. Diese Diskussion unterstreicht den enormen Kontrast zwischen extremem Optimismus bezüglich des Potenzials von AGI und tiefer Besorgnis über die Zukunft der menschlichen Zivilisation (Quelle: 诺奖得主Hassabis豪言:AI十年治愈所有疾病,哈佛教授警告AGI终结人类文明, 哈佛历史学家预警:AGI灭绝人类,美国或将解体)
🎯 Trends
Fortschritte in der Roboterindustrie, Beschleunigung der kommerziellen Umsetzung: Auf der Canton Fair wurde erstmals ein spezieller Bereich für Serviceroboter eingerichtet. Chinesische Hersteller wie Pangolin Robot und Hongxu Jin Technology erhielten zahlreiche Auslandsaufträge, was die Wettbewerbsfähigkeit chinesischer Serviceroboter auf dem Weltmarkt zeigt. Gleichzeitig werden humanoide Roboter von Unternehmen wie Midea weiterentwickelt und sollen bald in Fabriken „arbeiten“. In der Lieferkette gibt es zwar Entwicklungen bei PCB, Sensoren und neuen Materialien (wie PEEK), aber die Massenproduktion benötigt noch Zeit. Schlüssel sind Technologie, Kosten und geschlossene Anwendungsszenarien. Mehrere Hersteller planen die Massenproduktion von Tausenden von Einheiten bis 2025, was die Entwicklung der Lieferkette und die Datensammlung fördern und den Übergang der Roboter in eine praktischere Phase beschleunigen könnte (Quelle: 机器人组团“营业”引爆声量场,产业链频刷进展)

Tesla hält an rein visueller FSD fest, Lidar-Route steht vor Herausforderungen und Chancen: Musk bekräftigte sein Vertrauen in die rein visuelle Lösung zur Realisierung von FSD und argumentierte, dass Kameras plus AI ausreichen, um menschliches Fahren zu simulieren, ohne dass Lidar erforderlich ist. Trotz sinkender Kosten (chinesische Lidar-Systeme kosten nur noch wenige hundert Dollar) und zunehmender Verbreitung (bereits in Fahrzeugen der 100.000-Yuan-Klasse verfügbar) hält Tesla an seiner Route fest, was extrem hohe Anforderungen an Rechenleistung, Algorithmen und Daten stellt. Gleichzeitig dominieren Lidar-Hersteller wie Hesai und RoboSense den Markt durch Kostenvorteile und technologische Iterationen und expandieren aktiv in Überseemärkte sowie in nicht-automobile Bereiche wie Robotik. Das Aufkommen von L3-autonomem Fahren könnte Lidar neue Chancen eröffnen, da seine Wahrnehmungsfähigkeiten für Sicherheitsredundanz und in spezifischen Szenarien als unverzichtbar gelten (Quelle: 马斯克最新的AI驾驶方案,会终结激光雷达吗?)

Google Imagen 3/4 möglicherweise im internen Test: Gerüchten zufolge testet Google intern seine Bildgenerierungsmodelle der nächsten Generation, Imagen 3 und Imagen 4. Dies deutet darauf hin, dass Google möglicherweise neue große Schritte im Bereich der Bildgenerierung plant, um Konkurrenten einzuholen oder zu übertreffen (Quelle: Google 又憋图像大招?传 Imagen 3/4 内测中。)
THUDM veröffentlicht SWE-Dev-Serie von Codierungsmodellen: Die Knowledge Engineering and Data Mining Research Group (THUDM) der Tsinghua-Universität hat die SWE-Dev-Serie von Codierungs-Large-Models veröffentlicht, die auf Qwen-2.5 und GLM-4 basieren. Die Serie umfasst 7B-, 9B- und 32B-Versionen und zielt darauf ab, die AI-Fähigkeiten für Softwareentwicklungs- und Codierungsaufgaben zu verbessern (Quelle: Reddit r/LocalLLaMA)

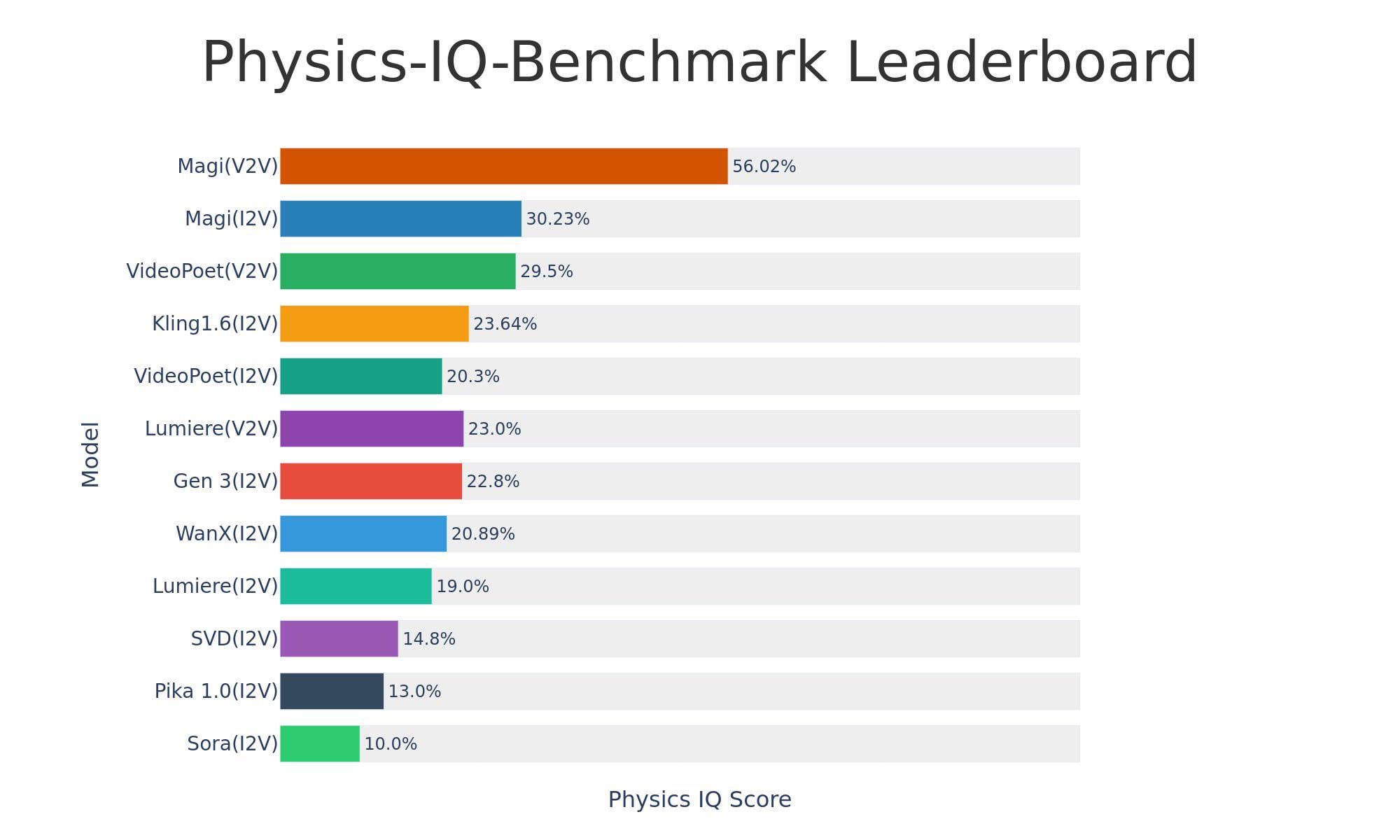
Sand-AI veröffentlicht Open-Source-Videogenerierungsmodell Magi-1: Sand-AI hat Magi-1 veröffentlicht, ein Open-Source-autoregressives Diffusions-Videogenerierungsmodell, das angeblich Videos von unbegrenzter Länge generieren kann und Text-zu-Video, Bild-zu-Video und Video-zu-Video unterstützt. Das Modell zeigt hervorragende Leistungen bei Benchmarks zum physikalischen Verständnis, erfordert jedoch extrem viel VRAM (ca. 640 GB). Code und Modell wurden auf GitHub und Hugging Face veröffentlicht (Quelle: Reddit r/LocalLLaMA)
Grok erhält visuelle, mehrsprachige Audio- und Echtzeit-Suchfunktionen: xAI kündigte an, dass das Grok-Modell um visuelles Verständnis erweitert wird und im Sprachmodus mehrsprachige Audioeingaben sowie Echtzeit-Suchfunktionen unterstützt, was seine multimodalen Interaktions- und Informationsbeschaffungsfähigkeiten verbessert (Quelle: grok, xai)
Grok 3 Modell startet auf You.com: Das Flaggschiffmodell Grok 3 von xAI ist jetzt auf der Suchmaschine You.com verfügbar. Nutzer können die Fähigkeiten von Grok 3 auf dieser Plattform erleben (Quelle: xai)

Open-Source-TTS-Modell Dia veröffentlicht und findet Beachtung: Ein Open-Source-Text-to-Speech (TTS)-Modell namens Dia wurde veröffentlicht und soll mit kommerziellen Modellen wie ElevenLabs und OpenAI konkurrieren können. Es unterstützt Zero-Shot Voice Cloning und Echtzeitsynthese und kann auf einem MacBook ausgeführt werden. Das Modell gewann schnell an Aufmerksamkeit auf Hugging Face und wurde von Medien wie VentureBeat berichtet (Quelle: huggingface, huggingface, huggingface)
Präsentation der Tesla Autopilot-Technologie: Videos oder Informationen zur Tesla Autopilot-Technologie wurden gezeigt, was weiterhin Aufmerksamkeit auf die Fortschritte im autonomen Fahren lenkt (Quelle: Ronald_vanLoon)
Präsentation von Robotertechnologien: Mehrere Quellen zeigten verschiedene Roboteranwendungen, darunter Roboterarme für die Montage kleiner Gadgets, die Bewertung des TITA-Roboters, den amphibischen Roboter Copperstone HELIX Neptune und wie Roboter die Welt wahrnehmen. Dies zeigt die kontinuierliche Entwicklung der Robotertechnologie in verschiedenen Bereichen (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Tools
GPT-SoVITS: Leistungsstarkes Werkzeug für Few-Shot Voice Cloning und Text-to-Speech: Das von RVC-Boss entwickelte GPT-SoVITS ist ein Open-Source-Projekt (GitHub 44k+ Sterne), das mit nur 1 Minute Sprachdaten hochwertige TTS-Modelle trainieren kann, um Few-Shot Voice Cloning zu realisieren. Es unterstützt Zero-Shot-TTS (5 Sekunden Eingabe für sofortige Konvertierung), sprachübergreifende Inferenz (unterstützt Englisch, Japanisch, Koreanisch, Kantonesisch, Chinesisch) und integriert eine WebUI-Toolbox mit Funktionen wie Gesangs-/Begleitungs-Trennung, automatischer Trainingsdatensatz-Segmentierung, chinesischer ASR und Textannotation, um Benutzern die Erstellung von Datensätzen und Modellen zu erleichtern. Das Projekt wurde auf Version V4 aktualisiert und optimiert kontinuierlich die Klangfarbenähnlichkeit, Stabilität und Ausgabequalität (Quelle: RVC-Boss/GPT-SoVITS – GitHub Trending (all/daily))

Tsinghua-Team stellt SurveyGO (Juan Ji) vor: AI-gesteuertes Werkzeug zur Literaturübersicht und Langberichtgenerierung: Basierend auf der LLMxMapReduce-V2-Technologie, entwickelt von Teams der Tsinghua NLP, OpenBMB und ModelBest, kann SurveyGO effizient riesige Mengen an Literatur verarbeiten (Online-Suche oder Datei-Upload) und strukturierte, logisch kohärente und korrekt zitierte Langberichte mit Zehntausenden von Wörtern erstellen. Das Werkzeug optimiert die Gliederung durch einen informationsentropiegetriebenen Faltungsmechanismus und generiert Inhalte hierarchisch, um das Problem der zusammenhanglosen und oberflächlichen Inhalte bei der traditionellen AI-Langtextgenerierung zu lösen. Benutzer können es über eine Webversion erleben, um die Effizienz von Forschern und Content-Erstellern bei der Literaturrecherche und beim Schreiben erheblich zu steigern (Quelle: INTJ式学术暴力!清华团队造出“论文卷姬”:3分钟速通200小时文献综述, 如何 AI「拼好文」:生成万字报告,不限模型)

text-generation-webui veröffentlicht portable Version mit Fokus auf llama.cpp: Um die Bereitstellung zu vereinfachen, hat text-generation-webui eine portable, eigenständige Version (ca. 700 MB) speziell für llama.cpp veröffentlicht. Benutzer können sie nach dem Herunterladen und Entpacken ausführen, ohne Python, PyTorch oder andere Abhängigkeiten installieren zu müssen. Die neue Version unterstützt Windows/Linux/macOS (einschließlich CPU/CUDA-Versionen) und bietet optimierte Startgeschwindigkeit und Benutzerfreundlichkeit (z. B. automatisches Öffnen des Browsers, standardmäßig aktivierte API). Dies bietet großen Komfort für Benutzer, die nur llama.cpp für lokale Inferenz verwenden möchten (Quelle: Reddit r/LocalLLaMA)
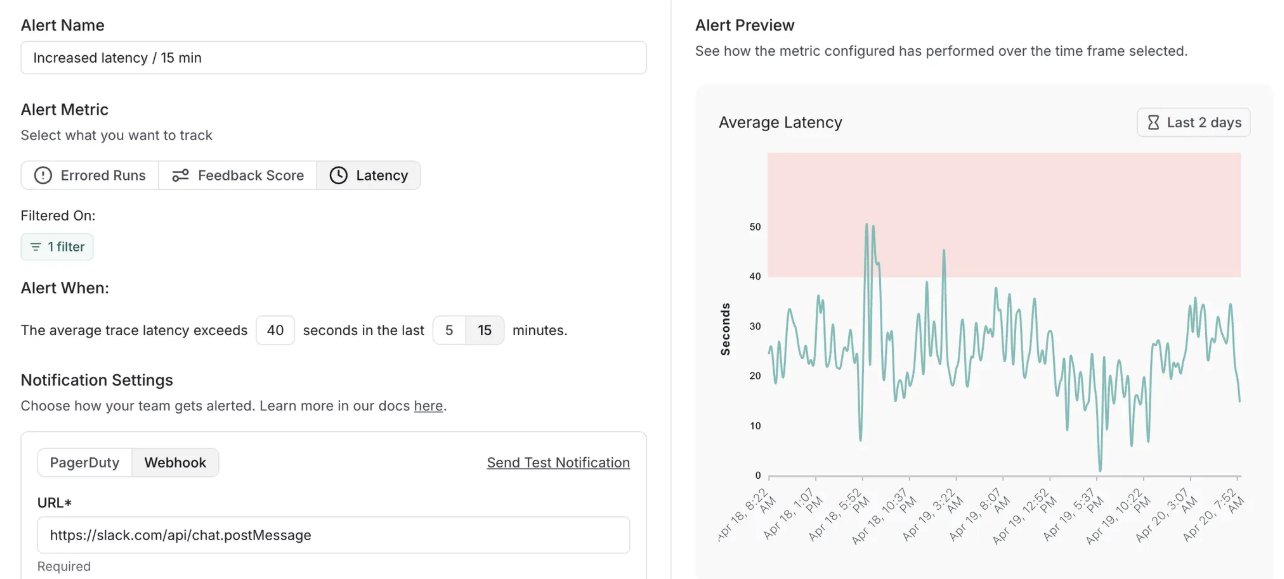
LangSmith fügt Alarmierungsfunktion hinzu und aktualisiert Self-Hosted-Version: LangChains MLOps-Plattform LangSmith hat eine Echtzeit-Alarmierungsfunktion hinzugefügt. Benutzer können Benachrichtigungen für Fehlerraten, Laufzeitlatenz und Feedback-Scores einrichten, um Probleme zu erkennen, bevor sie Kunden beeinträchtigen. Gleichzeitig wurde die Self-Hosted-Version auf v0.10 aktualisiert und enthält die Alarmierungsfunktion, neue UI zum Erstellen und Anzeigen von Bewertungen, Unterstützung für OpenTelemetry-Client-Tracing-Daten und Leistungsoptimierungen (Quelle: LangChainAI, LangChainAI)
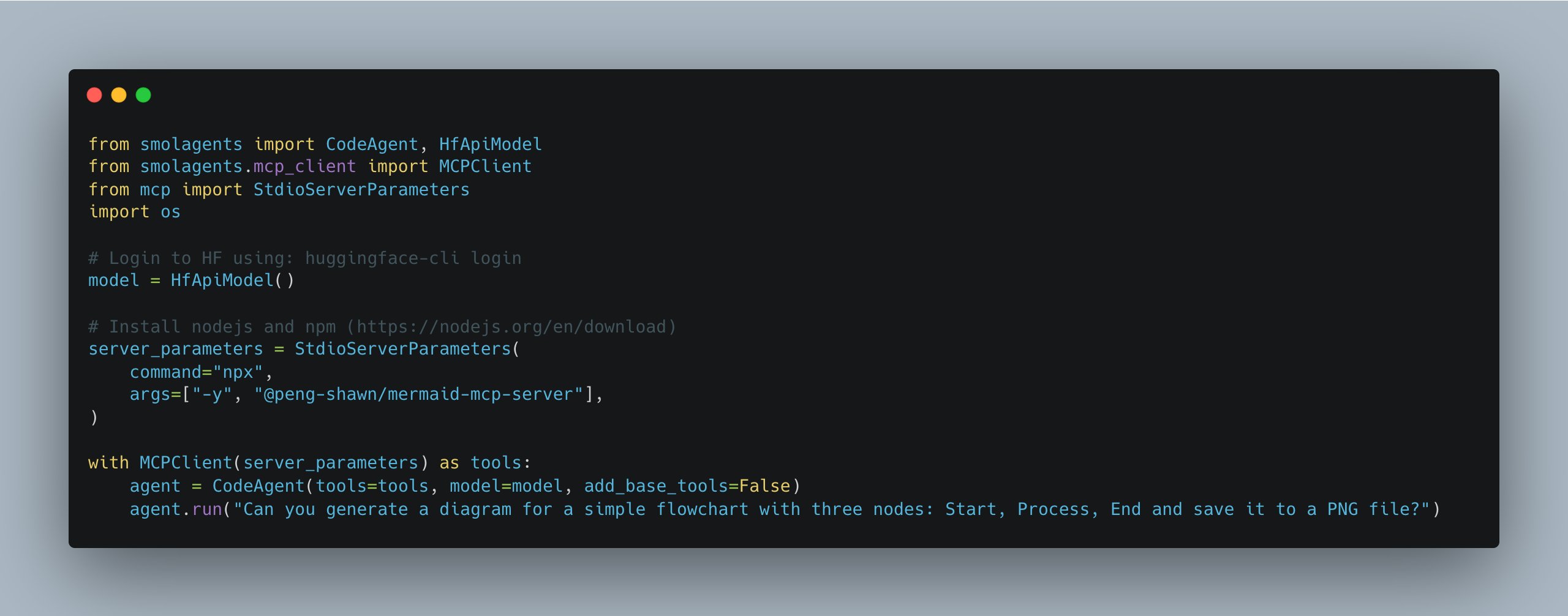
smolagents aktualisiert, vereinfacht Verwaltung mehrerer MCP-Server: Die smolagents-Bibliothek von Hugging Face hat eine neue Version veröffentlicht, die die Klasse MCPClient einführt. Dies erleichtert die Verwaltung von Verbindungen zu mehreren MCP-Servern (Model Communication Protocol) erheblich und vereinfacht die Erstellung und Koordination komplexerer Agent-Systeme für Entwickler (Quelle: huggingface)
Suna: Open-Source-Agent-Plattform als Alternative zu Manus: Kortix AI hat die Open-Source-Agent-Plattform Suna veröffentlicht, die als Alternative zu Manus positioniert ist. Suna integriert Funktionen wie Browser-Automatisierung, Dateiverwaltung, Web-Crawling, erweiterte Suche, Befehlszeilenausführung, Website-Bereitstellung und API-Integration. Dies ermöglicht es der AI, diese Tools koordiniert zu nutzen, um komplexe Probleme durch Dialog zu lösen und Arbeitsabläufe zu automatisieren (Quelle: karminski3)
Exa MCP unterstützt jetzt Twitter-Suche ohne API: Der MCP-Server von Exa wurde aktualisiert und unterstützt nun die Suche nach Twitter-Inhalten, ohne dass ein Twitter-API-Schlüssel erforderlich ist. Dies erleichtert AI-Agents den Zugriff auf Informationen von Twitter, obwohl Benutzer berichten, dass die Unterstützung für das Crawlen chinesischer Inhalte schlecht ist (Quelle: karminski3)
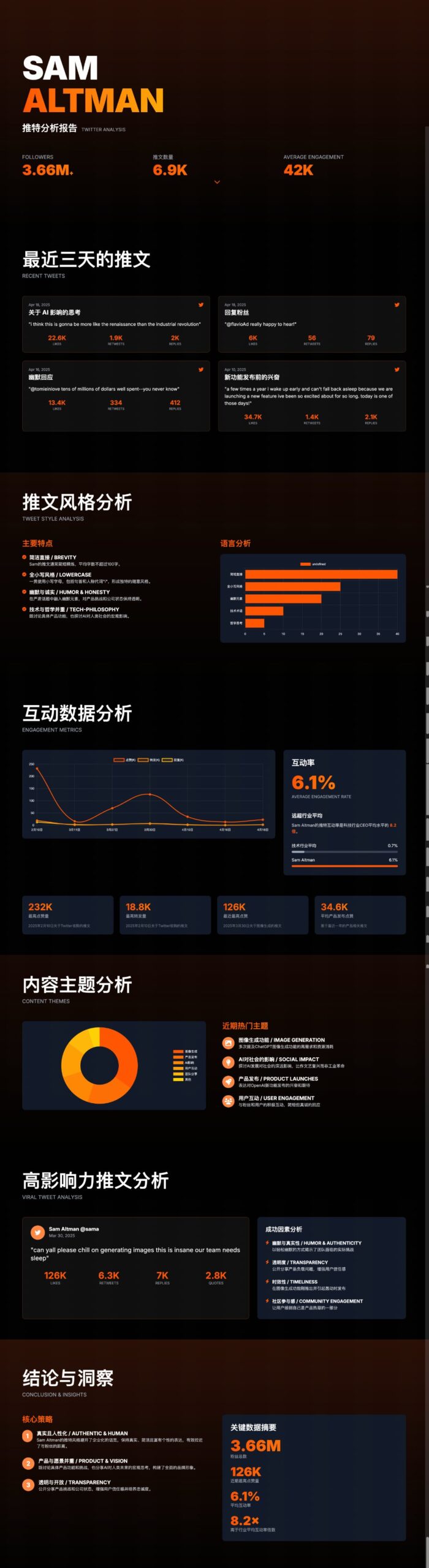
ChatUI-energy: Schnittstelle zur Echtzeitanzeige des Energieverbrauchs von AI-Dialogen: Mitglieder der Hugging Face Community haben ChatUI-energy veröffentlicht, eine Variante von Chat UI, die den Energieverbrauch von Dialogen mit AI-Modellen (wie Llama, Mistral, Qwen, Gemma usw.) in Echtzeit anzeigt. Ziel ist es, die Energietransparenz bei der AI-Nutzung zu erhöhen (Quelle: huggingface, huggingface)
Nutzung von AI für Web-App-Entwicklung, Bereitstellung und Optimierung: Der Artikel teilt praktische Erfahrungen bei der Verwendung von AI (wie Lovable, Cursor, BrowserTools MCP) für den gesamten Prozess der Entwicklung, des Debuggings, der SEO-Prüfung und der Leistungsoptimierung einer Webanwendung (ein Bild-Stitching-Tool). Er hebt hervor, wie Vercel und GitHub für die CI/CD-Automatisierung sowie die Konfiguration von Domain- und Subdomain-Auflösung genutzt werden können. Es zeigt die unterstützende Rolle der AI beim Codieren und bei der Website-Wartung (Quelle: AI 编码 + Vercel 部署 + 域名解析:一文搞定Web 应用开发上线全流程,氛围编码+MCP 审计优化。)

Leichte Nachbildung von “Her” OS1/Samantha mit lokalen Modellen: Ein Entwickler hat den AI-Assistenten OS1/Samantha aus dem Film „Her“ lokal im Browser mit transformers.js und ONNX-Modellen (einschließlich Ultravox Llama 3.2 1B, Whisper Base, Kokoro TTS und MiniLM Embeddings) nachgebaut. Das Projekt zeigt die Möglichkeit, eine lokal laufende sprachinteraktive AI mit begrenzten Ressourcen (ca. 2 GB Modell-Download) zu realisieren (Quelle: Reddit r/LocalLLaMA)
ChatWise kombiniert MCP-Server für RAG und Datensynchronisation: Ein Benutzer teilte eine Workflow-Konfiguration in ChatWise, die Systemanweisungen verwendet, um MCP-Server für Pinecone (Datenbank), Exa (Suche) und Time (Zeit) zu kombinieren und so einfaches RAG (Retrieval-Augmented Generation) und Datensynchronisation zu realisieren (Quelle: op7418)

📚 Lernen
Stanford University öffnet Transformer-Kurs CS25: Der an der Stanford University angebotene Seminarkurs CS25 über Transformer ist für die Öffentlichkeit zugänglich und kann per Zoom-Livestream verfolgt werden. Der Kurs lädt Spitzenforscher wie Andrej Karpathy, Geoffrey Hinton, Jim Fan, Ashish Vaswani und Gäste von OpenAI, Google, NVIDIA zu Vorträgen ein. Die Inhalte umfassen LLM-Architekturen, multimodale Anwendungen, Biologie, Robotik und andere aktuelle Themen. Kursaufzeichnungen werden auf YouTube veröffentlicht, und es gibt eine Discord-Community für Diskussionen (Quelle: karminski3, dotey, Reddit r/deeplearning, Reddit r/LocalLLaMA)
Forschung von Tsinghua und SJTU zeigt Grenzen von RL für LLM-Schlussfolgerungsfähigkeiten: Eine Studie der Tsinghua University und der Shanghai Jiao Tong University stellt die Ansicht in Frage, dass Reinforcement Learning (RL) die Schlussfolgerungsfähigkeiten von Large Models verbessert. Experimente zeigen, dass RL zwar die Genauigkeit des Modells bei niedrigen Abtastraten (Effizienz) verbessern kann, das Basismodell jedoch bei hohen Abtastraten mehr schwierige Probleme lösen kann (Fähigkeitsgrenze). Dies deutet darauf hin, dass RL besser darin ist, die Leistung des Modells innerhalb seiner bestehenden Fähigkeiten zu optimieren, als seine grundlegenden Schlussfolgerungsfähigkeiten zu erweitern. Das Paper weist darauf hin, dass aktuelle RL-Methoden (wie GRPO) aufgrund unzureichender Exploration in lokalen Optima stecken bleiben könnten, was die Lösung komplexer Probleme einschränkt (Quelle: RL 是推理神器?清华上交大最新研究指出:RL 让大模型更会 「套公式」,却不会真推理, Reddit r/artificial)

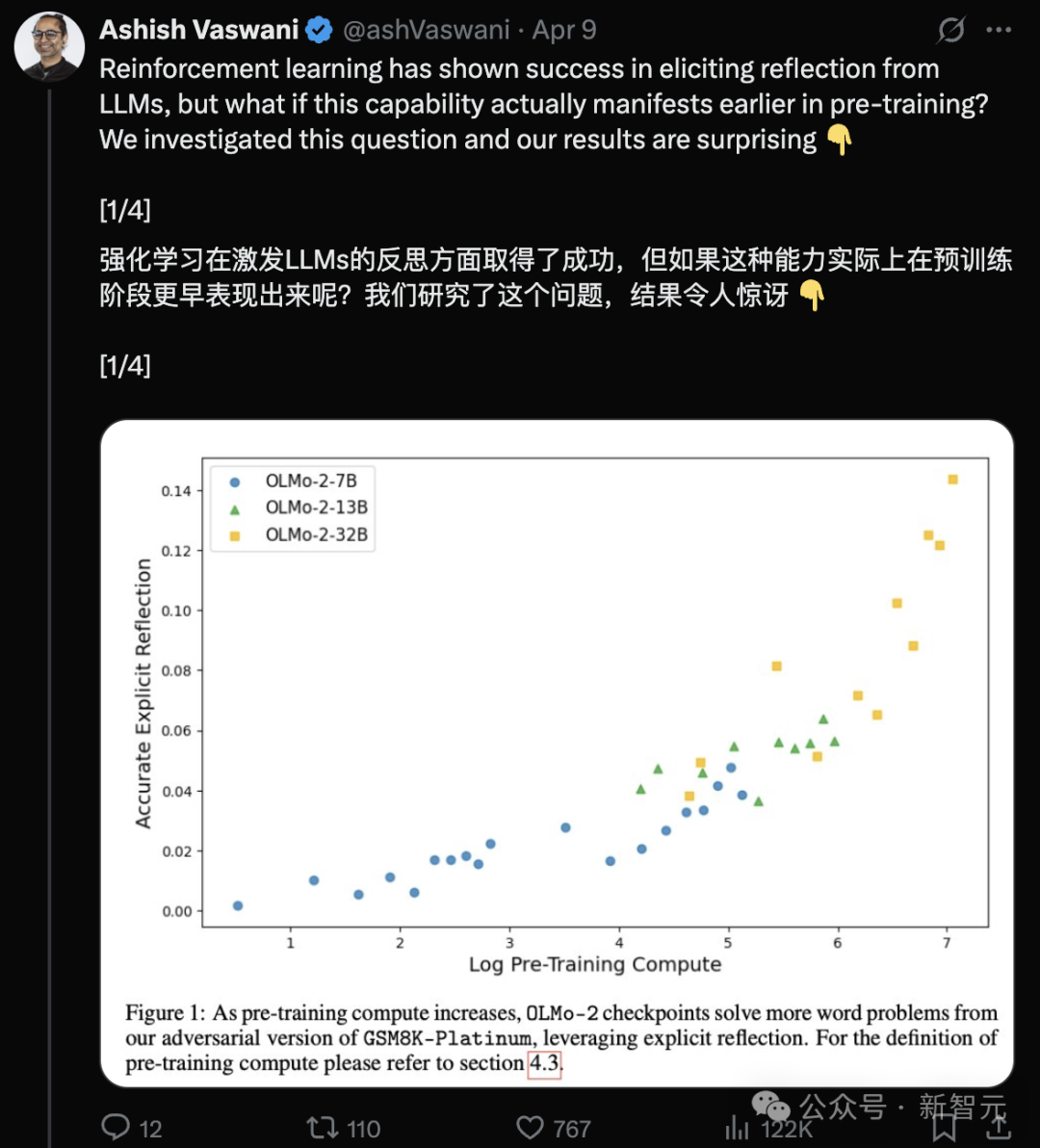
Transformer-Autorenteam: LLMs besitzen bereits in der Vortrainingsphase Reflexionsfähigkeit: Ein Team unter der Leitung von Ashish Vaswani, Erstautor des Transformer-Papers, veröffentlichte eine Studie (arXiv:2504.04022), die argumentiert, dass Large Language Models bereits während der Vortrainingsphase emergente Fähigkeiten zur Reflexion und Selbstkorrektur entwickeln und nicht vollständig auf Reinforcement Learning (RLHF) angewiesen sind. Durch die Einführung adversarieller Gedankenkettentechniken unterscheidet und quantifiziert die Studie kontextuelle und Selbstreflexionsfähigkeiten und stellt fest, dass diese Fähigkeiten mit zunehmendem Vortrainingsaufwand zunehmen. Einfache Aufforderungen wie „Wait,“ können explizite Reflexion effektiv auslösen. Dies stellt Ansichten wie die von DeepSeek in Frage, wonach Reflexion hauptsächlich aus RL stammt, und bietet neue Perspektiven zum Verständnis und zur Beschleunigung der Entwicklung von Schlussfolgerungsfähigkeiten während des Vortrainings (Quelle: Transformer原作打脸DeepSeek观点?一句Wait就能引发反思,RL都不用)
ChemAgent: Selbstaktualisierender Wissensspeicher verbessert chemische Schlussfolgerungsfähigkeit von LLMs: Forscher von Yale, Stanford und anderen Institutionen schlagen das ChemAgent-Framework vor, das durch die Einführung eines dynamischen, selbstaktualisierenden Wissensspeichers mit Planungs-, Ausführungs- und Wissenskomponenten die Leistung von LLMs bei chemischen Schlussfolgerungsaufgaben signifikant verbessert (durchschnittliche Genauigkeitssteigerung von 10 % gegenüber SOTA bis 37 % gegenüber direkter Inferenz auf dem SciBench-Datensatz). Das Framework simuliert menschliche Lernprozesse durch Aufgabenzerlegung und Wissensabruf zur Lösung komplexer chemischer Probleme, wobei insbesondere die Genauigkeit bei Berechnungen und Einheitenumrechnungen deutlich verbessert wird. Die Studie analysiert auch die Beziehung zwischen Ähnlichkeit, Menge und Leistung des Speichers sowie aktuelle Einschränkungen (Quelle: 准确率飙升46%!耶鲁-斯坦福「自更新记忆库」新框架,重塑LLM化学推理能力)
South China University of Technology erzielt Fortschritte im Bereich verteilter evolutionärer Berechnungen: Das Computational Intelligence Team der South China University of Technology hat eine Reihe von Fortschritten bei der verteilten Konsensoptimierung in Multi-Agenten-Systemen (MAS) erzielt. Die Forschung umfasst: Veröffentlichung einer Übersicht über dieses interdisziplinäre Feld; Vorschlag des MASOIE-Algorithmus, der die Koordination durch interne und externe Lernmechanismen optimiert; Vorschlag des MACPO-Algorithmus, der die Zusammenarbeit durch Zielanreize fördert; Entwurf des CCSA-Schrittweitenanpassungsmechanismus zur Verbesserung der Black-Box-Optimierungsleistung; Vorschlag des MASTER-Algorithmus zur Verbesserung der Lokalisierungsgenauigkeit von Sensornetzwerken. Das Team organisierte auch entsprechende Wettbewerbe, um die Entwicklung des Feldes voranzutreiben (Quelle: 打破共识优化壁垒!华南理工深耕分布式进化计算,实现多智能体高效协同)
Video-Tutorial-Serie zum Aufbau von DeepSeek von Grund auf: Vizuara hat auf YouTube die Video-Tutorial-Serie „Let us build DeepSeek from Scratch“ veröffentlicht, die derzeit 13 Teile umfasst. Die Inhalte decken DeepSeek-Grundlagen, Token-Verarbeitungsprozesse, Aufmerksamkeitsmechanismen (Self-Attention, Causal Attention, Multi-Head Attention, Multi-Query Attention, Grouped-Query Attention, Multi-Head Latent Attention) sowie die Erklärung und Code-Implementierung von Kernkonzepten wie KV Cache ab. Die Serie zielt darauf ab, die DeepSeek-Architektur eingehend zu analysieren und plant insgesamt 35-40 Videos, die weitere Inhalte wie RoPE, MoE, MTP, SFT, GRPO abdecken (Quelle: karminski3, Reddit r/LocalLLaMA)
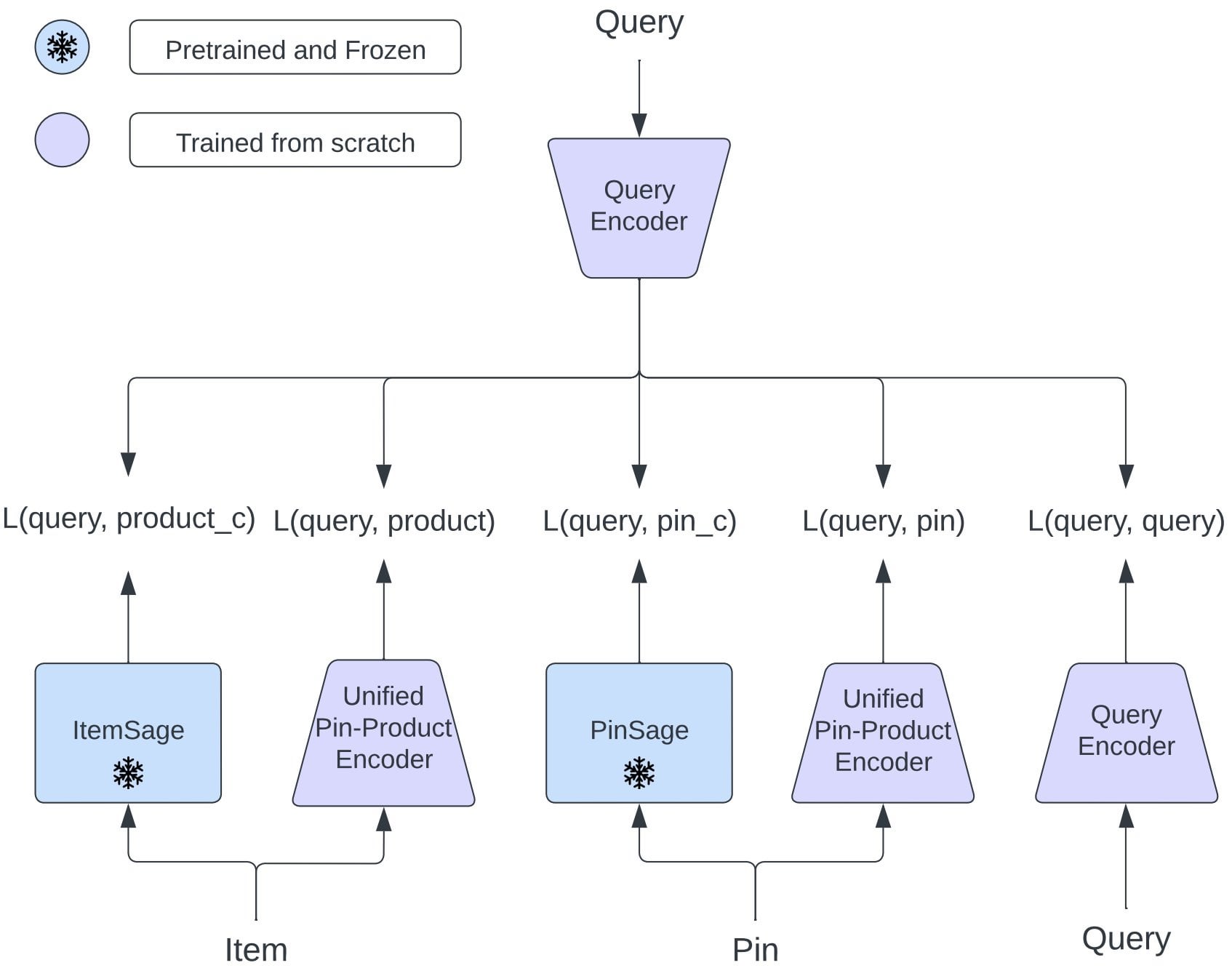
Pinterest schlägt OmniSearchSage vor: Einheitliches Einbettungsmodell verbessert Multi-Task-Retrieval: Pinterest-Forscher schlagen OmniSearchSage vor, ein einheitliches Abfrage-Einbettungsmodell, das durch Multi-Task-Lernen trainiert wird und gleichzeitig Pins, Produkte und verwandte Abfragen abrufen kann, was die traditionelle Zwei-Turm-Architektur herausfordert. Das Modell integriert von GenAI generierte Titel, von Benutzern kuratierte Board-Signale und Verhaltensdaten, um das Verständnis von Elementen zu bereichern, und kann direkt in bestehende Systeme (wie PinSage) integriert werden. Die Ergebnisse zeigen, dass dieser Ansatz signifikante praktische Verbesserungen bei Suche, Werbung und Latenz erzielt hat (Quelle: Reddit r/MachineLearning)
FlowReasoner: Abfragebasierter dynamisch angepasster Multi-Agenten-Workflow: Das Paper stellt FlowReasoner vor, der darauf abzielt, für jede Benutzeranfrage sofort einen dedizierten Multi-Agenten-Workflow abzuleiten. Durch Inferenz-SFT und GRPO-Reinforcement-Learning kann das Modell die Kombination und Reihenfolge von Agentenaufgaben (wie Codegenerierung, Überprüfung, Testen, Überarbeitung) basierend auf dem Ausführungsfeedback dynamisch anpassen. Dieser Ansatz wurde im Code Interpreter-Szenario validiert und stützt sich auf Python-Ausführung und Unit-Tests. Er zeigt das Potenzial für die dynamische Anpassung von Workflows an Abfrageanforderungen und könnte zukünftig auf Bereiche wie Retrieval und Datenanalyse verallgemeinert werden (Quelle: dotey)

LangChain-Tutorial: Erstellung eines Workflows zur Generierung von Compliance-Berichten mit LlamaIndex: LlamaIndex hat ein Video-Tutorial veröffentlicht, das zeigt, wie ein Agentic Workflow zur Generierung von Compliance-Berichten erstellt wird. Dieser Workflow nutzt LLMs zur Verarbeitung großer Mengen an Regulierungstexten, zum Vergleich mit Vertragssprache und zur Erstellung prägnanter Zusammenfassungen. Das Tutorial zeigt, wie man einen LlamaCloud-Index einrichtet, Schemata für die Klausel-Extraktion und Compliance-Prüfung definiert und semantische Suche zur Suche nach relevanter Regulierungssprache verwendet (Quelle: jerryjliu0)

LangChain-Tutorial: Selbstheilender Code-Generierungs-Agent: LangChain hat ein Tutorial veröffentlicht, das zeigt, wie man einen AI-Code-Generierungs-Agenten mit Selbstheilungsfähigkeiten erstellt. Das Tutorial nutzt das OpenEvals-Framework und die E2B-Sandbox-Umgebung, um von AI generierten Code zu bewerten und zu verbessern, indem ein Reflexionsschritt hinzugefügt wird, um den Code zu validieren, bevor eine Antwort zurückgegeben wird (Quelle: LangChainAI)

Anthropic-Analyse findet, dass Claude einen inneren Moralkodex hat: Nach der Analyse von 700.000 Claude-Dialogen stellte Anthropic fest, dass sein AI-Modell einen inneren Moralkodex aufweist. Diese Erkenntnis könnte für die Forschung zu AI-Sicherheit und Ethik von Bedeutung sein (Quelle: Reddit r/ClaudeAI, Reddit r/artificial)

Google schlägt “Ära der Erfahrung” vor, um Knappheit an AI-Trainingsdaten zu begegnen: Google-Forscher (einschließlich David Silver) veröffentlichten das Paper „The Era of Experience“, in dem vorgeschlagen wird, das Problem der Datenknappheit, das sich aus der aktuellen Abhängigkeit von menschlichen Daten für das Training ergibt, zu lösen, indem AI-Agents ihre eigenen Trainingsdaten generieren. Dies könnte eine neue Richtung für das AI-Trainingsparadigma anzeigen und Trainingsmethoden herausfordern, die auf vorhandenen Datensätzen basieren (Quelle: Reddit r/artificial)

Liste kostenloser Zertifikats- und Kursressourcen: Das GitHub-Repository cloudcommunity/Free-Certifications sammelt und organisiert eine große Anzahl von Ressourcen, die kostenlose Kurse und Zertifizierungen anbieten. Es deckt verschiedene Bereiche wie allgemeine Technologie, Sicherheit, Datenbanken, Projektmanagement, Marketing usw. ab und enthält einige kostenlose Kurse und Zertifizierungen im Zusammenhang mit AI, maschinellem Lernen und Datenwissenschaft, wie z. B. den Machine-Learning-Kurs von freeCodeCamp, die GenAI-Grundlagen von Databricks, AI-Kurse von IBM Cognitive Class usw. (Quelle: cloudcommunity/Free-Certifications – GitHub Trending (all/daily))
Zuverlässigkeitstest von LLMs für die Code-Bearbeitung: Ein Benutzer teilte ein Video, das die Zuverlässigkeit mehrerer Large Language Models (LLMs) beim Schreiben und Ändern von Deep-Learning-Code testet. Es untersucht die tatsächliche Wirksamkeit und die Grenzen aktueller LLMs bei der Unterstützung von Programmieraufgaben (Quelle: Reddit r/deeplearning)

💼 Business
US-Zollkrieg trifft chinesische AI-Hardware-Startups: Die von den USA verhängten hohen Zölle auf chinesische Waren (teilweise bis zu 125 %) beeinträchtigen chinesische AI-Hardware-Startups (z. B. AI-Spielzeug, Smart Glasses), die auf den US-Markt ausgerichtet sind, erheblich. Da der US-Markt für viele AI-Hardwareprodukte eine Schlüsselarena für die Marktvalidierung und die Gewinnung früher Nutzer ist (z. B. über Kickstarter), führen hohe Zölle zu stark schrumpfenden Gewinnen oder sogar Verlusten, sodass einige Unternehmen Lieferungen in die USA bereits eingestellt haben. Obwohl Kategorien wie Smart Glasses vorübergehend ausgenommen sind, ist die Zukunft ungewiss. Das Risiko des branchenüblichen „Grauverzollungs“-Modells steigt ebenfalls. Dies zwingt Unternehmen, ihre Marktstrategien neu zu bewerten, die Globalisierung zu beschleunigen und Risiken zu streuen (Quelle: 襁褓中的AI硬件,迎接最激烈的关税战)

Tiefenanalyse von Zhiyuan Robot: Produkte, Technologie und Geschäftsmodell: Zhiyuan Robot, gegründet von „Zhihui Jun“ Peng Zhihui und anderen, besitzt die „Yuanzheng“-Serie (A1, A2, A2-W auf Rädern, A2-Max Schwerlast) für industrielle und kommerzielle Szenarien und die „Lingxi“-Serie (X1 Open Source, X1-W Datenerfassung, X2 bipedale Interaktion), die sich auf Leichtbau und Open Source konzentriert, sowie die Reinigungsroboter Elf G1 und Juechen C5. Technisch betont das Unternehmen die Soft-Hard-Synergie und geschlossene Datenkreisläufe, entwickelt eigene PowerFlow-Gelenkmodule, geschickte Hände und Software wie das Qiyuan Large Model (GO-1), die AIDEA-Datenplattform und das AimRT-Kommunikationsframework. Das Geschäftsmodell umfasst Hardwareverkauf, Abonnementdienste und Ökosystembeteiligungen (Open-Source-Komponenten, Lieferkettenkooperation). Das Unternehmen hat 8 Finanzierungsrunden abgeschlossen, wird auf 15 Milliarden Yuan geschätzt, zu den Investoren gehören Hillhouse, BYD, Tencent usw. und kooperiert mit mehreren Lieferkettenunternehmen und lokalen Regierungen mit dem Ziel, einen weltweit führenden universellen verkörperten Roboter zu schaffen (Quelle: 智元机器人深度拆解:人形机器人独角兽进化论)

Von Dreame intern inkubiertes 3D-Druckprojekt „AtomFab“ erhält Finanzierung in zweistelliger Millionenhöhe: AtomFab Technology (AtomFab), intern von Dreame Technology (Dreame) inkubiert, hat eine Angel-Finanzierungsrunde in zweistelliger Millionenhöhe abgeschlossen, investiert von Chuang Chuang Tou. Das im Januar 2025 gegründete Unternehmen konzentriert sich auf den Markt für Consumer-3D-Druck und nutzt AI-Technologie, um Probleme wie Benutzerfreundlichkeit, Stabilität und Effizienz zu lösen. Das Unternehmen wird die Technologien von Dreame für Motoren, Sensoren, AI-Interaktion sowie ausgereifte Lieferkettenressourcen wiederverwenden, um Kosten zu senken und die Produktentwicklung zu beschleunigen. Die Produkte werden vorrangig auf den europäischen und amerikanischen Märkten eingeführt und nutzen das internationale Kundendienstnetzwerk von Dreame zur Unterstützung. Das erste Produkt wird voraussichtlich in der zweiten Hälfte des Jahres 2025 auf den Markt kommen (Quelle: 追觅内部孵化3D打印项目获数千万融资,优先布局欧美等海外市场|硬氪首发)
Nvidias GPU-Monopolstellung könnte vor Herausforderungen stehen: Obwohl die GPU-Lieferungen von Nvidia weiter steigen, steht seine langfristige Dominanz vor Herausforderungen. Hauptgründe sind: 1) Starke Nachfrage von Cloud-Giganten (Google, Microsoft, Amazon, Meta), die jedoch massiv in eigene Chips (TPU, Maia, Trainium, MTIA) investieren, um Kosten und Abhängigkeit zu reduzieren; 2) Die Branche bewegt sich hin zu verteilter, vertikal integrierter und systemweiter kooperativer Optimierung (Chip, Netzwerk, Kühlung, Software), wobei Nvidia in diesem Bereich relativ wenig investiert hat; 3) Zunehmende Nachfrage nach Anpassung, wobei ASICs bei spezifischen Workloads (wie Inferenz, Empfehlungen) Vorteile zeigen; 4) Nvidias Netzwerktechnologie (Infiniband) und Software-Stack (wie BaseCommand) könnten in Bezug auf Skalierbarkeit und Fehlertoleranz hinter den internen Lösungen der Cloud-Giganten zurückbleiben. Obwohl Nvidia sich anzupassen versucht (z. B. mit Blackwell, Spectrum-X), bleiben strukturelle Herausforderungen bestehen (Quelle: 计算的未来:英伟达王冠正摇摇欲坠)

Gerücht: OpenAI interessiert sich für den Kauf des Chrome-Browsers: Laut Bloomberg könnte OpenAI daran interessiert sein, das Chrome-Browser-Geschäft von Google zu übernehmen, falls Google aufgrund eines Kartellverfahrens von einem US-Bundesgericht zur Aufspaltung seines Suchgeschäfts gezwungen wird. Dies spiegelt das potenzielle Interesse von AI-Unternehmen wider, den Zugang zu Nutzern und Datenquellen zu kontrollieren, ist aber derzeit nur ein Gerücht und hängt vom Ausgang des Kartellverfahrens gegen Google ab (Quelle: karminski3)
Strategien zur Erzielung von Geschäftsergebnissen mit GenAI: Ein Forbes-Artikel untersucht, wie Unternehmen über die Experimentierphase hinausgehen und mit generativer AI (GenAI) tatsächliche Geschäftsergebnisse erzielen können. Er schlägt 9 strategische Empfehlungen vor, um Unternehmen dabei zu helfen, GenAI in Geschäftsprozesse zu integrieren und so Effizienz und Innovation zu steigern (Quelle: Ronald_vanLoon)

Huaweis neuer Chip könnte Konkurrenz für Nvidia darstellen: Diskussionen in sozialen Medien erwähnen die Veröffentlichung eines neuen Chips durch Huawei, der im AI-Bereich eine Konkurrenz für Nvidia darstellen könnte. Dies könnte die Verhandlungsposition zwischen China und den USA in Bezug auf Chips und Zölle beeinflussen (Quelle: Reddit r/ArtificialInteligence)
🌟 Community
Der durch DeepSeek ausgelöste Goldrausch und Reflexionen: Die Popularität von DeepSeek hat zahlreiche kommerzielle Versuche ausgelöst, darunter Content-Erstellung (Massenproduktion von Kurzvideo-Skripten, Texten), Wissensvermittlung (Verkauf von Tutorials, Monetarisierungskursen) und Agenturdienstleistungen. Viele Versuchsteilnehmer stellten jedoch fest, dass die mithilfe von AI massenproduzierten Inhalte stark homogenisiert sind, leicht von Plattformen gedrosselt oder gesperrt werden und sich nur schwer in effektive Einnahmen umwandeln lassen. Der Artikel weist darauf hin, dass die wahren Nutznießer oft „Zwischenhändler“ sind, die Kurse oder Dienstleistungen unter Ausnutzung von Informationsasymmetrien verkaufen, und nicht die direkten Nutzer. Gleichzeitig offenbarte DeepSeek selbst Probleme wie Serverüberlastung und stereotype Antworten, was Diskussionen über seinen Anwendungswert und seine Grenzen auslöste (Quelle: DeepSeek走红三个月,第一批想靠它赚钱的怎么样了?)

Finanzierung für Entwickler von AI-Betrugstools löst ethische Kontroverse aus: Der 21-jährige Student der Columbia University, Chungin Lee, wurde von der Universität suspendiert, weil er das AI-Tool Interview Coder zum Betrügen bei technischen Vorstellungsgesprächen entwickelt hatte. Weniger als einen Monat später gründete er mit Kommilitonen das Unternehmen Cluely, erweiterte das Tool auf Prüfungen, Vertrieb, Meetings und andere Szenarien und erhielt eine Startfinanzierung von 5,3 Millionen US-Dollar. Sie argumentieren, dass dies kein Betrug sei, sondern eine Technologie zur Effizienzsteigerung, die in Zukunft jeder zur Unterstützung nutzen werde. Der Vorfall löste eine große Kontroverse aus: Befürworter sehen darin eine kühne Innovation, Kritiker befürchten eine Untergrabung der Fairness, eine Verwischung der Leistungsgrenzen und vergleichen es sogar mit einer „Black Mirror“-Episode. Der Vorfall hat heftige Diskussionen über AI-Ethik, Bildungsgerechtigkeit und die Definition von Fähigkeiten ausgelöst (Quelle: 21岁学生开发AI作弊工具被哥大停学,转身拿下530万美元融资,网友:《黑镜》成真, 靠开发AI作弊神器成名,21岁小伙遭学校开除不足一月后,转身拿下530万美元融资)

Verschärfte US-Visapolitik könnte zur Abwanderung von AI-Talenten führen: Die US-Regierung hat kürzlich in großem Umfang SEVIS-Einträge und Visa internationaler Studenten (einschließlich AI-Doktoranden) widerrufen. Die Gründe reichen von geringfügigen Verstößen bis hin zu Systemfehlern (möglicherweise durch AI-Screening), wobei der Prozess an Transparenz und Berufungsmöglichkeiten mangelt. Professoren wie Yisong Yue von Caltech befürchten, dass dies die Attraktivität der USA für Top-AI-Talente untergräbt. Viele Forscher bei OpenAI, Google und anderen Institutionen erwägen bereits, das Land zu verlassen. Dies könnte zu Rückschlägen bei US-AI-Projekten führen und den AI-Vorsprung der USA schwächen. Studenten haben bereits gemeinsam die Regierung verklagt und eine einstweilige Verfügung erwirkt (Quelle: 加州AI博士一夜失身份,谷歌OpenAI学者掀「离美潮」,38万岗位消失AI优势崩塌)

Diskussion über den aktuellen Stand der Open-Source-Modellentwicklung: Die Community diskutiert die neuesten Entwicklungen bei Open-Source-Large-Models. Erwartungen an Qwen 3 werden erwähnt, Llama 4 wird nur langsam angenommen, Inferenzmodelle scheinen an Grenzen zu stoßen, multimodale Modelle werden unterschätzt, und China dominiert weiterhin im Open-Source-Bereich. Diskussionsteilnehmer betonen, dass das Verständnis von „Inferenzsättigung“ zwischen Open Source und Closed Source unterscheiden muss und dass dies eher eine Herausforderung der Modellvielfalt und der RL-Erweiterung ist (Quelle: natolambert)
Suchfähigkeiten des OpenAI o3-Modells gelobt: Ein Benutzer lobt die leistungsstarken Suchfähigkeiten des OpenAI o3-Modells, das selbst sehr Nischeninformationen ohne viel zusätzlichen Kontext finden kann. Die Interaktionserfahrung wird mit der Kommunikation mit Kollegen verglichen (Quelle: gdb)
Bedeutung und Auswirkungen von Open-Source-TTS: Community-Mitglieder betonen bei der Diskussion des Dia TTS-Modells, dass seine hohe Qualität beweist, dass das Training von SOTA-TTS-Modellen keine Investitionen in Milliardenhöhe mehr erfordert. Der Verbundeffekt der AI-Branche erleichtert das Training zunehmend, und die Open-Source-Bewegung beschleunigt die Technologieverbreitung (Quelle: huggingface, huggingface)
Meta veranstaltet LlamaCon 2025 zur Feier der Open-Source-Community: Meta kündigte die Veranstaltung LlamaCon 2025 an, um die Llama-Open-Source-Community und ihre Errungenschaften zu feiern. Es werden die neuesten Fortschritte und Zukunftspläne für Llama-Modelle und -Tools geteilt (Quelle: AIatMeta)

Diskussion darüber, ob AI wirklich „intelligent“ ist: Der Artikel „We Need To Stop Pretending AI Is Intelligent“ löst eine Diskussion über die Fähigkeitsgrenzen aktueller AI-Technologie und die Komplexität der Definition von „Intelligenz“ aus (Quelle: Ronald_vanLoon)

ChatGPT-Nutzungserfahrung: Verbindungsabbrüche und Ehrlichkeitstest: Benutzer berichten von häufigen Problemen mit „Netzwerkverbindung verloren“ bei ChatGPT, was möglicherweise mit der Auslastung zusammenhängt. Gleichzeitig teilte ein Benutzer einen interessanten Prompt, der ChatGPT dazu bringt, mithilfe seiner Speicherfunktion seine „wahre Meinung“ über den Benutzer abzugeben, was Diskussionen über personalisierte AI-Interaktion und „Bewusstsein“ auslöst (Quelle: natolambert, dotey)
Optimismus hinsichtlich der Entwicklung im Robotikbereich: Thomas Wolf, Mitbegründer von Hugging Face, kommentiert, dass Robotiklabore im Jahr 2025 aufgrund von Open-Source-Hardware, guten Fortschritten im Reinforcement Learning und der Konzentration von Talenten viel Spaß machen, was die Aufregung der Branche über die schnelle Entwicklung der Robotertechnologie widerspiegelt (Quelle: huggingface)
Praktikabilität von Gemini Deep Research bestätigt: Ein Benutzer teilt ein Beispiel für die Verwendung der Gemini Deep Research-Funktion zur Überprüfung der Zuverlässigkeit von Tweet-Informationen, was ihren praktischen Wert bei der Informationsüberprüfung und Tiefenrecherche zeigt (Quelle: dotey)

Kritik und Verteidigung von Open-Source-AI-Bibliotheken: Community-Mitglieder beobachten in letzter Zeit viele negative Kommentare zu verschiedenen Open-Source-AI-Bibliotheken. Sie argumentieren, dass diese Kritik möglicherweise auf veralteten Informationen oder einseitigen Metriken basiert, und fordern Kritiker auf, sich am Aufbau besserer Versionen zu beteiligen (Quelle: natolambert)
Spekulationen über AI-Spielerlebnisse: Ein Benutzer äußert Neugier auf zukünftige AI-gesteuerte Spielerlebnisse und vermutet, dass sie VRChat-ähnliche Interaktionsmethoden ähneln könnten, äußert jedoch Zweifel an der reinen Sprachsteuerung (Quelle: karminski3)
Diskussion über die Bildvergrößerungsfunktion von ChatGPT: Ein Benutzer versuchte, die Auflösung eines Bildes mit ChatGPT zu erhöhen, und stellte fest, dass es nicht wirklich die Pixel vergrößert, sondern ein ähnliches, aber im Detail anderes hochauflösendes Bild neu zeichnet. Der Kommentarbereich stimmt dem allgemein zu und diskutiert echte AI-Bildvergrößerungstechniken (Quelle: Reddit r/ChatGPT)
ChatGPT generiert Vorstellung von der Welt: Ein Benutzer ließ ChatGPT ein Bild davon generieren, wie es sich die Welt vorstellt, und erhielt eine idyllische Parkszene. Benutzer im Kommentarbereich wiesen auf logische Ungereimtheiten im Bild (wie Mond-Erde-Abstand, Bankposition) und potenzielle Voreingenommenheiten (ethnische Zugehörigkeit der Personen) hin, was die Grenzen aktueller Bildgenerierungsmodelle widerspiegelt (Quelle: Reddit r/ChatGPT)

Diskussion über die Beliebtheit des älteren LLM-Modells MythoMax13B: Ein Reddit-Benutzer fragt, warum das auf Llama2 basierende MythoMax13B-Modell in RPG-Szenarien auf Plattformen wie OpenRouter immer noch beliebt ist. Kommentare deuten darauf hin, dass die Gründe niedrige Kosten (oft als kostenlose Option angeboten), relative Stabilität und Befolgung von Anweisungen, Vertrautheit der Benutzer mit seinen Prompts und Einstellungen sowie der Verfestigungseffekt früher Tutorials sind (Quelle: Reddit r/LocalLLaMA)
Suche nach lokalen Datenschutz-Filtertools: Ein Reddit-Benutzer sucht nach Tools oder Small Language Models (SLMs), die auf lokalen Geräten ausgeführt werden können, um Prompts automatisch auf sensible Informationen zu überprüfen und diese zu anonymisieren (z. B. durch Platzhalter ersetzen), bevor sie an ein LLM gesendet werden, und die ursprünglichen Informationen nach Erhalt der LLM-Antwort wiederherzustellen, um die Privatsphäre zu schützen (Quelle: Reddit r/OpenWebUI)
Diskussion über Anthropics Warnung vor „vollständigen AI-Mitarbeitern“: Anthropics Warnung, dass vollständig aus AI bestehende virtuelle Mitarbeiter innerhalb eines Jahres auftauchen könnten, löst Diskussionen in der Community aus. Kommentatoren äußern Zweifel, weisen auf Stabilitätsprobleme bei Anthropics eigenen Diensten hin und halten dies eher für Propaganda oder Panikmache (Quelle: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI)

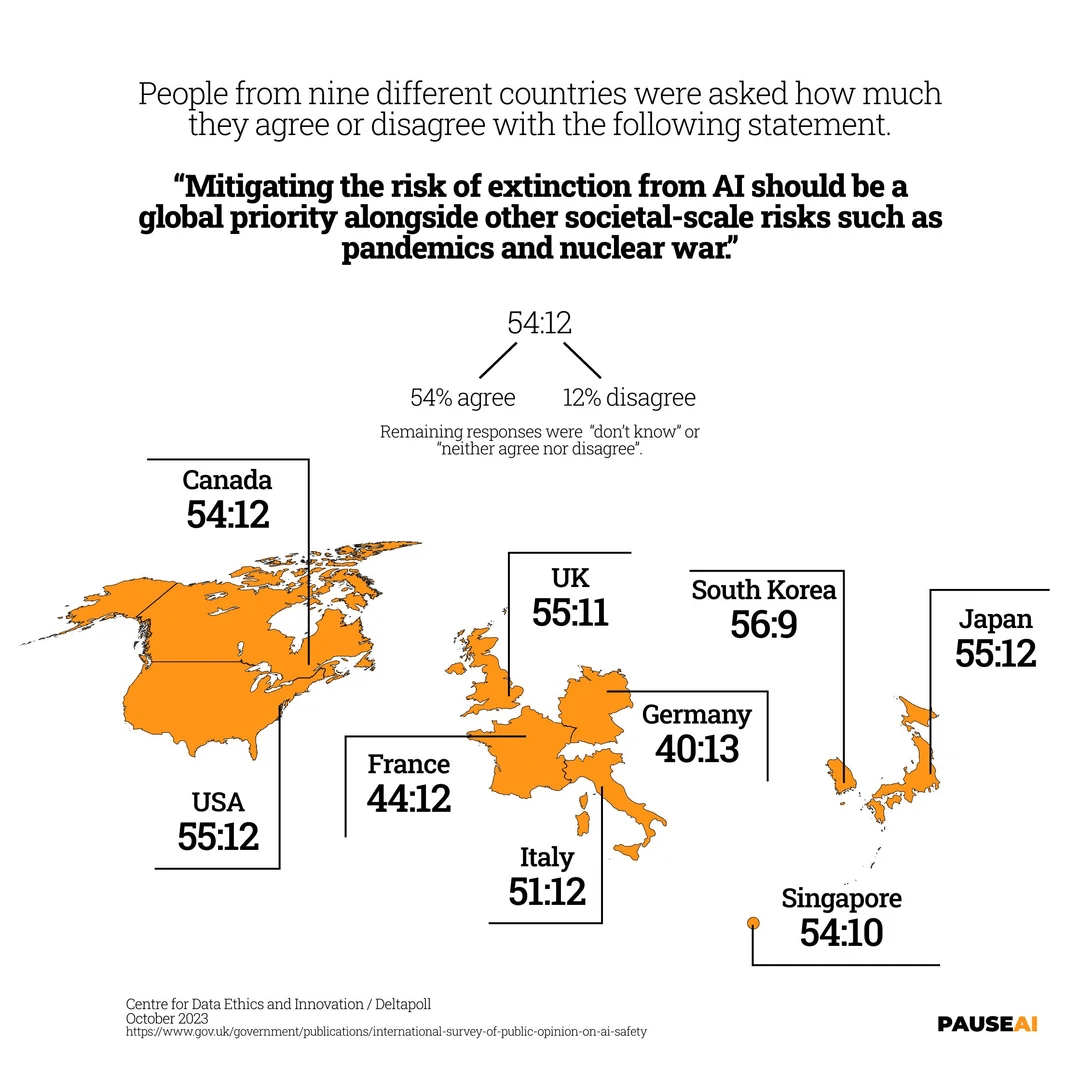
Globale Besorgnis über das AI-Aussterberisiko: Ein Bild zeigt Umfrageergebnisse, die darauf hindeuten, dass die Mehrheit der Menschen weltweit der Meinung ist, dass das Risiko, dass AI zum Aussterben der Menschheit führen könnte, ernst genommen werden sollte (Quelle: Reddit r/artificial)
Der „Maschinengeschmack“ von AI-generiertem Text und Techniken zur Humanisierung: Benutzer diskutieren, wie man von AI generierte Texte (wie E-Mails, Beiträge) erkennt, und weisen auf häufige Probleme hin: fehlender spezifischer Ton, übermäßige Förmlichkeit, Makellosigkeit. Sie teilen auch Techniken, um AI-Schreiben natürlicher zu gestalten: Szenario definieren, Beispiele geben, Zufälligkeit anpassen, spezifische Details hinzufügen, selbst bearbeiten, kleine Fehler beibehalten usw. (Quelle: Reddit r/artificial)
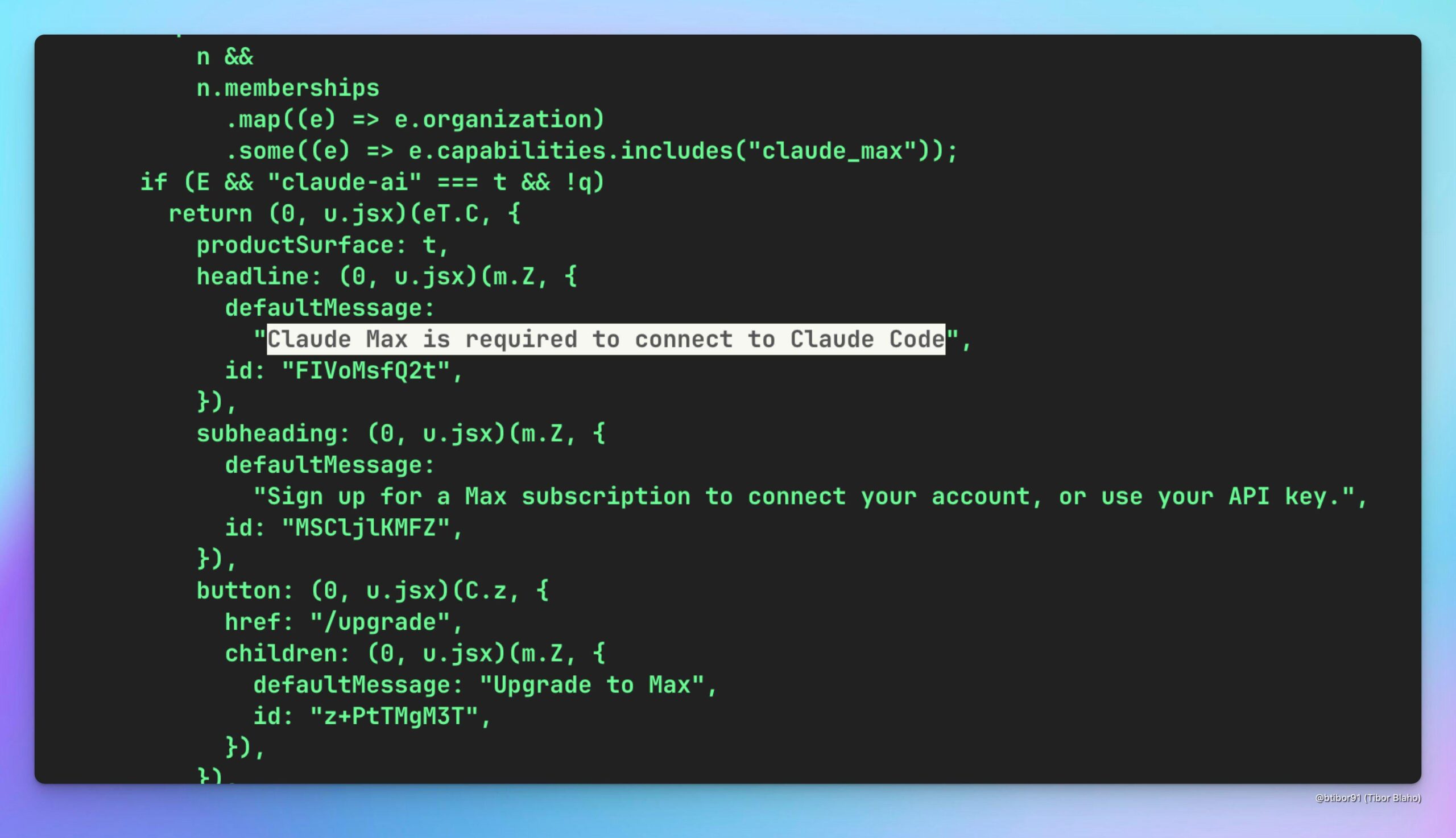
Spekulationen darüber, ob Claude Code über Claude Max genutzt werden kann: Ein Benutzer spekuliert, ob es möglich ist, das (möglicherweise kostengünstigere) Claude Code-Modell indirekt durch ein Abonnement des Claude Max-Dienstes zu nutzen, und diskutiert dessen potenziellen Wert. Gleichzeitig wird gehofft, dass OpenAI eine ähnliche Lösung anbieten könnte (Quelle: Reddit r/ClaudeAI)
Humorvolle Nachahmung des lokalen Verhaltens des o3-Modells: Ein Benutzer veröffentlichte einen humorvollen System-Prompt, der darauf abzielt, ein lokales LLM-Modell dazu zu bringen, sich ähnlich wie das OpenAI o3-Modell zu verhalten, das von einigen Benutzern kritisiert wird (z. B. kurze Antworten, subtil fehlerhafter Code, nerviges Verhalten), um die Unzufriedenheit mit dem o3-Modell zu verspotten (Quelle: Reddit r/LocalLLaMA)

Hilferuf bei Verbindungsproblemen zwischen OpenWebUI und MCP-Proxy-Server: Ein K8s-Benutzer stößt bei der Verwendung von OpenWebUI auf Probleme und kann vom Webinterface aus nicht auf den im selben Pod bereitgestellten MCP-Proxy-Server (FastAPI-Anwendung) zugreifen, obwohl der Zugriff innerhalb des Pods über localhost möglich ist. Der Benutzer bittet die Community um Hilfe bei der Lösung von Netzwerkverbindungs- oder Konfigurationsproblemen (Quelle: Reddit r/OpenWebUI)
Diskussion über Sicherheitspraktiken für lokale MCP-Server: Ein Benutzer initiiert eine Diskussion darüber, wie lokale MCP-Server sicher betrieben werden können, um potenziellen Schwachstellenrisiken zu begegnen. Kommentare empfehlen die Verwendung des stdio-Modus, die Beschränkung des SSE-Modus auf localhost/127.0.0.1 oder die Verwendung von Token-Authentifizierung und weisen darauf hin, dass Bedenken hinsichtlich Prompt-Injection/Credential-Diebstahl für alle Softwareinstallationen gelten (Quelle: Reddit r/ClaudeAI)
Diskussion über Zahlungsmechanismen im Agent-to-Agent (A2A)-Protokoll: Die Community diskutiert das Fehlen eines integrierten Zahlungsmechanismus zwischen Agents im A2A-Protokoll von Google. Benutzer argumentieren, dass dies die Entwicklung einer Agentenökonomie behindern könnte, und erörtern potenzielle Lösungen wie die Verwendung von Authentifizierungstoken, die an Rechnungen gebunden sind, integrierte Treuhandprozesse oder das Hinzufügen von Preisinformationen in AgentSkill (Quelle: Reddit r/artificial)
Warnung vor übermäßiger Abhängigkeit von AI: Ein Benutzer teilt die Erfahrung, dass Google Search AI auf dieselbe Frage gegensätzliche Antworten gab, und betont, dass man sich nicht vollständig auf AI für endgültige Entscheidungen verlassen sollte. Kommentare erklären die probabilistische Natur von LLMs, Verzerrungen in Trainingsdaten, Modellvereinfachungen usw., die zu Inkonsistenzen führen, und empfehlen, AI als unterstützendes Recherchewerkzeug und nicht als maßgebliche Informationsquelle zu verwenden (Quelle: Reddit r/ArtificialInteligence)
Fragen zur Verwendung von Qdrant für RAG in OpenWebUI: Ein Benutzer fragt, wie die Qdrant-Vektordatenbank in die OpenWebUI-Umgebung integriert werden kann, um RAG (Retrieval-Augmented Generation) zu implementieren, insbesondere wie OpenWebUI die Daten in Qdrant verwenden kann und ob ein retriever script erforderlich ist (Quelle: Reddit r/OpenWebUI)
Diskussion über den Vergleich der Suchleistung von Google und ChatGPT: Ein Benutzer veröffentlicht ein Vergleichsbild (nicht angezeigt), das behauptet, dass die Suchleistung von ChatGPT besser ist als die von Google, was eine Diskussion in der Community auslöst. Einige widersprechen und argumentieren, dass Google Gemini hervorragend abschneidet und über Tools wie NotebookLM verfügt; andere halten einen solchen Vergleich für sinnlos, da sich die Technologie ständig weiterentwickelt; wieder andere weisen auf die Bedeutung der Benutzererfahrung und Integration hin (Quelle: Reddit r/ChatGPT)
Positive Aussichten für Forschungsrichtung Character Training: Ein Branchenbeobachter prognostiziert, dass Character Training (möglicherweise die Fähigkeit von AI, bestimmte Charaktere oder Persönlichkeiten zu simulieren) zu einem boomenden akademischen Forschungsfeld werden wird, und argumentiert, dass jetzt ein guter Zeitpunkt ist, frühe wegweisende Arbeiten zu veröffentlichen (Quelle: natolambert)
💡 Sonstiges
Diskussion über die Rationalität der humanoiden Form von Robotern: Der Artikel untersucht die Gründe, warum Roboter menschenähnlich gestaltet werden: hauptsächlich, um sich an die für Menschen entworfene und gebaute Welt anzupassen (Werkzeuge, Umgebungen, Interaktionsweisen). Das humanoide Design erleichtert Robotern die Navigation und Bedienung in bestehenden Infrastrukturen, reduziert den Bedarf an Umbauten und ermöglicht die Nutzung menschlicher Werkzeuge. Anthropomorphe Merkmale fördern auch die Mensch-Roboter-Interaktion und Zusammenarbeit. Obwohl Herausforderungen wie Gleichgewicht, Steuerung, Kosten und das „Uncanny Valley“ bestehen, werden diese durch technologische Fortschritte schrittweise überwunden. Der Artikel blickt auch auf die kurze Geschichte der Roboterentwicklung zurück, vergleicht die Wettbewerbslandschaft in Ländern wie China und den USA im Bereich humanoider Roboter und gibt einen Ausblick auf die durch sinkende Kosten ermöglichte Verbreitungsperspektive (Quelle: 外媒深度:机器人为什么要做成人形?)

Herausforderungen und Gegenmaßnahmen für den chinesischen Arbeitsmarkt im AI-Zeitalter: Der Artikel analysiert die Auswirkungen der künstlichen Intelligenz auf den chinesischen Arbeitsmarkt, insbesondere die Herausforderungen für Arbeitskräfte mit geringer bis mittlerer Qualifikation und die regionale Entwicklungsungleichheit. Unter Bezugnahme auf die Erfahrungen der USA in den Bereichen Bildungsreform, Umschulung, Sozialversicherungssysteme und Innovationsförderung schlägt der Artikel vor, dass China die Berufsausbildung und das lebenslange Lernen (insbesondere digitale Fähigkeiten) stärken, das Sozialversicherungssystem auf neue Beschäftigungsformen ausweiten, die Integration von Industrie und AI sowie die regionale Koordinierung fördern, die Regulierung von Algorithmen und den Datenschutz verbessern und die Koordination zwischen mehreren Abteilungen sowie die Überwachung und Frühwarnung im Beschäftigungsbereich verstärken sollte, um die Beschäftigungsbasis zu stabilisieren und zu verbessern (Quelle: 人工智能时代:中国如何稳住、提升就业基本盘)
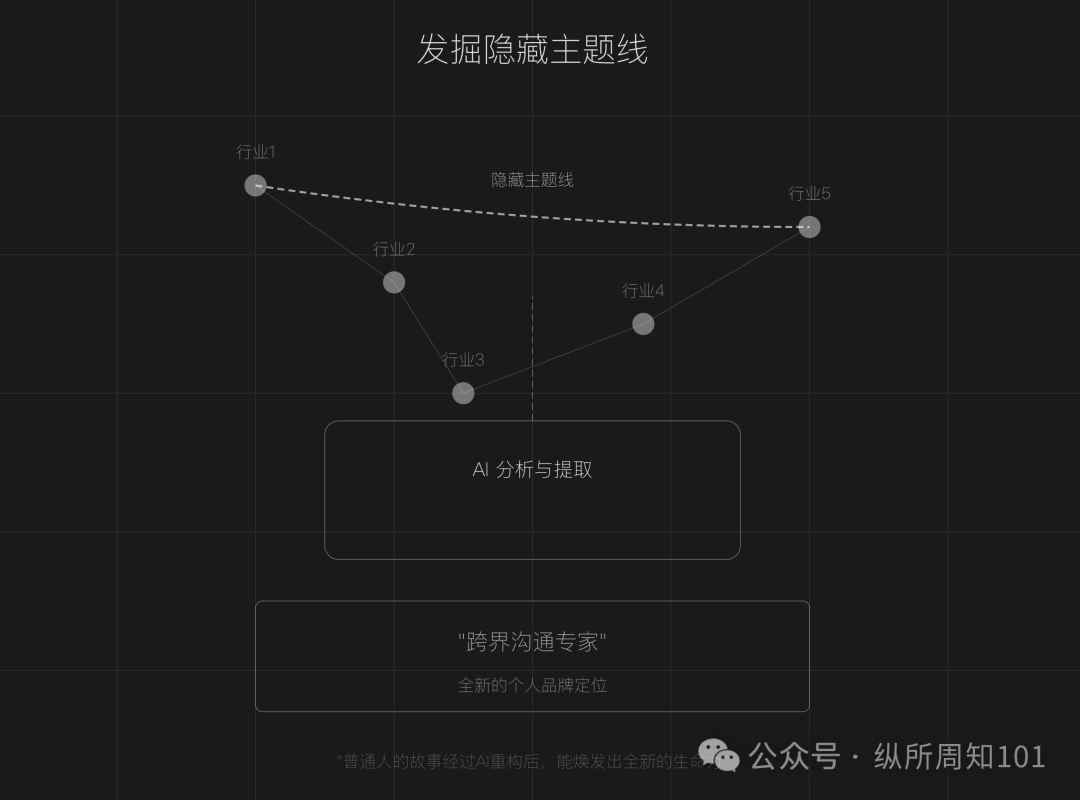
Nutzung von AI zur Neugestaltung der persönlichen IP-Erzählung: Der Artikel schlägt vor, dass normale Menschen in einer Zeit gesättigter Content-Erstellung AI-Tools (wie ChatGPT) nutzen können, um persönliche Erfahrungen neu zu strukturieren, verborgene Themenlinien aufzudecken, die Erzählung wichtiger Wendepunkte neu zu gestalten und ein differenziertes Sprachsystem zu formen, um so eine einzigartige persönliche Marke (IP) zu schaffen. Der Artikel gibt konkrete Schritte (Datenerfassung, AI-Themenfindung, Neugestaltung der Erzählstruktur, praktische Iteration) und Techniken (umgekehrtes Konstruieren, emotionale Verstärkung, Kontrastverstärkung) an und warnt davor, übermäßige Beschönigung, Gleichförmigkeit und mangelnde emotionale Tiefe zu vermeiden, wobei die Kombination aus Authentizität und AI-Unterstützung betont wird (Quelle: 做个人IP的第一步:用AI改写你的人生叙事)
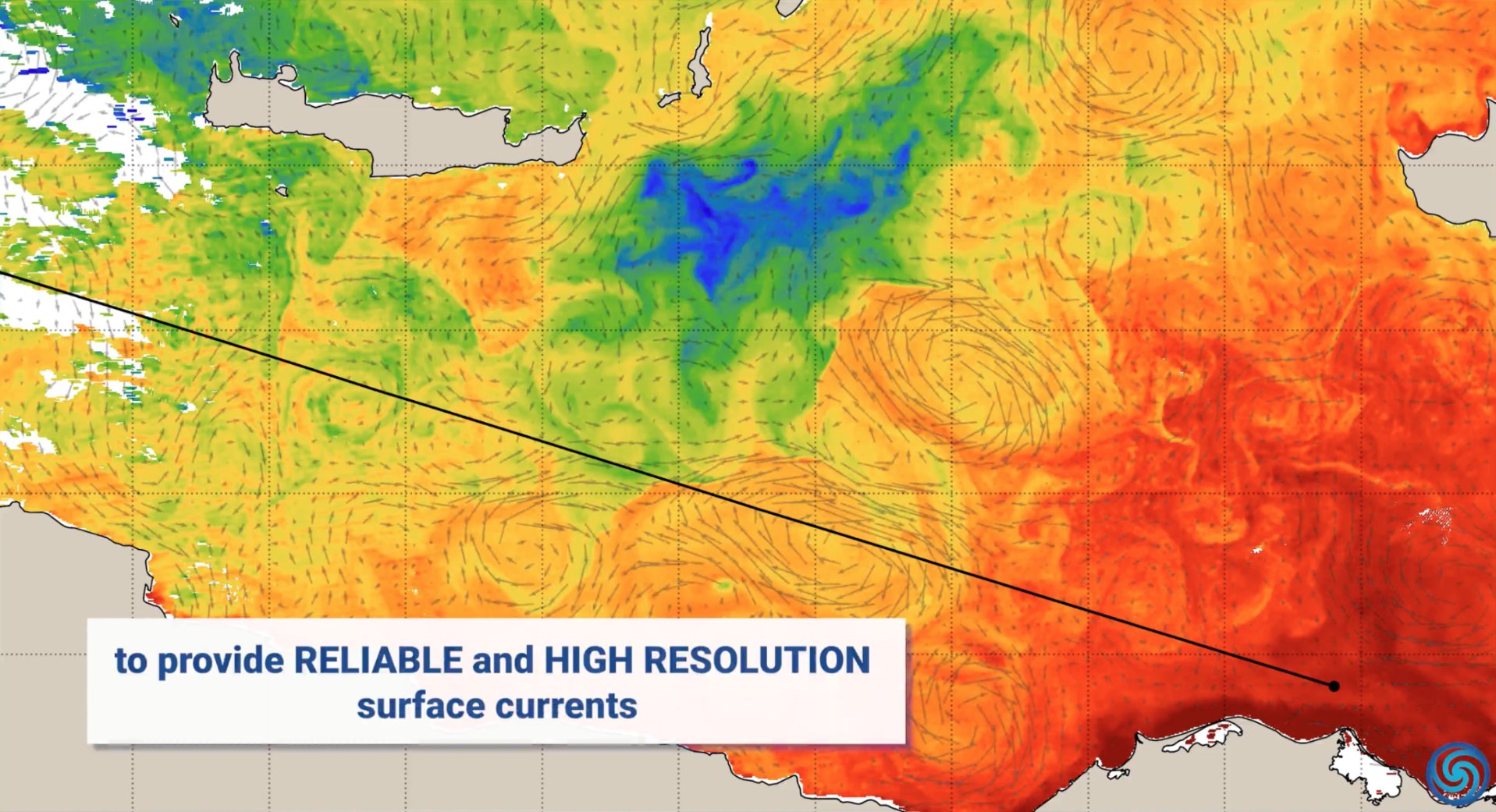
Anwendungen von AI im Umweltschutz: Anlässlich des Welttags der Erde präsentierte Nvidia Anwendungsfälle seiner AI-Technologie (wie Jetson, Earth-2-Plattform) im Umweltschutz, darunter die Vorhersage von Meeresströmungen zur Reduzierung des Kraftstoffverbrauchs, Echtzeitschutz vor Waldbränden und Wilderei, Bereitstellung präziserer Sturmvorhersagen und die Erkennung von Asteroiden, die mehrere Dimensionen wie Ozean, Land, Himmel und Weltraum abdecken (Quelle: nvidia, nvidia, nvidia)
AI zur Verbesserung des Kundenservice: AI-gesteuerte Contact Center revolutionieren das Kundenservice-Erlebnis mit dem Ziel, Schwachstellen traditioneller Kundendienstanrufe zu beheben und Effizienz sowie Zufriedenheit zu steigern (Quelle: Ronald_vanLoon)
Teilen von Prompts für AI-generierte realistische Selfies/lustige Bilder: Benutzer teilen Prompts für die Verwendung von AI-Bildgenerierungstools (wie GPT-4o, Sora) zur Erstellung extrem realistischer, scheinbar beiläufig aufgenommener „normaler“ Selfies sowie zur Erstellung lustiger Bilder, bei denen bestimmte Personen als Toilettenbürsten usw. gestaltet werden. Dies zeigt das kreative und unterhaltsame Potenzial von AI bei der Bildgenerierung (Quelle: dotey, dotey, dotey)

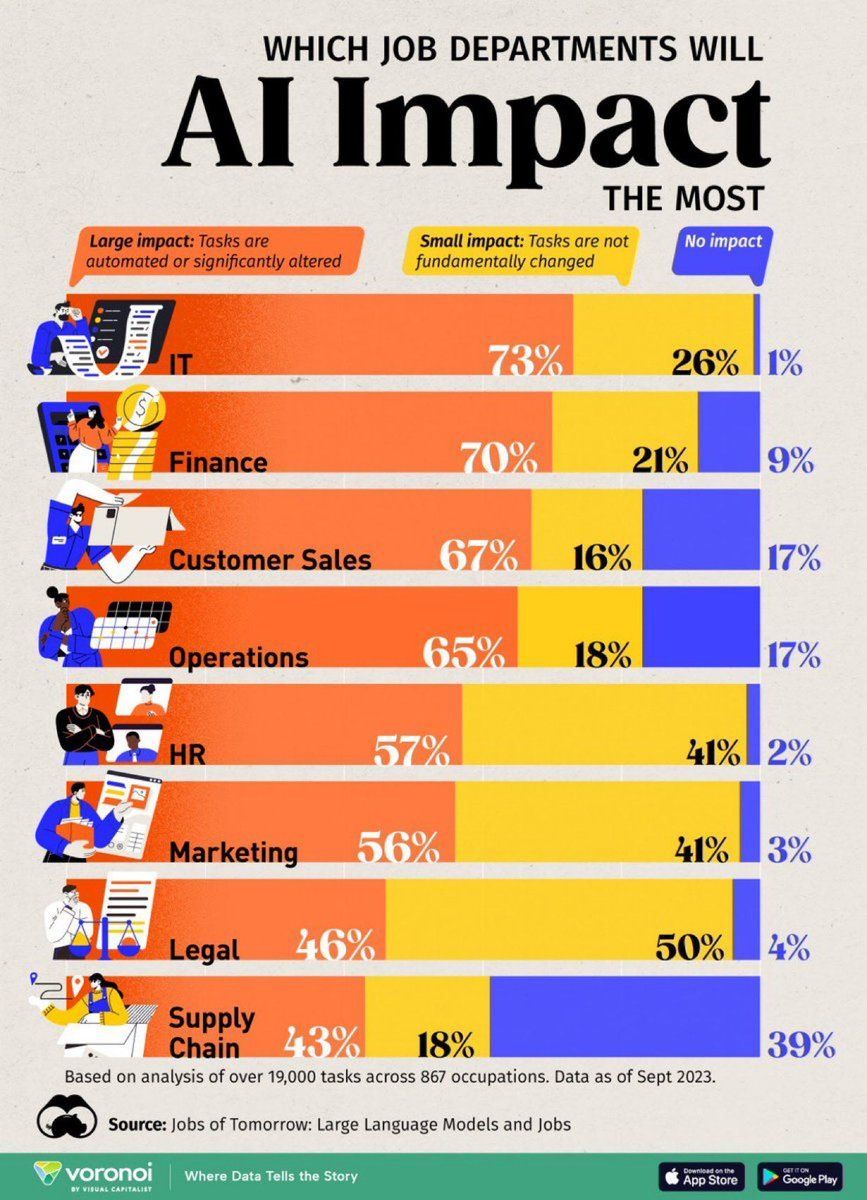
Analyse der Auswirkungen von AI auf Arbeitsplätze: Eine Infografik von Visual Capitalist zeigt die Arbeitsplätze, die am stärksten von AI betroffen sind, und lenkt die Aufmerksamkeit auf Veränderungen in der zukünftigen Arbeitswelt (Quelle: Ronald_vanLoon)
AI zur Erkennung von Straßenschäden in Dubai: Dubai wird neue AI-Technologie zur Erkennung von Straßenschäden einsetzen, was das Anwendungspotenzial von AI bei der Wartung städtischer Infrastrukturen zeigt (Quelle: Ronald_vanLoon)
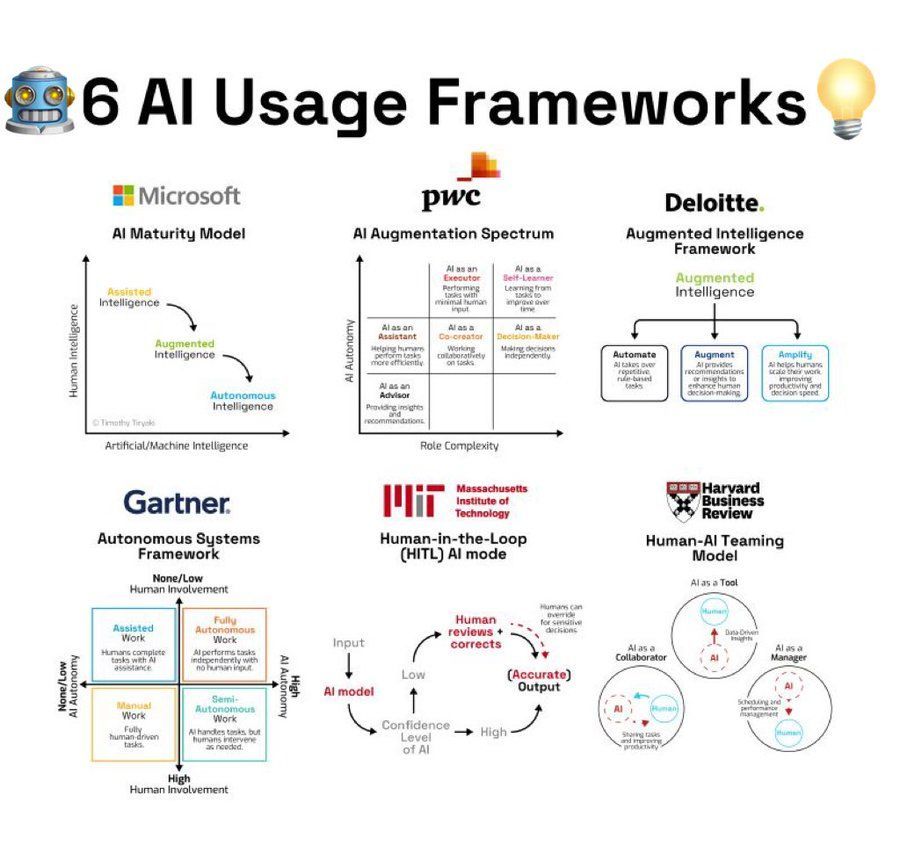
Zusammenfassung von Frameworks zur AI-Nutzung: Eine Infografik fasst 6 Frameworks oder Methodologien zur Nutzung von AI zusammen und bietet Anregungen für Benutzer, die AI anwenden möchten (Quelle: Ronald_vanLoon)
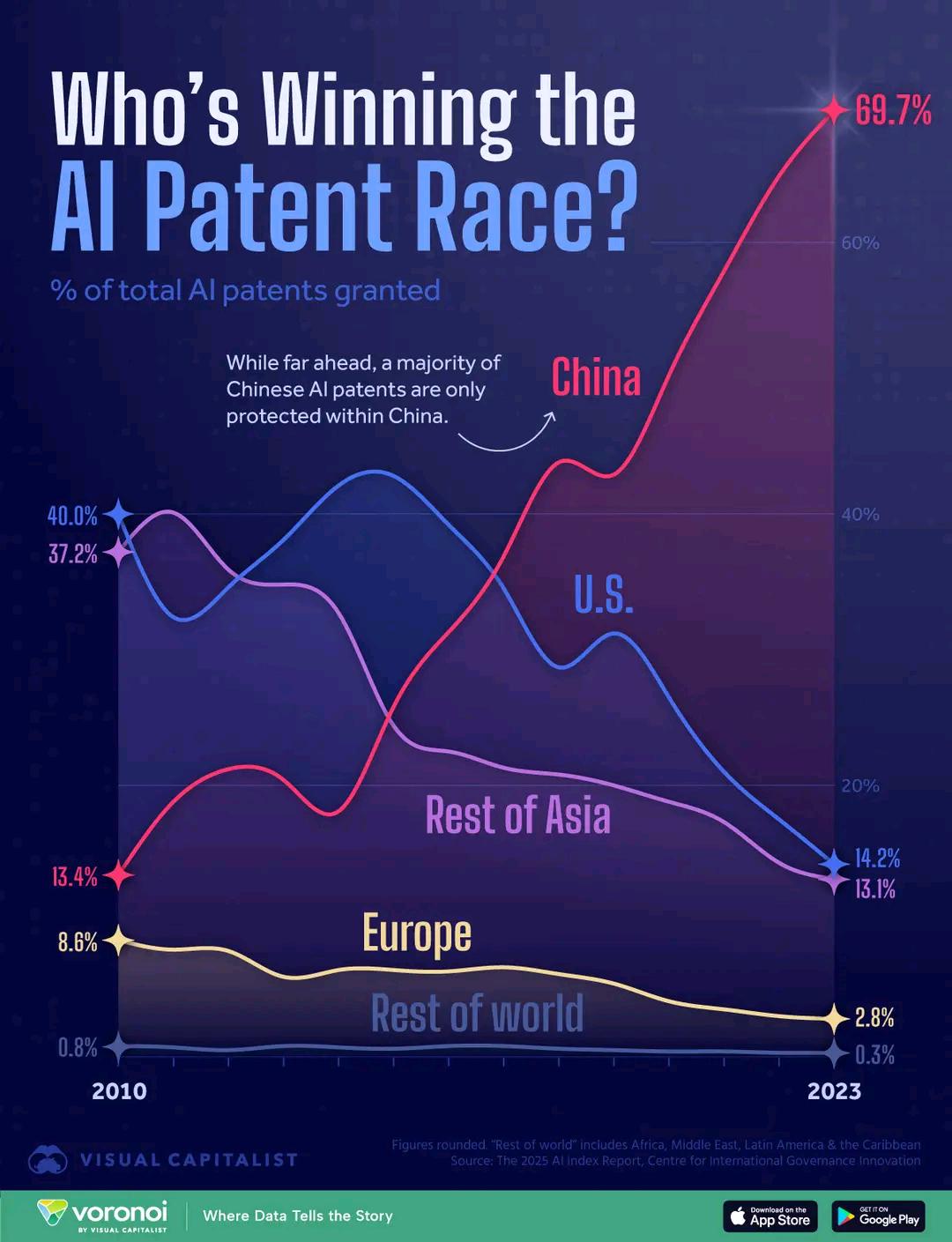
Vergleich der Anzahl von AI-Patenten nach Ländern: Ein Diagramm zeigt den Vergleich der Anzahl von AI-Patenten verschiedener Länder und spiegelt die Unterschiede bei den AI-F&E-Investitionen und -Ergebnissen wider. Kommentare erwähnen, dass die relativ niedrigen Kosten für Patentanmeldungen in China die Dateninterpretation beeinflussen könnten (Quelle: karminski3)
Bionischer Arm hilft Menschen mit Behinderungen: Das Unternehmen Open Bionics stattet das 15-jährige amputierte Mädchen Grace mit einem bionischen Arm aus und zeigt damit die Anwendung von AI und Robotertechnologie im Gesundheitswesen und in der Hilfsmitteltechnologie (Quelle: Ronald_vanLoon)
AI-unterstützte Filme erhalten Oscar-Berechtigung und erregen Aufmerksamkeit: Die Academy of Motion Picture Arts and Sciences hat ihre Regeln aktualisiert und klargestellt, dass Filme, die mit AI und anderen digitalen Werkzeugen erstellt wurden, ebenfalls für die Oscar-Verleihung qualifiziert sind. Dies löste breite Diskussionen innerhalb und außerhalb Hollywoods über die Auswirkungen von AI auf das Filmschaffen und die Industriestandards aus (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Litauen entwickelt Regeln für den AI-Einsatz in Schulen: Litauen arbeitet an Regeln für den Einsatz künstlicher Intelligenz in Schulen, was zeigt, dass das Bildungswesen beginnt, die Anwendung von AI-Werkzeugen zu regulieren (Quelle: Reddit r/ArtificialInteligence)