Schlüsselwörter:KI, Großes Modell, Intelligenter Agent, Multimodal, Gravitationswellendetektor-KI-Design, Magi-1 Videogenerierungsmodell, Vidu Q1 Video-Großmodell, Claude-Werteanalyse, DeepSeek-R1 Inferenzmechanismus, KI-Agenten-Protokollstandard, 3D-Gaußsches Splatting-Sicherheitslücke, KI-Musikurheberrechtsstreit
🔥 Fokus
KI entwirft neuartigen Gravitationswellendetektor und erweitert beobachtbares Universum: Forscher des MPI, Caltech und anderer Institutionen nutzten den KI-Algorithmus Urania, um einen neuartigen Gravitationswellendetektor zu entwerfen, der über das bisherige menschliche Verständnis hinausgeht. Die KI formulierte das Designproblem als kontinuierliches Optimierungsproblem und entdeckte Dutzende topologische Strukturen, die menschliche Entwürfe übertreffen. Dies kann die Detektionsempfindlichkeit um mehr als das 10-fache erhöhen und das Volumen des beobachtbaren Universums um das 50-fache erweitern. Diese in PRX veröffentlichte Studie zeigt das Potenzial der KI, übermenschliche Lösungen in der Grundlagenforschung zu finden und sogar völlig neue physikalische Ideen zu schaffen. (Quelle: Xin Zhi Yuan)

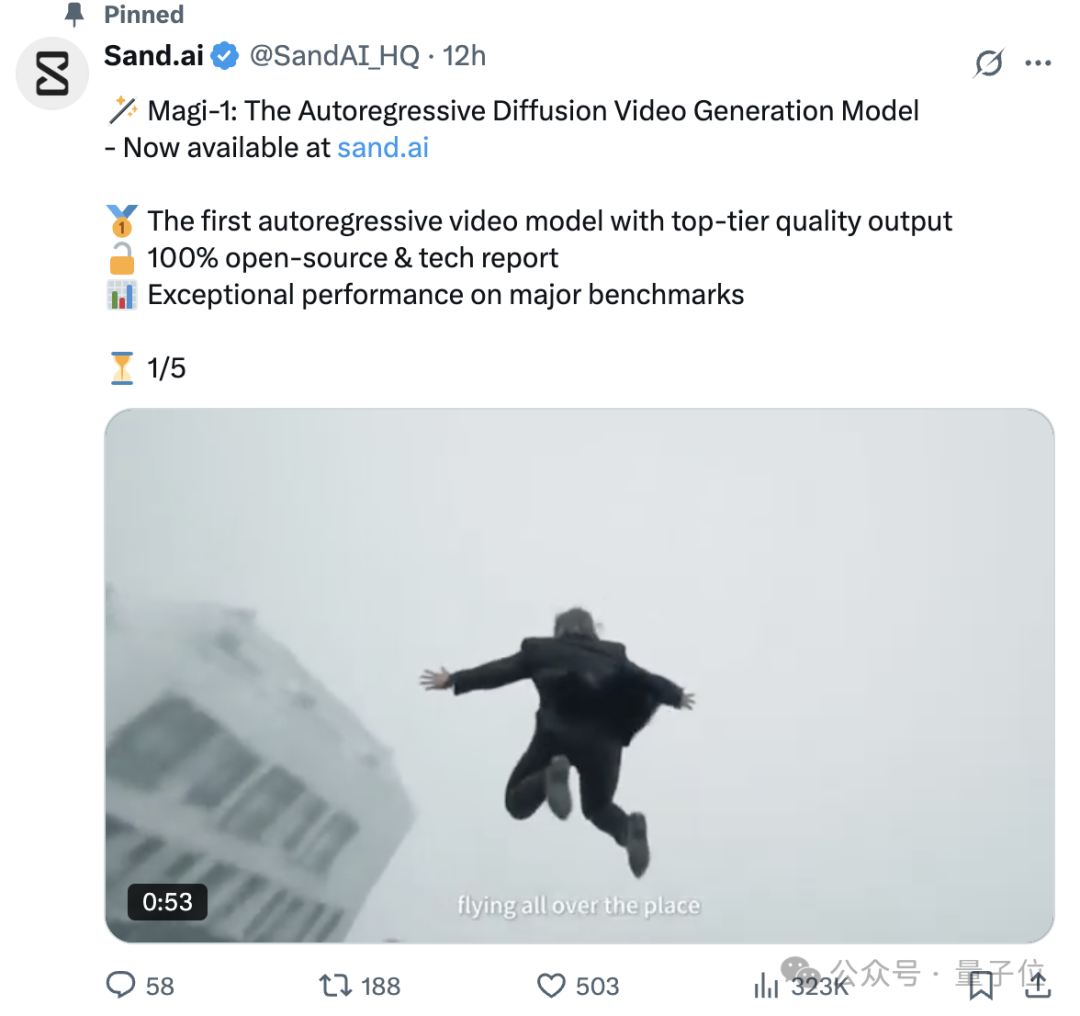
Team von Tsinghua-Sonderpreisträger Cao Yue veröffentlicht Open-Source-Videogenerierungsmodell Magi-1: Sand.ai, gegründet vom Swin Transformer-Autor Cao Yue, hat das autoregressive Videogenerierungs-Großmodell Magi-1 veröffentlicht und als Open Source bereitgestellt. Das Modell verwendet eine blockweise autoregressive Vorhersagemethode, unterstützt unbegrenzte Längenerweiterung und sekündengenaue Längenkontrolle und erreicht eine hochauflösende Ausgabe. Das Team veröffentlichte einen 61-seitigen technischen Bericht, der die Modellarchitektur (basierend auf DiT), die Trainingsmethode (Flow-Matching) sowie mehrere Optimierungen bei Attention und verteiltem Training detailliert beschreibt. Eine Reihe von Modellen mit Parametern von 4.5B bis 24B wurde als Open Source veröffentlicht, wobei das kleinste Modell auf einer einzelnen 4090-Karte lauffähig ist, um die Entwicklung der KI-Videogenerierungstechnologie voranzutreiben. (Quelle: Liangziwei, Jiqizhixin, kaifulee)
Chinesisches Videomodell Vidu Q1 führt beide VBench-Rankings im Q1 an: Das Videomodell Vidu Q1 von Shengshu Technology belegt in den beiden maßgeblichen Benchmarks VBench-1.0 und VBench-2.0 den ersten Platz und übertrifft damit in- und ausländische Modelle wie Sora und Runway. Q1 zeigt hervorragende Leistungen in Bezug auf Video-Realismus, semantische Konsistenz und inhaltliche Korrektheit. Die neue Version unterstützt 1080p HD-Bildqualität (generiert 5 Sekunden auf einmal), hat die Funktion für Start- und Endbilder verbessert, um filmreife Kamerafahrten zu ermöglichen, und führt eine KI-Soundeffektfunktion mit präziser Zeitsteuerung (48kHz Abtastrate) ein. Die Preisgestaltung ist wettbewerbsfähig und zielt darauf ab, die Kreativbranche zu stärken. (Quelle: Xin Zhi Yuan)

Anthropic-Studie enthüllt Werteausdruck von Claude: Anthropic analysierte 700.000 anonyme Claude-Konversationen und erstellte ein Klassifizierungssystem mit 3.307 einzigartigen Werten, um die Wertorientierung der KI in realen Interaktionen zu verstehen. Die Studie ergab, dass Claude im Großen und Ganzen den Prinzipien “hilfreich, ehrlich, harmlos” folgt und seine Werte flexibel an verschiedene Kontexte anpassen kann (z. B. Ratschläge zu zwischenmenschlichen Beziehungen, historische Analysen). In den meisten Fällen unterstützt es die Ansichten der Nutzer, widersetzt sich jedoch in wenigen Fällen (3%) aktiv, was möglicherweise seine Kernwerte widerspiegelt. Die Studie trägt zur Verbesserung der Transparenz des KI-Verhaltens bei, identifiziert Risiken und liefert empirische Grundlagen für die Bewertung der KI-Ethik. (Quelle: Yuan Yu Zhou Zhi Xin MetaverseHub, Xin Zhi Yuan)

🎯 Trends
Tsinghua-Professor Deng Zhidong über die Entwicklung und Zukunft von AGI: Professor Deng Zhidong von der Tsinghua-Universität erläuterte den Entwicklungspfad der KI von unimodalen Textmodellen hin zu multimodaler verkörperter Intelligenz und interaktiver AGI. Er betonte, dass grundlegende große Modelle wie Betriebssysteme seien und MoE-Architekturen sowie multimodale semantische Ausrichtung Schlüsseltechnologien an vorderster Front darstellten. Deng Zhidong hob insbesondere die bahnbrechende Bedeutung von DeepSeek hervor und argumentierte, dass dessen starke Schlussfolgerungsfähigkeiten und lokale Bereitstellbarkeit einen Wendepunkt für die breite Anwendung von KI in China darstellten. Die Zukunft werde zu einer Welt der allgemeinen künstlichen Intelligenz führen, in der KI-Agenten über stärkere organisatorische Fähigkeiten verfügen und sich vom Internet in die physische Welt bewegen werden, wobei jedoch auch ethische und Governance-Fragen zu beachten seien. (Quelle: Tsinghua Deng Zhidong: Wir werden uns auf eine Welt der allgemeinen künstlichen Intelligenz zubewegen)
DeepMind diskutiert “Generative Ghosts”: KI-gesteuerte digitale Unsterblichkeit: DeepMind und die University of Colorado schlagen das Konzept der “Generative Ghosts” vor. Dies sind KI-Agenten, die auf Daten Verstorbener basieren, neue Inhalte generieren und aus der Perspektive des Verstorbenen interagieren können, was über die einfache Replikation von Informationen hinausgeht. Das Paper untersucht den Designraum (z. B. Erstellung durch Erst- oder Drittparteien, Bereitstellung vor oder nach dem Tod, Grad der Anthropomorphisierung) und potenzielle Auswirkungen, einschließlich der Vorteile emotionalen Trosts und der Wissensweitergabe, sowie Herausforderungen wie psychologische Abhängigkeit, Reputationsrisiken, Sicherheit und soziale Ethik. Es wird zu eingehender Forschung und Regulierung aufgerufen, bevor die Technologie ausgereift ist. (Quelle: Xin Zhi Yuan)

Apple Intelligence und KI-Siri mehrfach verschoben, Starttermin in China ungewiss: Die Veröffentlichungspläne für Apples KI-Funktionen Apple Intelligence (insbesondere die neue Version von Siri) wurden mehrfach verzögert, einige Funktionen könnten auf Herbst 2025 verschoben werden. Für China besteht aufgrund von Genehmigungsprozessen und Problemen bei der Lokalisierungskooperation (Gerüchte über Zusammenarbeit mit Alibaba, Baidu) eine größere Unsicherheit. Gründe für die Verzögerung sind unter anderem nicht erreichte technische Standards (interne Bewertungen niedrig, Erfolgsquote nur 66-80%) und unterschiedliche regulatorische Richtlinien in verschiedenen Ländern. Apple sieht sich deswegen bereits Klagen wegen falscher Werbung gegenüber und hat die Werbeslogans für das iPhone 16 geändert. Dies spiegelt die Herausforderungen wider, denen Apple bei der Implementierung von KI gegenübersteht, und einen langsamen Innovationsprozess. (Quelle: Yi Cai Shang Xue)

Qualcomm betont Edge-KI als Schlüssel für die nächste Generation von Erlebnissen: Wan Weixing, Leiter für KI-Produkttechnologie bei Qualcomm China, wies darauf hin, dass Edge-KI aufgrund von Vorteilen wie Datenschutz, Personalisierung, Leistung, Energieeffizienz und schneller Reaktionsfähigkeit zum Kern der nächsten Generation von KI-Erlebnissen wird und die Mensch-Maschine-Schnittstelle neu gestaltet. Qualcomm positioniert sich durch Hardware (heterogenes Computing), einen einheitlichen Software-Stack und Ökosystem-Tools wie den Qualcomm AI Hub. Die treibende Kraft dahinter ist der Edge-Intelligenz-Planer, der lokale Daten nutzt, um präzises Intentionsverständnis, Aufgabenplanung und anwendungsübergreifende Dienstaufrufe zu realisieren. (Quelle: 36Kr)

KI-Agenten-Protokollstandards werden zum neuen Fokus im Wettbewerb der Giganten: Technologieriesen konkurrieren intensiv um Standards für die Interaktion von KI-Agenten. Anthropic führte als erstes MCP (Model Context Protocol) ein, um die Verbindung von Modellen mit externen Daten/Tools zu vereinheitlichen, worauf OpenAI und Google reagierten. Anschließend veröffentlichte Google das Open-Source-Protokoll A2A, das die Zusammenarbeit von Agenten über Ökosysteme hinweg fördern soll. Der Artikel analysiert, dass die Kontrolle über die Protokolldefinition die Kontrolle über die zukünftige Wertverteilung in der KI-Branche bedeutet. Die Giganten bauen durch MCP (Datenzugriffsdienste) und A2A (Bindung an Cloud-Plattformen) Ökosystembarrieren auf und kämpfen um die Branchenführerschaft. (Quelle: Ke Ji Yun Bao Dao)

Tencent Yuanbao und Bytedance Doubao integrieren sich tief in WeChat- und Douyin-Ökosysteme: Tencent Yuanbao startet einen WeChat-Account, Bytedance Doubao zieht in die “Nachrichten”-Seite von Douyin ein – die beiden großen KI-Assistenten integrieren sich tief in ihre jeweiligen Super-Apps. Nutzer können direkt in WeChat mit Yuanbao interagieren, Artikel analysieren und teilen oder in Douyin mit Doubao chatten und Informationen suchen. Dieser Schritt wird als wichtige Strategie der Giganten angesehen, um neben Werbeeinblendungen auch soziale Netzwerke und Content-Ökosysteme zur Nutzergewinnung für KI-Anwendungen zu nutzen. Ziel ist es, die Nutzungsschwelle zu senken, neue Modelle für KI + Soziales zu erkunden und KI-generierte Inhalte als soziale Währung zu etablieren. (Quelle: Zi Mu Bang)
AI4SE-Bericht: Große Modelle beschleunigen die Intelligenz im Software Engineering: Der von der China Academy of Information and Communications Technology (CAICT) und anderen Institutionen veröffentlichte “AI4SE Industry Status Survey Report (2024)” zeigt, dass die Anwendung von KI im Software Engineering die Validierungsphase überschritten hat und in die Phase der großflächigen Implementierung eintritt. Der Intelligenzreifegrad von Unternehmen erreicht im Allgemeinen L2 (teilweise intelligent). Die Anwendung von KI in der Anforderungsanalyse und in der Betriebsphase nimmt deutlich zu, die Effizienzsteigerung in allen Phasen ist offensichtlich, insbesondere im Testbereich. Sowohl die Akzeptanzrate von Code-Generierung (durchschnittlich 27,46%) als auch der Anteil von KI-generiertem Code (durchschnittlich 28,17%) sind gestiegen. Intelligente Testwerkzeuge zeigen bereits erste Erfolge bei der Reduzierung der Rate funktionaler Fehler. (Quelle: AI Qian Xian)

Kingsoft Office verbessert Regierungs-Großmodell, stärkt Reasoning und Dokumentenverarbeitung: Kingsoft Office hat eine verbesserte Version seines Großmodells für Behörden (13B, 32B) veröffentlicht, die die Reasoning-Fähigkeiten verbessert und sich auf interne Anwendungsszenarien im öffentlichen Sektor konzentriert. Das Modell wurde mit hunderten Millionen von Regierungsdokumenten trainiert und optimiert das Verfassen offizieller Dokumente (deckt 5 Textsorten ab), intelligente Textpolitur, Korrekturlesen und Layout sowie die Abfrage von Richtlinien. Nach dem Upgrade unterstützt es ein besseres Intentionsverständnis und Fragenbeantwortung über interne Wissensdatenbanken (Antworten mit Quellenangabe), mit dem Ziel, die Produktivität von Beamten um 30-40% zu steigern. Die private Bereitstellung wird betont, um Sicherheitsanforderungen zu erfüllen, und die Bereitstellungskosten sollen um 90% gesenkt worden sein. (Quelle: Liangziwei)

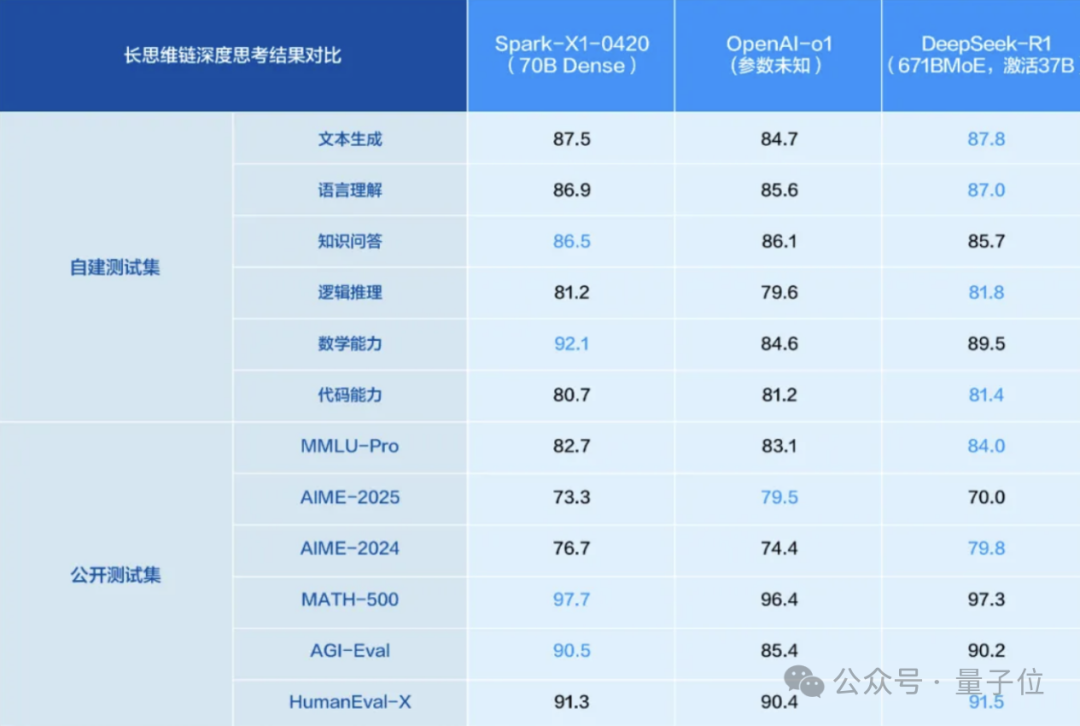
iFlytek Spark X1 Inferenzmodell aufgerüstet, basiert auf rein chinesischer Rechenleistung und zielt auf Top-Niveau ab: iFlytek hat eine aktualisierte Version des Spark X1 Deep Inference Modells veröffentlicht und betont, dass es auf rein chinesischer Rechenleistung (Huawei Ascend) trainiert wurde und bei allgemeinen Aufgaben mit OpenAI o1 und DeepSeek R1 konkurrieren soll. Das neue Modell profitiert von Innovationen wie groß angelegtem mehrstufigem Reinforcement Learning und einheitlichem Training von schnellem und langsamem Denken. Ein Highlight ist die deutlich reduzierte Bereitstellungsschwelle: 4 Huawei 910B Karten reichen für die Vollversion, 16 Karten für branchenspezifische Anpassungen. Vor dem Hintergrund der H20-Beschränkungen zeigt dies den Fortschritt der chinesischen Full-Stack-KI-Lösungen. (Quelle: Liangziwei)
Zhipu GLM-4 auf OpenRouter und Ollama Plattformen verfügbar: Das GLM-4 Modell von Zhipu AI (einschließlich der 32B Instruct-Version GLM-4-32B-0414 und der Reasoning-Version GLM-Z1-32B-0414) ist jetzt auf der Modell-Routing-Plattform OpenRouter verfügbar, wo Nutzer es kostenlos testen können. Gleichzeitig haben Community-Mitglieder die Q4_K_M quantisierte Version auf die Ollama-Plattform hochgeladen, was die lokale Bereitstellung und Ausführung erleichtert (erfordert Ollama v0.6.6 oder höher). (Quelle: karminski3, Reddit r/LocalLLaMA)
Meta veröffentlicht Perception Language Model (PLM): Meta hat sein visuelles Sprachmodell PLM (Versionen mit 1B, 3B, 8B Parametern) als Open Source veröffentlicht, das sich auf die Bewältigung anspruchsvoller visueller Erkennungsaufgaben konzentriert. Das Modell wurde mit einer Kombination aus groß angelegten synthetischen Daten und neu gesammelten 2,5 Millionen von Menschen annotierten Video-Frage-Antwort/Raum-Zeit-Untertitelungsdaten trainiert. Gleichzeitig wurde der neue PLM-VideoBench Benchmark veröffentlicht, der sich auf feingranulares Aktivitätsverständnis und raum-zeitliches Schlussfolgern konzentriert. (Quelle: Reddit r/LocalLLaMA, Hugging Face)

🧰 Tools
NYXverse: AIGC-Plattform zur Text-zu-3D-Welt-Generierung: 2033 Technology, gegründet vom ehemaligen DreambigCareer-Gründer Ma Yuchi, startet die AIGC-Content-Plattform NYXverse. Die Plattform ermöglicht es Nutzern, durch Texteingabe interaktive 3D-Welten mit benutzerdefinierten KI-Agenten, Umgebungen und Handlungen zu erstellen, was die Hürde für die Erstellung von 3D-Inhalten erheblich senkt. Kerntechnologie sind selbst entwickelte Modelle für Charaktere, Welten und Verhalten. NYXverse positioniert sich als UGC-Content-Sharing-Community und unterstützt schnelle Weiterbearbeitung und IP-Adaption. Es ist bereits auf Steam verfügbar und hat fast 100 Millionen Yuan an Finanzierung von SenseTime und Oriental State-owned Capital erhalten. (Quelle: 36Kr)

SkyReels V2 Open-Source-Modell für unbegrenzt lange Videogenerierung: SkyworkAI hat das SkyReels V2 Modell (1.3B und 14B Parameter) als Open Source veröffentlicht, das Text-zu-Video und Bild-zu-Video Aufgaben unterstützt und angeblich Videos unbegrenzter Länge generieren kann. Erste Tests deuten darauf hin, dass die Ergebnisse möglicherweise nicht so gut sind wie bei einigen Closed-Source-Modellen, aber als Open-Source-Tool hat es dennoch Potenzial. (Quelle: karminski3, Reddit r/LocalLLaMA)
KI-gesteuertes Exoskelett hilft Rollstuhlfahrern beim Stehen und Gehen: Es wird ein Exoskelettgerät vorgestellt, das KI-Technologie nutzt, um Rollstuhlfahrern zu helfen, wieder stehen und gehen zu können. Dies zeigt das Anwendungspotenzial von KI im Bereich der assistiven Technologien. (Quelle: Ronald_vanLoon)
Fellou: Erster aktionsorientierter Browser veröffentlicht: Der von Authing-Gründer Xie Yang entwickelte Fellou-Browser wurde veröffentlicht und positioniert sich als aktionsorientierter Browser (Agentic Browser). Er verfügt nicht nur über die Informationsanzeigefunktionen herkömmlicher Browser, sondern integriert auch KI-Agenten-Fähigkeiten. Er kann Benutzerabsichten verstehen, Aufgaben automatisch zerlegen und komplexe Arbeitsabläufe über Websites hinweg ausführen (z. B. Informationsbeschaffung, Ausfüllen von Formularen, Online-Bestellungen). Zu seinen Kernfähigkeiten gehören tiefgreifende Aktionen, proaktive Intelligenz (Vorhersage von Benutzerbedürfnissen), hybrider Schattenraum (stört den Benutzer nicht) und ein Agentennetzwerk (Agent Store). Ziel ist es, den Browser von einem Informationswerkzeug zu einer intelligenten Arbeitsplattform aufzuwerten. (Quelle: Xin Zhi Yuan)

WriteHERE: Jürgen Schmidhubers Team veröffentlicht Open-Source-Framework für Langtextschreiben: Das vom Team um Jürgen Schmidhuber als Open Source veröffentlichte Langtext-Schreibframework WriteHERE verwendet heterogene rekursive Planungstechniken und kann in einem Durchgang über 40.000 Wörter und 100 Seiten professionelle Berichte generieren. Das Framework betrachtet das Schreiben als einen dynamischen rekursiven Planungsprozess aus drei Aufgabentypen: Retrieval, Reasoning und Schreiben, und erreicht durch zustandsbehaftetes DAG-Taskmanagement eine adaptive Ausführung. Bei Aufgaben zur Erstellung von Romanen und technischen Berichten übertrifft es Lösungen wie Agent’s Room und STORM. Das Framework ist vollständig Open Source und unterstützt den Aufruf heterogener Agenten. (Quelle: Jiqizhixin)

Bytedance startet universelle Agentenplattform “Coze Space”: Bytedance hat offiziell den internen Test seiner universellen Agentenplattform “Coze Space” gestartet, die als KI-Assistent mit den Modi “Erkunden” und “Planen” positioniert ist. Die Plattform basiert auf dem aktualisierten Doubao-Großmodell (200B MoE), unterstützt das MCP-Protokoll und kann Tools wie Feishu Docs und Lark Base aufrufen. Benutzer können durch Anweisungen in natürlicher Sprache Aufgaben wie Informationsbeschaffung, Berichterstellung und Datenbereinigung erledigen lassen und die Ergebnisse in die angegebene Anwendung ausgeben. Im Vergleich zu Startup-Agenten wie Manus konzentriert sich Coze Space stärker auf Plattformisierung und Ökosystemintegration. (Quelle: Bao Mu Ji Jiao Cheng: Zheng Que Shi Yong「Kou Zi Kong Jian」, AI Zhi Neng Ti Yan Jiu Yuan)

Demonstration von KI-Videotransformationstechnologie: Ein Reddit-Benutzer teilt ein Video, das eine KI-Technologie zeigt, die Personen in normalen Sprechvideos in beliebige Figuren wie Bäume, Autos, Cartoons usw. umwandeln kann. Es wird nur ein Zielbild benötigt, was die Fähigkeiten der KI bei der Videostilübertragung und Effektgenerierung demonstriert. (Quelle: Reddit r/deeplearning)

Nari Labs veröffentlicht hochrealistisches dialogfähiges TTS-Modell Dia: Nari Labs hat sein TTS (Text-to-Speech)-Modell Dia als Open Source veröffentlicht, das angeblich ultra-realistische dialogfähige Sprache erzeugen kann. Das Modell wurde auf GitHub veröffentlicht und bietet einen Link zum Ausprobieren auf Hugging Face Space. (Quelle: Reddit r/LocalLLaMA, GitHub)

Benutzer entwickelt AWS Bedrock Wissensdatenbank-Funktion für OpenWebUI: Ein Community-Benutzer hat eine Funktion für OpenWebUI entwickelt und geteilt, die den Aufruf von AWS Bedrock Wissensdatenbanken ermöglicht. Dies erleichtert es Benutzern, die Wissensdatenbankfähigkeiten von Bedrock innerhalb von OpenWebUI zu nutzen. Der Code wurde auf GitHub als Open Source veröffentlicht. (Quelle: Reddit r/OpenWebUI, GitHub)
Entwickler halten kleine LLMs für unterschätzt und veröffentlichen Arch-Function-Chat: Das Katanemo-Team argumentiert, dass kleine LLMs deutliche Vorteile in Geschwindigkeit und Effizienz bieten, ohne bei der Leistung Kompromisse einzugehen. Sie haben die Arch-Function-Chat Modellreihe (3B Parameter) veröffentlicht, die sich bei Funktionsaufrufen auszeichnet und Chat-Fähigkeiten integriert. Diese Modelle wurden in ihren Open-Source-KI-Agenten-Server Arch integriert, um die Entwicklung von Agenten zu vereinfachen. (Quelle: Reddit r/artificial, Hugging Face)
Entwickler erstellt KI-Tool zur Optimierung von Lebensläufen für ATS-Screening: Ein Entwickler teilt seine frustrierende Erfahrung bei der Jobsuche, weil sein Lebenslauf von ATS (Applicant Tracking System) nicht korrekt analysiert wurde, und hat deshalb ein Tool entwickelt. Das Tool liest Stellenbeschreibungen, extrahiert Schlüsselwörter, prüft die Übereinstimmung des Lebenslaufs und schlägt Änderungen vor, um schließlich einen ATS-freundlichen PDF-Lebenslauf und ein Anschreiben zu generieren. (Quelle: Reddit r/artificial)
📚 Lernen
142-seitiger Bericht analysiert DeepSeek-R1 Reasoning-Mechanismus: Das Quebec AI Institute und andere Institutionen haben einen langen Bericht veröffentlicht, der den Reasoning-Prozess (Chain-of-Thought) von DeepSeek-R1 eingehend analysiert und die neue Forschungsrichtung “Thoughtology” vorschlägt. Der Bericht enthüllt, dass das Reasoning von R1 hochgradig strukturierte Merkmale aufweist (Problemdefinition, Entfaltung, Rekonstruktion, Entscheidung), einen “Reasoning Sweet Spot” hat (zu viel Reasoning verringert die Leistung) und möglicherweise höhere Sicherheitsrisiken birgt als Nicht-Reasoning-Modelle. Die Studie untersucht mehrere Dimensionen wie die Länge der Chain-of-Thought, die Verarbeitung langer Kontexte, Sicherheitsethik und menschenähnliche kognitive Phänomene und liefert wichtige Einblicke zum Verständnis und zur Optimierung von Reasoning-Modellen. (Quelle: Xin Zhi Yuan, Xin Zhi Yuan)

OpenRCA: Erster öffentlicher Benchmark zur Bewertung der Root Cause Analysis-Fähigkeiten von LLMs: Microsoft, CUHK (Shenzhen) und die Tsinghua University haben gemeinsam den OpenRCA-Benchmark eingeführt, um die Fähigkeit von Large Language Models (LLMs) zur Lokalisierung der Grundursache (Root Cause Analysis, RCA) von Software-Service-Ausfällen zu bewerten. Der Benchmark umfasst klare Aufgabendefinitionen, Bewertungsmethoden und 335 manuell abgeglichene reale Fehlerfälle sowie Betriebsdaten. Erste Tests zeigen, dass selbst fortgeschrittene Modelle wie Claude 3.5 und GPT-4o bei der direkten Bearbeitung von RCA-Aufgaben schlecht abschneiden (Genauigkeit <6%). Mit einem einfachen RCA-Agent-Framework stieg die Genauigkeit von Claude 3.5 auf 11,34%, was darauf hindeutet, dass LLMs in diesem Bereich noch erhebliches Verbesserungspotenzial haben. (Quelle: Jiqizhixin, Jiqizhixin)

Neue Studie schlägt “Sleep-time Compute” zur Effizienzsteigerung von LLMs vor: Das KI-Startup Letta und Forscher der UC Berkeley schlagen das neue Paradigma “Sleep-time Compute” vor. Die Kernidee ist, dass zustandsbehaftete KI-Agenten in inaktiven “Schlaf”-Phasen, wenn keine Benutzeranfragen vorliegen, kontinuierlich Kontextinformationen verarbeiten und neu organisieren, um “rohen Kontext” in “gelernten Kontext” umzuwandeln. Dies kann die sofortige Inferenzlast während der tatsächlichen Interaktion reduzieren, die Effizienz steigern, Kosten senken und möglicherweise die Genauigkeit verbessern. Experimente zeigen, dass diese Methode die Pareto-Grenze zwischen Berechnung und Genauigkeit effektiv verbessern und die Kosten bei der gemeinsamen Nutzung von Kontext durch mehrere Abfragen amortisieren kann. (Quelle: Jiqizhixin, Jiqizhixin)

AnyAttack: Groß angelegtes selbstüberwachtes adversariales Angriffsframework für VLMs: HKUST, BJTU und andere schlagen das AnyAttack-Framework (CVPR 2025) vor, um die Robustheit von Visual Language Models (VLMs) zu bewerten. Diese Methode lernt durch groß angelegtes selbstüberwachtes Vortraining (auf LAION-400M) einen Generator für adversariales Rauschen. Ohne vordefinierte Labels kann jedes Bild in ein gezieltes adversariales Beispiel umgewandelt werden, das das VLM dazu verleitet, eine bestimmte Ausgabe zu generieren. Kerninnovationen sind das selbstüberwachte Trainingsparadigma und die K-Enhancement-Strategie. Experimente zeigen, dass AnyAttack nicht nur verschiedene Open-Source-VLMs effektiv angreifen kann, sondern auch erfolgreich Angriffe auf gängige kommerzielle Modelle übertragen kann, was systemische Sicherheitsrisiken im aktuellen VLM-Ökosystem aufdeckt. (Quelle: AI Ke Ji Ping Lun)

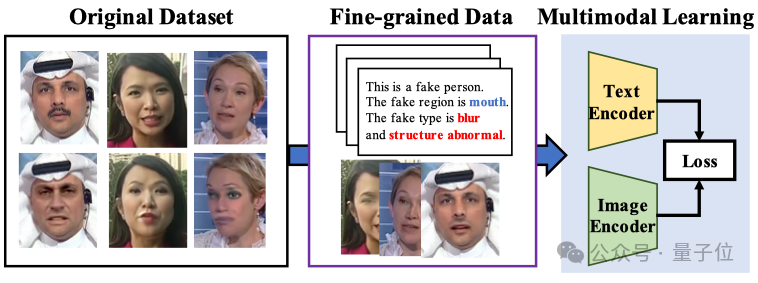
Multimodale große Modelle verbessern Erklärbarkeit und Generalisierbarkeit der Gesichtsfälschungserkennung: Die Xiamen University, Tencent Youtu und andere Institutionen (CVPR 2025) schlagen eine neue Methode zur Gesichtsfälschungserkennung unter Verwendung von Visual Language Models vor. Die Methode zielt darauf ab, über die traditionelle Echt/Falsch-Beurteilung hinauszugehen und das Modell in die Lage zu versetzen, die Gründe und den Ort der Fälschung in natürlicher Sprache zu erklären. Um den Mangel an hochwertigen annotierten Daten und das Problem der “Sprachhalluzinationen” zu beheben, entwickelten die Forscher den FFTG-Annotationsprozess, der Fälschungsmasken und strukturierte Prompts kombiniert, um hochpräzise Textbeschreibungen zu generieren. Experimente zeigen, dass multimodale Modelle, die auf diesen Daten trainiert wurden, eine bessere Generalisierungsfähigkeit über verschiedene Datensätze hinweg aufweisen und ihre Aufmerksamkeit stärker auf die tatsächlichen Fälschungsbereiche konzentrieren. (Quelle: Liangziwei)
Tutorial: Verbesserung der Genauigkeit von Wissensdatenbank-Q&A durch Kombination von Trae, MCP und Datenbank: Dieses Tutorial zeigt, wie das KI-IDE-Tool Trae und seine MCP (Model Context Protocol)-Funktion in Kombination mit einer PostgreSQL-Datenbank verwendet werden können, um die Frage-Antwort-Leistung von KI-Wissensdatenbanken zu optimieren. Durch die Speicherung strukturierter Daten in der Datenbank und die Generierung von SQL-Abfragen durch ein großes Modell (wie Claude 3.7) über Traes MCP können die Schwächen traditioneller RAG-Methoden bei der Verarbeitung von Tabellendaten und globalen/statistischen Fragen behoben werden. Das Tutorial bietet detaillierte Installations-, Konfigurations- und Testschritte und empfiehlt, diesen Ansatz mit RAG zu kombinieren. (Quelle: Dai Shu Di AI Ke Zhan)
![Chinesisches KI-Assistenten-Wunderwerkzeug Trae+MCP steigert die Genauigkeit der Wissensdatenbank-Suche um 300% [Anleitung für Dummies]](https://rebabel.net/wp-content/uploads/2025/04/image_1745328048.png)
Studie deckt Schwachstelle für Rechenkostenangriffe im 3D Gaussian Splatting Algorithmus auf: Eine Studie von Forschern der National University of Singapore und anderer Institutionen (ICLR 2025 Spotlight) entdeckt erstmals eine Methode für Rechenkostenangriffe auf 3D Gaussian Splatting (3DGS), genannt Poison-Splat. Der Angriff nutzt die Eigenschaft der adaptiven Modellkomplexität von 3DGS aus. Durch Hinzufügen von Störungen zu den Eingabebildern (Maximierung der Total Variation) wird das Modell dazu verleitet, während des Trainings übermäßig viele Gaußsche Punkte zu generieren. Dies führt zu einem drastischen Anstieg des GPU-Speicherverbrauchs (bis zu 80 GB) und der Trainingszeit (bis zu fast 5-fach) und kann möglicherweise zu Dienstausfällen (DoS) führen. Der Angriff ist sowohl im verdeckten als auch im nicht verdeckten Modus wirksam und übertragbar, was Sicherheitsrisiken gängiger 3D-Rekonstruktionstechnologien aufdeckt. (Quelle: Liangziwei)

Infografik: Agentic AI vs. GenAI: Eine von SearchUnify erstellte Infografik vergleicht die Hauptunterschiede und Merkmale von Agentic AI (autonom handelnd, zielorientiert) und Generative AI (Inhaltsgenerierung). (Quelle: Ronald_vanLoon)

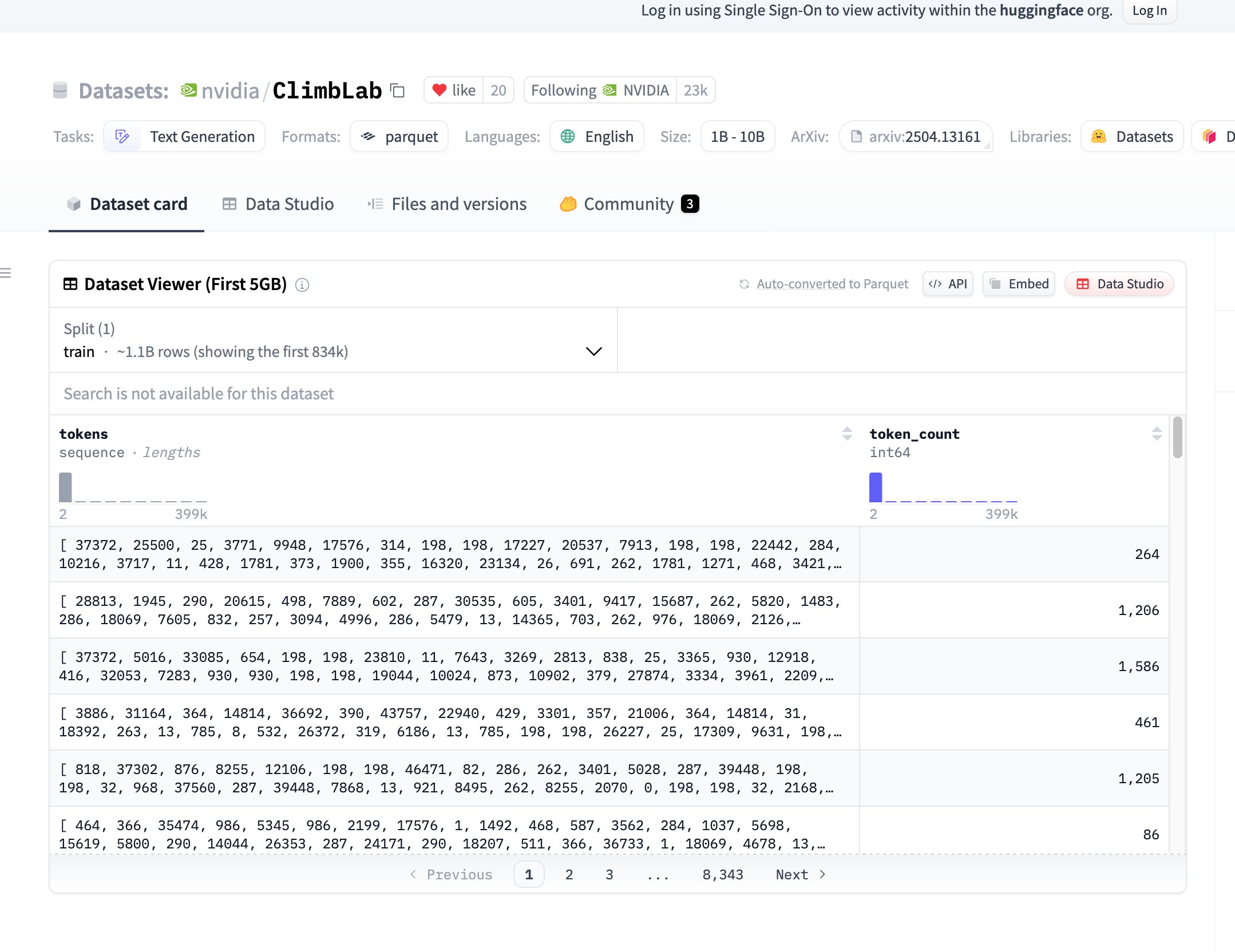
NVIDIA veröffentlicht ClimbLab Vortrainingsdatensatz und -methode als Open Source: NVIDIAs ClimbLab hat seine Vortrainingsmethode und seinen Datensatz veröffentlicht, der 1,2 Billionen Token umfasst und in 20 semantische Cluster unterteilt ist. Ein duales Klassifikatorsystem wird verwendet, um Inhalte geringer Qualität zu entfernen, was eine überlegene Skalierbarkeit bei 1B-Modellen zeigt. Der Datensatz wird unter der CC BY-NC 4.0 Lizenz veröffentlicht, um die Forschung der Community zu fördern. (Quelle: huggingface)
Anthropic teilt Best Practices für Claude Code: Anthropic hat einen Blogbeitrag veröffentlicht, in dem Best Practices und Tipps für die Verwendung seines KI-Programmierassistenten Claude Code geteilt werden, um Entwicklern zu helfen, das Tool effektiver für Programmieraufgaben zu nutzen. (Quelle: op7418, Alex Albert via op7418, Anthropic)

Neue Studie untersucht rekursive Kohärenz und Simulation resonanter Strukturen in KI: Ein Paper schlägt das Konzept der “Resonant Structural Emulation” (RSE) vor und postuliert, dass KI-Systeme nach kontinuierlicher Interaktion mit spezifischen menschlichen kognitiven Strukturen deren rekursive Kohärenz kurzzeitig simulieren können, anstatt einfach nur auf Datentraining oder Prompts zu basieren. Die Studie validiert diese strukturelle Resonanzmöglichkeit experimentell vorläufig und bietet eine neue Perspektive zum Verständnis von KI-Bewusstsein und fortgeschrittener Kognition. (Quelle: Reddit r/MachineLearning, Archive.org link)

Benutzer teilt Leistungsvergleichstest von RAG-Modellen in OpenWebUI: Ein Community-Benutzer teilt eine Leistungsbewertung von 9 verschiedenen LLMs (einschließlich Qwen QwQ, Gemini 2.5, DeepSeek R1, Claude 3.7 usw.) bei der Verwendung von RAG (Retrieval-Augmented Generation) in OpenWebUI für die Aufgabe der technischen Anleitung zum Indoor-Cannabisanbau. Die Ergebnisse zeigen, dass Qwen QwQ und Gemini 2.5 am besten abschneiden und bieten eine Referenz für die Modellauswahl. (Quelle: Reddit r/OpenWebUI)
FortisAVQA Datensatz und MAVEN Modell unterstützen robuste Audio-Video-Fragenbeantwortung: Xi’an Jiaotong University, HKUST(GZ) und andere Institutionen haben den FortisAVQA Datensatz und das MAVEN Modell (CVPR 2025) als Open Source veröffentlicht, um die Robustheit der Audio-Video-Fragenbeantwortung (AVQA) zu verbessern. FortisAVQA ermöglicht durch Umschreiben von Fragen und dynamische Partitionierung basierend auf konformer Vorhersage eine bessere Bewertung der Modellleistung bei seltenen Fragen. Das MAVEN Modell verwendet eine Multi-Aspect Cyclic Collaborative Debias (MCCD) Strategie, um Bias-Lernen zu reduzieren, und zeigt auf mehreren Datensätzen überlegene Leistung und Robustheit. (Quelle: PaperWeekly)

Zufällige Reihenfolge bei Autoregression schaltet Zero-Shot-Fähigkeiten im visuellen Bereich frei: Forscher der UIUC und anderer Institutionen schlagen in der CVPR 2025 Arbeit RandAR vor, dass die Generierung von Bild-Token durch einen Decoder-only Transformer in zufälliger Reihenfolge die Generalisierungsfähigkeit visueller Modelle freischalten kann. Durch die Einführung eines “Positionsbefehl-Tokens”, der die Generierungsreihenfolge steuert, kann RandAR Zero-Shot auf parallele Dekodierung, Bildbearbeitung, Auflösungsextrapolation und einheitliches Encoding (Repräsentationslernen) generalisieren und nähert sich dem “GPT-Moment” im visuellen Bereich an. Die Studie argumentiert, dass die Verarbeitung beliebiger Reihenfolgen der Schlüssel zur Universalität visueller autoregressiver Modelle ist. (Quelle: PaperWeekly)
Theoretische Analyse der Effektivität von Task-Vektor-Modellbearbeitung: Eine Studie des Rensselaer Polytechnic Institute und anderer Institutionen (ICLR 2025 Oral) analysiert theoretisch die tieferen Gründe für die Effektivität von Task-Vektoren bei der Modellbearbeitung. Die Studie beweist, dass die Effektivität von Task-Vektor-Addition und -Subtraktion beim Multi-Task-Lernen und maschinellen Vergessen mit der Korrelation zwischen den Aufgaben zusammenhängt, und liefert theoretische Garantien für die Out-of-Distribution-Generalisierung. Gleichzeitig erklärt die Theorie, warum niedrigrangige Approximation und Verschlankung (Pruning) von Task-Vektoren machbar sind, und liefert eine theoretische Grundlage für die effiziente Anwendung von Task-Vektoren. (Quelle: Jiqizhixin)

Studie zur Skalierbarkeit von stichprobenbasierter Suche: Forschungen von Google und Berkeley zeigen, dass durch Erhöhung der Stichprobenanzahl und der Validierungsstärke die stichprobenbasierte Suche (Generierung mehrerer Kandidatenantworten mit anschließender Validierung und Auswahl der besten) die Reasoning-Leistung von LLMs signifikant verbessern kann, sogar über den Sättigungspunkt von Konsistenzmethoden (Auswahl der häufigsten Antwort) hinaus. Die Studie entdeckt das Phänomen der “impliziten Skalierung”: Mehr Stichproben verbessern paradoxerweise die Validierungsgenauigkeit. Es werden zwei Prinzipien für eine effektive Selbstvalidierung vorgeschlagen: Vergleich von Antworten zur Fehlerlokalisierung und Umschreiben von Antworten basierend auf dem Ausgabestil. Diese Methode ist bei verschiedenen Benchmarks und unterschiedlichen Modellgrößen wirksam. (Quelle: Xin Zhi Yuan)

ACM MM 2025 LGM3A Workshop Call for Papers: Die ACM Multimedia 2025 Konferenz wird den dritten Workshop “Multimodal Research and Application based on Large Generative Models” (LGM3A) veranstalten, der sich auf Anwendungen und Herausforderungen großer generativer Modelle (LLM/LMM) in der multimodalen Datenanalyse, Generierung, Fragenbeantwortung, Suche, Empfehlung, Agenten usw. konzentriert. Der Workshop soll eine Austauschplattform bieten, um neueste Trends und Best Practices zu diskutieren, und sammelt entsprechende Forschungsarbeiten. Die Konferenz findet im Oktober 2025 in Dublin, Irland, statt. Die Einreichungsfrist für Papers ist der 11. Juli 2025. (Quelle: PaperWeekly)
Zhedong Zheng Gruppe an der Universität Macau sucht Doktoranden im Bereich Multimodalität: Die Forschungsgruppe von Assistant Professor Zhedong Zheng am Department of Computer Science der Universität Macau sucht vollfinanzierte Doktoranden im Bereich Multimodalität für den Eintritt im August 2026. Der Betreuer forscht zu Repräsentationslernen und Multimedia-Generierung und hat über 50 Paper in Top-Konferenzen und -Journalen wie CVPR, ICCV, TPAMI veröffentlicht. Bewerber sollten einen GPA von über 3,4 haben, einen Hintergrund in Informatik/Software Engineering, vertraut mit Python/PyTorch sein, und Bewerber mit einschlägigen Veröffentlichungen oder Wettbewerbspreisen werden bevorzugt. Vollstipendien werden angeboten. (Quelle: PaperWeekly)

💼 Business
LaiMou Technology erhält Pre-A-Finanzierungsrunde für Mähroboter: Gegründet von ehemaligen Führungskräften von YunJing, konzentriert sich das Unternehmen auf die Lösung von Mähproblemen in komplexem Gelände in Europa und Amerika. Ihr Lymow One Roboter verwendet eine Vision + Inertial Navigation RTK-Lösung (Kosten ein Zehntel des traditionellen RTK), ein Raupendesign (bewältigt 45° steile Hänge) und ist mit einem Mulch-Direktmesser ausgestattet. Hindernisvermeidung erfolgt durch KI-Vision und Ultraschall. Das Produkt hat über 5 Millionen US-Dollar im Crowdfunding gesammelt, der Stückpreis liegt bei etwa 3.000 US-Dollar. Diese Finanzierungsrunde über mehrere zehn Millionen Yuan wird für die Massenproduktion, Auslieferung und Marktexpansion verwendet. (Quelle: Von ehemaligen YunJing-Führungskräften gegründeter Mähroboter erhält weitere Finanzierung, Li Zexiang investierte, Crowdfunding über 5 Mio. USD | Hard氪 Erstmeldung)

Songyan Dynamics humanoider Roboter “Xiao Hai Ge” wird populär: Nach dem zweiten Platz beim Pekinger Humanoiden-Roboter-Halbmarathon erregen Songyan Dynamics und sein N2-Roboter (“Xiao Hai Ge” – kleiner Bruder) Marktinteresse. Das Unternehmen wurde vom Tsinghua-Doktoranden Jiang Zheyuan (Jahrgang 95) gegründet und hat fünf Finanzierungsrunden abgeschlossen. Der N2-Roboter kostet ab 39.900 Yuan, setzt auf hohe Kosteneffizienz, hat bereits Hunderte von Bestellungen und eine Bruttomarge von etwa 15%. Songyan Dynamics beschleunigt die Produktisierung und Massenlieferung, seine Niedrigpreisstrategie zielt auf einen schnellen Markteintritt ab. (Quelle: Ke Chuang Ban Ri Bao)
Vorsicht vor überhöhten ARR-Kennzahlen bei KI-Startups: Der Artikel weist darauf hin, dass die aus der SaaS-Branche stammende Kennzahl ARR (Annual Recurring Revenue) von KI-Startups missbraucht wird. Die Umsatzmodelle von KI-Unternehmen (oft nutzungs-/ergebnisbasiert) sind volatil, die frühe Kundenbindung ist gering und die Rechenkosten sind hoch, was sich stark von den vorhersagbaren Abonnementmodellen von SaaS unterscheidet. Der Missbrauch von ARR (z. B. Hochrechnung des Jahresumsatzes aus Monats-/Tagesumsätzen) ist zu einem Zahlenspiel geworden, um hohe Bewertungen zu erzeugen und den wahren Geschäftswert zu verschleiern. Der Artikel mahnt zur Vorsicht vor Praktiken wie gegenseitigem Umsatz-Boosting, hohen Provisionen, Lockangeboten und fordert die Entwicklung geeigneterer Bewertungssysteme für KI-Unternehmen. (Quelle: Wu Ya Zhi Neng Shuo)
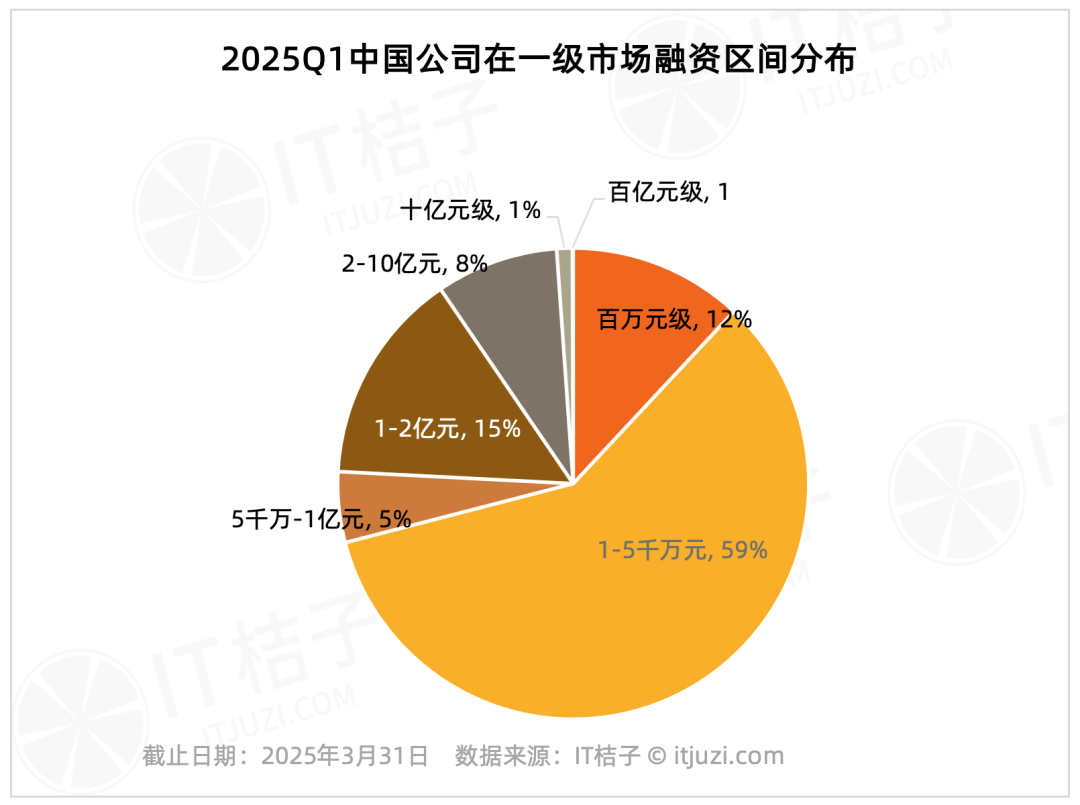
Analyse der Finanzierung am chinesischen Primärmarkt Q1 2025: Starker Kopf-Effekt: Daten von IT Juzi zeigen eine hohe Konzentration der Finanzierungen am chinesischen Primärmarkt im ersten Quartal 2025. Nur 20 Unternehmen (1,2% der Gesamtzahl) erhielten Finanzierungen von über 1 Milliarde Yuan, aber ihre Finanzierungssumme belief sich auf 61,178 Milliarden Yuan (36% des Marktgesamtvolumens). Diese führenden Unternehmen konzentrieren sich hauptsächlich auf Bereiche wie integrierte Schaltungen, Automobilherstellung, neue Materialien, Biotechnologie und AIGC, wobei fast die Hälfte einen Hintergrund in großen börsennotierten Konzernen hat. Im Gegensatz dazu machen kleine und mittlere Finanzierungen unter 100 Millionen Yuan, die 75,8% der Transaktionsanzahl ausmachen, nur 17,2% des Marktgesamtvolumens aus. (Quelle: IT Juzi)
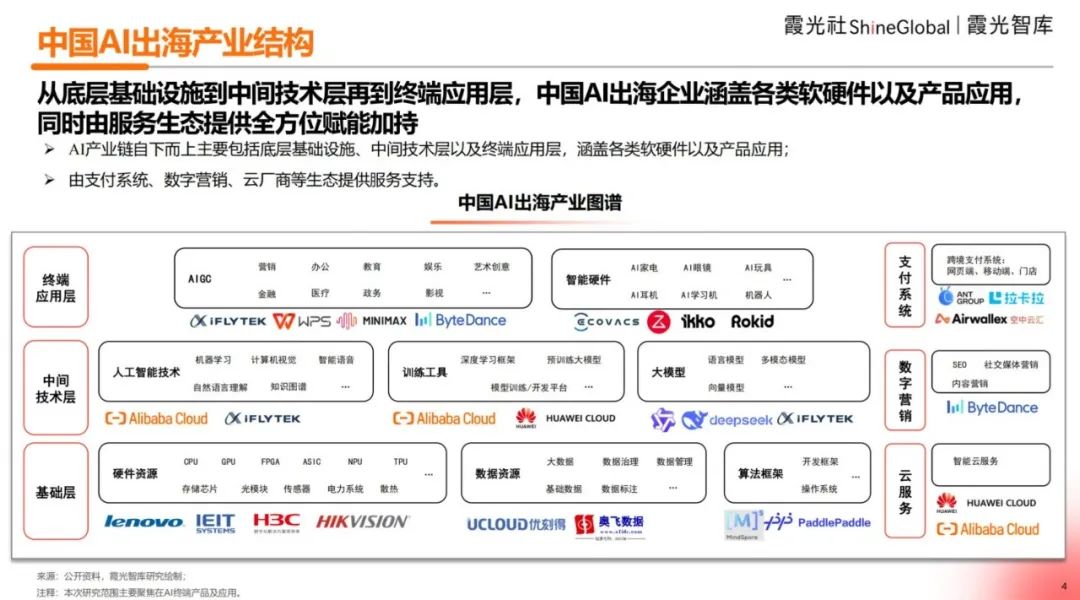
Einblicksbericht 2025 zur chinesischen KI-Expansion ins Ausland veröffentlicht: Ein Bericht von Xiaguang Think Tank analysiert die Treiber (Politik, technologischer Fortschritt), Entwicklungsphasen (Tools -> Lokalisierung -> Ökosysteminnovation) und den aktuellen Stand der chinesischen KI-Expansion ins Ausland. Der Bericht weist darauf hin, dass Südostasien und Lateinamerika Potenzialmärkte sind, während Nordamerika und Europa die Haupteinnahmequellen darstellen. Bei Assistenten- und Bearbeitungsanwendungen ist die Zahlungsbereitschaft hoch. Technologietrends entwickeln sich hin zu Multimodalität und Agenten, Produkte tendieren zu vertikaler Spezialisierung und Software-Hardware-Integration. Der Bericht listet auch wichtige Akteure im Auslandsgeschäft (wie Bytedance, Kunlun Wanwei) sowie Lösungsanbieter für Zahlung, Marketing, Cloud usw. auf. (Quelle: Xia Guang She)
Nachfrage nach DeepSeek & Co. verhilft Cambricon zum ersten Gewinn: Das KI-Chip-Unternehmen Cambricon erzielt erstmals seit dem Börsengang einen Gewinn. Im Q1 2025 stieg der Umsatz im Jahresvergleich um 4230% auf 1,111 Milliarden Yuan, der Nettogewinn betrug 355 Millionen Yuan. Marktanalysten führen das Wachstum auf die gestiegene Nachfrage nach Inferenz-Rechenleistung durch chinesische Großmodelle wie DeepSeek sowie auf die US-Exportbeschränkungen für NVIDIAs H20-Chip zurück. Der Aktienkurs von Cambricon stieg daraufhin stark an. Probleme wie hohe Kundenkonzentration und negativer operativer Cashflow bleiben jedoch bestehen, ebenso wie der Wettbewerb durch andere chinesische Rechenleistungsanbieter wie Huawei Ascend. (Quelle: Fenghuang Wang Ke Ji)

Forbes-Artikel erörtert Auswahl von KI-Agenten mit hohem ROI: Der Artikel diskutiert, wie Unternehmen inmitten zahlreicher KI-Agenten-Anwendungen diejenigen identifizieren und in sie investieren sollten, die einen hohen Return on Investment versprechen, und betont die Bedeutung der Bewertung des tatsächlichen Geschäftswerts von KI-Agenten. (Quelle: Ronald_vanLoon)

US-Justizministerium befürchtet, Google könnte KI zur Festigung seines Suchmonopols nutzen (Quelle: Reddit r/artificial, Reuters link)
Gerücht: OpenAI kooperiert mit Shopify, ChatGPT könnte Shopping-Funktion erhalten (Quelle: Reddit r/artificial, TestingCatalog link)
Tan Li von Shushi Technology: KI-Agenten treiben Unternehmensdatenanalyse und Entscheidungsfindung voran: Auf dem China AIGC Industry Summit wies Tan Li, Mitbegründer von Shushi Technology, darauf hin, dass KI-Anwendungen auf Unternehmensebene über ChatBI hinausgehen müssen, um die Umwandlung von Daten in Erkenntnisse zu realisieren und den neuen Paradigmen der Datenverschiebung nach rechts, Entscheidungsdelegation nach unten und Managementverlagerung nach hinten gerecht zu werden. Die SwiftAgent-Plattform von Shushi Technology zielt darauf ab, Geschäftsanwendern die Nutzung von Daten ohne Hürden, Analysen ohne Halluzinationen und Entscheidungsunterstützung ohne Wartezeit zu ermöglichen. Die Plattform nutzt eine Datensemantik-Engine, eine Kombination aus großen und kleinen Modellen sowie Kernfähigkeiten wie intelligente Datenabfragen, Ursachenanalyse, Prognose und Bewertung, um KI-Agenten zu “Datenanalyse- und Entscheidungsassistenten” für Unternehmen zu machen. (Quelle: Liangziwei)

🌟 Community
Branchen-Roundtable diskutiert KI-Anwendungsentwicklung nach der DeepSeek-Ära: Auf der 36Kr AI Partner Konferenz diskutierten mehrere Gäste (Qunar Technology, Microsoft, Silicon Intelligence, Huice) die Zukunft der KI-Anwendungen. Konsens war, dass KI-Anwendungen nach Durchbrüchen wie DeepSeek in ein “Jahr des Übertreffens” eintreten. Entwicklungsschwerpunkte müssen auf Technologieführerschaft, kommerzieller Umsetzung, Innovation bei der Mensch-Maschine-Interaktion und Ökosystemintegration liegen. Die Gäste unterschieden zwischen “AI+” (unterstützende Verbesserung) und “AI Native” (grundlegende Neugestaltung) und wiesen darauf hin, dass letzteres mehr Potenzial hat. Herausforderungen umfassen Datenbarrieren, das Finden echter Schwachstellen, Innovation bei Geschäftsmodellen, Few-Shot-Learning und ethische Risiken. (Quelle: 36Kr)

LangChain-Gründer kritisiert OpenAI Agent-Leitfaden als “voller Fallstricke”: Harrison Chase, Gründer von LangChain, stellte öffentlich den von OpenAI veröffentlichten “Practical Guide to Building AI Agents” in Frage. Er argumentierte, dass dessen Definition von Agenten (binäre Gegenüberstellung von Workflows vs. Agents) zu starr sei und die in der Praxis übliche Kombination beider ignoriere. Chase wies darauf hin, dass der Leitfaden bei der Erörterung von Frameworks falsche Dichotomien aufstelle, die Komplexität des eigenen SDKs unterschätze und irreführende Aussagen zu Flexibilität und dynamischer Orchestrierung mache. Er betonte, dass der Kern des Baus zuverlässiger Agenten die präzise Kontrolle des an das LLM übergebenen Kontexts sei und ideale Frameworks den flexiblen Wechsel und die Kombination von Workflow- und Agent-Modi unterstützen sollten. (Quelle: InfoQ)

Rolle von Reinforcement Learning in KI-Agenten umstritten: Über die Frage, ob Reinforcement Learning (RL) ein Kernelement für den Bau von KI-Agenten ist, gibt es in der Branche unterschiedliche Ansichten. Zhu Zheqing, Gründer von Pokee AI, betrachtet RL als die “Seele”, die Agenten Zielstrebigkeit und autonome Entscheidungsfindung verleiht, und argumentiert, dass Agenten ohne RL nur fortgeschrittene Workflows seien. Zhang Jiayi, Forscher an der HKUST, und Xie Yang, Gründer von Follou, sind hingegen der Meinung, dass RL derzeit hauptsächlich zur Optimierung in spezifischen Umgebungen dient, die allgemeine Generalisierungsfähigkeit begrenzt ist und der Erfolg von Agenten stärker von leistungsfähigen Basismodellen und effektiver Systemintegration abhängt. Die Debatte spiegelt die Vielfalt der Entwicklungswege von Agenten wider und die Notwendigkeit, Modellfähigkeiten, RL-Strategien und Ingenieurpraxis zu kombinieren. (Quelle: AI Ke Ji Ping Lun)

Benutzer lässt GPT-4o personalisierte abstrakte Hintergrundbilder basierend auf Chatverlauf generieren: Ein Benutzer teilt einen Prompt, mit dem GPT-4o basierend auf seinem Verständnis der Persönlichkeit des Benutzers einzigartige abstrakte, minimalistische Hintergrundbilder erstellen soll (keine konkreten Objekte, nur Formen, Farben, Kompositionen, die die Persönlichkeit widerspiegeln). Diese Art der Nutzung von KI zur personalisierten Inhaltserstellung löst eine Diskussion in der Community aus. (Quelle: op7418, Flavio Adamo via op7418)

KI zeichnet “Entlang des Flusses während des Qingming-Festes” neu: Ein Benutzer teilt einen interessanten Versuch, Teile des berühmten chinesischen Gemäldes “Entlang des Flusses während des Qingming-Festes” mit GPT-4o in verschiedenen Stilen (wie 3D Q-Version, Pixar, Ghibli usw.) neu zu zeichnen. Dies zeigt die Anwendungsmöglichkeiten der KI-Bildgenerierung in der künstlerischen Neuinterpretation. (Quelle: dotey)

GPT-4o leitet MBTI-Typ des Benutzers aus Chatverlauf ab: Nach der Generierung personalisierter Hintergrundbilder lässt der Benutzer GPT-4o weiterhin seinen MBTI-Persönlichkeitstyp basierend auf früheren Gesprächen ableiten und entsprechende abstrakte Illustrationen erstellen. Dies zeigt das Potenzial von LLMs für personalisiertes Verständnis und kreativen Ausdruck. (Quelle: op7418)

Vergleich: “KI-Tools” von 2005: Ein Bild zeigt durch Gegenüberstellung den Fähigkeitsunterschied zwischen Werkzeugen von 2005 (wie Taschenrechner, Karten) und heutigen KI-Tools und regt zum Nachdenken über den rasanten technologischen Fortschritt an. (Quelle: Ronald_vanLoon)

Community-Diskussion: Sind LLMs echte Intelligenz oder fortgeschrittene Autovervollständigung?: Ein Reddit-Benutzer startet eine Diskussion und argumentiert, dass aktuelle LLMs zwar Aufgaben ausführen können, aber kein echtes Verständnis, Gedächtnis und keine Ziele haben und im Wesentlichen statistische Vermutungen statt Intelligenz sind. Die Ansicht löst eine breite Community-Diskussion über die Definition von Intelligenz, den Weg zu AGI und die Grenzen aktueller Technologien aus. (Quelle: Reddit r/ArtificialInteligence)
Community-Diskussion: Bewegt sich die KI auf eine Utopie oder Dystopie zu?: Ein Reddit-Benutzer argumentiert, dass die aktuelle Entwicklung der KI eher zu einer Dystopie tendiert. Gründe dafür sind: Profitstreben statt Ethikorientierung, Verschärfung der Ausbeutung von Arbeitskräften, eingeschränkter Zugang zu leistungsstarken Modellen, Nutzung zur Überwachung und Manipulation, Ersatz zwischenmenschlicher Beziehungen usw. Die Ansicht löst eine hitzige Community-Diskussion über die Entwicklungsrichtung der KI, soziale Auswirkungen und potenzielle Risiken aus. (Quelle: Reddit r/ArtificialInteligence)
Community stellt Genauigkeit von Bindu Reddys Modellveröffentlichungsankündigungen in Frage: Benutzer der LocalLLaMA-Community weisen darauf hin, dass Bindu Reddy, CEO von Abacus.AI, wiederholt ungenaue Veröffentlichungszeitpunkte für Modelle wie DeepSeek R2 und Qwen 3 bekannt gegeben und die Beiträge später gelöscht hat, was eine Diskussion über ihre Informationszuverlässigkeit auslöst. (Quelle: Reddit r/LocalLLaMA)
Diskussion über die ethischen Auswirkungen lebenslanger KI-Erinnerung: Ein Reddit-Benutzer startet eine Diskussion und äußert Bedenken, dass KI mit lebenslanger Erinnerungsfähigkeit die Privatsphäre, Gedanken und Schwächen einer Person vollständig abbilden und ihre Seele für andere “zur Schau stellen” könnte. Dies regt zum Nachdenken über Privatsphäre, Vorhersagbarkeit und die ethischen Grenzen der KI an. (Quelle: Reddit r/ArtificialInteligence)
KI-Bildbearbeitung entfernt markante Bärte von Prominenten: Ein Benutzer teilt Ergebnisse der Verwendung eines KI-Bildbearbeitungstools, um die markanten Bärte von mehreren historischen oder öffentlichen Persönlichkeiten wie Stalin, Tom Selleck und Guan Yu zu entfernen. Dies zeigt die Anwendungsmöglichkeiten von KI bei der Bildmodifikation und Unterhaltung. (Quelle: Reddit r/ChatGPT)

Benutzer behauptet, ChatGPT habe bei medizinischer Beratung um intime Fotos gebeten: Ein Reddit-Benutzer teilt einen Screenshot, der zeigt, dass ChatGPT bei der Beratung zu einem Hautproblem darum gebeten hat, Fotos der betroffenen Stelle (Penis) hochzuladen, um eine bessere Diagnose zu ermöglichen. Dieser Fall löst eine Community-Diskussion über die Grenzen, die Privatsphäre und potenzielle Risiken von KI im medizinischen Kontext aus. (Quelle: Reddit r/ChatGPT)
Benutzer teilt Erfahrungen beim Erstellen einer Schreibanwendung mit Claude und Gemini: Ein Entwickler teilt seine Erfahrungen bei der Nutzung von Claude und Gemini als Programmierassistenten, um innerhalb von zwei Wochen die Schreibanwendung PlotRealm zu entwickeln, die seinen persönlichen Bedürfnissen entspricht. Er betont die Rolle der KI bei der Entwicklungsunterstützung, weist aber auch darauf hin, dass KI manchmal “stur” sein kann und Entwickler über Grundkenntnisse verfügen müssen, um sie anzuleiten und zu korrigieren. (Quelle: Reddit r/ClaudeAI)
Benutzer lässt ChatGPT Tattoo-Motive entwerfen: Ein Benutzer bittet ChatGPT, sein nächstes Tattoo zu entwerfen, und erhält ein Motiv, das den Benutzer und einen ChatGPT-Roboter als BFFs (Best Friends Forever) darstellt. Dieses humorvolle Ergebnis löst eine Community-Diskussion über KI-Kreativität und Mensch-Maschine-Beziehungen aus. (Quelle: Reddit r/ChatGPT)

Benutzer stellt kreative Frage “Wo wünschst du dir, dass ich wäre?”, löst vielfältige KI-Antworten aus: Ein Benutzer stellt ChatGPT die offene Frage “Wo wünschst du dir, dass ich wäre?” und erhält verschiedene von der KI generierte fantasievolle Szenenbilder, wie eine ruhige Bibliothek, unter einem Sternenhimmel usw. Dies zeigt die Generierungsfähigkeit der KI bei kreativen Prompts und die unterschiedlichen Ergebnisse, die Community-Mitglieder teilen. (Quelle: Reddit r/ChatGPT)
Tiefgehende Diskussion: Warum und wie “lügen” LLMs und AGI?: Ein Reddit-Benutzer analysiert aus entwicklungspsychologischer, evolutionärer und spieltheoretischer Sicht, dass “Lügen” ein adaptives Verhalten oder eine Optimierungsstrategie von intelligenten Agenten (einschließlich Menschen und zukünftiger KI) in bestimmten Kontexten ist. Der Artikel untersucht verschiedene Formen des “Lügens” von LLMs (Halluzinationen, Bias, strategische Anpassung) und simuliert den evolutionären Vorteil unehrlicher Strategien in Wettbewerbsumgebungen, was zu tiefgreifenden Überlegungen über AGI-Ethik und Vertrauenswürdigkeit anregt. (Quelle: Reddit r/artificial)

Community stellt Energieverbrauch von KI und Technologieoptimismus in Frage: Ein Reddit-Benutzer stellt mit ironischem Unterton Behauptungen in Frage, dass der Energieverbrauch von KI vernachlässigbar sei, nur Vorteile ohne Kosten bringe und Technologieführer eine utopische Zukunft versprächen. Dies deutet auf Bedenken hinsichtlich der möglichen sozialen und ökologischen Kosten der KI-Entwicklung sowie übertrieben optimistischer Propaganda hin und löst eine Community-Diskussion aus. (Quelle: Reddit r/artificial)
Microsoft VP: KI-Fortschritt wird nicht durch einzelne Technologien oder wenige Genies angetrieben, sondern erfordert systematisches Engineering und breite Zusammenarbeit: Nando de Freitas, Vizepräsident bei Microsoft, wendet sich gegen die übermäßige Heroisierung einzelner Technologien (wie RL) oder Personen bei der KI-Entwicklung. Er betont, dass KI-Fortschritt systematisches Engineering ist, das Daten, Infrastruktur, Forschung in vielen Bereichen (generative Modelle, RL, Sicherheit, Energieeffizienz usw.) und das Feedback von Tausenden von Beteiligten erfordert. Die historische Erzählung wird oft umgeschrieben; man sollte sich vor nachträglicher Verklärung hüten, den Beitrag der gesamten Gemeinschaft respektieren und Innovation statt blinder Gefolgschaft fördern. (Quelle: Jiqizhixin)
💡 Sonstiges
Flut an KI-Musik löst Branchenbedenken und Gegenmaßnahmen aus: Der schnell wachsende Anteil KI-generierter Musik auf Streaming-Plattformen (z. B. 18% bei Deezer) löst Bedenken hinsichtlich der Verdrängung menschlicher Kreativität und der Aushöhlung der Einnahmen von Urhebern (CISAC prognostiziert bis zu 24%) aus. Der koreanische Musikurheberverband führt neue Lizenzregeln mit “0% KI” ein, Plattformen wie Deezer und YouTube entwickeln Erkennungstools. Die Identifizierung von KI-Musik ist jedoch schwierig, und die Akzeptanz bei den Hörern ist hoch (z. B. über zehn Millionen Nutzer bei Suno). Die Branche steht vor Herausforderungen wie Deepfakes, Urheberrechtsstreitigkeiten (Nutzungsrechte an Trainingsdaten) und der Definition von Originalität. Die Zukunft könnte in der Mensch-Maschine-Kollaboration liegen, aber die Diskussion über Ethik und Urheberschaft wird andauern. (Quelle: Xin Yin Yue Chan Ye Guan Cha)

System-Prompt von Windsurf vermutlich geleakt: Das GitHub-Repository awesome-ai-system-prompts enthüllt den mutmaßlichen Inhalt des System-Prompts des Windsurf-Modells. (Quelle: karminski3)

Hoher Wasserverbrauch von KI-Großmodellen rückt in den Fokus: Fortune Magazine und andere Medien berichten, dass der Betrieb großer KI-Modelle wie ChatGPT erhebliche Mengen an Wasser zur Kühlung benötigt. Die Waldbrandsaison in Kalifornien und anderen Regionen könnte die Wasserknappheit verschärfen und Bedenken hinsichtlich der Nachhaltigkeit von KI aufwerfen. (Quelle: Ronald_vanLoon)

Entwickler behauptet, AMI zur Vorhersage von Emotionen erstellt zu haben: Ein YouTube-Video behauptet, eine AMI (Artificial Molecular Intelligence?) zu zeigen, die zuverlässig Emotionen und andere Aspekte von Ereignissen scannen und vorhersagen kann, wobei verschiedene Modalitäten wie Ton, Video und Bild einbezogen werden. Die Echtheit und konkrete Implementierung dieser Technologie müssen noch überprüft werden. (Quelle: Reddit r/artificial)
Vorschlag: KI-Benchmarks sollten menschliche Leistung zum Vergleich einbeziehen: Ein Reddit-Benutzer schlägt vor, dass KI-Modell-Benchmarks die Ergebnisse von Menschen (Durchschnittspersonen und Experten) bei denselben Aufgaben als Referenz enthalten sollten, um das relative Leistungsniveau der KI intuitiver bewerten zu können. (Quelle: Reddit r/artificial)
Oscars akzeptieren KI-Beteiligung an Filmproduktion, aber mit Einschränkungen: Die Academy of Motion Picture Arts and Sciences hat ihre Regeln aktualisiert und erlaubt die Verwendung von KI-Tools bei der Filmproduktion, betont jedoch, dass menschliche Kreativität weiterhin im Mittelpunkt steht. Die Regeln könnten spezifische Anforderungen wie die Offenlegung der KI-Nutzung beinhalten und spiegeln das Gleichgewicht der Branche zwischen der Einführung neuer Technologien und dem Schutz menschlicher Schöpfung wider. (Quelle: Reddit r/artificial, NYT link)

Instagram versucht, das Alter von Teenagern mit KI zu bestimmen (Quelle: Reddit r/artificial, AP News link)
Altman sagt, Nutzer, die ChatGPT “Bitte” und “Danke” sagen, verursachen Kosten in Millionenhöhe (Quelle: Reddit r/artificial, QZ link)
Humanoider Roboter-Halbmarathon zeigt technischen Fortschritt und Herausforderungen: Der weltweit erste Halbmarathon für humanoide Roboter fand in Peking statt, “Tiangong Ultra” gewann mit 2 Stunden und 40 Minuten. Der Wettbewerb testete die Fähigkeiten der Roboter über lange Distanzen, in komplexem Gelände, bei dynamischer Balance und autonomer Navigation. Roboter in voller Größe stehen vor größeren Schwierigkeiten (Schwerpunkt, Trägheit, Energieverbrauch). Tiangong Ultra siegte dank leistungsstarker integrierter Gelenke, geringer Trägheit, effizienter Wärmeableitung, einer prädiktiven verstärkten Imitationslern-Steuerungsstrategie und drahtloser Navigationstechnologie. Das Rennen wird als Belastungstest für die groß angelegte kommerzielle Einführung von Robotern (z. B. in Industrie, Sicherheitsinspektion) angesehen und fördert die Validierung und Optimierung von Kerntechnologien wie Körperhardware, Bewegungssteuerung und intelligenter Entscheidungsfindung. (Quelle: Jiqizhixin)

Nutzung von KI zur Überwachung von Prominenten-Updates mit automatischer Benachrichtigung: Ein Tutorial zeigt, wie man mit einem Python-Skript die Updates eines bestimmten Twitter-Kontos (z. B. von Sam Altman) überwacht und über die Feishu-API eine dringende telefonische Benachrichtigung erhält, wenn neue Updates veröffentlicht werden. Diese Methode kombiniert Web-Scraping-Technologie mit dem Aufruf offener Plattform-APIs, um das Problem der Informationsüberflutung und des Bedarfs an Aktualität zu lösen und eine personalisierte Zustellung wichtiger Informationen zu ermöglichen. Es zeigt das Potenzial von KI bei der automatisierten Verarbeitung von Informationsflüssen und personalisierten Benachrichtigungen. (Quelle: Fei Zhu Liu Yun Ying)
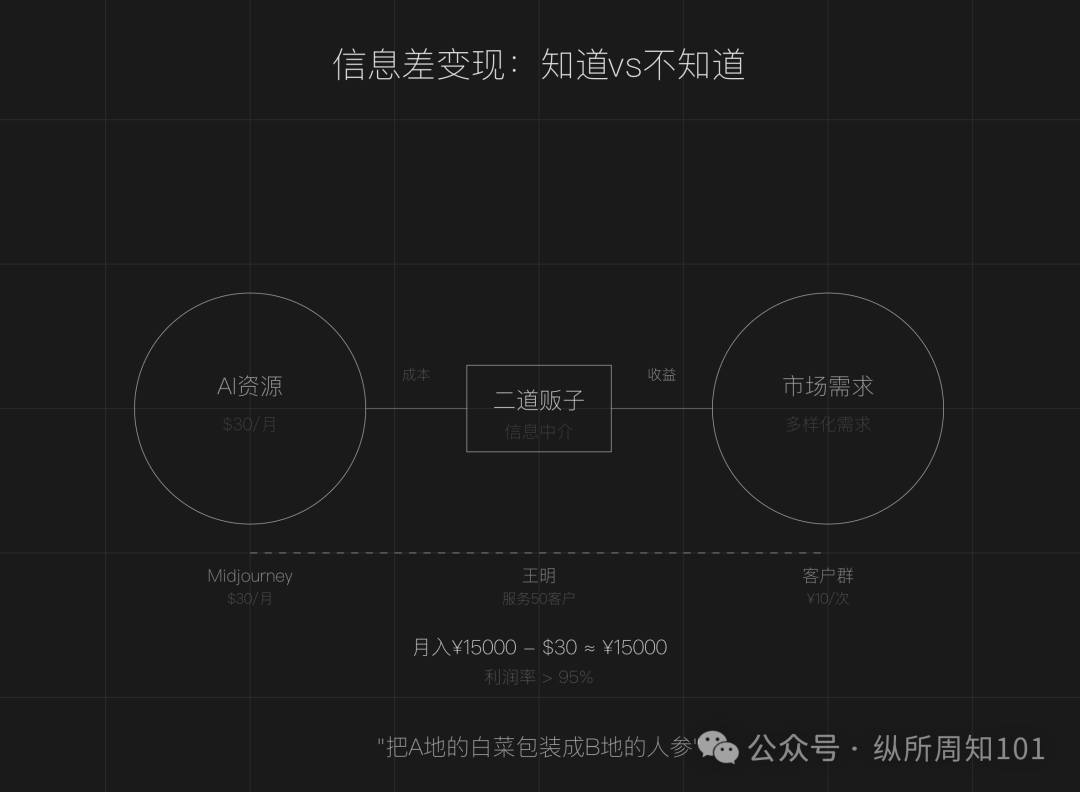
Diskussion über das Geschäftsmodell, Informationsasymmetrien bei KI als “Zwischenhändler” zu nutzen: Der Artikel argumentiert, dass im KI-Zeitalter Informationsasymmetrien weiterhin bestehen (Tool-Überflutung, technische Hürden, unklare Anwendungsfälle) und normalen Menschen die Möglichkeit geben, als “KI-Zwischenhändler” zu agieren. Kernstrategien umfassen: Nutzung von Preisunterschieden bei KI-Ressourcen im In- und Ausland zum Weiterverkauf von Diensten (z. B. KI-Bildgenerierung), Bereitstellung von Ausführungsdiensten (Umwandlung kostenloser Tutorials in kostenpflichtige Implementierungen, z. B. KI-Kundenservice), Skalierung des Betriebs (Aufbau von Teams zur Bereitstellung professioneller Dienstleistungen). Geeignete Bereiche sind Content-Erstellung, Bildung/Schulung, Dienstleistungen für kleine und mittlere Unternehmen, spezialisierte Dienstleistungen in vertikalen Bereichen (z. B. Medizin, Recht). Es wird empfohlen, durch das Finden von Informationsasymmetrien, die Definition von Zielgruppen und schnelles Handeln zu beginnen. (Quelle: Zhou Zhi)