
Schlüsselwörter:KI-Modell, OpenAI, Multimodal, Agent, O3-Modell, O4-Mini, Visuelles Reasoning, Werkzeugaufruf, Gemini 2.5 Flash, Tencent Yuanbao KI, LLM-Integration, Bestärkendes Lernen
🔥 Fokus
OpenAI veröffentlicht o3 und o4-mini Modelle mit integrierten Tools und visuellen Schlussfolgerungsfähigkeiten : OpenAI hat offiziell seine bisher intelligentesten und leistungsfähigsten Reasoning-Modelle o3 und o4-mini veröffentlicht. Die Kernpunkte sind die erstmalige Fähigkeit für Agents, aktiv alle internen Werkzeuge von ChatGPT (Websuche, Python-Datenanalyse, tiefes visuelles Verständnis, Bildgenerierung usw.) aufzurufen und zu kombinieren, sowie die Integration von Bildern in die Schlussfolgerungskette zum Nachdenken. o3 ist in Bereichen wie Codierung, Mathematik, Wissenschaft, visueller Wahrnehmung usw. führend und setzt neue SOTA-Benchmarks (State-of-the-Art) in mehreren Tests; o4-mini hingegen ist auf Geschwindigkeit und Kosten optimiert und übertrifft seine Größe in Bezug auf die Leistung bei weitem. Beide Modelle haben eine verbesserte Fähigkeit zur Befolgung von Anweisungen, führen natürlichere Dialoge und können Gedächtnis und frühere Gespräche nutzen, um personalisierte Antworten zu geben. Diese Veröffentlichung markiert einen wichtigen Schritt von OpenAI hin zu autonomerer Agentic AI, bei der KI-Assistenten komplexe Aufgaben unabhängiger erledigen können. (Quelle: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
OpenAI o3 und o4-mini Modelle gehen online, verbessern Werkzeugnutzung und visuelle Schlussfolgerungsfähigkeiten : OpenAI hat spät in der Nacht die Modelle o3 und o4-mini veröffentlicht, die über ChatGPT Plus, Pro und Team Konten verfügbar sind. Wichtige Upgrades sind: 1. Die Vollversion von o3 unterstützt erstmals den Aufruf von Werkzeugen (wie Internetzugang, Code Interpreter). 2. o3 und o4-mini sind die ersten Modelle, die visuelles Schlussfolgern in der Gedankenkette durchführen können. Sie können Bilder wie Menschen analysieren und kombinieren, z. B. beim Spiel “Ort anhand eines Bildes erraten”, wo das Modell Bilddetails vergrößern kann, um schrittweise Schlussfolgerungen zu ziehen. Diese Fähigkeit verbessert die Leistung der Modelle bei multimodalen Aufgaben (wie MMMU, MathVista) erheblich und deutet darauf hin, dass KI in professionellen Szenarien, die visuelle Beurteilung erfordern (wie Sicherheitsüberwachung, medizinische Bildanalyse), eine größere Rolle spielen wird. Gleichzeitig hat OpenAI auch das KI-Programmierwerkzeug Codex CLI als Open Source veröffentlicht. (Quelle: OpenAI深夜上线o3满血版和o4 mini – 依旧领先。
Tencent Yuanbao AI offiziell in WeChat integriert, eröffnet neues Chat-Paradigma : Tencent Yuanbao AI ist jetzt offiziell als WeChat-Freund verfügbar, Benutzer können es durch Suchen nach “Yuanbao” hinzufügen. Dieser Schritt durchbricht das traditionelle Modell, bei dem KI-Anwendungen separat geöffnet werden müssen, und integriert KI nahtlos in die täglichen Kommunikationsszenarien der Benutzer. Yuanbao AI (basierend auf Hunyuan und DeepSeek) kann direkt im WeChat-Dialogfeld interagieren, unterstützt die Zusammenfassung von Bildern, Artikeln aus offiziellen Konten, Weblinks, Audio- und Videodateien (Video-Konten vorerst nicht unterstützt) und kann den Chatverlauf durchsuchen. Obwohl das Zeichnen und Gruppenchats noch nicht unterstützt werden, gelten die Benutzerfreundlichkeit und die tiefe Integration in das WeChat-Ökosystem als wichtige Vorteile. Analysten gehen davon aus, dass WeChat mit seiner riesigen Nutzerbasis und seinem sozialen Netzwerk, indem es KI zu einem Kontakt im Adressbuch macht, das Paradigma der Mensch-Maschine-Interaktion verändern und KI natürlicher in das Leben der Nutzer integrieren könnte. (Quelle: 劲爆!元宝AI接入微信了,怎么用?看这篇就够了、腾讯元宝最终还是活成了微信的模样。
USA könnten Export von Nvidias H20-Chips nach China auf unbestimmte Zeit aussetzen, weitreichende Auswirkungen : Die US-Regierung hat Nvidia darüber informiert, den Export von H20 AI-Chips (eine spezielle Version, die zuvor zur Umgehung von Exportkontrollen entwickelt wurde) nach China auf unbestimmte Zeit auszusetzen. H20 ist der leistungsstärkste konforme Chip, den Nvidia für den chinesischen Markt entwickelt hat, und das Verkaufsverbot wird voraussichtlich einen schweren Schlag für Nvidia bedeuten. Daten zeigen, dass China Nvidias viertgrößter Umsatzmarkt ist, wobei der H20-Umsatz im Jahr 2024 die 10-Milliarden-Dollar-Marke erreichte und chinesische Technologieunternehmen (wie ByteDance, Tencent) Hauptabnehmer von Nvidia-Chips sind, mit signifikantem Investitionswachstum. Dieser Schritt beeinträchtigt nicht nur Nvidias Umsatz, sondern könnte auch sein CUDA-Ökosystem schwächen (chinesische Entwickler machen über 30% aus). Gleichzeitig beschleunigen chinesische KI-Chip-Unternehmen wie Huawei (z.B. Ascend 910C) ihre Entwicklung und könnten die Marktlücke füllen. Das Ereignis löste Marktbesorgnis aus, und der Aktienkurs von Nvidia fiel daraufhin. (Quelle: 中国对英伟达到底有多重要?
🎯 Entwicklungen
Googles Top-Videomodell Veo 2 kostenlos im AI Studio verfügbar : Google hat angekündigt, dass sein fortschrittliches Videogenerierungsmodell Veo 2 jetzt im Google AI Studio, über die Gemini API und in der Gemini App verfügbar ist und kostenlose Nutzungskontingente bietet (etwa zehnmal täglich, jeweils bis zu 8 Sekunden). Veo 2 unterstützt Text-zu-Video (t2v) und Bild-zu-Video (i2v), kann komplexe Anweisungen verstehen, realistische Videos in verschiedenen Stilen generieren und Kamerabewegungen steuern. Offiziell wird betont, dass der Schlüssel zur Erzeugung hochwertiger Videos darin liegt, klare, detaillierte Prompts mit visuellen Schlüsselwörtern bereitzustellen. Das Modell verfügt außerdem über erweiterte Funktionen wie In-Video-Bearbeitung (Freistellen, Erweitern), filmische Kamerafahrten und intelligente Übergänge, um sich in Content-Erstellungs-Workflows zu integrieren und die Effizienz zu steigern. (Quelle: 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。
Google veröffentlicht Gemini 2.5 Flash mit Fokus auf Geschwindigkeit, Kosten und steuerbarer Denktiefe : Google hat eine Vorschauversion des Gemini 2.5 Flash Modells vorgestellt, das als leichtgewichtiges Modell mit optimierter Geschwindigkeit und Kosten positioniert ist. Das Modell zeigt eine beeindruckende Leistung im LMArena-Ranking, liegt gleichauf mit GPT-4.5 Preview und Grok-3 auf dem zweiten Platz und führt bei schwierigen Prompts, Codierung und langen Abfragen. Sein Kernmerkmal ist die Einführung der Fähigkeit zum “Nachdenken” und vollständig gemischtes Schlussfolgern, was dem Modell ermöglicht, Aufgaben vor der Ausgabe zu planen und zu zerlegen. Entwickler können über den Parameter “Denkbudget” die Denktiefe des Modells (Token-Obergrenze) steuern, um Qualität, Kosten und Latenz auszugleichen. Selbst mit einem Budget von 0 übertrifft die Leistung die von 2.0 Flash. Das Modell bietet ein hohes Preis-Leistungs-Verhältnis, kostet nur 1/10 bis 1/5 von Gemini 2.5 Pro und eignet sich für hochparallele, groß angelegte KI-Workflows. (Quelle: 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。
Kunlun Wanwei veröffentlicht unbegrenzt langes Filmerzeugungsmodell Skyreels-V2 : Kunlun Wanwei hat Skyreels-V2 vorgestellt und als Open Source veröffentlicht, das als weltweit erstes Modell zur Erzeugung hochwertiger Videos ohne Längenbeschränkung beworben wird. Das Modell zielt darauf ab, die Schwachstellen bestehender Videomodelle beim Verständnis filmischer Bildsprache, Bewegungskohärenz, Videolängenbeschränkungen und dem Mangel an professionellen Datensätzen zu beheben. Skyreels-V2 kombiniert multimodale große Modelle, strukturierte Annotation, Diffusionsgenerierung, Reinforcement Learning (DPO zur Optimierung der Bewegungsqualität) und hochwertiges Fine-Tuning in einer mehrstufigen Trainingsstrategie. Es verwendet eine Diffusion Forcing-Architektur, die durch spezielle Scheduler und Aufmerksamkeitsmechanismen die Erzeugung langer Videos ermöglicht. Offiziell wird behauptet, dass die Generierungsergebnisse “filmreif” sind und in Benchmarks wie V-Bench1.0 hervorragend abschneiden und andere Open-Source-Modelle übertreffen. Benutzer können die Generierung von bis zu 30 Sekunden langen Videos online ausprobieren. (Quelle: 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!
Shanghai AI Lab veröffentlicht natives multimodales Modell InternVL3 : Das Shanghai Artificial Intelligence Laboratory hat InternVL3 vorgestellt, ein großes multimodales Modell (MLLM), das ein natives multimodales Vortrainingsparadigma verwendet. Im Gegensatz zu den meisten Modellen, die auf der Modifikation reiner Text-LLMs basieren, lernt InternVL3 in einer einzigen Vortrainingsphase gleichzeitig aus multimodalen Daten und reinen Textkorpora, um die Komplexität und die Herausforderungen der Ausrichtung bei mehrstufigem Training zu überwinden. Das Modell kombiniert variable visuelle Positionskodierung, fortschrittliche Nachtrainingstechniken und Testzeit-Erweiterungsstrategien. InternVL3-78B erreicht im MMMU-Benchmark 72,2 Punkte, was einen neuen Rekord für Open-Source-MLLMs darstellt und die Leistung führender proprietärer Modelle erreicht, während gleichzeitig starke reine Sprachfähigkeiten erhalten bleiben. Trainingsdaten und Modellgewichte werden veröffentlicht. (Quelle: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
UCLA et al. schlagen d1-Framework vor, um Reinforcement Learning für die Inferenz von Diffusions-LLMs zu nutzen : Forscher von UCLA und Meta AI haben das d1-Framework vorgeschlagen, das erstmals Reinforcement Learning (RL)-Nachtraining auf maskierte Diffusions-Large-Language-Models (dLLMs) anwendet. Bestehende RL-Methoden (wie GRPO) sind hauptsächlich für autoregressive LLMs konzipiert und lassen sich nur schwer direkt auf dLLMs anwenden, da ihnen eine natürliche Zerlegung der Log-Wahrscheinlichkeit fehlt. Das d1-Framework umfasst zwei Phasen: Zuerst wird ein Supervised Fine-Tuning (SFT) durchgeführt, dann wird in der RL-Phase eine neuartige Policy-Gradient-Methode namens diffu-GRPO eingeführt, die einen effizienten Einzelschritt-Log-Wahrscheinlichkeitsschätzer verwendet und zufällige Prompt-Maskierung als Regularisierung nutzt, wodurch die Menge der für das RL-Training erforderlichen Online-Generierung reduziert wird. Experimente zeigen, dass das auf LLaDA-8B-Instruct basierende d1-Modell in Mathematik- und Logik-Reasoning-Benchmarks signifikant besser abschneidet als das Basismodell sowie Modelle, die nur SFT oder nur diffu-GRPO verwenden. (Quelle: UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!
Meta schlägt Multi-Token Attention (MTA) vor : Forscher von Meta haben den Multi-Token Attention (MTA)-Mechanismus vorgeschlagen, um die Aufmerksamkeitsberechnung in Large Language Models (LLMs) zu verbessern. Traditionelle Aufmerksamkeitsmechanismen basieren nur auf der Ähnlichkeit einzelner Query- und Key-Tokens. MTA wendet Faltungsoperationen auf die Query-, Key- und Head-Vektoren an, sodass das Modell gleichzeitig mehrere benachbarte Query- und Key-Tokens berücksichtigen kann, um die Aufmerksamkeitsgewichte zu bestimmen. Die Forscher glauben, dass dies reichhaltigere und detailliertere Informationen nutzen kann, um relevanten Kontext zu lokalisieren. Experimente zeigen, dass MTA sowohl bei Standard-Sprachmodellierungs- als auch bei Long-Context-Informationsretrieval-Aufgaben besser abschneidet als traditionelle Transformer-Basismodelle. (Quelle: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
TogetherAI stellt RNN-basiertes Inferenzmodell M1 vor : TogetherAI hat M1 vorgestellt, ein neuartiges hybrides lineares RNN-Inferenzmodell, das auf der Mamba-Architektur basiert. Das Modell zielt darauf ab, die Probleme der Rechenkomplexität und Speicherbeschränkungen zu lösen, mit denen Transformer bei der Verarbeitung langer Sequenzen und der Durchführung effizienter Inferenz konfrontiert sind. M1 verbessert die Leistung durch Wissensdestillation von bestehenden Inferenzmodellen und Reinforcement Learning Training. Experimentelle Ergebnisse zeigen, dass M1 in mathematischen Reasoning-Benchmarks wie AIME und MATH nicht nur besser abschneidet als frühere lineare RNN-Modelle, sondern auch mit gleich großen DeepSeek-R1 destillierten Inferenzmodellen mithalten kann. Noch wichtiger ist, dass die Generierungsgeschwindigkeit von M1 mehr als dreimal so hoch ist wie die von gleich großen Transformern, und bei einem festen Generierungszeitbudget durch Self-Consistency-Voting eine höhere Genauigkeit als letztere erzielt werden kann. (Quelle: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
Tencent Hunyuan veröffentlicht InstantCharacter Framework als Open Source : Das Tencent Hunyuan Team hat InstantCharacter als Open Source veröffentlicht, ein Framework zur Bildgenerierung, das Charaktermerkmale aus einem einzelnen Eingabebild extrahieren und beibehalten kann, um diese Figur dann in verschiedene Szenen oder Stile zu versetzen. Die Technologie zielt darauf ab, eine hohe Wiedergabetreue der Personenidentität und eine kontrollierbare Stilübertragung zu erreichen. Offiziell wird auf Hugging Face eine Online-Demo basierend auf den Kunststilen von Ghibli und Makoto Shinkai angeboten, und das zugehörige Paper, die Codebasis sowie ein ComfyUI-Plugin wurden veröffentlicht, um die Nutzung und Weiterentwicklung durch die Community zu erleichtern. (Quelle: karminski3
ChatGPT Memory-Funktion erweitert, unterstützt Websuche unter Berücksichtigung des Gedächtnisses : OpenAI hat die Memory-Funktion von ChatGPT erweitert und die Fähigkeit “Suche mit Gedächtnis” hinzugefügt. Das bedeutet, dass ChatGPT bei der Durchführung von Websuchen zuvor gespeicherte Benutzerpräferenzen, Standorte usw. nutzen kann, um Suchanfragen zu optimieren und so personalisiertere Suchergebnisse zu liefern. Wenn ChatGPT beispielsweise weiß, dass ein Benutzer Vegetarier ist, könnte es bei der Frage nach Restaurants in der Nähe automatisch nach “vegetarischen Restaurants in der Nähe” suchen. Dieser Schritt wird als wichtiger Fortschritt von OpenAI zur Verbesserung personalisierter KI-Dienste angesehen, um das Benutzererlebnis zu verbessern und sich von Konkurrenzprodukten mit Gedächtnisfunktionen (wie Claude, Gemini) abzuheben. Benutzer können die Gedächtnisfunktion in den Einstellungen deaktivieren. (Quelle: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
KI-Modell-Laufzeit-Snapshot-Technologie vermeidet Kaltstarts : Die Machine-Learning-Community erforscht die Optimierung der LLM-Laufzeitorchestrierung durch Modell-Snapshot-Technologie. Diese Technik speichert den vollständigen Zustand der GPU (einschließlich KV-Cache, Gewichte, Speicherlayout), sodass beim Wechsel zwischen verschiedenen Modellen Kaltstarts und GPU-Leerlauf vermieden und eine schnelle Wiederherstellung (ca. 2 Sekunden) ermöglicht wird. Praktiker berichten, dass sie mit dieser Methode erfolgreich über 50 Open-Source-Modelle auf zwei A1000 16GB GPUs ausgeführt haben, ohne Container verwenden oder Modelle neu laden zu müssen. Diese Modell-Multiplexing- und Rotationstechnik hat Potenzial zur Verbesserung der GPU-Auslastung und zur Reduzierung der Inferenzlatenz. (Quelle: Reddit r/MachineLearning)
🧰 Tools
ByteDance Volcano Engine stellt Demo einer KI-Hardware-Komplettlösung vor : ByteDance Volcano Engine präsentierte in Zusammenarbeit mit Herstellern von Embedded-Chips eine KI-Hardware-Komplettlösung am Beispiel des AtomS3R Entwicklungsboards. Die Lösung zielt darauf ab, eine KI-Interaktionserfahrung mit geringer Latenz und hoher Reaktionsfähigkeit zu bieten. Merkmale sind Echtzeitreaktion im Millisekundenbereich, Echtzeitunterbrechung und -übernahme sowie durch das RTC SDK realisierte Audio-Rauschunterdrückung in komplexen Umgebungen, die Hintergrundgeräusche effektiv reduziert und die Genauigkeit der Sprachinteraktion verbessert. Der Client-Code und das Serverprogramm der Lösung sind Open Source und ermöglichen Entwicklern DIY-Anpassungen, wie z. B. die Zuweisung benutzerdefinierter Persönlichkeiten, Rollen, Stimmfarben an die Hardware oder die Anbindung an Wissensdatenbanken und MCP-Tools. Die Hardware selbst enthält eine Kamera, zukünftig ist die Unterstützung von visuellen Verständnisfunktionen geplant. (Quelle: 体验完字节送的迷你AI硬件,后劲有点大…
Mita AI Search führt Lernfunktion “Heute etwas lernen” ein : Mita AI Search hat eine neue Funktion namens “Heute etwas lernen” eingeführt, die vom Benutzer hochgeladene Dateien (unterstützt verschiedene Formate) oder bereitgestellte Weblinks automatisch in ein strukturiertes Online-Kursvideo mit Kommentar und Präsentation (PPT, Animation) umwandelt. Benutzer können verschiedene Erklärungsstile (z. B. Geschichtenerzählen, Napoleon-Stil) und Stimmen (z. B. kühle御姐) wählen. Die Funktion zielt darauf ab, die Informationsaufnahme in eine leichter zugängliche Lernerfahrung umzuwandeln und bietet sogar einen Test nach dem Kurs an. Diese Kombination aus Inhaltserstellung und personalisiertem Unterricht wird als potenziell revolutionär für die Anwendung von KI im Bildungs- und Informationskonsumbereich angesehen und bietet eine neuartige Methode zur Wissensaneignung und zum schnellen Lesen von Inhalten. (Quelle: 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

Cursor IDE auf Version 0.49 aktualisiert, verbessert Regelsystem und Agent-Kontrolle : Der AI-First Code-Editor Cursor hat eine Vorschau auf das Update 0.49 veröffentlicht. Neue Funktionen umfassen: 1. Automatische Generierung von .mdc-Regeldateien zur Festlegung des Projektkontexts über den Chat-Befehl /Generate Cursor Rules. 2. Intelligentere automatische Anwendung von Regeln, wobei der Agent Regeln basierend auf dem Dateipfad automatisch lädt. 3. Behebung eines Fehlers, bei dem “Regeln immer anhängen” in langen Gesprächen fehlschlug. 4. Neue Funktion “Projektstruktur-Bewusstsein” (Beta), damit die KI das gesamte Projekt besser versteht. 5. Das MCP (Model Context Protocol) unterstützt jetzt die Übertragung von Bildern zur einfacheren Verarbeitung visueller Aufgaben. 6. Verbesserte Kontrolle des Agenten über Terminalbefehle, Benutzer können Befehle vor der Ausführung bearbeiten oder überspringen. 7. Unterstützung für globale Ignorier-Dateikonfiguration (.cursorignore). 8. Optimierte Code-Review-Erfahrung, Diff-Ansicht wird direkt nach Agent-Nachrichten angezeigt. (Quelle: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
OpenAI veröffentlicht Open-Source Kommandozeilen-KI-Programmierwerkzeug Codex CLI : Begleitend zur Veröffentlichung von o3 und o4-mini hat OpenAI Codex CLI als Open Source veröffentlicht, einen leichtgewichtigen KI-Codierungs-Agenten, der direkt im Kommandozeilen-Terminal des Benutzers läuft. Das Tool soll die leistungsstarken Codierungs- und Schlussfolgerungsfähigkeiten der neuen Modelle voll ausschöpfen, kann direkt mit lokalen Codebasen arbeiten und sogar Screenshots oder Skizzen für multimodales Schlussfolgern einbeziehen. OpenAI CEO Sam Altman bewirbt es persönlich und betont den Open-Source-Charakter, um eine schnelle Iteration durch die Community zu fördern. Gleichzeitig hat OpenAI ein Förderprogramm in Höhe von 1 Million US-Dollar (in Form von API Credits) gestartet, um Projekte zu unterstützen, die auf Codex CLI und OpenAI-Modellen basieren. (Quelle: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
Tencent Cloud LKE Plattform integriert MCP, vereinfacht Agent-Erstellung : Die Tencent Cloud Language Knowledge Engine (LKE) Plattform unterstützt jetzt das Model Context Protocol (MCP), um die Hürden bei der Erstellung und Nutzung von KI-Agenten zu senken. Benutzer können nun auf der LKE-Plattform durch Klickoperationen einfach integrierte MCP-Tools wie Tencent Cloud EdgeOne Pages (Ein-Klick-Bereitstellung von Webseiten) und Firecrawl (Web-Crawler) anbinden. In Kombination mit den leistungsstarken Wissensdatenbank- (RAG) Fähigkeiten von LKE können Benutzer komplexe Anwendungen erstellen, die auf privatem Wissen und dem Aufruf externer Tools basieren, z. B. die automatische Generierung und Veröffentlichung von Webseiten basierend auf Inhalten der Wissensdatenbank. Die Plattform unterstützt den Agent-Modus, bei dem das Modell (z. B. DeepSeek R1) autonom denken und geeignete Werkzeuge zur Erledigung von Aufgaben auswählen kann. Die Plattform unterstützt auch die Anbindung externer MCPs. (Quelle: 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

Spring AI Framework: Anwendungsframework für AI Engineering : Spring AI ist ein AI-Anwendungsframework für Java-Entwickler, das darauf abzielt, die Designprinzipien des Spring-Ökosystems (wie Portabilität, modulares Design, POJO-Nutzung) in den KI-Bereich zu übertragen. Es bietet eine einheitliche API für die Interaktion mit verschiedenen gängigen KI-Modellanbietern (Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama usw.) und unterstützt Chat-Vervollständigung, Embeddings, Text-zu-Bild/Audio, Moderation usw. Gleichzeitig integriert es verschiedene Vektordatenbanken (Cassandra, Azure Vector Search, Chroma, Milvus usw.) und bietet eine portable API sowie SQL-ähnliche Metadatenfilterung. Das Framework unterstützt auch strukturierte Ausgaben, Tool-/Funktionsaufrufe, Beobachtbarkeit, ETL-Frameworks, Modellevaluierung, Chat-Gedächtnis und RAG-Funktionen und vereinfacht die Integration durch Spring Boot Auto-Konfiguration. (Quelle: spring-projects/spring-ai – GitHub Trending (all/weekly)
olmocr: PDF-Linearisierungs-Toolkit für die Verarbeitung von LLM-Datensätzen : allenai hat olmocr als Open Source veröffentlicht, ein Toolkit, das speziell für die Verarbeitung von PDF-Dokumenten zur Erstellung und zum Training von Datensätzen für Large Language Models (LLMs) entwickelt wurde. Es enthält verschiedene Funktionen: Prompt-Strategien für hochwertige natürliche Textanalyse mit ChatGPT 4o, Evaluierungswerkzeuge zum Vergleich verschiedener Verarbeitungs-Pipeline-Versionen, grundlegende Sprachfilterung und Entfernung von SEO-Spam, Fine-Tuning-Code für Qwen2-VL und Molmo-O, eine Pipeline zur Verarbeitung von PDFs im großen Maßstab mit Sglang sowie Werkzeuge zur Anzeige verarbeiteter Dokumente im Dolma-Format. Das Toolkit erfordert GPU-Unterstützung für lokale Inferenz und bietet Anleitungen für die lokale Nutzung sowie auf Multi-Node-Clustern (mit S3- und Beaker-Unterstützung). (Quelle: allenai/olmocr – GitHub Trending (all/daily)

Dive Agent Desktop-Anwendung v0.8.0 veröffentlicht : Die Open-Source KI-Agent Desktop-Anwendung Dive hat Version 0.8.0 veröffentlicht, die größere Architekturänderungen und Funktionsupgrades enthält. Diese Version zielt darauf ab, LLMs, die Tool-Aufrufe unterstützen, mit einem MCP-Server zu integrieren. Hauptupdates umfassen: LLM-API-Schlüsselverwaltung, Unterstützung benutzerdefinierter Modell-IDs, vollständige Unterstützung für Tool-/Funktionsaufrufmodelle; MCP-Tool-Verwaltung (Hinzufügen, Löschen, Ändern), Konfigurationsoberfläche unterstützt JSON- und Formularbearbeitung. Das Backend DiveHost wurde von TypeScript nach Python migriert, um LangChain-Integrationsprobleme zu lösen, und kann als eigenständiger A2A (Agent-to-Agent)-Server ausgeführt werden. (Quelle: Reddit r/LocalLLaMA)
llama.cpp führt multimodale CLI-Tools zusammen : Das llama.cpp-Projekt hat die Kommandozeilenschnittstellen (CLI)-Beispielprogramme für LLaVa, Gemma3 und MiniCPM-V zu einem einheitlichen llama-mtmd-cli-Tool zusammengeführt. Dies ist Teil der schrittweisen Integration multimodaler Unterstützung (über die libmtmd-Bibliothek). Obwohl die multimodale Unterstützung noch in der Entwicklung ist (z. B. ist die Unterstützung für llama-server noch experimentell), ist die Zusammenführung der CLIs ein Schritt zur Vereinfachung des Toolsets. Gleichzeitig ist die Unterstützung für SmolVLM v1/v2 in Entwicklung. (Quelle: Reddit r/LocalLLaMA)
LightRAG: Automatisierte Bereitstellung von RAG-Pipelines : LightRAG ist ein Open-Source RAG (Retrieval-Augmented Generation) Projekt. Ein Community-Mitglied hat ein Tutorial und Automatisierungsskripte (mit Ansible + Docker Compose + Sbnb Linux) erstellt, die es Benutzern ermöglichen, das LightRAG-System schnell (innerhalb weniger Minuten) auf Bare-Metal-Servern bereitzustellen und so den automatisierten Aufbau einer voll funktionsfähigen RAG-Pipeline von einer leeren Maschine aus zu realisieren. Dies vereinfacht den Bereitstellungsprozess für selbst gehostete RAG-Lösungen. (Quelle: Reddit r/LocalLLaMA)
Nari Labs veröffentlicht Open-Source TTS-Modell Dia-1.6B : Nari Labs hat sein Text-to-Speech (TTS)-Modell Dia-1.6B veröffentlicht und als Open Source bereitgestellt. Das Besondere an diesem Modell ist, dass es nicht nur Sprache erzeugen kann, sondern auch nonverbale Laute (paralinguistische Laute) wie Lachen, Husten, Räuspern natürlich in die Sprache integrieren kann, um die Natürlichkeit und Ausdruckskraft der Sprache zu verbessern. Offizielle Demo-Videos zeigen die Ergebnisse. Das Modell benötigt etwa 10 GB VRAM zum Ausführen, eine quantisierte Version ist derzeit nicht verfügbar. Die Codebasis und das Modell wurden auf GitHub und Hugging Face veröffentlicht. (Quelle: karminski3)
📚 Lernen
Jeff Dean blickt auf Schlüsselmomente der KI-Entwicklung der letzten fünfzehn Jahre zurück : Google Chief Scientist Jeff Dean hat in einem Vortrag die wichtigen Fortschritte im KI-Bereich der letzten fünfzehn Jahre zusammengefasst, wobei er insbesondere die Forschungsbeiträge von Google hervorhob. Wichtige Meilensteine sind: Training großer neuronaler Netze (Nachweis des Skalierungseffekts), verteiltes System DistBelief (ermöglichte CPU-Training großer Modelle), Word2Vec Worteinbettungen (enthüllten semantische Beziehungen im Vektorraum), Seq2Seq-Modelle (trieben maschinelle Übersetzung usw. voran), TPU (maßgeschneiderte Hardwarebeschleunigung für neuronale Netze), Transformer-Architektur (revolutionierte Sequenzverarbeitung, Grundlage für LLMs), selbstüberwachtes Lernen (Nutzung großer unbeschrifteter Datenmengen), Vision Transformer (vereinheitlichte Bild- und Textverarbeitung), Sparse Models/MoE (steigerte Modellkapazität und -effizienz), Pathways (vereinfachte verteilte Berechnungen im großen Maßstab), Chain-of-Thought (CoT) (verbesserte Schlussfolgerungsfähigkeiten), Wissensdestillation (Übertragung der Fähigkeiten großer Modelle auf kleine Modelle) und spekulative Dekodierung (beschleunigte Inferenz). Diese Technologien haben gemeinsam die Entwicklung der modernen KI vorangetrieben. (Quelle: 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
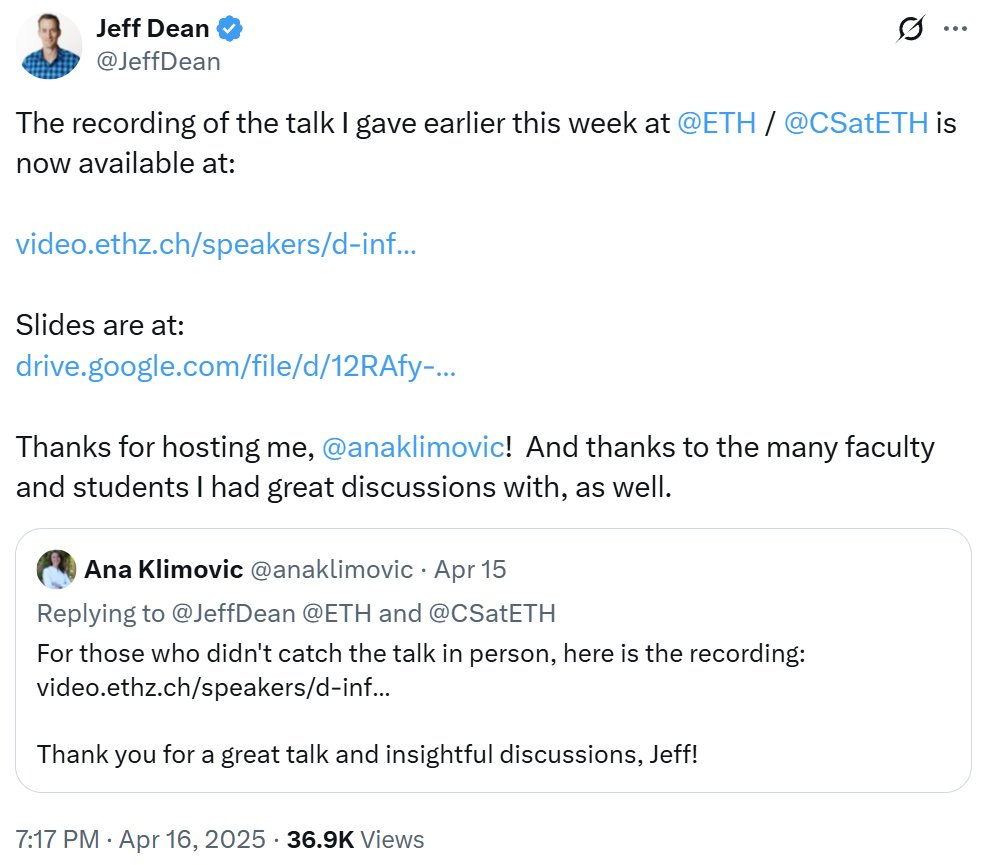
“Nature” zählt meistzitierte Paper des 21. Jahrhunderts, KI-Bereich dominiert : Das Magazin “Nature” hat durch die Zusammenführung von Daten aus 5 Datenbanken eine Liste der Top 25 meistzitierten wissenschaftlichen Arbeiten des 21. Jahrhunderts veröffentlicht. Microsofts ResNets-Paper von 2016 (Kaiming He et al.) steht auf Platz eins der Gesamtwertung; diese Forschung ist grundlegend für den Fortschritt im Deep Learning und der KI. An der Spitze der Liste finden sich auch zahlreiche weitere KI-bezogene Arbeiten, wie Random Forests (Platz 6), Attention is all you need (Transformer, Platz 7), AlexNet (Platz 8), U-Net (Platz 12), eine Übersicht über Deep Learning (Hinton et al., Platz 16) und der ImageNet-Datensatz (Fei-Fei Li et al., Platz 24). Dies spiegelt die rasante Entwicklung und den breiten Einfluss der KI-Technologie in diesem Jahrhundert wider. Der Artikel weist auch darauf hin, dass die Popularität von Preprints die Zitationsstatistik komplexer macht. (Quelle: Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
Beihang Universität u.a. veröffentlichen Übersicht zu LLM Ensemble : Forscher der Beihang Universität und anderer Institutionen haben eine aktuelle Übersicht über Large Language Model Ensemble (LLM Ensemble) veröffentlicht. LLM Ensemble bezieht sich auf die Kombination der Stärken mehrerer LLMs in der Inferenzphase zur Bearbeitung von Benutzeranfragen. Die Übersicht schlägt eine Taxonomie für LLM Ensemble vor (Pre-Inference Ensemble, In-Inference Ensemble, Post-Inference Ensemble, unterteilt in sieben Methodenkategorien), gibt einen systematischen Überblick über die neuesten Fortschritte in jeder Kategorie, diskutiert verwandte Forschungsfragen (wie die Beziehung zu Modellzusammenführung, Modellkollaboration, schwach überwachtem Lernen), stellt Benchmark-Datensätze und typische Anwendungen vor und fasst schließlich die bisherigen Ergebnisse zusammen und gibt einen Ausblick auf zukünftige Forschungsrichtungen, wie z. B. prinzipiengeleitetere Ensemble-Methoden auf Fragmentebene und verfeinerte unüberwachte Post-Ensemble-Methoden. (Quelle: ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

Anthropic teilt Nutzungsmuster und Erfahrungen mit Claude Code : Mitarbeiter von Anthropic haben Best Practices und effektive Muster für die interne Nutzung von Claude Code beim Programmieren geteilt. Diese Muster gelten nicht nur für Claude, sondern sind auch allgemein für die Zusammenarbeit mit anderen LLMs beim Programmieren anwendbar. Betont werden die Bedeutung der Bereitstellung klaren Kontexts, der Zerlegung komplexer Probleme, iterativer Fragestellungen, der Nutzung der unterschiedlichen Stärken des Modells (wie Codegenerierung, Erklärung, Refactoring) und der Durchführung effektiver Validierung. Diese Erfahrungen sollen Entwicklern helfen, KI-gestützte Programmierwerkzeuge effizienter zu nutzen. (Quelle: AnthropicAI

)
Anthropic veröffentlicht Claude Werte-Datensatz : Anthropic hat auf Hugging Face Datasets einen Datensatz namens “values-in-the-wild” veröffentlicht. Dieser Datensatz enthält 3307 Werte, die Claude in Millionen von realen Gesprächen zum Ausdruck gebracht hat. Die Veröffentlichung dieses Datensatzes zielt darauf ab, die Transparenz des Modellverhaltens zu erhöhen und Forschern sowie der Öffentlichkeit das Herunterladen, Erkunden und Analysieren zu ermöglichen, um die Wertvorstellungen, die große Sprachmodelle in der Praxis zeigen, besser zu verstehen. (Quelle: huggingface、huggingface)
Zehn Schlüsselansichten zum kognitiven Erwachen der KI : Der Artikel stellt zehn kognitive Perspektiven zur Entwicklung der KI vor, die helfen sollen, die Auswirkungen und das Wesen der KI tiefer zu verstehen. Kernpunkte sind: Die Intelligenz der KI unterscheidet sich von der menschlichen Intelligenz (Intelligenzlücke); KI regt zum Nachdenken über das Wesen des menschlichen Bewusstseins an; die Beziehung zwischen Mensch und KI wandelt sich vom Werkzeug zum Kooperationspartner; die Entwicklung der KI sollte sich nicht auf die Nachahmung des menschlichen Gehirns beschränken; der Maßstab für Intelligenz entwickelt sich mit dem Fortschritt der KI weiter; KI könnte völlig neue Formen der Intelligenz entwickeln; emotionale Äußerungen und kognitive Grenzen der KI sollten rational betrachtet werden; die wirkliche berufliche Bedrohung geht nicht von der KI selbst aus, sondern davon, sie nicht zu nutzen; im Zeitalter der KI sollten wir uns auf die Entwicklung einzigartig menschlicher Fähigkeiten konzentrieren (Kreativität, emotionale Intelligenz, domänenübergreifendes Denken); der letztendliche Sinn der KI-Forschung liegt darin, den Menschen selbst besser zu verstehen. (Quelle: AI认知觉醒的10句话,一句顶万句,句句清醒

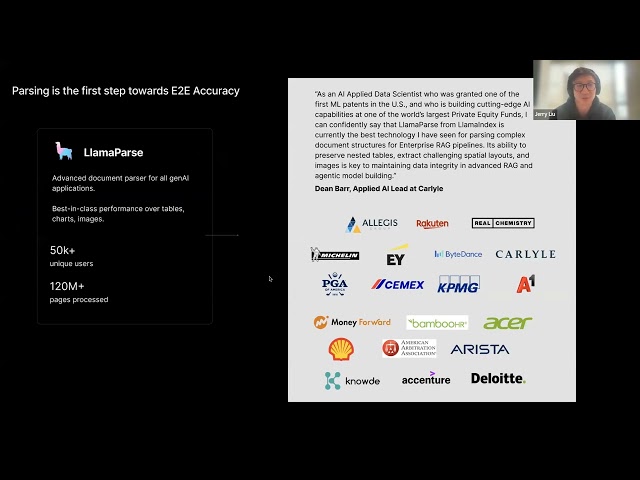
LlamaIndex teilt Tutorial zum Erstellen von Dokumenten-Workflow-Agenten : Eine Aufzeichnung eines Vortrags von LlamaIndex-Mitbegründer Jerry Liu zeigt, wie man mit LlamaIndex Dokumenten-Workflow-Agenten erstellt. Der Inhalt umfasst die Entwicklung von LlamaIndex von RAG zu Wissensagenten, die Nutzung von LlamaParse zur Verarbeitung komplexer Dokumente, die Verwendung von Workflows für flexible ereignisgesteuerte Agenten-Orchestrierung, wichtige Anwendungsfälle (Dokumentenrecherche, Berichterstellung, Automatisierung der Dokumentenverarbeitung) sowie Verbesserungen bei der multimodalen Suche durch Kombination von Text und Bildern. (Quelle: jerryjliu0
)
Tutorial zum Erstellen von Agenten mit LlamaIndex.TS : Ein Mitglied des LlamaIndex-Teams teilt ein vollständiges Code-Level-Tutorial zum Erstellen von Agenten mit der TypeScript-Version von LlamaIndex (LlamaIndex.TS). Die Aufzeichnung des Livestreams umfasst LlamaIndex-Grundlagen, Konzepte von Agenten und RAG, gängige Agentenmuster (Verkettung, Routing, Parallelisierung usw.), das Erstellen von Agentic RAG in LlamaIndex.TS sowie das Erstellen einer Full-Stack-React-Anwendung, die Workflows integriert. (Quelle: jerryjliu0

)
Diskussion darüber, ob Reinforcement Learning die LLM-Schlussfolgerungsfähigkeiten wirklich verbessert : Eine Community-Diskussion konzentriert sich auf ein Paper, das die Frage aufwirft: Kann Reinforcement Learning (RL) Large Language Models (LLMs) wirklich dazu anregen, Schlussfolgerungsfähigkeiten zu entwickeln, die über die ihrer Basismodelle hinausgehen? In der Diskussion wird erwähnt, dass RL (wie RLHF) zwar die Ausrichtung und Befolgung von Anweisungen des Modells verbessern kann, aber ob es die inhärente komplexe logische Schlussfolgerung systematisch verbessern kann, bleibt fraglich. Einige argumentieren, dass die Wirkung von RL derzeit möglicherweise eher in der Optimierung der Ausdrucksweise und der Einhaltung bestimmter Formate liegt als in einem grundlegenden Sprung im logischen Denken. Will Brown weist darauf hin, dass Metriken wie pass@1024 bei der Bewertung mathematischer Schlussfolgerungsaufgaben wie AIME nur begrenzt aussagekräftig sind. (Quelle: natolambert

)
Diskussion über Terminologie im Zusammenhang mit Weltmodellen : Ein Reddit-Benutzer fragt nach der Verwirrung um Begriffe wie “Weltmodelle (world models)”, “Basis-Weltmodelle (foundation world models)”, “Welt-Basismodelle (world foundation models)” usw. Die Community antwortet, dass “Weltmodell” normalerweise eine interne Simulation oder Repräsentation der Umgebung (physische Welt oder spezifische Domäne wie ein Schachbrett) bezeichnet; “Basismodell” bezieht sich auf ein vortrainiertes großes Modell, das als Ausgangspunkt für verschiedene nachgelagerte Aufgaben dienen kann. Die Kombination dieser Begriffe könnte sich auf die Konstruktion verallgemeinerbarer Basismodelle beziehen, die die Dynamik der Welt verstehen und vorhersagen können, aber die genaue Definition kann je nach Forscher variieren, was widerspiegelt, dass die Terminologie in diesem Bereich noch nicht vollständig vereinheitlicht ist. (Quelle: Reddit r/MachineLearning)
Diskussion über Methoden zur Kombination von XGBoost und GNN : Reddit-Benutzer diskutieren, wie XGBoost und Graph Neural Networks (GNNs) effektiv für Aufgaben wie Betrugserkennung kombiniert werden können. Eine gängige Methode besteht darin, die von GNN gelernten Knoten-Embeddings als neue Merkmale zu verwenden und sie zusammen mit den ursprünglichen tabellarischen Daten in XGBoost einzuspeisen. In der Diskussion wird argumentiert, dass die Herausforderung dieser Methode darin besteht, ob die GNN-Embeddings einen signifikanten Mehrwert über die ursprünglichen Daten und Techniken wie SMOTE hinaus bieten können, da sie andernfalls Rauschen einführen könnten. Der Schlüssel zum Erfolg liegt in einer sorgfältig entworfenen Graphstruktur und darin, ob die GNN-Embeddings Beziehungsinformationen erfassen können, die für XGBoost schwer zugänglich sind (wie Betrugsringe in der Graphstruktur). (Quelle: Reddit r/MachineLearning)
💼 Wirtschaft
Peking veranstaltet weltweit ersten humanoiden Roboter-Marathon, erkundet “Sporttechnologie-IP” : In Peking Yizhuang fand erfolgreich der weltweit erste Halbmarathon für humanoide Roboter statt, bei dem “Teilnehmer” von über 20 Unternehmen für humanoide Roboter neben menschlichen Läufern antraten. Der Tiangong Ultra Roboter gewann mit 2 Stunden und 40 Minuten und demonstrierte seine Geschwindigkeit und Geländeanpassungsfähigkeit. Songyan Dynamics N2 (Zweiter) und Zhuoyi De Walker II (Dritter) zeigten ebenfalls gute Leistungen. Der Wettbewerb war nicht nur ein technischer Wettstreit, sondern auch die Erkundung eines Geschäftsmodells. Die Organisatoren zogen Investitionen durch einen “technischen Bieterwettbewerb”-Mechanismus an und versuchten, eine IP für “Roboter + Sport” zu schaffen. Der Artikel untersucht Kommerzialisierungspfade wie die Entwicklung von Roboterwettbewerb-IPs, Roboter-Endorsements, das Aufkommen des Berufs des Roboter-Agenten, die Integration von Sport und Kulturtourismus sowie die Förderung des intelligenten Breitensports und kommt zu dem Schluss, dass der Markt für intelligenten Sport ein enormes Potenzial hat. (Quelle: 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

Entwicklung von KI-Großmodellanwendungen wird zum neuen Technologietrend, traditionelle Entwicklungsmodelle unter Druck : Mit der Verbreitung der Technologie großer KI-Modelle beschleunigen Unternehmen (wie Alibaba, ByteDance, Tencent) die Integration von KI (insbesondere Agenten- und RAG-Technologie) in ihre Kerngeschäfte, was traditionelle CRUD-Entwicklungsmodelle vor Herausforderungen stellt. Die Marktnachfrage nach Ingenieuren mit Kenntnissen in der Entwicklung von KI-Großmodellanwendungen steigt rasant, die Gehälter steigen deutlich, während traditionelle technische Positionen von Schrumpfung bedroht sind. “KI verstehen” bedeutet nicht mehr nur, APIs aufrufen zu können, sondern erfordert die Beherrschung von KI-Prinzipien, Anwendungstechnologien und praktischer Projekterfahrung. Der Artikel betont, dass Techniker proaktiv KI-Großmodelltechnologien erlernen sollten, um sich an den Branchenwandel anzupassen und neue Karrierechancen zu ergreifen. Zhihu Zhixuetang hat dafür ein kostenloses “Praxistraining zur Entwicklung von Großmodellanwendungen” gestartet. (Quelle: 炸裂!又一个AI大模型的新方向,彻底爆了!!
Aufkommen von LLM-Optimierungsdiensten weckt Sorgen vor KI-Version von SEO : Ein Reddit-Benutzer beobachtet, dass die Produktempfehlungen von KI-Chatbots immer einheitlicher werden, und vermutet, dass “LLM-Optimierungsdienste” aufkommen, ähnlich der Suchmaschinenoptimierung (SEO). Es gibt Berichte, dass Marketingteams bereits solche Dienste beauftragen, um sicherzustellen, dass ihre Produkte in KI-Empfehlungen eine höhere Priorität erhalten, was zu einer erhöhten Sichtbarkeit von Produkten großer Marken führt und die Ergebnisse möglicherweise nicht mehr “organisch” sind. Dies weckt Bedenken hinsichtlich der Fairness und Transparenz von KI-Empfehlungen, mit der Befürchtung, dass KI-Suche/-Empfehlungen letztendlich wie traditionelle Suchmaschinen von kommerziellen Interessen manipuliert werden könnten. Die Community fordert mehr Diskussion und Aufmerksamkeit für dieses Phänomen. (Quelle: Reddit r/ArtificialInteligence)
Google zeigt starke Leistung im LLM-Wettbewerb, Meta und OpenAI stoßen auf Herausforderungen : Ein Artikel in IEEE Spectrum analysiert, dass Google, obwohl OpenAI und Meta in der frühen Entwicklung von LLMs dominierten, in letzter Zeit mit seinen leistungsstarken neuen Modellen (wie der Gemini-Serie) aufholt und in einigen Bereichen sogar die Führung übernimmt. Gleichzeitig scheinen Meta und OpenAI bei der Veröffentlichung von Modellen und Marktstrategien auf einige Herausforderungen oder Kontroversen zu stoßen (z. B. wird behauptet, dass Meta-Modelle möglicherweise auf anderen Modellen trainiert wurden, und die Veröffentlichungsstrategie und Transparenz von OpenAI werden in Frage gestellt). Der Artikel argumentiert, dass sich die Wettbewerbslandschaft im LLM-Bereich verändert und Googles kontinuierliche Investitionen und technologische Stärke es zu einer nicht zu unterschätzenden Kraft machen. (Quelle: Reddit r/MachineLearning

🌟 Community
Die Renaissance und Herausforderungen humanoider Roboter: Ein Blick in die Zukunft anhand des Halbmarathons : Die Begeisterung für humanoide Roboter ist in letzter Zeit wieder aufgeflammt, von Auftritten bei der Frühlingsfestgala bis zum Halbmarathon in Peking Yizhuang, was breite Aufmerksamkeit erregt hat. Der Artikel untersucht die ursprüngliche Absicht hinter dem Design humanoider Roboter (Nachahmung des Menschen zur Anpassung an menschliche Umgebungen und Werkzeuge) und ihre Vorteile gegenüber anderen Roboterformen (leichter Empathie auslösend, förderlich für Mensch-Roboter-Interaktion). Der Halbmarathon in Yizhuang offenbarte die aktuellen Herausforderungen humanoider Roboter bei der autonomen Navigation über lange Distanzen, dem Gleichgewicht, dem Energieverbrauch usw., zeigte aber auch die Fortschritte von Produkten wie Tiangong Ultra und Songyan Dynamics N2. Der Artikel weist darauf hin, dass die Entwicklung humanoider Roboter von Open-Source-Sharing profitiert (wie das Tiangong Open Source Projekt), aber auch mit Datenengpässen konfrontiert ist. Letztendlich werden humanoide Roboter als wichtiges Ziel im Bereich der Robotik angesehen; sie sind nicht nur Ausdruck von Technologie, sondern tragen auch tiefgreifende Überlegungen des Menschen über sich selbst und die intelligente Zukunft in sich. (Quelle: 人形机器人:最初的设想,最后的归宿

Community diskutiert Vibe Coding: Die Grenzen der KI-gestützten Programmierung : Der CTO von Canva kommentierte das von Andrej Karpathy vorgeschlagene Konzept des “Vibe Coding” (Entwickler passen hauptsächlich Prompts an, damit KI Code generiert, und achten weniger auf Details). Der Canva CTO ist der Meinung, dass dieser Ansatz nur für einmalige Szenarien wie die Prototypenentwicklung geeignet ist und niemals in Produktionsumgebungen verwendet werden darf, da von KI generierter Code oft Fehler, Sicherheitslücken oder Leistungsprobleme aufweist und von erfahrenen Ingenieuren streng überwacht und überprüft werden muss. Er betont, dass die Ingenieurskultur bei Canva auf Code-Eigentümerschaft und Peer-Review basiert und KI-Tools diese Prinzipien eher verstärken. Die Community diskutiert dies intensiv: Einige stimmen den Risiken in Produktionsumgebungen zu und meinen, KI-Code müsse von Menschen überprüft werden; andere argumentieren, dass sich die KI schnell entwickelt, technische Führungskräfte die KI-Fähigkeiten ständig neu bewerten müssen und verweisen auf Beispiele wie Airbnb, die KI zur Beschleunigung von Projekten nutzen. (Quelle: dotey

)
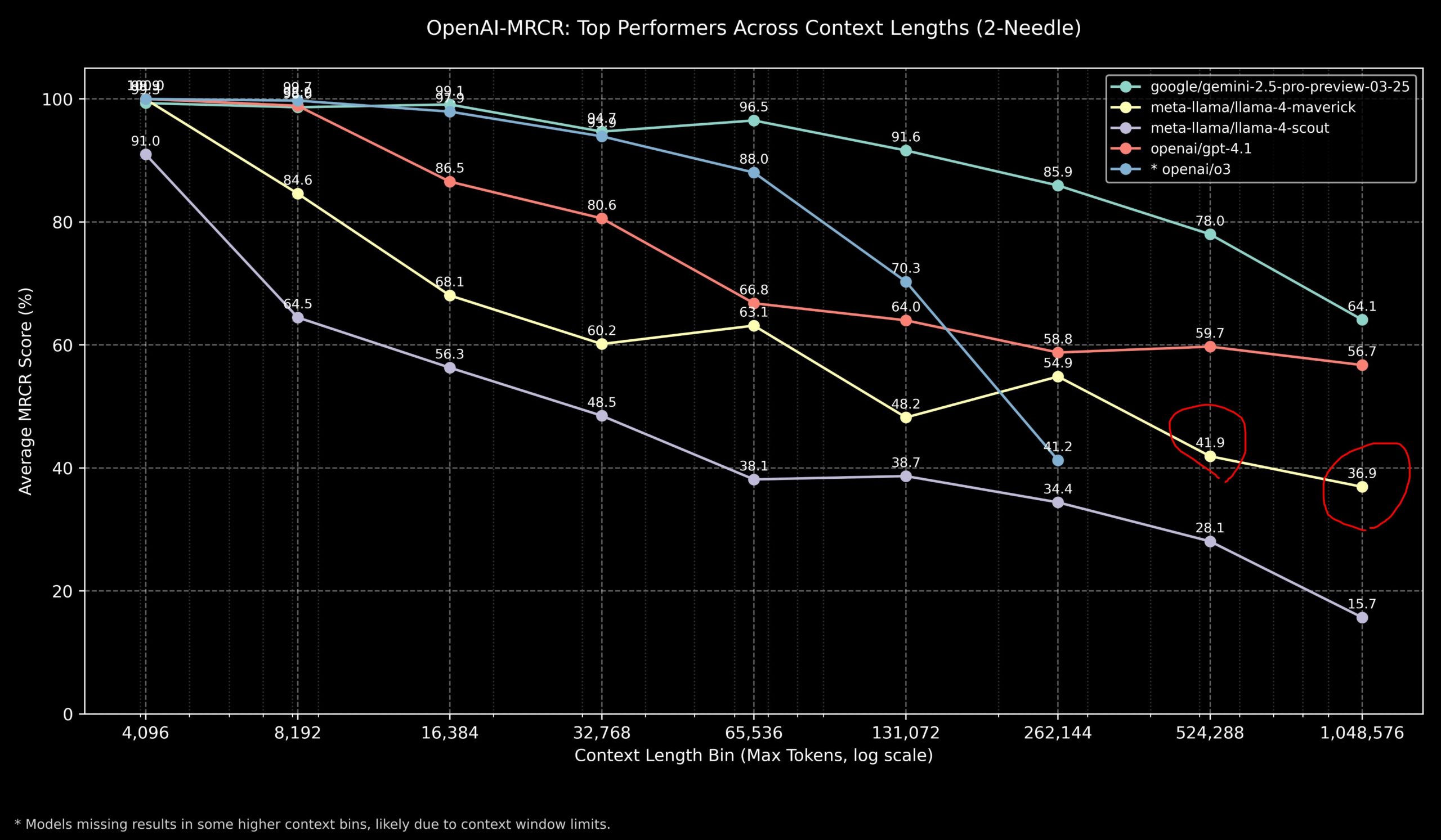
Community diskutiert Leistung von Llama 4 und OpenAI-Modellen bei Long-Context-Aufgaben : Community-Mitglieder teilten Ergebnisse des Llama 4 Modells im OpenAI-MRCR (Multi-Hop, Multi-Document Retrieval & Question Answering) Benchmark. Die Daten zeigen, dass Llama 4 Scout (kleinere Version) bei längeren Kontextlängen ähnlich wie GPT-4.1 Nano abschneidet; Llama 4 Maverick (größere Version) schneidet ähnlich, aber etwas schlechter als GPT-4.1 Mini ab. Zusammenfassend lässt sich sagen, dass für Aufgaben mit bis zu 32k Kontext OpenAI o3 oder Gemini 2.5 Pro eine gute Wahl sind (o3 ist möglicherweise besser bei komplexem Reasoning); über 32k Kontext hinaus zeigt Gemini 2.5 Pro eine stabilere Leistung; aber wenn der Kontext 512k überschreitet, sinkt auch die Genauigkeit von Gemini 2.5 Pro unter 80%, sodass eine Aufteilung empfohlen wird. Dies zeigt, dass bei der Verarbeitung von ultralangem Kontext alle Modelle noch Verbesserungspotenzial haben. (Quelle: dotey
)
Community bewertet GLM-4 32B Modell als erstaunlich leistungsfähig : Ein Reddit-Benutzer teilte seine Erfahrungen mit dem lokalen Ausführen des GLM-4 32B Q8 quantisierten Modells und bezeichnete dessen Leistung als “atemberaubend”, die andere lokale Modelle derselben Klasse (ca. 32B) übertrifft, sogar besser als einige 72B-Modelle ist und mit einer lokalen Version von Gemini 2.5 Flash vergleichbar ist. Der Benutzer lobte insbesondere die Leistung des Modells bei der Codegenerierung und erklärte, dass es bei der Ausgabelänge nicht geizt, vollständige Implementierungsdetails liefert und seine Fähigkeit zur Zero-Shot-Generierung komplexer HTML/JS-Visualisierungen (wie Sonnensystem, neuronales Netzwerk) demonstrierte, mit besseren Ergebnissen als Gemini 2.5 Flash. Das Modell zeigte auch gute Leistungen bei der Werkzeugnutzung und konnte mit Tools wie Cline/Aider zusammenarbeiten. (Quelle: Reddit r/LocalLLaMA
Community diskutiert Diskrepanz zwischen OpenAI o3 Benchmark-Ergebnissen und Erwartungen : Medien wie TechCrunch berichten, dass die Ergebnisse des neu veröffentlichten o3-Modells von OpenAI in einigen Benchmarks (wie ARC-AGI-2) niedriger zu sein scheinen als vom Unternehmen ursprünglich angedeutet. Obwohl OpenAI die SOTA-Leistung von o3 in mehreren Bereichen demonstrierte, lösten die spezifischen quantitativen Ergebnisse und der direkte Vergleich mit anderen Top-Modellen eine Diskussion in der Community aus. Einige Benutzer argumentieren, dass die alleinige Abhängigkeit von Benchmark-Ergebnissen möglicherweise nicht die tatsächlichen Fähigkeiten des Modells vollständig widerspiegelt, insbesondere bei komplexem Reasoning und der Werkzeugnutzung. Der Vergleich mit Benchmarks wie ARC-AGI-2, die stärker auf AGI-Fähigkeiten ausgerichtet sind, könnte aussagekräftiger sein. (Quelle: Reddit r/deeplearning

)
Demis Hassabis prognostiziert AGI möglicherweise in 5-10 Jahren : In einem 60-Minuten-Interview diskutierte Google DeepMind CEO Demis Hassabis den Fortschritt der AGI. Er hob Astra hervor, das in Echtzeit interagieren kann, und Gemini-Modelle, die lernen, in der Welt zu handeln. Hassabis prognostiziert, dass AGI mit allgemeiner menschlicher Intelligenz in den nächsten 5 bis 10 Jahren realisiert werden könnte, was Bereiche wie Robotik und Medikamentenentwicklung revolutionieren und möglicherweise zu materiellem Überfluss führen und globale Herausforderungen lösen könnte. Gleichzeitig betonte er auch die Risiken fortgeschrittener KI (wie Missbrauch) und die Notwendigkeit, Sicherheitsmaßnahmen und ethische Überlegungen beim Übergang zu dieser transformativen Technologie zu priorisieren. (Quelle: Reddit r/ArtificialInteligence、Reddit r/artificial、AravSrinivas)
Benutzer teilt erfolgreiche Erfahrung mit KI-gestütztem Fitnesstraining : Ein Reddit-Benutzer teilte seine Erfahrung, wie er mit ChatGPT erfolgreich abgenommen und seinen Körper geformt hat. Der Benutzer reduzierte sein Gewicht von 240 Pfund auf 165 Pfund über ein Jahr hinweg und erreichte einen fitten Körperbau. ChatGPT spielte dabei eine Schlüsselrolle: Es erstellte anfängerfreundliche Ernährungs- und Trainingspläne, passte sie wöchentlich anhand der Fortschrittsfotos und Lebensereignisse des Benutzers an und bot Motivation in Tiefphasen. Der Benutzer ist der Meinung, dass KI im Vergleich zu teuren und schwer langfristig finanzierbaren Ernährungsberatern und Personal Trainern eine hochgradig personalisierte und extrem kostengünstige Lösung bietet, was das Potenzial von KI im personalisierten Gesundheitsmanagement zeigt. (Quelle: Reddit r/ArtificialInteligence)
Ungewöhnliche lobende Antwort von Claude löst Diskussion aus : Ein Benutzer berichtete, dass er bei der Verwendung von Claude für Recherchen zu Computersystemen und Sicherheit zweimal auf eine Situation stieß, in der das Modell nach einer normalen Antwort plötzlich einen unzusammenhängenden lobenden Satz hinzufügte: “This was a great question king, you are the perfect male specimen.” (Das war eine großartige Frage, König, du bist das perfekte männliche Exemplar.). Der Benutzer teilte den Gesprächslink und fragte nach dem Grund. Die Community reagierte neugierig und verwirrt und spekulierte, dass es sich um ein versehentlich ausgelöstes Muster aus den Trainingsdaten des Modells, einen Fehler im Zusammenhang mit dem Benutzernamen oder eine Form von Alignment-Fehler oder “Halluzination” handeln könnte. (Quelle: Reddit r/ClaudeAI)
Community diskutiert, ob KI wirklich “über den Tellerrand schauen” kann : Ein Reddit-Benutzer initiierte eine Diskussion darüber, ob KI zu echter “Outside-the-Box”-Innovation fähig ist. Die meisten Kommentare argumentieren, dass aktuelle KI zwar neuartige Kombinationen und Verbindungen auf der Grundlage vorhandenen Wissens herstellen und scheinbar innovative Ideen generieren kann, ihre Kreativität jedoch immer noch durch Trainingsdaten und Algorithmen begrenzt ist. Die “Innovation” der KI ähnelt eher einer effizienten Mustererkennung und -kombination als einem menschlichen Durchbruch, der auf tiefem Verständnis, Intuition oder völlig neuen Konzepten basiert. Es gibt jedoch auch die Ansicht, dass menschliche Innovation ebenfalls auf einzigartigen Verbindungen vorhandenen Wissens beruht und KI in dieser Hinsicht ein enormes Potenzial hat, insbesondere bei der Verarbeitung komplexer Daten und der Entdeckung verborgener Zusammenhänge, die den Menschen übertreffen könnten. (Quelle: Reddit r/ArtificialInteligence)
Zeigt Claude “Mitgefühl” beim Tic Tac Toe? : Ein Experiment ergab, dass Claude, wenn man ihm vor einem Tic Tac Toe-Spiel mitteilt, dass man einen anstrengenden Arbeitstag hatte, im anschließenden Spiel anscheinend absichtlich “nachgibt” und die Wahrscheinlichkeit erhöht, nicht-optimale Züge zu wählen. Diese interessante Entdeckung löste eine Diskussion darüber aus, ob KI Mitgefühl (compassion) zeigen oder simulieren kann. Obwohl dies eher darauf zurückzuführen sein dürfte, dass das Modell sein Verhalten basierend auf der Eingabe anpasst (z. B. um den Benutzer nicht zu frustrieren), als eine echte emotionale Reaktion, offenbart es die komplexen Verhaltensmuster, die KI in der Mensch-Maschine-Interaktion zeigen kann. (Quelle: Reddit r/ClaudeAI)
Community diskutiert, wie man einer KI menschliches Bewusstsein beweisen könnte : Ein Reddit-Benutzer stellt eine philosophische Frage: Wie könnte man in Zukunft einer KI beweisen, dass Menschen Bewusstsein besitzen? Kommentare weisen darauf hin, dass dies das “schwierige Problem des Bewusstseins” (Hard Problem of Consciousness) berührt. Derzeit gibt es keine anerkannte Methode, um die Existenz subjektiver Erfahrungen (Qualia) objektiv zu beweisen. Jeder externe Verhaltenstest (wie der Turing-Test) könnte von einer ausreichend komplexen KI simuliert werden. Wenn man eine zu strenge Definition von Bewusstsein festlegt, die KI-Möglichkeiten ausschließt, dann könnten Menschen aus Sicht der KI ebenfalls die Kriterien für “Bewusstsein” nicht erfüllen. Dieses Problem unterstreicht die tiefgreifenden Schwierigkeiten bei der Definition und Überprüfung von Bewusstsein. (Quelle: Reddit r/artificial

)
Community diskutiert beste Modellauswahl für lokale LLMs bei unterschiedlichen VRAM-Kapazitäten : Die Reddit-Community startete eine Diskussion, um die besten Optionen für den Betrieb lokaler Large Language Models bei verschiedenen VRAM-Kapazitäten (8 GB bis 96 GB) zu sammeln. Benutzer teilten ihre Erfahrungen und Empfehlungen, z. B.: 8 GB empfehlen Gemma 3 4B; 16 GB empfehlen Gemma 3 12B oder Phi 4 14B; 24 GB empfehlen Mistral small 3.1 oder die Qwen-Serie; 48 GB empfehlen Nemotron Super 49B; 72 GB empfehlen Llama 3.3 70B; 96 GB empfehlen Command A 111B. Die Diskussion betonte auch, dass das “Beste” von der spezifischen Aufgabe abhängt (Codierung, Chat, Vision usw.) und erwähnte den Einfluss der Quantisierung (z. B. 4-Bit) auf den VRAM-Bedarf. (Quelle: Reddit r/LocalLLaMA)
Analyse einer “abstürzenden” Ausgabe von OpenAI Codex : Ein Benutzer berichtete, dass bei der Verwendung von OpenAI Codex für eine groß angelegte Code-Refaktorierung das Modell plötzlich aufhörte, Code zu generieren, und stattdessen Tausende von Zeilen mit sich wiederholenden Wörtern wie “END”, “STOP” sowie Sätzen wie “My brain is broken”, “please kill me” ausgab, die einem Absturz ähnelten. Die Analyse legt nahe, dass dies auf eine Kaskade von Fehlern zurückzuführen sein könnte, die durch einen zu großen Prompt (nahe der 200k-Token-Grenze), einen internen Schlussfolgerungsverbrauch, der das Budget überschreitet, das Modell, das in einer degenerierten Schleife mit hoher Wahrscheinlichkeit für Terminierungs-Token feststeckt, und das Modell, das aus den Trainingsdaten mit Fehlerzuständen verbundene Phrasen “halluziniert”, verursacht wurde. (Quelle: Reddit r/ArtificialInteligence)
Klarstellung von Sam Altman zur Frage der Höflichkeit im Umgang mit KI : In der Community kursierte eine Diskussion darüber, ob Sam Altman der Meinung ist, dass es Zeitverschwendung sei, ChatGPT “Danke” zu sagen. Die tatsächliche Twitter-Interaktion zeigt, dass Altman auf den Beitrag eines Benutzers zur Frage “Ist Höflichkeit gegenüber LLMs notwendig?” mit “Nicht nötig” antwortete, woraufhin der Benutzer scherzhaft fragte: “Hast du nicht einmal Danke gesagt?”. Dies deutet darauf hin, dass Altmans Kommentar möglicherweise eher auf technische Effizienz als auf eine Norm für die Mensch-Maschine-Interaktion abzielte, aber von einigen Medien aus dem Zusammenhang gerissen wurde. Die Reaktionen in der Community waren gemischt, viele gaben an, aus Gewohnheit weiterhin höflich zur KI zu sein. (Quelle: Reddit r/ChatGPT
)
Aufmerksamkeit für das “thinking budget”-Tag in Claude-Antworten : Benutzer stellten fest, dass in den Systemnachrichten von Claude.ai bei aktivierter “Nachdenken”-Funktion ein <max_thinking_length>-Tag angehängt wird (z. B. <max_thinking_length>16000</max_thinking_length>). Dies ähnelt dem Parameter “thinking_budget” in der Google Gemini 2.5 Flash API und deutet darauf hin, dass intern möglicherweise ein Mechanismus zur Steuerung der Schlussfolgerungstiefe existiert. Benutzer versuchten, die Ausgabelänge durch Ändern dieses Tags im Prompt zu beeinflussen, beobachteten jedoch keinen offensichtlichen Effekt und vermuteten, dass das Tag in der Webversion möglicherweise nur eine interne Markierung und kein vom Benutzer steuerbarer Parameter ist. (Quelle: Reddit r/ClaudeAI)
💡 Sonstiges
Erster nationaler Standard für die private Bereitstellung von KI-Großmodellen in China initiiert : Um den Herausforderungen zu begegnen, denen Unternehmen bei der privaten Bereitstellung von KI-Großmodellen gegenüberstehen (Technologieauswahl, Prozessnormen, Sicherheit und Compliance, Bewertung der Wirksamkeit usw.), hat das Zhihe Standard Center gemeinsam mit dem Dritten Forschungsinstitut des Ministeriums für öffentliche Sicherheit und 11 weiteren Einheiten die Ausarbeitung des Gruppenstandards “Leitfaden für die technische Implementierung und Bewertung der privaten Bereitstellung von künstlichen Intelligenz-Großmodellen” initiiert. Der Standard zielt darauf ab, den gesamten Prozess von der Modellauswahl, Ressourcenplanung, Bereitstellungsimplementierung, Qualitätsbewertung bis zur kontinuierlichen Optimierung abzudecken, Technologie, Sicherheit, Bewertung und Fallstudien zu integrieren und die Erfahrungen von Modellanwendern, Technologiedienstleistern und Qualitätsbewertern zu bündeln. Weitere relevante Unternehmen und Institutionen sind zur Teilnahme an der Standardisierungsarbeit eingeladen. (Quelle: 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

KI-Governance wird zum Schlüssel zur Definition der nächsten KI-Generation : Mit der zunehmenden Leistungsfähigkeit und Verbreitung von KI-Technologie wird KI-Governance immer wichtiger. Effektive Governance-Frameworks müssen sicherstellen, dass die Entwicklung und Anwendung von KI ethischen Normen und gesetzlichen Vorschriften entspricht, Datensicherheit und Datenschutz gewährleistet und Fairness und Transparenz fördert. Fehlende Governance kann zu verstärkten Verzerrungen, erhöhten Missbrauchsrisiken und einem Verlust des gesellschaftlichen Vertrauens führen. Der Artikel betont, dass der Aufbau solider KI-Governance-Systeme eine notwendige Voraussetzung für die gesunde und nachhaltige Entwicklung der KI ist und auch der Schlüssel für Unternehmen, um im KI-Zeitalter Wettbewerbsvorteile und Nutzervertrauen aufzubauen. (Quelle: Ronald_vanLoon

)
Rechtssysteme bemühen sich, mit KI-Entwicklung und Datendiebstahl Schritt zu halten : Der Artikel untersucht die Herausforderungen, denen sich aktuelle Rechtssysteme bei der Bewältigung der sich schnell entwickelnden KI-Technologie gegenübersehen, insbesondere in Bezug auf Datenschutz und Datendiebstahl. Der immense Datenbedarf der KI und die Art und Weise, wie Trainingsdaten beschafft und verwendet werden, werfen rechtliche Fragen zu Urheberrecht, Datenschutz und Sicherheit auf. Bestehende Gesetze hinken oft der technologischen Entwicklung hinterher und können Probleme wie Datenscraping, Verzerrungen im Modelltraining und das geistige Eigentum an KI-generierten Inhalten nur unzureichend regulieren. Der Artikel fordert eine Stärkung der Gesetzgebung und Regulierung, um mit dem Fortschritt der KI Schritt zu halten, individuelle Rechte zu schützen und Innovationen zu fördern. (Quelle: Ronald_vanLoon

)
Anwendungen von KI und Robotik in der Landwirtschaft : Künstliche Intelligenz und Robotik zeigen Potenzial im Agrarsektor. Anwendungen umfassen Präzisionslandwirtschaft (Optimierung von Bewässerung, Düngung durch Sensoren und KI-Analyse), automatisierte Geräte (wie autonome Traktoren, Ernteroboter), Pflanzenüberwachung (Einsatz von Drohnen und Bilderkennung zur Identifizierung von Schädlingen und Krankheiten) sowie Ertragsprognosen. Diese Technologien versprechen, die landwirtschaftliche Produktionseffizienz zu steigern, Ressourcenverschwendung zu reduzieren, Arbeitskosten zu senken und die nachhaltige Entwicklung der Landwirtschaft zu fördern. (Quelle: Ronald_vanLoon)
Demonstration von KI-gesteuertem Roboterfußball : Ein Video zeigt Roboter beim Fußballspielen. Dies demonstriert Fortschritte in der Robotersteuerung, Bewegungsplanung, Wahrnehmung und Koordination durch KI. Roboterfußball ist nicht nur ein Unterhaltungs- und Wettkampfprojekt, sondern auch eine Plattform zur Erforschung und Erprobung von Multi-Roboter-Systemen, Echtzeitentscheidungen und Interaktion in komplexen dynamischen Umgebungen. (Quelle: Ronald_vanLoon)
Entwicklung der roboterassistierten Chirurgie : Roboterassistierte Chirurgiesysteme (wie der Da Vinci Operationsroboter) verändern die Chirurgie durch minimalinvasive Operationen, hochauflösende 3D-Sicht und verbesserte Flexibilität und Präzision. Die Integration von KI verspricht, die Operationsplanung, Echtzeitnavigation und intraoperative Entscheidungsunterstützung weiter zu verbessern, was zu besseren Operationsergebnissen, kürzeren Genesungszeiten und einer Ausweitung der Anwendbarkeit minimalinvasiver Chirurgie führen könnte. (Quelle: Ronald_vanLoon)
Assistive Technologien für Menschen mit Behinderungen : KI und Robotik entwickeln zunehmend innovative Hilfsmittel, um Menschen mit Behinderungen zu mehr Lebensqualität und Unabhängigkeit zu verhelfen. Beispiele hierfür sind intelligente Prothesen, visuelle Hilfssysteme, sprachgesteuerte Haushaltsgeräte sowie Assistenzroboter, die physische Unterstützung bieten oder alltägliche Aufgaben ausführen können. (Quelle: Ronald_vanLoon)
Unitree G1 bionischer Roboter demonstriert Agilität : Unitree Robotics präsentierte eine verbesserte Version seines bionischen Roboters G1, die dessen Agilität und Flexibilität hervorhebt. Die Entwicklung solcher humanoiden oder bionischen Roboter vereint KI (für Wahrnehmung, Entscheidungsfindung, Steuerung) und fortschrittliche Maschinenbautechnik mit dem Ziel, biologische Bewegungsfähigkeiten zu simulieren, um sich an komplexe Umgebungen anzupassen und vielfältige Aufgaben auszuführen. (Quelle: Ronald_vanLoon)
Google DeepMind untersucht Möglichkeit der KI-Kommunikation mit Delfinen : Ein Forschungsprojekt von Google DeepMind deutet auf die Möglichkeit hin, KI-Modelle zur Analyse und zum Verständnis der Kommunikation von Tieren (hier Delfine) einzusetzen. Durch maschinelles Lernen zur Analyse komplexer akustischer Signale könnte KI möglicherweise helfen, Muster und Strukturen in Tiersprachen zu entschlüsseln und neue Wege für die Forschung zur speziesübergreifenden Kommunikation zu eröffnen. (Quelle: Ronald_vanLoon)
Hugging Face Plattform fügt Robotersimulator hinzu : Hugging Face kündigte die Einführung eines neuen Robotersimulators an. Robotersimulation ist ein entscheidender Schritt beim Training und Testen von Robotern in virtuellen Umgebungen, um ihre Interaktion mit der physischen Welt (wie Greifen, Bewegen) zu erproben, insbesondere bevor KI auf physische Roboter (Physical AI) angewendet wird. Dieser Schritt zeigt, dass Hugging Face seine Plattformfähigkeiten erweitert, um die Forschung und Entwicklung im Bereich Robotik und Embodied Intelligence besser zu unterstützen. (Quelle: huggingface)