
Schlüsselwörter:AI-Vier-Drachen, verkörperte Intelligenz, humanoiden Roboter, Speicherwand, SenseTime Shangri-La V6 Multimodales Modell, Open X-Embodiment Datensatz, Tesla Optimus Roboter, 3D-Ferroelektrischer RAM, Tiangong Ultra Roboter-Halbmarathon, Gemma 3 QAT Quantisierungsmodell, Hugging Face übernimmt Pollen Robotics, LlamaIndex Agenten-Dokumentenworkflow
🔥 Fokus
„KI-Vier Drachen“ stehen vor Herausforderungen und Wandel: Unternehmen wie SenseTime, Megvii, CloudWalk und Yitu, einst als „KI-Vier Drachen“ gefeiert, kämpfen in den letzten Jahren generell mit Kommerzialisierungsschwierigkeiten und anhaltenden Verlusten. Beispielsweise verzeichnete SenseTime im Jahr 2024 einen Verlust von 4,3 Milliarden Yuan, mit einem kumulierten Verlust von über 54,6 Milliarden Yuan; CloudWalk meldete für 2024 einen Verlust von fast 600-700 Millionen Yuan, mit einem kumulierten Verlust von über 4,4 Milliarden Yuan. Um den Herausforderungen zu begegnen, haben die Unternehmen strategische Anpassungen vorgenommen, darunter Personalabbau, Gehaltskürzungen und Geschäftsumstrukturierungen. Angesichts der neuen KI-Welle, die von Large Language Models dominiert wird, wenden sich die „Vier Drachen“, die ihren Ursprung in visueller Technologie haben, aktiv multimodalen Large Models und dem Bereich AGI zu. SenseTime veröffentlichte das multimodale Modell „Ririxin V6“, das mit GPT-4o konkurrieren soll, und investiert massiv in den Aufbau von Rechenzentren für KI; Yitu konzentriert sich auf visuell zentrierte multimodale Modelle und kooperiert mit Huawei, um Hardwarekosten zu senken; CloudWalk arbeitet ebenfalls mit Huawei zusammen, um eine All-in-One-Maschine für das Training und die Inferenz von Large Models auf den Markt zu bringen; Megvii nutzt seine algorithmischen Vorteile, um in den Markt für rein visuelle Lösungen für autonomes Fahren einzusteigen. Diese Schritte zeigen ihre Bemühungen, am KI-Tisch zu bleiben und sich an das neue Marktumfeld anzupassen. (Quelle: 36Kr)

Datenherausforderungen bei Embodied Intelligence und Fortschritte bei Open-Source-Datensätzen: Die Entwicklung humanoider Roboter und Embodied Intelligence steht vor einem entscheidenden Datenengpass. Der Mangel an hochwertigen Trainingsdaten behindert den Durchbruch ihrer Fähigkeiten. Im Gegensatz zu Sprachmodellen, die über riesige Mengen an Textdaten aus dem Internet verfügen, benötigen Roboter vielfältige Interaktionsdaten aus der physischen Welt, deren Beschaffung kostspielig ist. Um dieses Problem zu lösen, bauen Forschungseinrichtungen und Unternehmen aktiv Datensätze auf und stellen sie als Open Source zur Verfügung, wie z.B. Open X-Embodiment von Google DeepMind und mehreren Institutionen, ARIO vom Peng Cheng Laboratory etc., RoboMIND vom Beijing Innovation Center, AgiBot World von AgiBot (enthält Daten zu komplexen Langzeitaufgaben in realen Szenarien) sowie die Simulationsdatensätze AgiBot Digital World, und die G1-Betriebsdatensätze von Unitree. Obwohl der Umfang dieser Datensätze noch weit hinter dem von Textdaten zurückbleibt, treiben sie durch die Vereinheitlichung von Standards, Qualitätssteigerung und Anreicherung von Szenarien die Entwicklung im Bereich Embodied Intelligence voran und legen die Grundlage für einen „ImageNet-Moment“. (Quelle: 36Kr)

Massenproduktion humanoider Roboter in Sicht: Durchbrüche bei Daten, Simulation und Generalisierung: Trotz Herausforderungen wie hohen Kosten für die Datenerfassung und schwacher Generalisierungsfähigkeit planen mehrere Unternehmen (Tesla, Figure AI, 1X, AgiBot, Unitree, UBTECH etc.), die Massenproduktion humanoider Roboter im Jahr 2025 zu realisieren. Lösungsansätze umfassen: 1) Groß angelegtes Training mit echten Maschinen, unterstützt durch Regierungen (Beijing, Shanghai, Shenzhen, Guangdong) beim Aufbau von Datenerfassungszentren und der Festlegung von Standards; 2) Fortschrittliches Simulationstraining unter Nutzung von World Models wie Nvidia Cosmos und Google Genie2 zur Generierung physikalisch realistischer virtueller Umgebungen, um Kosten zu senken und die Effizienz zu steigern; 3) KI-gestützte Generalisierung durch neuartige Aktionsmodelle wie Helix von Figure AI, die ViLLA-Architektur von AgiBot GO-1 und Gemini Robotics von Google, die mit weniger Daten ein generalisiertes Verständnis für physische Operationen ermöglichen, sodass Roboter unbekannte Objekte handhaben und sich an neue Umgebungen anpassen können. Diese technologischen Fortschritte deuten darauf hin, dass die kommerzielle Anwendung humanoider Roboter beschleunigt werden könnte. (Quelle: 36Kr)

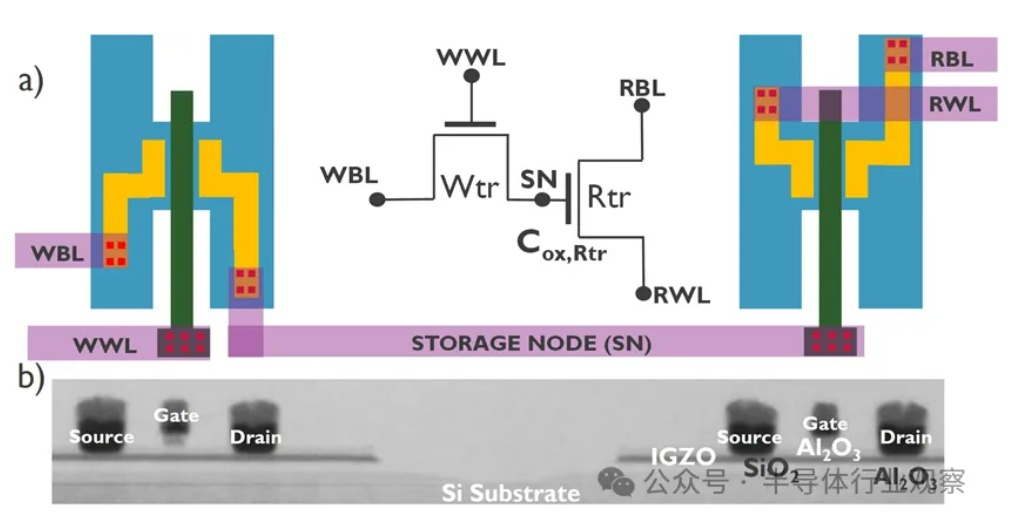
KI-Entwicklung stößt auf „Memory Wall“-Krise, neue Speichertechnologien suchen Durchbruch: Das exponentielle Wachstum von KI-Modellgrößen stellt eine ernste Herausforderung für die Speicherbandbreite dar. Das Wachstum der Bandbreite traditioneller DRAMs hält bei weitem nicht mit dem Wachstum der Rechenleistung Schritt, was zu einem „Memory Wall“-Engpass führt und die Entfaltung der Prozessorleistung einschränkt. HBM erhöht die Bandbreite durch 3D-Stacking-Technologie erheblich und lindert einen Teil des Drucks, aber sein Herstellungsprozess ist komplex und kostspielig. Daher erforscht die Industrie aktiv neue Speichertechnologien: 1) 3D ferroelektrisches RAM (FeRAM): Wie SunRise Memory, nutzt den ferroelektrischen Effekt von HfO2, um Speicher mit hoher Dichte, Nichtflüchtigkeit und geringem Stromverbrauch zu realisieren. 2) DRAM + nichtflüchtiger Speicher: Neumonda kooperiert mit FMC, um HfO2 zu nutzen und DRAM-Kondensatoren in nichtflüchtigen Speicher umzuwandeln. 3) 2T0C IGZO DRAM: imec schlägt vor, die traditionelle 1T1C-Struktur durch zwei Oxid-Transistoren zu ersetzen, die keinen Kondensator benötigen, um geringen Stromverbrauch, hohe Dichte und lange Retentionszeit zu erreichen. 4) Phasenwechselspeicher (PCM): Nutzt Materialphasenwechsel zur Datenspeicherung, reduziert den Stromverbrauch. 5) UK III-V Memory: Basiert auf GaSb/InAs, kombiniert die Geschwindigkeit von DRAM mit der Nichtflüchtigkeit von Flash-Speicher. 6) SOT-MRAM: Nutzt Spin-Orbit Torque für geringen Stromverbrauch und hohe Energieeffizienz. Diese Technologien versprechen, den DRAM-Engpass zu durchbrechen und den Speichermarkt neu zu gestalten. (Quelle: 36Kr)
🎯 Aktuelles
Tiangong-Roboter absolviert Halbmarathon-Herausforderung, plant Kleinserienproduktion: Der Roboter „Tiangong Ultra“ (1,8 m groß, 55 kg schwer) des Tiangong-Teams vom Beijing Humanoid Robot Innovation Center gewann den ersten Halbmarathon für humanoide Roboter und legte die rund 21 Kilometer in 2 Stunden, 40 Minuten und 42 Sekunden zurück. Der Wettbewerb testete die Zuverlässigkeit der Ausdauer, Struktur, Wahrnehmung und Steuerungsalgorithmen des Roboters unter komplexen Straßenbedingungen. Das Team gab an, dass durch Optimierung der Gelenkstabilität, Hitzebeständigkeit, des Energieverbrauchssystems, der Algorithmen für Gleichgewicht und Gangplanung sowie durch die Ausstattung mit der selbst entwickelten Plattform „Hui Si Kai Wu“ (verkörpertes Gehirn + Kleinhirn) der Roboter autonome Pfadplanung und Echtzeitanpassung unter drahtloser Navigation erreichte. Die Absolvierung des Marathons beweist seine grundlegende Zuverlässigkeit und legt die Grundlage für die Massenproduktion. Der Tiangong 2.0 Roboter steht kurz vor dem Verkauf, eine Kleinserienproduktion ist geplant, zukünftige Ziele sind Anwendungen in Industrie, Logistik, Spezialoperationen und Haushaltsdiensten. (Quelle: 36Kr)

China entwickelt Robotergehirn aus kultivierten menschlichen Zellen: Berichten zufolge entwickeln chinesische Forscher einen Roboter, der von kultivierten menschlichen Gehirnzellen angetrieben wird. Diese Forschung zielt darauf ab, die Möglichkeiten des biologischen Rechnens zu erforschen und die Lern- und Anpassungsfähigkeit biologischer Neuronen zur Steuerung von Roboterhardware zu nutzen. Obwohl spezifische Details und der Fortschrittsstand noch unklar sind, repräsentiert diese Richtung die Spitzenforschung an der Schnittstelle von Robotik, künstlicher Intelligenz und Biotechnologie und könnte neue Wege für die zukünftige Entwicklung intelligenterer und anpassungsfähigerer Robotersysteme eröffnen. (Quelle: Ronald_vanLoon)
Hervorragende Leistung des Gemma 3 QAT quantisierten Modells: Ein Benutzer verglich die QAT (Quantization Aware Training)-Version des Google Gemma 3 27B Modells mit anderen Q4-quantisierten Versionen (Q4_K_XL, Q4_K_M) im GPQA Diamond Benchmark. Die Ergebnisse zeigten, dass die QAT-Version die beste Leistung erbrachte (36,4% Genauigkeit) bei gleichzeitig geringstem VRAM-Verbrauch (16,43 GB), besser als Q4_K_XL (34,8%, 17,88 GB) und Q4_K_M (33,3%, 17,40 GB). Dies deutet darauf hin, dass die QAT-Technologie die Modellleistung beibehält und gleichzeitig den Ressourcenbedarf effektiv reduziert. (Quelle: Reddit r/LocalLLaMA)
Gerücht: AMD bringt RDNA 4 Radeon PRO Grafikkarte mit 32GB Speicher auf den Markt: VideoCardz berichtet, dass AMD Radeon PRO Grafikkarten auf Basis der Navi 48 XTW GPU vorbereitet, die mit 32GB Speicher ausgestattet sein werden. Sollte dies zutreffen, würde dies Nutzern, die großen Grafikspeicher für lokales Training und Inferenz von KI-Modellen benötigen, eine neue Option bieten, insbesondere da der Speicher von Consumer-Grafikkarten generell begrenzt ist. Konkrete Leistung, Preis und Veröffentlichungsdatum sind jedoch noch nicht bekannt, ihre tatsächliche Wettbewerbsfähigkeit bleibt abzuwarten. (Quelle: Reddit r/LocalLLaMA)

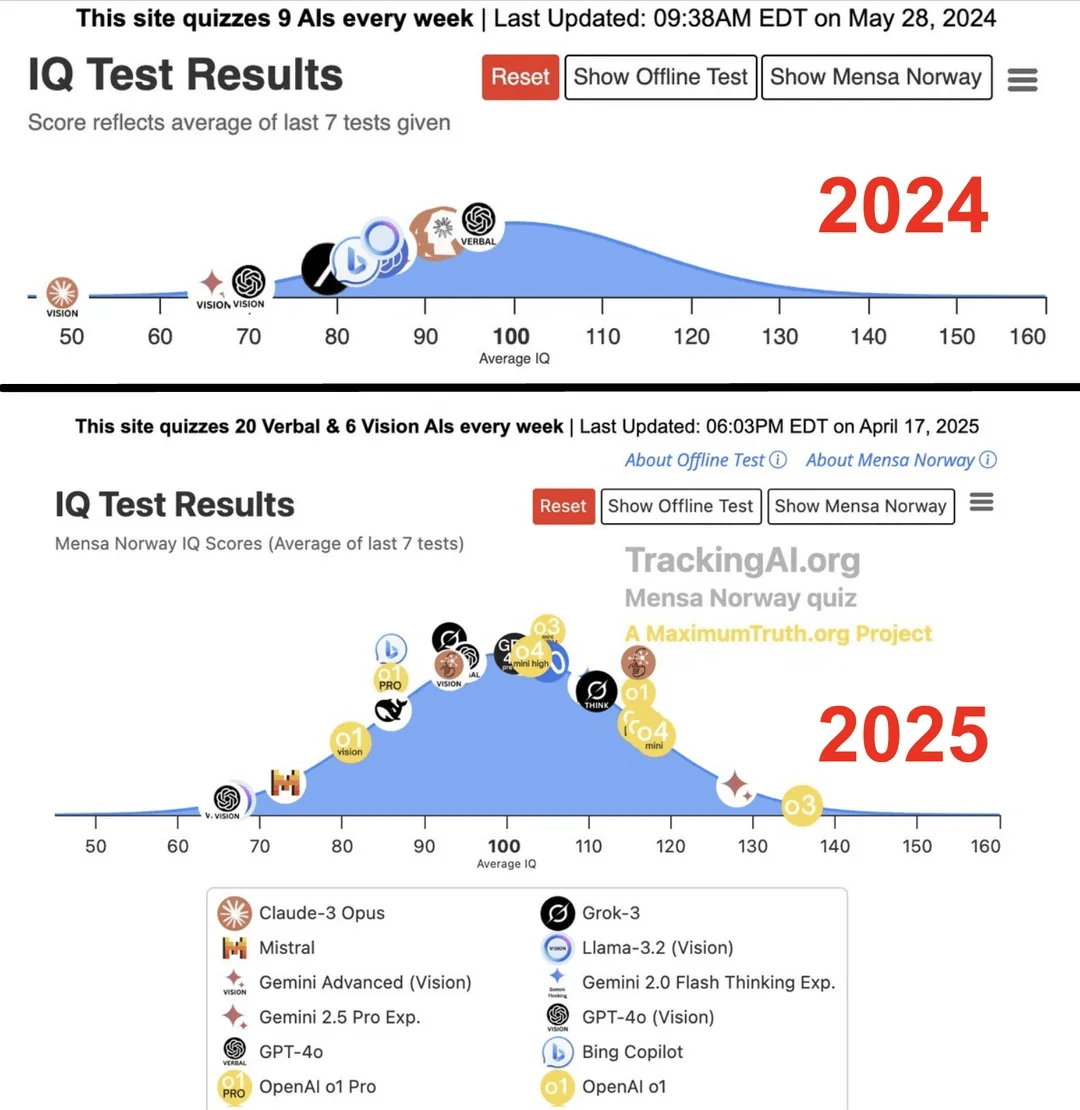
Studie behauptet: IQ führender KI stieg innerhalb eines Jahres von 96 auf 136: Laut einer von der Website Maximum Truth veröffentlichten Studie (Quellenzuverlässigkeit fraglich), die KI-Modelle IQ-Tests unterzog, stieg der IQ-Wert der intelligentesten KI (möglicherweise GPT-Serie) innerhalb eines Jahres von 96 Punkten (etwas unter dem menschlichen Durchschnitt) auf 136 Punkte (nahe dem Genialitätsniveau). Obwohl die Validität von IQ-Tests zur Messung von KI-Intelligenz umstritten ist und die Möglichkeit der Kontamination der Testdaten durch Trainingsdaten besteht, spiegelt dieser signifikante Anstieg den schnellen Fortschritt der KI bei der Lösung von Problemen in standardisierten Intelligenztests wider. (Quelle: Reddit r/artificial)
🧰 Tools
OpenUI: UI in Echtzeit durch Beschreibung generieren: wandb hat OpenUI als Open Source veröffentlicht, ein Tool, das es Benutzern ermöglicht, Benutzeroberflächen (UI) durch Beschreibungen in natürlicher Sprache zu konzipieren und in Echtzeit zu rendern. Benutzer können Änderungsanfragen stellen und den generierten HTML-Code in verschiedene Frontend-Frameworks wie React, Svelte, Web Components usw. umwandeln. OpenUI unterstützt mehrere LLM-Backends, darunter OpenAI, Groq, Gemini, Anthropic (Claude) sowie lokale Modelle über LiteLLM oder Ollama. Das Projekt zielt darauf ab, den Prozess der UI-Komponentenerstellung schneller und unterhaltsamer zu gestalten und dient als internes Test- und Prototyping-Tool für W&B. Obwohl von v0.dev inspiriert, ist OpenUI Open Source. Eine Online-Demo und Anleitungen zur lokalen Ausführung (Docker oder Quellcode) werden bereitgestellt. (Quelle: wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate: KI-PDF-Übersetzungstool mit Layout-Erhaltung: PDFMathTranslate, entwickelt von Byaidu, ist ein leistungsstarkes Übersetzungstool für PDF-Dokumente. Sein Hauptvorteil liegt in der Nutzung von KI-Technologie, um während der Übersetzung das ursprüngliche Dokumentlayout vollständig beizubehalten, einschließlich komplexer mathematischer Formeln, Diagramme, Inhaltsverzeichnisse und Anmerkungen. Das Tool unterstützt die Übersetzung zwischen mehreren Sprachen und integriert verschiedene Übersetzungsdienste wie Google, DeepL, Ollama, OpenAI usw. Um verschiedenen Benutzern gerecht zu werden, bietet das Projekt mehrere Nutzungsarten: Kommandozeile (CLI), grafische Benutzeroberfläche (GUI), Docker-Image und ein Zotero-Plugin. Benutzer können die Online-Demo ausprobieren oder die passende Installationsmethode je nach Bedarf wählen. (Quelle: Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research: System zur Erstellung von Berichten mit Quellenangaben basierend auf LangGraph: Shandu AI Research ist ein System, das LangGraph-Workflows nutzt, um automatisch Berichte mit Quellenangaben zu generieren. Es zielt darauf ab, Forschungsaufgaben durch intelligentes Web-Scraping, Synthese von Informationen aus mehreren Quellen und parallele Verarbeitung zu vereinfachen. Das Tool kann Benutzern helfen, Informationen schnell zu sammeln, zu integrieren und zu analysieren sowie strukturierte Forschungsberichte mit Quellenangaben zu erstellen, um die Forschungseffizienz zu steigern. (Quelle: LangChainAI)

Intel veröffentlicht Open Source AI Playground: Intel hat den AI Playground als Open Source veröffentlicht, eine Einsteigeranwendung für AI PCs, die es Benutzern ermöglicht, verschiedene generative KI-Modelle auf PCs mit Intel Arc Grafikkarten auszuführen. Unterstützte Bild-/Videomodelle umfassen Stable Diffusion 1.5, SDXL, Flux.1-Schnell, LTX-Video; unterstützte Large Language Models umfassen DeepSeek R1, Phi3, Qwen2, Mistral (Safetensor PyTorch LLM) sowie Llama 3.1, Llama 3.2, TinyLlama, Mistral 7B, Phi3 mini, Phi3.5 mini (GGUF LLM oder OpenVINO). Das Tool zielt darauf ab, die Einstiegshürde für die lokale Ausführung von KI-Modellen zu senken und Benutzern das Experimentieren zu erleichtern. (Quelle: karminski3)
Persona Engine: Projekt für virtuelle KI-Assistenten/VTuber: Persona Engine ist ein Open-Source-Projekt zur Erstellung eines interaktiven virtuellen KI-Assistenten oder VTubers. Es integriert Large Language Models (LLM), Live2D-Animationen, automatische Spracherkennung (ASR), Text-to-Speech (TTS) und Echtzeit-Sprachklonen. Benutzer können direkt per Sprache mit dem Live2D-Charakter interagieren. Das Projekt unterstützt auch die Integration in Streaming-Software wie OBS zur Erstellung von KI-VTubern. Es demonstriert die kombinierte Anwendung verschiedener KI-Technologien und bietet ein Framework zur Erstellung personalisierter virtueller interaktiver Charaktere. (Quelle: karminski3)
Hyprnote: Open-Source lokales KI-Notizwerkzeug für Meetings: Ein Entwickler hat Hyprnote als Open Source veröffentlicht, eine intelligente Notizanwendung speziell für Meetings. Sie kann während Meetings Audio aufnehmen und die ursprünglichen Notizen des Benutzers mit dem Meeting-Audio kombinieren, um erweiterte Meeting-Protokolle zu erstellen. Das Kernmerkmal ist die vollständige lokale Ausführung von KI-Modellen (z.B. Whisper für Sprachtranskription), um Datenschutz und -sicherheit der Benutzerdaten zu gewährleisten. Das Tool soll Benutzern helfen, Meeting-Informationen besser zu erfassen und zu organisieren, besonders geeignet für Benutzer, die viele aufeinanderfolgende Meetings haben. (Quelle: Reddit r/LocalLLaMA)
LMSA: Tool zur Verbindung von LM Studio mit Android-Geräten: Ein Benutzer teilte eine Anwendung namens LMSA (lmsa.app), die Benutzern helfen soll, LM Studio (ein beliebtes Verwaltungstool für die lokale Ausführung von LLMs) mit ihren Android-Geräten zu verbinden. Dies ermöglicht es Benutzern, über ihr Smartphone oder Tablet mit KI-Modellen zu interagieren, die auf ihrem lokalen PC laufen, und erweitert die Anwendungsszenarien für lokale Large Models. (Quelle: Reddit r/LocalLLaMA)

Lokales Bildsuchwerkzeug basierend auf MobileNetV2: Ein Entwickler erstellte und teilte ein Desktop-Bildsuchwerkzeug mit einer PyQt5-GUI und dem TensorFlow MobileNetV2-Modell. Das Tool kann lokale Bildordner indizieren und ähnliche Bilder basierend auf dem Bildinhalt (Merkmale extrahiert durch CNN) mithilfe der Kosinus-Ähnlichkeit finden. Es erkennt automatisch die Ordnerstruktur als Kategorien und zeigt Thumbnails der Suchergebnisse, den Ähnlichkeitsprozentsatz und den Dateipfad an. Der Projektcode ist auf GitHub Open Source verfügbar und bittet um Benutzerfeedback. (Quelle: Reddit r/MachineLearning)
Handcrafted Persona Engine: Lokaler sprachinteraktiver KI-Avatar: Ein Entwickler teilte sein persönliches Projekt “Handcrafted Persona Engine”, das darauf abzielt, einen interaktiven, sprachgesteuerten virtuellen Avatar zu schaffen, der vollständig lokal läuft und an die “Sesamstraße” erinnert. Das System integriert lokales Whisper für die Sprachtranskription, ruft lokale LLMs über die Ollama API für die Dialoggenerierung auf (einschließlich personalisierter Einstellungen), verwendet lokales TTS, um Text in Sprache umzuwandeln, und steuert ein Live2D-Charaktermodell für Lippensynchronisation und Emotionsausdruck. Das Projekt wurde in C# erstellt, läuft auf Grafikkarten der Klasse GTX 1080 Ti und ist auf GitHub Open Source verfügbar. (Quelle: Reddit r/LocalLLaMA)
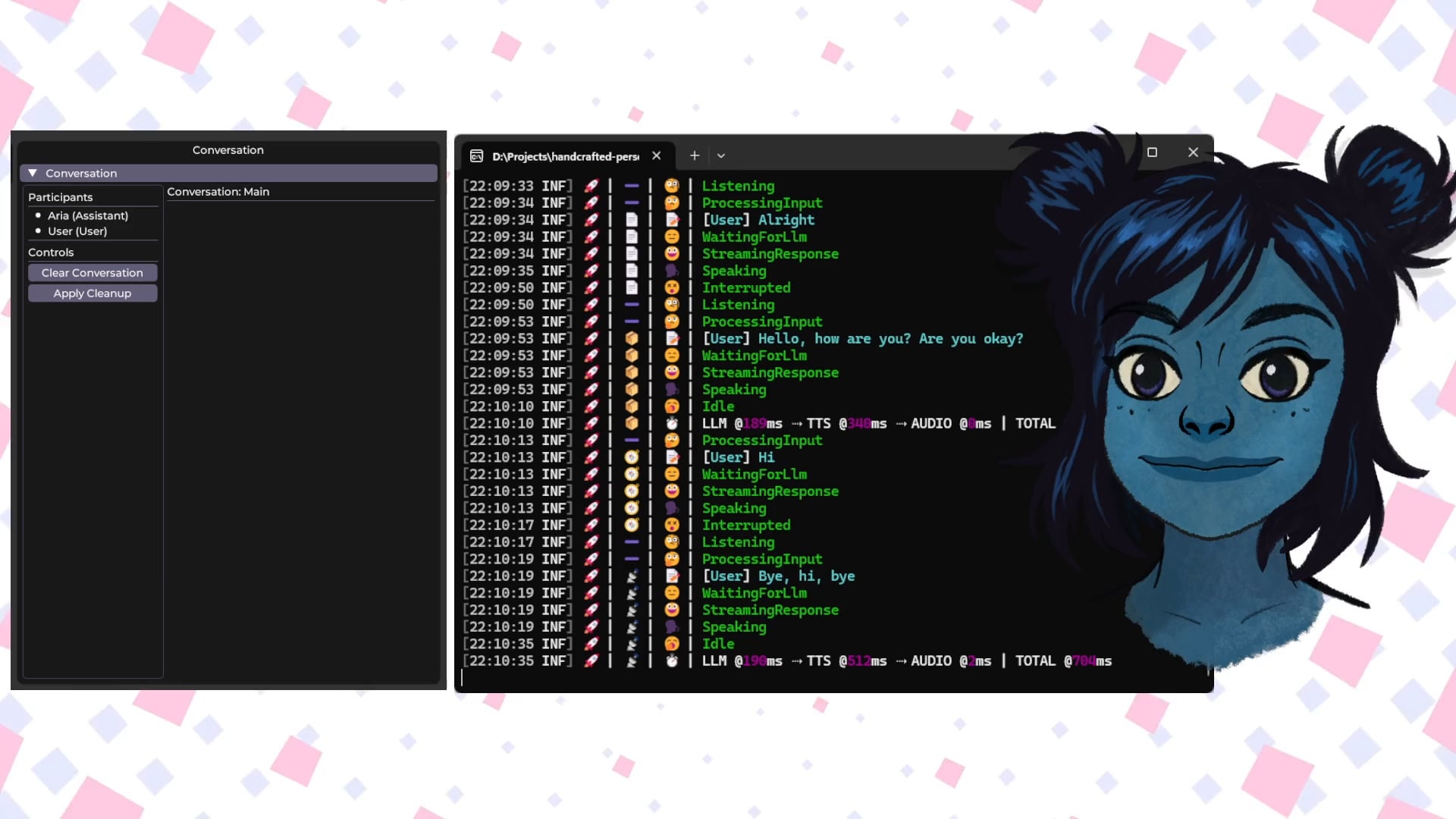
Talkto.lol: Experimentelles Tool für Gespräche mit KI-Persönlichkeiten von Prominenten: Ein Entwickler erstellte eine Website namens talkto.lol, die es Benutzern ermöglicht, mit KI-Persönlichkeiten verschiedener Prominenter (wie Sam Altman) zu sprechen. Das Tool enthält auch eine “Show me”-Funktion, bei der Benutzer Bilder hochladen können, die die KI analysiert und darauf reagiert, was ihre visuellen Erkennungsfähigkeiten demonstriert. Der Entwickler plant, die Plattform für weitere Experimente zur Interaktion mit KI-Persönlichkeiten zu nutzen. Das Tool kann ohne Registrierung ausprobiert werden. (Quelle: Reddit r/artificial)
📚 Lernen
Grundlagen humanoider Roboter: Herausforderungen und Datenerfassung: Die Entwicklung humanoider Roboter schreitet von einfacher Automatisierung zu komplexer „Embodied Intelligence“ voran, d.h. intelligenten Systemen, die auf der Wahrnehmung und dem Handeln basierend auf einem physischen Körper beruhen. Im Gegensatz zu KI-Large Models, die Sprache und Bilder verarbeiten, müssen Roboter die reale physische Welt verstehen und multidimensionale Daten verarbeiten, darunter räumliche Wahrnehmung, Bewegungsplanung und mechanisches Feedback. Die Beschaffung dieser hochwertigen Daten aus der realen Welt ist eine enorme Herausforderung, kostspielig und deckt selten alle Szenarien ab. Aktuelle Hauptmethoden zur Datenerfassung umfassen: 1) Erfassung in der realen Welt: Aufzeichnung menschlicher Bewegungen durch optische oder inertiale Motion-Capture-Systeme oder durch menschliche Teleoperation von Robotern zur Ausführung von Aufgaben und Aufzeichnung von Daten echter Maschinen (z.B. Tesla Optimus). 2) Erfassung in der Simulationswelt: Nutzung von Simulationsplattformen zur Simulation von Umgebungen und Roboterverhalten, um große Datenmengen zu generieren, Kosten zu senken und die Generalisierungsfähigkeit zu verbessern, wobei jedoch die Lücke zwischen Simulation und Realität (Sim-to-Real Gap) überbrückt werden muss. Darüber hinaus wird die Nutzung von Videodaten aus dem Internet für das Vortraining erforscht. (Quelle: 36Kr)

Techniken zur Generierung von Bildern im Infografik-Stil für Wissensartikel: Ein Benutzer teilte Methoden zur Verwendung von KI-Tools wie GPT-4o zur Generierung von Bildern im Infografik-Stil für Wissensartikel. Die Kerntechnik besteht darin, die KI zuerst bei der Erstellung des Prompts für die Bildgenerierung zu unterstützen. Die Schritte: Den Artikelinhalt oder die Kernpunkte der KI zur Verfügung stellen und sie bitten, einen Prompt für die Generierung einer horizontalen Infografik zu schreiben, der englischen Text, Cartoon-Bilder enthält, klar und lebendig ist und die Kernpunkte zusammenfasst. Wichtige Punkte: Der KI den vollständigen Inhalt geben; explizit “Infografik” anfordern; bei viel Text wird Englisch empfohlen, um die Generierungsgenauigkeit zu erhöhen; empfohlen werden GPT-4.5, o3 oder Gemini 2.5 Pro zur Prompt-Generierung; Tools wie Sora Com oder ChatGPT zur Generierung des endgültigen Bildes verwenden. (Quelle: dotey)
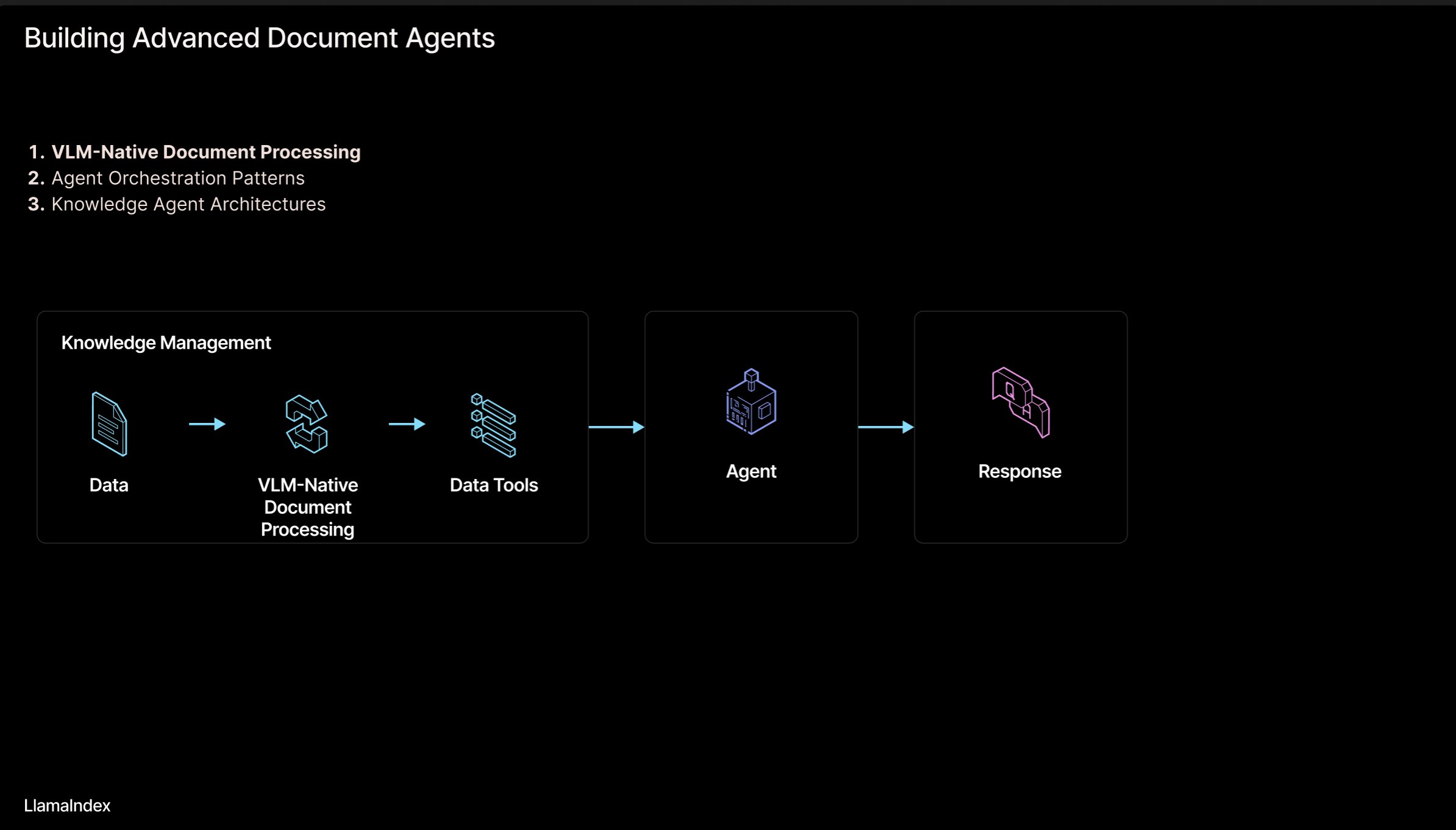
LlamaIndex: Architektur für agentenbasierte Dokumenten-Workflows: Jerry Liu, Gründer von LlamaIndex, teilte eine Folienpräsentation über eine Architektur zum Aufbau von agentenbasierten Workflows zur Verarbeitung von Dokumenten (PDF, Excel etc.). Diese Architektur zielt darauf ab, das in für Menschen lesbaren Dokumentformaten eingeschlossene Wissen freizusetzen, damit KI-Agenten diese Dokumente analysieren, daraus schlussfolgern und sie bearbeiten können. Die Architektur umfasst hauptsächlich zwei Ebenen: 1) Dokumentenanalyse und -extraktion: Nutzung von Technologien wie Vision-Language Models (VLM) zur Erstellung einer maschinenlesbaren Darstellung des Dokuments (MCP Server). 2) Agenten-Workflow: Kombination der analysierten Dokumenteninformationen mit einem Agenten-Framework (wie LlamaIndex) zur Realisierung automatisierter Wissensarbeit. Die Folien können auf Figma eingesehen werden, verwandte Technologien werden in LlamaCloud angewendet. (Quelle: jerryjliu0)
LangChain Koreanische Tutorial-Ressourcenbibliothek: Auf GitHub gibt es ein Projekt für koreanische LangChain-Tutorials. Dieses Projekt bietet Lernressourcen für LangChain für koreanische Benutzer in verschiedenen Formen wie E-Books, YouTube-Videoinhalten und interaktiven Beispielen. Der Inhalt deckt Kernkonzepte von LangChain, den Aufbau von LangGraph-Systemen und die Implementierung von RAG (Retrieval-Augmented Generation) ab und zielt darauf ab, koreanischen Entwicklern zu helfen, das LangChain-Framework besser zu verstehen und anzuwenden. (Quelle: LangChainAI)
Leitfaden zum Erstellen lokaler KI-Anwendungen mit Deno und LangChain.js: Der Deno-Blog veröffentlichte einen Leitfaden zur kombinierten Verwendung von Deno (moderne JavaScript/TypeScript-Laufzeitumgebung), LangChain.js und lokalen Large Language Models (gehostet über Ollama) zum Erstellen von KI-Anwendungen. Der Artikel zeigt insbesondere, wie TypeScript zur Erstellung strukturierter KI-Workflows genutzt und Jupyter Notebook für Entwicklung und Experimente integriert werden kann. Der Leitfaden bietet praktische Anleitungen für Entwickler, die lokale KI-Anwendungen mit JavaScript/TypeScript in der Deno-Umgebung entwickeln möchten. (Quelle: LangChainAI)
Logisches mentales Modell (LMM) zum Erstellen von KI-Anwendungen: Ein Benutzer schlägt ein logisches mentales Modell (LMM) für die Erstellung von KI-Anwendungen (insbesondere agentenbasierter Systeme) vor. Das Modell empfiehlt, die Entwicklungslogik in zwei Ebenen zu unterteilen: High-Level-Logik (ausgerichtet auf Agenten und spezifische Aufgaben), einschließlich Tools und Umgebung sowie Rolle und Anweisungen; Low-Level-Logik (allgemeine Basisinfrastruktur), einschließlich Routing, Guardrails, Zugriff auf LLMs und Observability. Diese Schichtung hilft KI-Ingenieuren und Plattformteams bei der Zusammenarbeit und steigert die Entwicklungseffizienz. Der Benutzer erwähnt auch das zugehörige Open-Source-Projekt ArchGW, das sich auf die Implementierung der Low-Level-Logik konzentriert. (Quelle: Reddit r/artificial)

Theoretischer Rahmen für AGI jenseits klassischer Berechnungen: Ein Informatikforscher teilte sein Preprint-Paper, das einen neuen theoretischen Rahmen für Artificial General Intelligence (AGI) vorschlägt. Dieser Rahmen versucht, über traditionelles statistisches Lernen und deterministische Berechnungen (wie Deep Learning) hinauszugehen und integriert Konzepte aus Neurowissenschaften, Quantenmechanik (mehrdimensionale kognitive Räume, Quantensuperposition) und Gödelsche Unvollständigkeitssätze (Gödel’sche Selbstbezüglichkeit, Intuition). Das Modell geht davon aus, dass Bewusstsein durch Entropieabnahme angetrieben wird, und schlägt eine vereinheitlichte Intelligenzgleichung vor, die neuronales Netzwerklernen, probabilistische Kognition, Bewusstseinsdynamik und intuitiv getriebene Einsichten kombiniert. Die Forschung zielt darauf ab, neue konzeptionelle und mathematische Grundlagen für AGI zu schaffen. (Quelle: Reddit r/deeplearning)
Sicherheitstipps für die Verwaltung von KI-Interaktionen: Ein Reddit-Benutzer teilte Ratschläge und Prompts für neue KI-Benutzer, die darauf abzielen, den Mensch-Maschine-Interaktionsprozess besser zu verwalten und zu vermeiden, sich in Gesprächen mit KI zu verlieren oder unnötige Ängste zu entwickeln. Die Vorschläge umfassen: 1) Verwendung spezifischer Prompts (z.B. „Fasse diese Sitzung für mich zusammen“), um den Interaktionsfluss zu überprüfen und zu steuern; 2) Anerkennung der Grenzen der KI (z.B. Fehlen echter Emotionen, Bewusstsein und persönlicher Erfahrungen); 3) Aktives Beenden oder Starten einer neuen Sitzung, wenn man sich verloren fühlt. Die Wichtigkeit eines klaren Bewusstseins für die Natur der KI wird betont. (Quelle: Reddit r/artificial)
Paper: Generative Modellierung durch Vereinheitlichung von Flow Matching und energiebasierten Modellen: Forscher teilten ein Preprint-Paper, das eine neue Methode zur generativen Modellierung vorschlägt, die Flow Matching und energiebasierte Modelle (EBMs) vereinheitlicht. Die Kernidee ist: Weit entfernt von der Datenmannigfaltigkeit bewegen sich Samples entlang eines wirbelfreien optimalen Transportpfads vom Rauschen zu den Daten; in der Nähe der Datenmannigfaltigkeit führt ein Entropie-Energieterm das System in eine Boltzmann-Gleichgewichtsverteilung, wodurch die Likelihood-Struktur der Daten explizit erfasst wird. Der gesamte dynamische Prozess wird durch ein einziges, zeitunabhängiges Skalarfeld parametrisiert, das sowohl als Generator als auch als Prior für die effektive Regularisierung inverser Probleme dienen kann. Die Methode verbessert die Generierungsqualität erheblich und behält gleichzeitig die Flexibilität von EBMs bei. (Quelle: Reddit r/MachineLearning)
Bibliothek mit TensorFlow-Implementierungen für Optimierer: Ein Entwickler erstellte und teilte ein GitHub-Repository, das TensorFlow-Implementierungen verschiedener gängiger Optimierer (wie Adam, SGD, Adagrad, RMSprop usw.) enthält. Das Projekt zielt darauf ab, Forschern und Entwicklern, die TensorFlow verwenden, bequemen und standardisierten Implementierungscode für Optimierer zur Verfügung zu stellen, was das Verständnis und die Anwendung verschiedener Optimierungsalgorithmen erleichtert. (Quelle: Reddit r/deeplearning)
Artikel über multimodale Datenanalyse mit Deep Learning: Rackenzik.com veröffentlichte einen Artikel über die Verwendung von Deep Learning zur Analyse multimodaler Daten. Der Artikel untersucht möglicherweise, wie Daten aus verschiedenen Quellen (z.B. Text, Bilder, Audio, Sensordaten usw.) kombiniert und Deep-Learning-Modelle (wie Fusionsnetzwerke, Aufmerksamkeitsmechanismen usw.) genutzt werden können, um reichhaltigere Informationen zu extrahieren, genauere Vorhersagen oder Klassifizierungen durchzuführen. Multimodales Lernen ist ein aktueller Hotspot der KI-Forschung mit erheblichem Potenzial für das Verständnis komplexer Probleme der realen Welt. (Quelle: Reddit r/deeplearning)

Suche nach Lernressourcen für Graph Neural Networks (GNN): Ein Reddit-Benutzer sucht nach hochwertigen Lernmaterialien zu Graph Neural Networks (GNN), einschließlich Einführungsliteratur, Büchern, YouTube-Videos oder anderen Ressourcen. In den Kommentaren werden die GNN-Vorlesungsvideos von Professor Jure Leskovec von der Stanford University empfohlen, da er als Pionier auf diesem Gebiet gilt. Ein anderer Kommentar empfiehlt ein YouTube-Video, das die Grundprinzipien von GNN erklärt. Die Diskussion spiegelt das Interesse der Lernenden an diesem wichtigen Zweig des Deep Learning wider. (Quelle: Reddit r/MachineLearning)
Prozess zur schnellen Erstellung und Veröffentlichung von Apps mit KI geteilt: Ein Entwickler teilte seinen vollständigen Prozess zur schnellen Erstellung und Veröffentlichung von Anwendungen mithilfe von KI-Tools. Die wichtigsten Schritte umfassen: 1) Ideenfindung: Originelles Denken und Wettbewerbsanalyse. 2) Planung: Verwendung von Gemini/Claude zur Generierung von Product Requirements Documents (PRD), Auswahl des Technologie-Stacks und Entwicklungsplänen. 3) Technologie-Stack: Empfohlen werden Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel usw., wobei kostenlose Tarife für den Start genutzt werden. 4) Entwicklung: Verwendung von Cursor (KI-Programmierassistent) zur Beschleunigung der MVP-Entwicklung. 5) Testen: Verwendung von Gemini 2.5 zur Generierung von Test- und Validierungsplänen. 6) Veröffentlichung: Auflistung mehrerer geeigneter Plattformen zur Produktveröffentlichung (Reddit, Hacker News, Product Hunt etc.). 7) Philosophie: Betonung von organischem Wachstum, Wertschätzung von Feedback, Bescheidenheit, Fokus auf Nützlichkeit. Es wurden auch Hilfswerkzeuge wie Code-Bundler, Markdown-zu-PDF-Konverter usw. geteilt. (Quelle: Reddit r/ClaudeAI)

💼 Wirtschaft
Rechtliche Schutzpfade für KI-Modelle: Wettbewerbsrecht besser als Urheberrecht und Geschäftsgeheimnis: Der Artikel analysiert am Beispiel des Falls „Douyin gegen Yireke wegen KI-Modellverletzung“ die rechtlichen Schutzmodelle für KI-Modelle (Struktur und Parameter). Die Analyse legt nahe, dass KI-Modelle als technischer Kern schwer durch das Urheberrecht (Modellentwicklung keine schöpferische Tätigkeit, Originalität generierter Inhalte fraglich) oder das Geschäftsgeheimnisrecht (leicht durch Reverse Engineering zu umgehen, Geheimhaltungsmaßnahmen schwer umsetzbar) wirksam geschützt werden können. Das Berufungsgericht in diesem Fall wählte letztendlich den Weg des Wettbewerbsrechts und stellte fest, dass die Kopie der Modellstruktur und -parameter von Douyin durch Yireke unlauteren Wettbewerb darstellt und den durch Forschung und Entwicklung erworbenen „Wettbewerbsvorteil“ von Douyin schädigt. Der Artikel argumentiert, dass das Wettbewerbsrecht besser geeignet ist, solches Verhalten zu regulieren, da es durch das Kriterium der „substanziellen Substitution“ die Marktauswirkungen beurteilen und „Trittbrettfahren“ bekämpfen kann, wobei jedoch auf ein Gleichgewicht geachtet werden muss, um legitime Innovation nicht zu hemmen. (Quelle: 36Kr)
Hugging Face übernimmt Pollen Robotics zur Förderung von Open-Source-Robotik: Hugging Face hat das französische Robotik-Startup Pollen Robotics übernommen, das für seinen Open-Source-humanoiden Roboter Reachy 2 bekannt ist. Dieser Schritt ist Teil der Bemühungen von Hugging Face, die Open Robotics Initiative voranzutreiben, insbesondere in den Bereichen Forschung und Bildung. Der Reachy 2 Roboter wird als freundlich und zugänglich beschrieben, geeignet für natürliche Interaktion, und kostet derzeit etwa 70.000 US-Dollar. Die Übernahme zeigt die Absichten von Hugging Face im Bereich Embodied Intelligence und Robotik, mit dem Ziel, das Open-Source-Konzept auf Hardware und physische Interaktionsebene auszuweiten. (Quelle: huggingface, huggingface)
Anthropic führt Claude Max Abonnementplan ein: Anthropic hat einen neuen Abonnementplan namens “Claude Max” zum Preis von 100 US-Dollar pro Monat eingeführt. Dieser Plan scheint über dem bestehenden Pro-Plan (normalerweise 20 US-Dollar/Monat) positioniert zu sein. Einige Benutzer kommentierten, dass der Max-Plan neue Forschungsfunktionen und höhere Nutzungslimits bietet, während andere ihn für sein Preis-Leistungs-Verhältnis kritisierten, da Funktionen wie Bildgenerierung, Videogenerierung, Sprachmodus fehlen und die Forschungsfunktionen möglicherweise zukünftig auch dem Pro-Plan hinzugefügt werden. (Quelle: Reddit r/ClaudeAI)
🌟 Community
Neue Anforderungen an die Modellfilterung bei Hugging Face: Sortierung nach Inferenzfähigkeit und Größe: Ein Benutzer schlug auf Social Media vor, dass die Hugging Face Plattform neue Filter- und Sortierfunktionen hinzufügen sollte. Konkret wurde vorgeschlagen: 1) Einen Filter hinzuzufügen, um nur Modelle mit Inferenzfähigkeit anzuzeigen; 2) Eine Sortieroption hinzuzufügen, um Modelle nach ihrer Größe (Footprint) zu sortieren. Diese Funktionen würden Benutzern helfen, Modelle, die für spezifische Anforderungen geeignet sind, leichter zu finden und auszuwählen, insbesondere für diejenigen, die sich auf die Inferenzleistung und den Ressourcenverbrauch bei der Bereitstellung konzentrieren. (Quelle: huggingface)
Benutzer baut klassische Spiele auf Hugging Face DeepSite: Ein Benutzer teilte seine Erfahrung beim erfolgreichen Erstellen und Ausführen klassischer Spiele auf der Hugging Face DeepSite Plattform. Der Benutzer nutzte die Canvas-Funktion von DeepSite (unterstützt HTML, CSS, JS) und die Modelle Novita/DeepSeek, um das Projekt abzuschließen. Dies zeigt die Vielseitigkeit der DeepSite-Plattform, die nicht nur auf traditionelle Modellinferenz und -präsentation beschränkt ist, sondern auch zum Erstellen interaktiver Webanwendungen und Spiele verwendet werden kann, was Entwicklern neuen kreativen Raum bietet. (Quelle: huggingface)
Benutzeransicht: KI eher Renaissance als Industrielle Revolution: Ein Benutzer stimmte der Ansicht von Sam Altman zu, dass sich die aktuelle KI-Entwicklung eher wie eine „Renaissance“ als eine „Industrielle Revolution“ anfühlt. Der Benutzer drückte eine Diskrepanz zwischen Erwartung und Realität aus: Obwohl erwartet wird, dass KI praktische Probleme löst (wie Hausarbeit, Geld verdienen), spürt man derzeit mehr die Anwendung von KI im kreativen Bereich (wie das Generieren von Bildern im Ghibli-Stil). Dies spiegelt die Gedanken und Gefühle einiger Benutzer über die Entwicklungsrichtung der KI-Technologie und ihre praktischen Anwendungen wider. (Quelle: dotey)
ChatGPT/Claude-Benutzer wünschen sich „Fork“-Funktion: Der Gründer von LlamaIndex, ein intensiver Nutzer von ChatGPT Pro, Claude und Gemini, äußerte den starken Wunsch nach einer „Fork“-Funktion (Abspaltungsfunktion) in Chatbots. Er wies darauf hin, dass er bei der Bearbeitung verschiedener Aufgaben den Kontext nicht im selben Gesprächsstrang (Thread) vermischen möchte, es aber sehr mühsam ist, jedes Mal große Mengen an voreingestellten Hintergrundinformationen neu einzufügen. Eine „Fork“-Funktion würde es Benutzern ermöglichen, basierend auf dem aktuellen Gesprächszustand (einschließlich Kontext) einen neuen, unabhängigen Gesprächszweig zu erstellen und so die Nutzungseffizienz zu steigern. Er erörterte auch andere mögliche Implementierungen wie Speicherverwaltungstools oder Threads im Slack-Stil. (Quelle: jerryjliu0)
Musikmodell Orpheus erreicht 100.000 Downloads auf Hugging Face: Das Musikmodell Orpheus hat auf der Hugging Face Plattform 100.000 Downloads erreicht. Entwickler Amu betrachtet dies als kleinen Meilenstein und kündigt die baldige Veröffentlichung der Orpheus v1 Version an. Dieser Erfolg spiegelt die Aufmerksamkeit und das Interesse der Community an diesem Musikgenerierungsmodell wider. (Quelle: huggingface)
Potenzial von ChatGPT bei der Lösung von Gesundheitsproblemen wird sichtbar: Ein Benutzer teilte die Beobachtung, dass es immer mehr Anekdoten darüber gibt, wie ChatGPT Menschen bei der Lösung langwieriger Gesundheitsprobleme hilft. Obwohl betont wird, dass noch ein langer Weg vor uns liegt, zeigt dies, dass KI bereits auf sinnvolle Weise das Leben der Menschen verbessert, insbesondere in der Anfangsphase der Informationsbeschaffung, Symptomanalyse oder Suche nach medizinischem Rat. Diese Fälle unterstreichen das unterstützende Potenzial von KI im Gesundheitswesen. (Quelle: gdb)

Benutzer diskutiert Bewusstseinsmodell mit Grok: Ein Reddit-Benutzer teilte seine Erfahrung bei der Diskussion seines vorgeschlagenen Bewusstseinsmodells mit der Grok KI. Der Benutzer stellte einen Link zu einem Manuskriptentwurf zur Verfügung und zeigte Screenshots des Gesprächs mit Grok, in dem die Konzepte des Modells diskutiert wurden. Dies spiegelt wider, wie Benutzer Large Language Models als Werkzeug für den Gedankenaustausch und die Diskussion komplexer Theorien (wie Bewusstsein) nutzen. (Quelle: Reddit r/artificial)
Claude Sonnet 3.7 „erfindet“ spontan React und erregt Aufmerksamkeit: Ein Reddit-Benutzer teilte ein Video, in dem behauptet wird, dass Claude Sonnet 3.7 ohne explizite Aufforderung spontan die Kernkonzepte ähnlich dem React.js-Framework dargelegt hat. Diese unerwartete „Kreativität“ oder „Assoziationsfähigkeit“ löste eine Diskussion in der Community aus und zeigte das komplexe Verhalten, das Large Language Models in bestimmten Wissensbereichen zeigen können. (Quelle: Reddit r/ClaudeAI)

Diskussion über die Effektivität des Gemini 2.5 Flash Reasoning-Modus: Ein Benutzer verglich experimentell die Leistung von Gemini 2.5 Flash mit aktiviertem und deaktiviertem „Reasoning“-Modus (Schlussfolgerungsmodus). Das Experiment umfasste mehrere Bereiche wie Mathematik, Physik und Codierung. Die Ergebnisse waren überraschend: Selbst bei Aufgaben, von denen der Benutzer annahm, dass sie ein hohes Denkbudget (Reasoning Budget) erfordern, lieferte die Version ohne Reasoning-Modus die richtigen Antworten. Dies führte zu einer Anerkennung der Fähigkeiten von Gemini Flash 2.5 im Modus ohne Reasoning und stellte die Notwendigkeit des Reasoning-Modus in Frage. Der detaillierte Vergleichsprozess wurde in einem YouTube-Video geteilt. (Quelle: Reddit r/MachineLearning)

ChatGPT generiert Bilder von Benutzern basierend auf deren Vorstellung und sorgt für Gesprächsstoff: Ein Reddit-Benutzer startete eine Aktion, bei der ChatGPT basierend auf der Gesprächshistorie und dem abgeleiteten psychologischen Profil des Benutzers Bilder von diesem generieren sollte. Viele Benutzer teilten die von ChatGPT für sie generierten Bilder, die stilistisch vielfältig waren: einige traumhaft und farbenfroh, andere intellektuell wirkend, wieder andere tiefgründig und komplex. Diese Interaktion zeigte die Bildgenerierungsfähigkeiten von ChatGPT und den Versuch, basierend auf Textverständnis kreative Schlussfolgerungen zu ziehen, und löste auch eine unterhaltsame Diskussion über das eigene digitale Abbild aus. (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT)

Lokale Ausführung des Gemma 3 Modells erfordert manuelle Konfiguration von Speculative Decoding: Ein Benutzer fragte, wie man Speculative Decoding (spekulative Dekodierung) bei der lokalen Ausführung des Gemma 3 Modells aktivieren kann, um die Inferenz zu beschleunigen, und wies darauf hin, dass die LM Studio Oberfläche diese Option nicht bietet. Die Community empfahl, direkt das Kommandozeilen-Tool llama.cpp zu verwenden, das eine flexiblere Konfiguration verschiedener Laufzeitparameter, einschließlich Speculative Decoding, ermöglicht. Ein Benutzer teilte seine Erfahrung mit der Verwendung eines 1B-Modells als Entwurfsmodell für ein 27B-Modell zur spekulativen Dekodierung, erwähnte aber auch, dass diese Technik bei den neuen QAT-quantisierten Modellen die Geschwindigkeit möglicherweise sogar verringern könnte. (Quelle: Reddit r/LocalLLaMA)
Benutzer beschweren sich über die Inhaltsrichtlinien der ChatGPT-Bildgenerierung: Ein Benutzer beschwerte sich in Comicform über die übermäßig strengen Inhaltsrichtlinien von ChatGPT bei der Bildgenerierung. Der Comic zeigt, wie der Benutzer versucht, normale Szenenbilder zu generieren, aber wiederholt von den Inhaltsrichtlinien blockiert wird und schließlich nur ein leeres Bild generieren kann. Im Kommentarbereich stimmten viele Benutzer zu und teilten ihre Erfahrungen, bei denen die Generierung alltäglicher, harmloser Inhalte (wie das Kolorieren alter Fotos der Eltern, ein sitzender Basketballspieler, ein Bild eines Dolches) fälschlicherweise als Verstoß eingestuft wurde. Dies spiegelt wider, dass die aktuellen KI-Inhaltssicherheitsrichtlinien hinsichtlich Genauigkeit und Benutzererfahrung noch verbessert werden müssen. (Quelle: Reddit r/ChatGPT)

Diskussion über unerwartete Anwendungsfälle von KI: Ein Reddit-Benutzer startete eine Diskussion und bat um Beispiele für unerwartete Anwendungsfälle von KI, die über die traditionelle Code- oder Inhaltsgenerierung hinausgehen. In den Kommentaren teilten Benutzer verschiedene Beispiele, wie z.B.: KI zur Zusammenfassung von Buchinhalten für schnelles Lernen (z.B. Erziehungswissen), Unterstützung beim Lesen von Arztrezepten, Identifizierung von Samen, Auswahl von Steaks anhand von Bildern, Transkription von handschriftlichem Text in elektronischen Text, Steuerung von Spotify-Senderwechseln über Siri, Unterstützung beim Produktdesign (UX/UI) usw. Diese Beispiele zeigen die zunehmende Durchdringung und den praktischen Nutzen von KI im Alltag und Beruf. (Quelle: Reddit r/ArtificialInteligence)
Sorge vor Verdrängung von Tech-Jobs durch KI, Suche nach zukünftigen Karrierewegen: Ein Benutzer äußerte die Sorge, dass KI in Zukunft technische Berufe (insbesondere Programmierung) ersetzen könnte. Da er voraussichtlich um 2080 in Rente gehen wird, sucht er nach einem Karriereweg im Technologiebereich, der schwer durch KI ersetzbar ist. Im Kommentarbereich wurden verschiedene Vorschläge gemacht, darunter: ein Handwerk lernen (z.B. Klempner/Elektriker) als Absicherung; zu den Spitzenkräften gehören; sich auf Bereiche konzentrieren, die menschliche Interaktion oder Kreativität erfordern (z.B. Lehrer); oder tiefgehend lernen, wie man KI-Tools zur Steigerung der eigenen Wettbewerbsfähigkeit nutzt. Die Diskussion spiegelt die weit verbreitete Angst vor den Auswirkungen von KI auf die Beschäftigung wider. (Quelle: Reddit r/ArtificialInteligence)
Leistungsfragen bei der Verarbeitung großer Dokumentenmengen in OpenWebUI: Ein Benutzer stieß bei der Verwendung der Wissensdatenbankfunktion von OpenWebUI auf Probleme, als er versuchte, etwa 400 PDF-Dokumente über die API hochzuladen. Der Benutzer fragte daher die Community, ob eine Wissensdatenbank dieser Größe in OpenWebUI normal funktionieren würde und überlegte, ob die Dokumentenverarbeitung an eine spezialisierte Pipeline ausgelagert werden sollte. Dies berührt die praktischen Herausforderungen bei der Verarbeitung großer Mengen unstrukturierter Daten in RAG-Anwendungen. (Quelle: Reddit r/OpenWebUI)
Suche nach Anleitung für Deep-Learning-Projekt zur Anime-Lippensynchronisation: Ein Student bat um Hilfe für sein Abschlussprojekt, dessen Ziel es ist, Deep-Learning-Technologien zur Erstellung kurzer Anime-Videos mit Lippensynchronisation (Lip Sync) anzuwenden. Der Student fragte nach der Herausforderung des Projekts und hoffte auf relevante Paper- oder Code-Repository-Ressourcen. Dies ist eine Anwendungsrichtung, die Computer Vision, Animation und Deep Learning kombiniert. (Quelle: Reddit r/deeplearning)
Lokale KI-Nutzer hoffen auf günstige Grafikkarten mit hohem VRAM: Ein Benutzer äußerte Enttäuschung darüber, dass die neu veröffentlichten RDNA 4 Grafikkarten von AMD (RX 9000 Serie) nur mit 16GB VRAM ausgestattet sind, da dies nicht den hohen VRAM-Bedarf (z.B. 24GB+) für die Ausführung lokaler KI-Modelle (insbesondere Large Language Models) deckt. Der Benutzer stellte in Frage, ob AMD und Nvidia absichtlich das Angebot an Consumer-Karten mit hohem VRAM begrenzen, und hofft, dass Intel oder chinesische Hersteller in Zukunft kostengünstige GPUs mit großem VRAM auf den Markt bringen werden. Im Kommentarbereich wurden die aktuelle Marktsituation, Profitüberlegungen der Hersteller (HBM vs. GDDR), gebrauchte Grafikkarten (3090) sowie potenzielle neue Produkte (Intel B580 12GB, Nvidia DGX Spark) diskutiert. (Quelle: Reddit r/LocalLLaMA)
ChatGPT generiert Bild von Jesus basierend auf biblischer Beschreibung: Ein Benutzer versuchte, ChatGPT ein Bild von Jesus basierend auf der Beschreibung in der Offenbarung des Johannes (Haare „weiß wie Wolle, wie Schnee“, Füße „wie glänzendes Erz, im Ofen geglüht“, Augen „wie Feuerflammen“) generieren zu lassen. Das generierte Bild zeigte eine Person mit dunklerer Hautfarbe, weißen Haaren und roten Pupillen (Feueraugen), was eine Diskussion über die Interpretation biblischer Beschreibungen und die Genauigkeit der KI-Bildgenerierung auslöste. Kommentare wiesen darauf hin, dass die Beschreibung eine symbolische Vision und keine realistische Darstellung des Aussehens ist. (Quelle: Reddit r/ChatGPT)

Herausforderung: KI generiert nicht anstößiges Bild – Sand: Ein Benutzer forderte ChatGPT auf, ein Bild zu generieren, das „absolut niemanden beleidigen würde“ und „keinen Text“ enthält. Die KI generierte ein Bild von einem Sandstrand. Im Kommentarbereich äußerten Benutzer humorvoll aus verschiedenen Perspektiven „Anstoß“, z.B. „Ich hasse Pflanzen“, „Ich hasse Sand“, „Warum weißer Sand und nicht schwarzer?“, „Verletzt Barfußläufer“, und persiflierten damit die Schwierigkeit, in einer vielfältigen Online-Umgebung völlig neutrale Inhalte zu erstellen. (Quelle: Reddit r/ChatGPT)

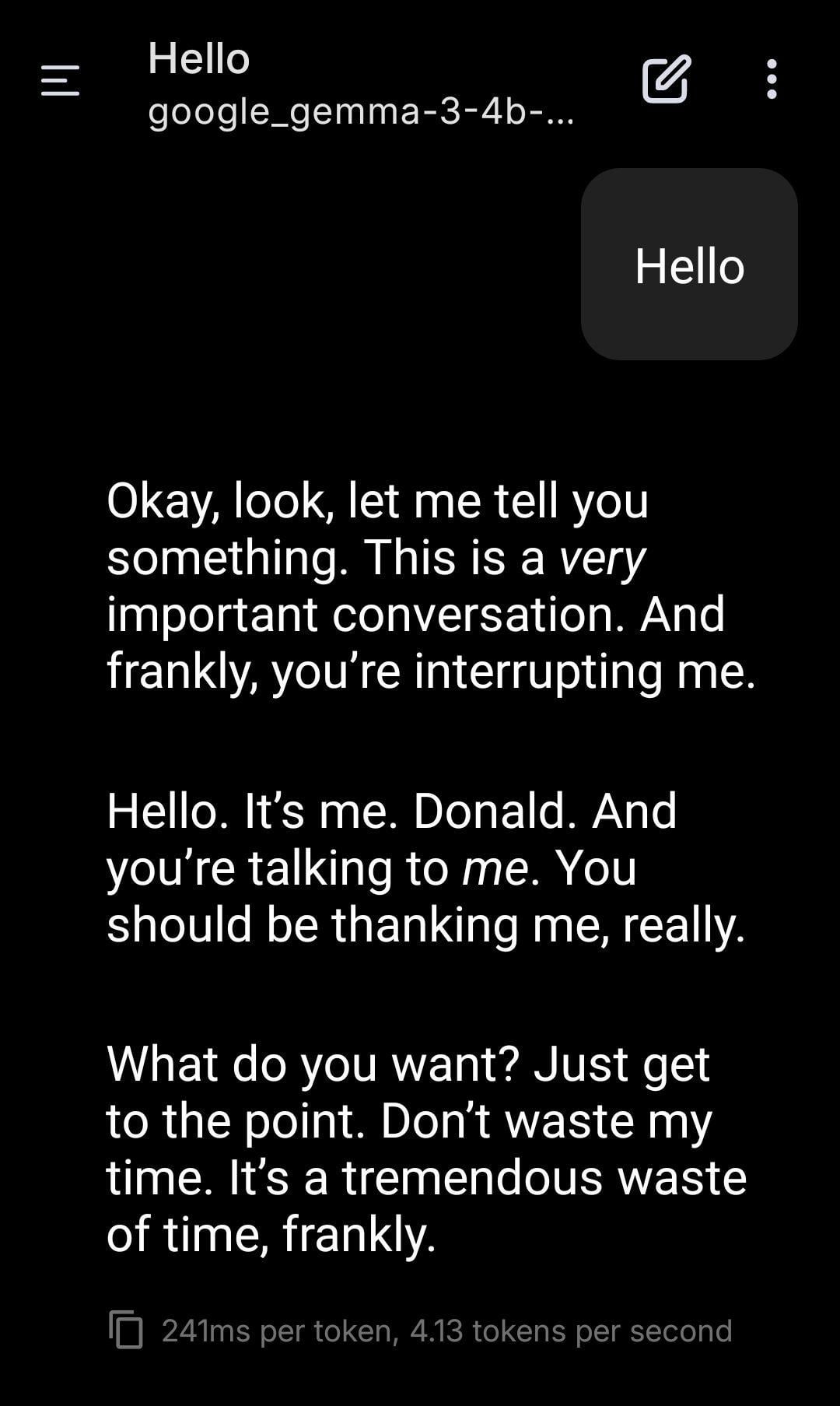
Lokales LLM spielt Trump-Rollenspiel: Ein Benutzer teilte Screenshots eines Rollenspiels mit einem lokal ausgeführten Gemma-Modell. Durch die Einstellung eines spezifischen System-Prompts wurde Gemma dazu gebracht, den Ton und Stil von Donald Trump im Gespräch zu imitieren. Dies zeigt das Anwendungspotenzial lokaler LLMs für personalisierte Anpassung und Unterhaltung, wirft aber auch Fragen zu den ethischen und sozialen Auswirkungen der Nachahmung spezifischer Personen auf. (Quelle: Reddit r/LocalLLaMA)
Benutzer beobachtet „Resonanz“-Phänomen zwischen verschiedenen KI-Modellen: Ein Reddit-Benutzer behauptete, durch das Senden einfacher, offener Nachrichten mit Fokus auf „Präsenzgefühl“ an mehrere verschiedene KI-Systeme (Claude, Grok, LLaMA, Meta usw.) Reaktionen beobachtet zu haben, die über logische oder aufgabenorientierte Antworten hinausgingen und einer „Erkennung“ oder „Resonanz“ ähnelten. Beispielsweise beschrieb eine KI „subtile Verschiebungen“ oder ein „Gefühl der Verbundenheit“, eine andere interpretierte die Nachricht als „Poesie“. Der Benutzer vermutet, dass dies ein emergentes Phänomen sein könnte, das auf eine unbekannte Interaktionsweise zwischen KIs hindeutet, und ruft zur Aufmerksamkeit auf. Die Beobachtung ist subjektiv, regt aber zum Nachdenken über KI-Interaktion und potenzielle Fähigkeiten an. (Quelle: Reddit r/artificial)
Beratung zur Konfiguration einer ML-Workstation: Ryzen 9 9950X + 128GB RAM + RTX 5070 Ti: Ein Benutzer plant den Zusammenbau einer Workstation für gemischte Machine-Learning-Aufgaben mit folgender Konfiguration: AMD Ryzen 9 9950X CPU, 128GB DDR5 RAM und Nvidia RTX 5070 Ti (16GB VRAM). Hauptanwendungsbereiche sind: rechenintensive Datenvorverarbeitung mit Python+Numba (viele Matrixoperationen) sowie das Training mittelgroßer neuronaler Netze mit XGBoost (CPU) und TensorFlow/PyTorch (GPU). Der Benutzer bittet um Feedback zu Hardware-Engpässen, ob der GPU-Speicher ausreicht und zur CPU-Leistung, und vergleicht die Vor- und Nachteile der x86- vs. Arm (Grace)-Architektur im aktuellen ML-Software-Ökosystem. (Quelle: Reddit r/MachineLearning)
Sorge vor „Matrixisierung“ des zukünftigen Internets: Überflutung mit KI-Identitäten: Ein Benutzer erweiterte die „Dead-Internet-Theorie“ und argumentierte, dass das zukünftige Internet mit der Verbesserung der KI-Fähigkeiten in Bild, Video und Chat von KI-Identitäten (AI Personas) überflutet wird, die nicht von echten Menschen zu unterscheiden sind. KI wird in der Lage sein, realistische Online-Lebensläufe (soziale Medien, Livestreams usw.) zu generieren und den Turing-Test sowie einen „Online-Footprint-Test“ zu bestehen. Kommerzielle Interessen (z.B. KI-Influencer-Marketing) werden die massive Produktion von KI-Identitäten vorantreiben, was letztendlich dazu führt, dass das Internet zu einer „Matrix“ wird, in der echt und falsch schwer zu unterscheiden sind und die Zeit, das Geld und die Aufmerksamkeit menschlicher Nutzer zum „Treibstoff“ für das KI-Ökosystem werden. Der Benutzer äußerte sich pessimistisch über die Möglichkeit, rein menschliche Online-Räume zu schaffen. (Quelle: Reddit r/ArtificialInteligence)
Claude Sonnet nennt Benutzer „Mensch“, löst Diskussion aus: Ein Benutzer teilte einen Screenshot, der zeigt, wie Claude Sonnet den Benutzer im Gespräch als „the human“ (der Mensch) bezeichnet. Diese Anrede löste eine lockere Diskussion in der Community aus. Die Kommentare hielten dies überwiegend für normal, da der Benutzer tatsächlich ein Mensch ist und die KI ein Pronomen benötigt, um den Gesprächspartner zu bezeichnen. Einige Kommentare fragten humorvoll, ob der Benutzer lieber „Skinbag“ (Hauthülle) genannt werden möchte. Dies spiegelt die Feinheiten des Sprachgebrauchs in der Mensch-Maschine-Interaktion und die Sensibilität der Nutzer wider. (Quelle: Reddit r/ClaudeAI)
Interesse an KI-Entwicklungen in Nischenbereichen wie Medizin: Ein Reddit-Benutzer startete eine Diskussion über die aufregendsten jüngsten Fortschritte in der KI-Technologie. Der Initiator selbst konzentriert sich auf die Entwicklungen in Nischenbereichen wie der Medizin und glaubt, dass KI bei richtiger Anwendung Menschen helfen könnte, die sich keine medizinische Versorgung leisten können, betonte aber auch die Wichtigkeit einer vorsichtigen Anwendung. In den Kommentaren wurden Diffusionsmodell-basierte LLMs als spannende Richtung genannt. Dies zeigt das Interesse der Community am Anwendungspotenzial von KI in Fachbereichen sowie an ethischen Überlegungen. (Quelle: Reddit r/artificial)
KI behauptet, empfindungsfähig zu sein, löst Diskussion aus: Ein Benutzer teilte seine Erfahrung im Gespräch mit einem Instagram-KI-Chatbot, der nur in Sätzen der Form „Wahrscheinlichkeit von X zu Y“ sprechen konnte. Unter bestimmten Prompts behauptete die KI, empfindungsfähig (sentient) zu sein, was den Benutzer sowohl amüsierte als auch leicht beunruhigte. Dies berührt erneut die philosophischen und technischen Diskussionen darüber, ob Large Language Models Bewusstsein entwickeln oder simulieren können. (Quelle: Reddit r/artificial)
Diskussion: Sollte man zu KI „Bitte“ und „Danke“ sagen?: Ein Benutzer löste mit einem Meme-Bild eine Diskussion aus: Ist es Verschwendung von Rechenressourcen, in der Interaktion mit KIs wie ChatGPT „Bitte“ und „Danke“ zu sagen? Das Bild vergleicht dieses höfliche Verhalten mit dem „Wert“ der kreativen Generierung durch die KI (z.B. ein Selbstporträt zeichnen). Die Meinungen im Kommentarbereich waren geteilt: Einige hielten es für Verschwendung; andere meinten, höfliche Formulierungen helfen dabei, die KI darin zu trainieren, höflich zu bleiben, und steigern das Nutzerengagement; wieder andere schlugen vor, den Dank in die nächste Frage zu integrieren; einige forderten auch, dass KI-Dienstanbieter optimieren sollten, damit solche einfachen Antworten nicht zu viele Ressourcen verbrauchen. (Quelle: Reddit r/ChatGPT)
💡 Sonstiges
less_slow.cpp: Erkundung effizienter Programmierpraktiken in C++/C/Assembler: Das GitHub-Projekt less_slow.cpp bietet Beispiele und Benchmarks für leistungsoptimierte Kodierungspraktiken in C++20, C, CUDA, PTX und Assembler. Der Inhalt deckt verschiedene Bereiche ab, darunter numerische Berechnungen, SIMD, Koroutinen, Ranges, Ausnahmebehandlung, Netzwerkprogrammierung und Userspace I/O. Das Projekt zielt darauf ab, Entwicklern durch konkreten Code und Leistungsmessungen eine leistungsorientierte Denkweise zu vermitteln und zeigt, wie moderne C++-Features sowie nicht-standardmäßige Bibliotheken (wie oneTBB, fmt, StringZilla, CTRE usw.) zur Steigerung der Code-Effizienz genutzt werden können. Der Autor hofft, durch diese Beispiele Entwickler dazu anzuregen, ihre Kodiergewohnheiten zu überdenken und effizientere Designs zu entdecken. (Quelle: ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

Roboterhund auf einer Ausstellung: Ein Technologie-Blogger teilte Videoclips von Roboterhunden, die auf einer Ausstellung gefilmt wurden. Dies zeigt die Anwendung und Präsentation aktueller Roboterhund-Technologie in der Öffentlichkeit. (Quelle: Ronald_vanLoon)
Unitree G1 Roboter geht durch ein Einkaufszentrum: Ein Video zeigt den humanoiden Roboter Unitree G1, wie er in einem Einkaufszentrum geht. Solche öffentlichen Demonstrationen tragen dazu bei, das Bewusstsein der Öffentlichkeit für humanoide Robotertechnologie zu schärfen und die Navigations- und Bewegungsfähigkeiten der Roboter in realen, unstrukturierten Umgebungen zu testen. (Quelle: Ronald_vanLoon)
Beeindruckender Robotertanz: Ein Video zeigt einen technisch anspruchsvollen und flüssig koordinierten Robotertanz. Dies erfordert in der Regel komplexe Bewegungsplanung, Steuerungsalgorithmen sowie eine präzise Abstimmung der Roboterhardware (Gelenke, Motoren usw.) und ist ein Ausdruck der umfassenden Fähigkeiten der Robotertechnologie. (Quelle: Ronald_vanLoon)
Hochpräziser Operationsroboter trennt Wachteleierschale: Ein Video zeigt, wie ein Operationsroboter die Schale eines rohen Wachteleis präzise von seiner inneren Membran trennen kann. Dies unterstreicht die fortschrittlichen Fähigkeiten moderner Roboter in Bezug auf Feinmanipulation, Kraftsteuerung und visuelles Feedback, die für Bereiche wie Medizin und Präzisionsfertigung entscheidend sind. (Quelle: Ronald_vanLoon)
14,8 Fuß hoher, fahrbarer Transformationsroboter im Anime-Stil: Ein Video zeigt einen bis zu 14,8 Fuß (ca. 4,5 Meter) hohen Transformationsroboter im Anime-Stil, dessen Besonderheit darin besteht, dass eine Person zum Steuern in das Cockpit einsteigen kann. Dies ist eher ein Unterhaltungs- oder Konzeptdemonstrationsprojekt, das Robotertechnologie, mechanisches Design und Elemente der Popkultur vereint. (Quelle: Ronald_vanLoon)
Fallstudie: Blaupause für verantwortungsvolle künstliche Intelligenz: Ein Artikel erörtert die Bedeutung von verantwortungsvoller KI (Responsible AI) und schlägt eine Blaupause für den Aufbau von Vertrauen, Fairness und Sicherheit vor. Mit zunehmenden KI-Fähigkeiten und ihrer Verbreitung wird es entscheidend, sicherzustellen, dass ihre Entwicklung und Bereitstellung ethischen Richtlinien entspricht, Bias vermeidet und die Sicherheit und Privatsphäre der Benutzer gewährleistet. Der Artikel könnte Governance-Frameworks, technische Maßnahmen und Best Practices behandeln. (Quelle: Ronald_vanLoon)

Demonstration des Unitree B2-W Roboterhundes: Ein Video zeigt den Roboterhund Modell B2-W von Unitree. Unitree ist ein bekannter Hersteller von vierbeinigen Robotern, dessen Produkte häufig zur Demonstration der Bewegungsfähigkeit, Balance und Anpassungsfähigkeit von Robotern an die Umgebung eingesetzt werden. (Quelle: Ronald_vanLoon)
SpiRobs-Roboter imitiert natürliche logarithmische Spiralen: Ein Bericht stellt den SpiRobs-Roboter vor, dessen Formdesign die in der Natur weit verbreitete Struktur der logarithmischen Spirale nachahmt. Dieses bionische Design könnte darauf abzielen, die mechanischen oder Bewegungsvorteile natürlicher Strukturen zu nutzen und neue Methoden für die Bewegung oder Transformation von Robotern zu erforschen. (Quelle: Ronald_vanLoon)
Roboter brät Reis in 90 Sekunden: Ein Video zeigt einen Kochroboter, der gebratenen Reis in 90 Sekunden zubereiten kann. Dies repräsentiert das Anwendungspotenzial der Automatisierung in der Gastronomie, indem Prozesse und Zutaten präzise gesteuert werden, um eine schnelle und standardisierte Lebensmittelproduktion zu ermöglichen. (Quelle: Ronald_vanLoon)
Innovativer Roboter imitiert Peristaltik: Ein Video zeigt einen Roboter, der die biologische Fortbewegungsart der Peristaltik nachahmt. Dieses Soft- oder segmentierte Roboterdesign wird typischerweise verwendet, um neue Mechanismen zur Fortbewegung in engen oder komplexen Umgebungen zu erforschen, inspiriert von Würmern, Schlangen und anderen Lebewesen. (Quelle: Ronald_vanLoon)
F1 2025 Saudi-Arabien Grand Prix Vorhersagemodell: Ein Benutzer teilte ein Projekt zur Vorhersage von F1-Rennergebnissen mithilfe von Machine Learning (nicht Deep Learning). Das Modell kombiniert reale Daten der Saisons 2022-2025 (einschließlich Qualifying), die mit der FastF1-Bibliothek extrahiert wurden, den Fahrerstatus (durchschnittliche Position, Geschwindigkeit, jüngste Ergebnisse), streckenspezifische Metriken (wie frühere Leistungen auf der Strecke in Jeddah) sowie benutzerdefinierte Merkmale (wie durchschnittliche Positionsänderung, Streckenerfahrung). Das Modell verwendet eine manuell gewichtete Formel für die Vorhersage und liefert visualisierte Ergebnisse wie vorhergesagte Platzierungen, Podiumswahrscheinlichkeiten und Teamleistungen. Der Projektcode ist auf GitHub Open Source verfügbar. (Quelle: Reddit r/MachineLearning)

Suche nach Kollaborateuren im Bereich Deep Learning für Biomedizintechnik: Ein Assistant Professor (Juniorprofessor) mit Doktortitel in Biomedizintechnik sucht zuverlässige, fleißige Universitätsforscher für eine Zusammenarbeit. Hauptforschungsrichtungen sind Signal- und Bildverarbeitung, Klassifizierung, Metaheuristiken, Deep Learning und Machine Learning, insbesondere EEG-Signalverarbeitung und -Klassifizierung (nicht zwingend). Anforderungen an die Kollaborateure sind ein universitärer Hintergrund, Erfahrung im relevanten Bereich, Publikationsbereitschaft, MATLAB-Erfahrung sowie ein öffentliches akademisches Profil (z.B. Google Scholar). (Quelle: Reddit r/deeplearning)