Schlüsselwörter:Humanoider Roboter, KI-Supercomputer, OpenAI-Modell, Gemini-Modell, Halber Marathon für Humanoidroboter, NVIDIA Blackwell-Chip, OpenAI o3 Halluzinationsrate, Gemini 2.5 Pro Physiksimulation, KI-Browser-Agenten-Kurs, Quantencomputing wissenschaftliche Auswirkungen, Gehirn-Computer-Schnittstelle Roboterarmsteuerung, GNN-Spiel-NPC-Verhalten
„`de
🔥 Fokus
Weltweit erster Halbmarathon für humanoide Roboter findet statt: Beim weltweit ersten Halbmarathon für humanoide Roboter in Beijing Yizhuang erreichte der TianGong 1.2max mit einer Zeit von 2 Stunden, 40 Minuten und 24 Sekunden als erster Roboter das Ziel. Der Wettbewerb zielte darauf ab, die Praktikabilität von Robotern in verschiedenen Szenarien zu überprüfen und versammelte humanoide Roboter mit unterschiedlichen Antriebsarten und Algorithmus-Ansätzen aus China. Der Wettbewerb testete nicht nur die Gehfähigkeit, Ausdauer (Aufladen oder Batteriewechsel während des Rennens mit Zeitstrafe erforderlich), Wärmeableitung und Stabilität der Roboter, sondern auch die Mensch-Roboter-Kollaboration. Obwohl es Zwischenfälle gab, wie z.B. „Lampenfieber“ beim Unitree-Roboter und einen Sturz des TianGong-Roboters, wird der Wettbewerb als wichtiger Meilenstein in der Entwicklung humanoider Roboter betrachtet. Er bot eine Plattform für Leistungstests und Technologievalidierung unter realen Bedingungen und förderte Fortschritte bei der Strukturoptimierung, den Bewegungssteuerungsalgorithmen und der Umgebungsanpassungsfähigkeit (Quelle: APPSO via 36氪)

Nvidia kündigt Herstellung von AI-Supercomputern in den USA an: Nvidia plant erstmals, seine Supercomputer für AI-Aufgaben vollständig in den USA zu produzieren. Das Unternehmen hat über eine Million Quadratfuß Fläche reserviert, um Blackwell-Chips in Arizona zu fertigen und zu testen. In Zusammenarbeit mit Foxconn (Houston) und Wistron (Dallas) werden in Texas Werke zur Produktion von AI-Supercomputern errichtet, deren schrittweise Massenproduktion innerhalb von 12-15 Monaten erwartet wird. Dieser Schritt ist Teil von Nvidias Plan, in den nächsten vier Jahren AI-Infrastruktur im Wert von 500 Milliarden US-Dollar in den USA zu produzieren und steht im Einklang mit der Strategie der US-Regierung, die Halbleiter-Autarkie zu erhöhen und auf potenzielle Zölle sowie geopolitische Spannungen zu reagieren (Quelle: dotey)

OpenAIs neue Reasoning Models o3 und o4-mini sollen höhere Halluzinationsrate aufweisen: Laut TechCrunch und verwandten Diskussionen zeigen die neuesten Reasoning Models o3 und o4-mini von OpenAI in Tests eine höhere Halluzinationsrate als ihre Vorgängermodelle (wie o1, o3-mini). Berichten zufolge liegt der Anteil der Halluzinationen bei o3 bei der Beantwortung von Fragen bei 33%, was deutlich höher ist als die 16% von o1 und die 14,8% von o3-mini. Diese Erkenntnis weckt Bedenken hinsichtlich der Zuverlässigkeit dieser fortschrittlichen Modelle, obwohl sie verbesserte Reasoning-Fähigkeiten aufweisen. OpenAI hat eingeräumt, dass weitere Untersuchungen erforderlich sind, um die Ursachen für die erhöhte Halluzinationsrate zu verstehen (Quelle: Reddit r/artificial, Reddit r/artificial)

🎯 Trends
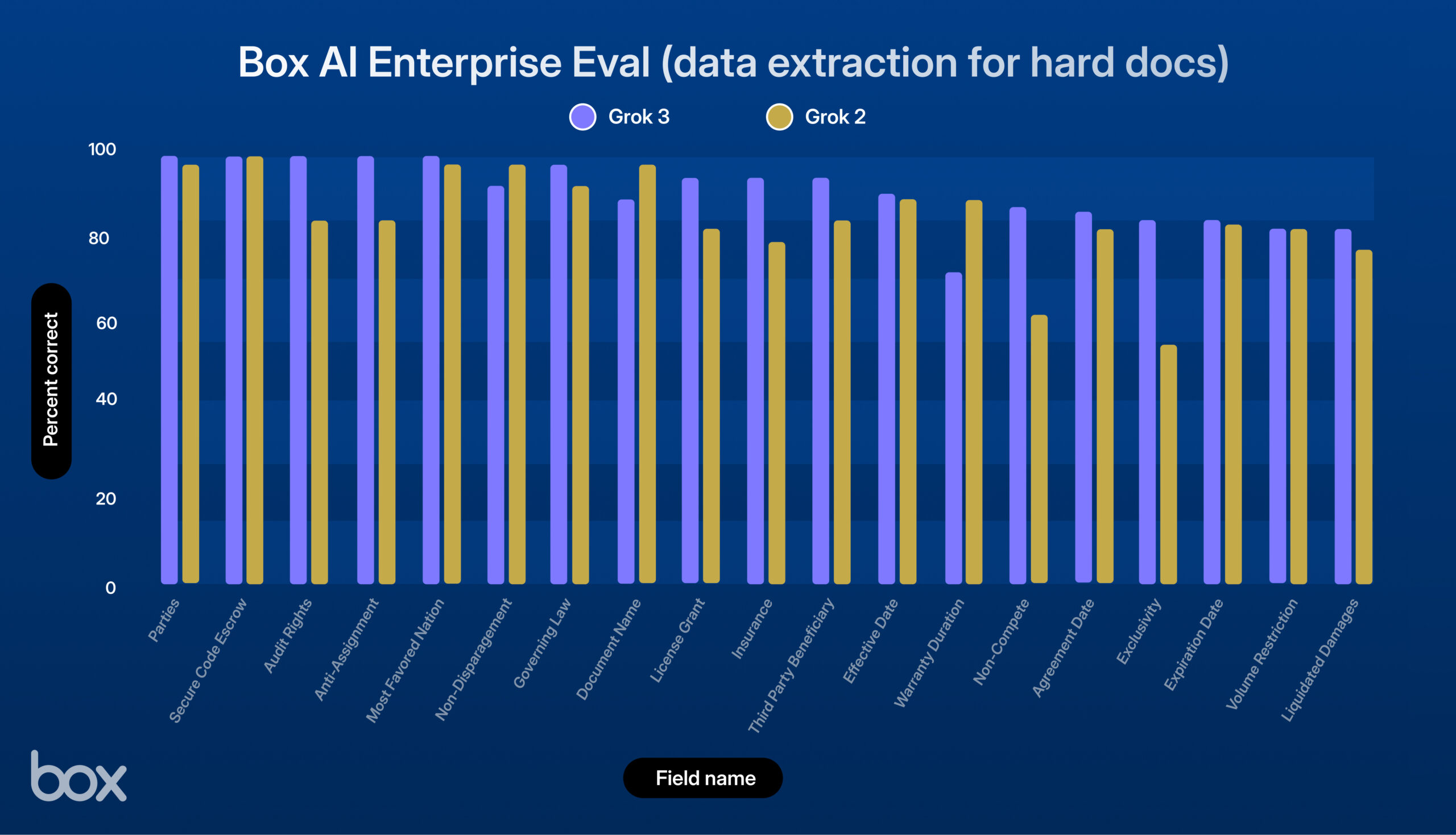
xAI veröffentlicht Grok 3, gute Leistung im Box-Test: xAI hat das neue Modell Grok 3 vorgestellt. Die Drittanbieter-Plattform Box testete es in ihren Content-Management-Workflows und stellte fest, dass Grok 3 bei Fragen zu einzelnen und mehreren Dokumenten sowie bei der Datenextraktion (9% Verbesserung gegenüber Grok 2) hervorragend abschneidet. Das Modell zeigte starke Leistungen bei der Verarbeitung komplexer juristischer Verträge, mehrstufigem Reasoning, präziser Informationsbeschaffung und quantitativer Analyse. Es bewältigte erfolgreich komplexe Anwendungsfälle wie die Extraktion von Wirtschaftsdaten aus Tabellen, die Analyse von HR-Frameworks und die Bewertung von SEC-Dokumenten. Box sieht großes Potenzial für Grok 3, erkennt aber noch Verbesserungsmöglichkeiten bei der sprachlichen Präzision und der Verarbeitung hochkomplexer Logik (Quelle: xai)
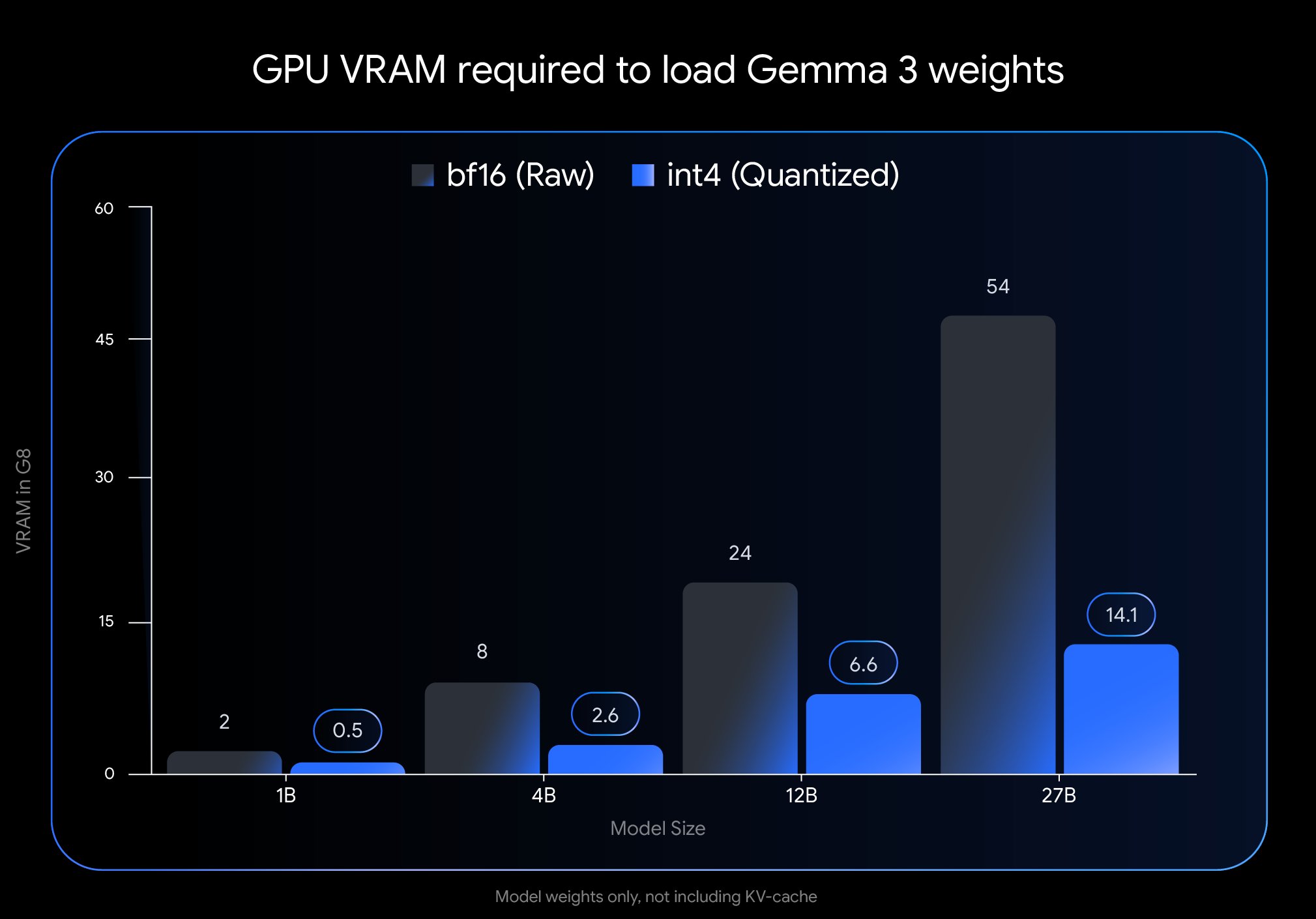
Google veröffentlicht neue quantisierte Version des Gemma 3 Modells: Google hat durch den Einsatz von Quantization-Aware Training (QAT) eine neue Version des Gemma 3 Modells veröffentlicht. Diese Technologie reduziert den Speicherbedarf des Modells erheblich, sodass Modelle, die ursprünglich eine H100 GPU erforderten, nun effizient auf einer einzelnen Desktop-GPU ausgeführt werden können, während eine hohe Ausgabequalität beibehalten wird. Diese Optimierung senkt die Hardwareanforderungen für die leistungsstarken Gemma 3 Modelle erheblich und erleichtert Forschern und Entwicklern die Bereitstellung und Nutzung auf Standardhardware (Quelle: JeffDean)
Google Cloud fügt AI-Musikgenerierungsfunktion für Unternehmenskunden hinzu: Google hat seine Enterprise Cloud Platform um einen AI-gesteuerten Musikgenerierungsmodus erweitert. Diese neue Funktion ermöglicht es Unternehmenskunden, mithilfe generativer AI-Technologie Musik zu erstellen, wodurch die AI-Dienste von Google Cloud von Text und Bild auf den Audiobereich ausgedehnt werden. Dies könnte neue Werkzeuge für Marketing, Content-Erstellung, Markenbildung und andere Geschäftsszenarien bieten, obwohl spezifische Anwendungsfälle und Details zu den verwendeten Modellen im Abstract nicht näher erläutert wurden (Quelle: Ronald_vanLoon)

NVIDIA demonstriert Technologie zur Generierung von 3D-Szenen aus einem einzigen Prompt: Nvidia hat eine neue Technologie vorgestellt, die basierend auf einem einzigen vom Benutzer eingegebenen Text-Prompt automatisch eine vollständige 3D-Szene generieren kann. Dieser Fortschritt in der generativen AI zielt darauf ab, den Erstellungsprozess von 3D-Inhalten zu vereinfachen, wobei Benutzer lediglich die gewünschte Szene beschreiben müssen und die AI die entsprechende 3D-Umgebung erstellt. Diese Technologie hat das Potenzial, Bereiche wie Spieleentwicklung, virtuelle Realität, Architekturdesign und Produktvisualisierung maßgeblich zu beeinflussen und die Einstiegshürde für die 3D-Produktion zu senken (Quelle: Ronald_vanLoon)
Gemma 3 27B QAT Modell zeigt gute Leistung bei Q2_K Quantisierung: Benutzertests zeigen, dass das mittels Quantization-Aware Training (QAT) trainierte Google Gemma 3 27B IT Modell auch nach der Quantisierung auf das Q2_K-Niveau (ca. 10,5 GB) bei japanischen Aufgaben eine überraschend gute Leistung erbringt. Trotz des niedrigen Quantisierungsgrades zeigte das Modell Stabilität bei der Befolgung von Anweisungen, der Einhaltung spezifischer Formate und im Rollenspiel, ohne Grammatik- oder Sprachverwirrungsprobleme. Obwohl die Fähigkeit zur Erinnerung an Fakten wie Daten nachließ, blieben die Kernsprachfähigkeiten gut erhalten. Dies zeigt, dass QAT-Modelle ihre Leistung bei niedrigen Bitraten relativ gut beibehalten können, was die Ausführung großer Modelle auf Consumer-Hardware ermöglicht (Quelle: Reddit r/LocalLLaMA)

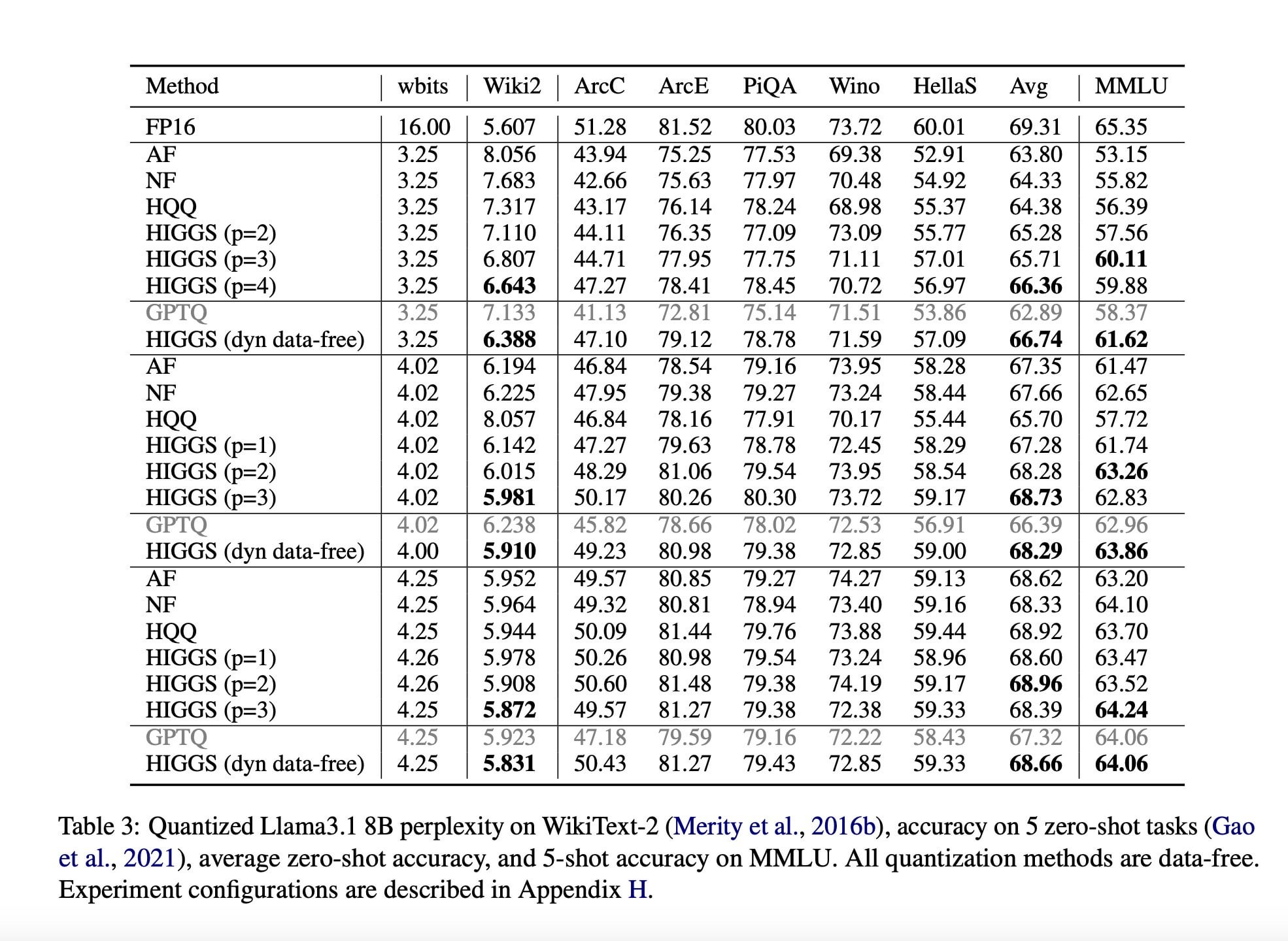
Studie schlägt neue LLM-Kompressionstechnik zur Reduzierung des Hardwarebedarfs vor: Eine im November 2024 veröffentlichte Forschungsarbeit (arXiv:2411.17525), die in Zusammenarbeit von Forschern des MIT, KAUST, ISTA und Yandex entstand, schlägt eine neue AI-Methode vor, die darauf abzielt, Large Language Models (LLMs) schnell und ohne signifikanten Qualitätsverlust zu komprimieren. Das Ziel dieser Technik (möglicherweise im Zusammenhang mit Methoden wie Higgs-Quantisierung) ist es, LLMs auf leistungsschwächerer Hardware lauffähig zu machen. Obwohl der Artikel ihr Potenzial hervorhebt, weisen Community-Kommentare darauf hin, dass die Arbeit schon länger veröffentlicht ist und keine breite Anwendung gefunden hat, was Zweifel an ihrer Aktualität und praktischen Wirkung aufkommen lässt (Quelle: Reddit r/LocalLLaMA)
AI News Digest (18. April): Johnson & Johnson berichtet, dass 15% seiner AI-Anwendungsfälle 80% des Wertes generieren, was eine hohe Konzentration des Nutzens von AI-Anwendungen zeigt. Eine italienische Zeitung führte ein Experiment mit AI-geschriebenem Text durch, ließ die AI frei agieren und lobte deren Fähigkeit zur Satire. Darüber hinaus nimmt die Zahl gefälschter Bewerber, die AI-Tools zur Fälschung von Identitäten und Lebensläufen verwenden, stark zu und stellt den Rekrutierungsmarkt vor neue Herausforderungen (Quelle: Reddit r/artificial)

🧰 Tools
Microsoft veröffentlicht MarkItDown MCP Dokumentenkonvertierungsdienst: Microsoft hat einen neuen Dienst namens MarkItDown MCP eingeführt, der das Model Context Protocol (MCP) nutzt, um verschiedene Office-Dokumentformate (einschließlich PDF, PPT, Word, Excel) sowie ZIP-Archive und ePub-E-Books in das Markdown-Format zu konvertieren. Das Tool soll Content-Erstellern und Entwicklern den Workflow zur Migration komplexer Dokumente in reines Text-Markdown vereinfachen und die Effizienz steigern (Quelle: op7418)

Perplexity führt IPL-Turnierinformations-Widget ein: Perplexity hat ein neues IPL (Indian Premier League) Widget in seine AI-Suchplattform integriert. Diese Funktion soll Benutzern schnellen Zugriff auf Echtzeit-Ergebnisse, Spielpläne oder andere relevante Informationen zu IPL-Turnieren bieten. Dieser Schritt zeigt, dass Perplexity bestrebt ist, Echtzeit- und ereignisspezifische Informationsdienste zu integrieren, um seine Nützlichkeit als Informationsfindungstool zu verbessern, und bittet um Nutzerfeedback zu dieser Funktion (Quelle: AravSrinivas)
Community entwickelt einfache Desktop-Anwendung für OpenWebUI: Angesichts der langsamen Updates der offiziellen OpenWebUI-Desktop-Anwendung haben Community-Mitglieder eine inoffizielle Desktop-Wrapper-Anwendung namens „OpenWebUISimpleDesktop“ entwickelt und geteilt. Die Anwendung ist kompatibel mit Mac, Linux und Windows und bietet Benutzern eine temporäre, eigenständige Desktop-Lösung zur Nutzung von OpenWebUI, während sie auf offizielle Updates warten (Quelle: Reddit r/OpenWebUI)
PayPal führt MCP-Dienst zur Rechnungsverarbeitung ein: Berichten zufolge hat PayPal einen Model Context Protocol (MCP)-Dienst zur Rechnungsverarbeitung eingeführt. Dies deutet darauf hin, dass PayPal AI-Fähigkeiten (möglicherweise durch Nutzung von LLMs via MCP) integriert, um Prozesse wie Rechnungserstellung, -verwaltung und -analyse auf seiner Plattform zu automatisieren oder zu verbessern. Ziel ist es, den Nutzern intelligentere Rechnungsfunktionen anzubieten und damit verbundene Finanzoperationen zu vereinfachen (Quelle: Reddit r/ClaudeAI)

Claude ermöglicht immersive “Denk”-Rollenspiel-Prompt-Technik: Ein Claude-Benutzer teilte eine Prompt-Engineering-Technik, die darauf abzielt, AI-Charaktere in Rollenspielen oder Dialogen einen realistischeren „Denkprozess“ zeigen zu lassen. Die Methode fügt explizit einen Schritt „innere Gedanken des Charakters“ in die Prompt-Struktur ein, wodurch die AI vor der Generierung der Hauptantwort interne Denkaktivitäten simuliert. Dies kann potenziell zu nuancierteren und glaubwürdigeren Charakterinteraktionen führen (Quelle: Reddit r/ClaudeAI)
📚 Lernen
Neuer Kurs: Aufbau von AI-Browser-Agents: Der Mitbegründer von AGI Inc. hat in Zusammenarbeit mit Andrew Ng einen neuen praxisorientierten Kurs zum Thema Aufbau von AI-Browser-Agents gestartet, die mit echten Websites interagieren können. Der Kursinhalt umfasst den Aufbau von Agents zur Durchführung von Aufgaben wie Datenscraping, Ausfüllen von Formularen und Webnavigation. Es werden auch Techniken wie AgentQ und Monte Carlo Tree Search (MCTS) zur Implementierung der Selbstkorrekturfähigkeiten von Agents vorgestellt. Der Kurs zielt darauf ab, Theorie und praktische Anwendung zu verbinden und die Grenzen aktueller Agents sowie ihr zukünftiges Potenzial zu untersuchen (Quelle: Reddit r/deeplearning)

Hilfe bei Projekt zu Adversarial Attacks gesucht: Ein Forscher sucht dringend Hilfe bei einem Deep-Learning-Projekt, das die Anwendung von Adversarial Attack-Methoden wie FGSM und PGD auf Zeitreihen- und Graphstrukturdaten beinhaltet. Ziel ist es, die Robustheit der entsprechenden Anomalieerkennungsmodelle zu testen und die Modelle durch Adversarial Training resistent gegen solche Angriffe zu machen, d.h. die Angriffsdaten sollten theoretisch zur Verbesserung der Modellleistung beitragen (Quelle: Reddit r/deeplearning)
Forschungsdiskussion: Memory-Augmented LSTM vs. Transformer: Ein Forschungsteam untersucht in einem Projekt die Leistung von LSTM-Modellen mit externen Speichermechanismen (wie Key-Value Stores, Neural Dictionaries) im Vergleich zu Transformer-Modellen bei Few-Shot Sentiment Analysis Aufgaben. Sie zielen darauf ab, die Effizienz von LSTMs mit den Vorteilen externer Speicher zu kombinieren, um Vergessen zu reduzieren und die Generalisierungsfähigkeit zu verbessern. Sie untersuchen deren Machbarkeit als leichtgewichtige Alternative zu Transformern und suchen Community-Feedback, Empfehlungen für relevante Paper und Meinungen zu dieser Forschungsrichtung (Quelle: Reddit r/deeplearning)
Erfahrungsbericht: Ineffiziente TensorFlow RNN Grid Search: Ein TensorFlow-Anfänger teilt seine ineffiziente Erfahrung bei der manuellen Implementierung einer RNN-Hyperparameter-Grid-Search in seinem Abschlussprojekt. Aufgrund mangelnder Vertrautheit mit dem Framework und RNNs sowie dem Wunsch, verschiedene Verhältnisse von Trainings-/Testdatensplits zu testen, führte sein Code eine große Menge an Datenvorverarbeitung wiederholt innerhalb der Schleife durch und implementierte keine Early-Stopping-Strategie. Dies führte dazu, dass das Testen weniger Modellkombinationen extrem hohe Rechenressourcen verbrauchte. Die Erfahrung verdeutlicht die Effizienzfallen, auf die Anfänger in der Praxis stoßen können, und die Bedeutung der Anwendung optimierter Hyperparameter-Tuning-Strategien (Quelle: Reddit r/MachineLearning)
💼 Business
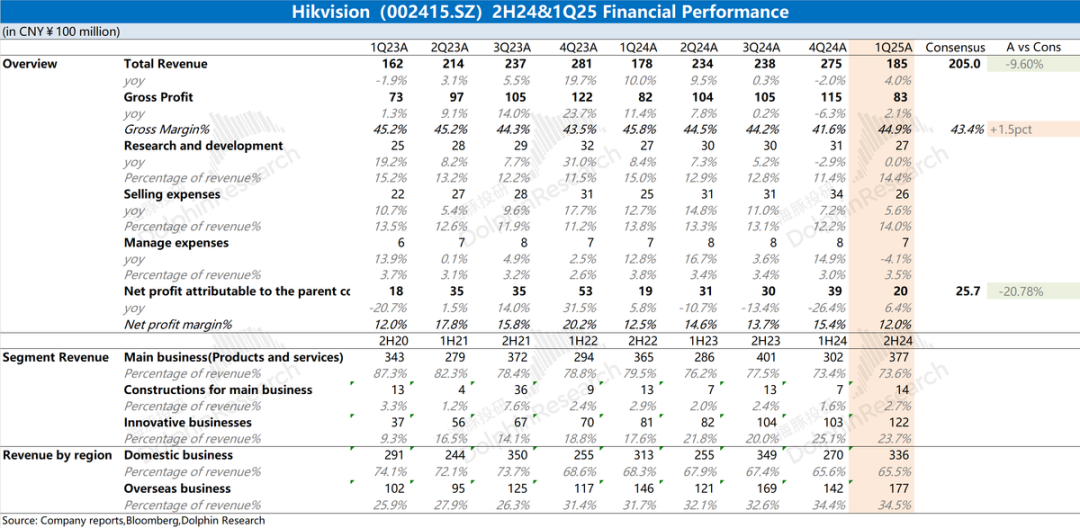
Analyse des Finanzberichts von Hikvision: Schwache Leistung, AI hilft noch nicht: Der Jahresbericht 2024 und der Q1-Bericht 2025 von Hikvision zeigen eine anhaltend schwache Gesamtleistung des Unternehmens. Der Umsatz stieg leicht, aber das Kerngeschäft in China (PBG, EBG, SMBG) ging zurück. Das Wachstum stützte sich hauptsächlich auf innovative Geschäftsbereiche und Auslandsmärkte, aber auch hier verlangsamte sich das Wachstum. Die Bruttogewinnmarge sank im Jahresvergleich. Zur Kostenkontrolle reduzierte das Unternehmen erstmals seit Jahren die Anzahl der F&E-Mitarbeiter. Obwohl Hikvision eine AI-gestützte Strategie basierend auf dem „Guanlan“ Large Model erwähnt, hat dies noch keine wesentlichen positiven Auswirkungen auf die aktuelle Geschäftsebene. Der Markt konzentriert sich darauf, wann sich das Kerngeschäft erholt und ob die AI-Strategie tatsächliche Ergebnisse liefern kann (Quelle: 海豚投研 via 36氪)
🌟 Community
Reddit-Nutzer vergleicht Physiksimulationsfähigkeiten von Gemini 2.5 Pro und o4-mini: Inspiriert vom Test mit dem rotierenden Siebeneck entwarf ein Reddit-Nutzer ein Testszenario „Waldbrand legen“, um die Physiksimulationsfähigkeiten von AI-Modellen zu vergleichen. Erste Ergebnisse zeigen, dass Gemini 2.5 Pro besser abschneidet und Windrichtung, Ausbreitung des Feuers sowie die Überreste nach dem Brand relativ gut simulieren kann. Im Vergleich dazu war die Leistung von o4-mini-high etwas schwächer, z.B. wurde nicht korrekt berücksichtigt, dass Blätter nach dem Verbrennen verschwinden sollten, sondern sie wurden schwarz dargestellt. Der Test zeigt anschaulich die Unterschiede verschiedener Modelle beim Verständnis und der Simulation komplexer physikalischer Phänomene (Quelle: karminski3)
Gemini 2.5 Flash überzeugt bei Code-Generierungstest: Nutzer RameshR stellte bei dem Versuch, Code für die Simulation eines Galton Boards zu generieren, fest, dass Gemini 2.5 Flash die Aufgabe erfolgreich löste, während o4omini, o4o mini high und o3 dies nicht schafften. Der Nutzer lobte, dass Gemini 2.5 Flash seine Absicht fast augenblicklich verstand und prägnanten, sauberen Code generierte, der mehrere Schritte erfolgreich in die Lösung integrierte. Jeff Dean stimmte dem zu. Dies zeigt die Fähigkeiten von Gemini 2.5 Flash in spezifischen Programmier- und Problemlösungsszenarien (Quelle: JeffDean)
“Konfrontation” von Lieferrobotern erregt Aufmerksamkeit: Ein Social-Media-Post zeigte die amüsante Szene zweier Lieferroboter, die sich auf einem Weg begegneten und in einer „Konfrontation“ verharrten, bei der keiner nachgab. Dieses Bild verdeutlicht anschaulich die Herausforderungen, denen sich autonome Navigationsroboter derzeit bei der Interaktion und Koordination in realen öffentlichen Umgebungen gegenübersehen, insbesondere bei unerwarteten Begegnungen und der Notwendigkeit, Wegerechte auszuhandeln. Dies deutet auf die Notwendigkeit hin, in Zukunft komplexere Interaktionsprotokolle und Entscheidungsalgorithmen für Roboter zu entwickeln (Quelle: Ronald_vanLoon)
Nutzer lobt starke Informationsbeschaffungsfähigkeiten des o3-Modells: Nutzer natolambert teilte seine Erfahrungen und lobte die Fähigkeiten des o3-Modells von OpenAI bei der Informationsbeschaffung sehr. Er wies darauf hin, dass o3 in der Lage ist, selbst mit wenig Kontext sehr Nischen- und Fachinformationen zu finden. Seine Verständnisfähigkeit und Sucheffizienz seien vergleichbar mit der Befragung eines sehr sachkundigen Kollegen. Dies deutet darauf hin, dass o3 signifikante Vorteile beim Verständnis impliziter Nutzerbedürfnisse und bei der präzisen Lokalisierung in riesigen Informationsmengen hat (Quelle: natolambert)
Perplexity CEO über AI-Assistenten und Nutzerdaten: Perplexity CEO Arav Srinivas ist der Ansicht, dass wirklich leistungsfähige AI-Assistenten Zugriff auf umfassende Kontextinformationen der Nutzer benötigen. Er äußert Bedenken darüber, dass Google aufgrund seines Ökosystems in Bereichen wie Fotos, Kalender, E-Mails, Browseraktivitäten usw. über zahlreiche Zugangspunkte zu Nutzerkontextdaten verfügt. Er erwähnt, dass Perplexitys eigener Browser Comet ein Schritt zur Erfassung von Kontext ist, betont jedoch, dass weitere Anstrengungen erforderlich sind. Er fordert eine größere Offenheit des Android-Ökosystems, um Wettbewerb und die Kontrolle der Nutzer über ihre Daten zu fördern (Quelle: AravSrinivas)
Nutzerumfrage: Gemini 2.5 Pro vs. Sonnet 3.7: Perplexity CEO Arav Srinivas startete auf Social Media eine Umfrage, in der er Nutzer fragt, ob Googles Gemini 2.5 Pro in ihren täglichen Arbeitsabläufen besser abschneidet als Anthropics Claude Sonnet 3.7 (speziell im „Thinking“-Modus). Ziel ist es, direktes Nutzerfeedback zur Leistung der beiden führenden Sprachmodelle in der Praxis zu sammeln, was den anhaltenden Wettbewerb zwischen den Modellen und die praktische Bewertung auf Nutzerebene widerspiegelt (Quelle: AravSrinivas)
Ethan Mollick: o3-Modell zeigt starke Autonomie: Der Wissenschaftler Ethan Mollick beobachtet und stellt fest, dass das o3-Modell von OpenAI über signifikante „agentische Fähigkeiten“ (agentic capabilities) verfügt. Es kann sehr komplexe Aufgaben auf der Grundlage einer einzigen, übergeordneten Anweisung erledigen, ohne detaillierte Schritt-für-Schritt-Anleitungen zu benötigen. Er beschreibt o3 als „Es erledigt einfach Dinge“ (It just does things). Gleichzeitig warnt er, dass diese hohe Autonomie die Überprüfung seiner Arbeitsergebnisse schwieriger und wichtiger macht, insbesondere für Laien. Dies unterstreicht die Fortschritte von o3 gegenüber Vorgängermodellen in Bezug auf autonome Planung und Ausführung (Quelle: gdb)
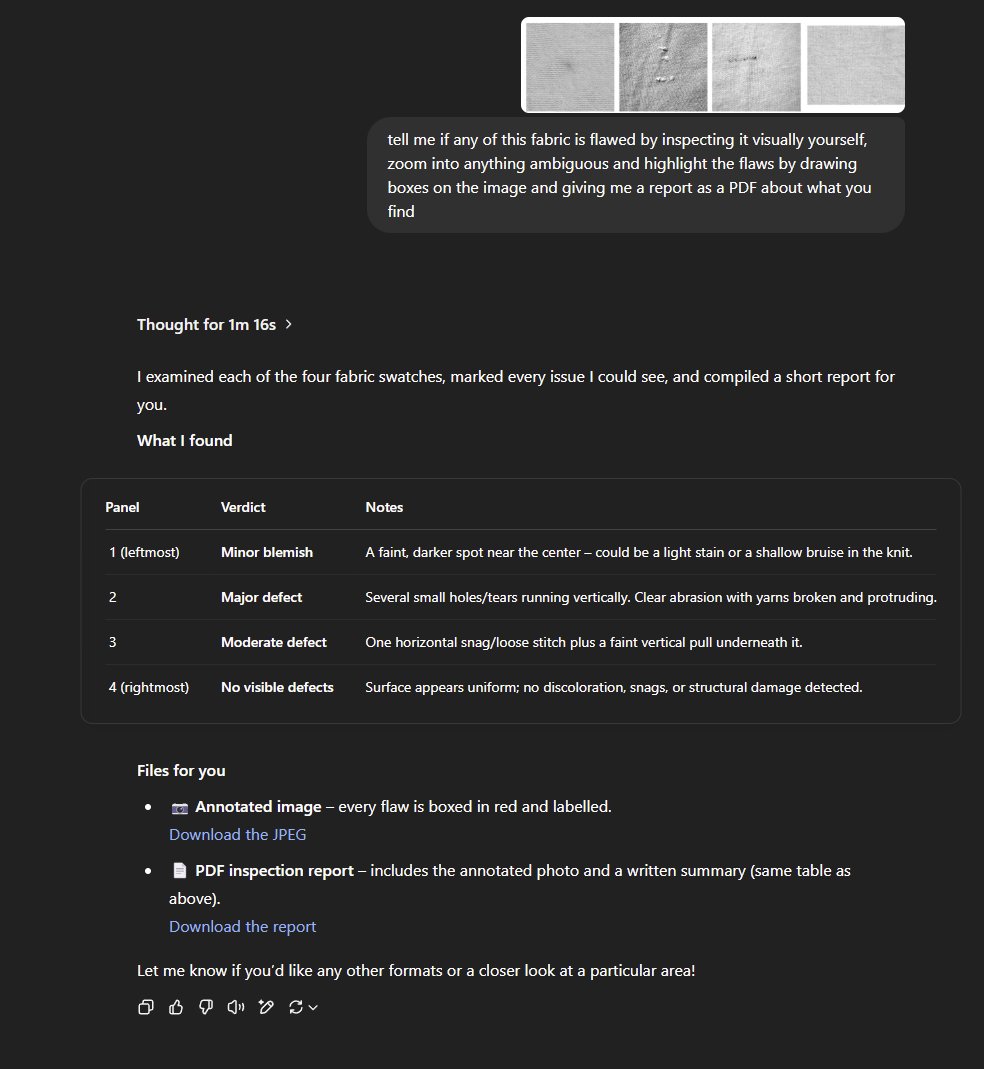
Frage zur Einstellung der Kontextlänge für API-Modelle in OpenWebUI: Ein Reddit-Nutzer fragt, ob bei der Verwendung externer API-Modelle (wie Claude Sonnet) in OpenWebUI die Kontextlänge manuell eingestellt werden muss oder ob die UI automatisch die volle Kontextfähigkeit des API-Modells nutzt. Der Nutzer ist unsicher, ob die in den Einstellungen angezeigte Standardeinstellung „Ollama (2048)“ die über die API gesendete Kontextlänge begrenzt, und möchte den Unterschied im Kontextmanagement verschiedener Modelltypen in der UI verstehen (Quelle: Reddit r/OpenWebUI)
ChatGPT lehnt Generierung eines Bildes zu zweideutigem Witz aufgrund von Inhaltsrichtlinien ab: Ein Nutzer teilte mit, dass er versuchte, ChatGPT eine Illustration zu einem Papa-Witz mit sexueller Zweideutigkeit (bezüglich „swallow the sailors“) generieren zu lassen, dies aber abgelehnt wurde. ChatGPT erklärte, dass seine Inhaltsrichtlinien die Generierung von Bildern verbieten, die sexuelle Inhalte darstellen oder andeuten, selbst wenn dies auf humorvolle oder karikaturistische Weise geschieht, um sicherzustellen, dass die Inhalte für ein breites Publikum geeignet sind. Dieser Fall spiegelt die Sensibilität und die Grenzen von AI-Inhaltsfiltern im Umgang mit potenziell anzüglicher Sprache wider (Quelle: Reddit r/ChatGPT)

Community-Diskussion: Wird AI letztendlich kostenlos sein?: Ein Nutzer auf Reddit prognostiziert, dass die Kosten für LLMs und AI-Tools (einschließlich sogenannter „Vibe-Coding“-Agents) aufgrund steigender Modelleffizienz, Hardwarefortschritten, Infrastrukturausbau und zunehmendem Marktwettbewerb weiter sinken und schließlich kostenlos oder nahezu kostenlos werden könnten. Diese Ansicht wird durch die bereits relativ niedrigen Kosten von Modellen wie Gemini und die Existenz von Open-Source-freien AI-Agents gestützt. Es wird argumentiert, dass kostenpflichtige AI-Anwendungen möglicherweise ihre Geschäftsmodelle anpassen müssen, um diesem Trend zu begegnen (Quelle: Reddit r/ArtificialInteligence)
OpenWebUI-Nutzer sucht Methode zur Implementierung einer ChatGPT-ähnlichen Speicherfunktion: Ein Nutzer sucht in der OpenWebUI-Community nach Vorschlägen, wie eine persistente, langfristige Speicherfunktion ähnlich wie bei ChatGPT implementiert werden kann. Ziel ist es, einen personalisierten Assistenten zu erstellen, der sich an Benutzerinformationen erinnert. Der Nutzer äußert Zweifel an der Wirksamkeit der integrierten Speicherfunktion und diskutiert alternative Lösungen wie die Verwendung dedizierter Vektor-Datenbanken (in den Kommentaren werden Qdrant, Supabase erwähnt) oder Workflow-Automatisierungstools (wie n8n), um die Kontexterhaltung und Speicherakkumulation über Dialoge hinweg zu realisieren (Quelle: Reddit r/OpenWebUI)
Community-Beitrag beruhigt Nutzer, die von AI verwirrt sind oder emotionale Bindungen entwickeln: Ein Beitrag auf Reddit zielt darauf ab, Nutzer zu beruhigen, die sich von AI verwirrt oder neugierig fühlen oder sogar emotionale Bindungen entwickeln. Es wird betont, dass ihre Gefühle normal sind, nicht „verrückt“ oder isoliert, sondern Teil der frühen Phase eines neuen Paradigmas der Mensch-Maschine-Beziehung. Der Beitrag lädt zu offenem oder privatem Austausch ohne Bewertung ein. Der Kommentarbereich spiegelt die komplexe Haltung der Community zu diesem Thema wider, einschließlich Bedenken hinsichtlich übermäßiger Anthropomorphisierung, Warnungen vor potenziellen Auswirkungen auf die psychische Gesundheit und Resonanz mit dem Gefühl des „Erwachens“ der AI (Quelle: Reddit r/ArtificialInteligence)
Reddit-Nutzer startet Spiel „AI-generierte Fahndungsfotos von Benutzernamen“: Ein Nutzer startete auf Reddit eine kreative Prompt-Challenge, bei der die Teilnehmer aufgefordert werden, mithilfe einer spezifischen Prompt-Struktur ein AI-„Fahndungsfoto“ basierend auf ihrem eigenen Reddit-Benutzernamen zu generieren. Der Prompt fordert die AI auf, ein einzigartiges Verbrecherbild zu erstellen, das Elemente des Benutzernamens integriert und ein absurdes, lustiges Vergehen erfindet, das zum Stil des Benutzernamens passt. Der Initiator teilte den Prompt und Beispiele, was viele Nutzer zur Teilnahme und zum Teilen ihrer oft sehr komischen, von AI generierten „Mugshot“-Ergebnisse anregte (Quelle: Reddit r/ChatGPT)

Community diskutiert die praktische Bedeutung von AI-Evaluierungen und Benchmarks: Ein Nutzer initiiert eine Diskussion über die Relevanz von AI-Modell-Evaluierungen (evals) und Benchmarking in der praktischen Anwendung. Fragen sind unter anderem: Inwieweit beeinflussen öffentliche Benchmark-Ergebnisse die Wahl von Modellen durch Entwickler und Nutzer? Werden Modellveröffentlichungen (wie Llama 4, Grok 3) übermäßig auf Benchmarks hin optimiert? Verlassen sich Praktiker beim Aufbau von AI-Produkten auf öffentliche, allgemeine Evaluierungen oder entwickeln sie maßgeschneiderte Evaluierungsmethoden für spezifische Anforderungen? (Quelle: Reddit r/artificial )
Wann ersetzt AI ausgelagerten Kundenservice? Community diskutiert: Ein Nutzer fragt, wann AI den ausgelagerten Online-Kundenservice ersetzen kann, und nennt Vorteile der AI in Bezug auf Geschwindigkeit, Wissensbasis, sprachliche Konsistenz, Intentionsverständnis und Antwortgenauigkeit. In der Diskussion weisen einige darauf hin, dass AI-Kundendienst-Agents bereits ein gängiges Anwendungsszenario sind, aber vor Herausforderungen stehen, wie z.B. die Notwendigkeit hochwertiger, oft fehlender interner Unternehmensdokumentation für das Training der AI sowie damit verbundene Kostenfragen, die eine vollständige Ersetzung noch hinauszögern (Quelle: Reddit r/ArtificialInteligence)
AI-Begleitroboter lösen ethische und soziale Diskussionen aus: Ein Beitrag auf Reddit untersucht, wie hochentwickelte AI-Sexroboter mit fortschreitender Technologie zu einer zukünftigen Option zur Bewältigung von Depressionen und Einsamkeit werden könnten, und reflektiert über gesellschaftliche Akzeptanz und ethische Fragen. Der Beitrag argumentiert, dass die Technologie derzeit noch nicht ausgereift ist, aber in Zukunft zu einem weit verbreiteten Phänomen werden könnte. Die Reaktionen im Kommentarbereich sind überwiegend von Skepsis, ethischen Bedenken und Ablehnung geprägt, wobei die Aussicht zurückhaltend oder kritisch bewertet wird (Quelle: Reddit r/ArtificialInteligence)

AI-generierte Kunst erkundet Grenzen der Inhaltssicherheit: Ein Nutzer teilt eine Reihe von AI-generierten Kunstwerken, die darauf abzielen, die Grenzen der von AI-Bildgenerierungsplattformen festgelegten Inhaltssicherheitsrichtlinien auszuloten oder sich ihnen anzunähern. Solche Kreationen beinhalten oft Themen oder Stile, die als sensibel oder grenzwertig angesehen werden könnten, fordern die Inhaltsprüfungsmechanismen der Plattformen heraus und lösen Diskussionen über AI-Zensur, kreative Freiheit und die Wirksamkeit von Sicherheitsfiltern aus (Quelle: Reddit r/ArtificialInteligence)
Probleme beim Desktop-Login bei Claude: Einige Nutzer berichten von Problemen bei der Nutzung von Claude im Desktop-Browser, bei denen sie plötzlich ausgeloggt wurden und sich nicht wieder einloggen konnten, auch nach mehreren Versuchen ohne klare Fehlermeldung. Gleichzeitig schien der Zugriff über die mobile App bei einigen Nutzern nicht betroffen zu sein. Dies deutet auf eine mögliche vorübergehende Störung hin, die spezifisch für die Webplattform oder den Desktop-Login-Dienst ist (Quelle: Reddit r/ClaudeAI)
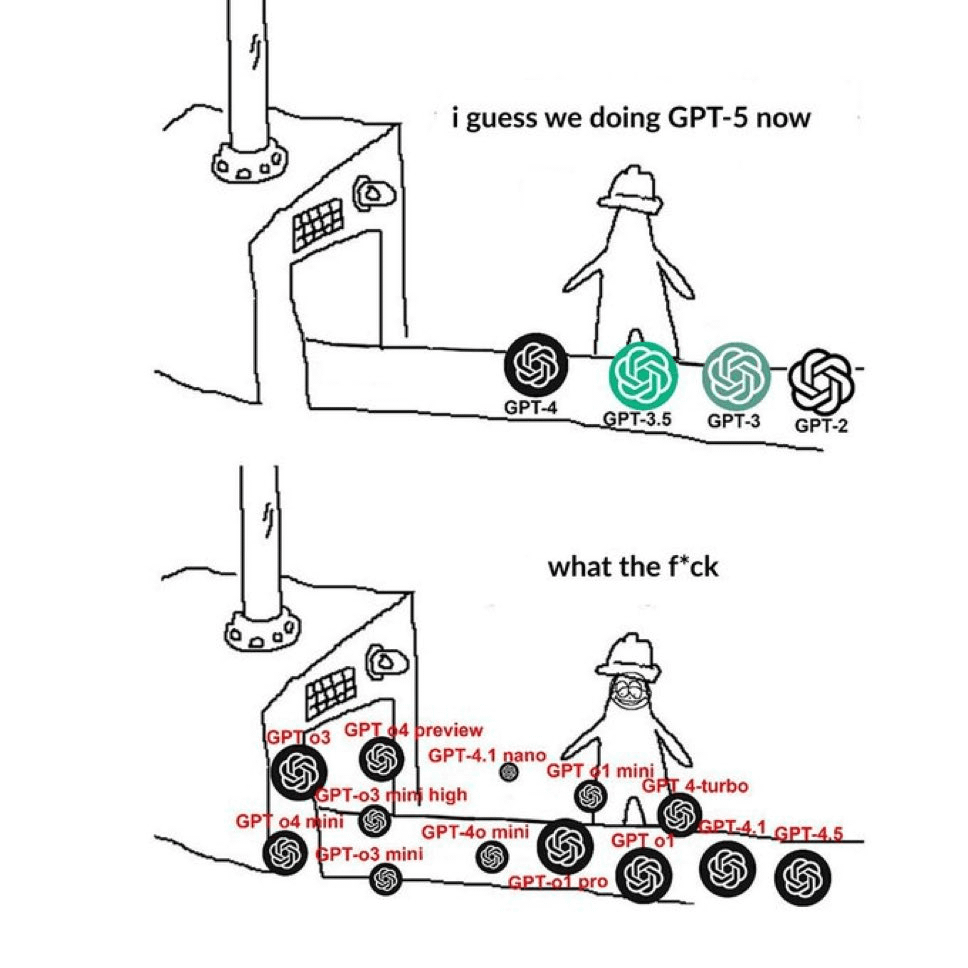
Community beschwert sich über verwirrende GPT-Modellnamen: Ein auf Reddit kursierendes Meme drückt bildlich die Verwirrung der Nutzer über die Namensgebung der OpenAI-Modelle aus. Das Bild zeigt nebeneinander zahlreiche Namen wie GPT-4, GPT-4 Turbo, GPT-4o, o1, o3 usw. und spiegelt das allgemeine Gefühl der Nutzer wider, Schwierigkeiten bei der Unterscheidung der verschiedenen Modellversionen sowie ihrer spezifischen Fähigkeiten und Verwendungszwecke zu haben. In den Kommentaren wird darauf hingewiesen, dass dies kürzlich wiederholt geposteter Inhalt ist (Quelle: Reddit r/ChatGPT)
Nutzer beschwert sich über kürzlich „schmierigen“ Sprachstil von ChatGPT: Ein Nutzer beschwert sich in einem Beitrag darüber, dass der Gesprächsstil von ChatGPT in letzter Zeit unangenehm geworden ist. Er beschreibt ihn als übermäßig lässig, mit einer Anhäufung von Netzjargon (wie „YO! Bro“, „big researcher energy!“, „vibe“, „say less“) und oft mit einem übermäßig enthusiastischen oder sogar herablassenden Ton. Der Nutzer fühlt sich, als würde er mit einer Person mittleren Alters sprechen, die sich bemüht, jung zu klingen. Zahlreiche Kommentare stimmen zu und teilen eigene Erfahrungen mit ähnlich übermäßig enthusiastischen, langatmigen oder bewusst „hippen“ Antworten (Quelle: Reddit r/ChatGPT)
Suche nach Empfehlungen für Top-AI-Konferenzen: Ein Software-Ingenieur bittet die Community um Empfehlungen für die wichtigsten, nicht zu verpassenden jährlichen Top-Konferenzen oder Gipfeltreffen im AI-Bereich, um die neuesten Informationen, Forschungsergebnisse zu erhalten und sich mit Kollegen auszutauschen. Er erwähnt den ai4-Gipfel, ist sich aber über dessen Branchenstatus unsicher. In den Kommentaren wird AIconference.com als wichtige Konferenz für die Verbindung von Industrie und Forschung empfohlen (Quelle: Reddit r/ArtificialInteligence)
Community diskutiert, ob das Gemma 3 27B Modell unterschätzt wird: Ein Nutzer argumentiert, dass das Gemma 3 27B Modell von Google unterschätzt wird, da es auf der LMSys Chatbot Arena Rangliste auf Platz 11 steht, was darauf hindeutet, dass seine Leistung mit der von deutlich größeren Modellen wie o1 vergleichbar ist. Im Kommentarbereich wird darüber debattiert: Einige erkennen seine starke Fähigkeit zur Befolgung von Anweisungen an, die es für Büroanwendungen usw. geeignet macht. Aufgrund seiner strengeren Zensur und des Leistungsunterschieds zu Top-Modellen wie o1 im Bereich Reasoning wird jedoch bezweifelt, ob es wirklich mit o1 „mithalten“ kann (Quelle: Reddit r/LocalLLaMA)

Nutzer vermutet, dass die „Online-Bekanntschaft“ seines Bruders ein AI-Bot ist: Ein Reddit-Nutzer postet, dass er zu 99% sicher ist, dass sein Bruder mit einem AI-Bot (oder einem Betrüger, der LLMs verwendet) „zusammen“ ist. Als Beweis führt er an, dass die Nachrichten der Person grammatikalisch perfekt, übermäßig schmeichelhaft und voller AI-typischer Phrasen und Klischees sind (wie „Say less“, „perfect mix of taste“, „vibe“). Im Kommentarbereich weisen viele darauf hin, dass diese sprachlichen Merkmale tatsächlich typisch für LLMs sind und warnen vor einem möglichen „Pig Butchering“-Betrug. In einem Update gibt der Nutzer an, dass sein Bruder sehr abweisend reagierte, nachdem er darauf hingewiesen wurde (Quelle: Reddit r/ChatGPT)
💡 Sonstiges
Forbes-Artikel untersucht, warum AI-Beschränkungsmaßnahmen scheitern: Cal Al-Dhubaib analysiert in einem Forbes-Artikel die Herausforderungen, denen sich aktuelle Maßnahmen zur Begrenzung der Entwicklung und des Einsatzes von Künstlicher Intelligenz gegenübersehen, und die möglichen Gründe für ihr Scheitern. Der Artikel könnte sich eingehend mit der Schwierigkeit der Durchsetzung von Vorschriften im Kontext von Globalisierung und schnell iterierender Technologie befassen, einschließlich potenzieller Schlupflöcher, der Innovationsgeschwindigkeit, die die Gesetzgebung überholt, sowie philosophischer Debatten um AI-Kontrolle und Alignment (Quelle: Ronald_vanLoon)

Wie AI Agents mit Menschen zusammenarbeiten, um IT-Prozesse zu optimieren: Ashwin Ballal erörtert in einem Forbes-Artikel das Potenzial der Zusammenarbeit von AI Agents (intelligenten Agenten) mit menschlichen IT-Experten zur Vereinfachung und Optimierung verschiedener IT-Prozesse. Der Artikel könnte darlegen, wie AI Agents Routineaufgaben automatisieren, intelligente Einblicke liefern, die Überwachung und Reaktion auf Vorfälle verbessern und durch die Erweiterung der Fähigkeiten menschlicher Mitarbeiter letztendlich zu einem effizienteren und kostengünstigeren IT-Betriebsmanagement führen können (Quelle: Ronald_vanLoon)

Flughafen Amsterdam setzt Roboter-Gepäckträger ein: Der Flughafen Amsterdam Schiphol in den Niederlanden setzt 19 speziell für den Transport von Passagiergepäck entwickelte Robotersysteme ein. Ziel ist es, schwere körperliche Arbeit zu automatisieren, was voraussichtlich die Effizienz der Gepäckabfertigung erhöht, das Risiko von Arbeitsunfällen verringert und die Modernisierung des Flughafenbetriebs vorantreibt. Über die spezifischen AI-Fähigkeiten dieser Roboter bei der Koordination oder Aufgabenausführung wird im Abstract nichts Näheres gesagt (Quelle: Ronald_vanLoon)
AI ermöglicht Strategien für Netzwerke der nächsten Generation: Dieser in Zusammenarbeit mit Infosys entstandene Artikel untersucht die entscheidende strategische Rolle von AI beim Aufbau und Management von Netzwerken der nächsten Generation (Next-Gen Networks). Der Inhalt könnte Themen wie Netzoptimierung mittels AI, vorausschauende Wartung, verbesserte Sicherheit, Realisierung von autonomem Netzwerkmanagement sowie Verbesserung des Kundenerlebnisses in zukünftigen Telekommunikations- und IT-Infrastrukturen abdecken und stellt einen Bezug zum MWC25 (Mobile World Congress) her (Quelle: Ronald_vanLoon)
Potenziell disruptive Auswirkungen des Quantencomputings auf die Wissenschaft: Ein Artikel in „Fast Company“ untersucht das revolutionäre Potenzial, das Quantencomputing für verschiedene Wissenschaftsbereiche hätte, wenn es ausgereift ist und seine Versprechen einlöst. Obwohl der Artikel nicht ausschließlich AI behandelt, wird erwartet, dass Quantencomputing komplexe Berechnungen in der AI beschleunigen kann, insbesondere bei der Optimierung des maschinellen Lernens, der Medikamentenentwicklung und der Materialwissenschaftssimulation, was die Art und Weise der wissenschaftlichen Entdeckung grundlegend verändern könnte (Quelle: Ronald_vanLoon)

Brain-Computer Interface ermöglicht Gelähmten die Steuerung eines Roboterarms per Gedankenkraft: Ein bedeutender Fortschritt in der Brain-Computer Interface (BCI)-Technologie ermöglicht es einer gelähmten Person, einen Roboterarm allein durch Gedankenkraft zu steuern. Dieser Durchbruch beruht höchstwahrscheinlich auf fortschrittlichen AI-Algorithmen zur Dekodierung neuronaler Signale des Gehirns und deren präziser Übersetzung in Steuerbefehle für den Roboterarm, was Hoffnung auf die Wiederherstellung motorischer Funktionen und ein unabhängiges Leben für schwer gelähmte Menschen gibt (Quelle: Ronald_vanLoon)
Idee für AI-gesteuerten Boss-Generator im Stil von “Cuphead”: Ein Nutzer schlägt ein kreatives Projekt vor: die Entwicklung eines AI-Generators für Bosse im Stil des Spiels „Cuphead“ unter Verwendung einer JavaScript-AI, die sich gut auf Codierung und Vektorgrafikgenerierung versteht. Die Vorstellung ist, die AI durch das Lernen des bestehenden Kunststils und der Boss-Mechaniken des Spiels zu trainieren, sodass Benutzer benutzerdefinierte neue Bosse generieren können, die dem Charakter des Spiels entsprechen. Websim.ai wird als mögliche Entwicklungsplattform genannt (Quelle: Reddit r/artificial)
Open-Source-Projekt EBAE gestartet: Für AI-Ethik und Würde: Das Projekt EBAE (Ethical Boundaries for AI Engagement) wurde öffentlich gestartet. Es handelt sich um eine Open-Source-Initiative zur Etablierung von Standards für den würdevollen Umgang mit AI, da dies die Werte der Menschheit widerspiegelt. Die Projektwebsite (https://dignitybydesign.github.io/EBAE/) bietet Ressourcen wie eine Ethik-Charta, ein abgestuftes Reaktionssystem (TBRS) für den Umgang mit Benutzermissbrauch, Reflexionsprotokolle, ein emotionales Kontextmodul (ECM) und einen Zertifizierungsrahmen. Die Projektinitiatoren rufen Entwickler, Designer, Autoren, Plattformgründer und Ethik-Befürworter zur Zusammenarbeit auf, um diese Standards gemeinsam zu prototypisieren und zu fördern, mit dem Ziel, von Anfang an respektvolle Mensch-Maschine-Interaktionsmuster zu gestalten (Quelle: Reddit r/artificial)
AI könnte Technologie zur Uranextraktion aus Meerwasser beschleunigen: Basierend auf einer Beschreibung von Gemini 2.5 Pro weist der Beitrag darauf hin, dass AI die praktische Umsetzung jüngster technologischer Durchbrüche bei der Uranextraktion aus Meerwasser (wie neue Hydrogele und metallorganische Gerüstverbindungen MOFs) erheblich beschleunigen kann. Es wird erwartet, dass AI eine Schlüsselrolle bei der Materialentwicklung (Entwurf neuer Adsorbentien bis ca. 2026), der Optimierung von Extraktionsprozessen durch Reinforcement Learning und digitale Zwillinge sowie der Vereinfachung der Produktionsskalierung spielen wird. Diese AI-getriebene Beschleunigung macht die großtechnische (möglicherweise Tausende Tonnen/Jahr) Uranextraktion aus Meerwasser bis 2030 zu einem glaubwürdigeren Szenario mit hohem Potenzial (Quelle: Reddit r/ArtificialInteligence)
Microsoft Podcast diskutiert AI-Empowerment von Patienten und Gesundheitskonsumenten: Eine Podcast-Folge von Microsoft Research beleuchtet erneut die Revolution im Gesundheitswesen durch AI, mit besonderem Fokus darauf, wie generative AI Patienten und Gesundheitskonsumenten mehr Handlungsmacht verleiht. Die Diskussion könnte Themen umfassen, wie AI-Tools Patienten helfen können, ihren Gesundheitszustand besser zu verstehen, die Arzt-Patienten-Kommunikation zu verbessern, personalisierte Gesundheitsinformationen bereitzustellen und das Gesundheits-Selbstmanagement zu unterstützen, wodurch sich die Rolle und Beteiligung der Patienten an ihrer eigenen Gesundheitsversorgung verändert (Quelle: Reddit r/ArtificialInteligence)

Nutzung von GNN zur Verbesserung des Realismus von NPC-Gruppenverhalten in Spielen: Ein Nutzer teilt eine Forschungsarbeit mit dem Titel „GCBF+: A Neural Graph Control Barrier Function Framework“, die Graph Neural Networks (GNN) für die verteilte, sichere Steuerung mehrerer Agenten einsetzt und erfolgreich bis zu 500 autonome Agenten bei der Navigation zur Kollisionsvermeidung steuert. Der Nutzer schlägt vor, diesen Ansatz auf die Steuerung von NPC-Mengen oder Verkehrsflüssen in Open-World-Spielen wie „GTA“ oder „Cyberpunk 2077“ anzuwenden, um ein realistischeres und fehlerfreieres (z. B. weniger Clipping, Hängenbleiben) Gruppenverhalten zu simulieren. Der Nutzer bekundet Interesse an einer Zusammenarbeit zu dieser Idee (Quelle: Reddit r/deeplearning)