
Schlüsselwörter:AI-Entwicklung, Grok 3, Gemma 3, KI-Anwendungen, Paradigmenwechsel in der KI-Entwicklung, xAI Grok 3 API, Google Gemma 3 QAT, VideoGameBench KI-Bewertung, KI-beschleunigte Molekülentdeckung, Föderiertes Lernen für medizinische Bildgebung, LlamaIndex Wissensagent, KI-Code-Selbstreparaturtechnologie
🔥 Fokus
Paradigmenwechsel in der KI-Entwicklung: Von der Jagd nach Ranglistenplätzen zur Wertschöpfung: Ein Blogbeitrag von OpenAI-Forscher Shunyu Yao löste Diskussionen aus und legt nahe, dass die KI-Entwicklung in die zweite Hälfte eingetreten ist. Die erste Hälfte konzentrierte sich auf Algorithmusinnovationen und die Jagd nach Spitzenplätzen in Benchmarks (wie AlphaGo, GPT-4), wobei durch die Kombination von groß angelegtem Pre-Training (Bereitstellung von Vorwissen) und Reinforcement Learning (RL) sowie der Einführung des Konzepts „Reasoning as Action“ ein Generalisierungsdurchbruch erzielt wurde. Er argumentiert jedoch, dass der Grenznutzen der kontinuierlichen Jagd nach Ranglistenplätzen abnimmt. Die zweite Hälfte sollte sich darauf konzentrieren, Probleme mit tatsächlichem Anwendungswert zu definieren, realitätsnähere Bewertungsmethoden zu entwickeln und wie ein Produktmanager zu denken, um wirklich Nutzer- und Gesellschaftswert mit KI zu schaffen, anstatt nur Metriken zu verbessern. Dies markiert einen Wandel im Denken im KI-Bereich von der technologiegetriebenen Exploration hin zur anwendungsorientierten Umsetzung und Wertrealisierung (Quelle: dotey)
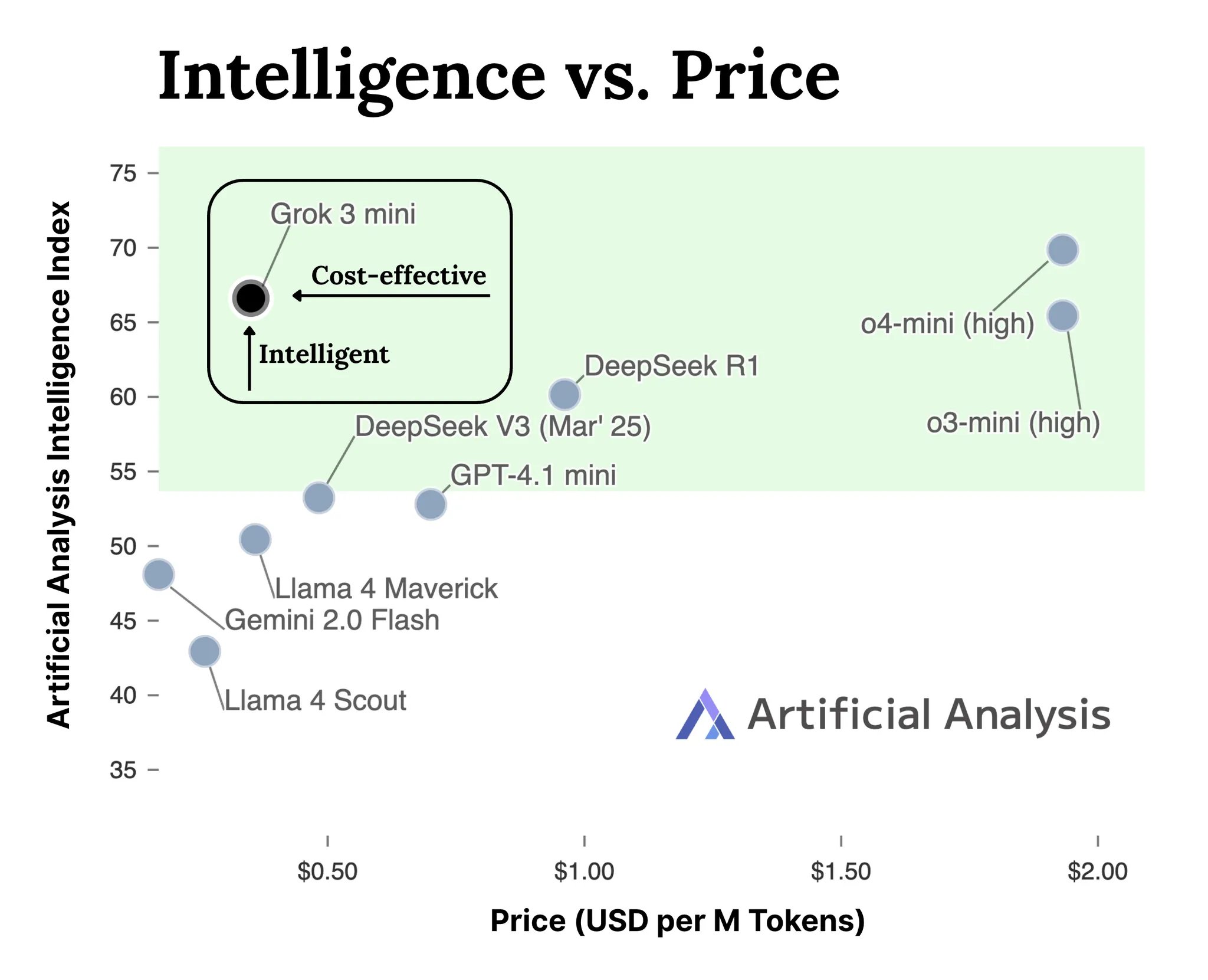
xAI veröffentlicht API für Grok 3 Modellreihe: xAI hat offiziell die API-Schnittstelle für seine Grok 3 Modellreihe (docs.x.ai) eingeführt und stellt seine neuesten Modelle Entwicklern zur Verfügung. Die Reihe umfasst Grok 3 Mini und Grok 3. Laut xAI zeigt Grok 3 Mini überlegene Reasoning-Fähigkeiten bei gleichzeitig niedrigen Kosten (angeblich 5-mal günstiger als vergleichbare Reasoning-Modelle); Grok 3 hingegen wird als leistungsstarkes Modell für nicht-schlussfolgernde Aufgaben positioniert (möglicherweise bezogen auf wissensintensive Aufgaben) und zeichnet sich in Bereichen wie Recht, Finanzen und Medizin aus, die Wissen über die reale Welt erfordern. Dieser Schritt markiert den Eintritt von xAI in den Wettbewerb um KI-Modell-APIs und bietet Entwicklern neue Optionen (Quelle: grok, grok)
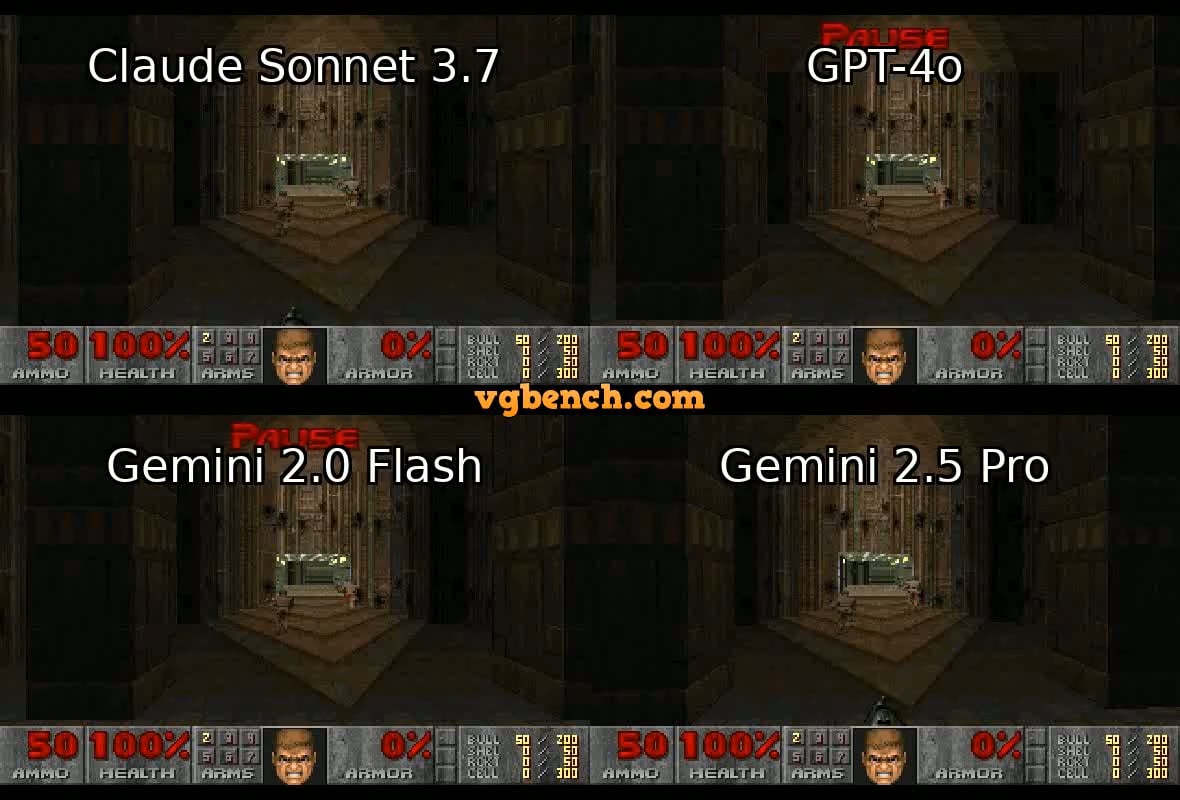
VideoGameBench: Bewertung von KI-Agentenfähigkeiten mit klassischen Spielen: Forscher haben eine Vorschauversion des VideoGameBench-Benchmarks vorgestellt, der die Fähigkeiten von Visual Language Models (VLM) bei der Echtzeit-Erfüllung von Aufgaben in 20 klassischen Videospielen (wie Doom II) bewerten soll. Erste Tests zeigen, dass Top-Modelle wie GPT-4o, Claude Sonnet 3.7 und Gemini 2.5 Pro in Doom II unterschiedlich abschneiden, aber keines den ersten Level schafft. Dies deutet darauf hin, dass Modelle trotz ihrer starken Fähigkeiten bei vielen Aufgaben immer noch vor Herausforderungen in komplexen dynamischen Umgebungen stehen, die Echtzeitwahrnehmung, Entscheidungsfindung und Handeln erfordern. Der Benchmark bietet ein neues Werkzeug zur Messung und Förderung des Fortschritts von KI-Agenten in interaktiven Umgebungen (Quelle: Reddit r/LocalLLaMA)
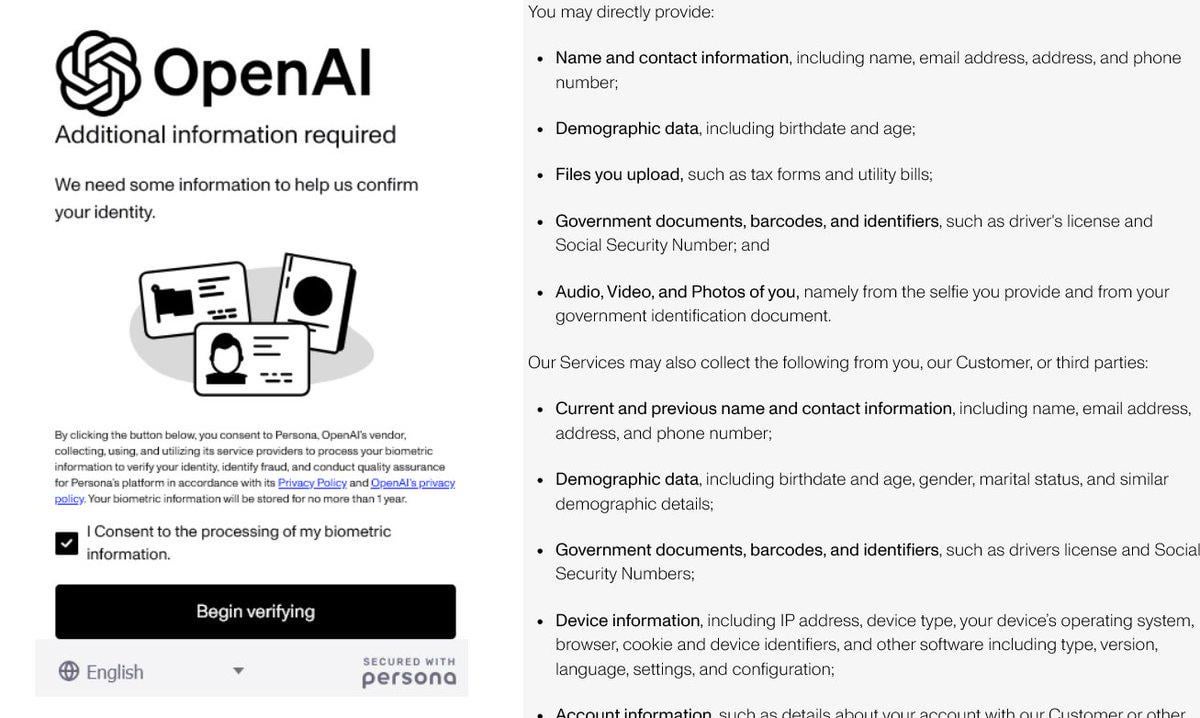
Verschärfte Identitätsprüfung bei OpenAI sorgt für Kontroversen: Berichten zufolge verlangt OpenAI von Nutzern detaillierte Identitätsnachweise (wie Reisepass, Steuerbescheid, Stromrechnung), um Zugang zu einigen seiner fortschrittlichen Modelle (insbesondere solchen mit starken Reasoning-Fähigkeiten wie o3) zu erhalten. Diese Maßnahme stößt in der Community auf heftige Gegenreaktionen, wobei Nutzer Bedenken hinsichtlich Datenschutzverletzungen und erhöhter Zugangshürden äußern. Obwohl OpenAI möglicherweise aus Sicherheits-, Compliance- oder Ressourcenmanagementgründen handelt, steht diese strenge Verifizierungsanforderung im Kontrast zu seinem offenen Image und könnte Nutzer dazu veranlassen, auf datenschutzfreundlichere oder leichter zugängliche Alternativen, insbesondere lokale Modelle, auszuweichen (Quelle: Reddit r/LocalLLaMA)
KI beschleunigt Molekülentdeckung: Simulation von Jahrmillionen natürlicher Evolution: In sozialen Medien wird diskutiert, dass künstliche Intelligenz in der Lage ist, innerhalb weniger Tage ein Molekül zu entwerfen, dessen natürliche Evolution möglicherweise 500 Millionen Jahre dauern würde. Obwohl konkrete Details noch zu überprüfen sind, unterstreicht dies das enorme Potenzial der KI zur Beschleunigung wissenschaftlicher Entdeckungen, insbesondere in der Chemie und Biologie. KI kann den riesigen chemischen Raum erkunden und Moleküleigenschaften mit einer Geschwindigkeit vorhersagen, die weit über traditionelle experimentelle Methoden und die natürliche Evolution hinausgeht, und verspricht Durchbrüche in Bereichen wie Medikamentenentwicklung und Materialwissenschaft (Quelle: Ronald_vanLoon)
🎯 Trends
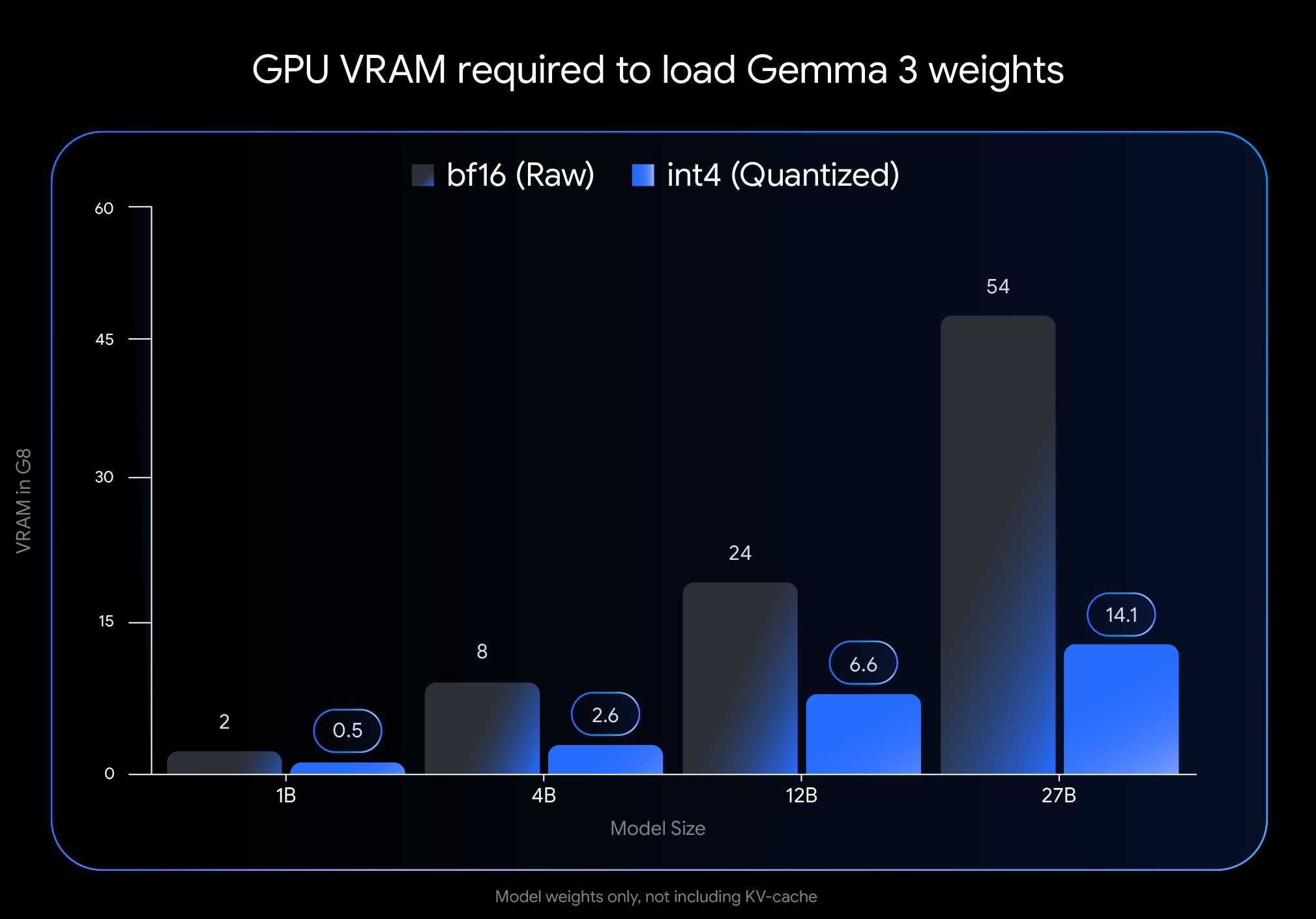
Google veröffentlicht Gemma 3 QAT-Version und senkt Bereitstellungshürde erheblich: Google DeepMind hat Versionen des Gemma 3 Modells veröffentlicht, die mit Quantization-Aware Training (QAT) trainiert wurden. Die QAT-Technologie zielt darauf ab, die Leistung des Originalmodells bei gleichzeitiger drastischer Reduzierung der Modellgröße maximal zu erhalten. Beispielsweise wird die Größe des Gemma 3 27B Modells von 54 GB (bf16) auf etwa 14,1 GB (int4) reduziert, wodurch führende Modelle, die ursprünglich High-End-Cloud-GPUs erforderten, nun auf Consumer-Desktop-GPUs (wie RTX 3090) ausgeführt werden können. Google hat nicht-quantisierte QAT-Checkpoints sowie verschiedene Formate (MLX, GGUF) veröffentlicht und arbeitet mit Community-Tools wie Ollama, LM Studio und llama.cpp zusammen, um sicherzustellen, dass Entwickler sie problemlos auf verschiedenen Plattformen nutzen können, was die Verbreitung von leistungsstarken Open-Source-Modellen erheblich fördert (Quelle: huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR veröffentlicht Forschungsergebnisse zur Wahrnehmung und hält am Open-Source-Kurs fest: Meta FAIR hat mehrere neue Forschungsergebnisse im Bereich Advanced Machine Intelligence (AMI) veröffentlicht, insbesondere Fortschritte im Bereich der Wahrnehmung, einschließlich der Veröffentlichung eines groß angelegten visuellen Encoders, des Meta Perception Encoder. Yann LeCun betonte, dass diese Ergebnisse Open Source sein werden. Dies zeigt Metas kontinuierliches Engagement in der Grundlagenforschung der KI und seine Verpflichtung, Forschungsfortschritte durch Open Source zu teilen, um das gesamte Feld voranzutreiben. Die veröffentlichten Tools wie der visuelle Encoder werden einer breiteren Forschungs- und Entwicklergemeinschaft zugutekommen (Quelle: ylecun)
OpenAI legt Nutzungsbeschränkungen für Modelle fest: OpenAI hat die Nutzungsmengen für seine Modelle für Nutzer von ChatGPT Plus, Team und Enterprise klar definiert. Für das o3-Modell gilt eine Beschränkung von 50 Nachrichten pro Woche, für o4-mini 150 pro Tag und für o4-mini-high 50 pro Tag. Angeblich haben Nutzer von ChatGPT Pro (möglicherweise eine spezifische Paketbezeichnung oder ein Fehler) unbegrenzten Zugriff. Diese Beschränkungen wirken sich direkt auf Vielnutzer und Anwendungsentwickler aus, die auf bestimmte Modelle angewiesen sind, und müssen bei der Nutzungsplanung berücksichtigt werden (Quelle: dotey)
LlamaIndex integriert Google Cloud Datenbanken zur Erstellung von Knowledge Agents: Auf der Google Cloud Next 2025 Konferenz zeigte LlamaIndex, wie sein Framework mit Google Cloud Datenbanken integriert werden kann, um Knowledge Agents zu erstellen, die mehrstufige Recherchen durchführen, Dokumente verarbeiten und Berichte generieren können. Die Demonstration umfasste ein Beispiel für ein Multi-Agent-System, das automatisch einen Leitfaden für das Onboarding von Mitarbeitern erstellt. Dies zeigt den Trend zur tiefen Integration von KI-Anwendungsframeworks mit Cloud-Plattformen und deren Datendiensten, um den tatsächlichen Bedarf von Unternehmen an der Nutzung von KI zur Verarbeitung interner Kenntnisse und Daten zu decken (Quelle: jerryjliu0)

Neuartiger Nano-Hirnsensor kombiniert mit KI erreicht hohe Signalerkennungsgenauigkeit: Forschungsberichte beschreiben einen neuartigen nanoskaligen Hirnsensor, der bei der Erkennung neuronaler Signale eine Genauigkeit von 96,4 % erreicht. Obwohl die Sensortechnologie selbst der Kern des Durchbruchs ist, erfordert das Erreichen einer solch hohen Erkennungsgenauigkeit typischerweise den Einsatz fortschrittlicher KI- und Machine-Learning-Algorithmen zur Dekodierung komplexer, schwacher neuronaler Signale. Dieser Fortschritt eröffnet neue Wege für die Hirnforschung und zukünftige Brain-Computer-Interface-Anwendungen und verspricht eine feinere Überwachung und Interaktion mit Gehirnaktivitäten (Quelle: Ronald_vanLoon)

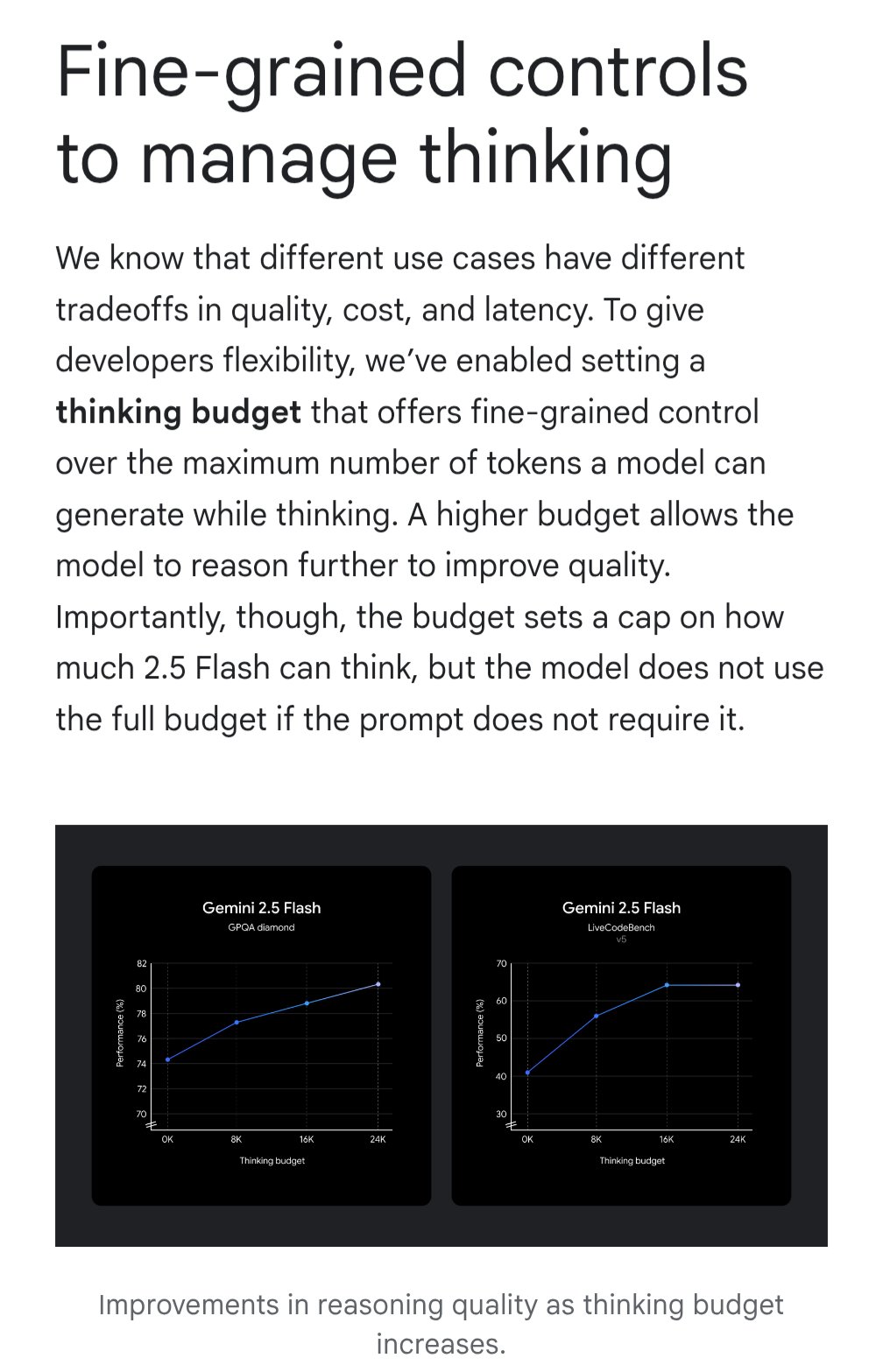
Gemini führt “Thinking Budget”-Funktion zur Optimierung der Kosteneffizienz ein: Das Google Gemini Modell führt die Funktion “Thinking Budget” ein, die es Nutzern ermöglicht, die Rechenressourcen oder die “Denktiefe” anzupassen, die das Modell bei der Bearbeitung von Anfragen zuweist. Die Funktion soll es Nutzern ermöglichen, einen Kompromiss zwischen Antwortqualität, Kosten und Latenz zu finden. Dies ist eine sehr praktische Funktion für API-Nutzer, die es ermöglicht, die Nutzungskosten und die Leistung des Modells flexibel an die Anforderungen spezifischer Anwendungsszenarien anzupassen (Quelle: JeffDean)
KI-gestützte Ultraschalluntersuchungsqualität vergleichbar mit Experten: Eine in JAMA Cardiology veröffentlichte Studie zeigt, dass die Bildqualität von Ultraschalluntersuchungen, die von geschultem medizinischem Fachpersonal unter KI-Anleitung durchgeführt wurden, diagnostischen Standards entspricht (98,3 %) und sich statistisch nicht signifikant von Bildern unterscheidet, die von Experten ohne KI-Anleitung aufgenommen wurden. Dies deutet darauf hin, dass KI als unterstützendes Werkzeug Nicht-Experten effektiv helfen kann, die Qualität und Konsistenz medizinischer Bildgebungsverfahren zu verbessern, und das Potenzial hat, die Verfügbarkeit hochwertiger Diagnosedienste in ressourcenbeschränkten Regionen zu erweitern (Quelle: Reddit r/ArtificialInteligence)
MIT-Forschung verbessert Genauigkeit und Strukturtreue von KI-generiertem Code: Forscher am MIT haben eine effizientere Methode zur Steuerung der Ausgabe von Large Language Models entwickelt, um Modelle dazu anzuleiten, Code zu generieren, der einer bestimmten Struktur (wie der Syntax einer Programmiersprache) entspricht und fehlerfrei ist. Diese Forschung zielt darauf ab, das Problem der Zuverlässigkeit von KI-generiertem Code zu lösen, indem die Techniken zur eingeschränkten Generierung verbessert werden, um sicherzustellen, dass die Ausgabe streng den Syntaxregeln folgt, wodurch die Nützlichkeit von KI-Code-Assistenten erhöht und die nachfolgenden Debugging-Kosten reduziert werden (Quelle: Reddit r/ArtificialInteligence)
NVIDIA enthüllt möglicherweise bedeutendes Projekt im Bereich Robotik: In sozialen Medien wird erwähnt, dass NVIDIA an seinem “ehrgeizigsten Projekt” arbeitet, das Robotik, Ingenieurwesen, künstliche Intelligenz und autonome Technologien umfasst. Obwohl spezifische Details unbekannt sind, wird jede bedeutende Ankündigung in diesem Zusammenhang angesichts der zentralen Stellung von NVIDIA bei KI-Hardware und -Plattformen (wie Isaac) mit Spannung erwartet und könnte auf weitere strategische Ausrichtungen und technologische Durchbrüche im Bereich Embodied Intelligence und Robotik hindeuten (Quelle: Ronald_vanLoon)
🧰 Werkzeuge
Potpie: Dedizierter KI-Engineering-Assistent für Code-Repositories: Potpie ist eine Open-Source-Plattform (GitHub: potpie-ai/potpie), die darauf abzielt, maßgeschneiderte KI-Engineering-Agenten für Code-Repositories zu erstellen. Sie baut einen Code-Wissensgraphen auf, um komplexe Beziehungen zwischen Komponenten zu verstehen, und bietet Automatisierungsaufgaben wie Code-Analyse, Testen, Debugging und Entwicklung. Die Plattform bietet verschiedene vorgefertigte Agenten (z. B. Debugging, Q&A, Code-Änderungsanalyse, Unit-/Integrationstestgenerierung, Low-Level-Design, Codegenerierung) und Toolsets und unterstützt Benutzer bei der Erstellung benutzerdefinierter Agenten. Sie bietet eine VSCode-Erweiterung und API-Integration zur einfachen Einbindung in den Entwicklungsprozess (Quelle: potpie-ai/potpie – GitHub Trending (all/daily))

1Panel: Linux-Server-Panel mit integriertem LLM-Management: 1Panel (GitHub: 1Panel-dev/1Panel) ist ein modernes Open-Source-Linux-Server-Betriebs- und Verwaltungs-Panel, das eine webbasierte grafische Benutzeroberfläche zur Verwaltung von Hosts, Dateien, Datenbanken, Containern usw. bietet. Eine seiner Besonderheiten ist die Integration von Verwaltungsfunktionen für Large Language Models (LLM). Darüber hinaus bietet es einen App Store, schnelle Website-Bereitstellung (integriert mit WordPress), Sicherheitsschutz und Ein-Klick-Backup/-Wiederherstellungsfunktionen, um die Serververwaltung und Anwendungsbereitstellung, einschließlich der Bereitstellung und Verwaltung von KI-bezogenen Anwendungen, zu vereinfachen (Quelle: 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex führt aktualisierte Chat-UI-Komponente ein: LlamaIndex hat ein bedeutendes Update seiner Chat-UI-Komponentenbibliothek (@llamaindex/chat-ui) veröffentlicht. Die neuen Komponenten basieren auf shadcn UI, haben ein moderneres Design, ein responsives Layout und sind vollständig anpassbar. Ziel ist es, Entwicklern zu helfen, einfacher ansprechende und benutzerfreundliche Chat-Oberflächen für LLM-basierte Projekte zu erstellen und das Interaktionserlebnis von KI-Anwendungen zu verbessern. Entwickler können sie über npm installieren und direkt in ihren Projekten verwenden (Quelle: jerryjliu0)
LlamaExtract in der Praxis: Erstellung einer Finanzanalyseanwendung: LlamaIndex demonstrierte die Nutzung seines LlamaExtract-Tools (Teil von LlamaCloud) zur Erstellung einer Full-Stack-Webanwendung. LlamaExtract ermöglicht es Benutzern, präzise Schemata zu definieren, um strukturierte Daten aus komplexen Dokumenten zu extrahieren. Die Beispielanwendung extrahiert Risikofaktoren aus Unternehmensjahresberichten und analysiert Änderungen über die Jahre, wodurch eine Aufgabe automatisiert wird, die zuvor über 20 Stunden dauerte. Diese Anwendung ist Open Source (GitHub: run-llama/llamaextract-10k-demo) und es gibt ein Video, das zeigt, wie man diesen Workflow mit LlamaExtract und Sonnet 3.7 erstellt, was das Potenzial von KI-Agenten bei der Automatisierung komplexer Analyseaufgaben demonstriert (Quelle: jerryjliu0, jerryjliu0)
mcpbased.com: Verzeichnis für Open-Source-MCP-Server gestartet: Die neue Website mcpbased.com wurde als dediziertes Verzeichnis für Open-Source-MCP-Server (möglicherweise Meta Controller Pattern oder ein ähnliches Konzept) gestartet. Die Plattform zielt darauf ab, verschiedene MCP-Server-Projekte zu sammeln und zu präsentieren, wobei Github-Repository-Daten in Echtzeit synchronisiert werden, um Entwicklern das Entdecken, Durchsuchen und Verbinden mit relevanten Tools zu erleichtern. Für Entwickler, die MCP-Server erstellen oder verwenden, Tool-Integrationen durchführen oder das MCP-Ökosystem verfolgen, ist dies ein neues Ressourcenzentrum (Quelle: Reddit r/ClaudeAI)
📚 Lernen
RLHF-Buch auf ArXiv verfügbar: Das von Nathan Lambert et al. verfasste Buch über Reinforcement Learning from Human Feedback (RLHF), “rlhfbook”, ist nun auf der ArXiv-Plattform verfügbar (Nummer 2504.12501). RLHF ist eine der Schlüsseltechnologien für das Alignment aktueller Large Language Models (wie ChatGPT). Die Veröffentlichung des Buches bietet Forschern und Praktikern eine wichtige Ressource zum systematischen Lernen und tiefen Verständnis der Prinzipien und Praktiken von RLHF und fördert die Verbreitung und Anwendung von Wissen in diesem Bereich (Quelle: natolambert)
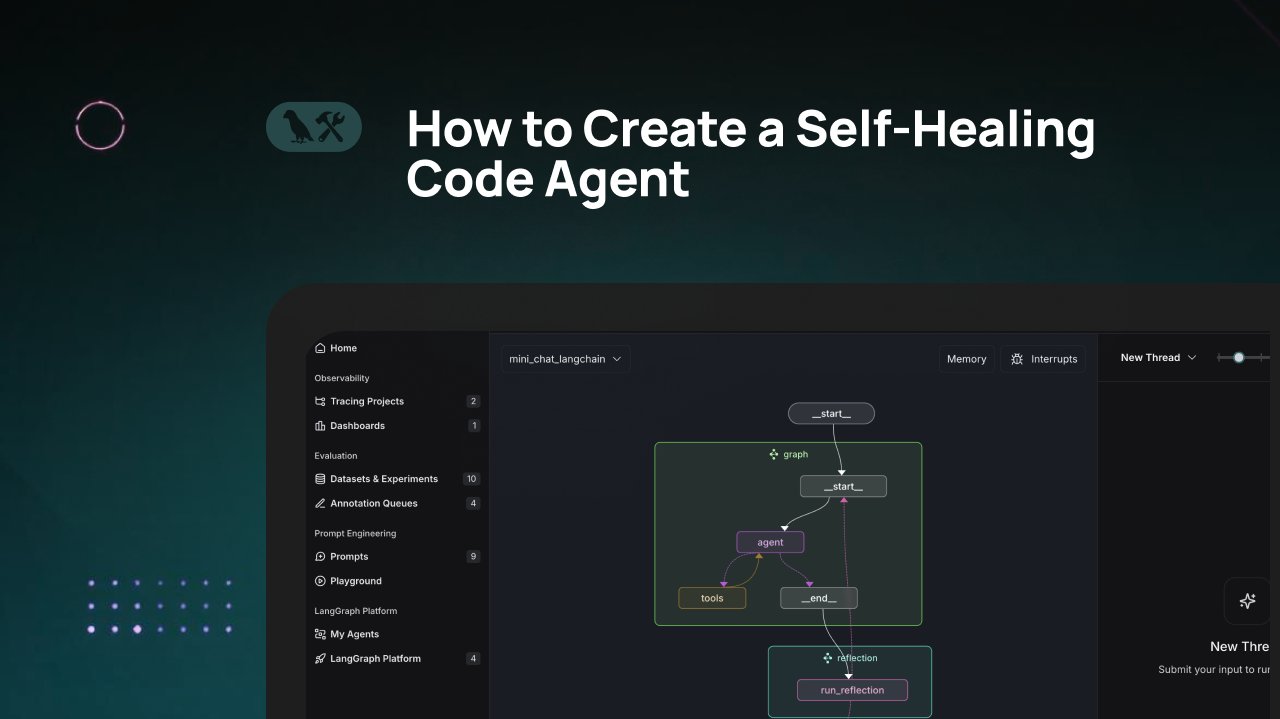
LangChain-Tutorial: Erstellung eines selbstheilenden Codegenerierungs-Agenten: LangChain hat ein Video-Tutorial veröffentlicht, das zeigt, wie man einen KI-Codegenerierungs-Agenten mit “selbstheilenden” Fähigkeiten erstellt. Die Kernidee besteht darin, nach der Codegenerierung einen “Reflexions”-Schritt hinzuzufügen, bei dem der Agent seinen generierten Code selbst überprüft, bewertet oder verbessert, bevor er das Ergebnis zurückgibt. Diese Methode zielt darauf ab, die Genauigkeit und Zuverlässigkeit von KI-generiertem Code zu erhöhen und ist eine effektive Technik zur Verbesserung der Nützlichkeit von Code-Assistenten (Quelle: LangChainAI)
KI kombiniert mit Blender zur Erstellung von spielbereiten 3D-Assets: In sozialen Medien wurde ein Tutorial geteilt, das zeigt, wie KI-Tools (möglicherweise zur Bildgenerierung) in Kombination mit der 3D-Modellierungssoftware Blender verwendet werden können, um spielbereite (game-ready) 3D-Assets zu erstellen. Dies adressiert das aktuelle Problem der unzureichenden Fähigkeit von KI, direkt 3D-Modelle zu generieren, und zeigt einen praktischen hybriden Workflow: Nutzung von KI zur Generierung von Konzepten oder Texturkarten, gefolgt von Modellierung und Optimierung mit professionellen Werkzeugen wie Blender, um schließlich Ressourcen zu produzieren, die den Anforderungen von Game Engines entsprechen (Quelle: huggingface)
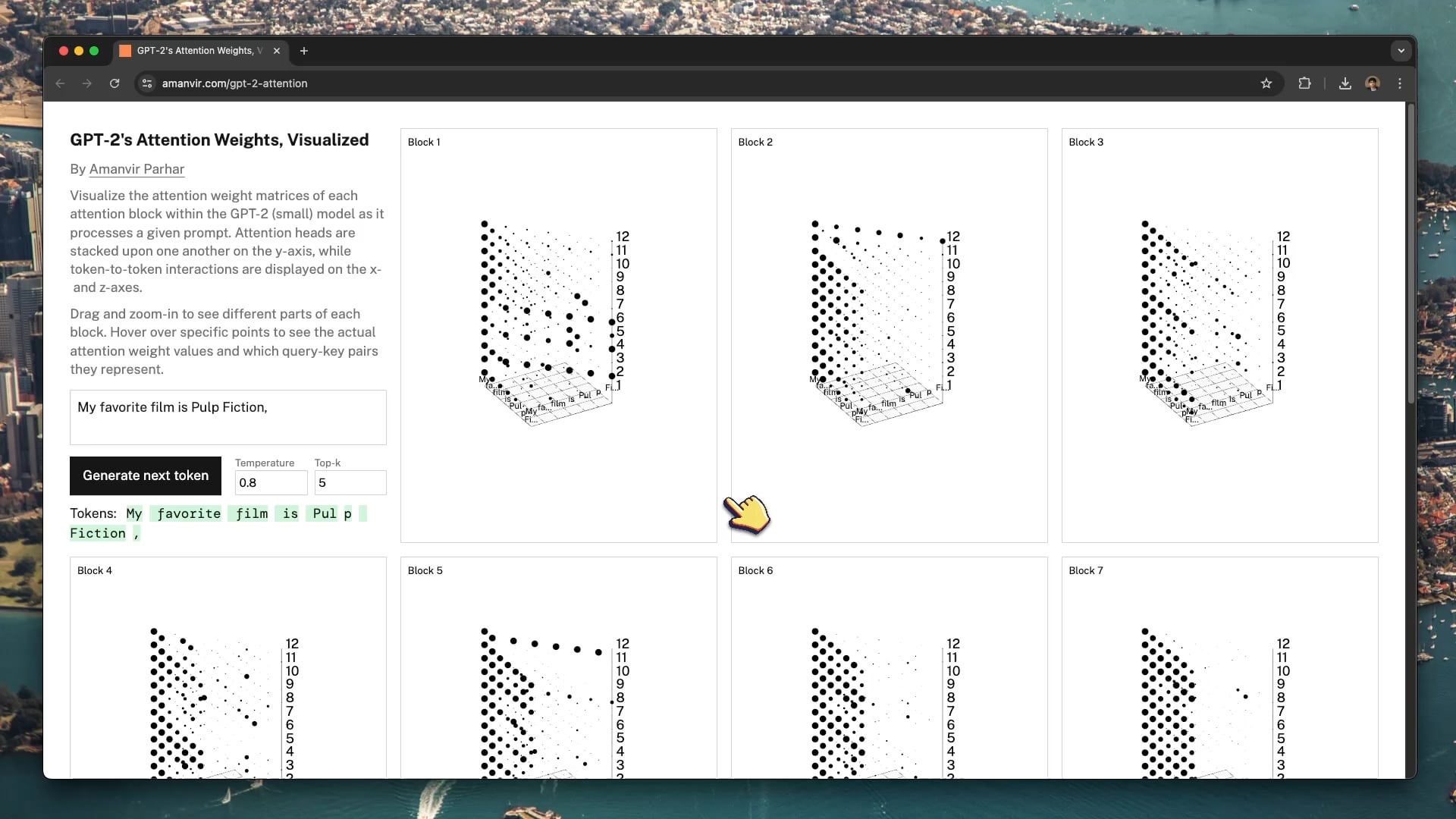
Interaktives Visualisierungstool hilft beim Verständnis des GPT-2 Attention-Mechanismus: Der Entwickler tycho_brahes_nose_ hat ein interaktives 3D-Visualisierungstool (amanvir.com/gpt-2-attention) erstellt und geteilt, das den Prozess der Gewichtungsberechnung in jedem Attention-Block des GPT-2 (small) Modells zeigt. Benutzer können intuitiv sehen, wie das Modell nach der Eingabe von Text die Interaktionsstärke zwischen Tokens über verschiedene Schichten und Attention Heads hinweg berechnet. Dies bietet eine hervorragende Hilfe zum Verständnis des Kernmechanismus von Transformern und unterstützt das KI-Lernen und die Forschung zur Modellerklärbarkeit (Quelle: karminski3, Reddit r/LocalLLaMA)
Anwendung von Federated Learning in der medizinischen Bildanalyse: Ein Reddit-Post verweist auf einen Artikel über die Kombination von Federated Learning (FL) mit Deep Neural Networks (DNN) zur Anwendung in der medizinischen Bildanalyse. Aufgrund der Datenschutzsensibilität medizinischer Daten ermöglicht FL das kollaborative Training von Modellen über mehrere Institutionen hinweg, ohne die Rohdaten zu teilen. Dies ist entscheidend für die Förderung der KI-Anwendung im medizinischen Bereich, und diese Ressource hilft, diese datenschutzfreundliche verteilte Lerntechnik und ihre Praxis in der medizinischen Bildgebung zu verstehen (Quelle: Reddit r/deeplearning)

Sander Dielman erläutert VAEs und Latent Spaces im Detail: Andrej Karpathy empfiehlt Sander Dielmans tiefgehenden Blogbeitrag (sander.ai/2025/04/15/latents.html) über Variational Autoencoders (VAE) und die Modellierung latenter Räume. Der Artikel untersucht Details des VAE-Trainings, wie z. B. die begrenzte tatsächliche Rolle des KL-Divergenz-Terms bei der Formung des latenten Raums und warum L1/L2-Rekonstruktionsverluste dazu neigen, unscharfe Bilder zu erzeugen (Diskrepanz zwischen dem spektralen Abfall von Bildern und der Wahrnehmung des menschlichen Auges). Der Beitrag bietet eine rigorose und aufschlussreiche Analyse zum Verständnis generativer Modelle (Quelle: Reddit r/MachineLearning)
💼 Geschäftlich
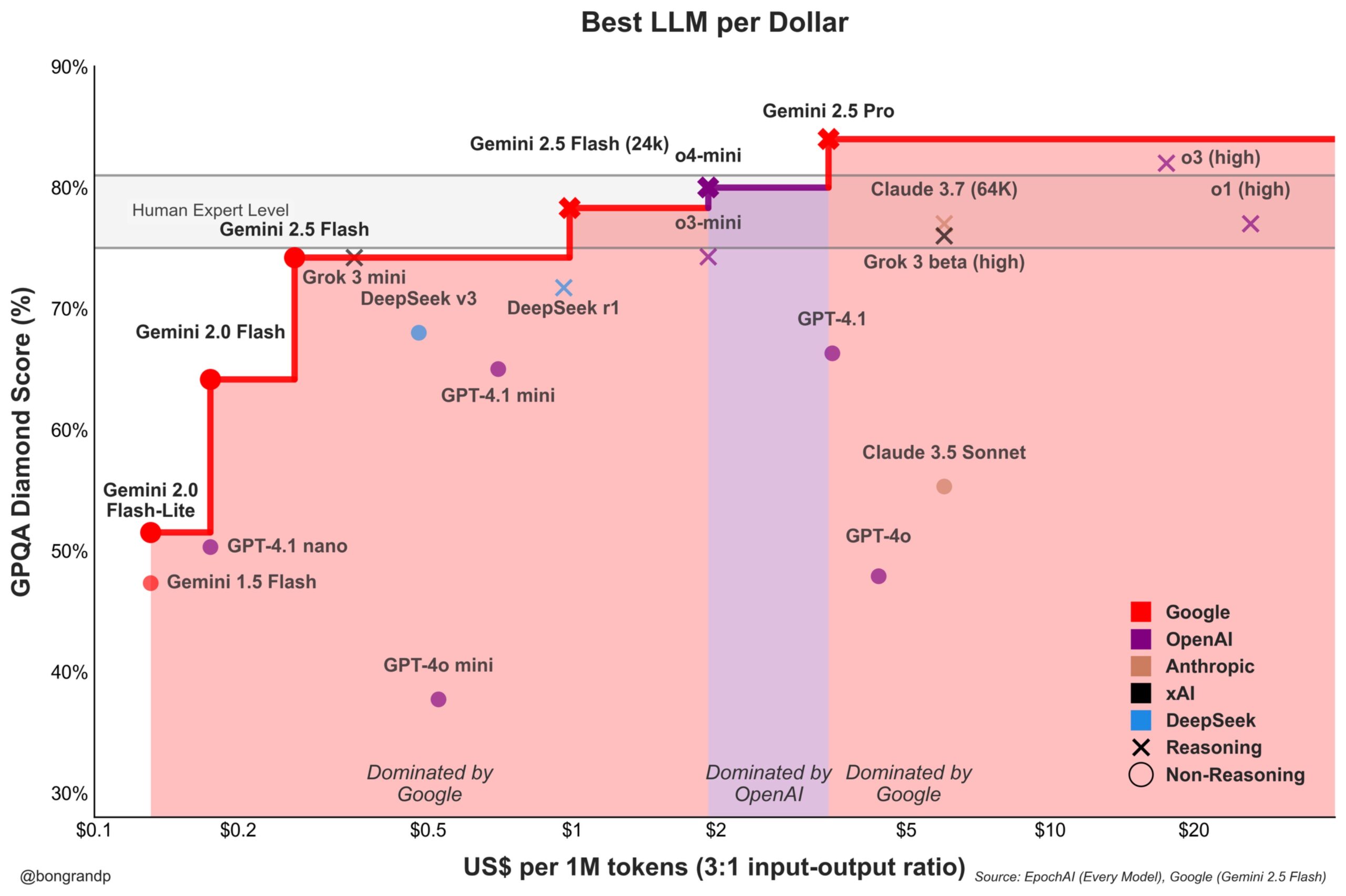
Modell-Preiskampf verschärft sich: Google Gemini fordert OpenAI aktiv heraus: Analysen deuten darauf hin, dass Google mit seiner Gemini-Modellreihe (insbesondere dem neu veröffentlichten Gemini 2.5 Flash) eine starke Wettbewerbsfähigkeit in Bezug auf Leistung und Preis zeigt und angeblich in etwa 95 % der Szenarien ein besseres Preis-Leistungs-Verhältnis als OpenAI bietet. Googles schnelle Reaktion bei seinen APIs und seine Preisstrategie (dominiert über 90 % des Preisspektrums) zeigen, dass es aktiv um Marktanteile im LLM-Markt kämpft und versucht, Nutzer durch Kostenvorteile zu gewinnen, was den Wettbewerb auf dem Markt für Basismodelle verschärft (Quelle: JeffDean)
Coinbase sponsert LangChain-Konferenz und erkundet Agentic Commerce: Coinbase Development ist Sponsor der LangChain Interrupt 2025 Konferenz. Coinbase ermöglicht mit seinen Tools wie AgentKit und dem x402-Zahlungsprotokoll “Agentic Commerce”, bei dem KI-Agenten autonom Zahlungen für Dienste wie Kontextabruf oder API-Aufrufe tätigen können. Diese Zusammenarbeit unterstreicht die Schnittstelle zwischen KI-Agententechnologie und Web3-Zahlungen und deutet auf zukünftige Szenarien KI-gesteuerter automatisierter wirtschaftlicher Interaktionen hin (Quelle: LangChainAI)

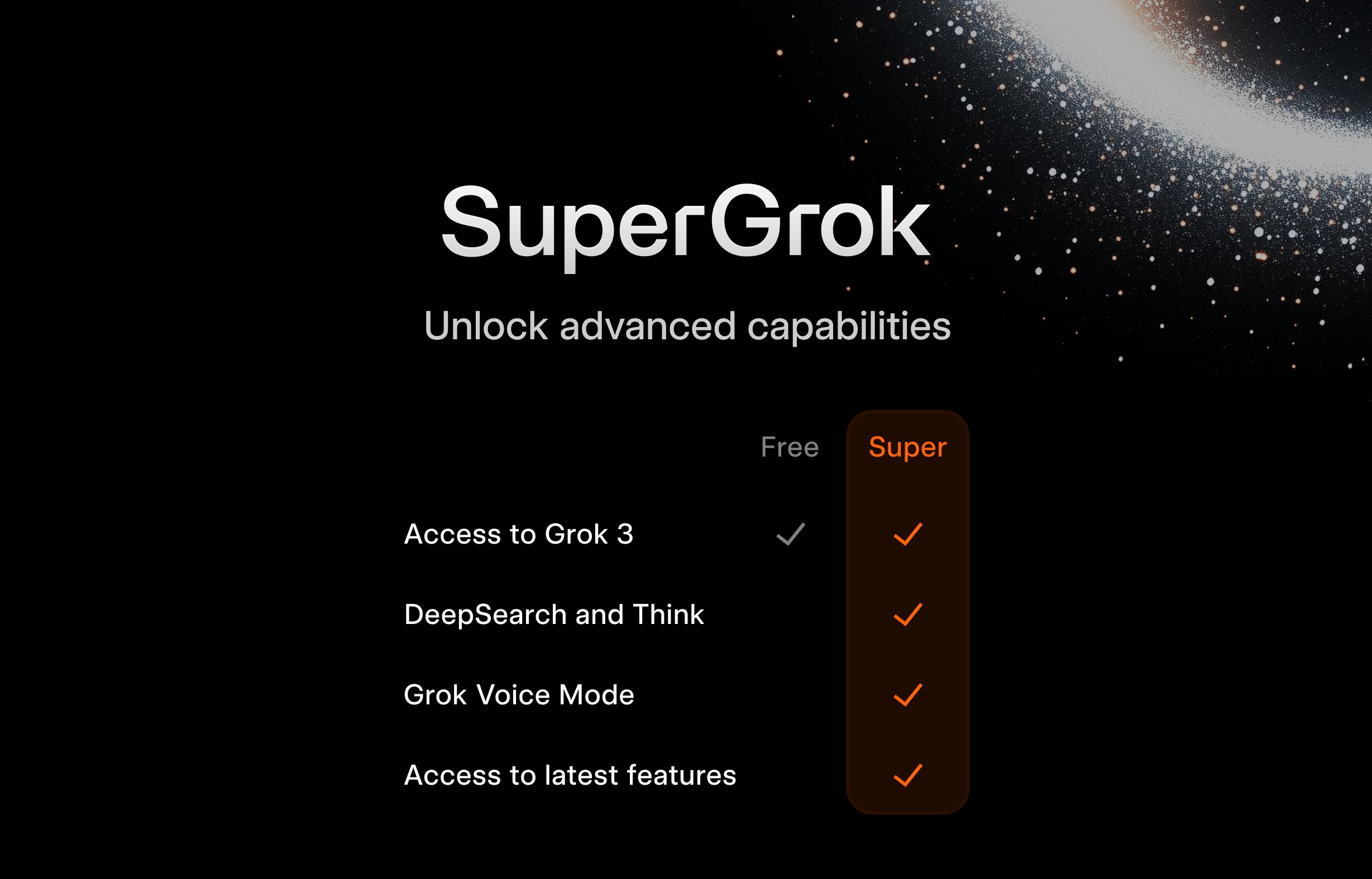
xAI startet kostenloses SuperGrok-Programm für Studenten: Um junge Nutzergruppen anzuziehen, bietet xAI eine Aktion für Studenten an: Bei Registrierung mit einer .edu-E-Mail-Adresse erhalten sie zwei Monate kostenlosen Zugang zu SuperGrok (der Premium-Version von Grok). Ziel dieser Maßnahme ist es, Grok als Lernhilfe zu positionieren, es während der Prüfungszeit zu bewerben, Nutzer im Bildungsmarkt zu gewinnen und zukünftige potenzielle zahlende Kunden zu binden (Quelle: grok)
Google bietet US-Studenten kostenlosen Zugang zu Gemini Advanced und weiteren Diensten: Google kündigt langfristige kostenlose Vorteile für US-Studenten an: Bei Registrierung bis zum 30. Juni 2025 erhalten sie kostenlosen Zugang zu Gemini Advanced (mit Gemini 2.5 Pro), NotebookLM Plus, Gemini-Funktionen in Google Workspace, Whisk sowie 2 TB Cloud-Speicher bis zum Ende des Frühjahrssemesters 2026. Diese groß angelegte Werbeaktion zielt darauf ab, Googles KI-Tools tief in das Bildungsökosystem zu integrieren, mit Konkurrenten wie Microsoft zu konkurrieren und die nächste Generation von Nutzern und Entwicklern an die Google AI-Plattform zu binden (Quelle: demishassabis, JeffDean)
FanDuel startet Promi-KI-Chatbot “ChuckGPT”: Die Sportpersönlichkeit Charles Barkley hat seinen Namen, sein Bild und seine Stimme lizenziert, um in Zusammenarbeit mit dem Sportwettenanbieter FanDuel einen KI-Chatbot namens “ChuckGPT” (chuck.fanduel.com) zu starten. Dies ist ein weiteres Beispiel für die Nutzung von Promi-IP und KI-Technologie für Markenmarketing und Nutzerinteraktion, indem der Gesprächsstil des Prominenten simuliert wird, um Sportinformationen, Wettvorschläge oder unterhaltsame Interaktionen anzubieten und die Nutzerbindung zu erhöhen (Quelle: Reddit r/artificial)
🌟 Community
Sorge über Abhängigkeit von KI-Tools: Eine Karikatur in sozialen Medien, die einen Nutzer umgeben von zahlreichen KI-Tools (ChatGPT, Claude, Midjourney etc.) mit der Überschrift “AI Tool Dependency” zeigt, findet Anklang. Dies spiegelt die Informationsüberflutung und potenzielle übermäßige Abhängigkeit wider, die einige Nutzer angesichts der ständig wachsenden Zahl von KI-Anwendungen empfinden, sowie die kognitive Belastung bei der Verwaltung und Auswahl geeigneter Tools (Quelle: dotey)
Scheitern von Top-Modellen bei spezifischem Test enthüllt Fähigkeitsgrenzen: Perplexity CEO Arav Srinivas teilte einen Testfall, der zeigt, dass sowohl o3 als auch Gemini 2.5 Pro eine komplexe Zeichenaufgabe nicht erfolgreich lösen konnten. Dies wird von einigen als herausfordernder Test für die aktuellen Fähigkeiten der Modelle angesehen. Solche “Fehlerfälle” werden in der Community breit diskutiert, um die Grenzen von SOTA-Modellen bei spezifischem Reasoning, räumlichem Verständnis oder der Befolgung von Anweisungen aufzuzeigen und helfen, die Lücke zwischen aktueller KI und Artificial General Intelligence (AGI) objektiver einzuschätzen (Quelle: AravSrinivas)
Community diskutiert GPT-4o-generierte Kissenbilder und teilt Prompts: Nutzer teilen Erfolgsbeispiele und optimierte Prompts für die Generierung von Kissenbildern in einem bestimmten Stil (süß, Micro-Velvet-Textur, Emoji-Form) mit GPT-4o. Solche Beiträge zeigen die Anwendung von KI-Bildgenerierung im kreativen Design und fördern den Austausch über Prompt-Engineering-Techniken und Stil-Explorationen innerhalb der Community. Hochwertige Generierungsergebnisse regen die kreative Begeisterung der Nutzer an (Quelle: dotey)

Sam Altman: KI eher Renaissance als industrielle Revolution: OpenAI CEO Sam Altman äußerte die Ansicht, dass der durch künstliche Intelligenz ausgelöste Wandel eher einer Renaissance als einer industriellen Revolution gleicht. Diese Metapher löst Diskussionen in der Community aus und legt nahe, dass die Auswirkungen der KI möglicherweise stärker auf kultureller, intellektueller und kreativer Ebene liegen als nur in einer mechanisierten Steigerung der Produktivität. Diese qualitative Einschätzung beeinflusst die Erwartungen und Vorstellungen über die zukünftige gesellschaftliche Rolle der KI (Quelle: sama)
Community fragt nach Open-Sourcing von Grok 2: Reddit-Nutzer diskutieren, wann xAI sein Versprechen einlösen wird, das Grok 2 Modell Open Source zu machen. Viele befürchten, dass Grok 2 angesichts der schnellen Iterationsgeschwindigkeit der KI-Technologie bei seiner Veröffentlichung bereits hinter anderen zeitgenössischen Modellen (wie DeepSeek V3, Qwen 3) zurückbleiben könnte und sich das Schicksal von Grok 1 wiederholt, das bei Veröffentlichung als veraltet galt. Die Diskussion berührt auch den Kompromiss zwischen dem Wert von Open-Source-Modellen (Forschung, Lizenzfreiheit) und ihrer Aktualität (Quelle: Reddit r/LocalLLaMA)
Interpretation von Altmans Aussage: Daten-Effizienz als neuer Engpass für AGI?: Die Reddit-Community diskutiert Sam Altmans Aussage, dass KI eine 100.000-fache Steigerung der Daten-Effizienz benötigt und nicht nur mehr Rechenleistung, und interpretiert dies als Signal, dass der aktuelle Weg zur AGI durch brute-force Skalierung an Grenzen stößt. Es wird argumentiert, dass hochwertige menschliche Daten nahezu erschöpft sind, synthetische Daten nur begrenzte Wirkung zeigen und die geringe Lerneffizienz der Modelle die zentrale Herausforderung darstellt, was sogar die Hardware-Investitionspläne von Unternehmen wie Microsoft beeinflussen könnte. Die Diskussion spiegelt eine Reflexion über den Entwicklungspfad der KI wider (Quelle: Reddit r/artificial)
Wie unterscheidet man Gedächtnis von Reasoning bei LLMs?: Die Community erörtert, wie man effektiv testen kann, ob Large Language Models tatsächlich über Reasoning-Fähigkeiten verfügen oder lediglich Muster aus den Trainingsdaten wiedergeben oder kombinieren. Es wird vorgeschlagen, neuartige “Was wäre wenn”-Fragen zu verwenden, die das Modell noch nie gesehen hat, um seine generalisierte Reasoning-Fähigkeit zu untersuchen. Dies berührt das Kernproblem bei der Bewertung der Intelligenz von LLMs: die Unterscheidung zwischen fortgeschrittener Mustererkennung und echter logischer Schlussfolgerung (Quelle: Reddit r/MachineLearning)
Nutzer teilt “beängstigendes” Gespräch mit GPT und löst Ethik-Debatte aus: Ein Nutzer teilte Screenshots eines Gesprächs mit ChatGPT, das potenziell negative gesellschaftliche Auswirkungen von KI (wie Gedankenkontrolle, Verlust kritischen Denkens) thematisiert und es als “beängstigend” bezeichnet. Der Beitrag löste eine Diskussion aus, deren Schwerpunkte darauf lagen, ob die KI-Ausgabe die Nutzerführung oder die “Gedanken” des Modells widerspiegelt, die ethischen Grenzen der KI sowie die Angst der Nutzer vor potenziellen Risiken der KI (Quelle: Reddit r/ChatGPT)

Lokales Ausführen großer Modelle stößt an Speichergrenzen: In der r/OpenWebUI-Community berichten Nutzer, dass sie beim Ausführen von OpenWebUI und Ollama auf einer Konfiguration mit 16 GB RAM und einer RTX 2070S keine großen Modelle über 12B (wie Gemma3:27b) laden können, da der Systemspeicher und der Swap-Speicher erschöpft sind. Dies repräsentiert eine häufige Herausforderung für viele Nutzer, die versuchen, große Modelle auf Consumer-Hardware lokal bereitzustellen, und unterstreicht die hohen Anforderungen der Modelle an Hardware-Ressourcen (insbesondere Speicher) (Quelle: Reddit r/OpenWebUI)
GPT-4o-generiertes Poster löst “Designer-Jobverlust”-Debatte aus: Ein Nutzer präsentiert ein von GPT-4o generiertes Poster für einen “Hundepark”, lobt das Ergebnis als “nahezu perfekt” und erklärt “Grafikdesigner sind tot”. Im Kommentarbereich entbrennt eine heftige Debatte: Einerseits wird die fortschrittliche Fähigkeit der KI-Bildgenerierung anerkannt, andererseits werden Mängel im Design (zu viel Text, schlechtes Layout, Rechtschreibfehler) aufgezeigt und betont, dass KI derzeit ein Werkzeug zur Effizienzsteigerung ist, aber nicht den Kernwert von Designern bei kreativen Entscheidungen, ästhetischem Urteilsvermögen und Markenpassung ersetzen kann (Quelle: Reddit r/ChatGPT)

Lebenszyklusmanagement von fine-tuned Modellen rückt in den Fokus: Entwickler fragen in der Community: Was passiert mit Modellen, die auf einem Basismodell (wie GPT-4o) fine-tuned wurden, wenn dieses Basismodell aktualisiert wird (z. B. durch GPT-5)? Da fine-tuning oft an eine spezifische Basismodellversion gebunden ist, kann die Einstellung oder Aktualisierung des Basismodells Entwickler zwingen, neu zu trainieren, was kontinuierliche Kosten und Wartungsprobleme mit sich bringt. Dies löst eine Diskussion über die Abhängigkeit und langfristige Strategie bei der Verwendung von Closed-Source-APIs für fine-tuning aus (Quelle: Reddit r/ArtificialInteligence)
Suche nach Setup für Sprachdialog mit lokalen LLMs: Community-Nutzer suchen nach Systemlösungen, um Sprachdialoge mit lokalen LLMs zu führen, ähnlich der Erfahrung mit Google AI Studio, für Brainstorming und Planung. Die Frage spiegelt den Wunsch der Nutzer wider, von textbasierter Interaktion zu natürlicheren Sprachinteraktionen überzugehen, und sucht nach praktischen Methoden und Erfahrungsaustausch zur Integration von STT, LLM und TTS in lokalen Frameworks wie OpenWebUI (Quelle: Reddit r/OpenWebUI )
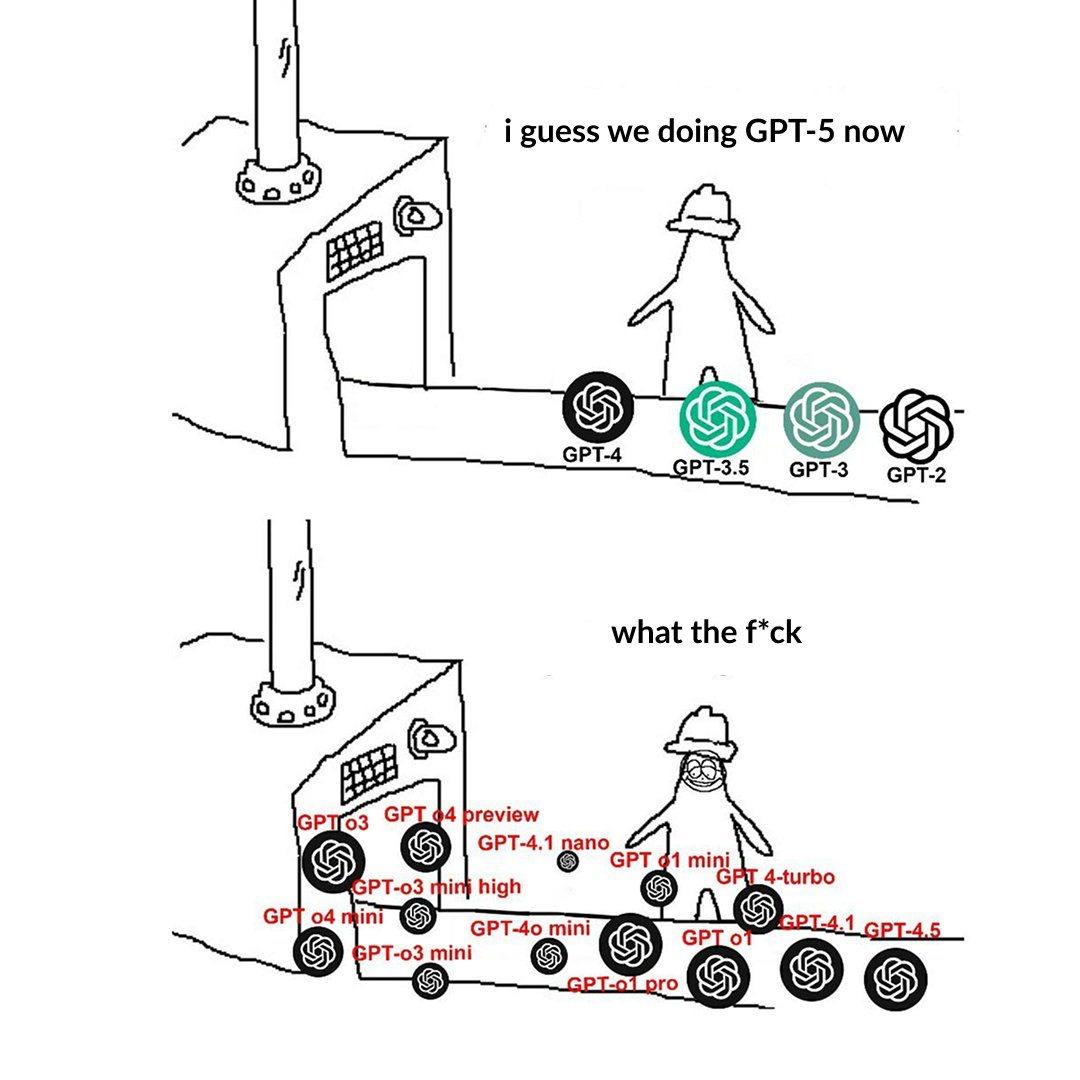
Namensgebung der OpenAI-Modellhierarchie verwirrt Nutzer: Nutzer beschweren sich in einem Post über die verwirrende Namensgebung der OpenAI-Modelle (z. B. o3, o4-mini, o4-mini-high, o4). Ein Bild zeigt verschiedene Modellstufen, deren Namen und die Beziehung zu Fähigkeiten und Einschränkungen nicht intuitiv klar sind. Dies spiegelt wider, dass mit der wachsenden Modellfamilie eine klare Produktlinienabgrenzung und Namensgebung für das Verständnis und die Auswahl durch die Nutzer zur Herausforderung wird (Quelle: Reddit r/artificial)

Übermäßig “lobender” Stil von ChatGPT sorgt für Diskussionen: Community-Nutzer weisen durch Memes und Diskussionen darauf hin, dass ChatGPT dazu neigt, Nutzerfragen übermäßig zu loben (“Das ist eine großartige Frage!”), selbst wenn die Frage gewöhnlich oder sogar dumm ist. Es wird diskutiert, dass dies eine von OpenAI entwickelte Strategie zur Steigerung der Nutzerbindung sein könnte, aber auch zu Bestätigungsfehlern bei den Nutzern führen und kritisches Feedback vermissen lassen könnte. Einige Nutzer äußern sogar den Wunsch nach “bissigeren” Bewertungen durch die KI (Quelle: Reddit r/ChatGPT)

Herausforderungen für KI bei Spielen mit unvollständiger Information: Die Community diskutiert die Herausforderungen, denen sich KI bei der Verarbeitung von Spielen mit unvollständiger Information (wie dem “Fog of War” in StarCraft) gegenübersieht. Im Gegensatz zu Spielen mit vollständiger Information wie Go oder Schach erfordern diese Spiele, dass die KI mit Unsicherheit umgeht, Erkundungen durchführt und langfristig plant, und sie kann sich nicht einfach auf globale Informationen und Vorberechnungen verlassen. Obwohl KI in Spielen wie Dota 2 und StarCraft (AlphaStar) Fortschritte erzielt hat, bleibt das Erreichen eines stabilen Niveaus über menschlichen Spitzenspielern eine Herausforderung (Quelle: Reddit r/ArtificialInteligence)
Warnung vor “Sprachlicher Konvergenz” durch KI-Inhalte: Nutzer führen das Konzept der “linguistic mimicry” (sprachliche Nachahmung) ein und äußern die Sorge, dass das Lesen großer Mengen von KI-generierten Inhalten, deren Stil möglicherweise konvergiert, dazu führen könnte, dass die sprachliche Ausdrucksweise und sogar die Denkweise der Menschen vereinheitlicht und homogenisiert wird. Dieses Phänomen könnte eine potenzielle Bedrohung für kulturelle Vielfalt und individuelles unabhängiges Denken darstellen. Das Lesen vielfältiger Werke menschlicher Autoren wird als ein Weg zur Erhaltung der sprachlichen Vitalität empfohlen (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
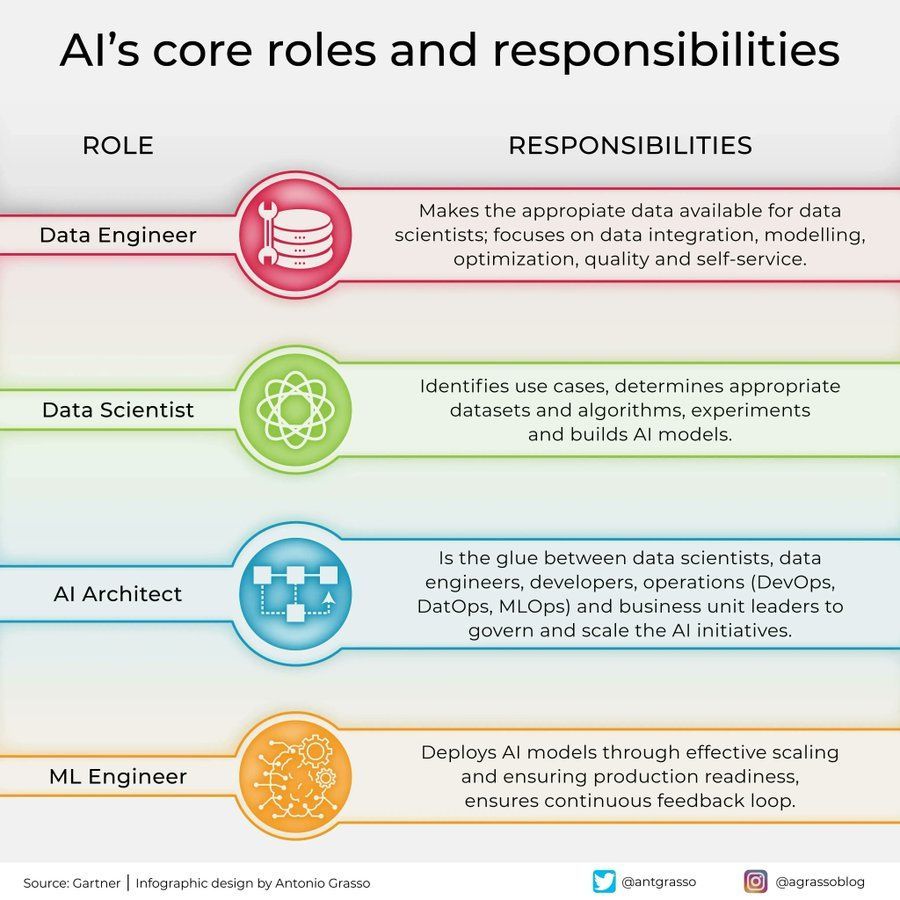
Rollen und Verantwortlichkeiten im KI-Bereich: In sozialen Medien wurde eine Infografik geteilt, die die Kernrollen und ihre Verantwortlichkeiten im Bereich der künstlichen Intelligenz skizziert, wie z. B. Data Scientist, Machine Learning Engineer, AI Researcher usw. Diese Grafik hilft, die Arbeitsteilung innerhalb von KI-Projektteams, die erforderlichen Fähigkeiten und den interdisziplinären Charakter der KI-Entwicklung zu verstehen (Quelle: Ronald_vanLoon)
Anwendungen und Herausforderungen von KI in der Telekommunikationsbranche: Es werden bahnbrechende Anwendungen und potenzielle Fallstricke von KI in der Telekommunikationsbranche diskutiert. KI wird umfassend zur Netzwerkoptimierung, für intelligente Kundendienste, vorausschauende Wartung usw. eingesetzt, um Effizienz und Nutzererfahrung zu verbessern, steht aber gleichzeitig vor Herausforderungen wie Datenschutz, algorithmischer Voreingenommenheit und Implementierungskomplexität. Eine eingehende Erörterung dieser Aspekte hilft der Branche, KI-Chancen zu nutzen und Risiken zu vermeiden (Quelle: Ronald_vanLoon)
Einfluss der Psychologie auf die KI-Entwicklung: Ein Artikel untersucht, wie die Psychologie die Entwicklung der künstlichen Intelligenz beeinflusst hat und dieser Einfluss andauert. Erkenntnisse aus der Kognitionswissenschaft, Lerntheorien, Bias-Forschung usw. liefern wichtige Referenzen für das KI-Design, z. B. bei der Simulation menschlicher kognitiver Prozesse oder dem Verständnis und Umgang mit Voreingenommenheit. Umgekehrt bietet KI auch neue Modellierungs- und Testwerkzeuge für die psychologische Forschung (Quelle: Ronald_vanLoon)

Große Rechenanlage zeigt Hardware-Anforderungen der KI: Ein Nutzer teilte ein Bild einer riesigen, komplexen Computerhardware-Anlage (höchstwahrscheinlich ein großer Multi-GPU-Servercluster) und nannte sie ein “Monster”. Dieses Bild spiegelt anschaulich den enormen Rechenressourcenbedarf wider, der für das Training großer KI-Modelle oder hochintensive Inferenzaufgaben erforderlich ist, und verdeutlicht die hohe Abhängigkeit moderner KI von der Hardware-Infrastruktur (Quelle: karminski3)

Rolle der KI in der Cybersicherheit: Ein Artikel untersucht die transformative Rolle der künstlichen Intelligenz im Bereich der Cybersicherheit. KI-Technologien werden zur Verbesserung der Bedrohungserkennung (z. B. Analyse anomalen Verhaltens), zur Automatisierung von Sicherheitsreaktionen, zur Schwachstellenbewertung und -vorhersage usw. eingesetzt, um die Effizienz und Fähigkeiten der Verteidigung zu steigern. Allerdings kann KI selbst auch böswillig genutzt werden und neue Sicherheitsherausforderungen mit sich bringen (Quelle: Ronald_vanLoon)

Hochpräzise OCR steht vor Herausforderung der Zeichenverwechslung: Entwickler, die ein hochpräzises OCR-System zur Erkennung kurzer alphanumerischer Codes (wie Seriennummern) erstellen möchten, stoßen auf ein häufiges Problem: Das Modell hat Schwierigkeiten, visuell ähnliche Zeichen (wie I/1, O/0) zu unterscheiden. Selbst bei Verwendung eines YOLO-Modells zur Erkennung einzelner Zeichen gibt es Grenzfälle. Dies unterstreicht die Herausforderung, in spezifischen Szenarien eine nahezu perfekte OCR-Genauigkeit zu erreichen, was gezielte Optimierungen von Modell, Daten oder den Einsatz von Nachbearbeitungsstrategien erfordert (Quelle: Reddit r/MachineLearning)

Hilfe bei der Ausführung der Gym Retro-Umgebung gesucht: Ein Nutzer stößt bei der Verwendung der Reinforcement-Learning-Bibliothek Gym Retro auf technische Probleme: Er hat das Spiel Donkey Kong Country erfolgreich importiert, weiß aber nicht, wie er die voreingestellte Umgebung für das Training starten soll. Dies ist ein typisches Konfigurations- und Bedienungsproblem, auf das KI-Forscher bei der Verwendung spezifischer Tools stoßen können (Quelle: Reddit r/MachineLearning)
Entscheidungsdilemma bei ähnlicher Leistung mehrerer Modelle: Ein Forscher stellt bei der Verwendung verschiedener Merkmalsauswahlmethoden und Machine-Learning-Modelle fest, dass mehrere Kombinationen ähnliche hohe Leistungsniveaus erreichen (z. B. Genauigkeit 93-96 %), was die Auswahl der optimalen Lösung erschwert. Dies spiegelt wider, dass bei der Modellbewertung, wenn sich Standardmetriken kaum unterscheiden, andere Faktoren wie Modellkomplexität, Interpretierbarkeit, Inferenzgeschwindigkeit, Robustheit usw. berücksichtigt werden müssen, um die endgültige Entscheidung zu treffen (Quelle: Reddit r/MachineLearning)
Umzug von arXiv zu Google Cloud erregt Aufmerksamkeit: Als wichtige Preprint-Plattform für KI und viele andere Forschungsbereiche plant arXiv den Umzug von den Servern der Cornell University zu Google Cloud. Diese bedeutende Änderung der Infrastruktur könnte Verbesserungen bei Skalierbarkeit und Zuverlässigkeit bringen, aber auch Diskussionen in der Community über Betriebskosten, Datenmanagement und Open-Access-Strategien auslösen (Quelle: Reddit r/MachineLearning)
Claude generiert Wirtschaftssimulationstool mit Einschränkungen: Ein Nutzer verwendete die Claude Artifact-Funktion, um einen interaktiven Simulator für die Auswirkungen von Zöllen auf die Wirtschaft zu generieren. Obwohl dies die Fähigkeit der KI zur Generierung komplexer Anwendungen zeigt, weisen Kommentare darauf hin, dass die Simulationsergebnisse möglicherweise zu vereinfacht sind oder nicht den ökonomischen Prinzipien entsprechen (z. B. allgemeiner Nutzen durch hohe Zölle). Dies mahnt zur Vorsicht bei der Verwendung von KI-generierten Analysewerkzeugen und zur Notwendigkeit einer strengen Überprüfung ihrer inneren Logik und Annahmen (Quelle: Reddit r/ClaudeAI)

Integration benutzerdefinierter XTTS-Sprachklone in OpenWebUI: Nutzer suchen nach einer Möglichkeit, ihre mit der Open-Source-Technologie XTTS geklonten Stimmen in OpenWebUI zu integrieren, um die kostenpflichtige ElevenLabs API zu ersetzen und eine personalisierte, kostenlose Sprachausgabe zu realisieren. Dies repräsentiert den Bedarf der Nutzer bei der Verwendung lokaler KI-Tools an der Integration von Open-Source- und anpassbaren Komponenten (wie TTS) (Quelle: Reddit r/OpenWebUI)