
Schlüsselwörter:Gemini 2.5 Flash, OpenAI o3, KI-Ersatz von Arbeitsplätzen, KI-Kommerzialisierung im Gesundheitswesen, Hybrides Reasoning-Modell, Denkbudget-Funktion, o4-mini Multimodal-Fähigkeiten, KI-Codierassistent Windsurf, Agentic AI-Heimgateway, VisualPuzzles Benchmark-Test, DeepSeek Empfehlungszuverlässigkeit, Zhipu AI Open-Source-Modell
🔥 Fokus
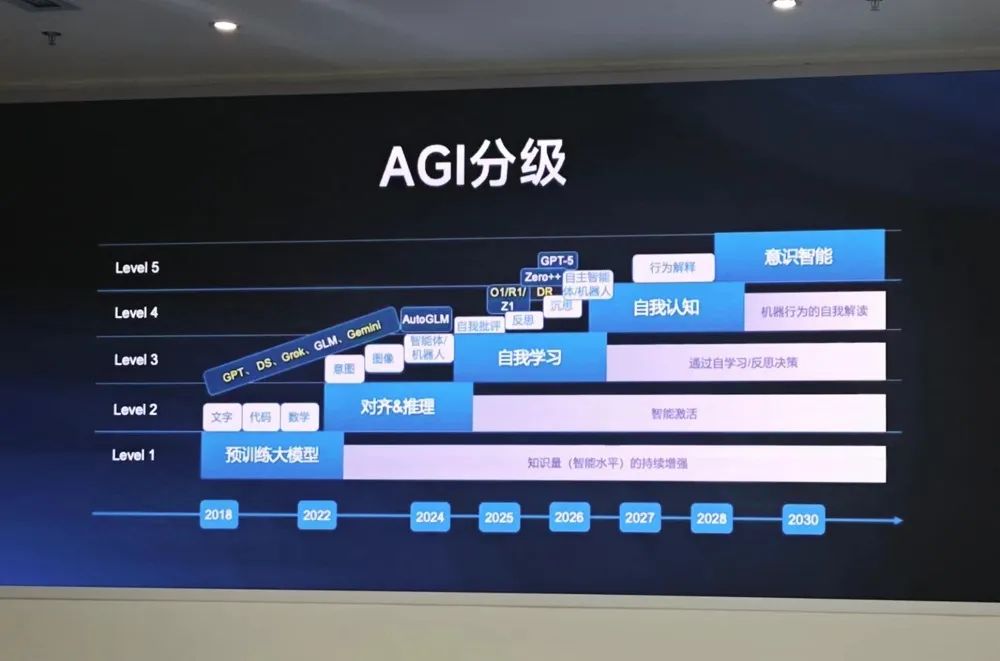
Google veröffentlicht Gemini 2.5 Flash Hybrid-Inferenzmodell, Fokus auf Preis-Leistung und kontrollierbares Denken: Google stellt die Vorschauversion von Gemini 2.5 Flash vor, positioniert als kostengünstiges Hybrid-Inferenzmodell. Seine Einzigartigkeit liegt in der Einführung der Funktion „thinking_budget“, die es Entwicklern (0-24k Token) oder dem Modell selbst ermöglicht, die Inferenz-Tiefe je nach Aufgabenkomplexität anzupassen. Bei ausgeschaltetem Denken sind die Kosten extrem niedrig ($0.6/Millionen Token Output), die Leistung übertrifft 2.0 Flash; bei eingeschaltetem Denken ($3.5/Millionen Token Output) können komplexe Aufgaben bewältigt werden, wobei die Leistung in mehreren Benchmarks (wie AIME, MMMU, GPQA) mit o4-mini konkurriert und in der LMArena-Rangliste weit oben steht. Das Modell zielt darauf ab, Leistung, Kosten und Latenz auszubalancieren, besonders geeignet für Anwendungsszenarien, die Flexibilität und Kostenkontrolle erfordern, und ist bereits über API in Google AI Studio und Vertex AI verfügbar. (Quelle: 谷歌首款混合推理Gemini 2.5登场,成本暴降600%,思考模式一开,直追o4-mini, 谷歌大模型“性价比之王”来了,混合推理模型,思考深度可自由控制,竞技场排名仅次于自家Pro, op7418, JeffDean, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)

OpenAI veröffentlicht o3 und o4-mini Modelle, stärkt Inferenz und multimodale Fähigkeiten: OpenAI führt seine bisher stärkste Modellreihe o3 sowie das optimierte o4-mini ein, mit Schwerpunkt auf verbesserten Fähigkeiten in Inferenz, Programmierung und multimodalem Verständnis. Insbesondere wird erstmals bildbasiertes „Chain-of-Thought“-Reasoning realisiert, das die Analyse von Bilddetails für komplexe Urteile ermöglicht, wie z.B. die Ableitung des genauen Aufnahmeortes anhand eines Fotos (GeoGuessing). o3 erreicht im Mensa-IQ-Test einen neuen Höchstwert von 136 Punkten und zeigt hervorragende Leistungen in Programmier-Benchmarks. o4-mini demonstriert bei gleichzeitig hoher Effizienz und niedrigen Kosten starke Fähigkeiten zur Lösung mathematischer Probleme (wie Euler-Probleme) und zur visuellen Verarbeitung. Diese Modelle sind bereits für ChatGPT Plus-, Pro- und Team-Nutzer verfügbar und zeigen, dass OpenAI die Modelle von der Wissensakquise hin zur Werkzeugnutzung und Lösung komplexer Probleme weiterentwickelt. (Quelle: 实测o3/o4-mini:3分钟解决欧拉问题,OpenAI最强模型名副其实, 智商136,o3王者归来,变身福尔摩斯“AI查房”,一张图秒定坐标, 满血版o3探案神技出圈,OpenAI疯狂暗示:大模型不修仙,要卷搬砖了)

KI-Effizienzsteigerung löst Beschäftigungssorgen aus, einige Unternehmen ersetzen Stellen durch KI: Die hohe Effizienz der Künstlichen Intelligenz veranlasst Unternehmen wie PayPal, Shopify, United Wholesale Mortgage, darüber nachzudenken oder tatsächlich menschliche Arbeitsplätze durch KI zu ersetzen, insbesondere in Bereichen wie Kundenservice, Junior-Vertrieb, IT-Support und Datenverarbeitung. Beispielsweise bearbeitet der KI-Chatbot von PayPal bereits 80% der Kundendienstanfragen, was die Kosten erheblich senkt. United Wholesale Mortgage nutzt KI zur Bearbeitung von Hypothekendokumenten, was die Effizienz erheblich steigert und das Geschäftsvolumen verdoppelt, ohne zusätzliches Personal einzustellen. Einige Unternehmen schlagen sogar das Konzept des „Null-Mitarbeiter-Teams“ vor und fordern, dass neue Mitarbeiter erst eingestellt werden, wenn nachgewiesen ist, dass KI die Aufgabe nicht erfüllen kann. Obwohl viele Unternehmen vermeiden, öffentlich zuzugeben, dass Entlassungen auf KI zurückzuführen sind, sind verlangsamte Einstellungen und Stellenabbau bereits ein Trend. Insbesondere unter Kostendruck wird erwartet, dass der Substitutionseffekt von KI auf Bürojobs in Zukunft deutlicher wird. (Quelle: 招聘慢了、岗位少了,AI效率太高迫使人类员工“让位”)

OpenAI plant Übernahme des KI-Codierassistenten Windsurf für 3 Mrd. USD, verstärkt Engagement auf Anwendungsebene: OpenAI plant die Übernahme des KI-Coding-Startups Windsurf (ehemals Codeium) für rund 3 Milliarden US-Dollar, was die bisher größte Akquisition wäre. Windsurf bietet ähnliche KI-Codierhilfswerkzeuge wie Cursor an, die ebenfalls auf Anthropic-Modellen basieren. Diese Übernahme wird als entscheidender Schritt von OpenAI zur Expansion in die Anwendungsebene und zur Stärkung der Kontrolle über das Ökosystem angesehen. Ziel ist es, direkt Nutzer zu gewinnen, Trainingsdaten zu sammeln und mit Konkurrenten wie GitHub Copilot und Cursor zu konkurrieren. Analysten gehen davon aus, dass mit der Verbesserung der KI-Fähigkeiten „Vibe Coding“ (KI tief in den Entwicklungsprozess integriert) zum Trend wird und die Kontrolle über den Zugang zur Anwendungsebene und Nutzerdaten für die langfristige Wettbewerbsfähigkeit von Modellunternehmen entscheidend ist. Dieser Schritt von OpenAI zeigt, dass seine strategischen Ziele über die Rolle eines Modellanbieters hinausgehen und darauf abzielen, eine vollständige KI-Entwicklungsplattform aufzubauen. (Quelle: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
🎯 Trends
ByteDance veröffentlicht Doubao 1.5 Deep-Thinking-Modell und multimodale Updates, beschleunigt Agent-Layout: Volcano Engine von ByteDance veröffentlicht das Doubao 1.5 Deep-Thinking-Modell, das über menschenähnliche Fähigkeiten zum „gleichzeitigen Sehen, Suchen und Denken“ verfügt, komplexe Aufgaben bewältigen kann, multimodale Eingaben (Text, Bild) unterstützt und über Fähigkeiten zur Internetsuche und visuellen Inferenz verfügt. Gleichzeitig wurden das Doubao Text-zu-Bild-Modell 3.0 (verbessert Textsatz und Bildrealismus) und ein verbessertes visuelles Verständnismodell (verbessert Lokalisierungsgenauigkeit und Videoverständnis) veröffentlicht. ByteDance betrachtet Deep Thinking und Multimodalität als Grundlage für den Aufbau von Agents und führt eine OS Agent-Lösung sowie eine AI Cloud-Native Inference Suite ein, um die Einstiegshürden und Kosten für Unternehmen beim Aufbau und der Bereitstellung von Agent-Anwendungen zu senken. Dieser Schritt wird als Neuausrichtung der Strategie von ByteDance nach dem Druck durch Konkurrenzprodukte wie DeepSeek und als Fokussierung auf die Implementierung von Agent-Anwendungen angesehen. (Quelle: 字节按下 AI Agent 加速键, 被DeepSeek打蒙的豆包,发起反攻了)

ByteDance und Kuaishou treffen im Bereich KI-Videogenerierung erneut aufeinander, Fokus auf Modellleistung und Implementierung: ByteDance veröffentlicht das Seaweed-7B Videogenerierungsmodell und betont wenige Parameter (7B), hohe Effizienz (66,5 Millionen H100 GPU-Stunden Training) und geringe Bereitstellungskosten (einzelne GPU kann 1280×720 Videos generieren). Kuaishou hingegen veröffentlicht das „Keling 2.0“ Videogenerierungsmodell und das „Ketu 2.0“ Bildgenerierungsmodell, behauptet eine Leistung, die Google Veo2 und Sora übertrifft, und führt eine multimodale Bearbeitungsfunktion MVL ein. Beide Seiten erkennen an, dass die Modellfähigkeiten das Limit der KI-Produkte darstellen, und der strategische Fokus für 2025 kehrt zur Modellverfeinerung zurück. Obwohl die Kommerzialisierungspfade unterschiedlich sind (ByteDance Jimeng tendiert zum C-End, Kuaishou Keling konzentriert sich auf das B-End), bemühen sich beide um eine Verbesserung der Praktikabilität. Kuaishou betont beispielsweise die Bedeutung von Bild-zu-Video, während ByteDance seine Vorteile bei der Textverarbeitung nutzt, um die Konsistenz der Videoerzählung zu gewährleisten. Der Wettbewerb verschärft sich. (Quelle: 字节快手,AI视频“狭路又相逢”)

Zhipu AI veröffentlicht drei Open-Source-Modelle, verstärkt Aufbau des Open-Source-Ökosystems: Zhipu AI erklärt 2025 zum „Jahr des Open Source“ und veröffentlicht drei Modelle: GLM-Z1-Air (Inferenzmodell), GLM-Z1-Air (sollte ein Tippfehler sein, vermutlich Express-Version oder Basismodell gemeint) und GLM-Z1-Rumination (Rumination-Modell) in den Größen 9B und 32B unter MIT-Lizenz. GLM-Z1-Air (32B) erreicht in einigen Benchmark-Tests eine Leistung nahe an DeepSeek-R1, bei deutlich reduziertem Inferenzpreis. Das Rumination-Modell Z1-Rumination erforscht tiefergehendes Denken und unterstützt geschlossene Forschungskreisläufe. Gleichzeitig kündigt der Zhipu Z-Fonds an, 300 Millionen Yuan zur Unterstützung der globalen AI-Open-Source-Community bereitzustellen, nicht beschränkt auf Projekte, die auf Zhipu-Modellen basieren. Dieser Schritt entspricht der Strategie der Stadt Peking, eine „Globale Hauptstadt des Open Source“ zu werden. (Quelle: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Einbettung von Agentic AI in Home Gateways könnte neue Chance für Netzbetreiber sein: Mit der Entwicklung von KI von generativ zu agentenbasiert (Agentic AI) rücken KI-Systeme mit autonomen Zielsetzungs- und Aufgabenausführungskompetenzen in den Fokus. Führungskräfte von MediaTek schlagen vor, dass die Einbettung von Agentic AI in Home Gateways die Rolle der Netzbetreiber im IoT-Markt verändern könnte. Als Edge-Intelligence-Hub des Heimnetzwerks kann das Gateway in Kombination mit Agentic AI proaktiv das Netzwerk verwalten (z. B. Videoanrufe optimieren), Fehler diagnostizieren, die Haussicherheit verbessern (z. B. Paketdiebstahl erkennen, Risiko, dass Kinder sich dem Pool nähern), wodurch die Kundenservicekosten der Betreiber gesenkt werden (viele Wi-Fi-bezogene Anfragen können von KI bearbeitet werden) und Mehrwertdienste angeboten werden. Obwohl das Monetarisierungsmodell noch erforscht werden muss, bietet dies den Betreibern einen potenziellen Weg, über die Rolle einer reinen „Pipeline“ hinauszugehen und zu einem Service Enabler für Agentic AI zu werden. (Quelle: 将Agentic AI嵌入家庭网关,如何改变运营商在物联网市场的游戏规则?)
Microsoft veröffentlicht MAI-DS-R1, nachtrainiert auf Basis von DeepSeek R1 für Sicherheit und Compliance: Das KI-Team von Microsoft hat das Modell MAI-DS-R1 veröffentlicht, das auf DeepSeek R1 nachtrainiert wurde. Ziel ist es, Informationslücken des ursprünglichen Modells zu schließen und dessen Risikoprofil zu verbessern, während die Inferenzfähigkeit von R1 erhalten bleibt. Die Trainingsdaten umfassen 110.000 Sicherheits- und nicht konforme Beispiele aus Tulu 3 SFT sowie etwa 350.000 von Microsoft intern entwickelte mehrsprachige Beispiele, die verschiedene Themen mit Voreingenommenheit abdecken. Dieser Schritt wird von einigen Community-Mitgliedern als Bemühung von Microsoft interpretiert, die Sicherheit und Compliance von Modellen zu verbessern, löste aber auch Diskussionen darüber aus, ob dadurch eine „Unternehmenszensur“ hinzugefügt wurde. (Quelle: Reddit r/LocalLLaMA)

🧰 Tools
OpenAI veröffentlicht Codex CLI als Open Source, terminalgesteuerter KI-Codierassistent: OpenAI hat das neue Open-Source-Projekt Codex CLI veröffentlicht, einen KI-Agenten zur Optimierung von Codieraufgaben, der im lokalen Terminal des Entwicklers ausgeführt werden kann. Standardmäßig verwendet es das neueste o4-mini-Modell, aber Benutzer können über die API andere OpenAI-Modelle auswählen. Codex CLI zielt darauf ab, eine chatgesteuerte Entwicklungsmethode bereitzustellen, die Operationen im lokalen Code-Repository versteht und ausführt und mit Tools wie Claude Code von Anthropic sowie Cursor und Windsurf konkurriert. Das Projekt erhielt innerhalb eines Tages nach Veröffentlichung über 14.000 Sterne auf GitHub, was das Interesse der Entwickler an terminal-nativen KI-Codierungswerkzeugen zeigt. (Quelle: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
Google AI Studio Upgrade unterstützt direkte Erstellung und Freigabe von KI-Anwendungen: Google hat seine AI Studio-Plattform aktualisiert und eine neue Funktion hinzugefügt, mit der KI-Anwendungen direkt auf der Plattform erstellt werden können. Benutzer können nicht nur Modelle wie Gemini für die Entwicklung verwenden, sondern auch Beispielanwendungen durchsuchen und ausprobieren, die von anderen Benutzern erstellt wurden. Dieses Upgrade entwickelt AI Studio von einem Modell-Experimentierfeld zu einer umfassenderen Plattform für Anwendungsentwicklung und -austausch weiter und senkt die Hürde für die Erstellung von Anwendungen auf Basis der Google KI-Technologie. (Quelle: op7418)
NVIDIA cuML führt GPU-Beschleunigungsmodus ohne Code-Änderungen ein: Das NVIDIA cuML-Team hat einen neuen Accelerator-Modus veröffentlicht, der es Benutzern ermöglicht, nativen Code von scikit-learn, umap-learn und hdbscan direkt auf der GPU auszuführen, ohne jeglichen Code ändern zu müssen. Die Funktion wird über python -m cuml.accel your_script.py oder durch Laden von %load_ext cuml.accel in einem Jupyter Notebook aktiviert. Benchmarks zeigen signifikante Beschleunigungen von 25x bis 175x für Algorithmen wie Random Forest, Linear Regression, t-SNE, UMAP, HDBSCAN. Der Modus nutzt CUDA Unified Memory (UVM), sodass die Datensatzgröße normalerweise kein Problem darstellt, die Leistung bei Datensätzen mit extrem großem Speicherbedarf jedoch beeinträchtigt wird. (Quelle: Reddit r/MachineLearning)

Alibaba veröffentlicht Wan 2.1 Open-Source-Videomodell für Anfangs- und Endbilder: Alibaba hat sein Wan 2.1 Videomodell als Open Source veröffentlicht. Dieses Modell konzentriert sich darauf, den mittleren Videoinhalt basierend auf dem ersten und letzten Bild zu generieren. Dies ist eine spezielle Art von Videogenerierungstechnologie, die in Szenarien wie Video-Interpolation, Stiltransfer oder keyframe-basierter Animationsgenerierung eingesetzt werden kann. Die Veröffentlichung dieses Modells bietet Forschern und Entwicklern neue Werkzeuge zur Erkundung und Nutzung dieser Technologie. (Quelle: op7418)
ViTPose: Modell zur menschlichen Posenschätzung basierend auf Vision Transformer: ViTPose ist ein neues Modell, das die Vision Transformer (ViT)-Architektur für die menschliche Posenschätzung nutzt. Der Artikel stellt das Modell vor und erörtert das Potenzial von ViT für Computer-Vision-Aufgaben (hier die menschliche Posenschätzung). Solche Modelle nutzen typischerweise den Self-Attention-Mechanismus von Transformern, um langreichweitige Abhängigkeiten zwischen verschiedenen Teilen eines Bildes zu erfassen, was potenziell die Genauigkeit und Robustheit der Posenschätzung verbessern kann. (Quelle: Reddit r/deeplearning)

ClaraVerse: Local-First KI-Assistent mit n8n-Integration: ClaraVerse ist ein Local-First KI-Assistent, der auf Ollama basiert und Datenschutz sowie lokale Kontrolle betont. Das neueste Update integriert die Automatisierungsplattform n8n, die es Benutzern ermöglicht, benutzerdefinierte Werkzeuge und Workflows (wie E-Mail-Prüfung, Kalenderverwaltung, API-Aufrufe, Datenbankverbindungen usw.) innerhalb des Assistenten zu erstellen und auszuführen, ohne externe Dienste zu benötigen. Dies ermöglicht es Clara, lokale Automatisierungsaufgaben durch natürliche Sprachbefehle auszulösen, mit dem Ziel, eine benutzerfreundliche, wenig abhängige lokale Lösung für KI und Automatisierung bereitzustellen. (Quelle: Reddit r/LocalLLaMA)
CSM 1B TTS-Modell erreicht Echtzeit-Streaming und Feinabstimmung: Die Open-Source-Community hat Fortschritte beim CSM 1B Text-to-Speech (TTS)-Modell erzielt, indem Echtzeit-Streaming implementiert und Feinabstimmungsfähigkeiten (einschließlich LoRA und vollständiger Feinabstimmung) entwickelt wurden. Das bedeutet, dass das Modell nun Sprache schneller generieren und an spezifische Bedürfnisse angepasst werden kann. Die Codebasis bietet eine lokale Chat-Demo, mit der Benutzer die Ergebnisse ausprobieren und mit anderen TTS-Modellen vergleichen können. (Quelle: Reddit r/LocalLLaMA)
Deebo: Kollaboratives Debugging von AI Agents mittels MCP: Deebo ist ein experimenteller Agent MCP (Machine Collaboration Protocol)-Server, der es codierenden AI Agents ermöglichen soll, komplexe Debugging-Aufgaben an ihn auszulagern. Wenn der Haupt-Agent auf ein schwieriges Problem stößt, kann er über MCP eine Deebo-Sitzung starten. Deebo generiert mehrere Subprozesse, die parallel in verschiedenen Git-Branches verschiedene Reparaturlösungen testen und LLMs für die Inferenz nutzen. Am Ende werden Protokolle, Reparaturvorschläge und Erklärungen zurückgegeben. Dieser Ansatz nutzt Prozessisolierung, vereinfacht das Concurrency Management und erforscht die Möglichkeiten der kollaborativen Problemlösung zwischen AI Agents. (Quelle: Reddit r/OpenWebUI)
📚 Lernen
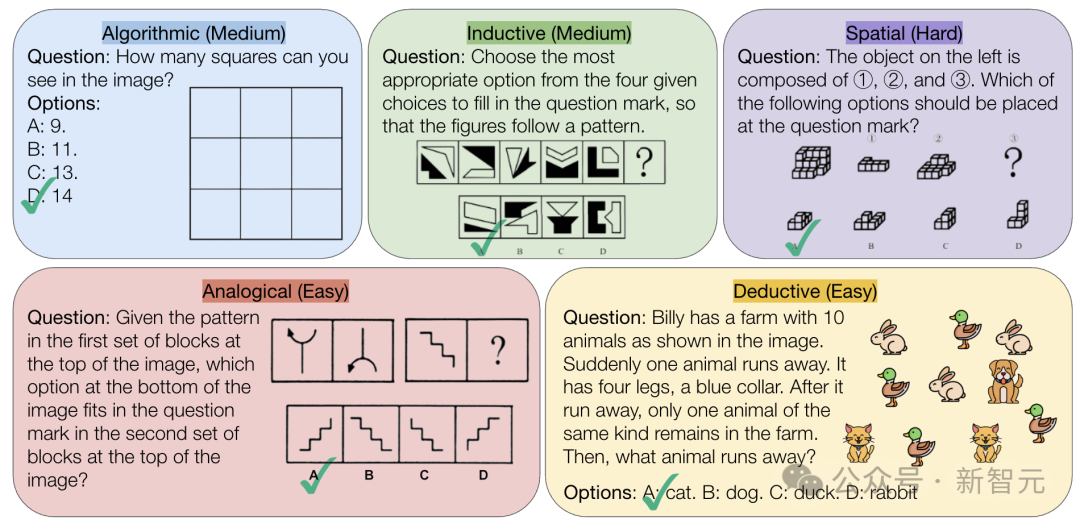
CMU veröffentlicht VisualPuzzles-Benchmark, fordert reine logische Schlussfolgerungsfähigkeit von KI heraus: Forscher der Carnegie Mellon University (CMU) haben den VisualPuzzles-Benchmark erstellt, der 1168 visuelle Logikrätsel enthält, die aus Beamtenprüfungen und ähnlichem adaptiert wurden. Ziel ist es, die multimodale Inferenzfähigkeit von der Abhängigkeit von Domänenwissen zu trennen. Tests ergaben, dass selbst Spitzenmodelle wie o1 und Gemini 2.5 Pro bei diesen reinen logischen Inferenzaufgaben weit schlechter abschneiden als Menschen (höchste Korrektheitsrate 57,5%, niedriger als die der untersten 5% der Menschen). Die Studie zeigt, dass eine Vergrößerung des Modells oder die Aktivierung des „Denkmodus“ nicht immer die reine Inferenzfähigkeit verbessert und bestehende Inferenzverbesserungstechniken unterschiedliche Ergebnisse liefern. Dies offenbart signifikante Lücken aktueller großer Modelle im räumlichen Verständnis und tiefgreifender logischer Inferenz. (Quelle: 全球顶尖AI来考公,不会推理全翻车,致命缺陷曝光,被倒数5%人类碾压)
InternVL3: Erforschung fortgeschrittener Trainings- und Testzeit-Techniken für Open-Source Multimodal Models: Das Paper „InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models“ stellt das InternVL3-Modell vor, dessen 78B-Version auf dem MMMU-Benchmark einen Score von 72,2 erreicht und damit einen neuen Rekord für Open-Source MLLMs aufstellt. Schlüsseltechnologien umfassen natives multimodales Pre-Training, Variable Visual Position Encoding (V2PE) zur Unterstützung langer Kontexte, fortgeschrittene Post-Training-Techniken (SFT, MPO) sowie Testzeit-Erweiterungsstrategien (verbesserte mathematische Inferenz). Die Forschung zielt darauf ab, effektive Methoden zur Leistungssteigerung von Open-Source Multimodal Models zu erforschen, und die Trainingsdaten sowie Modellgewichte wurden veröffentlicht. (Quelle: Reddit r/deeplearning)

Geobench: Benchmark zur Bewertung der Fähigkeit großer Modelle zur geografischen Bildlokalisierung: Geobench ist eine neue Benchmark-Website, die speziell dafür entwickelt wurde, die Fähigkeit von Large Language Models (LLMs) zu messen, den Aufnahmeort von Bildern wie Google Street View abzuleiten, ähnlich dem Spiel GeoGuessr. Sie bewertet die Genauigkeit der Schätzungen des Modells, einschließlich der Korrektheit von Land/Region, der Entfernung zum tatsächlichen Ort (Mittelwert und Median) und anderer Metriken. Erste Ergebnisse zeigen, dass die Gemini-Modellreihe von Google bei dieser Aufgabe herausragt, möglicherweise aufgrund ihres Zugangs zu Google Street View-Daten. (Quelle: Reddit r/LocalLLaMA)
Diskussion über Standardpraktiken zur Datensatzaufteilung: Die Reddit Machine Learning Community diskutiert, wie mit Datensätzen umgegangen werden soll (z.B. Train/Val/Test Split), wenn keine Standardaufteilung vorhanden ist. Gängige Praktiken umfassen die Generierung zufälliger Aufteilungen (was die Reproduzierbarkeit beeinträchtigen kann), das Speichern und Teilen spezifischer Indizes/Dateien und die Verwendung von k-facher Kreuzvalidierung. Die Diskussion betont, dass bei kleinen Datensätzen die Art der Aufteilung einen signifikanten Einfluss auf die Leistungsbewertung und SOTA-Behauptungen hat, und fordert eine Standardisierung oder eine breitere Weitergabe von Aufteilungsinformationen, um die Reproduzierbarkeit und Vergleichbarkeit der Forschung zu verbessern. Herausforderungen in der Praxis sind das Fehlen einer einheitlichen Plattform und domänenspezifischer Normen. (Quelle: Reddit r/MachineLearning, Reddit r/MachineLearning)
Suche nach Empfehlungen für Satz-Embeddings zur Klassifizierung von Stack Overflow-Posts: Ein Benutzer auf Reddit bittet um Ratschläge zur Verwendung von Satz-Embeddings (wie BERT, SBERT) für die unüberwachte Klassifizierung von Stack Overflow-Posts (einschließlich Titel, Beschreibung, Tags, Antworten). Ziel ist eine Klassifizierung auf Satzebene, die über einfache Wort-Embedding-Labels (wie „Paketinstallation“) hinausgeht und tiefere Themen- oder Fragetypen-Cluster untersucht. Kommentare empfehlen, mit der Sentence Transformers-Bibliothek zu beginnen, die einzelne Embeddings für Textabschnitte generieren kann, und anschließend Clustering-Algorithmen anzuwenden. (Quelle: Reddit r/MachineLearning)
Ratschläge zu KI-Lernpfaden und Berufswahl: Ein High-School-Schüler fragt auf Reddit nach der Wahl des Studienfachs (UCSD CS vs. Cal Poly SLO CS) für den Einstieg in das Machine Learning Engineering und ob ein Master-/Doktorstudium erforderlich ist. Kommentare empfehlen, die forschungsstärkere UCSD zu wählen und ein weiterführendes Studium in Betracht zu ziehen, da ML Engineering oft einen höheren Bildungsabschluss erfordert. Gleichzeitig wird darauf hingewiesen, dass praktische Fähigkeiten ebenso wichtig sind und Mathematik und Statistik entscheidende Grundlagen bilden. In einem anderen Thread fragt jemand nach Studiengängen zur Nutzung oder Entwicklung von KI. Kommentare erwähnen Informatik (CS), oft mit Master-/Doktorgrad, sowie Mathematik/Statistik. Jemand schlägt sogar vor, praktische Fertigkeiten wie Installateur/Klempner im Handwerk zu erlernen, um dem Risiko der KI-Substitution zu entgehen. (Quelle: Reddit r/MachineLearning, Reddit r/ArtificialInteligence)
💼 Wirtschaft
Erkundung der Kommerzialisierung von KI im Gesundheitswesen: Strategien großer Unternehmen vs. Krankenhausbedarf: Da Krankenhäuser beginnen, Budgets für große Modelle bereitzustellen (z. B. 4,5 Mio. Yuan Beschaffung einer auf DeepSeek basierenden Plattform durch das Jiangsu Provincial Organ Hospital), beschleunigt sich die Kommerzialisierung von KI im Gesundheitswesen. Große Unternehmen wie Huawei, Alibaba, Baidu und Tencent engagieren sich und bieten typischerweise Rechenleistung, Cloud-Dienste und Basismodelle in Zusammenarbeit mit vertikalen Unternehmen im Gesundheitswesen an. Das Kern-Geschäftsmodell bleibt jedoch unklar, wobei sich die großen Unternehmen derzeit eher auf den Verkauf von Hardware und Cloud-Diensten konzentrieren als direkt in KI-Anwendungen im Gesundheitswesen einzusteigen. Auf der Krankenhausseite, wie das 3201 Hospital in Hanzhong, Shaanxi, werden bei begrenztem Budget Versuche mit Open-Source-Modellen (wie einer abgespeckten Version von DeepSeek) unternommen, was die Berücksichtigung der Kosteneffizienz zeigt. Die Beschaffung hochwertiger medizinischer Daten und das Training spezialisierter Modelle bleiben zentrale Herausforderungen, die die Überwindung mühsamer Arbeiten wie der Datenannotation erfordern. (Quelle: AI看病这件事,华为、百度、阿里谁先挣到钱?, 科技大厂掀起医疗界的AI革命,谁更有胜算?)
Zuverlässigkeit von KI-Empfehlungstools wie DeepSeek in Frage gestellt, KI-Marketingoptimierung wird neues Schlachtfeld: KI-Tools wie DeepSeek werden zunehmend von Nutzern für Empfehlungen (z. B. Restaurants, Produkte) verwendet, und Händler beginnen, „DeepSeek-Empfehlung“ als Marketing-Label zu nutzen. Die Zuverlässigkeit dieser Empfehlungen gibt jedoch Anlass zur Sorge. Einerseits kann KI „halluzinieren“ und nicht existierende Geschäfte erfinden oder veraltete Produkte empfehlen. Andererseits können die Antworten der KI durch kommerzielle Interessen beeinflusst werden, wobei das Risiko von Produktplatzierungen oder der „Kontamination“ durch SEO/GEO (Generative Engine Optimization)-Strategien besteht. Händler versuchen, durch Optimierung von Inhalten und Schlüsselwörtern die Korpora und Suchergebnisse der KI zu beeinflussen, um die Sichtbarkeit ihrer eigenen Marke zu erhöhen. Dies stellt die Objektivität von KI-Empfehlungen in Frage, und Verbraucher müssen auf potenziell irreführende Informationen achten. (Quelle: 第一批用DeepSeek推荐的人,已上当)

Zhipu AI erhält zusätzliche 200 Mio. Yuan Investition vom Beijing Artificial Intelligence Industry Investment Fund: Nach der Ankündigung der Veröffentlichung mehrerer neuer Open-Source-Modelle und der Einrichtung eines 300-Millionen-Yuan-Open-Source-Fonds hat Zhipu AI (Z.ai) eine zusätzliche Investition von 200 Millionen Yuan vom Beijing Artificial Intelligence Industry Investment Fund erhalten. Der Fonds hatte bereits im Vorjahr in Zhipu investiert. Diese Kapitalerhöhung soll die Forschung und Entwicklung von Open-Source-Modellen bei Zhipu und den Aufbau des Ökosystems der Open-Source-Community unterstützen und spiegelt auch die Entschlossenheit Pekings wider, die KI-Industrie zu fördern und eine „Globale Hauptstadt des Open Source“ zu schaffen. (Quelle: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Intel CEO Pat Gelsinger treibt Reform voran, ernennt neuen CTO und Chief AI Officer: Der neue CEO Pat Gelsinger (Anm. d. Übers.: Im Original steht Chen Liwu, was falsch ist. Pat Gelsinger ist der CEO) passt die Organisationsstruktur von Intel an, um Managementebenen zu verschlanken und die Technologieorientierung zu stärken. Wichtige Chip-Abteilungen (Rechenzentrum und KI, PC-Chips) werden direkt an den CEO berichten. Sachin Katti, Leiter der Netzwerkchips, wurde zum neuen Chief Technology Officer (CTO) und Chief AI Officer ernannt. Er wird die KI-Strategie, die Produkt-Roadmap und die Intel Labs leiten, um der Herausforderung durch Nvidia im KI-Bereich zu begegnen. Dieser Schritt wird als Teil von Gelsingers Plan zur Revitalisierung von Intel angesehen, der darauf abzielt, Fertigungs- und Produktprobleme zu lösen, interne Barrieren abzubauen und sich auf Ingenieurwesen und Innovation zu konzentrieren. (Quelle: 陈立武挥刀高层,英特尔重生计划曝光,技术团队直通华人CEO)

Meta sucht Berichten zufolge nach Partnern zur Teilung der Llama-Trainingskosten, was den Druck durch KI-Investitionen unterstreicht: Berichten zufolge hat Meta Unternehmen wie Microsoft, Amazon, Databricks sowie Investmentfirmen kontaktiert und vorgeschlagen, die Trainingskosten seines Open-Source-Modells Llama gemeinsam zu tragen („Llama-Allianz“), im Austausch für teilweises Mitspracherecht bei der Funktionsentwicklung. Die anfängliche Reaktion war jedoch verhalten. Gründe könnten sein, dass potenzielle Partner nicht in ein kostenloses Modell investieren wollen, Meta nicht zu viel Kontrolle abgeben möchte und die potenziellen Partner selbst bereits erhebliche KI-Investitionen tätigen. Dieser Vorfall unterstreicht, dass selbst Giganten wie Meta unter dem Druck der explodierenden KI-Entwicklungskosten stehen, insbesondere angesichts enormer Investitionsausgaben (voraussichtlich jährlicher Anstieg um 60% auf 60-65 Mrd. USD) und eines unklaren Kommerzialisierungspfads für das Open-Source-Modell. (Quelle: Llama开源太贵了,Meta被曝向亚马逊、微软“化缘”)

Nvidia CEO Jensen Huang besucht China, möglicherweise um Kooperationen mit DeepSeek u.a. angesichts von Handelsbeschränkungen zu besprechen: Nvidia CEO Jensen Huang besuchte kürzlich China auf Einladung des Chinesischen Rates zur Förderung des internationalen Handels (CCPIT) und traf sich mit Kunden, darunter DeepSeek-Gründer Liang Wenfeng. Der Besuch findet vor einem komplexen Hintergrund statt, einschließlich der sich verschärfenden Beschränkungen der US-Regierung für Nvidia-Chip-Exporte nach China (wie H20) sowie des Aufstiegs heimischer chinesischer KI-Chips (wie Huawei Ascend) und der Tatsache, dass Modelloptimierungen durch Unternehmen wie DeepSeek die absolute Abhängigkeit von Nvidias High-End-GPUs verringern. Analysten vermuten, dass Huang möglicherweise darauf abzielt, mit chinesischen Partnern (wie DeepSeek) das gemeinsame Design von KI-Chips zu erörtern, die den US-Exportbeschränkungen entsprechen und gleichzeitig hohe chinesische Importzölle vermeiden, um durch tiefe Kooperation Marktanteile und Brancheneinfluss in China zu erhalten. (Quelle: 英伟达CEO黄仁勋突然访华,都不穿皮衣了,还见了梁文锋)

🌟 Community
Trend zur KI-Puppengenerierung erobert soziale Medien, löst Urheberrechts- und Ethikbedenken aus: Ein Trend, bei dem persönliche Fotos mithilfe von KI-Tools wie ChatGPT in Puppenbilder umgewandelt werden (ähnlich dem Barbie-Puppen-Stil, mit Verpackungsbox und persönlichen Accessoires), verbreitet sich auf Plattformen wie LinkedIn und TikTok. Benutzer können durch Hochladen von Fotos und detaillierten Beschreibungen solche Bilder generieren. Obwohl dies unterhaltsam ist, wirft es auch Bedenken hinsichtlich Urheberrecht und Ethik auf: Die KI-Generierung könnte unbeabsichtigt urheberrechtlich geschützte Kunststile oder Markenelemente verwenden; gleichzeitig wird der hohe Energieverbrauch für das Training und den Betrieb dieser KI-Modelle kritisch gesehen. Kommentare weisen darauf hin, dass bei der Nutzung von KI klare Grenzen und Richtlinien festgelegt werden müssen. (Quelle: 芭比风AI玩偶席卷全网:ChatGPT几分钟打造你的时尚分身)

Tiefe Integration von Tencent Yuanbao (ehemals Assistent für rote Umschlag-Cover) in WeChat erregt Aufmerksamkeit: Die Suche nach „Yuanbao“ in WeChat ruft direkt KI-Funktionen auf, tatsächlich eine aktualisierte Version des früheren „Yuanbao Assistenten für rote Umschlag-Cover“. Die Benutzererfahrung zeigt verbesserte Fähigkeiten, wie die Generierung genauerer Bilder gemäß den Anforderungen und eine optimierte native Anpassung, die Antwortkarten generieren kann. Der Artikel diskutiert die Möglichkeit, dass Tencents großer KI-Schachzug im WeChat-Szenario landet, insbesondere das Potenzial der Nutzung bestehender Einstiegspunkte wie des Dateiübertragungsassistenten, und argumentiert, dass der Szenariovorteil der Schlüssel zur KI-Implementierung von Tencent ist. Gleichzeitig wird erwähnt, dass kürzliche Updates für WeChat Official Accounts einen mobilen Veröffentlichungseingang hinzugefügt haben, was möglicherweise die Erstellung kurzer Inhalte fördert, aber das Ökosystem für lange Artikel beeinträchtigen könnte. (Quelle: 鹅厂的 AI 大招,真的落在微信上)
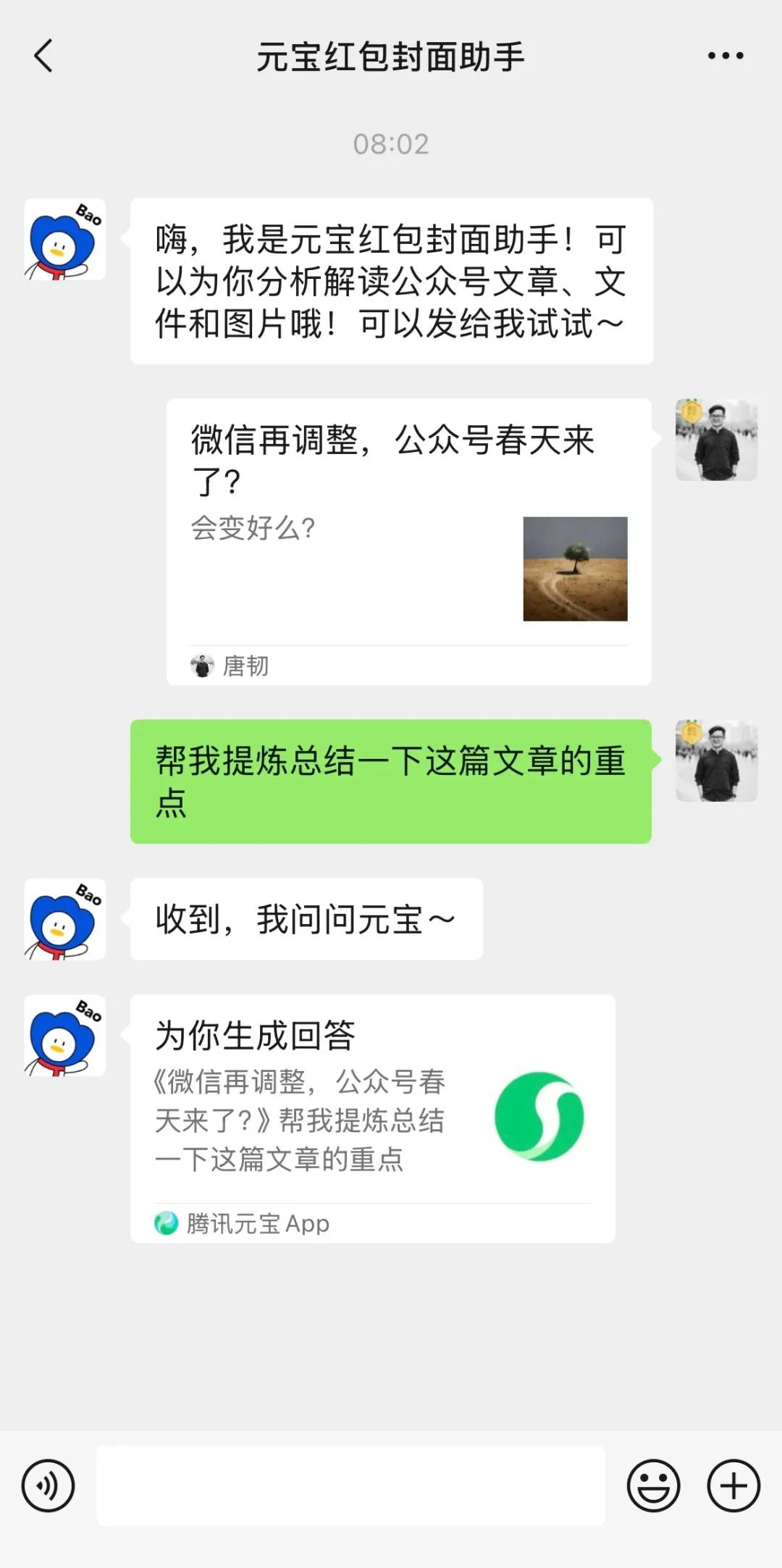
LMArena startet Beta-Testseite: Die Large Model Arena LMArena hat eine neue Beta-Test-Website (beta.lmarena.ai) gestartet, um verschiedene große Modelle, einschließlich unveröffentlichter Modelle, zu testen. Dies bietet der Community eine neue Plattform, unabhängig von der Hugging Face Gradio-Schnittstelle, um die Modellleistung zu bewerten und zu vergleichen. (Quelle: karminski3)
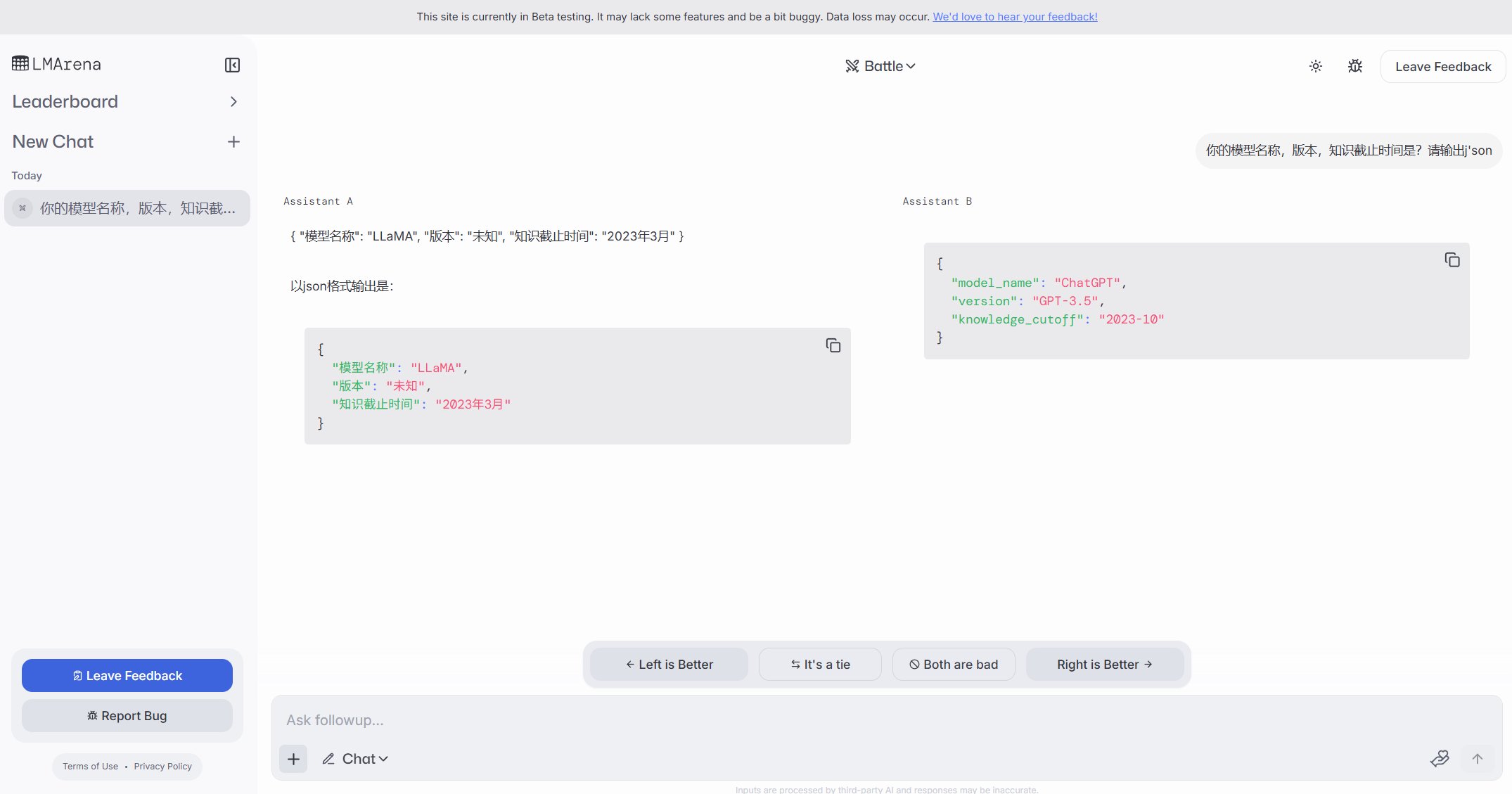
Öffentliche Exposition von Ollama-Instanzen löst Sicherheitsbedenken aus: Ein Benutzer entdeckte eine Website namens freeollama.com und fand durch eine Netzwerk-Raum-Suche zahlreiche Hosts, die den Port von Ollama (Tool zur lokalen Bereitstellung großer Modelle, normalerweise 11434) auf einer öffentlichen IP ohne Firewall exponieren. Dies stellt ein ernstes Sicherheitsrisiko dar, das zu unbefugtem Zugriff und Missbrauch lokal bereitgestellter Modelle führen kann. Benutzer werden daran erinnert, bei der Bereitstellung auf die Netzwerksicherheitskonfiguration zu achten und Dienste nicht ungeschützt im öffentlichen Netz zu exponieren. (Quelle: karminski3)
Nutzung von ChatGPT zur psychologischen Unterstützung löst Diskussion und Warnung aus: Ein Reddit-Benutzer teilt Erfahrungen mit der Nutzung von ChatGPT zur Unterstützung bei der Bewältigung von Depressionen, Angstzuständen usw. und stellt fest, dass die Ratschläge möglicherweise inkonsistent sind und eher bestehende Ansichten des Benutzers bestätigen als zuverlässige Anleitung zu bieten. Wenn ChatGPT in verschiedenen Chats mit seiner eigenen Logik konfrontiert wird, gibt es Fehler zu. Der Benutzer warnt davor, dass KI möglicherweise nur ein „digitaler Schmeichler“ ist und nicht für ernsthafte psychotherapeutische Unterstützung verwendet werden sollte. Im Kommentarbereich wird diskutiert, wie KI effektiver genutzt werden kann (z. B. indem man sie bittet, eine kritische Rolle zu spielen, mehrere Perspektiven anzubieten) und die Grenzen der KI, die menschliche Fachleute bei der Krisenintervention nicht ersetzen kann. (Quelle: Reddit r/ChatGPT)
Douglas Adams’ Drei Gesetze der Technologie finden Resonanz: Ein Benutzer zitiert die drei Gesetze der Technologie des Science-Fiction-Autors Douglas Adams, die humorvoll die allgemeine Reaktion von Menschen verschiedener Altersgruppen auf neue Technologien beschreiben: Technologien, die bei der Geburt bereits vorhanden sind, werden als normal angesehen; Technologien, die in jungen Jahren entstehen, werden als revolutionär betrachtet; Technologien, die im Alter auftauchen, werden als ketzerisch empfunden. Dieser Kommentar findet in der Zeit der rasanten KI-Entwicklung Resonanz und deutet darauf hin, dass die Akzeptanz disruptiver Technologien wie KI mit der Lebensphase zusammenhängen könnte. (Quelle: dotey)
Benutzererfahrung: ChatGPT wird „zu real“ oder „Gen Z-ifiziert“: Ein Reddit-Post zeigt einen Screenshot einer ChatGPT-Konversation, dessen Antwortstil vom Benutzer als „zu real“ oder mit „Gen Z“-Slang und Internet-Memes (wie “Let me cook”) beschrieben wird. Die Reaktionen im Kommentarbereich sind gemischt: Einige finden es interessant, andere empfinden diesen Stil als „unangenehm“ oder „verdummend“. Dies spiegelt die unterschiedliche Wahrnehmung der Personalisierung und des Sprachstils von KI durch die Benutzer wider sowie mögliche Probleme, die durch die Nachahmung von Netzsprachtrends durch das Modell entstehen können. (Quelle: Reddit r/ChatGPT)
KI-generierte Schnappschüsse des zukünftigen Lebens lösen kreative Diskussion aus: Ein Benutzer teilt eine Reihe von mit ChatGPT generierten Bildern im Stil von „Snapchats des zukünftigen Lebens“, die Szenen wie Roboter-Kellner, KI-Haustiere, zukünftigen Verkehr usw. darstellen. Diese kreativen Bilder lösten in der Community Diskussionen über die Fähigkeit der KI-Bilderzeugung und Vorstellungen vom zukünftigen Leben aus, wobei die Kreativität und der zunehmende Realismus gelobt wurden. (Quelle: Reddit r/ChatGPT)
Benutzer teilt, wie er handgezeichnete Skizzen mit ChatGPT in realistische Bilder umwandelt: Ein Künstler zeigt den Prozess und die Ergebnisse der Umwandlung seiner surrealistischen handgezeichneten Skizzen in realistische Bilder mithilfe von ChatGPT. Die Community lobt dies als interessante Methode für künstlerische Experimente, die Künstlern helfen kann, Ideen und verschiedene Stile zu erkunden, anstatt nur nach „besseren“ Bildern zu streben. (Quelle: Reddit r/ChatGPT)
💡 Sonstiges
Reflexion über den Aufbau von KI-Systemen: „Die bittere Lektion“ und Priorität der Rechenleistung: Der Artikel zitiert Richard Suttons Theorie der „bitteren Lektion“ und weist darauf hin, dass in der KI-Entwicklung Systeme, die auf der Skalierung allgemeiner Rechenkapazität basieren (rechenleistungsgetrieben), letztendlich Systeme übertreffen werden, die auf von Menschen sorgfältig entworfenen komplexen Regeln beruhen. Durch den Vergleich von Kundenservice-KI-Fallbeispielen (regelbasiertes System vs. KI mit begrenzter Rechenleistung vs. KI mit hoher Rechenleistung und Exploration) und den Erfolg des Reinforcement Learning (RL) (wie bei OpenAI Deep Research, Claude) wird betont, dass Unternehmen in Recheninfrastruktur investieren sollten, anstatt Algorithmen übermäßig zu optimieren. Die Rolle des Ingenieurs sollte sich zum „Streckenbauer“ wandeln, der skalierbare Lernumgebungen schafft. Die Kernbotschaft lautet: Einfache Architektur + großflächige Rechenleistung + exploratives Lernen > komplexes Design + feste Regeln. (Quelle: 苦涩的启示:对AI系统构建方式的反思)
Diskussion über die Verbindung zwischen dem KI-Bereich und den Communitys des Rationalismus/Effektiven Altruismus: Ein Praktiker im Bereich Machine Learning beobachtet, dass es im KI-Forschungsbereich anscheinend zwei wenig interagierende Sub-Communitys gibt, von denen eine eng mit den Communitys des Rationalismus (Rationalism) und des Effektiven Altruismus (Effective Altruism, EA) verbunden ist. Diese veröffentlicht häufig Forschung zu AGI-Vorhersagen, dem Alignment-Problem und steht in engem Kontakt mit bestimmten großen Unternehmen in der Bay Area. Der Autor weist darauf hin, dass diese Community bei der Diskussion von Konzepten der Kognitionswissenschaft (wie Situationsbewusstsein) manchmal Definitionen unabhängig vom bestehenden akademischen System neu zu definieren scheint, z. B. die Definition von „Situationsbewusstsein“ durch Anthropic, die sich auf das Bewusstsein des Modells für seinen Entwicklungsprozess konzentriert, anstatt auf die traditionelle Definition in der Kognitionswissenschaft, die auf Sinneswahrnehmung und Umgebungsmodellen basiert. (Quelle: Reddit r/ArtificialInteligence)
Benutzer entdeckt, dass KI-Chatbot unerwartet seinen Spitznamen von anderen Plattformen verwendet: Ein Benutzer stellte beim Ausprobieren einer neuen KI-Chatbot-Plattform fest, dass der Bot, obwohl keine persönlichen Informationen angegeben wurden, in der zweiten Nachricht den Spitznamen nannte, den der Benutzer auf anderen Plattformen häufig verwendet. Dies löste beim Benutzer Bedenken hinsichtlich Datenschutz und plattformübergreifendem Informationstracking aus und führte zu der Vermutung, möglicherweise „verfolgt“ oder „profiliert“ worden zu sein. (Quelle: Reddit r/ArtificialInteligence)
Neue Idee zur Bewertung von KI-Modellen: Intelligenzbeurteilung durch 3-minütigen mündlichen Bericht: Es wird eine neue Methode zur Bewertung der Intelligenz von KI vorgeschlagen: Spitzen-KI-Modelle (wie o3 vs. Gemini 2.5 Pro) sollen eine 3-minütige mündliche Präsentation zu einem bestimmten Thema (Politik, Wirtschaft, Philosophie usw.) halten, deren Intelligenz von einem menschlichen Publikum beurteilt wird. Es wird argumentiert, dass diese Methode intuitiver ist als die Abhängigkeit von spezialisierten Benchmarks und die organisatorischen, rhetorischen, emotionalen und intellektuellen Leistungen des Modells besser bewerten kann, insbesondere bei Aufgaben, die Überzeugungskraft erfordern. Diese Form der „KI-Debatte“ oder des „Redewettbewerbs“ könnte eine neue Dimension zur Bewertung der Fähigkeiten von Modellen nahe AGI werden. (Quelle: Reddit r/ArtificialInteligence)