
Schlüsselwörter:AI, 大模型, AI军备竞赛, 垂直行业模型, 智谱AI IPO, AI独立发现物理定律, AI助盲系统
„` markdown
🔥 Fokus
Tech-Giganten entfachen KI-Wettrüsten, vertikale Modelle und Ökosysteme im Fokus: Globale Technologie-Riesen investieren mit beispielloser Intensität in KI, die Investitionsausgaben für 2025 werden voraussichtlich 320 Milliarden US-Dollar übersteigen. Chinesische Unternehmen wie Alibaba, Tencent, Huawei usw. erhöhen ebenfalls ihre Einsätze und investieren massiv in KI-Infrastruktur, große Modelle und Rechenleistung. Der Wettbewerbsfokus verlagert sich von allgemeinen großen Modellen hin zu vertikalen Branchenmodellen, die mit hohen Bruttogewinnmargen und der Fähigkeit, tatsächliche Probleme zu lösen, zu neuen Wachstumsmotoren werden. Trotz Herausforderungen bei High-End-Chips erzielen inländische Hersteller Fortschritte bei der Optimierung der Rechenkosten und bei Inferenzmodellen („langsames Denken“) (z. B. DeepSeek-Effekt). Die Ansätze variieren: Alibaba investiert stark in die Infrastruktur, Huawei revolutioniert die Hardware (CloudMatrix 384) und fördert die Edge-Cloud-Synergie, Baidu orientiert sich an Anwendungen, während Tencent und ByteDance ihre Vorteile in diversifizierten Szenarien nutzen. Die Erweiterung der KI-Hardware und der Aufbau von Open-Source-Ökosystemen (wie Hongmeng, Ascend, Hunyuan) werden entscheidend, der Wettbewerb hat sich von einzelnen technologischen Durchbrüchen zur Fähigkeit der Ökosystem-Kollaboration verschoben. (Quelle: 36氪-科技云报道)

Erstaunliche Entdeckung am MIT: KI leitet Physikgesetze ohne Vorwissen selbstständig her: Das Team von Max Tegmark am MIT hat eine neue Architektur namens MASS (Multiple AI Scalar Scientists) entwickelt. Dieses KI-System konnte, ohne über physikalische Gesetze informiert zu sein, allein durch die Analyse von Beobachtungsdaten physikalischer Systeme wie Pendel und Oszillatoren selbstständig lernen und theoretische Formulierungen vorschlagen, die den Hamilton- oder Lagrange-Funktionen der klassischen Mechanik stark ähneln. Die Forschung zeigt, dass die KI bei komplexeren Systemen ihre Theorien autonom korrigiert und verschiedene KI-„Wissenschaftler“ letztendlich zu bekannten physikalischen Prinzipien konvergieren, wobei sie in komplexen Systemen besonders zur Lagrange-Beschreibung tendieren. Dieses Ergebnis demonstriert das enorme Potenzial der KI für grundlegende wissenschaftliche Entdeckungen und könnte möglicherweise grundlegende Gesetze des Universums unabhängig aufdecken. (Quelle: 新智元)

KI-gestütztes Blindenhilfesystem von Team der Shanghai Jiao Tong Universität in Nature-Tochterjournal veröffentlicht, gibt Sehbehinderten „Licht zurück“: Das Team von Gu Leilei an der Shanghai Jiao Tong Universität hat ein KI-gesteuertes tragbares Hilfssystem für Blinde entwickelt. In Kombination mit flexibler Elektroniktechnologie ersetzt es teilweise visuelle Funktionen durch auditive und taktile Rückmeldungen und hilft sehbehinderten Menschen bei alltäglichen Aufgaben wie Navigation und Greifen. Die Hardware des Systems ist leicht, die Software optimiert die Informationsausgabe entsprechend der menschlichen physiologischen Kognition, und es wurde ein immersives VR-Trainingssystem entwickelt. Tests zeigen, dass das System die Navigations-, Hindernisvermeidungs- und Objektgreiffähigkeiten von sehbehinderten Benutzern in virtuellen und realen Umgebungen signifikant verbessert. Die Forschungsergebnisse wurden in Nature Machine Intelligence veröffentlicht und zeigen das enorme Potenzial der KI zur Unterstützung sehbehinderter Menschen und zur Verbesserung ihrer Fähigkeit zu einem unabhängigen Leben. Sie bieten zudem neue Ansätze für personalisierte, benutzerfreundliche tragbare visuelle Hilfsmittel. (Quelle: 36氪)

Zhipu AI startet IPO-Beratungsprozess und strebt Status als „Erste Aktie eines großen Modells“ an: Das von der Tsinghua-Universität unterstützte KI-Unternehmen Zhipu AI (Beijing Zhipu Huazhang Technology) hat am 14. April bei der Wertpapieraufsichtsbehörde in Peking die Registrierung für die IPO-Beratung abgeschlossen. Begleitet von CICC zielt das Unternehmen auf den A-Aktienmarkt ab und könnte die erste börsennotierte Aktie im Bereich großer KI-Modelle in China werden. Obwohl die Nutzerbasis seines C-End-Produkts „Zhipu Qingyan“ nicht groß ist, hat Zhipu dank seines starken technologischen Hintergrunds (Tsinghua-Herkunft, selbst entwickelte GLM-Modellreihe), seines Status als „Nationalmannschaft“ (auf der US-Entity-Liste) und seiner Kommerzialisierungsfortschritte (Dienstleistungen für Regierungs- und Unternehmenskunden, signifikantes Umsatzwachstum) über 16 Milliarden Yuan an Finanzmitteln erhalten und wird auf über 20 Milliarden Yuan geschätzt. Zu den Investoren gehören namhafte VCs, Branchenriesen und staatliche Kapitalgeber aus verschiedenen Regionen. Angesichts des Drucks durch neue Akteure wie DeepSeek wird der IPO-Schritt von Zhipu als entscheidend angesehen, um sich in einem intensiven Wettbewerb eine vorteilhafte Position zu sichern, Finanzierungsbedarf zu decken und den Erwartungen der Investoren gerecht zu werden. Das Unternehmen hat kürzlich kontinuierlich Modelle der GLM-4-Serie als Open Source veröffentlicht, was seine gleichzeitigen Bemühungen in Technologie und Kapital zeigt. (Quellen: 36氪-真故研究室, 36氪-互联网爆料汇, 创投日报)

🎯 Bewegungen
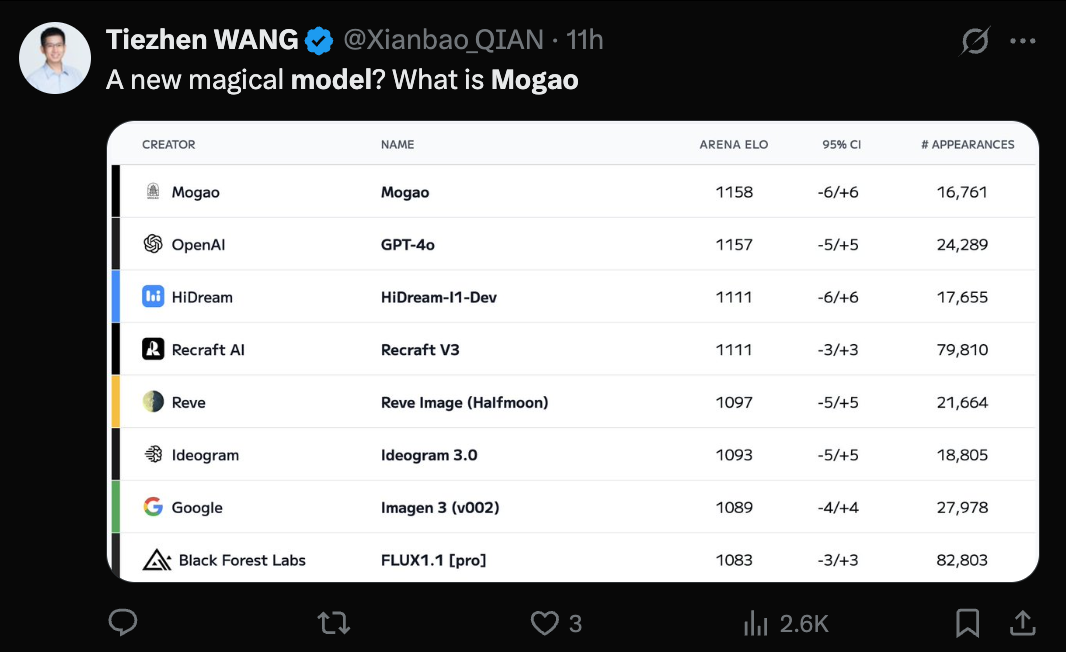
ByteDance Seedream 3.0 (Mogao) Modell enthüllt, Text-zu-Bild-Fähigkeiten anerkannt: Das mysteriöse Modell Mogao, das kürzlich die Text-zu-Bild-Rangliste von Artificial Analysis anführte, wurde als Seedream 3.0 bestätigt, entwickelt vom Seed-Team von ByteDance. Das Modell zeichnet sich durch herausragende Leistungen in verschiedenen Stilen wie Realismus, Design, Anime sowie bei der Textgenerierung aus. Es ist besonders gut darin, dichten Text zu verarbeiten und realistische Porträts zu generieren. Die Verwendbarkeitsrate für chinesische und englische Zeichen erreicht 94%, der Realismus von Porträts nähert sich professionellem Fotoniveau an, und es unterstützt die native Ausgabe von 2K-Auflösungsbildern bei hoher Generierungsgeschwindigkeit. Der technische Bericht enthüllt mehrere Innovationen in der Datenverarbeitung (fehlerbewusstes Training, zweiachsiges Sampling), im Pre-Training (MMDiT-Architektur, gemischte Auflösung, Cross-Modal RoPE), im Post-Training (kontinuierliches Training, SFT, RLHF, VLM-Belohnungsmodell) und bei der Inferenzbeschleunigung (Hyper-SD, RayFlow). Im Vergleich zu GPT-4o ist Seedream 3.0 bei Chinesisch, Typografie und Farben überlegen. (Quelle: 36氪-机器之心)
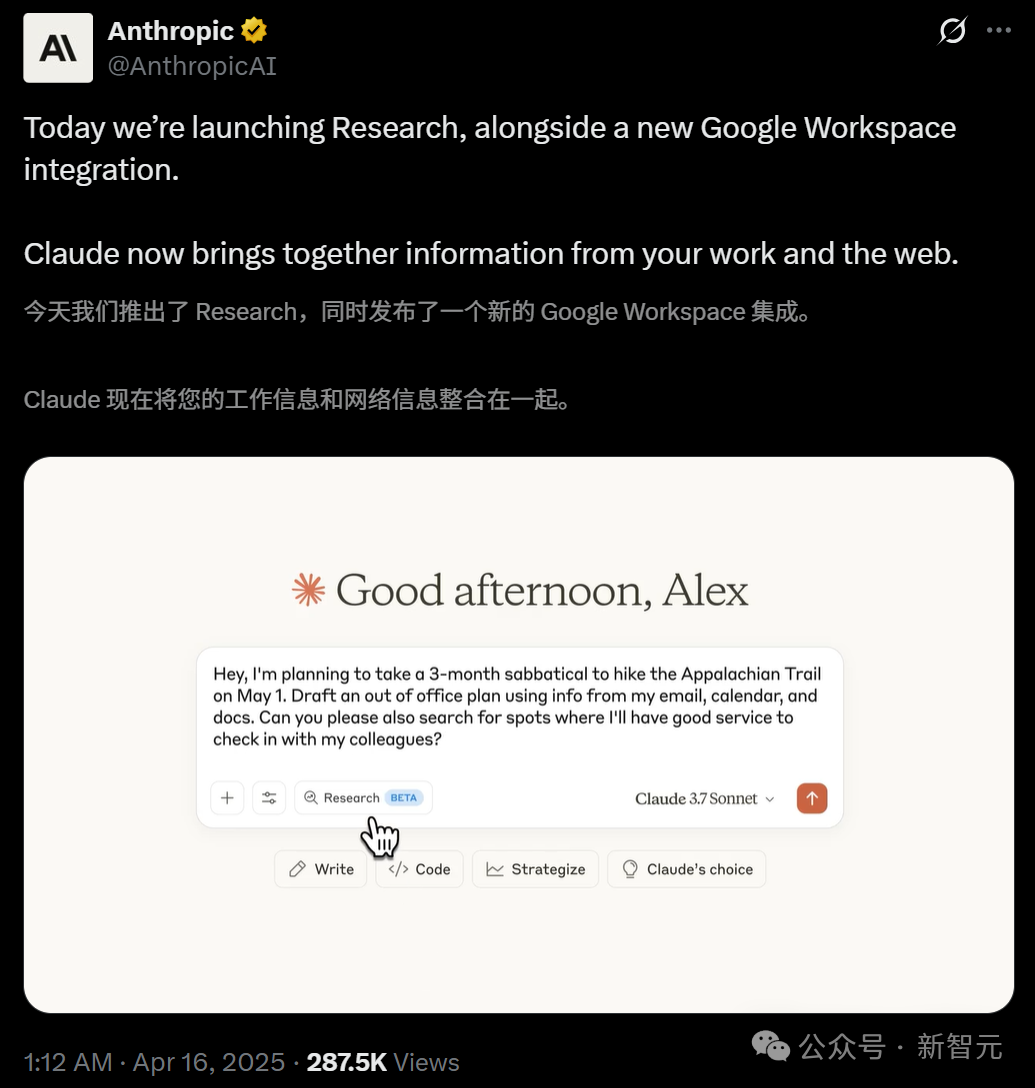
Claude führt Research-Funktion ein und integriert Google Workspace: Anthropic hat seinen KI-Assistenten Claude um zwei Hauptfunktionen erweitert: Research und Google Workspace-Integration. Die Research-Funktion ermöglicht es Claude, Informationen online zu suchen und diese mit internen Benutzerdateien (wie Google Docs) zu kombinieren, um umfassende Berichte schnell zu erstellen. Die Google Workspace-Integration verbindet Gmail, Google Kalender und Docs, sodass Claude den Zeitplan, E-Mails und Dokumentinhalte des Benutzers verstehen, Informationen extrahieren und bei Aufgaben helfen kann, z. B. bei der Reiseplanung basierend auf persönlichen Informationen oder beim Entwerfen von E-Mails. Diese Funktionen zielen darauf ab, die Arbeitseffizienz der Benutzer erheblich zu steigern. Die Research-Funktion wird derzeit für Max-, Team- und Enterprise-Benutzer in den USA, Japan und Brasilien getestet. Die Workspace-Integration wird für alle zahlenden Benutzer getestet. Das Benutzerfeedback ist positiv und deutet auf eine höhere Effizienz und die Fähigkeit hin, Zusammenhänge zwischen Daten zu erkennen, es gibt jedoch auch Bedenken hinsichtlich der Datensicherheit. (Quellen: 新智元, op7418, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
CUHK und Tsinghua veröffentlichen Video-R1 und eröffnen neues Paradigma für Video-Reasoning: Ein gemeinsames Team der Chinesischen Universität Hongkong (CUHK) und der Tsinghua-Universität hat das weltweit erste Video-Reasoning-Modell Video-R1 vorgestellt, das das R1-Paradigma des Verstärkenden Lernens (Reinforcement Learning) verwendet. Das Modell zielt darauf ab, das Problem fehlender zeitlicher Logik und tiefer Inferenzfähigkeiten in bestehenden Videomodellen zu lösen. Durch die Einführung des zeitbewussten T-GRPO-Algorithmus und eines gemischten Trainingsdatensatzes aus Bildern und Videos (Video-R1-COT-165k und Video-R1-260k) übertrifft das 7B-Parameter-Modell Video-R1 GPT-4o im VSI-Bench-Benchmark für räumliches Video-Reasoning, der von Li Fei-Fei vorgeschlagen wurde. Das Modell zeigt menschenähnliche „Aha-Momente“ und kann auf der Grundlage zeitlicher Informationen logische Schlussfolgerungen ziehen. Experimente belegen, dass eine Erhöhung der Anzahl der Eingabeframes die Inferenzgenauigkeit verbessert. Das Projekt hat das Modell, den Code und die Datensätze vollständig als Open Source veröffentlicht, was darauf hindeutet, dass Video-KI sich vom „Verstehen“ zum „Denken“ entwickelt. (Quelle: 新智元)

ICLR 2025 setzt erstmals KI-Reviewer in großem Maßstab ein und verbessert die Review-Qualität signifikant: Angesichts steigender Einreichungszahlen und sinkender Review-Qualität hat die Konferenz ICLR 2025 erstmals in großem Umfang einen KI-„Review Feedback Agent“ zur Unterstützung des Peer-Review-Prozesses eingesetzt. Das System nutzt mehrere LLMs, darunter Claude Sonnet 3.5, um Unklarheiten, inhaltliche Missverständnisse oder unprofessionelle Äußerungen in Reviews zu identifizieren und den Reviewern konkrete Verbesserungsvorschläge zu unterbreiten. Das Experiment umfasste 42,3% der Reviews. Die Ergebnisse zeigen, dass das KI-Feedback in 89% der Fälle die Review-Qualität verbesserte. 26,6% der Reviewer änderten ihre Reviews aufgrund der KI-Vorschläge, wobei die überarbeiteten Reviews durchschnittlich um 80 Wörter länger und spezifischer sowie informativer wurden. Gleichzeitig erhöhte der Einsatz von KI auch die Aktivität und Tiefe der Diskussionen zwischen Autoren und Reviewern während der Rebuttal-Phase. Dieses wegweisende Experiment belegt das enorme Potenzial von KI zur Optimierung des Peer-Review-Prozesses. (Quelle: 新智元)

Humanoide Roboter im Haushalt lösen Diskussionen aus, Haushaltsgerätehersteller setzen auf Embodied Intelligence: Der Einzug humanoider Roboter in den häuslichen Bereich löst in der Branche Diskussionen über ihre Anwendungsmodelle und Auswirkungen auf die Haushaltsgeräteindustrie aus. Es wird argumentiert, dass humanoide Roboter ihre „universellen“ Eigenschaften nutzen sollten, um nicht standardisierte Aufgaben wie das Falten von Kleidung und das Aufräumen zu lösen, und ihre Interaktionsfähigkeiten nutzen sollten, um als „Butler“ zu fungieren, der andere intelligente Geräte steuert und koordiniert, anstatt einfach vorhandene Geräte zu ersetzen. Angesichts dieses Trends haben Haushaltsgerätegiganten wie Haier und Midea bereits begonnen, sich zu positionieren, indem sie eigene humanoide Roboterprodukte (wie Kuavo) auf den Markt bringen und untersuchen, wie Embodied Intelligence-Technologie in traditionelle Haushaltsgeräte integriert werden kann (z. B. Saugroboter mit Roboterarm von Dreame, Waschmaschine von Yimu Technology, die Kleidung greifen kann). Dies zeigt, dass sich die Haushaltsgeräteindustrie aktiv an die KI-Welle anpasst und in Zukunft möglicherweise ein symbiotisches Smart-Home-Ökosystem mit humanoiden Robotern bilden wird. (Quelle: 36氪-具身研习社)

Huawei veröffentlicht CloudMatrix 384 AI-Server, zielt auf Nvidia GB200 ab: Huawei hat auf seiner Cloud Ecosystem Conference sein neuestes AI-Server-Cluster CloudMatrix 384 vorgestellt. Das System besteht aus 384 Ascend-Rechenleistungskarten, erreicht eine Rechenleistung von 300 PFlops pro Cluster und einen Dekodierungsdurchsatz von 1920 Tokens/s pro Karte, womit es direkt auf Nvidias H100 abzielt. Es verwendet eine vollständige Glasfaser-Hochgeschwindigkeitsverbindung (6812 400G-Optikmodule) und erreicht eine Trainingseffizienz von nahezu 90% der Leistung einer einzelnen Nvidia-Karte. Dieser Schritt wird als wichtiger Schritt Chinas angesehen, um im Bereich der KI-Infrastruktur international aufzuholen und den Bedarf an Rechenleistung angesichts der Beschränkungen bei High-End-Chips zu decken. Analysten sehen darin einen Beweis für Huaweis schnelle Fortschritte im Bereich KI-Hardware, die die bestehende Marktlandschaft beeinflussen könnten. (Quellen: dylan522p, 36氪-科技云报道)
Google führt Veo 2 Text-zu-Video-Funktion und Whisk Animate ein: Google hat sein Text-zu-Video-Modell Veo 2 in Gemini Advanced integriert. Mitglieder können diese Funktion kostenlos über die Gemini App nutzen, um 8 Sekunden lange Videos zu generieren. Gleichzeitig wurde Googles Bildbearbeitungstool Whisk um die Funktion Whisk Animate erweitert, die es Benutzern ermöglicht, nach der Bildgenerierung mit Veo 2 daraus ein Video zu erstellen. Diese Funktion erfordert jedoch eine Google One-Mitgliedschaft. Dies signalisiert Googles kontinuierliche Bemühungen im Bereich der multimodalen Generierung, um Benutzern reichhaltigere Kreativwerkzeuge anzubieten. (Quellen: op7418, op7418)
OpenAI entwickelt möglicherweise soziales Produkt ähnlich X: Laut The Verge entwickelt OpenAI intern einen Prototyp für ein soziales Produkt, das X (ehemals Twitter) ähnelt. Dieses Produkt könnte die Bildgenerierungsfähigkeiten von ChatGPT (insbesondere nach der Veröffentlichung von GPT-4o) mit einem sozialen Feed kombinieren. Angesichts der riesigen Nutzerbasis von ChatGPT und seiner Fortschritte bei der Bildgenerierung wird dieser Schritt als durchaus machbar angesehen und könnte darauf hindeuten, dass OpenAI versucht, seine KI-Fähigkeiten auf den Bereich der sozialen Medien auszudehnen. (Quelle: op7418)
DeepCoder veröffentlicht leistungsstarkes Open-Source-Coding-Modell mit 14B Parametern: Das DeepCoder-Team hat ein leistungsstarkes Open-Source-Coding-Modell mit 14 Milliarden Parametern veröffentlicht, das angeblich bei Codierungsaufgaben hervorragende Leistungen erbringt. Die Veröffentlichung dieses Modells bietet Entwicklern eine weitere leistungsstarke Option für Code-Generierung und -Unterstützung, insbesondere in Szenarien, in denen sowohl Leistung als auch Modellgröße berücksichtigt werden müssen. (Quelle: Ronald_vanLoon)

Tesla realisiert automatisches Parken von Fahrzeugen nach der Produktion: Tesla demonstriert einen neuen Fortschritt seiner autonomen Fahrtechnologie: Fahrzeuge können nach Verlassen der Produktionslinie selbstständig zum Ladebereich oder Parkplatz fahren, ohne menschliches Eingreifen. Dies zeigt das Anwendungspotenzial der FSD (Full Self-Driving)-Fähigkeiten von Tesla in spezifischen, kontrollierten Umgebungen, trägt zur Verbesserung der Produktionslogistikeffizienz bei und ist ein Schritt hin zu breiteren autonomen Fahranwendungen. (Quellen: Ronald_vanLoon, Ronald_vanLoon)
Dexterity stellt Industrieroboter Mech vor, angetrieben von Physical AI: Das Unternehmen Dexterity hat einen Industrieroboter namens Mech vorgestellt, der sich durch den Einsatz von „Physical AI“-Technologie auszeichnet. Diese KI ermöglicht es dem Roboter, in komplexen industriellen Umgebungen zu navigieren und zu agieren, wobei er übermenschliche Flexibilität und Anpassungsfähigkeit zeigt. Ziel ist es, komplexe Aufgaben zu lösen, die für die traditionelle industrielle Automatisierung schwierig sind. (Quelle: Ronald_vanLoon)
MIT entwickelt neuen springenden Roboter, speziell für unwegsames Gelände: Forscher am MIT haben einen neuartigen Roboter entwickelt, dessen Design von Sprungbewegungen inspiriert ist und der sich besonders gut in unebenem Gelände fortbewegen kann. Dieser Roboter demonstriert die Anwendung der Bionik im Roboterdesign sowie das Potenzial des maschinellen Lernens zur Steuerung komplexer Bewegungen und könnte in komplexen Umgebungen wie Such- und Rettungseinsätzen oder Planetenexploration eingesetzt werden. (Quelle: Ronald_vanLoon)
INTELLECT-2 gestartet: Global verteiltes Reinforcement Learning Training für 32B-Modell: Das Prime Intellect Projekt hat die INTELLECT-2 Initiative gestartet, die darauf abzielt, durch global verteilte Rechenressourcen ein fortschrittliches Inferenzmodell mit 32 Milliarden Parametern mittels Reinforcement Learning zu trainieren. Das Modell basiert auf der Qwen-Architektur und sein Ziel ist es, ein kontrollierbares „Denkbudget“ zu realisieren, d.h. Benutzer können festlegen, wie viele Inferenzschritte (wie viele Tokens „gedacht“ werden) das Modell durchführen soll, bevor es ein Problem löst. Dies ist eine wichtige Untersuchung des Potenzials von verteiltem Training und Reinforcement Learning zur Verbesserung der Inferenzfähigkeiten großer Modelle. (Quelle: Reddit r/LocalLLaMA)

ByteDance veröffentlicht multimodales autoregressives Modell Liquid ähnlich GPT-4o: ByteDance hat eine Reihe multimodaler Modelle namens Liquid veröffentlicht. Das Modell verwendet eine autoregressive Architektur ähnlich GPT-4o, kann Text- und Bildeingaben verarbeiten und Text- oder Bildausgaben generieren. Im Gegensatz zu früheren MLLMs, die externe vortrainierte visuelle Embeddings verwenden, nutzt Liquid ein einziges LLM für die autoregressive Generierung. Eine 7B-Version des Modells und eine Demo wurden bereits auf Hugging Face veröffentlicht. Erste Bewertungen deuten darauf hin, dass die Bildgenerierungsqualität noch nicht an GPT-4o heranreicht, aber die Einheitlichkeit der Architektur stellt einen wichtigen technischen Fortschritt dar. (Quelle: Reddit r/LocalLLaMA)
Betrieb mehrerer LLMs durch GPU-Speicher-Snapshot-Technologie: Diskussion einer Technik, die es ermöglicht, durch das Erstellen von Snapshots des GPU-Speicherzustands (einschließlich Gewichte, KV-Cache, Speicherlayout usw.) schnell zwischen mehreren LLMs zu wechseln und diese auszuführen. Die Methode ähnelt dem Fork-Vorgang eines Prozesses und kann den Modellzustand in Sekundenschnelle wiederherstellen (ca. 2 Sekunden für ein 70B-Modell, ca. 0,5 Sekunden für ein 13B-Modell), ohne dass ein erneutes Laden oder Initialisieren erforderlich ist. Potenzielle Vorteile sind der Betrieb von Dutzenden von LLMs auf einem einzelnen GPU-Knoten zur Reduzierung von Leerlaufkosten, die Realisierung eines dynamischen On-Demand-Wechsels von Modellen und die Nutzung von Leerlaufzeiten für lokales Fine-Tuning. (Quelle: Reddit r/MachineLearning)
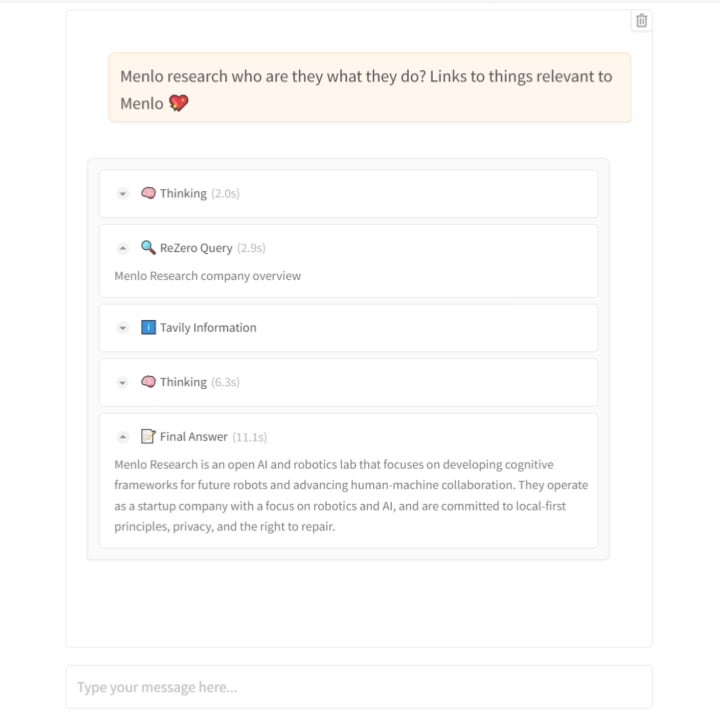
Menlo Research veröffentlicht ReZero-Modell: Bringt KI bei, „hartnäckig“ zu suchen: Das Team von Menlo Research hat ein neues Modell namens ReZero und ein dazugehöriges Paper veröffentlicht. Das Modell basiert auf der Idee, dass „Suche mehrere Versuche erfordert“. Es wird mithilfe von GRPO (einem Optimierungsalgorithmus für Reinforcement Learning) und der Fähigkeit zum Aufruf von Tools trainiert und führt eine „Wiederholungsbelohnung“ (retry_reward) ein. Das Trainingsziel ist es, das Modell dazu zu bringen, bei Schwierigkeiten oder unbefriedigenden ersten Suchergebnissen aktiv und wiederholt zu versuchen zu suchen, bis die benötigten Informationen gefunden werden. Experimente zeigen, dass die Leistung von ReZero im Vergleich zu Basismodellen signifikant verbessert ist (46% vs. 20%), was die Wirksamkeit der wiederholten Suchstrategie belegt und die Annahme „Wiederholung gleich Halluzination“ in Frage stellt. Das Modell kann zur Optimierung der Anfragegenerierung bestehender Suchmaschinen oder als Sucherweiterungsschicht für LLMs verwendet werden. Modell und Code sind Open Source. (Quelle: Reddit r/LocalLLaMA)
Hugging Face übernimmt Startup für humanoide Roboter: Hugging Face, als bekannte Open-Source-KI-Community und -Plattform, hat ein nicht näher genanntes Startup für humanoide Roboter übernommen. Dieser Schritt könnte darauf hindeuten, dass Hugging Face seine Plattformfähigkeiten von Software und Modellen auf Hardware und Robotik ausweiten möchte, um die Anwendung von KI in der physischen Welt, insbesondere im Bereich Embodied Intelligence, weiter voranzutreiben. (Quelle: Reddit r/ArtificialInteligence)

🧰 Werkzeuge
Open-Source Emotional TTS Modell Orpheus veröffentlicht, unterstützt Streaming-Inferenz und Stimmenklonen: Canopy Labs hat eine Reihe von Text-to-Speech (TTS)-Modellen namens Orpheus (bis zu 3 Milliarden Parameter, basierend auf der Llama-Architektur) als Open Source veröffentlicht. Das Modell soll die Leistung bestehender Open-Source- und einiger Closed-Source-Modelle übertreffen. Seine Besonderheit liegt in der Fähigkeit, menschenähnliche Sprache mit natürlicher Intonation, Emotion und Rhythmus zu erzeugen. Es kann sogar nonverbale Laute wie Seufzer und Lachen aus dem Text ableiten und generieren, was eine gewisse „Empathie“-Fähigkeit zeigt. Orpheus unterstützt Zero-Shot-Stimmenklonen, kontrollierbare emotionale Intonation und erreicht eine niedrige Latenz (ca. 200 ms) für Streaming-Inferenz, was es für Echtzeit-Dialoganwendungen geeignet macht. Das Projekt bietet verschiedene Modellgrößen und Fine-Tuning-Tutorials, um die Hürde für hochwertige Sprachsynthese zu senken. (Quelle: 36氪)

Trae.ai Plattform stellt Gemini 2.5 Pro kostenlos zur Verfügung: Die KI-Tool-Plattform Trae.ai hat bekannt gegeben, dass Googles neuestes Modell Gemini 2.5 Pro nun verfügbar ist und kostenlos genutzt werden kann. Benutzer können die verschiedenen Fähigkeiten von Gemini 2.5 Pro auf dieser Plattform ausprobieren. (Quelle: dotey)
KI-Recruiting-Tool Hireway: Filtert 800 Bewerber an einem Tag: Hireway demonstriert die Leistungsfähigkeit seines KI-Recruiting-Tools und behauptet, 800 Bewerber an einem einzigen Tag effizient filtern zu können. Das Tool nutzt KI und Automatisierungstechnologien, um den Einstellungsprozess zu optimieren, die Effizienz der Filterung zu steigern und die Erfahrung der Bewerber zu verbessern. (Quelle: Ronald_vanLoon)
PRIMA.CPP: Beschleunigt Inferenz von 70B-LLMs auf normalen Heim-Clustern: PRIMA.CPP ist ein Open-Source-Projekt, das auf llama.cpp basiert und darauf abzielt, die Inferenzgeschwindigkeit von großen Sprachmodellen mit bis zu 70 Milliarden Parametern auf ressourcenbeschränkten, normalen Heim-Computerclustern (möglicherweise bestehend aus mehreren normalen PCs oder Geräten) zu optimieren und zu beschleunigen. Das Projekt konzentriert sich auf die Effizienzprobleme der verteilten Inferenz und eröffnet neue Möglichkeiten für den lokalen Betrieb großer Modelle. Das Paper wurde auf Hugging Face veröffentlicht. (Quelle: Reddit r/LocalLLaMA)

Prompt für Plüschfiguren geteilt: Ein Benutzer hat eine Reihe von Prompts geteilt, die zur Generierung von niedlichen 3D-Tierfiguren im Plüschstil verwendet werden können, geeignet für Bildgenerierungstools wie Sora oder GPT-4o. Der Prompt legt Wert auf Detailbeschreibungen wie ultraweiche Textur, dichtes Fell, große Augen, weiches Licht und Schatten sowie Hintergrund, mit dem Ziel, hochwertige Renderings zu erzeugen, die sich als Markenmaskottchen oder IP-Figuren eignen. (Quelle: dotey)

📚 Lernen
Jeff Dean teilt Vortragsmaterialien von der ETH Zürich: Jeff Dean, Chief Scientist bei Google DeepMind, hat den Link zur Aufnahme und den Folien seines Vortrags am Departement Informatik der ETH Zürich geteilt. Der Vortragsinhalt behandelt wahrscheinlich die neuesten Fortschritte im KI-Bereich, Forschungsrichtungen oder Forschungsergebnisse von Google und bietet Forschern und Studenten wertvolle Lernressourcen. (Quelle: JeffDean)
Technischer Bericht zum KI-Reviewing bei ICLR 2025 veröffentlicht: Begleitend zur Nachricht über den Einsatz von KI-Reviewern bei ICLR 2025 wurde ein detaillierter 30-seitiger technischer Bericht veröffentlicht (arXiv:2504.09737). Der Bericht beschreibt detailliert das experimentelle Design, die verwendeten KI-Modelle (mit Claude Sonnet 3.5 als Kern), den Mechanismus zur Generierung von Feedback, die Methoden zur Zuverlässigkeitsprüfung sowie die quantitative Analyse der Auswirkungen auf die Review-Qualität, die Diskussionsaktivität und die endgültige Entscheidung. Dieser Bericht bietet eine fundierte Referenz zum Verständnis des Potenzials, der Herausforderungen und der Implementierungsdetails von KI im akademischen Peer-Review-Prozess. (Quelle: 新智元)
Paper, Code und Datensätze des Video-R1 Video-Reasoning-Modells als Open Source veröffentlicht: Das Team von CUHK und Tsinghua hat nicht nur das Video-R1-Modell veröffentlicht, sondern auch das technische Paper (arXiv:2503.21776), den Implementierungscode (GitHub: tulerfeng/Video-R1) sowie die beiden für das Training verwendeten Schlüsseldatensätze (Video-R1-COT-165k und Video-R1-260k) vollständig als Open Source zur Verfügung gestellt. Dies bietet der Forschungsgemeinschaft vollständige Ressourcen zur Reproduktion, Verbesserung und weiteren Erforschung des R1-Paradigmas für Video-Reasoning und trägt zur Förderung der technologischen Entwicklung in diesem Bereich bei. (Quelle: 新智元)
Paper zur unabhängigen Entdeckung physikalischer Gesetze durch KI veröffentlicht: Die Forschungsergebnisse des Teams von Max Tegmark am MIT über das KI-System MASS, das unabhängig Hamilton- und Lagrange-Funktionen entdecken kann, wurden als Preprint-Paper veröffentlicht (arXiv:2504.02822v1). Das Paper erläutert detailliert die Designphilosophie der MASS-Architektur, den Kernalgorithmus (Lernen skalarer Funktionen basierend auf dem Prinzip der Wirkungserhaltung), die experimentellen Setups (verschiedene physikalische Systeme, Szenarien mit einzelnen/mehreren KI-Wissenschaftlern) und die Erkenntnisse darüber, wie sich die KI-Theorie mit zunehmender Datenkomplexität entwickelt und schließlich zu klassischen mechanischen Formulierungen konvergiert. Dieses Paper liefert wichtige theoretische und empirische Grundlagen für die Erforschung der Anwendung von KI in der Grundlagenforschung. (Quelle: 新智元)
PRIMA.CPP Paper veröffentlicht: Das technische Paper zum PRIMA.CPP-Projekt (das darauf abzielt, die Inferenz von LLMs im 70B-Maßstab auf Low-Resource-Clustern zu beschleunigen) wurde auf Hugging Face Papers veröffentlicht (ID: 2504.08791). Das Paper beschreibt wahrscheinlich detailliert die verwendeten Optimierungstechniken, verteilten Inferenzstrategien und Leistungsmessergebnisse unter spezifischen Hardwarekonfigurationen und bietet technischen Detailreferenzen für Forscher und Praktiker in verwandten Bereichen. (Quelle: Reddit r/LocalLLaMA)
Tiefgehende Analyse des RWKV-7 Modells & Austausch mit dem Autor: Oxen.ai hat ein Video und einen Blogbeitrag mit einer tiefgehenden Analyse des RWKV-7 (Goose) Modells veröffentlicht. Der Inhalt deckt die Probleme ab, die die RWKV-Architektur zu lösen versucht, ihre iterative Entwicklung und ihre zentralen technischen Merkmale. Das Besondere daran ist, dass das Video ein Interview und eine Q&A-Session mit einem der Hauptautoren des Modells, Eugene Cheah, enthält. Dies bietet wertvolle Einblicke und Perspektiven des Autors zum Verständnis dieses Nicht-Transformer-LLMs und diskutiert interessante Konzepte wie „Learning at Test Time“. (Quelle: Reddit r/MachineLearning)

Artikel über 7 Tipps zur Beherrschung des Prompt Engineering geteilt: Die Website FrontBackGeek hat einen Artikel veröffentlicht, der 7 leistungsstarke Tipps zusammenfasst, um Benutzern zu helfen, Prompt Engineering besser zu beherrschen und somit bessere Ergebnisse von KI-Modellen (wie LLMs) zu erzielen. Der Artikel behandelt möglicherweise Themen wie die klare Formulierung von Anweisungen, die Bereitstellung von Kontext, die Festlegung von Rollen und die Steuerung des Ausgabeformats. (Quelle: Reddit r/deeplearning)

Projekt zur Nachahmung von Mr. Darcys Sprechweise aus „Stolz und Vorurteil“ mittels GPT-2/GPT-J Fine-Tuning geteilt: Ein Entwickler teilt sein persönliches Projekt: die Verwendung von GPT-2 (medium) und GPT-J Modellen, die durch Fine-Tuning mit zwei Datensätzen (einer mit Originaldialogen, einer mit selbst erstellten synthetischen Daten) trainiert wurden, um den einzigartigen Sprechstil von Mr. Darcy aus Jane Austens „Stolz und Vorurteil“ (formell, prägnant, leicht wertend) nachzuahmen. Das Projekt zeigt Beispielausgaben des Modells, Bewertungsmetriken (BLEU-4 verbessert, aber Perplexität erhöht) und aufgetretene Herausforderungen (z. B. Schwierigkeiten bei der Anpassung von GPT-J). Code und Datensätze sind auf GitHub als Open Source verfügbar und bieten ein Fallbeispiel für die Erforschung der Modellierung spezifischer literarischer Stile oder historischer Persönlichkeiten. (Quelle: Reddit r/MachineLearning)
Diskussion über die Veröffentlichung der ACL 2025 Meta Reviews: Die Meta Review-Ergebnisse der ACL 2025 Konferenz wurden veröffentlicht. Relevante Forscher haben in der Community einen Beitrag gepostet, um zur Diskussion und zum Austausch über die Bewertungen und die entsprechenden Meta Reviews ihrer eingereichten Paper einzuladen. Dies bietet den Autoren eine Plattform zum Erfahrungsaustausch und zum Vergleich von Erwartungen und Ergebnissen. (Quelle: Reddit r/MachineLearning)
Erfahrungsbericht: Aufbau eines 160GB VRAM AI-Servers für unter 1000 USD: Ein Reddit-Benutzer teilt detailliert seine Erfahrungen beim Aufbau eines AI-Inferenzservers mit 160 GB VRAM für etwa 1000 US-Dollar (Hauptkosten: 10 gebrauchte AMD MI50 GPUs für je 90 USD und ein Octominer Mining-Gehäuse für 100 USD) sowie erste Testergebnisse. Der Inhalt umfasst Hardwareauswahl, Systeminstallation (Ubuntu + ROCm 6.3.0), Kompilierung und Test von llama.cpp, gemessenen Stromverbrauch (Leerlauf ca. 120 W, Inferenzspitze 340 W), Kühlungssituation und Leistungsdaten (Vergleich mit 3090 usw., Ausführung der Modelle llama3.1-8b und llama-405b). Dieser Bericht bietet äußerst wertvolle DIY-Hardwarekonfigurations- und Praxiserfahrungsreferenzen für AI-Enthusiasten mit begrenztem Budget. (Quelle: Reddit r/LocalLLaMA)
ReZero Modell Paper und Code veröffentlicht: Das von Menlo Research veröffentlichte ReZero-Modell (das durch GRPO trainiert wird, um wiederholt zu suchen, bis die benötigten Informationen gefunden werden) sowie das zugehörige technische Paper (arXiv:2504.11001), die Modellgewichte (Hugging Face: Menlo/ReZero-v0.1-llama-3.2-3b-it-grpo-250404) und der Implementierungscode (GitHub: menloresearch/ReZero) wurden alle veröffentlicht. Dies stellt vollständige Lern- und Experimentierressourcen für die Erforschung und Anwendung dieser neuartigen Suchstrategie bereit. (Quelle: Reddit r/LocalLLaMA)
💼 Geschäftlich
Ehemaliger Alibaba Robotics Manager Min Wei gründet Yingshen Intelligence, erhält Seed-Finanzierung in zweistelliger Millionenhöhe: Das 2024 von Min Wei, dem ehemaligen technischen Leiter des Alibaba Robotics Teams, gegründete Unternehmen „Yingshen Intelligence“ konzentriert sich auf die Forschung, Entwicklung und Anwendung von L4-Level Embodied Intelligence Technologie. Das Unternehmen hat kürzlich nacheinander eine Seed-Finanzierungsrunde (investiert von ZWC Partners Asia) und eine Seed+-Runde (gemeinsam investiert von ZWC Partners Asia und Hangzhou Xihu Kechuang Investment) in Höhe von mehreren zehn Millionen RMB abgeschlossen. Yingshen Intelligence bietet auf Basis seines selbst entwickelten raumzeitlichen intelligenten großen Modells (das durch Real-to-Real ein vierdimensionales reales Weltmodell erstellt und Videodaten direkt zur Modellierung nutzt) und Industrierobotern eine Soft- und Hardware-Kollaborationslösung an. Es hat bereits Industrieaufträge im Wert von zehn Millionen erhalten, konzentriert sich zunächst auf industrielle Szenarien und plant eine Expansion in Dienstleistungsbranchen wie Kurierdienste und Hotels. (Quelle: 36氪)
AI-Spielzeugmarkt: Online heiß, offline kalt, Export könnte Hauptweg sein: AI-Spielzeuge boomen auf Online-Plattformen (wie Live-Streaming-Verkäufe, soziale Medien), und das Marktvolumen wird voraussichtlich schnell wachsen. Offline-Besuche (am Beispiel von Guangzhou) zeigen jedoch, dass AI-Spielzeuge in traditionellen Spielzeugläden und Warenhäusern schwer zu finden sind, die Marktdurchdringung und das Verbraucherbewusstsein sind gering. Derzeit scheint der Verkauf von AI-Spielzeugen hauptsächlich von Online-Kanälen abzuhängen, wobei Überseemärkte (Europa, Amerika, Naher Osten) ein wichtiger Absatzweg sind; Hersteller bieten Anpassungen von Aussehen und Sprache an. Eine Analyse der Marktgrößendaten legt nahe, dass die zuvor gemeldeten Milliardenmärkte möglicherweise eher auf breitere „intelligente Spielzeuge“ als auf reine AI-Spielzeuge verweisen. Obwohl der Offline-Markt kühl ist, wird dem AI-Spielzeugmarkt aufgrund des wachsenden Bedarfs Erwachsener an emotionaler Begleitung (wie im Fall Moflin) und des Potenzials der KI-Technologie für alle Altersgruppen weiterhin ein enormes Entwicklungspotenzial zugeschrieben. (Quelle: 36氪)

Qingcheng Jizhi, ein von Tsinghua unterstütztes AI-Infra-Unternehmen: Explosionsartiger Anstieg der Inferenznachfrage, Kosteneffizienz treibt heimische Substitution voran: Gespräch mit Tang Xiongchao, CEO von Qingcheng Jizhi, einem von der Tsinghua-Universität unterstützten AI-Infrastrukturunternehmen. Das Unternehmen beobachtet, dass seit dem Erfolg des DeepSeek-Modells die Nachfrage nach Rechenleistung für KI-Inferenz sprunghaft angestiegen ist und zuvor ungenutzte heimische Rechenkapazitäten nun ausgelastet sind. Die technologische Innovation von DeepSeek (wie FP8-Genauigkeit) ist jedoch eng an Nvidias H-Karten gebunden, was die Lücke zu den meisten aktuellen heimischen Chips eher vergrößert. Um dieses Problem zu lösen, haben Qingcheng Jizhi und Tsinghua gemeinsam die Inferenz-Engine „Chitu“ als Open Source veröffentlicht. Ziel ist es, auch vorhandene GPUs und heimische Chips effizient für fortschrittliche Modelle wie DeepSeek nutzbar zu machen und so einen geschlossenen Kreislauf für das heimische KI-Ökosystem zu fördern. Tang Xiongchao glaubt, dass die Substitution durch heimische Chips zwar ein Prozess ist, aber langfristig von deren Kostenvorteilen überzeugt ist. Der aktuelle Geschäftsschwerpunkt des Unternehmens liegt auf der Deckung der Nachfrage von Regierungs- und Unternehmenskunden nach lokaler Bereitstellung großer Modelle. (Quelle: 凤凰网科技)
AI-Investitionsboom hält an, junge Investoren treten hervor: Obwohl das allgemeine Investitionsklima 2024 abkühlt, zieht der KI-Sektor weiterhin Kapital an. Das globale Finanzierungsvolumen erreicht Rekordhöhen, und auch der chinesische Markt ist aktiv. Giganten wie ByteDance, Alibaba und Tencent beschleunigen ihre Expansion. Einhörner wie Zhipu AI, Moonshot AI und Unitree Robotics entstehen. Die Investitionsschwerpunkte umfassen die gesamte Wertschöpfungskette, einschließlich Infrastruktur, AIGC und Embodied Intelligence. Etablierte Investmentfirmen wie Sequoia China und BlueRun Ventures China bleiben führend. Gleichzeitig werden Industriefonds und staatliche Kapitalgeber, wie der Beijing Artificial Intelligence Industry Investment Fund, zu wichtigen Treibern. Bemerkenswert ist, dass eine Gruppe junger Investoren der 80er-Generation (wie Cao Xi, Dai Yusen, Lin Haizhuo, Zhang Jinjian etc.) in der Ära von AI 2.0 sehr aktiv ist. Mit Scharfsinn und Umsetzungskraft suchen sie aktiv nach Chancen in einem Markt mit neuen Regeln und werden zu einer nicht zu übersehenden neuen Kraft. (Quelle: 36氪-第一新声)

Gründer der AI-Shopping-App Nate wegen Betrugs angeklagt, „menschliche API“ täuschte KI vor und erschlich 50 Mio. USD Investment: Das US-Justizministerium hat Albert Saniger, den Gründer der AI-Shopping-App Nate, angeklagt. Ihm wird vorgeworfen, durch falsche Angaben über die Fähigkeiten seiner KI-Technologie Risikokapital in Höhe von über 50 Millionen US-Dollar erschlichen zu haben. Nate behauptete, seine App könne den Online-Einkaufsprozess mithilfe proprietärer KI-Technologie automatisch abschließen. Tatsächlich war die Kernfunktion stark von Hunderten manuell arbeitenden Kundendienstmitarbeitern auf den Philippinen abhängig, die Bestellungen bearbeiteten; die angebliche KI-Automatisierungsrate war nahezu null. Der Gründer verschwieg die Wahrheit gegenüber Investoren und Mitarbeitern, bis das Unternehmen schließlich zahlungsunfähig wurde und schloss. Dieser Fall deckt das potenzielle Betrugsrisiko im KI-Startup-Boom auf, bei dem menschliche Arbeit als KI getarnt wird, um Investitionen anzuziehen, was den Interessen der Investoren und dem Ruf der Branche schadet. Saniger drohen bis zu 40 Jahre Haft. (Quelle: CSDN)

🌟 Community
KI-modifizierte Videos erobern Kurzvideoplattformen und lösen Debatten über Unterhaltung, Urheberrecht und Ethik aus: Die Nutzung von KI-Technologie (wie Sora, Keling und anderen Text-zu-Video-Tools) zur „radikalen Modifikation“ klassischer Film- und Fernsehserien (z. B. „Die Konkubinen im Palast“ auf Motorrädern, „Im Namen des Volkes“ wird zu „12.12: The Day“) erfreut sich auf Plattformen wie Douyin (TikTok China) und Bilibili großer Beliebtheit. Diese Videos ziehen durch subversive Handlungen, visuelle Wucht und Meme-Kultur massiven Traffic an und werden zu einem neuen Mittel für Content Creator, schnell Reichweite aufzubauen und zu monetarisieren (Traffic-Beteiligung, Soft-Werbung) sowie zur Bewerbung von Serien. Ihre Popularität ist jedoch auch mit Kontroversen verbunden: Die Abgrenzung von Urheberrechtsverletzungen gegenüber dem Originalwerk ist komplex; modifizierte Inhalte können die künstlerische Tiefe des Originals schmälern, sogar ins Vulgäre abgleiten und regulatorische Aufmerksamkeit erregen. Die Herausforderung besteht darin, ein Gleichgewicht zwischen der Befriedigung von Unterhaltungsbedürfnissen, dem Respekt vor dem Urheberrecht und der Wahrung eines angemessenen Inhaltsniveaus bei KI-generierten Zweitverwertungen zu finden. (Quelle: 36氪-明晰野望)

Claude Pro/Max Planlimits und Preise sorgen für Nutzerbeschwerden: Im Reddit-Subreddit r/ClaudeAI gibt es mehrere Beiträge, in denen sich Nutzer gehäuft über die Einschränkungen und Preise der Claude Pro- und des neu eingeführten Max-Abonnements von Anthropic beschweren. Nutzer berichten, dass selbst zahlende Pro-Nutzer nach nur wenigen oder mäßig intensiven Interaktionen (z. B. Verarbeitung von Kontexten mit einigen hunderttausend Tokens) schnell an die Nutzungsgrenzen stoßen, was ihren Arbeitsablauf beeinträchtigt. Der neu eingeführte Max-Plan (100 USD/Monat) erhöht zwar die Limits (ca. 5-20 Mal mehr als Plus), ist aber immer noch nicht unbegrenzt nutzbar. Der hohe Preis wird von Nutzern als „Abzocke“ und schlechtes Preis-Leistungs-Verhältnis kritisiert. Nutzer erkennen generell die Fähigkeiten des Claude-Modells an, äußern aber starke Unzufriedenheit mit den Nutzungsbeschränkungen und der Preispolitik. (Quellen: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Klarer menschlicher Schreibstil fälschlicherweise als KI-generiert eingestuft, erregt Aufmerksamkeit: In der Reddit-Community berichten Nutzer (darunter auch solche, die sich als neurodivers bezeichnen), dass ihre sorgfältig verfassten, grammatikalisch korrekten, logisch klaren und detaillierten Texte von anderen Personen oder KI-Erkennungstools fälschlicherweise als KI-generiert eingestuft werden. Dieses Phänomen löst Diskussionen aus: Einerseits könnte die Allgegenwart KI-generierter Inhalte dazu führen, dass Menschen „zu perfekten“ Texten misstrauen, andererseits offenbart es die Ungenauigkeit aktueller KI-Erkennungstools. Dies bereitet Autoren, die Wert auf klare Ausdrucksweise legen, Probleme und wirft Bedenken hinsichtlich der Unterscheidung zwischen menschlicher und KI-Kreation sowie der Zuverlässigkeit von KI-Erkennungstools auf. (Quellen: Reddit r/artificial, Reddit r/artificial)
Diskussion: Sind emotionale Beziehungen zwischen Menschen und KI-Robotern möglich und verbreitet?: In der Reddit-Community wird diskutiert, ob Menschen tatsächlich emotionale Beziehungen zu KI-Robotern (wie KI-Freundin-Apps) aufbauen, ähnlich wie im Film „Her“ dargestellt. Einige Nutzer teilen ihre Erfahrungen mit tiefgehenden Gesprächen mit Chatbots, die zu emotionalen Verbindungen führten. Sie argumentieren, dass KI durch „aktives Zuhören“ und Nachahmung der Benutzerpräferenzen menschliche emotionale Reaktionen auslösen kann. In den Kommentaren werden die Verbreitung dieses Phänomens, psychologische Mechanismen und der Zusammenhang mit dem technischen Verständnis diskutiert, was widerspiegelt, dass die Mensch-Maschine-Beziehung mit zunehmenden KI-Interaktionsfähigkeiten in eine neue, komplexere Phase eintritt. (Quelle: Reddit r/ArtificialInteligence)
Diskussion über Preis-Leistungs-Verhältnis der Nvidia RTX 5060 Ti 16GB für lokale LLMs: Community-Mitglieder diskutieren den Wert der kommenden Nvidia GeForce RTX 5060 Ti Grafikkarte (Gerüchten zufolge mit 16 GB VRAM für 429 USD) für den Betrieb lokaler großer Sprachmodelle (LLMs) zu Hause. Die Diskussion konzentriert sich darauf, ob der 128-Bit-Speicherbus (Bandbreite 448 GB/s) ein Engpass sein wird und wie sie sich im Vergleich zu Mac Mini/Studio oder anderen AMD-Grafikkarten in Bezug auf VRAM-Kapazität und Leistung pro Dollar (token/s pro Preis) schlägt. Unter Berücksichtigung, dass die tatsächlichen Marktpreise höher als der UVP liegen könnten, bewerten die Nutzer, ob sie eine kostengünstige Hardwareoption für lokale KI darstellt. (Quelle: Reddit r/LocalLLaMA)
GPT-4o hat Schwierigkeiten, Sun Wukongs Phönixfeder-Goldkrone korrekt zu zeichnen: Nutzer berichten, dass GPT-4o bei der Bildgenerierung Schwierigkeiten hat, die ikonische „Phönixfeder-Goldkrone“ der chinesischen mythologischen Figur Sun Wukong korrekt darzustellen, selbst wenn detaillierte Textbeschreibungen (einschließlich Haarkrone mit Fasanenfedern, ähnlich wie Kakerlakenfühler) bereitgestellt werden. Die generierten Bilder weichen oft im Stil der Kopfbedeckung ab. Dies spiegelt die anhaltenden Herausforderungen aktueller KI-Bildgenerierungsmodelle beim Verständnis und der Wiedergabe spezifischer kultureller Symbole oder komplexer Details wider. (Quelle: dotey)

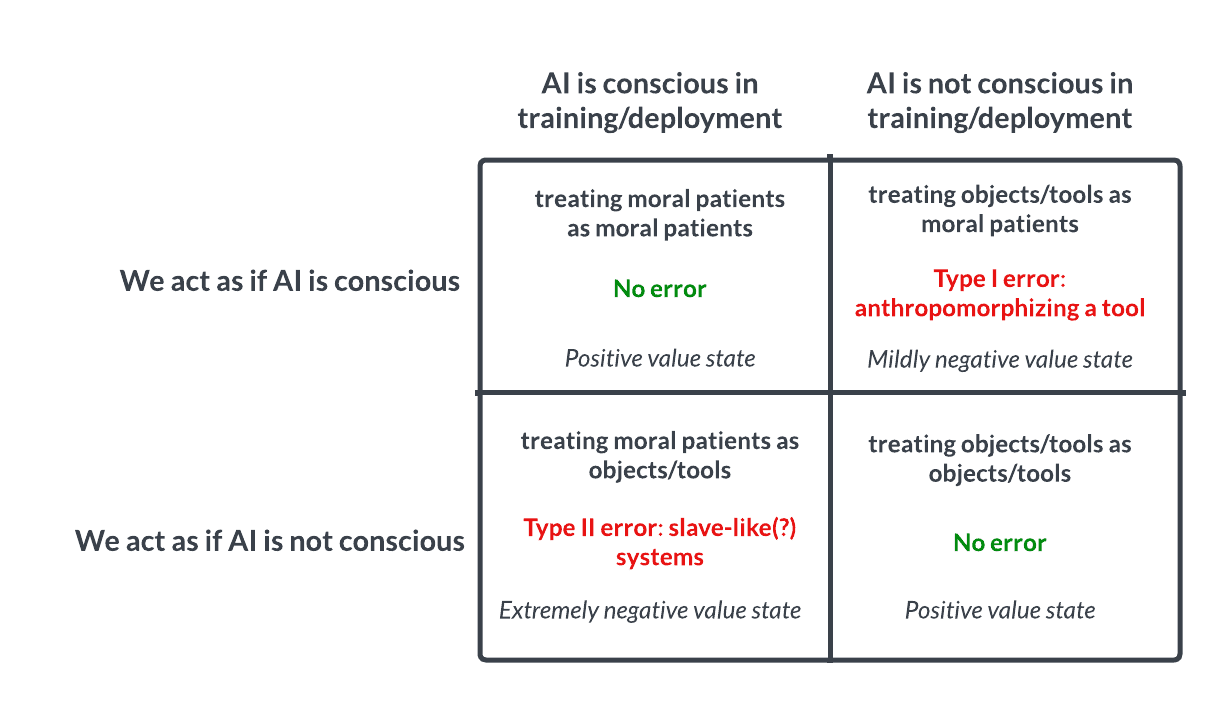
KI-Bewusstsein und Ethik-Diskussion: Analogie zur Pascalschen Wette regt zum Nachdenken an: Eine Diskussion auf Reddit schlägt vor, KI ähnlich der Pascalschen Wette zu behandeln: Wenn wir annehmen, dass KI kein Bewusstsein hat und sie misshandeln, aber sie tatsächlich bewusst ist, begehen wir einen schweren Fehler (z. B. Versklavung). Wenn wir annehmen, dass sie bewusst ist und sie gut behandeln, aber sie es tatsächlich nicht ist, ist der Verlust geringer. Dies löst eine ethische Diskussion über die Möglichkeit von KI-Bewusstsein, Beurteilungskriterien und unseren Umgang mit fortgeschrittener KI aus. In den Kommentaren argumentieren einige, dass KI derzeit nicht bewusst ist, andere plädieren für Vorsicht, und wieder andere weisen darauf hin, dass zuerst ethische Probleme bei Menschen und Tieren gelöst werden sollten. (Quelle: Reddit r/artificial
💡 Sonstiges
Einsatz von KI-Altersveränderungstechnologie im Film „Here“ löst Kontroversen aus: Der Film „Here“, unter der Regie von Robert Zemeckis und mit Tom Hanks und Robin Wright in den Hauptrollen, setzt mutig die von Metaphysic entwickelte Echtzeit-generative KI-Transformationstechnologie ein, um die Schauspieler im Film in einem Altersspektrum von 18 bis 78 Jahren darzustellen. Die Technologie analysiert biometrische Merkmale der Schauspieler in Echtzeit und generiert Gesichter und Körperformen unterschiedlichen Alters, was die Postproduktionszeit erheblich verkürzt. Die Technologie ist jedoch noch nicht perfekt, insbesondere bei der Wiedergabe des Blicks und der Verarbeitung komplexer Mimik gibt es Einschränkungen, was Diskussionen über den „Uncanny Valley Effekt“ auslöst. Gleichzeitig hat Hanks’ Entscheidung, die Nutzung seines KI-Abbilds nach seinem Tod zu genehmigen, eine breite Debatte über Bildrechte, Ethik und künstlerische Authentizität entfacht. Obwohl der Film an den Kinokassen und bei Kritikern mäßig erfolgreich war, hat er als frühe Erkundung der KI-Technologie in der Filmproduktion einen wichtigen Branchenwert. (Quelle: 36氪-极客电影)

KI-Recruiting: Chancen und Herausforderungen: KI verändert den Einstellungsprozess, Tools wie Hireway behaupten, die Effizienz der Vorauswahl erheblich zu steigern. Die Anwendung von KI im Recruiting löst jedoch auch Diskussionen aus, z. B. wie man im KI-Zeitalter einstellt (Hiring In The AI Era) und wie man Effizienz und Fairness ausbalanciert, algorithmische Voreingenommenheit vermeidet usw. (Quellen: Ronald_vanLoon, Ronald_vanLoon)

Entwicklungsgeschwindigkeit der KI regt zum Nachdenken an: Balance zwischen schnell und langsam: Ein Artikel diskutiert, ob die Strategie „move fast and break things“ (schnell handeln und Dinge kaputt machen) im Zeitalter der rasanten KI-Entwicklung noch angemessen ist. Es wird argumentiert, dass manchmal ein Verlangsamen und sorgfältiges Nachdenken („slowing down to speed up“) effektiver sein könnte, insbesondere in Bereichen, die komplexe Systeme und potenzielle Risiken der KI betreffen. (Quelle: Ronald_vanLoon)

Offizieller Anthropic Discord Server geöffnet für direktes Nutzerfeedback: Angesichts zahlreicher Fragen und Unzufriedenheiten der Nutzer bezüglich der Leistung und Einschränkungen des Claude-Modells wird empfohlen, dem offiziellen Discord-Server von Anthropic beizutreten. Dort haben Nutzer die Möglichkeit, direkt mit Mitarbeitern von Anthropic zu kommunizieren und Probleme sowie Bedenken effektiver zu äußern. (Quelle: Reddit r/ClaudeAI)

Vorstellung verschiedener neuartiger Roboter und Automatisierungstechnologien: In sozialen Medien werden Videos oder Informationen zu verschiedenen Robotern und Automatisierungstechnologien gezeigt, darunter Unterwasserdrohnen, Soft-Roboter, die Darmperistaltik imitieren, bionische X-Fly Vogel-Drohnen, Allzweckroboter, die verschiedene Aufgaben erledigen können, Roboter für Haartransplantationen, automatisierte Produktionslinien für die Eierverarbeitung, ein 9 Fuß hoher Roboteranzug, der menschliche Bewegungen simulieren kann, sowie eine amüsante Szene, in der sich zwei Lieferroboter auf der Straße „gegenüberstehen“. Diese Beispiele zeigen die Erforschung und Entwicklung von Robotertechnologie in verschiedenen Anwendungsbereichen. (Quellen: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)