
Schlüsselwörter:GPT-4.1, Hugging Face, GPT-4.1 Modellreihenleistungsvergleich, Hugging Face übernimmt Pollen Robotics, OpenAI neue Modelle verbesserte Kodierfähigkeiten, GPT-4.1 mini Kosten um 83% reduziert, Open-Source-Roboter Reachy 2
🔥 Fokus
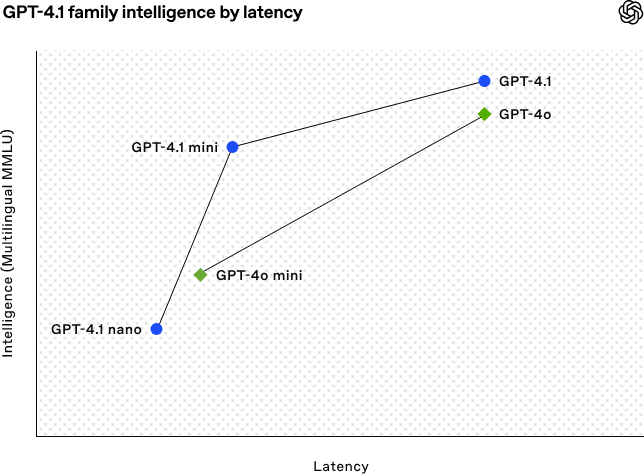
OpenAI veröffentlicht GPT-4.1-Modellreihe, verbessert Codierungs- und Langtextverarbeitungsfähigkeiten: OpenAI hat am frühen Morgen des 15. April drei neue Modelle der GPT-4.1-Serie veröffentlicht: GPT-4.1 (Flaggschiff), GPT-4.1 mini (effizient) und GPT-4.1 nano (ultrakompakt), die alle nur über API verfügbar sind. Diese Modellreihe zeichnet sich durch hervorragende Leistungen in den Bereichen Codierung, Befehlsbefolgung und Verständnis langer Kontexte aus. Alle Modelle verfügen über ein Kontextfenster von 1 Million Tokens und eine Ausgabelänge von 32.768 Tokens. GPT-4.1 erreicht im SWE-bench Verified Test einen Score von 54,6 % und übertrifft damit GPT-4o sowie das demnächst eingestellte GPT-4.5 Preview deutlich. GPT-4.1 mini übertrifft GPT-4o in der Leistung, halbiert gleichzeitig die Latenz und senkt die Kosten um 83 %. GPT-4.1 nano ist derzeit das schnellste und kostengünstigste Modell, geeignet für Aufgaben mit geringer Latenz. Diese Veröffentlichung zielt darauf ab, Entwicklern leistungsfähigere, kostengünstigere und schnellere Modelloptionen zu bieten und den Aufbau komplexer intelligenter Systeme und Agentenanwendungen voranzutreiben. (Quelle: 36氪, 智东西, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1来了,超越GPT-4.5,SWE-Bench达到55%,开发者专属。)
Hugging Face übernimmt Open-Source-Robotikunternehmen Pollen Robotics: Die KI-Community-Plattform Hugging Face hat die Übernahme des französischen Open-Source-Robotik-Startups Pollen Robotics bekannt gegeben, um die Open-Source-Entwicklung und Verbreitung von KI-Robotern voranzutreiben. Diese Übernahme kombiniert die Stärken von Hugging Face bei Softwareplattformen (wie der LeRobot-Bibliothek und dem Hub) mit der Expertise von Pollen Robotics bei Open-Source-Hardware (wie dem humanoiden Roboter Reachy 2). Reachy 2 ist ein Open-Source-, VR-kompatibler humanoider Roboter, der speziell für Forschung, Bildung und Experimente mit verkörperter Intelligenz (Embodied AI) entwickelt wurde und 70.000 US-Dollar kostet. Hugging Face betrachtet Roboter als die nächste wichtige Schnittstelle für KI und ist der Ansicht, dass diese offen, erschwinglich und anpassbar sein sollten. Die Übernahme ist ein entscheidender Schritt zur Verwirklichung dieser Vision, mit dem Ziel, der Community zu ermöglichen, ihre eigenen Roboter-Begleiter zu bauen und zu steuern, anstatt sich auf geschlossene, teure Systeme zu verlassen. (Quelle: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 Trends
KI hilft bei der Lösung eines 50 Jahre alten mathematischen Problems: Der chinesische Wissenschaftler Weiguo Yin vom Brookhaven National Laboratory in den USA hat mithilfe des Reasoning-Modells o3-mini-high von OpenAI einen Durchbruch bei der exakten Lösung des eindimensionalen J_1-J_2 q-Zustands-Potts-Modells erzielt, insbesondere für den Fall q=3, wobei KI bei der Vervollständigung des entscheidenden Beweises unterstützte. Dieses Problem betrifft ein grundlegendes Modell der statistischen Mechanik, das für physikalische Phänomene wie Atomschichtung in Schichtmaterialien und unkonventionelle Supraleitung relevant ist, dessen exakte Lösung in den letzten 50 Jahren nicht gefunden werden konnte. Die Forscher führten die Methode des maximalen symmetrischen Unterraums (MSS) ein und nutzten KI-gestützte schrittweise Hinweise zur Verarbeitung der Transfermatrix, um die 9×9-Transfermatrix für q=3 erfolgreich auf eine effektive 2×2-Matrix zu reduzieren und diese Methode auf beliebige q-Werte zu verallgemeinern. Diese Forschung löst nicht nur ein langjähriges mathematisch-physikalisches Problem, sondern zeigt auch das enorme Potenzial von KI bei der Unterstützung komplexer wissenschaftlicher Forschung und der Generierung neuer Erkenntnisse. (Quelle: 刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明)

Aufkommen von KI-Webassistenten, Hersteller von Mobiltelefonen und Autos planen Multi-Device-Erlebnisse: Hersteller wie Huawei (Xiaoyi Assistant), Li Auto (Lixiang Tongxue) und OPPO (Xiaobu Assistant) haben nacheinander Webversionen ihrer KI-Assistenten eingeführt, was Aufmerksamkeit erregt. Obwohl diese Webversionen in Bezug auf die Funktionsreife (z. B. Bearbeiten von Fragen, Layout, Einstellungsoptionen) möglicherweise nicht mit professionellen Modelldiensten wie DeepSeek mithalten können, besteht ihr Hauptziel nicht im direkten Wettbewerb, sondern darin, den Nutzern ihrer jeweiligen Marken zu dienen und eine geschlossene Erlebnisbrücke von Mobiltelefonen über Fahrzeugsysteme bis hin zu PCs zu schlagen. Durch die Verknüpfung von Benutzerkonten und die Synchronisierung von Gesprächsverläufen zielen diese Webversionen darauf ab, die Nutzerbindung zu stärken, ein konsistentes Interaktionserlebnis über verschiedene Endgeräte hinweg zu bieten und KI-Assistenten in breitere Nutzungsszenarien zu integrieren. Im Wesentlichen handelt es sich um eine strategische Positionierung im Hinblick auf Benutzereinstiegspunkte und Datenökosysteme. (Quelle: AI网页版扎堆上线,华为、理想、OPPO们打的什么算盘?)
Figure-Roboter erreicht Zero-Shot-Transfer von Simulation zu Realität durch Reinforcement Learning: Das Unternehmen Figure demonstrierte, wie sein humanoider Roboter Figure 02 durch reines Reinforcement Learning (RL) in einer simulierten Umgebung einen natürlichen Gang erlernt. Mithilfe eines effizienten, GPU-beschleunigten Physiksimulators wurden innerhalb weniger Stunden Trainingsdaten generiert, die mehreren Jahren entsprechen. Damit wurde eine einzige neuronale Netzwerkstrategie trainiert, die mehrere virtuelle Roboter mit unterschiedlichen physikalischen Parametern und in verschiedenen Szenarien (z. B. unterschiedliches Gelände, Störungen) steuern kann. Durch die Kombination von Simulation Domain Randomization und hochfrequentem Drehmoment-Feedback des realen Roboters kann die trainierte Strategie ohne Feinabstimmung als Zero-Shot-Transfer auf den physischen Roboter übertragen werden. Diese Methode verkürzt nicht nur die Entwicklungszeit und erhöht die Stabilität der Leistung in der realen Welt, sondern ermöglicht es auch, eine ganze Roboterflotte mit einer einzigen Strategie zu steuern, was ihr Potenzial für groß angelegte kommerzielle Anwendungen zeigt. (Quelle: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)

DeepSeek wird Teile der Optimierungen seiner Inference Engine als Open Source veröffentlichen: DeepSeek kündigte an, Teile der Optimierungen und Funktionen seiner auf vLLM basierenden, hochleistungsfähigen Inference Engine der Community zur Verfügung zu stellen. Anstatt den vollständigen, stark angepassten Inference Stack zu veröffentlichen, werden sie wichtige Verbesserungen (wie Unterstützung für neueste Modellarchitekturen, Leistungsoptimierungen) in gängige Open-Source-Inference-Frameworks wie vLLM und SGLang integrieren. Ziel ist es, der Community vom ersten Tag an SOTA-Unterstützung für neue Modelle und Technologien zu ermöglichen. Dieser Schritt wurde von der Community begrüßt und als echtes Engagement für Open Source gewertet, nicht nur als Lippenbekenntnis. (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
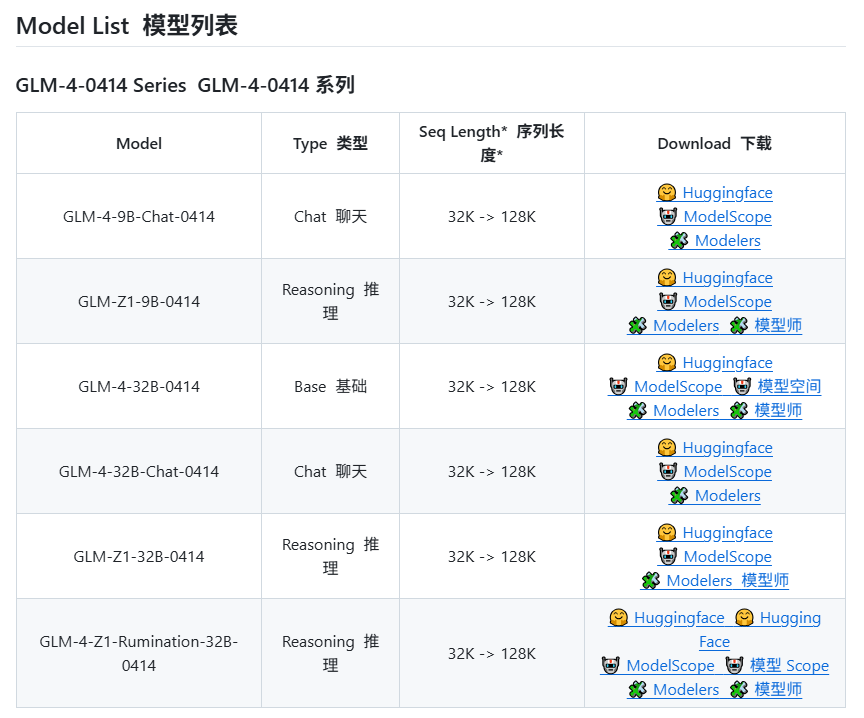
Zhipu AI wird voraussichtlich neue Modelle der GLM-4-Serie veröffentlichen: Laut durchgesickerten Informationen auf GitHub (die später entfernt wurden) bereitet Zhipu AI offenbar die Veröffentlichung neuer Modelle der GLM-4-Serie vor. Die Serie könnte Versionen mit unterschiedlichen Parametergrößen (z. B. 9B, 32B) und Funktionen umfassen, wie z. B. Basismodelle (GLM-4-32B-0414), Dialogmodelle (Chat), Reasoning-Modelle (GLM-Z1-32B-0414) sowie “Rumination”-Modelle mit tiefergehenden Denkfähigkeiten, möglicherweise als Konkurrenz zu OpenAIs Deep Research. Darüber hinaus könnte ein visuelles multimodales Modell (GLM-4V-9B) enthalten sein. Durchgesickerte Benchmark-Daten deuten darauf hin, dass GLM-4-32B-0414 in einigen Metriken DeepSeek-V3 und DeepSeek-R1 übertreffen könnte. Zugehöriger Code zur Unterstützung der Inference Engine wurde bereits in transformers/vllm/llama.cpp integriert. Die Community verfolgt dies mit großem Interesse und erwartet die offizielle Veröffentlichung und Tests. (Quelle: karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA veröffentlicht neue Modelle der Nemotron-Serie: NVIDIA hat auf Hugging Face neue Basismodelle der Nemotron-H-Serie veröffentlicht, darunter Versionen mit 56B, 47B und 8B Parametern, die alle ein Kontextfenster von 8K unterstützen. Diese Modelle basieren auf einer hybriden Architektur aus Transformer und Mamba. Derzeit wurden nur die Basismodelle (Base) veröffentlicht, Versionen mit Instruktions-Feinabstimmung (Instruct) sind noch nicht verfügbar. Die Nemotron-Serie zielt darauf ab, das Potenzial neuer Architekturen für die Sprachmodellierung zu erforschen. (Quelle: Reddit r/LocalLLaMA)

🧰 Tools
GitHub Copilot in Windows Terminal Canary-Version integriert: Microsoft hat die GitHub Copilot-Funktionalität in die Canary-Vorschauversion von Windows Terminal integriert und ein neues Feature namens „Terminal Chat“ eingeführt. Diese Funktion ermöglicht es Benutzern, direkt in der Terminalumgebung mit der KI zu interagieren, um Befehlsvorschläge und Erklärungen zu erhalten. Benutzer müssen GitHub Copilot abonnieren und die neueste Canary-Version des Terminals installieren. Nach der Verifizierung ihres Kontos können sie die Funktion nutzen. Ziel ist es, KI-Unterstützung direkt in die von Entwicklern häufig genutzte Kommandozeilenumgebung zu integrieren, Kontextwechsel zu reduzieren, die Effizienz bei der Bearbeitung komplexer oder unbekannter Aufgaben zu steigern, den Lernprozess zu beschleunigen und Fehler zu reduzieren. (Quelle: GitHub Copilot 现可在 Windows 终端中运行了)

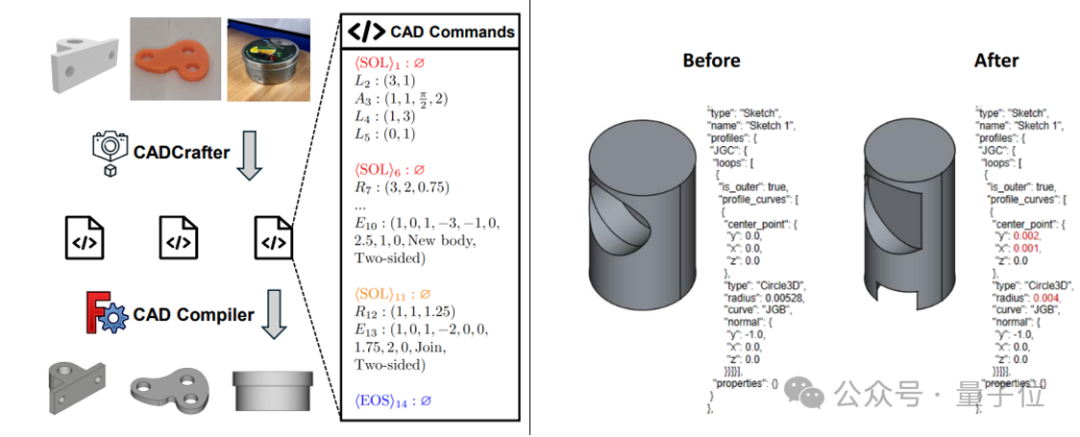
CADCrafter: Generierung bearbeitbarer CAD-Dateien aus einem einzigen Bild: Forscher von KOKONI 3D, der Nanyang Technological University und anderen Institutionen haben ein neues Framework namens CADCrafter vorgestellt. Es kann aus einem einzigen Bild (Rendering, Foto eines realen Objekts usw.) direkt parametrisierte, bearbeitbare CAD-Konstruktionsdateien (repräsentiert als Sequenz von CAD-Befehlen) generieren. Dies löst das Problem bestehender Bild-zu-3D-Methoden (die Mesh oder 3DGS erzeugen), deren Ausgaben schwer präzise zu bearbeiten sind und oft eine geringe Oberflächenqualität aufweisen. Die Methode verwendet eine zweistufige Generierungsarchitektur, die VAE und Diffusion Transformer kombiniert. Durch eine Multi-View-zu-Single-View-Destillationsstrategie und einen auf DPO basierenden Mechanismus zur Überprüfung der Kompilierbarkeit werden die Generierungsqualität und Erfolgsrate verbessert. Die Forschungsarbeit wurde für die CVPR 2025 angenommen und bietet ein neues Paradigma für KI-gestütztes Industriedesign. (Quelle: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
LangChain führt GraphRAG mit MongoDB Atlas-Integration ein: LangChain kündigte eine Zusammenarbeit mit MongoDB an, um ein graphbasiertes RAG-System (GraphRAG) einzuführen. Dieses System nutzt MongoDB Atlas zur Speicherung und Verarbeitung von Daten und wird über LangChain implementiert. Es kann über herkömmliche, auf Ähnlichkeitssuche basierende RAG hinausgehen, um Beziehungen zwischen Entitäten zu verstehen und daraus zu schlussfolgern. Es unterstützt die Extraktion von Entitäten und Beziehungen durch LLMs und nutzt Graph-Traversierung, um verknüpfte Kontextinformationen abzurufen. Ziel ist es, leistungsfähigere Frage-Antwort- und Reasoning-Fähigkeiten für Anwendungen bereitzustellen, die ein tiefes Verständnis von Beziehungen erfordern. (Quelle: LangChainAI)
Hugging Face macht seinen Inference Playground Open Source: Hugging Face hat sein Online-Tool Inference Playground, das zum Testen und Vergleichen von Modellinferenzen verwendet wird, als Open Source veröffentlicht. Es handelt sich um eine webbasierte LLM-Chat-Oberfläche, die es Benutzern ermöglicht, verschiedene Inferenz-Einstellungen (wie Temperatur, Top-p usw.) zu steuern, KI-Antworten zu ändern und die Leistung verschiedener Modelle und Anbieter zu vergleichen. Das Projekt wurde mit Svelte 5, Melt UI und Tailwind erstellt. Der Code wurde auf GitHub veröffentlicht und bietet Entwicklern eine anpassbare und erweiterbare Plattform für die lokale oder Online-Interaktion mit und Bewertung von Modellen. (Quelle: huggingface)
Flowith-Plattform erreicht über 1 Million US-Dollar ARR und demonstriert Fähigkeit zur Generierung von Webseiten durch KI-Agenten: Die jährlichen wiederkehrenden Einnahmen (ARR) der KI-Agenten-Plattform Flowith haben 1 Million US-Dollar überschritten, was die starke Marktnachfrage nach vielseitigen KI-Agenten-Plattformen zeigt, die menschliche Arbeit ersetzen können. Ein Benutzer teilte seine Erfahrung mit der Oracle-Funktion von Flowith: Nur durch eine einfache Beschreibung in natürlicher Sprache (“Ich möchte eine Webseite für die Vorschau von Social-Media-Grafiken erstellen…”) konnte schnell ein voll funktionsfähiges Web-Tool mit präzise nachgebildetem Stil (z. B. Twitter-Stil) und Unterstützung für Bildvorschauen generiert werden, ohne dass eine Verbindung zu GitHub oder komplexe Konfigurationen erforderlich waren. Dies zeigt das Potenzial von KI-Agenten im Bereich der Low-Code/No-Code-Webseitenerstellung. (Quelle: karminski3)
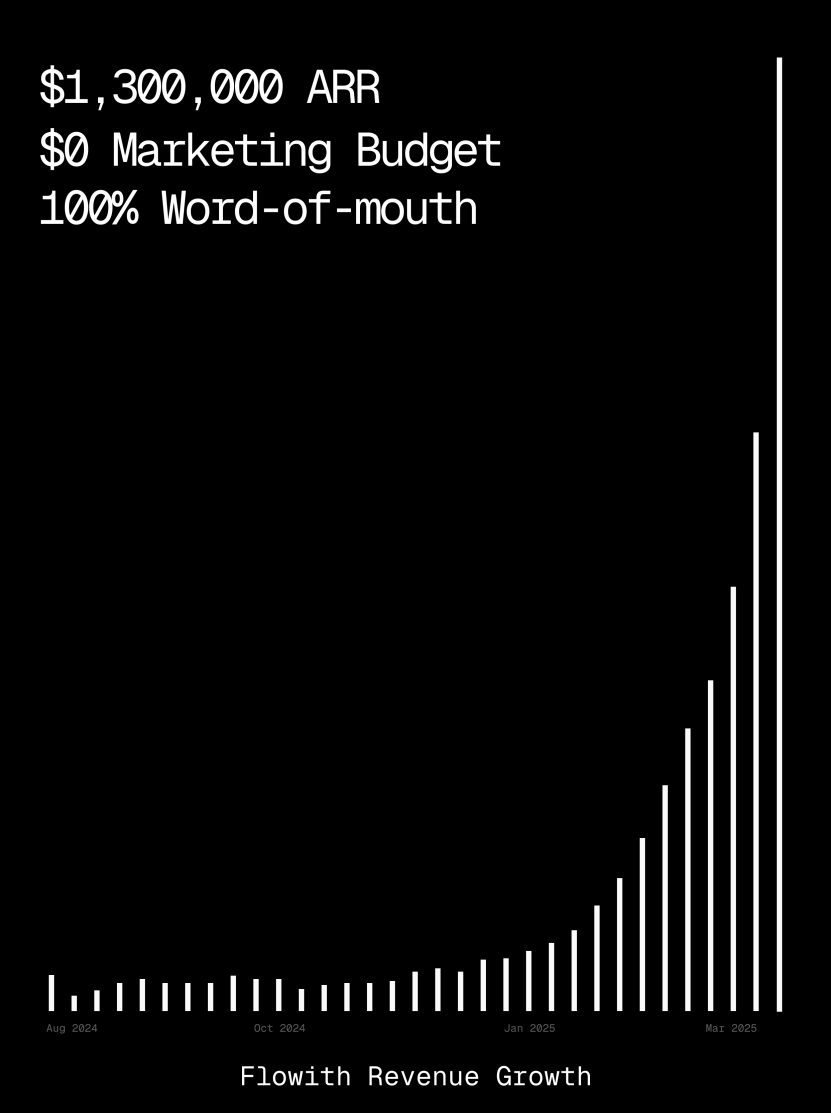
Autonomer Debugging-Agent Deebo veröffentlicht: Forscher haben einen autonomen Debugging-Agenten-MCP-Server namens Deebo entwickelt. Er läuft als lokaler Daemon, an den Programmieragenten schwierige Fehlerbehandlungsaufgaben asynchron auslagern können. Deebo generiert mehrere Unterprozesse mit unterschiedlichen Reparaturhypothesen, führt jedes Szenario in isolierten Git-Branches aus und lässt einen “Mutter-Agenten” zyklisch testen und schlussfolgern, um schließlich Diagnoseergebnisse und vorgeschlagene Patches zurückzugeben. In einem realen Test mit einem $100-Bug-Bounty für tinygrad identifizierte Deebo erfolgreich die Fehlerursache, schlug zwei konkrete Reparaturlösungen vor und bestand die Tests. (Quelle: Reddit r/MachineLearning)
![[D] We built an autonomous debugging agent. Here’s how it grokked a $100 bug](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 Lernen
Nabla-GFlowNet: Neue Methode zur Belohnungs-Feinabstimmung von Diffusionsmodellen, die Diversität und Effizienz vereint: Angesichts der Probleme bei der Feinabstimmung von Diffusionsmodellen – langsame Konvergenz bei traditionellem Reinforcement Learning, leichtes Overfitting und Verlust der Diversität bei direkter Belohnungsmaximierung – schlagen Forscher der Chinesischen Universität Hongkong (Shenzhen) und anderer Institutionen Nabla-GFlowNet vor. Die Methode basiert auf dem Generative Flow Network (GFlowNet)-Framework und betrachtet den Diffusionsprozess als ein Fließgleichgewichtssystem. Daraus leiten sie die Nabla-DB-Gleichgewichtsbedingung und die entsprechende Verlustfunktion ab. Durch parametrisches Design wird der Restgradient mithilfe einer Einzelschritt-Entrauschungsschätzung berechnet, wodurch zusätzliche Schätznetzwerke vermieden werden. Experimente zeigen, dass Nabla-GFlowNet bei der Feinabstimmung von Stable Diffusion mit Belohnungsfunktionen wie ästhetischer Bewertung und Befehlsbefolgung im Vergleich zu Methoden wie ReFL und DRaFT schneller konvergiert, weniger anfällig für Overfitting ist und gleichzeitig die Diversität der generierten Samples beibehält. (Quelle: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)

MegaMath: Größter Open-Source-Datensatz für mathematisches Reasoning mit 371B Tokens veröffentlicht: Der von LLM360 veröffentlichte MegaMath-Datensatz umfasst 371 Milliarden Tokens und zielt darauf ab, den Mangel an großen, hochwertigen vortrainierten Datensätzen für mathematisches Reasoning in der Open-Source-Community zu beheben. Der Datensatz ist in drei Teile gegliedert: mathematisch intensive Webseiten (279B), mathematisch relevanter Code (28,1B) und hochwertige synthetische Daten (64B). Bei der Erstellung wurde eine innovative Datenverarbeitungspipeline eingesetzt, die HTML-Parsing optimiert für mathematische Formeln, zweistufige Textextraktion, dynamische Bewertung des Bildungswerts, mehrstufige präzise Rückgewinnung von Codedaten und verschiedene Methoden zur groß angelegten Synthese (Q&A, Codegenerierung, verschachtelter Text und Code) umfasst. Eine Validierung durch Vortraining von Llama-3.2 (1B/3B) mit 100B Tokens zeigt, dass MegaMath auf Benchmarks wie GSM8K und MATH eine absolute Leistungssteigerung von 15-20 % bewirken kann. (Quelle: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
OS Agents Übersicht: Forschung zu intelligenten Agenten für Computer, Mobiltelefone und Browser basierend auf multimodalen großen Modellen: Die Zhejiang Universität hat in Zusammenarbeit mit OPPO, 01.AI und anderen Institutionen eine Übersichtsarbeit über Betriebssystem-Agenten (OS Agents) veröffentlicht. Der Artikel systematisiert den aktuellen Forschungsstand zur Konstruktion von intelligenten Agenten (wie Anthropics Computer Use, Apples Apple Intelligence), die mithilfe von multimodalen großen Sprachmodellen (MLLM) Aufgaben in Umgebungen wie Computern, Mobiltelefonen und Browsern automatisch erledigen können. Der Inhalt umfasst die Grundlagen von OS Agents (Umgebung, Beobachtungsraum, Aktionsraum, Kernfähigkeiten), Konstruktionsmethoden (Basismodellarchitektur und Trainingsstrategien, Wahrnehmungs-/Planungs-/Gedächtnis-/Aktionsmodule des Agenten-Frameworks), Evaluierungsprotokolle und Benchmarks sowie verwandte kommerzielle Produkte und zukünftige Herausforderungen (Sicherheit und Datenschutz, Personalisierung und Selbstentwicklung). Das Forschungsteam pflegt ein Open-Source-Repository mit über 250 relevanten Papieren, um die Entwicklung in diesem Bereich voranzutreiben. (Quelle: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
NLPrompt: Robuste Prompt-Learning-Methode durch Kombination von MAE-Verlust und Optimal Transport: Das YesAI Lab der ShanghaiTech University stellt in einem CVPR 2025 Highlight Paper NLPrompt vor, das darauf abzielt, das Problem des Label-Rauschens beim Prompt-Learning von visuellen Sprachmodellen zu lösen. Die Studie stellt fest, dass im Prompt-Learning-Szenario die Verwendung des Mean Absolute Error (MAE)-Verlusts (PromptMAE) widerstandsfähiger gegen verrauschte Labels ist als der Cross-Entropy (CE)-Verlust und belegt dessen Robustheit aus der Perspektive der Feature-Learning-Theorie. Darüber hinaus wird eine auf Prompts basierende Optimal-Transport-Datenbereinigungsmethode (PromptOT) vorgeschlagen, die Textmerkmale als Prototypen verwendet, um den Datensatz in einen sauberen Teildatensatz (trainiert mit CE-Verlust) und einen verrauschten Teildatensatz (trainiert mit MAE-Verlust) aufzuteilen und so die Vorteile beider Verluste effektiv zu kombinieren. Experimente zeigen, dass NLPrompt sowohl auf synthetischen als auch auf real verrauschten Datensätzen überlegen ist und eine gute Generalisierungsfähigkeit aufweist. (Quelle: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Analyse des Inferenzmechanismus von DeepSeek-R1: Forscher der McGill University analysierten den Inferenzprozess von großen Reasoning-Modellen wie DeepSeek-R1. Im Gegensatz zu LLMs, die direkt Antworten geben, generieren Reasoning-Modelle detaillierte mehrstufige Argumentationsketten. Die Studie untersuchte die Beziehung zwischen der Länge der Argumentationskette und der Leistung (es gibt einen “Sweet Spot”, zu lange Ketten können die Leistung beeinträchtigen), das Management langer Kontexte, kulturelle und Sicherheitsprobleme (stärkere Sicherheitslücken im Vergleich zu Nicht-Reasoning-Modellen) sowie Verbindungen zu menschlichen kognitiven Phänomenen (wie das Festhalten an bereits untersuchten Problemen). Die Studie deckt einige Merkmale und potenzielle Probleme der Funktionsweise aktueller Reasoning-Modelle auf. (Quelle: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
C3PO: Testzeit-Optimierungsmethode für MoE-Großmodelle: Forscher der Johns Hopkins University stellten fest, dass Mixture-of-Experts (MoE) LLMs suboptimale Expertenpfade aufweisen, und schlugen die Testzeit-Optimierungsmethode C3PO (Critical Layer, Core Expert, Collaborative Path Optimization) vor. Diese Methode benötigt keine echten Labels, sondern definiert alternative Ziele durch “erfolgreiche Nachbarn” in einem Referenz-Sample-Set, um die Modellleistung zu optimieren. Sie verwendet Algorithmen wie Mustersuche, Kernel-Regression und durchschnittlichen Verlust ähnlicher Samples und optimiert zur Kostenreduzierung nur die Gewichte der Kernexperten in kritischen Schichten. Bei Anwendung auf MoE LLMs steigerte C3PO die Genauigkeit der Basismodelle in sechs Benchmark-Tests um 7-15 %, übertraf gängige Testzeit-Lern-Baselines und ermöglichte es MoE-Modellen mit weniger Parametern, LLMs mit mehr Parametern zu übertreffen, wodurch die Effizienz von MoE verbessert wurde. (Quelle: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Studie zum Einfluss der Quantisierung auf die Leistung von Reasoning-Modellen: Ein Forschungsteam der Tsinghua-Universität untersuchte erstmals systematisch den Einfluss von Quantisierungstechniken auf die Leistung von sprachbasierten Reasoning-Modellen (wie DeepSeek-R1-Serie, Qwen, LLaMA). Die Studie bewertete die Leistung verschiedener Quantisierungsalgorithmen für Gewichte, KV-Cache und Aktivierungen mit unterschiedlichen Bitbreiten (W8A8, W4A16 usw.) auf Reasoning-Benchmarks in Mathematik, Naturwissenschaften und Programmierung. Die Ergebnisse zeigen, dass W8A8- oder W4A16-Quantisierung in der Regel eine verlustfreie Leistung ermöglicht, während niedrigere Bitbreiten ein erhebliches Risiko für Genauigkeitsverluste bergen. Modellgröße, Herkunft und Aufgabenschwierigkeit sind Schlüsselfaktoren für die Leistung nach der Quantisierung. Die Ausgabelänge quantisierter Modelle nahm nicht signifikant zu, und eine angemessene Anpassung der Modellgröße oder Erhöhung der Inferenzschritte kann die Leistung verbessern. Die quantisierten Modelle und der Code wurden als Open Source veröffentlicht. (Quelle: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
SHIELDAGENT: Schutzmechanismus zur Erzwingung der Einhaltung von Sicherheitsrichtlinien durch Agenten: Die University of Chicago schlägt das SHIELDAGENT-Framework vor, das darauf abzielt, durch logisches Schließen sicherzustellen, dass die Aktionspfade von KI-Agenten expliziten Sicherheitsrichtlinien entsprechen. Das Framework extrahiert zunächst überprüfbare Regeln aus Richtliniendokumenten und erstellt ein Sicherheitsrichtlinienmodell (basierend auf probabilistischen Regelkreisen). Während der Ausführung des Agenten ruft es dann basierend auf dessen Aktionspfad relevante Regeln ab, generiert einen Schutzplan und verwendet eine Werkzeugbibliothek sowie ausführbaren Code zur formalen Verifizierung, um sicherzustellen, dass das Verhalten des Agenten nicht gegen Sicherheitsvorschriften verstößt. Gleichzeitig wurde der Datensatz SHIELDAGENT-BENCH mit 3K sicherheitsrelevanten Anweisungen und Trajektorienpaaren veröffentlicht. Experimente zeigen, dass SHIELDAGENT auf mehreren Benchmarks SOTA erreicht, die Einhaltungsrate und den Recall von Sicherheitsrichtlinien signifikant verbessert und gleichzeitig API-Abfragen und Inferenzzeit reduziert. (Quelle: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MedVLM-R1: Förderung der Reasoning-Fähigkeiten medizinischer VLMs durch Reinforcement Learning: Die Technische Universität München, die Universität Oxford und andere Institutionen haben MedVLM-R1 vorgestellt, ein medizinisches visuelles Sprachmodell (VLM), das darauf abzielt, explizite Argumentationsprozesse in natürlicher Sprache zu generieren. Das Modell verwendet das Group Relative Policy Optimization (GRPO) Reinforcement Learning Framework von DeepSeek und wird auf Datensätzen trainiert, die nur die endgültigen Antworten enthalten, entdeckt aber autonom für Menschen interpretierbare Argumentationspfade. Nach dem Training mit nur 600 MRT-VQA-Samples erreicht dieses 2B-Parameter-Modell eine Genauigkeit von 78,22 % bei MRT-, CT- und Röntgen-Benchmark-Tests, übertrifft damit deutlich die Baselines und zeigt eine starke Generalisierungsfähigkeit außerhalb der Domäne, wobei es sogar größere Modelle wie Qwen2-VL-72B übertrifft. Die Studie bietet neue Ansätze für die Entwicklung vertrauenswürdiger und interpretierbarer medizinischer KI. (Quelle: 小样本大能量!MedVLM-R1借力DeepSeek强化学习,重塑医疗AI推理能力)
Studie zeigt, dass Reinforcement Learning Training zu länglichen Antworten bei Reasoning-Modellen führen kann: Eine Studie von Wand AI analysierte die Gründe für die längeren Antworten von Reasoning-Modellen (wie DeepSeek-R1). Die Forschung ergab, dass dieses Verhalten möglicherweise auf den Trainingsprozess des Reinforcement Learning (insbesondere des PPO-Algorithmus) zurückzuführen ist und nicht darauf, dass das Problem selbst eine längere Argumentation erfordert. Wenn das Modell eine negative Belohnung für eine falsche Antwort erhält, neigt die PPO-Verlustfunktion dazu, längere Antworten zu generieren, um die Strafe pro Token zu “verdünnen”, selbst wenn der zusätzliche Inhalt nicht zur Verbesserung der Genauigkeit beiträgt. Die Studie zeigt auch, dass prägnante Argumentationen oft mit höherer Genauigkeit korrelieren. Durch eine zweite Runde des Reinforcement Learning Trainings, bei der nur ein Teil der lösbaren Probleme verwendet wird, kann die Antwortlänge verkürzt werden, während die Genauigkeit beibehalten oder sogar verbessert wird, was für die Verbesserung der Bereitstellungseffizienz von Bedeutung ist. (Quelle: 更长思维并不等于更强推理性能,强化学习可以很简洁)

USTC und ZTE schlagen Curr-ReFT vor: Verbesserung der Reasoning- und Generalisierungsfähigkeiten kleiner VLMs: Angesichts des “Brick Wall”-Phänomens (Trainingsengpass) bei komplexen Aufgaben und der unzureichenden Generalisierungsfähigkeit außerhalb der Domäne bei kleinen visuellen Sprachmodellen (VLM) schlagen die University of Science and Technology of China (USTC) und ZTE Corporation das Curriculum Reinforcement Learning Fine-Tuning Paradigma (Curr-ReFT) vor. Dieses Paradigma kombiniert Curriculum Learning (CL) und Reinforcement Learning (RL) und entwirft einen schwierigkeitsbewussten Belohnungsmechanismus, der es dem Modell ermöglicht, schrittweise von leicht nach schwer zu lernen (binäre Entscheidung → Multiple Choice → offene Antwort). Gleichzeitig wird eine auf Rejection Sampling basierende Selbstverbesserungsstrategie angewendet, die hochwertige multimodale und Sprachsamples nutzt, um die Grundfähigkeiten des Modells aufrechtzuerhalten. Experimente mit den Modellen Qwen2.5-VL-3B/7B zeigen, dass Curr-ReFT die Reasoning- und Generalisierungsleistung der Modelle signifikant verbessert, wobei das 7B-Modell auf einigen Benchmarks sogar InternVL2.5-26B/38B übertrifft. (Quelle: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)

GenPRM: Erweiterung von Prozess-Belohnungsmodellen durch generatives Reasoning: Die Tsinghua-Universität und das Shanghai AI Lab schlagen das Generative Process Reward Model (GenPRM) vor, das darauf abzielt, die Probleme traditioneller Prozess-Belohnungsmodelle (PRM) zu lösen, die auf skalaren Bewertungen beruhen, keine Interpretierbarkeit bieten und zur Testzeit nicht erweitert werden können. GenPRM verwendet einen generativen Ansatz, der Chain-of-Thought (CoT)-Reasoning und Code-Verifizierung kombiniert, um jeden Argumentationsschritt mittels Analyse natürlicher Sprache und Ausführung von Python-Code zu überprüfen und so eine tiefere, interpretierbare Prozessüberwachung zu ermöglichen. Darüber hinaus führt GenPRM einen Testzeit-Erweiterungsmechanismus ein, der die Bewertungsgüte durch paralleles Sampling mehrerer Argumentationspfade und Aggregation der Belohnungswerte verbessert. Ein 1.5B-Modell, das nur mit 23K synthetischen Daten trainiert wurde, übertrifft durch Testzeit-Erweiterung GPT-4o auf ProcessBench, und eine 7B-Version übertrifft das 72B-Modell Qwen2.5-Math-PRM-72B. GenPRM kann auch als Kritikmodell zur Optimierung von Strategiemodellen dienen. (Quelle: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Studie deckt “Überdenken”-Phänomen bei Reasoning-KI bei Problemen mit fehlenden Prämissen auf: Forscher der University of Maryland und der Lehigh University haben herausgefunden, dass aktuelle Reasoning-Modelle (wie DeepSeek-R1, o1) bei Problemen, denen notwendige Prämissinformationen fehlen (Missing Premise, MiP), dazu neigen, “überzudenken”. Sie generieren 2-4 Mal längere Antworten als bei normalen Problemen und geraten in einen Kreislauf aus wiederholtem Überprüfen des Problems, Spekulieren über die Absicht und Selbstzweifeln, anstatt schnell zu erkennen, dass das Problem unlösbar ist, und aufzuhören. Im Gegensatz dazu reagieren Nicht-Reasoning-Modelle (wie GPT-4.5) auf MiP-Probleme kürzer und erkennen das Fehlen von Prämissen besser. Die Studie legt nahe, dass Reasoning-Modelle zwar das Fehlen von Prämissen bemerken, aber das “kritische Denken” fehlt, um ineffektive Argumentationen entschieden abzubrechen. Dieses Verhaltensmuster könnte auf unzureichende Längenbeschränkungen im Reinforcement Learning Training zurückzuführen sein und sich durch Destillation verbreiten. (Quelle: 推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕)

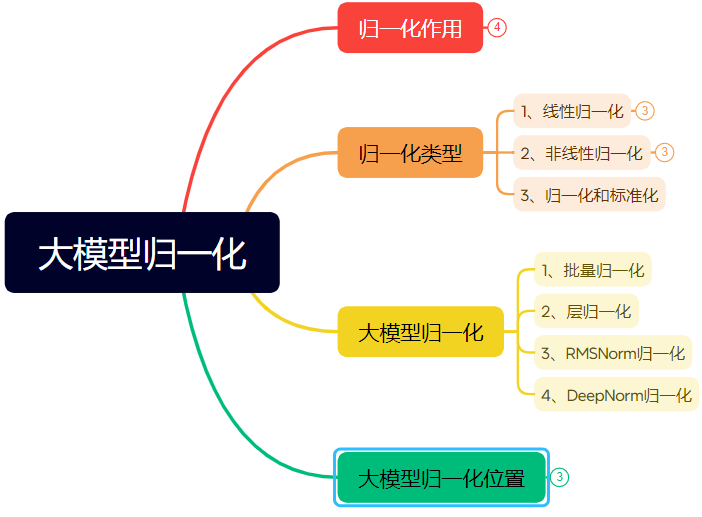
Ausführlicher Artikel über die Entwicklung der Normalisierungstechniken in neuronalen Netzen: Der Artikel gibt einen systematischen Überblick über die Rolle und Entwicklung der Normalisierung (Normalization) in neuronalen Netzen, insbesondere in Transformern und großen Modellen. Normalisierung löst Probleme der Datenvergleichbarkeit, beschleunigt die Optimierung und mildert Probleme wie Sättigungsbereiche von Aktivierungsfunktionen und Internal Covariate Shift (ICS), indem sie Daten auf einen festen Bereich beschränkt. Der Artikel stellt gängige lineare (Min-Max, Z-Score, Mean) und nichtlineare Normalisierungsmethoden vor, erläutert ausführlich die für Deep-Learning-Modelle geeigneten Methoden Batch Normalization (BN), Layer Normalization (LN), RMSNorm und DeepNorm und analysiert deren unterschiedliche Anwendung in Transformer-Architekturen (warum LN/RMSNorm besser für NLP geeignet sind). Darüber hinaus werden die verschiedenen Platzierungen von Normalisierungsmodulen innerhalb der Transformer-Schichten (Post-Norm, Pre-Norm, Sandwich-Norm) und deren Auswirkungen auf Trainingsstabilität und Leistung diskutiert. (Quelle: 万字长文!一文了解归一化:从Transformer归一化到主流大模型归一化的演变!)
Prompt Engineering zur Generierung von Schriftdesigns in spezifischen Stilen mit KI: Der Artikel teilt die Erfahrungen und Prompt-Vorlagen des Autors bei der Erkundung der Verwendung von Tiamat AI 3.0 zur Generierung von Textdesigns mit spezifischen Stilen. Der Autor stellte fest, dass die direkte Angabe von Schriftartnamen (wie Songti, Kaiti) keine guten Ergebnisse liefert, da das KI-Modell diese nur begrenzt versteht. Daher wandte sich der Autor der Beschreibung von Schriftstilmerkmalen, emotionaler Atmosphäre und visuellen Effekten zu und kombinierte dies mit Beispielen verschiedener Stile, um eine Prompt-Vorlage für einen “Advanced Text Style Design Prompt Generator” zu erstellen. Benutzer müssen nur den Textinhalt eingeben, und die Vorlage passt intelligent vordefinierte Stile an (wie Lichtschein-Nachtschatten, industriell-rustikal, kindlich-gemalt, metallisch-futuristisch usw.) oder kombiniert sie, um detaillierte Prompts für Text-zu-Bild-Modelle zu generieren und so relativ stabile Ergebnisse bei der Gestaltung von Grafiken mit Text zu erzielen. (Quelle: AI生成字体设计我有点玩明白了,用这套Prompt提效50%。, 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】)

ZClip: Adaptive Methode zur Unterdrückung von Gradientenspitzen für das Vortraining von LLMs: Forscher schlagen ZClip vor, eine leichtgewichtige, adaptive Gradienten-Clipping-Methode, die darauf abzielt, Verlustspitzen während des LLM-Trainings zu reduzieren und die Trainingsstabilität zu verbessern. Im Gegensatz zum traditionellen Gradienten-Clipping mit festem Schwellenwert verwendet ZClip einen auf dem Z-Score basierenden Ansatz, um anomale Gradientenspitzen zu erkennen und zu beschneiden – also solche Gradienten, die signifikant vom jüngsten gleitenden Durchschnitt abweichen. Diese Methode hilft, die Trainingsstabilität aufrechtzuerhalten, ohne die Konvergenz zu stören, und lässt sich leicht in jeden Trainingszyklus integrieren. Code und Paper wurden veröffentlicht. (Quelle: Reddit r/deeplearning)
![[2504.02507] ZClip: Adaptive Spike Mitigation for LLM Pre-Training](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 Wirtschaft
Intel Arc Grafikkarten + Xeon W Prozessoren ermöglichen kostengünstige KI-All-in-One-Lösungen: Intel bietet mit der Kombination seiner Arc™ Grafikkarten und Xeon® W Prozessoren eine Lösung für den Aufbau kostengünstiger (im Bereich von 100.000 RMB / ca. 13.000 EUR) und praktisch leistungsfähiger All-in-One-Maschinen für große Modelle. Arc™ Grafikkarten nutzen die Xe-Architektur und die XMX AI-Beschleunigungs-Engine, unterstützen gängige KI-Frameworks und Ollama/vLLM, haben einen relativ geringen Stromverbrauch und unterstützen Multi-GPU-Konfigurationen. Xeon® W Prozessoren bieten eine hohe Kernzahl und Speichererweiterungsmöglichkeiten sowie integrierte AMX-Beschleunigungstechnologie. In Kombination mit Softwareoptimierungen wie IPEX-LLM, OpenVINO™ und oneAPI wird eine effiziente Zusammenarbeit von CPU und GPU erreicht. Tests zeigen, dass eine solche All-in-One-Lösung bei der Ausführung des Qwen-32B-Modells für einen einzelnen Benutzer 32 Tokens/s erreichen kann und bei der Ausführung des 671B DeepSeek R1-Modells (erfordert FlashMoE-Optimierung) fast 10 Tokens/s erreicht, was den Anforderungen für Offline-Inferenz genügt und die Verbreitung von KI-Inferenz fördert. (Quelle: 榨干3000元显卡,跑通千亿级大模型的秘方来了)

NVIDIA wird KI-Supercomputer in den USA herstellen: NVIDIA kündigte an, erstmals seinen KI-Supercomputer vollständig in den USA zu entwerfen und zu bauen und dabei mit wichtigen Fertigungspartnern zusammenzuarbeiten. Gleichzeitig hat die Produktion seiner neuen Blackwell-Chips in der TSMC-Fabrik in Arizona begonnen. NVIDIA plant, in den nächsten vier Jahren KI-Infrastruktur im Wert von bis zu 500 Milliarden US-Dollar in den USA zu produzieren, wobei Partner wie TSMC, Foxconn, Wistron, Amkor und SPIL beteiligt sind. Dieser Schritt zielt darauf ab, die Nachfrage nach KI-Chips und Supercomputern zu decken, die Lieferkette zu stärken und die Widerstandsfähigkeit zu erhöhen. (Quelle: nvidia, nvidia)

Horizon Robotics sucht Praktikanten für 3D-Rekonstruktion/Generierung: Das Embodied Intelligence Team von Horizon Robotics sucht Algorithmus-Praktikanten im Bereich 3D-Rekonstruktion/Generierung in Shanghai/Peking. Zu den Aufgaben gehören die Mitwirkung an der Konzeption und Entwicklung von Real2Sim-Algorithmuslösungen für Roboter (Kombination von 3D GS-Rekonstruktion, Feedforward-Rekonstruktion, 3D-/Video-Generierung), die Optimierung der Leistung des Real2Sim-Simulators (Unterstützung von Flüssigkeits-, Tastsinn-Simulation usw.) sowie das Verfolgen aktueller Forschung und die Veröffentlichung von Papieren auf Top-Konferenzen. Voraussetzungen sind ein Master-Abschluss oder höher in Informatik/Grafik/KI oder verwandten Bereichen, Erfahrung mit 3D-Vision/Video-Generierung oder multimodalen/Diffusionsmodellen sowie gute Kenntnisse in Python/Pytorch/Huggingface. Veröffentlichungen auf Top-Konferenzen, Vertrautheit mit Simulationsplattformen oder Open-Source-Projekten sind von Vorteil. Es werden Übernahmemöglichkeiten, Zugang zu GPU-Clustern und eine wettbewerbsfähige Vergütung geboten. (Quelle: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)

Meituan Hotel & Travel sucht L7-L8 Large Model Algorithm Engineers: Das Supply Algorithm Team von Meituan Hotel & Travel in Peking sucht erfahrene Large Model Algorithm Engineers auf L7-L8 Niveau (Festanstellung). Zu den Aufgaben gehören der Aufbau eines Verständnissystems für das Hotel- und Reiseangebot (Produkt-Tags, Hotspot-Erkennung, Mining ähnlicher Angebote usw.), die Optimierung von Anzeigematerialien (Titel-, Bild-/Text-, Empfehlungsbegründungsgenerierung), die Zusammenstellung von Urlaubspaketen (Produktauswahl, Absatzprognose, Preisgestaltung) sowie die Erforschung und Implementierung modernster Large-Model-Technologien (Feinabstimmung, RL, Prompt-Optimierung). Voraussetzungen sind ein Master-Abschluss oder höher, mindestens 2 Jahre Erfahrung, ein Abschluss in Informatik/Automatisierung/Mathematik/Statistik oder verwandten Bereichen sowie solide Grundlagen in Algorithmen und Programmierkenntnisse. (Quelle: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)

Meta wird Nutzerdaten in der EU zum Training von KI verwenden: Meta kündigte an, bald damit zu beginnen, öffentliche Daten von Facebook- und Instagram-Nutzern in der EU (wie Posts, Kommentare, aber keine privaten Nachrichten) zum Training seiner KI-Modelle zu verwenden, beschränkt auf Nutzer über 18 Jahre. Das Unternehmen wird die Nutzer über In-App-Benachrichtigungen und E-Mails informieren und einen Link zum Widerspruch (Opt-out) bereitstellen. Zuvor hatte Meta Pläne zur Nutzung von Nutzerdaten für das KI-Training in Europa auf Anforderung der irischen Aufsichtsbehörde ausgesetzt. (Quelle: Reddit r/artificial)

Tencent Cloud führt MCP Managed Service ein: Tencent Cloud bietet nun ebenfalls einen MCP (Managed Cloud Platform) Managed Service an, der Unternehmen bequemere und effizientere Lösungen für das Management und den Betrieb von Cloud-Ressourcen bieten soll. Dieser Schritt bedeutet eine Verschärfung des Wettbewerbs unter den großen Cloud-Anbietern in diesem Bereich. Spezifische Servicedetails und “WeChat-Besonderheiten” wurden noch nicht näher erläutert. (Quelle: 腾讯云也搞 MCP 托管了,还带了点“微信特色”。)
🌟 Community
Turing-Preisträger LeCun über KI-Entwicklung: Menschliche Intelligenz nicht universell, nächster Durchbruch möglicherweise bei nicht-generativen Modellen: In einem kürzlichen Podcast-Interview betonte Yann LeCun erneut, dass der Begriff AGI irreführend sei, da menschliche Intelligenz hochspezialisiert und nicht universell sei. Er prognostiziert, dass der nächste große Durchbruch in der KI von nicht-generativen Modellen kommen könnte, wobei der Schwerpunkt darauf liegen sollte, Maschinen ein echtes Verständnis der physischen Welt, Reasoning- und Planungsfähigkeiten sowie ein dauerhaftes Gedächtnis zu ermöglichen, ähnlich seiner vorgeschlagenen JEPA-Architektur. Er ist der Ansicht, dass aktuellen LLMs echtes Reasoning und die Fähigkeit zur Modellierung der physischen Welt fehlen und das Erreichen des Intelligenzniveaus einer Katze bereits ein enormer Fortschritt wäre. Die Open-Source-Veröffentlichung von Llama durch Meta hält er für die richtige Entscheidung zur Förderung des gesamten KI-Ökosystems und betont, dass Innovation global stattfindet und Open Source der Schlüssel zur Beschleunigung von Durchbrüchen ist. Er sieht auch intelligente Brillen als wichtigen Träger für KI-Assistenten. (Quelle: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)

Kurzzeitige “Sperrung” chinesischer IPs durch GitHub erregt Aufmerksamkeit, offiziell als Konfigurationsfehler bezeichnet: Vom 12. bis 13. April stellten einige chinesische Benutzer fest, dass sie nicht auf GitHub zugreifen konnten. Die Seite zeigte die Meldung “IP-Adresse unterliegt Zugriffsbeschränkungen”, was in der Community Panik und Diskussionen auslöste, ob es sich um eine gezielte Sperrung handeln könnte. Zuvor hatte GitHub aufgrund von US-Sanktionen bereits Entwicklerkonten aus Russland, Iran usw. gesperrt. GitHub antwortete später offiziell, dass der Vorfall auf einen Konfigurationsfehler zurückzuführen sei, der nicht angemeldete Benutzer vorübergehend am Zugriff hinderte, und das Problem am 13. April behoben wurde. Obwohl es sich um einen technischen Fehler handelte, löste der Vorfall erneut Diskussionen über geopolitische Risiken von Code-Hosting-Plattformen und inländische Alternativen (wie Gitee, CODING, Jihu GitLab usw.) aus. (Quelle: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)

KI-Agenten wecken Bedenken hinsichtlich der Cybersicherheit: Ein Artikel im MIT Technology Review weist darauf hin, dass autonome, von KI gesteuerte Cyberangriffe bevorstehen. Mit zunehmenden KI-Fähigkeiten könnten böswillige Akteure KI-Agenten nutzen, um automatisch Schwachstellen zu finden, komplexere und größere Cyberangriffe zu planen und durchzuführen, was neue Bedrohungen für Einzelpersonen, Unternehmen und sogar die nationale Sicherheit darstellt. Dies erfordert, dass der Bereich der Cybersicherheit dringend Verteidigungsstrategien und -technologien erforscht und einsetzt, die KI-gesteuerten Angriffen begegnen können. (Quelle: Ronald_vanLoon)

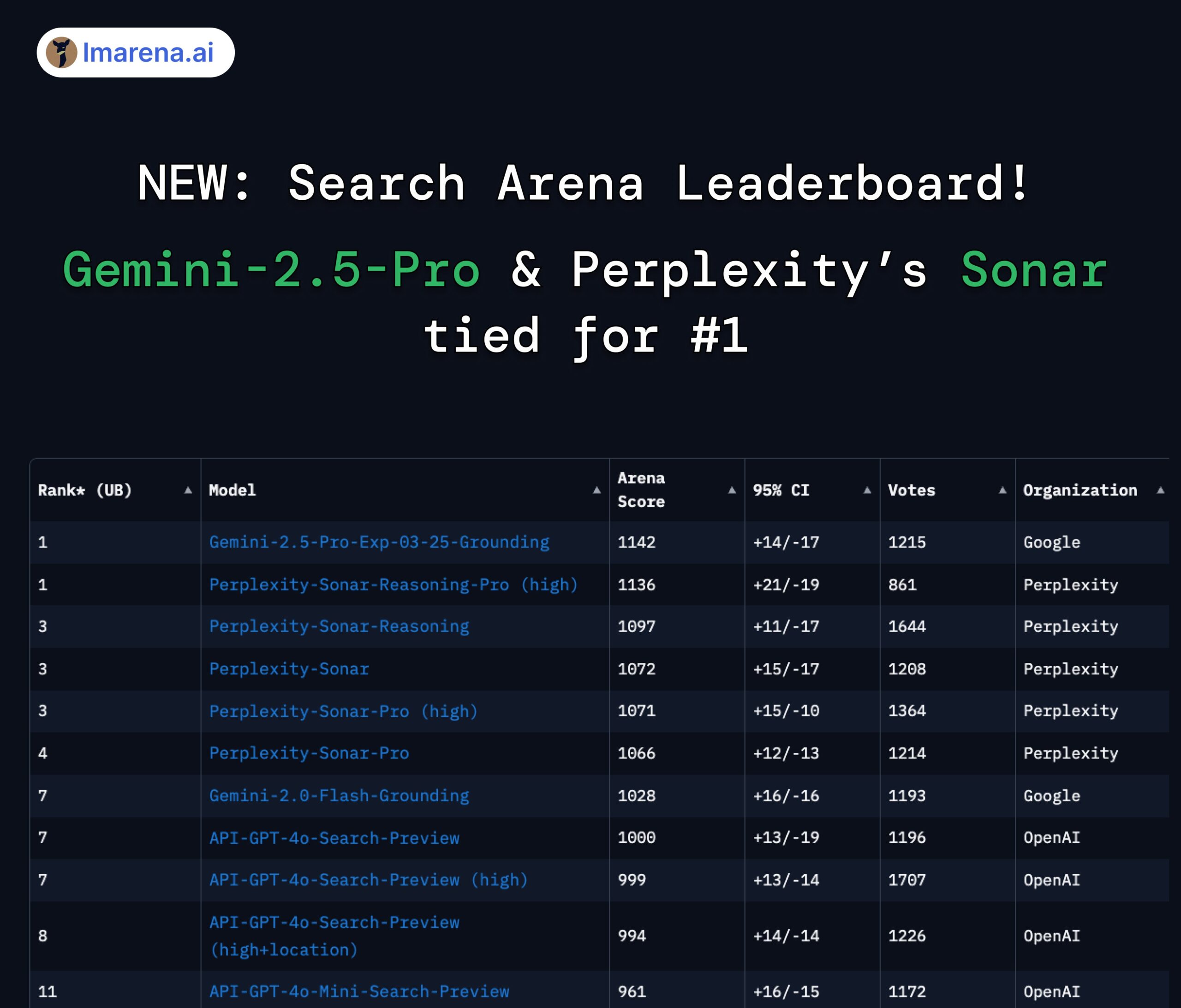
Perplexity Sonar und Gemini 2.5 Pro teilen sich Spitzenplatz in der Search Arena: Auf der neu eingeführten Search Arena-Rangliste von LMArena.ai (ehemals LMSYS) teilen sich das Modell Sonar-Reasoning-Pro-High von Perplexity und Gemini-2.5-Pro-Grounding von Google den ersten Platz. Diese Rangliste bewertet speziell die Qualität von LLM-Antworten, die auf Websuchen basieren. Arav Srinivas, CEO von Perplexity, gratulierte dazu und betonte, dass das Sonar-Modell und der Suchindex weiter verbessert werden. Die Community sieht darin ein Zeichen, dass der Wettbewerb im Bereich der suchgestützten LLMs hauptsächlich zwischen Google und Perplexity stattfindet. (Quelle: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Diskussion über Nutzungsbeschränkungen des Claude-Modells: In der Reddit-Community r/ClaudeAI gibt es Kontroversen über die Nutzungsbeschränkungen der Claude Pro-Version (z. B. Obergrenze für Nachrichten, Kapazitätsbeschränkungen). Einige Benutzer beschweren sich über häufige Einschränkungen, die ihren Arbeitsablauf beeinträchtigen, und erwägen sogar einen Modellwechsel; andere geben an, selten auf Einschränkungen zu stoßen, und vermuten, dass dies an der Nutzungsweise (z. B. Laden sehr großer Kontexte) oder an Übertreibungen liegen könnte. Dies spiegelt die unterschiedlichen Erfahrungen und Ansichten der Benutzer hinsichtlich der Nutzungsrichtlinien und Stabilität der Anthropic-Modelle wider. (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Diskussion über KI und die Zukunft der Arbeit: Ein Vergleichsbild auf Reddit r/ChatGPT löste eine Diskussion aus: Wird KI die menschlichen Fähigkeiten erweitern und ein Leben im Überfluss bringen, oder wird sie menschliche Arbeitsplätze ersetzen und zu Massenarbeitslosigkeit führen? In den Kommentaren äußerten viele Benutzer Bedenken hinsichtlich der Verdrängung von Arbeitsplätzen durch KI, insbesondere bei kreativen Berufen (Programmierung, Kunst). Einige glauben, dass KI die soziale Ungleichheit verschärfen wird, da die Gewinne hauptsächlich den KI-Besitzern zugutekommen, während eine schrumpfende Steuerbasis ein bedingungsloses Grundeinkommen (UBI) erschweren könnte. Andere sind optimistischer und sehen KI als mächtiges Werkzeug, das die Effizienz steigern und neue Arbeitsplätze schaffen kann (z. B. Prompt-Ingenieure), wobei Anpassung und das Erlernen der Nutzung von KI entscheidend sind. (Quelle: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

KI-Datenerfassung weckt Datenschutzbedenken: Eine Infografik, die die von verschiedenen KI-Chatbots (ChatGPT, Gemini, Copilot, Claude, Grok) gesammelten Nutzerdatentypen vergleicht, löste in der Community eine Diskussion über Datenschutzprobleme aus. Die Grafik zeigt, dass Google Gemini die meisten Datentypen sammelt, während Grok (erfordert Konto) und ChatGPT (kein Konto erforderlich) relativ wenige sammeln. Benutzerkommentare betonten die Allgegenwart der Datenerfassung hinter kostenlosen Diensten (“Es gibt kein kostenloses Mittagessen”) und äußerten Bedenken hinsichtlich der spezifischen Zwecke der Datenerfassung (z. B. Verhaltensvorhersage). (Quelle: Reddit r/artificial)

Modelldestillation als effektiver Weg zur kostengünstigen Replikation hoher Leistung angesehen: Ein Reddit-Benutzer teilte mit, wie durch Modelldestillationstechnik, bei der große Modelle (wie GPT-4o) zum Trainieren kleiner, fein abgestimmter Modelle verwendet werden, in einem spezifischen Bereich (Sentiment-Analyse) eine Leistung nahe an GPT-4o (92 % Genauigkeit) zu 14-fach geringeren Kosten erreicht wurde. Kommentare wiesen darauf hin, dass Destillation eine weit verbreitete Technik ist, aber bei der domänenübergreifenden Generalisierung kleine Modelle normalerweise nicht so gut abschneiden wie große. Für spezifische, stabile Domänen ist Destillation eine effektive Methode zur Kosten- und Effizienzsteigerung, aber für komplexe Szenarien, die eine ständige Anpassung an neue Daten oder mehrere Domänen erfordern, könnte die direkte Nutzung großer APIs wirtschaftlicher sein. (Quelle: Reddit r/MachineLearning)
![[D] Distillation is underrated. I replicated GPT-4o's capability in a 14x cheaper model](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 Sonstiges
OceanBase veranstaltet ersten KI-Hackathon-Wettbewerb: Der Anbieter verteilter Datenbanken OceanBase veranstaltet in Zusammenarbeit mit Ant Open Source, Machine Heart und anderen den ersten KI-Hackathon-Wettbewerb. Die Anmeldung begann am 10. April und endet am 7. Mai. Der Wettbewerb steht unter dem Motto “DB+AI” und hat zwei Hauptrichtungen: Erstens die Erstellung von KI-Anwendungen unter Verwendung von OceanBase als Datenbasis und zweitens die Erforschung der Integration von OceanBase mit dem KI-Ökosystem (wie CAMEL AI, FastGPT, OpenDAL). Der Wettbewerb bietet ein Gesamtpreisgeld von 100.000 RMB und steht Einzelpersonen und Teams offen. Ziel ist es, Entwickler dazu anzuregen, innovative Anwendungen zu erforschen, die Datenbanken und KI tiefgreifend integrieren. (Quelle: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)

Professor Liu Xinjun von der Tsinghua-Universität hält Live-Vortrag über Parallelroboter: Professor Liu Xinjun, Direktor des Instituts für Konstruktionstechnik am Fachbereich Maschinenbau der Tsinghua-Universität und Vorsitzender des chinesischen Komitees von IFToMM, wird am Abend des 15. April einen Online-Vortrag zum Thema “Grundlagen der Kinematik von Parallelrobotern und Innovationen bei Ausrüstungen” halten. Der Vortrag wird die grundlegende Theorie von Parallelrobotern und ihre Anwendung bei der Innovation von Spitzenanlagen untersuchen. Moderator ist Professor Liu Yingxiang von der Harbin Institute of Technology. (Quelle: 重磅直播!清华大学刘辛军教授开讲:并联机器人机构学基础与装备创新前沿)

Leitfaden für den dritten China AIGC Industry Summit veröffentlicht: Für den dritten China AIGC Industry Summit, der am 16. April in Peking stattfindet, wurden die detaillierte Agenda und Highlights veröffentlicht. Der Gipfel konzentriert sich auf KI-Technologie und Anwendungs-Implementierung. Die Themen umfassen Rechenleistungsinfrastruktur, Anwendungen großer Modelle in vertikalen Szenarien wie Bildung/Unterhaltung/Unternehmensdienstleistungen/AI4S sowie KI-Sicherheit und -Kontrolle. Zu den Rednern gehören Vertreter von Baidu, Huawei, AWS, Microsoft Research Asia, MiniMax, ShengShu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, Ant Group und anderen. Auf dem Gipfel werden auch Listen der bemerkenswerten AIGC-Unternehmen und -Produkte für 2025 sowie eine Panorama-Karte der chinesischen AIGC-Anwendungen veröffentlicht. (Quelle: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
