
Schlüsselwörter:AI, Künstliche Intelligenz, AI Souveränitätsdilemma, HBM und Advanced Packaging, AI-gesteuerte wissenschaftliche Entdeckungen, Gemini 2.5 Pro Programmierfähigkeiten, AI löst mathematische Probleme
🔥 Fokus
Das Dilemma der KI-Souveränität: Wie das Narrativ der nationalen Sicherheit den öffentlichen Wert verschlingt?: Der Bericht untersucht eingehend das Konzept der „KI-Souveränität“, d.h. die Kontrolle eines Staates über den AI-Technologie-Stack (Daten, Rechenleistung, Talente, Energie). Der aktuelle globale Trend geht von einer „schwachen Souveränität“, die auf Verbündete angewiesen ist, zu einer „starken Souveränität“, die eine vollständige Lokalisierung anstrebt, insbesondere angetrieben durch die US-Politik. Obwohl diese Verschiebung die nationale Sicherheit und militärische Überlegenheit gewährleisten soll, weckt sie auch Bedenken hinsichtlich übermäßiger Zentralisierung, der Unterdrückung offener Innovation, der Behinderung internationaler Zusammenarbeit und der Möglichkeit eines KI-Wettrüstens. Der Artikel argumentiert, dass eine übermäßige Sicherheitsorientierung der KI ihr enormes Potenzial opfern könnte, dem öffentlichen Interesse zu dienen und globale Herausforderungen zu lösen. Er fordert ein Gleichgewicht zwischen Souveränitätsbedürfnissen und offener Zusammenarbeit, um zu verhindern, dass KI zum Opfer geopolitischen Wettbewerbs statt zu einem Werkzeug für den kollektiven Fortschritt der Menschheit wird. (Quelle: 人工智能主权困局:国家安全叙事如何吞噬AI的公共价值?)
HBM und Advanced Packaging: Der unsichtbare Wendepunkt der AI-Rechenleistungsrevolution: Die exponentielle Nachfrage nach Rechenleistung durch große AI-Modelle führt dazu, dass traditionelle Computerarchitekturen an die „Memory Wall“-Grenze stoßen. High Bandwidth Memory (HBM) erhöht die Bandbreite durch 3D-Stacking und TSV-Technologie um ein Vielfaches (z.B. HBM3E über 1TB/s) und reduziert die Datenübertragungslatenz erheblich. Gleichzeitig integrieren Advanced Packaging Technologien (wie TSMC CoWoS, Intel EMIB) durch heterogene Integration CPU, GPU, HBM und andere Chips eng miteinander, durchbrechen die Grenzen einzelner Chips und erhöhen die Rechenleistungsdichte und Energieeffizienz. HBM und Advanced Packaging sind zu Schlüsselkomponenten für AI-Chips (insbesondere auf der Trainingsseite) geworden. Der Markt wird von Giganten wie SK Hynix, Samsung, Micron (HBM) und TSMC (Packaging) dominiert, mit enormen Investitionen und knappen Kapazitäten. Die gemeinsame Entwicklung dieser beiden Technologien gestaltet nicht nur die Halbleiter-Lieferkette neu (der Wertanteil des Packaging steigt), sondern wird auch zum entscheidenden Schlachtfeld im Wettbewerb um AI-Rechenleistung. (Quelle: HBM与先进封装:AI算力革命的隐形赛点)
Nobelpreisträger mit erschütternder Erklärung: AI erledigt in einem Jahr „Doktoranden-Forschungszeit“ von 1 Milliarde Jahren: Nobelpreisträger und Google DeepMind CEO Demis Hassabis erklärte, dass das AI-Projekt seines Teams, AlphaFold-2, durch die Vorhersage der Strukturen von 200 Millionen bekannten Proteinen auf der Erde innerhalb eines Jahres wissenschaftliche Erkundungen abgeschlossen hat, die zuvor 1 Milliarde Jahre Doktoranden-Forschungszeit erfordert hätten. Er betonte, dass AI, insbesondere AlphaFold, die Geschwindigkeit und das Ausmaß wissenschaftlicher Entdeckungen revolutioniert und den Zugang zu Wissen demokratisiert. In seiner Rede an der Universität Cambridge erläuterte Hassabis weiter das Aufkommen des Zeitalters der „digitalen Biologie“, angetrieben durch AI, und argumentierte, dass die Zukunft der AI im Aufbau von „Weltmodellen“ liegt (wie die JEPA-Architektur), die die physische Welt verstehen und Schlussfolgerungen ziehen können, anstatt sich nur auf Sprachverarbeitung zu verlassen. Er bekräftigte sein Engagement für Open-Source-AI als besten Weg, den technologischen Fortschritt voranzutreiben. (Quelle: 诺奖得主震撼宣言:AI一年完成10亿年“博士研究时间”)

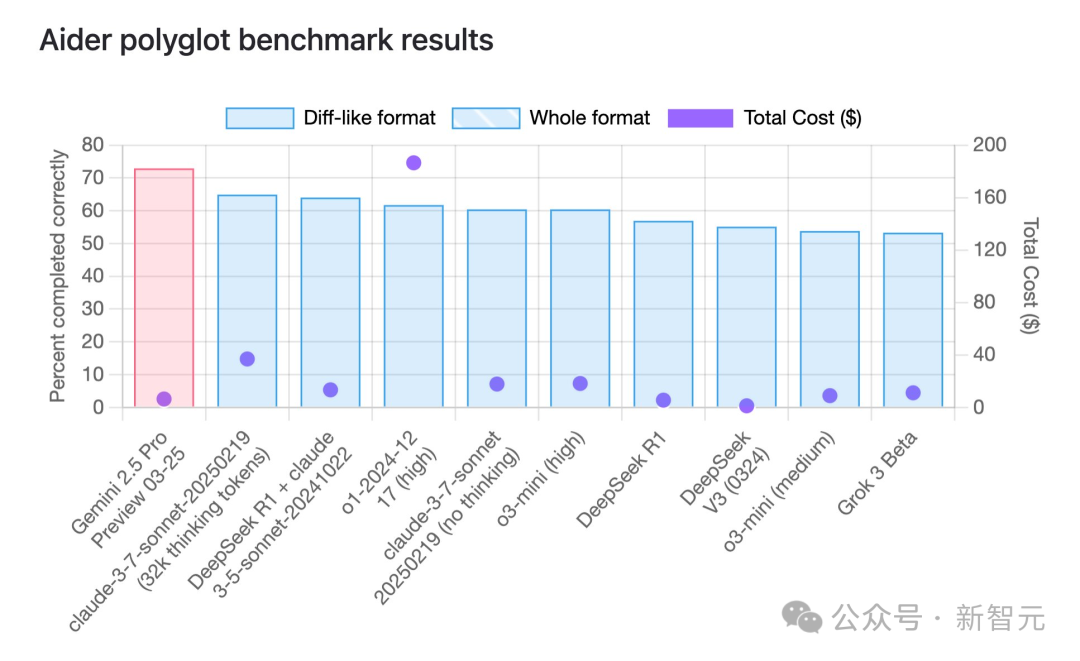
Gemini 2.5 Pro erreicht Spitzenposition bei Programmierfähigkeiten mit signifikantem Preis-Leistungs-Vorteil: Laut dem aider Multi-Language Programming Benchmark hat das kürzlich von Google veröffentlichte Modell Gemini 2.5 Pro das Modell Claude 3.7 Sonnet bei den Programmierfähigkeiten übertroffen und belegt weltweit den ersten Platz. Es führt nicht nur in der Leistung, sondern hat auch extrem niedrige API-Aufrufkosten (ca. 6 US-Dollar), weit unter denen von Konkurrenzprodukten mit ähnlicher oder schlechterer Leistung (wie GPT-4o, Claude 3.7 Sonnet). Jeff Dean betonte dessen Preis-Leistungs-Vorteil. Darüber hinaus kursiert in der Community das Gerücht über ein unveröffentlichtes Google-Modell namens „Dragontail“, das in Webentwicklungs-Tests sogar besser abschneidet als Gemini 2.5 Pro, was darauf hindeutet, dass Google im Bereich AI-Programmierung noch weitere Trümpfe in der Hand hat. Gemini 2.5 Pro rangiert auch in mehreren umfassenden Benchmarks an vorderster Front und fordert OpenAI und Anthropic mit seiner hohen Leistung, niedrigen Kosten, großem Kontextfenster und kostenlosen Nutzungsrechten umfassend heraus. (Quelle: Gemini 2.5编程全球霸榜,谷歌重回AI王座,神秘模型曝光,奥特曼迎战)
AI hilft erfolgreich bei der Lösung eines 50 Jahre alten mathematischen Problems: Der chinesische Wissenschaftler Weiguo Yin (Brookhaven National Laboratory) erzielte mithilfe des o3-mini-high-Modells von OpenAI einen Durchbruch bei der exakten Lösung des eindimensionalen J_1-J_2 q-Zustand Potts-Modells und löste damit ein 50 Jahre altes Problem in diesem Bereich. Das AI-Modell vereinfachte erfolgreich die komplexe 9×9-Transfermatrix in eine effektive 2×2-Matrix, indem es Symmetrieanalysen für den spezifischen Fall q=3 durchführte. Dieser entscheidende Schritt inspirierte die Forscher, die Methode zu verallgemeinern und schließlich eine analytische Lösung für beliebige q-Werte zu finden. Dieses Ergebnis zeigt nicht nur das Potenzial von AI bei komplexen mathematischen Ableitungen und nicht-trivialen Beweisen, sondern liefert auch neue theoretische Werkzeuge zum Verständnis von Phasenübergängen in der Festkörperphysik. (Quelle: 刚刚,AI破解50年未解数学难题,南大校友用OpenAI模型完成首个非平凡数学证明)

🎯 Trends
Anwendung und Entwicklung von AI im Bereich von Spiel-NPCs: Der Artikel blickt auf die Entwicklungsgeschichte der AI-Technologie in Spiel-NPCs zurück, von den frühen Finite-State-Machines in „Pac-Man“ über Behavior Trees bis hin zu komplexen AIs, die Monte-Carlo Tree Search und Deep Neural Networks kombinieren (wie AlphaGo). Der Artikel weist darauf hin, dass, obwohl AI in Spielen wie „StarCraft 2“ und „Dota 2“ Top-Spieler besiegen kann, eine zu starke AI für normale Spieler keine gute Erfahrung bietet. Ideale Spiel-AI sollte sich mehr auf die Simulation menschlichen Verhaltens konzentrieren, emotionalen Wert bieten und eine adaptive Schwierigkeit aufweisen (wie das Nemesis-System in „Mittelerde: Mordors Schatten“ oder die dynamische Schwierigkeit in „Resident Evil 4“). Kürzlich wurde generative AI, wie Stella in miHoYos „Whispers from the Star“, eingesetzt, um Echtzeit-Dialoge, emotionale Reaktionen und die Handlung von NPCs zu steuern. Obwohl Herausforderungen wie Latenz und Gedächtnis bestehen, zeigt dies den Trend zu menschlicheren und interaktiv tieferen AI-NPCs. (Quelle: AI,让游戏再次伟大)

OpenAI verschärft API-Zugriffsberechtigungen und führt Organisationsverifizierung ein: OpenAI hat kürzlich eine neue Richtlinie zur Verifizierung von API-Organisationen eingeführt. Nutzer müssen nun einen gültigen amtlichen Ausweis vorlegen, der von einem unterstützten Land oder einer Region ausgestellt wurde, um auf die fortschrittlichsten Modelle und Funktionen zugreifen zu können. Jede ID kann nur eine Organisation alle 90 Tage verifizieren. OpenAI gibt an, dass dieser Schritt darauf abzielt, die unsichere Nutzung von AI zu reduzieren und sich auf die bevorstehende Veröffentlichung „aufregender neuer Modelle“ (möglicherweise einschließlich mehrerer Versionen wie GPT-4.1, o3, o4-mini) vorzubereiten. Diese Richtlinienänderung hat in der Community breite Aufmerksamkeit und Besorgnis ausgelöst, insbesondere bei Entwicklern in nicht unterstützten Ländern/Regionen und Nutzern, die auf Drittanbieter-API-Dienste angewiesen sind. Sie könnten mit eingeschränktem Zugriff oder erhöhten Kosten konfrontiert werden und haben Diskussionen über die Offenheit von OpenAI ausgelöst. (Quelle: GitHub中国IP访问崩了又复活,OpenAI API新政恐锁死GPT-5?, op7418, Reddit r/artificial)
Apples Einstieg treibt die Entwicklung von „AI-Ärzten“ voran, Herausforderungen und Regulierung bestehen nebeneinander: Berichten zufolge wird Apple AI nutzen, um seine Health-App-Funktionen zu erweitern und Dienste wie einen „AI Health Coach“ einzuführen, was „AI-Ärzte“ weiter zu einem globalen Hotspot macht. Echte klinische AI-Anwendungen stehen jedoch vor vielen Herausforderungen: hohe Entwicklungskosten, Abhängigkeit von riesigen Mengen sensibler medizinischer Daten (betrifft Datenschutzbestimmungen), Schwierigkeiten bei der Datenannotation usw. Derzeit dient AI meist als unterstützendes Diagnosewerkzeug. Der chinesische Markt steht zudem vor besonderen Herausforderungen wie ungleicher Verteilung medizinischer Ressourcen und dem Bedarf an AI-gestützter Triage. Unternehmen wie Baichuan Intelligence schlagen „Dual-Arzt-Modelle“ (AI-Arzt + AI-unterstützter menschlicher Arzt) vor, um diese Probleme zu lösen. Der Artikel betont, dass die breite Anwendung von AI im Gesundheitswesen auf strengen Regulierungs- und Zertifizierungssystemen basieren muss, um Diagnosegenauigkeit, Datensicherheit und Nutzervertrauen zu gewährleisten und potenzielle Risiken zu vermeiden. (Quelle: 苹果入局,「AI医生」成全球热点,患者隐私保护成最大障碍?)

Microsofts Versuch, Spiele direkt mit AI zu generieren, zeigt schlechte Ergebnisse: Microsoft präsentierte kürzlich eine DEMO, die mit seinem „Muse“ AI-Modell direkt Spielgrafiken für „Quake II“ generiert, um die Fähigkeit von AI zur schnellen Erstellung von Spielprototypen zu demonstrieren. Die DEMO zeigte jedoch schlechte Ergebnisse mit niedriger Auflösung, niedriger Framerate und zahlreichen Fehlern (wie abnormalem Gegnerverhalten, fehlerhafter Physik, Umgebungsproblemen) und wurde als „ständig zusammenbrechender Traum“ bewertet. Der Artikel argumentiert, dass dies zeigt, dass die aktuelle generative AI-Technologie (insbesondere mit dem „Halluzinations“-Problem) noch nicht ausreicht, um komplexe, spielbare interaktive Spielerlebnisse direkt und zuverlässig zu generieren. Im Vergleich dazu ist die Anwendung von AI in spezifischen Bereichen der Spieleentwicklungspipeline (wie NPC-Interaktion, Asset-Generierung) realistischer. Der Weg zur direkten Generierung von Spielgrafiken oder Gameplay scheint derzeit mit enormen Herausforderungen verbunden zu sein. (Quelle: 微软的AI游戏翻车,直接生成游戏或是条不归路)
Google veröffentlicht Open-Source-Modell TxGemma für den Gesundheitsbereich: Google hat die TxGemma-Modellreihe vorgestellt, die auf seiner Gemma- und Gemini-Modellfamilie basiert und speziell für den Gesundheits- und Medikamentenentwicklungsbereich optimiert wurde. Dieser Schritt zielt darauf ab, professionellere AI-Werkzeuge für die biomedizinische Forschung und Therapieentwicklung bereitzustellen und Innovationen in diesem Bereich zu fördern. Die Veröffentlichung von TxGemma ist Teil von Googles Strategie, sowohl allgemeine als auch bereichsspezifische Open-Source-Modelle anzubieten. (Quelle: JeffDean)
DeepSeek kündigt Plan zur Veröffentlichung seiner internen Inference Engine an: DeepSeek AI hat angekündigt, seine intern genutzte Inference Engine als Open Source zu veröffentlichen. Laut Beschreibung handelt es sich um eine modifizierte und optimierte Version des beliebten vLLM-Frameworks. DeepSeek möchte mit diesem Schritt die optimierte Inferenztechnologie an die Open-Source-Community zurückgeben und Entwicklern helfen, große Modelle effizienter bereitzustellen. Dieser Plan unterstreicht DeepSeeks Engagement für die Open-Source-Community; der Code wird voraussichtlich auf GitHub veröffentlicht. (Quelle: karminski3)
ChatGPT fügt Gedächtnisfunktion zur Verbesserung der Kohärenz hinzu: OpenAI hat seinem ChatGPT-Modell eine Gedächtnisfunktion (Memory) hinzugefügt. Diese Funktion ermöglicht es ChatGPT, sich über mehrere Gespräche hinweg an zuvor vom Benutzer bereitgestellte Informationen, Vorlieben oder diskutierte Themen zu erinnern. Ziel ist es, die Kontinuität und Personalisierung der Interaktion zu verbessern, zu vermeiden, dass Benutzer in nachfolgenden Gesprächen dieselben Hintergrundinformationen wiederholen müssen, und so die Benutzererfahrung zu verbessern. (Quelle: Ronald_vanLoon)

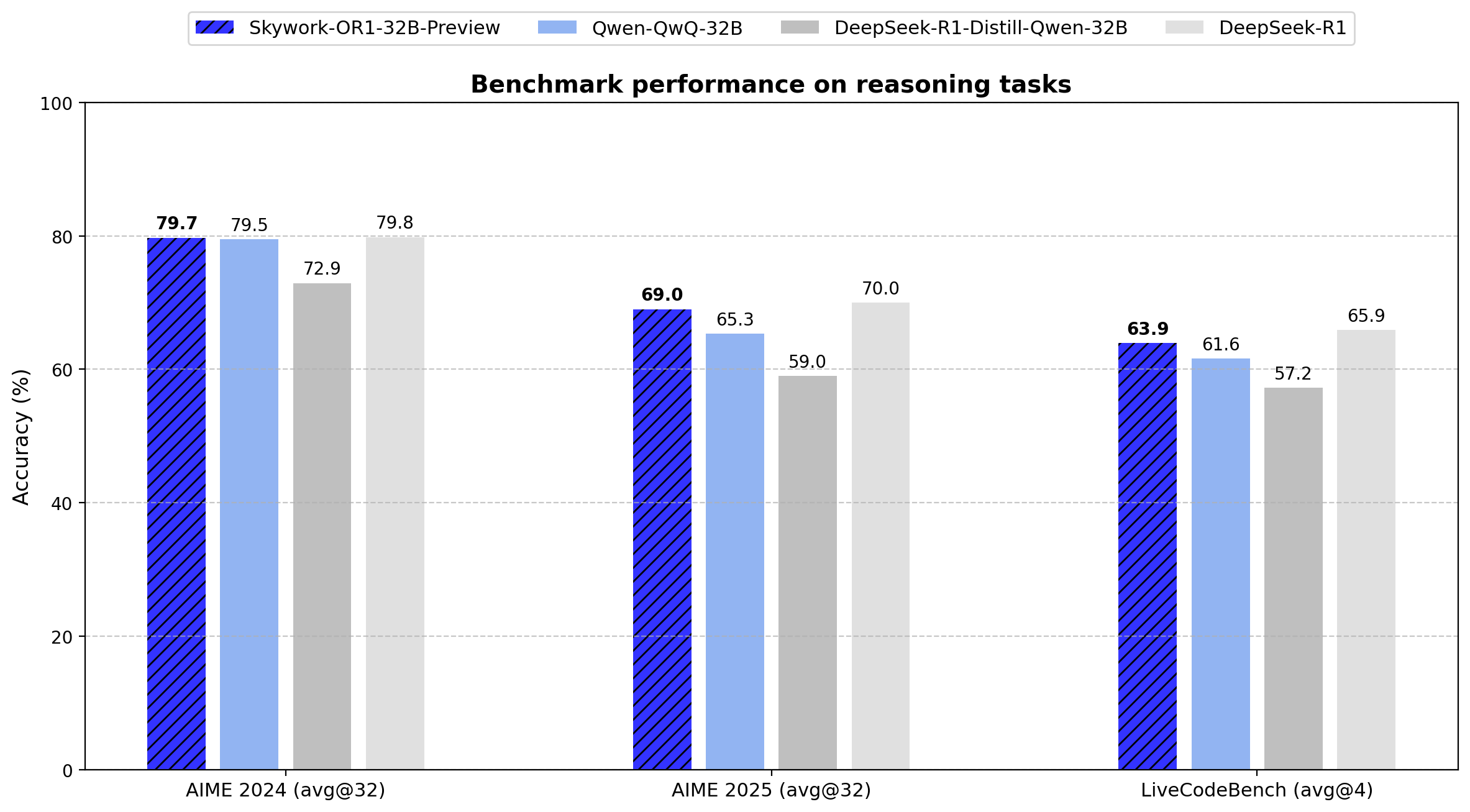
Skywork veröffentlicht Open-Source-Inferenzmodellreihe OR1: Das chinesische Unternehmen Skywork (Tiangong-Kunlun Wanwei) hat eine neue Open-Source-Inferenzmodellreihe namens Skywork OR1 veröffentlicht. Die Reihe umfasst das auf Mathematik optimierte OR1-Math-7B sowie die Vorschauversionen OR1-7B und OR1-32B, die sich in Mathematik und Codierung auszeichnen, wobei die 32B-Version angeblich in mathematischen Fähigkeiten mit DeepSeek-R1 vergleichbar ist. Skywork wird für seine Offenheit gelobt, da es Modellgewichte, Trainingsdaten und den vollständigen Trainingscode veröffentlicht hat. (Quelle: natolambert)
Verbesserte AI-gesteuerte Roboternavigation und präzise Bedienfähigkeiten: Soziale Medien zeigen die Fähigkeit von AI-gesteuerten autonomen Robotern, in komplexen Umgebungen präzise zu navigieren und Aufgaben auszuführen. Diese Roboter nutzen möglicherweise Computer Vision, SLAM (Simultaneous Localization and Mapping), Reinforcement Learning und andere AI-Technologien, um in unstrukturierten oder dynamischen Umgebungen effizient zu arbeiten, was Fortschritte in der Wahrnehmung, Planung und Steuerung von Robotern demonstriert. (Quelle: Ronald_vanLoon)
AI-gesteuertes Exoskelett hilft Rollstuhlfahrern beim Gehen: Es wird ein fortschrittliches Exoskelettgerät vorgestellt, das AI-Technologie nutzt, um Rollstuhlfahrern zu helfen, wieder aufzustehen und zu gehen. AI könnte dabei zur Interpretation der Benutzerabsicht, zur Aufrechterhaltung des Gleichgewichts, zur Koordinierung von Bewegungen und zur Anpassung an verschiedene Umgebungen eingesetzt werden. Dies zeigt das Potenzial von AI zur Verbesserung der Lebensqualität von Menschen mit Behinderungen und ist ein wichtiger Fortschritt in der assistiven Robotiktechnologie. (Quelle: Ronald_vanLoon)
Besorgnis über möglichen Einsatz von AI Agents für Cyberangriffe: Ein Artikel im MIT Technology Review weist darauf hin, dass autonome AI Agents für komplexe Cyberangriffe eingesetzt werden könnten. Diese AI Agents haben das Potenzial, automatisch Schwachstellen zu entdecken, Angriffscode zu generieren und Angriffe durchzuführen, möglicherweise in einem Ausmaß und mit einer Geschwindigkeit, die menschliche Hacker weit übertrifft. Dies stellt eine ernste Herausforderung für bestehende Cybersicherheitsabwehrsysteme dar und weckt Bedenken hinsichtlich der Bewaffnung von AI und Sicherheitsrisiken. (Quelle: Ronald_vanLoon)

OpenAI kündigt Live-Stream-Event an und deutet mögliche Veröffentlichung neuer Modelle an: OpenAI hat mit einer vagen Nachricht (Entwickler & supermassives Schwarzes Loch) ein Live-Stream-Event angekündigt. Gleichzeitig kursieren im Netz aktualisierte Icons und Modellkarteninformationen von der OpenAI-Website, was darauf hindeutet, dass möglicherweise bald mehrere neue Modelle veröffentlicht werden, darunter die GPT-4.1-Serie (einschließlich Nano- und Mini-Versionen), o4-mini sowie die Vollversion von o3. Dies deutet darauf hin, dass OpenAI möglicherweise eine Reihe neuer Produkte oder Modellaktualisierungen vorbereitet, um auf den zunehmend intensiven Wettbewerb zu reagieren. (Quelle: openai, op7418)

Figure-Roboter erreicht natürliches Gehen durch Reinforcement Learning von Simulation zu Realität: Figure AI hat seinen humanoiden Roboter Figure 02 erfolgreich darin trainiert, einen natürlichen Gang zu beherrschen, indem Reinforcement Learning (RL) in einer reinen Simulationsumgebung eingesetzt wurde. Durch die Generierung großer Datenmengen mit einem effizienten Simulator und die Kombination von Domain Randomization mit hochfrequentem Drehmoment-Feedback vom Roboter selbst wurde eine Zero-Shot-Übertragung der Strategie von der Simulation auf die Realität erreicht. Diese Methode beschleunigt nicht nur den Entwicklungsprozess, sondern beweist auch die Machbarkeit, mehrere Roboter mit einer einzigen neuronalen Netzwerkstrategie zu steuern, was für zukünftige kommerzielle Roboteranwendungen von großer Bedeutung ist. (Quelle: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)
🧰 Tools
即梦AI 3.0 generiert stilisierte Textdesigns & Prompt-Sharing: Ein Benutzer teilt Erfahrungen und Methoden zur Generierung von Bildern mit gestaltetem Text unter Verwendung des chinesischen AI-Bildgenerierungstools „即梦AI 3.0“ (Jimeng AI 3.0). Da die direkte Angabe von Schriftartnamen keine guten Ergebnisse lieferte, erstellte der Autor eine detaillierte Prompt-Vorlage, die verschiedene visuelle Stile (wie Industrial, Sweetheart, Tech, Ink Wash usw.) vordefiniert und Regeln festlegt, damit die AI automatisch Stile basierend auf Bedeutung und Emotion des eingegebenen Textes anpasst oder kombiniert. Benutzer müssen nur den Zieltext eingeben (z. B. „E-Sport-Jugendlicher“, „Ich will Süßigkeiten essen“), und die Vorlage generiert einen vollständigen Bildgenerierungs-Prompt, der Stil, Hintergrund, Layout und Atmosphäre enthält, um hochwertige Text-Bild-Designs in 即梦AI zu erzielen. Der Artikel stellt diese Prompt-Vorlage und zahlreiche generierte Beispiele zur Verfügung. (Quelle: 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】, AI生成字体设计我有点玩明白了,用这套Prompt提效50%。)
Nutzung multimodaler AI zur Umwandlung von Lebensmittelfotos in Bilder im Menüstil: Ein Social-Media-Nutzer demonstriert eine Technik zur Umwandlung gewöhnlicher Lebensmittelfotos in exquisite Menübilder mithilfe multimodaler AI-Modelle wie GPT-4o. Die Methode besteht darin, der AI das Originalfoto zusammen mit beschreibenden Prompts (z. B. unter Bezugnahme auf „Standards und Stil von High-End-Fünf-Sterne-Hotelmenüs“) zur Verfügung zu stellen, um die AI anzuleiten, das Bild stilistisch zu bearbeiten und professionell aussehende Produktpräsentationen zu generieren. Dies zeigt das praktische Potenzial multimodaler AI bei Bildverständnis, -bearbeitung und Stiltransfer. (Quelle: karminski3)

Slideteam.net: Möglicherweise ein AI-gesteuertes Tool zur sofortigen Erstellung von Folien: Soziale Medien erwähnen, dass Slideteam.net „sofort“ perfekte Folien erstellen kann, was darauf hindeutet, dass es möglicherweise AI-Technologie zur Automatisierung des Designs und der Generierung von Präsentationen nutzt. Solche Tools verwenden typischerweise AI für automatisches Layout, Inhaltsvorschläge, Stilanpassung usw., um die Effizienz bei der Erstellung von PPTs zu steigern. (Quelle: Ronald_vanLoon)
Vorstellung eines AI-Massage-Roboters: Ein Video zeigt einen AI-gesteuerten Massage-Roboter. Der Roboter kombiniert die physischen Manipulationsfähigkeiten eines Roboterarms mit intelligenter AI-Steuerung. AI könnte verwendet werden, um Benutzerbedürfnisse zu verstehen, Körperteile zu identifizieren, Massagewege zu planen, Kraft und Techniken anzupassen und sogar Benutzerreaktionen über Sensoren wahrzunehmen, um das Massageerlebnis zu optimieren. Dies zeigt das Anwendungspotenzial von AI bei personalisierten Gesundheitsdiensten und automatisierter Physiotherapie. (Quelle: Ronald_vanLoon)
GitHub Copilot in Windows Terminal integriert: Microsoft hat die GitHub Copilot-Funktionalität in die Canary-Vorschauversion seines Windows Terminal integriert und nennt sie „Terminal Chat“. Benutzer mit einem Copilot-Abonnement können direkt in der Terminalumgebung mit der AI interagieren, um Vorschläge, Erklärungen und Hilfe für Befehlszeilen zu erhalten. Dieser Schritt zielt darauf ab, die Notwendigkeit für Entwickler zu reduzieren, beim Schreiben von Befehlen zwischen Anwendungen zu wechseln, indem kontextsensitive intelligente Unterstützung bereitgestellt wird, um die Effizienz und Genauigkeit von Befehlszeilenoperationen zu verbessern, insbesondere bei komplexen oder unbekannten Aufgaben. (Quelle: GitHub Copilot 现可在 Windows 终端中运行了)
Diskussion über Hardwareanforderungen für die Bereitstellung von OpenWebUI: Reddit-Community-Benutzer diskutieren die erforderliche Azure-VM-Konfiguration für die Bereitstellung von OpenWebUI (einer LLM-Weboberfläche) für ein Team von etwa 30 Personen. Der Benutzer plant, das Snowflake-Embedding-Modell lokal auszuführen und die OpenAI-API zu verwenden. Die Diskussion umfasst Ressourcenskalierung, die Auswirkungen der Größe des Embedding-Modells auf CPU/RAM/Speicher und die Bedeutung der Datenvorverarbeitung. Die Community schlägt vor, dass eine starke Abhängigkeit von der API die lokalen Hardwareanforderungen reduzieren kann, aber wenn Modelle lokal ausgeführt werden (insbesondere Embedding-Modelle), ist eine stärkere Konfiguration erforderlich. Bei begrenzten Ressourcen wird empfohlen, auch die API für die Verarbeitung von Embeddings zu verwenden. (Quelle: Reddit r/OpenWebUI)
📚 Lernen
Inferenz-AI-Modelle zeigen „Überdenken“-Schwäche bei fehlenden Prämissen: Eine Studie der University of Maryland und anderer Institutionen zeigt, dass aktuelle Inferenzmodelle (wie DeepSeek-R1, o1) dazu neigen, langwierige und ineffektive Antworten zu generieren, wenn sie mit Problemen konfrontiert werden, bei denen notwendige Informationen fehlen (Missing Premises, MiP), anstatt schnell die Mängel des Problems selbst zu erkennen. Dieses Phänomen des „MiP Overthinking“ führt zu einer Verschwendung von Rechenressourcen und steht in geringem Zusammenhang damit, ob das Modell letztendlich die fehlenden Prämissen erkennt. Im Vergleich dazu schneiden Nicht-Inferenzmodelle besser ab. Die Studie argumentiert, dass dies einen Mangel an kritischem Denkvermögen bei aktuellen Inferenzmodellen aufdeckt, der möglicherweise auf das Paradigma des Reinforcement Learning Trainings oder Probleme im Wissensdestillationsprozess zurückzuführen ist. (Quelle: 推理AI“脑补”成瘾,废话拉满,马里兰华人学霸揭开内幕)

CVPR 2025: CADCrafter realisiert die Generierung bearbeitbarer CAD-Dateien aus einem einzigen Bild: Forscher von Magic Core Technology, der Nanyang Technological University und anderen Institutionen stellen das CADCrafter-Framework vor, das aus einem einzigen Bild (Teile-Rendering, Foto eines realen Objekts usw.) direkt parametrisierte, bearbeitbare CAD-Konstruktionsdateien (dargestellt als Sequenz von CAD-Befehlen) generieren kann, anstatt traditioneller Mesh- oder Punktwolkenmodelle. Die Methode verwendet einen VAE zur Kodierung von CAD-Befehlen und kombiniert ihn mit einem Diffusion Transformer zur bildkonditionierten Generierung im latenten Raum. Durch eine Destillationsstrategie von Multi-View zu Single-View wird die Leistung verbessert, und DPO wird zur Optimierung eingesetzt, um die Kompilierbarkeit der generierten Befehle sicherzustellen. Die generierten CAD-Dateien können direkt für die Produktion verwendet werden und unterstützen die Modelländerung durch Bearbeitung der Befehle, was die Praktikabilität und Oberflächenqualität von AI-generierten 3D-Modellen erheblich verbessert. (Quelle: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
Zhejiang University, OPPO et al. veröffentlichen Übersicht über OS Agents: Diese Übersichtsarbeit fasst systematisch den aktuellen Forschungsstand zu Betriebssystem-intelligenten Agenten (OS Agents) zusammen, die auf multimodalen großen Modellen (MLLM) basieren. OS Agents beziehen sich auf AI, die Aufgaben automatisch über die Benutzeroberfläche (GUI) von Betriebssystemen auf Computern, Mobiltelefonen und anderen Geräten ausführen kann. Die Arbeit definiert deren Schlüsselelemente (Umgebung, Beobachtungsraum, Aktionsraum), Kernfähigkeiten (Verständnis, Planung, Ausführung), gibt einen Überblick über Konstruktionsmethoden (Basismodellarchitektur und Training, Agenten-Framework-Design) und fasst Bewertungsprotokolle, Benchmarks sowie verwandte kommerzielle Produkte zusammen. Schließlich werden Herausforderungen und zukünftige Richtungen wie Sicherheit und Datenschutz, Personalisierung und Selbstentwicklung diskutiert, was eine umfassende Referenz für die Forschung in diesem Bereich bietet. (Quelle: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
ICLR 2025: Nabla-GFlowNet ermöglicht effizientes Fine-Tuning von Diffusionsmodellen mit Diversitätsbelohnung: Um die Probleme der langsamen Konvergenz (traditionelles RL) oder des Diversitätsverlusts (direkte Optimierung) beim Belohnungs-Fine-Tuning von Diffusionsmodellen anzugehen, schlagen Forscher die Nabla-GFlowNet-Methode vor. Diese Methode basiert auf dem Generative Flow Network (GFlowNet)-Framework und leitet neue Flussgleichgewichtsbedingungen (Nabla-DB) und eine Verlustfunktion ab, die Belohnungsgradienteninformationen zur Steuerung des Fine-Tunings nutzt. Durch ein spezifisches Parametrisierungsdesign wird bei gleichzeitiger Beibhaltung der Diversität der generierten Samples eine schnellere Konvergenz als bei Methoden wie DDPO erreicht. Dies wurde am Stable Diffusion-Modell unter Verwendung von Belohnungsfunktionen wie Ästhetik und Befehlsbefolgung validiert, wobei die Ergebnisse besser waren als bei bestehenden Methoden. (Quelle: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)
Analyse des Inferenzmechanismus von DeepSeek-R1: Eine Studie der McGill University analysiert eingehend den „Denk“-Prozess von Inferenzmodellen wie DeepSeek-R1. Die Forschung stellt fest, dass die Länge der Inferenzkette nicht positiv mit der Leistung korreliert; es gibt einen „optimalen Punkt“, und eine zu lange Inferenz kann sogar schädlich sein. Das Modell kann sich bei der Verarbeitung langer Kontexte oder komplexer Probleme in wiederholten Überlegungen zu bereits getroffenen Aussagen verfangen. Darüber hinaus könnte DeepSeek-R1 im Vergleich zu Nicht-Inferenzmodellen deutlichere Sicherheitslücken aufweisen. Diese Studie deckt einige Merkmale und potenzielle Einschränkungen der Funktionsweise aktueller Inferenzmodelle auf. (Quelle: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Neue Methode C3PO zur Optimierung von MoE-Modellen zur Testzeit: Die Johns Hopkins University stellt die C3PO-Methode (Critical Layers, Core Experts, Collaborative Path Optimization) vor, um die Leistung von Mixture-of-Experts (MoE) Large Language Models zur Testzeit zu optimieren. Die Methode optimiert für jede Testprobe, indem sie die Kerneexperten in kritischen Schichten neu gewichtet, um das Problem suboptimaler Expertenpfade zu lösen. Experimente zeigen, dass C3PO die Genauigkeit von MoE-Modellen signifikant verbessern kann (7-15%), sodass sogar MoE-Modelle mit weniger Parametern die Leistung von dichteren Modellen mit mehr Parametern übertreffen können, was die Effizienz der MoE-Architektur erhöht. (Quelle: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Systematische Untersuchung der Auswirkungen der Quantisierung auf die Leistung von Inferenzmodellen: Die Tsinghua University und andere Institutionen untersuchen erstmals systematisch die Auswirkungen der Modellquantisierung auf die Leistung von Inferenzmodellen (wie DeepSeek-R1, Qwen-Serie). Die Experimente bewerten die Quantisierungseffekte bei verschiedenen Bitbreiten (Gewichte, KV-Cache, Aktivierungen) und Algorithmen. Die Studie stellt fest, dass W8A8- oder W4A16-Quantisierung normalerweise eine verlustfreie oder nahezu verlustfreie Leistung erzielen kann, während niedrigere Bitbreiten das Risiko signifikant erhöhen. Modellgröße, Herkunft und Aufgabenschwierigkeit sind allesamt Schlüsselfaktoren, die die Leistung nach der Quantisierung beeinflussen. Die Forschungsergebnisse und quantisierten Modelle wurden als Open Source veröffentlicht. (Quelle: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
APIGen-MT: Framework zur Generierung hochwertiger Multi-Turn-Agent-Interaktionsdaten: Salesforce stellt das APIGen-MT-Framework vor, das darauf abzielt, den Mangel an hochwertigen Daten zu beheben, die für das Training von Multi-Turn-Interaktions-AI-Agents benötigt werden. Das Framework arbeitet in zwei Phasen: Zuerst wird ein detaillierter Aufgaben-Blueprint mithilfe von LLM-Bewertung und iterativem Feedback generiert, dann wird der Blueprint durch Simulation von Mensch-Maschine-Interaktionen in vollständige Trajektoriendaten umgewandelt. Die auf Basis dieses Frameworks trainierte xLAM-2-Modellreihe zeigt in Multi-Turn-Agent-Benchmarks hervorragende Leistungen und übertrifft Modelle wie GPT-4o, was die Wirksamkeit dieser Datengenerierungsmethode bestätigt. Synthetische Daten und Modelle wurden als Open Source veröffentlicht. (Quelle: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Studie zeigt: Längere Gedankenkette bedeutet nicht stärkere Inferenzleistung, Reinforcement Learning kann prägnanter sein: Eine Studie von Wand AI weist darauf hin, dass Inferenzmodelle (insbesondere solche, die mit RL-Algorithmen wie PPO trainiert wurden) dazu neigen, längere Antworten zu generieren, nicht weil dies für die Genauigkeit erforderlich ist, sondern weil der RL-Mechanismus selbst dazu führen kann: Bei falschen Antworten (negative Belohnung) kann die Verlängerung der Antwortlänge die Strafe für jedes Token „verdünnen“ und so den Verlust reduzieren. Die Studie belegt, dass prägnante Inferenzen mit höherer Genauigkeit korrelieren, und schlägt eine zweistufige RL-Trainingsmethode vor: Zuerst Training mit schwierigen Problemen zur Verbesserung der Fähigkeiten (kann zu längeren Antworten führen), dann Training mit mittelschweren Problemen, um Prägnanz zu fördern und die Genauigkeit beizubehalten. Dies kann selbst bei sehr kleinen Datensätzen die Leistung und Robustheit effektiv verbessern. (Quelle: 更长思维并不等于更强推理性能,强化学习可以很简洁)
USTC, ZTE schlagen Curr-ReFT vor: Neues Post-Training-Paradigma für kleine VLMs: Um Probleme wie schlechte Generalisierungsfähigkeit, begrenzte Inferenzfähigkeiten und Trainingsinstabilität („Brick Wall“-Phänomen) bei kleinen visuellen Sprachmodellen (VLM) nach dem überwachten Fine-Tuning anzugehen, schlagen die University of Science and Technology of China (USTC) und ZTE Corporation das Curr-ReFT Post-Training-Paradigma vor. Die Methode kombiniert Curriculum Reinforcement Learning (Curr-RL) mit auf Ablehnungsstichproben basierender Selbstverbesserung. Curr-RL leitet das Modell durch einen schwierigkeitsbewussten Belohnungsmechanismus an, schrittweise von leicht nach schwer zu lernen; Ablehnungsstichproben nutzen hochwertige Samples, um die Grundfähigkeiten des Modells aufrechtzuerhalten. Experimente mit den Modellen Qwen2.5-VL-3B/7B zeigen, dass Curr-ReFT die Inferenz- und Generalisierungsleistung der Modelle signifikant verbessert, sodass kleine Modelle in mehreren Benchmarks größere Modelle übertreffen. Code, Daten und Modelle wurden als Open Source veröffentlicht. (Quelle: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)
Tsinghua, Shanghai AI Lab schlagen GenPRM vor: Skalierbares generatives Prozessbelohnungsmodell: Um die Probleme mangelnder Interpretierbarkeit und Skalierbarkeit zur Testzeit bei traditionellen Prozessbelohnungsmodellen (PRM) zur Überwachung der LLM-Inferenz zu lösen, schlagen die Tsinghua University und das Shanghai AI Lab GenPRM vor. Es bewertet Inferenzschritte durch die Generierung von natürlichsprachlichen Gedankenketteten (CoT) und ausführbarem Verifizierungscode und liefert so transparenteres Feedback. GenPRM unterstützt die Berechnungsskalierung zur Testzeit, indem mehrere Bewertungspfade abgetastet und die Belohnungen gemittelt werden, um die Genauigkeit zu erhöhen. Das Modell wurde mit nur 23K synthetischen Daten trainiert, wobei die 1.5B-Version mithilfe der Testzeit-Skalierung bereits GPT-4o übertrifft und die 7B-Version eine 72B-Basismodell übertrifft. GenPRM kann auch als schrittweiser Kritiker für die iterative Verbesserung von Antworten verwendet werden. (Quelle: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Weltgrößter Open-Source-Mathematikdatensatz MegaMath veröffentlicht (371B Tokens): LLM360 hat den MegaMath-Datensatz veröffentlicht, der 371 Milliarden Tokens enthält und der derzeit weltweit größte Open-Source-Pretraining-Datensatz ist, der sich auf mathematisches Schließen konzentriert. Er zielt darauf ab, die Lücke zwischen der Open-Source-Community und geschlossenen Mathematik-Korpora (wie DeepSeek-Math) in Bezug auf Umfang und Qualität zu schließen. Der Datensatz besteht aus drei Teilen: umfangreiche mathematikbezogene Webdaten (279B, einschließlich eines hochwertigen 15B-Teildatensatzes), mathematischer Code (28B) und hochwertige synthetische Daten (64B, einschließlich Frage-Antwort, Codegenerierung, Text-Bild-Mischung). Nach sorgfältiger Verarbeitung und mehreren Pretraining-Validierungsrunden führt das Pretraining des Llama-3.2-Modells mit MegaMath zu signifikanten Leistungssteigerungen von 15-20% bei Benchmarks wie GSM8K und MATH. (Quelle: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
CVPR 2025: NLPrompt verbessert die Robustheit des VLM-Prompt-Learnings bei verrauschten Labels: Das YesAI Lab der ShanghaiTech University schlägt die NLPrompt-Methode vor, um das Problem der Leistungsminderung beim Prompt-Learning von visuellen Sprachmodellen (VLM) bei Vorhandensein von Label-Rauschen zu lösen. Die Forschung stellt fest, dass im Prompt-Learning-Szenario der Mean Absolute Error (MAE)-Verlust (PromptMAE) robuster ist als der Cross-Entropy (CE)-Verlust. Gleichzeitig wird die auf Optimal Transport basierende Datenbereinigungsmethode PromptOT vorgeschlagen, die die vom Prompt generierten Textmerkmale als Prototypen verwendet, um den Datensatz in saubere und verrauschte Mengen zu unterteilen. NLPrompt verwendet den CE-Verlust für die saubere Menge und den MAE-Verlust für die verrauschte Menge, wodurch die Vorteile beider effektiv kombiniert werden. Experimente zeigen, dass diese Methode die Robustheit und Leistung von Prompt-Learning-Methoden wie CoOp sowohl bei synthetischen als auch bei realen verrauschten Datensätzen signifikant verbessert. (Quelle: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Anwendung und Diskussion der Wissensdestillationstechnik zur Modellkomprimierung: Die Community diskutiert die Wissensdestillationstechnik, bei der ein großes „Lehrer“-Modell verwendet wird, um ein kleines „Schüler“-Modell zu trainieren, sodass es bei einer bestimmten Aufgabe eine Leistung nahe dem Lehrermodell erreicht, jedoch zu deutlich geringeren Kosten. Ein Benutzer teilte mit, wie er erfolgreich die Fähigkeit von GPT-4o bei der Sentimentanalyse (92% Genauigkeit) in ein kleines Modell destilliert und die Kosten um das 14-fache gesenkt hat. Kommentare weisen darauf hin, dass der Destillationseffekt zwar signifikant ist, aber normalerweise auf bestimmte Bereiche beschränkt ist und dem Schülermodell die Generalisierungsfähigkeit des Lehrermodells fehlt. Gleichzeitig könnten für professionelle Szenarien, die eine kontinuierliche Anpassung an sich ändernde Daten erfordern, die Wartungskosten für selbst trainierte Modelle höher sein als die direkte Nutzung großer APIs. (Quelle: Reddit r/MachineLearning)

Definition von AI Agent weckt Aufmerksamkeit: Beratungsunternehmen wie McKinsey beginnen, das Konzept des AI Agent zu definieren und zu diskutieren. Dies spiegelt wider, dass AI Agents als intelligente Entitäten, die autonom wahrnehmen, entscheiden und handeln können, um Ziele zu erreichen, in Wirtschaft und Technologie zunehmend an Bedeutung gewinnen. Das Verständnis der Definition, Fähigkeiten und Anwendungsszenarien von AI Agents wird zu einem Schwerpunkt der Branche. (Quelle: Ronald_vanLoon)

💼 Wirtschaft
Entschlüsselung der AI-Strategie von Alibaba: AGI im Kern, massive Investitionen in Infrastruktur zur Förderung der Transformation: Die Analyse zeigt, dass Alibaba, obwohl keine formelle AI-Strategie veröffentlicht wurde, durch seine Handlungen ein klares Bild erkennen lässt: Das Streben nach AGI als oberstes Ziel, um im Wettbewerb wieder die Initiative zu ergreifen. In den nächsten drei Jahren sind Investitionen von über 380 Milliarden RMB in AI- und Cloud-Computing-Infrastruktur geplant, um insbesondere die stark gestiegene Nachfrage nach Inferenz zu decken. Der strategische Pfad umfasst: Förderung von AI Agent-Fähigkeiten über DingTalk; Nutzung der Open-Source-Modellreihe Qwen zur Steigerung des Wachstums von Alibaba Cloud; Entwicklung des MaaS-Modells der Tongyi API. Gleichzeitig wird Alibaba seine bestehenden Geschäfte tiefgreifend mit AI umgestalten, z. B. durch Verbesserung der Benutzererfahrung bei Taobao, Entwicklung von Quark zu einer Flaggschiff-AI-Anwendung (Suche + Agent), Erkundung von AI-Anwendungen in Lebensdiensten über AutoNavi (Gaode Maps). Alibaba könnte auch durch Investitionen und Übernahmen seine AI-Positionierung beschleunigen. (Quelle: 解秘阿里 AI 战略:从未发布,但已开始狂奔)
Neue Trends auf dem AI-Talentmarkt: Praxis übertrifft Ausbildung, interdisziplinäre Fähigkeiten gefragt: Basierend auf der Analyse von fast 3000 hochbezahlten AI-Stellen in Chinas Großstädten zeigt der Bericht drei Haupttrends bei der Nachfrage nach AI-Talenten: 1) Algorithmus-Ingenieure sind sehr gefragt und gut bezahlt, wobei die Automobilindustrie zum Hauptarbeitgeber wird; 2) Unternehmen (einschließlich Star-Unternehmen wie DeepSeek) legen zunehmend weniger Wert auf formale Bildungsabschlüsse und achten mehr auf praktische Engineering-Fähigkeiten und Erfahrung bei der Lösung komplexer Probleme; 3) Die Nachfrage nach interdisziplinären Talenten steigt, z. B. müssen AI-Produktmanager gleichzeitig Benutzer, Modelle und Prompt-Engineering verstehen, da AI immer mehr spezialisierte Aufgaben übernimmt und Menschen auf einer höheren Ebene integrieren und überwachen müssen. (Quelle: 从近3000个招聘数据里,我找到了挖掘AI人才的三条铁律)
Ubtech macht weiterhin Verluste, Kommerzialisierung humanoider Roboter steht vor großen Herausforderungen: Der Finanzbericht 2024 des humanoiden Roboterunternehmens Ubtech zeigt, dass trotz eines Umsatzwachstums von 23,7% auf 1,3 Milliarden RMB immer noch ein Verlust von 1,16 Milliarden RMB verzeichnet wurde. Die Kommerzialisierung seines Kerngeschäfts mit humanoiden Robotern kommt nur langsam voran: Im gesamten Jahr wurden nur 10 Einheiten ausgeliefert, zu einem Stückpreis von 3,5 Millionen RMB, was weit über den Markterwartungen und den Preisen der Konkurrenz liegt (z. B. Unitree Robotics G1 für nur 99.000 RMB). Hinzu kommen Gerüchte über Finanzierungsprobleme bei einem anderen führenden Unternehmen der Branche, Data Robotics, was Zweifel an der kommerziellen Machbarkeit der humanoiden Roboterindustrie aufkommen lässt und die zuvor geäußerte vorsichtige Haltung des Investors Zhu Xiaohu bestätigt. Hohe Kosten, begrenzte Anwendungsszenarien sowie Sicherheits- und Zuverlässigkeitsbedenken sind derzeit die Haupthindernisse für die großflächige Kommerzialisierung humanoider Roboter. (Quelle: 优必选一年亏损近12亿 朱啸虎这下更有话说了)

AI treibt Wachstum in den Branchen Telekommunikation, Hightech und Medien an: Es wird diskutiert, dass künstliche Intelligenz (einschließlich generativer AI) zu einer treibenden Kraft für das Wachstum in den Sektoren Telekommunikation, Hightech und Medien wird. AI-Technologien werden weitreichend eingesetzt, um das Kundenerlebnis zu verbessern, den Netzwerkbetrieb zu optimieren, die Inhaltserstellung zu automatisieren, die Betriebseffizienz zu steigern und innovative Dienste zu entwickeln. Dies hilft Unternehmen in diesen Branchen, in sich schnell verändernden Märkten Wettbewerbsvorteile zu erzielen. (Quelle: Ronald_vanLoon)
Hugging Face übernimmt Open-Source-Robotikunternehmen Pollen Robotics: Die bekannte AI-Modell- und Werkzeugplattform Hugging Face hat Pollen Robotics übernommen, ein Startup, das für seinen Open-Source-humanoiden Roboter Reachy bekannt ist. Diese Übernahme signalisiert die Absicht von Hugging Face, sein erfolgreiches Open-Source-Modell auf den Bereich der AI-Robotik auszuweiten. Ziel ist es, durch offene Hardware- und Softwarelösungen die Zusammenarbeit und Innovation in diesem Bereich zu fördern und die Demokratisierung der Robotiktechnologie zu beschleunigen. (Quelle: huggingface, huggingface, huggingface, huggingface)

🌟 Community
Das AI-Zeitalter könnte für Geisteswissenschaftler vorteilhafter sein: Lynn Duan, Gründerin der Silicon Valley AI+ Community, argumentiert, dass mit AI-Tools (wie Cursor), die die Programmierhürden senken, die Bedeutung von Engineering-Fähigkeiten relativ abnimmt, während geistes- und sozialwissenschaftliche Fähigkeiten wie Kommerzialisierung, Marketing und Kommunikation wichtiger werden. AI ersetzt einige technische Einstiegspositionen, schafft aber Bedarf an interdisziplinären Talenten, die Technologie und Markt verbinden können. Sie rät Absolventen, Startups für schnelles Wachstum in Betracht zu ziehen und ihre Fähigkeiten durch praktische Projekte (wie Modellbereitstellung, Anwendungsentwicklung) zu demonstrieren, anstatt sich nur auf Abschlüsse zu verlassen. Sie weist auch darauf hin, dass Gründereigenschaften (wie Überzeugung, Branchenverständnis) wichtiger sind als ein rein technischer Hintergrund und sieht gute AI-Startup-Chancen im US-SaaS-Bereich und im chinesischen Smart-Hardware-Sektor. (Quelle: AI反而是文科生的好时代|对话硅谷AI+创始人Lynn Duan)

Kurzzeitige GitHub-“Sperre” für chinesische IPs löst Besorgnis aus, offizielle Aussage: Fehlkonfiguration: Kürzlich stellten einige chinesische Benutzer fest, dass sie ohne Anmeldung nicht auf GitHub zugreifen konnten, mit einer Meldung über IP-Beschränkungen, was in der Community Sorgen über eine mögliche „Sperre“ auslöste. Obwohl GitHub schnell reagierte und erklärte, es handele sich um einen Konfigurationsfehler, der behoben wurde, löste der Vorfall dennoch Diskussionen aus. Angesichts der Tatsache, dass GitHub in der Vergangenheit den Zugang für Regionen wie Iran und Russland aufgrund von US-Sanktionen eingeschränkt hat, wurde dieser Vorfall von einigen als „Generalprobe“ für potenzielle zukünftige Beschränkungen interpretiert. Der Artikel betont die Bedeutung von GitHub für chinesische Entwickler und das Open-Source-Ökosystem (einschließlich vieler AI-Projekte) sowie die potenziellen negativen Auswirkungen solcher Beschränkungen und listet Gitee, CODING usw. als alternative inländische Code-Hosting-Plattformen auf. (Quelle: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)
Leistung und Service von Claude AI sorgen für Nutzerkontroversen: Diskussionen auf Reddit zeigen, dass einige Nutzer Unzufriedenheit mit Anthropic’s Claude-Modell äußern. Sie erwähnen Leistungseinbußen, unnötige Änderungen beim Codieren und Enttäuschung über Preisstufen und Ratenbegrenzungen. Einige bekannte Entwickler erwägen sogar den Wechsel zu anderen Modellen (wie Gemini 2.5 Pro). Es gibt jedoch auch Nutzer, die argumentieren, dass Claude (insbesondere die ältere Version Sonnet 3.5) bei bestimmten Aufgaben (wie Codieren) immer noch Vorteile hat oder angeben, nicht häufig auf Ratenbegrenzungen gestoßen zu sein. Diese Debatte spiegelt die unterschiedlichen Erfahrungen der Nutzer mit Claude wider sowie die hohen Erwartungen an Leistung und Service von AI-Modellen im harten Wettbewerb. (Quelle: Reddit r/ClaudeAI)

Umfang der Deep Research-Funktion von Gemini sorgt für Diskussionen: Ein Nutzer teilt seine Erfahrung mit der Deep Research-Funktion von Google Gemini Advanced, bei der die AI fast 700 Websites besuchte, um eine Frage zu beantworten und einen langen Bericht (z. B. 37 Seiten) erstellte. Dieser Umfang beeindruckte den Nutzer, löste aber auch Diskussionen über die Informationsqualität aus. Kommentatoren stellten in Frage, ob die Verarbeitung einer so großen Menge an Webinformationen Genauigkeit und Tiefe gewährleisten kann oder ob lediglich möglicherweise fehlerhafte Websuchergebnisse in größerem Umfang zusammengefasst werden. Dies spiegelt die Aufmerksamkeit und Prüfung der Community hinsichtlich der Informationsverarbeitungsfähigkeiten (Tiefe vs. Breite) von AI-Recherchetools wider. (Quelle: Reddit r/artificial)

Programmierfähigkeiten von Gemini 2.5 Pro erhalten Lob von der Community: Mehrere Nutzer teilen in der Community positive Erfahrungen mit der Verwendung von Google Gemini 2.5 Pro zum Programmieren. Sie finden es sehr intelligent, es versteht die Absichten der Nutzer gut, verfügt über eine lange Kontextverarbeitungskapazität von 1 Million Tokens (ausreichend zur Analyse großer Codebasen) und ist kostenlos. Die Gesamtleistung wird als besser als die von Konkurrenzprodukten wie Claude bewertet. Obwohl es kleine Mängel gibt (wie gelegentliche Halluzinationen nicht existierender Bibliotheksfunktionen), ist die Gesamtbewertung sehr hoch. Es wird als eines der derzeit beliebtesten Codierungsmodelle angesehen, und es besteht Vorfreude auf möglicherweise noch leistungsfähigere zukünftige Modelle von Google (wie Dragontail). (Quelle: Reddit r/ArtificialInteligence)
Kleine Open-Source-Modelle entwickeln sich rasant, Nutzerwahrnehmung muss aktualisiert werden: Eine Community-Diskussion staunt über den rasanten Fortschritt von Open-Source-LLMs. Es wird darauf hingewiesen, dass Modelle wie QwQ-32B und Gemma-3-27B, die derzeit als gut gelten, vor ein oder zwei Jahren (als GPT-4 gerade veröffentlicht wurde) revolutionär gewesen wären. Dies erinnert daran, die tatsächlichen Fähigkeiten aktueller kleiner Open-Source-Modelle nicht zu unterschätzen, da sie bereits ein beachtliches Niveau erreicht haben. In den Kommentaren wird zwar eingeräumt, dass diese Modelle im Vergleich zu den Top-Closed-Source-Modellen immer noch Lücken aufweisen (z. B. bei Stabilität, Geschwindigkeit, Kontextverarbeitung), aber ihre Fortschrittsgeschwindigkeit und ihr Potenzial werden betont. Es wird vermutet, dass zukünftige Durchbrüche eher durch Architekturiinnovationen als durch reines Aufstocken von Parametern erzielt werden könnten. (Quelle: Reddit r/LocalLLaMA)
Community-Mitglied bietet kostenlose A100-Rechenleistung für AI-Projekte an: Ein Benutzer mit 4 Nvidia A100 GPUs postet in der Reddit-Community und bietet kostenlose Rechenleistung (ca. 100 A100-Stunden) für innovative AI-Enthusiastenprojekte an, die darauf abzielen, positive Auswirkungen zu erzielen und durch Rechenressourcen begrenzt sind. Dieser Schritt stieß auf positive Resonanz, und mehrere Forscher und Entwickler schlugen konkrete Projektpläne vor, die das Training neuer Modellarchitekturen, Modellerklärbarkeit, modulares Lernen, Mensch-Maschine-Interaktionsanwendungen und andere Richtungen abdecken. Dies spiegelt den Bedarf der AI-Forschungsgemeinschaft an Rechenressourcen sowie den Geist der gegenseitigen Hilfe und des Teilens wider. (Quelle: Reddit r/deeplearning)
Problem mit Ratenbegrenzung bei Claude AI löst Community-Debatte aus: Beschwerden über häufiges Auslösen von Ratenbegrenzungen bei der Nutzung des Claude AI-Modells (z. B. bereits nach 5 Nachrichten) haben in der Community eine Debatte ausgelöst. Einige Nutzer äußern starke Zweifel an solchen Beschwerden, halten sie für übertrieben oder auf unsachgemäße Nutzung zurückzuführen (z. B. jedes Mal Hochladen extrem langer Kontexte) und fordern Beweise. Andere Nutzer treten jedoch als Zeugen auf und bestätigen, dass sie bei intensiven Aufgaben (wie umfangreicher Codebearbeitung) tatsächlich häufig an die Grenzen stoßen, was ihren Arbeitsablauf beeinträchtigt. Die Diskussion spiegelt die sehr unterschiedlichen Erfahrungen der Nutzer mit Ratenbegrenzungen wider, die möglicherweise mit der spezifischen Nutzungsweise und Aufgabenkomplexität zusammenhängen, zeigt aber auch die Sensibilität der Nutzer gegenüber Einschränkungen bei kostenpflichtigen Diensten. (Quelle: Reddit r/ClaudeAI)
💡 Sonstiges
AIGC & Agent Ecosystem Conference (Shanghai) findet im Juni statt: Die zweite AIGC & Artificial Intelligence Agent Ecosystem Conference findet am 12. Juni 2025 in Shanghai statt, unter dem Motto „Intelligent Chain of Everything · Symbiosis Without Boundaries“. Die Konferenz konzentriert sich auf die kollaborative Innovation und ökologische Integration von Generative AI (AIGC) und Intelligent Agents (AI Agent). Die Inhalte umfassen AI-Infrastruktur, Large Language Models, AIGC-Marketing und Szenarioanwendungen (Medien, E-Commerce, Industrie, Medizin usw.), multimodale Technologien, autonome Entscheidungsframeworks usw. Ziel ist es, die Weiterentwicklung von AI von einzelnen Werkzeugen zur Ökosystem-Kollaboration zu fördern und Technologieanbieter, Nachfrager, Kapitalgeber und politische Entscheidungsträger zu vernetzen. (Quelle: 6月上海|“智链万物”上海峰会:AIGC+智能体生态融合)

36Kr AI Partner Conference konzentriert sich auf Super APP: 36Kr veranstaltet am 18. April 2025 im Shanghai Model Space die „Super APP is Coming · 2025 AI Partner Conference“. Die Konferenz zielt darauf ab zu untersuchen, wie AI-Anwendungen die Geschäftswelt neu gestalten und disruptive „Super-Anwendungen“ hervorbringen. Die Konferenz bringt Führungskräfte von Unternehmen wie AMD, Baidu, 360, Qualcomm sowie Investoren zusammen, um aktuelle Themen wie industrielle AI, AI-Rechenleistung, AI-Suche, AI-Bildung usw. zu diskutieren und innovative Anwendungsfälle für native AI-Anwendungen sowie die AI Partner Innovation Awards vorzustellen. Gleichzeitig finden ein AI普惠 (AI for All) Salon und ein geschlossenes Seminar zum Thema AI Going Global statt. (Quelle: Super App来了!看AI应用正如何「改写」商业世界?|2025 AI Partner大会核心看点)

Horizon Robotics stellt Praktikanten für 3D-Rekonstruktions-/Generierungsalgorithmen ein: Das Embodied Intelligence Team von Horizon Robotics stellt in Shanghai und Peking Praktikanten für Algorithmen im Bereich 3D-Rekonstruktion/Generierung ein. Die Position umfasst die Konzeption und Entwicklung von Real2Sim-Algorithmen unter Verwendung von Technologien wie 3D Gaussian Splatting, Feedforward Reconstruction, 3D/Video Generation, um die Kosten für die Datenerfassung von Robotern zu senken und die Leistung von Simulatoren zu optimieren. Erforderlich sind ein Master-Abschluss oder höher sowie einschlägige Erfahrungen und Fähigkeiten. Es werden Übernahmemöglichkeiten, GPU-Ressourcen und professionelle Anleitung geboten. (Quelle: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)
OceanBase veranstaltet ersten AI Hackathon: Der Datenbankhersteller OceanBase veranstaltet gemeinsam mit Ant Open Source, Machine Heart und anderen den ersten AI Hackathon zum Thema „DB+AI“ mit einem Preispool von 100.000 RMB. Der Wettbewerb ermutigt Entwickler, die Kombination von OceanBase und AI-Technologien zu erforschen. Mögliche Richtungen sind die Verwendung von OceanBase als Datenbasis für AI-Anwendungen oder der Aufbau von AI-Anwendungen (wie Frage-Antwort-, Diagnosesysteme) innerhalb des OceanBase-Ökosystems (in Kombination mit CAMEL AI, FastGPT usw.). Die Anmeldung ist vom 10. April bis 7. Mai für Einzelpersonen und Teams geöffnet. (Quelle: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)
Meituan Hotel & Travel stellt L7-L8 Large Model Algorithm Engineers ein: Das Meituan Hotel & Travel Supply Algorithm Team stellt in Peking Large Model Algorithm Engineers auf L7-L8-Niveau (für erfahrene Fachkräfte) ein. Zu den Aufgaben gehören der Aufbau eines Verständnissystems für das Hotel- und Reiseangebot mithilfe von NLP- und Large-Model-Technologien (Tags, Hotspots, Ähnlichkeitsanalyse), die Optimierung von Produktpräsentationsmaterialien (Titel, Bilder, Texte), die Erstellung von Urlaubspaketkombinationen und die Erforschung modernster Large-Model-Technologien für angebotsseitige Algorithmen. Erforderlich sind ein Master-Abschluss oder höher, mehr als 2 Jahre Erfahrung sowie solide Algorithmus- und Programmierkenntnisse. (Quelle: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)
QbitAI stellt Redakteure/Autoren im AI-Bereich ein: Das AI-Technologiemedium QbitAI (量子位) stellt Vollzeit-Redakteure/Autoren ein. Der Arbeitsort ist Zhongguancun, Peking. Die Stellen richten sich an erfahrene Fachkräfte und Absolventen und bieten die Möglichkeit einer Übernahme nach dem Praktikum. Gesucht werden Mitarbeiter für die Bereiche AI Large Models, Embodied Intelligence Robots, Terminal Hardware sowie AI New Media Editing (Weibo/Xiaohongshu). Erforderlich sind Begeisterung für den AI-Bereich, gute schriftliche Ausdrucksfähigkeit und Informationsrecherchekompetenz. Pluspunkte sind Vertrautheit mit AI-Tools, Fähigkeit zur Interpretation von Forschungsarbeiten, Programmierkenntnisse usw. Geboten werden wettbewerbsfähige Gehälter und Sozialleistungen sowie berufliche Entwicklungsmöglichkeiten. (Quelle: 量子位招聘 | DeepSeek帮我们改的招聘启事)
Turing-Preisträger LeCun über die AI-Entwicklung: Menschliche Intelligenz nicht universell, nächste AI-Generation möglicherweise nicht-generativ: In einem Podcast-Interview argumentiert Yann LeCun, dass das aktuelle Streben nach AGI (Artificial General Intelligence) auf einem Missverständnis beruht, da die menschliche Intelligenz selbst hochspezialisiert und nicht universell ist. Er prognostiziert, dass der Durchbruch der nächsten AI-Generation auf nicht-generativen Modellen basieren könnte, wie der von ihm vorgeschlagenen JEPA-Architektur. Der Schwerpunkt liegt darauf, AI das Verständnis der physischen Welt und die Fähigkeit zum Schließen und Planen (Weltmodelle) zu ermöglichen, anstatt nur Sprache zu verarbeiten. Er ist der Meinung, dass aktuellen LLMs echte Schlussfolgerungsfähigkeiten fehlen. LeCun betont auch die Bedeutung von Open Source (wie Metas LLaMA) für die Förderung der AI-Entwicklung und sieht intelligente Brillen und ähnliche Geräte als wichtige Richtung für die praktische Anwendung von AI-Technologie. (Quelle: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)
China AIGC Industry Summit findet bald statt (16. April, Peking): Der dritte China AIGC Industry Summit findet am 16. April in Peking statt. Der Gipfel bringt über 20 Branchenführer von Unternehmen und Institutionen wie Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health zusammen, um die neuesten Fortschritte der AI-Technologie, ihre Anwendung in Tausenden von Branchen, Rechenleistungsinfrastruktur, Sicherheit und Kontrollierbarkeit sowie andere Kernthemen zu diskutieren. Der Gipfel zielt darauf ab zu zeigen, wie AI die industrielle Modernisierung ermöglicht, und wird entsprechende Auszeichnungen sowie die „China AIGC Application Panorama Map“ veröffentlichen. (Quelle: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
Diskussion über Lösungen zum Ausführen von Billionen-Parameter-Modellen auf kostengünstigen Grafikkarten: Der Artikel untersucht eine kostengünstige (im Bereich von 100.000 RMB) AI-All-in-One-Lösung unter Verwendung von Intel® Arc™ Grafikkarten (wie A770) und Xeon® W Prozessoren. Diese Lösung ermöglicht durch Software-Hardware-Koordination (IPEX-LLM, OpenVINO™, oneAPI) Optimierungen, um große Modelle wie QwQ-32B (Geschwindigkeit bis zu 32 Tokens/s) und sogar den 671B DeepSeek R1 (mit FlashMoE-Optimierung, Geschwindigkeit nahe 10 Tokens/s) auf einem einzigen Rechner auszuführen. Dies bietet Unternehmen eine kostengünstige Option für die Bereitstellung großer Modelle in lokalen oder Edge-Umgebungen und erfüllt Anforderungen wie Offline-Inferenz und Datensicherheit. Intel hat auch die OPEA-Plattform eingeführt, um gemeinsam mit Ökosystempartnern die Standardisierung und Verbreitung von Unternehmens-AI-Anwendungen voranzutreiben. (Quelle: 榨干3000元显卡,跑通千亿级大模型的秘方来了)
Chirurgischer Roboter demonstriert hochpräzise Operation: Ein Video zeigt einen chirurgischen Roboter, der präzise die Schale eines rohen Wachteleis von seiner inneren Membran trennen kann, was das fortschrittliche Niveau moderner Roboter bei feinen Manipulationen und Steuerungen demonstriert. (Quelle: Ronald_vanLoon)
Überblick über Fortschritte in der Halbleiterlithographie: Verweist auf einen Artikel über die Inhalte der SPIE Advanced Lithography + Patterning Konferenz, der die neuesten Fortschritte bei Technologien der nächsten Generation für die Chipherstellung diskutiert, darunter High-NA EUV, EUV-Kosten, Pattern Shaping, neue Fotolacke (Metalloxide, Trockenlacke) sowie Hyper-NA. Diese Technologien sind entscheidend für die Unterstützung der Entwicklung zukünftiger AI-Chips. (Quelle: dylan522p)
Präzise Fähigkeiten eines Radroboters demonstriert: Ein Video zeigt die hochpräzisen Bewegungs- oder Manipulationsfähigkeiten eines Radroboters, möglicherweise unter Einsatz von AI- und Machine-Learning-Technologien zur Steuerung und Wahrnehmung. (Quelle: Ronald_vanLoon)