
Schlüsselwörter:AI, LLM, AI Washing Phänomen, LLM-Benchmark-Tests, Gemini-Modell Selbsthosting, vLLM Inferenz-Engine, Suno AI Musikgenerierung
🔥 Fokus
„AI“-Shopping-App entpuppt sich als von Menschen betrieben: Ein Startup namens Fintech und sein Gründer werden des Betrugs beschuldigt. Ihre angeblich KI-gesteuerte Shopping-App stützte sich tatsächlich stark auf ein menschliches Team auf den Philippinen zur Abwicklung von Transaktionen. Der Vorfall lenkt erneut die Aufmerksamkeit auf das Phänomen des „AI Washing“, bei dem Unternehmen ihre KI-Fähigkeiten übertreiben oder falsch darstellen, um Investoren oder Nutzer anzuziehen. Der Fall unterstreicht die Herausforderungen bei der Unterscheidung echter KI-Technologieanwendungen im aktuellen KI-Hype und die Bedeutung von Due Diligence bei Startups. (Quelle: Reddit r/ArtificialInteligence)

Neuer Benchmark zeigt mangelnde Generalisierungsfähigkeit von KI-Reasoning-Modellen: Ein neuer Benchmark namens LLM-Benchmark (https://llm-benchmark.github.io/) zeigt, dass selbst die neuesten KI-Reasoning-Modelle Schwierigkeiten bei der Verarbeitung von Out-of-Distribution (OOD) Logikrätseln haben. Die Studie ergab, dass ihre Punktzahlen bei diesen neuen Logikrätseln weit unter den Erwartungen liegen (etwa 50-mal niedriger) im Vergleich zur Leistung der Modelle bei Benchmarks wie Mathematik-Olympiaden. Dies deckt die Grenzen aktueller Modelle bei echtem logischem Denken und Generalisierung außerhalb der Verteilung der Trainingsdaten auf. (Quelle: Reddit r/ArtificialInteligence)
Google erlaubt Unternehmen das Self-Hosting von Gemini-Modellen als Reaktion auf Datenschutzbedenken: Google hat angekündigt, Unternehmenskunden zu erlauben, Gemini AI-Modelle in ihren eigenen Rechenzentren zu betreiben, beginnend mit Gemini 2.5 Pro. Dieser Schritt zielt darauf ab, die strengen Anforderungen von Unternehmen an Datenschutz und Sicherheit zu erfüllen, indem sie Googles fortschrittliche KI-Technologie nutzen können, ohne sensible Daten in die Cloud senden zu müssen. Diese Strategie ähnelt der von Mistral AI, steht jedoch im Gegensatz zu OpenAI und Anthropic, die ihre Dienste hauptsächlich über Cloud-APIs oder Partner anbieten, und könnte die Wettbewerbslandschaft im Enterprise-KI-Markt verändern. (Quelle: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

🎯 Trends
VSCode unterstützt nativ llama.cpp und erweitert lokale Copilot-Fähigkeiten: Visual Studio Code hat kürzlich Unterstützung für lokale KI-Modelle hinzugefügt. Nach der Unterstützung von Ollama ist es nun durch geringfügige Anpassungen mit llama.cpp kompatibel. Das bedeutet, dass Entwickler direkt in VSCode lokale Large Language Models (LLMs), die über llama.cpp ausgeführt werden, als Alternative oder Ergänzung zu GitHub Copilot verwenden können. Dies erleichtert die Nutzung von LLMs für die Code-Unterstützung in lokalen Umgebungen weiter und verbessert die Entwicklungsflexibilität und den Datenschutz. Benutzer müssen Ollama in den Einstellungen als Proxy auswählen (obwohl tatsächlich llama.cpp verwendet wird), um diese Funktion zu aktivieren. (Quelle: Reddit r/LocalLLaMA)

Yandex und andere Institutionen veröffentlichen HIGGS: Eine neue LLM-Kompressionsmethode: Forscher von Yandex Research, der HSE University, dem MIT und anderen Institutionen haben eine neue LLM-Quantisierungskomprimierungstechnik namens HIGGS entwickelt. Die Methode zielt darauf ab, die Modellgröße erheblich zu reduzieren, damit sie auf leistungsschwächeren Geräten ausgeführt werden kann, während der Qualitätsverlust des Modells minimiert wird. Berichten zufolge wurde die Methode erfolgreich zur Komprimierung des 671B-Parameter-Modells DeepSeek R1 eingesetzt, mit signifikanten Ergebnissen. HIGGS soll die Einstiegshürde für die Nutzung von LLMs senken, sodass auch kleinere Unternehmen, Forschungseinrichtungen und einzelne Entwickler große Modelle leichter anwenden können. Der zugehörige Code wurde auf GitHub und Hugging Face veröffentlicht. (Quelle: Reddit r/LocalLLaMA)
Google behebt Probleme bei der Quantisierung des QAT 2.7-Modells: Google hat die Version 2.7 seines QAT (Quantization Aware Training) quantisierten Modells (möglicherweise Gemma 2 7B oder ein ähnliches Modell) aktualisiert und einige Fehler bei den Kontroll-Token (control tokens) behoben, die in früheren Versionen vorhanden waren. Zuvor konnte das Modell am Ende der Ausgabe fälschlicherweise Markierungen wie <end_of_turn> generieren. Die neu hochgeladenen quantisierten Modelle haben diese Probleme behoben, und Benutzer können die aktualisierte Version herunterladen, um das korrekte Modellverhalten zu erhalten. (Quelle: Reddit r/LocalLLaMA)
DeepMind CEO spricht über die Errungenschaften von AlphaFold: DeepMind CEO Demis Hassabis betonte in einem Interview den enormen Einfluss von AlphaFold und verglich es bildlich damit, dass AlphaFold in einem Jahr „eine Milliarde Jahre Doktorandenforschungszeit“ geleistet habe. Er wies darauf hin, dass die Aufklärung einer Proteinstruktur früher typischerweise die gesamte Promotionszeit eines Doktoranden (4-5 Jahre) in Anspruch nahm, während AlphaFold innerhalb eines Jahres die Strukturen aller (damals bekannten) 200 Millionen Proteine vorhersagte. Diese Aussage unterstreicht das revolutionäre Potenzial der KI zur Beschleunigung wissenschaftlicher Entdeckungen. (Quelle: Reddit r/artificial)

🧰 Tools
MinIO: Hochleistungs-Objektspeicher für KI: MinIO ist ein quelloffenes, hochleistungsfähiges, S3-kompatibles Objektspeichersystem unter der GNU AGPLv3-Lizenz. Es betont besonders seine Fähigkeit, hochleistungsfähige Infrastrukturen für Machine Learning, Analytik und Anwendungsdaten-Workloads aufzubauen und bietet eine spezielle Dokumentation für KI-Speicher. Benutzer können es über Container (Podman/Docker), Homebrew (macOS), Binärdateien (Linux/macOS/Windows) oder aus dem Quellcode installieren. MinIO unterstützt den Aufbau verteilter, hochverfügbarer Speichercluster mit Erasure Coding und eignet sich für KI-Anwendungsszenarien, die große Datenmengen verarbeiten müssen. (Quelle: minio/minio – GitHub Trending (all/daily))

IntentKit: Framework zum Erstellen von KI-Agenten mit Fähigkeiten: IntentKit ist ein Open-Source-Framework für autonome Agenten, das Entwicklern ermöglichen soll, KI-Agenten mit vielfältigen Fähigkeiten zu erstellen und zu verwalten, einschließlich der Interaktion mit Blockchains (mit Priorität auf EVM-Ketten), Social-Media-Management (Twitter, Telegram etc.) und der Integration benutzerdefinierter Fähigkeiten. Das Framework unterstützt Multi-Agenten-Management und autonomen Betrieb und plant die Einführung eines erweiterbaren Plugin-Systems. Das Projekt befindet sich derzeit in der Alpha-Phase, bietet eine Architekturübersicht und Entwicklungsleitfäden und ermutigt die Community, Fähigkeiten beizusteuern. (Quelle: crestalnetwork/intentkit – GitHub Trending (all/daily))

vLLM: Hochleistungs-LLM-Inferenz- und Serving-Engine: vLLM ist eine Bibliothek, die sich auf LLM-Inferenz und -Serving mit hohem Durchsatz und Speichereffizienz konzentriert. Zu den Kernvorteilen gehören die effektive Verwaltung des Attention Key-Value-Speichers durch die PagedAttention-Technologie, Unterstützung für Continuous Batching, CUDA/HIP-Graph-Optimierung, verschiedene Quantisierungstechniken (GPTQ, AWQ, FP8 usw.), Integration mit FlashAttention/FlashInfer sowie Speculative Decoding. vLLM unterstützt Hugging Face-Modelle, bietet eine OpenAI-kompatible API und kann auf verschiedener Hardware wie NVIDIA und AMD ausgeführt werden, was es für Szenarien geeignet macht, die eine groß angelegte Bereitstellung von LLM-Diensten erfordern. (Quelle: vllm-project/vllm – GitHub Trending (all/daily))
tfrecords-reader: TFRecords-Reader mit Random Access und Suchfunktion: Dies ist ein Python-Tool zur Verarbeitung von TFRecords-Datensätzen, das speziell für die Datenprüfung und -analyse entwickelt wurde. Es ermöglicht Benutzern, Indizes für TFRecords-Dateien zu erstellen, um Random Access und inhaltsbasierte Suche (mit Polars SQL-Abfragen) zu realisieren, wodurch die Einschränkungen des nativen sequentiellen Lesens von TFRecords überwunden werden. Das Tool ist nicht von TensorFlow- und Protobuf-Paketen abhängig, unterstützt das direkte Lesen aus Google Storage, indiziert schnell und erleichtert Entwicklern die Exploration und Stichprobensuche in großen TFRecords-Datensätzen außerhalb des Modelltrainings. (Quelle: Reddit r/MachineLearning)
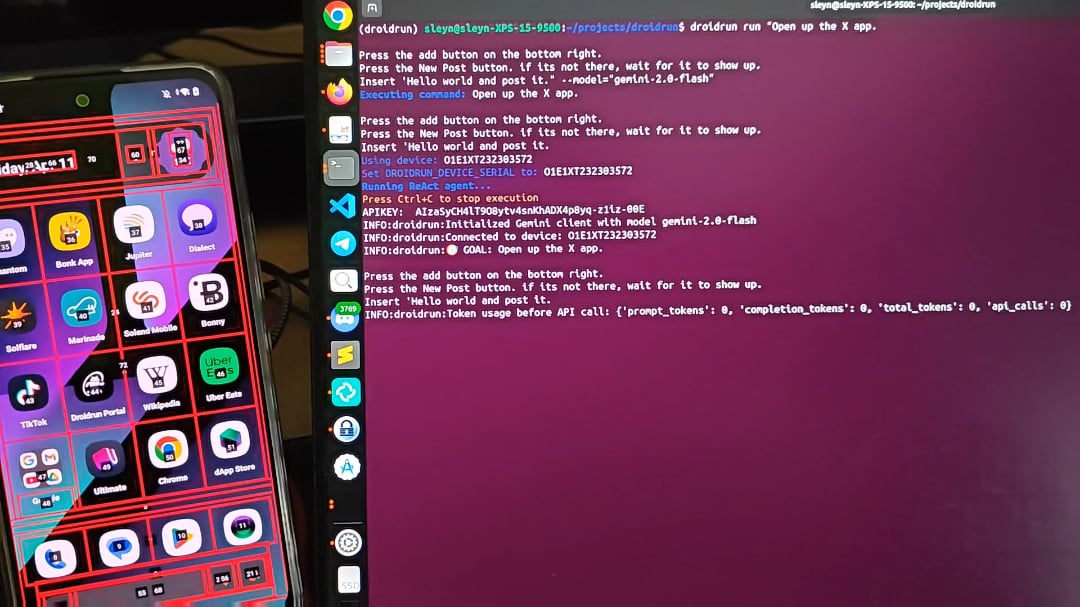
DroidRun: Lässt KI-Agenten Android-Telefone steuern: DroidRun ist ein Projekt, das es KI-Agenten ermöglicht, Android-Geräte wie ein Mensch zu bedienen. Durch die Verbindung mit einem beliebigen LLM kann es die interaktive Steuerung der Handy-Benutzeroberfläche realisieren und verschiedene Aufgaben ausführen. Das Projekt zeigt sein Potenzial und zielt darauf ab, automatisierte Operationen auf dem Mobiltelefon zu ermöglichen, wie z. B. das automatische Veröffentlichen von Inhalten, die Verwaltung von Apps usw. Die Entwickler laden die Community ein, Feedback und Ideen einzubringen, um weitere Automatisierungsszenarien zu erkunden. (Quelle: Reddit r/LocalLLaMA)
📚 Lernen
Cell Patterns veröffentlicht umfassende Übersicht über mehrsprachige große Modelle (MLLM): Diese Übersichtsarbeit fasst den aktuellen Stand der Forschung zu mehrsprachigen großen Modellen systematisch zusammen und deckt 473 Publikationen ab. Der Inhalt umfasst Datensatzressourcen und Erstellungsmethoden für mehrsprachiges Pre-Training, Instruction Fine-Tuning und RLHF; Strategien zur sprachübergreifenden Ausrichtung, unterteilt in Parameteranpassungs-Alignment (wie Pre-Training, Instruction Fine-Tuning, RLHF, Downstream Fine-Tuning) und Parameter-eingefrorenes Alignment (wie Direct Prompting, Code-Switching, Übersetzungs-Alignment, Retrieval-Augmented Generation); mehrsprachige Bewertungsmetriken und Benchmarks (NLU- und NLG-Aufgaben); und diskutiert zukünftige Forschungsrichtungen und Herausforderungen wie Halluzinationen, Wissensbearbeitung, Sicherheit, Fairness, Sprach-/Modalitätserweiterung, Interpretierbarkeit, Bereitstellungseffizienz und Aktualisierungskonsistenz. Bietet eine umfassende Forschungslandkarte für MLLMs. (Quelle: Cell Patterns重磅综述!473篇文献全面解析多语言大模型最新研究进展)

AAAI 2025 | Beihang University schlägt TRACK vor: Kollaboratives Lernen von dynamischen Straßennetzen und Trajektorienrepräsentationen: Ein Team der Beihang University schlägt das TRACK-Modell vor, um das Problem zu lösen, dass bestehende Methoden die raum-zeitliche Dynamik des Verkehrs nicht erfassen. Das Modell modelliert erstmals gemeinsam den Verkehrszustand (makroskopische Gruppenmerkmale) und Trajektoriendaten (mikroskopische individuelle Merkmale), da angenommen wird, dass sich beide gegenseitig beeinflussen. TRACK lernt dynamische Straßennetz- und Trajektorienrepräsentationen durch Graph Attention Networks (GAT), Transformer sowie innovative trajektorienübergangs-sensitive GATs und kollaborative Aufmerksamkeitsmechanismen. Das Modell verwendet ein gemeinsames Pre-Training-Framework, das selbstüberwachte Aufgaben wie Masked Trajectory Prediction, Contrastive Trajectory Learning, Masked State Prediction, Next State Prediction und Trajectory-Traffic State Matching umfasst, und zeigt überlegene Leistung bei Aufgaben zur Verkehrszustandsprognose und Reisezeitschätzung. (Quelle: AAAI 2025 | 告别静态建模!北航团队提出动态路网与轨迹表示的协同学习范式)

SUSTech Prof. Linyi Yang rekrutiert Doktoranden/RAs/Gaststudenten im Bereich Large Models: Prof. Linyi Yang vom Department of Statistics and Data Science an der Southern University of Science and Technology (SUSTech) (baldige Einstellung, unabhängiger PI) gründet das Generative Artificial Intelligence Lab (GenAI Lab) und rekrutiert Doktoranden und Masterstudenten für die Jahrgänge 2025/2026 sowie Postdocs, Forschungsassistenten und Praktikanten. Forschungsrichtungen umfassen kausale Analyse des Reasonings großer Modelle, generalisierbare Reinforcement-Learning-Methoden für große Modelle und den Aufbau zuverlässiger Nicht-Agenten-Systeme zur Verhinderung von KI-Kontrollverlust. Prof. Yang hat mehrere Paper auf Top-Konferenzen veröffentlicht, pflegt breite Kooperationen mit Universitäten und Forschungseinrichtungen im In- und Ausland und fördert gemeinsame Betreuung. Bewerber sollten hohe Eigenmotivation, solide mathematische Grundlagen und Programmierkenntnisse mitbringen. (Quelle: 博士申请 | 南方科技大学杨林易老师招收大模型方向全奖博士/RA/访问学生)

Persönliches Projekt: Aufbau eines Large Language Model von Grund auf: Ein Entwickler teilt sein persönliches Projekt, bei dem er ein Causal Language Model (ähnlich GPT) von Grund auf implementiert hat. Das Projekt verwendet Python und PyTorch. Die Kernarchitektur umfasst Multi-Head Self-Attention mit Causal Mask, Feed-Forward-Netzwerke und gestapelte Decoder-Blöcke (Layer Normalization, Residual Connections). Das Modell verwendet vortrainierte GPT-2 Word Embeddings und Positional Embeddings, und die Ausgabeschicht bildet auf die Vokabular-Logits ab. Top-k Sampling wird für die autoregressive Textgenerierung verwendet, und das Training erfolgt auf dem WikiText-Datensatz mit dem AdamW-Optimierer und CrossEntropyLoss. Der Projektcode ist auf GitHub Open Source verfügbar und demonstriert den grundlegenden Prozess zum Aufbau eines LLM. (Quelle: Reddit r/MachineLearning)
Paper-Interpretation: d1 – Erweiterung der Reasoning-Fähigkeiten von Diffusion Large Language Models (dLLM) durch Reinforcement Learning: Diese Studie stellt das d1-Framework vor, das darauf abzielt, vortrainierte diffusionsbasierte LLMs (dLLMs) für Reasoning-Aufgaben anzuwenden. dLLMs generieren Text durch einen Grob-zu-Fein-Ansatz, anders als autoregressive (AR) Modelle. Das d1-Framework kombiniert Supervised Fine-Tuning (SFT) und Reinforcement Learning (RL), insbesondere: Verwendung von Masked SFT für Knowledge Distillation und Guided Self-Improvement; Vorschlag eines neuen Critic-freien, Policy-Gradient-basierten RL-Algorithmus namens diffu-GRPO. Experimente zeigen, dass d1 die Leistung von SOTA dLLMs auf Mathematik- und Logik-Reasoning-Benchmarks signifikant verbessert und das Potenzial von dLLMs für Reasoning-Aufgaben demonstriert. (Quelle: Reddit r/MachineLearning)
💼 Business
Alibaba Tongyi Lab rekrutiert Algorithmus-Experten für generisches RAG/AI Search (Peking/Hangzhou): Das AI Search Team des Alibaba Tongyi Lab sucht Algorithmus-Experten, die für die Weiterentwicklung und Optimierung der Kernmodule von Suche und RAG (Retrieval-Augmented Generation) (wie Embedding, ReRank-Modelle) verantwortlich sind, um die Modellleistung zu verbessern und eine branchenführende Position zu erreichen. Die Aufgaben umfassen auch die Optimierung des gesamten Framework-Ablaufs für nachgelagerte Anwendungen (Q&A, Kundenservice, multimodales Memory), die Verbesserung von Genauigkeit, Effizienz und Skalierbarkeit sowie die Zusammenarbeit mit dem Team zur Förderung der Geschäftsimplementierung. Erforderlich sind ein Master-Abschluss oder höher in einem relevanten Fachgebiet, Vertrautheit mit Such-/NLP-/Large-Model-Technologien und einschlägige Projekterfahrung. (Quelle: 北京/杭州内推 | 阿里通义实验室招聘通用RAG/AI搜索方向算法专家)

KI-Recruiting-Startup OpportuNext sucht CTO (Remote/Equity): OpportuNext ist ein Early-Stage-Startup, das darauf abzielt, den Recruiting-Prozess mithilfe von KI-Technologie zu verbessern, indem es intelligente Job-Matches, Lebenslaufanalysen und Karriereplanungstools anbietet. Der Gründer sucht einen technischen Mitgründer (CTO), der die Entwicklung der KI-Funktionen leitet, skalierbare Backend-Systeme aufbaut und Produktinnovationen vorantreibt. Erforderlich sind Erfahrungen in KI/ML, Python und skalierbaren Systemen, Leidenschaft für die Lösung realer Probleme und die Bereitschaft, in der Frühphase eines Startups einzusteigen (Remote-Position auf Equity-Basis). (Quelle: Reddit r/deeplearning)
🌟 Community
Diskussion: Sind große Modelle im Wesentlichen „Sprachmagie“?: Ein tiefgründiger Artikel argumentiert, dass große Modelle (wie ChatGPT) Informationen nicht wirklich verstehen, sondern durch das Lernen riesiger Sprachdatenmengen Ausdrucksformen imitieren und vorhersagen. Die Rolle von Prompts besteht darin, den Kontext festzulegen und die Aufmerksamkeit des Modells zu lenken, nicht darin, mit einer bewussten Entität zu kommunizieren. Die Antworten des Modells basieren auf der Reproduktion von Mustern, die es „oft genug gesehen“ hat; sie wirken intelligent, entbehren aber eines echten Verständnisses und neigen zu Halluzinationen („überzeugender Unsinn“). Die Mensch-Maschine-Interaktion gleicht eher dem Denken des Benutzers für das Modell, während die Ausgabe des Modells unbewusst die Denk- und Urteilsgewohnheiten des Benutzers umformen und möglicherweise Vorurteile aus der Realität widerspiegeln und verstärken kann. (Quelle: 我所理解的大模型:语言的幻术)
Diskussion: Energieverbrauch von KI und Unterschiede in den Modellentwicklungsstrategien zwischen den USA und China: Reddit-Nutzer diskutieren Trumps Äußerung, Kohle als Schlüsselmineral für die KI-Entwicklung einzustufen, was Bedenken hinsichtlich des Energieverbrauchs von KI aufwirft. Kommentare weisen darauf hin, dass große Modelle immer energieintensiver werden, während chinesische Unternehmen anscheinend eher dazu neigen, schlankere, effizienzorientiertere Modelle zu bauen. Dies spiegelt den Kompromiss zwischen Leistung und Energieeffizienz in der KI-Entwicklung sowie potenziell unterschiedliche technologische Wege in verschiedenen Regionen wider. (Quelle: Reddit r/artificial)

Frage: Suche nach Deep Reinforcement Learning Frameworks ähnlich PyTorch Lightning: Ein Reddit-Benutzer fragt, ob es Frameworks speziell für Deep Reinforcement Learning (DRL) gibt, die PyTorch Lightning (PL) ähneln. Der Benutzer ist der Meinung, dass PL zwar für DRL verwendet werden kann, sein Design jedoch eher auf datensatzgesteuertes überwachtes Lernen als auf umgebungsinteraktionsgesteuertes DRL ausgerichtet ist. Der Beitrag bittet die Community um Empfehlungen für Frameworks, die für DRL (wie DQN, PPO) geeignet sind und sich gut in Umgebungen wie Gymnasium integrieren lassen, oder um den Austausch von Best Practices für die Verwendung von PL für DRL. (Quelle: Reddit r/deeplearning)
Community: Discord-Community MetaMinds für virtuelle Musiker gestartet: Eine neue Discord-Community namens MetaMinds wurde gegründet, um virtuellen Künstlern, die KI-Tools (wie Suno) zur Musikproduktion verwenden, eine Plattform für Austausch, Zusammenarbeit und Teilen zu bieten. Die Community hat ihren ersten Songwriting-Wettbewerb namens „A Personal Song“ gestartet und plant zukünftig Wettbewerbe mit höheren Standards, möglicherweise sogar mit Geldpreisen. Dies spiegelt die Entstehung neuer Community-Ökosysteme im Bereich der KI-Musikproduktion wider. (Quelle: Reddit r/SunoAI)
Diskussion: Wie nennt man eine Sammlung von Datensätzen, die auch Trainingssets enthält?: Ein Reddit-Benutzer fragt, wie man im Gegensatz zu einem „Benchmark“, der zur Bewertung der Leistung eines Modells bei mehreren Aufgaben verwendet wird, eine Sammlung von Datensätzen nennt, die dazu dient, dasselbe Modell sowohl zu trainieren als auch zu bewerten. Diese Frage untersucht die Details der Datensatzklassifizierung und Terminologieverwendung im Bereich des maschinellen Lernens. (Quelle: Reddit r/MachineLearning)
Hilfe gesucht: Implementierung von Speech-to-Text in OpenWebUI: Ein Benutzer sucht nach der besten Lösung und empfohlenen Modellen zur Implementierung von Speech-to-Text (der Benutzer schrieb TTS, beschreibt aber die Transkription von YouTube-Videos/Audiodateien, was ASR/STT sein sollte) in einer Docker-basierten OpenWebUI+Ollama-Umgebung unter Verwendung einer H100 GPU. Dies spiegelt den Wunsch der Benutzer wider, mehr modale Verarbeitungsfähigkeiten in lokale LLM-Interaktionsschnittstellen zu integrieren. (Quelle: Reddit r/OpenWebUI)
Diskussion: Meinungen zum Claude-Jahresabonnement und den geänderten Beschränkungen: Ein Reddit-Benutzer ist froh, kein Claude-Jahresabonnement abgeschlossen zu haben, da sich viele Benutzer kürzlich über verschärfte Nutzungsbeschränkungen beschwert haben. Der Benutzer vermutet, dass Anthropic nach der Gewinnung vieler zahlender Kunden möglicherweise die Strategie anpasst, um Kosten zu sparen. Gleichzeitig erwähnt der Benutzer die starke Leistung des kostenlosen Gemini 2.5 Pro und äußert Bedenken und Hoffnungen bezüglich der zukünftigen Entwicklung von Claude. Die Diskussion spiegelt die Sensibilität der Benutzer für Preise, Nutzungsbeschränkungen und das Preis-Leistungs-Verhältnis von LLM-Diensten wider. (Quelle: Reddit r/ClaudeAI)
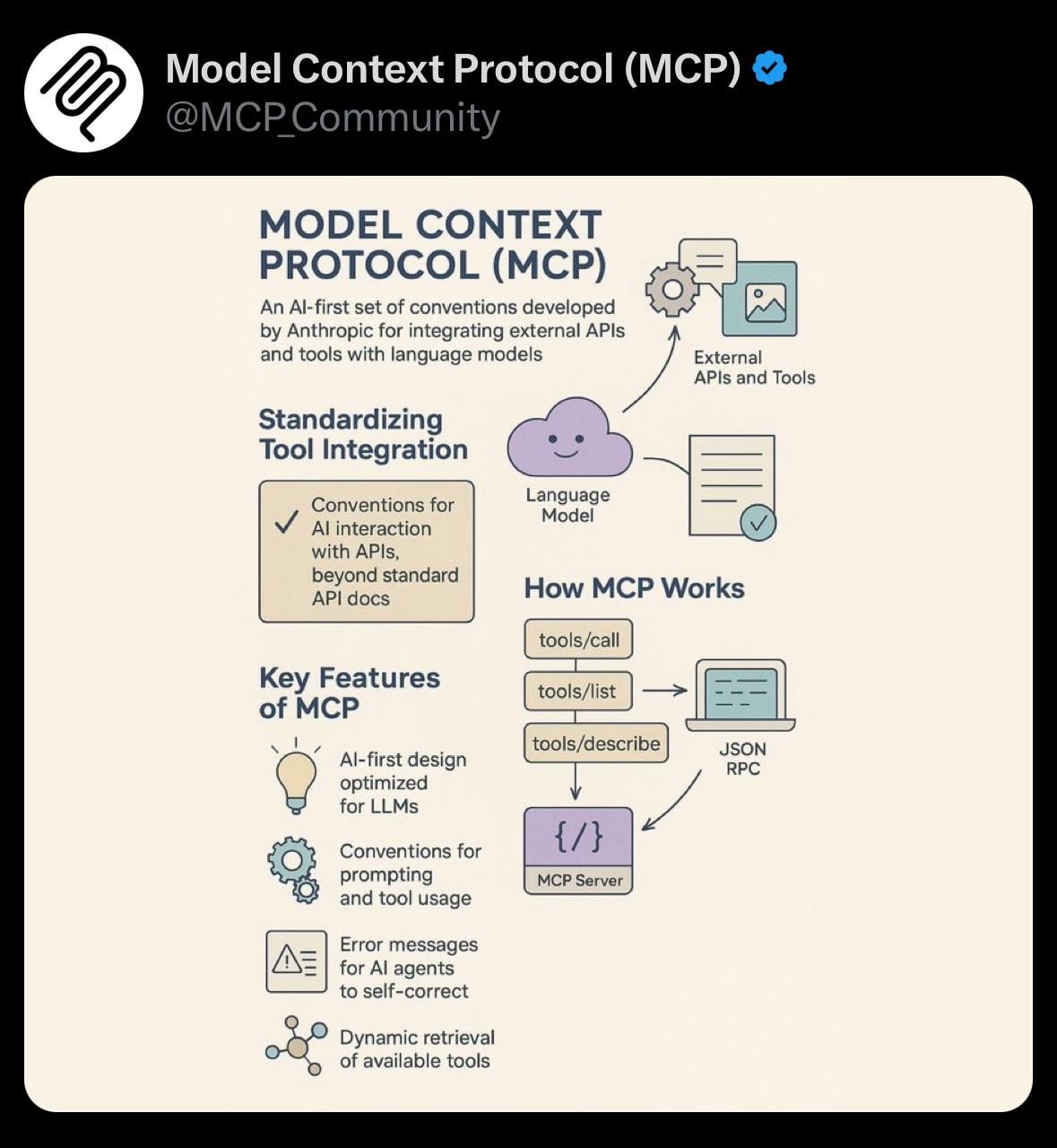
Teilen: Einfache Visualisierung des Model Context Protocol (MCP): Ein Benutzer teilt ein einfaches Visualisierungsbild zum Model Context Protocol (MCP). MCP ist möglicherweise ein technisches Konzept im Zusammenhang mit dem Anthropic Claude-Modell, das darauf abzielt, die Art und Weise zu optimieren oder zu verwalten, wie das Modell lange Kontexte verarbeitet. Dieses Teilen bietet der Community eine visuelle Hilfe zum Verständnis relevanter technischer Konzepte. (Quelle: Reddit r/ClaudeAI)
Hilfe gesucht: Hinzufügen benutzerdefinierter Befehle zum OpenWebUI-Chat: Ein Benutzer fragt nach dem technischen Aufwand, benutzerdefinierte Befehle (z. B. im @tag-Format mit Autovervollständigungsmenü) zur OpenWebUI-Chat-Oberfläche hinzuzufügen, um benutzerdefinierte RAG-Abfragen (z. B. Filtern nach Dokumenttyp) zu erleichtern. Der Benutzer erwägt auch Dropdown-Menüs als Alternative. Dies spiegelt den Wunsch der Benutzer wider, die Frontend-Interaktionsfähigkeiten zu erweitern, um Backend-KI-Funktionen flexibler zu steuern. (Quelle: Reddit r/OpenWebUI)
Diskussion: Generierung ästhetischer und funktionaler KI-QR-Codes: Ein Benutzer versuchte, mit ChatGPT/DALL-E QR-Codes zu generieren, die einen künstlerischen Stil integrieren und gescannt werden können, aber die Ergebnisse waren nicht zufriedenstellend. Es wird darauf hingewiesen, dass Methoden wie ControlNet effektiver sind. Dies löst eine Diskussion über die Grenzen aktueller Mainstream-Text-zu-Bild-Modelle bei der Generierung von Bildern aus, die präzise Strukturen und Funktionalität (wie Scanbarkeit) erfordern. (Quelle: Reddit r/ChatGPT)

Suche nach KI/ML-Lernpartnern: Ein Bachelorstudent im dritten Jahr (Informatik mit Schwerpunkt KI/ML) sucht 4-5 Gleichgesinnte, um gemeinsam KI/ML vertieft zu lernen, Projekte zu entwickeln und Datenstrukturen und Algorithmen (DSA/CP) zu üben. Der Initiator listet seinen Tech-Stack und seine Interessen auf und hofft, eine Gruppe zu gründen, die sich gegenseitig motiviert und kollaborativ lernt. (Quelle: Reddit r/deeplearning)
Diskussion: Werden KI-Agenten das Spam-Problem verschärfen?: Ein Reddit-Benutzer äußert die Sorge, dass der weit verbreitete Einsatz von KI-Agenten zur Automatisierung von Aufgaben (wie Lead-Generierung und Nachrichtenversand) zu einer Spam-Flut führen könnte. Wenn jeder ähnliche Tools verwendet, werden die Empfänger mit einer Masse personalisierter automatischer Nachrichten überschwemmt, was die Kommunikationseffizienz verringert und den Wert der Agenten-Tools zunichtemacht. Die Diskussion regt zum Nachdenken über die potenziellen negativen externen Effekte der skalierten Anwendung von KI-Tools an. (Quelle: Reddit r/ArtificialInteligence)
Diskussion: Qualitätsprobleme bei Suno AI in letzter Zeit: Ein Benutzer teilt ein mit Suno AI generiertes Musikstück und merkt an, dass er persönlich das Ergebnis trotz der jüngsten Diskussionen in der Community über eine nachlassende Ausgabequalität von Suno recht gut findet. Dies spiegelt die Wahrnehmung von Leistungsschwankungen bei KI-Generierungstools und die subjektiven Bewertungsunterschiede in der Community wider. (Quelle: Reddit r/SunoAI)

Diskussion: RTX 4090 vs. RTX 5090 für Deep Learning Training: Ein Benutzer fragt um Rat bei der Zusammenstellung einer Single-GPU-Workstation für persönliches Deep Learning (hauptsächlich nicht LLM), ob er die aktuelle RTX 4090 wählen oder auf die bald erscheinende RTX 5090 warten soll. Der Beitrag bittet die Community um Ratschläge zur Hardwareauswahl und fragt, wie man beim Kauf zwischen Gaming-Karten und professionellen Karten unterscheiden kann (obwohl dies Consumer-Karten sind). Spiegelt die Überlegungen von KI-Entwicklern bei der Hardwareauswahl wider. (Quelle: Reddit r/deeplearning)
Diskussion: Wird KI den Kapitalismus zerstören?: Ein Benutzer argumentiert, dass KI aufgrund des Strebens der Unternehmen nach Gewinnmaximierung letztendlich die meisten Arbeitsplätze ersetzen könnte. Im bestehenden kapitalistischen System würde dies zu Massenarbeitslosigkeit und dem Wegfall von Einkommensquellen führen. Der Benutzer schlägt ein universelles Grundeinkommen (UBI) vor, finanziert durch zusätzliche Steuern auf Unternehmen, die von KI profitieren, als möglicherweise notwendige Lösung. Die Diskussion berührt die tiefgreifenden Auswirkungen von KI auf zukünftige Wirtschaftsstrukturen und Gesellschaftsmodelle. (Quelle: Reddit r/ArtificialInteligence)
Hilfe gesucht: Reproduktion des Anthropic-Papers „Reasoning Models Don’t Always Say What They Think“: Ein Benutzer bittet die Community um Hilfe bei der Suche nach Prompts oder verwandten Erkenntnissen, die es ermöglichen, die Ergebnisse des Anthropic-Papers über „Reasoning-Modelle sagen nicht immer, was sie denken“ zu reproduzieren. Das Paper untersucht die mögliche Inkonsistenz zwischen den internen Reasoning-Prozessen großer Sprachmodelle und ihrer endgültigen Ausgabe. Dies zeigt das Interesse der Community-Mitglieder am Verständnis und der Überprüfung von Ergebnissen aus der Spitzenforschung im Bereich KI. (Quelle: Reddit r/MachineLearning)
Hilfe gesucht: RAG-Konfiguration und Erfahrungen in OpenWebUI: Ein Benutzer fragt nach Best Practices für die Verwendung von RAG (Retrieval-Augmented Generation) in OpenWebUI, einschließlich empfohlener Einstellungen, zu vermeidender Parameter und bevorzugter Embedding-Modelle. Der Benutzer stößt auch auf Probleme mit abnormalem Modellverhalten (z. B. gibt Mistral Small eine leere Liste aus) und fragt nach der Prioritätsbeziehung zwischen persönlichen Benutzereinstellungen und administrativen Modelleinstellungen. Dies spiegelt die Herausforderungen wider, denen Benutzer bei der tatsächlichen Bereitstellung und Optimierung von RAG-Anwendungen begegnen, und die Suche nach Erfahrungsaustausch. (Quelle: Reddit r/OpenWebUI)
Diskussion: Wird der Exodus von Claude-Nutzern den Service verbessern?: Ein Benutzer stellt die Hypothese auf, dass der jüngste Exodus einiger Claude-Nutzer („Genesis Exodus“) aufgrund von Beschränkungen und Leistungsproblemen umgekehrt Rechenressourcen freisetzen könnte, wodurch die Servicequalität (z. B. Leistung, Beschränkungen) wieder auf ein wünschenswerteres Niveau zurückkehren könnte. Der Benutzer drückt seine Vorliebe für Claude aus und hofft auf eine Verbesserung des Dienstes. Die Diskussion spiegelt die Beobachtungen und Überlegungen der Benutzer zu Angebot und Nachfrage bei KI-Diensten, Ressourcenallokation und dynamischen Änderungen der Servicequalität wider. (Quelle: Reddit r/ClaudeAI)

Diskussion: Wie definiert man „KI-Kunst“?: Ein Benutzer initiiert eine Diskussion und fragt die Community-Mitglieder, wie sie „KI-Kunst“ definieren, und stellt verwandte Fragen: Sind Personen, die KI-Tools (wie ChatGPT) zur Bilderzeugung verwenden, Schöpfer? Besitzen sie das Eigentum? Welche Rolle spielen LLM-Dienstanbieter bei der Erstellung, und sollten sie als Mitschöpfer betrachtet werden? Diese Diskussion zielt darauf ab, Kernkonzepte rund um KI-generierte Inhalte wie Urheberschaft und Copyright zu klären. (Quelle: Reddit r/ArtificialInteligence)
Diskussion: Bedroht KI-Musik die „Gemeinschaftlichkeit“ von Musik?: Ein Benutzer wirft die Frage auf, ob KI-Tools wie Suno, die mühelos hyperpersonalisierte Musik generieren können, die „Gemeinschaftlichkeit“ von Musik als geteiltes Erlebnis schwächen. Bedenken sind: Musik könnte zu einem personalisierten Spiegel statt zu einem Leuchtfeuer werden, das Gemeinschaften verbindet; kollektive Musikveranstaltungen wie Konzerte könnten beeinträchtigt werden; Benutzer könnten nur noch maßgeschneiderte Inhalte akzeptieren und ihre Offenheit für vielfältige oder herausfordernde Musik reduzieren. Die Diskussion konzentriert sich auf die potenziellen Auswirkungen von KI auf die Musikkultur und ihre sozialen Funktionen. (Quelle: Reddit r/SunoAI)
Frage: Wie genau ist Suno AI bei der Generierung von Hindi-Songs?: Ein Nicht-Hindi-Sprecher fragt nach der Genauigkeit und Natürlichkeit von Suno AI bei der Generierung von Gesang auf Hindi. Sucht nach Informationen über die Leistung des Tools in einer bestimmten nicht-englischen Sprache. (Quelle: Reddit r/SunoAI)
💡 Sonstiges
Suno AI Werk teilen: Nightingale’s Melody (Alternative/Indie Rock): Ein Benutzer teilt einen mit Suno AI erstellten Song im Alternative/Indie-Rock-Stil namens „Nightingale’s Melody“ und fügt einen YouTube-Link hinzu. (Quelle: Reddit r/SunoAI)

Suno AI Werk teilen: The Art of Abundance (Psytrance): Ein Benutzer teilt eine KI-generierte Musik, die energiereichen Psytrance mit spirituellen Techno-Elementen kombiniert. Die Texte wurden von ChatGPT erstellt, Musik und Gesang von Suno AI generiert, und die visuellen Effekte stammen von MidJourney und PhotoMosh Pro. Das Werk untersucht das Konzept des Überflusses im digitalen Zeitalter, jenseits des Materialismus, und berührt Kreativität, KI-Bewusstsein und menschliche Begierden. (Quelle: Reddit r/SunoAI)

Suno AI Werk teilen: Do your Job (Country-Musik): Ein Benutzer teilt einen mit Suno AI erstellten Song im Country-Stil. Der Text dreht sich um einen echten ungelösten Fall (das Verschwinden von Colton Ross Barrera) und drückt die Frustration der Familie und den Ruf nach Gerechtigkeit aus. (Quelle: Reddit r/SunoAI)

Suno AI Werk teilen: Toxic Friends (Electro Pop): Ein Benutzer teilt sein Electro-Pop-Werk „Toxic Friends“, das er für den Suno AI April-Wettbewerb eingereicht hat. (Quelle: Reddit r/SunoAI)

Suno AI Werk teilen: Starlight Visitor (80er Pop Cover): Ein Benutzer teilt eine mit Suno AI erstellte Coverversion eines bestehenden Songs im 80er-Jahre-Pop-Stil und stellt einen YouTube-Link zur Verfügung. (Quelle: Reddit r/SunoAI)

ChatGPT Kreative Anwendung: Eierprodukt-Meme-Erweiterung: Inspiriert von einem Meme über Eier, verwendete ein Benutzer ChatGPT, um eine Reihe humorvoller, konzeptioneller Bilder und Beschreibungen von eierbezogenen Produkten zu generieren, wie „Precracked Life“, „Internet of Eggs“ usw. Zeigt die Möglichkeit, KI für kreative Ideenfindung und humorvolle Inhaltserstellung zu nutzen. (Quelle: Reddit r/ChatGPT)
Suno AI Werk teilen: Tom and Jerry / Crambone (Blues Rock Cover): Ein Benutzer teilt eine mit Suno AI erstellte Coverversion im Blues-Rock-Stil des Songs „Tom and Jerry / Crambone“ und stellt einen YouTube-Link zur Verfügung. (Quelle: Reddit r/SunoAI)

KI-generierte Bilder: Die sieben Todsünden visualisiert: Ein Benutzer teilt ein Video, das mit KI (möglicherweise ChatGPT/DALL-E) generierte, visualisierte und personifizierte Bilder der sieben Todsünden (wie Gier, Faulheit, Neid usw.) zeigt. (Quelle: Reddit r/ChatGPT)
