
Schlüsselwörter:GPT-4.5, Großes Sprachmodell, Huawei PanGu Ultra Leistung, GPT-4.5 Trainingsdetails, Einfluss von RLHF auf Reasoning-Fähigkeiten, 4GB Obergrenze der menschlichen Lernfähigkeit Forschung, Open-Source Mathematik-Datensatz MegaMath
🔥 Fokus
OpenAI enthüllt Details und Herausforderungen beim Training von GPT-4.5: OpenAI CEO Sam Altman und das Kernteam von GPT-4.5 sprachen über die Entwicklungsdetails des Modells. Das Projekt startete vor zwei Jahren, beanspruchte fast das gesamte Personal und dauerte länger als erwartet. Während des Trainings traten „katastrophale Probleme“ wie Ausfälle eines 100.000-GPU-Clusters und versteckte Bugs auf, die Engpässe in der Infrastruktur offenbarten, aber auch zu einem Upgrade des Technologie-Stacks führten. Heute können GPT-4-Level-Modelle von nur 5-10 Personen repliziert werden. Das Team ist der Ansicht, dass der Schlüssel zur zukünftigen Leistungssteigerung eher in der Daten-Effizienz als in der Rechenleistung liegt und neue Algorithmen entwickelt werden müssen, um mehr aus der gleichen Datenmenge zu lernen. Die Systemarchitektur bewegt sich in Richtung Multi-Cluster, was zukünftig die Koordination von möglicherweise zehn Millionen GPUs erfordern und höhere Anforderungen an die Fehlertoleranz stellen könnte. Das Gespräch berührte auch Themen wie Scaling Law, das Zusammenspiel von Machine Learning und Systemdesign sowie die Natur des unüberwachten Lernens und zeigte die Überlegungen und Praktiken von OpenAI bei der Weiterentwicklung von Spitzen-Large-Models (Quelle: 36氪)

Huawei veröffentlicht Ascend-natives 135B Dense Large Model Pangu Ultra: Das Huawei Pangu Team hat das auf heimischen Ascend NPUs trainierte 135B-Parameter Dense General Language Large Model Pangu Ultra veröffentlicht. Das Modell verwendet eine 94-Layer Transformer-Struktur und führt Depth-scaled sandwich-norm (DSSN) sowie TinyInit Initialisierungstechniken ein, um Stabilitätsprobleme beim Training von ultra-tiefen Modellen zu lösen. Es erreichte ein stabiles Training ohne Loss Spikes auf 13,2T hochwertigen Daten. Auf Systemebene wurde durch Optimierungen wie hybrides Parallel Computing, Operator Fusion und Sub-Sequence Splitting die Rechenleistungsauslastung (MFU) auf einem 8.192-Karten Ascend Cluster auf über 50% gesteigert. Evaluierungen zeigen, dass Pangu Ultra mehrere Benchmarks übertrifft, darunter Dense Models wie Llama 405B und Mistral Large 2, und mit größeren MoE-Modellen wie DeepSeek-R1 konkurrieren kann, was die Machbarkeit der Entwicklung von Spitzen-Large-Models auf Basis heimischer Rechenleistung beweist (Quelle: 机器之心)

Studie stellt Signifikanz von Reinforcement Learning für die Verbesserung der LLM-Inferenzfähigkeit in Frage: Forscher der Universitäten Tübingen und Cambridge stellen jüngste Behauptungen in Frage, dass Reinforcement Learning (RL) die Inferenzfähigkeit von Sprachmodellen signifikant verbessern kann. Durch eine strenge Untersuchung gängiger Inferenz-Benchmarks (wie AIME24) stellten die Forscher fest, dass die Ergebnisse sehr instabil sind und allein die Änderung des Random Seeds zu erheblichen Schwankungen der Punktzahlen führen kann. Unter standardisierter Bewertung ist die durch RL erzielte Leistungssteigerung weitaus geringer als ursprünglich berichtet, oft statistisch nicht signifikant und sogar schwächer als die Effekte von Supervised Fine-Tuning (SFT), wobei auch die Generalisierungsfähigkeit schlechter ist. Die Studie weist darauf hin, dass Sampling-Unterschiede, Dekodierungskonfigurationen, Bewertungsframeworks und Hardware-Heterogenität die Hauptgründe für die Instabilität sind, und fordert strengere, reproduzierbare Bewertungsstandards, um den tatsächlichen Fortschritt der Modellinferenzfähigkeit nüchtern zu betrachten und zu messen (Quelle: 机器之心)

Altman auf TED-Talk: Wird leistungsstarkes Open-Source-Modell veröffentlichen, hält ChatGPT nicht für AGI: OpenAI CEO Altman kündigte auf der TED-Konferenz an, ein leistungsstarkes Open-Source-Modell zu entwickeln, das alle bestehenden Open-Source-Modelle übertreffen wird, als direkte Antwort auf Konkurrenten wie DeepSeek. Er betonte das anhaltend rasante Wachstum der ChatGPT-Nutzerzahlen und dass die neue Memory-Funktion das personalisierte Erlebnis verbessern wird. Er glaubt, dass KI Durchbrüche in der wissenschaftlichen Entdeckung und Softwareentwicklung (enorme Effizienzsteigerung) bringen wird, aber aktuelle Modelle wie ChatGPT besitzen noch nicht die Fähigkeit zum selbstständigen kontinuierlichen Lernen und zur domänenübergreifenden Generalisierung und sind daher keine AGI. Er diskutierte auch Urheberrechts- und „Stilrecht“-Fragen, die durch die kreativen Fähigkeiten von GPT-4o aufgeworfen werden, und bekräftigte das Vertrauen von OpenAI in die Modellsicherheit und seine Risikokontrollmechanismen (Quelle: 新智元)

Studie schätzt menschliche Lernkapazität auf ca. 4 GB, löst Debatte über Brain-Computer Interfaces und KI-Entwicklung aus: Eine im Cell-Journal Neuron veröffentlichte Studie des Caltech schätzt die Informationsverarbeitungsgeschwindigkeit des menschlichen Gehirns auf etwa 10 Bit pro Sekunde, weit unter der Datenerfassungsrate des sensorischen Systems von 1 Milliarde Bit pro Sekunde. Basierend darauf schlussfolgert die Studie, dass die Obergrenze der Wissensakkumulation eines Menschen über ein ganzes Leben (angenommen 100 Jahre ununterbrochenes Lernen ohne Vergessen) bei etwa 4 GB liegt, weit weniger als die Speicherkapazität von Large Models (z.B. kann ein 7B-Modell 14 Milliarden Bit speichern). Die Studie führt diesen Engpass auf den seriellen Verarbeitungsmechanismus des Zentralnervensystems zurück und prognostiziert, dass es nur eine Frage der Zeit ist, bis maschinelle Intelligenz die menschliche übertrifft. Die Studie stellt auch Musks Neuralink in Frage und argumentiert, dass es die grundlegenden strukturellen Beschränkungen des Gehirns nicht überwinden kann und es besser wäre, bestehende Kommunikationsmethoden zu optimieren. Diese Forschung löste eine breite Diskussion über die Grenzen menschlicher Kognition, das Potenzial der KI-Entwicklung und die Richtung von Brain-Computer Interfaces aus (Quelle: 量子位)

🎯 Trends
GPT-4 wird bald eingestellt, GPT-4.1 und mysteriöses neues Modell könnten erscheinen: OpenAI kündigte an, GPT-4, das vor zwei Jahren veröffentlicht wurde, ab dem 30. April in ChatGPT vollständig durch GPT-4o zu ersetzen. GPT-4 wird weiterhin über die API verfügbar sein. Gleichzeitig deuten Community-Informationen und Code-Leaks darauf hin, dass OpenAI möglicherweise bald eine Reihe neuer Modelle veröffentlichen wird, darunter GPT-4.1 (und seine Mini/Nano-Versionen), eine voll funktionsfähige o3-Inferenzversion sowie eine neue o4-Serie (wie o4-mini). Ein mysteriöses Modell namens Optimus Alpha ist bereits auf OpenRouter verfügbar, zeigt hervorragende Leistung (insbesondere beim Programmieren), unterstützt Millionen von Kontext-Token und wird weithin als eines der bevorstehenden neuen Modelle von OpenAI vermutet (möglicherweise GPT-4.1 oder o4-mini). Es weist viele Ähnlichkeiten mit OpenAI-Modellen auf (z.B. spezifische Bugs). Dies deutet darauf hin, dass OpenAI die Modelliteration beschleunigt und seine technologische Führungsposition aktiv festigt (Quellen: source, source)

Alibaba Qwen3 Large Model steht in den Startlöchern: Berichten zufolge plant Alibaba, in naher Zukunft das Qwen3 Large Model zu veröffentlichen. Das Entwicklungsteam bestätigte, dass sich das Modell in der letzten Vorbereitungsphase befindet, ein konkretes Veröffentlichungsdatum steht jedoch noch nicht fest. Qwen3 soll ein wichtiges Modellprodukt von Alibaba für die erste Hälfte des Jahres 2025 sein, dessen Entwicklung nach Qwen2.5 begann. Beeinflusst durch Konkurrenzmodelle wie DeepSeek-R1 hat das Alibaba Cloud Foundation Model Team seinen strategischen Fokus weiter auf die Verbesserung der Inferenzfähigkeiten des Modells verlagert, was die strategische Fokussierung auf spezifische Fähigkeiten im Wettbewerbsumfeld der Large Models zeigt (Quelle: InfoQ)

Kimi Open Platform senkt Preise und veröffentlicht leichtgewichtige visuelle Modelle als Open Source: Die Kimi Open Platform von Moonshot AI kündigte Preissenkungen für ihre Model Inference Services und Context Caching an, um die Kosten für Nutzer durch technische Optimierungen zu senken. Gleichzeitig hat Kimi zwei leichtgewichtige visuelle Sprachmodelle auf Basis der MoE-Architektur, Kimi-VL und Kimi-VL-Thinking, als Open Source veröffentlicht. Sie unterstützen 128K Kontext und haben nur etwa 3 Milliarden aktivierte Parameter. Angeblich übertreffen sie Large Models mit 10-facher Parameterzahl in multimodalen Inferenzfähigkeiten deutlich und sollen die Entwicklung und Anwendung kleiner, effizienter multimodaler Modelle fördern (Quelle: InfoQ)
Google veröffentlicht Agent Interoperability Protocol A2A und mehrere neue KI-Produkte: Auf der Google Cloud Next ’25 Konferenz stellte Google zusammen mit über 50 Partnern das offene Protokoll Agent2Agent (A2A) vor, das die Interoperabilität und Zusammenarbeit von KI-Agenten ermöglichen soll, die von verschiedenen Unternehmen und Plattformen entwickelt wurden. Gleichzeitig wurden mehrere KI-Modelle und Anwendungen veröffentlicht, darunter Gemini 2.5 Flash (hocheffiziente Version des Flaggschiff-Modells), Lyria (Text-zu-Musik), Veo 2 (Videoerstellung), Imagen 3 (Bilderzeugung), Chirp 3 (benutzerdefinierte Sprache), sowie der TPU-Chip der siebten Generation, Ironwood, der speziell für Inferenz optimiert ist. Diese Reihe von Veröffentlichungen spiegelt Googles umfassende Strategie und Offenheit in den Bereichen KI-Infrastruktur, Modelle, Plattformen und Agenten wider (Quelle: InfoQ)
ByteDance veröffentlicht 200B-Parameter Inferenzmodell Seed-Thinking-v1.5: Das Doubao-Team von ByteDance veröffentlichte einen technischen Bericht über sein MoE-Inferenzmodell Seed-Thinking-v1.5 mit insgesamt 200B Parametern. Das Modell aktiviert bei jeder Inferenz 20B Parameter und zeigt in mehreren Benchmarks hervorragende Leistungen, wobei es angeblich DeepSeek-R1 mit 671B Gesamtparametern übertrifft. In der Community wird vermutet, dass dies das Modell sein könnte, das derzeit im „Deep Thinking“-Modus der ByteDance Doubao App verwendet wird, was die Fortschritte von ByteDance bei der Entwicklung effizienter Inferenzmodelle zeigt (Quelle: InfoQ)
Midjourney veröffentlicht V7-Modell, verbessert Bildqualität und Generierungseffizienz: Das KI-Bilderzeugungstool Midjourney hat sein neues Modell V7 (Alpha-Version) veröffentlicht. Die neue Version verbessert die Kohärenz und Konsistenz der Bildgenerierung, insbesondere bei Händen, Körperteilen und Objektdetails, und kann realistischere und reichhaltigere Texturen erzeugen. V7 führt den Draft Mode ein, der eine zehnfache Rendergeschwindigkeit zum halben Preis ermöglicht und sich für schnelle iterative Exploration eignet. Gleichzeitig werden die Generierungsmodi Turbo (schneller, aber teurer) und Relax (langsamer, aber günstiger) angeboten, um unterschiedlichen Nutzerbedürfnissen gerecht zu werden (Quelle: InfoQ)
Amazon stellt KI-Sprachmodell Nova Sonic vor: Amazon hat Nova Sonic vorgestellt, ein neues Generationen-KI-Modell, das Sprache nativ verarbeitet. Angeblich kann das Modell in Schlüsselmetriken wie Geschwindigkeit, Spracherkennung und Dialogqualität mit den Spitzen-Sprachmodellen von OpenAI und Google mithalten. Nova Sonic wird über die Amazon Bedrock Entwicklerplattform angeboten, verwendet eine neue bidirektionale Streaming-API und ist etwa 80% günstiger als GPT-4o. Ziel ist es, hochleistungsfähige, kostengünstige natürliche Sprachinteraktionsfähigkeiten für Unternehmens-KI-Anwendungen bereitzustellen (Quelle: InfoQ)
Apple iPhone AI-Funktionen für China könnten Mitte des Jahres starten, integrieren Baidu- und Alibaba-Technologie: Berichten zufolge plant Apple, bis Mitte 2025 Apple Intelligence-Dienste für iPhones auf dem chinesischen Markt (möglicherweise in iOS 18.5) einzuführen. Die Funktion wird das Baidu Ernie Large Model für intelligente Fähigkeiten nutzen und die Zensur-Engine von Alibaba integrieren, um den Anforderungen an die Inhaltsregulierung zu entsprechen. Apple hat weder mit Baidu noch mit Alibaba Exklusivverträge unterzeichnet, was zeigt, dass das Unternehmen in Schlüsselmärkten auf lokale Kooperationsstrategien setzt, um KI-Funktionen schnell bereitzustellen (Quelle: InfoQ)
🧰 Tools
Volcano Engine veröffentlicht Enterprise Data Agent: Volcano Engine hat den Enterprise Data Agent vorgestellt, einen Daten-Agenten für Unternehmen. Das Tool nutzt die Inferenz-, Analyse- und Tool-Nutzungsfähigkeiten von Large Models, um Geschäftsanforderungen von Unternehmen tiefgehend zu verstehen und komplexe Datenanalyse- und Anwendungsaufgaben wie das Verfassen von Tiefenanalysen oder das Entwerfen von Marketingkampagnen zu automatisieren, wodurch die Effizienz der Datennutzung und die Entscheidungsfindung in Unternehmen verbessert werden sollen (Quelle: InfoQ)
Neuer Stil der GPT-4o Bilderzeugung findet Beachtung: Social-Media-Nutzer präsentieren neue Stile, die mit der Bilderzeugungsfunktion von GPT-4o erstellt wurden, z. B. die Kombination von Retro-Interface-Elementen von Windows 2000 mit Charakterbildern, um einzigartige Collage-Effekte zu erzielen. Nutzer teilen Prompt-Techniken, wie die Verwendung von Referenzbildern zur Orientierung und die Kombination von Stil- und Inhaltsbeschreibungen, was das Interesse der Community an der Erkundung des kreativen Potenzials von GPT-4o weckt (Quellen: source, source)

📚 Lernen
Größter Open-Source Mathematik-Pretraining-Datensatz MegaMath veröffentlicht: LLM360 hat MegaMath veröffentlicht, einen Open-Source-Pretraining-Datensatz für mathematisches Reasoning mit 371 Milliarden Tokens, der den DeepSeek-Math Corpus an Umfang übertrifft. Der Datensatz umfasst mathematikintensive Webseiten (279B), mathematikbezogenen Code (28B) und hochwertige synthetische Daten (64B). Durch einen verfeinerten Datenverarbeitungsprozess, einschließlich HTML-Strukturoptimierung, zweistufiger Extraktion, LLM-unterstützter Filterung und Verfeinerung, stellte das Team Umfang, Qualität und Vielfalt der Daten sicher. Validierungen durch Pretraining auf dem Llama-3.2-Modell zeigen, dass die Verwendung von MegaMath absolute Verbesserungen von 15-20% bei Benchmarks wie GSM8K und MATH bringen kann, was der Open-Source-Community eine starke Grundlage für das Training mathematischer Reasoning-Fähigkeiten bietet (Quelle: 机器之心)

Nabla-GFlowNet: Balance zwischen Diversität und Effizienz beim Fine-Tuning von Diffusionsmodellen: Forscher der CUHK (Shenzhen) und anderer Institutionen schlagen Nabla-GFlowNet vor, eine neue Methode für das Reward-Fine-Tuning von Diffusionsmodellen basierend auf Generative Flow Networks (GFlowNet). Die Methode zielt darauf ab, die Probleme der langsamen Konvergenz beim traditionellen Reinforcement Learning Fine-Tuning und der Tendenz zur Überanpassung und zum Verlust der Diversität bei direkter Reward-Optimierung zu lösen. Durch die Ableitung einer neuen Flow-Balance-Bedingung (Nabla-DB) und die Entwicklung spezifischer Verlustfunktionen sowie einer Log-Flow-Gradienten-Parametrisierung kann Nabla-GFlowNet das Modell effizient an Reward-Funktionen (wie ästhetische Bewertung, Befehlsbefolgung) anpassen, während die Diversität der generierten Samples erhalten bleibt. Experimente mit Stable Diffusion belegen die Überlegenheit gegenüber Methoden wie DDPO, ReFL und DRaFT (Quelle: 机器之心)
Llama.cpp behebt Probleme im Zusammenhang mit Llama 4: Das llama.cpp-Projekt hat zwei Fixes für Llama 4-Modelle zusammengeführt, die RoPE (Rotary Position Embedding) und fehlerhafte Norm-Berechnungen betreffen. Diese Korrekturen sollen die Qualität der Modellausgabe verbessern, aber Benutzer müssen möglicherweise GGUF-Modelldateien, die mit den korrigierten Konvertierungstools erstellt wurden, erneut herunterladen, damit die Änderungen wirksam werden (Quelle: source)
💼 Wirtschaft
Nvidia schließt Übernahme von Lepton AI ab: Berichten zufolge hat Nvidia das von Ex-Alibaba VP Jia Yangqing gegründete KI-Infrastruktur-Startup Lepton AI übernommen. Der Transaktionswert könnte mehrere hundert Millionen Dollar betragen. Das Hauptgeschäft von Lepton AI ist die Vermietung von Nvidia GPU-Servern und die Bereitstellung von Software, die Unternehmen beim Aufbau und Management von KI-Anwendungen unterstützt. Jia Yangqing und sein Mitgründer Bai Junjie sowie etwa 20 weitere Mitarbeiter sind zu Nvidia gewechselt. Dieser Schritt wird als strategischer Schachzug von Nvidia gewertet, um sein Cloud-Service- und Unternehmenssoftware-Geschäft auszubauen und der Konkurrenz durch selbstentwickelte Chips von AWS, Google Cloud etc. zu begegnen (Quelle: InfoQ)
US-Tech-Branche von Angst erfasst, KI trifft Arbeitsmarkt: Berichte deuten darauf hin, dass die US-Technologiebranche mit Stellenabbau, sinkenden Gehältern und längeren Jobsuche-Zyklen zu kämpfen hat. Massenentlassungen und der Einsatz von KI durch Unternehmen (wie Salesforce, Meta, Google) zur Ersetzung von Arbeitskräften oder Einstellungsstopps (insbesondere im Engineering und bei Einstiegspositionen) verschärfen die berufliche Angst der Beschäftigten. Daten zeigen einen Anstieg des Anteils derjenigen, die Gehaltsrückgänge melden und von Führungspositionen zu Einzelbeitragenden wechseln. KI gestaltet den Arbeitsmarkt neu und zwingt Arbeitssuchende, ihren Horizont auf nicht-technologische Branchen zu erweitern oder sich dem Unternehmertum zuzuwenden. Experten raten, Jobmöglichkeiten außerhalb der „Magnificent Seven“ zu suchen und KI-Tools zu beherrschen, um die Wettbewerbsfähigkeit zu steigern (Quelle: InfoQ)

Gerücht: OpenAI erwägt Übernahme des KI-Hardware-Unternehmens von Altman und Jony Ive: Berichten zufolge diskutiert OpenAI die Übernahme von io Products, einem von CEO Altman und dem ehemaligen Apple-Designchef Jony Ive gegründeten KI-Unternehmen, für nicht weniger als 500 Millionen US-Dollar. Das Unternehmen zielt darauf ab, KI-gesteuerte persönliche Geräte zu entwickeln, möglicherweise in Form eines bildschirmlosen „Telefons“ oder eines Heimgeräts. Das Ingenieurteam von io Products baut die Geräte, OpenAI liefert die Technologie, Ives Studio ist für das Design verantwortlich und Altman ist stark involviert. Bei einer Übernahme würde das Hardware-Team in OpenAI integriert, was dessen Vorstoß in den KI-Hardware-Bereich beschleunigen würde (Quelle: InfoQ)
Startup der ehemaligen OpenAI CTO wirbt erneut Schlüsselpersonal vom alten Arbeitgeber ab: Das von der ehemaligen OpenAI CTO Mira Murati gegründete KI-Unternehmen „Mind Machines Lab“ hat zwei ehemalige Schlüsselfiguren von OpenAI als Berater gewonnen: den ehemaligen Chief Research Officer Bob McGrew und den ehemaligen Forscher Alec Radford. Radford war Hauptautor wichtiger technischer Papiere zur GPT-Serie. Diese Anwerbung stärkt die technische Kompetenz des Startups weiter und spiegelt den intensiven Wettbewerb um Talente im KI-Bereich wider (Quelle: InfoQ)
Baichuan Intelligence passt Geschäftsschwerpunkt an, fokussiert auf Medizinbereich: Baichuan Intelligence Gründer Wang Xiaochuan bekräftigte in einem Brief an alle Mitarbeiter anlässlich des zweijährigen Bestehens des Unternehmens, dass sich das Unternehmen auf den Medizinbereich konzentrieren und Anwendungsdienste wie Baixiaoying, KI-Pädiatrie, KI-Allgemeinmedizin und Präzisionsmedizin entwickeln wird. Er betonte die Notwendigkeit, überflüssige Aktivitäten zu reduzieren und die Organisationsstruktur flacher zu gestalten. Zuvor wurde berichtet, dass die B2B-Gruppe des Unternehmens für den Finanzsektor aufgelöst wurde, der Geschäftspartner Deng Jiang das Unternehmen verlassen hat und mehrere Mitgründer ebenfalls gegangen sind oder kurz davor stehen, was auf eine strategische Neuausrichtung und organisatorische Anpassung des Unternehmens hindeutet (Quelle: InfoQ)
Alibaba Cloud startet KI-Ökosystempartnerprogramm „Fan Hua“: Alibaba Cloud hat das „Fan Hua“ (Blühen) Programm zur Unterstützung von KI-Ökosystempartnern gestartet. Das Programm wird je nach Produktreife der Partner Cloud-Ressourcen, Rechenleistungsunterstützung, Produktbündelung, Kommerzialisierungsplanung und Dienstleistungen über den gesamten Lebenszyklus hinweg anbieten. Gleichzeitig führt Alibaba Cloud einen Marktplatz für KI-Anwendungen und -Dienste ein, mit dem Ziel, ein florierendes KI-Ökosystem aufzubauen und die Implementierung von KI-Technologien und -Anwendungen zu beschleunigen (Quelle: InfoQ)
Kugou Music und DeepSeek gehen tiefgreifende Kooperation ein: Kugou Music kündigte eine Zusammenarbeit mit dem KI-Unternehmen DeepSeek an, um eine Reihe innovativer KI-Funktionen einzuführen. Dazu gehören die Generierung personalisierter Hörberichte mittels multimodaler Analyse, tägliche KI-Empfehlungen, intelligente Suche, KI-Playlist-Management, KI-generierte dynamische Cover sowie „KI-Rezensenten“ mit festgelegten Rollen. Ziel ist es, das Musikerlebnis der Nutzer und die Community-Interaktion durch KI-Technologie zu verbessern (Quelle: InfoQ)
Gerücht: Google setzt „aggressive“ Wettbewerbsverbote ein, um KI-Talente zu halten: Berichten zufolge setzt Google DeepMind bei einigen britischen Mitarbeitern einjährige Wettbewerbsverbote durch, um den Wechsel von Talenten zur Konkurrenz zu verhindern. Während dieser Zeit müssen die Mitarbeiter nicht arbeiten, erhalten aber weiterhin ihr Gehalt (bezahlter Urlaub). Dies führt jedoch dazu, dass sich einige Forscher an den Rand gedrängt fühlen und nicht am schnelllebigen Fortschritt der Branche teilhaben können. Diese Praxis wäre in den USA möglicherweise durch die FTC verboten, ist aber am Hauptsitz in London anwendbar und löst Diskussionen über Talentwettbewerb und Innovationsbeschränkungen aus (Quelle: InfoQ)
Ehemalige OpenAI-Mitarbeiter reichen Rechtsdokumente zur Unterstützung von Musks Klage ein: 12 ehemalige OpenAI-Mitarbeiter haben Rechtsdokumente eingereicht, die die Klage von Elon Musk gegen OpenAI unterstützen. Sie argumentieren, dass der Umstrukturierungsplan von OpenAI (Übergang zu einer gewinnorientierten Struktur) grundlegend gegen die ursprüngliche gemeinnützige Mission des Unternehmens verstoßen könnte, die ein Schlüsselfaktor für ihren Beitritt war. OpenAI entgegnete, dass sich seine Mission auch bei einer Strukturänderung nicht ändern werde (Quelle: InfoQ)
🌟 Community
Anthropic-Studie enthüllt Anwendungsmuster und Herausforderungen von KI in der Hochschulbildung: Anthropic analysierte Millionen anonymisierter Studentengespräche auf der Claude.ai-Plattform und stellte fest, dass Studierende der MINT-Fächer (insbesondere Informatik) frühe Anwender von KI sind. Die Interaktionsmuster der Studierenden mit KI umfassen vier Typen mit etwa gleichem Anteil: direkte Problemlösung, direkte Inhaltsgenerierung, kollaborative Problemlösung und kollaborative Inhaltsgenerierung. KI wird hauptsächlich für höherwertige kognitive Aufgaben wie Kreation (z.B. Programmieren, Schreiben von Übungsaufgaben) und Analyse (z.B. Erklärung von Konzepten) eingesetzt. Die Studie deckt auch potenzielles akademisches Fehlverhalten auf (z.B. Beschaffung von Antworten, Umgehung von Plagiatserkennung) und gibt Anlass zur Sorge hinsichtlich akademischer Integrität, Förderung kritischen Denkens und Bewertungsmethoden (Quelle: 新智元)

GPT-4o Bilderzeugung setzt neue Trends: Von Ghibli-Stil bis zu KI-Promi-Sammelkarten: Die leistungsstarke Bilderzeugungsfähigkeit von GPT-4o löst weiterhin einen kreativen Boom in den sozialen Medien aus. Nach dem viralen Erfolg von „Ghibli-Stil Familienporträts“ (angestoßen vom ehemaligen Amazon-Ingenieur Grant Slatton) erstellen Nutzer nun Sammelkarten im Stil von „Magic: The Gathering“ für KI-Persönlichkeiten (z.B. wird Altman als „AGI Overlord“ dargestellt) sowie personalisierte Tarotkarten. Diese Beispiele zeigen das Potenzial von KI bei der Nachahmung von Kunststilen und der kreativen Generierung, werfen aber auch Fragen zu Originalität, Urheberrecht, ästhetischem Wert und den Auswirkungen von KI auf den Beruf des Designers auf (Quelle: 新智元)

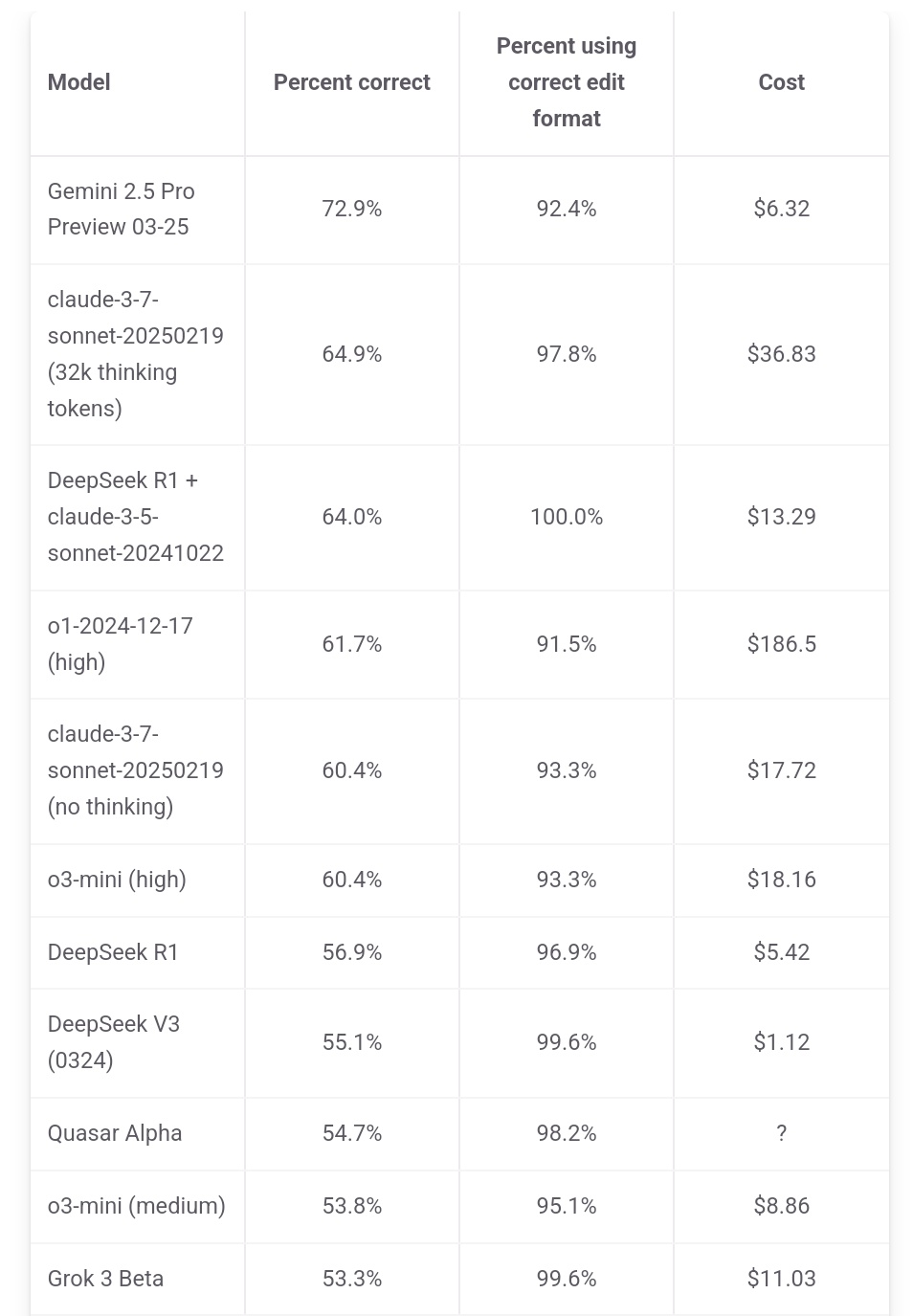
Jeff Dean betont Kostenvorteil von Gemini 2.5 Pro: Google AI-Chef Jeff Dean teilte die Ranglistendaten von aider.chat und wies darauf hin, dass Gemini 2.5 Pro im Polyglot-Programmierbenchmark nicht nur führend in der Leistung ist, sondern auch bei den Kosten (6 US-Dollar) deutlich günstiger als andere Top-10-Modelle (außer DeepSeek) ist, was dessen Preis-Leistungs-Verhältnis unterstreicht. Einige Konkurrenzmodelle kosten das Doppelte, Dreifache oder sogar 30-fache von Gemini 2.5 Pro (Quelle: JeffDean)
Reddit diskutiert heftig über Auswirkungen von KI auf den Arbeitsmarkt, insbesondere auf Einstiegspositionen: Ein Reddit-Beitrag löste eine hitzige Debatte aus. Der Verfasser (ein CIS-Masterstudent) äußerte tiefe Besorgnis darüber, dass KI Einstiegsjobs im nicht-manuellen Bereich (insbesondere Softwareentwicklung, Datenanalyse, IT-Support) ersetzen könnte, und argumentierte, dass die Aussage „KI wird keine Jobs wegnehmen“ die Notlage von Hochschulabsolventen ignoriere. Er wies darauf hin, dass große Unternehmen bereits das Campus-Recruiting reduzieren und der zukünftige Arbeitsmarkt düster aussehen könnte. Im Kommentarbereich gab es geteilte Meinungen: Einige stimmten der Krise zu, andere sahen darin den normalen Wandel durch Technologie und die Notwendigkeit, sich an neue Rollen anzupassen (z.B. Management von KI-Teams), wieder andere stellten die Aussage „90% der Jobs verschwinden“ in Frage und argumentierten, dass Konjunkturzyklen und Länderunterschiede groß seien und die Fähigkeiten der KI derzeit noch begrenzt seien (Quelle: source)
Claude-Nutzer beschweren sich über Leistungseinbußen und verschärfte Einschränkungen: Im Reddit-Subreddit r/ClaudeAI gab es eine konzentrierte Diskussion, in der mehrere Nutzer (einschließlich Pro-Nutzer) berichteten, dass sie kürzlich auf strengere Nutzungsbeschränkungen (Quota) gestoßen sind und selbst bei normalen Operationen häufig das Limit erreichen. Einige Nutzer vermuten, dass Anthropic die Quoten heimlich verschärft, und äußerten ihren Unmut darüber, da dies Nutzer zu Konkurrenzprodukten treiben könnte. Darüber hinaus berichteten einige Nutzer, dass sich die „Persönlichkeit“ von Claude verändert zu haben scheint, sie sei „kälter“ und „mechanischer“ geworden und habe den philosophischen und poetischen Touch früherer Versionen verloren, was einige Nutzer zur Kündigung ihres Abonnements veranlasste (Quellen: source, source, source, source)
ChatGPT Bilderzeugung sorgt für Spaß und Diskussionen: Reddit-Nutzer teilen verschiedene Versuche und Ergebnisse bei der Verwendung von ChatGPT zur Bilderzeugung. Jemand bat darum, einen Hund in einen Menschen zu „verwandeln“, was zu Bildern führte, die „Werwölfen/Furries“ ähnelten und eine Diskussion über Prompt-Verständnis und potenzielle Biases auslöste. Ein anderer Nutzer bat darum, sich selbst als Buntglasfenster-Version aus einem Multiversum zu malen, mit beeindruckendem Ergebnis. Wieder andere Nutzer baten um die Generierung metaphorischer Bilder über KI oder fragten nach den „Alpträumen“ der KI, was die Fähigkeiten und Grenzen der KI-Bilderzeugung im kreativen Ausdruck und der Visualisierung abstrakter Konzepte zeigt (Quellen: source, source, source, source, source)

Community diskutiert LLM-Modellauswahl und Nutzungsstrategien: Im Reddit-Subreddit r/LocalLLaMA schlug ein Nutzer vor, monatlich eine Diskussion über die Modellnutzung zu führen, um die besten Modelle (Open Source und Closed Source) für verschiedene Szenarien (Codierung, Schreiben, Forschung usw.) und die Gründe dafür zu teilen. Im Kommentarbereich teilten Nutzer ihre aktuell verwendeten Modellkombinationen, wie Deepseek V3.1/Gemini 2.5 Pro/4o/R1/Qwen 2.5 Max/Sonnet 3.7/Gemma 3/Claude 3.7/Mistral Nemo usw., und erwähnten spezifische Verwendungszwecke (z.B. Tool Calling, Klassifizierung, Rollenspiel), was den Trend widerspiegelt, dass Nutzer Modelle je nach Aufgabenanforderung auswählen und kombinieren (Quelle: source)
💡 Sonstiges
China AIGC Industry Summit steht bevor: Der dritte China AIGC Industry Summit findet am 16. April in Peking statt. Der Gipfel wird über 20 Branchenführer von Unternehmen wie Baidu, Huawei, Microsoft Research Asia, Amazon Web Services, MiniMax, ShengShu Technology zusammenbringen, um Themen wie technologische Durchbrüche in der KI (Rechenleistung, Large Models), Branchenanwendungen (Bildung, Unterhaltung, Forschung, Unternehmensdienstleistungen) und Ökosystemaufbau (Sicherheit, Kontrolle, Implementierungsherausforderungen) zu diskutieren. Auf dem Gipfel werden auch Ranglisten von AIGC-Unternehmen/Produkten und eine Übersichtskarte der chinesischen AIGC-Anwendungslandschaft veröffentlicht (Quelle: 量子位)

Stanford-Bericht: Leistungsunterschied zwischen Top-KI-Modellen aus China und den USA auf 0,3% geschrumpft: Der AI Index Report 2025 der Stanford University zeigt, dass sich der Leistungsunterschied zwischen den Top-KI-Modellen aus China und den USA von 20% im Jahr 2023 auf nur noch 0,3% signifikant verringert hat. Obwohl die USA bei der Anzahl bekannter Modelle (40 vs. 15) und bei branchenführenden Unternehmen weiterhin vorne liegen, holen chinesische Modelle schnell auf. Der Bericht stellt außerdem fest, dass sich auch der Leistungsunterschied zwischen den Top-Modellen insgesamt verringert, von 12% im Jahr 2024 auf 5%, was auf eine deutliche Konvergenz hindeutet (Quelle: InfoQ)