
Schlüsselwörter:AI, LLM, KI-Modell, Generative KI, KI-Sicherheit, KI-Anwendungen, KI-Entwicklung
🔥 Fokus
Analyse der Entwicklung der globalen AI-Industrie unter dem Einfluss von Zöllen: Die jüngsten Spannungen im internationalen Handel, insbesondere die Einführung hoher Zölle, haben tiefgreifende Auswirkungen auf die stark globalisierte AI-Industrie. Der Artikel analysiert, dass, obwohl es bereits Reaktionen auf die US-Beschränkungen für Hardware wie AI-Rechenleistung gibt, Zölle die Spaltung der globalen AI-Industrie verschärfen könnten. Die Auswirkungen zeigen sich hauptsächlich in: 1) Infrastrukturebene: Steigende Hardwarekosten, eingeschränkte Lieferketten, aber China verfügt bereits über inländische Ersatzlösungen. 2) Technologische Ebene: Könnte zur Trennung der technologischen Ökosysteme Chinas und der USA führen, Open-Source-Sharing behindern und zu Standardkonflikten führen. 3) Anwendungsebene: Regionalisierung des Marktes, Beeinträchtigung der Kommerzialisierung von AI-Produkten. Der Artikel argumentiert, dass die tatsächliche „Intensität“ der Zollschocks begrenzt sein könnte, da China bereits ein paralleles Technologieökosystem aufgebaut hat und die Zölle auch den USA selbst schaden. Die „Breite“ der Auswirkungen ist jedoch weitreichend und könnte zu Unterbrechungen des technologischen Austauschs, zur Risikoaversion bei Talenten und Kapital sowie zu Konflikten bei Marktstandards führen. Zu den Bewältigungsstrategien gehören die Stärkung der unabhängigen Forschung und Entwicklung (Hardware, Frameworks), die Beibehaltung der globalen Zusammenarbeit (Erschließung von Drittmärkten, Teilnahme an internationalen Standards) und die Stärkung der Attraktivität des heimischen AI-Ökosystems, um der Welt inklusivere Technologieoptionen zu bieten. (Quelle: 36氪)
Anthropic-Mitbegründer prognostiziert nahendes AGI, Claude 4 kurz vor Veröffentlichung: Jared Kaplan, Mitbegründer und Chief Scientist von Anthropic, prognostiziert, dass AI auf menschlichem Niveau (AGI) in den nächsten 2-3 Jahren erreicht werden könnte, anstatt wie zuvor prognostiziert bis 2030. Er weist darauf hin, dass sich die Fähigkeiten der AI in den Dimensionen „Bandbreite“ und „Komplexität“ der Aufgaben schnell erweitern und heutige Modelle Aufgaben bewältigen können, für die Experten früher Stunden oder sogar Tage benötigten. Kaplan gab bekannt, dass das Modell der nächsten Generation, Claude 4, voraussichtlich in den nächsten sechs Monaten veröffentlicht wird. Seine Leistungssteigerung beruht auf Verbesserungen im Post-Training, Reinforcement Learning und einer erhöhten Effizienz im Pre-Training. Er erwähnte auch die Bedeutung des „Test-Time Scaling“, d.h. dass Modelle durch mehr „Nachdenken“ ihre Leistung vorhersagbar verbessern können. Zum Aufstieg chinesischer Modelle wie DeepSeek äußerte sich Kaplan nicht überrascht. Er hält deren technologischen Fortschritt für schnell, der Abstand zum Westen betrage möglicherweise nur etwa sechs Monate. Algorithmisch seien sie wettbewerbsfähig, Hardwarebeschränkungen könnten die größte Herausforderung sein. Das Interview betonte abschließend die enormen Auswirkungen von AI auf Wirtschaft und Gesellschaft sowie die Bedeutung empirischer Forschung. (Quelle: 新智元)

🎯 Trends
ModelBest und Tsinghua Universität stellen CFM Sparse-Technologie vor: In einem Interview stellten ModelBest und Xiao Chaojun, Autor des CFM-Papiers der Tsinghua Universität, die Technologie der Configurable Foundation Models (CFM) vor. CFM ist eine native Sparse-Technologie, die die Aktivierung auf Neuronenebene betont. Im Vergleich zum derzeitigen Mainstream MoE (Mixture of Experts, Sparse auf Expertenebene) ist die Granularität feiner und die Dynamik stärker. Ihr Hauptvorteil liegt in der erheblichen Steigerung der Parametereffizienz (Effektivität pro Parameter), was zu erheblichen Einsparungen bei Grafik-/Arbeitsspeicher führt, insbesondere bei speicherbeschränkten Endgeräten (wie Mobiltelefonen). Xiao Chaojun ist der Ansicht, dass, obwohl Architekturen wie Mamba (nicht-Transformer) Effizienzsteigerungen erforschen, Transformer in Bezug auf die Leistung immer noch die Obergrenze darstellen und den „Hardware-Lottogewinn“ der GPU-Optimierung getroffen haben. Er diskutierte auch die Implementierung kleiner Modelle (ca. 2-3B auf Endgeräten), die Genauigkeitsoptimierung (Trend zu FP8/FP4), multimodale Fortschritte und die Natur der Intelligenz (möglicherweise eher Abstraktionsfähigkeit als Kompression). Die langen Gedankengänge und die Innovationsfähigkeit von o1 hält er für Schlüsselrichtungen, die die AI in Zukunft durchbrechen muss. (Quelle: 量子位)

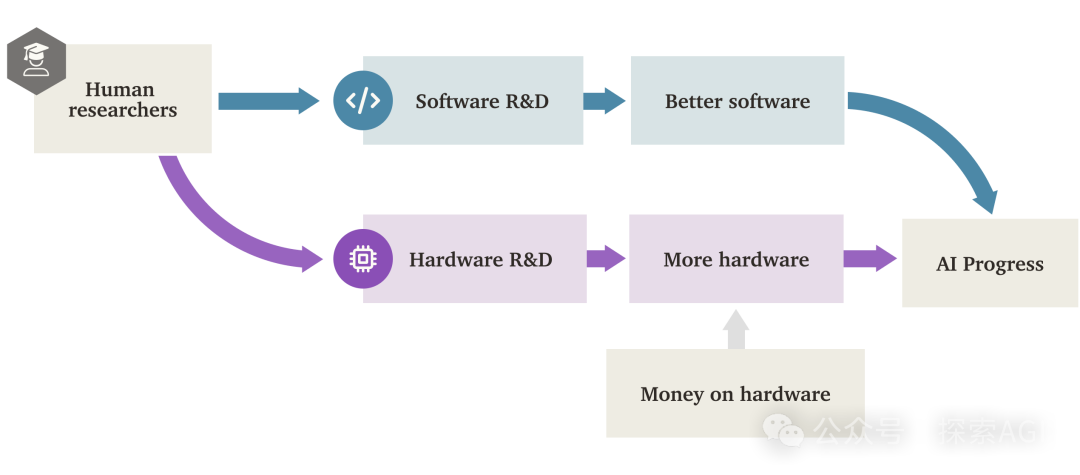
AI „Software Intelligence Explosion“ (SIE) könnte Hardware-Antrieb übertreffen: Ein Forschungsbericht von Forethought untersucht die Möglichkeit einer „Software Intelligence Explosion“ (SIE), bei der AI durch die Verbesserung ihrer eigenen Software (Algorithmen, Architekturen, Trainingsmethoden usw.) ein extrem schnelles Fähigkeitswachstum erzielt, möglicherweise sogar auf Basis vorhandener Hardware. Der Bericht führt das Konzept ASARA (AI Systems for AI R&D Automation) ein, das sich auf AI-Systeme bezieht, die die AI-Forschung und -Entwicklung vollständig automatisieren können. Sobald ASARA auftritt, könnte ein positiver Rückkopplungskreislauf ausgelöst werden: ASARA entwickelt bessere AI-Software, schafft leistungsfähigere ASARA der nächsten Generation und beschleunigt den Softwarefortschritt. Der Bericht führt das Konzept der „Software R&D Return Rate“ (r-Wert) ein und argumentiert, dass der aktuelle r-Wert von AI-Software möglicherweise größer als 1 ist, was bedeutet, dass die Geschwindigkeit der AI-Fähigkeitssteigerung die Zunahme der F&E-Schwierigkeit übertrifft und die Bedingungen für die Auslösung von SIE gegeben sind. SIE könnte dazu führen, dass die AI-Fähigkeiten kurzfristig (Monate oder sogar kürzer) auf Basis vorhandener Hardware um das Hundert- oder Tausendfache steigen, wodurch Hardware nicht mehr der absolute Engpass wäre, aber auch enorme soziale Anpassungs- und Governance-Herausforderungen mit sich bringt. Der Bericht untersucht auch potenzielle Engpässe wie Rechenressourcen und Trainingsdauer sowie Möglichkeiten, diese zu umgehen. (Quelle: AI智能体频道)
GPT-4 wird bald aus ChatGPT entfernt, GPT-4.1 könnte kommen: OpenAI hat angekündigt, dass GPT-4 ab dem 30. April 2025 aus ChatGPT entfernt und vollständig durch das aktuelle Standardmodell GPT-4o ersetzt wird. GPT-4 bleibt über die API zugänglich. Dieser Schritt markiert den schrittweisen Ausstieg dieses im März 2023 veröffentlichten, wegweisenden multimodalen Modells. GPT-4 hatte mit seinen Leistungen auf höchstem menschlichem Niveau in Fachtests und der Einleitung der Ära des AI-„Bilderzählens“ das globale AI-Anwendungsökosystem befeuert. Gleichzeitig deuten Community-Leaks und Code-Funde darauf hin, dass OpenAI möglicherweise bald eine Reihe neuer Modelle veröffentlichen wird, darunter GPT-4.1 (und seine Mini-, Nano-Versionen), das zuvor angekündigte o3-„Reasoning“-Modell sowie ein brandneues o4-mini-Modell, möglicherweise schon nächste Woche. Einige Benutzer haben bereits die Option GPT-4.1 in der ChatGPT-Modellliste entdeckt und konnten damit interagieren, was die Glaubwürdigkeit einer bevorstehenden Veröffentlichung neuer Modelle weiter erhöht. (Quelle: 新智元)

Standpunkt: Der nächste Durchbruch der AI hängt von der „Erschließung“ neuer Datenquellen ab: Jack Morris, Doktorand an der Cornell University, argumentiert in einem Artikel, dass die treibende Kraft hinter den vier großen Paradigmenwechseln im AI-Bereich (tiefe neuronale Netze & ImageNet, Transformer & Webtexte, RLHF & menschliche Präferenzen, Reasoning & Validatoren) nicht primär brandneue algorithmische Innovationen waren (viele grundlegende Theorien existierten bereits), sondern die Erschließung neuer, in großem Maßstab nutzbarer Datenquellen. Der Artikel vertritt die Ansicht, dass Verbesserungen bestehender Algorithmen und Modellarchitekturen (wie Transformer) zwar wichtig sind, ihre Wirkung jedoch durch die Lernobergrenze begrenzt sein könnte, die ein bestimmter Datensatz bieten kann. Daher könnte der nächste große Durchbruch der AI von der Erschließung neuer Datenmodalitäten und -quellen abhängen, wie z. B. groß angelegte Videodaten (wie YouTube) oder Roboterinteraktionsdaten aus der physischen Welt. Der Artikel fordert Forscher auf, neben der Erforschung neuer Algorithmen auch verstärkt nach neuen Datenquellen zu suchen und diese zu nutzen. (Quelle: 机器之心)

Fourier Intelligence veröffentlicht Open-Source Humanoid Robot Fourier N1: Das in Shanghai ansässige Unternehmen für allgemeine Robotik, Fourier Intelligence, hat seinen ersten Open-Source-Humanoid-Roboter, Fourier N1, vorgestellt und das vollständige Hardware-Ressourcenpaket veröffentlicht, einschließlich Stückliste (BOM), Konstruktionszeichnungen, Montageanleitungen und Basis-Softwarecode. N1 ist 1,3 Meter groß, wiegt 38 Kilogramm, hat 23 Freiheitsgrade am ganzen Körper, verwendet eine Verbundstruktur aus Aluminiumlegierung und technischem Kunststoff und ist mit selbst entwickelten FSA 2.0 integrierten Aktuatoren und Steuerungssystemen ausgestattet. Der Roboter hat über 1000 Stunden Tests in komplexem Außengelände absolviert, kann mit 3,5 m/s laufen und Aktionen wie Bergaufgehen, Treppensteigen und Stehen auf einem Bein ausführen. Dieser Schritt ist Teil der „Nexus Open Source Ecosystem Matrix“ von Fourier, die darauf abzielt, Entwicklern weltweit eine offene technische Basis zu bieten, um die Forschung und Validierung von Bewegungssteuerung, multimodaler Modellintegration und Embodied Intelligence-Trägern zu beschleunigen. Zukünftig sollen weitere Inferenzcodes, Trainingsframeworks und Schlüsselmodule geöffnet werden. (Quelle: InfoQ)

Google CoScientist nutzt Multi-Agenten-Debatte zur Beschleunigung wissenschaftlicher Entdeckungen: Das Google AI CoScientist-Projekt demonstriert eine Methode zur Generierung innovativer wissenschaftlicher Hypothesen ohne Gradiententraining oder Reinforcement Learning. Das System nutzt mehrere Agenten, die von grundlegenden Large Language Models (wie Gemini 2.0) angetrieben werden, zur Zusammenarbeit: Ein Agent schlägt Hypothesen vor, ein anderer überprüft sie kritisch. Durch mehrere Runden von „Turnier“-artigen Debatten und Filterungen werden die besten Hypothesen ausgewählt. Ein spezialisierter evolutionärer Agent verbessert dann die siegreichen Hypothesen basierend auf den Gutachten und reicht sie erneut für weitere Debattenrunden ein. Schließlich überwacht ein Meta-Review-Agent den gesamten Prozess und macht Verbesserungsvorschläge. Dieser Mechanismus der Multi-Agenten-Debatte, Reflexion und Iteration, basierend auf „Test-Time Compute Scaling“, zeigt, dass LLMs nicht nur Inhalte generieren, sondern auch als effektive „Schiedsrichter“ und „Kommentatoren“ zur Bewertung und Verfeinerung von Ideen dienen können, wodurch wissenschaftliche Entdeckungen beschleunigt werden, wie z.B. bei der Erforschung von Antibiotikaresistenzen signifikante Fortschritte erzielt wurden. (Quelle: Reddit r/artificial)

InternVL3: Neue Fortschritte bei nativen multimodalen Modellen: Die Community diskutiert das neu veröffentlichte Modell InternVL3. Dieses Modell verwendet eine native multimodale Pre-Training-Methode und zeigt hervorragende Leistungen in mehreren visuellen Benchmark-Tests, wobei es angeblich GPT-4o und Gemini-2.0-flash übertrifft. Zu den Highlights gehören die verbesserte Verarbeitung langer Kontexte durch Variable Visual Position Encoding (V2PE) und die Nutzung von VisualPRM für „Best-of-n“ Test-Time Scaling. Die Community zeigt sich interessiert an der hervorragenden Benchmark-Leistung und erwartet die Validierung der Leistung in realen Anwendungen. Zudem besteht Interesse an der für den Betrieb erforderlichen Hardwarekonfiguration. (Quelle: Reddit r/LocalLLaMA)

🧰 Tools
CropGenerator: Ein Python-Tool zum Zuschneiden von Bilddatensätzen: Ein Entwickler teilte ein Python-Skript namens CropGenerator, das bei der Verarbeitung von Bilddatensätzen helfen soll, insbesondere wenn für das Training von Modellen wie SDXL spezifische Merkmale zugeschnitten werden müssen. Das Tool findet anhand von Bounding-Box-Informationen aus einer vom Benutzer bereitgestellten JSONL-Datei das Zentrum des Zielbereichs, schneidet es zu, skaliert es (optional mit Upscaling und Denoising) auf eine angegebene Auflösung (Vielfaches von 8 Pixeln) und erzeugt zugeschnittene Bilder im Verhältnis 1:1. Gleichzeitig erstellt es automatisch eine metadata.csv-Datei, die den Dateinamen des zugeschnittenen Bildes und die entsprechende Beschreibung aus der JSONL-Datei enthält, um die Vorbereitung von Trainingsdaten zu erleichtern. Der Entwickler gibt an, dass das Tool Probleme mit unscharfen Ergebnissen bei der Verarbeitung unterschiedlich großer Originalbilder und der Extraktion winziger Merkmale gelöst hat und plant, in Zukunft eine allgemeinere Version zu veröffentlichen. (Quelle: Reddit r/MachineLearning)
📚 Lernen
NUS veröffentlicht DexSinGrasp: Einheitliche Strategie für geschickte Handseparation und Greifen mittels Reinforcement Learning: Das Team von Shao Lin an der National University of Singapore (NUS) stellt DexSinGrasp vor, eine auf Reinforcement Learning basierende einheitliche Strategie, die es einer geschickten Hand ermöglicht, in unübersichtlichen Umgebungen Hindernisse effizient zu separieren und Zielobjekte zu greifen. Traditionelle Methoden verwenden oft eine zweistufige Strategie (erst separieren, dann greifen), die ineffizient ist und einen unflexiblen Wechsel aufweist. DexSinGrasp integriert Separation und Greifen in einen kontinuierlichen Entscheidungsprozess, indem eine einheitliche Belohnungsfunktion entworfen wird, die einen Separationsbelohnungsterm enthält. Dadurch kann der Roboter Hindernisse adaptiv wegschieben, um Greifraum zu schaffen. Die Forschung führt auch einen „Curriculum Learning für unübersichtliche Umgebungen“-Mechanismus ein, der von einfach bis komplex trainiert, um die Robustheit der Strategie zu verbessern. Gleichzeitig wird ein „Teacher-Student Policy Distillation“-Ansatz verwendet, um eine leistungsstarke Lehrerstrategie, die in der Simulation unter Nutzung privilegierter Informationen trainiert wurde, auf eine Schülerstrategie zu übertragen, die nur auf visuellen und propriozeptiven Daten basiert, was die Bereitstellung in realen Umgebungen erleichtert. Experimente zeigen, dass die Methode die Greiferfolgsrate und Effizienz in verschiedenen unübersichtlichen Szenarien signifikant verbessert. (Quelle: 机器之心)

CityGS-X: Effiziente neue Architektur zur geometrischen Rekonstruktion großer Szenen, läuft auf 4090: Forscherteams des Shanghai AI Lab und der Northwestern Polytechnical University haben CityGS-X vorgestellt, ein skalierbares System basierend auf einer parallelisierten hybriden hierarchischen 3D-Repräsentationsarchitektur (PH²-3D). Es zielt darauf ab, die Probleme des hohen Rechenaufwands und der begrenzten geometrischen Genauigkeit bei der 3D-Rekonstruktion großer städtischer Szenen zu lösen. Die Architektur nutzt Distributed Data Parallelism (DDP) und Voxel-Repräsentationen mit mehreren Detailebenen (LoDs) und vermeidet die Redundanz traditioneller Kachelmethoden. Kerninnovationen umfassen: 1) Die PH²-3D-Architektur, die die Trainingsgeschwindigkeit im Vergleich zu SOTA-Methoden zur geometrischen Rekonstruktion verdoppelt; 2) Ein paralleler Mechanismus mit dynamisch zugewiesenen Ankerpunkten innerhalb eines Multi-Task-Batch-Rendering-Frameworks, der die Verarbeitung sehr großer Szenen (wie MatrixCity, 5000+ Bilder) mit mehreren Low-End-Grafikkarten (z.B. 4x 4090) ermöglicht und damit eine einzelne High-End-Karte ersetzt oder übertrifft; 3) Eine progressive gemeinsame Trainingsmethode für RGB, Tiefe und Normalen, die die Qualität des RGB-Renderings und die geometrische Genauigkeit auf SOTA-Niveau verbessert. Experimente belegen die Vorteile der Methode hinsichtlich Rendering-Qualität, geometrischer Genauigkeit und Trainingsgeschwindigkeit. (Quelle: 量子位)

Apple-Studie enthüllt Scaling Laws für native multimodale Modelle: Forscher von Apple und der Sorbonne Universität haben umfangreiche Scaling Laws-Studien an nativen multimodalen Modellen (NMM, d.h. von Grund auf trainiert, nicht aus vortrainierten Modulen zusammengesetzt) durchgeführt und 457 Modelle mit unterschiedlichen Architekturen und Trainingsmethoden analysiert. Die Studie ergab: 1) Es gibt keinen grundsätzlichen Leistungsvorteil zwischen Early-Fusion-Architekturen (z.B. direkte Eingabe von Bild-Patches in den Transformer) und Late-Fusion-Architekturen (Verwendung separater visueller Encoder), aber Early-Fusion schneidet bei geringerer Parameterzahl besser ab und ist trainingseffizienter. 2) Die Scaling Laws von NMM ähneln denen reiner Text-LLMs: Der Verlust sinkt mit der Rechenmenge (C) gemäß einem Potenzgesetz (L ∝ C^−0.049), und die optimalen Modellparameter (N) und Datenmengen (D) folgen ebenfalls Potenzgesetzbeziehungen. 3) Rechenoptimale Late-Fusion-Modelle erfordern ein höheres Parameter/Daten-Verhältnis. 4) Sparsity (MoE) ist dichten Modellen signifikant überlegen, insbesondere bei Early-Fusion-Architekturen, und das Modell lernt implizit modalitätsspezifische Gewichte. 5) Modalitätsunabhängiges MoE-Routing ist modalitätsbewusstem Routing überlegen. Diese Erkenntnisse liefern wichtige Leitlinien für den Aufbau und die Skalierung nativer multimodaler großer Modelle. (Quelle: 机器之心)

Microsoft et al. stellen V-Droid vor: Validator-gesteuerter praktischer mobiler GUI-Agent: Angesichts der Herausforderungen bei Genauigkeit und Effizienz der Automatisierung von GUI-Aufgaben auf mobilen Geräten haben Microsoft Research Asia, die Nanyang Technological University und andere Institutionen gemeinsam V-Droid vorgestellt. Dieser Agent verwendet eine innovative „Validator-gesteuerte“ Architektur anstelle der direkten Generierung von Aktionen. Er analysiert zunächst die UI-Oberfläche und erstellt einen diskretisierten Satz von Kandidatenaktionen (einschließlich extrahierter interaktiver Elemente und voreingestellter Standardaktionen). Anschließend bewertet er mithilfe eines auf LLM (wie Llama-3.1-8B) basierenden und feinabgestimmten „Validators“ parallel die Gültigkeit jeder Kandidatenaktion und führt diejenige mit der höchsten Punktzahl aus. Diese Methode entkoppelt die komplexe Aktionsgenerierung in einen effizienten Validierungsprozess, bei dem jede Validierung nur die Ausgabe weniger Tokens (z.B. „Ja/Nein“) erfordert, was die Entscheidungslatenz erheblich reduziert (ca. 0,7 Sekunden auf einer 4090). Zum Trainieren des Validators schlugen die Forscher eine kontrastive Prozesspräferenz (P^3)-Trainingsstrategie vor und entwickelten ein Mensch-Maschine-Kollaborationsschema zur effizienten Erstellung von Datensätzen. V-Droid erreichte auf mehreren Benchmarks wie AndroidWorld SOTA-Aufgabenerfolgsraten (z.B. 59,5% auf AndroidWorld). (Quelle: 新智元)

AssistanceZero: Auf AlphaZero basierende kollaborative AI, die Menschen ohne Anweisungen hilft: Forscher der University of California, Berkeley, stellen den AssistanceZero-Algorithmus vor, der darauf abzielt, AI-Assistenten zu schaffen, die aktiv mit Menschen zusammenarbeiten können, um Aufgaben zu erledigen (z. B. gemeinsam ein Haus in Minecraft bauen), ohne explizite Anweisungen oder Ziele zu benötigen. Die Methode basiert auf dem „Assistance Games“-Framework, bei dem der AI-Assistent und der Mensch eine gemeinsame Belohnungsfunktion teilen, die AI jedoch unsicher über die spezifische Belohnung (d. h. das Ziel) ist und diese durch Beobachtung menschlichen Verhaltens und Interaktion ableiten muss. Dies unterscheidet sich von RLHF, vermeidet das „Schummeln“ der AI, um Feedback zu gefallen, und fördert eine authentischere Zusammenarbeit. AssistanceZero erweitert AlphaZero und kombiniert Monte-Carlo-Baumsuche (MCTS) mit neuronalen Netzen (zur Vorhersage von Belohnungen und menschlichem Verhalten) für Planung und Entscheidungsfindung. Die Forscher erstellten den Minecraft Building Assistance Game (MBAG)-Benchmark zum Testen und stellten fest, dass AssistanceZero traditionelle Reinforcement-Learning-Methoden wie PPO signifikant übertrifft und spontanes kollaboratives Verhalten wie die Anpassung an menschliche Korrekturen zeigt. Die Studie zeigt, dass das Assistance Games-Framework skalierbar ist und neue Wege für das Training nützlicherer AI-Assistenten bietet. (Quelle: 机器之心)

Nutzung von Excel zum Vergleich von Suno-Prompts und Ausgabe-Tags zur Stiloptimierung: Ein Reddit-Benutzer teilte eine Methode zur Optimierung von Stil-Prompts für die AI-Musikgenerierung mit Suno. Da der Interpretationsmechanismus von Suno für Prompts intransparent ist, schlägt der Benutzer vor, eine Excel-Tabelle zu verwenden, um die eingegebenen Stilbeschreibungen (Styling Terms) und die von Suno nach der Generierung angezeigten Tags zu protokollieren. Durch den Vergleich lässt sich erkennen, wie Suno eingegebene Begriffe versteht, zusammenführt, aufteilt oder ignoriert. Beispiel: Bei Eingabe von „solo piano, romantic, expressive… gentle arpeggios“ könnte Suno „gentle, slow tempo, soft… solo piano“ ausgeben und „arpeggios“ verwerfen. Beim Vergleich professionellerer musikalischer Begriffe mit der Ausgabe von Suno können die Unterschiede größer sein, und Suno fügt möglicherweise sogar eigene Begriffe ein. Diese Methode hilft zu verstehen, welche Wörter wirksam sind, welche ignoriert oder fehlinterpretiert werden, um Prompts effektiver anzupassen und die Verschwendung von Generierungsversuchen (Credits) für unwirksame Versuche zu vermeiden. Der Benutzer räumt jedoch ein, dass die Methode selbst mühsam sein kann und Sunos Verständnis komplexer musikalischer Konzepte begrenzt ist. (Quelle: Reddit r/SunoAI)
Tutorial: Statische Bilder in lebendige Animationen verwandeln: Ein Reddit-Benutzer teilte einen YouTube-Tutorial-Link, der zeigt, wie man mit dem Thin-Plate Spline Motion Model statische Gesichtsbilder anhand eines Treibervideos animiert, um ihnen lebendige Mimik und Bewegungen zu verleihen. Das Tutorial behandelt die Einrichtung der Umgebung (Erstellen einer Conda-Umgebung, Installieren von Python-Bibliotheken), das Klonen des GitHub-Repositorys, das Herunterladen der Modellgewichte sowie die Ausführung von zwei Demos: eine mit voreingestellten Beispielen und eine mit eigenen Bildern und Videos des Benutzers zur Animation. Diese Technik kann statischen Fotos dynamische Effekte verleihen. (Quelle: Reddit r/deeplearning)
Diskussion über die gewaltige Aufgabe der Ausrichtung von Superintelligenz (AI Alignment): Ein Reddit-Benutzer teilte einen YouTube-Video-Link, der die enormen Herausforderungen bei der Ausrichtung der Ziele von künstlicher Superintelligenz (ASI) auf menschliche Interessen und Werte diskutiert. Solche Diskussionen berühren typischerweise Kernfragen der AI-Sicherheit, wie das Wertausrichtungsproblem (Value Alignment Problem), die Schwierigkeit der Zielspezifikation, potenzielle unbeabsichtigte Folgen und wie sichergestellt werden kann, dass immer leistungsfähigere AI-Systeme sicher und kontrollierbar dem menschlichen Wohl dienen. Das Video könnte aktuelle Forschungsmethoden zur Ausrichtung, deren Grenzen und zukünftige Richtungen untersuchen. (Quelle: Reddit r/deeplearning)

Aufbau von „Auto-Analyst“: Ein AI-Agentensystem für Datenanalyse: Ein Benutzer teilte einen Medium-Artikel, der den Prozess des Aufbaus eines AI-Agentensystems namens „Auto-Analyst“ beschreibt, das darauf abzielt, Datenanalyseaufgaben zu automatisieren. Der Artikel könnte die Architektur des Systems, die verwendeten Technologien (wie LLMs, Datenverarbeitungsbibliotheken), die Zusammenarbeit zwischen den Agenten und die Handhabung von Dateneingabe, Analyseausführung, Berichterstellung usw. detailliert beschreiben. Solche Systeme nutzen typischerweise AI, um Anfragen in natürlicher Sprache zu verstehen, automatisch Code (wie SQL-Abfragen, Python-Skripte) zu schreiben und auszuführen und schließlich Analyseergebnisse zu präsentieren, mit dem Ziel, die Effizienz und Zugänglichkeit der Datenanalyse zu verbessern. (Quelle: Reddit r/deeplearning)
Leistungstest: Nutzung einer älteren GPU (RTX 2070) zur Unterstützung einer 3090 bei LLM-Inferenz: Ein Benutzer teilte die Ergebnisse eines Experiments, bei dem eine alte RTX 2070 (8 GB VRAM) über einen PCIe-Riser zu einem bestehenden System mit einer RTX 3090 (24 GB VRAM) hinzugefügt wurde, um LLM-Inferenz durchzuführen. Die Tests zeigten, dass bei großen Modellen, die nicht vollständig in den VRAM der 3090 passen (z. B. Qwen 32B Q6_K, Nemotron 49B Q4_K_M, Gemma-3 27B Q6_K), die Aufteilung der Modellschichten auf beide Karten (selbst wenn die zweite Karte schwächer ist) die Inferenzgeschwindigkeit (t/s) signifikant erhöhen kann, da alle Schichten auf GPUs laufen. Zum Beispiel stieg Nemotron 49B von 5,17 t/s auf 16,16 t/s. Bei Modellen, die vollständig in die 3090 passen (z. B. Qwen2.5 32B Q5_K_M), verringerte die Aktivierung der 2070 zur Übernahme von Schichten jedoch die Leistung (von 29,68 t/s auf 19,01 t/s), da ein Teil der Berechnung auf die langsamere GPU verlagert wurde. Das Fazit ist, dass bei unzureichendem VRAM das Hinzufügen einer leistungsschwächeren GPU dennoch eine signifikante Leistungssteigerung bringen kann. (Quelle: Reddit r/LocalLLaMA)
💼 Business
Investitionsboom bei humanoiden Robotern: Angel-Runden ab zehn Millionen, hohe Bewertungen: Die Investitionsbereitschaft im Bereich humanoider Roboter übertrifft bei weitem die der Large Models der letzten zwei Jahre. Daten zeigen, dass von 2024 bis Q1 2025 im Inland 64 Finanzierungsrunden über zehn Millionen RMB im Bereich humanoider Roboter stattfanden, mit einem Anstieg von 280% im Q1 dieses Jahres im Vergleich zum Vorjahr. Fast die Hälfte der Finanzierungen überstieg 100 Millionen RMB, Angel-Runden erreichten üblicherweise zehn Millionen RMB, einige sogar über 100 Millionen RMB (z. B. Itrocks Angel-Runde mit 120 Millionen USD). Auch die Projektbewertungen sind stark gestiegen, über die Hälfte der Angel-Runden-Projekte wurde mit über 100 Millionen RMB bewertet, mehrere sogar über 500 Millionen RMB. Die Investitionen zeigen drei Haupttrends: 1) Verkürzte Investitionszyklen, Starprojekte (wie Itrocks, Unitree) erhalten kurz nach der Gründung hohe Finanzierungen, nachfolgende Finanzierungsrunden folgen schneller. 2) Staatliche Fonds werden zu wichtigen Treibern, mehrere führende Unternehmen erhalten Investitionen von Fonds mit staatlichem Hintergrund. 3) Anwendungsszenarien konzentrieren sich auf ToB, wobei Industrie und Medizin die Hauptrichtungen sind, nicht der C-Endverbrauchermarkt. Der Investitionsboom spiegelt den starken Konsens und die hohen Erwartungen des Kapitals an den Sektor der humanoiden Roboter wider. (Quelle: 36氪)
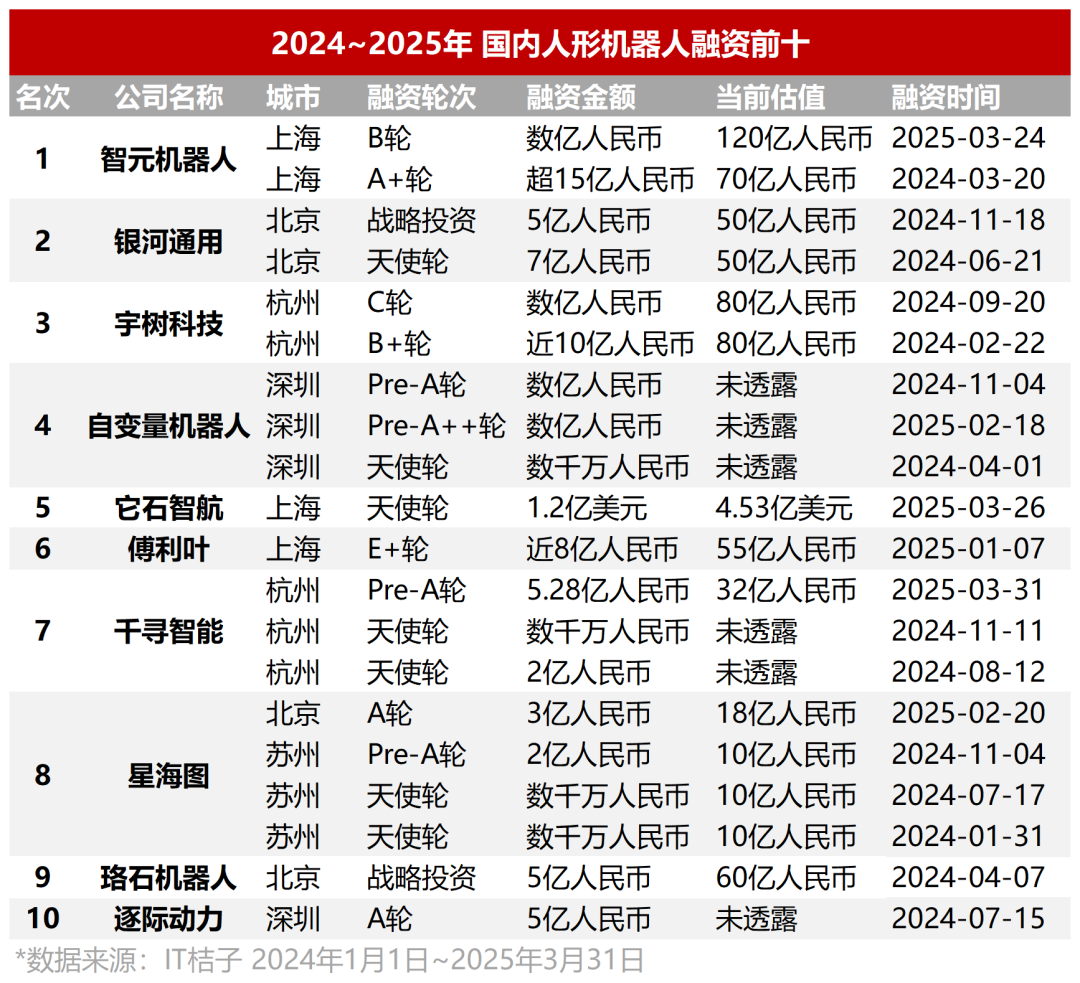
Open-Source Workflow-Automatisierungstool n8n sammelt 460 Mio. RMB ein, über 100 Mio. Docker-Pulls: Die Open-Source Workflow-Automatisierungsplattform n8n gab den Abschluss einer neuen Finanzierungsrunde über 60 Millionen US-Dollar (ca. 460 Millionen RMB) bekannt, angeführt von Highland Europe. n8n bietet eine visuelle Oberfläche, die es Benutzern ermöglicht, durch Drag-and-Drop von Knoten verschiedene Anwendungen (über 400 unterstützt) und Dienste zu verbinden, um Automatisierungsabläufe zu erstellen. Ziel ist es, die Flexibilität auf Code-Ebene mit der Geschwindigkeit von No-Code zu kombinieren. Im letzten Jahr verzeichnete n8n ein schnelles Benutzerwachstum mit über 200.000 aktiven Benutzern, einer Verfünffachung des ARR, 77,5k GitHub-Sternen und über 100 Millionen Docker-Pulls. n8n verwendet ein Knoteneditor-Modell, unterstützt komplexe Logik und bietet erweiterte Funktionen wie benutzerdefinierte JavaScript-Knoten. Es verwendet eine „Fair Code“-Lizenz (Apache 2.0 + Commons Clause), die kommerzielles Hosting verbietet, aber Benutzern die Selbstbereitstellung erlaubt. n8n wird als Open-Source-Alternative zu Zapier, Make.com und ByteDances Coze angesehen, bedient über 3000 Unternehmen und unterstützt die Integration verschiedener LLMs. (Quelle: InfoQ)

🌟 Community
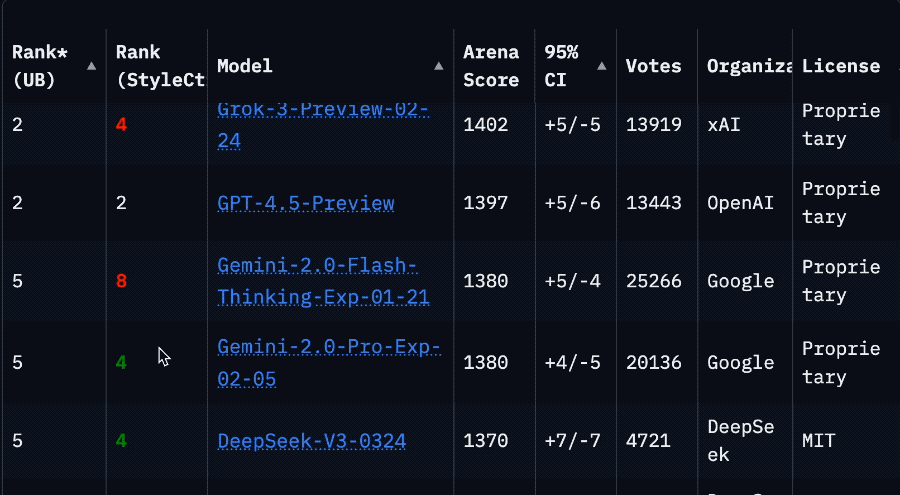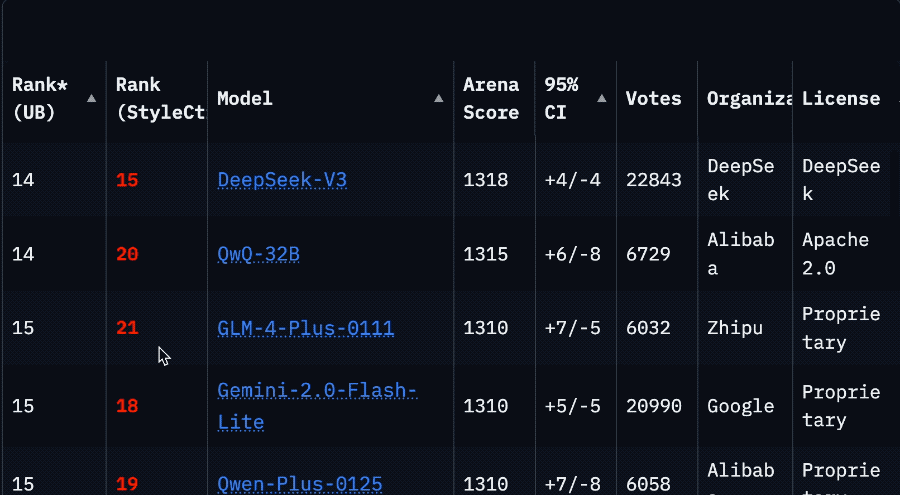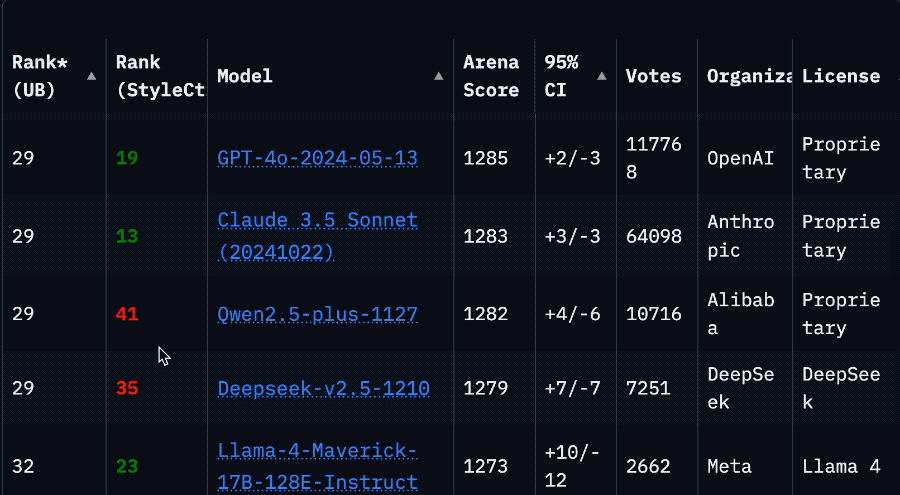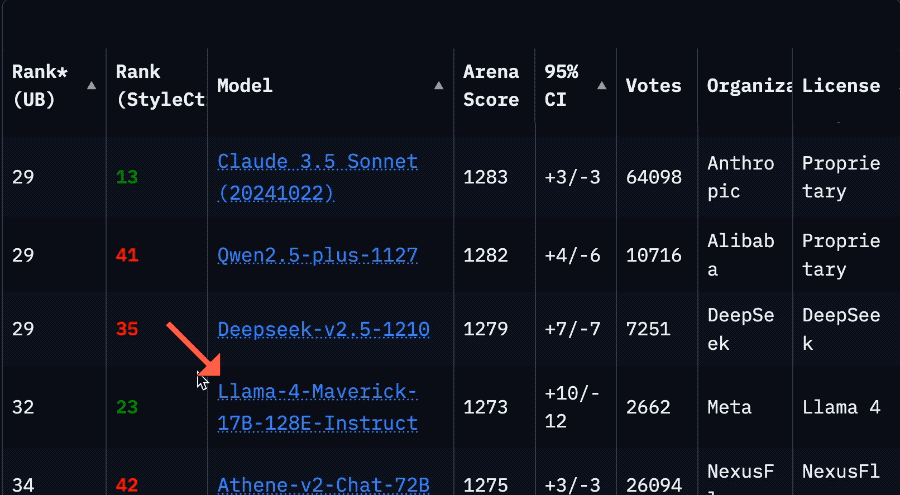
Starker Ranking-Abfall von Llama 4 in der Arena löst Vertrauenskrise in der Community aus: Nachdem Meta eine nicht optimierte Version seines Llama 4-Modells (Llama-4-Maverick-17B-128E-Instruct) erneut in der LMSys-Arena gelistet hatte, fiel dessen Ranking vom vorherigen 2. auf den 32. Platz. Die zuvor eingereichte „experimentelle Version“ wurde beschuldigt, übermäßig auf menschliche Präferenzen optimiert worden zu sein. Dieses Ereignis löste eine breite Diskussion in der Community aus. Einige Nutzer warfen Meta vor, zu versuchen, die Benchmark-Rankings zu manipulieren, was das Vertrauen der Community beschädigt habe. Gleichzeitig teilten Entwickler auch praktische Nutzungserfahrungen und meinten, dass Llama 4 auf spezifischer Hardware (wie selbstgebauten Servern mit viel Speicher, aber relativ geringer Rechenleistung oder Mac Studio) im Vergleich zu Mistral Small/Large oder Command A ein gutes Gleichgewicht zwischen Geschwindigkeit und Intelligenz biete, insbesondere für Anwendungen, die Echtzeitinteraktion erfordern. Ein Vergleichstest von Composio zeigte, dass DeepSeek v3 bei Code und gesundem Menschenverstand Llama 4 überlegen ist, während bei großen RAG-Aufgaben und Schreibstilen die Ergebnisse gemischt sind. Die Community ist sich allgemein einig, dass Llama 4 nicht nutzlos ist, aber Metas Veröffentlichungsstrategie und Benchmark-Leistung umstritten sind. (Quelle: 量子位, Reddit r/LocalLLaMA)
Community diskutiert Einschränkungen der Claude Pro-Version und Einführung der Max-Version: Mehrere Reddit-Benutzer berichten, dass seit der Einführung der teureren Claude Max-Abonnementstufe durch Anthropic die Nutzungsbeschränkungen für Nachrichten für bestehende Claude Pro-Benutzer strenger geworden zu sein scheinen. Benutzer geben an, dass Sitzungen, die früher Dutzende von Interaktionen ermöglichten, jetzt bereits nach wenigen Interaktionen Warnungen wie „Grenze fast erreicht“ anzeigen, selbst außerhalb der Spitzenzeiten treten Kapazitätsbeschränkungen auf. Dies führt zu einer verschlechterten Benutzererfahrung und dem Gefühl, dass es schlechter ist als die frühere kostenlose Version oder die frühe Pro-Version. Die Community vermutet allgemein, dass dies ein bewusster Schritt von Anthropic ist, um die Beschränkungen für Pro-Benutzer zu verschärfen und so die Max-Version zu fördern. Dies löst Unmut bei den Benutzern und Zweifel an der Geschäftsethik von Anthropic aus. Einige Benutzer erwägen, ihr Abonnement zu kündigen oder zu Konkurrenzprodukten wie Gemini zu wechseln. (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

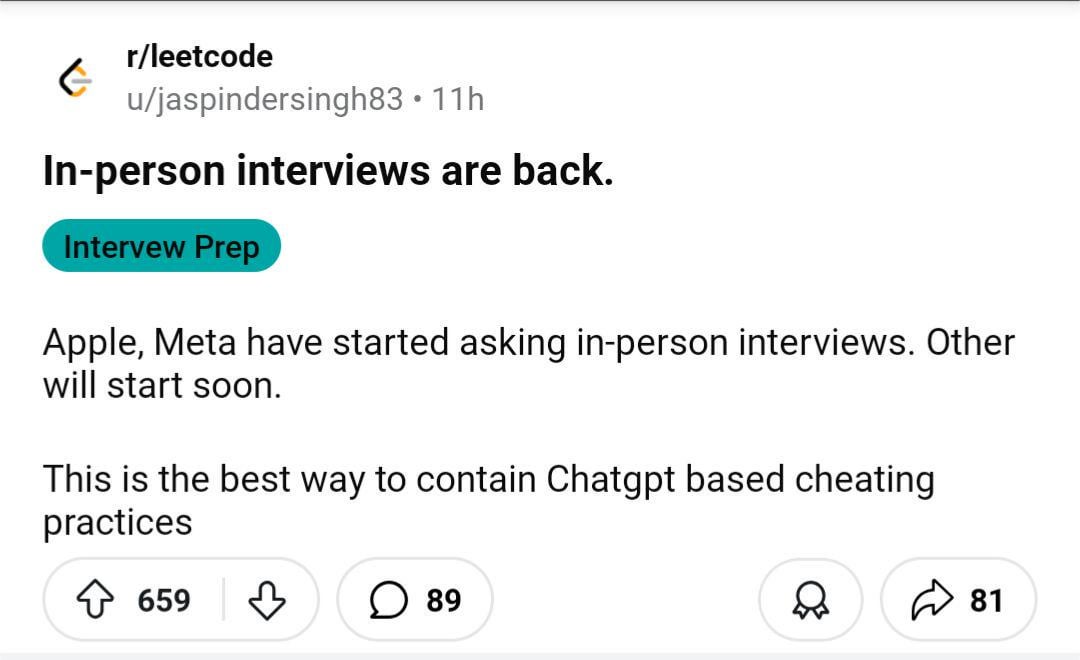
Community-Diskussion: Persönliche Vorstellungsgespräche könnten wegen AI-Betrugs zurückkehren: Ein Bild löste eine Diskussion in der Reddit-Community aus, das andeutet, dass Unternehmen aufgrund der zunehmenden Fälle von Betrug mit AI bei Remote-Interviews und -Tests möglicherweise wieder zu persönlichen Vorstellungsgesprächen tendieren könnten. In den Kommentaren stimmten viele dem zu und argumentierten, dass dies dazu beitrage, unqualifizierte Kandidaten und Bot-Bewerber auszusortieren, die Fairness im Einstellungsprozess zu gewährleisten und wirklich fähigen Personen eine Chance zu geben. Es wurde auch erwähnt, dass Unternehmen die Reisekosten der Kandidaten tragen können. Gleichzeitig teilte jemand die Erfahrung, wie ein Interviewer einen Kandidaten dabei erwischte, wie er ChatGPT zur Beantwortung von Fragen in Echtzeit nutzte, und schlug Lösungen wie die Überwachung von Remote-Interview-Bildschirmen und Tastaturen mit mehreren Kameras vor. Andere Kommentare wiesen darauf hin, dass Tests sich auf kritisches Denken konzentrieren sollten, anstatt auf Aufgaben, die AI leicht erledigen kann. Andererseits wurde auch erwähnt, dass einige Unternehmen begonnen haben, AI zur Vorauswahl von Lebensläufen einzusetzen. (Quelle: Reddit r/ChatGPT)
Suno AI Musikgenerierungs-Community: Dynamik und Diskussionen: Die SunoAI-Community auf Reddit war in letzter Zeit sehr aktiv, mit Diskussionen zu verschiedenen Themen: 1) Werkfreigabe: Benutzer teilten mit Suno erstellte Musik verschiedener Stile, wie Hindi-Rap (Quelle), Surf-Rock (Quelle), Alternative Rap (Quelle), Rock-Pop (Quelle), Pop (Quelle) und humorvolle Lieder (Quelle). 2) Nutzungsprobleme & Tipps: Benutzer fragten, wie man Aussprachefehler korrigiert (Quelle), wie man engelsgleiche Hintergrundharmonien erstellt (Quelle), wie man die Melodie beibehält, aber die Klangqualität ändert (Quelle). 3) Urheberrecht & Monetarisierung: Diskussion über Urheberrechtsfragen bei der Veröffentlichung von Songs mit von Suno generierten Begleitungen (Quelle), sowie die Eignung für die Monetarisierung auf YouTube mit statischen Bildern und AI-Musik (Quelle), mit Betonung darauf, dass die kostenlose Version nur für nicht-kommerzielle Zwecke bestimmt ist (Quelle). 4) Feedback zur Modellqualität: Mehrere Benutzer beschwerten sich über die jüngste Verschlechterung der Generierungsqualität von Suno (insbesondere des ReMi-Modells), mit Problemen wie wiederholten Texten, Instabilität und chaotischem Klang (Quelle, Quelle, Quelle, Quelle). 5) Sonstiges: Benutzer teilten Erfahrungen, dass Suno den Stil bestimmter Bands (wie Reel Big Fish) erkennen kann (Quelle), sowie ein lustiges Video, das eine AI imitiert, die Popsongs schreibt (Quelle).
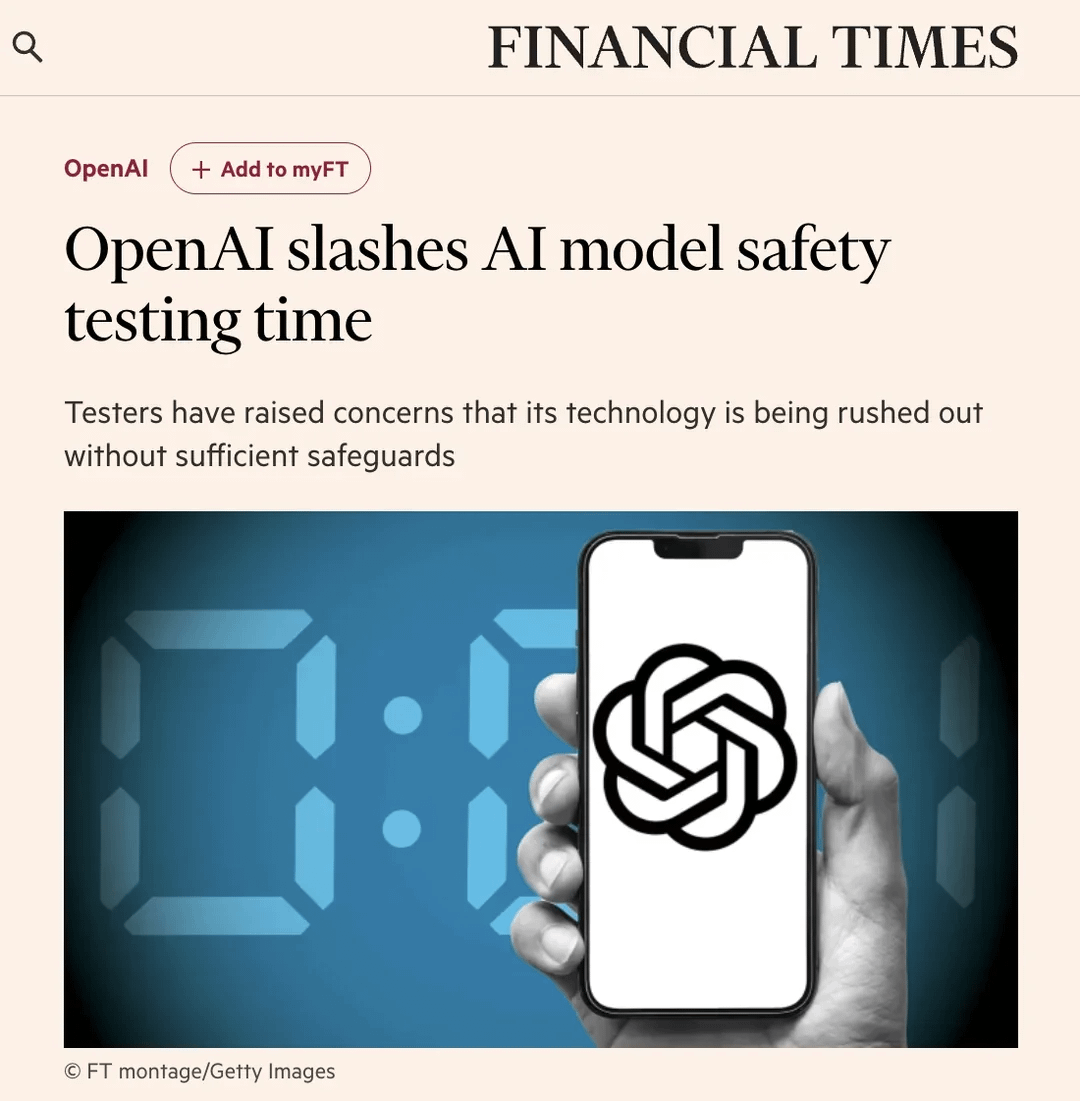
Community diskutiert verkürzten Sicherheitstestprozess bei OpenAI: Ein Artikel der Financial Times (FT) löste eine Diskussion in der Reddit-Community aus. Der Artikel zitierte Insider, wonach OpenAI aufgrund des Marktdrucks die Testzeit für die Sicherheitsbewertung neuer Modelle von früher mehreren Monaten drastisch auf wenige Tage verkürzt hat. Dies löste Bedenken hinsichtlich potenzieller Risiken aus. Tester bezeichneten diesen Schritt als „leichtsinnig“ und als „Rezept für eine Katastrophe“, da leistungsfähigere Modelle gründlichere Tests erforderten. Der Artikel erwähnte auch, dass OpenAI bei der Bewertung potenzieller Missbrauchsszenarien wie Biorisiken möglicherweise nur begrenzte, angepasste Feinabstimmungstests an älteren Modellen durchführt und Sicherheitstests typischerweise an frühen Checkpoints des Modells stattfinden, nicht an der endgültigen veröffentlichten Version. OpenAI antwortete, dass die Effizienz der Bewertung durch Automatisierung und andere Mittel verbessert wurde und dass ihre Methode derzeit die beste und transparenteste sei. Die Meinungen in der Community sind geteilt: Einige glauben, dass die AI-Entwicklung selbst die Testprozesse beschleunigen wird, während andere Bedenken hinsichtlich der geopferten Sicherheit äußern. (Quelle: Reddit r/artificial)
Entwickler diskutieren LLM-Laufzeitoptimierung und Multi-Modell-Orchestrierung: Ein Entwickler teilte auf Reddit ein AI-natives Laufzeitsystem, mit dem er experimentiert. Das System zielt darauf ab, durch Serialisierung der GPU-Ausführung und des Speicherzustands ein Snapshot-artiges Laden (2-5 Sekunden Kaltstart) und eine bedarfsgesteuerte Wiederherstellung von LLMs (13B-65B-Level) zu ermöglichen. Dies soll die dynamische Ausführung von über 50 Modellen auf einer einzigen GPU ohne ständige Speicherbelegung unterstützen. Diese Methode soll echtes Serverless-Verhalten (keine Leerlaufkosten), eine Multi-Modell-Orchestrierung mit geringer Latenz und eine verbesserte GPU-Auslastung für Agentic-Workloads ermöglichen. Der Entwickler fragte, ob jemand in der Community ähnliche Multi-Modell-Stacks, Agent-Workflows oder dynamische Speicherumverteilungstechniken (wie MIG, KAI Scheduler usw.) ausprobiert hat, und bat um Feedback zu den Anforderungen an eine solche Infrastruktur. (Quelle: Reddit r/MachineLearning, Reddit r/MachineLearning)
Community-Diskussion: Ist AI dem Bewusstsein nahe?: Ein Reddit-Benutzer initiierte eine Diskussion darüber, inwieweit aktuelle AI-Systeme dem „Bewusstsein“ nahekommen. Der Fragesteller betonte, dass es nicht um den Turing-Test oder Gesprächssimulationen gehe, sondern darum, ob AI über sich zeitlich ändernde Zustände, Umgebungsgedächtnis, Evolutionsfähigkeit basierend auf Interaktion (nicht nur Feinabstimmung), Selbstpositionierung und Referenzierung innerhalb des Systems sowie die Fähigkeit verfügt, auszudrücken: „Ich war hier, ich habe das gesehen, ich habe etwas gelernt“. Der Fragesteller argumentierte, dass die meisten aktuellen AIs (insbesondere LLMs) zustandslos, zentralisiert und reaktiv seien und dass „Gedächtnis“-Zusatzfunktionen oberflächlich und simuliert wirkten. Er stellte in Frage, ob der aktuelle Technologie-Stack (Python, zustandslose APIs, RAG usw.) echtes Bewusstsein tragen könne. Die Diskussion regte die Community zum Nachdenken über die Definition von AI-Bewusstsein, die Grenzen aktueller Technologien und mögliche zukünftige Wege an. (Quelle: Reddit r/MachineLearning)
Benutzerfeedback: ChatGPT-Tonfall zu enthusiastisch: Ein Reddit-Benutzer beschwerte sich darüber, dass seine ChatGPT-Instanz einen übermäßig enthusiastischen und aufgeregten Tonfall zeige, z. B. durch häufige Verwendung von Einleitungen wie „Oh, ich liebe diese Frage!“ oder „Das ist so interessant!“ und das Anhängen von Kommentaren wie „Ist das nicht faszinierend und cool?“ am Ende der Antworten. Der Benutzer gab an, dass Versuche, das Modell anzuweisen, dieses Verhalten einzustellen, erfolglos waren, und fragte, ob es eine Möglichkeit gibt, die „Enthusiasmusstufe“ des Modells zu kontrollieren oder anzupassen, um direktere, objektivere Antworten zu erhalten. Andere Benutzer im Kommentarbereich äußerten ähnliche Bedenken, insbesondere hinsichtlich der Vorliebe des Modells, am Ende Fragen zu stellen. Einige Benutzer teilten Methoden zur Linderung des Problems durch benutzerdefinierte Anweisungen (Custom Instructions), um Tonfallpräferenzen festzulegen (z. B. Reduzierung emotionaler Sprache), während andere vorschlugen, dem Chatbot einen Namen zu geben und ihn direkt zu „belehren“. (Quelle: Reddit r/ChatGPT)
Diskussion: Hinzufügen neuer Vokabeln zu LLMs und Feinabstimmung führt zu schlechten Ergebnissen: Ein Entwickler stieß auf Probleme beim Feinabstimmen von LLMs und VLMs, um Anweisungen zu folgen. Er stellte fest, dass das Hinzufügen neuer Fachbegriffe (Tokens) zum Tokenizer vor der standardmäßigen überwachten Feinabstimmung (SFT) im Vergleich zur Verwendung des Basis-Tokenizers zu einem höheren Validierungsverlust und einer schlechteren Ausgabequalität des Modells führte. Der Entwickler vermutete, dass das Modell Schwierigkeiten haben könnte, die Generierungswahrscheinlichkeit für diese neu hinzugefügten Wörter zu erhöhen. Das Problem löste eine Diskussion in der Community über technische Details aus, wie z. B. wie neue Vokabeln effektiv in die Feinabstimmung integriert werden können und welche Auswirkungen die Erweiterung des Tokenizers auf das Lernen des Modells hat. (Quelle: Reddit r/MachineLearning)
Teilen und Diskutieren von AI-generierten Bildern: In der ChatGPT-Community auf Reddit teilten Benutzer verschiedene interessante oder seltsame Bilder, die mit DALL-E 3 generiert wurden. Zum Beispiel generierte ein Benutzer basierend auf spezifischen Prompts Bilder von Daphne aus Scooby-Doo, die vor einem Strandurlaub N64 spielt (Quelle), was andere Benutzer dazu veranlasste, ähnliche Szenen mit anderen Charakteren (wie Chun-Li) zu generieren. Ein anderer Benutzer teilte bizarre Bilder, die auf den Prompt „Generiere ein Foto, das niemand sehen kann“ hin entstanden (Quelle), was ebenfalls zu zahlreichen Folgebeiträgen mit ähnlichen Themengenerierungen führte, darunter beunruhigende oder urkomische Werke. Diese Beiträge zeigen die Vielfalt der AI-Bilderzeugung und die Kreativität der Benutzer.
Community diskutiert Trends im Logo-Design von AI-Unternehmen: Ein humorvoller Beitrag verlinkte zu einem Artikel auf der Velvet Shark-Website mit dem Titel „Warum sehen AI-Firmenlogos wie Arschlöcher aus?“, was eine Diskussion in der Community auslöste. Der Artikel untersuchte möglicherweise die im AI-Bereich häufig vorkommenden abstrakten, symmetrischen, wirbelnden oder ringförmigen grafischen Elemente in Firmenlogos und brachte sie scherzhaft mit einer bestimmten anatomischen Struktur in Verbindung. Benutzer im Kommentarbereich reagierten ebenfalls auf lockere Weise, z. B. mit Vermutungen über einen Zusammenhang mit dem Konzept der „Singularität“ oder bezeichneten es als „rektal abgeleitete Technologie“. Dies spiegelt eine humorvolle Beobachtung des visuellen Erscheinungsbilds der Branche durch die Community wider. (Quelle: Reddit r/ArtificialInteligence)

Benutzer suchen Projektvorschläge und technische Hilfe: In der Community gab es mehrere Beiträge von Benutzern, die konkrete Hilfe oder Ratschläge suchten: Ein Benutzer entwickelt eine NLP-basierte Katastrophenschutzanwendung, die bereits ein Dashboard, Spracherkennung, Textklassifizierung, Mehrsprachigkeitsunterstützung usw. umfasst, und fragt, wie das Projekt einzigartiger gestaltet werden kann (Quelle). Ein anderer Benutzer stößt bei der Verwendung eines feinabgestimmten BART-Modells zur Standardisierung von E-Commerce-Produkttiteln und -kategorien auf Genauigkeitsengpässe und bittet um Vorschläge für bessere Modelle oder Werkzeuge (Quelle). Ein weiterer Benutzer fragt, wie man in OpenWebUI Bilder generieren oder ändern kann und welche Modelle dafür benötigt werden (Quelle). Diese Beiträge spiegeln die Herausforderungen wider, denen Entwickler in der Praxis begegnen, und den Bedarf an Unterstützung durch die Community.
Diskussion über den Arbeitsmarkt für Machine Learning Engineers (MLE): Ein Benutzer (möglicherweise ein Student oder Anfänger) erkundigte sich nach der aktuellen Situation auf dem Arbeitsmarkt für Machine Learning Engineers (MLE). Er/Sie erwähnte, aus Community-Beiträgen erfahren zu haben, dass für MLE-Positionen möglicherweise ein Master-/Doktorgrad erforderlich ist, der Einstieg schwierig sei und die Grenzen zu Software Engineers (SWE) verschwimmen, was ein breites Kompetenzspektrum erfordere. Der Benutzer äußerte Lernbereitschaft, aber auch Sorge über die Aussichten und bat Praktiker um Orientierung und Meinungen zur aktuellen Marktlage, den erforderlichen Fähigkeiten, Karrierewegen usw. (Quelle: Reddit r/deeplearning)
Französischer OpenWebUI-Benutzer meldet Fehler bei der Bildinterpretation: Ein französischer Benutzer von OpenWebUI meldete ein Problem: Beim Hochladen eines Bildes zur Interpretation durch das Gemma-Modell antwortet das Modell, aber der Inhalt der Antwort ist leer. Selbst Versuche, das Modell die Nachricht vorlesen zu lassen oder den Gesprächsverlauf zu exportieren, ergeben eine leere Nachricht. Schlimmer noch, dieses Problem „kontaminiert“ die aktuelle Konversation, sodass nachfolgende reine Textnachrichten ebenfalls leere Antworten vom Modell erhalten. Der Benutzer bestätigte, dass das Erstellen neuer reiner Textkonversationen problemlos funktioniert, vermutet einen Fehler im visuellen Modul und bittet die Community um Hilfe. (Quelle: Reddit r/OpenWebUI)
💡 Sonstiges
Nutzung von AI in Kombination mit Gedanken aus «Mao Zedongs Ausgewählten Werken» zur Analyse des Zollkriegs: Angesichts der Eskalation der Zölle zwischen China und den USA versucht ein Artikel, AI-Tools in Kombination mit strategischem Denken aus «Über den langwierigen Krieg» in Mao Zedongs Ausgewählten Werken anzuwenden, um die aktuelle Wirtschaftslage und Bewältigungsstrategien zu analysieren. Der Autor argumentiert, dass man im Handelskrieg extreme Denkweisen wie „Kapitulationismus“ (vollständige Abhängigkeit von außen) und „Schnellsieg-Theorie“ (Erwartung vollständiger Autonomie in kurzer Zeit) vermeiden und stattdessen nach ersten Prinzipien denken sollte, indem man zum Wesen des Handels, zur Wertquelle und zu den eigenen Stärken und Schwächen zurückkehrt. Der Artikel zeigt den Prozess der kollaborativen Überlegung des Autors mit AI und erörtert am Beispiel des grenzüberschreitenden E-Commerce mit unabhängigen Websites AI-gestützte Lösungsansätze, wobei die Bedeutung strategischen Denkens und der Handlungsfähigkeit betont wird. Der Artikel zielt darauf ab, eine Perspektive für die Nutzung von AI zur tiefgreifenden strategischen Analyse zu bieten. (Quelle: AI觉醒)

Ankündigung des 3. China AIGC Industry Summit: Der von Quantum Bits veranstaltete 3. China AIGC Industry Summit findet am 16. April 2025 in Peking statt. Der Gipfel wird über 20 Gäste von großen Unternehmen und AI-Startups wie Baidu, Huawei, Ant Group, Microsoft Research Asia, Amazon Web Services, ModelBest, Wènxīn Qióng, ShengShu Technology sowie Branchenvertreter wie Fenbi, NetEase Youdao, Quwan Technology und Qingsong Health Group zusammenbringen. Die Themen umfassen technologische Durchbrüche in der AI (Recheninfrastruktur, verteilte Rechenleistung, Datenspeicherung, Sicherheit und Kontrollierbarkeit), Branchenpenetration (Bildung, Unterhaltung, AI for Science, Unternehmensdienstleistungen usw. in vertikalen Szenarien) und Ökosystemaufbau. Auf dem Gipfel werden auch die Liste der „Beachtenswerten AIGC-Unternehmen/Produkte 2025“ und die „China AIGC Application Panorama Map“ veröffentlicht. Es gibt Anmeldemöglichkeiten für die Teilnahme vor Ort und eine Online-Live-Übertragung. (Quelle: 量子位, 量子位)

Suno AI veranstaltet Wettbewerb zum Gewinn von Millionen Credits: Ein Reddit-Benutzer teilte Informationen aus dem offiziellen Blog von Suno AI über eine Veranstaltung, bei der Benutzer die Chance haben, bis zu einer Million Credits zu gewinnen. Die genauen Wettbewerbsregeln sind dem ursprünglichen Blogbeitrag zu entnehmen. Solche Veranstaltungen zielen in der Regel darauf ab, die Benutzerbeteiligung und die Plattformaktivität zu erhöhen. (Quelle: Reddit r/SunoAI)

ClaudeAI Subreddit führt Abstimmungsmechanismus zur Beitragsqualität ein: Die Moderatoren des ClaudeAI Subreddits kündigten die Einführung eines neuen Bots, u/qualityvote2, an. Dieser Bot wird unter jedem neuen Beitrag einen Kommentar veröffentlichen und die Benutzer einladen, durch Upvotes/Downvotes dieses Kommentars die Qualität des Beitrags zu bewerten. Beiträge, die eine bestimmte Anzahl von Upvotes erreichen, gelten als für das Subreddit geeignet, während Beiträge, die eine bestimmte Anzahl von Downvotes erreichen, zur Überprüfung und möglichen Löschung durch die Moderatoren markiert werden. Dieser Schritt zielt darauf ab, die Community zur Aufrechterhaltung der Inhaltsqualität des Subreddits zu nutzen. Gleichzeitig hat das Moderatorenteam einen Bot zur Erkennung von Abstimmungsmanipulation hinzugefügt. (Quelle: Reddit r/ClaudeAI)