
Schlüsselwörter:AI, TPU, Google A2A Protokoll, siebte Generation TPU, AI Agent Kommunikation, Gemini Modell Optimierung, KI Inferenz Beschleunigung
🔥 Fokus
Google veröffentlicht A2A-Protokoll und siebte Generation TPU, beschleunigt die Ära der AI Agents und Inferenz: Google führt das Open-Source Agent2Agent (A2A) Protokoll ein, das darauf abzielt, sichere Kommunikation und Zusammenarbeit von AI Agents über verschiedene Anbieter und Frameworks hinweg zu ermöglichen. Es ergänzt, anstatt das MCP-Protokoll zu ersetzen (MCP verbindet Agents mit Tools, A2A verbindet Agents mit Agents). A2A folgt Prinzipien wie Fähigkeitserkennung (capability discovery), Aufgabenmanagement, Zusammenarbeit und Verhandlung der Benutzererfahrung und wird bereits von über 50 Partnern unterstützt. Gleichzeitig veröffentlicht Google die siebte Generation der TPU (Ironwood/TPU v7), die speziell für AI-Inferenz optimiert ist, mit einer FP8-Rechenleistung von 4614 TFlops, 192 GB HBM pro Chip, einer Bandbreite von 7,2 TBps und doppelter Energieeffizienz im Vergleich zur Vorgängergeneration. Das größte Cluster (mit 9216 Chips) erreicht eine Rechenleistung von 42,5 ExaFlops und zielt darauf ab, „denkende“ Modelle wie Gemini und die nächste Generation von AI Agent-Anwendungen zu unterstützen, was signalisiert, dass sich die KI von reaktiven Antworten hin zur proaktiven Generierung von Erkenntnissen wandelt. (Quelle: 36氪, 36氪, 微信公众号, 微信公众号, 微信公众号, 微信公众号)

MCP wird zum Knotenpunkt des AI Agent-Ökosystems, Alibaba und Tencent setzen voll darauf: Das Model Context Protocol (MCP) entwickelt sich schnell zur Standardschnittstelle für die Verbindung von AI Agents mit externen Tools und Datenquellen und wird als das „USB“ des KI-Ökosystems bezeichnet. Aliyun Bailian hat den branchenweit ersten Full-Lifecycle MCP-Service gestartet, der Function Compute, über 200 große Modelle und mehr als 50 MCP-Services integriert und den schnellen Aufbau eines Agents in 5 Minuten ermöglicht. Tencent Cloud hat ebenfalls ein „AI Development Kit“ veröffentlicht, das das Hosting von MCP-Plugins unterstützt. MCP entkoppelt Hosts, Server und Clients, senkt die Kosten für wiederholte Entwicklungen und verbessert die Interkonnektivität von KI-Tools, was für die Realisierung komplexer Agenten-Kollaborationen entscheidend ist. Obwohl es frühe Herausforderungen wie ein unreifes Ökosystem und unvollständige Toolchains gibt, wird erwartet, dass MCP mit der Unterstützung von OpenAI, Google, Microsoft, Amazon und großen chinesischen Unternehmen die explosionsartige Verbreitung von KI-Anwendungen und die Branchenentwicklung beschleunigen wird. (Quelle: 36氪)
KI erzielt bahnbrechende Fortschritte bei Mathematik-Olympiade: Die Ergebnisse der zweiten AI Mathematical Olympiad – Progress Prize 2 zeigen, dass KI signifikante Fortschritte bei der Lösung schwieriger mathematischer Probleme gemacht hat. Das beste Modell erzielte 34 von 50 Punkten in einem Test mit völlig neuen Aufgaben, begrenzten Rechenressourcen (Kosten unter 1 US-Dollar pro Aufgabe) und der Anforderung exakter ganzzahliger Antworten (0-999), was weit über der Einschätzung früherer Studien liegt, wonach menschliche Bewerter LLMs nur ein Niveau von etwa 5% zutrauten. Selbst ein relativ einfaches, von DeepSeek R1 abgeleitetes Modell erreichte 28 von 50 Punkten. Dieses Ergebnis zeigt, dass die mathematischen Schlussfolgerungsfähigkeiten der KI, insbesondere bei Problemen auf Olympiade-Niveau, die kreative Lösungsansätze erfordern, rapide zunehmen und nicht nur auf einfacher Mustererkennung oder Datenspeicherung beruhen. (Quelle: Reddit r/MachineLearning)
SenseTime veröffentlicht Rìrìxīn SenseNova V6, ein multimodales MoE-Modell mit 600 Milliarden Parametern: SenseTime Technology hat sein großes Modell der sechsten Generation, Rìrìxīn SenseNova V6, vorgestellt, das eine Mixture-of-Experts (MoE)-Architektur mit 600 Milliarden Parametern verwendet und nativ multimodale Eingaben wie Text, Bild und Video sowie deren fusionierte Verarbeitung unterstützt. Das Modell zeigt hervorragende Leistungen in mehreren reinen Text- und multimodalen Benchmarks und übertrifft GPT-4.5 sowie Gemini 2.0 Pro. Zu seinen Kernfähigkeiten gehören starkes Reasoning (multimodales und sprachliches Deep Reasoning übertrifft o1, Gemini 2.0 flash-thinking), starke Interaktion (Echtzeit-Audio-/Video-Verständnis, emotionaler Ausdruck) und langes Gedächtnis (unterstützt lange Videoanalysen, z. B. direkte Inferenz über mehrminütige Videoinhalte). Schlüsseltechnologien umfassen natives multimodales Fusionstraining, multimodale Synthese langer Gedankenkette (unterstützt 64K tokens), multimodales gemischtes Reinforcement Learning (RLHF+RFT) sowie einheitliche Repräsentation und dynamische Kompression langer Videos. SenseTime betont, dass KI alltäglichen Anwendungen dienen und die Implementierung von KI in verschiedenen Branchen vorantreiben sollte. (Quelle: 微信公众号)
🎯 Entwicklungen
Google Gemini 2.5 Flash kurz vor Veröffentlichung, Fokus auf effiziente Inferenz: Google hat auf der Cloud Next ’25 Konferenz das Modell Gemini 2.5 Flash angekündigt. Als leichtgewichtige Version des Flaggschiff-Modells Gemini 2.5 Pro wird sich Flash auf schnelle und kostengünstige Inferenzfähigkeiten konzentrieren. Seine Besonderheit liegt darin, die Tiefe der Inferenz dynamisch an die Komplexität der Eingabeaufforderung anzupassen, um übermäßige Berechnungen bei einfachen Fragen zu vermeiden. Entwickler können die Inferenz-Tiefe anpassen, um die Kosten zu kontrollieren. Das Modell wird voraussichtlich bald auf Vertex AI verfügbar sein und zielt darauf ab, den Bedarf an reaktionsschnellen Alltagsanwendungen zu decken. (Quelle: 微信公众号, X)

ByteDance veröffentlicht technischen Bericht zu Seed-Thinking-v1.5 mit starker Reasoning-Fähigkeit: ByteDance hat technische Details zu seinem auf Reinforcement Learning basierenden Reasoning-Modell Seed-Thinking-v1.5 veröffentlicht. Der Bericht zeigt, dass das Modell in mehreren Benchmarks hervorragende Leistungen erbringt, DeepSeek-R1 übertrifft und sich dem Niveau von Gemini-2.5-Pro und O3-mini-high annähert, wobei es im ARC-AGI-Test 40% erreicht. Das Modell verfügt über insgesamt 200 Milliarden Parameter und 20 Milliarden aktivierte Parameter. Die Modellgewichte wurden noch nicht veröffentlicht, aber seine ausgezeichnete Reasoning-Fähigkeit und die relativ geringe Anzahl aktivierter Parameter haben die Aufmerksamkeit der Community geweckt. (Quelle: X)

ChatGPT verbessert Speicherfunktion, kann auf alle bisherigen Gespräche zugreifen: OpenAI kündigt ein Upgrade der Speicherfunktion von ChatGPT an, das es dem Modell ermöglicht, auf alle bisherigen Chat-Verläufe des Benutzers zurückzugreifen, um personalisiertere Antworten zu geben. Diese Verbesserung zielt darauf ab, die Vorlieben und Interessen der Benutzer zu nutzen, um die Hilfe beim Schreiben, bei Empfehlungen, beim Lernen usw. zu verbessern. Wenn Benutzer einen neuen Chat starten, nutzt ChatGPT diese Erinnerungen auf natürliche Weise. Benutzer behalten die volle Kontrolle über diese Funktion und können das Referenzieren des Verlaufs in den Einstellungen deaktivieren, die Speicherfunktion vollständig ausschalten oder den temporären Chat-Modus verwenden. Die Funktion wird bereits an Plus- und Pro-Benutzer (außer in einigen Regionen) ausgerollt und wird bald auch für Team-, Enterprise- und Education-Benutzer verfügbar sein. (Quelle: X, X)
OpenAI veröffentlicht Podcast über die Entwicklung von GPT-4.5: Sam Altman und die OpenAI-Kernteammitglieder Alex Paino, Dan Selsam und Amin Tootoonchian haben einen Podcast aufgenommen, in dem sie den Entwicklungsprozess von GPT-4.5 und zukünftige Richtungen diskutieren. Das Team enthüllte, dass die Entwicklung von GPT-4.5 einen Wandel von der Optimierung der Recheneffizienz zur Optimierung der Dateneffizienz markiert, mit dem Ziel, eine zehnmal höhere Intelligenz als GPT-4 zu erreichen. Der Podcast erörterte die Bedeutung des „Kompressions“-Mechanismus im unüberwachten Lernen (in Anlehnung an die Solomonoff-Induktion), betonte die Notwendigkeit einer genauen Bewertung der Modellleistung zur Vermeidung von Auswendiglernen und teilte Erfahrungen bei der Überwindung technischer Hürden sowie die Bedeutung der Teammoral. (Quelle: X, X)
Perplexity integriert Gemini 2.5 Pro, plant Anbindung von Grok 3 und WhatsApp: Die KI-Suchmaschine Perplexity hat angekündigt, das neueste Google-Modell Gemini 2.5 Pro für Pro-Benutzer integriert zu haben und lädt Benutzer ein, es mit Modellen wie Sonar, GPT-4o, Claude 3.7 Sonnet, DeepSeek R1 und O3 zu vergleichen. Darüber hinaus bestätigte Perplexity-CEO Aravind Srinivas, dass nach zahlreichen positiven Rückmeldungen von Benutzern die Entwicklung einer WhatsApp-Integration für Perplexity in Angriff genommen wird. Gleichzeitig ist geplant, das Grok 3-Modell bald auf der Perplexity-Plattform zu unterstützen. (Quelle: X, X, X)

Alibaba Qwen3-Modellreihe in Vorbereitung, Veröffentlichung benötigt noch Zeit: Die Community erwartet mit Spannung die nächste Generation der Qwen3-Modellreihe von Alibaba, einschließlich nicht quelloffener Versionen, Qwen3-8B sowie Qwen3-MoE-15B-A2B. Laut Antworten von Qwen-Entwicklern in sozialen Medien wird die Veröffentlichung von Qwen3 jedoch nicht „innerhalb weniger Stunden“ erfolgen, sondern benötigt noch mehr Vorbereitungszeit. Dies deutet darauf hin, dass Alibaba aktiv an der neuen Modellgeneration arbeitet, der genaue Zeitplan für die Veröffentlichung jedoch noch nicht feststeht. (Quelle: X, Reddit r/LocalLLaMA)

Mysteriöse Hochleistungsmodelle „Dragontail“ & „Quasar Alpha“ auf LM Arena sorgen für Spekulationen: Auf der Plattform LMSYS Chatbot Arena (LM Arena) sind anonyme Modelle namens „Dragontail“ und „Quasar Alpha“ aufgetaucht. In Interaktionen mit Benutzern zeigen sie eine Leistung, die mit Top-Modellen (wie o3-mini-high, Claude 3.7 Sonnet) vergleichbar ist oder diese bei bestimmten mathematischen Problemen sogar übertrifft. Die Community spekuliert, dass „Dragontail“ eine Variante des bald erscheinenden Qwen3 oder Gemini 2.5 Flash sein könnte, während „Quasar Alpha“ von einigen Benutzern als Modell der o4-mini-Serie von OpenAI vermutet wird. Das Auftauchen dieser anonymen Modelle spiegelt die Rolle der Modell-Arena als Testfeld und Leistungsbewertungsplattform für Spitzenmodelle wider. (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Moonshot AI Kimi-VL-A3B-Thinking Modell-Demo auf Hugging Face verfügbar: Moonshot AI hat eine interaktive Demo seines multimodalen Modells Kimi-VL-A3B-Thinking auf Hugging Face Spaces online gestellt. Benutzer können das Modell nun öffentlich ausprobieren. Erste Tests zeigen, dass das Modell über Online-OCR- und Bilderkennungsfähigkeiten verfügt, aber bei bestimmten Aufgaben, die ein breites Wissensspektrum erfordern (wie das Verstehen des Witzes eines spezifischen Memes), möglicherweise eingeschränkte Leistung zeigt, was mit seiner Modellgröße zusammenhängen könnte. (Quelle: X, X)

AMD kündigt KI-Event zur Vorstellung neuer Rechenzentrums-GPUs an: AMD plant eine Veranstaltung namens „Advancing AI 2025“, auf der neue GPUs für Rechenzentren vorgestellt werden sollen. Die Ankündigung wird sich auf KI-Anwendungen konzentrieren, nicht auf Gaming-Grafikkarten. Dieser Schritt zeigt AMDs kontinuierliches Engagement im KI-Hardwaremarkt und die Absicht, im von Nvidia dominierten Bereich der KI-Beschleuniger zu konkurrieren. (Quelle: Reddit r/artificial)
🧰 Tools
Firecrawl: Open-Source-Tool zur Umwandlung von Websites in LLM-fähige Daten: Firecrawl von Mendable AI ist ein leistungsstarkes Open-Source-Tool (in TypeScript geschrieben), das darauf abzielt, ganze Websites über eine einzige API zu scrapen, zu crawlen und in LLM-fähiges Markdown oder strukturierte Daten umzuwandeln. Es bewältigt Herausforderungen wie Proxys, Anti-Bot-Mechanismen, dynamisches Content-Rendering und unterstützt benutzerdefiniertes Crawling (z. B. Ausschluss von Tags, authentifiziertes Crawling), Medien-Parsing (PDF, DOCX) und Seiteninteraktion (Klicken, Scrollen, Eingeben). Es bietet eine API, SDKs für Python/Node/Go/Rust und ist bereits in verschiedene LLM-Frameworks (Langchain, Llama Index, Crew.ai) und Low-Code-Plattformen (Dify, Langflow, Flowise) integriert. Firecrawl bietet einen gehosteten API-Service sowie eine lokal ausführbare Open-Source-Version. (Quelle: GitHub)
KrillinAI: Videotranslations- und Synchronisationstool basierend auf großen Sprachmodellen: KrillinAI ist ein in Go geschriebenes Open-Source-Projekt, das große Sprachmodelle (LLM) nutzt, um professionelle Videoübersetzungs- und Synchronisationsdienste anzubieten. Es unterstützt eine Ein-Klick-Bereitstellung für den gesamten Prozess und kann den kompletten Workflow abwickeln: vom Video-Download (unterstützt yt-dlp und lokale Uploads), hochpräziser Untertitelerstellung (Whisper), intelligenter Untertitel-Segmentierung und -Ausrichtung (LLM), mehrsprachiger Übersetzung, Termersetzung, KI-Synchronisation und Stimmklonung (CosyVoice) bis hin zur Videosynthese (automatische Anpassung an Quer-/Hochformat). Ziel ist die Erstellung von Inhalten, die für Plattformen wie YouTube, TikTok, Bilibili usw. geeignet sind. Das Projekt bietet Desktop-Versionen für Win/Mac und eine Nicht-Desktop-Version (Web UI) und unterstützt die Docker-Bereitstellung. (Quelle: GitHub)
Second Me: Aufbau eines lokalisierten, personalisierten „KI-Selbst“: Second Me ist ein Open-Source-Projekt, das darauf abzielt, einen „digitalen Zwilling“ oder ein „KI-Selbst“ des Benutzers mithilfe lokal ausgeführter KI-Modelle zu erstellen. Es betont Datenschutz (vollständig lokale Ausführung) und Personalisierung durch hierarchische Gedächtnismodellierung (HMM) und eine „Me-Alignment“-Struktur, um die Identität, Erinnerungen, Werte und Denkweisen des Benutzers zu simulieren. Das Projekt unterstützt die Docker-Bereitstellung (macOS, Windows, Linux) und eine OpenAI-kompatible API-Schnittstelle und erforscht derzeit die Unterstützung für MLX-Training. Die Community ist aktiv und hat bereits Integrationen wie einen WeChat-Bot und Mehrsprachigkeitsunterstützung beigesteuert. Die Vision ist, KI zu einer Erweiterung der Fähigkeiten des Benutzers zu machen, nicht zu einem Anhängsel von Plattformen. (Quelle: Reddit r/LocalLLaMA)

EasyControl: LoRA-ähnliche Bedingungsinjektion für Diffusion-Modelle mit DiT-Architektur: EasyControl ist ein neu veröffentlichtes Open-Source-Framework, das darauf abzielt, das Problem fehlender ausgereifter Plugins (wie LoRA) für neuere Diffusion-Modelle zu lösen, die auf der DiT (Diffusion Transformer)-Architektur basieren. Es bietet ein leichtgewichtige Bedingungsinjektionsmodul, das es Benutzern ermöglicht, DiT-Modellen einfach LoRA-ähnliche Kontrollfähigkeiten hinzuzufügen, um Aufgaben wie Stiltransfer zu realisieren. Das Projekt demonstriert die Ergebnisse eines Modells, das mit 100 Bildern asiatischer Gesichter und ihren entsprechenden Ghibli-Stil-Bildern (generiert von GPT-4o) trainiert wurde, und unterstützt bereits die Integration mit ComfyUI. (Quelle: X)

XplainMD: Biomedizinische erklärbare KI-Pipeline, die GNN und LLM kombiniert: XplainMD ist eine quelloffene End-to-End-KI-Pipeline, die speziell für biomedizinische Wissensgraphen entwickelt wurde. Sie kombiniert Graph Neural Networks (R-GCN) für die Vorhersage multirelationaler Verknüpfungen (wie Medikament-Krankheit, Gen-Phänotyp-Beziehungen), verwendet GNNExplainer zur Modellerklärbarkeit, visualisiert Vorhersage-Subgraphen mit PyVis und nutzt das LLaMA 3.1 8B Instruct-Modell zur Erklärung der Vorhersagen in natürlicher Sprache und zur Plausibilitätsprüfung. Der gesamte Prozess ist in einer interaktiven Gradio-Anwendung implementiert, die darauf abzielt, Vorhersagen zu liefern und gleichzeitig zu erklären, „warum“, um die Vertrauenswürdigkeit und Nutzbarkeit von KI in sensiblen Bereichen wie der Präzisionsmedizin zu erhöhen. (Quelle: Reddit r/deeplearning, Reddit r/MachineLearning)
LaMPlace: Neue KI-gesteuerte Methode zur Optimierung des Layouts von Chip-Makrozellen: Forscher der University of Science and Technology of China, des Huawei Noah’s Ark Lab und der Tianjin University stellen LaMPlace vor, eine KI-basierte Methode zur Optimierung des Layouts von Chip-Makrozellen. Die Methode verwendet einen strukturierten Metrik-Prädiktor (der den Einfluss des Abstands zwischen Makros auf Metriken wie WNS/TNS über verschiedene Phasen hinweg mithilfe von Laurent-Polynomen modelliert) und einen lernbaren Maskengenerierungsmechanismus, um Platzierungsentscheidungen bereits in frühen Phasen des Layouts zu steuern und so die endgültige Chipleistung (PPA) zu optimieren. LaMPlace zielt darauf ab, die Optimierungsziele von leicht berechenbaren Zwischenmetriken (wie Leitungslänge, Dichte) auf die endgültigen Designziele zu verlagern („Left-Shift-Optimierung“), um die Designeffizienz zu steigern. Die Methode wurde für einen Oral-Vortrag auf der ICLR 2025 ausgewählt. (Quelle: 微信公众号)
Google stellt Agent Development Kit (ADK) und Firebase Studio vor: Als Teil seiner Bemühungen, das Ökosystem für AI Agents voranzutreiben, hat Google das Agent Development Kit (ADK) veröffentlicht, ein Entwicklungsframework zum Erstellen von Multi-Agenten-Systemen. ADK unterstützt mehrere Modellanbieter (Gemini, GPT-4o, Claude, Llama usw.), bietet CLI-Tools, Artefaktverwaltung, AgentTool (für Aufrufe zwischen Agents) und weitere Funktionen und unterstützt die Bereitstellung auf Agent Engine oder Cloud Run. Gleichzeitig hat Google Firebase Studio eingeführt, ein cloudbasiertes KI-Programmiertool, das das Gemini-Modell integriert und die gesamte Anwendungsentwicklung unterstützt, vom KI-Codieren über Kompilieren und Erstellen bis hin zur Bereitstellung von Cloud-Diensten. (Quelle: 微信公众号, Reddit r/LocalLLaMA)
OpenFOAMGPT: Nutzung chinesischer großer Modelle zur Kostensenkung bei CFD-Simulationen: Ein Team der University of Exeter (UK) und der Beihang University (China) hat das OpenFOAMGPT-Projekt aktualisiert. Ziel des Projekts ist es, Benutzern die Steuerung von Computational Fluid Dynamics (CFD)-Simulationen mittels natürlicher Sprache zu ermöglichen. Die neue Version integriert erfolgreich die chinesischen großen Modelle DeepSeek V3 und Qwen 2.5-Max. Bei vergleichbarer Leistung zu GPT-4o/o1 können die Kosten um bis zu 100-fach gesenkt werden. Darüber hinaus hat das Team mit dem QwQ-32B-Modell eine lokale Bereitstellung (in einer Single-GPU-Umgebung) realisiert, was Forschern und KMUs in China eine wirtschaftlichere und bequemere KI-gestützte CFD-Lösung bietet und die fachliche Einstiegshürde senkt. (Quelle: 微信公众号)
Slop Forensics Toolkit: Analysetool für wiederholte Inhalte in LLM-Ausgaben: Ein neues Open-Source-Toolkit wurde veröffentlicht, um „Slop“ – also übermäßig wiederverwendete Wörter und Phrasen – in den Ausgaben großer Sprachmodelle (LLM) zu analysieren. Das Tool verwendet stilometrische Analysen, um Vokabular und n-Gramme zu identifizieren, die im Vergleich zu menschlichem Schreiben häufiger vorkommen, und erstellt ein „Slop-Profil“ des Modells. Es greift auch auf Methoden der Bioinformatik zurück, indem es lexikalische Merkmale als „Mutationen“ betrachtet, um Ähnlichkeitsbäume zwischen verschiedenen Modellen abzuleiten. Das Tool soll Forschern helfen, die generativen Eigenschaften verschiedener LLMs sowie potenzielle Datenkontamination oder Trainingsverzerrungen zu verstehen und zu vergleichen. (Quelle: Reddit r/MachineLearning)
vLLM Inferenz-Framework fügt Unterstützung für Google TPU hinzu: Das beliebte Open-Source-Framework für die Inferenz und Bereitstellung großer Modelle, vLLM, hat die Unterstützung für Google TPU angekündigt. In Kombination mit der kürzlich von Google vorgestellten siebten Generation der TPU (Ironwood) bedeutet dieses Update, dass Entwickler vLLM nutzen können, um Modelle effizient auf Googles Hochleistungs-KI-Hardware zu inferieren und bereitzustellen. Dies trägt zur Erweiterung des TPU-Software-Ökosystems bei und bietet Benutzern mehr Hardware-Optionen. (Quelle: X)

📚 Lernen
CUHK, Tsinghua et al. schlagen SICOG-Framework vor, erforschen neuen Weg der Selbstevolution großer Modelle: Angesichts der Abhängigkeit großer Modelle von hochwertigen Vortrainingsdaten und der Erschöpfung von Datenressourcen schlagen Institutionen wie die Chinese University of Hong Kong (CUHK) und die Tsinghua University das SICOG (Self-Improving Systematic Cognition)-Framework vor. Dieses Framework konstruiert einen dreiteiligen Selbstevolutionsmechanismus aus „Post-Training Enhancement – Inference Optimization – Re-Pretraining Reinforcement“. Durch „Chain of Description“ (CoD) wird die strukturierte visuelle Wahrnehmung verbessert, „Structured Chain of Thought“ (CoT) stärkt das multimodale Reasoning, und durch selbstgenerierte Datenkreisläufe und Konsistenzfilterung wird die kognitive Fähigkeit des Modells kontinuierlich ohne menschliche Annotation verbessert. Experimente zeigen, dass SICOG die Leistung des Modells bei mehreren Aufgaben signifikant steigern, Halluzinationen reduzieren und eine gute Skalierbarkeit aufweisen kann, was neue Ansätze zur Lösung des Vortrainings-Engpasses und zum Übergang zu autonom lernender KI bietet. (Quelle: 微信公众号)
OpenAI veröffentlicht Open-Source-Benchmark BrowseComp zur Bewertung der Web-Browsing-Fähigkeiten von AI Agents: OpenAI hat den Benchmark-Test BrowseComp (Browsing Competition) veröffentlicht und als Open Source bereitgestellt. Dieser Benchmark zielt darauf ab, die Fähigkeit von AI Agents zu bewerten, im Internet zu surfen, um schwer auffindbare Informationen zu finden, ähnlich einem Online-Schatzsuchspiel für Agents. OpenAI ist der Ansicht, dass solche Tests die entscheidenden Fähigkeiten von Agenten für tiefgreifendes, forschungsorientiertes Browsing erfassen und für die Bewertung des Intelligenzniveaus fortgeschrittener Web-Browsing-Agents unerlässlich sind. (Quelle: X, X)
Studie findet heraus: Reasoning-Modelle generalisieren besser bei OOD-Codierungsaufgaben: Eine neue Studie (arXiv:2504.05518v1) verglich die Generalisierungsfähigkeiten von Reasoning-Modellen und Nicht-Reasoning-Modellen anhand von Codierungsaufgaben. Die Ergebnisse zeigen, dass Reasoning-Modelle beim Übergang von In-Distribution-Aufgaben zu Out-of-Distribution (OOD)-Aufgaben keinen signifikanten Leistungsabfall aufwiesen, während Nicht-Reasoning-Modelle einen Leistungsabfall zeigten. Dies deutet darauf hin, dass Reasoning-Modelle mehr als nur Mustererkenner sind; sie können lernen und auf Aufgaben außerhalb ihrer Trainingsverteilung generalisieren und verfügen über stärkere Abstraktions- und Anwendungsfähigkeiten. (Quelle: Reddit r/ArtificialInteligence)
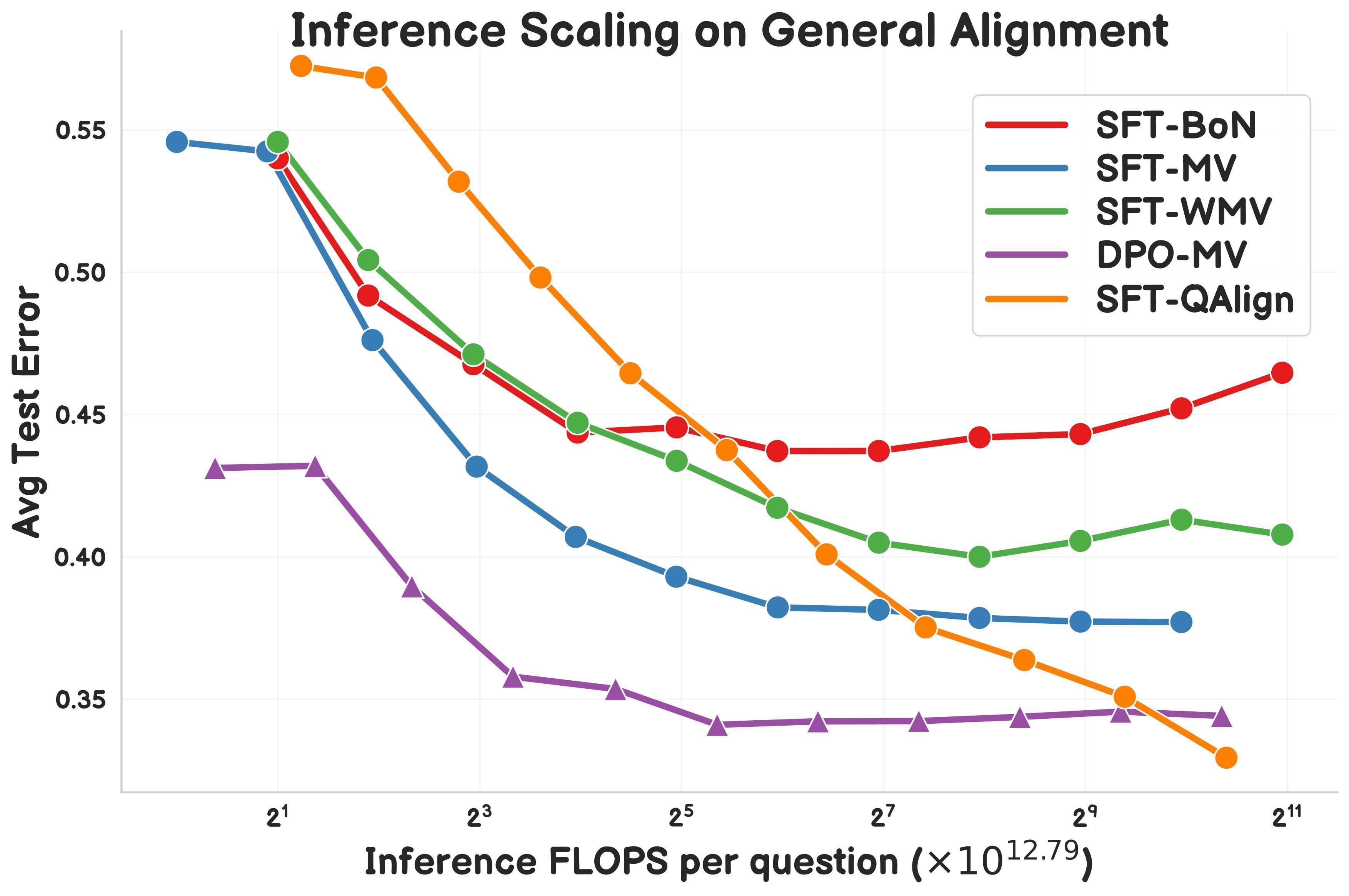
Studie stellt QAlign vor: MCMC-basierte Test-Time-Alignment-Methode: Gonçalo Faria et al. stellen QAlign vor, eine neue Test-Time-Alignment-Methode, die Markov-Chain-Monte-Carlo (MCMC) verwendet, um die Leistung von Sprachmodellen zu verbessern, ohne das Modell neu trainieren zu müssen. Die Studie zeigt, dass QAlign Modelle übertrifft, die mit DPO (Direct Preference Optimization) feinabgestimmt wurden (bei gleichem Inferenz-Rechenaufwand), und die Einschränkungen des traditionellen Best-of-N-Samplings (Tendenz zur Überoptimierung des Belohnungsmodells) und der Mehrheitsabstimmung (kann keine einzigartigen Antworten finden) überwinden kann. Es wird erwartet, dass es für Szenarien wie die Generierung hochwertiger Daten eingesetzt werden kann. (Quelle: X)
Yann LeCun betont erneut die Grenzen autoregressiver LLMs: In einem kürzlichen Vortrag bekräftigte Yann LeCun, Chief AI Scientist bei Meta, seine Ansicht über die Grenzen der derzeit vorherrschenden autoregressiven (Auto-Regressive) Architekturen großer Sprachmodelle und bezeichnete deren Muster als „zum Scheitern verurteilt“ (doomed). Er argumentiert, dass diese wortweise Vorhersagemethode die Fähigkeit der Modelle zu echter Planung und tiefem Reasoning einschränkt. Obwohl autoregressive Modelle derzeit noch State-of-the-Art sind, erforschen LeCun und andere Forscher aktiv Alternativen wie Joint Embedding Predictive Architectures (JEPA), um KI-Systeme zu realisieren, die der menschlichen Intelligenz näher kommen. (Quelle: Reddit r/MachineLearning)
LlamaIndex demonstriert die Erstellung eines Berichtsgenerierungs-Agents in Kombination mit Google Cloud: LlamaIndex-Gründer Jerry Liu demonstrierte auf der Google Cloud Next ’25, wie man durch die Kombination von LlamaIndex-Workflows und Google Cloud-Datenbanken (wie BigQuery, AlloyDB) einen Berichtsgenerierungs-Agent erstellen kann. Dieser Agent kann SOP-Dokumente (mit LlamaParse), Tutorial-Datenbanken, juristische Daten usw. analysieren, um personalisierte Onboarding-Leitfäden für neue Mitarbeiter zu erstellen. Dies verdeutlicht, dass wissensbasierte Agenten-Architekturen leistungsstarke Datenzugriffs- und Verarbeitungsfähigkeiten erfordern, und zeigt die Rolle von LlamaIndex bei der Erstellung solcher Agentenanwendungen. (Quelle: X)

Forscher teilt Symbolic Compression Engine und .sym-Dateiformat: Ein unabhängiger Forscher hat eine Engine namens Symbolic Compression und das dazugehörige .sym-Dateiformat als Open Source veröffentlicht. Das Projekt behauptet, Kompression durch Extrahieren der rekursiven Regeln und strukturellen Logik hinter Sequenzen (wie Primzahlen, Fibonacci-Folge) durchführen zu können (basierend auf dem vorgeschlagenen Miller’s Law: κ(x) = ((ψ(x) – x)/x)²), anstatt nur die Rohdaten zu komprimieren. Es zielt darauf ab, das Auftreten der Struktur selbst zu speichern und vorherzusagen und bietet ein Format ähnlich wie JSON, aber für rekursive Logik. Das Projekt umfasst CLI-Tools und Funktionen zur Kompression über mehrere Regionen. (Quelle: Reddit r/MachineLearning)

💼 Wirtschaft
Grok-3 API-Preise veröffentlicht, ab 0,3 USD/Million Tokens: xAI hat die Grok 3 Serien-API offiziell für die Öffentlichkeit zugänglich gemacht und verfolgt eine gestaffelte Preisstrategie. Grok 3 (Beta) richtet sich an Unternehmensanwendungen mit einem Eingabepreis von 3 USD/Million Tokens und einem Ausgabepreis von 15 USD/Million Tokens; das leichtgewichtige Grok 3 Mini (Beta) kostet 0,3 USD/Million Tokens für die Eingabe und 0,5 USD/Million Tokens für die Ausgabe. Beide bieten auch eine schnellere Version (fast-beta) zu einem höheren Preis an. Diese Preisstrategie positioniert es im Wettbewerb mit Modellen wie Google Gemini 2.5 Pro, dem Anthropic Claude Max-Paket (mindestens 100 USD) und Meta Llama 4 Maverick (ca. 0,36 USD/Million Tokens) hinsichtlich der Kosten. (Quelle: 微信公众号)
Stanford AI Report: Alibaba auf Platz 3 der globalen KI-Stärke, Kluft zwischen China und USA verringert sich: Der neueste „Artificial Intelligence Index Report 2025“ der Stanford University zeigt, dass bei den Beiträgen zu wichtigen großen Modellen weltweit Google und OpenAI mit jeweils 7 Modellen den ersten Platz teilen, während Alibaba mit 6 Modellen (Qwen-Serie) weltweit auf Platz drei und in China auf Platz eins liegt. Der Bericht stellt fest, dass sich der Leistungsunterschied zwischen chinesischen und US-amerikanischen Modellen signifikant verringert hat, von 17,5 Prozentpunkten (MMLU-Benchmark) Ende 2023 auf 0,3 Prozentpunkte Ende 2024. Die Alibaba Qwen-Modellfamilie (über 200 Modelle bereits Open Source) ist zur weltweit größten Open-Source-Modellreihe geworden, mit über 100.000 abgeleiteten Modellen. Der Bericht erwähnt auch, dass Chinas Top-Modelle (wie Qwen2.5, DeepSeek-V3) im Allgemeinen weniger Rechenleistung für das Training benötigen als vergleichbare US-Modelle, was auf eine höhere Effizienz hindeutet. (Quelle: 微信公众号)
Chinesische Medizintechnik-KI-Unternehmen suchen Durchbruch angesichts von Zöllen und technischen Barrieren: Angesichts des zunehmenden Drucks durch US-Zölle und technologische Monopole (z. B. Kontrolle von Bilddaten-Schnittstellen durch GPS-Giganten) beschleunigen chinesische Medizintechnikunternehmen die heimische Substitution und die intelligente Transformation. United Imaging Healthcare setzt auf Eigenentwicklung von Kerntechnologien, bringt High-End-Geräte wie 5.0T MRT auf den Markt und entwickelt medizinische große Modelle und intelligente Agenten. Mindray Medical baut durch eine „Geräte + IT + KI“-Strategie ein digitalisiertes Ökosystem auf (z. B. Ruiying Cloud++ Plattform mit DeepSeek-Integration) und erschließt intensiv internationale Märkte. Deshi Bio dringt mit dem iMedImage® Medical Imaging Large Model in die Präzisionsmedizin vor, beteiligt sich an der Entwicklung von Industriestandards und setzt auf Differenzierung im Wettbewerb. Diese Unternehmen nutzen KI als treibende Kraft, um Durchbrüche bei Kerntechnologien, Lieferketten und klinischer Akzeptanz zu erzielen und die Marktlandschaft neu zu gestalten. (Quelle: 微信公众号)
🌟 Community
Anwendung von KI im Bildungsbereich löst Diskussionen aus: Community-Diskussionen konzentrieren sich darauf, wie künstliche Intelligenz (KI) durch maßgeschneiderte Lernpläne die Bildung verändern kann. KI hat das Potenzial, Lehrmaterialien und -methoden an die individuellen Bedürfnisse, das Lerntempo und den Stil der Schüler anzupassen, um personalisierte Bildung zu ermöglichen und die Lerneffizienz und -effektivität zu steigern. (Quelle: X)

Komplexe Technik hinter dem Cursor-Editor weckt Interesse: In der Community wird diskutiert, dass die Implementierung des KI-Code-Editors Cursor keine leichte Aufgabe ist. Das Kernziel ist es, manuelles Kopieren und Einfügen von Code durch den Benutzer zu vermeiden. Dafür wurden umfangreiche Optimierungen der Benutzererfahrung und technische Innovationen vorgenommen, darunter die Erfindung neuer Code-Bearbeitungsparadigmen, die Eigenentwicklung des schnellen Bearbeitungsmodells FastApply und des Code-Vervollständigungs-Vorhersagemodells Fusion sowie die Implementierung eines zweistufigen RAG auf lokaler und Serverseite zur Optimierung der Kontextverarbeitung. Diese Bemühungen zeigen die technische Tiefe, die für die Schaffung einer reibungslosen KI-Programmiererfahrung erforderlich ist. (Quelle: X)
KI-Betrugstool löst Ethik- und Einstellungsdebatte aus: Roy Lee, ein Student der Columbia University, entwickelte das KI-Tool „Interview Coder“, um bei Programmierinterviews zu betrügen. Nachdem er Angebote von mehreren Top-Unternehmen erhalten hatte, wurde er von der Universität exmatrikuliert und verdiente anschließend durch den Verkauf des Tools in 50 Tagen 2,2 Millionen US-Dollar. Das Tool kann unsichtbar laufen und Antworten generieren, die menschlichen Codierungsstil imitieren. Der Vorfall löste eine breite Diskussion aus: Einerseits sind viele Entwickler unzufrieden mit starren, praxisfernen Programmierinterviews (wie LeetCode-Übungen); andererseits stellt die Zunahme von KI-Betrug (Berichten zufolge stieg der Anteil von 2% auf 10%) die Wirksamkeit bestehender technischer Interviews in Frage, könnte Unternehmen zwingen, ihre Einstellungsprozesse neu zu gestalten, und wirft ethische Fragen zur Definition von „Betrug“ im KI-Zeitalter auf. (Quelle: 36氪)
Innovative Anwendungen für allgemeine Agenten entstehen: Bei kürzlichen Agent-Hackathons (wie flowith, openmanus) sind viele innovative Anwendungen entstanden. Im Bereich Entwicklung & Design: Agenten können basierend auf UI-Skizzen automatisch vollständige Projekte mit Frontend-, Backend-Code und Datenbankstruktur generieren (maxcode) oder selbstständig Informationen sammeln, einen Stil festlegen und eine persönliche Website erstellen. Im Bereich Analyse & Entscheidung: Agenten können die beste Position zur Beobachtung von Polarlichtern auf einem Flug berechnen oder selbstiterative quantitative Handelsstrategien optimieren (一鹿向北). Im Bereich personalisierte Dienste: Agenten können intelligent Treffpunkte vorschlagen (Jarvis-CafeMeet), Douban-Daten analysieren und einen „Geschmacksbericht“ erstellen oder ältere Benutzer über Sprachinteraktion bedienen (老奶奶教你用OpenManus). Im Bereich künstlerische Kreation: Agenten können digitale Kunst in einem bestimmten Stil generieren, Tänze basierend auf Musik erstellen, benutzerdefinierte Malpinsel anfertigen, programmierbare Musik in Echtzeit generieren (strudel-manus) usw. Diese Beispiele zeigen das enorme Potenzial von Agenten in verschiedenen Bereichen. (Quelle: 微信公众号)
Andrew Ng kommentiert Auswirkungen von US-Zöllen auf die KI-Entwicklung: Andrew Ng äußerte sich besorgt über die breit angelegten hohen Zölle der USA und argumentierte, dass diese die Beziehungen zu Verbündeten schädigen, die Weltwirtschaft behindern, Inflation erzeugen und sich negativ auf die KI-Entwicklung auswirken würden. Er wies darauf hin, dass der freie Fluss von Ideen und Software (insbesondere Open Source) zwar möglicherweise nicht stark beeinträchtigt wird, Zölle jedoch den Zugang zu KI-Hardware (wie Server, Kühlung, Netzwerkgeräte) einschränken, die Kosten für den Bau von Rechenzentren erhöhen und indirekt die Versorgung mit Rechenleistung durch Beeinträchtigung der Importe von Stromversorgungsanlagen beeinflussen. Obwohl Zölle die heimische Nachfrage nach Robotik und Automatisierung leicht ankurbeln könnten, könne dies die Defizite im verarbeitenden Gewerbe kaum ausgleichen. Er rief die KI-Community auf, internationale Zusammenarbeit und Austausch aufrechtzuerhalten. (Quelle: X)
Community diskutiert Einsatz von KI zur Unterstützung der psychischen Gesundheit: Immer mehr Benutzer teilen ihre Erfahrungen mit der Nutzung von KI-Tools wie ChatGPT für psychologische Beratung und emotionale Unterstützung. Viele berichten, dass KI einen sicheren, urteilsfreien Raum zum Reden bietet, sofortiges Feedback und nützliche Ratschläge liefert und sich in manchen Fällen sogar besser angehört und verstanden fühlen lässt als menschliche Therapeuten, was zu positiven emotionalen Entlastungseffekten führt. Obwohl die Benutzer allgemein zustimmen, dass KI professionelle, lizenzierte Therapeuten nicht vollständig ersetzen kann, insbesondere bei der Behandlung schwerwiegender psychischer Probleme, zeigt sie großes Potenzial bei der Bereitstellung grundlegender Unterstützung, der Bewältigung von Alltagsstress und der ersten Erkundung persönlicher Probleme und wird wegen ihrer Zugänglichkeit und geringen Kosten geschätzt. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Qualifizierung von KI-übersetzten Inhalten löst Diskussion aus: In der Community wurde die Frage diskutiert: Wenn eine von Menschen geschriebene Geschichte mit KI (wie ChatGPT) übersetzt wird, sollte der Inhalt dann als menschliche Schöpfung oder als KI-Schöpfung betrachtet werden? Eine Ansicht ist, dass der Inhalt im Wesentlichen menschlich bleibt, wenn die KI nur als Übersetzungswerkzeug dient und die ursprünglichen Gedanken, die Struktur und den Ton nicht verändert. KI-Texterkennungs-Tools könnten ihn jedoch aufgrund der Analyse von Textmustern als KI-generiert markieren. Dies wirft Fragen zur Rollendefinition von KI im kreativen Prozess, zu den Grenzen von KI-Detektoren und dazu auf, wie der Stil des Originals bei der Übersetzung beibehalten werden kann. (Quelle: Reddit r/ArtificialInteligence)
Benutzer meldet Probleme mit Gemini 2.5 Pro bei der Verarbeitung langer Kontexte: Benutzer Nathan Lambert stellte beim Testen von Gemini 2.5 Pro fest, dass das Modell bei Anfragen mit sehr langen Kontexteingaben auf Verbindungsfehler stößt. Das beobachtete Phänomen war, dass das Modell während der Inferenz anscheinend fast alle Eingabe-Tokens neu generierte, was zu extrem hohen Inferenzkosten und schließlich zum Scheitern führte. Außerdem wies er darauf hin, dass er bei Auftreten von Fehlern die Gemini-Chat-Verläufe nicht teilen konnte. Diese Rückmeldungen deuten auf mögliche Stabilitäts- und Effizienzprobleme aktueller Modelle bei der Verarbeitung sehr langer Kontexte hin. (Quelle: X)

Community reagiert verhalten auf Llama 4-Veröffentlichung, stellt Leistung und Offenheit in Frage: Die von Meta veröffentlichte Llama 4-Modellreihe löste in der Community breite Diskussionen und negative Bewertungen aus. Benutzer sind allgemein der Meinung, dass das Maverick-Modell trotz eines Kontextfensters von bis zu 10 Millionen Tokens und akzeptabler Leistung bei Funktionsaufrufen mit seinen 400 Mrd. Gesamtparametern (17 Mrd. aktivierte Parameter) nicht die erwartete Steigerung der Reasoning-Leistung bringt und sogar Modellen wie QwQ 32B unterlegen ist. Darüber hinaus haben die restriktive Lizenz, das Fehlen technischer Papiere und Systemkarten sowie der Vorwurf des „Benchmark-Gamings“ auf Plattformen wie LMSYS dem Ruf von Meta in der Open-Source-Community geschadet. Die Community zeigt sich enttäuscht darüber, dass Meta nicht an die Offenheit und Führungsrolle von Llama 3 anknüpfen konnte. (Quelle: Reddit r/LocalLLaMA)

Claude Pro-Plan als verstecktes Downgrade kritisiert, Benutzer beschweren sich über erhöhte Nutzungslimits: Mit der Einführung des teureren Max-Pakets durch Anthropic (das angeblich die 5- oder 20-fache Nutzung des Pro-Plans bietet) berichten viele Claude Pro-Benutzer in der Community, dass die Nutzungslimits des Pro-Plans selbst strenger geworden zu sein scheinen und leichter erreicht werden. Benutzer vermuten, dass Anthropic möglicherweise das tatsächlich verfügbare Kontingent des Pro-Plans reduziert hat, um Benutzer zum Upgrade auf den Max-Plan zu bewegen. Diese intransparente Anpassung und die wahrgenommene Serviceverschlechterung haben zu Unzufriedenheit bei den Benutzern geführt, insbesondere da das Claude-Modell selbst immer noch Probleme mit dem Kontextfenster-Gedächtnis hat. (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

OpenWebUI Community diskutiert Funktionen und Probleme: OpenWebUI-Benutzer diskutieren in der Community über die Funktionen des Tools und aufgetretene Probleme. Ein Benutzer fragt, ob es möglich ist, Nextcloud als zusätzliche Cloud-Speicheroption zu integrieren. Ein anderer Benutzer berichtet von Problemen bei der Nutzung der Wissensdatenbankfunktion: Beim Hochladen mehrerer Dokumente scheint das LLM nur das erste Dokument zu berücksichtigen. Wieder ein anderer Benutzer stößt auf Timeout-Fehler beim Versuch, eine Verbindung zu einem Gemini-kompatiblen OpenAI API-Endpunkt herzustellen. Diese Diskussionen spiegeln die Bedürfnisse und Bedenken der Benutzer hinsichtlich der Erweiterbarkeit und Stabilität des Tools wider. (Quelle: Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Suno AI Community tauscht Nutzungstipps und Probleme aus: Die Suno AI-Benutzergemeinschaft ist aktiv und diskutiert Themen wie: Wie man bei der Verwendung der Cover-Funktion bestimmte Instrumente (wie Schlagzeug, Keyboards) ausschließt, um Soloinstrumente zu isolieren; Suche nach Ratschlägen zur Erzeugung bestimmter Musikstile (wie Trip Hop); Meldung von Problemen mit der Freundschaftswerbungsfunktion, bei der keine Credits gutgeschrieben werden; Diskussion über Urheberrechtsfragen bei Texten, z. B. ob bestimmte Phrasen (wie „You’re Dead“) Urheberrechtsbeschränkungen auslösen; und Teilen von Anwendungsfällen für kreative Nutzungen von Suno, wie das Erstellen von Hintergrundmusik für D&D-Charaktere. (Quelle: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)
💡 Sonstiges
Erkundung von KI-generierten „zufälligen Fotos“: Community-Benutzer versuchen, mit KI Bilder zu generieren, die wie unbeabsichtigt aufgenommen aussehen, mit zufälliger Komposition und sogar leichter Unschärfe oder Überbelichtung. Diese Erkundung zielt darauf ab, die Tendenz der KI zur Erzeugung perfekter Bilder herauszufordern und die Zufälligkeit und Unvollkommenheit menschlicher Fotografie nachzuahmen. Sie zeigt die Fähigkeit der KI, spezifische Fotostile (einschließlich „schlechter“ Fotostile) zu verstehen und zu simulieren. (Quelle: Reddit r/ChatGPT)

Potenzial von KI im Supply Chain Management: Diskussionen heben das Potenzial der künstlichen Intelligenz (KI) zur Verbesserung der Rückverfolgbarkeit und Transparenz in der Lieferkette hervor. Durch den Einsatz von maschinellem Lernen und Datenanalyse kann KI Unternehmen helfen, Warenströme besser zu überwachen, Unterbrechungsrisiken vorherzusagen, das Bestandsmanagement zu optimieren und Verbrauchern zuverlässigere Informationen zur Produktherkunft zu liefern. (Quelle: X)

Erkundung des Einsatzes von KI im Personalwesen: In der Community wird die Möglichkeit diskutiert, KI-Avatare für das Personalmanagement einzusetzen. Dies könnte Aufgaben wie die Vorauswahl von Bewerbern, Mitarbeiterschulungen, Beantwortung von Richtlinienfragen und sogar emotionale Unterstützung umfassen, mit dem Ziel, die Effizienz von HR-Prozessen und die Mitarbeitererfahrung zu verbessern. (Quelle: X)

Bank of England warnt vor möglicher KI-induzierter Marktkrise: Die Bank of England warnt davor, dass künstliche Intelligenz-Software zur Marktmanipulation oder sogar zur absichtlichen Herbeiführung einer Marktkrise zum Zwecke des Profits eingesetzt werden könnte. Dies weckt Bedenken hinsichtlich der Regulierung und Risikokontrolle von KI-Anwendungen im Finanzsektor. (Quelle: Reddit r/artificial)

Neue Methode zur Generierung realistischer 3D-Formen durch KI: Forscher am MIT haben eine neue generative KI-Methode entwickelt, die realistischere dreidimensionale Formen erstellen kann. Dies ist von großer Bedeutung für Bereiche wie Produktdesign, virtuelle Realität, Spieleentwicklung und 3D-Druck und treibt den technologischen Fortschritt bei der Generierung komplexer 3D-Modelle aus 2D-Bildern oder Textbeschreibungen voran. (Quelle: X)

Stromverbrauch und Kosten für KI-Inferenz deutlich gesenkt: Berichten zufolge haben neue technologische Fortschritte den Stromverbrauch für KI-Inferenzaufgaben (gemessen am MAC-Energieverbrauch) um das 100-fache und die Kosten um das 20-fache gesenkt. Diese Effizienzsteigerung ist entscheidend für die Machbarkeit und Wirtschaftlichkeit von KI-Modellen auf Edge-Geräten, Mobilgeräten und bei groß angelegten Cloud-Bereitstellungen. (Quelle: X)

Diskussion über die Auswirkungen von KI auf die menschliche Kognition: Die Community diskutiert die möglichen Auswirkungen einer übermäßigen Abhängigkeit von KI auf das menschliche Gehirn. Einige Meinungen zitieren Artikeltitel, die behaupten, dies könne dazu führen, dass das Gehirn „verkümmert und unvorbereitet“ (Atrophied And Unprepared) sei. Dies spiegelt die Besorgnis wider, dass nach der Verbreitung von KI-Tools Kernkompetenzen wie kritisches Denken, Gedächtnis und Problemlösungsfähigkeiten des Menschen verkümmern könnten. (Quelle: X)

Ausblick und Bedenken hinsichtlich zukünftiger KI-gesteuerter Arbeitsmodelle: Die Community-Diskussion zitiert Artikelmeinungen, die vorhersagen, dass KI bis 2025 die Arbeitsregeln neu schreiben und die aktuellen Arbeitsmodelle beenden könnte. Dies löst Diskussionen und Bedenken über die Auswirkungen der KI-Automatisierung auf den Arbeitsmarkt, den Wandel der erforderlichen Fähigkeiten und neue Modelle der Mensch-Maschine-Kollaboration aus. (Quelle: X)
