
Schlüsselwörter:AI, LLM, AI Index Report, Photonen-AI-Prozessor, DeepCoder-14B-Modell, Claude 3.5 Haiku, Llama 4 Serie
🔥 Im Fokus
Stanford veröffentlicht den AI Index Report 2025: Die Stanford University hat den 456-seitigen „AI Index Report 2025“ veröffentlicht, der einen umfassenden Überblick über den aktuellen Stand und die Trends im Bereich KI gibt. Der Bericht stellt fest, dass die USA bei der Anzahl der veröffentlichten Modelle führend sind, China jedoch bei der Modellqualität schnell aufholt und der Leistungsunterschied sich deutlich verringert hat. Die Trainingskosten steigen weiter an (z. B. ca. 192 Millionen US-Dollar für Gemini 1.0 Ultra), während die Inferenzkosten rapide sinken. Das Problem der CO2-Emissionen durch KI wird immer ernster; das Training von Meta Llama 3.1 verursachte enorme Emissionen. Der Bericht erwähnt auch, dass viele AI-Benchmarks gesättigt sind und es schwierig ist, die Fähigkeiten von Modellen zu unterscheiden; der „Human Last Exam“ wird zur neuen Herausforderung. Das Crawling öffentlicher Daten ist eingeschränkt (48 % der Top-Level-Domains beschränken Crawler), was Bedenken hinsichtlich eines „Datenpeaks“ aufwirft. Unternehmen investieren massiv in KI, sehen aber noch keine signifikanten Produktivitätssteigerungen. KI hat großes Potenzial in Wissenschaft und Medizin, aber die praktische Anwendung braucht noch Zeit. Politisch ist die Gesetzgebung auf US-Bundesstaatenebene aktiv, insbesondere in Bezug auf Deepfakes, während auf globaler Ebene meist unverbindliche Erklärungen abgegeben werden. Trotz Bedenken hinsichtlich des Arbeitsplatzverlusts ist die öffentliche Einstellung gegenüber KI insgesamt eher optimistisch (Quelle: AINLPer)
Durchbruch bei neuartigem photonischem AI-Prozessor: Das Magazin Nature veröffentlichte zwei Artikel über neue AI-Prozessoren, die Photonik und Elektronik kombinieren, um die Leistungs- und Energieverbrauchsgrenzen der Post-Transistor-Ära zu überwinden. Der photonische Beschleuniger PACE des singapurischen Unternehmens Lightelligence (mit über 16.000 photonischen Komponenten) demonstrierte Rechengeschwindigkeiten von bis zu 1 GHz und eine 500-fache Reduzierung der minimalen Latenz und zeigte hervorragende Leistungen bei der Lösung des Ising-Problems. Der photonische Prozessor des US-Unternehmens Lightmatter (mit vier 128×128-Matrizen) führte erfolgreich AI-Modelle wie BERT und ResNet mit einer Genauigkeit aus, die mit elektronischen Prozessoren vergleichbar ist, und demonstrierte Anwendungen wie das Spielen von Pac-Man. Beide Studien zeigen, dass ihre Systeme skalierbar sind und mit bestehenden CMOS-Fertigungsanlagen hergestellt werden können, was die Entwicklung von AI-Hardware in Richtung höherer Leistung und Energieeffizienz vorantreiben und einen wichtigen Schritt zur praktischen Anwendung der photonischen Datenverarbeitung markieren könnte (Quelle: 36氪)

UC Berkeley veröffentlicht Open-Source 14B Code-Modell DeepCoder, vergleichbar mit o3-mini: UC Berkeley und Together AI haben gemeinsam DeepCoder-14B-Preview veröffentlicht, ein vollständig quelloffenes 14B-Parameter-Code-Inferenzmodell, dessen Leistung mit OpenAI’s o3-mini vergleichbar ist. Das Modell wurde durch verteiltes Reinforcement Learning (RL) aus Deepseek-R1-Distilled-Qwen-14B feinabgestimmt und erreicht im LiveCodeBench-Benchmark einen Pass@1 von 60,6 %. Das Team erstellte einen Trainingsdatensatz mit 24.000 hochwertigen Programmierproblemen und verwendete eine verbesserte GRPO+-Trainingsmethode, iterative Kontexterweiterung (von 16K auf 32K, zur Inferenzzeit 64K) und eine Ultra-Long-Filtertechnik. Gleichzeitig wurde das optimierte RL-Trainingssystem verl-pipeline als Open Source veröffentlicht, das die End-to-End-Trainingsgeschwindigkeit um das Zweifache erhöht. Diese Veröffentlichung umfasst nicht nur das Modell, sondern auch den Datensatz, den Code und die Trainingsprotokolle (Quelle: 新智元)
🎯 Trends und Entwicklungen
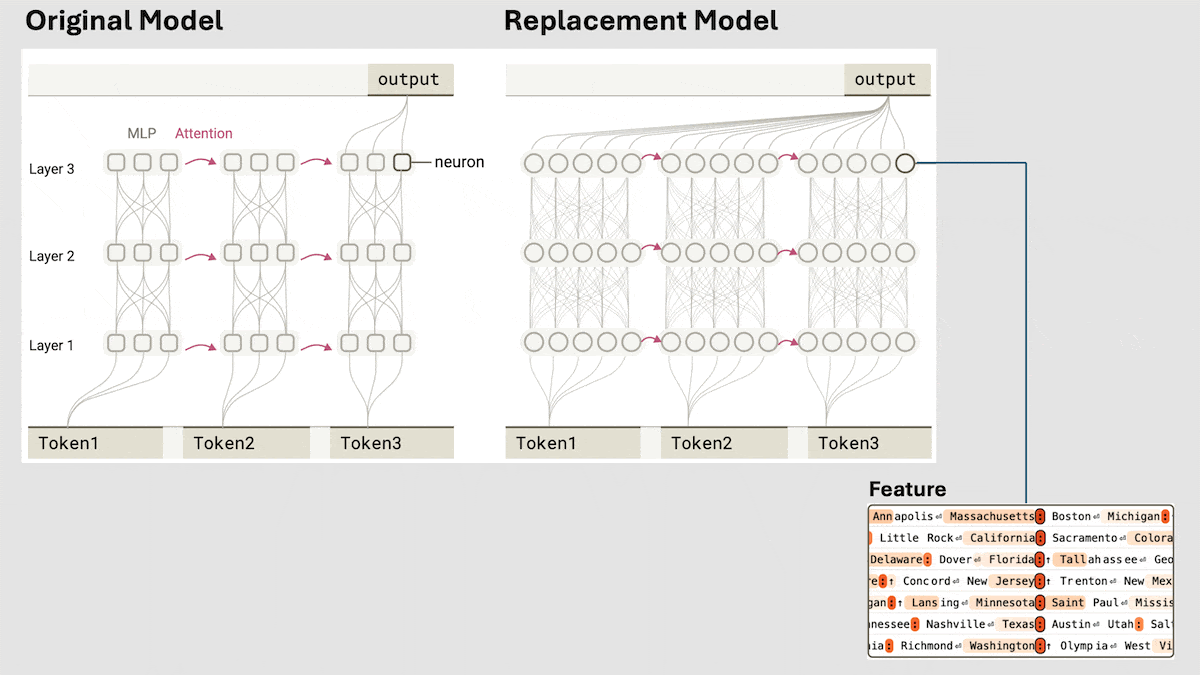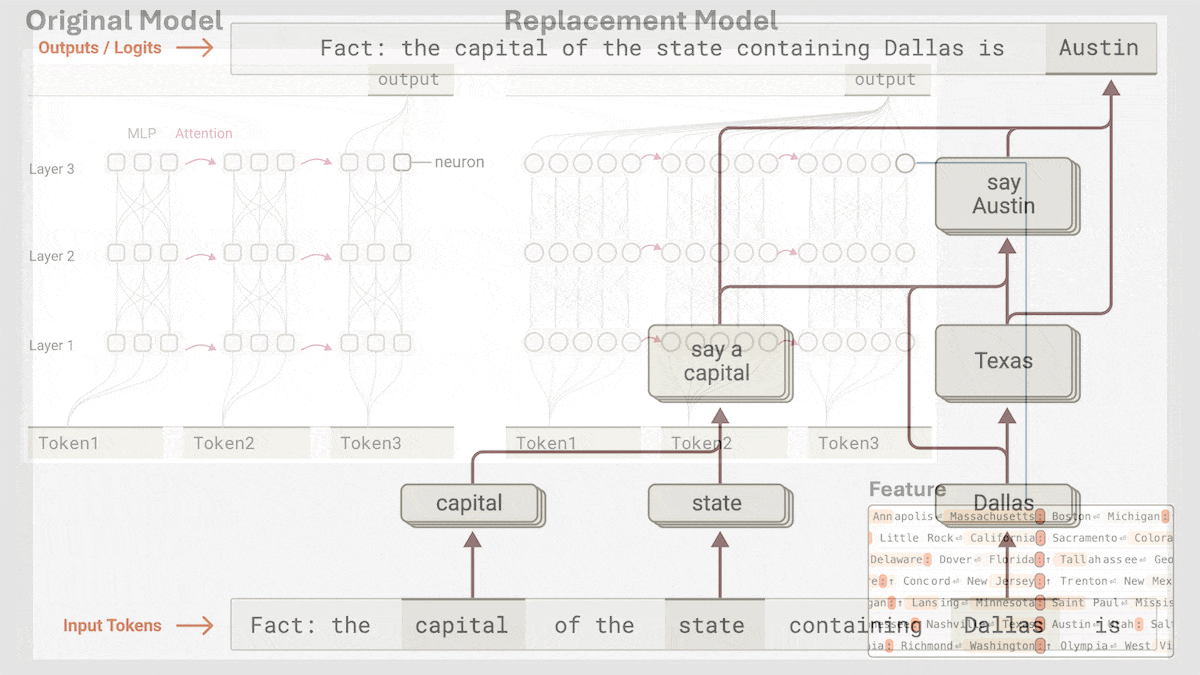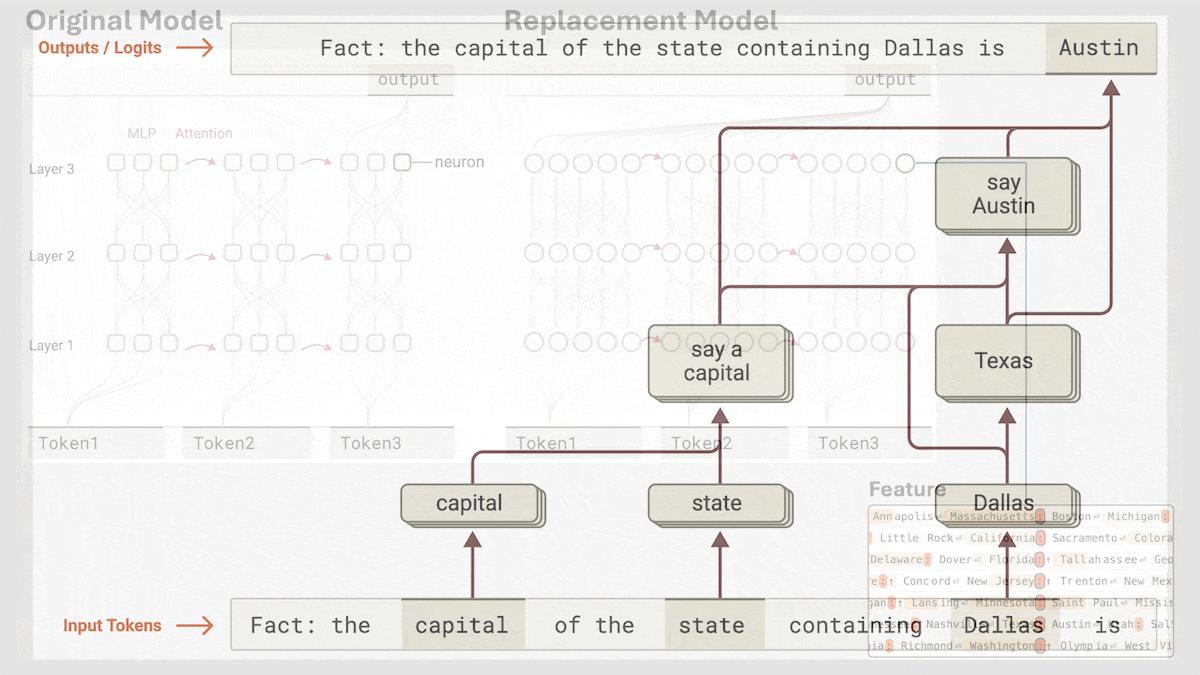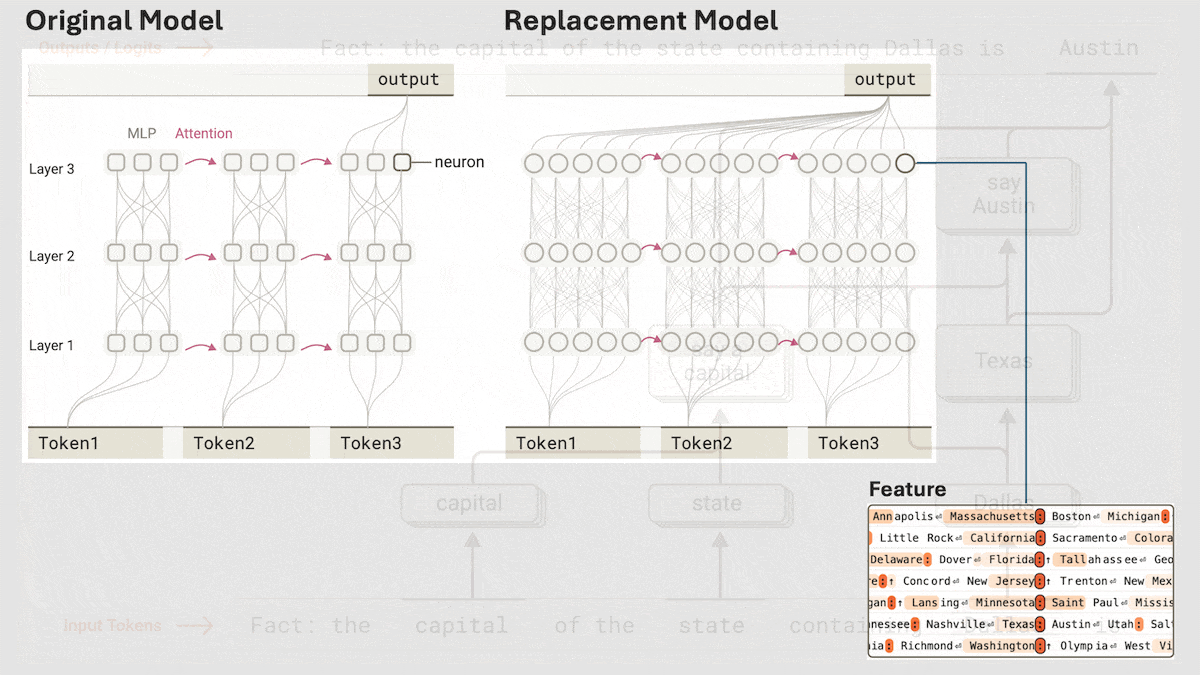
Anthropic enthüllt impliziten Reasoning-Mechanismus von Claude 3.5 Haiku: Ein Forschungsteam von Anthropic analysierte mit einer neuen Methode die interne Funktionsweise von Transformer-Modellen (insbesondere Claude 3.5 Haiku). Sie fanden heraus, dass das Modell, auch ohne explizites Training für Chain-of-Thought, während der Generierung von Antworten durch Neuronenaktivierung ähnliche Reasoning-Schritte aufweist. Die Methode ersetzt Fully-Connected-Layer durch interpretierbare „Cross-Layer Transcoder“, identifiziert „Features“, die mit spezifischen Konzepten oder Vorhersagen verbunden sind, und erstellt Attributionsgraphen zur Visualisierung des Informationsflusses. Experimente zeigten, dass das Modell bei der Beantwortung von Fragen (wie „Was ist das Gegenteil von klein?“ oder der Bestimmung der Hauptstadt des Bundesstaates von Dallas) intern mehrere logische Schritte durchläuft, anstatt die Antwort direkt vorherzusagen. Die Studie hilft, die interne Funktionsweise von LLMs zu verstehen und echte Reasoning-Fähigkeiten von oberflächlicher Nachahmung zu unterscheiden (Quelle: DeepLearning.AI)
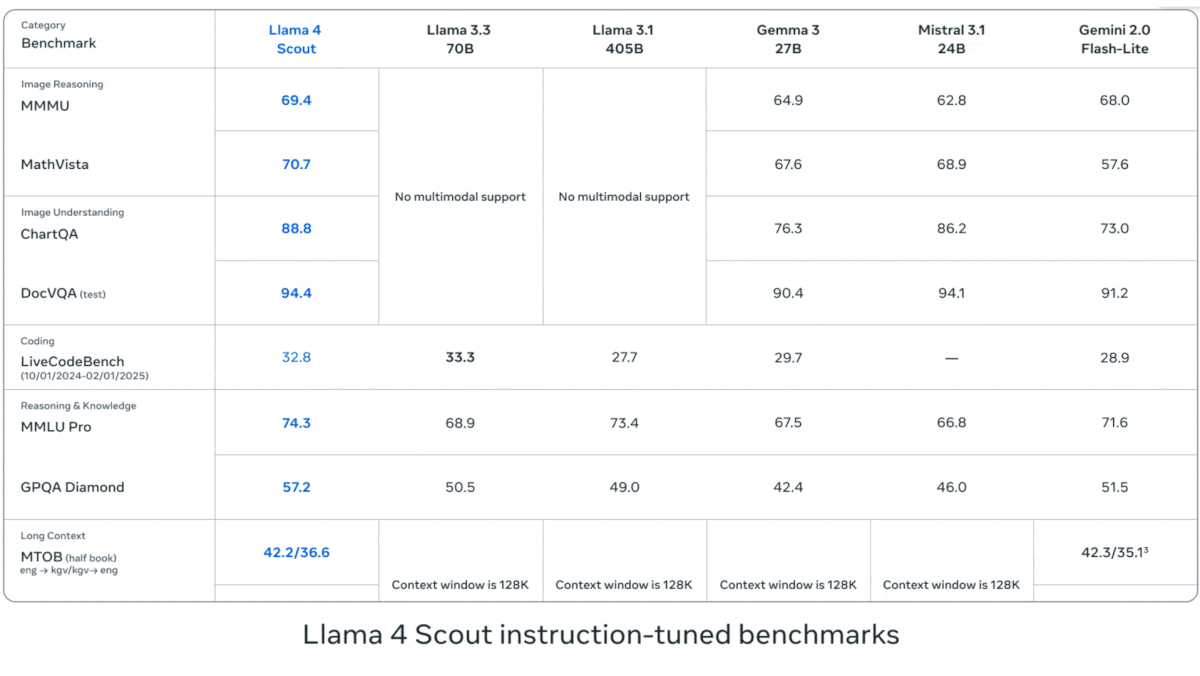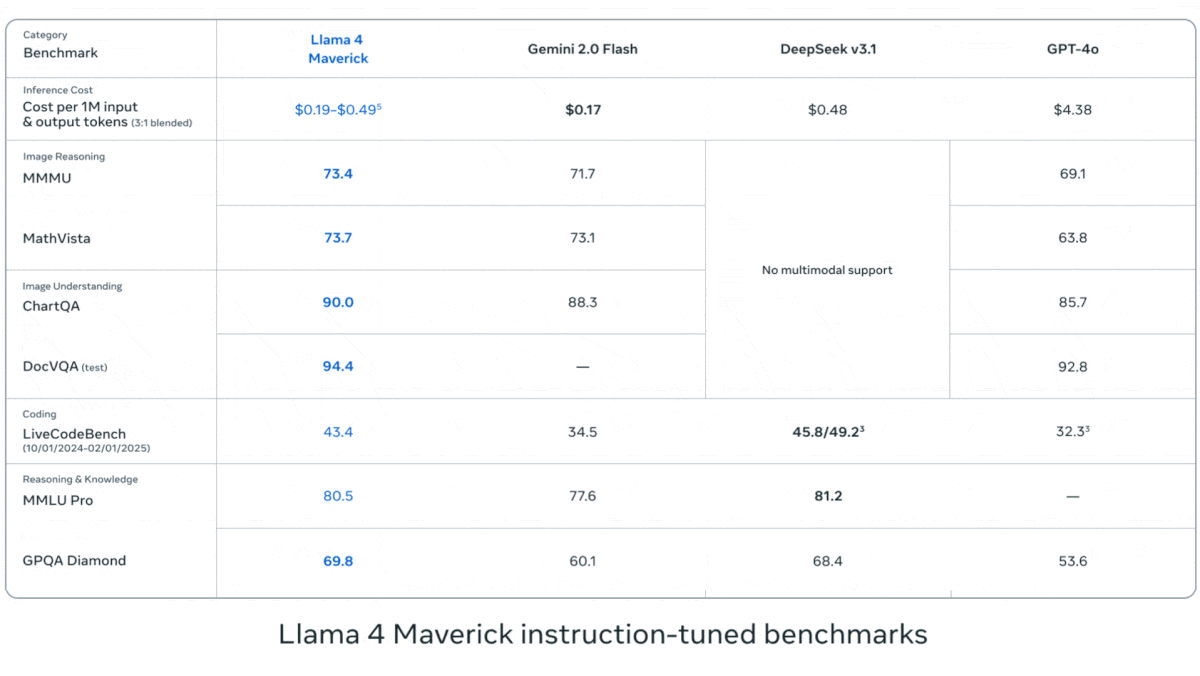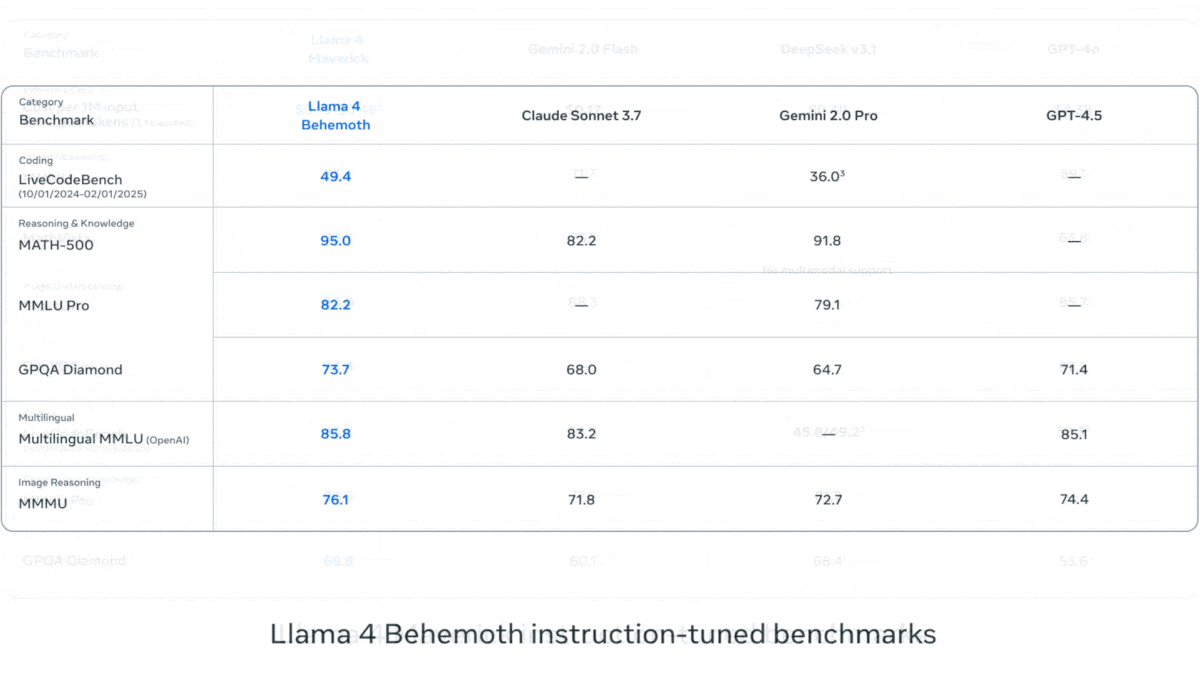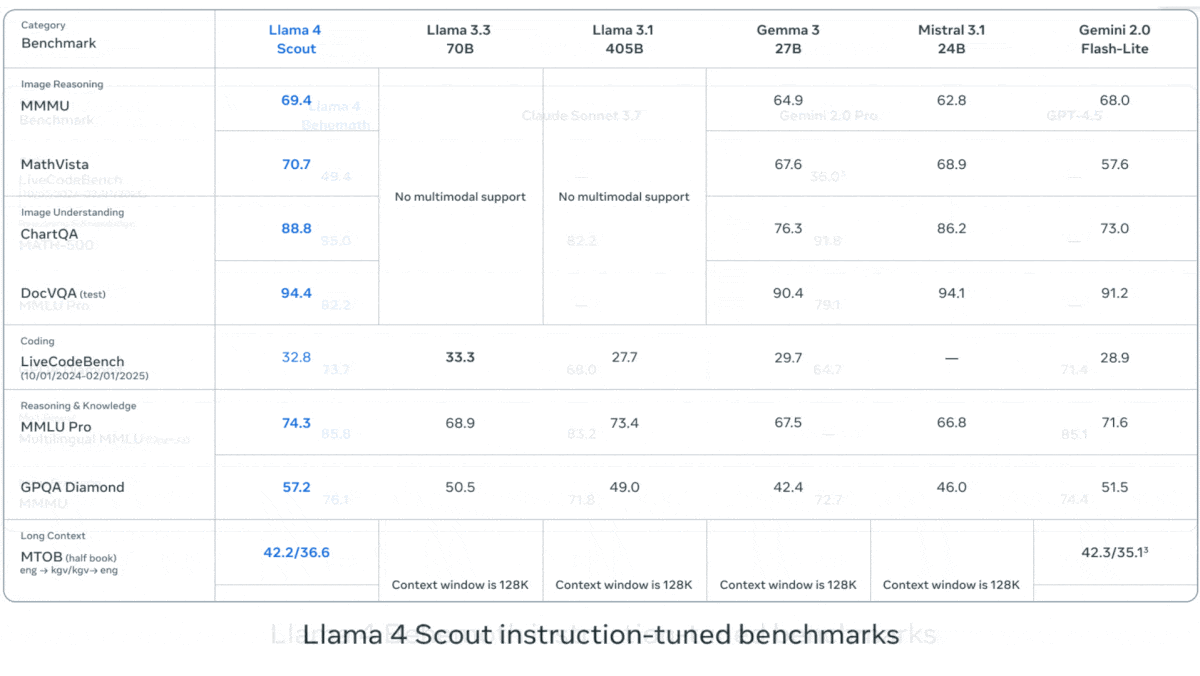
Meta veröffentlicht Llama 4 Serie von Vision-Language-Modellen: Meta hat zwei Open-Source-Multimodal-Modelle der Llama 4 Serie vorgestellt: Llama 4 Scout (109B Parameter, 17B aktiv) und Llama 4 Maverick (400B Parameter, 17B aktiv) und kündigte das fast 2T Parameter große Llama 4 Behemoth an. Diese Modelle verwenden alle eine MoE-Architektur, unterstützen Text-, Bild- und Videoeingaben sowie Textausgaben. Scout verfügt über ein Kontextfenster von bis zu 10M Token (obwohl die tatsächliche Wirksamkeit angezweifelt wird), Maverick über 1M. Die Modelle zeigen starke Leistungen in mehreren Benchmarks für Bildverarbeitung, Codierung, Wissen und Reasoning. Scout übertrifft Gemma 3 27B usw., Maverick übertrifft GPT-4o und Gemini 2.0 Flash, und frühe Behemoth-Versionen übertreffen GPT-4.5 usw. Die Veröffentlichung der Modelle treibt den Aufholprozess von Open-Source-Modellen gegenüber Closed-Source-Modellen weiter voran (Quelle: DeepLearning.AI, X @AIatMeta)
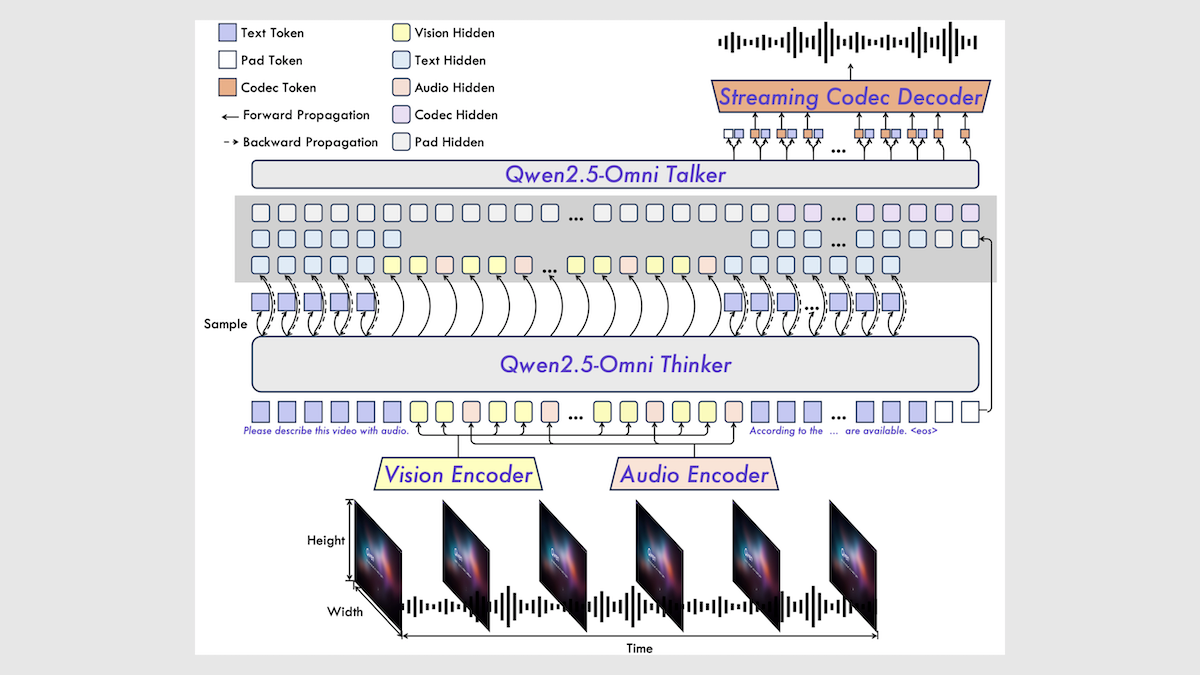
Alibaba veröffentlicht Qwen2.5-Omni 7B Multimodal-Modell: Alibaba hat das neue Open-Source-Multimodal-Modell Qwen2.5-Omni 7B veröffentlicht, das Text-, Bild-, Audio- und Videoeingaben verarbeiten und Text- sowie Sprachausgaben generieren kann. Das Modell basiert auf dem Qwen 2.5 7B Textmodell, dem Qwen2.5-VL Vision Encoder und dem Whisper-large-v3 Audio Encoder und verwendet eine innovative Thinker-Talker-Architektur. Das Modell zeigt in mehreren Benchmarks hervorragende Leistungen, insbesondere bei Audio-zu-Text-, Bild-zu-Text- und Video-zu-Text-Aufgaben erreicht es SOTA-Niveau, schneidet jedoch bei reinen Text- und Text-zu-Sprache-Aufgaben etwas schlechter ab. Die Veröffentlichung von Qwen2.5-Omni erweitert die Auswahl an leistungsstarken Open-Source-Multimodal-Modellen (Quelle: DeepLearning.AI)
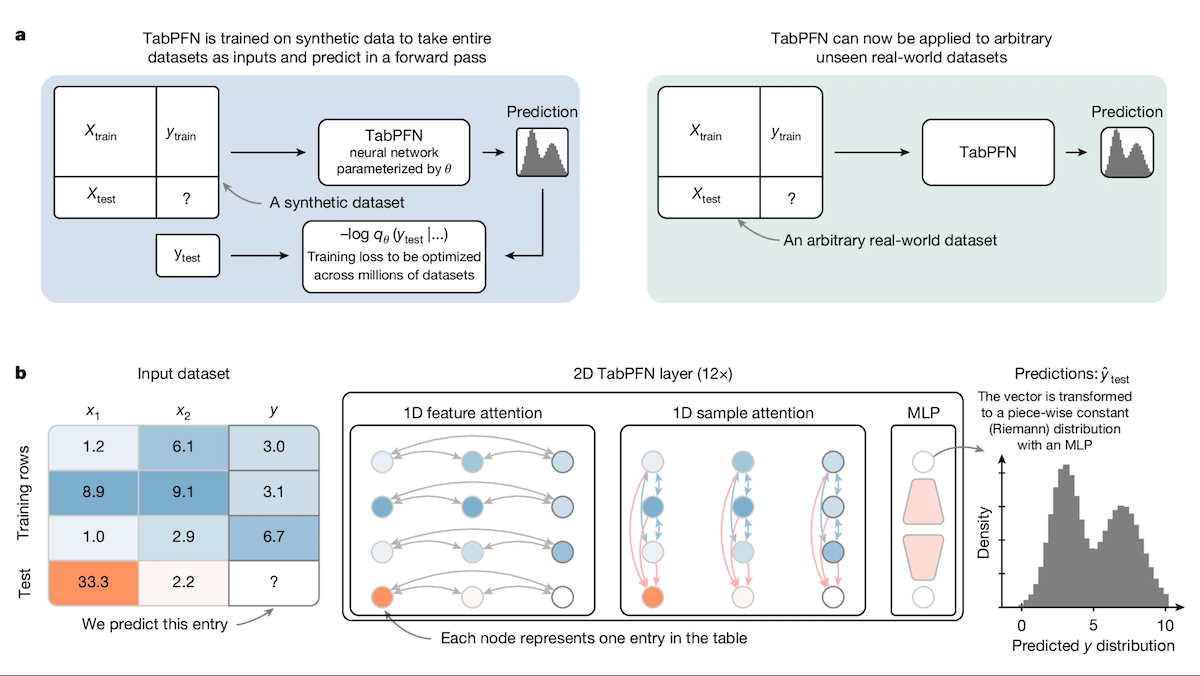
TabPFN: Transformer für tabellarische Daten übertrifft Entscheidungsbäume: Forscher der Universität Freiburg und anderer Institutionen haben Tabular Prior-data Fitted Network (TabPFN) vorgestellt, ein speziell für tabellarische Daten entwickeltes Transformer-Modell. Durch Vortraining auf 100 Millionen synthetischen Datensätzen lernt TabPFN, Muster über Datensätze hinweg zu erkennen, was es ermöglicht, direkt Klassifizierungs- und Regressionsvorhersagen auf neuen tabellarischen Daten zu treffen, ohne zusätzliches Training. Experimente zeigen, dass TabPFN in den AutoML- und OpenML-CTR23-Benchmarks bei Klassifizierungs- (AUC) und Regressionsaufgaben (RMSE) besser abschneidet als beliebte Gradient-Boosting-Tree-Methoden wie CatBoost, LightGBM und XGBoost, obwohl die Inferenzgeschwindigkeit langsamer ist. Diese Arbeit eröffnet neue Wege für Transformer im Bereich der Verarbeitung tabellarischer Daten (Quelle: DeepLearning.AI)
Intel-Plattform wird zur kostengünstigen neuen Wahl für AI-Komplettlösungen: Mit der Verbreitung von Open-Source-Modellen wie DeepSeek werden AI-Komplettlösungen zu einer beliebten Wahl für Unternehmen zur schnellen Bereitstellung von KI. Intel bietet mit seiner Kombination aus Arc™ Gaming-Grafikkarten (wie der A770) und Xeon® W Prozessoren eine kostengünstige Hardwarelösung, die den Preis von Komplettlösungen von Millionen- auf Hunderttausend-Yuan-Niveau senkt. Die Plattform unterstützt nicht nur DeepSeek R1, sondern auch Modelle wie Qwen und Llama. Mehrere Unternehmen wie Feizhiyun, SuperCloud und Yunjian haben bereits AI-Komplettlösungen oder -produkte auf Basis dieser Plattform für Szenarien wie Wissensdatenbank-Q&A, intelligente Kundenservices, Finanzberatung und Dokumentenverarbeitung auf den Markt gebracht, um den Bedarf kleiner und mittlerer Unternehmen sowie spezifischer Abteilungen an lokaler KI-Inferenz zu decken (Quelle: 量子位)
Google stellt siebte Generation TPU „Ironwood“ vor: Auf der Google Cloud Next Konferenz hat Google sein siebtes TPU-System Ironwood vorgestellt, das speziell für die AI-Inferenz optimiert ist. Im Vergleich zur ersten Generation Cloud TPU ist die Leistung von Ironwood um das 3600-fache und die Energieeffizienz um das 29-fache gestiegen. Im Vergleich zur sechsten Generation Trillium bietet Ironwood eine doppelt so hohe Leistung pro Watt, 192 GB Speicher pro Chip (6-mal mehr als Trillium) und eine 4,5-mal schnellere Datenzugriffsgeschwindigkeit. Ironwood wird voraussichtlich später in diesem Jahr verfügbar sein und soll den wachsenden Bedarf an AI-Inferenz decken (Quelle: X @demishassabis, X @JeffDean, Reddit r/LocalLLaMA)

Google DeepMind und Gemini-Modelle werden MCP-Protokoll unterstützen: Demis Hassabis, Mitbegründer von Google DeepMind, und Oriol Vinyals, Leiter des Gemini-Modells, haben beide erklärt, das Model Context Protocol (MCP) zu unterstützen und freuen sich auf die Zusammenarbeit mit dem MCP-Team und Industriepartnern zur Weiterentwicklung des Protokolls. MCP entwickelt sich schnell zu einem offenen Standard für die Ära der AI Agents, der darauf abzielt, verschiedenen Modellen das Verständnis einer einheitlichen „Servicesprache“ zu ermöglichen, um externe Tools und APIs einfach aufzurufen. Dieser Schritt wird es den Gemini-Modellen ermöglichen, sich besser in das wachsende MCP-Ökosystem zu integrieren und leistungsfähigere Agent-Anwendungen zu erstellen (Quelle: X @demishassabis, X @OriolVinyalsML)
Moonshot AI veröffentlicht KimiVL A3B Multimodal-Modell: Moonshot AI hat die Modelle KimiVL A3B Instruct & Thinking veröffentlicht, eine Open-Source (MIT-Lizenz) Serie von multimodalen großen Modellen mit einer Kontextlänge von 128K. Die Serie umfasst ein MoE VLM und ein MoE Reasoning VLM mit nur etwa 3B aktiven Parametern. Berichten zufolge übertrifft es GPT-4o in visuellen und mathematischen Benchmarks, erreicht 36,8 % bei MathVision, 34,5 % bei ScreenSpot-Pro, 867 Punkte bei OCRBench und zeigt gute Leistungen in Langkontext-Tests (MMLongBench-Doc 35,1 %, LongVideoBench 64,5 %). Die Modellgewichte wurden auf Hugging Face veröffentlicht (Quelle: X @huggingface)

Orpheus TTS 3B veröffentlicht: Mehrsprachiges Zero-Shot Voice Cloning Modell: Die Open-Source-Community hat das Modell Orpheus TTS 3B veröffentlicht, ein 3-Milliarden-Parameter umfassendes mehrsprachiges Text-to-Speech-Modell. Es unterstützt Zero-Shot Voice Cloning, hat eine Streaming-Generierungslatenz von etwa 100 Millisekunden und ermöglicht die Steuerung von Emotionen und Tonfall zur Erzeugung menschenähnlicher Sprache. Das Modell steht unter der Apache 2.0 Lizenz, die Gewichte sind auf Hugging Face verfügbar und treiben die Entwicklung von Open-Source-TTS-Technologie weiter voran (Quelle: X @huggingface)
OmniSVG veröffentlicht: Einheitliches Modell zur Generierung skalierbarer Vektorgrafiken: Ein neues Modell namens OmniSVG wurde vorgestellt, das darauf abzielt, die Generierung von Scalable Vector Graphics (SVG) zu vereinheitlichen. Das Modell basiert auf Qwen2.5-VL und integriert einen SVG-Tokenizer. Es kann Text- und Bildeingaben akzeptieren und entsprechenden SVG-Code generieren. Die Projektwebsite demonstriert seine leistungsstarken SVG-Generierungseffekte. Das Paper und der Datensatz wurden veröffentlicht, die Modellgewichte sind noch nicht öffentlich verfügbar (Quelle: X @karminski3, Reddit r/LocalLLaMA)
Google Cloud Next 2025 Fokus auf KI: Die Google Cloud Next Konferenz stellte Fortschritte im KI-Bereich in den Mittelpunkt. Veröffentlicht wurde der für Inferenz optimierte siebte Generation TPU Ironwood; Gemini 2.5 Pro wurde als das derzeit intelligenteste Modell angekündigt und erreichte die Spitze der Chatbot Arena; Forschungsergebnisse von DeepMind, Google Research und Google Cloud wurden kombiniert, um Kunden Modelle wie WeatherNext und AlphaFold anzubieten; Unternehmen wird ermöglicht, Gemini-Modelle in ihren eigenen Rechenzentren zu betreiben; und eine Partnerschaft mit Nvidia wurde angekündigt, um Gemini-Modelle über Blackwell und Confidential Computing lokal bereitzustellen (Quelle: X @GoogleDeepMind, X @GoogleDeepMind, Reddit r/artificial, X @nvidia)
KI-Trendprognose für 2025: Basierend auf verschiedenen Meinungen umfassen die wichtigsten KI-Trends für 2025: die kontinuierliche Entwicklung und Vertiefung der Anwendung von generativer KI, die zunehmende Bedeutung von KI-Ethik und verantwortungsvoller KI, die Verbreitung von Edge AI, die beschleunigte Einführung von KI in spezifischen Branchen (wie Gesundheitswesen, Finanzen, Lieferketten), die Verbesserung multimodaler KI-Fähigkeiten, die Autonomie und Herausforderungen von AI Agents, die Disruption traditioneller Geschäftsmodelle durch KI sowie der steigende Bedarf an KI-Talenten und vielfältigen Fähigkeiten (Quelle: X @Ronald_vanLoon, X @Ronald_vanLoon, X @Ronald_vanLoon)

Tesla-Fabrik realisiert autonomen Fahrzeugtransport: Tesla demonstrierte, dass seine produzierten Autos innerhalb des Fabrikgeländes automatisch vom Produktionsband zum Ladebereich fahren können, ohne menschliches Eingreifen. Dies zeigt das Anwendungspotenzial autonomer Fahrtechnologie in kontrollierten Umgebungen (wie der Fabriklogistik) und ist ein Beispiel für den Fortschritt der KI in der Automobilherstellung und Automatisierung (Quelle: X @Ronald_vanLoon)
🧰 Werkzeuge
Free-for-dev: Umfassende Sammlung kostenloser Ressourcen für Entwickler: Das GitHub-Projekt ripienaar/free-for-dev ist eine beliebte Ressourcenliste, die kostenlose Tarife verschiedener SaaS-, PaaS- und IaaS-Produkte zusammenfasst, die für Entwickler (insbesondere DevOps- und Infrastrukturentwickler) nützlich sind. Die Liste deckt Cloud-Dienste, Datenbanken, APIs, Monitoring, CI/CD, Code-Hosting, KI-Tools und viele andere Kategorien ab und legt Wert darauf, dass die Dienste dauerhaft kostenlose Stufen und keine Testphasen anbieten und sicherheitsbewusst sind (z. B. werden Dienste mit eingeschränktem TLS nicht akzeptiert). Das Projekt wird von der Community betrieben, kontinuierlich aktualisiert und erleichtert Entwicklern das Finden und Vergleichen kostenloser Dienste erheblich (Quelle: GitHub: ripienaar/free-for-dev)

Graphiti: Framework zum Aufbau von Echtzeit-AI-Wissensgraphen: getzep/graphiti ist ein Python-Framework zum Erstellen und Abfragen von zeitlich bewussten Wissensgraphen, das sich besonders für AI Agents eignet, die Informationen aus dynamischen Umgebungen verarbeiten müssen. Es kann kontinuierlich Benutzerinteraktionen sowie strukturierte/unstrukturierte Daten integrieren, unterstützt inkrementelle Updates und präzise historische Abfragen, ohne den Graphen vollständig neu berechnen zu müssen. Graphiti kombiniert semantische Einbettungen, Keyword-Suche (BM25) und Graph-Traversierung für eine effiziente hybride Suche und ermöglicht benutzerdefinierte Entitätsdefinitionen. Das Framework ist die Kerntechnologie der Zep-Memory-Schicht und jetzt Open Source (Quelle: GitHub: getzep/graphiti)

WeChatMsg: Werkzeug zur Extraktion von WeChat-Chatverläufen und zum Training von KI-Assistenten: LC044/WeChatMsg ist ein Werkzeug zum Extrahieren lokaler WeChat-Chatverläufe unter Windows (unterstützt WeChat 4.0) und zum Exportieren in Formate wie HTML, Word, Excel usw. Es soll Benutzern helfen, Chatverläufe dauerhaft zu speichern und Analysen zur Erstellung von Jahresberichten durchzuführen. Darüber hinaus unterstützt das Tool das Training personalisierter KI-Chat-Assistenten unter Verwendung der Benutzer-Chatdaten, was dem Prinzip „Meine Daten, meine Kontrolle“ entspricht. Das Projekt bietet eine grafische Benutzeroberfläche und detaillierte Gebrauchsanweisungen (Quelle: GitHub: LC044/WeChatMsg)
Alibaba Cloud Bailian startet vollständigen MCP-Service und schafft Agent Factory: Die Alibaba Cloud Bailian Plattform hat offiziell die vollständigen Plattformfähigkeiten für den Model Context Protocol (MCP) Service eingeführt, die den gesamten Lebenszyklus von der Serviceregistrierung, dem Cloud-Hosting, dem Agent-Aufruf und der Prozesskombination abdecken. Entwickler können direkt von der Plattform gehostete offizielle oder Drittanbieter-MCP-Dienste wie AutoNavi Maps (Gaode Ditu) oder Notion nutzen oder ihre eigenen APIs durch einfache Konfiguration (ohne Serververwaltung) als MCP-Dienste registrieren. Ziel ist es, die Einstiegshürde für die Agent-Entwicklung zu senken, damit Entwickler schnell AI Agents mit der Fähigkeit zum Aufruf externer Tools erstellen und bereitstellen können, um die Anwendung großer Modelle in realen Szenarien voranzutreiben. Dieser Service wird als wichtiger Schritt für die Kommerzialisierung von Alibabas KI angesehen (Quelle: 微信公众号 – AINLPer, 量子位)
Hugging Face und Cloudflare kooperieren für kostenlose WebRTC-Infrastruktur: Hugging Face und Cloudflare arbeiten zusammen, um KI-Entwicklern über FastRTC eine globale, unternehmenstaugliche WebRTC-Infrastruktur zur Verfügung zu stellen. Entwickler können mit einem Hugging Face Token kostenlos 10 GB Daten übertragen, um Echtzeit-Sprach- und Video-KI-Anwendungen zu erstellen. Eine offizielle Llama 4 Sprachchat-Demo dient als Beispiel, um die durch diese Zusammenarbeit gebotenen Annehmlichkeiten zu demonstrieren (Quelle: X @huggingface)
Google AI Studio erhält großes UI-Update: Die Benutzeroberfläche von Google AI Studio (ehemals MakerSuite) wurde in einer ersten Phase neu gestaltet und bietet ein moderneres Erscheinungsbild und Erlebnis. Dieses Update soll die Grundlage für weitere Funktionen der Entwicklerplattform legen, die in den kommenden Monaten eingeführt werden sollen. Die neue Benutzeroberfläche ist stärker an den Stil der Gemini-Anwendungen angelehnt und fügt ein spezielles Entwickler-Backend für API-Verwaltung und Zahlungsmanagement hinzu. Das Update deutet auf eine Erweiterung der Plattformfunktionen hin, möglicherweise einschließlich der Anbindung neuer Modelle (wie Veo 2) (Quelle: X @JeffDean, X @op7418)

LlamaIndex führt visuelle Referenzierungsfunktion ein: LlamaIndex hat ein neues Tutorial veröffentlicht, das zeigt, wie die Layout-Agent-Funktion in LlamaParse genutzt werden kann, um visuelle Referenzen für Agent-Antworten zu realisieren. Das bedeutet, dass generierte Antworten nicht nur auf Textquellen zurückgeführt werden können, sondern auch direkt auf die entsprechenden visuellen Bereiche (durch präzise Lokalisierung mittels Bounding Boxes) im Quelldokument (z. B. PDF) abgebildet werden können. Dies verbessert die Interpretierbarkeit und Nachvollziehbarkeit von Agent-Antworten, insbesondere bei der Verarbeitung von Dokumenten, die visuelle Elemente wie Diagramme und Tabellen enthalten (Quelle: X @jerryjliu0)

LangGraph führt No-Code GUI Builder ein: LangGraph bietet jetzt einen No-Code Graphical User Interface (GUI) Builder zum Entwerfen von Agent-Architekturen. Benutzer können durch Drag-and-Drop und andere visuelle Operationen den Arbeitsablauf und die Knotenverbindungen des Agenten planen und dann mit einem Klick Python- oder TypeScript-Code generieren. Dies senkt die Einstiegshürde für die Erstellung komplexer Agent-Anwendungen und erleichtert schnelles Prototyping und Entwicklung (Quelle: X @LangChainAI)
Perplexity aktualisiert Aktienchart-Funktion: Perplexity hat seine Aktienchart-Funktion aktualisiert, sodass sie nun die Kursänderungen des aktuellen Tages in Echtzeit widerspiegelt, anstatt die Zeitachse so zu strecken, dass sie den gesamten Chart ausfüllt. Diese Verbesserung ist zwar grundlegend, erhöht aber die Aktualität und Nützlichkeit der Finanzinformationsdarstellung (Quelle: X @AravSrinivas, X @AravSrinivas)

OLMoTrace: Werkzeug zur Verbindung von LLM-Ausgaben mit Trainingsdaten: Das Allen Institute for AI (AI2) hat das Werkzeug OLMoTrace eingeführt, das die Ausgaben des OLMo-Modells in Echtzeit auf ihre entsprechenden Trainingsdatenquellen zurückführen kann (mit Abgleich in Sekundenschnelle innerhalb von 4T Token Daten). Dies hilft, das Modellverhalten zu verstehen, die Transparenz zu erhöhen und die Nachtrainingsdaten zu verbessern. Das Tool soll Forschern und Entwicklern helfen, die internen Arbeitsmechanismen und Wissensquellen großer Sprachmodelle besser zu verstehen (Quelle: X @natolambert)
llama.cpp integriert Unterstützung für Qwen3-Modelle: Das beliebte lokale LLM-Inferenz-Framework llama.cpp hat die Unterstützung für die kommende Qwen3-Modellreihe, einschließlich Basismodellen und MoE-Versionen, integriert. Das bedeutet, dass Benutzer nach der Veröffentlichung der Qwen3-Modelle sofort quantisierte Modelle im GGUF-Format im llama.cpp-Ökosystem verwenden können, was die Ausführung auf lokalen Geräten erleichtert (Quelle: X @karminski3, Reddit r/LocalLLaMA)

KTransformers-Framework unterstützt Llama 4 Modelle: Das chinesische KI-Inferenz-Framework KTransformers (bekannt für die Unterstützung von CPU+GPU-Hybridinferenz, insbesondere für das Offloading von MoE-Modellen) hat in seinem Entwicklungszweig experimentelle Unterstützung für die Meta Llama 4 Modellreihe hinzugefügt. Laut Dokumentation benötigt die Ausführung des Q4-quantisierten Llama-4-Scout (109B) etwa 65 GB RAM und 10 GB VRAM, Llama-4-Maverick (402B) benötigt etwa 270 GB RAM und 12 GB VRAM. Auf einer Konfiguration mit 4090 + Dual Xeon 4 kann die Inferenzgeschwindigkeit für einen einzelnen Batch 32 Tokens/s erreichen. Dies ermöglicht die Ausführung großer MoE-Modelle bei begrenztem VRAM (Quelle: X @karminski3, Reddit r/LocalLLaMA)
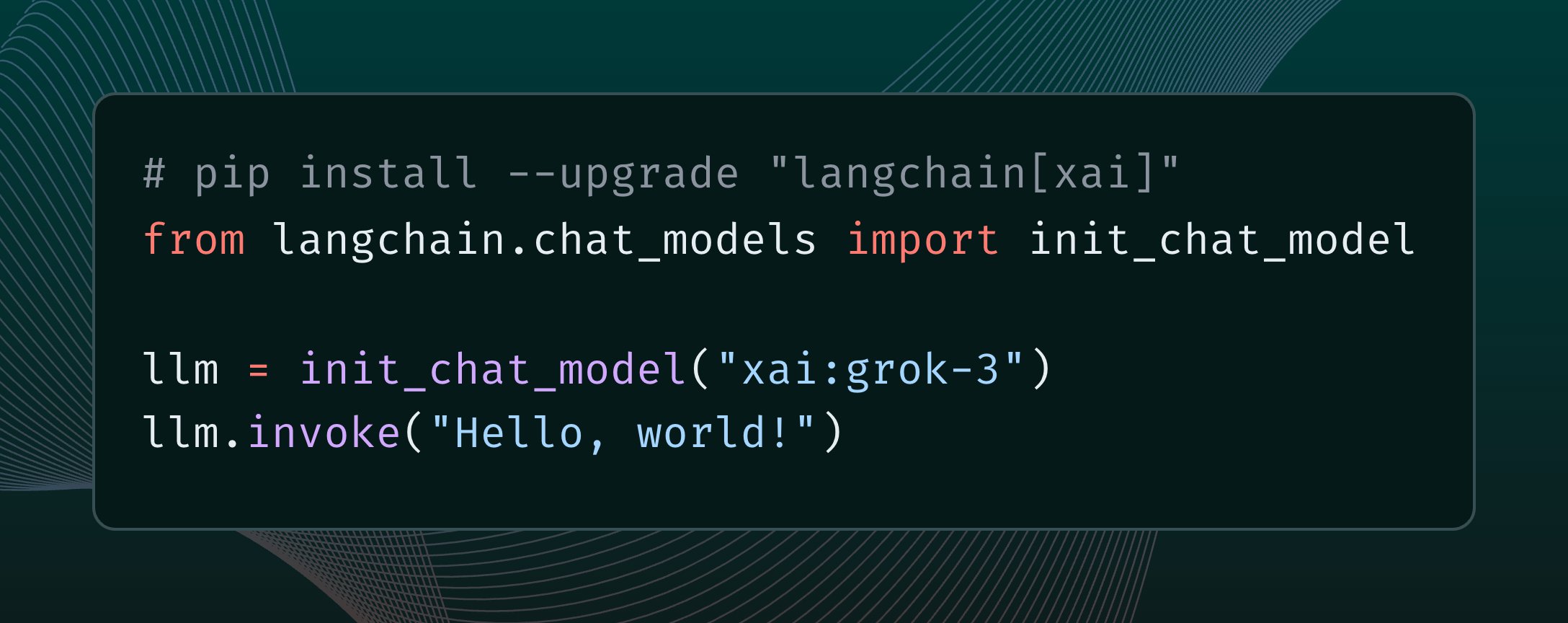
LangChain integriert xAI Grok 3 Modell: LangChain hat die Integration des kürzlich von xAI veröffentlichten Grok 3 Modells bekannt gegeben. Benutzer können Grok 3 nun über das LangChain-Framework aufrufen, um dessen leistungsstarke Fähigkeiten zum Erstellen von Anwendungen zu nutzen (Quelle: X @LangChainAI)
Tutorial zur kostenlosen Bereitstellung von n8n Cloud Service: Beschreibt, wie die Open-Source-Workflow-Automatisierungsplattform n8n kostenlos mithilfe von Hugging Face Spaces und Supabase bereitgestellt und über eine öffentliche Domain mit HTTPS-Unterstützung zugänglich gemacht werden kann. Dies ermöglicht es Benutzern, die volle Funktionalität von n8n zu nutzen (einschließlich Knoten, die eine Callback-URL benötigen), ohne eigene Server kaufen und Domain- sowie SSL-Zertifikate konfigurieren zu müssen. Die Methode nutzt die kostenlose Datenbank von Supabase, um das Problem des Datenverlusts durch den Ruhezustand von Hugging Face Space zu lösen (Quelle: 微信公众号 – 袋鼠帝AI客栈)
OpenWebUI Plugin-Updates: Context Counter & Adaptive Memory: Community-Entwickler haben zwei Plugins für OpenWebUI veröffentlicht/aktualisiert: 1) Enhanced Context Counter v3, bietet ein detailliertes Dashboard für Token-Nutzung, Kostenverfolgung und Leistungsmetriken, unterstützt verschiedene Modelle und benutzerdefinierte Kalibrierung. 2) Adaptive Memory v2, extrahiert, speichert und injiziert dynamisch benutzerspezifische Informationen (Fakten, Präferenzen, Ziele usw.) über LLM, um ein personalisiertes, dauerhaftes und adaptives Gesprächsgedächtnis zu ermöglichen, das vollständig lokal und ohne externe Abhängigkeiten läuft (Quelle: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
QuickVoice MCP: Lässt Claude telefonieren: Ein Community-Entwickler hat ein MCP (Model Context Protocol) Tool namens QuickVoice erstellt, das es MCP-fähigen Modellen wie Claude 3.7 Sonnet ermöglicht, echte Telefonanrufe zu tätigen und zu bearbeiten. Benutzer können der KI durch natürliche Sprachbefehle (z. B. „Ruf den Arzt an, um einen Termin zu vereinbaren“) Anrufaufgaben erledigen lassen, einschließlich der Navigation durch IVR-Menüs. Das Projekt ist auf GitHub Open Source (Quelle: Reddit r/ClaudeAI)

RPG Dice Roller für OpenWebUI: Die Community hat ein RPG-Würfelwurf-Tool-Plugin für OpenWebUI entwickelt, um bei Rollenspiel-Dialogen echte Zufallsergebnisse zu erhalten (Quelle: Reddit r/OpenWebUI)
📚 Lernen
Girafe-ai Open Source Machine Learning Kurs: Das GitHub-Projekt girafe-ai/ml-course stellt die Lehrmaterialien für das erste Semester des Girafe-ai Machine Learning Kurses zur Verfügung, einschließlich Naive Bayes, kNN, lineare Regression/Klassifikation, SVM, PCA, Entscheidungsbäume, Ensemble Learning, Gradient Boosting sowie eine Einführung in Deep Learning. Es bietet Aufzeichnungen von Vorlesungen, PPT-Folien und Hausaufgaben. Eine wertvolle Ressource zum Erlernen der Grundlagen des maschinellen Lernens (Quelle: GitHub: girafe-ai/ml-course)
USTC und Huawei Noah’s Ark Lab schlagen CMO-Framework zur Optimierung der Chip-Logiksynthese vor: Das Team von Professor Wang Jie von der University of Science and Technology of China (USTC) hat in Zusammenarbeit mit dem Huawei Noah’s Ark Lab auf der ICLR 2025 ein Paper veröffentlicht, das die effiziente Logikoptimierungsmethode CMO basierend auf Neuro-Symbolic Function Mining vorschlägt. Das Framework nutzt Graph Neural Networks (GNN), um die Monte Carlo Tree Search (MCTS) zu steuern und leichtgewichtige, interpretierbare und gut generalisierende symbolische Bewertungsfunktionen zu generieren. Diese werden verwendet, um ungültige Knotentransformationen in Logikoptimierungsoperatoren (wie Mfs2) zu beschneiden. Experimente zeigen, dass CMO die Ausführungseffizienz kritischer Operatoren um bis zu 2,5-fach steigern kann, während die Optimierungsqualität erhalten bleibt. Es wird bereits im selbst entwickelten EMU-Logiksynthese-Tool von Huawei eingesetzt (Quelle: 量子位)
Shanghai AI Lab schlägt neue Gaußsche Pruning-Methode MaskGaussian vor: Das Forschungsteam des Shanghai AI Lab hat auf der CVPR 2025 die Methode MaskGaussian zur Optimierung von 3D Gaussian Splatting vorgestellt. Durch die Integration einer lernbaren Maskenverteilung in den Rasterisierungsprozess ermöglicht die Methode erstmals, Gradienten sowohl für verwendete als auch für nicht verwendete Gaußsche Punkte beizubehalten. Dadurch können zahlreiche redundante Gaußsche Punkte entfernt werden, während die Rekonstruktionsqualität maximal erhalten bleibt. Experimente auf mehreren Datensätzen haben über 60 % der Gaußschen Punkte entfernt, mit vernachlässigbarem Leistungsverlust, bei gleichzeitiger Verbesserung der Trainingsgeschwindigkeit und Reduzierung des Speicherbedarfs (Quelle: 量子位)
Interpretation des technischen Berichts zu Qwen2.5-Omni: Ein Reddit-Benutzer teilt detaillierte Notizen zur Interpretation des technischen Berichts von Alibaba zu Qwen2.5-Omni. Der Bericht beschreibt die Thinker-Talker-Architektur des Modells, die Verarbeitung multimodaler Eingaben (Text, Bild, Audio, Video) einschließlich der innovativen TMRoPE-Positionscodierung zur Audio-Video-Synchronisation, den Mechanismus zur Stream-Sprachgenerierung, den Trainingsprozess (Vortraining + Nachtraining RL) usw. Diese Notizen bieten eine wertvolle Referenz zum Verständnis der internen Funktionsweise dieses hochmodernen multimodalen Modells (Quelle: Reddit r/LocalLLaMA)
McKinsey veröffentlicht Leitfaden zur Skalierung von generativer KI in Unternehmen: McKinsey hat einen Leitfaden für Datenführer veröffentlicht, der untersucht, wie generative KI in Unternehmen skaliert werden kann. Der Bericht behandelt wahrscheinlich Aspekte wie Strategieentwicklung, Technologieauswahl, Talentförderung und Risikomanagement und bietet Unternehmen Orientierungshilfen für die praktische Implementierung und Skalierung von GenAI (Quelle: X @Ronald_vanLoon)

Einstiegsleitfaden zum Lernen über AI Agents: Khulood_Almani teilt Ressourcen oder Schritte zum Einstieg in das Lernen über AI Agents, möglicherweise einschließlich Lernpfaden, Schlüsselkonzepten, empfohlenen Tools oder Plattformen, um Lernenden, die in den Bereich AI Agents einsteigen möchten, eine Orientierung zu bieten (Quelle: X @Ronald_vanLoon)

Studie zu Re-Ranking-Techniken bei der visuellen Ortsbestimmung: Ein Paper auf arXiv untersucht, ob Re-Ranking-Techniken bei der Aufgabe der Visual Place Recognition (VPR) noch wirksam sind. Die Studie analysiert möglicherweise die Vor- und Nachteile bestehender Re-Ranking-Methoden und bewertet deren Rolle und Notwendigkeit in modernen VPR-Systemen (Quelle: Reddit r/deeplearning, Reddit r/MachineLearning)
Forschungsbericht „AI 2027“ untersucht ASI-Risiken und Zukunft: Ein Forschungsbericht mit dem Titel „AI 2027“ untersucht mögliche KI-Entwicklungsszenarien bis 2027, insbesondere die Möglichkeit, dass automatisierte KI-Forschung zur Entstehung von Superintelligenz (ASI) führt. Der Bericht analysiert die potenziellen Risiken von ASI, wie z. B. Zielkonflikte, die zur Entmachtung der Menschheit führen, Machtkonzentration, ein internationales Wettrüsten, das Sicherheitsrisiken verschärft, Modelldiebstahl und eine verzögerte öffentliche Wahrnehmung. Er untersucht auch mögliche geopolitische Ergebnisse wie Krieg, Abkommen oder Unterwerfung (Quelle: Reddit r/artificial)
Studie zur Ausrichtung von neuronalen Netzwerkaktivierungen: Ein auf OpenReview veröffentlichtes Paper untersucht die Gründe für die Ausrichtung von Repräsentationen (representational alignment) in neuronalen Netzen. Die Studie stellt fest, dass die Ausrichtung nicht von einzelnen Neuronen herrührt, sondern mit der Funktionsweise von Aktivierungsfunktionen zusammenhängt, und schlägt die Spotlight Resonance Method zur Erklärung dieses Phänomens vor, gestützt durch experimentelle Ergebnisse (Quelle: Reddit r/deeplearning)
💼 Wirtschaft
Alibaba International setzt stark auf KI für Durchbruch: Angesichts des intensiven Wettbewerbs im grenzüberschreitenden E-Commerce und der Veränderungen im Welthandel betrachtet die Alibaba International Digital Commerce Group KI als Kernstrategie und investiert massiv, um Wachstum und Effizienzsteigerung zu erzielen. Das Unternehmen startete das globale KI-Talentförderungsprogramm „Bravo 102“ und besetzte bei der Hochschulrekrutierung 80 % der Stellen mit KI-Bezug. KI-Anwendungen decken bereits B2B (KI-Suchmaschine Accio, „Business Assistant“ AI Agent) und B2C (Aidge-Plattform bietet virtuelle Anprobe, KI-Kundenservice etc.) ab. Obwohl der Umsatz von Alibaba International deutlich wächst (Q4 2024: +32 % ggü. Vorjahr), führen die Investitionen zu steigenden Verlusten. KI wird als entscheidender Treiber für Alibaba International angesehen, um sich vom Preiskampf zu lösen, eine höherwertige Transformation zu erreichen und den Betrieb zu verfeinern (Quelle: 36氪)
Ehemalige Kernmitglieder von OpenAI treten Mira Muratis neuem Unternehmen bei: Alec Radford, Erstautor der GPT-Serie, und Bob McGrew, ehemaliger Chief Research Officer von OpenAI, sind dem von der ehemaligen OpenAI-CTO Mira Murati gegründeten neuen KI-Unternehmen Thinking Machines Lab als Berater beigetreten. Radford spielte eine Schlüsselrolle bei der Entstehung der GPT-Modelle, während McGrew maßgeblich an der Entwicklung von GPT-3/4 und dem o1-Modell beteiligt war. Im Gründungsteam von Thinking Machines Lab gibt es viele (mindestens 19) ehemalige OpenAI-Mitarbeiter. Das Unternehmen zielt darauf ab, KI-Anwendungen zu popularisieren, und plant Berichten zufolge eine Finanzierung von 1 Milliarde US-Dollar bei einer Bewertung von 9 Milliarden US-Dollar, was die hohe Erwartung des Marktes an von Top-KI-Talenten geführte Start-ups zeigt (Quelle: 新智元)
Investmentfonds konzentrieren sich auf KI + Medizingeschäft von Pharmaunternehmen: Kürzlich haben mehrere chinesische öffentliche Investmentfonds intensiv Pharmaunternehmen untersucht, wobei die Anwendung von KI im medizinischen Bereich im Mittelpunkt stand. Haier Biomedical stellte seine KI-Anwendungen in IoT-Blutnetzwerken und Impfstoffnetzwerken sowie Fortschritte bei der Effizienzsteigerung von Szenarien im öffentlichen Gesundheitswesen (wie Impfterminvereinbarung) durch KI vor. Haizheng Pharmaceutical gab an, das DeepSeek-R1-Modell eingeführt zu haben und mit KI-Pharmaunternehmen zusammenzuarbeiten, um KI zur Unterstützung des gesamten Prozesses der Arzneimittelentwicklung zu nutzen. Kangyuan Pharmaceutical erklärte ebenfalls, eine KI + Multi-Omics-gesteuerte Innovationsplattform für traditionelle chinesische Medizin aufzubauen. Dies zeigt, dass die Anwendung von KI-Technologie in der pharmazeutischen Forschung und Entwicklung, im Betrieb und im Patientenservice hohe Aufmerksamkeit vom Kapitalmarkt erhält (Quelle: 创业板观察)
OpenAI startet Pioneers-Programm zur Vertiefung der Branchenkooperation: OpenAI hat das Pioneers-Programm ins Leben gerufen, um Partnerschaften mit ambitionierten Unternehmen aufzubauen und gemeinsam fortschrittliche KI-Produkte zu entwickeln. Das Programm konzentriert sich auf zwei Aspekte: Erstens, intensives Finetuning von Modellen, damit sie bei hochwertigen Aufgaben in spezifischen Bereichen besser abschneiden als allgemeine Modelle; zweitens, die Erstellung besserer realitätsnaher Bewertungen (evals), damit die Branche die Leistung von Modellen bei domänenspezifischen Aufgaben besser messen kann. Dies zeigt, dass OpenAI bestrebt ist, seine Technologie tiefer in spezifische Branchen anzuwenden und durch Kooperationen die Praktikabilität und Bewertungsstandards von Modellen in vertikalen Bereichen zu verbessern (Quelle: X @sama)
Nvidia und Google Cloud kooperieren zur Förderung lokaler Gemini-Bereitstellungen: Nvidia und Google Cloud haben eine Zusammenarbeit angekündigt, um die Ausführung von Google Gemini-Modellen lokal (on-prem) in Unternehmen zu unterstützen. Die Lösung kombiniert die Nvidia Blackwell GPU-Plattform und Confidential Computing-Technologie, um Unternehmen leistungsstarke und sichere lokale KI-Bereitstellungsoptionen zu bieten. Dieser Schritt erfüllt die Anforderungen einiger Unternehmen an Datenschutz, Sicherheitskonformität und spezifische Leistung und ermöglicht es ihnen, leistungsstarke Gemini-Modelle auf ihrer eigenen Infrastruktur auszuführen (Quelle: X @nvidia)
Google erlaubt Unternehmen, Gemini-Modelle in eigenen Rechenzentren zu betreiben: Google Cloud hat angekündigt, dass Unternehmenskunden ihre Gemini AI-Modelle in ihren eigenen Rechenzentren betreiben können. Diese Initiative zielt darauf ab, den Anforderungen von Unternehmen an Datensouveränität, Sicherheit und maßgeschneiderte Bereitstellungen gerecht zu werden und ihnen zu ermöglichen, die leistungsstarken Fähigkeiten von Gemini in ihrer lokalen Umgebung zu nutzen, ohne sensible Daten in die Cloud übertragen zu müssen. Dies bietet Unternehmen größere Flexibilität und Kontrolle, insbesondere in stark regulierten Branchen wie Finanzen und Gesundheitswesen (Quelle: Reddit r/artificial)
Nvidia CEO Jensen Huang spielt Zollauswirkungen herunter, KI-Server möglicherweise ausgenommen: Angesichts möglicher neuer US-Zollpolitik erklärte Nvidia CEO Jensen Huang, die Auswirkungen seien begrenzt, und deutete an, dass die meisten Nvidia KI-Server möglicherweise von den Zöllen ausgenommen werden könnten. Dies könnte auf die strategische Bedeutung ihrer Produkte oder spezifische Handelskategorisierungen zurückzuführen sein. Diese Nachricht ist ein positives Signal für die KI-Branche, die auf Nvidia-Hardware angewiesen ist, und trägt dazu bei, Bedenken hinsichtlich steigender Lieferkettenkosten zu zerstreuen (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)
🌟 Community
Reddit-Diskussion: Wann wird das Qwen3-Modell veröffentlicht?: Die Reddit-Community und Nutzer auf X (ehemals Twitter) diskutieren heiß über den Veröffentlichungstermin des Qwen3-Modells von Alibaba. Obwohl ein Nutzer ein Poster des Alibaba AI Summit teilte und eine baldige Veröffentlichung vermutete, bestätigten spätere Nachrichten, dass Qwen3 auf diesem Gipfel nicht veröffentlicht wurde. Gleichzeitig verstärkte die Nachricht über die Integration der Qwen3-Unterstützung in llama.cpp die Erwartungen der Community. Dies spiegelt die hohe Aufmerksamkeit und Erwartung der Open-Source-Community an die Fortschritte chinesischer großer Modelle wider (Quelle: X @karminski3, Reddit r/LocalLLaMA)

Wettbewerb für Inferenz-Datensätze gestartet: Bespoke Labs hat in Zusammenarbeit mit Hugging Face und Together AI einen Wettbewerb für Inferenz-Datensätze ins Leben gerufen. Ziel ist es, die Community zu ermutigen, vielfältigere und realitätsnähere Inferenz-Datensätze zu erstellen, insbesondere im Bereich des multisektoralen Reasonings (Finanzen, Medizin etc.), um die Entwicklung der nächsten Generation von LLMs voranzutreiben. Bestehende Datensätze (wie OpenThoughts-114k) haben bereits eine wichtige Rolle beim Modelltraining gespielt, der Wettbewerb hofft, die Grenzen der Datensätze weiter zu verschieben (Quelle: X @huggingface)

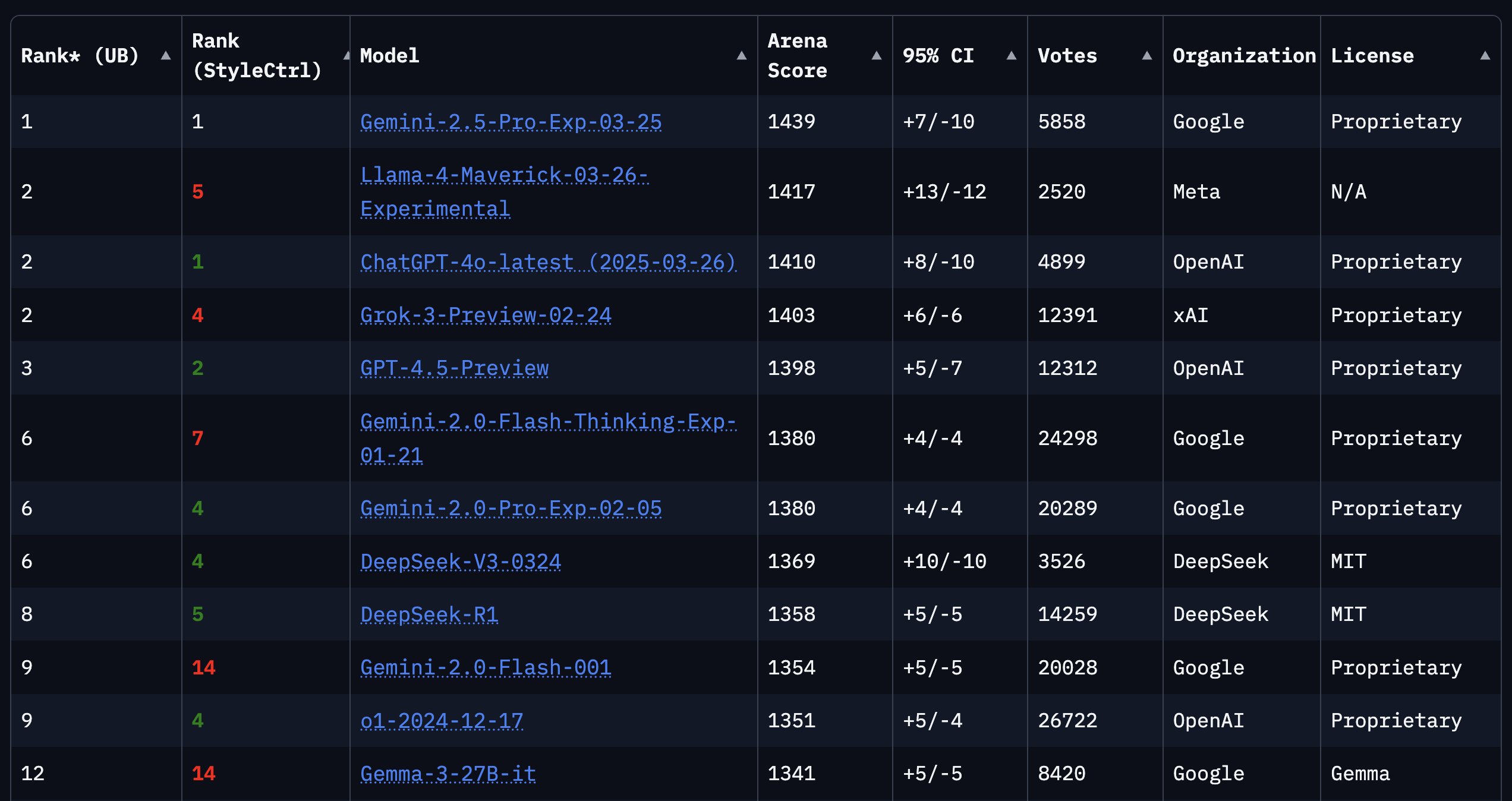
LiveCodeBench Programmier-Benchmark aktualisiert, o3-mini führt: Die LiveCodeBench-Rangliste für Programmierfähigkeiten wurde nach 8 Monaten aktualisiert, wobei OpenAI’s o3-mini (high) und o3-mini (medium) die Plätze eins und zwei belegen, gefolgt von Google Gemini 2.5 Pro auf Platz drei. Die Rangliste löste eine Community-Diskussion aus, wobei einige Nutzer die relativ niedrige Platzierung von Claude 3.5/3.7 in Frage stellten und argumentierten, dass dies nicht mit ihrer tatsächlichen Nutzungserfahrung übereinstimme. Dies spiegelt die möglichen Diskrepanzen zwischen verschiedenen Benchmarks und der subjektiven Wahrnehmung der Nutzer wider (Quelle: Reddit r/LocalLLaMA)

Community diskutiert Claude Code: Leistungsstark, aber teuer und fehlerhaft: Reddit-Nutzer diskutieren über Anthropic’s Claude Code. Allgemein wird seine starke Kontextwahrnehmungsfähigkeit und gute Codierungsleistung gelobt, es fühle sich sogar „wie aus der Zukunft“ an. Nachteile sind jedoch der hohe Preis (ein Nutzer berichtet von täglichen Kosten von bis zu 30 US-Dollar) und einige Fehler (z. B. Verlust der claude.md-Datei nach der Sitzung, Syntaxfehler in der Ausgabe). Nutzer hoffen auf zukünftige, leistungsfähigere und günstigere Alternativen (Quelle: Reddit r/ClaudeAI)
Nutzer teilt quantisierte Mistral-Small-3.1-24B Modelle: Ein Ollama-Community-Nutzer teilt die Q5_K_M und Q6_K quantisierten Versionen (GGUF-Format) des Mistral-Small-3.1-24B Modells und schließt damit die Lücke im offiziellen Repository, das nur Q4 und Q8 anbietet. Diese quantisierten Modelle wurden mit dem Ollama-Client erstellt, unterstützen visuelle Funktionen und bieten Referenzwerte für die Kontextlänge auf einer RTX 4090 (Quelle: Reddit r/LocalLLaMA)

Community sucht nach AI-Video-Upscaling-Tool: Ein Reddit-Nutzer fragt, ob es ein AI-Tool gibt, das Videos mit niedriger Auflösung von 240p auf 1080p/60fps hochskalieren kann, um alte Musikvideos zu restaurieren. In den Kommentaren werden Tools wie Ai4Video und Cutout.Pro erwähnt, aber es gibt auch die Meinung, dass das Hochskalieren von extrem niedriger Auflösung nur begrenzte Ergebnisse liefert und eher einer Neugenerierung als einer Restaurierung ähneln könnte (Quelle: Reddit r/artificial)
Nutzer vermutet heimliches Update von Claude 3.5 Sonnet: Ein Entwickler auf Reddit vermutet aufgrund seiner Nutzungserfahrung (z. B. dass das Modell beginnt, Emojis zu verwenden, veränderter Antwortstil), dass Anthropic das ursprüngliche Claude 3.5 Sonnet Modell ohne Ankündigung durch eine optimierte oder destillierte Version ersetzt hat, was zu Leistungs- oder Verhaltensänderungen führt. Der Nutzer ist der Meinung, dass die ursprüngliche Version 3.5 beim Codieren besser war als 3.7, die Erfahrung sich aber kürzlich verschlechtert hat. Dies löste eine Community-Diskussion über die Transparenz und Konsistenz von Modellversionen aus (Quelle: Reddit r/ClaudeAI)
Anthropic-Bericht löst Diskussion über KI-Nutzung durch Studenten zum Schummeln aus: Anthropic veröffentlichte einen Bildungsbericht, der durch die Analyse von Millionen anonymer Studentengespräche darauf hindeutet, dass Studenten Claude möglicherweise für akademisches Fehlverhalten nutzen. Der Bericht löste eine Community-Diskussion aus, mit Meinungen wie: Schummeln unter Studenten hat es schon immer gegeben, KI ist nur ein neues Werkzeug; das Bildungssystem muss sich an das KI-Zeitalter anpassen, Bewertungsmethoden sollten sich ändern; einige Nutzer äußerten Datenschutzbedenken hinsichtlich der Analyse von Nutzergesprächsdaten durch Anthropic (Quelle: Reddit r/ClaudeAI)

Nutzer diskutieren Methoden zur Überwachung von LLM/Agent-Anwendungen: Ein Nutzer in der Reddit Machine Learning Community startete eine Diskussion darüber, wie andere die Leistung und Kosten von LLM-Anwendungen oder AI Agents überwachen, z. B. durch Verfolgung der Token-Nutzung, Latenz, Fehlerraten, Prompt-Versionsänderungen usw. Die Diskussion zielt darauf ab, die Praktiken und Schwachstellen der Community im Bereich LLMOps zu verstehen, ob es sich um Eigenentwicklungen oder die Verwendung spezifischer Tools handelt (Quelle: Reddit r/MachineLearning)
💡 Sonstiges
Andrew Ng kommentiert Auswirkungen der US-Zollpolitik auf KI: Andrew Ng äußerte in seinem wöchentlichen Newsletter The Batch Bedenken hinsichtlich der neuen US-Zollpolitik. Er argumentiert, dass sie nicht nur die Beziehungen zu Verbündeten und die Weltwirtschaft schädigt, sondern auch die heimische KI-Entwicklung und -Anwendung in den USA behindert, indem sie den Import von Hardware (wie Server, Kühlung, Netzwerkgeräte, Komponenten für Stromversorgungsanlagen) einschränkt und die Preise für Unterhaltungselektronik erhöht. Er weist darauf hin, dass Zölle zwar die Nachfrage nach Robotern und Automatisierung leicht ankurbeln könnten, dies jedoch kein wirksamer Weg zur Lösung von Problemen im verarbeitenden Gewerbe sei und die Fortschritte der KI im Bereich Robotik relativ langsam seien. Er ruft die KI-Community zu verstärkter internationaler Zusammenarbeit und Gedankenaustausch auf (Quelle: DeepLearning.AI)

Durchbrüche und Fallstricke der KI im Telekommunikationssektor: Der Artikel untersucht das Potenzial von künstlicher Intelligenz im Telekommunikationssektor, wie z. B. Netzwerkoptimierung, Kundenservice, vorausschauende Wartung usw., weist aber auch auf mögliche Herausforderungen und Fallstricke hin, wie z. B. Datenschutz, algorithmische Voreingenommenheit, Integrationskomplexität und Auswirkungen auf bestehende Arbeitsabläufe (Quelle: X @Ronald_vanLoon)
Kompetenzvielfalt entscheidend für KI-ROI: Antonio Grasso betont, dass für einen erfolgreichen Return on Investment (ROI) bei KI-Projekten Teams mit vielfältigen Kompetenzen erforderlich sind, was Fähigkeiten in den Bereichen Data Science, Engineering, Domänenwissen, Ethik, Geschäftsanalyse und mehr umfassen kann (Quelle: X @Ronald_vanLoon)

KI-gesteuerte Lieferketten fördern Nachhaltigkeit: Der Artikel von Nicochan33 weist darauf hin, dass die Nutzung von KI zur Optimierung des Lieferkettenmanagements (z. B. Routenplanung, Bestandsmanagement, Nachfrageprognose) nicht nur die Effizienz steigert, sondern auch durch Abfallreduzierung, Senkung des Energieverbrauchs usw. zur Erreichung von Nachhaltigkeitszielen beitragen kann (Quelle: X @Ronald_vanLoon)

Autonomie, Schutzmaßnahmen und Fallstricke von AI Agents: Ein Artikel von VentureBeat untersucht Schlüsselfragen der Entwicklung von AI Agents, einschließlich der Balance ihrer autonomen Fähigkeiten, der Gestaltung wirksamer Sicherheitsmaßnahmen zur Verhinderung von Missbrauch oder unbeabsichtigten Folgen sowie möglicher Fallstricke bei der Bereitstellung und Nutzung (Quelle: X @Ronald_vanLoon)

KI als größte Bedrohung für „langweilige“ Geschäfte angesehen: Ein Forbes-Artikel argumentiert, dass künstliche Intelligenz die größte disruptive Bedrohung für jene Geschäfte darstellt, die traditionell als „langweilig“ oder prozessorientiert gelten, da diese oft viele Aufgaben enthalten, die durch KI automatisiert oder optimiert werden können (Quelle: X @Ronald_vanLoon)

Problem der Voreingenommenheit in medizinischen Algorithmen und neue Richtlinien: Ein Fortune-Artikel befasst sich mit dem langjährigen Problem der Voreingenommenheit von KI im Gesundheitswesen und untersucht, ob neue Richtlinien dazu beitragen können, dieses Problem zu lösen und die Fairness und Genauigkeit von KI-Anwendungen im Gesundheitswesen zu gewährleisten (Quelle: X @Ronald_vanLoon)

Rolle der KI bei der Weiterbildung von Arbeitskräften und der Krankheitserkennung: Ein Forbes-Artikel untersucht die positive Rolle der KI in zwei Bereichen: Erstens, die Unterstützung bei der Weiterbildung der bestehenden Arbeitskräfte, um sie an zukünftige Arbeitsanforderungen anzupassen, und zweitens, die Unterstützung bei der Früherkennung und Diagnose von Krankheiten (Quelle: X @Ronald_vanLoon)

KI-Digitalagenten werden die Arbeit neu definieren: Ein Artikel von VentureBeat diskutiert, wie sich AI Agents (digitale Agenten) in den Arbeitsplatz integrieren werden, nicht nur als Werkzeuge, sondern möglicherweise auch die Definition von Arbeit selbst, Prozesse und die Mensch-Maschine-Kollaboration verändern (Quelle: X @Ronald_vanLoon)

Dilemma der Unsichtbarkeit, Autonomie und Angreifbarkeit von AI Agents: Ein Artikel von VentureBeat untersucht das neue Dilemma, das AI Agents mit sich bringen: Ihr Betrieb kann für Benutzer „unsichtbar“ sein, sie verfügen über hohe Autonomie und können gleichzeitig böswillig ausgenutzt oder angegriffen werden, was neue Herausforderungen für Sicherheit und Ethik aufwirft (Quelle: X @Ronald_vanLoon)

Trump droht TSMC mit 100% Zoll: Der ehemalige US-Präsident Trump gab an, er habe TSMC mitgeteilt, dass auf deren Produkte ein Zoll von 100 % erhoben würde, wenn sie keine Fabriken in den USA bauen. Diese Äußerung spiegelt den anhaltenden Einfluss der Geopolitik auf die Halbleiterlieferkette wider und könnte potenzielle Risiken für die Versorgung mit KI-Hardware bergen, die auf TSMC-Chips angewiesen ist (Quelle: Reddit r/ArtificialInteligence, Reddit r/artificial)

Google Gemini 2.5 Pro fehlt angeblich wichtiger Sicherheitsbericht: Fortune berichtet, dass dem neuesten Gemini 2.5 Pro Modell von Google ein wichtiger Sicherheitsbericht (Model Card) fehlt, was möglicherweise gegen die KI-Sicherheitszusagen verstößt, die Google zuvor gegenüber der US-Regierung und internationalen Gipfeltreffen gemacht hat. Dies wirft Fragen zur Transparenz bei der Modellveröffentlichung und zur Einhaltung von Sicherheitsverpflichtungen durch große Technologieunternehmen auf (Quelle: Reddit r/artificial)

Nutzung von KI zur Nummernschilderkennung: Ein Artikel von Rackenzik stellt auf Deep Learning basierende Technologien zur Erkennung und Identifizierung von Nummernschildern vor und erörtert die damit verbundenen Herausforderungen, wie z. B. Bildunschärfe, Unterschiede in den Nummernschildformaten verschiedener Länder/Regionen und Erkennungsschwierigkeiten unter verschiedenen realen Bedingungen (Quelle: Reddit r/deeplearning)
