
Schlüsselwörter:TPU, HBM, 第七代TPU Ironwood, SK海力士 HBM市场份额, A2A智能体协作协议, 谷歌 Gemini 2.5推理, HBM3E芯片供应
🔥 Fokus
Google veröffentlicht TPU der siebten Generation und A2A-Agent-Kollaborationsprotokoll: Google hat auf der Cloud Next ’25 den TPU „Ironwood“ der siebten Generation vorgestellt, der speziell für KI-Inferenz entwickelt wurde. Die großflächige Bereitstellung erreicht eine Rechenleistung von 42,5 Exaflops und übertrifft damit bei weitem bestehende Supercomputer. Der Chip bietet erheblich mehr Speicher und Bandbreite (192 GB HBM, 7,2 Tb/s Bandbreite) und verdoppelt die Energieeffizienz. Er soll „Denkmodelle“ wie Gemini 2.5 unterstützen, die komplexe Inferenzfähigkeiten erfordern. Gleichzeitig hat Google das Open-Source-Protokoll Agent-to-Agent (A2A) eingeführt, das die sichere Kommunikation und Zusammenarbeit zwischen verschiedenen KI-Agenten standardisieren soll und bereits von über 50 Unternehmen unterstützt wird. A2A definiert die Erkennung von Agentenfähigkeiten, das Aufgabenmanagement, Kollaborationsmethoden usw. und ergänzt das MCP-Protokoll, das zur Verbindung von Tools verwendet wird. Google kündigte außerdem die Unterstützung des MCP-Protokolls in seinen Gemini-Modellen und SDKs an, um die Interkonnektivität des KI-Agenten-Ökosystems weiter zu fördern. (Quelle: 机器之心, 36氪, 卡兹克, 机器之心, AI前线)

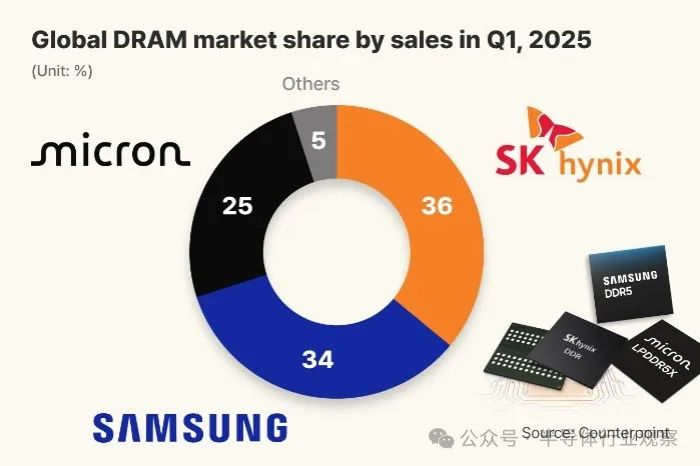
SK Hynix überholt dank HBM-Vorteil erstmals Samsung auf dem globalen DRAM-Markt: Ein Bericht des Marktforschungsunternehmens Counterpoint Research zeigt, dass SK Hynix im ersten Quartal 2025 mit einem Marktanteil von 36 % erstmals Samsung (34 %) überholt hat und zum weltweit größten DRAM-Anbieter aufgestiegen ist. Micron liegt mit 25 % auf dem dritten Platz. Der Erfolg von SK Hynix ist hauptsächlich auf seine dominante Stellung im Bereich High Bandwidth Memory (HBM) zurückzuführen (angeblich 70 % Marktanteil), da die boomende KI die HBM-Nachfrage stark antreibt. SK Hynix liefert exklusiv seine HBM3E-Chips für Nvidias KI-Beschleuniger und erwartet weiterhin ein hohes Wachstum der HBM-Nachfrage. Gleichzeitig berichten koreanische Medien, dass SK Hynix bei der 1c-DRAM-Fertigung (ca. 11-12 nm) eine Ausbeute von 80 % erreicht hat und damit technologisch vorübergehend vor Samsung liegt, das noch Schwierigkeiten hat, die Ausbeute zu verbessern. Dies legt den Grundstein für die Massenproduktion von HBM4. (Quelle: 半导体行业观察)
KI-Agent-Protokolle MCP und A2A sorgen für Aufmerksamkeit und Ökosystem-Wettbewerb: Kürzlich sind das von Anthropic vorgeschlagene Model Context Protocol (MCP) und das von Google eingeführte Agent-to-Agent (A2A)-Protokoll zu Hotspots im KI-Bereich geworden. MCP zielt darauf ab, die Interaktion zwischen KI-Modellen und externen Tools sowie Datenquellen zu standardisieren und wird als „USB-C“-Schnittstelle für KI-Anwendungen bezeichnet. Es wird bereits von Microsoft, Google sowie zahlreichen Start-ups und Open-Source-Communities unterstützt. A2A konzentriert sich auf die sichere Kommunikation und Zusammenarbeit zwischen KI-Agenten verschiedener Anbieter, wobei bereits über 50 Unternehmen beteiligt sind. Diese Protokolle sollen die Probleme der mangelnden Interoperabilität und der Fragmentierung des Ökosystems zwischen KI-Agenten lösen. Analysten weisen jedoch darauf hin, dass hinter der Förderung dieser Protokolle durch die Tech-Giganten auch strategische Absichten stehen, eigene Ökosystem-Barrieren aufzubauen und den Abfluss von Daten zu verhindern. Beispielsweise sind die ersten Partner von Googles A2A hauptsächlich mit dessen Ökosystem verbunden, und der von Alibaba Cloud eingeführte MCP-Dienst integriert ebenfalls hauptsächlich Anwendungen innerhalb seines Systems. Plattformen wie Meituan und Didi könnten aufgrund von Bedenken hinsichtlich der Datenhoheit und der Mitsprache im Ökosystem zögern, sich offenen Protokollen anzuschließen. Dieser Protokollstreit ist im Wesentlichen ein Kampf um die Vorherrschaft im KI-Ökosystem und die Kontrolle über Daten. (Quelle: 卡兹克, 王智远, AI前线, 机器之心)
🎯 Bewegungen
DeepSeek regt zum Nachdenken über die Zukunft von Unternehmenssoftware an: Der Open-Source-Release von DeepSeek erschüttert die Unternehmenssoftwarebranche und löst Diskussionen über die technologischen Barrieren von SaaS-Anbietern und darüber aus, ob digitale KI-Mitarbeiter traditionelle Software beenden werden. Guo Shunri, CEO von Woxing Technology, glaubt, dass Tool-basierte SaaS mit Einzelfunktionen (wie RPA) am gefährdetsten sind, da sie leicht durch die multimodalen Fähigkeiten großer Modelle ersetzt werden können. Yang Fangxian, CEO von 53AI, schätzt, dass die Anwendung großer Modelle noch begrenzt ist, aber in 10-20 Jahren wird traditionelles SaaS verschwinden und durch KI-Produktivität (Fusion von digitalen Menschen + SaaS) ersetzt werden. Shen Yang, Experte für Informatisierung und Digitalisierung, vertritt eine radikalere Ansicht und glaubt, dass das SaaS-Modell innerhalb von sechs Monaten bis einem Jahr untergraben werden könnte und zukünftig auf Echtzeitdaten oder Serviceeffekten basierende Abrechnungsmodelle erforderlich sein werden. Der Dialog betont, dass KI Geschäftsmodelle neu gestalten wird, Unternehmen, die KI gut nutzen können, Wettbewerbsvorteile erlangen werden, während langsam reagierende Unternehmen vor dem Aus stehen. Der aktuelle Engpass bei der KI-Implementierung liegt eher in den Datensilos der Unternehmen und der unzureichenden Wissensintegration als in der KI-Technologie selbst. (Quelle: 36氪)
Anwendung und Reflexion von KI im Bereich großer Haushaltsgeräte: KI-Technologie wird zunehmend in große Haushaltsgeräte wie Kühlschränke, Waschmaschinen und Klimaanlagen integriert, um Funktionen wie Sprachinteraktion und intelligente Steuerung (z. B. KI-Energiesparen, KI-Wäschepflege) anzubieten. Marken wie Haier, TCL und Samsung bringen KI-Haushaltsgeräte auf den Markt, wie z. B. Haier-Kühlschränke mit DeepSeek, die Vorschläge zur Lebensmittelverwaltung machen können, oder TCL-Klimaanlagen, die das Wetter ansagen können. Der Artikel weist jedoch darauf hin, dass der „KI-Gehalt“ aktueller KI-Haushaltsgeräte uneinheitlich ist und einige Funktionen (wie die Anzeige von Wechselkursen durch Klimaanlagen) überflüssig und unpraktisch erscheinen. Im Vergleich zu KI-Produkten wie Saugrobotern, die bereits einen relativ vollständigen „Wahrnehmungs-Entscheidungs-Ausführungs“-Zyklus realisiert haben, beschränkt sich die KI-Anwendung bei großen Haushaltsgeräten oft auf Wahrnehmung und Vorschläge und kann keine vollständig autonomen Entscheidungen treffen und ausführen. Der Artikel stellt in Frage, ob bestimmte „KI“-Funktionen wirklich notwendig sind, und betont, dass Verbraucher eher Haushaltsgeräte benötigen, deren Kernfunktionen gut funktionieren und Probleme lösen, anstatt zwanghaft den KI-Hype mitzumachen. Der Artikel argumentiert, dass die Rolle großer Haushaltsgeräte im KI-Zeitalter darin bestehen sollte, Teil des Smart-Home-Ökosystems zu sein, wobei die Kernfunktionen perfektioniert und die Kollaborationsfähigkeiten verbessert werden müssen, anstatt alle zu Chat-Tools zu werden. (Quelle: 36氪)

MoE-Modelle werden zum neuen Trend, Alibaba Cloud rüstet KI-Infrastruktur auf, um Herausforderungen zu begegnen: Die Mixture of Experts (MoE)-Architektur entwickelt sich zum Mainstream-Trend bei großen KI-Modellen, von Mixtral über DeepSeek und Qwen2.5-Max bis hin zu Llama 4 nutzen alle diese Architektur. Um den Herausforderungen von MoE (wie Token-Routing, Expertenauswahl usw.) zu begegnen, hat Alibaba Cloud das auf PAI-DLC basierende FlashMoE-Trainingsframework veröffentlicht, das extrem großes MoE-Mixed-Precision-Training unterstützt und die MFU auf einer Skala von Zehntausenden von Karten auf 35-40 % steigern kann. Gleichzeitig hat Alibaba Cloud die verteilte Inferenz-Engine Llumnix für MoE eingeführt, die die Latenz erheblich reduziert. Darüber hinaus hat Alibaba Cloud die 9. Generation von ECS-Instanzen, optimierte Lingjun-Cluster (HPN 7.0-Netzwerk, CPFS-Hochleistungsspeicher, Selbstheilungssystem für Fehler), verbesserten OSS-Objektspeicher (OSSFS 2.0) sowie den MaxCompute AI Function und den DataWorks Agent-Dienst mit Unterstützung für das MCP-Protokoll veröffentlicht, um die KI-Infrastruktur umfassend aufzurüsten und den neuen Paradigmen von MoE und Inferenzmodellen gerecht zu werden. (Quelle: 机器之心)
Keenon Robotics stellt humanoiden Serviceroboter XMAN-R1 vor: Keenon Robotics, ein weltweit führendes Unternehmen für Serviceroboter, hat seinen ersten humanoiden Embodied Serviceroboter XMAN-R1 vorgestellt, positioniert als „für den Service geboren“. Der Roboter basiert auf den umfangreichen realen Daten, die Keenon in Szenarien wie Gastronomie, Hotellerie und Gesundheitswesen gesammelt hat, und legt Wert auf Aufgabenorientierung, Freundlichkeit und Sicherheit. XMAN-R1 kann geschlossene Aufgaben in Serviceszenarien wie Bestellaufnahme, Essenszubereitung, Essenslieferung und Abräumen erledigen. Er verfügt über Fähigkeiten wie beidhändige Übergabe von Gegenständen, mobile Steuerung, menschenähnliche Interaktion (großes Sprachmodell, Mimik-Feedback) und ist mit 11 multimodalen Sensoren und intelligenter Hindernisvermeidungstechnologie ausgestattet, um sich an dicht besiedelte Umgebungen anzupassen. XMAN-R1 wird ein Ökosystem der multimodalen Zusammenarbeit mit den bestehenden spezialisierten Robotern von Keenon für Lieferung, Reinigung usw. bilden, um gemeinsam komplexere kommerzielle Serviceaufgaben zu erfüllen und die Matrix der multimodalen Embodied Serviceroboter von Keenon weiter zu vervollständigen. (Quelle: InfoQ)
Xi’an Jiaotong Universität et al. schlagen trainingsfreies Framework zur Dynamisierung von Gemälden vor: Every Painting Awakened: Um die Probleme der „Unbeweglichkeit“ oder „chaotischen Bewegung“ bei der Dynamisierung von Gemälden durch bestehende Image-to-Video (I2V)-Methoden zu lösen, haben die Xi’an Jiaotong Universität, die Hefei University of Technology und die Universität Macau gemeinsam das Zero-Shot-Framework „Every Painting Awakened“ vorgeschlagen. Das Framework nutzt vortrainierte Bildmodelle, um Proxy-Bilder als dynamische Anleitung zu generieren. Durch eine Dual-Path Score Distillation-Technik werden statische Details des Originalgemäldes beibehalten und dynamische Priors aus dem Proxy-Bild extrahiert. Anschließend werden dynamische und statische Merkmale im latenten Raum mithilfe eines Hybrid Latent Fusion-Mechanismus (sphärische lineare Interpolation) fusioniert und an ein bestehendes I2V-Modell zur Videogenerierung übergeben. Diese Methode verbessert bestehende I2V-Modelle ohne zusätzliches Training, kann Bewegungsanweisungen aus Text-Prompts präzise ausführen und gleichzeitig den Stil und Pinselstrich des Originalgemäldes beibehalten, um eine natürliche und flüssige Dynamisierung von Gemälden zu erreichen. Experimente zeigen, dass das Framework die semantische Übereinstimmung und die Stilerhaltung signifikant verbessert. (Quelle: PaperWeekly)
Universität Waterloo und Meta präsentieren MoCha: Generierung von Mehrpersonen-Dialogvideos basierend auf Sprache und Text: Um die Mängel bestehender Videogenerierungstechnologien bei charaktergetriebenen Erzählungen zu beheben (z. B. Beschränkung auf Gesichter, Abhängigkeit von Hilfsbedingungen, Unterstützung nur eines Charakters), haben die University of Waterloo in Kanada und Meta GenAI das MoCha-Framework vorgeschlagen. MoCha ist die erste Methode für die Aufgabe „Talking Characters“, die nur Sprache und Text als Eingabe benötigt, um Ganzkörper-Dialogvideos von Charakteren im Nah- bis Mittelbereich zu generieren, und unterstützt mehrere Charaktere und mehrere Gesprächsrunden. Kerntechnologien umfassen: 1) Speech-Video Window Attention-Mechanismus, der durch lokale zeitliche Konditionierung eine präzise Ausrichtung von Sprach- und Videozeitmerkmalen modelliert, um Lippensynchronität und Bewegungssynchronisation zu gewährleisten; 2) Gemeinsame Sprach-Text-Trainingsstrategie, die vorhandene sprach- und textannotierten Videodaten nutzt, um die Generalisierungsfähigkeit und Steuerbarkeit des Modells zu verbessern; 3) Strukturierte Prompt-Vorlagen und Charakter-Tags, die erstmals die Generierung von Mehrpersonen- und Mehrrunden-Dialogen ermöglichen und dabei Kontextkohärenz und Charakteridentität wahren. Experimente bestätigen seine Vorteile in Bezug auf Realismus, Ausdruckskraft und Steuerbarkeit und fördern die automatisierte Generierung filmischer Erzählungen. (Quelle: PaperWeekly)
Huazhong University of Science & Technology & Xiaomi Auto schlagen autonomes Fahrframework ORION vor: Um das Problem der begrenzten kausalen Inferenzfähigkeit von End-to-End-autonomen Fahrsystemen in geschlossenen Regelkreisen (Closed-Loop Interaction) anzugehen, haben die Huazhong University of Science and Technology und Xiaomi Auto das ORION-Framework vorgeschlagen. Dieses Framework kombiniert innovativ Vision-Language Models (VLM) und generative Modelle (wie VAE oder Diffusionsmodelle). Es nutzt VLM für Szenenverständnis, Inferenz und Befehlsgenerierung. Anschließend werden die semantischen Inferenzräume des VLM durch das generative Modell mit den rein numerischen Trajektorien-Aktionsräumen abgeglichen, um die Trajektoriengenerierung zu steuern. Gleichzeitig wird das QT-Former-Modul eingeführt, um langfristige historische visuelle Kontextinformationen effektiv zu aggregieren und die Token-Beschränkungen und den Rechenaufwand von VLMs bei der Verarbeitung mehrerer Bildframes zu überwinden. ORION erreicht eine einheitliche End-to-End-Optimierung von visuellen Frage-Antwort- (VQA) und Planungsaufgaben. In der Bench2Drive Closed-Loop-Bewertung erreichte ORION einen Fahr-Score von 77,74 Punkten und eine Erfolgsrate von 54,62 %, was deutlich besser ist als bisherige Bestmethoden. Code, Modell und Datensatz werden Open Source sein. (Quelle: 机器之心)
National University of Singapore stellt GEAL vor: Nutzung von 2D-Großmodellen zur Verbesserung der 3D-Affordance-Vorhersage: Um die Probleme der Datenknappheit, der teuren Annotation und der unzureichenden Generalisierungsfähigkeit und Robustheit von Modellen beim 3D Affordance Learning (Vorhersage von interaktiven Bereichen von Objekten) zu lösen, hat die National University of Singapore das GEAL-Framework vorgeschlagen. GEAL nutzt 3D Gaussian Splatting, um spärliche Punktwolken in realistische Bilder zu rendern, die dann an vortrainierte 2D-Vision-Großmodelle (wie DINOV2) zur Extraktion reichhaltiger semantischer Merkmale gesendet werden. Durch eine innovative Cross-Modal Consistency Alignment, einschließlich eines Granularity-Adaptive Fusion Module (GAFM) und eines Consistency Alignment Module (CAM), werden 2D-visuelle Merkmale effektiv mit 3D-räumlichen geometrischen Merkmalen fusioniert. GAFM aggregiert Merkmale auf mehreren Skalen adaptiv basierend auf Textanweisungen, während CAM durch das Rendern von 3D-Merkmalen in 2D und die Anwendung eines Konsistenzverlusts den bidirektionalen Informationsabgleich fördert. GEAL benötigt keine umfangreichen 3D-Annotationen und verbessert die Generalisierungsfähigkeit auf neue Objekte und Szenen sowie die Robustheit in verrauschten Umgebungen erheblich. Das Team hat außerdem einen Benchmark-Datensatz mit verschiedenen realen Störungen erstellt, um die Robustheit des Modells zu bewerten. (Quelle: 机器之心)
Moonshot AI veröffentlicht Kimi-VL MoE Klein- und Großmodelle mit Fokus auf multimodale Inferenz und langen Kontext: Moonshot AI hat die beiden Vision-Language Mixture of Experts (MoE)-Modelle Kimi-VL und Kimi-VL-Thinking vorgestellt. Diese Modelle haben eine Gesamtparameterzahl von 16B, wobei nur etwa 3B Parameter aktiviert werden, zeigen aber in mehreren Benchmarks hervorragende Leistungen. Kimi-VL-Thinking zeichnet sich durch multimodale Inferenz (MathVision erreicht 36,8 %) und Agentenfähigkeiten (ScreenSpot-Pro erreicht 34,5 %) aus und erreicht eine Leistung, die mit Modellen vergleichbar ist, die zehnmal so viele Parameter haben. Die Modelle verwenden die MoonViT-Technologie zur nativen Verarbeitung hochauflösender visueller Eingaben (OCRBench erreicht 867) und unterstützen ein langes Kontextfenster von bis zu 128K (MMLongBench-Doc erreicht 35,1 %, LongVideoBench erreicht 64,5 %). In wichtigen Benchmarks übertreffen sie größere Modelle wie GPT-4o. Die zugehörigen Paper und Hugging Face Modelle wurden veröffentlicht. (Quelle: Reddit r/LocalLLaMA)
🧰 Werkzeuge
Firebase Studio: Googles integrierte KI-gestützte Online-Full-Stack-Entwicklungsplattform: Google hat das Entwicklungstool Project IDX in Firebase integriert und in Firebase Studio umbenannt. Es bietet eine kostenlose browserbasierte Full-Stack-Anwendungsentwicklungsumgebung. Hauptmerkmale der neuen Plattform sind: 1) KI-gestützte Projekterstellung, die basierend auf natürlichsprachlichen Anweisungen initialen Code für Anwendungen wie Next.js generieren kann; 2) Umschalten zwischen zwei Arbeitsmodi, die einen nahtlosen Wechsel zwischen einem KI-gestützten Modus zur schnellen Generierung von Inhalten und einer traditionellen Cloud-Entwicklungsumgebung (Cloud-Workspace auf VM-Basis) ermöglichen; 3) Übernahme der IDX-Funktionen wie Full-Stack-Vorlagen, Android-Emulator, Teamkollaboration, Ein-Klick-Bereitstellung usw. Firebase Studio ist tief in die Firebase-Backend-Dienste (Datenbank, Authentifizierung usw.) integriert und zielt darauf ab, eine umfassende Entwicklungserfahrung zu schaffen, die Frontend- und Backend-Entwicklung sowie Cloud-Dienste vereint. Nutzerfeedback zeigt, dass das Tool sehr leistungsfähig ist, eine gute Interaktionserfahrung bietet, Anwendungen durch Prompts erstellen und in Echtzeit anzeigen kann und sogar die Markierung von UI-Elementen in Screenshots zur Modifikation unterstützt. Der Zugriff kann jedoch derzeit aufgrund hoher Nutzerzahlen eingeschränkt sein. (Quelle: 36氪, dotey)

OpenManus: Open-Source-Agent-Projekt zur schnellen Nachbildung der Kernfunktionen von Manus: Als Reaktion auf den Hype um den Manus AI Agent, dessen Code jedoch nicht Open Source ist, haben Liang Xinbing, Masterstudent an der East China Normal University, und Xiang Jinyu, Forscher bei DeepWisdom, zusammen mit anderen Entwicklern der Generation Z in ihrer Freizeit das OpenManus-Projekt schnell entwickelt und als Open Source veröffentlicht. Das Projekt zielt darauf ab, die Kernfunktionen von Manus nachzubilden und die Kernlogik eines Agenten (basierend auf Tool und Prompt) mit einfachem, verständlichem Code (ca. einige tausend Zeilen) darzustellen. Das Projekt nutzt das React-Muster von Function Calls und hat Kernwerkzeuge für Browser-Bedienung, Dateibearbeitung, Codeausführung usw. entwickelt. OpenManus erreichte schnell über 40.000 Sterne auf GitHub, was die Begeisterung der Open-Source-Community für die Agent-Technologie widerspiegelt. Die Entwickler teilten ihren Workflow zur Nutzung großer Modelle zur Unterstützung des Verständnisses von Codebasen, des Architekturentwurfs und der Codegenerierung und diskutierten die Herausforderungen des MCP-Protokolls (die Typ-C-Schnittstelle der KI-Welt) und der Multi-Agent-Kollaboration. Das Projekt wird kontinuierlich weiterentwickelt, mit Plänen zur Verbesserung des Tool-Ökosystems, der MCP-Unterstützung, der Multi-Agent-Koordinationsmechanismen und der Testfälle. (Quelle: CSDN)
Popularisierung des Konzepts und Anwendungsszenarien von AI Agents: Ein AI Agent ist eine Software, die autonom ihre Umgebung wahrnehmen, Entscheidungen treffen und Aufgaben ausführen kann. Im Gegensatz zu gewöhnlicher KI (wie Chatbots), die nur Informationen liefert, kann ein AI Agent für Sie „handeln“. Seine Hauptmerkmale sind Autonomie, Gedächtnisfähigkeit, Fähigkeit zur Werkzeugnutzung und Lern- und Anpassungsfähigkeit. Die Anwendungsszenarien sind breit gefächert, z. B. als persönlicher Assistent (automatische Reiseplanung, Verwaltung von Terminen und E-Mails), in Geschäftsanwendungen (Verbesserung der Softwareentwicklung, des Kundenservice, der Arzneimittelentdeckung) und zur Steigerung der Unternehmenseffizienz (Automatisierung von HR-Prozessen, Verwaltung der Inhaltserstellung). Der Aufbau eines AI Agenten umfasst die Phasen Wahrnehmung (Datenerfassung), Denken (Analyse und Planung durch KI-Modelle), Handeln (Aufruf von Tool-APIs) und Lernen (Verbesserung aus Ergebnissen). Große Unternehmen wie Microsoft, Google, BAT usw. investieren alle in diesen Bereich. Benutzer können über Plattformen wie Coze oder durch das Schreiben von Prompt-Vorlagen beginnen, einfache Aufgaben zu erledigen und schrittweise das Potenzial zu erkunden. (Quelle: 周知)
Color Reshape: Batch-Verarbeitungstool zur Korrektur von Farbstichen in GPT-4o-Bildern: Als Reaktion auf das häufige Auftreten von blauen oder gelben Farbstichen in von GPT-4o generierten Bildern hat der Entwickler „Guicang“ ein Tool namens „Color Reshape“ veröffentlicht. Das Tool zielt darauf ab, mit einem Klick die Farbbalance von KI-generierten Bildern stapelweise zu korrigieren, damit sie professionelleren Fotografien ähneln und realistische Farben wiederhergestellt werden. Zu den Merkmalen gehören die Unterstützung der Stapelverarbeitung, eine Vergleichsfunktion zwischen Originalbild und Ergebnisbild mit Schiebereglern sowie professionelle Optionen zur Steuerung der Farbbalance. Dies löst das Problem, dass Benutzer nach der Generierung von Bildern mit GPT-4o die Farben manuell anpassen müssen, und verbessert die Effizienz und das Endergebnis der KI-Kunstschaffung. (Quelle: op7418)
Notion veröffentlicht MCP Server: Notion hat die Implementierung seines MCP (Model Context Protocol) Servers veröffentlicht, der jetzt auf GitHub Open Source ist. Der Server ermöglicht es AI Agents, über das MCP-Protokoll mit Notion zu interagieren und implementiert verschiedene Notion-API-Funktionen, darunter das Abrufen von Seiteninhalten, Kommentaren und das Ausführen von Suchen. Dies bedeutet, dass AI Agents, die das MCP-Protokoll unterstützen (wie Claude usw.), bequemer auf die Daten und Funktionen der Benutzer in Notion zugreifen und diese bearbeiten können, was die Anwendungsszenarien und Fähigkeiten von AI Agents weiter erweitert. (Quelle: karminski3)

OLMoTrace: Neues Werkzeug zur Untersuchung von Gedächtnis und Synthese von Informationen in Sprachmodellen: Ai2 (Allen Institute for AI) hat OLMoTrace eingeführt, eine neue Funktion in seinem AI Playground. Sie soll helfen zu verstehen, inwieweit große Sprachmodelle (LLMs) Informationen lernen und synthetisieren und inwieweit sie lediglich Trainingsdaten speichern und wiedergeben. Benutzer können mit diesem Tool nun Trainingsdatensegmente anzeigen, die möglicherweise zur Generierung einer bestimmten Vervollständigung (Completion) durch das Modell beigetragen haben. Dies ist wichtig für die Untersuchung der internen Funktionsweise von LLMs, das Verständnis der Ursprünge ihres Verhaltens und die Bewertung des Gleichgewichts zwischen Generalisierung und Gedächtnis, insbesondere für Forscher und Entwickler, die sich für die Originalität und Zuverlässigkeit von Modellen interessieren. (Quelle: natolambert)
📚 Lernen
NVIDIA veröffentlicht offenes Foundation Model GR00T N1 zur Förderung universeller humanoider Roboter: NVIDIA hat GR00T N1 veröffentlicht, ein offenes Foundation Model, das speziell für universelle humanoide Roboter entwickelt wurde. Das Modell zielt darauf ab, das Problem der Knappheit von Roboter-Trainingsdaten zu lösen, indem es verschiedene Datenquellen zum Lernen kombiniert: 1) Nutzung von Omniverse zur Erstellung hochpräziser digitaler Zwillingsumgebungen (z. B. Fabriken), um große Mengen an automatisch gelabelten Simulationsdaten zu generieren; 2) Nutzung des Cosmos-Modells zur Umwandlung von Simulationsdaten in realistischere Videos, um den Trainingsdatensatz weiter zu erweitern; 3) Entwicklung eines KI-Systems zur automatischen Annotation vorhandener Videos im Internet, um Informationen wie Aktionen, Gelenke, Ziele usw. zu extrahieren, sodass auch reale Videos als Trainingsdaten verwendet werden können. GR00T N1 verwendet ein duales Denksystem: System 2 für langsame Inferenzplanung und System 1 (basierend auf Diffusionsmodellen) zur Generierung von Echtzeit-Bewegungssteuerungsbefehlen. Experimente zeigen eine Steigerung der Erfolgsrate von 46 % auf 76 % im Vergleich zu früheren Methoden. Das Modell ist Open Source, unterstützt Roboter unterschiedlicher Morphologie und soll die Forschung und Anwendung universeller Roboter beschleunigen. (Quelle: Two Minute Papers)
KI hilft bei der Linderung von Mathematikangst bei High-School-Schülern: Laut einer globalen Umfrage der Society for Industrial and Applied Mathematics (SIAM) in Philadelphia glauben über die Hälfte (56 %) der High-School-Schüler, dass KI zur Linderung von Mathematikangst beitragen kann. 15 % der Schüler gaben an, dass ihre persönliche Nutzung von KI ihre Mathematikangst reduziert hat, und 21 % verbesserten ihre Noten. Gründe für die Linderung der Angst durch KI sind: Bereitstellung sofortiger Hilfe und Rückmeldung (61 %), Aufbau von Selbstvertrauen (ermöglicht Fragen im eigenen Tempo, 44 %), personalisiertes Lernen (33 %) und Verringerung der Angst vor Fehlern (25 %). Allerdings glauben nur 19 % der Lehrer, dass KI die Mathematikangst reduzieren kann. Die Mehrheit der Lehrer und Schüler (64 % Lehrer, 43 % Schüler) ist der Meinung, dass KI in Zusammenarbeit mit menschlichen Lehrern eingesetzt werden sollte, als Tutor oder Lernpartner, um Konzepte zu verstehen, anstatt direkt Antworten zu geben. Die Verbreitung von KI wirft auch Fragen über die Beziehung zwischen Lehrern und Schülern und die sich wandelnde Rolle der Lehrer auf, wie z. B. eine stärkere Betonung von Prüfungen ohne KI-Nutzung, die Notwendigkeit für Lehrer, KI zu beherrschen, um Schüler anzuleiten, und die Möglichkeit für Lehrer, sich stärker auf individuelle Betreuung zu konzentrieren. (Quelle: 元宇宙之心MetaverseHub)

💼 Geschäftlich
Embodied AI-Unternehmen „QiongcHe Intelligence“ schließt Pre-A++ Finanzierungsrunde über Hunderte Millionen Yuan ab: Das von einem Stanford-Team gegründete Embodied AI-Unternehmen „QiongcHe Intelligence“ hat kürzlich eine Pre-A++ Finanzierungsrunde über Hunderte Millionen Yuan abgeschlossen. Zu den Investoren gehören Shengyu Investment, Tsingke Ventures, Vision Knight Capital, Yunqi Partners, Shanghai STVC Group usw. Bestehende Investoren Prosperity7 und Sequoia China beteiligten sich in drei aufeinanderfolgenden Runden. Die Mittel sollen den Durchbruch in Bereichen wie Embodied AI Foundation Models, Datenerfassung und -bewertung beschleunigen und die Kommerzialisierung in Szenarien wie Einzelhandelsabwicklung, Haushaltsdienstleistungen und Lebensmittelverarbeitung vorantreiben. Das Unternehmen wurde gemeinsam von Professor Lu Cewu von der Shanghai Jiao Tong University und Wang Shiquan, Gründer von Flexiv, gegründet und konzentriert sich auf die Lösung zentraler Herausforderungen der Embodied AI bei der Beschreibung und Interaktion mit der physischen Welt sowie der Datenerfassung. Sein Kernprodukt, das „QiongcHe Embodied Brain“, verfügt bereits über vollständige Closed-Loop-Fähigkeiten und senkt die Datenkosten durch das selbst entwickelte „Production-Accompanied“ Datenerfassungssystem (CoMiner). Das Unternehmen hat bereits mit Haushaltsgeräteherstellern zusammengearbeitet, um Haushaltsroboter zu entwickeln (wie den auf der AWE gezeigten Wasch- und Pflegeroboter), und hat Kooperationsabsichten mit Lebensmittelherstellern erzielt. (Quelle: 36氪)
Humanoider Roboter-Unternehmen „Stardust Intelligence“ schließt A- und A+-Finanzierungsrunden über Hunderte Millionen Yuan ab: Das Embodied Humanoid Robotik-Unternehmen „Stardust Intelligence“ hat nacheinander A- und A+-Finanzierungsrunden mit einem Gesamtvolumen von Hunderten Millionen Yuan abgeschlossen. Hauptinvestoren sind Jinqiu Fund und Ant Group, bestehende Investoren wie Yunqi Partners und Daotong Capital beteiligten sich ebenfalls. Das Unternehmen definiert das Paradigma „Design for AI“ und widmet sich der Entwicklung von KI-Roboterassistenten mit menschenähnlichen Manipulationsfähigkeiten. Sein Kernprodukt Astribot S1 verwendet ein einzigartiges seilgetriebenes Antriebsdesign, das ein hohes Nutzlast-Eigengewicht-Verhältnis (1:1), hohe Geschwindigkeit (Endeffektor über 10 m/s) und menschenähnliche flexible Manipulationsfähigkeiten ermöglicht. Stardust Intelligence hat einen technologischen Closed-Loop aus „Hardware + Daten + Modell“ aufgebaut, der die kostengünstige Nutzung von realen Videodaten und menschlichen Bewegungsdaten sowie die effiziente Erfassung multimodaler Interaktionsdaten ermöglicht. Dies verleiht dem Roboter Fähigkeiten zur Wahrnehmung komplexer Umgebungen, Kognition, Entscheidungsfindung und allgemeine Manipulationsgeneralisierung. Der S1 wurde bereits dreimal iteriert, wird in Zusammenarbeit mit Universitäten, Unternehmen usw. in der Praxis eingesetzt und das End-to-End-Großmodell wird kontinuierlich optimiert. (Quelle: 36氪)

Jony Ives und Sam Altmans KI-Hardware-Startup io Products möglicherweise von OpenAI übernommen: Das von Ex-Apple-Designchef Jony Ive und OpenAI-CEO Sam Altman gegründete KI-Hardware-Startup io Products könnte laut The Information für mindestens 500 Millionen US-Dollar von OpenAI übernommen werden. io Products wurde 2024 gegründet mit dem Ziel, KI-gesteuerte persönliche Geräte zu entwickeln, die weniger aufdringlich sind als Smartphones. Mögliche Richtungen könnten bildschirmlose Telefone, KI-gesteuerte Haushaltsgeräte oder tragbare KI-Assistenten sein. Diese potenzielle Übernahme signalisiert eine mögliche Expansion von OpenAI vom Softwarebereich in die Consumer Hardware. Angesichts des Scheiterns früherer KI-Hardwareprodukte wie dem Humane AI Pin und dem Rabbit R1 sowie der Präferenz der Nutzer für verbesserte KI-Funktionen auf bestehenden Telefonen gegenüber völlig neuen Geräteformen bleiben jedoch Zweifel an der Nachfrage und Akzeptanz für bildschirmlose KI-Geräte bestehen. (Quelle: 不客观实验室)

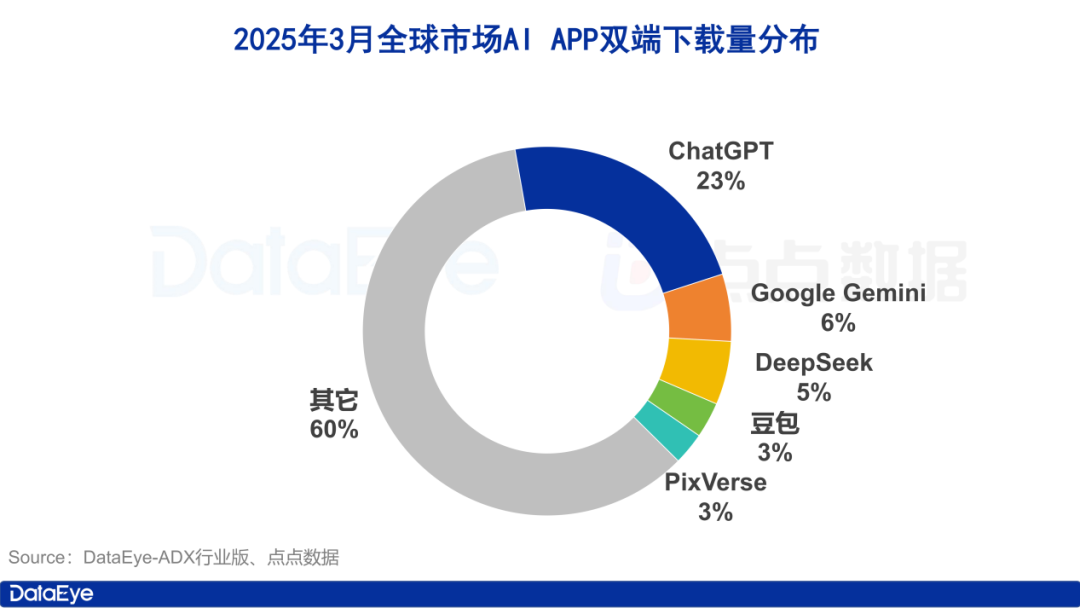
Beobachtung des KI-Anwendungsmarktes im März: Weltweit 260 Millionen Downloads, in China „Dreikampf“ zwischen Tencent, Alibaba und ByteDance: Ein Bericht des DataEye Research Institute zeigt, dass die geschätzten weltweiten Downloads von KI-Anwendungen (App Store & Google Play) im März 2025 260 Millionen Mal erreichten. ChatGPT führt mit einem Anteil von 23 % deutlich, Google Gemini überholte DeepSeek und liegt auf Platz zwei. Auf dem chinesischen Markt erreichten die Downloads auf der Apple-Seite 40,2 Millionen Mal, wobei DeepSeek, Jimi AI, Doubao, Quark und Tencent Yuanbao die Top 5 bildeten. Die Downloads von Kimi Smart Assistant brachen ein. Im Bereich der bezahlten Akquise erreichte die Anzahl der Werbematerialien für KI-Produkte (einschließlich Mini-Apps) auf dem chinesischen Festlandmarkt 957.000 Sets. Tencent Yuanbao (26 %), Quark (24 %) und Doubao (13 %) belegten die ersten drei Plätze, was einen intensiven Wettbewerb zwischen Tencent, Alibaba und ByteDance zeigt. Kimi fiel nach Einstellung der Werbemaßnahmen aus der Rangliste. Der Bericht ist der Ansicht, dass der Hype um DeepSeek und Alibabas „All in AI“-Strategie die großen Unternehmen dazu veranlasst haben, ihre Präsenz im C-End-KI-Anwendungsmarkt zu beschleunigen. (Quelle: 36氪)
Anthropic führt hochpreisigen Abonnementplan Claude Max ein: Als Konkurrenz zu OpenAIs ChatGPT Pro (200 USD/Monat) hat Anthropic den Abonnementdienst Claude Max eingeführt. Der Dienst bietet zwei Optionen: 100 USD/Monat für eine 5-mal höhere Nutzungsgrenze als das bestehende Claude Pro (20 USD/Monat); 200 USD/Monat für eine bis zu 20-mal höhere Nutzungsgrenze. Max-Plan-Nutzer erhalten bevorzugten Zugang zu Anthropics neuesten KI-Modellen und Funktionen, einschließlich des bevorstehenden Sprachmodus. Dieser Schritt wird als neuer Weg für KI-Unternehmen gesehen, Einnahmen zu steigern und Power-User zu bedienen. Der Produktleiter von Anthropic erklärte, dass dieser Plan hauptsächlich auf professionelle Power-User in Bereichen wie Codierung, Finanzen, Medienunterhaltung und Marketing abzielt und die Möglichkeit zukünftiger, teurerer Pläne nicht ausschließt. Gleichzeitig prüft Anthropic auch Dienste für spezifische Märkte wie Bildung. (Quelle: dotey, op7418)

xAI veröffentlicht Grok 3 API und gibt Preise bekannt: xAI hat offiziell den Beta-Test für die Grok 3 Serien-API eröffnet und bietet die Modelle Grok 3 und Grok 3 Mini an. Jedes Modell ist im regulären Modus und im Schnellmodus (schnellere Antwort, aber höhere Ausgabekosten) verfügbar. Grok 3 eignet sich für Unternehmensszenarien wie Datenextraktion und Programmierung und kostet $3/Million Token für die Eingabe und $15/Million Token für die Ausgabe (Schnellmodus: $5/$25). Grok 3 Mini ist ein leichtgewichtiges Modell für einfache Aufgaben und kostet $0.3/Million Token für die Eingabe und $0.5/Million Token für die Ausgabe (Schnellmodus: $0.6/$4). Dies bietet Entwicklern flexible Optionen, um den Anforderungen verschiedener Anwendungsszenarien an Leistung und Kosten gerecht zu werden. Gleichzeitig hat Google ebenfalls neue Pläne mit kostenlosen Kontingenten für Entwickler eingeführt, Anthropic bietet den hochpreisigen Max-Plan an, und Metas Llama 4 konkurriert mit niedrigen Kosten (ca. $0.36/Million Token), was die differenzierte Preisstrategie der KI-Giganten im API-Wettbewerb zeigt. (Quelle: 新智元, op7418)
36Kr veröffentlicht Liste innovativer KI-nativer Anwendungsfälle 2025: 36Kr hat die Liste „2025 AI Native Application Innovation Cases“ ausgewählt und veröffentlicht, in die letztendlich 45 Fälle aufgenommen wurden. Die Auswahl zielt darauf ab, KI-native Produkte und Anwendungen zu entdecken, die KI-Technologie als erste in realen Szenarien einsetzen, tatsächlichen Wert schaffen und den Branchenwandel anführen. Die aufgenommenen Fälle decken mehrere Bereiche ab, darunter intelligente Fertigung, Kundenservice, Inhaltserstellung, Unternehmensmanagement, Büroarbeit, Sicherheit, Marketing und Gesundheitswesen. Die Jury stellte fest, dass die aufgenommenen Fälle vier Hauptmerkmale aufweisen: 1) Beschleunigte branchenübergreifende Fusion zur Schaffung neuer Geschäftsmodelle; 2) Tiefe Integration mit Branchenproblemen zur Bereitstellung spezifischer Lösungen; 3) Fokus auf Verbesserung der Benutzererfahrung und personalisierter Dienste; 4) Stützung auf starke selbst entwickelte Technologien (Großmodelle, Multimodalität usw.) und aktiver Aufbau innovativer Ökosysteme. Die Liste spiegelt wider, dass KI-native Anwendungen ein explosives Wachstum erleben und tief in alle Branchen eindringen. (Quelle: 36氪)

🌟 Community
Google DeepMind soll angeblich 1-jährige Wettbewerbsverbote nutzen, um Talentabwanderung zu begrenzen: Laut Business Insider wird Google DeepMind vorgeworfen, Wettbewerbsverbotsklauseln von bis zu 12 Monaten (einschließlich obligatorischer bezahlter Freistellung / Garden Leave) zu nutzen, um zu verhindern, dass wichtige KI-Talente zu Konkurrenten wie OpenAI und Microsoft wechseln. Die Klauseln sind normalerweise in Arbeitsverträgen enthalten und treten in Kraft, wenn Mitarbeiter versuchen, zu einem direkten Konkurrenten zu wechseln. Die Dauer der Wettbewerbsverbotsfrist hängt von der Position ab und kann für Entwickler an vorderster Front 6 Monate betragen, für leitende Forscher bis zu 1 Jahr. Dieser Schritt sorgt für Kontroversen und wird als „goldene Handschellen am Arbeitsplatz“ kritisiert. In der sich schnell entwickelnden KI-Branche könnte dies dazu führen, dass Talente den Anschluss verlieren, Innovationen gehemmt und die Talentmobilität eingeschränkt werden. Da das britische Recht die Durchsetzung „angemessener“ Wettbewerbsverbote erlaubt und DeepMind seinen Hauptsitz in London hat, steht dies im Gegensatz zu Kalifornien, wo Wettbewerbsverbote verboten sind. Nando de Freitas, ehemaliger DeepMind-Manager und jetzt VP bei Microsoft, kritisierte diese Praxis öffentlich auf X (ehemals Twitter) und erklärte, dass DeepMind in Europa nicht so viel Macht haben sollte, was eine breite Diskussion auslöste. (Quelle: CSDN程序人生)

KI weckt Bedenken hinsichtlich „emotionaler Kokons“: Mit der Entwicklung der KI-Technologie nehmen ihre Anwendungen zur Befriedigung menschlicher Emotionen und Wünsche zu, wie z. B. intelligente Sexpuppen (Wmdoll erwartet 30 % Umsatzsteigerung), virtuelle KI-Begleiter, KI-Chat-Assistenten (Steigerung der Einnahmen von OnlyFans-Creators) usw. Der Artikel analysiert, dass KI stabilen, geduldigen und bestätigenden emotionalen Wert bieten kann, die Bedürfnisse nach geistigem Austausch befriedigt und sogar echte Menschen übertrifft. Diese „übermäßige Anpassung“ und „übermäßige Bevormundung“ könnten jedoch dazu führen, dass Menschen „emotionale Kokons“ bilden, sich bei der Verarbeitung von Beziehungen übermäßig auf subjektive Gefühle verlassen, die Toleranz gegenüber Komplexität und Frustration in echten zwischenmenschlichen Beziehungen verringern und emotionale Verletzlichkeit, Atomisierung und Geschlechterkonflikte verschärfen. Der Artikel argumentiert, dass KI zwar menschliche Zeit durch die Erledigung von Routineaufgaben freisetzt, aber auch durch ihre anpassungsfähige Natur Menschen in Komfortzonen und ultimativen Fantasien einschließen könnte, was persönliches Wachstum und echte zwischenmenschliche Interaktion behindert und letztendlich dazu führen könnte, dass Menschen einsamer werden und von KI „erobert“ werden. (Quelle: 周天财经)

Strategische Neuausrichtung von MiniMax: Von „Produkt-Modell-Integration“ zu Technologiepriorität, Fokus auf KI-Video: Angesichts des Wettbewerbsdrucks durch DeepSeek und andere passt das KI-Unternehmen MiniMax seine Strategie an. Ursprünglich verfolgte es eine „Produkt-Modell-Integration“, bei der Modelle den Anwendungen dienten (z. B. Textmodell für MiniMax Assistant, Videomodell für Hailuo AI sowie Talkie, Xingye usw.) und die Effizienz durch Modifikationen der zugrunde liegenden Transformer-Architektur (lineare Aufmerksamkeit) gesteigert wurde. Gründer Yan Junjie reflektierte, dass „bessere Anwendungen nicht unbedingt zu besseren Modellen führen“, und das Unternehmen richtet sich nun „technologiegetrieben“ aus, wobei Technologieforschung und Produktanwendung getrennt werden. Auf Produktebene konzentriert sich MiniMax auf die Marke „Hailuo“ für die Videogenerierung, das ursprüngliche „Hailuo AI“ wird in „MiniMax“ umbenannt, und es gibt Gerüchte über die Übernahme des KI-Videogenerierungsunternehmens Luying Technology (mit der Anime-Plattform YoYo). Dieser Schritt könnte darauf zurückzuführen sein, dass seine Haupteinnahmequelle Talkie (KI-Begleiter-App) auf dem Überseemarkt von der Entfernung aus den App Stores bedroht ist und neue Wachstumsquellen gesucht werden müssen. Gleichzeitig beginnt MiniMax, sich auf das B2B-Geschäft zu konzentrieren und gründet eine Allianz für Innovationen in der intelligenten Hardwareindustrie. Sein B2B-Geschäft ist jedoch noch schwach und steht vor Herausforderungen. (Quelle: guangzi0088)

Great Wall Motor und Unitree Robotics kooperieren zur Erkundung von „Geländewagen + Roboterhund“: Great Wall Motor und das Robotikunternehmen Unitree Robotics haben eine strategische Partnerschaft vereinbart, um in Bereichen wie Robotertechnologie und intelligenter Fertigung zusammenzuarbeiten. Die erste Phase der Zusammenarbeit wird sich auf Anwendungsszenarien von „Geländewagen + Roboterhund“ konzentrieren, um Möglichkeiten wie Ausrüstungstransport und Begleitung bei Outdoor-Abenteuern zu erkunden. Der Artikel erörtert die Anwendung von Robotern (insbesondere humanoiden Robotern) in der Automobilindustrie und kommt zu dem Schluss, dass Roboter in Autofabriken derzeit hauptsächlich unterstützende Rollen spielen (z. B. das Heben schwerer Gegenstände) und ein Ersatz für Menschen noch unrealistisch ist, da Flexibilität und Anpassungsfähigkeit noch unzureichend sind. Die Erweiterung der Szenarien „Auto + Roboter“ (ähnlich wie bei BYDs „Auto + Drohne“) zielt darauf ab, die Nutzungsgrenzen von Autos zu erweitern. Für „Geländewagen + Roboterhund“ sieht der Artikel potenziellen Wert für Hardcore-Offroad-Enthusiasten oder bestimmte Branchen (wie Wildnisrettung) (z. B. Ausrüstungstransport, Erkundung), aber die Verbreitung steht vor Herausforderungen wie hohen Kosten, Nischennachfrage und technischer Reife. Derzeit erscheint es eher als eine Erkundung zukünftiger intelligenter Outdoor-Szenarien denn als dringender Bedarf. (Quelle: 电车通)

Diskussion über die Eignung der Llama 4-Architektur für spezifische Workflows von Mac-Nutzern: Ein Mac Studio-Benutzer (M3 Ultra, 512 GB RAM) teilt seine Erfahrungen zur Eignung des Llama 4 Maverick-Modells für seinen Workflow. Der Benutzer bevorzugt Workflows mit mehreren Iterations- und Validierungsschritten, um die LLM-Leistung zu verbessern. Bisher war das Ausführen großer Modelle (32B-70B) auf dem Mac jedoch zu langsam (dauerte 20-30 Minuten), während kleinere Modelle (8-14B) zwar schnell, aber qualitativ nicht ausreichend waren. Obwohl Llama 4 Maverick eine große Parameterzahl hat (400B) und viel Speicher benötigt (was der Mac gerade erfüllt), sorgt seine MoE-Architektur dafür, dass die tatsächliche Ausführungsgeschwindigkeit der eines 17B-Modells nahekommt (ca. 16,8 T/s Generierungsgeschwindigkeit bei Q8-Quantisierung). Diese Eigenschaft – „großer Speicherbedarf, aber relativ hohe Geschwindigkeit“ – passt genau zum Problem der Mac-Benutzer („viel Speicher, aber begrenzte Geschwindigkeit“) und macht es zur idealen Wahl für den spezifischen Workflow dieses Benutzers, obwohl das Modell insgesamt nicht hoch bewertet wird und möglicherweise Probleme mit dem Tokenizer hat. (Quelle: Reddit r/LocalLLaMA)
💡 Sonstiges
Google Gemini verbessert Deep Research-Funktion: Demis Hassabis, CEO von Google DeepMind, kündigte an, dass die Deep Research-Funktion in der Gemini-App (erfordert Gemini Advanced-Abonnement) nun vom Gemini 2.5 Pro-Modell angetrieben wird. Google bezeichnet dies als die leistungsfähigste Deep-Research-Fähigkeit auf dem Markt, mit einer 2:1-Nutzerpräferenz gegenüber dem nächstbesten Konkurrenzprodukt. Das verbesserte Deep Research kann Informationen besser analysieren und für Benutzer tiefgehende Berichte zu nahezu jedem Thema generieren. (Quelle: demishassabis)

Nutzung von GPT-4o zur Umwandlung von Fotos in mehrschichtigen Scherenschnitt-Kunststil: Ein Benutzer teilte einen Prompt-Trick zur Verwendung von GPT-4o oder Sora, um normale Fotos in Bilder im Stil mehrschichtiger Scherenschnittkunst umzuwandeln. Die Kernidee besteht darin, das Modell aufzufordern, Mittelgrund und Hintergrund des Fotos zu identifizieren und zu trennen, dann den mehrschichtigen Scherenschnitt-Kunststil anzuwenden und optional einen Titel hinzuzufügen. Das Beispiel zeigt die erfolgreiche Umwandlung eines Fotos der Stadt Chicago in ein Werk im Scherenschnittstil mit dem Titel „Chicago 2016“. (Quelle: dotey)

Nutzung von GPT-4o zur Generierung von Modekalender-Illustrationen basierend auf Datum: Ein Benutzer teilte eine Prompt-Vorlage und Methode zur Verwendung von GPT-4o, um Modekalender-Illustrationen im Stil des chinesischen Almanachs (Huangli) zu generieren. Die Methode erfolgt in zwei Schritten: Erstens, Eingabe des Datums, damit das Modell die entsprechenden Almanach-Informationen (Wochentag, Mondkalenderdatum, Feiertage, günstige/ungünstige Aktivitäten, inspirierendes Zitat) und saisonale Beschreibungen der Kleidung von Personen abruft und basierend auf der Vorlage einen detaillierten Bildgenerierungs-Prompt erstellt; zweitens, das Modell auffordern, das Bild basierend auf dem generierten Prompt zu zeichnen. Die Vorlage verlangt ein Bild im Hochformat (9:16) im frischen handgezeichneten Illustrationsstil, das eine modische, niedliche weibliche Figur, das gut sichtbare gregorianische Datum, den englischen Monatsnamen, den Wochentag auf Chinesisch und Englisch, das Mondkalenderdatum, Feiertage, vertikal angeordnete „günstige“ Aktivitäten und ein inspirierendes Zitat enthält, wobei auf Leerraum und Layout geachtet werden soll. Das Beispiel zeigt eine nach dieser Methode generierte Neujahrskalender-Illustration. (Quelle: dotey)
