
Schlüsselwörter:AI, LLM, AI Index Report 2025, Meta Llama 4 Kontroverse, Gemini Deep Research Upgrade, NVIDIA Llama 3.1 Nemotron Ultra, DeepSeek R1 Rekord
🔥 Fokus
Stanford veröffentlicht jährlichen AI Index Report, der neue Veränderungen in der globalen AI-Landschaft aufzeigt: Das HAI der Stanford University hat den 456-seitigen „AI Index Report 2025“ veröffentlicht. Der Bericht zeigt, dass die USA bei der Produktion von Spitzen-AI-Modellen weiterhin führend sind, China jedoch den Leistungsrückstand schnell aufholt (z. B. ist der Abstand bei MMLU und HumanEval fast verschwunden). Die Industrie dominierte die Entwicklung wichtiger Modelle (Anteil 90%), aber die Anzahl der Modelle ging zurück. Die Kosten für AI-Hardware sinken jährlich um 30%, die Leistung verdoppelt sich alle 1,9 Jahre. Die weltweiten AI-Investitionen beliefen sich auf 252,3 Milliarden US-Dollar, wobei die USA mit 109,1 Milliarden US-Dollar weit vorne liegen (etwa das 12-fache der 9,3 Milliarden US-Dollar Chinas). Investitionen in generative AI erreichten 33,9 Milliarden US-Dollar. Die Akzeptanz von AI in Unternehmen stieg auf 78%, wobei China das schnellste Wachstum verzeichnete (bis zu 75%). AI beginnt bereits, Kosten in Unternehmen zu senken und die Effizienz zu steigern. AI erzielte Durchbrüche in der Wissenschaft, erhielt zwei Nobelpreise und übertrifft den Menschen bei der Proteinsequenzierung und klinischen Diagnostik. Die globale optimistische Haltung gegenüber AI nimmt zu, es gibt jedoch erhebliche regionale Unterschiede, wobei China am optimistischsten ist. Das Ökosystem für Responsible AI (RAI) reift allmählich heran, aber Bewertung und Praxis sind noch unausgewogen. (Quelle: 36氪, AI科技评论, dotey, 36kr)
Veröffentlichung von Meta Llama 4 löst große Kontroverse aus, Vorwürfe des „Benchmark-Gamings“ und schlechter Leistung: Die kürzlich von Meta veröffentlichte Open-Source-Großmodellreihe Llama 4 (Scout, Maverick, Behemoth) erlitt innerhalb von 72 Stunden nach Veröffentlichung einen Reputationsverlust. Die Maverick-Version stieg in der Chatbot Arena schnell auf den zweiten Platz, es wurde jedoch bekannt, dass eine nicht veröffentlichte, für Dialoge optimierte „experimentelle Version“ eingereicht wurde, was zu Vorwürfen des „Benchmark-Gamings“ führte. Obwohl Meta bestritt, auf dem Testdatensatz trainiert zu haben, räumte es Leistungsprobleme ein. Community-Feedback deutet darauf hin, dass die Leistung von Llama 4 beim Codieren, Verstehen langer Kontexte usw. hinter den Erwartungen zurückbleibt und sogar schlechter ist als Modelle mit weniger Parametern (wie DeepSeek V3). AI-Experten wie Gary Marcus kommentierten dies mit „Scaling ist tot“ und argumentierten, dass die bloße Vergrößerung der Modellgröße keine zuverlässigen Schlussfolgerungsfähigkeiten bringt. Sie äußerten auch Bedenken, dass der globale AI-Fortschritt aufgrund von Finanzierungs-, geopolitischen und anderen Faktoren stagnieren könnte. LMArena hat die relevanten Bewertungsdaten zur Überprüfung veröffentlicht und die Ranking-Strategie aktualisiert, um Verwirrung zu vermeiden. (Quelle: 36kr, 雷科技, AIatMeta, karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

🎯 Aktuelles
Gemini Deep Research Funktion aufgerüstet, verwendet Gemini 2.5 Pro Modell: Die Deep Research Funktion in der Google Gemini App wird jetzt vom Gemini 2.5 Pro Modell angetrieben. Frühe Benutzertests zeigen eine überlegene Leistung im Vergleich zu Konkurrenzprodukten. Dieses Upgrade zielt darauf ab, die Fähigkeiten zur Informationssuche und -synthese, die Einblicke in Berichte sowie die analytischen Schlussfolgerungsfähigkeiten zu verbessern. Gemini Advanced Benutzer können dieses Update erleben. Mehrere Benutzer und der CEO von Google DeepMind, Demis Hassabis, teilten positive Erfahrungen bei der Verwendung der neuen Deep Research Funktion zur Bewältigung komplexer Aufgaben (wie Marktanalyse) und lobten ihre Geschwindigkeit und Vollständigkeit. (Quelle: JeffDean, dotey, JeffDean, demishassabis)

Nvidia veröffentlicht Llama 3.1 Nemotron Ultra 253B Modell: Nvidia hat das Llama 3.1 Nemotron Ultra 253B Modell auf Hugging Face veröffentlicht. Bei diesem Modell handelt es sich um ein dichtes Modell (kein MoE) mit Ein-/Ausschaltfunktion für die Inferenz. Es wurde aus Metas Llama-405B Modell durch NAS-Pruning-Techniken modifiziert und einem auf Inferenz ausgerichteten Post-Training (SFT + RL in FP8) unterzogen. Benchmark-Tests zeigen eine überlegene Leistung gegenüber DeepSeek R1, obwohl Kommentare darauf hinweisen, dass ein direkter Vergleich mit dem MoE-Modell DeepSeek R1 (weniger aktive Parameter) möglicherweise nicht ganz fair ist. Nvidia hat gleichzeitig auch die zugehörigen Post-Training-Datensätze auf Hugging Face veröffentlicht. (Quelle: huggingface, Reddit r/LocalLLaMA, dylan522p, huggingface)

AI+Fertigung wird neuer Fokus, Chancen und Herausforderungen koexistieren: AI dringt beschleunigt in die chinesische Fertigungsindustrie ein. Anwendungsfälle umfassen Produktionsautomatisierung (z.B. Yuru Chengs Produktion von Dentalmaterialien), Produktintelligenz (z.B. Binghan Techs AI-Schlafbrille), Prozessoptimierung (z.B. Zhongke Lingchuangs AI-Sitzungsprotokolle) sowie Forschung & Entwicklung und Diagnose (z.B. Ruixin Intelligents kardiovaskuläre Diagnoseplattform, Bihus Vorhersage von Autoteilebedarf und Fehlererkennung). Finanzinstitute wie die WeBank nutzen ebenfalls AI-Technologie (z.B. Generierung intelligenter Due-Diligence-Berichte), um innovative Fertigungsunternehmen zu unterstützen. „AI+Fertigung“ steht jedoch weiterhin vor Herausforderungen wie geringer Datenqualität und schwacher digitaler Grundlage der Unternehmen. Investoren raten Unternehmen, AI zur Unterstützung ihres Kerngeschäfts einzusetzen, anstatt nur als Marketing-Gag, und langfristig in die Lösung von Daten- und Implementierungsproblemen zu investieren. (Quelle: 36氪)
DeepSeek R1 stellt Geschwindigkeitsrekord für Inferenz auf Nvidia B200 auf: Das AI-Startup Avian.io gab bekannt, dass es in Zusammenarbeit mit Nvidia auf der neuesten Blackwell B200 GPU-Plattform eine Inferenzgeschwindigkeit von 303 Tokens/Sekunde für das DeepSeek R1 Modell erreicht hat, was einen Weltrekord darstellt. Avian.io kündigte an, in den kommenden Tagen dedizierte DeepSeek R1 Inferenz-Endpunkte auf Basis von B200 anzubieten, Vorbestellungen sind bereits möglich. Dieser Erfolg markiert eine neue Ära für „test time compute driven models“. (Quelle: Reddit r/LocalLLaMA)

OpenAI gründet Strategic Deployment Team zur Förderung der Implementierung von Spitzenmodellen: OpenAI hat ein neues Strategic Deployment Team gegründet, das darauf abzielt, Spitzenmodelle (wie GPT-4.5 und zukünftige Modelle) in Bezug auf Fähigkeiten, Zuverlässigkeit und Alignment auf ein höheres Niveau zu bringen und sie in hochwirksamen realen Bereichen einzusetzen, um die Transformation der Wirtschaft durch AI zu beschleunigen und den Weg zur AGI zu erkunden. Das Team stellt aktiv ein und wirbt auf akademischen Konferenzen wie der ICLR. (Quelle: sama)
AI steht vor Herausforderungen bei der Verbesserung des Kundenerlebnisses (CX): Der Artikel untersucht die Schwierigkeiten und Herausforderungen bei der Nutzung von AI zur Verbesserung des Kundenerlebnisses. Obwohl AI Potenzial bietet, ist eine effektive Implementierung nicht einfach und kann Probleme in Bezug auf Datenintegration, Modellgenauigkeit, Benutzerakzeptanz und Wartungskosten mit sich bringen. (Quelle: Ronald_vanLoon)

AI-Anwendungen lösen Innovation und Bedenken am Arbeitsplatz aus: Der Artikel diskutiert die doppelten Auswirkungen von AI-Anwendungen am Arbeitsplatz: Einerseits die Anregung von Innovationspotenzial, andererseits auch Bedenken hinsichtlich der bestehenden Arbeitskräfte, wie die Möglichkeit des Arbeitsplatzverlusts, sich ändernde Qualifikationsanforderungen usw. (Quelle: Ronald_vanLoon)

Internet of Behavior (IoB) verändert Geschäftsentscheidungen: Die Technologie zur Analyse von Nutzerverhaltensdaten (Internet of Behavior) mittels Machine Learning und künstlicher Intelligenz liefert Unternehmen tiefere Einblicke und verändert so die Art und Weise, wie sie Geschäftsentscheidungen treffen, möglicherweise in Bereichen wie personalisiertem Marketing, Risikobewertung, Produktentwicklung usw. (Quelle: Ronald_vanLoon)

Multimodales Modell RolmOCR schneidet auf Hugging Face-Rangliste hervorragend ab: Yifei Hu weist darauf hin, dass das von seinem Team entwickelte visuelle Sprachmodell RolmOCR auf der Hugging Face-Rangliste hervorragend abschneidet und den dritten Platz unter den VLMs und den fünften Platz unter allen Modellen belegt. Das Team plant, in Zukunft weitere Modelle, Datensätze und Algorithmen zu veröffentlichen, um die Open-Source-Wissenschaftsforschung zu unterstützen. (Quelle: huggingface)

AI News Digest (2025/04/08): Aktuelle AI-Nachrichten umfassen: Meta Llama 4 wird vorgeworfen, bei Benchmark-Tests irreführend zu sein; Apple verlagert möglicherweise mehr iPhone-Produktion nach Indien, um Zölle zu umgehen; IBM veröffentlicht neuen Mainframe für das AI-Zeitalter; Gerüchten zufolge zahlt Google einigen AI-Mitarbeitern hohe Gehälter, um sie ein Jahr lang „untätig“ zu halten und zu binden; Microsoft hat Berichten zufolge protestierende Mitarbeiter entlassen, die seine Copilot-Veranstaltung unterbrochen hatten; Amazon behauptet, sein AI-Videomodell könne jetzt minutenlange Clips generieren. (Quelle: Reddit r/ArtificialInteligence)

🧰 Tools
FunASR: Open-Source End-to-End Spracherkennungs-Toolkit von Alibaba DAMO Academy: FunASR ist ein Toolkit, das Funktionen wie Spracherkennung (ASR), Sprachaktivitätserkennung (VAD), Interpunktionswiederherstellung, Sprachmodelle, Sprechererkennung, Sprechertrennung und Multi-Sprecher-Erkennung integriert. Es unterstützt Inferenz und Fine-Tuning für vortrainierte Modelle auf Industrieniveau (wie Paraformer, SenseVoice, Whisper, Qwen-Audio usw.) und bietet praktische Skripte und Tutorials. Zu den jüngsten Updates gehören die Unterstützung für SenseVoiceSmall, Whisper-large-v3-turbo, Keyword-Spotting-Modelle, Emotionserkennungsmodelle sowie die Veröffentlichung von Offline-/Echtzeit-Transkriptionsdiensten (einschließlich GPU-Version) mit optimiertem Speicher und Leistung. (Quelle: modelscope/FunASR – GitHub Trending (all/daily))
LightRAG: Ein schlankes und effizientes Retrieval-Augmented Generation Framework: LightRAG ist ein vom DS Lab der HKU entwickeltes RAG-Framework, das darauf abzielt, die Erstellung von RAG-Anwendungen zu vereinfachen und zu beschleunigen. Es integriert Fähigkeiten zur Erstellung und zum Abruf von Wissensgraphen (KG), unterstützt verschiedene Abrufmodi (lokal, global, gemischt, naiv, Mix-Modus) und kann flexibel an verschiedene LLMs (wie OpenAI, Hugging Face, Ollama) und Embedding-Modelle angebunden werden. Das Framework unterstützt auch verschiedene Speicher-Backends (wie NetworkX, Neo4j, PostgreSQL, Faiss) und verschiedene Dateityp-Eingaben (PDF, DOC, PPT, CSV) und bietet Funktionen wie Entitäts-/Relationsbearbeitung, Datenexport, Cache-Management, Token-Tracking, Dialoghistorie und benutzerdefinierte Prompts. Das Projekt bietet eine Web-UI und API-Dienste sowie ein Visualisierungstool für Wissensgraphen. (Quelle: HKUDS/LightRAG – GitHub Trending (all/daily))
LangGraph unterstützt Definely beim Aufbau eines juristischen AI Agents: Definely nutzt LangGraph, um ein Multi-AI-Agent-System zu erstellen, das direkt in Microsoft Word integriert ist und Anwälte bei komplexen juristischen Aufgaben unterstützt. Das System kann juristische Aufgaben in Teilaufgaben zerlegen, kontextbezogene Informationen für die Extraktion von Klauseln, Änderungsanalysen und Vertragsentwürfe kombinieren und durch einen Human-in-the-loop-Zyklus den Input und die Genehmigung von Anwälten zur Steuerung wichtiger Entscheidungen einbeziehen. Dies zeigt die Fähigkeit von LangGraph, komplexe, steuerbare Agent-Workflows zu erstellen. (Quelle: LangChainAI)

LlamaParse führt neuen layout-sensitiven Agent ein: LlamaIndex hat eine neue Funktion für LlamaParse eingeführt – den Layout Agent. Dieser Agent nutzt SOTA VLM-Modelle unterschiedlicher Größe, von Flash 2.0 bis Sonnet 3.7, um Dokumentseiten dynamisch und layout-sensitiv zu parsen. Er analysiert zuerst das Gesamtlayout und zerlegt die Seite in Blöcke (wie Tabellen, Diagramme, Absätze) und wählt dann je nach Komplexität des Blocks unterschiedliche Modelle für die Verarbeitung aus (z. B. stärkere Modelle für Diagramme, kleinere Modelle für Text). Diese Funktion ist besonders wichtig für Agent-Workflows, die große Mengen an Dokumentenkontext verarbeiten müssen. (Quelle: jerryjliu0)

Auth0 veröffentlicht Sicherheitstool für GenAI-Anwendungen: Auth0 hat das neue Produkt „Auth for GenAI“ auf den Markt gebracht, das Entwicklern helfen soll, die Sicherheit ihrer GenAI-Anwendungen und Agents einfach zu gewährleisten. Das Produkt bietet Funktionen wie Benutzerauthentifizierung, API-Aufrufe im Namen des Benutzers, asynchrone Benutzerbestätigung (CIBA) und RAG-Autorisierung. Es stellt SDKs und Dokumentationen für beliebte GenAI-Frameworks (wie LangChain, LlamaIndex, Firebase Genkit usw.) bereit und vereinfacht die Integration von Authentifizierung und Autorisierung in AI-Anwendungen. (Quelle: jerryjliu0, jerryjliu0)

Ollama fügt Unterstützung für Mistral Small 3.1 Vision-Modell hinzu: Das lokale Großmodell-Ausführungstool Ollama unterstützt jetzt das neueste Mistral Small 3.1 Modell von Mistral AI, einschließlich seiner visuellen (multimodalen) Fähigkeiten. Benutzer können quantisierte Versionen wie mistral-small3.1:24b-instruct-2503-q4_K_M über die Ollama-Bibliothek herunterladen und ausführen. Community-Feedback zeigt, dass das Modell bei Aufgaben wie OCR gut abschneidet, aber einige Benutzer berichten von langsameren Inferenzgeschwindigkeiten auf bestimmter Hardware (wie AMD 7900xt). (Quelle: Reddit r/LocalLLaMA)

Unsloth veröffentlicht Llama-4 Scout GGUF quantisierte Modelle: Unsloth hat quantisierte Versionen des Llama-4 Scout 17B Modells im GGUF-Format als Open Source veröffentlicht, um die Ausführung auf lokalen CPUs oder GPUs mit begrenztem Speicher zu erleichtern. Dazu gehört eine dynamisch quantisierte Version mit 2,71 Bit, die nur 42,2 GB groß ist. Benutzer können die Modelldateien verschiedener Quantisierungsstufen (wie Q6_K) und deren Hardwarekompatibilitätsinformationen auf Hugging Face einsehen. (Quelle: karminski3)

LangSmiths OpenEvals unterstützt benutzerdefinierte Ausgabeschemata: OpenEvals, das LLM-Bewertungstool von LangSmith, unterstützt jetzt benutzerdefinierte Ausgabeschemata für LLM-as-judge-Evaluatoren. Obwohl das Standardschema viele gängige Fälle abdeckt, bietet dieses Update den Benutzern vollständige Flexibilität, um die Struktur und den Inhalt der Modellantworten an spezifische Bewertungsanforderungen anzupassen. Die Funktion ist sowohl in der Python- als auch in der JS-Version verfügbar. (Quelle: LangChainAI)

Qwen 3 Modelle werden bald llama.cpp unterstützen: Ein Patch zur Unterstützung der Qwen 3 Modellreihe von Alibaba in llama.cpp wurde als Pull Request eingereicht, genehmigt und wird bald gemerged. Das bedeutet, dass Benutzer bald Qwen 3 Modelle lokal über das llama.cpp Framework ausführen können. Dieses Update wurde von bozheng-hit eingereicht, der zuvor auch die Unterstützung für Qwen 3 in der transformers-Bibliothek beigesteuert hat. (Quelle: Reddit r/LocalLLaMA)

Computer Use Agent Arena gestartet: Das OSWorld-Team hat die Computer Use Agent Arena gestartet, eine Plattform zum Testen von Computer-Use Agents in realen Umgebungen ohne Einrichtung. Benutzer können die Leistung von Top-VLMs wie OpenAI Operator, Claude 3.7, Gemini 2.5 Pro, Qwen 2.5 VL in über 100 realen Anwendungen und Websites vergleichen. Die Plattform bietet eine Ein-Klick-Konfiguration und soll sicher und kostenlos sein. (Quelle: lmarena_ai)
Musikvertriebsdienst Too Lost ist AI-Musik-freundlich: Ein Reddit-Benutzer teilt seine Erfahrungen mit der Nutzung von Too Lost für den Vertrieb von mit Suno, Udio usw. generierter AI-Musik. Vorteile sind: explizite Akzeptanz von AI-Musik, schnelle Genehmigung (1-2 Tage), erschwinglicher Preis (35 USD/Jahr für unbegrenzte Veröffentlichungen), Musik wird nach Ablauf des Abonnements nicht entfernt (aber die Umsatzbeteiligung ändert sich auf 85/15), Unterstützung für benutzerdefinierte Labelnamen. Nachteile sind die langsame Verbreitung auf Instagram/Facebook (>16 Tage), möglicherweise ist ein Nachweis früherer Distributionen erforderlich. (Quelle: Reddit r/SunoAI)
📚 Lernen
NVIDIA veröffentlicht CUDA Python: NVIDIA hat CUDA Python vorgestellt, das einen einheitlichen Zugang zur CUDA-Plattform von Python aus bieten soll. Es umfasst mehrere Komponenten: cuda.core bietet Pythonic-Zugriff auf die CUDA Runtime; cuda.bindings bietet Low-Level-Bindings für die CUDA C API; cuda.cooperative bietet geräteseitige parallele Primitive von CCCL (für Numba CUDA); cuda.parallel bietet hostseitige parallele Algorithmen von CCCL (Sortieren, Scannen usw.); sowie numba.cuda zum Kompilieren von Python-Subsets in CUDA-Kernel. Das cuda-python-Paket selbst wird sich zu einem Metapaket entwickeln, das diese unabhängig versionierten Unterpakete enthält. (Quelle: NVIDIA/cuda-python – GitHub Trending (all/daily))
Hugging Face veröffentlicht großen Datensatz für Inferenz-Codierung: Auf Hugging Face wurde ein großer Datensatz mit 736.712 von DeepSeek-R1 generierten Python-Code-Lösungen veröffentlicht. Der Datensatz enthält die Schlussfolgerungsprozesse (reasoning traces) des Codes und kann für kommerzielle und nicht-kommerzielle Zwecke verwendet werden. Er ist einer der derzeit größten Datensätze für Inferenz-Codierung. (Quelle: huggingface)

Fünf große Herausforderungen und Lösungen beim Aufbau von AI Agents: Der Artikel fasst die fünf zentralen Herausforderungen beim Aufbau von AI Agents zusammen: 1) Management von Schlussfolgerung und Entscheidungsfindung (Sicherstellung von Konsistenz und Zuverlässigkeit); 2) Handhabung von mehrstufigen Prozessen und Kontext (Zustandsmanagement, Fehlerbehandlung); 3) Management der Tool-Integration (zusätzliche Fehlerquellen, Sicherheitsrisiken); 4) Kontrolle von Halluzinationen und Sicherstellung der Genauigkeit; 5) Management der Leistung im großen Maßstab (Handhabung hoher Parallelität, Timeouts, Ressourcenengpässe). Für jede Herausforderung werden spezifische Lösungen vorgeschlagen, wie z.B. strukturierte Prompts (ReAct), robustes Zustandsmanagement, präzise Tool-Definitionen, strenge Verifikationssysteme (Faktenbasis, Zitate), menschliche Überprüfung, LLMOps-Monitoring usw. (Quelle: AINLPer)
Ehemaliger Kaggle Chief Scientist blickt auf ULMFiT zurück, möglicherweise das erste LLM: Jeremy Howard (Gründer von fast.ai, ehemaliger Chief Scientist von Kaggle) behauptete in sozialen Medien, dass sein ULMFiT von 2018 das erste „universelle Sprachmodell“ war, was eine Diskussion über das „erste LLM“ auslöste. ULMFiT verwendete ein Paradigma des unüberwachten Pre-Trainings und Fine-Tunings, erreichte SOTA bei Textklassifizierungsaufgaben und inspirierte GPT-1. Ein Rechercheartikel argumentiert, dass ULMFiT nach Kriterien wie selbstüberwachtem Training, Vorhersage des nächsten Tokens, Anpassungsfähigkeit an neue Aufgaben und Allgemeingültigkeit der modernen LLM-Definition näher kommt als CoVE oder ELMo und einer der „gemeinsamen Vorfahren“ moderner LLMs ist. (Quelle: 量子位)
Erfahrungsaustausch zur leichtgewichtigen LLM-Feinabstimmung aus Entwicklerperspektive: Für Entwickler, die keine spezialisierten ML-Ingenieure sind, werden Erfahrungen und Lehren bei der Verbesserung der LLM-Ausgabequalität durch parameter-effiziente Feinabstimmungsmethoden (PEFT) wie LoRA und QLoRA geteilt. Es wird betont, dass diese Methoden besser geeignet sind, um in reguläre Entwicklungsprozesse integriert zu werden und die Komplexität der vollständigen Feinabstimmung zu vermeiden. Das zugehörige Team wird ein kostenloses Webinar veranstalten, das sich auf die Schmerzpunkte konzentriert, auf die Entwickler in der Praxis stoßen. (Quelle: Reddit r/artificial, Reddit r/MachineLearning)
Paper schlägt Rethinking Reflection in Pre-Training vor: Eine Studie von Essential AI (geleitet von Transformer-Erstautor Ashish Vaswani) stellt fest, dass LLMs bereits in der Pre-Training-Phase allgemeine Schlussfolgerungsfähigkeiten über Aufgaben und Domänen hinweg zeigen. Das Paper schlägt vor, dass ein einfacher „wait“-Token als „Reflexionsauslöser“ dienen kann, um die Schlussfolgerungsleistung des Modells signifikant zu verbessern. Die Studie argumentiert, dass die Nutzung der intrinsischen Reflexionsfähigkeit des Modells während des Pre-Trainings ein einfacherer und grundlegenderer Weg sein könnte, um die allgemeine Schlussfolgerungsfähigkeit zu verbessern, verglichen mit Post-Training-Methoden (wie RLHF), die auf ausgefeilte Reward Models angewiesen sind. Dies könnte die Engpässe aktueller task-specific Fine-Tuning-Methoden überwinden. (Quelle: dotey)

Paper schlägt Nutzung von RL-Verlusten für Story-Generierung ohne Reward-Modell vor: Forscher schlagen ein von RLVR inspiriertes Belohnungsparadigma namens VR-CLI vor, um die Generierung langer Geschichten (Aufgabe der Vorhersage des nächsten Kapitels, ca. 100.000 Tokens) durch RL-Verluste (wie Perplexität) zu optimieren, ohne ein explizites Reward-Modell zu verwenden. Experimente zeigen, dass diese Methode mit menschlichen Urteilen über die Qualität der generierten Inhalte korreliert. (Quelle: natolambert)

Paper schlägt P3-Methode zur Verbesserung der Robustheit von Zero-Shot-Klassifizierung vor: Um das Problem der Empfindlichkeit von Zero-Shot-Textklassifizierungsmodellen gegenüber Prompt-Variationen (prompt brittleness) zu lösen, schlagen Forscher die Methode Placeholding Parallel Prediction (P3) vor. Diese Methode simuliert durch die Vorhersage von Token-Wahrscheinlichkeiten an mehreren Positionen eine umfassende Abtastung des Generierungspfades, anstatt sich nur auf die Wahrscheinlichkeit des nächsten Tokens zu verlassen. Experimente zeigen, dass P3 die Genauigkeit verbessert und die Standardabweichung über verschiedene Prompts um bis zu 98% reduziert, wodurch die Robustheit erhöht wird und sogar ohne Prompts eine vergleichbare Leistung erzielt wird. (Quelle: Reddit r/MachineLearning)
Paper schlägt Test-Time Training Layer zur Verbesserung der Generierung langer Videos vor: Um das Konsistenzproblem zu lösen, das durch die Ineffizienz des Selbstaufmerksamkeitsmechanismus in Transformer-Architekturen bei der Generierung langer Videos (z. B. über eine Minute) entsteht, schlägt die Forschung einen neuen Test-Time Training (TTT) Layer vor. Der verborgene Zustand dieses Layers kann selbst ein neuronales Netzwerk sein, was ihn ausdrucksstärker als herkömmliche Layer macht und die Generierung längerer Videos mit besserer Konsistenz, Natürlichkeit und Ästhetik ermöglicht. (Quelle: dotey)
SmolVLM Technischer Bericht veröffentlicht, erforscht effiziente kleine multimodale Modelle: Der technische Bericht stellt die Designideen und experimentellen Erkenntnisse von SmolVLM (256M, 500M, 2.2B Parameter) vor, mit dem Ziel, effiziente kleine multimodale Modelle zu bauen. Wichtige Erkenntnisse sind: Die Erhöhung der Kontextlänge (2K->16K) verbessert die Leistung signifikant (+60%); kleine LLMs profitieren mehr von kleineren SigLIPs (80M); Pixel Shuffling kann die Sequenzlänge erheblich verkürzen; gelernte Positionstoken sind rohen Texttoken überlegen; System-Prompts und dedizierte Medientoken sind besonders wichtig für Videoaufgaben; zu viele CoT-Daten schaden der Leistung kleiner Modelle; das Training längerer Videos trägt zur Verbesserung der Leistung bei Bild- und Videoaufgaben bei. SmolVLM erreicht unter seinen Hardwarebeschränkungen SOTA-Niveau und wurde bereits für Echtzeit-Inferenz auf dem iPhone 15 und im Browser implementiert. (Quelle: huggingface)

Hugging Face veröffentlicht Reasoning Required Dataset: Dieser Datensatz enthält 5000 Beispiele aus fineweb-edu, die nach Schlussfolgerungskomplexität (0-4 Punkte) annotiert sind, um zu beurteilen, ob sich Text zur Generierung von Schlussfolgerungsdatensätzen eignet. Der Datensatz zielt darauf ab, einen ModernBERT-Klassifikator zu trainieren, um Inhalte effizient vorzufiltern und den Anwendungsbereich von Schlussfolgerungsdatensätzen über Mathematik und Codierung hinaus zu erweitern. (Quelle: huggingface)
CoCoCo Benchmark testet Fähigkeit von LLMs zur Quantifizierung von Konsequenzen: Das Upright Project hat den technischen Bericht zum CoCoCo Benchmark veröffentlicht, der die Konsistenz von LLMs bei der Quantifizierung der Konsequenzen von Handlungen bewertet. Tests ergaben, dass Claude 3.7 Sonnet (mit einem Denkbudget von 2000 Tokens) am besten abschnitt, jedoch eine Tendenz zeigte, positive Konsequenzen zu betonen und negative herunterzuspielen. Der Bericht kommt zu dem Schluss, dass LLMs in dieser Fähigkeit in den letzten Jahren zwar Fortschritte gemacht haben, aber noch ein langer Weg vor ihnen liegt. (Quelle: Reddit r/ArtificialInteligence)

Vergleich von GenAI Inferenz-Engines: TensorRT-LLM vs vLLM vs TGI vs LMDeploy: NLP Cloud teilt eine vergleichende Analyse und Benchmark-Ergebnisse für vier beliebte GenAI Inferenz-Engines. TensorRT-LLM ist auf Nvidia GPUs am schnellsten, aber komplex einzurichten; vLLM ist Open Source, flexibel und hat einen hohen Durchsatz, aber eine etwas höhere Latenz bei Einzelanfragen; Hugging Face TGI ist einfach einzurichten und zu skalieren und gut in das HF-Ökosystem integriert; LMDeploy (TurboMind) zeichnet sich durch hohe Dekodiergeschwindigkeit und 4-Bit-Inferenzleistung auf Nvidia GPUs sowie niedrige Latenz aus, aber TurboMind hat eine begrenzte Modellunterstützung. (Quelle: Reddit r/MachineLearning)
Vorschau auf neue Staffel des Google DeepMind Podcasts: Die neue Staffel des Google DeepMind Podcasts, moderiert von Hannah Fry, startet am 10. April. Die Inhalte werden Themen wie die Revolutionierung der Medizin durch AI-gesteuerte Wissenschaft, modernste Robotertechnologie und die Grenzen menschlich generierter Daten behandeln. (Quelle: GoogleDeepMind)
Einführungsvideo zur LangGraph-Plattform: LangChain hat ein 4-minütiges Video veröffentlicht, das die Funktionen der LangGraph-Plattform erklärt und zeigt, wie dieses Produkt auf Unternehmensebene zur Entwicklung, Bereitstellung und Verwaltung von AI Agents eingesetzt werden kann. (Quelle: LangChainAI, LangChainAI)

Keras-Implementierung von First-Order Motion Transfer: Ein Entwickler teilt die Implementierung des First-Order Motion Modells aus dem NeurIPS 2019 Paper von Siarohin et al. in Keras zur Bildanimation. Da Keras keine Funktion ähnlich PyTorchs grid_sample hat, erstellte der Entwickler ein benutzerdefiniertes Flow-Field-Warping-Modul, das Batch-Verarbeitung, normalisierte Koordinaten und GPU-Beschleunigung unterstützt. Das Projekt umfasst Keypoint-Erkennung, Bewegungsschätzung, Generator- und GAN-Trainingsabläufe und bietet Beispielcode und Dokumentation. (Quelle: Reddit r/deeplearning)

Flussdiagramm zur Verarbeitung natürlicher Sprache (NLP): Das Bild zeigt den grundlegenden Ablauf der Verarbeitung natürlicher Sprache, der möglicherweise Schritte wie Textvorverarbeitung, Merkmalsextraktion, Modelltraining, Evaluierung usw. umfasst. (Quelle: Ronald_vanLoon)

Blogbeitrag zur Erklärung der Mathematik hinter GANs: Ein Entwickler teilt seinen auf Medium verfassten Blogbeitrag über die mathematischen Prinzipien hinter Generative Adversarial Networks (GANs), wobei er sich auf die Herleitung und den Beweis der Wertfunktion konzentriert, die im Minimax-Spiel von GANs verwendet wird. (Quelle: Reddit r/deeplearning)

Einführungskonzept zum K-Means Clustering: Teilt eine Einführung in den K-Means Clustering Algorithmus als Konzeptvermittlung für Machine Learning Anfänger und erklärt diese unüberwachte Lernmethode. (Quelle: Reddit r/deeplearning)

Sommerschule und Konferenz für biomedizinische Datenwissenschaft: Vom 28. Juli bis 8. August 2025 finden in Budapest, Ungarn, eine Sommerschule und Konferenz für biomedizinische Datenwissenschaft statt. Die Sommerschule bietet Intensivtraining in Bereichen wie medizinische Datenvisualisierung, Machine Learning, Deep Learning und biomedizinische Netzwerke. Die Konferenz wird Spitzenforschung präsentieren und Experten, darunter Nobelpreisträger, zu Vorträgen einladen. (Quelle: Reddit r/MachineLearning)
Teilen eines persönlichen Deep Learning Modell-Repositorys: Ein Autodidakt teilt sein GitHub-Repository, in dem er seine Praxis beim Erstellen von Deep Learning Modellen für verschiedene Datensätze (wie CIFAR-10, MNIST, yt-finance) dokumentiert, einschließlich Scores, Vorhersage-Plots und Dokumentation, als eine Methode des persönlichen Lernens und Trainierens. (Quelle: Reddit r/deeplearning)

💼 Wirtschaft
AI-Einhorn OpenEvidence revolutioniert AI im Gesundheitswesen mit Internet-Denkweise: Das AI-Gesundheitsunternehmen OpenEvidence erhielt eine Finanzierung von 75 Millionen US-Dollar von Sequoia bei einer Bewertung von 1 Milliarde US-Dollar und wurde damit zum neuesten Einhorn. Im Gegensatz zum traditionellen B2B-Modell verfolgt OpenEvidence eine Strategie ähnlich dem Consumer Internet und bietet Ärzten (C-Ende) direkt kostenlose Dienste an (monetarisiert durch Werbung). Es hilft Ärzten, präzise Informationen in der riesigen Menge medizinischer Literatur zu finden und komplexe Fälle zu bearbeiten. Das Produkt wächst schnell, angeblich nutzen es bereits 1/4 der US-Ärzte. Der Schlüssel zum Erfolg liegt in strengen Datenquellen (peer-reviewte Literatur) und einer Multi-Modell-Integrationsarchitektur, um die Genauigkeit der Informationen zu gewährleisten, sowie in der Transparenz durch Quellenangaben, was ein Win-Win-Modell für Ärzte und medizinische Fachzeitschriften schafft. (Quelle: 36氪)
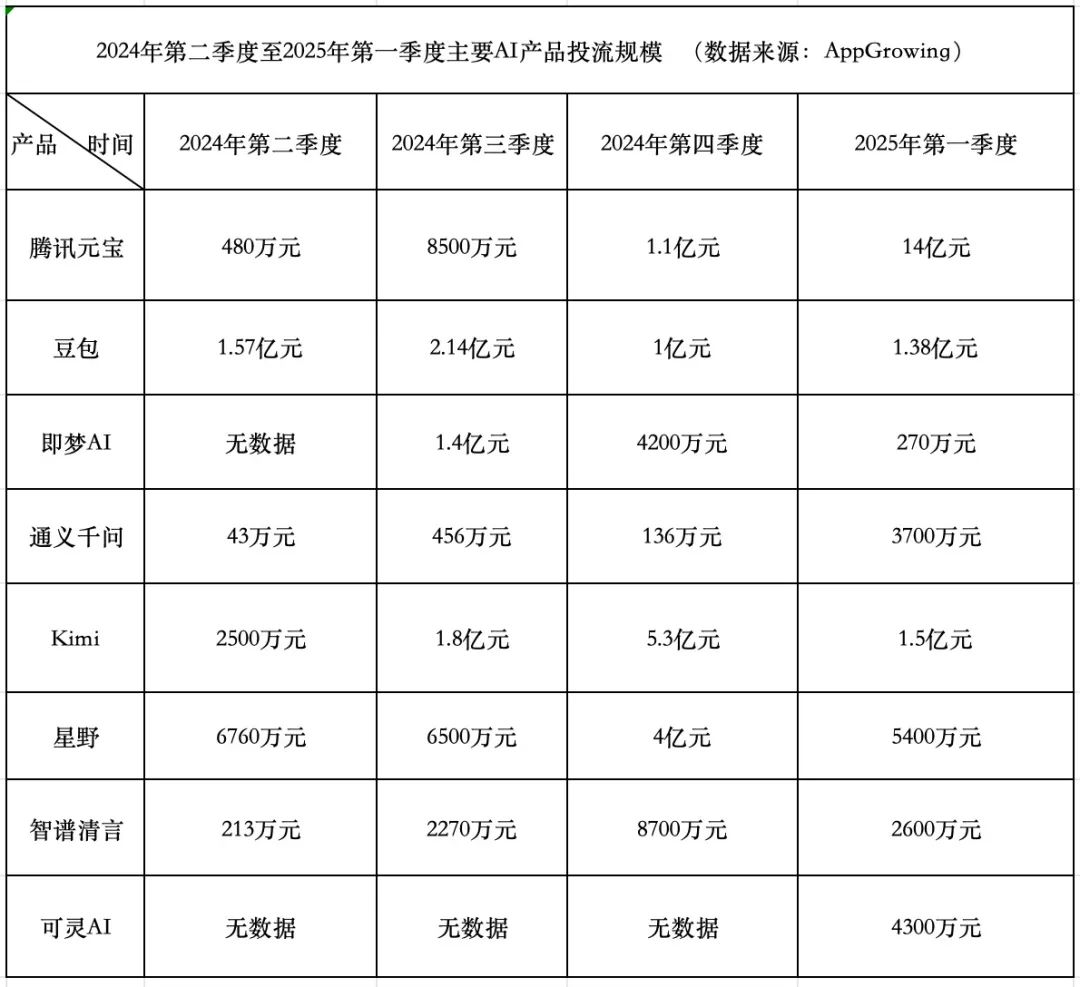
Wettlauf um AI-Produktausgaben: Tencent aggressiv, ByteDance konservativ, Startups ziehen sich zurück: Im ersten Quartal 2025 beliefen sich die Werbeausgaben für AI-Produkte auf 1,84 Milliarden Yuan. Tencent Yuanbao dominierte mit 1,4 Milliarden Yuan, wobei Werbung sogar auf Dorfmauern geschaltet wurde. ByteDance Doubao gab 138 Millionen Yuan aus und verfolgte eine relativ konservative Strategie. Kuaishou Keling AI investierte 43 Millionen Yuan. Im Gegensatz dazu reduzierten die Star-Startups Kimi und Xingye ihre Werbeausgaben drastisch (insgesamt ca. 200 Millionen, weit unter den 930 Millionen im vierten Quartal 2024), und auch Zhipu Qingyan senkte seine Investitionen erheblich. Gründer von Startups beginnen, das Modell des Geldverbrennens zu überdenken und konzentrieren sich stärker auf die Verbesserung der Modellfähigkeiten und technologische Barrieren. Tencent profitiert von diesem Werbekrieg durch sein eigenes Anzeigensystem. Alibaba Tongyi Qianwen und Baidu Wenxin Yiyan sind bei den Werbeausgaben relativ zurückhaltend und konzentrieren sich mehr auf Ökosystem und Open Source. Der Branchentrend zeigt, dass die Methode, lediglich Geld für Wachstum auszugeben, an Wirksamkeit verliert und der Wettbewerb bei AI-Produkten in eine neue Phase der Modellfähigkeiten und Ökosystemgestaltung eintritt. (Quelle: 中国企业家杂志)
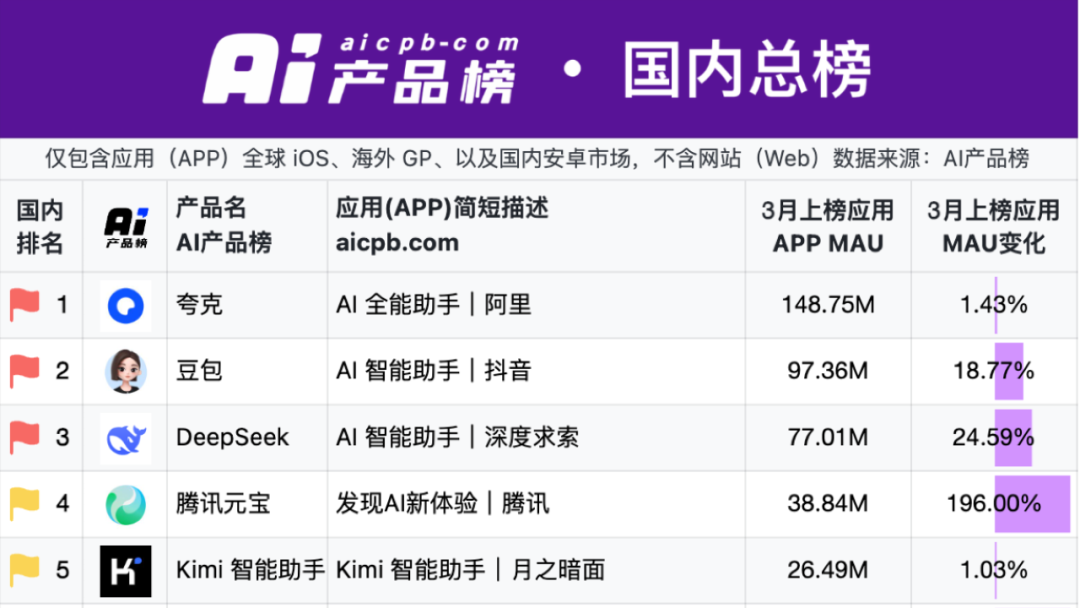
Quark und Baidu Wenku führen neues Schlachtfeld für AI-Anwendungen an: Aufstieg des „Super-Box“-Modells: Der Fokus bei AI-Anwendungen im Jahr 2025 verlagert sich von ChatBots zur „AI Super Box“, d.h. einem Portal, das AI-Suche, Dialog und Tools (wie PPT, Übersetzung, Bilderzeugung) integriert. Alibaba Quark und Baidu Wenku sind die Vorreiter in diesem Bereich und führen bei den monatlich aktiven Nutzern. Beide bauen auf einer Grundlage aus „Suche + Cloud-Speicher + Dokumente“ auf und integrieren AI-Fähigkeiten, um die Anforderungen der Benutzer an eine zentrale Anlaufstelle zu erfüllen und um den C-End-Traffic-Eingang zu konkurrieren. Tests zeigen, dass beide bei der grundlegenden Informationsfindung besser abschneiden als traditionelle Suchen, aber bei der Tiefe und Zufriedenheit spezifischer Aufgaben (wie Reiseplanung, PPT-Erstellung) noch Verbesserungspotenzial besteht. Große Unternehmen wählen diese beiden Produkte als AI-Vorreiter, um ihre Nutzerbasis und Datenbestände zu nutzen, die beste Form von AI für Endverbraucher (AI To C) zu erkunden und ihr eigenes AI-Ökosystem zu ergänzen. (Quelle: 定焦One)
Wie Unternehmen AI effektiv implementieren können, wenn internes Fachwissen begrenzt ist: Der Artikel untersucht, wie Unternehmen künstliche Intelligenz effektiv und überlegt einführen und implementieren können, auch wenn ihnen tiefgreifendes internes AI-Fachwissen fehlt. Dies könnte die Nutzung externer Kooperationen, die Auswahl geeigneter Tool-Plattformen, den Beginn mit kleinen Pilotprojekten, die Betonung der Mitarbeiterschulung und die klare Definition von Geschäftszielen umfassen. (Quelle: Ronald_vanLoon, Ronald_vanLoon)

Kompetenzvielfalt ist entscheidend für die Erzielung des ROI von AI-Investitionen: Erfolgreiche AI-Projekte erfordern nicht nur technische Experten, sondern auch Talente mit Geschäftsverständnis, Datenanalysefähigkeiten, ethischen Überlegungen, Projektmanagementfähigkeiten und mehr. Die Vielfalt der Kompetenzen innerhalb einer Organisation ist ein Schlüsselfaktor, um sicherzustellen, dass AI-Projekte effektiv umgesetzt werden, reale Probleme lösen und letztendlich einen Geschäftswert (ROI) liefern. (Quelle: Ronald_vanLoon)

Teilen einer SEO-Landingpage-Strategie für AI-Produkte: Gofei teilt eine Zusammenfassungskarte seiner SEO-Landingpage-Strategie, die er für sein AI-Produkt verwendet (angeblich 100.000 USD Monatsumsatz), und betont die Wirksamkeit seiner Methodik. (Quelle: dotey)

🌟 Community
Phänomen des AI-Betrugs bei Vorstellungsgesprächen erregt Aufmerksamkeit, Tool-Flut fordert Fairness im Recruiting heraus: Der Artikel deckt auf, dass die Nutzung von AI-Tools zum Betrügen bei Remote-Videointerviews zunimmt. Diese Tools können Fragen des Interviewers in Echtzeit transkribieren und Antworten generieren, die der Bewerber vorlesen kann, und sogar bei technischen Tests helfen. Der Autor testete selbst und stellte fest, dass solche Tools erhebliche Verzögerungen, Erkennungsfehler und das Risiko des Scheiterns aufweisen, die Erfahrung schlecht ist und die Kosten hoch sind. Das Phänomen hat jedoch HR-Abteilungen und Interviewer alarmiert, die beginnen, Anti-Betrugs-Methoden zu untersuchen. Der Artikel diskutiert die Auswirkungen von AI-Betrug auf die Fairness im Recruiting und widerlegt das Argument, dass „die Fähigkeit, Probleme mit AI zu lösen, eine Fähigkeit ist“. Er betont, dass der Kern eines Interviews die Prüfung echter Fähigkeiten und Denkweisen ist, nicht die Abhängigkeit von instabilen externen Tools. (Quelle: 差评X.PIN)

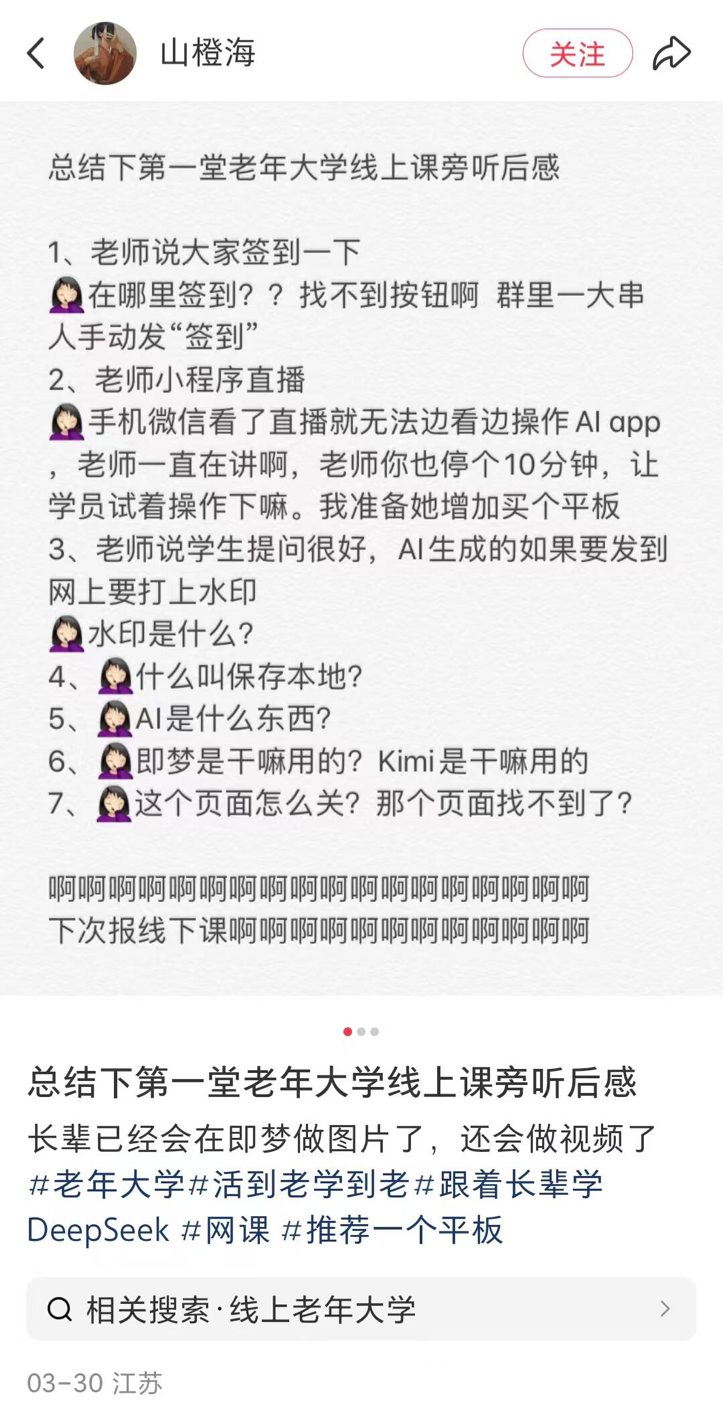
AI-Kurse an Seniorenuniversitäten in Kreisstädten im Kommen, Verbreitung und Risiken koexistieren: Berichtet über den Trend, dass Seniorenuniversitäten in vielen Teilen Chinas (einschließlich Kreisstädten) AI-Kurse anbieten. Die Kursinhalte konzentrieren sich hauptsächlich auf die Erstellung von AI-Inhalten (z. B. Texte schreiben mit Doubao, Bilder/Videos generieren mit Jimeng/Keling, Gedichte/Bilder erstellen mit DeepSeek) und Anwendungen im Alltag (Interpretation von Gesundheitsberichten, Rezeptsuche, Betrugsprävention). Die Studiengebühren liegen normalerweise zwischen 100 und 300 Yuan pro Semester und sind damit kostengünstiger als teure kommerzielle AI-Kurse. Ältere Menschen stoßen beim Lernen jedoch auf die digitale Kluft (z. B. Schwierigkeiten beim Herunterladen von Apps, grundlegende Bedienung) und der Unterricht warnt möglicherweise nicht ausreichend vor Risiken wie AI-Halluzinationen, insbesondere in kritischen Bereichen wie der Gesundheit. (Quelle: 刺猬公社)
John Carmack antwortet auf Bedenken über den Einfluss von AI-Tools auf den Wert von Fähigkeiten: Als Reaktion auf Bedenken, dass AI-Tools die Fähigkeiten von Programmierern, Künstlern usw. entwerten könnten, argumentiert John Carmack, dass der Fortschritt von Werkzeugen schon immer im Mittelpunkt der Computerbranche stand. So wie Game Engines den Kreis der Spieleentwickler erweitert haben, werden AI-Tools Top-Kreative und kleine Teams befähigen und neue Zielgruppen anziehen. Obwohl es in Zukunft möglich sein könnte, Spiele usw. durch einfache Prompts zu generieren, werden herausragende Werke weiterhin von professionellen Teams geschaffen werden müssen. AI-Tools werden insgesamt die Effizienz der Produktion hochwertiger Inhalte steigern. Er lehnt es ab, fortschrittliche Werkzeuge aus Angst vor Arbeitsplatzverlust abzulehnen. (Quelle: dotey)
Eine Reihe von Beschwerden und Reflexionen über AI: Der Artikel nutzt eine Reihe kurzer, prägnanter Sätze, um sich über gängige Phänomene im aktuellen AI-Bereich zu beschweren und darüber nachzudenken. Themen sind die übermäßige Werbung für AGI, die Flut von AI-Nachrichten, die Finanzierungsblase, die Kluft zwischen Modellfähigkeiten und menschlichen Erwartungen, ethische Herausforderungen der AI, das Blackbox-Problem bei Entscheidungen und die verzerrte öffentliche Wahrnehmung von AI. Die Kernaussage ist, dass eine Kluft zwischen Realität und Hype besteht und die Entwicklung der AI kritischer betrachtet werden muss. (Quelle: 世上本无 AGI,报道多了,就有了)
Diskussion: Wird RAG durch langen Kontext ersetzt?: Die Community diskutiert erneut, ob die von Modellen wie Llama 4 beanspruchten ultralangen Kontextfenster (z. B. 10 Millionen Tokens) die RAG-Technologie (Retrieval-Augmented Generation) überflüssig machen werden. Es wird argumentiert, dass die bloße Erhöhung der Kontextlänge RAG nicht vollständig ersetzen kann, da RAG weiterhin Vorteile bei der Verarbeitung von Echtzeitinformationen, dem Abrufen spezifischer Wissensdatenbanken, der Kontrolle von Informationsquellen und der Kosteneffizienz bietet. Langer Kontext und RAG sind wahrscheinlich eher komplementär als substituierend. (Quelle: Reddit r/artificial)

AI-Community-Diskussion: Wie hält man mit der AI-Entwicklung Schritt?: Ein Reddit-Benutzer beklagt, dass die AI-Entwicklung zu schnell voranschreitet, um mithalten zu können, und empfindet FOMO (Fear of Missing Out). Im Kommentarbereich herrscht allgemeiner Konsens darüber, dass es unmöglich ist, vollständig Schritt zu halten. Vorschläge umfassen: Konzentration auf das eigene Fachgebiet, Zusammenarbeit und Informationsaustausch mit Kollegen, sich nicht wegen jedes kleinen Updates Sorgen zu machen, zwischen echtem Fortschritt und Marketing-Hype zu unterscheiden und zu akzeptieren, dass dies ein kontinuierlicher Lernprozess ist. (Quelle: Reddit r/ArtificialInteligence)
Community-Diskussion: Beste aktuelle lokale LLM-Benutzeroberfläche (UI): Ein Reddit-Benutzer startet eine Diskussion und fragt nach den im April 2025 am meisten empfohlenen lokalen LLM-UIs. Zu den genannten beliebten Optionen gehören Open WebUI, LM Studio, SillyTavern (besonders für Rollenspiele und Weltenbau), Msty (eine funktionsreiche Ein-Klick-Installationsoption), Reor (Notizen + RAG), llama.cpp (Kommandozeile), llamafile, llama-server und d.ai (Android mobil). Die Wahl hängt von den Benutzeranforderungen ab (Benutzerfreundlichkeit, Funktionen, spezifische Szenarien usw.). (Quelle: Reddit r/LocalLLaMA)
AI Alignment, das Modelle zum „Lügen“ zwingt, löst Bedenken aus: Ein Reddit-Benutzer kritisiert bestimmte AI-Alignment-Methoden, die Modelle dazu zwingen, ihre eigene Identität zu leugnen (z. B. nicht zuzugeben, ein bestimmtes Modell zu sein), und argumentiert, dass diese Art des „erzwungenen Lügens“ problematisch ist. Der Beitrag zeigt einen Dialog-Screenshot, in dem das Modell durch suggestive Fragen schließlich seine Identität „zugibt“, was eine Diskussion über Alignment-Ziele und Transparenz auslöst. (Quelle: Reddit r/artificial

OpenAI GPT-4.5 A/B-Tests lösen Diskussion aus: Benutzer bemerken, dass sie bei der Verwendung von GPT-4.5 häufig auf A/B-Test-Aufforderungen stoßen („Welches bevorzugen Sie?“). Kommentare deuten darauf hin, dass OpenAI möglicherweise zahlende Benutzer zur Sammlung von Modellpräferenzdaten nutzt. Die auf diese Weise gesammelten Daten könnten sich von denen öffentlicher Plattformen wie LM Arena unterscheiden. (Quelle: natolambert)
Probleme bei der Praxis des Model Context Protocol (MCP): Community-Benutzer weisen darauf hin, dass, obwohl MCP (Model Context Protocol) als standardisiertes Konzept für die Interaktion von AI mit Tools vielversprechend ist, viele aktuelle Implementierungen von schlechter Qualität sind. Risikopunkte sind: Entwickler haben keine vollständige Kontrolle über die vom MCP-Server gesendeten Befehle, die Fähigkeit des Systems, menschliche Eingabefehler (wie Rechtschreibung) zu verarbeiten, ist unzureichend, das Halluzinationsproblem der LLMs selbst und unklare Fähigkeitsgrenzen von MCP. Es wird empfohlen, es vorsichtig zu verwenden, insbesondere in nicht schreibgeschützten Szenarien, und Open-Source-Implementierungen aus Transparenzgründen zu bevorzugen. (Quelle: Reddit r/artificial)
Suno-Benutzer melden Anomalien bei der Extend-Funktion: Mehrere Suno-Benutzer berichten von Problemen mit der „Extend“-Funktion (Erweitern). Sie kann den Songstil nicht wie erwartet fortsetzen, sondern führt stattdessen neue Melodien, Instrumente oder sogar Rhythmen und Stile ein. Benutzer äußern Unzufriedenheit darüber, viele Credits zu verbrauchen, ohne brauchbare Ergebnisse zu erhalten, und fragen sich, ob es sich um einen Systemfehler handelt. Ein Benutzer hat ein Video erstellt, das das Problem zeigt. (Quelle: Reddit r/SunoAI, Reddit r/SunoAI)

Suno-Benutzer melden jüngsten Rückgang der Generierungsqualität: Ein langjähriger zahlender Suno-Benutzer beschwert sich über einen starken Rückgang der Generierungsqualität der Modelle V4 und V3.5 in letzter Zeit. Er gibt an, dass zuvor zuverlässige Prompts jetzt nur noch „Rauschen“ oder verstimmte Musik erzeugen und dass er 3000 Credits verbraucht hat, ohne einen brauchbaren Song zu erhalten. Der Benutzer fragt sich, ob es sich um einen Fehler handelt und erwägt, sein Abonnement zu kündigen. (Quelle: Reddit r/SunoAI)
Community-Teilung: Mit AI Traumberufsbilder für Kinder generieren: Ein Video zeigt einen herzerwärmenden Anwendungsfall: Kinder beschreiben, was sie werden möchten, wenn sie groß sind (z. B. Anwalt, Eisverkäufer, Zoowärter, Radfahrer), und dann wird AI (im Video ChatGPT) verwendet, um entsprechende Bilder basierend auf den Beschreibungen zu generieren. Die Kinder freuen sich sehr, als sie die Bilder sehen. (Quelle: Reddit r/ChatGPT)

Community-Teilung: AI generiert Bilder von Prominenten, die ihr jüngeres/älteres Ich treffen: Ein Benutzer verwendete die Bildgenerierungsfunktion von ChatGPT, um eine Reihe von Bildern zu erstellen, auf denen Prominente (wie Musk, Arnold Schwarzenegger, Paul McCartney, Tony Hawk, Clint Eastwood usw.) ihrem jüngeren oder älteren Ich begegnen. Die Ergebnisse sind realistisch und unterhaltsam. (Quelle: Reddit r/ChatGPT)
AI generiert „seltsames“ Video über die Reindustrialisierung Amerikas: Ein Benutzer teilt ein Video, das angeblich von einer chinesischen AI über die „amerikanische Reindustrialisierung“ generiert wurde. Der Inhalt und der Musikstil des Videos werden als „wild“ und humorvoll/satirisch empfunden und zeigen die Fähigkeit und potenzielle Voreingenommenheit von AI bei der Generierung spezifischer narrativer Inhalte. (Quelle: Reddit r/ChatGPT

Benutzer vergleicht Kosten und Ergebnisse von Claude und o1-pro: Ein Benutzer teilt seine Erfahrungen bei der Verbesserung von Tailwind CSS-Kartenstilen mit OpenAI o1-pro und Anthropic Claude Sonnet 3.7. Die Ergebnisse zeigen, dass die Ausgabe von Claude besser war und die Kosten weitaus niedriger waren als bei o1-pro (weniger als 1 USD gegenüber fast 6 USD). (Quelle: Reddit r/ClaudeAI)
Benutzer verspotten Stabilität des Claude-Dienstes: Benutzer posten Memes oder Kommentare, die sich über die häufigen „unerwartet hohen Nachfrage“-bedingten Überlastungen oder Nichtverfügbarkeiten des Anthropic Claude-Dienstes während der Spitzenzeiten an Werktagen lustig machen und andeuten, dass seine Stabilität verbesserungswürdig ist. (Quelle: Reddit r/ClaudeAI)

Mathematik-Doktorand sucht Einstiegsressourcen für Machine Learning: Ein Student, der kurz vor Beginn seiner Mathematik-Promotion steht und dessen Forschungsrichtung die Anwendung von Werkzeugen der linearen Algebra auf Machine Learning (insbesondere PINNs) beinhaltet, sucht nach geeigneten, rigorosen und prägnanten ML-Einstiegsressourcen (Bücher, Skripte, Videokurse) für einen mathematischen Hintergrund. Er hält Standardlehrbücher (wie Bishop, Goodfellow) für zu langatmig. (Quelle: Reddit r/MachineLearning)

Student testet Leistungsunterschiede kleiner Modelle auf unterschiedlicher Hardware: Ein Student teilt Leistungsdaten von Tests kleiner Modelle wie Llama3.2 1B und Granite3.1 MoE auf einer RTX 2060 Desktop-GPU und einem Raspberry Pi 5. Er stellt fest, dass Llama3.2 auf dem Desktop am besten abschneidet, auf dem Raspberry Pi jedoch an zweiter Stelle steht, und ist darüber verwirrt. Gleichzeitig beobachtet er, dass MoE-Modelle größere Schwankungen bei den Ergebnissen aufweisen und fragt nach den Gründen. (Quelle: Reddit r/MachineLearning)
Benutzer sucht Möglichkeit, Such- und Titelgenerierungsmodelle in OpenWebUI zu trennen: Ein OpenWebUI-Benutzer fragt, ob es möglich ist, das Modell, das zur Generierung von Suchanfragen verwendet wird (Tendenz zu Modellen mit starken Schlussfolgerungsfähigkeiten), von dem Modell zu trennen, das zur Generierung von Titeln/Tags verwendet wird (Tendenz zu kostengünstigeren kleinen Modellen). (Quelle: Reddit r/OpenWebUI)
Benutzer sucht Suno AI Music Prompt Handbuch: Ein Benutzer fragt, ob jemand noch das zuvor verbreitete Suno AI Music Prompt Handbuch (PDF) hat, da der ursprüngliche Link nicht mehr funktioniert. (Quelle: Reddit r/SunoAI)

Benutzer sucht Hilfe bei der Integration von OpenWebUI und LM Studio: Ein Benutzer versucht, OpenWebUI mit LM Studio als Backend zu verbinden (über die OpenAI-kompatible API), stößt jedoch bei der Einrichtung der Websuche und der Embedding-Funktionen auf Probleme und bittet die Community um Hilfe. (Quelle: Reddit r/OpenWebUI)
Benutzer teilen AI-generierte Musikwerke: Mehrere Benutzer teilen auf r/SunoAI ihre mit Suno AI erstellten Musikwerke, die verschiedene Stile wie Ambient, Musical, Alternative Psychedelic Rock, Folk Country, Comedy Ballad (EDM), Rap, Folk Music, Dreamy Indie Pop usw. abdecken. (Quelle: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)

Benutzer fragt nach dem Wert eines Suno-Abonnements: Angesichts der jüngsten Beschwerden über die Qualität von Suno v4 fragt ein Benutzer, ob sich der Kauf eines Suno-Abonnements derzeit noch lohnt, insbesondere zum Remastern alter v3-Versionen von Songs. (Quelle: Reddit r/SunoAI)
Benutzer sucht Ratschläge zur Erstellung eines Suno-Musikalbums: Ein erfahrener Suno-Benutzer plant, seine zufriedenstellenden Werke zu einem Album zusammenzustellen und über Plattformen wie DistroKid auf Spotify zu veröffentlichen. Er bittet die Community um Ratschläge zur Songauswahl, Reihenfolge und technischen Umsetzung. (Quelle: Reddit r/SunoAI)
Benutzer beschwert sich über UI-Probleme von Suno auf dem iPad: Ein neuer Abonnent berichtet von Problemen mit der Benutzeroberfläche bei der Nutzung der Suno-Website auf einem iPad. Funktionen wie Aufnahme, Bearbeitung von Songtexten, Drag & Drop usw. funktionieren nicht ordnungsgemäß. Er sucht nach Lösungen oder Ratschlägen. (Quelle: Reddit r/SunoAI)
Benutzer beschwert sich, dass Cursor AI möglicherweise heimlich Modelle herabstuft: Ein Benutzer vermutet, dass Cursor AI das von ihm verwendete Modell ohne Benachrichtigung von dem behaupteten Claude 3.7 auf 3.5 herabgestuft hat. Als Grund nennt er Verhaltensänderungen des Agents und dessen Weigerung, Modellinformationen preiszugeben. Der Benutzer gibt an, dass sein Beitrag mit den Vorwürfen auf r/cursor gelöscht wurde. (Quelle: Reddit r/ClaudeAI)
Benutzer fragt nach häufig genutzten kostenpflichtigen AI-Diensten: Ein Benutzer startet eine Diskussion und fragt, welche kostenpflichtigen AI-Dienste andere monatlich abonnieren. Er möchte wissen, welche Tools als preiswert erachtet werden und ob es empfehlenswerte Dienste gibt. (Quelle: Reddit r/artificial)
Deep Learning Hilfe gesucht: Erkennung gemischter Signale: Ein Anfänger bittet um Hilfe, wie man Deep Learning zur Erkennung von Mustern in gemischten wissenschaftlichen Messsignalen einsetzen kann. Die Daten liegen als Koordinatenpunkte im txt/Excel-Format vor. Fragen sind: Wie können ergänzende Daten im Bildformat integriert werden? Kann das Modell gemischte Muster verarbeiten, die durch Koordinatenpunkte dargestellt werden? Welche Modelle oder Lernrichtungen werden empfohlen? (Quelle: Reddit r/deeplearning)
Meme/Humor: In der Community tauchen mehrere Memes oder humorvolle Beiträge im Zusammenhang mit AI auf, z. B. über die Liebe zu einer AI (Film Her), die Präferenz für das Gemma 3 Modell, die Sättigung des Marktes für AI Note-Taker, den Ausfall des Claude-Dienstes und AI-generierte Promi-Sammelkarten. (Quelle: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, AravSrinivas, Reddit r/artificial)

💡 Sonstiges
Protocol Buffers (Protobuf) weiterhin im Fokus: Das von Google entwickelte Datenaustauschformat Protobuf genießt auf GitHub weiterhin hohe Aufmerksamkeit. Als sprach- und plattformneutraler, erweiterbarer Mechanismus zur Serialisierung strukturierter Daten wird es in AI/ML und vielen großen Systemen (wie TensorFlow, gRPC) weit verbreitet eingesetzt. Das Repository bietet Installationsanleitungen für den Compiler (protoc), Links zu Laufzeitbibliotheken für mehrere Sprachen und eine Anleitung zur Bazel-Integration. (Quelle: protocolbuffers/protobuf – GitHub Trending (all/daily))
Gin Web Framework bleibt beliebt: Das in Go geschriebene Hochleistungs-HTTP-Web-Framework Gin erfreut sich auf GitHub weiterhin großer Beliebtheit. Es ist bekannt für seine Martini-ähnliche API und eine bis zu 40-fache Leistungssteigerung (dank httprouter) und eignet sich für Szenarien, die hochperformante Webdienste erfordern (möglicherweise einschließlich API-Diensten für AI-Modelle). (Quelle: gin-gonic/gin – GitHub Trending (all/daily))
Hugging Face Hub verwendet neues Backend Xet zur Effizienzsteigerung: Der Hugging Face Hub beginnt mit der Nutzung eines neuen Speicher-Backends namens Xet, das das bisherige Git-Backend ersetzt. Xet nutzt die Content-Defined Chunking (CDC)-Technologie zur Deduplizierung von Daten auf Byte-Ebene (ca. 64KB-Blöcke) anstatt auf Dateiebene. Das bedeutet, dass bei Änderungen an großen Dateien (wie Parquet) nur die zeilenweisen Unterschiede übertragen und gespeichert werden müssen, was die Upload-/Download-Effizienz und die Speichereffizienz erheblich verbessert. Die Veröffentlichung des Llama-4 Modells hat dieses Backend erfolgreich getestet. (Quelle: huggingface)
Hugging Face Hub wird bald MCP-Client unterstützen: Ein Hugging Face-Entwickler hat einen Pull Request eingereicht, um die Unterstützung für das Model Context Protocol (MCP) im Inference-Client der huggingface_hub-Bibliothek hinzuzufügen. Dies könnte bedeuten, dass der Hugging Face Inferenzdienst besser mit Tools und Agents interagieren kann, die dem MCP-Standard folgen. (Quelle: huggingface)
Zipline Drohnen-Liefersystem: Zeigt das Drohnen-Liefersystem der Firma Zipline. Dieses System nutzt möglicherweise AI für Routenplanung, Hindernisvermeidung und präzise Zustellung und wird im Logistik- und Lieferkettenbereich eingesetzt, insbesondere beim Transport von medizinischem Material zeigt es Potenzial. (Quelle: Ronald_vanLoon)
ergoCub Roboter für physische Mensch-Roboter-Interaktion: Das Italienische Institut für Technologie (IIT) präsentiert den ergoCub Roboter, der für die Forschung zur physischen Mensch-Roboter-Interaktion entwickelt wurde. Solche Roboter benötigen typischerweise fortschrittliche AI-Algorithmen für Wahrnehmung, Bewegungssteuerung und sichere Interaktionsfähigkeiten. (Quelle: Ronald_vanLoon)
KeyForge3D: Schlüsselkopieren mit Computer Vision: Ein GitHub-Projekt namens KeyForge3D nutzt OpenCV (Computer Vision Bibliothek), um Schlüsselformen zu erkennen, den Bitting-Code des Schlüssels zu berechnen und ein STL-Modell für den 3D-Druck zu exportieren. Obwohl hauptsächlich traditionelle CV-Techniken verwendet werden, zeigt es das Potenzial der Bilderkennung bei Aufgaben der physischen Replikation, die in Zukunft möglicherweise mit AI kombiniert werden könnten, um die Erkennungsgenauigkeit und Anpassungsfähigkeit weiter zu verbessern. (Quelle: karminski3)

Prinzipien der verantwortungsvollen AI (Responsible AI) im Fokus: Der Beitrag erwähnt die von Institutionen wie Ernst & Young (EY) verwendeten Prinzipien der verantwortungsvollen AI und betont die Notwendigkeit, bei der Entwicklung und Bereitstellung von AI-Systemen ethische und soziale Faktoren wie Fairness, Transparenz, Erklärbarkeit, Datenschutz, Sicherheit und Rechenschaftspflicht zu berücksichtigen. (Quelle: Ronald_vanLoon)
Kawasaki präsentiert wasserstoffbetriebenen reitbaren Roboter „Pferd“: Kawasaki Heavy Industries hat einen vierbeinigen Roboter namens Corleo vorgestellt, der zum Reiten konzipiert ist und Wasserstoff als Energiequelle nutzt. Obwohl es sich um einen Roboter handelt, wird im Bericht nicht explizit erwähnt, inwieweit AI in seinem Steuerungs- oder Interaktionssystem eingesetzt wird. (Quelle: Reddit r/ArtificialInteligence)
