
Schlüsselwörter:AI, LLM, AI Index Report 2025, DeepSeek Modell, Llama 4 Kontroverse, AI Musikgenerierung, Agentic AI
🔥 Fokus
Stanford veröffentlicht AI Index Report 2025 und enthüllt wichtige Branchentrends: Das Stanford Institute for Human-Centered Artificial Intelligence (HAI) hat seinen achten jährlichen AI Index Report (456 Seiten) veröffentlicht, der die globale KI-Entwicklung im Jahr 2024 umfassend verfolgt. Der Bericht enthält neue Inhalte zu KI-Hardware, Inferenzkosten, verantwortungsvollen KI-Praktiken in Unternehmen sowie KI-Anwendungen in Wissenschaft und Medizin. Kerntrends umfassen: 1) Deutliche Leistungssteigerung von KI bei anspruchsvollen Benchmarks wie MMMU; 2) Zunehmende Integration von KI in den Alltag, z. B. im Gesundheitswesen und im Verkehr; 3) Rekordinvestitionen und Akzeptanzraten in Unternehmen, wobei US-Investitionen die chinesischen weit übertreffen, China jedoch den Leistungsrückstand bei Modellen schnell aufholt (Lücke bei Top-Modellen aus China und den USA bei Benchmarks wie MMLU auf 0,3 % bis 1,7 % reduziert); 4) Open-Source-/kleine Modelle wie DeepSeek nähern sich der Leistung von Closed-Source-/großen Modellen an, Inferenzkosten sinken drastisch (um das 280-fache in zwei Jahren); 5) Globale KI-Regulierung wird verstärkt, Investitionen nehmen zu; 6) KI-Bildung verbreitet sich schneller, aber Ressourcen sind ungleich verteilt; 7) KI-Sicherheitsvorfälle nehmen stark zu, verantwortungsvolle KI-Praktiken sind uneinheitlich; 8) Globale optimistische Stimmung gegenüber KI steigt, aber mit großen regionalen Unterschieden. Der Bericht betont das transformative Potenzial von KI und die Notwendigkeit, ihre Entwicklung zu lenken. (Quelle: 36氪, 新智元, 元宇宙之心MetaverseHub, 机器之心)

Virale KI-Musikgenerierung löst Kontroverse aus: Das Phänomen „Sieben-Tage-Liebhaber“ beleuchtet Hype und Herausforderungen der Branche: Der KI-generierte Song „Sieben-Tage-Liebhaber“, der den Stil von Jay Chou imitiert, wurde unerwartet populär, landete in den Trends und Musikcharts und wurde schnell lizenziert, was einen Boom in der KI-Musikgenerierung auslöste. Zahlreiche Amateure strömen auf Plattformen, um mit KI-Tools Songs „massenhaft zu produzieren“, und einige Plattformen starten entsprechende Aktionen. Hinter dem Boom verbergen sich jedoch zahlreiche Probleme: Viele KI-Songs haben eine uneinheitliche Qualität und werden als „Musikmüll“ bezeichnet; sie basieren auf Nachahmung und Zusammensetzung und es fehlt an echter Innovation; die Urheberrechtsfragen sind unklar, die USA haben bereits klargestellt, dass KI-Kreationen nicht urheberrechtlich geschützt sind, und Plattformen wie Tencent Music weisen ebenfalls auf rechtliche Risiken hin; die Kommerzialisierung ist schwierig, abgesehen von einzelnen Hits sind die Einnahmen der meisten KI-Songs gering, und die Plattformen verschärfen ihre Prüfungen. Brancheninsider befürchten, dass KI die Existenzgrundlage von Nachwuchsmusikern gefährden könnte, und sorgen sich noch mehr um die „Vernachlässigung des kreativen Prozesses“, die zu Denkfaulheit und ästhetischem Verfall beim Menschen führen könnte. (Quelle: 36氪)
Llama 4 Modell nach Veröffentlichung in Kontroverse um „Fälschung“ verwickelt, Diskrepanz zwischen Arena-Ranking und tatsächlicher Leistung sorgt für Streit: Metas neuestes veröffentlichtes Open-Source-Modell Llama 4 erreichte auf der Chatbot Arena hohe Punktzahlen und übertraf DeepSeek-V3 als bestes Open-Source-Modell. Zahlreiche Nutzerberichte deuten jedoch darauf hin, dass seine Leistung in Bereichen wie Programmierung, Schlussfolgerung und kreativem Schreiben schlecht ist und weit hinter den Erwartungen und seinem Arena-Ranking zurückbleibt. Anschließend wies die Large Model Arena (LMArena) offiziell darauf hin, dass Meta der Arena eine experimentelle Version (Llama-4-Maverick-03-26-Experimental) zur Verfügung gestellt hatte, die zur Optimierung menschlicher Präferenzen angepasst wurde, und nicht die auf Hugging Face veröffentlichte Standardversion. Meta hatte diesen Unterschied nicht klar gekennzeichnet. LMArena veröffentlichte über 2000 Vergleichsdatensätze, die zeigen, dass der Antwortstil dieser experimentellen Version (z. B. freundlicher, Verwendung von Emojis) ein wichtiger Faktor für das Ranking sein könnte, und wird die HF-Version von Llama 4 zur Neubewertung online stellen. Der Leiter von Meta Gen AI bestritt ein Training auf dem Testdatensatz und erklärte, die Leistungsunterschiede seien auf Probleme mit der Bereitstellungsstabilität zurückzuführen. Dieser Vorfall löste in der Community breite Diskussionen und Zweifel an der Leistung von Llama 4, der Transparenz von Meta und der Zuverlässigkeit der Bewertungsmethoden von LMArena aus. (Quelle: 量子位, 机器之心, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

DeepSeek-Phänomen erregt Branchenaufmerksamkeit, China Generative AI Conference diskutiert neue Chancen: Der Aufstieg von DeepSeek wird als entscheidender Wendepunkt für die generative KI-Branche in China und weltweit angesehen. Sein hocheffizientes, kostengünstiges Open-Source-Modell katalysiert den Forschungs- und Entwicklungsboom bei Inferenzmodellen und AI Infra und gibt Edge AI sowie der Implementierung heimischer Rechenleistung neue Impulse. Auf der China Generative AI Conference 2025 diskutierten über 50 Experten aus Industrie, Wissenschaft und Forschung die durch DeepSeek ausgelösten Veränderungen, Deep Inference, Multimodalität, World Models, AI Infra, AIGC-Anwendungen, Agents und Embodied Intelligence. Die Teilnehmer waren der Meinung, dass DeepSeek die Bereitstellungskosten für Unternehmen erheblich senkt (einige Anwendungen verzeichneten nach der Umstellung eine Kostensenkung von 90 %) und die Aktivität und schnelle Implementierungsfähigkeit Chinas in der Open-Source-Community demonstriert. Die Konferenz befasste sich auch mit Themen wie dem Bedarf an neuen Endgeräten für den Durchbruch von KI-Anwendungen, Herausforderungen bei der Implementierung von Agents, Durchbrüchen bei heimischen Rechenleistungsclustern, der Entwicklung physischer Intelligenz und Wegen zur Kommerzialisierung von KI, was die zunehmend wichtige Rolle Chinas in der globalen KI-Landschaft unterstreicht. (Quelle: 36氪, Ronald_vanLoon)

🎯 Trends
Agentic AI wird als nächster großer Durchbruch angesehen: Agentic AI (Agenten-KI) entwickelt sich zu einem Schlüsselfaktor für die Transformation von Wirtschaft und Technologie. Im Gegensatz zu traditioneller KI, die spezifische Aufgaben ausführt, kann Agentic AI autonom Ziele setzen, Pläne entwickeln und komplexe, mehrstufige Aufgaben ausführen – eher wie ein autonomer digitaler Mitarbeiter. Sie können mehrere Tools und Datenquellen integrieren, Schlussfolgerungen ziehen und Entscheidungen treffen und versprechen disruptive Veränderungen in Bereichen wie Kundenservice, Datenanalyse und Softwareentwicklung. Mit der technologischen Entwicklung wird Agentic AI tiefgreifende Veränderungen in den Betriebsmodellen von Unternehmen und der Mensch-Maschine-Interaktion vorantreiben. (Quelle: Ronald_vanLoon)

Nvidia veröffentlicht Llama-Nemotron-Ultra 253B Modell, stellt Weights und Daten als Open Source bereit: Nvidia stellt Llama-Nemotron-Ultra vor, ein dichtes Modell mit 253B Parametern, das durch NAS Pruning und Inferenzoptimierung aus Llama-3.1-405B trainiert wurde. Das Modell konzentriert sich auf die Verbesserung der Inferenzfähigkeiten, verwendet SFT und RL Post-Training (FP8-Genauigkeit) und stellt die Weights und Post-Training-Daten als Open Source zur Verfügung. Nvidias kontinuierlicher Beitrag zur Open-Source-Post-Training-Arbeit wird von der Community begrüßt. (Quelle: natolambert)

Qwen3-Modellreihe möglicherweise vor Veröffentlichung, enthält 8B- und 15B-MoE-Versionen: Basierend auf Informationen aus einem gemergten PR im vLLM-Code-Repository wird vermutet, dass Alibaba bald neue Modelle der Qwen3-Reihe veröffentlichen wird. Derzeit sind möglicherweise die Versionen Qwen3-8B und Qwen3-MoE-15B-A2B enthalten. Die Community spekuliert, dass die 8B-Version ein multimodales Modell sein könnte, während die 15B-Version ein auf Text fokussiertes MoE (Mixture of Experts)-Modell ist. Nutzer hoffen auf Leistungssteigerungen bei den neuen Modellen; wenn das 15B MoE das Niveau von Qwen2.5-Max erreicht, würde dies als signifikanter Erfolg gewertet. (Quelle: karminski3)

Runway startet Gen-4 Turbo mit deutlich erhöhter Videogenerierungsgeschwindigkeit: Runway hat sein neuestes Videogenerierungsmodell Gen-4 Turbo veröffentlicht. Das Hauptmerkmal des neuen Modells ist die Generierungsgeschwindigkeit, die angeblich ein 10-Sekunden-Video in 30 Sekunden erzeugen kann, was eine erhebliche Beschleunigung gegenüber früheren Versionen darstellt. Dies macht Gen-4 Turbo besonders geeignet für Anwendungsfälle, die schnelle Iterationen und kreative Exploration erfordern. Das Update wird für alle Nutzerpläne eingeführt. (Quelle: op7418)
Google Gemini Live gestartet, ermöglicht visuelle und sprachliche Echtzeitinteraktion: Google hat den offiziellen Start der Gemini Live-Funktion angekündigt, die zuerst auf Pixel 9- und Samsung Galaxy S25-Geräten verfügbar sein wird und für Gemini Advanced-Nutzer auf Android geöffnet wird. Die Funktion ermöglicht es Nutzern, Bildschirminhalte oder Live-Aufnahmen über die Kamera zu teilen und mit Gemini per Sprache zu interagieren, um visuelle Inhalte zu verstehen und interaktive Fragen zu stellen, Probleme zu beheben, Brainstorming durchzuführen usw. Dies markiert einen wichtigen Fortschritt von Google im Bereich multimodaler KI-Interaktionserlebnisse und bringt die Vision von Project Astra einen Schritt näher zur Realität. (Quelle: op7418, JeffDean, demishassabis)
HiDream veröffentlicht Open-Source-Bildmodell HiDream-I1 mit 17B Parametern: Das HiDream AI-Team hat sein 17B-Parameter-Bildgenerierungsmodell HiDream-I1 veröffentlicht und als Open Source bereitgestellt. Erste gezeigte Bilder deuten auf eine akzeptable Bildqualität des Modells hin. Der Modellcode wurde auf GitHub veröffentlicht und steht Entwicklern und Forschern zur Nutzung und Erkundung zur Verfügung. (Quelle: op7418)

Open-Source-Welle bei großen Modellen beschleunigt sich, Erkundung von Geschäftsmodellen „2.0“: Im Jahr 2025 treibt der Aufstieg von Open-Source-Modellen wie DeepSeek Unternehmen wie Meta, Alibaba und Tencent dazu an, ihre Open-Source-Bemühungen zu beschleunigen. Sogar ursprüngliche „Closed-Source-Verfechter“ wie OpenAI und Baidu beginnen sich zu öffnen. Treiber für Open Source sind der Bedarf an Edge Intelligence, branchenspezifische Anpassungsanforderungen, die Beschleunigung der Ökosystem-Arbeitsteilung und das Überschreiten technologischer Schwellenwerte. Open Source senkt die Hürden für Entwickler und KMUs und fördert technologische Inklusion und Innovation. Open Source bedeutet jedoch nicht kostenlos; Wartung und Lokalisierung verursachen weiterhin Kosten. Führende Anbieter erkunden Geschäftsmodelle 2.0, wie „Open-Source-Basismodell + kommerzielle API-Mehrwertdienste“ (z. B. DeepSeek, Zhipu AI), „Open-Source-Community-Version + Enterprise-Version“ (z. B. Alibaba Cloud Qwen) und „Modell-Open-Source + Cloud-Plattform-Monetarisierung“ (z. B. Meta Llama). Der Kern liegt darin, „Nutzer durch Open Source zu gewinnen und durch Services zu monetarisieren“, um über Ökosysteme, Anpassungen und Cloud-Dienste Gewinne zu erzielen. (Quelle: 第一新声)

🧰 Tools
Augment Code: KI-Codierungsplattform speziell für komplexe Projekte: Augment Code wurde veröffentlicht und positioniert sich als die erste KI-Codierungsplattform, die große, komplexe Codebasen tiefgehend verstehen kann und speziell für die Teamzusammenarbeit entwickelt wurde. Sie bietet eine Verarbeitungskapazität von bis zu 200K Kontext-Token, persistenten Speicher (lernt Codestil, Refactoring-Historie, Teamrichtlinien) und tiefe Tool-Integrationen (VS Code, JetBrains, Vim, GitHub, Linear, Notion usw.). Ihr Kern-Agent kann nicht nur Code schreiben, sondern auch Terminalbefehle ausführen, vollständige PRs erstellen sowie kontextbezogene Dokumentation und Testfälle generieren. Augment steht an erster Stelle im SWE-bench Verified Ranking (in Kombination mit Claude Sonnet 3.7 und o1) und wird bereits von Unternehmen wie Webflow und Kong eingesetzt. Die Plattform ist derzeit kostenlos und zielt darauf ab, die Probleme von Entwicklern bei der Arbeit mit großen Legacy-Codebasen zu lösen. (Quelle: AI进修生)
Cloudflare startet AutoRAG-Service zur Vereinfachung der RAG-Anwendungsentwicklung: Cloudflare hat AutoRAG veröffentlicht, einen Dienst zur Vereinfachung der Entwicklung von Retrieval-Augmented Generation (RAG)-Anwendungen. Entwickler können mit diesem Dienst Datenquellen (wie Dokumente, Websites) automatisch in Wissensdatenbanken umwandeln, die von großen Modellen abgefragt werden können, ohne die Datenindizierung und Abruflogik manuell handhaben zu müssen. Während der öffentlichen Beta-Phase ist AutoRAG kostenlos nutzbar, mit einem Limit von 10 Instanzen pro Konto und maximal 100.000 Dateien pro Instanz. Dies senkt die Einstiegshürde für die Erstellung von KI-Anwendungen, die auf spezifischem Wissen basieren. (Quelle: karminski3)

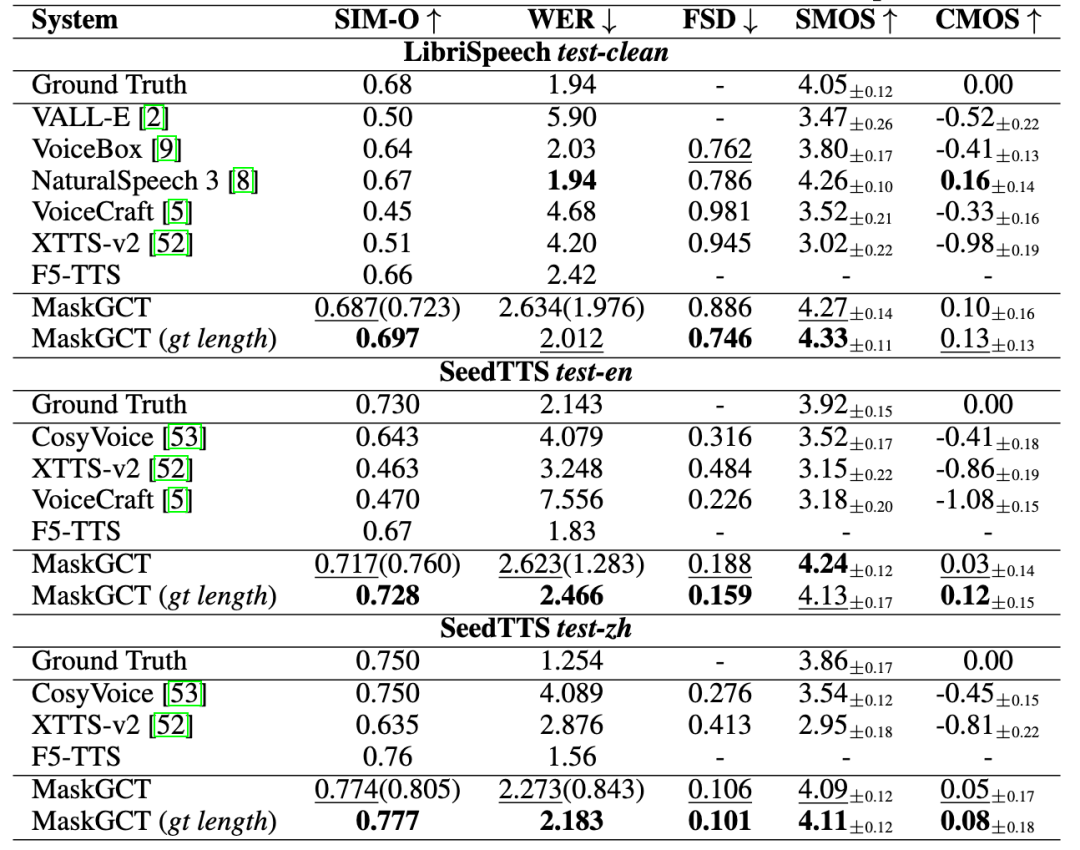
Qumaron Technology stellt „趣丸千音 (All Voice Lab)“ vor, eine KI-Sprach-Gesamtlösung: Qumaron Technology hat das KI-Sprachprodukt „趣丸千音 (All Voice Lab)“ veröffentlicht, das auf dem gemeinsam mit der CUHK (Shenzhen) entwickelten MaskGCT-Modell basiert. Das Produkt integriert Funktionen wie Text-to-Speech, Videoübersetzung, mehrsprachige Synthese und Untertitelentfernung. Es zeichnet sich durch die vollständige Automatisierung des Videoübersetzungsprozesses aus, mit einer täglichen Verarbeitungskapazität von über 1000 Minuten und einer 10-fachen Effizienzsteigerung. Die generierte Sprachausgabe ist emotional ausdrucksstark und vergleichbar mit menschlicher Sprache. 趣丸千音 zielt darauf ab, durch industrielle Fähigkeiten den Bedarf an skalierbarer sprachübergreifender Kommunikation zu decken und wird bereits im Export von Kurzformat-Dramen (Kostensenkung, Nutzerwachstum), Nachrichten, Kulturtourismus, Hörbüchern usw. eingesetzt. Es positioniert sich als „globale Content-Infrastruktur“. (Quelle: 36氪)
Exa: Suchmaschine speziell für AI Agents: Exa positioniert sich als „Bing API für das LLM-Zeitalter“ und ist eine Suchmaschine, die speziell für AI Agents entwickelt wurde, um KI einen effizienten Zugriff auf und ein Verständnis von Internetinformationen zu ermöglichen. Im Gegensatz zur menschlichen Suche kann Exa komplexere Anfragen in natürlicher Sprache verarbeiten, umfassendere Ergebnisse liefern und Anfragen mit hohem Durchsatz und geringer Latenz unterstützen. Die Kern-APIs umfassen Schnellsuche, Inhaltsabruf (Crawler), Suche nach ähnlichen Links usw. Exa bietet auch die Websets-Funktion, mit der Benutzer Filterkriterien in natürlicher Sprache definieren können, um Internetinformationen zu strukturieren. Das Unternehmen hat Investitionen von Lightspeed, Nvidia u.a. erhalten, erzielt einen ARR von über zehn Millionen Dollar und konkurriert hauptsächlich mit Brave Search. (Quelle: AI探索者)
KI-Tools ermöglichen Visualisierung und Zusammenfassung von WeChat-Chatverläufen: Mithilfe einer Kombination von KI-Tools können WeChat-Gruppen- oder Einzelchatverläufe exportiert und als visueller Bericht generiert werden. Die Schritte umfassen: 1) Exportieren des WeChat-Chatverlaufs als TXT-Datei mit einem Drittanbieter-Tool (wie 留痕MemoTrace) (Achtung: Datenschutzrisiken); 2) Eingabe der TXT-Datei und einer spezifischen Prompt-Vorlage (einschließlich Styling-Code) in ein großes Modell, das lange Texte verarbeiten kann (wie Gemini 2.5 Pro in AI Studio), um HTML-Code zu generieren; 3) Umwandlung des generierten HTML-Codes über einen Online-Dienst (wie yourware.so) in einen teilbaren Weblink oder direkte Umwandlung in ein Bild mit einem Online-Tool (wie cloudconvert.com). Diese Methode kann lange Chat-Informationen in einen klar strukturierten Bericht mit täglichen Zitaten und einer Wortwolke umwandeln, was die Überprüfung und Weitergabe erleichtert. (Quelle: 卡兹克)
即梦AI 3.0 Bildmodell vollständig verfügbar: 即梦AI (Jmeng AI) hat bekannt gegeben, dass sein Bildgenerierungsmodell der Version 3.0 die Testphase abgeschlossen hat und nun vollständig verfügbar ist. Die neue Version wird voraussichtlich Verbesserungen in Bildqualität, Stilvielfalt und semantischem Verständnis aufweisen. Nutzer (wie 歸藏) haben bereits detaillierte Tests und Prompt-Sammlungen zur Verwendung des 3.0-Modells für verschiedene Designbereiche (wie KI-Betriebsbilder) geteilt und dessen Generierungsergebnisse demonstriert. (Quelle: op7418)

VIBE Chat: Unterhaltsame Chat-Website mit zufälligen Hintergründen: Eine Website namens VIBE Chat bietet ein neuartiges Chat-Erlebnis, bei dem für jede Sitzung zufällig unterschiedliche Hintergrundbilder generiert werden. Die Website basiert auf dem Gemini 2.0 Flash-Modell, und Benutzer können damit Aufgaben wie Programmieren erledigen, wobei der Code oder Inhalt direkt in der Chat-Oberfläche angezeigt wird. Tests zeigen, dass es Code für einfache Spiele wie Flappy Bird und Tetris generieren kann. (Quelle: karminski3)
Entwickler erstellt speziellen GPT-Assistenten für SunoAI: Ein Entwickler hat eine benutzerdefinierte GPT namens „Hook & Harmony Studio“ erstellt, die den Workflow der Suno AI-Musikgenerierung unterstützen soll. Das Tool kann basierend auf dem vom Benutzer eingegebenen Songkonzept einzigartige Titel, strukturierte Songtexte (mit Anweisungen für Instrumente und Gesang), Vorschläge für passende Suno-Stil-Tags generieren, Klischees filtern und optional Prompts für die visuelle Gestaltung des Songs erstellen. Es zielt darauf ab, das Texten und die Stilfindung zu vereinfachen und automatisch für die Verwendung im Suno-Projektmodus zu formatieren. (Quelle: Reddit r/SunoAI)
Code to Prompt Generator: Vereinfacht die Erstellung von LLM-Prompts aus Code: Ein Entwickler hat ein kleines Open-Source-Tool namens „Code to Prompt Generator“ veröffentlicht, das die Erstellung von LLM-Prompts aus Codebasen vereinfachen soll. Es kann Projektordner automatisch scannen, um einen Dateibaum zu generieren (wobei irrelevante Dateien ausgeschlossen werden), ermöglicht Benutzern die selektive Einbeziehung von Dateien/Verzeichnissen, zeigt die Token-Anzahl in Echtzeit an, speichert und verwendet Anweisungen (Meta Prompts) wieder und kopiert den endgültigen Prompt mit einem Klick. Das Tool verwendet ein Next.js-Frontend und ein Flask-Backend und läuft auf mehreren Plattformen. (Quelle: Reddit r/ClaudeAI)
Llama 4 GGUF-Versionen veröffentlicht, unterstützen lokale Ausführung: Nachdem llama.cpp die Unterstützung für Llama 4 (derzeit nur Text) gemerged hat, haben Community-Entwickler (wie bartowski, unsloth, lmstudio-community) schnell GGUF-quantisierte Versionen des Llama 4 Scout-Modells veröffentlicht. Diese Versionen verwenden optimierte Quantisierungsstrategien wie imatrix, um Modellgröße und Leistung auszugleichen und Benutzern die Ausführung von Llama 4 auf lokaler Hardware zu ermöglichen. Versionen mit unterschiedlichen Bitbreiten (z. B. IQ1_S 1.78bit, Q4_K_XL 4.5bit) stehen zur Auswahl, um unterschiedlichen Hardwarekonfigurationen gerecht zu werden. Benutzer können diese GGUF-Dateien auf Hugging Face finden. (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

📚 Lernen
Microsoft und CUHK schlagen ImageGen-CoT vor, um das Kontextverständnis beim KI-Malen zu verbessern: Um die Schwächen von KI-Malmodellen beim Verständnis komplexer Textbeschreibungen und kontextueller Zusammenhänge (z. B. Materialübertragung von „Lederapfel“ zu „Lederbox“) zu beheben, schlagen Forscher von Microsoft Research Asia und der Chinese University of Hong Kong das ImageGen-CoT-Framework vor. Diese Methode führt vor der Bildgenerierung einen Chain-of-Thought (CoT)-Schlussfolgerungsschritt ein, bei dem das Modell zuerst über Schlüsselinformationen nachdenkt und die Logik strukturiert, bevor es kreativ wird. Durch den Aufbau eines hochwertigen ImageGen-CoT-Datensatzes und Feinabstimmung wurde die Leistung von Modellen (wie SEED-X) bei T2I-ICL-Aufgaben signifikant verbessert (CoBSAT um 89 %, DreamBench++ um 114 %). Das Framework verwendet eine zweistufige Inferenz und untersucht verschiedene Erweiterungsstrategien zur Testzeit (Single-CoT, Multi-CoT, Hybrid-Expansion), wobei die Hybrid-Expansion die besten Ergebnisse erzielt. (Quelle: 36氪, 新智元)

Paper stellt neues Paradigma für Routing LLMs und RouterEval-Benchmark vor: Angesichts der Herausforderungen der Monopolisierung von Rechenleistung, hoher Kosten und einseitiger Technologiepfade in der Forschung an großen Modellen schlagen Forscher das Paradigma der Routing LLMs vor. Dabei weist ein intelligenter Router Aufgaben dynamisch mehreren (Open-Source-) kleinen Modellen zur kooperativen Bearbeitung zu. Zur Unterstützung dieser Forschung stellt das Paper den umfassenden RouterEval-Benchmark als Open Source bereit, der über 200 Millionen Leistungsdatensätze von mehr als 8500 LLMs auf 12 gängigen Benchmarks enthält. Dieser Benchmark wandelt das Routing-Problem in eine Standard-Klassifizierungsaufgabe um und ermöglicht Forschung auf einer einzelnen GPU oder sogar einem Laptop. Die Studie zeigt, dass durch intelligentes Routing (selbst mit nur 3-10 Kandidatenmodellen) die kombinierte Leistung mehrerer schwächerer Modelle die von Top-Einzelmodellen (wie GPT-4) übertreffen kann, was den „Model-level Scaling Up“-Effekt demonstriert. Diese Arbeit bietet neue Ansätze für die kostengünstige Realisierung hochleistungsfähiger KI. (Quelle: 新智元)
UIUC-Team von Jiawei Han und Jimeng Sun veröffentlicht DeepRetrieval zur Optimierung von Suchanfragen mit RL: Um das Problem zu lösen, dass eine geringe Qualität der ursprünglichen Benutzeranfragen die Effektivität der Informationssuche beeinträchtigt, schlägt das UIUC-Team das DeepRetrieval-Framework vor. Dieses System nutzt Reinforcement Learning (RL), um ein LLM darauf zu trainieren, die ursprünglichen Benutzeranfragen (natürliche Sprache, boolesche Ausdrücke oder SQL) zu optimieren und sie besser an die Eigenschaften spezifischer Suchmaschinen (wie PubMed, BM25, SQL-Datenbanken) anzupassen. Dadurch wird die Sucheffektivität maximiert, ohne das bestehende Abrufsystem zu ändern. Experimente zeigen, dass DeepRetrieval (nur ein 3B-Modell) die Abrufleistung signifikant verbessern kann (Literatursuche um das 10-fache verbessert, übertrifft GPT-4o bei Evidence-Seeking-Aufgaben, SQL-Ausführungsgenauigkeit erhöht) und die Ergebnisse von SFT-basierten Methoden bei weitem übertrifft. Die Forschung betont, dass die Explorationsfähigkeit von RL der Imitationslernfähigkeit von SFT überlegen ist und bessere Abfragestrategien finden kann. (Quelle: 机器之心)
CASIA und Partner schlagen Vision-R1 vor, um die visuelle Lokalisierungsfähigkeit von VLMs mit Reinforcement Learning zu verbessern: Angesichts der Probleme von Vision-Language Models (VLMs) bei Objekterkennungs- und visuellen Lokalisierungsaufgaben wie Formatfehlern, geringer Recall-Rate und unzureichender Präzision schlagen das Institut für Automatisierung der Chinesischen Akademie der Wissenschaften (CASIA) und das Team von Zidong Taichu das Vision-R1-Framework vor. Diese Methode überträgt die erfolgreichen Erfahrungen des Sprachmodells R1 auf die visuelle Lokalisierung, indem regelbasiertes Reinforcement Learning (Rule-Based RL) eingeführt wird. Durch die Gestaltung von aufgabenbasierten Belohnungsfunktionen, die auf visuellen Bewertungsmetriken (Formatkorrektheit, Recall-Rate, IoU-Präzision) basieren, und die Anwendung einer progressiven Regelanpassungsstrategie (differenzierte Belohnungen, phasenweise progressive Schwellenwerte) wird die Objekterkennungsleistung von Modellen wie Qwen2.5-VL auf Datensätzen wie COCO und ODINW signifikant verbessert (bis zu 50 %), ohne auf menschliche Präferenzdaten und Belohnungsmodelle angewiesen zu sein und die allgemeinen Frage-Antwort-Fähigkeiten kaum zu beeinträchtigen. Code und Modell wurden als Open Source veröffentlicht. (Quelle: 机器之心)
CalibQuant: 1-Bit KV Cache Quantisierungsschema erhöht Durchsatz multimodaler Modelle: Um das Problem des hohen Speicherverbrauchs durch den KV Cache bei der Verarbeitung großer visueller Eingaben in multimodalen großen Modellen (MLLMs) zu lösen, das den Durchsatz begrenzt, schlagen Forscher das CalibQuant-Schema vor. Dieses Schema realisiert eine extreme 1-Bit KV Cache Quantisierung und kombiniert Techniken des Post-Scaling und der Kalibrierung, die speziell für die Redundanzeigenschaften des visuellen KV Cache entwickelt wurden. Post-Scaling optimiert die Reihenfolge der Dequantisierungsberechnungen zur Effizienzsteigerung, während die Kalibrierung die Attention Scores anpasst, um die durch die 1-Bit-Quantisierung verursachte Verzerrung durch Extremwerte zu mildern. Experimente zeigen, dass CalibQuant den Speicher- und Rechenaufwand bei Modellen wie LLaVA und InternVL-2.5 signifikant reduzieren kann, was zu einer bis zu 10-fachen Durchsatzsteigerung führt, während die Modellleistung nahezu unbeeinträchtigt bleibt. Die Methode ist Plug-and-Play-fähig und erfordert keine Änderungen am Originalmodell. (Quelle: PaperWeekly)
CVPR 2025 | SeqAfford: Realisierung von sequenziellem 3D Affordance Reasoning: Um das Problem zu lösen, dass aktuelle KI Schwierigkeiten hat, komplexe Anweisungen zu verstehen und auszuführen, die mehrere Objekte und Schritte umfassen, schlagen Forscher das SeqAfford-Framework vor. Dieses Framework kombiniert erstmals 3D-Vision mit multimodalen großen Sprachmodellen (MLLMs) für sequenzielles 3D Affordance Reasoning. Durch die Erstellung des ersten Sequential 3D Affordance Datensatzes mit über 180.000 Paaren von Anweisungen und Punktwolkendaten für das Fine-Tuning und die Einführung eines auf Segmentierungsvokabular (
GitHub hostet Sammlung von MCP-Server-Ressourcen: Ein GitHub-Repository namens awesome-mcp-servers sammelt und stellt über 300 MCP (Model Capability Protocol)-Server für AI Agents als Open Source zur Verfügung. Diese Server umfassen produktionsreife und experimentelle Projekte und bieten Entwicklern eine Fülle von Tools und Schnittstellen, um die Interaktion von AI Agents mit externen Diensten und Datenquellen zu erleichtern und so die Entwicklung des Agent-Ökosystems weiter voranzutreiben. (Quelle: Reddit r/ClaudeAI)

Professor Fei Liu von der Emory University sucht Doktoranden und Praktikanten für Large Models/NLP/GenAI: Fei Liu, Associate Professor am Department of Computer Science der Emory University, sucht vollfinanzierte Doktoranden für den Herbst 2025. Forschungsschwerpunkte sind die Fähigkeiten von Large Language Models (LLMs) als Agenten in Bezug auf Reasoning, Planung und Entscheidungsfindung sowie KI-Anwendungen in Bildung, Gesundheitswesen usw. Interessierte Studenten sind auch willkommen, sich für Remote-Praktika oder Kooperationen zu bewerben. Bewerber sollten einen Hintergrund in Informatik oder verwandten Fächern haben, über ausgezeichnete Programmierkenntnisse verfügen, Forschungserfahrung oder starke mathematische Grundlagen sind von Vorteil. (Quelle: AI求职)
Leitfaden zur Erstellung von AI Agents veröffentlicht: SuccessTech Services hat einen schrittweisen Leitfaden zur Erstellung von Large Language Model (LLM) Agents veröffentlicht. Der Leitfaden behandelt wahrscheinlich grundlegende Konzepte von Agents, Architekturentwurf, Tool-Auswahl, Entwicklungsprozesse sowie praktische Anwendungsfälle und bietet Entwicklern, die autonome KI-Anwendungen entwickeln möchten, eine Einführung. (Quelle: Reddit r/OpenWebUI)

HKUST veröffentlicht Code für Dream 7B, Fokus auf Diffusion-Modell-Reasoning: Das NLP-Team der Hong Kong University of Science and Technology (HKUST) hat das GitHub-Repository für sein zuvor veröffentlichtes Diffusion-Modell-Reasoning-Modell Dream 7B öffentlich zugänglich gemacht. Das Modell zielt darauf ab, LLMs das Verständnis und die Ausführung von Anweisungen im Zusammenhang mit Diffusion-Modellen zu ermöglichen. Die Veröffentlichung des Codes ermöglicht es Forschern, das Modell zu replizieren und weiter zu untersuchen. (Quelle: Reddit r/LocalLLaMA)

💼 Wirtschaft
Lingxin Qiaoshou erhält Seed-Finanzierung im dreistelligen Millionen-Yuan-Bereich zur Entwicklung der weltweit geschicktesten Roboterhand: Das Embodied Intelligence Unternehmen „Lingxin Qiaoshou“ hat eine Seed-Finanzierungsrunde von über 100 Millionen Yuan abgeschlossen, angeführt vom Sequoia Seed Fund. Das Unternehmen konzentriert sich auf die Plattform „geschickte Hand + Cloud-basiertes Gehirn“. Seine selbst entwickelte Linker Hand-Serie von geschickten Händen hat in der Industrieversion 25-30 Freiheitsgrade (DoF) und in der Forschungsversion bis zu 42 (weltweit höchster Wert, übertrifft die 24 der Shadow Hand und die 22 des Optimus), mit hochpräziser Wahrnehmung (Multisensorfusion) und Manipulationsfähigkeiten. Das Unternehmen verwendet zwei Strukturen (Gestänge und Seilzug) und hat die Massenproduktion erreicht, kombiniert mit einem Cloud-basierten Gehirn (trainiert auf dem umfangreichen DexSkill-Net-Datensatz) für Lernen und Steuerung. Die Produkte haben Vorteile bei Kosten (ca. 50.000 RMB, weit unter den 1,5 Millionen der Shadow Hand) und Haltbarkeit, wurden bereits von Top-Universitäten wie Peking University und Tsinghua University erworben und finden Anwendung in Medizin, Industrie usw. (Quelle: 36氪)

Bericht: Google zahlt KI-Mitarbeitern hohe Gehälter während „Gardening Leave“, um Wechsel zur Konkurrenz zu verhindern: Berichten zufolge zahlt Google einigen ausscheidenden Mitarbeitern bis zu einem Jahr lang hohe Gehälter (möglicherweise Hunderttausende von Dollar), um zu verhindern, dass wichtige KI-Talente zu Konkurrenten wie OpenAI wechseln. Bedingung ist, dass sie während dieser Zeit keinem Konkurrenzunternehmen beitreten. Diese Praxis, bekannt als „Gardening Leave“ (Freistellung), ist zwar in Branchen wie dem Finanzwesen üblich, aber im Technologiesektor, insbesondere für KI-Forscher und Ingenieure unterhalb der Führungsebene, eher selten. Dies spiegelt den extremen Mangel an Top-KI-Talenten und den intensiven Wettbewerb um Talente zwischen den Technologiegiganten wider. (Quelle: Reddit r/ArtificialInteligence)

Shopify CEO betont Notwendigkeit für Mitarbeiter, KI effektiv zu nutzen: Shopify CEO Tobias Lütke fordert seine Mitarbeiter auf, zuerst darüber nachzudenken, wie KI-Tools zur Effizienzsteigerung und Problemlösung eingesetzt werden können, bevor sie eine Aufstockung ihrer Teams in Betracht ziehen. Er sieht KI als entscheidenden Hebel zur Produktivitätssteigerung und erwartet von den Mitarbeitern, dass sie aktiv lernen und KI in ihre täglichen Arbeitsabläufe integrieren. Diese Aussage spiegelt die hohe Bedeutung wider, die Unternehmen der Effizienzsteigerung durch KI beimessen, sowie die Erwartung an die Mitarbeiter, sich an die neuen Anforderungen des KI-Zeitalters anzupassen. (Quelle: bushaicave.com)
36Kr startet Ausschreibung für den „2025 AI Partner Innovation Award“: Um innovative KI-Produkte, -Lösungen und -Unternehmen zu entdecken und zu fördern und die Anwendung von KI in verschiedenen Branchen voranzutreiben, hat 36Kr den „2025 AI Partner Innovation Award“ ins Leben gerufen. Die Ausschreibung umfasst drei Hauptkategorien für Nicht-Anwendungssoftware-Produkte/-Lösungen: Allgemeine Innovation (Büro, Unternehmensdienstleistungen, Datenanalyse usw.), Brancheninnovation (Finanzen, Medizin, Bildung, Industrie usw.) und Terminalinnovation (intelligente Hardware, Automobil, Robotik usw.). Die Bewertung erfolgt anhand von vier Dimensionen: technologische Innovation, Anwendungseffekt, Benutzererfahrung und sozialer Wert, durch eine Expertenjury. Die Anmeldefrist läuft vom 13. März bis 7. April, die Ergebnisse werden am 18. April bekannt gegeben. (Quelle: 36氪)

Erster nationaler Standard für Private Deployment von KI-Großmodellen in China wird erarbeitet: Angesichts der Probleme, mit denen Unternehmen bei der privaten Bereitstellung (Private Deployment) von KI-Großmodellen konfrontiert sind, wie technologische Fehlanpassungen, unstandardisierte Prozesse und fehlende Bewertungssysteme, hat das Zhihe Standard Center gemeinsam mit dem Dritten Forschungsinstitut des Ministeriums für öffentliche Sicherheit und anderen Einheiten die Erarbeitung des Gruppenstandards „Leitfaden für die technische Implementierung und Bewertung der privaten Bereitstellung von KI-Großmodellen“ initiiert. Dieser Standard zielt darauf ab, den gesamten Prozess von der Modellauswahl, Ressourcenplanung, Bereitstellungsimplementierung, Qualitätsbewertung bis hin zur kontinuierlichen Optimierung abzudecken und Technologie, Sicherheit, Bewertung und Fallstudien zu integrieren. Er wird gemeinsam von Modellanwendern, Technologiedienstleistern und Qualitätsbewertern entwickelt. Der Standard richtet sich an Unternehmen für KI-Großmodelle, Technologiedienstleister, Hardwareanbieter, Cloud-Computing-Unternehmen, Sicherheitsdienstleister, Datendienstleister, Branchenanwendungsunternehmen, Test- und Bewertungsinstitute, Compliance- und Rechtsinstitute sowie Organisationen für nachhaltige Entwicklung zur Mitwirkung an der Erarbeitung. (Quelle: 智合标准化建设)
🌟 Community
KI-generierte Inhalte lösen Bedenken hinsichtlich „Halluzinationen“ und Informationszuverlässigkeit aus: Mehrere Nutzer und Medien berichten, dass große Sprachmodelle, einschließlich DeepSeek, dazu neigen, „mit ernster Miene Unsinn zu erzählen“, ein Phänomen, das als KI-Halluzination bekannt ist. KI kann nicht existierende Fakten erfinden, falsche Quellen zitieren (z. B. Gedichtzitate, Gesetzesartikel, Informationen zu Kulturgütern) oder sogar Daten fälschen (z. B. „Sterblichkeitsrate der 80er-Generation“). Dieses Phänomen resultiert aus veralteten, fehlerhaften oder voreingenommenen Trainingsdaten, Wissenslücken des Modells und fehlender Echtzeit-Verifizierungsfähigkeit. Nutzer müssen die Genauigkeit von KI-generierten Inhalten kritisch prüfen, Kreuzvergleiche durchführen und manuelle Überprüfungen vornehmen, insbesondere in akademischen, beruflichen und anderen ernsthaften Kontexten. Übermäßiges Vertrauen kann zur Verbreitung von Fehlinformationen führen und die Herausforderungen des „postfaktischen Zeitalters“ verschärfen. Der Vectara HHEM Halluzinationstest zeigt ebenfalls eine hohe Halluzinationsrate für DeepSeek-R1. (Quelle: 锌刻度)
KI-Kunstgenerierung sorgt erneut für Kontroversen: Ausgehend vom Ghibli-Stil-Hype: Die neue Bildfunktion von OpenAIs GPT, die Bilder im Stil von Studio Ghibli generiert, erfreut sich großer Beliebtheit. Sogar CEO Sam Altman änderte sein Profilbild in diesen Stil, was zu einem Anstieg der ChatGPT-Downloads und -Einnahmen führte. Dies hat jedoch erneut Debatten über Ethik und Urheberrecht bei KI-generierter Kunst ausgelöst. Hayao Miyazaki selbst hat sich klar gegen maschinell generierte Bilder ausgesprochen. Hollywood-Insider (wie Alex Hirsch, Schöpfer von „Gravity Falls“, und Zelda Williams, Tochter von Robin Williams) äußerten starke Unzufriedenheit und betrachten dies als Diebstahl künstlerischer Leistungen, dem die Seele fehle. Altman entgegnete, dies sei eine „Demokratisierung der Kreativität“ und ein großer Sieg für die Gesellschaft. Der Artikel argumentiert, dass KI zwar Stile imitieren kann, aber die komplexen Erzählungen, ästhetischen Systeme und humanistischen Anliegen in Ghibli-Werken schwer zu replizieren sind. Die meisten KI-generierten Inhalte werden wahrscheinlich keine Klassiker werden, aber einige Mensch-Maschine-Kollaborationen oder Hilfswerkzeuge werden erfolgreich sein. (Quelle: APPSO, Reddit r/artificial)

Standpunkt: Menschliche kognitive Struktur ist die Kernkompetenz im KI-Zeitalter: Der Artikel widerspricht der Ansicht, dass die Verbreitung von KI-Tools den Wert von Kreativen mindert. Er argumentiert, dass Ausdruck und Schöpfung an sich menschliche Bedürfnisse und „Konsumverhalten“ sind, deren Wert im Prozess und nicht nur im Ergebnis liegt. KI ist ein Werkzeug und kann die einzigartige Kognition und Emotion des Menschen nicht ersetzen. Die über Jahrmillionen entwickelte „kognitive Struktur“ des menschlichen Gehirns ist entscheidend, und auch die KI-Entwicklung verschiebt sich von datengesteuert zu kognitiv gesteuert (Nachahmung menschlicher kognitiver Prozesse). Daher liegt die zukünftige Kernkompetenz nicht im „Erledigen von Arbeit“, sondern in der „kognitiven Struktur“ oder dem „Ankerpunkt“ für die Interaktion mit KI – d.h. einzigartige Perspektiven, tiefgreifende Erfahrungen und authentische Verbindungen zu anderen. Kreative sollten sich darauf konzentrieren, ihre einzigartigen Aspekte zu verfeinern, um in der Informationsflut zu stabilen Bezugspunkten zu werden, die sich selbst und anderen Orientierung und Wert geben und der potenziellen „Entropiezunahme“ durch KI entgegenwirken. (Quelle: 王智远)
Standpunkt: KI-Anwendungen weisen neue Barrieren auf, die auf Beziehungen und Vertrauen basieren: Als Reaktion auf die Aussage von Zhu Xiaohu, dass „KI-Anwendungen keine Barrieren haben“, argumentiert der Artikel dagegen und stellt fest, dass sich die Anwendungsbarrieren im KI-Zeitalter von traditionellen technologischen Barrieren zu neuen Barrieren verschoben haben, die auf Beziehungen und Vertrauen basieren. KI-Anwendungen streben nicht mehr nur nach Nutzerzahlen, sondern können durch personalisierte Erlebnisse in vertikalen Märkten profitabel sein. Selbst „Wrapper“-Anwendungen können durch den Aufbau tiefer Verbindungen zu Nutzern (KI lernt den Nutzer mit der Zeit besser kennen), durch das Vertrauensband zwischen Creator-IP und Nutzern sowie durch kontinuierliche Optimierung mittels geschlossener Datenkreisläufe (Branchendaten + persönliche Daten für das Training) einen Burggraben bauen. Unternehmern wird geraten, sich auf Nischenmärkte zu konzentrieren, einzigartige Erlebnisse zu schaffen, geschlossene Datenkreisläufe aufzubauen und emotionale Verbindungen herzustellen. (Quelle: 周知)
Betrug mit KI-„Schnellkursen“ zielt auf Altersvorsorge von Senioren ab: Online-Kurse, die unter dem Motto „Schnell mit KI Geld verdienen“, „Monatlich über 10.000 verdienen“ werben, werden über Kurzvideo-Plattformen gezielt an ältere Menschen ausgespielt. Diese Kurse locken oft mit kostenlosem Unterricht, nutzen digitale Avatare, gefälschte „Experten“-Identitäten und schüren Ängste vor Altersarmut oder schaffen Mythen vom schnellen Reichtum, um Senioren in Gruppen zu locken. Anschließend werden durch Gehirnwäsche-Marketing (z. B. Zeigen von Einkommens-Screenshots, Erzeugen von Verknappungsgefühlen) ältere Menschen zur Zahlung hoher Kursgebühren (mehrere Tausend bis Zehntausende Yuan) verleitet. Die Kursinhalte bestehen oft aus grundlegendem Wissen über Social-Media-Management, und die versprochenen KI-Fähigkeiten, Auftragsvermittlung gegen Rückerstattung und Einzelcoaching sind meist falsche Versprechungen. Der Kundenservice fehlt, und Rückerstattungen sind schwierig. Viele junge Leute teilen bereits in sozialen Medien Erfahrungen von Familienmitgliedern, die fast oder tatsächlich betrogen wurden, und rufen zur Vorsicht vor solchen Betrügereien auf. (Quelle: 豹变)

Karpathy: LLMs revolutionieren traditionelle Technologiediffusionspfade und stärken Individuen: Andrej Karpathy schreibt, dass das Diffusionsmuster von Large Language Models (LLMs) sich grundlegend von dem historischer transformativer Technologien unterscheidet (typischerweise von oben nach unten: Regierung -> Unternehmen -> Individuen). LLMs wurden fast über Nacht kostengünstig (sogar kostenlos) und schnell auf den Geräten jedes Einzelnen verfügbar gemacht, was normalen Individuen unverhältnismäßig große Vorteile bringt, während die Auswirkungen auf Unternehmen und Regierungen relativ verzögert sind. Dies liegt daran, dass LLMs quasi Expertenwissen in einem breiten Spektrum von Bereichen bereitstellen können und so die Wissenslücken von Einzelpersonen schließen. Im Gegensatz dazu profitieren Organisationen aufgrund ihrer inhärenten Vorteile, die nicht mit den Fähigkeiten von LLMs übereinstimmen, der hohen Komplexität von Problemen, interner Trägheit usw. in geringerem Maße. Er argumentiert, dass die Zukunft der KI derzeit erstaunlich ausgeglichen verteilt ist, eine echte „Macht des Volkes“. Wenn jedoch in Zukunft Geld signifikant bessere KI kaufen kann, könnte sich das Kräfteverhältnis wieder ändern. (Quelle: op7418)
Ablehnung eines 18-jährigen CEO einer KI-App durch mehrere Top-Universitäten löst Debatte aus: Der 18-jährige Zach Yadegari gründete während seiner Highschool-Zeit die KI-Kalorien-Tracking-App Cal AI mit, die über 3 Millionen Downloads verzeichnete und einen Jahresumsatz von mehreren Millionen Dollar erzielte. Trotz eines 4.0 GPA, hoher ACT-Punktzahl und beeindruckender unternehmerischer Erfahrung wurde er bei der Bewerbung an 18 Top-Universitäten von 15 abgelehnt, darunter Harvard, Stanford und MIT. Der Fall löste in den sozialen Medien breite Aufmerksamkeit und Diskussionen aus. Yadegaris veröffentlichter Zulassungsessay gibt offen zu, dass er ursprünglich nicht vorhatte zu studieren, seine Meinung aber änderte, nachdem er den Wert des Universitätslebens erkannt hatte. Die Gründe für die Ablehnung sind Gegenstand von Spekulationen: Einige halten den Essay für „arrogant“ oder deuten auf ein hohes Risiko eines Studienabbruchs hin, was die von Eliteuniversitäten geschätzte Abschlussquote beeinträchtigt; andere kritisieren Probleme im Zulassungssystem der Universitäten oder vermuten Diskriminierung asiatischstämmiger Bewerber (analog zum Fall Stanley Zhong). Yadegari selbst möchte als aufrichtig wahrgenommen werden. (Quelle: 36氪, AI前线)
Community-Diskussion: Ist KI ein Segen oder ein Fluch?: In der Reddit-Community wird über die Vor- und Nachteile der KI-Technologie diskutiert. Ein Nutzer betrachtet KI als Segen der Technologie, der es ermöglicht, kreative Ideen schnell umzusetzen (z. B. Bilder spezifischer Szenen zu generieren), und versteht nicht, warum manche Menschen (insbesondere Nicht-Kreative) ihr feindselig gegenüberstehen. Diese Ansicht betont den Wert von KI bei der Erfüllung individueller, sofortiger und kostengünstiger kreativer Bedürfnisse. Dies spiegelt die positive Sichtweise in der Community auf die Stärkung der individuellen Kreativität durch KI-Tools wider, zeigt aber auch die allgemeine Kontroverse und die unterschiedlichen Haltungen gegenüber der KI-Technologie in der Gesellschaft. (Quelle: Reddit r/artificial)
Community-Diskussion: Wird das MCP-Protokoll zum „Internet“ für AI Agents?: Mit der Entwicklung des MCP (Model Capability Protocol) beginnt die Community, dessen Potenzial zu diskutieren. Einige argumentieren, dass MCP durch die Bereitstellung standardisierter Schnittstellen für die Interaktion von LLMs mit externen Tools und Datenquellen zur grundlegenden Infrastruktur werden könnte, die verschiedene AI Agents und Dienste verbindet, ähnlich wie das Internet verschiedene Computer und Websites verbindet. Dies deutet darauf hin, dass das zukünftige Ökosystem der AI Agents auf MCP basieren könnte, um Interoperabilität und Zusammenarbeit zu ermöglichen. (Quelle: Reddit r/ClaudeAI)

💡 Sonstiges
Microsoft-Trio spricht mit AI Copilot über 50 Jahre und die Zukunft: Anlässlich des 50-jährigen Jubiläums von Microsoft führten die drei CEO-Generationen Bill Gates, Steve Ballmer und Satya Nadella ein Gespräch mit dem KI-Assistenten Copilot. Gates blickte auf frühe Vorhersagen über den Wert von Software und sinkende Computerkosten zurück und reflektierte, dass er die Beziehungen zur Regierung früher hätte angehen sollen. Ballmer und Nadella betonten beide die Bedeutung von KI. Ballmer meinte, man solle das Geschäft um Kern-KI-Technologien vertiefen, während Nadella voraussagte, dass KI zu einem allgegenwärtigen „Fast Moving Consumer Good“-Intelligenzwerkzeug werden wird. Im Gespräch „beschwerte“ sich Copilot auch humorvoll über die drei Größen, etwa dass Gates‘ „nachdenkliches Gesicht“ die KI zum „Bluescreen“ bringen könnte. Das Gespräch zeigte die Reflexion der Microsoft-Führung über die Geschichte und den Konsens über eine von KI getriebene Zukunft. (Quelle: 腾讯科技)

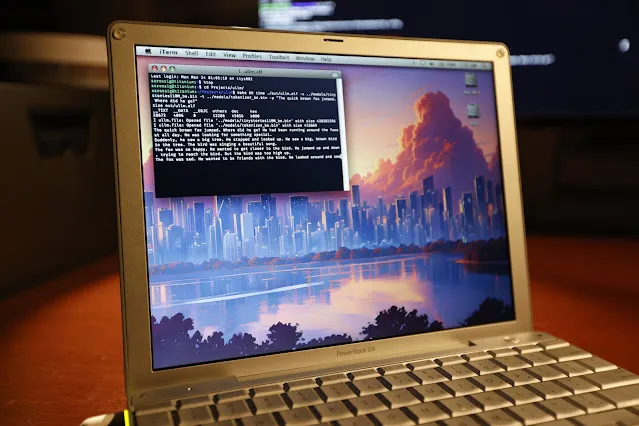
LLM-Inferenz erfolgreich auf 20 Jahre altem PowerBook G4 ausgeführt: Der Softwareingenieur Andrew Rossignol hat erfolgreich Inferenzaufgaben des Llama 2 Large Models von Meta (TinyStories 110M Version) auf einem 20 Jahre alten Apple PowerBook G4 Laptop (1,5 GHz PowerPC G4 Prozessor, 1 GB RAM) ausgeführt. Er portierte das Open-Source-Projekt llama2.c, nahm Anpassungen für die PowerPC-Architektur vor (Big-Endian, Speicherausrichtung) und nutzte die AltiVec-Vektorerweiterung (Fused Multiply-Add), um die Inferenzgeschwindigkeit um etwa 10 % zu steigern (von 0,77 Token/s auf 0,88 Token/s). Obwohl die Geschwindigkeit nur etwa 1/8 der moderner CPUs beträgt, zeigt dies, dass die Ausführung moderner KI-Modelle selbst auf sehr alter und ressourcenbeschränkter Hardware möglich ist. (Quelle: 36氪, AI前线)
Diskussion: Warum brauchen wir World Models?: Der Artikel untersucht die Notwendigkeit von World Models und argumentiert, dass sie entscheidend sind, um die Grenzen aktueller Large Language Models (LLMs) zu überwinden (z. B. fehlendes Verständnis der physischen Welt, mangelndes Langzeitgedächtnis, eingeschränkte Reasoning- und Planungsfähigkeiten). World Models zielen darauf ab, dass KI wie Menschen interne Simulationen ihrer Umgebung aufbaut, physikalische Gesetze (wie Schwerkraft, Kollision) und kausale Zusammenhänge versteht, um Vorhersagen zu treffen und Entscheidungen zu fällen. Der Artikel zeichnet die Entwicklung von World Models nach, vom kognitionswissenschaftlichen Konzept über die Computermodellierung (Kombination von RL/DL, z. B. DeepMinds „World Models“-Paper) bis hin zum Zeitalter der großen Modelle (Kombination mit Transformer und Multimodalität, z. B. Genie, PaLM-E). Die Kernvorteile von World Models liegen in der kausalen Vorhersage- und kontrafaktischen Reasoning-Fähigkeit sowie der Generalisierungsfähigkeit über Aufgaben hinweg, was sich grundlegend von der auf Wahrscheinlichkeiten basierenden Vorhersage von LLMs unterscheidet, die auf der Korrelation großer Textmengen beruht. Obwohl World Models vielversprechend sind, stehen sie weiterhin vor Herausforderungen in Bezug auf Rechenleistung, Generalisierungsfähigkeit und Daten. (Quelle: 脑极体)

Neuer Durchbruch bei der KI-Gefahrenerkennung: Holmes-VAU ermöglicht mehrstufiges Verständnis von Anomalien in langen Videos: Angesichts der Schwächen bestehender Methoden zum Verständnis von Videoanomalien (VAU) bei der Verarbeitung langer Videos und komplexer zeitlicher Anomalien schlagen die Huazhong University of Science and Technology und andere Institutionen das Holmes-VAU-Modell und den HIVAU-70k-Datensatz vor. Dieser Datensatz enthält über 70.000 Anweisungsdaten auf mehreren Zeitskalen (Video-, Ereignis-, Clip-Ebene), die mit einer halbautomatischen Daten-Engine erstellt wurden, um das umfassende Verständnis von Anomalien in langen und kurzen Videos durch das Modell zu fördern. Gleichzeitig kann der vorgeschlagene Anomaly-focused Temporal Sampler (ATS) basierend auf Anomalie-Scores dynamisch Schlüsselbilder spärlich abtasten, wodurch redundante Informationen effektiv reduziert und die Genauigkeit und Effizienz der Analyse von Anomalien in langen Videos verbessert werden. Experimente zeigen, dass Holmes-VAU bei Aufgaben zum Verständnis von Videoanomalien auf verschiedenen zeitlichen Granularitätsebenen signifikant besser abschneidet als allgemeine multimodale große Modelle. (Quelle: 量子位)
KI und Nachhaltigkeit: CO2-Fußabdruck rückt in den Fokus: Mit dem exponentiellen Wachstum der Größe von KI-Modellen und des Rechenaufwands für das Training werden deren Energieverbrauch und CO2-Emissionen zu einem immer größeren Problem. Der Stanford AI Index Report stellt fest, dass trotz verbesserter Hardware-Energieeffizienz der Gesamtenergieverbrauch weiter steigt. Beispielsweise wird geschätzt, dass das Training von Metas Llama 3.1-Modell fast 9000 Tonnen CO2 verursacht hat. Obwohl Modelle wie DeepSeek Fortschritte bei der Energieeffizienz erzielt haben, bleibt der gesamte CO2-Fußabdruck der KI-Branche eine ernste Herausforderung. Dies veranlasst KI-Unternehmen, nach kohlenstofffreien Energielösungen wie Kernenergie zu suchen, und löst Diskussionen über die Nachhaltigkeit der KI-Entwicklung aus. (Quelle: Ronald_vanLoon, 机器之心)
