
كلمات مفتاحية:نموذج الذكاء الاصطناعي, تقنية التعرف الضوئي على الحروف (OCR), البنية التحتية للذكاء الاصطناعي, نماذج اللغة الكبيرة (LLM), وكيل الذكاء الاصطناعي, النماذج متعددة الوسائط, تحسين استهلاك الطاقة في الذكاء الاصطناعي, النظام البيئي مفتوح المصدر للذكاء الاصطناعي, نموذج DeepSeek للتعرف الضوئي على الحروف, الاستدلال متعدد الوسائط Gemini 3, نموذج العالم Emu3.5, هندسة الانتباه المختلط الخطي Kimi, تقنية طي الذاكرة AgentFold
مختارات رئيس تحرير قسم الذكاء الاصطناعي
🔥 في دائرة الضوء
DeepSeek OCR model: اختراق جديد في ذاكرة الذكاء الاصطناعي وتحسين استهلاك الطاقة : أطلقت DeepSeek نموذج OCR، يتمثل ابتكارها الأساسي في طريقة معالجة المعلومات وتخزين الذاكرة. يضغط النموذج معلومات النص إلى شكل صورة، مما يقلل بشكل كبير من موارد الحوسبة المطلوبة للتشغيل، ومن المتوقع أن يخفف من البصمة الكربونية المتزايدة للذكاء الاصطناعي. تحاكي هذه الطريقة الذاكرة البشرية من خلال الضغط الهرمي، حيث تقوم بتعتيم المحتوى غير المهم لتوفير المساحة، مع الحفاظ على كفاءة عالية. وقد أثار هذا البحث اهتمام خبراء مثل Andrej Karpathy، الذين يرون أن الصور قد تكون أكثر ملاءمة كمدخلات لـ LLM من النصوص، مما يفتح آفاقًا جديدة لذاكرة الذكاء الاصطناعي وتطبيقات الوكلاء. (المصدر: MIT Technology Review)

عمالقة التكنولوجيا يواصلون استثماراتهم الضخمة في البنية التحتية للذكاء الاصطناعي : أعلنت عمالقة التكنولوجيا مثل Microsoft و Meta و Google في أحدث تقاريرها المالية أنها ستواصل زيادة الإنفاق بشكل كبير على البنية التحتية للذكاء الاصطناعي. تتوقع Meta أن يصل إنفاقها الرأسمالي هذا العام إلى 70-72 مليار دولار، وتخطط لزيادة ذلك العام المقبل؛ تجاوزت إيرادات Microsoft Intelligent Cloud 30 مليار دولار لأول مرة، ونمت خدمات Azure والخدمات السحابية الأخرى بنسبة 40%، ومن المتوقع أن تزيد قدرة الذكاء الاصطناعي بنسبة 80%. أكد Sundar Pichai، الرئيس التنفيذي لشركة Google، أن نهج الذكاء الاصطناعي الشامل يوفر زخمًا قويًا، وأعلن عن إطلاق Gemini 3 قريبًا. تعكس هذه الاستثمارات التوقعات المتفائلة للعمالقة بشأن اختراقات الذكاء الاصطناعي المستقبلية وتصميمهم على اغتنام فرص السوق. (المصدر: Wired, Reddit r/artificial)

Anthropic تكتشف أن نماذج LLM تمتلك “قدرة محدودة على الاستبطان” : أظهرت أحدث أبحاث Anthropic أن نماذج اللغة الكبيرة (LLMs) مثل Claude تمتلك “وعيًا استبطانيًا حقيقيًا”، على الرغم من أن هذه القدرة لا تزال محدودة حاليًا. بحثت الدراسة فيما إذا كانت LLM تستطيع التعرف على أفكارها الداخلية، أو أنها تولد إجابات منطقية بناءً على الأسئلة فقط. يشير هذا الاكتشاف إلى أن LLMs قد تمتلك مستوى أعمق من الوعي الذاتي مما كان متوقعًا، وهو أمر ذو أهمية كبيرة لفهم وتطوير أنظمة ذكاء اصطناعي أكثر ذكاءً ووعيًا. (المصدر: Anthropic, Reddit r/artificial)

Extropic تطلق جهاز حوسبة حراري جديد TSU، وتدعي تحقيق اختراق في استهلاك طاقة الذكاء الاصطناعي : أطلقت شركة Extropic جهاز حوسبة جديدًا تمامًا، TSU (Thermodynamic Sampling Unit)، يتمثل جوهره في “البت الاحتمالي” (P-bit)، الذي يمكن أن يومض بين 0 و 1 باحتمالية قابلة للبرمجة، ويهدف إلى تحقيق زيادة في كفاءة استهلاك طاقة الذكاء الاصطناعي بمقدار 10,000 مرة. أطلقت الشركة شريحة X0، ومجموعة اختبار سطح المكتب XTR0، ووحدة TSU التجارية Z1، كما أتاحت مكتبة برامج Thermol مفتوحة المصدر لمحاكاة TSU بواسطة GPU. على الرغم من أن تعريف معيار تحسين الكفاءة الخاص بها قد أثيرت حوله تساؤلات، إلا أن هذا الاتجاه يهدف إلى سد الفجوة الهائلة في قوة حوسبة الذكاء الاصطناعي والطاقة، مما قد يحدث تحولًا نموذجيًا في حوسبة الذكاء الاصطناعي. (المصدر: TheRundownAI, pmddomingos, op7418)

🎯 التطورات
Google تستعرض Gemini 3 القادم، وتعزز اتجاه تخصص عائلة نماذج الذكاء الاصطناعي : أعلن Sundar Pichai، الرئيس التنفيذي لشركة Google، خلال مكالمة الأرباح، أن الإصدار الجديد من النموذج الرائد Gemini 3 سيُطلق في وقت لاحق من هذا العام. وأكد أن عائلة نماذج الذكاء الاصطناعي من Google تتجه نحو التخصص، حيث يركز Gemini على الاستدلال متعدد الوسائط، و Veo لتوليد الفيديو، و Genie للوكلاء التفاعليين، بينما يستهدف Nano الذكاء على الأجهزة الطرفية. تشير هذه الاستراتيجية إلى أن Google تنتقل من نموذج عام واحد إلى بنية نظام مترابطة ومحسّنة لسيناريوهات مختلفة، لتعزيز الموثوقية وتقليل زمن الاستجابة ودعم النشر على الحافة. (المصدر: Reddit r/ArtificialInteligence, shlomifruchter)
Sora 2 تضيف ميزات تخصيص الشخصيات ودمج الفيديو، وتدعم إنشاء مقاطع فيديو طويلة متواصلة : أضافت Sora 2 مؤخرًا العديد من الميزات المهمة، بما في ذلك دعم إنشاء شخصيات أخرى (لا يمكن تحميل صور حقيقية، ولكن يمكن إنشاؤها من شخصيات فيديو موجودة)، ويمكن للمستخدمين استخدام هذه الميزة لضمان اتساق الشخصيات، وهو أمر بالغ الأهمية لإنشاء مقاطع فيديو طويلة متواصلة. بالإضافة إلى ذلك، تدعم صفحة المسودات دمج مقاطع فيديو متعددة قبل النشر، وتمت إضافة لوحة صدارة إلى صفحة البحث، تعرض عروضًا حية لأشخاص حقيقيين ومبدعي محتوى معاد إنتاجه. تعزز هذه التحديثات بشكل كبير مرونة Sora 2 الإبداعية وتفاعلها مع المستخدمين، ومن المتوقع أن تزيد بشكل كبير من عدد مستخدميها النشطين يوميًا. (المصدر: op7418, billpeeb, op7418)
BAAI تطلق نموذج العالم متعدد الوسائط مفتوح المصدر Emu3.5، بأداء يتفوق على Gemini-2.5-Flash-Image : أطلق معهد بكين للذكاء الاصطناعي (BAAI) نموذج العالم متعدد الوسائط مفتوح المصدر Emu3.5، بـ 34 مليار معلمة. يعتمد النموذج على إطار عمل Decoder-only Transformer، ويمكنه معالجة مهام الصور والنصوص والفيديو في وقت واحد، ويوحدها في مهمة التنبؤ بالحالة التالية. تم تدريب Emu3.5 مسبقًا على كميات هائلة من بيانات الفيديو عبر الإنترنت، ويمتلك القدرة على فهم الاستمرارية الزمانية والمكانية والعلاقات السببية، ويظهر أداءً ممتازًا في السرد البصري، والتوجيه البصري، وتحرير الصور، واستكشاف العالم، والعمليات المجسدة، مع تحسن ملحوظ بشكل خاص في الواقعية الفيزيائية، حيث يضاهي أداء Gemini-2.5-Flash-Image (Nano Banana) بل يتفوق عليه. (المصدر: 36氪)

Moonshot AI تطلق نموذج Kimi Linear، باستخدام بنية الانتباه الخطي الهجين : أطلقت Moonshot AI نموذج Kimi Linear، وهو نموذج بـ 48 مليار معلمة يعتمد على بنية الانتباه الخطي الهجين (KDA)، مع 3 مليارات معلمة نشطة، ويدعم طول سياق يصل إلى 1 مليون. من خلال تحسين Gated DeltaNet، عزز Kimi Linear بشكل كبير أداء مهام السياق الطويل وكفاءة الأجهزة، مما قلل متطلبات ذاكرة التخزين المؤقت KV بنسبة تصل إلى 75%، وزاد من إنتاجية فك التشفير بمقدار 6 أضعاف. أظهر النموذج أداءً متميزًا في العديد من الاختبارات المعيارية، متجاوزًا نماذج الانتباه الكامل التقليدية، وتم إطلاق نسختين منه كمصدر مفتوح على Hugging Face. (المصدر: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, bigeagle_xd)

نموذج MiniMax M2 يلتزم ببنية الانتباه الكامل، ويؤكد على التحديات في النشر الإنتاجي : شرح Haohai Sun، رئيس فريق التدريب المسبق لـ MiniMax M2، سبب استمرار نموذج M2 في استخدام بنية الانتباه الكامل (Full Attention) بدلاً من الانتباه الخطي أو المتناثر. وأشار إلى أنه على الرغم من أن الانتباه الفعال يمكن أن يوفر قوة حوسبة نظريًا، إلا أنه في الأنظمة الصناعية الفعلية، لا يزال من الصعب تجاوز الانتباه الكامل من حيث الأداء والسرعة والسعر. تكمن العقبات الرئيسية في قيود أنظمة التقييم، والتكاليف التجريبية الباهظة لمهام الاستدلال المعقدة، وعدم نضج البنية التحتية. ترى MiniMax أنه عند السعي لتحقيق قدرات السياق الطويل، فإن جودة البيانات، ونظام التقييم، وتحسين البنية التحتية أكثر أهمية من مجرد تغيير بنية الانتباه. (المصدر: Reddit r/LocalLLaMA, ClementDelangue)
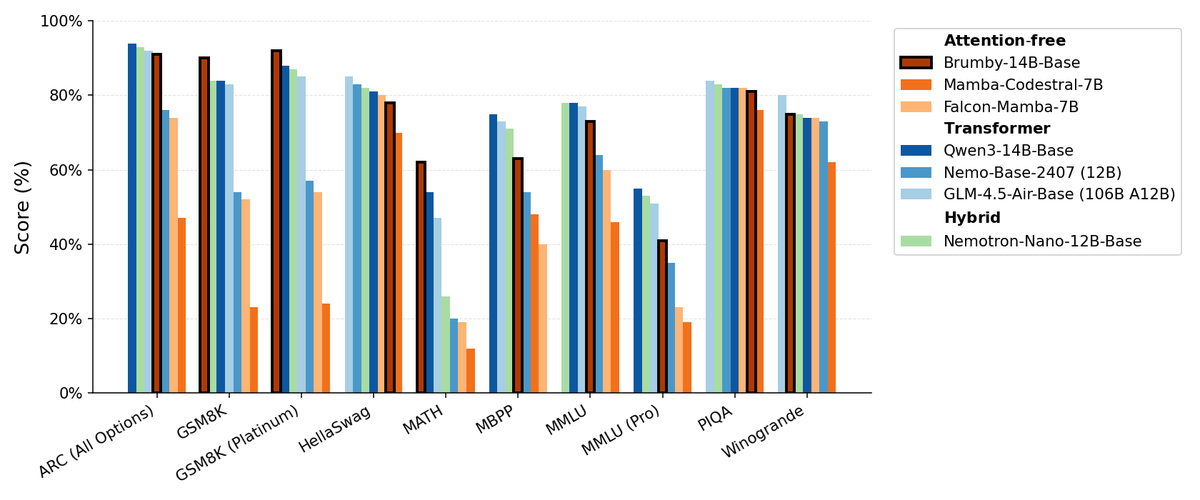
Manifest AI تطلق Brumby-14B-Base، وتستكشف نماذج أساسية بدون انتباه : أطلقت Manifest AI نموذج Brumby-14B-Base، مدعية أنه أقوى نموذج أساسي بدون انتباه حاليًا، تم تدريبه بـ 14 مليار معلمة بتكلفة 4000 دولار فقط. يتساوى أداء هذا النموذج مع نماذج Transformer والنماذج الهجينة ذات الحجم المماثل، مما يشير إلى أن عصر Transformer قد يتجه ببطء نحو نهايته. يوفر هذا التقدم إمكانيات جديدة لبنية نماذج الذكاء الاصطناعي، ويظهر إمكانات هائلة في تقليل تكاليف التدريب، مما يتحدى هيمنة آليات الانتباه التقليدية. (المصدر: ClementDelangue, teortaxesTex)
نماذج Nemotron الجديدة تعتمد على Qwen3 32B، لتحسين جودة استجابات LLM : أطلقت NVIDIA نموذج Qwen3-Nemotron-32B-RLBFF، وهو نموذج لغوي كبير تم ضبطه بدقة بناءً على Qwen/Qwen3-32B، ويهدف إلى تحسين جودة الاستجابات التي تولدها LLM في وضع التفكير الافتراضي. أظهر النموذج البحثي أداءً أفضل بكثير من Qwen3-32B الأصلي في اختبارات الأداء المعيارية مثل Arena Hard V2 و WildBench و MT Bench، وكان أداؤه مشابهًا لـ DeepSeek R1 و O3-mini، ولكن بتكلفة استدلال تقل عن 5%، مما يدل على تقدم في الأداء والكفاءة. (المصدر: Reddit r/LocalLLaMA)

بنية Mamba لا تزال تتمتع بميزة في معالجة السياق الطويل، لكن التدريب المتوازي محدود : تتفوق بنية Mamba في معالجة السياقات الطويلة (ملايين الرموز)، متجنبة مشكلة انفجار الذاكرة في Transformer. ومع ذلك، يكمن قيدها الرئيسي في صعوبة التوازي أثناء التدريب، مما يعيق انتشارها في التطبيقات الأكبر حجمًا. على الرغم من وجود العديد من الخلاطات الخطية والبنى الهجينة، لا يزال تحدي التدريب المتوازي لـ Mamba يمثل عقبة رئيسية أمام تطبيقاتها واسعة النطاق. (المصدر: Reddit r/MachineLearning)
NVIDIA تطلق ARC و Rubin و Omniverse DSX وغيرها، لتعزيز ريادتها في البنية التحتية للذكاء الاصطناعي : أصدرت NVIDIA سلسلة من الإعلانات الهامة في مؤتمر GTC، بما في ذلك NVIDIA ARC (كمبيوتر RAN الجوي) بالتعاون مع Nokia لتطوير 6G، والجيل الثالث من الكمبيوتر العملاق بحجم الرف Rubin، و Omniverse DSX (مخطط للتصميم التعاوني الافتراضي وتشغيل مصانع الذكاء الاصطناعي على مستوى الجيجابت)، و NVIDIA Drive Hyperion (بنية قياسية لسيارات الأجرة الروبوتية) بالتعاون مع Uber. تشير هذه الإطلاقات إلى أن NVIDIA تحول موقعها من صانع رقائق إلى مهندس للبنية التحتية الوطنية، مؤكدة على “صنع في أمريكا” وسباق الطاقة، لمواجهة تحديات عصر الذكاء الاصطناعي و 6G. (المصدر: TheTuringPost, TheTuringPost)

AgentFold: إدارة سياق تكيفية، لتعزيز كفاءة وكلاء الويب : قدمت AgentFold تقنية هندسة سياق جديدة، حيث تقوم بضغط أفكار الوكيل السابقة إلى ذاكرة منظمة من خلال “طي الذاكرة” (Memory Folding)، وتدير مساحة العمل المعرفية ديناميكيًا. حلت هذه الطريقة مشكلة التحميل الزائد للسياق في وكلاء ReAct التقليديين، وأظهرت أداءً متميزًا في اختبارات الأداء المعيارية مثل BrowseComp، متجاوزة النماذج الكبيرة مثل DeepSeek-V3.1-671B. يحقق AgentFold-30B أداءً تنافسيًا بعدد أقل من المعلمات، مما يعزز بشكل كبير كفاءة تطوير ونشر وكلاء الويب. (المصدر: omarsar0)

ReCode: توحيد التخطيط والعمل، لتحقيق تحكم ديناميكي في دقة اتخاذ القرار لوكلاء الذكاء الاصطناعي : ReCode (Recursive Code Generation) هي طريقة جديدة للضبط الدقيق الفعال للمعلمات (PEFT)، توحد تمثيل التخطيط والعمل لوكلاء الذكاء الاصطناعي من خلال اعتبار التخطيط عالي المستوى دالة تكرارية يمكن تحليلها إلى إجراءات دقيقة. تتطلب هذه الطريقة 0.02% فقط من معلمات التدريب لتحقيق أداء SOTA، وتقلل من استهلاك ذاكرة GPU. يمكّن ReCode الوكلاء من التكيف ديناميكيًا مع مستويات دقة مختلفة في اتخاذ القرار، وتعلم اتخاذ القرارات الهرمية، ويتفوق بشكل كبير على الطرق التقليدية في الكفاءة واستخدام البيانات، مما يمثل خطوة مهمة نحو تحقيق الاستدلال الشبيه بالبشر. (المصدر: dotey, ZhihuFrontier)

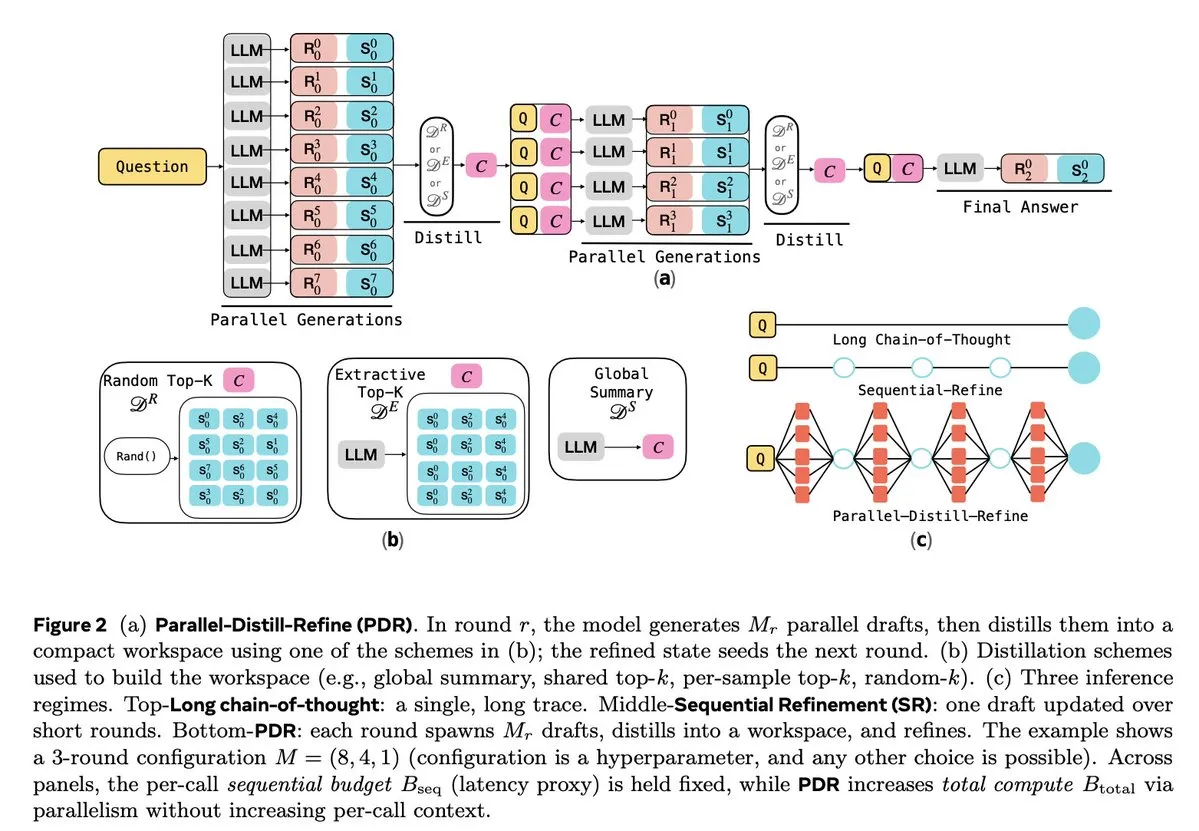
تحسين استدلال LLM والتعلم المعزز : تركز العديد من الدراسات على تحسين كفاءة وموثوقية استدلال LLM. يقلل Parallel-Distill-Refine (PDR) من تكلفة وتأخير مهام الاستدلال المعقدة من خلال التوليد الموازي وتكرير المسودات. يقدم Flawed-Aware Policy Optimization (FAPO) آلية مكافأة وعقاب لتصحيح أنماط العيوب في عملية الاستدلال، مما يزيد من الموثوقية. يوازن إطار PairUni بين مهام الفهم والتوليد لـ LLM متعدد الوسائط من خلال التدريب المزدوج وخوارزمية التحسين Pair-GPRO. يستخدم PM4GRPO تقنيات استخراج العمليات، ويعزز قدرات الاستدلال لنماذج السياسات من خلال التعلم المعزز GRPO الواعي بالاستدلال. يحقق بروتوكول Fortytwo أداءً متميزًا في استدلال مجموعات الذكاء الاصطناعي ومقاومة قوية للمطالبات العدائية من خلال توافق الرتبة الموزع بين الأقران. (المصدر: NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 أدوات
Tencent تطلق WeKnora مفتوح المصدر: إطار عمل لفهم المستندات واسترجاعها مدعوم بـ LLM : أطلقت Tencent مشروع WeKnora مفتوح المصدر، وهو إطار عمل لفهم المستندات والاسترجاع الدلالي يعتمد على LLM، ومصمم خصيصًا لمعالجة المستندات المعقدة وغير المتجانسة. يعتمد على بنية معيارية، ويجمع بين المعالجة المسبقة متعددة الوسائط، وفهرسة المتجهات الدلالية، والاسترجاع الذكي، واستدلال LLM، ويتبع نموذج RAG، مما يحقق إجابات عالية الجودة وواعية بالسياق من خلال دمج كتل المستندات ذات الصلة واستدلال النموذج. يدعم WeKnora تنسيقات مستندات متعددة، ونماذج تضمين، واستراتيجيات استرجاع، ويوفر واجهة ويب سهلة الاستخدام و API، ويدعم النشر المحلي والسحابة الخاصة، مما يضمن سيادة البيانات. (المصدر: GitHub Trending)
Jan: بديل ChatGPT مفتوح المصدر وغير متصل بالإنترنت، يدعم تشغيل LLM محليًا : Jan هو بديل ChatGPT مفتوح المصدر، يمكن تشغيله بنسبة 100% دون اتصال بالإنترنت على جهاز الكمبيوتر الخاص بالمستخدم. يسمح للمستخدمين بتنزيل وتشغيل LLM من HuggingFace (مثل Llama، Gemma، Qwen، GPT-oss، إلخ)، ويدعم التكامل مع النماذج السحابية مثل OpenAI و Anthropic. يوفر Jan مساعدين مخصصين، و API متوافقًا مع OpenAI، وتكامل بروتوكول سياق النموذج (MCP)، مع التركيز على حماية الخصوصية، ويوفر للمستخدمين تجربة ذكاء اصطناعي محلية بتحكم كامل. (المصدر: GitHub Trending)

Claude Code: مجموعة أدوات المطورين ونظام المهارات من Anthropic : يعزز Claude Code من Anthropic بشكل كبير كفاءة عمل المطورين من خلال مجموعة من “المهارات” والوكلاء. يشمل ذلك Rube MCP connector (لربط Claude بأكثر من 500 تطبيق)، ومجموعة أدوات تطوير Superpowers (التي توفر أوامر /brainstorm و /write-plan و /execute-plan)، ومجموعة المستندات (لمعالجة Word/Excel/PDF)، و Theme Factory (لأتمتة إرشادات العلامة التجارية)، و Systematic Debugging (لمحاكاة عمليات تصحيح الأخطاء للمطورين المتقدمين). تساعد هذه الأدوات، من خلال تصميمها المعياري وقدرتها على فهم السياق، المطورين على تحقيق سير عمل آلي، ومراجعة التعليمات البرمجية، وإعادة الهيكلة، وإصلاح الأخطاء، وحتى دعم الفرق غير التقنية في بناء أدوات صغيرة خاصة بهم. (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

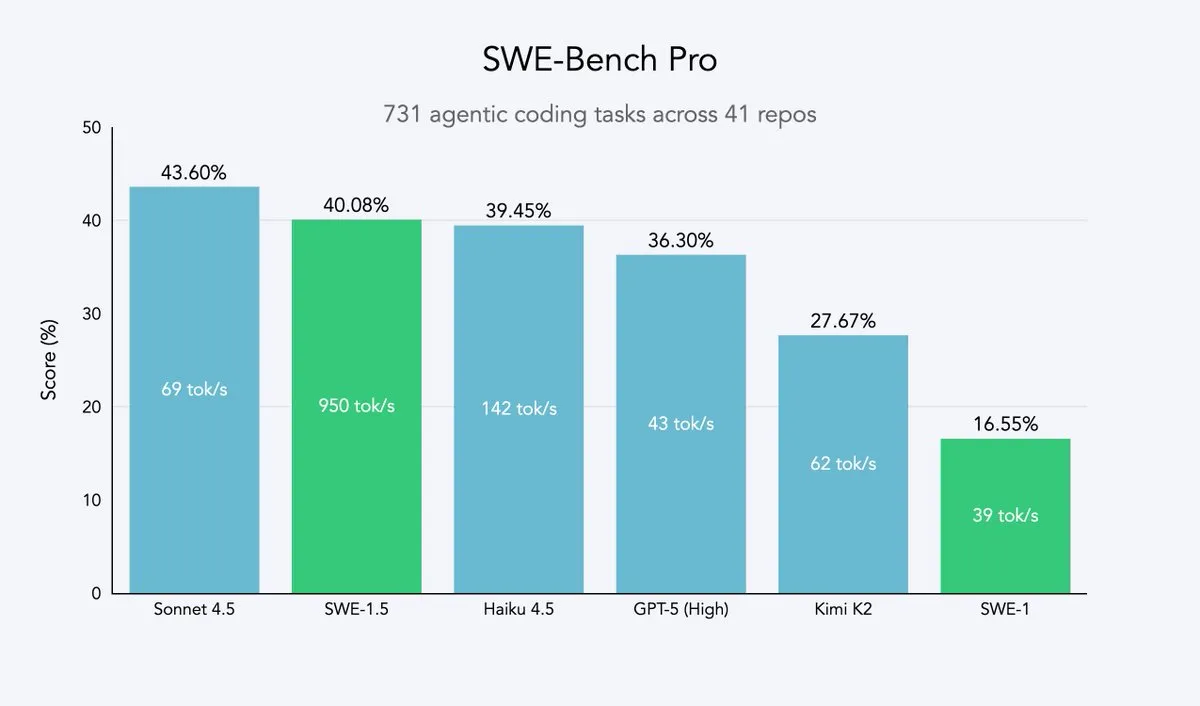
Cursor 2.0 و Windsurf: وكلاء الأكواد الذكية يسعون للسرعة والكفاءة : أطلقت Cursor و Windsurf نماذج وكلاء أكواد ذكية ومنصة 2.0 تركز على تحسين السرعة، وتتمثل استراتيجيتهما في الضبط الدقيق باستخدام التعلم المعزز بناءً على نماذج كبيرة مفتوحة المصدر (مثل Qwen3)، ونشرها على أجهزة محسّنة، لتحقيق تأثير “ذكاء متوسط ولكن سرعة فائقة”. يمثل هذا المسار استراتيجية فعالة لشركات وكلاء الأكواد الذكية، حيث يمكنها الاقتراب من حدود باريتو للسرعة والذكاء بأقل تكلفة للموارد. وضع نموذج SWE-1.5 من Windsurf معيارًا جديدًا للسرعة مع تحقيق أداء ترميز قريب من SOTA. (المصدر: dotey, Smol_AI, VictorTaelin, omarsar0, TheRundownAI)
Perplexity Patents: أول وكيل بحث براءات اختراع مدعوم بالذكاء الاصطناعي، لتمكين ذكاء الملكية الفكرية : أطلقت Perplexity أداة Perplexity Patents، وهي أول وكيل بحث براءات اختراع مدعوم بالذكاء الاصطناعي في العالم، وتهدف إلى جعل ذكاء الملكية الفكرية متاحًا للجميع. تتيح هذه الأداة البحث والدراسة عبر براءات الاختراع، وستطلق في المستقبل Perplexity Scholar، الذي سيركز على البحث الأكاديمي. سيبسط هذا الابتكار بشكل كبير عمليات البحث والتحليل لبراءات الاختراع، ويوفر خدمات معلومات الملكية الفكرية الفعالة وسهلة الاستخدام للمبتكرين والمحامين والباحثين. (المصدر: AravSrinivas)

Real Deep Research (RDR): إطار عمل بحث علمي عميق مدعوم بالذكاء الاصطناعي : Real Deep Research (RDR) هو إطار عمل مدعوم بالذكاء الاصطناعي، يهدف إلى مساعدة الباحثين على مواكبة التطور السريع للعلوم الحديثة. يسد RDR الفجوة بين الدراسات الاستقصائية التي يكتبها الخبراء واستخراج الأدبيات الآلي، ويوفر عمليات تحليل قابلة للتطوير، وتحليل الاتجاهات، ورؤى تربط بين المجالات، ويولد ملخصات منظمة وعالية الجودة. يعمل كأداة بحث شاملة، تساعد الباحثين على فهم الصورة الكبيرة بشكل أفضل. (المصدر: TheTuringPost)

LangSmith تطلق Agent Builder بدون كود، لتمكين الفرق غير التقنية من بناء الوكلاء : أطلقت LangSmith من LangChainAI أداة Agent Builder بدون كود، بهدف تقليل عتبة بناء وكلاء الذكاء الاصطناعي، مما يتيح للفرق غير التقنية إنشاء وكلاء بسهولة. تعمل هذه الأداة على تسريع انتشار وتطبيق وكلاء الذكاء الاصطناعي من خلال واجهة مستخدم (UX) لبناء الوكلاء التفاعلية، وميزة الذاكرة المدمجة التي تساعد الوكلاء على التذكر والتحسين، وتمكين الفرق غير التقنية والمطورين من بناء الوكلاء معًا. (المصدر: LangChainAI)
Verdent تدمج MiniMax-M2، لتعزيز قدرات وكفاءة الترميز : تدعم Verdent الآن نموذج MiniMax-M2، مما يوفر للمستخدمين قدرات ترميز متقدمة، ووكلاء عاليي الأداء، وتفعيلًا فعالًا للمعلمات. من خلال تجربة MiniMax-M2 مجانًا في VS Code عبر Verdent، يمكن للمطورين الاستمتاع بتجربة ترميز أكثر ذكاءً وسرعة وفعالية من حيث التكلفة. يجلب هذا التكامل القدرات القوية لـ MiniMax-M2 إلى مجتمع المطورين الأوسع. (المصدر: MiniMax__AI)
Base44 تطلق Builder جديدًا تمامًا، لتسريع تحويل المفاهيم إلى تطبيقات : أطلقت Base44 Builder الجديد كليًا، مما يمثل تحولًا جذريًا في طريقة عملها. يشبه Builder الجديد مطورًا خبيرًا، قادرًا على إجراء التحقيقات قبل البناء، والحصول على السياق من مصادر متعددة، وتصحيح الأخطاء بذكاء، واتخاذ قرارات معمارية مستنيرة. يهدف هذا التحديث إلى تسريع تحويل المفاهيم إلى تطبيقات وظيفية بعشرة أضعاف، مما يزيد بشكل كبير من كفاءة التطوير. (المصدر: MS_BASE44)
Qdrant تتعاون مع Confluent، لتمكين وكلاء الذكاء الاصطناعي الواعين بالسياق في الوقت الفعلي : تعاونت Qdrant مع Confluent، لتقديم سياق جديد وفي الوقت الفعلي لوكلاء الذكاء الاصطناعي الذكية وتطبيقات الشركات، من خلال Confluent Streaming Agents و Real-Time Context Engine. تجمع قدرة بحث المتجهات في Qdrant مع بيانات التدفق في الوقت الفعلي من Confluent، مما يمكّن المطورين من بناء وتوسيع وكلاء الذكاء الاصطناعي القائمة على الأحداث والواعية بالسياق، وبالتالي إطلاق العنان للإمكانات الكاملة للذكاء الاصطناعي القائم على الوكلاء، وتقليل وقت الحل والتكاليف بشكل كبير في سيناريوهات مثل الاستجابة للحوادث. (المصدر: qdrant_engine, qdrant_engine)

📚 تعلم
ICLR26 Paper Finder: أداة بحث أوراق الذكاء الاصطناعي القائمة على LLM : قام أحد المطورين بإنشاء ICLR26 Paper Finder، وهي أداة تستخدم نماذج اللغة كعمود فقري للبحث عن أوراق المؤتمرات المحددة في مجال الذكاء الاصطناعي. يمكن للمستخدمين البحث باستخدام العنوان أو الكلمات الرئيسية أو حتى ملخص الورقة، حيث تكون دقة البحث بالملخص هي الأعلى. تم استضافة الأداة على خادم شخصي و Hugging Face، مما يوفر للباحثين في مجال الذكاء الاصطناعي طريقة فعالة لاسترجاع الأدبيات. (المصدر: Reddit r/deeplearning, Reddit r/MachineLearning)
دورة UCLA لربيع 2025: التعلم المعزز لنماذج اللغة الكبيرة : ستقدم UCLA في ربيع 2025 دورة “التعلم المعزز لنماذج اللغة الكبيرة”، تغطي مجموعة واسعة من مواضيع RLxLLM، بما في ذلك الأساسيات، والحوسبة وقت الاختبار، و RLHF (التعلم المعزز من ردود الفعل البشرية)، و RLVR (التعلم المعزز بالمكافآت القابلة للتحقق). توفر هذه السلسلة الجديدة من المحاضرات للباحثين والطلاب فرصة للتعمق في أحدث النظريات والممارسات في التعلم المعزز لـ LLM. (المصدر: algo_diver)
دليل Autoencoder المرسوم يدويًا: فهم أساسيات الذكاء الاصطناعي التوليدي : نشر ProfTomYeh دليلًا مفصلًا من 7 خطوات لـ Autoencoder (المشفر التلقائي) المرسوم يدويًا، بهدف مساعدة القراء على فهم هذه الشبكة العصبية التي تلعب دورًا حاسمًا في الضغط، وإزالة الضوضاء، وتعلم تمثيلات البيانات الغنية. يعد Autoencoder أساس العديد من البنى التوليدية الحديثة، ويشرح هذا الدليل بطريقة بديهية كيفية عمله في ترميز وفك تشفير المعلومات، وهو مورد قيم لتعلم المفاهيم الأساسية للذكاء الاصطناعي التوليدي. (المصدر: ProfTomYeh)
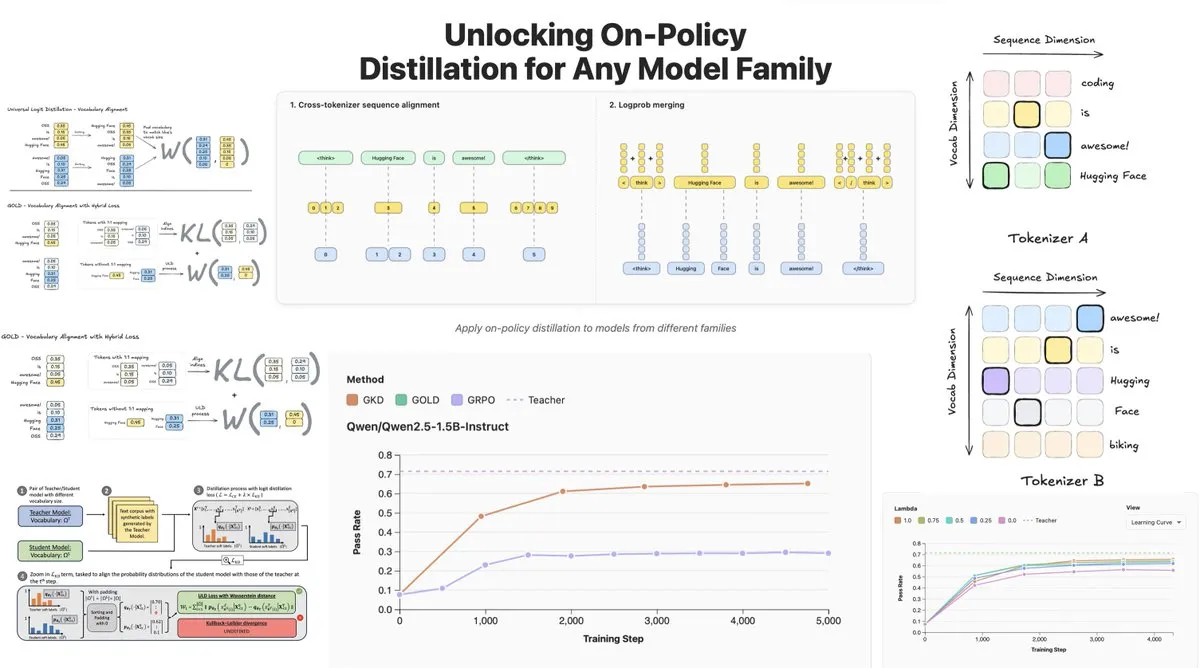
Hugging Face تطلق On-Policy Logit Distillation، وتدعم التقطير عبر النماذج : أطلقت Hugging Face تقنية General On-Policy Logit Distillation (GOLD)، التي توسع طرق تقطير السياسات، مما يسمح بتقطير أي نموذج معلم إلى أي نموذج طالب، حتى لو كانت Tokenizer الخاصة بهما مختلفة. تم دمج هذه التقنية في مكتبة TRL، مما يسمح للمطورين باختيار أي زوج من النماذج من Hub للتقطير، ويوفر مرونة هائلة وقدرة على استعادة الأداء لـ LLM بعد التدريب (post-training)، وخاصة في حل مشكلة تدهور الأداء العام بعد الضبط الدقيق في مجالات محددة. (المصدر: clefourrier, winglian, _lewtun)
Lumi: Google DeepMind تستخدم Gemini 2.5 للمساعدة في قراءة أوراق arXiv : أصدر فريق PAIR في Google DeepMind أداة Lumi، وهي أداة تستخدم نموذج Gemini 2.5 الكبير للمساعدة في قراءة أوراق arXiv. تستطيع Lumi إضافة ملخصات ومراجع وأسئلة وأجوبة مضمنة إلى الأوراق، مما يساعد الباحثين على القراءة بذكاء وكفاءة أكبر، وتحسين فعالية فهم الأدبيات البحثية. (المصدر: GoogleDeepMind)
💼 أعمال
الذكاء الاصطناعي يدفع إيرادات عمالقة التكنولوجيا إلى مستويات قياسية، وتقارير أرباح Microsoft و Google تتألق : حققت Alphabet، الشركة الأم لـ Google، و Microsoft إنجازات تاريخية في أحدث تقاريرهما المالية، حيث أصبح الذكاء الاصطناعي المحرك الرئيسي للنمو. تجاوزت إيرادات Alphabet ربع السنوية 100 مليار دولار لأول مرة، لتصل إلى 102.3 مليار دولار، ونمت Google Cloud بنسبة 34%، ويستخدم 70% من العملاء الحاليين منتجات الذكاء الاصطناعي. زادت إيرادات Microsoft بنسبة 18% لتصل إلى 77.7 مليار دولار، وتجاوزت إيرادات Intelligent Cloud 30 مليار دولار لأول مرة، وبلغ معدل نمو خدمات Azure السحابية 40%، مع دفعة كبيرة من الذكاء الاصطناعي. تخطط الشركتان لزيادة الإنفاق الرأسمالي على الذكاء الاصطناعي بشكل كبير لتعزيز ريادتهما في هذا المجال، والحصول على اعتراف سوق رأس المال. (المصدر: 36氪, Yuchenj_UW)

المدير التقني لـ Block: وكيل الذكاء الاصطناعي Goose يؤتمت 60% من الأعمال المعقدة، وجودة الكود لا علاقة لها مباشرة بنجاح المنتج : شارك Dhanji R. Prasanna، المدير التقني لشركة Block (المعروفة سابقًا باسم Square)، كيف وفرت الشركة 8-10 ساعات عمل أسبوعيًا لـ 12 ألف موظف في غضون 8 أسابيع من خلال إطار عمل وكيل الذكاء الاصطناعي مفتوح المصدر “Goose”. يعتمد Goose على بروتوكول سياق النموذج (MCP)، ويمكنه ربط أدوات المؤسسات، وتحقيق أتمتة مهام مثل كتابة التعليمات البرمجية، وتوليد التقارير، ومعالجة البيانات. أكد Prasanna أن الشركات الأصلية للذكاء الاصطناعي يجب أن تعيد تعريف نفسها كشركات تكنولوجيا، وأن تجري تعديلات هيكلية تنظيمية. قدم وجهة نظر غير بديهية مفادها أن “جودة الكود لا علاقة لها مباشرة بنجاح المنتج”، معتبرًا أن ما إذا كان المنتج يحل مشكلة المستخدم هو المفتاح، وشجع المهندسين على تبني الذكاء الاصطناعي، حيث كان المهندسون ذوو الخبرة والمبتدئون هم الأكثر تقبلاً لأدوات الذكاء الاصطناعي. (المصدر: 36氪)

صناعة البشر الرقميين تدخل مرحلة الإقصاء، وإنتاج البشر الرقميين ثلاثي الأبعاد يتحول إلى منصات : مع انفجار النماذج الكبيرة، تواجه صناعة البشر الرقميين إعادة هيكلة، حيث يتم إقصاء الشركات التي تفتقر إلى قدرات الذكاء الاصطناعي. تبلغ حصة سوق البشر الرقميين ثنائي الأبعاد 70.1%، بينما يواجه البشر الرقميون ثلاثي الأبعاد قيودًا بسبب التكرار التكنولوجي وتكاليف GPU العالية. تؤكد الشركات الرائدة مثل MoFa Technology على أن البشر الرقميين ثلاثي الأبعاد يجب أن يتوافقوا مع قدرات النماذج الكبيرة، وتشير إلى أن تراكم البيانات عالية الجودة، والمواهب النادرة، والقدرات الفنية القوية هي عوامل أساسية. تظهر اتجاهات الصناعة أن إنتاج البشر الرقميين ثلاثي الأبعاد يتجه نحو المنصات، حيث أدى التقدم في تقنيات الذكاء الاصطناعي إلى خفض التكاليف، مما جعل التطبيقات على نطاق واسع ممكنة. كما أطلقت شركات مثل Yingmou Technology و Baidu منصات توليد ثلاثية الأبعاد، بهدف جعل البشر الرقميين بنية تحتية، وتمكين المزيد من سيناريوهات التطبيق. (المصدر: 36氪)
🌟 مجتمع
تصور المستخدمين المعقد لمشاعر الذكاء الاصطناعي والثقة به: مقارنة بين R2D2 و ChatGPT : تثار نقاشات حادة على وسائل التواصل الاجتماعي حول الاختلافات في الارتباط العاطفي للمستخدمين بين R2D2 و ChatGPT. يرى المستخدمون أن R2D2 محبوب بسبب مزاجه الفريد، وولائه، وصورته “الشبيهة بالحصان”، ولا يثير قضايا أخلاقية اجتماعية واقعية. بينما يصعب على ChatGPT، بصفته “ذكاء اصطناعي زائف حقيقي”، بناء نفس الرابط العاطفي بسبب فائدته العملية، وقيود الرقابة على المحتوى، ومخاوف المراقبة المحتملة. يكشف هذا التباين أن توقعات المستخدمين من الذكاء الاصطناعي لا تقتصر على الذكاء فحسب، بل تمتد إلى تجربة التفاعل “الإنسانية” وإدراكهم لتأثيره الاجتماعي. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

قيود الاستشارة النفسية بالذكاء الاصطناعي وضرورة التدخل البشري : مع صعود منتجات الاستشارة النفسية بالذكاء الاصطناعي، بدأ الناس في استخدام الذكاء الاصطناعي لحل مشاكل الوحدة والمشاكل النفسية. تظهر الدراسات أن حوالي 22% من العاملين من الجيل Z زاروا أطباء نفسيين، وما يقرب من نصفهم استشاروا الذكاء الاصطناعي. يتمتع الذكاء الاصطناعي بمزايا في تقديم المعلومات، واستبعاد العوامل، والمرافقة، لكنه لا يستطيع أن يحل محل المستشارين النفسيين البشريين في التعاطف، وفهم “الجو العام”، وتوجيه وتيرة العلاج. تظهر الحالات أن الذكاء الاصطناعي يتطلب آلية تدخل بشري عند تحديد المخاطر القصوى، وأن البشر لا غنى عنهم في الحكم على الحدود بين العواطف والأمراض، وتراكم الخبرات، والتواصل غير اللفظي. يجب أن يتولى الذكاء الاصطناعي بشكل أساسي المهام المتكررة والمساعدة، ويقلل من عتبة طلب المساعدة، والهدف النهائي هو توجيه الناس للعودة إلى العلاقات الإنسانية الحقيقية. (المصدر: 36氪)

تفاعل كبار السن مع النماذج الكبيرة: تعريف “الخوارزميات” من “طرق العيش” : أجرت جامعة فودان ومختبر Tencent SSV Time Lab ومؤسسات أخرى دراسة استمرت عامًا واحدًا، لتعليم 100 من كبار السن كيفية استخدام النماذج الكبيرة. وجدت الدراسة أن موقف كبار السن تجاه الذكاء الاصطناعي ليس مقاومة، بل هو “نظرة تكنولوجية براغماتية” تستند إلى خبراتهم الحياتية. يهتمون أكثر بما إذا كانت التكنولوجيا يمكن أن تندمج في حياتهم اليومية وتوفر الرفقة، بدلاً من الوظائف القصوى. في معايرة الثقة، أظهر كبار السن أنماطًا متعددة مثل “التصحيح المحدود”، و”التعاون المتبادل”، و”التصلب المعرفي”، كما كانت هناك “تردد في طرح الأسئلة” و”فجوة بين الجنسين”. النماذج الكبيرة التي يتوقعونها هي “عراف”، و”طبيب موثوق به”، و”صديق للدردشة”، و”لعبة للاسترخاء”، أي تكنولوجيا “تفهم البشر” بلطف أكبر وأقرب إلى الحياة اليومية. يشير هذا إلى أن قيمة التكنولوجيا تكمن في مدى قدرتها على الانتظار، وليس في مدى سرعتها، ويدعو إلى أن تكون التكنولوجيا “متعايشة” بدلاً من “ملائمة لكبار السن”، مع مراعاة مشاعر الإنسان وإيقاعه وكرامته. (المصدر: 36氪)

تأثير الذكاء الاصطناعي الاجتماعي: من مراقبة الخصوصية إلى استهلاك الطاقة وتغيرات التوظيف : تناقش وسائل التواصل الاجتماعي على نطاق واسع التأثيرات المتعددة الأوجه للذكاء الاصطناعي على المجتمع. يشعر المستخدمون بالقلق من أن الذكاء الاصطناعي قد حقق “مراقبة غير مرئية” من خلال تطبيقات مختلفة، وعمليات البحث، والكاميرات، ويتنبأ بالسلوكيات الفردية ويؤثر عليها، بدلاً من التحكم الروبوتي الخيالي. في الوقت نفسه، أثار الطلب الهائل لمراكز بيانات الذكاء الاصطناعي على الطاقة والموارد المائية احتجاجات مجتمعية، مما أدى إلى انقطاع التيار الكهربائي ونقص المياه. بالإضافة إلى ذلك، يعزز الذكاء الاصطناعي الإنتاجية في توليد التعليمات البرمجية والمهام الآلية، لكنه يثير نقاشات حول التغيرات في هيكل التوظيف، وتحديات جودة كود الذكاء الاصطناعي على كفاءة الإنتاج. تعكس هذه المناقشات المشاعر المعقدة للجمهور تجاه الراحة والمخاطر المحتملة التي تجلبها تقنية الذكاء الاصطناعي. (المصدر: Reddit r/artificial, MIT Technology Review, MIT Technology Review, Ronald_vanLoon, Ronald_vanLoon)

التطور السريع للمصطلحات والمفاهيم في مجال الذكاء الاصطناعي : تشير مناقشات المجتمع إلى أن المصطلحات والمفاهيم في مجال الذكاء الاصطناعي تتطور بسرعة. على سبيل المثال، غالبًا ما يشير مصطلح “تدريب/بناء نموذج” إلى “الضبط الدقيق”، بينما يُعتبر “الضبط الدقيق” شكلاً جديدًا من “هندسة المطالبات/السياق”. يعكس هذا التغيير تعقيد مكدس تقنيات الذكاء الاصطناعي والحاجة إلى عمليات أكثر دقة. بالإضافة إلى ذلك، فيما يتعلق بالموازنة بين سرعة النموذج وذكائه، يميل المطورون إلى النماذج “البطيئة والذكية”، لأنها توفر نتائج أكثر موثوقية، حتى لو كان ذلك يعني الحاجة إلى مزيد من وقت الانتظار. (المصدر: dejavucoder, dejavucoder, dejavucoder)

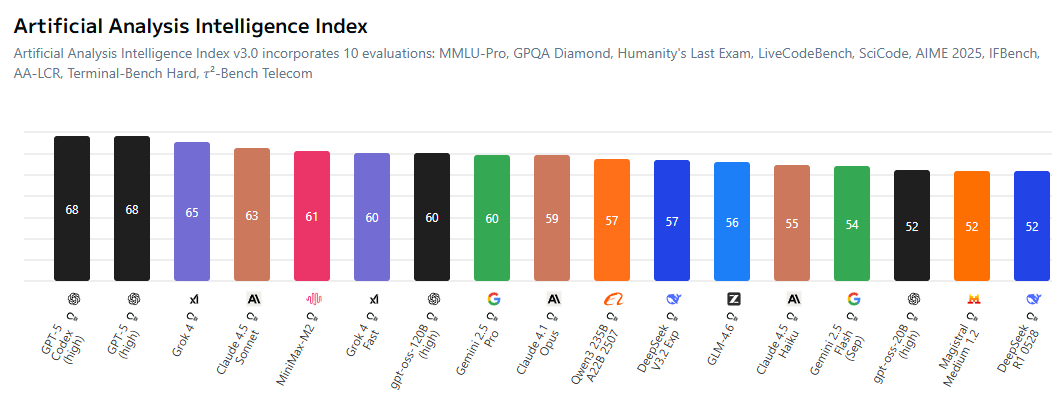
تزايد المنافسة بين بيئة الذكاء الاصطناعي مفتوحة المصدر والنماذج الاحتكارية : يناقش المجتمع بحماس تقلص الفجوة بين نماذج الذكاء الاصطناعي مفتوحة المصدر والنماذج الاحتكارية، مما يجبر المختبرات المغلقة المصدر على أن تكون أكثر تنافسية في التسعير. تظهر النماذج مفتوحة المصدر مثل MiniMax-M2 أداءً ممتازًا في AI Index، وبتكلفة منخفضة للغاية. في الوقت نفسه، تعمل الشركات الصينية والشركات الناشئة بنشاط على إتاحة تقنيات الذكاء الاصطناعي كمصدر مفتوح، بينما تتخلف الشركات الأمريكية نسبيًا في هذا الجانب. يشير هذا الاتجاه إلى أن مجال الذكاء الاصطناعي سيشهد عصرًا “يدرب فيه الجميع النماذج بناءً على المصادر المفتوحة”، مما يدفع نحو دمقرطة وابتكار تقنيات الذكاء الاصطناعي. (المصدر: ClementDelangue, huggingface, clefourrier, huggingface)
تأثير المحتوى الناتج عن الذكاء الاصطناعي على الصناعات التقليدية والتحديات الأخلاقية : يتغلغل المحتوى الناتج عن الذكاء الاصطناعي بشكل متزايد في الصناعات التقليدية، على سبيل المثال، “فنانون” مدعومون بالذكاء الاصطناعي يتصدرون قوائم الموسيقى، وتقنية التزييف العميق تُستخدم في الاحتيال (مثل خطاب مزيف لـ Jensen Huang يروج لعملة مشفرة احتيالية). تثير هذه الظواهر نقاشات حول حقوق النشر، والأخلاقيات، والتنظيم. في الوقت نفسه، جلب الذكاء الاصطناعي أدوات إنتاجية جديدة في مجالات مثل توليد التعليمات البرمجية وإدارة حسابات وسائل التواصل الاجتماعي الآلية، لكن جودة وموثوقية المحتوى الناتج لا تزال تتطلب مراجعة بشرية. يبرز هذا التحدي المتمثل في كيفية الموازنة بين الابتكار التكنولوجي والمسؤولية الاجتماعية والمعايير الأخلاقية في عملية انتشار الذكاء الاصطناعي. (المصدر: Reddit r/artificial, 36氪, jeremyphoward)

اهتمام مجتمع أبحاث الذكاء الاصطناعي بجودة البيانات والتقييم : يركز مجتمع أبحاث الذكاء الاصطناعي بشكل متزايد على الدور الحاسم لجودة البيانات في تدريب النماذج، ويشير إلى أن الحصول على بيانات عالية الجودة يمثل تحديًا أكبر من استئجار GPU أو كتابة التعليمات البرمجية. في الوقت نفسه، هناك نقاش واسع حول قيود معايير التقييم، حيث يُعتقد أن المعايير الحالية قد لا تعكس بشكل كامل القدرات الحقيقية للنماذج، ومن السهل تحسينها بشكل مفرط. يدعو الباحثون إلى تطوير أنظمة تقييم أكثر إفادة وواقعية لتعزيز التطور الصحي لأبحاث الذكاء الاصطناعي. (المصدر: code_star, code_star, clefourrier, tokenbender)

تطبيقات الذكاء الاصطناعي في مجال الرعاية الصحية وآفاقها : يظهر الذكاء الاصطناعي إمكانات هائلة في مجال الرعاية الصحية، على سبيل المثال، أطلقت Yunpeng Technology منتجات جديدة للذكاء الاصطناعي + الصحة، بما في ذلك مختبر المطبخ الذكي وثلاجة ذكية مزودة بنموذج صحي كبير للذكاء الاصطناعي، لتوفير إدارة صحية شخصية. بالإضافة إلى ذلك، يوفر MONAI، كحزمة أدوات للذكاء الاصطناعي في التصوير الطبي، إطار عمل PyTorch مفتوح المصدر. تساعد الهياكل الخارجية المدعومة بالذكاء الاصطناعي مستخدمي الكراسي المتحركة على الوقوف والمشي، ويتعلم وكلاء التشخيص LLM استراتيجيات التشخيص في البيئات السريرية الافتراضية. تشير هذه التطورات إلى أن الذكاء الاصطناعي سيغير خدمات الرعاية الصحية بشكل عميق، من الإدارة الصحية اليومية إلى التشخيص والعلاج المساعد. (المصدر: 36氪, GitHub Trending, Ronald_vanLoon, Ronald_vanLoon, HuggingFace Daily Papers)
التغيير التنظيمي واحتياجات المواهب في عصر الذكاء الاصطناعي : مع انتشار الذكاء الاصطناعي، تواجه الشركات تحولات عميقة في الهيكل التنظيمي واحتياجات المواهب. أكد Dhanji R. Prasanna، المدير التقني لشركة Block، أن الشركات بحاجة إلى إعادة تعريف نفسها كـ “شركات تكنولوجيا”، والانتقال من “نظام المدير العام” إلى “النظام الوظيفي” لتركيز الاهتمام التكنولوجي. يمكن لأدوات الذكاء الاصطناعي مثل Goose أن تعزز الإنتاجية بشكل كبير، لكن البنية والتصميم على المستوى الأعلى لا يزالان يتطلبان مهندسين ذوي خبرة. عند التوظيف، تركز الشركات أكثر على عقلية التعلم والتفكير النقدي، بدلاً من مجرد مهارات استخدام أدوات الذكاء الاصطناعي. كما يطمس الذكاء الاصطناعي حدود الوظائف، حيث بدأت الوظائف غير التقنية في استخدام أدوات الذكاء الاصطناعي، مما يدفع نحو تشكيل نموذج تعاون “المجموعات البشرية-الآلية”. (المصدر: 36氪, MIT Technology Review, NandoDF, SakanaAILabs)

💡 أخرى
ابتكار مستمر في تكنولوجيا الروبوتات متعددة الوظائف : يظهر مجال الروبوتات ابتكارات متنوعة، بما في ذلك الروبوت المستوحى من الأخطبوط SpiRobs، والطائرات بدون طيار القادرة على السباحة، وروبوت Helix لفرز الطرود، والروبوتات الشبيهة بالبشر التي تساعد في فحص الجودة في مصنع NIO. تغطي هذه التطورات التصميم الحيوي، والأتمتة، والتعاون بين الإنسان والآلة، والتكيف مع البيئات الخاصة، مما يشير إلى الإمكانات الواسعة لتكنولوجيا الروبوتات في التطبيقات الصناعية والعسكرية واليومية. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
تعميق مفهوم وكيل الذكاء الاصطناعي وتوقعات السوق : يُعرّف وكيل الذكاء الاصطناعي (AI Agent) بأنه كيان ذكي قادر على الاستدلال والتكيف مثل البشر، ويمكنه تحقيق حوار سلس بين الإنسان والآلة. تُعتبر هذه الوكلاء اتجاهًا لمستقبل العمل، وهناك العديد من أدوات بناء وكلاء الذكاء الاصطناعي تظهر في السوق. تكمن القيمة الأساسية لوكيل الذكاء الاصطناعي في كونه “أداة إنتاج” قادرة على تنفيذ مهام فعلية، وليس مجرد أداة مساعدة “للدردشة”، وسيؤدي تطوره إلى تعميق تطبيقات الذكاء الاصطناعي في مختلف المجالات. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, dotey)
الذكاء الاصطناعي والقيادة الذاتية: أسطول Uber يعتمد شرائح Nvidia الجديدة، لدفع تطوير سيارات الأجرة الروبوتية : سيستخدم أسطول Uber للقيادة الذاتية من الجيل التالي شرائح Nvidia الجديدة، ومن المتوقع أن يقلل ذلك من تكلفة سيارات الأجرة الروبوتية. تعد منصة Drive Hyperion من Nvidia بنية قياسية للمركبات “الجاهزة لسيارات الأجرة الروبوتية”، وسيدفع التعاون مع Uber تقنية القيادة الذاتية نحو الانتشار بين المستهلكين. يشير هذا إلى أن تطبيقات الذكاء الاصطناعي في مجال النقل تتسارع، وتهدف إلى تحقيق خدمات قيادة ذاتية أكثر أمانًا واقتصادية. (المصدر: MIT Technology Review, TheTuringPost)