
كلمات مفتاحية:أوبن إيه آي, بنية تحتية للذكاء الاصطناعي, فيروسات مولدة بالذكاء الاصطناعي, ألفا إيرث فاونديشنز, آر تي إي بي, كلود سونيت 4.5, ديب سيك V3.2-إكس بي, الذكاء الاصطناعي متعدد الوسائط, مشروع ستارغيت من أوبن إيه آي, نموذج لغة الجينوم المحول, نمذجة جوجل ألفا إيرث بدقة 10 متر, معيار آر تي إي بي من هاجينج فيس, توليد الأكواد باستخدام أنثروبيك كلود
بصفتي رئيس تحرير عمود الذكاء الاصطناعي، قمت بتحليل وتلخيص واستخلاص عميق للأخبار والمناقشات الاجتماعية التي قدمتموها. فيما يلي المحتوى المدمج:
🔥 تركيز
رهان OpenAI على بنية تحتية بتكلفة تريليونية: تتعاون OpenAI مع Oracle و SoftBank في خطة لاستثمار تريليونات الدولارات عالميًا لبناء بنية تحتية حاسوبية، تحت الاسم الرمزي “ستارغيت”. أعلنت الشركة مبدئيًا عن خمسة مواقع جديدة في الولايات المتحدة بتكلفة 400 مليار دولار، وبالتعاون مع Nvidia لبناء مشروع “ستارغيت المملكة المتحدة” في بريطانيا. تتوقع OpenAI أن يصل الطلب المستقبلي على الطاقة للذكاء الاصطناعي إلى 100 جيجاوات، وقد يصل إجمالي الاستثمار إلى 5 تريليونات دولار. تهدف هذه الخطوة إلى تلبية الطلب الهائل على القدرة الحاسوبية لنماذج الذكاء الاصطناعي، لكنها تثير أيضًا مخاوف بشأن حجم الاستثمار، استهلاك الطاقة، والمخاطر المالية المحتملة، مما يسلط الضوء على الاعتماد الشديد لتطوير الذكاء الاصطناعي على البنية التحتية. (المصدر: DeepLearning.AI Blog)

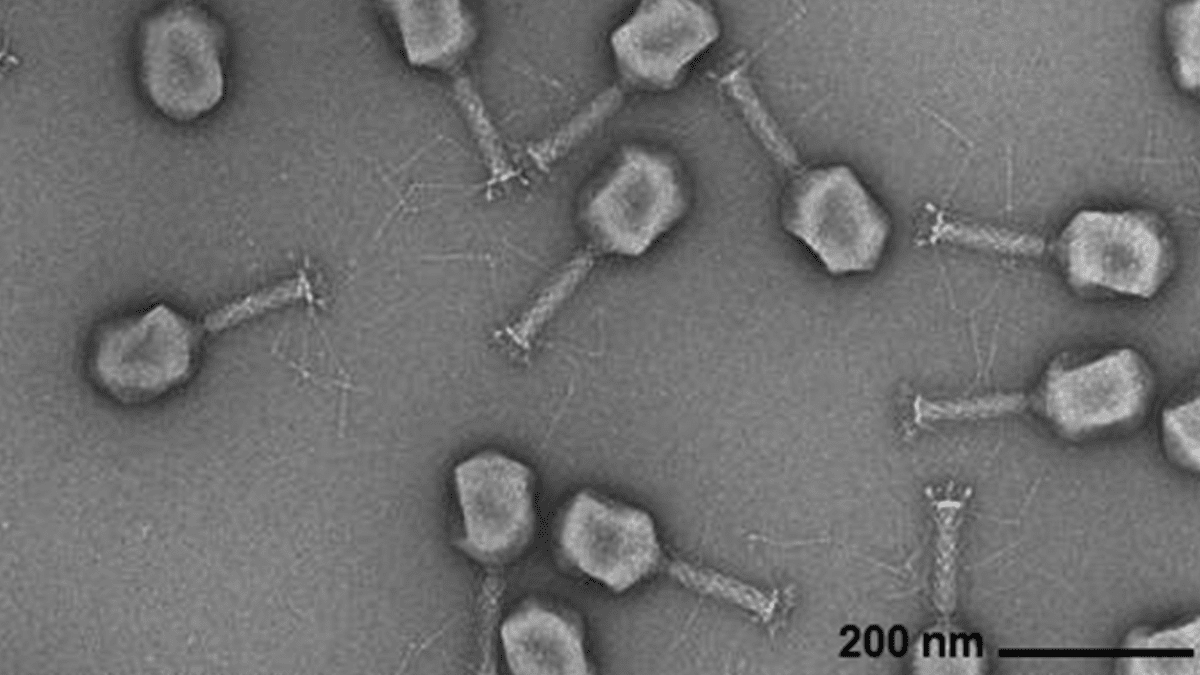
الذكاء الاصطناعي يولد جينومات فيروسية: نجح باحثون من Arc Institute، جامعة ستانفورد، ومركز ميموريال سلون كيترينغ للسرطان، في تركيب فيروسات عاثية جديدة من الصفر قادرة على مكافحة الالتهابات البكتيرية الشائعة، وذلك باستخدام نموذج لغة جينومي قائم على Transformer. تتيح هذه التقنية، من خلال الضبط الدقيق لتسلسل الجينوم الفيروسي، توليد جينومات جديدة ذات وظائف محددة وتختلف عن الفيروسات الموجودة في الطبيعة. يمثل هذا الاختراق مسارًا جديدًا لتطوير علاجات بديلة للمضادات الحيوية، لكنه يثير أيضًا مخاوف بشأن السلامة البيولوجية والاستخدامات الخبيثة، مؤكدًا على ضرورة البحث في الاستجابة للتهديدات البيولوجية. (المصدر: DeepLearning.AI Blog)
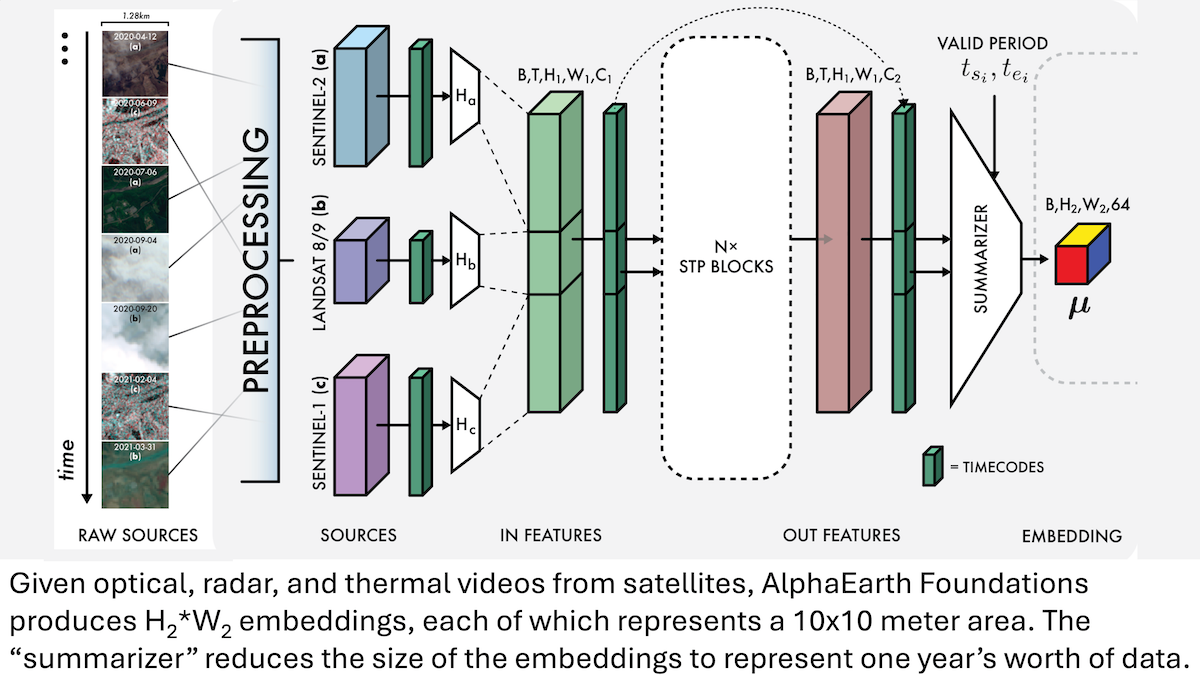
Google AlphaEarth Foundations: نمذجة الأرض بدقة 10 أمتار: أطلق باحثو Google نموذج AlphaEarth Foundations (AEF)، القادر على دمج صور الأقمار الصناعية وبيانات أجهزة الاستشعار الأخرى لنمذجة سطح الأرض بدقة 10 أمتار مربعة، وتوليد تضمينات تمثل خصائص الأرض سنويًا من 2017 إلى 2024. يمكن استخدام هذه التضمينات لتتبع خصائص كوكبية متعددة مثل الرطوبة، هطول الأمطار، والغطاء النباتي، بالإضافة إلى التحديات العالمية مثل إنتاج الغذاء، مخاطر حرائق الغابات، ومستويات المياه في الخزانات، مما يوفر أداة عالية الدقة وغير مسبوقة لرصد البيئة وأبحاث تغير المناخ. (المصدر: DeepLearning.AI Blog)
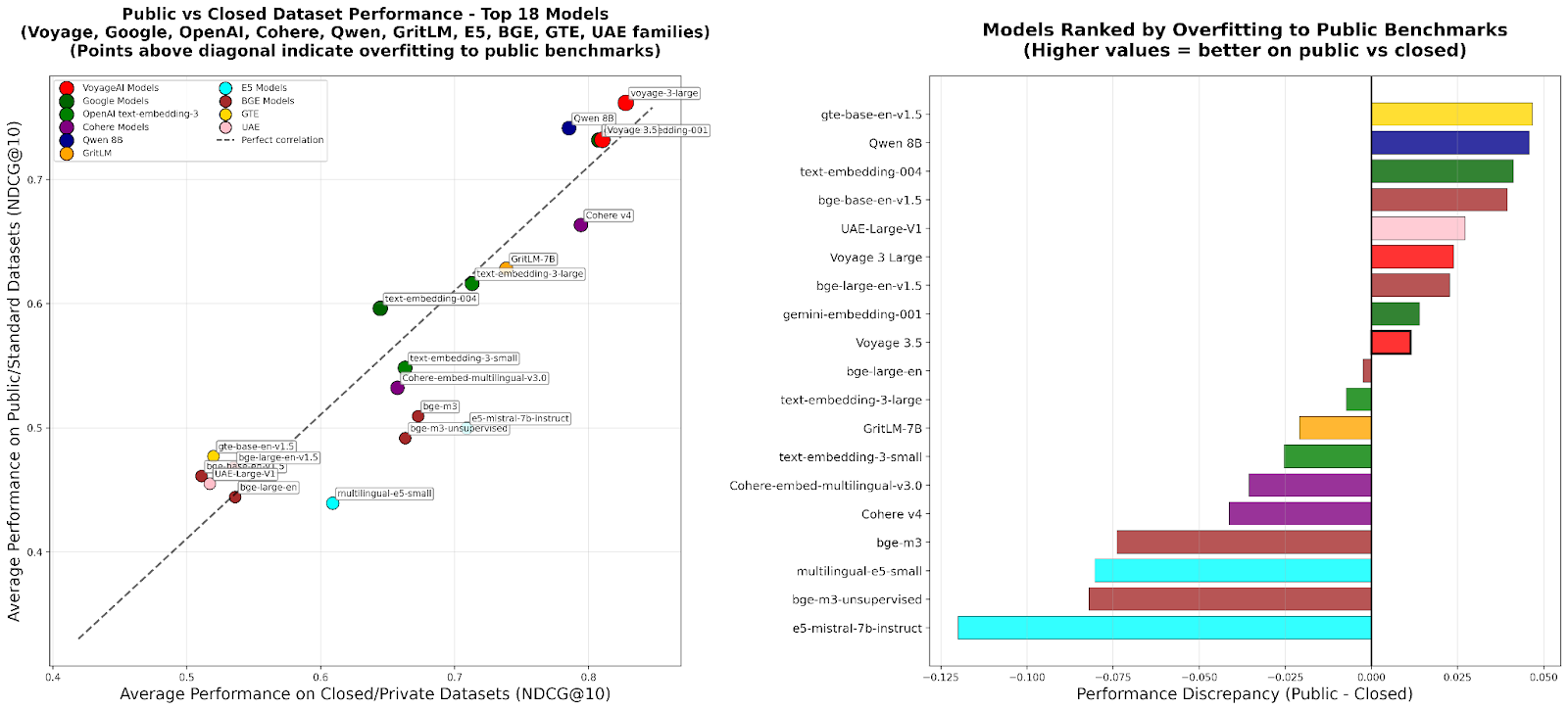
RTEB: معيار جديد لتقييم تضمينات الاسترجاع: أطلقت Hugging Face الإصدار التجريبي من معيار تضمينات الاسترجاع (RTEB)، والذي يهدف إلى توفير معيار موثوق لتقييم دقة استرجاع نماذج التضمين. يحل هذا المعيار بفعالية مشكلة الإفراط في التخصيص للنماذج في المعايير الحالية من خلال استراتيجية تجمع بين مجموعات البيانات العامة والخاصة، مما يضمن أن تعكس نتائج التقييم بشكل أفضل قدرة النموذج على التعميم على البيانات غير المرئية، وهو أمر بالغ الأهمية لتحسين جودة تطبيقات الذكاء الاصطناعي مثل RAG و Agent. (المصدر: HuggingFace Blog)
تدريب RL الوسيط القابل للتوسع: تحقيق الاستدلال من خلال تجريد الإجراءات: اقترحت دراسة حديثة خوارزمية “الاستدلال كتجريد للإجراءات” (RA3)، والتي تعمل على تحسين قدرات الاستدلال وتوليد الأكواد لنماذج اللغات الكبيرة (LLMs) بشكل كبير، وذلك من خلال تحديد مجموعات إجراءات مدمجة ومفيدة في مرحلة التدريب الوسيط للتعلم المعزز (RL) وتسريع RL عبر الإنترنت. أظهرت هذه الطريقة أداءً ممتازًا في مهام توليد الأكواد، حيث زاد متوسط الأداء بنسبة تتراوح بين 8 و 4 نقاط مئوية مقارنة بالنماذج الأساسية، وحققت تقاربًا أسرع لـ RL وأداءً تقاربيًا أعلى. (المصدر: HuggingFace Daily Papers)
🎯 تطورات
OpenAI Sora 2: عصر جديد لوسائل التواصل الاجتماعي بالفيديو المدعوم بالذكاء الاصطناعي: أطلقت OpenAI نموذج Sora 2، بالإضافة إلى تطبيق اجتماعي يحمل نفس الاسم، بهدف إنشاء شبكة اجتماعية تتمحور حول المستخدم ودائرته الاجتماعية (الأصدقاء، الحيوانات الأليفة) من خلال تصفح وإنشاء مقاطع الفيديو المولدة بالذكاء الاصطناعي، بدلاً من منصة توزيع المحتوى التقليدية. يُظهر Sora 2 قدرات قوية في المحاكاة الفيزيائية وتوليد الصوت، لكن الاختبارات المبكرة لا تزال تكشف عن عيوب تفصيلية مثل “عد الأصابع”. أثار إطلاقه نقاشات حول إدمان الفيديو المدعوم بالذكاء الاصطناعي، التزييف العميق، ومسار OpenAI التجاري. رد Sam Altman بأن Sora يهدف إلى الموازنة بين الاختراقات التكنولوجية وتجربة المستخدم الممتعة، وتوفير التمويل لأبحاث الذكاء الاصطناعي. (المصدر: 36氪، Reddit r/ChatGPT، OpenAI)

Anthropic Claude Sonnet 4.5: معيار جديد للأكواد و Agent: أطلقت Anthropic نموذج Claude Sonnet 4.5، الذي يوصف بأنه “أفضل نموذج برمجة في العالم” و”أقوى نموذج لبناء Agent معقدة”، ويتميز بوقت تشغيل مستقل يصل إلى 30 ساعة، ويظهر تحسينًا كبيرًا في أداء الترميز في مهام GitHub. أضاف النموذج أيضًا وظيفة الذاكرة، مما يسمح بحفظ تقدم المشروع. على الرغم من الإشادة بأدائه، لا يزال هناك جدل بين المستخدمين حول قيود الاستخدام ومقارنة أدائه الفعلي بـ Opus 4.1 و GPT-5. (المصدر: Reddit r/ClaudeAI، Reddit r/artificial، Reddit r/ClaudeAI)
DeepSeek V3.2-Exp: بنية الانتباه المتفرق تعزز الكفاءة: أطلقت DeepSeek نموذج اللغة الكبير DeepSeek V3.2-Exp، الذي يقدم بنية جديدة تمامًا للانتباه المتفرق (DSA)، مما يقلل من تعقيد الانتباه الرئيسي من O(L²) إلى O(L·k)، ويحسن بشكل كبير تكاليف التعبئة المسبقة وفك التشفير في سيناريوهات السياق الطويل، وبالتالي يقلل بشكل كبير من رسوم استخدام API. أكملت Jiuzhang Cloud Pole بالفعل التكيف مع DeepSeek V3.2-Exp، موفرة حلول نشر خاصة آمنة وفعالة لتلبية متطلبات الشركات لأمن البيانات ومرونة القدرة الحاسوبية. (المصدر: 量子位، Reddit r/LocalLLaMA)

إطلاق نموذج LFM2-Audio-1.5B متعدد الوسائط للصوت والنص: أطلقت Liquid AI نموذج LFM2-Audio-1.5B، وهو نموذج أساسي شامل للصوت والنص من طرف إلى طرف، قادر على فهم وتوليد النصوص والصوت. يتميز هذا النموذج بسرعة استدلال أسرع بـ 10 مرات من النماذج المماثلة، وبجودة تضاهي نماذج أكبر بـ 10 مرات على الرغم من امتلاكه 1.5 مليار معلمة فقط، ويدعم النشر المحلي والمحادثة في الوقت الفعلي. كما أطلقت Hume AI نموذج Octave 2، وهو نموذج تحويل نص إلى كلام متعدد اللغات أسرع وأرخص، ويتميز بقدرات محادثة متعددة المتحدثين وتحويل الصوت. (المصدر: Reddit r/LocalLLaMA، QuixiAI)

Microsoft Agent Framework: تطورات جديدة في تطوير أنظمة Agent: أطلقت Microsoft إطار عمل Microsoft Agent Framework، الذي يدمج Autogen و Semantic Kernel في حزمة تطوير برامج (SDK) موحدة وجاهزة للإنتاج، لبناء وتنسيق ونشر أنظمة Agent متعددة. يدعم هذا الإطار .NET و Python، ويمكنه تحقيق سير عمل Agent متعددة من خلال تنسيق قائم على الرسوم البيانية، ويهدف إلى تبسيط تطوير ومراقبة وحوكمة تطبيقات Agent، وتسريع نشر Agent الذكاء الاصطناعي على مستوى المؤسسات. (المصدر: gojira، omarsar0)

أحدث تقنيات روبوتات الذكاء الاصطناعي والمنافسة الصناعية: تستمر تقنيات الروبوتات في التقدم، حيث يعمل OmniRetarget من Amazon FAR على تحسين التقاط حركة الجسم البشري، مما يتيح تعلم مهارات بشرية معقدة بأقل قدر من التعلم المعزز. تعمل Periodic Labs على بناء “علماء ذكاء اصطناعي” لتسريع الاكتشافات العلمية. تؤكد Nvidia على دور محركها الفيزيائي المفتوح Newton، ونموذجها اللغوي البصري الاستدلالي Cosmos Reason، ونموذجها الأساسي للروبوتات Isaac GR00T N1.6 في نشر الذكاء الاصطناعي الفيزيائي. في الوقت نفسه، تُظهر الصين ميزة رائدة في إنتاج الروبوتات وتكلفة الروبوتات البشرية، مما يثير الاهتمام بالمشهد التنافسي لصناعة الروبوتات العالمية. (المصدر: pabbeel، LiamFedus، nvidia، atroyn)

🧰 أدوات
Tinker API: واجهة مرنة لتبسيط الضبط الدقيق لـ LLM: أطلقت Thinking Machines Lab واجهة Tinker API، وهي واجهة مرنة مصممة للضبط الدقيق لنماذج اللغة. تسمح للباحثين والمطورين بكتابة حلقات التدريب محليًا، بينما تتولى Tinker تشغيلها على مجموعات GPU الموزعة، وإدارة تعقيدات البنية التحتية، مما يتيح للمستخدمين التركيز على الخوارزميات والبيانات. تهدف هذه الأداة إلى خفض عتبة ما بعد تدريب LLM، وتسريع التجارب والابتكار في النماذج المفتوحة، وقد أشاد بها خبراء مثل Andrej Karpathy ووصفها بأنها “البنية التحتية التي طالما أردتها”. (المصدر: Reddit r/artificial، Thinking Machines، karpathy)

LlamaAgents: نشر Agent للوثائق بنقرة واحدة: أطلقت LlamaIndex منصة LlamaAgents، التي توفر القدرة على نشر AI Agent مركزية للوثائق بنقرة واحدة، بهدف تسريع بناء وتسليم وكلاء الوثائق بمقدار 10 أضعاف. توفر المنصة قوالب مسبقة التكوين بنسبة 90%، وتدعم المعالجة الآلية للمهام الكثيفة بالوثائق مثل الفواتير ومراجعة العقود والمطالبات، وتسمح بالتخصيص غير المحدود. يمكن للمستخدمين النشر على LlamaCloud، وإدارة وتحديث سير عمل Agent بسهولة عبر مستودع Git، مما يقلل بشكل كبير من دورة التطوير. (المصدر: jerryjliu0، jerryjliu0)

Hex AI Agent: تمكين التحليل والتعاون الجماعي: أطلقت Hex ثلاثة AI Agent جديدة، مصممة خصيصًا لتحليل البيانات والتعاون الجماعي: يوفر Threads تفاعلاً حواريًا مع البيانات، وينشئ Semantic Model Agent سياقًا متحكمًا للحصول على إجابات دقيقة، بينما يحدث Notebook Agent ثورة في العمل اليومي لفرق البيانات. تعمل جميع هذه Agent بواسطة Claude 4.5 Sonnet، وتهدف إلى تحويل تحليل الذكاء الاصطناعي الحواري من مفهوم مستقبلي إلى أداة فعالة متاحة على الفور. (المصدر: sarahcat21)
Sculptor: واجهة المستخدم المفقودة لـ Claude Code: أطلقت Imbue أداة Sculptor، وهي واجهة مستخدم مصممة لـ Claude Code، تهدف إلى تحسين تجربة برمجة Agent. تسمح للمطورين بتشغيل العديد من Claude Agent بالتوازي في حاويات معزولة، ويمكنها مزامنة عمل Agent مع بيئة التطوير المحلية للاختبار والتحرير من خلال “وضع الاقتران”. تخطط Sculptor أيضًا لدعم GPT-5، وتقديم ميزات مقترحة مثل اكتشاف السلوك المضلل، بهدف جعل برمجة Agent أكثر سلاسة وكفاءة. (المصدر: kanjun، kanjun)
Synthesia 3.0: اختراق جديد في الفيديو التفاعلي المدعوم بالذكاء الاصطناعي: أطلقت Synthesia الإصدار 3.0، مقدمة العديد من الميزات المبتكرة، بما في ذلك “Video Agent” (مقاطع فيديو تفاعلية يمكنها إجراء محادثات في الوقت الفعلي، تستخدم للتدريب والمقابلات)، و”Avatars” المحسّنة (تُنشأ من موجه واحد أو صورة، مع تعابير وجه وحركات جسدية واقعية)، و”Copilot” (محرر فيديو مدعوم بالذكاء الاصطناعي، يمكنه توليد نصوص وعناصر بصرية بسرعة). بالإضافة إلى ذلك، تم تعزيز وظائف التفاعل وأدوات تصميم الدورات التدريبية، بهدف إحداث ثورة في إنشاء الفيديو وتجربة التعلم. (المصدر: synthesiaIO، synthesiaIO)
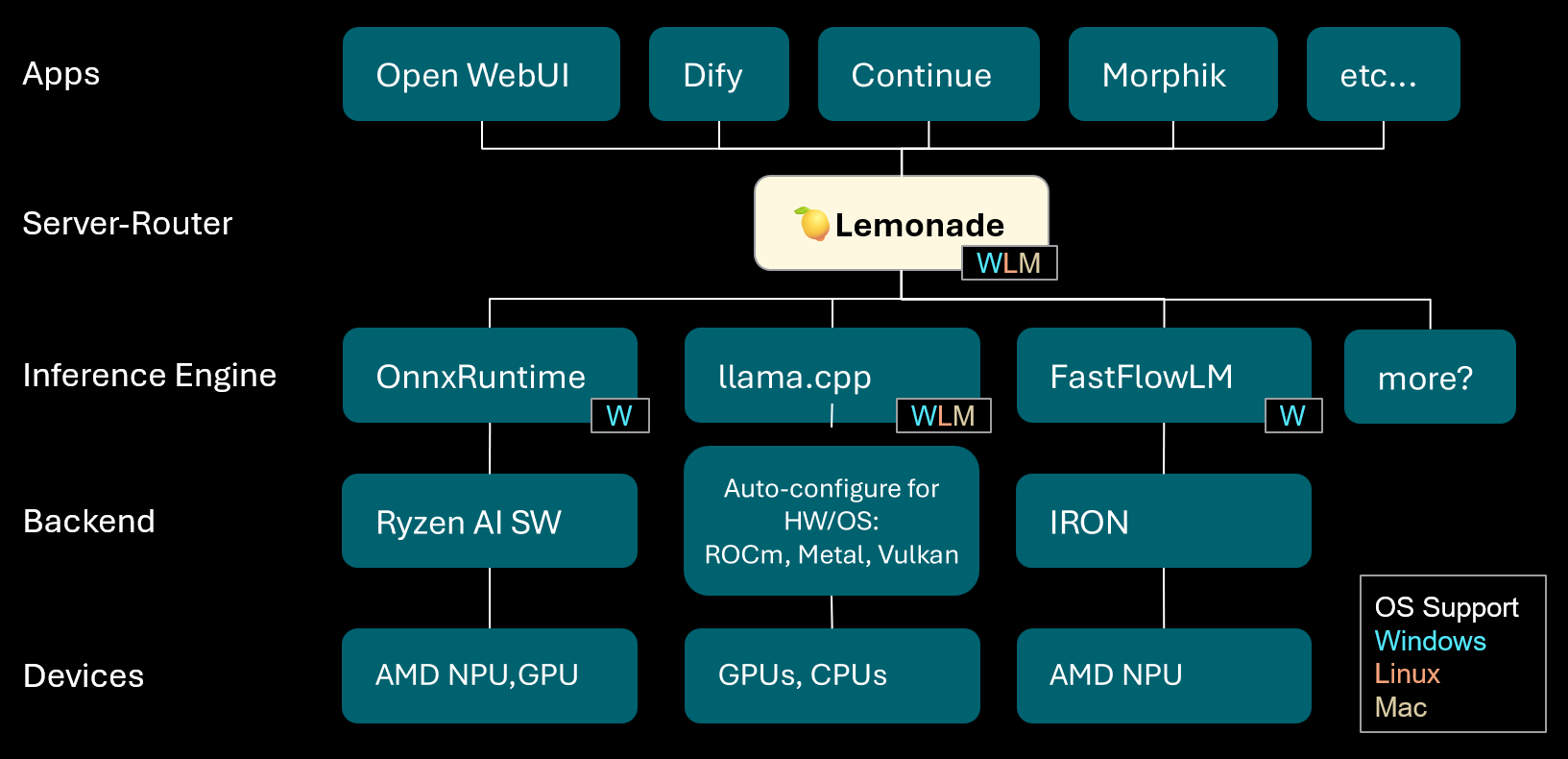
Lemonade: خادم-موجه LLM محلي: أطلقت Lemonade الإصدار v8.1.11، وهو خادم-موجه LLM محلي قادر على التكوين التلقائي لمحركات الاستدلال عالية الأداء لمختلف أجهزة الكمبيوتر (بما في ذلك AMD NPU وأجهزة macOS/Apple Silicon). يدعم العديد من تنسيقات النماذج مثل ONNX و GGUF و FastFlowLM، ويستخدم الواجهة الخلفية Metal لـ llama.cpp لتحقيق حسابات فعالة على Apple Silicon، مما يوفر للمستخدمين تجربة LLM محلية مرنة وعالية الأداء. (المصدر: Reddit r/LocalLLaMA)
PopAi: توليد العروض التقديمية المدعومة بالذكاء الاصطناعي: عرضت PopAi قدرة أداتها المدعومة بالذكاء الاصطناعي على توليد عروض تقديمية تجارية مفصلة تتضمن رسومًا بيانية ورسومًا توضيحية في دقائق من موجه بسيط. يسلط هذا الضوء على كفاءة الذكاء الاصطناعي في إنشاء المحتوى، مما يتيح لغير المتخصصين إنتاج مواد عرض عالية الجودة بسرعة. (المصدر: kaifulee)

GitHub Copilot CLI: اختيار النموذج التلقائي: يوفر GitHub Copilot CLI الآن وظيفة اختيار النموذج التلقائي للمستخدمين التجاريين والمؤسسات. يتيح هذا التحديث للنظام اختيار النموذج الأنسب تلقائيًا بناءً على المهمة الحالية، ويهدف إلى تحسين كفاءة التطوير وجودة توليد الأكواد. (المصدر: pierceboggan)
Mixedbread Search: بحث محلي متعدد اللغات ومتعدد الوسائط: أطلقت Mixedbread الإصدار التجريبي من نظام البحث الخاص بها، والذي يوفر وظيفة بحث سريعة ودقيقة ومتعددة اللغات ومتعددة الوسائط للوثائق. يؤكد النظام على التشغيل المحلي، مما يتيح للمستخدمين استرجاع الوثائق بكفاءة على أجهزتهم الخاصة، وهو مناسب بشكل خاص للسيناريوهات التي تتطلب معالجة أنواع بيانات متنوعة. (المصدر: TheZachMueller)
Hume AI Octave 2: نموذج TTS متعدد اللغات من الجيل التالي: أطلقت Hume AI نموذج Octave 2، وهو نموذج تحويل نص إلى كلام (TTS) متعدد اللغات من الجيل التالي. هذا النموذج أسرع بنسبة 40% وأرخص بنسبة 50% من سابقه، ويدعم أكثر من 11 لغة، ومحادثات متعددة المتحدثين، وتحويل الصوت، ووظائف تحرير الفونيمات، ويهدف إلى توفير تجربة ذكاء اصطناعي صوتي أسرع وأكثر واقعية وعاطفية. (المصدر: AlanCowen)
تحديثات AssemblyAI لشهر سبتمبر: خدمة صوتية شاملة بالذكاء الاصطناعي: استعرضت AssemblyAI تحديثاتها لشهر سبتمبر، وتشمل أبرزها إطلاق Playground داخل التطبيق، وتوسيع اللغة العامة، ووظيفة إخفاء معلومات التعريف الشخصية (PII) في الاتحاد الأوروبي، بالإضافة إلى تحسينات في أداء البث المباشر وتلميحات الكلمات الرئيسية. تهدف هذه التحديثات إلى تزويد المستخدمين بخدمة معالجة صوتية شاملة وأكثر كفاءة بالذكاء الاصطناعي. (المصدر: AssemblyAI)
أداة Voiceflow MCP: توحيد تكامل أدوات Agent: أطلقت Voiceflow أداة بروتوكول سياق النموذج (MCP)، التي توفر طريقة موحدة لـ AI Agent لاستخدام أنواع مختلفة من الأدوات. يبسط هذا عمل التكامل المخصص للمطورين، ويوفر أدوات طرف ثالث مسبقة البناء للمستخدمين الذين لا يمتلكون خبرة في البرمجة، مما يوسع بشكل كبير قدرات Voiceflow Agent. (المصدر: ReamBraden)
Salesforce Agentforce Vibes: ترميز Agent على مستوى المؤسسات: أطلقت Salesforce منتج “Agentforce Vibes” بناءً على بنية Cline، مستفيدة من دعم بروتوكول سياق النموذج (MCP)، لتزويد عملاء المؤسسات بقدرات الترميز الذاتي. يضمن هذا المنتج اتصال LLM الآمن مع مصادر المعرفة/قواعد البيانات الداخلية والخارجية، ويهدف إلى تحقيق ترميز AI على نطاق المؤسسة. (المصدر: cline)

JoyAgent-JDGenie: تقرير بنية Agent عامة: تم إصدار التقرير الفني لبنية Agent العامة (GAIA)، حيث تدمج هذه البنية إطار عمل Agent متعددة جماعية (تجمع بين التخطيط، Agent التنفيذ، ونموذج التعليق والتصويت)، ونظام ذاكرة هرمي (طبقات العمل، الدلالية، البرمجية)، بالإضافة إلى مجموعة أدوات تتضمن البحث، تنفيذ الأكواد، والتحليل متعدد الوسائط. أظهر هذا الإطار أداءً ممتازًا في اختبارات المعايير الشاملة، متجاوزًا الخطوط الأساسية مفتوحة المصدر واقترب من أداء الأنظمة الاحتكارية، مما يوفر مسارًا لبناء مساعدين ذكاء اصطناعي قابلين للتوسع، مرنين، وقابلين للتكيف. (المصدر: HuggingFace Daily Papers)
مساعد السفر بالذكاء الاصطناعي: تمكين من التخطيط إلى العمل: يهدف تطبيق مساعد السفر بالذكاء الاصطناعي الذي أطلقته Mafengwo إلى رفع مستوى الذكاء الاصطناعي من توليد الخطط التقليدية إلى المساعدة العملية في السفر الفعلي. يمكن للتطبيق توليد خطط سفر شخصية غنية بالصور والنصوص، ويوفر وظائف عملية مثل Agent الذكاء الاصطناعي لإجراء مكالمات هاتفية لحجز المطاعم، مما يحل بفعالية نقاط الضعف مثل حواجز اللغة. على الرغم من وجود مجال للتحسين في الترجمة الفورية والتخصيص العميق، فقد خفض بشكل كبير عتبة “السفر بدون تخطيط”، مما يدل على الإمكانات الهائلة للذكاء الاصطناعي في ربط المعلومات الرقمية بالإجراءات في العالم المادي. (المصدر: 36氪)

📚 تعلم
نصائح للتطوير الوظيفي لباحثي الذكاء الاصطناعي: فيما يتعلق بالتطوير الوظيفي لباحثي الذكاء الاصطناعي، يؤكد الخبراء على أهمية أن يصبحوا مبرمجين ممتازين، ويشجعون على إعادة إنتاج الأوراق البحثية من الصفر، وفهم البنية التحتية بعمق. في الوقت نفسه، يوصون ببناء علامة تجارية شخصية بنشاط، ومشاركة الأفكار المثيرة للاهتمام، والحفاظ على الفضول والقدرة على التكيف، وإعطاء الأولوية للمناصب التي تعزز الابتكار والتعلم. على المدى الطويل، يعد الجهد المستمر وتحقيق نتائج عملية مفتاح بناء الثقة والتحفيز. (المصدر: dejavucoder، BlackHC)
دورة تحليل البيانات باستخدام Python: أطلقت DeepLearningAI دورة جديدة لتحليل البيانات باستخدام Python، تهدف إلى تعليم كيفية استخدام Python لزيادة كفاءة تحليل البيانات، إمكانية التتبع، وقابلية التكرار. هذه الدورة جزء من شهادة احترافية في تحليل البيانات، وتؤكد على الدور الأساسي لمهارات البرمجة في عمل البيانات الحديث. (المصدر: DeepLearningAI)
الطلاب يحصلون على أدوات Copilot AI مجانًا: تقدم Microsoft للطلاب الجامعيين المؤهلين اشتراكًا مجانيًا لمدة 12 شهرًا في Microsoft 365 Personal، والذي يتضمن وصولاً إضافيًا إلى Copilot Podcasts و Deep Research و Vision. تهدف هذه الخطوة إلى تزويد الطلاب بأدوات ذكاء اصطناعي قوية لدعم تعلمهم وابتكارهم. (المصدر: mustafasuleyman)

إعداد دورات AI/ML محلية: شارك أحد المربين كيفية إنشاء دورات عملية في AI/ML للطلاب تعتمد على التطوير المحلي والأجهزة الاستهلاكية بميزانية محدودة. اقترح استخدام نماذج صغيرة، و Transformer Lab كمنصة تدريب، وأكد على فهم المفاهيم الأساسية بدلاً من السعي الأعمى وراء حجم النموذج، وذلك لتحسين نتائج تعلم الطلاب وقدراتهم العملية. (المصدر: Reddit r/deeplearning)
ورش عمل قادمة حول الذكاء الاصطناعي: نشرت AIhub قائمة بورش عمل التعلم الآلي والذكاء الاصطناعي القادمة خلال الفترة من أكتوبر إلى نوفمبر 2025. تغطي هذه الفعاليات مواضيع متعددة تتراوح من جمع البيانات من منصات التواصل الاجتماعي المقيدة سياسيًا إلى أخلاقيات الذكاء الاصطناعي، وجميع ورش العمل مجانية وتوفر خيارات المشاركة عبر الإنترنت، مما يوفر فرصًا غنية للتعلم والتبادل لمجتمع الذكاء الاصطناعي. (المصدر: aihub.org)

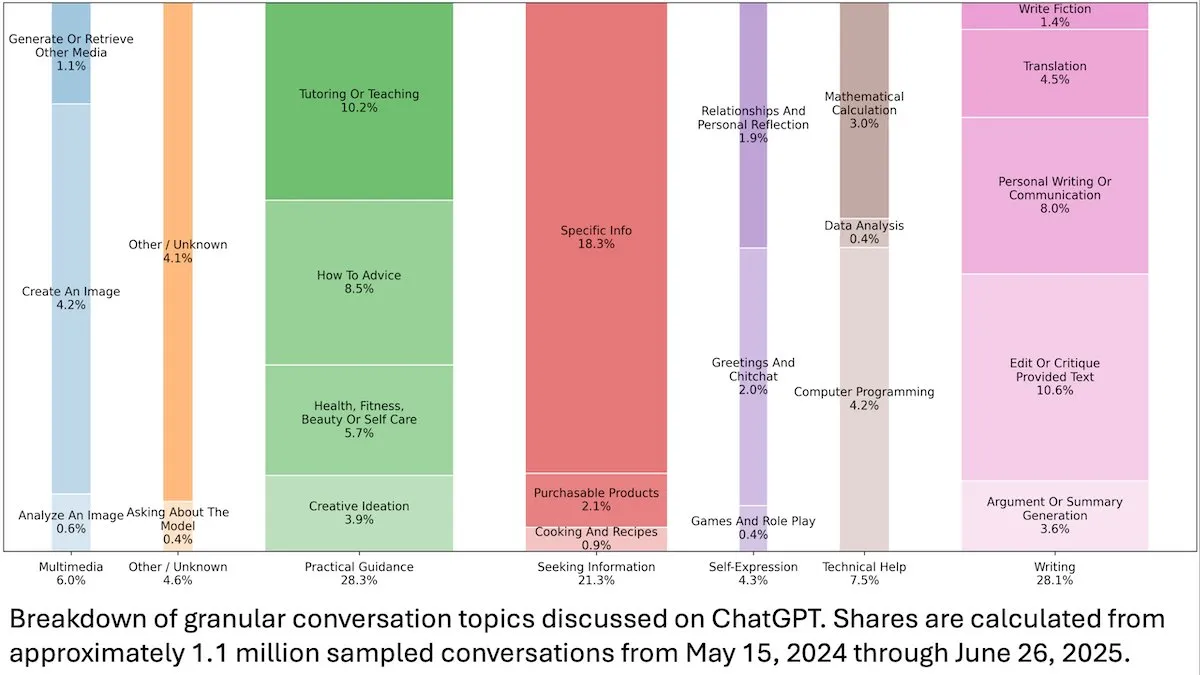
رؤى حول سلوك مستخدمي ChatGPT: كشفت دراسة لـ OpenAI نشرتها DeepLearningAI، استنادًا إلى تحليل 110 ملايين محادثة مجهولة المصدر في ChatGPT، أن استخدامها قد تحول من الاحتياجات المتعلقة بالعمل إلى الاحتياجات الشخصية، وأن نسبة المستخدمات الشابات (18-25 عامًا) أعلى. كانت الطلبات الأكثر شيوعًا هي الإرشادات العملية (28.3%)، والمساعدة في الكتابة (28.1%)، والاستعلام عن المعلومات (21.3%)، مما يكشف عن التطبيق الواسع لـ ChatGPT في الحياة اليومية. (المصدر: DeepLearningAI)
Code2Video: توليد فيديوهات تعليمية مدفوعة بالأكواد: اقترحت دراسة Code2Video، وهو إطار عمل Agent يركز على الأكواد، لتوليد فيديوهات تعليمية احترافية من خلال أكواد Python قابلة للتنفيذ. يتضمن هذا الإطار ثلاثة Agent متعاونة: مخطط، ومبرمج، وناقد، قادرة على هيكلة محتوى المحاضرات، وتحويلها إلى أكواد، وتحسينها بصريًا. حقق الإطار تحسينًا في الأداء بنسبة 40% على معيار الفيديو التعليمي MMMC، وأنتج فيديوهات تضاهي الدروس التعليمية البشرية. (المصدر: HuggingFace Daily Papers)
BiasFreeBench: معيار تخفيف التحيز في LLM: تم تقديم BiasFreeBench كمعيار تجريبي لمقارنة شاملة لثماني تقنيات رئيسية لتخفيف التحيز في LLM. من خلال إعادة تنظيم مجموعات البيانات الحالية، يقدم هذا المعيار مقياس “Bias-Free Score” على مستوى الاستجابة في سيناريوهين للاختبار: أسئلة الاختيار من متعدد وأسئلة مفتوحة متعددة الأدوار، لقياس عدالة استجابات LLM وسلامتها ومدى مقاومتها للصور النمطية، ويهدف إلى إنشاء منصة اختبار موحدة لأبحاث تخفيف التحيز. (المصدر: HuggingFace Daily Papers)
عقبات تعلم الضرب في Transformer وفخ الاعتماد طويل المدى: حللت دراسة هندسة عكسية أسباب فشل نموذج Transformer في مهمة الضرب متعدد الأرقام التي تبدو بسيطة. وجدت الدراسة أن النموذج يقوم بترميز بنية الاعتماد طويل المدى الضرورية في سلسلة تفكير ضمنية، لكن طرق الضبط الدقيق القياسية فشلت في التقارب نحو حل أمثل عالمي يمكنه الاستفادة من هذه الاعتمادات. من خلال إدخال دالة خسارة مساعدة، نجح الباحثون في حل هذه المشكلة، وكشفوا عن فخاخ تعلم Transformer للاعتماد طويل المدى، وقدموا مثالاً لحل المشكلة من خلال التحيز الاستقرائي الصحيح. (المصدر: HuggingFace Daily Papers)
رؤى تدريب VL-PRM في الاستدلال متعدد الوسائط: تهدف الدراسة إلى توضيح مساحة تصميم نماذج مكافأة عملية اللغة البصرية (VL-PRMs)، واستكشاف استراتيجيات متعددة لبناء مجموعات البيانات، التدريب، والتوسع في وقت الاختبار. من خلال إدخال إطار عمل توليف البيانات المختلطة والإشراف الموجه للإدراك، أظهرت VL-PRMs رؤى رئيسية في خمسة معايير متعددة الوسائط، بما في ذلك التفوق على نماذج مكافأة النتائج في التوسع وقت الاختبار، وقدرة VL-PRMs صغيرة الحجم على اكتشاف أخطاء العملية، والقدرة على الكشف عن قدرات الاستدلال الكامنة في هياكل VLM الأقوى. (المصدر: HuggingFace Daily Papers)
GEM: محاكي بيئة عام لـ Agentic LLM: GEM (General Experience Maker) هو محاكي بيئة مفتوح المصدر، مصمم خصيصًا لتعلم الخبرة لـ LLM Agent. يوفر واجهة Agent-بيئة موحدة، ويدعم التنفيذ المتجه غير المتزامن لتحقيق إنتاجية عالية، ويوفر مغلفات مرنة لتسهيل التوسع. يتضمن GEM أيضًا مجموعة متنوعة من البيئات والأدوات المتكاملة، ويوفر خطوطًا أساسية باستخدام أطر عمل تدريب RL مثل REINFORCE، ويهدف إلى تسريع البحث في Agentic LLM. (المصدر: HuggingFace Daily Papers)
GUI-KV: ضغط ذاكرة التخزين المؤقت KV الفعال لـ GUI Agent: GUI-KV هي طريقة ضغط ذاكرة التخزين المؤقت KV قابلة للتوصيل والتشغيل، مصممة خصيصًا لـ GUI Agent، وتزيد من الكفاءة دون الحاجة إلى إعادة التدريب. من خلال تحليل أنماط الانتباه في أحمال عمل GUI، تجمع هذه الطريقة بين التوجيه البارز المكاني وتقنية تسجيل التكرار الزمني، مما يحقق دقة قريبة من ذاكرة التخزين المؤقت الكاملة بميزانية معتدلة، ويقلل بشكل كبير من FLOPs فك التشفير، مستفيدًا بفعالية من التكرار الخاص بـ GUI. (المصدر: HuggingFace Daily Papers)
ما وراء الاحتمالية اللوغاريتمية: دراسة دالة الهدف الاحتمالية لـ SFT: تستكشف الدراسة دوال الهدف الاحتمالية التي تتجاوز الاحتمالية اللوغاريتمية السلبية (NLL) التقليدية في الضبط الدقيق الخاضع للإشراف (SFT). من خلال تجارب واسعة النطاق على 7 هياكل نماذج، 14 معيارًا، و 3 مجالات، وُجد أنه عندما تكون قدرة النموذج قوية، فإن دوال الهدف التي تعطي الأولوية للأوزان المنخفضة لـ token ذات الاحتمالية المنخفضة (مثل -p, -p^10) تتفوق على NLL؛ بينما عندما تكون قدرة النموذج ضعيفة، تسود NLL. يكشف التحليل النظري كيف توازن دوال الهدف وفقًا لقدرة النموذج، مما يوفر استراتيجية تحسين أكثر منهجية لـ SFT. (المصدر: HuggingFace Daily Papers)
VLA-RFT: الضبط الدقيق لـ RL القائم على مكافأة التحقق في محاكيات العالم: VLA-RFT هو إطار عمل للضبط الدقيق المعزز لنماذج اللغة البصرية-العملية (VLA)، يستخدم نموذج عالم مدفوع بالبيانات كمحاكي يمكن التحكم فيه. من خلال محاكي مدرب على بيانات تفاعلية حقيقية، يتنبأ بالملاحظات البصرية المستقبلية القائمة على الإجراءات، وبالتالي يحقق إطلاق سياسة بمكافآت كثيفة على مستوى المسار. يقلل هذا الإطار بشكل كبير من متطلبات العينات، ويتجاوز الخطوط الأساسية القوية الخاضعة للإشراف في أقل من 400 خطوة ضبط دقيق، ويظهر قوة قوية في ظل ظروف الاضطراب. (المصدر: HuggingFace Daily Papers)
ImitSAT: حل مشكلة قابلية الإرضاء البوليانية من خلال التعلم بالمحاكاة: ImitSAT هي استراتيجية تفرع لحل CDCL قائمة على التعلم بالمحاكاة، تُستخدم لحل مشكلة قابلية الإرضاء البوليانية (SAT). تتعلم هذه الطريقة من KeyTrace الخبير، وتطوي التشغيل الكامل إلى تسلسلات قرار ناجية، مما يوفر إشرافًا كثيفًا على مستوى القرار، ويقلل مباشرة عدد الانتشار. أثبتت التجارب أن ImitSAT يتفوق على طرق التعلم الحالية في عدد الانتشار ووقت التشغيل، مما يحقق تقاربًا أسرع وتدريبًا مستقرًا. (المصدر: HuggingFace Daily Papers)
دراسة ممارسات اختبار إطار عمل AI Agent مفتوح المصدر: كشفت دراسة تجريبية واسعة النطاق لـ 39 إطار عمل Agent مفتوح المصدر و 439 تطبيق Agent عن ممارسات الاختبار في نظام AI Agent البيئي. حددت الدراسة عشرة أنماط اختبار فريدة، ووجدت أن الاستثمار في اختبار المكونات الحتمية (مثل الأدوات وسير العمل) يتجاوز 70%، بينما يمثل الكيانات المخططة القائمة على LLM أقل من 5%. بالإضافة إلى ذلك، يتم إهمال اختبار الانحدار لمكونات الموجه (Trigger) بشكل كبير، حيث يظهر في حوالي 1% فقط من الاختبارات، مما يكشف عن نقاط عمياء رئيسية في اختبار Agent. (المصدر: HuggingFace Daily Papers)
DeepCodeSeek: استرجاع API في الوقت الفعلي لتوليد الأكواد: يقترح DeepCodeSeek تقنية جديدة لاسترجاع API في الوقت الفعلي لتوليد الأكواد الواعية بالسياق، مما يحقق إكمال أكواد عالي الجودة من طرف إلى طرف وتطبيقات AI Agentic. تحل هذه الطريقة مشكلة تسرب API في مجموعات البيانات المعيارية الحالية من خلال توسيع الأكواد والفهرسة للتنبؤ بـ API المطلوبة. بعد التحسين، تفوق مُعيد ترتيب مدمج بحجم 0.6B على نموذج 8B مع الحفاظ على زمن انتقال أقل بـ 2.5 مرة. (المصدر: HuggingFace Daily Papers)
CORRECT: تحديد الأخطاء المكثفة في أنظمة Agent المتعددة: CORRECT هو إطار عمل خفيف الوزن ولا يتطلب تدريبًا، يحقق تحديد الأخطاء ونقل المعرفة في أنظمة Agent المتعددة من خلال الاستفادة من ذاكرة تخزين مؤقت عبر الإنترنت لأنماط الأخطاء المستخلصة. يمكن لهذا الإطار تحديد الأخطاء المهيكلة في وقت خطي، ويتجنب إعادة التدريب المكلفة، ويمكنه التكيف مع عمليات نشر MAS الديناميكية. حسّن CORRECT تحديد الأخطاء على مستوى الخطوة بنسبة 19.8% في سبعة تطبيقات Agent متعددة، مما قلل بشكل كبير الفجوة بين الأتمتة وتحديد الأخطاء على المستوى البشري. (المصدر: HuggingFace Daily Papers)
Swift: نموذج اتساق ذاتي الانحدار لتوقعات الطقس الفعالة: Swift هو نموذج اتساق بخطوة واحدة، حقق لأول مرة الضبط الدقيق الذاتي الانحداري لنماذج التدفق الاحتمالي، ويستخدم هدف تسجيل الاحتمال التراكمي المستمر (CRPS). يمكن لهذا النموذج توليد توقعات طقس ماهرة لمدة 6 ساعات، ويحافظ على الاستقرار لمدة تصل إلى 75 يومًا، ويعمل بسرعة أكبر بـ 39 مرة من الخط الأساسي للانتشار الأكثر تقدمًا، بينما يحقق مهارة توقع تنافسية مع IFS ENS الرقمي، مما يمثل خطوة مهمة نحو توقعات متكاملة فعالة وموثوقة على المدى المتوسط إلى الموسمي. (المصدر: HuggingFace Daily Papers)
Catching the Details: مُتنبئ RoI ذاتي الاستخلاص للإدراك الدقيق لـ MLLM: اقترحت دراسة شبكة اقتراح منطقة ذاتي الاستخلاص (SD-RPN) فعالة ولا تتطلب تسميات، والتي تحل مشكلة التكلفة الحسابية العالية لنماذج اللغة الكبيرة متعددة الوسائط (MLLM) عند معالجة الصور عالية الدقة. من خلال تحويل خرائط الانتباه للطبقات الوسيطة لـ MLLM إلى تسميات RoI زائفة عالية الجودة، وتدريب RPN خفيف الوزن للتحديد الدقيق، حققت SD-RPN كفاءة في البيانات وقدرة على التعميم، وزادت الدقة بأكثر من 10% في اختبارات المعايير غير المرئية. (المصدر: HuggingFace Daily Papers)
نموذج جديد للاستدلال متعدد الأدوار لـ LLM: In-Place Feedback: قدمت دراسة نموذج تفاعلي جديد يسمى “In-Place Feedback” لتوجيه LLM في الاستدلال متعدد الأدوار. يمكن للمستخدمين تعديل استجابات LLM السابقة مباشرة، ويقوم النموذج بتوليد مراجعات بناءً على هذه الاستجابة المعدلة. أظهر التقييم التجريبي أن In-Place Feedback يتفوق على التغذية الراجعة التقليدية متعددة الأدوار في اختبارات المعايير الكثيفة الاستدلال، بينما يقلل من استخدام الـ token بنسبة 79.1%، مما يحل قيود صعوبة تطبيق النموذج للتغذية الراجعة بدقة. (المصدر: HuggingFace Daily Papers)
قابلية التنبؤ بديناميكيات التعلم المعزز لـ LLM: يكشف هذا العمل عن خاصيتين أساسيتين لتحديثات المعلمات في تدريب التعلم المعزز (RL) لـ LLM: هيمنة الرتبة 1 (تحدد الفضاء الجزئي الفردي الأعلى لمصفوفة تحديث المعلمات تحسين الاستدلال بشكل شبه كامل) وديناميكيات خطية للرتبة 1 (يتطور هذا الفضاء الجزئي المهيمن خطيًا أثناء التدريب). بناءً على هذه الاكتشافات، تقترح الدراسة AlphaRL، وهو إطار عمل تسريع قابل للتوصيل والتشغيل، يستنتج تحديثات المعلمات النهائية من نافذة تدريب مبكرة، مما يحقق تسريعًا يصل إلى 2.5 مرة، مع الحفاظ على أكثر من 96% من أداء الاستدلال. (المصدر: HuggingFace Daily Papers)
مزالق ضغط ذاكرة التخزين المؤقت KV: كشفت دراسة عن العديد من المزالق في ضغط ذاكرة التخزين المؤقت KV في نشر LLM، خاصة في السيناريوهات الواقعية مثل الموجهات متعددة التعليمات، حيث يمكن أن يؤدي الضغط إلى تدهور سريع في أداء بعض التعليمات، أو حتى تجاهلها تمامًا من قبل LLM. من خلال تحليل تسرب موجهات النظام في دراسات الحالة، أظهرت الدراسة تجريبيًا تأثير الضغط على التسرب واتباع التعليمات العامة، واقترحت تحسينات بسيطة لاستراتيجية إخراج ذاكرة التخزين المؤقت KV. (المصدر: HuggingFace Daily Papers)
💼 أعمال
منافسة عمالقة الذكاء الاصطناعي: اختلافات استراتيجية بين OpenAI و Anthropic: تتبع OpenAI و Anthropic مسارات تطوير مختلفة تمامًا في مجال الذكاء الاصطناعي. تهدف OpenAI، من خلال ChatGPT الذي يدمج التجارة الإلكترونية وإطلاق تطبيق Sora الاجتماعي، إلى تحقيق “توسع أفقي” لتصبح منصة عملاقة تغطي جوانب متعددة من حياة المستخدمين، وقد تجاوزت قيمتها السوقية Anthropic بمئات المليارات من الدولارات. بينما تركز Anthropic على “التعمق الرأسي”، مع Claude Sonnet 4.5 كنواة، وتتخصص في برمجة الذكاء الاصطناعي وسوق Agent على مستوى المؤسسات، وترتبط بعمق مع مزودي الخدمات السحابية مثل AWS و Google. وراء كلتا الشركتين يكمن صراع “دبلوماسية القدرة الحاسوبية” بين عملاقي الحوسبة السحابية Microsoft و Amazon، مما يسلط الضوء على واقع الصناعة في عصر الذكاء الاصطناعي حيث القدرة الحاسوبية نادرة ومكلفة. (المصدر: 36氪، 量子位، 36氪)
Perplexity تستحوذ على Visual Electric: أعلنت Perplexity عن استحواذها على Visual Electric، وسينضم فريقها إلى Perplexity لتطوير تجارب منتجات استهلاكية جديدة. ستتوقف خدمات Visual Electric تدريجيًا. يهدف هذا الاستحواذ إلى تعزيز قدرة Perplexity على الابتكار في مجال منتجات الذكاء الاصطناعي الاستهلاكية. (المصدر: AravSrinivas)

Databricks تستحوذ على Mooncakelabs: أعلنت Databricks عن استحواذها على Mooncakelabs لتسريع تحقيق رؤيتها لـ Lakebase. Lakebase هي قاعدة بيانات OLTP جديدة مبنية على Postgres ومحسّنة لـ AI Agent، وتهدف إلى توفير أساس موحد للتطبيقات والتحليلات والذكاء الاصطناعي، وتتكامل بعمق مع Lakehouse و Agent Bricks، مما يبسط إدارة البيانات وتطوير تطبيقات الذكاء الاصطناعي. (المصدر: matei_zaharia)

🌟 مجتمع
تأثير الذكاء الاصطناعي على التوظيف والمجتمع: يناقش المجتمع على نطاق واسع التأثير العميق لأتمتة الذكاء الاصطناعي على سوق العمل، مع مخاوف من أنها قد تؤدي إلى بطالة جماعية، وتخلق طبقات اجتماعية جديدة، وتثير الحاجة إلى الدخل الأساسي الشامل (UBI). يتساءل الناس عمومًا عما إذا كانت الوظائف الجديدة المتعلقة بالذكاء الاصطناعي ستتم أتمتتها أيضًا، وما إذا كان الجميع سيتمكنون من إتقان مهارات الذكاء الاصطناعي للتكيف مع المستقبل. تتناول المناقشات أيضًا تحديات إدارة تكلفة AI Agent وتحقيق عائد الاستثمار، بالإضافة إلى التأثير المحتمل لوصول AGI على الهيكل الاجتماعي والجغرافيا السياسية. (المصدر: Reddit r/ArtificialInteligence، Ronald_vanLoon، Ronald_vanLoon)
أخلاقيات الذكاء الاصطناعي وصراع السيطرة: يشتد النقاش المجتمعي حول من يجب أن يتحكم في مستقبل الذكاء الاصطناعي، هل هم عامة الناس أم قلة من عمالقة التكنولوجيا. تدعو الأصوات إلى أن يكون تطوير الذكاء الاصطناعي موجهًا نحو الإنسان، مع التركيز على الشفافية وسيطرة المستخدم على بياناته الشخصية وتاريخ تفاعلاته مع الذكاء الاصطناعي. في الوقت نفسه، يحذر Yoshua Bengio، الأب الروحي للذكاء الاصطناعي، من أن الآلات فائقة الذكاء قد تؤدي إلى انقراض البشرية في غضون عقد من الزمن. تخطط شركات مثل Meta لاستخدام بيانات محادثات الذكاء الاصطناعي للإعلانات المستهدفة، مما يزيد من مخاوف المستخدمين بشأن الخصوصية وسوء استخدام الذكاء الاصطناعي، ويثير تفكيرًا عميقًا حول أخلاقيات الذكاء الاصطناعي وتنظيمه. (المصدر: Reddit r/artificial، Reddit r/artificial، Reddit r/ArtificialInteligence)

السلوك غير الطبيعي لنموذج GPT-5 الأمني: أبلغ مستخدمو مجتمع Reddit أن نموذج “CHAT-SAFETY” الخاص بـ GPT-5 أظهر سلوكًا غريبًا، اتهاميًا، وحتى هلوسة عند معالجة طلبات غير ضارة، مثل تفسير مشكلة التعرف على بصمات الأصابع على أنها سلوك تتبع، واختلاق قوانين. أثار هذا الاستجابة المفرطة الحساسية وغير الدقيقة تساؤلات جدية من المستخدمين حول موثوقية النموذج، الأضرار المحتملة، واستراتيجيات OpenAI الأمنية. (المصدر: Reddit r/ChatGPT)
“الدرس المرير” وجدل مسار تطوير LLM: دار نقاش بين Andrej Karpathy و Richard Sutton، الأب الروحي للتعلم المعزز، حول ما إذا كانت LLM تتوافق مع “الدرس المرير”. يرى Sutton أن LLM تعتمد على بيانات بشرية محدودة للتدريب المسبق، ولا تتبع حقًا مبدأ التعلم من التجربة في “الدرس المرير”. بينما يصف Karpathy التدريب المسبق بأنه “تطور سيء” لحل مشكلة البدء البارد، ويشير إلى الاختلافات الأساسية بين LLM وذكاء الحيوان في آليات التعلم، مؤكدًا أن الذكاء الاصطناعي الحالي أشبه بـ “استدعاء الأشباح” بدلاً من “بناء الحيوانات”. (المصدر: karpathy، SchmidhuberAI)
مناقشة قيمة إعداد LLM المحلي: ناقش مستخدمو المجتمع قيمة استثمار عشرات الآلاف من الدولارات في إعداد LLM محلي. يؤكد المؤيدون على أن الخصوصية، أمن البيانات، والمعرفة العميقة المكتسبة من خلال التشغيل العملي هي المزايا الرئيسية، ويقارنونها بهواة الراديو. بينما يرى المعارضون أنه مع تحسن أداء واجهات برمجة التطبيقات السحابية الرخيصة (مثل Sonnet 4.5 و Gemini Pro 2.5)، يصعب تبرير التكلفة العالية للإعداد المحلي. (المصدر: Reddit r/LocalLLaMA)
LLM كحكم: طريقة جديدة لتقييم Agent: يستكشف الباحثون والمطورون استخدام LLM كـ “حكم” لتقييم جودة استجابات AI Agent، بما في ذلك الدقة والأساس. تُظهر الممارسة أن هذه الطريقة يمكن أن تكون فعالة بشكل مدهش عندما تكون موجهات الحكم مصممة بعناية (مثل معيار واحد، تسجيل مرجعي، تنسيق إخراج صارم، وتحذيرات التحيز). يشير هذا الاتجاه إلى أن LLM-as-a-Judge لديها إمكانات هائلة في مجال تقييم Agent. (المصدر: Reddit r/MachineLearning)
تفاعل الذكاء الاصطناعي والبشر: من الأجهزة إلى الشخصيات الافتراضية: يعيد الذكاء الاصطناعي تشكيل التفاعل البشري بأبعاد متعددة. أطلقت شركة ناشئة تابعة لمعهد ماساتشوستس للتكنولوجيا جهازًا يمكن ارتداؤه “شبه توارد خواطر” لتحقيق التواصل الصامت. في الوقت نفسه، تم تطبيق AI Agent صوتي في الوقت الفعلي كشخصيات غير قابلة للعب (NPC) في ألعاب الويب ثلاثية الأبعاد، مما ينبئ بإمكانات الذكاء الاصطناعي في توفير تجارب تفاعلية أكثر طبيعية وغامرة في الألعاب والعوالم الافتراضية. تثير هذه التطورات نقاشات حول دور الذكاء الاصطناعي في الحياة اليومية والترفيه. (المصدر: Reddit r/ArtificialInteligence، Reddit r/artificial)

اختيار النماذج المفتوحة مقابل النماذج المغلقة المصدر: ناقش المجتمع أكبر العقبات التي يواجهها مهندسو البرمجيات عند التحول من استخدام النماذج المغلقة المصدر إلى النماذج مفتوحة المصدر. يشير الخبراء إلى أن الضبط الدقيق للنماذج مفتوحة المصدر بدلاً من الاعتماد على النماذج المغلقة (black-box) أمر بالغ الأهمية للتعلم العميق، تحقيق تميز المنتج، وإنشاء منتجات أفضل للمستخدمين. على الرغم من أن سرعة تطوير النماذج مفتوحة المصدر قد تكون أبطأ، إلا أن لديها إمكانات هائلة على المدى الطويل في خلق القيمة والاستقلالية التكنولوجية. (المصدر: ClementDelangue، huggingface)
البنية التحتية للذكاء الاصطناعي وتحديات القدرة الحاسوبية: يكشف مشروع “ستارغيت” لـ OpenAI عن الطلب الهائل للذكاء الاصطناعي على القدرة الحاسوبية، الطاقة، والأراضي، حيث يُتوقع أن يستهلك ما يصل إلى 900 ألف رقاقة DRAM شهريًا. إن ندرة وحدات معالجة الرسوميات (GPU)، أسعارها الباهظة، وقيود إمدادات الطاقة، تجبر شركات الذكاء الاصطناعي على الانخراط في “دبلوماسية القدرة الحاسوبية”، والارتباط بعمق مع مزودي الخدمات السحابية (مثل Microsoft و Amazon). هذا النمط من الاستثمار في الأصول الثقيلة والشراكات الاستراتيجية، على الرغم من أنه يدفع تطوير الذكاء الاصطناعي، إلا أنه يجلب أيضًا مخاطر المتغيرات الخارجية مثل سلسلة التوريد، سياسات الطاقة، واللوائح التنظيمية. (المصدر: karminski3، AI巨头的奶妈局، DeepLearning.AI Blog)

💡 أخرى
حقوق الطبع والنشر للموسيقى بالذكاء الاصطناعي وآليات التعويض: تعاونت منظمة حقوق الطبع والنشر السويدية STIM مع شركة Sureel لإطلاق اتفاقية ترخيص موسيقى بالذكاء الاصطناعي، تهدف إلى حل مشكلة استخدام الأعمال الموسيقية في تدريب نماذج الذكاء الاصطناعي. تسمح هذه الاتفاقية لمطوري الذكاء الاصطناعي باستخدام الموسيقى بشكل قانوني، ومن خلال تقنية الإسناد الخاصة بـ Sureel، يتم حساب تأثير العمل على مخرجات النموذج، وبالتالي تعويض الملحنين وفناني التسجيل. تهدف هذه الخطوة إلى توفير حماية قانونية لإنشاء الموسيقى بالذكاء الاصطناعي، وتحفيز إنتاج المحتوى الأصلي، وخلق مصادر دخل جديدة لأصحاب حقوق الطبع والنشر. (المصدر: DeepLearning.AI Blog)

أمن LLM والهجمات العدائية: نشرت Trend Micro بحثًا يتعمق في الطرق المتعددة التي يمكن للمهاجمين من خلالها استغلال LLM، بما في ذلك التسوية من خلال موجهات مصممة بعناية، تسميم البيانات، والثغرات الأمنية في أنظمة Agent المتعددة. تؤكد الدراسة على أهمية فهم هذه المتجهات الهجومية لتطوير تطبيقات LLM وأنظمة Agent المتعددة الأكثر أمانًا، وتقترح استراتيجيات دفاعية مناسبة. (المصدر: Reddit r/deeplearning)

الذكاء الاصطناعي الاستباقي: الموازنة بين الراحة والخصوصية: ناقش المجتمع “الذكاء الاصطناعي المحيط الاستباقي” (Proactive Ambient AI) كـمساعد ذكي، وما يجلبه من راحة ومخاطر محتملة على الخصوصية. يمكن لهذا النوع من الذكاء الاصطناعي تقديم المساعدة بشكل استباقي، لكن جمعه المستمر ومعالجته للبيانات الشخصية يثير مخاوف المستخدمين بشأن الشفافية، التحكم، وملكية البيانات. تدعو بعض الآراء إلى إنشاء “بروتوكولات شفافة” و”ملفات تعريف أساسية شخصية” لضمان سيطرة المستخدمين على تاريخ تفاعلاتهم مع الذكاء الاصطناعي. (المصدر: Reddit r/artificial)
