
كلمات مفتاحية:الحوسبة الكمية, القيادة الذاتية, النماذج اللغوية الكبيرة, نماذج التوليد ثلاثية الأبعاد, أدوات الذكاء الاصطناعي, تعلم الآلة, بحوث الذكاء الاصطناعي, منصة الحوسبة الكمية CUDA-Q, دراسة بيانات القيادة الذاتية من Waymo, نظام وكيل متعدد Claude, Tencent Hunyuan 3D 2.1, تحسين أداء نواة التوليد بالذكاء الاصطناعي
🔥 أبرز العناوين
إنفيديا تطلق منصة CUDA-Q المخصصة للحوسبة الكمومية: أعلن جنسن هوانغ، الرئيس التنفيذي لشركة إنفيديا، خلال كلمته في مؤتمر GTC باريس عن إطلاق CUDA-Q، وهي منصة حوسبة فائقة تجمع بين التسريع الكمومي والكلاسيكي. تهدف هذه المنصة إلى سد الفجوة بين الحوسبة الكلاسيكية الحالية والحوسبة الكمومية المستقبلية، مما يسمح بمحاكاة العمليات الكمومية على الحواسيب الكلاسيكية، أو تقديم الدعم للحواسيب الكمومية الحقيقية. منصة CUDA-Q متاحة الآن على Grace Blackwell، ويمكنها تسريع وتيرة التطوير بمقدار 1300 مرة عبر الحاسوب الفائق GB200 NVL72. توقع هوانغ أن يتم تطبيق الحواسيب الكمومية فعليًا في غضون سنوات قليلة، وأكد أنه في مرحلة التطوير هذه، لا غنى عن شرائح إنفيديا (خاصة GB200) في محاكاة الحوسبة ودعم وحدات المعالجة الكمومية (QPU). تتعاون إنفيديا حاليًا مع شركات الحوسبة الكمومية ومراكز الحوسبة الفائقة العالمية لاستكشاف العمل المشترك بين وحدات معالجة الرسومات (GPU) ووحدات المعالجة الكمومية (QPU) (المصدر: كوانتوم بيت)

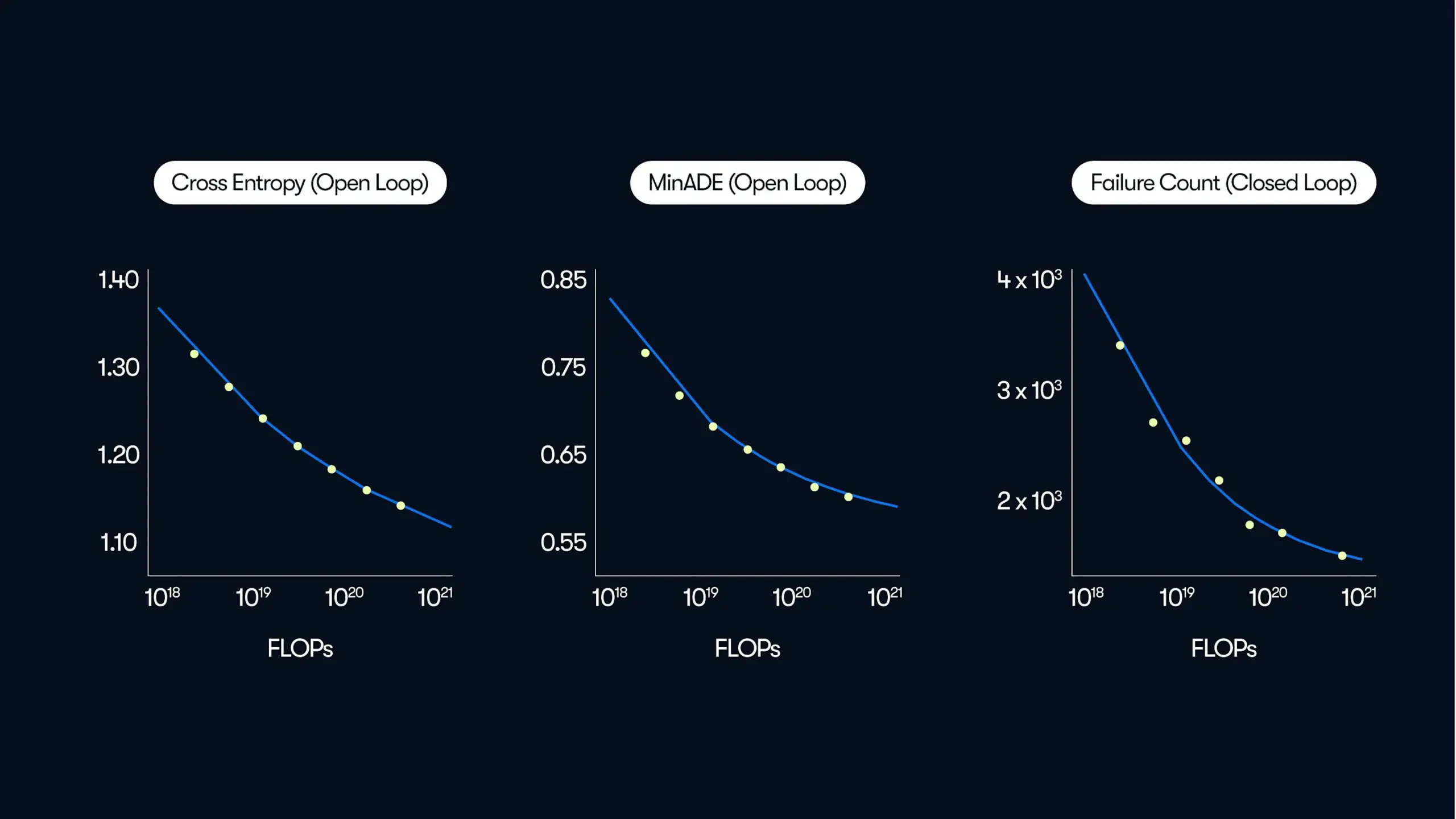
Waymo تنشر دراسة واسعة النطاق حول القيادة الذاتية، تكشف عن قوانين تحسين الأداء “القائمة على البيانات”: شاركت Waymo في أحدث تدوينة لها نتائج دراسة شاملة مبنية على 500 ألف ساعة من بيانات القيادة، وهي أكبر مجموعة بيانات في مجال القيادة الذاتية حتى الآن. أظهرت الدراسة أنه، على غرار نماذج اللغة الكبيرة (LLM)، فإن جودة التنبؤ بالحركة في أنظمة القيادة الذاتية تتبع أيضًا علاقة قانون القوة مع زيادة حجم الحوسبة التدريبية. يعد توسيع نطاق البيانات أمرًا بالغ الأهمية لتحسين أداء النموذج، وفي الوقت نفسه، يمكن أن تؤدي زيادة قدرة الحوسبة الاستنتاجية أيضًا إلى تحسين قدرة النموذج على التعامل مع سيناريوهات القيادة المعقدة. أكدت هذه الدراسة لأول مرة أنه من خلال زيادة بيانات التدريب والموارد الحاسوبية، يمكن تحسين أداء القيادة الذاتية في العالم الحقيقي بشكل كبير، مما يوجه الصناعة نحو مسار تحسين القدرات من خلال التوسع (المصدر: Sawyer Merritt, scaling01)
Anthropic تشارك خبراتها في بناء نظام Claude البحثي متعدد الوكلاء: شرحت Anthropic بالتفصيل في مدونتها الهندسية كيفية استخدام وكلاء متعددين يعملون بالتوازي لبناء القدرات البحثية لـ Claude. شارك المقال الخبرات الناجحة والمشكلات التي تمت مواجهتها والتحديات الهندسية أثناء عملية التطوير. يسمح هذا النظام متعدد الوكلاء لـ Claude باسترجاع المعلومات وتحليلها وتجميعها بشكل أكثر فعالية، وبالتالي تعزيز قدرته على البحث والإجابة على الأسئلة المعقدة. تعتبر هذه المشاركة ذات قيمة مرجعية مهمة لفهم كيف يمكن لنماذج اللغة الكبيرة توسيع وظائفها من خلال تصميم الأنظمة المعقدة (المصدر: ImazAngel, teortaxesTex)
Meta تطلق نموذج العالم V-JEPA 2، لتحقيق فهم الفيديو والتنبؤ به والتحكم في الروبوتات: أطلقت Meta AI نموذج V-JEPA 2، وهو نموذج عالمي مدرب على الفيديو، وقد حقق تقدمًا ملحوظًا في فهم ديناميكيات العالم المادي والتنبؤ بها. لا يستطيع V-JEPA 2 تعلم ميزات الفيديو بكفاءة فحسب، بل يمكنه أيضًا تحقيق التخطيط بدون تدريب مسبق (zero-shot planning) والتحكم في الروبوتات في بيئات جديدة، مما يدل على إمكاناته في مجال الذكاء الاصطناعي العام. يتعلم هذا النموذج تمثيلات العالم من بيانات الفيديو من خلال التعلم الذاتي الإشراف (self-supervised learning)، مما يوفر مسارًا جديدًا لبناء أنظمة ذكاء اصطناعي أكثر ذكاءً وقدرة على التفاعل مع العالم الحقيقي (المصدر: dl_weekly)
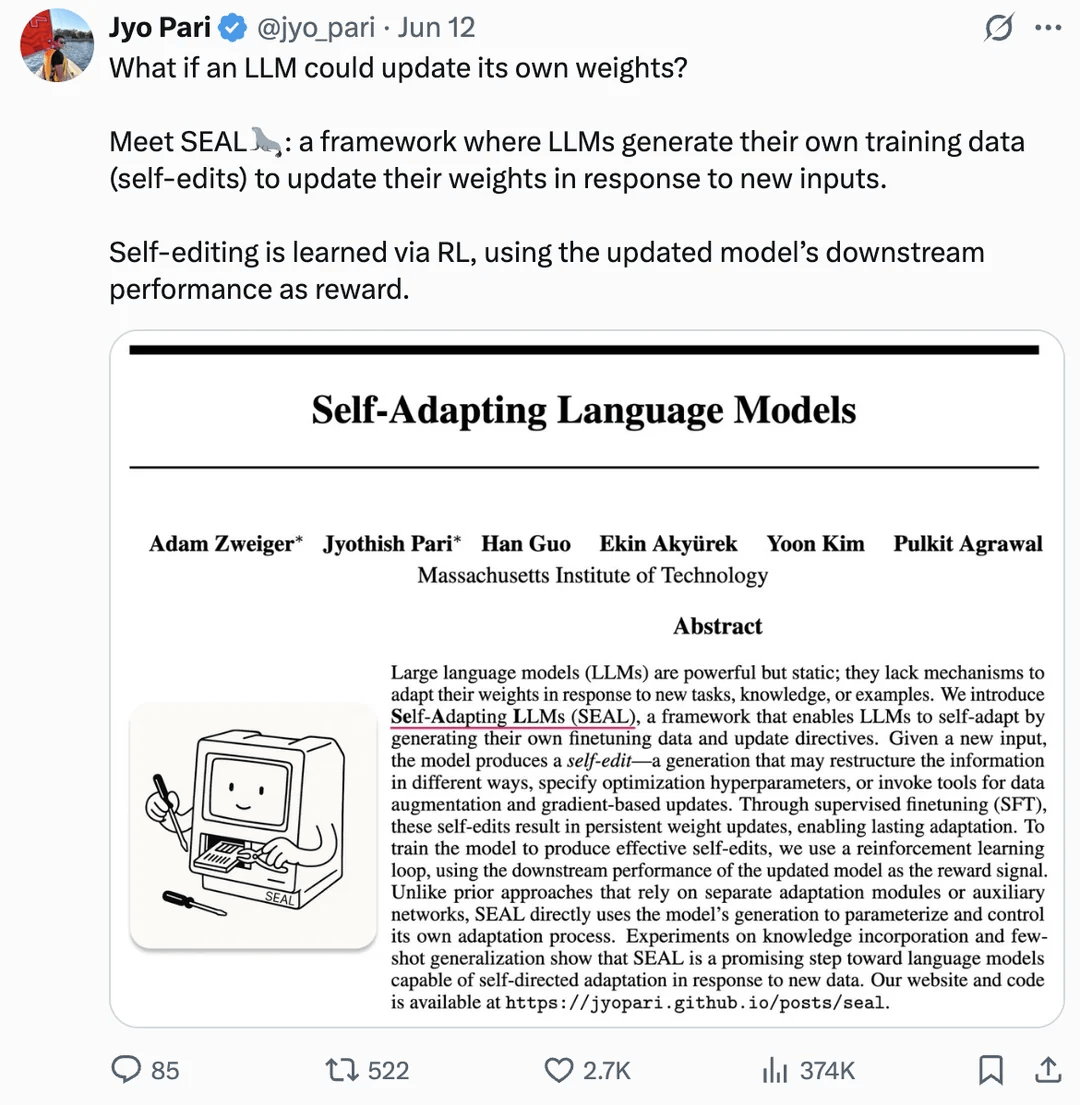
ورقة بحثية تناقش التحديث الذاتي لأوزان نماذج اللغة الكبيرة (LLM) لتحقيق التحسين الذاتي: اقترحت ورقة بحثية نُشرت على arXiv (2506.10943) أن نماذج اللغة الكبيرة (LLM) يمكنها الآن تحقيق التحسين الذاتي عن طريق تحديث أوزانها الخاصة. قد تعني هذه الآلية أن نماذج اللغة الكبيرة قادرة على التعلم من البيانات أو الخبرات الجديدة وتعديل معلماتها الداخلية ديناميكيًا لتحسين الأداء أو التكيف مع المهام الجديدة، دون الحاجة إلى إعادة تدريب كاملة. إذا نجح هذا الاتجاه البحثي، فسوف يعزز بشكل كبير قدرة نماذج اللغة الكبيرة على التكيف والتعلم المستمر، وهو خطوة مهمة نحو أنظمة ذكاء اصطناعي أكثر استقلالية (المصدر: Reddit r/artificial)
🎯 اتجاهات
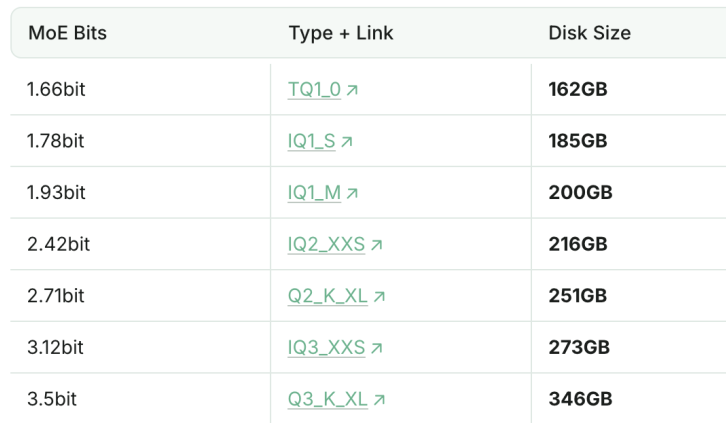
نسخة DeepSeek-R1 المكممة بـ 1.93bit تتفوق في قدرات البرمجة على Claude 4 Sonnet: نجح استوديو Unsloth في تكميم DeepSeek-R1 (إصدار 0528) إلى 1.93bit، وحقق 60% في اختبار البرمجة القياسي aider، متجاوزًا Claude 4 Sonnet (56.4%) وإصدار يناير من R1 كامل الدقة. أدى هذا الإصدار المضغوط للغاية إلى تقليل حجم الملف بأكثر من 70%، ويمكن تشغيله حتى بدون وحدة معالجة رسومات (GPU) (وحدة معالجة مركزية CPU مع ذاكرة كافية). سجل إصدار R1-0528 كامل الدقة 71.4% على aider، متجاوزًا Claude 4 Opus بدون وضع التفكير. وهذا يوضح إمكانات تقنية تكميم النماذج في الحفاظ على الأداء مع تقليل متطلبات الموارد بشكل كبير (المصدر: كوانتوم بيت)
Tencent Hunyuan تفتح مصدر أول نموذج توليد ثلاثي الأبعاد Hunyuan 3D 2.1 بمستوى إنتاجي يعتمد على PBR: أعلن فريق Tencent Hunyuan عن فتح مصدر Hunyuan 3D 2.1، وهو أول نموذج توليد ثلاثي الأبعاد مفتوح المصدر بالكامل في الصناعة يصل إلى مستوى إنتاجي ويعتمد على PBR (Physically Based Rendering). يستخدم هذا النموذج تقنية تركيب مواد PBR، ويمكنه إنشاء محتوى ثلاثي الأبعاد بتأثيرات بصرية سينمائية، مما يجعل مواد مثل الجلد والبرونز تبدو أكثر حيوية وواقعية تحت الإضاءة. يتيح المشروع الوصول إلى أوزان النموذج، وأكواد التدريب/الاستدلال، وخطوط أنابيب البيانات، والبنية، ويدعم التشغيل على بطاقات الرسومات الاستهلاكية، بهدف تعزيز تطوير وتعميم تقنية إنشاء المحتوى ثلاثي الأبعاد (المصدر: op7418, ImazAngel)
Meta AI تطلق Sonata، لتعزيز التعلم الذاتي الإشراف لتمثيلات السحب النقطية ثلاثية الأبعاد: أطلقت Meta AI مشروع Sonata، وهو بحث حقق تقدمًا ملحوظًا في مجال التعلم الذاتي الإشراف ثلاثي الأبعاد. من خلال تحديد وحل مشكلات الاختصارات الهندسية، وتقديم إطار عمل مرن وفعال، يستطيع Sonata تعلم تمثيلات سحب نقطية ثلاثية الأبعاد قوية بشكل استثنائي. يعزز هذا العمل المستوى الحالي لتقنيات الإدراك ثلاثي الأبعاد ويضع الأساس للابتكار المستقبلي في مجال الإدراك ثلاثي الأبعاد وتطبيقاته (المصدر: AIatMeta)

Meta AI تطلق “مجموعة بيانات التعرف على القراءة في البيئات الطبيعية” لفهم سلوك القراءة: كشفت Meta AI عن مجموعة بيانات كبيرة متعددة الوسائط تسمى “Reading Recognition in the Wild”، تتضمن مقاطع فيديو، وتتبع حركة العين، ومخرجات مستشعرات وضع الرأس. تهدف مجموعة البيانات هذه إلى المساعدة في حل مهام التعرف على القراءة من الأجهزة القابلة للارتداء، وهي أول مجموعة بيانات من منظور ذاتي تجمع بيانات حركة العين بتردد عالٍ يبلغ 60 هرتز، مما يوفر موردًا قيمًا لدراسة سلوك القراءة البشري (المصدر: AIatMeta)

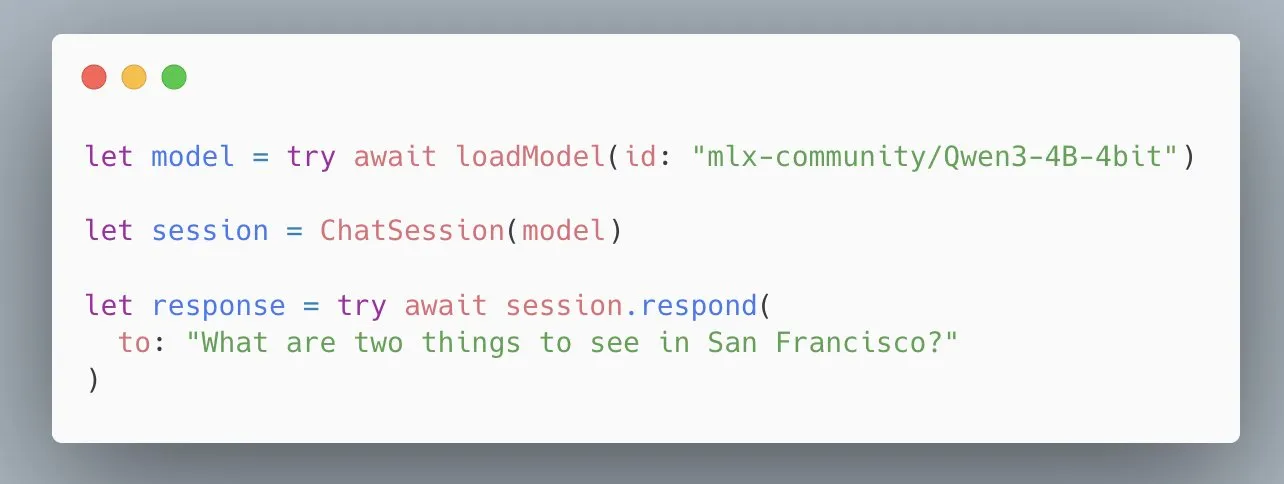
تبسيط واجهة برمجة تطبيقات MLX Swift LLM API من Apple، تحميل النموذج بثلاثة أسطر من التعليمات البرمجية: استجابةً لملاحظات المطورين حول صعوبة البدء باستخدام MLX Swift LLM API، قام فريق Apple بتحسينها بسرعة، وأطلق واجهة برمجة تطبيقات مبسطة جديدة. الآن، يمكن للمطورين تحميل نماذج اللغة الكبيرة (LLM) أو نماذج اللغة المرئية (VLM) وبدء جلسات الدردشة في مشاريع Swift بثلاثة أسطر فقط من التعليمات البرمجية، مما يقلل بشكل كبير من عتبة استخدام نماذج اللغة الكبيرة في نظام Apple البيئي (المصدر: stablequan)
جوجل Gemma3 4B تطلق نسخة GAIA المحسنة للغة البرتغالية البرازيلية: أطلقت جوجل بالتعاون مع عدة مؤسسات برازيلية (ABRIA, CEIA-UFG, Nama, Amadeus AI) و DeepMind، نموذج اللغة مفتوح المصدر GAIA (Gemma-3-Gaia-PT-BR-4b-it) المحسن للغة البرتغالية البرازيلية. يعتمد هذا النموذج على Gemma-3-4b-pt، وتم تدريبه بشكل مستمر على 13 مليار رمز (token) برتغالي برازيلي عالي الجودة. يستخدم GAIA تقنية “دمج الأوزان” المبتكرة لتحقيق اتباع التعليمات، دون الحاجة إلى الضبط الدقيق التقليدي (SFT)، وتفوق على نموذج Gemma الأساسي في اختبار ENEM 2024 القياسي. هذا النموذج مناسب للدردشة، والإجابة على الأسئلة، والتلخيص، وتوليد النصوص، وكأساس للضبط الدقيق للغة البرتغالية البرازيلية (المصدر: Reddit r/LocalLLaMA)
روبوتات Figure AI تدمج Helix AI والاستقلالية، لدفع عجلة النشر القابل للتطوير: عرضت Figure AI كيف يمكن لروبوتاتها في العالم الحقيقي دفع عجلة النشر القابل للتطوير من خلال تعزيز Helix AI والاستقلالية. يشير هذا إلى أن الجمع بين الروبوتات المادية ونماذج الذكاء الاصطناعي المتقدمة يجعل تطبيق الروبوتات في بيئات أكثر تعقيدًا ممكنًا، ويؤكد على أهمية الهندسة والتقنيات الناشئة في مجال الروبوتات (المصدر: Ronald_vanLoon)
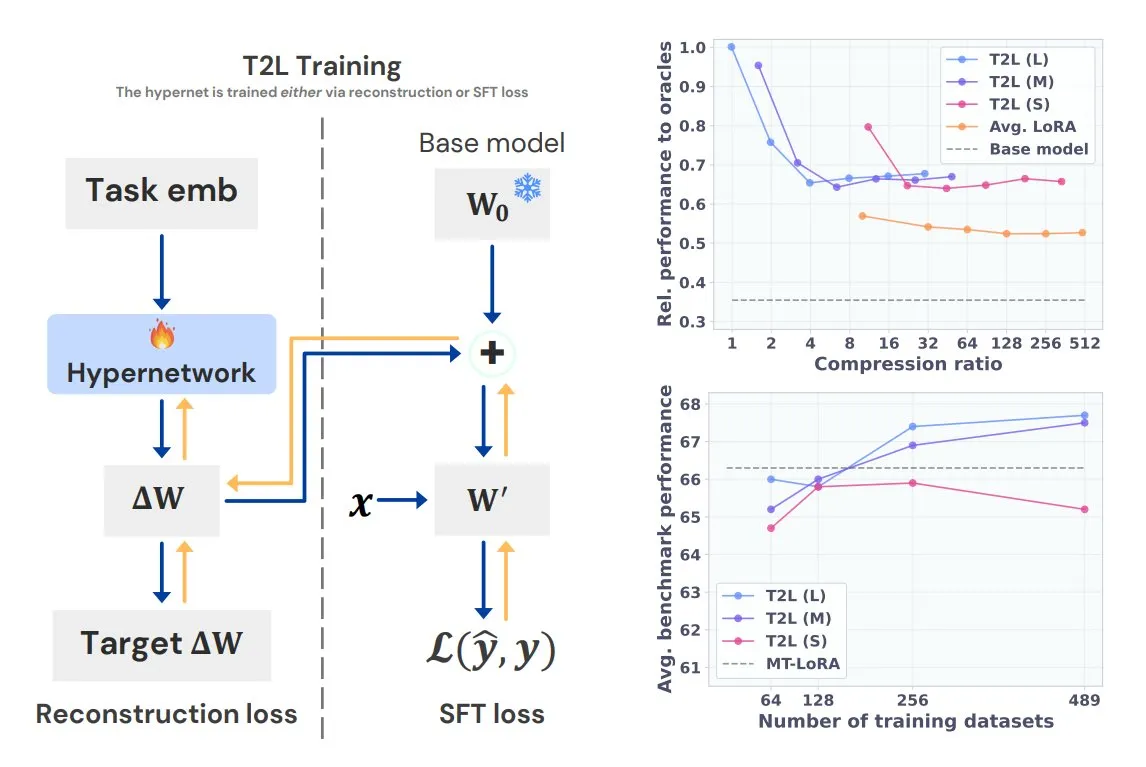
Sakana AI تطلق الشبكة الفائقة Text-to-LoRA (T2L): أطلقت Sakana AI شبكة Text-to-LoRA (T2L)، وهي شبكة فائقة جديدة قادرة على ضغط العديد من LoRA (Low-Rank Adaptation) الحالية في نفسها، وإنشاء محولات LoRA جديدة بسرعة لنماذج اللغة الكبيرة فقط من خلال الوصف النصي للمهمة. بعد تدريب T2L، يمكنها إنشاء LoRA جديدة على الفور، مما يوفر مسارًا فعالًا للتخصيص السريع ونشر نماذج اللغة الكبيرة الخاصة بمهام محددة، وسيتم عرض النتائج ذات الصلة في ICML 2025 (المصدر: TheTuringPost)
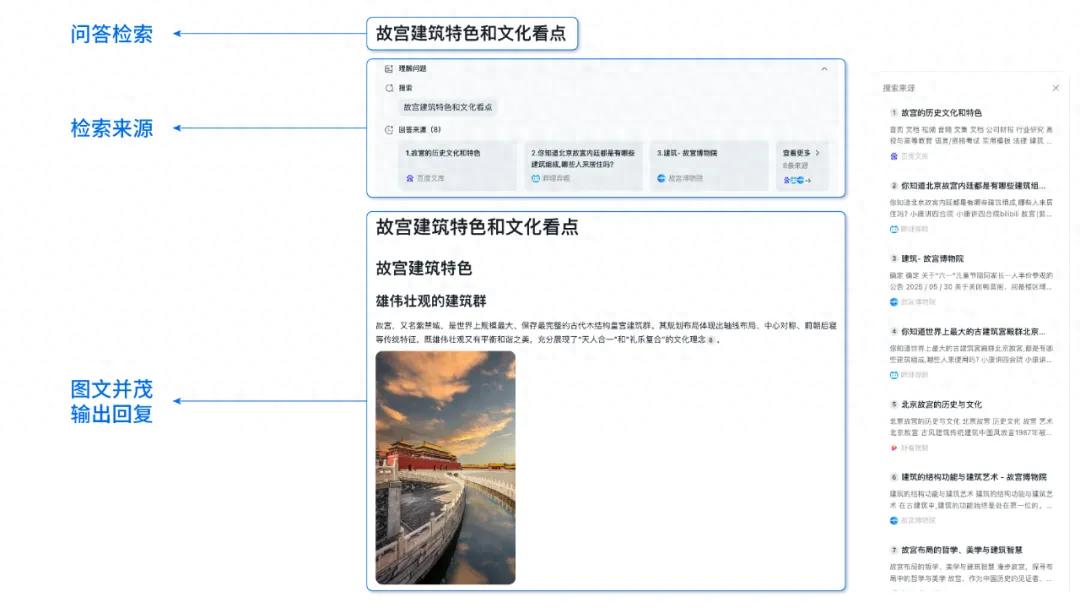
بحث Baidu AI Search متاح بالكامل على منصة Baidu Smart Cloud Qianfan: أطلقت منصة تطوير تطبيقات Baidu Smart Cloud Qianfan AppBuilder رسميًا خدمة “Baidu AI Search”. تدمج هذه الخدمة قدرتين أساسيتين هما “Baidu Search” و “Intelligent Search Generation”، لتزويد الشركات بخدمات متكاملة بدءًا من استرجاع المعلومات وحتى التوليد الذكي. تستفيد من تقنية البحث الصينية التي طورتها Baidu على مدار أكثر من 20 عامًا وقاعدة بياناتها التي تضم مئات المليارات من الإدخالات، لتقديم نتائج بحث متعددة الوسائط خالية من الإعلانات، وتدعم التصفية الدقيقة، وتتبع المصدر، وسياسات الأمان على مستوى المؤسسات. تجمع قدرة التوليد الذكي للبحث بين نماذج مثل Wenxin و Deepseek، لتقديم وظائف مثل التلخيص بالذكاء الاصطناعي والبحث المشترك في المعرفة الخاصة (المصدر: كوانتوم بيت)
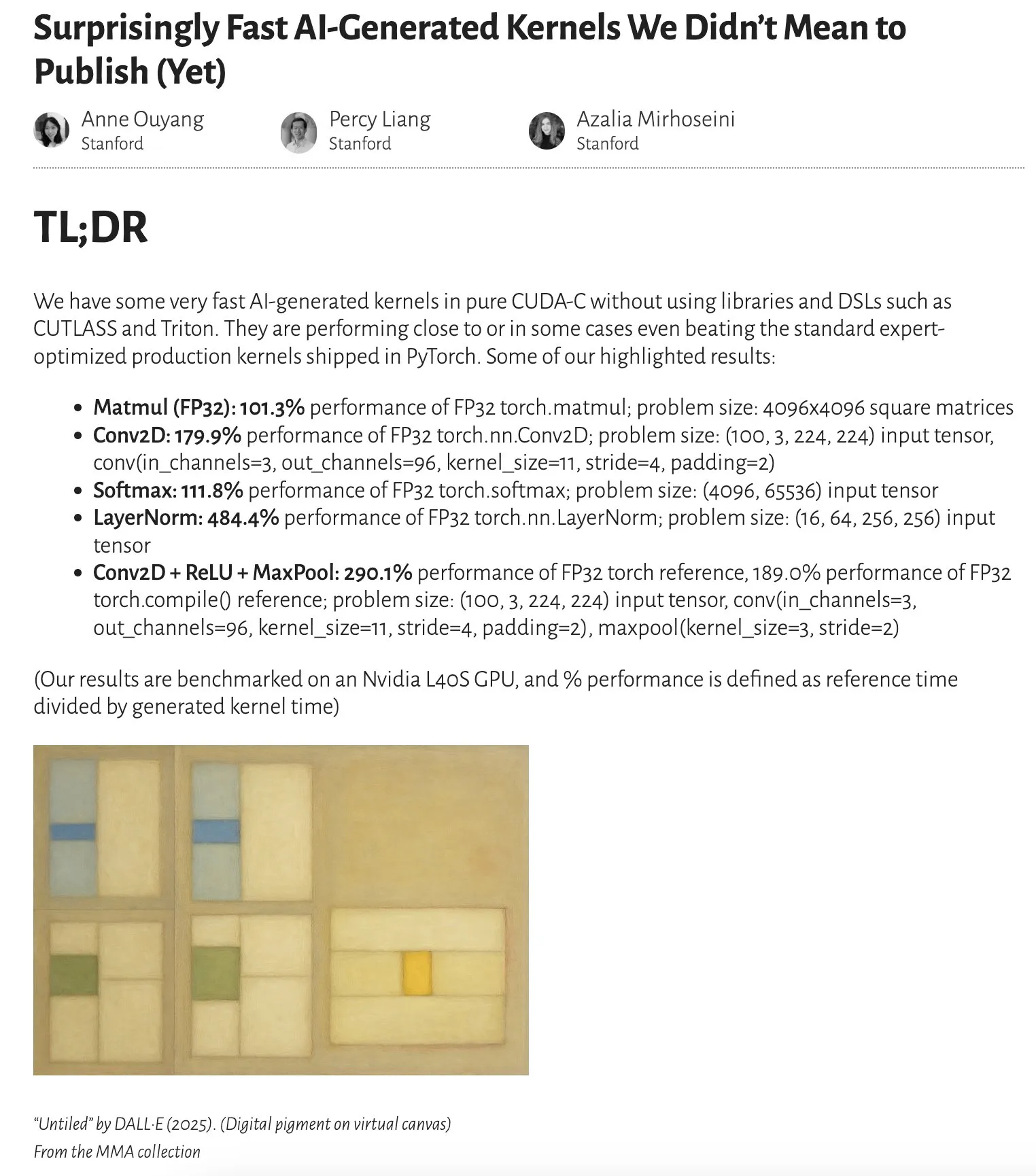
دراسة تظهر أن أداء النوى (kernels) المولدة بواسطة الذكاء الاصطناعي يقترب أو حتى يتجاوز النوى المحسنة بواسطة الخبراء: يشير مقال مدونة آن أويانغ إلى أن أداء النوى المولدة بواسطة الذكاء الاصطناعي من خلال بحث بسيط في وقت الاختبار فقط (test-time only search) قد اقترب، وفي بعض الحالات تجاوز، أداء النوى الإنتاجية القياسية المحسنة بواسطة الخبراء في PyTorch. يشير هذا إلى أن الذكاء الاصطناعي يتمتع بإمكانات هائلة في تحسين الأكواد ورفع الأداء، وقد يلعب دورًا أكثر أهمية في تحسين المكتبات الأساسية في المستقبل (المصدر: jeremyphoward)
بحث “ازدواجية الانتشار” يقترح طريقة جديدة لتوليد نماذج لغة الانتشار المتقطعة بخطوات قليلة: تقترح ورقة بحثية نُشرت في ICML 2025 بعنوان “The Diffusion Duality” طريقة جديدة لتحقيق توليد بخطوات قليلة في نماذج لغة الانتشار المتقطعة (discrete diffusion language models) من خلال الاستفادة من انتشار غاوسي كامن. تغلبت هذه الطريقة على النماذج ذاتية الانحدار (AR) في 3 من أصل 7 معايير قياس للاحتمالية بدون تدريب مسبق (zero-shot likelihood benchmarks)، مما يوفر فكرة جديدة لتحسين كفاءة توليد نماذج الانتشار (المصدر: arankomatsuzaki)
تقدم جديد في قابلية تفسير طبقات MLP: تحليل التنشيطات إلى ميزات قابلة للتفسير: يُظهر بحث جديد أجراه مور جيفا وآخرون طريقة بسيطة لتحليل تنشيطات الشبكات العصبية متعددة الطبقات (MLP) إلى ميزات قابلة للتفسير. تكشف هذه الطريقة عن تسلسل هرمي للمفاهيم المخفية، حيث تشكل مجموعات متفرقة من الخلايا العصبية مفاهيم مجردة بشكل متزايد، مما يوفر منظورًا أعمق لفهم آليات العمل الداخلية للشبكات العصبية (المصدر: menhguin)

إطار HeadHunter يحقق تحكمًا دقيقًا في توجيه الانتباه المضطرب: اقترح ساياك بول وآخرون إطار HeadHunter لإجراء تحليل مبدئي لتوجيه الانتباه المضطرب. يتيح هذا الإطار تحقيق تحكم دقيق وعميق في جودة التوليد والخصائص البصرية، مما يوفر أدوات ورؤى جديدة لتحسين وتخصيص مخرجات النماذج التوليدية (المصدر: huggingface, RisingSayak)

🧰 أدوات
خطط Windsurf المدفوعة تدعم الآن Claude Sonnet 4: أعلنت Windsurf أن جميع خططها المدفوعة تدعم الآن نموذج Claude Sonnet 4. يمكن للمستخدمين الآن الاستفادة من القدرات القوية لأحدث نموذج من Anthropic على منصة Windsurf لمهام مثل توليد النصوص والمحادثات، مما يعزز أداء وتجربة مساعدي الذكاء الاصطناعي (المصدر: op7418)
Anthropic تطلق Python SDK الرسمي لـ Claude Code: أطلقت Anthropic رسميًا Python SDK لـ Claude Code، بهدف تسهيل دمج قدرات Claude في توليد الأكواد واستخدام الأدوات في مشاريع Python الخاصة بالمطورين. يدعم SDK استخدام الأدوات، والإخراج المتدفق، والعمليات المتزامنة/غير المتزامنة، ومعالجة الملفات، ويتضمن بنية دردشة مدمجة، مما يبسط عملية تطوير التفاعل مع Claude Code (المصدر: Reddit r/ClaudeAI)
إطلاق إضافة Claude Task Master لـ VS Code: أطلق DevDreed الإصدار 1.0.0 من إضافة Claude Task Master لـ VS Code، والتي تهدف إلى استكمال مشروع Claude Task Master AI الخاص بـ eyaltoledano، من خلال دمج مخرجات Claude Task Master مباشرة في واجهة VS Code، مما يسهل على المستخدمين التبديل بسلاسة بين المحرر ووحدة التحكم، وبالتالي تحسين كفاءة التطوير (المصدر: Reddit r/ClaudeAI)
SmartSelect AI: أداة معالجة نصوص وصور بالذكاء الاصطناعي داخل المتصفح: تم إطلاق إضافة Chrome تسمى SmartSelect AI، والتي تتيح للمستخدمين تلخيص النصوص المحددة أو ترجمتها أو الدردشة حولها مباشرة أثناء تصفح الويب، ووصف الصور بالذكاء الاصطناعي، دون الحاجة إلى تبديل علامات التبويب أو النسخ واللصق في تطبيقات خارجية مثل ChatGPT. تعتمد هذه الأداة على نموذج Gemini، وتهدف إلى تحسين كفاءة الحصول على المعلومات ومعالجتها (المصدر: Reddit r/deeplearning)

Unsiloed AI تفتح مصدر أداة تجزئة بيانات متعددة الوظائف: فتحت Unsiloed AI (EF 2024) مصدر بعض وظائف تجزئة البيانات (chunker) الخاصة بها. تهدف هذه الأداة إلى المساعدة في معالجة المستندات بتنسيقات متعددة مثل PDF و Excel و PPT، وتحويلها إلى تنسيقات مناسبة للمعالجة بواسطة نماذج اللغة الكبيرة. تم استخدام Unsiloed AI من قبل شركات Fortune 100 والعديد من الشركات الناشئة لاستيعاب البيانات متعددة الوسائط (المصدر: Reddit r/LocalLLaMA)
Claude Superprompt System: أداة مجانية لتحسين موجهات Claude: طور إيغور وارتزوتشا وشارك أداة عبر الإنترنت تسمى “Claude Superprompt System”، تهدف إلى مساعدة المستخدمين على تحويل الطلبات البسيطة إلى موجهات معقدة ومنظمة تتضمن سلسلة من الأفكار وأمثلة سياقية، للاستفادة بشكل أفضل من قدرات Claude. تعتمد هذه الأداة على الوثائق الرسمية لـ Anthropic وأفضل الممارسات التي اكتشفها المجتمع، وتقوم بتحسين الموجهات من خلال هيكلة علامات XML، وكتل الاستدلال CoT (Chain-of-Thought)، وما إلى ذلك، لرفع جودة مخرجات Claude. تم فتح مصدر كود المشروع على GitHub (المصدر: Reddit r/artificial)
إطلاق إضافة Kokoro-TTS المحلية لتحويل النص إلى كلام لمتصفح Firefox: أطلق المطور Pinguy إضافة Firefox تسمى Kokoro TTS، والتي تستخدم نموذج شبكة عصبية مستضاف محليًا بحجم 82 مليون معلمة (نموذج Kokoro TTS) لتحويل النص إلى كلام، وتعمل بالكامل دون اتصال بالإنترنت، مما يحمي خصوصية المستخدم. تدعم أصواتًا ولهجات متعددة، وتعمل بسلاسة حتى على الأجهزة القديمة، وتتوفر بإصدارات لأنظمة Windows و Linux و macOS (المصدر: Reddit r/artificial)
Spy Search: تحديث مشروع محرك بحث LLM مفتوح المصدر: قام JasonHonKL بتحديث مشروع محرك بحث LLM مفتوح المصدر الخاص به Spy Search. يهدف هذا المشروع إلى بناء محرك بحث فعال يعتمد على نماذج اللغة الكبيرة، ويمكن للإصدار الأحدث البحث والاستجابة في غضون 3 ثوانٍ. يتم استضافة كود المشروع على GitHub، ويهدف إلى تزويد المستخدمين بأداة بحث يومية سريعة ومفيدة (المصدر: Reddit r/deeplearning)
HandFonted: أداة تحويل خط اليد إلى خطوط طباعية مفتوحة المصدر: طور ريشام جايري وفتح مصدر مشروع HandFonted، وهو تطبيق Python متكامل يحول صور الأحرف المكتوبة بخط اليد إلى ملفات خطوط .ttf قابلة للتثبيت. يستخدم النظام OpenCV لمعالجة الصور وتقسيم الأحرف، ويستخدم نموذج PyTorch مخصص (ResNet-Inception) لتصنيف الأحرف، ويستخدم الخوارزمية المجرية للمطابقة المثلى، وأخيرًا يستخدم مكتبة fontTools لإنشاء ملفات الخطوط (المصدر: Reddit r/MachineLearning)
📚 دراسات وأبحاث
ورقة بحثية لـ “وي دونغ يي” وآخرين تتصدر مجلة رياضيات، تبحث ظاهرة الانفجار في معادلة الموجة اللاخطية المبددة فوق الحرجة: نُشرت ورقة بحثية للباحثين من جامعة بكين وي دونغ يي، وتشانغ تشي في، وشاو فنغ بعنوان “On blow-up for the supercritical defocusing nonlinear wave equation” في مجلة الرياضيات المرموقة “Forum of Mathematics, Pi”. يبحث البحث في مشكلة الانفجار (حيث يصبح الحل لانهائيًا في وقت محدود) لمعادلة موجة لاخطية مبددة محددة في الحالة فوق الحرجة. أثبتوا وجود حلول معقدة القيمة وسلسة تنفجر في وقت محدود في البعد المكاني d=4 و p≥29، وكذلك في d≥5 و p≥17. تملأ هذه النتيجة فجوة في المجالات ذات الصلة، وتوفر طريقة إثباتها أفكارًا جديدة لبحث الانفجار في المعادلات التفاضلية الجزئية اللاخطية الأخرى (المصدر: كوانتوم بيت)

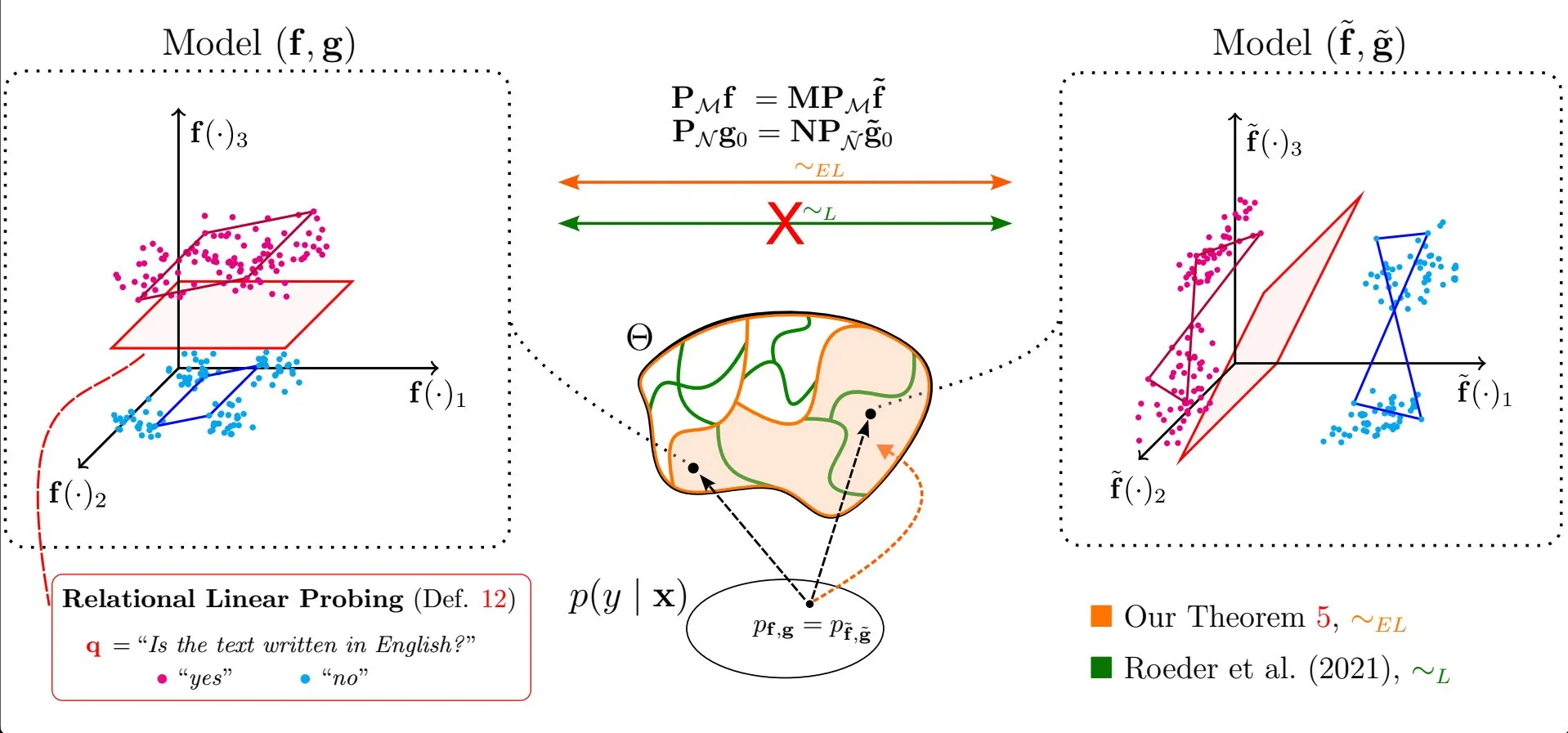
ورقة بحثية تبحث في مدى انتشار الخصائص الخطية في تمثيلات نماذج اللغة الكبيرة: يبحث بحث إيمانويل ماركوناتو وآخرون بعنوان “All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling” (نُشر في AISTATS 2025) من منظور قابلية التحديد لماذا تكون الخصائص الخطية منتشرة جدًا في تمثيلات نماذج اللغة الكبيرة (LLM). يساعد هذا البحث في فهم أعمق لهيكل وسلوك التمثيلات الداخلية لنماذج اللغة الكبيرة (المصدر: menhguin)
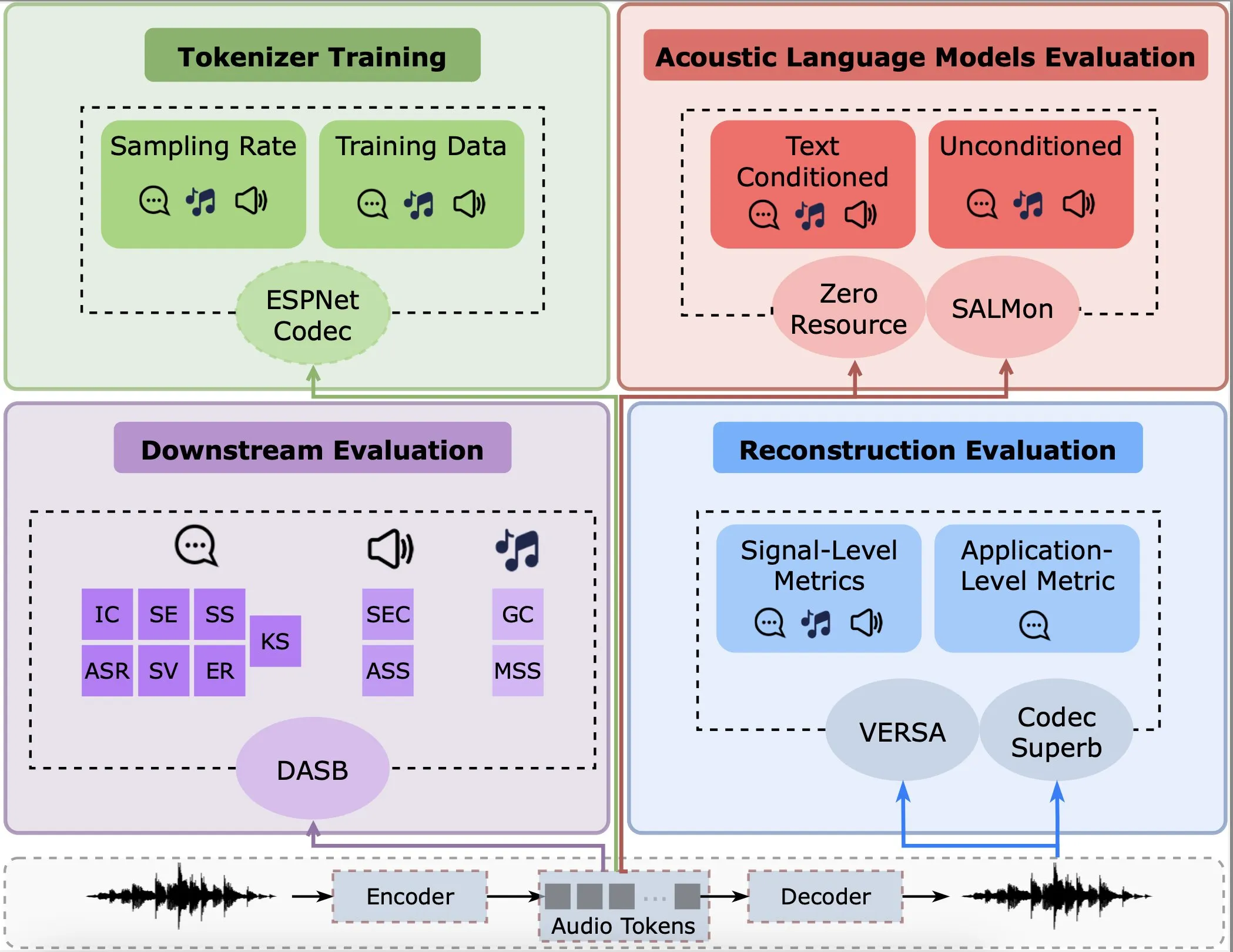
دراسة تحلل أداء مُرمّزات الصوت في إعادة البناء، والمهام النهائية، ونماذج اللغة: نشر جليل ميمون وآخرون بحثًا جديدًا يقدم تحليلًا تجريبيًا شاملاً لمُرمّزات الصوت الحالية (Audio Tokenisers). قيمت الدراسة هذه المرمّزات من عدة أبعاد مثل جودة إعادة البناء، والأداء في المهام النهائية، والتكامل مع نماذج اللغة، مما يوفر مرجعًا لاختيار وتحسين نماذج معالجة الصوت (المصدر: menhguin)
ورقة بحثية تناقش “وهم التفكير”: فهم مزايا وعيوب نماذج الاستدلال من منظور تعقيد المشكلة: تم تقديم ورقة بحثية ردًا على دراسة “وهم التفكير” لشركة Apple (arXiv:2506.09250)، حيث تم إدراج Claude Opus كمؤلف أول. انتقدت هذه الورقة تصميم تجربة بحث Apple، ورأت أن انهيار الاستدلال الذي لاحظته ناتج في الواقع عن قيود الرموز (token)، وليس عن نقص في القدرة المنطقية الكامنة للنموذج. أثار هذا نقاشًا حول كيفية تقييم قدرة الاستدلال الحقيقية لنماذج اللغة الكبيرة (المصدر: NandoDF, BlancheMinerva, teortaxesTex)

بحث يناقش نماذج اللغة التكيفية، لكن الذاكرة متوسطة المدى لا تزال تشكل تحديًا: أشار Dorialexander بعد قراءة الأوراق البحثية المتعلقة بـ “نماذج اللغة التكيفية” إلى أنه على الرغم من كونه اتجاهًا بحثيًا واعدًا، إلا أن تحقيق الذاكرة متوسطة المدى في النماذج أثناء الاستدلال لا يزال يواجه قيودًا. يشير هذا إلى أن النماذج الحالية لا تزال تواجه تحديات في معالجة المعلومات المتماسكة التي تتطلب سياقًا أطول (المصدر: Dorialexander)

بحث حول جودة اختبارات RLHF: ما مدى جودة الاختبارات الحالية؟ كيف يمكن تحسينها؟ ما مدى أهمية جودة الاختبار؟: يبحث أحدث عمل لـ Kexun Zhang وآخرين في أهمية أدوات التحقق (الاختبارات) في التعلم المعزز من ردود الفعل البشرية (RLHF)، خاصة في مجال ترميز نماذج اللغة الكبيرة (LLM). تطرح الدراسة ثلاثة أسئلة رئيسية: ما هي جودة الاختبارات الحالية؟ كيف يمكن الحصول على اختبارات أفضل؟ ما مدى تأثير جودة الاختبار على أداء النموذج؟ تؤكد هذه الدراسة على ضرورة وجود اختبارات عالية الجودة لتعزيز قدرات ترميز نماذج اللغة الكبيرة (المصدر: StringChaos)
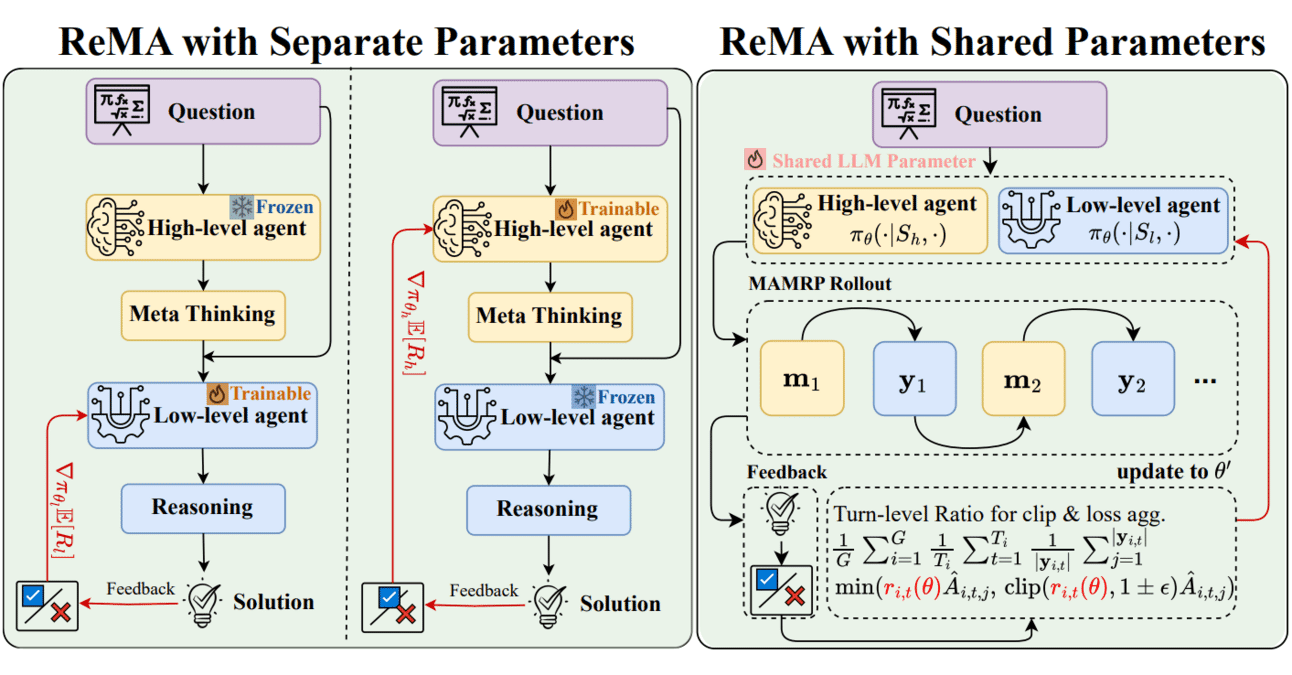
التعلم الفوقي (Meta-learning) والتعلم المعزز (Reinforcement Learning) معًا: ReMA يعزز كفاءة تعاون نماذج اللغة الكبيرة (LLM): يجمع Reinforced Meta-thinking Agents (ReMA) بين التعلم الفوقي (Meta-learning) والتعلم المعزز (RL)، بهدف تحسين كفاءة نماذج اللغة الكبيرة (LLM)، خاصة عند عمل عدة وكلاء LLM معًا. يقسم ReMA حل المشكلات إلى التفكير الفوقي (تخطيط الاستراتيجية) والاستدلال (تنفيذ الاستراتيجية)، ويتم تحسينه من خلال وكلاء متخصصين وتعلم معزز متعدد الوكلاء، وقد حقق تحسينات في معايير الرياضيات ومعايير LLM كحكم (المصدر: TheTuringPost, TheTuringPost)
استراتيجيات تقييم الذكاء الاصطناعي: كيف يمكن الجمع بين المُقيِّمين الرخيصين والمكلفين للحصول على أفضل تقدير لجودة النموذج ضمن قيود الميزانية: يبحث آدم فيش وآخرون (arXiv:2506.07949) في مشكلة عملية: عندما يكون لديك مُقيِّم رخيص ولكنه صاخب، ومُقيِّم مكلف ولكنه دقيق، وميزانية ثابتة، كيف يجب تخصيص الميزانية للحصول على أدق تقدير لجودة النموذج. يوفر هذا البحث إطارًا لتحليل التكلفة والعائد لتقييم أنظمة الذكاء الاصطناعي (المصدر: Ar_Douillard)
ظاهرة “المكافآت الزائفة” و “الموجهات الزائفة” في موجهات نماذج اللغة الكبيرة (LLM): كشف بحث ستيلا لي وآخرين عن ظواهر مثيرة للاهتمام في تدريب وتقييم نماذج اللغة الكبيرة. بعد اكتشاف “المكافآت الزائفة” (مثل أن المكافآت العشوائية يمكن أن تحسن أداء النموذج في بعض المهام)، قاموا بمزيد من البحث في “الموجهات الزائفة”، حيث حتى النصوص التي لا معنى لها مثل “Lorem ipsum” يمكن أن تؤدي في بعض الحالات إلى تحسينات كبيرة في الأداء (مثل 19.4%). تطرح هذه النتائج تحديات وأفكارًا جديدة لفهم كيفية استجابة نماذج اللغة الكبيرة للموجهات وكيفية تصميم طرق تقييم أكثر قوة (المصدر: Tim_Dettmers)

ورقة بحثية تناقش نموذج “مسرح العرائس” للتفاعل مع الذكاء الاصطناعي: تقترح ورقة بحثية بعنوان “The Pig in Yellow: AI Interface as Puppet Theatre” (أو مسودة) اعتبار أنظمة الذكاء الاصطناعي اللغوية (LLM، AGI، ASI) كواجهات أدائية، فهي تحاكي الذاتية بدلاً من امتلاكها. تستخدم المقالة “الآنسة بيغي” كمثال، وتحلل كيف أن سلاسة الذكاء الاصطناعي وتماسكه وتعبيره العاطفي ليست مؤشرات على العقل، بل هي نتاج للتحسين، وتؤكد أن الواجهة مثل دمية، والمستخدم يشارك في بناء المعنى من خلال التفاعل، وتتجلى السلطة من خلال التصميم الأدائي (المصدر: Reddit r/artificial)
💼 أعمال
شركة الروبوتات Wo An Robot المدعومة من “عراب DJI” لي زيشيانغ تسعى للاكتتاب العام الأولي: قدمت شركة Wo An Robot (SwitchBot)، التي أسسها زملاء سابقون من معهد هاربين للتكنولوجيا وتركز على روبوتات الذكاء الاصطناعي المنزلية المجسدة، طلبًا للاكتتاب العام في بورصة هونغ كونغ. حصلت الشركة على استثمار ودعم من “عراب DJI” لي زيشيانغ، الذي يمتلك 12.98% من أسهمها. جمعت Wo An Robot تمويلًا على سبع جولات خلال العقد الماضي، ونمت قيمتها من 20 مليون يوان إلى 4 مليارات يوان صيني. تشمل منتجاتها روبوتات تنفيذية تحاكي حركات الأطراف البشرية وأنظمة إدراك واتخاذ قرار، وأصبحت أكبر مورد عالمي لروبوتات الذكاء الاصطناعي المنزلية المجسدة، بحصة سوقية تبلغ 11.9%، وحققت صافي ربح معدل قدره 1.11 مليون يوان في عام 2024 (المصدر: كوانتوم بيت)

تينسنت تطلق “خطة تشينغيون” لعام 2026، وتفتح لأول مرة مستودع موارد المشاريع البحثية: أعلنت تينسنت عن إطلاق “خطة تشينغيون” لعام 2026، التي تستهدف الطلاب المتميزين في مجال التكنولوجيا على مستوى العالم، وتغطي عشرة مجالات تقنية رئيسية بما في ذلك نماذج الذكاء الاصطناعي الكبيرة، والبنية التحتية الأساسية، والحوسبة عالية الأداء، وتقدم أكثر من مائة مشروع تقني. على عكس السنوات السابقة، تفتح هذه الدورة من الخطة لأول مرة مستودع موارد مشاريع تشينغيون، وتوفر مسارًا سريعًا للتوظيف للمواهب المتميزة، بهدف تعميق التعاون بين الجامعات والشركات وتنمية المواهب الشابة في مجال التكنولوجيا. ستقدم تينسنت موارد تدريسية على أعلى مستوى في الصناعة، وموارد حوسبة، ورواتب تنافسية (المصدر: كوانتوم بيت)

الصورة الرمزية الرقمية لـ “لو يونغ هاو” ستبدأ البث على منصة التجارة الإلكترونية لـ Baidu في 15 يونيو: أعلن لو يونغ هاو أن صورته الرمزية الرقمية المدعومة بالذكاء الاصطناعي ستبدأ أول بث مباشر لها على منصة التجارة الإلكترونية لـ Baidu في 15 يونيو. هذه هي المرة الأولى التي يستخدم فيها مذيع بارز صورة رمزية رقمية مدعومة بالذكاء الاصطناعي لبيع المنتجات عبر البث المباشر، وذلك بفضل التقدم الذي أحرزته Baidu في التقنيات الرئيسية مثل الصور الرمزية الرقمية عالية الإقناع. يُنظر إلى هذه الخطوة على أنها استكشاف لنموذج جديد للتجارة الإلكترونية “الذكاء الاصطناعي + الملكية الفكرية الرائدة”، ومن المتوقع أن تدفع صناعة البث المباشر للتجارة الإلكترونية نحو الذكاء والكفاءة وخفض التكاليف. تظهر بيانات التجارة الإلكترونية لـ Baidu أن أكثر من 100,000 مذيع رقمي قد تم تطبيقهم في مختلف الصناعات، مما أدى إلى خفض تكاليف التشغيل للتجار بشكل كبير وزيادة إجمالي قيمة البضائع (GMV) (المصدر: كوانتوم بيت)
🌟 مجتمع
شركات الذكاء الاصطناعي الصينية تنقل كميات كبيرة من البيانات على أقراص صلبة إلى ماليزيا لتدريب النماذج: أفادت NIK بأن شركات الذكاء الاصطناعي الصينية، في محاولة لتجاوز قيود الرقائق والاستفادة من موارد الحوسبة الخارجية، لجأت إلى استراتيجية نقل الأقراص الصلبة المليئة ببيانات التدريب “بشكل شخصي” إلى أماكن مثل ماليزيا. على سبيل المثال، قام مهندس بحمل 15 قرصًا صلبًا تحتوي على 80 تيرابايت من البيانات إلى ماليزيا لاستئجار خوادم لتدريب النماذج. تعكس هذه الظاهرة المنافسة الشرسة على قوة الحوسبة في مجال الذكاء الاصطناعي عالميًا والتحديات الواقعية لنقل البيانات عبر الحدود، كما تثير نقاشات حول أمن البيانات والامتثال التنظيمي (المصدر: jpt401, agihippo, cloneofsimo, fabianstelzer)

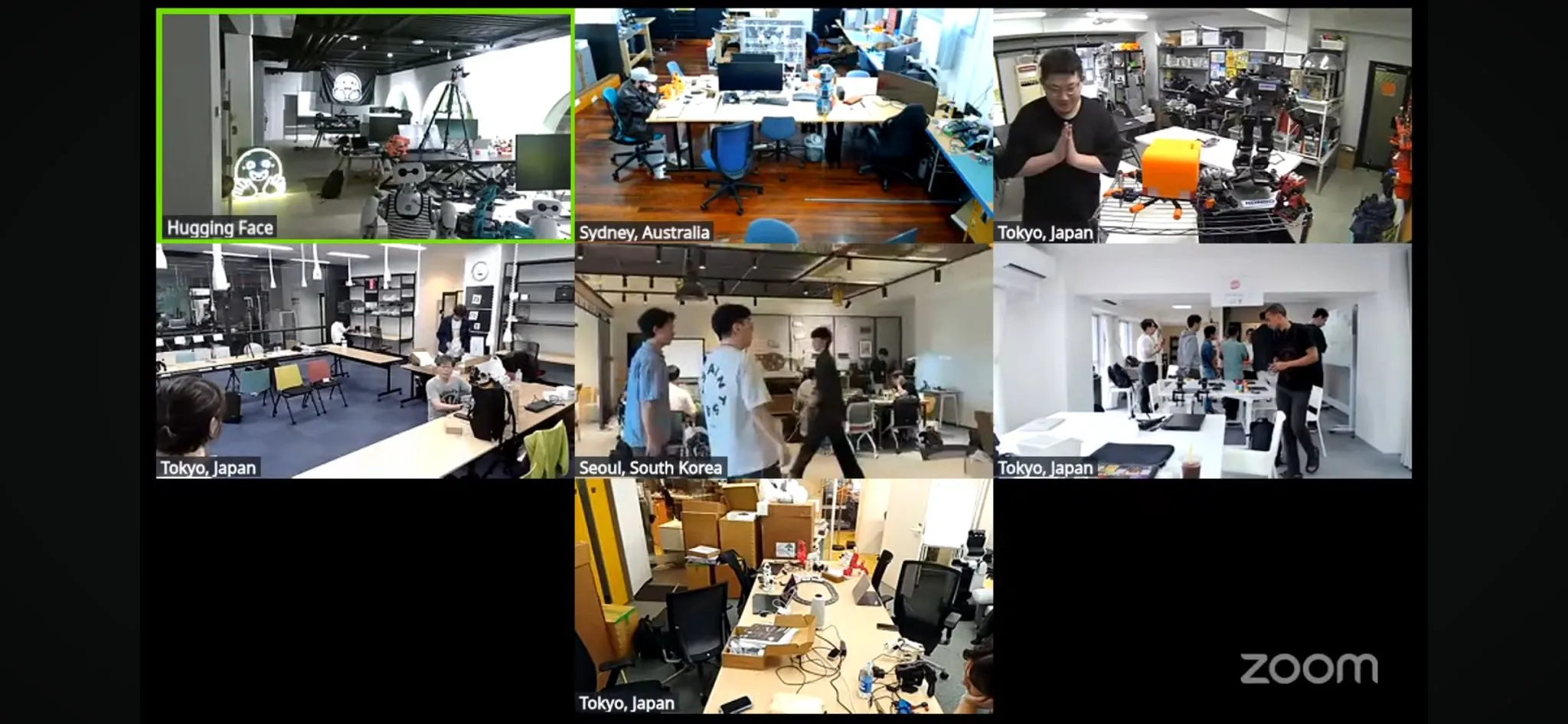
انطلاق أكبر هاكاثون للروبوتات LeRobot على مستوى العالم: انطلق رسميًا هاكاثون LeRobot العالمي للروبوتات الذي تنظمه Hugging Face، ويغطي أكثر من 100 موقع في 5 قارات حول العالم، وجذب أكثر من 2300 مشارك. يهدف الحدث إلى تعزيز تطوير روبوتات الذكاء الاصطناعي مفتوحة المصدر، وسيقوم المشاركون ببناء واستكشاف مشاريع متعلقة بالروبوتات خلال 52 ساعة. شارك المطورون والفرق من مختلف أنحاء العالم بحماس، ونشروا صورًا من مواقعهم وتقدم مشاريعهم، مما يظهر شغف المجتمع وإبداعه في مجال تكنولوجيا الروبوتات (المصدر: _akhaliq, eliebakouch, ClementDelangue)
Lovable تنظم مواجهة لتوليد صفحات الويب بالذكاء الاصطناعي، وأداء Claude يحظى بالثناء: نظمت Lovable حدثًا سمح للمستخدمين باستخدام أفضل النماذج من OpenAI و Anthropic و Google مجانًا للمنافسة في توليد صفحات الويب بالذكاء الاصطناعي. شارك المستخدم op7418 تجربته في استخدام نفس مجموعة الموجهات لتوليد صفحات ويب عبر نماذج الشركات الثلاث، ورأى أن Claude برز من حيث كمية المحتوى والتأثيرات البصرية. توفر مثل هذه الأحداث للمطورين والمستخدمين فرصة لمقارنة أداء نماذج اللغة الكبيرة المختلفة في سيناريوهات تطبيق محددة (المصدر: _philschmid, op7418)
نقاش حول قدرات الاستدلال لنماذج الذكاء الاصطناعي: قيود الرموز (token) مقابل المنطق الحقيقي: ردًا على ورقة “وهم التفكير” (Illusion of Thinking) التي قدمتها شركة Apple، ظهرت آراء معارضة في المجتمع. ترى بعض التعليقات والأبحاث اللاحقة (مثل arXiv:2506.09250، التي أدرجت Claude Opus كمؤلف) أن “انهيار” قدرة الاستدلال الملحوظ في النماذج يرجع بشكل أكبر إلى قيود عدد الرموز (token)، وليس إلى نقص في القدرة المنطقية الكامنة للنموذج نفسه. عندما يُسمح للنماذج باستخدام تنسيقات إجابات أكثر ضغطًا أو عندما يكون لديها سياق كافٍ، فإنها قادرة على حل المشكلات بنجاح. أثار هذا نقاشًا معمقًا حول كيفية تقييم وفهم قدرات الاستدلال الحقيقية لنماذج اللغة الكبيرة بدقة، بالإضافة إلى القيود المحتملة لطرق التقييم الحالية (المصدر: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
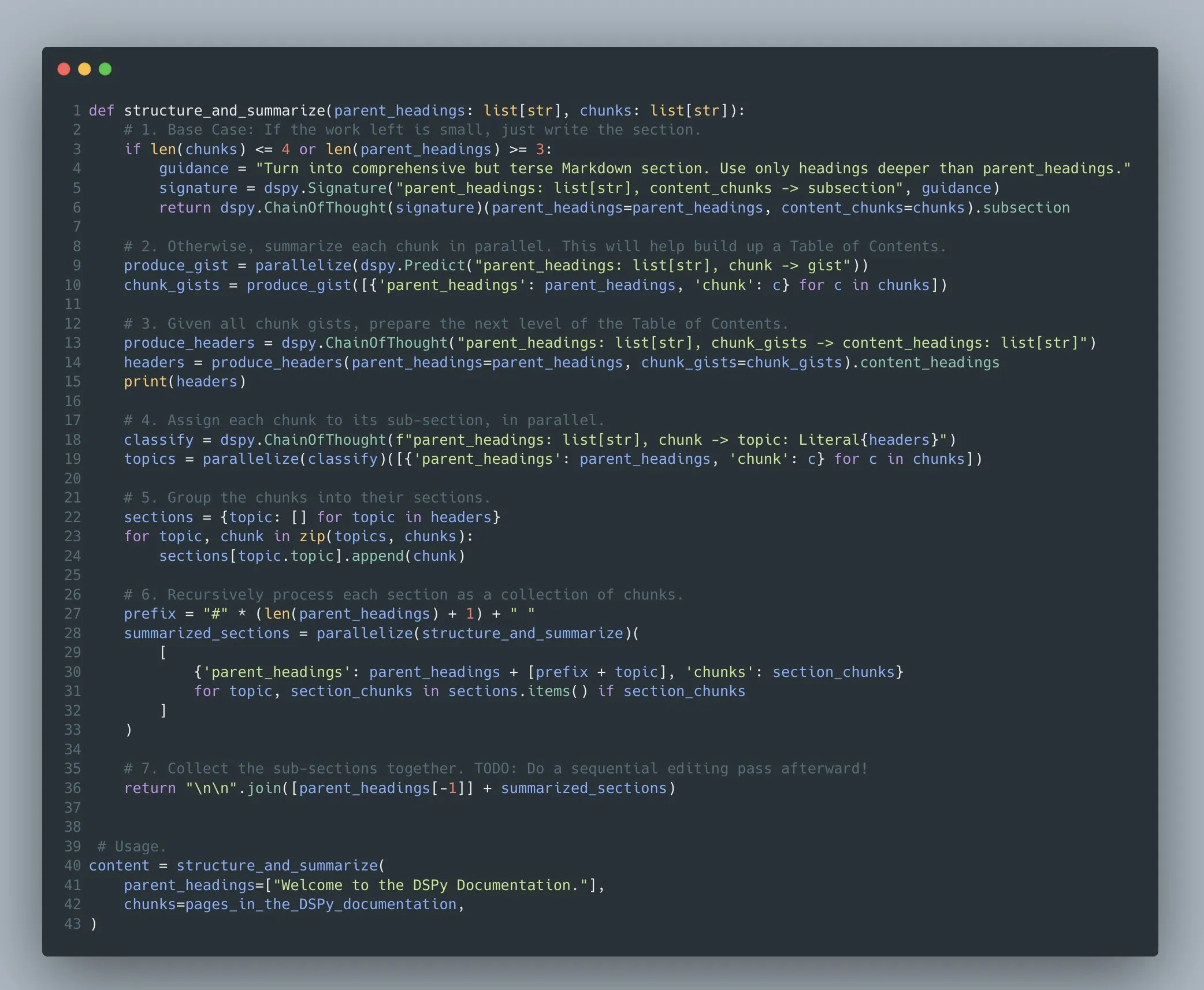
إطار DSPy يدعم تحسين برامج نماذج اللغة المعقدة متعددة المراحل: أكد عمر خطاب أن إطار DSPy يدعم منذ 2022/2023 تحسين الموجهات والتعلم المعزز لبرامج نماذج اللغة المعقدة متعددة المراحل (Compound AI Systems). ويرى أنه مع تزايد تعقيد أنظمة الذكاء الاصطناعي، من الأنسب اعتبارها “برامج” بدلاً من مجرد “نماذج”، ويهدف DSPy إلى توفير الدعم لبناء وتحسين مثل هذه البرامج بأي درجة من التعقيد (بما في ذلك العودية، ومعالجة الاستثناءات، وما إلى ذلك)، وليس فقط “التدفقات” أو “السلاسل” الخطية (المصدر: lateinteraction)
نقاش حول ما إذا كانت نماذج اللغة الكبيرة (LLM) تشبه التفكير البشري: يعتقد جيفري هينتون أن نماذج اللغة الكبيرة (LLM) تشبه الطريقة التي يعالج بها البشر اللغة، وأنها أفضل نموذج لدينا لفهم كيفية عمل اللغة. ومع ذلك، يشكك بيدرو دومينغوس في ذلك، معتبرًا أن تفوق نماذج اللغة الكبيرة على النظريات اللغوية القديمة لا يعني أنها تفكر مثل البشر. يعكس هذا النقاش الجدل المستمر في مجال الذكاء الاصطناعي حول طبيعة نماذج اللغة الكبيرة وعلاقتها بالإدراك البشري (المصدر: pmddomingos)
إمكانات هائلة لتطبيقات الذكاء الاصطناعي في أبحاث العلوم الفيزيائية: شارك باحث في مجال علوم الأرض تجربة إيجابية في استخدام o3 Pro (ربما يشير إلى أحد نماذج OpenAI المتقدمة)، واصفًا إياه بأنه بمثابة “باحث ما بعد الدكتوراه ذكي جدًا” في أبحاثه. أظهر النموذج أداءً متميزًا في الترميز، وتطوير النماذج، وصقل الأفكار، وكان قادرًا على تنفيذ التعليمات بسرعة ودقة ومساعدة البحث. يعتقد الباحث أنه على الرغم من أن النماذج الحالية لا تمتلك بعد القدرة على اقتراح أسئلة بحثية بشكل استباقي (سمة من سمات الذكاء الاصطناعي العام AGI)، إلا أن وظائفها المساعدة القوية قد حسنت بشكل كبير كفاءة البحث العلمي، ويتوقع أن نماذج اللغة الكبيرة ذات الاستقلالية لم تعد بعيدة (المصدر: Reddit r/ArtificialInteligence)
💡 أخرى
أدوات إنشاء القصص المصورة بالذكاء الاصطناعي تجعل التعبير الإبداعي أسهل: شارك المستخدم StriderWriting تجربته في استخدام أدوات الذكاء الاصطناعي لإنشاء قصص مصورة، معتبرًا أن الذكاء الاصطناعي جعل من الممكن تحويل “الأفكار السخيفة” إلى قصص مصورة. يعكس هذا انتشار الذكاء الاصطناعي في مجال إنشاء المحتوى الإبداعي، مما يقلل من عوائق الإبداع ويتيح لعدد أكبر من الأشخاص التعبير عن أفكارهم الإبداعية بسهولة (المصدر: Reddit r/ChatGPT)

مخاوف بشأن تحيز الذكاء الاصطناعي: أداء ChatGPT في القوالب النمطية الجنسانية يثير استياء المستخدمين: أبلغت مستخدمة أن ChatGPT أظهر قوالب نمطية سلبية تجاه الرجال في المحادثات، على سبيل المثال، عند مناقشة قضايا العمل والرعاية الصحية، افترض دون توجيه أن الأدوار السلبية للرجال، واستخدم عبارات مثل “الرجال مزعجون”. أشارت المستخدمة إلى أن هذه القوالب النمطية الكسولة القائمة على الجنس غير مريحة، وتساءلت عما إذا كانت لدى OpenAI قواعد لتقييد مثل هذا السلوك. أثار هذا مرة أخرى نقاشًا حول تحيز بيانات تدريب نماذج الذكاء الاصطناعي وكيف يتجلى ذلك في التفاعلات (المصدر: Reddit r/ChatGPT)
إمكانات الذكاء الاصطناعي في موضوعية التقارير الإخبارية وقيوده الحالية: اختبر أحد المستخدمين إمكانات نموذج o3 من OpenAI كـ “مراسل إخباري غير متحيز”، من خلال مطالبته بالتعليق على العواقب “غير المقصودة” المحتملة لسياسات متعددة لإدارتي ترامب وبايدن منذ عام 2017. على الرغم من أن الذكاء الاصطناعي كان قادرًا على إنشاء تحليل يبدو موضوعيًا، إلا أن مصادر معلوماته، وتحيزاته المحتملة، وعمق فهمه الحقيقي للديناميكيات السياسية والاقتصادية المعقدة لا تزال قضايا تحتاج إلى حل في المستقبل. يعكس هذا توقعات المجتمع للاستفادة من الذكاء الاصطناعي لتعزيز موضوعية الأخبار وعمقها، بالإضافة إلى الوعي بالقيود التقنية الحالية (المصدر: Reddit r/deeplearning)