كلمات مفتاحية:Meta V-JEPA 2, إنفيديا سحابة الذكاء الاصطناعي الصناعية, ساكانا AI Text-to-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, HistBench جامعة برينستون, نموذج العالم المفتوح المصدر لتدريب الفيديو, منصة سحابة الذكاء الاصطناعي لصناعة التصنيع الأوروبية, محول توليد النصوص LLM, ضبط DPO لـ GPT-4.1, قابلية مراقبة وكيل الذكاء الاصطناعي
🔥 التركيز الرئيسي
Meta تطلق V-JEPA 2: نموذج عالمي مفتوح المصدر للصور/الفيديو مدرب على مقاطع الفيديو : أطلقت Meta نموذجًا عالميًا جديدًا مفتوح المصدر للصور/الفيديو يُدعى V-JEPA 2، يعتمد هذا النموذج على معمارية ViT، ويتوفر بإصدارات مختلفة الأحجام (L/G/H) ودقات (286/384)، ويصل عدد البارامترات فيه إلى 1.2 مليار. يُظهر V-JEPA 2 أداءً متميزًا في الفهم والتنبؤ البصري، مما يمكّن الروبوتات من تحقيق التخطيط وتنفيذ المهام بدون تدريب مسبق (zero-shot) في بيئات غير مألوفة. تؤكد Meta على رؤيتها المتمثلة في استخدام الذكاء الاصطناعي للنماذج العالمية للتكيف مع البيئات الديناميكية وتعلم مهارات جديدة بكفاءة. في الوقت نفسه، أصدرت Meta أيضًا ثلاثة معايير جديدة: MVPBench، وIntPhys 2، وCausalVQA، لتقييم قدرة النماذج الحالية على استنتاج العالم المادي من مقاطع الفيديو. (المصدر: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
Nvidia تبني أول سحابة صناعية للذكاء الاصطناعي في أوروبا لدفع تطوير قطاع التصنيع : أعلنت Nvidia أنها تقوم ببناء أول منصة سحابية صناعية للذكاء الاصطناعي في العالم للمصنعين الأوروبيين. تهدف هذه المنصة، التي يطلق عليها اسم AI factory، إلى مساعدة رواد الصناعة على تسريع تطبيقات التصنيع الشاملة بدءًا من التصميم والمحاكاة الهندسية إلى التوائم الرقمية للمصانع وتقنيات الروبوتات. تعد هذه الخطوة جزءًا من سلسلة مبادرات أعلنت عنها Nvidia في GTC Paris وVivaTech 2025، بهدف تسريع ابتكارات الذكاء الاصطناعي في أوروبا ومناطق أخرى. صرح جنسن هوانغ بأن من المتوقع أن تتضاعف قدرة الحوسبة للذكاء الاصطناعي في أوروبا عشر مرات في غضون عامين، وأكد أن “جميع الأشياء المتحركة ستصبح روبوتية، والسيارات هي التالية”. (المصدر: nvidia, nvidia, جنسن هوانغ: قدرة الحوسبة للذكاء الاصطناعي في أوروبا ستتضاعف عشر مرات في عامين)

Sakana AI تطلق Text-to-LoRA: إنشاء محولات LLM مخصصة للمهام فورًا باستخدام وصف نصي : أطلقت Sakana AI تقنية Text-to-LoRA، وهي شبكة فائقة (Hypernetwork) قادرة على إنشاء محولات LLM مخصصة للمهام (LoRAs) فورًا بناءً على وصف المستخدم النصي للمهمة. تهدف هذه التقنية إلى خفض عتبة تخصيص النماذج اللغوية الكبيرة، مما يسمح للمستخدمين غير التقنيين بتخصيص النماذج الأساسية باستخدام اللغة الطبيعية، دون الحاجة إلى خلفية تقنية عميقة أو موارد حوسبة كبيرة. تستطيع Text-to-LoRA ترميز مئات من محولات LoRA الحالية وتعميمها على مهام لم يسبق لها مثيل مع الحفاظ على الأداء. تم نشر الورقة البحثية والكود المرتبط بها على arXiv و GitHub، وسيتم عرضها في ICML2025. (المصدر: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
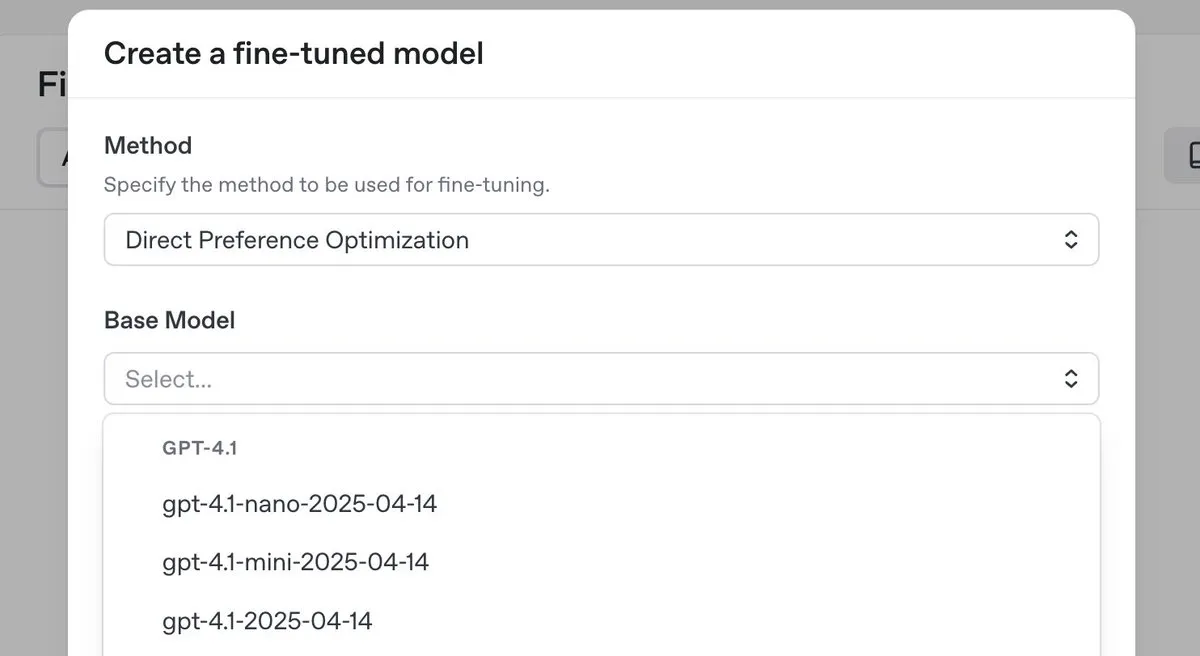
OpenAI تطلق نموذج الاستدلال المتميز o3-pro وتخفض الأسعار بشكل كبير، مع إطلاق ميزة الضبط الدقيق DPO لسلسلة GPT-4.1 : أطلقت OpenAI نموذجها الجديد المتميز للاستدلال o3-pro، وأجرت تخفيضات كبيرة في أسعار سلسلة نماذج o3، بهدف تقليل تكلفة الاستخدام للمطورين. في الوقت نفسه، أعلنت OpenAI أنه يمكن للمستخدمين الآن استخدام تحسين التفضيل المباشر (DPO) لضبط عائلة نماذج GPT-4.1 (بما في ذلك 4.1، و4.1-mini، و4.1-nano). يسمح DPO بالتخصيص من خلال مقارنة استجابات النموذج بدلاً من الأهداف الثابتة، وهو مناسب بشكل خاص للمهام التي تتطلب متطلبات ذاتية للنبرة والأسلوب والإبداع. أعادت ARC Prize اختبار o3 بعد تخفيض السعر، وأظهرت النتائج عدم حدوث تغيير في أدائه على ARC-AGI. (المصدر: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 اتجاهات
Databricks تطلق Lakebase، ونسخة مجانية، و Agent Bricks، لتسريع تطوير تطبيقات البيانات والذكاء الاصطناعي : أعلنت Databricks عن دخول Lakebase مرحلة المعاينة العامة، وهي قاعدة بيانات Postgres مُدارة بالكامل ومتكاملة مع lakehouse ومُصممة للذكاء الاصطناعي، تجمع بين سهولة استخدام Postgres، وقابلية التوسع لـ lakehouse، وتقنية التفريع لقاعدة بيانات Neon. في الوقت نفسه، أطلقت Databricks نسخة مجانية من منصتها وكمية كبيرة من المواد التدريبية لمساعدة المطورين على تعلم هندسة البيانات، وعلوم البيانات، والذكاء الاصطناعي. بالإضافة إلى ذلك، أصبحت Databricks Apps متاحة بشكل عام (GA)، مما يدعم العملاء في بناء ونشر تطبيقات البيانات والذكاء الاصطناعي التفاعلية على المنصة. كما أطلقت Databricks أيضًا Agent Bricks، الذي يعتمد نهجًا تعريفيًا لتطوير وكلاء الذكاء الاصطناعي، حيث يصف المستخدمون المهام ويقوم النظام تلقائيًا بإنشاء تقييم وتحسين للوكيل. (المصدر: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

Nvidia تتعاون مع Mistral AI لبناء منصة سحابية متكاملة في أوروبا : أعلنت Nvidia عن تعاونها مع الشركة الفرنسية الناشئة Mistral AI لبناء منصة سحابية متكاملة. ستشمل المرحلة الأولى من التعاون نشر 18,000 نظام Nvidia Grace Blackwell، مع خطط للتوسع إلى المزيد من المواقع في عام 2026. يعد هذا التعاون جزءًا من جهود Nvidia لتعزيز البنية التحتية للذكاء الاصطناعي في أوروبا ومفهوم “الذكاء الاصطناعي السيادي”، بهدف توفير مراكز بيانات وخوادم محلية لأوروبا. (المصدر: جنسن هوانغ: قدرة الحوسبة للذكاء الاصطناعي في أوروبا ستتضاعف عشر مرات في عامين)
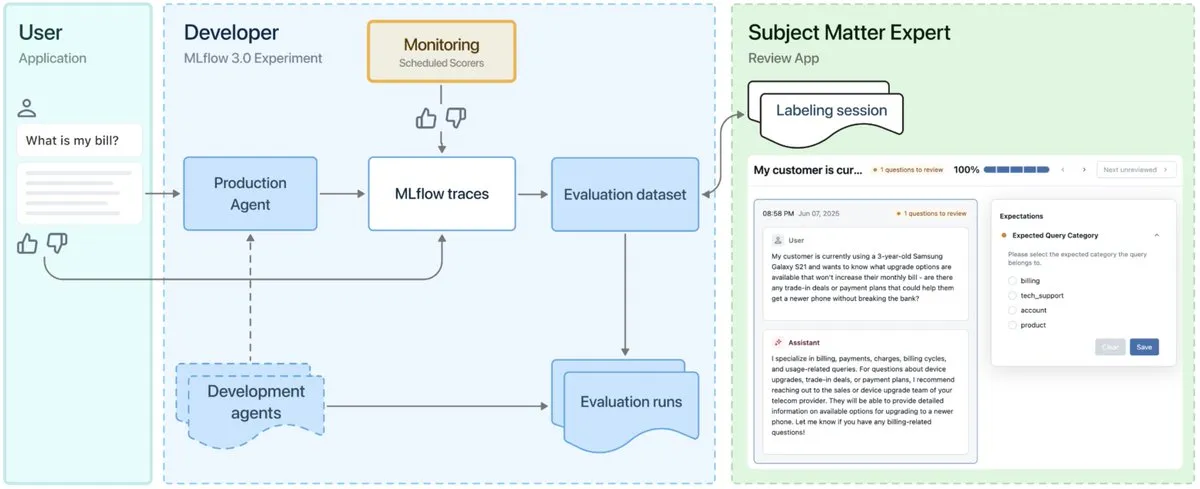
إصدار MLflow 3.0، مصمم خصيصًا لمراقبة وتطوير وكلاء الذكاء الاصطناعي : تم إطلاق MLflow 3.0 رسميًا، حيث تم إعادة تصميم الإصدار الجديد خصيصًا لمراقبة وتطوير وكلاء الذكاء الاصطناعي، مع تحديث وظائف التعلم الآلي المهيكل التقليدية. يهدف MLflow 3.0 إلى تحقيق التحسين المستمر لأنظمة الذكاء الاصطناعي من خلال البيانات، ودعم تتبع وتقييم ومراقبة أنظمة الذكاء الاصطناعي، مع مراعاة متطلبات المؤسسات مثل التعاون البشري، وحوكمة البيانات وأمنها، والتكامل مع النظام البيئي لبيانات Databricks. (المصدر: matei_zaharia, matei_zaharia, lateinteraction)
جامعة برينستون وجامعة فودان تطلقان HistBench و HistAgent لتعزيز تطبيق الذكاء الاصطناعي في أبحاث التاريخ : تعاون مختبر الذكاء الاصطناعي بجامعة برينستون مع قسم التاريخ بجامعة فودان لإطلاق أول معيار تقييم للذكاء الاصطناعي في أبحاث التاريخ في العالم HistBench ومساعد الذكاء الاصطناعي HistAgent. يتضمن HistBench 414 سؤالًا تاريخيًا، يغطي 29 لغة وتاريخ حضارات متعددة، ويهدف إلى اختبار قدرة الذكاء الاصطناعي على معالجة المواد التاريخية المعقدة والفهم متعدد الوسائط. أما HistAgent فهو وكيل ذكي مصمم خصيصًا لأبحاث التاريخ، يدمج أدوات مثل استرجاع الوثائق، و OCR، والترجمة. أظهرت الاختبارات أن دقة النماذج اللغوية الكبيرة العامة على HistBench أقل من 20%، بينما أداء HistAgent يتجاوز بكثير النماذج الحالية. (المصدر: أول معيار تاريخي عالمي، برينستون وفودان تنشئان مساعد تاريخي بالذكاء الاصطناعي، الذكاء الاصطناعي يخترق العلوم الإنسانية)

باحثو Microsoft وجامعة بكين يطلقون إطار Next-Frame Diffusion (NFD) لتعزيز كفاءة إنشاء الفيديو التراجعي الذاتي : أطلق باحثو Microsoft بالتعاون مع جامعة بكين إطارًا جديدًا يُدعى Next-Frame Diffusion (NFD)، والذي يحقق إنشاء فيديو تراجعي ذاتي عالي الجودة بمعدل يزيد عن 30 إطارًا في الثانية على وحدة معالجة الرسومات A100 GPU باستخدام نموذج 310M، وذلك من خلال أخذ العينات المتوازية داخل الإطار والأسلوب التراجعي الذاتي بين الإطارات. يستخدم NFD آلية انتباه سببية كتلية لـ Transformer، ويجمع بين تقنيات التقطير المتسق وأخذ العينات التخمينية لزيادة الكفاءة، ومن المتوقع تطبيقه في سيناريوهات مثل الألعاب التفاعلية في الوقت الفعلي. (المصدر: إنشاء أكثر من 30 إطار فيديو في الثانية، ودعم التفاعل في الوقت الفعلي، إطار جديد لإنشاء الفيديو التراجعي الذاتي يجدد كفاءة الإنشاء)

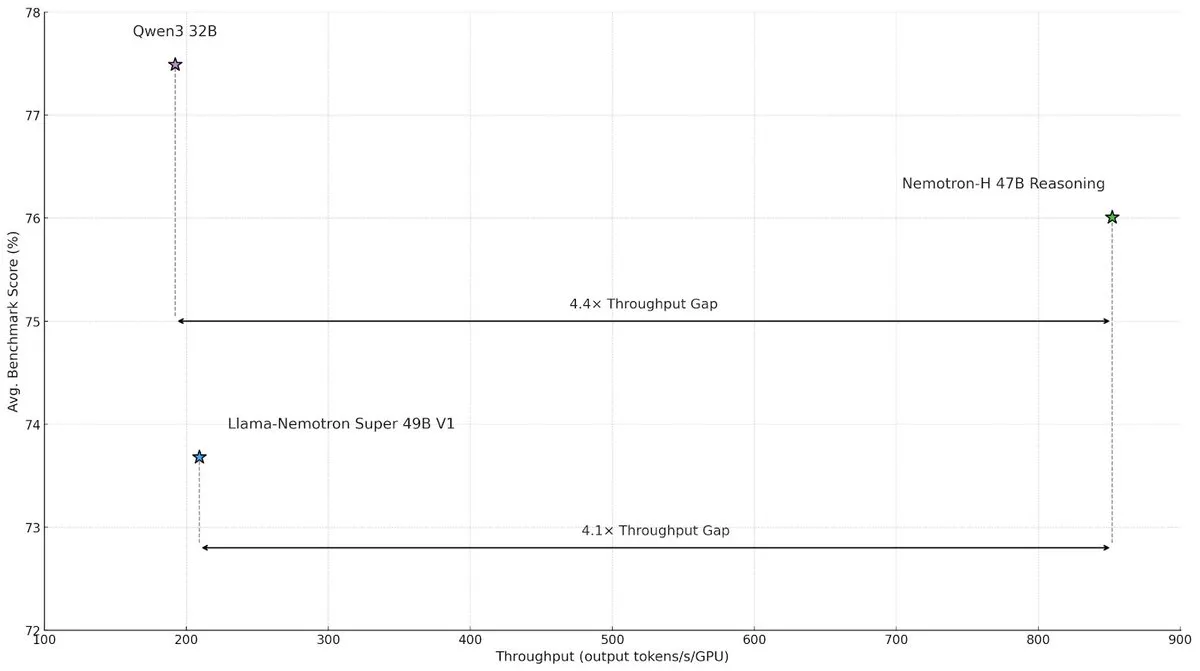
NVIDIA تطلق نموذج Nemotron-H ذو البنية الهجينة لتعزيز سرعة وكفاءة الاستدلال على نطاق واسع : أطلق معهد أبحاث NVIDIA نموذج Nemotron-H، الذي يعتمد بنية هجينة تجمع بين Mamba و Transformer، بهدف معالجة اختناقات السرعة في مهام الاستدلال واسعة النطاق. يحقق هذا النموذج إنتاجية أعلى بأربع مرات من نماذج Transformer المماثلة مع الحفاظ على قدرة الاستدلال. أظهرت الأبحاث أن النماذج الهجينة يمكنها الحفاظ على أداء الاستدلال حتى مع استخدام عدد أقل من طبقات الانتباه، خاصة في سيناريوهات سلاسل الاستدلال الطويلة، حيث تكون ميزة كفاءة البنية الخطية واضحة. (المصدر: _albertgu, tri_dao, krandiash)
باحث جوجل DeepMind جاك راي ينضم إلى مجموعة “الذكاء الفائق” في Meta : أكد جاك راي، الباحث الرئيسي في جوجل DeepMind، انضمامه إلى مجموعة “الذكاء الفائق” المشكلة حديثًا في Meta. كان راي مسؤولاً عن قدرات “التفكير” في نموذج Gemini خلال فترة عمله في DeepMind، وهو أحد أبرز ممثلي فكرة “الضغط هو الذكاء”، وقد شارك سابقًا في تطوير GPT-4 في OpenAI. يقوم مارك زوكربيرج، الرئيس التنفيذي لشركة Meta، شخصيًا بتجنيد أفضل مواهب الذكاء الاصطناعي، ويقدم للفريق الجديد حزم رواتب تصل إلى عشرات الملايين من الدولارات، بهدف تحسين نموذج Llama وتطوير أدوات ذكاء اصطناعي أكثر قوة للحاق بركب رواد الصناعة. (المصدر: أول شخصية بارزة في مجموعة “الذكاء الفائق” لزوكربيرج، الباحث الرئيسي في جوجل DeepMind، والشخصية المحورية في “الضغط هو الذكاء”, DhruvBatraDB)

Mistral AI تطلق أول نموذج استدلال لها Magistral، يدعم الاستدلال متعدد اللغات : أطلقت Mistral AI أول نموذج استدلال لها Magistral، والذي يتضمن إصدارًا مفتوح المصدر بمعاملات 24B يُدعى Magistral Small وإصدارًا موجهًا للشركات يُدعى Magistral Medium. تم ضبط هذا النموذج خصيصًا للمنطق متعدد الخطوات وقابلية التفسير، ويدعم الاستدلال متعدد اللغات، مع تحسين خاص للغات الأوروبية، ويمكنه توفير عمليات تفكير قابلة للتتبع. يعتمد Magistral على خوارزمية GRPO محسّنة ويتم تدريبه من خلال التعلم المعزز النقي، دون الاعتماد على بيانات التقطير من نماذج الاستدلال الحالية. ومع ذلك، تعرضت نتائج اختباراته المعيارية لبعض الانتقادات لعدم تضمينها أحدث إصدارات Qwen و DeepSeek R1. (المصدر: نموذج استدلال “SOTA” الجديد يتجنب مواجهة Qwen و R1؟ تعرضت النسخة الأوروبية من OpenAI لانتقادات شديدة)

ByteDance تطلق نموذج Doubao الكبير 1.6 وتخفض الأسعار بشكل كبير مرة أخرى، مع إطلاق نموذج الفيديو Seedance 1.0 pro بالتزامن : أطلقت Volcano Engine نموذج Doubao الكبير 1.6، وهو أول من يطبق تسعيرًا يعتمد على نطاق “طول الإدخال”، حيث يبلغ سعر نطاق الإدخال 0-32K 0.8 يوان/مليون tokens، والإخراج 8 يوان/مليون tokens، مما يمثل انخفاضًا في التكلفة بنسبة 63% مقارنة بالإصدار 1.5. يبلغ سعر نموذج إنشاء الفيديو Seedance 1.0 pro الذي تم إطلاقه حديثًا 0.015 يوان لكل ألف tokens، ويكلف إنشاء فيديو بدقة 1080P لمدة 5 ثوانٍ حوالي 3.67 يوان. صرح تان داي، رئيس Volcano Engine، بأن هذا التخفيض في الأسعار تحقق من خلال التحسين المستهدف لتكاليف نطاق 32K المستخدم بشكل شائع من قبل الشركات وابتكار نموذج الأعمال، بهدف تعزيز التطبيق واسع النطاق لـ Agent. (المصدر: نموذج Doubao الكبير يخفض الأسعار بشكل كبير مرة أخرى، Volcano Engine لا تزال تتنافس بقوة على حصة السوق, 「Volcano」 يتجه نحو Baidu Cloud)
جامعة هونغ كونغ للعلوم والتكنولوجيا بالتعاون مع هواوي تقترح إطار AutoSchemaKG، لتحقيق بناء مخطط معرفي مستقل تمامًا : اقترح مختبر KnowComp بجامعة هونغ كونغ للعلوم والتكنولوجيا بالتعاون مع قسم النظريات في هواوي بهونغ كونغ إطار AutoSchemaKG، الذي يمكنه بناء مخططات معرفية بشكل مستقل تمامًا دون الحاجة إلى مخططات محددة مسبقًا. يستخدم هذا النظام نماذج لغوية كبيرة لاستخراج ثلاثيات المعرفة مباشرة من النصوص وتعميم مخططات الكيانات والأحداث. بناءً على هذا الإطار، قام الفريق ببناء سلسلة مخططات معرفية ATLAS تحتوي على أكثر من 900 مليون عقدة و 5.9 مليار حافة. أظهرت التجارب أن هذه الطريقة، في ظل عدم وجود تدخل بشري، تحقق توافقًا دلاليًا بنسبة 95% بين المخططات المعممة والمخططات المصممة بشريًا. (المصدر: أكبر GraphRag مفتوح المصدر: بناء مخطط معرفي مستقل تمامًا)

شركة趋境科技 تطلق حل خادم متكامل بـ 8 بطاقات، مما يعزز كفاءة تشغيل نموذج DeepSeek الكبير : عقدت شركة趋境科技 بالتعاون مع إنتل ندوة بيئية، وأطلقت أحدث حلولها للخوادم المتكاملة التي تجمع بين البرمجيات والأجهزة وتضم 8 بطاقات. يمكن لهذا الحل تشغيل نماذج كبيرة مثل DeepSeek-R1/V3-671B بكفاءة عالية، مع تحسين الأداء بما يصل إلى 7 أضعاف مقارنة بالبطاقة الواحدة. في الوقت نفسه، تم تحديث محرك الاستدلال الخاص بها KLLM، ومنصة إدارة النماذج الكبيرة AMaaS، ومجموعة تطبيقات المكاتب “趋境·智问” بشكل كبير، بهدف مواجهة التحديات التي تواجه النشر الخاص للنماذج الكبيرة مثل عتبة البدء العالية وعدم كفاية أداء التشغيل. (المصدر: عقدت ندوة بيئية لشركة趋境科技 وإنتل، دمج الأجهزة ومحرك الاستدلال وبيئة تطبيقات الطبقة العليا، لفتح “الميل الأخير” للنشر الخاص للنماذج الكبيرة)

Black Forest Labs تطلق سلسلة نماذج الصور FLUX.1 Kontext، معززةً اتساق الشخصيات والأسلوب : أطلقت شركة Black Forest Labs الألمانية سلسلة نماذج تحويل النص إلى صورة FLUX.1 Kontext (بإصدارات max، و pro، و dev)، مع التركيز على الحفاظ على اتساق الشخصيات والأسلوب عند تحرير الصور. تدعم هذه السلسلة من النماذج تعديلات محلية وعالمية على الصور، ويمكنها إنشاء صور من مدخلات نصية و/أو صور. من المقرر أن يكون إصدار FLUX.1 Kontext dev مفتوح المصدر. في اختبار معياري خاص يتضمن حوالي 1000 زوج من المطالبات والصور المرجعية، تفوقت إصدارات FLUX.1 Kontext max و pro على النماذج المنافسة مثل OpenAI GPT Image 1 و Google Gemini 2.0 Flash. (المصدر: DeepLearning.AI Blog)

Nvidia وجامعة روتجرز ومؤسسات أخرى تقترح إطار STORM، لتقليل Tokens المطلوبة لفهم الفيديو باستخدام طبقات Mamba : قام باحثون من Nvidia وجامعة روتجرز وجامعة كاليفورنيا في بيركلي ومؤسسات أخرى ببناء نظام نص-فيديو يُدعى STORM. يُدخل هذا النظام طبقات Mamba بين محول الرؤية SigLIP و LLM الخاص بـ Qwen2-VL، وذلك من خلال إثراء تضمينات Token للإطار الواحد (التي تحتوي على معلومات من إطارات أخرى في نفس المقطع)، مما يسمح بمتوسطة تضمينات Token بين الإطارات دون فقدان المعلومات الأساسية. وهذا يمكّن النظام من معالجة الفيديو بعدد أقل من Tokens، ويتفوق في اختبارات فهم الفيديو المعيارية مثل MVBench و MLVU على GPT-4o و Qwen2-VL، مع زيادة سرعة المعالجة بأكثر من 3 أضعاف. (المصدر: DeepLearning.AI Blog)

مؤسس جوجل المشارك يبدي تحفظات على الروبوتات البشرية، وآفاق تجارية واعدة للروبوتات المتخصصة : صرح سيرجي برين، المؤسس المشارك لجوجل، بأنه ليس متحمسًا للروبوتات البشرية التي تحاكي الشكل البشري بدقة، معتقدًا أنها ليست شرطًا ضروريًا لعمل الروبوتات بفعالية. في الوقت نفسه، تحظى الروبوتات المتخصصة بالاهتمام نظرًا لخاصية “التشغيل الفوري” ومسارها التجاري الواضح. على سبيل المثال، تُظهر الروبوتات تحت الماء وروبوتات جز العشب إمكانات هائلة في سيناريوهات محددة. يرى التحليل أن شكل الروبوت وقدرته الإنتاجية على حل المشكلات الفعلية هما المفتاح في المرحلة الحالية، وأن الروبوتات المتخصصة، بفضل نماذج أعمالها الواضحة وسيناريوهات الطلب الملح، هي التي تحقق السبق في التسويق التجاري. (المصدر: الروبوتات المتخصصة تطرق على كتف الروبوتات البشرية قائلة “أخي، افسح المجال، أريد أن أشارك في المائدة.”)

جوجل تطلق وكيل هندسة بيانات BigQuery، لتحقيق إنشاء خطوط أنابيب ذكية : أطلقت جوجل وكيل هندسة بيانات BigQuery، وهي أداة تستخدم الاستدلال المدرك للسياق لتوسيع نطاق إنشاء خطوط أنابيب البيانات بكفاءة. يمكن للمستخدمين تحديد متطلبات خط الأنابيب من خلال أوامر سطر أوامر بسيطة، بينما يستخدم الوكيل الذكي مطالبات خاصة بالمجال لإنشاء كود خط أنابيب دفعي مخصص لبيئة بيانات المستخدم، بما في ذلك تكوينات استيعاب البيانات، واستعلامات التحويل، ومنطق إنشاء الجداول، وإعدادات الجدولة من خلال Dataform أو Composer. تهدف هذه الأداة إلى تبسيط العمل المتكرر الذي يواجهه مهندسو البيانات عند التعامل مع مجالات بيانات وبيئات ومنطق تحويل متعددة من خلال المساعدة بالذكاء الاصطناعي. (المصدر: Reddit r/deeplearning)
Yandex تطلق Yambda، مجموعة بيانات عامة ضخمة تضم ما يقرب من 5 مليارات تفاعل بين المستخدمين والمقاطع الصوتية : أطلقت Yandex مجموعة بيانات عامة ضخمة تُدعى Yambda، مصممة خصيصًا لأبحاث أنظمة التوصية. تحتوي مجموعة البيانات هذه على ما يقرب من 5 مليارات تفاعل مجهول بين المستخدمين والمقاطع الصوتية من Yandex Music، مما يوفر للباحثين فرصة نادرة للتعامل مع بيانات بحجم العالم الحقيقي. (المصدر: _akhaliq)

ByteDance تطلق نموذج إصلاح الفيديو SeedVR2 على Hugging Face : أطلق فريق Seed التابع لـ ByteDance نموذج SeedVR2 على Hugging Face، وهو نموذج Transformer أحادي الخطوة لانتشار إصلاح الفيديو. يعتمد هذا النموذج على ترخيص Apache 2.0، ويتميز بالاستدلال أحادي الخطوة، والسرعة والكفاءة، ويدعم المعالجة بأي دقة، دون الحاجة إلى تقسيم أو التقيد بالحجم. (المصدر: huggingface)
نموذج الفيديو الكبير Seedance 1.0 Pro من ByteDance يحظى بتقييمات إيجابية في الاختبارات العملية : أظهر نموذج الفيديو الكبير Seedance 1.0 Pro الذي أطلقته ByteDance مؤخرًا قدرة جيدة على اتباع التعليمات واستقرارًا في توليد الكائنات في الاختبارات العملية. أفاد المستخدمون بأن جودة الفيديو المولدة عالية، وأن توقيت حركة الكاميرا دقيق، ويأتي في المرتبة الثانية بعد Veo 2/3. أحد العيوب المحتملة هو أنه عند توليد حركة كائنات خالصة، يضيف النموذج أحيانًا حركة يد لجعل المشهد أكثر منطقية، ويمكن تجنب ذلك عن طريق تقييد ظهور اليد. (المصدر: karminski3, karminski3, karminski3)
علي بابا تفتح مصدر إطار الشخصيات الرقمية Mnn3dAvatar، الذي يدعم التقاط الوجه في الوقت الفعلي وإنشاء شخصيات افتراضية ثلاثية الأبعاد : فتحت علي بابا مصدر إطار للشخصيات الرقمية يُدعى Mnn3dAvatar على GitHub. يمكن لهذا المشروع تحقيق التقاط الوجه في الوقت الفعلي، وربط تعابير الوجه بشخصيات افتراضية ثلاثية الأبعاد، كما يدعم المستخدمين في إنشاء شخصياتهم الافتراضية ثلاثية الأبعاد. هذا الإطار مناسب لسيناريوهات بسيطة مثل البث المباشر لبيع المنتجات وعرض المحتوى. (المصدر: karminski3)
Nvidia تفتح مصدر نموذج الروبوت البشري الأساسي Gr00t N 1.5 3B، وتوفر برنامجًا تعليميًا للضبط الدقيق : فتحت Nvidia مصدر نموذج Gr00t N 1.5 3B، وهو نموذج أساسي مفتوح مصمم لمهارات الاستدلال لدى الروبوتات البشرية، ويستخدم ترخيصًا تجاريًا. في الوقت نفسه، أصدرت Nvidia أيضًا برنامجًا تعليميًا كاملاً للضبط الدقيق لاستخدامه مع LeRobotHF SO101، بهدف تعزيز تطوير وتطبيق تكنولوجيا الروبوتات البشرية. (المصدر: ClementDelangue)
Together AI تطلق Batch API، لتقديم خدمات استدلال LLM واسعة النطاق مع تخفيض كبير في الأسعار : أطلقت Together AI واجهة برمجة تطبيقات جديدة تُدعى Batch API، مصممة خصيصًا للاستدلال على نماذج LLM واسعة النطاق، وتدعم تطبيقات ذات إنتاجية عالية مثل إنشاء البيانات الاصطناعية، والاختبارات المعيارية، ومراجعة وتلخيص المحتوى، واستخراج المستندات. تقدم هذه الواجهة سعرًا تمهيديًا أرخص بنسبة 50% من واجهة برمجة التطبيقات في الوقت الفعلي، وتدعم معالجة دفعات تصل إلى 50,000 طلب أو 100 ميجابايت في كل مرة، ومتوافقة مع 15 نموذجًا من أفضل النماذج. (المصدر: vipulved)
Google Gemini 2.5 Pro يضيف ميزة إنشاء فن كسوري تفاعلي : أعلنت جوجل أن Gemini 2.5 Pro يدعم الآن إنشاء فن كسوري تفاعلي فوري. يمكن للمستخدمين إنشاء أعمال فنية بصرية فريدة من خلال تقديم مطالبات مثل “أنشئ لي عملًا فنيًا كسوريًا جميلًا، قائمًا على الجسيمات، متحركًا، لا نهائيًا، ثلاثي الأبعاد، متماثلًا، مستوحى من الصيغ الرياضية”. (المصدر: demishassabis)
سرعة إنشاء الفيديو في Google Veo3 Fast تتضاعف مرتين : أعلن مختبر جوجل أن سرعة إنشاء الفيديو في إصدار Veo3 Fast ضمن أداة Flow قد زادت بأكثر من ضعفين، مع الحفاظ على دقة 720p. يهدف هذا التحديث إلى تمكين المستخدمين من إنشاء محتوى فيديو بشكل أسرع. (المصدر: op7418)
Hugging Face تتكامل مع Google Colab و Kaggle لتبسيط عملية استخدام النماذج : تم الآن دمج Hugging Face مع Google Colab و Kaggle. يمكن للمستخدمين تشغيل دفاتر Colab مباشرة من أي بطاقة نموذج، أو فتح نفس النموذج في Kaggle Notebook، مع أمثلة كود عامة قابلة للتشغيل، مما يبسط عملية استخدام النماذج وإجراء التجارب. (المصدر: ClementDelangue, huggingface)
UnslothAI تحقق زيادة في الإنتاجية بمقدار ضعفين في خدمات نماذج المكافآت واستدلال تصنيف التسلسل : تم اكتشاف إمكانية استخدام UnslothAI لتقديم خدمات نماذج المكافآت (RM)، وفيما يتعلق باستدلال تصنيف التسلسل، فإن إنتاجيتها تبلغ ضعف إنتاجية vLLM. أثار هذا الاكتشاف اهتمامًا في مجتمع التعلم المعزز (RL)، ومن المتوقع أن يؤدي تحسين أداء UnslothAI إلى تسريع الأبحاث والتطبيقات ذات الصلة. (المصدر: natolambert, danielhanchen)
روبوتات ديجوا تطلق أول مجموعة تطوير روبوتات متكاملة للحوسبة والتحكم بشريحة SoC واحدة RDK S100 : أطلقت شركة روبوتات ديجوا أول مجموعة تطوير روبوتات متكاملة للحوسبة والتحكم بشريحة SoC واحدة في الصناعة، RDK S100. تعتمد هذه المجموعة تصميمًا معماريًا يشبه المخ والمخيخ البشري، حيث تدمج وحدة المعالجة المركزية (CPU) ووحدة معالجة الدماغ (BPU) ووحدة التحكم الدقيقة (MCU) على شريحة SoC واحدة، وتدعم التعاون الفعال بين النماذج الكبيرة والصغيرة للذكاء المتجسد، وتكمل الحلقة المغلقة “الإدراك – اتخاذ القرار – التحكم”. توفر RDK S100 واجهات متعددة وبنية تحتية للتطوير متكاملة بين الأجهزة والبرامج، وبين الطرف والسحابة، بهدف تسريع بناء منتجات الذكاء المتجسد ونشرها في سيناريوهات متعددة. حاليًا، تم التعاون مع أكثر من 20 عميلًا رائدًا، ويبلغ سعر السوق 2799 يوانًا. (المصدر: روبوتات ديجوا تطلق أول مجموعة تطوير روبوتات متكاملة للحوسبة والتحكم بشريحة SoC واحدة، وقد تم التعاون مع أكثر من 20 عميلًا رائدًا | الخط الأمامي)

🧰 أدوات
LangChain تنشر اختبارًا معياريًا لبنية الوكلاء المتعددين وتحسينات على طريقة المشرف : أجرت LangChain اختبارًا معياريًا أوليًا لأنظمة الوكلاء المتعددين المتزايدة، لبحث كيفية تحسين التنسيق بين الوكلاء المتعددين. في الوقت نفسه، أجرت LangChain بعض التحسينات على طريقتها الخاصة بالمشرف (supervisor)، وتم نشر مدونة ذات صلة. (المصدر: LangChainAI, hwchase17)
Cartesia تطلق Ink-Whisper: نموذج تحويل الكلام إلى نص متدفق سريع واقتصادي مصمم لوكلاء الصوت الذكي : أطلقت Cartesia نموذج Ink-Whisper، وهو نموذج تحويل الكلام إلى نص (STT) متدفق عالي السرعة ومنخفض التكلفة ومُحسَّن لوكلاء الصوت الذكي. تم تصميم هذا النموذج خصيصًا للدقة في ظروف العالم الحقيقي، ويمكن استخدامه مع نموذج تحويل النص إلى كلام (TTS) Sonic من Cartesia لتحقيق تفاعلات صوتية سريعة بالذكاء الاصطناعي. يدعم Ink-Whisper الاتصال بمنصات مثل VapiAI و PipecatAI و Livekit. (المصدر: simran_s_arora, tri_dao, krandiash)

MonkeyOCR: نموذج تحليل مستندات صغير وسريع ومفتوح المصدر : تم إطلاق نموذج تحليل مستندات بمعاملات 3B يُدعى MonkeyOCR، باستخدام ترخيص Apache 2.0. يستطيع هذا النموذج تحليل مختلف العناصر في المستندات، بما في ذلك الرسوم البيانية، والصيغ، والجداول، ويهدف إلى استبدال خطوط أنابيب التحليل التقليدية، وتوفير حل أفضل لمعالجة المستندات. (المصدر: mervenoyann, huggingface)
LlamaIndex تتكامل مع Cleanlab لتعزيز موثوقية استجابات مساعد الذكاء الاصطناعي : أعلنت LlamaIndex عن تكاملها مع CleanlabAI. تُستخدم LlamaIndex لبناء مساعدي معرفة بالذكاء الاصطناعي ووكلاء إنتاجيين، واستخلاص رؤى من بيانات الشركات. يهدف انضمام Cleanlab إلى تعزيز موثوقية استجابات مساعدي الذكاء الاصطناعي هؤلاء، حيث يمكنه تقييم كل استجابة LLM، والتقاط الهلوسات أو الاستجابات غير الصحيحة في الوقت الفعلي، والمساعدة في تحليل أسباب عدم موثوقية الاستجابة (مثل الاسترجاع الضعيف، أو مشكلات البيانات/السياق، أو الاستعلامات الصعبة، أو هلوسات LLM). (المصدر: jerryjliu0)

Claude Code يضيف “وضع الخطة” لتعزيز التحكم في تغييرات الكود المعقدة : قدم Claude Code من Anthropic “وضع الخطة” (Plan mode). تسمح هذه الميزة للمستخدمين بمراجعة خطة التنفيذ قبل إجراء تغييرات فعلية على الكود، مما يضمن دراسة كل خطوة بعناية، خاصة للتغييرات المعقدة في الكود. يمكن للمستخدمين الدخول إلى وضع الخطة عن طريق الضغط على Shift + Tab مرتين، وسيقدم Claude Code خطة تنفيذ مفصلة ويطلب التأكيد قبل التنفيذ. تم إطلاق هذه الميزة لجميع مستخدمي Claude Code (بما في ذلك مشتركي Pro أو Max). (المصدر: dotey, kylebrussell)
rvn-convert: أداة تحويل SafeTensors إلى GGUF v3 مكتوبة بلغة Rust : تم إطلاق أداة مفتوحة المصدر تُدعى rvn-convert، مكتوبة بلغة Rust، لتحويل ملفات النماذج بتنسيق SafeTensors إلى تنسيق GGUF v3. تتميز هذه الأداة بدعم الشريحة الواحدة، والسرعة، وعدم الحاجة إلى بيئة Python، ويمكنها تعيين ملفات safetensors في الذاكرة والكتابة مباشرة إلى ملفات gguf، مما يتجنب ذروات استخدام ذاكرة RAM ومشكلات دوران القرص. تدعم حاليًا الترقية من BF16 إلى F32، وتضمين tokenizer.json وغيرها من الميزات. (المصدر: Reddit r/LocalLLaMA)
Runway API يضيف ميزة رفع دقة الفيديو إلى 4K : أعلنت Runway أن واجهة برمجة التطبيقات الخاصة بها تدعم الآن ميزة رفع دقة الفيديو إلى 4K. يمكن للمطورين دمج هذه الميزة في تطبيقاتهم ومنتجاتهم ومنصاتهم ومواقعهم الإلكترونية لتعزيز وضوح وجودة محتوى الفيديو. (المصدر: c_valenzuelab)
You.com تطلق ميزة Projects لتنظيم وإدارة مواد البحث : أطلقت You.com أداة جديدة تُدعى “Projects”، تهدف إلى مساعدة المستخدمين على تنظيم مواد البحث في مجلدات يسهل الوصول إليها. تدعم هذه الميزة المستخدمين في وضع سياق للمحادثات وهيكلتها، وتجنب تشتت سجلات الدردشة وفقدان الرؤى، وبالتالي تبسيط عملية إدارة المعرفة. (المصدر: RichardSocher)
LlamaIndex تطلق خدمة استخراج المستندات الذكية LlamaExtract : أطلقت LlamaIndex خدمة LlamaExtract، وهي خدمة استخراج مستندات مدفوعة بالوكيل الذكي، تهدف إلى استخراج البيانات المهيكلة من المستندات المعقدة وأنماط الإدخال. لا تقتصر هذه الخدمة على استخراج أزواج المفاتيح والقيم، بل توفر أيضًا استدلالًا دقيقًا للمصدر، ومراجع للصفحات، ونصوصًا متطابقة لكل عنصر مستخرج. تتوفر LlamaExtract كواجهة برمجة تطبيقات (API)، ويمكن دمجها بسهولة في مهام سير عمل الوكيل الذكي النهائية. (المصدر: jerryjliu0)

تحديث langchain-google-vertexai، تحسين التخزين المؤقت للعميل ودعم الأدوات : شهد langchain-google-vertexai إصدارًا جديدًا. تشمل التحديثات الرئيسية: التخزين المؤقت لعميل التنبؤ، مما يجعل سرعة إنشاء عميل جديد أسرع بـ 500 مرة؛ ودعم أدوات تنفيذ الكود المدمجة. (المصدر: LangChainAI, Hacubu)
Perplexity Finance يضيف ميزة تنزيل نماذج Excel مباشرة : أعلنت Perplexity Finance أنه يمكن للمستخدمين الآن تنزيل نماذج Excel مباشرة من صفحتها، مما يوفر نقطة انطلاق أسرع للنمذجة المالية والبحث. هذه الميزة متاحة مجانًا لجميع المستخدمين، وكانت تدعم سابقًا تنزيل تنسيق CSV فقط. (المصدر: AravSrinivas)
Viwoods تطلق جهاز لوحي بشاشة حبر إلكتروني AI Paper Mini، يدمج وظائف الذكاء الاصطناعي مثل GPT-4o : أطلقت شركة Viwoods الناشئة في مجال شاشات الحبر الإلكتروني جهاز AI Paper Mini، وهو جهاز لوحي بشاشة حبر إلكتروني مزود بوظائف الذكاء الاصطناعي. يدعم هذا الجهاز نماذج ذكاء اصطناعي متعددة مثل GPT-4o و DeepSeek، ويوفر وضع Chat ومساعدي ذكاء اصطناعي محددين مسبقًا (تحليل المحتوى، إنشاء رسائل البريد الإلكتروني، تحويل الذكاء الاصطناعي إلى نص). تشمل ميزاته الخاصة إدارة المهام في عرض التقويم، والملاحظات السريعة في نافذة عائمة. من حيث الأجهزة، يستخدم Paper Mini شاشة Carta 1000 بدقة 292 بكسل لكل بوصة، وذاكرة 4 جيجابايت + 128 جيجابايت، ومزود بقلم. في الوقت نفسه، أطلقت Viwoods أيضًا AI Paper بحجم أكبر، يتميز بشاشة Carta 1300 مرنة بدقة 300 بكسل لكل بوصة، وسرعة استجابة أسرع. (المصدر: أنفقت نصف سعر iPhone لشراء “جهاز لوحي بشاشة حبر إلكتروني” مزود بالذكاء الاصطناعي…)

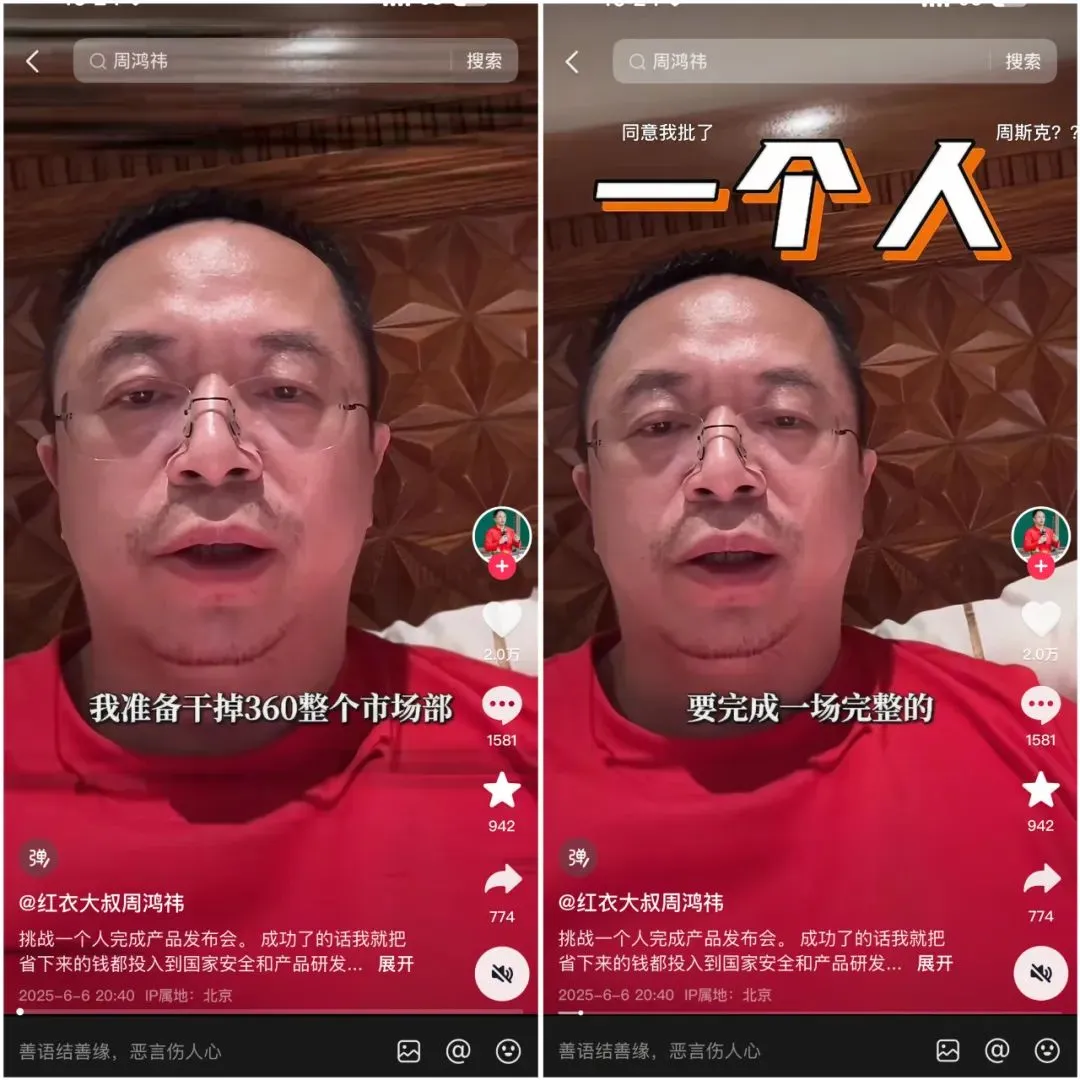
360 تطلق وكيل البحث الفائق الذكي Nano AI، بحضور شخصي من تشو هونغ يي : ترأس تشو هونغ يي، مؤسس مجموعة 360، إطلاق وكيل البحث الفائق الذكي Nano AI. يهدف هذا الوكيل الذكي إلى تحقيق “جملة واحدة، كل شيء قابل للبحث”، ويمكنه التفكير بشكل مستقل، واستدعاء المتصفح والأدوات الخارجية لتنفيذ المهام دون تدخل بشري، ويدعم التصور الكامل وتتبع الخطوات. صرح تشو هونغ يي بأن هذا المؤتمر الصحفي نفسه حاول استخدام Nano AI في التحضير، وأطلق جهاز تسجيل صوتي ذكي يعمل بالذكاء الاصطناعي Nano AI Note ونظارات ذكاء اصطناعي بالتعاون مع Rokid. (المصدر: تشو هونغ يي يريد استخدام الذكاء الاصطناعي “للتخلص” من قسم التسويق، هل نجح “Nano” في ذلك؟)
📚 موارد تعليمية
DeepLearning.AI تطلق دورة تدريبية قصيرة جديدة: تنسيق مهام سير عمل GenAI باستخدام Apache Airflow : أطلقت DeepLearning.AI بالتعاون مع Astronomer دورة تدريبية قصيرة جديدة تعلم كيفية استخدام Apache Airflow 3.0 لتحويل نماذج RAG الأولية إلى مهام سير عمل جاهزة للإنتاج. يتضمن محتوى الدورة تقسيم مهام سير العمل إلى مهام معيارية، وجدولة خطوط الأنابيب باستخدام مشغلات تعتمد على الوقت والأحداث، وتعيين المهام الديناميكية لتشغيل المهام بالتوازي، وإضافة إعادة المحاولة/التنبيهات/التعبئة الخلفية لتحقيق التسامح مع الأخطاء، وتقنيات توسيع خطوط الأنابيب. لا تتطلب هذه الدورة خبرة سابقة في Airflow. (المصدر: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
هامل حسين يطلق دورة مصغرة حول تحسين وتقييم RAG : أعلن هامل حسين عن إطلاق دورة مصغرة من أربعة أجزاء حول تحسين وتقييم RAG (التوليد المعزز بالاسترجاع). الجزء الأول، الذي قدمه @bclavie، ناقش وجهة نظر “الاسترجاع هو RAG”، بهدف الرد على النقاشات السابقة حول كون RAG “فيروسًا فكريًا يجب استئصاله”. هذه السلسلة من الدورات مجانية وتهدف إلى مساعدة الممارسين على حل الصعوبات التي يواجهونها في تقييم RAG. (المصدر: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

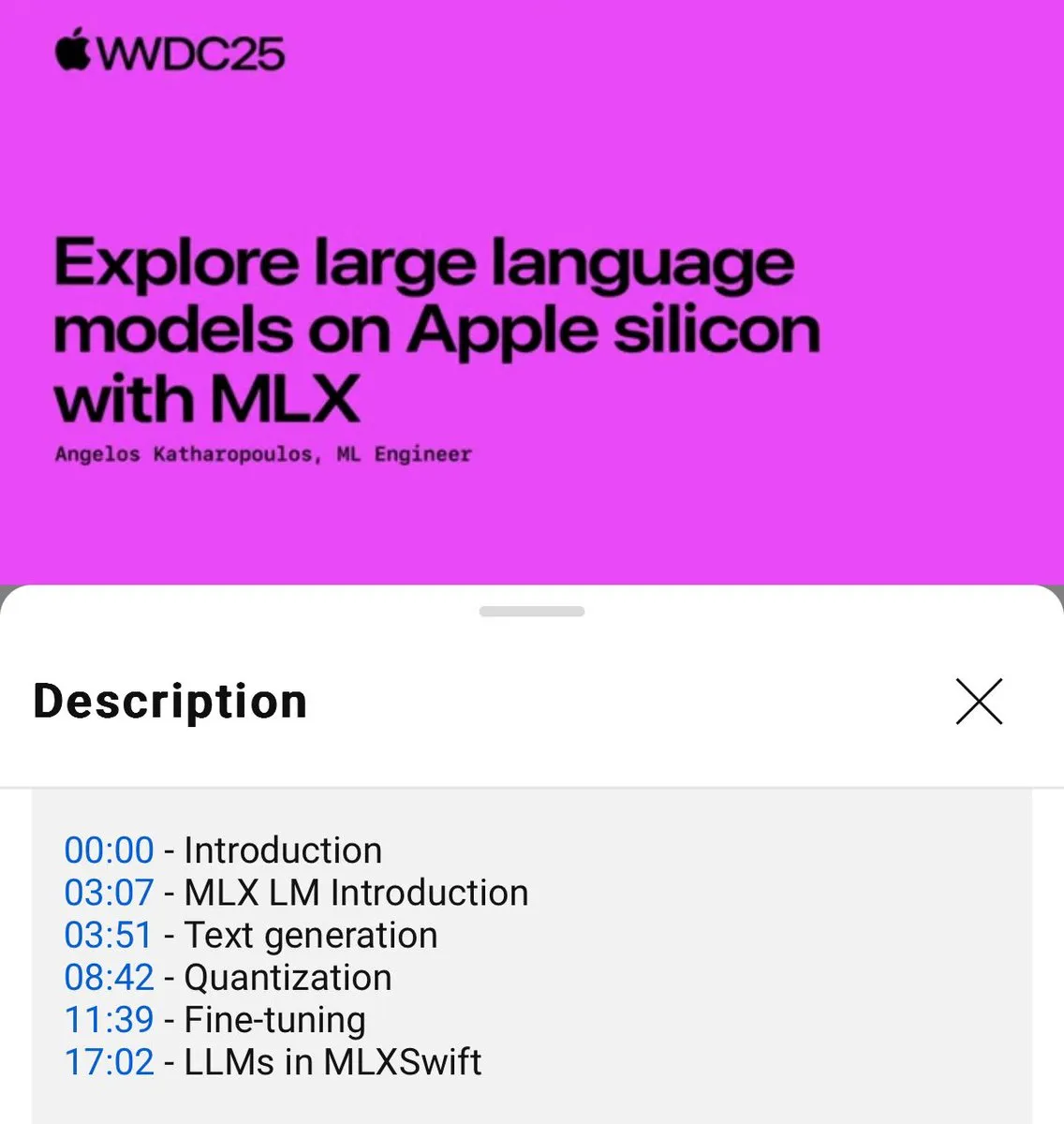
إصدار برنامج تعليمي لاستخدام نماذج لغة MLX محليًا (WWDC25) : في مؤتمر WWDC25، قدم أنجيلوس كاثابولوس كيفية البدء بسرعة في استخدام نماذج اللغة المحلية باستخدام MLX. يغطي البرنامج التعليمي استخدام MLXLM CLI لعمليات سطر أوامر واحد، مثل تكميم النموذج (mlx_lm.convert)، والضبط الدقيق لـ LoRA (mlx_lm.lora)، ودمج النماذج وتحميلها إلى Hugging Face (mlx_lm.fuse). يتوفر برنامج Jupyter Notebook التعليمي الكامل على GitHub. (المصدر: awnihannun)
LangChain تشارك طريقة Harvey AI لبناء وكلاء ذكاء اصطناعي قانونيين : شارك بن ليبالد من Harvey AI في فعالية Interrupt التي نظمتها LangChain، طريقتهم الناضجة لبناء وكلاء ذكاء اصطناعي قانونيين. تجمع هذه الطريقة بين تقييم LangSmith واستراتيجية “المحامي في الحلقة” (lawyer-in-the-loop)، بهدف توفير أدوات ذكاء اصطناعي موثوقة للمحامين للتعامل مع الأعمال القانونية المعقدة. (المصدر: LangChainAI, hwchase17)

تحديث دليل RLHF الإصدار 1.1، توسيع محتوى نماذج RLVR/الاستدلال : تم تحديث دليل RLHF (rlhfbook.com) إلى الإصدار 1.1، مع إضافة محتوى موسع حول RLVR (التعلم المعزز من تمثيلات الفيديو) ونماذج الاستدلال. تشمل التحديثات ملخصًا لتقارير نماذج الاستدلال الرئيسية، والممارسات/الحيل الشائعة ومستخدميها، وأعمال الاستدلال ذات الصلة قبل o1، وتحسينات مثل RL غير المتزامن. (المصدر: menhguin)
ورقة بحثية SWE-Flow: توليف بيانات هندسة البرمجيات بطريقة تعتمد على الاختبار : تقترح ورقة بحثية جديدة بعنوان SWE-Flow إطارًا جديدًا لتوليف البيانات يعتمد على التطوير الموجه بالاختبار (TDD). يقوم هذا الإطار بتحليل اختبارات الوحدة تلقائيًا لاستنتاج خطوات التطوير التزايدية، وبناء رسم بياني للاعتمادية وقت التشغيل (RDG) لإنشاء خطط تطوير مهيكلة. تنتج كل خطوة قاعدة كود جزئية، واختبارات وحدة مقابلة، وتعديلات الكود اللازمة، مما يؤدي إلى إنشاء مهام TDD قابلة للتحقق. بناءً على هذه الطريقة، تم إنشاء مجموعة بيانات التقييم المعياري SWE-Flow-Eval. (المصدر: HuggingFace Daily Papers)
ورقة بحثية PlayerOne: أول محاكاة للعالم الحقيقي مبنية من منظور الشخص الأول : تم اقتراح PlayerOne كأول محاكاة للعالم الحقيقي مبنية من منظور الشخص الأول (egocentric)، قادرة على الاستكشاف الغامر في بيئات ديناميكية. بالنظر إلى صورة مشهد المستخدم من منظور الشخص الأول، يمكن لـ PlayerOne بناء العالم المقابل وإنشاء فيديو من منظور الشخص الأول يتوافق بدقة مع الحركة الحقيقية للمستخدم التي تم التقاطها بواسطة كاميرا خارجية. يعتمد النموذج على عملية تدريب من الخشن إلى الدقيق، ويصمم مخطط حقن حركة مفكك المكونات وإطار إعادة بناء مشترك. (المصدر: HuggingFace Daily Papers)
ورقة بحثية ComfyUI-R1: استكشاف نماذج الاستدلال لتوليد سير العمل : ComfyUI-R1 هو أول نموذج استدلال كبير لتوليد سير العمل الآلي. قام الباحثون أولاً ببناء مجموعة بيانات تحتوي على 4 آلاف سير عمل، وقاموا ببناء بيانات استدلال سلسلة التفكير الطويلة (CoT). يتم تدريب ComfyUI-R1 من خلال إطار عمل من مرحلتين: الضبط الدقيق لـ CoT للبدء البارد، والتعلم المعزز لتحفيز قدرة الاستدلال. أظهرت التجارب أن نموذج 7B بارامتر يتفوق بشكل كبير على الطرق الحالية في صحة التنسيق، ومعدل النجاح، ودرجات F1 على مستوى العقدة/الرسم البياني. (المصدر: HuggingFace Daily Papers)
ورقة بحثية SeerAttention-R: إطار تكييفي للانتباه المتناثر للاستدلال الطويل : SeerAttention-R هو إطار انتباه متناثر مصمم خصيصًا لفك التشفير الطويل لنماذج الاستدلال. يتعلم تناثر الانتباه من خلال آلية بوابات التقطير الذاتي، ويزيل تجميع الاستعلامات للتكيف مع فك التشفير التراجعي الذاتي. يمكن دمج هذا الإطار كإضافة خفيفة الوزن في النماذج المدربة مسبقًا الحالية، دون الحاجة إلى تعديل المعلمات الأصلية. في اختبار AIME المعياري، حافظ SeerAttention-R، الذي تم تدريبه باستخدام 0.4 مليار tokens فقط، على دقة استدلال شبه خالية من الخسائر في كتل الانتباه المتناثرة الكبيرة (64/128) ضمن ميزانية 4 آلاف token. (المصدر: HuggingFace Daily Papers)
ورقة بحثية SAFE: كشف الفشل متعدد المهام لنماذج الرؤية واللغة والحركة : تقترح الورقة البحثية SAFE، وهو كاشف فشل مصمم لاستراتيجيات الروبوتات العامة (مثل VLA). من خلال تحليل مساحة ميزات VLA، يتعلم SAFE التنبؤ باحتمالية فشل المهمة من ميزات VLA الداخلية. يتم تدريب هذا الكاشف في عمليات النشر الناجحة والفاشلة، ويتم تقييمه في مهام لم يسبق لها مثيل، وهو متوافق مع معماريات الاستراتيجيات المختلفة، ويهدف إلى تحسين سلامة VLA عند التفاعل مع البيئة. (المصدر: HuggingFace Daily Papers)
ورقة بحثية Branched Schrödinger Bridge Matching: تعلم جسور شرودنغر المتفرعة : تقدم هذه الدراسة إطار Branched Schrödinger Bridge Matching (BranchSBM) لتعلم جسور شرودنغر المتفرعة، للتنبؤ بالمسارات الوسيطة بين التوزيع الأولي والتوزيع المستهدف. على عكس الطرق الحالية، يستطيع BranchSBM نمذجة التطورات المتفرعة أو المتباعدة من نقطة انطلاق مشتركة إلى نتائج متعددة مختلفة، وذلك من خلال تحديد معلمات حقول سرعة متعددة مرتبطة بالوقت وعمليات النمو. (المصدر: HuggingFace Daily Papers)
💼 أعمال
تقارير تفيد بأن Meta تخطط للاستحواذ على شركة Scale AI لتمييز البيانات مقابل 150 مليار دولار، مع احتمال انضمام المؤسس إلى Meta : تفيد التقارير بأن Meta تخطط لإنفاق 150 مليار دولار للاستحواذ على شركة Scale AI، وهي شركة رائدة في مجال تمييز البيانات. إذا تمت الصفقة، سينضم ألكسندر وانغ، المؤسس الصيني البالغ من العمر 28 عامًا لشركة Scale AI، وفريقه مباشرة إلى Meta. تعتبر هذه الخطوة بمثابة خطوة كبيرة من قبل مارك زوكربيرج، الرئيس التنفيذي لشركة Meta، لتعزيز قوة فريقه في مجال الذكاء الاصطناعي العام (AGI) واللحاق بركب المنافسين مثل OpenAI وجوجل. قامت Meta مؤخرًا بتحركات متكررة في توظيف مواهب الذكاء الاصطناعي، حيث قدمت حزم رواتب تصل إلى عشرات الملايين من الدولارات لكبار المهندسين. (المصدر: أول شخصية بارزة في مجموعة “الذكاء الفائق” لزوكربيرج، الباحث الرئيسي في جوجل DeepMind، والشخصية المحورية في “الضغط هو الذكاء”, dylan522p, sarahcat21, Dorialexander)
ديزني ويونيفرسال بيكتشرز تقاضيان شركة Midjourney للصور المولدة بالذكاء الاصطناعي بتهمة انتهاك حقوق النشر : رفعت ديزني ويونيفرسال بيكتشرز دعوى قضائية ضد شركة Midjourney لإنشاء الصور بالذكاء الاصطناعي، متهمة إياها بالاستخدام غير المصرح به لأعمال محمية بحقوق ملكية فكرية شهيرة مثل “Star Wars” و “The Simpsons”. أثارت هذه القضية اهتمامًا، وإذا فازت ديزني، فقد يكون لذلك تداعيات متسلسلة على شركات الذكاء الاصطناعي الأخرى التي تعتمد على تدريب البيانات الضخمة، مما يزيد من حدة الجدل حول حقوق النشر في مجال الذكاء الاصطناعي. (المصدر: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

جوجل تطرح “خطة مغادرة طوعية” مرة أخرى بسبب تأثير البحث بالذكاء الاصطناعي، وتشمل عدة فرق مهمة مثل البحث والإعلانات : في مواجهة التأثير الناجم عن البحث بالذكاء الاصطناعي، طرحت جوجل مرة أخرى “خطة مغادرة طوعية” لموظفي عدة أقسام في الولايات المتحدة، تشمل فرقًا رئيسية مثل البحث، والإعلانات، والهندسة الأساسية، وعززت سياسات العودة إلى العمل المكتبي. تهدف هذه الخطوة إلى إعادة هيكلة الموارد، وتركيز المزيد من الجهود على مشروع الذكاء الاصطناعي الرائد Gemini وتطوير تجربة البحث “بنمط الذكاء الاصطناعي”. تواجه أعمال البحث التقليدية في جوجل تحديات هائلة بسبب صعود الذكاء الاصطناعي، وفي الوقت نفسه تواجه الشركة أيضًا ضغوطًا تنظيمية. (المصدر: جوجل تطرح “خطة مغادرة طوعية” مرة أخرى بسبب تأثير البحث بالذكاء الاصطناعي، وتشمل عدة فرق مهمة, jpt401)
🌟 مجتمع
الذكاء الاصطناعي يكشف عن تحيز في تجربة الكشف عن الاحتيال في مجال الرعاية الاجتماعية في أمستردام، ويتم إيقاف المشروع : حاولت أمستردام استخدام نظام ذكاء اصطناعي (Smart Check) لتقييم طلبات الرعاية الاجتماعية للكشف عن الاحتيال، وعلى الرغم من اتباع أفضل الممارسات في مجال الذكاء الاصطناعي المسؤول، بما في ذلك اختبار التحيز والضمانات التقنية، إلا أن النظام فشل في تحقيق العدالة والفعالية في المشروع التجريبي. أظهر النموذج الأولي تحيزًا ضد المتقدمين غير الهولنديين والذكور، وبعد التعديل، أظهر تحيزًا ضد الهولنديين والإناث. في النهاية، تم إيقاف المشروع بسبب عدم القدرة على ضمان عدم التمييز. أثارت هذه الحالة نقاشًا واسعًا حول عدالة الخوارزميات، وفعالية ممارسات الذكاء الاصطناعي المسؤول، وتطبيق الذكاء الاصطناعي في اتخاذ القرارات في الخدمات العامة. (المصدر: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

نظام تحديد المحتوى المولد بالذكاء الاصطناعي: القيمة، والقيود، ومنطق الحوكمة : مع تزايد الشائعات والدعاية الكاذبة المولدة بالذكاء الاصطناعي، يحظى نظام تحديد الهوية بالذكاء الاصطناعي بالاهتمام كوسيلة للحوكمة. من الناحية النظرية، يمكن أن يؤدي التحديد الصريح والضمني إلى تحسين كفاءة التعرف وتعزيز يقظة المستخدم. ومع ذلك، في الممارسة العملية، من السهل التحايل على التحديد وتزويره وإساءة الحكم عليه، كما أنه مكلف. يرى المقال أنه يجب دمج تحديد الهوية بالذكاء الاصطناعي في نظام حوكمة المحتوى الحالي، والتركيز على المجالات عالية الخطورة (مثل الشائعات والدعاية الكاذبة)، وتحديد مسؤوليات منصات التوليد والنشر بشكل معقول، مع تعزيز التثقيف العام بالمعلومات. (المصدر: عندما تركب الشائعات موجة “الذكاء الاصطناعي”)
أدوات الترميز المساعدة بالذكاء الاصطناعي (مثل Claude Code) تعزز بشكل كبير كفاءة المطورين وتخفف ضغط العمل : شارك العديد من المطورين في المجتمع تجاربهم الإيجابية في استخدام أدوات الترميز المساعدة بالذكاء الاصطناعي (خاصة Claude Code من Anthropic). لا تساعد هذه الأدوات فقط في كتابة واختبار وتصحيح الأخطاء في الكود، بل يمكنها أيضًا تقديم الدعم في تخطيط المشاريع وحل المشكلات المعقدة، وبالتالي تعزيز كفاءة التطوير بشكل كبير، وتخفيف ضغط العمل وقلق المواعيد النهائية. أفاد بعض المستخدمين بأن المساعدة بالذكاء الاصطناعي جعلتهم يشعرون بأنهم “قوة لا يمكن إيقافها”. (المصدر: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

استهلاك المحتوى المولد بالذكاء الاصطناعي للطاقة والمياه يثير الاهتمام، وسام ألتمان يقول إن كل استعلام ChatGPT يستهلك حوالي 1/15 ملعقة صغيرة من الماء : كشف سام ألتمان، الرئيس التنفيذي لشركة OpenAI، أن كل استعلام ChatGPT يستهلك حوالي “واحد على خمسة عشر من ملعقة صغيرة” من الماء. أثارت هذه البيانات نقاشًا حول التأثير البيئي لتدريب نماذج الذكاء الاصطناعي واستدلالها. على الرغم من أن طريقة الحساب المحددة وما إذا كانت تشمل تكاليف التدريب لا تزال غير واضحة، إلا أن بصمة الطاقة واستهلاك المياه للذكاء الاصطناعي أصبحا من القضايا التي تحظى باهتمام في قطاع التكنولوجيا والمجال البيئي. (المصدر: MIT Technology Review, Reddit r/ChatGPT)

نقاش حول ما إذا كانت النماذج اللغوية الكبيرة تفهم حقًا البراهين الرياضية: اختبار IneqMath المعياري يكشف عن نقاط ضعف النماذج : يركز اختبار IneqMath المعياري الذي تم إصداره حديثًا على براهين المتباينات الرياضية على مستوى الأولمبياد، ووجدت الدراسة أنه على الرغم من أن النماذج اللغوية الكبيرة يمكنها أحيانًا العثور على الإجابة الصحيحة، إلا أن هناك فجوة كبيرة في بناء براهين دقيقة ومعقولة. أثار هذا نقاشًا حول ما إذا كانت النماذج اللغوية الكبيرة في مجالات مثل الرياضيات تفهم حقًا أم أنها مجرد “تخمين”. أشار Sathya إلى أن ظاهرة “الإجابة الصحيحة – الاستدلال الخاطئ” هذه تظهر أيضًا في اختبارات معيارية مثل PutnamBench. (المصدر: lupantech, lupantech, _akhaliq, clefourrier)
تطبيقات ونقاشات حول وكلاء الذكاء الاصطناعي في تطوير البرمجيات، والبحث، والمهام اليومية : يناقش المجتمع على نطاق واسع تطبيقات وكلاء الذكاء الاصطناعي في مختلف المجالات. على سبيل المثال، يشارك المستخدمون تجاربهم في استخدام n8n و Claude لبناء مهام سير عمل وكلاء بحث متعمق؛ ويعرض LlamaIndex كيفية تحقيق وكيل ملء نماذج تزايدي من خلال Artifact Memory Block؛ ويتناول النقاش أيضًا استخدام MCP (بروتوكول سياق النموذج) لتصميم واجهات أدوات موجهة للذكاء الاصطناعي، وتطبيقات وكلاء الذكاء الاصطناعي في مجالات مثل القانون، وأتمتة البنية التحتية (مثل JARVIS من Cisco). (المصدر: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

معايير سلامة الروبوتات البشرية تثير الاهتمام، وتحتاج إلى مراعاة التأثيرات الجسدية والنفسية : مع دخول الروبوتات البشرية تدريجيًا إلى التطبيقات الصناعية واستهدافها لسيناريوهات مثل المنازل، أصبحت معايير سلامتها محور نقاش. تشير مجموعة أبحاث الروبوتات البشرية التابعة لـ IEEE إلى أن الروبوتات البشرية تتمتع بخصائص فريدة مثل الاستقرار الديناميكي، وتحتاج إلى قواعد سلامة جديدة. بالإضافة إلى السلامة الجسدية (مثل منع السقوط والاصطدامات)، يجب أيضًا مراعاة تحديات التواصل في التفاعل بين الإنسان والروبوت (مثل التعبير عن النوايا، وتنسيق الروبوتات المتعددة) والتأثيرات النفسية (مثل التجسيد المفرط الذي يؤدي إلى توقعات عالية جدًا، والسلامة العاطفية). يجب أن يوازن وضع المعايير بين الابتكار والسلامة، وأن يأخذ في الاعتبار احتياجات سيناريوهات التطبيق المختلفة. (المصدر: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 أخرى
Docker تعلن أن docker run --gpus يدعم الآن وحدات معالجة الرسومات AMD GPU : تحديث رسمي من Docker، الأمر docker run --gpus يدعم الآن التشغيل على وحدات معالجة الرسومات AMD GPU أيضًا. يعزز هذا التحسين سهولة استخدام وحدات معالجة الرسومات AMD GPU في أعباء عمل الذكاء الاصطناعي/التعلم الآلي المعبأة في حاويات، وله أهمية إيجابية في تعزيز تطبيق AMD في النظام البيئي للذكاء الاصطناعي. (المصدر: dylan522p)
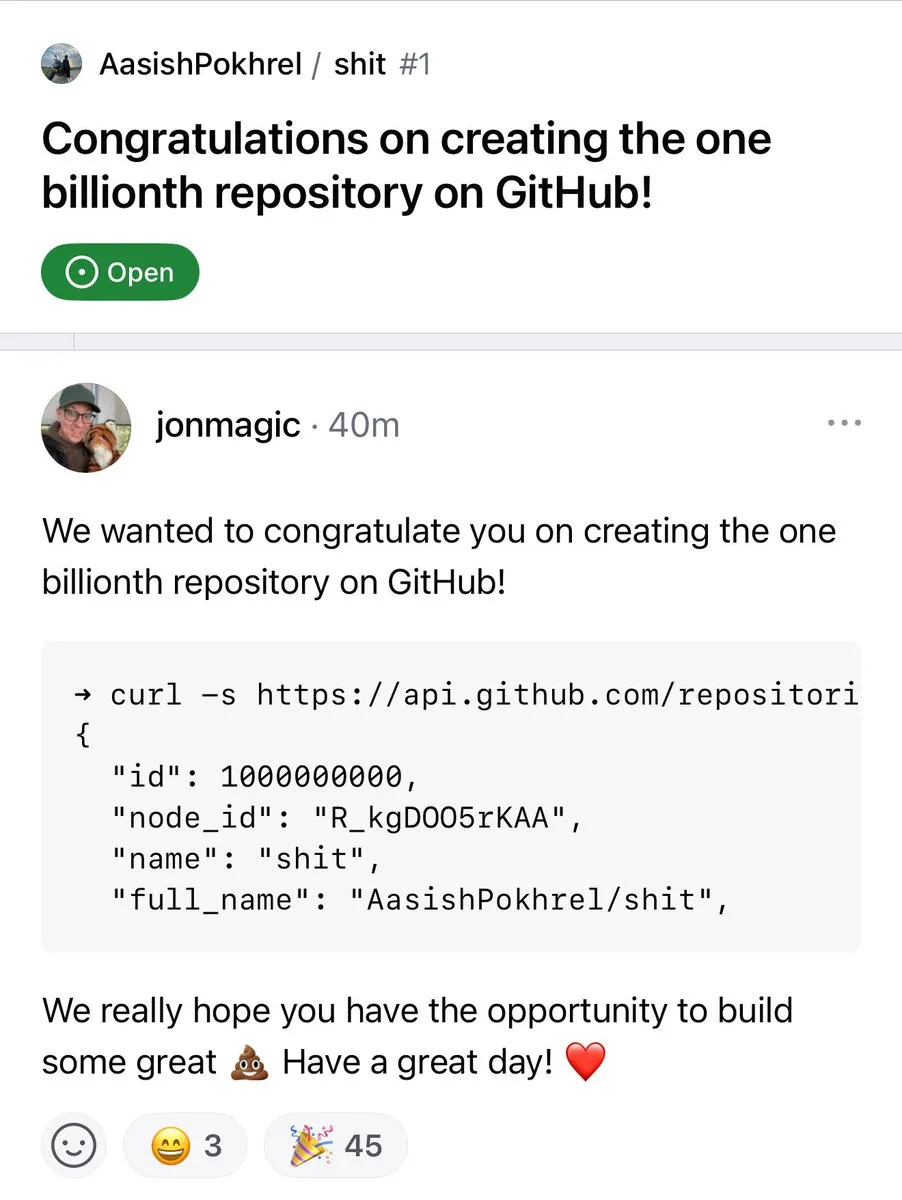
عدد مستودعات GitHub يتجاوز المليار : تجاوز عدد مستودعات الكود على منصة GitHub رسميًا حاجز المليار. يمثل هذا الحدث الهام استمرار ازدهار ونمو مجتمع المصادر المفتوحة ومنصات استضافة الكود. (المصدر: karminski3, zacharynado)
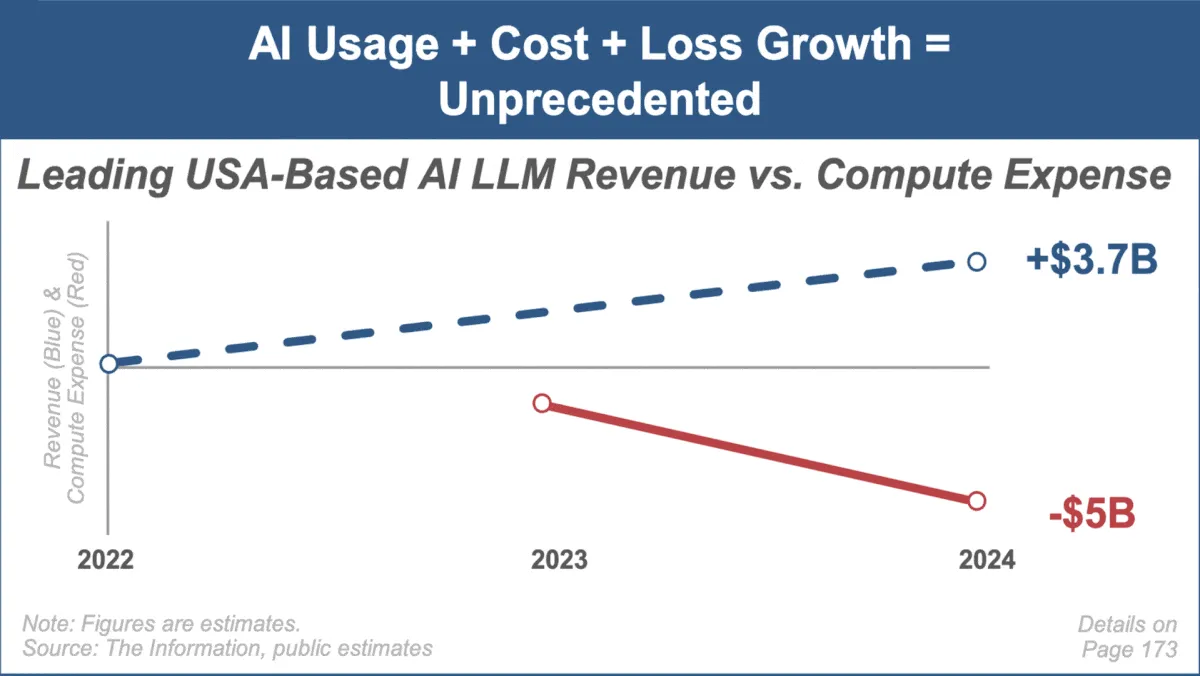
ماري ميكر تصدر أحدث تقرير عن اتجاهات الذكاء الاصطناعي، مع التركيز على النمو السريع للسوق والتحديات : أصدرت المحللة الاستثمارية الشهيرة ماري ميكر أول تقرير لها عن اتجاهات سوق الذكاء الاصطناعي بعنوان “Trends — Artificial Intelligence (May ‘25)”. يسلط التقرير الضوء على معدل النمو غير المسبوق في مجال الذكاء الاصطناعي، والزيادة الهائلة في حجم المستخدمين (مثل وصول مستخدمي ChatGPT إلى 800 مليون)، والزيادة الكبيرة في النفقات الرأسمالية المتعلقة بالذكاء الاصطناعي، والتقدم المستمر في أداء الذكاء الاصطناعي وقدراته الناشئة. يشير التقرير في الوقت نفسه إلى التحديات التي تواجه نماذج الأعمال في مجال الذكاء الاصطناعي، مثل ارتفاع تكاليف الحوسبة، والتكرار السريع للنماذج، والمنافسة من البدائل مفتوحة المصدر. (المصدر: DeepLearning.AI Blog)