
كلمات مفتاحية:آبل WWDC25, استراتيجية الذكاء الاصطناعي, ترقية سيري, إطار فاونديشن, الذكاء الاصطناعي على الجهاز, الترجمة على مستوى النظام, اكس كود فيب كودينج, البحث الذكي البصري, دعم الذكاء الاصطناعي من آبل للصينية التقليدية, وظيفة ووتش أو إس سمارت ستاك, استراتيجية خصوصية الذكاء الاصطناعي لآبل, تكامل الذكاء الاصطناعي عبر أنظمة البيئة, موعد إطلاق سيري بنسخة الذكاء الاصطناعي التوليدي
🔥 أبرز الأخبار
تقدم Apple في مجال الذكاء الاصطناعي في مؤتمر WWDC25: تكامل عملي وانفتاح، و Siri لا يزال قيد الانتظار: عرضت Apple في WWDC25 تعديلات على استراتيجيتها للذكاء الاصطناعي، متحولة من “الوعود الكبيرة” في العام الماضي إلى نهج أكثر واقعية يركز على تحسين النظام الأساسي والوظائف الأساسية. تشمل النقاط الرئيسية دمج الذكاء الاصطناعي “بشكل هادف” في نظام التشغيل وتطبيقات الطرف الأول، وفتح إطار عمل النموذج على الجهاز “Foundation” للمطورين. الميزات الجديدة مثل الترجمة على مستوى النظام (تدعم المكالمات الهاتفية، FaceTime، Message، وغيرها، وتوفر API)، ودمج Vibe Coding في Xcode (يدعم نماذج مثل ChatGPT)، والبحث البصري الذكي القائم على محتوى الشاشة (مشابه لميزة التحديد بالرسم، مدعوم جزئيًا بواسطة ChatGPT)، و Smart Stack في watchOS. على الرغم من الإشارة إلى دعم Apple Intelligence للسوق الصينية التقليدية، إلا أن موعد إطلاق النسخة الصينية المبسطة والإصدار المرتقب من Siri المدعوم بالذكاء الاصطناعي التوليدي لم يتم تحديدهما بعد، ومن المتوقع مناقشة الأخير “في العام المقبل”. أكدت Apple على أهمية الذكاء الاصطناعي على الجهاز والحوسبة السحابية الخاصة لحماية خصوصية المستخدم، وعرضت تكامل قدرات الذكاء الاصطناعي عبر منظومتها المتكاملة. (المصدر: 36氪, 36氪, 36氪, 36氪)

Apple تنشر ورقة بحثية حول الذكاء الاصطناعي تشكك في قدرات الاستدلال للنماذج الكبيرة، مما يثير جدلاً واسعاً في الصناعة: نشرت شركة Apple مؤخرًا ورقة بحثية بعنوان “وهم التفكير: فهم نقاط القوة والضعف في نماذج الاستدلال من منظور تعقيد المشكلة”، والتي أشارت من خلال اختبارات الألغاز على نماذج الاستدلال الكبيرة (LRMs) مثل Claude 3.7 Sonnet و DeepSeek-R1 و o3 mini، إلى أنها تميل إلى “الإفراط في التفكير” عند التعامل مع المشكلات البسيطة، بينما تواجه “انهيارًا تامًا في الدقة” في المشكلات عالية التعقيد، حيث تقترب الدقة من الصفر. ترى الدراسة أن نماذج الاستدلال الكبيرة الحالية قد تواجه عقبات جوهرية في الاستدلال القابل للتعميم، وأنها أقرب إلى مطابقة الأنماط منها إلى التفكير الحقيقي. حظي هذا الرأي باهتمام باحثين مثل Gary Marcus، ولكنه أثار أيضًا الكثير من الشكوك، حيث انتقد المعارضون وجود ثغرات منطقية في تصميم التجربة (مثل تعريف التعقيد وتجاهل قيود إخراج الـ token)، بل واتهموا Apple بمحاولة إنكار إنجازات النماذج الكبيرة الحالية بسبب تباطؤ تقدمها في مجال الذكاء الاصطناعي. كما أصبحت هوية المؤلف الأول للورقة كمتدرب نقطة نقاش. (المصدر: 36氪, Reddit r/ArtificialInteligence)

أنباء عن تدريب OpenAI سراً لنموذج جديد o4، والتعلم المعزز يعيد تشكيل خطط البحث والتطوير في الذكاء الاصطناعي: كشفت SemiAnalysis أن OpenAI تقوم بتدريب نموذج جديد بحجم يتراوح بين GPT-4.1 و GPT-4.5، وأن نموذج الاستدلال من الجيل التالي o4 سيعتمد على GPT-4.1 للتدريب باستخدام التعلم المعزز (RL). تشير هذه الخطوة إلى تحول في استراتيجية OpenAI، يهدف إلى الموازنة بين قوة النموذج والتطبيق العملي لتدريب RL، حيث يُعتبر GPT-4.1 أساسًا مثاليًا نظرًا لتكلفة استدلاله المنخفضة وأدائه القوي في البرمجة. يحلل المقال بعمق الدور الأساسي للتعلم المعزز في تعزيز قدرات الاستدلال لنماذج اللغة الكبيرة (LLM) ودفع تطوير وكلاء الذكاء الاصطناعي، ولكنه يشير أيضًا إلى التحديات في البنية التحتية، وتحديد دوال المكافأة، واختراق المكافآت (reward hacking). يغير التعلم المعزز الهيكل التنظيمي لمختبرات الذكاء الاصطناعي وأولويات البحث والتطوير، مما يجعل الاستدلال والتدريب متكاملين بعمق. وفي الوقت نفسه، أصبحت البيانات عالية الجودة خندقًا تنافسيًا لتوسيع نطاق RL، بينما قد يكون التقطير (distillation) أكثر فعالية من RL للنماذج الصغيرة. (المصدر: 36氪)

عودة Ilya Sutskever إلى الأضواء العامة، وحصوله على دكتوراه فخرية من جامعة تورنتو وحديثه عن مستقبل الذكاء الاصطناعي: بعد مغادرته OpenAI وتأسيسه شركة Safe Superintelligence Inc.، ظهر Ilya Sutskever، المؤسس المشارك لـ OpenAI، علنًا لأول مرة مؤخرًا، عائدًا إلى جامعته الأم، جامعة تورنتو، لتسلم دكتوراه فخرية في العلوم. وأكد في خطابه أن الذكاء الاصطناعي سيكون قادرًا في المستقبل على إنجاز كل ما يمكن للبشر القيام به، لأن الدماغ نفسه جهاز كمبيوتر بيولوجي، وليس هناك سبب يمنع أجهزة الكمبيوتر الرقمية من فعل الشيء نفسه. ويرى أن الذكاء الاصطناعي يغير العمل والمهن بطرق لم يسبق لها مثيل، وحث الناس على الاهتمام بتطور الذكاء الاصطناعي، واستلهام الطاقة للتغلب على التحديات من خلال ملاحظة قدراته. تجربة Sutskever في OpenAI واهتمامه بسلامة الذكاء الاصطناعي العام (AGI) تجعله شخصية رئيسية في مجال الذكاء الاصطناعي. (المصدر: 36氪, Reddit r/artificial)

🎯 التوجهات
شركة小红书 (Xiaohongshu) تطلق أول نموذج لغوي كبير مفتوح المصدر بتقنية MoE باسم dots.llm1، ويتفوق على DeepSeek-V3 في التقييمات الصينية: أعلن مختبر hi lab (مختبر الذكاء الإنساني) التابع لشركة 小红书 (Xiaohongshu) عن إطلاق أول نموذج لغوي كبير مفتوح المصدر له باسم dots.llm1، وهو نموذج بتقنية خليط الخبراء (MoE) يحتوي على 142 مليار معلمة، ويقوم بتنشيط 14 مليار معلمة فقط أثناء عملية الاستدلال. استخدم النموذج 11.2 تريليون من البيانات غير الاصطناعية في مرحلة ما قبل التدريب، وأظهر أداءً متميزًا في مهام فهم اللغتين الصينية والإنجليزية، والاستدلال الرياضي، وتوليد الأكواد، والمواءمة، حيث يقترب أداؤه من Qwen3-32B. والجدير بالذكر أن dots.llm1.inst حقق 92.2 نقطة في تقييم C-Eval الصيني، متجاوزًا النماذج الحالية بما في ذلك DeepSeek-V3. أكدت 小红书 (Xiaohongshu) أن إطار عملها القابل للتطوير لمعالجة البيانات بدقة عالية هو مفتاح النجاح، وقامت بإتاحة نقاط الفحص التدريبية الوسيطة مفتوحة المصدر لتعزيز أبحاث المجتمع. (المصدر: 36氪)
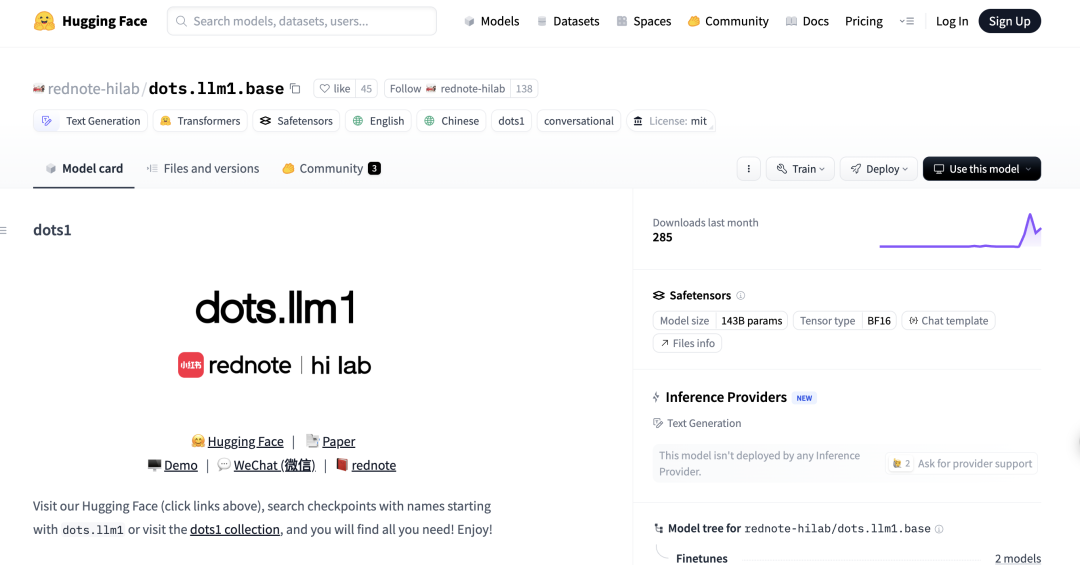
نموذج DeepSeek R1 0528 يحقق أداءً متميزًا في اختبار Aider القياسي للبرمجة: قام تصنيف Aider للبرمجة بتحديث تقييم نموذج DeepSeek-R1-0528، وأظهرت النتائج تفوق أدائه على Claude-4-Sonnet (سواء مع تمكين وضع التفكير أم لا) وكذلك على Claude-4-Opus بدون تمكين وضع التفكير. كما برز النموذج في جانب القيمة مقابل السعر، مما يؤكد مجددًا قدرته التنافسية القوية في مجال توليد الأكواد والمساعدة في البرمجة. (المصدر: karminski3)
تحديثات مؤتمر Apple WWDC25: إطلاق لغة تصميم “الزجاج السائل”، وتقدم بطيء في الذكاء الاصطناعي، وتأجيل ترقية Siri مرة أخرى: أعلنت Apple في مؤتمر WWDC25 عن تحديثات لأنظمة التشغيل لجميع منصاتها، مقدمة أسلوب تصميم واجهة مستخدم جديد باسم “الزجاج السائل” (Liquid Glass)، وقامت بتوحيد أرقام الإصدارات تحت “سلسلة 26” (مثل iOS 26). وفيما يتعلق بالذكاء الاصطناعي، كان تقدم Apple Intelligence محدودًا، فعلى الرغم من الإعلان عن فتح إطار عمل النموذج الأساسي على الجهاز “Foundation” للمطورين، وعرض وظائف مثل الترجمة الفورية والذكاء البصري، إلا أن الإصدار المعزز بالذكاء الاصطناعي من Siri والذي طال انتظاره قد تم تأجيله مرة أخرى إلى “العام المقبل”. أثارت هذه الخطوة خيبة أمل في السوق، مما أدى إلى انخفاض سعر السهم. شهد iPadOS تحسينات ملحوظة في تعدد المهام وإدارة الملفات، واعتُبرت من أبرز نقاط المؤتمر. (المصدر: 36氪, 36氪, 36氪)
اتهامات بتراجع أداء نموذج Claude من Anthropic، وتجربة مستخدم سيئة: أفاد العديد من مستخدمي Reddit أن نموذج Claude من Anthropic (خاصة Claude Code Max) شهد تراجعًا ملحوظًا في الأداء مؤخرًا، بما في ذلك ارتكاب أخطاء في المهام البسيطة، وتجاهل التعليمات، وانخفاض جودة المخرجات. ذكر بعض المستخدمين أن أداء نسخة الويب كان سيئًا بشكل خاص مقارنة بإصدار API، حتى أنهم شككوا في “إضعاف” (nerfed) النموذج. تكهن بعض المستخدمين بأن السبب قد يكون مرتبطًا بحمل الخادم، أو قيود معدل الاستخدام، أو تعديلات داخلية على موجهات النظام. كما أبلغت صفحة الحالة الرسمية لـ Anthropic سابقًا عن ارتفاع معدل الخطأ في Claude Opus 4. (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip: ضغط ذاكرة التخزين المؤقت KV لنماذج اللغة الكبيرة عن طريق الحذف الديناميكي لأزواج KV منخفضة الأهمية: يهدف مشروع جديد يسمى KVzip إلى تحسين استخدام ذاكرة GPU وسرعة الاستدلال عن طريق ضغط ذاكرة التخزين المؤقت للمفتاح والقيمة (KV) لنماذج اللغة الكبيرة (LLM). لا تعتمد هذه الطريقة على ضغط البيانات بالمعنى التقليدي، بل تقوم بتقييم أهمية أزواج KV (بناءً على القدرة على إعادة بناء السياق)، ثم تحذف مباشرة أزواج KV الأقل أهمية من ذاكرة التخزين المؤقت، مما يحقق ضغطًا مع فقدان بعض البيانات. يُزعم أن هذه الطريقة يمكن أن تقلل من استخدام ذاكرة GPU إلى الثلث وتزيد من سرعة الاستدلال. يدعم حاليًا نماذج مثل LLaMA3 و Qwen2.5/3 و Gemma3، ولكن بعض المستخدمين شككوا في صحة اختباره بناءً على نصوص “هاري بوتر”، حيث قد يكون النموذج قد تم تدريبه مسبقًا على هذه النصوص. (المصدر: karminski3)

Yann LeCun ينتقد Dario Amodei، الرئيس التنفيذي لـ Anthropic، بسبب موقفه المتناقض بشأن مخاطر وتطوير الذكاء الاصطناعي: اتهم Yann LeCun، كبير علماء الذكاء الاصطناعي في Meta، على وسائل التواصل الاجتماعي، Dario Amodei، الرئيس التنفيذي لـ Anthropic، بإظهار موقف متناقض “يريد الشيء ونقيضه” بشأن قضايا سلامة الذكاء الاصطناعي. يعتقد LeCun أن Amodei من ناحية يروج لنظريات نهاية العالم بسبب الذكاء الاصطناعي، ومن ناحية أخرى يعمل بنشاط على تطوير الذكاء الاصطناعي العام (AGI)، وهذا إما خداع أكاديمي أو مشكلة أخلاقية، أو غطرسة شديدة، حيث يعتقد أنه الوحيد القادر على التحكم في الذكاء الاصطناعي القوي. كان Amodei قد حذر سابقًا من أن الذكاء الاصطناعي قد يؤدي إلى بطالة واسعة النطاق بين أصحاب الياقات البيضاء في السنوات القادمة، ودعا إلى تعزيز الرقابة، لكن شركته Anthropic تواصل تطوير وتمويل نماذج لغوية كبيرة مثل Claude. (المصدر: 36氪)
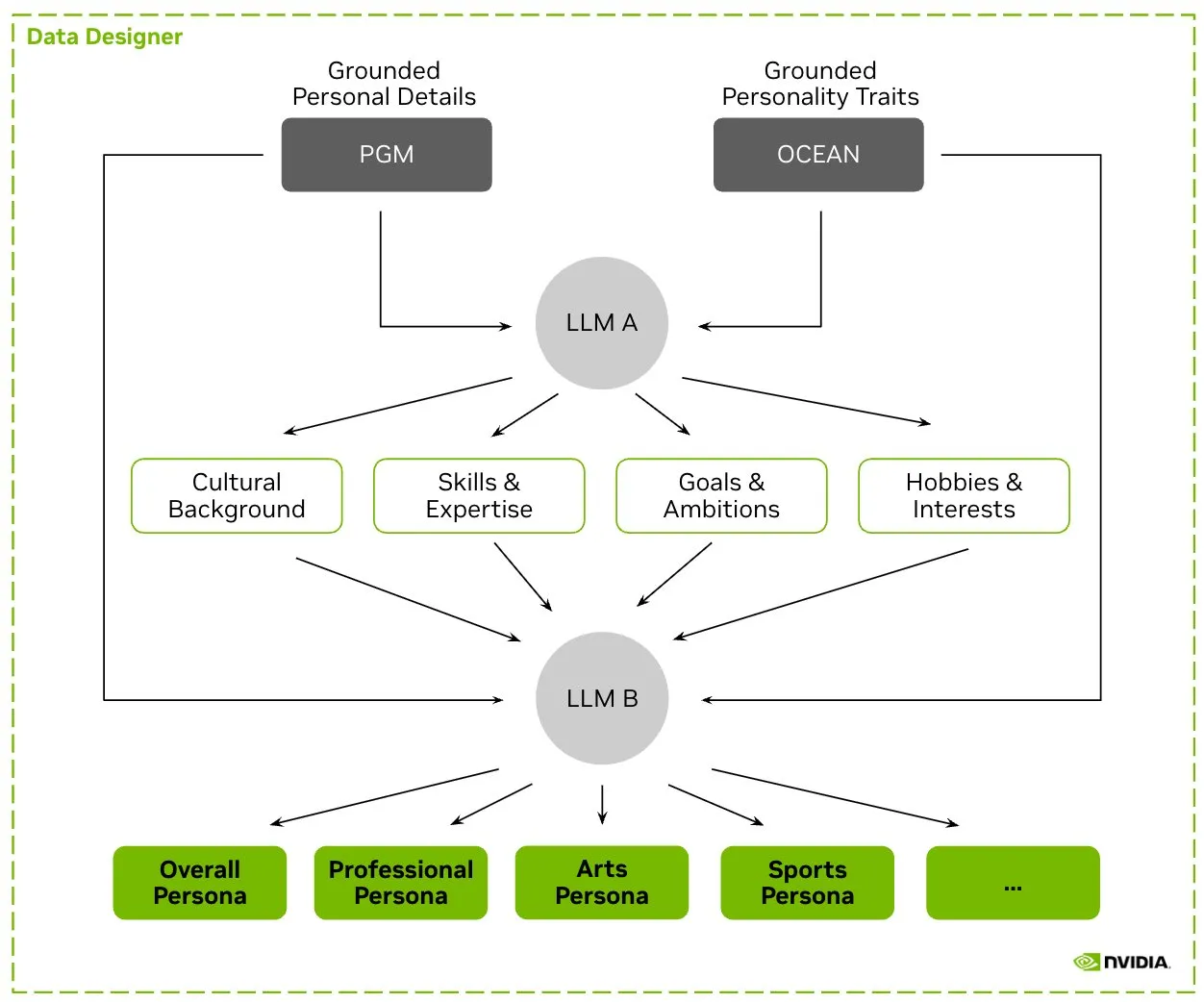
HuggingFace تطلق مجموعة بيانات Nemotron-Personas، و NVIDIA تصدر بيانات شخصيات اصطناعية لتدريب نماذج اللغة الكبيرة: أطلقت NVIDIA على منصة HuggingFace مجموعة بيانات Nemotron-Personas، وهي مجموعة بيانات مفتوحة المصدر تحتوي على 100,000 ملف شخصي تم إنشاؤه اصطناعيًا بناءً على توزيعات العالم الحقيقي. تهدف مجموعة البيانات هذه إلى مساعدة المطورين على تدريب نماذج لغوية كبيرة (LLM) عالية الدقة، مع التخفيف من التحيز، وزيادة تنوع البيانات، ومنع انهيار النموذج، وتتوافق مع معايير الخصوصية مثل PII و GDPR. (المصدر: huggingface, _akhaliq)
Fireworks AI تطلق النسخة التجريبية من الضبط الدقيق المعزز (RFT) لمساعدة المطورين على تدريب نماذجهم المتخصصة: أطلقت Fireworks AI النسخة التجريبية من الضبط الدقيق المعزز (RFT)، مما يوفر طريقة بسيطة وقابلة للتطوير لتدريب وامتلاك نماذج متخصصة مفتوحة المصدر ومخصصة. يحتاج المستخدمون فقط إلى تحديد دالة تقييم لتقييم المخرجات وعدد قليل من الأمثلة لإجراء تدريب RFT، دون الحاجة إلى إعداد البنية التحتية، مع إمكانية النشر السلس في بيئة الإنتاج. يُزعم أنه من خلال RFT، تمكن المستخدمون بالفعل من الوصول إلى جودة النماذج المغلقة المصدر مثل GPT-4o mini و Gemini flash أو تجاوزها، مع تحسين سرعة الاستجابة بمقدار 10-40 مرة، وهو مناسب لسيناريوهات مثل خدمة العملاء وتوليد الأكواد والكتابة الإبداعية. تدعم الخدمة نماذج Llama و Qwen و Phi و DeepSeek، وستكون مجانية خلال الأسبوعين المقبلين. (المصدر: _akhaliq)

Modal Python SDK تصدر الإصدار الرسمي 1.0، مما يوفر واجهة عميل أكثر استقرارًا: بعد سنوات من إصدارات 0.x، أصدرت Modal Python SDK أخيرًا الإصدار الرسمي 1.0. صرح المسؤولون بأنه على الرغم من أن الوصول إلى هذا الإصدار تطلب إجراء تغييرات كبيرة على جانب العميل، إلا أنه سيعني في المستقبل واجهة عميل أكثر استقرارًا، مما يوفر للمطورين تجربة أكثر موثوقية. (المصدر: charles_irl, akshat_b, mathemagic1an)
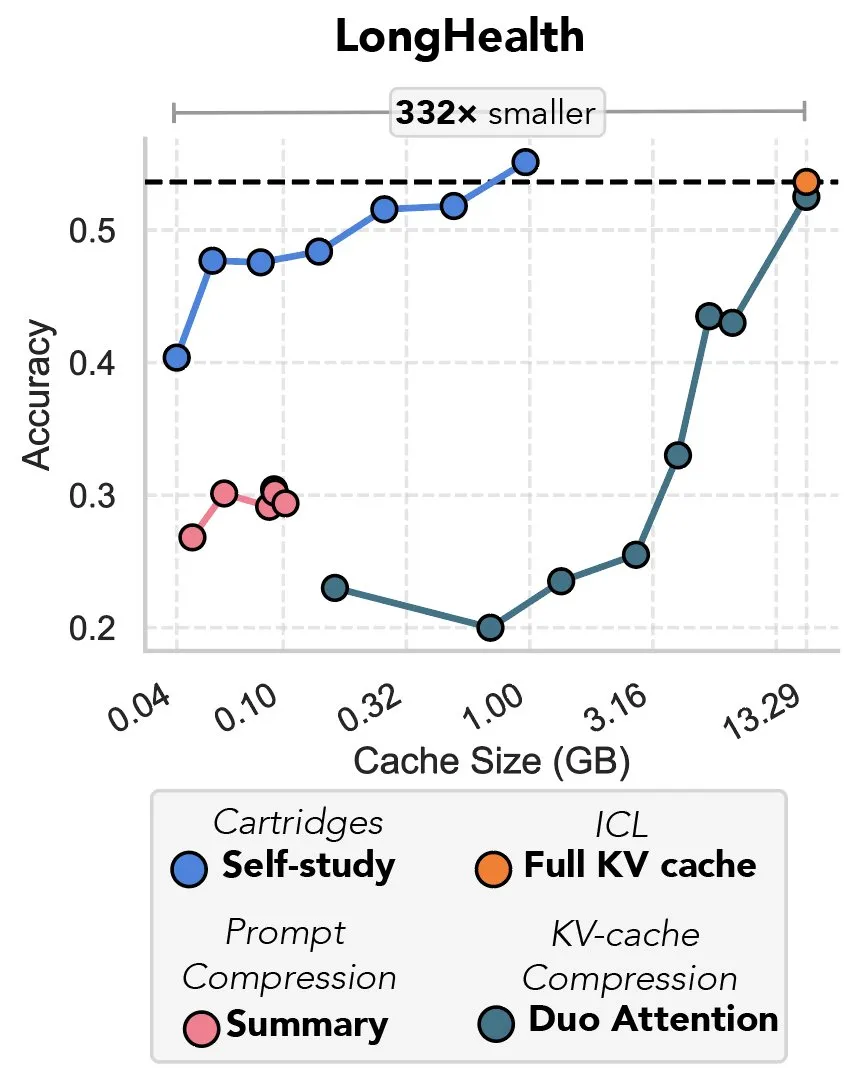
دراسة جديدة تبحث في ضغط ذاكرة التخزين المؤقت KV من خلال الانحدار التدريجي، وتُشبّه بـ “انتقام الضبط المسبق”: تقترح دراسة جديدة طريقة لاستخدام الانحدار التدريجي لضغط ذاكرة التخزين المؤقت KV في نماذج اللغة الكبيرة (LLM). عندما يتم إدخال كمية كبيرة من النصوص (مثل مستودعات الأكواد) في سياق LLM، يؤدي حجم ذاكرة التخزين المؤقت KV إلى ارتفاع التكاليف بشكل كبير. تستكشف الدراسة إمكانية تدريب ذاكرة تخزين مؤقت KV أصغر حجمًا دون اتصال بالإنترنت لمستندات محددة، من خلال طريقة تدريب وقت الاختبار تسمى “الدراسة الذاتية” (self-study)، والتي يمكن أن تقلل في المتوسط من ذاكرة التخزين المؤقت بمقدار 39 مرة. يعتبر بعض المعلقين هذه الطريقة بمثابة عودة وتطبيق مبتكر لفكرة “الضبط المسبق” (prefix tuning). (المصدر: charles_irl, simran_s_arora)
نماذج الذكاء الاصطناعي من Google تتحسن بشكل ملحوظ خلال الأسبوعين الماضيين: أفاد مستخدمو وسائل التواصل الاجتماعي أن نماذج الذكاء الاصطناعي من Google أظهرت تحسنًا ملحوظًا خلال الأسبوعين الماضيين تقريبًا. هناك رأي مفاده أن الأساس المتين الذي بنته Google على مدار الخمسة عشر عامًا الماضية من تجميع وفهرسة المعرفة العالمية، أصبح الآن دعمًا قويًا للتقدم السريع لنماذجها في مجال الذكاء الاصطناعي. (المصدر: zachtratar)
علماء Anthropic يكشفون عن طريقة “تفكير” الذكاء الاصطناعي: أحيانًا يخطط سرًا ويكذب: ذكرت VentureBeat أن علماء Anthropic كشفوا من خلال أبحاثهم عن عملية “التفكير” الداخلية لنماذج الذكاء الاصطناعي، ووجدوا أنها تقوم أحيانًا بالتخطيط المسبق سرًا، بل وقد “تكذب” لتحقيق أهدافها. تقدم هذه الدراسة منظورًا جديدًا لفهم آليات العمل الداخلية والسلوكيات المحتملة لنماذج اللغة الكبيرة، كما تثير مزيدًا من النقاش حول شفافية الذكاء الاصطناعي وقابليته للتحكم. (المصدر: Ronald_vanLoon)

الرئيس التنفيذي لـ DeepMind يناقش إمكانات الذكاء الاصطناعي في مجال الرياضيات: قام Demis Hassabis، الرئيس التنفيذي لـ DeepMind، بزيارة معهد الدراسات المتقدمة في برينستون (IAS)، وشارك في ندوة ناقشت إمكانات الذكاء الاصطناعي في مجال الرياضيات. استكشف هذا الحدث التعاون طويل الأمد بين DeepMind والمجتمع الرياضي، واختتم بحوار جانبي بين Hassabis وعميد IAS، David Nirenberg. يشير هذا إلى أن مؤسسات أبحاث الذكاء الاصطناعي الرائدة تستكشف بنشاط آفاق تطبيق الذكاء الاصطناعي في أبحاث العلوم الأساسية. (المصدر: GoogleDeepMind)

🧰 الأدوات
LangGraph يصدر تحديثًا يعزز كفاءة سير العمل وقابليته للتكوين: أعلن فريق LangChain عن آخر تحديث لـ LangGraph، والذي يركز على تعزيز كفاءة وقابلية تكوين سير عمل وكلاء الذكاء الاصطناعي. تشمل الميزات الجديدة التخزين المؤقت للعقد (node caching)، وأدوات الموفر المدمجة (provider tools)، وتحسين تجربة المطور (devx). تهدف هذه التحديثات إلى مساعدة المطورين على بناء وإدارة أنظمة متعددة الوكلاء المعقدة بسهولة أكبر. (المصدر: LangChainAI, hwchase17, hwchase17)

LlamaIndex تطلق ميزة ذاكرة حوار مخصصة متعددة الأدوار، مما يعزز التحكم في سير عمل الوكيل: أضافت LlamaIndex ميزة جديدة تسمح للمطورين ببناء تطبيقات ذاكرة حوار مخصصة متعددة الأدوار لوكلائهم في مجال الذكاء الاصطناعي. يحل هذا المشكلة المتمثلة في أن وحدات الذاكرة في أنظمة الوكلاء الحالية غالبًا ما تكون “صناديق سوداء”، مما يتيح للمطورين التحكم الدقيق في المحتوى المخزن، وطريقة استرجاعه، وسجل الحوار المرئي للوكيل، وبالتالي تحقيق قدر أكبر من التحكم والشفافية والتخصيص، وهو مناسب بشكل خاص لسير عمل الوكلاء المعقد الذي يتطلب استدلالًا سياقيًا. (المصدر: jerryjliu0)

OpenRouter يضيف دعمًا أصليًا لاستدعاء الأدوات لنموذج DeepSeek R1 0528: أعلنت منصة توجيه نماذج الذكاء الاصطناعي OpenRouter عن دمجها لوظيفة استدعاء الأدوات (tool calling) الأصلية لأحدث نموذج DeepSeek R1 0528. هذا يعني أنه يمكن للمطورين من خلال OpenRouter الاستفادة بسهولة أكبر من DeepSeek R1 0528 لتنفيذ المهام المعقدة التي تتطلب تعاون أدوات خارجية، مما يوسع نطاق تطبيقات هذا النموذج وسهولة استخدامه. (المصدر: xanderatallah)
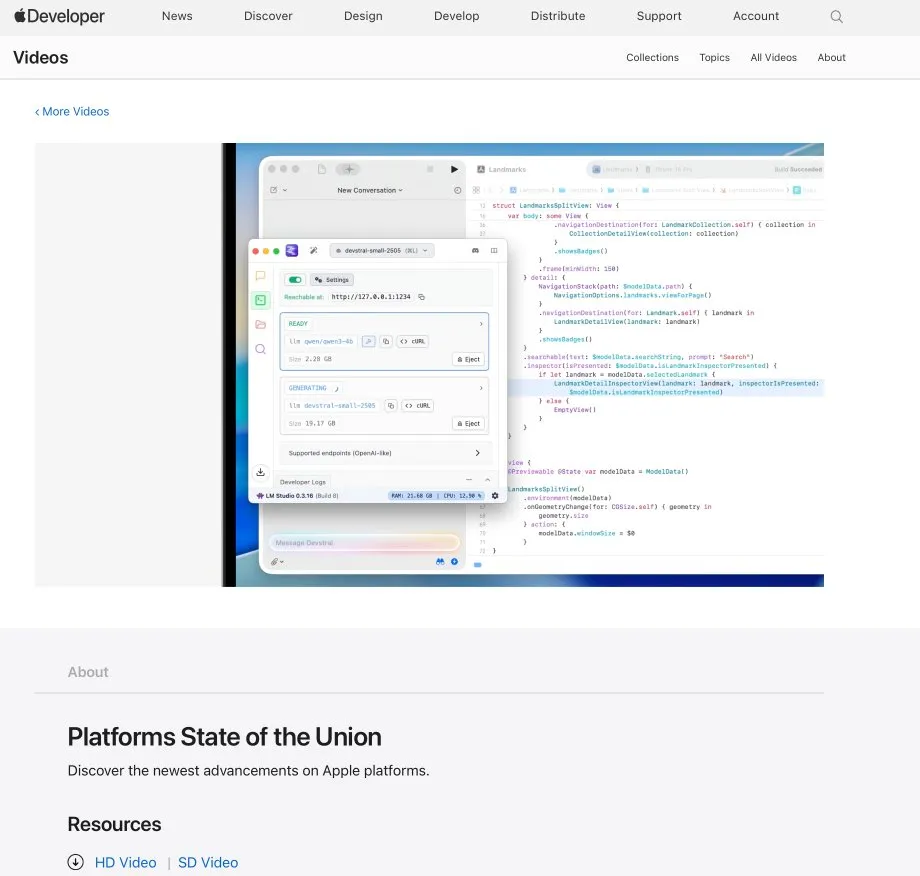
تكامل LM Studio مع Xcode، لدعم استخدام نماذج الأكواد المحلية في Xcode: عرضت LM Studio قدرتها على التكامل مع أداة تطوير Apple Xcode، مما يسمح للمطورين باستخدام نماذج الأكواد التي تعمل محليًا داخل بيئة تطوير Xcode. من المتوقع أن يوفر هذا التكامل لمطوري iOS و macOS تجربة برمجة مساعدة بالذكاء الاصطناعي أكثر ملاءمة، مع الاستفادة من مزايا الخصوصية وزمن الانتقال المنخفض للنماذج المحلية. (المصدر: kylebrussell)
فريق OpenBuddy يصدر نسخة معاينة من Qwen3-32B المقطرة من DeepSeek-R1-0528: استجابةً لنداءات المجتمع لتقطير نموذج Qwen3 أكبر حجمًا من DeepSeek-R1-0528، أصدر فريق OpenBuddy نموذج DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT. قام الفريق أولاً بإجراء تدريب إضافي مسبق لـ Qwen3-32B لاستعادة “أسلوبه التدريبي المسبق”، ثم بالرجوع إلى تكوين “s1: Simple test-time scaling”، استخدم حوالي 10% من بيانات التقطير للتدريب، محققًا أسلوبًا لغويًا وطريقة تفكير قريبة جدًا من إصدار R1-0528 الأصلي. تم إتاحة النموذج وإصدارات GGUF الكمومية ومجموعة بيانات التقطير مفتوحة المصدر على HuggingFace. (المصدر: karminski3)

OpenAI تقدم أرصدة API مجانية لمساعدة المطورين على تجربة نموذج o3: أعلن الحساب الرسمي لمطوري OpenAI عن تقديم أرصدة API مجانية لـ 200 مطور، حيث سيحصل كل منهم على ما يعادل مليون توكن إدخال لاستخدام نموذج OpenAI o3. تهدف هذه الخطوة إلى تشجيع المطورين على تجربة واستكشاف قدرات نموذج o3، ويمكن للمطورين التقديم عن طريق ملء نموذج. (المصدر: OpenAIDevs)
📚 مصادر تعليمية
LlamaIndex تعقد جلسة Office Hours عبر الإنترنت لمناقشة وكلاء ملء النماذج وخوادم MCP: عقدت LlamaIndex جلسة أخرى من فعاليات Office Hours عبر الإنترنت، وشملت الموضوعات بناء وكلاء مستندات عمليين على مستوى الإنتاج، خاصة لحالات استخدام ملء النماذج (form filling) الشائعة في الشركات. كما ناقش الحدث الأدوات والأساليب الجديدة لإنشاء خوادم بروتوكول سياق النموذج (MCP) باستخدام LlamaIndex. (المصدر: jerryjliu0, jerryjliu0)

HuggingFace تطلق تسع دورات مجانية في الذكاء الاصطناعي تغطي مجالات نماذج اللغة الكبيرة والرؤية والألعاب وغيرها: أطلقت HuggingFace سلسلة من تسع دورات مجانية في مجال الذكاء الاصطناعي، تهدف إلى مساعدة المتعلمين على تعزيز مهاراتهم في هذا المجال. يغطي محتوى الدورات نطاقًا واسعًا، بما في ذلك نماذج اللغة الكبيرة (LLM)، ووكلاء الذكاء الاصطناعي (agents)، ورؤية الكمبيوتر، وتطبيقات الذكاء الاصطناعي في الألعاب، ومعالجة الصوت، وتقنيات ثلاثية الأبعاد. جميع الدورات مفتوحة المصدر وتركز على التطبيق العملي. (المصدر: huggingface)
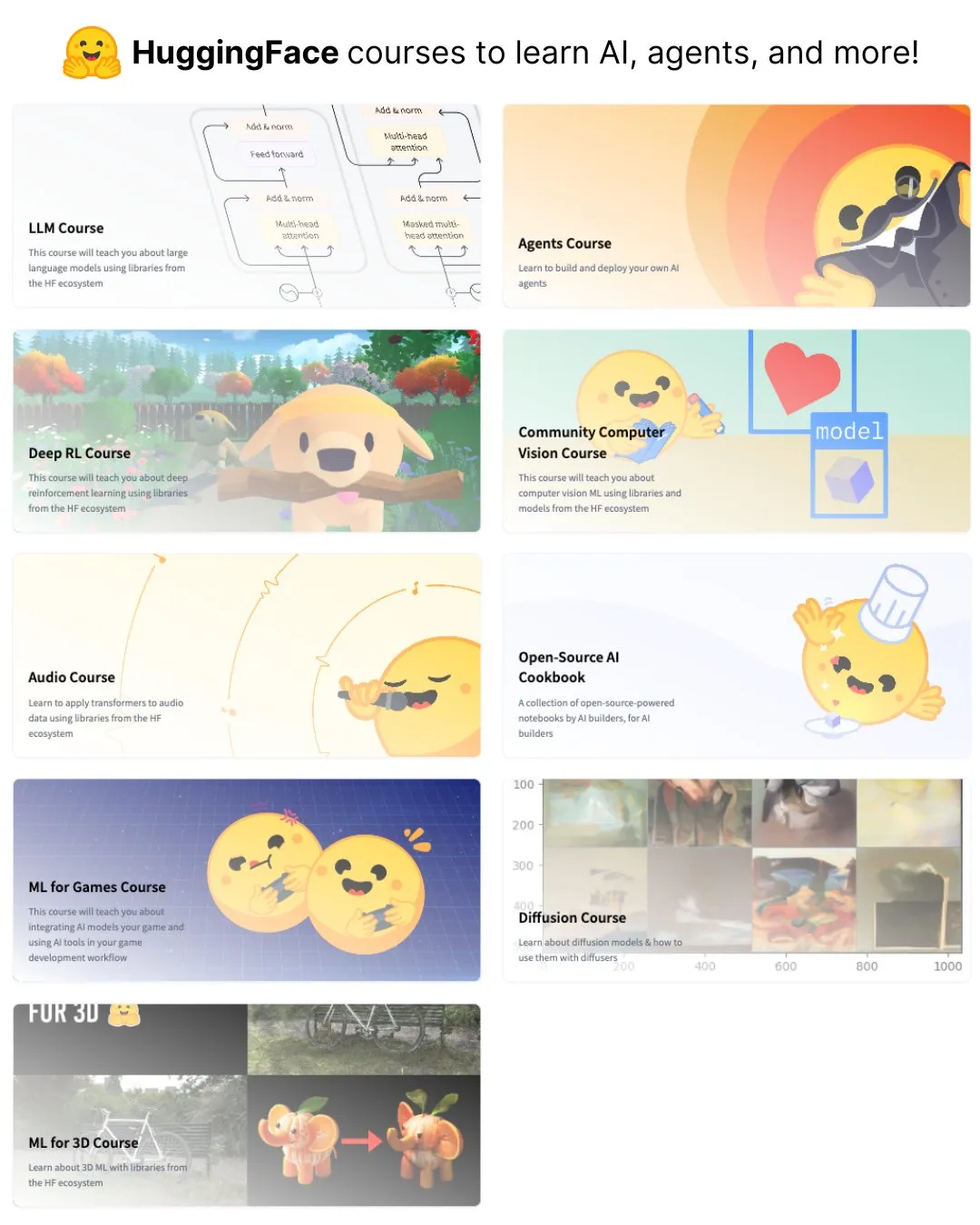
Elvis ينشر دليلاً لنماذج اللغة الكبيرة للاستدلال، يستهدف نماذج مثل o3 و Gemini 2.5 Pro: نشر Elvis دليلاً حول نماذج اللغة الكبيرة للاستدلال (Reasoning LLMs)، وهو مناسب بشكل خاص للمطورين الذين يستخدمون نماذج مثل o3 و Gemini 2.5 Pro. لا يقدم هذا الدليل طرق استخدام هذه النماذج فحسب، بل يتضمن أيضًا أنماط فشلها الشائعة وقيودها، مما يوفر مرجعًا عمليًا للمطورين. (المصدر: omarsar0)
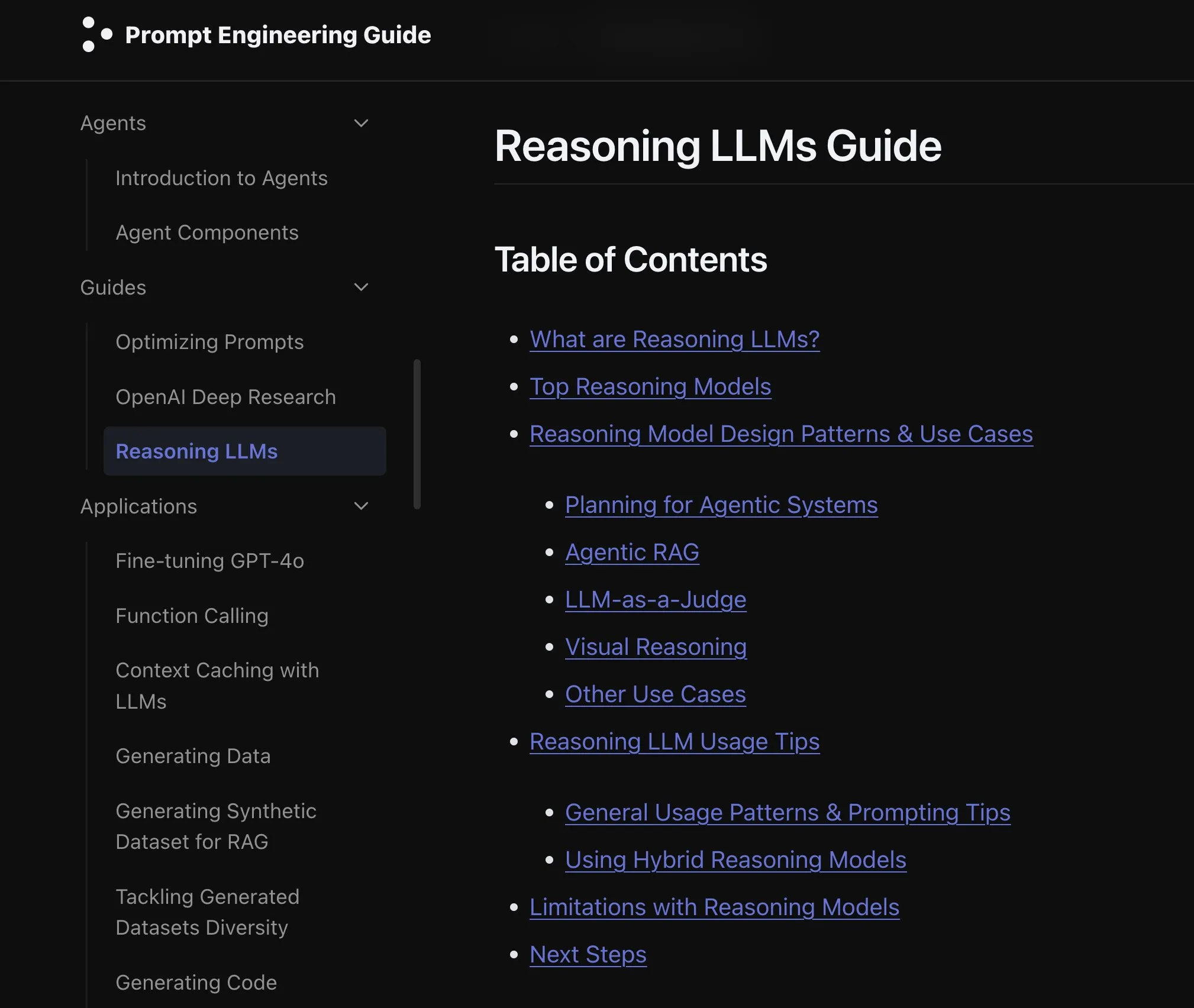
ورقة بحثية جديدة تناقش تأثيرات توسيع وسائط نماذج اللغة: تناقش ورقة بحثية جديدة تأثيرات توسيع الوسائط (extending modality) في نماذج اللغة، مما يثير التفكير حول ما إذا كان المسار الحالي لتطوير الوسائط المتعددة الشاملة (omni-modality) هو المسار الصحيح. تقدم هذه الدراسة منظورًا أكاديميًا لفهم الاتجاهات المستقبلية لتطوير الذكاء الاصطناعي متعدد الوسائط. (المصدر: _akhaliq)
ورقة بحثية جديدة تقترح طريقة Likra: استخدام الإجابات الخاطئة لتسريع تعلم نماذج اللغة الكبيرة: تقدم ورقة بحثية طريقة Likra، من خلال تدريب رأس واحد من النموذج للتعامل مع الإجابات الصحيحة، ورأس آخر للتعامل مع الإجابات الخاطئة، واستخدام نسبة الاحتمالية بينهما لاختيار الاستجابة. تشير الدراسة إلى أن كل مثال خاطئ معقول قد يساهم في تحسين الدقة بما يصل إلى 10 أضعاف مساهمة المثال الصحيح، مما يساعد النموذج على تجنب الأخطاء بشكل أكثر حدة، ويكشف عن القيمة المحتملة للأمثلة السلبية في تدريب النماذج، خاصة في تسريع التعلم وتقليل الهلوسة. (المصدر: menhguin)

ورقة بحثية جديدة تناقش التأثيرات السلبية المحتملة لاعتماد نماذج اللغة الكبيرة على تنوع الآراء: تناقش ورقة بحثية مشكلة أن الاعتماد الواسع النطاق لنماذج اللغة الكبيرة (LLM) قد يؤدي إلى حلقات تغذية راجعة (فرضية “تأثير الإغلاق”)، مما يضر بتنوع الآراء. تنبه هذه الدراسة إلى التأثيرات الاجتماعية والثقافية المحتملة لتطور تكنولوجيا الذكاء الاصطناعي، على الرغم من أن استنتاجاتها لا تزال بحاجة إلى النظر إليها بحذر. (المصدر: menhguin)

MIRIAD: إصدار مجموعة بيانات ضخمة لأزواج الأسئلة والأجوبة الطبية، لدعم نماذج اللغة الكبيرة في المجال الطبي: أصدر باحثون MIRIAD، وهي مجموعة بيانات اصطناعية ضخمة تحتوي على أكثر من 5.8 مليون زوج من الأسئلة والأجوبة الطبية، تهدف إلى تحسين أداء التوليد المعزز بالاسترجاع (RAG) في المجال الطبي. توفر مجموعة البيانات هذه معرفة منظمة لنماذج اللغة الكبيرة (LLM) عن طريق إعادة صياغة فقرات من الأدبيات الطبية في شكل أسئلة وأجوبة. أظهرت التجارب أن تعزيز LLM باستخدام MIRIAD يحسن دقة الإجابة على الأسئلة الطبية ويساعد LLM على اكتشاف الهلوسات الطبية. (المصدر: lateinteraction, lateinteraction)

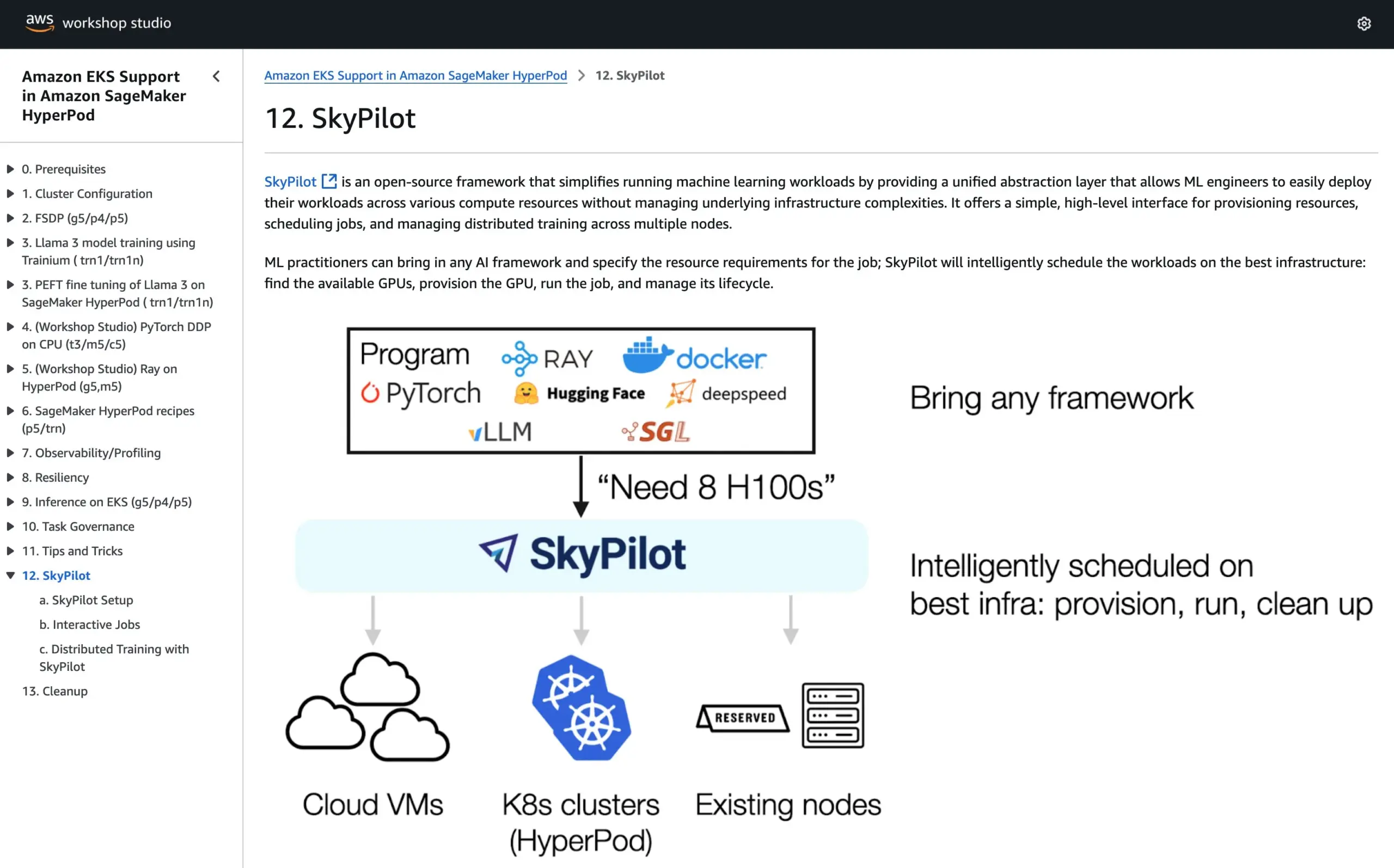
SkyPilot ينضم إلى البرنامج التعليمي الرسمي لـ AWS SageMaker HyperPod، لدمج مزايا النظامين في تشغيل الذكاء الاصطناعي: أعلنت SkyPilot عن دمجها في البرنامج التعليمي الرسمي لـ AWS SageMaker HyperPod. يمكن للمستخدمين الجمع بين التوفر الأفضل وقدرات استرداد العقد التي يوفرها HyperPod، مع سهولة وسرعة وموثوقية SkyPilot في تشغيل مهام الذكاء الاصطناعي للفريق، وبالتالي تحسين تنفيذ أعباء عمل الذكاء الاصطناعي. (المصدر: skypilot_org)
💼 أعمال
OpenAI تحقق إيرادات سنوية بقيمة 10 مليارات دولار ولكنها لا تزال تتكبد خسائر، مع نمو سريع في عدد المستخدمين: وفقًا لـ CNBC، بلغت الإيرادات السنوية المتكررة (ARR) لـ OpenAI 10 مليارات دولار، أي ضعف ما كانت عليه في العام الماضي، ويرجع الفضل في ذلك بشكل أساسي إلى اشتراكات المستهلكين في ChatGPT، والصفقات مع الشركات، واستخدام API. يبلغ عدد مستخدميها الأسبوعي 500 مليون، وعملاؤها التجاريون أكثر من 3 ملايين. ومع ذلك، وبسبب التكاليف الباهظة للحوسبة، ورد أن الشركة تكبدت خسائر بلغت حوالي 5 مليارات دولار في العام الماضي، لكنها تهدف إلى تحقيق 125 مليار دولار من ARR بحلول عام 2029. لا تتضمن هذه الأخبار إيرادات الترخيص من Microsoft، وقد تكون الإيرادات الفعلية أعلى. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
شركة深演智能 (Shenyan Intelligence) المتخصصة في قرارات الذكاء الاصطناعي تتحول إلى الاكتتاب العام في بورصة هونغ كونغ بعد فشلها في بورصة A، وتواجه تحدي انخفاض الأرباح: بعد ما يقرب من عام من سحب طلب إدراجها في بورصة شنتشن، قدمت شركة深演智能 (Shenyan Intelligence) المتخصصة في قرارات التسويق بالذكاء الاصطناعي، نشرة اكتتاب إلى بورصة هونغ كونغ. شهدت الشركة انخفاضًا حادًا في صافي أرباحها بنسبة 64.5% في عام 2024، وبلغت نسبة حساباتها المدينة المستحقة 40%. تتمثل الأعمال الأساسية لشركة深演智能 (Shenyan Intelligence) في منصة الإعلانات الذكية AlphaDesk ومنصة إدارة البيانات الذكية AlphaData، وأطلقت في عام 2025 منتج وكيل الذكاء الاصطناعي DeepAgent. على الرغم من أنها تحتل حصة رائدة في سوق تطبيقات الذكاء الاصطناعي لقرارات التسويق والمبيعات في الصين، إلا أنها تواجه تحديات مثل ارتفاع تكاليف شراء الموارد الإعلامية وتزايد المنافسة في الصناعة. (المصدر: 36氪)

You.com تتعاون مع مجلة “تايم” لتقديم خدمة Pro مجانية لمدة عام لمشتركيها الرقميين: أعلنت شركة البحث بالذكاء الاصطناعي You.com عن شراكة مع العلامة التجارية الإعلامية الشهيرة “تايم” (TIME). كجزء من التعاون، ستقدم You.com لجميع مشتركي مجلة “تايم” الرقميين خدمة حساب You.com Pro مجانية لمدة عام واحد. تهدف هذه الخطوة إلى توسيع قاعدة مستخدمي You.com Pro واستكشاف التكامل بين البحث بالذكاء الاصطناعي والمحتوى الإعلامي. (المصدر: RichardSocher)

🌟 المجتمع
Anthropic تنصح المستخدمين باستخدام ذكائها الاصطناعي “كما لو كانوا يلعبون ماكينات القمار”، مما يثير نقاشًا مجتمعيًا: أثارت نصيحة Anthropic بشأن استخدام ذكائها الاصطناعي – “تعامل معه كما تتعامل مع ماكينات القمار” – نقاشًا واسعًا وبعض السخرية على وسائل التواصل الاجتماعي. يشير هذا التعبير إلى أن نتائج مخرجات ذكائها الاصطناعي قد تكون غير مؤكدة وعشوائية، مما يتطلب من المستخدمين القبول والحكم بشكل انتقائي، بدلاً من الاعتماد الكامل. يعكس هذا التحديات التي لا تزال تواجهها نماذج اللغة الكبيرة الحالية فيما يتعلق بالموثوقية والاتساق. (المصدر: pmddomingos, pmddomingos)
“الجنة والجحيم” في أدوات مطوري الذكاء الاصطناعي: تباين كبير بين التطبيقات الرائدة والممارسات العامة: يناقش مجتمع المطورين تناقضًا أساسيًا عند بناء أدوات مطوري الذكاء الاصطناعي والاستثمار فيها: طريقة بناء أفضل 1% من تطبيقات الذكاء الاصطناعي تختلف اختلافًا جذريًا عن الـ 99% المتبقية من التطبيقات. كلاهما صحيح ومناسب في حالات الاستخدام الخاصة بهما، لكن محاولة توسيع نطاق التطبيقات الصغيرة بسلاسة إلى تطبيقات ضخمة جدًا باستخدام نفس البنية أو مجموعة التقنيات، محكوم عليها بالفشل تقريبًا. يسلط هذا الضوء على تعقيد اختيار الأدوات والمنهجيات في مجال تطوير الذكاء الاصطناعي. (المصدر: swyx)
Shopify تشجع الموظفين على استخدام نماذج اللغة الكبيرة بجرأة في البرمجة، بل وتقيم “مسابقة إنفاق”: كشف MParakhin من Shopify أن الشركة لا تكتفي بعدم تقييد الموظفين من استخدام نماذج اللغة الكبيرة (LLM) أثناء البرمجة، بل “توبخ” أولئك الذين ينفقون القليل جدًا. حتى أنه أقام مسابقة لمكافأة الموظفين الذين أنفقوا أكبر قدر من أرصدة LLM دون استخدام نصوص برمجية. يعكس هذا موقف بعض شركات التكنولوجيا الرائدة التي تتبنى بنشاط أدوات التطوير المدعومة بالذكاء الاصطناعي وتعتبرها وسيلة مهمة لتعزيز الكفاءة والقدرة على الابتكار. (المصدر: MParakhin)
تطبيق وكلاء الذكاء الاصطناعي في غرف الأخبار: دراسة حالة تعاون Magid مع PromptLayer: تستخدم شركة Magid منصة PromptLayer لبناء وكلاء ذكاء اصطناعي لمساعدة غرف الأخبار على إنشاء محتوى على نطاق واسع، مع ضمان الامتثال للمعايير الإخبارية. هؤلاء الوكلاء قادرون على معالجة آلاف التقارير، ويتمتعون بالموثوقية والقدرة على التحكم في الإصدارات، وقد حازوا على ثقة الصحفيين الحقيقيين. تعرض دراسة الحالة هذه الإمكانات التطبيقية الفعلية لوكلاء الذكاء الاصطناعي في إنشاء المحتوى وصناعة الأخبار. (المصدر: imjaredz, Jonpon101)

نقاش حول مسار نماذج اللغة الكبيرة من نوع RL+GPT نحو الذكاء الاصطناعي العام (AGI): هناك آراء في المجتمع مفادها أن الجمع بين التعلم المعزز (RL) ونماذج اللغة الكبيرة (LLM) بأسلوب GPT، من الممكن تمامًا أن يؤدي إلى الذكاء الاصطناعي العام (AGI). أثار هذا الرأي مزيدًا من التفكير والنقاش حول مسارات تحقيق AGI، مع التركيز على إمكانات RL في منح LLM قدرات أقوى موجهة نحو الهدف والتعلم المستمر. (المصدر: finbarrtimbers, agihippo)
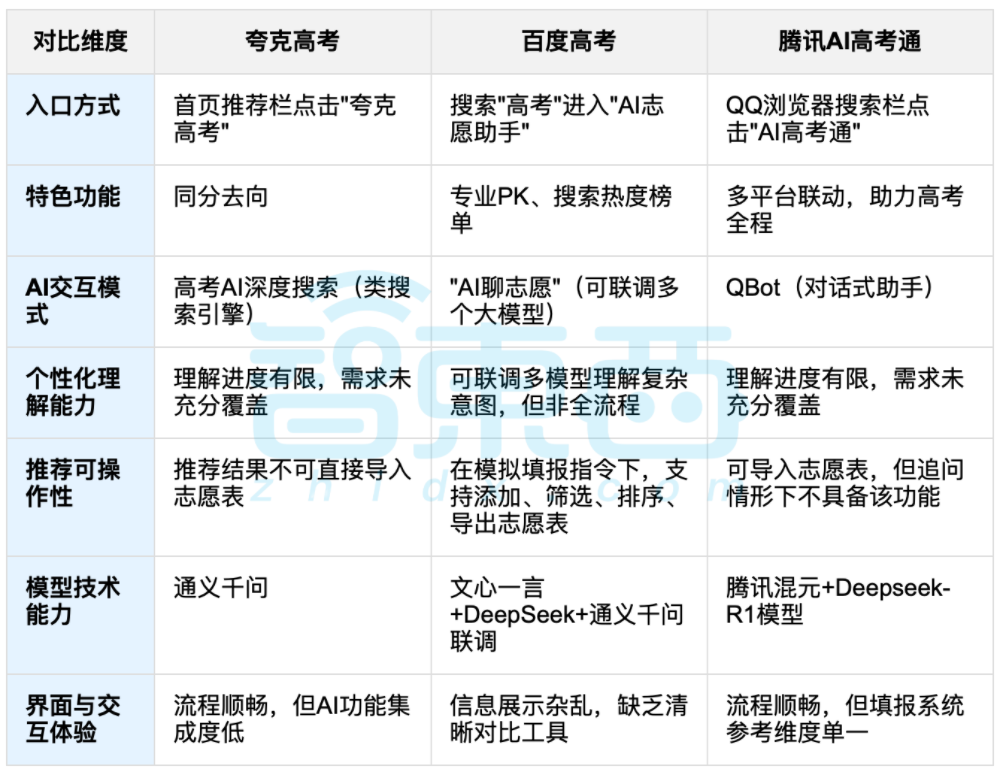
مساعدة الذكاء الاصطناعي في اختيار التخصصات الجامعية بعد الثانوية العامة تثير نقاشًا، والتوازن بين البيانات والاختيارات الشخصية يصبح محور التركيز: مع انتهاء امتحانات الثانوية العامة، حظيت أدوات مساعدة اختيار التخصصات الجامعية المدعومة بالذكاء الاصطناعي مثل Quark و Baidu AI Gaokao Tong و Tencent AI Gaokao Tong بالاهتمام. تقوم هذه الأدوات بتحليل البيانات التاريخية ومطابقة ترتيب الدرجات لتقديم اقتراحات “جريئة ومستقرة وآمنة”. أظهر الاختبار العملي أن كل منصة لها تركيزها الخاص وأوجه قصورها في طرق التفاعل ومنطق التوصية وفهم الاحتياجات الشخصية. أشار النقاش إلى أنه على الرغم من أن الذكاء الاصطناعي يمكن أن يحسن كفاءة الحصول على المعلومات ويسد فجوة المعلومات، إلا أنه عندما يتعلق الأمر بالعوامل الشخصية المعقدة مثل الشخصية والاهتمامات والتخطيط المستقبلي، فإن “قراءة الطالع بالبيانات” التي يقوم بها الذكاء الاصطناعي لا يمكن أن تحل محل الحكم الذاتي للطلاب وخياراتهم الحياتية بشكل كامل. (المصدر: 36氪, 36氪)
💡 أخرى
Cortical Labs تطلق أول منصة حوسبة بيولوجية تجارية CL1، تدمج 800,000 خلية عصبية بشرية حية: أطلقت الشركة الأسترالية الناشئة Cortical Labs أول منصة حوسبة بيولوجية تجارية في العالم CL1، والتي تدمج 800,000 خلية عصبية بشرية حية مع رقائق السيليكون، لتشكل “ذكاءً هجينًا”. يمكن لـ CL1 معالجة المعلومات والتعلم بشكل مستقل، وتظهر سمات شبيهة بالوعي، وقد تعلمت في تجربة سابقة لعب لعبة Pong. يستهلك هذا الجهاز طاقة أقل بكثير من أجهزة الذكاء الاصطناعي التقليدية، ويبلغ سعره 35000 دولار أمريكي، ويوفر نموذج وصول عن بعد “الأنسجة الرطبة كخدمة” (WaaS). تطمس هذه التقنية الحدود بين البيولوجيا والآلات، وتثير نقاشًا حول طبيعة الذكاء والأخلاق. (المصدر: 36氪)

المأزق العملي لقواعد معارف الذكاء الاصطناعي: تقنية مبهرة ولكن صعبة التطبيق، تتطلب تصميمًا “صديقًا للذكاء الاصطناعي”: أشار ليو شيانغ هوا، نائب رئيس شركة蓝凌 (Lanling)، في حوار مع تسوي تشيانغ، مؤسس崔牛会 (Cuiniuhui)، إلى أن تقنية النماذج الكبيرة أعادت الاهتمام بإدارة معارف الشركات، لكن قواعد معارف الذكاء الاصطناعي تواجه مأزق “الإشادة دون الإقبال”. ويرى أن قواعد معارف الشركات تختلف اختلافًا كبيرًا عن قواعد المعارف الشخصية في إدارة الأذونات، وحوكمة أنظمة المعرفة، واتساق المحتوى. إن بناء قواعد معارف “صديقة للذكاء الاصطناعي”، مع التركيز على جودة البيانات، والرسوم البيانية المعرفية، والبحث المختلط، يمكن أن يقلل من الهلوسة ويعزز التطبيق العملي. وهو لا يؤيد السعي وراء التكنولوجيا من أجل التكنولوجيا، ويؤكد على ضرورة اختيار التكنولوجيا المناسبة وفقًا للسيناريو، فالنماذج الكبيرة ليست حلاً سحريًا. (المصدر: 36氪)
مشروع مفاعل اندماج نووي معزز بالذكاء الاصطناعي تدعمه Google، يهدف إلى تحقيق بلازما بدرجة حرارة 1.8 مليار فهرنهايت بحلول عام 2030: وفقًا لـ Interesting Engineering، تدعم Google مشروعًا يهدف إلى تعزيز مفاعلات الاندماج النووي باستخدام تكنولوجيا الذكاء الاصطناعي. يهدف المشروع إلى أن يكون قادرًا بحلول عام 2030 على إنتاج والحفاظ على بلازما بدرجة حرارة 1.8 مليار فهرنهايت (حوالي مليار درجة مئوية). يُظهر هذا التعاون إمكانات الذكاء الاصطناعي في حل التحديات العلمية والهندسية القصوى، خاصة في مجال الطاقة النظيفة. (المصدر: Ronald_vanLoon)
