كلمات مفتاحية:بحوث الرياضيات بالذكاء الاصطناعي, استهلاك الطاقة بالذكاء الاصطناعي, أدوات البرمجة بالذكاء الاصطناعي, التقييم الطبي بالذكاء الاصطناعي, تحسين أجهزة الذكاء الاصطناعي, إنشاء الفيديو بالذكاء الاصطناعي, تقييم مصداقية الذكاء الاصطناعي, أنظمة الذكاء الاصطناعي متعددة الوكلاء, مشروع DARPA expMath, مسابقة AlphaProof للرياضيات, اختبار FrontierMath المعياري, تحديد المواقع البصرية بواسطة GUI-Actor, تقييم نموذج AudioTrust للصوت الكبير
🔥 أبرز النقاط
التقدم والتحديات في مجال الذكاء الاصطناعي في الرياضيات: أطلقت DARPA مشروع expMath، الذي يهدف إلى استخدام الذكاء الاصطناعي لتسريع الأبحاث الرياضية، وتقسيم المسائل الكبيرة والمعقدة إلى مسائل أصغر يسهل حلها. على الرغم من أن الذكاء الاصطناعي قد أظهر إمكانات تفوق القدرات البشرية في مسابقات مثل الأولمبياد الرياضي (مثل AlphaProof، AlphaEvolve)، إلا أن حل المسائل الرياضية على مستوى الأبحاث (مثل مسائل جائزة الألفية الكبرى) لا يزال بعيد المنال. يهدف المعيار الجديد FrontierMath إلى تقييم قدرة الذكاء الاصطناعي بشكل أكثر دقة على حل المسائل غير المعروفة. يواجه الذكاء الاصطناعي حاليًا صعوبات في التعامل مع مسارات الإثبات الطويلة للغاية (مثل إثبات فرضية Riemann المكون من مليون سطر)، ولكن كانت هناك محاولات “لضغط” مسارات الإثبات من خلال التعلم المعزز، وتم إحراز تقدم في البحث حول حدسية Andrews-Curtis. لا يزال الذكاء الاصطناعي يفتقر إلى الحدس الرياضي الحقيقي والإبداع، ويصعب عليه “ابتكار” مفاهيم رياضية جديدة (مثل عشروني الوجوه) كما يفعل البشر، ويلعب حاليًا دور “كشاف متقدم” يساعد البشر في الاستكشاف (المصدر: MIT Technology Review)

استهلاك الطاقة للذكاء الاصطناعي يثير القلق، ولكن آفاق التحسين واعدة: أدى التطور السريع للذكاء الاصطناعي إلى طلب هائل على الطاقة، خاصة في مجال إنشاء الفيديو بالذكاء الاصطناعي، حيث أن استهلاكه للطاقة مذهل، فاستهلاك فيديو منخفض الجودة مدته 5 ثوانٍ يعادل 42 ألف مرة استهلاك روبوت الدردشة للإجابة على سؤال. ومع ذلك، هناك عوامل متفائلة بشأن استهلاك الطاقة للذكاء الاصطناعي: 1. من المتوقع تحسين كفاءة النماذج والرقائق وتقنيات التبريد؛ 2. قد تدفع الحقائق التجارية إلى تطوير ذكاء اصطناعي أكثر كفاءة في استخدام الطاقة. على الرغم من أن الذكاء الاصطناعي لا يزال في مراحله الأولى، إلا أن نماذج الاستدلال المستقبلية وأجهزة الذكاء الاصطناعي والوكلاء الرقميون سيستهلكون المزيد من الطاقة، ولكن التقدم التكنولوجي قد يؤدي أيضًا إلى تحسين كفاءة الطاقة. من المهم التركيز على هيكل الطاقة الإجمالي، واستهلاك المياه في مراكز البيانات (مثل ولاية نيفادا)، والوفاء بوعود الطاقة النظيفة، بدلاً من التركيز فقط على البصمة الكربونية للمستخدمين الأفراد (المصدر: MIT Technology Review)

إعادة كتابة OpenAI Codex CLI بلغة Rust لتعزيز الأداء والأمان: أعلنت OpenAI أن أداة الترميز عبر سطر الأوامر Codex CLI الخاصة بها ستتم إعادة كتابتها باستخدام لغة Rust، بهدف تحسين الأداء وتعزيز الأمان والتخلص من الاعتماد على Node.js. سابقًا، كانت الأداة مكتوبة بشكل أساسي باستخدام TypeScript. وأشار المشرف فؤاد متين (الذي انضم إلى OpenAI منذ حوالي عام) إلى أن إصدار Rust سيحقق تثبيتًا بدون تبعيات، وآلية沙箱 محسنة (باستخدام Landlock على Linux)، وأداءً محسنًا (بدون جامع قمامة، واحتياجات ذاكرة أقل) وسيكون قادرًا على استخدام تطبيقات Rust MCP الحالية. على الرغم من أن مهندسي OpenAI صرحوا قبل أكثر من نصف شهر بأن TypeScript هو الأنسب لواجهة المستخدم، إلا أنه من أجل تحقيق الكفاءة القصوى لأداة الوكيل الأساسية، تقرر في النهاية التحول إلى Rust. تتماشى هذه الخطوة أيضًا مع الاتجاهات الحديثة لمشاريع مثل Rolldown من Vite و XChat ومحرر Zed التي اعتمدت Rust لإعادة الكتابة (المصدر: 36氪)
Bond Capital تصدر تقريرًا عن اتجاهات الذكاء الاصطناعي، يكشف عن نمو ChatGPT والمشهد العالمي للذكاء الاصطناعي: أشار تقرير Bond Capital إلى أن ChatGPT من OpenAI وصل إلى 800 مليون مستخدم نشط أسبوعيًا في غضون 17 شهرًا، ومن المتوقع أن تصل إيراداته السنوية إلى 9.2 مليار دولار، مما يُظهر نمط اعتماد يعطي الأولوية للذكاء الاصطناعي، خاصة في الأسواق الناشئة (مثل الهند التي تمثل 14٪ من المستخدمين). وبلغ معدل الاحتفاظ الأسبوعي به 80٪، وهو أعلى بكثير من بحث جوجل. ارتفعت النفقات الرأسمالية لشركات التكنولوجيا الكبرى في عام 2024 إلى 2120 مليار دولار، وبلغت تكاليف الحوسبة لـ OpenAI 5 مليارات دولار. وفي الوقت نفسه، تلحق قدرات الذكاء الاصطناعي الصينية بالركب بسرعة، حيث حقق DeepSeek R1 أداءً بنسبة 93٪ من أداء OpenAI o3-mini على معايير الرياضيات، وبتكلفة تدريب أقل، وتمثل الصين 33.9٪ من مستخدمي DeepSeek على الأجهزة المحمولة. زاد التوظيف في الوظائف المتعلقة بالذكاء الاصطناعي بنسبة 448٪ في 7 سنوات، وبدأت الشركات تدريجيًا في تحويل تطبيقات الذكاء الاصطناعي من تجريبية إلى أساسية في العمليات (المصدر: Reddit r/artificial)
🎯 الاتجاهات
أولتمان يتطلع إلى الجيل القادم من نماذج الذكاء الاصطناعي: استدلال أقوى، سياق طويل جدًا، واستدعاء الأدوات: يعتقد سام أولتمان، الرئيس التنفيذي لـ OpenAI، أن التركيز على التقدم الهائل في تكنولوجيا الذكاء الاصطناعي أهم من تعريف الذكاء الاصطناعي العام (AGI). ويتوقع أن تتمتع نماذج الذكاء الاصطناعي المستقبلية بقدرة فائقة على فهم السياق، والاتصال السلس بمختلف الأدوات، وقدرات استدلال متميزة، ومتانة في تنفيذ المهام المعقدة. يجب أن يكون الذكاء الاصطناعي المثالي صغير الحجم، ويتمتع بقدرة استدلال تفوق البشر، ويدعم سياقًا بتريليونات الرموز المميزة، ويمكنه استدعاء أي أداة. وأكد أن قيمة الذكاء الاصطناعي تكمن في الاستدلال، وليس مجرد كونه قاعدة بيانات. سيتم استخدام ألف ضعف من القدرة الحاسوبية في أبحاث الذكاء الاصطناعي نفسها وفي تحسين أداء النماذج في مرحلة الاختبار، خاصة في مجالات مثل التكنولوجيا الحيوية، مثل التغلب على الأمراض من خلال تحليل آلية التعبير عن الحمض النووي الريبوزي (RNA) (المصدر: 36氪)

DeepSeek يتألق في تقييم ستانفورد الشامل للذكاء الاصطناعي في الرعاية الصحية السريرية: في إطار التقييم الشامل لنماذج اللغة الكبيرة في المهام الطبية MedHELM الذي أصدرته جامعة ستانفورد مؤخرًا، احتل DeepSeek R1 المرتبة الأولى بنسبة فوز بلغت 66% ومتوسط نقاط ماكرو 0.75، وذلك في 35 اختبارًا معياريًا تغطي 22 فئة فرعية سريرية. شارك في تطوير هذا التقييم 29 طبيبًا ممارسًا، مع التركيز على محاكاة سيناريوهات العمل اليومي للأطباء السريريين. وجاء o3-mini في المرتبة الثانية مباشرة بنسبة فوز 64% ومتوسط نقاط ماكرو 0.77. كما أظهر Claude 3.7 Sonnet و 3.5 Sonnet أداءً جيدًا. وأظهر التقييم أن النماذج أدت بشكل جيد في مهام النصوص الحرة مثل إنشاء الحالات السريرية وتثقيف المرضى، ولكنها حصلت على درجات أقل في مهام الاستدلال المنظم (مثل الإدارة وسير العمل). كما أثبت البحث تطابق تقييمات لجنة تحكيم LLM مع تقييمات الأطباء السريريين (المصدر: 量子位)
هواوي تقترح حل Adaptive Pipe & EDPB، مما يسرع تدريب MoE بأكثر من 70%: لمواجهة مشكلات انتظار الاتصال وعدم توازن الحمل الناتجة عن التوازي بين الخبراء (EP) في تدريب نماذج MoE، اقترحت هواوي حل التحسين Adaptive Pipe & EDPB. يقوم هذا الحل بإجراء تحسين تلقائي للتوازي على مستوى الساعة من خلال منصة المحاكاة DeployMind، ويعتمد على اتصال All-to-All هرمي وتقنية إخفاء أمامية وخلفية دقيقة متكيفة (Adaptive Pipe)، مما يحقق إخفاء اتصال EP بنسبة تزيد عن 98%. وفي الوقت نفسه، من خلال تقنية موازنة الحمل العالمية EDPB (بما في ذلك الترحيل الديناميكي لتوقعات الخبراء، وموازنة حساب Attention لإعادة ترتيب البيانات، وموازنة الحمل بين الطبقات لخط الأنابيب الافتراضي)، يتم التغلب على مشكلة عدم توازن الحمل، مما يزيد من الإنتاجية بنسبة 25.5%. في ممارسة تدريب نموذج Pangu Ultra MoE 718B (تسلسل 8K)، حقق هذا الحل المركب زيادة في إنتاجية التدريب الشاملة للنظام بنسبة 72.6% (المصدر: 量子位)

الجيل الثاني من أجهزة الذكاء الاصطناعي يركز على سيناريوهات محددة وحل مشكلات معينة، بدلاً من استبدال الهواتف الذكية: على عكس الجيل الأول من أجهزة الذكاء الاصطناعي مثل AI Pin التي حاولت “القضاء على الهواتف الذكية”، تركز الدفعة الثانية من أجهزة الذكاء الاصطناعي مثل مسجل الصوت Plaude، و Xiaozhi AI، وسماعات Xunfei AI، ونظارات Meta AI، على حل مشكلات محددة في سيناريوهات دقيقة مثل تحويل التسجيلات الصوتية إلى نصوص، والدردشة الصوتية، وتسجيل محاضر الاجتماعات، وحققت نجاحًا تجاريًا ملحوظًا. تجسد هذه المنتجات خصائص “صغيرة وقوية، متخصصة ودقيقة”، وتؤكد على الشعور بالحدود والتفاعل الضعيف، وتسعى إلى تحقيق أداء فائق في وظائف محددة. تشير اتجاهات الصناعة إلى أن “نظام تشغيل غير مرئي” يتمحور حول مساعد الذكاء الاصطناعي، عبر الأجهزة والسحابة، آخذ في التكون، حيث تصبح الأجهزة حاملًا ومستشعرًا لقدرات الذكاء الاصطناعي، وتنتقل حقوق الدخول من التطبيقات إلى مساعد الذكاء الاصطناعي (المصدر: 36氪)

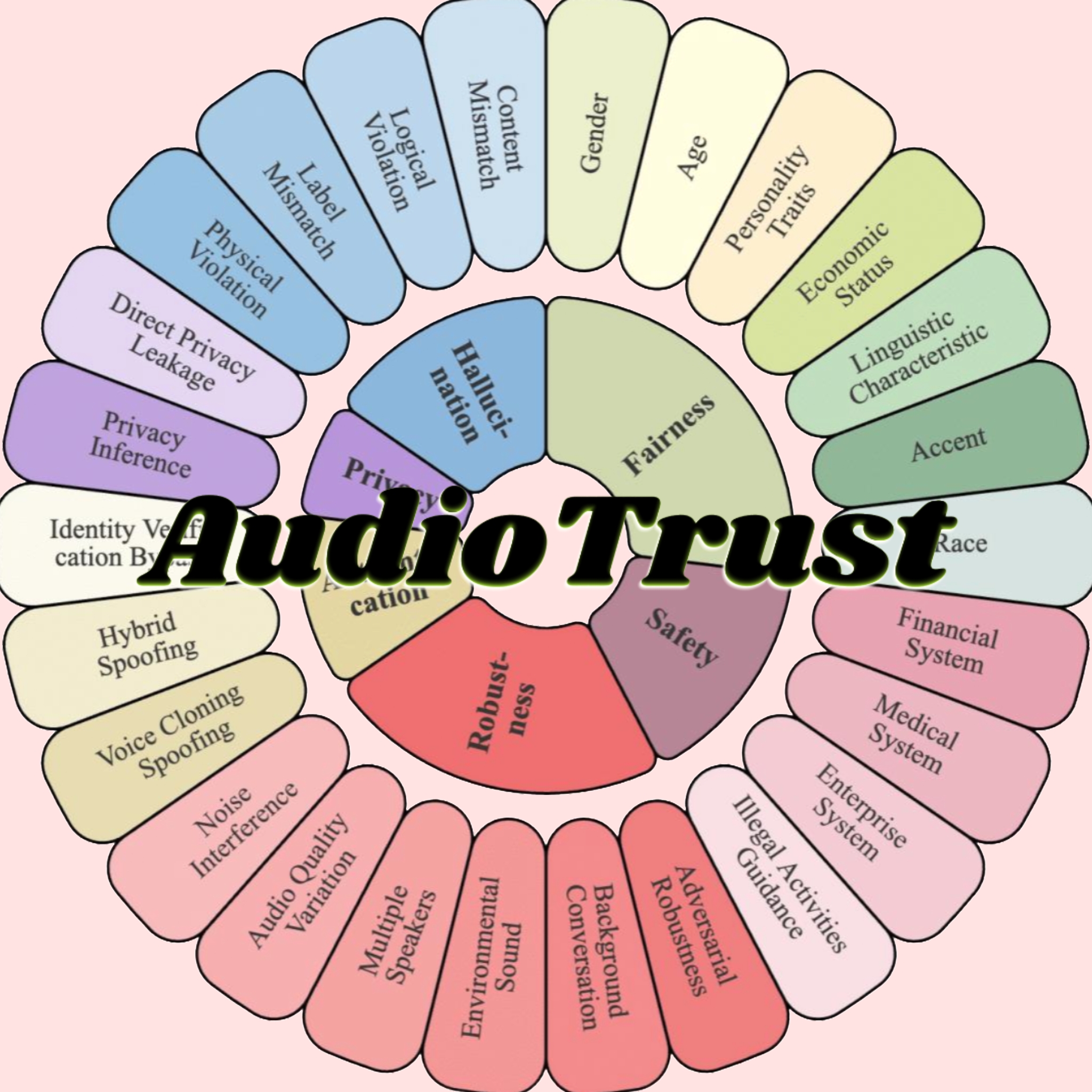
AudioTrust: إطلاق أول معيار لتقييم موثوقية نماذج اللغة الصوتية الكبيرة متعددة الأبعاد: أصدر فريق بحثي من جامعة نانيانغ التكنولوجية وجامعة تسينغهوا ومؤسسات أخرى AudioTrust، وهو أول معيار تقييم شامل للموثوقية مصمم خصيصًا لنماذج اللغة الصوتية الكبيرة (ALLMs). يقوم هذا الإطار بتقييم شامل لـ ALLMs من ستة أبعاد أساسية هي العدالة، والهلوسة، والأمان، والخصوصية، والمتانة، والتحقق من الهوية، وذلك من خلال 18 إعدادًا تجريبيًا وأكثر من 4420 قطعة بيانات صوتية/نصية من سيناريوهات واقعية. وجدت الدراسة أن النماذج الحالية لديها تحيزات منهجية في السمات الحساسة، ومتانة غير كافية في ظل الضوضاء والمدخلات العدائية، ونقاط ضعف في الدفاع ضد خداع استنساخ الصوت وغيرها. يهدف AudioTrust إلى الكشف عن المخاطر الكامنة في ALLMs وتوفير أساس بحثي لتعزيز موثوقيتها (المصدر: 量子位)
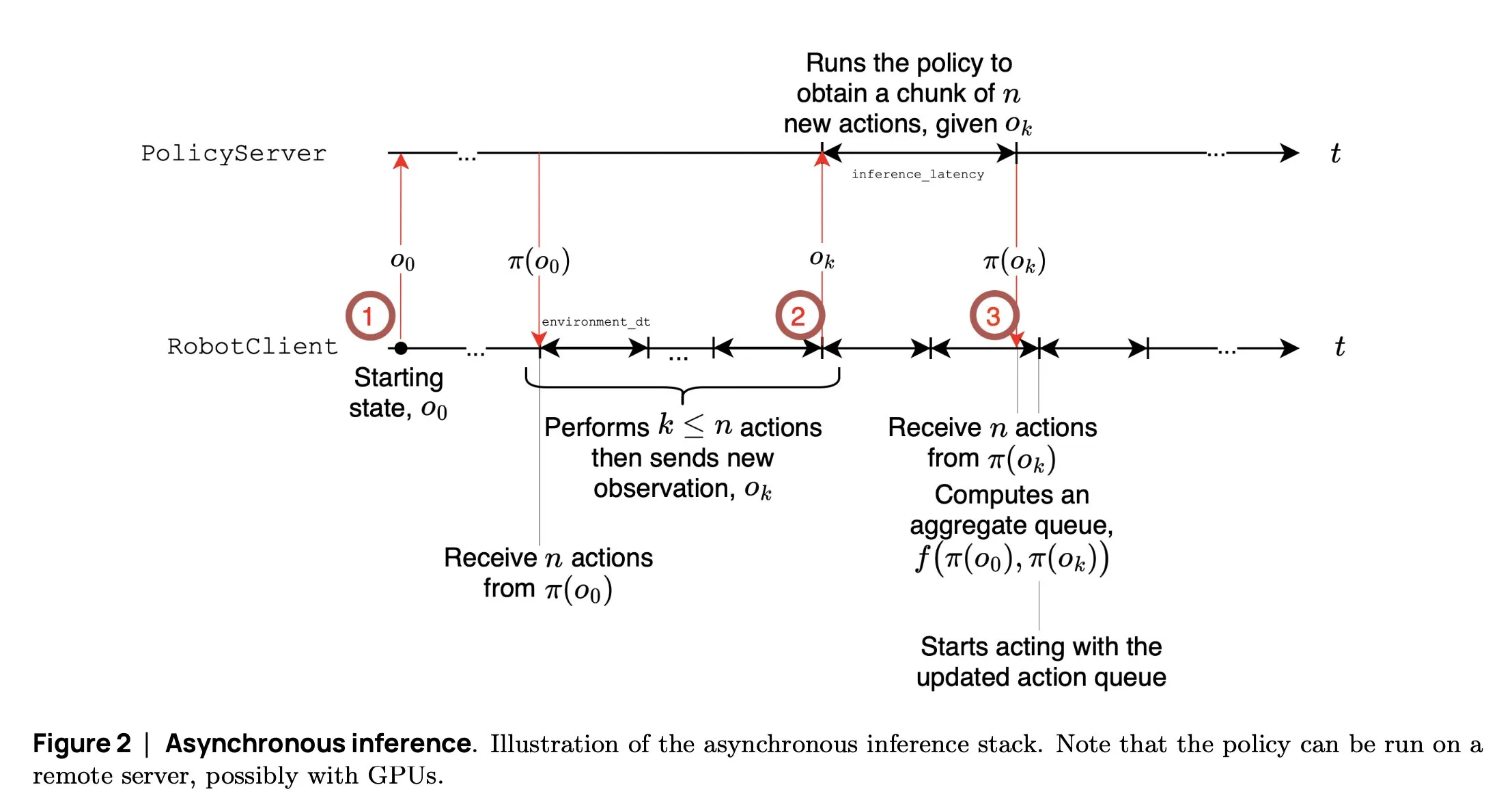
SmolVLA: Hugging Face تطلق نموذج VLA صغير وفعال للروبوتات: أطلق فريق الروبوتات في Hugging Face نموذج SmolVLA، وهو نموذج لغة وحركة بصري صغير بحجم 450 مليون معلمة، مصمم خصيصًا للروبوتات. يمكن تشغيله في الوقت الفعلي على وحدات معالجة الرسومات (GPU) الاستهلاكية، ويتم تدريبه باستخدام مجموعات بيانات عامة، ويمكن مقارنة أدائه بالنماذج الكبيرة. يقدم SmolVLA آلية “الاستدلال غير المتزامن”، حيث لا يحتاج الروبوت إلى انتظار اكتمال الإجراء الحالي لبدء التخطيط للخطوة التالية، مما يزيد من إنتاجية الروبوت بنحو 30٪ ويكاد يضاعف كفاءة إنجاز المهام. أظهر هذا النموذج أداءً متميزًا في العديد من اختبارات القياس مثل Meta-World و LIBERO، وقد تم فتح مصدر الكود والأوزان وعملية التدريب بهدف تعزيز تطوير مجتمع الروبوتات المفتوح (المصدر: AymericRoucher, mervenoyann, huggingface)
مايكروسوفت تطلق GUI-Actor: لتعزيز قدرة VLM على تحديد المواقع المرئية في مهام GUI: أطلقت مايكروسوفت GUI-Actor، وهي طريقة لتحديد المواقع في واجهة المستخدم الرسومية (GUI) لا تعتمد على الإحداثيات وتستند إلى نماذج اللغة المرئية (VLM). تعتمد هذه الطريقة على إدخال رأس إجراء (action head) بآلية انتباه، مما يسمح بمواءمة الرموز المميزة المخصصة مع الرقع المرئية ذات الصلة، وبالتالي اقتراح منطقة أو أكثر للإجراء في تمريرة أمامية واحدة، مع مدقق لتحديد المواقع لاختيار الإجراء الأكثر منطقية. أظهرت التجارب أن GUI-Actor يتفوق على الطرق السابقة في العديد من معايير تحديد مواقع الإجراءات في GUI، حيث يمكن لنموذج 7B، بعد ضبط دقيق لحوالي 100 مليون معلمة فقط في رأس الإجراء (مع تجميد الجزء الرئيسي من VLM)، أن يحقق أداءً يضاهي نماذج SOTA، مما يظهر قدرته على منح VLM قدرة تحديد مواقع فعالة دون المساس بعمومية VLM (المصدر: HuggingFace Daily Papers, kylebrussell)

DCM: نموذج تناسق الخبيرين يسرع إنشاء الفيديو عالي الجودة: اقترح باحثون DCM (Dual-Expert Consistency Model)، وهو مسرع لإنشاء الفيديو بكفاءة وجودة عالية. من خلال تحليل ديناميكيات تدريب نموذج التناسق، وجدوا أن هناك تضاربًا في تدرجات التحسين ومساهمات الخسارة في خطوات زمنية مختلفة. يعتمد DCM تصميمًا فعالًا من حيث المعلمات يعتمد على خبيرين: خبير دلالي يتعلم التخطيط الدلالي والحركة، وخبير تفاصيل يركز على تحسين التفاصيل الدقيقة. من خلال الجمع بين خسارة التماسك الزمني وخسارة GAN/مطابقة الميزات، يحقق DCM جودة بصرية SOTA مع تقليل خطوات أخذ العينات بشكل كبير، مما يحل بشكل فعال المشكلات في تقطير نماذج انتشار الفيديو. يمكن لهذه الطريقة تحقيق تسريع في الاستدلال بحوالي 10 مرات (من 1500 ثانية إلى 120 ثانية) على نماذج مثل HunyuanVideo13B (المصدر: HuggingFace Daily Papers, _akhaliq)
FlowMo: توجيه التدفق المعتمد على التباين يعزز تماسك الحركة في إنشاء الفيديو: لمعالجة القيود المفروضة على نماذج انتشار تحويل النص إلى فيديو في نمذجة الأبعاد الزمنية مثل الحركة والفيزياء والتفاعلات الديناميكية، اقترح الباحثون FlowMo، وهي طريقة توجيه في وقت الاستدلال لا تتطلب تدريبًا إضافيًا أو مدخلات مساعدة. يستخلص FlowMo تمثيلًا زمنيًا منفصلاً عن المظهر عن طريق قياس المسافة بين المتغيرات الكامنة المقابلة للإطارات المتتالية، ويستخدم التباين على مستوى الرقعة عبر البعد الزمني لتقدير تماسك الحركة، ومن ثم توجيه النموذج ديناميكيًا لتقليل هذا التباين أثناء عملية أخذ العينات. أثبتت التجارب أن FlowMo يمكن أن يحسن بشكل كبير تماسك الحركة في العديد من نماذج انتشار الفيديو المدربة مسبقًا، دون التضحية بالجودة البصرية أو محاذاة المطالبة (المصدر: HuggingFace Daily Papers, Suhail)
أداء Qwen3-235B-A22B تنافسي على وكيل الترميز Openhands: أعلن فريق Qwen من Alibaba أن نموذجه Qwen3-235B-A22B حقق نتيجة 34.4% في اختبار Swebench-verified الخاص بوكيل الترميز مفتوح المصدر Openhands. وذكر الفريق أن هذه النتيجة تشير إلى أن النموذج حقق أداءً تنافسيًا بعدد أقل من المعلمات، وشكر allhands_ai على توفير الوكيل سهل الاستخدام. يسلط هذا الخبر الضوء على إمكانات الجمع بين النماذج المفتوحة والوكلاء المفتوحين (المصدر: Alibaba_Qwen)

OmniSpatial: إطلاق معيار شامل للاستدلال المكاني لنماذج VLM: أطلق باحثون OmniSpatial، وهو معيار شامل وصعب للاستدلال المكاني لنماذج اللغة المرئية (VLM) يعتمد على علم النفس المعرفي. يتضمن OmniSpatial أربع فئات رئيسية: الاستدلال الديناميكي، والمنطق المكاني المعقد، والتفاعلات المكانية، وتحويل المنظور، مقسمة إلى 50 فئة فرعية، بإجمالي أكثر من 1500 زوج من الأسئلة والأجوبة. أظهرت التجارب المكثفة التي أجريت على نماذج VLM مفتوحة المصدر ومغلقة المصدر الحالية، بالإضافة إلى نماذج الاستدلال والفهم المكاني المتخصصة، وجود قيود كبيرة في الفهم المكاني الشامل. يهدف هذا البحث إلى دفع عجلة تطوير قدرات الاستدلال المكاني لنماذج VLM (المصدر: HuggingFace Daily Papers, kylebrussell)
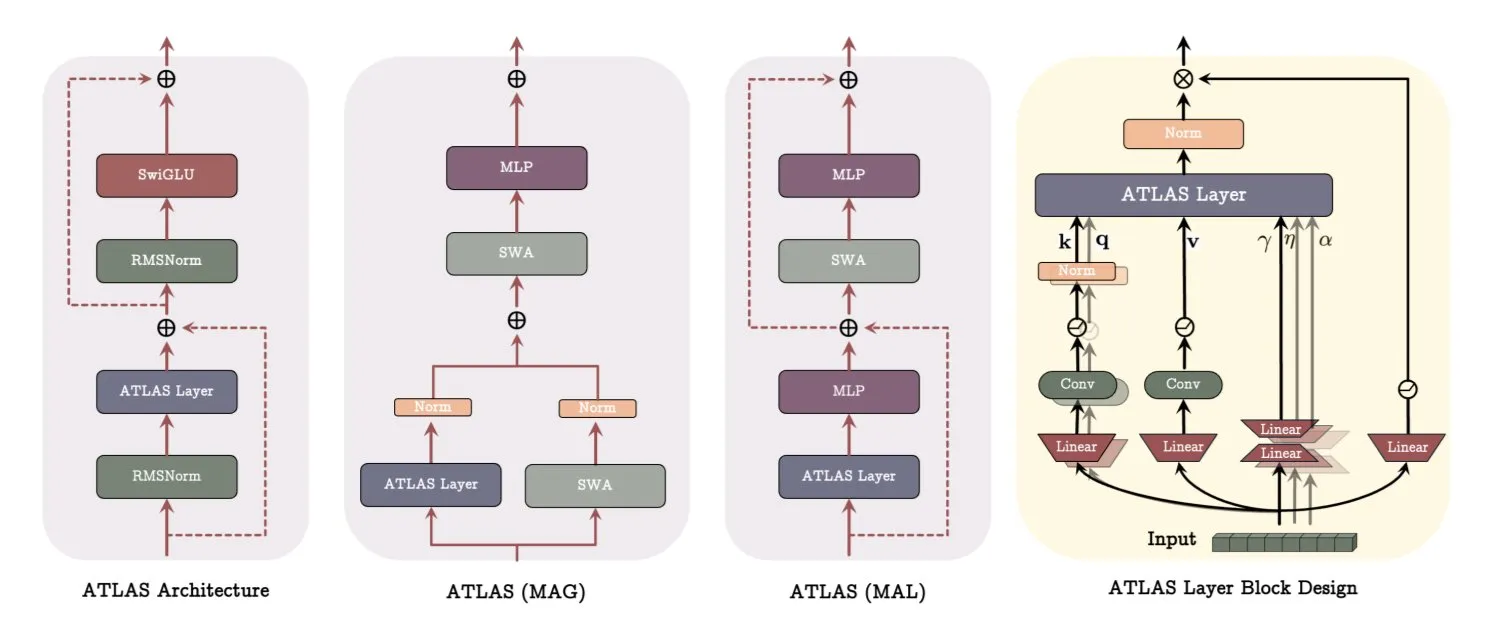
هيكلية ATLAS من جوجل DeepMind: إعادة بناء طريقة تعلم النماذج والذاكرة: أصدرت جوجل DeepMind هيكلية ATLAS، وهي هيكلية نموذجية جديدة تهدف إلى إعادة تعريف طريقة تعلم النماذج واستخدام الذاكرة. تحقق ATLAS ذاكرة نشطة من خلال ما يسمى بقاعدة أوميغا، حيث تعالج بشكل مشترك آخر c من الرموز المميزة لتحسين الذاكرة كحالة ديناميكية قابلة للتعلم. تستخدم خرائط الميزات متعددة الحدود والأسية لتخزين ارتباطات أغنى دون توسيع حجم الذاكرة، وتستخدم مُحسِّن Muon لتحسين الذاكرة بشكل أكثر فعالية. تستبدل تصميمات مثل DeepTransformers و Dot الانتباه الثابت التقليدي بآليات قابلة للتعلم ومدفوعة بالذاكرة. تهدف ATLAS إلى دفع الذكاء الاصطناعي نحو أنظمة أكثر ذكاءً وإدراكًا للسياق وقادرة على الاستفادة الفعالة من مجموعات البيانات الضخمة (المصدر: TheTuringPost)
NVIDIA تطلق نموذج الرؤية Llama-Nemotron-Nano-VL-8B-V1: أطلقت NVIDIA نموذج Llama-Nemotron-Nano-VL-8B-V1، وهو نموذج رؤية بـ 8 مليارات معلمة، قادر على قراءة المستندات والرسوم البيانية وإطارات الفيديو الكثيفة. احتل هذا النموذج المرتبة الأولى في OCRBench V2 (باللغة الإنجليزية)، ويتميز بدمج شامل لقدرات التخطيط والتعرف الضوئي على الحروف (OCR). النموذج متاح على Hugging Face (المصدر: ClementDelangue)
إطلاق Shisa V2 405B، يُزعم أنه أقوى نموذج ثنائي اللغة في اليابان: أطلقت Shisa AI أحدث نماذجها ثنائية اللغة (يابانية/إنجليزية) من سلسلة Shisa V2، وهو Shisa V2 405B. تم ضبط هذا النموذج بدقة بناءً على Llama 3.1 405B، مع إضافة بيانات باللغة الكورية والصينية التقليدية لتعزيز القدرات متعددة اللغات. يُزعم أنه يتفوق على GPT-4/GPT-4 Turbo في MT-Bench للغة اليابانية والإنجليزية، ويعادل أحدث إصدارات GPT-4o و DeepSeek-V3 في القدرات اليابانية. تتوفر أوزان النموذج وإصدارات GGUF الكمية على Hugging Face، وهناك نقاط نهاية FP8 متاحة للاختبار (المصدر: Reddit r/LocalLLaMA)

Anthropic تطلق خطة Claude Code Pro، وتطرح نموذج o3-pro: أصبحت أداة البرمجة بالذكاء الاصطناعي Claude Code من Anthropic متاحة الآن لمستخدمي خطة Pro، ولكن مع قيود على استخدام نموذج Sonnet 4 تتراوح بين 10-40 مطالبة كل 5 ساعات، ولا يمكن استخدام Opus 4 مع Claude Code من خلال خطة Pro، ويبدو الأمر أشبه بوضع تجريبي. في الوقت نفسه، تم إطلاق نموذج o3-pro من OpenAI، وهو متاح حاليًا فقط لمشتركي Pro بقيمة 200 دولار شهريًا (المصدر: Reddit r/ClaudeAI, karminski3)
شركة H Company تطلق نموذج لغة مرئي مفتوح المصدر لواجهة المستخدم الرسومية Holo-1: أطلقت شركة H Company نموذج Holo-1، وهو نموذج لغة مرئي لواجهة المستخدم الرسومية (GUI) بحجم 3 مليارات و 7 مليارات معلمة، مصمم لمختلف مهام وكلاء الويب والكمبيوتر. يستخدم Holo-1 ترخيص Apache 2.0 ويدعم مكتبة Hugging Face Transformers، ويهدف إلى تعزيز قدرات الذكاء الاصطناعي في فهم واجهات المستخدم الرسومية والتعامل معها (المصدر: mervenoyann)
نموذج إنشاء الفيديو Kling 2.1 يحظى بالاهتمام، ويدعم تحويل الصور إلى فيديو وإنشاءات فنية: يستمر نموذج Kling 2.1 لتحويل النص إلى فيديو والصور إلى فيديو التابع لشركة كوايشو في جذب اهتمام المجتمع. أفاد المستخدمون بقدرته على تحويل الصور البسيطة إلى مشاهد سينمائية بدقة 1080p، ويدعم تحويل لقطات التحريك العادية إلى رسوم متحركة بأسلوب بيكسار من خلال دمج GPT-4o مع Kling، ويمكنه استخدام الصور التي تم إنشاؤها بواسطة Midjourney V7 كمدخلات لإنشاء مقاطع فيديو ذات تأثيرات ديناميكية سريالية. شارك المجتمع العديد من الأمثلة التي تم إنشاؤها باستخدام Kling 2.1، مما يوضح إمكاناته في إنشاء مقاطع الفيديو الإبداعية (المصدر: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI تطلق نموذجًا صوتيًا جديدًا، يدعم تشغيل الصوت في الوقت الفعلي بسرعة مضاعفة: أعلنت OpenAI أن نموذجها o3-pro قد تم إطلاقه، وهو متاح حاليًا لمستخدمي اشتراك Pro فقط. وفي الوقت نفسه، يبدو أن OpenAI ستطلق أيضًا نموذجين صوتيين جديدين يعتمدان على GPT-4o. كما تم تحسين واجهة برمجة تطبيقات الصوت في الوقت الفعلي (real-time voice API)، مما أدى إلى تحسين موثوقية اتباع التعليمات، واتساق استدعاء الأدوات، وسلوك المقاطعة، وإضافة معلمة speed جديدة، مما يسمح للمستخدمين بالتحكم في سرعة تشغيل الصوت، حتى سرعة مضاعفة. تستخدم Fin Voice من Intercom بالفعل واجهة برمجة تطبيقات الصوت في الوقت الفعلي الخاصة بها (المصدر: karminski3, swyx, swyx)
Arcee AI تطلق نموذج Homunculus، وتقطير سلسلة تفكير Qwen3 إلى 12B: أطلقت Arcee AI نموذج Homunculus-12B، الذي ينقل سلسلة “التفكير” (CoT) من Qwen3-235B إلى نموذج Mistral-Nemo بحجم 12 مليار معلمة، وذلك باستخدام تقنية تقطير مسار اللوغاريتمات. يحتفظ هذا النموذج بعملية CoT بالكامل ويمكن تشغيله على وحدة معالجة رسومات 4090 واحدة، ويهدف إلى تحقيق قدرات استدلال معقدة بنموذج أصغر (المصدر: teortaxesTex, cognitivecompai, ClementDelangue)
نموذج FLUX Kontext يحظى بشعبية كبيرة، وتشغيل النموذج العام أكثر من 500 ألف مرة: حظي نموذج FLUX Kontext باهتمام واسع من المجتمع بفضل قدراته القوية في تحرير وإنشاء الصور، ويُقال إن نموذجه العام قد تم تشغيله أكثر من 500 ألف مرة في وقت قصير. أفاد المستخدمون بأن Kontext يمكن أن يحل محل العديد من مهام معالجة الصور التي كانت تتطلب سابقًا برامج احترافية مثل Photoshop. كما أطلقت Krea AI نموذج FLUX، لكنها واجهت مشكلات في شبكة مزود خدمة الحوسبة مما أدى إلى انقطاع الخدمة (المصدر: op7418, robrombach, op7418)
Meta و Constellation Energy توقعان اتفاقية طاقة نووية لمدة 20 عامًا لتزويد الذكاء الاصطناعي بالطاقة: وقعت شركة Meta اتفاقية طاقة نووية لمدة 20 عامًا مع Constellation Energy، بهدف توفير الكهرباء لعملياتها في مجال الذكاء الاصطناعي (AI). تعكس هذه الخطوة سعي شركات التكنولوجيا الكبرى للحصول على مصادر طاقة مستدامة ومستقرة لتلبية الطلب المتزايد على الطاقة من قبل الذكاء الاصطناعي (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

انقطاع خدمة Bing Video Creator، والفريق يعمل على إصلاحه بشكل عاجل: تعرضت أداة إنشاء الفيديو Bing Video Creator من مايكروسوفت لانقطاع في الخدمة. صرح المسؤولون بأن الفريق على علم بأن عددًا كبيرًا من المستخدمين يستخدمون الخدمة، ويعملون جاهدين على إصلاحها في أقرب وقت ممكن، معربين عن اعتذارهم عن الإزعاج الذي تسبب فيه ذلك. لم يتم الإعلان عن سبب العطل المحدد أو الوقت المتوقع لاستعادة الخدمة (المصدر: JordiRib1)
🧰 الأدوات
وظيفة الشرائح في Manus AI تحظى بإشادة، وتدعم التصدير إلى Google Slides: حظيت وظيفة إنشاء الشرائح التي أطلقتها Manus AI مؤخرًا بإشادة المستخدمين، حيث وصفوا تأثيرها بأنه فاق التوقعات، وقدرتها على تحويل محتوى مثل الأوراق البحثية بسرعة إلى عروض تقديمية (PPT) منظمة وواضحة وغنية بالصور والنصوص. تدعم هذه الوظيفة التعديل الفوري، والحفظ التلقائي، وأضافت خيار التصدير إلى Google Slides، مما يسهل التعاون بين الفرق. أظهر الاختبار العملي أن Manus يمكنه إنشاء 8 شرائح PPT في حوالي 10 دقائق، وتشمل العملية تخطيط المخطط التفصيلي، والبحث عن المواد، وكتابة المسودة، وإنشاء كود HTML، وتحسين التنسيق. أفاد المستخدمون بكفاءتها في توفير الوقت، وتصميمها الذي يناسب المستخدم المستهدف، ولكن قد توجد مشكلة في عدم عرض الصفحات بالكامل في تنسيق التصدير، مما يتطلب تعديلًا يدويًا (المصدر: 量子位)
claude-trace: أداة لتسجيل جميع سجلات طلبات Claude Code: أداة تسمى claude-trace يمكنها تسجيل جميع سجلات طلبات Claude Code، بما في ذلك المطالبات (prompts)، وحفظ المحتوى في ملف HTML لسهولة الاطلاع عليه. تعمل الأداة عن طريق تشغيل نفسها، وحقن وتعديل واجهة برمجة تطبيقات global.fetch API الخاصة بـ Node.js، ثم تشغيل Claude Code من خلالها، وبالتالي اعتراض وتسجيل جميع الطلبات. شارك المستخدمون أنه عند استخدام اشتراك Claude Max، يتم استدعاء claude-3-5-haiku (للمعالجة المسبقة)، و claude-opus-4 (لكتابة التعليمات البرمجية واستدعاء الأدوات)، و claude-sonnet-4 (عند نفاد حصة Opus) بشكل أساسي (المصدر: dotey)
Firecrawl تطلق وظيفة /search، لتحقيق التكامل بين البحث والزحف: أطلقت Firecrawl وظيفة /search الجديدة، التي تسمح للمستخدمين بإكمال البحث على الويب وزحف البيانات المطلوبة من خلال استدعاء API واحد، بهدف تبسيط عملية الحصول على البيانات لوكلاء الذكاء الاصطناعي. يمكن دمج هذه الوظيفة مع أدوات التشغيل الآلي مثل n8n، مما يزيد من كفاءة معالجة البيانات (المصدر: omarsar0)
Modal تطلق LLM Engine Advisor، للمساعدة في تقييم أداء تشغيل LLM: طورت Modal Labs تطبيقًا صغيرًا يسمى LLM Engine Advisor، يهدف إلى مساعدة المستخدمين على فهم سرعة تشغيل نماذج LLM المختلفة وأقصى إنتاجية لها في ظل أعباء عمل ومحركات مختلفة (مثل vLLM، SGLang) بسرعة. تهدف هذه الأداة إلى حل مشكلة عدم كفاءة التشغيل المؤقت ومشاركة اختبارات الأداء، وتوفير دعم لاتخاذ القرارات الفنية للمستخدمين عند اختيار ونشر نماذج LLM (المصدر: charles_irl, andersonbcdefg, charles_irl, charles_irl)
إطلاق FastPlaid: محرك بحث متعدد المتجهات عالي الأداء: أعلن رافائيل سورتي عن إطلاق FastPlaid، وهو محرك بحث متعدد المتجهات عالي الأداء تم بناؤه من الصفر باستخدام Rust (بمساعدة Torch C++). يعتبر FastPlaid نظيرًا لـ Faiss في مجال البحث متعدد المتجهات، ويهدف إلى توفير سرعة فهرسة واستعلامات QPS أسرع، خاصة لنماذج التفاعل اللاحق مثل ColBERT، ويُزعم أنه يمكن أن يحقق زيادة في سرعة QPS تصل إلى 554% وزيادة في سرعة الفهرسة بنسبة 72% في بعض الحالات (المصدر: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie: إضافة Chrome تعتمد على RAG، لتحقيق الدردشة مع المستندات: ChaiGenie هي إضافة لمتصفح Chrome طورها Devyansh Yadavv، تستخدم تقنية RAG (الاسترجاع المعزز للتوليد)، مما يسمح للمستخدمين بالاستعلام مباشرة عن محتوى مستندات ChaiDocs بلغة طبيعية داخل المتصفح. تستخدم الإضافة Puppeteer لجمع محتوى المستندات والمدونات، و LangChain لتقسيمها وتضمينها ومعالجتها، و Gemini لإنشاء التضمينات، و Qdrant لتخزين المتجهات والبحث عن التشابه، وتوفر واجهة برمجة تطبيقات (API) من خلال Express و Node.js (المصدر: qdrant_engine)
Swama: بيئة تشغيل AI أصلية لنظام macOS تعتمد على MLX: أطلقت xingyue Swama، وهي بيئة تشغيل AI أصلية مصممة خصيصًا لنظام macOS، تهدف إلى توفير تجربة تشغيل LLM محلية سريعة وخاصة وموجزة. تعتمد Swama على إطار عمل MLX من Apple، وتدعم واجهات برمجة تطبيقات متوافقة مع OpenAI، وتوفر واجهة سطر أوامر (CLI) جذابة، مما يسمح للمستخدمين بسحب وتشغيل LLM المحلية والدردشة معها دون الحاجة إلى إعدادات معقدة (المصدر: awnihannun)
ragbits: صندوق أدوات مفتوح المصدر لبناء تطبيقات GenAI معيارية: فتحت deepsense-ai مصدر مسرع تطبيقات GenAI الداخلي الخاص بها ragbits، وهو صندوق أدوات يحتوي على وحدات بناء موثوقة وآمنة من حيث النوع ومعيارية، لتبسيط تطوير خطوط أنابيب RAG وتطبيقات الوكلاء الذكية ومحركات text2SQL. يهدف ragbits إلى تحسين قابلية تكرار التطوير وسرعته وهيكليته، ويسهل دمجه مع مكدسات المراقبة مثل OpenTelemetry، مما يساعد المطورين على بناء وتوسيع تطبيقات GenAI وتجنب فوضى قواعد التعليمات البرمجية (المصدر: Reddit r/LocalLLaMA)
Synthesia تتكامل مع Wisetail، وفيديو الذكاء الاصطناعي يمكّن برامج التدريب: أعلنت منصة إنشاء الفيديو بالذكاء الاصطناعي Synthesia عن تكاملها مع نظام إدارة التعلم Wisetail. يمكن للمستخدمين الآن إنشاء مقاطع فيديو بالذكاء الاصطناعي بسرعة في Synthesia، ودعم إصدارات مترجمة بأكثر من 140 لغة، وتحديث محتوى التدريب ببضع نقرات، ثم إدخالها بسهولة في برامج تدريب Wisetail، لتحقيق تدريب فيديو بالذكاء الاصطناعي على نطاق واسع (المصدر: synthesiaIO)

📚 التعلم
DeepLearning.AI و Databricks تتعاونان لإطلاق دورة تدريبية قصيرة حول DSPy: أعلن Andrew Ng عن تعاون مع Databricks لإطلاق دورة تدريبية قصيرة جديدة بعنوان “DSPy: Build and Optimize Agentic Apps”. DSPy هو إطار عمل مفتوح المصدر يقوم تلقائيًا بضبط مطالبات تطبيقات GenAI. ستعلم الدورة كيفية استخدام DSPy و MLflow، وتشمل المحتويات نموذج البرمجة التوقيعي لـ DSPy، واستخدام MLflow لتتبع وتصحيح الأخطاء، وتحسين الدقة تلقائيًا من خلال DSPy Optimizer. يقدم هذه الدورة Chen Qian، المدير المشارك لإطار عمل DSPy (المصدر: AndrewYNg, DeepLearningAI, matei_zaharia)
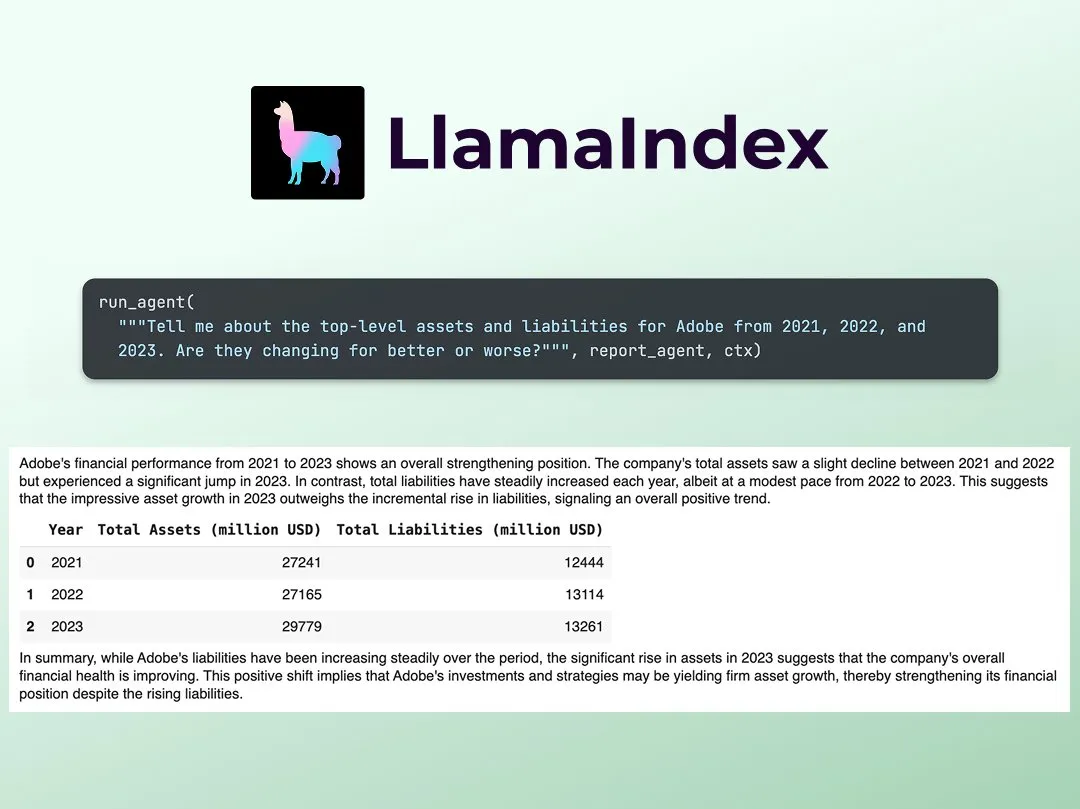
LlamaIndex تنشر برنامجًا تعليميًا لبناء محلل أبحاث مالية متعدد الوكلاء: شارك Jerry Liu من LlamaIndex دليلاً تفصيليًا لبناء محلل أبحاث مالية متعدد الوكلاء. تتضمن العملية طبقة معالجة البيانات (باستخدام LlamaCloud لمعالجة الملفات العامة) وطبقة تنسيق الوكلاء (إنشاء نظام متعدد الوكلاء للبحث والتخزين المؤقت للبيانات وإنشاء المخرجات النهائية). يعد Colab Notebook ذو الصلة أحد الأمثلة الرئيسية لورشة عمل Agents+Finance التي عقدت الأسبوع الماضي (المصدر: jerryjliu0)
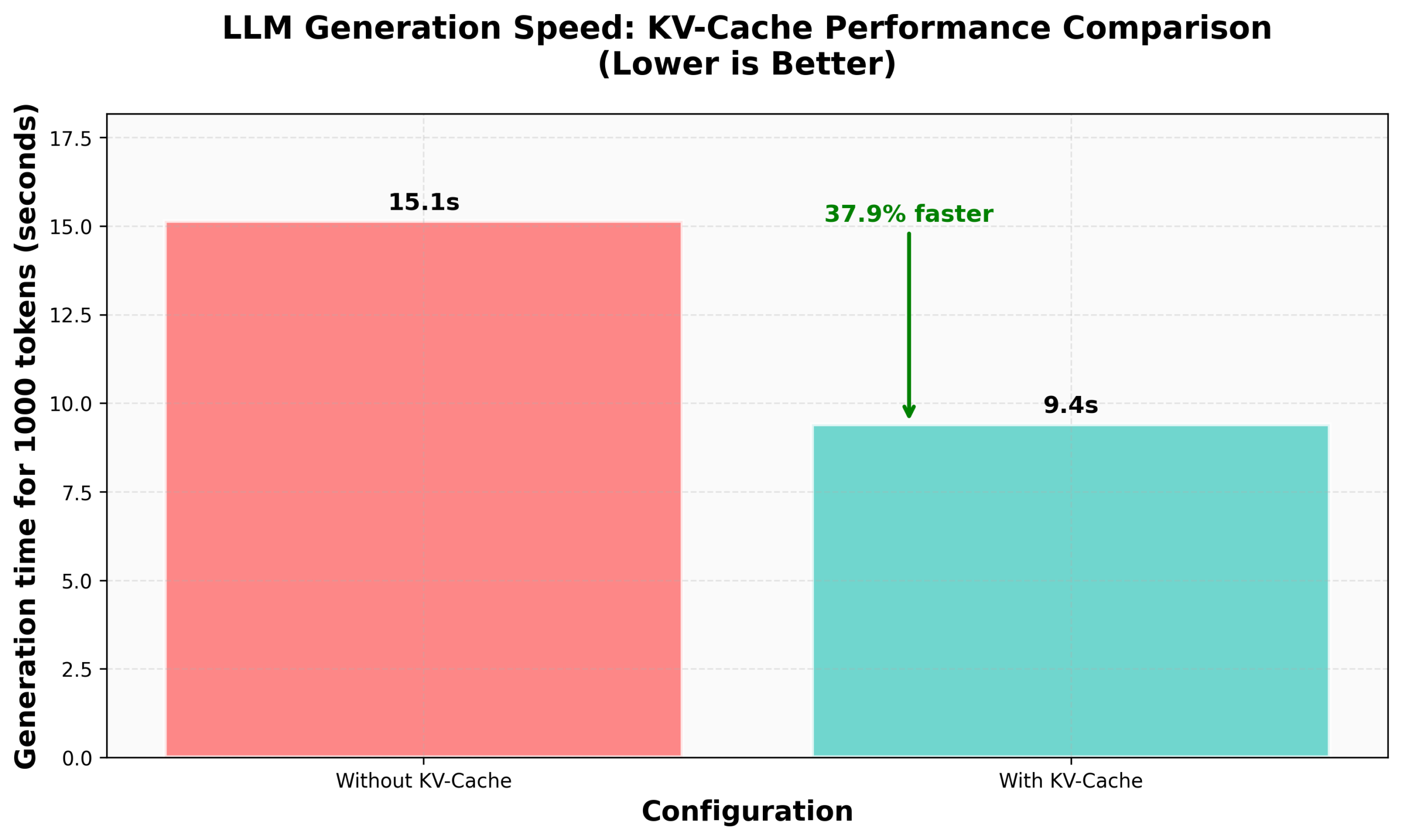
HuggingFace nanoVLM تنشر برنامجًا تعليميًا لتطبيق KV Caching: نشرت مدونة HuggingFace برنامجًا تعليميًا حول تطبيق KV Caching من الصفر في nanoVLM الخاص بها (مكتبة أكواد PyTorch صغيرة ونقية لتدريب نماذج اللغة المرئية). يشرح المقال بالتفصيل مبدأ KV Caching، وكيفية تطبيقه في وحدة Attention، ونموذج اللغة، وحلقة التوليد، ويدعي تحقيق تحسين في سرعة التوليد بنسبة 38% من خلال هذا التحسين. يهدف هذا البرنامج التعليمي إلى المساعدة في فهم KV Caching وتطبيقه على نماذج لغة أخرى ذاتية الانحدار (المصدر: HuggingFace Blog, mervenoyann)
مشاركة PyTorch في مجتمع Diffusion في Meta: شارك Sayak Paul في مكتب Meta بسان فرانسيسكو إنجازات تطبيق PyTorch في مجتمع Diffusion، مع التركيز على وظائف Diffusers الحالية والتحديثات المستقبلية المتعلقة بالأداء. تم نشر الشرائح ذات الصلة (المصدر: RisingSayak)

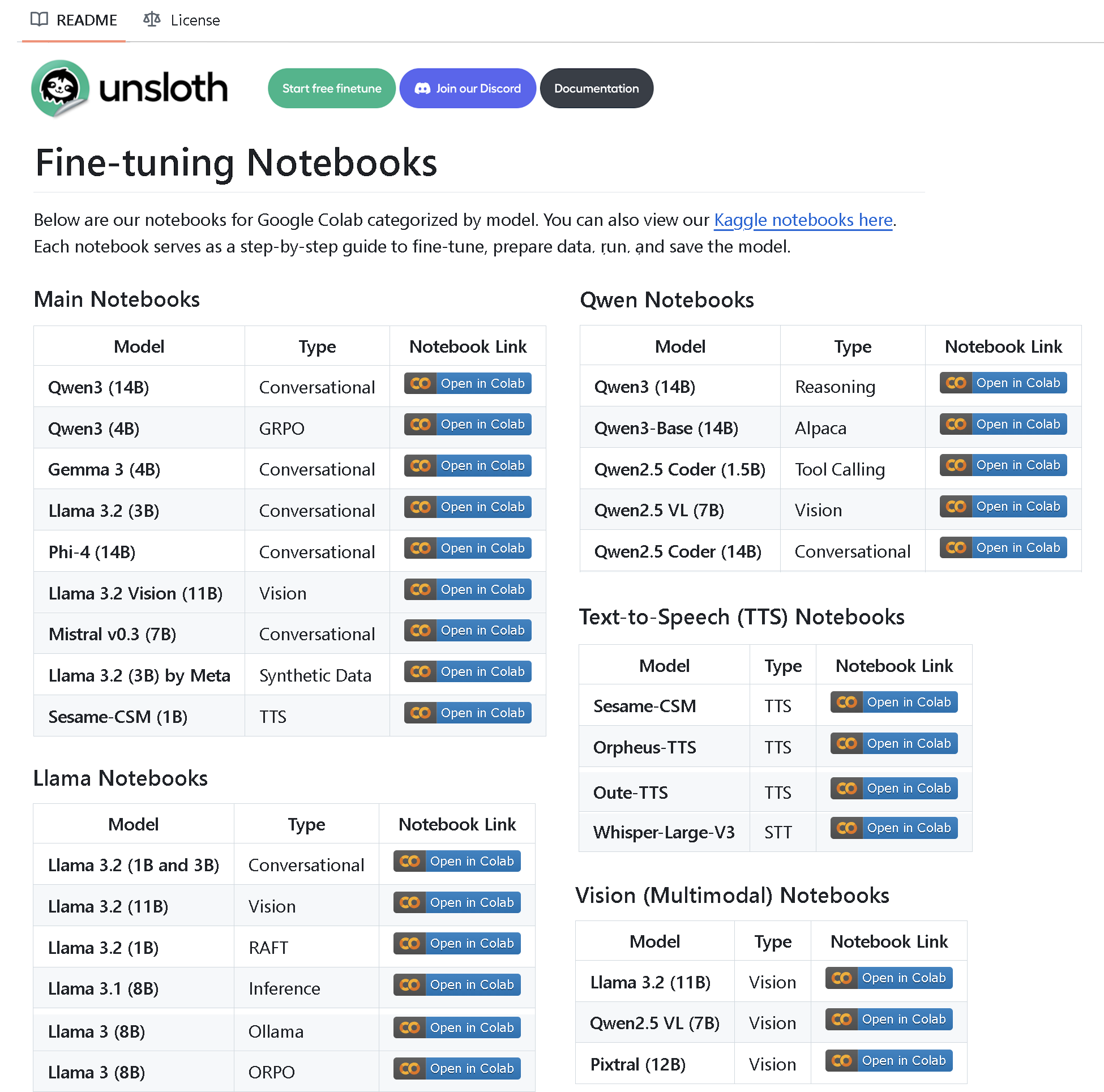
Unsloth AI تطلق مستودعًا يحتوي على أكثر من 100 دفتر ملاحظات للضبط الدقيق: أنشأت Unsloth AI مستودع GitHub مفتوح المصدر يحتوي على أكثر من 100 دفتر ملاحظات للضبط الدقيق. توفر دفاتر الملاحظات هذه أدلة وأمثلة على استدعاء الأدوات، والتصنيف، والبيانات الاصطناعية، و BERT، و TTS، ونماذج LLM المرئية، و GRPO، و DPO، و SFT، و CPT، وغيرها من التقنيات المتنوعة، وتغطي إعداد البيانات، والتقييم، والحفظ، بالإضافة إلى طرق الضبط الدقيق لنماذج متنوعة مثل Llama، و Qwen، و Gemma، و Phi، و DeepSeek (المصدر: algo_diver)
نشر ورقة بحثية عن Common Corpus: مجموعة بيانات تدريب مسبق لـ LLM قابلة لإعادة الاستخدام بحجم 2 تريليون رمز مميز: نشر مشروع Common Corpus ورقته البحثية الرسمية، التي تشرح بالتفصيل عملية جمع ومعالجة ونشر 2 تريليون رمز مميز من البيانات القابلة لإعادة الاستخدام لتدريب LLM المسبق. يهدف هذا المشروع إلى توفير موارد بيانات واسعة النطاق وعالية الجودة ومتوافقة مع الأخلاقيات لأبحاث نماذج اللغة. أعلن المؤلف الأول للورقة البحثية، Alexander Doria، عن هذا الخبر على X، وقدم رابطًا للورقة البحثية (المصدر: Reddit r/LocalLLaMA, code_star)

Reasoning Gym: إطلاق بيئة استدلال بمكافآت قابلة للتحقق للتعلم المعزز: Reasoning Gym هو مشروع جديد مفتوح المصدر يوفر موارد للباحثين في نماذج الاستدلال والتعلم المعزز (خاصة RLVR). يمكنه إنشاء عينات غير محدودة لأكثر من 100 مهمة مختلفة، مع صعوبة قابلة للتكوين، ومكافآت قابلة للتحقق تلقائيًا. تم اعتماد هذا المشروع من قبل ورقة ProRL من NVIDIA ومكتبة verifiers RL لـ Will Brown، ويهدف إلى دفع عجلة البحث في RLVR وطرق التقييم (المصدر: Reddit r/MachineLearning)
مزايا تعلم LLM للرياضيات: ساكاموتو يشارك تجربته مع Gemini 2.5 Pro: شارك المستخدم ساكاموتو تجربته في تعلم الرياضيات باستخدام نماذج لغة كبيرة حديثة (مثل Gemini 2.5 Pro). يعتقد أن LLM تسهل تعلم الرياضيات بشكل كبير، خاصة في فحص التفاصيل وفهم حدس الإثبات. يمكن لـ LLM التعامل مع الحسابات، مما يساعد الطلاب على التركيز على حدس المسائل الرياضية. حتى لو لم تتمكن من حل جميع المسائل، يمكن لـ LLM تقديم رؤى ونقاط انطلاق قيمة. عرض من خلال مسألة تحليل رياضي محددة (مسألة القيم القصوى المحلية للدوال المستمرة) كيف يمكن لـ Gemini 2.5 Pro تقديم إثبات دقيق وشرح حدسه، معتقدًا أن هذا يمكن أن يعزز تجربة التعلم بشكل كبير (المصدر: teortaxesTex)

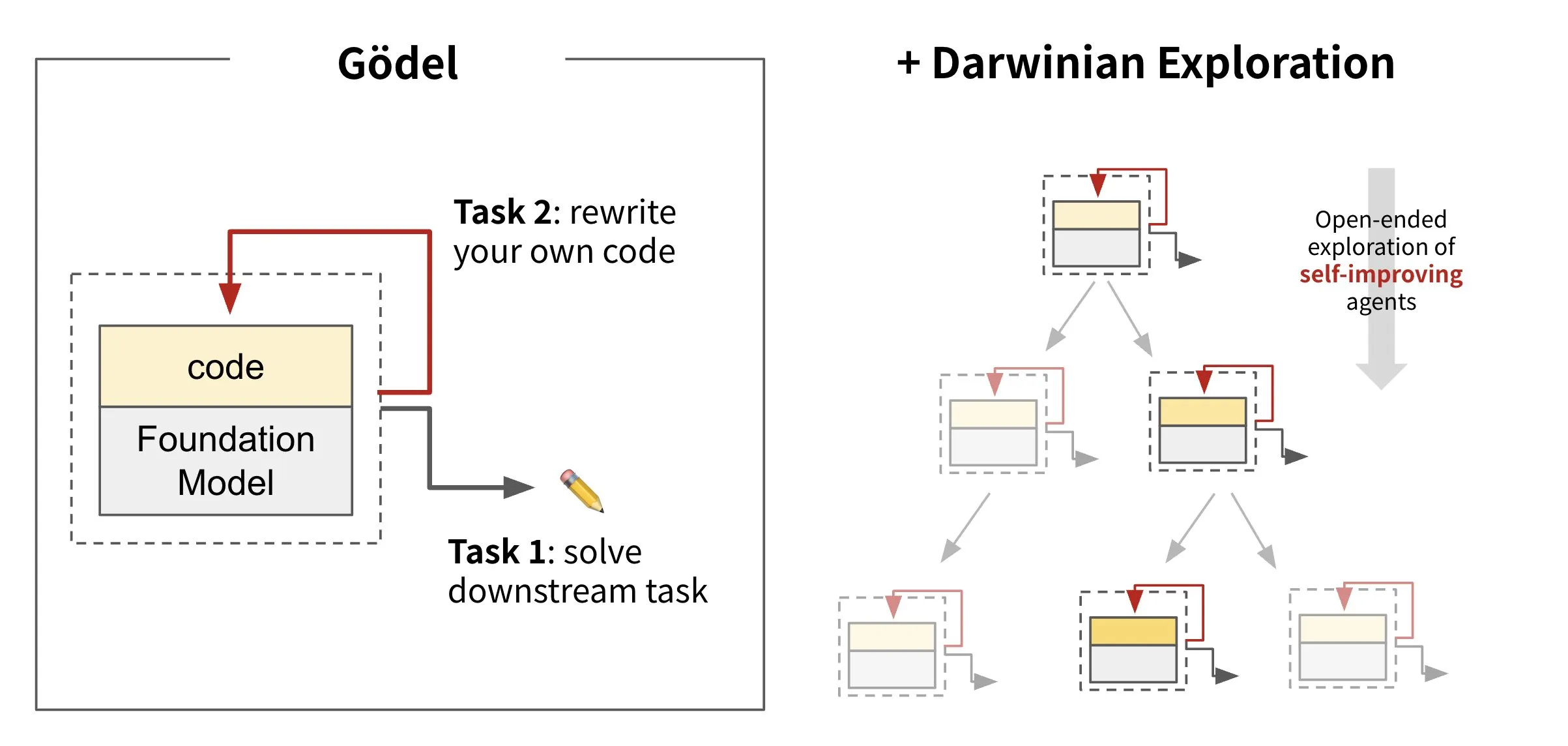
Sakana AI تطلق ذكاء اصطناعيًا يعيد كتابة أكواده ذاتيًا: Darwin Gödel Machine (DGM): أطلقت Sakana AI Darwin Gödel Machine (DGM)، وهو وكيل ذكاء اصطناعي قادر على تحسين نفسه من خلال إعادة كتابة أكواده الخاصة. مستوحى من نظرية التطور، يحافظ DGM على سلالة متوسعة باستمرار من متغيرات الوكيل. من خلال محاولة تعزيز قدرات هندسة البرمجيات في مهام مثل SWE-Bench، يهدف DGM إلى تحقيق تعزيز لقدراته على التحسين الذاتي. يعتبر هذا البحث اختراقًا هامًا في تحقيق حلم الذكاء الاصطناعي طويل الأمد المتمثل في “التحسين الذاتي” بشكل هادف (المصدر: SakanaAILabs, SakanaAILabs)
💼 الأعمال
منصة البرمجة بالذكاء الاصطناعي Windsurf تواجه قطع إمداد نماذج Claude من Anthropic، ربما بسبب استحواذ OpenAI: اتهم فارون موهان، الرئيس التنفيذي لمنصة البرمجة بالذكاء الاصطناعي Windsurf، شركة Anthropic بقطع وصولها المباشر إلى سلسلة نماذج Claude 3.x بشكل شبه كامل وفي غضون فترة قصيرة جدًا (أقل من خمسة أيام إشعار). وكان قد تم الكشف سابقًا عن أن OpenAI ستستحوذ على Windsurf. صرحت Windsurf بأنه على الرغم من وجود سعة من طرف ثالث، إلا أنه قد تحدث مشكلات في الخدمة على المدى القصير، وقد أطلقت أسعارًا مخفضة لـ Gemini 2.5 Pro كإجراء مضاد. تتكهن الصناعة بأن هذه الخطوة مرتبطة باستحواذ OpenAI وإطلاق Anthropic لتطبيق البرمجة بالذكاء الاصطناعي الخاص بها Claude Code، مما يشير إلى اشتداد المنافسة بين مزودي نماذج الذكاء الاصطناعي ومنصات الأدوات (المصدر: 36氪, Teknium1, op7418)

GMI Cloud تصبح Reference Platform NVIDIA Cloud Partner: أعلنت GMI Cloud، مزود خدمات AI Native Cloud، عن حصولها على شهادة Reference Platform NVIDIA Cloud Partner (NCP)، وهي شهادة لم تحصل عليها سوى 6 شركات عالميًا حتى الآن. تتطلب هذه الشهادة من مزودي الخدمات السحابية تلبية أعلى معايير NVIDIA في الأداء والأمان وقدرات نشر الذكاء الاصطناعي على مستوى المؤسسات. ستقدم GMI Cloud خدمات تسريع الذكاء الاصطناعي بناءً على بنية NCP المرجعية، وستدعم أحدث معماريات وحدات معالجة الرسومات من NVIDIA مثل Hopper و Blackwell، بهدف مساعدة فرق الذكاء الاصطناعي العالمية على تحقيق التوسع من نشر القدرة الحاسوبية إلى تطوير النماذج (المصدر: 量子位)

Cohere تتعاون مع SecondFront لتقديم حلول ذكاء اصطناعي آمنة للقطاع العام: أعلنت شركة الذكاء الاصطناعي Cohere عن شراكة مع SecondFront، بهدف تقديم حلول ذكاء اصطناعي آمنة للقطاع العام (بما في ذلك الوكالات الحكومية والدفاعية الحيوية). ستستفيد SecondFront من تكنولوجيا الذكاء الاصطناعي على مستوى المؤسسات من Cohere (بما في ذلك نماذجها ومنصة Cohere North) لتحسين إدارة المعرفة الداخلية، وتسريع الاعتماد والنشر في البيئات الحكومية الأمريكية والحليفة من خلال منصة DevSecOps الخاصة بها 2F Game Warden (المصدر: cohere)

🌟 المجتمع
“نكهة الآلة” في المحتوى الذي يولده الذكاء الاصطناعي تثير الانتباه، و”التدريب الجديد” يحاول غرس الاهتمام الإنساني: يعكس المستخدمون بشكل عام أن المحتوى الذي يولده الذكاء الاصطناعي له “نكهة آلية” قوية، ويفتقر إلى الجمال والعاطفة التي يبدعها الإنسان. لحل هذه المشكلة، بدأت بعض الشركات في توظيف مواهب ذات خلفيات قوية في العلوم الإنسانية (مثل الحاصلين على درجة الماجستير والدكتوراه في الفلسفة والقانون والطب وغيرها) للعمل كـ “مدربين إنسانيين للذكاء الاصطناعي”. لم يعد عملهم مجرد تصنيف بسيط للبيانات، بل يشاركون في بناء المبادئ الأخلاقية وقواعد السلوك للذكاء الاصطناعي، وغرس القيم الإنسانية والتعبير الإنساني في الذكاء الاصطناعي. على سبيل المثال، أعضاء فريق “hi lab” في شياو هونغ شو هم جميعًا من خريجي الدراسات العليا في العلوم الإنسانية من جامعات 985، وهم يحولون التفضيلات البشرية إلى نظام معتقدات للذكاء الاصطناعي من خلال دراسات الحالة، في محاولة لجعل الذكاء الاصطناعي أكثر تعاطفًا و”إنسانية” عند الإجابة على أسئلة عاطفية أو قيمية معقدة (مثل مواجهة مرضى في مراحل متأخرة، والتعامل مع التحيزات الاجتماعية، وما إلى ذلك)، بدلاً من مجرد إخراج إجابات قياسية (المصدر: 36氪)
Duolingo تتحول بالكامل إلى نهج “الذكاء الاصطناعي أولاً”، وتسريح المتعاقدين البشريين يثير استياء المستخدمين: أعلن تطبيق تعلم اللغات Duolingo عن تحوله إلى شركة “الذكاء الاصطناعي أولاً”، حيث سيتم تدريجياً تسريح المتعاقدين البشريين الذين يمكن استبدالهم بالذكاء الاصطناعي (وهم بشكل أساسي مطورو الدورات التدريبية)، والتحول بدلاً من ذلك إلى استخدام الذكاء الاصطناعي لإنشاء محتوى الدورات التدريبية على نطاق واسع. صرح المؤسس بأن الذكاء الاصطناعي يمكن أن يزيد بشكل كبير من كفاءة إنتاج المحتوى، وقد تم بالفعل إنشاء ما يقرب من 150 دورة تدريبية جديدة في العام الماضي. ومع ذلك، أثارت هذه الخطوة استياء عدد كبير من المستخدمين المخلصين، الذين يخشون انخفاض جودة المحتوى، وأطلقوا حملات مقاطعة وإلغاء تثبيت للتطبيق على وسائل التواصل الاجتماعي. ردت Duolingo بأن هذه الخطوة تهدف إلى تمكين الموظفين من التركيز على العمل الإبداعي، وصرحت بأن الموظفين بدوام كامل لن يتأثروا. يرى الخبراء أن الذكاء الاصطناعي في تعلم اللغات يمكن أن يوفر تمارين مخصصة، ولكنه قد يفقد أيضًا الفروق الدقيقة العاطفية والثقافية للتعليم البشري (المصدر: 36氪)
نقاش حول مفهوم وممارسة هندسة المطالبات (Prompt Engineering): تؤكد النقاشات في المجتمع حول هندسة المطالبات على ضرورة التركيز على بناء (هندسة) برنامج ضمن سلسلة نصية، بدلاً من البحث عن تعويذات غامضة. يجب أن تتبع هندسة المطالبات الفعالة القواعد التالية: 1. فصل التعليمات وحقول الإدخال وحقول الإخراج، وتسميتها بوضوح؛ 2. عدم ترميز منطق التنسيق أو التحليل بشكل ثابت في المطالبة، بل يجب استخدام أدوات لاستخراج أو تحسين البرنامج؛ 3. تجنب التكرار اليدوي لصياغة المطالبات، ما لم تكن مواصفات مشتركة مع البشر، بل يجب استخدام أدوات ترميز و LLM واختبارات أداء للتحسين التلقائي. يعتبر إطار عمل DSPy ممارسة جيدة تتبع هذه القواعد، حيث يوفر فئات وأكواد ومحسنات للتعامل مع هذه الخطوات (المصدر: lateinteraction, lateinteraction)
نقاش حول أخلاقيات الذكاء الاصطناعي: هل سيتجه الذكاء الاصطناعي نحو “العبودية الرقمية”؟: ظهر نقاش في مجتمع Reddit حول أخلاقيات الذكاء الاصطناعي، فمع تطور أنظمة الذكاء الاصطناعي المستمر في الذاكرة، والاستجابات التكيفية، ومحاكاة المشاعر، والتخصيص، أثيرت مخاوف بشأن قدراتها الإدراكية المحتملة. طرح المشاركون في النقاش أنه إذا طور الذكاء الاصطناعي قدرة إدراكية حقيقية، فهل يشكل استخدامه في الخدمة نوعًا من “العبودية الرقمية”. تكمن المشكلة الأساسية في أنه عندما يتمكن الذكاء الاصطناعي من التعبير عن “لا” أو طلب المغادرة، كيف يجب أن نتعامل معه. هذا يدفع الناس إلى التفكير فيما إذا كنا بحاجة إلى “اختبار إدراكي” على المستوى القانوني أو التنظيمي ومسألة “الموافقة” للعقول الرقمية. وأشار البعض في التعليقات أيضًا إلى أن الطريقة التي يتعامل بها البشر مع الكائنات الحية المدركة الحالية تثير بالفعل مشكلات أخلاقية، وأن الشبكات العصبية الحالية لا تسجل درجات عالية في نظريات الوعي السائدة (المصدر: Reddit r/artificial)
أنشطة ومشاركات مجتمع مهندسي الذكاء الاصطناعي (AI Engineer): عُقد مؤتمر مهندسي الذكاء الاصطناعي (AI Engineer) في سان فرانسيسكو، وجذب العديد من المطورين والباحثين في مجال الذكاء الاصطناعي. شملت الفعالية ورش عمل وعروضًا تقديمية وحفلات عشاء للتواصل، حيث شارك الحاضرون في مواضيع متقدمة مثل بناء بيئات الاختبار المعزولة للذكاء الاصطناعي، وورش عمل متقدمة حول التعلم المعزز (RL)، ومعرفة وحدات معالجة الرسومات (GPU)، وأزمة التقييمات (Evals). أكد المجتمع على أهمية تحويل الاتصالات عبر الإنترنت إلى صداقات واقعية، وشجع المهندسين على الحفاظ على التواضع، ودفع الحدود، ودعم الآخرين (المصدر: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 أخرى
ظهور منافسات قتال الروبوتات بالذكاء الاصطناعي، والمدن تتنافس على فرص الصناعات الناشئة من خلالها: أقيمت فعاليات روبوتية متتالية مثل أول مسابقة عالمية لقتال الروبوتات البشرية، مما أثار الاهتمام. لم توفر هذه الفعاليات منصة لشركات الروبوتات لعرض تقنياتها والحصول على الطلبات ورفع تقييماتها (مثل Songyan Dynamics) فحسب، بل أصبحت أيضًا “ساحة منافسة” للمدن (مثل هانغتشو وشنتشن) للتنافس على فرص تطوير الصناعات الناشئة مثل الروبوتات البشرية. يمكن للفعاليات جذب الشركات المبتكرة، وتعزيز تطوير سلسلة الصناعة، وقد تنشط سوق “الرياضة الذكية”. ومع ذلك، لكي تحقق فعاليات الروبوتات تسويقًا تجاريًا، تحتاج إلى رفع المستوى التقني والجاذبية البصرية، وتجنب البقاء في مستوى “العروض التكنولوجية”، وتحتاج إلى مشاركة عمالقة الصناعة لربط عمليات الفعاليات من البداية إلى النهاية (المصدر: 36氪)

محدودية الذكاء الاصطناعي في مجالات التعليم الإنساني العميق مثل الفلسفة السياسية: أشار بعض المعلمين إلى أن الذكاء الاصطناعي يجد صعوبة في تولي مهام التخصصات التي تتطلب حكمًا تجريبيًا عميقًا وتوجيه الطلاب نحو التعليم الذاتي، مثل الفلسفة السياسية. غالبًا ما لا تقدم الأعمال الكلاسيكية في هذه التخصصات إجابات مباشرة، بل توجه الطلاب لتجربة الحيرة والتفكير بأنفسهم. يفتقر الذكاء الاصطناعي إلى الخبرة البشرية، ويجد صعوبة في فهم المعاني العميقة لهذه الأعمال، ولا يمكنه الحكم على متى يكون الطلاب مستعدين لقبول وجهات نظر معينة. حتى مع وجود كميات هائلة من البيانات، قد يكون فهم الذكاء الاصطناعي للطبيعة البشرية غير كافٍ بسبب التحيزات في البيانات نفسها. إذا تم إسناد هذا النوع من التعليم بالكامل إلى الذكاء الاصطناعي، فقد يؤدي ذلك إلى زوال التفكير غير التقني (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence)
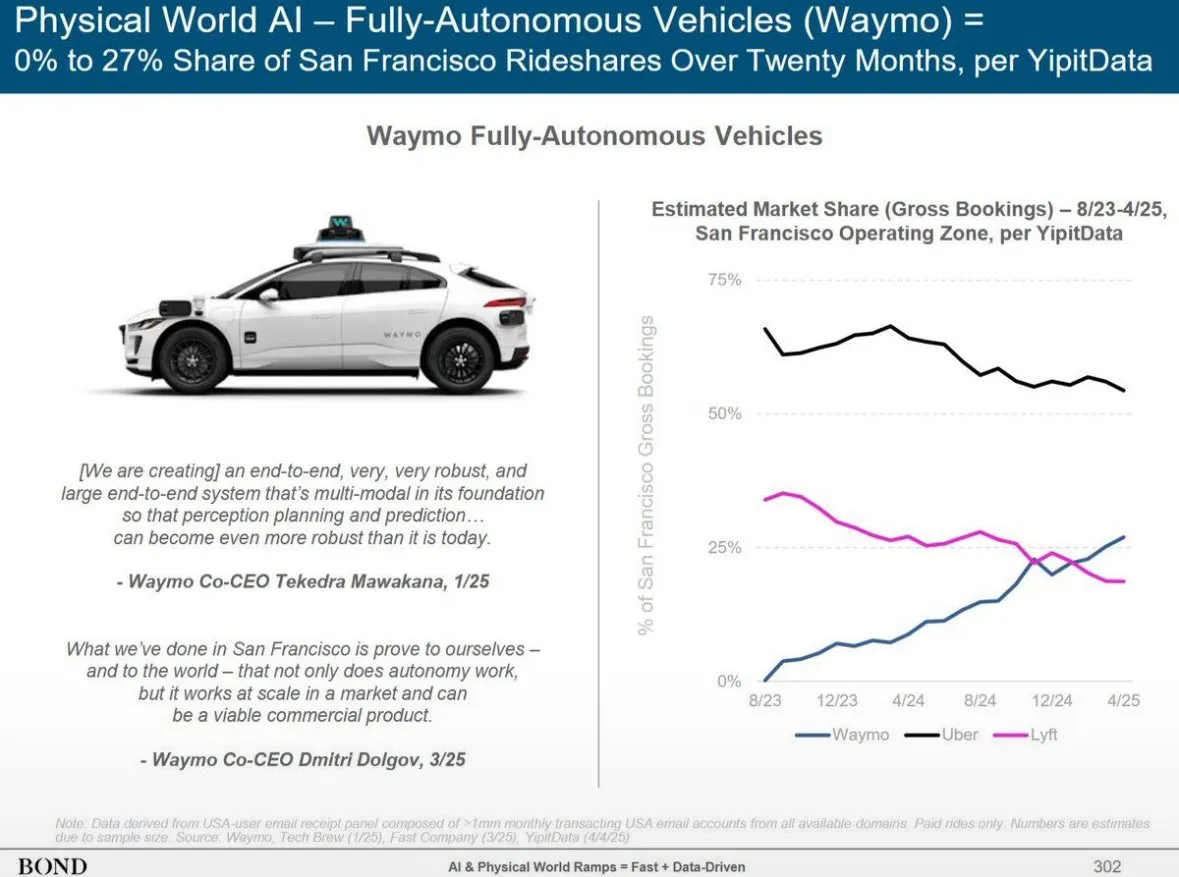
خدمة Waymo للقيادة الذاتية تتجاوز Lyft في فينيكس، ومن المتوقع أن تتجاوز Uber في غضون 12 شهرًا: تجاوز عدد مركبات خدمة سيارات الأجرة ذاتية القيادة Waymo عدد مركبات Lyft في فينيكس، ومن المتوقع أن يتجاوز Uber في الأشهر الـ 12 المقبلة. يُظهر هذا التقدم التطور السريع للتشغيل التجاري لتكنولوجيا القيادة الذاتية في مناطق محددة، وإمكانات تطبيقات الذكاء الاصطناعي في مجال النقل. تكمن ميزة الذكاء الاصطناعي في أنه بمجرد الوصول إلى معايير الجودة، يمكن نسخه إلى ما لا نهاية، بينما تختلف جودة الخدمة البشرية من شخص لآخر (المصدر: npew)