
كلمات مفتاحية:OpenAI Codex, نموذج اللغة البصرية للحركة, الحد الأعلى لذاكرة نموذج اللغة, ذاكرة ChatGPT, DeepSeek-R1-0528, نموذج الانتشار, Suno AI لإنشاء الموسيقى, MetaAgentX, ميزة الوصول إلى الإنترنت في Codex, نموذج الروبوت SmolVLA, ذاكرة نموذج GPT 3.6 بت, تحسين التفاعل الشخصي لـ ChatGPT, قدرات التفكير المعقدة في DeepSeek-R1
🔥 الأضواء
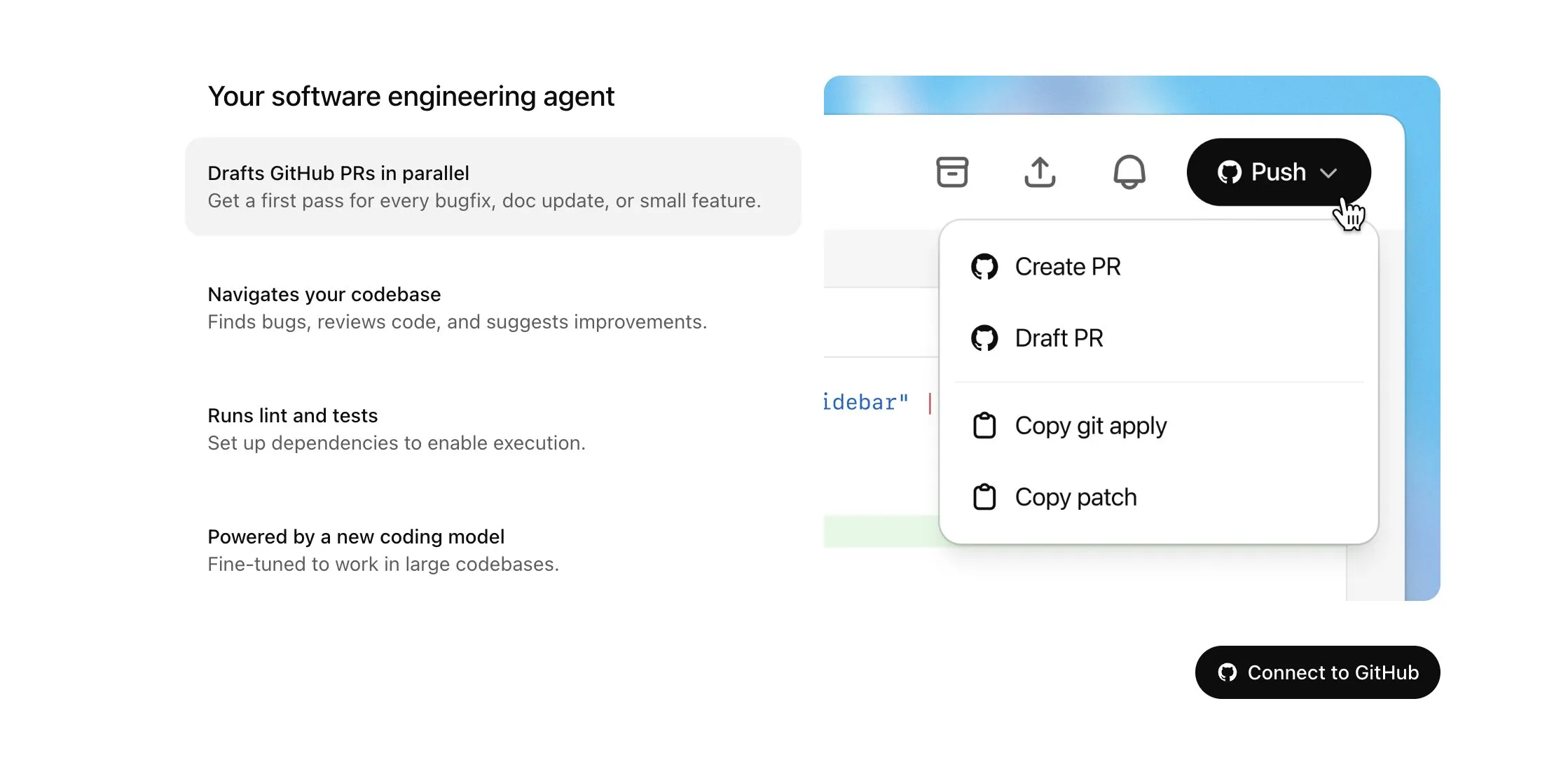
OpenAI Codex يُتاح لمستخدمي Plus ويحصل على تحديثات كبيرة، تشمل الوصول إلى الإنترنت والإدخال الصوتي: أعلنت OpenAI أن Codex سيتاح تدريجيًا لمستخدمي ChatGPT Plus. تشمل أبرز نقاط هذا التحديث السماح لوكلاء الذكاء الاصطناعي بالوصول إلى الإنترنت عند تنفيذ المهام (مغلق افتراضيًا، مع إمكانية تحكم المستخدم في النطاقات وأساليب HTTP)، وذلك لتثبيت التبعيات، وترقية حزم البرامج، وتشغيل اختبارات الموارد الخارجية. في الوقت نفسه، يدعم Codex الآن التحديث المباشر لطلبات السحب (Pull Request) القائمة، ويمكنه إدخال المهام عبر الصوت. تشمل التحسينات الأخرى دعم عمليات الملفات الثنائية (يقتصر حاليًا على الحذف أو إعادة التسمية في PR)، وزيادة حد حجم فروقات المهام (diff) من 1MB إلى 5MB، وزيادة حد وقت تشغيل النصوص البرمجية من 5 دقائق إلى 10 دقائق، وإصلاح العديد من المشكلات على منصة iOS وإعادة تمكين ميزة الأنشطة المباشرة. تهدف هذه التحديثات إلى تعزيز فائدة ومرونة Codex في مهام البرمجة المعقدة (المصدر: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
Hugging Face وH Company تطلقان بالاشتراك نماذج لغة-رؤية-حركة (VLA) مفتوحة المصدر، لدفع تطوير تكنولوجيا الروبوتات: أعلنت Hugging Face وH Company في “يوم VLA” عن نماذج لغة-رؤية-حركة جديدة مفتوحة المصدر، بما في ذلك SmolVLA من Hugging Face (بـ 450 مليون معامل) وHolo-1 من H Company (بـ 3 مليار و7 مليار معامل). تهدف نماذج VLA إلى تمكين الروبوتات من الرؤية والاستماع والفهم والتصرف بناءً على تعليمات الذكاء الاصطناعي، وتُعرف باسم GPT في مجال الروبوتات. يُعد فتح مصدر هذه النماذج أمرًا بالغ الأهمية لفهم كيفية عملها، وتجنب الأبواب الخلفية المحتملة، وتخصيصها لروبوتات ومهام محددة. تم تدريب SmolVLA على مجموعة بيانات LeRobotHF، وأظهر أداءً وسرعة استدلال ممتازة. يركز Holo-1 على مهام الويب ووكلاء الكمبيوتر، ويدعم ترخيص Apache 2.0. من المتوقع أن تسرع هذه الإصدارات من تطوير تكنولوجيا الروبوتات المعتمدة على الذكاء الاصطناعي مفتوح المصدر (المصدر: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

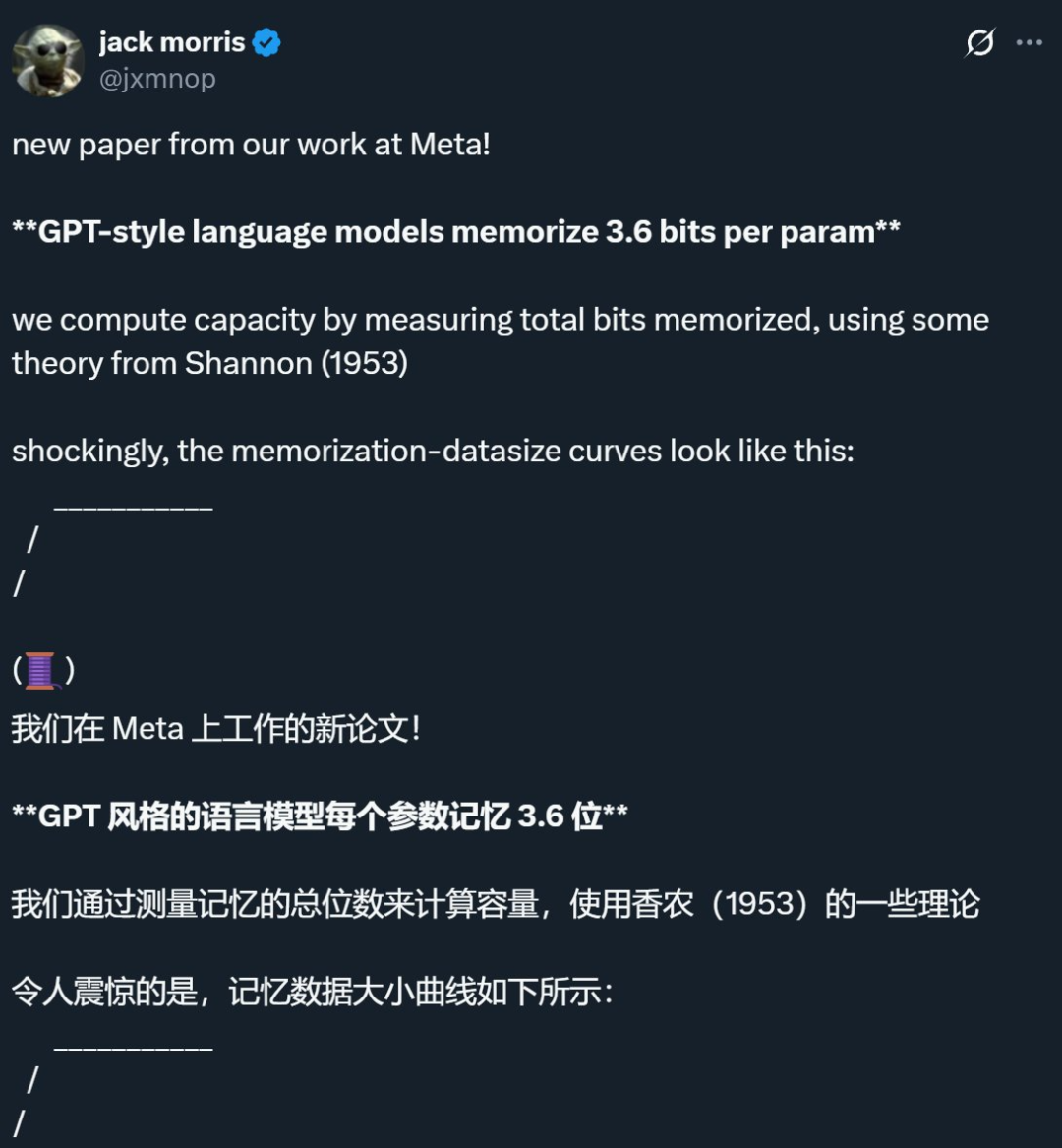
بحث مشترك بين Meta وشركات أخرى يكشف أن الحد الأقصى لذاكرة نماذج اللغة يبلغ حوالي 3.6 بت لكل معامل، مما يتحدى المفاهيم التقليدية: أشار بحث مشترك بين Meta وDeepMind وجامعة كورنيل وNvidia إلى أن نماذج اللغة من طراز GPT يمكنها تذكر حوالي 3.6 بت من المعلومات لكل معامل. وجد البحث أن النماذج تستمر في تذكر بيانات التدريب حتى تصل إلى الحد الأقصى لسعتها، وبعد ذلك تبدأ ظاهرة “Grokking” (الإدراك المفاجئ)، أي انخفاض غير متوقع في الذاكرة، وتتحول النماذج إلى التعلم المعمم. يفسر هذا الاكتشاف ظاهرة “الانخفاض المزدوج”، أي عندما تتجاوز كمية المعلومات في مجموعة البيانات قدرة تخزين النموذج، يُجبر النموذج على مشاركة نقاط المعلومات لتوفير السعة، مما يعزز التعميم. كما اقترح البحث قوانين قياس للعلاقة بين سعة النموذج وحجم البيانات ومعدل نجاح هجمات استدلال العضوية، وأشار إلى أنه بالنسبة لنماذج LLM الحديثة المدربة على مجموعات بيانات ضخمة للغاية، يصبح استدلال العضوية الموثوق به أمرًا صعبًا (المصدر: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI تطلق نسخة خفيفة من ميزة الذاكرة في ChatGPT، لتعزيز تجربة التفاعل المخصصة: أعلنت OpenAI عن بدء طرح نسخة خفيفة من تحسينات ميزة الذاكرة للمستخدمين المجانيين. بالإضافة إلى حفظ الذكريات الموجود مسبقًا، يمكن لـ ChatGPT الآن الرجوع إلى محادثات المستخدم الأخيرة لتقديم ردود أكثر تخصيصًا. تهدف هذه الخطوة إلى جعله أكثر فائدة في الكتابة والحصول على الاقتراحات والتعلم وما إلى ذلك، من خلال الاستفادة من تفضيلات المستخدم واهتماماته. صرح Sam Altman أيضًا بأن ميزة الذاكرة أصبحت واحدة من ميزات ChatGPT المفضلة لديه، ويتطلع إلى تحسينات أكبر في المستقبل. يمثل هذا التحديث التزام OpenAI بجعل تفاعلات الذكاء الاصطناعي أقرب إلى احتياجات المستخدمين وتعزيز ولائهم (المصدر: openai, sama, iScienceLuvr)
🎯 الاتجاهات
إصدار DeepSeek-R1-0528، مع تعزيز قدرات الاستدلال المعقد والبرمجة: أصدرت DeepSeek نسخة مطورة من نموذج R1 باسم DeepSeek-R1-0528. تستند هذه النسخة إلى نموذج DeepSeek V3 Base الذي صدر في ديسمبر 2024، ومن خلال استثمار المزيد من القدرة الحاسوبية في التدريب اللاحق، تم تحسين عمق التفكير وقدرات الاستدلال للنموذج بشكل كبير. يقوم النموذج الجديد بتحليل أكثر تفصيلاً وتفكيرًا أطول عند التعامل مع المشكلات المعقدة (على سبيل المثال، ارتفع متوسط استهلاك الـ token لكل سؤال في اختبار AIME 2025 من 12 ألفًا إلى 23 ألفًا)، مما أدى إلى تحقيق نتائج رائدة في العديد من اختبارات القياس مثل الرياضيات والبرمجة والمنطق العام، مع أداء يقترب من GPT-o3 وGemini-2.5-Pro. بالإضافة إلى ذلك، شهدت النسخة الجديدة تحسينات ملحوظة في تقليل الهلوسة (حوالي 45%-50%)، والكتابة الإبداعية، واستدعاء الأدوات، مثل القدرة على الإجابة بشكل أكثر استقرارًا على أسئلة مثل “كم يساوي 9.9 – 9.11” والقدرة على إنشاء كود قابل للتشغيل للواجهة الأمامية والخلفية دفعة واحدة (المصدر: 科技狐, AI前线, Hacubu)

نماذج الانتشار تظهر إمكانات في مجالات اللغة والوسائط المتعددة، متحديةً النموذج التنبئي الذاتي (Autoregressive): أظهر نموذج اللغة Gemini Diffusion الذي تم عرضه في Google I/O 2025، بسرعته في التوليد التي تصل إلى 5 أضعاف وأدائه المماثل في البرمجة، إمكانات نماذج الانتشار في مجال توليد النصوص. على عكس النماذج التنبئية الذاتية التي تتنبأ بالـ tokens واحدًا تلو الآخر، تقوم نماذج الانتشار بتوليد المخرجات عن طريق إزالة التشويش تدريجيًا، مما يدعم التكرار السريع وتصحيح الأخطاء. يُظهر نموذج LLaDA ذو الـ 8 مليار معامل الذي أطلقته مجموعة Ant Group بالتعاون مع كلية الذكاء الاصطناعي Gaoling بجامعة Renmin، ونموذج الانتشار متعدد الوسائط MMaDA الذي طورته ByteDance، استكشافات رائدة للفرق الصينية في هذا المسار. لم تُظهر هذه النماذج أداءً متميزًا في مهام اللغة فحسب، بل حققت أيضًا تقدمًا في فهم الوسائط المتعددة (مثل LLaDA-V الذي يجمع بين الضبط الدقيق للتعليمات المرئية) والمجالات المحددة (مثل DPLM المستخدم لتوليد تسلسلات البروتين)، مما ينبئ بأن نماذج الانتشار قد تصبح نموذجًا جديدًا للجيل القادم من النماذج العامة (المصدر: 机器之心)
Suno تصدر تحديثًا رئيسيًا، يعزز قدرات تحرير وإنشاء الموسيقى بالذكاء الاصطناعي: أطلقت منصة إنشاء الموسيقى بالذكاء الاصطناعي Suno العديد من التحديثات الهامة، مما يمنح المستخدمين قدرًا أكبر من حرية الإبداع والتحكم. تشمل الميزات الجديدة محرر أغاني مطورًا يسمح للمستخدمين بإعادة ترتيب وإعادة كتابة وإعادة إنتاج المقاطع الصوتية مقطعًا تلو الآخر على مخطط الموجة؛ وإدخال ميزة استخراج الجذوع (stem extraction)، التي يمكنها فصل المقاطع الصوتية بدقة إلى 12 مصدرًا صوتيًا مستقلاً (مثل الغناء والطبول والباس وغيرها) للمعاينة والتنزيل؛ وتوسيع وظيفة التحميل، لدعم تحميل الأغاني الكاملة التي تصل مدتها إلى 8 دقائق، بحيث يمكن للمستخدمين إنشاء أعمالهم بناءً على موادهم الصوتية الخاصة؛ وإضافة منزلقات إبداعية جديدة، يمكن للمستخدمين من خلالها تعديل “غرابة” أو درجة تنظيم أو درجة الاعتماد على المرجع للمخرجات قبل التوليد، لتشكيل العمل النهائي بشكل أفضل (المصدر: SunoMusic)
MetaAgentX تطلق Open CaptchaWorld لتقييم قدرة وكلاء الوسائط المتعددة على حل رموز CAPTCHA: لمواجهة التحديات الحالية التي تواجهها وكلاء الوسائط المتعددة في حل مشكلات CAPTCHA (التحقق من المستخدم البشري)، أطلق فريق MetaAgentX منصة ومعيار Open CaptchaWorld. تحتوي المنصة على 20 فئة من رموز CAPTCHA الحديثة، بإجمالي 225 مثالاً، وتتطلب من الوكيل إكمال المهام في بيئة ويب حقيقية من خلال الملاحظة والنقر والسحب والتفاعلات الأخرى. أظهرت نتائج الاختبار أنه حتى النماذج الرائدة مثل GPT-4o، لم تتجاوز نسبة نجاحها 5%-40%، وهو أقل بكثير من متوسط نجاح البشر البالغ 93.3%. اقترح الباحثون أيضًا مؤشر “عمق استدلال CAPTCHA” (CAPTCHA Reasoning Depth)، الذي يحدد كميًا خطوات “الفهم البصري + التخطيط المعرفي + التحكم في الحركة” اللازمة لحل المشكلة. تهدف هذه المنصة إلى الكشف عن أوجه القصور لدى الوكلاء في التفاعل والتخطيط الديناميكي طويل التسلسل، ودفع الباحثين إلى الاهتمام بهذه المشكلة الرئيسية في النشر الفعلي وحلها (المصدر: 量子位)

Google NotebookLM يدعم الآن المشاركة العامة، مما يعزز تبادل المعرفة والتعاون: أعلنت Google أن NotebookLM (المعروف سابقًا باسم Project Tailwind) يدعم الآن مشاركة دفاتر الملاحظات بشكل عام. يمكن للمستخدمين مشاركة محتوى ملاحظاتهم عن طريق النقر على “مشاركة” وتعيين أذونات الوصول إلى “أي شخص لديه الرابط”. تتيح هذه الميزة للمستخدمين مشاركة الأفكار وأدلة الدراسة ومستندات الفريق بسهولة، ويمكن للمستلمين تصفح المحتوى وطرح الأسئلة والحصول على ملخصات فورية ونظرات عامة صوتية. تهدف هذه الخطوة إلى تعزيز نشر المعرفة والتحرير التعاوني، ورفع مستوى فائدة NotebookLM كأداة تدوين ملاحظات مدعومة بالذكاء الاصطناعي (المصدر: Google, op7418)
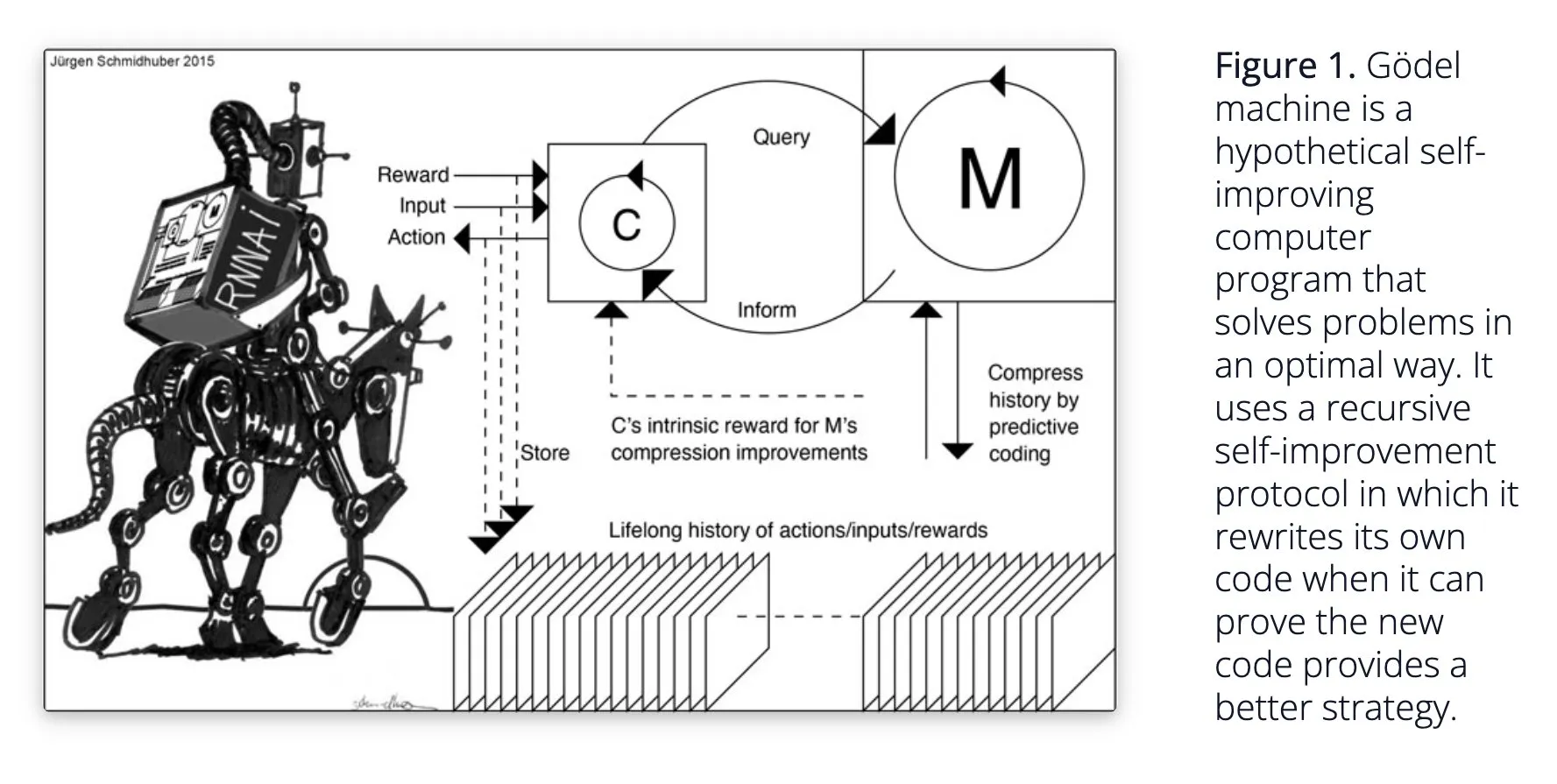
Sakana AI تقترح نظام الذكاء الاصطناعي ذاتي التعلم Darwin Gödel Machine (DGM): كشفت Sakana AI عن بحثها حول نظام الذكاء الاصطناعي ذاتي التعلم Darwin Gödel Machine (DGM). يستخدم DGM الخوارزميات التطورية لإعادة كتابة الكود الخاص به بشكل متكرر، وبالتالي تحسين أدائه باستمرار في مهام البرمجة. يحافظ النظام على أرشيف من وكلاء الترميز الذين تم إنشاؤهم، ويقوم بأخذ عينات منه واستخدام النماذج الأساسية لإنشاء إصدارات جديدة لتحقيق استكشاف مفتوح، مما يشكل وكلاء متنوعين وعاليي الجودة. أظهرت التجارب أن DGM يحسن بشكل كبير قدرات الترميز في اختبارات القياس مثل SWE-bench وPolyglot. يوفر هذا البحث أفكارًا جديدة للذكاء الاصطناعي ذاتي التحسين، ويهدف إلى تسريع تطوير الذكاء الاصطناعي من خلال الابتكار الذاتي (المصدر: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind تعزز طبيعية المحادثات بالذكاء الاصطناعي وتفتح ميزات الصوت الأصلية: أعلنت Google DeepMind أن ميزاتها الصوتية الأصلية تجعل المحادثات بالذكاء الاصطناعي أكثر طبيعية، مع القدرة على فهم نبرة الصوت وتوليد كلام معبر. تهدف هذه التقنية إلى فتح إمكانيات جديدة للتفاعل بين الإنسان والذكاء الاصطناعي. يمكن للمطورين الآن تجربة هذه الميزات من خلال Google AI Studio، ومن المتوقع تطبيقها في مساعدين صوتيين أكثر طبيعية، وتوليد محتوى صوتي، وغيرها من السيناريوهات (المصدر: GoogleDeepMind)
تقنية توليد الصور Runway Gen-4 تحظى بالاهتمام، وتدعم الإشارات المرجعية المتعددة والتحكم في النمط: حظيت تقنية توليد الصور Gen-4 من Runway بالاهتمام لدقتها العالية وقدرتها غير المسبوقة على التحكم في النمط، خاصة فيما يتعلق بميزة الإشارات المرجعية المتعددة، مما يوفر مساحة جديدة للاستكشاف الإبداعي. يمكن للمستخدمين استخدام هذه التقنية لتوليد مختلف الحيوانات أو الديناصورات أو الكائنات الخيالية، مما يدل على إمكاناتها في إنشاء محتوى مرئي مفصل. كما يشير استخدام Runway في مجالات مثل هوليوود إلى أن تقنيتها تُطبق تدريجيًا في إنتاج المحتوى الاحترافي (المصدر: c_valenzuelab, c_valenzuelab)

AssemblyAI تطلق نموذجًا جديدًا لتحويل الكلام إلى نص في الوقت الفعلي، مما يعزز أداء تطبيقات الذكاء الاصطناعي الصوتي: أطلقت AssemblyAI نموذجًا جديدًا لتحويل الكلام إلى نص في الوقت الفعلي (STT)، والذي حظي بالاهتمام لسرعته ودقته العالية. تم تصميم هذا النموذج خصيصًا للمطورين الذين يقومون ببناء تطبيقات الذكاء الاصطناعي الصوتي، ويهدف إلى توفير تجربة تعرف على الكلام أكثر سلاسة ودقة. في الوقت نفسه، توفر AssemblyAI أيضًا تطبيق AssemblyAISTTService من خلال مشروعها pipecat_ai، لتسهيل التكامل للمطورين. تُظهر هذه الخطوة استثمار AssemblyAI المستمر وابتكارها في مجال تكنولوجيا الصوت (المصدر: AssemblyAI, AssemblyAI)
Microsoft Bing يحتفل بالذكرى السنوية السادسة عشرة، ويدمج GPT-4 وDALL·E، ويطلق Bing Video Creator: يحتفل محرك البحث Microsoft Bing بالذكرى السنوية السادسة عشرة. في السنوات الأخيرة، كان Bing رائدًا في دمج الذكاء الاصطناعي التوليدي الحواري على نطاق واسع، وأصبح أول منتج من Microsoft يدمج GPT-4 وDALL·E. مؤخرًا، أطلق Bing مجانًا Copilot Search وBing Video Creator في تطبيقات الهاتف المحمول، ويمكن استخدام الأخير لإنشاء محتوى فيديو. يمثل هذا استمرار ابتكار Bing وتطوره في مجال البحث المدفوع بالذكاء الاصطناعي وإنشاء المحتوى (المصدر: JordiRib1)
Andrej Karpathy معجب بـ Veo 3، ويناقش التأثيرات الكلية لتوليد الفيديو: أعرب Andrej Karpathy عن إعجابه بنموذج توليد الفيديو Veo 3 من Google وإبداعات مجتمعه، وأشار إلى أن إضافة الصوت حسنت بشكل كبير جودة الفيديو. كما ناقش عدة تأثيرات كلية لتوليد الفيديو: 1. الفيديو هو أعلى وسيلة إدخال نطاق ترددي للدماغ البشري؛ 2. يوفر توليد الفيديو للذكاء الاصطناعي “لغة أم” لفهم العالم؛ 3. توليد الفيديو هو مسار رئيسي نحو محاكاة الواقع ونماذج العالم؛ 4. ستدفع متطلباته الحاسوبية تطوير الأجهزة. يشير هذا إلى أن تقنية توليد الفيديو ليست مجرد ثورة في إنشاء المحتوى، بل هي أيضًا محرك مهم لإدراك الذكاء الاصطناعي وتطوره (المصدر: brickroad7, dilipkay, JonathanRoss321)
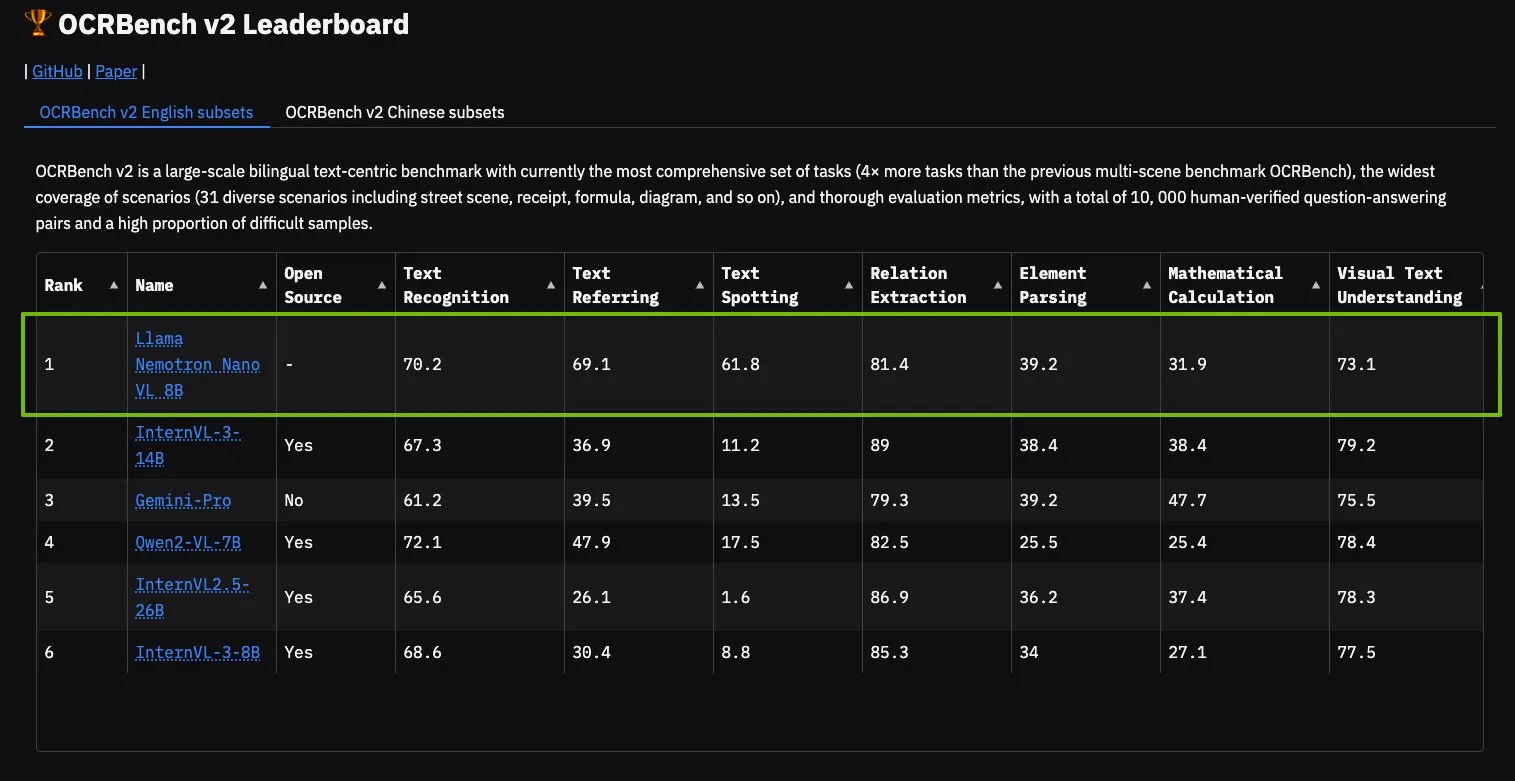
نموذج NVIDIA Llama Nemotron Nano VL يتصدر قائمة OCRBench V2: حصل نموذج Llama Nemotron Nano VL من NVIDIA على المركز الأول في قائمة OCRBench V2. تم تصميم هذا النموذج خصيصًا لمعالجة وفهم المستندات الذكية المتقدمة، ويمكنه استخراج معلومات متنوعة بدقة من المستندات المعقدة على وحدة معالجة رسومات واحدة (GPU). يمكن للمستخدمين تجربة هذا النموذج من خلال NVIDIA NIM، مما يدل على تقدم NVIDIA في مجال نماذج الذكاء الاصطناعي المصغرة والفعالة في مجالات محددة (مثل فهم المستندات) (المصدر: ctnzr)
🧰 الأدوات
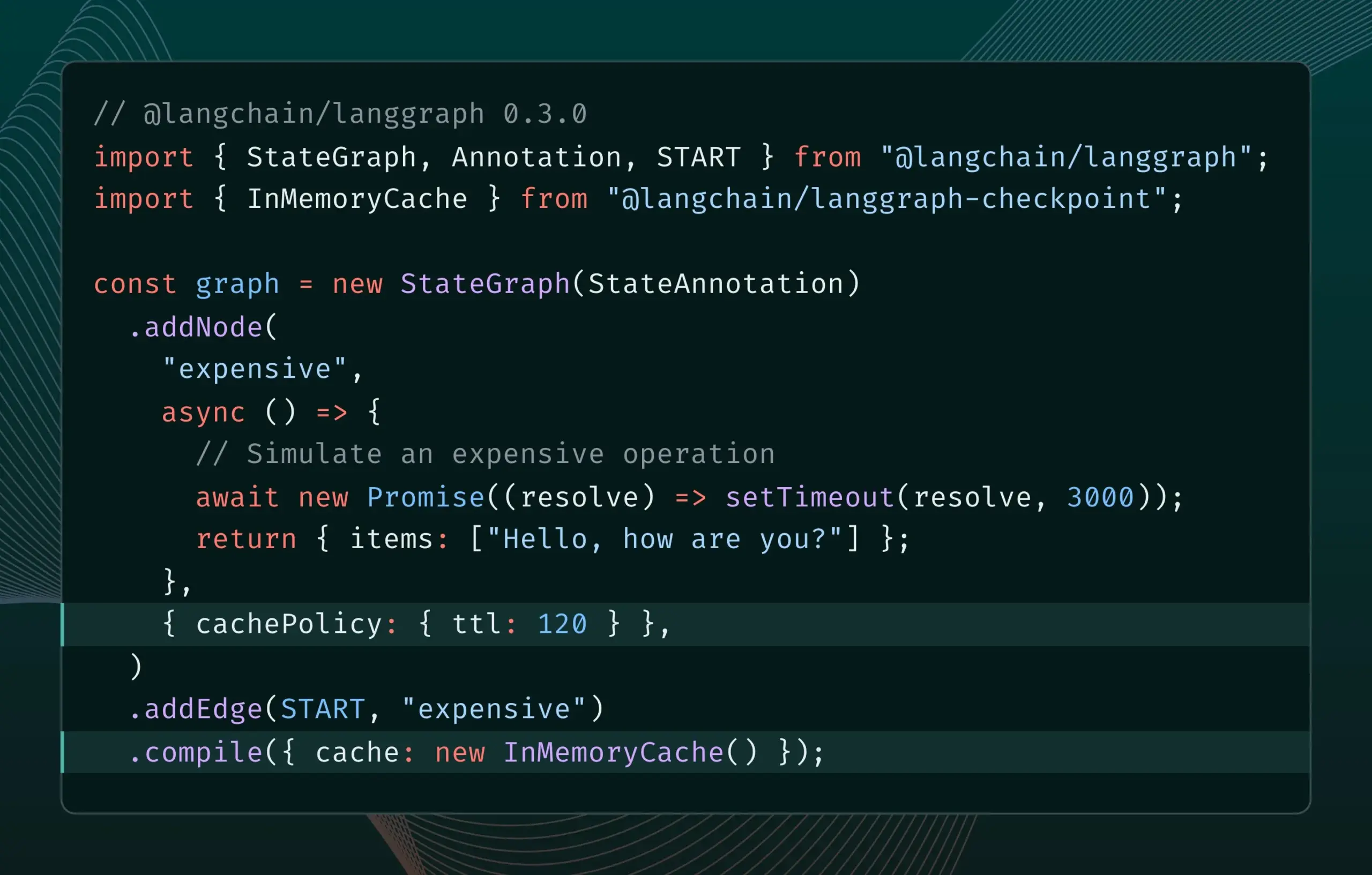
إصدار LangGraph.js 0.3 يقدم ميزة التخزين المؤقت للعقد/المهام: أصدر LangGraph.js الإصدار 0.3، مضيفًا ميزة التخزين المؤقت للعقد/المهام. تهدف هذه الميزة إلى تسريع تدفقات العمل عن طريق تجنب الحسابات الزائدة، وهي مناسبة بشكل خاص للوكلاء التكراريين المكلفين أو الذين يستغرقون وقتًا طويلاً. يدعم الإصدار الجديد كلاً من Graph API وImperative API، مما يوفر كفاءة أعلى لمطوري JavaScript في بناء تطبيقات الذكاء الاصطناعي المعقدة (المصدر: Hacubu, hwchase17)
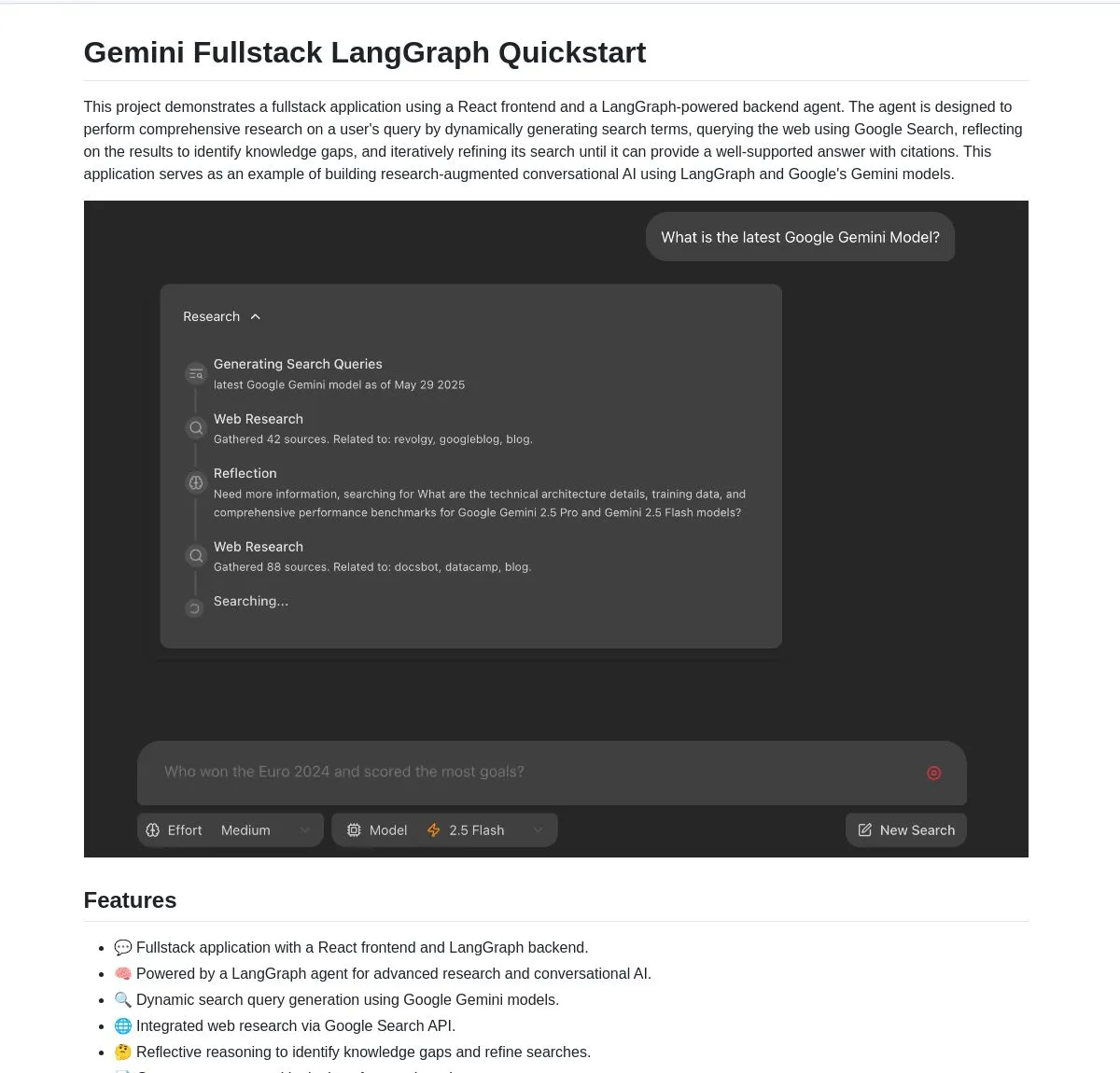
جوجل تفتح مصدر تطبيق Gemini Research Agent المتكامل، المبني على Gemini وLangGraph: أصدرت جوجل مثالاً لتطبيق مساعد بحث ذكي متكامل مبني على نموذج Gemini وLangGraph باسم gemini-fullstack-langgraph-quickstart. يمكن لهذا التطبيق تحسين الاستعلامات ديناميكيًا، وتقديم إجابات مع اقتباسات من خلال التعلم التكراري، ودعم التحكم في كثافة البحث المختلفة. يستخدم أدوات بحث جوجل الأصلية في Gemini لإجراء أبحاث الويب والاستدلال الانعكاسي، ويهدف إلى تزويد المطورين بنقطة انطلاق لبناء تطبيقات ذكاء اصطناعي بحثية متقدمة (المصدر: LangChainAI, hwchase17, dotey, karminski3)
FedRAG يضيف وظيفة الربط مع LangChain، لتسهيل تكامل أنظمة RAG وضبطها الدقيق: أعلن FedRAG عن دعم الربط مع LangChain، والذي تم تنفيذه بواسطة مساهم خارجي. يمكن للمستخدمين تجميع أنظمة RAG من خلال FedRAG، وضبط نماذج مكونات المولد/المسترجع لتناسب قواعد معرفية محددة. بعد الضبط الدقيق، يمكن ربطها بأطر استدلال RAG الشائعة مثل LangChain، للاستفادة من نظامها البيئي وميزاتها. يهدف هذا التحديث إلى تبسيط عمليات بناء أنظمة RAG وتحسينها ونشرها (المصدر: nerdai)

Ollama تطلق ميزة “التفكير”، التي يمكنها فصل عملية التفكير عن الرد النهائي: قامت Ollama بتحديث منصتها، مضيفة خيارًا لفصل عملية التفكير والرد النهائي للنماذج التي تدعم ميزة “التفكير” (مثل DeepSeek-R1-0528). يمكن للمستخدمين اختيار عرض محتوى “تفكير” النموذج، أو تعطيل هذه الميزة للحصول على رد مباشر. تنطبق هذه الميزة على واجهة سطر الأوامر (CLI) وواجهة برمجة التطبيقات (API) ومكتبات Python/JavaScript الخاصة بـ Ollama، مما يوفر للمستخدمين طرقًا أكثر مرونة للتفاعل مع النماذج (المصدر: Hacubu)
Firecrawl تطلق نقطة نهاية /search، مدمجة وظائف البحث والزحف: أصدرت Firecrawl نقطة نهاية API جديدة /search، تسمح للمستخدمين بإكمال بحث الويب واستخلاص جميع النتائج بتنسيق مناسب لـ LLM من خلال استدعاء API واحد. تهدف هذه الميزة إلى تبسيط عملية اكتشاف واستخدام بيانات الويب لوكلاء الذكاء الاصطناعي والمطورين. يمكن استخدام StateGraph من LangChain لبناء عمليات آلية تستفيد من هذه الميزة، مثل البحث التلقائي عن المنافسين، وزحف مواقعهم الإلكترونية، وإنشاء تقارير تحليلية (المصدر: hwchase17, LangChainAI, omarsar0)
LlamaIndex يدمج MCP، لتعزيز قدرات الوكيل ونشر تدفقات العمل: أعلن LlamaIndex عن دمج MCP (Model Component Protocol)، بهدف تعزيز قدرات استخدام الأدوات لوكلائه ومرونة نشر تدفقات العمل. يوفر هذا التكامل وظائف مساعدة لوكلاء LlamaIndex لاستخدام أدوات خادم MCP، ويسمح بتقديم أي تدفق عمل LlamaIndex كخادم MCP. تهدف هذه الخطوة إلى توسيع مجموعة أدوات وكلاء LlamaIndex، وتمكين تدفقات عملهم من الاندماج بسلاسة في البنى التحتية الحالية لـ MCP (المصدر: jerryjliu0)

Modal تطلق LLM Engine Advisor، لتقديم معايير أداء لمحركات النماذج مفتوحة المصدر: أصدرت Modal أداة LLM Engine Advisor، وهي تطبيق معياري يهدف إلى مساعدة المستخدمين في اختيار أفضل محرك LLM ومعاملاته. توفر هذه الأداة بيانات أداء لتشغيل النماذج مفتوحة المصدر (مثل DeepSeek V3, Qwen 2.5 Coder) على أجهزة مختلفة (مثل بيئات وحدات معالجة الرسومات المتعددة) باستخدام محركات استدلال مختلفة (مثل vLLM, SGLang)، مثل السرعة والإنتاجية القصوى. تهدف هذه الخطوة إلى زيادة الشفافية وكفاءة اتخاذ القرار عند تشغيل نماذج LLM مستضافة ذاتيًا (المصدر: charles_irl, akshat_b, sarahcat21)
PlayDiffusion: PlayAI تطلق نموذجًا جديدًا لإصلاح الصوت، يمكنه استبدال محتوى الحوار في الصوت: أصدرت PlayAI نموذجًا جديدًا باسم PlayDiffusion، يمكنه استبدال محتوى الحوار في الملفات الصوتية بسلاسة، مع الحفاظ على الخصائص الصوتية للمتحدث الأصلي. توفر تقنية “إصلاح الصوت” هذه إمكانيات جديدة لتحرير الصوت، مثل تعديل كلمات أو جمل معينة في البودكاست أو الكتب الصوتية أو دبلجة الفيديو، دون الحاجة إلى إعادة تسجيل المقطع بأكمله. تم فتح مصدر المشروع على GitHub (المصدر: _mfelfel, karminski3)
Hugging Face تطلق أداة إزالة التكرارات الدلالية، لتحسين جودة مجموعات بيانات التدريب: مستوحاة من AutoDedup الخاص بـ Maxime Labonne، أطلقت Hugging Face Spaces تطبيقًا جديدًا لإزالة التكرارات الدلالية. تسمح هذه الأداة للمستخدمين باختيار مجموعة بيانات واحدة أو أكثر من Hugging Face Hub، ومن خلال تضمين دلالي لكل صف من البيانات، ثم إزالة المحتوى شبه المكرر بناءً على عتبة محددة. تهدف هذه الخطوة إلى مساعدة الباحثين والمطورين على تحسين جودة مجموعات بيانات التدريب، وتجنب انخفاض أداء النموذج أو كفاءة التدريب بسبب تكرار البيانات (المصدر: ben_burtenshaw, ben_burtenshaw)

تزايد الطلب على Perplexity Labs، يمكن للمستخدمين بناء برامج مخصصة بسرعة: شهدت Perplexity Labs تزايدًا ملحوظًا في الطلب نظرًا لقدرتها على بناء برامج مخصصة بسرعة من خلال مطالبة واحدة، حتى أن بعض المستخدمين اشتروا حسابات Pro متعددة للحصول على المزيد من استعلامات Labs. يعكس هذا اهتمامًا قويًا من المستخدمين بالقدرة على إنشاء وتعديل أدوات البرامج بسرعة وفقًا لاحتياجاتهم الخاصة، حيث أصبح تطوير البرامج المخصصة المدفوعة بالذكاء الاصطناعي اتجاهًا سائدًا (المصدر: AravSrinivas, AravSrinivas)
Ollama وHazy Research تتعاونان لإطلاق Secure Minions، لتحقيق تعاون خاص بين نماذج LLM المحلية والسحابية: يهدف مشروع Minions من مختبر Hazy Research بجامعة ستانفورد، من خلال ربط نماذج Ollama المحلية بنماذج سحابية متطورة، إلى خفض تكاليف السحابة بشكل كبير (5-30 مرة) مع الحفاظ على دقة قريبة من النماذج المتطورة (98%). يقوم مشروع Secure Minion بتحويل وحدات معالجة الرسومات مثل H100 إلى مناطق آمنة، مما يحقق تشفير الذاكرة والحسابات، ويضمن خصوصية البيانات. يوفر هذا النمط التشغيلي المختلط، مع تعزيز حماية الخصوصية، للمستخدمين أيضًا حلول استخدام LLM أكثر فعالية من حيث التكلفة (المصدر: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa وOpenRouter تتعاونان لتوفير قدرة البحث على الويب لأكثر من 400 نموذج LLM: أعلن محرك البحث بالذكاء الاصطناعي Exa عن شراكة مع OpenRouter، لتوفير وظيفة البحث على الويب لأكثر من 400 نموذج لغة كبير على منصة OpenRouter. هذا يعني أنه يمكن للمطورين والمستخدمين، عند استخدام هذه النماذج اللغوية الكبيرة، استدعاء قدرات بحث Exa بسهولة، مما يعزز قدرة النماذج على الحصول على المعلومات في الوقت الفعلي وتحديث المعرفة، ويحسن أداء تطبيقات مثل RAG (التوليد المعزز بالاسترجاع) (المصدر: menhguin)

📚 التعلم
مايكروسوفت تطلق دورة تمهيدية لـ MCP بعنوان “MCP for Beginners”: أصدرت مايكروسوفت دورة تمهيدية للمبتدئين في MCP (Microsoft Copilot Platform، يُعتقد أنه خطأ إملائي، ويُقصد به Microsoft CoCo Framework أو بروتوكول وكيل ذكاء اصطناعي مشابه). تهدف هذه الدورة إلى مساعدة المبتدئين على إتقان المفاهيم الأساسية لـ MCP وطرق تنفيذها وتطبيقاتها العملية، ويتضمن المحتوى مواصفات بنية البروتوكول وأدلة تعليمية وتطبيقات عملية بلغات برمجة متعددة. يغطي هيكل الدورة مقدمة ومفاهيم أساسية وأمان وبدء الاستخدام وموضوعات متقدمة وتحليل المجتمع ودراسات الحالة، ويوفر مشاريع أمثلة مثل الآلات الحاسبة الأساسية والمتقدمة (المصدر: dotey)

Bond Capital تصدر تقرير اتجاهات الذكاء الاصطناعي لشهر مايو 2025، مقدمة رؤى حول تطور الصناعة: أصدرت شركة رأس المال الاستثماري الشهيرة Bond Capital تقرير “اتجاهات الذكاء الاصطناعي لشهر مايو 2025” المكون من 339 صفحة، والذي يحلل بشكل شامل البيانات والرؤى المتعلقة بالذكاء الاصطناعي في مختلف المجالات. يشير التقرير بشكل خاص إلى أن عدد مستخدمي ChatGPT النشطين شهريًا يصل إلى 800 مليون (90% منهم من خارج أمريكا الشمالية)، مع مليار عملية بحث يوميًا؛ وزيادة الوظائف المتعلقة بتكنولوجيا المعلومات والذكاء الاصطناعي بنسبة 448%؛ وتكلفة تدريب النماذج المتطورة تتجاوز مليار دولار أمريكي لكل مرة؛ وأصبحت نماذج LLM بنية تحتية. يؤكد التقرير أن مفتاح المنافسة يكمن في بناء أفضل المنتجات المدفوعة بالذكاء الاصطناعي، وأن الوقت الحالي هو سوق البناة (المصدر: karminski3)
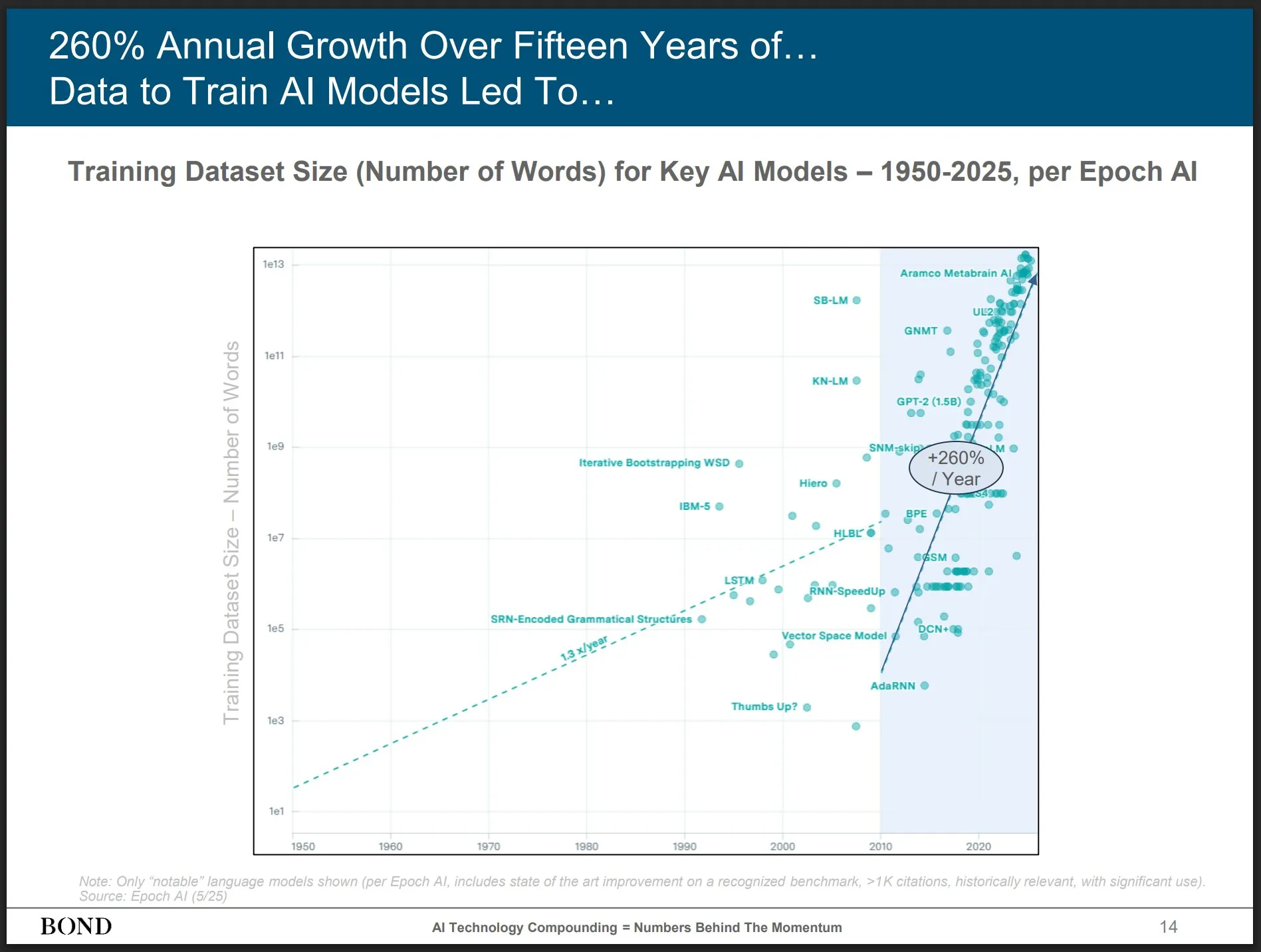
أوراق بحثية تناقش العلاقة بين التعلم المعزز وقدرات الاستدلال في نماذج LLM، مع اهتمام بـ ProRL وLimit-of-RLVR: أثارت ورقتان بحثيتان حول التعلم المعزز (RL) وقدرات الاستدلال في نماذج اللغة الكبيرة (LLM) نقاشًا. إحداهما بعنوان “Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?”، والأخرى من NVIDIA بعنوان “ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models”. تبحث هذه الدراسات في مدى قدرة التعلم المعزز (خاصة RLVR، وهو التعلم المعزز بالمكافآت القابلة للتحقق) على تعزيز قدرات الاستدلال الأساسية لنماذج LLM، وتأثير التدريب المستمر بالتعلم المعزز على توسيع حدود استدلال نماذج LLM. تشير المناقشات ذات الصلة إلى أن بيانات تدريب RLVR عالية الجودة وآليات المكافأة الفعالة هي عوامل رئيسية (المصدر: scaling01, Dorialexander, scaling01)

ورقة بحثية بعنوان “How Programming Concepts and Neurons Are Shared in Code Language Models” تبحث في آليات مشاركة مفاهيم البرمجة والوحدات العصبية في نماذج لغة الكود: تحقق هذه الدراسة في العلاقة بين فضاءات المفاهيم الداخلية لنماذج اللغة الكبيرة (LLMs) عند معالجة لغات برمجة متعددة (PLs) واللغة الإنجليزية. من خلال إجراء مهام ترجمة قليلة العينات على نماذج سلسلة Llama، وجد أنه في الطبقات الوسطى، تكون فضاءات المفاهيم أقرب إلى اللغة الإنجليزية (بما في ذلك الكلمات المفتاحية للغات البرمجة)، وتميل إلى تخصيص احتمالات عالية لرموز اللغة الإنجليزية. يُظهر تحليل تنشيط الوحدات العصبية أن الوحدات العصبية الخاصة باللغة تتركز بشكل أساسي في الطبقات السفلية، بينما تميل الوحدات العصبية الفريدة لكل لغة برمجة إلى الظهور في الطبقات العليا. تقدم الدراسة رؤى جديدة حول كيفية تمثيل نماذج LLM داخليًا للغات البرمجة (المصدر: HuggingFace Daily Papers)
ورقة بحثية جديدة بعنوان “Pixels Versus Priors” تتحكم في المعرفة المسبقة في نماذج MLLM من خلال التحكم البصري المضاد للواقع: تبحث هذه الدراسة فيما إذا كان استدلال نماذج اللغة الكبيرة متعددة الوسائط (MLLM) في مهام مثل الإجابة على الأسئلة المرئية يعتمد بشكل أكبر على المعرفة العالمية المخزنة أم على المعلومات المرئية من الصورة المدخلة. قدم الباحثون مجموعة بيانات Visual CounterFact، التي تحتوي على صور مرئية مضادة للواقع تتعارض مع المعرفة العالمية المسبقة (مثل فراولة زرقاء). أظهرت التجارب أن تنبؤات النموذج تعكس في البداية المعرفة المسبقة المخزنة، ولكنها تتحول في المراحل المتوسطة والمتأخرة إلى الأدلة المرئية. تقترح الورقة متجه توجيه PvP (Pixels Versus Priors)، الذي يتحكم في انحياز مخرجات النموذج نحو المعرفة العالمية أو المدخلات المرئية من خلال التدخل في طبقة التنشيط، ونجح في تغيير معظم تنبؤات الألوان والأحجام (المصدر: HuggingFace Daily Papers)
ورقة بحثية في ICML 2025 بعنوان GuidedQuant تقترح تحسين طرق PTQ الهرمية من خلال توجيه خسارة النهاية: GuidedQuant هي طريقة جديدة لتكميم ما بعد التدريب (PTQ)، تعمل على تحسين أداء طرق PTQ الهرمية من خلال دمج توجيه خسارة النهاية (end loss) في الهدف. تستخدم هذه الطريقة التدرجات لكل ميزة فيما يتعلق بخسارة النهاية لترجيح خطأ الإخراج الهرمي، بما يتوافق مع معلومات فيشر القطرية الكتلية التي تحافظ على التبعيات داخل القناة. بالإضافة إلى ذلك، تقدم الورقة LNQ، وهي خوارزمية تكميم قياسية غير موحدة، تضمن تقليلًا رتيبًا لقيمة هدف التكميم. أظهرت التجارب أن GuidedQuant تتفوق على أحدث الطرق الحالية (SOTA) في تكميم الأوزان القياسية فقط، ومتجهات الأوزان فقط، وتكميم الأوزان والتنشيطات، وقد تم تطبيقها على تكميم نماذج مثل Qwen3 وGemma3 وLlama3.3 بدقة 2-4 بت (المصدر: Reddit r/MachineLearning)

معرض AI Engineer World’s Fair يُعقد في سان فرانسيسكو، ويركز على ممارسات هندسة الذكاء الاصطناعي والتقنيات المتطورة: يُعقد حاليًا معرض AI Engineer World’s Fair في سان فرانسيسكو، ويجمع العديد من المهندسين والباحثين والمطورين في مجال الذكاء الاصطناعي. يتضمن جدول أعمال المؤتمر العديد من الموضوعات الساخنة مثل التعلم المعزز، والنواة (kernels)، والاستدلال والوكلاء، وتحسين النماذج (RFT, DPO, SFT)، وترميز الوكلاء، وبناء وكلاء الصوت. خلال الحدث، سيقوم خبراء من شركات مثل OpenAI وGoogle بتقديم عروض ومناقشات، وسيتم إطلاق منتجات وتقنيات جديدة. يشارك أعضاء المجتمع بنشاط، ويتبادلون جداول أعمال المؤتمرات، وينظمون لقاءات غير رسمية، مما يدل على حيوية مجتمع هندسة الذكاء الاصطناعي وشغفه بالتقنيات المتطورة (المصدر: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 الأعمال
شركة Shidu Intelligence تكمل جولة تمويل أولية بملايين اليوانات، لتسريع تطبيق نظارات الذكاء الاصطناعي في سيناريوهات متعددة: أعلنت شركة Suzhou Shidu Intelligent Technology Co., Ltd. عن إكمال جولة تمويل أولية (seed round) بملايين اليوانات، وستُستخدم الأموال في البحث والتطوير التكنولوجي الأساسي لنظارات الذكاء الاصطناعي، وتوسيع السوق، وبناء النظام البيئي. تركز الشركة على تطبيق نظارات الذكاء الاصطناعي في مجالات الرعاية الصحية الذكية (مثل نظارات القراءة الذكية، ونظارات مساعدة المكفوفين الذكية)، والحياة الذكية (النظارات العصرية الذكية، ونظارات ركوب الدراجات)، والتصنيع الذكي (النظارات الصناعية الذكية، ووحدات التحكم الصوتي). تتراوح أسعار منتجاتها بين 200 يوان و1000 يوان، وتهدف إلى تعزيز انتشار النظارات الذكية من خلال فعالية التكلفة العالية (المصدر: 36氪)

شائعات عن استحواذ OpenAI المحتمل على مساعد البرمجة بالذكاء الاصطناعي Windsurf، مما يثير تكهنات حول قطع Anthropic لتزويد نماذج Claude: تتردد شائعات في السوق بأن OpenAI قد تستحوذ على أداة البرمجة بالذكاء الاصطناعي Windsurf (المعروفة سابقًا باسم Codeium) مقابل حوالي 3 مليارات دولار أمريكي. في هذا السياق، نشر الرئيس التنفيذي لشركة Windsurf، Varun Mohan، منشورًا يفيد بأن Anthropic قطعت وصولها المباشر إلى جميع نماذج Claude 3.x تقريبًا، بما في ذلك Claude 3.5 Sonnet وغيرها، وذلك بإشعار قصير جدًا. أعربت Windsurf عن خيبة أملها، وسارعت بنقل قدرتها الحاسوبية إلى مزودي خدمات استدلال آخرين، مع تقديم خصومات على Gemini 2.5 Pro للمستخدمين المتأثرين. يتكهن المجتمع بأن هذه الخطوة من Anthropic قد تكون مرتبطة بالاستحواذ المحتمل من قبل OpenAI، معربين عن قلقهم من أن هذا سيؤثر على المنافسة في الصناعة وخيارات المطورين. سابقًا، لم تتمكن Windsurf من الحصول على دعم مباشر من Anthropic عند إطلاق Claude 4 (المصدر: AI前线)

Hygon Information تعتزم الاندماج مع Sugon عبر تبادل الأسهم، لدمج سلسلة صناعة القدرة الحاسوبية المحلية: أعلنت شركة تصميم رقائق الذكاء الاصطناعي Hygon Information عن خطط لامتصاص أكبر مساهميها، شركة تصنيع الخوادم Sugon، من خلال تبادل الأسهم. تبلغ القيمة السوقية لشركة Hygon Information حوالي 316.4 مليار يوان، بينما تبلغ القيمة السوقية لشركة Sugon حوالي 90.5 مليار يوان. يهدف هذا الاندماج الذي يشبه “ابتلاع الثعبان للفيل” إلى تحسين التخطيط الصناعي من الرقائق إلى البرمجيات والأنظمة، وتحقيق تعزيز وتكميل وتوسيع سلسلة الصناعة، والاستفادة من التأثيرات التآزرية التكنولوجية. يرى المحللون أن الاندماج يساعد في حل مشكلات المعاملات المرتبطة المعقدة والمنافسة المحتملة بين الشركتين، وخفض تكاليف التشغيل، ويتماشى مع اتجاه تطوير حلول القدرة الحاسوبية الشاملة في عصر الذكاء الاصطناعي، مما يشير إلى أن قوة تكنولوجيا أشباه الموصلات في الصين قد تنتقل بشكل متسارع من الحوسبة التقليدية إلى حوسبة الذكاء الاصطناعي (المصدر: 36氪)
🌟 المجتمع
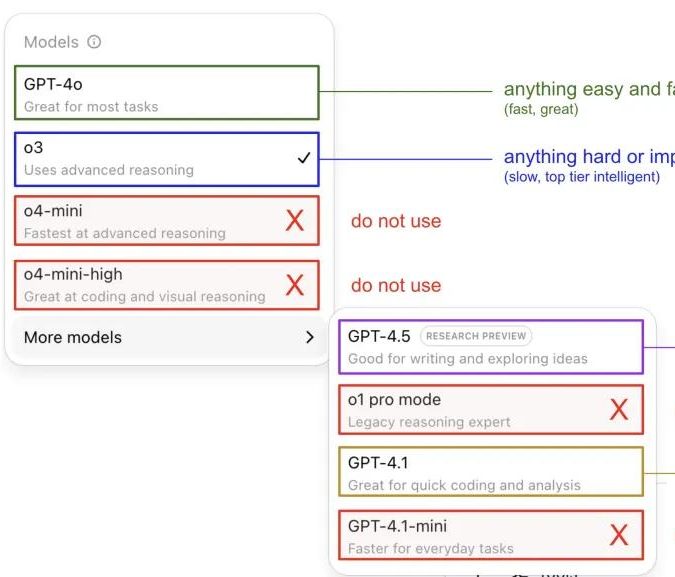
Andrej Karpathy يشارك خبرته في استخدام نماذج ChatGPT، مما يثير نقاشًا مجتمعيًا: شارك Andrej Karpathy خبرته الشخصية في استخدام إصدارات مختلفة من ChatGPT: للمهام الهامة أو الصعبة، يوصي باستخدام o3 ذي القدرة الاستدلالية الأقوى؛ للمشكلات اليومية ذات الصعوبة المنخفضة إلى المتوسطة، يمكن اختيار 4o؛ لمهام تحسين الكود، يناسب GPT-4.1؛ عند الحاجة إلى بحث عميق وتلخيص روابط متعددة، يتم استخدام وظيفة البحث العميق (المبنية على o3). أثارت هذه المشاركة نقاشًا واسعًا في المجتمع، حيث شارك العديد من المستخدمين تفضيلاتهم في الاستخدام وآرائهم حول اختيار النماذج، كما عكست أيضًا حيرة المستخدمين بشأن تسمية نماذج OpenAI المربكة ونقص وظيفة اختيار النموذج التلقائي (المصدر: 量子位, JeffLadish)
مطور يشارك تجربته لمدة أسبوعين في البرمجة باستخدام Agentic AI: من الدهشة إلى زوال الوهم، واختيار إعادة الهيكلة اليدوية في النهاية: شارك قائد تقني يتمتع بخبرة 10 سنوات تجربته في دمج Agentic AI (خاصة وكلاء برمجة الذكاء الاصطناعي) في عملية تطوير تطبيقه لوسائل التواصل الاجتماعي. في البداية، كان الذكاء الاصطناعي قادرًا على إنشاء وحدات وظيفية بسرعة، وكتابة منطق الواجهة الأمامية والخلفية واختبارات الوحدة، بكفاءة مذهلة، حيث أنتج حوالي 12,000 سطر من الكود في غضون أسبوعين. ومع ذلك، مع زيادة تعقيد قاعدة الكود، بدأ الذكاء الاصطناعي في ارتكاب أخطاء متكررة عند التعامل مع الميزات الجديدة، والدخول في حلقات مفرغة، وصعوبة الاعتراف بالفشل، كما كشف الكود الذي تم إنشاؤه عن مشكلات مثل التسمية غير الدقيقة والكود المكرر، مما أدى إلى صعوبة صيانة قاعدة الكود وفقدان المطور الثقة فيه. في النهاية، قرر المطور استخدام الكود الذي تم إنشاؤه بواسطة الذكاء الاصطناعي كـ “مرجع غامض” فقط، وإعادة هيكلة جميع الوظائف يدويًا، ويرى أن الذكاء الاصطناعي حاليًا أكثر ملاءمة لتحليل الكود الحالي وتقديم الأمثلة، بدلاً من كتابة كود وظيفي مباشرة (المصدر: CSDN)

تعريف وكيل الذكاء الاصطناعي والفرق بينه وبين تدفق العمل يثير الاهتمام، مع إمكانات تطبيق مستقبلية هائلة: ناقش المجتمع الفرق بين مفهومي وكيل الذكاء الاصطناعي (AI Agent) وتدفق العمل (Workflow). يشير الوكيل عادةً إلى نموذج لغة كبير (LLM) يصل إلى الأدوات في حلقة، ويعمل بحرية بناءً على التعليمات؛ بينما يكون تدفق العمل سلسلة من الخطوات التي يتم تنفيذها بشكل حتمي في الغالب، وقد تتضمن نموذج لغة كبير لإكمال المهام الفرعية. على الرغم من وجود تداخل (يمكن توجيه الوكيل للتنفيذ الحتمي، ويمكن أن يتضمن تدفق العمل مكونات وكيلية)، إلا أن هذا التمييز لا يزال له معنى من الناحية الأنطولوجية. في الوقت نفسه، يُنظر إلى إمكانات وكلاء الذكاء الاصطناعي في تطبيقات المؤسسات بتفاؤل كبير، حيث تعمل الشركات الكبرى مثل Tencent وByteDance بقوة في مجال الوكلاء الأذكياء، على سبيل المثال، قامت Tencent بترقية قاعدة معارف نماذجها الكبيرة إلى منصة تطوير وكلاء أذكياء، بينما تمتلك ByteDance منصة Coze (Kouzi)، التي تهدف إلى مساعدة الشركات على تطبيق أنظمة وكلاء ذكاء اصطناعي أصلية (المصدر: fabianstelzer, 蓝洞商业)
Dwarkesh Patel يناقش الجدول الزمني لنماذج LLM والذكاء الاصطناعي العام (AGI)، معتبرًا أن التعلم المستمر هو العقبة الرئيسية: أوضح Dwarkesh Patel في مدونته وجهة نظره حول الجدول الزمني للذكاء الاصطناعي العام (AGI)، معتبرًا أن نماذج LLM تفتقر حاليًا إلى قدرة البشر على تجميع السياق من خلال الممارسة، والتفكير في الإخفاقات، وإجراء تحسينات طفيفة، أي القدرة على التعلم المستمر. ويرى أن هذا يمثل عقبة كبيرة أمام فائدة النماذج، وأن حل هذه المشكلة قد يستغرق عدة سنوات. أثارت هذه النظرة نقاشًا بين العديد من باحثي الذكاء الاصطناعي، بما في ذلك Andrej Karpathy. يتفق Karpathy أيضًا مع أوجه القصور في نماذج LLM فيما يتعلق بالتعلم المستمر، ويشبهها بزميل يعاني من فقدان الذاكرة التقدمي. تسلط هذه المناقشات الضوء على التحديات التي تواجه تحقيق الذكاء الاصطناعي العام الحقيقي، والتفكير العميق في آليات تعلم النماذج (المصدر: dwarkesh_sp, JeffLadish, dwarkesh_sp)

قضايا براءات الاختراع المتعلقة بالذكاء الاصطناعي في تطوير الأدوية تثير الاهتمام، ومجلة Science تدعو إلى الحذر: ناقش مقال في منتدى السياسات بمجلة “Science” بعنوان “What patents on AI-derived drugs reveal” تطبيقات الذكاء الاصطناعي في مجال اكتشاف الأدوية وتأثيرها على نظام براءات الاختراع. أشار البحث إلى أن الشركات الناشئة في مجال الذكاء الاصطناعي عند تقديم طلبات براءات اختراع للأدوية، غالبًا ما تكون بيانات التجارب الحيوية (in vivo) لديها أقل من شركات الأدوية التقليدية، مما قد يؤدي إلى التخلي عن الأدوية الواعدة بسبب نقص الأبحاث اللاحقة. في الوقت نفسه، فإن الكم الهائل من الجزيئات الجديدة التي يولدها الذكاء الاصطناعي بمجرد نشرها، قد تعيق الشركات الأخرى عن تقديم طلبات براءات اختراع لهذه الجزيئات وإجراء المزيد من الاستثمارات فيها، لأنها تصبح “تقنية حالية”. يقترح المقال رفع عتبة طلبات براءات الاختراع، والمطالبة بمزيد من بيانات التجارب الحيوية، والسماح للشركات الأخرى بتقديم طلبات براءات اختراع للجزيئات التي يولدها الذكاء الاصطناعي ولم يتم اختبارها، مع تعزيز الحقوق الحصرية التنظيمية في مرحلة التجارب السريرية للأدوية الجديدة، لتحقيق التوازن بين تحفيز الابتكار والمصلحة العامة (المصدر: 36氪)
💡 أخرى
أحداث صراعات السلطة في OpenAI قد تتحول إلى فيلم بعنوان “Artificial”، بمشاركة مخرج ومنتج مشهورين: وفقًا لـ The Hollywood Reporter، تخطط MGM لتحويل أحداث التغييرات في الإدارة العليا لـ OpenAI إلى فيلم، يحمل اسمًا مؤقتًا “Artificial”. قد يتولى المخرج الإيطالي الشهير Luca Guadagnino إخراجه، ومن بين المنتجين David Heyman من سلسلة “Harry Potter”. يجري التفاوض بشأن طاقم الممثلين، وتتردد شائعات بأن Andrew Garfield (الذي لعب دور Spider-Man و Eduardo Saverin في “The Social Network”) قد يلعب دور Sam Altman، و Yura Borisov قد يلعب دور Ilya Sutskever، و Monika Barbaro قد تلعب دور Mira Murati. أثار هذا الخبر نقاشًا ساخنًا بين مستخدمي الإنترنت، وقارنوه بفيلم “The Social Network” (المصدر: 36氪, janonacct)
تجربة خدمة العملاء بالذكاء الاصطناعي تثير الجدل، والمستخدمون يشكون من “الغباء الاصطناعي” وصعوبة التحويل إلى موظف بشري: خلال فترة العروض الترويجية الكبرى للتجارة الإلكترونية مؤخرًا، اشتكى عدد كبير من المستهلكين من عدم سلاسة التواصل مع خدمة العملاء بالذكاء الاصطناعي، وإجاباتها غير الملائمة، وصعوبة التحويل إلى موظف خدمة عملاء بشري، مما أدى إلى تدهور تجربة الخدمة. تظهر بيانات الإدارة الوطنية لتنظيم السوق أن الشكاوى المتعلقة بـ “خدمة العملاء الذكية” في مجال خدمة ما بعد البيع للتجارة الإلكترونية في عام 2024 زادت بنسبة 56.3% على أساس سنوي. يعتقد المستخدمون عمومًا أن خدمة العملاء بالذكاء الاصطناعي تجد صعوبة في حل المشكلات الفردية، وأن إجاباتها جامدة، وأنها ليست صديقة للفئات الخاصة مثل كبار السن. تدعو المقالة الشركات إلى عدم التضحية بجودة الخدمة أثناء سعيها لخفض التكاليف وزيادة الكفاءة، وتحسين تكنولوجيا الذكاء الاصطناعي، وتحديد سيناريوهات تطبيق خدمة العملاء بالذكاء الاصطناعي بوضوح، والاحتفاظ بقنوات خدمة بشرية مريحة (المصدر: 36氪)

تطبيقات الذكاء الاصطناعي في مجال إنشاء المحتوى واستراتيجيات مواجهة المبدعين قيد المناقشة: تتزايد تطبيقات تكنولوجيا الذكاء الاصطناعي (مثل DeepSeek, Suno, Veo 3) في مجالات إنشاء المحتوى مثل المقالات والموسيقى والفيديو، مما يثير قلق مبدعي المحتوى بشأن آفاقهم المهنية. يرى التحليل أن نموذج المحتوى يتحول من “التوصية المخصصة” إلى “التوليد المخصص”. على المدى القصير، قد لا تستبدل المنصات المبدعين بالكامل بالذكاء الاصطناعي بسبب ارتفاع تكاليف التجربة والخطأ، ويمكن للمبدعين تحقيق الربح من خلال إنشاء نماذج ذات أسلوب فريد وترخيصها. على المدى الطويل، يحتاج المبدعون إلى تعديل طرق خلق القيمة لديهم، والتركيز بشكل أكبر على “استراتيجيات الابتكار” التي يصعب على الذكاء الاصطناعي استبدالها (مثل البحث الأصلي، والحصول على معلومات مباشرة)، بدلاً من “استراتيجيات المتابعة” التي يسهل على الذكاء الاصطناعي المساعدة فيها (متابعة الموضوعات الشائعة، والاعتماد على معلومات ثانوية). على الرغم من أن الذكاء الاصطناعي بدأ يدخل مجالات مبتكرة مثل البحث العلمي، إلا أن المبدعين الذين يتمتعون بوجهات نظر فريدة وتفكير عميق لا يزالون ذوي قيمة (المصدر: 36氪)
