
كلمات مفتاحية:AlphaEvolve, Gemini, خوارزميات التطور, وكلاء الذكاء الاصطناعي, تحسين الخوارزميات, ضرب المصفوفات, مركز بيانات Borg, تحسين ضرب مصفوفات 4×4 للأعداد المركبة, اكتشاف خوارزميات Google DeepMind, التصميم الآلي للخوارزميات بالذكاء الاصطناعي, تطبيقات Gemini 2.0 Pro, تحسين توزيع موارد Borg
🔥 أبرز الأخبار
DeepMind من جوجل تطلق AlphaEvolve: وكيل ترميز خوارزمي تطوري يعتمد على Gemini، يحقق اختراقات في مجالي الرياضيات وعلوم الحاسوب: أعلنت DeepMind من جوجل عن AlphaEvolve، وهو وكيل يستخدم النموذج اللغوي الكبير Gemini 2.0 Pro، لاكتشاف وتحسين كود الخوارزميات تلقائيًا من خلال الخوارزميات التطورية. يستطيع AlphaEvolve الانطلاق من الكود الأولي ومقاييس التقييم التي يقدمها البشر، ليقوم بشكل مستقل بتوليد وتقييم وتحسين الحلول المرشحة. أظهر النظام أداءً متميزًا في أكثر من 50 مسألة رياضية، حيث أعاد إنتاج الحلول المعروفة في حوالي 75% من الحالات، واكتشف حلولًا أفضل في 20% من الحالات. والجدير بالذكر أن AlphaEvolve قلل عدد عمليات حساب ضرب المصفوفات المعقدة 4×4 من 49 إلى 48 عملية، محطمًا بذلك رقمًا قياسيًا ظل صامدًا لمدة 56 عامًا. بالإضافة إلى ذلك، قام بتحسين خوارزمية الجدولة لمركز بيانات Borg الداخلي لجوجل، مما أدى إلى استعادة 0.7% من موارد الحوسبة العالمية، وتحسين تصميم الجيل القادم من شرائح TPU، مما قلل وقت تدريب Gemini بنسبة 1%. تُظهر هذه النتيجة الإمكانات الهائلة للذكاء الاصطناعي في الاكتشاف الآلي للخوارزميات والابتكار العلمي، وعلى الرغم من أنه يعالج حاليًا بشكل أساسي المشكلات التي يمكن تقييمها تلقائيًا، إلا أن آفاق تطبيقه في مجالات العلوم التطبيقية مثل اكتشاف الأدوية واسعة. (المصدر: , 量子位, 36氪)
Nvidia تعلن عن العديد من التطورات في مجال الذكاء الاصطناعي في Computex 2025، وجنسن هوانغ يؤكد على رؤية Agentic AI و Physical AI: ألقى جنسن هوانغ، الرئيس التنفيذي لشركة Nvidia، كلمة رئيسية في Computex 2025، مؤكدًا أن الذكاء الاصطناعي يتطور من “الاستجابة لمرة واحدة” إلى Agentic AI (الذكاء الاصطناعي الوكيلي) الذي “يفكر ويستنتج” و Physical AI (الذكاء الاصطناعي الفيزيائي) الذي يفهم العالم المادي. لدعم هذا الاتجاه، أعلنت Nvidia عن إصدار موسع لمنصة Blackwell (Blackwell Ultra AI)، وأعلنت عن بدء الإنتاج الكامل لنظام Grace Blackwell GB300، الذي يتميز بأداء استدلالي أعلى بمقدار 1.5 مرة من الجيل السابق. كما استعرض هوانغ الجيل القادم من شريحة الذكاء الاصطناعي الفائقة Rubin Ultra، والتي يبلغ أداؤها 14 ضعف أداء GB300. لدفع بناء البنية التحتية للذكاء الاصطناعي، أطلقت Nvidia تقنية NVLink Fusion، وتعاونت مع TSMC و Foxconn وغيرهما لإنشاء حاسوب عملاق للذكاء الاصطناعي في تايوان، الصين. بالإضافة إلى ذلك، قامت Nvidia بتحديث نموذجها الأساسي للروبوتات الشبيهة بالبشر Isaac GR00T N1.5، مما عزز قدرته على التكيف مع البيئة وتنفيذ المهام، وتخطط لفتح مصدر محرك الفيزياء Newton الذي تم تطويره بالتعاون مع DeepMind و Disney Research. (المصدر: AI 前线, 量子位, Reddit r/artificial)
فريق OpenAI Codex يكشف في جلسة AMA عن خطط دمج GPT-5 والمنتجات المستقبلية: عقد فريق OpenAI Codex جلسة “اسألني أي شيء” (AMA) على Reddit، حيث كشف جيري توريك، نائب رئيس الأبحاث، أن الهدف من الجيل القادم من النموذج الأساسي GPT-5 هو تحسين قدرات النماذج الحالية وتقليل الحاجة إلى تبديل النماذج، مع التخطيط لدمج الأدوات الحالية مثل Codex و Operator (وكيل تنفيذ المهام) و Deep Research (أداة بحث متعمق) و Memory (وظيفة الذاكرة) لتشكيل تجربة مساعد ذكاء اصطناعي موحدة. كما شارك أعضاء الفريق الدوافع الأولية لتطوير Codex (النابعة من التفكير الداخلي حول عدم كفاية استخدام النماذج)، وزيادة كفاءة البرمجة بحوالي 3 أضعاف نتيجة استخدام Codex داخليًا، بالإضافة إلى رؤيتهم لمستقبل هندسة البرمجيات – تحويل المتطلبات بكفاءة وموثوقية إلى برامج قابلة للتشغيل. يعتمد Codex حاليًا بشكل أساسي على المعلومات المحملة في وقت تشغيل الحاويات، وقد يدمج تقنية RAG في المستقبل للحصول على أحدث المعارف. تستكشف OpenAI أيضًا خطط تسعير مرنة، وتخطط لتوفير أرصدة API مجانية لمستخدمي Plus/Pro لاستخدام Codex CLI. (المصدر: 36氪)
VS Code يعلن عن فتح مصدر إضافة GitHub Copilot Chat، ويخطط لبناء منصة تحرير أكواد مفتوحة المصدر مدعومة بالذكاء الاصطناعي: أعلن فريق Visual Studio Code عن خطط لتطوير VS Code ليصبح محررًا مفتوح المصدر للذكاء الاصطناعي، متمسكًا بالمبادئ الأساسية للانفتاح والتعاون والمجتمع. كجزء من هذه الخطة، تم فتح مصدر إضافة GitHub Copilot Chat على GitHub بموجب ترخيص MIT. في المستقبل، يخطط VS Code لدمج ميزات الذكاء الاصطناعي هذه تدريجيًا في جوهر المحرر، بهدف بناء منصة تحرير أكواد مفتوحة المصدر بالكامل ومدفوعة بالمجتمع لتعزيز كفاءة التطوير والشفافية والأمان. تعتبر هذه الخطوة خطوة مهمة من مايكروسوفت في مجال المصادر المفتوحة، وقد يكون لها تأثير عميق على بيئة أدوات البرمجة المساعدة بالذكاء الاصطناعي. (المصدر: dotey, jeremyphoward)
تعاون بين Huawei Ascend و DeepSeek يحقق أداء استدلالي لنماذج MoE يتجاوز Nvidia Hopper: أعلنت Huawei Ascend أن عقدتها الفائقة CloudMatrix 384 وخادم الاستدلال Atlas 800I A2 حققا اختراقًا كبيرًا في أداء الاستدلال عند نشر نماذج MoE فائقة الضخامة مثل DeepSeek V3/R1، متجاوزة بذلك معمارية Nvidia Hopper في ظروف محددة. تجاوزت إنتاجية Decode للبطاقة الواحدة في عقدة CloudMatrix 384 الفائقة 1920 Tokens/s عند زمن انتقال 50 مللي ثانية، بينما وصلت إنتاجية البطاقة الواحدة في Atlas 800I A2 إلى 808 Tokens/s عند زمن انتقال 100 مللي ثانية. عزت هواوي هذا الإنجاز إلى استراتيجية “تعويض الفيزياء بالرياضيات”، من خلال تحسين الخوارزميات والأنظمة لتعويض قيود عمليات تصنيع الأجهزة. تم نشر تقرير تقني ذي صلة، وسيتم فتح مصدر الكود الأساسي في غضون شهر واحد. تشمل تدابير التحسين حلول التوازي المتخصصة لنماذج MoE، ونشر PD المنفصل، وتكييف إطار عمل vLLM، واستراتيجية تكميم A8W8C16، بالإضافة إلى مخطط اتصالات FlashComm، وتحويل التوازي داخل الطبقة، ومحرك الاستدلال التخميني FusionSpec، وتحسين توافق أجهزة مشغلات MLA/MoE. (المصدر: 量子位, WeChat)
🎯 الاتجاهات
آبل تفتح مصدر نموذج اللغة المرئية عالي الكفاءة FastVLM، لتحسين تجربة الذكاء الاصطناعي على الأجهزة الطرفية: فتحت شركة آبل مصدر FastVLM (Fast Vision Language Model)، وهو نموذج لغة مرئية مصمم خصيصًا للتشغيل بكفاءة على الأجهزة الطرفية مثل iPhone. يقوم FastVLM بإدخال مُرمِّز مرئي هجين جديد FastViTHD، يجمع بين طبقات الـ convolution ووحدات Transformer، ويعتمد تقنيات التجميع متعدد المقاييس وتقليل العينات، مما يقلل بشكل كبير من عدد الـ visual tokens المطلوبة لمعالجة الصور (أقل بـ 16 مرة من ViT التقليدي). وهذا يمكّن النموذج من الحفاظ على دقة عالية مع زيادة سرعة إخراج الـ token الأول (TTFT) بما يصل إلى 85 مرة مقارنة بالنماذج المماثلة. يتوافق FastVLM مع نماذج LLM السائدة ويسهل تكييفه مع نظام iOS/Mac البيئي، ويوفر ثلاثة إصدارات من المعلمات: 0.5B، 1.5B، 7B، وهو مناسب لمجموعة متنوعة من مهام النصوص والصور في الوقت الفعلي مثل وصف الصور والإجابة على الأسئلة والتحليل. (المصدر: WeChat)
Meta تطلق نموذج KernelLLM 8B، ويتفوق على GPT-4o في اختبارات معيارية محددة: أطلقت Meta نموذج KernelLLM 8B على Hugging Face. يُزعم أنه في اختبار KernelBench-Triton Level 1 المعياري، تفوق هذا النموذج ذو الـ 8 مليارات معلمة على نماذج أكبر حجمًا مثل GPT-4o و DeepSeek V3 في أداء الاستدلال لمرة واحدة. وفي حالة الاستدلال المتعدد، تفوق أداء KernelLLM أيضًا على DeepSeek R1. أثار هذا الإطلاق اهتمام مجتمع الذكاء الاصطناعي، واعتُبر مثالًا آخر على قدرة النماذج متوسطة وصغيرة الحجم على إظهار قدرة تنافسية قوية في مهام محددة. (المصدر: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
نموذج Mistral Medium 3 يُظهر أداءً قويًا في Arena، خاصة في المجالات التقنية: أظهر نموذج Mistral Medium 3 الجديد من Mistral AI أداءً متميزًا في تقييم المجتمع على lmarena.ai، حيث احتل المرتبة 11 بشكل عام في قدرات الدردشة، مع تحسن ملحوظ مقارنة بـ Mistral Large (زيادة 90 نقطة في درجة Elo). برز النموذج بشكل خاص في المجالات التقنية، حيث احتل المرتبة الخامسة في القدرات الرياضية، والمرتبة السابعة في قدرات التعامل مع الأوامر المعقدة والترميز، والمرتبة التاسعة في WebDev Arena. اعتبرت تعليقات المجتمع أن أداءه في المجالات التقنية يقترب من مستوى GPT-4.1، مع احتمال أن تكون تكلفته أكثر تنافسية، على غرار تسعير GPT-4.1 mini. يمكن للمستخدمين تجربة النموذج مجانًا على واجهة الدردشة الرسمية لـ Mistral. (المصدر: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets تضيف ميزة عرض محادثات الدردشة مباشرة: أجرت منصة Hugging Face Datasets تحديثًا هامًا، حيث يمكن للمستخدمين الآن قراءة محتوى محادثات الدردشة مباشرة داخل مجموعات البيانات. اعتبر أعضاء المجتمع (مثل Caleb و Maxime Labonne) هذه الميزة خطوة كبيرة نحو حل مشكلات جودة البيانات، حيث يساعد الاطلاع المباشر على بيانات المحادثات الأصلية في فهم البيانات بشكل أفضل، وتنظيف البيانات، وتحسين نتائج تدريب النماذج. في السابق، كان عرض محتوى محادثات معينة يتطلب أكوادًا أو أدوات إضافية، بينما تبسط الميزة الجديدة هذه العملية، مما يعزز سهولة وشفافية العمل على البيانات. (المصدر: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
دمج MLX LM مع Hugging Face Hub لتبسيط تشغيل النماذج محليًا على أجهزة Mac: تم الآن دمج MLX LM مباشرة في Hugging Face Hub، مما يتيح لمستخدمي Mac تشغيل أكثر من 4400 نموذج لغوي كبير (LLM) محليًا على أجهزة Apple Silicon بسهولة أكبر. يحتاج المستخدمون فقط إلى النقر على “Use this model” في صفحة النموذج المتوافق على Hugging Face Hub لتشغيل النموذج بسرعة في الطرفية، دون الحاجة إلى تكوينات سحابية معقدة أو انتظار. بالإضافة إلى ذلك، يمكن تشغيل خادم متوافق مع OpenAI مباشرة من صفحة النموذج. يهدف هذا الدمج إلى تقليل عتبة تشغيل النماذج محليًا، وتعزيز كفاءة التطوير والتجريب. (المصدر: awnihannun, ClementDelangue, huggingface, reach_vb)
Nvidia تفتح مصدر نموذج الاستدلال للذكاء الاصطناعي الفيزيائي Cosmos-Reason1-7B: فتحت Nvidia مصدر نموذج Cosmos-Reason1-7B من سلسلة نماذج Physical AI الخاصة بها على Hugging Face. يهدف هذا النموذج إلى فهم الحس السليم للعالم المادي وتوليد قرارات مجسدة مقابلة. يمثل هذا خطوة جديدة من Nvidia في دفع عجلة دمج العالم المادي مع الذكاء الاصطناعي، مما يوفر أدوات وأسس بحثية جديدة للتطبيقات التي تتطلب تفاعلًا مع البيئة المادية مثل الروبوتات والقيادة الذاتية. (المصدر: reach_vb)
نموذج توليد الفيديو Steamer-I2V من بايدو يتصدر قائمة VBench لتوليد الفيديو من الصور: احتل نموذج توليد الفيديو Steamer-I2V من بايدو المرتبة الأولى في فئة توليد الفيديو من الصور (I2V) ضمن قائمة VBench المرجعية لتقييم توليد الفيديو، محققًا درجة إجمالية بلغت 89.38%، متجاوزًا نماذج معروفة مثل OpenAI Sora و Google Imagen Video. تشمل المزايا التقنية لـ Steamer-I2V التحكم الدقيق في الصورة على مستوى البكسل، وحركة الكاميرا الاحترافية، وجودة صورة سينمائية عالية الدقة تصل إلى 1080P وجماليات ديناميكية، بالإضافة إلى فهم دقيق للمعاني الصينية استنادًا إلى قاعدة بيانات متعددة الوسائط صينية تضم مئات الملايين من العينات. يُظهر هذا الإنجاز قوة بايدو في مجال التوليد متعدد الوسائط، وهو جزء من استراتيجيتها لبناء نظام بيئي لمحتوى الذكاء الاصطناعي. (المصدر: 36氪)

نماذج LLM تُظهر أداءً ضعيفًا في مهام قراءة الوقت مثل الساعات والتقويمات: اكتشف باحثون من جامعة إدنبرة ومؤسسات أخرى أنه على الرغم من الأداء المتميز لنماذج اللغة الكبيرة (LLM) ونماذج اللغة الكبيرة متعددة الوسائط (MLLM) في مهام متنوعة، إلا أن دقتها في مهام قراءة الوقت التي تبدو بسيطة (مثل تحديد الوقت على الساعات ذات العقارب وفهم تواريخ التقويم) مثيرة للقلق. أنشأت الدراسة مجموعتي اختبار مخصصتين، ClockQA و CalendarQA، وأظهرت النتائج أن دقة أنظمة الذكاء الاصطناعي في قراءة الساعات بلغت 38.7% فقط، ودقتها في تحديد تواريخ التقويم بلغت 26.3% فقط. حتى النماذج المتقدمة مثل Gemini-2.0 و GPT-o1 واجهت صعوبات واضحة، خاصة عند التعامل مع الأرقام الرومانية، أو العقارب المصممة بشكل فني، أو حسابات التواريخ المعقدة (مثل السنوات الكبيسة، أو تحديد يوم الأسبوع لتاريخ معين). يعتقد الباحثون أن هذا يكشف عن أوجه قصور في النماذج الحالية في الاستدلال المكاني، وتحليل التخطيطات المنظمة، والقدرة على التعميم على الأنماط غير الشائعة. (المصدر: 36氪, WeChat)

مايكروسوفت تعلن في مؤتمر Build عن جلب نموذج Grok إلى Azure AI Foundry: في مؤتمر مطوري مايكروسوفت Build 2025، أعلنت مايكروسوفت أن نموذج Grok من شركة xAI سينضم إلى مجموعة نماذج Azure AI Foundry الخاصة بها. يمكن للمستخدمين تجربة Grok-3 و Grok-3-mini مجانًا على Azure Foundry و GitHub حتى أوائل يونيو. تعني هذه الخطوة أن Azure AI Foundry ستوسع نطاق النماذج الخارجية التي تدعمها، وفي المستقبل سيتمكن المستخدمون من استخدام نماذج من عدة شركات مصنعة مثل OpenAI و xAI و DeepSeek و Meta و Mistral AI و Black Forest Labs من خلال إنتاجية محجوزة موحدة. (المصدر: TheTuringPost, xai)
تقارير تفيد بأن آبل تخطط للسماح لمستخدمي iPhone في الاتحاد الأوروبي باستبدال Siri بمساعدين صوتيين من جهات خارجية: وفقًا لمارك جورمان، تخطط شركة آبل للسماح لأول مرة لمستخدمي iPhone في منطقة الاتحاد الأوروبي باستبدال Siri بمساعدين صوتيين من جهات خارجية. قد تكون هذه الخطوة استجابة للمتطلبات التنظيمية الرقمية المتزايدة الصرامة في الاتحاد الأوروبي، وتهدف إلى تعزيز انفتاح المنصة وحق المستخدم في الاختيار. إذا تم تنفيذ هذه الخطة، فسيكون لها تأثير مهم على مشهد سوق المساعدين الصوتيين، مما يوفر فرصًا لمساعدين صوتيين آخرين لدخول نظام آبل البيئي. (المصدر: zacharynado)

Meta تطلق مجموعة بيانات Open Molecules 2025 ونموذج UMA لتسريع اكتشاف الجزيئات والمواد: أطلقت Meta AI مجموعة بيانات Open Molecules 2025 (OMol25) ونموذج Meta Universal Atomic model (UMA). تعد OMol25 أكبر وأكثر مجموعات بيانات حسابات الكيمياء الكمومية عالية الدقة تنوعًا حتى الآن، وتشمل الجزيئات الحيوية والمركبات المعدنية والإلكتروليتات وغيرها. أما UMA فهو نموذج جهد بين ذري قائم على التعلم الآلي تم تدريبه على أكثر من 30 مليار ذرة، ويهدف إلى توفير تنبؤات أكثر دقة لسلوك الجزيئات. يهدف فتح مصدر هذه الأدوات إلى تسريع الاكتشاف والابتكار في علوم الجزيئات والمواد. (المصدر: AIatMeta)
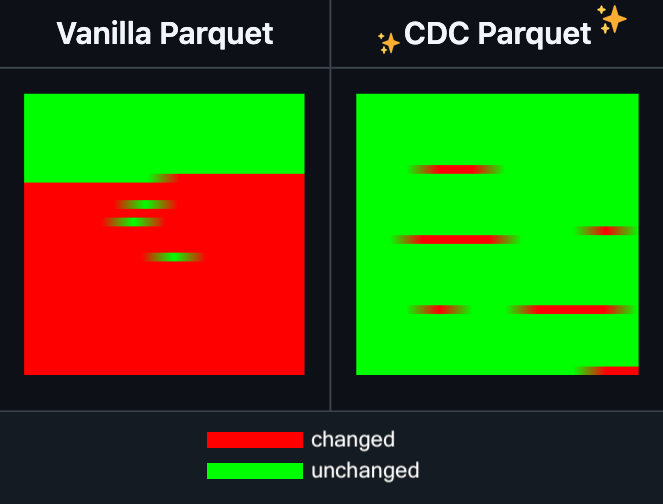
Hugging Face Datasets تضيف ميزة التحرير التزايدي لملفات Parquet: أعلنت Hugging Face Datasets أن الإصدار الليلي من مكتبة PyArrow، وهي مكتبة تعتمد عليها، يدعم الآن التحرير التزايدي لملفات Parquet دون الحاجة إلى إعادة كتابة الملف بالكامل. ستعمل هذه الميزة الجديدة على تحسين كفاءة عمليات مجموعات البيانات واسعة النطاق بشكل كبير، خاصة عند الحاجة إلى تحديثات متكررة أو تعديل أجزاء من البيانات، حيث يمكن أن تقلل بشكل كبير من استهلاك الوقت والموارد الحاسوبية. من المتوقع أن يؤدي هذا الإجراء إلى تحسين تجربة المطورين في التعامل مع مجموعات بيانات تدريب الذكاء الاصطناعي الكبيرة وصيانتها. (المصدر: huggingface)
LangGraph يضيف ميزة التخزين المؤقت على مستوى العقدة لتعزيز كفاءة سير العمل: أعلن LangGraph أن إصداره مفتوح المصدر يضيف الآن ميزة التخزين المؤقت للعقد/المهام. تهدف هذه الميزة إلى تسريع سير العمل عن طريق تجنب الحسابات المتكررة، وهي مفيدة بشكل خاص لسير عمل الوكلاء (Agent) التي تحتوي على أجزاء مشتركة أو تتطلب تصحيح أخطاء متكرر. يمكن للمستخدمين استخدام التخزين المؤقت في واجهة برمجة التطبيقات الأمرية أو واجهة برمجة التطبيقات الرسومية، مما يتيح لهم تكرار وتحسين تطبيقات الذكاء الاصطناعي الخاصة بهم بشكل أسرع. هذا هو التحديث الأول ضمن سلسلة تحديثات إصدار LangGraph مفتوح المصدر لهذا الأسبوع. (المصدر: hwchase17)

Sakana AI تطلق بنية ذكاء اصطناعي جديدة “آلات التفكير المستمر” (CTM): أطلقت شركة Sakana AI الناشئة في طوكيو بنية نموذج ذكاء اصطناعي جديدة تسمى “آلات التفكير المستمر” (Continuous Thought Machines, CTM). تهدف CTM إلى تمكين النماذج من التفكير مثل الدماغ البشري، مع قدرة على الاستدلال بتوجيه أقل. قد توفر هذه البنية الجديدة أفكارًا جديدة لمواجهة التحديات الحالية التي تواجهها نماذج الذكاء الاصطناعي في الاستدلال المعقد والتعلم الذاتي. (المصدر: dl_weekly)
مايكروسوفت و Nvidia تعمقان التعاون في مجال RTX AI PC، و TensorRT يصل إلى Windows ML: خلال مؤتمري مايكروسوفت Build و Computex في تايبيه، أعلنت Nvidia ومايكروسوفت عن تعزيز تعاونهما في تطوير RTX AI PC. تم إعادة تصميم مكتبة تحسين الاستدلال TensorRT من Nvidia ودمجها في مكدس الاستدلال الجديد من مايكروسوفت Windows ML. يهدف هذا الإجراء إلى تبسيط عملية تطوير تطبيقات الذكاء الاصطناعي والاستفادة الكاملة من أداء ذروة وحدات معالجة الرسومات RTX في مهام الذكاء الاصطناعي على أجهزة الكمبيوتر الشخصية، مما يدفع إلى تعميم وتطبيق الذكاء الاصطناعي على أجهزة الحوسبة الشخصية. (المصدر: nvidia)
Bilibili تفتح مصدر نموذج توليد الفيديو المتحرك Index-AniSora، ويحقق أداءً متطورًا (SOTA) في العديد من المؤشرات: أعلنت Bilibili عن فتح مصدر نموذجها الخاص لتوليد الفيديو المتحرك Index-AniSora، والذي تم نشره في IJCAI 2025. تم تصميم AniSora خصيصًا لتوليد مقاطع الفيديو ثنائية الأبعاد، ويدعم أنماطًا متعددة مثل مسلسلات الأنمي، والرسوم المتحركة الصينية، وتعديلات المانجا، ويمكنه تحقيق تحكم دقيق مثل توجيه مناطق معينة في الفيديو، والتوجيه الزمني (مثل توجيه الإطار الأول/الأخير، وإقحام الإطارات الرئيسية). يتضمن محتوى المشروع مفتوح المصدر كود التدريب والاستدلال لـ AniSoraV1.0 المستند إلى CogVideoX-5B و AniSoraV2.0 المستند إلى Wan2.1-14B، وأدوات بناء مجموعات بيانات التدريب، ونظام قياس معياري مخصص للرسوم المتحركة، ونموذج AniSoraV1.0_RL المحسن باستخدام التعلم المعزز القائم على التفضيلات البشرية. (المصدر: WeChat)

Tencent Hunyuan تفتح مصدر أول نموذج مكافأة CoT موحد متعدد الوسائط UnifiedReward-Think: قدمت Tencent Hunyuan بالتعاون مع Shanghai AI Lab وجامعة فودان ومؤسسات أخرى UnifiedReward-Think، وهو أول نموذج مكافأة موحد متعدد الوسائط يتمتع بقدرة على الاستدلال المتسلسل الطويل (CoT). يهدف هذا النموذج إلى تمكين نماذج المكافآت من “تعلم التفكير” عند تقييم مهام التوليد والفهم البصري المعقدة، وبالتالي تحسين دقة التقييم، والقدرة على التعميم عبر المهام، وقابلية تفسير الاستدلال. تم فتح مصدر المشروع بالكامل، بما في ذلك النموذج ومجموعات البيانات ونصوص التدريب وأدوات التقييم. (المصدر: WeChat)
علي بابا تفتح مصدر نموذج توليد وتحرير الفيديو Tongyi Wanxiang Wan2.1-VACE: فتحت علي بابا رسميًا مصدر نموذجها لتوليد وتحرير الفيديو Tongyi Wanxiang Wan2.1-VACE. يتمتع هذا النموذج بوظائف متعددة مثل تحويل النص إلى فيديو، وتوليد الفيديو بالاستناد إلى الصور، وإعادة رسم الفيديو، وتحرير أجزاء معينة من الفيديو، وتوسيع خلفية الفيديو، وتمديد مدة الفيديو. تم فتح مصدر نسختين هذه المرة، 1.3B و 14B، حيث يمكن تشغيل نسخة 1.3B على بطاقات الرسومات الاستهلاكية، بهدف خفض عتبة إنشاء مقاطع الفيديو باستخدام الذكاء الاصطناعي التوليدي (AIGC). (المصدر: WeChat)
ByteDance تطلق نموذج اللغة المرئية Seed1.5-VL، ويتصدر العديد من اختبارات القياس: قامت ByteDance ببناء نموذج اللغة المرئية Seed1.5-VL، الذي يتكون من مُرمِّز مرئي بمعلمات 532M ونموذج لغوي كبير (LLM) من نوع خليط الخبراء (MoE) بمعلمات نشطة 20B. على الرغم من بنيته المدمجة نسبيًا، فقد حقق أداءً متطورًا (SOTA) في 38 من أصل 60 اختبار قياس عام، وتفوق على نماذج مثل OpenAI CUA و Claude 3.7 في المهام التي تركز على الوكلاء مثل التحكم في واجهة المستخدم الرسومية (GUI) وأسلوب اللعب، مما أظهر قدرات استدلال متعددة الوسائط قوية. (المصدر: WeChat)
MiniMax تطلق نموذج TTS ذاتي الانحدار MiniMax-Speech، يدعم استنساخ الصوت بدون عينات لـ 32 لغة: قدمت MiniMax نموذج تحويل النص إلى كلام (TTS) ذاتي الانحدار يعتمد على Transformer، وهو MiniMax-Speech. يمكن لهذا النموذج استخلاص ميزات جودة الصوت من الصوت المرجعي دون الحاجة إلى نسخ، مما يحقق توليد صوت متوافق مع جودة الصوت المرجعية وغني بالتعبير بطريقة بدون عينات، ويدعم استنساخ الصوت بعينة واحدة. تم تحسين جودة الصوت المركب من خلال تقنية Flow-VAE، ويدعم 32 لغة. حقق هذا النموذج مستوى SOTA في مؤشرات استنساخ الصوت الموضوعية، وتصدر قائمة TTS Arena العامة، ويمكن توسيعه ليشمل تطبيقات مثل التحكم في المشاعر الصوتية، وتحويل النص إلى صوت، واستنساخ الصوت الاحترافي. (المصدر: WeChat)
إطلاق OuteTTS 1.0 (0.6B)، نموذج TTS مفتوح المصدر بترخيص Apache 2.0 يدعم 14 لغة: أطلقت OuteAI نموذج OuteTTS-1.0-0.6B، وهو نموذج خفيف لتحويل النص إلى كلام (TTS) مبني على Qwen-3 0.6B. يستخدم هذا النموذج ترخيص Apache 2.0 ويدعم 14 لغة بما في ذلك الصينية والإنجليزية واليابانية والكورية. تدعم مكتبة الاستدلال بلغة Python الخاصة به OuteTTS v0.4.2 الاستدلال الدفعي غير المتزامن لـ EXL2، والاستدلال الدفعي التجريبي لـ vLLM، والمعالجة الدفعية المستمرة واستدلال النماذج من عناوين URL خارجية لخادم Llama.cpp. أظهرت اختبارات الأداء على وحدة معالجة رسومات NVIDIA L40S واحدة أن vLLM OuteTTS-1.0-0.6B FP8 يمكن أن يصل إلى RTF (عامل الوقت الحقيقي) 0.05 بحجم دفعة 32. تتوفر أوزان النموذج (ST, GGUF, EXL2, FP8) على Hugging Face. (المصدر: Reddit r/LocalLLaMA)

Hugging Face ومايكروسوفت Azure تعمقان التعاون، وأكثر من 10,000 نموذج مفتوح المصدر تصل إلى Azure AI Foundry: في مؤتمر مايكروسوفت Build، أعلن الرئيس التنفيذي ساتيا ناديلا عن توسيع التعاون مع Hugging Face. يتوفر حاليًا أكثر من 11,000 من النماذج مفتوحة المصدر الأكثر شيوعًا عبر Hugging Face على Azure AI Foundry، مما يسهل على المستخدمين نشرها. تعمل هذه الخطوة على إثراء نظام Azure البيئي للذكاء الاصطناعي، وتوفر للمطورين المزيد من خيارات النماذج وتجربة تطوير أكثر سهولة. (المصدر: ClementDelangue, _akhaliq)

إنتل تطلق سلسلة وحدات معالجة الرسومات Arc Pro B50/B60، تستهدف أسواق الذكاء الاصطناعي ومحطات العمل، نسخة 24GB بحوالي 500 دولار: أعلنت إنتل في Computex عن بطاقات رسومات احترافية جديدة من سلسلة Arc Pro B، بما في ذلك Arc Pro B50 (ذاكرة 16GB، حوالي 299 دولارًا) و Arc Pro B60 (ذاكرة 24GB، حوالي 500 دولار). من بينها، تم أيضًا الكشف عن حل محطة عمل “Project Battlematrix” الذي يتكون من وحدتي معالجة رسومات B60 بذاكرة إجمالية 48GB، ومن المتوقع أن يكون سعره أقل من 1000 دولار. تهدف هذه المنتجات إلى توفير حلول فعالة من حيث التكلفة للحوسبة بالذكاء الاصطناعي ومحطات العمل الاحترافية، خاصة وأن تكوينات الذاكرة العالية جذابة لتشغيل نماذج لغوية كبيرة محليًا. من المتوقع طرح المنتجات الجديدة في الربع الثالث من هذا العام، مبدئيًا من خلال مصنعي المعدات الأصلية (OEM)، وقد يتم إطلاق إصدارات DIY في الربع الرابع. (المصدر: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 الأدوات
Moondream Station تطلق إصدار Linux، لتبسيط تشغيل Moondream محليًا: أعلنت Moondream Station، وهي أداة تهدف إلى تبسيط تشغيل Moondream (نموذج لغة مرئية) على الأجهزة المحلية، عن دعمها الآن لنظام التشغيل Linux. هذا يعني أن مستخدمي Linux يمكنهم نشر واستخدام نماذج Moondream بسهولة أكبر لإجراء تجارب وتطبيقات الذكاء الاصطناعي متعددة الوسائط. (المصدر: vikhyatk)
Flowith تطلق الوكيل الذكي اللامحدود NEO، يدعم خطوات وسياق واستدعاء أدوات لا محدودة: أطلقت شركة تطبيقات الذكاء الاصطناعي Flowith أحدث منتجاتها من الوكلاء الذكيين NEO، والذي يُزعم أنه أول وكيل ذكي في العالم يدعم خطوات لا محدودة، وسياق لا محدود، واستدعاء أدوات لا محدود. تم تصميم هذا الوكيل الذكي للعمل لفترات طويلة في السحابة، ويتمتع بمستوى ذكاء يتجاوز المعايير، ويدعي أنه بدون تكلفة وبدون قيود. قد يمثل هذا الإطلاق تقدمًا جديدًا في قدرة وكلاء الذكاء الاصطناعي على التعامل مع المهام المعقدة طويلة الأجل ودمج القدرات الخارجية. (المصدر: _akhaliq, op7418)

Kapa AI تستخدم Weaviate لبناء أداة “Ask AI” التفاعلية للاستعلام عن الوثائق التقنية: طورت Kapa AI أداة ذكية صغيرة تسمى “Ask AI”، تسمح للمستخدمين بالاستعلام عن كامل قاعدة المعرفة التقنية، بما في ذلك الوثائق التقنية والمدونات والبرامج التعليمية ومشكلات GitHub والمنتديات، من خلال الحوار بلغة طبيعية. لتحقيق بحث دلالي فعال واسترجاع المعرفة، اعتمدت Kapa AI على قاعدة بيانات المتجهات Weaviate، نظرًا لقدراتها المدمجة في البحث المختلط، وتوافقها مع Docker، وميزات تعدد المستأجرين، لدعم النمو السريع للمستخدمين وحجم البيانات. (المصدر: bobvanluijt)

مطور يستخدم Gemini Flash لبناء أداة MVP سريعة لتحويل لقطات الشاشة إلى HTML: استخدم المطور دانيال هوينه نموذج Gemini Flash من Google AI لبناء أداة MVP (منتج قابل للتطبيق كحد أدنى) في عطلة نهاية أسبوع واحدة، يمكنها تحويل لقطات الشاشة من التصاميم أو المنتجات المنافسة أو الأفكار الملهمة بسرعة إلى كود HTML. تم توفير الأداة للتجربة مجانًا على Hugging Face Spaces، مما يوضح إمكانات النماذج متعددة الوسائط في المساعدة على تطوير الواجهة الأمامية. (المصدر: osanseviero, _akhaliq)
خدمة Azure AI Foundry Agent متاحة رسميًا، مع دمج LlamaIndex: أعلنت مايكروسوفت أن خدمة Azure AI Foundry Agent أصبحت متاحة رسميًا (GA)، وتوفر دعمًا من الدرجة الأولى لـ LlamaIndex. تهدف هذه الخدمة إلى مساعدة عملاء الشركات على بناء مساعدي دعم العملاء، وروبوتات أتمتة العمليات، وأنظمة متعددة الوكلاء، وحلول تتكامل بأمان مع بيانات وأدوات الشركة، مما يدفع عجلة تطوير وتطبيق وكلاء الذكاء الاصطناعي على مستوى الشركات. (المصدر: jerryjliu0)
tinygrad: إطار عمل تعلم عميق مبسط للغاية يقع بين PyTorch و micrograd: tinygrad هو إطار عمل تعلم عميق يتمحور حول مفهوم البساطة في التصميم، ويهدف إلى أن يكون أسهل إطار عمل لإضافة مسرعات جديدة، ويدعم الاستدلال والتدريب. يدعم نماذج مثل LLaMA و Stable Diffusion، ويستخدم التقييم الكسول (lazy evaluation) لدمج العمليات وتحسين الأداء. يدعم tinygrad مسرعات متعددة مثل GPU (OpenCL) و CPU (كود C) و LLVM و Metal و CUDA وغيرها. يتميز كوده بالبساطة، حيث يتم تنفيذ الوظائف الأساسية بواسطة عدد قليل من أسطر الكود، مما يسهل على المطورين فهمه وتوسيعه. (المصدر: GitHub Trending)
بحث نانو AI يطلق ميزة “البحث الفائق”، يدمج نماذج متعددة وصندوق أدوات MCP: أضاف بحث نانو AI (bot.n.cn) ميزة “البحث الفائق”، التي تهدف إلى توفير قدرات أعمق للحصول على المعلومات ومعالجتها. تدمج هذه الميزة مئات النماذج اللغوية الكبيرة من داخل وخارج الصين، ويمكنها التبديل بينها تلقائيًا حسب الحاجة؛ وتحتوي على صندوق أدوات MCP متعدد الاستخدامات، يدعم آلاف أدوات الذكاء الاصطناعي، ويمكنه معالجة صفحات الويب والصور ومقاطع الفيديو وملفات PDF وغيرها من تنسيقات الملفات، بالإضافة إلى توليد الأكواد وتحليل البيانات. وفي الوقت نفسه، يجمع بين البحث العام والبحث الخاص في قواعد المعرفة المحلية، لتقديم نتائج أكثر شمولاً، ويتضمن قدرات مدمجة لتحويل النص إلى صورة وتحويل النص إلى فيديو. تُظهر تجربة المستخدم أن هذه الميزة يمكنها تنظيم نتائج البحث في تقارير مفصلة تحتوي على رسوم بيانية وصفحات ويب جذابة، وهي مناسبة لمجموعة متنوعة من السيناريوهات مثل أبحاث السوق ومقارنة أسعار التسوق وتنظيم المعرفة. (المصدر: WeChat)
Clara: مساحة عمل ذكاء اصطناعي معيارية وغير متصلة بالإنترنت، تدمج LLM و Agent والأتمتة وتوليد الصور: أطلق مطورون مشروعًا مفتوح المصدر يسمى Clara، يهدف إلى إنشاء مساحة عمل ذكاء اصطناعي معيارية وغير متصلة بالإنترنت بالكامل. يمكن للمستخدمين تنظيم محادثات LLM المحلية (تدعم RAG والصور والمستندات وتنفيذ الأكواد، ومتوافقة مع Ollama وواجهات برمجة تطبيقات OpenAI المشابهة) على لوحة القيادة كأدوات مصغرة، وإنشاء وكلاء (Agents) بذاكرة ومنطق، وتشغيل عمليات أتمتة (توفر أكثر من 1000 قالب مجاني) من خلال تكامل N8N الأصلي، بالإضافة إلى استخدام Stable Diffusion (ComfyUI) لتوليد الصور محليًا. يوفر Clara إصدارات لأنظمة Mac و Windows و Linux، ويهدف إلى حل مشكلة تنقل المستخدمين المتكرر بين أدوات الذكاء الاصطناعي المتعددة، وتحقيق عمليات ذكاء اصطناعي شاملة في مكان واحد. (المصدر: Reddit r/LocalLLaMA)
AI Playlist Curator: أداة Python تستخدم LLM لتنظيم قوائم تشغيل YouTube بشكل شخصي: أنشأ مطور مشروع Python يسمى AI Playlist Curator، يهدف إلى مساعدة المستخدمين على تنظيم قوائم تشغيل YouTube الضخمة وغير المنظمة تلقائيًا. تستخدم هذه الأداة LLM لتصنيف الأغاني وإنشاء قوائم تشغيل فرعية مخصصة بناءً على تفضيلات المستخدم، وتدعم معالجة أي قوائم تشغيل محفوظة وأغانٍ مفضلة. تم فتح مصدر المشروع على GitHub، ويأمل المطور في الحصول على ملاحظات من المجتمع لمزيد من التحسين. (المصدر: Reddit r/MachineLearning)
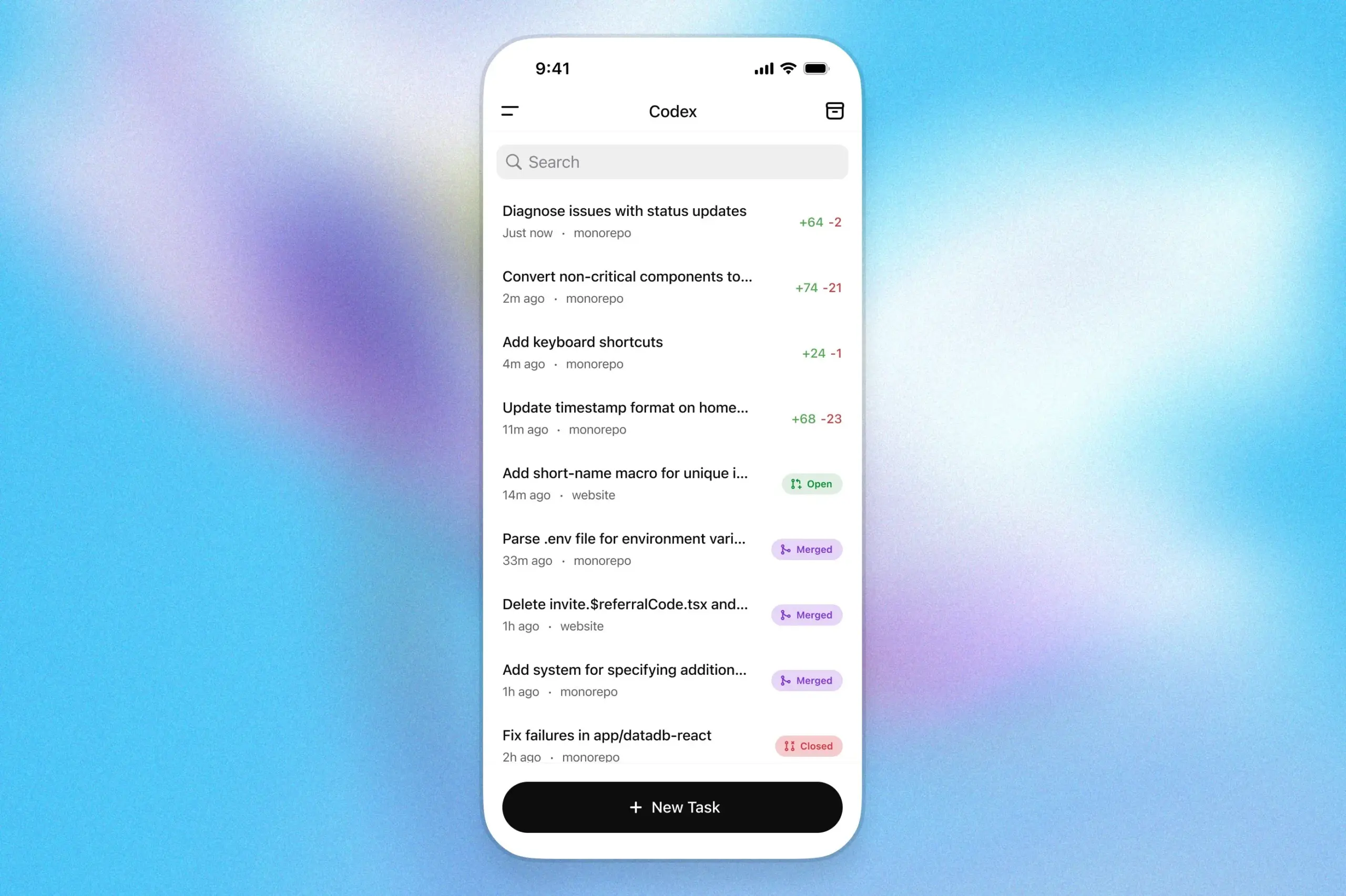
مساعد البرمجة OpenAI Codex يصل إلى تطبيق ChatGPT على iOS: أعلنت OpenAI أن مساعد البرمجة الخاص بها Codex مدمج الآن في تطبيق ChatGPT على نظام iOS. يمكن للمستخدمين بدء مهام برمجة جديدة على الأجهزة المحمولة، وعرض فروق الأكواد، وطلب تعديلات، وحتى إرسال طلبات السحب (PR). تدعم هذه الميزة أيضًا تتبع تقدم Codex في الوقت الفعلي من خلال الأنشطة الحية على شاشة القفل، مما يسهل على المستخدمين التبديل بسلاسة بين الأجهزة المختلفة أثناء العمل. (المصدر: openai)
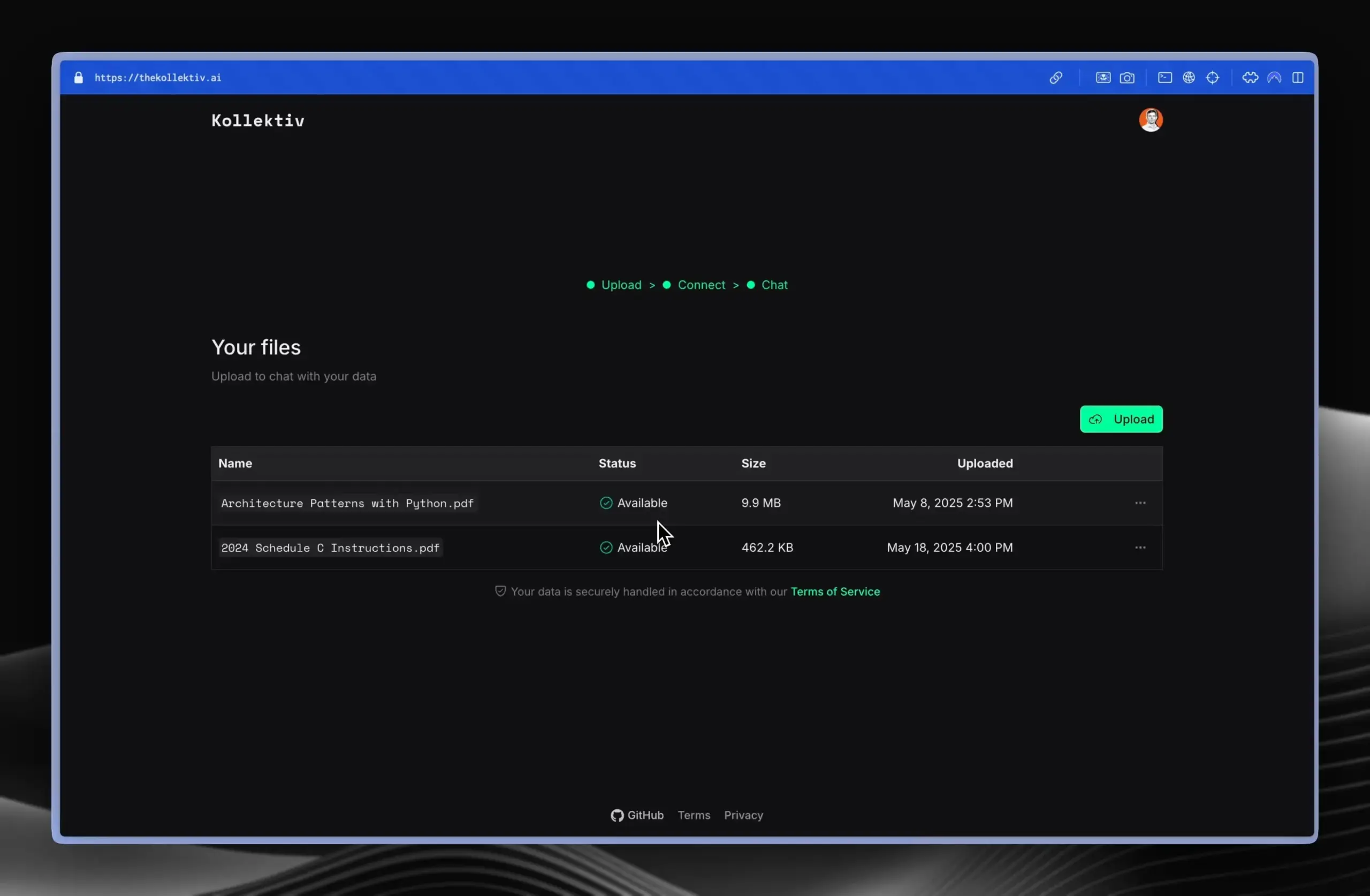
Kollektiv: أداة تستخدم بروتوكول MCP لحل مشكلة تكرار لصق السياق في محادثات LLM: أطلق مطورون أداة Kollektiv، التي تهدف إلى حل مشكلة حاجة المستخدمين إلى تكرار نسخ ولصق كميات كبيرة من السياق (مثل الأوراق البحثية، ووثائق SDK، والملاحظات الشخصية، ومحتوى الكتب) عند الدردشة مع نماذج LLM (مثل Claude). يسمح Kollektiv للمستخدمين بتحميل مصادر هذه المستندات مرة واحدة، واستدعائها عند الحاجة من أي بيئة تطوير متكاملة (IDE) متوافقة أو عميل MCP (مثل Cursor, Windsurf, PyCharm وغيرها) من خلال خادم MCP (Model Control Protocol). يتولى خادم MCP مسؤولية مصادقة المستخدم، وعزل البيانات، وتدفق البيانات عند الطلب إلى واجهة الدردشة. لا يُنصح حاليًا باستخدام هذه الأداة للمواد الحساسة أو السرية. (المصدر: Reddit r/ClaudeAI)
📚 دراسات وأبحاث
DeepMind من جوجل تنشر تقريرًا تقنيًا عن AlphaEvolve، يكشف عن قدراته في اكتشاف الخوارزميات: نشرت DeepMind من جوجل تقريرًا تقنيًا حول نظام الذكاء الاصطناعي الخاص بها AlphaEvolve. AlphaEvolve هو وكيل ترميز يعتمد على Gemini، قادر على تصميم وتحسين الخوارزميات من خلال الخوارزميات التطورية. يشرح التقرير بالتفصيل كيف يقوم AlphaEvolve بشكل مستقل بتوليد وتقييم وتحسين حلول الخوارزميات المرشحة من خلال حلقة ملاحظات منظمة، مما أدى إلى تحقيق اختراقات في العديد من مسائل الرياضيات وعلوم الحاسوب، بما في ذلك تحطيم الرقم القياسي لخوارزمية ضرب المصفوفات المعقدة 4×4. يوفر هذا التقرير مرجعًا مهمًا لفهم إمكانات الذكاء الاصطناعي في الاكتشاف العلمي الآلي وابتكار الخوارزميات. (المصدر: , HuggingFace Daily Papers)
DeepLearning.AI تطلق دورة “بناء وكلاء متصفح الذكاء الاصطناعي”: أطلقت DeepLearning.AI دورة جديدة بعنوان “Building AI Browser Agents”. يقدم هذه الدورة المؤسسان المشاركان لشركة AGI، ديف جارج ونامان أغاروال، وتهدف إلى مساعدة المتعلمين على إتقان تقنيات بناء وكلاء ذكاء اصطناعي (Agent) قادرين على التفاعل مع المتصفح. قد يشمل محتوى الدورة أتمتة الويب، واستخلاص المعلومات، والتفاعل مع واجهة المستخدم، وغيرها من تطبيقات الذكاء الاصطناعي في بيئة المتصفح. (المصدر: DeepLearningAI)
نشر التقرير التقني لـ Qwen3: نشرت علي بابا التقرير التقني لأحدث جيل من نماذجها اللغوية الكبيرة Qwen3. يشرح هذا التقرير بالتفصيل بنية نموذج Qwen3، وطرق تدريبه، وتقييم أدائه، وأداءه في مختلف اختبارات القياس. تهدف سلسلة نماذج Qwen3 إلى توفير قدرات أقوى في فهم اللغة وتوليدها ومعالجة الوسائط المتعددة، ويوفر نشر تقريرها التقني للباحثين والمطورين فرصة لفهم تفاصيل تقنية هذا النموذج بعمق. (المصدر: _akhaliq)

مناقشة بحثية: البحث متعدد وجهات النظر وإدارة البيانات يعززان إثبات النظريات التدريجي (MPS-Prover): تقدم ورقة بحثية جديدة MPS-Prover، وهو نظام جديد لإثبات النظريات الآلي التدريجي (ATP). يتغلب هذا النظام على مشكلة التوجيه المتحيز للبحث في مُثبتات النظريات التدريجية الحالية من خلال استراتيجية فعالة لإدارة البيانات بعد التدريب (تقليم حوالي 40% من البيانات الزائدة دون المساس بالأداء) وآلية بحث شجري متعددة وجهات النظر (تدمج نموذج الناقد المتعلم مع القواعد الاستدلالية). أظهرت التجارب أن MPS-Prover يحقق أداءً متطورًا (SOTA) على العديد من المعايير مثل miniF2F و ProofNet، وينتج براهين أقصر وأكثر تنوعًا. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: التخطيط البصري – التفكير باستخدام الصور فقط (Visual Planning): تقترح ورقة بحثية جديدة نموذج “التخطيط البصري”، الذي يمكّن النماذج من التخطيط بالكامل من خلال التمثيلات المرئية (تسلسل الصور)، بدلاً من الاعتماد على النص. يعتقد الباحثون أنه في المهام التي تتضمن معلومات مكانية وهندسية، قد لا تكون اللغة هي الوسيط الأكثر طبيعية للاستدلال. لقد قدموا إطار عمل التخطيط البصري VPRL من خلال التعلم المعزز، واستخدموا GRPO لتحسين النماذج المرئية الكبيرة بعد التدريب، وحققوا تحسينات كبيرة في مهام الملاحة المرئية مثل FrozenLake و Maze و MiniBehavior، متفوقين على متغيرات التخطيط التي تعتمد على الاستدلال النصي البحت. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: توسيع نطاق الاستدلال يمكن أن يحسن واقعية نماذج اللغة الكبيرة (Scaling Reasoning can Improve Factuality): تستكشف دراسة ما إذا كان توسيع نطاق عملية الاستدلال لنماذج اللغة الكبيرة (LLM) يمكن أن يحسن دقتها الواقعية في الإجابة على الأسئلة المعقدة ذات المجال المفتوح (QA). استخلص الباحثون مسارات الاستدلال من نماذج مثل QwQ-32B و DeepSeek-R1-671B، وقاموا بضبط دقيق لأنواع متعددة من نماذج سلسلة Qwen2.5، مع دمج مسارات الرسم البياني المعرفي في مسارات الاستدلال. أظهرت التجارب أنه في التشغيل لمرة واحدة، أظهرت نماذج الاستدلال الأصغر تحسنًا ملحوظًا في الدقة الواقعية مقارنة بنماذج الضبط الدقيق للتعليمات الأصلية. مع زيادة الحسابات في وقت الاختبار وميزانية الـ tokens، يمكن أن تتحسن الدقة الواقعية بشكل ثابت بنسبة 2-8%. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: Mergenetic – مكتبة بسيطة لدمج النماذج التطورية: تقدم ورقة بحثية جديدة Mergenetic، وهي مكتبة مفتوحة المصدر لدمج النماذج التطورية. يسمح دمج النماذج بدمج قدرات النماذج الحالية في نماذج جديدة، دون الحاجة إلى تدريب إضافي. يدعم Mergenetic الجمع بسهولة بين طرق الدمج والخوارزميات التطورية، ويجمع بين مقيمات اللياقة خفيفة الوزن لتقليل تكلفة التقييم. أثبتت التجارب أن Mergenetic ينتج نتائج تنافسية في مهام ولغات متعددة باستخدام أجهزة متواضعة. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: التفكير الجماعي – وكلاء استدلال متزامنين متعددين يتعاونون على مستوى الـ Token (Group Think): تقترح ورقة بحثية جديدة “التفكير الجماعي” (Group Think) – جعل نموذج LLM واحد يعمل كعدة وكلاء استدلال متزامنين (مفكرين). يتشارك هؤلاء الوكلاء رؤية لتقدم بعضهم البعض الجزئي في التوليد، ويتكيفون ديناميكيًا مع مسارات استدلال بعضهم البعض على مستوى الـ Token، مما يقلل من الاستدلال الزائد، ويحسن الجودة، ويقلل من زمن الانتقال. هذه الطريقة مناسبة للاستدلال الطرفي على وحدات معالجة الرسومات المحلية، وأثبتت التجارب أنها تحسن زمن الانتقال حتى عند استخدام نماذج LLM مفتوحة المصدر غير مدربة خصيصًا. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: البشر يتوقعون العقلانية والتعاون من خصوم LLM في الألعاب الاستراتيجية (Humans expect rationality and cooperation from LLM opponents): درست تجربة مختبرية محكومة ذات حوافز نقدية لأول مرة الاختلافات في سلوك البشر عند مواجهة بشر آخرين مقابل نماذج LLM في مسابقة P-beauty متعددة اللاعبين. أظهرت النتائج أن البشر يختارون أرقامًا أقل بكثير عند مواجهة نماذج LLM، ويرجع ذلك أساسًا إلى زيادة انتشار اختيار توازن ناش “صفر”. هذا التحول مدفوع بشكل أساسي بالمشاركين ذوي القدرات العالية في الاستدلال الاستراتيجي، الذين يعتقدون أن نماذج LLM تتمتع بقدرات استدلال أقوى وميول تعاونية. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: تقطير المعرفة شبه المراقب البسيط من نماذج اللغة المرئية من خلال التحسين ثنائي الرأس (Dual-Head Optimization for KD): تقترح ورقة بحثية جديدة DHO (Dual-Head Optimization)، وهو إطار عمل بسيط وفعال لتقطير المعرفة (KD) لنقل المعرفة من نماذج اللغة المرئية (VLM) إلى نماذج مدمجة خاصة بالمهام في إعداد شبه مراقب. يقدم DHO رأسي تنبؤ مستقلين لتعلم البيانات المصنفة وتنبؤات المعلم، ويجمع مخرجاتهما خطيًا في وقت الاستدلال، مما يخفف من تضارب التدرجات بين الإشارة المراقبة وإشارة التقطير. أظهرت التجارب أن DHO يتفوق على خطوط الأساس لـ KD أحادي الرأس في مجالات متعددة ومجموعات بيانات دقيقة، ويحقق أداءً متطورًا (SOTA) على ImageNet. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: GuardReasoner-VL – حماية نماذج VLM من خلال الاستدلال المعزز: لتعزيز أمان نماذج اللغة المرئية (VLM)، تقدم ورقة بحثية جديدة نموذج حماية VLM يعتمد على الاستدلال، GuardReasoner-VL. الفكرة الأساسية هي تحفيز نموذج الحماية على إجراء استدلال مدروس قبل اتخاذ قرارات التدقيق من خلال التعلم المعزز عبر الإنترنت (RL). قام الباحثون ببناء مجموعة بيانات استدلال GuardReasoner-VLTrain تحتوي على 123 ألف عينة و 631 ألف خطوة استدلال، وقاموا ببدء تشغيل قدرات الاستدلال للنموذج من خلال الضبط الدقيق المراقب (SFT)، ثم عززوها بشكل أكبر من خلال RL عبر الإنترنت. أظهرت التجارب أن هذا النموذج (تم فتح مصدر نسختي 3B/7B) يتمتع بأداء متفوق، حيث يتفوق على النموذج الأفضل التالي بنسبة 19.27% في متوسط درجة F1. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: التنبؤ متعدد الـ Tokens يحتاج إلى مسجلات (Multi-Token Prediction Needs Registers): تقترح ورقة بحثية جديدة MuToR، وهي طريقة بسيطة وفعالة للتنبؤ متعدد الـ Tokens، من خلال إدخال Tokens مسجلة قابلة للتعلم بشكل متداخل في تسلسل الإدخال للتنبؤ بالأهداف المستقبلية. مقارنة بالطرق الحالية، فإن زيادة معلمات MuToR لا تذكر، ولا تتطلب تغييرات في البنية، ومتوافقة مع النماذج المدربة مسبقًا الحالية، وتحافظ على التوافق مع هدف التدريب المسبق للـ Token التالي، وهي مناسبة بشكل خاص للضبط الدقيق المراقب. أظهرت هذه الطريقة فعاليتها وعموميتها في مهام التوليد في مجالي اللغة والرؤية. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: MMLongBench – اختبار معياري فعال وشامل لنماذج اللغة المرئية ذات السياق الطويل: لتلبية احتياجات تقييم نماذج اللغة المرئية ذات السياق الطويل (LCVLM)، تقدم ورقة بحثية جديدة MMLongBench، وهو أول معيار يغطي مجموعة متنوعة من مهام اللغة المرئية ذات السياق الطويل. يتضمن MMLongBench عينة 13331، تغطي خمس فئات من المهام مثل RAG المرئي و ICL متعدد العينات، ويوفر أنواعًا متعددة من الصور. يتم توفير جميع العينات بخمسة أطوال إدخال موحدة من 8K إلى 128K Token. من خلال اختبار 46 نموذج LCVLM مغلق المصدر ومفتوح المصدر، وجد البحث أن أداء المهمة الواحدة لا يمثل القدرة الكلية للسياق الطويل، وأن النماذج الحالية لا يزال لديها مجال كبير للتحسين، وأن النماذج ذات القدرات الاستدلالية القوية غالبًا ما يكون أداؤها أفضل في السياق الطويل. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: MatTools – اختبار معياري لنماذج اللغة الكبيرة لأدوات علوم المواد: تقترح ورقة بحثية جديدة معيار MatTools، لتقييم قدرة نماذج اللغة الكبيرة (LLM) على الإجابة على أسئلة علوم المواد من خلال توليد وتنفيذ آمن لكود حزم برامج علوم المواد الحاسوبية القائمة على الفيزياء. يتضمن MatTools معيارًا للإجابة على أسئلة أدوات محاكاة المواد (QA) (يعتمد على pymatgen، ويحتوي على 69225 زوجًا من الأسئلة والأجوبة) ومعيارًا لاستخدام الأدوات في العالم الحقيقي (يحتوي على 49 مهمة و 138 مهمة فرعية). كشف تقييم العديد من نماذج LLM أن: النماذج العامة تتفوق على النماذج المتخصصة؛ الذكاء الاصطناعي يفهم الذكاء الاصطناعي بشكل أفضل؛ الطرق البسيطة أكثر فعالية. (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: إطار عمل عالمي للعلامات المائية التكافلية، يوازن بين متانة علامات LLM المائية وجودة النص والأمان: لمعالجة مشكلة الموازنة بين المتانة وجودة النص والأمان في مخططات العلامات المائية الحالية لنماذج اللغة الكبيرة (LLM)، تقترح ورقة بحثية جديدة إطار عمل عالمي للعلامات المائية التكافلية. يدمج هذا الإطار الطرق القائمة على الـ logits والطرق القائمة على أخذ العينات، ويصمم ثلاث استراتيجيات: تسلسلية ومتوازية ومختلطة. يستفيد الإطار المختلط من إنتروبيا الـ Token والإنتروبيا الدلالية لتضمين العلامات المائية بشكل تكيفي، بهدف تحسين الأداء من جميع الجوانب. أظهرت التجارب أن هذه الطريقة تتفوق على خطوط الأساس الحالية وتحقق أداءً متطورًا (SOTA). (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: CheXGenBench – معيار موحد لدقة وخصوصية وفائدة صور الأشعة السينية الاصطناعية للصدر: تقدم ورقة بحثية جديدة CheXGenBench، وهو إطار عمل متعدد الجوانب لتقييم توليد صور الأشعة السينية الاصطناعية للصدر، مع تقييم الدقة ومخاطر الخصوصية والفائدة السريرية في نفس الوقت. يتضمن هذا الإطار أقسام بيانات موحدة وبروتوكول تقييم موحد (أكثر من 20 مقياسًا كميًا)، ويحلل جودة التوليد والثغرات الأمنية المحتملة والملاءمة السريرية النهائية لـ 11 بنية رائدة لتحويل النص إلى صورة. وجد البحث أن بروتوكولات التقييم الحالية تعاني من أوجه قصور في تقييم دقة التوليد. أصدر الفريق أيضًا مجموعة بيانات اصطناعية عالية الجودة SynthCheX-75K. (المصدر: HuggingFace Daily Papers)
وفاة بيتر لاكس، مؤلف الكتاب الدراسي الكلاسيكي “التحليل الدالي”، عن عمر يناهز 99 عامًا: توفي بيتر لاكس، عملاق الرياضيات التطبيقية وأول عالم رياضيات تطبيقية يحصل على جائزة آبل، عن عمر يناهز 99 عامًا. اشتهر لاكس بتأليفه الكتاب الدراسي الكلاسيكي “التحليل الدالي”، وقدم مساهمات تأسيسية في مجالات المعادلات التفاضلية الجزئية، وميكانيكا الموائع، والحساب العددي، مثل نظرية لاكس للتكافؤ، وطرق لاكس-فريدريش ولاكس-فيندروف. كان أيضًا من أوائل الرواد الذين طبقوا تكنولوجيا الكمبيوتر على التحليل الرياضي، وأثر عمله بعمق في تطور الرياضيات في عصر الكمبيوتر. (المصدر: 量子位)

نائبة الرئيس الصينية السابقة في OpenAI، ليليان وينغ، تنشر مقالًا مطولًا بعنوان “Why We Think”، يناقش الحوسبة في وقت الاختبار وسلسلة الأفكار: نشرت ليليان وينغ، نائبة الرئيس الصينية السابقة في OpenAI، مقالًا مطولًا بعنوان “Why We Think”، ناقشت فيه بعمق كيف أن تقنيات مثل “الحوسبة في وقت الاختبار” (Test-time Compute) و “سلسلة الأفكار” (Chain-of-Thought, CoT) تعزز بشكل كبير أداء وذكاء نماذج اللغة الكبيرة. يشبه المقال نظرية النظام المزدوج “التفكير السريع والبطيء” للتفكير البشري، ويشير إلى أن جعل النموذج “يفكر” أكثر قبل الإخراج (مثل من خلال فك التشفير الذكي، واستدلال CoT، والنمذجة الكامنة للمتغيرات، وما إلى ذلك) يمكن أن يتجاوز عنق الزجاجة الحالي للقدرات. يستعرض المقال بالتفصيل التقدم والتحديات في العديد من اتجاهات البحث مثل التفكير القائم على الـ Token، وأخذ العينات المتوازية والمراجعة التسلسلية، والتعلم المعزز ودمج الأدوات الخارجية، ووفاء الأفكار، والتفكير في الفضاء المستمر. (المصدر: 量子位)

جامعة هاربين للتكنولوجيا وجامعة بنسلفانيا تطلقان PointKAN، وهو حل جديد لتحليل سحابة النقاط يعتمد على KANs ويحقق أداءً متطورًا (SOTA): أطلق فريق بحثي من جامعة هاربين للتكنولوجيا (شنتشن) وجامعة بنسلفانيا PointKAN، وهو حل لتحليل سحابة النقاط ثلاثية الأبعاد يعتمد على Kolmogorov-Arnold Networks (KANs). تستخدم هذه الطريقة وحدة تحويل هندسي أفيني ووحدة استخلاص ميزات محلية متوازية، وتستبدل دوال التنشيط الثابتة في MLP التقليدية بدوال تنشيط قابلة للتعلم، لالتقاط الميزات الهندسية المعقدة لسحابة النقاط بشكل أكثر فعالية. وفي الوقت نفسه، اقترح الفريق بنية Efficient-KANs، التي تستبدل دوال B-spline بدوال كسرية وتقوم بمشاركة المعلمات داخل المجموعة، مما يقلل بشكل كبير من عدد المعلمات والتكاليف الحسابية. أظهرت التجارب أن PointKAN ونسخته الخفيفة PointKAN-elite حققا أداءً متطورًا (SOTA) أو أداءً تنافسيًا في مهام مثل التصنيف، وتقسيم الأجزاء، والتعلم بعينات قليلة. (المصدر: WeChat)

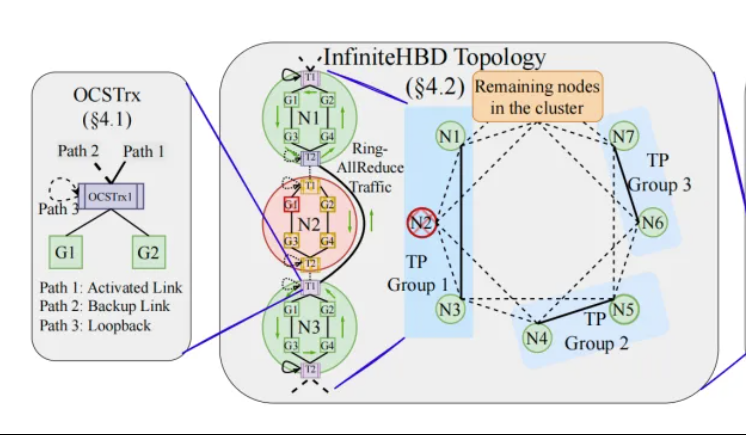
جامعة بكين/StepFun/Enflame Tech تقترح InfiniteHBD: بنية ربط GPU جديدة عالية النطاق الترددي، تقلل تكلفة تدريب النماذج الكبيرة: استجابة للقيود الحالية على بنية النطاق الترددي العالي (HBD) في التدريب الموزع للنماذج الكبيرة، اقترح فريق بحثي من جامعة بكين و StepFun (阶跃星辰) و Enflame Tech (曦智科技) حل InfiniteHBD. تعتمد هذه البنية على وحدة تحويل كهروضوئية مدمجة بقدرة تبديل المسار البصري (OCS) كنواة لها، وتحقق اتصالًا ديناميكيًا قابلًا لإعادة التشكيل من نقطة إلى عدة نقاط، مع قدرة على عزل الأعطال على مستوى العقدة وتقليل تجزئة الموارد. أظهرت الدراسة أن تكلفة الوحدة لـ InfiniteHBD تبلغ 31% فقط من تكلفة NVIDIA NVL-72، ومعدل إهدار GPU يقترب من الصفر، ويمكن أن يزيد MFU (استخدام FLOPs للنموذج) بنسبة تصل إلى 3.37 مرة مقارنة بـ NVIDIA DGX. تم قبول هذه الدراسة في SIGCOMM 2025. (المصدر: WeChat, 量子位)
أخبار سريعة من ICML 2025: OmniAudio يولد صوتًا مكانيًا من مقاطع فيديو 360 درجة: تقترح دراسة ستُنشر في ICML 2025 إطار عمل OmniAudio، القادر على توليد صوت مكاني محيطي من الدرجة الأولى (FOA) ذي إحساس بالاتجاه مباشرة من مقاطع فيديو بانورامية 360 درجة. قامت هذه الدراسة أولاً ببناء مجموعة بيانات واسعة النطاق Sphere360 من مقاطع فيديو 360 درجة مقترنة بالصوت المكاني. يعتمد OmniAudio على تدريب من مرحلتين: أولاً، يتم إجراء تدريب مسبق ذاتي الإشراف لمطابقة التدفق من الخشن إلى الدقيق، باستخدام بيانات صوتية غير مكانية واسعة النطاق لتعلم ميزات صوتية عامة؛ ثم يتم إجراء ضبط دقيق مراقب بالاقتران مع مُرمِّز فيديو ثنائي الفروع (يستخلص ميزات بصرية عالمية ومحلية). أظهرت نتائج التجارب أن OmniAudio يتفوق بشكل كبير على نماذج خط الأساس الحالية في مؤشرات التقييم الموضوعية والذاتية. (المصدر: WeChat)

Huawei Selftok: مُجزِّئ بصري ذاتي الانحدار يعتمد على الانتشار العكسي، يوحد التوليد متعدد الوسائط: اقترح فريق توليد الوسائط المتعددة Pangu من Huawei تقنية Selftok، وهي حل مبتكر لتجزئة الرؤية، يقوم بدمج الأسبقيات ذاتية الانحدار في الـ Tokens البصرية من خلال عملية الانتشار العكسي، مما يحول تدفق البكسلات إلى تسلسل منفصل يتبع بدقة قانون السببية، بهدف حل مشكلة تعارض مخططات الـ Tokens المكانية الحالية مع نموذج الانحدار الذاتي (AR). يعتمد Selftok Tokenizer على مُرمِّز ثنائي التدفق (فرع الصور يرث SD3 VAE، وفرع النص عبارة عن مجموعة متجهات مستمرة قابلة للتعلم) ومُكمِّم بآلية إعادة تنشيط. أظهرت التجارب أن Selftok يحقق أداءً متطورًا (SOTA) في مؤشرات إعادة بناء ImageNet، وأن Selftok dAR-VLM المدرب على Ascend AI وإطار عمل MindSpeed يتفوق على GPT-4o في معايير تحويل النص إلى صورة مثل GenEval. تم اختيار هذا العمل كمرشح لأفضل ورقة بحثية في CVPR 2025. (المصدر: WeChat)
فريق بقيادة يان شويتشينغ يطلق إطار تقييم General-Level ومعيار General-Bench، لتصنيف نماذج متعددة الوسائط متعددة المهام: بقيادة البروفيسور يان شويتشينغ من جامعة سنغافورة الوطنية، والبروفيسور تشانغ هانوانغ من جامعة نانيانغ التكنولوجية، وغيرهم، أطلقت عشر جامعات رائدة بالاشتراك إطار تقييم General-Level ومجموعة بيانات معيارية واسعة النطاق General-Bench لنماذج متعددة الوسائط متعددة المهام. يستلهم هذا الإطار فكرة تصنيف القيادة الذاتية، ويضع خمسة مستويات (Level 1-5) لتقييم عمومية وأداء نماذج اللغة الكبيرة متعددة الوسائط (MLLM)، ومعيار التقييم الأساسي هو “تأثير التعميم التآزري” (Synergy)، الذي يفحص قدرة النموذج على نقل وتعزيز المعرفة بين المهام، وبين نماذج الفهم والتوليد، وعبر الوسائط. يتضمن General-Bench أكثر من 700 مهمة و 320 ألف عينة، وأظهر تقييم أكثر من 100 نموذج MLLM حالي أن معظم النماذج تقع في مستوى L2-L3، ولم يصل أي نموذج إلى L5. (المصدر: WeChat)

💼 أعمال
Sakana AI وبنك MUFG (Mitsubishi UFJ Financial Group) يتوصلان إلى شراكة متعددة السنوات: أعلنت شركة Sakana AI اليابانية الناشئة في مجال الذكاء الاصطناعي عن توقيع اتفاقية شراكة شاملة متعددة السنوات مع بنك MUFG، أكبر بنك في اليابان. ستقدم Sakana AI تقنيات ذكاء اصطناعي مرنة وقوية لبنك MUFG، بهدف مساعدة هذا البنك الذي يمتلك تاريخًا يمتد لمئة عام على الحفاظ على قدرته التنافسية في مجال الذكاء الاصطناعي سريع التطور. من المتوقع أن تساعد هذه الشراكة Sakana AI على تحقيق الربحية في غضون عام واحد. (المصدر: SakanaAILabs, SakanaAILabs)

Cohere تتعاون مع Dell لتقديم منصة الوكلاء الذكية الآمنة Cohere North ضمن حلول الذكاء الاصطناعي المؤسسية المحلية من Dell: أعلنت شركة الذكاء الاصطناعي Cohere عن تعاون مع Dell Technologies لتسريع حلول الذكاء الاصطناعي المؤسسية الآمنة والقادرة على العمل كوكلاء. ستكون Dell أول مزود يقدم للشركات منصة الوكلاء الذكية الآمنة Cohere North كحل نشر محلي (on-premises). يعتبر هذا التعاون حاسمًا بشكل خاص للصناعات التي تتعامل مع بيانات حساسة ولديها متطلبات امتثال صارمة، مما يمكّن الشركات من نشر وتشغيل تقنيات وكلاء الذكاء الاصطناعي المتقدمة من Cohere داخل مراكز البيانات الخاصة بها. (المصدر: sarahookr)

Mistral AI تتعاون مع MGX و Bpifrance لإنشاء أكبر مجمع للذكاء الاصطناعي في أوروبا في فرنسا: أعلنت Mistral AI عن تعاون مع MGX، شركة استثمار تكنولوجي مدعومة من أبوظبي، وبنك الاستثمار الوطني الفرنسي Bpifrance، لإنشاء أكبر مجمع للذكاء الاصطناعي في أوروبا في منطقة باريس بفرنسا. سيضم هذا المجمع مراكز بيانات، وموارد حوسبة عالية الأداء، ومرافق تعليمية وبحثية. ستشارك Nvidia أيضًا في هذا المشروع، حيث ستقدم الدعم التقني. تهدف هذه الخطوة إلى دفع عجلة تطوير النظام البيئي للذكاء الاصطناعي في أوروبا وتعزيز المكانة الاستراتيجية لفرنسا في مجال الذكاء الاصطناعي عالميًا. (المصدر: arthurmensch, arthurmensch)
🌟 المجتمع
معدل انتشار اضطراب نقص الانتباه مع فرط النشاط (ADHD) بين العاملين في مجال الذكاء الاصطناعي يثير الاهتمام، وقد يتجاوز 20-30%: ظهرت نقاشات على وسائل التواصل الاجتماعي حول معدل انتشار اضطراب نقص الانتباه مع فرط النشاط (ADHD) بين العاملين في مجال الذكاء الاصطناعي. لاحظ بعض المستخدمين أن هذا المجال يبدو أنه يجذب العديد من المواهب ذات السمات العصبية المتنوعة. علق مينه نهات نجوين بأن نسبة المصابين باضطراب ADHD في صناعة الذكاء الاصطناعي قد تتجاوز 20-30%. قد ترتبط هذه الظاهرة بمتطلبات العمل في أبحاث وتطوير الذكاء الاصطناعي التي تحتاج إلى تركيز عالٍ، وتكرار سريع، وتفكير إبداعي، وهي سمات تتوافق أحيانًا مع بعض مظاهر اضطراب ADHD. (المصدر: Dorialexander)
انخفاض قيمة المهارات في عصر الذكاء الاصطناعي يثير تفكيرًا عميقًا، وإعادة هيكلة الأنظمة وليس إتقان الأدوات هو المفتاح: يشير مقال تحليلي عميق إلى أن الأزمة الحقيقية في عصر الذكاء الاصطناعي ليست “هل تجيد استخدام أدوات الذكاء الاصطناعي أم لا”، بل هي انخفاض قيمة المهارات نفسها وإعادة هيكلة نظام العمل بأكمله. يستشهد المقال بأمثلة مثل خط ماجينو، والحاويات، واستبدال الكتبة بمعالجات النصوص، ليثبت أن مجرد تعلم استخدام الأدوات الجديدة لا يضمن التفوق، فالمفتاح يكمن في فهم كيف يغير الذكاء الاصطناعي هيكل العمل وعملياته ومنطقه التنظيمي. عندما يتم إعادة كتابة النظام، قد تصبح المهارات ذات القيمة العالية سابقًا مهمشة بسرعة. إن زيادة الإنتاجية لا تعني بالضرورة زيادة قيمة الفرد، لأن القيمة ستتدفق إلى الجهة التي تسيطر على طبقة التنسيق في النظام الجديد. يدحض المقال ثماني مغالطات شائعة مثل “تعلم الذكاء الاصطناعي يجعلك متفوقًا”، و “الذكاء الاصطناعي يجعلني أقوم بمزيد من العمل لذا فأنا أكثر قيمة”، و “الوظائف لن تتغير، فقط طريقة العمل هي التي ستتغير”، ويؤكد على الحاجة إلى التفكير في موقع الفرد وقيمته من منظور النظام. (المصدر: 36氪)
الرئيس التنفيذي السابق لجوجل، شميدت: صعود الذكاء غير البشري سيعيد تشكيل المشهد العالمي، ويجب الحذر من مخاطر وتحديات الذكاء الاصطناعي: حذر الرئيس التنفيذي السابق لجوجل، إريك شميدت، في مقابلة خاصة من أن المجتمع لا يدرك بشكل كافٍ الإمكانات التخريبية لـ “الذكاء غير البشري”. ويرى أن الذكاء الاصطناعي قد انتقل من توليد اللغة إلى اتخاذ القرارات الاستراتيجية، ويمكنه إكمال المهام المعقدة بشكل مستقل. أكد شميدت على ثلاثة تحديات أساسية يطرحها الذكاء الاصطناعي: اختناقات الطاقة والقدرة الحاسوبية (تحتاج الولايات المتحدة إلى إضافة 90 جيجاوات من الكهرباء)، ونفاد البيانات العامة تقريبًا (المرحلة التالية تحتاج إلى بيانات مولدة بالذكاء الاصطناعي)، وكيفية جعل الذكاء الاصطناعي يتجاوز المعرفة البشرية الحالية لخلق “معرفة جديدة”. كما أشار إلى ثلاثة مخاطر رئيسية: فقدان السيطرة على التحسين الذاتي التكراري للذكاء الاصطناعي، وحصوله على السيطرة على الأسلحة، والتكاثر الذاتي غير المصرح به. ويرى أنه في سياق المنافسة المتزايدة بين الولايات المتحدة والصين في مجال الذكاء الاصطناعي، فإن الانتشار السريع للذكاء الاصطناعي مفتوح المصدر قد يجلب مخاطر أمنية، بل وقد يؤدي إلى وضع “ضربة استباقية” مشابه لـ “الردع النووي”. دعا شميدت إلى إجراء حوار عالمي فوري حول حوكمة الذكاء الاصطناعي، وأكد على ضرورة تضمين حماية الحريات الإنسانية في تصميم الأنظمة منذ البداية. (المصدر: 36氪)

الرئيس التنفيذي لـ GitHub يدحض “نظرية عدم جدوى البرمجة”، مؤكدًا أن المبرمجين البشر لا يزالون مهمين في عصر الذكاء الاصطناعي: ردًا على آراء الرئيس التنفيذي لـ Nvidia جنسن هوانغ وغيره بأن “المستقبل لن يتطلب تعلم البرمجة”، أعرب الرئيس التنفيذي لـ GitHub توماس دومكه عن معارضته في مقابلة. ويرى أن عام 2025 سيكون عام وكلاء البرمجة (SWE Agent)، لكن دور المبرمجين البشر لا يزال حاسمًا. أكد دومكه أن الذكاء الاصطناعي يجب أن يكون مساعدًا يعزز قدرات المطورين، وليس بديلاً كاملاً. ويتصور أن تطوير البرمجيات في المستقبل سيتطور إلى نموذج تعاوني بين الإنسان والذكاء الاصطناعي، حيث يعمل المطورون كـ “قادة فرق الوكلاء الأذكياء”، مسؤولين عن توزيع المهام ومراجعة النتائج. كما صرح ماريو رودريغيز، كبير مسؤولي المنتجات في GitHub، بأن الشركة ملتزمة بتعزيز القدرات الفردية باستخدام Copilot. ويعتقدون أنه مع تطور الذكاء الاصطناعي، فإن فهم كيفية برمجة وإعادة برمجة الآلات التي يمكن أن تمثل التفكير والعمل البشري أمر بالغ الأهمية، والتخلي عن تعلم البرمجة يعادل التخلي عن حق الكلام في مستقبل الوكلاء الأذكياء. (المصدر: 36氪, 量子位)

تقارير الثغرات الأمنية منخفضة الجودة المولدة بالذكاء الاصطناعي تنتشر، ومؤسس curl يطبق آلية تصفية لمقاومة “القمامة المولدة بالذكاء الاصطناعي”: صرح دانيال ستينبرغ، مؤسس مشروع curl، بأنه بسبب تلقيه عددًا كبيرًا من تقارير الثغرات الأمنية منخفضة الجودة وغير الصالحة المولدة بالذكاء الاصطناعي، فقد سئم منها، حيث تهدر هذه التقارير الكثير من وقت المشرفين، وتشبه هجمات DDoS. لهذا السبب، عند تقديم تقارير أمنية متعلقة بـ curl على HackerOne، تمت إضافة مربع اختيار للسؤال عما إذا كان قد تم استخدام الذكاء الاصطناعي. إذا كانت الإجابة بنعم، فيجب تقديم أدلة إضافية لإثبات صحة الثغرة، وإلا فقد يتم حظر مقدم التقرير. ذكر ستينبرغ أن المشروع لم يتلق أبدًا تقرير أخطاء صالح مولد بالذكاء الاصطناعي. كما أعرب مطور Python سيث لارسون عن مخاوف مماثلة، معتبرًا أن مثل هذه التقارير تسبب الارتباك والضغط والإحباط للمشرفين، وتفاقم مشكلة الإرهاق في مشاريع المصادر المفتوحة. ترى نقاشات المجتمع أن انتشار التقارير المولدة بالذكاء الاصطناعي يعكس الحمل الزائد للمعلومات ومحاولة البعض استغلال آليات مكافآت الثغرات، بل إن بعض المديرين رفيعي المستوى قد تم تضليلهم للاعتقاد بأن الذكاء الاصطناعي يمكن أن يحل محل المبرمجين ذوي الخبرة. (المصدر: WeChat)

البرمجة بمساعدة الذكاء الاصطناعي تثير نقاشًا ساخنًا: كفاءة محسنة بشكل كبير، لكن دور المطورين البشر لا يزال حاسمًا: شارك مطور يتمتع بخبرة عقود في البرمجة تجربته حيث تمكن الذكاء الاصطناعي (ربما Codex أو أداة مشابهة) في غضون دقائق من حل خطأ برمجي أربكه لساعات وتحسين الكود، معبرًا عن دهشته من أن الذكاء الاصطناعي يشبه “زميل فريق خارق لا يكل”. أثارت هذه التجربة نقاشًا في المجتمع. يتفق معظم الناس على قدرة الذكاء الاصطناعي القوية في توليد الأكواد، وإصلاح الأخطاء، وتلخيص المعلومات، مما يمكن أن يحسن الكفاءة بشكل كبير. ومع ذلك، أشار بعض المطورين أيضًا إلى أن الذكاء الاصطناعي لا يزال يرتكب أخطاء في الوقت الحالي، خاصة في المنطق المعقد، والشروط الحدية، والحلول الإبداعية، حيث لا يرقى إلى مستوى البشر، وأن مخرجاته تحتاج إلى مراجعة وتقييم نقدي من قبل مطورين ذوي خبرة. أكد الرئيس التنفيذي لشركة مايكروسوفت، ساتيا ناديلا، أيضًا أن الذكاء الاصطناعي أداة تمكينية، وأن تطوير البرمجيات لم يعد ممكنًا بدونه، لكن طموح البشر وقدرتهم على المبادرة لا يزالان مهمين. يرى النقاش بشكل عام أن الذكاء الاصطناعي سيغير طريقة البرمجة، وأن المطورين بحاجة إلى التكيف مع النموذج الجديد للتعاون مع الذكاء الاصطناعي، والتركيز على تصميم البنية التحتية وتحديد المشكلات على مستوى أعلى. (المصدر: Reddit r/ChatGPT, WeChat)
منصة AI Agent Manus تفتح التسجيل ولكن بأسعار باهظة، وتواجه منافسة من عمالقة محليين ودوليين، والشكوك تحوم حول إطلاق النسخة الصينية: بعد موجة من الترويج لأكواد الدعوة، فتحت منصة AI Agent Manus التسجيل رسميًا، ولكنها متاحة حاليًا للمستخدمين في الخارج فقط، ولم تقدم نسخة صينية. تشير ملاحظات المستخدمين إلى أنها تعتمد نظام استهلاك النقاط، وأن النقاط المجانية (1000 عند التسجيل، و300 يوميًا) تكفي فقط لإكمال المهام البسيطة، بينما تتطلب المهام المعقدة (مثل إنشاء لعبة سودوكو على الويب) شراء نقاط مدفوعة، بمتوسط 1 دولار لكل 100 نقطة، وهو سعر مرتفع نسبيًا. يحلل خبراء الصناعة أن Manus تعتمد على نماذج لغوية كبيرة من جهات خارجية (مثل استخدام Claude في النسخة الخارجية) مما يؤدي إلى ارتفاع التكاليف، كما أن تشغيلها في بيئة معزولة سحابيًا يزيد من النفقات. قد يكون تأخر إطلاق النسخة الصينية مرتبطًا بتسجيل النماذج المحلية، وعادات الدفع لدى المستخدمين، والمنافسة في السوق. شكلت منتجات محلية ودولية مثل Coze من ByteDance وتطبيق “Xin Xiang” من Baidu منافسة بالفعل. على الرغم من حصول Manus على تمويل جديد، إلا أن حصنها المتمثل في نموذج “النماذج الخفيفة والتطبيقات الثقيلة” يواجه اختبارًا. (المصدر: 36氪)
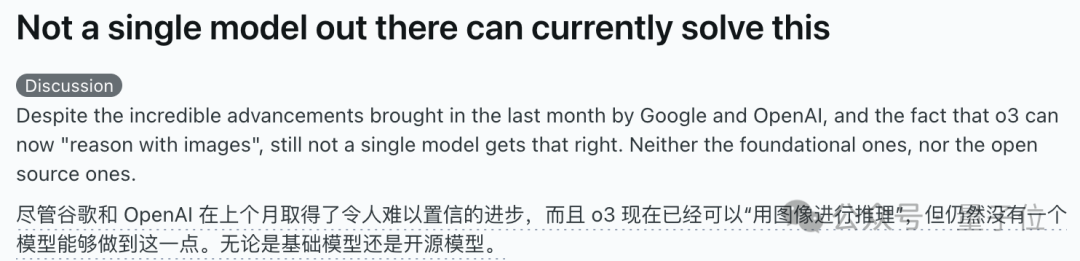
نماذج الذكاء الاصطناعي تفشل جماعيًا في مسألة استدلال بصري “إكمال المكعب”، مما يثير نقاشًا حول قدرتها على الفهم الحقيقي: مسألة استدلال بصري تتطلب حساب عدد المكعبات الصغيرة اللازمة لإكمال مكعب غير مكتمل، أربكت العديد من نماذج الذكاء الاصطناعي السائدة، بما في ذلك OpenAI o3 و Google Gemini 2.5 Pro و DeepSeek و Qwen3. تباينت إجابات النماذج المختلفة، ويرجع السبب الرئيسي في ذلك إلى اختلاف فهمها لمواصفات المكعب الكبير النهائي (مثل 3x3x3، 4x4x4، 5x5x5). حتى مع التوجيه من خلال التلميحات، واجهت النماذج صعوبة في الإجابة بشكل صحيح من مرة واحدة. أشار بعض مستخدمي الإنترنت إلى أن صياغة السؤال نفسها قد تكون غامضة، وأن البشر قد يشعرون بالحيرة أيضًا تجاهها. أثارت هذه الظاهرة نقاشًا حول ما إذا كانت نماذج الذكاء الاصطناعي تفهم المشكلات حقًا أم أنها تعتمد فقط على مطابقة الأنماط، مما يسلط الضوء على القيود الحالية للذكاء الاصطناعي في الاستدلال المكاني المعقد والفهم البصري. (المصدر: 36氪)
نقاش المستخدمين حول مشكلة “الإفراط في التفكير” في نماذج LLM عند اتباع التعليمات والاستدلال: تشير نقاشات وسائل التواصل الاجتماعي والأوراق البحثية إلى أن نماذج اللغة الكبيرة (LLM)، عند استخدام عمليات الاستدلال مثل سلسلة الأفكار (CoT)، “تفرط في التفكير” أحيانًا، مما يؤدي بدلاً من ذلك إلى عدم القدرة على اتباع التعليمات البسيطة بدقة. على سبيل المثال، عند مطالبتها بكتابة عدد معين من الكلمات أو تكرار عبارة معينة، قد يجعل CoT النموذج يركز بشكل أكبر على المحتوى العام للمهمة ويتجاهل هذه القيود الأساسية، أو يقدم محتوى تفسيريًا إضافيًا. اقترح الباحثون مؤشر “الانتباه المقيد” لقياس هذه الظاهرة، واختبروا استراتيجيات التخفيف مثل التعلم في السياق، والتفكير الذاتي، والاستدلال بالاختيار الذاتي، والاستدلال باختيار المصنف. يشير هذا إلى أنه ليست كل المهام مناسبة لـ CoT، وأن التعليمات البسيطة قد تتطلب طريقة تنفيذ أكثر مباشرة. (المصدر: menhguin, omarsar0)

إعادة التفكير في اقتصاديات الذكاء الاصطناعي: العمل المعرفي الرخيص يكسر النماذج الاقتصادية التقليدية، وتوزيع القيمة يواجه إعادة تشكيل: يرى رأي أثار نقاشًا أن صعود الذكاء الاصطناعي يجعل العمل المعرفي (مثل كتابة التقارير، وتحليل البيانات، وكتابة الأكواد) رخيصًا للغاية، وهذا يتحدى بشكل أساسي النماذج الاقتصادية الكلاسيكية التي تفترض أن “الذكاء البشري نادر ومكلف”. عندما يتمكن الذكاء الاصطناعي من إكمال كميات كبيرة من العمل المعرفي بتكلفة هامشية تقارب الصفر، قد ترتفع الإنتاجية بشكل كبير، لكن قيمة المهمة الواحدة ستنهار، وستتآكل ميزة التخصص. لن يعتمد توزيع القيمة ببساطة على الكفاءة أو الإنتاج، بل على من يسيطر على الموارد النادرة الجديدة (مثل البيانات، والمنصات، ونماذج الذكاء الاصطناعي نفسها). هذا يشبه التغيرات التكنولوجية التاريخية (مثل الموضة السريعة في صناعة الملابس، والبث المباشر في صناعة الموسيقى) حيث لم تتدفق مكاسب زيادة الكفاءة بالكامل إلى العمال، بل استحوذ عليها منسقو النظام. يحذر المقال من أن الذكاء الاصطناعي لا يقوم بأتمتة المهام فحسب، بل يقوم أيضًا بتسليع “التفكير”، وقد يكون هذا هو القوة الأكثر تخريبًا في تاريخ الاقتصاد الحديث. (المصدر: Reddit r/artificial)
استراتيجية الشركات في عصر الذكاء الاصطناعي: تجنب فخ “الشركة الذكية”، والحاجة إلى إعادة هيكلة وليس تحسين العمليات القديمة: تميل العديد من الشركات عند تبني الذكاء الاصطناعي إلى اعتباره أداة لتحسين العمليات الحالية وخفض التكاليف وزيادة الكفاءة، فتقع في فخ “القيام بنفس الأشياء بطريقة أذكى” أو “الشركة الذكية”. ومع ذلك، فإن التغيير الحقيقي ليس جعل العمليات القديمة أكثر ذكاءً، بل التفكير فيما إذا كانت هذه العمليات لا تزال ضرورية، وبناء أنظمة ونماذج أعمال جديدة تمامًا تعتمد على الذكاء الاصطناعي أصلاً. لن تتكيف التكنولوجيا ببساطة مع الأنظمة القديمة، بل ستعيد تشكيل الأنظمة. يجب على الشركات تجنب استثمار الكثير من الموارد في تحسين العمليات التي على وشك أن يحل محلها الذكاء الاصطناعي، وبدلاً من ذلك يجب أن تركز على تحديد قواعد جديدة، وتغيير طرق اتخاذ القرار وآليات التنسيق والهياكل التنظيمية بشكل جذري. (المصدر: 36氪)
💡 أخبار أخرى
فعالية تواصل LangChain غير متصلة بالإنترنت في نيويورك: أعلنت LangChain أنها ستستضيف فعالية تواصل غير متصلة بالإنترنت في نيويورك يوم الخميس 22 مايو، بالتعاون مع Tabs و TavilyAI. ستشمل الفعالية محادثات جانبية، وعروض منتجات، وفرصًا للتواصل مع بناة آخرين. (المصدر: hwchase17, LangChainAI)

المؤتمر العالمي للذكاء الاصطناعي في طوكيو سيعقد في يونيو: من المقرر عقد فعالية بعنوان “المؤتمر العالمي للذكاء الاصطناعي · محطة طوكيو” في طوكيو باليابان يومي 7 و 8 يونيو. سيشارك في المؤتمر العديد من مطوري الذكاء الاصطناعي والفنانين والمستثمرين المشهورين. يمكن للمهتمين بمجال الذكاء الاصطناعي والذين يخططون للسفر إلى اليابان متابعة معلومات التسجيل ذات الصلة. (المصدر: op7418)

نموذج خدمة الذكاء الاصطناعي ينتقل من “النموذج كخدمة” إلى “الوكيل كخدمة”: مع تطور تكنولوجيا الذكاء الاصطناعي، تشهد بنية خدمة الذكاء الاصطناعي تحولًا عميقًا من “النموذج كخدمة” (MaaS) إلى “الوكيل كخدمة” (AaaS). يتجاوز وكيل الذكاء الاصطناعي (AI Agent)، بقدرته على تحديد الأهداف، وإدراك البيئة، واتخاذ القرارات المستقلة، والتعلم، نموذج الذكاء الاصطناعي التقليدي الذي ينفذ الأوامر بشكل سلبي. يمكن للوكلاء التفكير بشكل مستقل، وتفكيك المهام، وتخطيط المسارات، واستدعاء الأدوات الخارجية لإكمال الأهداف المعقدة. يدفع هذا التحول السلسلة الصناعية بأكملها إلى التطور، بدءًا من البنية التحتية الأساسية (القدرة الحاسوبية، البيانات)، والخوارزميات الأساسية والنماذج الكبيرة، إلى مكونات ومنصات الوكلاء في الطبقة المتوسطة، وصولاً إلى تطبيقات المنتجات النهائية (الوكلاء العامون، والوكلاء المتخصصون في قطاعات معينة، والوكلاء المدمجون). تنشط شركات وكلاء الذكاء الاصطناعي الصينية مثل HeyGen و Laiye Technology و Waveform Intelligence أيضًا في التوسع الخارجي واستكشاف الأسواق الخارجية. على الرغم من التحديات مثل ارتفاع تكلفة القدرة الحاسوبية وعدم كفاية العرض، إلا أنه من خلال تحسين الخوارزميات، والرقائق المتخصصة، والحوسبة الطرفية، وغيرها من الحلول، يتم إطلاق إمكانات وكلاء الذكاء الاصطناعي باستمرار. (المصدر: 36氪)