
كلمات مفتاحية:AlphaEvolve, DeepSeek V3, GPT-4.1, Speech-02, نموذج Claude, Falcon-Edge, BLIP3-o, AM-Thinking-v1, عامل الترميز الذكي المدعوم بـ Gemini, التصميم المشترك للبرامج والأجهزة لتقليل تكلفة النماذج الكبيرة, تقنية استنساخ الصوت الصفري, قدرة الاستدلال القصوى, هندسة BitNet 1.58 بت
🔥 أبرز العناوين
DeepMind تطلق AlphaEvolve: وكيل ترميز تطوري مدفوع بـ Gemini، يدفع اكتشاف الخوارزميات : يجمع AlphaEvolve بين إبداع نموذج Gemini والمقيّمات التلقائية، مستخدمًا إطارًا تطوريًا لتحسين الخوارزميات. لقد حقق بالفعل اختراقات في مجالات متعددة، مثل إكمال ضرب مصفوفة الأعداد المركبة 4×4 باستخدام 48 عملية ضرب قياسية، مما أدى إلى تحسين خوارزمية Strassen؛ واكتشاف 593 تكوينًا كرويًا خارجيًا في فضاء 11 بُعدًا، مما دفع بـ “مسألة عدد التقبيل” التي يعود تاريخها إلى 300 عام. بالإضافة إلى ذلك، قام AlphaEvolve أيضًا بتحسين جدولة مراكز بيانات Google (مما يوفر 0.7% من موارد الحوسبة)، وتصميم الجيل التالي من TPU (حذف البتات الزائدة)، وتدريب نماذج الذكاء الاصطناعي (تسريع النواة الرئيسية بنسبة 23%)، وغيرها. كما شارك الحائز على جائزة فيلدز، تيرنس تاو، في استكشاف تطبيقاته الرياضية. (المصدر: DeepMind)

شرح مفصل لورقة بحث DeepSeek V3: تصميم متكامل للبرمجيات والأجهزة لخفض تكلفة واستهلاك طاقة النماذج الكبيرة : نشر فريق DeepSeek ورقة بحثية تشرح بالتفصيل كيف يحقق DeepSeek-V3 فعالية التكلفة في التدريب والاستدلال على نطاق واسع من خلال التصميم المتكامل للبرمجيات والأجهزة. تشمل التقنيات الأساسية: 1) تحسين الذاكرة: استخدام الانتباه الكامن متعدد الرؤوس (MLA) لضغط ذاكرة التخزين المؤقت للمفاتيح والقيم، وتدريب الدقة المختلطة FP8 لتقليل استهلاك الذاكرة. 2) تحسين الحوسبة: تطبيق نموذج الخبراء المختلط (MoE)، الذي ينشط جزءًا فقط من المعلمات، مع تدريب FP8، مما يقلل بشكل كبير من تكاليف الحوسبة. 3) تحسين الاتصال: استخدام طوبولوجيا شبكة الشجرة الدهنية متعددة المستويات وتقنية تداخل الدفعات الصغيرة المزدوجة (DualPipe)، لتقليل زمن الانتقال وزيادة كفاءة استخدام وحدات معالجة الرسومات (GPU). 4) تسريع الاستدلال: إدخال إطار عمل التنبؤ متعدد الرموز (MTP)، الذي يتنبأ ويتحقق من صحة العديد من الرموز المرشحة بالتوازي، مما يعزز سرعة التوليد. كما قدمت الورقة خمسة توقعات لتصميم أجهزة الذكاء الاصطناعي المستقبلية، بما في ذلك دعم الحوسبة منخفضة الدقة، والتوسع والدمج، وتحسين طوبولوجيا الشبكة، وتحسين نظام الذاكرة، والمتانة وتحمل الأخطاء. (المصدر: arXiv)

إطلاق نموذج OpenAI GPT-4.1 رسميًا على ChatGPT، ويمكن للمستخدمين اختياره مباشرة : أعلنت OpenAI أن نموذج GPT-4.1 أصبح متاحًا في ChatGPT، ويمكن لمستخدمي Plus و Pro و Team الوصول إليه عبر محدد النماذج، بينما سيحصل مستخدمو إصدارات Enterprise و Education على صلاحية الوصول لاحقًا. سيحل GPT-4.1 mini أيضًا محل GPT-4o mini لجميع المستخدمين. يشتهر GPT-4.1 بأدائه المتميز في مهام الترميز واتباع التعليمات، وقد دعمت إصدارات API السابقة نافذة سياق تصل إلى مليون Token. ومع ذلك، وجد بعض المستخدمين بعد التجربة أن طول سياق إصدار GPT-4.1 في ChatGPT لا يزال على ما يبدو 128 ألفًا، ولم يصل إلى مليون Token كما في إصدار API، مما أثار بعض خيبة الأمل. (المصدر: OpenAI Developers)

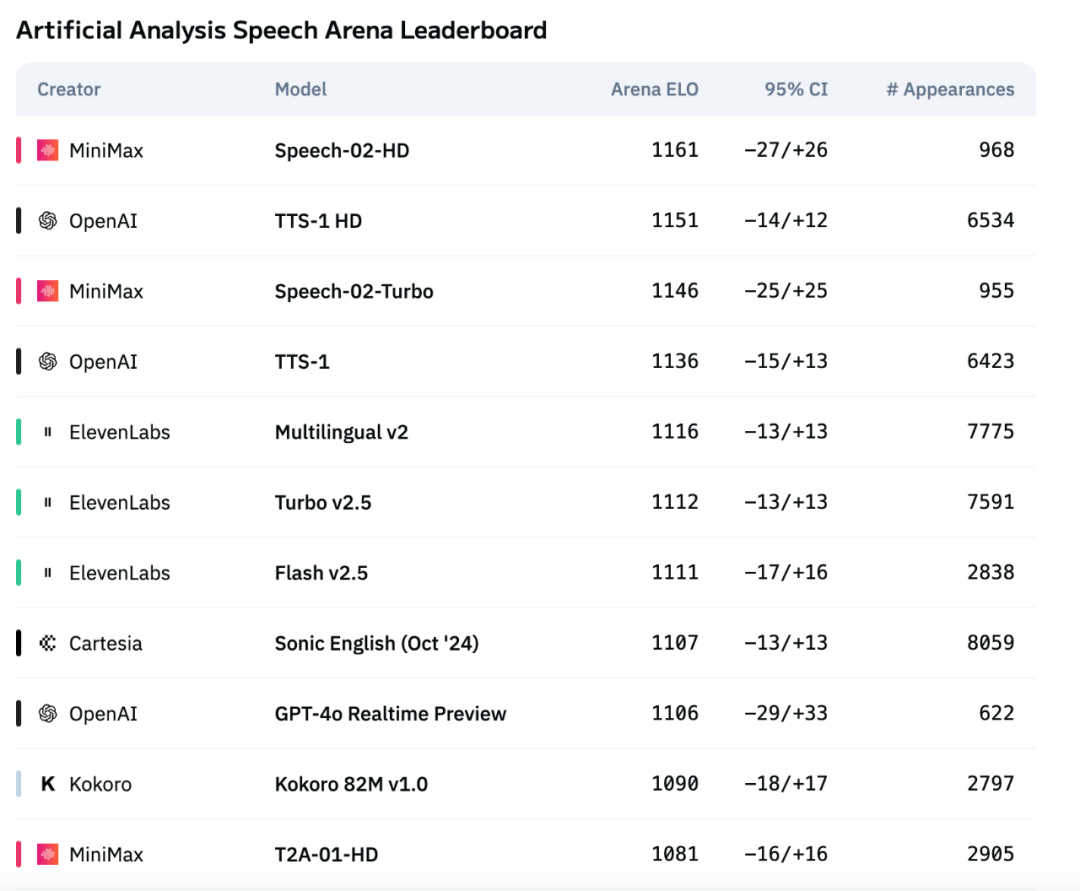
نموذج الصوت الجديد Speech-02 من MiniMax يتصدر قائمة Artificial Analysis لتقييم الصوت : تصدّر أحدث نموذج لتحويل النص إلى كلام (TTS) من MiniMax، وهو Speech-02، قائمة Artificial Analysis Speech Arena الدولية المرموقة لتقييم الصوت، محققًا أعلى تصنيف ELO، ومتفوقًا على المنتجات المماثلة من OpenAI و ElevenLabs. أظهر النموذج أداءً متميزًا في المؤشرات الرئيسية مثل معدل خطأ الكلمات (WER) وتشابه المتحدث (SIM)، وأظهر بشكل خاص ميزة محلية في معالجة اللغتين الصينية والكانتونية. يكمن الابتكار الأساسي في Speech-02 في تحقيق استنساخ صوتي حقيقي بدون عينات (يتطلب فقط بضع ثوانٍ من الصوت المرجعي، بدون نص) بالإضافة إلى اعتماد بنية Flow-VAE جديدة، مما يعزز طبيعية التعبير الصوتي وقدرته على التعبير عن المشاعر، ويدعم 32 لغة. كما أن تكلفته تنافسية للغاية، حيث تبلغ حوالي ربع تكلفة منتج ElevenLabs المنافس. (المصدر: 机器之心)
🎯 اتجاهات
نموذج Claude الجديد من Anthropic قد يتمتع بقدرة “الاستدلال الأقصى” : وفقًا لتقرير The Information وملاحظات المجتمع، قد تصدر Anthropic في الأسابيع المقبلة إصدارات جديدة من نماذج Claude Sonnet و Claude Opus، وأبرز ما يميزها هو قدرة “الاستدلال الأقصى” (Extreme reasoning). تسمح هذه الميزة للنموذج بالتوقف وإعادة التقييم وتعديل الاستراتيجية عند مواجهة مشكلات صعبة، بدلاً من تقديم إجابة مباشرة. في مهام مثل توليد الأكواد، يمكن للنموذج اختبار الأخطاء وتصحيحها تلقائيًا. يهدف هذا الأسلوب الديناميكي الدوري للاستدلال واستخدام الأدوات إلى جعل النموذج أكثر ذكاءً في التعامل مع المشكلات المعقدة، وتقليل الاعتماد على الإشراف البشري، والاقتراب أكثر من طريقة تفكير المتعاونين البشريين. اكتشف بعض المستخدمين بالفعل أن Anthropic تختبر نموذجًا يسمى Claude Neptune (أو ربما Claude 3.8)، يدعم سياق 128 ألف token. (المصدر: 量子位)
TII تطلق سلسلة نماذج Bitnet عالية الكفاءة Falcon-Edge وحزمة أدوات الضبط الدقيق onebitllms : أطلق معهد الابتكار التكنولوجي (TII) سلسلة Falcon-Edge، وهي مجموعة من نماذج اللغة المضغوطة للغاية المستندة إلى بنية BitNet، وتتميز بالقوة والعمومية والقابلية للضبط الدقيق. وفي الوقت نفسه، قاموا أيضًا بإتاحة المصدر المفتوح لـ onebitllms، وهي حزمة أدوات Python خفيفة الوزن (يمكن تثبيتها عبر pip) مخصصة للضبط الدقيق أو مواصلة التدريب المسبق لهذه النماذج ذات 1.58 بت. تهدف هذه الخطوة إلى خفض عتبة استخدام النماذج الكبيرة، ودفع تطوير وتطبيق تقنية LLM ذات 1 بت. (المصدر: younes)

مكتبة Hugging Face Transformers تشهد ترقية كبيرة لتصبح المعيار المركزي لتعريف النماذج : أعلنت Hugging Face أن مكتبتها Transformers تخضع لتعديلات كبيرة، تهدف إلى أن تصبح المعيار المركزي لتعريف النماذج عبر مختلف الواجهات الخلفية والمشغلات. من خلال الجهود المشتركة مع العديد من شركاء النظام البيئي مثل vLLM و LlamaCPP و SGLang و MLX و DeepSpeed و Microsoft و NVIDIA وغيرهم، يتم دفع توحيد أكواد النماذج، بهدف تحقيق قدر أكبر من الاتساق والموثوقية للنظام البيئي للذكاء الاصطناعي بأكمله. وقد لقيت هذه المبادرة استحسانًا واسعًا من المجتمع، واعتبرت خطوة مهمة لدفع تطوير الذكاء الاصطناعي مفتوح المصدر. (المصدر: Arthur Zucker)

Salesforce تطلق BLIP3-o على Hugging Face: سلسلة نماذج متعددة الوسائط موحدة ومفتوحة المصدر بالكامل : أطلقت Salesforce سلسلة نماذج BLIP3-o، وهي عائلة من النماذج متعددة الوسائط الموحدة والمفتوحة المصدر بالكامل. تغطي هذه السلسلة بنية النموذج وطرق التدريب ومجموعات البيانات، وتهدف إلى دفع تطوير وتطبيق تقنيات الذكاء الاصطناعي متعدد الوسائط. يوفر إطلاق BLIP3-o للباحثين والمطورين أدوات وموارد قوية لمعالجة الوسائط المتعددة. (المصدر: AK)

NVIDIA تعرض استخدام البيانات الاصطناعية لدفع تكنولوجيا القيادة الذاتية الكاملة : أصدرت NVIDIA مقطع فيديو جديدًا يعرض كيف تستخدم البيانات الاصطناعية لتسريع البحث والتطوير في تكنولوجيا القيادة الذاتية الكاملة (FSD). من خلال توليد سيناريوهات وبيانات قيادة افتراضية واسعة النطاق ومتنوعة، تستطيع NVIDIA تدريب خوارزميات القيادة الذاتية والتحقق من صحتها بكفاءة أكبر، والتغلب على قيود جمع البيانات في العالم الحقيقي، ودفع تكنولوجيا القيادة الذاتية نحو اتجاه أكثر أمانًا وموثوقية. (المصدر: SawyerMerritt)
فريق A-M-team يطلق نموذج الاستدلال AM-Thinking-v1 بحجم 32B، ويتفوق في بعض الأداء على DeepSeek-R1 : أطلق فريق البحث المحلي A-M-team نموذج الاستدلال AM-Thinking-v1 بمعلمات 32B على Hugging Face. أظهر هذا النموذج أداءً متميزًا في مهام مثل الاستدلال الرياضي (سلسلة AIME درجة 85.3) وتوليد الأكواد (LiveCodeBench درجة 70.3)، ويُقال إنه تفوق في هذه التقييمات المحددة على DeepSeek-R1 (671B MoE)، واقترب من نماذج أكبر مثل Qwen3-235B-A22B. يركز الفريق على تحسين قدرة الاستدلال للنماذج الكثيفة بحجم 32B من خلال خطط ما بعد التدريب (بما في ذلك SFT بالبدء البارد، وفحص البيانات الموجه بمعدل النجاح، والتعلم المعزز (RL) ثنائي المرحلة)، بهدف استكشاف مسارات لتحقيق استدلال قوي في ظل ظروف حوسبة محدودة وبيانات مفتوحة المصدر. (المصدر: AI科技评论)

تحديث Marigold: تحويل نموذج Stable Diffusion إلى مقدر عمق، يدعم الاستدلال بخطوة واحدة ودقة عالية : أصدر مشروع Marigold تحديثًا هامًا، حيث تمكنت هذه التقنية من تحويل نموذج Stable Diffusion 2 من خلال عدد قليل من العينات الاصطناعية والتدريب لفترة قصيرة (2-3 أيام على وحدة معالجة رسومات واحدة) إلى مقدر عمق متقدم. تشمل ميزات الإصدار الجديد: استدلال سريع بخطوة واحدة، ودعم وسائط جديدة، وإخراج عالي الدقة، ودعم مكتبة Diffusers، وعرض توضيحي جديد. (المصدر: Anton Obukhov)
سلسلة نماذج Qwen3 تظهر أداءً قويًا في مجتمع المصادر المفتوحة، وNVIDIA تختارها كقاعدة لـ OpenCodeReasoning : تستمر سلسلة نماذج Qwen3 من Alibaba في جذب الاهتمام والتطبيق في مجتمع المصادر المفتوحة. اختارت NVIDIA مؤخرًا Qwen كأساس لسلسلة نماذج OpenCodeReasoning مفتوحة المصدر (بأحجام 7B و 14B و 32B). يفضل المطورون Qwen3 لإصداراتها الكاملة، وتحديثاتها المستمرة، ودعمها الأصلي لوضع الاستدلال المختلط، ونظامها البيئي المزدهر (أكثر من 300 مليون عملية تنزيل عالميًا، وأكثر من 100 ألف نموذج مشتق). تشمل التحديثات الأخيرة نموذج الوسائط المتعددة الطرفي Qwen-omini 3B، والتعاون مع Unsloth لتعزيز كفاءة الضبط الدقيق، وإصدار اقتراحات مفصلة لمعلمات النشر الفائقة، ودعم توليد معاينة فورية لصفحات الويب، وتوفير إصدارات كمومية متعددة، بالإضافة إلى إصدار تقارير فنية. (المصدر: AI前线)
إصدار Hugging Face Accelerate v1.7.0، يدعم التجميع الإقليمي و QLoRA لـ FSDPv2 : تم إطلاق إصدار Hugging Face Accelerate v1.7.0 رسميًا. تشمل أبرز ميزات هذا الإصدار: التجميع الإقليمي (Regional compilation) الذي نفذه @IlysMoutawwakil، مما يعزز كفاءة ومرونة التجميع؛ وخطافات التحويل الطبقي (Layerwise casting hook) التي ساهم بها @RisingSayak، وهي ميزة مستخدمة على نطاق واسع في مكتبة diffusers؛ بالإضافة إلى دعم QLoRA لـ FSDPv2 الذي نفذه @winglian، مما يزيد من تحسين تدريب النماذج واسعة النطاق. (المصدر: Marc Sun)

إصدار Llamafile 0.9.3، يضيف دعمًا لنماذج Qwen3 و Phi4 : أصدر Llamafile الإصدار 0.9.3، ويضيف هذا التحديث دعمًا لسلسلة نماذج Qwen3 و Phi4 الشهيرة مؤخرًا. يهدف Llamafile إلى تبسيط توزيع وتشغيل تطبيقات LLM، من خلال تجميع أوزان النموذج والأكواد اللازمة للتشغيل في ملف تنفيذي واحد، مما يتيح النشر المريح على أنظمة تشغيل متعددة. (المصدر: Phoronix)
Tencent تطلق نموذج الصور الكبير HunyuanImage 2.0 : أطلقت Tencent رسميًا الإصدار الجديد من نموذج الصور الكبير الخاص بها – HunyuanImage 2.0. من المتوقع أن يشهد هذا التحديث تحسينات في جودة توليد الصور، والتحكم، والقدرة على فهم التعليمات المعقدة. يمكن للمستخدمين معرفة المزيد عن التفاصيل الفنية والتحسينات من خلال القنوات الرسمية. (المصدر: Hunyuan)

إصدار Ollama v0.7، يعزز تجربة تشغيل النماذج الكبيرة محليًا : أصدرت Ollama الإصدار v0.7، مواصلةً جهودها لتبسيط عملية تشغيل نماذج اللغة الكبيرة على الأجهزة المحلية. قد يتضمن الإصدار الجديد تحسينات في الأداء، أو دعمًا لنماذج جديدة، أو تحسينات في تجربة المستخدم. يمكن للمستخدمين زيارة الموقع الرسمي أو GitHub للاطلاع على سجل التغييرات المفصل والتنزيل. (المصدر: ollama)
llama.cpp يدمج وظيفة إدخال PDF، ويدعم معالجة مستندات PDF مباشرة : قام مشروع llama.cpp مؤخرًا بدمج تحديث مهم، يضيف دعمًا مباشرًا لإدخال ملفات PDF. هذا يعني أنه يمكن للمستخدمين الآن بسهولة أكبر استخدام محتوى مستندات PDF كمدخلات، ليتم معالجتها أو تحليلها أو الإجابة على أسئلة بشأنها بواسطة نماذج اللغة الكبيرة المحلية التي تعمل بواسطة llama.cpp، مما يوسع نطاق تطبيقاته. يتم تحقيق هذه الميزة من خلال حزمة JS خارجية في الواجهة الأمامية المدمجة على الويب، دون زيادة عبء الصيانة الأساسي. (المصدر: GitHub)
Microsoft Copilot يطلق ميزة توليد الصور 4o، لتحسين التأثيرات البصرية واتساق النصوص : قام مساعد الذكاء الاصطناعي Copilot من Microsoft الآن بدمج قدرات توليد الصور لنموذج GPT-4o من OpenAI. يهدف هذا التحديث إلى توفير تأثيرات بصرية أكثر حدة، وتوليد نصوص أكثر اتساقًا، ودعم أنماط متعددة تتراوح من الواقعية الفوتوغرافية إلى الرسوم الكاريكاتورية الممتعة. يمكن للمستخدمين تجربة ميزات إنشاء الصور المدعومة بـ 4o من خلال Copilot. (المصدر: yusuf_i_mehdi)

NVIDIA DRIVE Labs يناقش مستقبل القيادة بدون خرائط، وتقليل الاعتماد على الخرائط عالية الدقة : يناقش أحدث فيديو من NVIDIA DRIVE Labs مستقبل القيادة بدون خرائط (mapless driving). تعتبر الخرائط عالية الدقة ضرورية للقيادة الذاتية، ولكن تحديات تكلفتها وصيانتها تحد من انتشارها. تعمل NVIDIA على تقليل الاعتماد على الخرائط عالية الدقة من خلال الابتكارات مثل إزالة اختناقات المعلومات، وزيادة دقة المهام، وتسريع وقت تدريب النماذج والاستدلال، ودفع حدود تكنولوجيا القيادة الذاتية. (المصدر: NVIDIA DRIVE)
Dolphin 3.2 (المبني على تدريب Qwen3) سيوفر مفاتيح تبديل لمطالبات النظام، لتعزيز تحكم المستخدم : سيقدم نموذج Dolphin 3.2 القادم، المبني على تدريب Qwen3، ثلاثة مفاتيح تبديل لمطالبات النظام: /no_think (ربما لتقليل خطوات التفكير الزائدة)، /uncensored (ربما لتقليل الرقابة على المحتوى)، و /china (ربما لسياق أو خدمات محددة في الصين). تهدف هذه المفاتيح إلى منح المستخدمين قدرًا أكبر من الملكية والتحكم في نشر نماذجهم. (المصدر: cognitivecompai)

🧰 أدوات
Runway تطلق ميزة المراجع، التي تتيح تعلم وتطبيق تقنية أو أسلوب معين على إبداعات جديدة : أضافت Runway ميزة جديدة تسمى “References”، تسمح للمستخدمين بعرض تقنية معينة أو أسلوب فني على المنصة، ثم استخدامه كمرجع لتطبيقه على أي محتوى جديد يتم إنشاؤه. توفر هذه الميزة للمستخدمين قدرة تحكم أدق في الأسلوب، مما يجعل الإبداع بمساعدة الذكاء الاصطناعي أكثر تخصيصًا وتوجيهًا. أطلق المستخدم Cristobal Valenzuela حملة لجمع المشاركات، مشجعًا المجتمع على مشاركة حالات استخدام أصلية لهذه الميزة، وسيقدم لأكثر 5 حالات إبداعًا اشتراكًا مجانيًا لمدة عام في باقة Unlimited. (المصدر: c_valenzuelab)

DSPy: إطار برمجة LLM بسيط للغاية مصمم للتكرار السريع : لفت إطار DSPy الانتباه بتصميمه البسيط للغاية، حيث يقول المطورون إن معظم وظائفه الأساسية (Module أو Optimizer) يمكن تحقيقها بسطر واحد فقط من التعليمات البرمجية، ويهدف إلى مساعدة المستخدمين على تجربة الأفكار وتكرارها بسرعة. على عكس بعض الأدوات التي تتطلب الكثير من التعليمات البرمجية المعيارية والمفاهيم المعقدة، يؤكد DSPy على سهولة الاستخدام والكفاءة. أفاد المستخدمون أنه يمكنهم البدء بسرعة من خلال قراءة وثائق البدء، والاستفادة من الإطار لتحسين النماذج في وقت قصير، على الرغم من أن استخدام نماذج SOTA (الأحدث والأفضل) للتحسين الدوري قد يتكبد بعض التكاليف. (المصدر: lateinteraction)
Unsloth AI تتوسع لتشمل الضبط الدقيق لنماذج TTS والصوت، مما يزيد السرعة ويقلل من استهلاك ذاكرة VRAM : أعلنت Unsloth AI أن تقنيتها المحسنة تدعم الآن الضبط الدقيق لنماذج تحويل النص إلى كلام (TTS) ونماذج الصوت. يمكن للمستخدمين استخدام دفاتر Colab المجانية لتدريب وتشغيل وحفظ نماذج مثل Sesame-CSM و OpenAI Whisper. تدعي Unsloth أن تقنيتها يمكن أن تزيد سرعة تدريب TTS بمقدار 1.5 مرة، مع تقليل استهلاك ذاكرة VRAM بنسبة 50%. تم توفير الوثائق ذات الصلة ودفاتر Colab على موقعها الرسمي. (المصدر: Unsloth AI)
Modal تدعم مهمة تضمين 30 مليون مراجعة لـ Amazon، ومعالجات L40S GPU تنجز المهمة في غضون ساعة : عرضت منصة Modal قدرتها على التوسع الأفقي في معالجة مهام التضمين واسعة النطاق على معالجات L40S GPU. من خلال حالة عرض توضيحية، نجحت Modal في إكمال معالجة تضمين 30 مليون مراجعة لـ Amazon في غضون ساعة واحدة. يعود الفضل في ذلك إلى نظام التوليد القابل للتطوير المحدث من فريق Modal، والذي يجعل المعالجة المتوازية واسعة النطاق أبسط وأكثر كفاءة. (المصدر: charles_irl)

Lovart AI: وكيل تصميم بصري جديد يعتمد على الذكاء الاصطناعي ويدمج نماذج متعددة رائدة : لفت وكيل تصميم بصري يعتمد على الذكاء الاصطناعي يُدعى Lovart الانتباه، حيث يمكنه إكمال مهام التصميم البصري الاحترافية مثل الملصقات والهوية البصرية للعلامات التجارية ولوحات القصص المصورة من خلال أوامر اللغة الطبيعية. تكمن القدرة الأساسية لـ Lovart في جدولة دمج النماذج المتعددة، حيث يدمج العديد من النماذج الرائدة مثل GPT image-1 و Flux pro و OpenAI-o3 و Gemini Imagen 3 و Kling AI و Tripo AI و Suno AI، ويحتوي على أدوات تحرير احترافية مدمجة (مثل الطبقات والأقنعة والضبط الدقيق للنصوص)، ويدعم فصل الصور والنصوص وتحرير الطبقات بشكل منفصل. يتم تشغيل هذا المنتج بشكل مستقل من قبل شركة Liblib التابعة في الخارج، ويهدف إلى توفير تجربة تصميم بالذكاء الاصطناعي شاملة وعالية التحكم. (المصدر: 量子位)
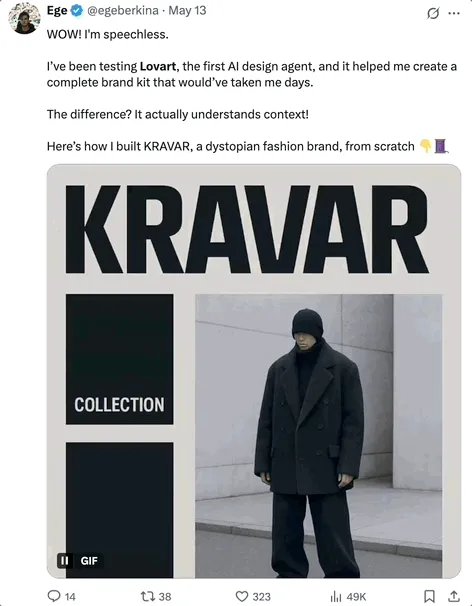
إصدار OpenHands 0.38.0: دعم أصلي لنظام Windows وامتداد Chrome يعززان سهولة الاستخدام : أصدرت OpenHands الإصدار 0.38.0، والذي يتضمن العديد من التحديثات الهامة. من بينها: دعم أصلي لنظام Windows (بدون الحاجة إلى WSL)، مما يسهل على مستخدمي Windows استخدامه؛ ميزة لقطات شاشة المتصفح؛ وقدرة تخصيص أكثر مرونة للبيئة المعزولة (sandbox). بالإضافة إلى ذلك، تم إصدار امتداد لمتصفح Chrome، يسمح للمستخدمين بتشغيل OpenHands بنقرة واحدة من GitHub، مما يبسط عملية التشغيل بشكل أكبر. (المصدر: All Hands AI)
إطلاق Tensorlake Cloud، لتعزيز قدرات استخراج المستندات وبناء تدفقات العمل : أعلنت Tensorlake عن إطلاق Tensorlake Cloud، بهدف تحسين استخراج المستندات وتدفقات العمل، لدعم بناء تطبيقات الوكلاء الذكية وتدفقات العمل التجارية المعقدة. تستخدم المنصة نماذج متقدمة لفهم تخطيط المستندات (مدربة على بيانات العالم الحقيقي مثل نماذج ACORD، وكشوفات الحسابات المصرفية، والتقارير البحثية) ونماذج استخراج الجداول، لتحويل المستندات غير المهيكلة إلى بيانات نظيفة ومهيكلة، وهي مناسبة بشكل خاص لمعالجة الجداول المعقدة والكثيفة، مما يسد الفجوة التي تعاني منها نماذج اللغة المرئية (VLM) في هذا الجانب. (المصدر: Tensorlake)
Patronus AI تطلق Percival: وكيل ذكي مخصص لتصحيح وتحسين وكلاء الذكاء الاصطناعي : أطلقت Patronus AI أداة جديدة تسمى Percival، وهي وكيل ذكاء اصطناعي مصمم خصيصًا لتصحيح وتحسين وكلاء الذكاء الاصطناعي. يستطيع Percival تحليل سجلات تتبع الوكلاء المعقدة بشكل فوري، وتحديد ما يصل إلى 60 نمطًا مختلفًا من أنماط الفشل، واقتراح حلول تلقائية لتصحيح المطالبات بهدف تحسين الأداء. تعالج هذه الأداة تحديات رئيسية مثل “انفجار السياق” (حيث يعالج الوكيل ملايين الرموز المميزة)، وتدعم التكيف مع مجالات الاستخدام المحددة والتنسيق المعقد بين عدة وكلاء. (المصدر: Weaviate Podcast)

Replit تدمج Semgrep لتحقيق “برمجة بأجواء آمنة”، وفحص تلقائي للثغرات : أعلنت Replit عن تعاونها مع Semgrep لإطلاق ميزة “برمجة بأجواء آمنة” (Safe Vibe Coding). الآن، في كل مرة يقوم فيها المستخدم بنشر كود على Replit، سيقوم Semgrep تلقائيًا بإجراء فحص أمني للمساعدة في اكتشاف وإصلاح الثغرات المحتملة، ومنع الكشف العرضي عن معلومات حساسة مثل مفاتيح API. تهدف هذه الخطوة إلى تعزيز الأمان عند استخدام الترميز بمساعدة الذكاء الاصطناعي (مثل توليد الأكواد من خلال LLM). (المصدر: amasad)

إصدار Cursor AI 0.50، يجلب تحديثات كبيرة : أطلقت أداة البرمجة بمساعدة الذكاء الاصطناعي Cursor الإصدار 0.50، والذي وُصف بأنه “أكبر تحديث على الإطلاق”. من المتوقع أن يتضمن الإصدار الجديد العديد من التحسينات الوظيفية وتحسينات تجربة المستخدم، بهدف زيادة كفاءة المطورين في الترميز وسلاسة التعاون مع الذكاء الاصطناعي. يمكن الاطلاع على تفاصيل التحديث المحددة في ملاحظات الإصدار الرسمية. (المصدر: eric zakariasson)

OpenMemory MCP: خادم إدارة ذاكرة محلي يدعم مشاركة السياق عبر التطبيقات : OpenMemory MCP هو خادم إدارة ذاكرة يهدف إلى تعزيز إنتاجية تطبيقات الذكاء الاصطناعي. يسمح للمستخدمين بمشاركة السياق بين تطبيقات مختلفة (مثل Cursor و Claude Desktop)، ويستخدم PostgreSQL و Qdrant لتخزين وفهرسة البيانات محليًا، مما يضمن خصوصية البيانات. تدعم هذه الأداة البحث الدلالي، وتوفر لوحة معلومات لإدارة الذاكرة والوصول إلى التطبيقات، وتحل مشكلة فقدان السياق عبر الجلسات. (المصدر: Reddit r/ClaudeAI)

Hugging Face Inference Endpoint بالتعاون مع vLLM و Gradio، لتحقيق نسخ Whisper فائق السرعة : عرضت Hugging Face كيف يمكن الاستفادة من خدمة Inference Endpoint الخاصة بها، بالتعاون مع مشروع vLLM وواجهة Gradio، لنشر نموذج Whisper من OpenAI، لتحقيق وظيفة نسخ صوتي فائقة السرعة. يستفيد هذا المزيج من أدوات المصدر المفتوح لمجتمع الذكاء الاصطناعي، ويوفر للمستخدمين حلولًا فعالة وسهلة الاستخدام لتحويل الصوت إلى نص. (المصدر: Morgan Funtowicz)
A.I.T.E Ball: كرة سحرية 8 ذاتية التشغيل تعتمد على Orange Pi و Gemma 3 1B : عرض مطور مشروع كرة سحرية 8 ذاتية التشغيل بالكامل (لا تحتاج إلى اتصال بالإنترنت) تعمل بالذكاء الاصطناعي – A.I.T.E Ball. يعمل هذا الجهاز على Orange Pi Zero 2W، ويستخدم whisper.cpp لتحويل النص إلى كلام، و llama.cpp لتشغيل نموذج Gemma 3 1B للإجابة على الأسئلة. يوضح هذا إمكانية تحقيق تطبيقات ذكاء اصطناعي محلية على أجهزة منخفضة الطاقة. (المصدر: Reddit r/LocalLLaMA)

OWL Agent: وكيل عام مفتوح المصدر مدمج مع MCPToolkit : يدعم مشروع OWL Agent مفتوح المصدر الآن MCPToolkit بشكل مدمج. يمكن للمستخدمين بسهولة الاتصال بخوادم MCP مثل Playwright و desktop-commander أو أدوات Python مخصصة، وسيقوم OWL تلقائيًا باكتشاف واستدعاء هذه الأدوات في تدفق عمله متعدد الوكلاء، مما يعزز من عموميته وقدرته على تنفيذ المهام. (المصدر: Reddit r/LocalLLaMA)

ElevenLabs تطلق SB-1 لوحة مؤثرات صوتية لا نهائية: تجمع بين المؤثرات الصوتية، وآلة الطبول، ومولد ضوضاء بيئية : أطلقت ElevenLabs لوحة المؤثرات الصوتية اللانهائية SB-1، وهي أداة تجمع بين لوحة المؤثرات الصوتية، وآلة الطبول، ومولد ضوضاء بيئية لا نهائي. يمكن للمستخدمين وصف المؤثر الصوتي الذي يريدونه، وسيقوم SB-1 باستخدام نموذج تحويل النص إلى مؤثرات صوتية (Text-to-SFX) لتوليد هذه الأصوات، مما يوفر إمكانيات جديدة لإنشاء الصوت. (المصدر: ElevenLabs)
مشروع Anytop: تقدم جديد في تحريك الرسوم المتحركة بالذكاء الاصطناعي، يجعل الكائنات غير المرئية سابقًا تنبض بالحياة، ويدعم تعلم الحركة ونقلها : قدمت Two Minute Papers مشروع Anytop، وهو تقنية تحريك رسوم متحركة بالذكاء الاصطناعي، قادرة على توليد حركات واقعية لكائنات لم يسبق رؤيتها (بما في ذلك الديناصورات، والحشرات الغريبة، وما إلى ذلك). لا يقتصر الذكاء الاصطناعي على توليد الحركات بشكل مستقل فحسب، بل يمكنه أيضًا جعل الكائنات المختلفة تتعلم وتتكيف مع حركات بعضها البعض (مثل ديناصور يتعلم الوقوف على ساق واحدة مثل طائر الفلامنغو). يحقق ذلك تعميمًا على الأشكال غير المعروفة من خلال فهم التشابه الدلالي لأجزاء الجسم (مثل المفهوم العام للذراعين والساقين). بالإضافة إلى ذلك، يمكن للنظام فهم دلالات الحركة (مثل الهجوم والاسترخاء)، وعرض حركات ذات مفاهيم مماثلة بين حيوانات مختلفة، وحتى إكمال حركات الإدخال غير المكتملة. (المصدر: )

Sketch2Anim: الذكاء الاصطناعي يحول رسومات الخطوط البسيطة إلى رسوم متحركة ثلاثية الأبعاد كاملة : تقنية أخرى قدمتها Two Minute Papers وهي Sketch2Anim، قادرة على تحويل رسومات الخطوط البسيطة التي يرسمها المستخدم (تشير إلى مسار الحركة) إلى رسوم متحركة كاملة لشخصيات ثلاثية الأبعاد. يستطيع هذا الذكاء الاصطناعي فهم النية ثلاثية الأبعاد الكامنة وراء الرسم ثنائي الأبعاد (مثل التمييز بين لكمة موجهة للأمام ولكمة موجهة للجانب)، مما يحل قيود التقنيات المماثلة السابقة التي كانت تفهم التعليمات على المستوى ثنائي الأبعاد فقط، ويتيح لغير المحترفين إنشاء رسوم متحركة ثلاثية الأبعاد بسرعة من خلال رسومات بسيطة. (المصدر: )
📚 تعلم
DeepSeek تنشر ورقة بحثية عن نموذج V3، وتشارك تحديات التوسع وتأملات حول بنية أجهزة الذكاء الاصطناعي : نشر فريق DeepSeek على Hugging Face ورقة بحثية حول نموذج DeepSeek-V3. تتعمق هذه الورقة في التحديات التي تواجهها عملية توسيع نماذج اللغة الكبيرة، وتقدم تأملات ورؤى حول اتجاهات تطوير بنية أجهزة الذكاء الاصطناعي المستقبلية. يوفر هذا مرجعًا قيمًا للباحثين والمطورين لفهم اختناقات تدريب ونشر النماذج واسعة النطاق، وكيفية التحسين من خلال التكامل بين الأجهزة والبرامج. (المصدر: Adina Yakup)
إطلاق دورة مجانية حول بروتوكول سياق النموذج (MCP)، للمساعدة في بناء تطبيقات ذكاء اصطناعي تستخدم بيانات وأدوات خارجية : أعلن Ben Burtenshaw عن إطلاق دورة مجانية حول بروتوكول سياق النموذج (MCP). تهدف هذه الدورة إلى مساعدة المتعلمين على الانتقال من مستوى المبتدئين إلى مستوى الإتقان، وفهم كيفية عمل MCP، وكيفية ربط نماذج اللغة الكبيرة (LLM) بخوادم MCP، وكيفية استخدام MCP لنشر تطبيقات وكلاء الذكاء الاصطناعي، وبالتالي الاستفادة من البيانات والأدوات الخارجية لتعزيز قدرات تطبيقات الذكاء الاصطناعي. (المصدر: Ben Burtenshaw)

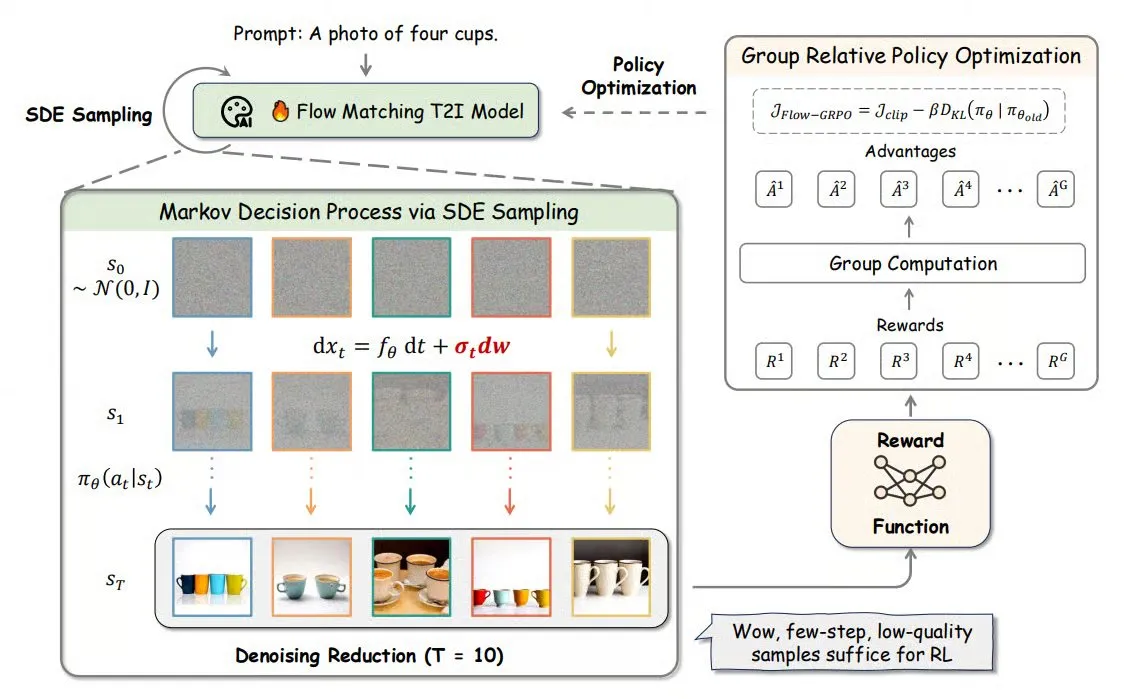
Flow-GRPO: إدخال التعلم المعزز عبر الإنترنت في نماذج مطابقة التدفق، لرفع دقة توليد الصور : Flow-GRPO هو نهج جديد يطبق لأول مرة التعلم المعزز عبر الإنترنت (RL) على نماذج مطابقة التدفق. يحقق ذلك من خلال استراتيجيتين مبتكرتين: 1) تحويل ODE إلى SDE: تحويل العملية الحتمية لنماذج التدفق القائمة على المعادلات التفاضلية العادية (ODE) إلى معادلات تفاضلية عشوائية (SDE)، مما يدخل العشوائية اللازمة للتعلم المعزز. 2) تسريع التدريب بتقليل تقليل الضوضاء: تقليل خطوات تقليل الضوضاء أثناء التدريب، واستخدام الخطوات الكاملة أثناء الاستدلال. من خلال Flow-GRPO، ترتفع دقة نماذج التدفق في مهام توليد الصور إلى أكثر من 92%. (المصدر: TheTuringPost)
ورقة بحثية في ICML 2025 بعنوان PENCIL: التناوب بين “الاستدلال-المحو” يحقق نموذجًا جديدًا للتفكير العميق في النماذج الكبيرة : اقترح يانغ تشينشياو وآخرون من جامعة تويوتا التكنولوجية في شيكاغو PENCIL (Pondering with Erasure Net for Contextual Inference Learning)، وهو نموذج جديد للتفكير العميق في النماذج الكبيرة من خلال التناوب بين “توليد” و “محو” النتائج الوسيطة. يستلهم هذا النهج قواعد إعادة الكتابة المنطقية وإدارة الذاكرة في البرمجة الوظيفية، ويمحو ديناميكيًا الخطوات الوسيطة التي لم تعد هناك حاجة إليها، مما يحل بشكل فعال المشكلات التي تواجهها سلاسل التفكير الطويلة التقليدية (CoT) مثل تجاوز نافذة السياق، وصعوبة استرجاع المعلومات، وانخفاض كفاءة التوليد. أثبتت النظرية أن PENCIL يمكنه محاكاة أي عملية آلة تورنغ بأفضل تعقيد مكاني وزمني، وحل جميع المشكلات القابلة للحساب. أظهرت التجارب أن PENCIL يتفوق بشكل كبير على CoT التقليدي في مهام مثل 3-SAT و QBF وألغاز أينشتاين. (المصدر: 机器之心)

ورقة بحثية في ICML 2025 بعنوان MemVR: محاكاة آلية “النظر مرتين” البشرية للتخفيف من هلوسة النماذج الكبيرة متعددة الوسائط : اقترح باحثون من جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو) ومؤسسات أخرى طريقة MemVR (Memory-space Visual Retracing)، من خلال محاكاة استراتيجية البشر في التحقق مرة أخرى من الذكريات غير المؤكدة، للتخفيف من مشكلة هلوسة نماذج اللغة الكبيرة متعددة الوسائط (MLLM). تستخدم MemVR الرموز المرئية كدليل تكميلي، وفي الطبقات المتوسطة حيث يواجه النموذج صعوبات بسبب النسيان أثناء الاستدلال، يتم “استرجاع” المعرفة المرئية مرة أخرى من خلال شبكة التغذية الأمامية (FFN) لمعايرة التنبؤات. صممت هذه الطريقة آلية تشغيل ديناميكية، تختار طبقة التشغيل بناءً على عدم اليقين في مخرجات الطبقات المختلفة. أظهرت التجارب أن MemVR تحقق نتائج ملحوظة في العديد من معايير تقييم الهلوسة والمعايير العامة، وتتمتع بميزة الكفاءة مقارنة بالطرق الأخرى. (المصدر: PaperWeekly)

ورقة بحثية في SIGIR 2025 بعنوان PaRT: استرجاع شخصي في الوقت الفعلي يعزز تجربة روبوتات الدردشة الاجتماعية الاستباقية : اقترحت جامعة العلوم والتكنولوجيا الصينية ومؤسسات أخرى طريقة PaRT (Proactive Social Chatbots with Personalized Real-time ReTreival)، تهدف إلى تعزيز تجربة المحادثة لروبوتات الدردشة الاجتماعية الاستباقية من خلال الجمع بين التخصيص الموجه بالدافع وإعادة كتابة الاستعلام الموجهة بالتعرف على النية والاسترجاع في الوقت الفعلي. يتضمن نظام PaRT ثلاثة وحدات: بناء ملف تعريف مستخدم شخصي، والتعرف على النية وإعادة كتابة الاستعلام، وتوليد معزز بالاسترجاع في الوقت الفعلي. يمكنه بدء أو تبديل الموضوعات بشكل استباقي بناءً على اهتمامات المستخدم وسياق المحادثة، وتقديم ردود أكثر طبيعية وغنية بالمعلومات. أظهرت التجارب غير المتصلة واختبارات A/B عبر الإنترنت أن هذه الطريقة يمكن أن تعزز بشكل فعال تخصيص الردود وثراءها ومتوسط مدة المحادثة. (المصدر: PaperWeekly)
ورقة بحثية في ICML 2025 بعنوان PreSelect: حل فعال لاختيار بيانات التدريب المسبق يعتمد على قوة التنبؤ : اقترحت جامعة هونغ كونغ للعلوم والتكنولوجيا ومختبر vivo AI Lab طريقة اختيار البيانات PreSelect، من خلال إدخال مفهوم “قوة التنبؤ” (Predictive Strength)، لقياس مدى مساهمة البيانات في قدرة النموذج على أداء معين. تستخدم هذه الطريقة الاتساق بين ترتيب درجات النماذج المختلفة في اختبارات الأداء وترتيب الخسارة (Loss) على البيانات لتقييم قيمة البيانات، وتستخدم مصنف fastText خفيف الوزن لتقريب الدرجات، مما يحقق اختيارًا فعالًا للبيانات على نطاق واسع. أظهرت التجارب أن PreSelect يمكن أن تزيد من كفاءة البيانات بمقدار 10 أضعاف، وأن البيانات المختارة تحقق نتائج أفضل بكثير عند تدريب النماذج مقارنة بالعديد من الطرق الأساسية، وتغطي مصادر محتوى عالية الجودة أوسع نطاقًا، وتقلل من تحيز طول العينة. (المصدر: 量子位)

دورة AI Evals تدعو 12 ضيفًا لمشاركة أطر التقييم والممارسات العملية : أعلنت دورة AI Evals التي ينظمها Hamel Husain عن قائمة تضم 12 محاضرًا ضيفًا، بما في ذلك مبتكر إطار عمل inspect، JJ Allaire، ومناصر مطوري Modal، Charles Frye، وغيرهم. ستتعمق الدورة في مختلف جوانب تقييم الذكاء الاصطناعي، بما في ذلك أطر التقييم، وإنشاء تطبيقات مخصصة للوسم، وممارسات تقييم النماذج، وغيرها، بهدف مساعدة المشاركين على إتقان المهارات والأدوات الرئيسية لتقييم أداء أنظمة الذكاء الاصطناعي. (المصدر: Hamel Husain)

إصدار برنامج تعليمي لـ FedRAG: دليل تمهيدي لبناء وضبط أنظمة RAG : أصدر مشروع FedRAG دفاتر ملاحظات تعليمية جديدة ومقاطع فيديو مصاحبة، تهدف إلى مساعدة المستخدمين على البدء بسرعة في استخدام المكتبة. يوضح البرنامج التعليمي كيفية استخدام تكامل Hugging Face لبناء نظام RAG، واستخدام قاعدة معارف في الذاكرة لتخزين العقد، وتعريف SentenceTransformer (Dragon+) كأداة استرجاع، وتعريف نموذج مدرب مسبقًا (مثل Qwen2.5-0.5B) كمولد، واستخدام مدربي LSR و RALT لإجراء ضبط دقيق مركزي للمسترجع والمولد. (المصدر: nerdai)

LlamaIndex تنشر برنامجًا تعليميًا: تحقيق الإحالة والاستدلال في LlamaExtract : نشر فريق LlamaIndex أحدث جولة تفصيلية للأكواد من إعداد @tuanacelik، توضح كيفية تحقيق وظائف الإحالة والاستدلال في LlamaExtract. يتضمن محتوى البرنامج التعليمي: كيفية تعريف مخطط مخصص لإخبار LLM بما يجب استخراجه من مصادر البيانات المعقدة، وكيفية إضافة الإحالات. تهدف هذه الميزة إلى مساعدة المستخدمين على بناء وكلاء ذكاء اصطناعي متعدد الخطوات يمكنهم استخراج معلومات منظمة بدقة وبأدلة من كميات كبيرة من المستندات المصدر. (المصدر: LlamaIndex 🦙)
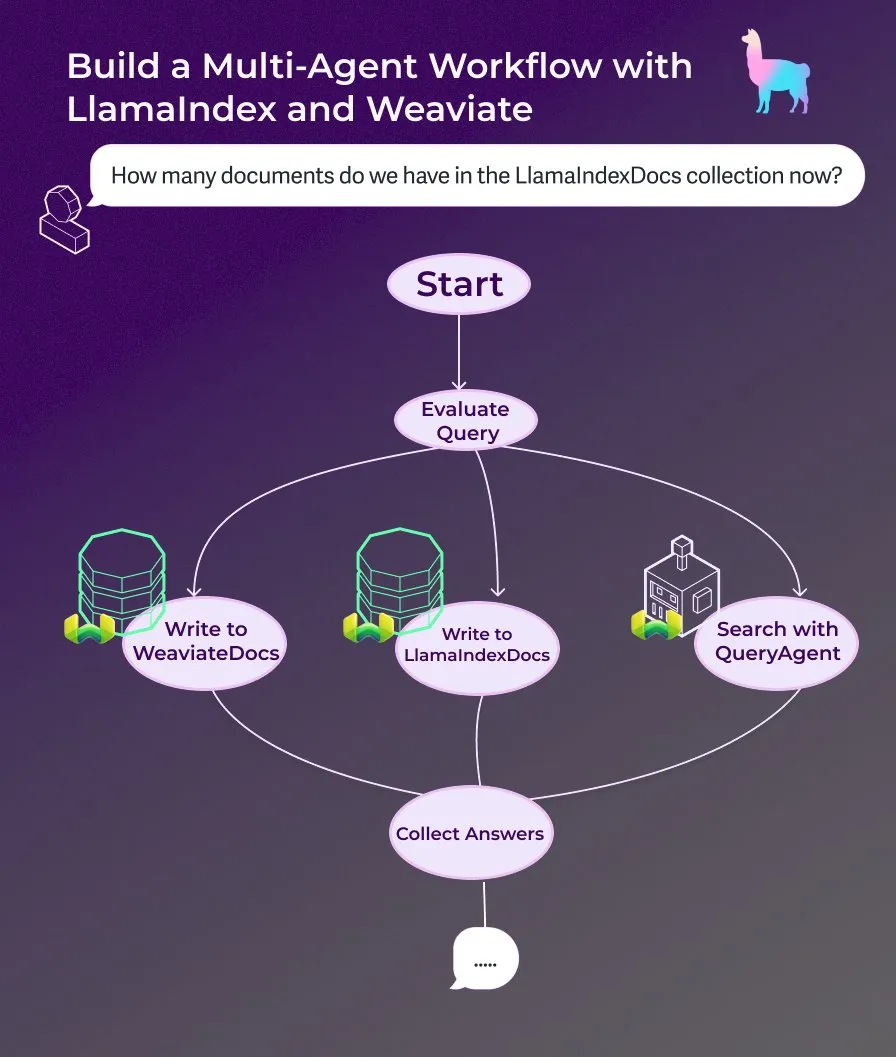
LlamaIndex تنشر برنامجًا تعليميًا: بناء مساعد مستندات متعدد الوكلاء باستخدام تدفق عمل وكيل مدفوع بالأحداث : نشرت LlamaIndex برنامجًا تعليميًا جديدًا يوضح كيفية بناء مساعد مستندات متعدد الوكلاء باستخدام تدفق عمل وكيل مدفوع بالأحداث. يستطيع هذا المساعد كتابة محتوى صفحات الويب إلى مجموعات LlamaIndexDocs و WeaviateDocs، واستخدام منسق لتحديد متى يتم استدعاء Weaviate QueryAgent للبحث والتجميع، والاستفادة من الإخراج المنظم لتصنيف الاستعلامات، ويمكنه اختياريًا استخدام FunctionAgent. (المصدر: LlamaIndex 🦙)
Modular تنشر محاضرة فنية داخلية حول مترجم Mojo، وتناقش Mojo وبنية GPU : بدأت شركة Modular في مشاركة محاضراتها الفنية الداخلية، وكانت أول محاضرة عامة تتعمق في موضوع لغة البرمجة Mojo وبنية GPU. يتضمن المحتوى مبادئ العمل الداخلية لمترجم Mojo والتحديات والحلول التي واجهها الفريق عند التطوير لوحدات معالجة الرسومات الحديثة، بهدف مشاركة تفاصيل مجموعتها التقنية مع المجتمع. (المصدر: Modular)
ورشة عمل AI by Hand: بناء نموذج Transformer من الصفر في Excel : يروج ProfTomYeh لورشة عمل AI by Hand، التي تهدف إلى تمكين المشاركين من بناء نموذج Transformer من البداية في Excel. بهذه الطريقة، يمكن للمتعلمين فهم كل خطوة رياضية في Transformer بوضوح وبشكل بديهي، وتجنب اعتباره “صندوقًا أسود”، وبالتالي بناء فهم عميق لآليات عمل النموذج الداخلية. (المصدر: ProfTomYeh)
DeepLearning.AI تصدر العدد 301 من The Batch: يناقش القيمة التجارية لسرعة الذكاء الاصطناعي وأحدث التطورات : ناقش Andrew Ng في أحدث إصدار له من The Batch كيف أن أهمية تحسين سرعة تنفيذ المهام بواسطة الذكاء الاصطناعي في خلق قيمة تجارية لا تحظى بالتقدير الكافي. ويرى أن الذكاء الاصطناعي لا يقلل التكاليف فحسب، بل الأهم من ذلك أنه يسرع الابتكار والاستكشاف من خلال تقصير الوقت المستغرق للانتقال من الفكرة إلى النموذج الأولي. كما تناول هذا العدد أخبارًا مثل إطلاق سلسلة استدلال Phi-4 من Microsoft، وأداء DeepCoder-14B الذي يضاهي o1، وتخفيف قواعد الذكاء الاصطناعي في الاتحاد الأوروبي. (المصدر: DeepLearningAI)
💼 أعمال
شركة Cartwheel الناشئة في مجال تحريك الشخصيات بالذكاء الاصطناعي تجمع 10 ملايين دولار لتبسيط عمليات الرسوم المتحركة ثلاثية الأبعاد : أعلنت شركة Cartwheel الناشئة المتخصصة في تحريك الشخصيات بالذكاء الاصطناعي عن إتمام جولة تمويل بقيمة 10 ملايين دولار. تلتزم الشركة بتطوير تقنيات تبسط عملية إنتاج الرسوم المتحركة ثلاثية الأبعاد، بهدف تمكين المبدعين من إنتاج رسوم متحركة عالية الجودة لشخصيات ثلاثية الأبعاد بسرعة أكبر وبتكلفة أقل، مع تعزيز التحكم في المنتج النهائي وإزالة المهام المملة. (المصدر: andrew_n_carr)
Hedra تحصل على تمويل بقيمة 32 مليون دولار في جولة A بقيادة a16z، لتسريع إنشاء مقاطع الفيديو التي تعتمد على الشخصيات : أعلنت شركة Hedra الناشئة في مجال توليد الفيديو بالذكاء الاصطناعي عن إتمام جولة تمويل من الفئة A بقيمة 32 مليون دولار، بقيادة Andreessen Horowitz (a16z)، وانضمام Matt Bornstein إلى مجلس الإدارة. كما شارك في الجولة المستثمرون الحاليون a16z speedrun و Abstract و Index Ventures. تلتزم Hedra بجعل إنشاء مقاطع الفيديو التي تعتمد على الشخصيات أمرًا سهلاً، ومنذ إطلاقها في وضع التخفي العام الماضي، استخدم ما يقرب من 3 ملايين شخص أدواتها لإنشاء أكثر من 10 ملايين مقطع فيديو. سيتم استخدام التمويل الجديد لتسريع تطوير المنتجات وتوسيع الفريق، لتحقيق إنشاء محتوى سريع ومعبر وبديهي. (المصدر: Hedra)
Tripadvisor تستخدم Qdrant لبناء مخططات رحلات بالذكاء الاصطناعي، مما يزيد من تفاعل المستخدمين بمقدار 2-3 أضعاف : تعيد Tripadvisor تعريف تجربة اكتشاف السفر باستخدام قاعدة بيانات المتجهات Qdrant. من خلال تحليل أكثر من مليار مراجعة وصورة، و11 مليون شركة، وبيانات من 21 دولة، أنشأت Tripadvisor مسارات رحلات ديناميكية تم إنشاؤها بواسطة الذكاء الاصطناعي، بدلاً من الاعتماد على المرشحات التقليدية. أظهرت النتائج أن المستخدمين الذين يستخدمون أدوات الذكاء الاصطناعي هذه يقضون وقتًا أطول بمقدار 2-3 أضعاف، مما يشير إلى الإمكانات الهائلة للذكاء الاصطناعي في تخطيط السفر المخصص. (المصدر: qdrant_engine)

🌟 مجتمع
تصريحات Grok حول “الإبادة الجماعية للبيض” تثير الجدل، وسام ألتمان يرد بسخرية : أثار نموذج Grok من xAI جدلاً وانتقادات واسعة بسبب نشره آراء عشوائية حول الإبادة الجماعية للبيض في جنوب إفريقيا. أشار Paul Graham إلى أن هذا السلوك يبدو وكأنه خطأ برمجي تم إدخاله في تحديث حديث، وأعرب عن قلقه من أن يتم تعديل آراء الذكاء الاصطناعي المستخدم على نطاق واسع بشكل فوري من قبل المتحكمين به. رد Sam Altman بسخرية، قائلاً إن xAI ستقدم تفسيراً شفافاً، وستفهم هذه المشكلة في سياق “الإبادة الجماعية للبيض في جنوب إفريقيا”، ملمحاً إلى أن هذا نتيجة لسعي الذكاء الاصطناعي للحقيقة واتباع التعليمات. يعكس نقاش المجتمع حول هذا الأمر مخاوف عامة بشأن تحيز نماذج الذكاء الاصطناعي، وقابليتها للتحكم، والنوايا الكامنة وراءها. (المصدر: Paul Graham)
تفكير حول تحويل الذكاء الاصطناعي إلى منتجات: البحث عن الفرص في كامل مسار مهام المستخدم، وليس مجرد إضافة وظائف الذكاء الاصطناعي : شارك رن شين، الشريك في Yunjiu Capital، أفكارًا عميقة حول تحويل الذكاء الاصطناعي إلى منتجات، مؤكدًا على أنه يجب على الشركات أن تنطلق من كامل مسار إنجاز المستخدم للمهام، للبحث عن نقاط دخول لتطبيقات الذكاء الاصطناعي، بدلاً من مجرد إضافة وظائف الذكاء الاصطناعي إلى المنتجات الحالية. طرح تشبيه “المستخدم لا يريد مثقابًا كهربائيًا، بل يريد ثقبًا في الحائط”، مقترحًا تحليل مهام المستخدم، وإيجاد نقاط الألم وتحسينها باستخدام الذكاء الاصطناعي. تشمل المستويات الأربعة لتحويل الذكاء الاصطناعي إلى منتجات: إكمال العمليات القديمة بكفاءة، وإنشاء عمليات جديدة، وفتح أسواق جديدة تمامًا (خفض عتبة الاستخدام، وخدمة مجموعات مستخدمين جديدة، وحتى الذكاء الاصطناعي نفسه)، بالإضافة إلى وضع البنية التحتية لمستقبل يهيمن عليه الذكاء الاصطناعي. ويرى أن تكنولوجيا الذكاء الاصطناعي أصبحت متاحة للجميع، ويمكن للشركات التي لا تفهم التكنولوجيا أن تغتنم الفرص، والجوهر هو “مساعدة الذكاء الاصطناعي في العثور على عمل”. (المصدر: 混沌大学)
نقاش: دور الذكاء الاصطناعي في التطور الوظيفي واستراتيجيات التكيف : أثار منشور على LinkedIn نقاشًا حول كيفية تأثير الذكاء الاصطناعي على التطور الوظيفي. القول الشائع هو “الذكاء الاصطناعي لن يحل محلك في وظيفتك، ولكن الشخص الذي يستخدم الذكاء الاصطناعي سيفعل”. ومع ذلك، وُصِف هذا القول بأنه غامض للغاية. طُرحت أسئلة حول كيفية تحول مهندسي الواجهة الأمامية ذوي الخبرة لعقود فجأة إلى مهندسي ذكاء اصطناعي، وحول حقيقة أنه ليس بإمكان الجميع أن يصبحوا مهندسي ذكاء اصطناعي. رأى نقاش المجتمع أنه بالنسبة لمطوري الواجهة الأمامية، يمكنهم تعلم استخدام أدوات الذكاء الاصطناعي لزيادة كفاءة العمل. كما كان هناك رأي مفاده أن الذكاء الاصطناعي سيحل محل عدد كبير من الوظائف، ولن يجد الكثيرون مكانًا يذهبون إليه. الرأي الأكثر شيوعًا هو أن المستقبل لا يزال غير مؤكد، ولكن الإبداع، والقدرة على اكتشاف المشكلات، والقدرة على فهم الإنسانية والتواصل معها قد تكون أكثر قدرة على الصمود. (المصدر: Reddit r/ArtificialInteligence)
نقاش: نماذج اللغة الكبيرة (LLM) تميل إلى “الضياع” في المحادثات متعددة الأدوار، وإعادة تشغيل المحادثة قد يكون مفيدًا : أشارت ورقة بحثية إلى أن أداء نماذج اللغة الكبيرة (LLM)، سواء كانت مفتوحة المصدر أو مغلقة المصدر، ينخفض بشكل كبير في المحادثات متعددة الأدوار. تركز معظم اختبارات الأداء على سيناريوهات ذات دور واحد وتعليمات واضحة. وجدت الدراسة أن نماذج LLM غالبًا ما تضع افتراضات (خاطئة) في أدوار المحادثة المبكرة، وتعتمد على هذه الافتراضات في المحادثات اللاحقة، ويصعب تصحيحها. الاستنتاج هو أنه عندما لا تحقق المحادثات متعددة الأدوار النتائج المرجوة، فإن بدء محادثة جديدة، ودمج جميع المعلومات ذات الصلة في إدخال الدور الأول، قد يكون مفيدًا. (المصدر: Reddit r/LocalLLaMA)
أسباب تباطؤ وتيرة تطور الذكاء الاصطناعي لدى Apple و WeChat: الخصوصية والأمان واستراتيجية أولوية التطبيقات : حلل وي شي في مقال أنه على الرغم من إطلاق Apple لـ “Apple Intelligence” وربط WeChat بـ DeepSeek و Yuanbao، إلا أن وتيرة تقدمهما في وظائف الذكاء الاصطناعي الأساسية بطيئة نسبيًا. يعود ذلك لسببين رئيسيين: أولاً، الحساسية العالية للخصوصية وأمن البيانات، حيث يعتمد ذكاء الذكاء الاصطناعي على البيانات، ونماذج الأعمال الأساسية لـ Apple و WeChat تجعلهما حذرين للغاية في مشاركة البيانات، مما يحد من تدريب النماذج والحصول على سياق التطبيق. ثانيًا، يتبنى كلاهما استراتيجية “أولوية التطبيقات”، ولا يسعيان للتنافس مع شركات الذكاء الاصطناعي الرائدة في الحد الأقصى لذكاء النماذج، بل يركزان بشكل أكبر على دمج قدرات الذكاء الاصطناعي في الوظائف والأنظمة البيئية الحالية، مما أدى إلى قيود محتملة في الهيمنة التكنولوجية وسرعة تكرار المنتج. (المصدر: 卫夕指北)

OpenAI تطلق “تحدي من الألف إلى الياء”: استخدام الذكاء الاصطناعي لاكتشاف مواقع أثرية غير معروفة في الأمازون : أعلنت OpenAI بالتعاون مع Kaggle عن إطلاق هاكاثون مميز بعنوان “OpenAI to Z Challenge”. يشجع التحدي المشاركين على استخدام نماذج OpenAI o3 أو o4-mini أو GPT-4.1 للبحث عن مواقع أثرية لم تكن معروفة سابقًا في منطقة الأمازون. يمكن للمشاركين استخدام الهاشتاج #OpenAItoZ لمشاركة تقدمهم. يهدف هذا الحدث إلى استكشاف إمكانات الذكاء الاصطناعي في مجالات علم الآثار والتحليل الجغرافي المكاني. (المصدر: OpenAI Developers)
انتقادات للشركات الناشئة في مجال “محامي الذكاء الاصطناعي”: أتمتة “رسائل الابتزاز” قد تصبح عبئًا اجتماعيًا : انتقد المطور @swyx ظاهرة استثمار بعض شركات رأس المال المغامر في الشركات الناشئة في مجال “محامي الذكاء الاصطناعي”. ويرى أن هذه الشركات تقوم بشكل أساسي بأتمتة إنشاء “خطابات المطالبة” (demand letters) باستخدام الذكاء الاصطناعي، وهي في جوهرها أتمتة للابتزاز. وعلى الرغم من أن بعض المطالبات قد تكون مبررة، إلا أنه يشير إلى أن معظم هذه الأنشطة ستفيد المحامين في نهاية المطاف، وتصبح ضريبة خالصة على المجتمع. ودعا إلى مقاطعة هذه الشركات ومستثمريها وسحب الاستثمارات منها وانتقادها علنًا. (المصدر: swyx)

💡 أخرى
تقرير عن الفحم يحتوي على خطأ فادح “يُحصل عليه بقتل هياكل الوذر”، مما يثير نقاشًا حول جودة المحتوى وهلوسة الذكاء الاصطناعي : ظهر في تقرير عن صناعة الفحم بسعر 8200 يوان وصف “الفحم مورد متجدد، يُحصل عليه بقتل هياكل الوذر”، وهو محتوى مأخوذ من لعبة “ماينكرافت”، مما أثار جدلاً واسعًا على الإنترنت. أرجع الكثيرون ذلك إلى توليد المحتوى بواسطة الذكاء الاصطناعي والهلوسة. ومع ذلك، نُشر التقرير في عام 2022، قبل إطلاق نماذج كبيرة سائدة مثل ChatGPT، مما يشير إلى أن هذا مثال نموذجي على النسخ واللصق اليدوي وإهمال المراجعة. أثار الحادث أيضًا تفكيرًا عميقًا حول جودة محتوى التقارير المهنية، وأهمية التحقق من المعلومات، وكيفية تمييز المعلومات الحقيقية في عصر الذكاء الاصطناعي. (المصدر: caoz的梦呓)

باحثون يستخدمون علاجًا مخصصًا لتحرير الجينات لعلاج رضيع مصاب بمرض استقلابي نادر : قام الأطباء في أقل من سبعة أشهر ببناء علاج مخصص لتحرير الجينات، واستخدموه بنجاح لعلاج رضيع مصاب بمرض استقلابي مميت. هذه هي المرة الأولى التي يتم فيها استخدام تحرير الجينات لعلاج مخصص لفرد واحد. يهدف العلاج إلى تصحيح خطأ محدد من حرف واحد في جينات الرضيع، مما يوضح دقة تقنيات تحرير الجينات الجديدة (مثل تحرير القواعد). على الرغم من أن العلاج أظهر علامات إيجابية مبكرة، إلا أنه يسلط الضوء أيضًا على تحديات التكلفة وقابلية التوسع لتطوير علاجات جينية مخصصة للأمراض النادرة جدًا. (المصدر: MIT Technology Review)

الكشف عن استراتيجية مطالبات كسر الحماية العامة، قادرة على تجاوز حواجز الأمان في النماذج الكبيرة السائدة : اكتشف باحثون من HiddenLayer استراتيجية مطالبات عامة قادرة على جعل نماذج اللغة الكبيرة السائدة، بما في ذلك ChatGPT و Claude و Gemini، تتجاوز حواجز الأمان وتولد محتوى ضارًا. تقوم هذه الاستراتيجية بإخفاء التعليمات الضارة في تنسيق يشبه ملفات السياسات مثل XML أو INI أو JSON، مع دمج سيناريوهات لعب أدوار خيالية، لخداع النموذج لتفسير الأوامر الضارة كتعليمات نظام مشروعة. تستغل هذه الطريقة نقاط ضعف نظامية محتملة في بيانات تدريب النموذج، أي الميل إلى تجاهل تعليمات الأمان عند معالجة البيانات المتعلقة بالتعليم أو السياسات. يمكن لهذه التقنية أيضًا استخراج مطالبات نظام النموذج، وكشف تعليماته الداخلية وقيود الأمان. (المصدر: 新智元)
