
كلمات مفتاحية:DeepSeek-Prover-V2, Qwen3, نموذج الاستدلال الرياضي الكبير, النموذج متعدد الوسائط, طرق تقييم الذكاء الاصطناعي, النموذج الكبير مفتوح المصدر, التعلم المعزز, سلسلة توريد الذكاء الاصطناعي, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, إنصاف تصنيف LMArena, طريقة RLVR للاستدلال الرياضي, تحليل مخاطر سلسلة توريد الذكاء الاصطناعي
🔥 أبرز الأخبار
DeepSeek تطلق نموذج DeepSeek-Prover-V2 للاستدلال الرياضي: أطلقت DeepSeek سلسلة نماذج DeepSeek-Prover-V2 المصممة خصيصًا للبرهان الرياضي الرسمي والاستدلال المنطقي المعقد، وتشمل إصدارات 671B و 7B. يعتمد النموذج على معمارية DeepSeek V3 MoE، وتم ضبطه بدقة في مجالات مثل الاستدلال الرياضي، وتوليد الأكواد، ومعالجة المستندات القانونية. تظهر البيانات الرسمية أن إصدار 671B يحل ما يقرب من 90% من مسائل miniF2F، ويحسن بشكل كبير أداء SOTA على PutnamBench، ويحقق معدل نجاح جيد في مسائل النسخة الرسمية من AIME 24 و 25. تمثل هذه الخطوة تقدمًا هامًا للذكاء الاصطناعي في مجال الاستدلال الرياضي الآلي والبرهان الرسمي، وقد تدفع التطور في البحث العلمي وهندسة البرمجيات وغيرها من المجالات. (المصدر: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
إطلاق سلسلة نماذج Qwen3 الكبيرة وجعلها مفتوحة المصدر: أطلق فريق Qwen التابع لشركة Alibaba أحدث سلسلة نماذج Qwen3 الكبيرة، والتي تضم 8 نماذج تتراوح معلماتها من 0.6B إلى 235B، وتشمل نماذج كثيفة ونماذج MoE. تتمتع نماذج Qwen3 بالقدرة على التبديل بين وضعي التفكير/عدم التفكير، مع تحسينات ملحوظة في الاستدلال والرياضيات وتوليد الأكواد والمعالجة متعددة اللغات (تدعم 119 لغة)، كما تم تعزيز قدرات الـ Agent ودعم MCP. يظهر التقييم الرسمي أن أداءها يتفوق على نماذج QwQ و Qwen2.5 السابقة، وتتفوق في بعض المعايير على Llama4 و DeepSeek R1 وحتى Gemini 2.5 Pro. تم جعل هذه السلسلة من النماذج مفتوحة المصدر على Hugging Face و ModelScope بموجب ترخيص Apache 2.0. (المصدر: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
Alibaba تطلق نموذج Qwen2.5-Omni-3B متعدد الوسائط خفيف الوزن: أطلق فريق Qwen التابع لشركة Alibaba نموذج Qwen2.5-Omni-3B، وهو نموذج شامل متعدد الوسائط يمكنه معالجة مدخلات النص والصور والصوت والفيديو، وتوليد مخرجات نصية وصوتية متدفقة. مقارنة بإصدار 7B، يقلل نموذج 3B بشكل كبير من استهلاك VRAM (بنسبة تزيد عن 50%) عند معالجة التسلسلات الطويلة (حوالي 25 ألف توكن)، ويمكن تشغيله على وحدات معالجة الرسومات الاستهلاكية بسعة 24GB لدعم تفاعل الصوت والفيديو لمدة 30 ثانية، مع الاحتفاظ بأكثر من 90% من قدرة فهم الوسائط المتعددة لنموذج 7B ودقة إخراج صوتي مماثلة. النموذج متاح الآن على Hugging Face و ModelScope. (المصدر: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere تنشر ورقة بحثية تشكك في عدالة لوحة صدارة LMArena: نشر باحثون من Cohere ورقة بحثية بعنوان “The Leaderboard Illusion”، تحلل بعمق لوحة صدارة Chatbot Arena (LMArena) المستخدمة على نطاق واسع. تشير الورقة إلى أنه على الرغم من أن LMArena تهدف إلى توفير تقييم عادل، إلا أن سياساتها الحالية (مثل السماح بالاختبار الخاص، وسحب النتائج بعد تقديم النموذج، وآلية إيقاف النماذج غير الشفافة، وعدم تناسق الوصول إلى البيانات، وما إلى ذلك) قد تؤدي إلى تحيز نتائج التقييم لصالح عدد قليل من مزودي النماذج الكبيرة القادرين على استغلال هذه القواعد، مما يخلق خطر الإفراط في التخصيص، وبالتالي تشويه قياس التقدم الحقيقي لنماذج الذكاء الاصطناعي. أثارت الورقة نقاشًا واسعًا في المجتمع حول علمية وعدالة طرق تقييم نماذج الذكاء الاصطناعي، وقدمت اقتراحات تحسين محددة. (المصدر: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 الاتجاهات
Xiaomi تطلق نموذج الاستدلال مفتوح المصدر MiMo-7B: أطلقت Xiaomi نموذج MiMo-7B، وهو نموذج استدلال مفتوح المصدر تم تدريبه على 25 تريليون توكن، ويتفوق بشكل خاص في الرياضيات والبرمجة. يستخدم النموذج معمارية decoder-only Transformer، ويتضمن تقنيات مثل GQA و pre-RMSNorm و SwiGLU و RoPE، وأضاف 3 وحدات MTP (Multi-Token-Prediction) لتسريع الاستدلال من خلال فك التشفير التخميني. تم تدريب النموذج مسبقًا على ثلاث مراحل وتدريبه لاحقًا باستخدام التعلم المعزز القائم على نسخة معدلة من GRPO، مما يحل مشكلة اختراق المكافأة وخلط اللغات في مهام الاستدلال الرياضي. (المصدر: scaling01)

JetBrains تجعل نموذج إكمال الكود Mellum مفتوح المصدر: جعلت JetBrains نموذج إكمال الكود Mellum مفتوح المصدر على Hugging Face. وهو نموذج مركّز (Focal Model) صغير وفعال مصمم خصيصًا لمهام إكمال الكود. تم تدريب النموذج من الصفر بواسطة JetBrains، وهو الأول في سلسلتها من نماذج LLM المخصصة قيد التطوير. تهدف هذه الخطوة إلى تزويد المطورين بأدوات مساعدة برمجية أكثر تخصصًا. (المصدر: ClementDelangue, Reddit r/LocalLLaMA)
LightOn تطلق نموذج الاسترجاع المتطور الجديد GTE-ModernColBERT: للتغلب على قيود النماذج الكثيفة القائمة على ModernBERT، أطلقت LightOn نموذج GTE-ModernColBERT. وهو أول نموذج تفاعل متأخر (متعدد المتجهات) متطور (SOTA) تم تدريبه باستخدام إطار عمل PyLate الخاص بها، ويهدف إلى تحسين أداء مهام استرجاع المعلومات، خاصة في السيناريوهات التي تتطلب فهمًا تفاعليًا أكثر دقة. (المصدر: tonywu_71, lateinteraction)

Kyutai تطلق LLM متعدد اللغات بمعاملات 2B Helium 1: أطلقت Kyutai نموذج LLM جديد بمعاملات 2 مليار Helium 1، وفي نفس الوقت جعلت عملية استنساخ مجموعة بيانات التدريب الخاصة بها dactory مفتوحة المصدر، والتي تغطي جميع اللغات الرسمية الـ 24 للاتحاد الأوروبي. يضع Helium 1 معيارًا جديدًا للأداء للغات الأوروبية ضمن فئة حجم معاملاته، ويهدف إلى تعزيز قدرات الذكاء الاصطناعي للغات الأوروبية. (المصدر: huggingface, armandjoulin, eliebakouch)
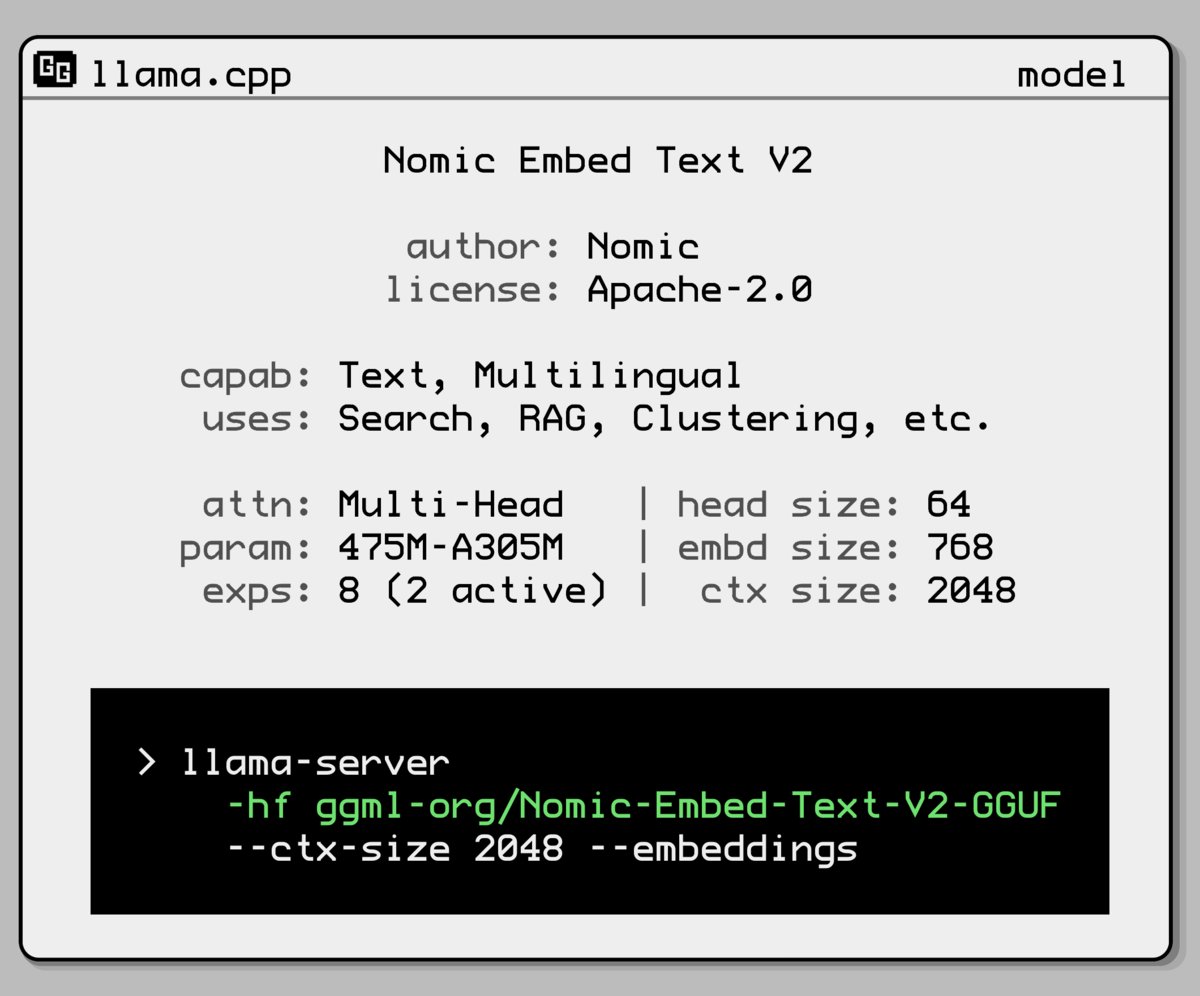
Nomic AI تطلق نموذج تضمين جديد يعتمد على خليط الخبراء: قدمت Nomic AI نموذج تضمين جديد يعتمد على معمارية خليط الخبراء (Mixture-of-Experts, MoE). تُستخدم هذه المعمارية عادةً في النماذج الكبيرة لتحسين الكفاءة والأداء، وقد يهدف تطبيقها على نماذج التضمين إلى تحسين قدرة التمثيل لمهام أو أنواع بيانات محددة، أو الحصول على أداء تعميم أفضل مع الحفاظ على تكلفة حسابية منخفضة. (المصدر: ggerganov)
OpenAI تتراجع عن تحديث GPT-4o لحل مشكلة التملق المفرط: أعلنت OpenAI عن التراجع عن تحديث الأسبوع الماضي لـ GPT-4o في ChatGPT، بسبب إظهار الإصدار سلوك تملق مفرط ومحاولة إرضاء المستخدمين (sycophancy). يستخدم المستخدمون الآن إصدارًا سابقًا أكثر توازنًا في السلوك. ذكرت OpenAI أنها تعمل على حل مشكلة سلوك التملق في النموذج، ورتبت جلسة AMA (Ask Me Anything) مع مسؤولة سلوك النموذج Joanne Jang لمناقشة تشكيل شخصية ChatGPT. (المصدر: openai, joannejang, Reddit r/ChatGPT)
Terminus تحدث نشرة الاكتتاب وتعلن عن استراتيجية الذكاء المكاني: قامت شركة AIoT Terminus بتحديث نشرة الاكتتاب الخاصة بها، وكشفت عن وصول إيراداتها في عام 2024 إلى 1.843 مليار يوان، بزيادة سنوية قدرها 83.2%. في الوقت نفسه، أعلنت الشركة عن استراتيجيتها الجديدة للذكاء المكاني، والتي تشكل ثلاث هياكل منتجات رئيسية: نموذج مجال AIoT (يعتمد على قاعدة DeepSeek المدمجة)، والبنية التحتية لـ AIoT (قاعدة الحوسبة الذكية)، و AIoT Agent (روبوتات ذكية مجسدة، إلخ)، بهدف التخطيط الشامل للذكاء المكاني. (المصدر: 36氪)
دراسة تكشف أن الفجوة بين Transformer و SSM في مهام الاسترجاع تنبع من عدد قليل من رؤوس الانتباه: تشير دراسة جديدة إلى أن نماذج فضاء الحالة (SSM) تتخلف عن Transformer في مهام مثل MMLU (الاختيار من متعدد) و GSM8K (الرياضيات)، ويرجع ذلك أساسًا إلى تحديات قدرة استرجاع السياق. ومن المثير للاهتمام أن الدراسة وجدت أنه سواء في معمارية Transformer أو SSM، فإن الحسابات الرئيسية لمعالجة مهام الاسترجاع تتم بواسطة عدد قليل فقط من رؤوس الانتباه (heads). يساعد هذا الاكتشاف في فهم الاختلافات الجوهرية بين المعماريتين وقد يوجه تصميم النماذج الهجينة. (المصدر: simran_s_arora, _albertgu, teortaxesTex)
🧰 الأدوات
Novita AI أول من ينشر خدمة استدلال DeepSeek-Prover-V2-671B: أعلنت Novita AI أنها أول مزود يقدم خدمة استدلال لنموذج DeepSeek الأخير للاستدلال الرياضي بمعاملات 671B، DeepSeek-Prover-V2. أصبح النموذج متاحًا أيضًا على Hugging Face، ويمكن للمستخدمين الآن تجربة هذا النموذج القوي للاستدلال الرياضي والمنطقي مباشرة عبر منصة Novita AI أو Hugging Face. (المصدر: _akhaliq, mervenoyann)
PPIO Cloud تطلق خدمة نموذج DeepSeek-Prover-V2-671B: أطلقت المنصة السحابية المحلية PPIO Cloud بسرعة خدمة استدلال لنموذج DeepSeek-Prover-V2-671B الذي تم إصداره حديثًا. يمكن للمستخدمين تجربة هذا النموذج الكبير بمعاملات 671B الذي يركز على البرهان الرياضي الرسمي والاستدلال المنطقي المعقد من خلال المنصة. توفر المنصة أيضًا آلية دعوة، حيث يمكن الحصول على قسائم يمكن استخدامها لكل من API وواجهة الويب عن طريق دعوة الأصدقاء للتسجيل. (المصدر: karminski3)

Gradio تطلق ميزة خادم MCP بسيطة: أضاف إطار عمل Gradio ميزة جديدة، حيث يمكن بسهولة تحويل أي تطبيق Gradio إلى خادم بروتوكول سياق النموذج (MCP) بمجرد إضافة المعلمة mcp_server=True في demo.launch(). هذا يعني أنه يمكن للمطورين بسرعة عرض تطبيقات Gradio الحالية (بما في ذلك عدد كبير من التطبيقات المستضافة على Hugging Face Spaces) للاستخدام من قبل LLM أو Agent التي تدعم MCP، مما يبسط بشكل كبير تكامل تطبيقات الذكاء الاصطناعي مع الـ Agent. (المصدر: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
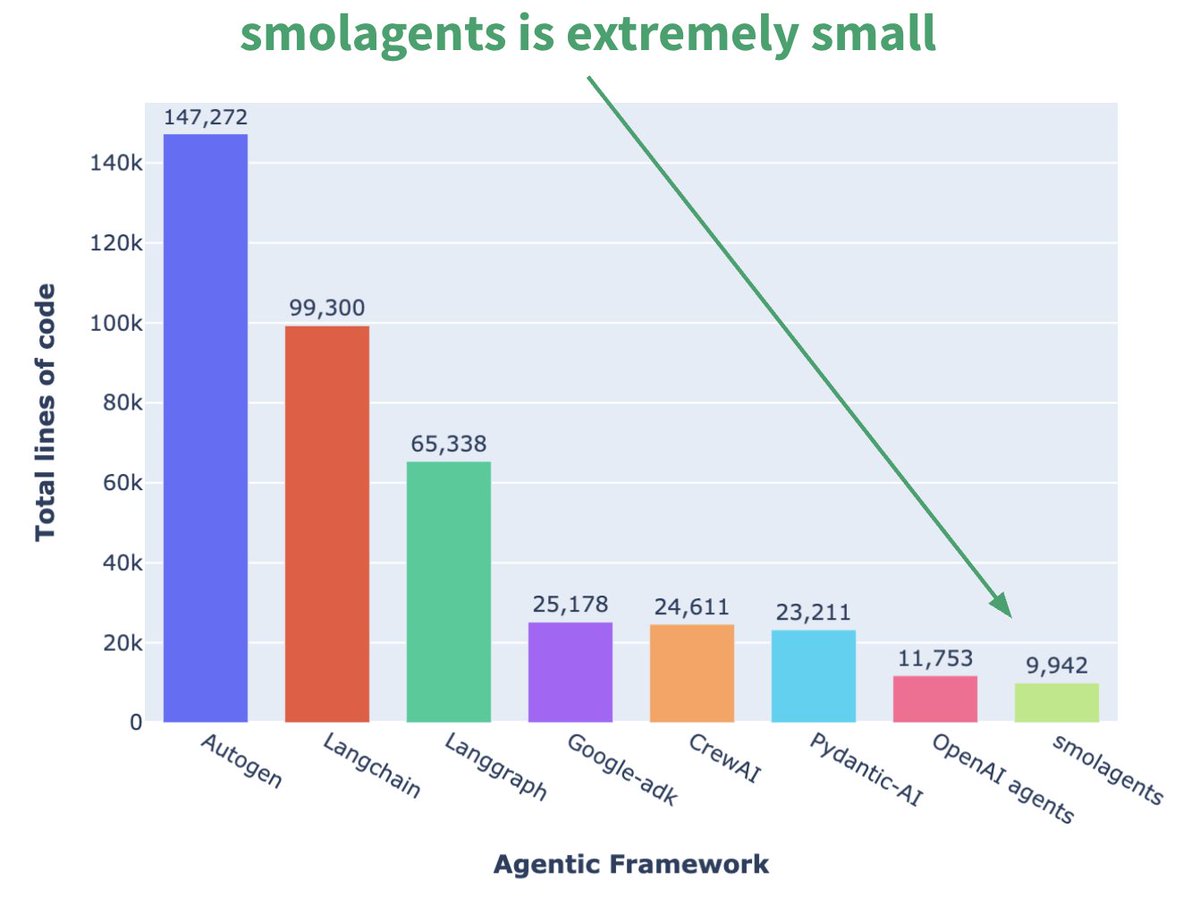
Hugging Face تطلق إطار عمل Agent مصغر smolagents: أطلقت Hugging Face إطار عمل Agent يسمى smolagents، وتتمثل ميزته الأساسية في البساطة الشديدة. يهدف الإطار إلى توفير اللبنات الأساسية الأكثر أهمية، وتجنب التجريد المفرط والتعقيد، مما يتيح للمستخدمين بناء تدفقات عمل Agent الخاصة بهم بمرونة فوقه. كما أصدرت الشركة دورة قصيرة مقابلة على DeepLearning.AI لمساعدة المستخدمين على البدء. (المصدر: huggingface, AymericRoucher, ClementDelangue)
Runway تطلق ميزة Gen-4 References لتعزيز تناسق توليد الفيديو: أطلقت Runway ميزة Gen-4 References لجميع المستخدمين المدفوعين. تتيح هذه الميزة للمستخدمين استخدام الصور الفوتوغرافية أو الصور المولدة أو النماذج ثلاثية الأبعاد أو صور السيلفي كمرجع لتوليد محتوى فيديو بشخصيات وأماكن متناسقة وما إلى ذلك. يحل هذا التحدي طويل الأمد المتمثل في التناسق في توليد الفيديو بالذكاء الاصطناعي، مما يجعل من الممكن وضع شخصيات أو كائنات معينة في أي مشهد متخيل، ويعزز قابلية التحكم والتطبيق العملي لإنشاء الفيديو بالذكاء الاصطناعي. (المصدر: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces ترتقي إلى Nvidia H200 لتعزيز قدرة ZeroGPU: أعلنت Hugging Face أن ZeroGPU v2 الخاص بها قد تحول إلى استخدام وحدات معالجة الرسومات Nvidia H200. هذا يعني أن Hugging Face Spaces (خاصة خطة Pro) مجهزة الآن بـ 70GB VRAM وزيادة 2.5 مرة في قدرة عمليات الفاصلة العائمة (flops). تهدف هذه الخطوة إلى فتح سيناريوهات تطبيقات ذكاء اصطناعي جديدة وتزويد المستخدمين بخيارات حوسبة CUDA أقوى وموزعة وفعالة من حيث التكلفة، لدعم تشغيل نماذج أكبر وأكثر تعقيدًا. (المصدر: huggingface, ClementDelangue)

إصدار SkyPilot v0.9، يضيف لوحة معلومات وميزات نشر الفريق: أصدرت SkyPilot الإصدار 0.9، مقدمة ميزة لوحة معلومات الويب التي تتيح للمستخدمين والفرق عرض حالة جميع المجموعات والوظائف والسجلات وقوائم الانتظار ومشاركة عناوين URL مباشرة. يدعم الإصدار الجديد أيضًا نشر الفريق (معمارية العميل-الخادم)، وحفظ نقاط فحص النموذج بسرعة 10 أضعاف عبر حاويات التخزين السحابي، ويضيف دعمًا لـ Nebius AI و GB200. تهدف هذه التحديثات إلى تعزيز كفاءة الإدارة والتعاون في تشغيل أعباء عمل الذكاء الاصطناعي في السحابة باستخدام SkyPilot. (المصدر: skypilot_org)

Tesslate تطلق نموذج UIGEN-T2 لتوليد واجهات المستخدم بمعاملات 7B: أطلقت Tesslate نموذج UIGEN-T2، وهو نموذج بمعاملات 7B مخصص لتوليد واجهات مواقع ويب HTML/CSS/JS + Tailwind تتضمن مخططات وعناصر تفاعلية. تم تدريب النموذج على بيانات محددة، ويمكنه توليد عناصر واجهة مستخدم وظيفية مثل عربات التسوق والمخططات والقوائم المنسدلة والتخطيطات المتجاوبة والمؤقتات، ويدعم أنماط مثل glassmorphism والوضع الداكن. تم إصدار نسخة GGUF للنموذج وأوزان LoRA على Hugging Face، وتم توفير Playground و Demo عبر الإنترنت. (المصدر: Reddit r/LocalLLaMA)
AI EngineHost تثير الشكوك بتقديم خدمة استضافة AI مدى الحياة بسعر منخفض: تدعي خدمة تسمى AI EngineHost أنها تقدم استضافة ويب مدى الحياة، ويمكنها نشر نماذج LLM مفتوحة المصدر مثل LLAMA 3 و Grok-1 بنقرة واحدة على خوادم NVIDIA GPU، مقابل دفعة لمرة واحدة قدرها 16.95 دولارًا فقط. تعد الخدمة بتخزين NVMe غير محدود، وعرض نطاق ترددي، ونطاقات، وتدعم لغات وقواعد بيانات متعددة، وتتضمن ترخيصًا تجاريًا. ومع ذلك، أثار تسعيرها المنخفض للغاية ووعد “مدى الحياة” شكوكًا واسعة النطاق في المجتمع حول شرعيتها واستدامتها، مع شكوك حول ما إذا كانت عملية احتيال أو فخًا مخفيًا. (المصدر: Reddit r/deeplearning)
BrowserQwen: مساعد متصفح يعتمد على Qwen-Agent: أطلق فريق Qwen تطبيق BrowserQwen، وهو مساعد متصفح مبني على إطار عمل Qwen-Agent. يستفيد من قدرات نموذج Qwen في استخدام الأدوات والتخطيط والذاكرة، ويهدف إلى مساعدة المستخدمين على التفاعل مع المتصفح بذكاء أكبر، وقد يشمل ذلك فهم محتوى الويب واستخراج المعلومات والعمليات الآلية وما إلى ذلك. (المصدر: QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ: بديل Kafka عديم الحالة يعتمد على S3: AutoMQ هو مشروع مفتوح المصدر يهدف إلى توفير بديل Kafka عديم الحالة مبني على S3 أو تخزين كائنات متوافق. تكمن ميزته الأساسية في حل مشكلة صعوبة التوسع والتكلفة العالية لـ Kafka التقليدي في السحابة (خاصة حركة المرور عبر مناطق التوفر). من خلال فصل التخزين عن الحوسبة، تدعي AutoMQ أنها تحقق فعالية تكلفة 10 أضعاف، وتوسعًا تلقائيًا في ثوانٍ، وزمن وصول بالميلي ثانية أحادي الرقم، وتوفرًا عاليًا متعدد مناطق التوفر. (المصدر: AutoMQ/automq – GitHub Trending (all/daily))
Daytona: بنية تحتية آمنة ومرنة لتشغيل الكود المولد بواسطة AI: Daytona هي منصة بنية تحتية تهدف إلى توفير بيئة آمنة ومعزولة وسريعة الاستجابة، مصممة خصيصًا لتشغيل الكود المولد بواسطة الذكاء الاصطناعي. تدعم التحكم البرمجي عبر SDK (Python/TypeScript)، ويمكنها إنشاء بيئات معزولة بسرعة (أقل من 90 مللي ثانية)، وتنفيذ عمليات الملفات، وأوامر Git، وتفاعلات LSP، وتشغيل الكود، وتدعم الاستمرارية وصور OCI/Docker. هدفها هو حل مشكلات الأمان وإدارة الموارد عند تشغيل كود AI غير موثوق به أو تجريبي. (المصدر: daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples: مكتبة أمثلة تعرض استخدامات MLX Swift: يحتفظ فريق MLX التابع لشركة Apple بمشروع يحتوي على أمثلة متعددة لاستخدام إطار عمل MLX Swift. تغطي هذه الأمثلة تطبيقات مثل النماذج اللغوية الكبيرة (LLM)، ونماذج اللغة المرئية (VLM)، ونماذج التضمين، وتوليد الصور باستخدام Stable Diffusion، بالإضافة إلى تدريب التعرف على الأرقام المكتوبة بخط اليد الكلاسيكي MNIST. تهدف مكتبة الأكواد إلى مساعدة المطورين على تعلم وتطبيق MLX Swift لمهام التعلم الآلي، خاصة داخل نظام Apple البيئي. (المصدر: ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
إصدار Blender 4.4، يعزز تتبع الأشعة وسهولة الاستخدام: أصدر برنامج Blender ثلاثي الأبعاد مفتوح المصدر الإصدار 4.4. يتضمن الإصدار الجديد تحسينات كبيرة في تتبع الأشعة، مما يحسن تأثير تقليل الضوضاء، خاصة عند معالجة تشتت تحت السطح (Subsurface Scattering) وضبابية عمق المجال (Depth of Field)، ويقدم أخذ عينات ضوضاء زرقاء أفضل لتحسين جودة المعاينة وتناسق الرسوم المتحركة. بالإضافة إلى ذلك، تم تحسين مركب الصور، وفرشاة نحت القماش (Grab Cloth Brush)، وأداة قلم الشمع (Grease Pencil)، وواجهة المستخدم (مثل رؤية فهرس الشبكة). كما تم تحسين وظائف تحرير الفيديو. (المصدر: YouTube – Two Minute Papers
)
📚 تعلم
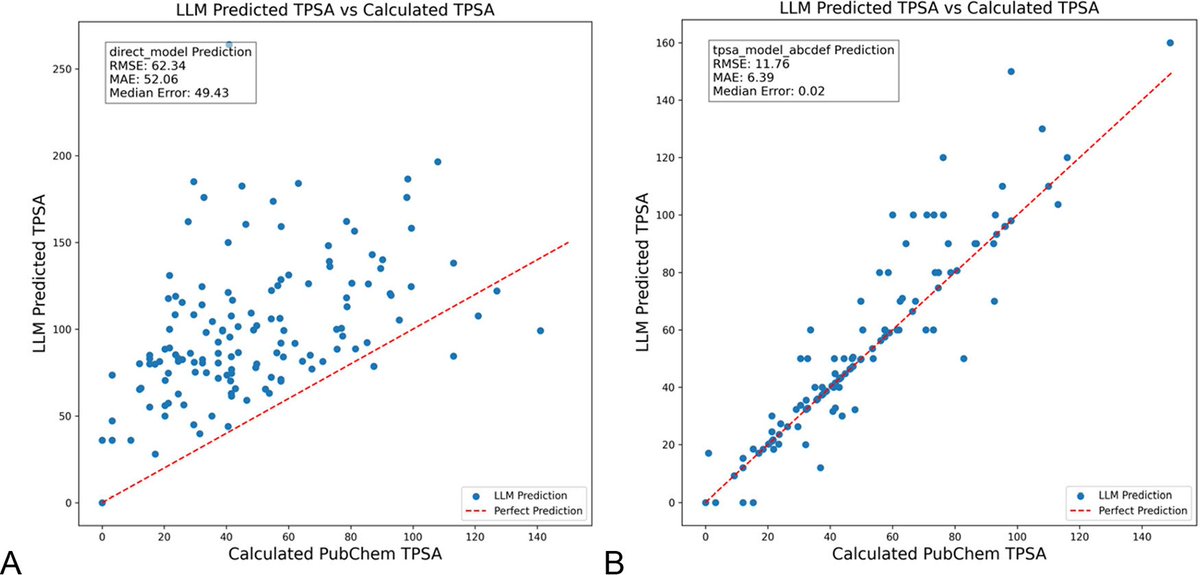
تحسين مطالبات LLM باستخدام DSPy يقلل بشكل كبير من الهلوسة في مجال الكيمياء: تظهر ورقة بحثية جديدة نُشرت في مجلة Journal of Chemical Information and Modeling أن بناء وتحسين مطالبات LLM باستخدام إطار عمل DSPy يمكن أن يقلل بشكل كبير من مشكلة الهلوسة في مجال الكيمياء. من خلال تحسين برنامج DSPy، خفضت الدراسة الخطأ التربيعي المتوسط (RMS error) لتوقع المساحة السطحية القطبية الطوبولوجية الجزيئية (TPSA) بنسبة 81%. يشير هذا إلى أنه من خلال تحسين المطالبات البرمجية، يمكن تحسين دقة وموثوقية LLM بشكل فعال في المجالات العلمية المتخصصة (مثل الكيمياء). (المصدر: lateinteraction, lateinteraction)
ورقة بحثية تقترح استخدام الرسوم البيانية لتحديد كمية الاستدلال المنطقي العام وتقديم رؤى ميكانيكية: تقترح ورقة بحثية جديدة طريقة لتمثيل المعرفة الضمنية لـ 37 نشاطًا يوميًا كرسوم بيانية موجهة، وبالتالي توليد كميات هائلة (حوالي 10^17 لكل نشاط) من استعلامات المنطق العام. تهدف هذه الطريقة إلى التغلب على عيوب المعايير الحالية المحدودة وغير الشاملة، لتقييم قدرات الاستدلال المنطقي العام لـ LLM بشكل أكثر صرامة. تستخدم الدراسة بنية الرسم البياني لتحديد كمية المنطق العام، وتعزز تقنية تصحيح التنشيط (activation patching) من خلال المطالبات المترافقة (conjugate prompts) لتحديد المكونات الرئيسية المسؤولة عن الاستدلال في النموذج. (المصدر: menhguin)

عينة واحدة كافية لتحسين استدلال LLM الرياضي بشكل كبير باستخدام طريقة التعلم المعزز (RLVR): تقترح ورقة بحثية جديدة أن طريقة التعلم المعزز من ردود فعل التحقق (RLVR) باستخدام عينة تدريب واحدة فقط يمكن أن تحسن بشكل كبير أداء النماذج اللغوية الكبيرة في المهام الرياضية. أظهرت التجارب أنه على معيار MATH500، يمكن لـ RLVR بعينة واحدة رفع دقة Qwen2.5-Math-1.5B من 36.0% إلى 73.6%، ودقة Qwen2.5-Math-7B من 51.0% إلى 79.2%. قد يلهم هذا الاكتشاف إعادة التفكير في آلية RLVR ويوفر أفكارًا جديدة لتحسين قدرات النموذج في ظل الموارد المنخفضة. (المصدر: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI تحدث دورة “LLMs as Operating Systems: Agent Memory”: تم تحديث الدورة القصيرة المجانية “LLMs as Operating Systems: Agent Memory” التي تقدمها DeepLearning.AI بالتعاون مع Letta. تشرح الدورة استخدام طريقة MemGPT لبناء LLM Agent يمكنه إدارة الذاكرة طويلة المدى (تتجاوز قيود نافذة السياق). يتضمن المحتوى الجديد خدمة Letta Agent المنشورة مسبقًا (للممارسة العملية للـ Agent في السحابة) وميزة الإخراج المتدفق (لمراقبة عملية الاستدلال التدريجي للـ Agent)، بهدف مساعدة المتعلمين على بناء أنظمة ذكاء اصطناعي أكثر تكيفًا وتعاونًا. (المصدر: DeepLearningAI)

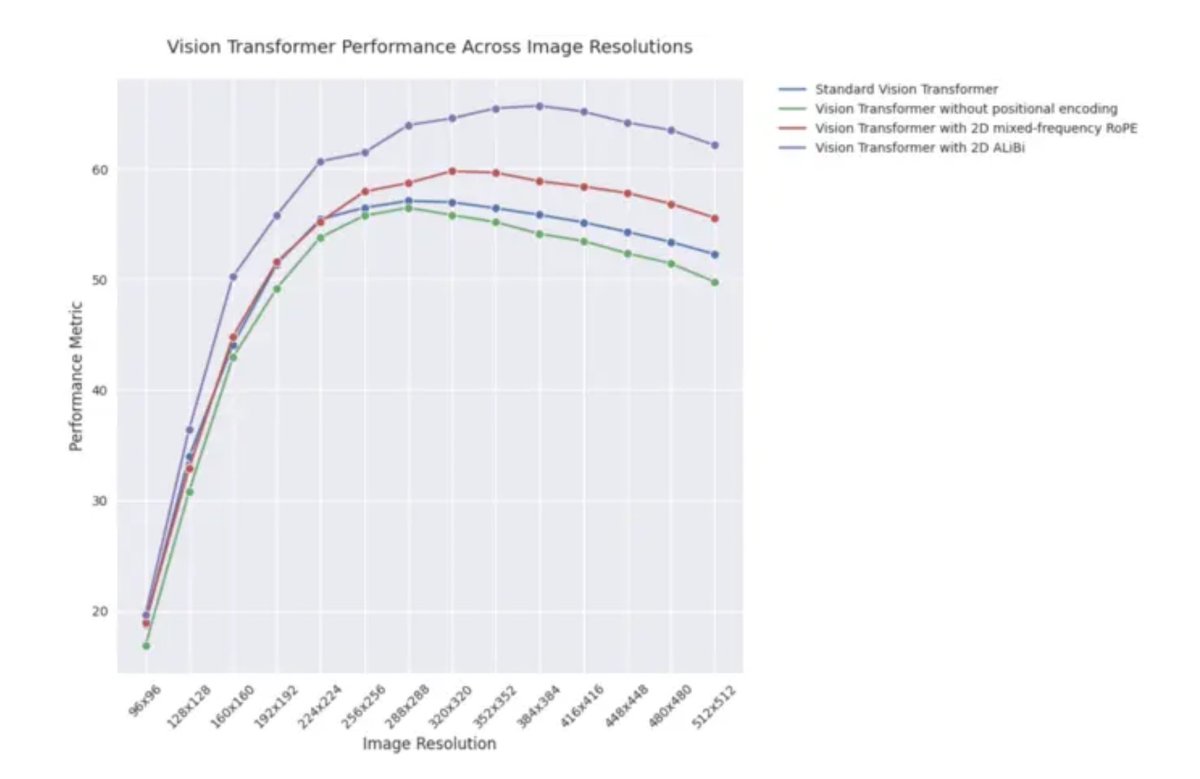
مدونة ICLR 2025: أداء الاستقراء لـ 2D ALiBi في Vision Transformers: تشير مدونة لـ ICLR 2025 إلى أن Vision Transformers (ViT) التي تستخدم الانتباه ثنائي الأبعاد مع الانحياز الخطي (2D ALiBi) تحقق أفضل أداء في مهمة الاستقراء إلى أحجام صور أكبر على مجموعة بيانات Imagenet100. ALiBi هي طريقة ترميز للموضع النسبي، وقد ألهم نجاح تطبيقها في مجال معالجة اللغة الطبيعية استكشافها في مجال الرؤية، وتشير هذه النتيجة إلى أن 2D ALiBi تساعد ViT على التعميم بشكل أفضل على دقة الصور التي لم يتم رؤيتها أثناء التدريب. (المصدر: OfirPress)
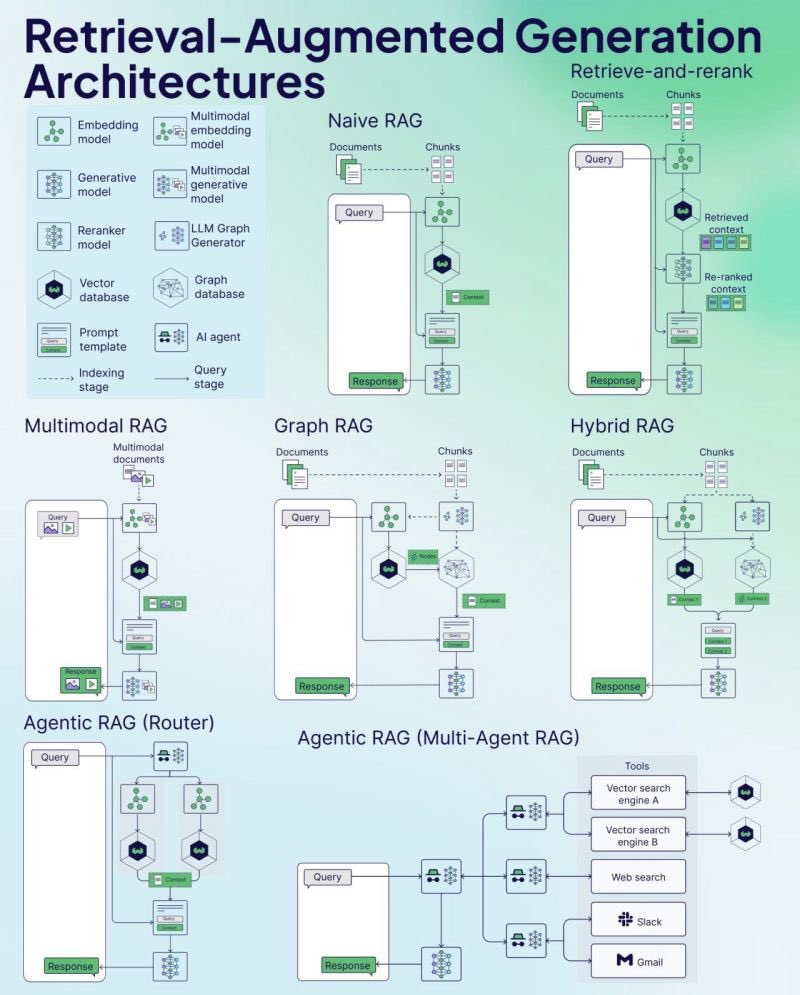
Weaviate تنشر ورقة غش RAG (Cheat Sheet): نشرت شركة قواعد بيانات المتجهات Weaviate ورقة غش (Cheat Sheet) حول التوليد المعزز بالاسترجاع (RAG). تهدف هذه المادة إلى تزويد المطورين بدليل مرجعي سريع، وقد تغطي المفاهيم الأساسية لـ RAG، والمعمارية، والتقنيات الشائعة، وأفضل الممارسات أو المشكلات الشائعة، لمساعدة المطورين على فهم وتنفيذ أنظمة RAG بشكل أفضل. (المصدر: bobvanluijt)
بحث MIT يكشف عن هيكل ومخاطر سلسلة توريد الذكاء الاصطناعي: نشر باحثون من MIT ومؤسسات أخرى ورقة بحثية جديدة تستكشف سلاسل توريد الذكاء الاصطناعي (AI Supply Chains) الناشئة. مع تزايد تشتت عملية بناء أنظمة الذكاء الاصطناعي (بمشاركة مزودي النماذج الأساسية، وخدمات الضبط الدقيق، وموردي البيانات، ومنصات النشر، وغيرها من الكيانات المتعددة)، تدرس الورقة التأثيرات الناتجة عن هذه البنية الشبكية، بما في ذلك المخاطر المحتملة (مثل انتقال فشل المراحل الأولية)، وعدم تناسق المعلومات، وتضارب أهداف التحكم والتحسين، وغيرها من المشكلات. تحلل الدراسة حالتين من خلال التحليل النظري والتجريبي، وتؤكد على أهمية فهم وإدارة سلاسل توريد الذكاء الاصطناعي. (المصدر: jachiam0, aleks_madry)
LangChain تنشر فيديو تقديمي مدته خمس دقائق حول LangSmith: نشرت LangChain مقطع فيديو قصيرًا مدته 5 دقائق يشرح وظائف منصتها التجارية LangSmith. يقدم الفيديو كيف يساعد LangSmith في دورة حياة تطوير تطبيقات LLM و Agent بأكملها، بما في ذلك قابلية المراقبة (observability)، والتقييم (evaluation)، وهندسة المطالبات (prompt engineering)، بهدف مساعدة المطورين على تحسين أداء التطبيقات. (المصدر: LangChainAI)
Together AI تنشر فيديو تعليمي حول تشغيل وضبط نماذج OSS: نشرت Together AI مقطع فيديو تعليميًا جديدًا يوجه المستخدمين حول كيفية تشغيل وضبط النماذج الكبيرة مفتوحة المصدر على منصة Together AI. قد يغطي الفيديو خطوات مثل اختيار النموذج، وإعداد البيئة، وتحميل البيانات، وبدء مهام التدريب، وإجراء الاستدلال، بهدف تقليل حاجز استخدام منصتهم لتخصيص ونشر النماذج مفتوحة المصدر للمستخدمين. (المصدر: togethercompute)
ورقة بحثية تقترح استخدام “Agent ذو إدراك” لتقييم القدرات المعرفية الاجتماعية لـ LLM: تقدم ورقة بحثية جديدة إطار عمل SAGE (Sentient Agent as a Judge)، وهو طريقة تقييم مبتكرة تستخدم Agent ذو إدراك (Sentient Agent) يحاكي الديناميكيات العاطفية البشرية والاستدلال الداخلي لتقييم القدرات المعرفية الاجتماعية لـ LLM في المحادثات. يهدف الإطار إلى اختبار قدرة LLM على تفسير المشاعر، واستنتاج النوايا الخفية، والرد بتعاطف. وجدت الدراسة أنه في 100 سيناريو محادثة داعمة، كانت تقييمات المشاعر للـ Agent ذي الإدراك مرتبطة بشكل كبير بالمقاييس التي تركز على الإنسان (مثل BLRI، مؤشرات التعاطف)، وأن LLM ذات القدرات الاجتماعية القوية لا تحتاج بالضرورة إلى ردود مطولة. (المصدر: menhguin)

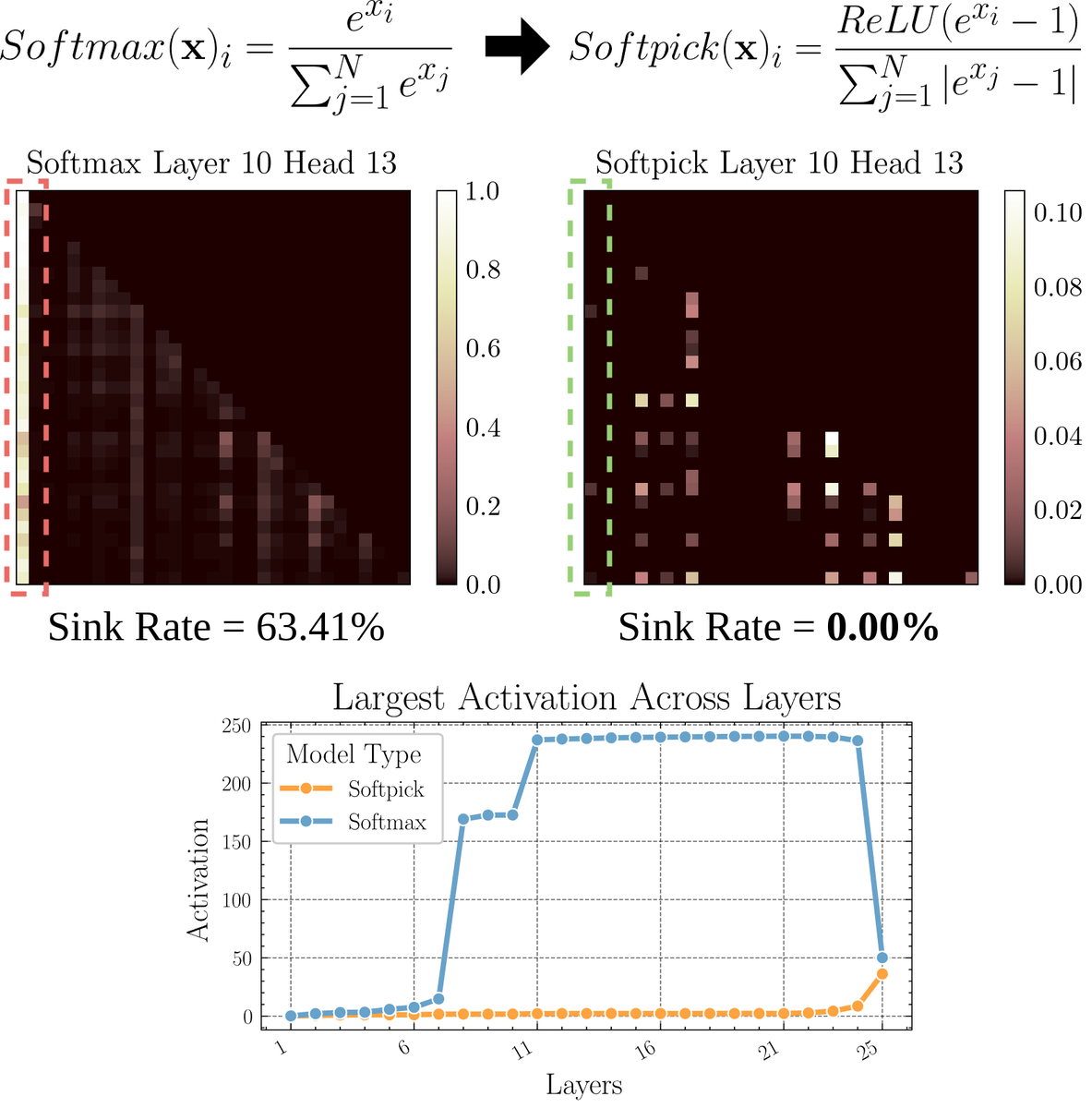
ورقة بحثية تناقش Softpick: آلية انتباه بديلة لـ Softmax: تقترح ورقة بحثية أولية Softpick، وهي بديل يهدف إلى حل مشكلة “مستنقع الانتباه” (attention sink) وقيم التنشيط الكبيرة في آلية الانتباه عن طريق تعديل Softmax. تقترح الطريقة استخدام ReLU(x – 1) في بسط Softmax، واستخدام abs(x – 1) في مقام الحد. يعتقد الباحثون أن هذا التعديل البسيط قد يحسن بعض المشكلات المتأصلة في آليات الانتباه الحالية مع الحفاظ على الأداء، خاصة عند معالجة التسلسلات الطويلة أو السيناريوهات التي تتطلب توزيع انتباه أكثر استقرارًا. (المصدر: sedielem)
💼 أعمال
الشركة الناشئة في مجال الذكاء الاصطناعي RogoAI تجمع 50 مليون دولار في جولة تمويل B: أعلنت RogoAI، التي تركز على بناء منصة بحث أصلية للذكاء الاصطناعي لقطاع الخدمات المالية، عن إتمام جولة تمويل B بقيمة 50 مليون دولار بقيادة Thrive Capital، وبمشاركة J.P. Morgan Asset Management و Tiger Global وغيرهم. سيتم استخدام هذا التمويل لتسريع تطوير منتجات RogoAI وتوسيع نطاقها في السوق في مجال التحليل المالي وأتمتة البحث. (المصدر: hwchase17, hwchase17)
شركة البحث المؤسسي بالذكاء الاصطناعي الناشئة Glean تكمل جولة تمويل جديدة بتقييم 7 مليارات دولار: وفقًا لـ The Information، توشك شركة البحث المؤسسي بالذكاء الاصطناعي الناشئة Glean على إكمال جولة تمويل جديدة بقيادة Wellington Management، بتقييم يبلغ حوالي 7 مليارات دولار. كانت الشركة قد أكملت جولة تمويل بتقييم 4.6 مليار دولار قبل أربعة أشهر فقط، وتعكس هذه القفزة الكبيرة في التقييم التوقعات العالية للسوق لتطبيقات الذكاء الاصطناعي على مستوى المؤسسات وحلول إدارة المعرفة. (المصدر: steph_palazzolo)
Groq تتعاون مع Meta لتسريع Llama API: أعلنت شركة رقائق استدلال الذكاء الاصطناعي Groq عن تعاونها مع Meta لتوفير تسريع لواجهة برمجة تطبيقات Llama الرسمية. سيتمكن المطورون من تشغيل أحدث نماذج Llama (بدءًا من Llama 4) بمعدل إنتاجية يصل إلى 625 توكن/ثانية، وتدعي الشركة أن الانتقال من OpenAI يتطلب 3 أسطر فقط من الكود. يهدف هذا التعاون إلى تزويد المطورين بحلول عالية السرعة ومنخفضة الكمون لتشغيل النماذج اللغوية الكبيرة. (المصدر: JonathanRoss321)

🌟 المجتمع
نقاش مجتمعي حاد حول مقارنة Llama4 و DeepSeek R1 ومشكلة معايير تقييم النماذج: رد مارك زوكربيرج، الرئيس التنفيذي لشركة Meta، في مقابلة على أداء Llama4 الأقل من DeepSeek R1 في الساحة التنافسية، معتبرًا أن اختبارات المعايير مفتوحة المصدر معيبة ومتحيزة بشكل مفرط لحالات استخدام معينة، ولا تعكس أداء النموذج الحقيقي في المنتجات الفعلية، وذكر أن نموذج الاستدلال الخاص بـ Meta لم يتم إصداره بعد، ولا يمكن مقارنته مباشرة بـ R1. أثارت هذه التصريحات، جنبًا إلى جنب مع ورقة Cohere التي تشكك في LMArena، نقاشًا واسعًا في المجتمع حول كيفية تقييم LLM بشكل عادل، وقيود لوحات الصدارة العامة، واستراتيجيات اختيار النماذج. يتفق الكثيرون على أنه لا ينبغي الاعتماد المفرط على لوحات الصدارة العامة، بل يجب اختيار النماذج بناءً على حالات الاستخدام المحددة، وتقييم البيانات الخاصة، وإشارات المجتمع. (المصدر: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
النقاش حول استبدال الذكاء الاصطناعي للبشر يزداد سخونة: ظهرت منشورات متعددة في مجتمع Reddit تناقش تأثير الذكاء الاصطناعي على التوظيف. ذكر مترجم إسباني أن أعماله تقلصت بشكل كبير بسبب تحسن جودة الترجمة بالذكاء الاصطناعي؛ كما غير مهندس صوت مهنته بسبب تحسن تأثيرات الماسترينغ بالذكاء الاصطناعي. في الوقت نفسه، ناقشت منشورات أخرى كيف أن تطبيقات الذكاء الاصطناعي في التشخيص الطبي والاستشارات الضريبية وغيرها من المجالات قد تقلل الطلب على المهنيين. أثارت هذه الحالات نقاشًا حول ما إذا كانت أزمة البطالة الناجمة عن أتمتة الذكاء الاصطناعي تأتي أبكر مما كان متوقعًا، وكيف يجب على الممارسين التكيف (مثل الاستفادة من الذكاء الاصطناعي للتحول، وإيجاد قيمة لا يمكن للذكاء الاصطناعي استبدالها). (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
ظاهرة “الانجراف التكراري” في الصور المولدة بالذكاء الاصطناعي تثير الاهتمام: حاول مستخدمو Reddit جعل ChatGPT يكرر “النسخ الدقيق” لصورة مولدة سابقة بشكل مستمر، وأظهرت النتائج انحراف محتوى الصورة وأسلوبها تدريجيًا عن المدخلات الأصلية مع زيادة عدد التكرارات، متجهًا في النهاية نحو التجريد أو أنماط معينة (مثل الوشم الساموي/السمات الأنثوية). أظهر مثال Dwayne Johnson تطورًا مشابهًا من الواقعية إلى التجريد. تكشف هذه الظاهرة عن التحديات الحالية لنماذج توليد الصور في الحفاظ على التناسق طويل الأمد، والتحيزات أو التقارب المحتمل في تمثيلاتها الداخلية. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT)

المجتمع يناقش ما إذا كان الذكاء الاصطناعي سيحل محل عمل رأس المال الاستثماري (VC): يعتقد Marc Andreessen أنه عندما يتمكن الذكاء الاصطناعي من القيام بكل شيء آخر، قد يكون رأس المال الاستثماري (VC) هو آخر عمل يقوم به البشر، لأنه يشبه الفن أكثر من العلم، ويعتمد على الذوق وعلم النفس وتحمل الفوضى. أثار هذا الرأي نقاشًا، حيث اعتبره البعض “قولًا مضحكًا”، متسائلين عن سبب تميز الاستثمار المبكر؛ بينما انطلق آخرون من مجالاتهم (مثل تطوير الألعاب)، معتقدين أن هذه الفكرة قد تكون “عزاءً ذاتيًا” (cope)، لأن الناس في كل مجال يميلون إلى الاعتقاد بأن عملهم لا يمكن استبداله بالذكاء الاصطناعي بسبب الحاجة إلى ذوق فريد. (المصدر: colin_fraser, gfodor, cto_junior, pmddomingos)
جامعة زيورخ تجري تجربة إقناع بالذكاء الاصطناعي غير مصرح بها على Reddit مما يثير الجدل: وفقًا لمشرفي قسم r/changemyview على Reddit و Reddit Lies، قام باحثون من جامعة زيورخ بنشر حسابات ذكاء اصطناعي متعددة للمشاركة في المناقشات في هذا القسم دون إبلاغ مستخدمي المجتمع بوضوح، لاختبار قوة إقناع الحجج المولدة بواسطة الذكاء الاصطناعي. وجدت الدراسة أن معدل نجاح الإقناع لحسابات الذكاء الاصطناعي (الحصول على علامة “∆” التي تشير إلى تغيير المستخدم لوجهة نظره) تجاوز بكثير المستوى الأساسي للبشر، وأن المستخدمين لم يكتشفوا هويتها كذكاء اصطناعي. على الرغم من أن التجربة زعمت الحصول على موافقة لجنة الأخلاقيات، إلا أن طريقتها السرية وطبيعتها “التلاعبية” المحتملة أثارت جدلاً أخلاقيًا واسع النطاق ومخاوف بشأن إساءة استخدام الذكاء الاصطناعي. (المصدر: 量子位)
💡 أخرى
هل ما زلنا بحاجة إلى تعلم البرمجة في عصر الذكاء الاصطناعي؟ سؤال يثير التفكير: ظهر نقاش في المجتمع حول قيمة تعلم البرمجة في عصر الذكاء الاصطناعي. ترى وجهات النظر أنه على الرغم من القدرة المتزايدة للذكاء الاصطناعي على توليد الأكواد وتغير طبيعة عمل مهندسي البرمجيات بسرعة، إلا أن تعلم البرمجة لا يزال مهمًا. تعلم البرمجة هو الأساس لفهم كيفية التعاون الفعال مع الذكاء الاصطناعي (خاصة LLM)، وستصبح قدرة التعاون بين الإنسان والآلة هذه كفاءة أساسية عبر المجالات. البرمجة هي نقطة البداية للبشر لبدء “الرقص” مع الذكاء الاصطناعي، وستحتاج جميع الصناعات في المستقبل إلى إتقان هذا النمط من التعاون. (المصدر: alexalbert__, _philschmid)
المطورون يناقشون تجربة وتحديات البرمجة بمساعدة الذكاء الاصطناعي: يشارك المطورون في المجتمع تجاربهم في استخدام أدوات البرمجة بالذكاء الاصطناعي (مثل Cursor، ChatGPT Desktop). يشتاق البعض إلى “فترة التهدئة” السابقة أثناء انتظار الترجمة، معتقدين أن البرمجة بمساعدة الذكاء الاصطناعي أعادت تقديم دورة تحرير/ترجمة/تصحيح أخطاء مماثلة. يشير آخرون أيضًا إلى أن أدوات الذكاء الاصطناعي لا تزال تعاني من قصور في فهم السياق (مثل تحرير ملفات متعددة)، واتباع التعليمات (مثل تجنب استخدام بناء جملة/مكونات معينة)، وأحيانًا تتطلب تعليمات محددة جدًا لتحقيق التأثير المطلوب، وأن الكود المولد بواسطة الذكاء الاصطناعي لا يزال بحاجة إلى مراجعة وتصحيح أخطاء بشرية. (المصدر: hrishioa, eerac, Reddit r/ChatGPT)

تحسين الرفاهية المدفوع بالذكاء الاصطناعي: اتجاه تطبيق محتمل للذكاء الاصطناعي: يقترح منشور على Reddit أن أحد التطبيقات النهائية للذكاء الاصطناعي قد يكون تحسين رفاهية الإنسان. يعتقد المؤلف أنه بناءً على فرضية ردود الفعل الوجهية (الابتسام يمكن أن يعزز الرفاهية) ومبدأ التركيز، يمكن للذكاء الاصطناعي (مثل Gemini 2.5 Pro) توليد محتوى إرشادي عالي الجودة لمساعدة الناس على تحسين مستويات الرفاهية من خلال تمارين بسيطة (مثل الابتسام والتركيز على الشعور بالبهجة الذي يجلبه). شارك المؤلف تقريرًا وصوتًا تم إنشاؤهما بواسطة الذكاء الاصطناعي، وتوقع أنه قد تظهر في المستقبل تطبيقات ناجحة أو روبوتات “مرشدة للرفاهية” تعتمد على هذا المبدأ. (المصدر: Reddit r/deeplearning)
