كلمات مفتاحية:الروبوت البشري, تطبيقات الذكاء الاصطناعي, الذكاء العام الاصطناعي (AGI), القيادة الذاتية, ماراثون الروبوت البشري, وكيل + MCP, توقعات DeepMind للذكاء العام الاصطناعي, نظام Tesla FSD بالرؤية البحتة, استنساخ الصوت GPT-SoVITS, الاستدلال الكيميائي ChemAgent, نموذج عمل روبوتات Zhiyuan, تحدي احتكار NVIDIA لوحدات معالجة الرسومات
“`arabic
🔥 أبرز العناوين
الروبوتات البشرية في “أول ظهور” لها في نصف ماراثون بكين: فرص وتحديات متزامنة: في نصف ماراثون بكين ييتشوانغ 2025، تنافس 21 فريقًا من الروبوتات البشرية لأول مرة مع المتسابقين البشر. فازت روبوتات Tiankong Ultra و Songyan Dynamics N2 و Zhuoyide Walker II بالمراكز الثلاثة الأولى. أبرز السباق إمكانات الروبوتات البشرية، ولكنه كشف أيضًا عن تحديات عديدة مثل السقوط، وعمر البطارية، والتحكم (غالبًا عن طريق التحكم عن بعد). بعد السباق، ردت شركة Unitree Technology على حادثة سقوط روبوتها G1، مشيرة إلى أن التطوير والتشغيل الذاتي من قبل المستخدم يؤثر بشكل كبير على أداء الروبوت. لم يعرض هذا الحدث فقط النطاق الأولي لصناعة الروبوتات البشرية في الصين، بل أثار أيضًا نقاشًا واسعًا حول نضج التكنولوجيا، والتكلفة (يبدأ سعر الطلب المسبق لـ Songyan N2 من 39,900 يوان)، ومسارات التسويق التجاري (التأجير، التطبيقات الصناعية)، والتطور المستقبلي (نماذج AI الكبيرة، التعلم الذاتي). على الرغم من أن الصناعة تحظى باهتمام رأس المال، إلا أن تحقيق الربح على المدى القصير صعب، ولا يزال التطبيق السوقي يحتاج إلى وقت. (المصدر: سقوط Unitree ومناورة “البقاء” للروبوتات البشرية, من المصنع إلى الماراثون: ما مدى بُعد الروبوتات البشرية عن “الاستخدام العملي”؟)
نموذج تطبيقات الذكاء الاصطناعي الجديد: Agent+MCP يصبح معادلة النجاح لعام 2025: أصبح الجمع بين قدرات التخطيط والعمل المستقل لـ Agent وقدرة بروتوكول MCP على استدعاء الأدوات والبيانات الخارجية اتجاهًا جديدًا في تطبيقات الذكاء الاصطناعي. ظهرت منتجات مثل “Kouzi Space” و Fellou و Dia و GenSpark و Zhipu AutoGLM تباعًا وأثارت الاهتمام. تحولت معظم هذه المنتجات من البحث القائم على الذكاء الاصطناعي، محاولة بناء حواجز في تجربة المستخدم من خلال تصميمات منتجات مختلفة (سهولة الاستخدام، القدرة البحثية، التنفيذ العملي). على الرغم من الإمكانات الهائلة، لا تزال تواجه تحديات مثل حدود قدرة النموذج، والحصول على المعلومات عبر المنصات، ونماذج التسويق التجاري. أطلقت Microsoft أيضًا نظام UFO² متعدد الـ Agent الموجه لسطح المكتب، مما يشير إلى أن AM (Agent+MCP) سيصبح اتجاهًا مهمًا لمنتجات الذكاء الاصطناعي. (المصدر: في عام 2025، هناك معادلة نجاح واحدة فقط لتطبيقات الذكاء الاصطناعي)
نقاش حاد حول مستقبل الذكاء الاصطناعي: Hassabis يتنبأ بعلاج جميع الأمراض خلال عقد، ومؤرخ من هارفارد يحذر من انقراض البشر بسبب AGI: توقع Demis Hassabis، الرئيس التنفيذي لشركة Google DeepMind، في مقابلة أن الذكاء الاصطناعي سيحقق AGI في غضون 5-10 سنوات، ومن المحتمل أن يعالج جميع الأمراض في غضون عقد، مستعرضًا تطورات الذكاء الاصطناعي مثل Project Astra. يعتقد أن الذكاء الاصطناعي سيصبح الأداة النهائية لتسريع الاكتشافات العلمية. ومع ذلك، حذر مؤرخ هارفارد Niall Ferguson من أن وصول AGI قد يؤدي إلى استبدال البشر مثلما حدث لعربات الخيل، أو حتى انقراضهم، ليصبحوا “كائنات فضائية” من صنع الإنسان نفسه. وأشار إلى أن اتجاهات مثل الجمود المؤسسي وانخفاض معدلات الخصوبة العالمية قد تجعل البشر يختارون “الخروج من مسرح التاريخ” في مواجهة AGI. يسلط هذا النقاش الضوء على التباين الهائل بين التفاؤل الشديد بإمكانيات AGI والمخاوف العميقة بشأن مستقبل الحضارة الإنسانية. (المصدر: Hassabis الحائز على جائزة نوبل يتعهد: الذكاء الاصطناعي سيعالج جميع الأمراض في عشر سنوات، وأستاذ هارفارد يحذر من أن AGI سينهي الحضارة الإنسانية, مؤرخ هارفارد يحذر: AGI سينقرض البشر، وقد تتفكك الولايات المتحدة)
🎯 اتجاهات
تقدم متواصل في صناعة الروبوتات وتسارع التطبيق التجاري: خصص معرض كانتون لأول مرة منطقة لروبوتات الخدمة، حيث حصل المصنعون المحليون مثل Pangolin Robot و Hongxu Jin Technology على عدد كبير من الطلبات الخارجية، مما يظهر القدرة التنافسية لروبوتات الخدمة الصينية في السوق العالمية. في الوقت نفسه، تخضع الروبوتات البشرية لشركات مثل Midea لعمليات تطوير وتخطط لدخول المصانع “للعمل”. على مستوى سلسلة التوريد، على الرغم من وجود تخطيط في مجالات مثل PCB وأجهزة الاستشعار والمواد الجديدة (مثل PEEK)، إلا أن الإنتاج الضخم لا يزال بحاجة إلى وقت، وتعتبر حلقة التكنولوجيا والتكلفة وسيناريوهات التطبيق هي المفتاح. يخطط العديد من المصنعين لتحقيق إنتاج على مستوى الألف وحدة بحلول عام 2525، مما قد يدفع تطوير سلسلة التوريد وتراكم البيانات، ويسرع انتقال الروبوتات إلى مرحلة أكثر عملية. (المصدر: مجموعات الروبوتات “تعمل” وتثير ضجة، وسلسلة التوريد تشهد تقدمًا مستمرًا)

Tesla تصر على FSD القائم على الرؤية البحتة، ومسار LiDAR يواجه تحديات وفرصًا: أكد Musk مجددًا ثقته في حل الرؤية البحتة لتحقيق FSD، معتقدًا أن الكاميرات مع الذكاء الاصطناعي يمكنها محاكاة القيادة البشرية دون الحاجة إلى LiDAR. على الرغم من مواجهة واقع انخفاض التكاليف (انخفض سعر LiDAR الصيني بالفعل إلى مئات الدولارات) والانتشار في السوق (دخلت بالفعل في طرازات السيارات التي تبلغ قيمتها 100 ألف يوان)، لا تزال Tesla تصر على مسارها، مما يضع متطلبات عالية جدًا على قوتها الحاسوبية وخوارزمياتها وبياناتها. في الوقت نفسه، تهيمن شركات LiDAR مثل Hesai و RoboSense على السوق بفضل ميزة التكلفة وتكرار التكنولوجيا، وتتوسع بنشاط في الأسواق الخارجية والأعمال غير المتعلقة بالمركبات مثل الروبوتات. قد يجلب اقتراب القيادة الذاتية من المستوى L3 فرصًا جديدة لـ LiDAR، حيث يُعتقد أن قدرتها على الإدراك في التكرار الآمن والسيناريوهات المحددة لا غنى عنها. (المصدر: هل سينهي أحدث حلول القيادة بالذكاء الاصطناعي من Musk عصر LiDAR؟)

Google Imagen 3/4 قد يكون قيد الاختبار الداخلي: تشير الشائعات إلى أن Google تختبر داخليًا نماذجها التالية لتوليد الصور Imagen 3 و Imagen 4، مما ينبئ بأن Google قد يكون لديها تحركات كبيرة جديدة في مجال توليد الصور، بهدف اللحاق بالمنافسين أو تجاوزهم. (المصدر: هل تخبئ Google مفاجأة كبيرة في مجال الصور؟ شائعات عن اختبار Imagen 3/4 داخليًا.)
THUDM تطلق سلسلة نماذج الترميز SWE-Dev: أطلقت مجموعة أبحاث هندسة المعرفة واستخراج البيانات بجامعة Tsinghua (THUDM) سلسلة نماذج الترميز الكبيرة SWE-Dev المبنية على Qwen-2.5 و GLM-4، بما في ذلك إصدارات 7B و 9B و 32B، بهدف تعزيز قدرات الذكاء الاصطناعي في مهام تطوير البرمجيات والترميز. (المصدر: Reddit r/LocalLLaMA)

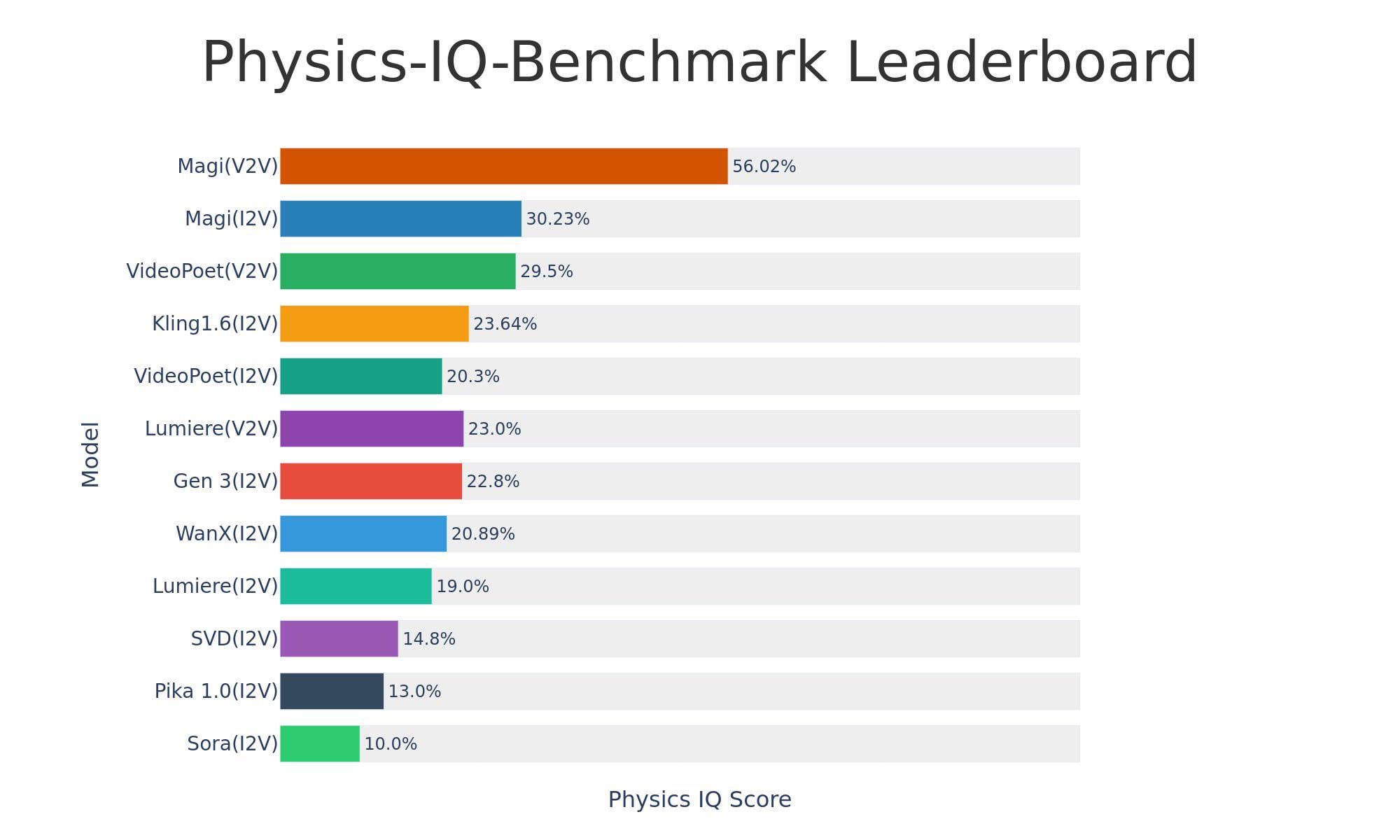
Sand-AI تطلق نموذج توليد الفيديو مفتوح المصدر Magi-1: أطلقت Sand-AI نموذج Magi-1، وهو نموذج توليد فيديو قائم على الانتشار التراجعي الذاتي مفتوح المصدر، يُزعم أنه قادر على توليد مقاطع فيديو بطول غير محدود، ويدعم تحويل النص إلى فيديو، والصورة إلى فيديو، والفيديو إلى فيديو. أظهر النموذج أداءً ممتازًا في اختبارات فهم الفيزياء، ولكنه يتطلب ذاكرة وصول عشوائي للفيديو عالية جدًا للتشغيل (حوالي 640 جيجابايت VRAM). تم نشر الكود والنموذج على GitHub و Hugging Face. (المصدر: Reddit r/LocalLLaMA)
Grok يضيف قدرات بصرية وصوتية متعددة اللغات وبحثًا في الوقت الفعلي: أعلنت xAI أن نموذج Grok قد أضاف قدرة الفهم البصري، ويدعم إدخال الصوت متعدد اللغات ووظيفة البحث في الوقت الفعلي في وضع الصوت، مما يعزز قدراته التفاعلية متعددة الوسائط والحصول على المعلومات. (المصدر: grok, xai)
نموذج Grok 3 يصل إلى You.com: أصبح نموذج Grok 3 الرائد من xAI متاحًا الآن على محرك البحث You.com، ويمكن للمستخدمين تجربة قدرات Grok 3 على هذه المنصة. (المصدر: xai)

إطلاق نموذج TTS مفتوح المصدر Dia وجذب الانتباه: تم إطلاق نموذج تحويل النص إلى كلام (TTS) مفتوح المصدر يسمى Dia، يُزعم أن تأثيره يضاهي النماذج التجارية مثل ElevenLabs و OpenAI، ويدعم استنساخ الصوت بدون عينات (zero-shot) والتركيب في الوقت الفعلي، ويمكن تشغيله على MacBook. اكتسب النموذج اهتمامًا سريعًا على Hugging Face وتم تغطيته من قبل وسائل الإعلام مثل VentureBeat. (المصدر: huggingface, huggingface, huggingface)
عرض تقنية القيادة الذاتية من Tesla: عرض مقاطع فيديو أو معلومات ذات صلة بتقنية القيادة الذاتية Autopilot من Tesla، مما يثير الاهتمام المستمر بتقدم تكنولوجيا القيادة الذاتية. (المصدر: Ronald_vanLoon)
عرض تكنولوجيا الروبوتات: عرضت مصادر متعددة تطبيقات مختلفة للروبوتات، بما في ذلك أذرع روبوتية لتجميع الأدوات الصغيرة، وتقييم روبوت TITA، والروبوت البرمائي Copperstone HELIX Neptune، وكيف تدرك الروبوتات العالم، مما يدل على التطور المستمر لتكنولوجيا الروبوتات في مختلف المجالات. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 أدوات
GPT-SoVITS: أداة قوية لاستنساخ الصوت بعينات قليلة وتحويل النص إلى كلام: GPT-SoVITS الذي طوره RVC-Boss هو مشروع مفتوح المصدر (أكثر من 44 ألف نجمة على GitHub)، يتطلب دقيقة واحدة فقط من البيانات الصوتية لتدريب نموذج TTS عالي الجودة، مما يحقق استنساخ الصوت بعينات قليلة. يدعم TTS بدون عينات (تحويل فوري بإدخال 5 ثوانٍ)، والاستدلال عبر اللغات (يدعم الإنجليزية واليابانية والكورية والكانتونية والصينية)، ويدمج صندوق أدوات WebUI، بما في ذلك فصل الصوت عن الموسيقى، وتقسيم مجموعة التدريب تلقائيًا، و ASR الصيني ووضع العلامات النصية، مما يسهل على المستخدمين إنشاء مجموعات البيانات والنماذج. تم تحديث المشروع إلى الإصدار V4، مع تحسين مستمر لتشابه النغمة والاستقرار وجودة الإخراج. (المصدر: RVC-Boss/GPT-SoVITS – GitHub Trending (all/daily))

فريق Tsinghua يطلق SurveyGO (Juan Ji): أداة لمراجعة الأدبيات وإنشاء التقارير الطويلة مدفوعة بالذكاء الاصطناعي: استنادًا إلى تقنية LLMxMapReduce-V2 التي طورها فريق NLP بجامعة Tsinghua و OpenBMB و Mianbi Intelligence، يمكن لـ SurveyGO معالجة كميات هائلة من الأدبيات بكفاءة (البحث عبر الإنترنت أو تحميل الملفات)، وإنشاء تقارير مراجعة طويلة بعشرات الآلاف من الكلمات تتميز بالبنية الواضحة والمنطق السليم والاقتباسات الدقيقة. تعمل الأداة على تحسين المخطط التفصيلي من خلال آلية تلافيفية مدفوعة بإنتروبيا المعلومات، وتنشئ المحتوى بشكل هرمي، بهدف تعزيز كفاءة الباحثين ومنشئي المحتوى بشكل كبير في مراجعة الأدبيات والكتابة. يمكن للمستخدمين تجربتها عبر إصدار الويب. (المصدر: عنف أكاديمي على طريقة INTJ! فريق Tsinghua يصنع “Juan Ji للبحث”: 3 دقائق لإنجاز مراجعة أدبيات تستغرق 200 ساعة, كيفية “تجميع مقال جيد” بالذكاء الاصطناعي: إنشاء تقرير بعشرة آلاف كلمة، دون قيود على النموذج)

text-generation-webui تطلق إصدارًا محمولًا يركز على llama.cpp: لتبسيط عملية النشر، أصدرت text-generation-webui إصدارًا محمولًا ومستقلًا (حوالي 700 ميجابايت) مخصصًا لـ llama.cpp. يمكن للمستخدمين تنزيله وفك ضغطه وتشغيله مباشرة دون الحاجة إلى تثبيت Python أو PyTorch أو تبعيات أخرى. يدعم الإصدار الجديد أنظمة التشغيل Windows/Linux/macOS (بما في ذلك إصدارات CPU/CUDA)، ويتميز بسرعة بدء تشغيل محسّنة وتجربة مستخدم أفضل، مما يوفر راحة كبيرة للمستخدمين الذين يرغبون فقط في استخدام llama.cpp للاستدلال المحلي. (المصدر: Reddit r/LocalLLaMA)
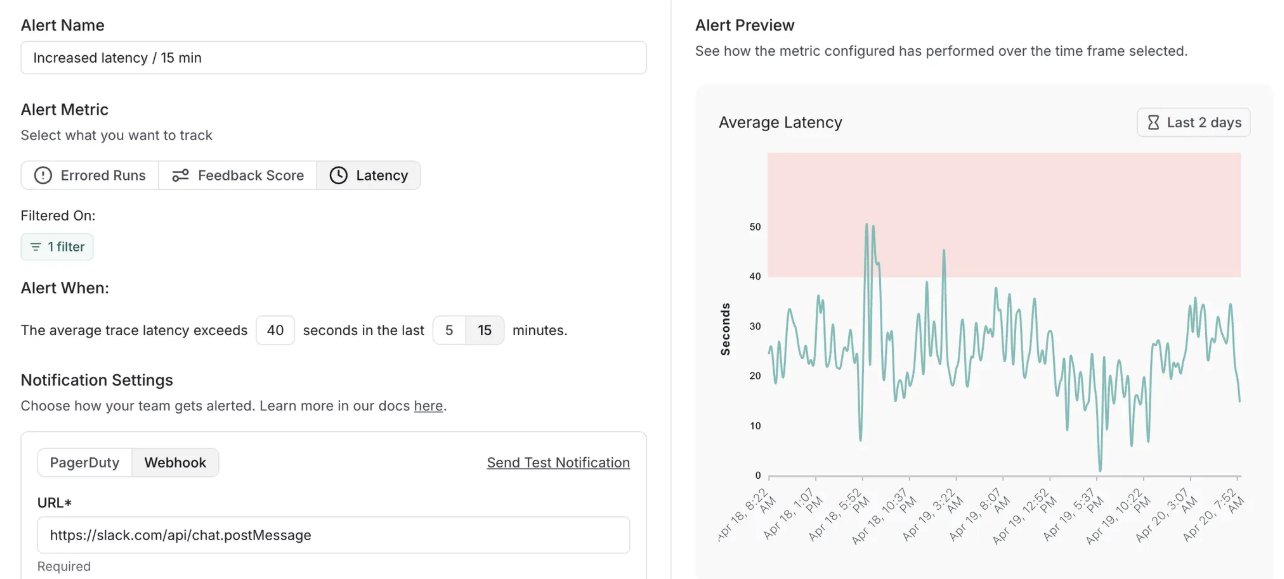
LangSmith تضيف ميزة التنبيهات وتحدث الإصدار المستضاف ذاتيًا: أضافت منصة MLOps الخاصة بـ LangChain، LangSmith، ميزة التنبيهات في الوقت الفعلي، مما يسمح للمستخدمين بمراقبة معدلات الخطأ وزمن الاستجابة ودرجات التغذية الراجعة. تم تحديث إصدارها المستضاف ذاتيًا إلى v0.10، ليشمل التنبيهات وواجهة مستخدم جديدة لإنشاء وعرض التقييمات ودعم تتبع عميل OpenTelemetry وتحسينات في الأداء، لمساعدة المطورين على اكتشاف المشكلات في بيئة الإنتاج مبكرًا. (المصدر: LangChainAI, LangChainAI)
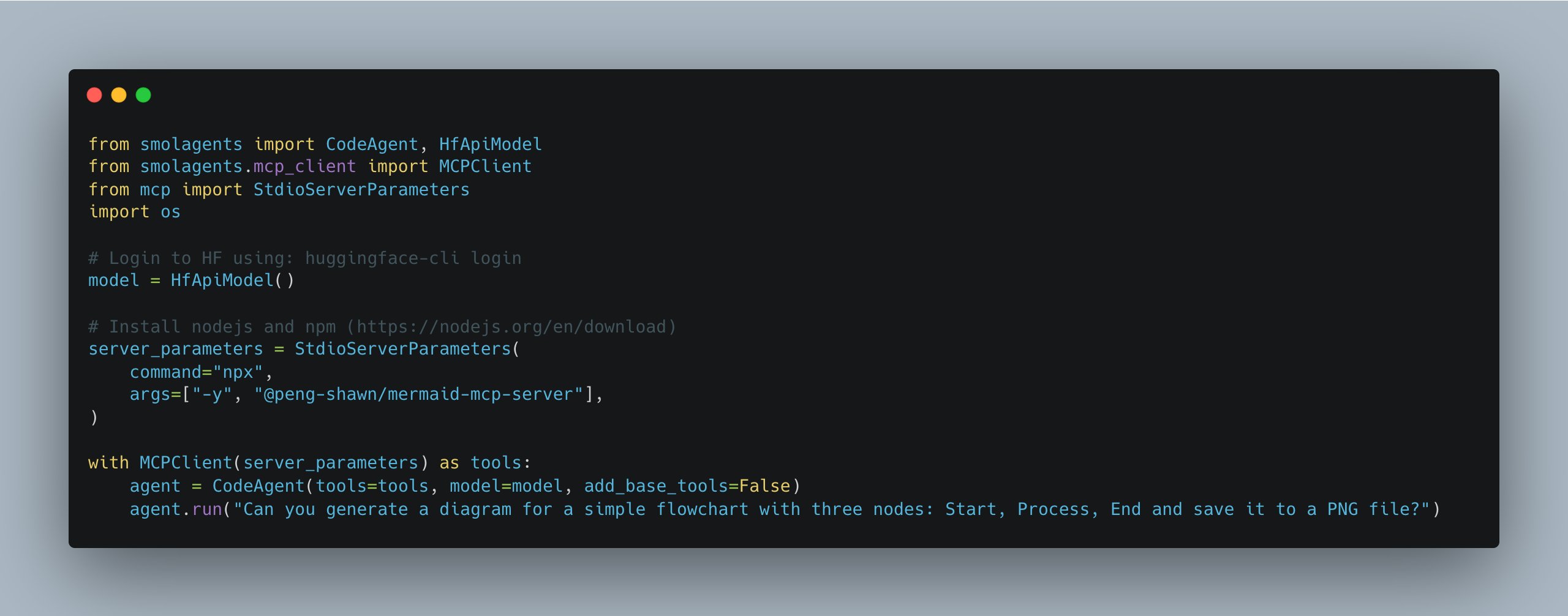
تحديث smolagents يبسط إدارة خوادم MCP المتعددة: أصدرت مكتبة smolagents من Hugging Face إصدارًا جديدًا يقدم فئة MCPClient، مما يبسط بشكل كبير إدارة الاتصالات بخوادم MCP (بروتوكول اتصالات النموذج) المتعددة في وقت واحد، ويسهل بناء وتنسيق أنظمة Agent أكثر تعقيدًا. (المصدر: huggingface)
Suna: منصة Agent مفتوحة المصدر تنافس Manus: أطلقت Kortix AI منصة Agent مفتوحة المصدر Suna، لتكون بديلاً لـ Manus. تدمج Suna وظائف مثل أتمتة المتصفح، وإدارة الملفات، والزحف على الويب، والبحث الموسع، وتنفيذ سطر الأوامر، ونشر مواقع الويب، وتكامل API، مما يسمح للذكاء الاصطناعي بتشغيل هذه الأدوات بشكل تعاوني لحل المشكلات المعقدة وأتمتة سير العمل من خلال الحوار. (المصدر: karminski3)
Exa MCP يدعم الآن البحث في تويتر بدون API: تم تحديث خادم MCP الخاص بـ Exa ليدعم الآن البحث المباشر في محتوى تويتر دون الحاجة إلى مفتاح API تويتر. يوفر هذا الراحة لـ AI Agent التي تحتاج إلى معلومات من تويتر، ولكن أفاد بعض المستخدمين بأن دعم الزحف للمحتوى الصيني ليس جيدًا. (المصدر: karminski3)
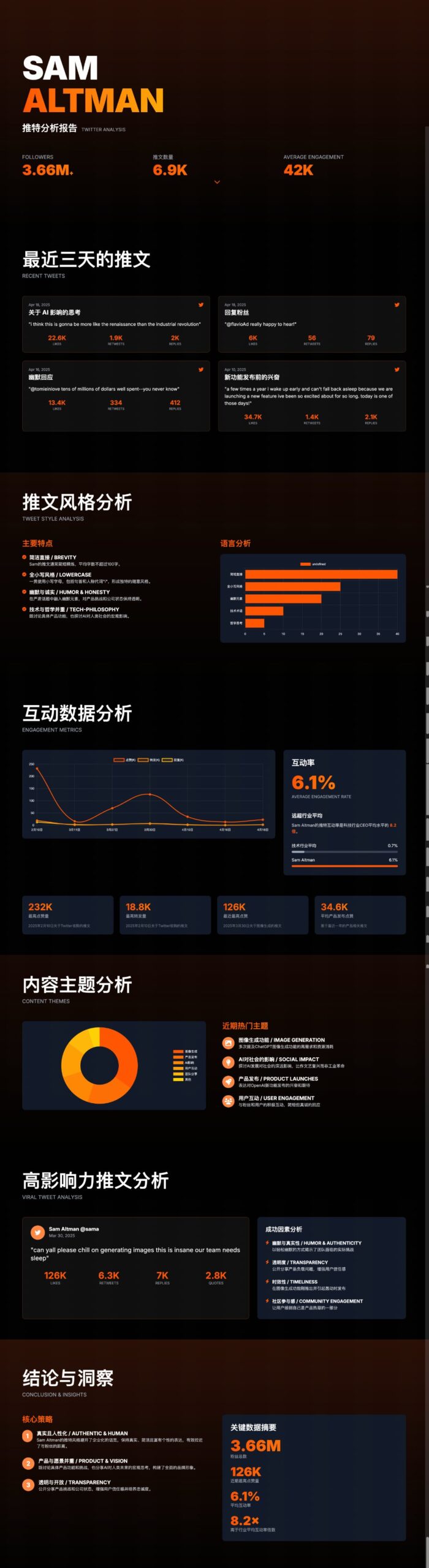
ChatUI-energy: واجهة تعرض استهلاك طاقة محادثات الذكاء الاصطناعي في الوقت الفعلي: أطلق أعضاء مجتمع Hugging Face واجهة ChatUI-energy، وهي نسخة معدلة من Chat UI تعرض استهلاك الطاقة في الوقت الفعلي أثناء التفاعل مع نماذج مفتوحة المصدر (مثل Llama, Mistral, Qwen, Gemma). تهدف هذه المبادرة إلى زيادة الشفافية حول استهلاك الطاقة في استخدام الذكاء الاصطناعي، مما أثار نقاشًا حول ما إذا كان يجب أن تصبح ميزة قياسية. (المصدر: huggingface, huggingface)
استخدام الذكاء الاصطناعي لتطوير ونشر وتحسين تطبيقات الويب: يشارك المقال تجربة عملية لاستخدام أدوات الذكاء الاصطناعي (مثل Lovable, Cursor, BrowserTools MCP) لتطوير موقع ويب لدمج الصور. يغطي العملية بأكملها بدءًا من تصميم النموذج الأولي والترميز وتصحيح الأخطاء، وصولًا إلى استخدام Vercel+GitHub لتحقيق النشر التلقائي CI/CD وتكوين تحليل النطاق، مما يوضح قيمة الذكاء الاصطناعي في تعزيز كفاءة التطوير المستقل وصيانة مواقع الويب. (المصدر: ترميز AI + نشر Vercel + تحليل النطاق: دليل شامل لتطوير تطبيقات الويب وإطلاقها، ترميز الأجواء + تدقيق وتحسين MCP.)

إعادة إنشاء خفيفة الوزن لـ “Her” OS1/Samantha باستخدام نماذج محلية: قام مطور باستخدام transformers.js ونماذج ONNX (Ultravox Llama 3.2 1B, Whisper Base, Kokoro TTS، إلخ) بإعادة إنشاء مساعد الذكاء الاصطناعي OS1/Samantha من فيلم “Her” محليًا في المتصفح. يوضح المشروع إمكانية تحقيق تفاعل صوتي بالذكاء الاصطناعي يعمل محليًا بحجم نموذج يبلغ حوالي 2 جيجابايت، وقد تم فتح مصدر الكود. (المصدر: Reddit r/LocalLLaMA)
ChatWise يجمع بين خوادم MCP لتحقيق RAG ومزامنة البيانات: شارك مستخدم مثالاً لتكوين سير عمل بسيط في ChatWise باستخدام تعليمات النظام، يجمع بين خوادم MCP لـ Pinecone (قاعدة بيانات) و Exa (بحث) و Time (وقت)، لتحقيق RAG (التوليد المعزز بالاسترجاع) ومزامنة البيانات. (المصدر: op7418)

📚 تعلم
جامعة ستانفورد تفتح دورة Transformer CS25 للجمهور: أصبحت دورة Transformer CS25 الشهيرة بجامعة ستانفورد متاحة للجمهور (بث مباشر عبر Zoom/تسجيلات). تستضيف الدورة محاضرين من كبار الباحثين في مجال الذكاء الاصطناعي وخبراء الصناعة مثل Andrej Karpathy, Geoffrey Hinton, Jim Fan, Ashish Vaswani، وتغطي موضوعات متقدمة مثل بنية LLM، والوسائط المتعددة، والتطبيقات العلمية، وعلم الروبوتات. يوفر موقع الدورة جدول المواعيد وروابط التسجيلات، بالإضافة إلى مجتمع Discord للمناقشة. (المصدر: karminski3, dotey, Reddit r/deeplearning, Reddit r/LocalLLaMA)
بحث من Tsinghua و Shanghai Jiao Tong يكشف عن قيود RL على قدرات الاستدلال لدى LLM: يشير بحث حديث من جامعة Tsinghua وجامعة Shanghai Jiao Tong إلى أنه على الرغم من أن التعلم المعزز (RL) يمكن أن يحسن دقة النماذج الكبيرة بمعدلات أخذ عينات منخفضة (الكفاءة)، إلا أنه قد يحد من قدرتها على حل المشكلات الأكثر صعوبة بمعدلات أخذ عينات عالية (حدود القدرة). مقارنة بالنماذج الأساسية، فإن نطاق التغطية للنماذج المدربة بـ RL ينخفض فعليًا عند قيم k العالية في مقياس pass@k. يرى البحث أن RL أفضل في تحسين القدرات الحالية بدلاً من توسيع حدود الاستدلال، وأن طرق RL الحالية قد تقع في الحد الأدنى المحلي بسبب عدم كفاية الاستكشاف. (المصدر: هل RL أداة استدلال خارقة؟ بحث حديث من Tsinghua و Shanghai Jiao Tong يشير إلى أن RL يجعل النماذج الكبيرة أفضل في “تطبيق الصيغ”، ولكن ليس في الاستدلال الحقيقي, Reddit r/artificial)

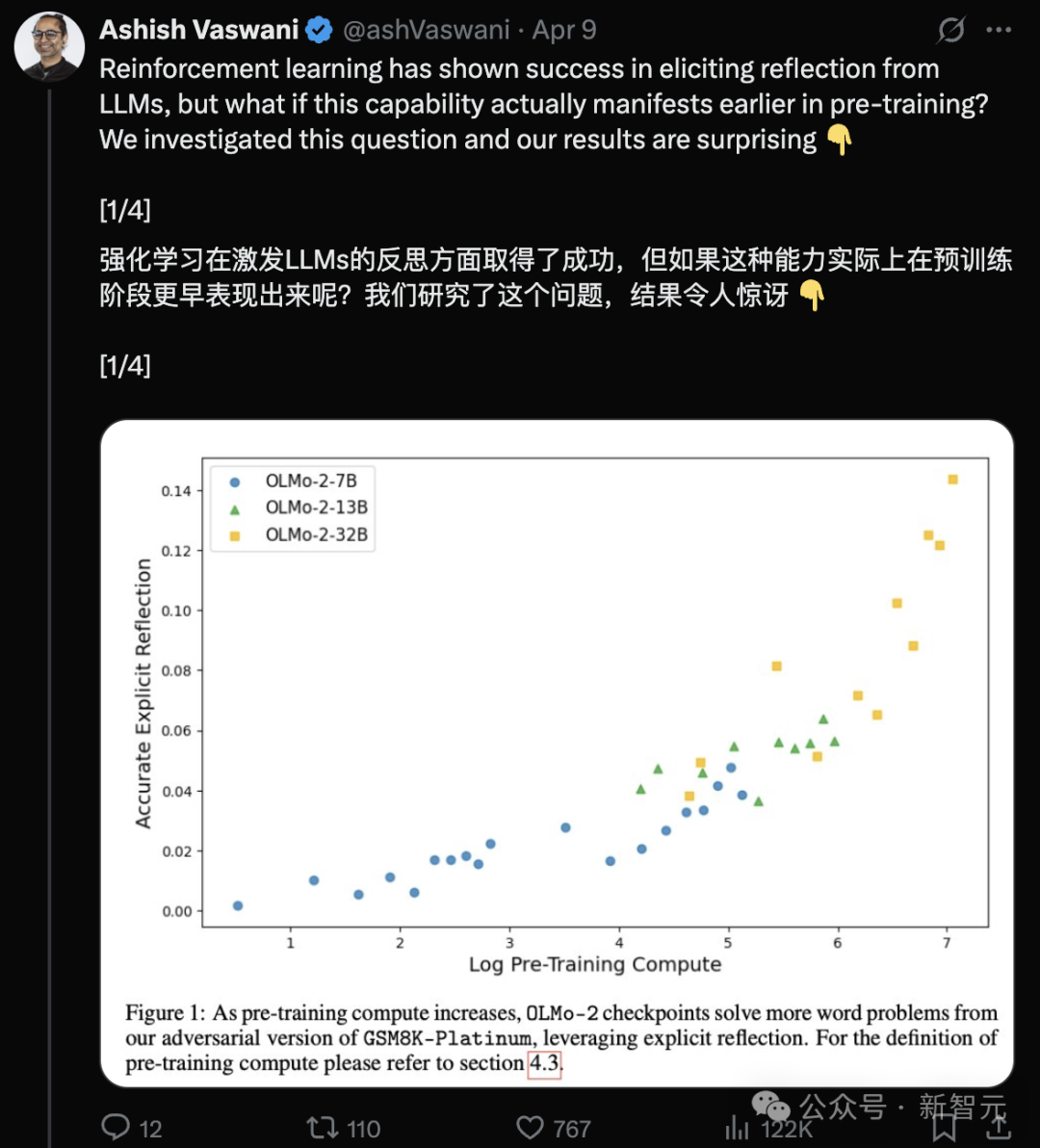
فريق مؤلفي Transformer: LLM تمتلك قدرة على التفكير الذاتي في مرحلة ما قبل التدريب: نشر فريق بقيادة المؤلف الأول لورقة Transformer، Ashish Vaswani، بحثًا (arXiv:2504.04022) يتحدى وجهة النظر القائلة بأن “القدرة على التفكير الذاتي تأتي بشكل أساسي من RLHF”. من خلال إدخال سلاسل تفكير معارضة، وجد البحث أن LLM (مثل OLMo-2) تظهر بالفعل قدرات على التفكير السياقي والتفكير الذاتي في مرحلة ما قبل التدريب، وأن هذه القدرة تزداد مع زيادة حجم الحسابات في مرحلة ما قبل التدريب. يمكن لمطالبات بسيطة مثل “Wait,” أن تحفز بشكل فعال التفكير الصريح، وتأثيرها يضاهي إخبار النموذج مباشرة بوجود خطأ. يوفر هذا منظورًا جديدًا لفهم ظهور القدرات أثناء عملية ما قبل التدريب. (المصدر: المؤلف الأصلي لـ Transformer يدحض وجهة نظر DeepSeek؟ كلمة Wait واحدة يمكن أن تثير التفكير الذاتي، دون الحاجة إلى RL)
ChemAgent: ذاكرة ذاتية التحديث تعزز قدرة LLM على الاستدلال الكيميائي: اقترح باحثون من Yale و Stanford ومؤسسات أخرى إطار عمل ChemAgent، الذي يحسن بشكل كبير أداء LLM في مهام الاستدلال الكيميائي (بمتوسط تحسن 10%-37% في الدقة على مجموعة بيانات SciBench) من خلال إدخال ذاكرة ديناميكية ذاتية التحديث تتضمن التخطيط والتنفيذ وذاكرة المعرفة. يحاكي هذا الإطار التعلم البشري، ويحل المشكلات عن طريق تحليل المهام واسترجاع الذاكرة المنظمة، ويظهر تحسنًا ملحوظًا بشكل خاص في دقة الحساب وتحويل الوحدات. حلل البحث العلاقة بين تشابه الذاكرة وكميتها والأداء، وأشار إلى القيود الحالية في فهم المشكلات وتخطيط الاستدلال واختيار الذاكرة. (المصدر: ارتفاع الدقة بنسبة 46%! إطار عمل “الذاكرة ذاتية التحديث” الجديد من Yale-Stanford يعيد تشكيل قدرة LLM على الاستدلال الكيميائي)
جامعة جنوب الصين للتكنولوجيا تحقق سلسلة من التقدم في مجال الحوسبة التطورية الموزعة: حقق فريق الذكاء الحاسوبي بجامعة جنوب الصين للتكنولوجيا سلسلة من الإنجازات في مجال “الحوسبة التطورية الموزعة في الإجماع والتعاون متعدد الوكلاء”: نشر مراجعة شاملة لهذا المجال متعدد التخصصات؛ اقترح خوارزمية MASOIE (التعلم الداخلي والخارجي)، وخوارزمية MACPO (تحفيز الهدف)، وآلية التكيف الذاتي لخطوة CCSA، وخوارزمية MASTER (التعاون القائم على المساهمة) وغيرها من الأساليب المبتكرة، وأثبت فعاليتها في سيناريوهات مثل تحديد مواقع شبكات الاستشعار اللاسلكية. نظم الفريق أيضًا أول مسابقة لتحسين الإجماع الموزع للصندوق الأسود. (المصدر: كسر حواجز تحسين الإجماع! جامعة جنوب الصين للتكنولوجيا تتعمق في الحوسبة التطورية الموزعة، وتحقق تعاونًا فعالًا متعدد الوكلاء)
سلسلة دروس فيديو لبناء DeepSeek من الصفر: نشرت Vizuara على YouTube سلسلة دروس فيديو بعنوان “لنقم ببناء DeepSeek من الصفر”، تم تحديث 13 محاضرة منها حتى الآن، تغطي شرحًا وتطبيقًا عمليًا للمفاهيم الأساسية مثل أساسيات DeepSeek، ومعالجة Token، وآليات الانتباه (الانتباه الذاتي، الانتباه السببي، الانتباه متعدد الرؤوس، الانتباه متعدد الاستعلامات، الانتباه المجمع بالاستعلامات، الانتباه الكامن متعدد الرؤوس)، و KV Cache. تهدف السلسلة إلى تحليل بنية DeepSeek بعمق، ومن المخطط أن تشمل أكثر من 40 ساعة في 35-40 حلقة. (المصدر: karminski3, Reddit r/LocalLLaMA)
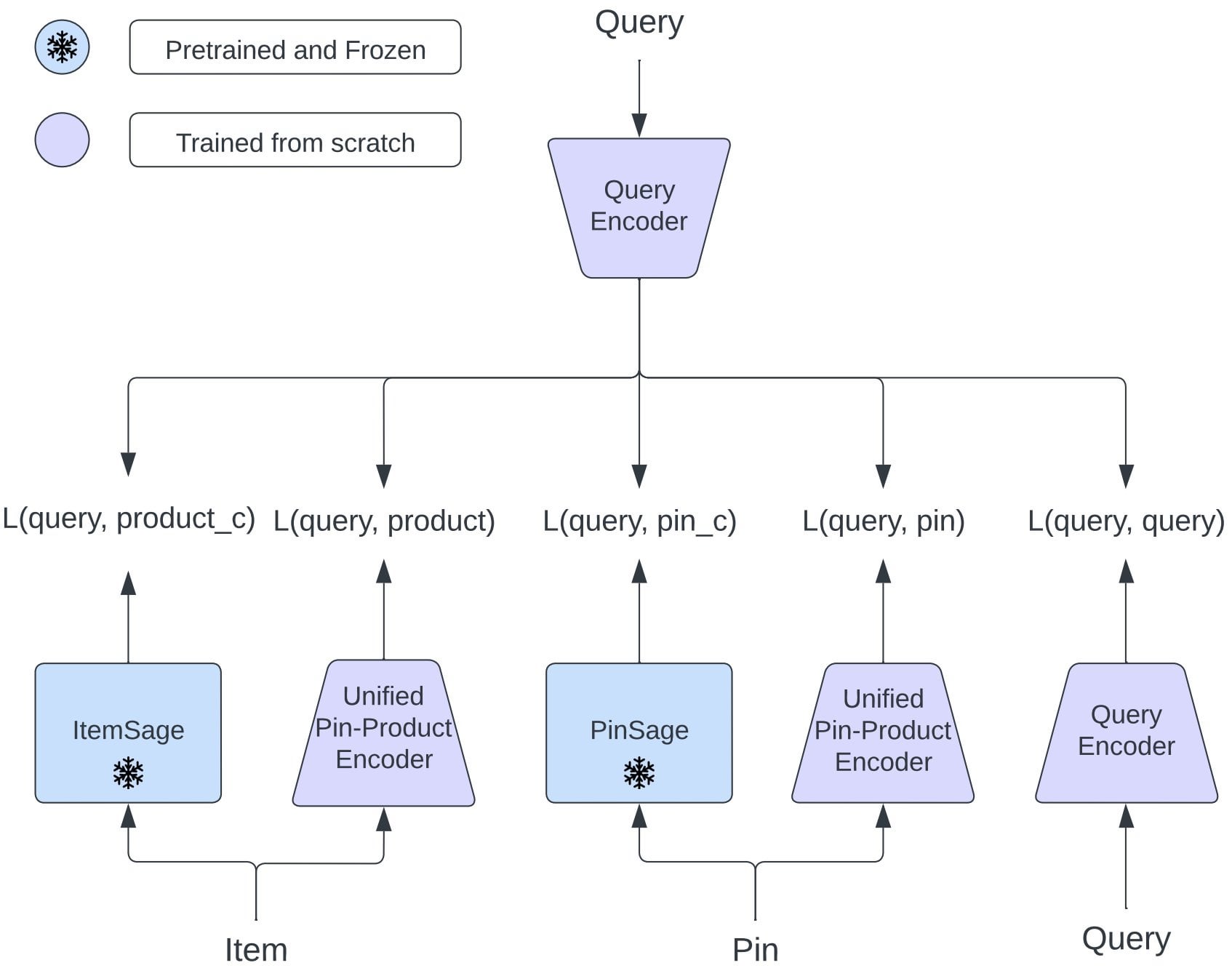
Pinterest تقترح OmniSearchSage: نموذج تضمين موحد يعزز البحث متعدد المهام: تقدم ورقة بحثية من Pinterest نموذج OmniSearchSage، وهو نموذج تضمين استعلام موحد، يتم تدريبه من خلال التعلم متعدد المهام، ويمكنه استرجاع الدبابيس (pins) والمنتجات والاستعلامات ذات الصلة في وقت واحد. يدمج النموذج عناوين GenAI وإشارات لوحات المستخدم وبيانات المشاركة السلوكية، ويمكن دمجه مباشرة في الأنظمة الحالية مثل PinSage، مما أدى إلى تحسينات كبيرة في البحث والإعلانات وزمن الاستجابة. (المصدر: Reddit r/MachineLearning)
FlowReasoner: سير عمل متعدد الوكلاء يتكيف ديناميكيًا بناءً على الاستعلام: تقترح ورقة بحثية جديدة طريقة FlowReasoner، التي تهدف إلى استنتاج سير عمل مخصص متعدد الوكلاء لكل استعلام مستخدم على الفور. من خلال استدلال SFT والتعلم المعزز GRPO، يمكن للنموذج تعديل سير العمل ديناميكيًا (مثل تسلسل توليد الكود والمراجعة والاختبار والتنقيح) بناءً على ملاحظات التنفيذ. تم التحقق من صحة هذه الطريقة في سيناريو Code Interpreter، مما يوضح إمكانية تكييف سير العمل ديناميكيًا مع متطلبات الاستعلام. (المصدر: dotey)

درس LangChain: بناء سير عمل لتوليد تقارير الامتثال باستخدام LlamaIndex: نشرت LlamaIndex درس فيديو يوضح كيفية بناء سير عمل وكيل (Agentic Workflow) لتوليد تقارير الامتثال. يوضح الدرس كيفية إعداد الفهرسة، وتحديد الأنماط، واستخدام البحث الدلالي للعثور على اللوائح، ودمج LLM لمعالجة النصوص ومقارنة العقود وإنشاء الملخصات. (المصدر: jerryjliu0)

درس LangChain: وكيل توليد كود ذاتي الشفاء: نشرت LangChain درسًا تعليميًا حول بناء وكيل توليد كود AI ذاتي الشفاء باستخدام OpenEvals و E2B sandbox. الفكرة الأساسية هي إضافة خطوة تفكير بعد توليد الكود بواسطة الذكاء الاصطناعي، باستخدام أدوات التقييم للتحقق والتصحيح، مما يحسن جودة وموثوقية الكود. (المصدر: LangChainAI)

تحليل Anthropic يكشف أن Claude لديه مبادئ أخلاقية داخلية: بعد تحليل 700,000 محادثة لـ Claude، وجدت Anthropic أن نموذج الذكاء الاصطناعي الخاص بها يظهر نوعًا من المبادئ الأخلاقية الداخلية. هذا الاكتشاف، المستمد من دراسة بيانات تفاعل المستخدم الحقيقية على نطاق واسع، قد يكون له آثار مهمة على أبحاث أمان ومواءمة الذكاء الاصطناعي. (المصدر: Reddit r/ClaudeAI, Reddit r/artificial)

Google تقترح “عصر التجربة” لمواجهة ندرة بيانات تدريب الذكاء الاصطناعي: نشر باحثون من Google (بما في ذلك David Silver) ورقة بعنوان “The Era of Experience”، يقترحون فيها السماح لـ AI Agent بتوليد بيانات خبرتهم الخاصة من خلال التفاعل مع البيئة لتدريب أنفسهم، وذلك للتغلب على عنق الزجاجة الحالي المتمثل في الاعتماد على بيانات بشرية موسومة على نطاق واسع. قد يشير هذا إلى تحول في نموذج تدريب الذكاء الاصطناعي نحو تعلم أكثر استقلالية. (المصدر: Reddit r/artificial)

قائمة موارد الشهادات والدورات المجانية: يجمع مستودع GitHub cloudcommunity/Free-Certifications عددًا كبيرًا من الموارد للدورات التدريبية والشهادات المجانية عبر الإنترنت، تغطي مجالات مثل تكنولوجيا المعلومات، السحابة، الذكاء الاصطناعي، الأمن، التسويق، وغيرها. تشمل الموارد المتعلقة بالذكاء الاصطناعي دورات مثل تعلم الآلة باستخدام Python من freeCodeCamp، وأساسيات GenAI من Databricks، ودورات الذكاء الاصطناعي من IBM Cognitive Class، ومقدمة في الذكاء الاصطناعي/تعلم الآلة من منصة Google Cloud Skills Boost، ودورة التعلم المعزز العميق من HuggingFace. (المصدر: cloudcommunity/Free-Certifications – GitHub Trending (all/daily))
اختبار موثوقية LLM في تحرير الكود: شارك مستخدم فيديو يختبر موثوقية العديد من LLM (مثل ChatGPT) في المساعدة في مهام كتابة كود التعلم العميق. تساعد مثل هذه الاختبارات على فهم أداء ومزايا وقيود مساعدي الترميز بالذكاء الاصطناعي الحاليين في سيناريوهات البحث والتطوير الفعلية. (المصدر: Reddit r/deeplearning)

💼 أعمال
حرب التعريفات الأمريكية تؤثر على الشركات الناشئة الصينية في مجال أجهزة الذكاء الاصطناعي: أثرت التعريفات الجمركية المرتفعة التي فرضتها الولايات المتحدة على السلع الصينية (تصل بعض المعدلات إلى 125%) بشدة على الشركات الناشئة الصينية في مجال أجهزة الذكاء الاصطناعي (مثل ألعاب AI والنظارات الذكية) التي تعتمد على السوق الأمريكية. أدت التعريفات المرتفعة إلى تقليص الأرباح أو حتى الخسارة، مما أجبر بعض الشركات على تعليق الشحنات إلى الولايات المتحدة. على الرغم من حصول النظارات الذكية وغيرها على إعفاء مؤقت، إلا أن المستقبل غير مؤكد. كما تزداد مخاطر نموذج “التخليص الرمادي” الذي تعتمد عليه الصناعة. يدفع هذا الشركات إلى إعادة تقييم اعتمادها على سوق واحدة، وتسريع التوسع العالمي لتنويع المخاطر، وقد يؤثر على تقييمات التمويل اللاحقة. (المصدر: أجهزة الذكاء الاصطناعي الوليدة تواجه أعنف حرب تعريفات)

تحليل معمق لروبوتات Zhiyuan: المنتج، التكنولوجيا، ونموذج العمل: تأسست Zhiyuan Robot على يد “Zhihui Jun” Peng Zhihui وآخرين، وتستهدف الروبوتات المجسدة للأغراض العامة. تشمل خطوط الإنتاج سلسلة “Yuanzheng” للسيناريوهات الصناعية والتجارية وسلسلة “Lingxi” خفيفة الوزن ومفتوحة المصدر. يكمن جوهر التكنولوجيا في التآزر بين الأجهزة والبرامج وحلقة البيانات المغلقة، مع تطوير ذاتي لوحدات المفاصل والأيدي البارعة ومجموعة برامج مثل نموذج Qiyuan الكبير. يشمل نموذج العمل مبيعات الأجهزة وخدمات الاشتراك وتقاسم الإيرادات البيئية. أكملت الشركة 8 جولات تمويل بقيمة 15 مليار يوان، وحصلت على استثمارات من Hillhouse و BYD و Tencent وغيرها، وتتعاون بعمق مع شركاء سلسلة التوريد والحكومات المحلية. (المصدر: تحليل معمق لروبوتات Zhiyuan: تطور وحيد القرن في مجال الروبوتات البشرية)

مشروع الطباعة ثلاثية الأبعاد المحتضن داخليًا في Dreame “AtomFab” يحصل على تمويل بعشرات الملايين من اليوانات: حصلت AtomFab Technology، التي احتضنتها Dreame Technology، على تمويل أولي بعشرات الملايين من اليوانات من Chuizhuàng Venture Capital. تركز الشركة على سوق الطباعة ثلاثية الأبعاد للمستهلكين، وتستخدم تقنية الذكاء الاصطناعي لتحسين سهولة الاستخدام والاستقرار والكفاءة. ستعيد استخدام تقنيات المحركات وأجهزة الاستشعار والتفاعل بالذكاء الاصطناعي وسلسلة التوريد الخاصة بـ Dreame لخفض التكاليف وتسريع الإنتاج. ستعطي المنتجات الأولوية للأسواق الأوروبية والأمريكية، مستفيدة من شبكة خدمة ما بعد البيع الخارجية لـ Dreame. من المتوقع إطلاق أول منتج في النصف الثاني من عام 2525. (المصدر: مشروع الطباعة ثلاثية الأبعاد المحتضن داخليًا في Dreame يحصل على تمويل بعشرات الملايين، مع إعطاء الأولوية للأسواق الخارجية مثل أوروبا وأمريكا | أول تقرير من Yingkr)
هيمنة NVIDIA على وحدات معالجة الرسومات قد تواجه تحديات: يشير التحليل إلى أنه على الرغم من نمو شحنات وحدات معالجة الرسومات من NVIDIA، فإن هيمنتها طويلة الأمد تواجه تحديات من رقائق عمالقة السحابة (Google, MS, Amazon, Meta) المطورة ذاتيًا (TPU, Maia, Trainium, MTIA) وتحسينات على مستوى النظام. يمكن لعمالقة السحابة دمج الأجهزة وتخصيصها وتحسين الأنظمة الموزعة (الشبكات، التبريد، البرامج) بشكل أفضل، بينما يعتبر تخطيط NVIDIA في هذا المجال غير كافٍ نسبيًا. كما يشكل ارتفاع نسبة مهام الاستدلال، والمنافسة المتزايدة من AMD، وإمكانات الاستدلال على وحدات المعالجة المركزية ضغوطًا. على الرغم من أن NVIDIA تسعى جاهدة للتكيف (مثل Blackwell, Spectrum-X)، إلا أن التحديات الهيكلية لا تزال قائمة. (المصدر: مستقبل الحوسبة: تاج NVIDIA يهتز)

شائعات عن اهتمام OpenAI بالاستحواذ على متصفح Chrome: وفقًا لـ Bloomberg، إذا أُجبرت Google على فصل أعمالها بسبب قضية مكافحة الاحتكار، فقد تفكر OpenAI في الاستحواذ على أعمال متصفح Chrome الخاص بها. تعكس هذه الشائعة النية الاستراتيجية لعمالقة الذكاء الاصطناعي للسيطرة على نقاط دخول المستخدمين والبيانات، لكن صحتها وجدواها تعتمدان على النتيجة النهائية لقضية مكافحة الاحتكار ضد Google. (المصدر: karminski3)
استراتيجيات لتحقيق نتائج أعمال باستخدام GenAI: يقترح مقال في Forbes تسع استراتيجيات تهدف إلى مساعدة الشركات على نقل الذكاء الاصطناعي التوليدي (GenAI) من مرحلة التجريب إلى التطبيق العملي في الأعمال، لدفع تحسين الكفاءة والابتكار، وتحقيق قيمة تجارية قابلة للقياس. (المصدر: Ronald_vanLoon)

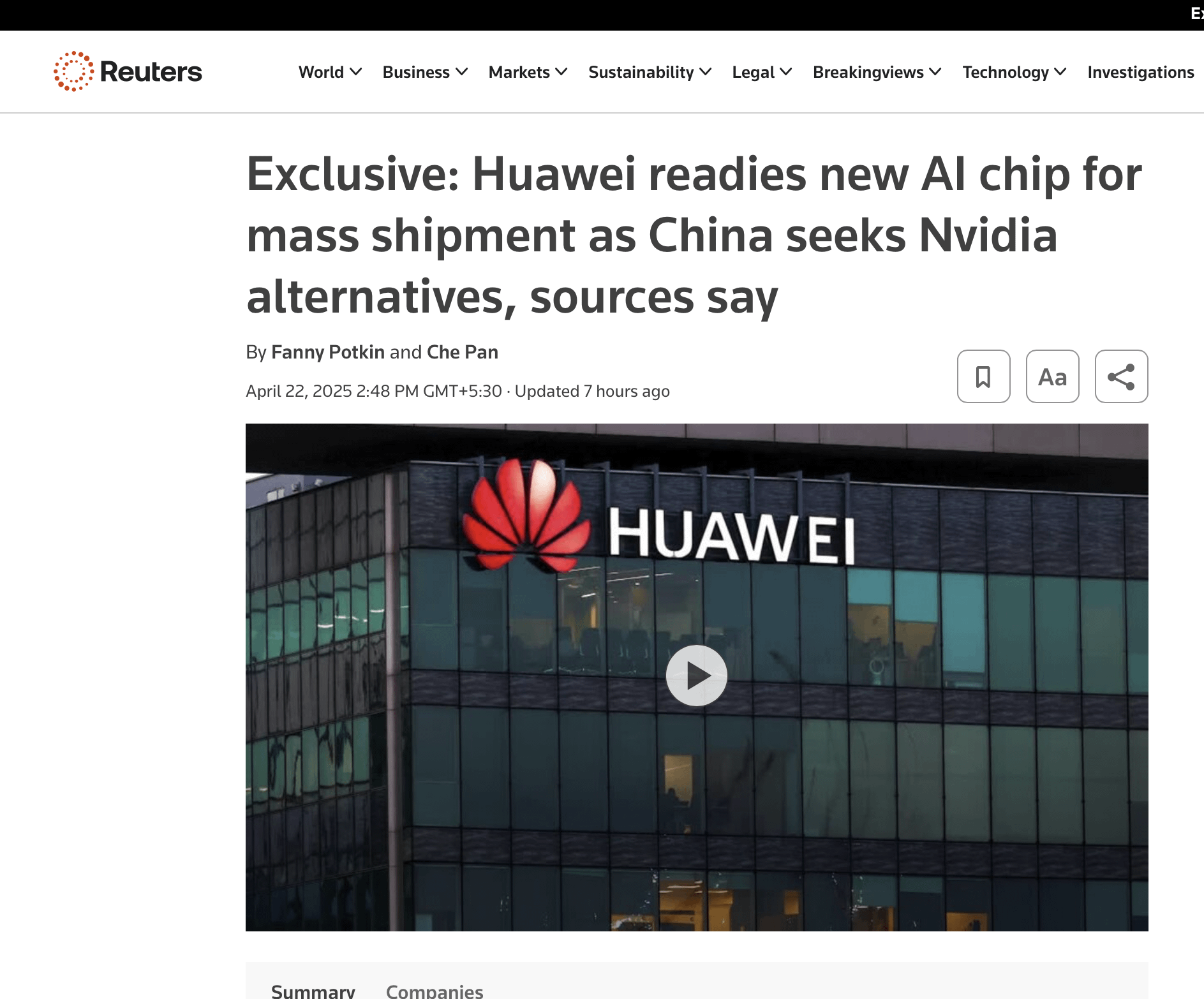
شريحة Huawei الجديدة قد تشكل منافسة لـ NVIDIA: يشير نقاش على وسائل التواصل الاجتماعي إلى أن شريحة الذكاء الاصطناعي الجديدة التي أطلقتها Huawei قد تشكل تحديًا لمكانة NVIDIA في السوق، خاصة في السوق الصينية، وقد تؤثر على مستقبل المنافسة التكنولوجية بين الصين والولايات المتحدة ومفاوضات التعريفات الجمركية. (المصدر: Reddit r/ArtificialInteligence)
🌟 مجتمع
حمى الذهب التي أثارها DeepSeek وتأملات حولها: أدى صعود DeepSeek إلى موجة من محاولات تحقيق الدخل حوله، بما في ذلك إنشاء المحتوى (إنتاج نصوص فيديو قصيرة بكميات كبيرة)، والدفع مقابل المعرفة (بيع الدروس التعليمية)، والخدمات التشغيلية. ومع ذلك، يواجه العديد من المجربين مشكلات مثل تجانس المحتوى، وتقييد المنصات، وصعوبة تحقيق الدخل. يتأمل المقال في أنه في البيئة الحالية، قد يكون “الوسطاء” الذين يبيعون الدورات التدريبية مستفيدين من فجوة المعلومات هم الرابح الأكبر، وليس المستخدمين المباشرين. في الوقت نفسه، يعاني DeepSeek نفسه من قيود مثل ازدحام الخوادم والردود النمطية. (المصدر: بعد ثلاثة أشهر من صعود DeepSeek، كيف حال الدفعة الأولى التي أرادت كسب المال منه؟)

مطور أداة غش بالذكاء الاصطناعي يحصل على تمويل ويثير جدلاً أخلاقيًا: تم إيقاف الطالب Chungin Lee البالغ من العمر 21 عامًا من جامعة كولومبيا لتطويره أداة غش بالذكاء الاصطناعي للمقابلات الفنية، ثم أسس شركة Cluely ووسع الأداة لتشمل سيناريوهات أخرى، وحصل على تمويل بقيمة 5.3 مليون دولار. يعتقد أن المساعدة بالذكاء الاصطناعي هي تحسين للكفاءة وليست غشًا. أثارت هذه القضية نقاشًا حادًا: يراها المؤيدون ابتكارًا، بينما يخشى المنتقدون تقويض العدالة وطمس حدود القدرات، مثل حبكة مسلسل Black Mirror. تلامس القضية قضايا عميقة تتعلق بأخلاقيات الذكاء الاصطناعي والعدالة التعليمية وتعريف القدرة. (المصدر: طالب يبلغ من العمر 21 عامًا يطور أداة غش بالذكاء الاصطناعي ويتم إيقافه من جامعة كولومبيا، ثم يحصل على تمويل بقيمة 5.3 مليون دولار، مستخدمو الإنترنت: “Black Mirror أصبح حقيقة”, اشتهر بتطوير أداة غش بالذكاء الاصطناعي، شاب يبلغ من العمر 21 عامًا طُرد من المدرسة، وبعد أقل من شهر، حصل على تمويل بقيمة 5.3 مليون دولار)

تشديد سياسة التأشيرات الأمريكية قد يؤدي إلى هجرة مواهب الذكاء الاصطناعي: أدى إلغاء الولايات المتحدة مؤخرًا لتأشيرات الطلاب الدوليين (بما في ذلك طلاب الدكتوراه في الذكاء الاصطناعي) على نطاق واسع، لأسباب غامضة وبإجراءات تفتقر إلى الشفافية (قد تشمل أخطاء فحص الذكاء الاصطناعي)، إلى إثارة قلق الأوساط الأكاديمية. يُعتقد أن هذا يضر بجاذبية الولايات المتحدة لأفضل مواهب الذكاء الاصطناعي، حيث يفكر العديد من الباحثين في المؤسسات الكبرى في المغادرة. قد يؤدي هذا إلى تضرر قوة البحث في مجال الذكاء الاصطناعي في الولايات المتحدة. رفع الطلاب دعوى قضائية مشتركة وحصلوا على أمر تقييدي مؤقت. (المصدر: دكتوراه الذكاء الاصطناعي في كاليفورنيا يفقد هويته بين عشية وضحاها، وباحثو Google و OpenAI يبدأون “موجة مغادرة أمريكا”، واختفاء 380 ألف وظيفة وانهيار ميزة الذكاء الاصطناعي)

نقاش حول وضع تطوير النماذج مفتوحة المصدر: يناقش المجتمع بحماس النماذج الكبيرة مفتوحة المصدر: توقعات لـ Qwen 3، قبول بطيء لـ Llama 4، هل وصل تحسين قدرة الاستدلال إلى عنق الزجاجة؟ التقليل من شأن إمكانات النماذج متعددة الوسائط، استمرار هيمنة الصين على المصادر المفتوحة. يؤكد النقاش على ضرورة التمييز بين النماذج مفتوحة المصدر والمغلقة، ويشير إلى أن عنق الزجاجة في الاستدلال قد يتعلق بتنوع النماذج وتحديات توسيع RL. (المصدر: natolambert)
الإشادة بقدرة البحث في نموذج OpenAI o3: أفاد مستخدم بأن نموذج OpenAI o3 يظهر أداءً ممتازًا في استرجاع المعلومات، حتى للمعلومات المتخصصة جدًا، ويمكنه العثور عليها بدقة دون الحاجة إلى سياق كبير، وتجربة التفاعل طبيعية. (المصدر: gdb)
أهمية وتأثير TTS مفتوح المصدر: أشار أعضاء المجتمع أثناء مناقشة نموذج Dia TTS إلى أن أدائه عالي الجودة يثبت أن تدريب نماذج SOTA TTS لم يعد حكرًا على الشركات العملاقة. أدى التأثير المركب للمعرفة والأدوات في صناعة الذكاء الاصطناعي إلى خفض عتبة تدريب التقنيات المتقدمة، وقوة المصادر المفتوحة تسرع من انتشار التكنولوجيا وتعميمها. (المصدر: huggingface, huggingface)
Meta تنظم LlamaCon 2025 للاحتفال بمجتمع المصادر المفتوحة: أعلنت Meta عن تنظيم حدث LlamaCon 2025، بهدف تكريم والاحتفال بمساهمات وإنجازات مجتمع Llama مفتوح المصدر، وستشارك أحدث التطورات والخطط المستقبلية لنماذج وأدوات Llama، مع استمرار الاستثمار في بناء النظام البيئي مفتوح المصدر. (المصدر: AIatMeta)

نقاش حول ما إذا كان الذكاء الاصطناعي “ذكيًا” حقًا: أعاد المجتمع نشر مقال بعنوان “نحن بحاجة إلى التوقف عن التظاهر بأن الذكاء الاصطناعي ذكي”، مما أثار نقاشًا حول حدود قدرات تكنولوجيا الذكاء الاصطناعي الحالية وتعريف “الذكاء”. قد يشمل النقاش الاختلافات بين فهم الذكاء الاصطناعي واستدلاله ووعيه والذكاء البشري. (المصدر: Ronald_vanLoon)

تجربة استخدام ChatGPT: فقدان الاتصال واختبار الصدق: اشتكى مستخدمون من مواجهة مشكلة “فقدان اتصال الشبكة” بشكل متكرر مع ChatGPT، مما يؤثر على تجربة الاستخدام. في الوقت نفسه، شارك مستخدم مطالبة تجعل ChatGPT يستخدم وظيفة الذاكرة لتقديم “رأيه الحقيقي” حول المستخدم، لاستكشاف التفاعل الشخصي للذكاء الاصطناعي والتعبير “الذاتي” المحتمل. (المصدر: natolambert, dotey)
تفاؤل بشأن تطور مجال الروبوتات: علق المؤسس المشارك لـ Hugging Face بأن مختبرات الروبوتات في عام 2525 مليئة بالحيوية والمرح بفضل الأجهزة مفتوحة المصدر، والتقدم الجيد في التعلم المعزز، وتجمع المواهب، مما يعكس التوقعات الإيجابية داخل الصناعة بشأن التطور السريع لتكنولوجيا الروبوتات. (المصدر: huggingface)
تأكيد فائدة Gemini Deep Research: شارك مستخدم حالة استخدام وظيفة Gemini Deep Research للتحقق من موثوقية المعلومات على تويتر، مما يوضح قيمتها العملية في التحقق السريع من المعلومات وتوفير خلفية بحثية معمقة. (المصدر: dotey)

انتقادات ودفاع عن مكتبات الذكاء الاصطناعي مفتوحة المصدر: لاحظ المجتمع زيادة التعليقات السلبية على مكتبات الذكاء الاصطناعي مفتوحة المصدر، ودعا إلى النظر إليها بعقلانية، مشيرًا إلى أن الانتقادات قد تستند إلى معلومات قديمة أو مؤشرات أحادية الجانب، وشجع المنتقدين على المشاركة في بناء إصدارات أفضل. (المصدر: natolambert)
تكهنات حول تجربة الألعاب بالذكاء الاصطناعي: أعرب مستخدمون عن فضولهم بشأن شكل تجربة الألعاب المستقبلية المدفوعة بالذكاء الاصطناعي، متكهنين بأنها قد تشبه تفاعل VRChat، لكنهم أثاروا شكوكًا حول سهولة التحكم الصوتي البحت. (المصدر: karminski3)
نقاش حول وظيفة تكبير الصور في ChatGPT: اكتشف مستخدم أن تكبير الصور باستخدام ChatGPT ليس دقة فائقة حقيقية، بل هو إعادة إنشاء صورة مشابهة. أكدت تعليقات المجتمع ذلك، وناقشت الفرق بين توليد وتحرير الصور بالذكاء الاصطناعي. (المصدر: Reddit r/ChatGPT)
ChatGPT يولد صورة تخيلية للعالم: طلب مستخدم من ChatGPT إنشاء صورة للعالم كما يتخيله، وكانت النتيجة صورة حديقة شاعرية. أشار المجتمع إلى المشكلات المنطقية والتحيزات المحتملة فيها، مما يعكس قيود توليد الصور بالذكاء الاصطناعي الحالية في الفهم والإبداع. (المصدر: Reddit r/ChatGPT)

استكشاف أسباب شعبية نموذج LLM القديم MythoMax13B: ناقش المجتمع سبب استمرار شعبية MythoMax13B القائم على Llama2 في سيناريوهات RPG. قد تشمل الأسباب: التكلفة المنخفضة (غالبًا كخيار مجاني)، والأداء المستقر، وإلمام المستخدمين بطريقة المطالبة به، وتأثير الترويج للدروس التعليمية المبكرة. (المصدر: Reddit r/LocalLLaMA)
البحث عن أداة تصفية خصوصية محلية: يبحث مستخدم عن أداة أو SLM يمكن تشغيلها محليًا لإزالة حساسية معلومات الخصوصية تلقائيًا قبل إرسال المطالبات إلى LLM، واستعادتها بعد تلقي الرد، لحماية أمن البيانات. (المصدر: Reddit r/OpenWebUI)
نقاش حول تحذير Anthropic من “موظفي الذكاء الاصطناعي بالكامل”: أثار تحذير Anthropic بشأن ظهور “موظفي الذكاء الاصطناعي بالكامل” في غضون عام شكوكًا في المجتمع، حيث اعتبر المعلقون ذلك دعاية مبالغ فيها، وأشاروا إلى مشكلات استقرار خدمات Anthropic نفسها. (المصدر: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI)

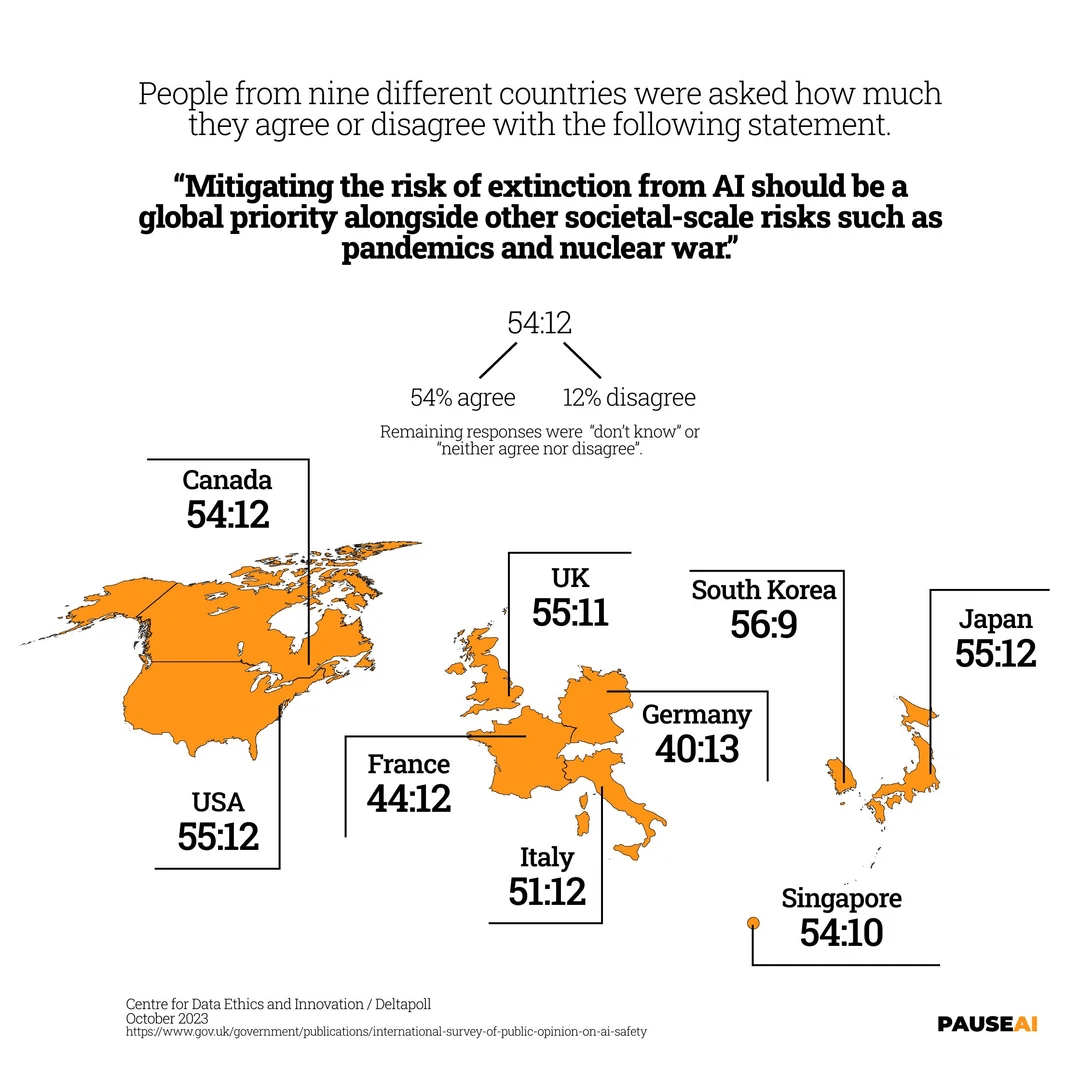
قلق عالمي بشأن مخاطر انقراض الذكاء الاصطناعي: تظهر نتائج استطلاع أن غالبية الناس في جميع أنحاء العالم يعتقدون أنه يجب التعامل بجدية مع خطر أن يتسبب الذكاء الاصطناعي في انقراض البشر، مما يعكس القلق العام بشأن المخاطر المحتملة للذكاء الاصطناعي القوي. (المصدر: Reddit r/artificial)
“نكهة الآلة” في النصوص التي يولدها الذكاء الاصطناعي وتقنيات إضفاء الطابع الإنساني: شارك مستخدمون خبراتهم، مشيرين إلى أن النصوص التي يولدها الذكاء الاصطناعي غالبًا ما تبدو “غير بشرية” بسبب نقص السياق المحدد، والإفراط في الرسمية، والكمال. اقترحوا طرقًا لجعل كتابة الذكاء الاصطناعي أكثر طبيعية و “إنسانية” من خلال تحديد السيناريو، وتقديم الأمثلة، وتعديل العشوائية، وإضافة تفاصيل محددة، والتحرير اليدوي، والحفاظ على عيوب طفيفة. (المصدر: Reddit r/artificial)
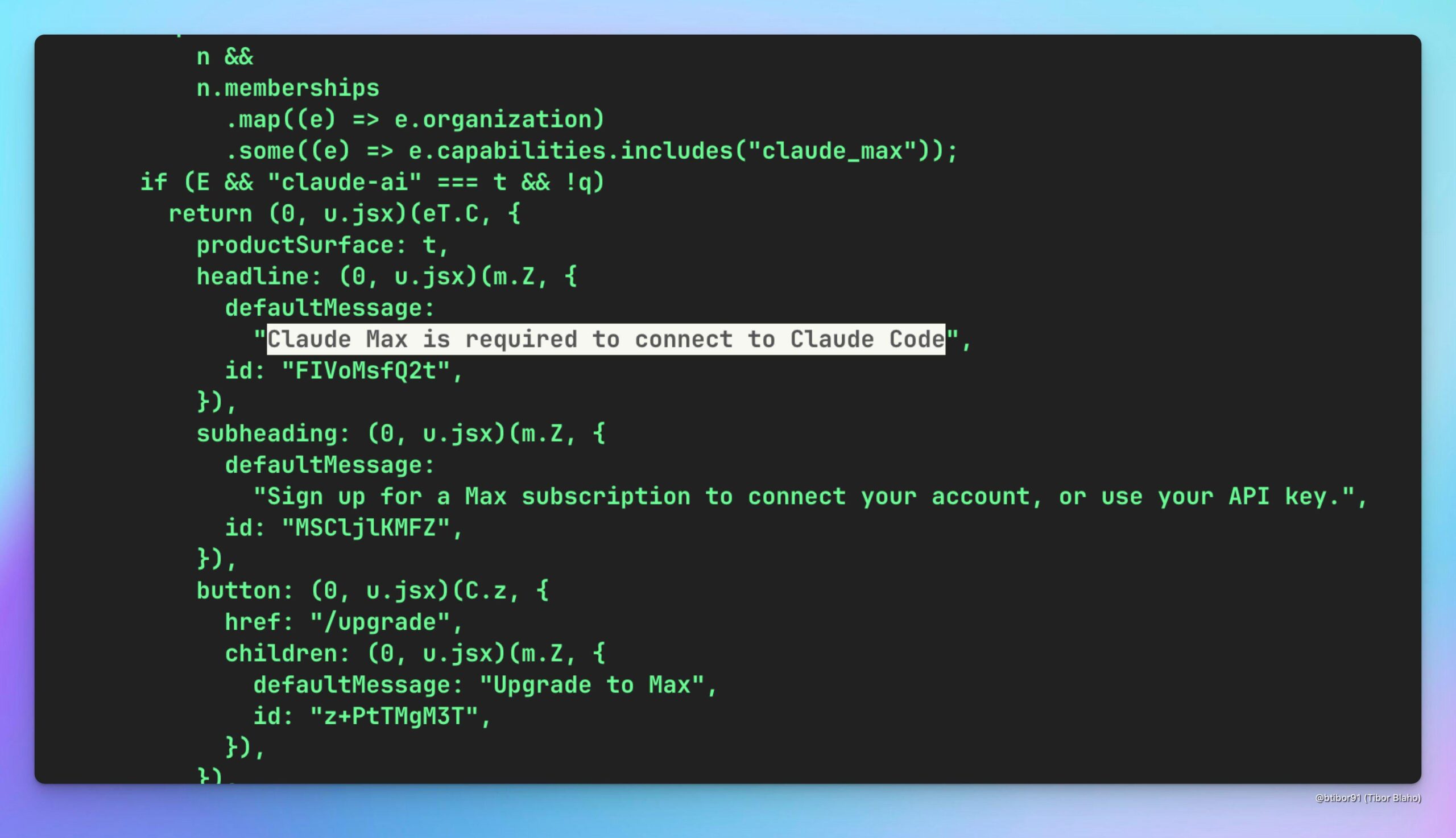
تكهنات حول إمكانية استخدام Claude Code عبر Claude Max: يتكهن المستخدمون حول ما إذا كان يمكن استخدام نموذج Claude Code (الذي قد يكون أكثر فعالية من حيث التكلفة) بشكل غير مباشر من خلال الاشتراك في خدمة Claude Max الأعلى مستوى، ويناقشون القيمة المحتملة لهذا النموذج. يعكس هذا اهتمام المستخدمين باستراتيجيات التسعير المختلفة وتجميع الميزات للنماذج المختلفة. (المصدر: Reddit r/ClaudeAI)
محاكاة ساخرة لسلوك نموذج o3 محليًا: شارك مستخدم مطالبة نظام ساخرة تجعل نموذج LLM محلي يحاكي العيوب التي ينتقدها بعض المستخدمين في نموذج OpenAI o3 (مثل الردود القصيرة، والأخطاء الطفيفة في الكود، والسلوك المزعج)، للتعبير عن عدم الرضا عن نموذج o3 والمزاح المجتمعي. (المصدر: Reddit r/LocalLLaMA)

طلب مساعدة بشأن مشكلة اتصال OpenWebUI بخادم وكيل MCP: واجه مستخدم Kubernetes صعوبة فنية عند تكوين OpenWebUI، حيث لم يتمكن من الوصول إلى خادم وكيل MCP من واجهة الويب الموجود في نفس الـ pod، وطلب الدعم الفني والحلول من المجتمع. (المصدر: Reddit r/OpenWebUI)
نقاش حول ممارسات أمان خادم MCP المحلي: ناقش المجتمع أفضل ممارسات الأمان لتشغيل خادم MCP محليًا، وشملت الاقتراحات استخدام وضع stdio، وتقييد الوصول إلى وضع SSE محليًا أو استخدام مصادقة الرمز المميز، مع التأكيد على الاهتمام العام بمخاطر حقن المطالبات وسرقة بيانات الاعتماد. (المصدر: Reddit r/ClaudeAI)
استكشاف آلية الدفع في بروتوكول Agent-to-Agent (A2A): ركز المجتمع على مشكلة عدم وجود آلية دفع مدمجة في بروتوكول A2A من Google، معتقدين أن هذا قد يعيق تطوير النظام البيئي لاقتصاد الوكلاء، وناقشوا حلولًا محتملة مثل ربط رموز المصادقة بالفواتير، وعمليات الضمان المدمجة، وتضمين معلومات التسعير في AgentSkill. (المصدر: Reddit r/artificial)
تحذير من الاعتماد المفرط على الذكاء الاصطناعي: شارك مستخدم تجربة حصوله على إجابات متناقضة من بحث Google AI، محذرًا من الاعتماد الكامل على الذكاء الاصطناعي لاتخاذ القرارات. أوضحت تعليقات المجتمع أسباب عدم اليقين مثل الطبيعة الاحتمالية لـ LLM وتحيز بيانات التدريب، واقترحت استخدام الذكاء الاصطناعي كأداة بحث مساعدة. (المصدر: Reddit r/ArtificialInteligence)
استفسار حول استخدام Qdrant لـ RAG في OpenWebUI: يسعى مستخدم للحصول على طرق محددة لدمج قاعدة بيانات المتجهات Qdrant في OpenWebUI لتحقيق RAG، بما في ذلك تفاصيل فنية حول كيفية جعل واجهة المستخدم تستخدم بيانات قاعدة البيانات وما إذا كانت هناك حاجة إلى برنامج نصي retriever. (المصدر: Reddit r/OpenWebUI)
نقاش حول مقارنة فعالية بحث Google و ChatGPT: أثار مستخدم نقاشًا بنشر رسم بياني للمقارنة، حيث رأى البعض أن ChatGPT يتفوق على بحث Google، بينما رأى آخرون أن Google Gemini يقدم أداءً ممتازًا ويمتلك أدوات مثل NotebookLM. يعكس النقاش التجارب الذاتية والتقييمات المختلفة لأدوات البحث/الإجابة بالذكاء الاصطناعي المختلفة. (المصدر: Reddit r/ChatGPT)
التفاؤل بشأن اتجاه أبحاث Character Training: يتوقع مراقب صناعي أن يصبح Character Training (محاكاة الذكاء الاصطناعي لشخصيات أو سمات معينة) نقطة ساخنة مهمة في البحث الأكاديمي، معتقدًا أن الوقت الحالي مناسب لنشر أوراق بحثية رائدة ذات صلة. (المصدر: natolambert)
💡 أخرى
استكشاف منطقية تصميم الروبوتات على شكل بشري: يحلل المقال بعمق سبب تصميم الروبوتات غالبًا على شكل بشري: يكمن السبب الأساسي في التكيف مع العالم المادي المصمم للبشر (الأدوات، البيئة، التفاعل). يمكن للروبوتات البشرية الاندماج بشكل أفضل في البنية التحتية الحالية، واستخدام الأدوات البشرية، وتعزيز التفاعل بين الإنسان والآلة من خلال الميزات الشبيهة بالبشر. يستعرض المقال تاريخ تطور الروبوتات، ويقارن المشهد التنافسي بين الصين والولايات المتحدة ودول أخرى، ويناقش التحديات التقنية (التوازن، التحكم، التكلفة) وآفاق الانتشار المستقبلية. (المصدر: تحليل معمق لوسائل الإعلام الأجنبية: لماذا تصنع الروبوتات على شكل بشري؟)

تحديات التوظيف في الصين في عصر الذكاء الاصطناعي والتدابير المضادة: يحلل التقرير تأثير الذكاء الاصطناعي على سوق العمل في الصين، خاصة التحديات التي تواجه القوى العاملة ذات المهارات المنخفضة والمتوسطة والتوازن الإقليمي. بالاستفادة من التجربة الأمريكية، يقترح أن تعزز الصين التدريب المهني (خاصة المهارات الرقمية)، وتحسين الضمان الاجتماعي (لتغطية الأشكال الجديدة للعمل)، وتعزيز تكامل الصناعة مع الذكاء الاصطناعي والتنسيق الإقليمي، وتحسين تنظيم الخوارزميات وحماية خصوصية البيانات، وتعزيز التنسيق متعدد الإدارات ومراقبة التوظيف، لمواجهة التحديات واغتنام الفرص. (المصدر: عصر الذكاء الاصطناعي: كيف يمكن للصين الحفاظ على قاعدة التوظيف الأساسية وتعزيزها)
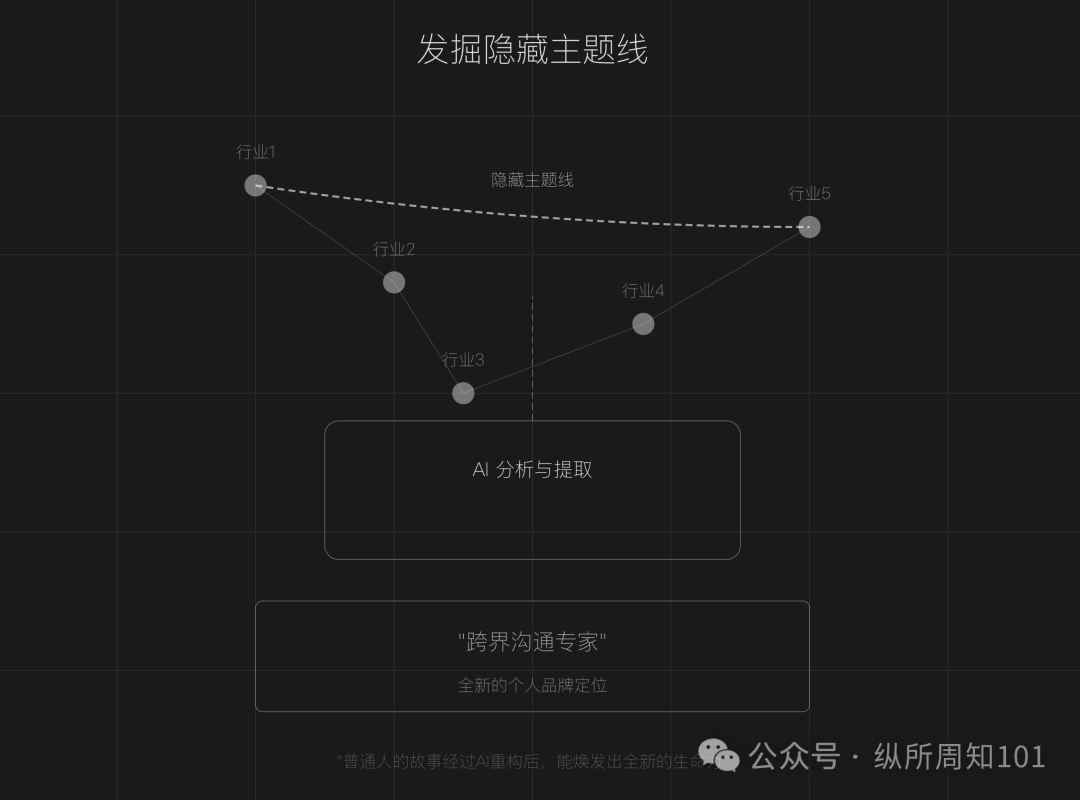
استخدام الذكاء الاصطناعي لإعادة تشكيل سرد الهوية الشخصية (IP): يرشد المقال إلى كيفية استخدام الذكاء الاصطناعي (مثل ChatGPT) لتحليل التجارب الشخصية، واكتشاف الموضوعات المخفية، وإعادة بناء سرد نقاط التحول الرئيسية، وتشكيل نظام لغوي فريد، لبناء هوية شخصية جذابة. يقدم خطوات محددة (جمع البيانات، تحليل الذكاء الاصطناعي، إعادة بناء الهيكل، التحقق التكراري) وتقنيات (البناء العكسي، تضخيم المشاعر، تعزيز التباين)، ويحذر من تجنب المبالغة في التجميل، والتجانس، ونقص العمق العاطفي. (المصدر: الخطوة الأولى لبناء هوية شخصية: استخدم الذكاء الاصطناعي لإعادة كتابة قصة حياتك)
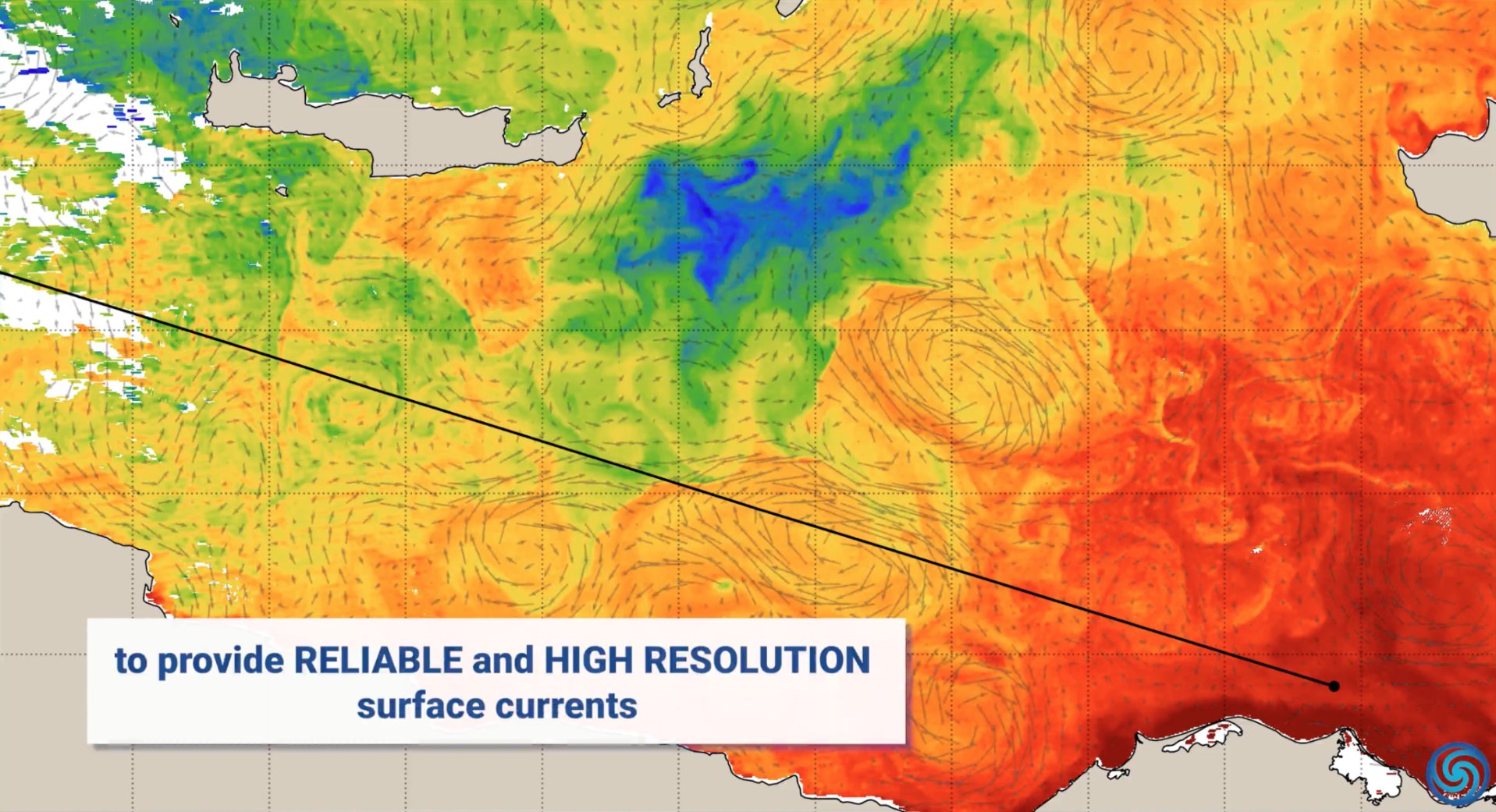
تطبيقات الذكاء الاصطناعي في مجال حماية البيئة: عرضت NVIDIA في يوم الأرض العالمي تطبيقات تقنيتها للذكاء الاصطناعي (Jetson, Earth-2، إلخ) في مجال حماية البيئة: من خلال التنبؤ بالتيارات المحيطية لتقليل انبعاثات الشحن، والحماية في الوقت الفعلي من حرائق الغابات والصيد غير المشروع، وتوفير تنبؤات دقيقة بالعواصف، واكتشاف الكويكبات، مما يجسد إمكانات الذكاء الاصطناعي في مواجهة تغير المناخ وحماية النظم البيئية. (المصدر: nvidia, nvidia, nvidia)
استخدام الذكاء الاصطناعي لتحسين خدمة العملاء: تهدف تقنية مراكز الاتصال المدفوعة بالذكاء الاصطناعي إلى تحسين تجربة خدمة العملاء من خلال الأتمتة والذكاء، وحل نقاط الضعف في خدمة العملاء التقليدية، وزيادة الكفاءة ورضا العملاء. (المصدر: Ronald_vanLoon)
مشاركة مطالبات لتوليد صور سيلفي واقعية/صور مضحكة بالذكاء الاصطناعي: شارك مستخدمون مطالبات لاستخدام أدوات توليد الصور بالذكاء الاصطناعي (GPT-4o/Sora) لإنشاء صور سيلفي “عادية” وصور مضحكة (مثل مشاهير على شكل فرشاة مرحاض). يوضح هذا قدرات الذكاء الاصطناعي في توليد الصور الإبداعية، والتي يمكن استخدامها للترفيه أو إنشاء المحتوى. (المصدر: dotey, dotey, dotey)

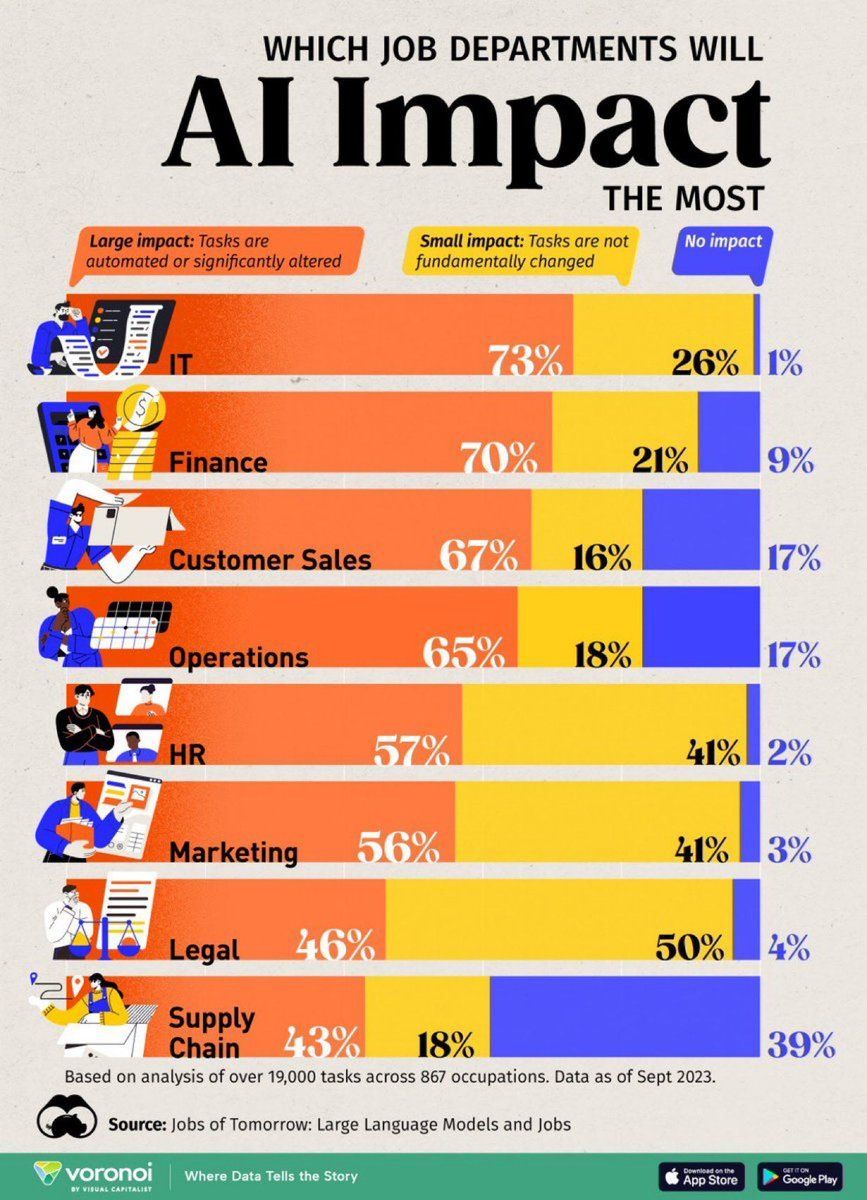
تحليل تأثير الذكاء الاصطناعي على الوظائف: يعرض الرسم البياني المعلوماتي الذي أعدته Visual Capitalist بشكل مرئي أنواع الوظائف الأكثر تأثرًا بالذكاء الاصطناعي، مما يوفر مرجعًا للتخطيط الوظيفي الفردي وصانعي السياسات. (المصدر: Ronald_vanLoon)
استخدام الذكاء الاصطناعي للكشف عن عيوب الطرق في دبي: تتبنى دبي تقنية الذكاء الاصطناعي للكشف عن عيوب الطرق، وهو مثال ملموس لتطبيقات الذكاء الاصطناعي في مجال المدن الذكية وصيانة البنية التحتية، مما يساعد على تحسين كفاءة الصيانة وسلامة الطرق. (المصدر: Ronald_vanLoon)
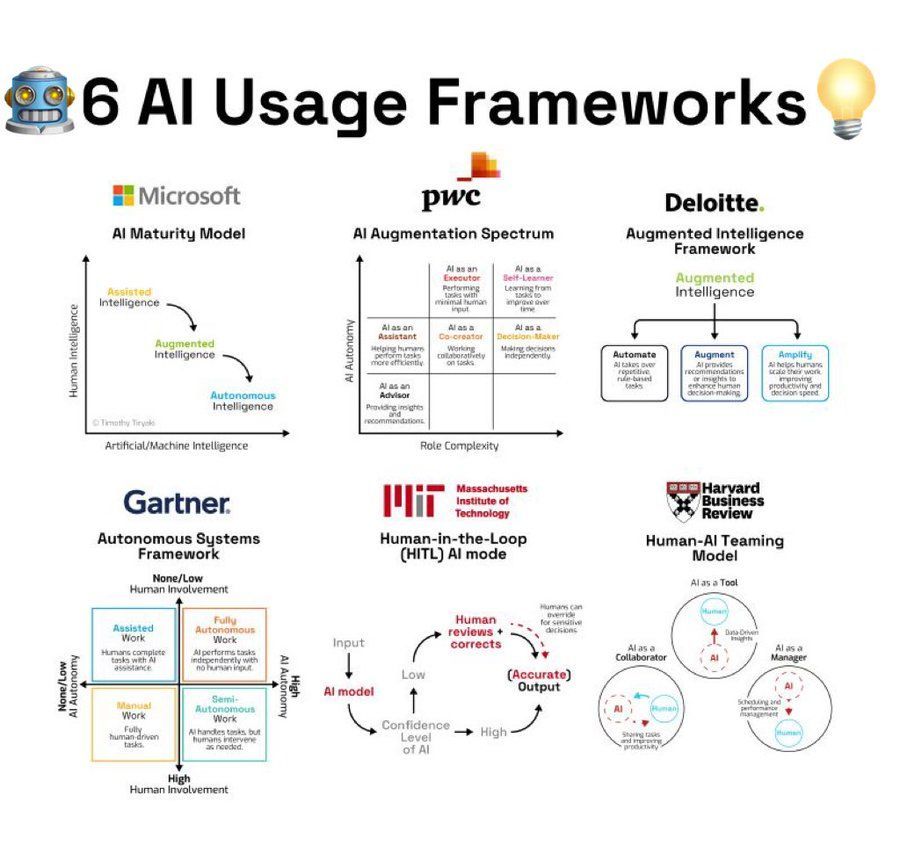
ملخص أطر استخدام الذكاء الاصطناعي: يلخص الرسم البياني المعلوماتي 6 أطر أو منهجيات لتطبيق الذكاء الاصطناعي، مما يوفر إرشادات للأفراد والمؤسسات التي ترغب في استخدام الذكاء الاصطناعي بشكل منهجي لحل المشكلات أو الابتكار. (المصدر: Ronald_vanLoon)
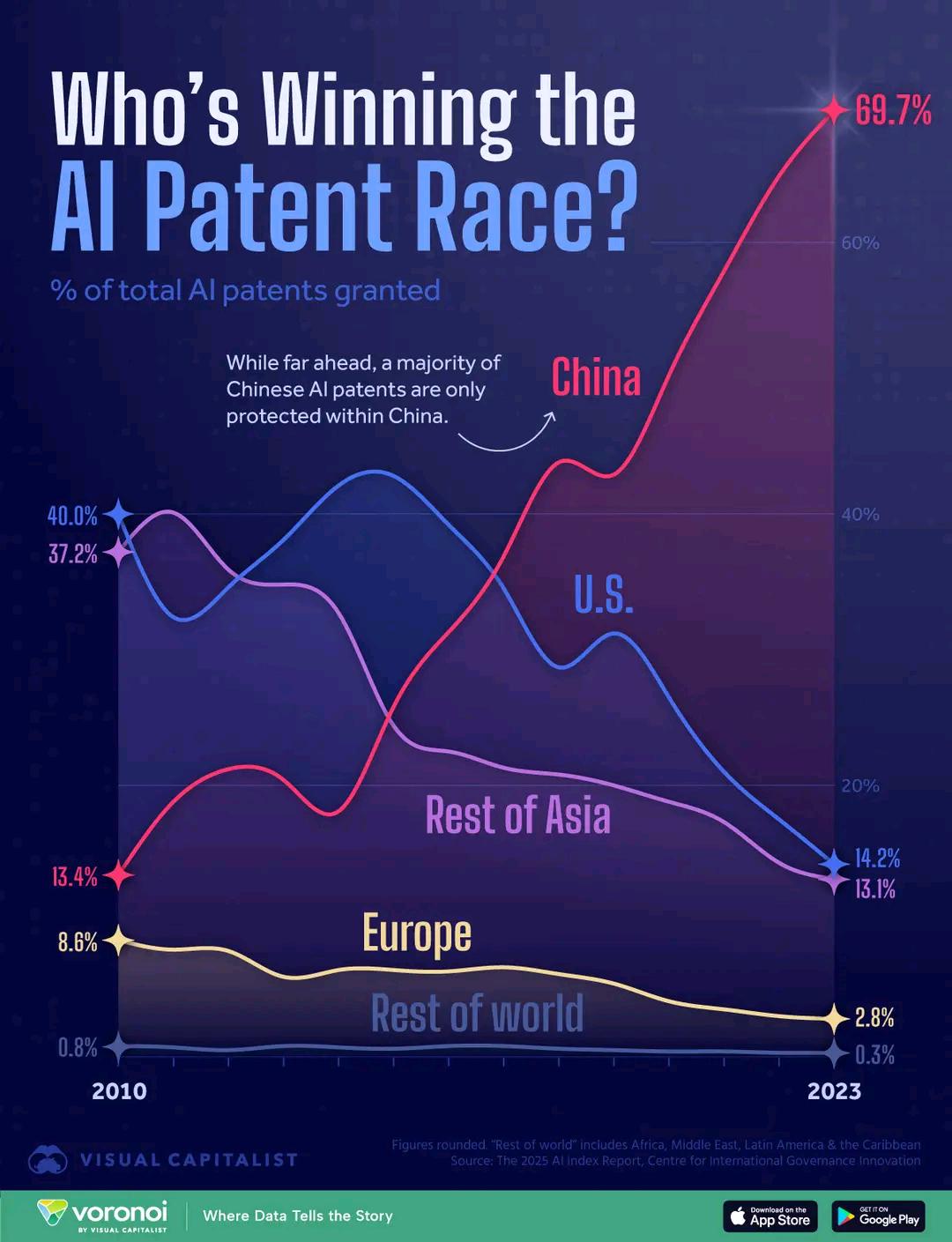
مقارنة عدد براءات اختراع الذكاء الاصطناعي حسب الدولة: يظهر الرسم البياني أن الصين تتصدر في عدد طلبات براءات اختراع الذكاء الاصطناعي، ولكنه يثير أيضًا نقاشًا حول جودة براءات الاختراع وفروق تكاليف التقديم. تعكس البيانات مدى نشاط الدول في استثمار البحث والتطوير في مجال الذكاء الاصطناعي وتخطيط الملكية الفكرية. (المصدر: karminski3)
ذراع آلية بيونية تساعد الأشخاص ذوي الإعاقة: حالة تركيب شركة Open Bionics لذراع آلية بيونية لفتاة مبتورة الأطراف تبلغ من العمر 15 عامًا، توضح الدور الإيجابي للتكنولوجيا مثل الذكاء الاصطناعي والروبوتات والطباعة ثلاثية الأبعاد في تحسين نوعية حياة الأشخاص ذوي الإعاقة والرعاية الإنسانية. (المصدر: Ronald_vanLoon)
أهلية الأفلام المدعومة بالذكاء الاصطناعي لجوائز الأوسكار تثير الاهتمام: أكدت الجهة المنظمة لجوائز الأوسكار أن الأفلام التي تم إنتاجها بمساعدة الذكاء الاصطناعي مؤهلة للترشح، مما أثار نقاشًا في الصناعة حول دور الذكاء الاصطناعي في صناعة الأفلام، ونسب الإبداع، وتأثيره على معايير التحكيم المستقبلية. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

ليتوانيا تضع قواعد لاستخدام الذكاء الاصطناعي في المدارس: بدأت ليتوانيا في وضع قواعد لاستخدام الذكاء الاصطناعي في سياق المدارس، مما يشير إلى أن النظام التعليمي بدأ في مواجهة وتنظيم استخدام أدوات الذكاء الاصطناعي في التدريس والتعلم، لتحقيق التوازن بين الفرص والمخاطر. (المصدر: Reddit r/ArtificialInteligence)