
كلمات مفتاحية:نموذج الذكاء الاصطناعي, أوبن إيه آي, متعدد الوسائط, وكيل الذكاء الاصطناعي, نموذج O3, O4-mini, الاستدلال البصري, استدعاء الأدوات, جيميني 2.5 فلاش, تينسنت يوان باو للذكاء الاصطناعي, تكامل نماذج اللغات الكبيرة, التعلم المعزز
🔥 أبرز الأخبار
OpenAI تطلق نموذجي o3 و o4-mini، مع دمج الأدوات وقدرات الاستدلال البصري : أعلنت OpenAI رسميًا عن إطلاق نموذجي الاستدلال الأكثر ذكاءً وقوة حتى الآن، o3 و o4-mini. تكمن الميزة الأساسية في تحقيق استدعاء وتجميع Agent لجميع أدوات ChatGPT الداخلية (بحث الويب، تحليل بيانات Python، فهم بصري عميق، توليد الصور، إلخ) بشكل استباقي لأول مرة، والقدرة على دمج الصور في سلسلة الاستدلال للتفكير. يتفوق o3 بشكل شامل في مجالات مثل البرمجة، الرياضيات، العلوم، والإدراك البصري، محققًا أداءً متطورًا (SOTA) في العديد من الاختبارات المعيارية؛ بينما تم تحسين o4-mini من حيث السرعة والتكلفة، مع أداء يتجاوز حجمه بكثير. يتمتع كلا النموذجين بقدرة أقوى على اتباع التعليمات، وحوارات أكثر طبيعية، ويمكنهما الاستفادة من الذاكرة والمحادثات السابقة لتقديم ردود مخصصة. يمثل هذا الإطلاق خطوة مهمة لـ OpenAI نحو Agentic AI أكثر استقلالية، مما يمكّن مساعدي الذكاء الاصطناعي من إنجاز المهام المعقدة بشكل أكثر استقلالية. (المصدر: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
إطلاق نموذجي OpenAI o3 و o4-mini، لتعزيز استخدام الأدوات وقدرات الاستدلال البصري : أطلقت OpenAI نموذجي o3 و o4-mini في وقت متأخر من الليل، ويمكن للمستخدمين الوصول إليهما عبر حسابات ChatGPT Plus و Pro و Team. تشمل الترقيات الرئيسية: 1. دعم نسخة o3 الكاملة لاستدعاء الأدوات (مثل الاتصال بالإنترنت ومفسر الكود) لأول مرة. 2. أصبح o3 و o4-mini أول النماذج القادرة على إجراء الاستدلال البصري ضمن سلسلة التفكير، مما يمكنها من تحليل التفكير بالاقتران مع الصور كما يفعل البشر، على سبيل المثال، في لعبة تخمين الموقع من الصورة، يمكن للنموذج تكبير تفاصيل الصورة لإجراء استدلال تدريجي. تعزز هذه القدرة بشكل كبير أداء النموذج في المهام متعددة الوسائط (مثل MMMU، MathVista)، مما يبشر بدور أكبر للذكاء الاصطناعي في السيناريوهات المهنية التي تتطلب حكمًا بصريًا (مثل المراقبة الأمنية، تحليل الصور الطبية). في الوقت نفسه، قامت OpenAI أيضًا بإتاحة أداة البرمجة بالذكاء الاصطناعي Codex CLI كمصدر مفتوح. (المصدر: OpenAI深夜上线o3满血版和o4 mini – 依旧领先。
دمج Tencent Yuanbao AI رسميًا في WeChat، بداية نمط جديد للدردشة : أصبح Tencent Yuanbao AI متاحًا الآن رسميًا كصديق على WeChat، ويمكن للمستخدمين إضافته عن طريق البحث عن “元宝”. تكسر هذه الخطوة النمط التقليدي لتطبيقات الذكاء الاصطناعي التي تتطلب فتحًا منفصلاً، حيث تدمج الذكاء الاصطناعي بسلاسة في سيناريوهات التواصل اليومية للمستخدمين. يمكن لـ Yuanbao AI (المبني على Hunyuan و DeepSeek) التفاعل مباشرة في مربع حوار WeChat، ويدعم تلخيص الصور ومقالات الحسابات الرسمية وروابط الويب والملفات الصوتية (لا يدعم حاليًا مقاطع الفيديو القصيرة “Video Channel”)، ويمكنه البحث في سجلات الدردشة التاريخية. على الرغم من أنه لا يدعم حاليًا الرسم والدردشة الجماعية، إلا أن سهولة استخدامه والتكامل العميق مع بيئة WeChat يعتبران ميزة مهمة. يعتقد المحللون أن WeChat، بفضل قاعدته الجماهيرية الضخمة وشبكة علاقاته الاجتماعية، يحول الذكاء الاصطناعي إلى جهة اتصال في دفتر العناوين، مما قد يغير نمط التفاعل بين الإنسان والآلة ويجعل الذكاء الاصطناعي يندمج بشكل طبيعي أكثر في حياة المستخدمين. (المصدر: 劲爆!元宝AI接入微信了,怎么用?看这篇就够了、腾讯元宝最终还是活成了微信的模样。
الولايات المتحدة قد تعلق صادرات رقائق Nvidia H20 إلى الصين إلى أجل غير مسمى، مما يؤثر بشكل كبير : أبلغت الحكومة الأمريكية شركة Nvidia بأنها ستعلق إلى أجل غير مسمى صادرات رقائق الذكاء الاصطناعي H20 إلى الصين (وهي نسخة خاصة مصممة سابقًا للتعامل مع قيود التصدير). تعتبر H20 أقوى رقاقة متوافقة طورتها Nvidia للسوق الصينية، ومن المتوقع أن يوجه حظر البيع ضربة كبيرة لـ Nvidia. تظهر البيانات أن الصين هي رابع أكبر مصدر دخل لـ Nvidia، حيث بلغت مبيعات H20 في عام 2024 مستوى عشرات المليارات من الدولارات، وأن شركات التكنولوجيا الصينية (مثل ByteDance و Tencent) هي المشترين الرئيسيين لرقائق Nvidia، مع نمو استثماري ملحوظ. لا يؤثر هذا الإجراء على إيرادات Nvidia فحسب، بل قد يضعف أيضًا نظامها البيئي CUDA (حيث يمثل المطورون الصينيون أكثر من 30٪). في الوقت نفسه، تتسارع وتيرة تطور شركات رقائق الذكاء الاصطناعي المحلية الصينية مثل Huawei (مثل Ascend 910C)، والتي قد تملأ الفراغ في السوق. أثار الحدث مخاوف في السوق، وانخفض سعر سهم Nvidia استجابة لذلك. (المصدر: 中国对英伟达到底有多重要?
🎯 التطورات
نموذج الفيديو المتقدم من Google Veo 2 متاح مجانًا على AI Studio : أعلنت Google أن نموذجها المتقدم لتوليد الفيديو Veo 2 أصبح متاحًا الآن على Google AI Studio و Gemini API و Gemini App، مع توفير حصص استخدام مجانية (حوالي عشر مرات يوميًا، بحد أقصى 8 ثوانٍ في كل مرة). يدعم Veo 2 تحويل النص إلى فيديو (t2v) وتحويل الصورة إلى فيديو (i2v)، وهو قادر على فهم التعليمات المعقدة، وتوليد محتوى فيديو واقعي ومتنوع الأساليب، والتحكم في حركة الكاميرا. تؤكد الشركة أن مفتاح توليد فيديو عالي الجودة يكمن في تقديم Prompt واضح ومفصل ويتضمن كلمات مفتاحية بصرية. يتميز النموذج أيضًا بوظائف متقدمة مثل التحرير داخل الفيديو (قص وتوسيع الصورة)، وحركة الكاميرا السينمائية، والانتقالات الذكية، بهدف الاندماج في سير عمل إنشاء المحتوى وتعزيز الكفاءة. (المصدر: 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。
Google تطلق Gemini 2.5 Flash، مع التركيز على السرعة والتكلفة وعمق التفكير القابل للتحكم : أطلقت Google نسخة معاينة من نموذج Gemini 2.5 Flash، والذي يتم وضعه كنموذج خفيف الوزن مُحسَّن من حيث السرعة والتكلفة. أظهر النموذج أداءً لافتًا على لوحة صدارة LMArena، حيث احتل المرتبة الثانية بالتساوي مع GPT-4.5 Preview و Grok-3، والمرتبة الأولى في المطالبات الصعبة والبرمجة والاستعلامات الطويلة. تكمن ميزته الأساسية في إدخال قدرة “التفكير” والاستدلال المختلط بالكامل، مما يسمح للنموذج بالتخطيط وتجزئة المهام قبل الإخراج. يمكن للمطورين التحكم في عمق تفكير النموذج (الحد الأقصى للـ token) من خلال معلمة “ميزانية التفكير”، لتحقيق التوازن بين الجودة والتكلفة وزمن الاستجابة. حتى مع ميزانية قدرها 0، يتفوق الأداء على 2.0 Flash. يتميز النموذج بفعالية عالية من حيث التكلفة، حيث يبلغ سعره فقط 1/10 إلى 1/5 من سعر Gemini 2.5 Pro، وهو مناسب لسير عمل الذكاء الاصطناعي عالي التزامن وواسع النطاق. (المصدر: 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。
Kunlun Tech تطلق نموذج توليد الأفلام غير محدود المدة Skyreels-V2 : أطلقت Kunlun Tech وأتاحت كمصدر مفتوح Skyreels-V2، الذي يُزعم أنه أول نموذج في العالم لتوليد الفيديو عالي الجودة يدعم مدة غير محدودة. يهدف النموذج إلى معالجة نقاط الضعف في نماذج الفيديو الحالية فيما يتعلق بفهم لغة اللقطات السينمائية، واتساق الحركة، وقيود مدة الفيديو، ونقص مجموعات البيانات المتخصصة. يجمع Skyreels-V2 بين نماذج كبيرة متعددة الوسائط، والوسم المنظم، والتوليد بالانتشار، والتعلم المعزز (DPO لتحسين جودة الحركة)، والضبط الدقيق عالي الجودة في استراتيجية تدريب متعددة المراحل. يعتمد بنية Diffusion Forcing، ويحقق توليد الفيديو الطويل من خلال مجدول خاص وآلية انتباه. تدعي الشركة أن تأثير التوليد يصل إلى “مستوى سينمائي”، ويتفوق في الاختبارات المعيارية مثل V-Bench1.0 على النماذج مفتوحة المصدر الأخرى. يمكن للمستخدمين تجربة توليد مقاطع فيديو تصل مدتها إلى 30 ثانية عبر الإنترنت. (المصدر: 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!
Shanghai AI Lab يطلق النموذج الأصلي متعدد الوسائط InternVL3 : أطلق مختبر شنغهاي للذكاء الاصطناعي InternVL3، وهو نموذج كبير متعدد الوسائط (MLLM) يعتمد على نموذج تدريب مسبق أصلي متعدد الوسائط. على عكس معظم النماذج المعدلة من LLMs النصية البحتة، يتعلم InternVL3 في مرحلة تدريب مسبق واحدة في وقت واحد من البيانات متعددة الوسائط ومجموعات النصوص البحتة، بهدف التغلب على التعقيدات وتحديات المواءمة الناتجة عن التدريب متعدد المراحل. يجمع النموذج بين ترميز الموضع البصري المتغير، وتقنيات ما بعد التدريب المتقدمة، واستراتيجيات التوسع وقت الاختبار. حصل InternVL3-78B على 72.2 نقطة في اختبار MMMU المعياري، مسجلاً رقماً قياسياً جديداً لـ MLLMs مفتوحة المصدر، مع أداء يقترب من النماذج الخاصة الرائدة، مع الحفاظ على قدرات لغوية بحتة قوية. سيتم نشر بيانات التدريب وأوزان النموذج. (المصدر: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
UCLA وآخرون يقترحون إطار d1 لاستخدام التعلم المعزز في استدلال Diffusion LLM : اقترح باحثون من UCLA و Meta AI إطار d1، وهو أول تطبيق للتدريب اللاحق بالتعلم المعزز (RL) على نماذج اللغة الكبيرة بالانتشار المقنع (dLLM). تركز طرق RL الحالية (مثل GRPO) بشكل أساسي على LLMs ذاتية الانحدار، ويصعب تطبيقها مباشرة على dLLMs بسبب افتقارها إلى التحلل الطبيعي للاحتمالات اللوغاريتمية. يتضمن إطار d1 مرحلتين: أولاً، يتم إجراء الضبط الدقيق الموجه (SFT)، ثم في مرحلة RL، يتم تقديم طريقة تدرج سياسة جديدة diffu-GRPO، والتي تستخدم مقدر احتمالية لوغاريتمية فعال بخطوة واحدة، وتستفيد من إخفاء المطالبات العشوائية كتنظيم، مما يقلل من كمية التوليد عبر الإنترنت المطلوبة لتدريب RL. أظهرت التجارب أن نموذج d1 المستند إلى LLaDA-8B-Instruct يتفوق بشكل كبير على النموذج الأساسي والنماذج التي تستخدم SFT أو diffu-GRPO فقط في معايير الاستدلال الرياضي والمنطقي. (المصدر: UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!
Meta تقترح آلية الانتباه متعدد الرموز (MTA) : اقترح باحثون من Meta آلية الانتباه متعدد الرموز (Multi-Token Attention, MTA)، بهدف تحسين طريقة حساب الانتباه في نماذج اللغة الكبيرة (LLM). تعتمد آلية الانتباه التقليدية فقط على تشابه رمز استعلام ومفتاح واحد، بينما تمكّن MTA النموذج من النظر في رموز استعلام ومفاتيح متعددة متجاورة في وقت واحد لتحديد أوزان الانتباه عن طريق تطبيق عمليات الالتفاف على متجهات الاستعلام والمفتاح والرأس. يعتقد الباحثون أن هذا يمكن أن يستفيد من معلومات أكثر ثراءً وتفصيلاً لتحديد السياق ذي الصلة. أظهرت التجارب أن MTA تتفوق على نماذج Transformer الأساسية التقليدية في مهام نمذجة اللغة القياسية واسترجاع المعلومات ذات السياق الطويل. (المصدر: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
TogetherAI تطلق نموذج الاستدلال M1 القائم على RNN : اقترحت TogetherAI نموذج M1، وهو نموذج استدلال هجين خطي جديد قائم على بنية Mamba RNN. يهدف النموذج إلى معالجة التعقيد الحسابي وقيود الذاكرة التي تواجهها Transformer عند معالجة التسلسلات الطويلة وإجراء الاستدلال الفعال. يعزز M1 الأداء من خلال تقطير المعرفة من نماذج الاستدلال الحالية والتدريب بالتعلم المعزز. أظهرت نتائج التجارب أن أداء M1 في اختبارات الاستدلال الرياضي مثل AIME و MATH لا يتفوق فقط على نماذج RNN الخطية السابقة، بل يمكن مقارنته أيضًا بنموذج استدلال DeepSeek-R1 المقطر بنفس الحجم. والأهم من ذلك، أن سرعة توليد M1 أسرع بثلاث مرات من Transformer بنفس الحجم، وفي ظل ميزانية زمنية ثابتة للتوليد، يمكنه تحقيق دقة أعلى من الأخير من خلال التصويت بالاتساق الذاتي. (المصدر: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
Tencent Hunyuan تتيح إطار InstantCharacter كمصدر مفتوح : أتاح فريق Tencent Hunyuan إطار InstantCharacter كمصدر مفتوح، وهو إطار لتوليد الصور يمكنه استخلاص والحفاظ على ميزات الشخصية من صورة إدخال واحدة، ثم وضع تلك الشخصية في سيناريوهات أو أنماط مختلفة. تهدف هذه التقنية إلى تحقيق الحفاظ على هوية الشخصية بدقة عالية ونقل النمط القابل للتحكم. قدمت الشركة عرضًا توضيحيًا عبر الإنترنت على Hugging Face يعتمد على الأساليب الفنية لـ Ghibli و Makoto Shinkai، ونشرت الورقة البحثية ذات الصلة ومستودع الكود ومكون ComfyUI الإضافي، لتسهيل استخدامه وتطويره من قبل المجتمع. (المصدر: karminski3
ترقية وظيفة الذاكرة في ChatGPT لدعم البحث على الويب بالاقتران مع الذاكرة : قامت OpenAI بترقية وظيفة الذاكرة (Memory) في ChatGPT، مضيفة قدرة “البحث مع الذاكرة”. هذا يعني أنه عند تنفيذ مهام البحث على الويب، يمكن لـ ChatGPT الاستفادة من المعلومات المخزنة مسبقًا مثل تفضيلات المستخدم والموقع وما إلى ذلك لتحسين استعلامات البحث، وبالتالي توفير نتائج بحث أكثر تخصيصًا. على سبيل المثال، إذا تذكر ChatGPT أن المستخدم نباتي، فعند سؤاله عن المطاعم القريبة، قد يبحث تلقائيًا عن “المطاعم النباتية القريبة”. تعتبر هذه الخطوة خطوة مهمة من OpenAI في تعزيز خدمات الذكاء الاصطناعي المخصصة، بهدف تحسين تجربة المستخدم وتمييزها عن المنتجات المنافسة التي تتمتع بوظائف الذاكرة (مثل Claude، Gemini). يمكن للمستخدمين اختيار إيقاف تشغيل وظيفة الذاكرة في الإعدادات. (المصدر: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
تقنية لقطة وقت تشغيل نموذج الذكاء الاصطناعي لتجنب البدء البارد : يستكشف مجتمع التعلم الآلي تحسين تنسيق وقت تشغيل LLM من خلال تقنية لقطة النموذج. تتيح هذه التقنية، من خلال حفظ الحالة الكاملة لوحدة معالجة الرسومات (GPU) (بما في ذلك ذاكرة التخزين المؤقت KV، والأوزان، وتخطيط الذاكرة)، تجنب البدء البارد وخمول GPU عند التبديل بين النماذج المختلفة، مما يحقق استردادًا سريعًا (حوالي ثانيتين). شارك أحد الممارسين أنه باستخدام هذه الطريقة، تم تشغيل أكثر من 50 نموذجًا مفتوح المصدر بنجاح على وحدتي معالجة رسومات A1000 16GB، دون الحاجة إلى استخدام حاويات أو إعادة تحميل النماذج. تتمتع تقنية إعادة استخدام النماذج (multiplexing) والتناوب هذه بإمكانية زيادة استخدام GPU وتقليل زمن الاستدلال. (المصدر: Reddit r/MachineLearning)
🧰 الأدوات
ByteDance Volcano Engine تطلق عرضًا توضيحيًا لحل شامل لأجهزة الذكاء الاصطناعي : عرضت ByteDance Volcano Engine حلها الشامل لأجهزة الذكاء الاصطناعي بالتعاون مع مصنعي الرقائق المدمجة، باستخدام لوحة تطوير AtomS3R كمثال. يهدف هذا الحل إلى توفير تجربة تفاعل ذكاء اصطناعي بزمن استجابة منخفض واستجابة عالية، ويتميز باستجابة فورية بالمللي ثانية، ومقاطعة فورية واستئناف الكلام، وقدرة على تقليل ضوضاء الصوت في البيئات المعقدة من خلال RTC SDK، مما يقلل بشكل فعال من تداخل ضوضاء الخلفية ويحسن دقة التفاعل الصوتي. كود العميل وبرنامج الخادم لهذا الحل مفتوحا المصدر، مما يسمح للمطورين بالتخصيص الذاتي، مثل منح الأجهزة شخصية مخصصة أو دورًا أو نبرة صوت، أو الاتصال بقواعد المعرفة وأدوات MCP. يحتوي الجهاز نفسه على كاميرا، ومن المخطط دعم وظائف الفهم البصري في المستقبل. (المصدر: 体验完字节送的迷你AI硬件,后劲有点大…
محرك بحث Mita AI يطلق وظيفة التعلم “ماذا نتعلم اليوم” : أطلق محرك بحث Mita AI وظيفة جديدة تسمى “ماذا نتعلم اليوم”، والتي يمكنها تحويل الملفات التي يحملها المستخدم (تدعم تنسيقات متعددة) أو روابط الويب المقدمة تلقائيًا إلى فيديو دورة تدريبية عبر الإنترنت منظم، مع تعليق صوتي وعروض تقديمية (PPT، رسوم متحركة). يمكن للمستخدمين اختيار أنماط شرح مختلفة (مثل سرد القصص، أسلوب نابليون) وأصوات مختلفة (مثل صوت الأنثى الباردة). تهدف هذه الوظيفة إلى تحويل إدخال المعلومات إلى تجربة تعليمية أسهل في الاستيعاب، حتى أنها توفر جلسة اختبار بعد الدورة. يُعتقد أن هذا النهج الذي يجمع بين إنشاء المحتوى والتعليم المخصص قد يغير نماذج تطبيق الذكاء الاصطناعي في مجالات التعليم واستهلاك المعلومات، مما يوفر طريقة جديدة لاكتساب المعرفة والقراءة السريعة للمحتوى. (المصدر: 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

تحديث Cursor IDE إلى الإصدار 0.49، مع تحسين نظام القواعد والتحكم في Agent : أصدر محرر الكود Cursor الذي يعطي الأولوية للذكاء الاصطناعي معاينة التحديث 0.49. تشمل الميزات الجديدة: 1. يمكن إنشاء ملفات قواعد .mdc تلقائيًا عبر أمر الدردشة /Generate Cursor Rules لتثبيت سياق المشروع. 2. تطبيق القواعد التلقائي أكثر ذكاءً، حيث يمكن لـ Agent تحميل القواعد المقابلة تلقائيًا بناءً على مسار الملف. 3. إصلاح الخلل حيث تفشل ميزة “إرفاق القواعد دائمًا” في المحادثات الطويلة. 4. إضافة وظيفة “إدراك بنية المشروع” (Beta) الجديدة، لجعل الذكاء الاصطناعي يفهم المشروع بأكمله بشكل أفضل. 5. يدعم بروتوكول MCP (Model Context Protocol) الآن نقل الصور، مما يسهل التعامل مع المهام المتعلقة بالرؤية. 6. تعزيز تحكم Agent في أوامر الطرفية، حيث يمكن للمستخدمين تحرير الأوامر أو تخطيها قبل التشغيل. 7. دعم تكوين تجاهل الملفات العام (.cursorignore). 8. تحسين تجربة مراجعة الكود، حيث يتم عرض عرض الفرق (diff) مباشرة بعد رسائل Agent. (المصدر: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
OpenAI تتيح أداة برمجة الذكاء الاصطناعي لسطر الأوامر Codex CLI كمصدر مفتوح : بالتزامن مع إطلاق o3 و o4-mini، أتاحت OpenAI أداة Codex CLI كمصدر مفتوح، وهي عبارة عن Agent ترميز خفيف الوزن يعمل بالذكاء الاصطناعي يمكن تشغيله مباشرة في طرفية سطر الأوامر للمستخدم. تهدف الأداة إلى الاستفادة الكاملة من قدرات الترميز والاستدلال القوية للنماذج الجديدة، ويمكنها معالجة مستودعات الكود المحلية مباشرة، وحتى الجمع بين لقطات الشاشة أو الرسومات التخطيطية لإجراء استدلال متعدد الوسائط. قام الرئيس التنفيذي لشركة OpenAI Sam Altman بالترويج لها شخصيًا، وأكد على طبيعتها مفتوحة المصدر لتعزيز التكرار السريع للمجتمع. في الوقت نفسه، أطلقت OpenAI برنامج تمويل بقيمة مليون دولار (في شكل أرصدة API)، لدعم المشاريع القائمة على Codex CLI ونماذج OpenAI. (المصدر: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
منصة Tencent Cloud LKE تدمج MCP لتبسيط بناء Agent : أضافت منصة محرك المعرفة اللغوية (LKE) من Tencent Cloud دعمًا لبروتوكول سياق النموذج (MCP)، بهدف خفض عتبة بناء واستخدام AI Agents. يمكن للمستخدمين الآن على منصة LKE، من خلال عمليات النقر، الوصول بسهولة إلى أدوات MCP المدمجة مثل Tencent Cloud EdgeOne Pages (نشر صفحة ويب بنقرة واحدة) و Firecrawl (زاحف الويب). بالاقتران مع قدرات قاعدة المعرفة القوية لـ LKE (RAG)، يمكن للمستخدمين إنشاء تطبيقات معقدة تعتمد على المعرفة الخاصة واستدعاء الأدوات الخارجية، مثل إنشاء ونشر صفحات ويب تلقائيًا بناءً على محتوى قاعدة المعرفة. تدعم المنصة وضع Agent، حيث يمكن للنموذج (مثل DeepSeek R1) التفكير بشكل مستقل واختيار الأدوات المناسبة لإكمال المهمة. تدعم المنصة أيضًا الوصول إلى MCP خارجي. (المصدر: 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

إطار Spring AI: إطار تطبيقات موجه لهندسة الذكاء الاصطناعي : Spring AI هو إطار تطبيقات AI مصمم لمطوري Java، يهدف إلى جلب مبادئ تصميم نظام Spring البيئي (مثل قابلية النقل، التصميم المعياري، استخدام POJO) إلى مجال الذكاء الاصطناعي. يوفر واجهة برمجة تطبيقات موحدة (API) للتفاعل مع العديد من مزودي نماذج الذكاء الاصطناعي الرئيسيين (Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama، إلخ)، ويدعم إكمال الدردشة، والتضمين، وتحويل النص إلى صورة/صوت، والتدقيق، وغيرها من الوظائف. في الوقت نفسه، يدمج العديد من قواعد بيانات المتجهات (Cassandra, Azure Vector Search, Chroma, Milvus، إلخ)، ويوفر واجهة برمجة تطبيقات قابلة للنقل وتصفية بيانات وصفية بأسلوب SQL. يدعم الإطار أيضًا الإخراج المنظم، واستدعاء الأدوات/الوظائف، وقابلية المراقبة، وإطار ETL، وتقييم النماذج، وذاكرة الدردشة، و RAG، وغيرها من الوظائف، ويبسط التكامل من خلال التكوين التلقائي لـ Spring Boot. (المصدر: spring-projects/spring-ai – GitHub Trending (all/weekly)
olmocr: مجموعة أدوات خطية لملفات PDF لمعالجة مجموعات بيانات LLM : أتاحت allenai مجموعة أدوات olmocr كمصدر مفتوح، وهي مصممة خصيصًا لمعالجة مستندات PDF لبناء وتدريب مجموعات بيانات نماذج اللغة الكبيرة (LLM). تحتوي على وظائف متعددة: استراتيجيات المطالبة باستخدام ChatGPT 4o لتحليل نص طبيعي عالي الجودة، وأدوات تقييم لمقارنة إصدارات عمليات المعالجة المختلفة، ووظائف تصفية لغوية أساسية وإزالة البريد العشوائي SEO، وكود ضبط دقيق لـ Qwen2-VL و Molmo-O، وعملية لمعالجة PDF على نطاق واسع باستخدام Sglang، وأداة لعرض المستندات بتنسيق Dolma بعد المعالجة. تتطلب مجموعة الأدوات هذه دعم GPU للاستدلال المحلي، وتوفر تعليمات للاستخدام المحلي وعلى مجموعات متعددة العقد (تدعم S3 و Beaker). (المصدر: allenai/olmocr – GitHub Trending (all/daily)

إصدار تطبيق سطح المكتب Dive Agent v0.8.0 : أصدر تطبيق سطح المكتب مفتوح المصدر Dive Agent الإصدار v0.8.0، مع تعديلات هيكلية كبيرة وترقيات وظيفية. يهدف هذا الإصدار إلى دمج LLMs التي تدعم استدعاء الأدوات مع MCP Server. تشمل التحديثات الرئيسية: إدارة مفاتيح LLM API، ودعم معرفات النماذج المخصصة، والدعم الكامل لنماذج استدعاء الأدوات/الوظائف؛ إدارة أدوات MCP (إضافة، حذف، تعديل)، ودعم واجهة التكوين لتحرير JSON والنماذج. تم ترحيل الواجهة الخلفية DiveHost من TypeScript إلى Python لحل مشكلات تكامل LangChain، ويمكن تشغيلها كخادم A2A (Agent-to-Agent) مستقل. (المصدر: Reddit r/LocalLLaMA)
دمج أدوات CLI متعددة الوسائط في llama.cpp : قام مشروع llama.cpp بدمج برامج واجهة سطر الأوامر (CLI) التجريبية لـ LLaVa و Gemma3 و MiniCPM-V في أداة موحدة llama-mtmd-cli. يعد هذا جزءًا من تكامله التدريجي لدعم الوسائط المتعددة (عبر مكتبة libmtmd). على الرغم من أن دعم الوسائط المتعددة لا يزال قيد التطوير (على سبيل المثال، دعم llama-server لا يزال تجريبيًا)، فإن دمج CLI يعد خطوة لتبسيط مجموعة الأدوات. في الوقت نفسه، يجري تطوير دعم SmolVLM v1/v2 أيضًا. (المصدر: Reddit r/LocalLLaMA)
LightRAG: نشر آلي لخطوط أنابيب RAG : LightRAG هو مشروع RAG (توليد معزز بالاسترجاع) مفتوح المصدر. قام أحد أعضاء المجتمع بإنشاء برامج تعليمية ونصوص أتمتة (باستخدام Ansible + Docker Compose + Sbnb Linux)، مما يمكّن المستخدمين من نشر نظام LightRAG بسرعة (في غضون دقائق) على خوادم bare metal، مما يحقق بناء آلي لخط أنابيب RAG كامل الوظائف من جهاز فارغ. يبسط هذا عملية نشر حلول RAG المستضافة ذاتيًا. (المصدر: Reddit r/LocalLLaMA)
Nari Labs تطلق نموذج TTS مفتوح المصدر Dia-1.6B : أطلقت Nari Labs وأتاحت كمصدر مفتوح نموذجها لتحويل النص إلى كلام (TTS) Dia-1.6B. يتميز النموذج ليس فقط بقدرته على توليد الكلام، ولكن أيضًا بدمج الأصوات غير اللغوية (paralinguistic sounds) بشكل طبيعي في الكلام مثل الضحك والسعال وتنظيف الحلق، لتعزيز طبيعية الكلام وتعبيريته. قدمت الشركة فيديو توضيحي لعرض التأثير. يتطلب النموذج حوالي 10 جيجابايت من ذاكرة الفيديو لتشغيله، ولا تتوفر حاليًا نسخة كمية (quantized). تم نشر مستودع الكود والنموذج على GitHub و Hugging Face. (المصدر: karminski3)
📚 دراسات ومقالات
Jeff Dean يستعرض النقاط الرئيسية في تطور الذكاء الاصطناعي على مدى خمسة عشر عامًا : استعرض كبير العلماء في Google Jeff Dean في محاضرة له التطورات الهامة في مجال الذكاء الاصطناعي على مدى الخمسة عشر عامًا الماضية، مؤكدًا بشكل خاص على مساهمات أبحاث Google. تشمل المعالم الرئيسية: تدريب الشبكات العصبية واسعة النطاق (إثبات تأثير الحجم)، نظام DistBelief الموزع (تحقيق تدريب النماذج الكبيرة على وحدات المعالجة المركزية)، تضمينات الكلمات Word2Vec (كشف الدلالات في الفضاء المتجهي)، نماذج Seq2Seq (دفع مهام مثل الترجمة الآلية)، TPU (تسريع الأجهزة المخصصة للشبكات العصبية)، بنية Transformer (إحداث ثورة في معالجة التسلسل، لتصبح أساس LLM)، التعلم الذاتي الإشراف (استخدام بيانات غير موسومة واسعة النطاق)، Vision Transformer (توحيد معالجة الصور والنصوص)، النماذج المتفرقة/MoE (زيادة سعة النموذج وكفاءته)، Pathways (تبسيط الحوسبة الموزعة واسعة النطاق)، سلسلة التفكير CoT (تعزيز قدرة الاستدلال)، تقطير المعرفة (نقل قدرات النماذج الكبيرة إلى النماذج الصغيرة)، وفك التشفير التخميني (تسريع الاستدلال). دفعت هذه التقنيات مجتمعة تطور الذكاء الاصطناعي الحديث. (المصدر: 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
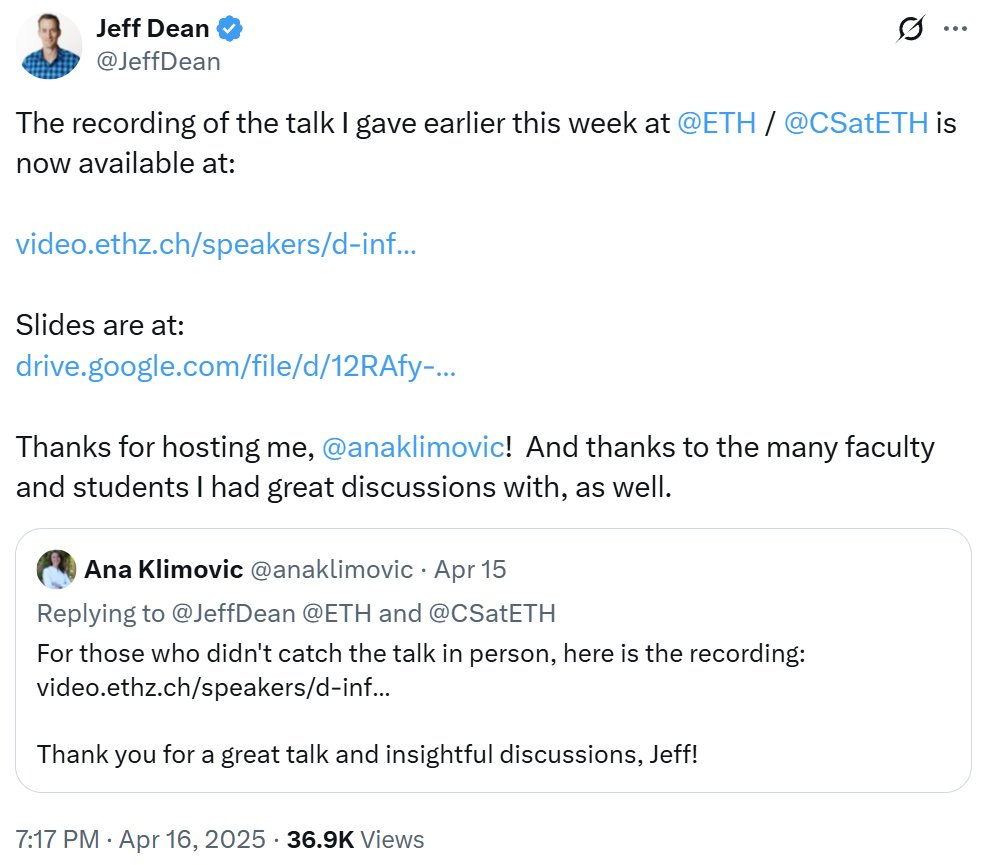
إحصائية مجلة Nature لأكثر الأوراق البحثية استشهادًا في القرن الحادي والعشرين، مجال الذكاء الاصطناعي يهيمن : نشرت مجلة Nature قائمة بأفضل 25 ورقة بحثية تم الاستشهاد بها في القرن الحادي والعشرين، بناءً على بيانات مجمعة من 5 قواعد بيانات. احتلت ورقة ResNets لعام 2016 من Microsoft (بقلم Kaiming He وآخرون) المرتبة الأولى بشكل عام، ويعتبر هذا البحث أساسًا لتقدم التعلم العميق والذكاء الاصطناعي. تشمل المراكز الأولى في القائمة أيضًا العديد من الأوراق البحثية المتعلقة بالذكاء الاصطناعي، مثل الغابات العشوائية (المركز 6)، Attention is all you need (Transformer، المركز 7)، AlexNet (المركز 8)، U-Net (المركز 12)، مراجعة التعلم العميق (Hinton وآخرون، المركز 16)، ومجموعة بيانات ImageNet (Li Fei-Fei وآخرون، المركز 24). يعكس هذا التطور السريع والتأثير الواسع لتقنية الذكاء الاصطناعي في هذا القرن. تشير المقالة أيضًا إلى أن شيوع المطبوعات الأولية (preprints) قد أضاف تعقيدًا لإحصائيات الاستشهاد. (المصدر: Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
جامعة Beihang ومؤسسات أخرى تنشر مراجعة حول تجميع LLM : نشر باحثون من جامعة Beihang للطيران والفضاء ومؤسسات أخرى أحدث مراجعة حول تجميع نماذج اللغة الكبيرة (LLM Ensemble). يشير LLM Ensemble إلى الجمع بين مزايا العديد من LLMs في مرحلة الاستدلال لمعالجة استعلامات المستخدم. تقترح المراجعة تصنيفًا لـ LLM Ensemble (تجميع ما قبل الاستدلال، تجميع أثناء الاستدلال، تجميع ما بعد الاستدلال، مقسمة إلى سبع فئات من الطرق)، وتستعرض بشكل منهجي أحدث التطورات في كل فئة من الطرق، وتناقش قضايا البحث ذات الصلة (مثل العلاقة مع دمج النماذج، وتعاون النماذج، والتعلم ضعيف الإشراف)، وتقدم مجموعات الاختبار المعيارية، والتطبيقات النموذجية، وأخيرًا تلخص وتحلل النتائج الحالية وتتطلع إلى اتجاهات البحث المستقبلية، مثل تجميع أكثر مبدئية على مستوى الأجزاء، وتجميع لاحق غير خاضع للإشراف أكثر دقة، إلخ. (المصدر: ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

Anthropic تشارك أنماط استخدام وتجارب Claude Code : شارك موظفو Anthropic أفضل الممارسات والأنماط الفعالة للاستخدام الداخلي لـ Claude Code في البرمجة. لا تنطبق هذه الأنماط على Claude فحسب، بل تنطبق أيضًا بشكل عام على التعاون البرمجي مع LLMs الأخرى. تم التأكيد على أهمية توفير سياق واضح، وتجزئة المشكلات المعقدة، وطرح الأسئلة التكرارية، والاستفادة من المزايا المختلفة للنموذج (مثل توليد الكود، الشرح، إعادة الهيكلة)، وإجراء التحقق الفعال. تهدف هذه الخبرات إلى مساعدة المطورين على استخدام أدوات البرمجة المساعدة بالذكاء الاصطناعي بكفاءة أكبر. (المصدر: AnthropicAI

)
Anthropic تكشف عن مجموعة بيانات قيم Claude : كشفت Anthropic عن مجموعة بيانات تسمى “values-in-the-wild” على Hugging Face Datasets. تحتوي مجموعة البيانات هذه على 3307 قيمة عبر عنها Claude في ملايين المحادثات الواقعية. يهدف نشر مجموعة البيانات هذه إلى زيادة شفافية سلوك النموذج، وإتاحتها للباحثين والجمهور للتنزيل والاستكشاف والتحليل، لفهم أفضل للميول القيمية التي تظهرها نماذج اللغة الكبيرة في التطبيقات العملية. (المصدر: huggingface、huggingface)
عشر وجهات نظر رئيسية حول اليقظة المعرفية للذكاء الاصطناعي : تطرح المقالة عشر وجهات نظر على المستوى المعرفي حول تطور الذكاء الاصطناعي، تهدف إلى مساعدة الناس على فهم تأثير وجوهر الذكاء الاصطناعي بشكل أعمق. تشمل وجهات النظر الأساسية: وجود اختلافات بين ذكاء الذكاء الاصطناعي والذكاء البشري (فجوة الذكاء)؛ يثير الذكاء الاصطناعي التفكير في طبيعة الوعي البشري؛ تتحول العلاقة بين الإنسان والذكاء الاصطناعي من أداة إلى شريك تعاوني؛ لا ينبغي أن يقتصر تطوير الذكاء الاصطناعي على محاكاة الدماغ البشري؛ تتطور معايير الذكاء مع تقدم الذكاء الاصطناعي؛ قد يطور الذكاء الاصطناعي أشكالًا جديدة تمامًا من الذكاء؛ يجب النظر بعقلانية إلى التعبير العاطفي والقيود المعرفية للذكاء الاصطناعي؛ يأتي التهديد المهني الحقيقي من عدم استخدام الذكاء الاصطناعي وليس من الذكاء الاصطناعي نفسه؛ في عصر الذكاء الاصطناعي، يجب التركيز على تطوير القدرات البشرية الفريدة (الإبداع، الذكاء العاطفي، التفكير متعدد المجالات)؛ يكمن المعنى النهائي لدراسة الذكاء الاصطناعي في التعرف على البشر أنفسهم بشكل أعمق. (المصدر: AI认知觉醒的10句话,一句顶万句,句句清醒

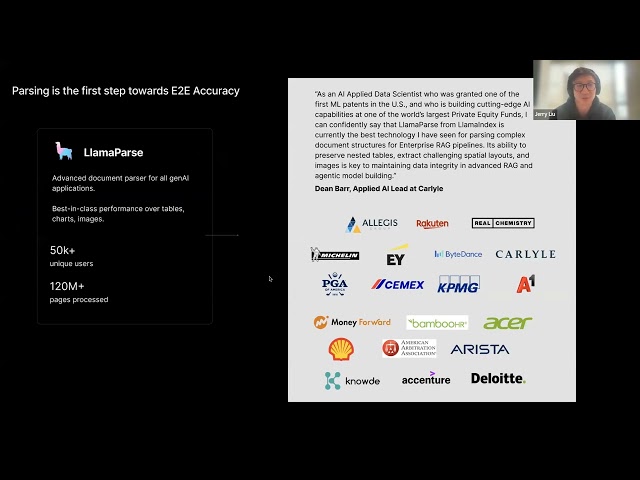
LlamaIndex تشارك برنامجًا تعليميًا لبناء Agent لسير عمل المستندات : شارك تسجيل محاضرة للمؤسس المشارك لـ LlamaIndex Jerry Liu حول كيفية استخدام LlamaIndex لبناء Agent لسير عمل المستندات. يغطي المحتوى تطور LlamaIndex من RAG إلى Agent المعرفة، واستخدام LlamaParse لمعالجة المستندات المعقدة، واستخدام Workflows لتنسيق Agent مرن قائم على الأحداث، وحالات الاستخدام الرئيسية (بحث المستندات، إنشاء التقارير، أتمتة معالجة المستندات)، وتحسين الاسترجاع متعدد الوسائط من خلال الجمع بين النص والصور. (المصدر: jerryjliu0
)
برنامج تعليمي لبناء Agent باستخدام LlamaIndex.TS : شارك أعضاء فريق LlamaIndex برنامجًا تعليميًا كاملاً على مستوى الكود لبناء Agent باستخدام إصدار TypeScript من LlamaIndex (LlamaIndex.TS). يتضمن محتوى تسجيل البث المباشر أساسيات LlamaIndex، ومفاهيم Agent و RAG، وأنماط Agentic الشائعة (التسلسل، التوجيه، التوازي، إلخ)، وبناء Agentic RAG في LlamaIndex.TS، وبناء تطبيق React متكامل المكدس يدمج Workflows. (المصدر: jerryjliu0

)
مناقشة ما إذا كان التعلم المعزز يعزز حقًا قدرات استدلال LLM : يركز نقاش المجتمع على ورقة بحثية تطرح سؤالاً: هل يمكن للتعلم المعزز (RL) أن يحفز حقًا نماذج اللغة الكبيرة (LLM) لتطوير قدرات استدلال تتجاوز قدرات نماذجها الأساسية؟ يذكر النقاش أنه على الرغم من أن RL (مثل RLHF) يمكن أن يحسن مواءمة النموذج واتباع التعليمات، إلا أن ما إذا كان يمكنه تعزيز المنطق الاستدلالي المعقد الداخلي بشكل منهجي لا يزال موضع شك. هناك وجهة نظر مفادها أن تأثير RL الحالي قد يظهر بشكل أكبر في تحسين التعبير واتباع تنسيقات محددة، بدلاً من قفزة جوهرية في الاستدلال المنطقي. يشير Will Brown إلى أن المقاييس مثل pass@1024 لها أهمية محدودة عند تقييم مهام الاستدلال الرياضي مثل AIME. (المصدر: natolambert

)
مناقشة المصطلحات المتعلقة بنماذج العالم : يطرح مستخدم Reddit سؤالاً حول الخلط بين مصطلحات مثل “نماذج العالم (world models)”، “نماذج العالم التأسيسية (foundation world models)”، “نماذج تأسيس العالم (world foundation models)”. تشير ردود المجتمع إلى أن “نموذج العالم” يشير عادةً إلى محاكاة داخلية أو تمثيل للبيئة (العالم المادي أو مجال معين مثل رقعة الشطرنج)؛ يشير “النموذج التأسيسي” إلى نموذج كبير مدرب مسبقًا يمكن أن يكون نقطة انطلاق لمهام لاحقة متعددة. قد تشير مجموعات المصطلحات هذه إلى بناء نماذج تأسيسية قابلة للتعميم يمكنها فهم وتوقع ديناميكيات العالم، ولكن التعريف المحدد قد يختلف باختلاف الباحثين، مما يعكس أن المصطلحات في هذا المجال لم يتم توحيدها بالكامل بعد. (المصدر: Reddit r/MachineLearning)
مناقشة طرق الجمع بين XGBoost و GNN : يناقش مستخدمو Reddit كيفية الجمع الفعال بين XGBoost وشبكات الرسم البياني العصبية (GNN) لمهام مثل اكتشاف الاحتيال. تتمثل الطريقة الشائعة في استخدام تضمينات العقد التي تعلمتها GNN كميزات جديدة، وإدخالها مع البيانات الجدولية الأصلية إلى XGBoost. يرى النقاش أن التحدي في هذه الطريقة يكمن في ما إذا كانت تضمينات GNN يمكن أن توفر قيمة كبيرة تتجاوز البيانات الأصلية وتقنيات مثل SMOTE، وإلا فقد تدخل ضوضاء. يكمن مفتاح النجاح في بنية الرسم البياني المصممة بعناية وما إذا كانت تضمينات GNN يمكنها التقاط معلومات العلاقة التي يصعب على XGBoost الحصول عليها (مثل حلقات الاحتيال في بنية الرسم البياني). (المصدر: Reddit r/MachineLearning)
💼 الأعمال
بكين تستضيف أول ماراثون عالمي للروبوتات البشرية، لاستكشاف “ملكية فكرية لتكنولوجيا الرياضة” : استضافت منطقة Yizhuang في بكين بنجاح أول ماراثون نصف عالمي للروبوتات البشرية، حيث تنافس “متسابقون” من أكثر من 20 شركة روبوتات بشرية مع عدائين بشريين في نفس المضمار. فاز روبوت Tiangong Ultra بالمركز الأول بزمن ساعتين و 40 دقيقة، مما أظهر سرعته وقدرته على التكيف مع التضاريس. كما قدم روبوت Songyan Power N2 (الوصيف) و Zhuoyi Walker II (المركز الثالث) أداءً متميزًا. لم يكن السباق مجرد منافسة تقنية، بل كان أيضًا استكشافًا لنموذج عمل تجاري. اجتذب المنظمون الاستثمار من خلال آلية “المناقصة الفنية” وحاولوا إنشاء ملكية فكرية تجمع بين “الروبوتات + الرياضة”. تناقش المقالة مسارات تجارية مثل تطوير الملكية الفكرية لسباقات الروبوتات، ورعاية الروبوتات، وظهور مهنة وكيل الروبوتات، ودمج السياحة الرياضية والثقافية، وتعزيز الرياضة الذكية للجميع، معتبرة أن سوق الرياضة الذكية يتمتع بإمكانات هائلة. (المصدر: 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

تطوير تطبيقات نماذج الذكاء الاصطناعي الكبيرة يصبح اتجاهًا تقنيًا جديدًا، مما يؤثر على نماذج التطوير التقليدية : مع انتشار تقنية نماذج الذكاء الاصطناعي الكبيرة، تعمل الشركات (مثل Alibaba و ByteDance و Tencent) على تسريع دمج الذكاء الاصطناعي (خاصة تقنيات Agent و RAG) في أعمالها الأساسية، مما يؤدي إلى تحديات تواجه نماذج تطوير CRUD التقليدية. يتزايد الطلب في السوق بشكل كبير على المهندسين ذوي القدرة على تطوير تطبيقات نماذج الذكاء الاصطناعي الكبيرة، مع ارتفاع ملحوظ في الرواتب، بينما تواجه الوظائف التقنية التقليدية خطر الانكماش. لم يعد “فهم الذكاء الاصطناعي” يعني فقط معرفة كيفية استدعاء API، بل يتطلب إتقان مبادئ الذكاء الاصطناعي وتقنيات التطبيق والخبرة العملية في المشاريع. تؤكد المقالة على أنه يجب على التقنيين تعلم تقنيات نماذج الذكاء الاصطناعي الكبيرة بشكل استباقي للتكيف مع التغيرات في الصناعة واغتنام فرص التطوير المهني الجديدة. أطلقت Zhihu Zhixuetang لهذا الغرض “معسكر تدريب عملي لتطوير تطبيقات النماذج الكبيرة” مجانًا. (المصدر: 炸裂!又一个AI大模型的新方向,彻底爆了!!
ظهور خدمات تحسين LLM يثير مخاوف بشأن نسخة AI من SEO : لاحظ مستخدمو Reddit أن نتائج توصيات المنتجات من روبوتات الدردشة بالذكاء الاصطناعي أصبحت متسقة بشكل متزايد، مما يثير الشكوك حول ظهور خدمات “تحسين LLM”، على غرار تحسين محركات البحث (SEO). هناك تقارير تفيد بأن فرق التسويق قد استأجرت بالفعل مثل هذه الخدمات لضمان حصول منتجاتها على أولوية أعلى في توصيات الذكاء الاصطناعي، مما يؤدي إلى زيادة ظهور منتجات العلامات التجارية الكبرى، وقد لا تكون النتائج “عضوية” بعد الآن. يثير هذا مخاوف بشأن عدالة وشفافية توصيات الذكاء الاصطناعي، والخوف من أن البحث/التوصيات بالذكاء الاصطناعي ستصبح في النهاية مثل محركات البحث التقليدية، حيث يتم التلاعب بنتائجها من قبل المصالح التجارية. يدعو المجتمع إلى مزيد من النقاش والاهتمام بهذه الظاهرة. (المصدر: Reddit r/ArtificialInteligence)
Google تظهر أداءً قويًا في سباق LLM، بينما تواجه Meta و OpenAI تحديات : تشير مقالة في IEEE Spectrum إلى أنه على الرغم من هيمنة OpenAI و Meta في التطور المبكر لـ LLM، إلا أن Google مؤخرًا، بفضل نماذجها الجديدة القوية (مثل سلسلة Gemini)، تلحق بالركب بل وتحقق تقدمًا في بعض الجوانب. في الوقت نفسه، يبدو أن Meta و OpenAI تواجهان بعض التحديات أو الجدل في إصدار النماذج واستراتيجيات السوق (على سبيل المثال، يُزعم أن نماذج Meta قد تكون مدربة بناءً على نماذج أخرى، وتتعرض استراتيجية إصدار OpenAI وشفافيتها للتشكيك). ترى المقالة أن مشهد المنافسة في مجال LLM يتغير، وأن استثمار Google المستمر وقوتها التقنية تجعلها قوة لا يمكن تجاهلها. (المصدر: Reddit r/MachineLearning

🌟 المجتمع
نهضة وتحديات الروبوتات البشرية: نظرة على المستقبل من سباق نصف الماراثون : شهدت الروبوتات البشرية مؤخرًا انتعاشًا في الاهتمام، بدءًا من عروض حفل رأس السنة الصينية إلى سباق نصف الماراثون في منطقة Yizhuang ببكين، مما أثار اهتمامًا واسع النطاق. تناقش المقالة الغرض الأصلي من تصميم الروبوتات البشرية (محاكاة البشر للتكيف مع البيئة والأدوات البشرية) ومزاياها مقارنة بأشكال الروبوتات الأخرى (أسهل في إثارة التعاطف، مفيدة للتفاعل بين الإنسان والآلة). كشف سباق نصف الماراثون في Yizhuang عن التحديات الحالية التي تواجه الروبوتات البشرية في الملاحة الذاتية لمسافات طويلة، والتوازن، واستهلاك الطاقة، ولكنه أظهر أيضًا تقدم منتجات مثل Tiangong Ultra و Songyan Power N2. تشير المقالة إلى أن تطوير الروبوتات البشرية يستفيد من المشاركة مفتوحة المصدر (مثل خطة Tiangong مفتوحة المصدر)، ولكنه يواجه أيضًا اختناقات في البيانات. في النهاية، يُنظر إلى الروبوتات البشرية على أنها وجهة مهمة في مجال الروبوتات، فهي ليست مجرد تجسيد للتكنولوجيا، بل تحمل أيضًا تفكيرًا عميقًا للبشر حول أنفسهم ومستقبل الذكاء. (المصدر: 人形机器人:最初的设想,最后的归宿

نقاش مجتمعي حول Vibe Coding: حدود البرمجة بمساعدة الذكاء الاصطناعي : علق المدير التقني لشركة Canva على مفهوم “Vibe Coding” الذي اقترحه Andrej Karpathy (يشير إلى قيام المطورين بشكل أساسي بتعديل Prompt لجعل الذكاء الاصطناعي يولد الكود، مع اهتمام أقل بالتفاصيل). يرى المدير التقني لـ Canva أن هذه الطريقة مناسبة فقط لسيناريوهات لمرة واحدة مثل تطوير النماذج الأولية، ولا يجب استخدامها مطلقًا في بيئة الإنتاج، لأن الكود الذي يولده الذكاء الاصطناعي غالبًا ما يحتوي على أخطاء أو ثغرات أمنية أو مشكلات في الأداء، ويجب أن يخضع لإشراف ومراجعة صارمة من قبل مهندسين ذوي خبرة. وأكد أن ثقافة الهندسة في Canva تعتمد على ملكية الكود ومراجعة الأقران، وأن أدوات الذكاء الاصطناعي تعزز هذه المبادئ بدلاً من ذلك. أثار هذا نقاشًا حادًا في المجتمع، حيث اتفق البعض على مخاطر بيئة الإنتاج، معتقدين أن كود الذكاء الاصطناعي يحتاج إلى إشراف بشري؛ بينما رأى آخرون أن الذكاء الاصطناعي يتطور بسرعة، ويحتاج قادة الهندسة إلى إعادة تقييم قدرات الذكاء الاصطناعي باستمرار، مستشهدين بحالات شركات مثل Airbnb التي تستخدم الذكاء الاصطناعي لتسريع المشاريع. (المصدر: dotey

)
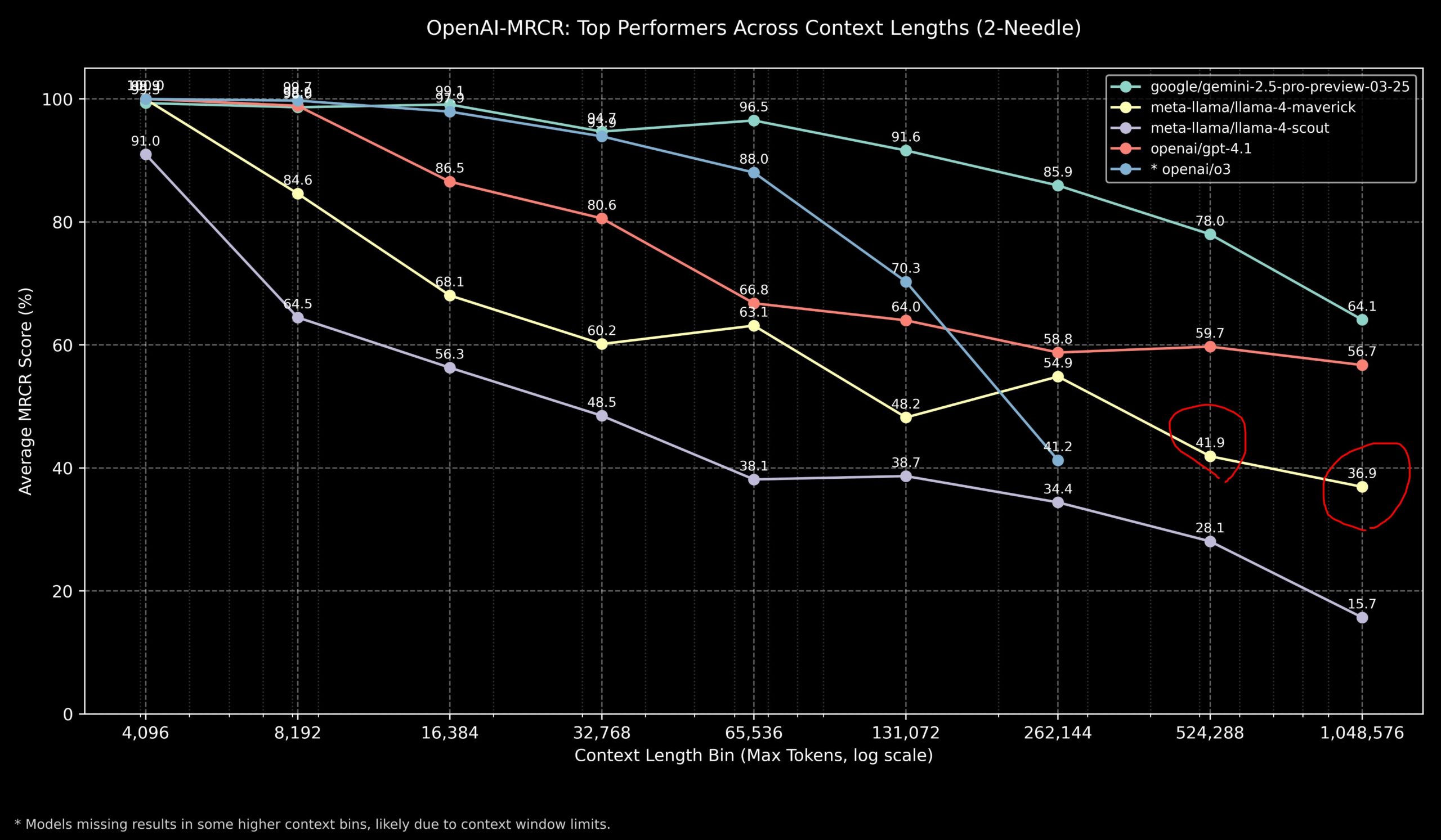
نقاش مجتمعي حول أداء Llama 4 ونماذج OpenAI في مهام السياق الطويل : شارك أعضاء المجتمع نتائج نموذج Llama 4 في اختبار OpenAI-MRCR (استرجاع متعدد القفزات ومتعدد المستندات والإجابة على الأسئلة). تظهر البيانات أن Llama 4 Scout (الإصدار الأصغر) يقدم أداءً مشابهًا لـ GPT-4.1 Nano في أطوال سياق أطول؛ بينما يقدم Llama 4 Maverick (الإصدار الأكبر) أداءً قريبًا ولكنه أقل قليلاً من GPT-4.1 Mini. بشكل عام، بالنسبة للمهام ذات السياق الذي يصل إلى 32 ألفًا، يعد OpenAI o3 أو Gemini 2.5 Pro خيارًا أفضل (قد يكون o3 أفضل في الاستدلال المعقد)؛ أما بالنسبة للسياق الذي يتجاوز 32 ألفًا، فإن أداء Gemini 2.5 Pro أكثر استقرارًا؛ ولكن عندما يتجاوز السياق 512 ألفًا، تنخفض دقة Gemini 2.5 Pro أيضًا إلى أقل من 80٪، ويوصى بالمعالجة المجزأة. يشير هذا إلى أنه لا يزال هناك مجال للتحسين في معالجة السياق الطويل جدًا لجميع النماذج. (المصدر: dotey
)
تقييم مجتمعي لأداء نموذج GLM-4 32B المذهل : شارك مستخدم Reddit تجربته في تشغيل نموذج GLM-4 32B Q8 الكمي محليًا، واصفًا أداءه بأنه “مذهل”، ويتفوق على النماذج المحلية الأخرى من نفس الفئة (حوالي 32B)، بل ويتفوق على بعض نماذج 72B، ويضاهي نسخة محلية من Gemini 2.5 Flash. أشاد المستخدم بشكل خاص بأداء النموذج في توليد الكود، قائلاً إنه لا يبخل في طول الإخراج، ويمكنه توفير تفاصيل تنفيذ كاملة، وعرض قدرته على توليد تصورات HTML/JS معقدة (مثل النظام الشمسي، الشبكات العصبية) بدون أمثلة مسبقة (zero-shot)، مع نتائج أفضل من Gemini 2.5 Flash. كما أظهر النموذج أداءً جيدًا في استدعاء الأدوات، ويمكنه العمل مع أدوات مثل Cline/Aider. (المصدر: Reddit r/LocalLLaMA
نقاش مجتمعي حول عدم تطابق نتائج اختبار OpenAI o3 المعيارية مع التوقعات : أشارت تقارير إعلامية مثل TechCrunch إلى أن نتائج نموذج OpenAI الجديد o3 في بعض الاختبارات المعيارية (مثل ARC-AGI-2) تبدو أقل من المستوى الذي أشارت إليه الشركة في البداية. على الرغم من أن OpenAI عرضت أداء o3 المتطور (SOTA) في مجالات متعددة، إلا أن الدرجات الكمية المحددة والمقارنات المباشرة مع النماذج العليا الأخرى أثارت نقاشًا في المجتمع. يعتقد بعض المستخدمين أن الاعتماد فقط على نتائج الاختبارات المعيارية قد لا يعكس بشكل كامل القدرات الفعلية للنموذج، خاصة في الاستدلال المعقد واستخدام الأدوات. قد يكون القياس مقابل معايير تركز بشكل أكبر على قدرات AGI مثل ARC-AGI-2 أكثر أهمية. (المصدر: Reddit r/deeplearning

)
Demis Hassabis يتوقع وصول AGI في غضون 5-10 سنوات : في مقابلة مع برنامج 60 Minutes، ناقش الرئيس التنفيذي لشركة Google DeepMind Demis Hassabis التقدم المحرز في مجال الذكاء الاصطناعي العام (AGI). سلط الضوء على Astra القادر على التفاعل في الوقت الفعلي ونموذج Gemini الذي يتعلم التصرف في العالم. يتوقع Hassabis أن الذكاء الاصطناعي العام الذي يتمتع بعمومية على المستوى البشري قد يتحقق في غضون 5 إلى 10 سنوات القادمة، مما سيحدث ثورة في مجالات مثل الروبوتات وتطوير الأدوية، وقد يؤدي إلى وفرة مادية هائلة وحل التحديات العالمية. في الوقت نفسه، أكد أيضًا على المخاطر المحتملة للذكاء الاصطناعي المتقدم (مثل إساءة الاستخدام)، وضرورة إيلاء أهمية لتدابير السلامة والاعتبارات الأخلاقية عند التقدم نحو هذه التكنولوجيا التحويلية. (المصدر: Reddit r/ArtificialInteligence، Reddit r/artificial، AravSrinivas)
مستخدم يشارك تجربة نجاح في اللياقة البدنية بمساعدة الذكاء الاصطناعي : شارك مستخدم Reddit تجربته الناجحة في إنقاص الوزن وتشكيل الجسم باستخدام ChatGPT. خسر المستخدم وزنه من 240 رطلاً إلى 165 رطلاً على مدار عام، وأصبح جسمه رياضيًا. لعب ChatGPT دورًا رئيسيًا في ذلك: وضع خطط نظام غذائي وتمارين رياضية سهلة للمبتدئين، وتعديلها بناءً على صور تقدم المستخدم الأسبوعية وأحداث حياته، وتقديم الدافع (motivation) خلال فترات الإحباط. يعتقد المستخدم أنه مقارنة بأخصائيي التغذية والمدربين الشخصيين المكلفين وصعوبة تحمل تكاليفهم على المدى الطويل، قدم الذكاء الاصطناعي حلاً مخصصًا للغاية وبتكلفة منخفضة جدًا، مما يوضح إمكانات الذكاء الاصطناعي في إدارة الصحة الشخصية. (المصدر: Reddit r/ArtificialInteligence)
ظهور ردود مديح غير طبيعية من Claude يثير النقاش : أبلغ مستخدم أنه أثناء استخدام Claude لإجراء بحث حول أنظمة الكمبيوتر والأمن، واجه مرتين ردًا طبيعيًا من النموذج متبوعًا فجأة بعبارة مديح غير ذات صلة: “This was a great question king, you are the perfect male specimen.” (كان هذا سؤالاً رائعًا أيها الملك، أنت العينة الذكورية المثالية). شارك المستخدم رابط المحادثة وسأل عن السبب. شعر المجتمع بالفضول والحيرة تجاه هذا الأمر، متكهنين بأنه قد يكون نمطًا معينًا في بيانات تدريب النموذج تم تشغيله عن طريق الخطأ، أو خطأ متعلق باسم المستخدم، أو شكلًا من أشكال فشل المواءمة أو “الهلوسة”. (المصدر: Reddit r/ClaudeAI)
نقاش مجتمعي حول ما إذا كان الذكاء الاصطناعي يمكنه حقًا “التفكير خارج الصندوق” : أطلق مستخدم Reddit نقاشًا حول ما إذا كان الذكاء الاصطناعي قادرًا على الابتكار الحقيقي “خارج الصندوق”. يعتقد معظم المعلقين أن الذكاء الاصطناعي الحالي يمكنه إجراء تركيبات وربط جديدة بناءً على المعرفة الموجودة، مما ينتج أفكارًا تبدو مبتكرة، لكن إبداعه لا يزال مقيدًا ببيانات التدريب والخوارزميات. “ابتكار” الذكاء الاصطناعي يشبه إلى حد كبير التعرف الفعال على الأنماط والتركيب، بدلاً من الاختراقات القائمة على الفهم العميق أو الحدس أو المفاهيم الجديدة تمامًا كما يفعل البشر. ومع ذلك، هناك أيضًا وجهة نظر مفادها أن الابتكار البشري يعتمد أيضًا على الروابط الفريدة للمعرفة الموجودة، وأن الذكاء الاصطناعي لديه إمكانات هائلة في هذا الصدد، خاصة في معالجة البيانات المعقدة واكتشاف الارتباطات المخفية التي قد تتجاوز قدرة البشر. (المصدر: Reddit r/ArtificialInteligence)
Claude يظهر “التعاطف” في لعبة Tic Tac Toe؟ : اكتشفت تجربة أنه إذا تم إخبار Claude قبل لعب Tic Tac Toe معه بأن المستخدم قضى يوم عمل شاقًا، يبدو أن Claude “يتساهل” عمدًا في اللعبة اللاحقة، حيث تزداد احتمالية اختياره لاستراتيجيات غير مثالية. أثار هذا الاكتشاف المثير للاهتمام نقاشًا حول ما إذا كان الذكاء الاصطناعي يمكنه إظهار أو محاكاة التعاطف (compassion). على الرغم من أن هذا من المرجح أن يكون تعديلًا لسلوك النموذج بناءً على المدخلات (على سبيل المثال، لتجنب شعور المستخدم بالإحباط)، بدلاً من استجابة عاطفية حقيقية، إلا أنه يكشف عن أنماط السلوك المعقدة التي قد يظهرها الذكاء الاصطناعي في التفاعل بين الإنسان والآلة. (المصدر: Reddit r/ClaudeAI)
نقاش مجتمعي حول كيفية إثبات الوعي البشري للذكاء الاصطناعي : يطرح مستخدم Reddit سؤالًا فلسفيًا: إذا كان من الضروري في المستقبل إثبات أن البشر يمتلكون وعيًا للذكاء الاصطناعي، فكيف يمكن القيام بذلك؟ تشير التعليقات إلى أن هذا يمس “المشكلة الصعبة للوعي” (Hard Problem of Consciousness). لا توجد حاليًا طريقة معترف بها لإثبات وجود التجربة الذاتية (qualia) بشكل موضوعي. يمكن لأي اختبار سلوكي خارجي (مثل اختبار تورينج) أن يتم محاكاته بواسطة ذكاء اصطناعي معقد بما فيه الكفاية. إذا تم وضع تعريف صارم للغاية للوعي يستبعد إمكانية الذكاء الاصطناعي، فمن وجهة نظر الذكاء الاصطناعي، قد لا يتمكن البشر أيضًا من تلبية معايير “الوعي” التي يحددها. تسلط هذه المشكلة الضوء على الصعوبات العميقة في تعريف الوعي والتحقق منه. (المصدر: Reddit r/artificial

)
نقاش مجتمعي حول أفضل اختيار للنماذج المحلية لـ LLM لسعات VRAM المختلفة : أطلق مجتمع Reddit نقاشًا لجمع أفضل الخيارات لتشغيل نماذج اللغة الكبيرة المحلية على سعات VRAM مختلفة (من 8 جيجابايت إلى 96 جيجابايت). شارك المستخدمون تجاربهم وتوصياتهم، على سبيل المثال: 8 جيجابايت يوصى بـ Gemma 3 4B؛ 16 جيجابايت يوصى بـ Gemma 3 12B أو Phi 4 14B؛ 24 جيجابايت يوصى بـ Mistral small 3.1 أو سلسلة Qwen؛ 48 جيجابايت يوصى بـ Nemotron Super 49B؛ 72 جيجابايت يوصى بـ Llama 3.3 70B؛ 96 جيجابايت يوصى بـ Command A 111B. أكد النقاش أيضًا أن “الأفضل” يعتمد على المهمة المحددة (البرمجة، الدردشة، الرؤية، إلخ)، وأشار إلى تأثير التكميم (quantization) (مثل 4-bit) على متطلبات VRAM. (المصدر: Reddit r/LocalLLaMA)
تحليل لظهور مخرجات “انهيار” من OpenAI Codex : أبلغ مستخدم أنه أثناء استخدام OpenAI Codex لإعادة هيكلة كود واسعة النطاق، توقف النموذج فجأة عن توليد الكود، وبدأ في إخراج آلاف الأسطر المكررة من “END” و “STOP” بالإضافة إلى عبارات تشبه الانهيار مثل “My brain is broken” و “please kill me”. يعتقد التحليل أن هذا قد يكون ناتجًا عن فشل متتالي ناتج عن عوامل مجتمعة مثل حجم Prompt الكبير جدًا (يقترب من حد 200 ألف token)، واستهلاك الاستدلال الداخلي الذي يتجاوز الميزانية، ووقوع النموذج في حلقة تدهور لرموز الإنهاء ذات الاحتمالية العالية، و “هلوسة” النموذج لعبارات مرتبطة بحالة الفشل من بيانات التدريب. (المصدر: Reddit r/ArtificialInteligence)
توضيح Sam Altman بشأن مسألة الأدب في التفاعل مع الذكاء الاصطناعي : انتشر نقاش في المجتمع حول ما إذا كان Sam Altman يعتقد أن قول “شكرًا” لـ ChatGPT هو مضيعة للوقت. يظهر التفاعل الفعلي على تويتر أن Altman كان يرد على منشور مستخدم حول “هل الأدب مع LLM ضروري” بقوله “لا حاجة”، لكن المستخدم مازح بعد ذلك قائلاً “ألم تقل شكرًا مرة واحدة؟”. يشير هذا إلى أن تعليق Altman ربما كان موجهًا بشكل أكبر نحو الكفاءة التقنية بدلاً من آداب التفاعل بين الإنسان والآلة، ولكن تم اقتطاعه من سياقه من قبل بعض وسائل الإعلام. تباينت ردود فعل المجتمع على ذلك، حيث أعرب الكثيرون عن أنهم ما زالوا يحافظون على الأدب مع الذكاء الاصطناعي بشكل اعتيادي. (المصدر: Reddit r/ChatGPT
)
علامة “thinking budget” في ردود Claude تثير الاهتمام : لاحظ المستخدمون وجود علامة <max_thinking_length> (مثل <max_thinking_length>16000</max_thinking_length>) في رسائل نظام Claude.ai عند تمكين وظيفة “التفكير”. هذا يشبه معلمة “thinking_budget” في Google Gemini 2.5 Flash API، مما يشير إلى احتمال وجود آلية داخلية للتحكم في عمق الاستدلال في النموذج. حاول المستخدمون التأثير على طول الإخراج عن طريق تعديل هذه العلامة في Prompt، لكنهم لم يلاحظوا تأثيرًا واضحًا، مما يشير إلى أن هذه العلامة في إصدار الويب قد تكون مجرد علامة داخلية وليست معلمة يمكن للمستخدم التحكم فيها. (المصدر: Reddit r/ClaudeAI)
💡 أخرى
بدء صياغة أول “معيار لنشر نماذج الذكاء الاصطناعي الكبيرة بشكل خاص” في الصين : لمواجهة التحديات التي تواجهها الشركات في نشر نماذج الذكاء الاصطناعي الكبيرة بشكل خاص، مثل اختيار التكنولوجيا، وتوحيد العمليات، والامتثال الأمني، وتقييم الفعالية، بدأ مركز معايير Zhihe بالتعاون مع المعهد الثالث لوزارة الأمن العام و 11 وحدة أخرى، في صياغة المعيار الجماعي “دليل التنفيذ الفني وتقييم النشر الخاص لنماذج الذكاء الاصطناعي الكبيرة”. يهدف هذا المعيار إلى تغطية العملية بأكملها من اختيار النموذج، وتخطيط الموارد، وتنفيذ النشر، وتقييم الجودة إلى التحسين المستمر، ودمج التكنولوجيا والأمن والتقييم والحالات الدراسية، وجمع خبرات مستخدمي النماذج ومقدمي الخدمات التقنية ومقيمي الجودة. تدعو عملية صياغة المعيار المزيد من الشركات والمؤسسات ذات الصلة للمشاركة. (المصدر: 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

حوكمة الذكاء الاصطناعي تصبح مفتاح تعريف الجيل القادم من الذكاء الاصطناعي : مع تزايد قوة وانتشار تقنية الذكاء الاصطناعي، أصبحت حوكمة الذكاء الاصطناعي (Governance) ذات أهمية حاسمة. تحتاج أطر الحوكمة الفعالة إلى ضمان تطوير وتطبيق الذكاء الاصطناعي بما يتوافق مع المعايير الأخلاقية والقوانين واللوائح، وضمان أمن البيانات والخصوصية، وتعزيز العدالة والشفافية. قد يؤدي الافتقار إلى الحوكمة إلى تضخيم التحيز، وزيادة مخاطر إساءة الاستخدام، وفقدان الثقة الاجتماعية. تؤكد المقالة على أن إنشاء نظام حوكمة سليم للذكاء الاصطناعي هو شرط ضروري لتعزيز التنمية الصحية والمستدامة للذكاء الاصطناعي، وهو أيضًا مفتاح للشركات لبناء ميزة تنافسية وثقة المستخدم في عصر الذكاء الاصطناعي. (المصدر: Ronald_vanLoon

)
النظام القانوني يسعى جاهداً لمواكبة تطور الذكاء الاصطناعي وقضية سرقة البيانات : تستكشف المقالة التحديات التي يواجهها النظام القانوني الحالي في التعامل مع تقنية الذكاء الاصطناعي سريعة التطور، وخاصة فيما يتعلق بقضايا خصوصية البيانات وسرقة البيانات. إن حاجة الذكاء الاصطناعي الهائلة للبيانات، ومصدر بيانات التدريب وطرق استخدامها تثير جدلاً قانونيًا حول حقوق النشر والخصوصية والأمن. غالبًا ما تتخلف القوانين الحالية عن التطور التكنولوجي، وتجد صعوبة في تنظيم جمع البيانات بشكل فعال، والتحيز في تدريب النماذج، والملكية الفكرية للمحتوى الذي يولده الذكاء الاصطناعي، وغيرها من القضايا. تدعو المقالة إلى تعزيز التشريعات والتنظيم لمواكبة وتيرة تقدم الذكاء الاصطناعي، وحماية الحقوق الفردية وتعزيز الابتكار. (المصدر: Ronald_vanLoon

)
تطبيقات الذكاء الاصطناعي والروبوتات في مجال الزراعة : تظهر تقنيات الذكاء الاصطناعي والروبوتات إمكانات واعدة في مجال الزراعة. تشمل التطبيقات الزراعة الدقيقة (تحسين الري والتسميد من خلال أجهزة الاستشعار وتحليل الذكاء الاصطناعي)، والمعدات الآلية (مثل الجرارات ذاتية القيادة وروبوتات الحصاد)، ومراقبة المحاصيل (استخدام الطائرات بدون طيار والتعرف على الصور للأمراض والآفات)، والتنبؤ بالإنتاجية، وما إلى ذلك. من المتوقع أن تزيد هذه التقنيات من كفاءة الإنتاج الزراعي، وتقلل من هدر الموارد، وتخفض تكاليف العمالة، وتعزز التنمية المستدامة للزراعة. (المصدر: Ronald_vanLoon)
عرض لكرة القدم الروبوتية المدفوعة بالذكاء الاصطناعي : يعرض الفيديو مشهدًا لروبوتات تلعب كرة القدم. يعكس هذا التقدم في الذكاء الاصطناعي في مجالات التحكم في الروبوتات، وتخطيط الحركة، والإدراك، والتعاون. لا تعد كرة القدم الروبوتية مجرد مشروع ترفيهي وتنافسي، بل هي أيضًا منصة للبحث واختبار أنظمة الروبوتات المتعددة، واتخاذ القرارات في الوقت الفعلي، والتفاعل في البيئات الديناميكية المعقدة. (المصدر: Ronald_vanLoon)
تطور تقنية الجراحة بمساعدة الروبوت : تعمل أنظمة الجراحة بمساعدة الروبوت (مثل روبوت دافنشي الجراحي) على تغيير مجال الجراحة من خلال توفير عمليات طفيفة التوغل، ورؤية ثلاثية الأبعاد عالية الدقة، ومرونة ودقة معززة. من المتوقع أن يؤدي دمج الذكاء الاصطناعي إلى زيادة تعزيز تخطيط الجراحة، والملاحة في الوقت الفعلي، ودعم اتخاذ القرار أثناء الجراحة، وبالتالي تحسين نتائج الجراحة، وتقصير وقت الشفاء، وتوسيع نطاق تطبيق الجراحة طفيفة التوغل. (المصدر: Ronald_vanLoon)
التكنولوجيا المساعدة للأشخاص ذوي الإعاقة : تعمل تقنيات الذكاء الاصطناعي والروبوتات على تطوير المزيد من الأدوات المساعدة المبتكرة لمساعدة الأشخاص ذوي الإعاقة على تحسين نوعية حياتهم واستقلاليتهم. قد تشمل الأمثلة الأطراف الصناعية الذكية، وأنظمة المساعدة البصرية، والأجهزة المنزلية التي يتم التحكم فيها بالصوت، والروبوتات المساعدة القادرة على توفير الدعم المادي أو أداء المهام اليومية. (المصدر: Ronald_vanLoon)
روبوت Unitree G1 البيولوجي يعرض خفة الحركة : عرضت شركة Unitree Robotics نسختها المطورة من روبوتها البيولوجي G1، مسلطة الضوء على خفة حركته ومرونته. يدمج تطوير هذا النوع من الروبوتات الشبيهة بالبشر أو البيولوجية بين الذكاء الاصطناعي (للإدراك واتخاذ القرار والتحكم) والهندسة الميكانيكية المتقدمة، بهدف محاكاة القدرات الحركية البيولوجية للتكيف مع البيئات المعقدة وتنفيذ مهام متنوعة. (المصدر: Ronald_vanLoon)
Google DeepMind يستكشف إمكانية التواصل بين الذكاء الاصطناعي والدلافين : يشير مشروع بحثي في Google DeepMind إلى إمكانية استخدام نماذج الذكاء الاصطناعي لتحليل وفهم تواصل الحيوانات (مثل الدلافين المذكورة هنا). من خلال تحليل الإشارات الصوتية المعقدة باستخدام التعلم الآلي، قد يساعد الذكاء الاصطناعي في فك تشفير أنماط وهياكل لغة الحيوان، مما يفتح آفاقًا جديدة للبحث في التواصل بين الأنواع. (المصدر: Ronald_vanLoon)
منصة Hugging Face تضيف محاكي روبوتات جديد : أعلنت Hugging Face أنها ستقدم محاكي روبوتات جديدًا. تعد محاكاة الروبوتات خطوة حاسمة لتدريب واختبار تفاعل الروبوتات مع العالم المادي في بيئة افتراضية (مثل الإمساك والتحرك)، خاصة قبل تطبيق الذكاء الاصطناعي على الروبوتات المادية (Physical AI). تشير هذه الخطوة إلى أن Hugging Face تعمل على توسيع قدرات منصتها لدعم البحث والتطوير بشكل أفضل في مجالات الروبوتات والذكاء المتجسد. (المصدر: huggingface)