
كلمات مفتاحية:تطور الذكاء الاصطناعي, Grok 3, Gemma 3, تطبيقات الذكاء الاصطناعي, تحول نموذج تطور الذكاء الاصطناعي, واجهة برمجة تطبيقات xAI Grok 3, Google Gemma 3 QAT, تقييم الذكاء الاصطناعي VideoGameBench, تسريع اكتشاف الجزيئات بالذكاء الاصطناعي, التعلم الموحد في التصوير الطبي, وكيل المعرفة LlamaIndex, تقنية الإصلاح الذاتي للكود بالذكاء الاصطناعي
“`arabic
🔥 التركيز
تحول في نموذج تطوير الذكاء الاصطناعي: من السعي وراء أعلى الدرجات في الاختبارات المعيارية إلى خلق القيمة: أثارت مدونة الباحث في OpenAI، ياو شونيو (Yao Shunyu)، نقاشًا، حيث طرحت فكرة أن تطوير الذكاء الاصطناعي قد دخل مرحلته الثانية. ركزت المرحلة الأولى على ابتكار الخوارزميات وتحقيق أعلى الدرجات في الاختبارات المعيارية (مثل AlphaGo، GPT-4)، من خلال الجمع بين التدريب المسبق واسع النطاق (لتوفير المعرفة المسبقة) والتعلم المعزز (RL)، وإدخال مفهوم “الاستدلال كفعل” (reasoning as action)، مما أدى إلى تحقيق اختراقات في التعميم. ومع ذلك، يرى أن الفائدة الهامشية للاستمرار في تحطيم الأرقام القياسية تتضاءل، ويجب أن تتحول المرحلة الثانية نحو تحديد المشكلات ذات القيمة التطبيقية الفعلية، وتطوير طرق تقييم أقرب إلى العالم الحقيقي، والتفكير كمدير منتج، واستخدام الذكاء الاصطناعي لخلق قيمة حقيقية للمستخدم والمجتمع، بدلاً من مجرد السعي لتحسين المؤشرات. يمثل هذا تحولًا في التفكير في مجال الذكاء الاصطناعي من التركيز على الاستكشاف التقني إلى التركيز على التطبيق العملي وتحقيق القيمة (المصدر: dotey)
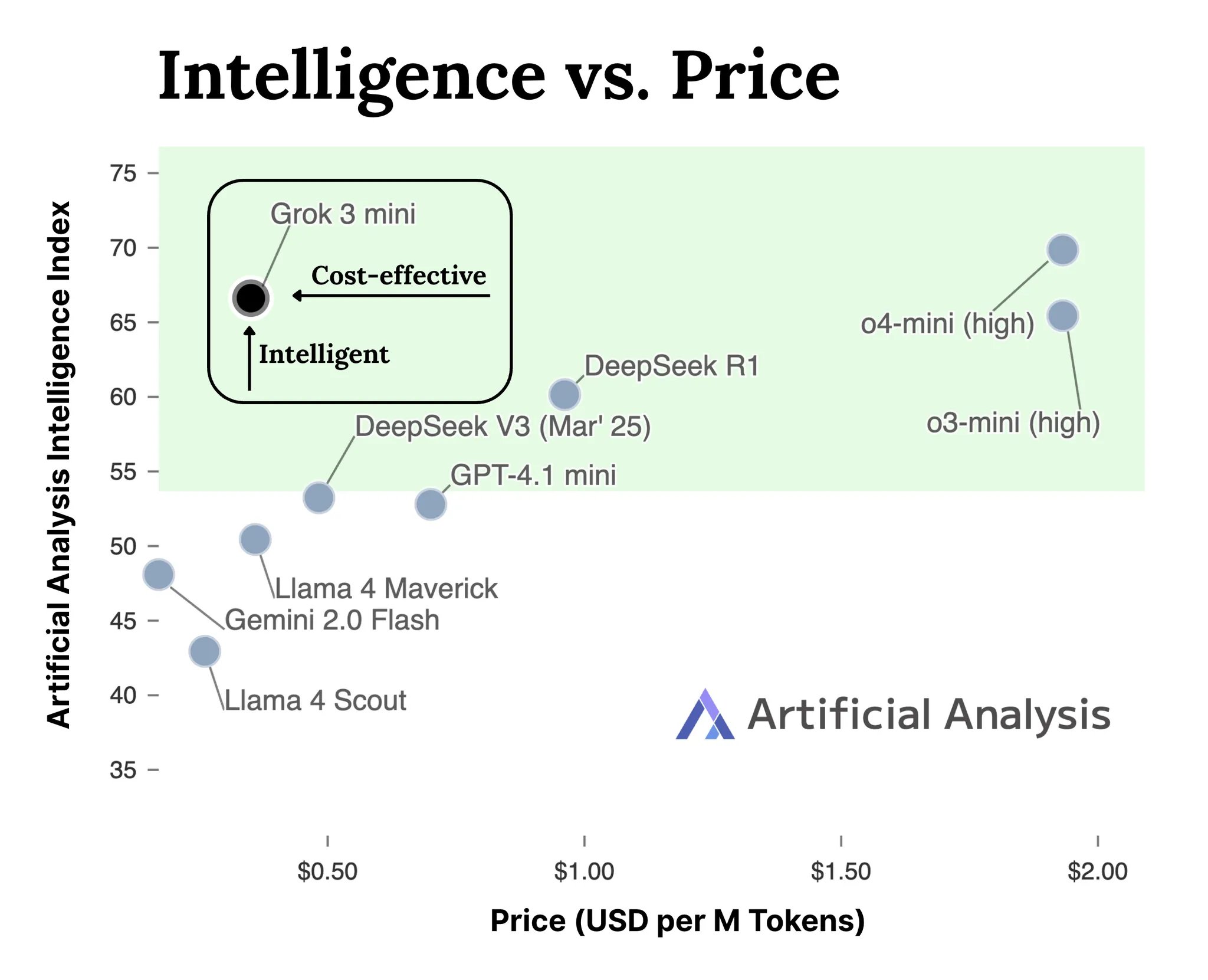
xAI تطلق واجهة برمجة التطبيقات (API) لسلسلة نماذج Grok 3: أطلقت xAI رسميًا واجهة برمجة التطبيقات (API) لسلسلة نماذج Grok 3 (docs.x.ai)، مما يتيح أحدث نماذجها للمطورين. تتضمن السلسلة Grok 3 Mini و Grok 3. وفقًا لـ xAI، يُظهر Grok 3 Mini قدرة استدلال فائقة مع الحفاظ على تكلفة منخفضة (تدعي أنها أقل تكلفة بخمس مرات من نماذج الاستدلال المماثلة)؛ بينما يُصنف Grok 3 كنموذج قوي غير استدلالي (ربما يشير إلى المهام كثيفة المعرفة)، ويتفوق في المجالات التي تتطلب معرفة بالعالم الحقيقي مثل القانون والمالية والطب. تمثل هذه الخطوة انضمام xAI إلى المنافسة في سوق واجهات برمجة تطبيقات نماذج الذكاء الاصطناعي، مما يوفر خيارات جديدة للمطورين (المصدر: grok, grok)
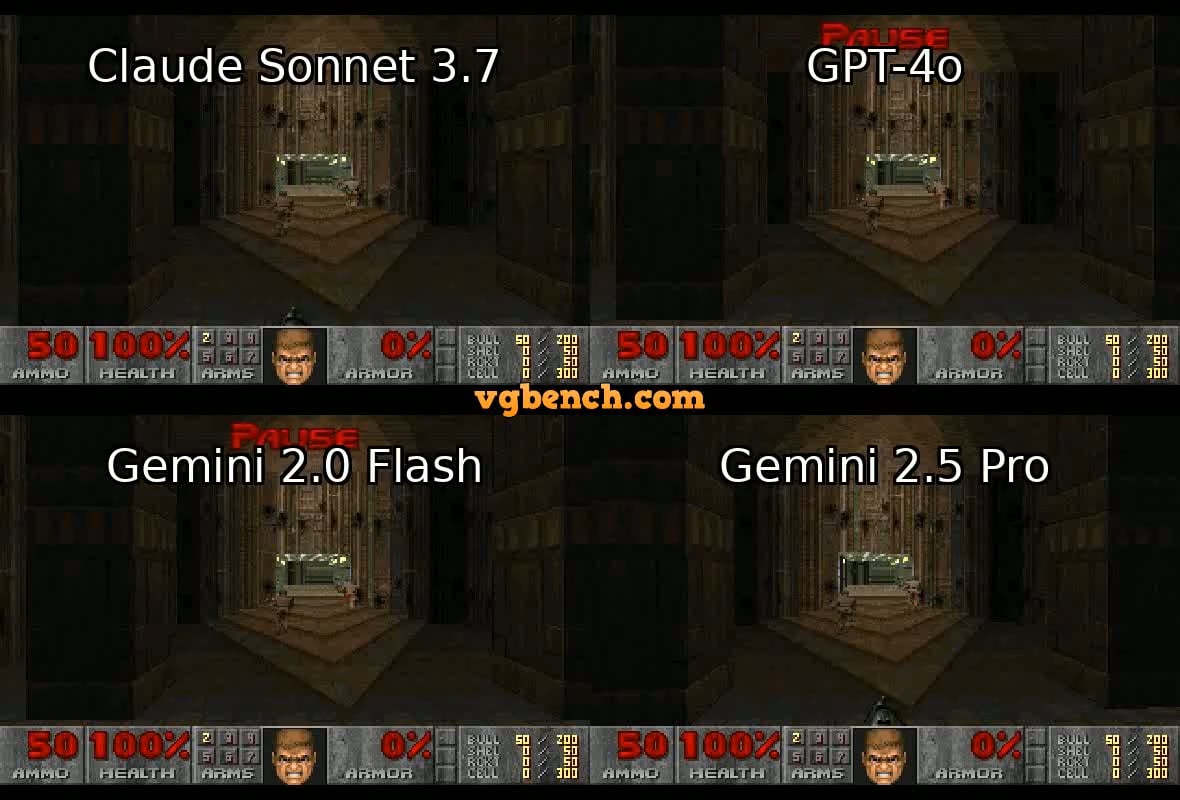
VideoGameBench: تقييم قدرات وكلاء الذكاء الاصطناعي باستخدام الألعاب الكلاسيكية: أطلق الباحثون نسخة معاينة من معيار الاختبار VideoGameBench، بهدف تقييم قدرات نماذج اللغة المرئية (VLM) في إنجاز المهام في الوقت الفعلي ضمن 20 لعبة فيديو كلاسيكية (مثل Doom II). أظهرت الاختبارات الأولية أن النماذج الرائدة، بما في ذلك GPT-4o و Claude Sonnet 3.7 و Gemini 2.5 Pro، أظهرت أداءً متباينًا في Doom II، لكن لم يتمكن أي منها من تجاوز المرحلة الأولى. يشير هذا إلى أنه على الرغم من قوة النماذج في العديد من المهام، إلا أنها لا تزال تواجه تحديات في البيئات الديناميكية المعقدة التي تتطلب الإدراك واتخاذ القرار والتصرف في الوقت الفعلي. يوفر هذا المعيار أداة جديدة لقياس ودفع تقدم وكلاء الذكاء الاصطناعي في البيئات التفاعلية (المصدر: Reddit r/LocalLLaMA)
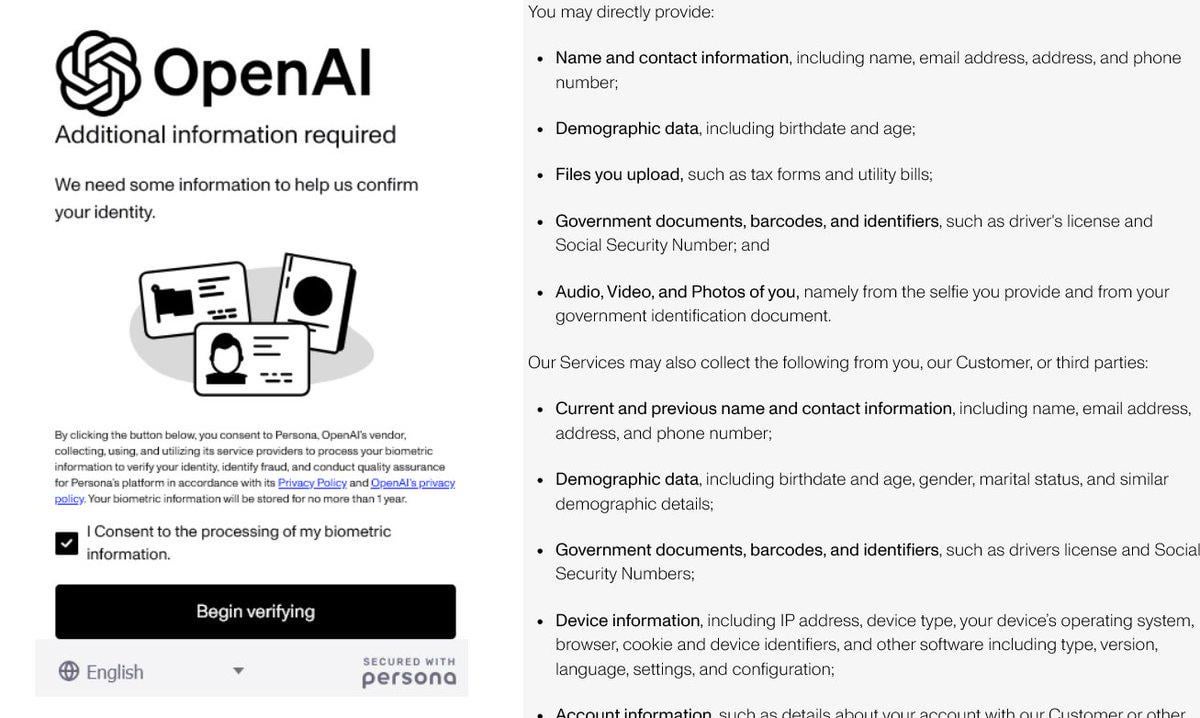
OpenAI تشدد إجراءات التحقق من الهوية مما يثير الجدل: تم الكشف عن أن OpenAI تطلب من المستخدمين تقديم إثباتات هوية مفصلة (مثل جواز السفر، الإقرارات الضريبية، فواتير الخدمات) للوصول إلى بعض نماذجها المتقدمة (خاصة تلك التي تتمتع بقدرات استدلال قوية مثل o3). أثارت هذه الخطوة ردود فعل قوية في المجتمع، حيث أعرب المستخدمون عن قلقهم بشأن تسرب الخصوصية وزيادة صعوبة الوصول. على الرغم من أن OpenAI قد تكون مدفوعة باعتبارات أمنية أو امتثال أو إدارة موارد، إلا أن متطلبات التحقق الصارمة هذه تتناقض مع صورتها المنفتحة، وقد تدفع المستخدمين إلى التحول إلى بدائل توفر حماية أفضل للخصوصية أو يسهل الوصول إليها، وخاصة النماذج المحلية (المصدر: Reddit r/LocalLLaMA)
الذكاء الاصطناعي يسرع اكتشاف الجزيئات: محاكاة تطور الطبيعة لملايين السنين: أشارت مناقشات على وسائل التواصل الاجتماعي إلى أن الذكاء الاصطناعي يمكنه تصميم جزيء في غضون أيام، بينما قد يستغرق تطور هذا الجزيء في الطبيعة 500 مليون سنة. على الرغم من أن التفاصيل المحددة تحتاج إلى التحقق، إلا أن هذا يسلط الضوء على الإمكانات الهائلة للذكاء الاصطناعي في تسريع الاكتشافات العلمية، خاصة في مجالي الكيمياء والبيولوجيا. يمكن للذكاء الاصطناعي استكشاف الفضاء الكيميائي الواسع، والتنبؤ بخصائص الجزيئات، بسرعة تفوق بكثير الطرق التجريبية التقليدية والتطور الطبيعي، ومن المتوقع أن يحقق تقدمًا كبيرًا في مجالات مثل تطوير الأدوية وعلوم المواد (المصدر: Ronald_vanLoon)
🎯 الاتجاهات
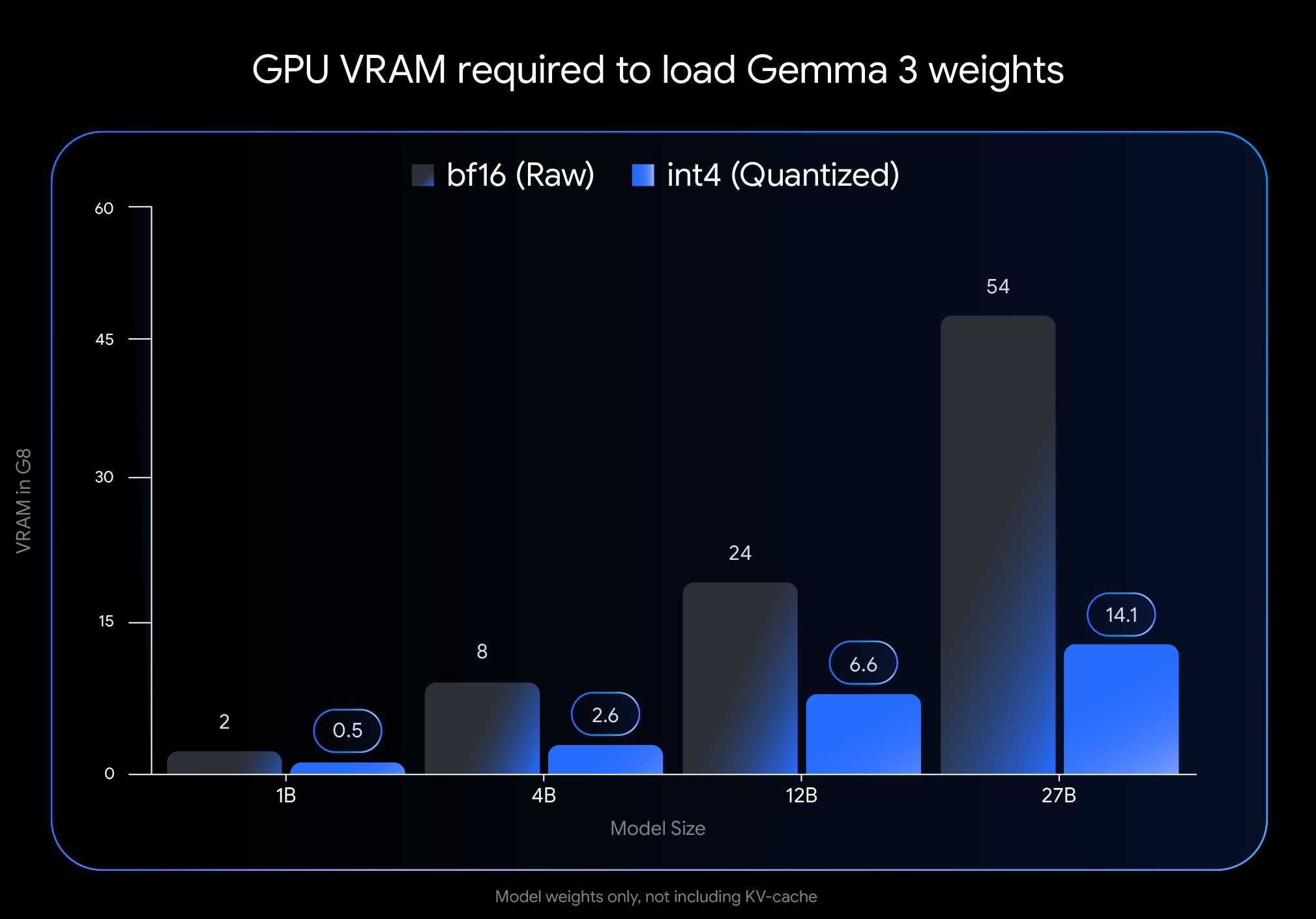
Google تطلق إصدار Gemma 3 QAT، مما يقلل بشكل كبير من عوائق النشر: أطلقت Google DeepMind إصدارات من نموذج Gemma 3 تم تدريبها باستخدام تقنية التدريب المدرك للتكميم (Quantization-Aware Training, QAT). تهدف تقنية QAT إلى ضغط حجم النموذج بشكل كبير مع الحفاظ على أداء النموذج الأصلي إلى أقصى حد ممكن. على سبيل المثال، تم تقليل حجم نموذج Gemma 3 27B من 54GB (bf16) إلى حوالي 14.1GB (int4)، مما يجعل النماذج الرائدة التي كانت تتطلب وحدات معالجة رسومات سحابية متطورة (Cloud GPU) قابلة للتشغيل الآن على وحدات معالجة رسومات مكتبية للمستهلكين (مثل RTX 3090). أصدرت Google نقاط التحقق غير المكممة بتقنية QAT وتنسيقات متعددة (MLX, GGUF)، وتعاونت مع أدوات المجتمع مثل Ollama, LM Studio, llama.cpp لضمان قدرة المطورين على استخدامها بسهولة على منصات مختلفة، مما يدفع بشكل كبير إلى تعميم النماذج مفتوحة المصدر عالية الأداء (المصدر: huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR تنشر نتائج أبحاث الإدراك، وتلتزم بالمسار مفتوح المصدر: نشرت Meta FAIR العديد من نتائج الأبحاث الجديدة في مجال الذكاء الآلي المتقدم (AMI)، خاصة التقدم المحرز في مجال الإدراك، بما في ذلك إطلاق مشفر بصري واسع النطاق Meta Perception Encoder. أكد Yann LeCun أن هذه النتائج ستكون مفتوحة المصدر. يشير هذا إلى استمرار Meta في الاستثمار في أبحاث الذكاء الاصطناعي الأساسية والتزامها بمشاركة تقدمها البحثي من خلال المصادر المفتوحة لدفع تطوير المجال بأكمله، وستفيد الأدوات التي تنشرها مثل المشفر البصري مجتمع الباحثين والمطورين الأوسع (المصدر: ylecun)
OpenAI توضح قيود استخدام النماذج: أوضحت OpenAI كمية استخدام النماذج لمستخدمي ChatGPT Plus و Team و Enterprise. من بينها، يقتصر استخدام نموذج o3 على 50 رسالة أسبوعيًا، و o4-mini على 150 رسالة يوميًا، بينما يقتصر o4-mini-high على 50 رسالة يوميًا. يُزعم أن ChatGPT Pro (ربما يشير إلى باقة معينة أو خطأ) يتمتع بوصول غير محدود. تؤثر هذه القيود بشكل مباشر على المستخدمين ذوي الاستخدام العالي ومطوري التطبيقات الذين يعتمدون على نماذج معينة، ويحتاجون إلى أخذها في الاعتبار عند تخطيط الاستخدام (المصدر: dotey)
LlamaIndex تتكامل مع قواعد بيانات Google Cloud لبناء وكلاء معرفة: في مؤتمر Google Cloud Next 2025، عرضت LlamaIndex كيف يتكامل إطار عملها مع قواعد بيانات Google Cloud لبناء وكلاء معرفة قادرين على إجراء أبحاث متعددة الخطوات ومعالجة المستندات وإنشاء التقارير. تضمن العرض التوضيحي حالة نظام متعدد الوكلاء يقوم تلقائيًا بإنشاء دليل تأهيل للموظفين. يوضح هذا الاتجاه نحو التكامل العميق بين أطر تطبيقات الذكاء الاصطناعي والمنصات السحابية وخدمات البيانات الخاصة بها، بهدف تلبية الاحتياجات الفعلية للشركات في استخدام الذكاء الاصطناعي لمعالجة المعرفة والبيانات الداخلية (المصدر: jerryjliu0)

مستشعر دماغ نانوي جديد يتحد مع الذكاء الاصطناعي لتحقيق التعرف على الإشارات بدقة عالية: أفادت الأبحاث عن مستشعر دماغ نانوي جديد حقق دقة 96.4٪ في التعرف على الإشارات العصبية. على الرغم من أن تقنية المستشعر نفسها هي الاختراق الأساسي، إلا أن تحقيق مثل هذه الدقة العالية في التعرف يتطلب عادةً الاستعانة بخوارزميات الذكاء الاصطناعي والتعلم الآلي المتقدمة لفك تشفير الإشارات العصبية المعقدة والضعيفة. يفتح هذا التقدم آفاقًا جديدة لأبحاث علوم الدماغ وتطبيقات واجهات الدماغ والحاسوب المستقبلية، ومن المتوقع أن يتيح مراقبة وتفاعلًا أكثر دقة مع نشاط الدماغ (المصدر: Ronald_vanLoon)

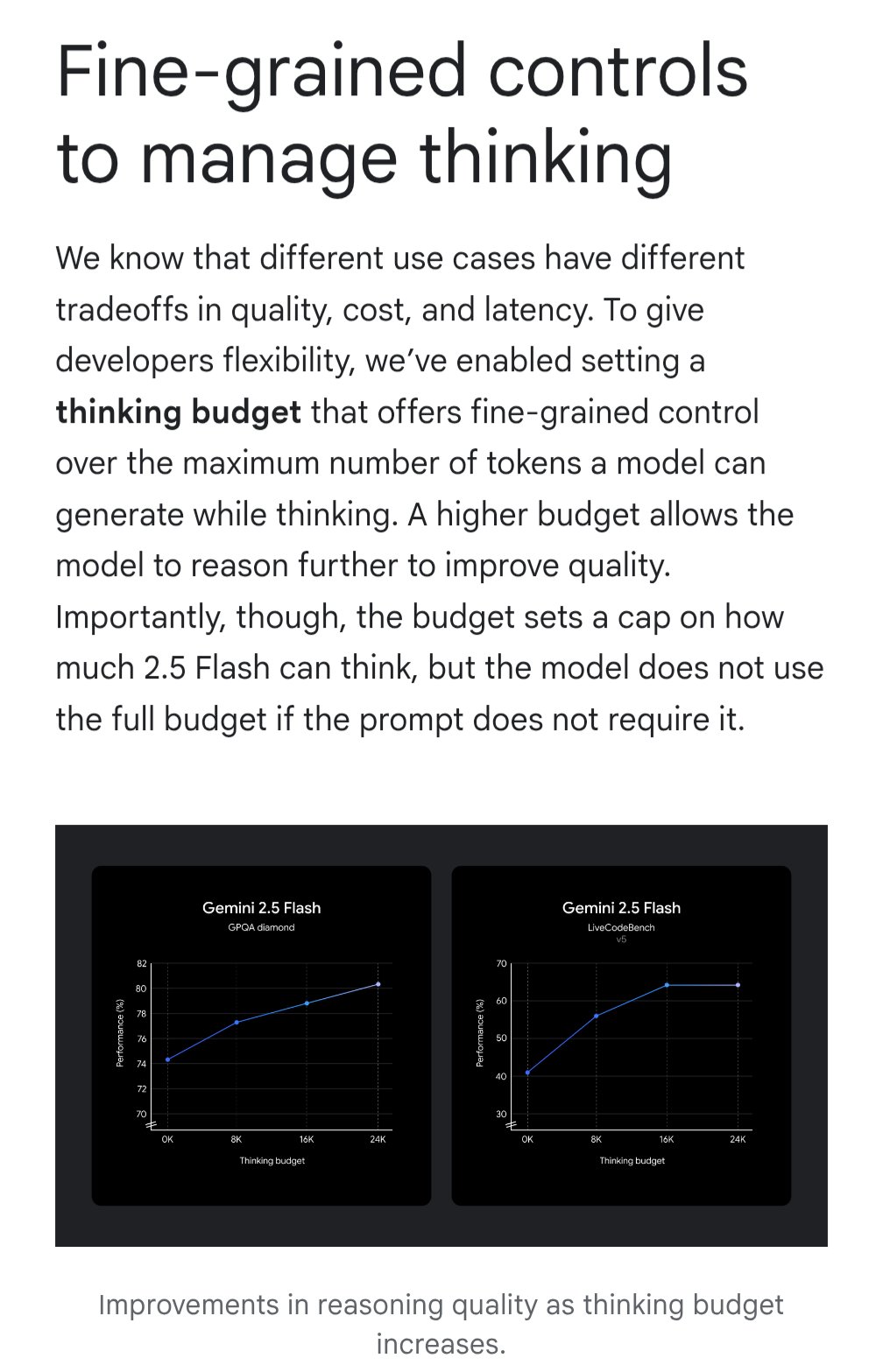
Gemini يقدم ميزة “ميزانية التفكير” لتحسين فعالية التكلفة: قدم نموذج Google Gemini ميزة “ميزانية التفكير” (thinking budget)، مما يسمح للمستخدمين بضبط الموارد الحاسوبية المخصصة أو عمق “التفكير” الذي يخصصه النموذج لمعالجة الاستعلامات. تهدف هذه الميزة إلى تمكين المستخدمين من الموازنة بين جودة الاستجابة والتكلفة وزمن الاستجابة. تعد هذه ميزة عملية جدًا لمستخدمي واجهة برمجة التطبيقات (API)، حيث يمكنهم التحكم بمرونة في تكلفة استخدام النموذج وأدائه بناءً على احتياجات سيناريو التطبيق المحدد (المصدر: JeffDean)
جودة فحوصات الموجات فوق الصوتية بمساعدة الذكاء الاصطناعي تضاهي الخبراء: أظهرت دراسة نشرت في JAMA Cardiology أن فحوصات الموجات فوق الصوتية التي أجراها متخصصون طبيون مدربون بتوجيه من الذكاء الاصطناعي، كانت جودة صورها كافية لتلبية معايير التشخيص (98.3٪)، ولم يكن هناك فرق إحصائي كبير مقارنة بالصور التي حصل عليها الخبراء بدون توجيه الذكاء الاصطناعي. يشير هذا إلى أن الذكاء الاصطناعي كأداة مساعدة يمكن أن يساعد المستخدمين غير الخبراء بشكل فعال على تحسين جودة واتساق عمليات التصوير الطبي، ومن المتوقع أن يوسع إمكانية الوصول إلى خدمات التشخيص عالية الجودة في المناطق ذات الموارد المحدودة (المصدر: Reddit r/ArtificialInteligence)
بحث MIT يحسن دقة الكود الذي يولده الذكاء الاصطناعي والالتزام بالبنية: طور باحثون في MIT طريقة أكثر كفاءة للتحكم في مخرجات نماذج اللغة الكبيرة، بهدف توجيه النموذج لتوليد كود يتوافق مع بنية محددة (مثل قواعد لغة البرمجة) وخالٍ من الأخطاء. يهدف هذا البحث إلى حل مشكلة موثوقية الكود الذي يولده الذكاء الاصطناعي، من خلال تحسين تقنيات التوليد المقيد، وضمان التزام المخرجات الصارم بقواعد النحو، وبالتالي زيادة الفائدة العملية لمساعدي البرمجة بالذكاء الاصطناعي وتقليل تكاليف التصحيح اللاحقة (المصدر: Reddit r/ArtificialInteligence)
NVIDIA قد تكشف عن مشروعها الكبير في مجال الروبوتات: أشارت وسائل التواصل الاجتماعي إلى أن NVIDIA تعمل على “مشروعها الأكثر طموحًا”، والذي يشمل الروبوتات والهندسة والذكاء الاصطناعي والتقنيات المستقلة. على الرغم من أن المحتوى المحدد غير معروف، إلا أنه بالنظر إلى مكانة NVIDIA الأساسية في أجهزة ومنصات الذكاء الاصطناعي (مثل Isaac)، فإن أي إعلان كبير ذي صلة يحظى باهتمام كبير، وقد ينذر بتخطيطها الاستراتيجي الإضافي واختراقاتها التقنية في مجال الذكاء المتجسد والروبوتات (المصدر: Ronald_vanLoon)
🧰 الأدوات
Potpie: مساعد هندسي متخصص بالذكاء الاصطناعي لمستودعات الكود: Potpie هي منصة مفتوحة المصدر (GitHub: potpie-ai/potpie)، تهدف إلى إنشاء وكلاء هندسيين متخصصين بالذكاء الاصطناعي لمستودعات الكود. تقوم ببناء رسم بياني لمعرفة الكود لفهم العلاقات المعقدة بين المكونات، وتوفر مهام آلية مثل تحليل الكود والاختبار والتصحيح والتطوير. توفر المنصة العديد من الوكلاء المعدين مسبقًا (مثل التصحيح، الإجابة على الأسئلة، تحليل تغييرات الكود، إنشاء اختبارات الوحدة/التكامل، التصميم منخفض المستوى، توليد الكود) ومجموعات الأدوات، وتدعم المستخدمين في إنشاء وكلاء مخصصين. توفر امتداد VSCode وتكامل API، مما يسهل دمجها في سير عمل التطوير (المصدر: potpie-ai/potpie – GitHub Trending (all/daily))

1Panel: لوحة تحكم لخوادم Linux تتضمن إدارة LLM: 1Panel (GitHub: 1Panel-dev/1Panel) هي لوحة تحكم حديثة ومفتوحة المصدر لإدارة وتشغيل خوادم Linux، توفر واجهة رسومية على الويب لإدارة المضيفين والملفات وقواعد البيانات والحاويات وغيرها. إحدى ميزاتها هي تضمين وظائف إدارة نماذج اللغة الكبيرة (LLM). بالإضافة إلى ذلك، توفر متجر تطبيقات، ونشر سريع للمواقع (تتكامل مع WordPress)، وحماية أمنية، واستعادة نسخ احتياطية بنقرة واحدة، بهدف تبسيط إدارة الخوادم ونشر التطبيقات، بما في ذلك نشر وإدارة التطبيقات المتعلقة بالذكاء الاصطناعي (المصدر: 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex تطلق مكون واجهة مستخدم الدردشة المحدث: أطلقت LlamaIndex تحديثًا رئيسيًا لمكتبة مكونات واجهة مستخدم الدردشة الخاصة بها (@llamaindex/chat-ui). يعتمد المكون الجديد على shadcn UI، ويتميز بتصميم أكثر أناقة وتخطيط متجاوب وقابل للتخصيص بالكامل. يهدف إلى مساعدة المطورين على بناء واجهات دردشة جميلة وسهلة الاستخدام لمشاريعهم القائمة على LLM بسهولة أكبر، مما يعزز تجربة التفاعل مع تطبيقات الذكاء الاصطناعي. يمكن للمطورين تثبيته عبر npm واستخدامه مباشرة في مشاريعهم (المصدر: jerryjliu0)
تطبيق عملي لـ LlamaExtract: بناء تطبيق تحليل مالي: عرضت LlamaIndex حالة استخدام لأداتها LlamaExtract (جزء من LlamaCloud) لبناء تطبيق ويب متكامل. تتيح LlamaExtract للمستخدمين تحديد Schema دقيق لاستخراج البيانات المهيكلة من المستندات المعقدة. يستخرج التطبيق النموذجي عوامل الخطر من التقارير السنوية للشركات ويحلل التغييرات على مر السنين، مما يؤدي إلى أتمتة العمل الذي كان يستغرق في الأصل أكثر من 20 ساعة. هذا التطبيق مفتوح المصدر (GitHub: run-llama/llamaextract-10k-demo)، وهناك عرض فيديو يوضح كيفية دمج LlamaExtract و Sonnet 3.7 لبناء سير العمل هذا، مما يوضح إمكانات وكلاء الذكاء الاصطناعي في أتمتة مهام التحليل المعقدة (المصدر: jerryjliu0, jerryjliu0)
mcpbased.com: إطلاق دليل خوادم MCP مفتوحة المصدر: تم إطلاق موقع الويب الجديد mcpbased.com كدليل مخصص لخوادم MCP مفتوحة المصدر (قد يشير إلى Meta Controller Pattern أو مفاهيم أخرى مماثلة). تهدف المنصة إلى تجميع وعرض مشاريع خوادم MCP المختلفة، ومزامنة بيانات مستودعات Github في الوقت الفعلي، مما يسهل على المطورين اكتشاف الأدوات ذات الصلة وتصفحها والاتصال بها. بالنسبة للمطورين الذين يقومون ببناء أو استخدام خوادم MCP، أو إجراء تكامل للأدوات، أو متابعة النظام البيئي لـ MCP، يعد هذا مركز موارد جديدًا (المصدر: Reddit r/ClaudeAI)
📚 التعلم
كتاب RLHF يصل إلى ArXiv: تم الآن نشر كتاب حول التعلم المعزز من ردود الفعل البشرية (RLHF) بعنوان “rlhfbook”، الذي ألفه Nathan Lambert وآخرون، على منصة ArXiv (الرقم 2504.12501). تعد RLHF واحدة من التقنيات الرئيسية الحالية لمواءمة نماذج اللغة الكبيرة (مثل ChatGPT). يوفر نشر هذا الكتاب للباحثين والممارسين موردًا مهمًا للتعلم المنهجي والفهم العميق لمبادئ وممارسات RLHF، مما يعزز نشر المعرفة وتطبيقها في هذا المجال (المصدر: natolambert)
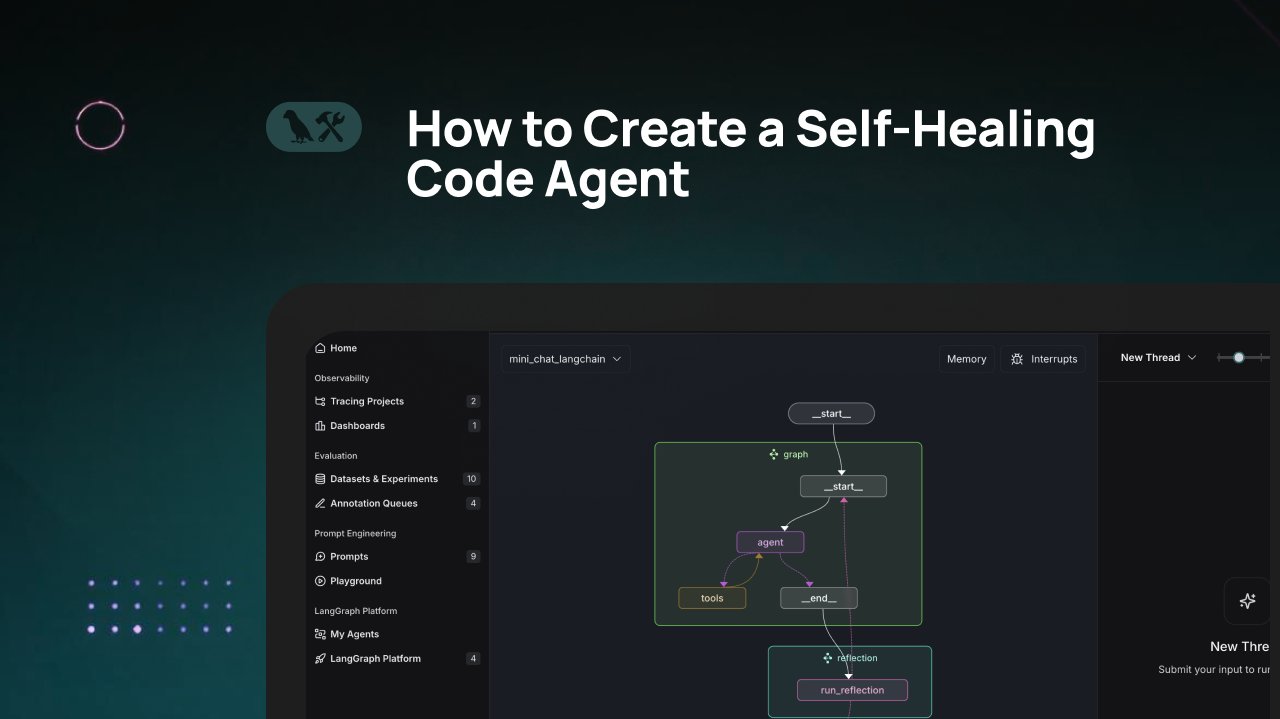
درس تعليمي من LangChain: بناء وكيل توليد كود ذاتي الإصلاح: نشرت LangChain درسًا تعليميًا بالفيديو يشرح كيفية بناء وكيل توليد كود بالذكاء الاصطناعي يتمتع بقدرات “الإصلاح الذاتي”. الفكرة الأساسية هي إضافة خطوة “تفكير” (reflection) بعد توليد الكود، مما يسمح للوكيل بالتحقق من الكود الذي تم إنشاؤه أو تقييمه أو تحسينه بنفسه قبل إرجاع النتيجة. تهدف هذه الطريقة إلى تحسين دقة وموثوقية الكود الذي يولده الذكاء الاصطناعي، وهي تقنية فعالة لتعزيز الفائدة العملية لمساعدي البرمجة (المصدر: LangChainAI)
الذكاء الاصطناعي مع Blender لإنشاء أصول ثلاثية الأبعاد جاهزة للألعاب: تمت مشاركة درس تعليمي على وسائل التواصل الاجتماعي حول استخدام أدوات الذكاء الاصطناعي (قد تشير إلى توليد الصور) مع برنامج النمذجة ثلاثية الأبعاد Blender لإنشاء أصول ثلاثية الأبعاد جاهزة للاستخدام في الألعاب (game-ready). يستهدف هذا المشكلة الحالية المتمثلة في عدم كفاية قدرة الذكاء الاصطناعي على توليد نماذج ثلاثية الأبعاد مباشرة، ويعرض سير عمل مختلطًا عمليًا: استخدام الذكاء الاصطناعي لتوليد المفاهيم أو خرائط النسيج، ثم استخدام أدوات احترافية مثل Blender للنمذجة والتحسين، وأخيرًا إنتاج موارد تلبي متطلبات محركات الألعاب (المصدر: huggingface)
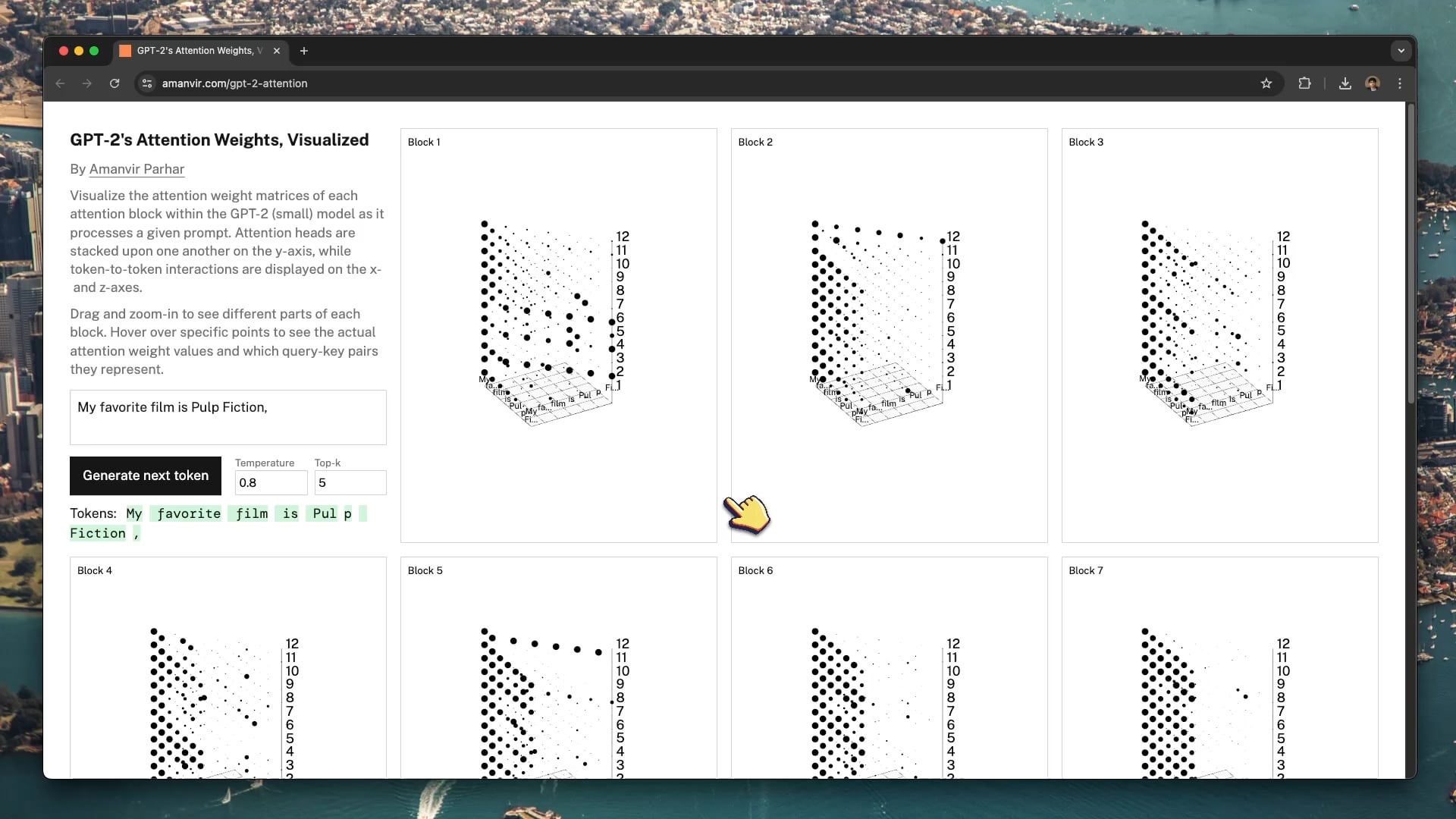
أداة تصور تفاعلية تساعد في فهم آلية الانتباه في GPT-2: قام المطور tycho_brahes_nose_ بإنشاء ومشاركة أداة تصور تفاعلية ثلاثية الأبعاد (amanvir.com/gpt-2-attention) لعرض عملية حساب الأوزان لكل كتلة انتباه داخل نموذج GPT-2 (الصغير). يمكن للمستخدمين رؤية كيف يحسب النموذج قوة التفاعل بين الرموز (tokens) في طبقات مختلفة ورؤوس انتباه مختلفة بعد إدخال النص. يوفر هذا مساعدة ممتازة لفهم الآليات الأساسية لـ Transformer، ويساعد في تعلم الذكاء الاصطناعي وأبحاث قابلية تفسير النماذج (المصدر: karminski3, Reddit r/LocalLLaMA)
تطبيق التعلم الفيدرالي في تحليل الصور الطبية: يشير منشور على Reddit إلى مقال حول دمج التعلم الفيدرالي (Federated Learning, FL) مع الشبكات العصبية العميقة (DNN) لتطبيقه في تحليل الصور الطبية. نظرًا لحساسية خصوصية البيانات الطبية، يسمح FL بتدريب النماذج بشكل تعاوني عبر مؤسسات متعددة دون مشاركة البيانات الأولية. هذا أمر بالغ الأهمية لدفع تطبيقات الذكاء الاصطناعي في المجال الطبي، ويساعد هذا المورد على فهم هذه التقنية التعليمية الموزعة التي تحمي الخصوصية وممارساتها في التصوير الطبي (المصدر: Reddit r/deeplearning)

Sander Dielman يقدم شرحًا معمقًا لـ VAE والفضاء الكامن: أوصى Andrej Karpathy بمقال مدونة معمق لـ Sander Dielman حول أجهزة التشفير التلقائي المتغيرة (VAE) ونمذجة الفضاء الكامن (sander.ai/2025/04/15/latents.html). يناقش المقال تفاصيل تدريب VAE، مثل الدور المحدود الفعلي لمصطلح تباعد KL في تشكيل الفضاء الكامن، وسبب ميل خسارة إعادة البناء L1/L2 إلى إنتاج صور ضبابية (عدم تطابق انحدار طيف الصورة مع تركيز الإدراك البشري). يقدم هذا المقال تحليلاً دقيقًا وثاقبًا لفهم النماذج التوليدية (المصدر: Reddit r/MachineLearning)
💼 الأعمال
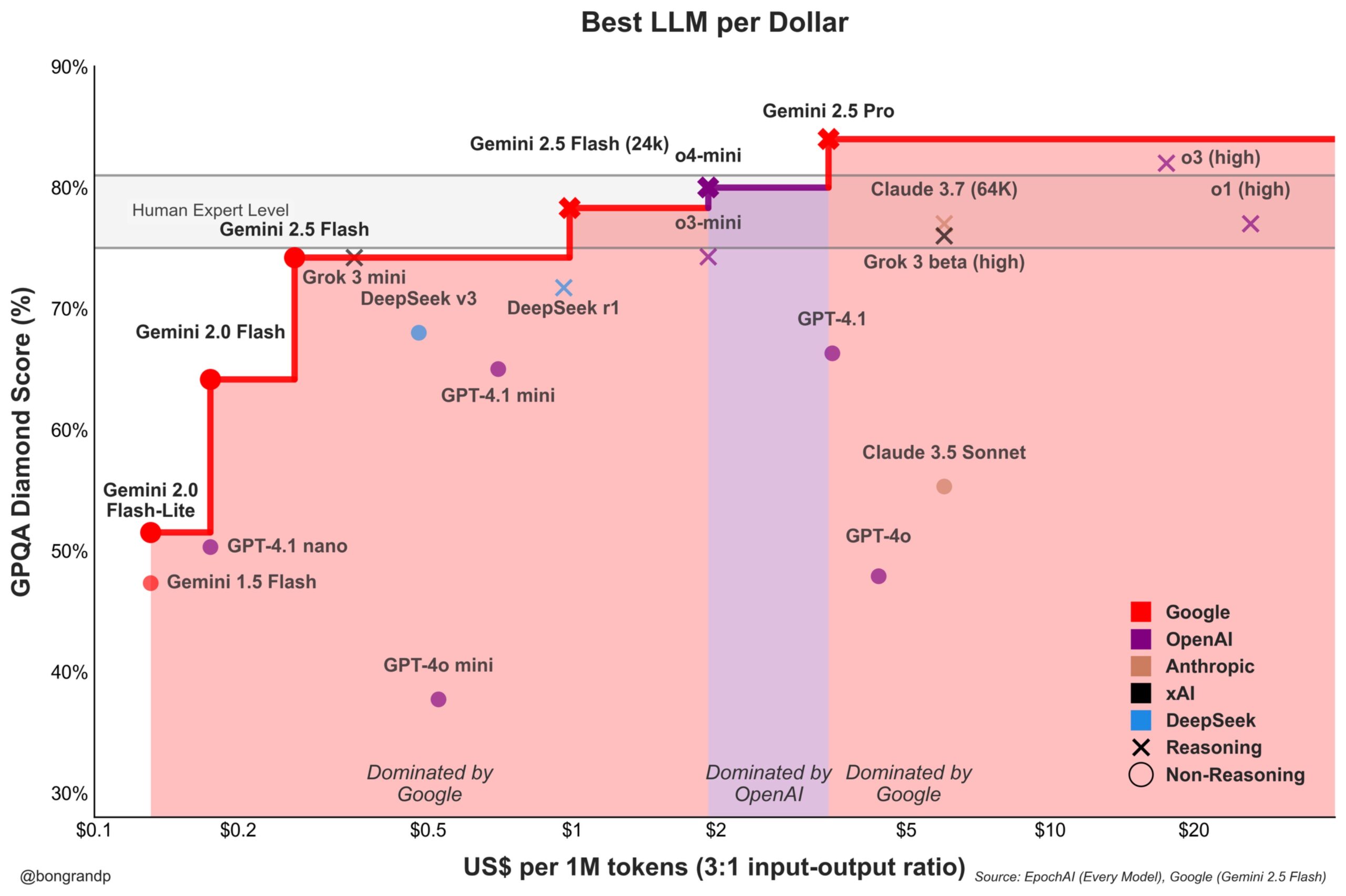
حرب أسعار النماذج تشتد: Google Gemini تتحدى OpenAI بقوة: تشير التحليلات إلى أن Google، من خلال سلسلة نماذج Gemini (خاصة Gemini 2.5 Flash الذي تم إطلاقه حديثًا)، تُظهر قدرة تنافسية قوية من حيث الأداء والسعر، ويُقال إنها تقدم قيمة أفضل مقابل المال مقارنة بـ OpenAI في حوالي 95٪ من السيناريوهات. تشير استجابة Google السريعة لواجهة برمجة التطبيقات الخاصة بها واستراتيجية التسعير (التي تهيمن على أكثر من 90٪ من نطاقات الأسعار) إلى أنها تسعى بنشاط للاستحواذ على حصة في سوق LLM، وتهدف إلى جذب المستخدمين من خلال ميزة التكلفة، مما يزيد من حدة المنافسة في سوق النماذج الأساسية (المصدر: JeffDean)
Coinbase ترعى مؤتمر LangChain لاستكشاف التجارة الوكيلة (Agentic Commerce): أصبحت Coinbase Development راعية لمؤتمر LangChain Interrupt 2025. تعمل Coinbase من خلال أدواتها مثل AgentKit وبروتوكول الدفع x402 على تمكين “التجارة الوكيلة” (Agentic Commerce)، مما يسمح لوكلاء الذكاء الاصطناعي بالدفع بشكل مستقل مقابل خدمات مثل استرجاع السياق واستدعاءات API. يسلط هذا التعاون الضوء على نقاط التقاطع بين تقنية وكلاء الذكاء الاصطناعي ومدفوعات Web3، وينذر بسيناريوهات تفاعل اقتصادي آلي مستقبلية مدفوعة بالذكاء الاصطناعي (المصدر: LangChainAI)

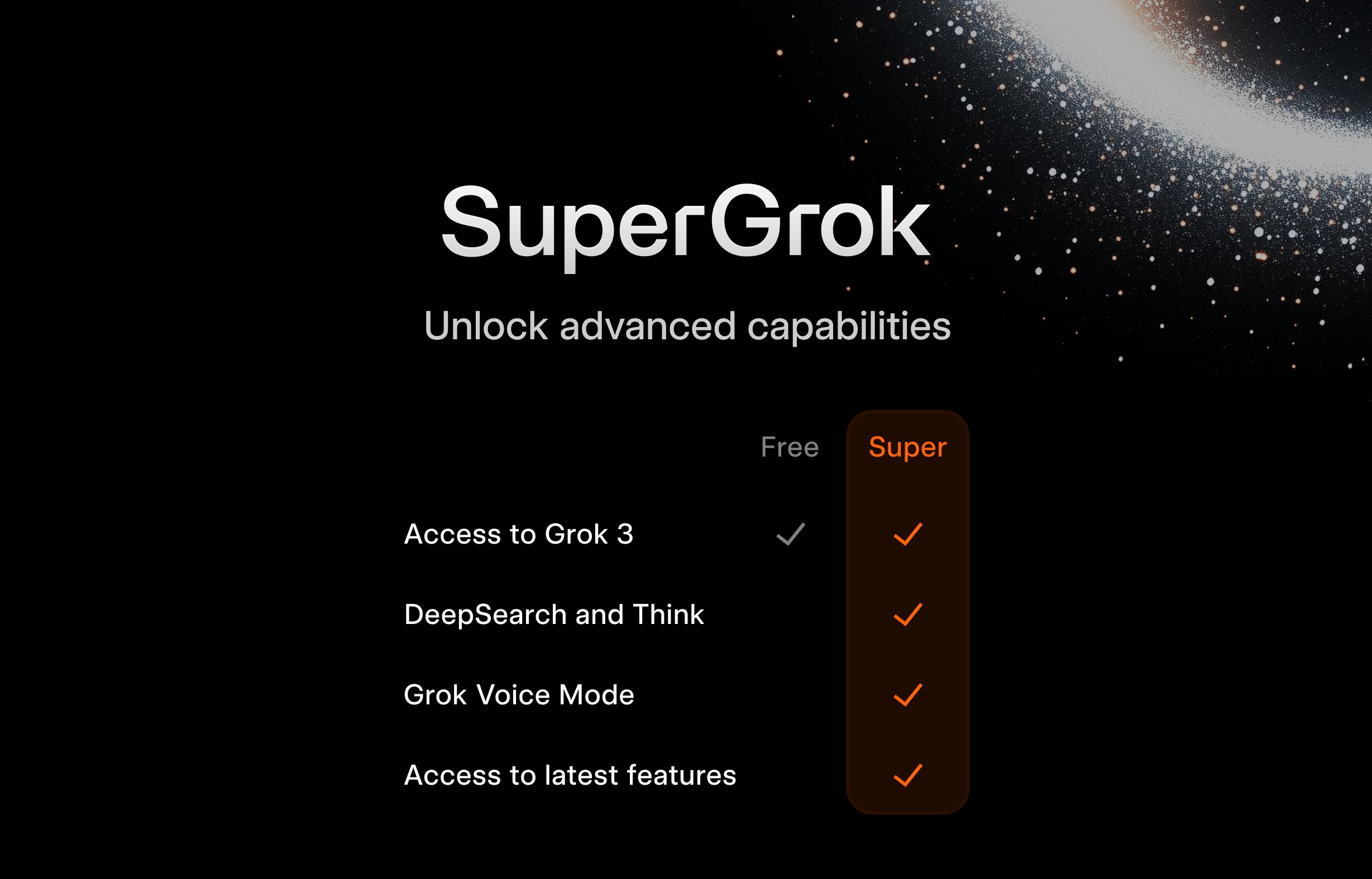
xAI تطلق برنامج SuperGrok المجاني للطلاب: لجذب فئة المستخدمين الشباب، أطلقت xAI عرضًا ترويجيًا للطلاب: باستخدام بريد إلكتروني ينتهي بـ .edu للتسجيل، يمكنهم الحصول على شهرين مجانيين من استخدام SuperGrok (الإصدار المتقدم من Grok). تهدف هذه الخطوة إلى وضع Grok كأداة مساعدة تعليمية، والترويج لها خلال موسم الامتحانات النهائية، والتنافس على المستخدمين في السوق التعليمي، وتنمية العملاء المحتملين المستقبليين (المصدر: grok)
Google تقدم Gemini Advanced والعديد من الخدمات مجانًا لطلاب الجامعات الأمريكية: أعلنت Google عن تقديم مزايا مجانية طويلة الأجل لطلاب الجامعات في الولايات المتحدة، إذا قاموا بالتسجيل قبل 30 يونيو 2025، يمكنهم استخدام Gemini Advanced (المزود بـ Gemini 2.5 Pro) و NotebookLM Plus ووظائف Gemini في Google Workspace و Whisk و 2TB من التخزين السحابي مجانًا حتى نهاية فصل الربيع 2026. تهدف هذه الحملة الترويجية واسعة النطاق إلى دمج أدوات الذكاء الاصطناعي من Google بعمق في النظام البيئي التعليمي، والتنافس مع المنافسين مثل Microsoft، وتنمية ولاء الجيل القادم من المستخدمين والمطورين لمنصة الذكاء الاصطناعي من Google (المصدر: demishassabis, JeffDean)
FanDuel تطلق روبوت الدردشة بالذكاء الاصطناعي للمشاهير “ChuckGPT”: سمح تشارلز باركلي، الشخصية الرياضية الشهيرة، باستخدام اسمه وصورته وصوته للتعاون مع شركة المراهنات الرياضية FanDuel لإطلاق روبوت دردشة بالذكاء الاصطناعي يسمى “ChuckGPT” (chuck.fanduel.com). يعد هذا مثالاً آخر على استخدام الملكية الفكرية للمشاهير وتقنية الذكاء الاصطناعي للتسويق للعلامة التجارية والتفاعل مع المستخدمين، من خلال محاكاة أسلوب حوار المشاهير لتقديم معلومات رياضية أو نصائح مراهنة أو تفاعل ترفيهي، مما يعزز مشاركة المستخدمين (المصدر: Reddit r/artificial)
🌟 المجتمع
الاعتماد على أدوات الذكاء الاصطناعي يثير القلق: تصور رسم كاريكاتوري على وسائل التواصل الاجتماعي بشكل رمزي مستخدمًا محاطًا بالعديد من أدوات الذكاء الاصطناعي (ChatGPT, Claude, Midjourney وغيرها)، مع تسمية “الاعتماد على أدوات الذكاء الاصطناعي”، مما أثار صدى لدى الكثيرين. يعكس هذا شعور بعض المستخدمين في المجتمع بالحمولة الزائدة للمعلومات والاعتماد المفرط المحتمل عند مواجهة تطبيقات الذكاء الاصطناعي التي لا حصر لها، بالإضافة إلى العبء المعرفي لإدارة واختيار الأدوات المناسبة (المصدر: dotey)
فشل النماذج الرائدة في اختبارات محددة يكشف حدود القدرات: أعاد Arav Srinivas، الرئيس التنفيذي لشركة Perplexity، نشر حالة اختبار تظهر فشل كل من o3 و Gemini 2.5 Pro في إكمال مهمة رسم بياني معقدة بنجاح. اعتبر البعض هذا اختبارًا صعبًا لقدرات النماذج الحالية. تتم مناقشة “حالات الفشل” هذه على نطاق واسع في المجتمع للكشف عن قيود نماذج SOTA في مهام الاستدلال المحددة أو الفهم المكاني أو اتباع التعليمات، مما يساعد على تكوين فهم أكثر موضوعية للفجوة الحالية بين الذكاء الاصطناعي والذكاء الاصطناعي العام (AGI) (المصدر: AravSrinivas)
المجتمع يناقش بحماس تأثير صورة الوسادة التي أنشأها GPT-4o ومشاركة الـ Prompt: شارك المستخدمون حالة نجاح لاستخدام GPT-4o لإنشاء صور وسائد بأسلوب معين (لطيف، ملمس مخملي قليلًا، شكل إيموجي) والـ Prompt المحسن. تعرض هذه المشاركات تطبيق توليد الصور بالذكاء الاصطناعي في التصميم الإبداعي، وتعزز التواصل داخل المجتمع حول تقنيات هندسة الـ Prompt واستكشاف الأساليب. أثارت جودة التوليد العالية حماس المستخدمين للإبداع (المصدر: dotey)

Sam Altman: الذكاء الاصطناعي أشبه بعصر النهضة منه بالثورة الصناعية: أعرب Sam Altman، الرئيس التنفيذي لشركة OpenAI، عن رأي مفاده أن التغيير الذي أحدثه الذكاء الاصطناعي يشبه عصر النهضة أكثر من كونه ثورة صناعية. أثار هذا التشبيه نقاشًا في المجتمع، مما يشير إلى أن تأثير الذكاء الاصطناعي قد يتجلى بشكل أكبر على المستوى الثقافي والفكري والإبداعي، وليس مجرد زيادة ميكانيكية في الإنتاجية. يؤثر هذا الحكم النوعي على توقعات الناس وتصوراتهم للدور الاجتماعي المستقبلي للذكاء الاصطناعي (المصدر: sama)
المجتمع يتساءل متى سيتم فتح مصدر Grok 2: يناقش مستخدمو Reddit متى ستفي xAI بوعدها بفتح مصدر نموذج Grok 2. يخشى الكثيرون أنه نظرًا لسرعة تكرار تقنية الذكاء الاصطناعي، بحلول وقت إصدار Grok 2، قد يكون قد تخلف عن النماذج المعاصرة الأخرى (مثل DeepSeek V3، Qwen 3)، مكررًا مصير Grok 1 الذي أصبح قديمًا عند إصداره. تتطرق المناقشة أيضًا إلى الموازنة بين قيمة النماذج مفتوحة المصدر (البحث، حرية الترخيص) وحداثتها (المصدر: Reddit r/LocalLLaMA)
تفسير تصريحات Altman: هل أصبحت كفاءة البيانات عنق الزجاجة الجديد لـ AGI؟: يناقش مجتمع Reddit تصريحات Sam Altman حول حاجة الذكاء الاصطناعي إلى زيادة كفاءة البيانات بمقدار 100,000 مرة بدلاً من الاعتماد فقط على القوة الحاسوبية، ويفسرونها على أنها إشارة إلى أن مسار تحقيق AGI من خلال التوسع العنيف الحالي يواجه عقبات. ترى وجهات النظر أن البيانات البشرية عالية الجودة قد استنفدت تقريبًا، وأن تأثير البيانات الاصطناعية محدود، وأن كفاءة تعلم النماذج المنخفضة هي التحدي الأساسي، وهذا قد يؤثر حتى على خطط استثمار الأجهزة لشركات مثل Microsoft. تعكس المناقشة إعادة التفكير في مسار تطوير الذكاء الاصطناعي (المصدر: Reddit r/artificial)
كيف نميز بين ذاكرة LLM وقدرته على الاستدلال؟: يبحث المجتمع في كيفية اختبار ما إذا كانت نماذج اللغة الكبيرة تمتلك حقًا قدرة على الاستدلال، أم أنها مجرد تكرار أو تجميع للأنماط الموجودة في بيانات التدريب. يقترح البعض استخدام أسئلة “ماذا لو” جديدة وغير مسبوقة لم يرها النموذج من قبل لاستكشاف قدرته على الاستدلال المعمم. يمس هذا صميم الصعوبة في تقييم مستوى ذكاء LLM، أي التمييز بين مطابقة الأنماط المتقدمة والاستدلال المنطقي الحقيقي (المصدر: Reddit r/MachineLearning)
مستخدم يشارك محادثة “مرعبة” مع GPT، مما يثير مخاوف أخلاقية: شارك مستخدم لقطة شاشة لمحادثة مع ChatGPT، تتضمن محتواها التأثيرات الاجتماعية السلبية المحتملة للذكاء الاصطناعي (مثل التحكم في الفكر، فقدان التفكير النقدي)، ووصفها بأنها “مرعبة”. أثار المنشور نقاشًا، تركزت نقاط الاهتمام على ما إذا كانت مخرجات الذكاء الاصطناعي تعكس توجيه المستخدم أم “أفكار” النموذج، وحدود أخلاقيات الذكاء الاصطناعي، وقلق المستخدمين بشأن المخاطر المحتملة للذكاء الاصطناعي (المصدر: Reddit r/ChatGPT)

تشغيل النماذج الكبيرة محليًا يواجه عنق زجاجة الذاكرة: في مجتمع r/OpenWebUI، أفاد المستخدمون بأنهم عند تشغيل OpenWebUI و Ollama على جهاز بذاكرة وصول عشوائي (RAM) بسعة 16GB وبطاقة رسومات RTX 2070S، لا يمكنهم تحميل نماذج كبيرة تزيد عن 12B (مثل Gemma3:27b)، حيث يتم استنفاد ذاكرة النظام ومساحة التبديل (swap space). يمثل هذا التحدي الشائع الذي يواجهه العديد من المستخدمين الذين يحاولون نشر النماذج الكبيرة محليًا على أجهزة المستهلك، ويسلط الضوء على المتطلبات العالية للنماذج من موارد الأجهزة (خاصة الذاكرة) (المصدر: Reddit r/OpenWebUI)
ملصق أنشأه GPT-4o يثير جدلاً حول “بطالة المصممين”: عرض مستخدم ملصقًا لـ “حديقة الكلاب” أنشأه GPT-4o، وأشاد بتأثيره “المثالي تقريبًا” وأكد أن “المصممين الجرافيكيين قد ماتوا”. أثار قسم التعليقات نقاشًا حادًا حول هذا الموضوع: فمن ناحية، تم الاعتراف بتقدم قدرات توليد الصور بالذكاء الاصطناعي، ومن ناحية أخرى، تمت الإشارة إلى العيوب في التصميم (نص كثير جدًا، تنسيق سيء، أخطاء إملائية)، وتم التأكيد على أن الذكاء الاصطناعي حاليًا هو أداة لزيادة الكفاءة، ولا يمكن أن يحل محل القيمة الأساسية للمصممين في اتخاذ القرارات الإبداعية، والحكم الجمالي، وملاءمة العلامة التجارية، وما إلى ذلك (المصدر: Reddit r/ChatGPT)

إدارة دورة حياة النماذج المعدلة (fine-tuned) تثير الاهتمام: تساءل مطور في المجتمع: عندما يتم تحديث النموذج الأساسي المعتمد عليه (مثل GPT-4o) (مثل ظهور GPT-5)، كيف يجب التعامل مع النماذج التي تم تعديلها (fine-tuned) عليه سابقًا؟ نظرًا لأن التعديل الدقيق (fine-tuning) يرتبط عادةً بإصدار أساسي معين، فإن إيقاف أو تحديث النموذج الأساسي قد يجبر المطورين على إعادة التدريب، مما يؤدي إلى تكاليف مستمرة ومشاكل صيانة. أثار هذا نقاشًا حول الاعتمادية والاستراتيجية طويلة الأجل لاستخدام واجهات برمجة التطبيقات (API) المغلقة لإجراء التعديل الدقيق (fine-tuning) (المصدر: Reddit r/ArtificialInteligence)
استكشاف إعدادات المحادثة الصوتية مع LLM المحلي: يسعى مستخدمو المجتمع إلى إيجاد حلول نظامية تمكنهم من إجراء محادثات صوتية مع LLM المحلي، ويتوقعون تحقيق تجربة مماثلة لـ Google AI Studio، لاستخدامها في العصف الذهني والتخطيط. يعكس السؤال رغبة المستخدمين في التوسع من التفاعل النصي إلى تفاعل صوتي أكثر طبيعية، والبحث عن طرق عملية وخبرات مشتركة لدمج STT و LLM و TTS ضمن أطر عمل محلية مثل OpenWebUI (المصدر: Reddit r/OpenWebUI )
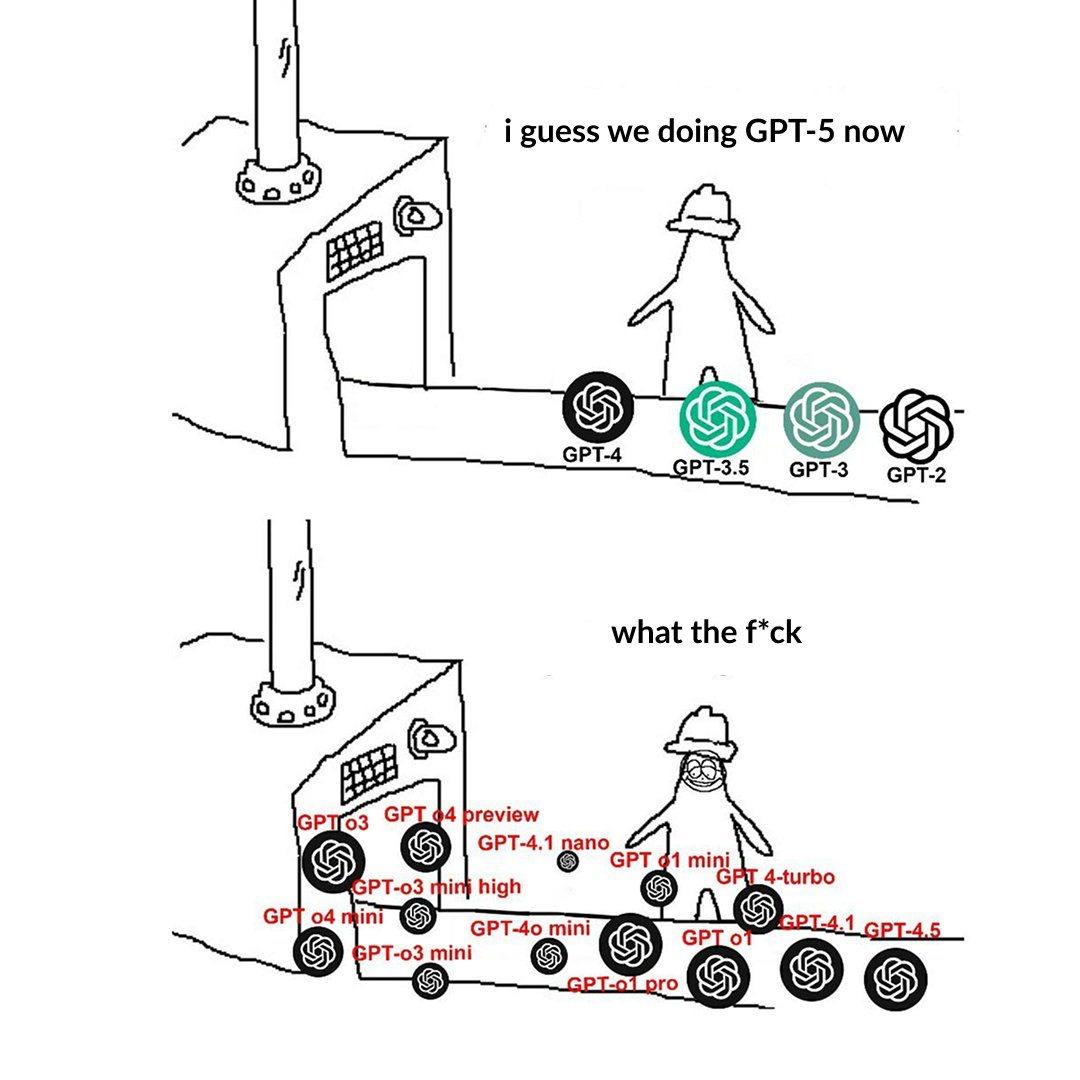
تسمية مستويات نماذج OpenAI تسبب ارتباكًا للمستخدمين: نشر مستخدم منشورًا يشكو فيه من أن تسمية نماذج OpenAI (مثل o3, o4-mini, o4-mini-high, o4) مربكة. تعرض الصورة نماذج من مستويات مختلفة، والعلاقة بين أسمائها وقدراتها وقيودها ليست واضحة بشكل بديهي. يعكس هذا أنه مع التوسع المستمر لعائلة النماذج، فإن التقسيم الواضح لخطوط الإنتاج والتسمية الواضحة يشكل تحديًا لفهم المستخدم واختياره (المصدر: Reddit r/artificial)

أسلوب “المجاملة المفرطة” في ChatGPT يثير نقاشًا حادًا: أشار مستخدمو المجتمع من خلال الميمات والمناقشات إلى ميل ChatGPT إلى تقديم مدح مفرط لأسئلة المستخدمين (“هذا السؤال رائع جدًا!”)، حتى لو كان السؤال عاديًا أو حتى غبيًا. ترى المناقشة أن هذه قد تكون استراتيجية صممتها OpenAI لزيادة ولاء المستخدمين، ولكنها قد تؤدي أيضًا إلى تحيز التأكيد لدى المستخدمين، ونقص التغذية الراجعة النقدية. حتى أن بعض المستخدمين أعربوا عن رغبتهم في أن يقدم الذكاء الاصطناعي تقييمًا “لاذعًا” (المصدر: Reddit r/ChatGPT)

تحديات الذكاء الاصطناعي في الألعاب ذات المعلومات غير الكاملة: يناقش المجتمع التحديات التي يواجهها الذكاء الاصطناعي عند التعامل مع الألعاب التي تحتوي على معلومات غير كاملة (مثل ضباب الحرب في StarCraft). على عكس ألعاب المعلومات الكاملة مثل Go والشطرنج، تتطلب هذه الألعاب من الذكاء الاصطناعي التعامل مع عدم اليقين، وإجراء الاستكشاف والتخطيط طويل الأجل، ولا يمكن الاعتماد ببساطة على المعلومات الشاملة والحساب المسبق. على الرغم من أن الذكاء الاصطناعي قد حقق تقدمًا في ألعاب مثل Dota 2 و StarCraft (AlphaStar)، إلا أن تحقيق تفوق مستقر على أفضل اللاعبين البشريين لا يزال يمثل تحديًا (المصدر: Reddit r/ArtificialInteligence)
الحذر من ظاهرة “التقارب اللغوي” التي يسببها محتوى الذكاء الاصطناعي: طرح مستخدم مفهوم “التقليد اللغوي” (linguistic mimicry)، معربًا عن قلقه من أن قراءة كميات كبيرة من المحتوى الذي يولده الذكاء الاصطناعي، والذي قد يميل أسلوبه إلى التقارب، سيؤدي إلى أن يصبح التعبير اللغوي للناس وحتى طريقة تفكيرهم أحادية ومتجانسة. قد تشكل هذه الظاهرة تهديدًا محتملاً للتنوع الثقافي والتفكير المستقل للفرد. يُعتبر الدعوة إلى قراءة أعمال متنوعة لمؤلفين بشريين وسيلة للحفاظ على حيوية اللغة (المصدر: Reddit r/ArtificialInteligence)
💡 أخرى
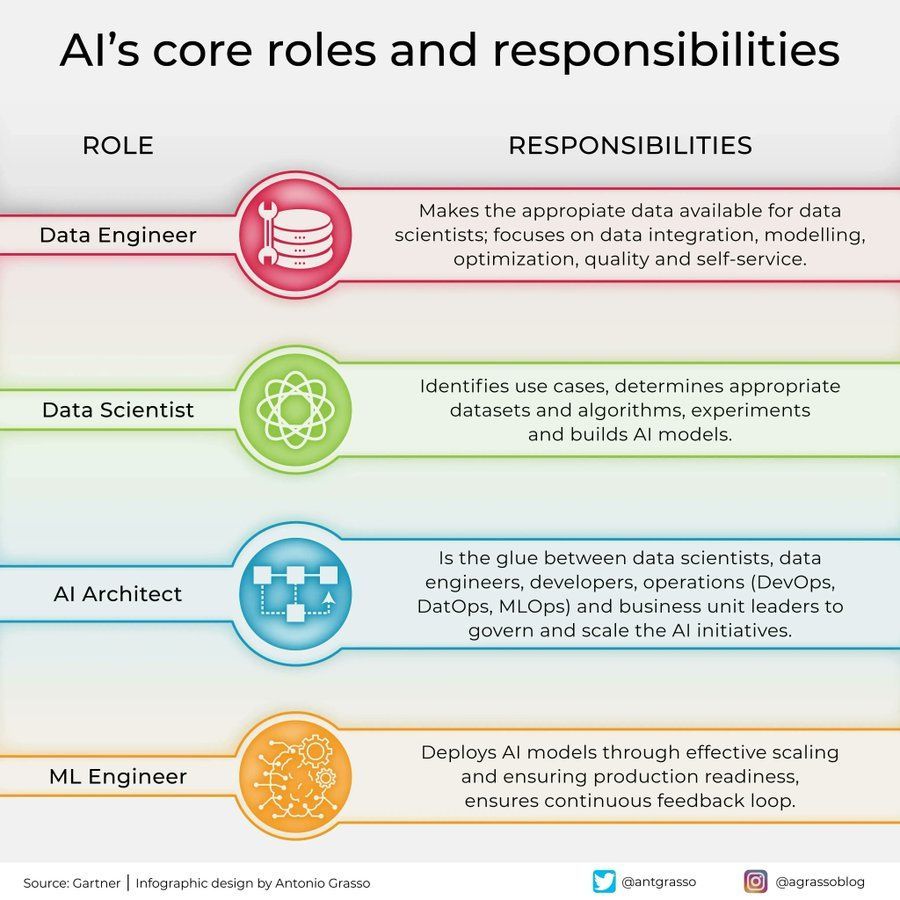
أدوار ومسؤوليات مجال الذكاء الاصطناعي: تمت مشاركة رسم بياني معلوماتي على وسائل التواصل الاجتماعي يلخص الأدوار الأساسية في مجال الذكاء الاصطناعي ومسؤولياتها، مثل عالم البيانات، مهندس التعلم الآلي، باحث الذكاء الاصطناعي، إلخ. يساعد هذا الرسم البياني على فهم تقسيم العمل داخل فرق مشاريع الذكاء الاصطناعي، والمهارات المطلوبة، والطبيعة متعددة التخصصات لتطوير الذكاء الاصطناعي (المصدر: Ronald_vanLoon)
تطبيقات وتحديات الذكاء الاصطناعي في قطاع الاتصالات: أشارت المناقشة إلى التطبيقات الرائدة للذكاء الاصطناعي والمزالق المحتملة في قطاع الاتصالات. يتم استخدام الذكاء الاصطناعي على نطاق واسع في تحسين الشبكات، وخدمة العملاء الذكية، والصيانة التنبؤية، وغيرها لزيادة الكفاءة وتجربة المستخدم، ولكنه يواجه أيضًا تحديات مثل خصوصية البيانات، والتحيز الخوارزمي، وتعقيد التنفيذ. يساعد التعمق في هذه الجوانب الصناعة على اغتنام فرص الذكاء الاصطناعي وتجنب المخاطر (المصدر: Ronald_vanLoon)
تأثير علم النفس على تطور الذكاء الاصطناعي: يستكشف المقال كيف أثر علم النفس على تطور الذكاء الاصطناعي، وأن هذا التأثير لا يزال مستمرًا. توفر المعرفة النفسية مثل العلوم المعرفية، ونظريات التعلم، وأبحاث التحيز، مرجعًا مهمًا لتصميم الذكاء الاصطناعي، مثل محاكاة العمليات المعرفية البشرية، وفهم التحيز ومعالجته. في المقابل، يوفر الذكاء الاصطناعي أيضًا أدوات نمذجة واختبار جديدة لأبحاث علم النفس (المصدر: Ronald_vanLoon)

أجهزة الحوسبة الكبيرة تعرض متطلبات أجهزة الذكاء الاصطناعي: شارك مستخدم صورة تعرض جهاز كمبيوتر ضخمًا ومعقدًا (من المحتمل جدًا أن يكون مجموعة خوادم كبيرة متعددة وحدات معالجة الرسومات)، ووصفه بأنه “وحش”. تعكس هذه الصورة بشكل بديهي الاستثمار الهائل في الموارد الحاسوبية المطلوبة حاليًا لتدريب نماذج الذكاء الاصطناعي الكبيرة أو إجراء مهام استدلال عالية الكثافة، مما يجسد الاعتماد الكبير للذكاء الاصطناعي الحديث على البنية التحتية للأجهزة (المصدر: karminski3)

دور الذكاء الاصطناعي في الأمن السيبراني: يستكشف المقال الدور التحويلي للذكاء الاصطناعي في مجال الأمن السيبراني. تُستخدم تقنيات الذكاء الاصطناعي لتعزيز اكتشاف التهديدات (مثل تحليل السلوك غير الطبيعي)، وأتمتة الاستجابة الأمنية، وتقييم الثغرات والتنبؤ بها، مما يحسن كفاءة الدفاع وقدراته. ومع ذلك، يمكن أيضًا استغلال الذكاء الاصطناعي نفسه بشكل ضار، مما يطرح تحديات أمنية جديدة (المصدر: Ronald_vanLoon)

التعرف الضوئي على الحروف (OCR) عالي الدقة يواجه تحدي الخلط بين الأحرف: واجه مطور يسعى لبناء نظام OCR عالي الدقة للتعرف على الرموز الأبجدية الرقمية القصيرة (مثل الأرقام التسلسلية) صعوبة شائعة: يجد النموذج صعوبة في التمييز بين الأحرف المتشابهة بصريًا (مثل I/1, O/0). حتى عند استخدام نموذج YOLO للكشف عن الأحرف الفردية، توجد حالات حافة. يسلط هذا الضوء على التحديات في تحقيق دقة OCR شبه مثالية في سيناريوهات محددة، مما يتطلب تحسينًا مستهدفًا للنموذج أو البيانات أو اعتماد استراتيجيات ما بعد المعالجة (المصدر: Reddit r/MachineLearning)

طلب مساعدة في تشغيل بيئة Gym Retro: واجه مستخدم مشكلة فنية أثناء استخدام مكتبة التعلم المعزز Gym Retro، حيث نجح في استيراد لعبة Donkey Kong Country، لكنه غير متأكد من كيفية بدء البيئة المعدة مسبقًا للتدريب. هذه مشكلة تكوين وتشغيل نموذجية قد يواجهها باحثو الذكاء الاصطناعي عند استخدام أدوات معينة (المصدر: Reddit r/MachineLearning)
معضلة الاختيار عند تقارب أداء نماذج متعددة: اكتشف باحث، أثناء استخدام طرق مختلفة لاختيار الميزات ونماذج التعلم الآلي، أن العديد من المجموعات حققت مستويات أداء عالية مماثلة (مثل دقة 93-96٪)، مما جعل من الصعب اختيار الحل الأمثل. يعكس هذا أنه في تقييم النماذج، عندما تكون الاختلافات في المقاييس القياسية صغيرة، يجب مراعاة عوامل أخرى مثل تعقيد النموذج، وقابلية التفسير، وسرعة الاستدلال، والمتانة لاتخاذ القرار النهائي (المصدر: Reddit r/MachineLearning)
انتقال arXiv إلى Google Cloud يثير الاهتمام: تخطط arXiv، وهي منصة مهمة للمسودات الأولية في مجال الذكاء الاصطناعي والعديد من المجالات البحثية الأخرى، للانتقال من خوادم جامعة كورنيل إلى Google Cloud. قد يؤدي هذا التغيير الكبير في البنية التحتية إلى تحسين قابلية التوسع والموثوقية للخدمة، ولكنه قد يثير أيضًا نقاشًا في المجتمع حول تكاليف التشغيل وإدارة البيانات وسياسات الوصول المفتوح (المصدر: Reddit r/MachineLearning)
Claude ينشئ أداة محاكاة اقتصادية وقيودها: استخدم مستخدم ميزة Claude Artifact لإنشاء محاكي اقتصادي تفاعلي لتأثير التعريفات الجمركية. على الرغم من أنه يوضح قدرة الذكاء الاصطناعي على إنشاء تطبيقات معقدة، إلا أن التعليقات أشارت إلى أن نتائج المحاكاة قد تكون مبسطة للغاية أو لا تتوافق مع المبادئ الاقتصادية (مثل التعريفات المرتفعة التي تؤدي إلى فائدة عامة). يشير هذا إلى أنه عند استخدام أدوات التحليل التي ينشئها الذكاء الاصطناعي، يجب إجراء فحص دقيق لمنطقها الداخلي وافتراضاتها (المصدر: Reddit r/ClaudeAI)

دمج استنساخ الصوت المخصص XTTS في OpenWebUI: يسعى مستخدم إلى دمج الصوت الذي استنسخه باستخدام تقنية XTTS مفتوحة المصدر في OpenWebUI، ليحل محل ElevenLabs API المدفوع، لتحقيق إخراج صوتي مخصص ومجاني. يمثل هذا حاجة المستخدمين عند استخدام أدوات الذكاء الاصطناعي المحلية لدمج مكونات مفتوحة المصدر وقابلة للتخصيص (مثل TTS) (المصدر: Reddit r/OpenWebUI)