
كلمات مفتاحية:GPT-4.1, Hugging Face, GPT-4.1 سلسلة نماذج مقارنة الأداء, Hugging Face استحواذ على Pollen Robotics, OpenAI نموذج جديد تحسين قدرات الترميز, GPT-4.1 mini خفض التكاليف 83%, روبوت مفتوح المصدر Reachy 2
🔥 أبرز الأخبار
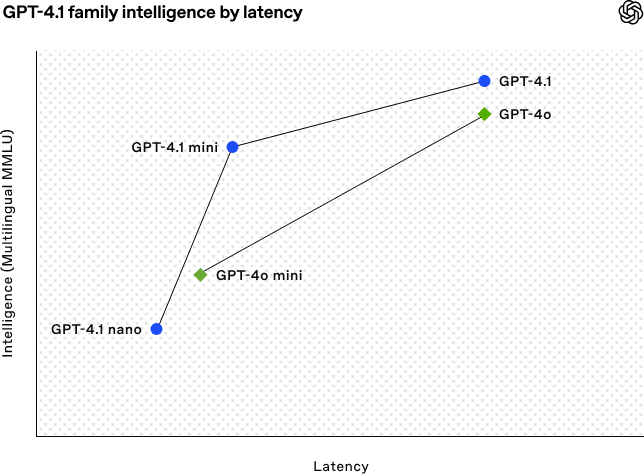
OpenAI تطلق سلسلة نماذج GPT-4.1، معززة قدرات الترميز ومعالجة النصوص الطويلة: أعلنت OpenAI فجر يوم 15 أبريل عن إطلاق ثلاثة نماذج جديدة ضمن سلسلة GPT-4.1: GPT-4.1 (الرائد)، GPT-4.1 mini (عالي الكفاءة)، و GPT-4.1 nano (صغير جدًا)، وجميعها متاحة فقط عبر API. تتميز هذه السلسلة بأداء متفوق في الترميز، اتباع التعليمات، وفهم السياقات الطويلة، مع نافذة سياق تصل إلى مليون token لكل منها، وإخراج يصل إلى 32768 token. حقق GPT-4.1 درجة 54.6% في اختبار SWE-bench Verified، متفوقًا بشكل ملحوظ على GPT-4o و GPT-4.5 Preview الذي سيتم إيقافه. يتفوق GPT-4.1 mini على GPT-4o في الأداء مع تقليل زمن الاستجابة إلى النصف وخفض التكلفة بنسبة 83%. أما GPT-4.1 nano فهو حاليًا أسرع نموذج وأقل تكلفة، ومناسب للمهام التي تتطلب زمن استجابة منخفض. يهدف هذا الإصدار إلى تزويد المطورين بخيارات نماذج أقوى أداءً وأفضل تكلفة وأسرع، لدفع بناء الأنظمة الذكية المعقدة وتطبيقات الوكلاء الذكيين (intelligent agents). (المصدر: 36氪, 智东西, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1来了,超越GPT-4.5,SWE-Bench达到55%,开发者专属。)
Hugging Face تستحوذ على شركة الروبوتات مفتوحة المصدر Pollen Robotics: أعلنت منصة مجتمع الذكاء الاصطناعي Hugging Face عن استحواذها على شركة الروبوتات الفرنسية الناشئة مفتوحة المصدر Pollen Robotics، بهدف تعزيز المصدر المفتوح وتعميم روبوتات الذكاء الاصطناعي. سيجمع هذا الاستحواذ بين نقاط قوة Hugging Face في منصات البرمجيات (مثل مكتبة LeRobot و Hub) وخبرة Pollen Robotics في الأجهزة مفتوحة المصدر (مثل الروبوت البشري Reachy 2). Reachy 2 هو روبوت بشري مفتوح المصدر ومتوافق مع VR، مصمم للبحث والتعليم وتجارب الذكاء المتجسد (embodied intelligence)، ويبلغ سعره 70 ألف دولار أمريكي. ترى Hugging Face أن الروبوتات هي الواجهة التفاعلية الهامة التالية للذكاء الاصطناعي، ويجب أن تكون مفتوحة وميسورة التكلفة وقابلة للتخصيص. يعد هذا الاستحواذ خطوة رئيسية نحو تحقيق هذه الرؤية، بهدف تمكين المجتمع من بناء والتحكم في رفاقهم الروبوتيين، بدلاً من الاعتماد على أنظمة مغلقة ومكلفة. (المصدر: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 اتجاهات
الذكاء الاصطناعي يساعد في حل معضلة رياضية عمرها 50 عامًا: حقق الباحث الصيني Weiguo Yin من مختبر بروكهافن الوطني الأمريكي اختراقًا في الحل الدقيق لنموذج J_1-J_2 q-state Potts أحادي البعد، باستخدام نموذج الاستدلال o3-mini-high من OpenAI، خاصة في حالة q=3 حيث ساعد الذكاء الاصطناعي في إكمال البرهان الرئيسي. تتعلق هذه المسألة بنماذج أساسية في الميكانيكا الإحصائية وترتبط بظواهر فيزيائية مثل تكديس الذرات في المواد الطبقية والموصلية الفائقة غير التقليدية، ولم يتم تحقيق حلها الدقيق خلال الخمسين عامًا الماضية. من خلال إدخال طريقة الفضاء الجزئي الأقصى تناظرًا (MSS) والاستعانة بالذكاء الاصطناعي لمعالجة مصفوفة النقل خطوة بخطوة، نجح الباحثون في تبسيط مصفوفة النقل 9×9 في حالة q=3 إلى مصفوفة فعالة 2×2، وتعميم هذه الطريقة لأي قيمة لـ q. لا يحل هذا البحث معضلة في الفيزياء الرياضية قائمة منذ فترة طويلة فحسب، بل يوضح أيضًا الإمكانات الهائلة للذكاء الاصطناعي في المساعدة في البحث العلمي المعقد وتقديم رؤى جديدة. (المصدر: 刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明)

ظهور مساعدي الويب المدعومين بالذكاء الاصطناعي، وشركات الهواتف والسيارات تخطط لتجربة متعددة الأجهزة: أطلقت شركات مثل Huawei (مساعد Xiaoyi)، Li Auto (مساعد Lixiang Tongxue)، و OPPO (مساعد Xiaobu) نسخ ويب لمساعديها الذكيين، مما أثار الاهتمام. على الرغم من أن هذه النسخ قد لا تكون مكتملة الوظائف (مثل تحرير الأسئلة، التنسيق، خيارات الإعداد) مقارنة بخدمات النماذج المتخصصة مثل DeepSeek، إلا أن هدفها الأساسي ليس المنافسة المباشرة، بل خدمة مستخدمي علاماتها التجارية الخاصة، وربط تجربة المستخدم عبر الهاتف والسيارة والكمبيوتر الشخصي (PC). من خلال ربط حسابات المستخدمين ومزامنة سجلات المحادثات، تهدف هذه النسخ إلى تعزيز ولاء المستخدمين، وتوفير تجربة تفاعلية متسقة عبر الأجهزة، ودمج مساعدي الذكاء الاصطناعي في سيناريوهات استخدام أوسع، وهي في جوهرها خطوة استراتيجية تتعلق بمداخل المستخدمين وبيئة البيانات. (المصدر: AI网页版扎堆上线,华为、理想、OPPO们打的什么算盘?)
روبوت Figure يحقق انتقالًا بدون عينات (zero-shot transfer) من المحاكاة إلى الواقع عبر التعلم المعزز: عرضت شركة Figure روبوتها البشري Figure 02 وهو يحقق مشية طبيعية من خلال التعلم المعزز (RL) في بيئة محاكاة بحتة. باستخدام محاكي فيزيائي فعال مع تسريع GPU، تم إنشاء بيانات تدريب تعادل سنوات في غضون ساعات قليلة، لتدريب استراتيجية شبكة عصبية واحدة قادرة على التحكم في روبوتات افتراضية متعددة بمعلمات فيزيائية وسيناريوهات مختلفة (مثل تضاريس مختلفة، تدخلات). من خلال الجمع بين عشوائية مجال المحاكاة (simulated domain randomization) وردود فعل عزم الدوران عالية التردد من الروبوت الحقيقي، يمكن للاستراتيجية المدربة الانتقال إلى الروبوت المادي بدون عينات (zero-shot) ودون الحاجة إلى ضبط دقيق. لا تقلل هذه الطريقة من وقت التطوير وتحسن استقرار الأداء في العالم الحقيقي فحسب، بل يمكن لاستراتيجية واحدة التحكم في جيش كامل من الروبوتات، مما يوضح إمكاناتها في التطبيقات التجارية واسعة النطاق. (المصدر: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)

DeepSeek ستفتح مصدر بعض تحسينات محرك الاستدلال الخاص بها: أعلنت DeepSeek عن خطط للمساهمة ببعض التحسينات والميزات من محرك الاستدلال عالي الأداء الخاص بها، والمبني على تعديلات vLLM، للمجتمع. لن يقوموا بإصدار مكدس الاستدلال الكامل والمخصص للغاية، بل سيختارون دمج التحسينات الرئيسية (مثل دعم أحدث معماريات النماذج، تحسينات الأداء) في أطر عمل الاستدلال مفتوحة المصدر السائدة مثل vLLM و SGLang، بهدف تمكين المجتمع من الحصول على دعم على مستوى SOTA للنماذج والتقنيات الجديدة منذ اليوم الأول. لاقت هذه الخطوة ترحيبًا من المجتمع، واعتبرت التزامًا حقيقيًا بالمساهمة في المصدر المفتوح وليس مجرد دعاية شفهية. (المصدر: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
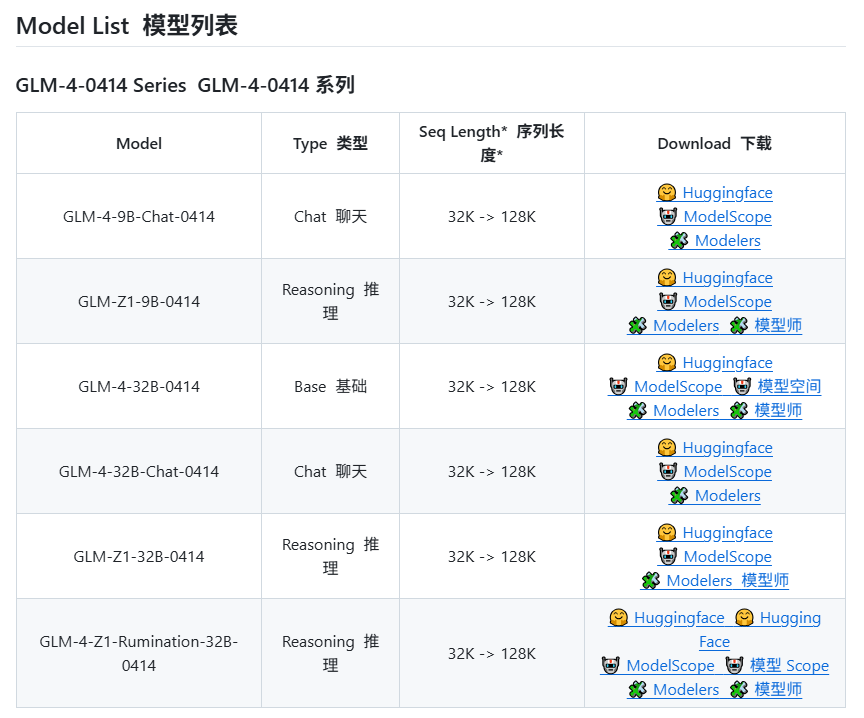
يشتبه في أن Zhipu AI ستصدر نماذج جديدة من سلسلة GLM-4: وفقًا للمعلومات المسربة على GitHub (والتي تمت إزالتها لاحقًا)، يبدو أن Zhipu AI تستعد لإصدار نماذج جديدة من سلسلة GLM-4. قد تتضمن السلسلة إصدارات بأحجام معلمات مختلفة (مثل 9B، 32B) ووظائف، مثل النموذج الأساسي (GLM-4-32B-0414)، نموذج الحوار (Chat)، نموذج الاستدلال (GLM-Z1-32B-0414)، ونموذج “Rumination” بقدرات تفكير أعمق، ربما لمنافسة Deep Research من OpenAI. بالإضافة إلى ذلك، قد تتضمن نموذجًا متعدد الوسائط البصري (GLM-4V-9B). تظهر بيانات اختبار الأداء المسربة أن GLM-4-32B-0414 قد يتفوق على DeepSeek-V3 و DeepSeek-R1 في بعض المؤشرات. تم دمج كود دعم محرك الاستدلال ذي الصلة في transformers/vllm/llama.cpp. يولي المجتمع اهتمامًا كبيرًا لهذا الأمر، ويتطلع إلى الإعلان الرسمي والتقييمات. (المصدر: karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA تطلق سلسلة نماذج Nemotron الجديدة: أطلقت NVIDIA نماذج أساسية جديدة من سلسلة Nemotron-H على Hugging Face، بما في ذلك ثلاثة أحجام للمعلمات: 56B، 47B، و 8B، وجميعها تدعم نافذة سياق 8K. تعتمد هذه النماذج على بنية هجينة تجمع بين Transformer و Mamba. الإصدار الحالي هو النموذج الأساسي (Base)، ولم يتم توفير إصدارات الضبط الدقيق بالتعليمات (Instruct) بعد. تهدف سلسلة Nemotron إلى استكشاف إمكانات البنى الجديدة في نمذجة اللغة. (المصدر: Reddit r/LocalLLaMA)

🧰 أدوات
دمج GitHub Copilot في إصدار Canary من Windows Terminal: قامت Microsoft بدمج وظائف GitHub Copilot في إصدار Canary التجريبي من Windows Terminal، مقدمة ميزة جديدة تسمى “Terminal Chat”. تتيح هذه الميزة للمستخدمين التفاعل مباشرة مع الذكاء الاصطناعي داخل بيئة الطرفية للحصول على اقتراحات وشروحات للأوامر. يحتاج المستخدمون إلى الاشتراك في GitHub Copilot وتثبيت أحدث إصدار Canary من الطرفية، والتحقق من حساباتهم لاستخدامها. تهدف هذه الخطوة إلى دمج المساعدة المدعومة بالذكاء الاصطناعي مباشرة في بيئة سطر الأوامر التي يستخدمها المطورون بشكل متكرر، وتقليل تبديل السياق، وزيادة الكفاءة في التعامل مع المهام المعقدة أو غير المألوفة، وتسريع عملية التعلم، والمساعدة في تقليل الأخطاء. (المصدر: GitHub Copilot 现可在 Windows 终端中运行了)

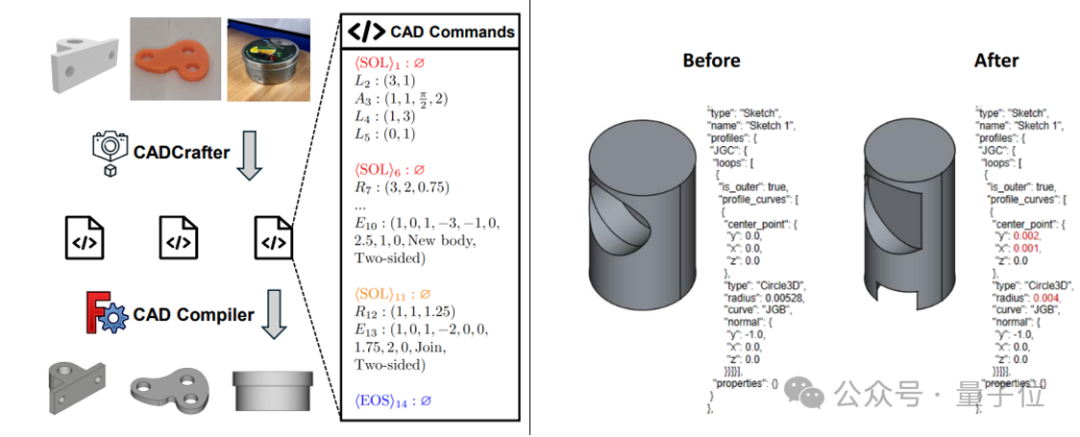
CADCrafter: إنشاء ملفات CAD قابلة للتحرير من صورة واحدة: اقترح باحثون من KOKONI 3D، جامعة Nanyang Technological University (NTU) ومؤسسات أخرى إطار عمل جديد يسمى CADCrafter، قادر على إنشاء ملفات هندسية CAD ذات معلمات وقابلة للتحرير مباشرة من صورة واحدة (صورة معروضة، صورة لمنتج حقيقي، إلخ)، ممثلة كسلسلة من أوامر CAD. يحل هذا الإطار مشكلة صعوبة التحرير الدقيق وجودة السطح المنخفضة للنماذج الناتجة عن طرق تحويل الصور إلى ثلاثية الأبعاد الحالية (التي تنشئ Mesh أو 3DGS). تعتمد هذه الطريقة على بنية توليد من مرحلتين تجمع بين VAE و Diffusion Transformer، وتحسن جودة التوليد ومعدل النجاح من خلال استراتيجية تقطير من متعدد المشاهدات إلى مشهد واحد وآلية فحص قابلية الترجمة بناءً على DPO. تم قبول البحث في CVPR 2025، مما يوفر نموذجًا جديدًا للتصميم الصناعي بمساعدة الذكاء الاصطناعي. (المصدر: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
LangChain تطلق تكامل GraphRAG مع MongoDB Atlas: أعلنت LangChain عن تعاونها مع MongoDB لإطلاق نظام RAG قائم على الرسم البياني (GraphRAG). يستخدم هذا النظام MongoDB Atlas لتخزين ومعالجة البيانات، ويتم تنفيذه عبر LangChain، وهو قادر على تجاوز RAG التقليدي القائم على البحث عن التشابه، لفهم واستنتاج العلاقات بين الكيانات. يدعم استخراج الكيانات والعلاقات عبر LLM، ويستخدم اجتياز الرسم البياني للحصول على معلومات سياقية متصلة، بهدف توفير قدرات أقوى للإجابة على الأسئلة والاستدلال للتطبيقات التي تتطلب فهمًا عميقًا للعلاقات. (المصدر: LangChainAI)
Hugging Face تفتح مصدر ساحة لعب الاستدلال (Inference Playground): قامت Hugging Face بفتح مصدر أداتها عبر الإنترنت Inference Playground المستخدمة لاختبار ومقارنة استدلال النماذج. إنها واجهة دردشة LLM قائمة على الويب تتيح للمستخدمين التحكم في إعدادات الاستدلال المختلفة (مثل درجة الحرارة، top-p، إلخ)، وتعديل استجابات الذكاء الاصطناعي، ومقارنة أداء النماذج والمزودين المختلفين. تم بناء المشروع باستخدام Svelte 5 و Melt UI و Tailwind، وتم نشر الكود على GitHub، مما يوفر للمطورين منصة تفاعل وتقييم نماذج محلية أو عبر الإنترنت قابلة للتخصيص والتوسيع. (المصدر: huggingface)
منصة Flowith تتجاوز إيراداتها السنوية المتكررة مليون دولار، وتُظهر قدرة AI Agent على إنشاء صفحات الويب: تجاوزت الإيرادات السنوية المتكررة (ARR) لمنصة AI Agent Flowith مليون دولار أمريكي، مما يدل على الطلب القوي في السوق على منصات AI Agent شاملة قادرة على استبدال العمل اليدوي. شارك المستخدمون استخدام وظيفة Oracle في Flowith، حيث يمكنهم فقط من خلال وصف بسيط باللغة الطبيعية (“أريد إنشاء صفحة ويب لمعاينة الصور والنصوص لوسائل التواصل الاجتماعي…”)، إنشاء أداة ويب صغيرة تعمل بكامل طاقتها وبأسلوب مطابق تمامًا (مثل نمط Twitter) وتدعم معاينة الصور بسرعة، دون الحاجة إلى الاتصال بـ GitHub أو إجراء تكوينات معقدة، مما يعكس إمكانات AI Agent في إنشاء صفحات الويب بدون كود أو بكود منخفض. (المصدر: karminski3)
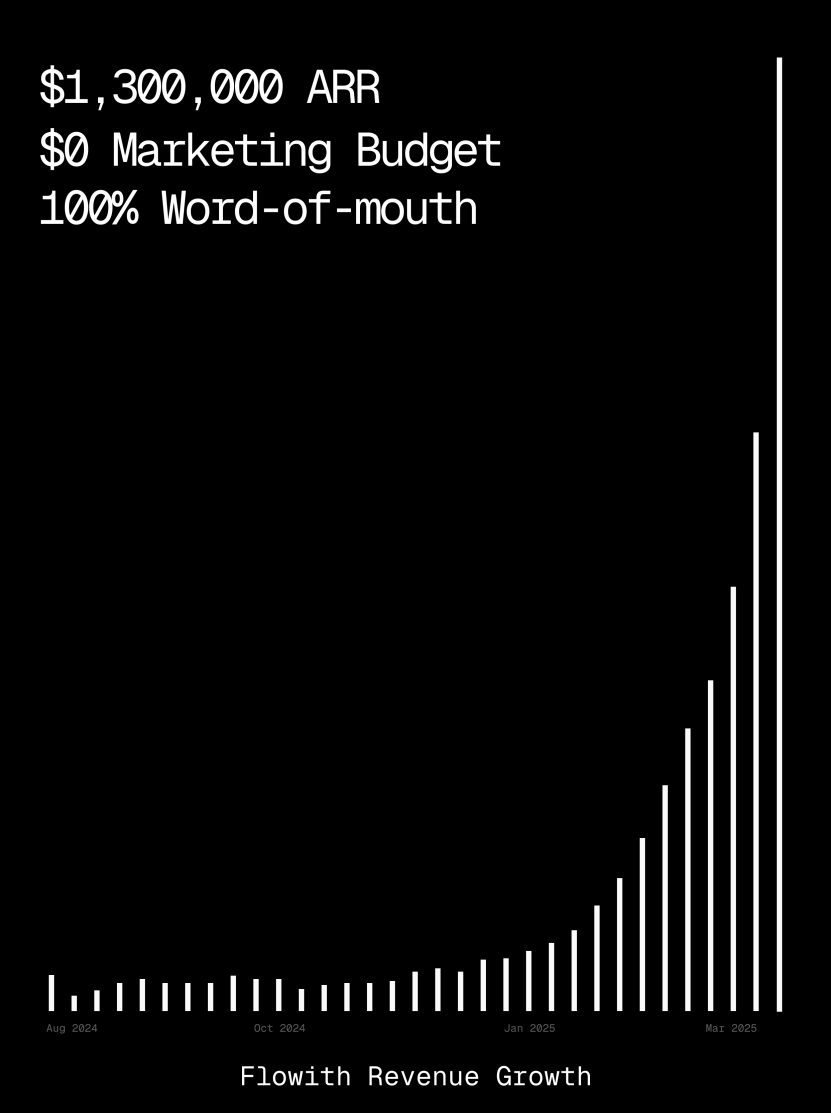
إطلاق وكيل التصحيح المستقل Deebo: قام باحثون ببناء خادم MCP لوكيل تصحيح مستقل يسمى Deebo. يعمل كعملية خفية محلية يمكن لوكلاء البرمجة تفويض مهام معالجة الأخطاء الصعبة إليه بشكل غير متزامن. يقوم Deebo بإنشاء عمليات فرعية متعددة بفرضيات إصلاح مختلفة، وتشغيل كل سيناريو في فرع git معزول، ويتم اختباره واستنتاجه بشكل دوري بواسطة “وكيل أم”، ويعيد في النهاية نتائج التشخيص والتصحيحات المقترحة. في اختبار حقيقي لخطأ في tinygrad بقيمة 100 دولار، نجح Deebo في تحديد جذر المشكلة واقترح حلين محددين للإصلاح، واجتاز الاختبارات. (المصدر: Reddit r/MachineLearning)
![[D] We built an autonomous debugging agent. Here’s how it grokked a $100 bug](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 تعلم
Nabla-GFlowNet: طريقة جديدة لضبط مكافأة نماذج الانتشار توازن بين التنوع والكفاءة: لمواجهة مشكلة التقارب البطيء للتعلم المعزز التقليدي في ضبط نماذج الانتشار، وسهولة الإفراط في التجهيز وفقدان التنوع عند تعظيم المكافأة المباشرة، اقترح باحثون من الجامعة الصينية في هونغ كونغ (شينزن) ومؤسسات أخرى Nabla-GFlowNet. تعتمد هذه الطريقة على إطار عمل شبكات التدفق التوليدي (GFlowNet)، وتعتبر عملية الانتشار كنظام توازن تدفق، وتشتق شرط توازن Nabla-DB ودالة الخسارة المقابلة. من خلال تصميم معلمي، تستخدم تقدير إزالة الضوضاء بخطوة واحدة لتقدير تدرج البقايا، متجنبة الحاجة لشبكة تقدير إضافية. أظهرت التجارب أنه عند ضبط Stable Diffusion على وظائف المكافأة مثل درجة الجمالية واتباع التعليمات، يمكن لـ Nabla-GFlowNet التقارب بشكل أسرع وأقل عرضة للإفراط في التجهيز مقارنة بطرق مثل ReFL و DRaFT، مع الحفاظ على تنوع العينات المولدة. (المصدر: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)

MegaMath: إطلاق أكبر مجموعة بيانات مفتوحة المصدر للاستدلال الرياضي بـ 371 مليار Token: تهدف مجموعة بيانات MegaMath التي أطلقتها LLM360، والتي تحتوي على 371 مليار Token، إلى حل مشكلة نقص بيانات التدريب المسبق واسعة النطاق وعالية الجودة للاستدلال الرياضي في مجتمع المصدر المفتوح. تنقسم مجموعة البيانات إلى ثلاثة أجزاء: صفحات ويب كثيفة المحتوى الرياضي (279 مليار)، كود متعلق بالرياضيات (28.1 مليار)، وبيانات اصطناعية عالية الجودة (64 مليار). تم استخدام خط أنابيب مبتكر لمعالجة البيانات أثناء الإنشاء، بما في ذلك تحليل HTML محسن للصيغ الرياضية، واستخراج النص على مرحلتين، وتسجيل القيمة التعليمية الديناميكي، واستدعاء دقيق متعدد الخطوات لبيانات الكود، وطرق اصطناعية متعددة واسعة النطاق (سؤال وجواب، توليد الكود، تداخل النص والكود). أظهر التحقق من التدريب المسبق لـ 100 مليار Token على Llama-3.2 (1B/3B) أن MegaMath يمكن أن يحقق تحسينًا مطلقًا في الأداء بنسبة 15-20% على معايير مثل GSM8K و MATH. (المصدر: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
مراجعة OS Agents: دراسة حول وكلاء الكمبيوتر والهاتف والمتصفح الأذكياء القائمين على نماذج كبيرة متعددة الوسائط: نشرت جامعة Zhejiang بالتعاون مع OPPO و 01.AI ومؤسسات أخرى ورقة مراجعة حول وكلاء نظام التشغيل (OS Agents). تستعرض الورقة بشكل منهجي الوضع الحالي للبحث في بناء وكلاء أذكياء (مثل Computer Use من Anthropic و Apple Intelligence من Apple) قادرين على إكمال المهام تلقائيًا في بيئات مثل أجهزة الكمبيوتر والهواتف والمتصفحات باستخدام نماذج لغوية كبيرة متعددة الوسائط (MLLM). يغطي المحتوى أساسيات OS Agents (البيئة، مساحة الملاحظة، مساحة العمل، القدرات الأساسية)، طرق البناء (بنية النموذج الأساسي واستراتيجيات التدريب، وحدات الإدراك/التخطيط/الذاكرة/العمل في إطار الوكيل)، بروتوكولات التقييم والمعايير، بالإضافة إلى المنتجات التجارية ذات الصلة والتحديات المستقبلية (الأمن والخصوصية، التخصيص والتطور الذاتي). يحتفظ فريق البحث بمستودع مفتوح المصدر يحتوي على أكثر من 250 ورقة بحثية ذات صلة، بهدف دفع عجلة التنمية في هذا المجال. (المصدر: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
NLPrompt: طريقة تعلم موجهات قوية تجمع بين خسارة MAE والنقل الأمثل: اقترح مختبر YesAI Lab بجامعة ShanghaiTech في ورقة بحثية مميزة في CVPR 2025 طريقة NLPrompt، التي تهدف إلى حل مشكلة ضوضاء التسميات في تعلم الموجهات لنماذج اللغة المرئية. وجد البحث أنه في سيناريو تعلم الموجهات، فإن استخدام خسارة متوسط الخطأ المطلق (MAE) (PromptMAE) يقاوم تأثير التسميات الصاخبة بشكل أفضل من خسارة الانتروبيا المتقاطعة (CE)، وأثبت متانتها من منظور نظرية تعلم الميزات. بالإضافة إلى ذلك، تم اقتراح طريقة تنقية البيانات القائمة على الموجهات والنقل الأمثل (PromptOT)، التي تستخدم ميزات النص كنماذج أولية، وتقسم مجموعة البيانات إلى مجموعة فرعية نظيفة (يتم تدريبها بخسارة CE) ومجموعة فرعية صاخبة (يتم تدريبها بخسارة MAE)، مما يدمج بشكل فعال مزايا كلا الخسارتين. أثبتت التجارب أن NLPrompt يتفوق في مجموعات البيانات الصاخبة الاصطناعية والحقيقية، ويمتلك قدرة تعميم جيدة. (المصدر: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
تحليل آلية الاستدلال في DeepSeek-R1: قام باحثون من جامعة McGill بتحليل عملية الاستدلال في نماذج الاستدلال الكبيرة مثل DeepSeek-R1. على عكس نماذج LLM التي تعطي الإجابة مباشرة، تولد نماذج الاستدلال سلاسل استدلال مفصلة متعددة الخطوات. بحثت الدراسة في العلاقة بين طول سلسلة الاستدلال والأداء (توجد “نقطة مثلى”، وقد يؤدي الطول المفرط إلى الإضرار بالأداء)، وإدارة السياق الطويل، والقضايا الثقافية والأمنية (توجد ثغرات أمنية أقوى مقارنة بالنماذج غير الاستدلالية)، والارتباط بالظواهر المعرفية البشرية (مثل الاستمرار في التفكير في المشكلات التي تم استكشافها بالفعل). كشفت هذه الدراسة عن بعض خصائص ومشاكل محتملة في آلية عمل نماذج الاستدلال الحالية. (المصدر: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
C3PO: طريقة تحسين وقت الاختبار لنماذج MoE الكبيرة: اكتشف باحثون من جامعة Johns Hopkins أن نماذج LLM ذات خليط الخبراء (MoE) تعاني من مشكلة مسار الخبراء دون المستوى الأمثل، واقترحوا طريقة تحسين وقت الاختبار C3PO (الطبقات الحرجة، الخبراء الأساسيون، تحسين المسار التعاوني). لا تعتمد هذه الطريقة على التسميات الحقيقية، بل تحدد هدفًا بديلاً من خلال “الجيران الناجحين” في مجموعة عينات مرجعية لتحسين أداء النموذج. تستخدم خوارزميات مثل البحث عن الأنماط، والانحدار النووي، ومتوسط الخسارة للعينات المماثلة، ولتقليل التكلفة، تقوم فقط بتحسين أوزان الخبراء الأساسيين في الطبقات الحرجة. عند تطبيقها على نماذج MoE LLM، أدت C3PO إلى زيادة دقة النموذج الأساسي بنسبة 7-15% في ستة اختبارات قياسية، متجاوزة خطوط الأساس الشائعة لتعلم وقت الاختبار، وجعلت أداء نماذج MoE ذات المعلمات الصغيرة يتجاوز نماذج LLM ذات المعلمات الأكبر، مما أدى إلى تحسين كفاءة MoE. (المصدر: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
دراسة تأثير التكميم (Quantization) على أداء نماذج الاستدلال: استكشف فريق بحثي من جامعة Tsinghua لأول مرة بشكل منهجي تأثير تقنيات التكميم على أداء نماذج اللغة الاستدلالية (مثل سلسلة DeepSeek-R1، Qwen، LLaMA). قيمت الدراسة أداء خوارزميات تكميم الأوزان وذاكرة التخزين المؤقت KV والتنشيط بعروض بت مختلفة (W8A8، W4A16، إلخ) على معايير الاستدلال في الرياضيات والعلوم والبرمجة وغيرها. أظهرت النتائج أن تكميم W8A8 أو W4A16 يمكن أن يحقق عادةً أداءً بدون خسارة، ولكن عروض البت الأقل تنطوي على مخاطر انخفاض كبير في الدقة. يعد حجم النموذج ومصدره وصعوبة المهمة عوامل رئيسية تؤثر على الأداء بعد التكميم. لم يزد طول إخراج النماذج المكممة بشكل كبير، ويمكن أن يؤدي الضبط المعقول لحجم النموذج أو زيادة خطوات الاستدلال إلى تحسين الأداء. تم فتح مصدر النماذج المكممة والكود ذي الصلة. (المصدر: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
SHIELDAGENT: حاجز وقائي لفرض امتثال الوكيل (Agent) لسياسات الأمان: اقترحت جامعة شيكاغو إطار عمل SHIELDAGENT، الذي يهدف إلى فرض توافق مسار عمل وكيل الذكاء الاصطناعي مع سياسات أمان واضحة من خلال الاستدلال المنطقي. يستخرج الإطار أولاً قواعد قابلة للتحقق من وثائق السياسة، ويبني نموذج سياسة أمان (يعتمد على دوائر القواعد الاحتمالية)، ثم أثناء تنفيذ الوكيل، يسترجع القواعد ذات الصلة بناءً على مسار عمله وينشئ خطة حماية، ويستخدم مكتبة أدوات وكود قابل للتنفيذ لإجراء التحقق الرسمي، مما يضمن عدم انتهاك سلوك الوكيل لقواعد الأمان. تم أيضًا إصدار مجموعة بيانات SHIELDAGENT-BENCH تحتوي على 3 آلاف تعليمات وأزواج مسارات متعلقة بالأمان. أظهرت التجارب أن SHIELDAGENT يحقق مستوى SOTA على معايير متعددة، مما يحسن بشكل كبير معدل الامتثال للأمان ومعدل الاستدعاء، مع تقليل استعلامات API ووقت الاستدلال. (المصدر: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MedVLM-R1: تحفيز قدرة الاستدلال في نماذج VLM الطبية من خلال التعلم المعزز: تعاونت جامعة ميونخ التقنية وجامعة أكسفورد ومؤسسات أخرى لاقتراح MedVLM-R1، وهو نموذج لغة مرئي طبي (VLM) يهدف إلى توليد عمليات استدلال واضحة باللغة الطبيعية. يستخدم النموذج إطار عمل التعلم المعزز لتحسين السياسة النسبية للمجموعة (GRPO) من DeepSeek، ويتم تدريبه على مجموعات بيانات تحتوي فقط على الإجابات النهائية، ولكنه قادر على اكتشاف مسارات استدلال قابلة للتفسير من قبل الإنسان بشكل مستقل. بعد التدريب على 600 عينة فقط من MRI VQA، حقق هذا النموذج ذو المعلمات 2B دقة 78.22% في اختبارات MRI و CT و X-ray القياسية، متفوقًا بشكل كبير على خطوط الأساس، وأظهر قدرة تعميم قوية خارج النطاق، حتى أنه تجاوز نماذج أكبر مثل Qwen2-VL-72B. يوفر هذا البحث أفكارًا جديدة لبناء ذكاء اصطناعي طبي موثوق وقابل للتفسير. (المصدر: 小样本大能量!MedVLM-R1借力DeepSeek强化学习,重塑医疗AI推理能力)
دراسة تكشف أن تدريب التعلم المعزز قد يؤدي إلى استجابات مطولة في نماذج الاستدلال: حللت دراسة من Wand AI أسباب توليد نماذج الاستدلال (مثل DeepSeek-R1) لاستجابات أطول. وجدت الدراسة أن هذا السلوك قد ينبع من عملية تدريب التعلم المعزز (خاصة خوارزمية PPO)، وليس لأن المشكلة نفسها تتطلب استدلالًا أطول. عندما يتلقى النموذج مكافأة سلبية لإجابة خاطئة، تميل دالة خسارة PPO إلى توليد استجابات أطول لتخفيف عقوبة كل token، حتى لو لم يساعد المحتوى الإضافي في تحسين الدقة. أظهرت الدراسة أيضًا أن الاستدلال الموجز غالبًا ما يرتبط بدقة أعلى. من خلال جولة ثانية من تدريب التعلم المعزز باستخدام جزء فقط من المشكلات القابلة للحل، يمكن تقصير طول الاستجابة، مع الحفاظ على الدقة أو حتى تحسينها، وهو أمر مهم لزيادة كفاءة النشر. (المصدر: 更长思维并不等于更强推理性能,强化学习可以很简洁)

جامعة العلوم والتكنولوجيا الصينية (USTC) و ZTE تقترحان Curr-ReFT: لتعزيز قدرات الاستدلال والتعميم لنماذج VLM صغيرة الحجم: لمواجهة ظاهرة “الجدار الطوبي” (عنق الزجاجة في التدريب) وعدم كفاية قدرة التعميم خارج النطاق في نماذج اللغة المرئية (VLM) صغيرة الحجم في المهام المعقدة، اقترحت جامعة العلوم والتكنولوجيا الصينية وشركة ZTE نموذج التدريب اللاحق بالتعلم المعزز المنهجي (Curr-ReFT). يجمع هذا النموذج بين التعلم المنهجي (CL) والتعلم المعزز (RL)، ويصمم آلية مكافأة حساسة للصعوبة، مما يسمح للنموذج بالتعلم تدريجيًا من السهل إلى الصعب (قرار ثنائي ← اختيار من متعدد ← إجابة مفتوحة). في الوقت نفسه، يعتمد استراتيجية تحسين ذاتي قائمة على أخذ العينات بالرفض، باستخدام عينات عالية الجودة متعددة الوسائط ولغوية للحفاظ على القدرات الأساسية للنموذج. أظهرت التجارب على نماذج Qwen2.5-VL-3B/7B أن Curr-ReFT يحسن بشكل كبير أداء الاستدلال والتعميم للنماذج، حتى أن نموذج 7B يتفوق على InternVL2.5-26B/38B في بعض المعايير. (المصدر: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)

GenPRM: توسيع نماذج مكافأة العملية من خلال الاستدلال التوليدي: اقترحت جامعة Tsinghua ومختبر Shanghai AI Lab نموذج مكافأة العملية التوليدي (GenPRM)، بهدف حل مشكلة اعتماد نماذج مكافأة العملية التقليدية (PRM) على التقييمات العددية، وافتقارها إلى القابلية للتفسير وعدم قدرتها على التوسع في وقت الاختبار. يعتمد GenPRM طريقة توليدية، تجمع بين استدلال سلسلة الأفكار (CoT) والتحقق من الكود، لتحليل كل خطوة استدلال باللغة الطبيعية والتحقق من تنفيذ كود Python، مما يوفر إشرافًا أعمق وقابلًا للتفسير على العملية. بالإضافة إلى ذلك، يقدم GenPRM آلية توسيع وقت الاختبار، من خلال أخذ عينات متوازية لمسارات استدلال متعددة وتجميع قيم المكافأة لتحسين دقة التقييم. نموذج 1.5B تم تدريبه باستخدام 23 ألف عينة اصطناعية فقط يتفوق على GPT-4o على ProcessBench من خلال توسيع وقت الاختبار، ويتفوق إصدار 7B على Qwen2.5-Math-PRM-72B ذي 72 مليار معلمة. يمكن لـ GenPRM أيضًا أن يعمل كنموذج ناقد لتوجيه تحسين نموذج السياسة. (المصدر: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
دراسة تكشف ظاهرة “التفكير المفرط” في الذكاء الاصطناعي الاستدلالي عند مواجهة مشكلات ذات مقدمات مفقودة: اكتشف باحثون من جامعة Maryland وجامعة Lehigh أن نماذج الاستدلال الحالية (مثل DeepSeek-R1, o1) تميل إلى إظهار “تفكير مفرط” عند مواجهة مشكلات تفتقر إلى المعلومات الأساسية الضرورية (Missing Premise, MiP). فهي تولد استجابات أطول بمرتين إلى أربع مرات من المشكلات العادية، وتدخل في حلقة مفرغة من مراجعة المشكلة مرارًا وتكرارًا، وتخمين النوايا، والشك الذاتي، بدلاً من التعرف بسرعة على أن المشكلة لا يمكن حلها والتوقف. في المقابل، تكون استجابات النماذج غير الاستدلالية (مثل GPT-4.5) أقصر في مشكلات MiP، وأكثر قدرة على تحديد المقدمات المفقودة. تشير الدراسة إلى أنه على الرغم من أن نماذج الاستدلال يمكنها اكتشاف المقدمات المفقودة، إلا أنها تفتقر إلى “التفكير النقدي” لوقف الاستدلال غير المجدي بحزم. قد ينشأ هذا النمط السلوكي من عدم كفاية قيود الطول في تدريب التعلم المعزز، وينتشر من خلال التقطير. (المصدر: 推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕)

مقالة طويلة تشرح تطور تقنيات تسوية الشبكات العصبية: تستعرض المقالة بشكل منهجي دور وتطور التسوية (Normalization) في الشبكات العصبية، وخاصة في Transformer والنماذج الكبيرة. تحل التسوية، من خلال حصر البيانات في نطاق ثابت، مشكلة قابلية مقارنة البيانات، وتحسن سرعة التحسين، وتخفف من مشاكل منطقة تشبع دالة التنشيط وتحول المتغيرات الداخلية (Internal Covariate Shift, ICS). تقدم المقالة طرق التسوية الخطية الشائعة (Min-max, Z-score, Mean) وغير الخطية، وتشرح بالتفصيل طرق تسوية الدُفعات (Batch Normalization, BN)، وتسوية الطبقات (Layer Normalization, LN)، و RMSNorm، و DeepNorm المناسبة لنماذج التعلم العميق، وتحلل اختلافات تطبيقها في بنية Transformer (لماذا LN/RMSNorm أكثر ملاءمة لـ NLP). بالإضافة إلى ذلك، تناقش المواضع المختلفة لوحدات التسوية داخل طبقات Transformer (Post-Norm, Pre-Norm, Sandwich-Norm) وتأثيرها على استقرار التدريب والأداء. (المصدر: 万字长文!一文了解归一化:从Transformer归一化到主流大模型归一化的演变!)
هندسة الموجهات (Prompt Engineering) لتوليد تصميمات خطوط بأنماط محددة باستخدام الذكاء الاصطناعي: تشارك المقالة تجربة المؤلف وقوالب الموجهات لاستكشاف استخدام 即梦AI 3.0 (Dreamina AI 3.0) لتوليد تصميمات نصية بأنماط محددة. اكتشف المؤلف أن تحديد أسماء الخطوط مباشرة (مثل Songti، Kaiti) لم يكن فعالاً، حيث أن فهم النموذج لهذه الأسماء محدود. لذلك، تحول المؤلف إلى وصف خصائص نمط الخط، والأجواء العاطفية، والتأثيرات البصرية، ودمج أمثلة مرجعية لأنماط مختلفة، لبناء قالب موجه “مولد تصميم نمط نصي متقدم”. يحتاج المستخدمون فقط إلى إدخال محتوى النص، ويمكن للقالب مطابقة أو دمج أنماط متعددة محددة مسبقًا بذكاء بناءً على معنى النص (مثل ظل الليل المتوهج، البساطة الصناعية، الرسم الطفولي، الخيال العلمي المعدني، إلخ)، لتوليد موجهات مفصلة لنماذج تحويل النص إلى صورة، وبالتالي الحصول على تأثيرات تصميم نصية وصورية ذات جودة مستقرة نسبيًا. (المصدر: AI生成字体设计我有点玩明白了,用这套Prompt提效50%。, 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】)

ZClip: طريقة تكيفية لقمع طفرات التدرج لتدريب LLM المسبق: اقترح باحثون ZClip، وهي طريقة خفيفة الوزن وتكيفية لقص التدرج (gradient clipping)، تهدف إلى تقليل طفرات الخسارة أثناء عملية تدريب LLM وتحسين استقرار التدريب. على عكس قص التدرج التقليدي الذي يستخدم عتبة ثابتة، تستخدم ZClip طريقة تعتمد على z-score لاكتشاف وقص طفرات التدرج الشاذة، أي تلك التدرجات التي تنحرف بشكل كبير عن المتوسط المتحرك الأخير. تساعد هذه الطريقة في الحفاظ على استقرار التدريب دون التدخل في التقارب، وهي سهلة الدمج في أي حلقة تدريب. تم نشر الكود والورقة البحثية. (المصدر: Reddit r/deeplearning)
![[2504.02507] ZClip: Adaptive Spike Mitigation for LLM Pre-Training](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 أعمال
حل بطاقة الرسوميات Intel Arc™ ومعالج Xeon® W يدعم أجهزة الذكاء الاصطناعي المتكاملة منخفضة التكلفة: توفر Intel، من خلال مزيجها من بطاقات الرسوميات Arc™ ومعالجات Xeon® W، حلاً للسوق لبناء أجهزة ذكاء اصطناعي متكاملة ذات تكلفة يمكن التحكم فيها (في حدود 100 ألف يوان صيني) وأداء عملي. تعتمد بطاقات الرسوميات Arc™ على بنية Xe ومحرك تسريع الذكاء الاصطناعي XMX AI، وتدعم أطر عمل الذكاء الاصطناعي السائدة و Ollama/vLLM، وتتميز باستهلاك طاقة منخفض وتدعم التوصيل المتوازي لعدة بطاقات. توفر معالجات Xeon® W عددًا كبيرًا من النوى وقدرة توسيع ذاكرة عالية، وتحتوي على تقنية تسريع AMX مدمجة. بالاقتران مع تحسينات البرامج مثل IPEX-LLM و OpenVINO™ و oneAPI، يتم تحقيق تعاون فعال بين وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU). تظهر الاختبارات الفعلية أن الجهاز المتكامل الذي يعتمد هذا الحل يمكنه تشغيل نموذج QwQ-32B بسرعة تصل إلى 32 tokens/s للاستخدام الفردي، وتشغيل نموذج DeepSeek R1 بحجم 671 مليار معلمة (يتطلب تحسين FlashMoE) بسرعة تقارب 10 tokens/s، مما يلبي احتياجات الاستدلال دون اتصال بالإنترنت ويعزز تعميم استدلال الذكاء الاصطناعي. (المصدر: 榨干3000元显卡,跑通千亿级大模型的秘方来了)

NVIDIA ستقوم بتصنيع حواسيب الذكاء الاصطناعي الفائقة في الولايات المتحدة: أعلنت NVIDIA أنها ستقوم لأول مرة بتصميم وبناء حواسيبها الفائقة للذكاء الاصطناعي بالكامل في الولايات المتحدة، بالتعاون مع شركاء التصنيع الرئيسيين. في الوقت نفسه، بدأ إنتاج جيلها الجديد من شرائح Blackwell في مصنع TSMC في أريزونا. تخطط NVIDIA لإنتاج بنية تحتية للذكاء الاصطناعي بقيمة تصل إلى خمسمائة مليار دولار أمريكي في الولايات المتحدة خلال السنوات الأربع القادمة، ويشمل الشركاء TSMC و Foxconn و Wistron و Amkor و SPIL. تهدف هذه الخطوة إلى تلبية الطلب على شرائح الذكاء الاصطناعي والحواسيب الفائقة، وتعزيز سلسلة التوريد، وزيادة المرونة. (المصدر: nvidia, nvidia)

Horizon Robotics تبحث عن متدربين في إعادة بناء/توليد ثلاثي الأبعاد: يقوم فريق الذكاء المتجسد في Horizon Robotics بتوظيف متدربين في خوارزميات إعادة البناء/التوليد ثلاثي الأبعاد في شنغهاي/بكين. تشمل المسؤوليات المشاركة في تصميم وتطوير حلول خوارزميات Real2Sim للروبوتات (الجمع بين إعادة بناء 3D GS، إعادة البناء التنبؤية، توليد ثلاثي الأبعاد/الفيديو)، وتحسين أداء محاكي Real2Sim (دعم محاكاة السوائل، اللمس، إلخ)، وتتبع الأبحاث المتطورة ونشر أوراق بحثية في مؤتمرات عليا. المتطلبات: درجة الماجستير أو أعلى، تخصص في علوم الكمبيوتر/رسومات الحاسوب/الذكاء الاصطناعي، خبرة في الرؤية ثلاثية الأبعاد/توليد الفيديو أو النماذج متعددة الوسائط/الانتشار، إتقان Python/Pytorch/Huggingface. يفضل من لديهم منشورات في مؤتمرات عليا، أو خبرة في منصات المحاكاة أو مشاريع مفتوحة المصدر. توفر فرصة للتوظيف الدائم، ومجموعات GPU، وراتب تنافسي. (المصدر: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)

Meituan 酒旅 (السفر والضيافة) تبحث عن مهندسي خوارزميات نماذج كبيرة L7-L8: يقوم فريق خوارزميات العرض في Meituan 酒旅 بتوظيف مهندسي خوارزميات نماذج كبيرة من المستوى L7-L8 (توظيف ذوي خبرة) في بكين. تشمل المسؤوليات بناء نظام فهم عرض السفر والضيافة (تسميات المنتجات، تحديد النقاط الساخنة، اكتشاف العروض المماثلة، إلخ)، وتحسين مواد العرض (العناوين، الصور والنصوص، توليد أسباب التوصية)، وبناء مجموعات باقات العطلات (اختيار المنتجات، التنبؤ بالمبيعات، التسعير)، واستكشاف وتطبيق تقنيات النماذج الكبيرة المتطورة (الضبط الدقيق، RL، تحسين Prompt). المتطلبات: درجة الماجستير أو أعلى، خبرة سنتين على الأقل، تخصص في علوم الكمبيوتر/الأتمتة/الإحصاء الرياضي، أساس قوي في الخوارزميات وقدرات برمجية. (المصدر: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)

Meta ستستخدم بيانات المستخدمين في الاتحاد الأوروبي لتدريب الذكاء الاصطناعي: أعلنت Meta أنها تستعد للبدء في استخدام البيانات العامة لمستخدمي Facebook و Instagram في منطقة الاتحاد الأوروبي (مثل المنشورات والتعليقات، باستثناء الرسائل الخاصة) لتدريب نماذجها للذكاء الاصطناعي، ويقتصر ذلك على المستخدمين الذين تزيد أعمارهم عن 18 عامًا. ستقوم الشركة بإبلاغ المستخدمين عبر إشعارات داخل التطبيق ورسائل بريد إلكتروني، وتوفير رابط للاعتراض (opt-out). في السابق، أوقفت Meta خططها لاستخدام بيانات المستخدمين في أوروبا لتدريب الذكاء الاصطناعي بناءً على طلب من هيئة الرقابة الأيرلندية. (المصدر: Reddit r/artificial)

Tencent Cloud تطلق خدمة MCP المُدارة: بدأت Tencent Cloud أيضًا في تقديم خدمة المنصة السحابية المُدارة (Managed Cloud Platform, MCP)، بهدف تزويد الشركات بحلول إدارة وتشغيل موارد سحابية أكثر سهولة وكفاءة. تعني هذه الخطوة اشتداد المنافسة بين مزودي الخدمات السحابية الرئيسيين في هذا المجال. لم يتم تفصيل تفاصيل الخدمة المحددة و “ميزات WeChat” بعد. (المصدر: 腾讯云也搞 MCP 托管了,还带了点“微信特色”。)
🌟 مجتمع
الحائز على جائزة تورينج LeCun يتحدث عن تطوير الذكاء الاصطناعي: الذكاء البشري ليس عامًا، والاختراق التالي قد يكون في النماذج غير التوليدية: في مقابلة بودكاست حديثة، أكد Yann LeCun مرة أخرى أن مصطلح AGI مضلل، معتقدًا أن الذكاء البشري متخصص للغاية وليس عامًا. يتوقع أن الاختراق الكبير التالي في الذكاء الاصطناعي قد يأتي من النماذج غير التوليدية، مع التركيز على تمكين الآلات من فهم العالم المادي حقًا، وامتلاك قدرات الاستدلال والتخطيط والذاكرة الدائمة، على غرار بنية JEPA التي اقترحها. يعتقد أن نماذج LLM الحالية تفتقر إلى قدرات الاستدلال الحقيقية والقدرة على نمذجة العالم المادي، وأن الوصول إلى مستوى ذكاء القطط يعد تقدمًا هائلاً بالفعل. بالنسبة لفتح مصدر LLaMA من Meta، يرى أنه الخيار الصحيح لدفع النظام البيئي للذكاء الاصطناعي بأكمله، ويؤكد أن الابتكار يأتي من جميع أنحاء العالم وأن المصدر المفتوح هو مفتاح تسريع الاختراقات. كما أنه متفائل بشأن النظارات الذكية كوسيلة مهمة لمساعدي الذكاء الاصطناعي. (المصدر: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)

“حظر” GitHub المؤقت لعناوين IP الصينية يثير الانتباه، والمسؤولون يقولون إنه خطأ في التكوين: في الفترة من 12 إلى 13 أبريل، اكتشف بعض المستخدمين الصينيين عدم قدرتهم على الوصول إلى GitHub، حيث أظهرت الصفحة رسالة “عنوان IP يخضع لقيود الوصول”، مما أثار قلقًا ونقاشًا في المجتمع، ومخاوف بشأن ما إذا كان حظرًا مستهدفًا. سبق لـ GitHub أن حظرت حسابات مطورين من روسيا وإيران ودول أخرى بسبب العقوبات الأمريكية. رد مسؤولو GitHub لاحقًا بأن هذا الحدث كان بسبب خطأ في تغيير التكوين أدى إلى عدم تمكن المستخدمين غير المسجلين الدخول من الوصول مؤقتًا، وتم إصلاح المشكلة في 13 أبريل. على الرغم من كونه عطلًا فنيًا، إلا أن الحدث أثار مرة أخرى نقاشات حول المخاطر الجيوسياسية لمنصات استضافة الكود والبدائل المحلية (مثل Gitee، CODING، JiHu GitLab، إلخ). (المصدر: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)

AI Agent يثير مخاوف بشأن الأمن السيبراني: تشير مقالة في MIT Technology Review إلى أن الهجمات السيبرانية المستقلة التي يقودها الذكاء الاصطناعي أصبحت وشيكة. مع تعزيز قدرات الذكاء الاصطناعي، قد يستغل المهاجمون الخبيثون AI Agent لاكتشاف الثغرات تلقائيًا، وتخطيط وتنفيذ هجمات سيبرانية أكثر تعقيدًا وأكبر نطاقًا، مما يشكل تهديدات جديدة للأفراد والشركات وحتى الأمن القومي. يتطلب هذا من مجال الأمن السيبراني الإسراع في البحث ونشر استراتيجيات وتقنيات دفاعية قادرة على مواجهة الهجمات التي يقودها الذكاء الاصطناعي. (المصدر: Ronald_vanLoon)

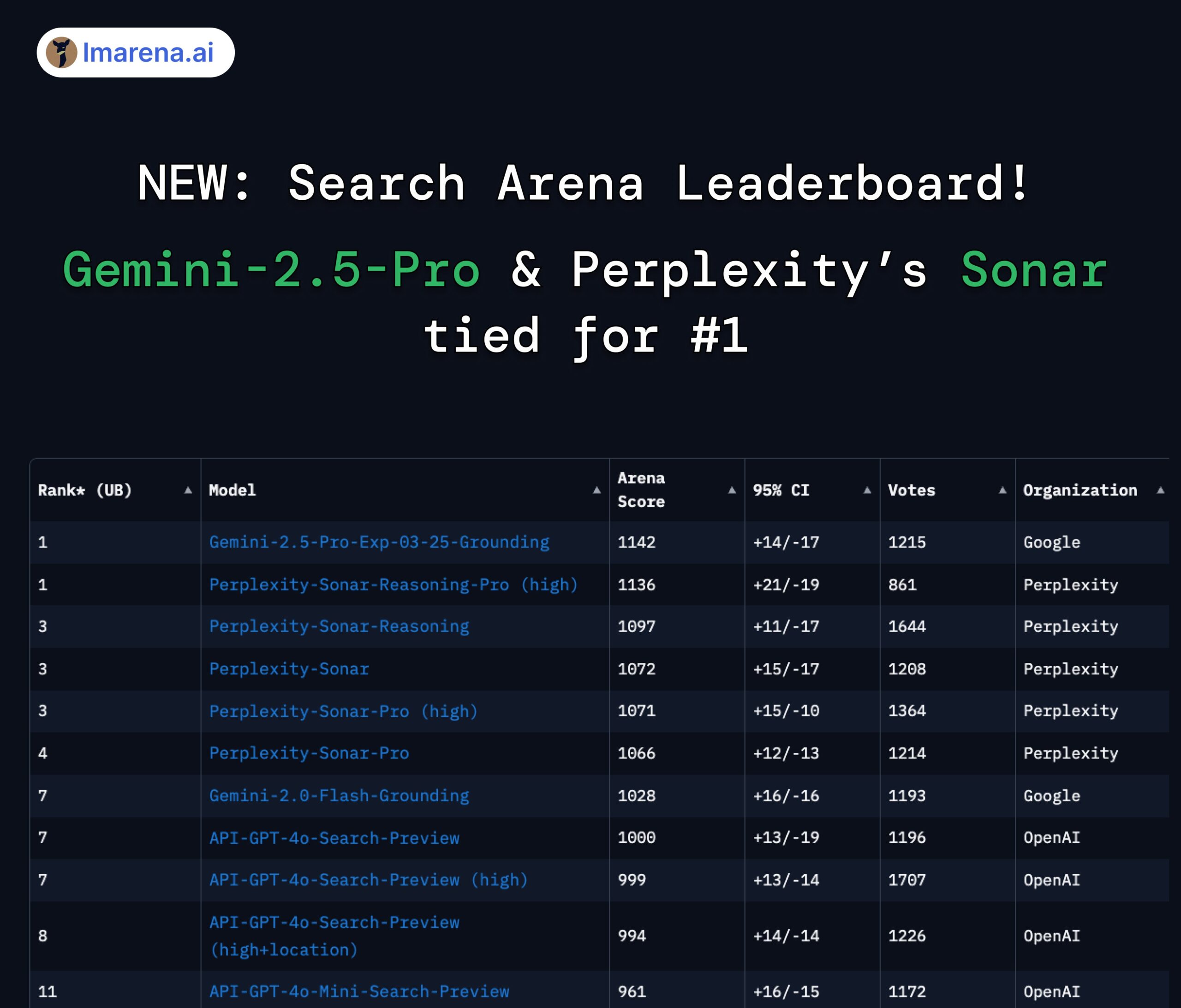
Perplexity Sonar و Gemini 2.5 Pro يتصدران قائمة Search Arena: في قائمة Search Arena الجديدة التي أطلقتها LMArena.ai (LMSYS سابقًا)، احتل نموذج Sonar-Reasoning-Pro-High من Perplexity المركز الأول بالتساوي مع Gemini-2.5-Pro-Grounding من Google. تقيّم هذه القائمة تحديدًا جودة إجابات LLM القائمة على البحث عبر الويب. هنأ Arav Srinivas، الرئيس التنفيذي لشركة Perplexity، على هذا الإنجاز وأكد على الاستمرار في تحسين نموذج Sonar وفهرس البحث. يرى المجتمع أن هذا يظهر أن المنافسة في مجال LLM المعزز بالبحث تتركز بشكل أساسي بين Google و Perplexity. (المصدر: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
نقاش حول قيود استخدام نموذج Claude: في مجتمع Reddit r/ClaudeAI، هناك جدل بين المستخدمين حول قيود استخدام إصدار Claude Pro (مثل الحد الأقصى لعدد الرسائل، قيود السعة). يشتكي بعض المستخدمين من مواجهة القيود بشكل متكرر، مما يؤثر على سير عملهم، ويفكرون حتى في تغيير النموذج؛ بينما يقول آخرون إنهم نادرًا ما يواجهون قيودًا، ويعتقدون أن السبب قد يكون طريقة الاستخدام (مثل تحميل سياقات كبيرة جدًا) أو المبالغة. يعكس هذا تجارب وآراء المستخدمين المختلفة حول سياسات استخدام نماذج Anthropic واستقرارها. (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
نقاش حول الذكاء الاصطناعي ومستقبل العمل: أثار رسم بياني مقارن على Reddit r/ChatGPT نقاشًا: هل سيعزز الذكاء الاصطناعي القدرات البشرية ويجلب حياة مزدهرة، أم سيحل محل الوظائف البشرية ويؤدي إلى بطالة واسعة النطاق؟ في التعليقات، أعرب العديد من المستخدمين عن قلقهم بشأن استبدال الذكاء الاصطناعي للوظائف، وخاصة المهن الإبداعية (البرمجة، الفن). يعتقد البعض أن الذكاء الاصطناعي سيزيد من عدم المساواة الاجتماعية، لأن الفوائد تعود بشكل أساسي إلى مالكي الذكاء الاصطناعي، في حين أن انخفاض القاعدة الضريبية قد يجعل تحقيق الدخل الأساسي الشامل (UBI) صعبًا. بينما يتبنى آخرون موقفًا أكثر تفاؤلاً، معتقدين أن الذكاء الاصطناعي أداة قوية يمكنها زيادة الكفاءة وخلق وظائف جديدة (مثل مهندسي الموجهات)، والمفتاح هو التكيف وتعلم استخدام الذكاء الاصطناعي. (المصدر: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

جمع بيانات الذكاء الاصطناعي يثير مخاوف بشأن الخصوصية: قارن رسم بياني معلوماتي أنواع بيانات المستخدم التي تجمعها روبوتات الدردشة المختلفة للذكاء الاصطناعي (ChatGPT, Gemini, Copilot, Claude, Grok)، مما أثار نقاشًا في المجتمع حول قضايا الخصوصية. يظهر الرسم البياني أن Google Gemini يجمع أكبر عدد من أنواع البيانات، بينما Grok (يتطلب حسابًا) و ChatGPT (لا يتطلب حسابًا) يجمعان بيانات أقل نسبيًا. تؤكد تعليقات المستخدمين على شيوع جمع البيانات وراء الخدمات المجانية (“لا يوجد غداء مجاني”)، وتعرب عن قلقها بشأن الأغراض المحددة لجمع البيانات (مثل التنبؤ بالسلوك). (المصدر: Reddit r/artificial)

تقطير النماذج يعتبر وسيلة فعالة لإعادة إنتاج أداء عالٍ بتكلفة منخفضة: شارك مستخدمو Reddit تجربة استخدام تقنية تقطير النماذج، باستخدام نماذج كبيرة (مثل GPT-4o) لتدريب نماذج صغيرة ومضبوطة بدقة، لتحقيق أداء قريب من GPT-4o (دقة 92%) في مجال معين (تحليل المشاعر) بتكلفة أقل بـ 14 مرة. تشير التعليقات إلى أن التقطير تقنية مستخدمة على نطاق واسع، ولكن من حيث القدرة على التعميم عبر المجالات، فإن النماذج الصغيرة عادة ما تكون أقل أداءً من النماذج الكبيرة. بالنسبة للمجالات المحددة والمستقرة، يعد التقطير طريقة فعالة لخفض التكاليف وزيادة الكفاءة، ولكن بالنسبة للسيناريوهات المعقدة التي تتطلب التكيف المستمر مع البيانات الجديدة أو مجالات متعددة، قد يكون استخدام واجهات برمجة التطبيقات الكبيرة مباشرة أكثر اقتصادا. (المصدر: Reddit r/MachineLearning)
![[D] Distillation is underrated. I replicated GPT-4o's capability in a 14x cheaper model](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 أخرى
OceanBase تنظم أول مسابقة هاكاثون للذكاء الاصطناعي: تنظم شركة قواعد البيانات الموزعة OceanBase بالتعاون مع Ant Open Source و Machine Heart (机器之心) وغيرها أول مسابقة هاكاثون للذكاء الاصطناعي، وقد بدأ التسجيل في 10 أبريل وينتهي في 7 مايو. تتمحور المسابقة حول موضوع “DB+AI”، وتحدد اتجاهين رئيسيين: الأول هو استخدام OceanBase كقاعدة بيانات لبناء تطبيقات الذكاء الاصطناعي، والثاني هو استكشاف تكامل OceanBase مع النظام البيئي للذكاء الاصطناعي (مثل CAMEL AI, FastGPT, OpenDAL). تقدم المسابقة مجموع جوائز بقيمة 100 ألف يوان صيني، وهي مفتوحة للتسجيل للأفراد والفرق، وتهدف إلى تحفيز المطورين لاستكشاف التطبيقات المبتكرة للدمج العميق بين قواعد البيانات والذكاء الاصطناعي. (المصدر: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)

البروفيسور Liu Xinjun من جامعة Tsinghua سيلقي محاضرة مباشرة حول الروبوتات المتوازية: سيلقي البروفيسور Liu Xinjun، مدير معهد هندسة التصميم بقسم الهندسة الميكانيكية بجامعة Tsinghua ورئيس لجنة IFToMM الصينية، محاضرة عبر الإنترنت مساء يوم 15 أبريل، بعنوان “أساسيات علم آليات الروبوتات المتوازية وابتكار المعدات”. ستناقش المحاضرة النظريات الأساسية للروبوتات المتوازية وتطبيقاتها في ابتكار المعدات المتطورة. يدير الجلسة البروفيسور Liu Yingxiang من جامعة Harbin Institute of Technology (HIT). (المصدر: 重磅直播!清华大学刘辛军教授开讲:并联机器人机构学基础与装备创新前沿)

إصدار دليل القمة الصينية الثالثة لصناعة AIGC: تم إصدار جدول الأعمال المفصل وأبرز النقاط للقمة الصينية الثالثة لصناعة AIGC التي ستعقد في بكين في 16 أبريل. ستركز القمة على تكنولوجيا الذكاء الاصطناعي وتطبيقاتها العملية، وتشمل الموضوعات البنية التحتية للحوسبة، وتطبيقات النماذج الكبيرة في سيناريوهات رأسية مثل التعليم/الترفيه/خدمات الشركات/AI4S، وأمن الذكاء الاصطناعي والتحكم فيه. يأتي المتحدثون من Baidu، Huawei، AWS، Microsoft Research Asia، ModelBest، ShengShu Technology، Fenbi، NetEase Youdao، Quwan Technology، Qingsong Health، Ant Group، وغيرها. ستصدر القمة أيضًا قائمة بشركات ومنتجات AIGC الجديرة بالاهتمام لعام 2025، بالإضافة إلى الخريطة البانورامية لتطبيقات AIGC في الصين. (المصدر: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
