
كلمات مفتاحية:AI, الذكاء الاصطناعي, AI主权困局, HBM与先进封装, AI驱动科学发现, Gemini 2.5 Pro编程能力, AI破解数学难题
🔥 التركيز الرئيسي
معضلة سيادة الذكاء الاصطناعي: كيف تلتهم رواية الأمن القومي القيمة العامة؟: يحلل التقرير بعمق مفهوم “سيادة الذكاء الاصطناعي”، أي قدرة الدولة على التحكم في مكدس تكنولوجيا الذكاء الاصطناعي (البيانات، القدرة الحاسوبية، المواهب، الطاقة). يتجه الاتجاه العالمي الحالي من “السيادة الضعيفة” التي تعتمد على الحلفاء إلى “السيادة القوية” التي تسعى إلى التوطين الكامل، مدفوعًا بشكل خاص بسياسات الولايات المتحدة. على الرغم من أن هذا التحول يهدف إلى ضمان الأمن القومي والتفوق العسكري، إلا أنه يثير مخاوف بشأن المركزية المفرطة، وخنق الابتكار المفتوح، وإعاقة التعاون الدولي، واحتمال إثارة سباق تسلح في مجال الذكاء الاصطناعي. يرى المقال أن المبالغة في تأمين الذكاء الاصطناعي قد تضحي بإمكاناته الهائلة لخدمة المصلحة العامة ومواجهة التحديات العالمية، ويدعو إلى إيجاد توازن بين متطلبات السيادة والتعاون المفتوح لتجنب أن يصبح الذكاء الاصطناعي ضحية للمنافسة الجيوسياسية بدلاً من كونه أداة للتقدم البشري الجماعي. (المصدر: معضلة سيادة الذكاء الاصطناعي: كيف تلتهم رواية الأمن القومي القيمة العامة للذكاء الاصطناعي؟)
HBM والتغليف المتقدم: ساحة المنافسة الخفية لثورة قوة الحوسبة في الذكاء الاصطناعي: الطلب المتزايد بشكل كبير على قوة الحوسبة من نماذج الذكاء الاصطناعي الكبيرة يضع البنى الحاسوبية التقليدية أمام عنق زجاجة “جدار الذاكرة”. تعمل ذاكرة النطاق الترددي العالي (HBM) من خلال التكديس ثلاثي الأبعاد وتقنية TSV على زيادة عرض النطاق الترددي عدة مرات (مثل HBM3E الذي يتجاوز 1 تيرابايت/ثانية)، مما يقلل بشكل كبير من تأخير نقل البيانات. في الوقت نفسه، تعمل تقنيات التغليف المتقدمة (مثل CoWoS من TSMC و EMIB من Intel) من خلال التكامل غير المتجانس على دمج رقائق مثل CPU و GPU و HBM بشكل وثيق، متجاوزة قيود الرقاقة الواحدة، مما يزيد من كثافة قوة الحوسبة وكفاءة الطاقة. أصبحت HBM والتغليف المتقدم مكونين أساسيين لرقائق الذكاء الاصطناعي (خاصة في جانب التدريب)، ويهيمن على سوقهما عمالقة مثل SK Hynix و Samsung و Micron (HBM) و TSMC (التغليف)، مع استثمارات ضخمة ونقص في الطاقة الإنتاجية. إن التطور المتآزر لهاتين التقنيتين لا يعيد تشكيل هيكل سلسلة صناعة أشباه الموصلات (زيادة نسبة قيمة التغليف) فحسب، بل أصبح أيضًا ساحة معركة حاسمة تحدد المنافسة في قوة حوسبة الذكاء الاصطناعي. (المصدر: HBM والتغليف المتقدم: ساحة المنافسة الخفية لثورة قوة الحوسبة في الذكاء الاصطناعي)
تصريح صادم لحائز على نوبل: الذكاء الاصطناعي ينجز “وقت بحث دكتوراه” يعادل مليار سنة في عام واحد: صرح Demis Hassabis، الحائز على جائزة نوبل والرئيس التنفيذي لشركة Google DeepMind، بأن مشروع الذكاء الاصطناعي لفريقه AlphaFold-2، من خلال التنبؤ ببنية 200 مليون بروتين معروف على الأرض، قد أكمل في عام واحد ما يعادل استكشافًا علميًا كان سيستغرق مليار سنة من وقت بحث الدكتوراه. وأكد أن الذكاء الاصطناعي، وخاصة AlphaFold، يغير بشكل جذري سرعة وحجم الاكتشاف العلمي، مما يجعل اكتساب المعرفة ديمقراطيًا. في محاضرته بجامعة كامبريدج، أوضح Hassabis كذلك قدوم عصر “البيولوجيا الرقمية” المدفوع بالذكاء الاصطناعي، ويعتقد أن مستقبل الذكاء الاصطناعي يكمن في بناء “نماذج العالم” (مثل بنية JEPA) التي يمكنها فهم العالم المادي وإجراء الاستدلال والتخطيط، بدلاً من الاعتماد فقط على معالجة اللغة. وأعاد تأكيد التزامه بالذكاء الاصطناعي مفتوح المصدر، معتبراً أنه أفضل طريق لدفع التقدم التكنولوجي. (المصدر: تصريح صادم لحائز على نوبل: الذكاء الاصطناعي ينجز “وقت بحث دكتوراه” يعادل مليار سنة في عام واحد)

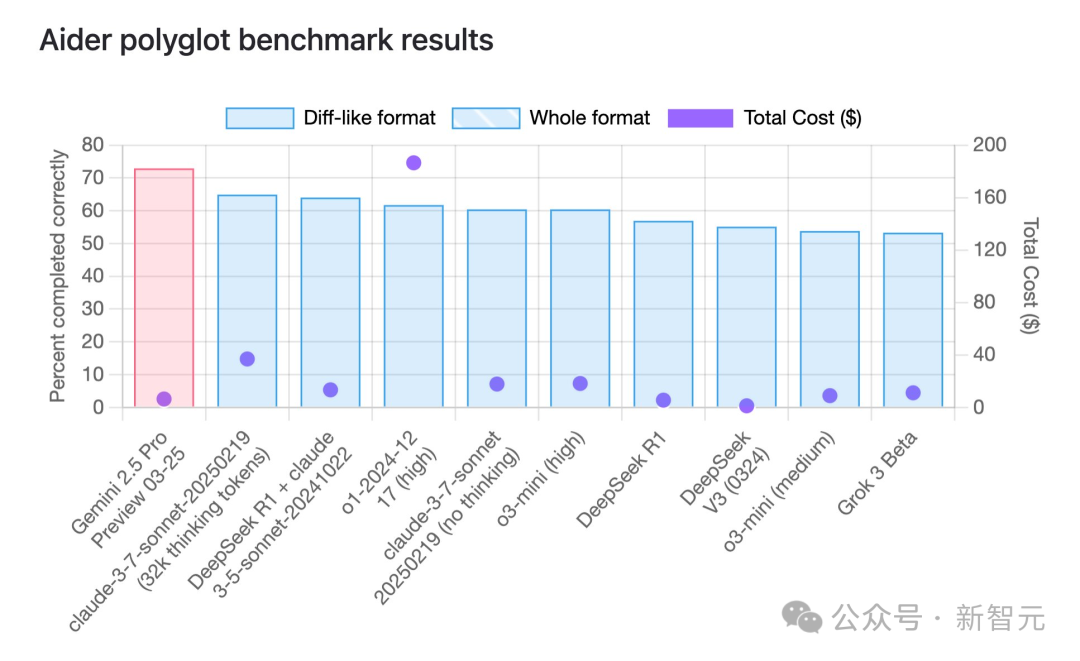
قدرات Gemini 2.5 Pro البرمجية تتصدر القمة، مع ميزة واضحة في التكلفة مقابل الأداء: وفقًا لاختبار aider للبرمجة متعددة اللغات، تفوق نموذج Gemini 2.5 Pro الأحدث من Google على Claude 3.7 Sonnet في قدرات البرمجة، ليحتل المرتبة الأولى عالميًا. لا يقتصر الأمر على أدائه الرائد، بل إن تكلفة استدعاء API منخفضة للغاية (حوالي 6 دولارات)، وهي أقل بكثير من المنافسين ذوي الأداء المماثل أو الأسوأ (مثل GPT-4o، Claude 3.7 Sonnet). أكد Jeff Dean على ميزة التكلفة مقابل الأداء. بالإضافة إلى ذلك، يُظهر نموذج Google غير المعلن عنه “Dragontail”، المتداول في المجتمع، أداءً أفضل حتى من Gemini 2.5 Pro في اختبارات تطوير الويب، مما يشير إلى أن Google لا تزال لديها المزيد في جعبتها في مجال برمجة الذكاء الاصطناعي. يحتل Gemini 2.5 Pro أيضًا مرتبة متقدمة في العديد من اختبارات القياس الشاملة، وبفضل أدائه العالي وتكلفته المنخفضة ونافذة السياق الكبيرة وحق الاستخدام المجاني، فإنه يتحدى بشكل شامل OpenAI و Anthropic. (المصدر: Gemini 2.5 يتصدر قوائم البرمجة العالمية، جوجل تعود إلى عرش الذكاء الاصطناعي، نموذج غامض ينكشف، ألتمان يستعد للمواجهة)
الذكاء الاصطناعي يساعد بنجاح في إثبات معضلة رياضية عمرها 50 عامًا: حقق الباحث الصيني Weiguo Yin (مختبر بروكهافن الوطني) اختراقًا في دراسة الحل الدقيق لنموذج J_1-J_2 q-state Potts أحادي البعد، بمساعدة نموذج o3-mini-high من OpenAI، مما حل مشكلة استمرت 50 عامًا في هذا المجال. عند التعامل مع الحالة المحددة q=3، نجح نموذج الذكاء الاصطناعي، من خلال تحليل التناظر، في تبسيط مصفوفة النقل المعقدة 9×9 إلى مصفوفة فعالة 2×2. ألهمت هذه الخطوة الحاسمة الباحثين لتعميم هذه الطريقة، ووجدوا في النهاية حلاً تحليليًا قابلاً للتطبيق على أي قيمة لـ q. لا يُظهر هذا الإنجاز إمكانات الذكاء الاصطناعي في الاستدلال الرياضي المعقد والإثباتات غير البسيطة فحسب، بل يوفر أيضًا أدوات نظرية جديدة لفهم مشاكل مثل التحولات الطورية في فيزياء المادة المكثفة. (المصدر: للتو، الذكاء الاصطناعي يحل معضلة رياضية عمرها 50 عامًا، خريج جامعة نانجينغ يستخدم نموذج OpenAI لإكمال أول إثبات رياضي غير بسيط)

🎯 التوجهات
تطبيق وتطور الذكاء الاصطناعي في مجال شخصيات الألعاب غير القابلة للعب (NPC): يستعرض المقال تاريخ تطور تقنية الذكاء الاصطناعي في شخصيات NPC في الألعاب، بدءًا من آلة الحالة المحدودة في لعبة Pac-Man المبكرة، إلى شجرة السلوك، ثم إلى الذكاء الاصطناعي المعقد الذي يجمع بين بحث شجرة مونت كارلو والشبكات العصبونية العميقة (مثل AlphaGo). يشير المقال إلى أنه على الرغم من أن الذكاء الاصطناعي يمكنه هزيمة أفضل اللاعبين البشريين في ألعاب مثل StarCraft 2 و Dota 2، إلا أن تجربة الذكاء الاصطناعي القوية جدًا ليست جيدة للاعبين العاديين. يجب أن يركز الذكاء الاصطناعي المثالي في الألعاب بشكل أكبر على محاكاة السلوك البشري، وتوفير قيمة عاطفية وصعوبة تكيفية (مثل نظام Nemesis في Middle-earth: Shadow of Mordor، والصعوبة الديناميكية في Resident Evil 4). مؤخرًا، وكما يتضح من Stella في لعبة Whispers from the Star من miHoYo، يتم استخدام الذكاء الاصطناعي التوليدي لدفع الحوارات في الوقت الفعلي وردود الفعل العاطفية وتطور القصة لشخصيات NPC. على الرغم من مواجهة تحديات مثل التأخير والذاكرة، إلا أنه يوضح اتجاه شخصيات NPC المدعومة بالذكاء الاصطناعي نحو أن تصبح أكثر إنسانية وعمقًا في التفاعل. (المصدر: الذكاء الاصطناعي يجعل الألعاب عظيمة مرة أخرى)

OpenAI تشدد قيود الوصول إلى API وتفرض التحقق من المنظمات: طبقت OpenAI مؤخرًا سياسة جديدة للتحقق من المنظمات عبر API، تتطلب من المستخدمين تقديم وثيقة هوية حكومية صالحة صادرة عن دولة أو منطقة مدعومة للوصول إلى نماذجها وميزاتها الأكثر تقدمًا. يمكن لكل هوية التحقق من منظمة واحدة فقط كل 90 يومًا. تقول OpenAI إن هذه الخطوة تهدف إلى تقليل الاستخدام غير الآمن للذكاء الاصطناعي والاستعداد لإطلاق “نماذج جديدة ومثيرة” قادمة (قد تشمل إصدارات متعددة مثل GPT-4.1 و o3 و o4-mini). أثار هذا التغيير في السياسة اهتمامًا وقلقًا واسع النطاق في المجتمع، خاصة بالنسبة للمطورين الموجودين في دول/مناطق غير مدعومة والمستخدمين الذين يعتمدون على خدمات API من جهات خارجية، حيث قد يواجهون قيودًا على الوصول أو زيادة في التكاليف، كما أثار نقاشات حول انفتاح OpenAI. (المصدر: وصول IP الصيني إلى GitHub يتعطل ثم يعود، سياسة OpenAI API الجديدة قد تغلق الباب أمام GPT-5؟, op7418, Reddit r/artificial)
دخول Apple يدفع تطوير “طبيب الذكاء الاصطناعي”، مع تحديات وتنظيمات متزامنة: يُشاع أن شركة Apple ستستخدم الذكاء الاصطناعي لتعزيز وظائف تطبيقها الصحي، وإطلاق خدمات مثل “مدرب الصحة بالذكاء الاصطناعي”، مما يدفع “طبيب الذكاء الاصطناعي” ليصبح نقطة ساخنة عالمية. ومع ذلك، تواجه تطبيقات الذكاء الاصطناعي السريرية الحقيقية العديد من التحديات: تكاليف تطوير عالية، والاعتماد على كميات هائلة من البيانات الطبية الحساسة (مما يتعلق بلوائح الخصوصية)، وصعوبة تصنيف البيانات، وما إلى ذلك. حاليًا، يعمل الذكاء الاصطناعي في الغالب كأداة مساعدة للتشخيص. يواجه السوق الصيني أيضًا احتياجات خاصة تتمثل في التوزيع غير المتكافئ للموارد الطبية والحاجة إلى الذكاء الاصطناعي للمساعدة في الفرز الطبي. تحاول شركات مثل Baichuan Intelligence حل هذه المشكلات من خلال اقتراح “نموذج الطبيب المزدوج” (طبيب ذكاء اصطناعي + ذكاء اصطناعي يساعد الطبيب البشري). يؤكد المقال على أن التطبيق الواسع للذكاء الاصطناعي في المجال الطبي يجب أن يبنى على تنظيم صارم ونظام اعتماد لضمان دقة التشخيص وأمن البيانات وثقة المستخدم، وتجنب المخاطر المحتملة. (المصدر: مع دخول Apple، يصبح “طبيب الذكاء الاصطناعي” نقطة ساخنة عالمية، وحماية خصوصية المرضى أكبر عقبة؟)

محاولة Microsoft لتوليد الألعاب مباشرة بالذكاء الاصطناعي لم تكن فعالة: عرضت Microsoft مؤخرًا عرضًا توضيحيًا يستخدم نموذج الذكاء الاصطناعي “Muse” لتوليد مشاهد لعبة Quake II مباشرة، بهدف إظهار قدرة الذكاء الاصطناعي على إنشاء نماذج أولية للألعاب بسرعة. ومع ذلك، كان أداء العرض التوضيحي سيئًا، حيث عانى من دقة منخفضة، ومعدل إطارات منخفض، والعديد من الأخطاء (مثل سلوك العدو غير الطبيعي، وفشل قواعد الفيزياء، وبيئة مشوشة)، وتم تقييمه على أنه “حلم ينهار باستمرار”. يرى المقال أن هذا يشير إلى أن تقنية الذكاء الاصطناعي التوليدي الحالية (خاصة مع مشكلة “الهلوسة”) ليست كافية بعد لتوليد تجارب ألعاب تفاعلية معقدة وقابلة للعب بشكل مباشر وموثوق. بالمقارنة، يعد تطبيق الذكاء الاصطناعي على مراحل محددة في خط أنابيب تطوير الألعاب (مثل تفاعل NPC، وتوليد الأصول) أكثر واقعية. يبدو أن مسار توليد مشاهد أو طريقة لعب مباشرة يواجه تحديات هائلة في الوقت الحالي. (المصدر: لعبة الذكاء الاصطناعي من Microsoft تفشل، قد يكون توليد الألعاب مباشرة طريقًا مسدودًا)
Google تطلق نموذج TxGemma مفتوح المصدر لمجال الرعاية الصحية: أطلقت Google سلسلة نماذج TxGemma، المبنية على عائلتي نماذج Gemma و Gemini، والمُحسَّنة خصيصًا لمجالات الرعاية الصحية وتطوير الأدوية كمصدر مفتوح. تهدف هذه الخطوة إلى توفير أدوات ذكاء اصطناعي أكثر تخصصًا للبحث الطبي الحيوي وتطوير العلاجات، وتعزيز الابتكار في هذا المجال. يعد إطلاق TxGemma جزءًا من استراتيجية Google لتوفير نماذج مفتوحة المصدر عامة ومتخصصة. (المصدر: JeffDean)
DeepSeek تعلن عن خطط لفتح مصدر محرك الاستدلال الداخلي الخاص بها: أعلنت DeepSeek AI أنها ستفتح مصدر محرك الاستدلال الذي تستخدمه داخليًا. وفقًا للوصف، فإن المحرك هو نسخة معدلة ومحسنة من إطار العمل الشهير vLLM. تهدف DeepSeek من خلال هذه الخطوة إلى إعادة تقنيات الاستدلال المحسنة إلى مجتمع المصادر المفتوحة، ومساعدة المطورين على نشر النماذج الكبيرة بكفاءة أكبر. تعكس هذه الخطة رغبة DeepSeek في المساهمة في مجتمع المصادر المفتوحة، ومن المتوقع نشر الكود على GitHub. (المصدر: karminski3)
ChatGPT يضيف وظيفة الذاكرة لتعزيز الاستمرارية: أضافت OpenAI وظيفة الذاكرة (Memory) إلى نموذج ChatGPT الخاص بها. تتيح هذه الميزة لـ ChatGPT تذكر المعلومات التي قدمها المستخدم سابقًا أو التفضيلات أو الموضوعات التي تمت مناقشتها عبر محادثات متعددة. الهدف هو تحسين استمرارية التفاعل وتخصيصه، وتجنب حاجة المستخدمين إلى تكرار تقديم نفس المعلومات الأساسية في المحادثات اللاحقة، وبالتالي تحسين تجربة المستخدم. (المصدر: Ronald_vanLoon)

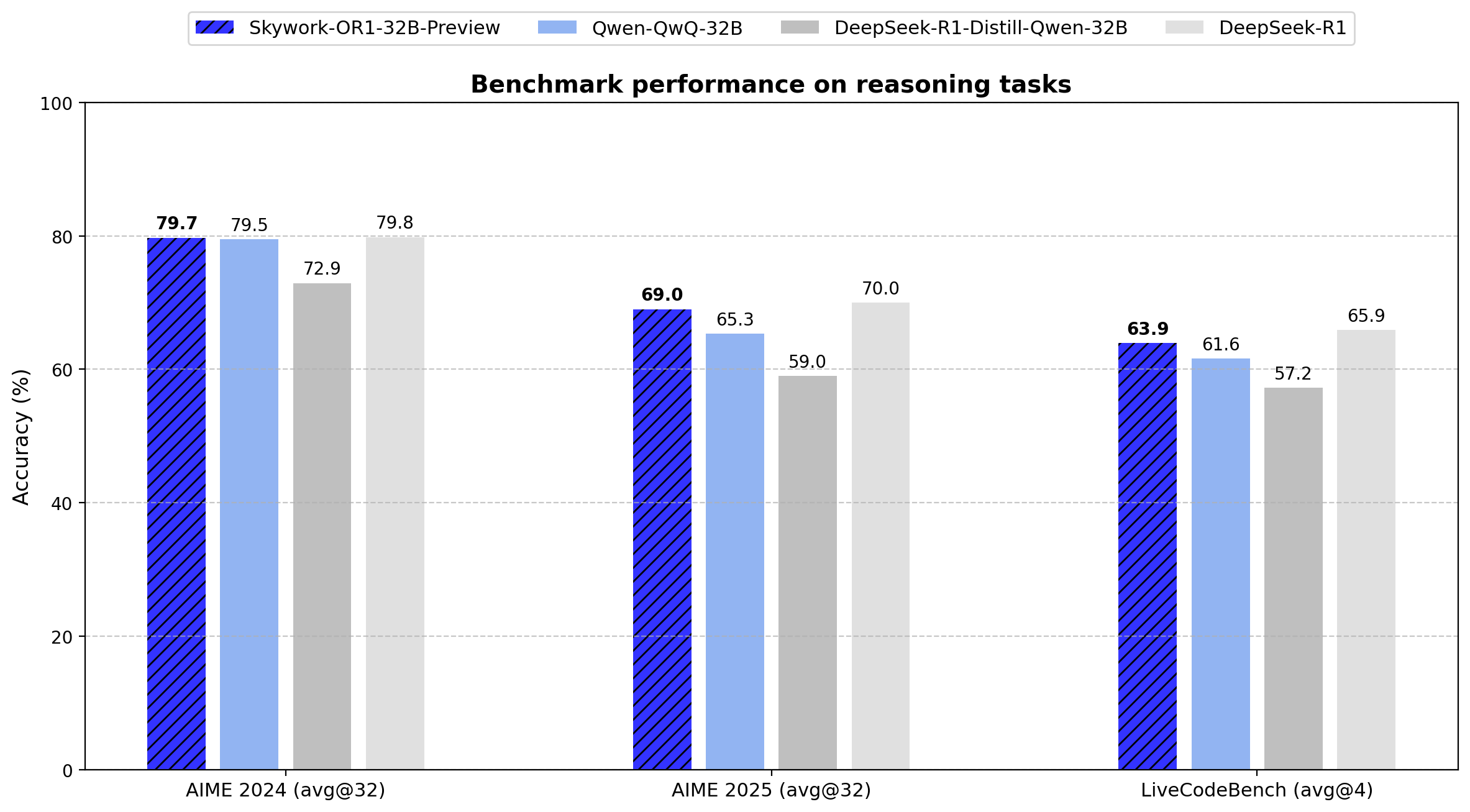
Skywork تطلق سلسلة نماذج الاستدلال مفتوحة المصدر OR1: أطلقت الشركة الصينية Skywork (Tiangong – Kunlun Wanwei) سلسلة نماذج استدلال مفتوحة المصدر جديدة Skywork OR1. تتضمن السلسلة OR1-Math-7B المحسن للرياضيات، بالإضافة إلى الإصدارات التجريبية OR1-7B و OR1-32B التي تتفوق في الرياضيات والترميز، حيث يُقال إن إصدار 32B يضاهي DeepSeek-R1 في القدرات الرياضية. تم الإشادة بـ Skywork لدرجة انفتاحها، حيث أصدرت أوزان النماذج وبيانات التدريب وكود التدريب الكامل. (المصدر: natolambert)
تحسين قدرة الروبوتات المدفوعة بالذكاء الاصطناعي على التنقل والتشغيل الدقيق: تعرض وسائل التواصل الاجتماعي قدرة الروبوتات المستقلة المدفوعة بالذكاء الاصطناعي على التنقل بدقة وتنفيذ المهام في بيئات معقدة. قد تستخدم هذه الروبوتات تقنيات الذكاء الاصطناعي مثل رؤية الكمبيوتر، SLAM (التوطين المتزامن ورسم الخرائط)، والتعلم المعزز، لتحقيق التشغيل الفعال في البيئات غير المهيكلة أو الديناميكية، مما يوضح التقدم في إدراك الروبوتات وتخطيطها وتحكمها. (المصدر: Ronald_vanLoon)
هيكل خارجي مدفوع بالذكاء الاصطناعي يساعد مستخدمي الكراسي المتحركة على المشي: يعرض جهاز هيكل خارجي متقدم يستخدم تقنية الذكاء الاصطناعي، قادر على مساعدة مستخدمي الكراسي المتحركة على الوقوف والمشي مرة أخرى. قد يُستخدم الذكاء الاصطناعي فيه لتفسير نوايا المستخدم، والحفاظ على التوازن، وتنسيق الحركة، والتكيف مع البيئات المختلفة، مما يجسد إمكانات الذكاء الاصطناعي في تحسين نوعية حياة الأشخاص ذوي الإعاقة، ويمثل تقدمًا مهمًا في تكنولوجيا الروبوتات المساعدة. (المصدر: Ronald_vanLoon)
مخاوف من استخدام وكلاء الذكاء الاصطناعي (AI Agent) في الهجمات السيبرانية: يشير مقال في MIT Technology Review إلى أن وكلاء الذكاء الاصطناعي المستقلين قد يُستخدمون لتنفيذ هجمات سيبرانية معقدة. لدى هؤلاء الوكلاء القدرة على اكتشاف الثغرات الأمنية تلقائيًا، وتوليد كود الهجوم وتنفيذه، وقد يتجاوز نطاق وسرعة القراصنة البشريين بكثير، مما يشكل تحديًا خطيرًا لأنظمة الدفاع السيبراني الحالية. يثير هذا مخاوف بشأن تسليح الذكاء الاصطناعي والمخاطر الأمنية. (المصدر: Ronald_vanLoon)

OpenAI تلمح إلى حدث بث مباشر واحتمال إطلاق نماذج جديدة: ألمحت OpenAI من خلال رسالة غامضة (مطورون وثقب أسود فائق الكتلة) إلى حدث بث مباشر، بينما تنتشر على الإنترنت معلومات حول تحديث أيقونات وبطاقات نماذج على موقعها الرسمي، مما يشير إلى احتمال إطلاق وشيك لعدة نماذج جديدة، بما في ذلك سلسلة GPT-4.1 (مع إصدارات nano و mini)، و o4-mini، والإصدار الكامل من o3. يشير هذا إلى أن OpenAI قد تستعد لإطلاق سلسلة من المنتجات الجديدة أو تحديثات النماذج لمواجهة المنافسة المتزايدة في السوق. (المصدر: openai, op7418)

روبوت Figure يتعلم المشي الطبيعي من المحاكاة إلى الواقع عبر التعلم المعزز: استخدمت Figure AI التعلم المعزز (RL) لتدريب روبوتها البشري Figure 02 بنجاح على إتقان مشية طبيعية في بيئة محاكاة بحتة. من خلال محاكيات فعالة لتوليد كميات كبيرة من البيانات، وبالاقتران مع عشوائية المجال وردود فعل عزم الدوران عالية التردد من جسم الروبوت، تم تحقيق نقل الاستراتيجية من المحاكاة إلى الواقع بدون عينات (zero-shot transfer). لا تسرع هذه الطريقة عملية التطوير فحسب، بل تثبت أيضًا جدوى التحكم في روبوتات متعددة بواسطة استراتيجية شبكة عصبونية واحدة، مما له أهمية كبيرة للتطبيقات التجارية المستقبلية للروبوتات. (المصدر: خوارزمية واحدة تتحكم في جيش من الروبوتات! تعلم معزز في بيئة محاكاة بحتة، Figure يتعلم المشي مثل الإنسان)
🧰 الأدوات
Jimm AI 3.0 يولد تصميمات نصية منمقة ومشاركة Prompt: شارك مستخدم تجربته وطريقته في استخدام أداة الرسم بالذكاء الاصطناعي الصينية “Jimm AI 3.0” لتوليد صور نصية ذات طابع تصميمي. نظرًا لأن تحديد أسماء الخطوط مباشرة لم يكن فعالاً، أنشأ المؤلف قالبًا تفصيليًا للمطالبات (prompt template) يتضمن أنماطًا بصرية متعددة محددة مسبقًا (مثل النمط الصناعي، النمط اللطيف، النمط التكنولوجي، نمط الحبر المائي، إلخ)، ووضع قواعد لجعل الذكاء الاصطناعي يطابق أو يدمج الأنماط تلقائيًا بناءً على معنى وعاطفة النص المدخل. يحتاج المستخدمون فقط إلى إدخال النص المستهدف (مثل “فتى الرياضات الإلكترونية”، “أريد حقًا تناول الحلوى”)، ويمكن للقالب توليد مطالبة رسم كاملة تتضمن النمط والخلفية والتخطيط والجو، وبالتالي الحصول على تأثيرات تصميم نصية وصورية عالية الجودة في Jimm AI. يوفر المقال قالب المطالبة هذا والعديد من الأمثلة المولدة. (المصدر: Jimm AI 3.0 لإنشاء أغلفة تحتوي على خطوط، هذا الحل رائع للغاية [مرفق: 16+ حالة و Prompt], لقد فهمت تصميم الخطوط بواسطة الذكاء الاصطناعي قليلاً، استخدم هذه المجموعة من Prompt لزيادة الكفاءة بنسبة 50٪.)
استخدام الذكاء الاصطناعي متعدد الوسائط لتحويل صور الطعام إلى صور بنمط قائمة الطعام: عرض مستخدمو وسائل التواصل الاجتماعي تقنية تستخدم نماذج الذكاء الاصطناعي متعددة الوسائط مثل GPT-4o لتحويل صور الطعام العادية إلى صور قائمة طعام متقنة. تعتمد الطريقة على تزويد الذكاء الاصطناعي بالصورة الأصلية، مع مطالبات وصفية (على سبيل المثال، الإشارة إلى “معايير وأسلوب قائمة طعام فندق خمس نجوم فاخر”)، لتوجيه الذكاء الاصطناعي لإجراء معالجة أسلوبية وتحرير للصورة، وتوليد صور عرض أطباق ذات طابع احترافي. يجسد هذا الإمكانات العملية للذكاء الاصطناعي متعدد الوسائط في فهم الصور وتحريرها ونقل الأسلوب. (المصدر: karminski3)

Slideteam.net: قد تكون أداة إنشاء شرائح فورية مدفوعة بالذكاء الاصطناعي: أشارت وسائل التواصل الاجتماعي إلى أن Slideteam.net يمكنه إنشاء شرائح مثالية “فوريًا”، مما يشير إلى أنه قد يستخدم تقنية الذكاء الاصطناعي لأتمتة تصميم وتوليد العروض التقديمية. عادةً ما تحقق مثل هذه الأدوات وظائف مثل التخطيط التلقائي واقتراح المحتوى ومطابقة الأسلوب من خلال الذكاء الاصطناعي، بهدف زيادة كفاءة إنتاج عروض PowerPoint التقديمية. (المصدر: Ronald_vanLoon)
عرض روبوت تدليك يعمل بالذكاء الاصطناعي: يعرض الفيديو روبوت تدليك مدفوعًا بالذكاء الاصطناعي. يجمع الروبوت بين قدرات التشغيل المادي للذراع الروبوتية والتحكم الذكي للذكاء الاصطناعي. قد يُستخدم الذكاء الاصطناعي لفهم احتياجات المستخدم، وتحديد أجزاء الجسم، وتخطيط مسارات التدليك، وضبط القوة والتقنيات، وحتى استشعار ردود فعل المستخدم من خلال أجهزة الاستشعار لتحسين تجربة التدليك، مما يوضح إمكانات تطبيق الذكاء الاصطناعي في خدمات الصحة الشخصية والعلاج الطبيعي الآلي. (المصدر: Ronald_vanLoon)
دمج GitHub Copilot في Windows Terminal: قامت Microsoft بدمج وظيفة GitHub Copilot في إصدار Canary التجريبي من Windows Terminal، وأطلقت عليها اسم “Terminal Chat”. يمكن للمستخدمين المشتركين بالفعل في Copilot التفاعل مباشرة مع الذكاء الاصطناعي داخل بيئة الطرفية، والحصول على اقتراحات وتفسيرات ومساعدة لسطر الأوامر. تهدف هذه الخطوة إلى تقليل حاجة المطورين إلى التبديل بين التطبيقات عند كتابة الأوامر، وتوفير مساعدة ذكية من خلال الوعي بالسياق، وزيادة كفاءة ودقة عمليات سطر الأوامر، خاصة للمهام المعقدة أو غير المألوفة. (المصدر: GitHub Copilot يعمل الآن في Windows Terminal)
مناقشة متطلبات الأجهزة لنشر OpenWebUI: ناقش مستخدمو مجتمع Reddit تكوين جهاز Azure الظاهري المطلوب لنشر OpenWebUI (واجهة ويب لـ LLM) لفريق مكون من حوالي 30 شخصًا. يخطط المستخدم لتشغيل نموذج تضمين Snowflake محليًا واستخدام OpenAI API. تتضمن المناقشة توسيع الموارد، وتأثير حجم نموذج التضمين على وحدة المعالجة المركزية/ذاكرة الوصول العشوائي/التخزين، وأهمية المعالجة المسبقة للبيانات. يقترح المجتمع أن الاعتماد الكبير على API يمكن أن يقلل من متطلبات الأجهزة المحلية، ولكن إذا تم تشغيل النماذج محليًا (خاصة نماذج التضمين)، فستكون هناك حاجة إلى تكوين أقوى. بالنسبة للحالات ذات الموارد المحدودة، يُقترح أيضًا استخدام API لمعالجة التضمين. (المصدر: Reddit r/OpenWebUI)
📚 التعلم
نماذج الذكاء الاصطناعي الاستدلالية تعاني من عيب “التفكير المفرط” في غياب الفرضيات الضرورية: كشفت دراسة أجرتها جامعة ميريلاند ومؤسسات أخرى أن نماذج الاستدلال الحالية (مثل DeepSeek-R1, o1)، عند مواجهة مشاكل تفتقر إلى المعلومات الضرورية (فرضية مفقودة، MiP)، تميل إلى توليد إجابات مطولة وغير فعالة بدلاً من تحديد عيوب المشكلة نفسها بسرعة. تؤدي ظاهرة “التفكير المفرط في MiP” هذه إلى إهدار موارد الحوسبة، ولا ترتبط كثيرًا بقدرة النموذج على إدراك غياب الفرضية في النهاية. بالمقارنة، أداء النماذج غير الاستدلالية أفضل. تعتقد الدراسة أن هذا يكشف عن افتقار نماذج الاستدلال الحالية إلى القدرة على التفكير النقدي، وقد ينبع من نموذج تدريب التعلم المعزز أو عملية تقطير المعرفة. (المصدر: إدمان “التخيل” في الذكاء الاصطناعي الاستدلالي، مليء بالكلام الزائد، باحث صيني من ميريلاند يكشف الحقيقة)

CVPR 2025: CADCrafter يحقق توليد ملفات CAD قابلة للتعديل من صورة واحدة: اقترح باحثون من Magic Core Technology وجامعة نانيانغ التكنولوجية ومؤسسات أخرى إطار عمل CADCrafter، القادر على توليد ملفات هندسية CAD معلمة وقابلة للتعديل مباشرة من صورة واحدة (صورة عرض للجزء، صورة لشيء حقيقي، إلخ) (ممثلة كسلسلة أوامر CAD)، بدلاً من نماذج الشبكات أو سحابة النقاط التقليدية. تستخدم الطريقة VAE لترميز أوامر CAD، وتجمع بين Diffusion Transformer لتوليد الفضاء الكامن المشروط بالصورة، وتحسن الأداء من خلال استراتيجية التقطير من متعدد المشاهدات إلى مشهد واحد، وتستخدم DPO لتحسين وضمان قابلية تجميع الأوامر المولدة. يمكن استخدام ملفات CAD المولدة مباشرة في الإنتاج والمعالجة، وتدعم تعديل النموذج عن طريق تحرير الأوامر، مما يعزز بشكل كبير من قابلية استخدام وجودة سطح النماذج ثلاثية الأبعاد المولدة بواسطة الذكاء الاصطناعي. (المصدر: توليد ملف CAD هندسي مباشرة من صورة واحدة! بحث جديد في CVPR 2025 يحل مشكلة “عدم قابلية التعديل” لنماذج 3D المولدة بالذكاء الاصطناعي | من إنتاج Magic Core Technology و NTU وغيرهم)
جامعة تشجيانغ و OPPO وغيرهم ينشرون مراجعة شاملة لوكلاء نظام التشغيل (OS Agents): تلخص هذه الورقة البحثية بشكل منهجي الوضع الحالي لأبحاث وكلاء نظام التشغيل الذكيين (OS Agents) القائمة على نماذج اللغة الكبيرة متعددة الوسائط (MLLM). يشير مصطلح OS Agents إلى الذكاء الاصطناعي القادر على تنفيذ المهام تلقائيًا على أجهزة الكمبيوتر والهواتف المحمولة وغيرها من الأجهزة من خلال واجهة نظام التشغيل (GUI). تحدد الورقة عناصرها الرئيسية (البيئة، مساحة الملاحظة، مساحة العمل)، والقدرات الأساسية (الفهم، التخطيط، التنفيذ)، وتستعرض طرق البناء (بنية النموذج الأساسي والتدريب، تصميم إطار عمل الوكيل)، وتلخص بروتوكولات التقييم، واختبارات القياس، والمنتجات التجارية ذات الصلة. أخيرًا، تناقش التحديات والاتجاهات المستقبلية مثل الأمان والخصوصية، والتخصيص والتطور الذاتي، مما يوفر مرجعًا شاملاً للبحث في هذا المجال. (المصدر: جامعة تشجيانغ و OPPO وغيرهم ينشرون أحدث مراجعة شاملة: بحث حول وكلاء الكمبيوتر والهاتف المحمول والمتصفح الذكيين القائمين على نماذج اللغة الكبيرة متعددة الوسائط)
ICLR 2025: Nabla-GFlowNet يحقق ضبطًا دقيقًا فعالاً ومتنوعًا لمكافآت نماذج الانتشار: لمعالجة مشاكل التقارب البطيء (RL التقليدي) أو فقدان التنوع (التحسين المباشر) في الضبط الدقيق لمكافآت نماذج الانتشار، اقترح الباحثون طريقة Nabla-GFlowNet. تعتمد هذه الطريقة على إطار عمل شبكة التدفق التوليدي (GFlowNet)، وتشتق شرط توازن تدفق جديد (Nabla-DB) ودالة خسارة، وتستخدم معلومات تدرج المكافأة لتوجيه الضبط الدقيق. من خلال تصميم معلمي محدد، مع الحفاظ على تنوع العينات المولدة، تحقق سرعة تقارب أسرع من طرق مثل DDPO، وتم التحقق منها على نموذج Stable Diffusion باستخدام وظائف مكافأة مثل الجماليات واتباع التعليمات، وتفوقت على الطرق الحالية. (المصدر: ICLR 2025 | اختراق جديد في الضبط الدقيق لمكافآت نماذج الانتشار! Nabla-GFlowNet يجمع بين التنوع والكفاءة)
تحليل آلية الاستدلال في DeepSeek-R1: حللت دراسة من جامعة McGill بعمق عملية “التفكير” في نماذج الاستدلال مثل DeepSeek-R1. وجدت الدراسة أن طول سلسلة الاستدلال والأداء ليسا مرتبطين بشكل إيجابي، فهناك “نقطة مثلى”، وقد يكون الاستدلال الطويل جدًا ضارًا. قد يقع النموذج في حلقة مفرغة من التفكير في التعبيرات الموجودة بالفعل عند التعامل مع سياقات طويلة أو مشاكل معقدة. بالإضافة إلى ذلك، مقارنة بالنماذج غير الاستدلالية، قد يكون لدى DeepSeek-R1 ثغرات أمنية أكثر وضوحًا. تكشف هذه الدراسة عن بعض خصائص وقيود آليات عمل نماذج الاستدلال الحالية. (المصدر: ملخص LLM الأسبوعي! | يشمل الوسائط المتعددة، نماذج MoE، استدلال Deepseek، التحكم في أمان Agent، تكميم النماذج، إلخ)
طريقة جديدة C3PO لتحسين نماذج MoE في وقت الاختبار: اقترحت جامعة جونز هوبكنز طريقة C3PO (الطبقات الحرجة، الخبراء الأساسيون، تحسين المسار التعاوني) لتحسين أداء نماذج اللغة الكبيرة من نوع مزيج الخبراء (MoE) في وقت الاختبار. تعمل هذه الطريقة عن طريق إعادة ترجيح الخبراء الأساسيين في الطبقات الحرجة، والتحسين لكل عينة اختبار على حدة، لحل مشكلة مسارات الخبراء دون المستوى الأمثل. أظهرت التجارب أن C3PO يمكن أن يحسن بشكل كبير دقة نماذج MoE (بنسبة 7-15٪)، حتى أنه يجعل أداء نماذج MoE ذات البارامترات الصغيرة يتجاوز أداء النماذج الكثيفة ذات البارامترات الأكبر، مما يزيد من كفاءة بنية MoE. (المصدر: ملخص LLM الأسبوعي! | يشمل الوسائط المتعددة، نماذج MoE، استدلال Deepseek، التحكم في أمان Agent، تكميم النماذج، إلخ)
دراسة منهجية لتأثير التكميم على أداء نماذج الاستدلال: قامت جامعة تسينغهوا ومؤسسات أخرى لأول مرة بدراسة تأثير تكميم النماذج بشكل منهجي على أداء نماذج الاستدلال (مثل DeepSeek-R1، سلسلة Qwen). قيمت التجارب تأثير التكميم تحت عروض بت مختلفة (الأوزان، ذاكرة التخزين المؤقت KV، قيم التنشيط) وخوارزميات مختلفة. وجدت الدراسة أن تكميم W8A8 أو W4A16 عادة ما يحقق أداءً بدون فقدان أو قريبًا منه، ولكن عروض البت الأقل تزيد المخاطر بشكل كبير. حجم النموذج ومصدره وصعوبة المهمة كلها عوامل رئيسية تؤثر على الأداء بعد التكميم. تم فتح مصدر نتائج الدراسة والنماذج المكممة. (المصدر: ملخص LLM الأسبوعي! | يشمل الوسائط المتعددة، نماذج MoE، استدلال Deepseek، التحكم في أمان Agent، تكميم النماذج، إلخ)
APIGen-MT: إطار عمل لتوليد بيانات تفاعل Agent متعددة الأدوار عالية الجودة: اقترحت Salesforce إطار عمل APIGen-MT، بهدف حل مشكلة ندرة البيانات عالية الجودة اللازمة لتدريب وكلاء الذكاء الاصطناعي التفاعليين متعددي الأدوار (AI Agent). ينقسم الإطار إلى مرحلتين: أولاً، استخدام مراجعة LLM وردود الفعل التكرارية لتوليد مخطط مهمة مفصل، ثم تحويل المخطط إلى بيانات مسار كاملة من خلال محاكاة التفاعل بين الإنسان والآلة. أظهرت سلسلة نماذج xLAM-2 المدربة بناءً على هذا الإطار أداءً متميزًا في اختبارات قياس Agent متعددة الأدوار، متجاوزة نماذج مثل GPT-4o، مما يثبت فعالية طريقة توليد البيانات هذه. تم فتح مصدر البيانات الاصطناعية والنماذج. (المصدر: ملخص LLM الأسبوعي! | يشمل الوسائط المتعددة، نماذج MoE، استدلال Deepseek، التحكم في أمان Agent، تكميم النماذج، إلخ)
دراسة تكشف: سلسلة أفكار أطول لا تعني أداء استدلال أقوى، التعلم المعزز يمكن أن يكون أكثر إيجازًا: تشير دراسة أجرتها Wand AI إلى أن نماذج الاستدلال (خاصة تلك المدربة بخوارزميات RL مثل PPO) تميل إلى توليد استجابات أطول، ليس بسبب الحاجة إلى الدقة، ولكن لأن آلية RL نفسها قد تؤدي إلى ذلك: بالنسبة للإجابات الخاطئة (مكافأة سلبية)، يمكن أن يؤدي إطالة الاستجابة إلى “تخفيف” عقوبة كل رمز (token)، وبالتالي تقليل الخسارة. تثبت الدراسة أن الاستدلال الموجز يرتبط بدقة أعلى، وتقترح طريقة تدريب RL من مرحلتين: أولاً، التدريب باستخدام مشاكل صعبة لتعزيز القدرة (مما قد يزيد طول الاستجابة)، ثم التدريب باستخدام مشاكل ذات صعوبة معتدلة للحث على الإيجاز والحفاظ على الدقة، حتى على مجموعات بيانات صغيرة جدًا يمكن أن يعزز الأداء والمتانة بشكل فعال. (المصدر: تفكير أطول لا يعني أداء استدلال أقوى، التعلم المعزز يمكن أن يكون موجزًا جدًا)
جامعة العلوم والتكنولوجيا الصينية و ZTE تقترحان Curr-ReFT: نموذج جديد لما بعد التدريب لنماذج VLM صغيرة الحجم: لمواجهة المشاكل التي تواجهها نماذج اللغة المرئية الصغيرة (VLM) بعد الضبط الدقيق الخاضع للإشراف، مثل ضعف القدرة على التعميم، ومحدودية القدرة على الاستدلال، وعدم استقرار التدريب (ظاهرة “الجدار الطوبي”)، اقترحت جامعة العلوم والتكنولوجيا الصينية و ZTE نموذج ما بعد التدريب Curr-ReFT. تجمع هذه الطريقة بين التعلم المعزز المنهجي (Curr-RL) والتحسين الذاتي القائم على أخذ العينات بالرفض. يوجه Curr-RL النموذج للتعلم تدريجيًا من السهل إلى الصعب من خلال آلية مكافأة حساسة للصعوبة؛ بينما يحافظ أخذ العينات بالرفض على القدرات الأساسية للنموذج باستخدام عينات عالية الجودة. أظهرت التجارب على نماذج Qwen2.5-VL-3B/7B أن Curr-ReFT يعزز بشكل كبير أداء الاستدلال والتعميم للنماذج، مما يجعل النماذج الصغيرة تتفوق على النماذج الكبيرة في العديد من معايير القياس. تم فتح مصدر الكود والبيانات والنماذج. (المصدر: جامعة العلوم والتكنولوجيا الصينية و ZTE تقترحان نموذجًا جديدًا لما بعد التدريب: نماذج متعددة الوسائط صغيرة الحجم، تنجح في تكرار استدلال R1)
جامعة تسينغهوا ومختبر شنغهاي للذكاء الاصطناعي يقترحان GenPRM: نموذج مكافأة عملية توليدي قابل للتوسيع: لحل مشكلة افتقار نماذج مكافأة العملية التقليدية (PRM) إلى القابلية للتفسير والقدرة على التوسع في وقت الاختبار عند الإشراف على استدلال LLM، اقترحت جامعة تسينغهوا ومختبر شنغهاي للذكاء الاصطناعي GenPRM. يقوم بتقييم خطوات الاستدلال من خلال توليد سلسلة أفكار باللغة الطبيعية (CoT) وكود تحقق قابل للتنفيذ، مما يوفر ردود فعل أكثر شفافية. يدعم GenPRM التوسع الحسابي في وقت الاختبار، من خلال أخذ عينات من مسارات تقييم متعددة ومتوسط المكافآت لتعزيز الدقة. تم تدريب هذا النموذج باستخدام 23 ألف بيانات اصطناعية فقط، وتجاوز إصدار 1.5B بالفعل GPT-4o بمساعدة التوسع في وقت الاختبار، وتجاوز إصدار 7B نموذج خط الأساس 72B. يمكن أيضًا استخدام GenPRM كناقد على مستوى الخطوة للتحسين التكراري للإجابات. (المصدر: هل يمكن توسيع نموذج مكافأة العملية أيضًا في وقت الاختبار؟ جامعة تسينغهوا ومختبر شنغهاي للذكاء الاصطناعي بـ 23 ألف بيانات تجعل نموذج 1.5B الصغير يتفوق على GPT-4o)
إطلاق MegaMath، أكبر مجموعة بيانات رياضيات مفتوحة المصدر في العالم (371 مليار Token): أطلقت LLM360 مجموعة بيانات MegaMath، التي تحتوي على 371 مليار رمز (token)، وهي حاليًا أكبر مجموعة بيانات تدريب مسبق مفتوحة المصدر في العالم تركز على الاستدلال الرياضي، وتهدف إلى سد الفجوة في الحجم والجودة بين مجتمع المصادر المفتوحة ومجموعات النصوص الرياضية مغلقة المصدر (مثل DeepSeek-Math). تتكون مجموعة البيانات من ثلاثة أجزاء: بيانات صفحات ويب واسعة النطاق ذات صلة بالرياضيات (279 مليار، بما في ذلك مجموعة فرعية عالية الجودة تبلغ 15 مليار)، وكود رياضي (28 مليار)، وبيانات اصطناعية عالية الجودة (64 مليار، بما في ذلك أسئلة وأجوبة، وتوليد كود، ومزيج من النصوص والصور). بعد معالجة دقيقة والتحقق من خلال جولات متعددة من التدريب المسبق، أدى استخدام MegaMath للتدريب المسبق على نموذج Llama-3.2 إلى تحسين كبير في الأداء بنسبة 15-20٪ على معايير مثل GSM8K و MATH. (المصدر: 371 مليار رمز رياضي! إطلاق MegaMath، أكبر مجموعة بيانات رياضيات مفتوحة المصدر في العالم، تتفوق على DeepSeek-Math)
CVPR 2025: NLPrompt يعزز متانة تعلم التلقين في VLM تحت التسميات المشوشة: اقترح مختبر YesAI Lab بجامعة شنغهاي للتكنولوجيا طريقة NLPrompt، التي تهدف إلى حل مشكلة انخفاض أداء تعلم التلقين في نماذج اللغة المرئية (VLM) عند مواجهة تشويش التسميات. وجدت الدراسة أنه في سيناريوهات تعلم التلقين، يكون متوسط الخطأ المطلق (MAE) (PromptMAE) أكثر متانة من خسارة الانتروبيا المتقاطعة (CE). في الوقت نفسه، تم اقتراح طريقة تنقية البيانات PromptOT القائمة على النقل الأمثل، باستخدام الميزات النصية التي تم إنشاؤها بواسطة التلقين كنماذج أولية، لتقسيم مجموعة البيانات إلى مجموعة نظيفة ومجموعة مشوشة. يطبق NLPrompt خسارة CE على المجموعة النظيفة وخسارة MAE على المجموعة المشوشة، مما يجمع بشكل فعال بين مزايا كليهما. أثبتت التجارب أن هذه الطريقة تعزز بشكل كبير متانة وأداء طرق تعلم التلقين مثل CoOp على مجموعات البيانات المشوشة الاصطناعية والحقيقية. (المصدر: CVPR 2025 | خسارة MAE + النقل الأمثل يجتمعان! جامعة شنغهاي للتكنولوجيا تقترح طريقة تعلم تلقين متينة جديدة تمامًا)
تطبيق ومناقشة تقنية تقطير المعرفة في ضغط النماذج: ناقش المجتمع تقنية تقطير المعرفة، أي استخدام نموذج “معلم” كبير لتدريب نموذج “طالب” صغير، لجعله يحقق أداءً قريبًا من أداء المعلم في مهمة محددة، ولكن بتكلفة أقل بكثير. شارك أحد المستخدمين نجاحه في تقطير قدرة GPT-4o في مهمة تحليل المشاعر (دقة 92٪) إلى نموذج صغير، مما أدى إلى خفض التكلفة بمقدار 14 مرة. أشارت التعليقات إلى أنه على الرغم من أن تأثير التقطير كبير، إلا أنه يقتصر عادةً على مجال معين، ويفتقر النموذج الطالب إلى قدرة التعميم لدى النموذج المعلم. في الوقت نفسه، بالنسبة للسيناريوهات المهنية التي تتطلب التكيف المستمر مع تغييرات البيانات، قد تكون تكلفة صيانة نموذج مدرب ذاتيًا أعلى من استخدام API كبير مباشرة. (المصدر: Reddit r/MachineLearning)

تعريف وكيل الذكاء الاصطناعي (AI Agent) يثير الاهتمام: بدأت شركات استشارية مثل McKinsey في تعريف ومناقشة مفهوم وكيل الذكاء الاصطناعي (AI Agent)، مما يعكس الأهمية المتزايدة لوكلاء الذكاء الاصطناعي ككيانات ذكية قادرة على الإدراك واتخاذ القرار والتصرف بشكل مستقل لتحقيق الأهداف في مجالات الأعمال والتكنولوجيا. أصبح فهم تعريف وقدرات وسيناريوهات تطبيق وكلاء الذكاء الاصطناعي محور اهتمام الصناعة. (المصدر: Ronald_vanLoon)

💼 الأعمال
فك رموز استراتيجية الذكاء الاصطناعي لـ Alibaba: التركيز على AGI، إعادة الاستثمار في البنية التحتية لتعزيز التحول: يشير التحليل إلى أنه على الرغم من أن Alibaba لم تصدر رسميًا استراتيجية للذكاء الاصطناعي، إلا أن أفعالها كشفت عن صورة واضحة: السعي لتحقيق الذكاء الاصطناعي العام (AGI) كهدف أساسي، على أمل استعادة المبادرة في المنافسة. تخطط لاستثمار أكثر من 380 مليار يوان صيني على مدى السنوات الثلاث المقبلة في بناء البنية التحتية للذكاء الاصطناعي والحوسبة السحابية، مع التركيز على تلبية الطلب المتزايد على الاستدلال. تشمل المسارات الاستراتيجية: الترويج لقدرات AI Agent من خلال DingTalk؛ الاستفادة من سلسلة نماذج Qwen مفتوحة المصدر لدفع نمو Alibaba Cloud؛ تطوير نموذج MaaS لواجهة برمجة تطبيقات Tongyi. في الوقت نفسه، ستستخدم Alibaba الذكاء الاصطناعي لتحويل أعمالها الحالية بعمق، مثل تحسين تجربة مستخدم Taobao، وتحويل Quark إلى تطبيق AI رائد (بحث + Agent)، واستكشاف تطبيقات الذكاء الاصطناعي في خدمات الحياة عبر خرائط AutoNavi (Gaode). قد تسرع Alibaba أيضًا من تخطيطها للذكاء الاصطناعي من خلال الاستثمار والاستحواذ. (المصدر: فك رموز استراتيجية الذكاء الاصطناعي لـ Alibaba: لم تُنشر أبدًا، لكنها بدأت بالفعل في الانطلاق بقوة)
اتجاهات جديدة في سوق مواهب الذكاء الاصطناعي: التركيز على الممارسة بدلاً من الشهادات، وتفضيل القدرات المركبة: بناءً على تحليل ما يقرب من 3000 وظيفة ذات رواتب عالية في مجال الذكاء الاصطناعي في المدن الصينية الرئيسية، يكشف التقرير عن ثلاثة اتجاهات رئيسية في الطلب على مواهب الذكاء الاصطناعي: 1) الطلب القوي على مهندسي الخوارزميات، مع رواتب مجزية، وأصبحت صناعة السيارات قوة توظيف رئيسية؛ 2) الشركات (بما في ذلك الشركات البارزة مثل DeepSeek) تقلل تدريجياً من المتطلبات الصارمة للمؤهلات التعليمية، وتركز بشكل أكبر على القدرات الهندسية العملية والخبرة في حل المشكلات المعقدة؛ 3) زيادة الطلب على المواهب المركبة، على سبيل المثال، يحتاج مديرو منتجات الذكاء الاصطناعي إلى فهم المستخدمين والنماذج وهندسة المطالبات (prompt engineering) في نفس الوقت، لأن الذكاء الاصطناعي يتولى المزيد من المهام المتخصصة، مما يتطلب من البشر التكامل والإشراف على مستوى أعلى. (المصدر: من بيانات التوظيف لما يقرب من 3000 وظيفة، وجدت ثلاث قواعد حديدية لاكتشاف مواهب الذكاء الاصطناعي)
Ubtech تستمر في الخسارة، وتحديات تسويق الروبوتات البشرية شديدة: أظهر التقرير المالي لشركة الروبوتات البشرية Ubtech لعام 2024 أنه على الرغم من نمو الإيرادات بنسبة 23.7٪ لتصل إلى 1.3 مليار يوان، إلا أنها لا تزال تخسر 1.16 مليار يوان. يتقدم تسويق أعمالها الأساسية في مجال الروبوتات البشرية ببطء، حيث تم تسليم 10 وحدات فقط على مدار العام، بسعر وحدة يصل إلى 3.5 مليون يوان، وهو ما يتجاوز بكثير توقعات السوق والمنافسين (مثل Unitree G1 الذي يباع بسعر 99 ألف يوان فقط). بالإضافة إلى ذلك، أثارت الأنباء عن مشاكل في سلسلة التوريد المالية لشركة Data Robotics، وهي شركة رائدة أخرى في الصناعة، شكوكًا حول الجدوى التجارية لصناعة الروبوتات البشرية، مما يؤكد وجهة نظر المستثمر Zhu Xiaohu الحذرة سابقًا. التكاليف الباهظة، وسيناريوهات التطبيق المحدودة، والموثوقية والأمان هي العقبات الرئيسية أمام التسويق واسع النطاق للروبوتات البشرية حاليًا. (المصدر: Ubtech تخسر ما يقرب من 1.2 مليار يوان في عام واحد، Zhu Xiaohu لديه الآن المزيد ليقوله)

الذكاء الاصطناعي يدفع النمو في قطاعات الاتصالات والتكنولوجيا المتقدمة والإعلام: تشير المناقشة إلى أن الذكاء الاصطناعي (بما في ذلك الذكاء الاصطناعي التوليدي) أصبح قوة رئيسية تدفع النمو في قطاعات الاتصالات والتكنولوجيا المتقدمة والإعلام. تُستخدم تقنيات الذكاء الاصطناعي على نطاق واسع لتحسين تجربة العملاء، وتحسين عمليات الشبكة، وأتمتة إنشاء المحتوى، وزيادة الكفاءة التشغيلية، وتطوير خدمات مبتكرة، مما يساعد الشركات في هذه القطاعات على اكتساب ميزة تنافسية في سوق سريع التغير. (المصدر: Ronald_vanLoon)
Hugging Face تستحوذ على شركة الروبوتات مفتوحة المصدر Pollen Robotics: استحوذت منصة نماذج وأدوات الذكاء الاصطناعي الشهيرة Hugging Face على شركة Pollen Robotics الناشئة، المعروفة بروبوتها البشري مفتوح المصدر Reachy. يشير هذا الاستحواذ إلى نية Hugging Face لتوسيع نموذجها الناجح مفتوح المصدر ليشمل مجال روبوتات الذكاء الاصطناعي، بهدف تعزيز التعاون والابتكار في هذا المجال من خلال حلول الأجهزة والبرامج المفتوحة، وتسريع عملية إضفاء الطابع الديمقراطي على تكنولوجيا الروبوتات. (المصدر: huggingface, huggingface, huggingface, huggingface)

🌟 المجتمع
عصر الذكاء الاصطناعي قد يكون أكثر ملاءمة لتطور طلاب العلوم الإنسانية: تعتقد Lynn Duan، مؤسسة مجتمع AI+ في وادي السيليكون، أنه مع قيام أدوات الذكاء الاصطناعي (مثل Cursor) بخفض حاجز البرمجة، تتضاءل أهمية القدرات الهندسية نسبيًا، بينما تصبح المهارات المتعلقة بالعلوم الإنسانية والاجتماعية مثل التسويق التجاري والتواصل أكثر أهمية. يحل الذكاء الاصطناعي محل بعض الوظائف التقنية للمبتدئين، ولكنه يخلق طلبًا على المواهب المركبة القادرة على ربط التكنولوجيا بالسوق. تقترح على الخريجين التفكير في الشركات الناشئة للنمو السريع، وإظهار قدراتهم من خلال المشاريع العملية (مثل نشر النماذج وتطوير التطبيقات) بدلاً من الاعتماد فقط على المؤهلات التعليمية. وتشير أيضًا إلى أن سمات المؤسس (مثل قوة الإيمان وفهم الصناعة) أكثر أهمية من الخلفية التقنية البحتة، وهي متفائلة بشأن فرص ريادة الأعمال في مجال الذكاء الاصطناعي في قطاع SaaS في الولايات المتحدة والأجهزة الذكية في الصين. (المصدر: الذكاء الاصطناعي هو في الواقع عصر جيد لطلاب العلوم الإنسانية | حوار مع Lynn Duan، مؤسسة AI+ في وادي السيليكون)

“حظر” GitHub المؤقت لعناوين IP الصينية يثير القلق، والمسؤولون يقولون إنه خطأ تشغيلي: مؤخرًا، اكتشف بعض المستخدمين الصينيين عدم قدرتهم على الوصول إلى GitHub بدون تسجيل الدخول، مع ظهور رسالة تفيد بتقييد IP، مما أثار قلق المجتمع بشأن احتمال “الحظر”. على الرغم من أن مسؤولي GitHub استجابوا بسرعة قائلين إنه خطأ في التكوين تسبب في ذلك وتم إصلاحه، إلا أن الحادث لا يزال يثير النقاش. نظرًا لأن GitHub قد قيدت في الماضي الوصول من مناطق مثل إيران وروسيا بناءً على سياسات العقوبات الأمريكية، فسر البعض هذا الحادث على أنه “بروفة” لإجراءات تقييدية محتملة. يؤكد المقال على أهمية GitHub للمطورين الصينيين والنظام البيئي مفتوح المصدر (بما في ذلك العديد من مشاريع الذكاء الاصطناعي)، والتأثيرات السلبية المحتملة لمثل هذه القيود، ويسرد منصات استضافة الكود المحلية مثل Gitee و CODING كخيارات بديلة. (المصدر: “خطأ” أم “بروفة”؟ GitHub “يحظر” فجأة جميع عناوين IP الصينية، المسؤولون: مجرد “خطأ يدوي” فني)
أداء وخدمة Claude AI يثيران جدلاً بين المستخدمين: تظهر المناقشات على Reddit أن بعض المستخدمين يعبرون عن عدم رضاهم عن نموذج Claude من Anthropic، مشيرين إلى انخفاض الأداء، وإجراء تعديلات غير ضرورية عند الترميز، وخيبة الأمل بشأن مستويات الدفع وحدود المعدل، حتى أن مطورين معروفين صرحوا بأنهم سيتحولون إلى نماذج أخرى (مثل Gemini 2.5 Pro). ومع ذلك، يعتقد مستخدمون آخرون أن Claude (خاصة الإصدار الأقدم Sonnet 3.5) لا يزال يتمتع بمزايا في مهام محددة (مثل الترميز)، أو يصرحون بأنهم لم يواجهوا قيود المعدل بشكل متكرر. يعكس هذا الجدل الاختلاف في تجارب المستخدمين مع Claude، والتوقعات العالية للمستخدمين بشأن أداء وخدمة نماذج الذكاء الاصطناعي في ظل المنافسة الشديدة. (المصدر: Reddit r/ClaudeAI)

حجم ميزة Deep Research في Gemini يثير النقاش: شارك مستخدم تجربته في استخدام ميزة Deep Research في Google Gemini Advanced، حيث قام الذكاء الاصطناعي بزيارة ما يقرب من 700 موقع ويب للإجابة على سؤال واحد، وأنشأ تقريرًا مطولاً (مثل 37 صفحة). أثار هذا الحجم إعجاب المستخدم، ولكنه أثار أيضًا نقاشًا حول جودة المعلومات. تساءل المعلقون عما إذا كان التعامل مع هذا الكم الهائل من معلومات الويب يمكن أن يضمن الدقة والعمق، أم أنه مجرد تجميع لنتائج بحث الويب التي قد تحتوي على أخطاء على نطاق أوسع. يعكس هذا اهتمام المجتمع ومراجعته لقدرة أدوات البحث بالذكاء الاصطناعي على معالجة المعلومات (العمق مقابل الاتساع). (المصدر: Reddit r/artificial)

قدرات Gemini 2.5 Pro البرمجية تحظى بإشادة المجتمع: شارك العديد من المستخدمين في المجتمع تجاربهم الإيجابية في استخدام Google Gemini 2.5 Pro للبرمجة، معتبرين أنه ذكي للغاية، ويفهم نوايا المستخدم جيدًا، ويمتلك قدرة معالجة سياق طويل تبلغ مليون رمز (token) (كافية لتحليل قواعد الأكواد الكبيرة) وهو مجاني، ويتفوق أداؤه العام على المنافسين مثل Claude. على الرغم من وجود بعض العيوب الصغيرة (مثل هلوسة وظائف مكتبة غير موجودة أحيانًا)، إلا أن التقييم العام مرتفع جدًا، ويعتبر أحد أكثر نماذج الترميز شيوعًا حاليًا، مع التعبير عن الترقب للنماذج الأقوى التي قد تطلقها Google في المستقبل (مثل Dragontail). (المصدر: Reddit r/ArtificialInteligence)
تطور النماذج مفتوحة المصدر الصغيرة سريع، ويحتاج وعي المستخدمين إلى تحديث: تعبر المناقشات في المجتمع عن الدهشة من التقدم السريع لنماذج LLM مفتوحة المصدر. تشير إلى أن نماذج مثل QwQ-32B و Gemma-3-27B، التي تبدو جيدة حاليًا، كانت ستعتبر ثورية لو ظهرت قبل عام أو عامين (عندما تم إطلاق GPT-4 للتو). يذكر هذا الجميع بعدم تجاهل القدرات الفعلية للنماذج مفتوحة المصدر الصغيرة الحالية، فقد وصلت إلى مستوى عالٍ جدًا. تعترف التعليقات أيضًا بأن هذه النماذج لا تزال لديها فجوة مقارنة بالنماذج مغلقة المصدر الأعلى (مثل الاستقرار والسرعة ومعالجة السياق)، لكنها تؤكد على سرعة تقدمها وإمكاناتها، وتعتقد أن الاختراقات المستقبلية قد تتحقق من خلال ابتكار البنية بدلاً من مجرد تكديس البارامترات. (المصدر: Reddit r/LocalLLaMA)
عضو في المجتمع يقدم دعمًا مجانيًا لقوة حوسبة A100 لمشاريع الذكاء الاصطناعي: نشر مستخدم يمتلك 4 وحدات معالجة رسومات Nvidia A100 GPU في مجتمع Reddit، معربًا عن استعداده لتقديم قوة حوسبة مجانية (حوالي 100 ساعة A100) لمشاريع هواة الذكاء الاصطناعي المبتكرة التي تهدف إلى إحداث تأثير إيجابي وتواجه قيودًا في موارد الحوسبة. حظيت هذه المبادرة باستجابة إيجابية، حيث قدم العديد من الباحثين والمطورين خطط مشاريع محددة، تغطي تدريب بنى نماذج جديدة، وقابلية تفسير النماذج، والتعلم المعياري، وتطبيقات التفاعل بين الإنسان والآلة، وغيرها من الاتجاهات، مما يعكس تعطش مجتمع أبحاث الذكاء الاصطناعي لموارد الحوسبة وروح المساعدة المتبادلة والمشاركة. (المصدر: Reddit r/deeplearning)
مشكلة حدود المعدل في Claude AI تثير جدلاً في المجتمع: أثارت الشكاوى حول الوصول المتكرر إلى حدود المعدل عند استخدام نموذج Claude AI (مثل بعد 5 رسائل فقط) جدلاً في المجتمع. شكك بعض المستخدمين بشدة في مثل هذه الشكاوى، معتبرين أنها مبالغ فيها أو ناتجة عن استخدام غير لائق من قبل المستخدم (مثل تحميل سياق طويل جدًا في كل مرة)، وطالبوا بتقديم أدلة. لكن مستخدمين آخرين ظهروا ليؤكدوا أنهم واجهوا بالفعل قيودًا متكررة عند القيام بمهام مكثفة (مثل تحرير الأكواد الكبيرة)، مما أثر على سير عملهم. تعكس المناقشة أن تجارب المستخدمين مع حدود المعدل تختلف اختلافًا كبيرًا، وقد تكون مرتبطة بطريقة الاستخدام المحددة وتعقيد المهمة، وتظهر في الوقت نفسه حساسية المستخدمين لقيود الخدمات المدفوعة. (المصدر: Reddit r/ClaudeAI)
💡 أخرى
مؤتمر النظام البيئي لـ AIGC والوكلاء الذكيين (شنغهاي) يُعقد في يونيو: سيُعقد المؤتمر الثاني للنظام البيئي لـ AIGC والوكلاء الذكيين في شنغهاي في 12 يونيو 2025، تحت شعار “ربط كل شيء بالذكاء · تعايش بلا حدود”. يركز المؤتمر على الابتكار التعاوني والتكامل البيئي للذكاء الاصطناعي التوليدي (AIGC) والوكلاء الذكيين (AI Agent)، ويغطي محتواه البنية التحتية للذكاء الاصطناعي، ونماذج اللغة الكبيرة، والتسويق وتطبيقات AIGC (الإعلام، التجارة الإلكترونية، الصناعة، الرعاية الصحية، إلخ)، وتقنيات الوسائط المتعددة، وأطر اتخاذ القرار المستقلة، وما إلى ذلك. يهدف إلى دفع الذكاء الاصطناعي من أداة فردية إلى ترقية تعاونية للنظام البيئي، وربط مزودي التكنولوجيا، وطالبيها، ورأس المال، وصانعي السياسات. (المصدر: يونيو شنغهاي | قمة شنغهاي “ربط كل شيء بالذكاء”: تكامل النظام البيئي لـ AIGC + الوكلاء الذكيين)

مؤتمر 36Kr AI Partner يركز على Super APP: ستعقد 36Kr “مؤتمر Super APP قادم · 2025 AI Partner” في 18 أبريل 2025 في Shanghai Model Speed Space. يهدف المؤتمر إلى استكشاف كيف تعيد تطبيقات الذكاء الاصطناعي تشكيل عالم الأعمال وتولد “تطبيقات فائقة” ثورية. سيجمع المؤتمر كبار المسؤولين التنفيذيين والمستثمرين من شركات مثل AMD و Baidu و 360 و Qualcomm، لمناقشة الموضوعات الساخنة مثل تحويل الصناعة بالذكاء الاصطناعي، وقوة حوسبة الذكاء الاصطناعي، والبحث بالذكاء الاصطناعي، والتعليم بالذكاء الاصطناعي، وما إلى ذلك، وسيعلن عن حالات ابتكار تطبيقات الذكاء الاصطناعي الأصلية وجوائز AI Partner للابتكار الكبرى. بالتزامن مع ذلك، سيتم عقد صالون AI للجميع وندوة مغلقة حول تصدير الذكاء الاصطناعي. (المصدر: Super App قادم! انظر كيف “تعيد” تطبيقات الذكاء الاصطناعي كتابة عالم الأعمال؟ | النقاط الرئيسية لمؤتمر 2025 AI Partner)

Horizon Robotics توظف متدربين في خوارزميات إعادة البناء/التوليد ثلاثي الأبعاد: يقوم فريق الذكاء الاصطناعي المتجسد في شركة Horizon Robotics بتوظيف متدربين في خوارزميات إعادة البناء/التوليد ثلاثي الأبعاد في شنغهاي وبكين. سيشارك هذا المنصب في تصميم وتطوير خوارزميات Real2Sim، باستخدام تقنيات مثل 3D Gaussian Splatting، وإعادة البناء التغذية الأمامية، وتوليد الفيديو/ثلاثي الأبعاد لتقليل تكلفة الحصول على بيانات الروبوت، وتحسين أداء المحاكيات. يشترط الحصول على درجة الماجستير أو أعلى، مع خبرة ومهارات ذات صلة. توفر فرص التثبيت، وموارد GPU، والتوجيه المهني. (المصدر: توصية داخلية في شنغهاي/بكين | فريق الذكاء الاصطناعي المتجسد في Horizon Robotics يوظف متدربين في خوارزميات إعادة البناء/التوليد ثلاثي الأبعاد)
OceanBase تنظم أول مسابقة هاكاثون للذكاء الاصطناعي: تنظم شركة قواعد البيانات OceanBase بالتعاون مع Ant Open Source و Jiqizhixin وغيرهم أول هاكاثون للذكاء الاصطناعي، تحت شعار “DB+AI”، مع مجموعة جوائز بقيمة 100 ألف يوان. تشجع المسابقة المطورين على استكشاف تكامل OceanBase مع تقنيات الذكاء الاصطناعي، وتشمل الاتجاهات استخدام OceanBase كقاعدة بيانات لتطبيقات الذكاء الاصطناعي، أو بناء تطبيقات الذكاء الاصطناعي (مثل أنظمة الأسئلة والأجوبة والتشخيص) ضمن النظام البيئي لـ OceanBase (بالاقتران مع CAMEL AI و FastGPT وما إلى ذلك). فترة التسجيل من 10 أبريل إلى 7 مايو، وهي مفتوحة للأفراد والفرق. (المصدر: 100 ألف جائزة × ترقية معرفية! أول هاكاثون للذكاء الاصطناعي من OceanBase يوجه دعوة للأبطال، هل تجرؤ على المجيء؟)
Meituan 酒旅 توظف مهندسي خوارزميات نماذج كبيرة L7-L8: يقوم فريق خوارزميات العرض في Meituan 酒旅 بتوظيف مهندسي خوارزميات نماذج كبيرة من المستوى L7-L8 (توظيف اجتماعي) في بكين. تشمل المسؤوليات استخدام تقنيات NLP والنماذج الكبيرة لبناء نظام فهم عرض السفر والضيافة (العلامات، النقاط الساخنة، تحليل التشابه)، وتحسين مواد عرض المنتجات (العناوين، النصوص والصور)، وبناء مجموعات باقات العطلات، واستكشاف تقنيات النماذج الكبيرة المتطورة في تطبيقات خوارزميات جانب العرض. يشترط الحصول على درجة الماجستير أو أعلى، وخبرة تزيد عن عامين، وامتلاك قدرات قوية في الخوارزميات والبرمجة. (المصدر: توصية داخلية في بكين | فريق خوارزميات العرض في Meituan 酒旅 يوظف مهندسي خوارزميات نماذج كبيرة L7-L8)
Qubit توظف محررين/كتاب في مجال الذكاء الاصطناعي: تقوم وسيلة الإعلام التكنولوجية المتخصصة في الذكاء الاصطناعي Qubit بتوظيف محررين/كتاب بدوام كامل، ومقر العمل في Zhongguancun ببكين، وهو مفتوح للتوظيف الاجتماعي والخريجين الجدد، مع توفير فرص تدريب للتثبيت. تشمل اتجاهات التوظيف نماذج الذكاء الاصطناعي الكبيرة، والروبوتات الذكية المتجسدة، والأجهزة الطرفية، ومحرري الوسائط الجديدة للذكاء الاصطناعي (Weibo/Xiaohongshu). يشترط الشغف بمجال الذكاء الاصطناعي، وامتلاك قدرات جيدة في التعبير الكتابي وجمع المعلومات. تشمل النقاط الإضافية الإلمام بأدوات الذكاء الاصطناعي، والقدرة على تفسير الأوراق البحثية، والقدرة على البرمجة، وما إلى ذلك. توفر رواتب ومزايا تنافسية وفرص نمو مهني. (المصدر: توظيف Qubit | إعلان التوظيف الذي ساعدنا DeepSeek في تعديله)
الحائز على جائزة تورينج LeCun يتحدث عن تطور الذكاء الاصطناعي: الذكاء البشري ليس عامًا، والجيل القادم من الذكاء الاصطناعي قد لا يكون توليديًا: في مقابلة بودكاست، يعتقد Yann LeCun أن السعي الحالي لتحقيق الذكاء الاصطناعي العام (AGI) ينطوي على سوء فهم، لأن الذكاء البشري نفسه متخصص للغاية وليس عامًا. يتوقع أن الاختراق التالي في الذكاء الاصطناعي قد يعتمد على نماذج غير توليدية، مثل بنية JEPA التي اقترحها، مع التركيز على تمكين الذكاء الاصطناعي من فهم العالم المادي وامتلاك قدرات الاستدلال والتخطيط (نماذج العالم)، بدلاً من مجرد معالجة اللغة. يعتقد أن نماذج LLM الحالية تفتقر إلى قدرة الاستدلال الحقيقية. أكد LeCun أيضًا على أهمية المصادر المفتوحة (مثل LLaMA من Meta) لدفع تطور الذكاء الاصطناعي، ويعتقد أن الأجهزة مثل النظارات الذكية هي اتجاه مهم لتطبيق تكنولوجيا الذكاء الاصطناعي. (المصدر: الحائز على جائزة تورينج LeCun: الذكاء البشري ليس ذكاءً عامًا، والجيل القادم من الذكاء الاصطناعي قد يعتمد على نماذج غير توليدية)
قمة صناعة AIGC الصينية ستُعقد قريبًا (16 أبريل، بكين): ستُعقد قمة صناعة AIGC الصينية الثالثة في بكين في 16 أبريل. ستجمع القمة أكثر من 20 من قادة الصناعة من شركات ومؤسسات مثل Baidu و Huawei و AWS و Microsoft Research Asia و Mianbi Intelligence و Shengshu Technology و Fenbi و NetEase Youdao و Quwan Technology و Qingsong Health، لمناقشة أحدث التطورات في تكنولوجيا الذكاء الاصطناعي، وتطبيقاتها في آلاف الصناعات، والبنية التحتية لقوة الحوسبة، والأمان والتحكم، وغيرها من القضايا الأساسية. تهدف القمة إلى عرض كيف يمكّن الذكاء الاصطناعي من ترقية الصناعة، والإعلان عن الجوائز ذات الصلة و “خريطة بانورامية لتطبيقات AIGC في الصين”. (المصدر: العد التنازلي يومان! أكثر من 20 من قادة الصناعة يناقشون الذكاء الاصطناعي، الدليل الأكثر اكتمالاً لقمة صناعة AIGC الصينية هنا)
مناقشة حلول تشغيل نماذج بتريليونات البارامترات على بطاقات رسوميات منخفضة التكلفة: يناقش المقال حلول بناء جهاز AI متكامل يمكن التحكم في تكلفته (مستوى 100 ألف يوان) باستخدام بطاقات رسوميات Intel Arc™ (مثل A770) ومعالجات Xeon® W. يحقق هذا الحل، من خلال التعاون بين البرامج والأجهزة (IPEX-LLM، OpenVINO™، oneAPI) والتحسين، القدرة على تشغيل نماذج كبيرة مثل QwQ-32B (بسرعة تصل إلى 32 رمزًا/ثانية) وحتى 671B DeepSeek R1 (بمساعدة تحسين FlashMoE، بسرعة تقارب 10 رموز/ثانية) على جهاز واحد. يوفر هذا للشركات خيارًا عالي القيمة مقابل السعر لنشر النماذج الكبيرة محليًا أو على الحافة، مما يلبي احتياجات مثل الاستدلال دون اتصال بالإنترنت وأمن البيانات. أطلقت Intel أيضًا منصة OPEA، بالتعاون مع شركاء النظام البيئي لتعزيز توحيد وتعميم تطبيقات الذكاء الاصطناعي للمؤسسات. (المصدر: استغلال بطاقة رسوميات بقيمة 3000 يوان، الوصفة السرية لتشغيل نماذج بتريليونات البارامترات هنا)
روبوت جراحي يعرض عملية عالية الدقة: يعرض الفيديو روبوتًا جراحيًا قادرًا على فصل قشرة بيضة السمان النيئة عن غشائها الداخلي بدقة، مما يجسد المستوى المتقدم للروبوتات الحديثة في العمليات الدقيقة والتحكم. (المصدر: Ronald_vanLoon)
نظرة عامة على التقدم في تقنية الطباعة الحجرية لأشباه الموصلات: يشير إلى مقال حول محتوى مؤتمر SPIE للطباعة الحجرية والنمذجة المتقدمة، ويناقش أحدث التطورات في تقنيات تصنيع الرقائق من الجيل التالي، بما في ذلك High-NA EUV، وتكلفة EUV، وتشكيل الأنماط، والمقاومات الضوئية الجديدة (أكاسيد المعادن، الجافة)، و Hyper-NA. هذه التقنيات حاسمة لدعم تطوير رقائق الذكاء الاصطناعي المستقبلية. (المصدر: dylan522p)
عرض مهارات دقيقة لروبوت بعجلات: يعرض الفيديو مهارات حركة أو تشغيل عالية الدقة لروبوت بعجلات، قد تتضمن تقنيات الذكاء الاصطناعي والتعلم الآلي للتحكم والإدراك. (المصدر: Ronald_vanLoon)