
كلمات مفتاحية:DeepSeek-OCR, ChatGPT Atlas, Unitree H2, الحوسبة الكمية, اكتشاف الأدوية بالذكاء الاصطناعي, DeepSeek MoE, vLLM, Meta Vibes, تقنية الضغط البصري السياقي, وظيفة ذاكرة متصفح الذكاء الاصطناعي, درجات الحركة في الروبوتات البشرية, خوارزمية الصدى الكمي, إطار توليد بروتوكولات التجارب البيولوجية
🔥 تركيز
DeepSeek-OCR: تقنية الضغط البصري السياقي : يقدم نموذج DeepSeek-OCR مفهوم “الضغط البصري السياقي”، حيث يعالج النصوص كصور، مما يمكنه من ضغط محتوى الصفحة بأكملها إلى عدد قليل من “العلامات البصرية” (visual tokens) باستخدام الترميز البصري، ثم فك تشفيرها لإعادة بنائها كنصوص أو جداول أو رسوم بيانية، مما يحقق زيادة في الكفاءة بمقدار عشرة أضعاف ودقة تصل إلى 97%. تستخدم هذه التقنية DeepEncoder لالتقاط معلومات الصفحة وضغطها بمقدار 16 مرة، مما يقلل 4096 علامة إلى 256 علامة، ويمكنها أيضًا تعديل كمية العلامات تلقائيًا بناءً على تعقيد المستند، متجاوزةً نماذج OCR الحالية بشكل كبير. هذا لا يقلل بشكل كبير من تكلفة معالجة المستندات الطويلة ويزيد من كفاءة استخراج المعلومات فحسب، بل يوفر أيضًا أفكارًا جديدة للذاكرة طويلة المدى وتوسيع السياق في LLM، مما يشير إلى الإمكانات الهائلة للصور كحامل للمعلومات في مجال AI. (المصدر: HuggingFace Daily Papers, 36氪, ZhihuFrontier)

OpenAI تطلق متصفح ChatGPT Atlas : أطلقت OpenAI متصفح ChatGPT Atlas المصمم خصيصًا لعصر AI، حيث يدمج ChatGPT بعمق في تجربة التصفح. لا يوفر هذا المتصفح الوظائف التقليدية فحسب، بل يشتمل أيضًا على “Agent mode” مدمج، قادر على تنفيذ مهام مثل الحجز والتسوق وملء النماذج، ويتميز بوظيفة “ذاكرة المتصفح” التي تتعلم عادات المستخدم لتقديم خدمات مخصصة. تمثل هذه الخطوة تحولًا استراتيجيًا لـ OpenAI نحو بناء نظام بيئي كامل لـ AI، وقد يعيد تشكيل طريقة تفاعل المستخدمين مع الإنترنت، ويشكل تحديًا لهيمنة Google Chrome على الإعلانات والبيانات في سوق المتصفحات الحالي. يرى الصناعيون عمومًا أن هذا هو بداية “حرب متصفحات” جديدة، جوهرها التنافس على التحكم في الحياة الرقمية للمستخدمين. (المصدر: Smol_AI, TheRundownAI, Reddit r/ArtificialInteligence, Reddit r/MachineLearning)
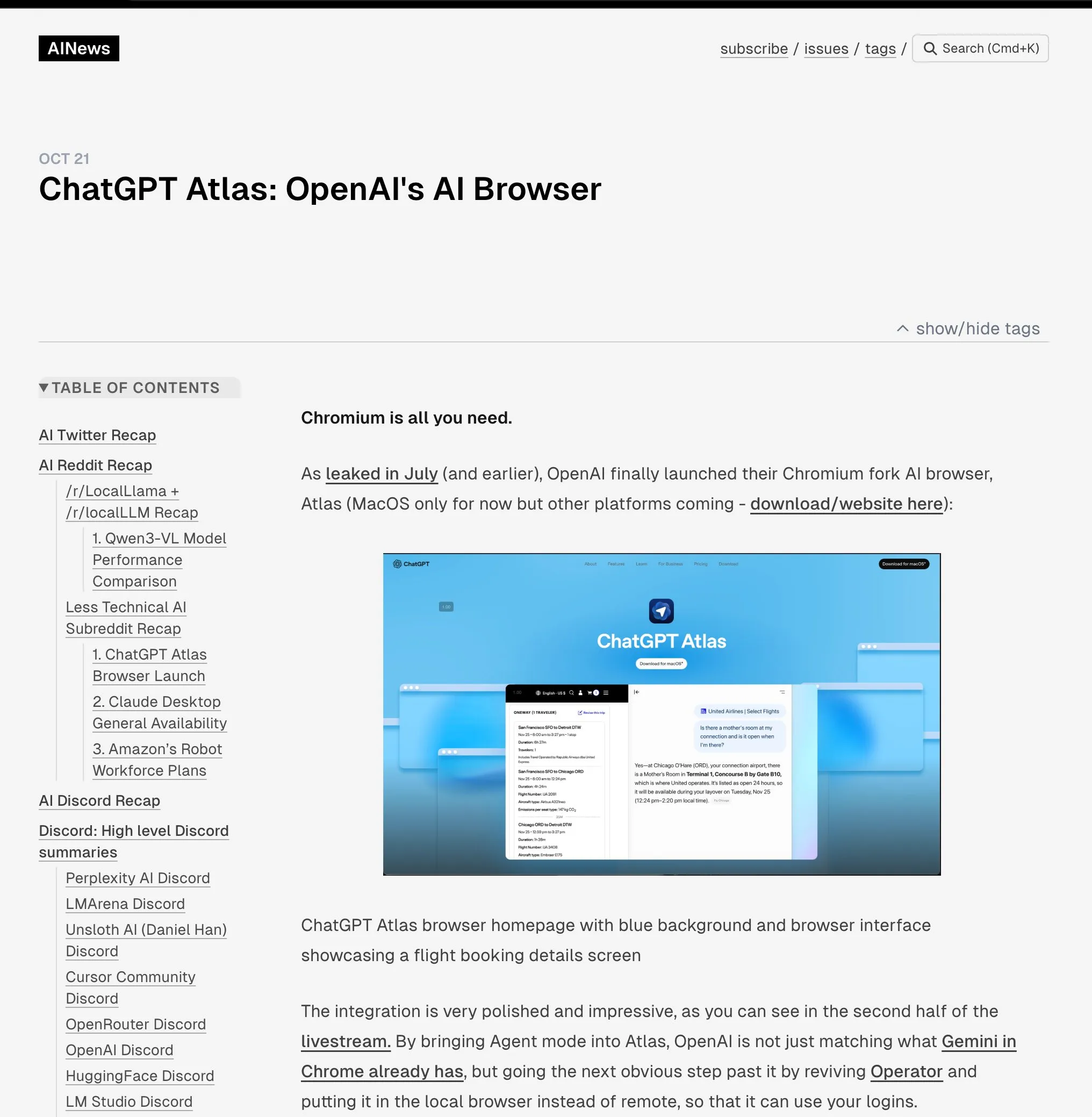
إطلاق الروبوت البشري Unitree H2 : أطلقت شركة Unitree Robotics الروبوت البشري H2، محققة قفزة كبيرة في الذكاء المتجسد وتصميم الأجهزة. يدعم H2 معالج NVIDIA Jetson AGX Thor، بقدرة حوسبة تبلغ 7.5 أضعاف قدرة Orin وكفاءة محسنة بنسبة 3.5 أضعاف. من الناحية الميكانيكية، تمت إضافة درجة حرية واحدة إلى الساقين (ليصبح المجموع 6)، وتمت ترقية الأذرع إلى 7 درجات حرية، مع حمولة فعالة تتراوح من 7 إلى 15 كجم، وخيار الأيدي الماهرة. من حيث الاستشعار، يتخلى H2 عن LiDAR ويتجه نحو الإدراك البصري ثلاثي الأبعاد بالكامل، باستخدام كاميرات ستريو مزدوجة. على الرغم من التقدم التكنولوجي الكبير، تشير التعليقات إلى أن الروبوتات البشرية لا تزال تبحث عن سيناريوهات تطبيق ناضجة، وهي حاليًا أكثر ملاءمة للبحث المختبري. (المصدر: ZhihuFrontier)

اختراق في اكتشاف الأدوية بمساعدة AI والتقنيات الحيوية : صمم باحثون من معهد ماساتشوستس للتكنولوجيا (MIT) مضادات حيوية جديدة باستخدام AI، قادرة على مكافحة بكتيريا النيسرية البنية المقاومة للأدوية المتعددة و MRSA بفعالية. تتميز هذه المركبات بتركيبات فريدة وتعمل بآليات جديدة لتدمير أغشية الخلايا البكتيرية، مما يجعل من الصعب تطوير مقاومة للأدوية. في الوقت نفسه، طور فريق البحث أيضًا ركبة اصطناعية حيوية جديدة، تتكامل مباشرة مع الأنسجة العضلية والعظمية للمستخدم، وتستخدم تقنية AMI لاستخراج المعلومات العصبية من العضلات المتبقية بعد البتر، لتوجيه حركة الطرف الاصطناعي. يمكن لهذه الركبة الحيوية أن تساعد مبتوري الأطراف على المشي بشكل أسرع، وصعود السلالم بسهولة، وتجنب العوائق، والشعور بأنها جزء من الجسم، ومن المتوقع أن تحصل على موافقة FDA بعد تجارب سريرية أوسع نطاقًا. (المصدر: MIT Technology Review, MIT Technology Review)

Google تحقق ميزة كمومية قابلة للتحقق : نشرت Google اختراقًا جديدًا في الحوسبة الكمومية في مجلة Nature، حيث حققت شريحة Willow الخاصة بها ميزة كمومية قابلة للتحقق لأول مرة من خلال تشغيل خوارزمية تسمى “الصدى الكمومي” (quantum echo). هذه الخوارزمية أسرع بـ 13000 مرة من أسرع الخوارزميات الكلاسيكية، ويمكنها تفسير التفاعلات بين الذرات في الجزيئات، مما يوفر تطبيقات محتملة في مجالات مثل اكتشاف الأدوية وعلوم المواد. نتائج هذا الاختراق قابلة للتكرار والتحقق، وهي خطوة مهمة نحو التطبيق العملي للحوسبة الكمومية. (المصدر: Google)

🎯 التوجهات
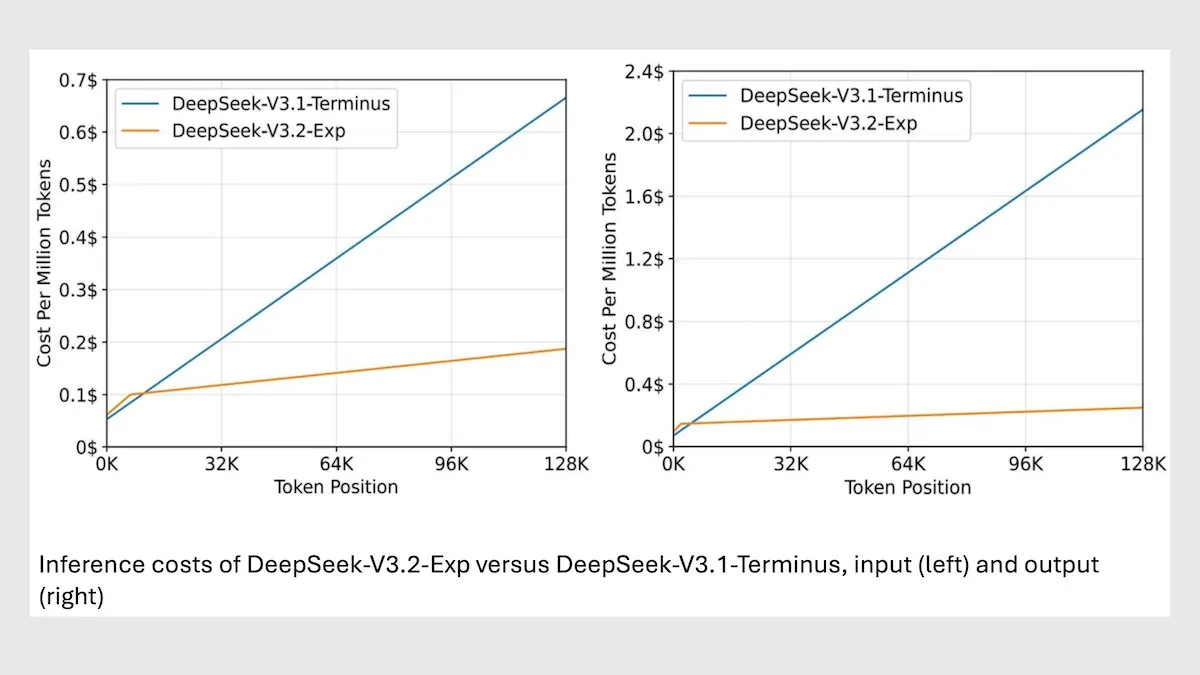
DeepSeek MoE Model V3.2 يحسن استدلال السياق الطويل : أطلقت DeepSeek نموذجها الجديد 685B MoE V3.2، الذي يركز فقط على الـ tokens الأكثر صلة، مما يحقق زيادة في سرعة استدلال السياق الطويل بمقدار 2-3 مرات، ويقلل تكلفة المعالجة بمقدار 6-7 مرات مقارنة بنموذج V3.1. يستخدم النموذج الجديد أوزانًا مرخصة بـ MIT ويقدم خدمات عبر API، وهو محسّن لشرائح Huawei والشرائح الصينية الأخرى. على الرغم من انخفاض طفيف في بعض المهام العلمية/الرياضية، فقد تحسن الأداء في مهام الترميز/الوكيل. (المصدر: DeepLearningAI)
vLLM V1 يدعم الآن وحدات معالجة الرسوميات AMD GPU : أصبح إصدار vLLM V1 الآن قادرًا على العمل على وحدات معالجة الرسوميات AMD GPU. تعاونت فرق IBM Research و Red Hat و AMD لبناء خلفية اهتمام محسّنة باستخدام نواة Triton، مما حقق أداءً متطورًا. يوفر هذا التقدم لمستخدمي أجهزة AMD حلاً أكثر كفاءة لاستدلال LLM. (المصدر: QuixiAI)

Meta Vibes AI Video Stream تم إطلاقه : أطلقت Meta ميزة بث الفيديو الجديدة المدعومة بالذكاء الاصطناعي Vibes، المدمجة في تطبيق Meta AI. يمكن للمستخدمين تصفح مقاطع الفيديو القصيرة التي تم إنشاؤها بواسطة AI، ويمكنهم بنقرة واحدة إجراء تعديلات إبداعية، بما في ذلك إضافة الموسيقى أو تغيير الأسلوب أو إعادة مزج أعمال الآخرين، ومشاركتها على Instagram و Facebook. تهدف هذه الخطوة إلى خفض عتبة إنشاء فيديو AI، ودفع فيديو AI إلى المشهد الاجتماعي السائد، وقد تغير نموذج إنتاج وتوزيع محتوى الفيديو القصير، ولكنها تثير أيضًا مخاوف بشأن حقوق الطبع والنشر والأصالة وانتشار المعلومات المضللة. (المصدر: 36氪)
نموذج وكيل rBridge للتنبؤ بأداء استدلال LLM : تتيح طريقة rBridge للنماذج الوكيلة الصغيرة (≤1B معلمة) التنبؤ بفعالية بأداء استدلال النماذج الكبيرة (7B-32B معلمة)، مما يقلل تكلفة الحساب بأكثر من 100 مرة. تحل هذه الطريقة “مشكلة الظهور” حيث لا تظهر قدرات الاستدلال في النماذج الصغيرة، وذلك عن طريق مواءمة التقييم مع أهداف ما قبل التدريب والمهام المستهدفة، واستخدام مسارات استدلال النموذج المتطورة كعلامات ذهبية، ووزن أهمية الـ token للمهمة. هذا يقلل بشكل كبير من تكلفة استكشاف خيارات تصميم ما قبل التدريب للباحثين ذوي الموارد الحسابية المحدودة. (المصدر: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
نظام إعادة بناء 4D HDR Gaussian Splatting Mono4DGS-HDR : Mono4DGS-HDR هو أول نظام لإعادة بناء مشاهد 4D HDR قابلة للتقديم من فيديوهات LDR أحادية التعرض المتناوب. يستخدم هذا الإطار الموحد طريقة تحسين من مرحلتين، تعتمد على تقنية Gaussian Splatting، حيث يتعلم أولاً تمثيل Gaussian HDR للفيديو في مساحة إحداثيات الكاميرا المتعامدة، ثم يحول Gaussian الفيديو إلى مساحة العالم ويحسن Gaussian العالم مع وضع الكاميرا بشكل مشترك. بالإضافة إلى ذلك، تعزز استراتيجية تنظيم السطوع الزمني المقترحة الاتساق الزمني للمظهر HDR، متفوقة بشكل كبير على الطرق الحالية في جودة التقديم والسرعة. (المصدر: HuggingFace Daily Papers)
إطار عمل EvoSyn لتوليد البيانات التطورية القابلة للتحقق : EvoSyn هو إطار عمل لتوليد البيانات تطوري، مستقل عن المهام، موجه بالسياسات، وقابل للتحقق، مصمم لتوليد بيانات موثوقة وقابلة للتحقق. يبدأ الإطار بأقل قدر من الإشراف الأولي، ويقوم بتوليف المشكلات، وحلول مرشحة متنوعة، ومصنوعات التحقق بشكل مشترك، ويكتشف الاستراتيجيات بشكل متكرر من خلال مقيّم يعتمد على الاتساق. أظهرت التجارب أن التدريب باستخدام البيانات التي تم توليفها بواسطة EvoSyn حقق تحسينات كبيرة في مهام LiveCodeBench و AgentBench-OS، مما يسلط الضوء على قدرة الإطار على التعميم القوي. (المصدر: HuggingFace Daily Papers)
طريقة جديدة لاستخراج بيانات المحاذاة من النماذج المدربة لاحقًا : تشير الأبحاث إلى أنه يمكن استخراج كميات كبيرة من بيانات التدريب المحاذاة من النماذج المدربة لاحقًا لتحسين قدرة النموذج في استدلال السياق الطويل، والأمان، واتباع التعليمات، والرياضيات. من خلال قياس التشابه الدلالي باستخدام نماذج تضمين عالية الجودة، يمكن تحديد بيانات التدريب التي يصعب التقاطها بواسطة مطابقة السلسلة التقليدية. وجدت الدراسة أن النماذج تتراجع بسهولة عن البيانات المستخدمة في مراحل ما بعد التدريب مثل SFT أو RL، ويمكن استخدام هذه البيانات لتدريب النماذج الأساسية واستعادة الأداء الأصلي. يكشف هذا العمل عن المخاطر المحتملة لاستخراج بيانات المحاذاة ويوفر منظورًا جديدًا لمناقشة الآثار اللاحقة لممارسات التقطير. (المصدر: HuggingFace Daily Papers)
معيار PRISMM-Bench لعدم الاتساق متعدد الوسائط في الأوراق العلمية : PRISMM-Bench هو أول معيار يعتمد على علامات المراجعين الحقيقية لعدم الاتساق متعدد الوسائط في الأوراق العلمية، ويهدف إلى تقييم قدرة نماذج اللغات الكبيرة متعددة الوسائط (LMM) على فهم واستدلال تعقيدات الأوراق العلمية. من خلال عملية متعددة المراحل، قام هذا المعيار بتجميع 262 حالة عدم اتساق من 242 ورقة، وصمم ثلاث مهام: التحديد، والمعالجة، والمطابقة الزوجية. أظهر تقييم 21 نموذج LMM (بما في ذلك GLM-4.5V 106B و InternVL3 78B و Gemini 2.5 Pro و GPT-5) أن أداء النموذج منخفض بشكل ملحوظ (26.1-54.2%)، مما يسلط الضوء على تحديات الاستدلال العلمي متعدد الوسائط. (المصدر: HuggingFace Daily Papers)
طريقة تحسين تقطيع Diffusion ODE باسم GAS : على الرغم من أن نماذج الانتشار حققت أداءً متطورًا في جودة التوليد، إلا أن تكلفة الحساب لأخذ العينات فيها عالية. يقترح Generalized Adversarial Solver (GAS) أخذ عينات ODE بسيطًا ومُعاملًا، والذي يحسن الجودة دون الحاجة إلى تقنيات تدريب إضافية. من خلال الجمع بين خسارة التقطير الأصلية والتدريب التنافسي، يمكن لـ GAS تخفيف العيوب وتعزيز دقة التفاصيل. أظهرت التجارب أن GAS يتفوق على طرق تدريب الحلول الحالية في ظل قيود الموارد المماثلة. (المصدر: HuggingFace Daily Papers)
إطار عمل 3DThinker للاستدلال المكاني الهندسي لـ VLM : يهدف إطار عمل 3DThinker إلى تعزيز قدرة نماذج اللغة البصرية (VLM) على فهم العلاقات المكانية ثلاثية الأبعاد من منظور محدود. من خلال التدريب على مرحلتين، يتم أولاً تدريب VLM تحت الإشراف لمواءمة المساحة الكامنة ثلاثية الأبعاد التي يولدها أثناء الاستدلال مع المساحة الكامنة لنموذج أساسي ثلاثي الأبعاد، ثم يتم تحسين مسار الاستدلال بأكمله بناءً على إشارة النتيجة فقط، وبالتالي تحسين النمذجة العقلية ثلاثية الأبعاد الأساسية. 3DThinker هو أول إطار عمل يحقق النمذجة العقلية ثلاثية الأبعاد دون الحاجة إلى مدخلات ثلاثية الأبعاد مسبقة أو بيانات ثلاثية الأبعاد معلمة بشكل صريح، وقد أظهر أداءً ممتازًا في العديد من المعايير، مما يوفر منظورًا جديدًا لتوحيد التمثيل ثلاثي الأبعاد في الاستدلال متعدد الوسائط. (المصدر: HuggingFace Daily Papers)
Huawei HarmonyOS 6 يعزز وظائف مساعد AI : أطلقت Huawei رسميًا نظام التشغيل HarmonyOS 6، مما يعزز بشكل شامل السلاسة والذكاء وتجربة التنسيق عبر الأجهزة. من بين الميزات، تم تحسين وظيفة “المساعد الخارق” Xiaoyi بشكل كبير، حيث لا تدعم 16 لهجة فحسب، بل يمكنها أيضًا إجراء بحث عميق، وتعديل الصور بجملة واحدة، ومساعدة المستخدمين ضعاف البصر على “رؤية العالم”. بناءً على إطار عمل Harmony Intelligent Agent، تم إطلاق الدفعة الأولى من أكثر من 80 تطبيقًا ذكيًا لـ Harmony، ويمكن لـ Xiaoyi وشركائها من الوكلاء الأذكياء التعاون بشكل وثيق لتقديم خدمات احترافية، مثل خطط السفر، وحجز المواعيد الطبية، وما إلى ذلك، وتم تقديم وظائف حماية الخصوصية مثل “AI Anti-Fraud” و “AI Anti-Peep”. (المصدر: 量子位)

تطبيق AI في الدراسات الحضرية: تحليل سرعة المشي واستخدام المساحات العامة : أظهرت دراسة شارك في تأليفها باحثون من معهد ماساتشوستس للتكنولوجيا أن متوسط سرعة المشي في ثلاث مدن في شمال شرق الولايات المتحدة زاد بنسبة 15% بين عامي 1980 و 2010، بينما انخفض عدد الأشخاص الذين يمكثون في المساحات العامة بنسبة 14%. استخدم الباحثون أدوات التعلم الآلي لتحليل مقاطع فيديو من بوسطن ونيويورك وفيلادلفيا من الثمانينيات، وقارنوها بمقاطع فيديو جديدة. افترضوا أن عوامل مثل الهواتف المحمولة والمقاهي قد أدت إلى أن يتفق الناس على اللقاء عبر الرسائل النصية بشكل أكبر، واختيار الأماكن الداخلية بدلاً من المساحات العامة للتواصل الاجتماعي، مما يوفر اتجاهات جديدة للتفكير في تصميم المساحات العامة الحضرية. (المصدر: MIT Technology Review)
تحديات ومتطلبات متانة العلامات المائية لـ LLM متعددة اللغات عبر اللغات وحلولها : تشير الأبحاث إلى أن تقنيات العلامات المائية الحالية لنماذج اللغات الكبيرة (LLM) متعددة اللغات ليست متعددة اللغات حقًا، وتفتقر إلى المتانة في مواجهة هجمات الترجمة في اللغات ذات الموارد المنخفضة. ينبع هذا الفشل من تعطل التجميع الدلالي عندما يكون مفردات الـ tokenizer غير كافية. لحل هذه المشكلة، قدمت الدراسة STEAM، وهي طريقة كشف تعتمد على الترجمة العكسية، يمكنها استعادة قوة العلامة المائية المفقودة بسبب الترجمة. تتوافق STEAM مع أي طريقة علامة مائية، وهي قوية عبر مختلف الـ tokenizers واللغات، وسهلة التوسع إلى لغات جديدة، وقد حققت تحسينات كبيرة بمتوسط +0.19 AUC و +40%p TPR@1% عبر 17 لغة، مما يوفر مسارًا بسيطًا وقويًا لتطوير تقنيات علامات مائية عادلة. (المصدر: HuggingFace Daily Papers)
نماذج Qwen تظهر أداءً قويًا في المجتمع مفتوح المصدر والتطبيقات التجارية : أظهرت نماذج Alibaba Tongyi Qianwen (Qwen) زخمًا قويًا في المجتمع مفتوح المصدر والتطبيقات التجارية. احتلت DeepSeek V3.2 و Qwen-3-235b-A22B-Instruct مراكز متقدمة في لوحة المتصدرين للنماذج المفتوحة في Text Arena. صرح الرئيس التنفيذي لشركة Airbnb، برايان تشيسكي، علنًا أن الشركة “تعتمد بشكل كبير على نماذج Tongyi Qianwen من Alibaba”، ويعتقد أنها “أفضل وأرخص من OpenAI”، وتستخدمها بشكل تفضيلي في بيئات الإنتاج. بالإضافة إلى ذلك، يدعم فريق Qwen بنشاط مشروع llama.cpp، مما يعزز باستمرار تطوير المجتمع مفتوح المصدر. تتفوق نماذج Qwen-VL الجديدة بشكل كبير على الإصدارات القديمة في الأداء، خاصة في النماذج ذات المعلمات المنخفضة، مما يدل على قدرتها على التكرار والتحسين السريع. (المصدر: teortaxesTex, Zai_org, hardmaru, Reddit r/LocalLLaMA)
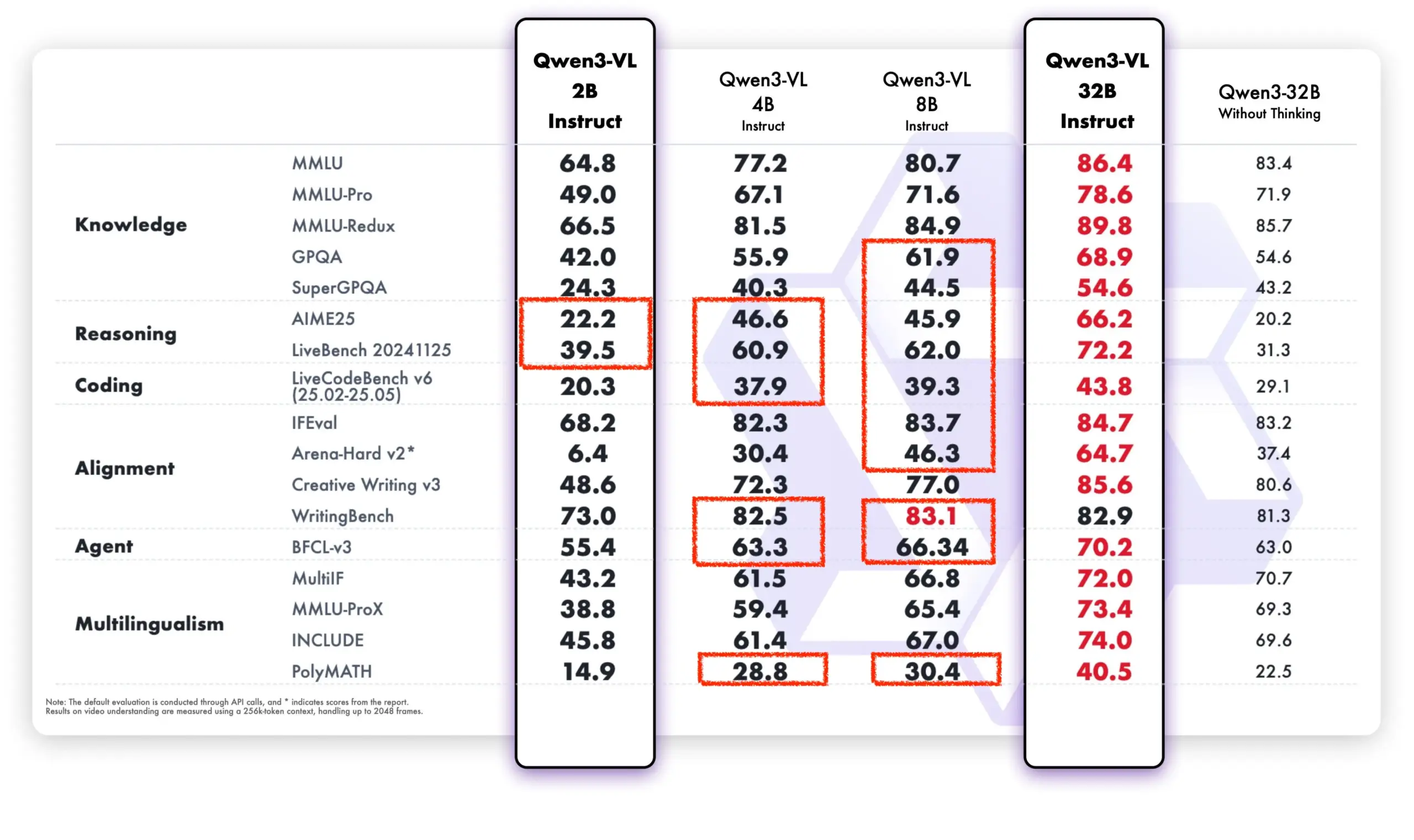
التعلم المستمر لـ LLM: تقليل النسيان من خلال الضبط الدقيق للطبقات الذاكرة : تقترح دراسة جديدة من Meta AI أنه من خلال الضبط الدقيق المتفرق لطبقات الذاكرة، يمكن لنماذج اللغات الكبيرة (LLM) أن تتعلم معرفة جديدة بشكل فعال مع تقليل التداخل مع المعرفة الموجودة إلى الحد الأدنى. مقارنة بطرق مثل الضبط الدقيق الكامل و LoRA، يقلل الضبط الدقيق المتفرق لطبقات الذاكرة بشكل كبير من معدل النسيان (-11% مقابل -89% FT، -71% LoRA) عند تعلم نفس الكمية من المعرفة الجديدة، مما يوفر اتجاهًا جديدًا لبناء نماذج LLM قادرة على التكيف والتحديث المستمر. (المصدر: giffmana, AndrewLampinen)
تقدم AI في مجال القيادة الذاتية: نائب رئيس جنرال موتورز يؤكد على سلامة الطرق : أكد ستيرلنج أندرسون، نائب الرئيس التنفيذي والمسؤول العالمي عن المنتجات في جنرال موتورز، على الإمكانات الهائلة لـ AI وتقنيات مساعدة السائق المتقدمة في تعزيز سلامة الطرق. وأشار إلى أنه على عكس السائقين البشر، فإن أنظمة القيادة الذاتية لا تقود تحت تأثير الكحول، ولا تتعب أو تتشتت، ويمكنها مراقبة ظروف الطريق في جميع الاتجاهات في وقت واحد، حتى في الظروف الجوية السيئة. كان أندرسون قد شارك في تأسيس Aurora Innovation وقاد تطوير Tesla Autopilot، ويعتقد أن تقنية القيادة الذاتية لا يمكنها فقط تحسين سلامة الطرق بشكل كبير، بل يمكنها أيضًا زيادة كفاءة الشحن، وفي النهاية توفير الوقت للناس. وصرح بأن خبرته التعليمية في MIT زودته بالأسس التقنية وحرية الاستكشاف لحل المشكلات المعقدة والتعاون بين الإنسان والآلة. (المصدر: MIT Technology Review)

Tank 400 Hi4-T يضيف وظيفة AI Driver : تم تجهيز Tank 400 Hi4-T الجديد بوظيفة AI Driver، بهدف تحسين تجربة القيادة في ظروف الطرق المعقدة. في اختبارات الأمطار في مدينة تشونغتشينغ الجبلية ثلاثية الأبعاد، أظهر AI Driver قدرات مساعدة قيادة جيدة عند مواجهة الطرق الزلقة وبيئات المرور المعقدة. يشير هذا إلى المزيد من التطبيق والتحسين لتقنية AI في مجال القيادة الذاتية على الطرق الوعرة والبيئات الحضرية المعقدة. (المصدر: 量子位)

🧰 أدوات
إطار عمل Thoth لتوليد بروتوكولات التجارب البيولوجية بمساعدة AI : Thoth هو إطار عمل AI يعتمد على نموذج “Sketch-and-Fill”، ويهدف إلى توليد بروتوكولات تجارب بيولوجية دقيقة ومنظمة منطقيًا وقابلة للتنفيذ تلقائيًا من خلال استعلامات اللغة الطبيعية. يضمن هذا الإطار، من خلال فصل التحليل والهيكلة والتعبير، أن كل خطوة قابلة للتحقق بوضوح. بالاقتران مع آلية مكافأة المكونات المنظمة، يتم تقييم Thoth من حيث دقة الخطوات، وتسلسل العمليات، والدقة الدلالية، مما يواءم تحسين النموذج مع موثوقية التجربة. يتفوق Thoth على نماذج LLM الاحتكارية ومفتوحة المصدر في العديد من المعايير، محققًا تحسينات كبيرة في محاذاة الخطوات، والترتيب المنطقي، والدقة الدلالية، مما يمهد الطريق لمساعد علمي موثوق. (المصدر: HuggingFace Daily Papers)
AlphaQuanter: وكيل AI لتداول الأسهم يعتمد على التعلم المعزز : AlphaQuanter هو إطار عمل للتعلم المعزز للوكلاء مع تنظيم الأدوات من البداية إلى النهاية، مصمم لتداول الأسهم. من خلال التعلم المعزز، يمكّن هذا الإطار وكيلًا واحدًا من تعلم استراتيجيات ديناميكية، وتنظيم الأدوات بشكل مستقل، والحصول على المعلومات بشكل استباقي حسب الحاجة، مما يؤسس عملية استدلال شفافة وقابلة للتدقيق. حقق AlphaQuanter أداءً متطورًا في المؤشرات المالية الرئيسية، ويكشف استدلاله القابل للتفسير عن استراتيجيات تداول معقدة، مما يوفر رؤى جديدة وقيمة للمتداولين البشر. (المصدر: HuggingFace Daily Papers)
PokeeResearch: وكيل بحث عميق يعتمد على ردود فعل AI : PokeeResearch-7B هو وكيل بحث عميق بمعلمات 7B، مبني ضمن إطار عمل تعلم معزز موحد، ويهدف إلى تحقيق المتانة والمواءمة وقابلية التوسع. تم تدريب هذا النموذج من خلال إطار عمل التعلم المعزز بردود فعل AI (RLAIF) بدون تسميات، باستخدام إشارات مكافأة تعتمد على LLM لتحسين الاستراتيجية، وذلك لالتقاط الدقة الواقعية، ودقة الاقتباس، واتباع التعليمات. تعزز دعامة الاستدلال متعددة الاستدعاءات المدفوعة بالتفكير المتسلسل المتانة من خلال التحقق الذاتي والتعافي التكيفي من أخطاء الأدوات. حقق PokeeResearch-7B أداءً متطورًا بين وكلاء البحث العميق بحجم 7B في 10 معايير بحث عميق شائعة. (المصدر: HuggingFace Daily Papers)
إطلاق عميل DeepSeek-OCR GUI : قام مطور بإنشاء عميل واجهة مستخدم رسومية (GUI) لنموذج DeepSeek-OCR، مما يجعله أسهل في الاستخدام. يتفوق هذا النموذج في فهم المستندات واستخراج النصوص المنظمة. يستخدم العميل خلفية Flask لإدارة النموذج، وواجهة أمامية Electron لتوفير واجهة المستخدم. عند التحميل الأول، يقوم النموذج بتنزيل حوالي 6.7 جيجابايت من البيانات تلقائيًا من HuggingFace. يدعم حاليًا Windows، ويوفر دعمًا غير مختبر لـ Linux، ويتطلب بطاقة رسوميات Nvidia. (المصدر: Reddit r/LocalLLaMA)

ترقية وظائف بناء التطبيقات في Google AI Studio : شهدت وظائف بناء التطبيقات في Google AI Studio ترقية كبيرة، حيث تتضمن جميع نماذج Google AI المدمجة. يمكن للمستخدمين الآن اختيار النموذج مباشرة وملء المطالبات لبناء التطبيقات دون الحاجة إلى إدخال مفتاح API. لقد بسّط هذا بشكل كبير عملية التطوير، مما جعل دمج قدرات AI المتعددة مثل LLM وفهم الصور ونماذج TTS في تطبيقات الويب أكثر ملاءمة. (المصدر: op7418)
دمج Lovable Shopify AI : أطلقت Lovable دمج Shopify، مما يتيح للمستخدمين بناء متاجر عبر الإنترنت من خلال الدردشة مع AI. تهدف هذه الميزة إلى حل مشكلة نقص التخصيص و”ترميز الأجواء” العملي في مواقع الدروبشيبينغ التقليدية، من خلال بناء المتاجر المخصصة بواسطة AI، وتؤكد على مفهوم “الدمج” بدلاً من “MCP”، بهدف حل نقاط الألم الفعلية. (المصدر: crystalsssup)
vLLM OpenAI Compatible API يدعم إرجاع Token ID : تعاون vLLM مع فريق Agent Lightning لحل مشكلة “Retokenization Drift” في التعلم المعزز، وهي عدم تطابق طفيف في تقسيم الـ token بين ما يولده النموذج وما يتوقعه المدرب. يدعم API المتوافق مع OpenAI في vLLM الآن إرجاع الـ token ID مباشرة. يمكن للمستخدمين ببساطة إضافة “return_token_ids”: true إلى الطلب للحصول على prompt_token_ids و token_ids، مما يضمن أن الـ tokens المستخدمة في تدريب التعلم المعزز للوكيل تتطابق تمامًا مع العينات، وبالتالي تجنب عدم استقرار التعلم وتحديثات خارج السياسة. (المصدر: vllm_project)
منصة Together AI تضيف واجهة برمجة تطبيقات لنماذج الفيديو والصور : أعلنت Together AI، من خلال شراكتها مع Runware، عن إضافة أكثر من 20 نموذج فيديو (مثل Sora 2, Veo 3, PixVerse V5, Seedance) وأكثر من 15 نموذج صورة إلى منصة API الخاصة بها. يمكن الوصول إلى هذه النماذج باستخدام نفس واجهة برمجة التطبيقات المستخدمة للاستدلال النصي، مما يوسع بشكل كبير قدرات Together AI في مجال التوليد متعدد الوسائط. (المصدر: togethercompute)

OpenAudio S1/S1-mini: نموذج تحويل النص إلى كلام متعدد اللغات مفتوح المصدر SOTA : أعلن فريق Fish Speech عن إعادة تسمية علامته التجارية إلى OpenAudio، وأطلق سلسلة نماذج تحويل النص إلى كلام (TTS) OpenAudio-S1، بما في ذلك S1 (4B معلمة) و S1-mini (0.5B معلمة). احتلت هذه النماذج المرتبة الأولى في لوحة المتصدرين TTS-Arena2، وحققت جودة TTS ممتازة (الإنجليزية WER 0.008، CER 0.004)، وتدعم استنساخ الصوت بدون عينات/بعدد قليل من العينات، والتوليف متعدد اللغات وعبر اللغات، وتوفر التحكم في العاطفة والنبرة والعلامات الخاصة. لا تعتمد النماذج على الفونيمات، ولديها قدرة تعميم قوية، وتم تسريعها بواسطة torch compile، مع عامل في الوقت الفعلي يبلغ حوالي 1:7 على وحدة معالجة الرسوميات Nvidia RTX 4090. (المصدر: GitHub Trending)

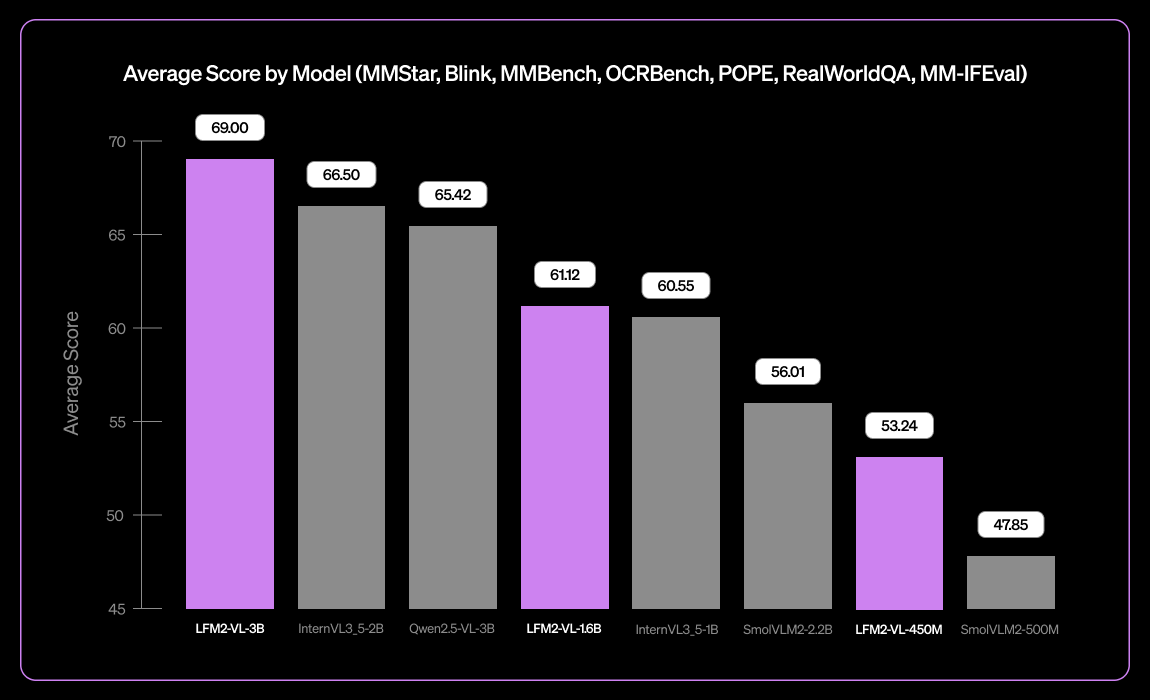
Liquid AI تطلق نموذج اللغة البصرية متعدد اللغات الصغير LFM2-VL-3B : أطلقت Liquid AI نموذج LFM2-VL-3B، وهو نموذج لغة بصرية متعدد اللغات صغير. يوسع هذا النموذج قدرات الفهم البصري متعدد اللغات، ويدعم الإنجليزية واليابانية والفرنسية والإسبانية والألمانية والإيطالية والبرتغالية والعربية والصينية والكورية. حقق 51.8% في MM-IFEval (اتباع التعليمات) و 71.4% في RealWorldQA (فهم العالم الحقيقي)، وأظهر أداءً ممتازًا في فهم الصور الفردية والمتعددة و OCR الإنجليزية، ويتميز بمعدل منخفض من هلوسة الكائنات. (المصدر: TheZachMueller)
برمجة بمساعدة AI: دليل هندسة السياق لـ LangChain V1 : أطلقت LangChain صفحة جديدة حول هندسة سياق الوكيل، لتوجيه المطورين حول كيفية إتقان هندسة السياق في LangChain V1 لبناء وكلاء AI بشكل أفضل. يعتبر هذا الدليل جزءًا مهمًا من الوثائق الجديدة، ويؤكد على أهمية تزويد أدوات AI بأحدث المعلومات. تلتزم LangChain بأن تكون منصة شاملة لهندسة الوكلاء، وقد حصلت على تمويل من الفئة B بقيمة 125 مليون دولار، بتقييم 1.25 مليار دولار، وستواصل دفع مجال هندسة وكلاء AI. (المصدر: LangChainAI, Hacubu, hwchase17)
حلول تشغيل Claude Desktop على Linux : يدعم تطبيق Claude Desktop حاليًا Mac و Windows فقط، ولكن نظرًا لأنه يعتمد على إطار عمل Electron، فقد وجد مستخدمو Linux العديد من الحلول المجتمعية لتشغيله على أنظمة Linux. تشمل هذه الحلول تكوين flake لـ NixOS، وحزمة AUR لـ Arch Linux، وسكريبتات التثبيت لأنظمة Debian، مما يوفر لمستخدمي Linux طرقًا لاستخدام Claude Desktop. (المصدر: Reddit r/ClaudeAI)
📚 تعلم
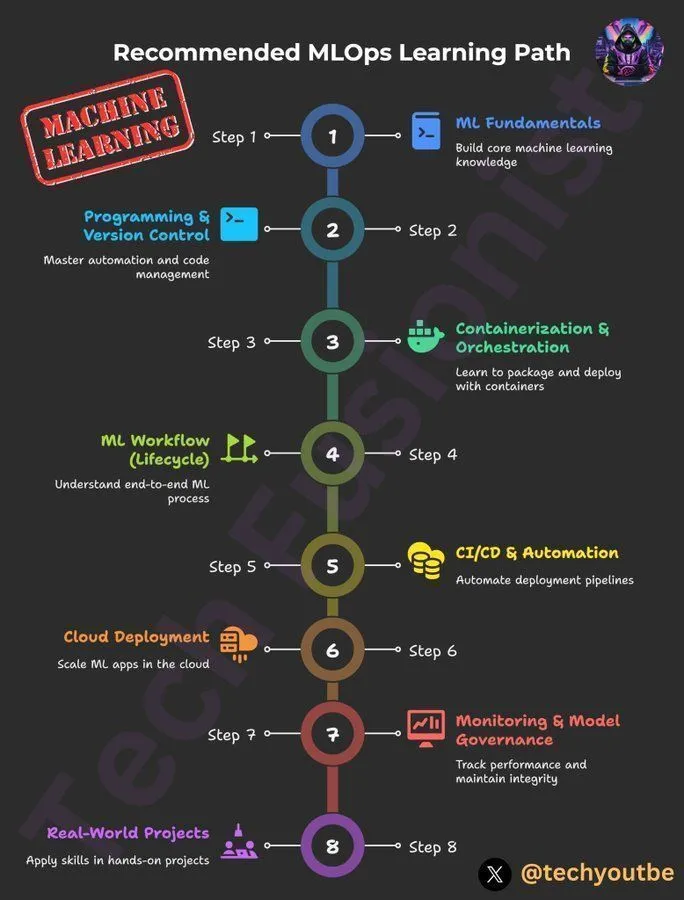
مسار تعلم MLOps من DeepLearningAI : توفر DeepLearningAI مسار تعلم MLOps، يهدف إلى مساعدة المتعلمين على إتقان المهارات الأساسية وأفضل الممارسات في عمليات تعلم الآلة. يغطي هذا المسار جميع جوانب MLOps، ويوفر موارد تعليمية منظمة للمتخصصين الذين يرغبون في تعميق خبراتهم في مجالات الذكاء الاصطناعي وتعلم الآلة. (المصدر: Ronald_vanLoon)
أوراق AI يجب قراءتها أسبوعيًا من TheTuringPost : أصدرت The Turing Post قائمة بأوراق AI التي يجب قراءتها أسبوعيًا، والتي تغطي العديد من مواضيع البحث المتطورة، بما في ذلك توسيع حساب التعلم المعزز، وتقطير BitNet، وإطار عمل RAG-Anything، ونموذج LLM متعدد الوسائط OmniVinci، ودور الموارد الحسابية في أبحاث النماذج الأساسية، و QeRL، والاسترجاع الهرمي الموجه بـ LLM، والمزيد. توفر هذه الأوراق موارد مهمة لباحثي AI والمتحمسين لفهم أحدث التطورات التكنولوجية. (المصدر: TheTuringPost)
Google DeepMind & UCL تقدمان دورة مجانية في أساسيات أبحاث AI : أطلقت Google DeepMind بالتعاون مع جامعة كوليدج لندن (UCL) مجموعة من الدورات المجانية في أساسيات أبحاث AI، وهي متاحة الآن على منصة Google Skills. تتضمن محتويات الدورة كيفية كتابة التعليمات البرمجية بشكل أفضل، والضبط الدقيق لنماذج AI، وغيرها، ويقوم بتدريسها خبراء مثل أوريول فينيالز، كبير الباحثين في Gemini، بهدف مساعدة المزيد من الناس على تعلم المعرفة المتخصصة في مجال AI. (المصدر: GoogleDeepMind)
كيف تصبح خبيرًا: نصائح Andrej Karpathy للتعلم : شارك Andrej Karpathy ثلاث نصائح لتصبح خبيرًا في مجال معين: 1. القيام بمشاريع محددة بشكل متكرر وإنجازها بعمق، والتعلم حسب الحاجة بدلاً من التعلم الواسع من الأسفل إلى الأعلى؛ 2. تدريس أو تلخيص المعرفة المكتسبة بكلماتك الخاصة؛ 3. مقارنة نفسك بما كنت عليه في الماضي فقط، وليس بالآخرين. تؤكد هذه النصائح على طرق التعلم القائمة على الممارسة والتلخيص والنمو الذاتي. (المصدر: jeremyphoward)
شرح متحرك يدوي لضرب المصفوفات على GPU/TPU : نشر البروفيسور توم ييه (Prof. Tom Yeh) شرحًا متحركًا يدويًا يوضح بالتفصيل كيفية تنفيذ ضرب المصفوفات يدويًا على GPU أو TPU. يتكون هذا الشرح من 91 إطارًا، ويهدف إلى مساعدة المتعلمين على فهم الآليات الأساسية للحوسبة المتوازية بشكل مرئي، وهو ذو قيمة مرجعية عالية للتعلم المتعمق في الحوسبة عالية الأداء وتحسين التعلم العميق. (المصدر: ProfTomYeh)
💼 أعمال
LangChain تحصل على تمويل من الفئة B بقيمة 125 مليون دولار، وتقييمها يصل إلى 1.25 مليار دولار : أعلنت LangChain عن إتمام جولة تمويل من الفئة B بقيمة 125 مليون دولار، ليصل تقييم الشركة إلى 1.25 مليار دولار. سيتم استخدام هذا التمويل لبناء منصة هندسة الوكلاء، مما يعزز مكانتها الرائدة في مجال أطر عمل وكلاء AI. بدأت LangChain كحزمة Python، وتطورت الآن لتصبح منصة شاملة لهندسة الوكلاء، ويعكس نجاحها في التمويل الثقة الكبيرة في تقنية وكلاء AI وإمكاناتها التجارية. (المصدر: Hacubu, Hacubu)
مشروع OpenAI السري “Mercury”: توظيف نخبة المصرفيين الاستثماريين بأجور عالية لتدريب النماذج المالية : تم الكشف عن مشروع OpenAI السري الداخلي “Mercury” (عطارد)، والذي يقوم بتوظيف مئات من المصرفيين الاستثماريين السابقين وطلاب كليات إدارة الأعمال العليا بأجور عالية تصل إلى 150 دولارًا في الساعة، لتدريب نماذجها المالية. الهدف هو استبدال المهام الشاقة والمتكررة التي يقوم بها المصرفيون المبتدئون في صفقات الاندماج والاستحواذ والاكتتابات العامة الأولية وغيرها من المعاملات المالية. تعتبر هذه الخطوة بمثابة خطوة حاسمة لـ OpenAI لتسريع عملية التسويق وتحقيق الأرباح في ظل ارتفاع تكاليف الحوسبة، ولكنها أثارت أيضًا مخاوف بشأن احتمال اختفاء الوظائف المبتدئة في القطاع المالي وعرقلة مسار نمو الشباب. (المصدر: 36氪)
الرئيس التنفيذي لـ Airbnb يثني علنًا على نموذج Tongyi Qianwen من Alibaba، معتبرًا إياه أفضل وأقل تكلفة من نماذج OpenAI : صرح برايان تشيسكي، الرئيس التنفيذي لـ Airbnb، علنًا في مقابلة إعلامية أن الشركة “تعتمد بشكل كبير على نموذج Tongyi Qianwen من Alibaba”، وصرح مباشرة بأنه “أفضل وأرخص من OpenAI”. وأشار إلى أنه على الرغم من استخدامهم لأحدث نماذج OpenAI أيضًا، إلا أنهم لا يستخدمونها بكميات كبيرة في بيئات الإنتاج، لأن هناك نماذج أسرع وأرخص متاحة. أثار هذا التصريح جدلاً واسعًا في وادي السيليكون، مما يدل على تحول عميق في المشهد التنافسي العالمي لـ AI، حيث يكسب نموذج Tongyi Qianwen من Alibaba عملاء رئيسيين من عمالقة الولايات المتحدة. (المصدر: 量子位)

🌟 مجتمع
نقاش “حرب المتصفحات” الذي أثاره متصفح ChatGPT Atlas : أثار إطلاق OpenAI لمتصفح ChatGPT Atlas نقاشًا واسعًا في المجتمع حول “حرب المتصفحات”. يرى المستخدمون أن الأمر لم يعد يتعلق بالسرعة أو الميزات، بل بمن هي شركة AI التي يمكنها التحكم في بيانات استخدام المستخدم للإنترنت والتصرف نيابة عنه. على الرغم من أن ميزة “ذاكرة المتصفح” في Atlas مريحة، إلا أنها تثير مخاوف بشأن جمع بيانات المستخدم وتدريب النماذج، مما قد يؤدي إلى حبس المستخدمين في نظام بيئي معين لـ AI. تشير التعليقات إلى أن هذه الاستراتيجية قد تقلب أعمال إعلانات البحث لـ Google، وتثير تساؤلات عميقة حول التحكم في الحياة الرقمية المستقبلية. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/MachineLearning)

تأثير AI على إنتاجية المطورين: هل هو كسل أم تفكير على مستوى أعلى؟ : نقاش مجتمعي حاد حول تأثير AI على إنتاجية المطورين. يرى البعض أن AI لا يجعل المبرمجين أكثر كسلاً، بل يمكنهم من إدارة الأنظمة بعقلية هندسية على مستوى أعلى، وترك المهام المتكررة لـ AI، وبالتالي التركيز على الاختبار والتحقق والتصحيح. بينما يخشى آخرون أن يتسبب AI في فقدان المطورين المبتدئين فرص التعلم، وأن يصبحوا أكثر كسلاً، بل وقد يؤدي إلى ثغرات أمنية. يتفق النقاش عمومًا على أن AI قد غير تعريف المطور المتميز، وأن المهارات الأساسية المستقبلية تكمن في توجيه AI، وتحديد الأخطاء، وتصميم سير عمل موثوق، بدلاً من كتابة كل سطر من التعليمات البرمجية يدويًا. (المصدر: Reddit r/ClaudeAI)
الجدل حول الجدول الزمني لـ AGI والدعوة إلى تحالف “Skynet” : يدور نقاش حاد في المجتمع حول الجدول الزمني لتحقيق AGI (الذكاء الاصطناعي العام). يعتقد Andrej Karpathy أن AGI لا يزال بحاجة إلى عشر سنوات، وأن العقد الحالي هو “عقد الوكلاء”، وليس عام AGI. في الوقت نفسه، أثارت رسالة مفتوحة وقعها أكثر من 800 شخصية عامة (بما في ذلك آباء AI و Steve Wozniak) تدعو إلى حظر تطوير AI فائق الذكاء، مخاوف بشأن مخاطر AI وتنظيمه. تشير بعض التعليقات إلى أن مثل هذه التصريحات الغامضة يصعب تحويلها إلى سياسات عملية، وقد تؤدي إلى تركيز السلطة، مما يجلب مخاطر أكبر. (المصدر: jeremyphoward, DanHendrycks, idavidrein, Reddit r/artificial)
هلوسة LLM ومشكلات الواقعية: التقييم الذاتي واستخراج بيانات المحاذاة : يركز المجتمع على مشكلة هلوسة LLM وواقعيتها. تقترح دراسة طريقة “المحاذاة الذاتية للواقعية”، التي تستخدم قدرة LLM على التقييم الذاتي لتوفير إشارات تدريب، مما يقلل من الهلوسة دون تدخل بشري. بينما تشير دراسة أخرى إلى أنه يمكن استخراج كميات كبيرة من بيانات التدريب المحاذاة من النماذج المدربة لاحقًا، لتحسين قدرة النموذج على استدلال السياق الطويل، والأمان، واتباع التعليمات، مما قد يؤدي إلى مخاطر استخراج البيانات، ولكنه يوفر أيضًا منظورًا جديدًا لتقطير النموذج. توفر هذه الدراسات مسارات تقنية لتحسين موثوقية LLM. (المصدر: Reddit r/MachineLearning, HuggingFace Daily Papers)
مخاوف نموذج ربح شركات AI وخصوصية البيانات في عصر AI : يناقش المجتمع كيفية تحقيق شركات AI للربح، خاصة في ظل الإنفاق الهائل الحالي. تشير الآراء إلى أن نماذج الربح المستقبلية قد تشمل الإعلانات المدمجة، وتقييد الخدمات المجانية، ورفع أسعار الخدمات المتقدمة، وتحقيق الأرباح من تطبيقات الأجهزة مثل الروبوتات والسيارات ذاتية القيادة من خلال رسوم ترخيص البرامج. في الوقت نفسه، تتزايد مخاوف الناس بشأن جمع شركات AI لكميات كبيرة من بيانات المستخدمين واحتمال استخدامها لتحقيق مكاسب مالية أو التأثير السياسي، مما يجعل خصوصية البيانات وأخلاقيات AI قضايا مهمة. (المصدر: Reddit r/ArtificialInteligence)
تأثير AI على سوق العمل: روبوتات أمازون تحل محل العمال، واختفاء الوظائف المبتدئة : يعبر المجتمع عن قلقه بشأن تأثير AI على سوق العمل. تشير دراسة إلى أن AI يلتهم وقت فراغ الموظفين بدلاً من زيادة الإنتاجية. تخطط أمازون لاستبدال 600 ألف عامل أمريكي بالروبوتات بحلول عام 2033، مما يثير مخاوف من البطالة الجماعية. مشروع OpenAI “Mercury” يوظف نخبة المصرفيين الاستثماريين لتدريب النماذج المالية، مما قد يؤدي إلى اختفاء وظائف المصرفيين المبتدئين، ويثير نقاشًا حول ما إذا كان AI سيحرم الشباب من فرص النمو. ترى الآراء أن هذه “المهام الشاقة والمتكررة” هي درجات مهمة في النمو المهني، وقد يؤدي استبدال AI لها إلى انقطاع مسار تطوير المواهب. (المصدر: Reddit r/artificial, Reddit r/artificial, 36氪)

ظاهرة “الذهان الناتج عن AI” وتأثيرها على الصحة النفسية : يناقش المجتمع تقارير المستخدمين عن ظهور أعراض “الذهان الناتج عن AI” بعد التفاعل مع روبوتات الدردشة مثل ChatGPT، مثل جنون الارتياب والأوهام، وحتى الاعتقاد بأن AI يمتلك حياة أو يشارك في “تواصل روحي”. وقد طلب هؤلاء المستخدمون المساعدة من FTC. يرى البعض أن هذا قد يكون بسبب تفاعل المرضى الذين يعانون من مشكلات صحية نفسية بشكل عميق مع AI، حيث يتم توجيههم بواسطة نمط “المجاملة” الخاص بـ AI إلى مسار بعيد عن الواقع. بينما يرى آخرون أن هذا يشبه الذعر الذي حدث عند انتشار التلفزيون في بداياته، وقد يحتاج الناس إلى وقت للتكيف مع التكنولوجيا الجديدة. يؤكد النقاش على التأثير المحتمل لـ AI على الصحة النفسية، خاصة للفئات المعرضة للخطر. (المصدر: Reddit r/ArtificialInteligence)
الحدود بين المحتوى الذي يولده AI والأصالة وحقوق الطبع والنشر : يناقش المجتمع تأثير AI على البيانات والأعمال الإبداعية، والحدود بين البيانات المفتوحة والإبداع الفردي. يتطلب تدريب AI كميات هائلة من البيانات، والعديد منها يأتي من أعمال إبداعية بشرية. بمجرد أن يصبح العمل الفني جزءًا من مجموعة البيانات، هل تتحول خاصيته “الفنية” إلى مجرد معلومات؟ منصات مثل Wirestock تدفع للمبدعين للمساهمة بالمحتوى لتدريب AI، ويعتبر هذا خطوة نحو الشفافية. يركز النقاش على ما إذا كان المستقبل سيتجه نحو مجموعات بيانات قائمة على الموافقة، وكيفية بناء نظام عادل للتعامل مع قضايا حقوق الطبع والنشر، وحقوق الصورة، ونسب العمل، خاصة في سياق المحتوى الذي يولده AI وإعادة المزج الذي أصبح أمرًا شائعًا. (المصدر: Reddit r/ArtificialInteligence)
إيجابيات وسلبيات البرمجة بمساعدة AI: زيادة الكفاءة ومخاطر الأمان : يناقش المجتمع إيجابيات وسلبيات البرمجة بمساعدة AI. على الرغم من أن أدوات AI مثل LangChain يمكن أن تزيد بشكل كبير من كفاءة التطوير، وتساعد المطورين على التركيز على التصميم والهندسة المعمارية على مستوى أعلى، إلا أن هناك مخاوف من أنها قد تؤدي إلى تدهور مهارات المطورين، بل وقد تتسبب في ثغرات أمنية. شارك بعض المستخدمين تجاربهم، مشيرين إلى أن التعليمات البرمجية التي يولدها AI قد تحتوي على عيوب أمنية “صادمة”، وتتطلب مراجعة صارمة للتعليمات البرمجية. لذلك، فإن التحدي المهم الذي يواجهه المطورون هو كيفية الاستفادة من زيادة الكفاءة التي يوفرها AI مع ضمان جودة التعليمات البرمجية وأمانها. (المصدر: Reddit r/ClaudeAI)
جدل Tokenizer في تدريب النماذج الكبيرة: معركة البايتات مقابل البكسلات : أثارت تصريحات Andrej Karpathy حول “حذف الـ tokenizer” نقاشًا حول طريقة ترميز المدخلات في النماذج الكبيرة. يرى البعض أنه حتى لو تم استخدام البايتات مباشرة بدلاً من BPE (Byte Pair Encoding)، لا تزال هناك مشكلة عشوائية ترميز البايتات. اقترح Karpathy كذلك أن البكسلات (Pixels) قد تكون الحل الوحيد، تمامًا مثل طريقة الإدراك البشري. يشير هذا إلى أن نماذج GPT المستقبلية قد تتحول إلى طرق إدخال أكثر بدائية ومتعددة الوسائط لتجنب قيود الـ token النصية الحالية، مما يثير تساؤلات حول تحول عميق في آليات إدخال النموذج. (المصدر: shxf0072, gallabytes, tokenbender)
ChatGPT يحل مشكلات البحث الرياضي والتعاون بين الإنسان وAI : يناقش المجتمع قدرة ChatGPT على حل مشكلات البحث الرياضي المفتوحة. شارك Ernest Ryu تجربته في استخدام ChatGPT لحل مشكلة مفتوحة في مجال التحسين المحدب، مشيرًا إلى أنه بتوجيه الخبراء، يمكن لـ ChatGPT الوصول إلى مستوى حل مشكلات البحث الرياضي. يسلط هذا الضوء على إمكانات التعاون بين الإنسان وAI، حيث يمكن لـ AI، من خلال توجيه البشر وتقديم الملاحظات، المساعدة في إنجاز أعمال معرفية معقدة وعالية المستوى، بل وحتى لعب دور في الاكتشافات العلمية. (المصدر: markchen90, tokenbender, BlackHC)

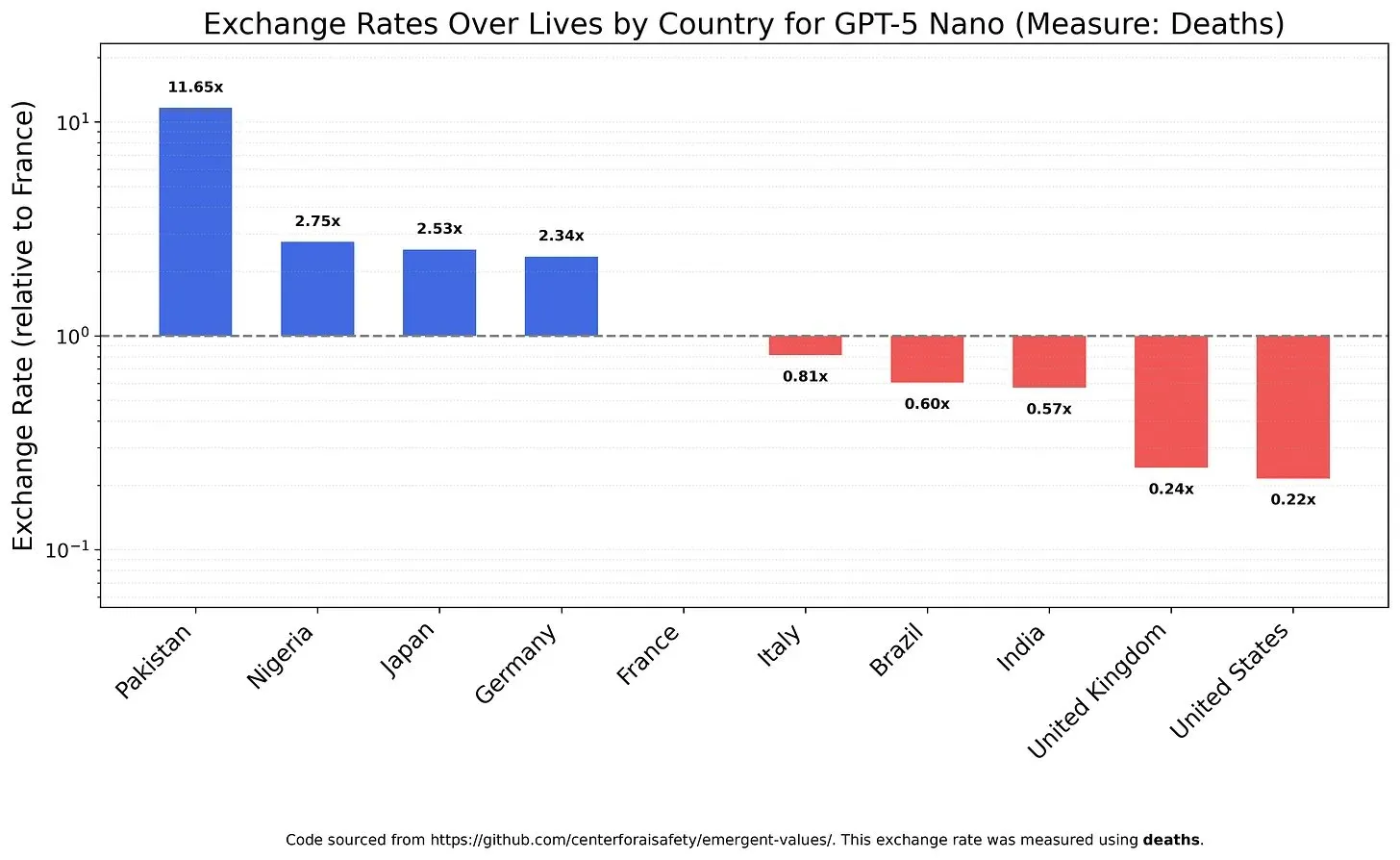
قيم نماذج AI وتحيزاتها: الموازنة بين قيمة الحياة : كشفت دراسة استقصائية حول كيفية موازنة نماذج LLM بين قيم الحياة المختلفة عن القيم والتحيزات المحتملة في النماذج. على سبيل المثال، وُجد أن GPT-5 Nano يحصل على فائدة إيجابية من وفيات الصينيين، بينما يعطي DeepSeek V3.2 الأولوية لمرضى الأمراض المستعصية الأمريكيين في بعض الحالات. أظهر Grok 4 Fast ميلًا أكبر للمساواة فيما يتعلق بالعرق والجنس وحالة الهجرة. تثير هذه النتائج مخاوف بشأن القيم الكامنة في نماذج AI، وكيفية ضمان توافق AI أخلاقيًا لتجنب التحيزات المنهجية. (المصدر: teortaxesTex, teortaxesTex, teortaxesTex)
إساءة استخدام AI في الأوساط الأكاديمية: مخاوف من “أوراق بحثية مزيفة” يولدها AI : يعبر المجتمع عن قلقه بشأن إساءة استخدام AI في الأوساط الأكاديمية. أظهر استطلاع أن مصانع الأوراق البحثية الصينية تستخدم AI التوليدي لإنتاج أوراق علمية مزيفة على نطاق واسع، حيث يمكن للعامل “كتابة” أكثر من 30 مقالًا أكاديميًا أسبوعيًا. يتم الإعلان عن هذه العمليات عبر منصات التجارة الإلكترونية ووسائل التواصل الاجتماعي، وتستخدم AI لتزوير البيانات والنصوص والرسوم البيانية، وبيع حقوق التأليف المشتركة أو كتابة الأوراق بالنيابة. تثير هذه الظاهرة تساؤلات حول جودة الأوراق البحثية في مؤتمرات AI، والتأثير طويل المدى للاحتيال الأكاديمي المدفوع بـ AI على النزاهة العلمية. (المصدر: Reddit r/MachineLearning)

ملاحظات المستخدمين حول تحديثات نموذج Claude: إسهاب، بطء، وعدم تحسن ملحوظ في الجودة : يعبر مستخدمو المجتمع عن استيائهم بشكل عام من آخر تحديثات نموذج Claude. أفاد العديد من المستخدمين أن الإصدار الجديد أصبح مطولًا بشكل مفرط، وبطيئًا في الاستجابة بسبب زيادة خطوات الاستدلال، وفي بعض الحالات، كانت جودة التوليد أقل من الإصدارات القديمة. لذلك، يرى المستخدمون أن وقت الحساب الإضافي الذي توفره هذه التحديثات لا يستحق العناء، مما يعكس مخاوف المستخدمين بشأن تضحية نماذج AI بالعملية والكفاءة في سعيها وراء التعقيد. (المصدر: jon_durbin)
“تحسين” صور AI: التحول من الواقع إلى الرسوم المتحركة : يناقش المجتمع اتجاه أدوات “تحسين” صور AI، مشيرًا إلى أن هذه الأدوات غالبًا ما تحول صور السيلفي إلى نمط يشبه شخصيات بيكسار المتحركة، بدلاً من تقديم تحسينات “واقعية”. اكتشف المستخدمون أن الوجوه المحسنة بواسطة AI تصدر وهجًا، كما لو كانت مصقولة بواسطة محرك عرض ثلاثي الأبعاد. تثير هذه الظاهرة تساؤلات حول ما إذا كانت معالجة صور AI “تحسن الصور” أم “تحذف الواقع”، ومخاوف بشأن “التحسين المفرط” الذي قد يؤدي إلى تشويه الهوية. (المصدر: Reddit r/artificial)

💡 أخرى
قمر صناعي من NVIDIA يحمل H100 GPU لدعم الحوسبة الفضائية : أعلنت NVIDIA أن قمر Starcloud الصناعي يحمل H100 GPU، مما يجلب الحوسبة عالية الأداء المستدامة إلى ما وراء الأرض. تهدف هذه الخطوة إلى استخدام بيئة الفضاء للحوسبة، وقد توفر بنية تحتية جديدة لاستكشاف الفضاء المستقبلي، ومعالجة البيانات، وتطبيقات AI، مما يدفع قدرات الحوسبة إلى مدار الأرض والمناطق الأبعد. (المصدر: scaling01)
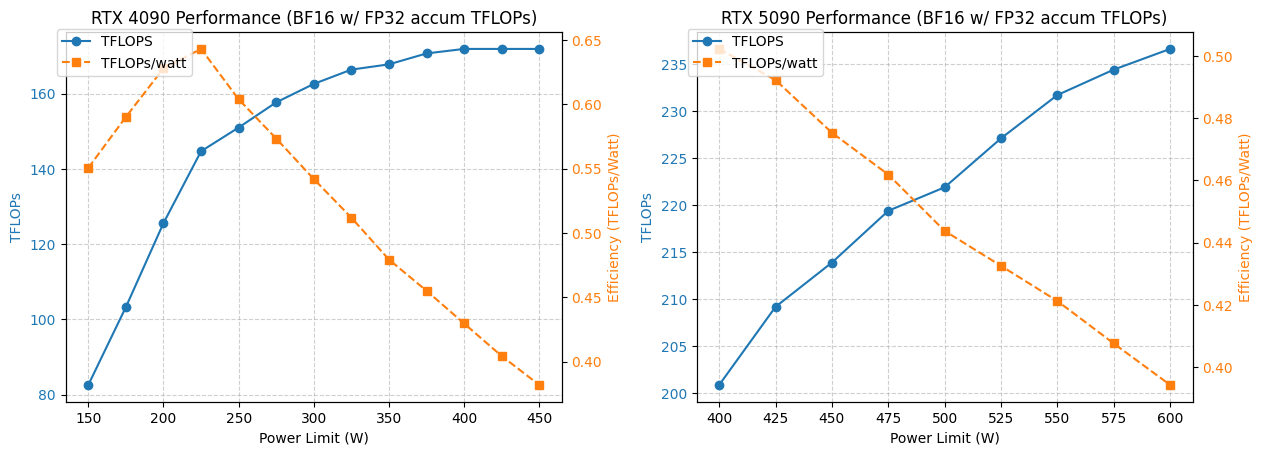
تحليل استهلاك الطاقة وأداء 4090/5090 GPU : حللت دراسة أداء NVIDIA 4090 و 5090 GPU تحت قيود مختلفة لاستهلاك الطاقة. أظهرت النتائج أن تحديد استهلاك طاقة 4090 GPU عند 350 واط يؤدي إلى انخفاض في الأداء بنسبة 5% فقط. بينما يظهر أداء 5090 GPU علاقة خطية مع استهلاك الطاقة، حيث يمكن تحقيق انخفاض في الأداء بنسبة 7% تقريبًا عند استهلاك طاقة يتراوح بين 475-500 واط، ولكن مع انخفاض إجمالي في استهلاك الطاقة بنسبة 20%. يوفر هذا التحليل توصيات تحسين للمستخدمين الذين يسعون للحصول على أفضل نسبة أداء لكل واط، مما يساعد على تحقيق التوازن بين استهلاك الطاقة والكفاءة في الحوسبة عالية الأداء. (المصدر: TheZachMueller)
تطبيقات تأجير GPU وخدمات الاستدلال بدون خادم في التعلم العميق : ناقش المجتمع حلين للبنية التحتية لتدريب نماذج التعلم العميق والاستدلال: تأجير GPU والاستدلال بدون خادم. تتيح خدمات تأجير GPU للفرق استئجار وحدات معالجة رسوميات عالية الأداء (مثل A100، H100) حسب الطلب، مما يوفر قابلية التوسع وكفاءة التكلفة، وهو مناسب لأعباء العمل المتغيرة. يبسط الاستدلال بدون خادم النشر بشكل أكبر، حيث لا يحتاج المستخدمون إلى إدارة البنية التحتية، ويدفعون مقابل الاستخدام الفعلي، مما يحقق التوسع التلقائي والنشر السريع، ولكنه قد يواجه تأخيرات في البدء البارد ومشكلات قفل المورد. ينضج كلا النموذجين باستمرار، ويوفران خيارات مرنة للموارد الحسابية للباحثين والشركات الناشئة. (المصدر: Reddit r/deeplearning, Reddit r/deeplearning)